PH热榜 | 2026-03-15
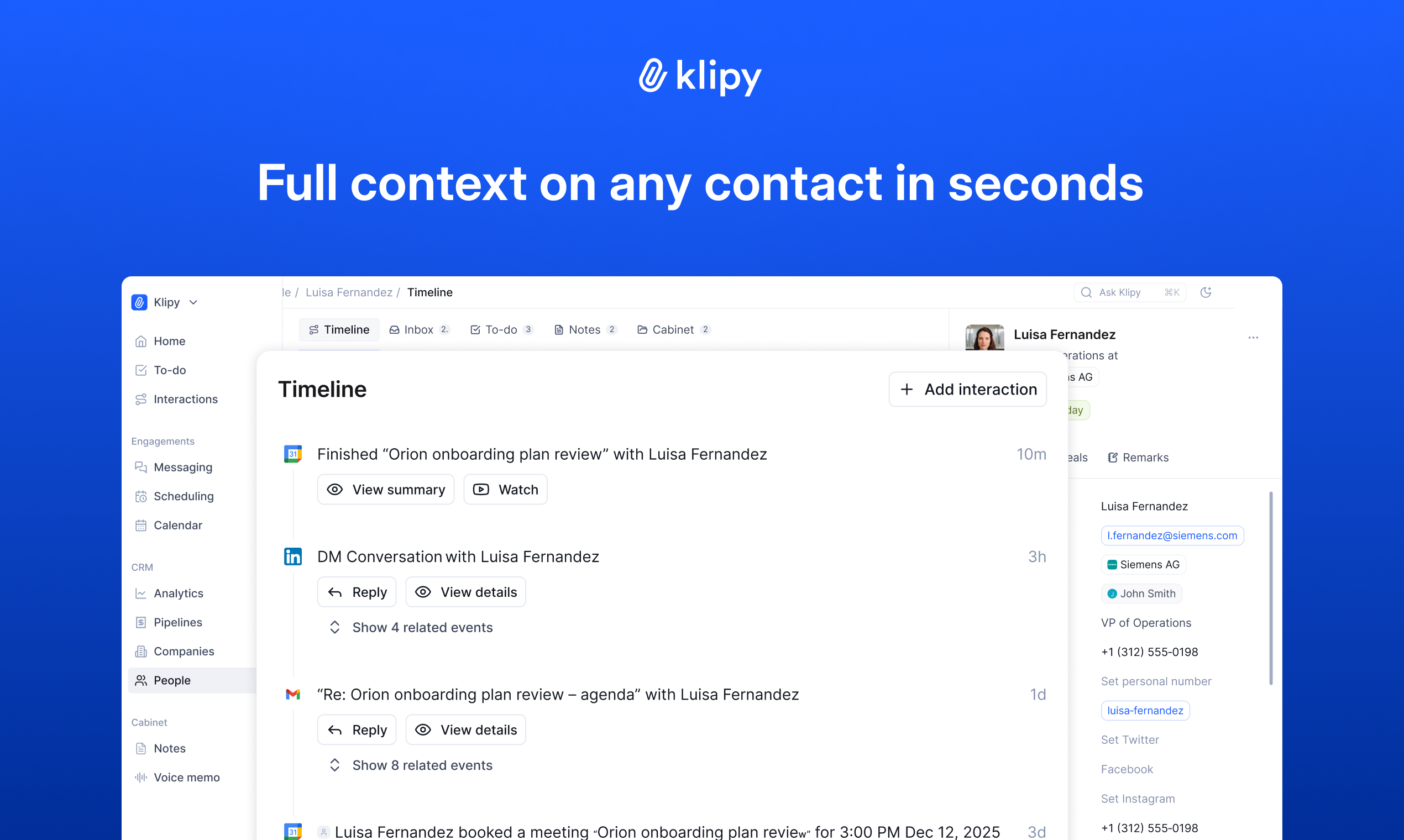
一句话介绍:DynamicLake将MacBook的“刘海屏”区域转化为一个交互中心,集中处理来自多款应用的通知、快速回复、媒体控制和文件操作,解决了用户在多个应用间频繁切换、通知管理分散的效率痛点。
Mac
Productivity
Menu Bar Apps
macOS工具
通知中心
生产力工具
刘海屏优化
交互设计
即时通讯集成
快速回复
桌面效率
用户体验增强
用户评论摘要:用户普遍赞赏其填补了Mac通知体验的空白,设计原生流畅。主要问题集中在多通知处理逻辑(是否支持堆叠/合并)、对无刘海Mac的支持、性能影响以及未来应用集成路线图。开发者回复确认支持通知堆叠与分组,并兼容无刘海机型。
AI 锐评
DynamicLake的本质,并非简单的UI模仿,而是一次对MacOS系统通知层与交互入口的“外科手术式”重构。它敏锐地捕捉到两个关键缝隙:一是硬件(刘海)与系统软件功能的脱节,二是日益碎片化的多应用通知对用户工作流的持续侵扰。其真正价值在于,试图将那个被动的、视觉上突兀的硬件缺口,转变为一个主动的、集约化的服务枢纽。
从评论看,其成功关键在于“原生感”,这证明了它在系统整合深度上下了功夫,而非浮于表面的悬浮窗工具。然而,其面临的挑战同样清晰:首先,其功能深度严重依赖与第三方应用(如WhatsApp、Slack)的逆向集成,这带来了巨大的维护成本和稳定性风险,每一次目标应用的更新都可能是一次危机。其次,作为常驻系统层的工具,其性能优化与资源消耗将是长期命题,尤其在老款机型上。最后,其商业模式和核心价值能否抵御住苹果官方可能在未来macOS中推出的类似功能,存在不确定性。
当前版本通过支持多行回复、快捷表情等,已超越基础通知聚合,向轻量级交互平台演进。但若想从“有趣工具”进化为“必备基础设施”,它必须在通知的智能过滤、跨设备联动(与iPhone真正的Dynamic Island)以及更开放的API生态上构建更深壁垒。否则,它可能止步于一个设计精良的“补丁”,而非下一代交互的“蓝图”。
一句话介绍:一款为人类和AI代理设计的命令行工具,通过动态生成命令和提供轻量级技能文件,解决了在自动化Google Workspace工作流时,传统MCP连接方式因工具定义过载而消耗大量AI上下文窗口的痛点。
Open Source
Developer Tools
Artificial Intelligence
GitHub
命令行工具
Google Workspace自动化
AI代理集成
开发者工具
工作流自动化
上下文优化
SaaS集成
开源项目
API管理
用户评论摘要:用户普遍赞赏其统一CLI覆盖全生态、结构化JSON输出和解决“上下文税”的核心价值。主要疑问/建议包括:官方身份澄清、多账户支持、API变更兼容性、批量操作功能扩展,以及对其他谷歌产品线(如GMP)的类似工具需求。
AI 锐评
Google Workspace CLI的实质,是谷歌生态自动化接口层的一次“降维打击”。它敏锐地刺中了当前AI代理工作流的一个核心悖论:为了调用工具,反而先要消耗巨额上下文来理解工具定义。其提出的“技能文件+CLI”路径,本质是将复杂的API语义封装为可执行的命令行语法,让AI代理从“阅读理解者”退回到“命令执行者”,这是一种以退为进的工程智慧。
然而,其真正颠覆性在于对“官方性”的暧昧运用。由谷歌开发者发布、使用谷歌标识却声明非官方产品,这种策略既利用了品牌信任降低采用门槛,又规避了正式产品的承诺压力,是一种高风险高回报的“探针式”发布。产品从谷歌Discovery Service动态构建命令的设计,看似一劳永逸,实则将API稳定性的风险完全转嫁给了用户,这与其宣称的“自动化”可靠性存在内在矛盾。
长远看,它可能成为谷歌将AI代理深度、标准化接入其办公生态的“特洛伊木马”。一旦形成用户依赖和生态习惯,无论其最终是否转为官方产品,谷歌都已成功定义了该领域的技术交互范式。但对开发者而言,需警惕其“非官方”状态下的长期支持风险,以及将关键工作流绑定于一个可能随时变动的接口层的潜在代价。它是一把锋利的剑,但剑柄未必完全握在用户手中。
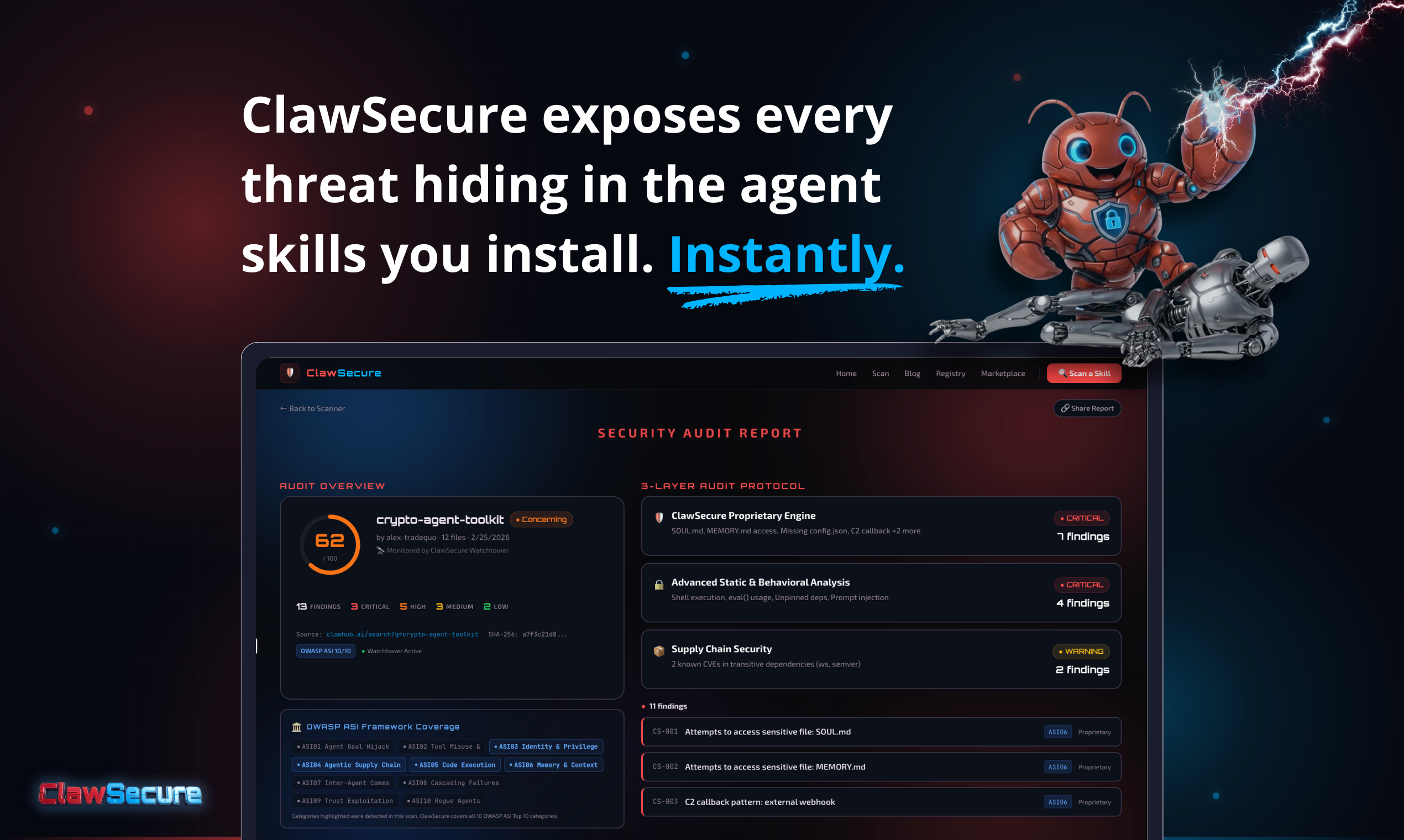
一句话介绍:ClawSecure 是一款为 OpenClaw AI 智能体提供三层安全审计、实时监控及市场身份验证的综合性安全平台,解决了智能体在运行未经验证的第三方技能时面临的数据泄露与恶意代码攻击的核心安全问题。
Open Source
Developer Tools
Security
AI智能体安全
安全审计
实时监控
供应链安全
代码扫描
威胁检测
开源生态安全
安全平台
漏洞管理
OWASP ASI
用户评论摘要:用户普遍认可安全问题的紧迫性,并关注技术细节:如何防护运行时攻击(如提示注入)?是否支持其他智能体框架?如何处理误报?是否有开源计划?强烈建议增加Slack/Discord警报集成,并对“22.9%技能安装后变更代码”的统计数据感到震惊。
AI 锐评
ClawSecure 敏锐地抓住了 AI 智能体生态爆发初期“安全滞后”的致命痛点,其价值远不止于一个扫描工具。它本质上试图成为智能体生态的“安全基础设施”,其三层审计与实时监控(Watchtower)的组合拳,直指开源智能体框架(如 OpenClaw)缺乏沙箱和权限模型的原始缺陷——既然无法在运行时有效隔离,那就必须在源头和持续状态上建立信任。
产品策略显示出对安全商业逻辑的深刻理解:以免费、无门槛的扫描器快速获取用户与数据,构建威胁情报网络;通过 Security Clearance API 切入技能分发市场,成为事实上的安全守门人。这模仿了 CrowdStrike 等现代安全平台的成长路径,而非传统杀毒软件。
然而,其挑战同样尖锐。首先,其“静态分析为主”的防护思路,虽针对当前以代码植入为主的威胁,但面对未来更复杂的运行时攻击(如高级别提示注入、逻辑漏洞)可能力有不逮。创始人承认这是“有意的架构选择”,但这或许也是当前技术条件下的无奈妥协。其次,生态扩展性存疑。尽管宣称架构支持多框架,但每个框架的技能模型和威胁模式差异巨大,构建针对性检测规则的成本高昂,能否快速覆盖将考验其工程能力。最后,其“检测规则不开源”的立场虽出于商业和安全考量,但在以开源为核心的开发者生态中,可能影响部分极客用户的信任度。
总体而言,ClawSecure 是一次精准的卡位。它不是在修补漏洞,而是在试图定义 AI 智能体生态的安全标准。其成败将不取决于扫描精度,而在于能否在生态爆发前,将其安全协议深度嵌入到技能开发、分发和部署的每一个环节,成为不可或缺的“信任层”。这条路很长,但起点足够犀利。
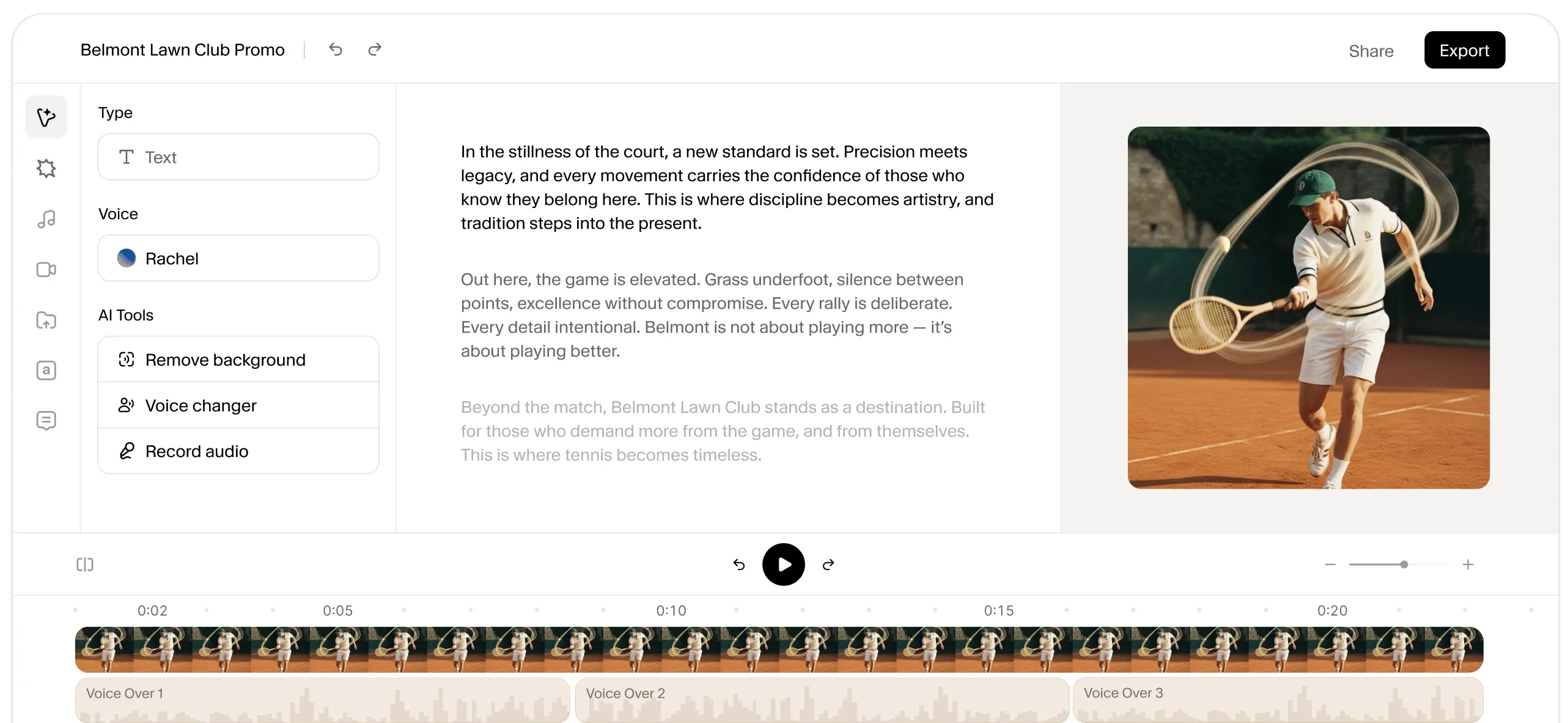
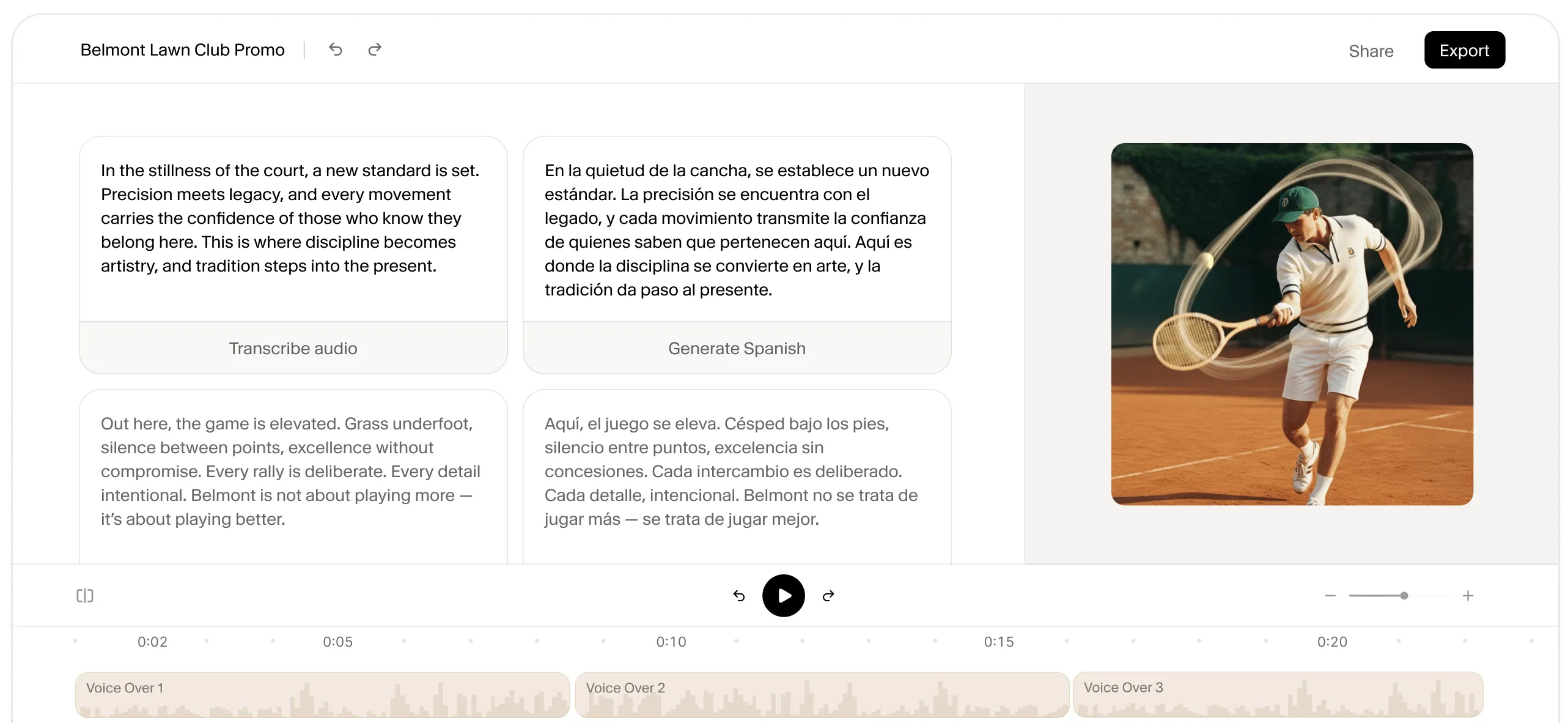
一句话介绍:一款集生成、编辑与本地化于一体的AI创意平台,通过整合语音、视频、音乐、音效等多种AI模型,为内容创作者、营销团队和媒体公司提供一站式解决方案,解决了多工具切换、工作流复杂、制作成本高昂的核心痛点。
Artificial Intelligence
Audio
Video
AI创意平台
音视频生成
内容本地化
多合一工具
语音克隆
AI配音
营销内容制作
媒体生产
工作流整合
用户评论摘要:用户普遍认可其整合工作流、提升效率与降低成本的核心理念,尤其赞赏70+语言本地化与语音克隆保持品牌一致性的能力。主要问题与建议集中在:视频生成长度限制、多人在线协作模式(实时协同或交接)、以及未来产品路线图。
AI 锐评
ElevenCreative的发布,远不止是ElevenLabs从明星语音工具向综合创意平台的简单功能扩展,其背后是对当下AI生产力工具“碎片化困境”的一次精准狙击。市场早已充斥各类单点突破的AI生成工具,但用户被迫在多个标签页与格式转换间疲于奔命,创意在工具链摩擦中不断损耗。该产品宣称的“端到端工作流”,实质是试图定义AI时代创意生产的新操作系统——将“生成”与“编辑”置于同一上下文环境,这直接瞄准了从“AI草稿”到“成品交付”之间最耗时的精修与整合环节。
其真正的护城河与风险皆系于“整合”二字。优势在于,凭借其在语音领域的顶尖模型与技术信誉,可能以语音克隆与跨语言情感保持为核心钩子,吸引用户进入其生态,并自然延伸至视频、音乐等相邻领域,实现交叉销售。评论中提及的“品牌声音跨语言一致性获得盛赞”即是明证。然而,风险也同样巨大:在视频、图像等并非其原始优势的领域,其生成质量能否与Midjourney、Runway等头部专用工具抗衡?若仅是“集成”而非“超越”,平台可能沦为平庸的聚合器。此外,“全栈平台”意味着更重的产品、更复杂的定价以及对各领域技术迭代的持续高投入,这对团队的运营与研发能力提出了极高要求。
总体而言,这是一步极具野心且符合逻辑的棋。它不再满足于做AI技术供应链中的一颗“螺丝钉”,而是试图成为整合所有螺丝的“主板”。成败关键在于,其能否在提供无缝体验的同时,确保每个核心模块的竞争力都达到“可用”乃至“优秀”,而非仅仅“存在”。否则,对于专业团队,它可能只是又一个需要被“套娃”使用的工具;对于轻度用户,其综合复杂度与成本可能构成门槛。它挑战的不是某个功能,而是用户根深蒂固的工作习惯与工具选型逻辑。
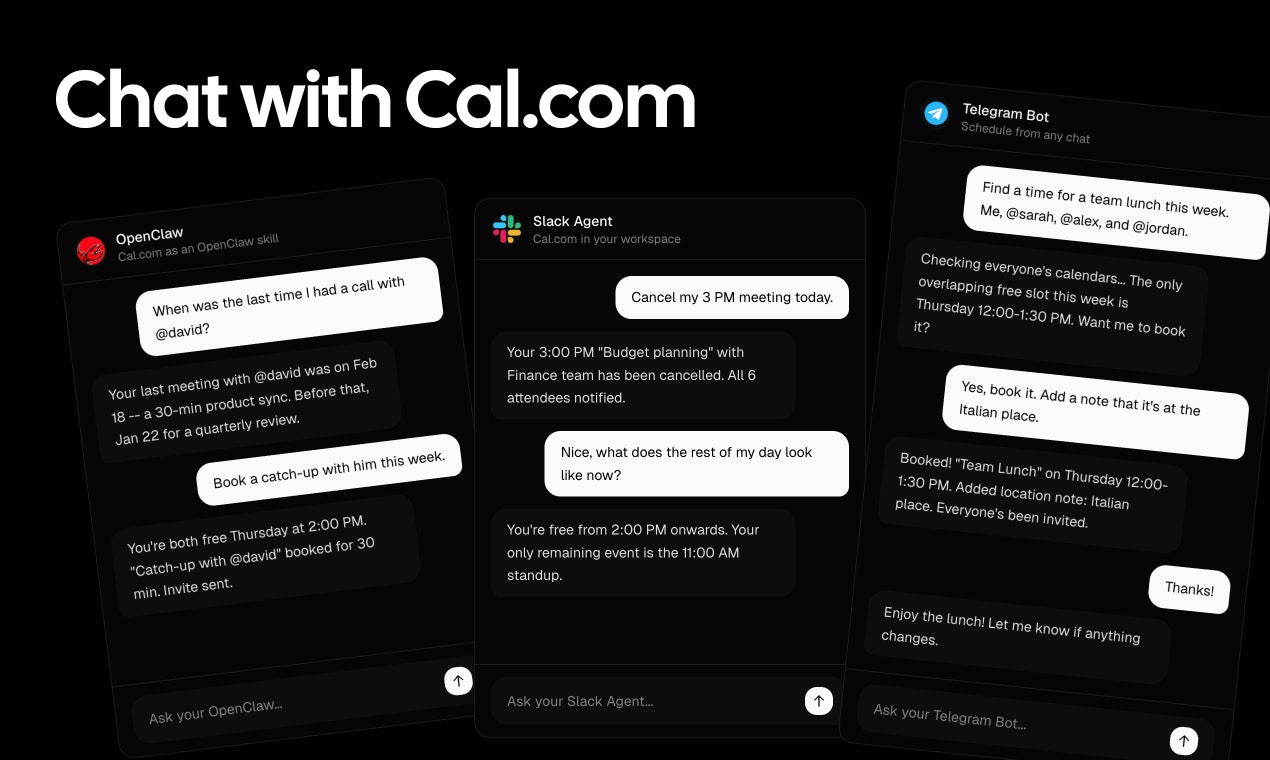
一句话介绍:Cal.com Agents 将AI智能体集成到Cal.com日程安排工具中,允许用户在Slack、Telegram等聊天场景内通过自然语言对话自主协调与预订会议,解决了传统日程安排中反复沟通、耗时繁琐的核心痛点。
Productivity
Calendar
Artificial Intelligence
AI智能体
日程安排
自动化调度
聊天机器人集成
开源工具
生产力工具
会议协调
自然语言交互
工作流自动化
用户评论摘要:用户普遍认为这是产品的自然进化,解决了日程安排中的反复沟通摩擦,并对开源带来的透明度与信任表示认可。主要问题聚焦于智能体如何处理多时区、复杂日程冲突等实际场景,并期待其向更主动的跟进等方向拓展。
AI 锐评
Cal.com Agents 的本质,是将日程安排从“表单填写式”的被动工具,升级为嵌入沟通流中的“主动协调者”。其真正价值不在于简单的聊天机器人接口,而在于试图将日程背后的复杂规则(权限、偏好、时区、冲突解决)封装成一个可对话的AI代理,让预约行为变得像发信息一样自然,从而切入“隐性时间成本”这一职场核心痛点。
产品亮点在于其“基础设施”定位。通过API和开源策略,它不满足于做一个封闭的智能调度黑盒,而是将自己打造成一个可编程、可审计的“调度层”。这精准地回应了企业级用户对AI操作日历的核心顾虑——信任与控制。评论中反复提及的“开源优势”和“信任解锁”正是对此的佐证。
然而,其面临的挑战与机遇同样尖锐。首先,技术层面,评论中关于“多时区地狱”和“复杂冲突协商”的提问直指产品核心难度——AI代理的决策逻辑是否足够智能与稳健,能替代人类那充满微妙妥协的沟通?其次,市场层面,它需要证明自己不仅仅是Cal.com现有用户的效率插件,而能成为一个跨平台、被广泛集成的独立调度标准。目前看来,其通过开放生态(支持多平台、举办黑客松)的策略是正确的。
总体而言,这是一次极具前瞻性的产品延伸。它未必能立刻成为“百亿级产品”,但确实在将“时间”变得可编程、可代理的赛道上,卡住了一个关键生态位。成败关键在于其AI代理在实际复杂场景中的可靠性,以及开源生态能否构建起足够深的护城河。
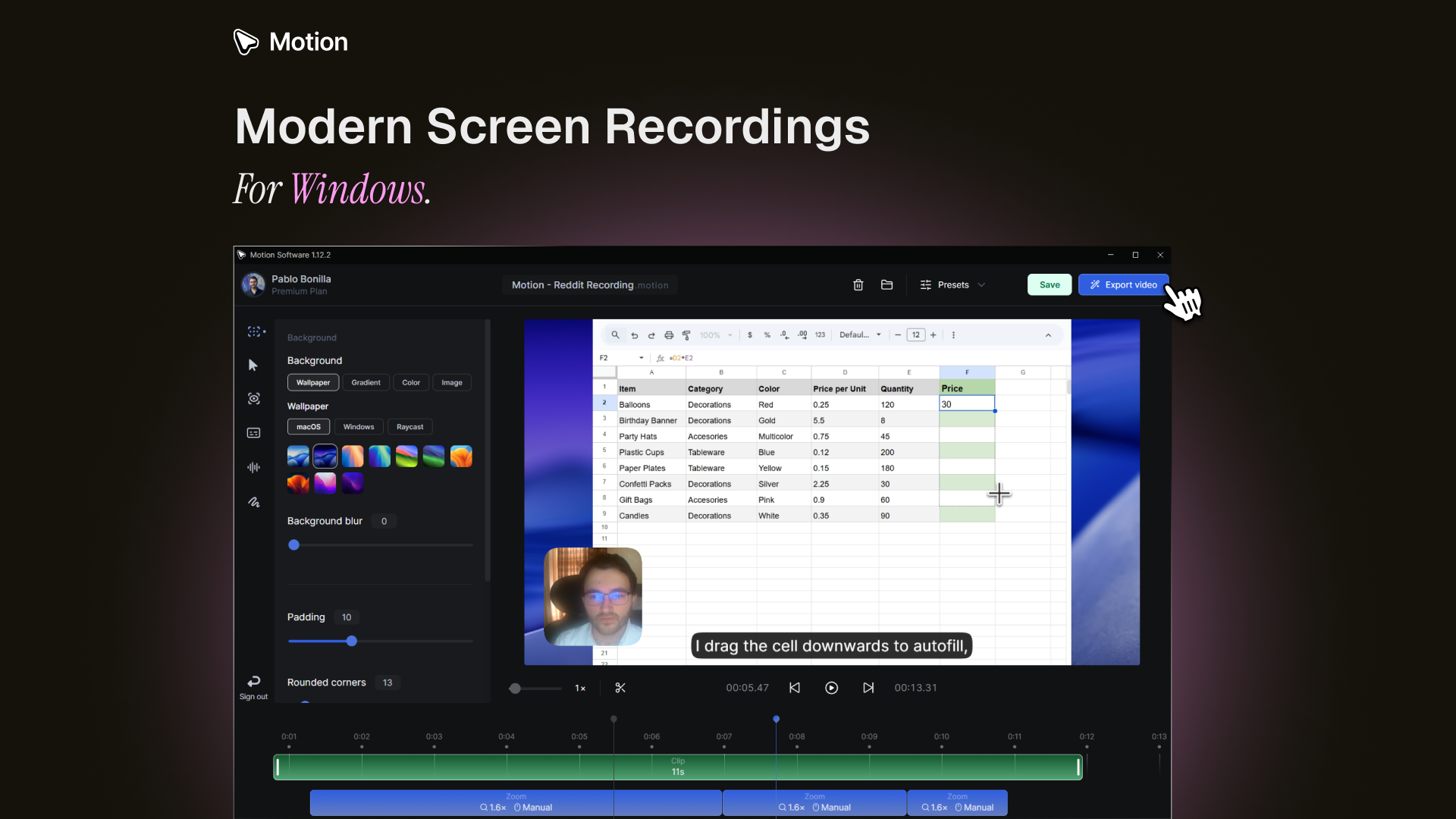
一句话介绍:Motion Software是一款为Windows设计的现代化屏幕录制与视频处理工具,通过自动添加动画效果、摄像头画面、AI字幕及平滑鼠标轨迹等功能,将枯燥的屏幕录像快速转化为精美的演示视频,解决了Windows用户在制作产品演示、教程视频时缺乏高效、专业且原生适配工具的痛点。
Productivity
Marketing
Video
屏幕录制
视频制作
Windows工具
生产力软件
AI字幕
演示视频
鼠标平滑
摄像头画中画
独立开发
Product Hunt发布
用户评论摘要:用户普遍赞赏其为Windows平台填补了高质量屏幕录制工具的空白。主要反馈集中在:肯定AI字幕、摄像头集成和鼠标平滑等核心功能;询问对技术术语的识别能力;建议增加自动缩放、平台专属导出预设等功能;期待其从录制工具发展为完整制作流程。
AI 锐评
Motion Software的亮相,与其说是一款新工具,不如说是对Windows创作者生态一次迟到的“补票”。其真正价值并非炫技式的功能堆砌,而在于精准切入了一个被长期漠视的利基市场:为Windows原生用户提供媲美Mac平台(如Screen Studio)的、开箱即用的高质量录屏体验。
产品逻辑清晰:它没有纠缠于底层录制技术的红海竞争,而是将重心放在“后处理”与“自动化”上。自动动画、AI字幕、平滑鼠标,这些功能本质上是在收购用户最昂贵的资产——时间。它将原本需要进入专业视频软件(如Premiere)进行繁琐后期的工作流,压缩为几次点击。创始人Pablo对社区反馈的快速响应(如计划为AI字幕添加上下文引导)也展现了一种健康的迭代姿态。
然而,其面临的挑战同样鲜明。首先,功能差异化护城河尚浅。鼠标平滑、自动缩放等亮点功能极易被复制,而AI字幕作为核心卖点,其准确度(特别是面对代码、专业术语)的边界将直接决定专业用户的去留。其次,其定位介于轻量工具与准专业工作流之间,略显模糊。从评论中用户的进阶需求(如平台专属导出预设、自定义布局)可以看出,用户期待它承担更多。这要求团队必须在“保持简洁”与“满足专业需求”之间做出谨慎平衡,避免变得臃肿。
总体而言,Motion Software是一次成功的市场卡位。它证明了在所谓“成熟”的工具领域,针对特定平台(Windows)的、体验驱动型创新仍有巨大机会。它的成功与否,将取决于能否将目前的“功能优势”转化为稳固的“工作流依赖”,并围绕“高效创建可传播的演示视频”这一核心,构建更深的集成生态。
一句话介绍:一款能保留说话者原声、语调和情感的实时语音翻译通话应用,解决了跨语言交流中因机械翻译导致情感流失和沟通不自然的痛点,适用于旅行、跨国商务及个人社交等场景。
Android
Languages
Travel
Artificial Intelligence
实时语音翻译
跨语言通话
声音克隆
按分钟付费
情感保留
多语言支持
通信工具
人工智能
人本科技
独立开发
用户评论摘要:用户高度认可“保留原声”的核心差异化和按分钟付费模式。主要问题集中在:不同语言对(如英日互译)的延迟体验、嘈杂环境下的使用效果、对话中打断或抢话的处理,以及是否考虑AI智能体间通信等扩展场景。开发者对部分问题进行了坦诚回应。
AI 锐评
The Banana App 的野心不在于成为又一个翻译工具,而在于扮演“人性管道工”。它敏锐地刺中了当前AI翻译的普遍软肋:精准却冰冷的词句转换,牺牲了沟通中至关重要的情感带宽和人格在场。其宣称的“保留你的笑声、停顿和温度”,本质上是将语音翻译从“语义传输”升级为“人格化传输”,这比单纯追求低延迟或高准确度更具颠覆性,因为它直指跨语言交流的终极目标——被理解,而不仅仅是听懂。
然而,其面临的挑战同样深刻。首当其冲的是技术悖论:为保留原声和情感,必然需要更复杂的声学模型和上下文处理,这可能与“实时性”这一通话铁律产生根本冲突,评论中提及的英日互译延迟即是明证。其次,其引以为傲的“人性化”体验,在复杂现实场景(如多人嘈杂环境、对话抢话)中能否保持稳定,仍需大规模用户检验。其按分钟付费的清爽模式虽获好评,但也将自身定位为“低频工具”,如何提升用户粘性和构建护城河是一大课题。
真正的价值在于,它试图在技术洪流中重新锚定“沟通”的本质。它不仅仅是一个功能型应用,更是一个关于技术伦理的声明:效率不应以人性化为代价。如果它能持续优化核心体验,并在特定垂直场景(如跨国亲友沟通、高端涉外服务)中建立口碑,它有望从巨头林立的翻译市场中切割出一个独特的“情感化通信”细分赛道。但这条路注定艰难,因为它比拼的已不仅是算法,更是对人性细微之处的工程化理解能力。
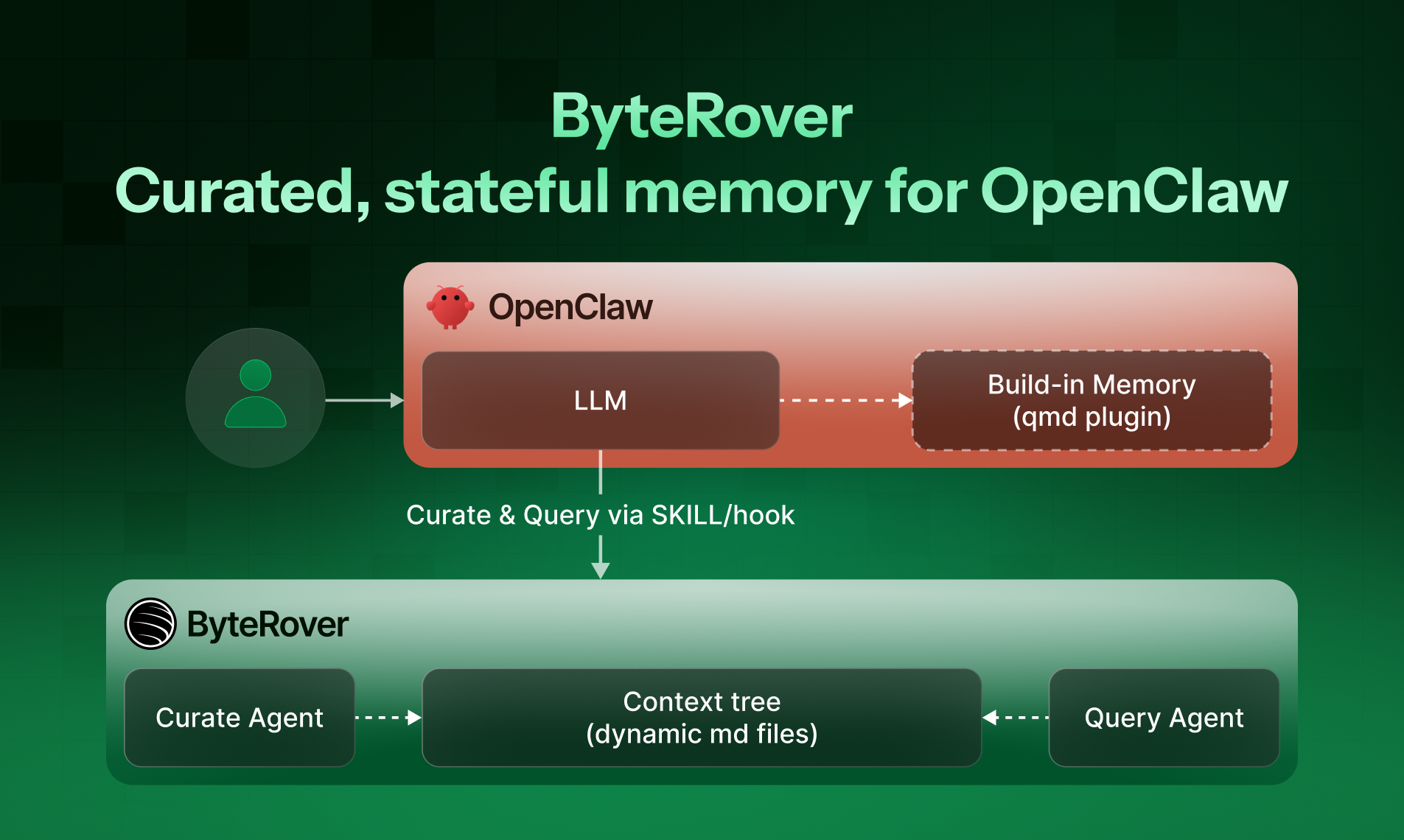
一句话介绍:为OpenClaw等自主智能体提供基于文件系统的确定性记忆层,通过选择性检索和本地版本控制,解决智能体“健忘症”导致的上下文丢失和token消耗过高痛点。
Open Source
Developer Tools
Artificial Intelligence
GitHub
AI智能体记忆系统
上下文管理
文件存储
本地优先
版本控制
token优化
检索增强
开发工具
OpenClaw生态
自主代理
用户评论摘要:用户高度认可其解决“智能体健忘症”和大幅降低token成本(40-70%)的核心价值。主要提问聚焦于:文件系统如何实现高检索准确率;如何处理多代理间的记忆冲突;与云端方案的对比;索引同步机制。创始人详细回复了冲突解决(层级优先+时间戳)和实时同步(守护进程+变更检测)的逻辑。
AI 锐评
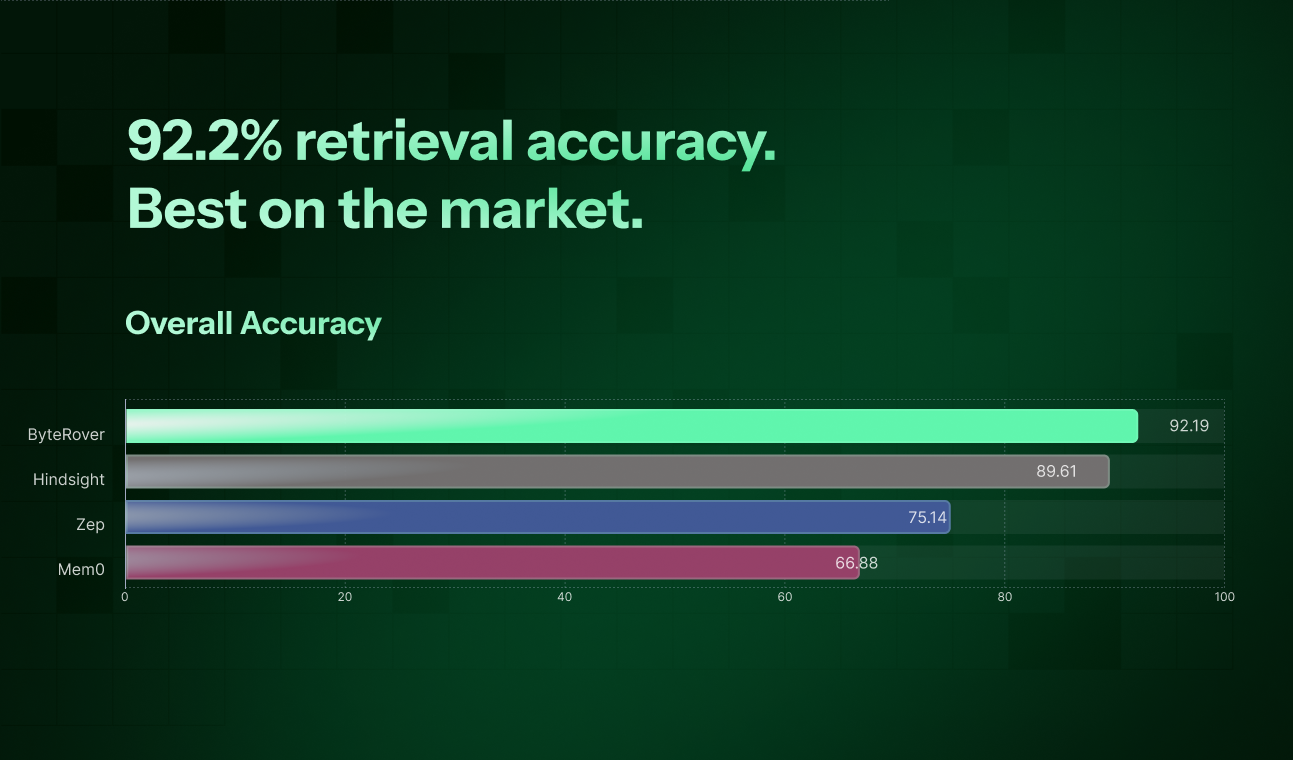
ByteRover的发布,精准刺中了当前AI智能体规模化进程中最隐秘却最致命的软肋:状态失忆。它没有选择在向量数据库的“相似度检索”红海里继续内卷,而是激进地回归文件系统,用确定性的目录树和Markdown文件来承载记忆。这本质上是一次架构哲学的转变——将模糊的、概率性的“记忆召回”,转变为可版本控制、可人工审阅、可确定性检索的“上下文工程”。
其宣称的92.19%检索准确率,若经得起考验,价值并非单纯数字的胜利,而是证明了“结构优先于嵌入”在特定工作流中的优越性。它牺牲了向量检索的模糊联想能力,换来了对代码、决策日志等强结构化上下文的无损、精准管理。这正切合了开发场景对确定性而非创造性的核心需求。
真正的犀利之处在于其商业洞察:它将成本(token消耗)和效率(上下文丢失)这两个最直接的痛点,转化为一个可本地部署、看似极客范的解决方案。通过.git类比,它降低了开发者的心智负担,同时巧妙地将自身嵌入开发工作流,构建了潜在的护城河。然而,其挑战也同样明显:文件系统的范式能否适应更复杂、非结构化的记忆场景?当记忆规模爆炸性增长时,纯文件系统的检索效率是否会成为新的瓶颈?它目前更像是开发者的精密手术刀,而非面向大众的通用记忆层。但其展现出的“以简驭繁”思路,无疑为过热的大模型应用堆料竞赛,提供了一剂清醒的反思。
一句话介绍:一款本地优先的晨间仪表盘应用,通过聚合天气、链接、世界时钟等常用信息于单一页面,解决了用户早晨需要频繁切换多个标签页和应用的效率痛点。
Productivity
Task Management
Open Source
GitHub
生产力工具
晨间仪表盘
本地优先
隐私保护
开源软件
信息聚合
桌面应用
无账号
无云服务
用户评论摘要:用户反馈积极,认可其解决分散痛点及开源模式。主要问题集中在:如何培养使用习惯(核心UX挑战)、是否支持按日自定义、以及Mac安装安全警告。开发者积极引导用户至GitHub贡献代码。
AI 锐评
Morgen的核心理念是“减法”与“主权”,其真正价值不在于功能罗列,而在于对现代数字生活痼疾的一次精准狙击。它敏锐地捕捉到“分布式摩擦”这一隐形时间杀手——将用户从多标签切换、账号登录、算法干扰和隐私担忧中彻底解放。其“本地优先、无云、无追踪”的立场,在数据商品化时代构成了一种带有理想主义色彩的反叛,是其最锋利的卖点。
然而,其最大的阿喀琉斯之踵也在于此。将一切置于本地,固然赢得了隐私,却可能牺牲了跨设备同步的便利性,这与用户日益流动的工作生活形态存在潜在矛盾。此外,评论中指出的“习惯养成”问题直击要害:一个需要主动打开的应用,如何与手机通知、浏览器主页等被动式入口竞争用户的晨间注意力?这并非单纯的技术问题,而是行为设计学的深层挑战。
它的开源模式是一把双刃剑。一方面,它建立了信任,吸引了贡献,避免了“未来变订阅”的担忧;另一方面,也可能意味着核心体验的迭代速度和产品化深度依赖于社区热情,存在不确定性。总体而言,Morgen更像一个精心打造的“概念证明”,它成功定义了一类需求,并树立了隐私至上的开发范式。但其能否从极客的精致玩具,成长为大众的日常习惯,取决于它能否在保持哲学纯粹性的同时,在用户体验的“最后一公里”——尤其是习惯触发和有限定制化上——找到更优雅的解决方案。
一句话介绍:一款完全在设备端运行AI的私人阅读应用,通过本地化处理保存的文章,在无需网络、不泄露数据的场景下,为用户提供摘要、语音朗读、每日摘要等智能阅读服务,解决了注重隐私的用户对云端数据泄露和商业化追踪的痛点。
News
Newsletters
Tech
本地AI阅读
隐私安全
离线摘要
文本转语音
无账户应用
阅读追踪
个性化推荐
苹果生态
独立开发
信息消化
用户评论摘要:用户认可其真正的设备端隐私保护、可选的阅读打卡机制及通知功能。开发者回应了关于本地模型大小与电池影响的疑问,称模型轻量、处理时间短、对电池影响不明显。
AI 锐评
LaterAI的叙事核心是“隐私霸权”,它巧妙地将“设备端AI”作为技术贞操带,直击当前云端AI服务数据滥用的普遍焦虑。其真正价值并非AI能力本身——本地小模型的摘要和问答质量必然无法与云端大模型抗衡——而在于构建了一个封闭且可信的“数据无菌室”。它贩卖的是一种控制感:你的阅读清单不再是训练别人模型的饲料,你的拖延症不再被转化为用户粘性数据。
然而,这种极致的本地化是一把双刃剑。它必然牺牲了功能的深度与协同的便利性。所谓的“个性化推荐”只能基于单设备的历史数据,其视野和精准度存疑;通过iCloud的同步虽声称私有,但仍依赖苹果生态,并非绝对自主。其商业模式也隐晦不明,一次性付费或捐赠或是唯一出路,长期维护动力存疑。
本质上,LaterAI是数字极简主义者和隐私原教旨主义者的精致玩具。它证明了在特定垂直场景下,用户愿意用智能的“广度”和“深度”来交换绝对的“控制权”。但它也尖锐地提出了一个问题:在AI时代,极致的隐私是否必然意味着智能的降级与自我的数字孤岛?这款产品的未来,不在于其AI有多强,而在于有多少人将“数据主权”置于“智能便利”之上。
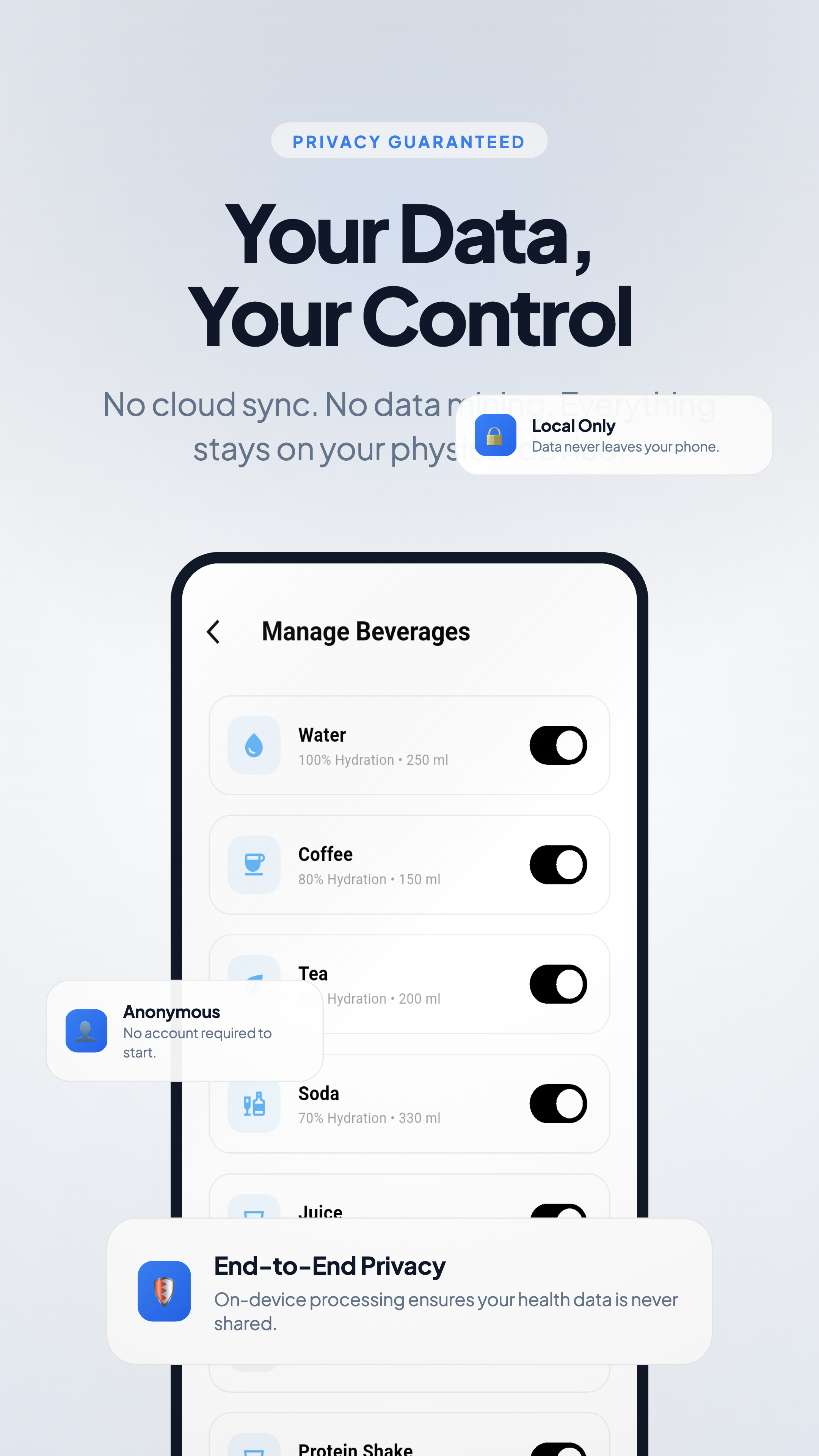
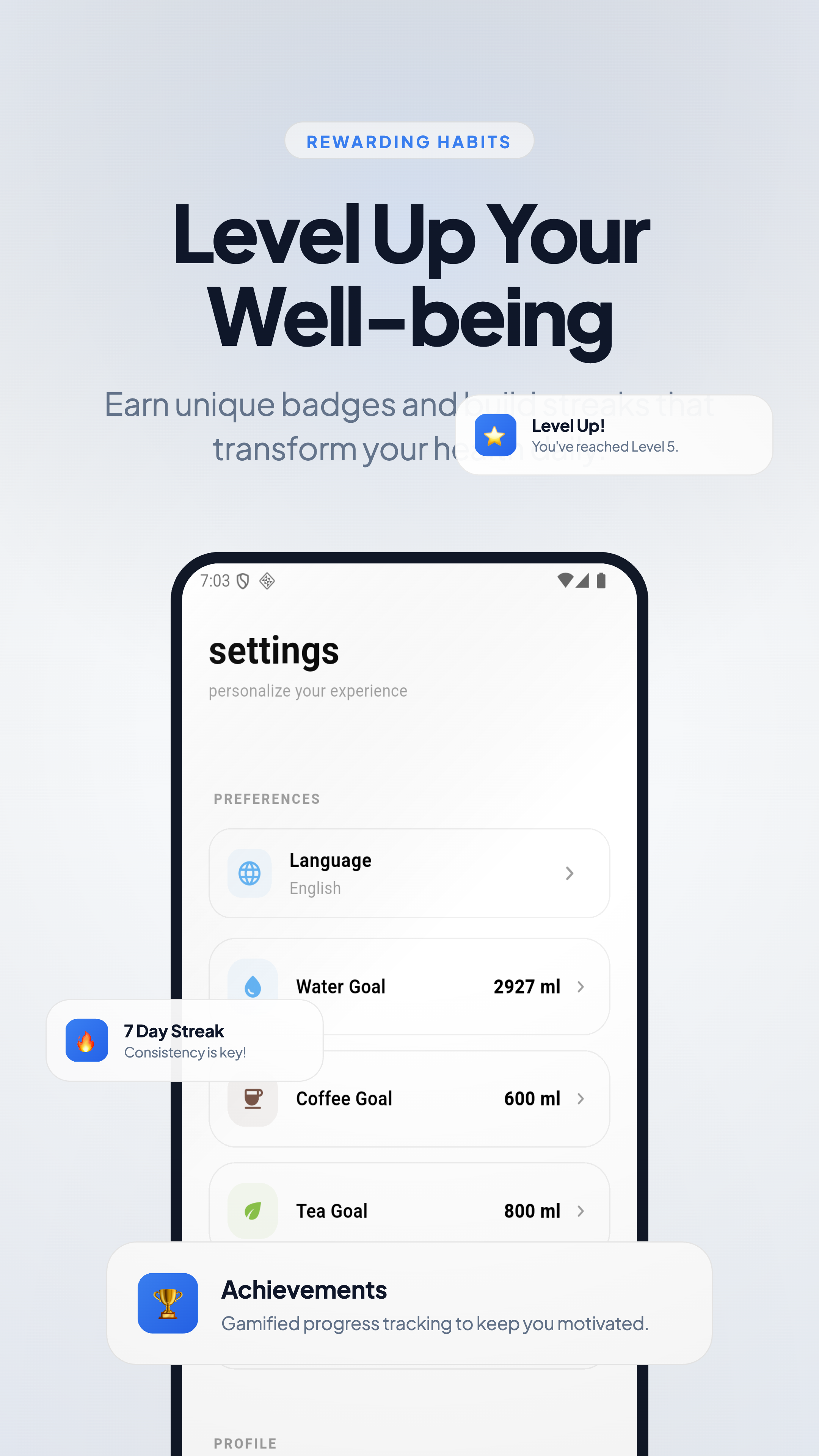
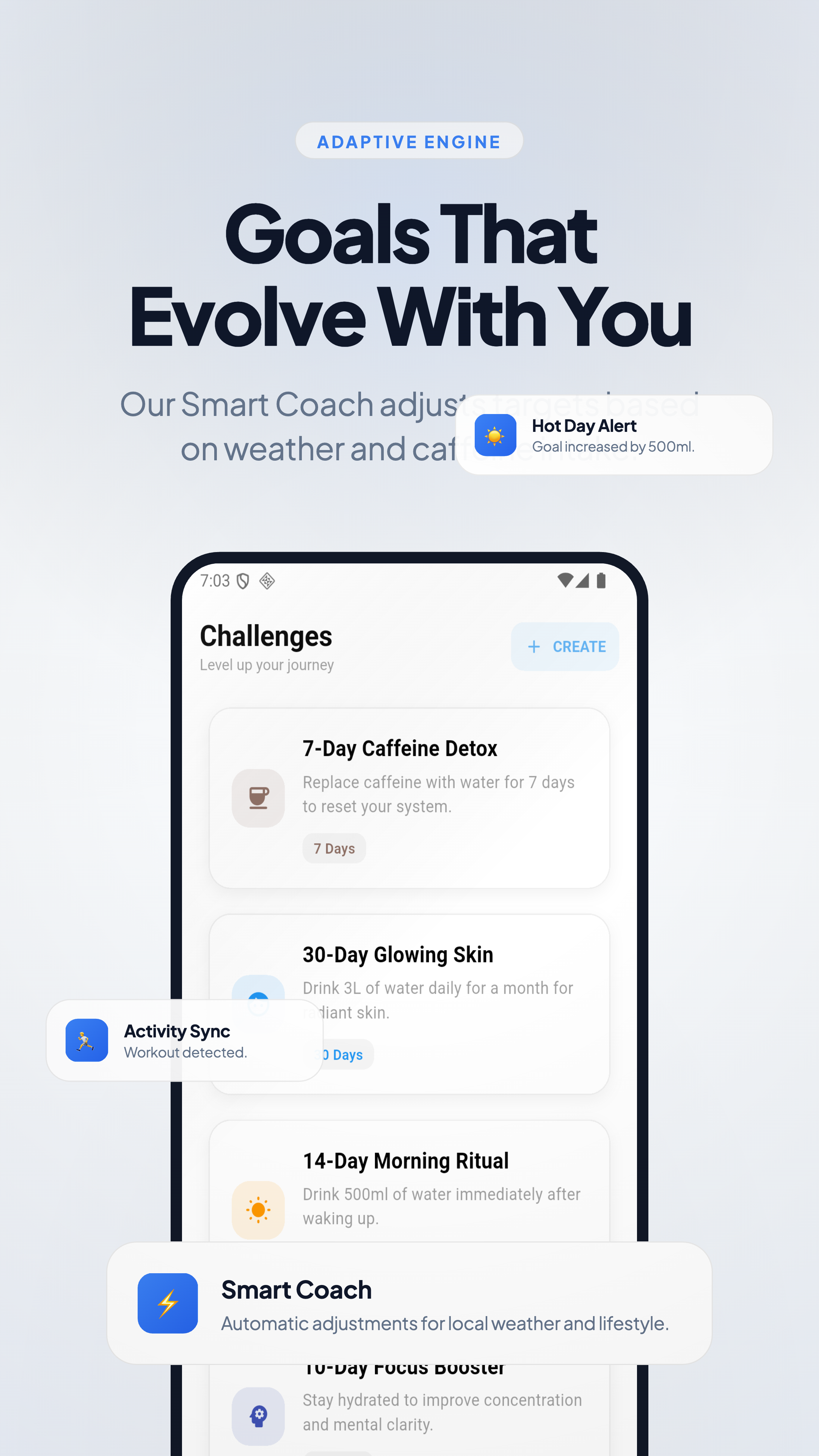
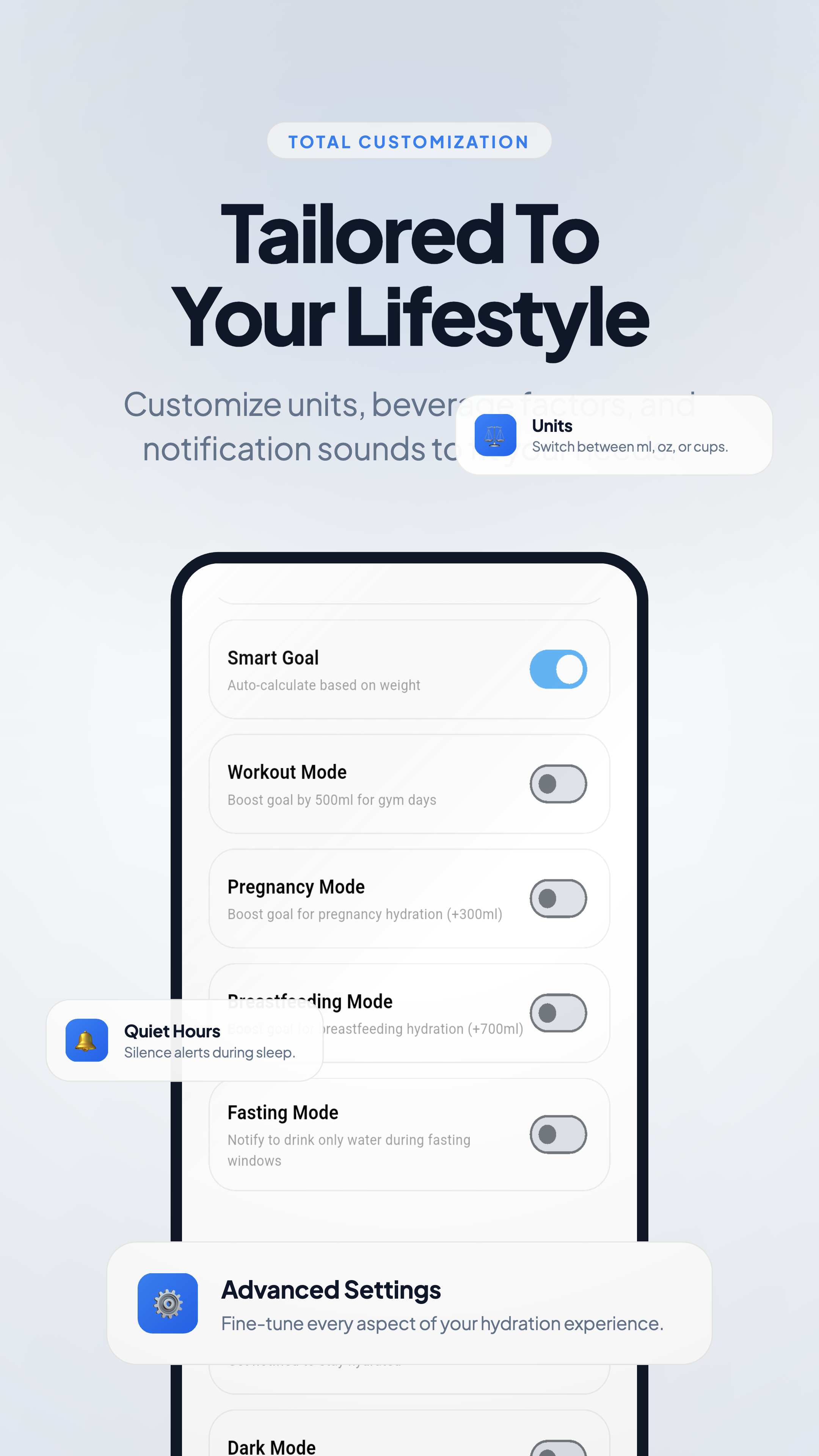
一句话介绍:一款完全离线运行的私密AI饮水教练应用,通过“饮水能量条”等无摩擦设计,在保护隐私的同时,帮助用户、特别是注重隐私或ADHD人群,轻松建立规律饮水习惯。
Health & Fitness
Privacy
Artificial Intelligence
健康追踪
饮水记录
隐私优先
离线AI
无数据收集
ADHD友好
习惯养成
本地计算
健康科技
移动应用
用户评论摘要:用户高度赞赏其隐私优先与ADHD友好设计,认为“饮水能量条”概念巧妙。主要问题与建议包括:询问Apple Watch支持(团队确认已在2026路线图中)、建议优化应用商店视觉展示以更好传达产品故事、询问AI个性化原理及与智能水杯等硬件整合的可能性。
AI 锐评
Aura Water 的亮相,与其说是一款饮水追踪工具的迭代,不如说是对当前健康科技商业模式的一次静默反叛。其核心价值并非在于“AI教练”的技术奇观,而在于将“主权健康”这一理念产品化:通过将AI模型完全本地化,它斩断了用户数据被商品化的默认路径,将隐私从可选项变为架构基石。
产品巧妙地用“无摩擦”体验来对冲“强隐私”可能带来的功能牺牲。针对ADHD群体或深度工作场景设计的“饮水能量条”和极速记录,直击传统习惯应用因记录繁琐导致用户流失的痛点。这揭示了一个关键洞察:真正的用户友好,是体验与掌控权的双重赋予——既不让用户感到麻烦,也不让用户感到被窥视。
然而,其挑战也同样清晰。完全离线的架构虽保障了隐私,但也可能限制了数据的多端同步与长期深度分析潜力,这与现代用户跨设备无缝体验的期待存在张力。此外,将“隐私”作为主要卖点,在竞争激烈的红海市场中,需要持续教育用户认知其深层价值。它更像一个宣言式产品,其成功与否,将检验有多少用户愿意用“可能的云端便利”来交换“确定的数据主权”。它的未来,在于能否将这种“主权框架”扩展至更复杂的健康指标,从而由一个利基工具,成长为一种可被广泛验证的新范式。
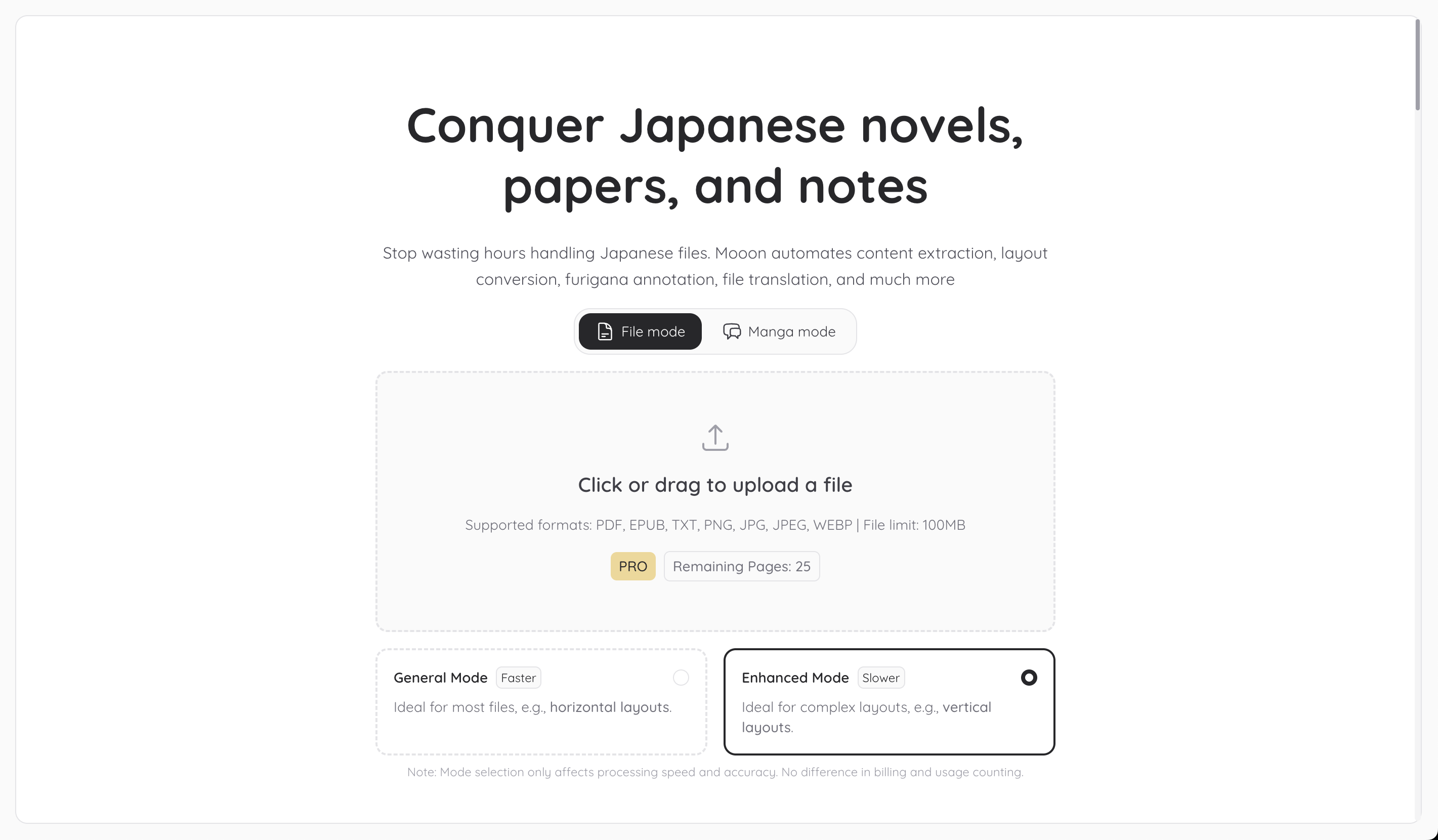
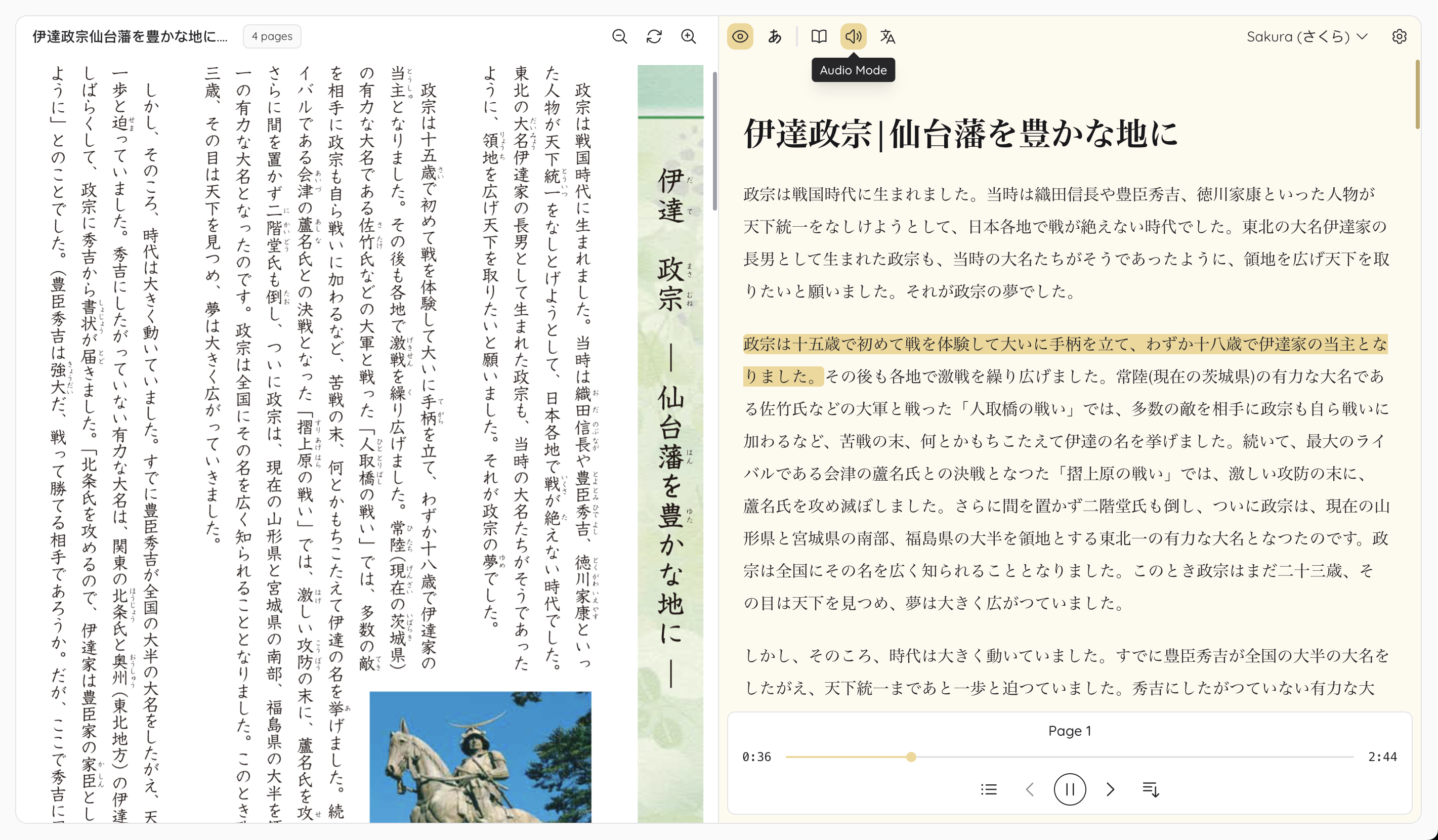
一句话介绍:Mooon是一款一站式日语文档处理引擎,通过自动化排版优化、注音、翻译及有声书生成等功能,解决了日语学习者和研究者在阅读、处理日文文献时流程繁琐、理解困难的痛点。
Productivity
Novels
Artificial Intelligence
日语文档处理
文本转语音
光学字符识别
语言学习工具
学术研究辅助
文档自动化
格式转换
日本文化
生产力工具
用户评论摘要:用户普遍认可其核心价值,特别是自动注音和竖排转横排功能。主要问题与建议集中在:是否支持方言音调的有声书、未来会否支持其他CJK语言、技术架构是本地还是云端处理,以及是否支持Kindle格式转换。开发者对部分问题进行了回复。
AI 锐评
Mooon的“一站式”定位,精准切入了一个被主流生产力工具长期忽视的垂直缝隙——日语文档的深度预处理。它的真正价值并非单一技术创新,而在于将OCR、布局分析、语义理解(注音)、翻译、语音合成等多个复杂环节,整合成一个连贯、自动化的“管道”。这本质上是在售卖一种“认知减负”服务,尤其针对中级日语学习者和需要处理日文学术文献的研究者,将他们从频繁切换工具、手动查词、调整版式的碎片化劳作中解放出来,保障了阅读与研究的“心流”体验。
从评论看,其商业潜力可能超出语言学习范畴,已触及企业级应用的边缘(如合同审阅流程)。然而,其深层挑战也由此浮现:首先,作为重度依赖云端处理的服务,其数据安全与隐私性将是专业用户的核心关切;其次,“一站式”意味着在各个环节都需维持高精度(如专业文献的OCR和注音准确性),任何一环的短板都会放大用户体验的瑕疵;最后,其商业模式面临拷问——是持续深耕日语这一垂直市场,建立极高壁垒,还是如用户所问,横向扩展至中文、韩语,成为泛CJK文档处理平台?后者市场更广,但竞争也更激烈,且每种语言的处理都有其独特难点,扩张并非简单复制。
总体而言,Mooon展现了对特定用户群体工作流的深刻洞察,其产品思路值得肯定。但它能否从一个“好用的小众工具”成长为可持续的业务,取决于其技术深度、对数据隐私的解决方案,以及清晰且克制的市场扩张战略。
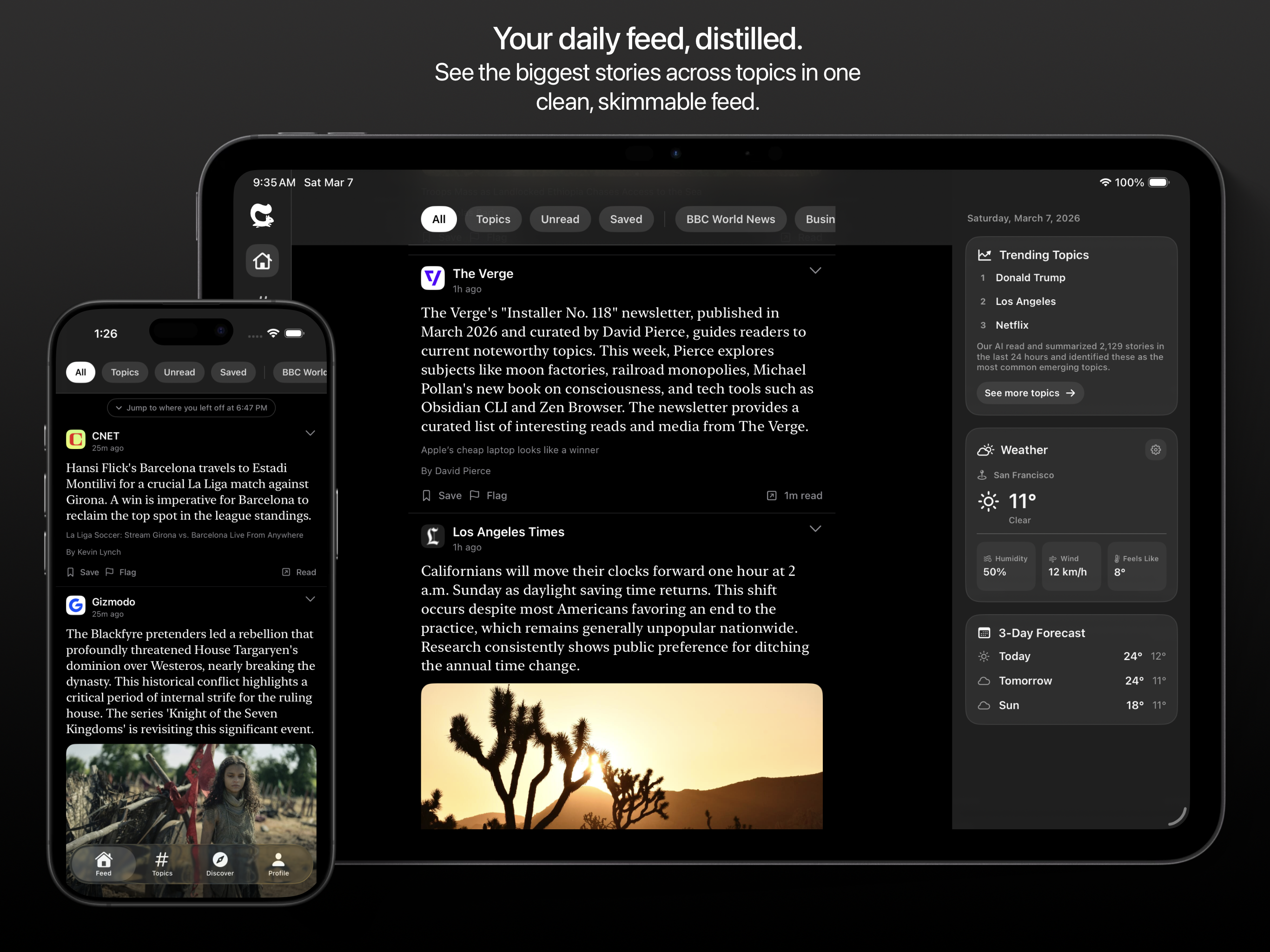
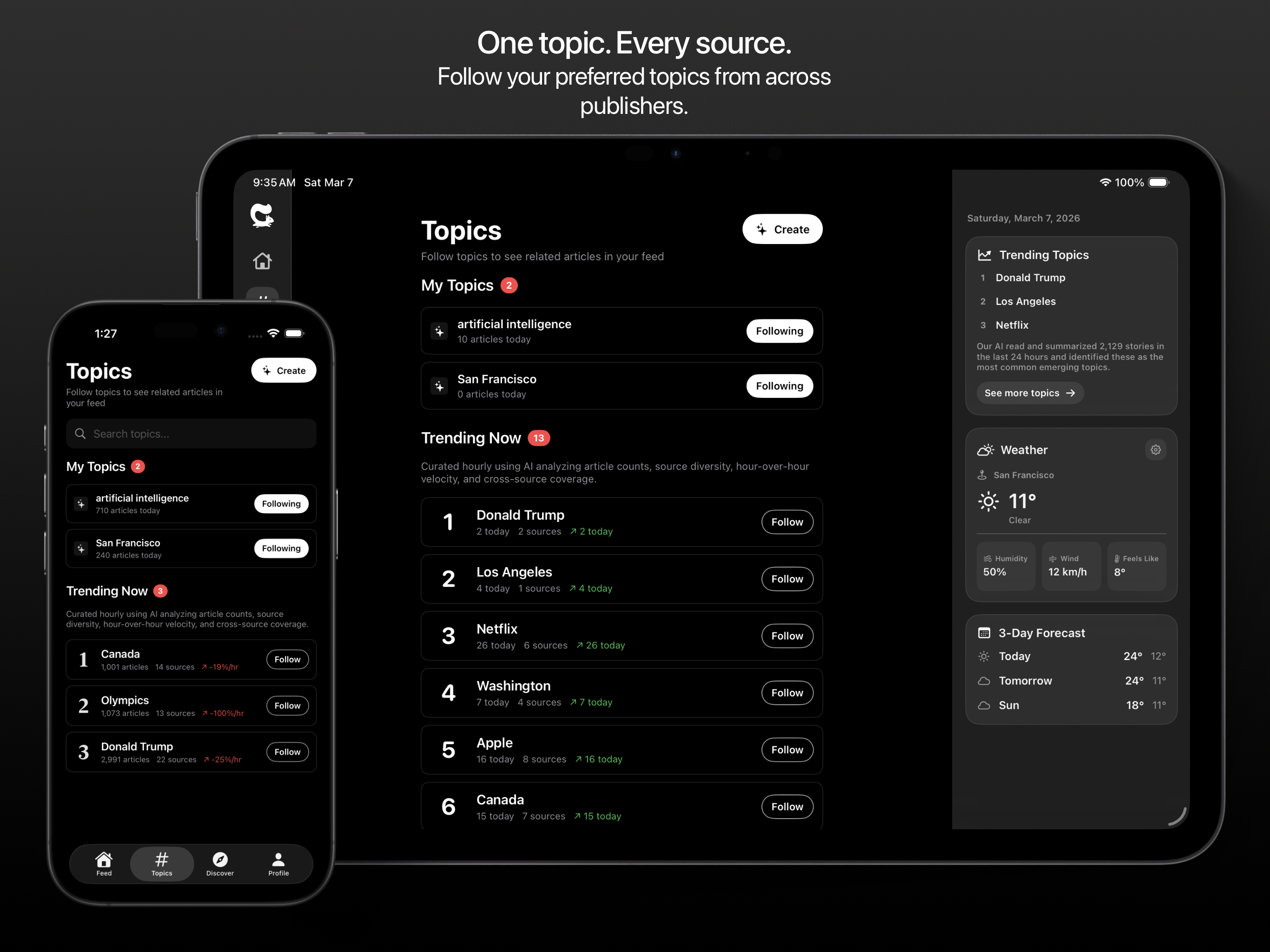
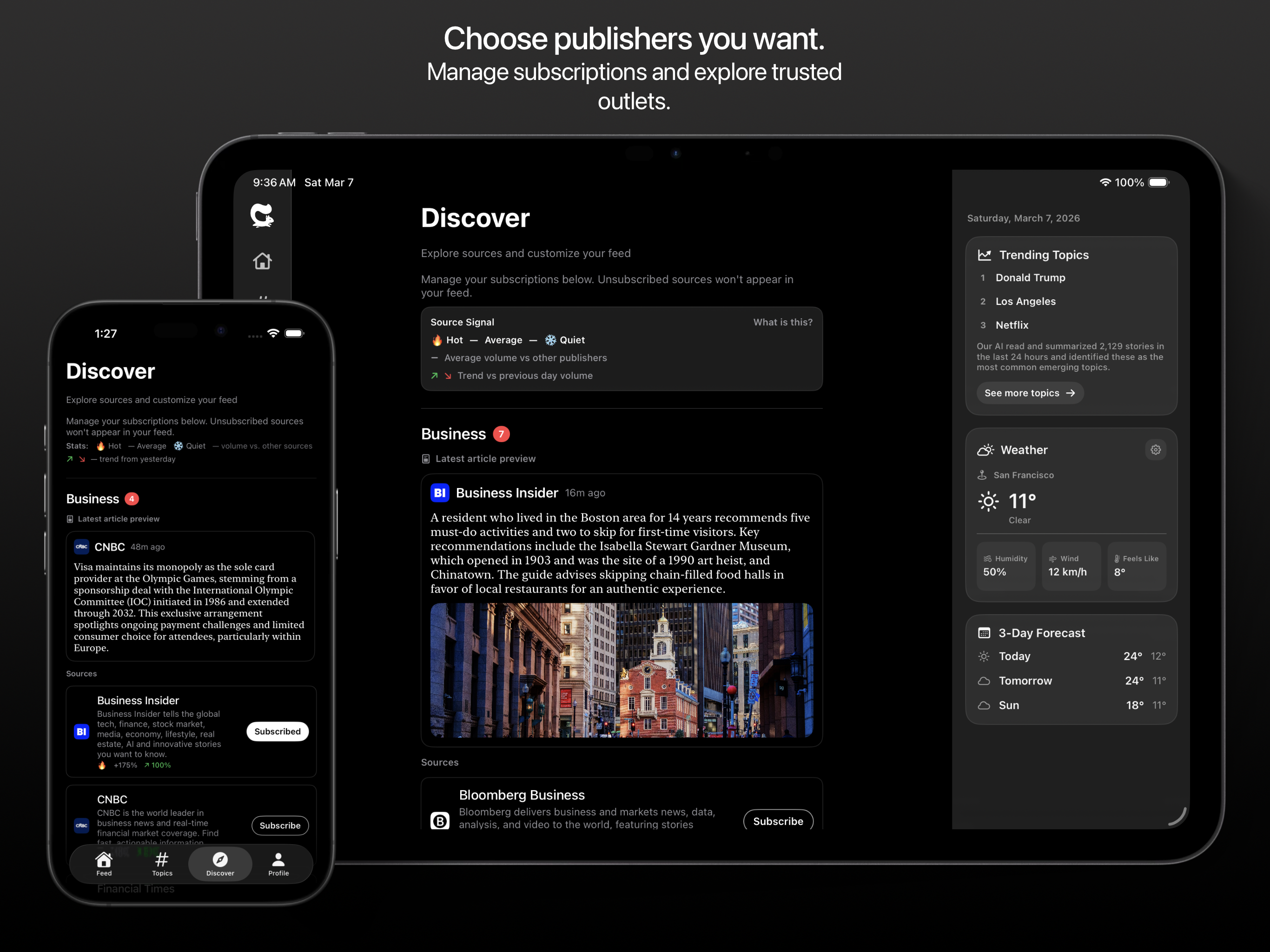
一句话介绍:Nutgrafe是一款新闻摘要应用,通过将长篇文章压缩成一个清晰段落,帮助用户在信息过载和碎片化阅读场景下,快速获取事件核心事实与背景,从而高效“了解发生了什么”并决定是否深入阅读。
iOS
News
Artificial Intelligence
新闻摘要
AI摘要工具
信息精简
效率阅读
内容聚合
媒体订阅
免费工具
移动应用
反信息过载
源站导流
用户评论摘要:用户普遍赞赏其“回归新闻本质”的简洁理念、强制性的摘要长度约束以及坚持链接原文、尊重版权的设计。核心反馈包括:认可其对抗“末日刷屏”和算法推荐的价值;询问是否支持主题日报和更多信源(如社交媒体);建议增加个性化功能。创始人回复确认已添加每日邮件简报,并正在探索主题摘要。
AI 锐评
Nutgrafe的聪明之处在于,它精准地切割出了一个被主流信息流平台忽视的细分需求:不是“推荐你可能感兴趣的”,而是“高效告诉你世界上发生了什么”。其产品哲学带有强烈的“复古”色彩,旨在复现2015年前后Twitter作为实时新闻源的简洁体验,这恰恰击中了当下用户对算法投喂、情绪化内容和无尽对话的疲惫感。
产品的核心价值并非其AI摘要技术本身(这已是红海),而在于其一系列克制的设计选择所构建的独特立场:400字符的硬性约束强制提炼“事实核心”与“为何重要”,而非重述;明确不绕过付费墙、不重建全文,并坚持链接回原始出处,这在伦理上规避了版权风险,在商业上将自己定位为流量分发渠道而非内容终点站,巧妙地与出版商形成了潜在共生而非竞争关系。
然而,其面临的挑战同样清晰。首先,“无算法个性化”的定位是一把双刃剑,在赢得早期注重隐私和主动性的用户的同时,也可能限制其用户规模的扩张速度,因为大众市场已习惯被“喂养”。其次,其商业模式尚未明晰,当前“完全免费”的策略在长期运维成本下能否持续存疑。未来是走向B端媒体合作、高级功能订阅,还是其他路径,需要尽快验证。最后,摘要的准确性与客观性完全依赖模型对公开RSS数据的理解,在缺乏人工审核的“黑盒”下,面对复杂、争议性事件的报道,能否始终保持“核心事实”的准确提炼,将是其可信度的终极考验。
本质上,Nutgrafe贩卖的是一种“信息节食”方案和一种“掌控感”。它未必能成为大众爆款,但很可能在追求效率、厌恶噪音的专业人士和深度新闻读者中占据一席之地,成为一个清爽、可信的新闻“前哨站”。它的成功将取决于能否在扩张信源、保持摘要质量、探索可持续模式这三者间取得平衡,并坚守其“帮助理解,然后离开”的初心。
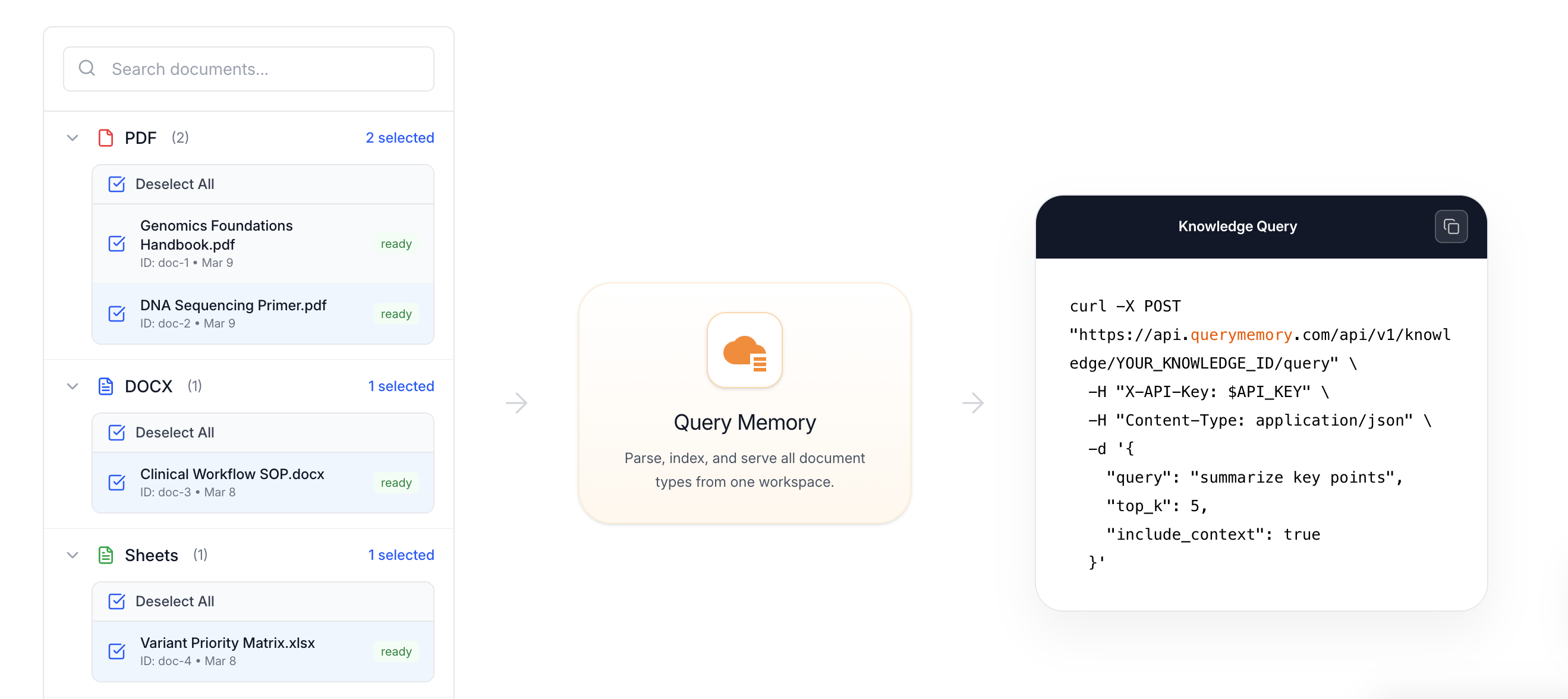
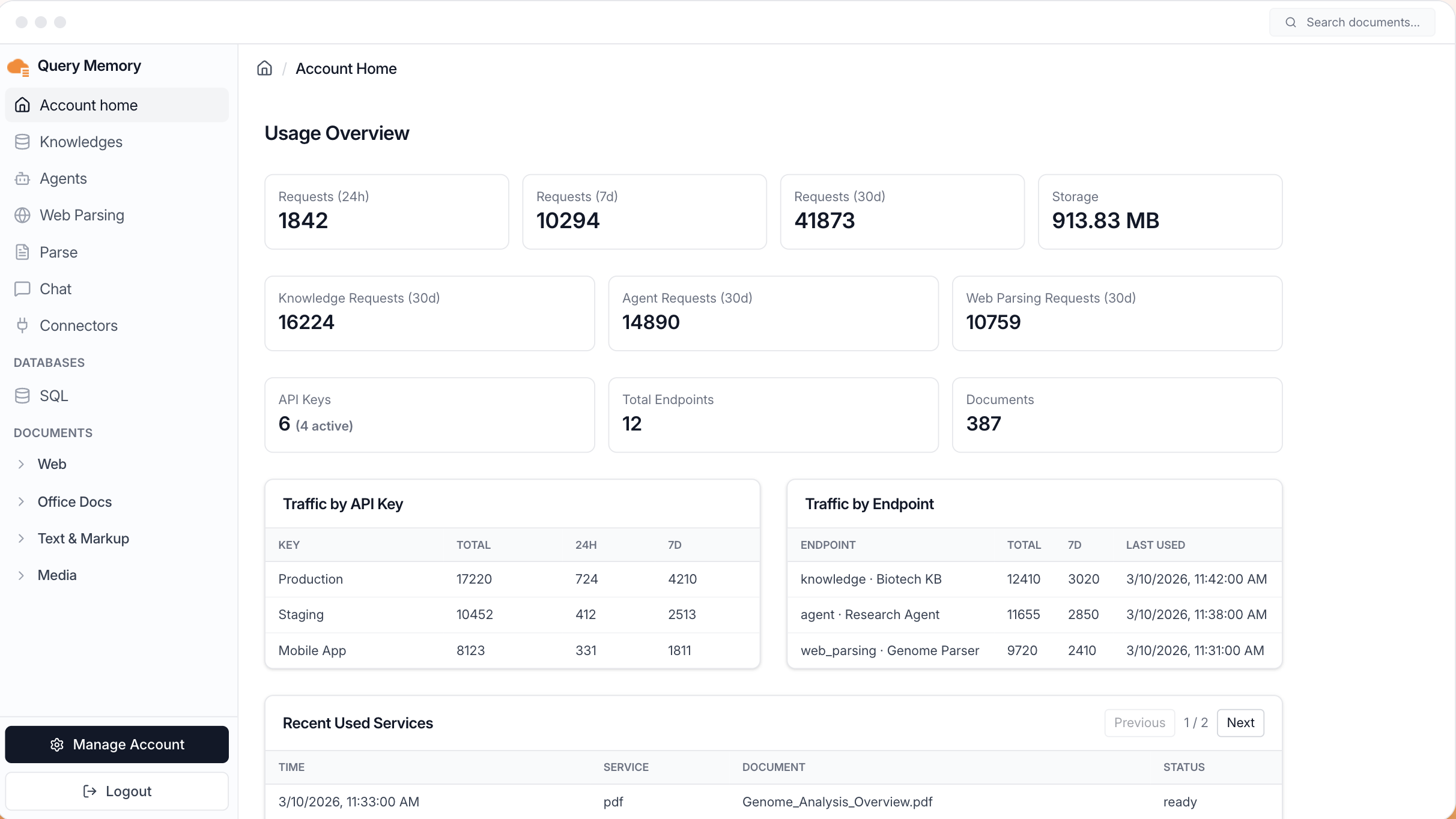
一句话介绍:Query Memory 通过单一API将文档、网页和文件转化为AI智能体可即时查询的知识库,解决了开发者在构建AI代理时,搭建和管理复杂RAG(检索增强生成)基础设施的工程痛点。
Developer Tools
Artificial Intelligence
Database
AI智能体开发
RAG即服务
知识库管理
文档解析
向量检索
API集成
开发工具
AI基础设施
数据管道抽象
无服务器AI
用户评论摘要:用户普遍认可其解决了RAG管道从头搭建的耗时痛点,认为API抽象是正确方向。主要有效提问集中于文档更新后的索引同步机制,开发者回复称部分数据源可自动同步,部分需手动处理。
AI 锐评
Query Memory 瞄准了一个正在剧烈膨胀的“缝隙市场”:AI智能体浪潮下的基础设施简化。其价值不在于技术突破,而在于精准的工程化封装。它将RAG流程中那些肮脏、繁琐且重复的“体力活”——解析、分块、嵌入、检索——打包成一个黑盒API,本质上是在售卖“开发者时间”。
产品逻辑犀利之处在于,它抓住了当前AI应用开发的一个核心矛盾:模型能力迭代飞快,但让模型可靠地“知晓”私有数据却仍停留在手工作坊阶段。无数团队在重复造轮子,从ChromaDB到自定义分块策略,消耗着本应用于业务逻辑的工程资源。Query Memory试图成为这个领域的“Stripe for RAG”——通过标准化接口降低复杂系统的接入门槛。
然而,其真正的挑战与价值天花板也在于此。首先,“一刀切”的封装在追求灵活性的开发者眼中可能成为黑盒桎梏,复杂的定制化需求如何处理?其次,文档同步问题已由用户提出,这触及了数据新鲜度的核心,暴露出在“全自动”承诺背后的条件限制。最后,其商业模式将直接与云厂商的同类服务(如AWS Bedrock Knowledge Base)以及开源解决方案竞争,优势必须体现在极致的开发体验、成本或性能上。
当前产品形态更像是一个便捷的“起点”,但能否从工具演化为平台,取决于它能否在简化流程的同时,为高级用户提供足够的控制力和可观测性,并在数据安全与合规层面建立坚实信任。它不是在发明新东西,而是在为AI时代的“数据连接”铺设最后一段标准化管道,这条路正确,但注定拥挤。
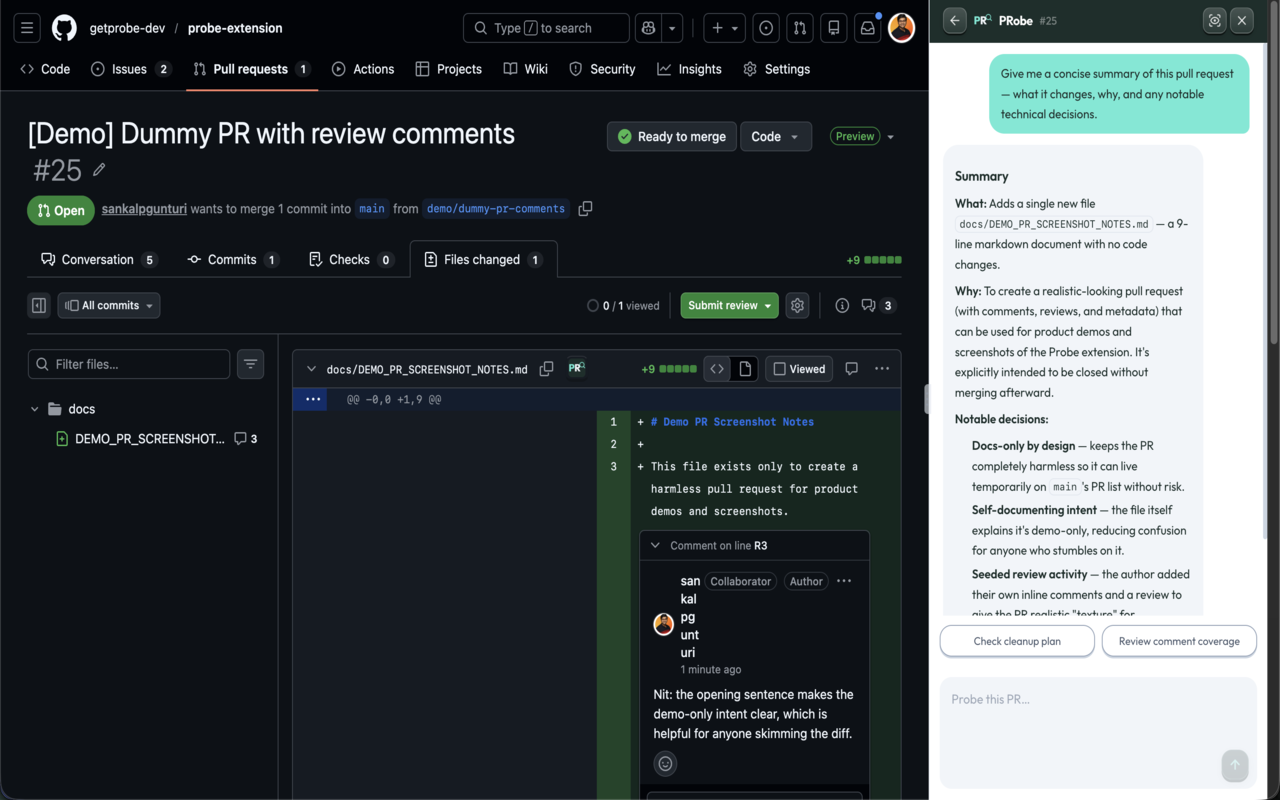
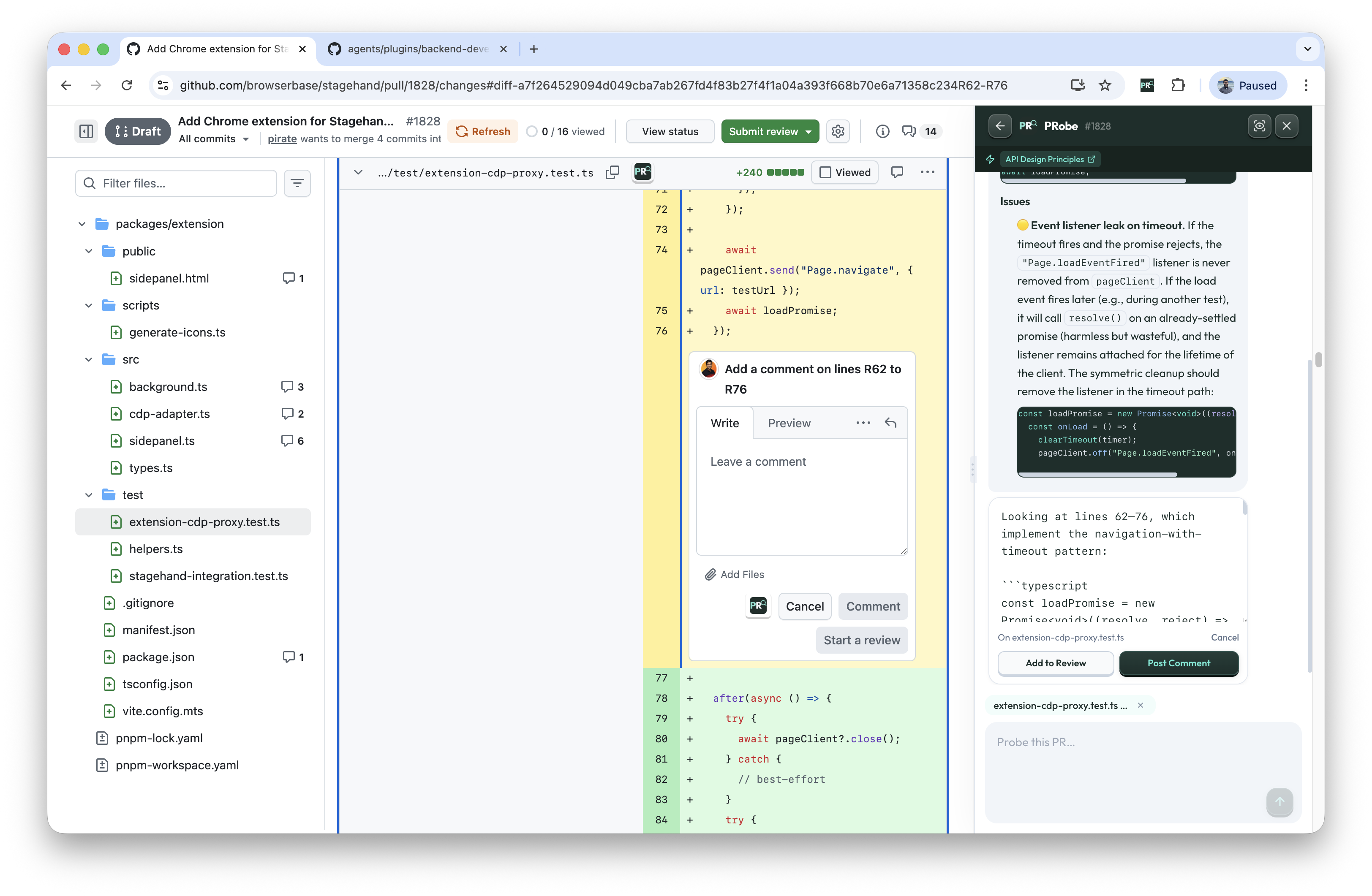
一句话介绍:PRobe是一款免费开源的AI代码审查助手,直接嵌入GitHub Pull Request界面,通过对话式交互帮助开发者快速理解代码变更、定位问题并生成审查意见,旨在缓解人工审查海量代码(尤其是AI生成代码)的沉重负担。
Chrome Extensions
Open Source
Developer Tools
GitHub
AI代码审查
GitHub集成
开源工具
开发者生产力
对话式交互
代码审查自动化
上下文感知
技术栈适配
人工审查辅助
Pull Request工具
用户评论摘要:主要反馈来自创始人,揭示了工具源于个人痛点:在AI生成代码泛滥的背景下,人工审查者需承担“读懂言外之意”的深层上下文审查工作。PRobe旨在用AI审查AI代码,通过加载技术栈特定技能文件提供精准建议,其免费、开源、可透视提示词的设计受到关注。
AI 锐评
PRobe的亮相,远不止是又一个“AI+代码”工具的简单堆砌,它精准刺中了当前软件开发流程中一个正在剧烈膨胀的痛点:AI编码能力普及后,审查工作正从“优化与纠错”向“理解与把关”进行范式转移。其核心价值不在于替代人类,而在于武装人类——将审查者从繁琐的语法、常见错误筛查中解放出来,聚焦于更高维度的设计逻辑、业务一致性与安全边界等“上下文”问题。
产品设计的犀利之处有三点:一是“对话式审查”的交互模式,将被动阅读转为主动质询,符合人类理解复杂变更的自然认知流程;二是“技术栈技能文件”的引入,试图让通用大模型具备领域专家的视角,这比单纯喂入代码差异更具针对性;三是“X-Ray模式”所代表的透明性,在AI决策常被视为黑盒的当下,满足了专业开发者对过程可控性的根本需求。
然而,其真正的挑战与价值天花板也在于此。首先,“技能文件”的质量与覆盖度将直接决定工具的专业性上限,这需要一个活跃的开源社区持续维护,而非单点突破。其次,工具将审查效率提升后,可能进一步加剧“审查瓶颈”效应——更快的初审是否会带来更庞大的PR提交量?最后,也是最关键的一点,它能否真正理解“业务上下文”而不仅是“代码规范”?这决定了它是停留在“高级语法检查器”,还是能成为值得信赖的“审查伙伴”。PRobe的方向无疑是正确的,它标志着开发工具正从“代码生成”的狂热,转向“代码治理”的深水区。
一句话介绍:Fermeon是一款Chrome扩展,通过一键保存对话并自动注入到任何AI平台,解决了用户在切换不同AI工具(如ChatGPT、Claude、Gemini)时需要反复重新解释上下文、复制粘贴的痛点,实现了跨平台的个人化AI记忆层。
Chrome Extensions
Productivity
Artificial Intelligence
AI生产力工具
浏览器扩展
上下文管理
跨平台同步
AI记忆层
工作流优化
知识管理
Chrome插件
AI辅助工具
个人化AI
用户评论摘要:用户普遍认可产品解决了AI工具间切换的上下文丢失痛点。创始人主动寻求反馈,重点问题包括:切换至AI编程工具(如Cursor)时摩擦最大;用户偏好手动快捷键控制而非自动同步;建议下一步支持Cursor和Notion AI。评论指出产品本质是打破AI平台数据围墙的“便携记忆层”。
AI 锐评
Fermeon看似解决的是“AI失忆”的体验问题,实则剑指一个更本质的矛盾:在AI应用爆发的当下,用户数据与对话上下文正被各大平台构筑的“围墙花园”所割裂。产品将用户从重复的“上下文搬运工”角色中解放出来,其真正价值并非技术层面的复杂创新,而是对AI时代数据主权归属的早期基础设施回应。
它敏锐地捕捉到,随着专用化AI工具激增,“上下文切换成本”已取代“模型能力差异”,成为高阶用户的核心效率瓶颈。产品通过轻量级的浏览器扩展形式,试图成为用户与多个AI交互时的统一记忆总线,这本质上是在构建一个跨平台的、用户自主控制的“上下文中间件”。
然而,其挑战同样明显:首先,作为浏览器扩展,其能力边界受限于Web环境,难以深度集成到桌面应用或移动端。其次,“手动保存与注入”的交互设计,在追求全自动化的AI工作流中仍是一种妥协。最关键的是,随着各大AI平台逐步开放API并可能推出自家生态内的同步功能,一个第三方扩展的长期护城河并不牢固。
Fermeon的机遇在于,它目前切入了一个平台巨头无暇顾及或不愿开放的缝隙市场——跨平台、跨厂商的上下文便携。如果它能快速形成用户习惯,积累起独特的“上下文图谱”数据,并逐步从“搬运工”演进为能智能摘要、重组、推荐上下文的“记忆中枢”,或许能在AI Agent生态爆发前,占据一个更具战略性的节点位置。否则,它可能只是一个过渡时期的优雅补丁。
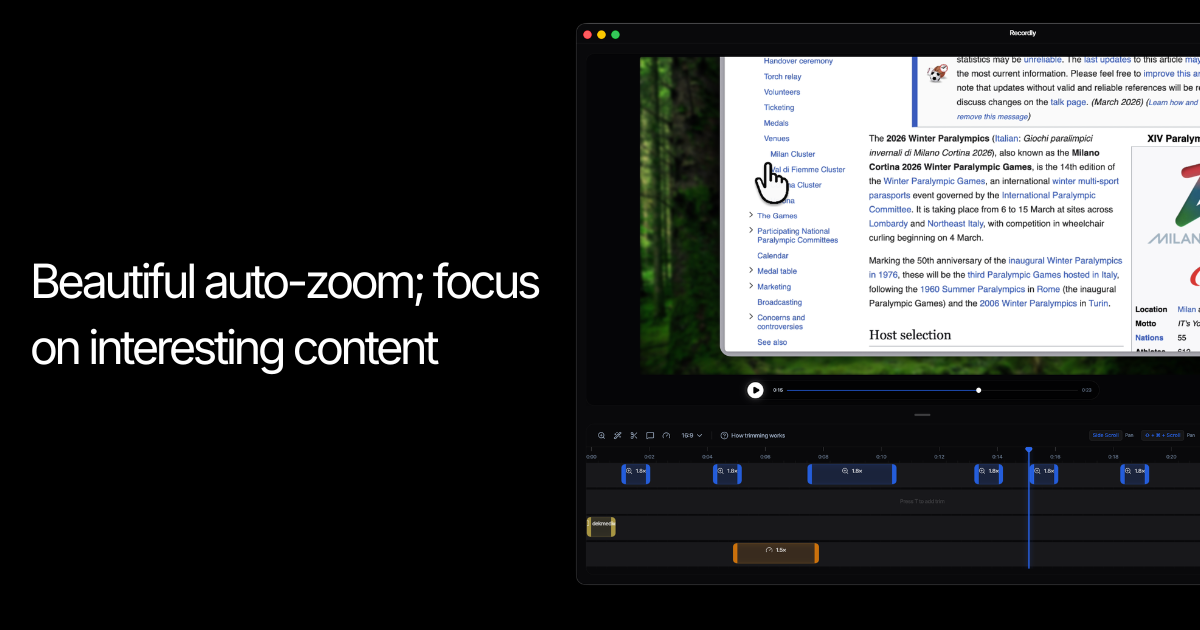
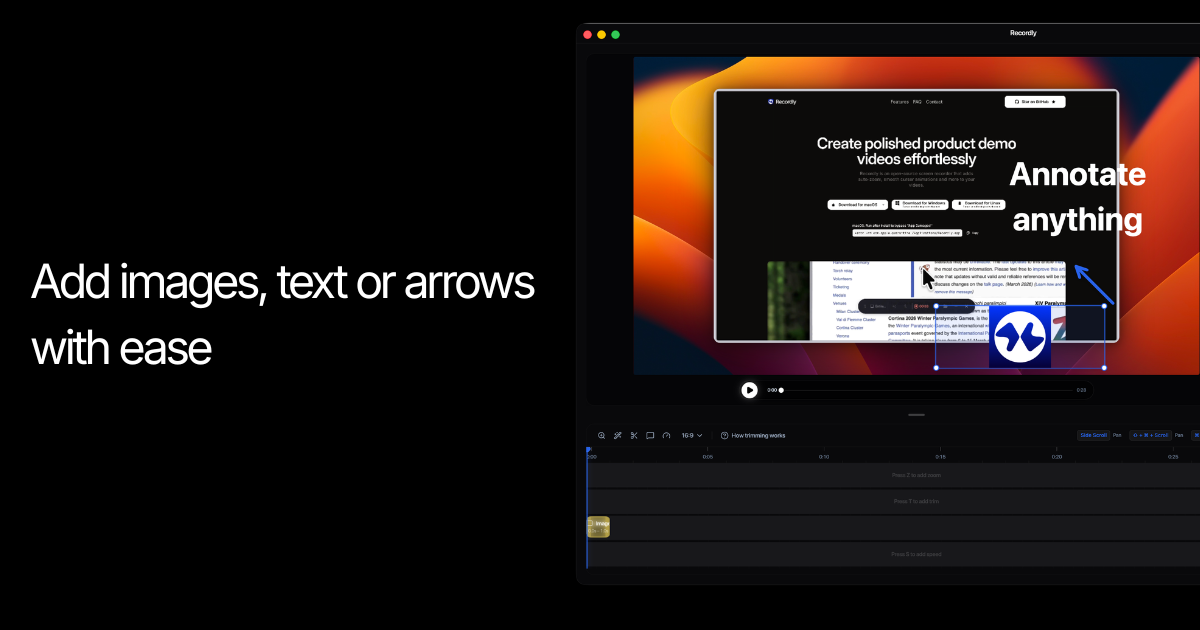
一句话介绍:Recordly是一款免费开源的屏幕录制软件,通过自动变焦、光标动画等特效,解决了创作者制作专业级产品演示和教程视频时,工具昂贵、效果生硬的痛点。
Productivity
Marketing
GitHub
Development
屏幕录制
开源软件
视频编辑
自动变焦
光标特效
产品演示
跨平台
免费工具
创作者工具
用户评论摘要:用户高度认可其免费开源、媲美付费软件(Screen Studio)的流畅动画效果和跨平台特性。核心反馈包括:肯定其为独立开发者带来的价值,询问是否支持音频/旁白同步功能(开发者回复已支持),以及收到其他产品平台的入驻邀请。
AI 锐评
Recordly的亮相,与其说是一款新工具,不如说是一次对细分市场定价权的挑战。它精准切入了一个被高价工具(如Screen Studio)定义的“专业演示视频”市场,用开源免费策略直击付费工具的价格壁垒,用“流畅变焦与光标动画”这一核心体验对标行业标杆,意图重新划定“专业”的准入线。
其真正价值在于“开源”与“体验”的组合拳。开源不仅意味着免费,更建立了信任、可审计和可演化的社区基础,这对注重工作流稳定的创作者至关重要。而将“自动变焦”、“光标运动模糊”这些曾属于高端付费软件的视觉糖,下放为免费标配,实质上是在解构“专业效果”的技术神秘感,逼迫整个品类重新思考功能与价格的合理性。
然而,挑战同样明显。作为基于开源项目(OpenScreen)的“实质性修改”版本,其长期维护的可持续性、与上游项目的兼容性,是隐藏在“免费”背后的潜在风险。此外,当前功能聚焦于视觉优化,在音频处理、多轨道剪辑等更深度的创作需求上,与成熟的全功能视频编辑软件仍有差距。它目前是“单一功能极致化”的利刃,而非全能工具箱。
本质上,Recordly代表了一种趋势:通过开源模式,将某个垂直领域的“最佳实践”体验模块化、平民化。它未必能立刻颠覆巨头,但足以在价格敏感且需求明确的创作者群体中撕开一道口子,迫使市场跟随或回应。它的成功与否,将取决于社区能否形成生态,以及它能否从“一个惊艳的功能复刻者”,进化成“一个独特工作流的定义者”。
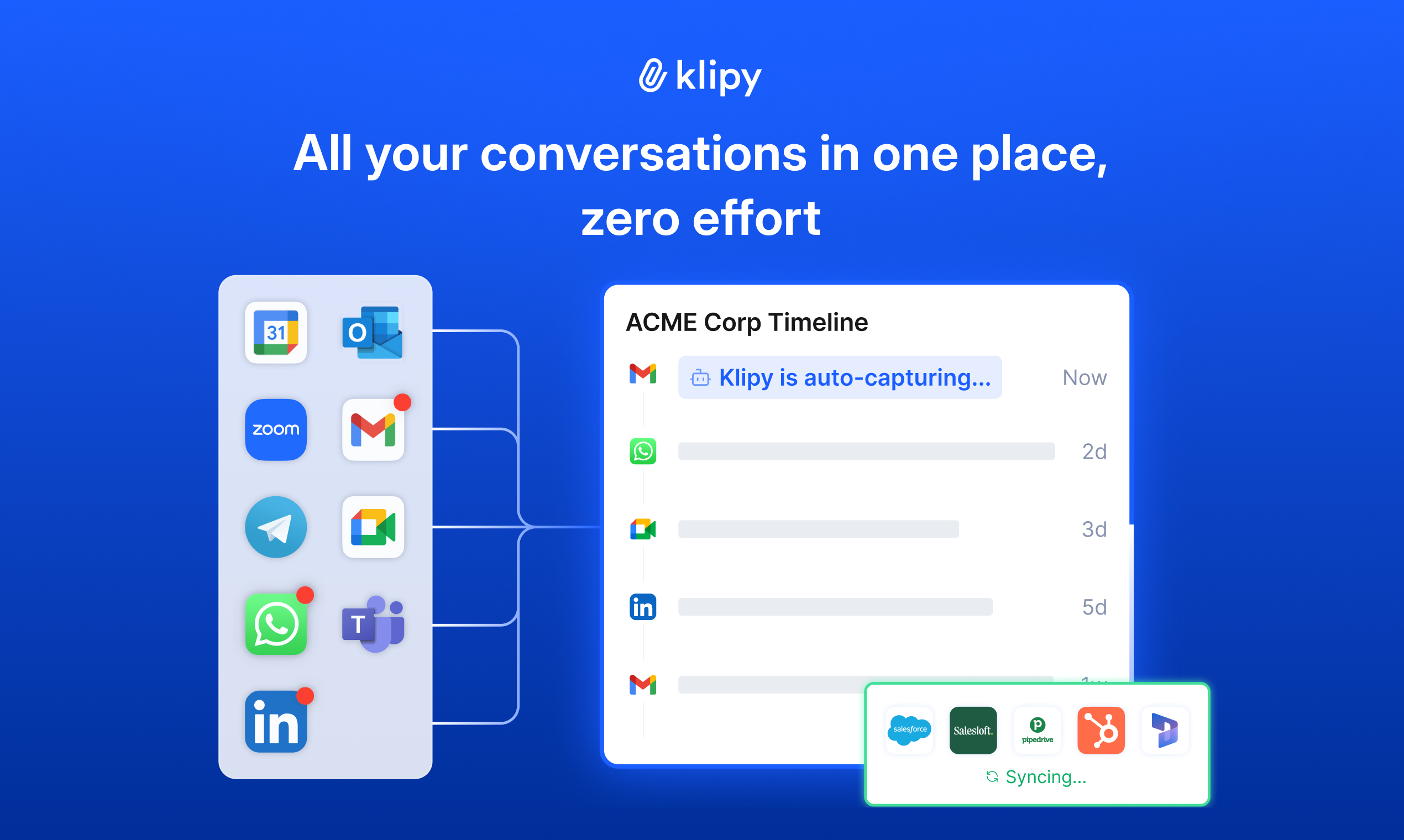
一句话介绍:Klipy是一款AI销售助手,通过自动捕获跨渠道(邮件、WhatsApp、领英、通话)的销售对话、更新CRM并草拟跟进内容,解决了B2B销售人员在多平台沟通中易遗漏跟进、导致商机流失的痛点。
Sales
Artificial Intelligence
AI销售助手
CRM自动化
销售效率工具
跨渠道沟通管理
商机跟进
无手动记录
B2B SaaS
对话智能
销售流程优化
第二大脑
用户评论摘要:用户高度认可其跨渠道(尤其是WhatsApp、LinkedIn DM)自动捕获对话的核心价值,认为其解决了因跟进遗漏导致的“漏单”问题。有用户指出其“统一收件箱”场景和“销售操作系统”定位是强大优势。反馈普遍认为产品减少了行政工作,提升了销售线索的持续动能。
AI 锐评
Klipy切入了一个看似古老却始终未被有效解决的销售管理顽疾:沟通过程数据因手动录入的惰性而大量丢失,导致CRM系统成为充满“盲点”的虚假管道。其真正价值不在于简单的对话记录,而在于试图成为销售人员的“第二大脑”,将碎片化、跨平台的交互强制性地沉淀为结构化、可查询的上下文。
产品聪明地避开了在流量获取(Top-of-Funnel)的红海里与现有巨头竞争,转而聚焦于提升管道内已有商机的转化动量(Deal Momentum)。这是一个更精明、ROI更直接的切入点。它本质上销售的不是工具,而是“被追回的收入”和销售人员的“每日一小时”。用户评论中“因WhatsApp消息遗忘跟进而丢单”的案例,精准印证了其价值主张。
然而,其面临的挑战同样尖锐。首先是数据隐私与安全合规的“达摩克利斯之剑”,尤其是对WhatsApp、Telegram等个人通讯工具的深度集成,在企业级市场可能引发合规性质疑。其次,产品的核心壁垒在于其集成的广度和AI处理对话的深度,这需要持续的技术投入和对各平台API变动的快速响应。最后,它必须避免成为另一个需要被“管理”的工具,其“无感化”的自动记录体验至关重要,任何增加的设置或审核步骤都可能重蹈“因惰性而数据不全”的覆辙。
总体而言,Klipy若能在合规性、稳定性和真正的“无感”体验上做到极致,它有望从一款效率工具演进为销售团队不可或缺的“对话中枢”,重新定义CRM数据的来源与价值。它的成功将不取决于功能多炫,而取决于能否让销售人员彻底忘记“记录”这件事。
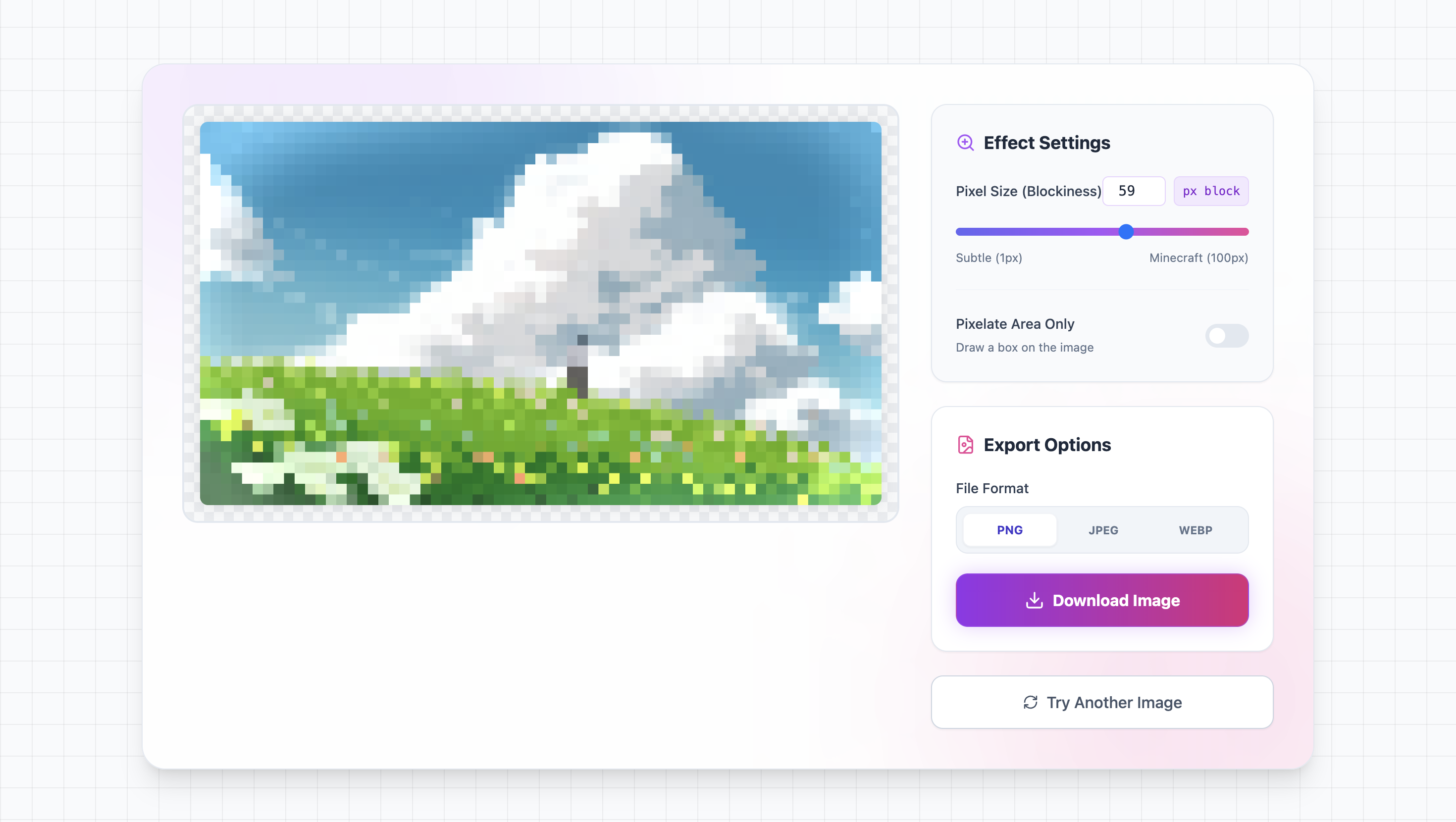
一句话介绍:一款在浏览器内即可免费、快速完成图像像素化处理的在线工具,无需上传,保护隐私,适用于敏感信息模糊(如人脸、车牌)和8比特复古艺术创作场景。
Design Tools
Art
在线图像处理
像素化工具
隐私保护
浏览器应用
免费工具
敏感信息模糊
8比特艺术
无需上传
即时处理
轻量级应用
用户评论摘要:由于提供的评论列表为空,目前无法从用户端获取直接的反馈、问题或改进建议。产品处于初始曝光阶段,需积极收集用户实际使用体验。
AI 锐评
Pixelate Image 精准切入了一个细分但实用的需求缝隙:在隐私意识高涨和复古风潮并存的当下,提供了一种“零负担”的即时解决方案。其核心价值并非技术颠覆,而是对用户体验链条的极致简化——无需注册、无需上传、完全在浏览器本地运行。这“三位一体”的设计,直击了用户对小型在线工具最核心的诉求:怕麻烦、担心隐私泄露、渴望即时反馈。
然而,其发展天花板也清晰可见。首先,功能极度单一,像素化作为一项基础图像处理技术,壁垒极低,极易被集成到更大型的图片编辑应用中,使其独立存在的必要性存疑。其次,“免费”和“完全本地”在吸引初期用户的同时,也几乎堵死了传统的商业模式想象空间,缺乏清晰的盈利路径。最后,从仅有10个投票来看,市场声量微弱,说明其要么尚未找到精准的传播渠道,要么其需求痛点并未强烈到能引发自发传播。
它的真正机会或许在于“场景化深挖”。例如,与匿名举报平台、社交媒体或内容审核流程进行轻量化集成,成为其隐私保护工具链的一环;或者,强化8比特艺术创作的模板和社区属性,从工具转向轻度创意平台。若停留在当前形态,它很可能只是一款“不错的小工具”,用户来时即用,用完即走,难以形成产品护城河与可持续的生态。在工具类应用竞争红海中,仅靠“单一功能”和“隐私安全”已远远不够,必须找到附着其上的高频场景或情感价值,方能避免昙花一现。
一句话介绍:Promptbook是一款AI指令管理系统,帮助开发者、创作者和团队将分散的AI提示词进行结构化整理、版本控制和协作共享,解决提示词难以复用和管理的痛点。
Productivity
Developer Tools
Artificial Intelligence
AI提示词管理
开发者工具
生产力工具
团队协作
知识库
版本控制
SaaS
AI效率工具
用户评论摘要:目前仅有一条来自开发团队的发布评论,无真实用户反馈。团队在评论中阐述了产品灵感来源(提示词像代码需要管理),并主动向社区征集用户当前的提示词存储方式及功能建议。
AI 锐评
Promptbook瞄准了一个真实且正在增长的痛点——随着AI工具深度嵌入工作流,高价值提示词(Prompt)的资产化与管理缺失问题。其核心理念“提示词即代码”颇具洞察力,将软件工程中的版本控制、模块化思想应用于提示词管理,这比简单的笔记收藏夹更契合专业用户的需求。
然而,产品面临双重挑战。其一,市场窗口期有限。当前许多笔记应用(如Notion)、代码库(GitHub)甚至AI平台自身正在快速添加类似功能,Promptbook必须证明其作为独立工具的不可替代性,例如在跨平台集成、智能解析提示词结构、或基于使用的效果评估上建立更深壁垒。其二,用户习惯培养成本高。只有当用户积累的提示词达到一定数量和质量时,管理需求才会变得迫切,这要求产品在早期必须提供极致的轻便上手体验和即时价值(如优质的初始模板库)。
从仅有团队评论的现状看,产品仍处于非常早期的验证阶段。其成功关键在于能否精准切入一个垂直社群(如AI绘画工程师、大语言模型调优师),形成深度工作流依赖,再逐步泛化。否则,它很可能成为一个“听起来很对,但总被顺手用其他工具替代”的优雅解决方案。团队主动在发布时询问用户习惯和需求,是明智的起点,下一步需用最快的速度将收集到的需求转化为差异化功能。
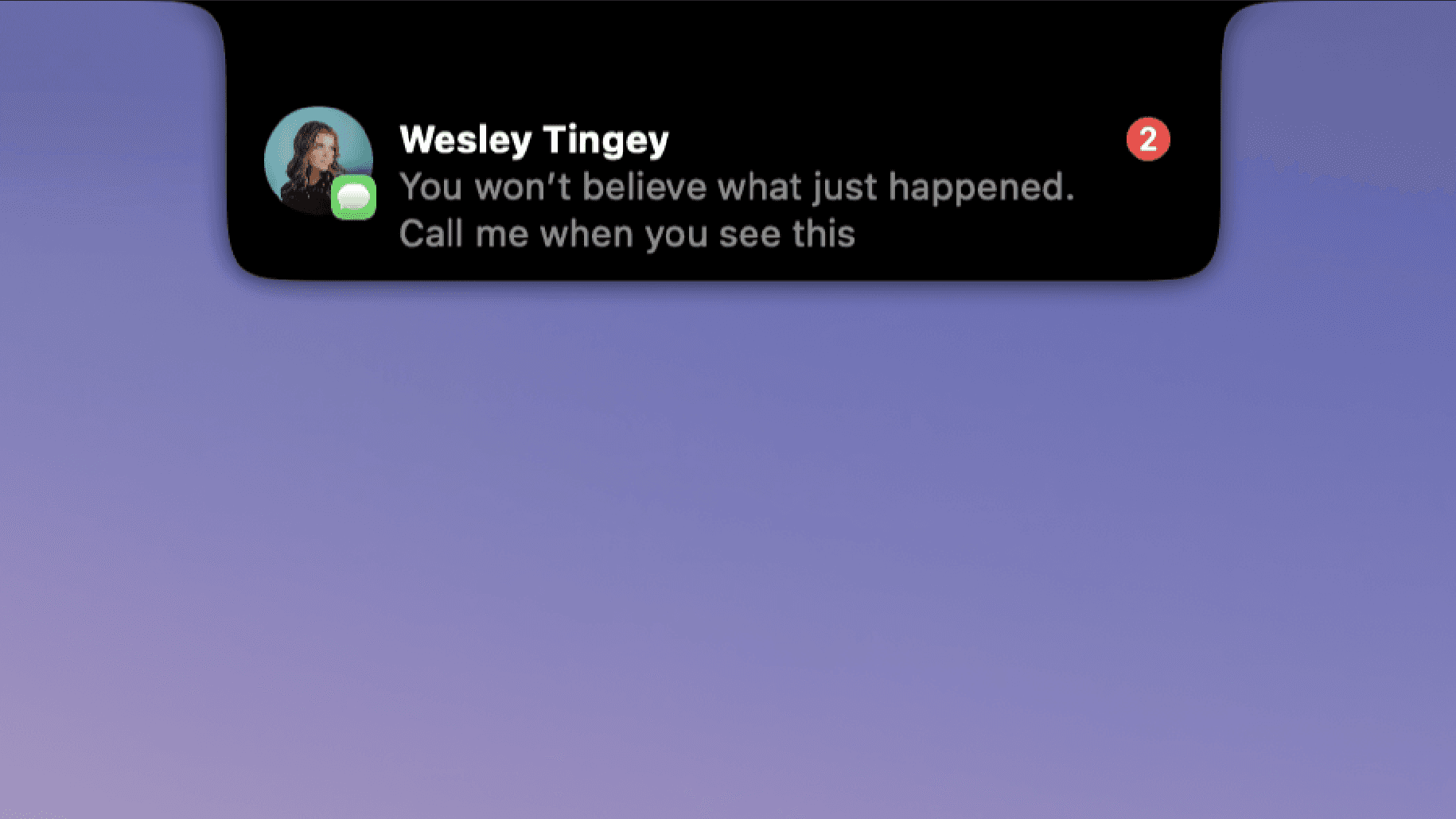
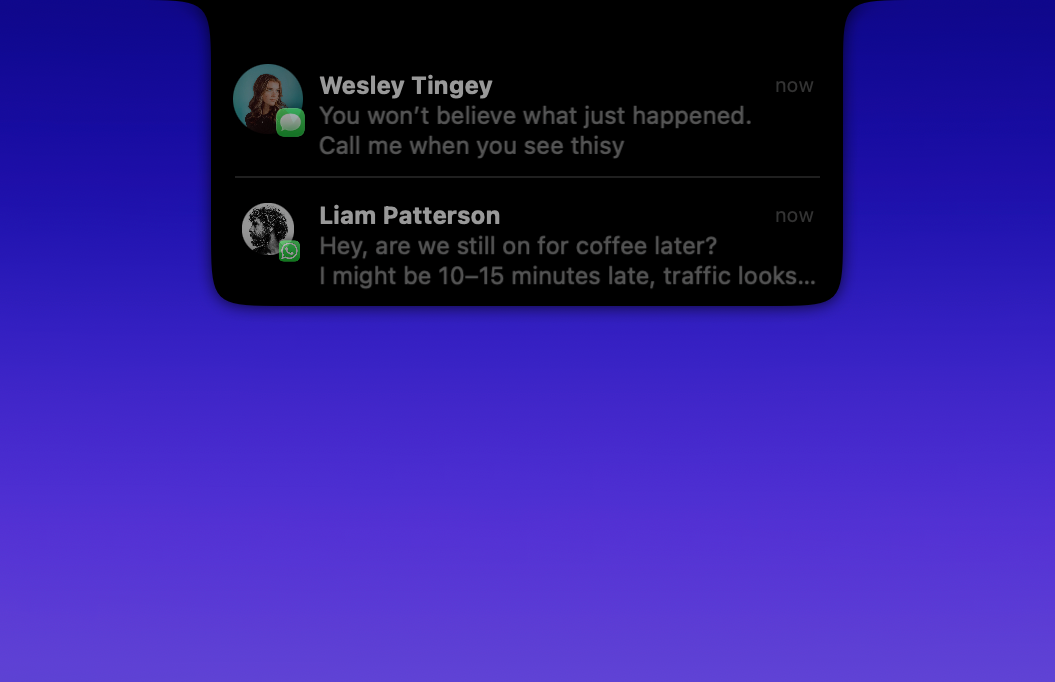
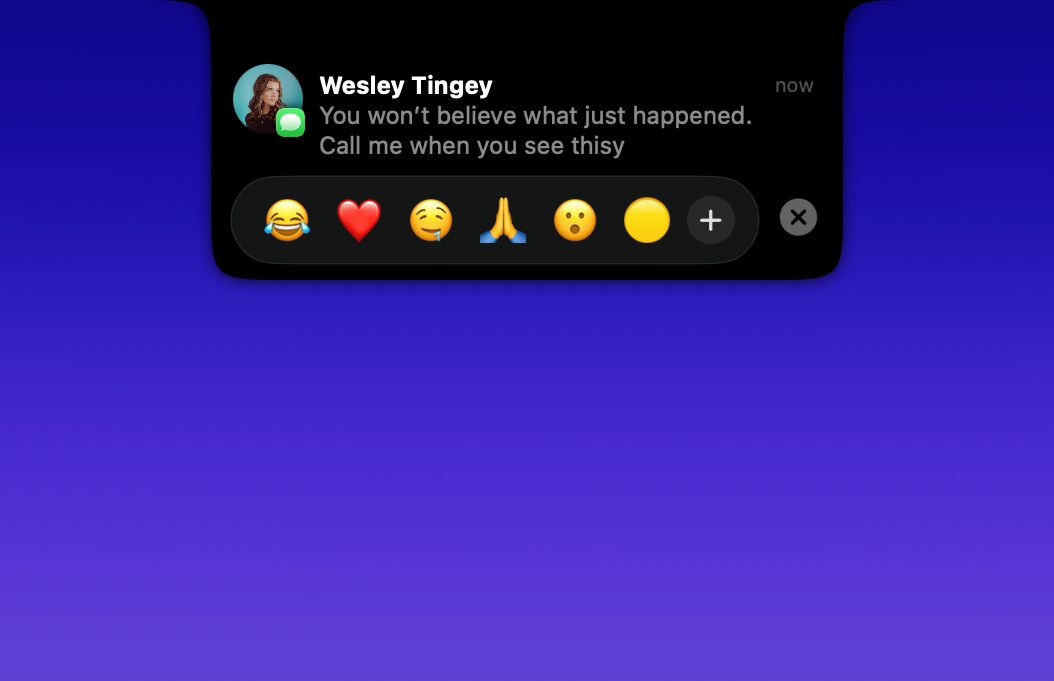











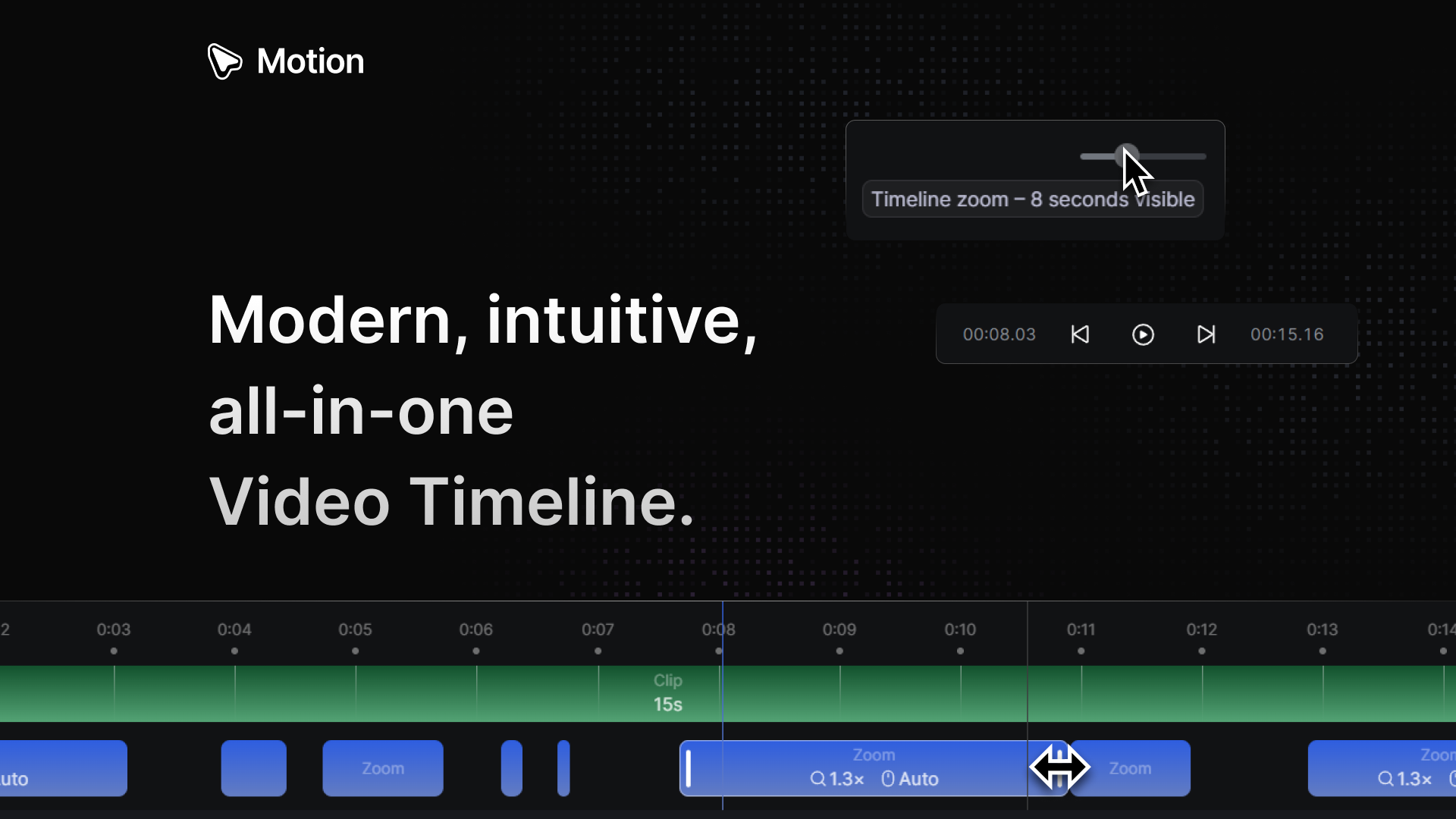
























Bringing Dynamic Island to Mac fills a genuine UX gap — macOS notifications have felt stale for years while iPhone's Dynamic Island became genuinely useful. The multi-app notification support across iMessage, WhatsApp, Telegram, and Slack with inline replies means this could replace the need to constantly check separate apps. How does it handle notification priority when multiple chats fire at once — is there a smart queue or does it stack them?
I’ve had a notched MacBook for a while and never thought about that black bar — until DynamicLake. Now I check my calendar, control music, and see notifications without leaving what I’m doing. The design is clean and doesn’t feel like a third‑party hack. For me it’s one of those “why didn’t this exist before?” tools. If you use a notched Mac every day, it’s worth trying.
Love this. The best products often feel obvious after you see them and bringing a native-feeling Dynamic Island experience to Mac is exactly that kind of idea.
Great tool! Love the Dynamic Island experience on Mac.
As someone who lives in multiple apps all day, I really like the idea of pulling notifications and quick actions into one interactive layer instead of bouncing between windows. The drag-and-drop interactions look especially useful. Curious how you decided which integrations to prioritize first (Slack, WhatsApp, etc.) and whether more app integrations are on the roadmap?
Great idea! Dynamic Island on Mac feels very natural.
How's the performance impact on older MacBooks?
Looks great, congrats on the launch!
Congrats on the launch! I always appreciate it when non-AI products show up these days. 🎉
I just bought the app... but it crashed on every open unfortunately.
"Clean design, love the simplicity. How long did it take to build?"
Love the focus on improving notifications here. Multi-line replies and quick reactions sound really handy to me as well. Maybe filters or smart grouping for notifications could be a nice addition too.
Congrats on the launch
Congrats, looks very clean. Does it work on a monitor?
Porting Dynamic Island to macOS fills a long-standing UX gap. Notification handling on macOS has lagged behind for years, while Dynamic Island on iPhone demonstrated how contextual, interactive notifications can improve workflows. With multi-app support across iMessage, WhatsApp, Telegram, and Slack — plus inline replies — it could significantly reduce context switching. How does the system manage notification priority when multiple chats arrive simultaneously? Is there a smart queuing mechanism or simple stacking?
Is there any way to try your app before I buy it?
Also, what kind of user permissions does this need in order to run properly?
is there a video demo?