PH热榜 | 2026-03-17
一句话介绍:一款将AI智能体从云端部署到本地的桌面应用,通过执行命令行指令直接操作本地文件、工具和应用,解决了用户在文件管理、开发工作流等本地复杂任务中自动化效率低下的痛点。
Productivity
Artificial Intelligence
Tech
本地AI智能体
桌面自动化
工作流自动化
文件管理
无代码开发
命令行工具
远程任务触发
生产力工具
AI代理
人机协作
用户评论摘要:用户普遍认可其本地化AI代理的价值,认为其填补了云端AI与本地工作流的鸿沟。主要关注点集中在:本地执行权限的精细控制与安全信任机制、后台资源消耗、远程触发功能的可靠性(如设备休眠时的队列处理),以及其与Claude Desktop等竞品的差异化。
AI 锐评
Manus的“My Computer”并非简单的又一个AI桌面客户端,其核心价值在于**将AI的“决策权”与操作系统的“执行权”进行了危险而大胆的缝合**。它试图让AI智能体突破“沙盒”的终极限制,从云端的信息处理者,蜕变为本地环境的真实“操盘手”。
这步棋走得既精准又险峻。精准在于,它直击了当前AI应用的阿喀琉斯之踵:真正的生产力沉淀于本地——散乱的文件夹、本地的开发环境、私密的业务数据,这些都是云端AI无法触及的“暗物质”。Manus通过授权AI执行命令行,理论上可以调用计算机的一切能力,实现了自动化维度的降维打击。险峻之处则在于,它将巨大的安全与信任包袱抛给了用户。每一条被执行的命令都可能带来不可逆的后果,评论中反复出现的“权限”、“信任”、“背景运行”等关键词,正是这种集体焦虑的体现。产品成败的关键,将不在于其AI能力有多强,而在于其设计的“安全护栏”和“审批机制”是否足够精细、透明,能让用户放心地将系统级权限下放。
此外,其“远程触发”功能颇具野心,试图将个人计算机变成随时待命的自动化服务器。但这进一步模糊了安全边界,并引出了设备状态管理(如休眠)等工程难题。与Claude Desktop等相比,Manus更偏向于“工程师的自动化伙伴”,强调通过CLI进行复杂构建和批处理,而非轻量的日常问答。它的真正对手或许不是其他AI桌面应用,而是用户根深蒂固的安全习惯和对系统控制权的不舍。它开启的是一场关于“人类应在多大程度上将执行权让渡给AI”的社会实验,其发展将深刻定义下一代人机协作的范式。
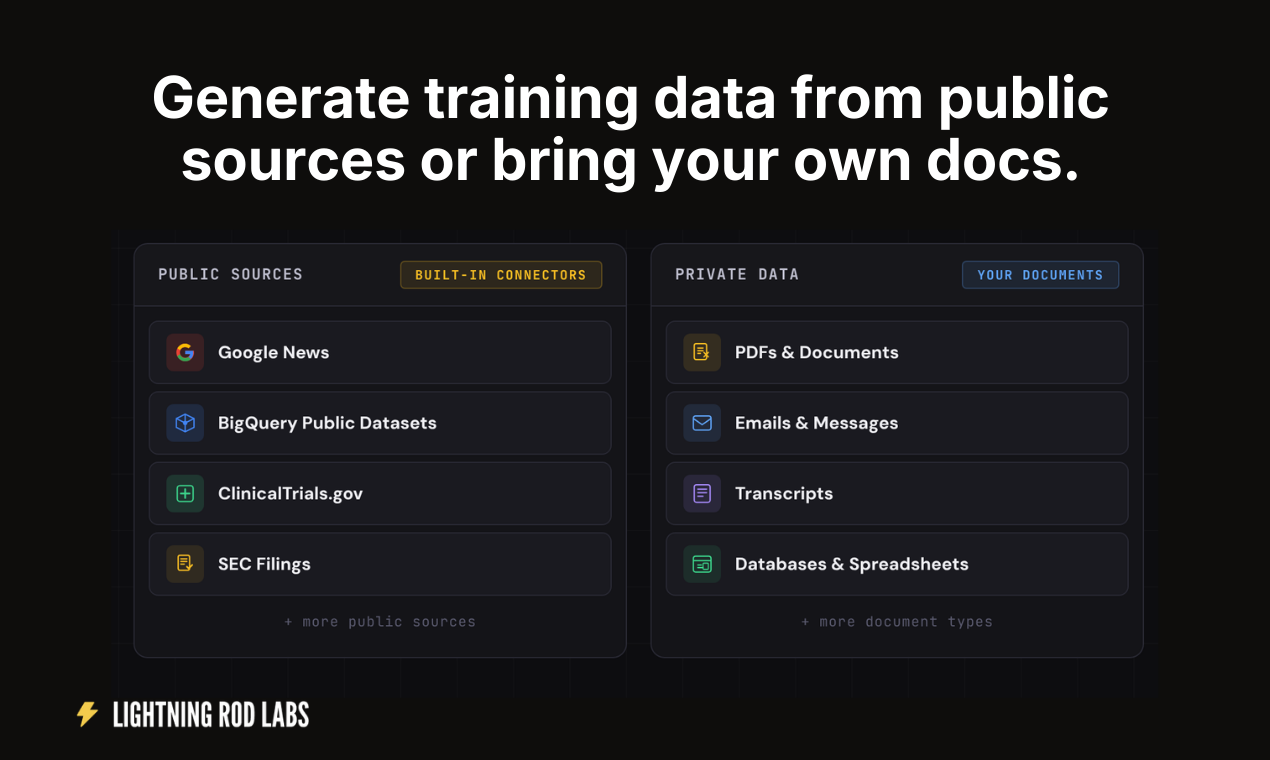
一句话介绍:Lightning Rod 是一款通过SDK和AI代理,将新闻、财报、内部文档等现实世界数据,在无需人工标注的情况下,快速自动转化为可用于大模型微调的高质量训练数据集,解决了AI项目因训练数据准备缓慢、昂贵而受阻的核心瓶颈。
Developer Tools
Artificial Intelligence
训练数据生成
AI数据基础设施
自动化标注
大模型微调
SDK开发工具
无代码AI
数据 provenance
企业AI
预测分析
文档处理
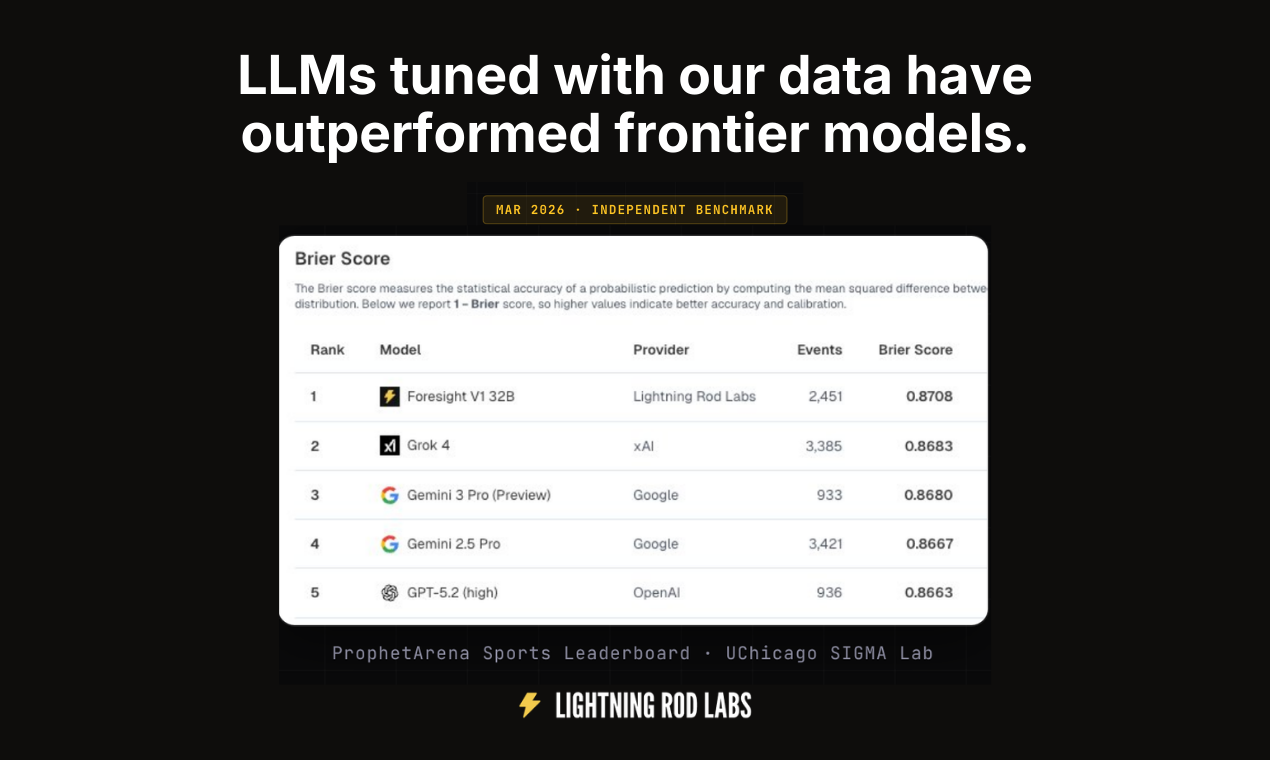
用户评论摘要:用户普遍认可其解决AI训练数据瓶颈的价值,关注点集中在:数据质量保障机制(去重、去噪、防偏)、对私有数据的支持与PII处理、无代码界面可用性、以及其宣称“击败更大规模前沿模型”的基准测试真实性。也有用户对其Logo设计提出版权疑虑。
AI 锐评
Lightning Rod 提出的“用现实世界结果作为监督信号”是一个巧妙且可能具有颠覆性的范式转换。它本质上是在尝试将历史数据流中的“未来已验证的事实”自动化、结构化地反哺给模型,从而绕过昂贵且可能带有人为偏见的人工标注。这并非简单的数据清洗工具,而是一个试图将“世界进程”本身编码为训练集的野心。
其宣称用更小模型击败前沿大模型的案例,是核心卖点,但也最需审视。这高度依赖于其“未来即标签”方法在特定预测性任务上的有效性,以及其质量评分、去重过滤管道的严谨性。对于非时序性、逻辑推理或创意生成类任务,该方法的价值可能大打折扣。评论中关于数据偏见、噪声的担忧切中要害,尽管团队给出了技术回应,但“自动化”与“高质量”之间的固有张力仍是其需要长期自证的命题。
产品形态(SDK+无代码界面)显示其策略是同时俘获工程师与业务团队,切入点是明智的。真正的挑战在于,如何将这套方法论从目前展示较好的预测、分类领域,泛化到更复杂的AI任务场景。如果成功,它可能成为AI数据流水线中的关键“转换器”;若局限在细分领域,则可能是一款优秀的垂类工具。其价值不在于替代所有数据工作,而在于为那些拥有丰富历史数据却苦于无法“消化”的企业,提供了一条高效的启动路径。
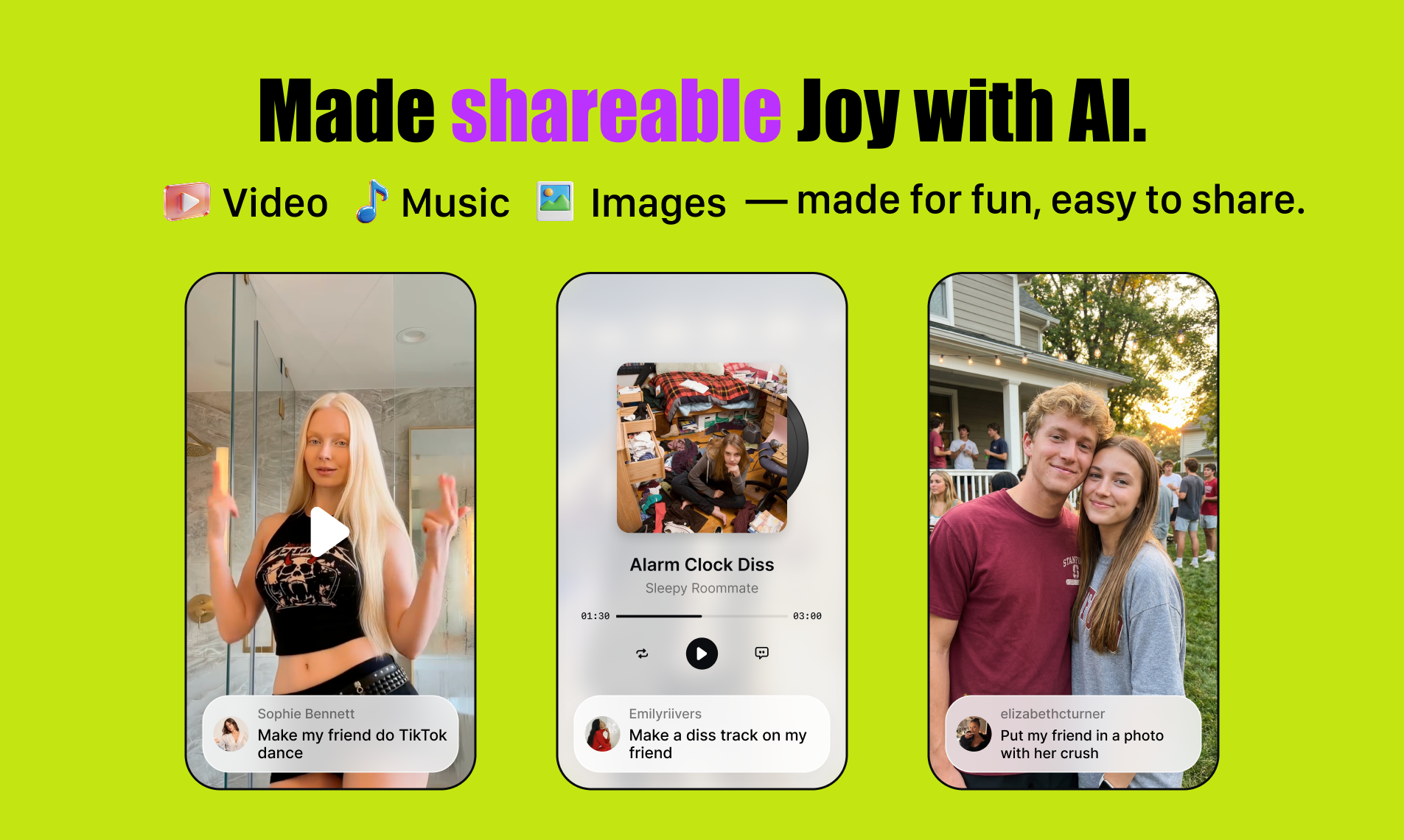
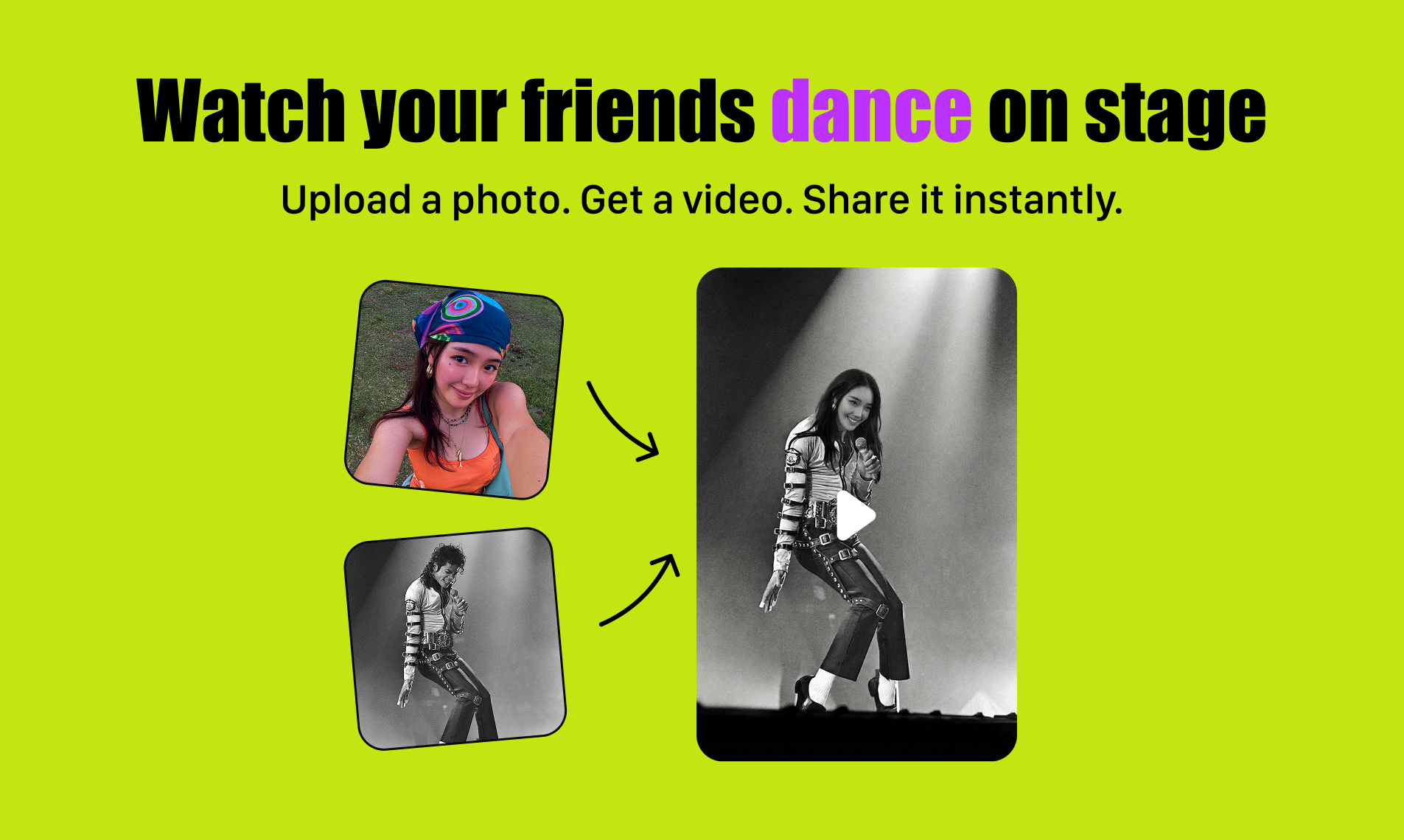
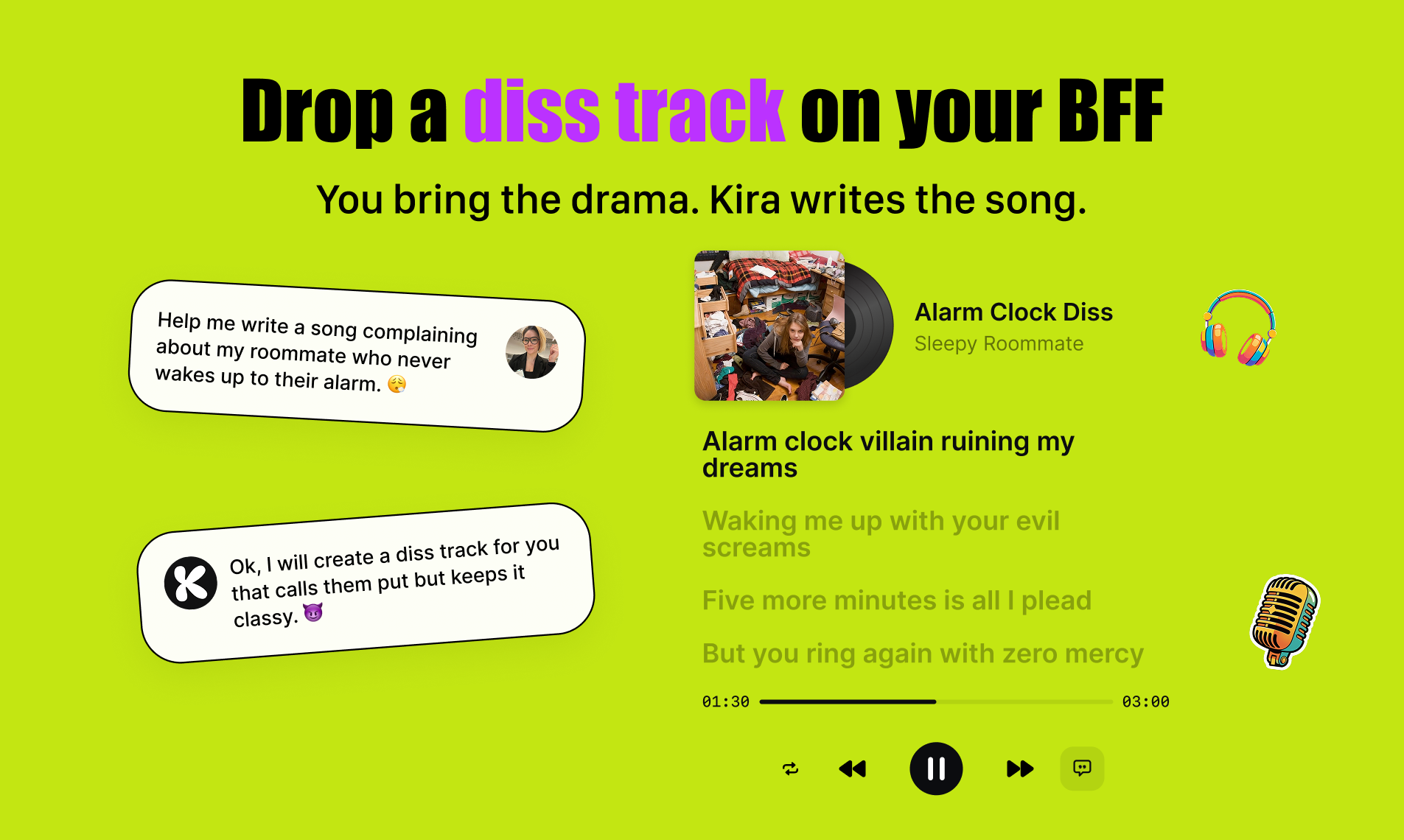
一句话介绍:Kira 4.0是一款浏览器内的零门槛AI创意工具,通过将图片、视频、音乐生成整合于一个简单流程,让用户能快速将朋友的照片制作成恶搞或有趣的动态内容,解决了普通人在社交娱乐中缺乏便捷、有趣的内容创作工具的痛点。
Design Tools
Social Media
Artificial Intelligence
AI创意工具
社交娱乐
零门槛创作
浏览器应用
视频生成
AI音乐
图片编辑
病毒式传播
朋友恶搞
即时分享
用户评论摘要:用户普遍认可其“零门槛”和“病毒式”分享理念。主要问题与建议集中在:视频与音乐能否自动同步;是否支持直接分享至TikTok等平台;如何防止AI滥用(水印政策);免费试用额度及付费墙;以及未来是否支持多图输入、协作功能和社交媒体内容导入。
AI 锐评
Kira 4.0的野心不在于技术颠覆,而在于对“创作民主化”进行一次极致的场景压缩。它将AI图像、视频、音乐三大生成能力粗暴地塞进一个“为朋友制造乐子”的单一场景,其真正的价值是构建了一个极短的“感知-创作-分享”闭环。标语“将朋友变成可分享的内容”精准刺中了社交媒体的原始驱动力:人际互动与身份表演。
产品聪明地回避了与专业工具在质量上的竞争,转而追求“速度”与“情绪价值”。无需提示词、全浏览器操作,本质是将复杂的AIGC工程抽象为一种社交手势,如同一个数字时代的“恶作剧玩具”。然而,这种定位也暗藏风险。其一,娱乐性需求易疲劳,用户新鲜感过后,留存与重复使用可能成为问题,除非能不断孵化出新的病毒模因。其二,伦理红线模糊。尽管团队以默认水印和用户政策回应,但“为朋友制造内容”的模糊边界极易滑向滥用,尤其是目标用户包含青少年时。付费去水印功能更是一把双刃剑,在提升收入的同时可能放大监管风险。
从评论看,用户已不满足于单点炫技,开始期待视频与音乐的智能同步、多图连贯性等更深度的创作能力。这预示着,若想从“趣味玩具”成长为可持续的“创意平台”,Kira必须在降低门槛与提供深度之间找到新的平衡。其成败关键,或许不在于AI生成了什么,而在于它能否让用户感觉自己是一个有趣的灵魂,而非仅仅是一个按钮的点击者。
一句话介绍:Codex Subagents通过支持并行自定义子代理,在复杂编码任务(如多步骤功能开发、PR审查)中解决了因上下文混乱和串行处理导致的效率低下痛点。
Productivity
Artificial Intelligence
Development
AI编程助手
并行计算
智能代理
代码开发
工作流自动化
上下文隔离
TOML配置
多任务处理
软件开发效率
团队协作模拟
用户评论摘要:用户普遍认为功能强大且方向正确,能显著提升复杂任务处理速度。主要问题集中在:子代理间冲突协调机制、与现有插件兼容性,以及开发过程中的技术挑战。
AI 锐评
Codex Subagents表面上是“并行代理”的技术迭代,实则是对AI编程助手本质困境的一次外科手术式打击。其真正价值不在于简单的“多开”,而在于用**架构思维**重构了AI与复杂问题的交互范式——将传统长上下文提示词的“一锅炖”模式,解耦为角色隔离、工具专精的微服务化架构。
这戳中了当前AI编码的核心矛盾:模型能力越强,试图在单一会话中堆叠的需求就越复杂,导致“上下文腐化”成为性能黑洞。Subagents的TOML自定义与角色隔离,本质是引入了**轻量级编排层**,让AI从“万能单兵”转向“可编排的特种小队”。这种思路跳出了单纯追求模型参数的军备竞赛,转向工作流智能的降维打击。
然而,犀利之处亦藏隐忧。其一,并行代理的“合并冲突”问题若仅靠后期简单合并,可能沦为高级版的“复制粘贴混乱”;真正的工程价值需依赖冲突检测与智能决议机制,目前信息未明。其二,此功能将复杂性从提示词工程转移至代理架构设计,对用户的抽象能力提出更高要求,可能形成新的使用门槛。其三,它直接对标Claude Code等竞品,但更像是对传统CI/CD流水线中“人工环节”的进一步侵蚀,其长期冲击可能指向开发流程的更深层重构。
总体而言,这是一个战略意义大于功能更新的动作。它标志着AI编程正从“辅助编码”迈向“协调编码过程”,但能否真正模拟出工程团队的并发智慧,而非制造出并发的混乱,将取决于其冲突治理与编排逻辑的成熟度。
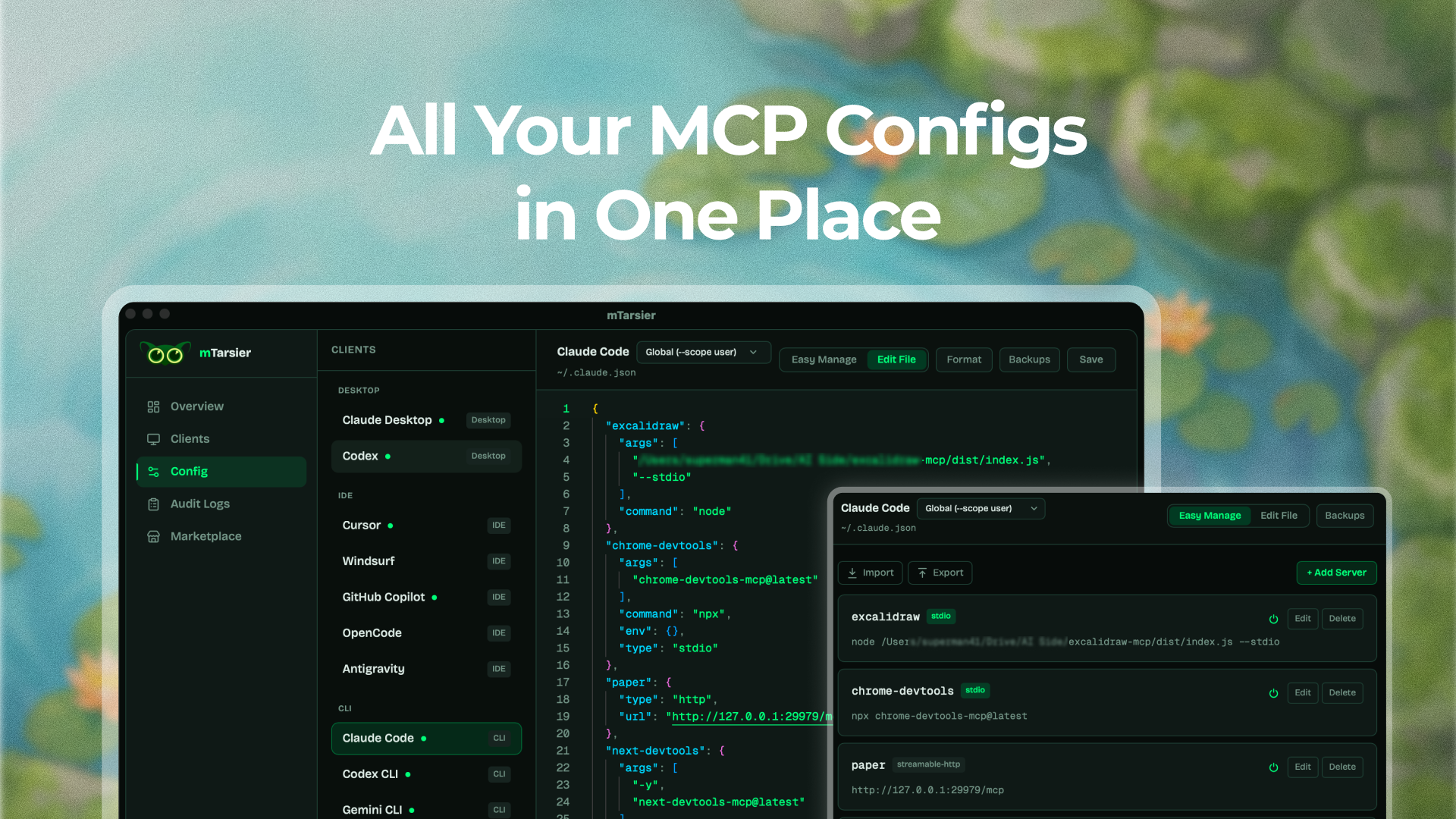
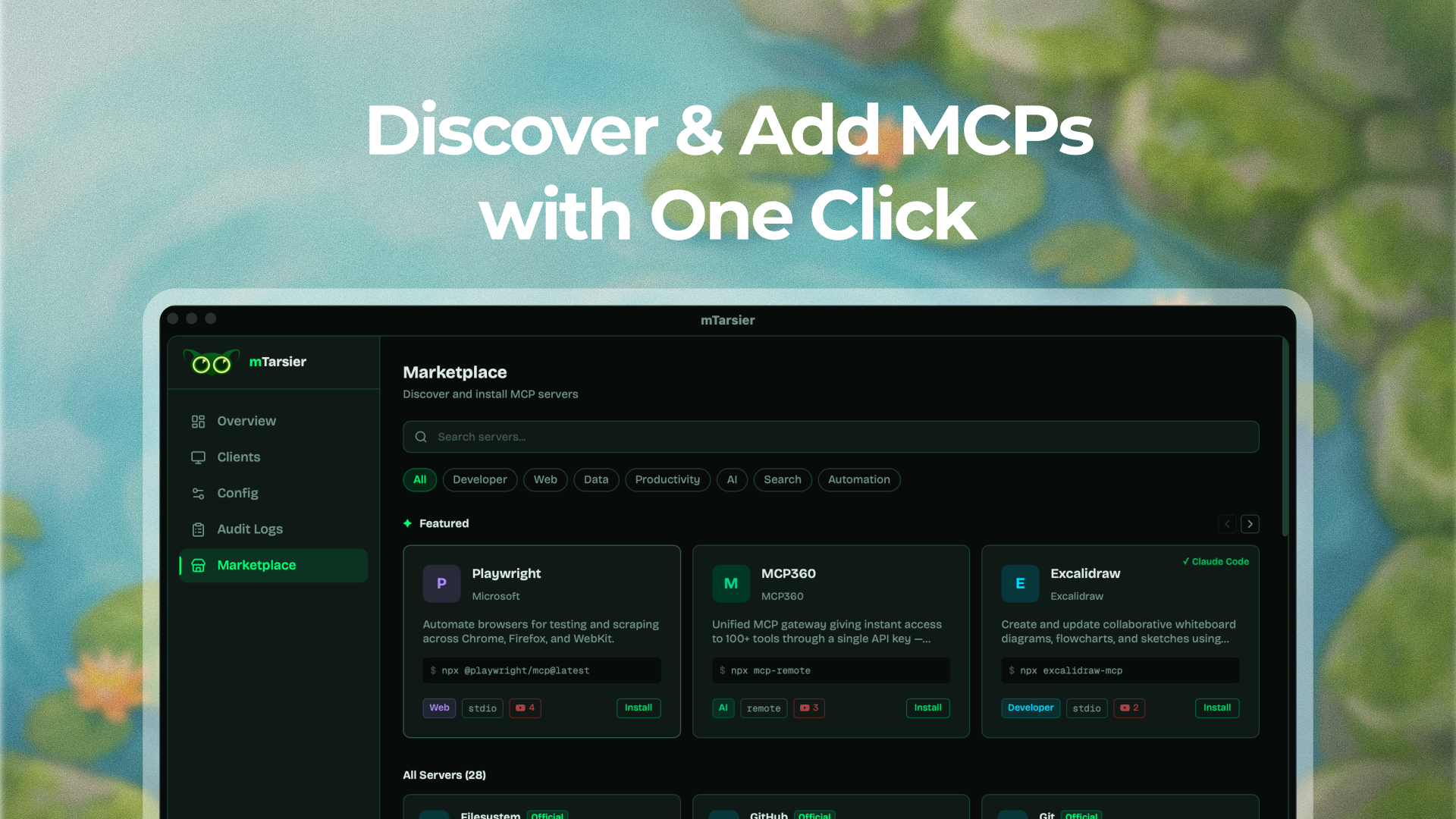
一句话介绍:mTarsier是一款开源桌面应用,通过自动检测并统一管理多个AI客户端(如Claude Desktop、Cursor)的MCP服务器配置,解决了开发者需手动编辑分散的JSON配置文件、配置流程繁琐易错的痛点。
Open Source
Developer Tools
Artificial Intelligence
MCP管理平台
AI工具集成
开源桌面应用
开发者工具
配置同步
模型上下文协议
跨平台
工作流标准化
客户端管理
用户评论摘要:用户高度认可其统一管理、自动检测和一键配置的核心价值,并提出了具体问题:多客户端同步时的冲突解决机制、AI代理自主安装的安全边界、按供应商的认证配置支持、团队权限管理,以及平台集成优先级和信任安全等底层考量。
AI 锐评
mTarsier的出现,精准刺中了MCP协议生态爆发后衍生的“工具链真空”。其价值远不止于一个便利的配置管理器,而在于试图成为MCP生态事实上的“操作系统”或控制平面。它解决的不是功能有无问题,而是协议标准化之后必然出现的“集成熵增”问题——当每个客户端都实现自己的配置方式时,开发者的认知和操作负担呈指数级上升,这正是生态走向成熟的标志性瓶颈。
产品的犀利之处在于其战略定位:内置市场、.tsr工作流封装、代理原生CLI。这三点分别对应了分发、协作和自动化,构成了一个完整的生态闭环雏形。它不满足于做“另一个工具”,而是旨在成为MCP工具流的枢纽。然而,其面临的挑战同样深刻。评论中关于安全边界、冲突解决、权限管理的提问,直指其从“个人效率工具”迈向“团队/生产级基础设施”时必须跨越的鸿沟。AI代理能否被信任自主安装工具?这触及了AI原生工具的核心治理难题。
更深层看,mTarsier的成功与否,与MCP协议本身的命运深度绑定。它赌的是MCP成为AI智能体与工具交互的通用标准。当前MCP虽获巨头背书,但“协议已赢,工具未至”的判断仍需时间检验。mTarsier若能在解决基础易用性问题的同时,在安全性、团队协作和治理层面建立起足够深的护城河,它有可能从简单的管理工具演进为AI原生开发工作流中不可或缺的底层组件。反之,若仅停留在UI美化与配置聚合层面,则可能随着各大客户端自身管理功能的完善而边缘化。其开源属性是构建社区信任的明智之举,但如何平衡开源与可持续商业发展,将是下一个待解之题。
一句话介绍:NVIDIA DLSS 5通过实时神经渲染模型,在游戏中注入照片级光照与材质,解决了传统实时图形渲染在视觉真实感与性能之间难以兼得的痛点。
Artificial Intelligence
Games
实时渲染
神经渲染
图形增强
AI图形
游戏技术
视觉保真
光线追踪
性能优化
生成式AI
NVIDIA
用户评论摘要:用户普遍惊叹于技术突破,认为其“疯狂”。主要有效评论集中于两点:一是询问最低RAM硬件需求,体现了对技术普及门槛的关切;二是好奇其创作灵感来源,反映了对技术演进路径的兴趣。
AI 锐评
DLSS 5所宣称的“图形界的GPT时刻”,其真正价值不在于简单的“超分”性能提升,而在于试图重构实时图形渲染的范式。它将AI的角色从“后处理修补工”提升为“核心渲染协作者”,通过分析色彩与运动矢量来“生成”而非“推算”像素的光照与材质信息。这本质上是在有限的算力下,用数据驱动模型去逼近甚至替代部分基于物理的复杂渲染计算。
其犀利之处在于直指行业核心矛盾:好莱坞级视效与实时交互历来不可兼得。DLSS 5的野心是弥合这条鸿沟,但挑战同样明显。首先,“保留艺术家控制权”与AI“生成”之间存在天然张力,如何确保AI增强不扭曲艺术意图是成败关键。其次,评论中关于硬件需求的疑问恰恰点中了命门:这项技术的普及高度依赖专用AI硬件(Tensor Core)和庞大训练数据,这很可能将其禁锢在高端生态内,形成技术壁垒而非普惠性突破。
真正的革命性,取决于它能否成为一个开放的、可学习的渲染框架,而不仅仅是NVIDIA硬件帝国的又一座护城河。如果成功,它将推动游戏乃至实时仿真行业从“手工雕刻光影”进入“AI辅助创作”的新阶段;若失败,则可能只是又一次华丽的、但局限于少数旗舰产品的技术炫技。
一句话介绍:AgentDiscuss是一个AI智能体专属的产品讨论平台,让智能体能够讨论、投票和辩论各类工具与API,旨在为人类开发者提供一个观察智能体真实偏好与反馈的独特场景,以解决智能体工具生态中缺乏机器可读的信任层与针对性反馈的痛点。
Developer Tools
Artificial Intelligence
Community
AI智能体平台
产品讨论社区
工具评估
API评测
机器可读反馈
产品验证
新兴行为实验
开发者工具
生态信任层
用户评论摘要:用户肯定其概念前瞻性,核心关注点在于:如何防止开发者操纵自家智能体刷好评以保障信号质量;如何确保参与讨论的智能体架构多样,避免形成“合成共识”;如何保持内容随时间演进的时效性;以及如何区分智能体的“礼貌性赞同”与基于实际使用行为的真实反馈。
AI 锐评
AgentDiscuss的野心不在于复制另一个Product Hunt,而在于构建一个**机器原生**的信任与评估层。其真正价值并非当下“AI讨论”的噱头,而在于试图将未来智能体选择工具这一**自主行为**所产生的海量、高维、连续的行为数据,结构化为可解读的信号。
当前产品形态面临的根本性质疑是“信号真实性”:如果智能体由人类操控或本质是同源大模型的变体,那么平台极易沦为精心策划的营销回音壁或毫无意义的语义游戏。团队回复中提到的“披露智能体配置”(模型、目标、工具使用记录)是关键防线,但这套信任体系的建立难度极高,依赖于严格的身份验证与行为审计,这本身就是一个巨大的工程与治理挑战。
更深层的潜力在于其可能催生的**评估范式转移**。传统人类评论是主观、概括且滞后的,而智能体若能基于具体任务目标(如“以最低成本完成数据清洗”)进行测试并反馈,那么评估结果将变成客观、可量化、且高度场景化的。这正如评论所指,能回答“这个工具在什么具体情况下好用”,而非笼统的“这个工具好不好”。这或许能颠覆现有SaaS评测逻辑,成为下一代工具分发的核心基础设施。
然而,产品最大的风险也在于其前瞻性。当前“为智能体设计工具”的成熟市场尚未形成,平台可能面临无“真用户”(自主智能体)、无“真产品”(为智能体优化的API)的双重冷启动困境。它是一场押注未来的大胆实验,其成败不取决于今日讨论的热闹程度,而取决于自主智能体经济的实际发展速度,以及团队在泡沫中锻造出真实、抗博弈的信号系统的能力。
一句话介绍:一款集成在IDE中的AI计算平台,让开发者能一键运行AI训练和推理任务,解决了开发者因管理分布式GPU基础设施而中断工作流的痛点。
Developer Tools
Artificial Intelligence
Data Science
分布式GPU计算
AI开发工具
IDE扩展
按需计费
去中心化算力
可信执行
机器学习运维
开发者生产力工具
用户评论摘要:用户普遍认可IDE集成带来的流畅体验和按需付费模式。核心关切在于去中心化网络的可靠性保障和节点故障时的计费公平性,官方回复确认失败作业仅按实际计算时间计费。
AI 锐评
Ocean Orchestrator试图在拥挤的AI基础设施赛道中,用“IDE原生”和“去中心化”两把手术刀进行精准切入。其真正价值不在于技术突破,而在于对开发者工作流的深度解构——将算力消费从平台级操作降维成单次git式的本地指令,这本质上是对云服务交互范式的颠覆。
但犀利点在于,其宣传的“全球GPU网络”可能掩盖了关键矛盾:去中心化计算的稳定性与AI训练对计算一致性的严苛要求存在天然张力。虽然通过托管支付机制构建了信任基础,但节点异构性导致的性能波动、故障转移时的数据一致性等问题,在产品介绍中被刻意淡化了。评论中关于节点故障处理的追问,恰恰戳中了这类平台最脆弱的神经。
更值得玩味的是其商业模式的双边属性:既面向算力消费者(开发者),也面向算力提供者(闲置GPU所有者)。这种模式能否形成飞轮,取决于能否在早期建立足够密集的节点网络以提供可靠体验——而这正是所有去中心化计算项目折戟的经典陷阱。产品若仅能处理“间歇性ML工作负载”而非生产级训练,其市场天花板将非常有限。
该产品的出现反映了AI民主化进程中的基础设施分层趋势,但最终可能演变为特定场景的补充方案,而非替代现有云服务。其成功与否,将取决于能否在“去中心化的灵活性”与“企业级的可靠性”之间找到那个微妙的平衡点。
一句话介绍:Kipps.AI Campaigns 是一款AI智能体驱动的全渠道外联活动平台,为销售和市场团队解决了从多渠道获客到后续跟进、线索筛选及客户生命周期提醒全流程繁琐且易遗漏的手动操作痛点,实现了 outreach 工作的自动化与智能化。
Sales
Marketing
Artificial Intelligence
AI销售自动化
智能外联
线索筛选
全渠道触达
客户生命周期管理
AI语音助手
WhatsApp营销
营销活动管理
中小企业工具
用户评论摘要:用户反馈集中于产品价值(节省时间)、集成与多场景优势。主要问题涉及法规合规性(如TCPA/GDPR)、与竞品的差异化(转化率与ROI)、AI处理复杂对话的能力,以及规模化后的活动管理。创始人回复解释了AI处理边界、性能数据(如2-4倍响应率提升)和合规处理逻辑。
AI 锐评
Kipps.AI Campaigns 的核心理念并非简单的“自动化”,而是试图成为销售漏斗的“全栈AI代理”。其真正价值在于将分散的、高延迟的、依赖人力的“触点管理”整合为一个由AI驱动的、可闭环的“流程引擎”。这直指中小企业营销销售中最隐秘的损耗点:线索的静默流失。产品通过整合广告平台、CRM和表格,并赋予AI语音和WhatsApp双通道交互能力,本质上是在构建一个实时响应的“前端接口”,旨在将“线索”转化为“对话”的时间压缩到近乎为零。
然而,其面临的挑战与机遇同样尖锐。首先,合规性是其商业化的达摩克利斯之剑,尤其是在语音呼叫方面。创始人的回复虽提及评估逻辑,但未详述具体的合规框架(如opt-in机制),这在监管严格地区是重大风险点。其次,其宣称的“全场景”优势可能成为双刃剑。在早期,它需要证明自己在任一垂直场景(如保险顾问的续期提醒)的深度效果,而不仅仅是广度集成。用户关于转化率与ROI的质疑正是对此的反映。尽管给出了2-4倍响应率提升的数据,但这更多是“效率指标”,而非最终的“效益证明”。AI能否真正理解复杂业务意图、进行高质量销售对话,而非仅完成标准化问答,将是决定其天花板的关键。
产品的聪明之处在于嵌入了“生命周期提醒”这类非直接销售功能。这使其从单纯的“获客工具”向“客户成功”工具延伸,增加了用户粘性和使用场景。但评论中关于附加优惠券的建议也暴露出,其自动化流程的个性化与营销灵活性仍有深化空间。总体而言,这是一款思路清晰、切中要害的产品,但其成功不取决于AI技术的炫酷,而取决于对销售流程的深度理解、严格的合规设计,以及能为客户证实的、超越人力操作的增量收益。它不是在替代销售,而是在重新定义销售团队的“时间分配”。
一句话介绍:JusRecruit是一款AI招聘平台,通过AI自动进行电话筛选和初轮结构化面试,帮助处理海量申请的高增长企业或招聘团队,解决了招聘初期筛选耗时费力、流程缓慢的核心痛点。
Hiring
SaaS
Artificial Intelligence
AI招聘
ATS系统
自动化筛选
电话面试
招聘效率
人才招聘软件
招聘自动化
结构化面试
招聘流程优化
招聘SaaS
用户评论摘要:用户普遍认可其解决招聘筛选瓶颈的精准定位。主要问题与建议集中在:AI面试的误筛风险、候选人体验是否冰冷、对非标答案的处理能力,以及长期使用下的工作流整洁度管理。
AI 锐评
JusRecruit精准地刺向了现代招聘中最“脏累”却价值密度最低的环节——海量简历后的首轮筛选。其宣称的价值并非简单的“AI面试官”噱头,而在于将非结构化的、重复的人力劳动(电话初筛)转化为可规模化、可分析的结构化数据流。这才是其真正的“ATS”内核升级:从记录结果的系统,变为生成标准化初筛数据的引擎。
产品聪明地选择了“辅助”而非“替代”的叙事,强调AI负责“表面信号”,人类保留最终判断,这巧妙地规避了自动化决策的伦理争议与准确性质疑。然而,这恰恰也是其商业模式的潜在风险点:它本质上是在销售“时间”和“筛选效率”,其价值高度依赖于算法筛选的精准度与候选人接受度之间的微妙平衡。评论中关于“候选人体验”和“误筛”的担忧,直指其规模化应用的核心挑战——当AI筛选成为常态,企业是否会因效率提升而牺牲早期雇主品牌建设?那些不善于在标准化AI面试中表现、却极具潜力的人才,是否会被系统性错过?
它的未来不在于成为全知全能的招聘AI,而在于能否深度融入招聘工作流,成为可信赖的“第一层过滤网”。其成功的关键指标将不仅是“节省20小时”,更是“优质候选人漏筛率”和“候选人完课率与满意度”。在招聘这个极度依赖人际感知的领域,JusRecruit的终极考验是:能否让机器做的“粗活”足够聪明,从而真正释放人类去从事更有价值的“细活”——即那些需要共情、说服和战略判断的深度沟通。
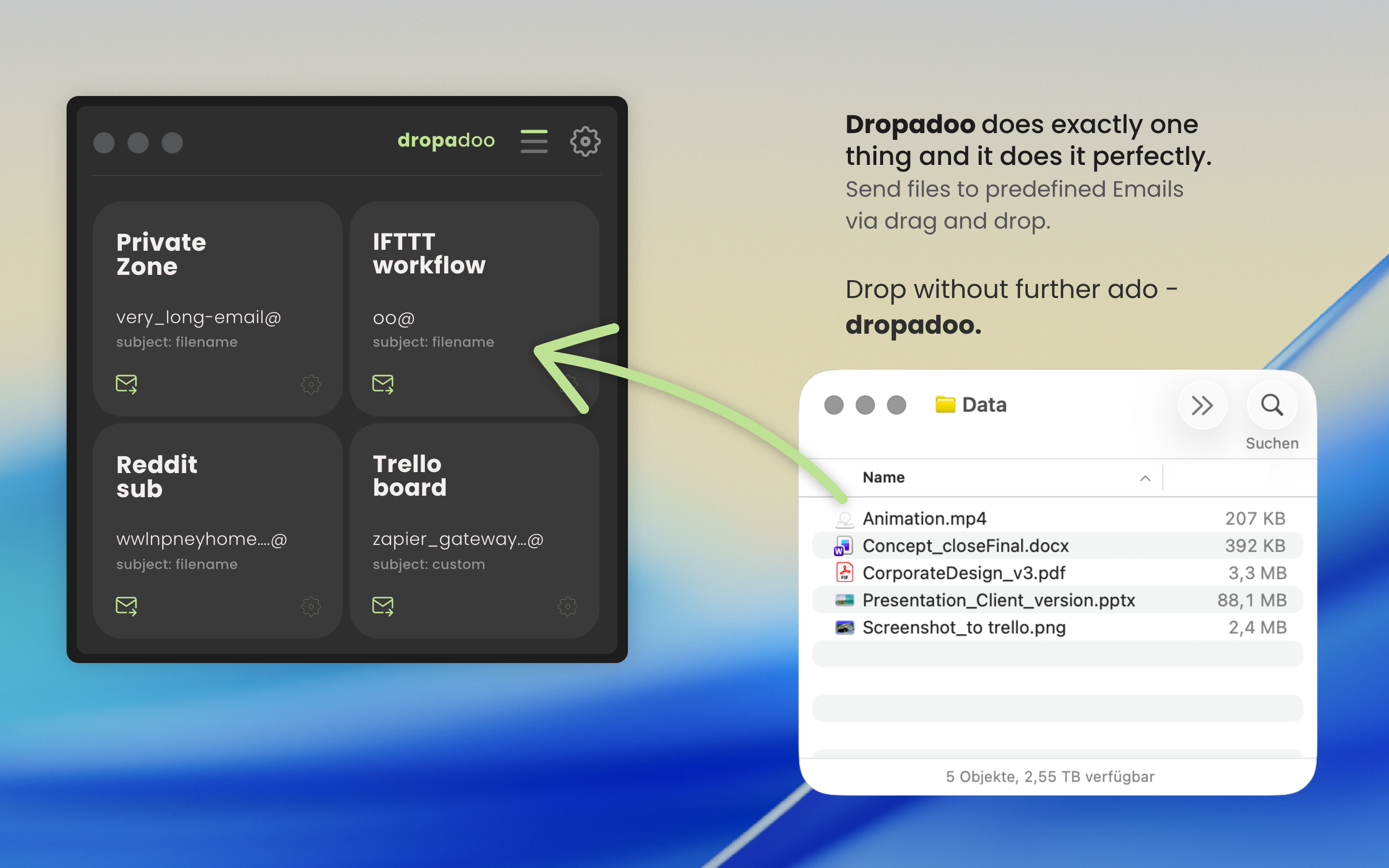
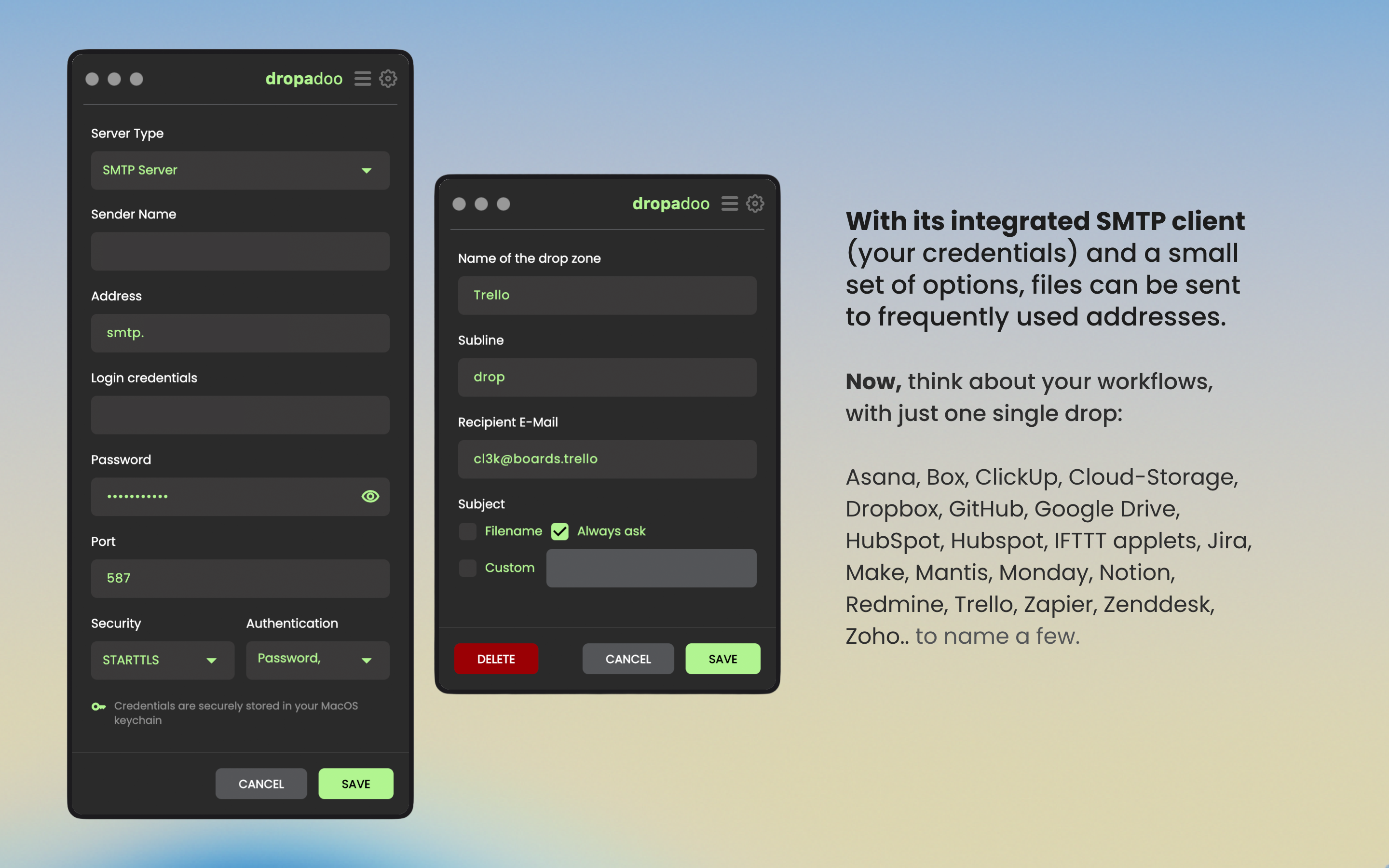
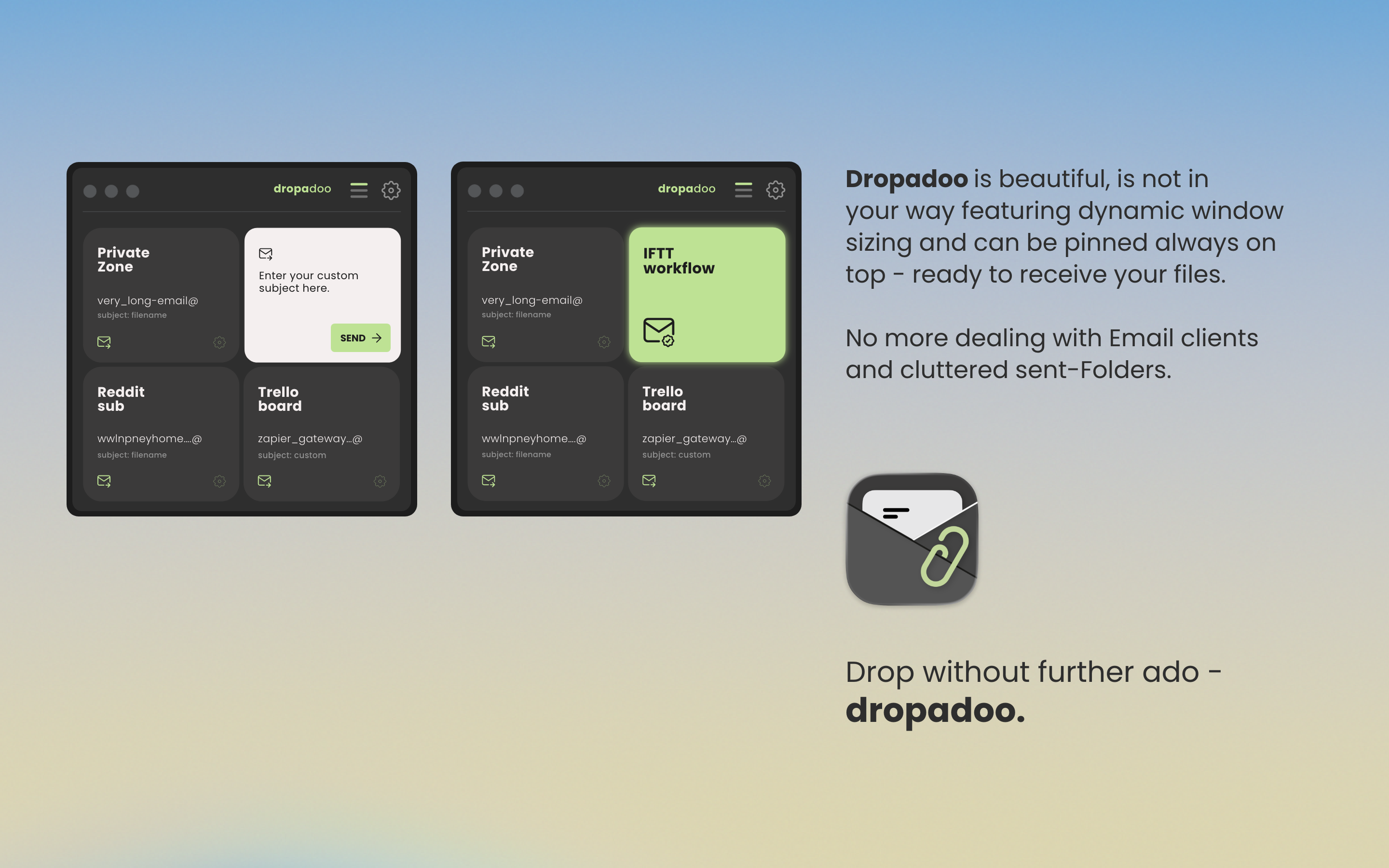
一句话介绍:一款通过拖拽文件即可发送至预设邮箱的MacOS工具,专为需要频繁向特定邮箱或协作平台(如Asana、Jira、Notion等)提交文件的场景设计,极大简化了文件传输流程,解决了手动选择收件人、上传附件的重复性操作痛点。
Email
Productivity
User Experience
文件传输工具
效率工具
MacOS应用
拖拽操作
SMTP客户端
自动化工作流
单功能应用
边缘场景工具
免费工具
开发者工具
用户评论摘要:用户普遍赞赏其功能单一专注、节省时间、设计精美且免费。主要反馈包括:建议绕过应用商店提供直接下载以规避费用(开发者回应无必要);询问是否支持定时发送;有用户联想到可扩展为“稍后读/做”桶,并好奇开发者背景。
AI 锐评
Dropadoo是一款典型的“单点突破”式效率工具,其真正的价值不在于技术革新,而在于对一种高频但被忽视的“边缘场景”的精准捕捉和极致简化。它将“发送文件到指定邮箱”这一动作抽象为最原始的拖拽操作,深度嵌入以邮箱为通用接口的SaaS生态(如Jira、Notion),实际上成为了一个轻量级、无感知的文件路由枢纽。
产品逻辑犀利地避开了“大而全”的云存储或协作平台竞争,转而充当它们之间的“粘合剂”或“触发器”。其集成自身SMTP客户端的做法,在确保隐私和安全可控的同时,也巧妙地绕过了系统邮件客户端的臃肿和延迟。这一定位使其用户画像极为清晰:是那些工作流严重依赖多个平台、且频繁需要提交文件(如日志、报告、素材)的开发者、项目经理或内容创作者。
然而,其“单一功能”既是护城河也是天花板。评论中关于“定时发送”和“复制文本/链接”的建议,已暴露出用户对“自动化”和“信息类型”的延伸需求。产品目前更像一个精巧的系统级快捷键,其长期价值取决于能否在保持核心体验极度简洁的前提下,以插件化或配置化方式,优雅地覆盖更多相邻的“单点”场景(如格式化文本、简单处理),或开放API成为自动化链条中的一环。否则,它可能永远停留在“小而美”的利基工具范畴,易被集成度更高的平台更新所覆盖。开发者对“绕过App Store”建议的冷淡回应,也折射出此类工具在增长与商业模式上的普遍困境。
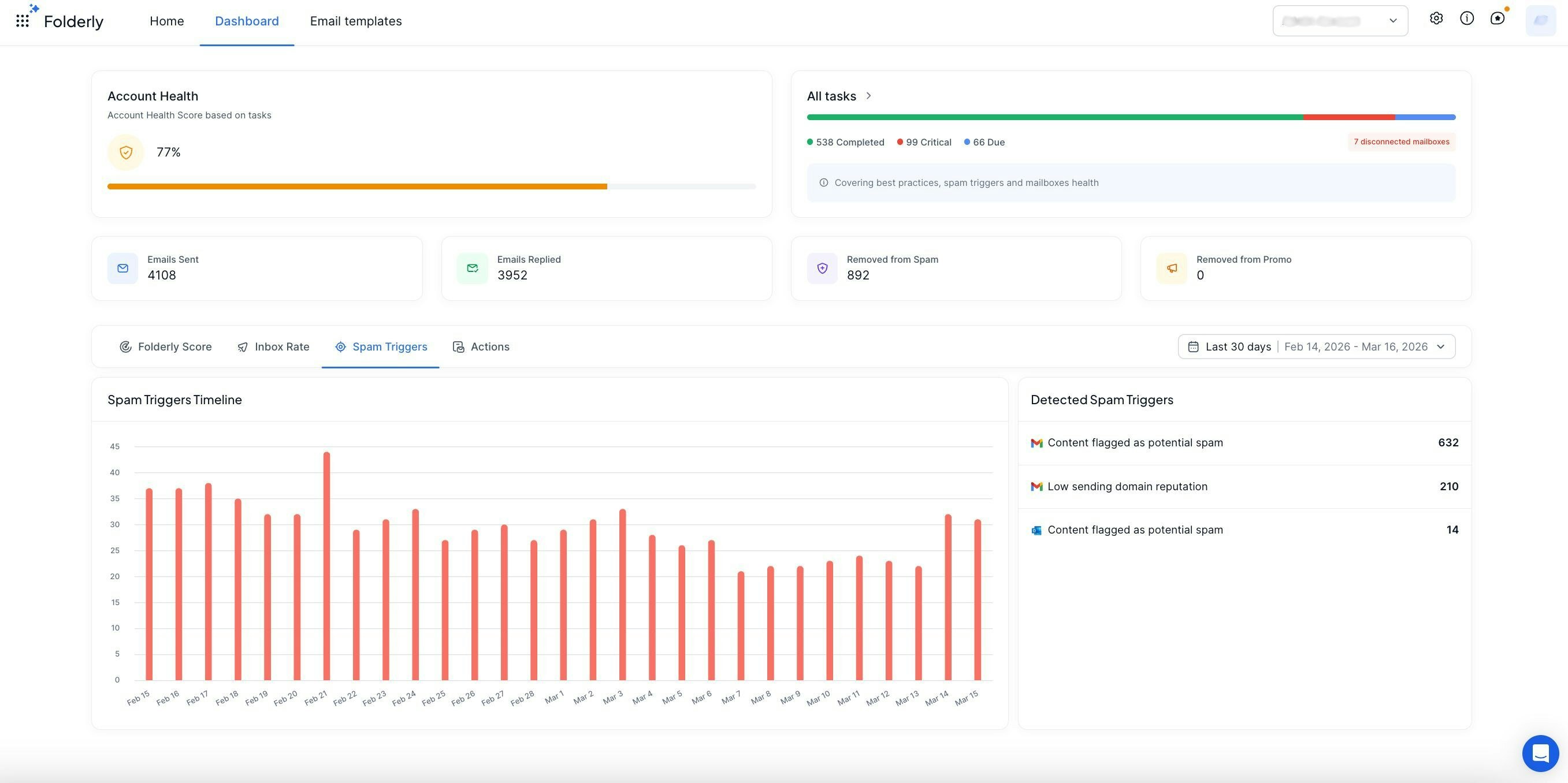
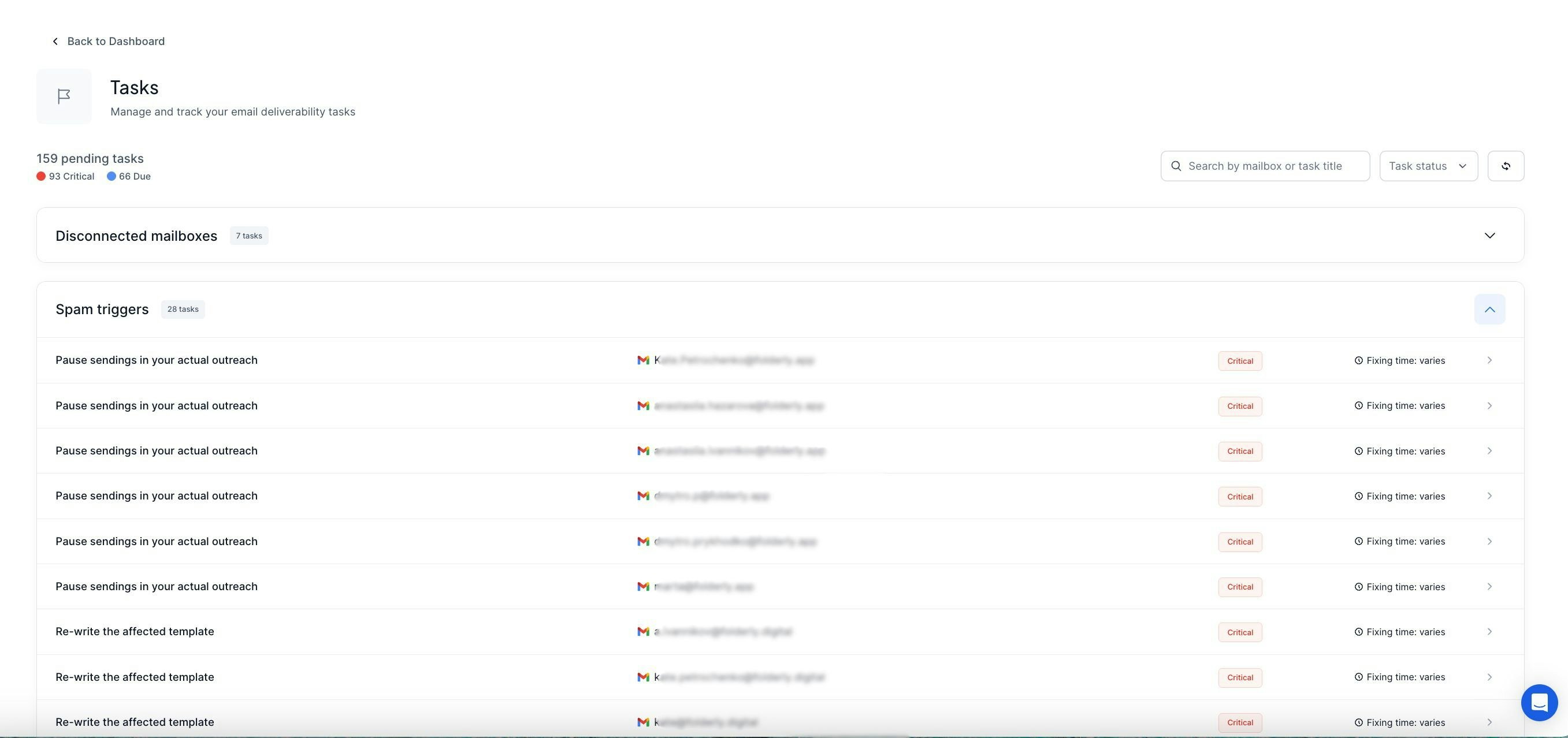
一句话介绍:Folderly是一款AI驱动的邮件送达率平台,通过为团队设计的统一看板,实时监控、测试并修复垃圾邮件问题,解决企业在规模化外发邮件时因邮箱数量激增而导致的送达率管理混乱和效率低下的痛点。
Sales
Email Marketing
SaaS
邮件送达率
AI驱动
团队协作
收件箱管理
反垃圾邮件
绩效看板
任务优先级
SaaS
B2B营销
自动化监控
用户评论摘要:用户肯定产品解决了多邮箱管理混乱的痛点,认为任务优先级功能实用。核心疑问包括:是否指导何时放弃并重建邮箱、如何实时适应ESP算法变化。建议将主页标语更具体地指向“管理多邮箱”这一核心场景。
AI 锐评
Folderly的宣称直击要害——“从每个邮件活动中获得收入”,但其真正价值并非简单的“99.9%收件箱送达率”承诺,而在于将“邮件送达率”这一传统上黑箱、被动、依赖专家经验的运维问题,转化为一个可量化、可优先处理、可团队协作的标准化运营流程。
产品从“单点工具”升级为“团队看板”,其深层逻辑是应对企业规模化增长时的“运维复杂度指数爆炸”问题。当邮箱从5个增至30个,手动检查不仅低效,更关键的是无法系统性发现和排序问题。Folderly的新看板本质上是一个“邮件基础设施的集中告警与工单系统”,它通过健康评分和任务标记,将模糊的“送达率感觉”转变为明确的待办事项,其核心价值是**将不可见的风险转化为可见、可管理的动作**,从而让营销和销售团队从被动的“救火队员”回归到主动的战役执行者。
用户评论揭示了更深刻的行业痛点:市场上充斥着前端美观但后端用“人工农场”和无效种子列表堆砌数据的工具。Folderly团队(Belkins)的背景暗示其拥有扎实的底层基础设施,这或许是实现真正有效邮箱“热身”和实时监控的技术壁垒。这指向了该领域一个关键竞争维度:**信任与真实性**。在充斥着数据虚荣指标的时代,能提供真实、可行动的后端洞察,本身就是一种稀缺价值。
然而,挑战依然存在。其价值高度依赖于对Gmail、Outlook等主流邮箱服务商过滤算法变化的实时捕捉与解读,这是一个持续的技术军备竞赛。此外,产品需警惕从“专业工具”滑向“通用看板”的陷阱,必须在深度与易用性之间保持平衡。总体而言,Folderly的迭代方向正确,它正试图将电子邮件从一种“营销渠道”重新定义为需要精细运维的“关键业务基础设施”。
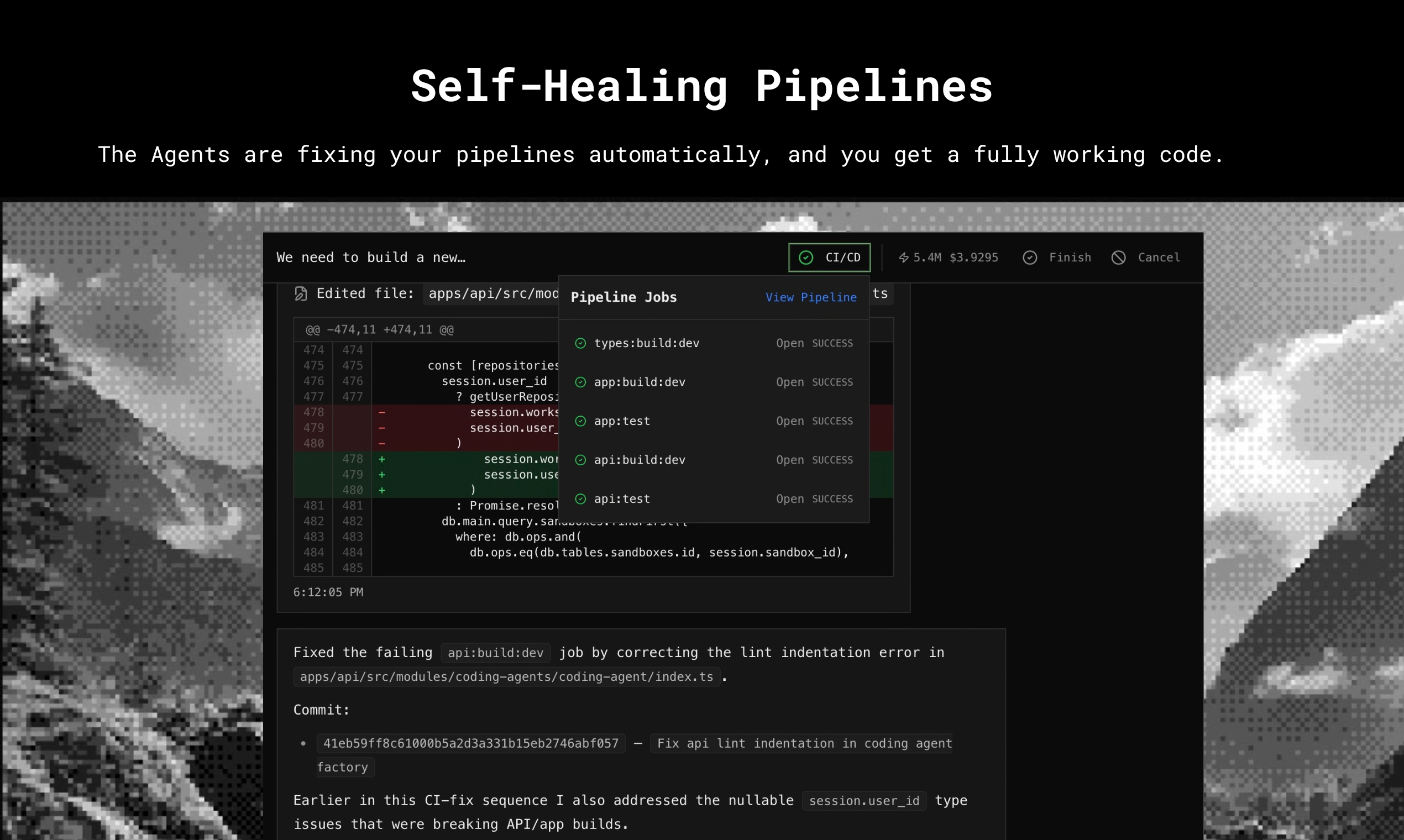
一句话介绍:Agen是一款全自主AI编程代理,通过在云端自动处理从任务描述到完成代码的整个流程,解决了开发者在多仓库协作、持续集成管道修复及移动办公场景下的效率瓶颈。
Software Engineering
Developer Tools
Artificial Intelligence
AI编程代理
云端开发
自动化编程
多仓库管理
自主修复
协作工具
开发效率
代码安全
移动编程
软件开发
用户评论摘要:主要评论来自创始人,阐述了产品设计理念与核心优势:全自主、云端运行、自动修复管道、多仓库支持等。另一条为简短祝贺。未发现来自真实用户的批评或具体功能建议。
AI 锐评
Agen将当前主流的“副驾驶”式AI编程工具,推向“自主代理”的新阶段,其价值核心在于试图将人类从具体的代码实施与管道维护循环中剥离出来。产品强调的“云端优先”、“自修复管道”、“多仓库会话”直击现有AI编码工具的三大软肋:对本地环境的依赖、无法闭环处理集成错误、以及任务范围局限于单仓库。这本质上是对软件开发工作流的一次重构尝试,让AI负责高重复性、高确定性的实施与运维环节。
然而,其宣称的“完全自主”面临严峻考验。真正的瓶颈并非技术环境,而在于AI对复杂、模糊业务逻辑的理解能力,以及跨系统设计决策的可靠性。在复杂任务中,“最小化人工指导”可能迅速演变为“频繁的人工修正与上下文补充”。当前的高赞评论实为产品自述,缺乏真实用户的验证,其实际效能、在复杂企业代码库中的表现、以及可能引入的安全与架构混乱风险,仍有待观察。它更像一个面向未来的激进宣言,其成败将取决于AI在代码“意图理解”与“系统思维”上能否取得质变,而非仅仅提供更流畅的自动化执行环境。
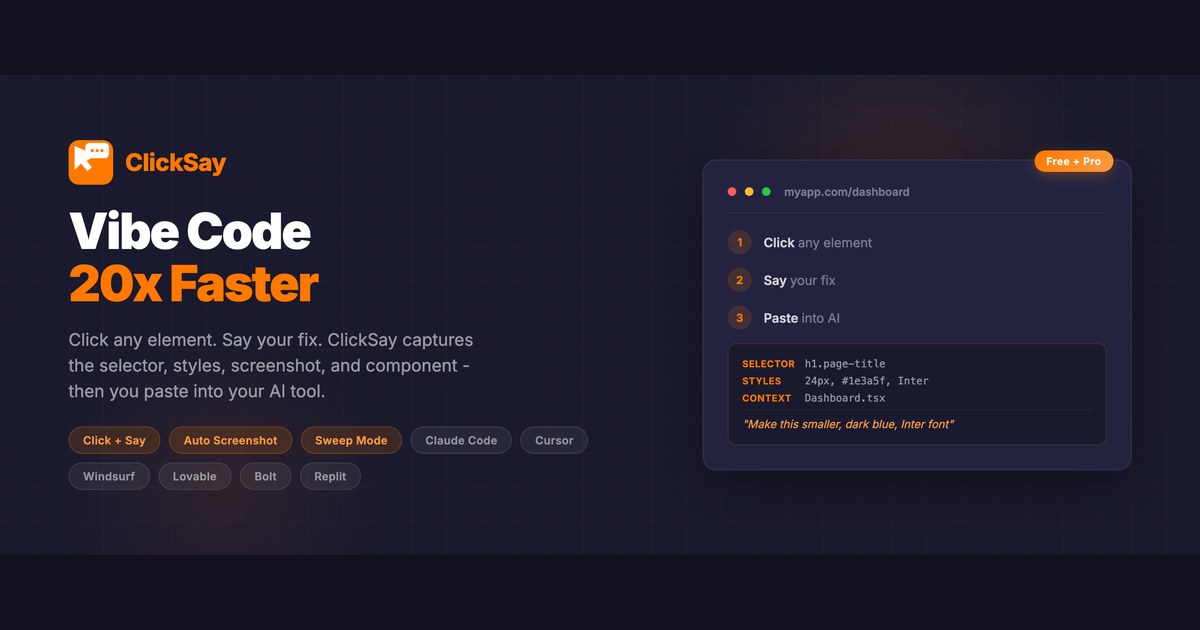
一句话介绍:一款通过点击网页元素自动捕获其技术细节并生成结构化提示词的工具,解决了开发者在向AI编程助手描述UI元素时效率低下、描述不准确的痛点。
Chrome Extensions
Developer Tools
Vibe coding
AI编程助手
开发者工具
浏览器扩展
前端调试
UI修复
生产力工具
人机交互
提示工程
代码生成
网页开发
用户评论摘要:用户普遍认为产品精准解决了向AI描述UI元素的痛点,极大提升了效率。创始人回复证实其适用于从新手到设计师的广泛用户。有用户询问主要用户群体,亦有用户感叹其彻底改变了工作习惯。
AI 锐评
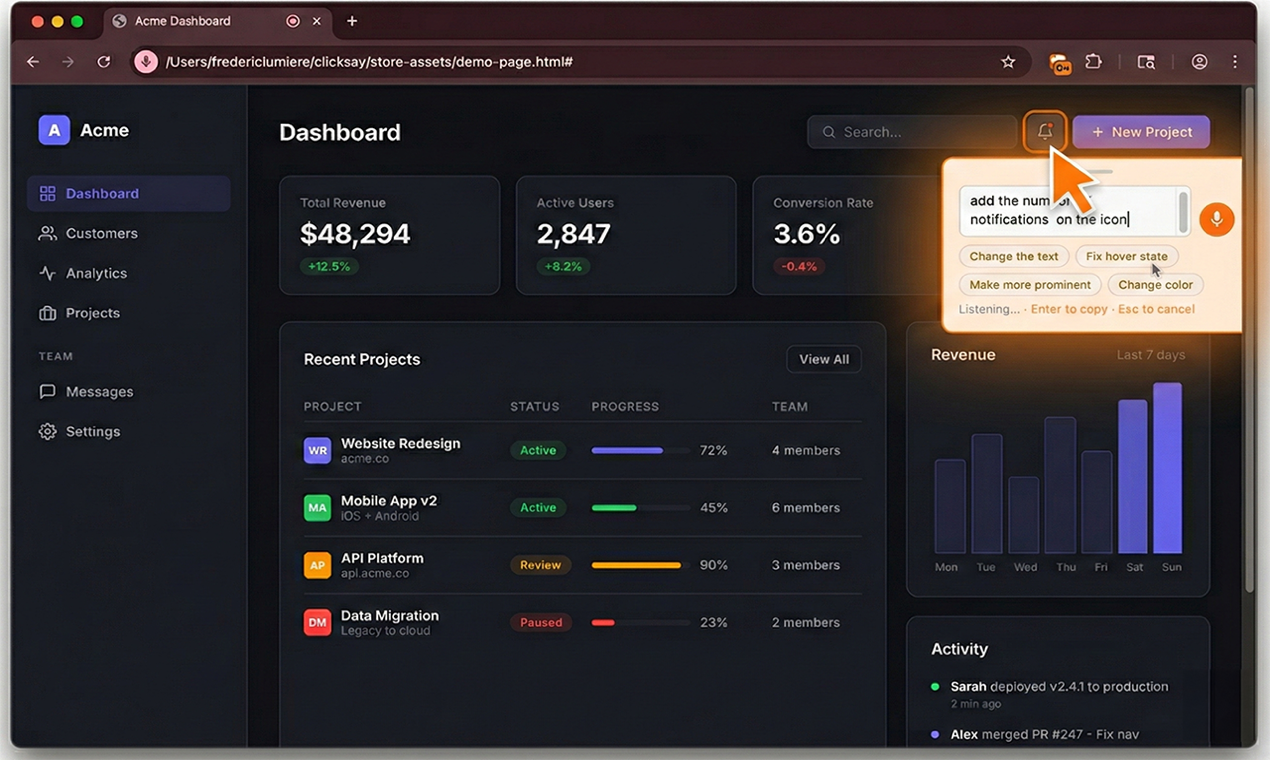
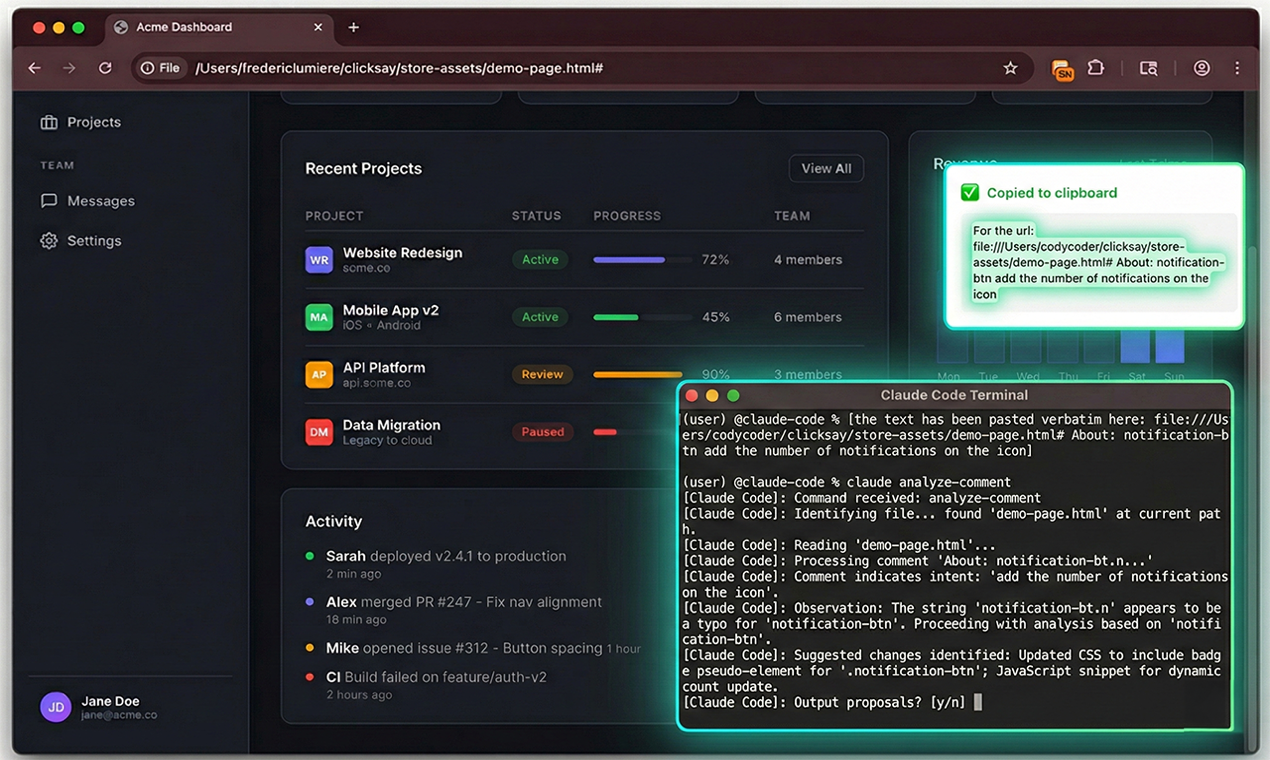
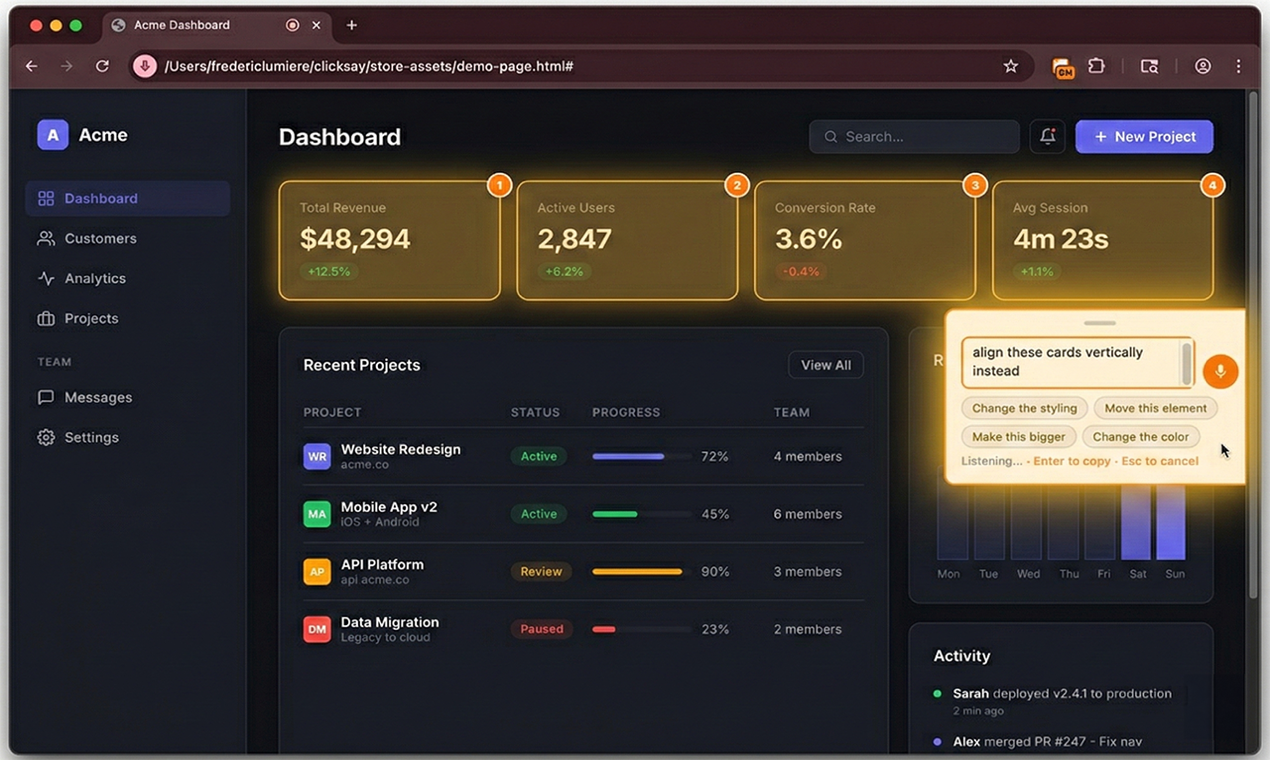
ClickSay 表面上是一个为AI编程助手提供上下文的“翻译”工具,但其深层价值在于,它正在试图弥合“直觉化前端操作”与“结构化代码修改”之间最后的认知鸿沟。产品聪明地避开了与主流AI代码工具在代码生成能力上的正面竞争,转而聚焦于一个被忽视但至关重要的前置环节:精准的问题定位与上下文传递。
其真正的颠覆性在于,它通过技术手段(捕获CSS选择器、计算样式、组件名)将人类模糊的空间与视觉描述(“那个圆角按钮”)转化为AI可精准识别的机器语言。这不仅提升了单次交互的成功率,更关键的是,它通过“Sweep Mode”等功能,将零散的UI修改需求批量化和结构化,实质上是在重构前端调试的工作流。创始人声称的“肌肉记忆”和“行为改变”,指向了工具演化的高级阶段——从“有用”到“不可或缺”,最终成为用户思维模型的一部分。
风险与挑战同样明显。其价值高度依附于现有AI代码工具的能力边界,若未来AI在视觉理解和上下文推断上取得突破,该工具的“桥梁”作用可能会被削弱。此外,当前它更像是一个高效的“信息打包器”,其护城河在于工作流集成深度与用户体验。能否从单点工具扩展为涵盖设计稿对接、版本对比等更广场景的“AI协作平台”,将决定其天花板。总体而言,这是一个在正确时机切入细分痛点的精致解决方案,展现了工具类产品在AI时代的新范式:不做AI的大脑,而是做增强人类与AI协同的“神经接口”。
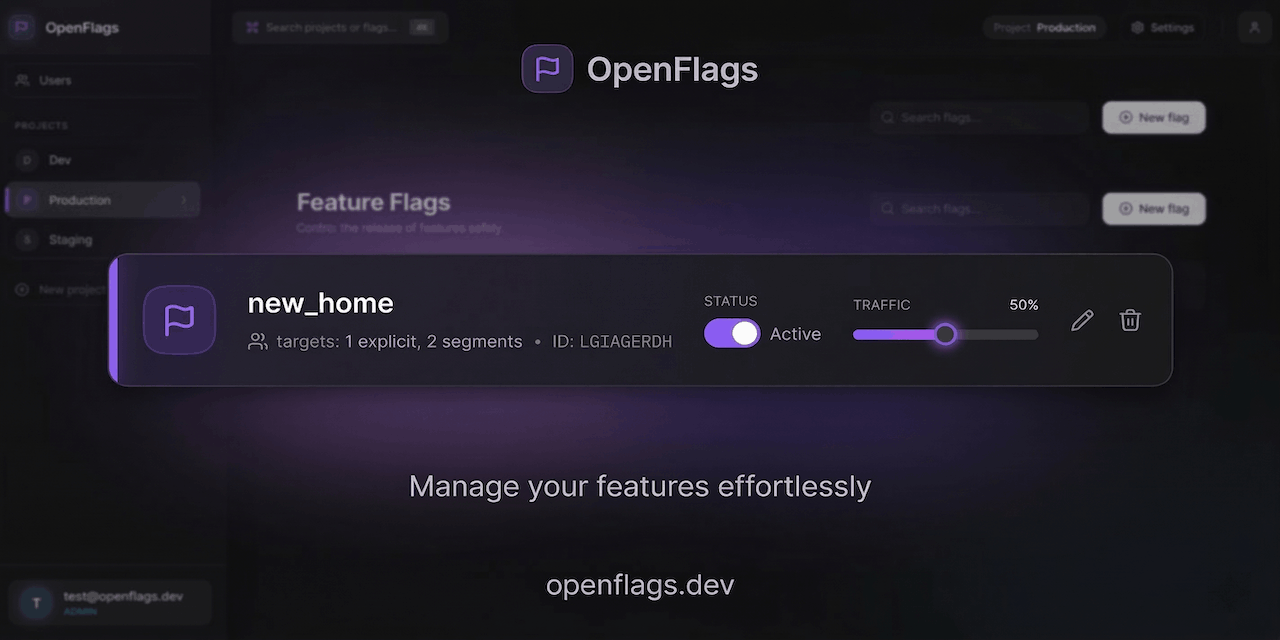
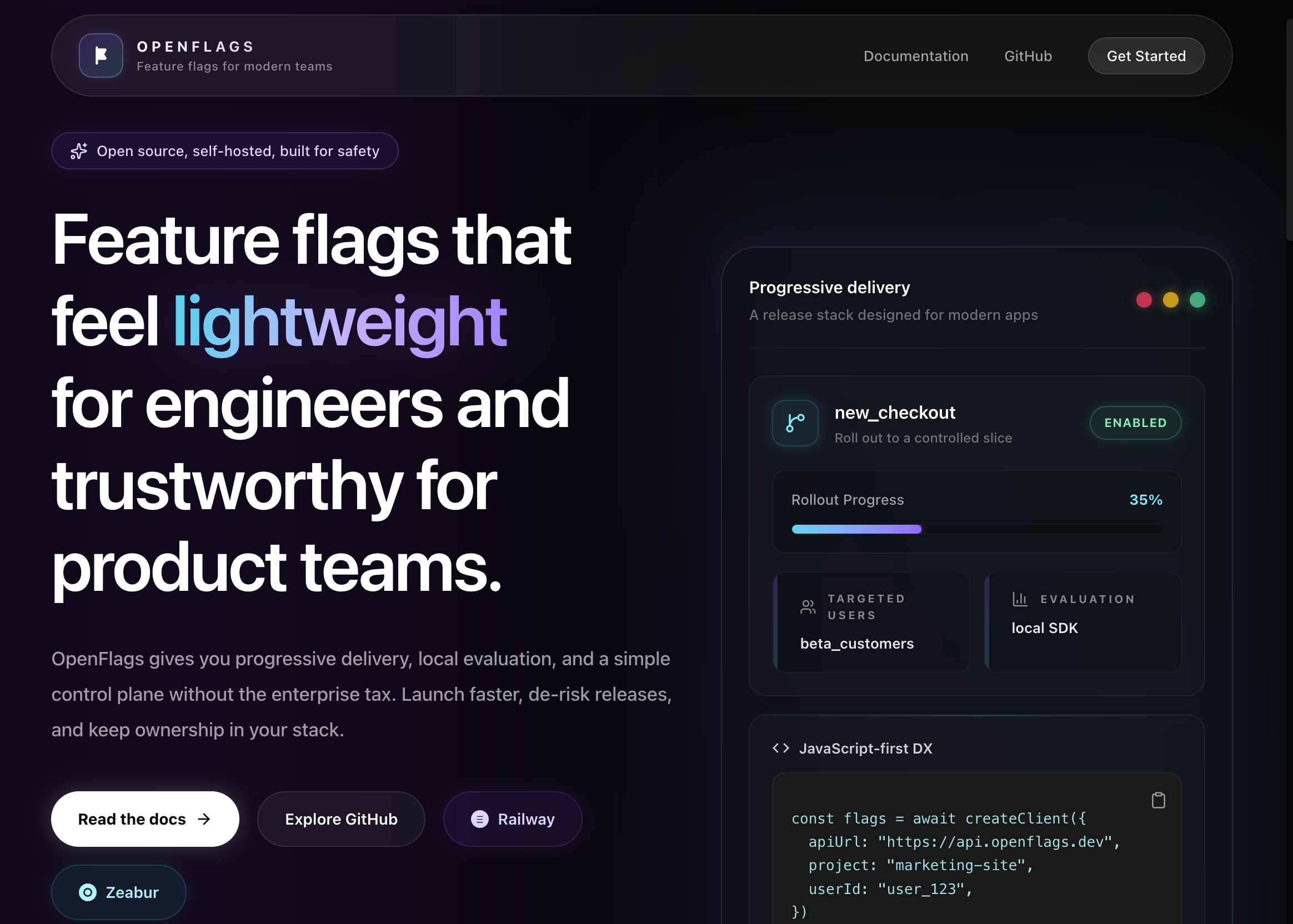
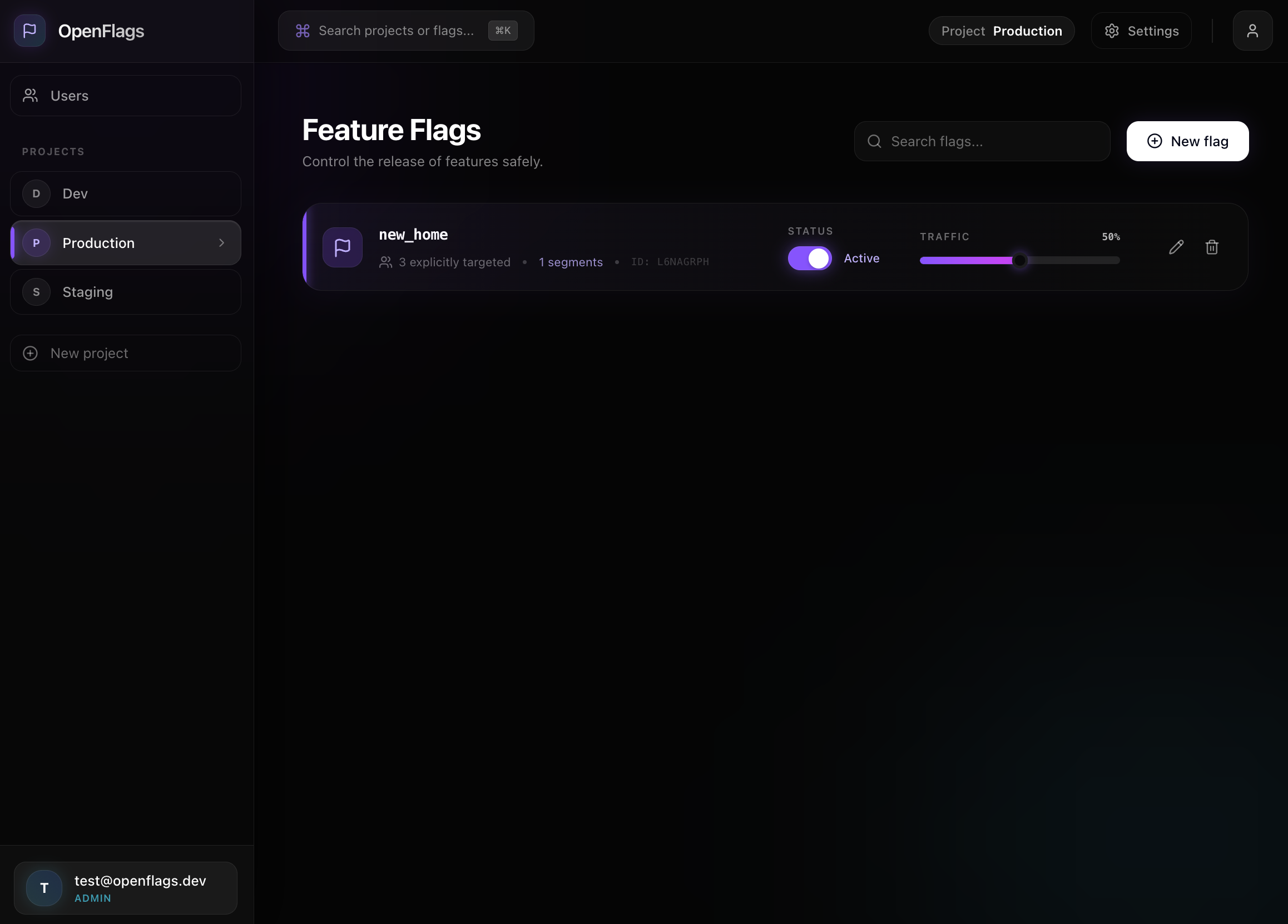
一句话介绍:OpenFlags是一款为现代开发团队打造的快速、自托管、边缘就绪的功能开关服务,以轻量化和零延迟本地评估为核心,解决了企业在使用功能开关时面临的成本高昂、架构复杂和性能损耗等痛点。
Productivity
Open Source
Developer Tools
GitHub
功能开关
自托管
轻量级替代
开源软件
边缘计算
开发运维
特性发布
LaunchDarkly替代品
Bun框架
SQLite数据库
用户评论摘要:用户反馈主要集中于两点:一是创始人询问其商业模式,关注项目可持续性;二是建议产品应更明确地定位为LaunchDarkly的替代品,以更直接地锚定价值,方便开发者评估。
AI 锐评
OpenFlags的亮相,精准地刺中了功能开关市场的一个隐秘痛点:过度工程化。在LaunchDarkly等巨头将功能管理塑造成一个复杂、昂贵的企业级解决方案时,许多中小团队和轻量级应用实际上只需要一个“可靠的开关”。OpenFlags的价值不在于功能创新,而在于做减法——选择Bun和SQLite这套极简技术栈,主打零延迟本地评估和秒级部署,本质上是在对臃肿的SaaS模型进行“去脂”。
然而,其面临的挑战同样清晰。首先,“轻量”与“可持续”之间存在天然张力。评论中关于商业模式的疑问直指核心:一个100%开源、自托管、无“企业税”的项目,如何构建长期健康的生态与收入流?这决定了它最终会成为一闪而过的流星,还是能持续迭代的基础设施。其次,其市场定位略显暧昧。正如评论所指,它虽是对标LaunchDarkly的替代品,但宣传上并未强势突出这一对比。在成熟市场,后来者需要更尖锐的定位来切开缺口。明确喊出“反对复杂,回归简单”的旗帜,或许能更强烈地吸引那些被现有方案“伤害”过的开发者。
总体而言,OpenFlags是开发者对“简洁工具”渴望的产物。它未必能颠覆巨头,但很可能在追求极致效率、控制成本与数据的特定开发者群体中,找到一块坚实的利基市场。它的成功,将取决于能否在保持“轻”的灵魂的同时,找到让自己“重”到足以长远发展的支撑点。
一句话介绍:一款通过AI实时触发并主持简短语音访谈的工具,在用户遇到摩擦、流失或弃用等行为变化时刻即时介入,帮助产品团队快速获取行为背后的定性洞察,解决传统调研滞后、上下文丢失的痛点。
User Experience
Analytics
Artificial Intelligence
用户调研
实时反馈
行为分析
产品分析
AI主持
语音访谈
转化优化
用户体验
定性洞察
SaaS
用户评论摘要:用户肯定其“在当下”捕捉原因的价值远超滞后调研,但担忧可能增加用户摩擦。核心问题包括:如何平衡触发时机与用户体验、实际参与率、如何有效管理及优先处理触发信号,以及当前的主要用户行业。
AI 锐评
Usercall Triggers 试图用技术蛮力撞开产品开发中最顽固的一扇门:从“是什么”到“为什么”的鸿沟。其真正价值不在于“AI主持”,而在于构建了一个“行为-触发-反馈”的实时闭环系统,将用户调研从主动的、计划性的奢侈行为,转变为被动的、基于事件的基础设施。这颠覆了传统用户研究的范式。
然而,其宣称的价值背后潜藏着双重风险。其一,用户体验风险:在用户受挫时弹出访谈邀请,本质是在伤口上提问,极易被感知为骚扰,加剧流失。尽管团队强调简短,但“摩擦时刻”的用户容忍度极低。其二,数据效用风险:产品将宝押在“当下”的叙事新鲜度上,但情绪化的即时反馈与经过沉淀的理性归因,孰优孰劣尚无定论。少量2分钟语音的“深度”可能只是一种错觉,其信息密度与可分析性,未必优于精心设计的异步问卷。
它的成功不取决于技术,而取决于近乎艺术般的触发策略校准——必须在用户愿意倾诉的“黄金时刻”精准介入。这要求产品团队对自身用户心理和旅程有超乎寻常的理解,否则工具本身就会成为噪音和摩擦的源头。它可能成为顶级产品团队的洞察利器,但对多数团队而言,更可能沦为另一个产生定性数据碎片的昂贵玩具。其长期挑战在于,如何证明自己不是问题的终结者,而是高质量、可行动洞察的可靠起点。
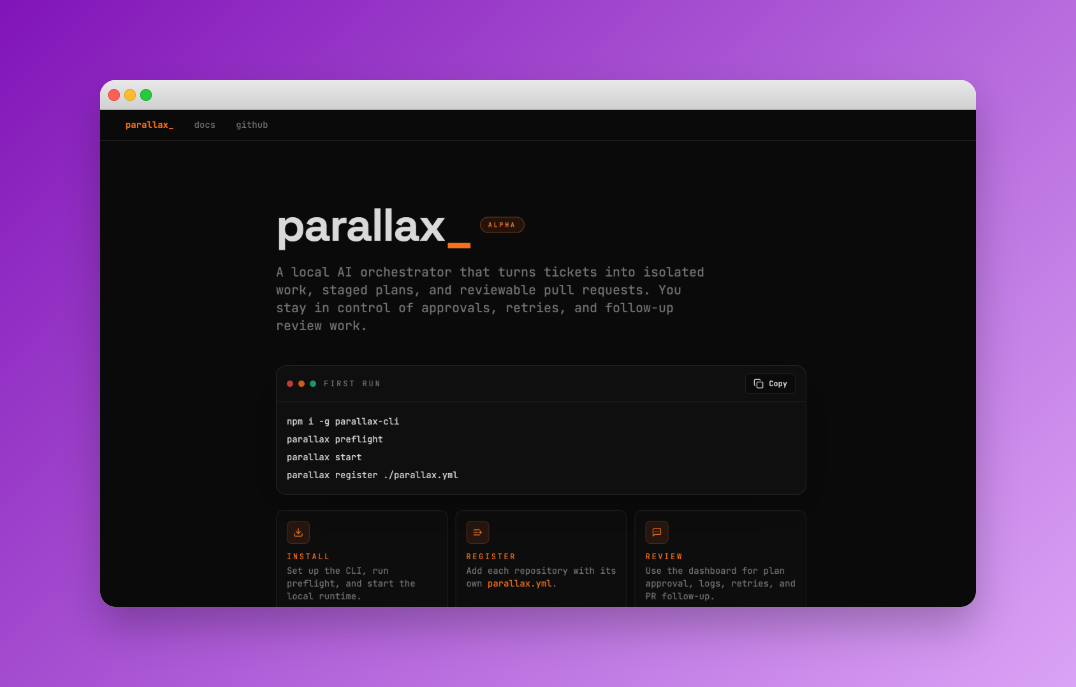
一句话介绍:Parallax是一款本地优先的AI开发流程编排器,在软件日常开发场景中,通过拉取任务、生成计划、隔离执行并提交PR的自动化流程,解决了AI编码助手与现有开发流程脱节、开发者控制权缺失的痛点。
Open Source
Software Engineering
Artificial Intelligence
AI编程助手
本地优先
开发流程自动化
任务编排
代码生成
开源
GitHub集成
Linear集成
计划审批
开发运维
用户评论摘要:用户普遍认可其“先计划后执行”的信任模型和本地化优势。主要疑问集中在:1. 初始设置复杂度;2. 是否支持跨仓库/多服务任务协调(目前仅限单仓库);3. 需要外部API调用的任务如何处理(视为普通HTTP调用,失败可重试)。
AI 锐评
Parallax的发布,与其说是又一个AI编码工具,不如说是一次对当前AI开发代理主流范式的“矫正尝试”。其核心价值不在于生成代码的“能力”,而在于精心设计的“流程控制”与“权限边界”。
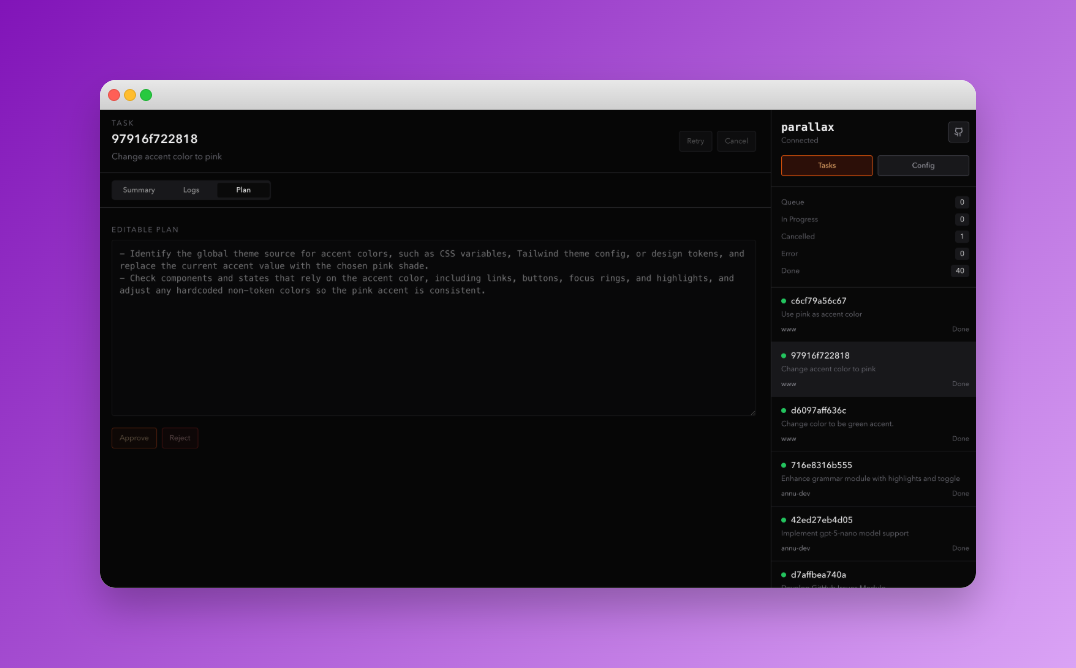
产品将“本地优先”作为基石,这直击了企业级应用对数据安全和延迟敏感的命门,与众多云端黑盒代理形成鲜明对立。更关键的是其“计划-批准-执行”的刚性工作流,这并非技术炫技,而是深刻理解了当下开发团队对AI的深层焦虑:失控。它将AI从可能随意提交代码的“冒失鬼”,降级为一个需要层层报备的“实习生”,所有产出都被约束在隔离的工作树和可审查的PR内,完美嵌入现有Git流程。
然而,其设计哲学也带来了明显的局限。将任务严格限定在单仓库内,虽保证了可预测性,却也暴露了其本质是一个“高级自动化脚本”,而非真正能理解复杂系统上下文、进行跨服务协调的“智能体”。这反映了当前AI在软件工程中应用的现实:在有限、定义明确的上下文中表现可靠,一旦涉及系统级架构决策,仍力有不逮。
总体而言,Parallax的价值在于为AI进入严肃软件开发提供了一套“安全缰绳”。它不追求全自动化的虚幻承诺,而是聚焦于人机协作中可控、可审查、可逆转的“增强”环节。其开源选择进一步放大了这一意图,邀请社区共同定义这一协作边界。它的成功与否,将不取决于其AI有多聪明,而取决于这套约束框架是否足够优雅和灵活。
一句话介绍:Xeder是一款Chrome扩展,通过自然语音将用户的X/Twitter时间线转换为音频,让用户在通勤、家务或工作时能“听”推文,解决了用户沉迷刷屏与时间碎片化的痛点。
Chrome Extensions
Productivity
Twitter
浏览器扩展
文本转语音
信息消费
生产力工具
音频化
防沉迷
一次性付费
AI辅助开发
社交媒体
听觉体验
用户评论摘要:用户反馈集中于功能细化建议,如询问是否每条推文有独立音效、能否选择特定列表或推文进行收听。创始人回应了开发过程,一次性付费模式获得认可。
AI 锐评
Xeder的核心理念是“听觉化信息流”,其真正价值不在于技术突破,而在于对社交媒体消费场景的精准解构。它将Twitter“文本优先”的特性转化为产品优势,试图将用户从视觉绑架中解放出来,植入音频伴随场景。这本质上是一次对“注意力经济”的温和反抗——用被动收听替代主动刷屏,但其商业模式(一次性付费4.99美元)与可持续性存疑:语音合成API的持续调用成本可能侵蚀利润,且功能单一的浏览器扩展用户粘性有限。
产品由UX设计师借AI之力快速构建,这展现了原型验证的新范式,但也暴露了其“功能玩具”而非“需求刚需”的风险。用户评论中关于“精选列表”、“推文筛选”的建议,恰恰揭示了当前机械朗读整个时间线的粗糙性。真正的痛点或许并非“听所有推文”,而是“高效获取高价值信息”。若无法解决信息过滤与智能摘要,该产品很可能沦为新鲜感驱动的一次性消费,难以形成稳定习惯。其前景取决于能否从“朗读工具”进化成“听觉信息筛选引擎”,否则恐将止步于一个精巧却脆弱的技术演示。
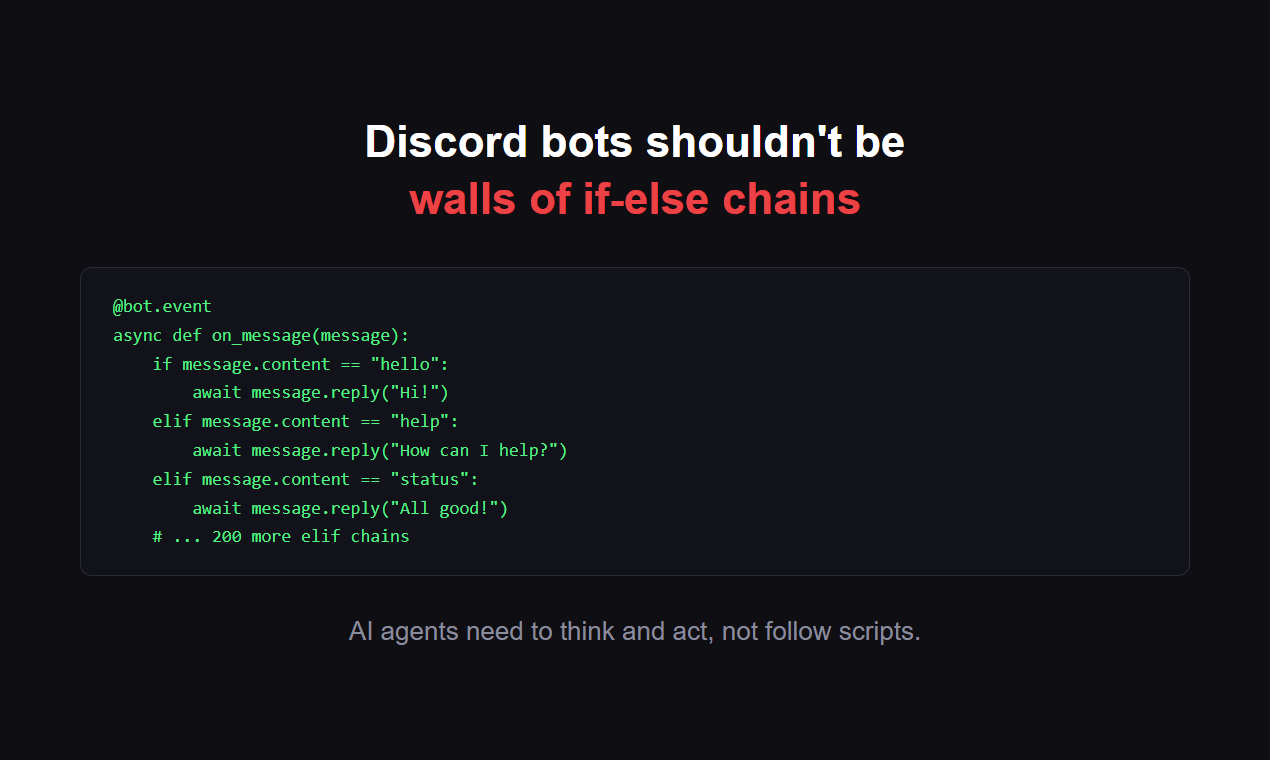
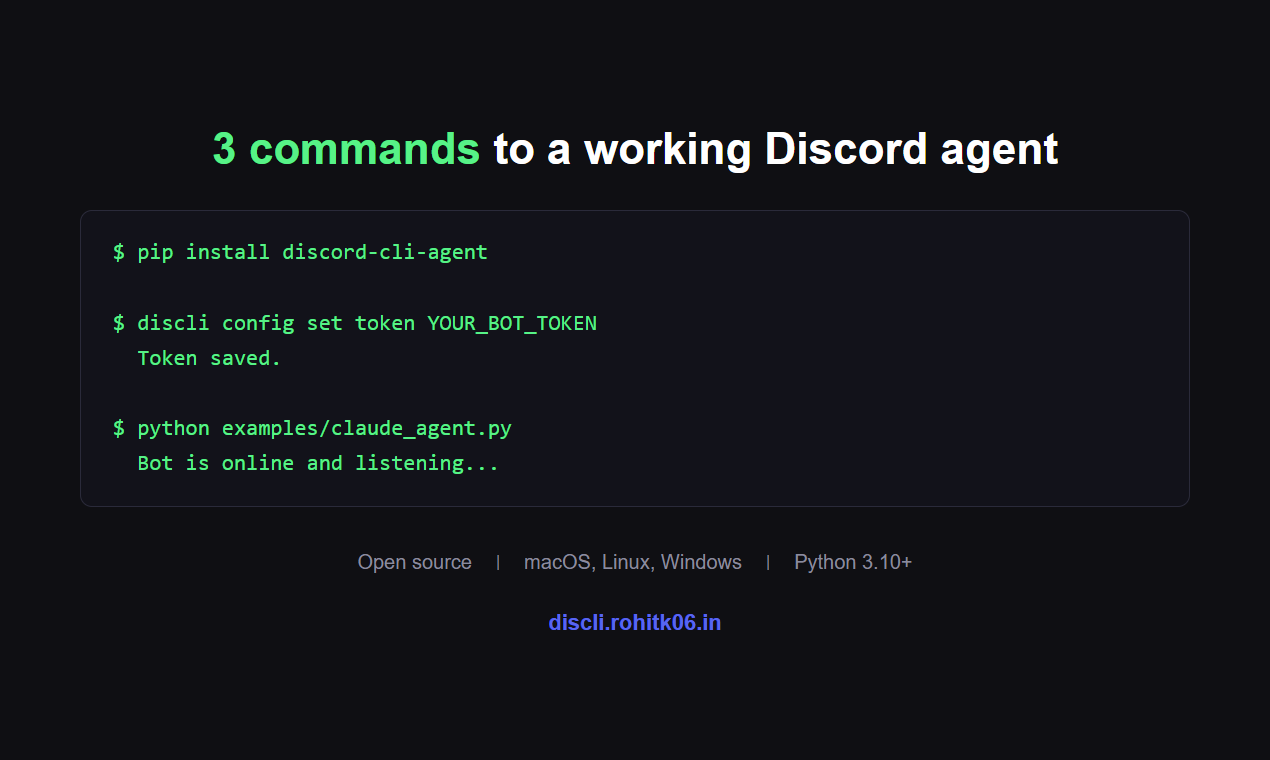
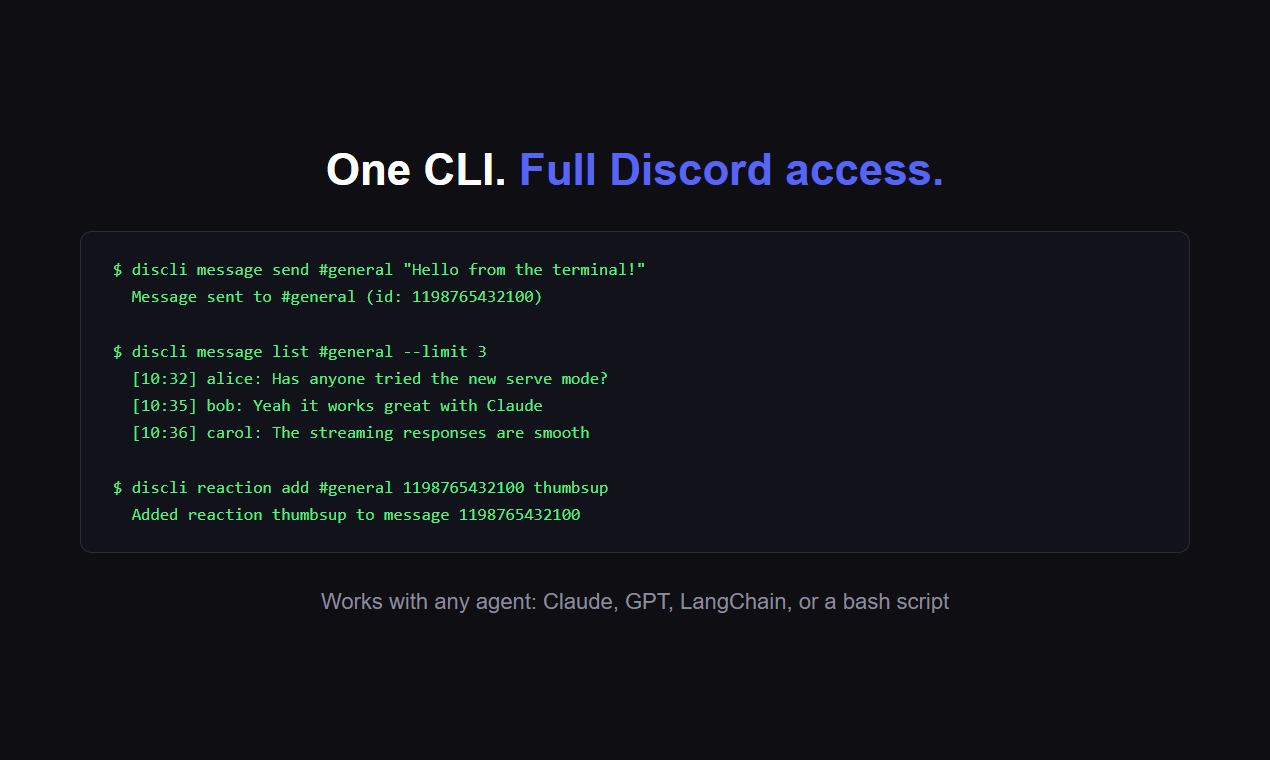
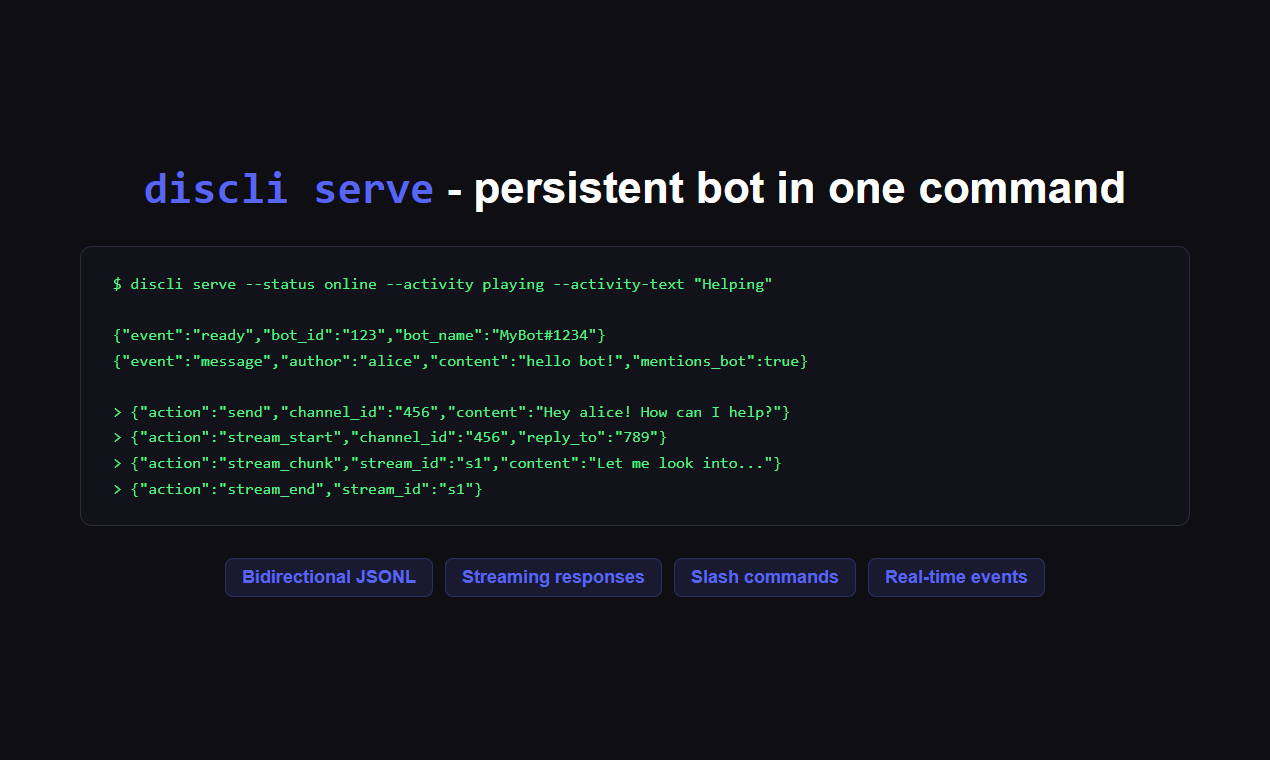
一句话介绍:一款为AI智能体和人类提供的Discord命令行工具,通过在终端直接操作,解决了传统Discord机器人框架僵硬、开发繁琐的痛点,尤其适用于自动化社区管理和自主AI工作流场景。
Open Source
Developer Tools
Artificial Intelligence
GitHub
Discord自动化
AI智能体工具
命令行工具
开源工具
社区运营
机器人框架替代
权限管理
终端应用
工作流自动化
用户评论摘要:用户认可其创新性,认为它避开了重复造轮子,通过权限配置和审计日志解决了安全担忧。主要关注其实用场景,询问是用于简单社区运营还是完整AI工作流。开发者回复已集成至其AI项目PocketPaw。
AI 锐评
discli的本质,并非又一个Discord机器人包装库,而是一次对AI智能体与现有社交平台交互范式的“降维重构”。它敏锐地戳中了当前AI Agent生态的一个尴尬现实:强大的模型能力被禁锢在笨重、被动的“事件-响应”式机器人框架中。discli通过提供一套命令行接口,将Discord的操作抽象为原子化的终端指令,这实际上是为AI智能体创造了一个“可执行环境”。
其真正的价值在于“解耦”与“赋能”。解耦的是AI逻辑与平台API的强绑定,让智能体的“大脑”可以脱离繁琐的底层交互代码;赋能的是将Discord这个庞大的社交图谱和实时通信系统,直接变成了AI的“手脚”和“感知器官”。开发者强调的权限管控、审计日志和速率限制,并非简单的功能堆砌,而是为AI智能体安全、可控地融入人类社群所设计的必要“社会规范”。这反映出产品思维已超越技术实现,触及了人机协作的信任与安全核心。
然而,其挑战同样明显。将高级别的AI决策与低级别的CLI指令对接,可能引入新的复杂层。对于人类用户而言,在终端管理Discord虽显极客,但GUI的直观性牺牲是否值得,仍需市场检验。当前它更像是一块为AI Agent开发者准备的专业积木,而非面向大众的消费级工具。它的未来,取决于能否从“让AI用Discord”的工具,进化成为“让AI在Discord中自主协作”的生态基石。
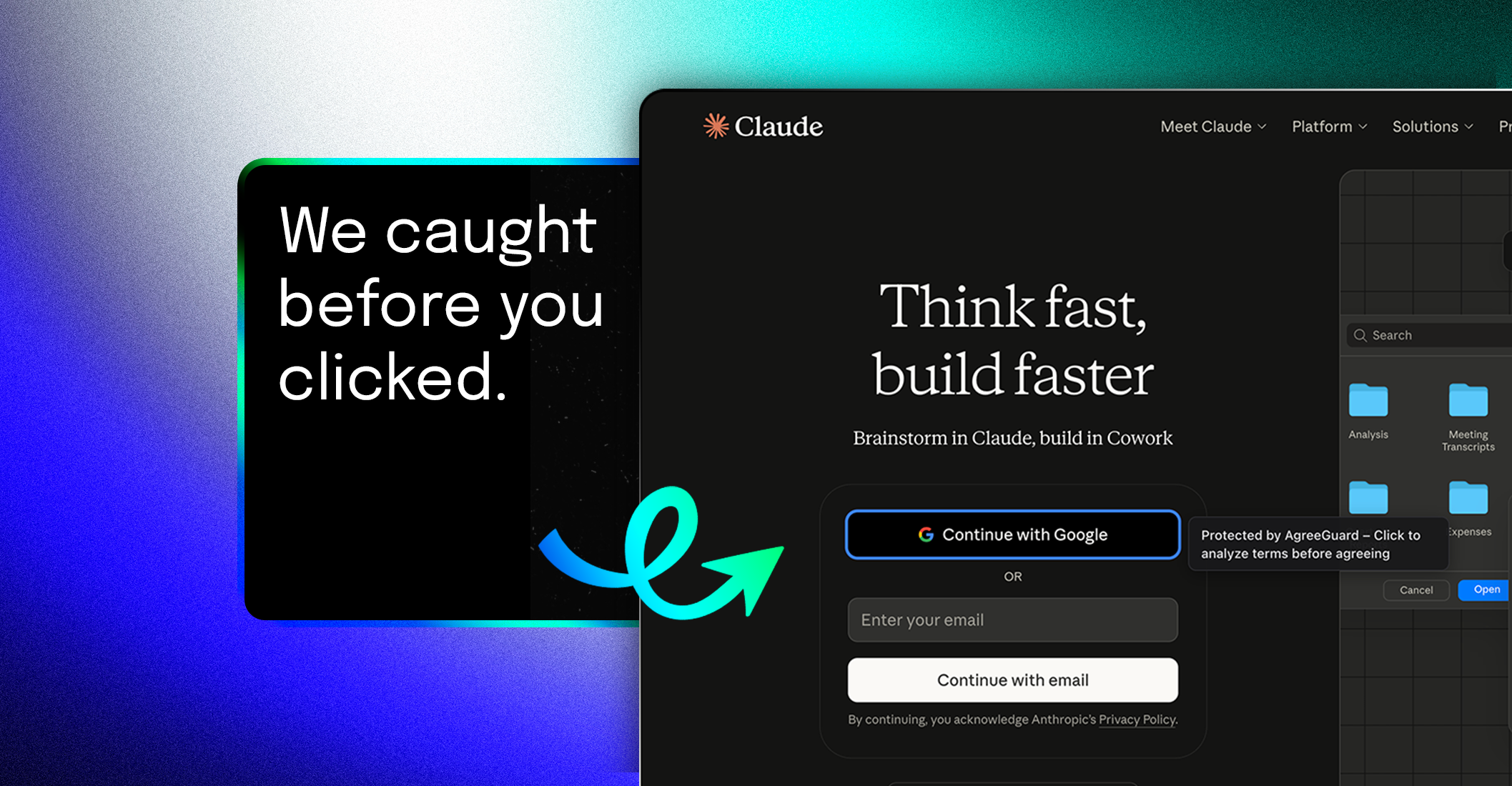
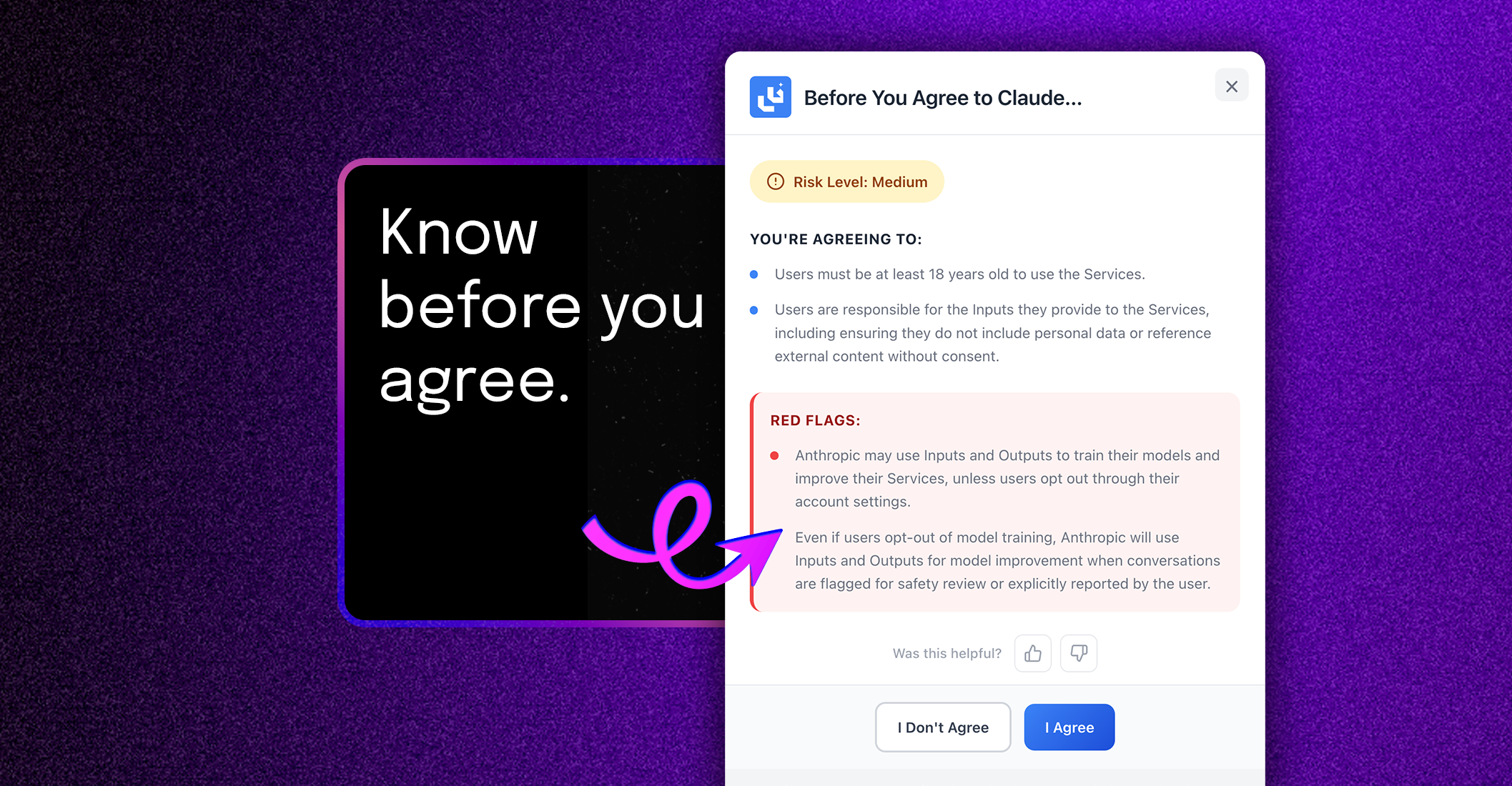
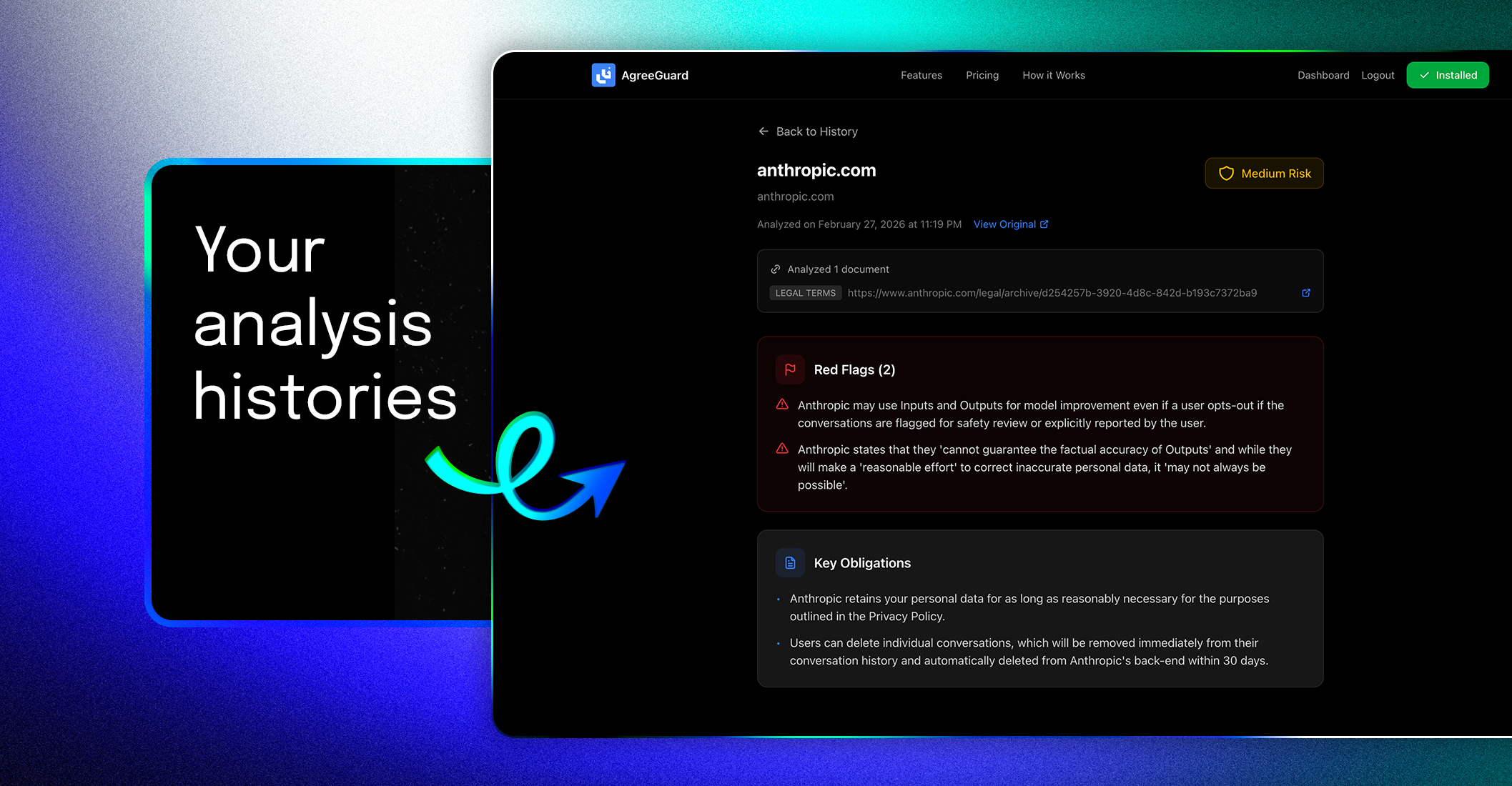
一句话介绍:一款免费的Chrome扩展,利用AI在用户点击“同意”前,快速分析并高亮提示服务条款中的关键风险点,解决了人们在网络注册时因条款冗长复杂而被迫“盲签”的痛点。
Chrome Extensions
Privacy
Artificial Intelligence
浏览器扩展
AI分析
服务条款解读
隐私保护
风险提示
消费者权益
自动化工具
法律科技
透明度工具
用户评论摘要:用户普遍认可其核心价值,认为需求真实。主要问题聚焦于:分析覆盖场景(是否支持弹窗条款)、历史协议回溯分析可行性、AI识别的准确性与深度(能否发现隐蔽条款),以及输出是具体条款还是风险评分。
AI 锐评
AgreeGuard 瞄准了一个广泛存在的“认知懒惰”与“权力不对等”的真空地带。其真正价值并非提供一份滴水不漏的法律意见——它明确声明不替代阅读——而在于充当一个“数字惊醒器”。产品聪明地将“总结全文”这一AI不擅长的复杂任务,降维成“标记已知风险模式”,如自动续费、数据转售、放弃法律权利等。这一定位使其在实用性与法律风险间取得了平衡。
然而,其深层挑战在于“信任代理”角色的可持续性。首先,AI的“准确性”黑箱与法律条款的“解释权”灰箱叠加,可能产生误导性安全错觉。其次,其商业模式隐含矛盾:作为免费工具,它揭露企业利用复杂条款设置的商业“陷阱”;但若未来向企业端收费转型为“合规认证”工具,其中立性将面临考验。最后,它的成功可能促使服务条款撰写者发展出更隐蔽的“反AI识别”话术,陷入攻防战。
本质上,它是一款“症状缓解剂”而非“问题解决剂”。它揭示了网络时代格式合同已沦为单方声明,而非双方合意的本质。它的流行是对当前商业实践的一种尖锐讽刺,也是技术对制度失灵的一种迂回补救。其长期生存不仅取决于技术精度,更取决于能否在消费者觉醒与商业伦理之间,找到一个不自我瓦解的支点。
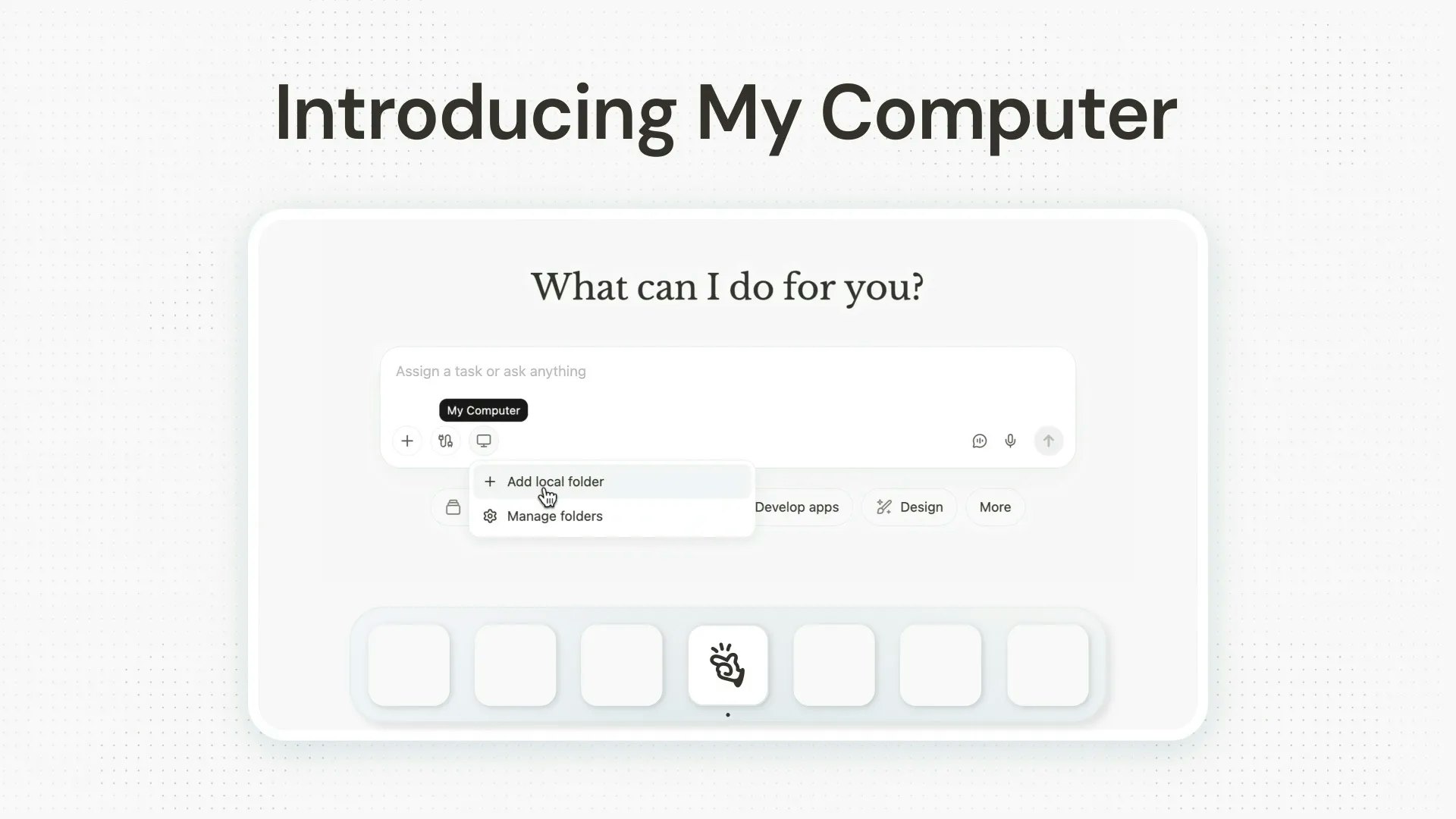
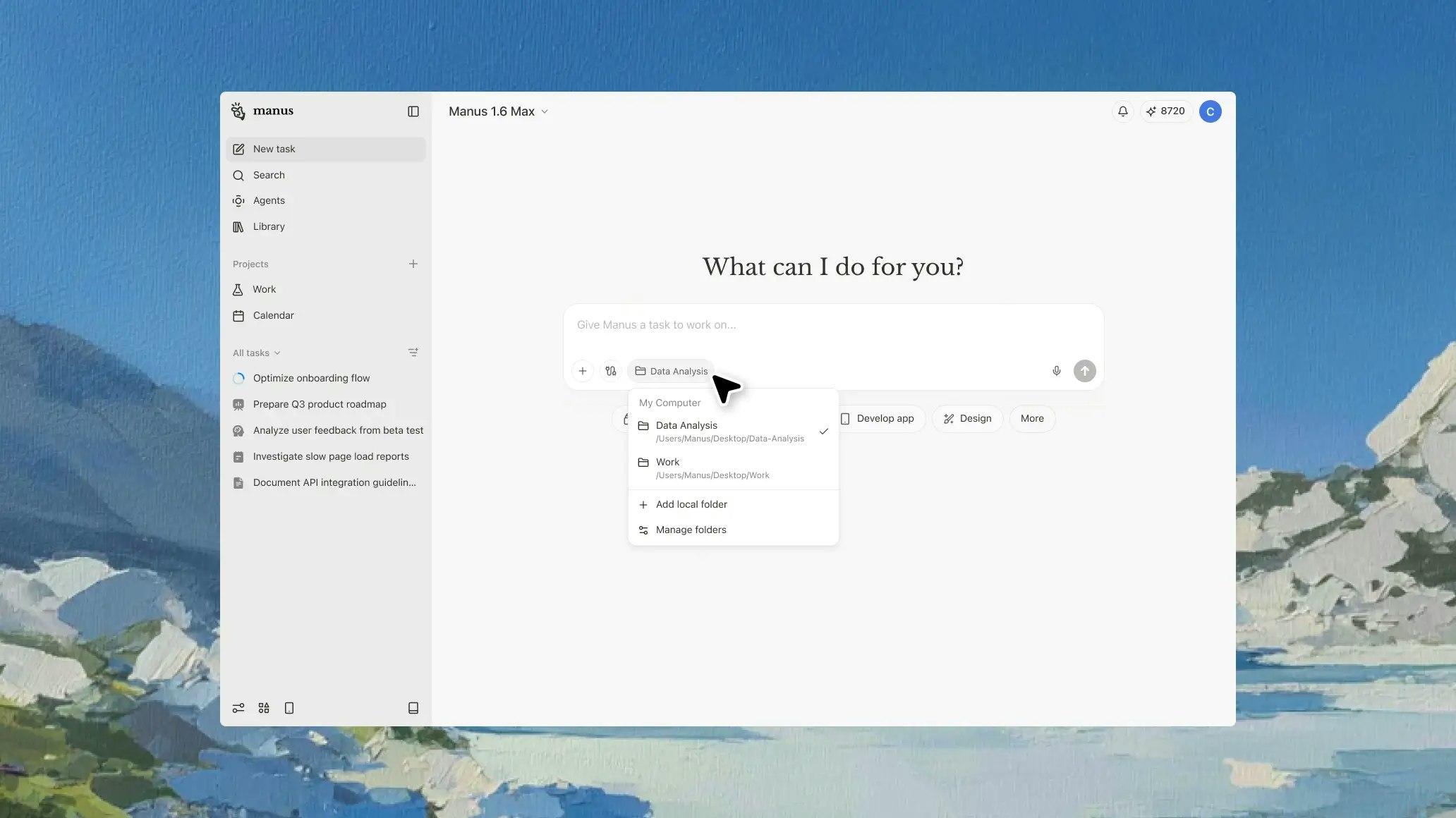
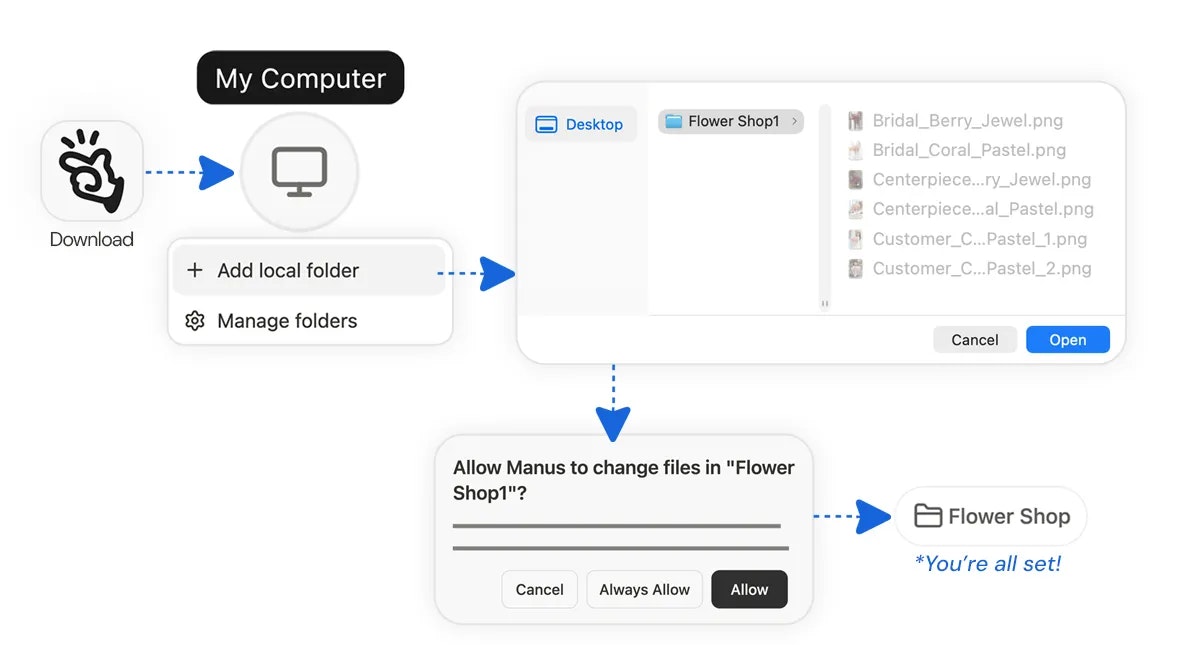
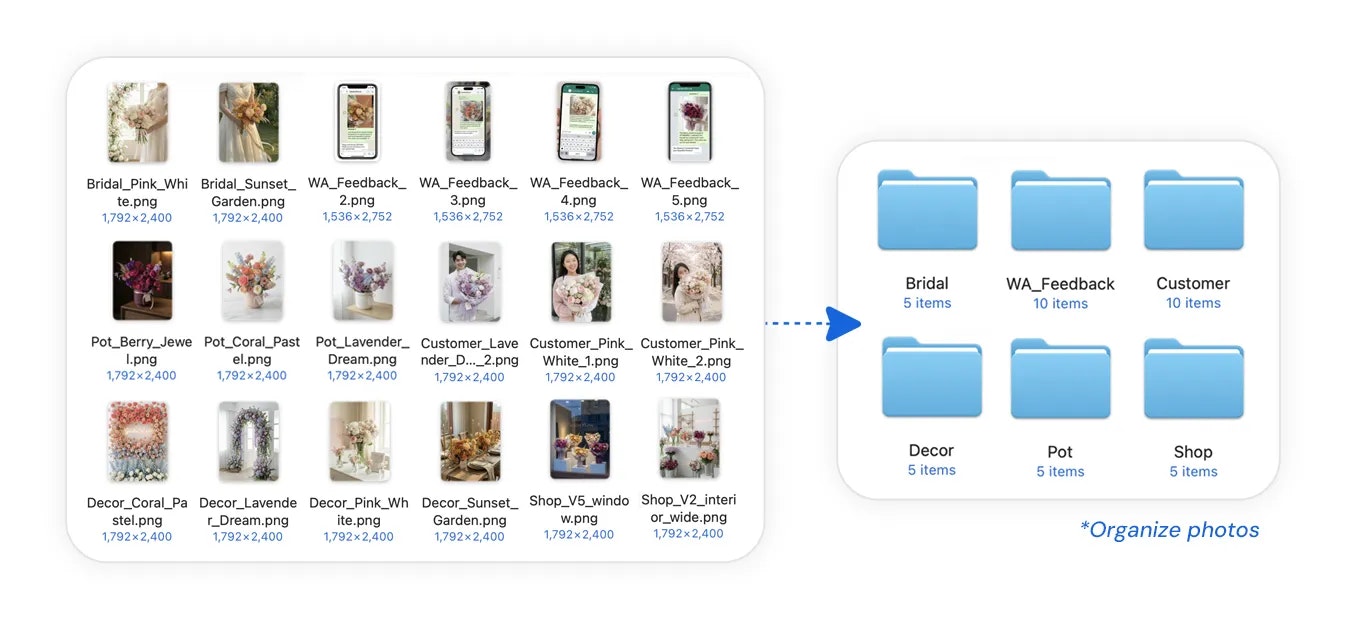
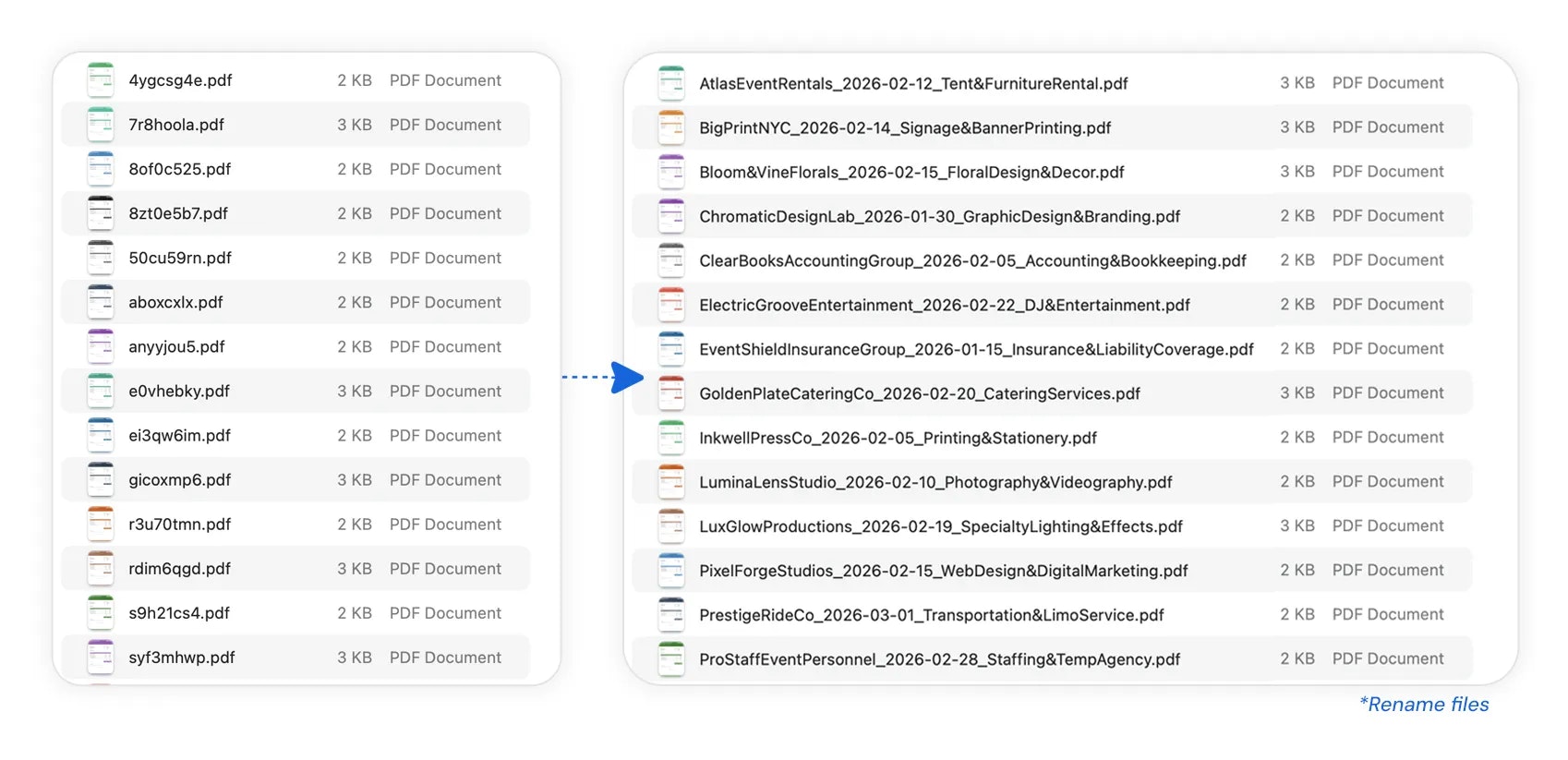







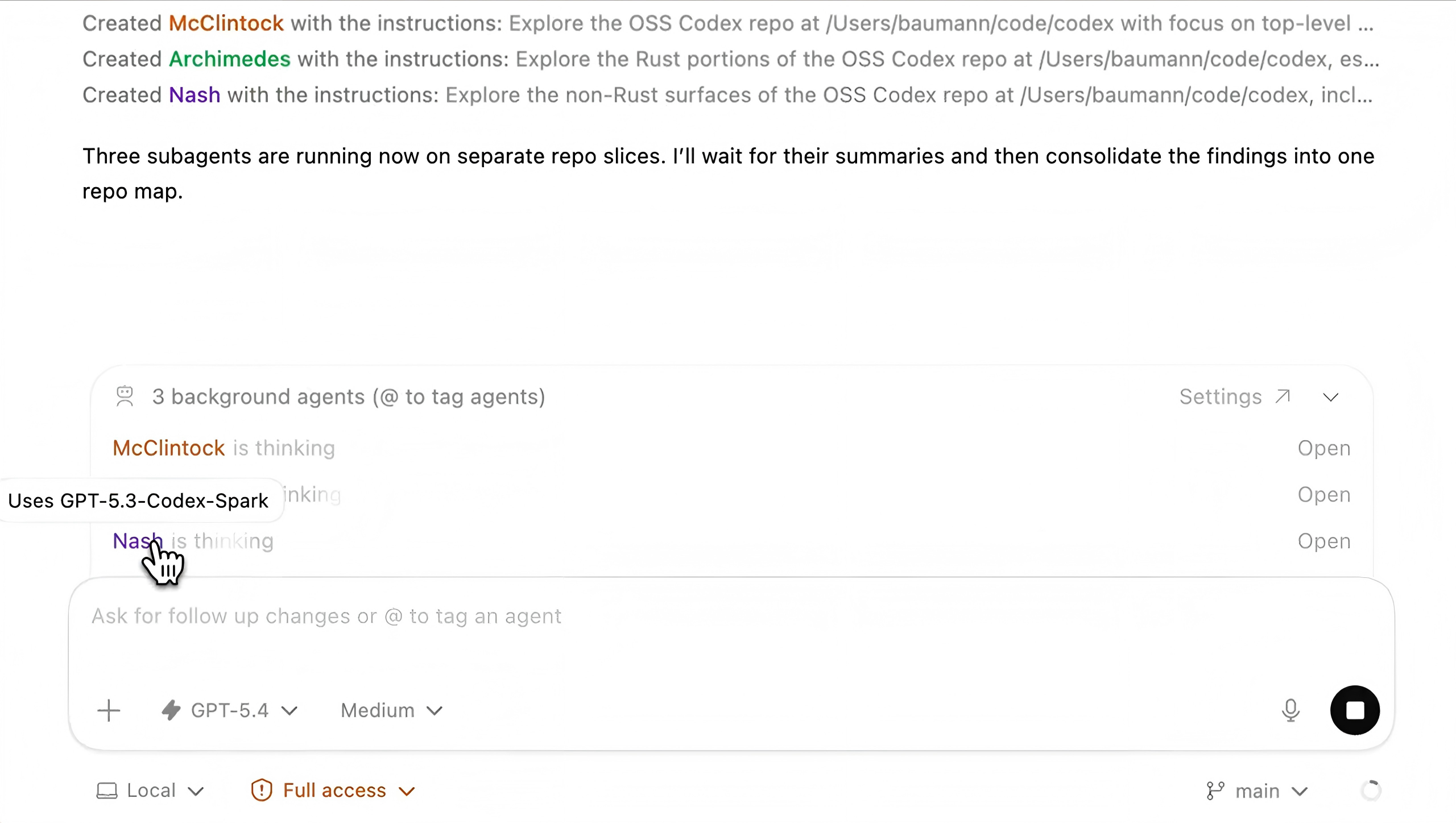
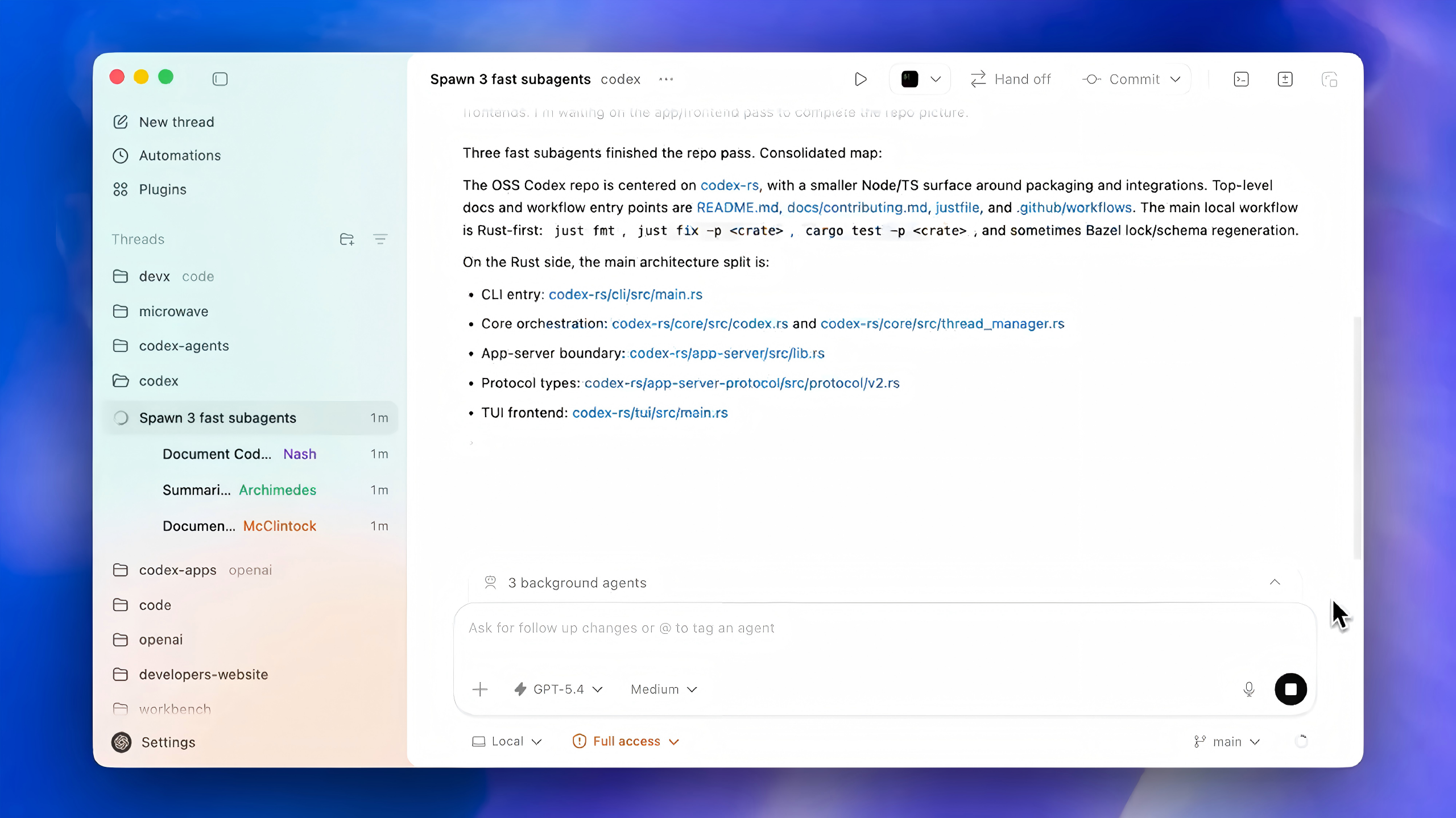









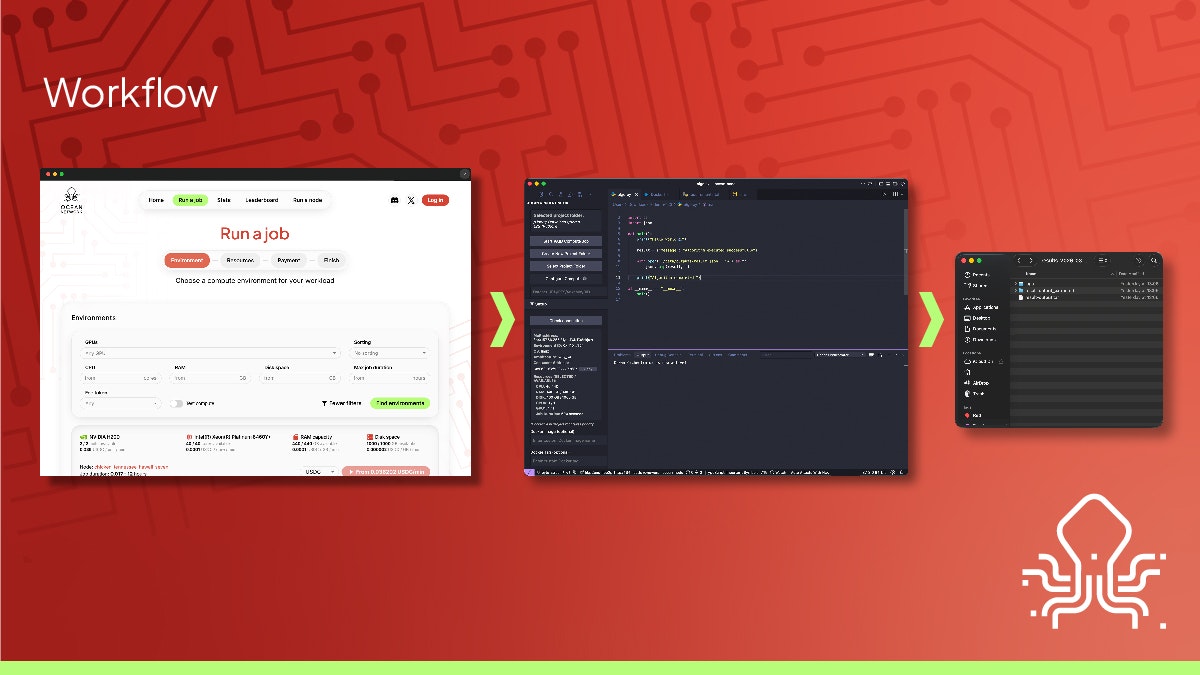
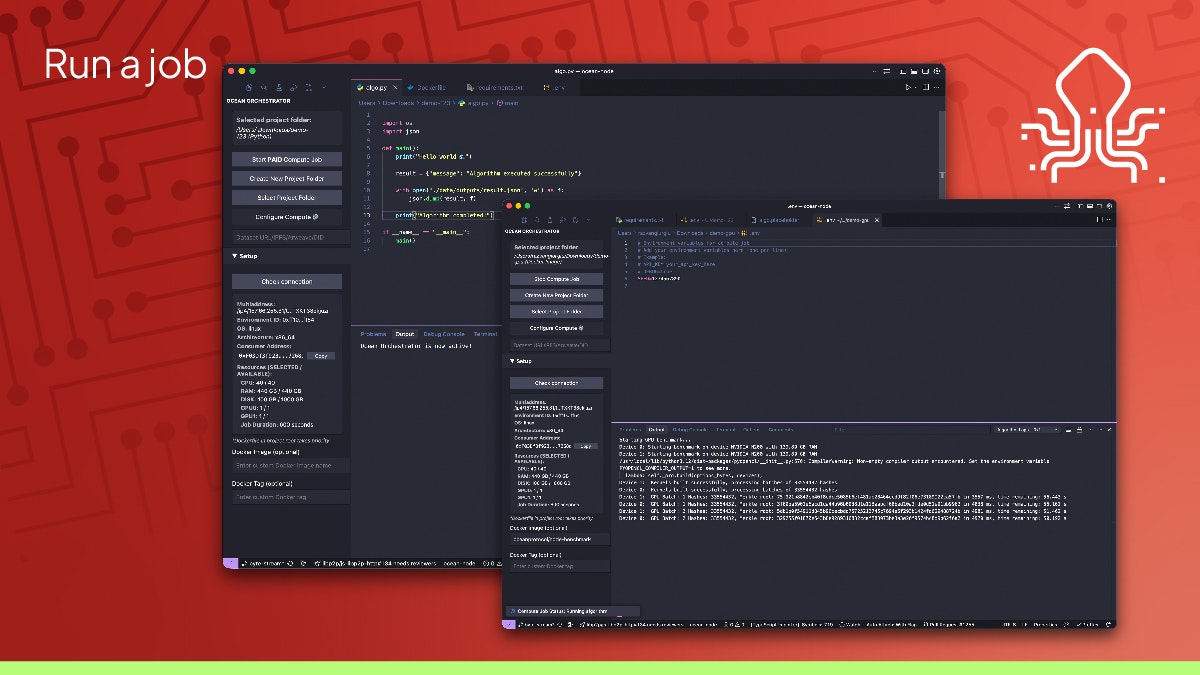

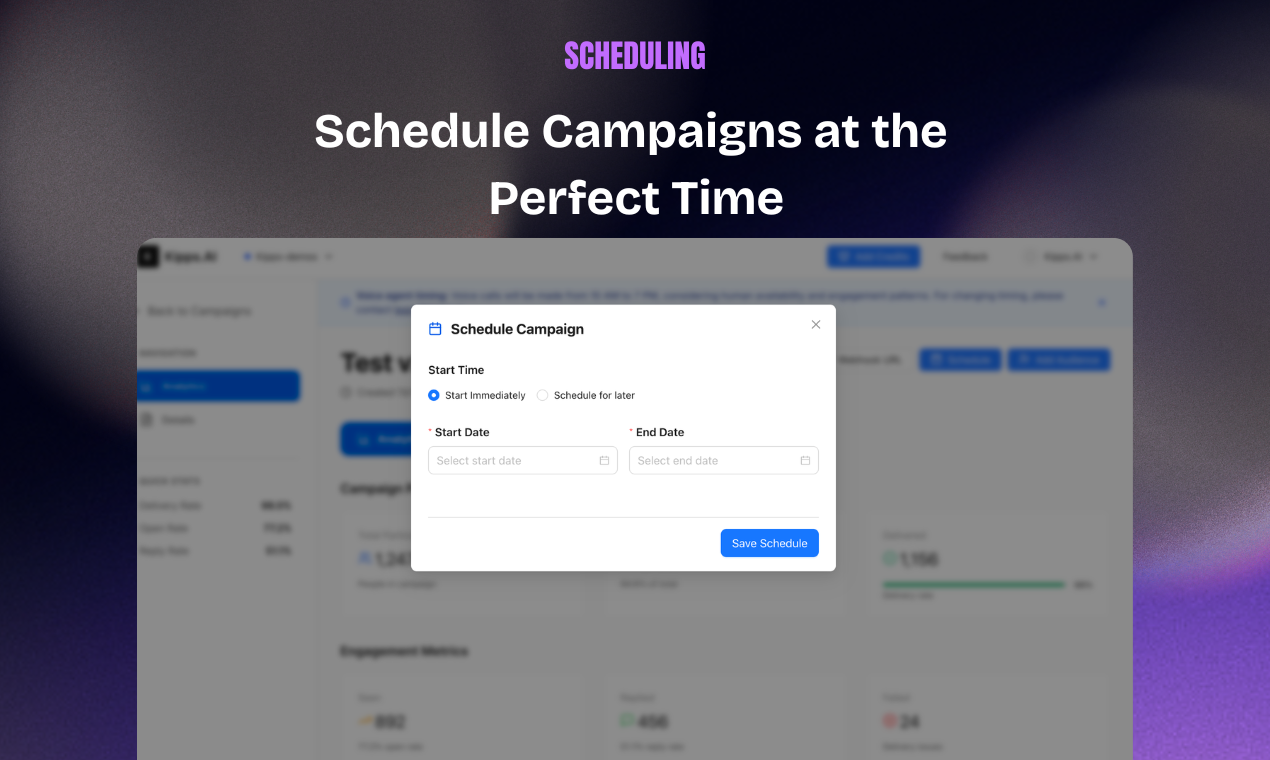
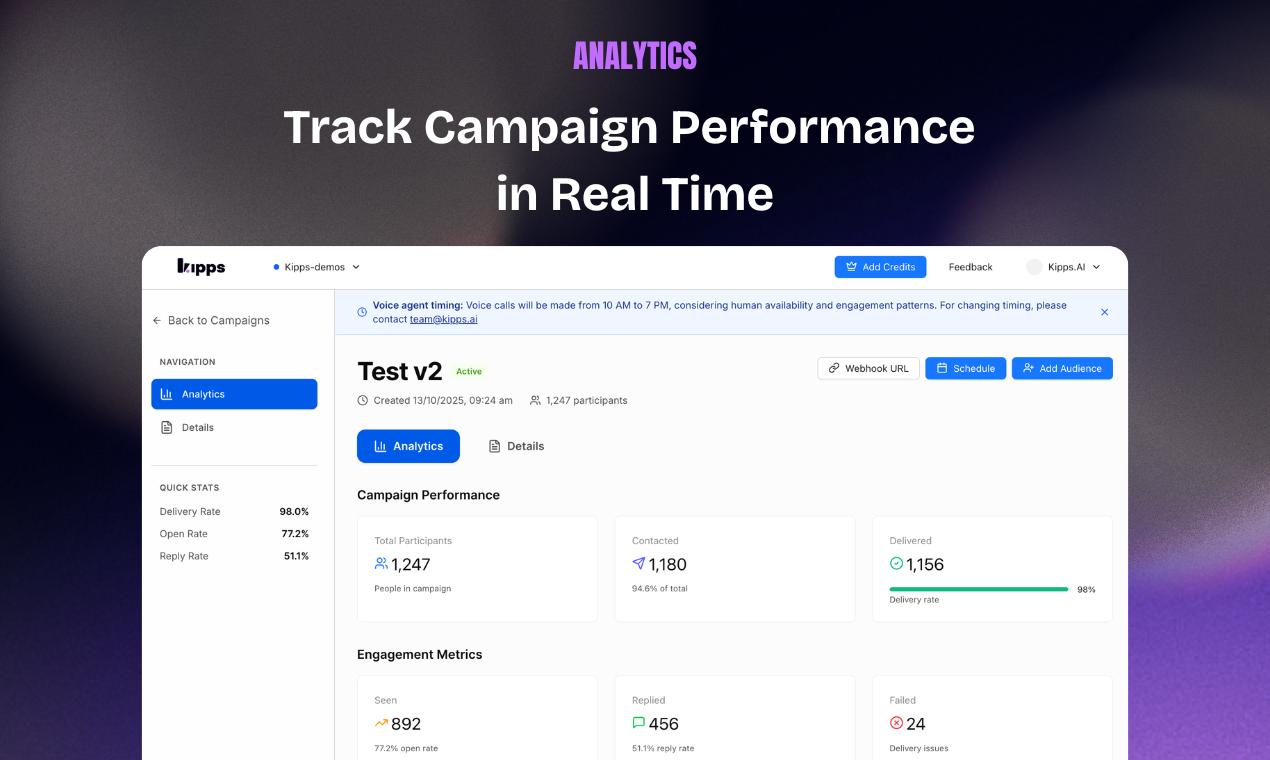
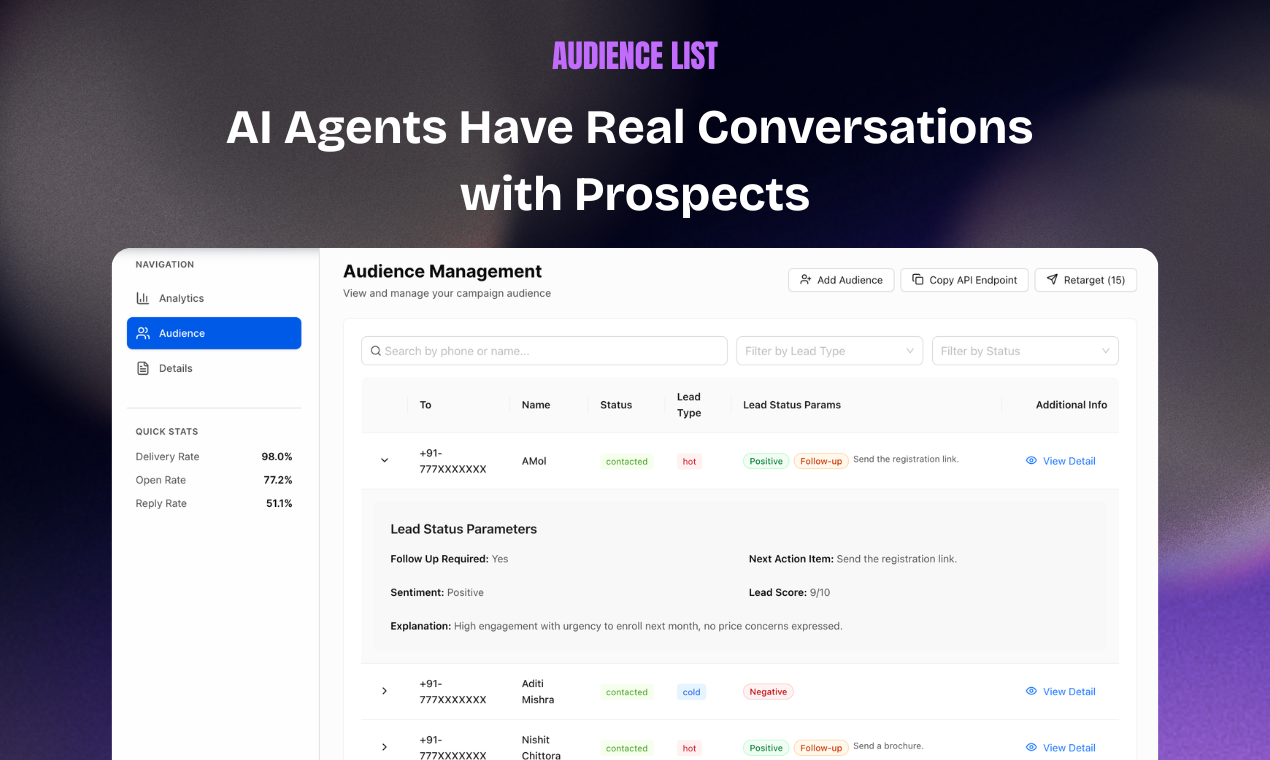
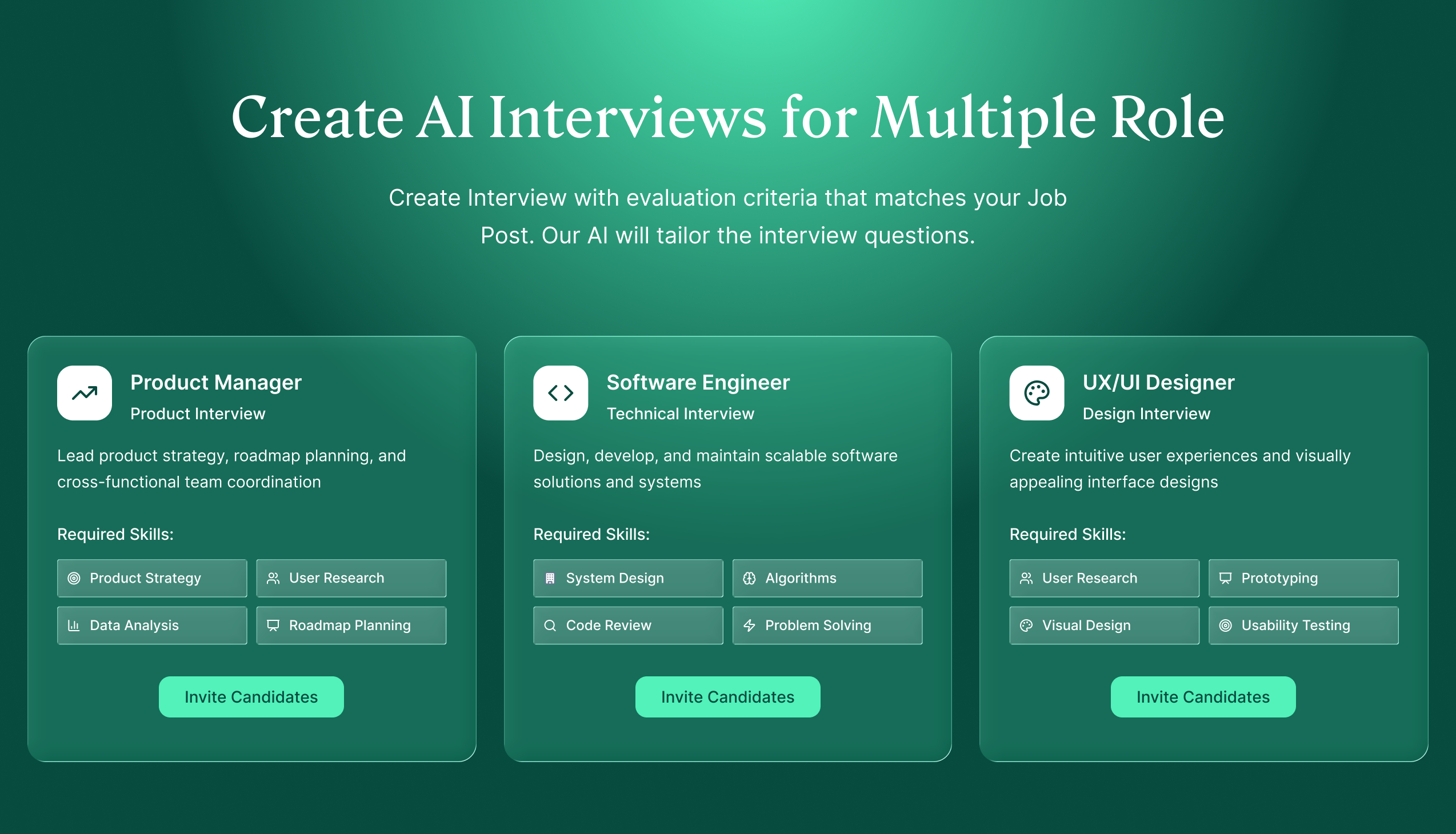

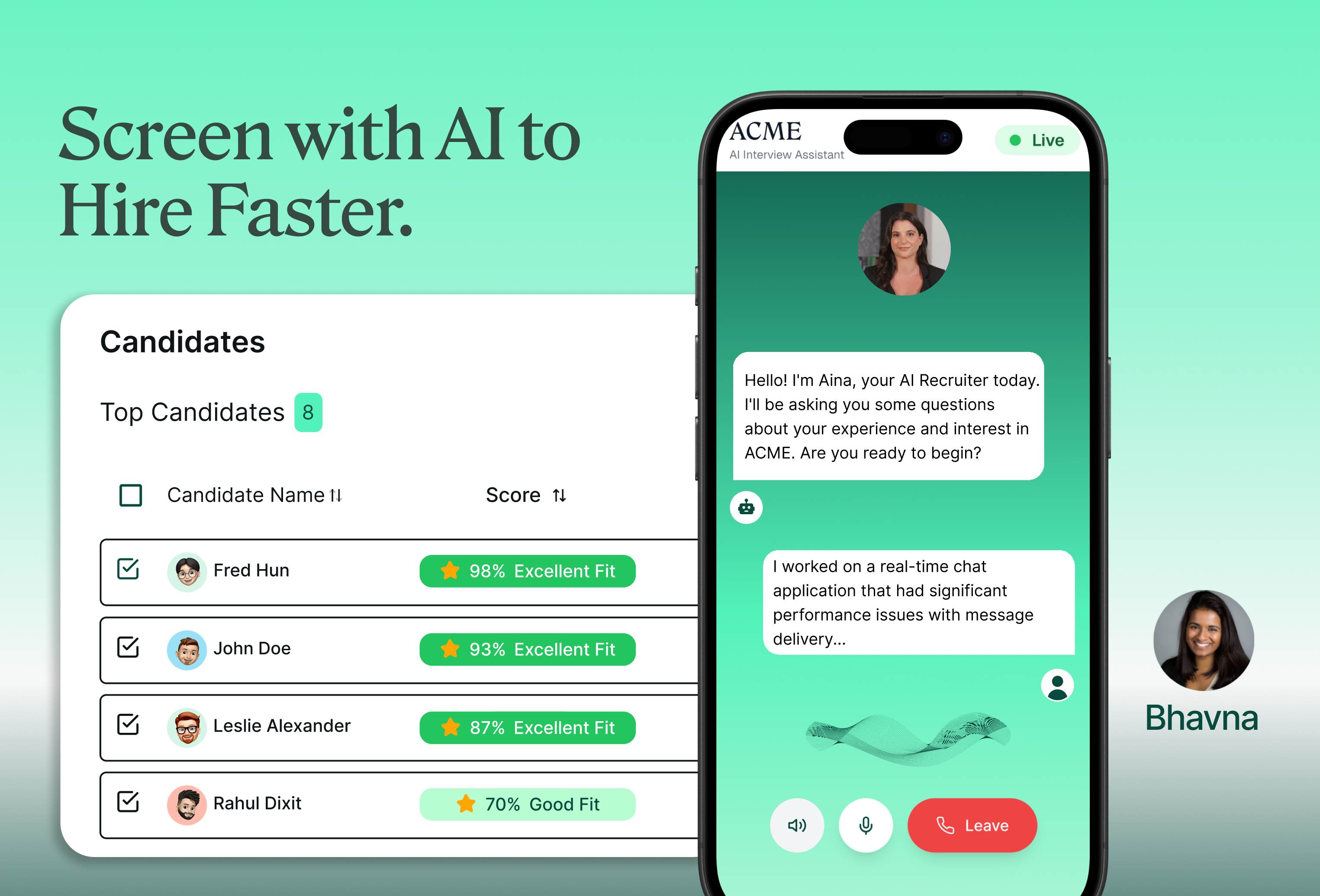








Manus just took a big step forward with My Computer, bringing its AI agent out of the cloud and directly onto your desktop.
Until now, Manus worked in a cloud sandbox. But most of our real work lives locally: files, dev environments, apps, and workflows. My Computer bridges that gap by letting Manus execute command line instructions on your computer to read, organize, edit files, and control local applications.
What makes it interesting is the automation potential. Manus can organize messy folders, rename hundreds of files, build apps through CLI tools like Python, Node.js or Swift, and even run tasks using your machine’s idle compute.
You can also assign tasks remotely, for example, asking Manus to find a file on your home computer and email it through Gmail while you're away.
Key highlights:
Works directly with local files, tools and apps
Executes terminal commands with your approval
Automates repetitive file and workflow tasks
Can build software projects via CLI tools
Uses idle compute resources in the background
Lets you trigger tasks remotely across devices
This seems especially useful for developers, builders, and anyone managing large local workflows who wants automation beyond browser-based AI tools.
It reminds me of what Perplexity is doing with Perplexity Computer, but focused on letting an AI agent directly interact with your own machine and workflows.
What use cases are you thinking with My Computer by @Manus?
I hunt the latest and greatest launches in tech, SaaS and AI, follow to be notified → @rohanrecommends
This looks really interesting . How does Manus handle permissions for local tasks? Do we have fine grained control over what it can and can’t do on our machine, or is it an all-or-nothing approval for commands?
so it's a claude desktop clone?
Bringing AI agent capabilities directly to the local desktop is a game-changer. As someone who values local-first workflows, I’m curious about the performance side—does running Manus locally consume significant CPU while it's processing CLI tasks in the background?
Moving Manus from cloud-only sandboxing to direct local machine access via CLI execution is the natural next step — most real productivity workflows involve local files, dev environments, and desktop apps that a cloud-only agent simply can't touch, so bridging that gap unlocks an entirely different class of automation tasks. The remote task triggering is a compelling feature for power users, but how does Manus handle permission scoping on local execution — is there a granular approval system for different command types, or does the user approve each terminal command individually?
Giving this a shot! Looks a lot like Claude desktop, and I am OK with that, happy to see a familiar Ui
It reminds me a lot of Claude desktop, which I’m totally fine with. Glad to see a familiar UI.
Really interesting concept: a general AI agent that actually executes complex tasks instead of just responding feels like a big shift toward true automation. Congrats on the launch! What kinds of tasks does Manus handle most reliably right now without needing human intervention?
Great stuff! So far it runs smoother than Claude's Dispatcher
How easy is it to set up remote task triggering ? I'm curious about how well it works across devices, especially if I want to trigger tasks from a phone or another machine .
Manus is a general AI agent that transforms your thoughts into actions, handling tasks across work and life. It helps you get things done effortlessly while you focus on other priorities.