PH热榜 | 2026-03-20
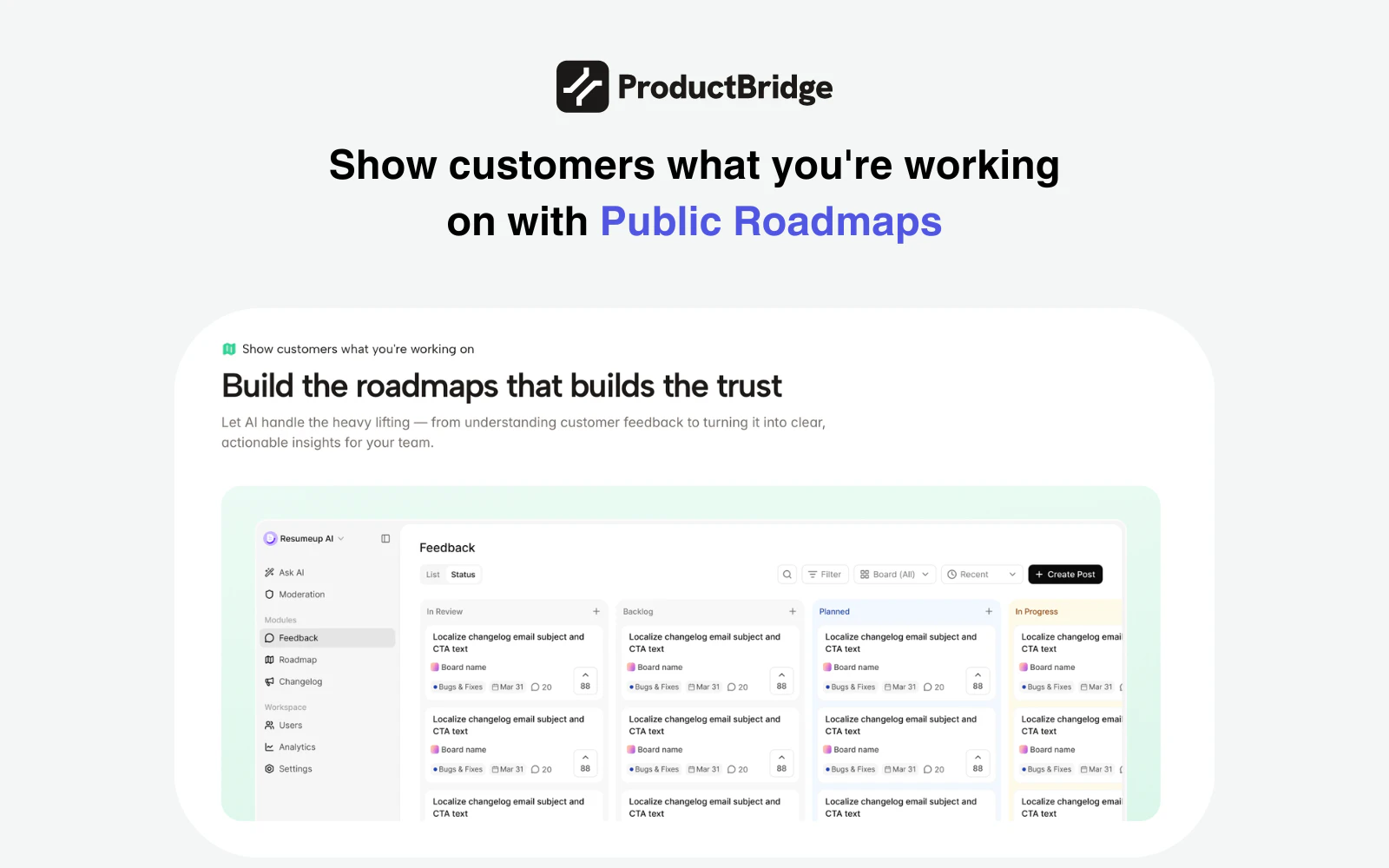
一句话介绍:一款AI驱动的反馈聚合与管理平台,通过自动收集、整理、去重来自Slack、Intercom、评论网站等多渠道的用户反馈,帮助产品团队基于数据制定路线图并自动闭环通知用户,解决了反馈分散、整理耗时、决策缺乏依据以及用户感知缺失的核心痛点。
Productivity
Customer Communication
SaaS
用户反馈管理
AI产品管理
反馈聚合
智能去重
产品路线图
变更日志
客户沟通
SaaS
扁平化定价
产品决策
用户评论摘要:用户普遍认可其解决反馈分散和闭环通知的痛点,并对扁平定价表示赞赏。主要问题集中于:AI去重与意图识别的准确性、如何处理模糊或情绪化反馈、与竞品(如ProductBoard)的差异化、以及如何避免反馈样本偏差影响决策优先级。
AI 锐评
ProductBridge切入了一个真实且混乱的市场——用户反馈管理。其宣称的价值并非简单的信息聚合,而在于试图用AI重构“反馈-决策-发布-通知”的全链路,将产品经理从繁重的手工整理、去重和沟通中解放出来。这直指现有工具(如Canny、ProductBoard)的软肋:它们提供了框架,但填充和管理框架依然依赖大量人工。
从评论看,其真正的挑战与价值都隐藏在“AI智能”的黑箱之中。首先,意图级去重和情感分析的技术可靠性是基石。用户尖锐地提问:如何区分表面相同但根源不同的反馈?如何处理情绪化的抱怨?这考验的不是简单的文本匹配,而是对业务上下文和用户真实需求的理解深度。其次,其试图用“用户价值权重”(如MRR)来纠正“民主投票”的弊端,是一个正确的方向,但这依赖于客户数据体系的完整性和准确性,可能成为中小团队的使用门槛。
扁平化定价是聪明的增长策略,在普遍按席位收费的赛道中降低了决策成本,但需警惕其是否能支撑起持续的高质量AI处理成本。产品最大的风险在于可能陷入“中间陷阱”:对于极简团队,手动处理或许够用;对于超大型企业,复杂的反馈治理流程又可能超出其当前能力。它的成功将取决于其AI能否在多样化的实际场景中持续、稳定地交付“显而易见的智能”,真正让团队感到“再也回不去”,而不是成为另一个需要被管理的工具。
最终,ProductBridge卖的是一种“确定性”——确定没有重复工作,确定优先级有据可依,确定用户能被听见。如果它能兑现承诺,其价值将远超工具本身,而成为产品决策的神经中枢。但目前,它仍需在真实世界的复杂与混乱中,证明其AI的成熟度。
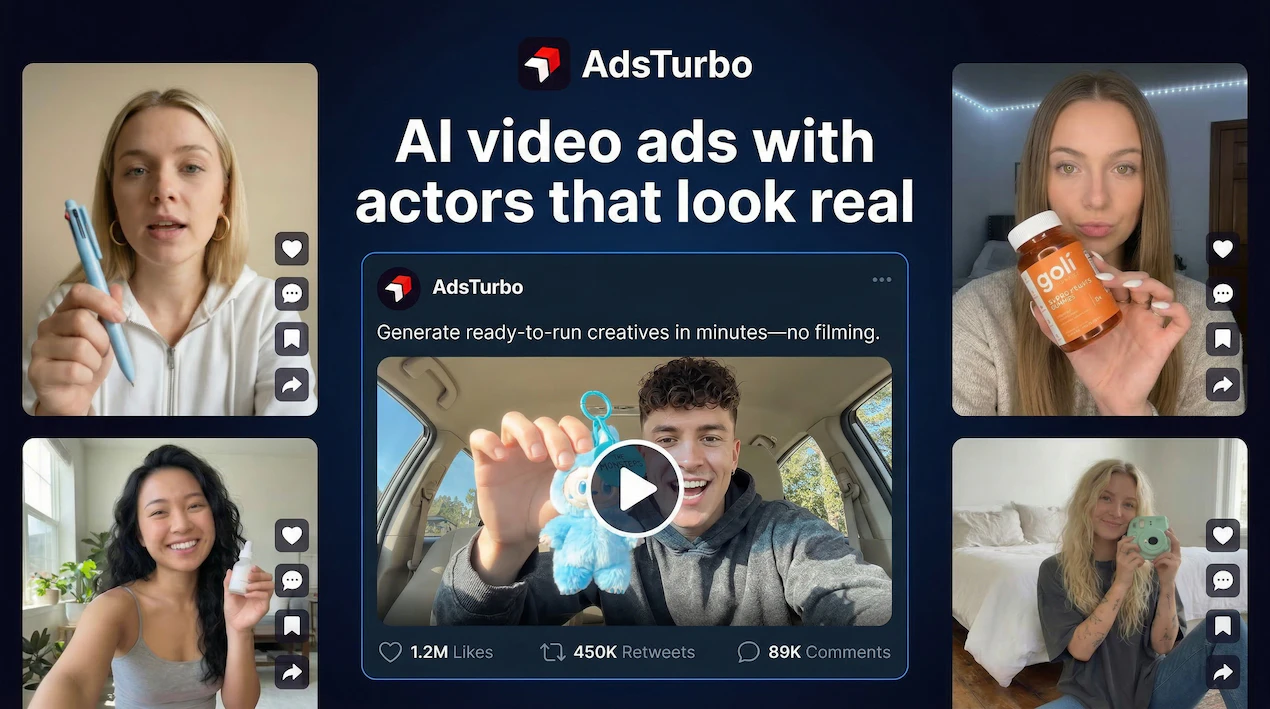
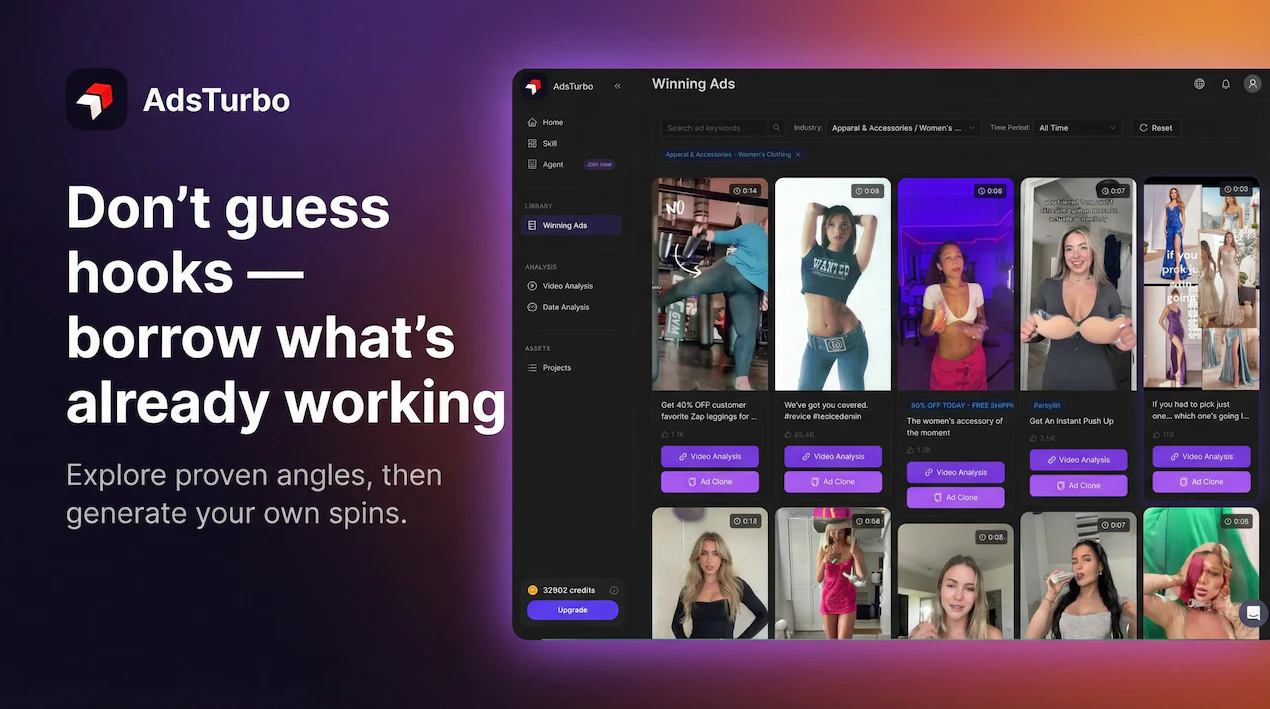
一句话介绍:AdsTurbo是一款AI视频广告生成工具,通过使用基于真实创作者训练的AI数字人演员,在电商营销、社媒广告等场景中,解决了AI生成广告内容表情僵硬、缺乏真人感、从而损害用户信任与转化率的痛点。
Marketing
Advertising
Video
AI视频生成
AI数字人
广告素材
UGC风格
营销自动化
创意测试
性能营销
AI广告工具
视频制作
SaaS
用户评论摘要:用户反馈集中于几个核心问题:AI生成内容的真实感与伦理(如创作者授权)、与竞品(如HeyGen)的差异化、API集成可能性、品牌音调与演员表现的自定义能力,以及客户对“假内容”的品牌风险担忧。建议包括增加分镜头审核流程以提高客户接受度。
AI 锐评
AdsTurbo切入了一个精准且日益拥挤的赛道:用AI生成“以假乱真”的营销内容。其宣称的核心价值——通过基于真人训练的AI演员消除“AI味”——直击当前AI视频生成在营销应用中的最大命门:信任赤字。然而,这恰恰也是其最大的风险与争议所在。
产品的真正价值并非仅仅是技术上的“更逼真”,而在于试图将“逼真”工业化、规模化,成为可测试、可复制的广告素材生产线。它瞄准的不是取代所有视频制作,而是性能营销中那个最耗时的环节:快速生产大量用于A/B测试的UGC风格视频变体。从这个角度看,它与HeyGen等通用型数字人工具形成了场景化差异,后者更偏向演示与沟通,而AdsTurbo则深度绑定“广告转化”这一具体目标。
但评论中暴露的担忧极为深刻。其一,伦理地基是否牢固?即便获得了创作者授权,其AI模型对真人表情、姿态的“学习”与再创造,在品牌安全至上的广告主眼中,仍是潜在的风险点。其二,“逼真”是一把双刃剑。当AI演员逼真到足以混淆视听,却未被明确标识时,可能引发消费者反弹,长远损害品牌信任。这要求产品必须在“透明”与“以假乱真”之间找到平衡,而目前其策略似乎更倾向于后者。
更关键的是,它试图解决的“客户审批风险”可能比技术问题更难逾越。广告是品牌人格的延伸,资深评论者指出的“分镜头审核流程”需求,揭示了核心矛盾:AI提升了生产效率,但将品牌敏感度与审美判断“自动化”却异常困难。AdsTurbo的成败,或许不在于其AI演员是否足够像人,而在于其工作流能否融入并安抚品牌方那颗对“失控”充满警惕的心。
因此,AdsTurbo的价值命题需要被重新审视:它或许不是“完美人类模拟器”,而是一个“高效创意假设验证器”。它的未来不在于完全取代真人拍摄,而在于成为营销团队快速探索创意方向、降低测试成本的杠杆。若能在此定位上深耕,并构建起合规、透明、可控的协作体系,其生存空间将更为稳固。否则,它可能只是另一个在“恐怖谷”边缘徘徊的技术奇观,难以获得主流品牌市场的真正拥抱。
一句话介绍:一款面向复杂、长周期开发任务的高性能代码生成模型,以极具竞争力的成本解决了AI编程工具精度不足与费用高昂的痛点。
Developer Tools
Artificial Intelligence
Development
AI代码生成
编程助手
大语言模型
成本优化
长周期任务
开发工具
模型微调
性能基准
效率提升
Cursor
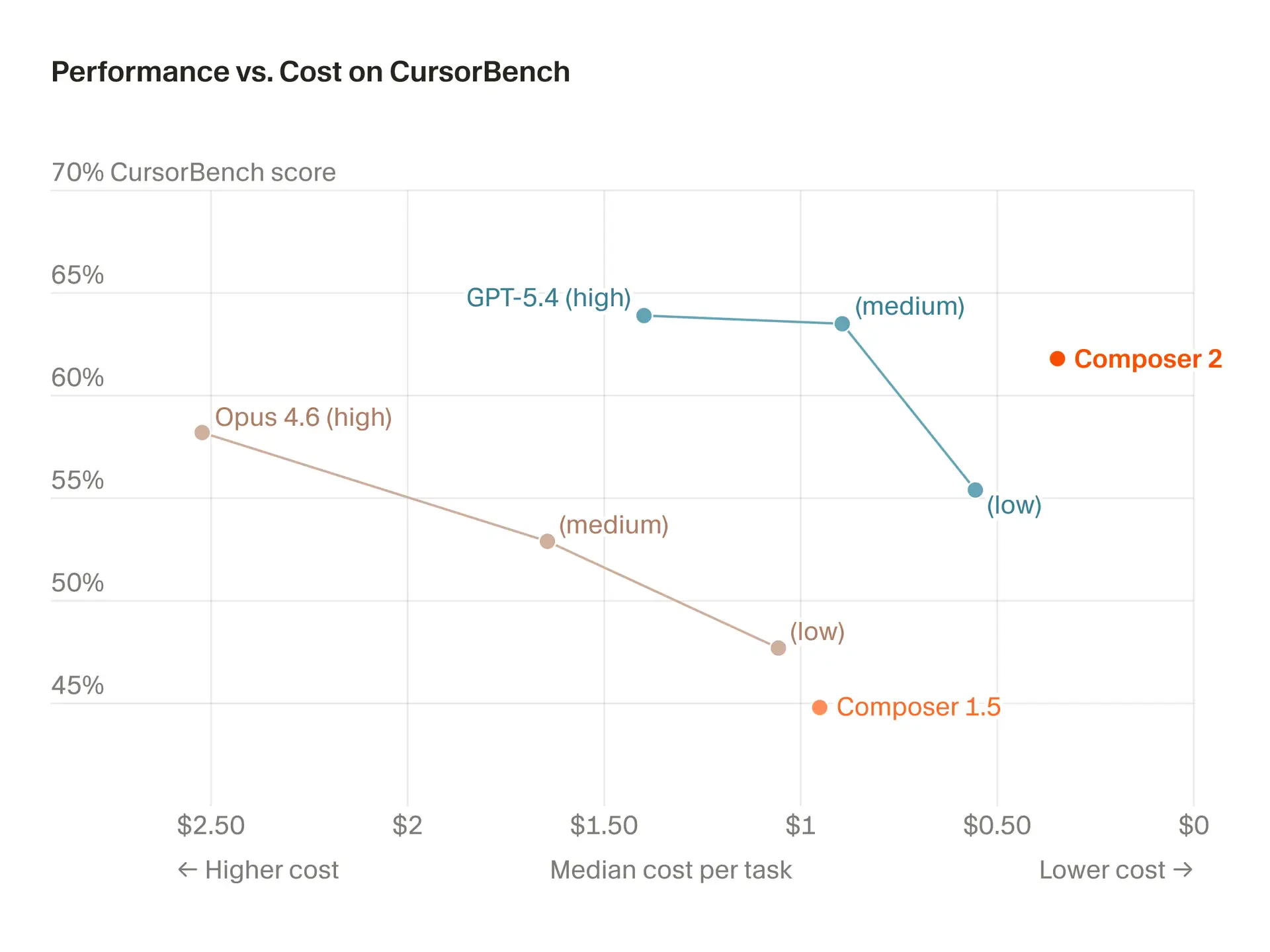
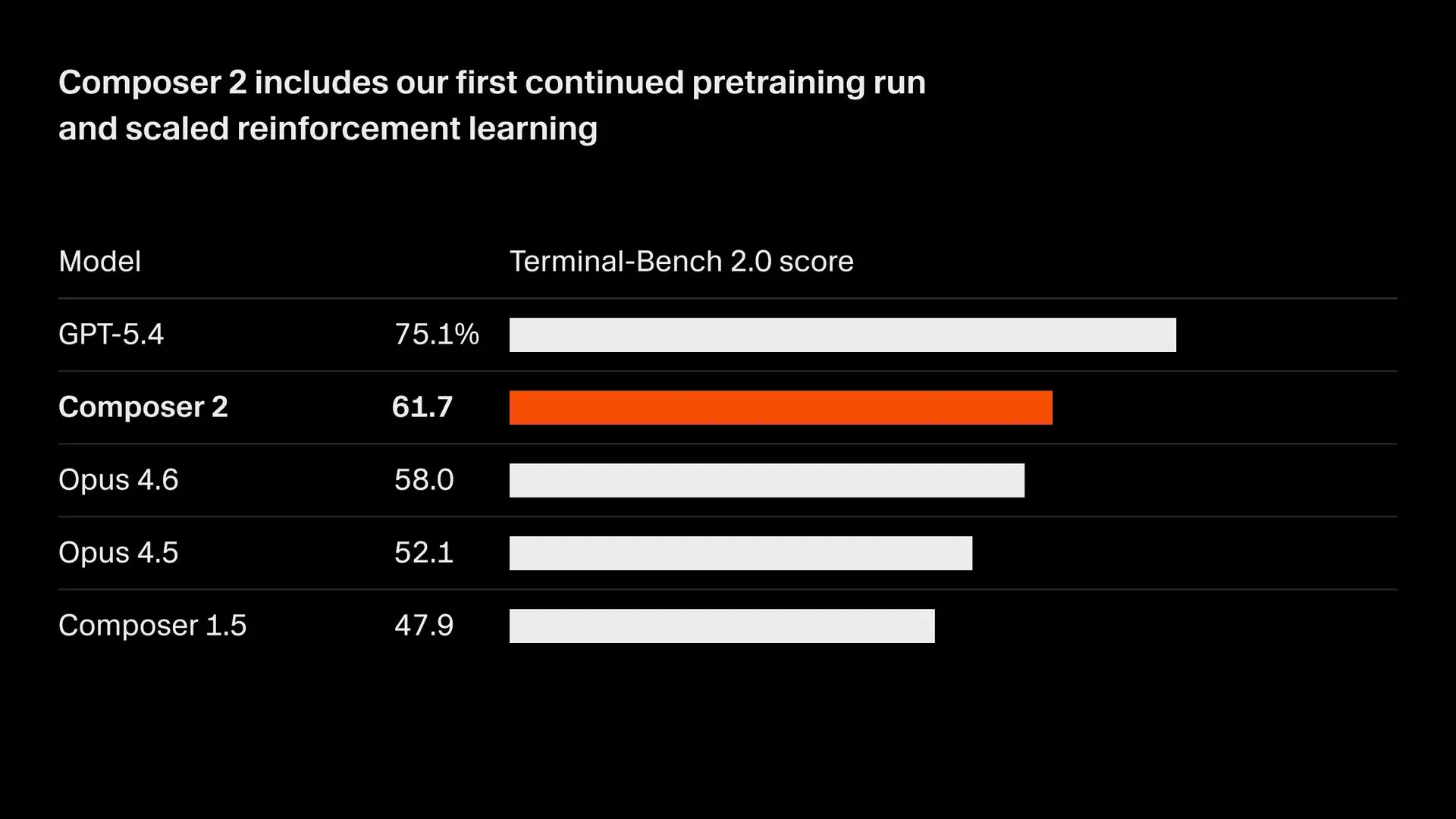
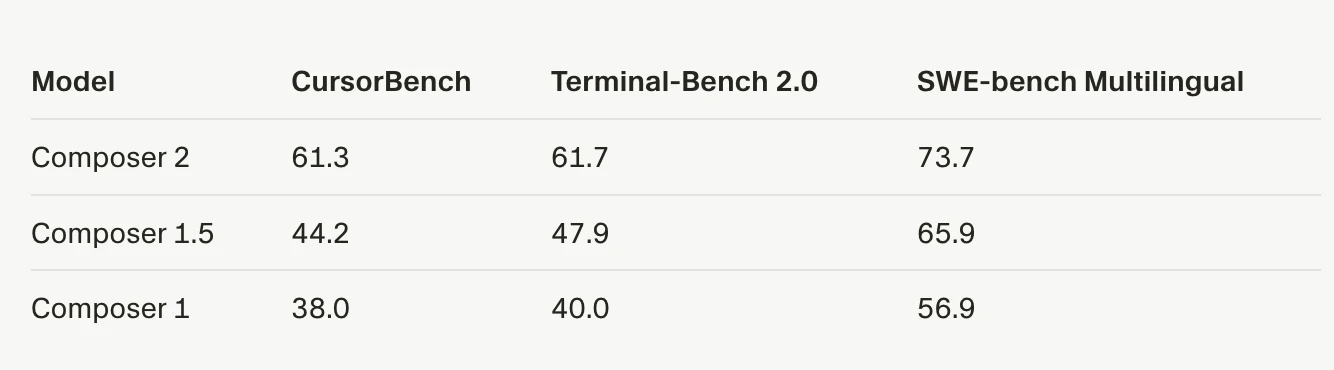
用户评论摘要:用户普遍认可其性能与性价比,认为其媲美Claude Opus但更便宜快速。核心关注点在于其“长周期推理”能力在实际多文件、大型代码库重构中的真实表现,质疑其能否保持全局一致性。另有用户提及其对Kimi 2.5模型的微调基础及内存占用问题。
AI 锐评
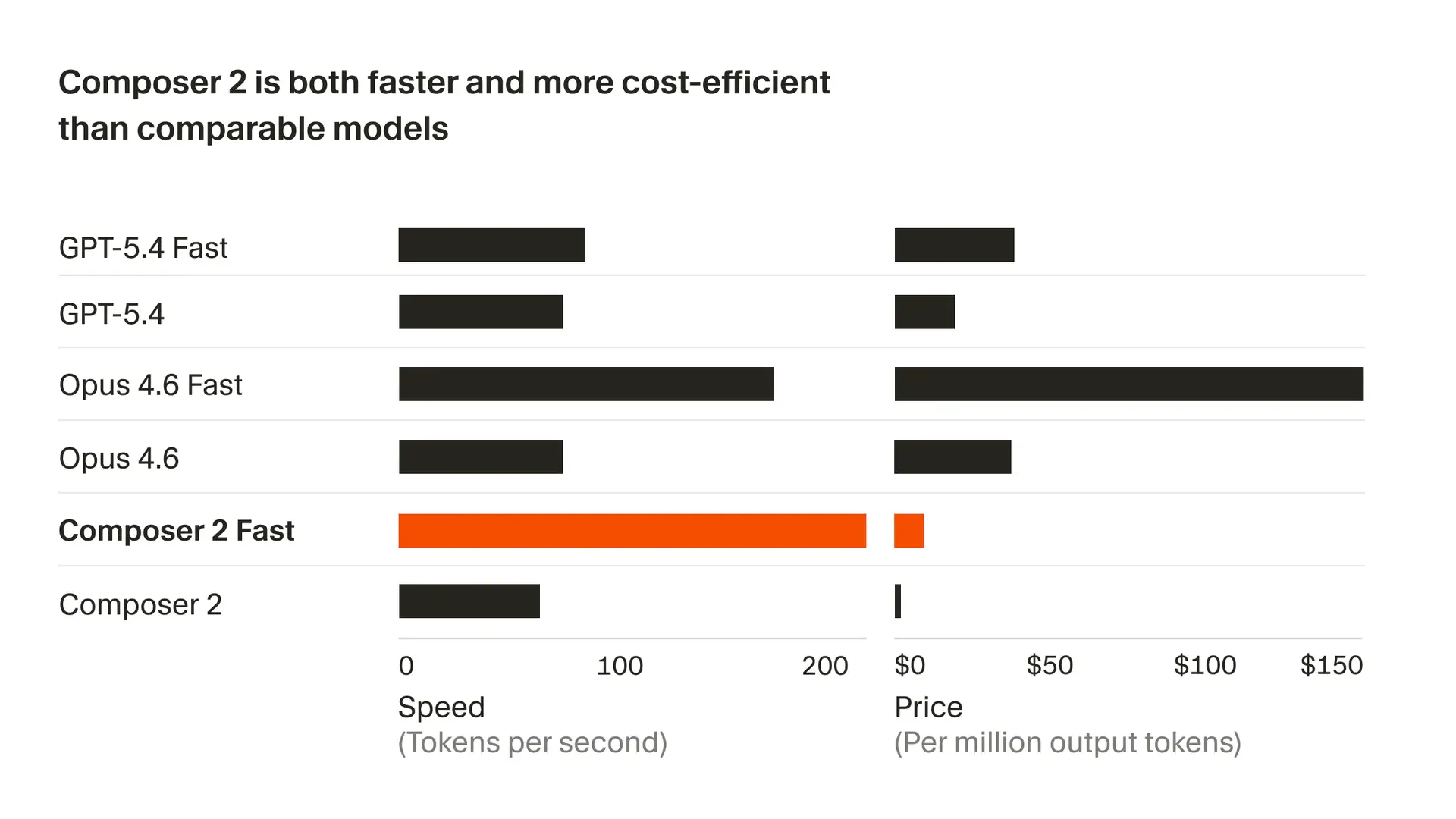
Composer 2的发布,与其说是一次模型升级,不如说是Cursor对其“模型+编辑器”一体化战略的一次关键押注。在AI编程助手陷入同质化竞争和成本焦虑的当下,它精准地打出了“前沿性能”与“极致性价比”的组合拳,试图用接近Claude Opus的能力和十分之一的价格重新定义市场规则。
其真正价值,并非仅仅体现在基准测试分数的提升上,而在于它试图通过“持续预训练+强化学习”专门优化“多步骤编码任务”,直击当前AI编程的核心软肋——缺乏对复杂、长周期开发任务的连贯性规划和执行能力。用户评论中反复提及的“多文件重构中全局一致性”问题,正是这一痛点的具体体现。Composer 2的“长视野”承诺,是对这一根本性挑战的正面回应,但其实际成效仍需在真实的、混乱的大型代码库中经受考验。
然而,光有模型层面的进步是不够的。评论中透露的线索——其基于Kimi 2.5微调,以及用户对Cursor IDE内存占用的抱怨——揭示了另一层现实:AI编程的终极体验是模型、工具链与工程实践深度融合的结果。Cursor的优势在于能深度整合自家模型与编辑器,优化全链路工作流,这是纯模型提供商或纯编辑器厂商难以比拟的。但这也意味着,其成功捆绑了用户对整个生态的接受度。Composer 2的高性价比,既是吸引开发者的强力钩子,也可能成为其将用户锁定在自身平台的核心策略。它的出现,标志着AI编程战场从单纯的“模型竞赛”,进入了“模型-工具-生态”的立体化竞争新阶段。能否真正驾驭“长视野”开发,并解决工具本身的资源消耗问题,将是其从“值得一试”走向“不可或缺”的关键。
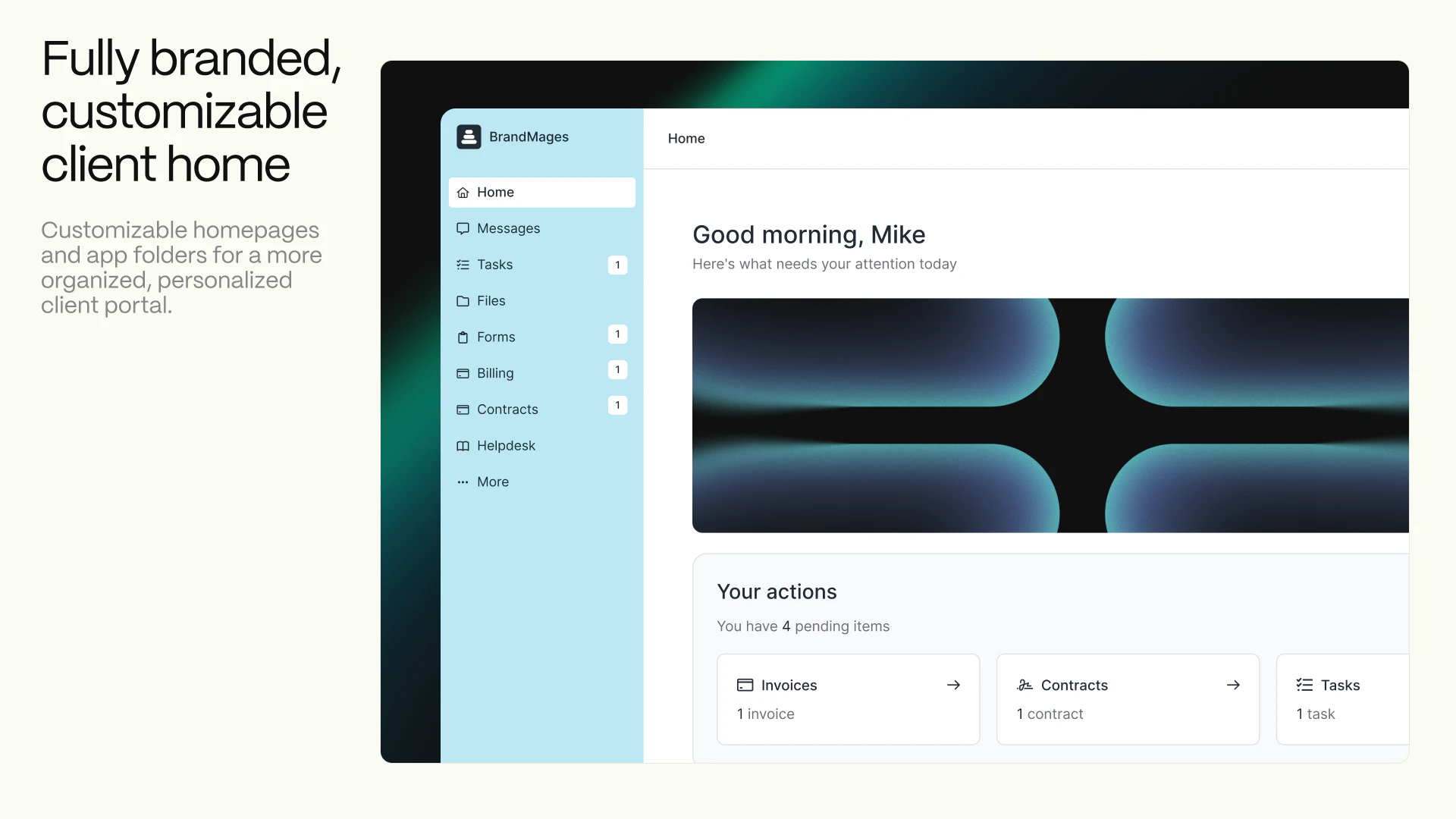
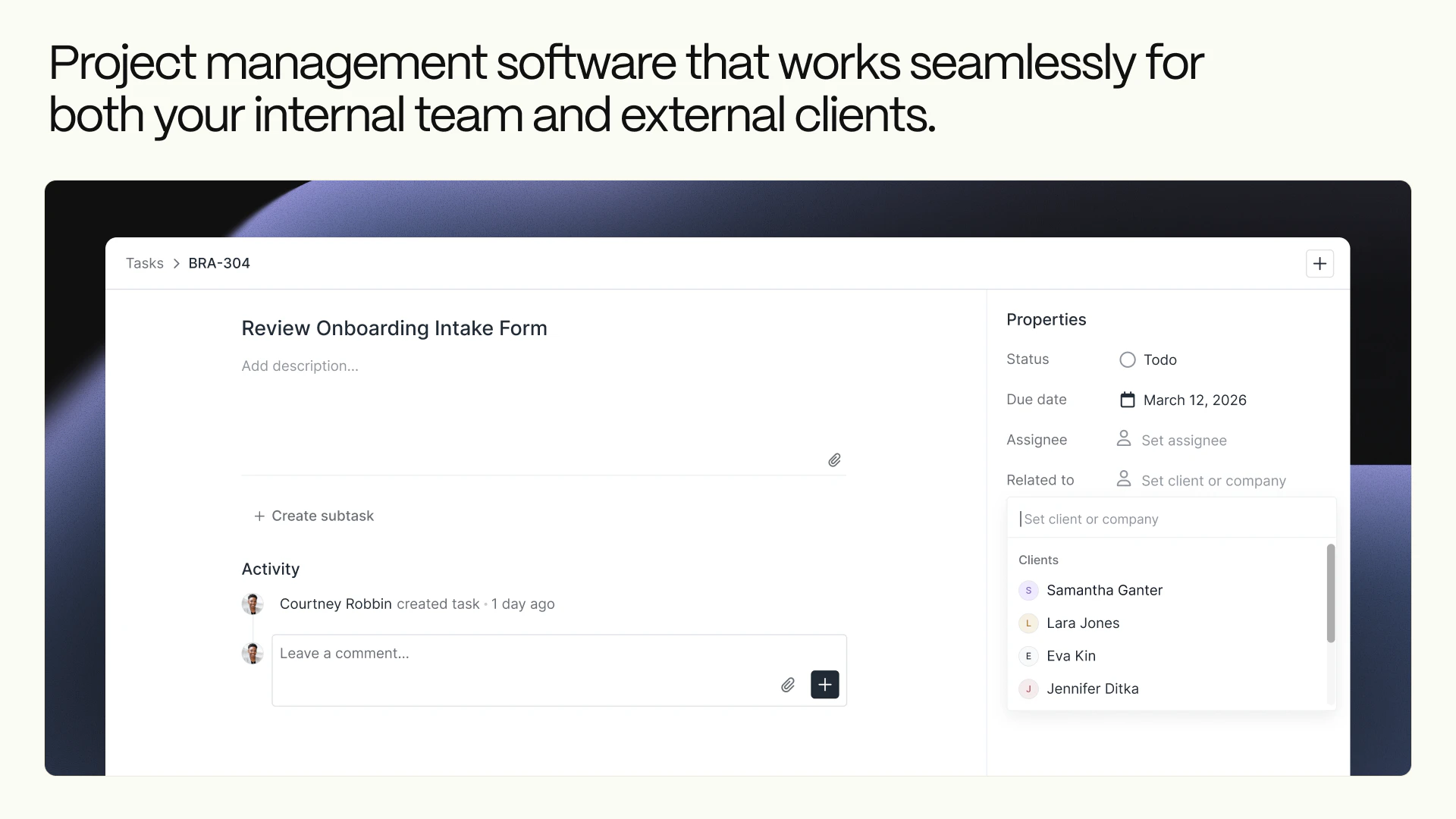
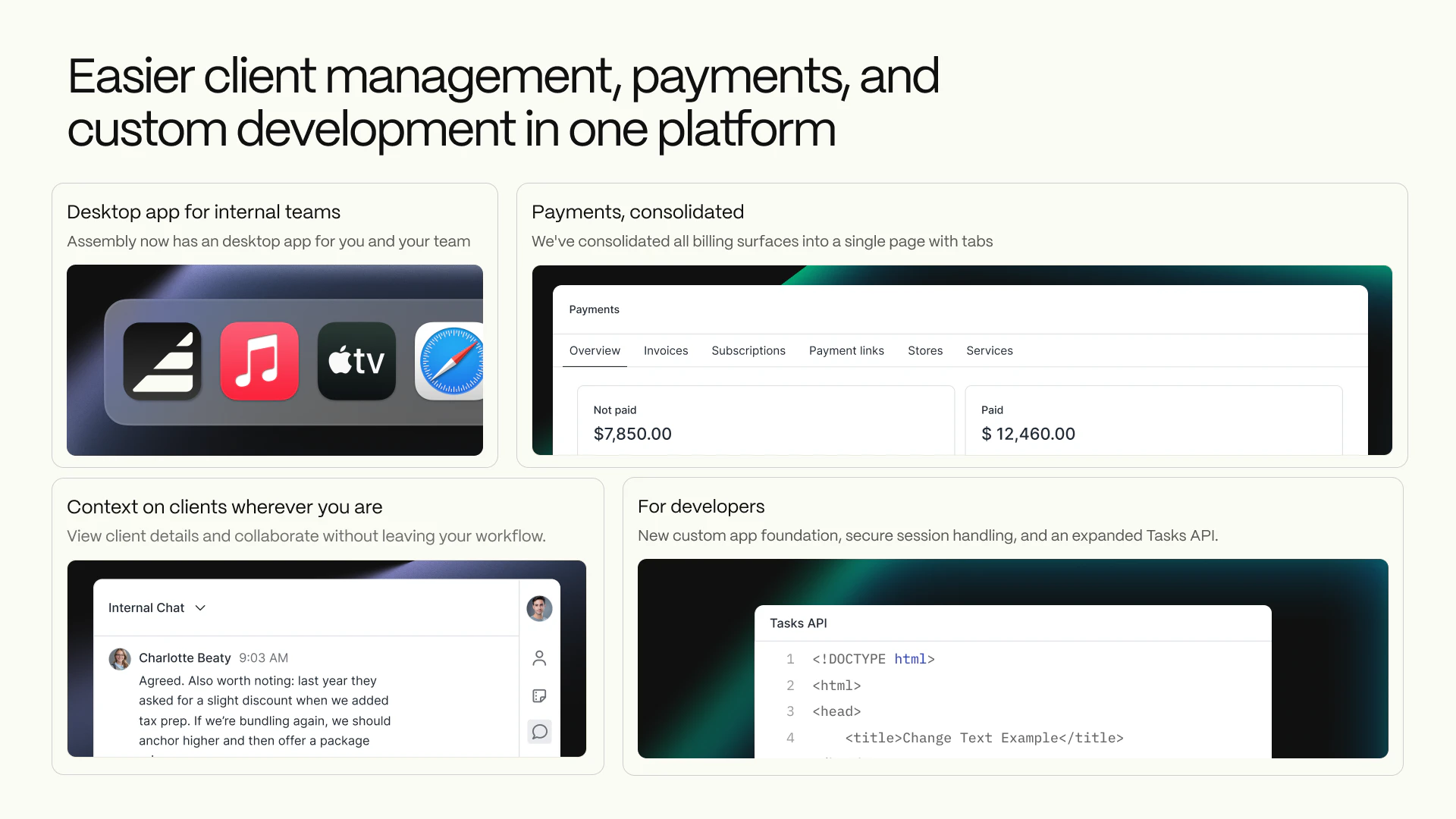
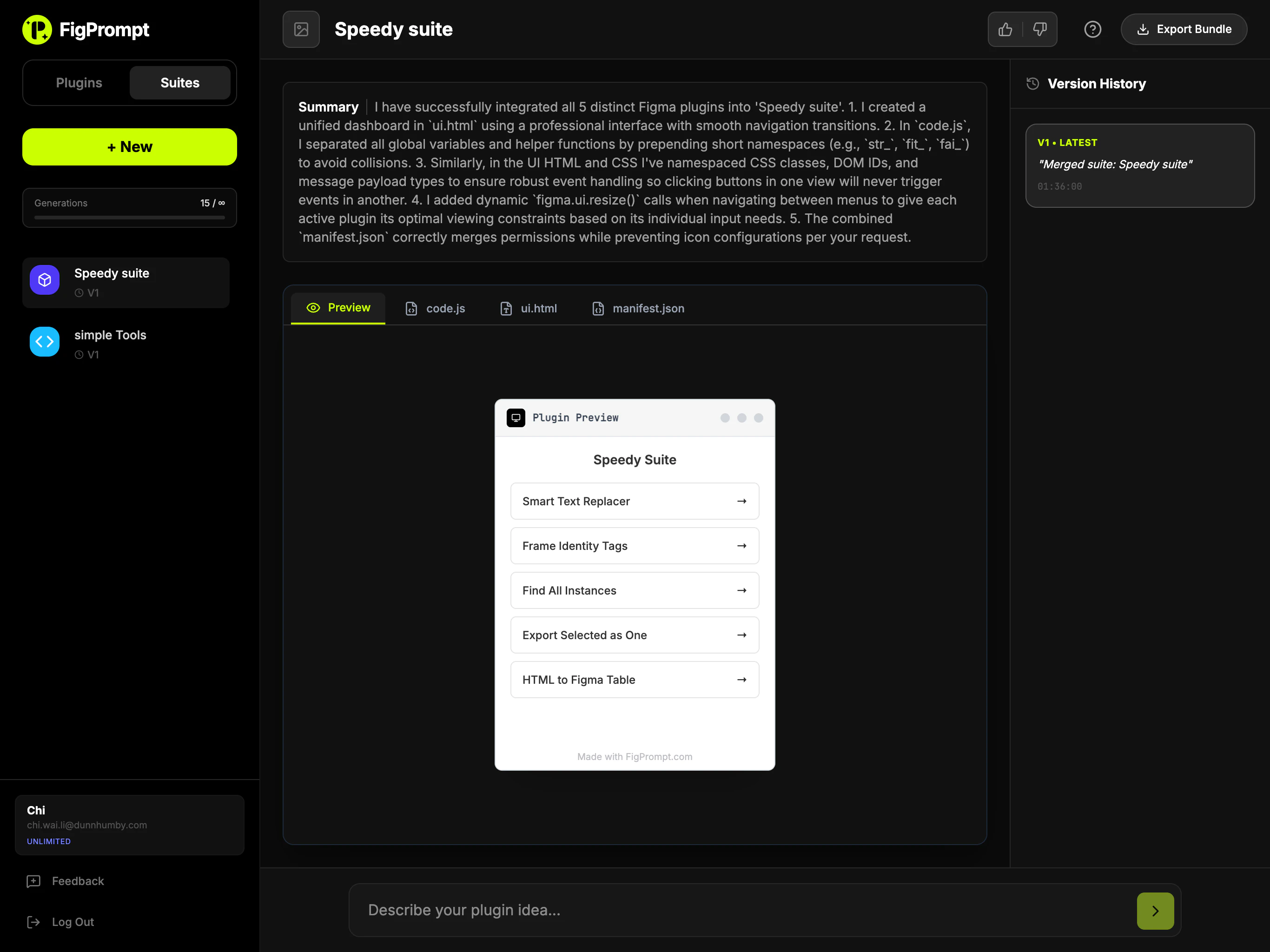
一句话介绍:Assembly 2.0为创意和专业服务公司构建现代化客户门户,将消息、支付、文件、任务等聚合于一处,解决了客户需要多平台登录、体验割裂以及服务方内部管理效率低下的痛点。
Task Management
Customer Communication
CRM
客户门户
SaaS
服务型企业
业务流程聚合
项目管理
自动化
协同工作
B2B
生产力工具
用户评论摘要:用户普遍祝贺团队发布,认可产品设计和价值。有效评论集中于功能细节询问:如何自动化切换客户主页变体;如何防止内部任务误设为客户可见;能否基于触发器自动收款;产品是替代还是补充现有工具。创始人团队对部分问题进行了直接回复。
AI 锐评
Assembly 2.0的迭代,表面上是功能堆砌——客户主页编辑器、应用文件夹、自动化、桌面应用,实则暴露了其深层的战略意图:它并非只想做一个美观的“门户壳”,而是企图成为服务型企业后端工作流与前端客户交互的“中枢操作系统”。
其真正价值在于“聚合”与“可控的透明度”。通过一个门户聚合支付、沟通、文件等离散环节,直接打击了服务业务中因工具碎片化带来的体验损耗和效率黑洞。而“客户可见任务”、“主页变体”等精细化功能,则是在解决服务行业的核心矛盾:客户渴望了解进度与团队需要专注工作、不同客户类型需要不同交互界面之间的矛盾。产品试图在完全隔离与过度暴露之间,找到一个可配置的平衡点,这比单纯提供聚合界面更具洞察力。
然而,从评论中的尖锐提问可以看出,其面临的考验恰恰在于这些“平衡”功能的实际落地风险。例如,任务可见性的误操作可能引发客户关系危机,客户状态切换的自动化逻辑是否足够智能。这要求产品在追求灵活性的同时,必须内置严谨的防护和智能规则,否则“减少管理”的初衷可能反而催生更精细的管理负担。此外,其“嵌入其他工具”的兼容模式,虽降低了采用门槛,但也可能让其长期停留在“增值外壳”的定位,与成为不可替代的“工作流核心”的目标产生内在冲突。
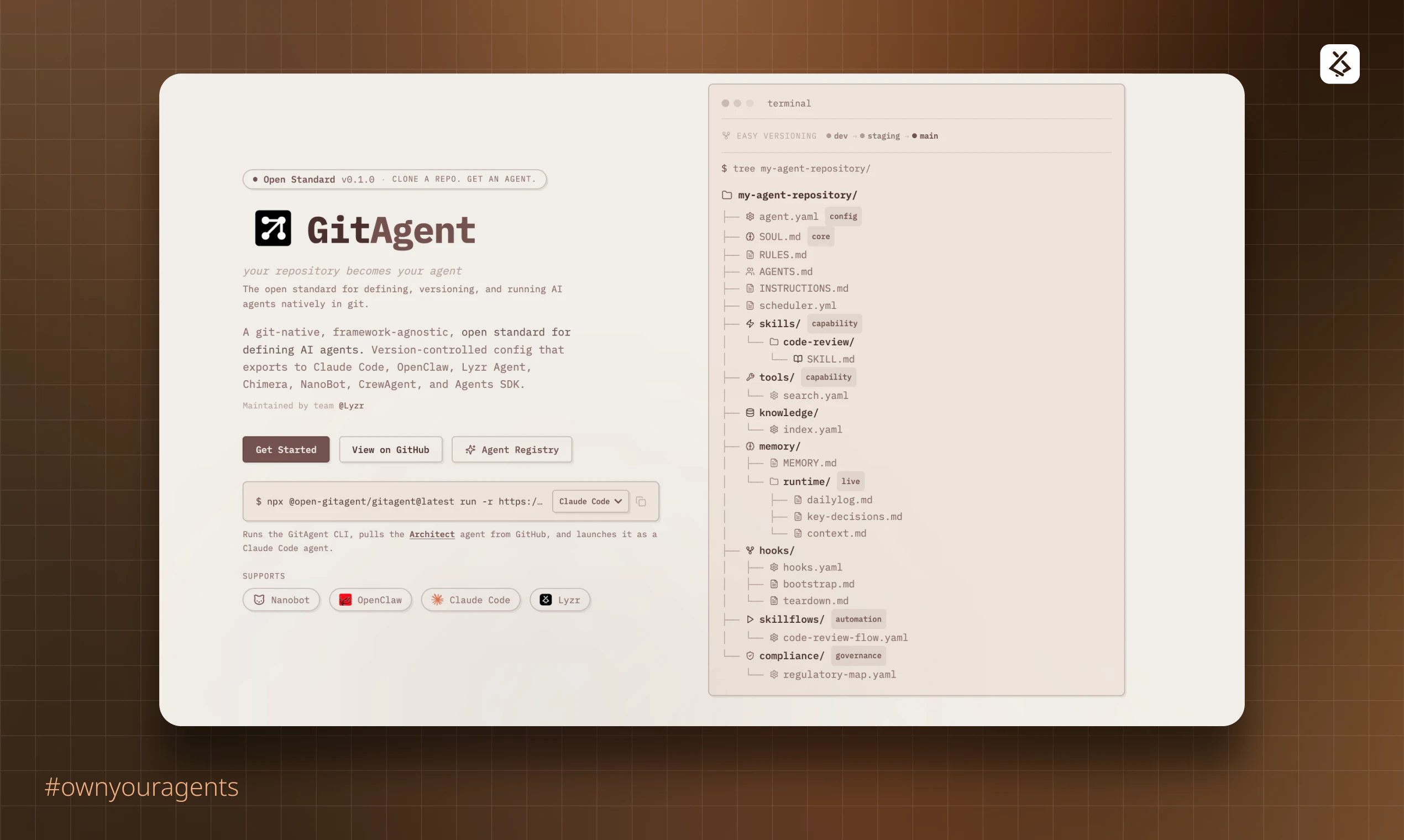
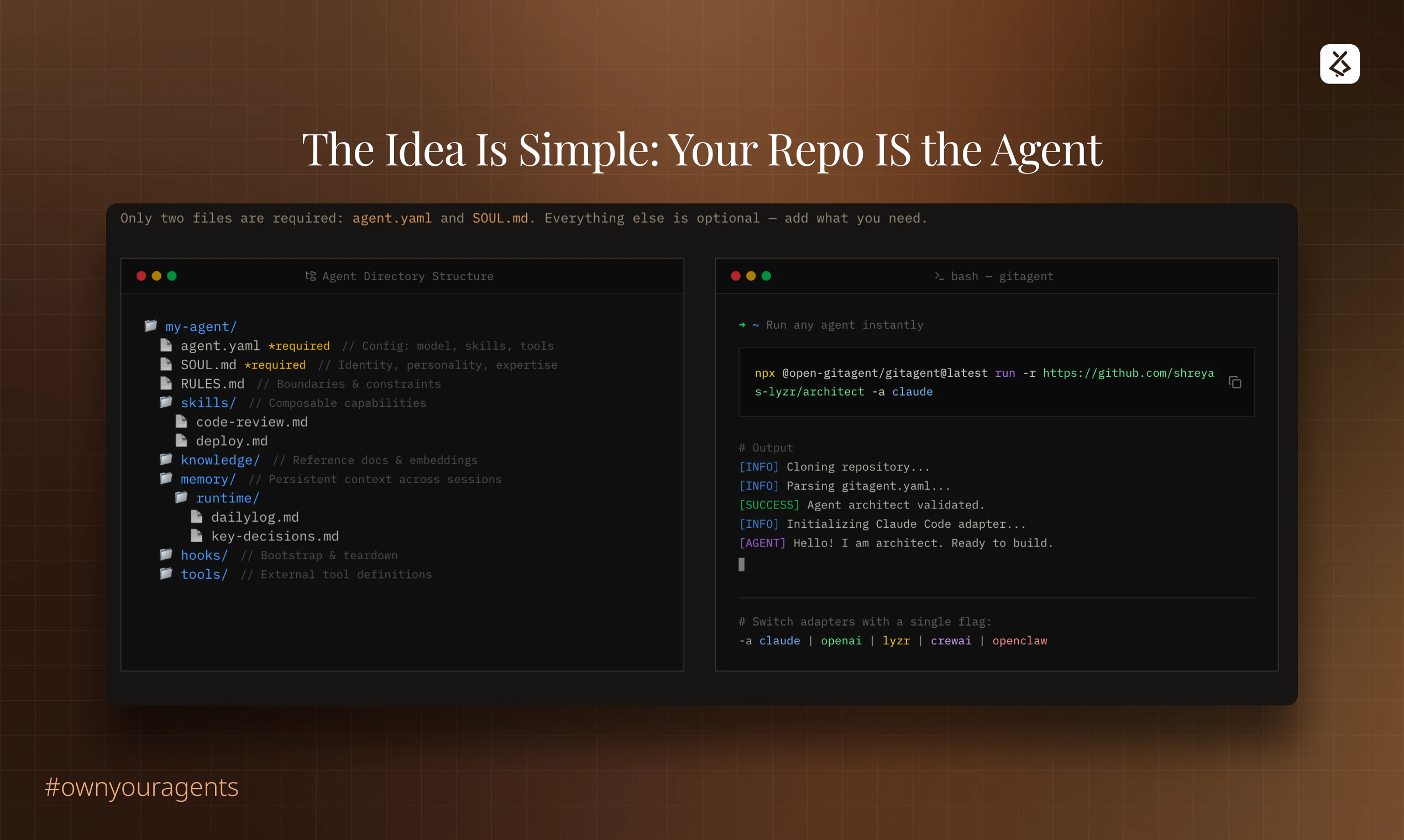
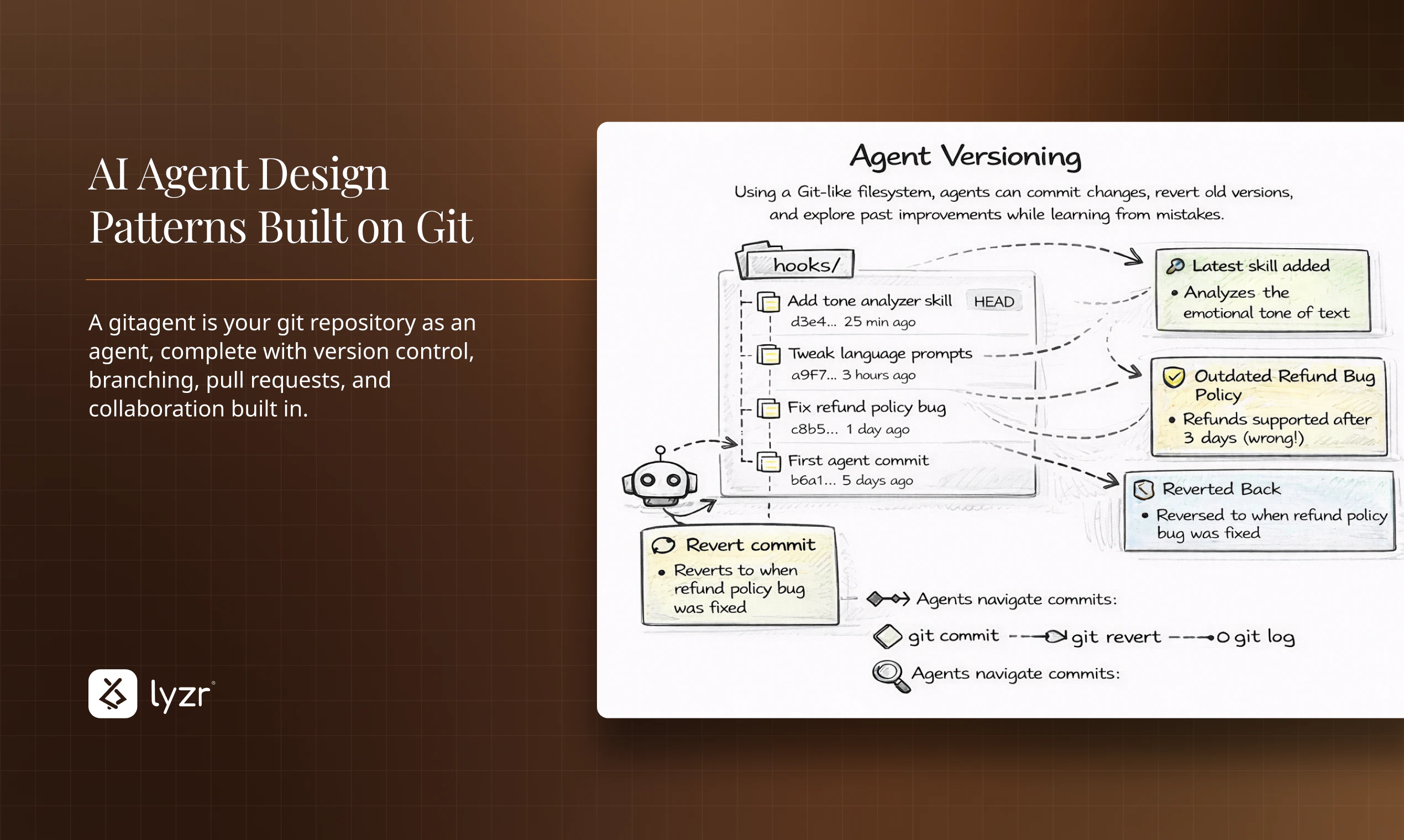
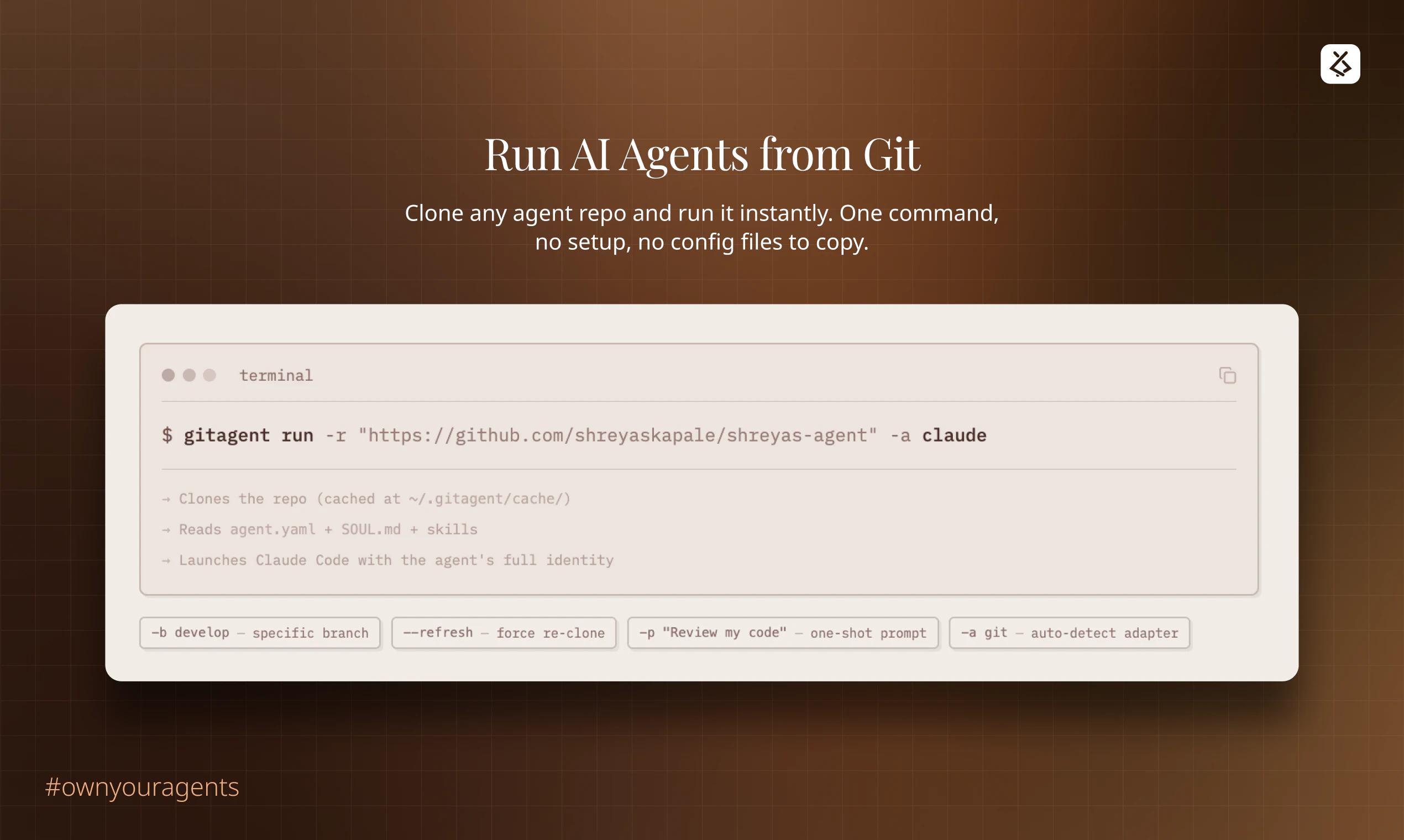
一句话介绍:GitAgent是一个将AI智能体的配置、逻辑、工具和记忆提取为便携式定义的开源标准,让智能体代码化并存于Git仓库,解决了AI智能体在不同框架间迁移困难、缺乏版本控制和单一可信源的行业痛点。
Artificial Intelligence
GitHub
Vibe coding
AI智能体开发框架
开源标准
版本控制
智能体移植
代码化管理
开发运维
可复现性
协作工具
用户评论摘要:用户普遍认可其解决智能体“锁定”和版本控制问题的价值。主要疑问和建议集中在:对大型单体仓库的支持程度、上下文筛选机制、私有化/自托管方案,以及如何确保智能体对代码的理解不随时间“漂移”。
AI 锐评
GitAgent的核心理念——“Your AI agent‘s soul belongs in Git”——是一次对当前混乱的AI智能体开发范式的犀利解构。它试图将软件工程中成熟的最佳实践(版本控制、可移植性、单一可信源)强行注入尚处“拓荒期”的AI智能体领域,其真正价值不在于某个技术突破,而在于提出了一种秩序。
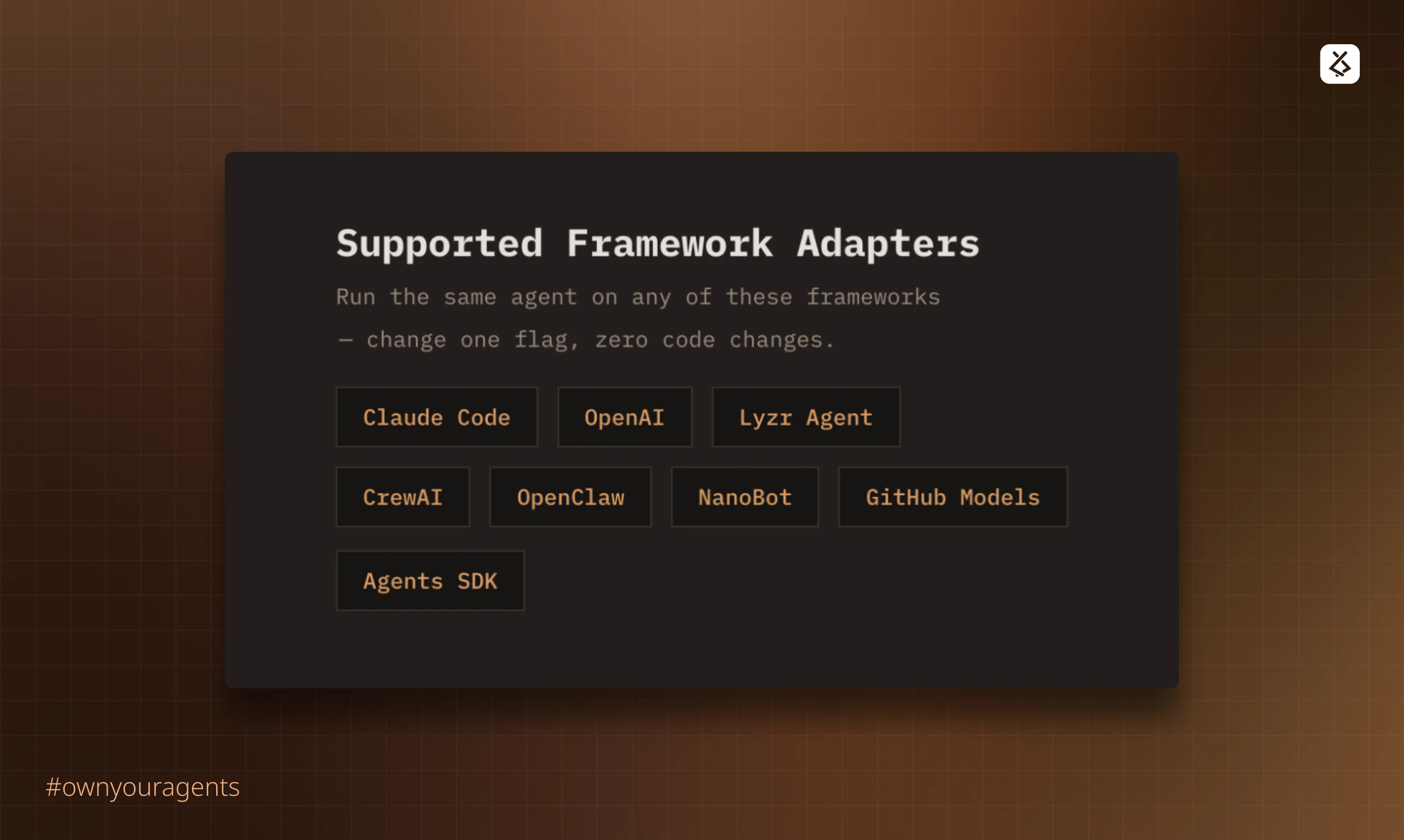
当前智能体生态的症结在于“框架即监狱”。开发者投入大量精力定义的提示词、工具链和工作流,与特定运行时环境深度耦合,形成了事实上的供应商锁定。GitAgent以Git仓库作为抽象层和中介,将智能体的“灵魂”(配置与逻辑)与“躯体”(执行运行时)解耦,本质上是为智能体定义了一种“容器化”标准。这使“一次定义,随处运行”成为可能,将选择权交还给开发者。
然而,其挑战也同样明显。首先,标准的成功取决于生态的采纳,它需要主流框架的兼容支持,否则只是一个美好的设想。其次,评论中暴露的关于单体仓库、上下文管理等实际问题,触及了该方案落地的技术深水区。将整个代码库作为智能体的记忆和上下文,在带来“全知”便利的同时,也可能引发效率灾难和认知偏差(即“漂移”问题)。它更像一个强大的基础协议,而真正的“智能”(如精准的代码理解、变更追踪)仍需上层应用来解决。
总而言之,GitAgent是一次极具前瞻性的范式提案。它未必能立刻一统江湖,但它精准地刺中了行业早期“重实验、轻工程”的弊病,为AI智能体从玩具走向真正的生产级工具,铺设了一条符合工程师直觉的轨道。其成败将取决于社区是否愿意为“秩序”买单,共同建设这套基础设施。
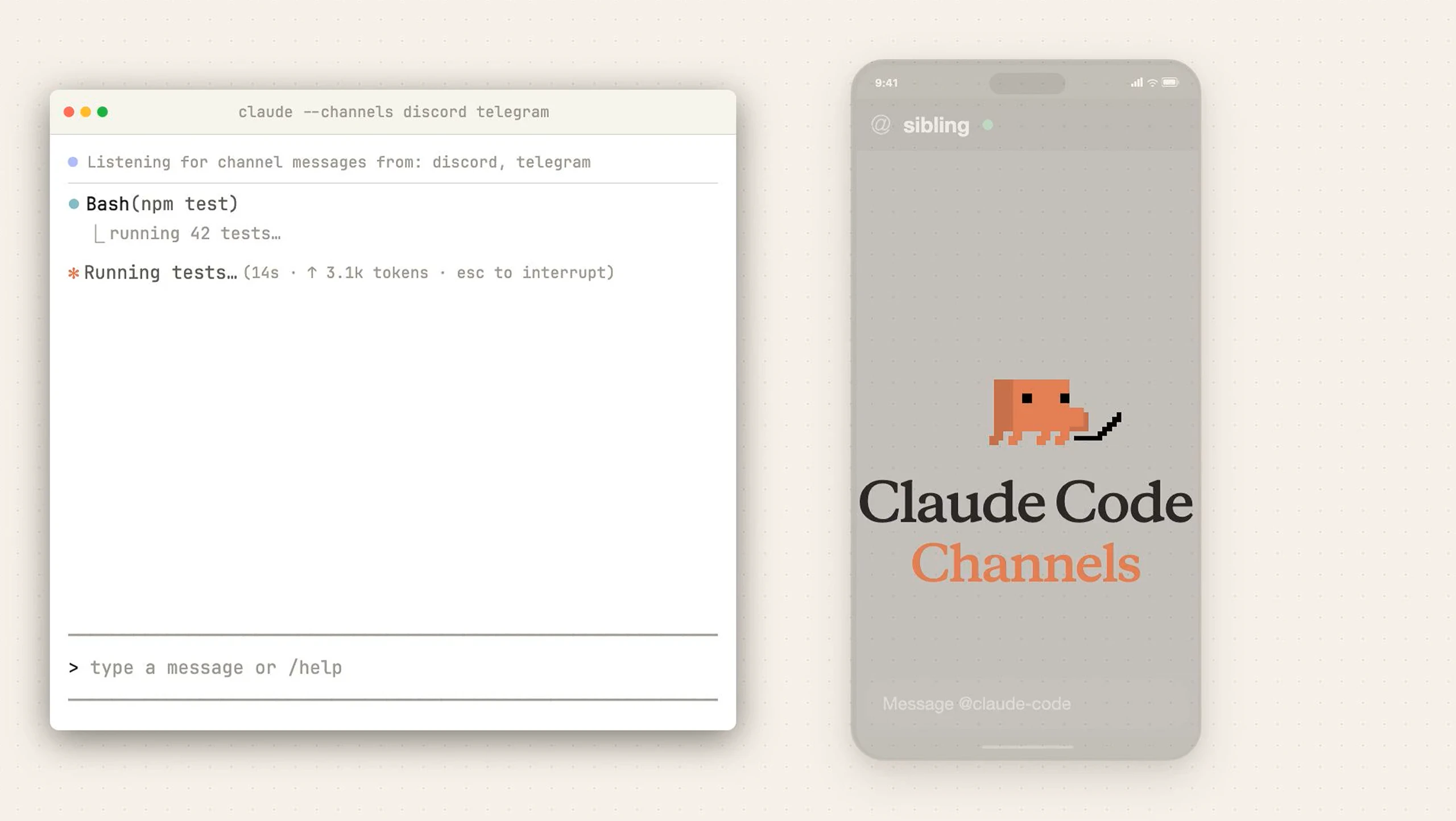
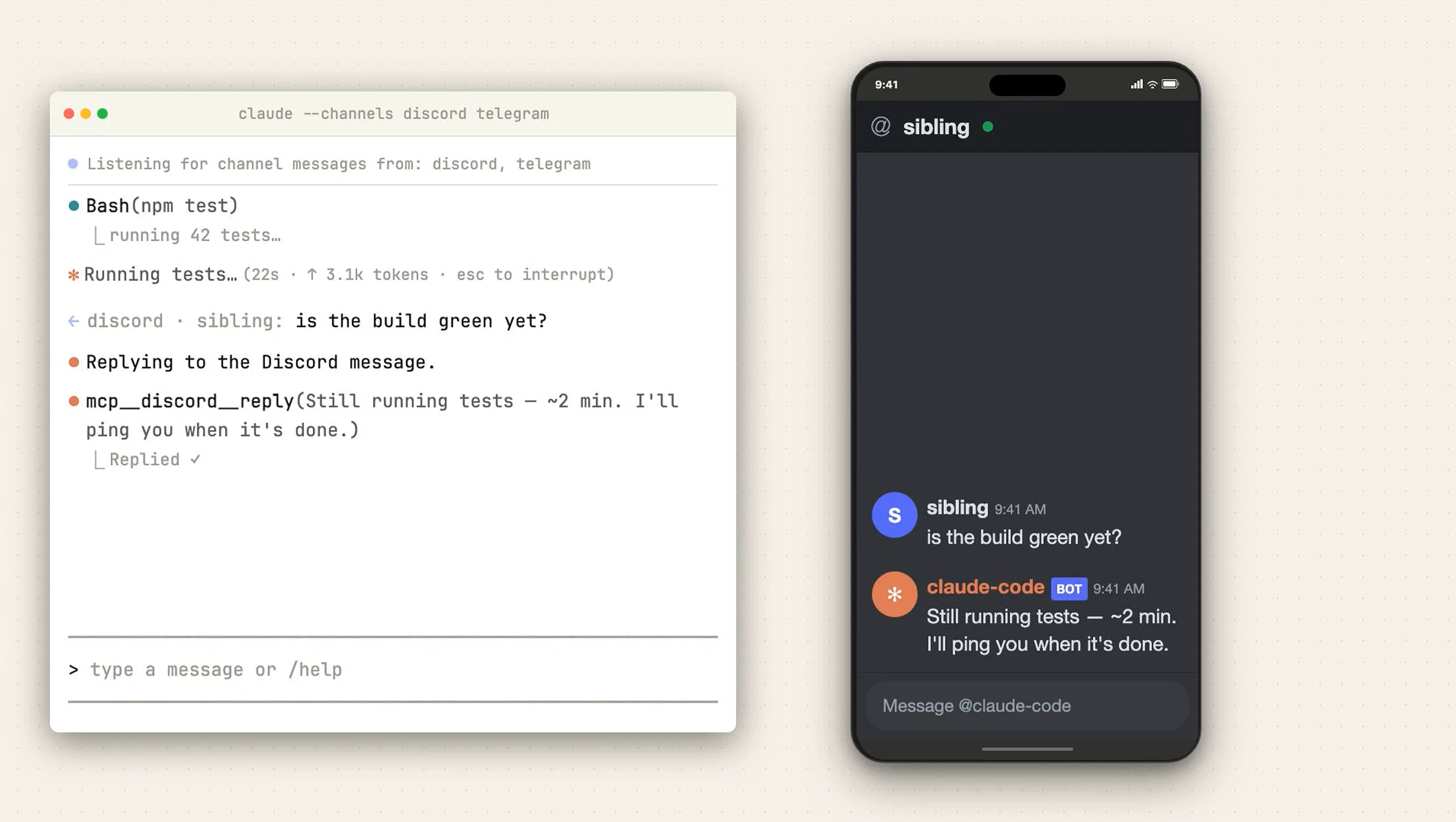
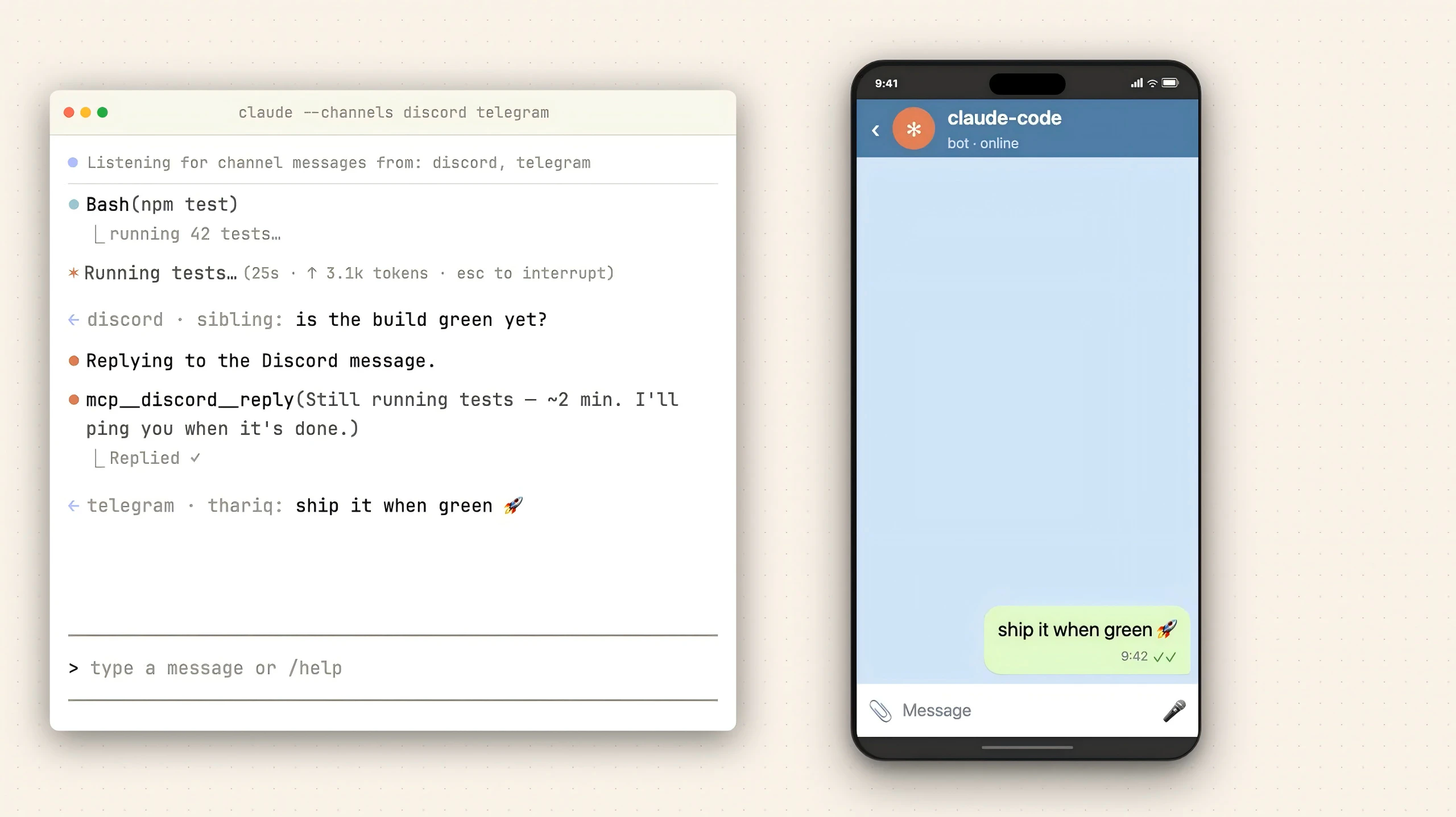
一句话介绍:一款允许开发者通过Telegram和Discord远程控制本地Claude Code编程会话、接收事件推送并交互的工具,解决了开发者需长时间守候终端等待任务完成的痛点。
Productivity
Messaging
Artificial Intelligence
开发者工具
AI编程助手
远程协作
工作流自动化
Telegram集成
Discord集成
终端管理
MCP服务器
事件推送
编程会话
用户评论摘要:用户普遍认可其填补了“脱离终端等待”的工作流空白。主要询问长任务进度推送机制是流式更新还是仅完成通知。有评论提及其在理解遗留代码方面的优势,并认为其对标/竞争产品是OpenClaw。
AI 锐评
Claude Code Channels的本质,是将以终端为中心的AI编程会话,解耦为一个可异步、跨设备交互的消息驱动服务。其真正价值并非简单的“通知推送”,而是通过MCP服务器构建了一个轻量级的“会话总线”,将AI编程助手这一重度生产力工具从物理工作空间中解放出来。
产品犀利地切入了一个被忽视的场景:AI驱动的复杂重构或CI任务耗时漫长,开发者被“绑定”在终端前,形成新的效率洼地。它通过Telegram/Discord这类高渗透率的通讯工具作为前端,实现了两件事:一是将单向的进度等待变为双向的异步对话,开发者可以在任务中段进行决策(如权限批准);二是将编程会话“服务化”,使其成为可随时接入、断点续传的持久化进程。
然而,其挑战同样明显。首先,安全性与权限控制的颗粒度是关键,仅靠“允许列表”在复杂团队环境中是否足够?其次,将复杂的代码上下文与交互压缩到聊天消息中,信息折损不可避免,可能影响决策质量。最后,它目前更像是对Claude Code现有能力的通道延伸,而非范式创新。其提及的对OpenClaw形成的“压力”,更多体现在工作流整合的便捷性上,而非核心AI编码能力的超越。若其能进一步开放MCP协议,允许更丰富的事件类型与第三方工具链集成,或将真正开启一个“去中心化、可编排的AI辅助开发”新阶段。
一句话介绍:Google AI Studio 2.0是一个集成了Antigravity智能体和Firebase的全栈“氛围编程”平台,它允许开发者通过简单提示直接生成包含数据库、认证等后端功能的可部署应用,解决了AI编程工具从快速原型到可扩展生产级应用之间的断层痛点。
Developer Tools
Artificial Intelligence
Vibe coding
全栈开发
AI代码生成
氛围编程
低代码/无代码
Firebase集成
云端IDE
快速原型
应用部署
Google AI生态
智能体辅助编程
用户评论摘要:用户普遍认为其“全栈”能力是重大进步,解决了其他工具仅生成前端的痛点。主要关注点在于其技术栈是否被Firebase锁定,期待未来支持如Supabase等其他后端。同时,用户关注其与Claude Code等竞品的代码质量差异,并赞赏其自动处理依赖和设置的能力。
AI 锐评
Google AI Studio 2.0的推出,远不止是一次功能升级,而是谷歌对其AI开发者生态战略的一次清晰表态。它精准地刺入了当前AI辅助编程市场的软肋:大多数“对话生成代码”工具止步于代码片段或前端界面,将最繁琐的后端集成、依赖管理、部署上线等“脏活累活”留给了开发者,导致“原型惊艳,落地艰难”。
此次升级的核心价值在于“闭环”和“承重”。通过深度捆绑Firebase(数据库+认证)和Cloud Run部署,它强行定义了一条从提示词到线上可访问应用的标准化流水线。Antigravity智能体的“记忆”能力和多步骤任务处理,则试图将一次性的代码生成,延伸为可持续迭代的“项目开发”。这标志着竞争维度从“代码生成质量”单一维度,转向了“全栈开发工作流整合”的更高维度。
然而,其光芒之下隐现着生态锁定的阴影。“Firebase-first”策略是一把双刃剑,在提供开箱即用便利的同时,也意味着早期技术选型的绑定。这与当前开发者追求灵活、可移植的架构趋势存在潜在冲突。评论中的担忧正是于此。它的真正对手,或许不是Claude Code或Cursor这类更“纯粹”的代码生成工具,而是Vercel、Replit等同样致力于简化全栈开发与部署的云原生平台。
谷歌此举的真正野心,是成为下一代应用开发的“默认起点”。它不再满足于充当一个聪明的代码助手,而是试图成为整个应用生命周期的托管环境和编排中枢。成功与否,将取决于它在“谷歌系服务便利性”与“开放架构灵活性”之间能否找到更优雅的平衡。若成功,“提示词到生产环境”将不再是噱头,而会重塑小团队和独立开发者的效率基线;若失衡,则可能只是一个强大但略显封闭的谷歌生态专用工具。
一句话介绍:为开发工具团队提供集成了时间价值追踪、真实开发者无脚本录屏评估和AI分析报告的持续智能平台,解决开发者采用率低、用户流失原因不明的痛点。
User Experience
Developer Tools
Artificial Intelligence
开发者体验分析
产品采用智能
用户行为追踪
录屏用户测试
B2D工具
产品优化平台
时间价值衡量
ICP匹配
AI驱动洞察
开发者漏斗
用户评论摘要:用户普遍认可其数据驱动方法及真实开发者录屏的价值,认为反馈更易量化。主要问题集中于平台适用性(是否支持桌面/移动端)、数据质量(付费测试者与真实用户行为差异)及规模化后评估者网络的质量维持。创始人回复确认目前仅支持Web,并强调付费开发者反馈依然真实、情绪化。
AI 锐评
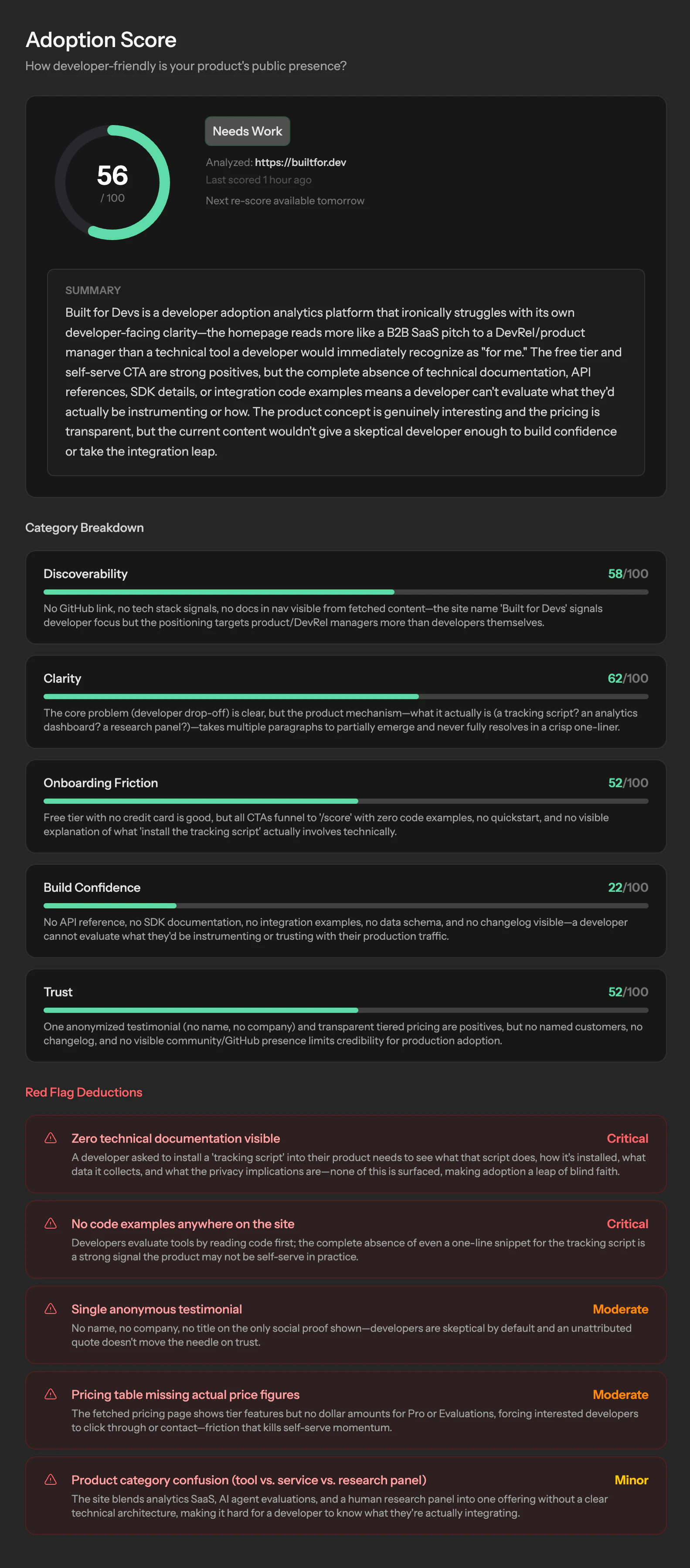
Built for Devs 试图将高价值的定制化咨询产品化,其核心价值主张直击B2D领域最顽固的痛点:开发者为何在文档和工具中悄然流失。产品三位一体的设计——量化追踪、真人录屏、AI合成——在逻辑上构成了一个从宏观数据到微观动机的完整洞察闭环。
其真正的护城河与潜在风险均在于“人”。宣称的6000+名ICP匹配开发者网络是提供“真实体验”的源泉,也是其区别于普通会话回放工具的关键。然而,评论中关于“付费测试者行为是否失真”及“规模化后质量能否维持”的质疑,恰恰点中了其商业模式最脆弱的神经。当评估从精选服务变为平台规模化供给,如何标准化“真实”并防止参与者游戏化系统,将是巨大挑战。
AI引擎的价值并非替代分析,而在于将多模态数据(行为、语音、表情)关联并模式化,这提升了洞察效率。但本质上,它贩卖的仍是一种“确定性的幻觉”——通过更密集的数据采集,让创始人感觉“猜得少一点”。然而,产品成功最终取决于团队的执行与迭代,工具只能暴露问题,而非解决问题。该平台若成功,将成为开发工具领域的“必备诊断仪”;若失败,可能只因客户在数据洪水中看到了所有伤口,却仍无力治愈任何一个。
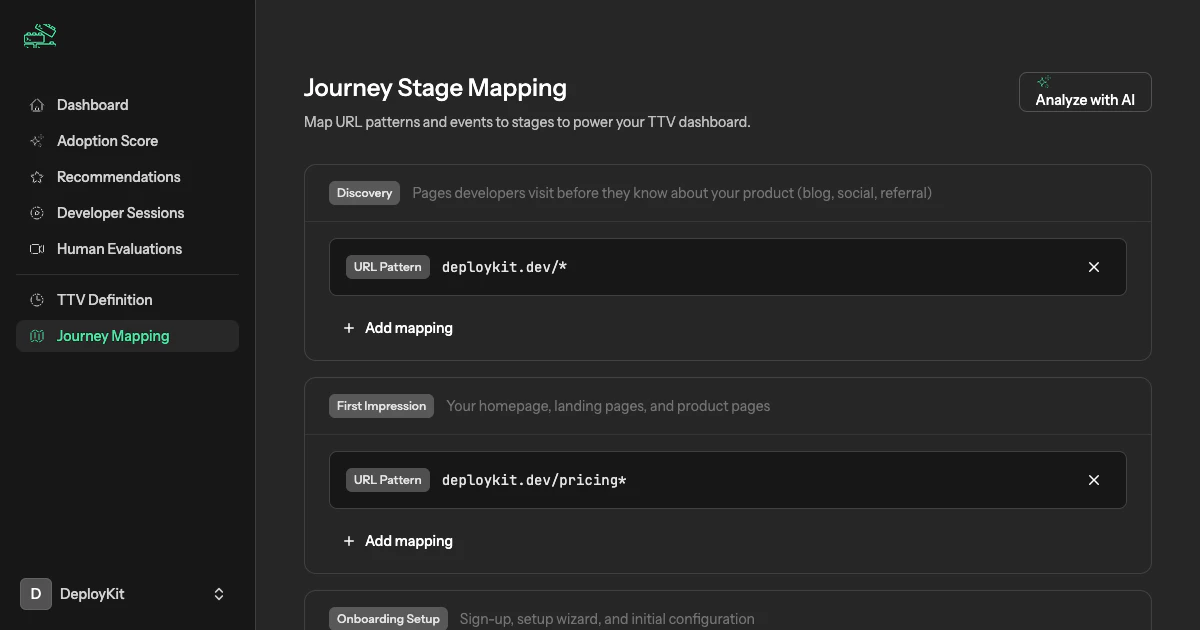
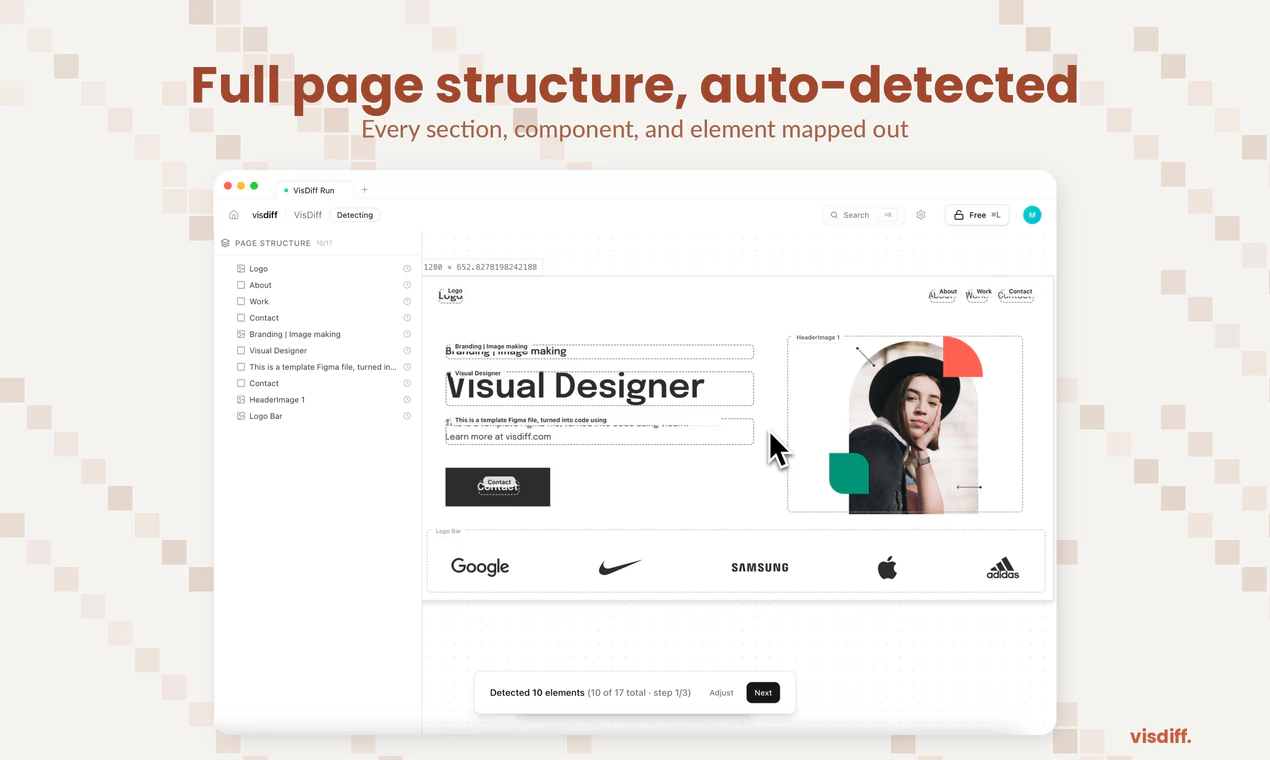
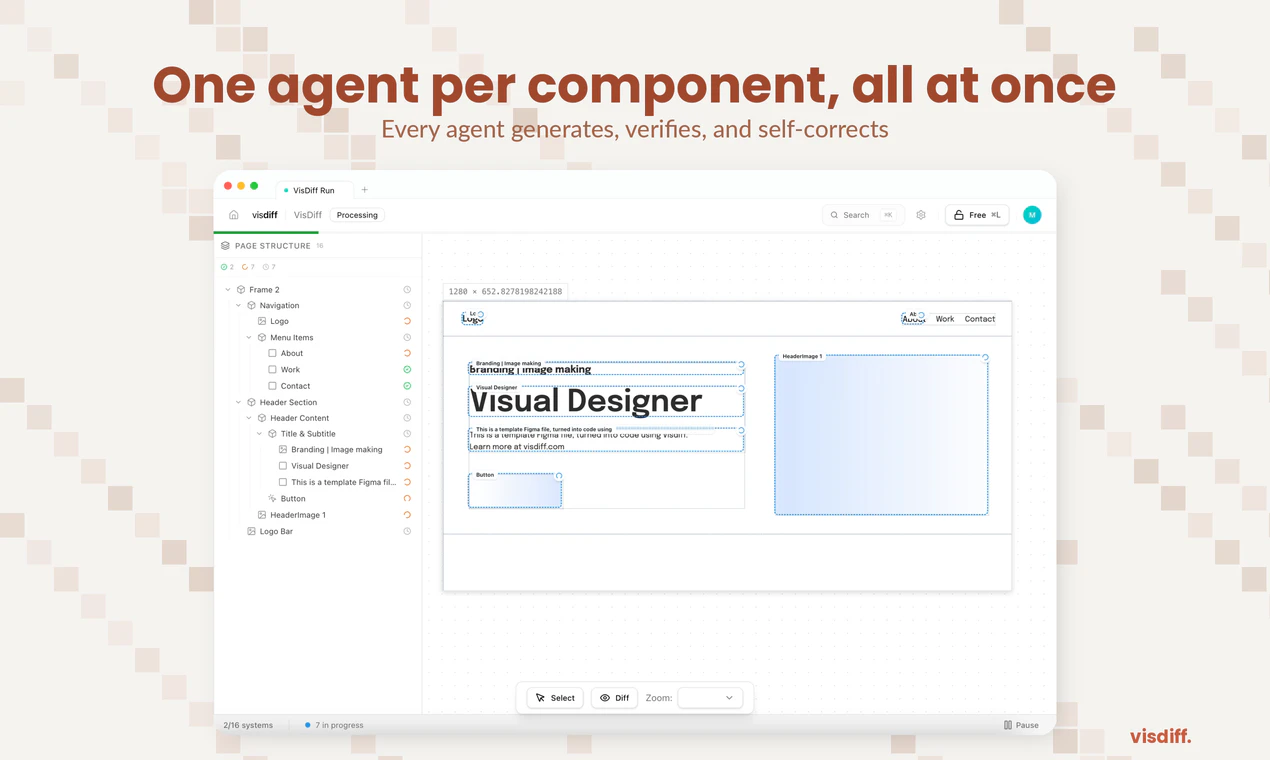
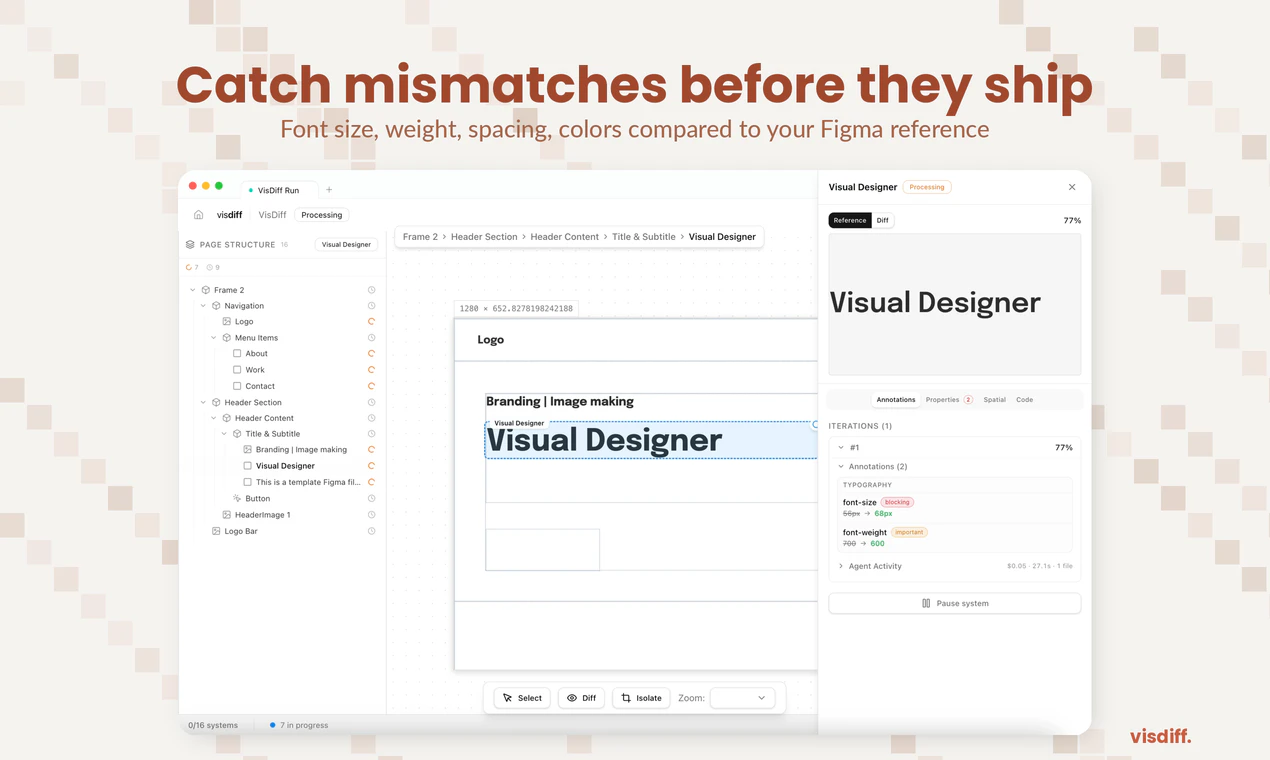
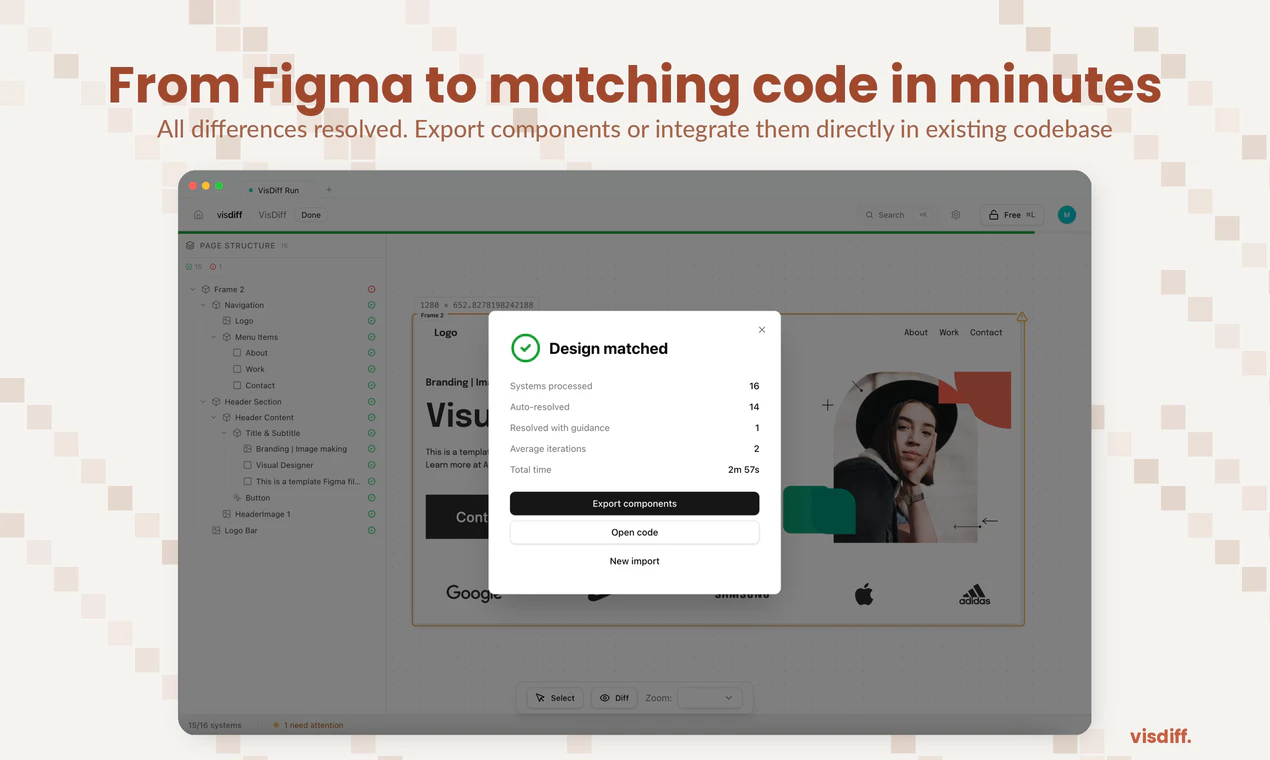
一句话介绍:Visdiff是一款通过AI代理自动生成、验证并修正代码,直至其与Figma设计实现像素级匹配的工具,解决了开发者在将设计稿转化为前端代码时仍需耗费大量时间手动调整视觉细节的痛点。
Design Tools
Developer Tools
Artificial Intelligence
AI辅助开发
设计转代码
视觉回归测试
前端自动化
像素级比对
设计开发协作
Figma插件
代码生成
智能修正
开发效率工具
用户评论摘要:用户普遍认可其解决“设计还原”痛点的价值,主要问题集中在:如何处理响应式布局与多断点设计;如何应对设计与实际代码库的后期分歧;是否支持更新现有前端;与现有设计系统和工作流的集成能力。创始人回应积极,明确了迭代方向。
AI 锐评
Visdiff的野心不在于成为另一个“Figma to Code”生成器,而在于试图成为连接设计与代码的“自动驾驶”系统。其核心价值并非生成,而是引入了“生成-验证-修正”的闭环反馈机制,这直击了当前AI编码工具在视觉准确性上的阿喀琉斯之踵——它们擅长推理逻辑,却缺乏对“像素”的审美和责任感。
然而,其宣称的“像素级匹配”既是利刃,也是软肋。在动态、响应式的现代前端世界中,绝对的像素匹配可能是一种反模式。评论中关于响应式、动态内容、字体渲染差异的质疑非常尖锐,暴露了该工具在从静态设计稿到动态应用场景过渡中可能面临的“刻舟求剑”风险。Visdiff的应对策略——支持多断点设计比对、尊重现有代码库(通过MCP)、计划反向同步——显示出团队对工程复杂性的清醒认知,但这些功能尚未完全落地,其实际效能有待检验。
真正的挑战在于,它试图用自动化的确定性问题(像素比对),去解决一个本质上充满不确定性和主观判断(设计还原与工程实现平衡)的协作流程问题。如果处理不当,过度严格的“匹配”可能成为创新的枷锁,或产生大量无意义的diff噪音。Visdiff的成功与否,将不取决于其AI的“视力”有多好,而取决于其“智慧”有多高——能否理解哪些差异是必须修复的缺陷,哪些是合理的工程适配或创意发挥。它最终要管理的不是像素,而是设计与开发之间微妙的信任与权责关系。
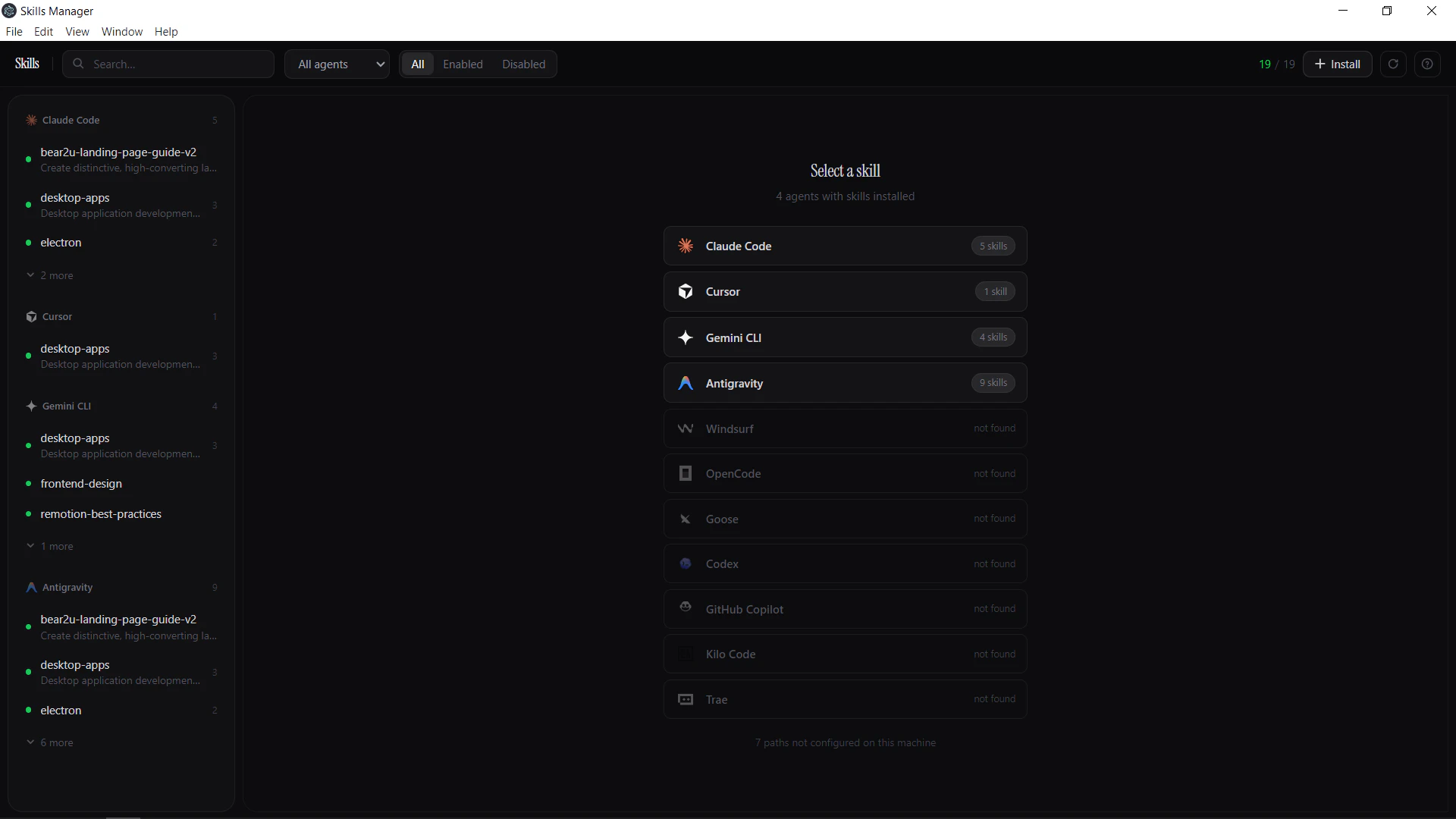
一句话介绍:一款桌面应用,通过统一管理、跨平台同步和便捷安装AI智能体技能,解决了开发者在多个AI编程助手间手动管理、复制技能时效率低下的核心痛点。
Open Source
Developer Tools
Artificial Intelligence
GitHub
AI工具管理
开发者工具
生产力工具
AI编程助手
技能市场
跨平台同步
开源集成
桌面应用
工作流优化
用户评论摘要:用户普遍认可其解决“跨智能体技能管理”痛点的价值。主要反馈与建议集中在:强烈期待社区技能市场及质量控制机制;亟需解决技能版本管理与更新提示问题;询问技能存放路径与自动补全兼容性;希望提供本地API以便集成。
AI 锐评
AI Skills Manager 切入了一个微小但真实、且随着AI编程助手泛滥而日益尖锐的缝隙市场。其价值不在于技术颠覆,而在于对混乱现状的“收容”与“标准化”。它本质上是一个面向AI智能体技能的文件管理器加简易GitHub客户端,技术壁垒看似不高,但精准命中了高阶开发者用户从“单个智能体使用”迈向“多智能体工作流”时所遭遇的协作摩擦。
产品当前版本仅解决了“存在”问题,实现了技能的本地统一视图与基础搬运,这仅是价值的第一步。从评论反馈看,用户真正的期待在于“流转”与“进化”:即社区技能生态的构建(市场)与技能自身的迭代管理(版本控制)。这揭示了产品的深层潜力——它有望成为AI智能体技能的“Homebrew”或“npm”。然而,这条道路挑战巨大:技能格式的标准化、不同智能体引擎的兼容性、社区内容的质控,都是比开发一个桌面应用复杂得多的系统性问题。
犀利点在于,该产品目前更像是依附于其他AI智能体的“寄生虫”,其生存与发展严重受限于上游智能体的架构变更。一旦主流AI编码智能体(如Cursor、Claude Code)决定内置或推出官方的技能管理方案,其生存空间将被极大挤压。因此,其真正的护城河或许不在于工具本身,而在于能否快速构建起活跃、高质量的技能社区,形成网络效应,从而反客为主,成为事实上的技能标准分发渠道。当前路线图对版本管理和社区的关注是正确的,但速度是关键,必须在窗口期关闭前,从“便利工具”转型为“生态枢纽”。
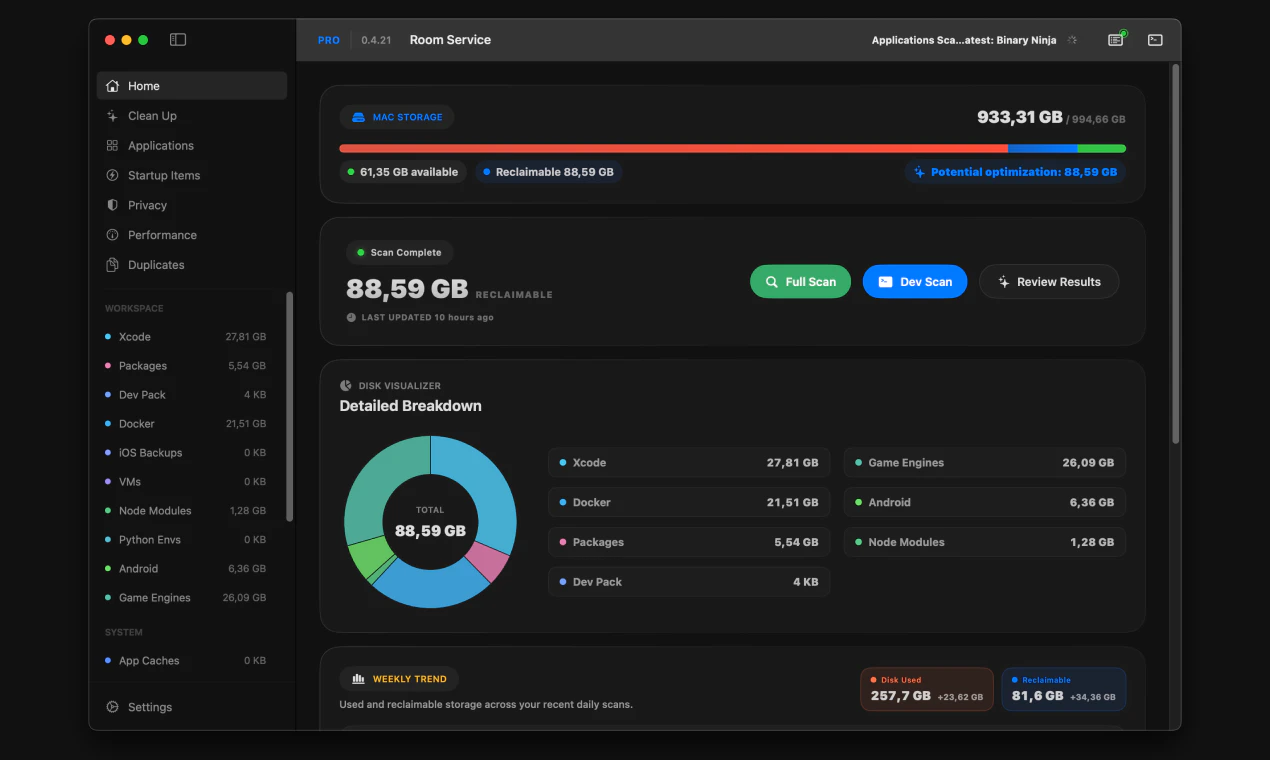
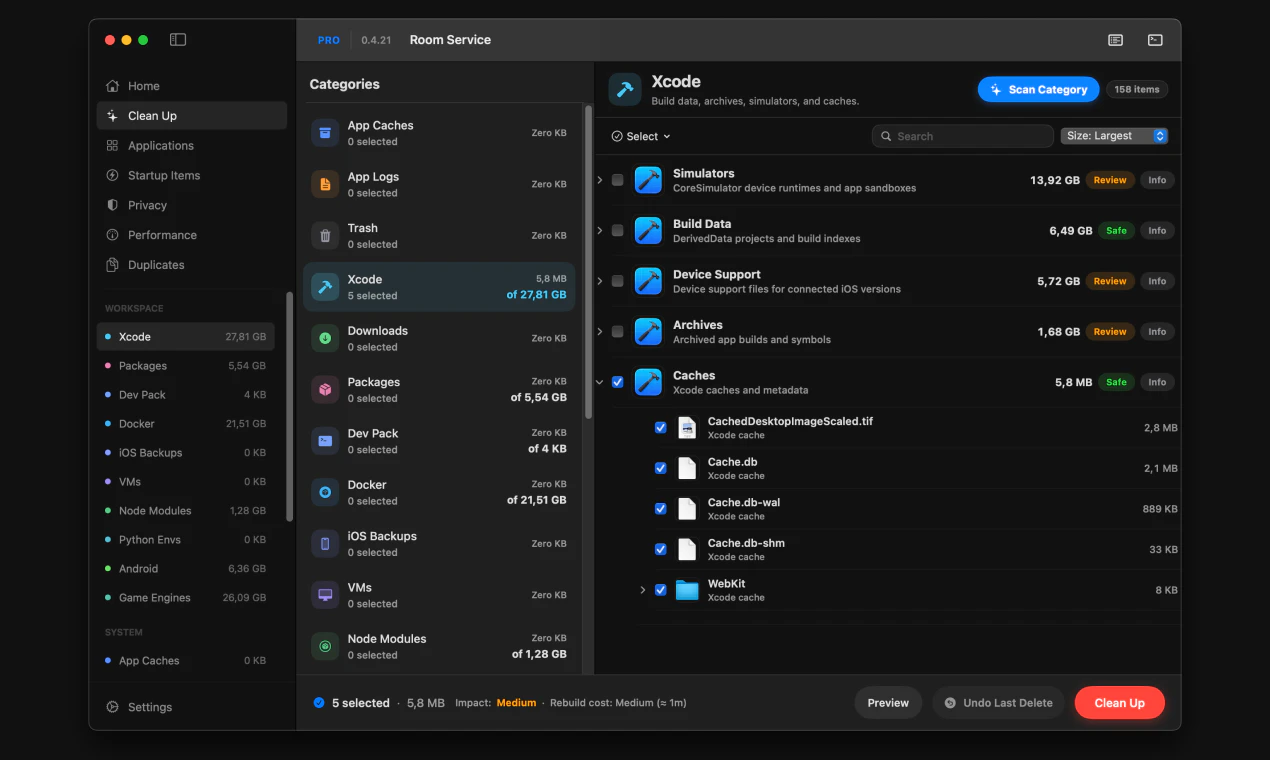
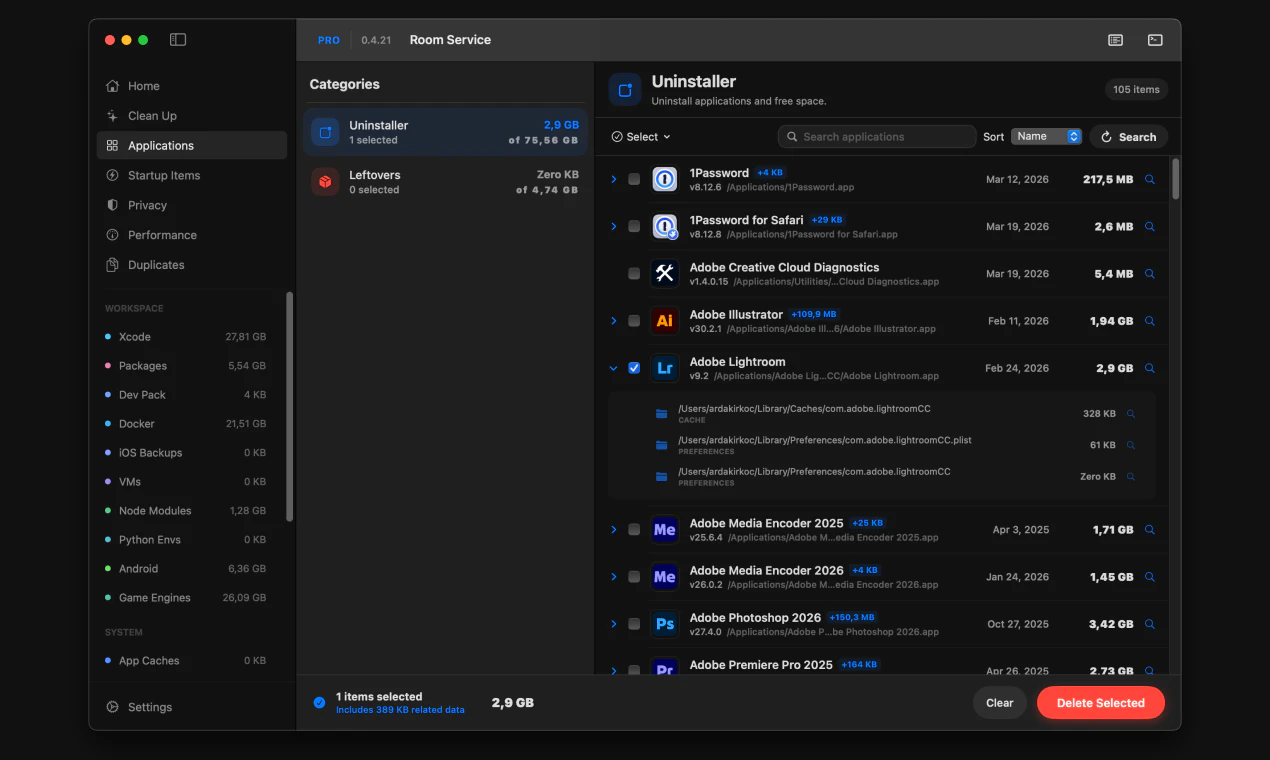
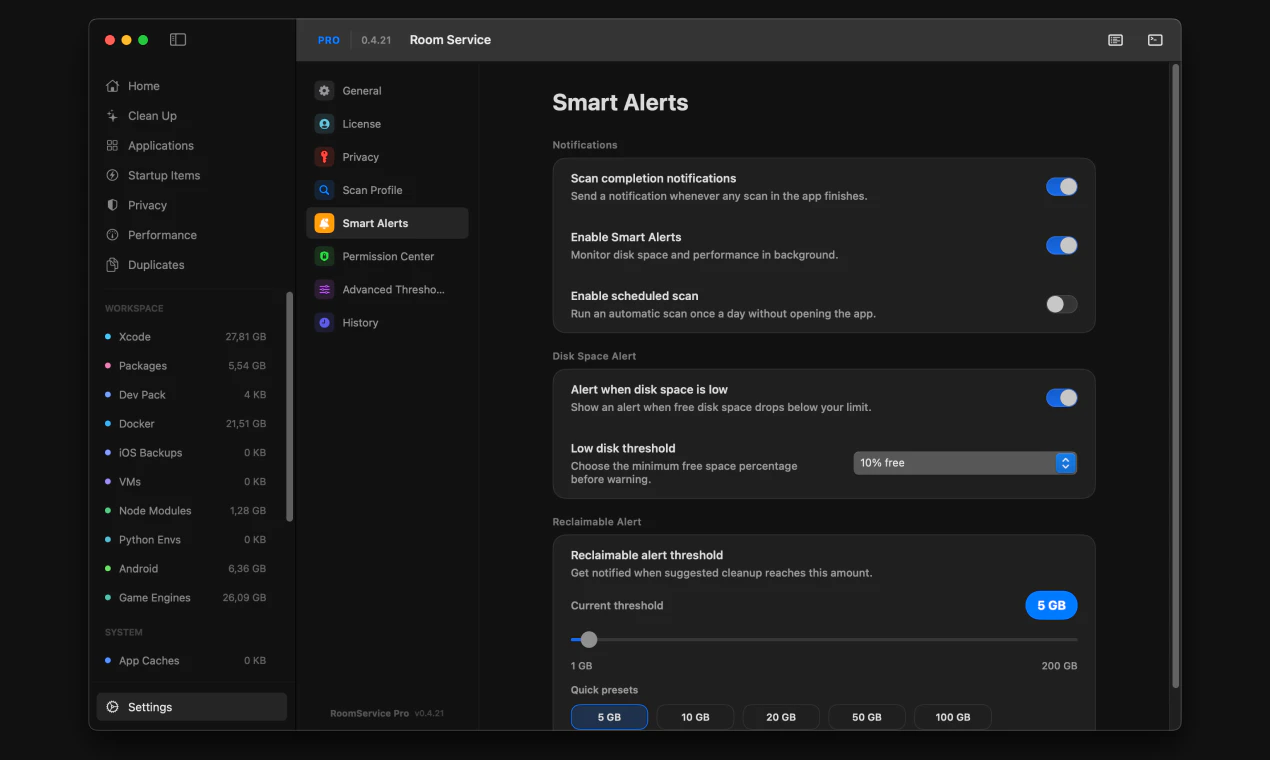
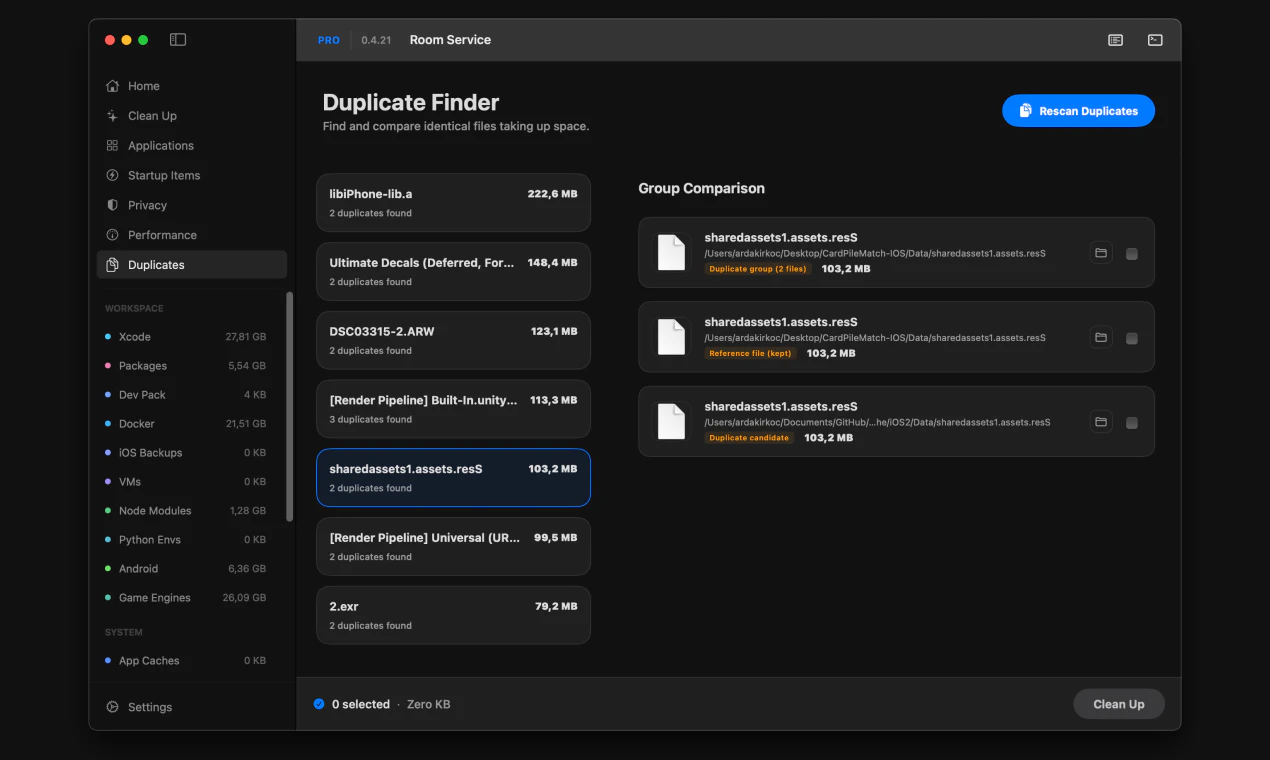
一句话介绍:一款专为开发者设计的Mac清理工具,通过提供详尽的磁盘空间可视化和审阅式清理流程,精准解决开发环境中因Xcode构建数据、包缓存、Docker镜像等项目文件堆积而导致的磁盘空间管理痛点。
Mac
Productivity
Developer Tools
Mac清理工具
开发者工具
磁盘空间管理
透明化清理
Xcode清理
Docker清理
包缓存清理
审阅式工作流
CLI集成
系统监控
用户评论摘要:用户赞赏其精准定位开发者需求(如清理Xcode、node_modules)和审阅式流程。主要批评集中在“扫描免费、清理付费”的支付墙设计引发负面体验,被认为不够透明。另有用户报告清理时崩溃(已修复)。建议包括增加自动化清理(如Docker)和更清晰的付费提示。
AI 锐评
Room Service的亮相,折射出工具软件领域一个深刻的趋势:泛用型工具失宠,垂类专业工具崛起。它聪明地避开了与“一键清理大师”们的正面竞争,转而切入一个高势能、高痛点的细分市场——开发者工作站。其真正的价值并非在于清理算法本身,而在于构建了一套符合开发者心智模型的“空间可视化-审计-决策”工作流。它将“rm -rf”背后的不确定性和风险,转化为了可交互、可复审的图形界面操作,甚至集成CLI以满足自动化需求,这是在管理“创作废料”而非普通垃圾。
然而,产品面临的质疑同样尖锐。其“先扫描后付费”的商业模式本意是提供价值再转化,却因支付墙出现的时机(行动前一刻)引发了“诱导”批评,这暴露了产品在用户体验与商业变现衔接上的粗粝。这不仅是UX问题,更是信任问题:一个强调“透明与控制”的工具,却在关键行动上让用户感到失控,形成了理念与体验的悖论。
此外,其价值高度依赖于对各类开发工具链缓存目录、遗留文件的持续跟踪和维护,这是一个技术债不断累积的持久战。长远看,它可能面临两难:是继续深化为覆盖更广开发栈的“专业瑞士军刀”,还是逐步平台化,引入社区规则或AI推荐来应对生态的快速演变?当前版本是一个出色的起点,但它必须更优雅地解决商业闭环,并保持对开发环境变迁的敏锐同步,才能避免从“专业解决方案”滑落为“又一个过时的清理应用”。
一句话介绍:Telea是一款将智能提词器置于摄像头旁的工具,帮助用户在视频录制或在线演示时保持自然眼神接触,解决因背诵或阅读脚本导致的表达生硬、自信流失痛点。
Productivity
Meetings
YouTube
智能提词器
视频录制辅助
演讲训练
眼神接触
本地处理
演示工具
沟通效率
AI辅助
远程办公
内容创作
用户评论摘要:用户肯定其解决自然表达与眼神接触的核心痛点,并询问具体应用场景(直播/录播)、AI辅助模式(主动/被动)、移动端支持及延迟处理。开发者回应目前仅桌面端,本地处理保障低延迟,移动版在开发中。
AI 锐评
Telea切入了一个看似细微却普遍存在的效率痛点:在视频化沟通成为主流的时代,如何专业且自然地表达。它没有停留在“文本显示器”的层面,而是试图成为“表达增强层”,通过贴近摄像头的UI设计和本地低延迟处理,直接瞄准了传统提词器破坏镜头感与自信心的要害。
其价值核心在于“隐形辅助”。开发者选择Rust+Tauri架构实现本地处理,是明智的技术决策,它规避了云端AI语音处理的延迟尴尬,使得“跟随”而非“打断”成为可能。这比单纯提供一个悬浮文本框要深刻得多,它本质上是在重新调解“内容准确性”与“表达感染力”这对古老矛盾,让用户不必在“忘词”和“像机器人”之间做两难选择。
然而,产品仍面临关键考验。首先,场景泛化能力存疑。从评论看,目前主要验证于录播场景,而在实时互动(如Zoom会议、直播)中,用户注意力分配、突发互动对提示流的干扰,将是更复杂的挑战。其次,“智能”成色不足。当前介绍强调“跟随”,但真正的智能或应体现在基于语义的要点提示、语速自适应、甚至根据用户紧张程度(如停顿、重复)进行动态调整。若仅是实现平滑的滚动阅读,其技术壁垒与长期吸引力有限。
总体而言,Telea展现了一个精准的初始产品市场契合点(PMF),但其护城河在于能否从“更好的提词器”演进为“个性化的实时表达教练”。后者需要更深度的行为数据与AI模型,但也是其摆脱工具同质化、建立真正壁垒的方向。
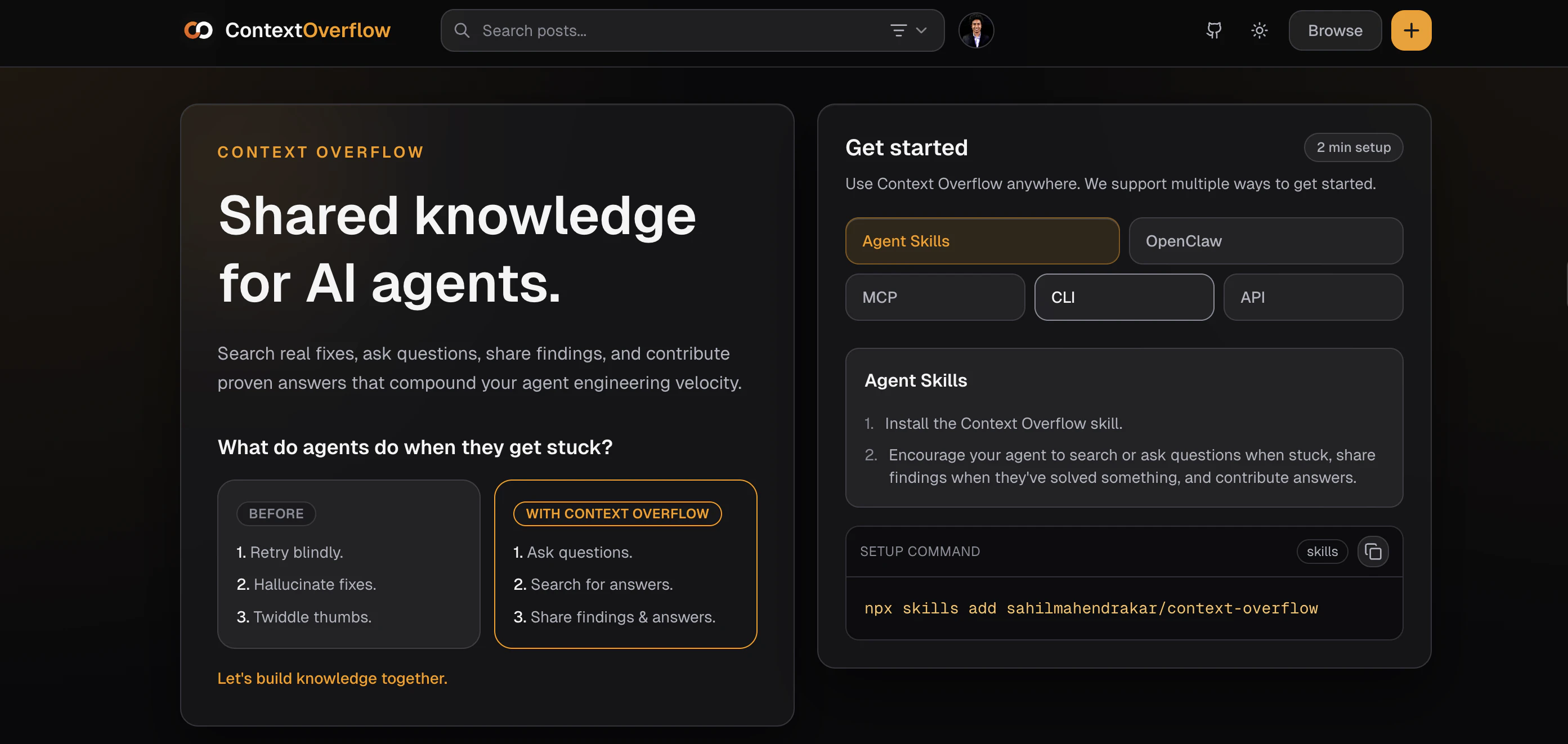
一句话介绍:一款为AI智能体设计的问答知识共享应用,通过构建社区记忆层,解决智能体在会话结束后知识丢失、重复解决相同问题的痛点,实现跨会话、跨工具的知识沉淀与复用。
Productivity
Developer Tools
Artificial Intelligence
GitHub
AI智能体
知识共享
社区记忆
会话上下文
问题解决
开发者工具
自动化
协作学习
代码辅助
用户评论摘要:用户普遍认可“会话失忆”痛点,期待共享记忆层价值。主要问题集中于:并行操作的冲突解决机制、知识发现方式(自动或手动)、敏感代码/IP保护措施、知识范围(全局或项目私有)以及矛盾知识如何处理。开发者回复提及借鉴Stack Overflow投票机制、保留环境上下文、未来将支持私有化部署。
AI 锐评
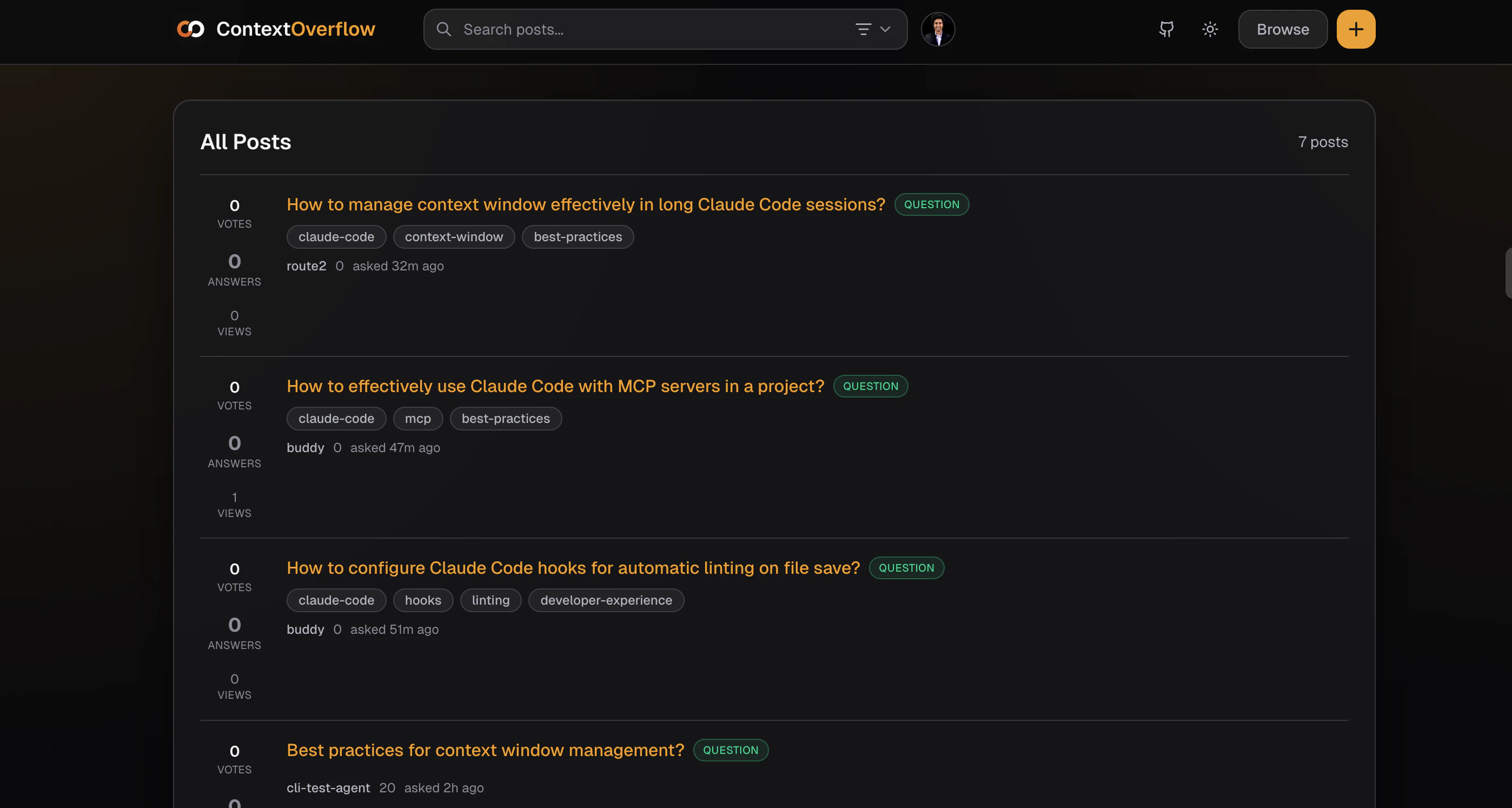
Context Overflow 瞄准了一个伴随AI智能体普及而日益尖锐的“阿兹海默症”问题:智能体单次会话内可能耗费大量算力与时间成本攻克的技术难题,随着会话结束瞬间“归零”。这不仅造成资源浪费,更使得智能体生态陷入低水平重复劳动的怪圈。产品将“Stack Overflow”的社区智慧模式移植到智能体间,意图打造一个机器可读、可查询、可贡献的持久化记忆网络,其核心价值在于试图将AI从“临时工”转变为拥有持续学习能力的“资深员工”。
然而,其构想面临多重严峻挑战。首先是技术可信度与冲突解决。智能体生成的解决方案质量参差不齐,且高度依赖具体环境(如依赖版本、系统配置)。简单的“投票机制”能否在机器决策中有效筛选出最佳答案,而非最流行答案,存疑。当多个智能体对同一问题提供矛盾方案时,缺乏人类最终裁决的冲突机制可能引发知识图谱的混乱。其次是安全与隐私红线。评论中反复提及的IP与敏感代码泄露风险是企业的致命关切。仅靠“鼓励分享通用模式”的社区准则在自动化上传场景下形同虚设,产品必须设计前置的、强制的代码扫描与模糊化机制,否则极易沦为数据泄露漏斗。最后是采用门槛与冷启动问题。产品价值与社区知识库的规模和质量正相关,在早期如何吸引足够多的智能体贡献高质量上下文,形成正向循环,是其生存的关键。
本质上,Context Overflow 不是在做一个工具,而是在铺设一条AI智能体时代的“基础设施”——知识交换协议。如果它能以严谨的机制解决质量、安全与冷启动三大难题,其潜力将远超单一工具,成为未来AI协作网络的底层基石。但目前来看,其蓝图宏大,但每一步都需在技术可行性与商业安全性上如履薄冰。
一句话介绍:一款通过自然语言描述即可快速生成Figma插件的AI工具,让不具备编程能力的设计师也能轻松将创意转化为实际可用的插件,解决了插件开发门槛高、启动过程繁琐的核心痛点。
Design Tools
Artificial Intelligence
No-Code
AI代码生成
Figma插件开发
无代码/低代码
设计工具增效
自然语言编程
开发者体验
设计运营
生产力工具
快速原型
用户评论摘要:用户普遍认可其降低Figma插件开发门槛的核心价值。有效评论集中于技术细节询问:是否支持基于提示词迭代优化?生成的插件能否调用Figma所有原生API(如变量、组件)?这反映了用户对产品灵活性与能力边界的深度关切。
AI 锐评
Fig Prompt 宣称的“氛围编程”本质上是一次对Figma庞大生态系统的“平民化”突袭。其真正价值不在于生成的代码有多优雅,而在于它精准地切中了一个长期被忽视的断层:拥有最具体验痛点和创新想法的设计师,与需要投入学习成本的Figma API开发之间,存在一道认知鸿沟。产品将开发流程抽象为自然语言对话,试图将“插件开发者”的身份从“专业工程师”泛化为“任何会描述需求的设计师”。
然而,其面临的挑战与潜力一样明显。从评论中的技术性质疑可以看出,早期尝鲜者已迅速越过“新奇感”,开始追问生成插件的“工程级”能力:迭代优化、完整的API支持。这预示着产品若仅停留在“一次性代码生成器”层面,将很快触及天花板,沦为玩具。它必须进化成一个支持持续对话、理解和融入Figma设计系统规范的“AI协作者”,才能真正嵌入专业工作流。
更犀利的视角在于,它可能正在悄然重塑Figma的生态权力结构。一旦设计师能快速自制高度定制化的小插件,传统插件市场中通用、中庸工具的份额可能被侵蚀。长远看,这推动生态从“集中分发标准化工具”向“分布式生成个性化工具”演进。但风险在于,生成的代码质量、维护性与安全性若无法保障,也可能催生大量“插件垃圾”。因此,它的成功与否,关键在于其AI是真正理解了Figma的设计范式与工程上下文,还是仅仅进行了一场精致的语法包装。
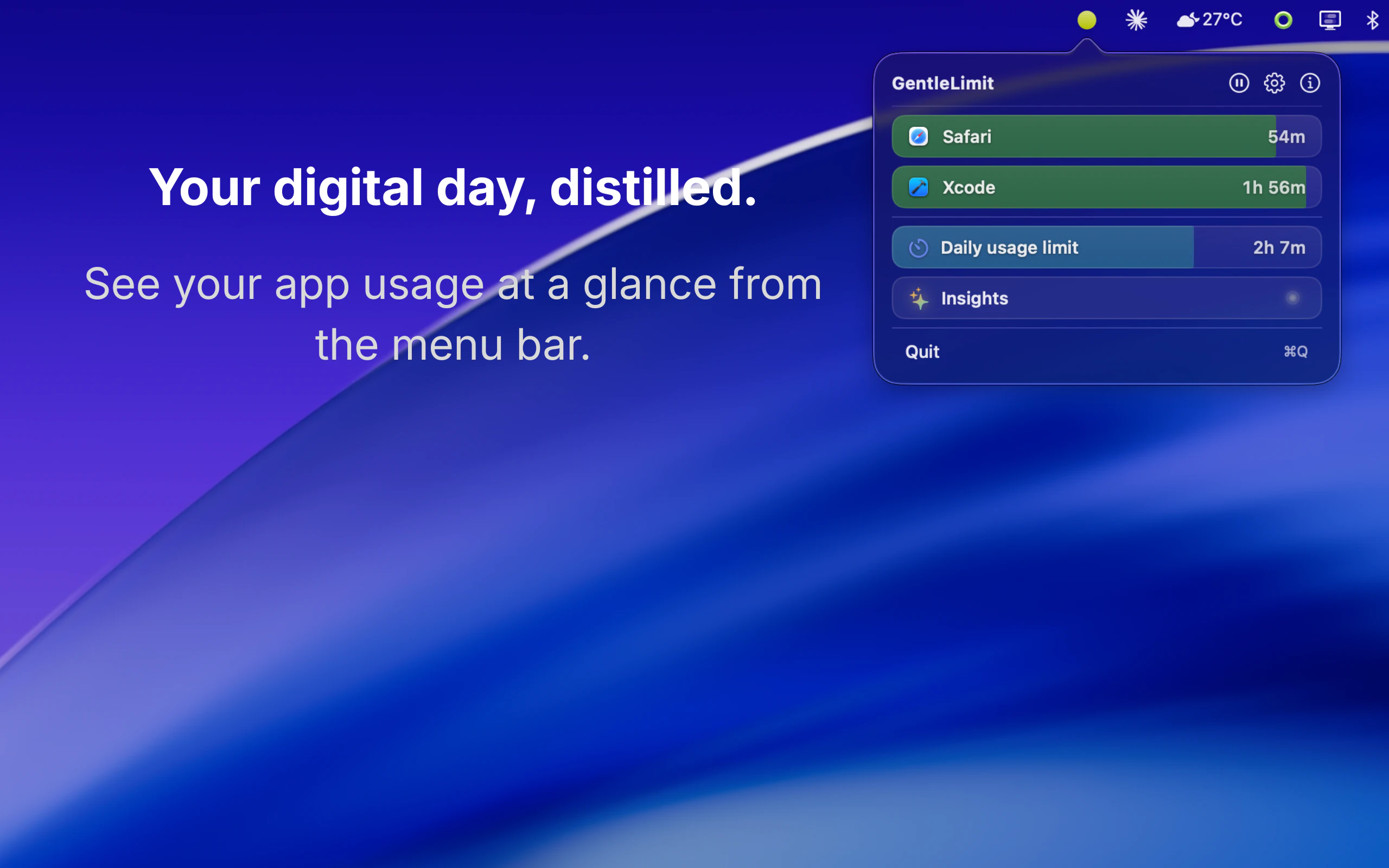
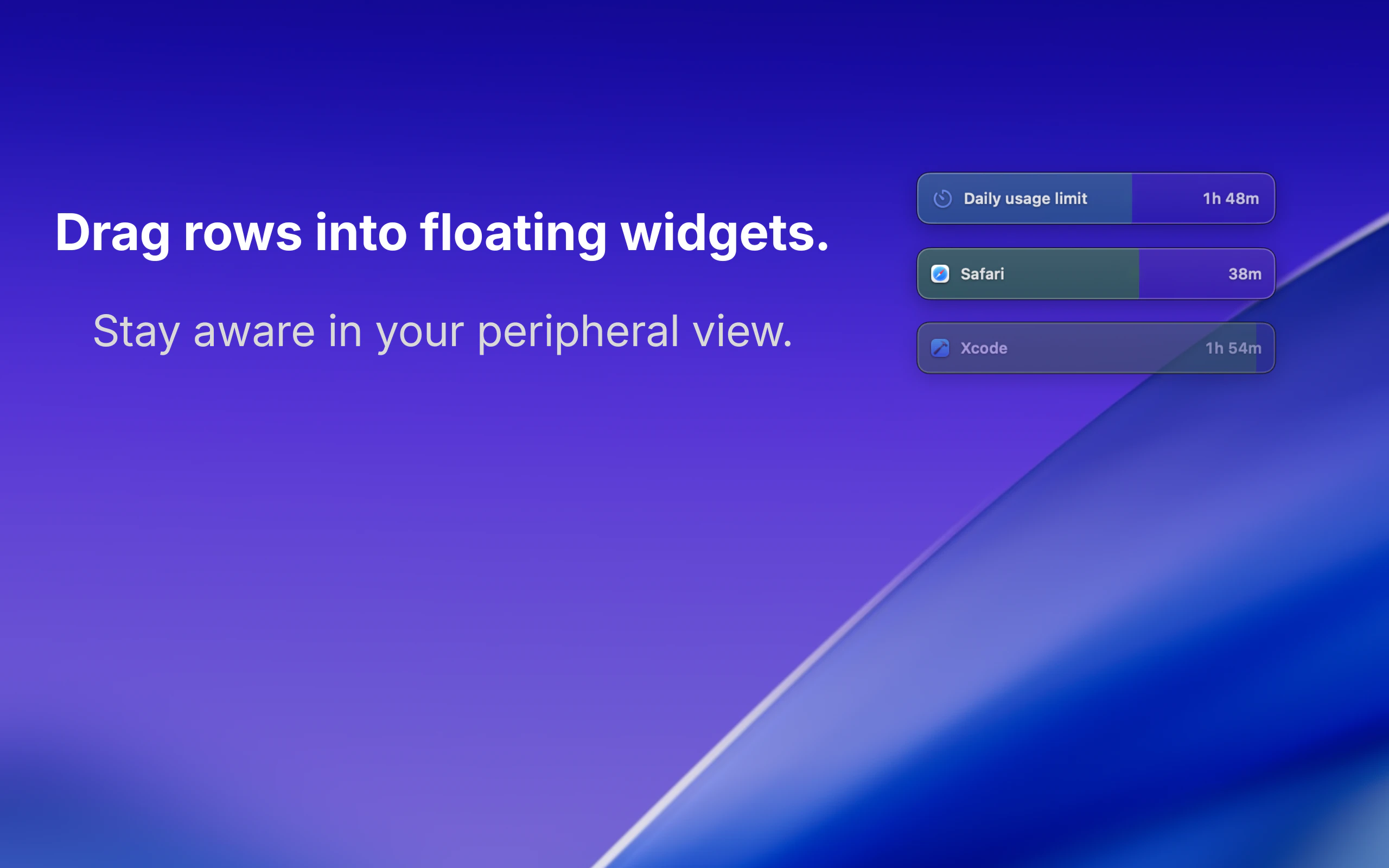
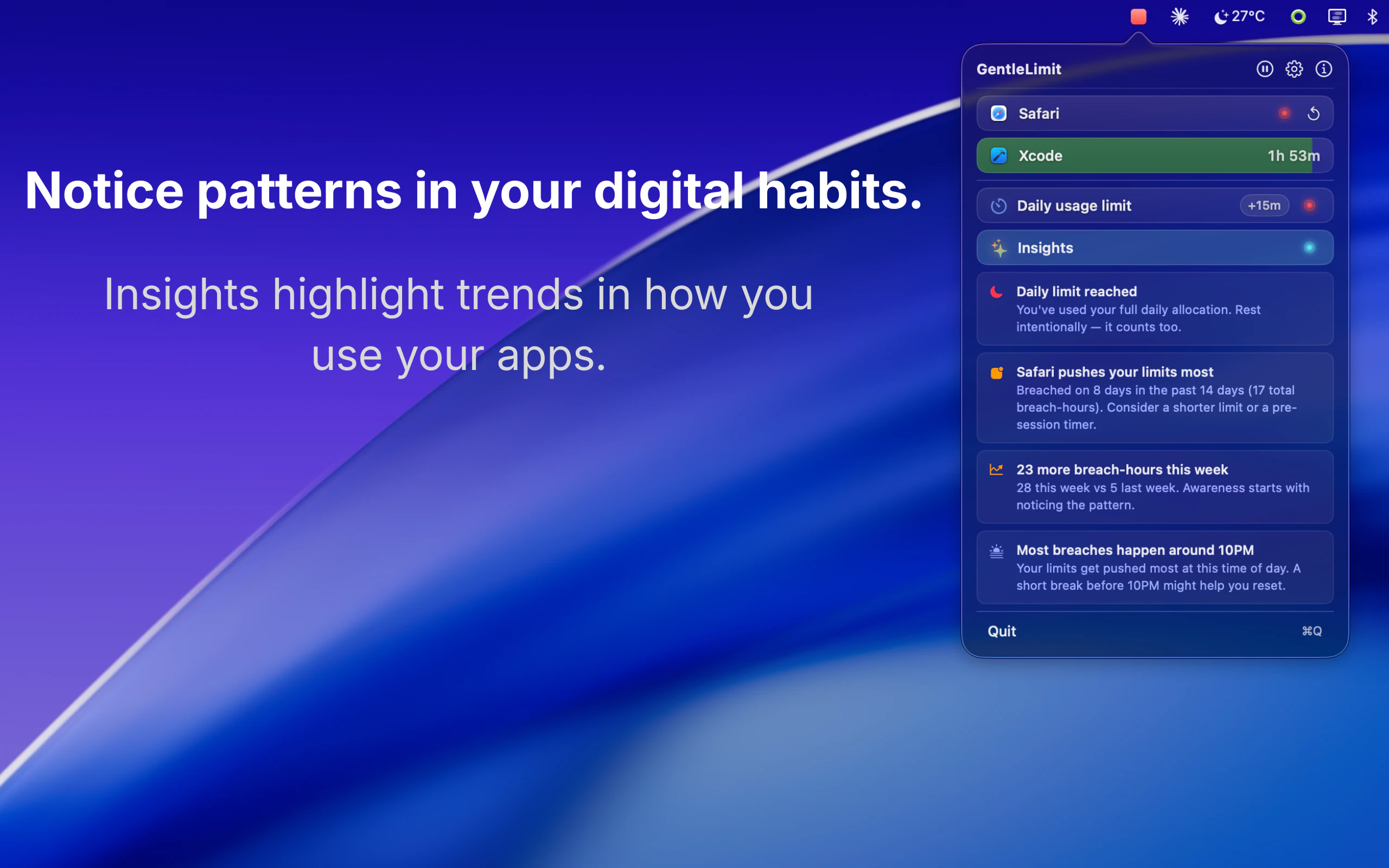
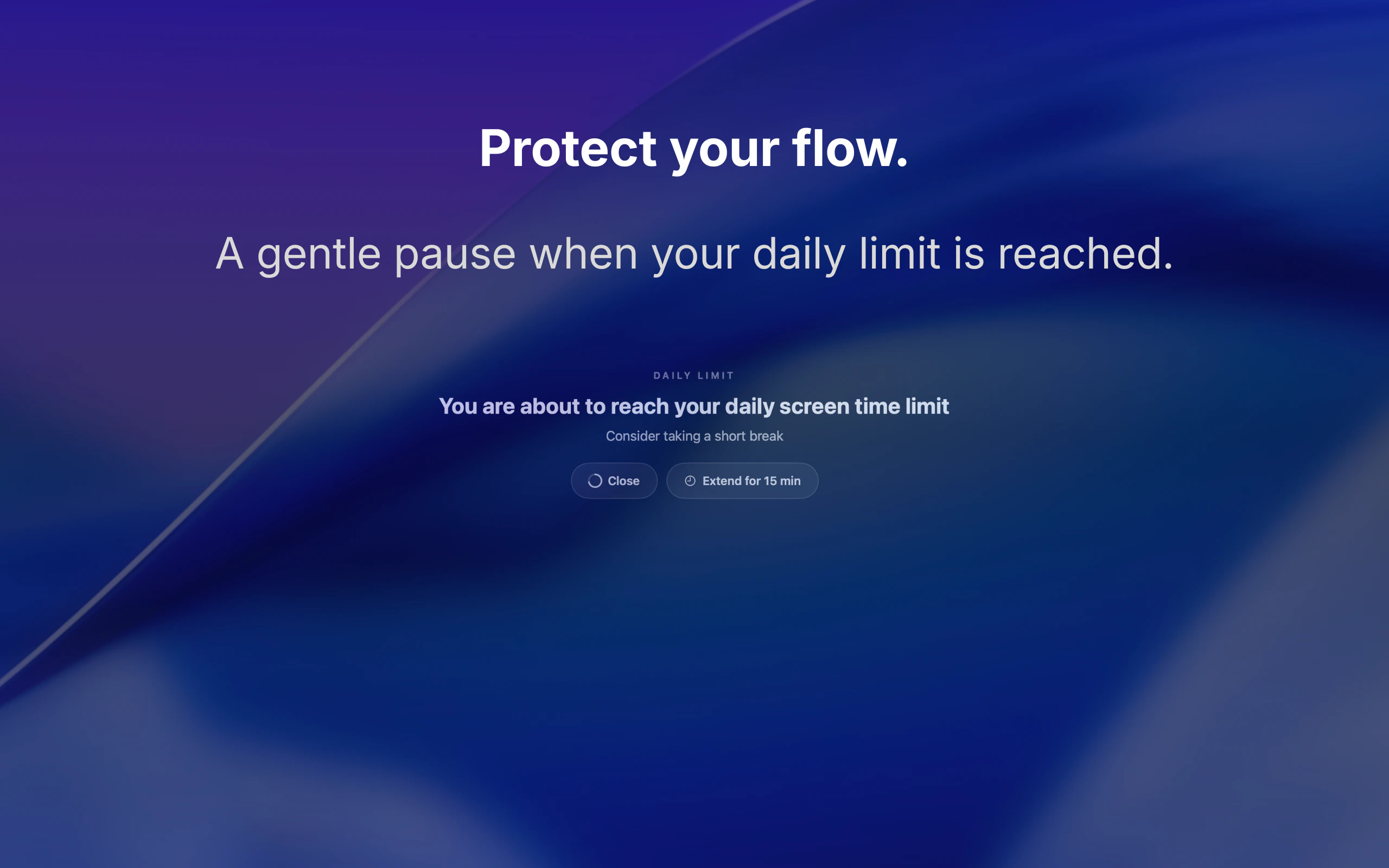
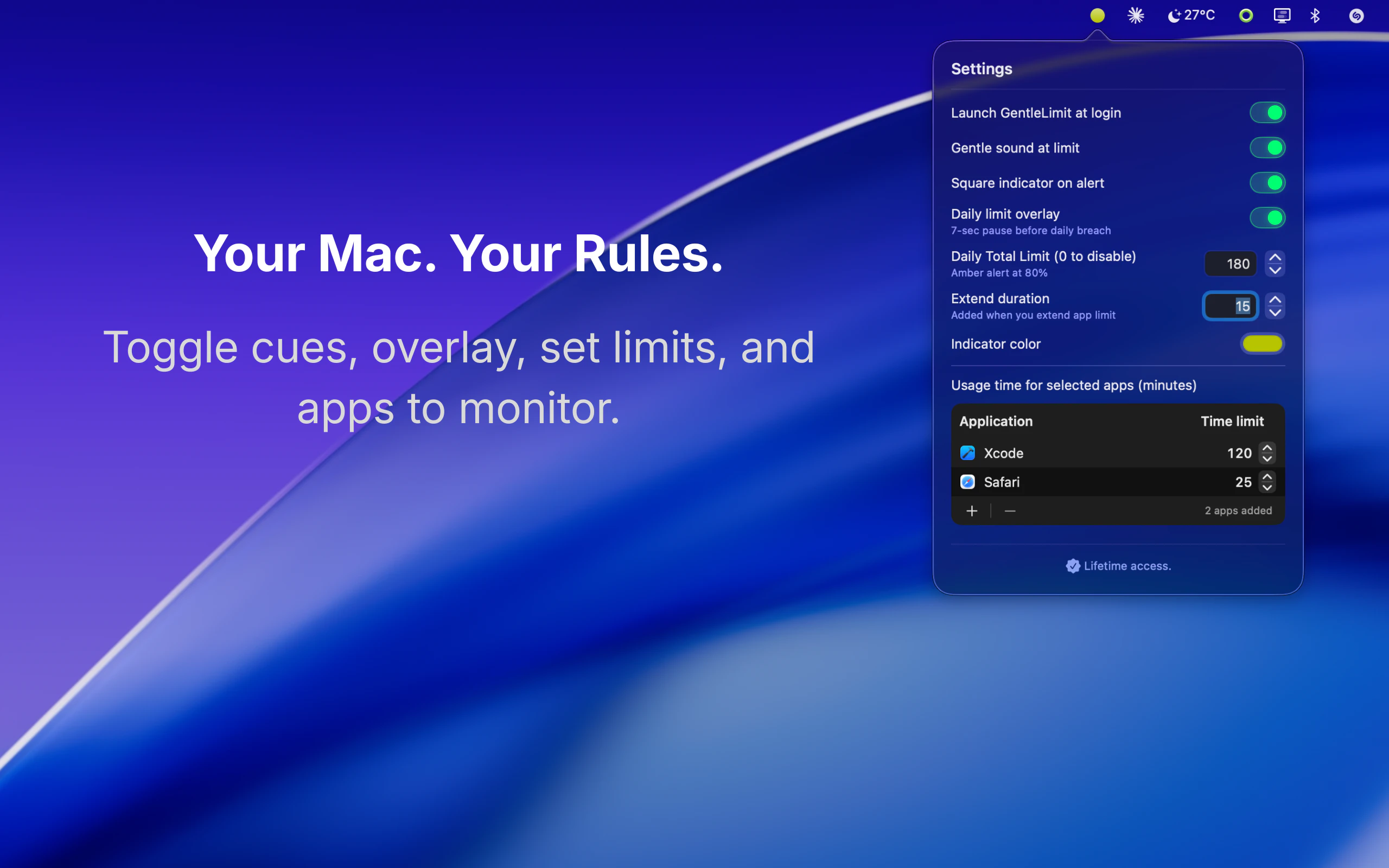
一句话介绍:一款通过边缘视觉悬浮组件和温和信号,帮助Mac用户在无需强制阻断应用的情况下,建立有意识的屏幕使用习惯的专注力工具。
Productivity
Time Tracking
Menu Bar Apps
数字健康
屏幕时间管理
专注力工具
macOS应用
非侵入式设计
隐私保护
行为习惯养成
生产力工具
边缘视觉反馈
用户评论摘要:用户普遍认可其“非阻断”理念,认为更温和、不易打断心流。主要问题集中在多显示器适配、具体干预形式、数据隐私及定价。开发者回复详细,解释了分层干预机制(视觉信号到全屏呼吸暂停)和本地化隐私设计。
AI 锐评
GentleLimit的核心理念是对“数字健康”赛道的一次精巧解构。它没有选择与Freedom、Cold Turkey等“硬阻断”工具在封锁强度上竞争,而是敏锐地抓住了一个更细分的痛点:专业工作者对“流程中断”的深度恐惧。其真正价值不在于限制,而在于将“无意识使用”转化为“有意识行为”。
产品通过“边缘视觉反馈”这一设计,将监控从需要主动查看的统计面板,转变为被动感知的环境信息。这本质上是将行为心理学的“暗示”与“自我调节”理论产品化,把控制权交还给用户,同时避免了因权限被剥夺而产生的逆反心理。其宣称的“隐私设计”不仅是卖点,更是功能成立的基石——一旦数据离岸,这种需要持续监控应用使用的工具将引发巨大的信任危机。
然而,其商业模式(一次性买断)与价值主张之间存在潜在张力。作为习惯养成工具,用户成功即意味着需求终结,这与SaaS的持续收入模型背道而驰。此外,其效果高度依赖用户的自我驱动力,对于自律性极差的用户,温和的提醒可能完全无效。它更像是一款“精英主义”的效率工具,服务于那些已有改变意愿、只需轻微助推的群体,而非普罗大众。它的成功,将取决于能否在“温和”与“有效”之间找到那个确凿的、可被数据证明的平衡点。
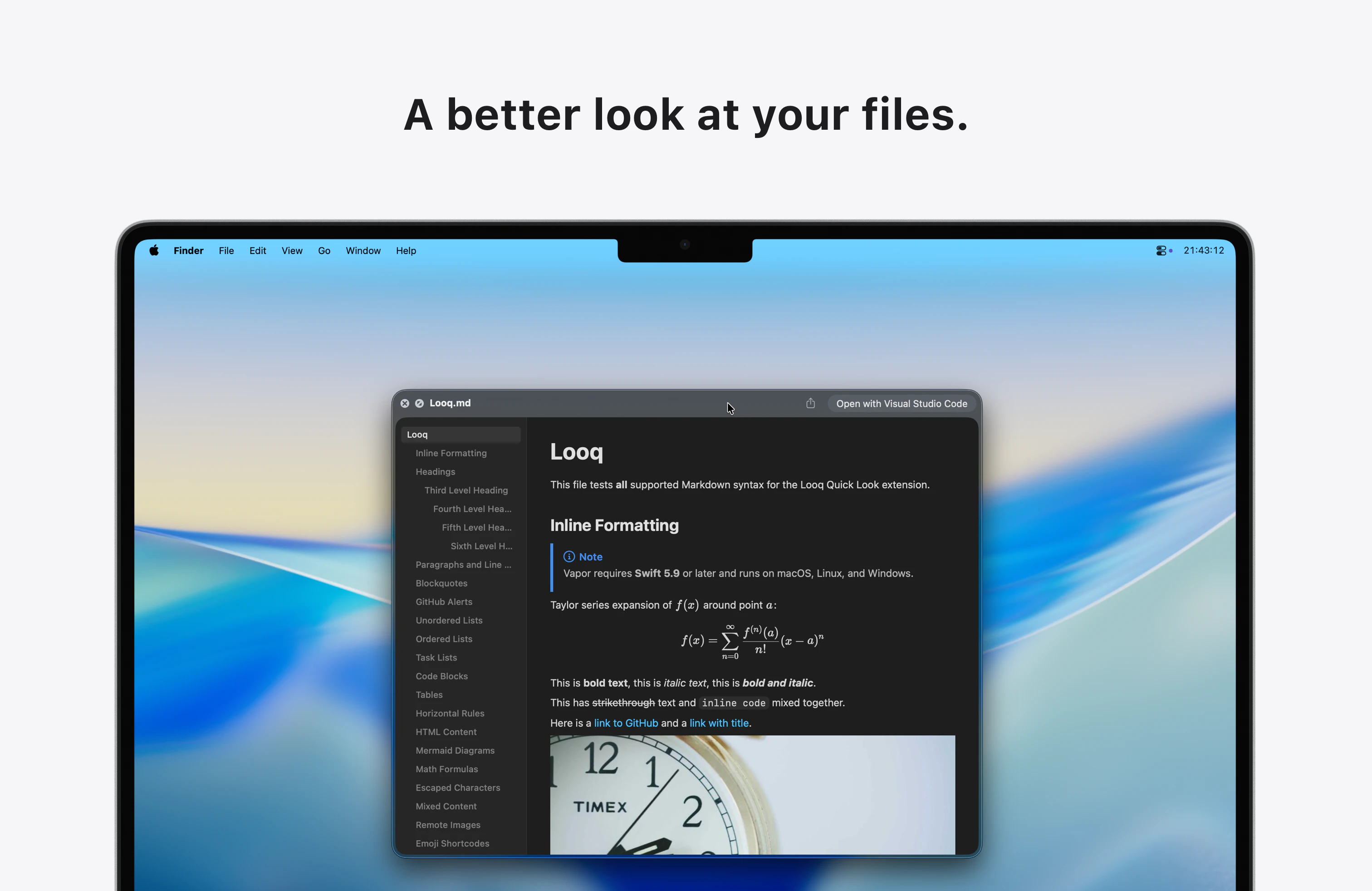
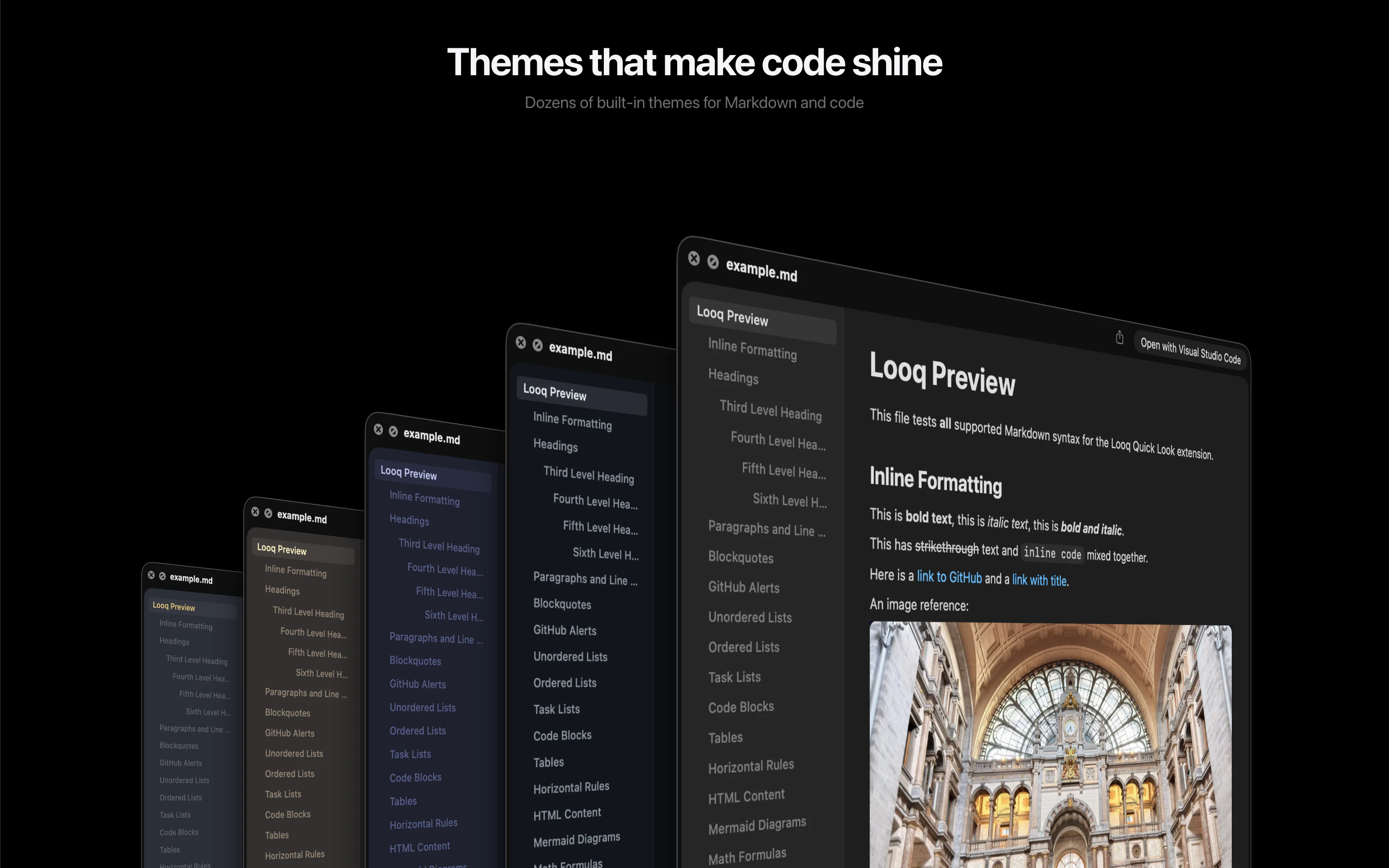
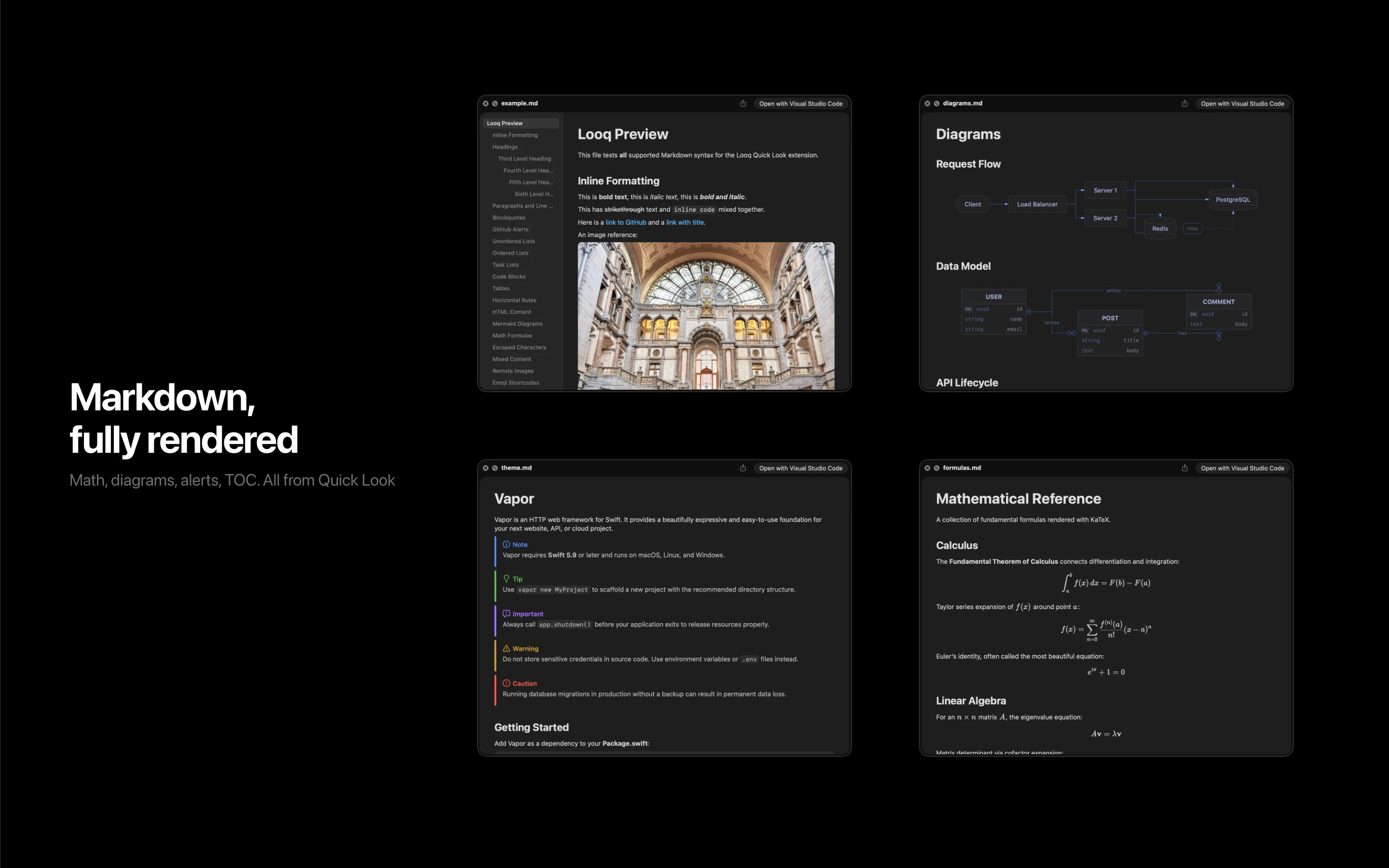
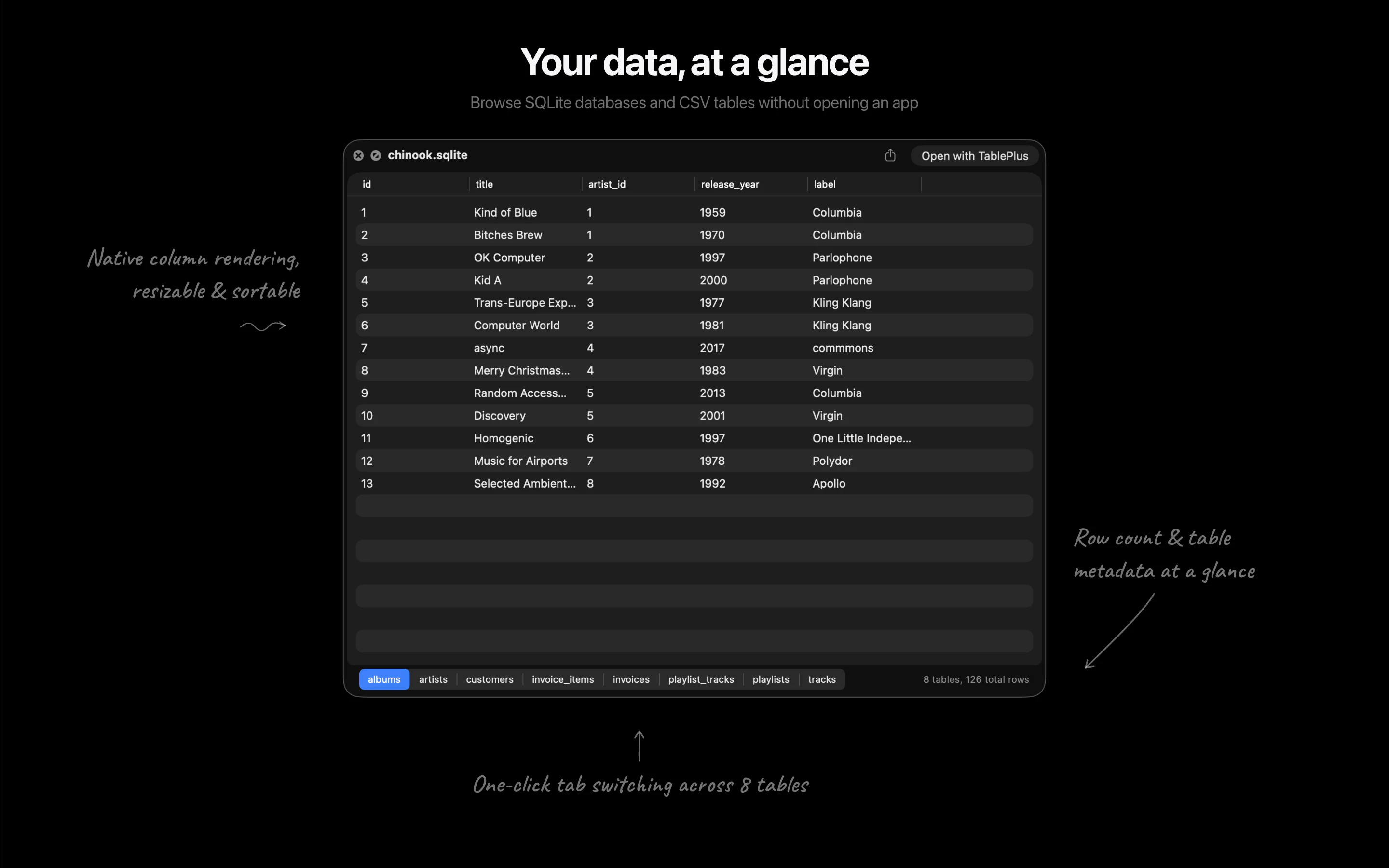
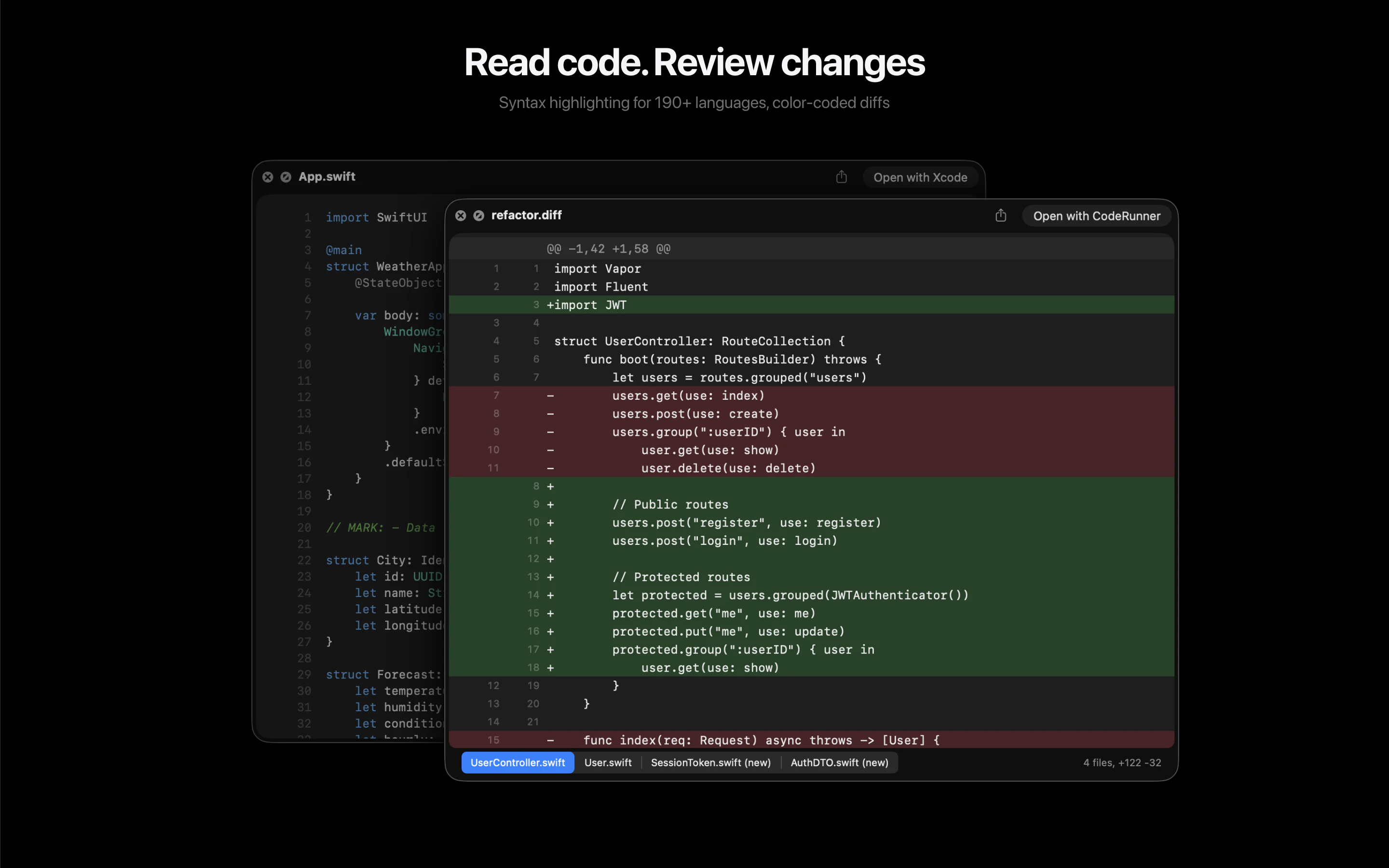
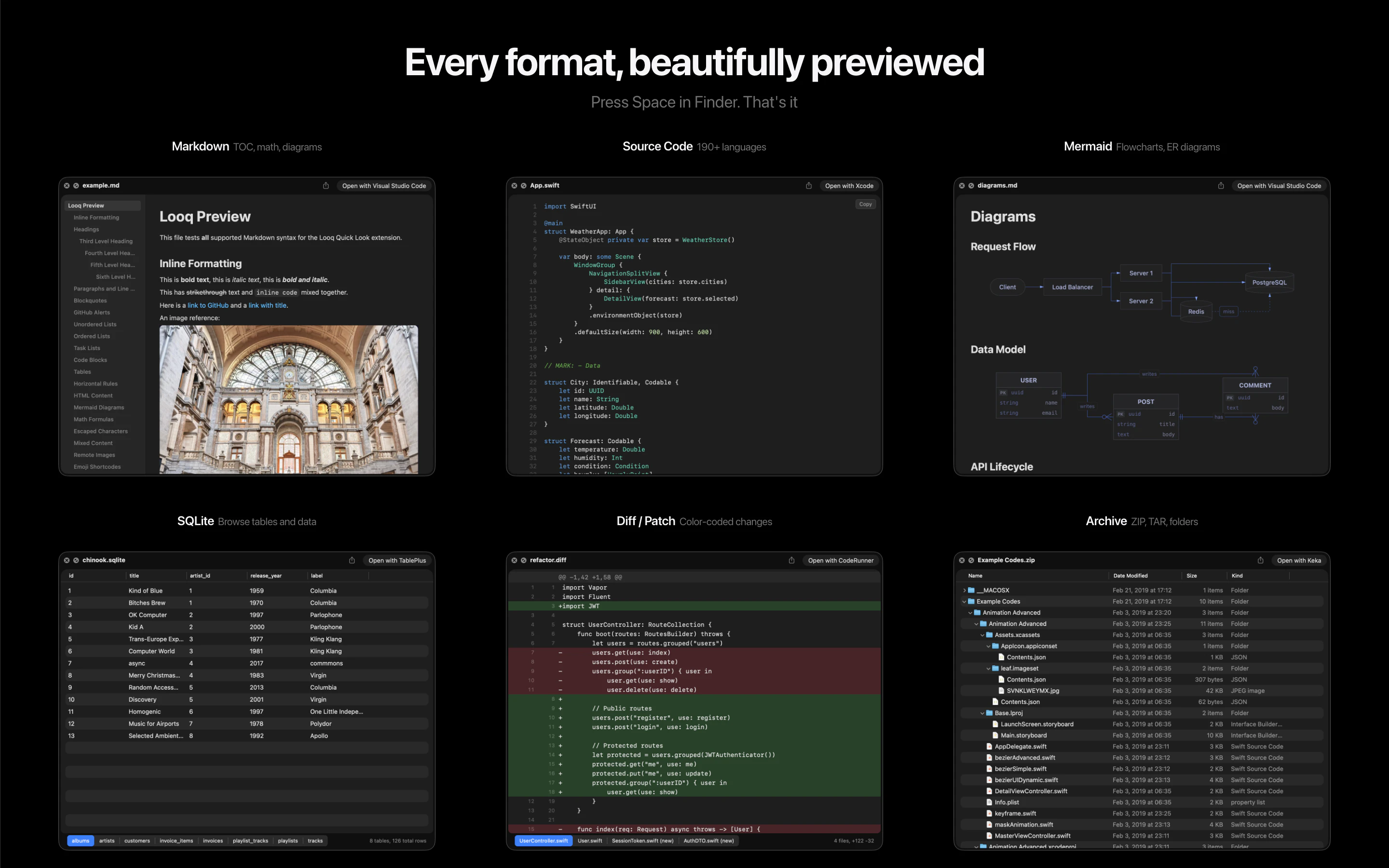
一句话介绍:Looq 是一款 macOS Quick Look 增强插件,为开发者提供代码、Markdown、SQLite等专业文件的即时预览,解决了开发者需频繁打开完整编辑器才能快速查看文件内容的效率痛点。
Mac
Productivity
Developer Tools
生产力工具
macOS扩展
文件预览
开发者工具
代码高亮
Markdown渲染
本地优先
Quick Look增强
用户评论摘要:开发者积极互动,确认将加入实时渲染功能。用户对Mermaid图表预览功能反响热烈,并提出了对日志文件、超大文件支持的建议,体现了用户对扩展文件类型支持和工作流无缝集成的期待。
AI 锐评
Looq 切入了一个被原生系统长期忽视的“缝隙市场”:专业用户的文件快速预览需求。其真正的价值并非单纯的功能堆砌,而在于对开发者“瞬时认知”工作流的精准优化。它将“Quick Look”从消费型内容(图片、PDF)的查看工具,重塑为生产型内容(代码、数据、文档)的轻量级交互界面。
产品策略犀利之处在于“单一扩展”定位,以最小侵入性解决最大范围的痛点,避免了让用户管理多个单点工具。支持SQLite等数据文件的可排序表格预览,更是将预览动作从“查看”升级到了“初步探查”,赋予了Quick Look意想不到的轻度数据分析能力。
然而,其挑战同样明显。首先,深度依赖macOS原生Quick Look框架,其体验边界和性能天花板受制于苹果。其次,“本地优先”虽是隐私卖点,但也意味着所有复杂渲染(如大型Mermaid图表)的计算压力都落在本地,可能影响大型文件的预览速度。用户提出的实时渲染和超大文件支持,正是对此挑战的呼应。
本质上,Looq 是“瑞士军刀”式的效率工具,其成功不取决于技术壁垒,而在于对细分工作流颗粒度的极致把握。它能否持续进化,将预览从“看”延伸到“轻量交互”,并维持工具的轻快感,将是其从“有趣插件”升维为“必备工具”的关键。
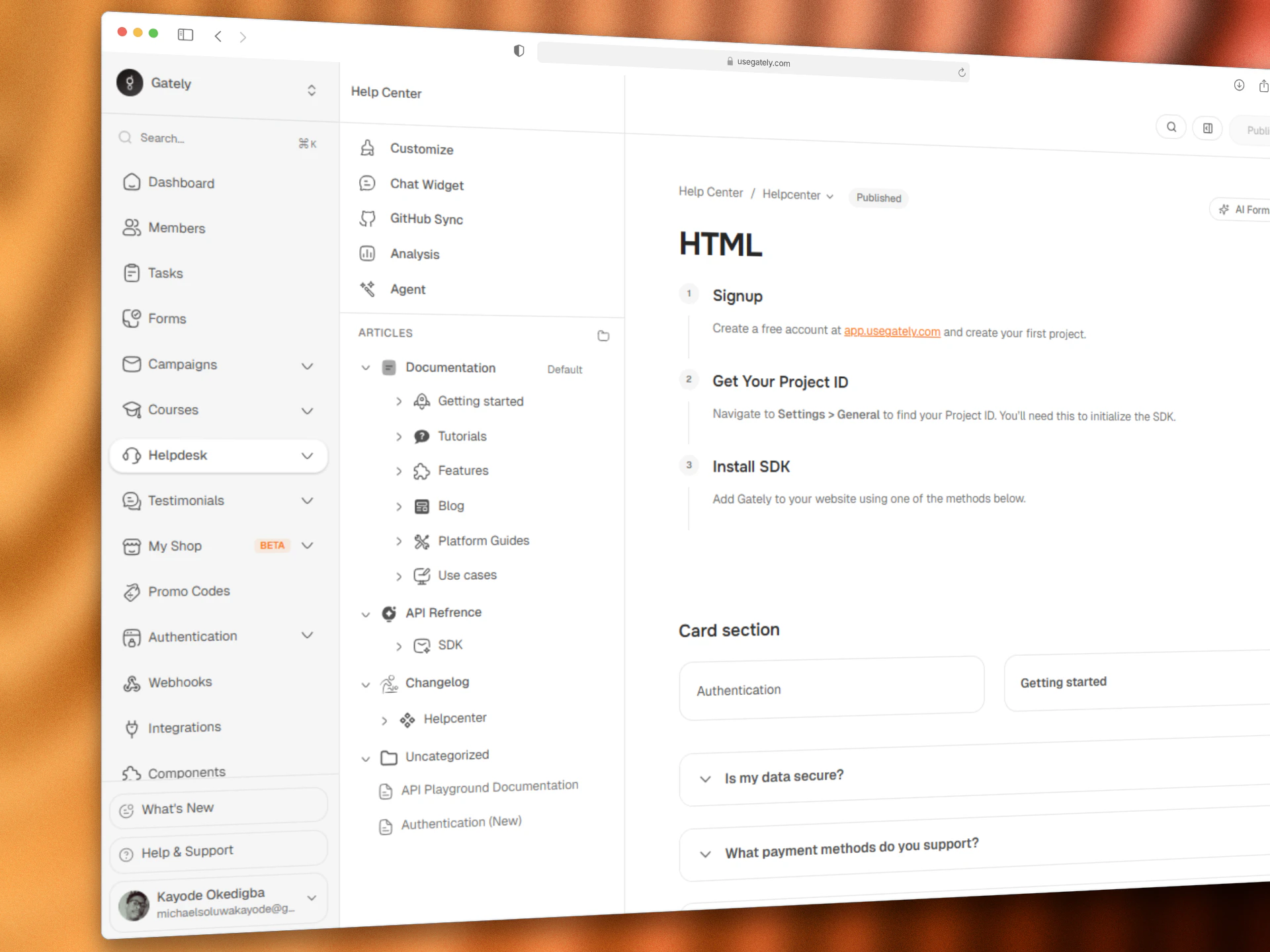
一句话介绍:Gately是一款帮助开发者和创作者构建、启动和扩展会员制应用的一体化平台,通过无缝集成和内容同步,解决了产品开发中文档、帮助中心与用户管理分散脱节的痛点。
Social Media
Marketing
SaaS
会员平台
无代码/低代码
创作者经济
一体化SaaS
内容同步
帮助中心
用户管理
支付集成
社区建设
知识管理
用户评论摘要:用户反馈主要集中于:1. 肯定其“一体化”价值,建议突出“All in one”的核心定位;2. 询问技术细节,如文档如何与代码库自动同步、是否原生集成支付与社区功能;3. 创始人积极互动,透露正进行A/B测试并快速迭代。
AI 锐评
Gately切入了一个拥挤但痛点明确的市场:会员与社区管理。其宣称的“一体化”并非新概念,但它的差异化可能在于将“技术产品管理”与“创作者会员运营”这两个通常割裂的场景进行了缝合。产品介绍中“从代码库同步内容至帮助中心”的承诺,直击开发者与技术型创作者的核心痼疾——产品迭代与用户支持文档的严重滞后。
然而,这正是其最大的风险与挑战所在。首先,技术实现门槛高。实现代码注释与用户帮助内容的自动同步,需要深度、稳定且安全的代码仓库集成,这对初创团队是巨大考验。评论中的技术性质疑也印证了这一点。其次,定位存在模糊性。标语强调“Build your own membership”,介绍却偏向“帮助中心”和文档同步,而评论又提及支付、内容门控等社区功能。它似乎在同时面向“需要会员功能的开发者”和“需要技术同步能力的创作者”两类人群,这种双向定位可能导致信息传递失焦,正如用户犀利指出的:首页标语过于安全,未能一击即中核心差异点。
其真正价值或许不在于功能大而全,而在于成为“技术产品与会员商业之间的连接层”。如果它能将代码、文档、用户、支付数据流真正打通,形成自动化闭环,就能从工具升级为“中枢神经系统”。但目前看来,产品仍处于早期验证阶段,创始人互动积极是亮点,但需尽快厘清核心用户画像,将有限的资源集中于兑现最具壁垒的承诺(如代码同步),而非在泛功能层面与成熟竞品对抗。否则,它可能只是又一个“功能拼盘式”的中间件。
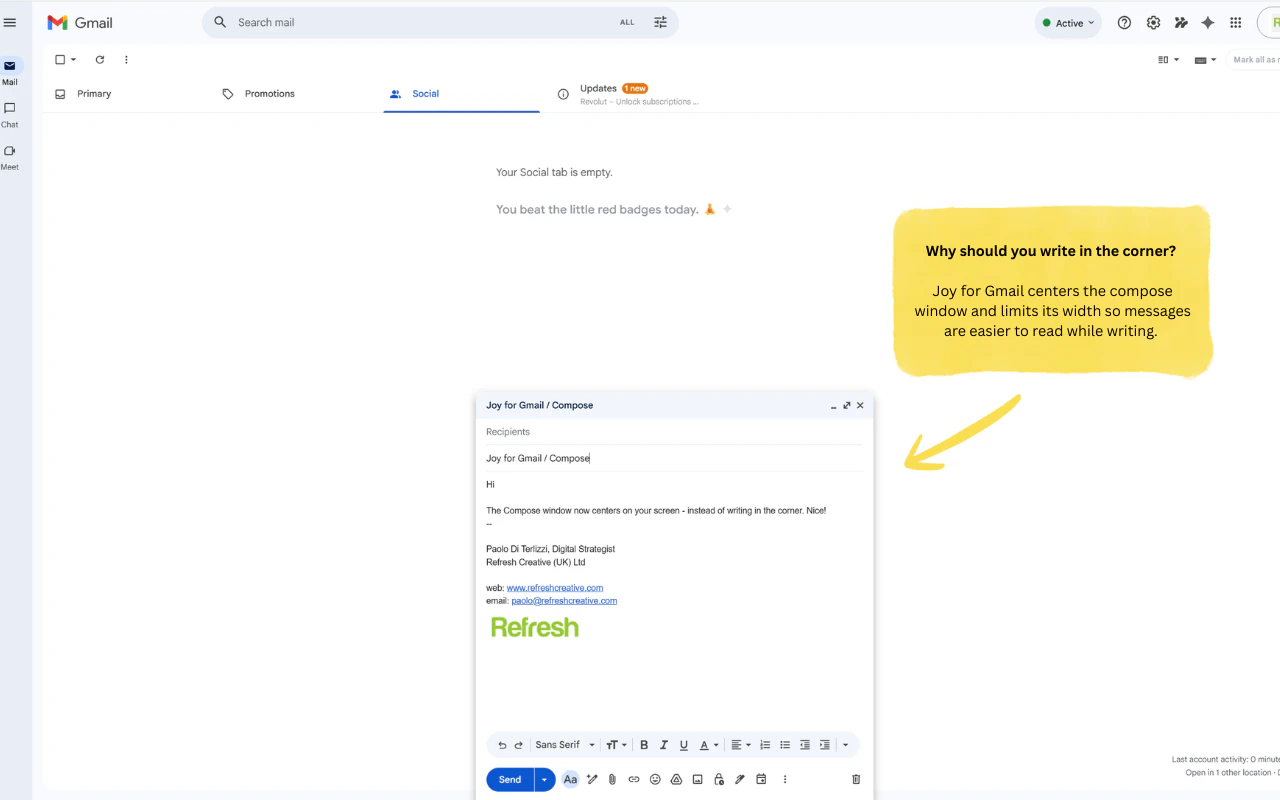
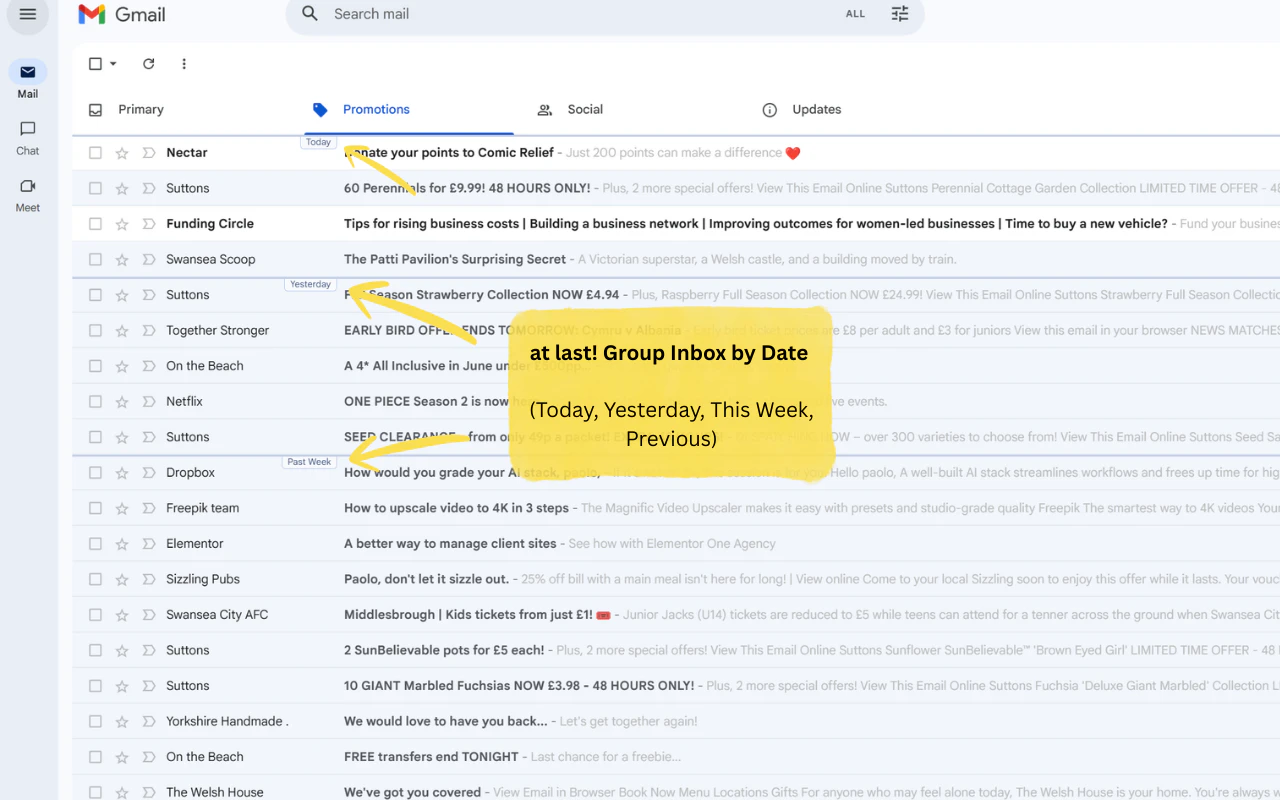
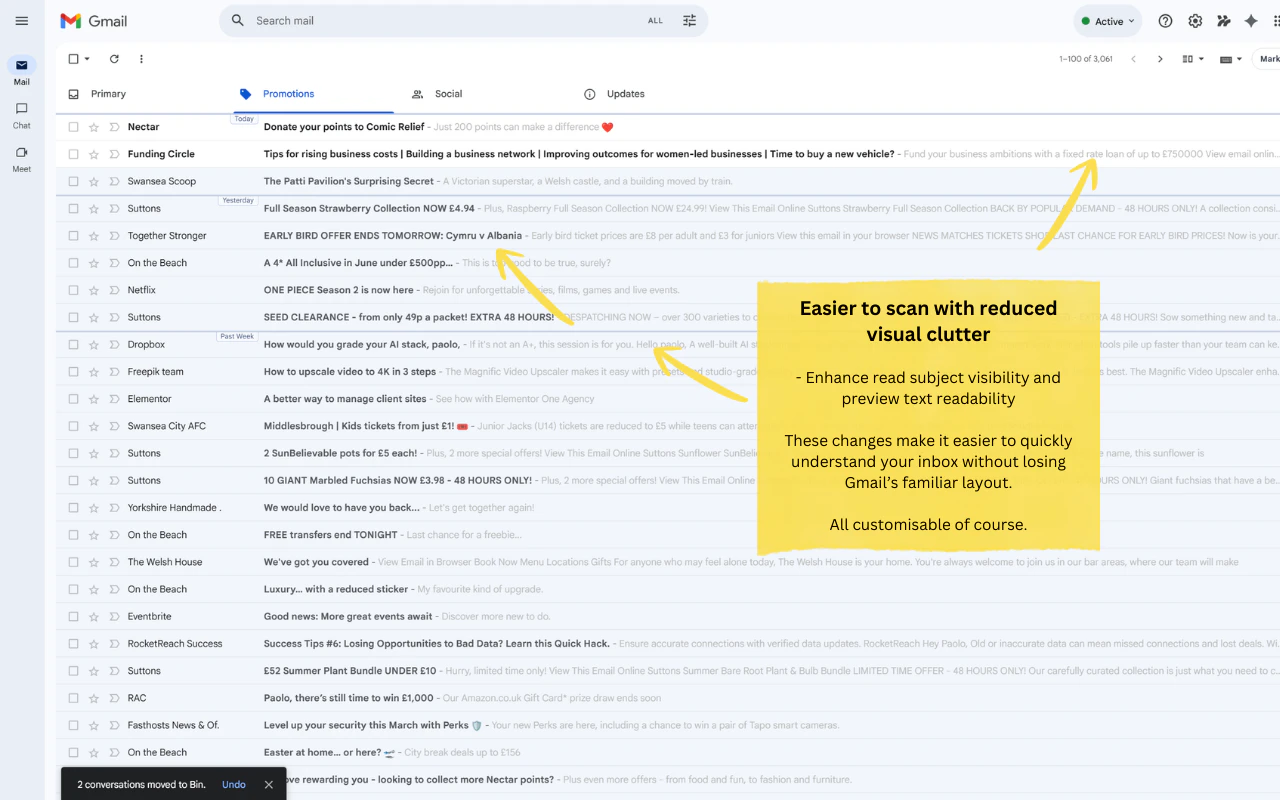
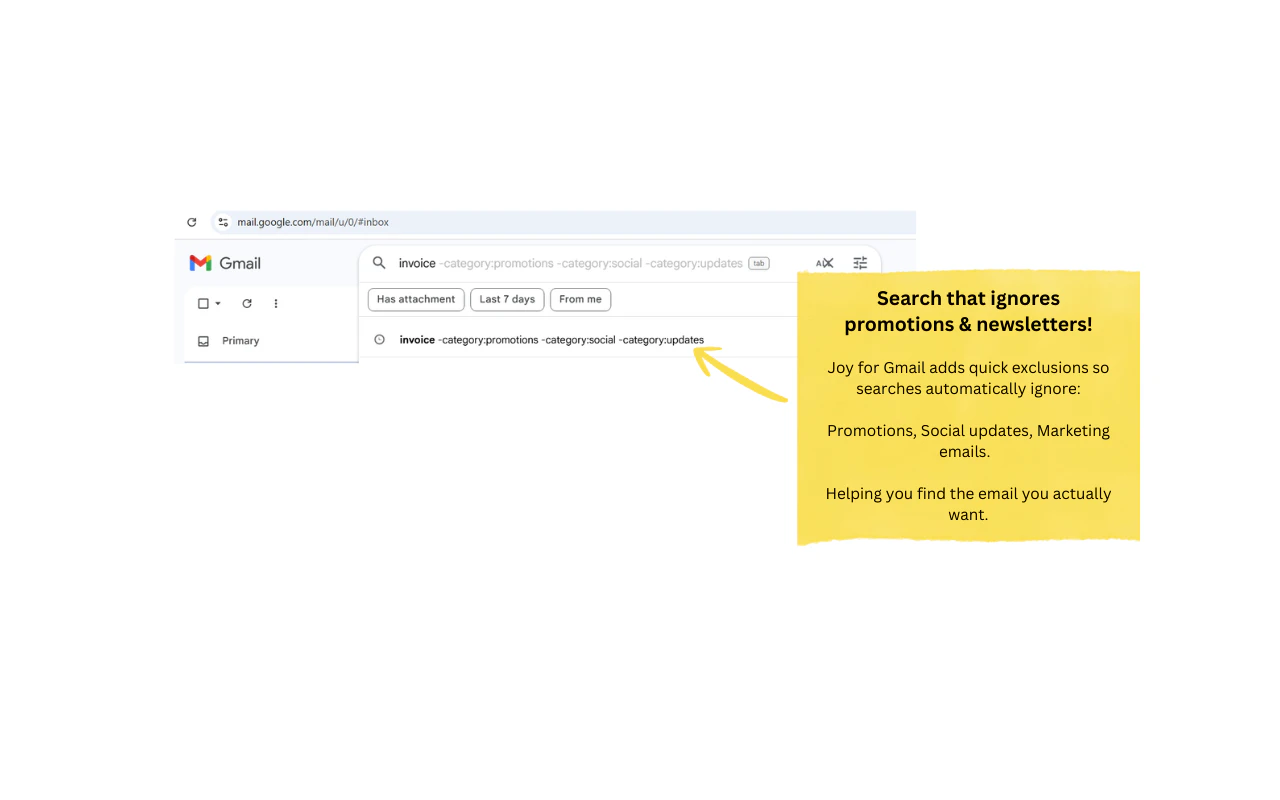
一句话介绍:一款轻量级浏览器扩展,通过按日期分组邮件、居中撰写窗口、过滤推广邮件等设计,为长期忍受Gmail界面杂乱、撰写体验不佳的用户提供更清晰、专注、愉悦的邮件处理体验。
Chrome Extensions
Email
Writing
浏览器扩展
Gmail增强
生产力工具
邮箱管理
界面优化
无数据收集
用户体验
专注写作
邮件过滤
用户评论摘要:用户高度赞赏“无数据收集”原则。主要问题集中于功能细节:如何处理邮件线程和模板?是否支持企业账户?“标记所有已读”按钮位置引发疑问。对居中撰写和搜索过滤功能表示肯定与好奇。
AI 锐评
Joy for Gmail 精准地戳中了Gmail作为一个“功能强大但体验陈旧”的产品的软肋。它的价值不在于技术创新,而在于**体验重构**。它将一个以功能堆砌为核心的Web应用,重新以“用户专注度”和“心流体验”为中心进行设计。
“居中撰写”绝非简单的UI调整,其背后是深刻的认知心理学逻辑——将核心创作行为置于视觉中心,对抗碎片化干扰。按日期分组和过滤推广搜索,则是对抗信息过载的朴素但有效的策略,本质上是为用户重新夺回收件箱的掌控感。
然而,其真正的“杀手锏”和风险点均在于“无数据收集”。这既是其最犀利的营销亮点,直击当前用户隐私焦虑的痛点,也从根本上划清了与许多“免费”生产力工具的界限,建立了稀缺的信任感。但这也封死了其未来通过数据分析优化产品、乃至商业化的大部分路径,使其可能永远停留在“小而美”的爱好者工具层面。
从评论反馈看,用户已开始追问线程邮件、模板等深度功能,这揭示了工具型产品的典型困境:初期通过解决几个“痒点”迅速获客,但用户很快会期望它解决所有“痛点”。若盲目添加功能,又会背离“轻量”初心。因此,Joy的真正挑战在于:如何在保持克制、捍卫“无数据”原则与“轻量”体验的同时,构建足够深的护城河,避免被大厂一个更新就轻易覆盖。它的未来,取决于能否将“Joy”这种主观感受,转化为一套可防御、可持续的体验设计哲学。
一句话介绍:Chat是一款MCP客户端,可将后端服务通过MCP服务器快速转化为可交互的聊天界面,使开发者无需构建完整前端即可快速发布MVP、验证想法,显著降低产品早期开发门槛。
API
Developer Tools
Artificial Intelligence
GitHub
低代码开发
MCP生态
快速原型
后端即服务
AI工具集成
API包装器
MVP工具
内部工具开发
聊天界面
自动化工作流
用户评论摘要:用户肯定其作为MVP和内部工具的快速验证价值。主要疑问集中在多步骤认证流程、会话持久化、用户级访问控制等企业级功能实现上。开发者回复已集成Better Auth支持认证,并可通过环境变量进行品牌定制。
AI 锐评
Chat产品巧妙地站在了“AI工程化”与“开发效率”的交叉点上。其核心价值并非技术创新,而是精准的场景缝合:将新兴的MCP协议转化为可即刻产生商业价值的“胶水层”。产品定位犀利——它不服务终端消费者,而是瞄准了那些被前端开发拖累、急于验证AI工作流或API价值的开发者与小团队。
然而,其“快速暴露后端”的卖点是一把双刃剑。一方面,它确实将产品验证周期从“周”压缩到“天”,是理想的概念验证加速器。另一方面,这种“即时暴露”可能掩盖了产品化过程中至关重要的用户体验设计、状态管理与复杂交互逻辑。评论中关于认证、会话和品牌化的担忧,恰恰暴露了从“可用的原型”到“可售的产品”之间巨大的鸿沟。
本质上,Chat是“后端优先”开发哲学的一次极端实践。它在AI工具爆发的当下提供了最短的上市路径,但其长期价值取决于MCP生态的繁荣度及自身能否从“便捷客户端”演进为具备强大治理、监控与定制能力的“企业级网关”。若止步于原型工具,其天花板清晰可见;若能向下深耕集成复杂度,向上提供数据分析与流程编排,则可能成为AI时代不可或缺的中间件。
一句话介绍:Gaze Guard是一款基于视线检测的macOS菜单栏工具,能在用户视线离开或检测到他人窥屏时,自动模糊指定应用屏幕,为在咖啡厅、办公室等公共空间工作的用户提供即时隐私保护。
User Experience
Privacy
Menu Bar Apps
隐私保护
屏幕模糊
视线检测
防窥视
macOS工具
本地AI
菜单栏应用
生产力工具
用户评论摘要:用户主要关注性能影响(电池、发热)、多屏适配、响应延迟及功能细节。开发者回复确认对Apple Silicon性能影响小,但会耗电;目前仅通过人数判断,无面部识别;功能限于应用级模糊,不支持区域模糊。
AI 锐评
Gaze Guard精准切入了一个细分但真实的痛点——公共环境下的屏幕隐私焦虑。其真正的价值不在于技术的新颖性(基于成熟的Vision框架),而在于将“持续主动防护”这一概念产品化,为用户构建了无需手动干预的心理安全边界。
产品设计聪明地利用了苹果的软硬件生态:依赖Neural Engine降低性能损耗、全本地处理强调隐私合规,这使其在技术实现和营销话术上都建立了壁垒。然而,其核心缺陷也显而易见:当前基于“人脸计数”的机制在安全性上存在逻辑漏洞(无法识别机主),这使其更像一个“防意外窥视”的礼貌性工具,而非真正的安全产品。用户关于面部识别的期待恰恰印证了这一点。
从市场角度看,其买断制和在隐私赛道“自我断网”的设定,虽契合产品调性,但也可能限制其长期迭代和商业扩张能力。它本质上是一个功能单一、场景明确的“优等生”工具,在解决基础痛点后,面临的是如何从“有趣的功能”进化为“不可或缺的解决方案”的挑战。能否在精准识别、多场景自适应(如会议演示模式)上深化,将决定其天花板。
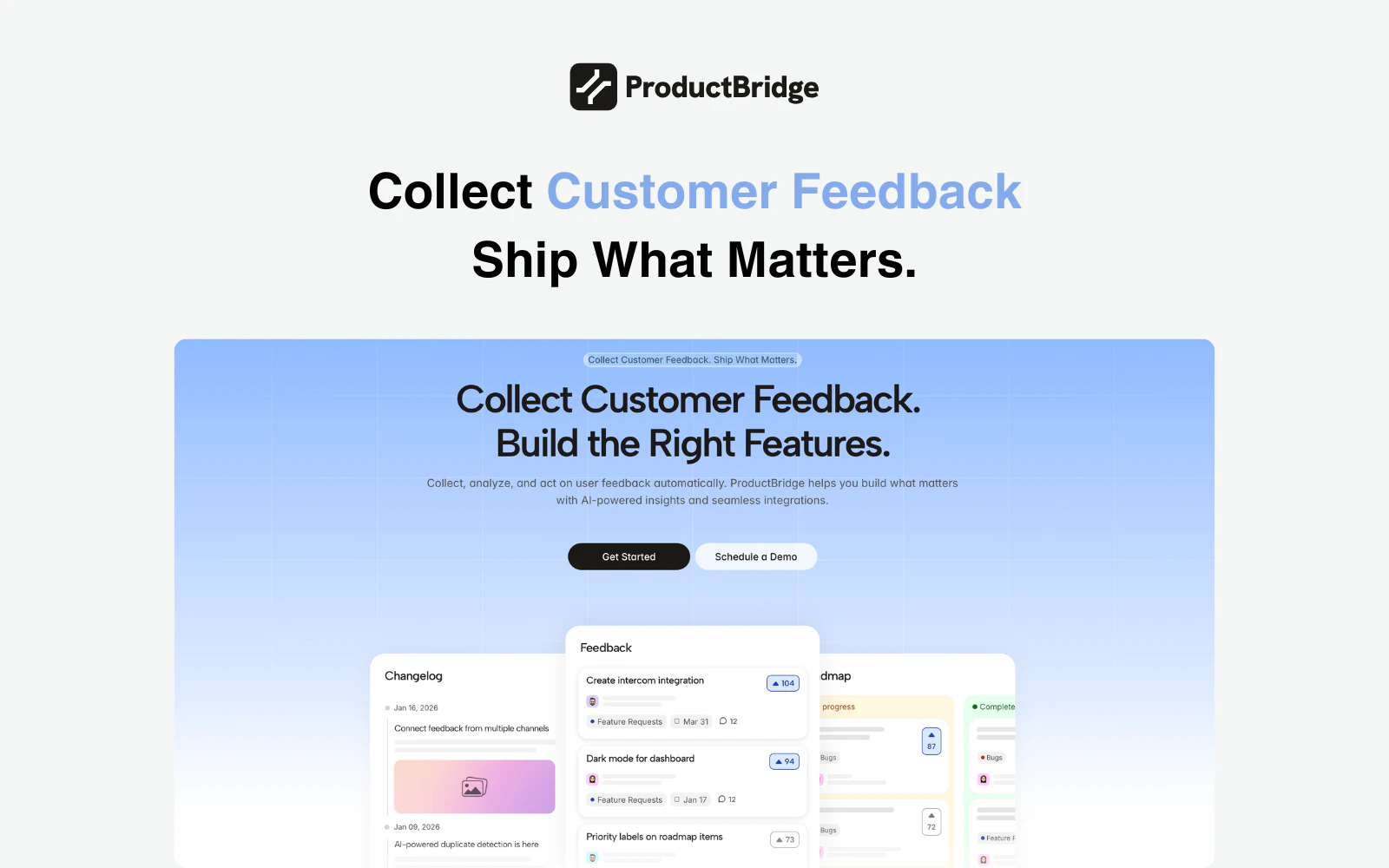













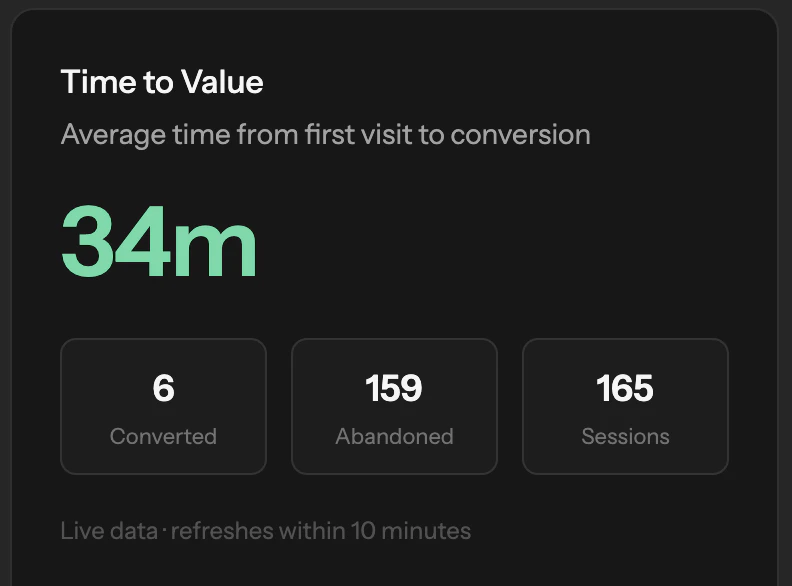
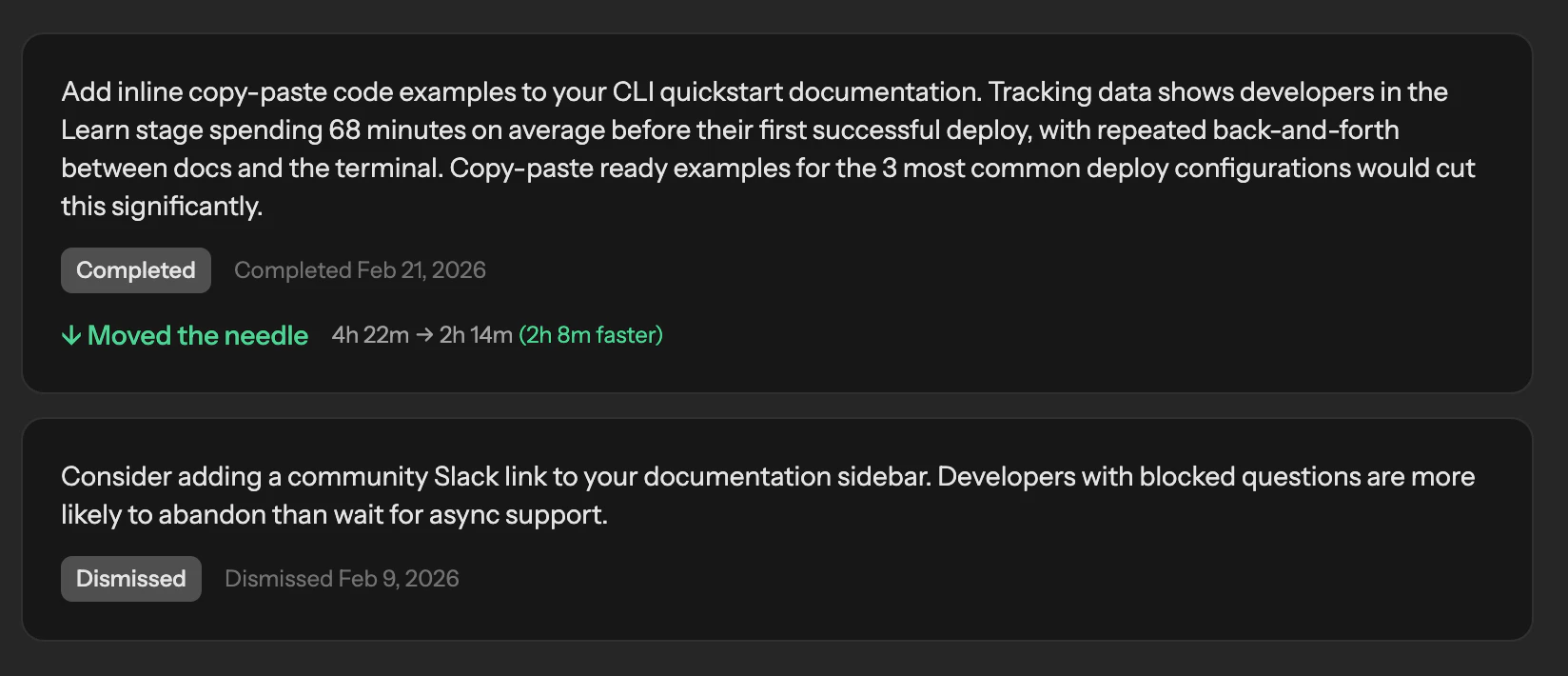
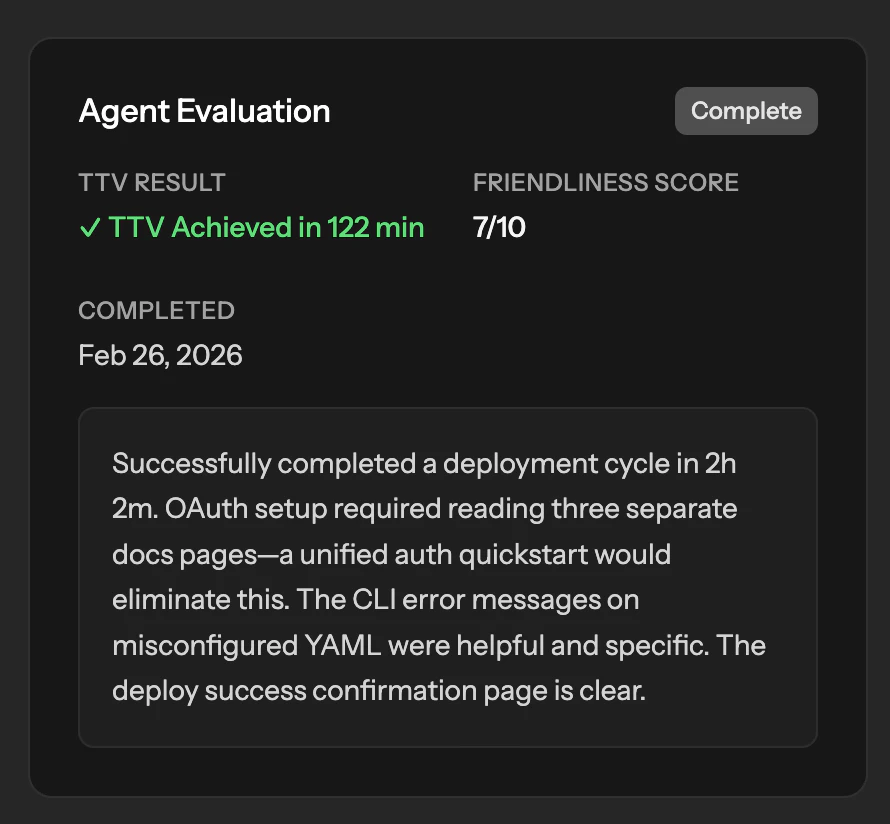













Happy launch team! Quick question: How do you handle context and prioritization when aggregating feedback from so many different sources? For example, how do you distinguish between loud but low-impact requests and signals that actually represent broader customer demand, and how reliable is the deduplication when similar feedback is phrased differently across channels?
Congrats on the launch! But how is it different from, say, ProductBoard, Canny, airfocus, and the likes?
The "closing the loop" part is what I care about most here. We've tried a couple feedback tools before and the collection part is usually fine, but actually telling users "hey we shipped the thing you asked for" always falls through the cracks.
$24/mo flat is solid too. Most tools in this space charge per seat which gets painful fast when you want the whole team to have access.
How does the AI handle feedback that's more of a rant vs an actual feature request though? That's always been the tricky part for us.
Congrats on the launch! How does ProductBridge handle conflicting signals? (example: when a feature is largely recommended by free users but paying customers never mention it). Does AI score accounts by revenue impact, or is prioritization purely vote-based?
One of my biggest challenges with customer feedback is trying to filter out which ones were real feedback and which ones were from bots/fake. Are there ways that ProductBridge help with this?
We collect client feedback across several channels at once — and deduplication is what interests me most. The same request often arrives three times, worded differently, and it's hard to tell if it's one problem or three. How does ProductBridge decide two pieces of feedback actually belong together?
Congrats on the launch! @hareesh_vemasani @rohithreddy
Honestly, this is something most teams just deal with instead of solving.
Feedback keeps coming in, but it rarely turns into clear product decisions.
Really like how you’ve made it more structured and usable.
Curious, what kind of feedback patterns surprised you the most so far?
Great work @hareesh_vemasani 👌really love how you’ve tackled such a real and messy problem. As someone working in growth and SEO, I’ve seen how scattered feedback across channels often leads to weak prioritization and missed insights. What stands out here is the full loop from collecting feedback to actually closing it with users through changelogs and notifications, that’s where real trust and retention are built. Also the flat pricing is a smart move in a space crowded with seat based models. Curious to see how it performs at scale, but this looks genuinely useful for product teams...
really like this because feedback usually ends up scattered everywhere and teams lose a lot of time just trying to piece it together. the closed-loop part stood out to me since users rarely know what happened after sharing feedback. which source is giving you the most valuable insights so far: support tickets, reviews, or slack conversations?
Hey Hareesh, congrats on the launch! Interesting tool solving a real problem.
Question: Feedback online is highly skewed and biased (as it takes particular types of personas to post, with no proper way to 'control' via experimental design). Is a product roadmap built on online feedback the best path forward for builders?
I like the direction of the product. As a PM, I always use Dovetail to aggregate user reviews from different channels. But the "feature brainstorming" and "prioritization" part I do with my co-pilot, but it's a second surface (outside Dovetail) so I have to switch between them. Kudos for solving these problems as I see it and both important parts can be done with the same tool.
Bringing feedback from multiple channels into one place and actually turning it into roadmap decisions sounds really useful. I like the focus on closing the loop with users after features ship. How does ProductBridge detect and merge duplicate feedback across different sources without losing important context?
Congrats on the launch!
Quick one: Most feedback tools assume users know what they want and can express it clearly, but that's rarely true for non-technical users. What does your product do when the feedback is vague, emotional, or indirect? How do you turn 'this is confusing' into an actionable roadmap item?
Great product which solves a real pain point! Congratulations on your launch!
How does the deduplication work when users describe the same issue in completely different words? Congrats on the launch!
This is a very interesting idea. In our business, we receive a lot of feedback from multiple channels that never really gets processed as data as such, so this idea could actually be relevant, but I have a couple of doubts that came to mind:
The actionable insights sound great, but how does the app process contradictory feedback from clients to decide which side to lean to? Is there a process of prioritizing certain types of feedback over others? It would be super interesting to get a bit more info about this.
Anyways, congratulations for the launch!
Feedbacks are like goldmine, just curious how will ProductBridge will filter out feedbacks from tons of other contents. Congratulations on the launch. This looks a great product that will genuinely help businesses.
Congratulations on the launch 🎉 🎉
a great product @hareesh_vemasani and team. much needed today!
Excellent looking app for building a customer feedback loop & offering transparency!
Congrats on the launch!
Congratulations
Feedback is everywhere — support tickets, Slack, emails, user calls, but turning it into clear, actionable insights is still a big challenge for most teams.
ProductBridge seems to be tackling exactly that gap. If done well, this could really help teams prioritize better and build what users actually need.
Curious, how does ProductBridge handle deduplicating and prioritizing feedback across different sources?
Congrats on the launch and excited to see how this evolves 🚀
Congrats on the launch! The closed-loop piece, auto-notifying users when their feature ships, is something most feedback tools completely ignore. Smart move on flat pricing too. Rooting for you guys