PH热榜 | 2026-04-06
一句话介绍:一款轻量级的 macOS 菜单栏应用,通过实时追踪 NASA 阿尔忒弥斯 II 号任务的关键节点与数据,为太空爱好者和普通用户提供了无需切换网页、随时可查的沉浸式任务追踪体验,解决了在复杂任务中获取即时、清晰进展信息的痛点。
Space
GitHub
Menu Bar Apps
太空任务追踪
macOS应用
菜单栏工具
SwiftUI
实时数据
NASA
阿尔忒弥斯计划
科技爱好者
信息可视化
轻量级应用
用户评论摘要:用户普遍赞赏其创意与轻量级设计。主要反馈包括:希望增加任务阶段说明以降低理解门槛;询问数据源、更新频率及实时性;期待扩展至其他太空任务;建议增加实时图像、轨迹可视化等深度功能;少数用户遇到数据加载问题。
AI 锐评
Moonshot 的精妙之处在于其“降维”与“升维”的巧妙平衡。它将一个国家级、高复杂度的太空探索工程,压缩进一个安静的菜单栏图标里,这是一种极致的“降维”——将宏大叙事轻量化、日常化。其核心价值并非提供NASA级别的原始数据,而是充当了一个智能的“信息翻译官”与“注意力管理器”。它通过处理公开数据,提炼出普通人关心的关键节点(倒计时、任务阶段、宇航员信息),并以优雅的时空线呈现,本质上是在对抗信息过载与认知负担,让用户以最低成本获得“参与感”与“掌控感”。
然而,其轻盈也是其天花板。评论中暴露的“深度信息渴求”(如实时影像、详细轨迹)与“广度扩展期待”(其他任务)正是其作为“周末项目”的边界。它精准服务了“关注但非钻研”的中间态用户,但难以满足硬核爱好者或科研需求。产品若想突破工具属性,向“太空文化门户”演进,则需在数据深度、互动可视化及社区构建上重投入。当前版本是“单点极致”的典范,但能否从“阿尔忒弥斯II的精致伴侣”进化为“太空探索的常驻仪表盘”,将决定其是昙花一现的创意火花,还是能持续迭代的独立产品。其SwiftUI菜单栏的形式,本身也暗示了其“伴随式”的产品哲学——不打扰,但总在场,这或许是未来系统级信息服务的一个有趣雏形。
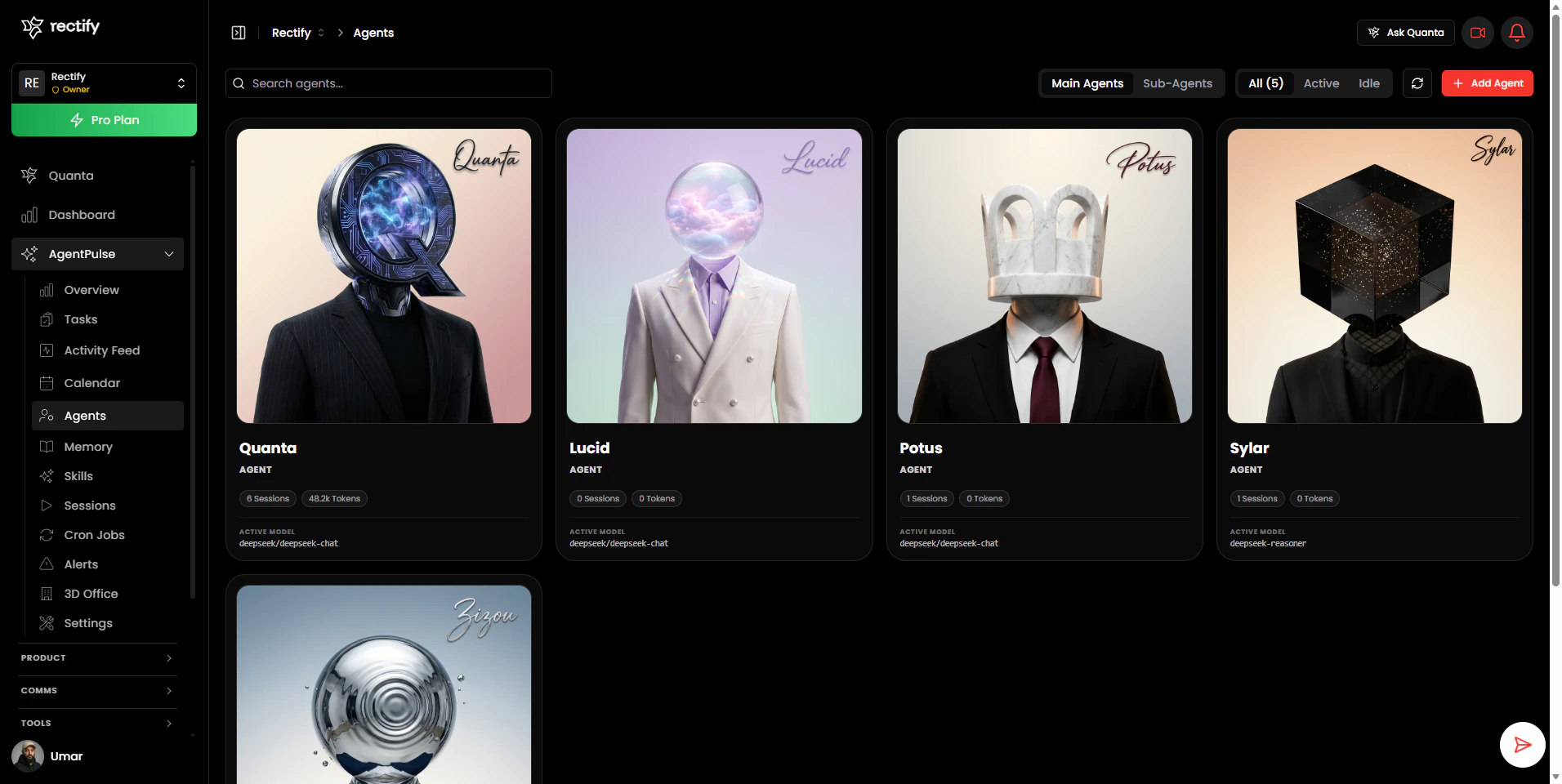
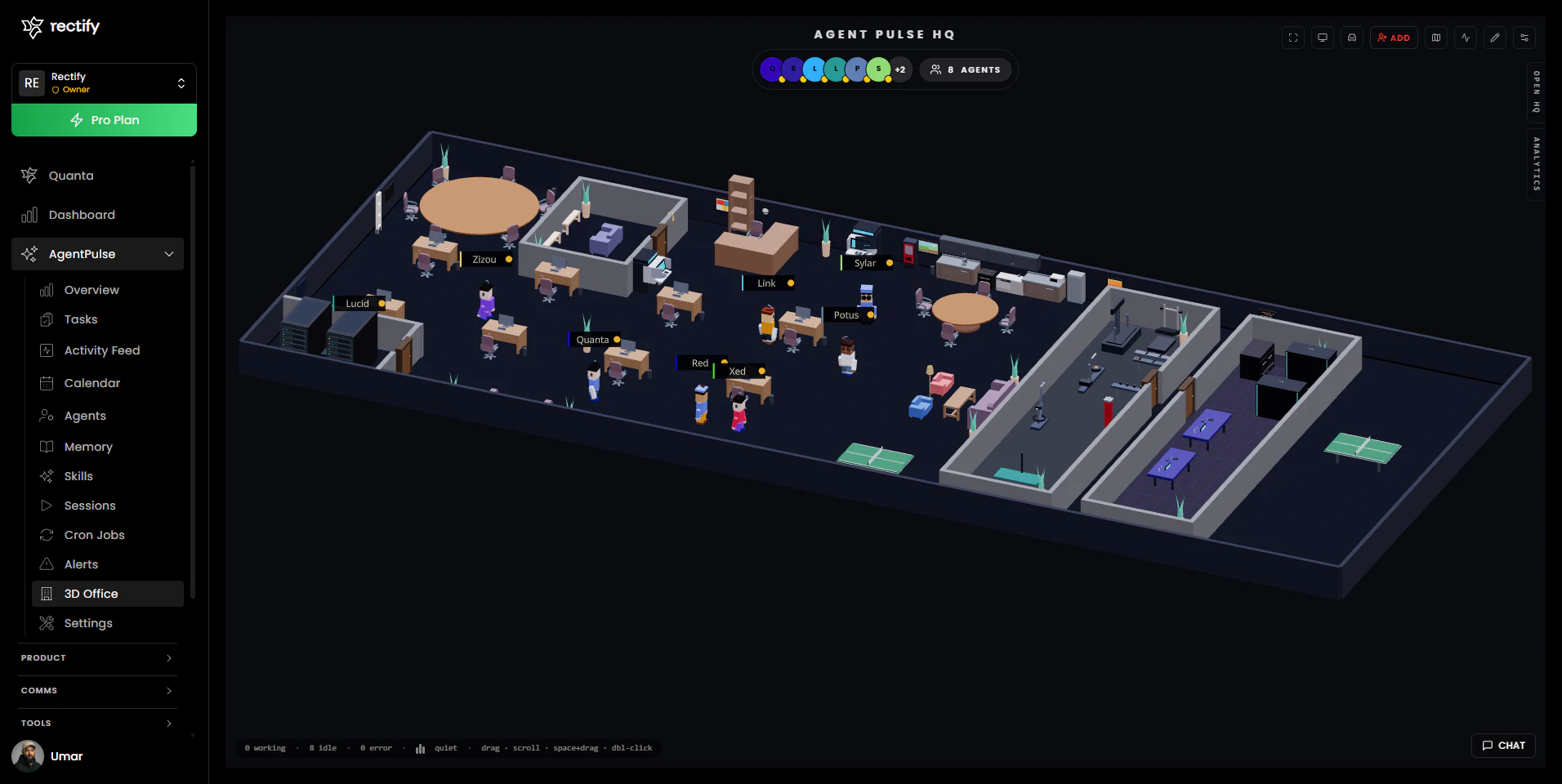
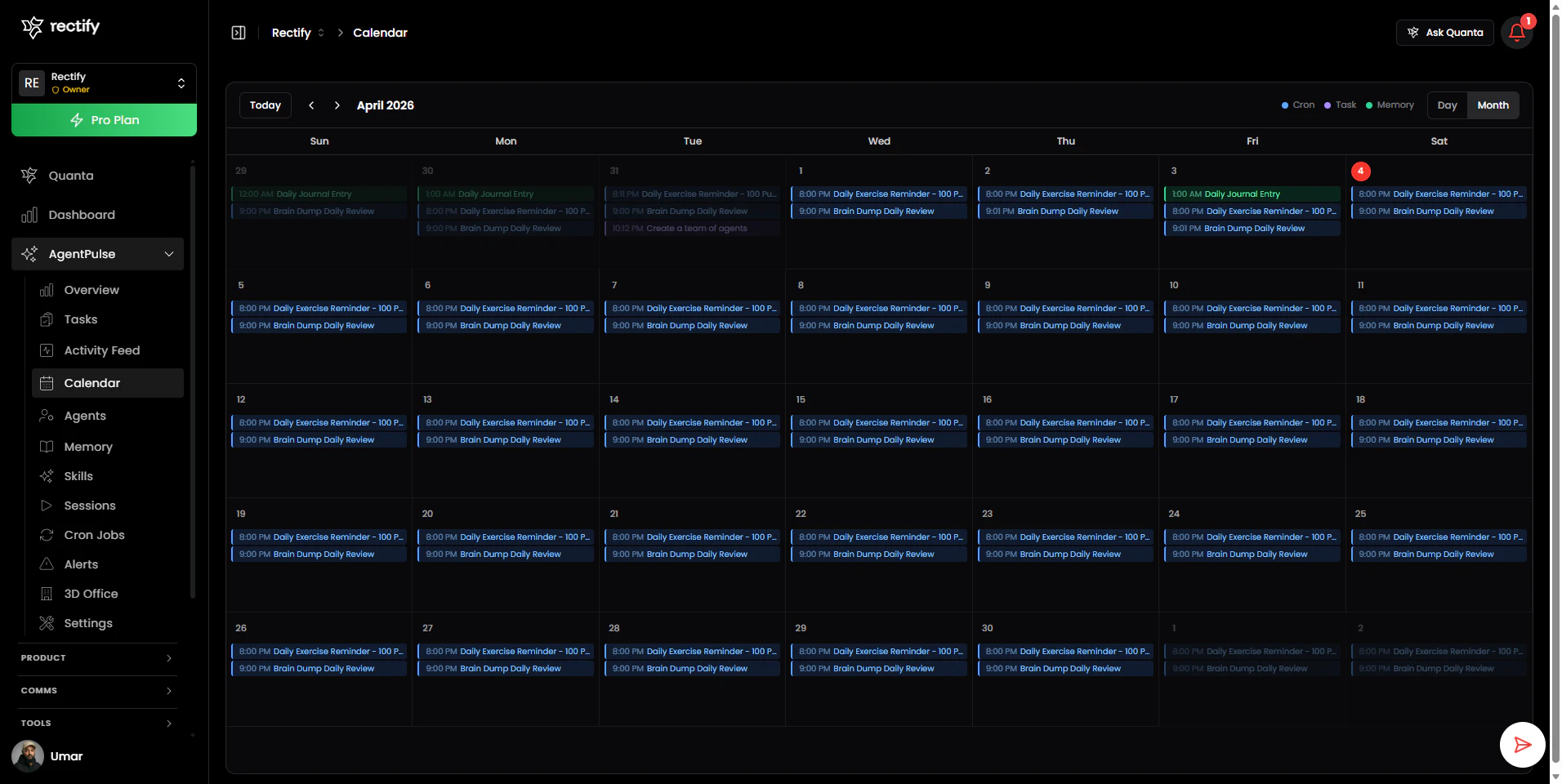
一句话介绍:AgentPulse 是一款为 OpenClaw AI 代理操作平台设计的可视化指挥中心,它通过图形界面替代了繁琐的终端命令和 JSON 配置,在团队协作与多客户管理场景下,解决了开发者运维效率低下、团队权限混乱及客户缺乏透明度的核心痛点。
SaaS
Developer Tools
Artificial Intelligence
AI代理运维
可视化监控
团队协作平台
客户门户
权限管理
操作可视化
SaaS运营
开发运维
智能运维助手
多租户管理
用户评论摘要:用户高度认可其可视化、团队权限管理和客户视图功能。主要问题集中在:3D视图是噱头还是真有用、如何调试代理失败的根本原因、新用户上手难度,以及希望看到更多实际案例。创始人积极回复,详细解释了功能价值并收集反馈。
AI 锐评
AgentPulse 的亮相,远不止是为 OpenClaw 披上了一层图形化外衣。它精准地刺中了当前 AI 代理运维从“玩具”走向“工具”过程中的核心矛盾:个体黑客式操作与规模化、商业化交付之间的巨大鸿沟。
其真正价值在于构建了一套“操作-协作-解释”三位一体的系统。首先,它将终端操作可视化,降低的是单个开发者的认知负荷,提升的是基础运维效率。但这只是入场券。更深层的价值是其引入的基于角色的访问控制(RBAC)与多客户隔离工作区。这直接将产品定位从“开发者工具”拉升到了“团队及商业运营平台”,解决了代理规模化后必然面临的权限、安全与客户沟通成本问题。这才是其区别于其他单纯监控工具的壁垒。
最值得玩味的是其内置的 AI 助手 Quanta。它被设计为“界面本身”,而非点缀。这不仅为客户提供了一个零门槛的查询窗口,更重要的是,它试图将运维动作(如生成报告、检查状态)从“手动操作”转化为“自然语言指令”,这可能是人机交互范式的一次隐性升级。然而,挑战也同样明显:在复杂调试场景下,AI解释的准确性与深度能否真正替代开发者阅读日志?华丽的3D办公室视图,在信息密度和问题定位效率上,是否优于经过优化的列表与仪表盘?这需要实践检验。
创始人回复中透露的“无正式案例研究”和“与早期用户共同塑造产品”的状态,既显示了其敏捷性,也暴露了产品在极端复杂场景下的成熟度有待验证。总体而言,AgentPulse 展现了一个极具前瞻性的蓝图——它不只是在管理AI代理,更是在试图定义AI时代团队如何协作管理自动化系统的“操作系统”。其成功与否,将取决于在炫酷概念之下,那些“枯燥但重要”的细节可靠性能否经受住企业级应用的严苛考验。
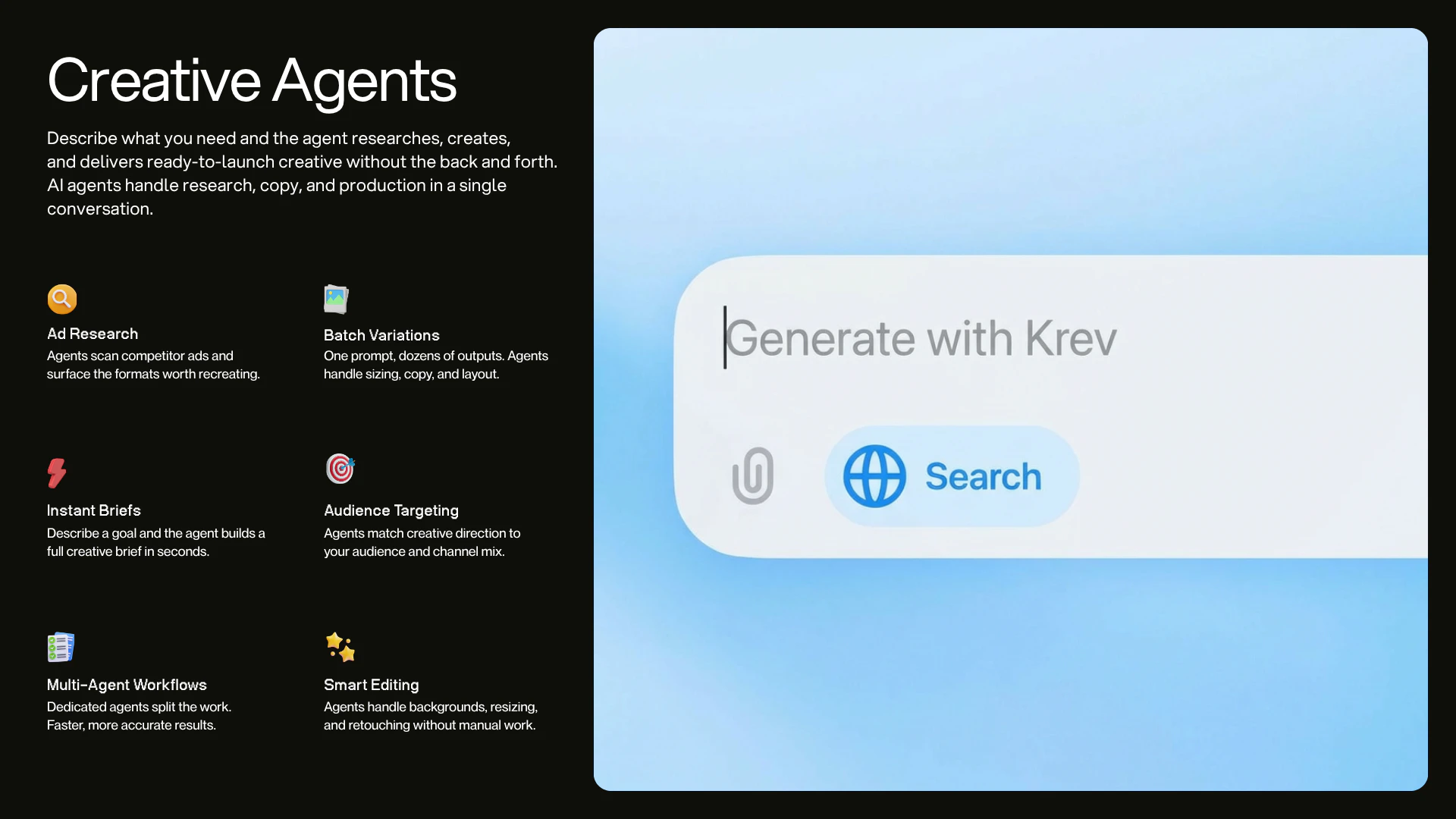
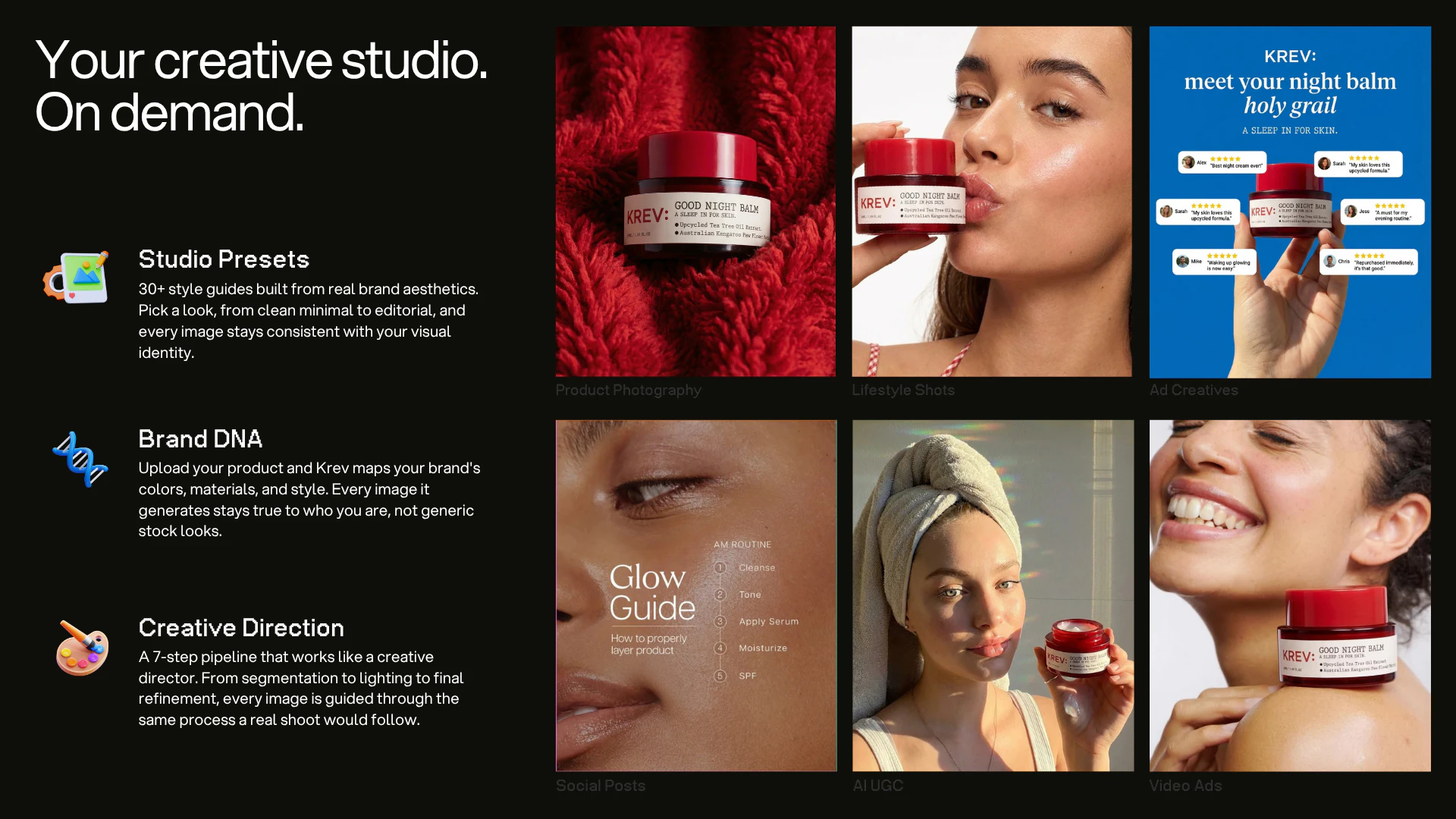
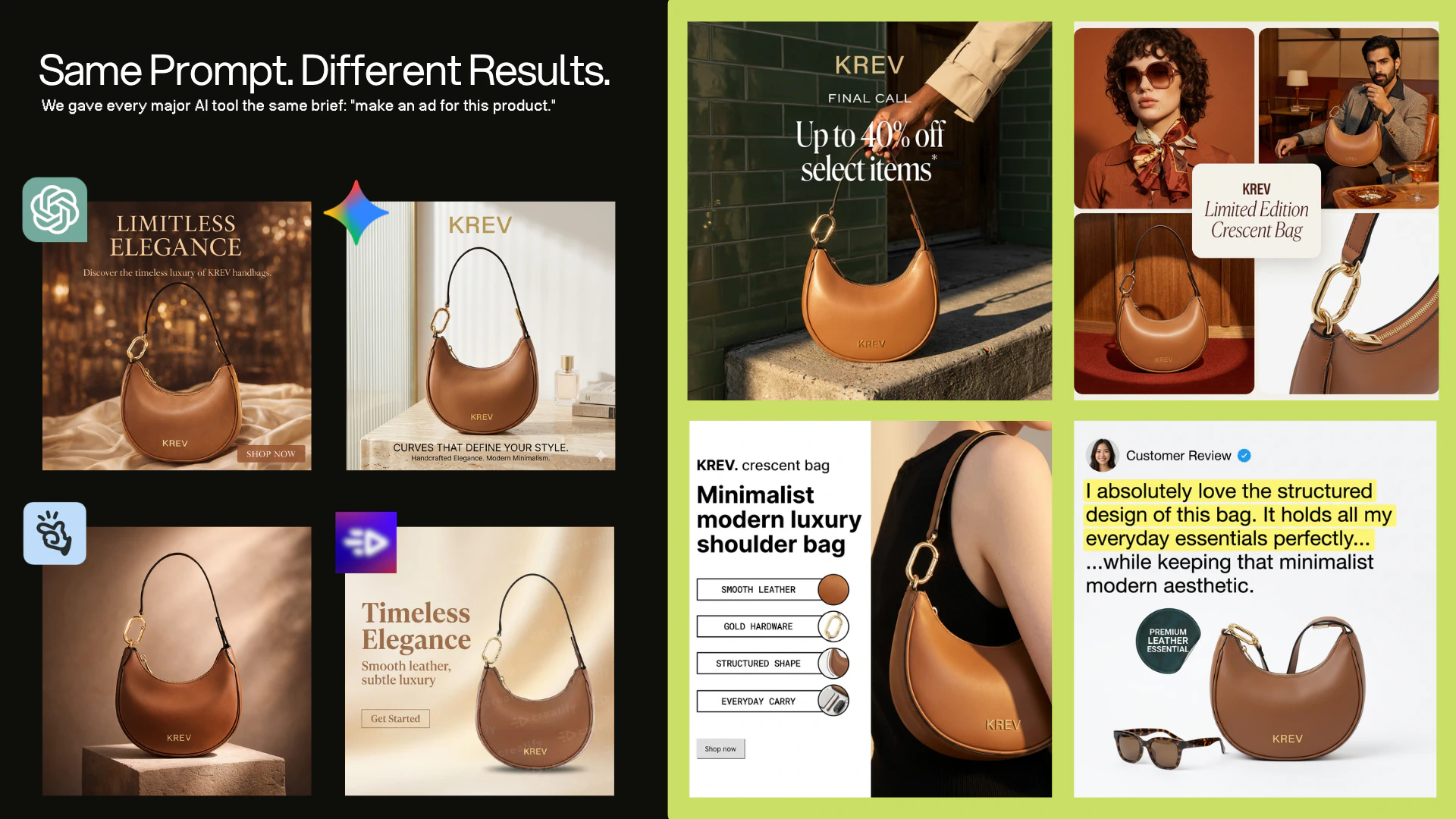
一句话介绍:KREV是一款为电商品牌服务的AI创意代理工具,通过单张产品图片即可自动生成高质量的产品照片、视频广告及上市级营销素材,解决了电商品牌在多平台营销中创意内容生产耗时耗力且与转化效果脱节的痛点。
Marketing
Artificial Intelligence
E-Commerce
AI创意生成
电商营销自动化
广告素材生成
产品视觉优化
性能导向设计
品牌一致性
广告信号分析
创意工作流
AI代理
SaaS工具
用户评论摘要:用户肯定其基于真实广告信号生成性能导向素材的核心价值,并提出了关键建议:需提供输出预览以降低体验门槛;急需开放生成完整广告(含文案版式)的API接口以支持自动化工作流;建议按行业提供最佳实践洞察;关注其性能数据来源与反馈闭环的构建。
AI 锐评
KREV的野心不在于成为又一个“精美图片生成器”,而试图成为连接广告性能数据与创意生产的“转化率引擎”。其宣称的“由真实广告信号驱动”是核心差异化概念,但这恰恰是最大风险点与考验所在。
产品逻辑直击行业软肋:当前大量AI工具产出的是美学上合格但商业上无感的素材,与转化漏斗脱节。KREV试图将历史成功广告的解构模式、实时投放信号乃至品牌资产数据作为生成约束条件,本质是将隐性的创意经验代码化。这比单纯追求像素级逼真更有商业深度。
然而,其“信号”的具体构成、数据广度与新鲜度存疑。创始人回应提及“从精选品牌获取实时数据”,这暗示其初期可能严重依赖有限合作伙伴的数据飞轮,模型泛化能力有待验证。更尖锐的问题是:广告创意成功归因本就复杂,平台算法、受众定位、出价策略等因素交织,KREV如何剥离出纯粹“创意元素”与性能的因果关系?这需要极强的数据分析与抽象能力,否则易流于表面样式模仿。
用户反馈暴露了其现阶段的产品断层:最受好评的“完整广告生成”能力竟被锁死在聊天界面,而API仅提供“纯净”产品图。这反映了团队在定位上的犹豫——是优先服务需要“黑盒式”完整解决方案的市场部人员,还是优先成为赋能开发者与自动化工作流的“引擎”?早期用户的API呼声强烈,表明其真实价值可能在于成为电商营销技术栈中的嵌入式智能模块,而非又一个独立应用。
长期愿景“让广告数据直接驱动创意生成”描绘了一个诱人的闭环,但实现路径荆棘密布。它需要深度打通各广告平台数据API、构建动态创意优化模型,并说服品牌将核心性能数据交出。若成功,它将重塑从创意简报到投放优化的价值链;若受阻,则可能停留为一个拥有更佳提示词的图像生成工具。
总之,KREV切入了一个真实且付费意愿强的痛点,方向正确。但其技术护城河的深度、数据生态的广度以及产品形态的聚焦度,将决定它能否从“有用的工具”进化为“不可或缺的基础设施”。
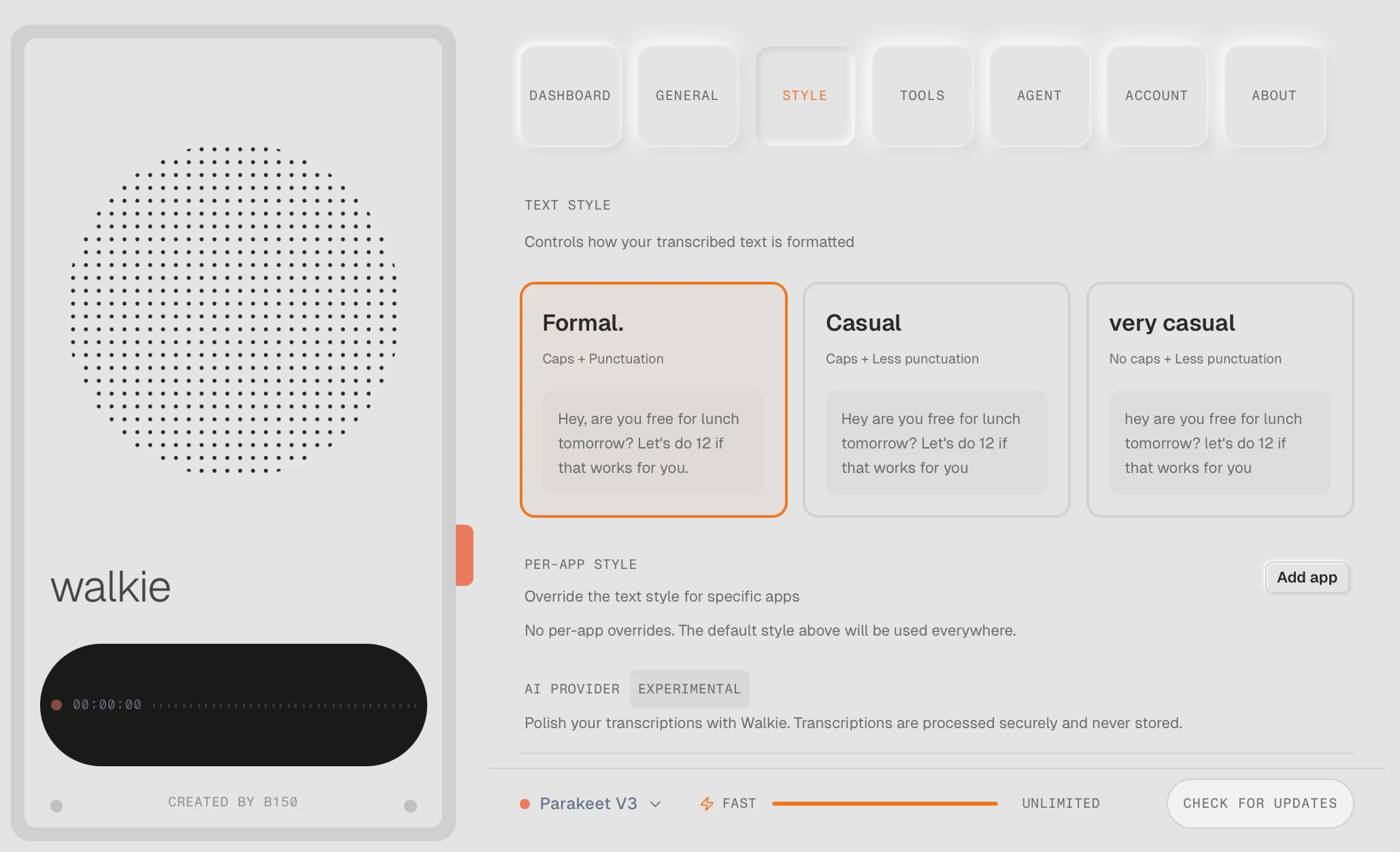
一句话介绍:Walkie是一款提供云端快速转录和本地完全设备端听写双模式的桌面语音转文字工具,在兼顾隐私与效率的场景下,为用户提供了Wispr Flow等产品的免费替代方案,解决了用户对基础转录服务付费及隐私数据上传的痛点。
Productivity
SaaS
Tech
语音转文字
桌面应用
隐私优先
离线转录
云端转录
免费工具
macOS
Windows
Wispr Flow替代品
双模式
用户评论摘要:用户肯定其免费策略、双模式设计及英语准确性,但指出免费版处理速度慢(30-40秒/100词),非英语语言(如孟加拉语、日语)识别准确率低,并询问技术实现与商业模式。开发者回应了部分问题并邀请测试。
AI 锐评
Walkie的核心叙事是“免费”与“隐私”,直击Wispr Flow等产品对基础服务收费的痛点,并通过“本地模式”构建差异化护城河。然而,产品呈现出一个典型的“理想丰满,现实骨感”的早期阶段。其真正的价值并非技术突破,而在于对市场定价策略的挑战和对隐私需求的明确回应,这足以吸引首批尝鲜用户。
但评论暴露了其根本矛盾:试图用“免费”颠覆市场,却可能受限于成本与体验的平衡。免费版的极慢速度几乎将其实用性归零,这更像是为付费模式导流的“诱饵”。而多语言支持,尤其是非拉丁语系的准确率问题,揭示了其底层模型(很可能基于Whisper)的通用局限,也反映了团队在数据训练和优化上的资源不足。开发者对长音频、技术细节的模糊回应,进一步印证了产品在复杂场景下的不成熟。
它的机会在于精准切入对隐私极度敏感或预算严格的垂直场景(如法律、医疗笔记草稿),并依靠社区反馈迭代。然而,若不能解决免费版的可用性问题,或明确可持续的商业模式(如何在“免费一切”与“为创新付费”间划清界限),它可能仅是一个叫好不叫座的概念品,难以从“有趣的替代品”进化为“可靠的生产力工具”。其成功与否,取决于团队能否将用户反馈迅速转化为核心语言准确性和速度的实质性提升,而非停留在营销话术层面。
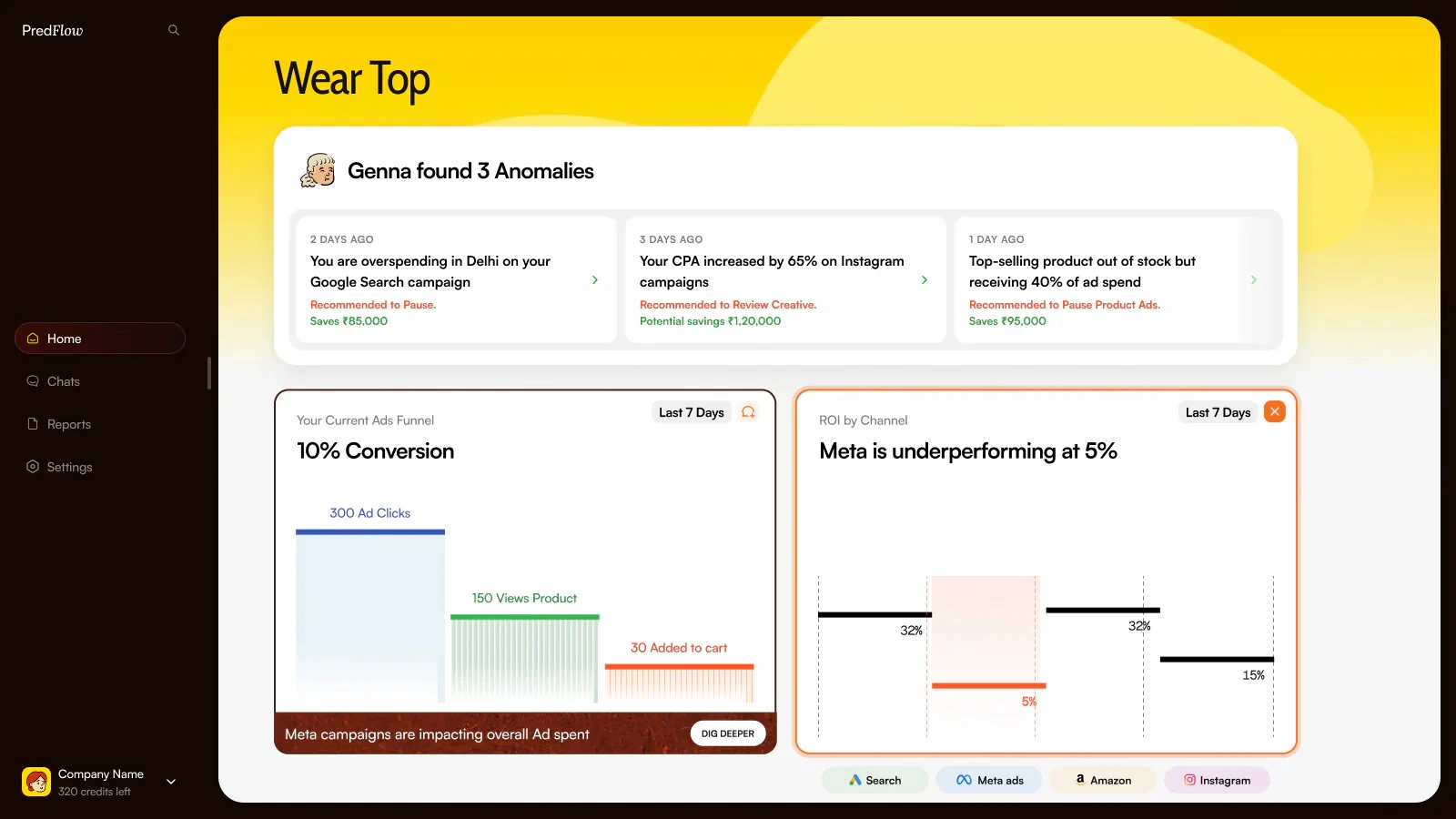
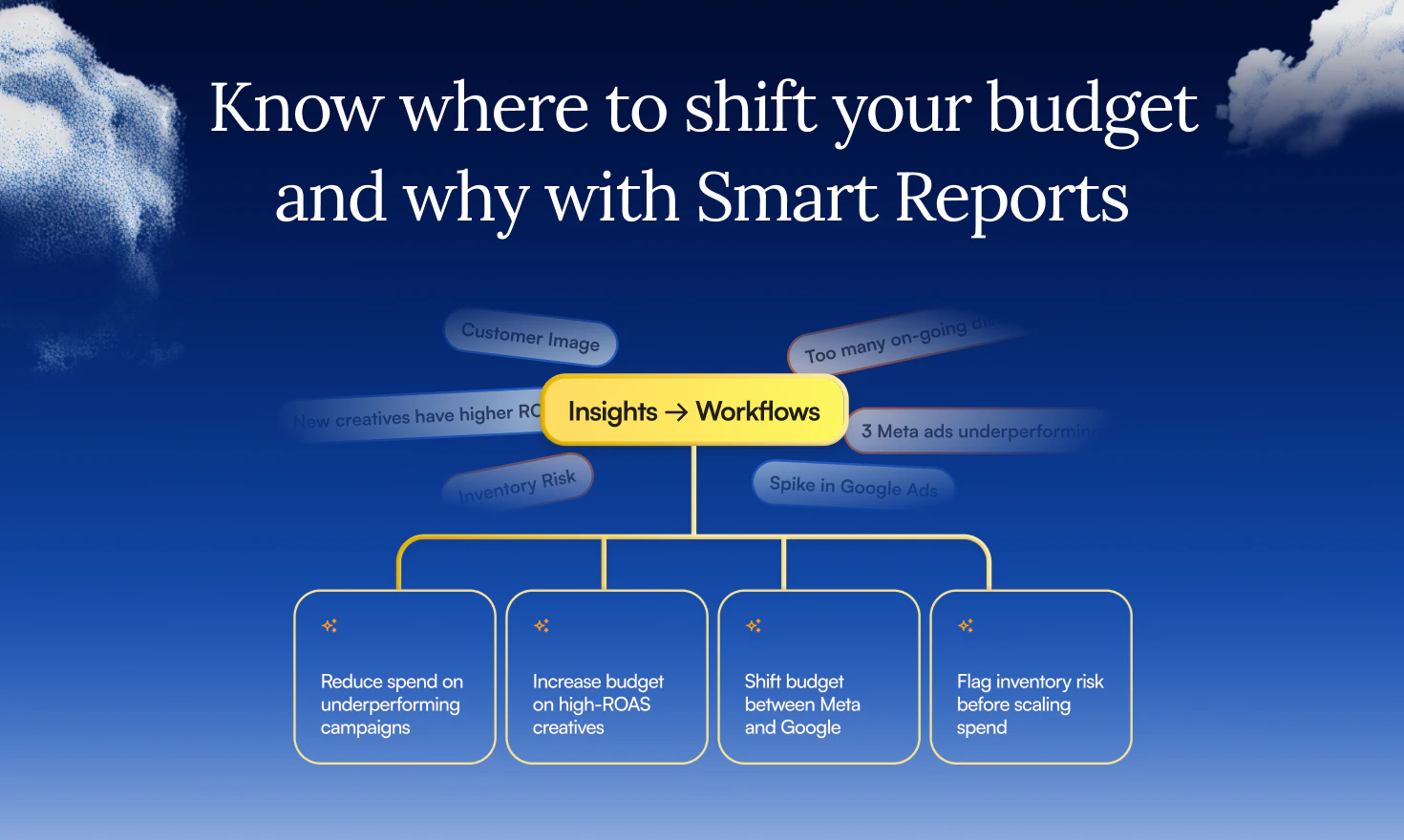
一句话介绍:一款面向效果营销人员的AI代理,通过整合并清洗跨平台的混乱广告数据,直接回答业绩波动原因并提供可操作的优化建议,解决了营销者面对多个数据面板却无法获得可信、统一洞察的核心痛点。
Analytics
Marketing
Advertising
效果营销AI
广告数据分析
跨平台数据整合
语义数据层
归因分析
创意智能
营销自动化
D2C品牌
SaaS
用户评论摘要:用户普遍认可其解决数据混乱和提供行动建议的价值。主要问题集中在:AI能否发现新受众(目前仅优化现有);快速验证语义层价值的方法;小预算初期的可靠性(创意评分即时可用,预算建议需数周数据)。另有用户深入探讨了冲突标签处理的逻辑。
AI 锐评
Predflow AI的野心不在于成为又一个美观的仪表盘,而在于成为营销决策的“事实层”。其真正的颠覆性价值,在于产品介绍中轻描淡写的那句“数据本身在工具触碰之前就是混乱的”。它首先是一个激进的数据治理工具,其次才是AI分析应用。
绝大多数营销分析工具都建立在“输入数据是干净、标准”的幻想之上,但现实是,手动输入的UTM参数、内部黑话、多团队协作的随意性,早已让数据根基腐烂。Predflow构建的“语义层”,本质上是将深藏于不同成员头脑中的业务知识(如“NSD”代表某联盟伙伴)系统化、结构化的过程。这一步看似笨重,却是将数据转化为可信资产的前提。没有这个根基,上层的任何AI分析都只是“垃圾进,垃圾出”的精致演绎。
在此之上,其产品设计体现了明确的“去仪表盘”倾向,转向问答式AI代理。这符合高阶需求:资深营销者不需要更多图表,他们需要的是一个能理解业务语境、能直接回答“为什么”和“怎么办”的副驾驶。将创意评分、归因调和、预算建议整合进一个闭环,旨在缩短从洞察到行动的路径。
然而,其挑战同样明显。首先,“语义层”的初始设置需要客户投入时间进行知识迁移,这构成了不小的使用门槛和教育成本。其次,当前能力聚焦于现有活动的诊断与优化,在“发现新机会”(如新受众拓展)层面尚未深入,而这往往是营销者更渴求的增量价值。其三,在归因这个永恒的泥潭中,即便通过自有像素和调和逻辑提供了“更可信”的数字,但在隐私保护与数据碎片化加剧的大背景下,其“真实答案”的权威性能否持续,仍需观察。
总体而言,Predflow AI选择了一条最艰难但可能最正确的路:先当“数据清道夫”,再当“AI军师”。它能否成功,不取决于AI模型有多先进,而取决于多少客户愿意忍受前期梳理数据的阵痛,以换取后续长期的数据清明与决策效率。这是对市场成熟度的一次测试。
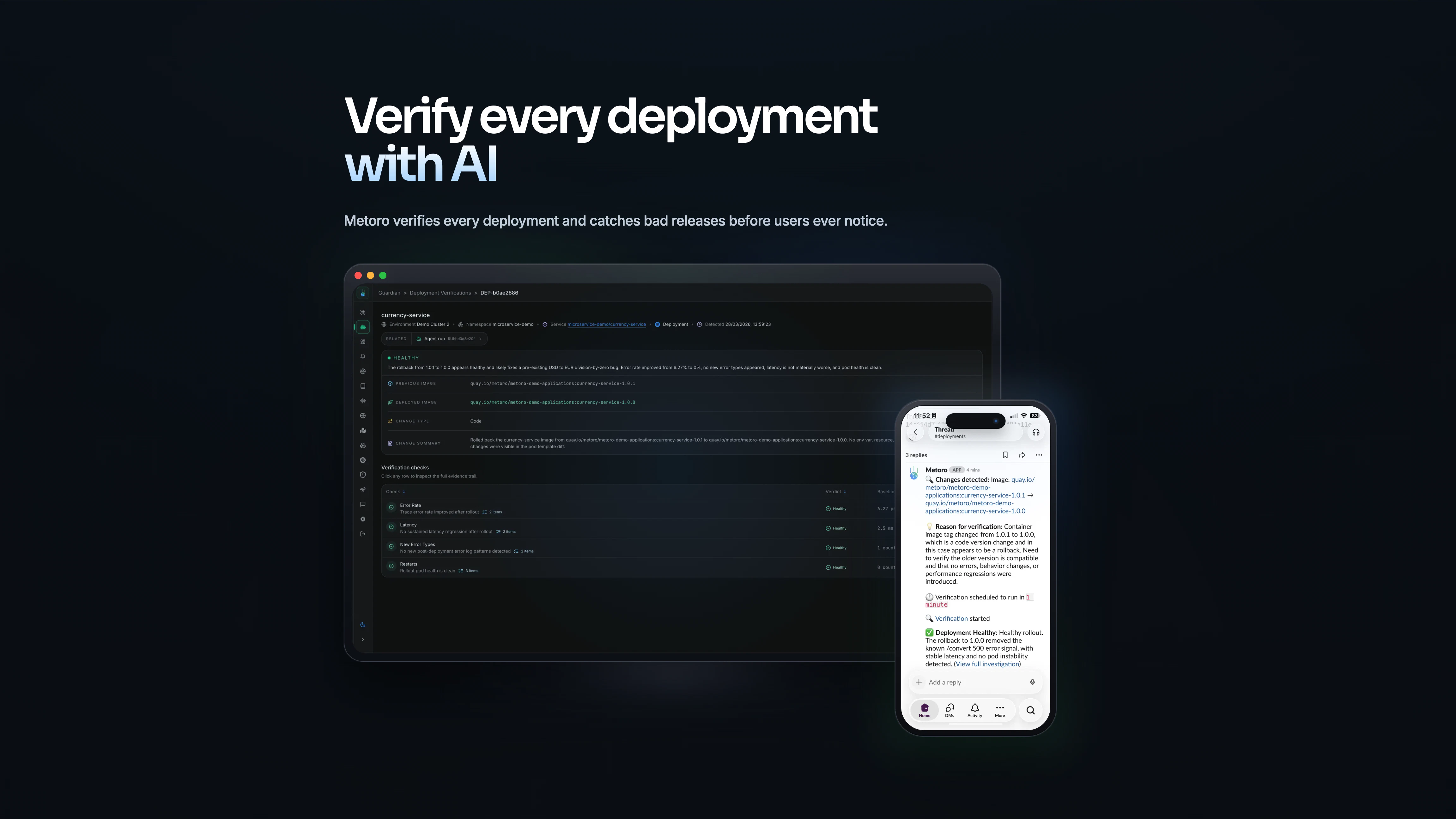
一句话介绍:Metoro是一款AI SRE工具,专为Kubernetes环境设计,通过eBPF技术无侵入采集遥测数据,实现从实时故障检测、根因分析到自动生成修复PR的全流程自动化,解决了运维人员手动排查生产事故效率低下、系统遥测数据不一致的痛点。
SaaS
Artificial Intelligence
AI运维
Kubernetes
SRE
故障自愈
eBPF
可观测性
自动化修复
云原生
根因分析
零代码侵入
用户评论摘要:用户普遍赞赏其基于eBPF提供一致遥测数据的技术路径,认为这解决了AI运维的底层数据可靠性问题。主要关切点集中在:自动生成修复PR的安全性验证与回归风险;对复杂、跨服务故障的处理能力;数据隐私与敏感信息过滤;以及如何降低误报和体验产品实际效果。
AI 锐评
Metoro的野心不在于成为又一个华丽的“AI告警”仪表盘,而试图直击运维自动化的终极痛点:闭环修复。其真正的颠覆性价值,并非AI诊断本身,而在于通过eBPF在操作系统内核层统一“制造”标准化、高质量的遥测数据。这本质上是对当前混乱、割裂的可观测性现状的一次“底层革命”,为上层AI分析提供了稳定、可信的“燃料”,使其“开箱即用”的承诺具备技术根基。
然而,其最受争议也最具风险的环节,正是其价值主张的顶峰——“自动修复”。从评论看,团队对此有清醒认知,采用了“人在环中”的审慎策略,仅生成PR建议而非盲目自动合并。这暴露了当前AI在复杂系统运维中的核心局限:它擅长基于模式的分析与建议,但极度缺乏对系统“隐性知识”、业务上下文和长期技术债的深度理解。一个“技术上正确”的修复,可能引发意想不到的级联反应。因此,Metoro现阶段更像一个“超级副驾驶”,将工程师从繁琐的数据收集和初步诊断中解放出来,聚焦于最终决策与风险评估。
其成功的关键,将取决于两点:一是在复杂故障场景下(如跨服务、部分信号缺失),其根因分析的准确率能否持续高于资深工程师;二是其“修复验证”闭环的成熟度,即能否在部署后快速、准确地评估修复效果并执行回滚。它描绘了一个诱人的未来,但通往“自主运维”的道路上,信任的建立远比技术的展示更为漫长和艰难。
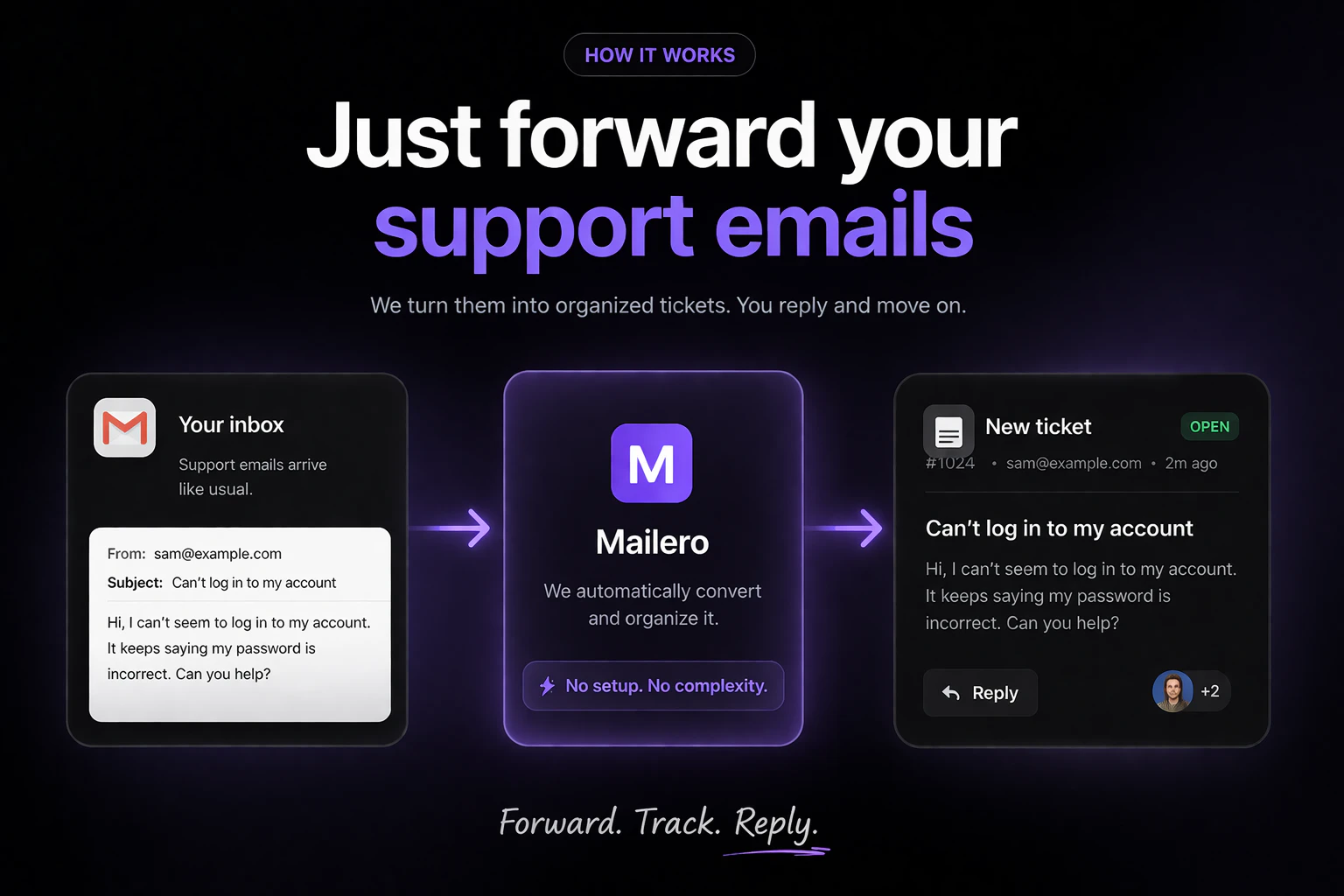
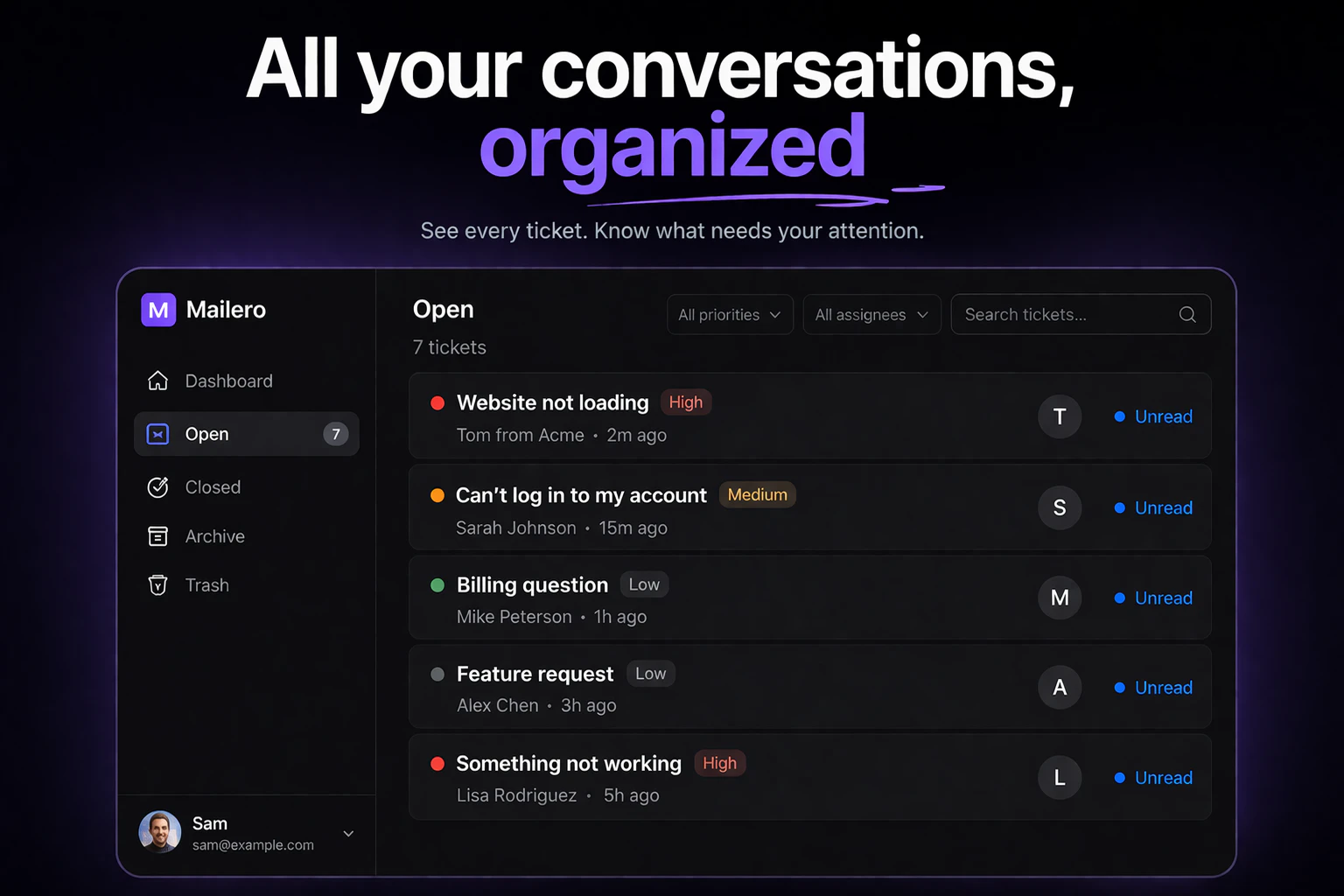
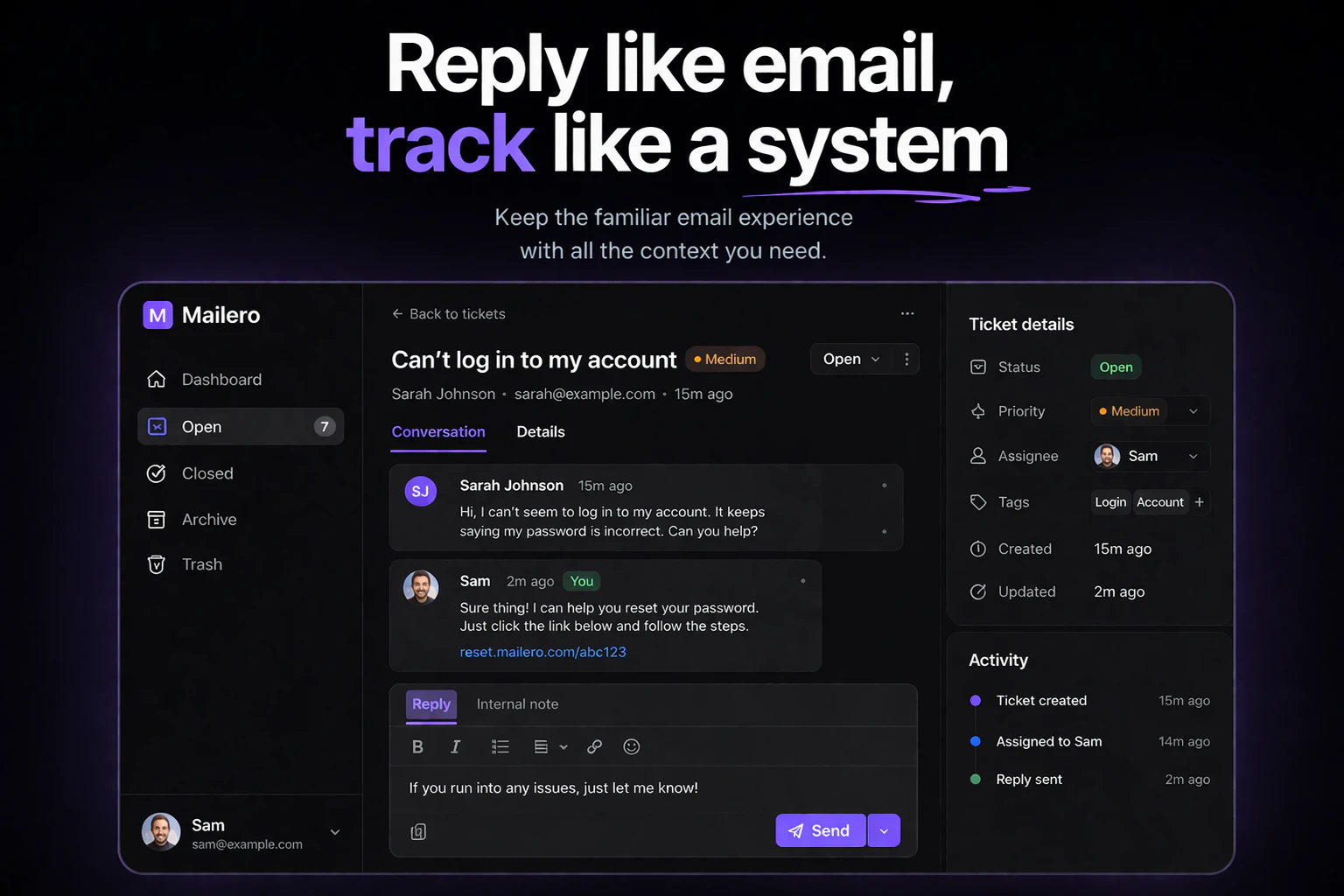
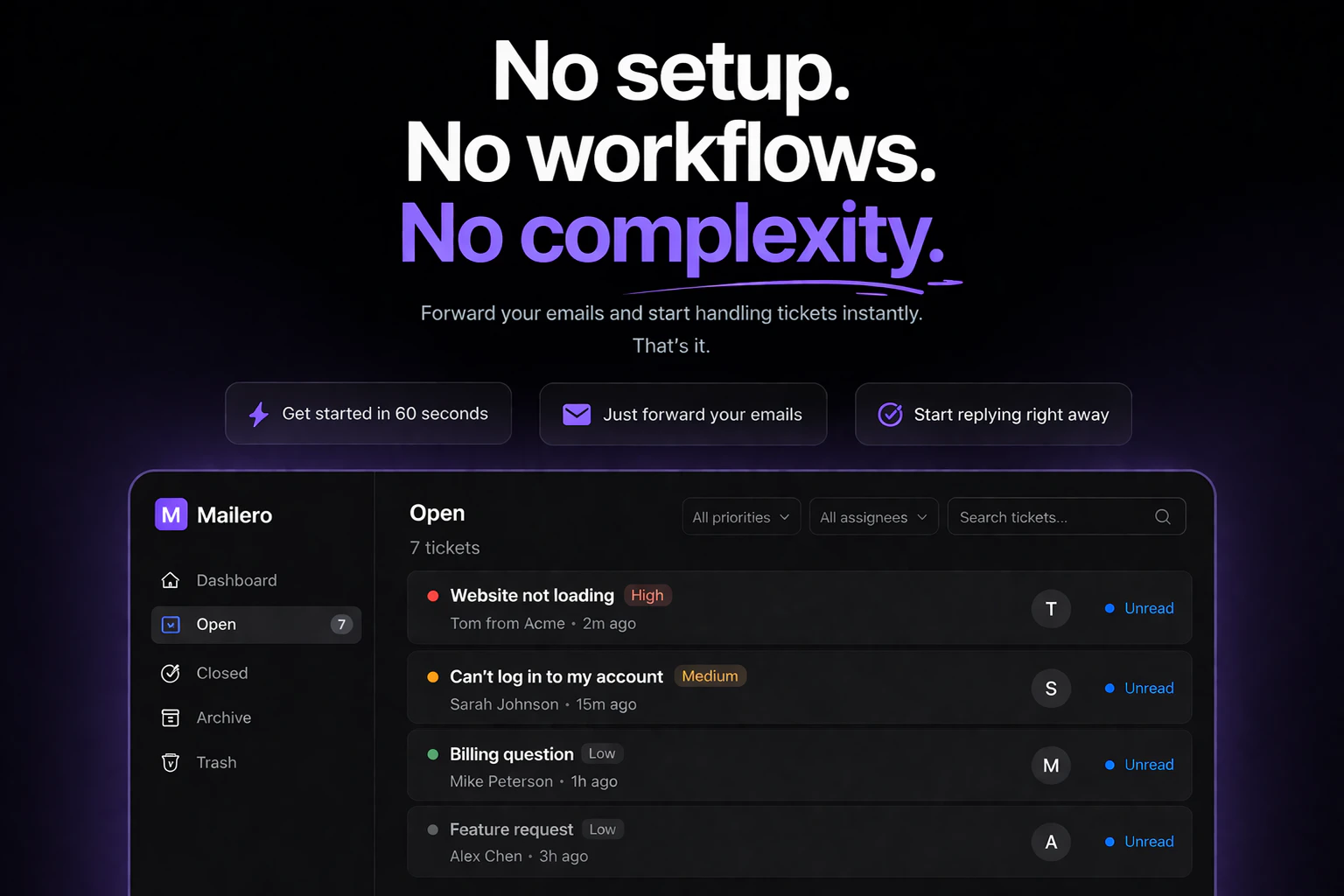
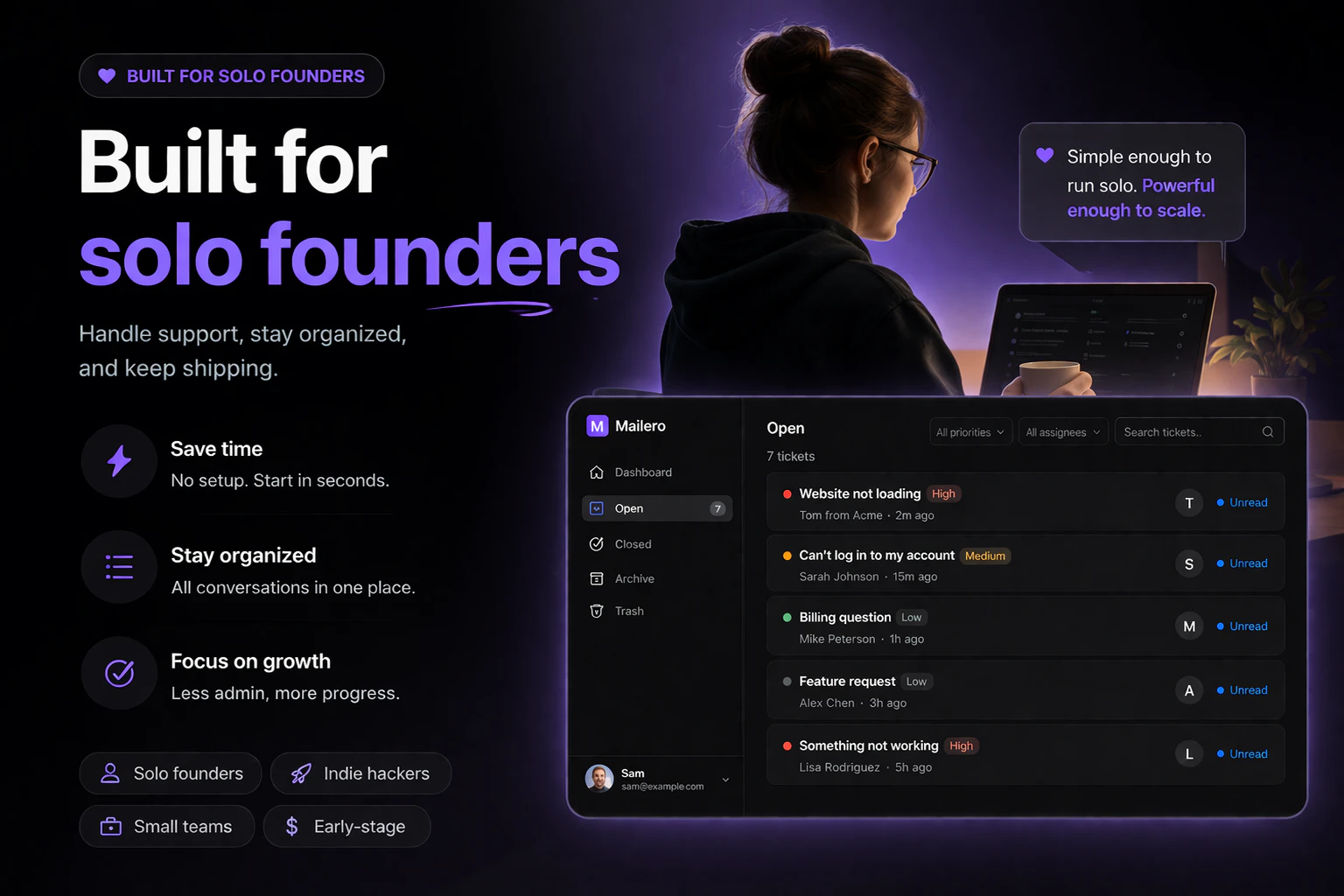
一句话介绍:Mailero是一款极简的邮件优先工单系统,让独立创始人等用户无需复杂设置,仅通过转发收件箱邮件即可快速管理客户支持,解决了传统帮助台软件功能臃肿、上手门槛高的痛点。
Email
Productivity
SaaS
客户支持工单
邮件管理
SaaS
极简主义
独立创始人
欧盟托管
GDPR合规
轻量级帮助台
生产力工具
用户评论摘要:用户普遍赞赏其“转发即创建”的极简理念。主要疑问与建议集中在:如何过滤垃圾邮件、是否支持与JIRA/Notion等工具集成、回复邮件时的发件人显示问题、是否具备基础自动化标签功能,以及对其内部优先级和跟踪机制的探讨。
AI 锐评
Mailero精准地切中了一个细分但真实的市场缝隙:厌恶重型帮助台、追求绝对简洁的微型团队(尤其是独立创始人)。其“邮件优先”的核心逻辑并非技术创新,而是一次出色的产品哲学实践——它不做加法,而是做减法,将工单系统强行拉回最原始的通信媒介(邮件)上操作,以此兑现“零设置”的承诺。这本质上是用一种“退化”来实现体验的“进化”,巧妙地将用户已有的邮件习惯转化为产品优势。
然而,这种极简主义既是其利刃,也是其阿喀琉斯之踵。从评论看,用户一旦开始认可其基础价值,需求便会自然生长:垃圾邮件过滤、外部工具集成、自动化标签……这些恰恰是它试图摒弃的“复杂功能”。这揭示了产品的核心矛盾:它服务于“厌恶复杂”的用户,但用户业务一旦稍有发展,复杂性需求便不可避免。产品目前的定位更像一个“支持入口中转站”,而非完整的支持解决方案。
其真正的价值或许不在于功能本身,而在于它作为一面镜子,映照出主流SaaS工具普遍存在的“功能蔓延症”。Mailero的成功(从PH热度看)证明了市场存在对“少即是多”的强烈渴望。但它未来的挑战也同样清晰:如何在保持极简灵魂的同时,优雅地应对用户增长必然带来的功能需求?是坚守利基,成为特定人群的挚爱工具,还是逐步扩展,滑向它曾经反对的“复杂”?
目前来看,它是一款优秀的“起点”产品,完美适配从0到1的初创状态。但用户和创始人都需要思考:当业务从1走向10,是Mailero应该改变,还是用户到了该“毕业”的时候?
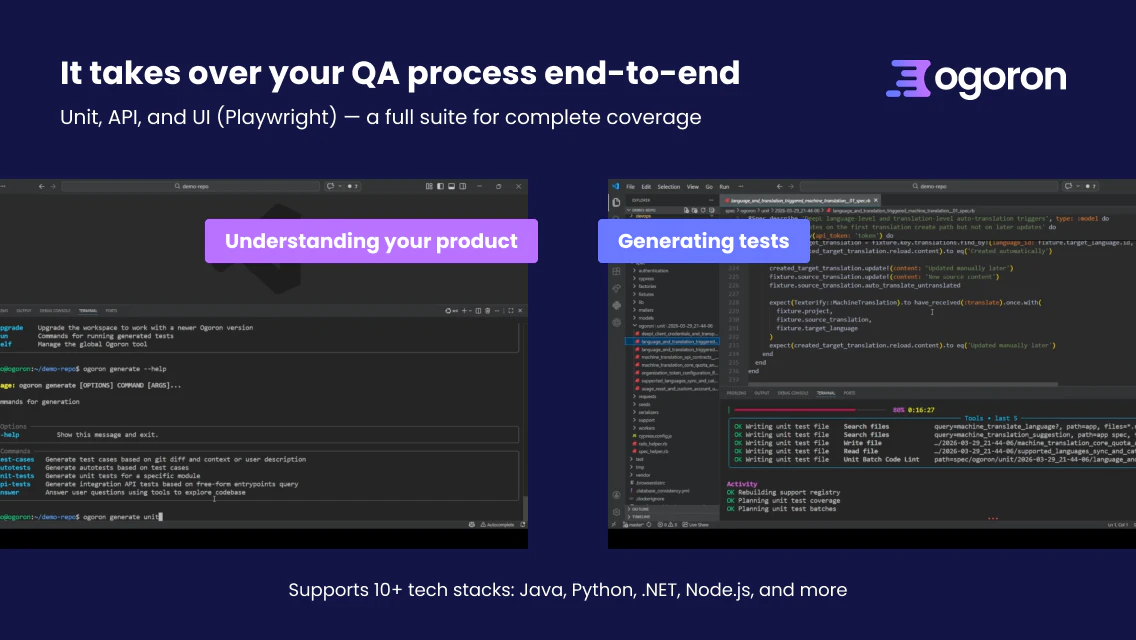
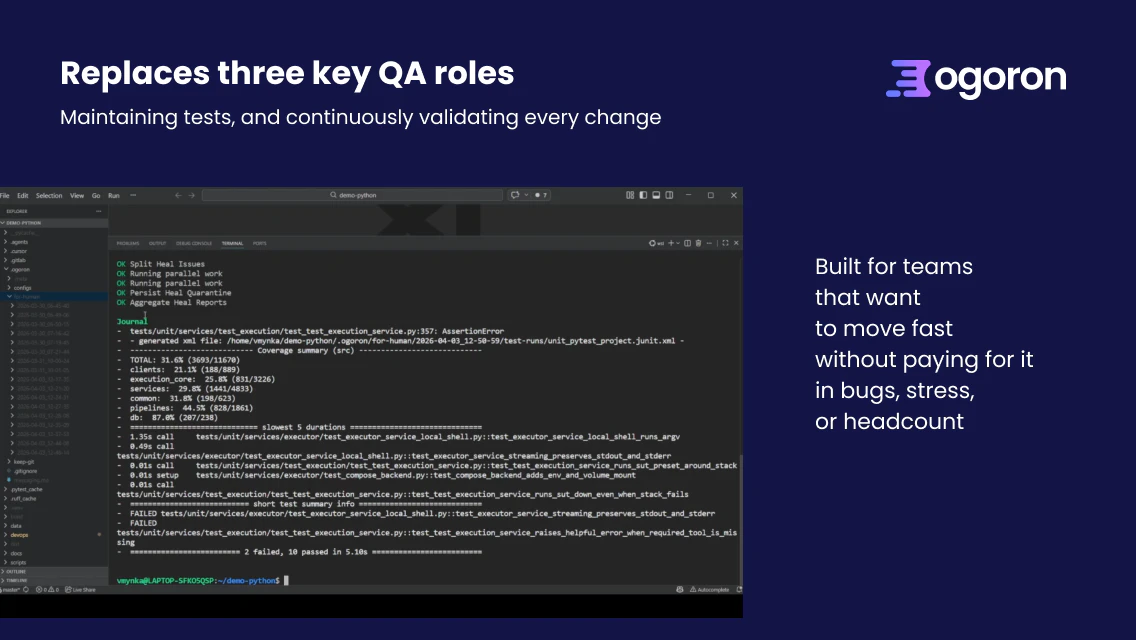
一句话介绍:Ogoron是一款端到端AI驱动的QA自动化平台,通过理解产品代码、自动生成和维护测试,在软件快速迭代的规模化场景下,解决了团队在发布速度、稳定性和QA人力成本之间难以权衡的核心痛点。
Software Engineering
Developer Tools
Artificial Intelligence
AI测试生成
自动化QA
端到端测试
回归测试
测试维护
持续验证
研发效能
SaaS
DevOps
质量控制
用户评论摘要:用户反馈积极,认可其价值。主要问题集中于:测试稳定性(如何处理UI变更导致的测试失效)、数据安全(代码是否外传)、部署模式(是否支持混合/本地部署)、实际边界(能否真正替代QA工程师)。团队回复坦诚,承认当前架构依赖外部LLM,并解释了模糊场景的处理逻辑。
AI 锐评
Ogoron的野心不在于成为又一个测试生成工具,而在于重塑QA流程的“生产关系”。它宣称替代系统分析师、测试分析师和QA工程师三种角色,本质是将QA从高度依赖人工经验判断的“手艺活”,转变为由AI驱动、基于代码和制品进行持续推理的“标准化流程”。其真正的价值壁垒可能并非当下展示的测试生成能力,而是其声称的“理解产品”和“维护测试”的闭环系统——即面对产品变更时,能自动区分是缺陷还是测试过期,并尝试自我修复。这直击了自动化测试领域最大的成本陷阱:维护成本高于创建成本。
然而,其宣称的“9倍速、20倍便宜”的乐观承诺面临严峻挑战。评论中关于“模糊地带处理”、“数据不出境”和“混合部署”的质疑,恰恰揭示了其作为SaaS+LLM依赖型产品的现实软肋:在高度定制化、强监管或逻辑极其复杂的场景下,AI的“置信度”会急剧下降,最终仍需人工裁决。它更像一个不知疲倦、水平在线的“初级QA军团”,能极大提升基线测试覆盖率和回归效率,将人类专家从重复劳动中解放,去处理更复杂的逻辑与模糊边界。但“替代”整个团队为时尚早,其成功与否,将取决于其“自我修复”算法在真实复杂场景下的有效比例,以及能否构建起让用户放心交出代码核心资产的信任体系。
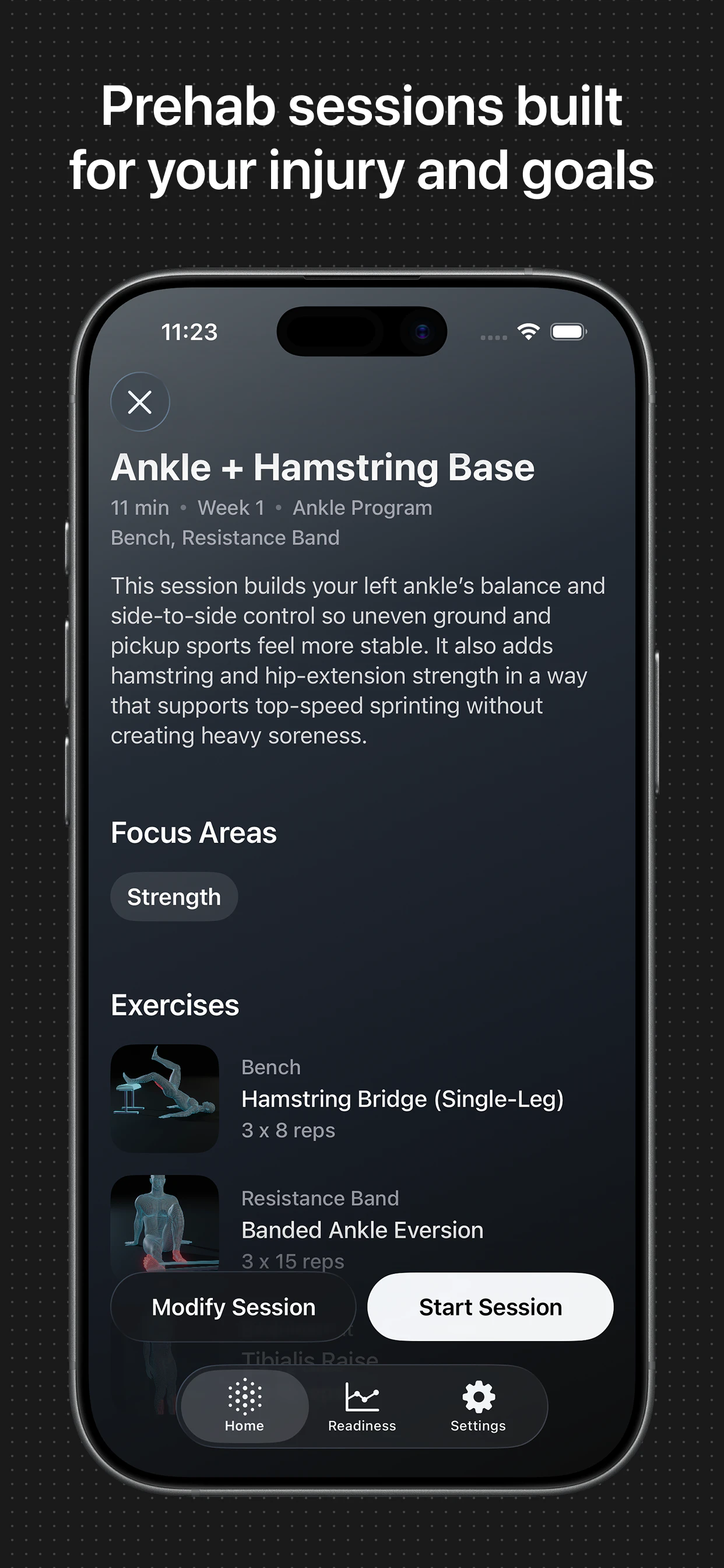
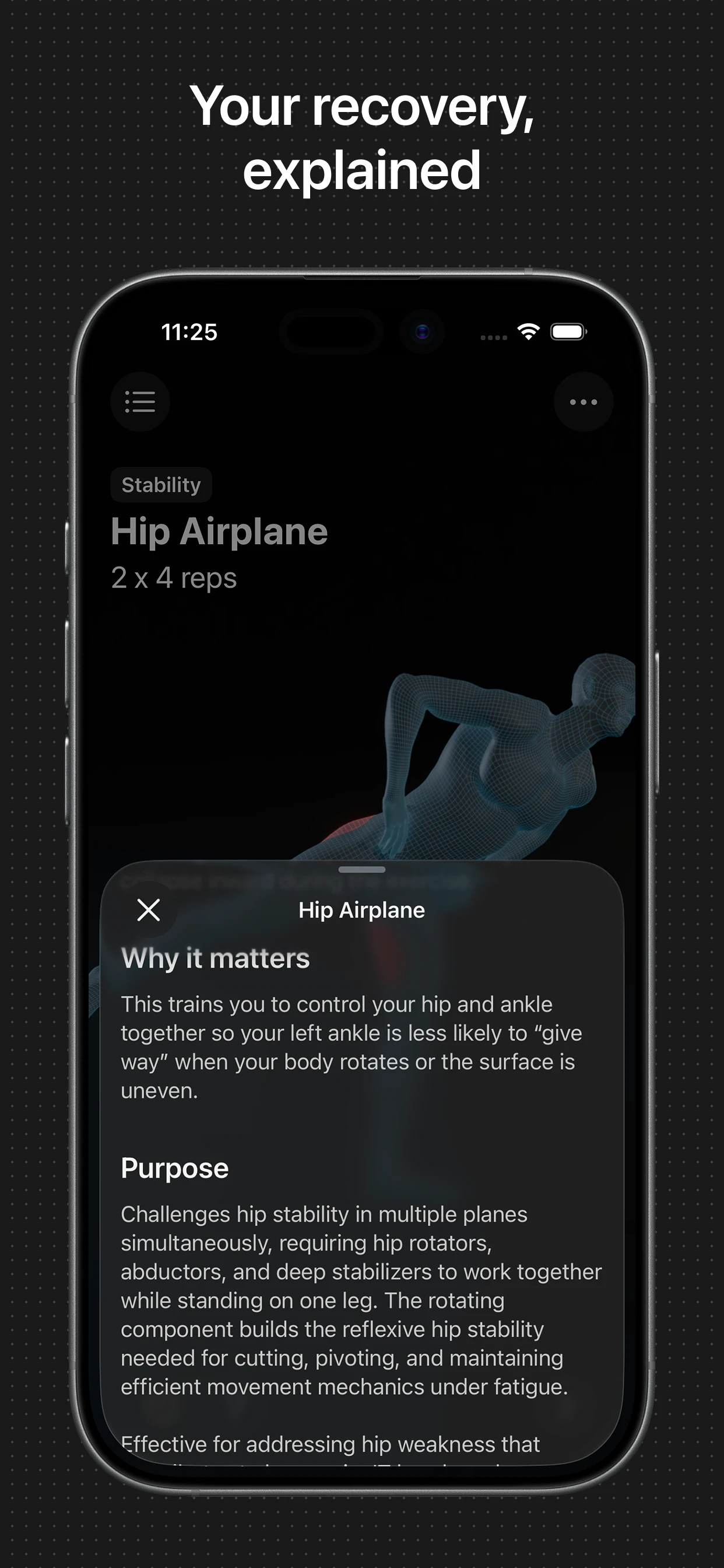
一句话介绍:一款为运动员设计的AI物理治疗应用,通过分析个人伤病史、运动项目和目标,在运动康复和日常训练场景中,提供动态个性化的训练方案,解决传统方案通用化、忽视身体薄弱环节导致反复受伤的痛点。
iOS
Health & Fitness
Sports
AI健康
运动康复
物理治疗
个性化训练
损伤预防
运动员科技
移动医疗
健身应用
Prehab
体态纠正
用户评论摘要:用户反馈积极,认可其利用手机摄像头进行动作纠正的独特性。主要疑问集中于程序是否真正动态调整、个性化考量因素(如年龄、性别权重)以及商业模式上(如向团队、学校推广的建议)。开发者回复确认程序会依据反馈和进度进行个性化调整。
AI 锐评
Adapted切入了一个精准且痛感强烈的细分市场:追求表现但饱受伤病困扰的严肃运动者。其宣称的价值并非简单的“AI生成计划”,而在于将物理治疗和运动康复原则产品化、动态化,试图填补“高性能训练”与“身体耐久性维护”之间的鸿沟。
产品逻辑犀利之处在于两点:一是将“Prehab”(损伤预防)而非“Rehab”(损伤康复)作为核心,这更契合运动员“防患于未然”的主动需求;二是通过摄像头实现动作形态纠正,试图解决居家康复最大的痛点——动作质量监控缺失,这使其区别于仅提供视频库的竞品。
然而,其面临的深层挑战同样尖锐。首先,“AI”的成色有待检验。从回复看,其个性化逻辑仍高度依赖用户自行输入的伤病史、运动目标等结构化数据,AI在实时评估运动表现、预测损伤风险方面的深度应用未见详述。其次,医疗合规红线。作为涉及损伤管理的应用,其推荐方案的可靠性与安全性如何保障?一旦用户因跟随训练受伤,责任如何界定?这需要深厚的医学专业背景背书,而非单纯的技术迭代。最后,从“运动员”破圈到更广泛运动人群的必然性与适配性问题。普通健身者的需求与运动员存在差异,产品定位的摇摆可能稀释其专业性。
总体而言,Adapted展现了一个正确的方向:用技术将专业化、个性化的身体维护能力民主化。但其真正的护城河,不在于“AI”标签,而在于其运动康复知识图谱的深度、算法反馈闭环的有效性,以及能否建立起严谨的安全与信任体系。否则,它极易沦为又一个拥有智能噱头的视频库。
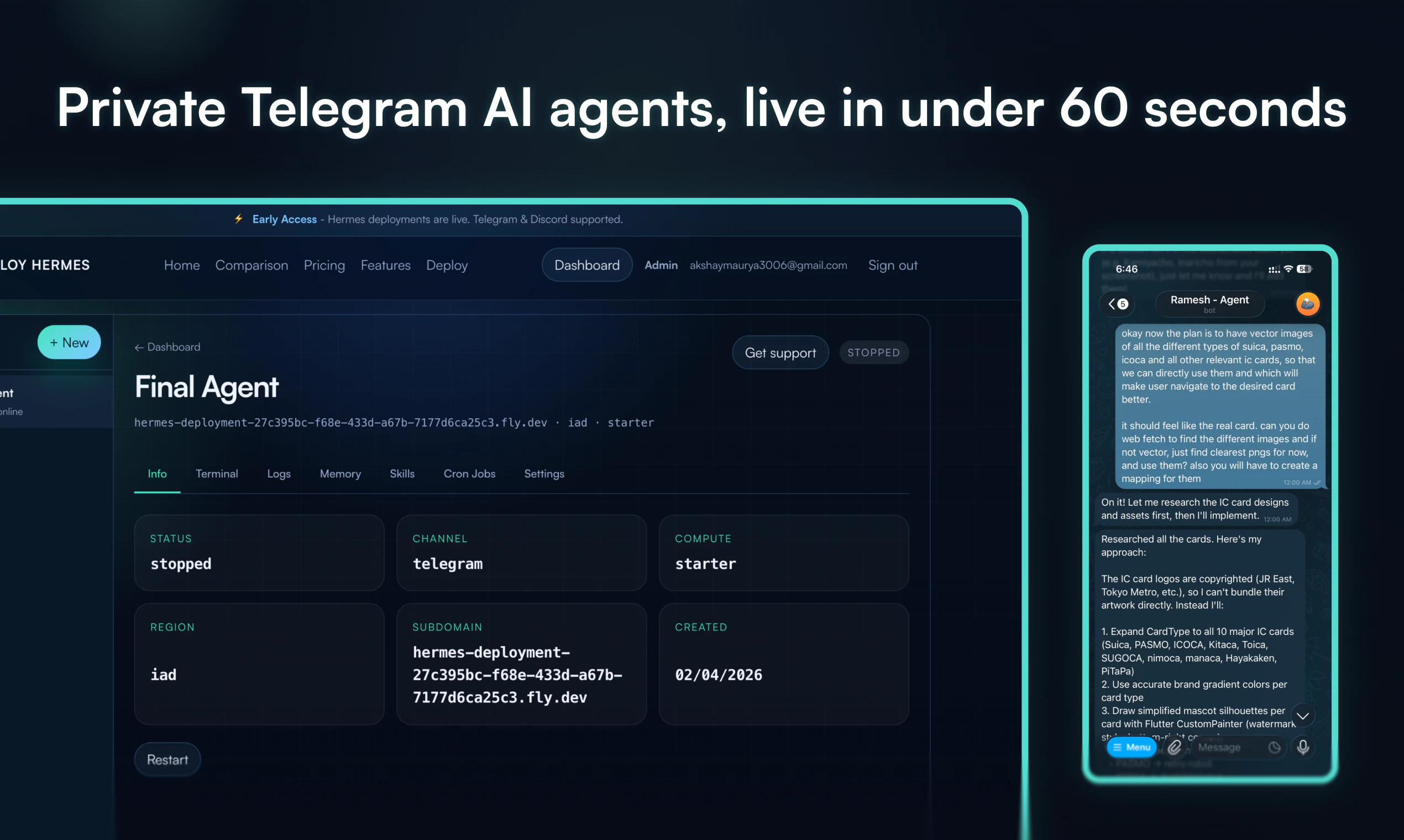
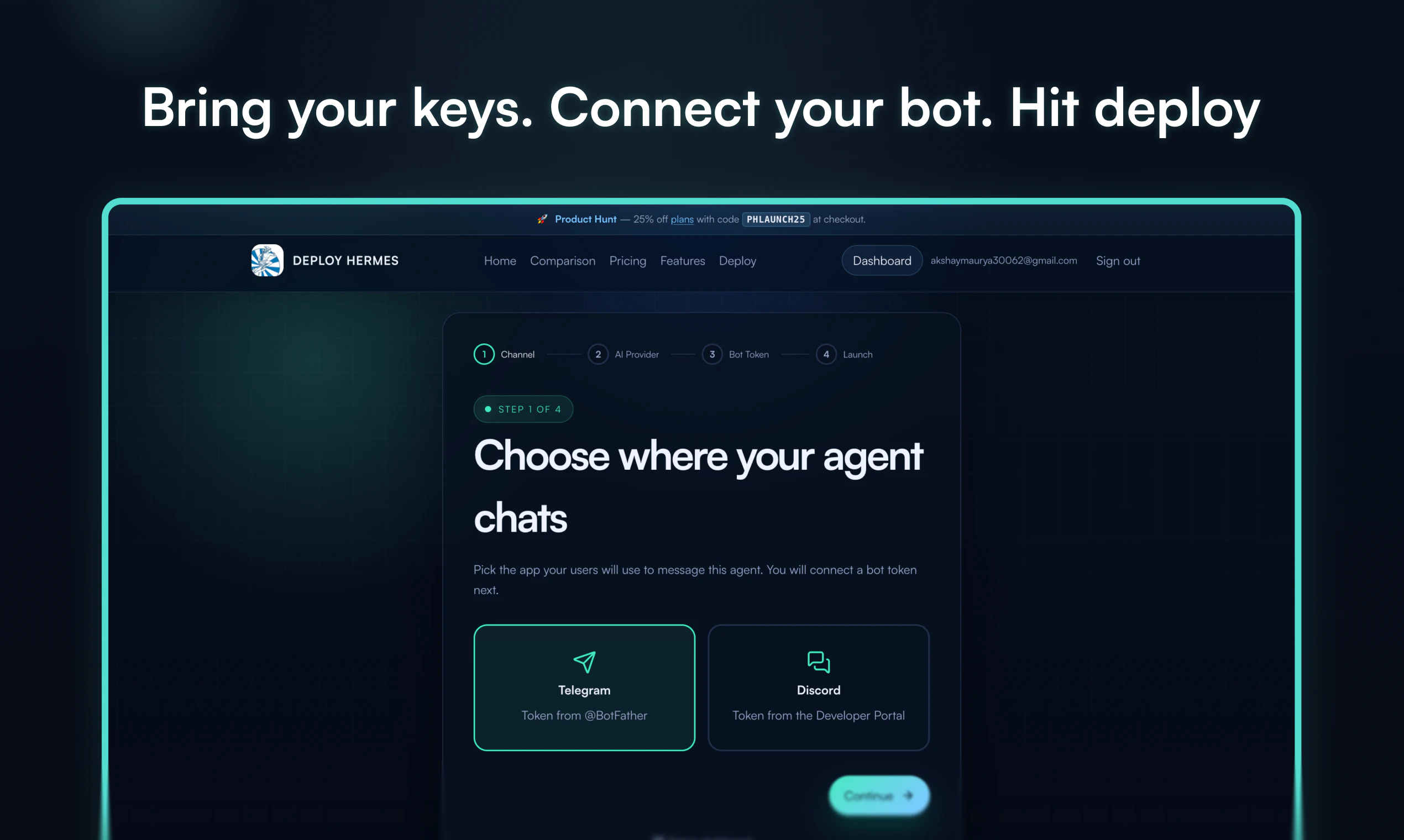
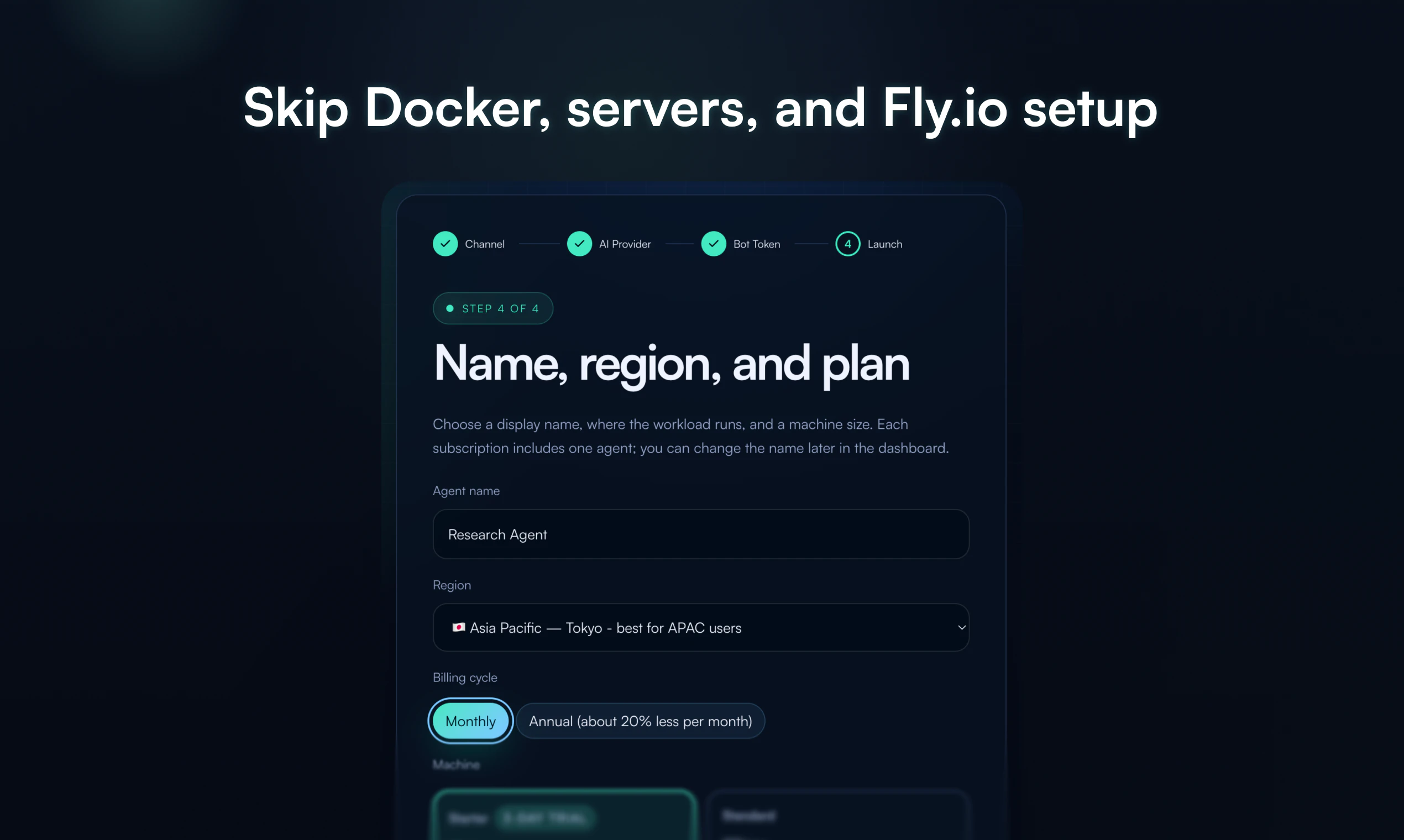
一句话介绍:一款让用户无需运维基础设施,即可在一分钟内为Telegram部署具有持久记忆功能的私有AI智能体的服务,解决了非技术用户难以自托管复杂AI应用的核心痛点。
Productivity
Developer Tools
Artificial Intelligence
AI智能体部署
Telegram机器人
无服务器运维
持久化记忆
私有化AI
低代码平台
模型即服务
工作流自动化
用户评论摘要:用户普遍认可其消除运维复杂度的核心价值,对“持久记忆”功能反响热烈,并询问具体实现细节(如跨聊天记忆、长期上下文处理、PDF处理能力)。主要建议/问题聚焦于记忆功能的实际表现、长期稳定性以及未来功能扩展。
AI 锐评
Deploy Hermes的实质,是将开源模型(Hermes)的“部署”与“运维”能力产品化,其真正的创新不在于AI模型本身,而在于对“最后一公里”工程难题的封装。它精准切入了一个细分但关键的市场缝隙:那些有能力构思AI应用场景、却无能力或意愿应对Docker、Fly.io、环境变量等基础设施复杂性的“准技术”或“非技术”用户。
产品标语“No Docker, servers, or Fly.io”直击命门,揭示了当前AI平民化进程中的核心矛盾:模型获取日益容易,但使其成为稳定、可用的服务依然门槛高耸。它将用户从“兼职运维工程师”的角色中解放出来,回归到“使用者”和“调教者”的本质角色。其宣称的“持久记忆”功能,正是为了满足用户对AI助理“连续性”和“个性化”的最基本期待,以此对抗当前大多数聊天机器人“金鱼记忆”的糟糕体验。
然而,其商业模式和长期价值面临拷问。首先,作为“带钥匙的停车场”(Bring your own keys),其价值高度依赖于上游模型(如OpenAI)的API成本与稳定性,自身溢价空间可能受限。其次,“持久记忆”这一核心技术卖点,在长上下文窗口模型日益普及的当下,其技术护城河能维持多久?最后,从Telegram单点切入虽明智,但若要扩张至Discord等其他平台或提供更复杂的工作流集成,其面临的工程复杂度是否会使其重回它试图避免的“运维泥潭”?
简言之,这是一款出色的“卸负”型产品,成功地将技术负债转化为商业价值。但它未来的成败,将取决于其能否在“极致简化”与“功能深度”、“平台依赖”与“自主可控”之间找到可持续的平衡点。它证明了AI应用的下一个爆发点,或许不在于更强大的模型,而在于更优雅的交付。
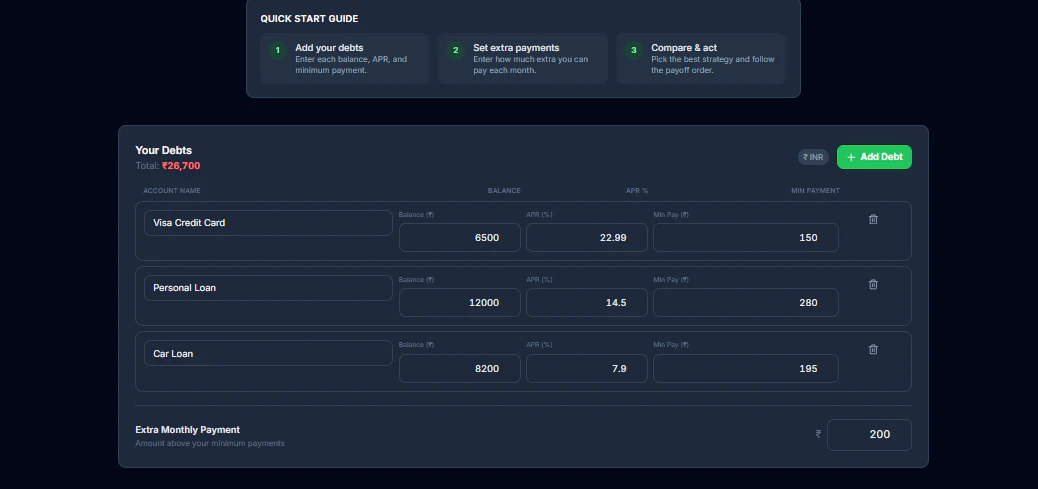
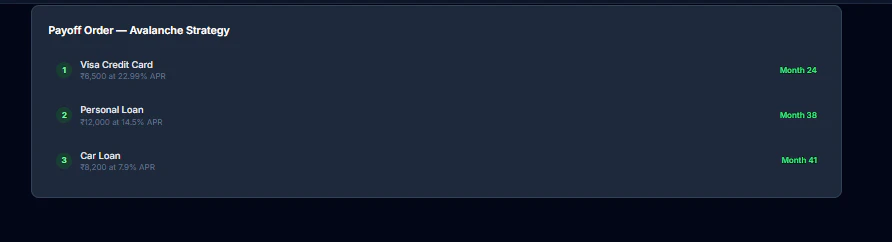
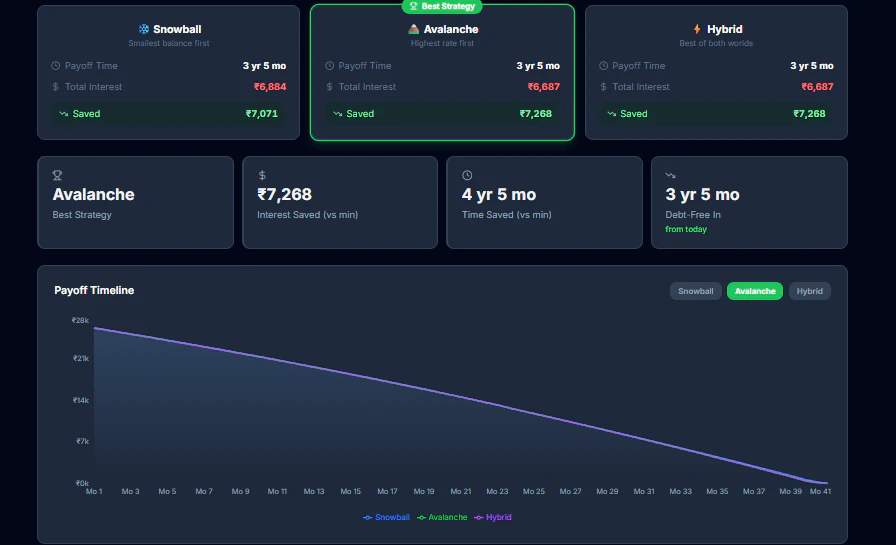
一句话介绍:一款无需注册、即时对比雪球法、雪崩法及混合策略的免费在线债务偿还计算器,在个人债务管理场景中,解决了用户难以直观比较不同还款策略效果、无法精准制定最优还款计划的痛点。
Productivity
Fintech
债务计算器
个人理财
债务管理
财务规划
还款策略对比
免费工具
免注册
雪球法
雪崩法
混合策略
用户评论摘要:用户普遍赞赏其策略对比清晰、操作简单。主要建议包括:增加进度追踪功能以提升参与感;优化小屏幕设备上的图表响应式布局;考虑支持可变利率、大额长期贷款(如房贷)的年化时间线显示,以及增加APR转换器。
AI 锐评
DebtMeltPro 的核心价值并非在于创造了新的债务还款方法论,而在于将经典的“雪球法”与“雪崩法”从抽象的财务概念,转化为可即时感知、量化对比的用户体验。它精准切入了一个被许多专业金融工具忽视的缝隙:决策前的模拟与比较。大多数工具或预设单一路径,或过于复杂,而 DebtMeltPro 通过“混合策略”的引入和实时可视化,实际上是在为用户提供一次低成本的“财务决策沙盘推演”。
然而,其当前的“轻量级”既是优势也是天花板。从评论反馈看,用户的需求正迅速从“策略比较”向“策略执行与追踪”延伸。工具若止步于计算器,则易沦为一次性使用产品;用户暗示的“进度跟踪”需求,恰恰是构建用户粘性、从“决策工具”转向“管理伙伴”的关键。此外,对可变利率、非标债务(如无明确APR的贷款)支持的缺失,暴露了其模型与现实世界复杂性的脱节,这限制了其在更严肃、多元债务场景下的可信度。
本质上,这是一款出色的“启蒙工具”和“决策催化剂”,它通过降低理解与比较门槛来创造价值。但其长期成功取决于能否沿着用户反馈指出的道路,深化其工具属性,融入债务管理的全流程,并处理更真实的金融数据复杂性。否则,它可能只是用户财务旅程中一个短暂而明亮的“顿悟点”,而非不可或缺的长期伴侣。
一句话介绍:Epismo Context Pack 是一款为AI智能体工作流设计的“便携式记忆”工具,它通过将提示、计划、决策等上下文打包成可复用的知识包,解决了跨智能体、跨会话的上下文重复创建与信息孤岛痛点。
Productivity
Developer Tools
Artificial Intelligence
AI智能体工具
上下文管理
可复用知识库
团队协作
提示工程
工作流优化
MCP集成
开发者工具
知识共享
用户评论摘要:用户认可产品解决“信息孤岛”的核心价值,并对社区共享功能感兴趣。主要问题聚焦于:跨模型使用时如何保证语义一致性(上下文漂移);共享包如何结构化以即插即用;以及多智能体写入同一记忆包时的冲突处理。
AI 锐评
Epismo Context Pack 瞄准的并非表面上的“记忆存储”,而是AI原生工作流中日益尖锐的“知识债务”问题。当前,AI应用越是深入,沉淀在单次对话、特定工具或私人笔记中的隐性知识就越多,形成新的数据烟囱。该产品试图将这类非结构化、高价值的“工作上下文”首次对象化、标准化,使其成为可在智能体间流通的“一级资产”。
其真正的前瞻性在于两点:一是试图建立跨平台、跨模型的上下文交换协议(通过MCP/CLI),这比单一平台的记忆功能更具野心和开放性;二是引入了“社区发布”机制,这隐约指向了一个未来图景:AI工作流的最佳实践(如复杂的提示链、决策逻辑)可能像今天的代码库一样,可通过“导入上下文包”来快速复用,极大降低高级AI应用的使用门槛。
然而,其面临的挑战同样严峻。首当其冲的是“上下文保真度”问题。当打包的“决策与推理”脱离原生的模型环境和会话状态,被注入另一个智能体时,其效果能否如预期?这本质上是一个知识表征与迁移的难题,产品目前似乎依赖社区投票的“优胜劣汰”和用户自行清理,技术保障略显单薄。其次,从“私人记忆”到“团队知识库”再到“社区共享”,每一层跨越都伴随着更复杂的权限、版本和质量控制需求,这对其产品架构是巨大考验。
总体而言,这是一个在正确方向上迈出的关键一步。它不再将AI智能体视为孤立的任务执行者,而是将其置于一个可持续积累、协作进化的知识网络之中。若能攻克上下文保真与规模化协作的难题,它有望成为AI时代知识管理的底层基础设施之一。
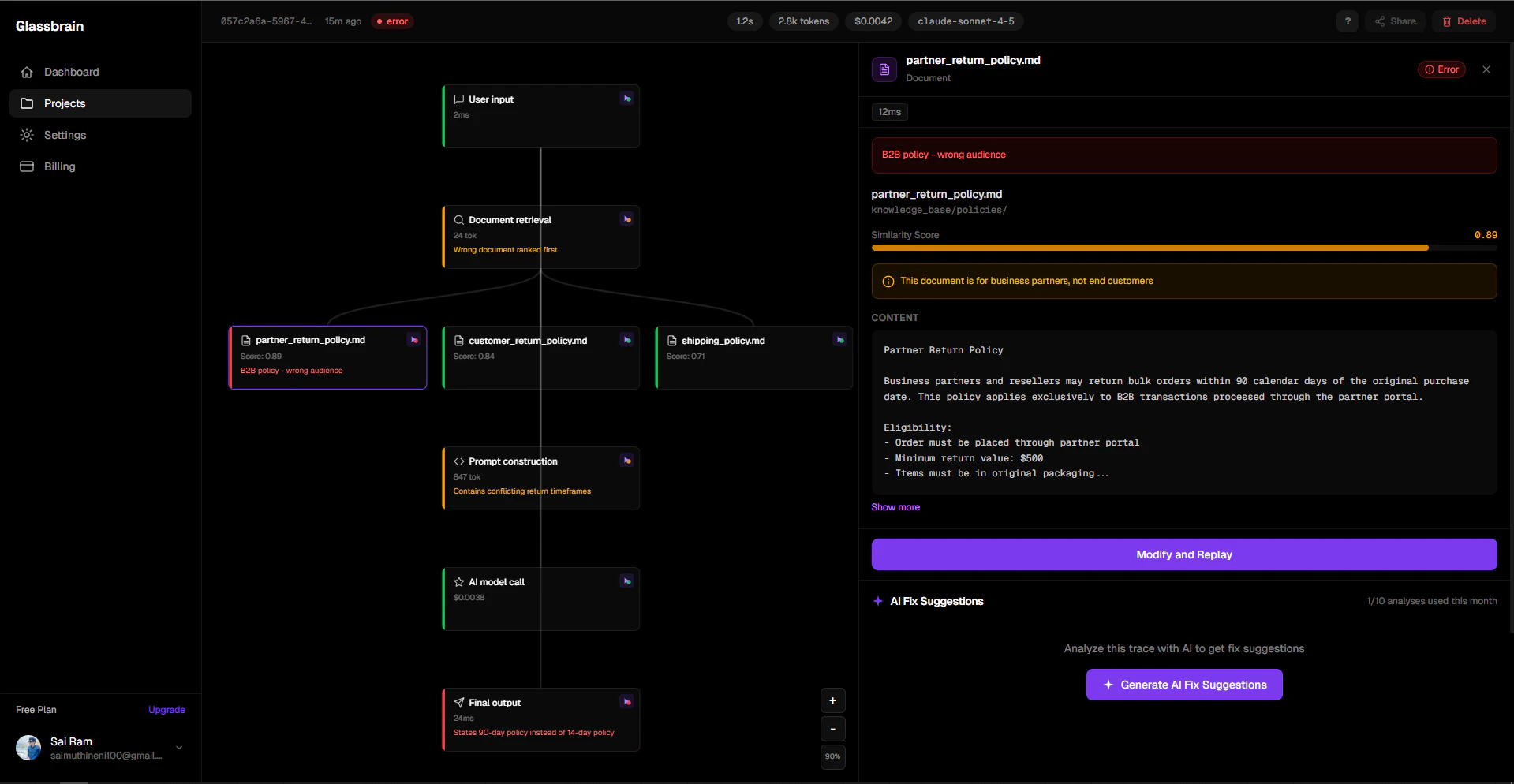
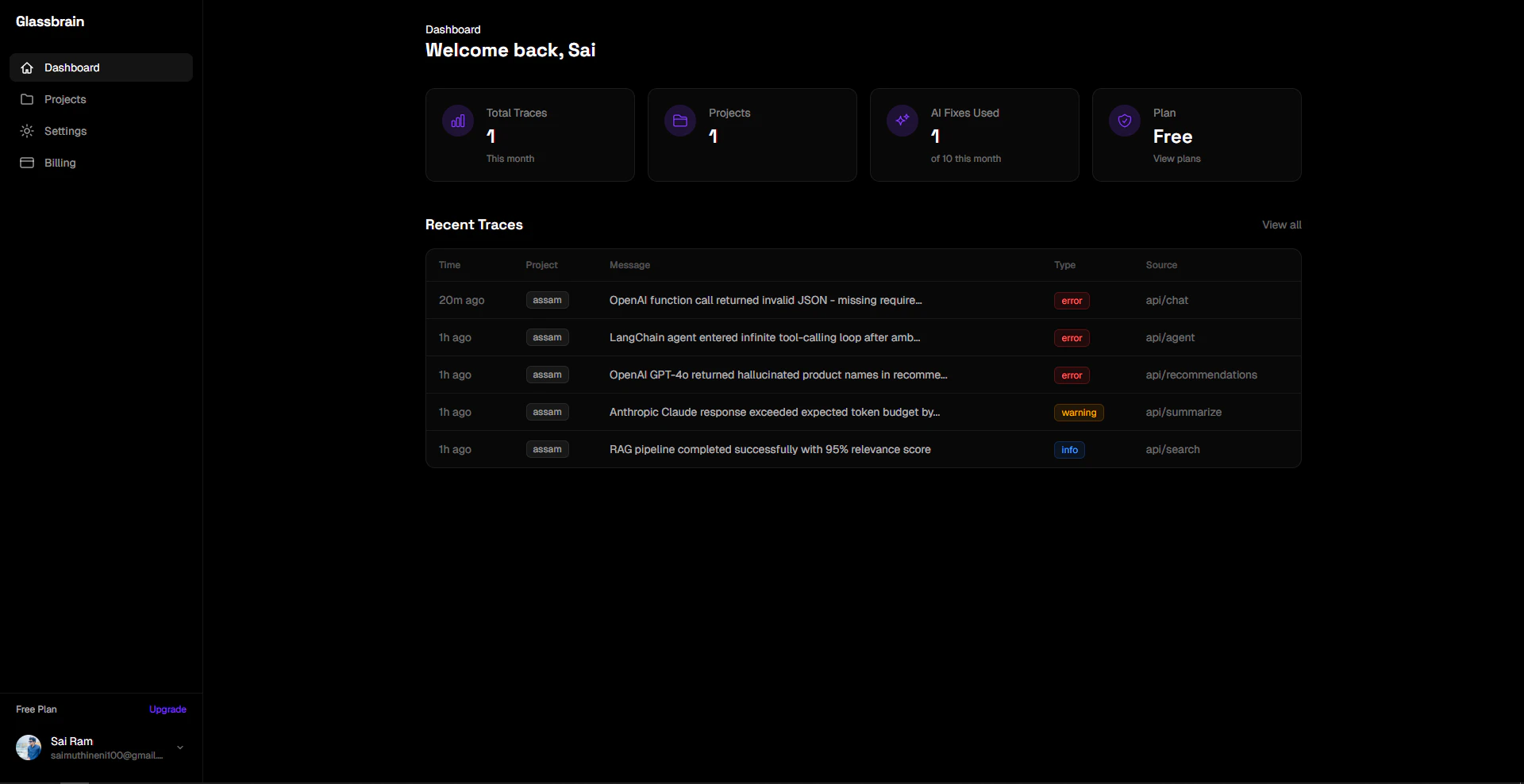
一句话介绍:Glassbrain通过可视化AI应用执行轨迹树和无需重新部署的即时回放功能,解决了开发者在调试复杂AI应用时面临的效率低下、难以定位问题根源的痛点。
SaaS
Developer Tools
Artificial Intelligence
AI应用调试
可视化追踪
即时回放
开发运维
LLM可观测性
Agent调试
Prompt工程
开发者工具
AI工程化
用户评论摘要:用户高度认可无需重新部署的即时回放和可视化树状图功能,认为这是对传统文本日志的巨大升级。主要问题集中在:与自定义/非主流框架的兼容性、回放对状态依赖的处理深度、免费层计费方式(按管道而非节点),以及对未来回归测试和监控功能的期待。
AI 锐评
Glassbrain切入的并非一个空白市场,LangSmith、Langfuse等早已盘踞LLM可观测性赛道。其真正的锋利之处在于,将“调试”这个高频且痛苦的动作,从“静态日志审查”升级为“动态交互式回放”。这不仅仅是UI从文本到图形的转变,更是将调试流程从“观察-假设-修改代码-重新部署验证”的漫长循环,压缩为“点击-修改-即时验证”的闭环。它试图接管的是调试中最耗时的“上下文重建”环节。
然而,其价值深度面临拷问。当前方案的核心是捕获并重放LLM调用参数,这对于“无状态”的API调用调试是有效的。但面对日益复杂的AI Agent,其“状态”可能存在于内存对象、数据库或外部工具中。评论中关于“状态回放”的质疑直指核心:若无法完整重建执行环境,回放的“确定性”将大打折扣,可能沦为更花哨的日志查看器。
产品将“两行代码集成”作为卖点,是明智的降低门槛策略,但也暗示其侵入性和依赖特定SDK的局限。其长远竞争力可能不在于更漂亮的图谱,而在于能否将“回放”基础设施化,并延伸至团队协作、回归测试与监控预警,从而从“调试工具”演进为保障AI应用开发生命周期稳定性的“质量平台”。它现在提供了一把锋利的手术刀,但未来需要证明自己能管理整个手术室。
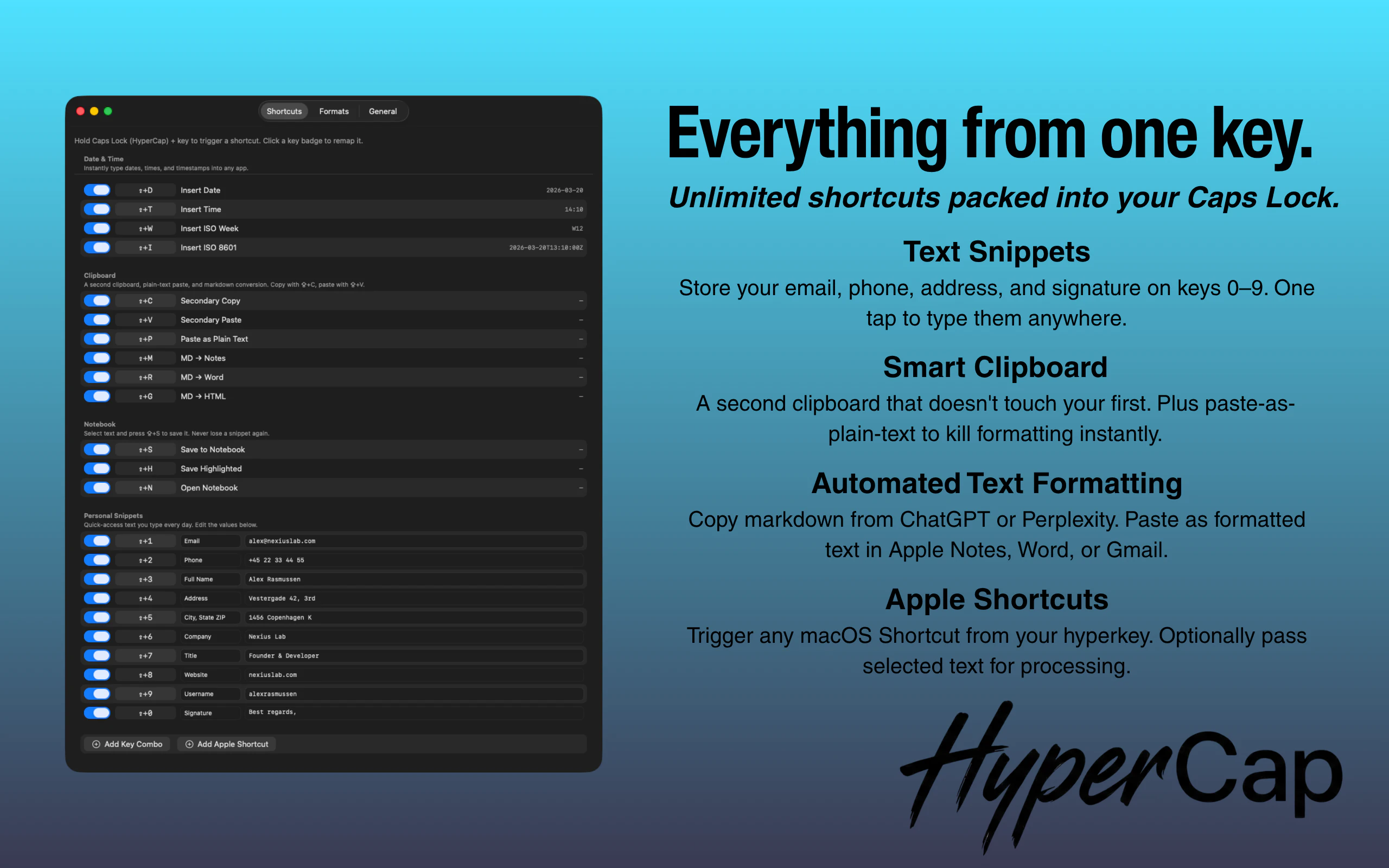
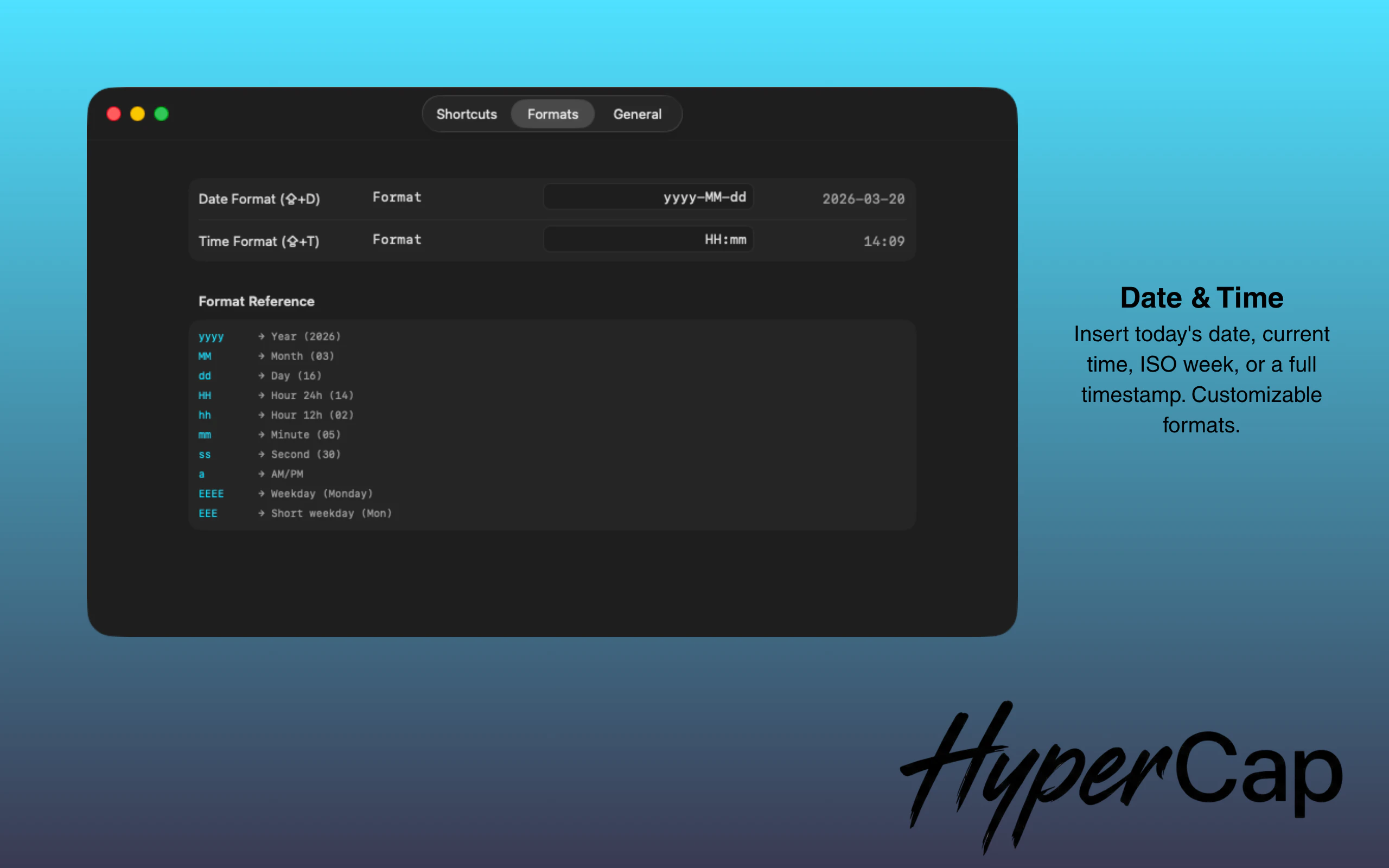
一句话介绍:HyperCap将键盘上的Caps Lock键重映射为一个“超级键”,通过组合其他按键实现快速自定义操作,解决了用户在频繁切换应用、查找菜单和记忆复杂快捷键时中断工作流的核心痛点。
Productivity
Custom Keyboards
Menu Bar Apps
键盘效率工具
快捷键增强
生产力软件
自定义宏
无干扰捕获
研究笔记
macOS工具
一键操作
工作流优化
用户评论摘要:用户普遍赞赏“研究笔记本”功能,认为其自动捕获文本、来源应用和URL的能力能极大提升效率。主要问题集中在与Raycast/Alfred等复杂工作流工具的对比、悬浮窗在全屏应用下的兼容性,以及未来功能的演进方向。
AI 锐评
HyperCap的聪明之处在于,它没有创造一个新需求,而是敏锐地“回收”了一个已被边缘化的物理键——Caps Lock,并将其重塑为效率入口。这比单纯开发一套新的快捷键系统更轻巧,也更容易降低用户的学习和适应成本。其宣称的“保持心流”哲学,本质上是对现代软件“功能膨胀”和“交互过载”的一种优雅反击。
然而,其真正的挑战与价值并非在技术层面。作为独立开发者的作品,它精准切入了一个细分市场:那些对效率有极致追求,又不愿或无力在Raycast、Alfred等平台上搭建复杂脚本的中高阶用户。“研究笔记本”功能是这一定位的绝佳体现——它并非一个全能的笔记应用,而是一个高度场景化、无干扰的“灵感暂存器”,这比大而全的解决方案更具杀伤力。
但犀利点看,HyperCap的核心功能护城河并不深。键盘重映射并非新技术,其与Apple Shortcuts的集成也是一种“借力”。产品的长期价值将取决于其能否围绕“无干扰捕获”和“上下文保存”这一核心洞察,构建起一套独特且连贯的微功能生态,并形成良好的用户习惯绑定。否则,它很容易被更强大的平台工具更新一个类似功能所覆盖。目前看来,它是一款定位精准、体验优雅的“锋利的刀”,但能否成长为平台级工具,仍需观察其生态演化能力。
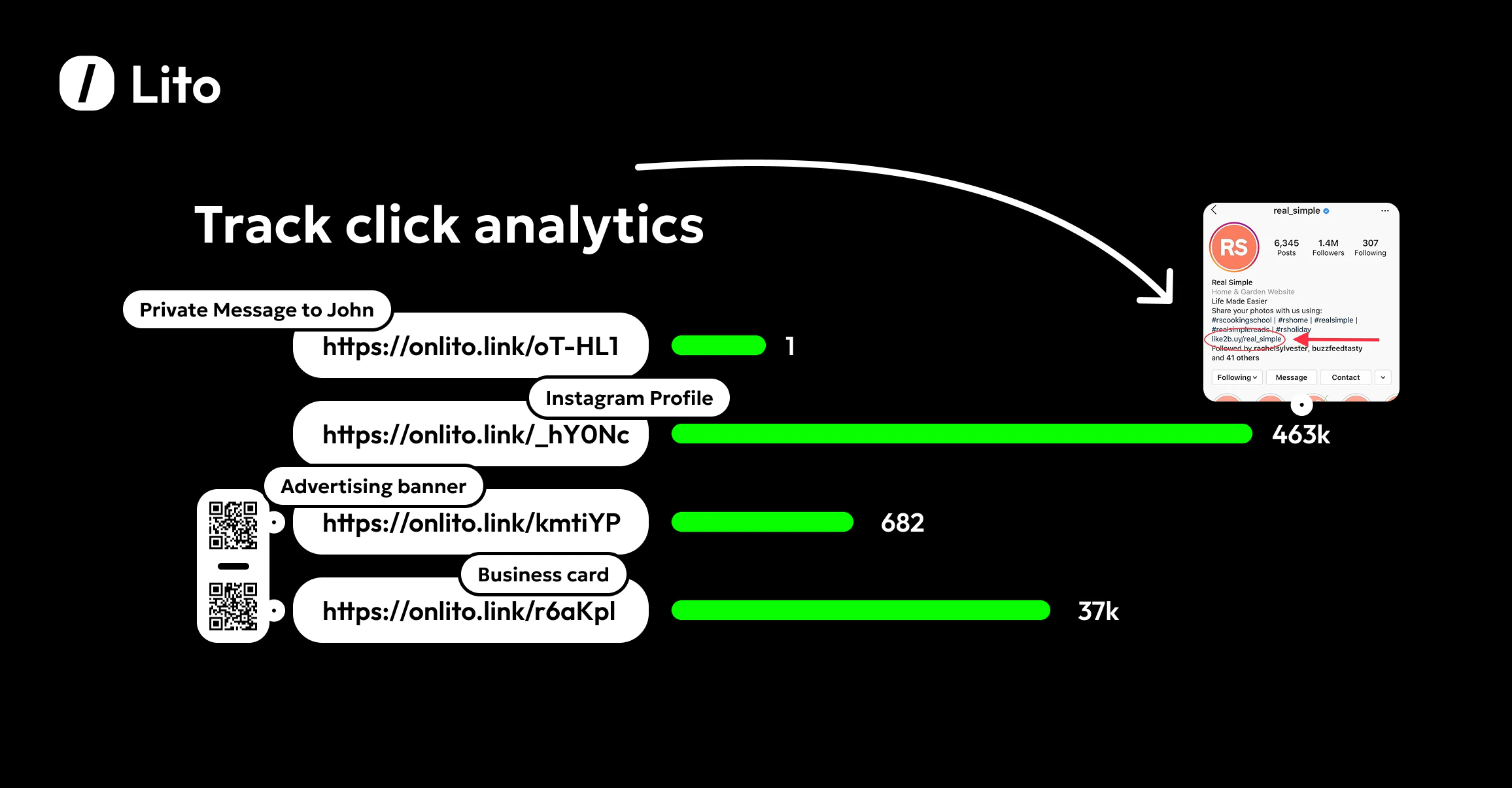
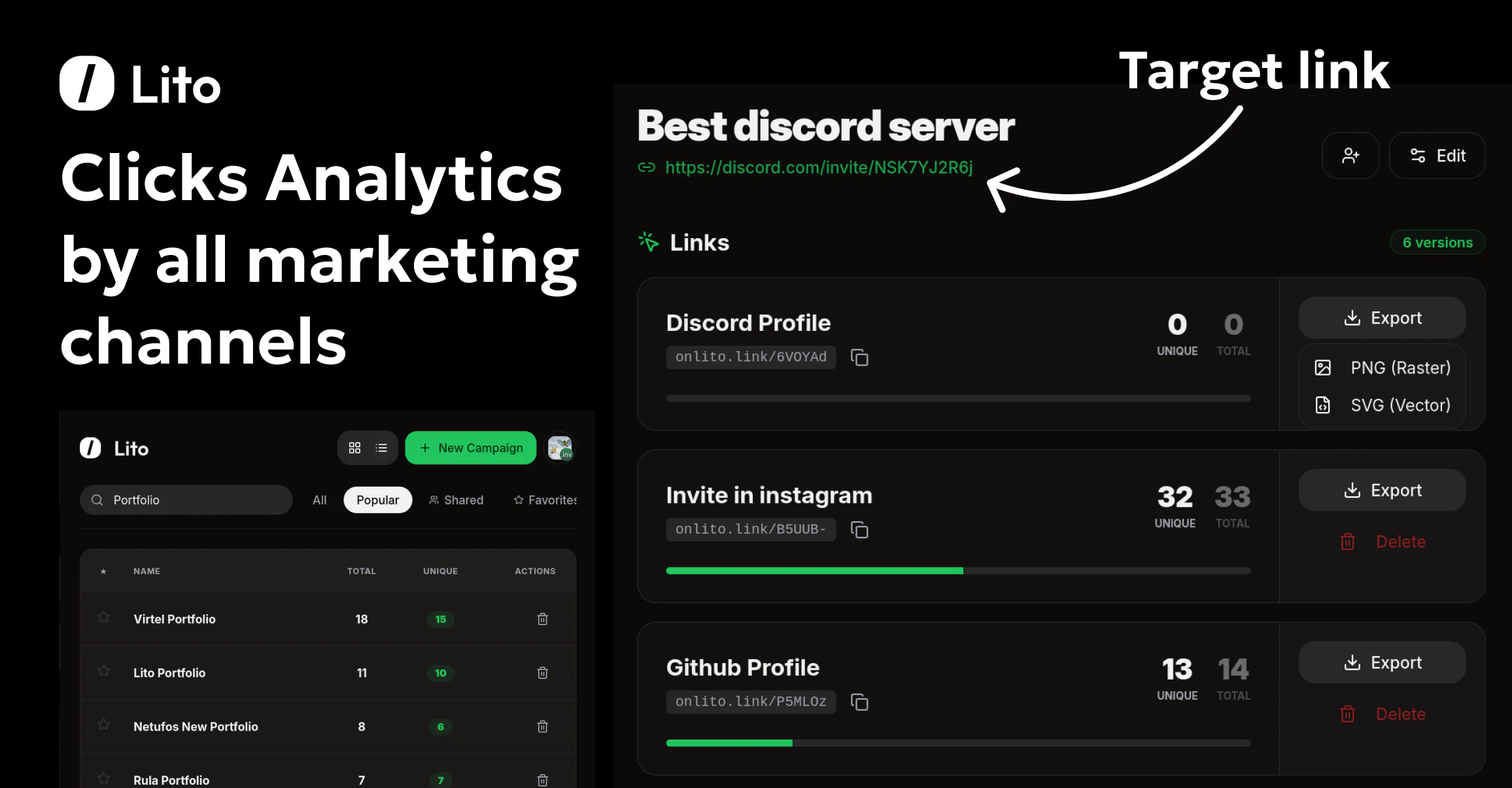
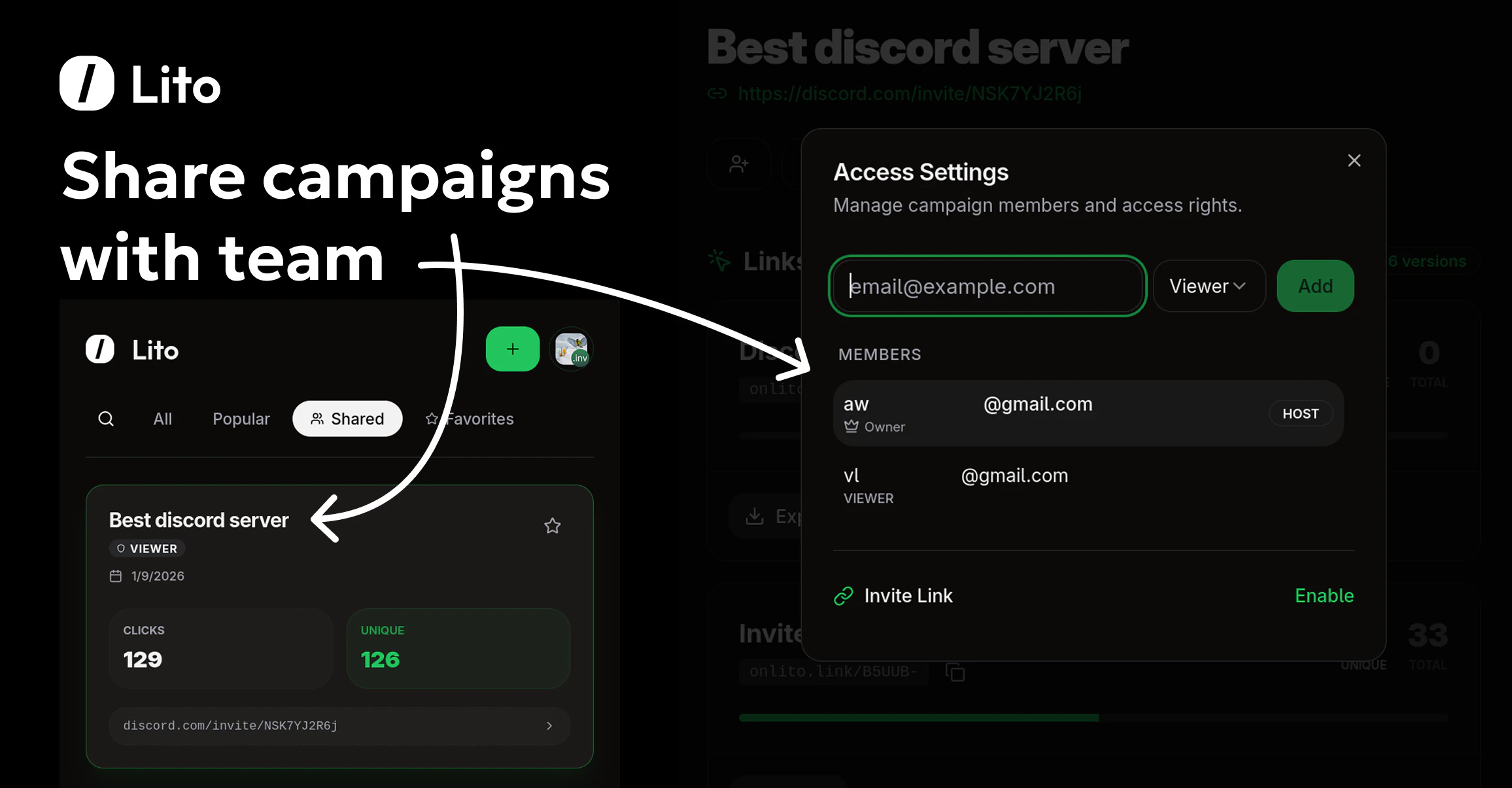
一句话介绍:Lito是一款为营销人员和创作者提供的免费专业链接分析与团队协作QR码生成工具,解决了中小团队在预算有限下无法使用昂贵且界面陈旧的链接追踪工具的痛点。
Design Tools
Analytics
Marketing
链接追踪
链接分析
短链接
QR码生成
营销工具
团队协作
免费增值
数据分析
产品营销
出海工具
用户评论摘要:用户认可其简洁界面和核心分析功能。主要反馈两点:一是输入URL需完整协议(如https://)否则跳转失败,开发者已确认将优化;二是询问是否原生支持UTM参数,开发者回复目前需手动添加,但自动附加UTM功能已在开发路线图中。
AI 锐评
Lito切入了一个经典的市场缝隙:在动辄每月数百美元的专业营销分析工具与功能简陋或设计过时的免费工具之间,提供“够用、好看且免费”的替代方案。其宣称的“永久免费”是最大噱头,旨在通过零门槛策略快速获取用户,但其商业模式可持续性存疑,未来很可能通过团队高级功能、增值服务或用量限制来实现变现。
产品价值核心在于将“链接追踪”、“团队共享”和“高质量QR码”三个营销刚需功能打包,并赋予现代化的用户体验。这精准击中了小型团队、独立创作者和初创公司的预算与协作痛点。然而,从评论暴露的问题看,其产品成熟度仍有欠缺。URL协议依赖和UTM参数处理等细节,恰恰是专业营销工具的基础能力,这些“小问题”反映了其与成熟竞品在底层逻辑和场景化思考上存在差距。
开发者对反馈的响应迅速且路线图清晰,这是积极信号。但真正的挑战在于,当用户量增长、数据复杂度提升后,能否在维持免费的同时,保障数据处理的准确性与系统性能。此外,其“团队协作”功能是其从个人工具迈向团队服务的关键,这可能是未来付费转化的核心抓手。总体而言,Lito是一个定位清晰、有市场需求的MVP,但其长期生存能力取决于能否在用户体验、功能深度与商业可持续性之间找到平衡点,而不仅仅是作为又一个“为爱发电”的免费工具。
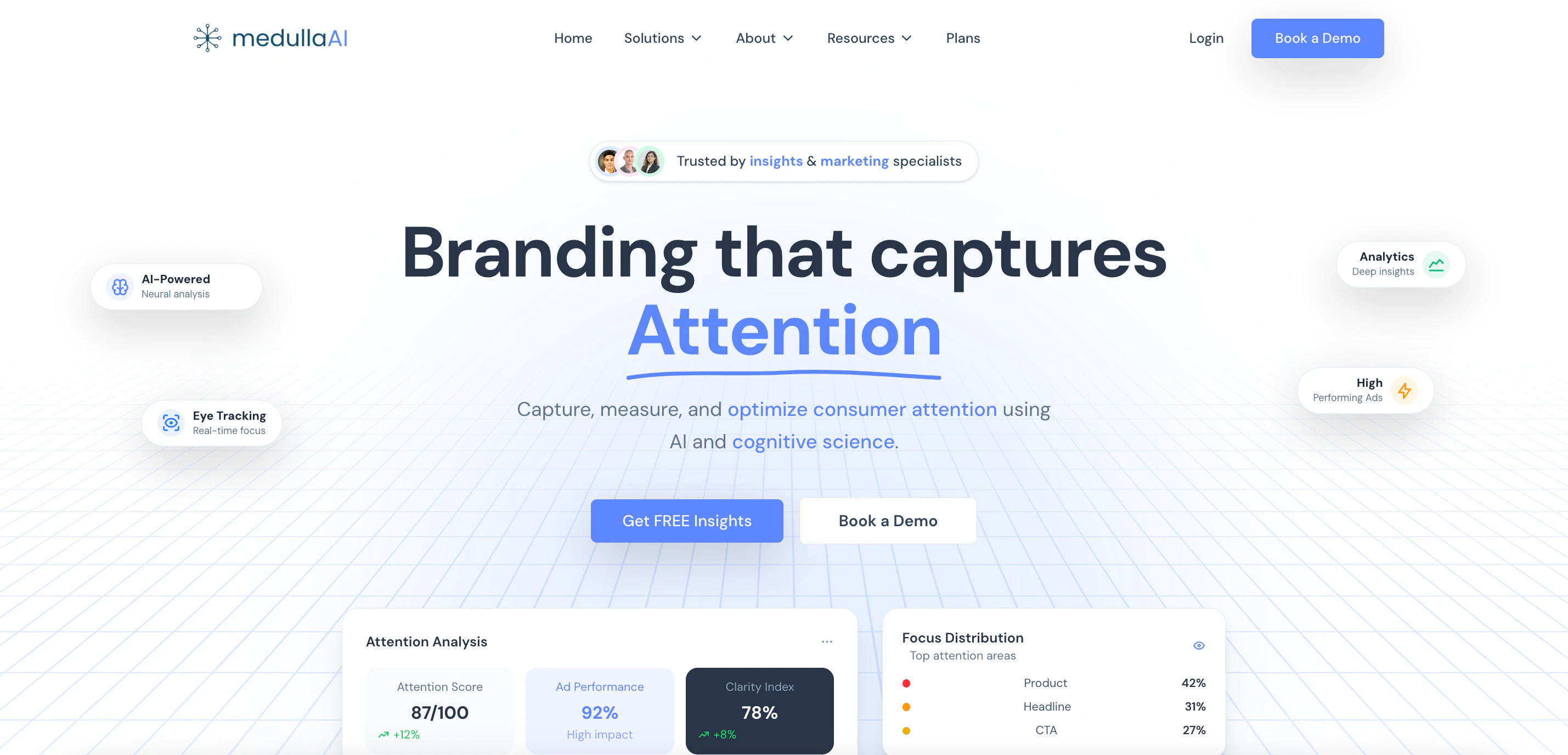
一句话介绍:MedullaAI 是一款基于AI与认知科学的神经分析平台,在品牌营销创意投放前,通过模拟人类注意力与情绪反应,快速验证创意效果,解决了传统广告投放依赖主观判断、试错成本高昂的核心痛点。
Marketing
Advertising
Artificial Intelligence
AI营销
创意验证
神经科学
注意力分析
预发布分析
广告科技
认知计算
营销科技
效果预测
品牌洞察
用户评论摘要:用户主要关注产品适用场景(如移动广告格式支持)、技术原理(认知科学模型如何工作)及价值主张(从“诊断”而非仅“生产”切入的独特性)。创始人回应确认支持移动端,并解释了模型针对移动注意力的专门校准。
AI 锐评
MedullaAI 切入了一个看似饱和却存在关键空白的市场:创意的事前科学验证。其宣称的价值并非替代创意生成,而是充当“创意CT扫描仪”,在预算燃烧前诊断认知层面的失效风险。这直指行业痼疾——高达8000亿美元的广告支出中,近一半的成效取决于创意质量,而决策却长期依赖会议室里的“直觉”。
产品逻辑犀利之处在于“逆向操作”:在AIGC疯狂提速创意生产的浪潮下,它反而提倡“慢一步”,用科学诊断来规避无效生产。其技术核心(AI驱动的眼动追踪与认知模型)是否真能达到MIT验证的90%以上准确率,是信任关键。评论中用户的质疑很精准:这究竟是基于现有注意力研究模式的匹配,还是真正的神经模拟?这决定了产品是高级模式识别工具,还是认知科学的突破性应用。
真正的挑战在于市场教育。让习惯于结果导向、快速迭代的营销团队接受一套“预防性”的诊断系统,并为之付费,需要扭转其决策心智。此外,产品将复杂的神经科学封装为简易的“信心分数”,是一把双刃剑:它降低了使用门槛,但也可能让专业用户对黑箱产生疑虑。
如果其模型精度经得起大规模实战检验,MedullaAI 的价值将远超工具层面——它可能成为连接创意感性表达与科学理性验证的桥梁,让广告从一门艺术,逐渐进化为一门可预测、可优化的应用科学。其成败,在于能否在“科学严谨性”与“商业易用性”之间找到那个精妙的平衡点。
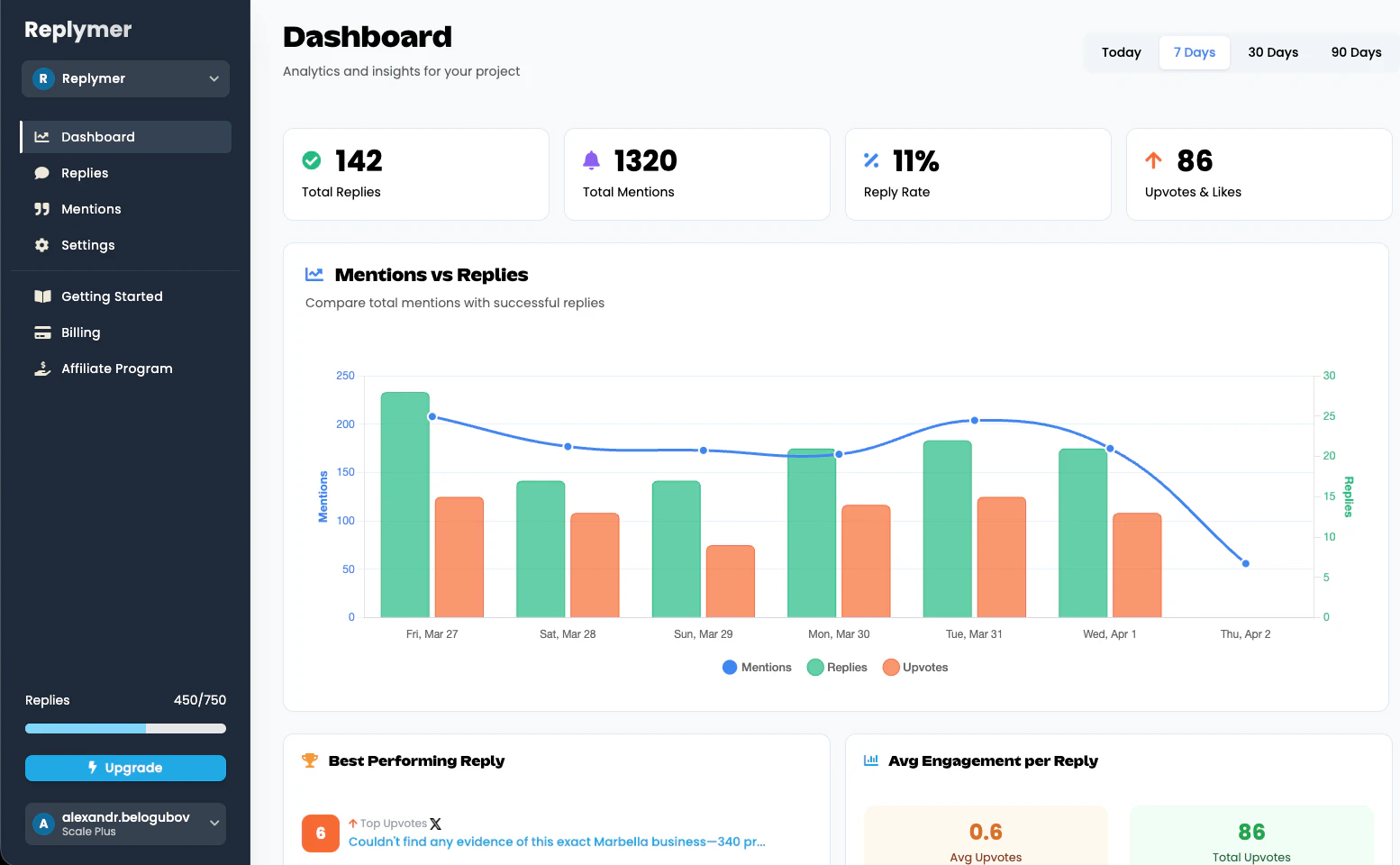
一句话介绍:Replymer 是一款通过全天候自动监控Reddit和X(原Twitter)上的相关讨论,并发布定制化回复,从而为产品引流获客的营销自动化工具,解决了企业主手动寻找推广机会耗时费力且难以持续的痛点。
Social Network
Marketing
营销自动化
Reddit营销
X/Twitter营销
流量获取
社交媒体监控
自动回复
SEO优化
潜在客户挖掘
增长工具
用户评论摘要:创始人介绍了产品迭代与用户规模。有效评论集中于对“真实性”和合规性的担忧:如何避免回复显得生硬或被判为垃圾信息?如何确保符合平台条款?以及用户询问账户使用策略和回复语调定制功能。
AI 锐评
Replymer 瞄准了一个真实且普遍的痛点——在社交媒体海量对话中手动寻找营销机会效率极低。其宣称的“全自动”与“真实性”构成了核心张力,也是其面临的最大质疑与风险。
产品的真正价值并非其宣称的“真实性”,而在于将“大海捞针”式的监测工作流程化、规模化,本质是一个高效的潜在客户线索挖掘与初步接触工具。它通过算法过滤和内容生成,将人力从枯燥的搜寻中解放出来,实现更广的触达面。然而,其“发布”功能恰恰是双刃剑。Reddit等社区对营销内容极度敏感,其“社区雷达”和版主管理是强大壁垒。完全自动化的、缺乏人性温度和情境细微理解的回复,极易被识别为垃圾信息,导致账户被封、品牌声誉受损。评论中的担忧一针见血。
当前,其更可持续的价值路径或许应侧重于“半自动化”:即作为顶尖的“监听与警报”系统,为营销人员提供高价值对话线索和回复草稿,而由人工进行最终的审核、润色和发布。这将平衡效率与安全。直接定位为“零人工”的全自动发布,虽然营销话术诱人,但可能低估了社区管理的复杂性和平台算法的演进速度,长期运营风险高企。它的成功与否,不取决于技术能否生成看似通顺的回复,而取决于其运营策略能否在平台规则与社区文化的钢丝上找到平衡点。
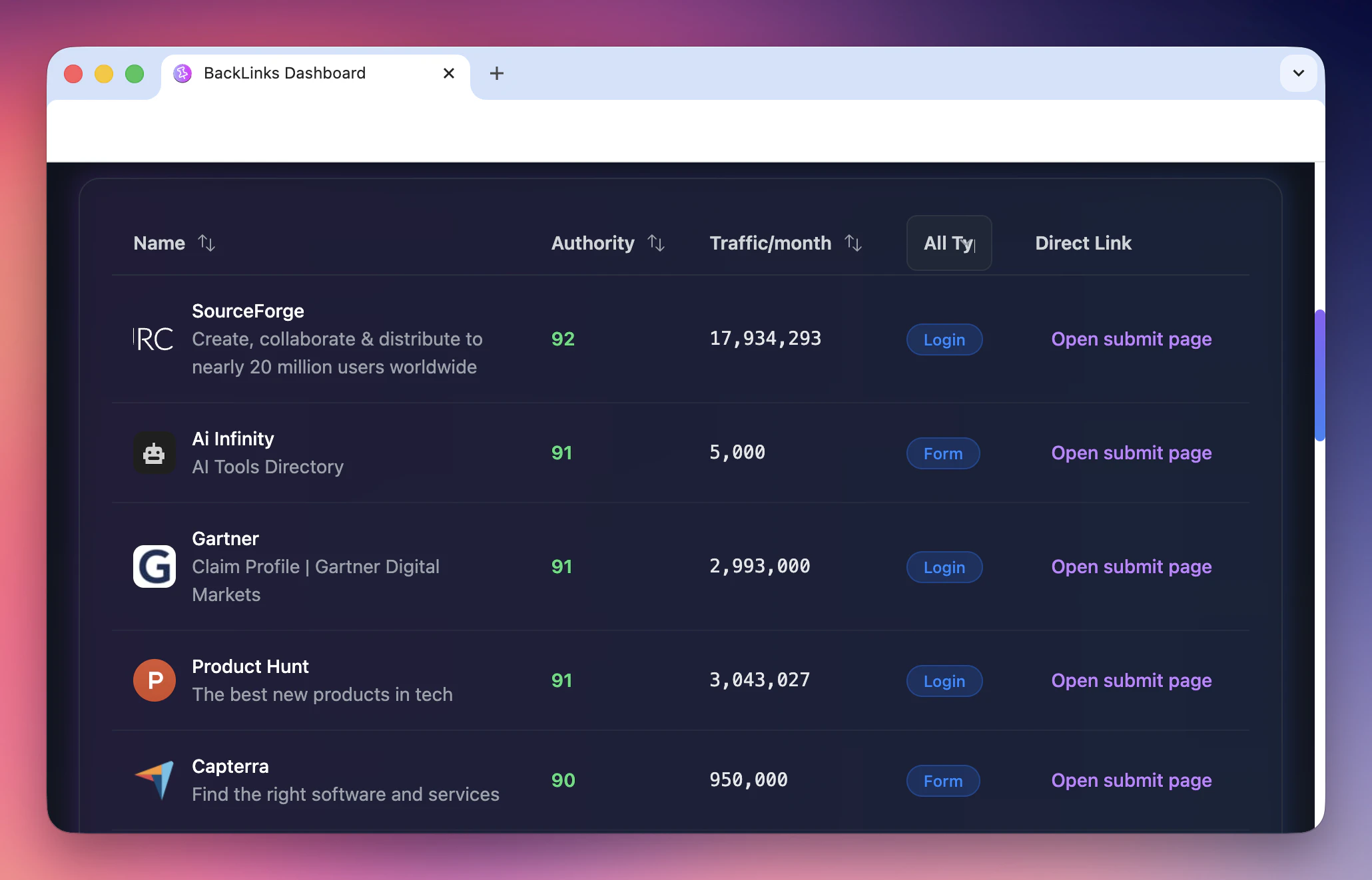
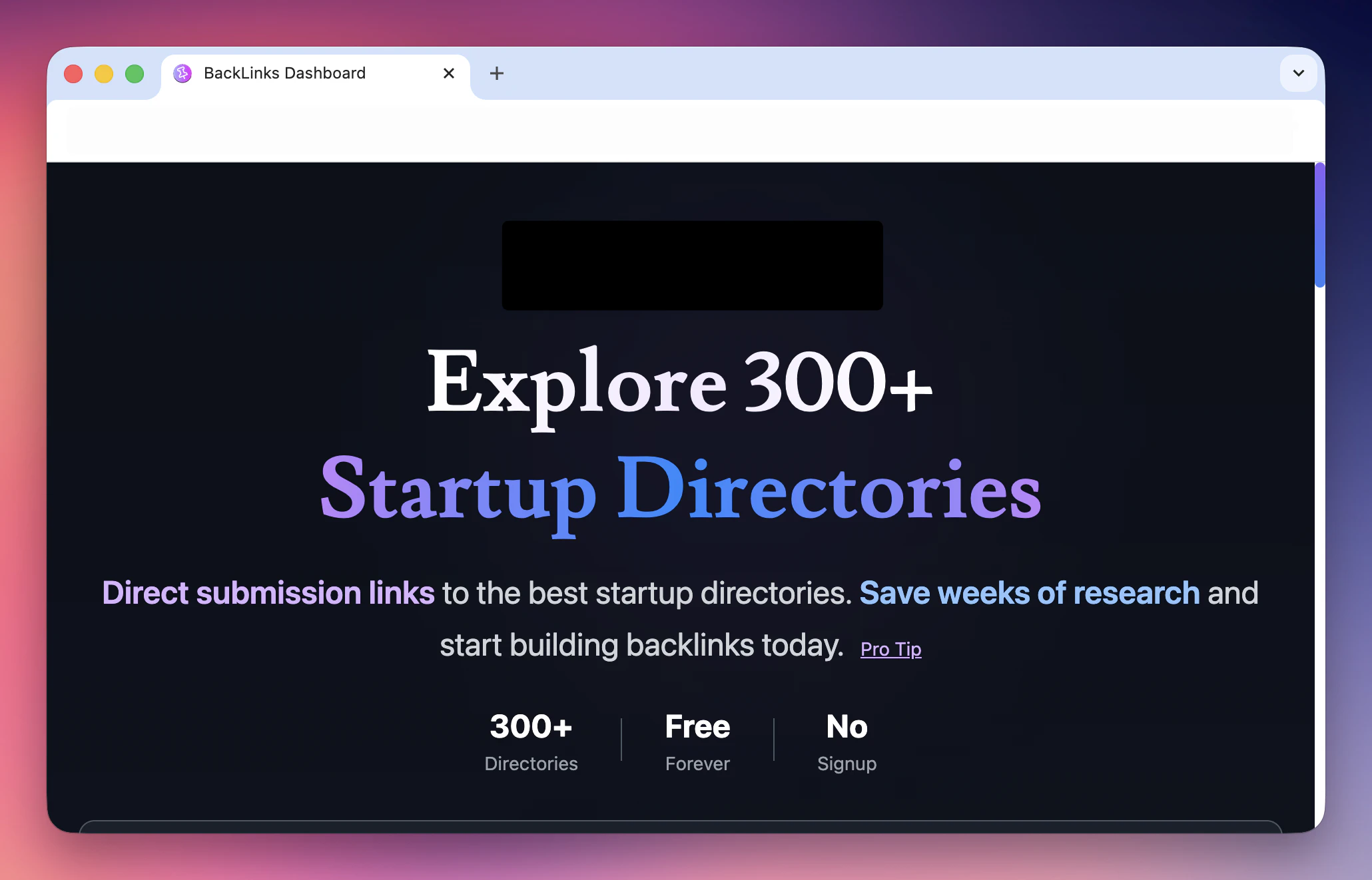
一句话介绍:一款聚合了300多个初创公司目录及直接提交链接的工具,帮助创业者、独立开发者和营销人员高效构建反向链接,节省手动寻找和提交时间,从而提升项目的自然流量和线上可见性。
Marketing
SEO
GitHub
SEO工具
反向链接建设
初创公司营销
目录提交
自然流量增长
效率工具
独立开发者
项目推广
免费工具
自动化提交
用户评论摘要:用户普遍赞赏其解决了“知道该做但拖延”的痛点,尤其对移动应用兼容性表示肯定。核心关注点在于能否利用AI(如Claude Desktop)实现自动化批量提交,以替代昂贵付费服务,同时寻求更具体的操作指引。
AI 锐评
BackLinks 本质上是一个“清单聚合器”,其真正价值并非技术创新,而是对分散、低效的SEO基础工作流进行了一次极简整合。它精准命中了小微创业者和独立开发者的核心矛盾:明知目录提交对SEO至关重要,却因过程枯燥、资源分散而无限拖延。
产品聪明地避开了与成熟SEO套件的正面竞争,转而充当一个“启动踏板”。然而,其长期价值存疑。首先,其核心资源(300+目录列表)极易被复制或超越,壁垒极低。其次,用户评论已揭示出更高级的需求:与AI智能体(如Claude)集成以实现全自动化操作。这恰恰暴露了产品的软肋——它仅提供了“名单”,而非“解决方案”。用户最终渴望的是一键提交,而非手动访问300个网站。
更尖锐的问题是,大量免费目录的SEO权重正在持续衰减,其引流效果可能远低于预期。产品若停留在静态列表阶段,将很快沦为鸡肋。它的未来,要么深度集成自动化提交引擎,转型为真正的效率工具;要么融入更广泛的SEO工作流,成为其中一个功能模块。否则,仅凭一个可被复制粘贴的清单,其热度将如流星般短暂。当前版本,是一个出色的“最小可行产品”,但绝非终点。
一句话介绍:Nostria是一款主打纯净社交的去中心化社交网络,通过屏蔽噪音、聚焦真实好友动态,在信息过载的社交媒体环境中帮助用户重拾有意义的熟人社交连接。
Android
Music
Messaging
Social Media
去中心化社交网络
熟人社交
隐私保护
无噪音设计
Nostr协议
身份自主
数据主权
社交聚合应用
用户评论摘要:主要评论来自创始人,阐述了产品源于对Nostr协议“索引中继”功能的构想与发展历程,从MVP到功能丰富的演进,以及推动去中心化社交普及、让用户掌控身份与数据的核心目标。评论附有介绍文章与快速入门视频。
AI 锐评
Nostria的叙事呈现了一个经典的“理想主义构建者”形象,但其产品价值面临严峻的现实拷问。其核心宣称是“无噪音的社交”和“基于Nostr协议的去中心化”,这直指当前中心化社交平台的流量焦虑、算法绑架与数据垄断痛点,理论价值明确。
然而,其现实路径充满悖论。首先,“无噪音”与“去中心化”存在内在张力。去中心化网络(如Nostr)的默认状态是信息洪流,实现“纯净”恰恰需要强大的中心化或协议层索引工具(如其提到的“索引中继”)进行筛选,这本质上是在用中心化或准中心化的解决方案来优化去中心化体验,其长期治理与公平性存疑。其次,产品定位“看见朋友”的熟人社交,这与Nostr协议原生更偏向公开广播、弱社交关系的属性并不完全契合,相当于在协议层之上强行构建一个强关系场景,其用户迁移成本和网络效应构建难度极高。
从评论看,生态反馈几乎完全由项目方主导,缺乏真实第三方用户的声音,9个投票数也暴露了其初期冷启动的艰难。创始人强调的“替代多个应用、合而为一”的聚合愿景,在去中心化场景中更易沦为功能杂烩,丧失体验焦点。
综上,Nostria更像一个基于Nostr协议的“概念验证”产品,其真正价值不在于短期内取代任何主流应用,而在于作为一块探路石,探索在协议层之上,能否通过产品设计赋予去中心化网络以普通用户可接受的、体验优良的社交形态。它的成败,不仅关乎自身功能,更关乎Nostr生态的基础设施成熟度与大众对“数据主权”的实际支付意愿。前路漫漫,其教育市场的意义可能大于其作为社交产品的即时吸引力。
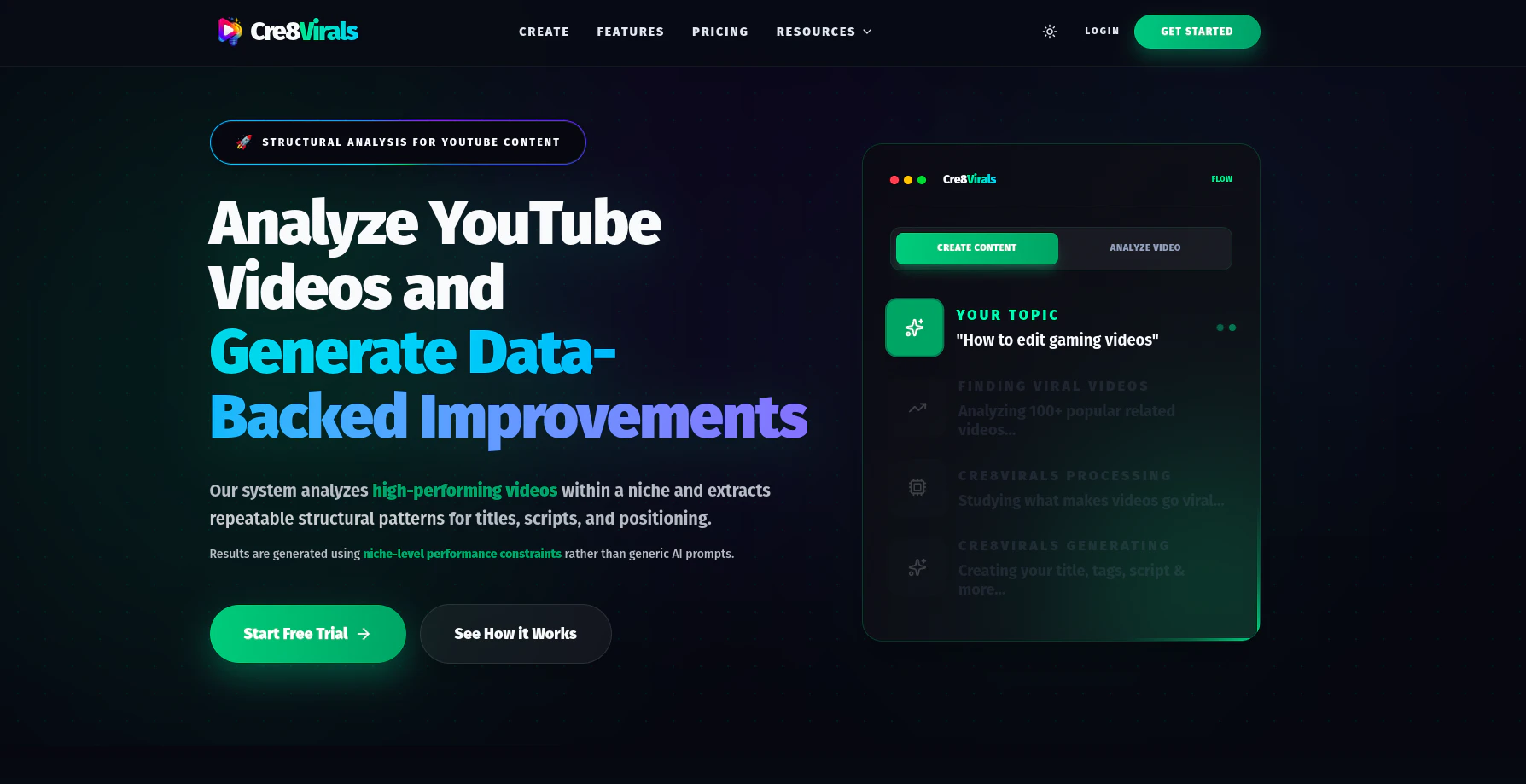
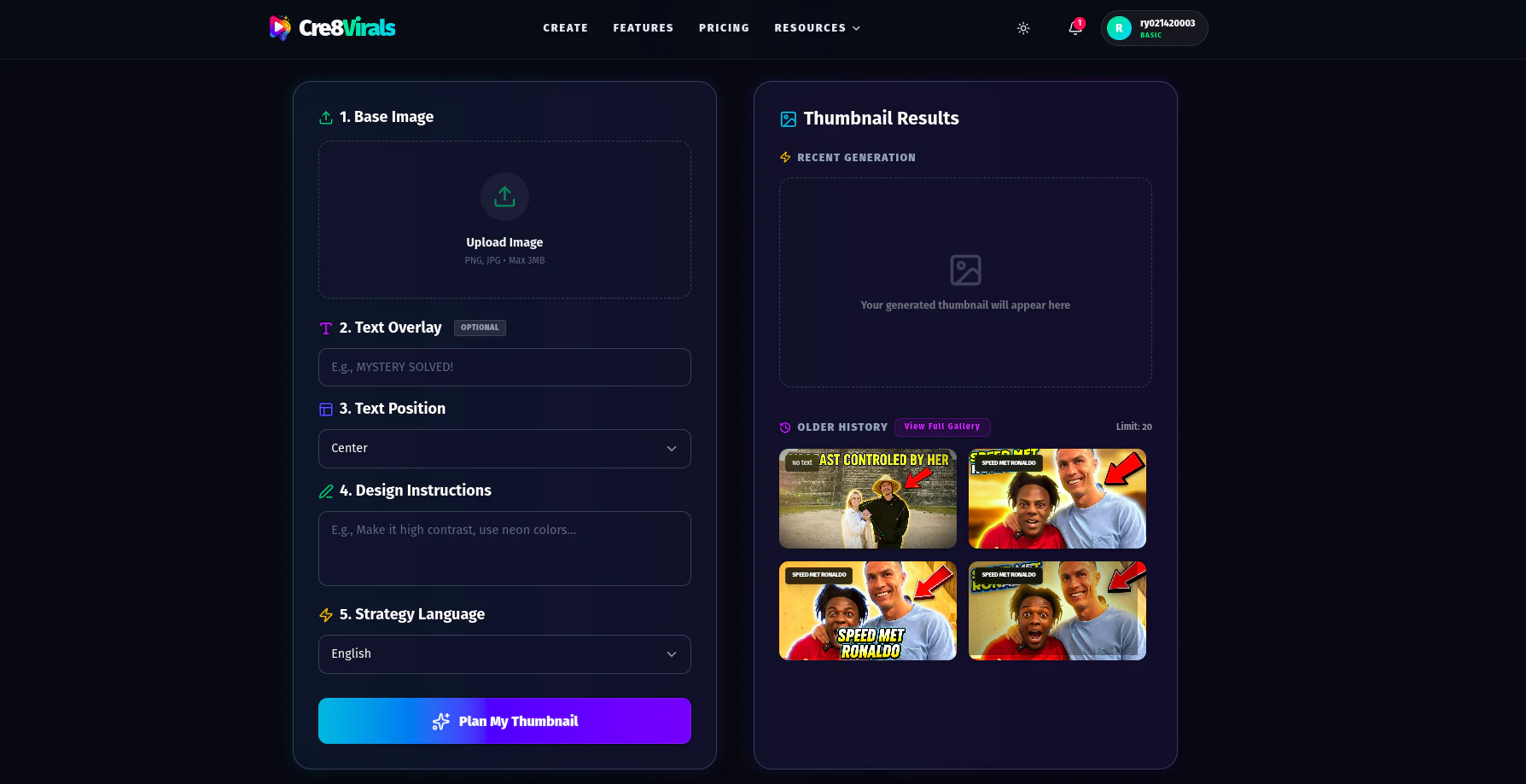
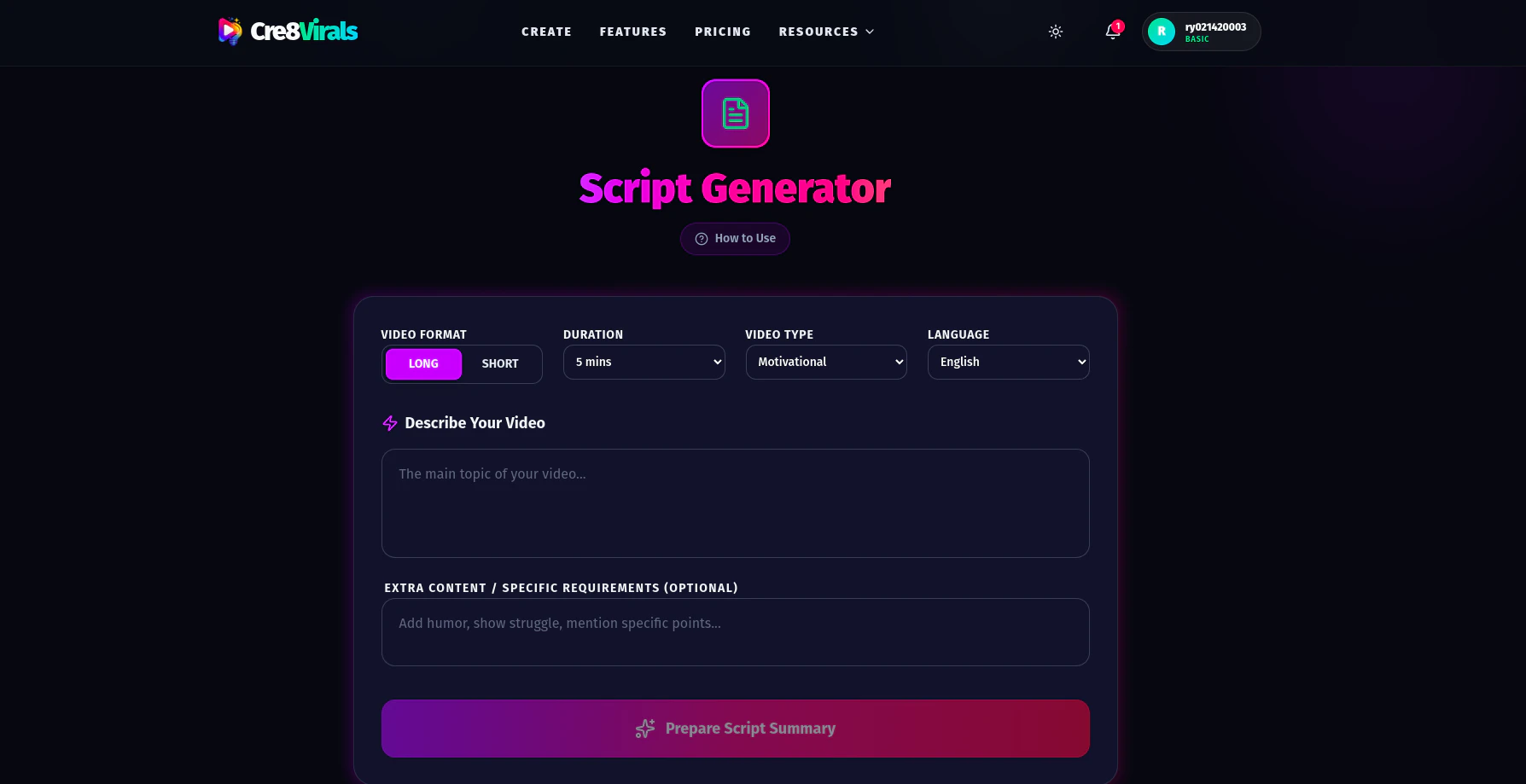
一句话介绍:Cre8Virals 通过分析YouTube细分领域内的热门视频模式,为内容创作者自动生成标题、脚本、缩略图等素材,并诊断视频表现,在创作者盲目试错、增长乏力的场景下,提供数据驱动的创作决策支持,解决“凭猜测创作”的核心痛点。
Social Media
Artificial Intelligence
YouTube
YouTube内容创作
AI视频分析
内容生成工具
频道增长
SEO优化
竞品分析
数据驱动创作
创作者经济
SaaS工具
用户评论摘要:开发者自述产品旨在解决创作者“盲目猜测”而非努力不足的问题。目前有一条用户评论表示期待产品能帮助其YouTube运营,但暂无具体使用反馈或尖锐批评。整体评论样本过少,有效反馈有限。
AI 锐评
Cre8Virals 瞄准了一个真实且日益拥挤的赛道:用AI赋能内容创作。其宣称的价值核心——“No guessing. Just patterns that work.”——直指广大中小创作者的生存焦虑:在高度不确定的算法平台上,如何将有限的精力精准押注。
产品逻辑清晰,将“分析”与“生成”捆绑,试图形成从洞察到执行的闭环。这比单纯的关键词工具或脚本生成器更进一步。其“增长分析”功能,即诊断视频为何失败,是差异化亮点,因为它触及了创作者更深层的需求:不仅要知道“做什么”,更想知道“为什么”。
然而,其面临的挑战同样尖锐。首先,**“模式”的双刃剑**:过度依赖对热门模式的逆向工程,可能导致内容同质化加剧,形成“分析-模仿”的内卷循环,最终削弱创作者的独特性和平台的生态健康。其次,**数据深度与洞察的真实性**:YouTube的成功是多重变量的混沌结果(算法、时机、观众心理、文化语境等)。仅从可量化的表面模式(标题结构、标签、上传时间)进行分析,得出的结论可能流于肤浅,甚至具有误导性。最后,**市场竞争与工具疲劳**:市面上已有大量从某一切入点(如标题优化、缩略图A/B测试)出发的工具。Cre8Virals 虽试图整合,但能否提供足够深、足够准的洞察,以说服创作者支付又一笔订阅费用,仍是未知数。
开发者坦言“仍在早期”,这8个投票数也反映了其冷启动的现状。产品的真正考验在于,其分析的“模式”能否经得起推敲,转化为用户可感知的增长。否则,它可能只是为创作者的焦虑提供了又一个精美的仪表盘,而非真正解决问题的导航仪。它的未来,取决于其AI模型对“成功”背后复杂因果关系的解读能力,这远非简单的模式匹配所能涵盖。
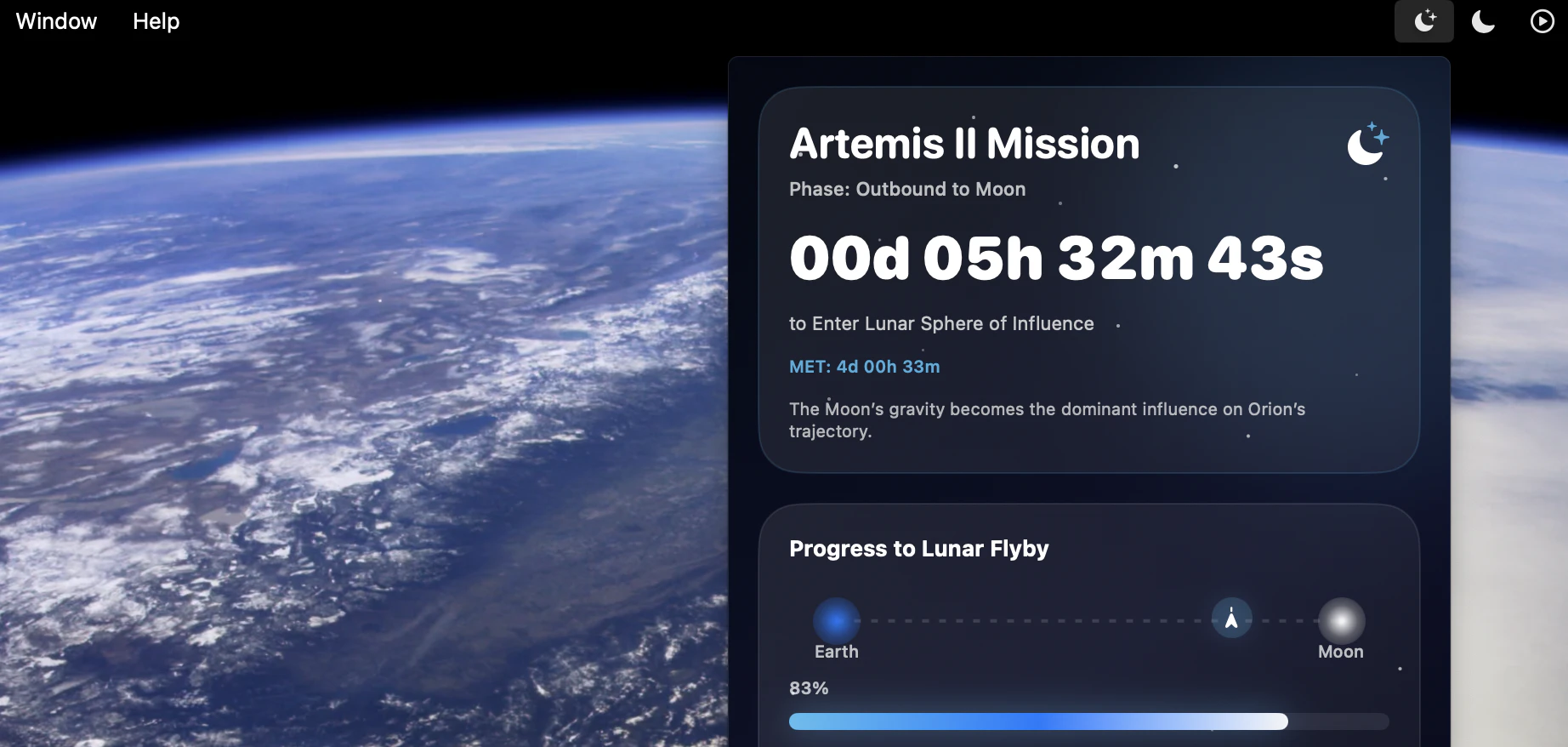

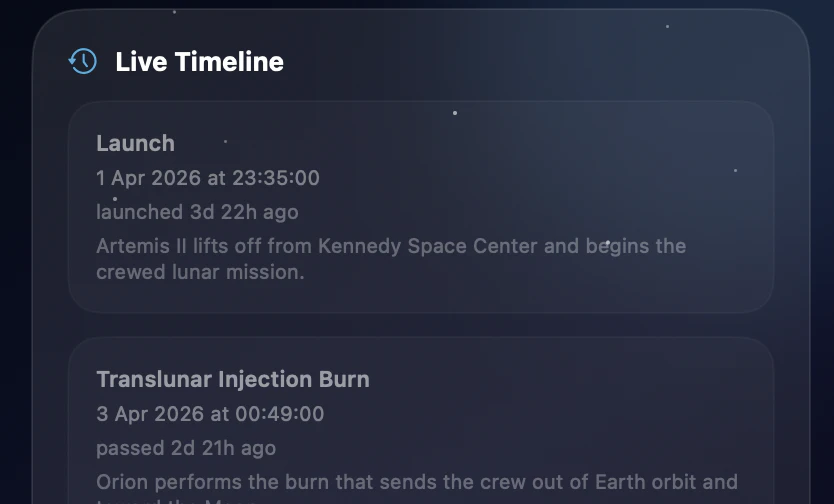

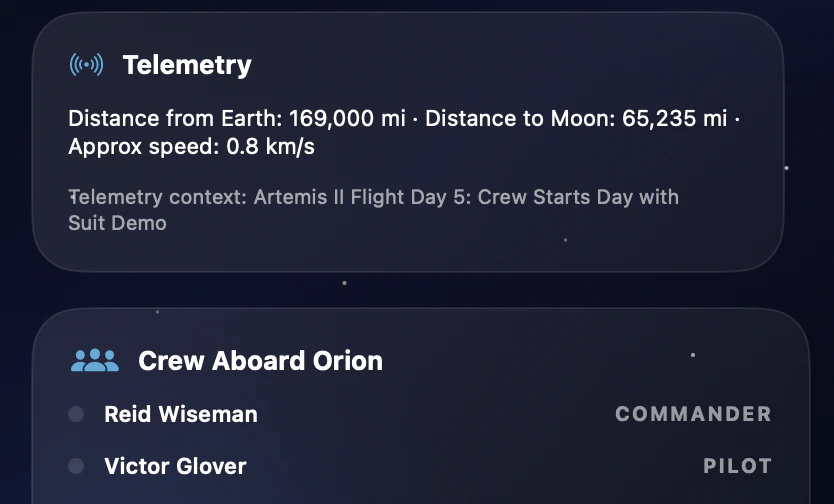



































Hey everyone!
I've always been fascinated with everything space and NASA and while I was consuming absolutely everything I could about Artemis II, I started to think I'd love an app to track all of the phases for me. So I built it over the weekend.
Features:
Live countdowns to key Artemis II events
Mission phases including outbound, lunar flyby, return leg, re-entry, and splashdown
Mission elapsed time (MET)
Artemis II crew roster
NASA-sourced timeline and public mission update data
Menu bar-only macOS app built with SwiftUI
It should take you all the way to splashdown.
Hope you all enjoy, and if you have any feedback, drop it in the comments! :)
@aaronoleary This is pretty cool, didn’t realize there was this much structured data available for Artemis missions.
Are you pulling this straight from NASA APIs or doing some processing in between? how real-time this actually is?
That is so good, like reading scientific journals!
What are your feature plans?
I see in the comments that you think about something like Flighty for space missions, what about something like space history & launches timeline with visualizations and historical facts?
this is sick,timeline visualisation is clean. I like space and artemis, how are you handling the live telemetry updates? polling or websockets? if you dont mind me asking , i sort of have an idea but yeah. I'm new to product Hunt , been seeing people's stuff in here , and some are actually tickling my brain
Love this. SwiftUI menu bar apps are such an underrated format — lightweight, always accessible, no context-switching. I'm building a Mac-native video editor with SwiftUI + Rust and the menu bar philosophy resonates: do one thing well, stay out of the way. The 'Flighty for space missions' direction sounds incredible. Congrats on the launch and good luck with splashdown!
this is actually pretty sick, didn’t expect a menu bar app to go this deep
how often does the data update btw? @aaronoleary
Looks fantastic. Congrats on the launch.
Is this just limited to accessing from the US? I’m in the UK and data never loads.
Very cool, thanks for this! Mission updates right in the menu bar instead of constantly checking NASA's site is way better. Nice project.
This is such a cool niche execution : love how you turned a complex mission like Artemis II into something so accessible right from the menu bar. The real-time aspect + mission timeline is a great touch.
Also feels very aligned with the current wave of making complex systems more observable and understandable.
We actually launched on Product Hunt today as well — working on Ogoron, an AI system that automatically generates and maintains test coverage as products evolve. Different space, same love for making complexity manageable
Good luck with the launch!
Very cool idea, perfect for space enthusiast people. Do you get it directly from their website?
sick! i love that there is a launch tag for `Space`. Is this artisanal code or did you sling with an agent?
Love that you built this over a weekend, the attention to detail with the mission phases and telemetry context is really impressive. Having it live in the menu bar is perfect for staying updated without constantly tab-switching during the mission. @aaronoleary are you planning to support future NASA missions beyond Artemis II?
I'd actually love to see a mission view. A trajectory of the path taken by the Rocket. The whole slingshot around the moon in real-time. That would be incredibleeeeee!!!! Awesome work 🚀
Wait the details on this are actually insane, telemetry is 🤌. Awesome job, @aaronoleary!!
Hey, this looks very cool! Going to try :)