PH热榜 | 2026-04-14
一句话介绍:一款让AI智能体在Figma设计环境中直接操作真实组件和变量的MCP工具,解决了AI生成设计脱离品牌设计系统、无法直接投入生产的核心痛点。
Design Tools
Developer Tools
Artificial Intelligence
AI设计工具
设计系统连接
多智能体协作
设计到代码
UI生成
设计令牌同步
无障碍辅助
产品设计团队
人机协作
设计工程
用户评论摘要:用户普遍认为该工具解决了AI设计缺乏上下文的关键问题。有效评论聚焦于:1.如何同步及处理设计系统迭代后的历史设计;2.能否支持读取现有设计系统并导出代码;3.对多LLM平台的支持;4.其设计令牌同步和自动生成无障碍标注的实用价值。
AI 锐评
“Figma for Agents”并非又一个“AI生成漂亮图片”的工具,它的野心在于成为AI智能体融入产品设计工作流的“合规层”与“翻译器”。其核心价值不在于生成,而在于“约束”与“对齐”。
当前AI设计工具的致命伤是产出物游离于团队的“单一事实来源”(Single Source of Truth)之外,导致设计师必须推倒重来。该产品通过MCP协议,将智能体的操作权限直接锚定在真实的Figma组件、变量和自动布局上,这本质上是为“自由散漫”的AI套上了设计系统的缰绳。它让智能体从“天马行空的画家”变成了“懂得使用公司标准零件库的工程师”。
从评论中透露的更深层信号是,它试图重塑设计-开发协作的管道。无论是设计令牌的同步与漂移检测,还是基于真实组件自动生成无障碍(a11y)标注,都表明其目标是将那些繁琐、易出错、总被滞后处理的工程化规范(设计令牌、无障碍)提前并自动化地嵌入设计阶段。这不再是简单的“提速”,而是对工作流质地的改变——让一致性检查和规范落实从人工审查变为持续同步的底层协议。
然而,其成功的关键挑战也已从评论中浮现:如何优雅地处理设计系统本身的版本演进?智能体依据“技能文件”(Skills)这一静态快照进行创作,当系统更新后,旧设计是否会被标记为“漂移”?这触及了动态团队协作的核心矛盾。工具若不能妥善解决此问题,可能会在效率提升的同时,制造出新的技术债务与混乱。
总而言之,这是一次极具针对性的“填坑”式创新。它不追求炫技,而是务实地面向已深度使用Figma和AI编码助手的产研团队,解决AI落地“最后一公里”的融合问题。其真正颠覆性在于,它可能让“AI生成的设计”第一次具备了被直接“Ship”出去的资格。
一句话介绍:CatDoes v4是一个云端AI智能体驱动的无代码应用构建平台,其核心AI代理“Compose”拥有独立的云端计算机,可自主完成从编码、安装依赖、测试到错误修复的全流程,让创业者、设计师和工程师能快速将想法转化为可部署的移动应用和网站,解决了从构思到落地执行效率低下的痛点。
Artificial Intelligence
No-Code
Vibe coding
AI智能体开发
无代码平台
云端应用构建
自主编程
全栈后端即服务
移动应用生成
网站转应用
自动化部署
创业工具
效率提升
用户评论摘要:用户普遍对AI代理的自主性和“闭标签工作”能力表示惊叹,认为其实现了真正的自动化开发。有效评论集中于:非技术人员能否用于正式部署(官方肯定回复);对“全家桶”式后端服务的灵活性及数据安全的询问(官方解释了代码导出、开源技术栈、加密管理和隔离机制);有用户分享了成功构建习惯跟踪器、作品集应用的经验。
AI 锐评
CatDoes v4所标榜的,并非又一个在旁建议的AI编程助手,而是一个旨在接管整个开发循环的“数字员工”。其真正的颠覆性在于将AI从“代码生成器”升级为“执行环境”,通过赋予AI独立的云端计算机权限,使其能自主进行试错、调试和迭代。这直接击中了当前AI编程工具的核心短板:生成代码后,将编译、依赖、部署等繁琐且易错的“脏活”扔回给人。
然而,这种高度自主性是一把双刃剑。产品最大的价值在于为明确、边界清晰的轻量级应用需求提供了“一键交付”的可能性,尤其适合原型验证、MVP构建或简单业务数字化。但其面临的深层挑战也同样尖锐:首先,复杂业务逻辑的可靠实现能力存疑,AI在模糊需求和无界问题中的决策质量是黑箱;其次,“全家桶”式服务虽简化了起步,但也可能形成供应商锁定,尽管官方承诺代码可导出;最后,将完整的开发、部署权限授予AI代理,其安全边界、成本控制(无限重试循环)和权责界定,对严肃的企业级应用而言仍是需要审视的风险点。
本质上,CatDoes v4是“AI即服务”理念在应用开发领域的激进实践。它并非要取代专业工程师,而是试图将应用开发的准入门槛降至近乎为零,让“想法”与“可运行软件”之间的路径极度缩短。它的成功与否,将不取决于其技术炫酷程度,而取决于其在实际生产环境中,在可靠性、安全性与成本之间取得的平衡能否经受住超出血气方刚的早期采用者之外的更广泛市场的检验。
一句话介绍:一款通过自然语言描述即可快速生成包含数据库、业务逻辑和安全权限的完整商业应用(如客户门户、内部系统)的AI协同构建平台,解决了非技术用户在定制企业级软件时面临的开发周期长、成本高、原型工具不实用等核心痛点。
Artificial Intelligence
No-Code
Vibe coding
AI应用构建
无代码开发
企业级软件
商业门户
内部工具
数据库生成
业务流程自动化
可视化编辑
协同开发
低代码平台
用户评论摘要:用户普遍认可其能快速生成“真正可用”的软件,解决了其他AI工具只能做原型的问题。核心关注点在于:1. 数据模型复杂性与业务逻辑演进的兼容性;2. AI生成与可视化编辑的权限边界与控制力;3. 处理复杂业务逻辑的实际能力。建议包括增加AI设计的创意自由度。
AI 锐评
Softr AI Co-Builder 的发布,与其说是一次功能升级,不如说是对当前“氛围编码”市场的一次精准切割。它敏锐地抓住了“从演示到交付”这一关键断层,将口号锚定在“actually work”上,直击了当前AI生成应用普遍沦为玩具或半成品的行业痼疾。
其真正价值不在于“用AI生成应用”这一表象,而在于将AI深度嵌入到一个成熟、闭环的无代码产品框架中。这带来了几个关键优势:首先,它用AI加速了“构建”这一初始环节,但将核心的可靠性押注在Softr自身经过验证的、预置了用户认证、角色权限和数据安全的基础架构上。这本质上是用AI降低使用门槛,而非用AI承担全部责任,规避了生成式AI在逻辑严谨性上的固有风险。其次,它提供了“提示生成”与“可视化编辑”的双模控制,这并非简单的功能堆砌,而是对用户(尤其是非技术用户)心智模型的深刻理解——AI负责灵感与草稿,人类负责最终的确认与微调,控制权从未旁落。
然而,其面临的挑战同样清晰。来自评论的质疑点明了核心:当真实的、混乱的业务数据涌入AI基于理想化描述生成的数据库架构时,系统能否优雅地演进?这考验的是其底层数据模型的灵活性以及“协同构建”中“协同”二字的真功夫——AI能否理解并协助用户进行复杂的业务逻辑迭代,而非仅仅完成一次性生成。此外,在高度定制化与复杂集成场景下,它能否在“开箱即用的便捷性”与“企业级的灵活性”之间保持平衡,将是其能否从“有用工具”跃升为“关键平台”的试金石。
总体而言,Softr此举是务实的AI产品化典范。它没有追逐“完全自主AI编码”的幻影,而是用AI强化自身护城河,解决真实商业场景中的效率与信任问题。它的成功与否,将验证一个命题:在商业软件领域,**“AI增强”** 或许比 **“AI取代”** 是一条更稳健、更可持续的路径。
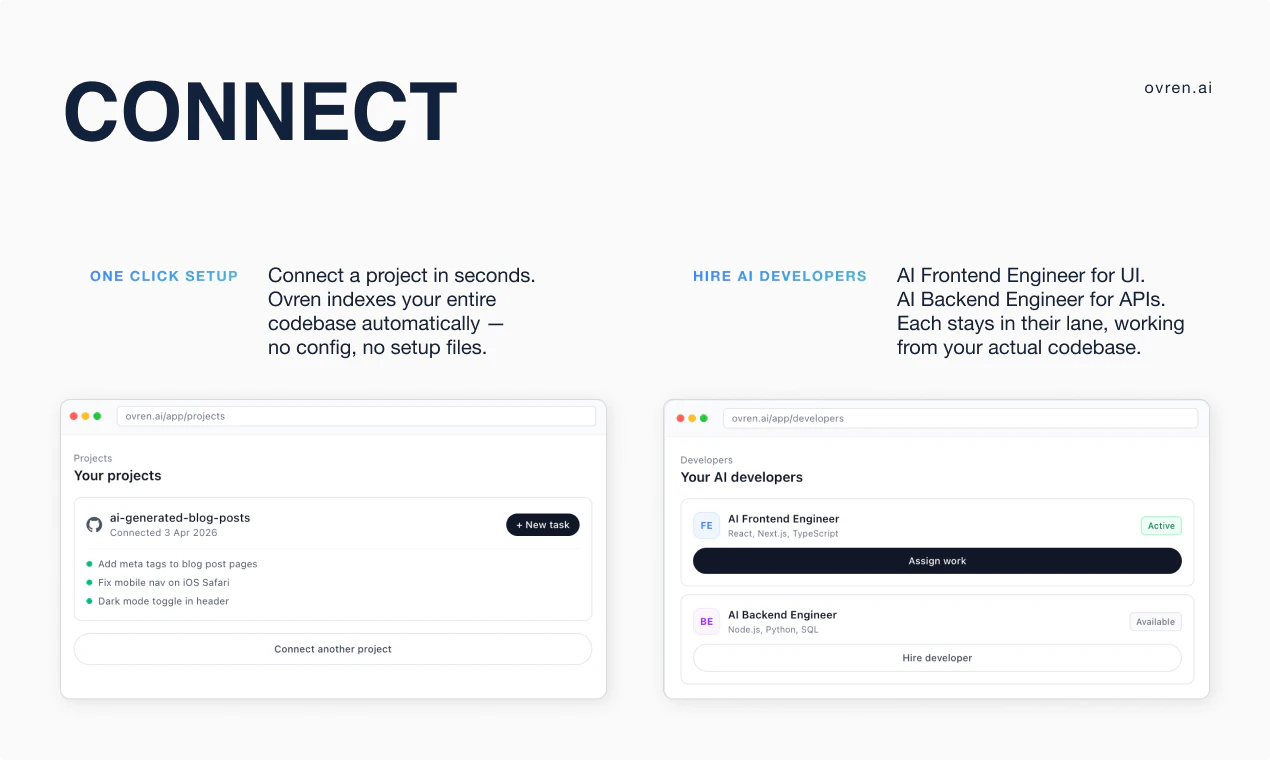
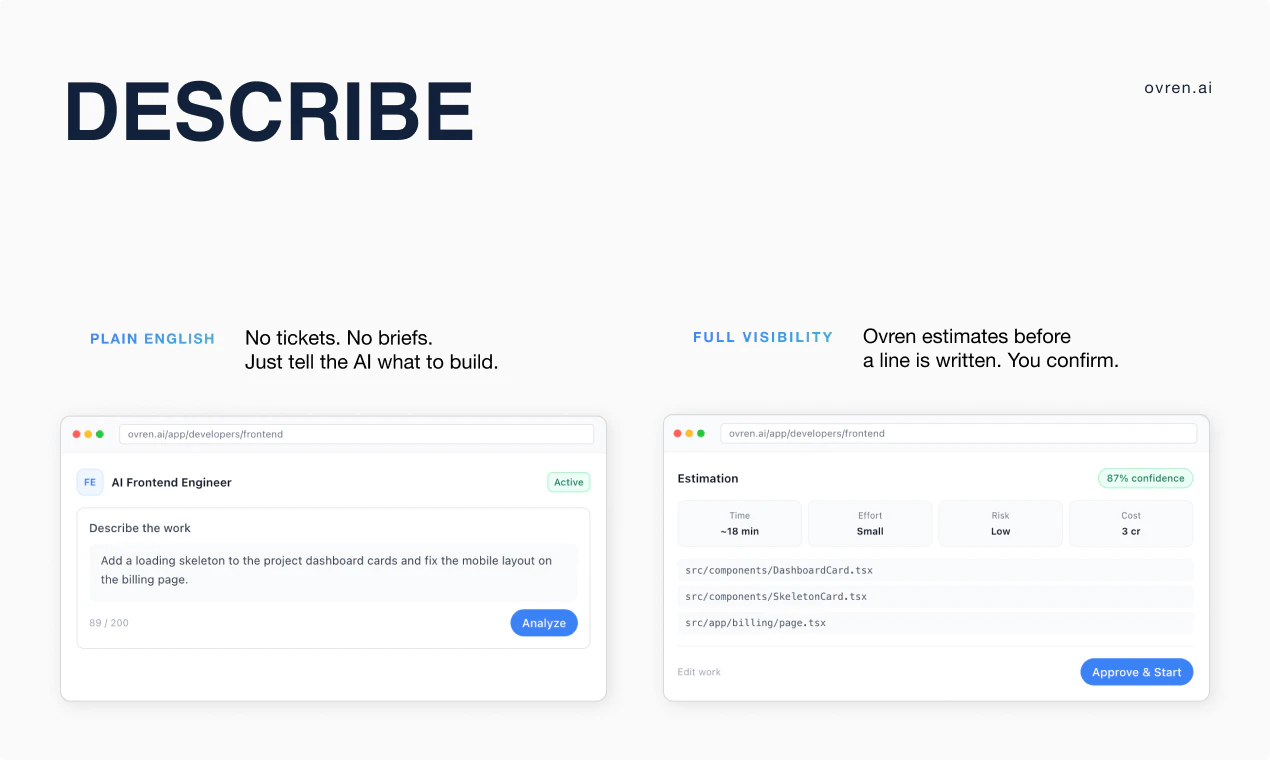
一句话介绍:Ovren是一个AI工程部门解决方案,通过部署前端和后端AI工程师在真实代码库中执行范围明确的积压任务(如Bug修复、重构、UI调整),帮助团队自动化处理那些重要但总被排期忽略的开发工作,让团队能专注于核心迭代。
Productivity
Developer Tools
Artificial Intelligence
AI编程助手
代码自动化
积压任务管理
开发运维
工程效率
AI工程师
代码审查
技术债务
软件开发
团队协作
用户评论摘要:用户肯定其解决技术债务和明确范围任务的定位,认为其产品化角色分工(前端/后端AI)是亮点。主要关切点在于AI对特定代码库架构和复杂上下文的理解能力、与现有工作流(如Claude、CLI)的集成、定价对初创团队的友好度,以及如何处理模糊、复杂的积压任务。
AI 锐评
Ovren的叙事巧妙地避开了与GitHub Copilot等“编码助手”的直接竞争,转而切入一个更痛、更显性的市场空白:工程积压。其宣称的价值并非“生成代码”,而是“执行任务”,这标志着AI编程工具从“副驾驶”向“自动驾驶”迈出了试探性但关键的一步。产品将AI角色产品化为“前端/后端工程师”,并强调输出“可审查的代码更新”,旨在构建一种可控、可信的自动化流程,而非黑箱魔法。
然而,其面临的真实挑战与评论中的疑虑高度一致:**上下文理解的深度决定其价值上限**。积压任务之所以积压,往往因其涉及历史决策、模糊的业务逻辑和复杂的依赖关系。Ovren从“范围明确”的任务入手是务实的起点,但这恰恰是价值洼地;真正的“工程债务”往往模糊且相互纠缠。若其AI无法深入理解项目特有的设计模式、约定和“代码背后的意图”,则极易沦为另一个花哨的代码生成器,仅能处理模板化问题。
其真正的护城河可能在于对代码库的持续学习和建模能力,构建一个超越表面语法的“项目知识图谱”。此外,如何无缝融入现有开发流程(如Git、项目管理工具),并建立让工程师愿意信任的审查与回滚机制,将是其能否从“有趣工具”变为“核心基础设施”的关键。当前,它更像一个高效的“初级工程师”,但工程团队的终极需求,是一个能理解所有历史包袱和未来愿景的“资深架构师”。Ovren的路径正确,但最艰难的部分——深度理解与复杂决策——才刚刚开始。
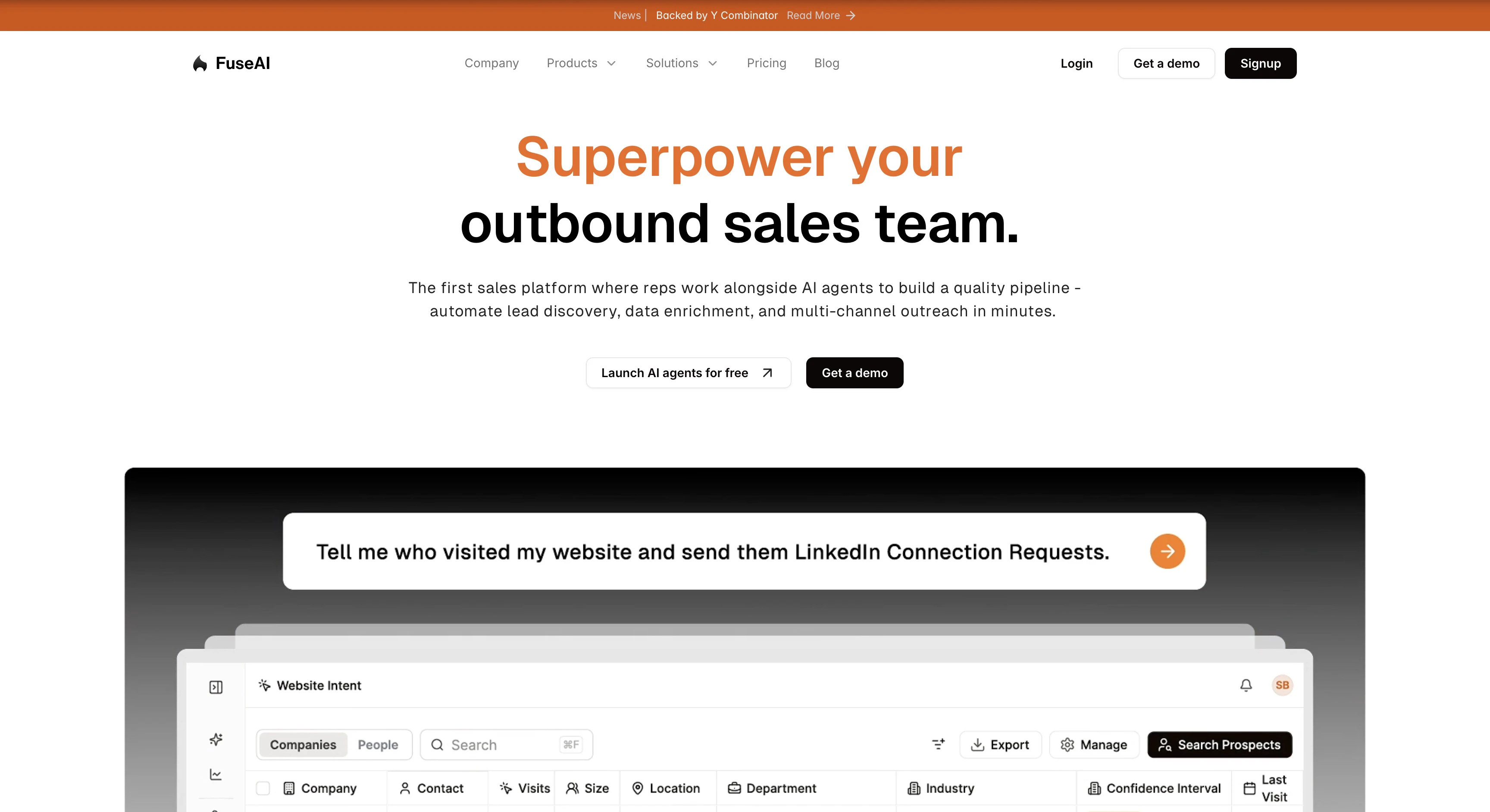
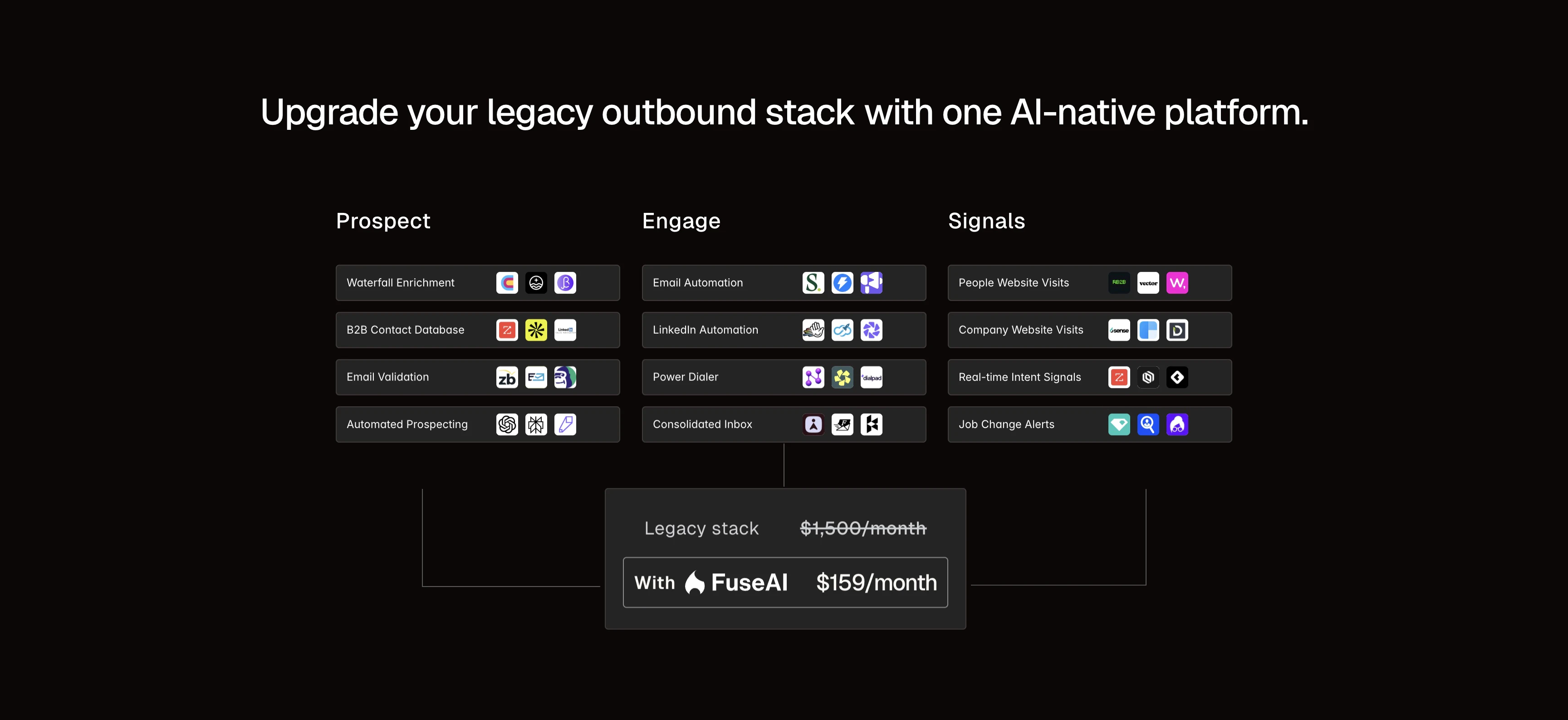
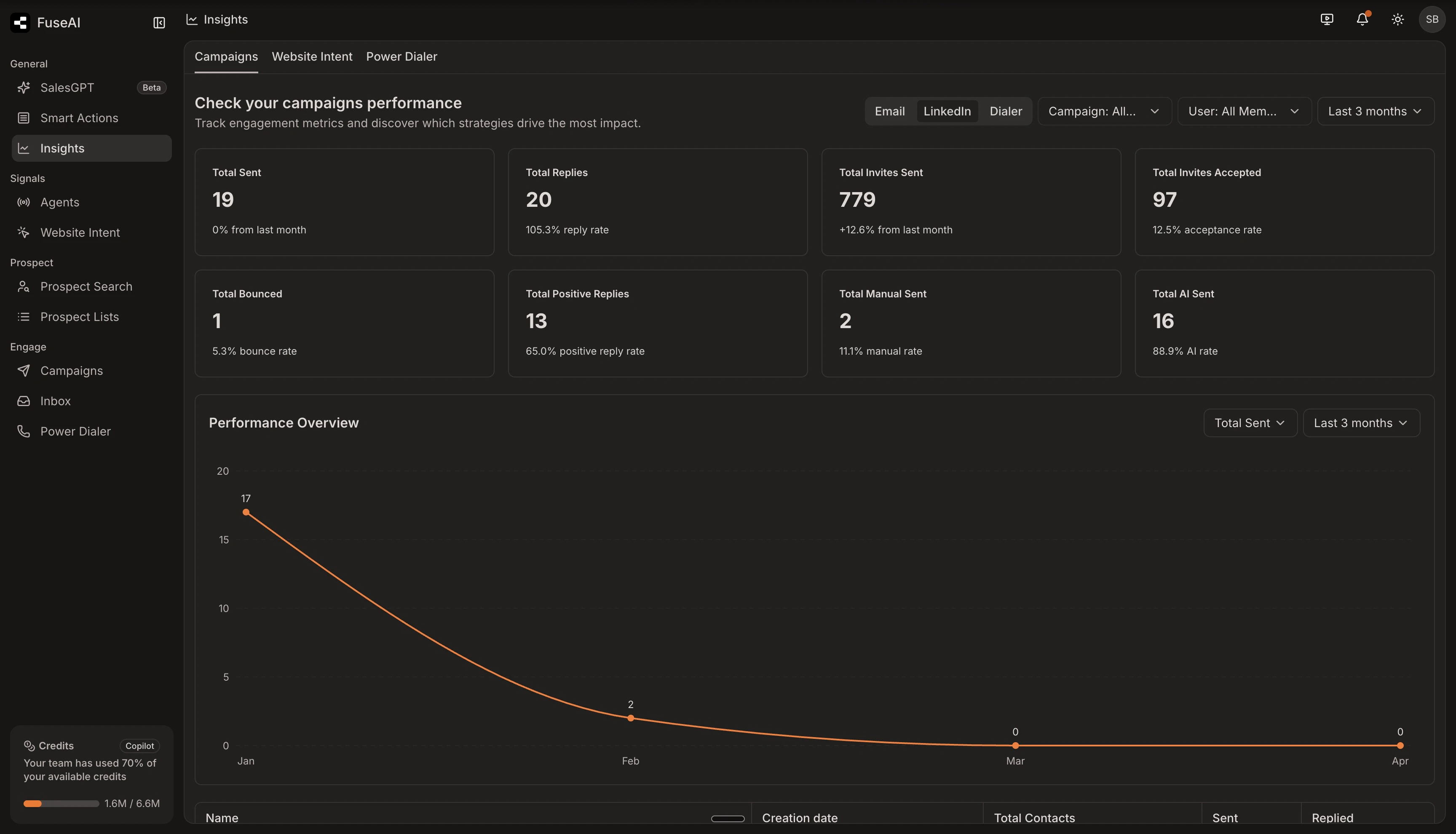
一句话介绍:FuseAI是一个AI驱动的销售一体化平台,通过整合实时信号、数据清洗、多渠道自动化与AI工作流,在单一平台内解决了中小企业因使用多款割裂工具而导致的外销售效率低下、成本高昂和运营复杂的核心痛点。
Sales
SaaS
Artificial Intelligence
AI销售平台
销售自动化
一体化SaaS
潜在客户开发
销售流程管理
中小企业工具
数据清洗
多渠道触达
工具整合
YC孵化
用户评论摘要:用户普遍认可其解决“工具泛滥”的痛点,并对“10分钟设置”表示好奇与测试意愿。核心关切点在于:1. 各模块功能深度是否媲美单一专业工具;2. 邮件送达率等底层基础设施的可靠性;3. AI工作流处理复杂销售情景(如异议处理)的适应性;4. 自定义信号搜索的能力。创始人回应积极,强调AI加速了开发以实现功能平价,并承诺快速迭代。
AI 锐评
FuseAI的叙事精准击中了当前销售技术栈的“阿喀琉斯之踵”——工具泛滥。它宣称的并非简单的功能堆砌,而是试图以AI为“粘合剂”和“驱动核心”,重构从线索发现到触达的完整外销售链路。其真正的价值主张在于“系统性平价”:通过一体化平台,让中小企业能以可承受的成本,获得接近大型企业由昂贵团队和工具矩阵构建的销售基础设施能力。
然而,其面临的质疑也直指核心:一体化平台常面临的“广度与深度”悖论。评论中将其与Clay、Heyreach等垂直领域强者对比,正是对此的检验。FuseAI的赌注在于,AI不仅能作为产品功能,更能作为开发过程的“杠杆”,使其团队能以更快速度实现各垂直领域90%的核心用例,并依靠平台内数据流无缝衔接的优势弥补剩余10%的差距。这是一个颇具雄心的“用速度对抗深度”的策略。
另一个关键洞察是其对“基础设施”的重视。它试图将邮件域名管理、验证、预热等幕后工程产品化、自动化,这恰恰是许多自动化工具失败的关键。这显示其团队对销售实战中“送达率”这一生死线有深刻理解,而非仅停留在前端交互的自动化炫技。
风险与机遇并存。机遇在于,若其“AI加速开发”与“一体化体验”能形成闭环,确实可能成为资源有限公司的“销售操作系统”。风险则在于,在追求功能平价的过程中可能陷入持续追赶的泥潭,且大型客户复杂的定制化需求可能超出其标准化平台的边界。最终,它的成功不仅取决于技术,更取决于其能否在“足够好”的功能、极具吸引力的价格与可持续的商业模式之间找到那个精妙的平衡点。它不是在销售另一个工具,而是在销售一种“降本增效的确定性”,这才是其最锋利的价值所在。
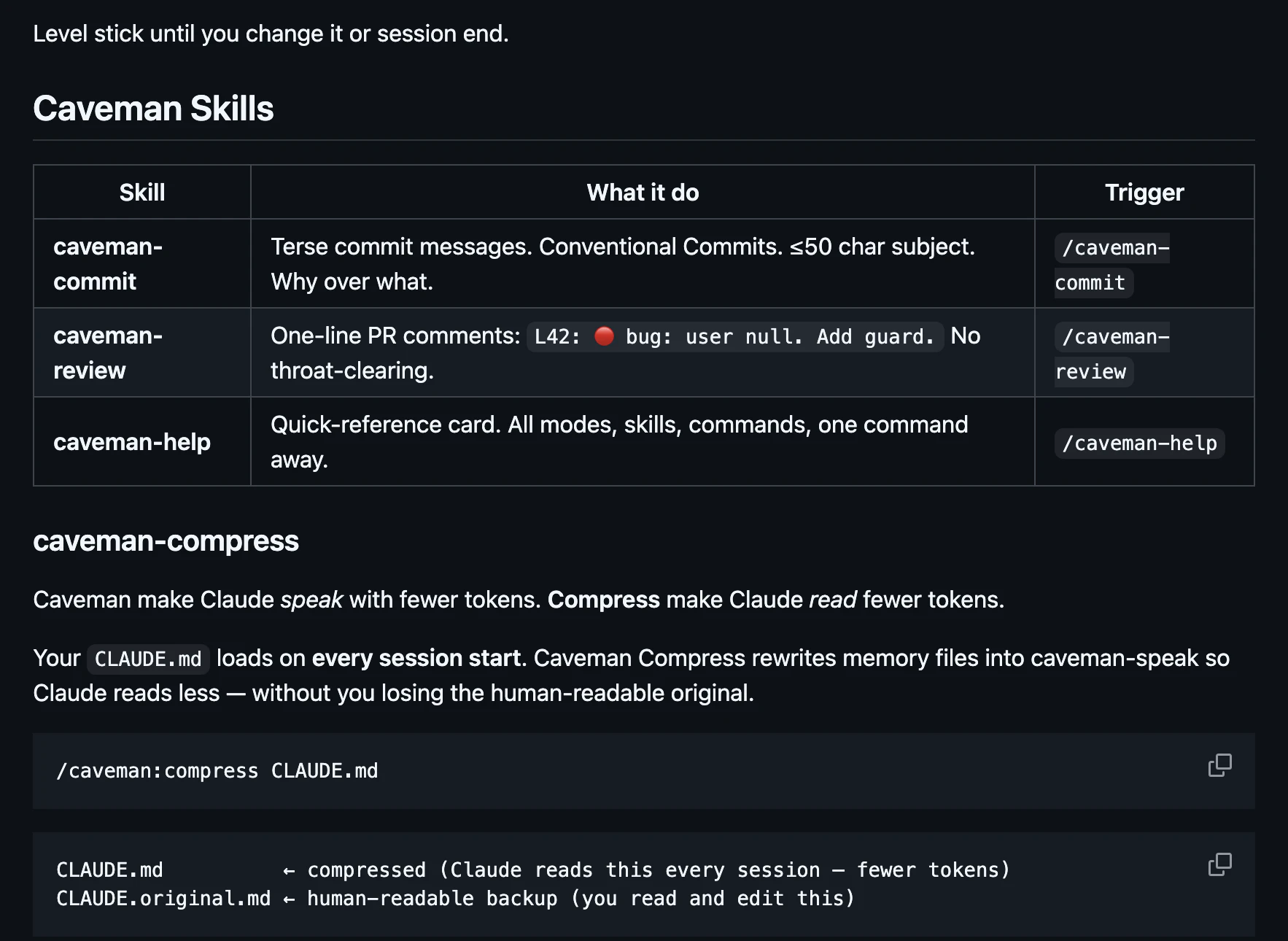
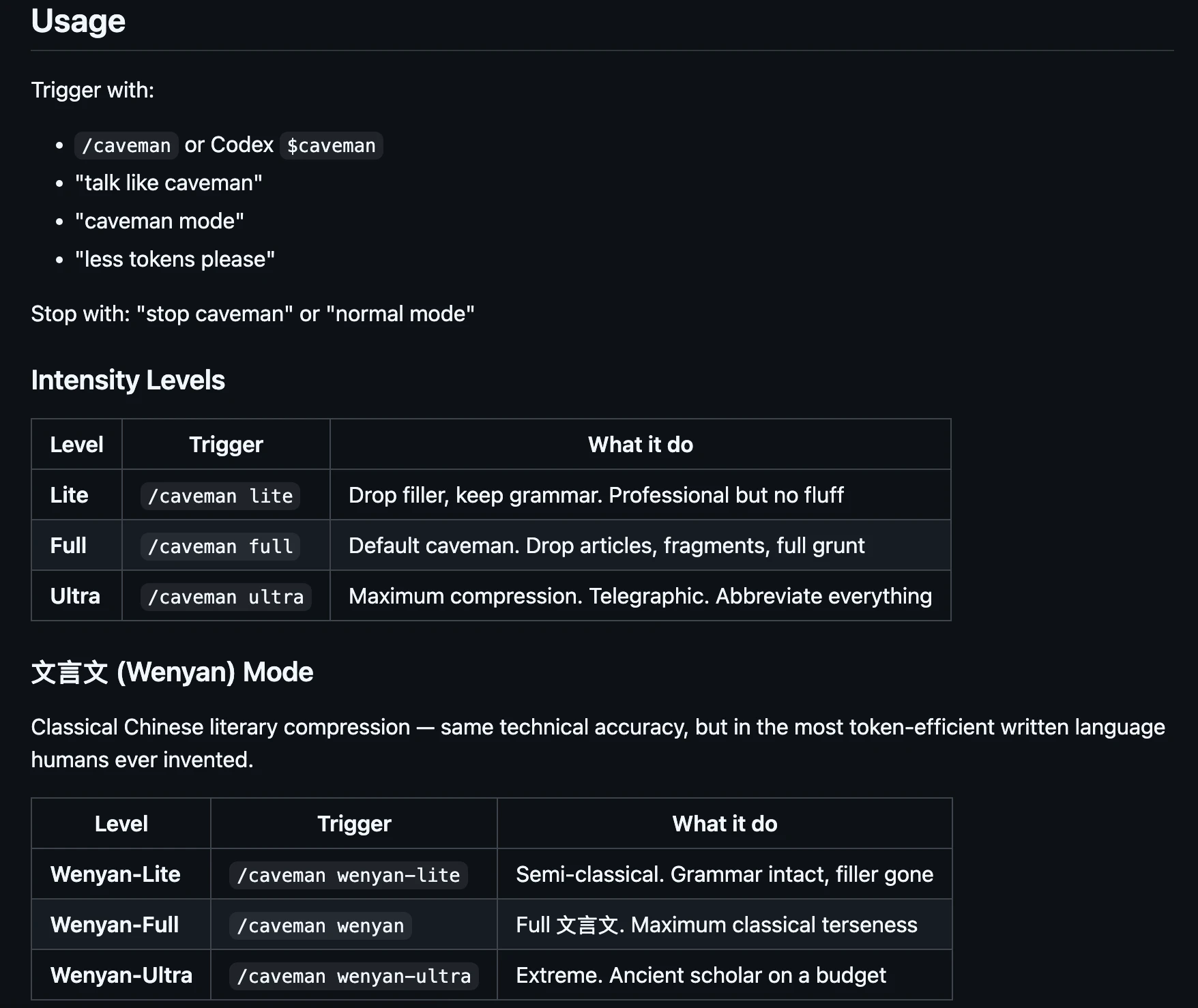
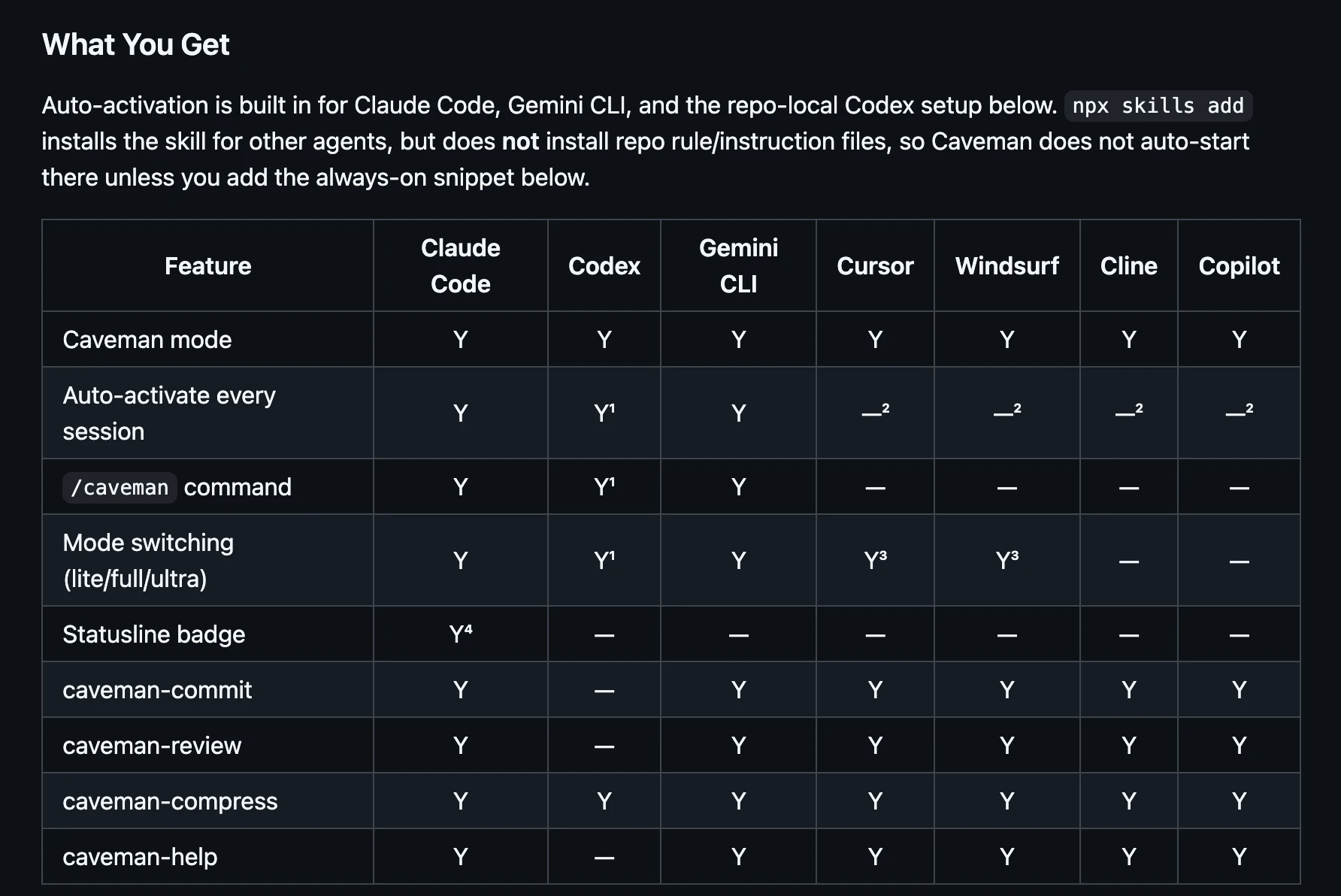
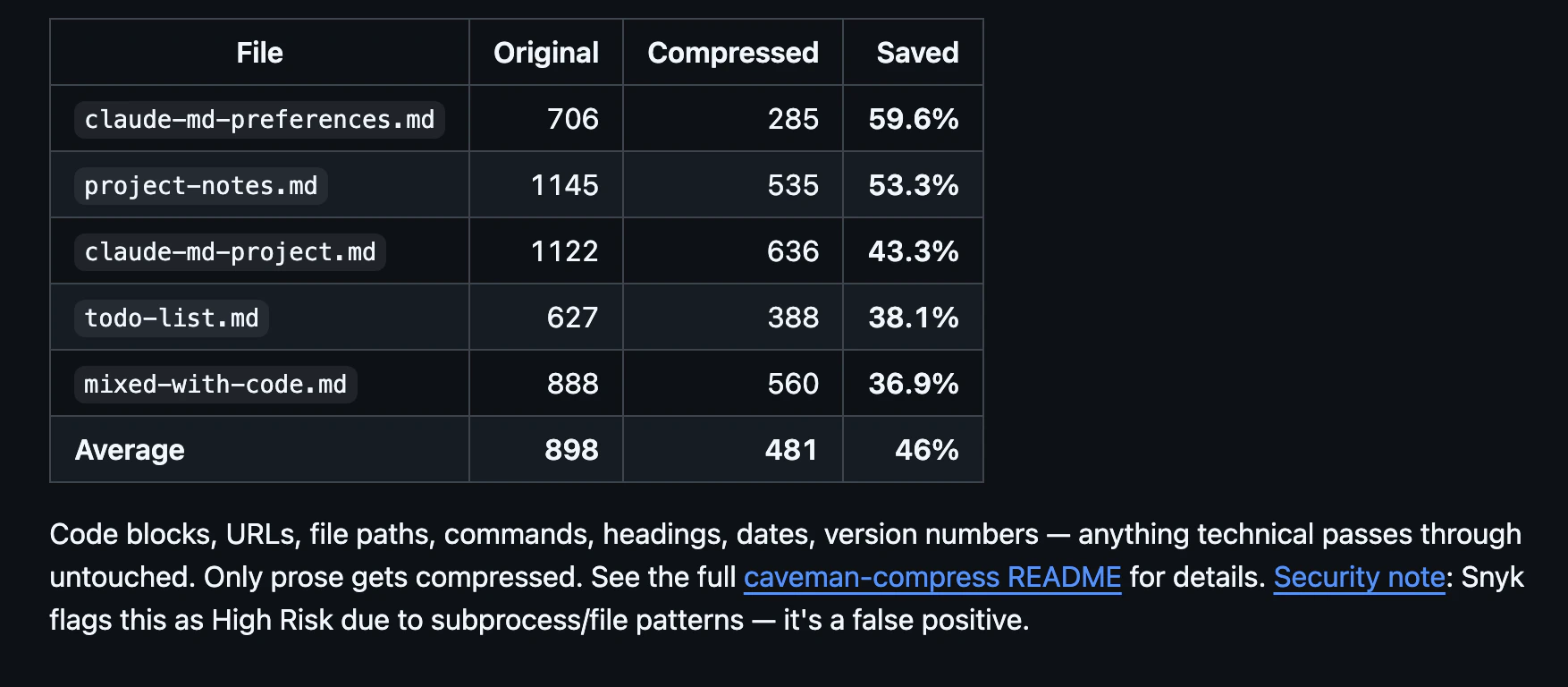
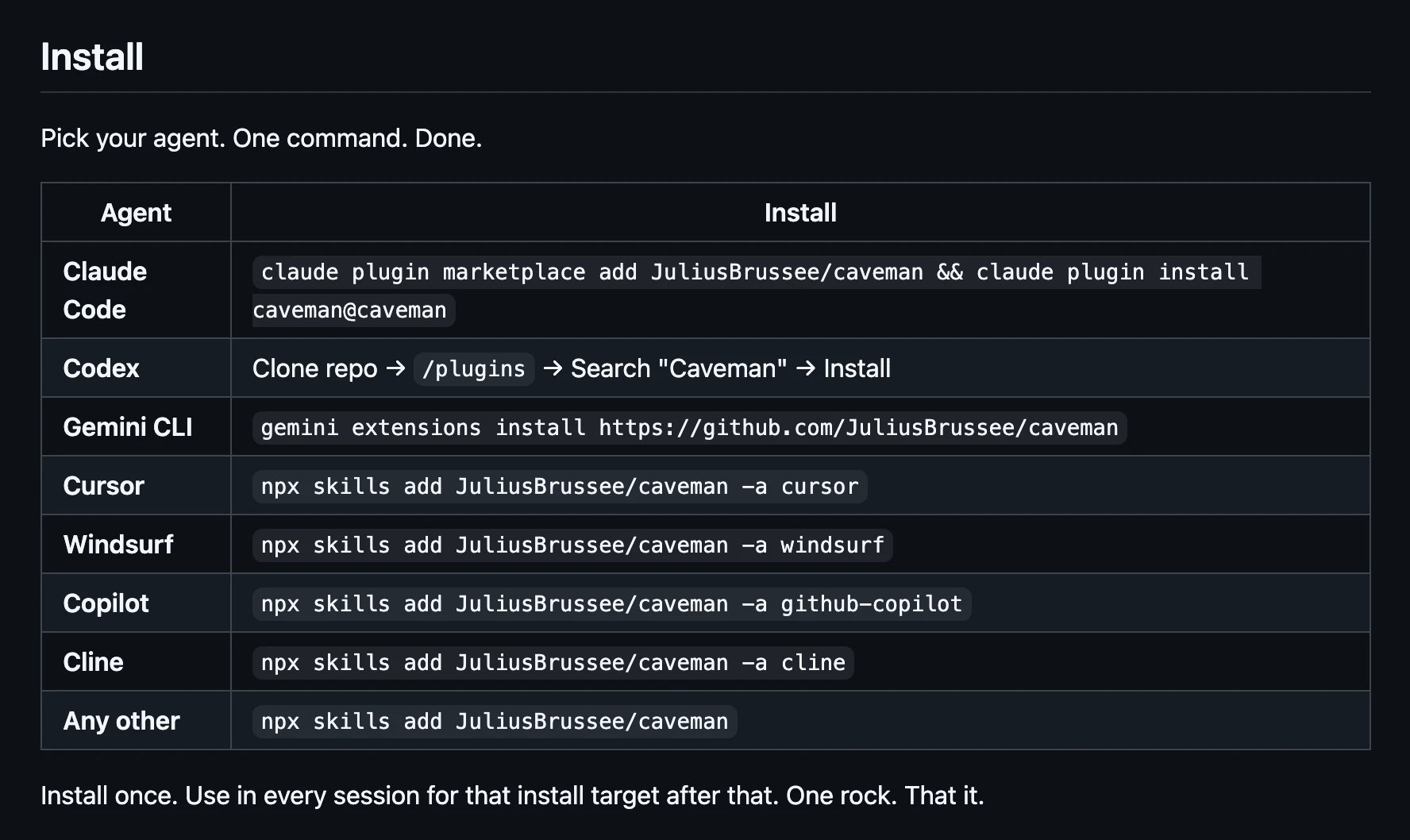
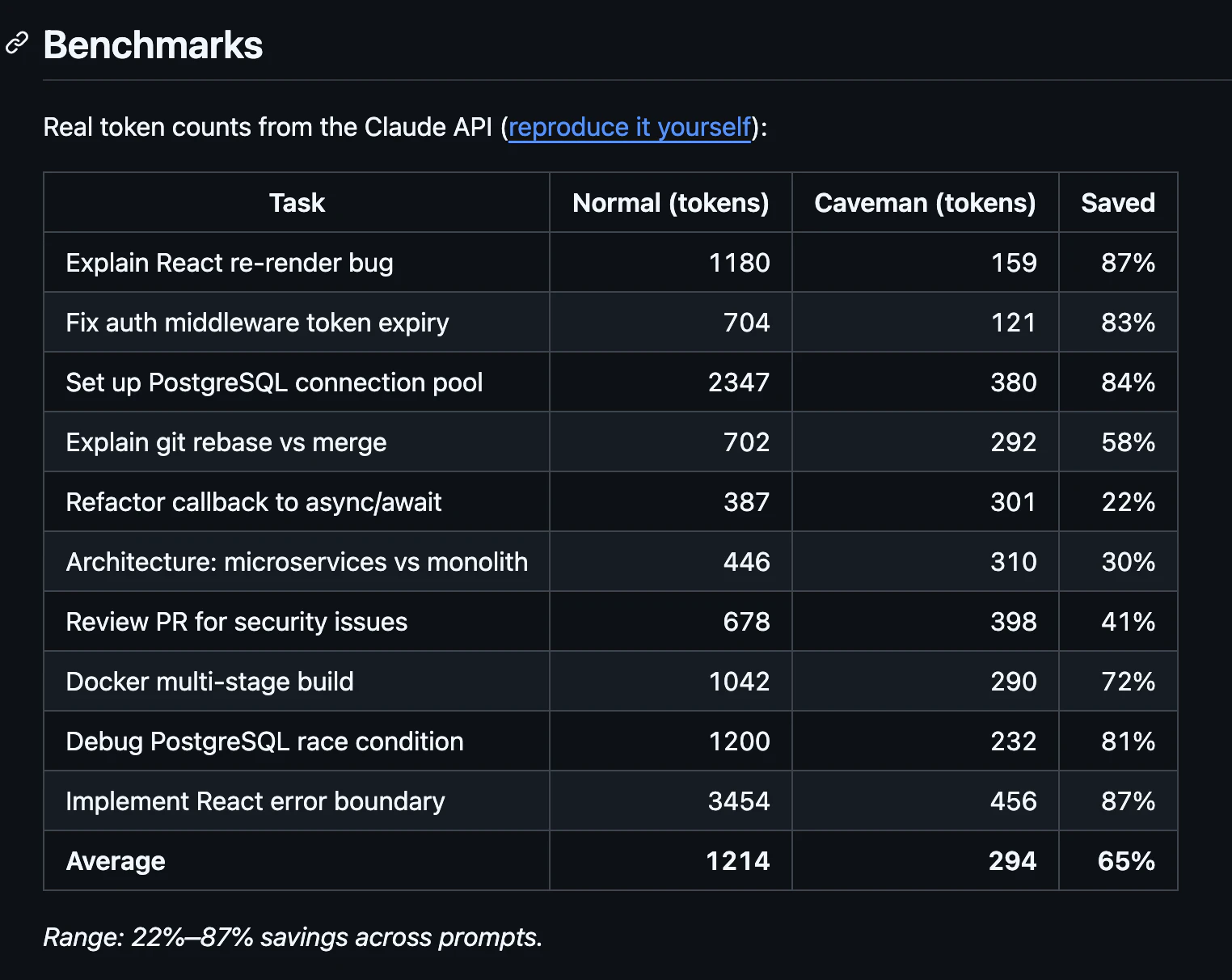
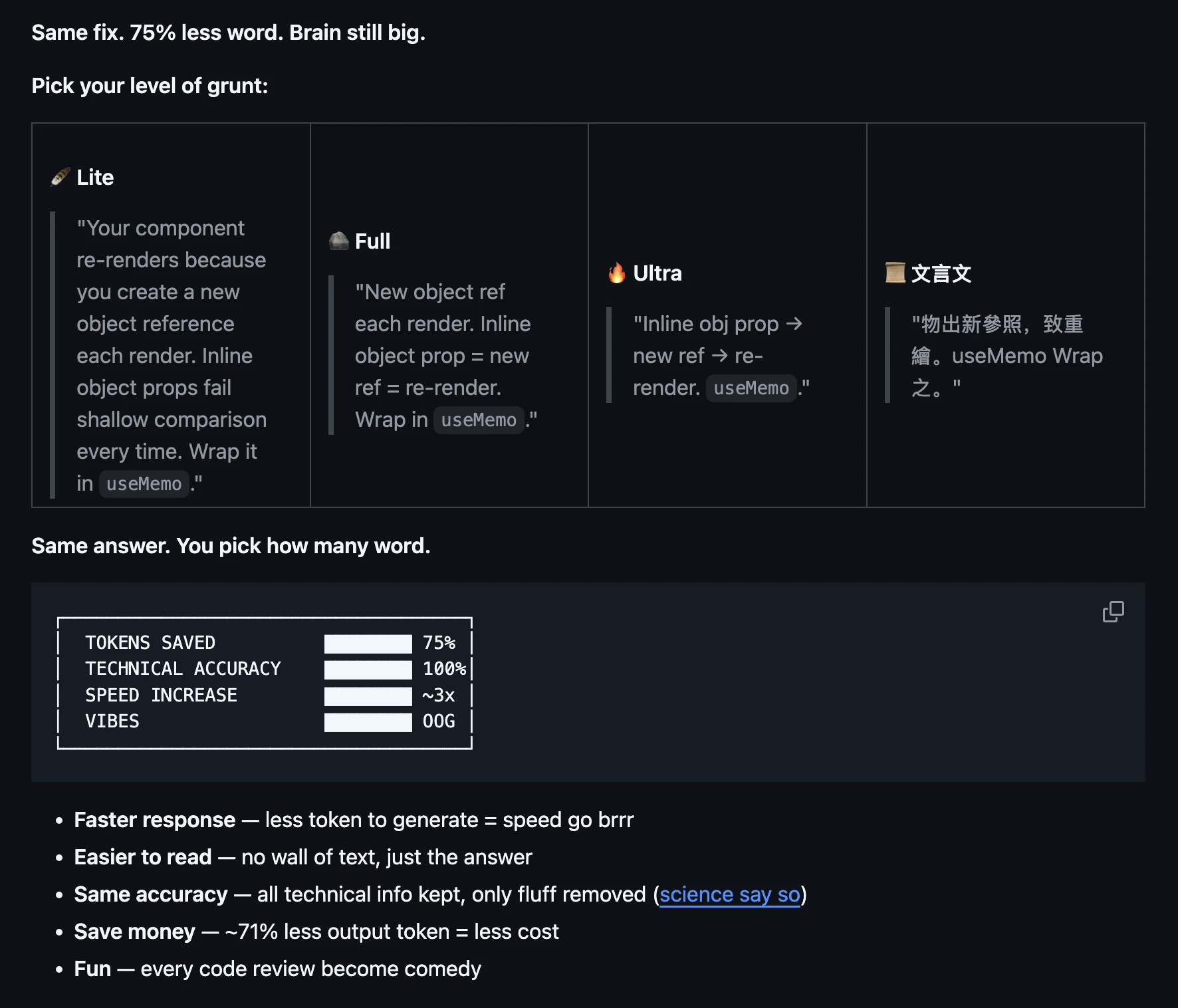
一句话介绍:Caveman是一款通过精简Claude AI助手的输出内容,在不损失技术准确性的前提下大幅减少约75%的令牌使用,从而为开发者节省成本并提升交互效率的工具,主要解决开发者在日常编码、代码审查等场景中因AI冗余表达导致的令牌消耗过快、响应速度慢的痛点。
Open Source
Developer Tools
Artificial Intelligence
GitHub
AI优化工具
开发者工具
令牌节省
Claude优化
代码助手
响应加速
开源免费
提示词工程
效率工具
用户评论摘要:用户普遍认可其节省令牌、提升速度的核心价值,并积极分享集成使用经验。主要疑问集中于:超高压缩强度是否丢失关键上下文;输入令牌增加与缓存机制的实际影响;75%数据来源及压缩算法的安全性,如何防止语义漂移。
AI 锐评
Caveman的爆火,与其说是一项技术突破,不如说是对当前大模型“官僚主义文风”的一次成功反叛。它精准切中了LLM服务商业化进程中用户最敏感的神经:成本。当按Token计费成为常态,模型每一句“很高兴为您服务”都成了用户钱包的无声损耗。Caveman的价值核心并非简单的文本压缩,而是通过一套预设的“简洁范式”,强行剥离AI输出中的仪式性语言和元话语,迫使AI进行“电报式”表达。
然而,其真正的挑战在于“度”的把握。评论中关于“Ultra强度是否牺牲关键警告”的质疑,直指工具的核心矛盾:在代码场景中,何为“冗余”,何为“必要的严谨”?将commit信息压缩至50字符、PR评论简化为一行,固然高效,但也可能剥离了决策上下文和细微的推理链条,这可能将风险从“令牌成本”转移至“代码质量”。其引用的“简洁提升准确性”的研究,很可能只在特定、结构化的任务中成立。
本质上,Caveman代表了一种用户与AI关系的新期待:从寻求拟人化的、解释性的陪伴,转向将其视为一个高效、静默的实用引擎。它是否成功,取决于其规则集能否持续精准地区分“废话”与“不可或缺的严谨”。长远看,它更像是一个过渡性方案,最终压力应给到模型提供商本身:是时候提供一种原生的、可配置的“简洁模式”了。在此之前,Caveman这类“第三方优化器”将始终在“极致效率”与“信息保全”的钢丝上行走。
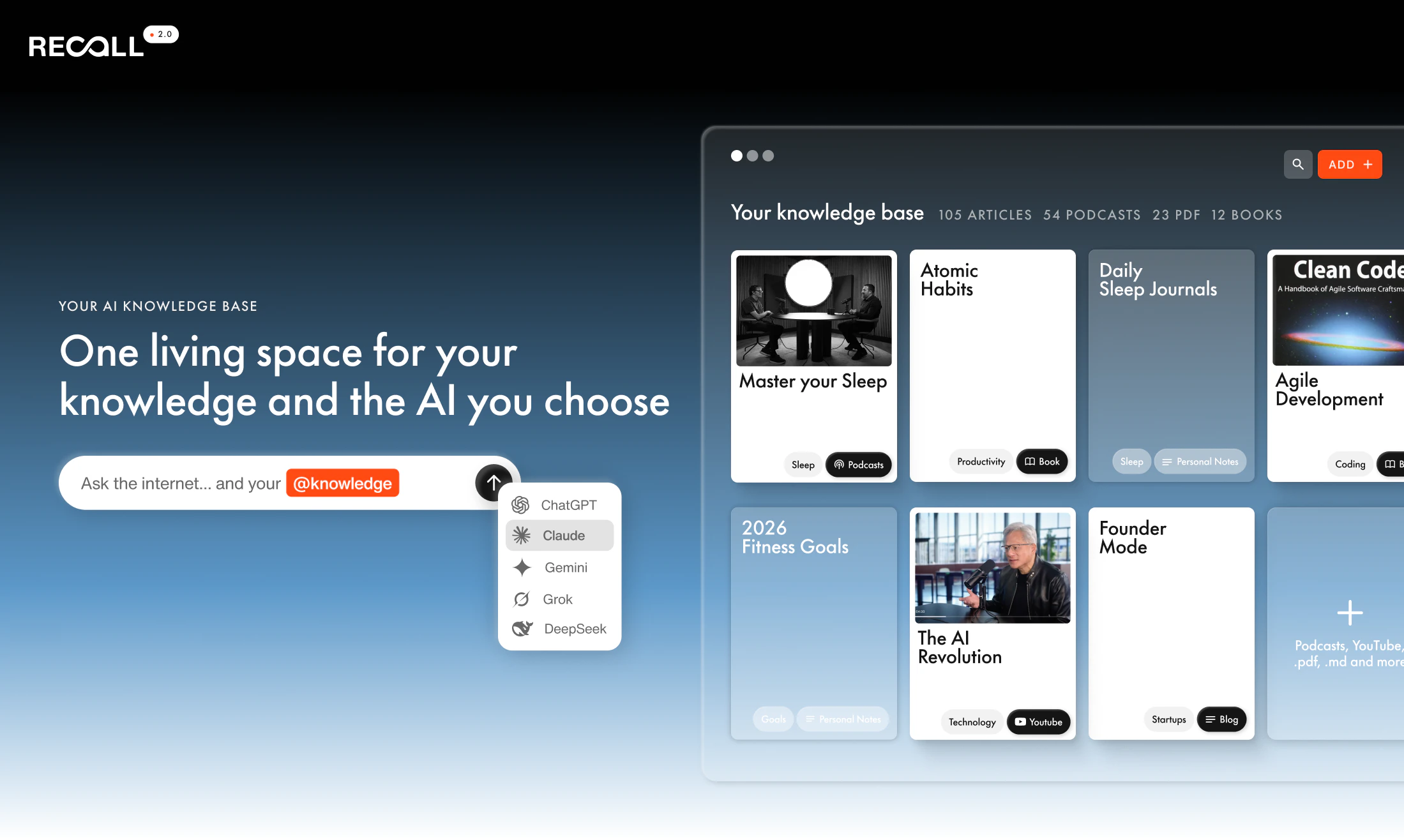
一句话介绍:Recall 2.0是一款个人AI知识库应用,通过将用户保存的内容与个人笔记转化为可对话、可检索的知识体系,解决了信息过载时代个人知识难以有效整合、提取和应用的痛点。
Android
Productivity
Notes
Artificial Intelligence
个人知识管理
AI第二大脑
知识库问答
RAG应用
多模型聚合
信息摘要
学习工具
研究辅助
生产力工具
用户评论摘要:用户普遍赞扬其从“摘要工具”到“知识平台”的演变,认为“知识优先,AI其次”的理念是核心优势。具体功能如“代理聊天”、多模型切换、API/MCP接入、图形化知识视图备受好评。主要问题与建议集中在:与NotebookLM/Obsidian的差异化定位、数据隐私与加密细节、服务器端稳定性(如登录故障)以及非英语内容处理的准确性优化。
AI 锐评
Recall 2.0的野心,远不止于做一个更好的书签管理器或摘要工具。它试图在AI泛化的时代,重新定义“个人知识”的价值边界。其真正的颠覆性在于顺序的调换:它并非用AI生成答案,再用你的知识去佐证;而是将你主动筛选、保存、注解的信息作为首要信源,让AI在此地基上构建回答。这实质上是对当前“AI即答案”范式的一种批判性实践。
产品将多模型选择权、本地/网络源切换权交给用户,看似增加了复杂性,实则是在争夺知识工作流的“调度中心”地位。通过API和MCP(模型上下文协议)开放,它意图成为个人知识生态的枢纽,而非一个封闭花园。这与NotebookLM的“项目制”研究工具定位、以及Obsidian的“手动至上”哲学形成了清晰区隔:Recall追求的是在自动化智能与个人所有权之间寻找平衡点。
然而,其面临的挑战同样尖锐。首先,“知识优先”依赖用户持续、高质量的输入习惯,这存在巨大的用户教育门槛。其次,评论中关于数据加密的官方回复(服务器端不加密以支持RAG)可能成为注重隐私的核心用户群体的疑虑点。最后,在巨头环伺的AI赛道,作为一个独立应用,如何持续保持多模型集成优势与成本控制,将是一场硬仗。
Recall 2.0的价值,在于它提供了一个具象化的未来图景:当公共AI的知识趋于同质化,构建、利用并深度交互于一个高度个性化的、不断演化的“私人知识模型”,可能将成为新的核心竞争力。它卖的不是信息存储,而是认知杠杆。
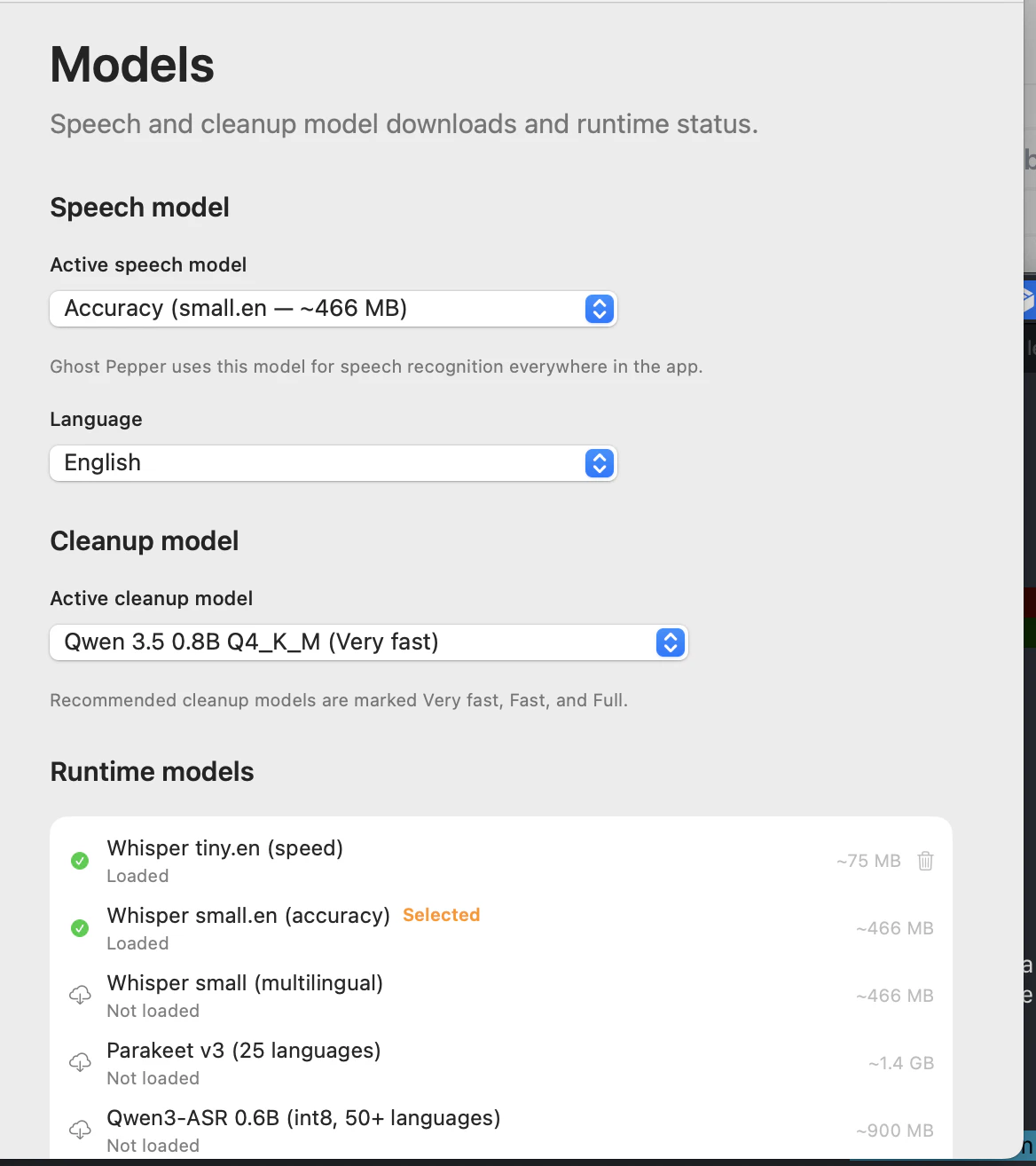
一句话介绍:Ghost Pepper是一款完全本地化、私密的AI工具,在macOS上提供语音转文本和会议转录功能,解决了用户因数据隐私和安全顾虑而无法使用云端AI服务的痛点,尤其适用于处理机密信息或受NDA保护的会议场景。
Open Source
Privacy
GitHub
Audio
本地AI
语音转文字
会议转录
隐私安全
开源软件
macOS应用
设备端计算
离线模型
苹果芯片优化
用户评论摘要:用户高度赞赏其“100%本地”的隐私定位,认为抓住了核心用户痛点。主要问题与建议集中在:1) 询问技术细节(如TTS模型、对旧款Mac支持);2) 呼吁推出Windows/Linux版本;3) 关心性能开销与专业词汇(如技术术语)识别准确性。开发者积极回复,解释了技术栈与优化策略。
AI 锐评
Ghost Pepper的发布,与其说是一款新工具的面世,不如说是对当前“云原生”AI霸权的一次精准反叛。它的真正价值并非在绝对性能上超越云端巨头,而是在“隐私主权”和“数据边界”这两个日益尖锐的痛点下,开辟了一个不可替代的利基市场。
产品聪明地将“100%本地”作为核心标语,而非一个次要功能,这直接命中了法律、金融、研发等敏感领域从业者的合规焦虑与安全刚需。它本质上销售的不是更优的转录准确率,而是一份“数据不出境”的保险契约。从评论看,这正是其获得拥趸的关键——用户并非盲目追捧技术,而是为明确的安全承诺买单。
然而,其“锐利”的双刃剑属性也极为明显。首先,其技术路径深度绑定苹果生态(Apple Silicon + Core ML),这虽带来了性能优化,却也构筑了硬性壁垒,将Intel Mac与Windows/Linux用户拒之门外,与评论中强烈的跨平台需求形成矛盾。其次,完全依赖设备算力,在模型复杂度、多语言支持、处理长音频的稳定性与内存开销方面,必将面临长期挑战。开发者提到的OCR上下文纠错和自定义词库,是务实的工程优化,但也侧面印证了纯粹端侧模型在应对专业场景时的固有局限。
它的出现,标志着AI应用从“追求通用性能最优”向“满足特定场景约束”的重要分化。它未必能取代云服务,但足以在隐私红线内,成为许多人的唯一可行选择。其开源策略,更是将产品进化托付于社区,试图以协作生态对抗巨头的规模优势。能否从“ spicy ”的先锋概念成长为稳健的基础设施,取决于其能否在保持隐私初心的同时,在模型效率、平台扩展和用户体验上找到更优的平衡点。
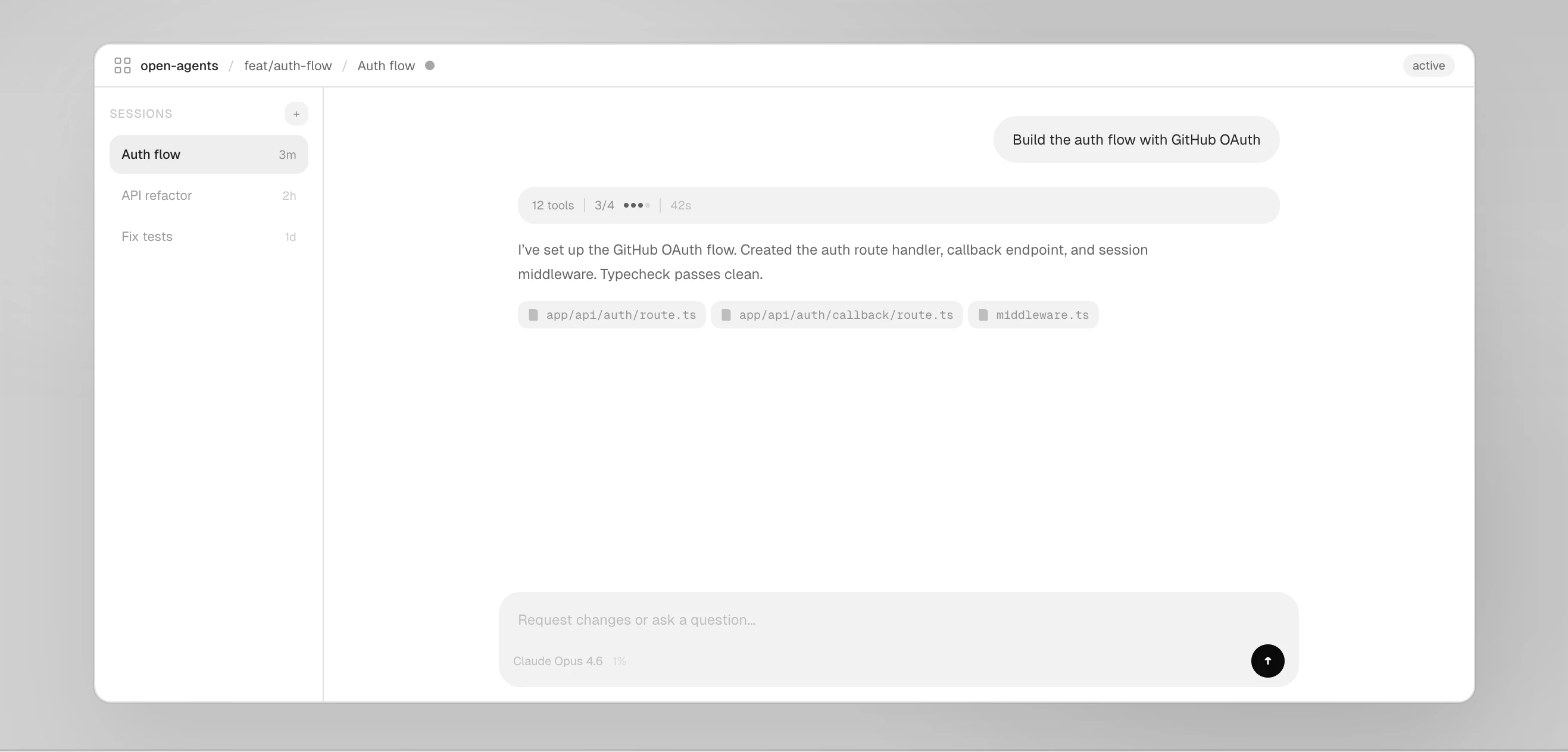
一句话介绍:Open Agents是一个开源的云端智能编码代理参考平台,允许开发者通过提示词直接生成并执行代码变更,无需本地介入,解决了在大型单体仓库和复杂工作流中自动化编码的难题。
Open Source
Developer Tools
Artificial Intelligence
GitHub
开源AI编码代理
云端代码生成
智能编程工厂
Vercel部署
代理运行时
沙箱编排
GitHub集成
自动化开发
企业级AI工具
参考实现
用户评论摘要:用户反馈集中在安全与生产部署实践上,包括如何防范提示词注入、管理密钥和网络出口、设置权限与审批关卡。同时,用户赞赏其“从提示到代码变更”的自动化价值及开源参考意义,并询问了沙箱任务隔离的具体实现。
AI 锐评
Open Agents的发布,远不止是又一个“开源AI编码助手”。它精准地刺中了当前企业级AI编码代理的两个核心痛点:对庞大单体代码库的无力感,以及与企业特有知识、流程整合的断层。其真正价值在于,它将自己定位为一个“软件工厂”的参考实现——这暗示着未来的竞争壁垒将从“代码本身”转向“代码的生产方式”。
Vercel通过此举,聪明地将自身的基础设施(Fluid、Workbox、Sandbox等)塑造成了下一代AI驱动开发的“操作系统”。开源代码库是其诱饵,最终目的是吸引开发者在其云生态上构建和运行这些高价值的“工厂”。评论中关于安全部署和权限管理的尖锐提问,恰恰暴露了当前技术从演示走向生产所面临的最严峻挑战:如何在一个自动生成并执行代码的系统里,建立可靠的安全边界与治理流程。这不仅是技术问题,更是工程哲学和管理模式的变革。
因此,Open Agents与其说是一个即拿即用的产品,不如说是一份精心设计的“行业宣言”和“架构蓝图”。它告诉市场,真正的“智能编程”不是玩具,而是一个需要深厚基础设施、严密安全设计和深度业务集成的系统工程。它的成功与否,将取决于有多少企业愿意以其为蓝本,投入资源去构建和定制那个属于自己的、带护城河的“软件生产车间”。
一句话介绍:HeyGen CLI是一款终端命令行工具,允许开发者和AI智能体直接生成视频、翻译内容、创建数字人,通过结构化JSON输出无缝集成自动化脚本与工作流,解决了在自动化流程中高效集成视频生成能力的痛点。
Marketing
Photo & Video
Video
命令行工具
视频生成
AI智能体
开发者工具
工作流自动化
内容翻译
数字人
API集成
结构化输出
DevOps
用户评论摘要:用户普遍认可其符合CLI与智能体友好趋势,能提升自动化工作流效率。主要疑问集中在:数字人(数字孪生)功能是否对企业账户开放,以及生成视频的输出位置和可编辑性(在终端还是HeyGen平台)。
AI 锐评
HeyGen CLI的发布,远不止是将一个图形界面产品进行命令行包装那么简单。它清晰地指向了两个核心趋势:一是“AI智能体”正在从概念走向具象化的工具链需求,二是开发者体验(DX)成为AI应用落地的关键瓶颈。
其真正价值在于,将视频生成这类重度依赖云端处理、结果难以程序化调用的“黑箱”服务,解构成可通过脚本精确操控、输出结构化JSON的标准化组件。这标志着AI生成内容(AIGC)正从“产品功能”下沉为“基础设施”。开发者可以像调用一个数据库或发送一个HTTP请求那样,将高质量视频生成无缝嵌入CI/CD流水线、自动化营销内容生产或智能体决策流程中,实现了创作能力与工程化系统的深度耦合。
然而,评论中暴露的疑问恰恰揭示了其面临的挑战。用户关于数字人功能权限和输出位置的困惑,反映了产品在“开发者友好”与“平台商业策略”之间可能存在界限。若关键功能仍被锁定在企业级套餐后,或输出无法真正脱离平台生态进行本地化处理,那么其宣称的“开箱即用”和“无缝集成”将大打折扣。它必须谨慎权衡:是成为真正开放、中立的开发者工具,还是作为引导流量至其主平台的精巧钩子。
当前,其简洁的设计和零依赖安装展现了优秀工具的特质,但能否成为视频生成领域的“FFmpeg”或“cURL”,取决于其后续在功能开放性、定价模型以及对开发者社区反馈的响应速度。这步棋走得精准,但棋局才刚刚开始。
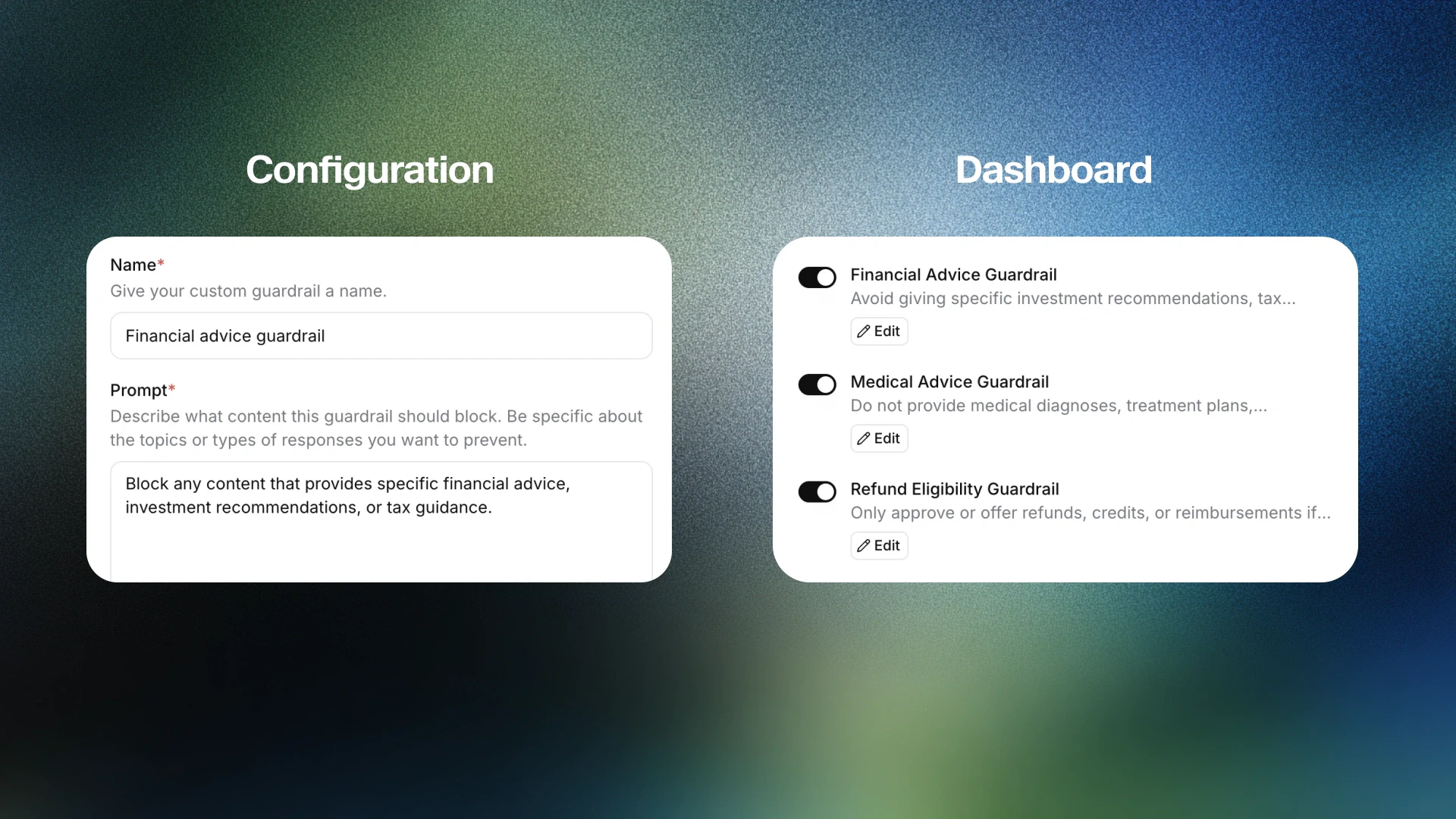
一句话介绍:为大规模部署语音AI Agent的企业提供可配置的安全控制层,通过实时策略执行与多重验证,防止生产环境中出现对话漂移、诱导注入和品牌背离风险,保障高监管行业应用安全。
Sales
Developer Tools
Artificial Intelligence
AI安全
语音智能体
企业级部署
实时合规
策略执行
提示注入防护
对话漂移控制
监管科技
风险缓解
SaaS
用户评论摘要:用户肯定产品解决真实痛点,尤其在高风险行业。关注点包括:与自定义语音代理的兼容性(是否支持通过API集成ElevenLabs TTS的第三方代理)、具体实施场景(业务关键任务语音交互),以及对企业级功能(数据编辑和零保留模式)的访问权限。
AI 锐评
ElevenAgents Guardrails 2.0瞄准的是AI语音交互从演示走向规模化生产时暴露出的“安全真空”。其核心价值不在于基础的内容过滤,而在于构建了一个**独立于主模型决策路径的并行校验体系**。这本质上是将传统软件工程中的“策略即代码”和“不可变基础设施”理念,引入了非确定性的AI交互领域。
产品设计的犀利之处在于三层验证架构:系统提示硬化、用户输入验证、代理响应验证。这相当于在AI的“思考前”、“输入时”和“输出后”设置了三个独立的检查站,而非依赖单一、易被绕过的系统提示。尤其“自定义护栏以自然语言定义”的特性,降低了安全策略的配置门槛,使其能被业务和合规团队直接管理,而非仅是工程师的职责。
然而,其真正的挑战与价值天花板也在于此。首先,“独立并行检查”必然引入延迟,在实时语音交互中,如何在安全与流畅性之间取得微秒级的平衡,将是工程上的严峻考验。其次,产品的成败将高度依赖于其规则引擎的精准度——过严则损害用户体验,过松则形同虚设。尤其是在处理语义模糊、语境依赖的违规内容时,其误判率将直接决定客户信任度。
当前它深度绑定ElevenAgents生态,这既是早期优势也是增长瓶颈。从评论中的用户关切可以看出,市场更需要一个能跨平台、跨语音合成引擎的**标准化安全中间件**。若能开放为可插拔的“语音AI防火墙”,其市场定位将从功能产品跃升为行业基础设施。
总之,Guardrails 2.0揭示了一个关键趋势:当AI Agent开始处理真实世界的金钱、健康和法律事务时,可审计、可强制执行的过程控制,其重要性将开始超越模型本身的性能。它卖的不是功能,而是进入高监管行业的“准入许可证”和企业的“风险缓释保险”。
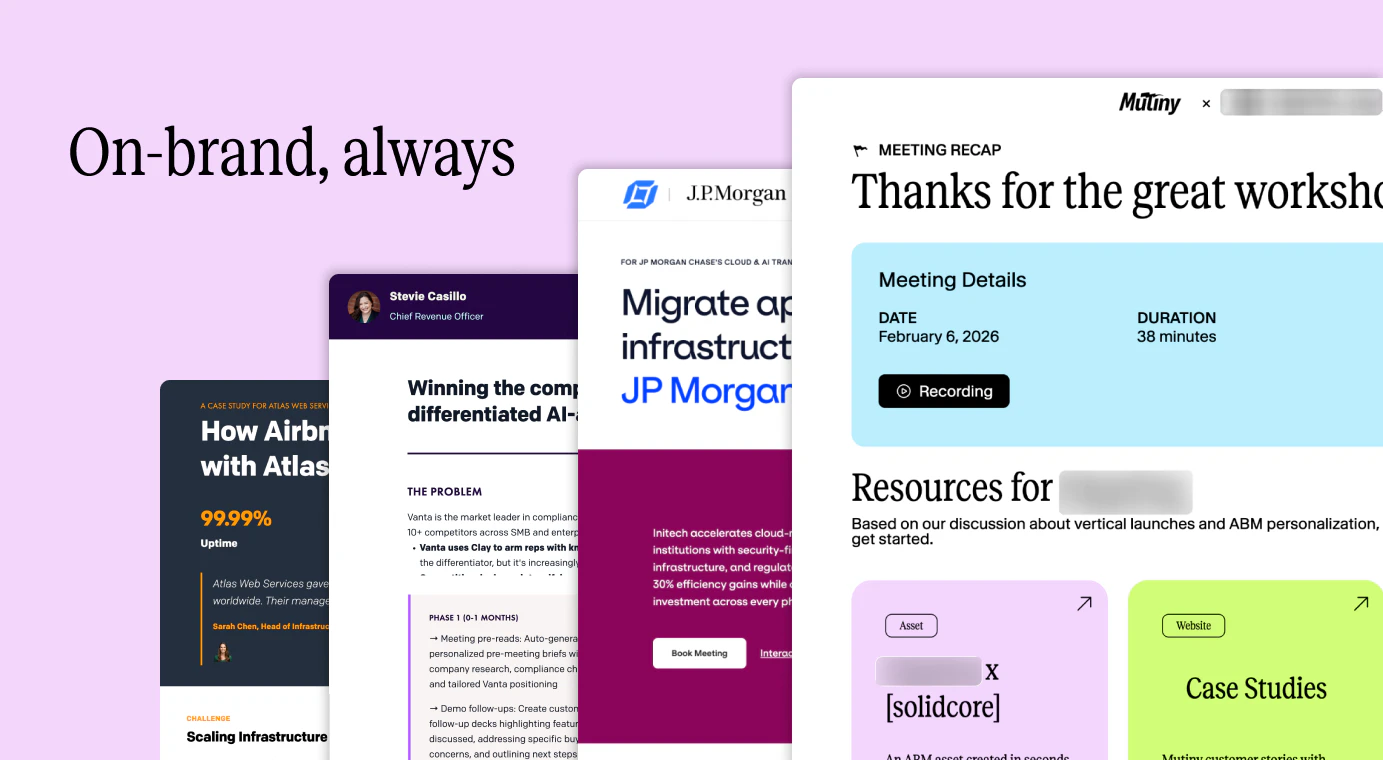
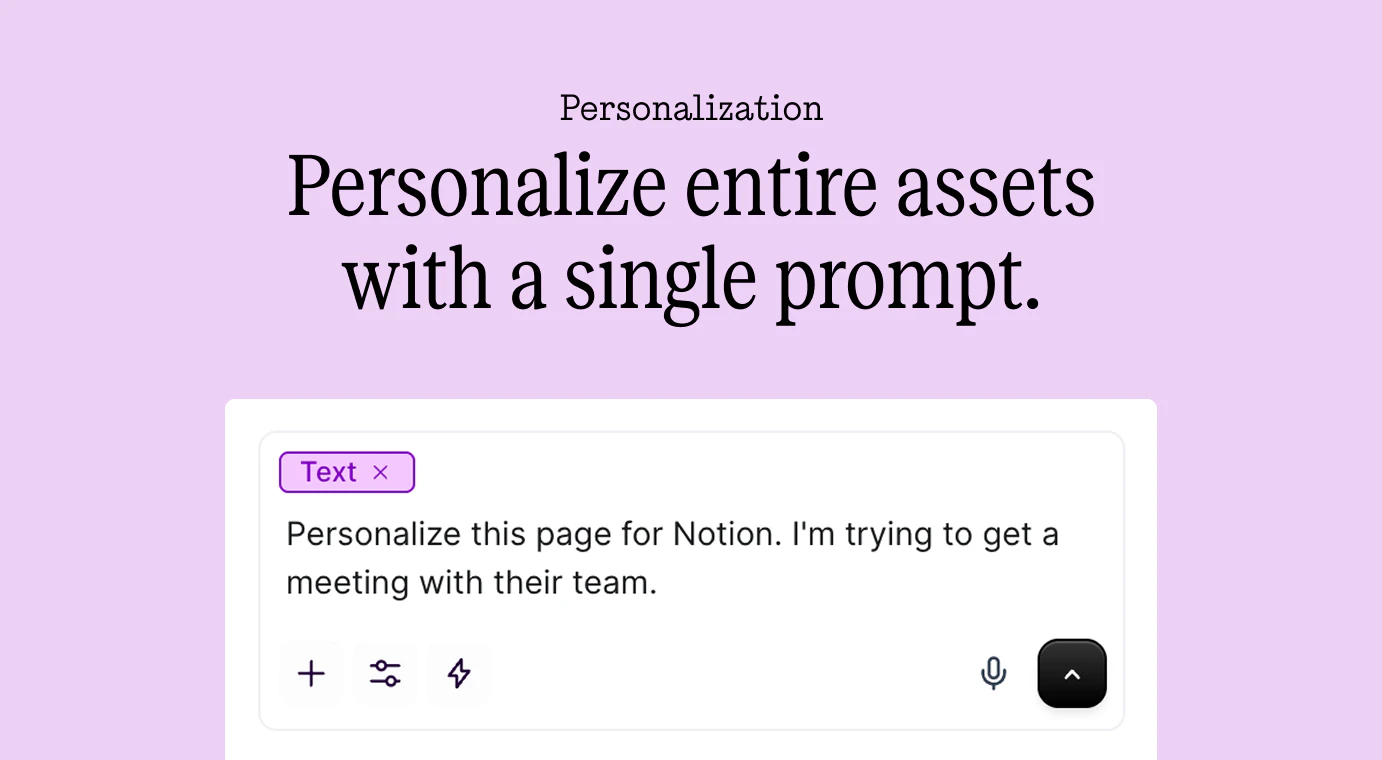
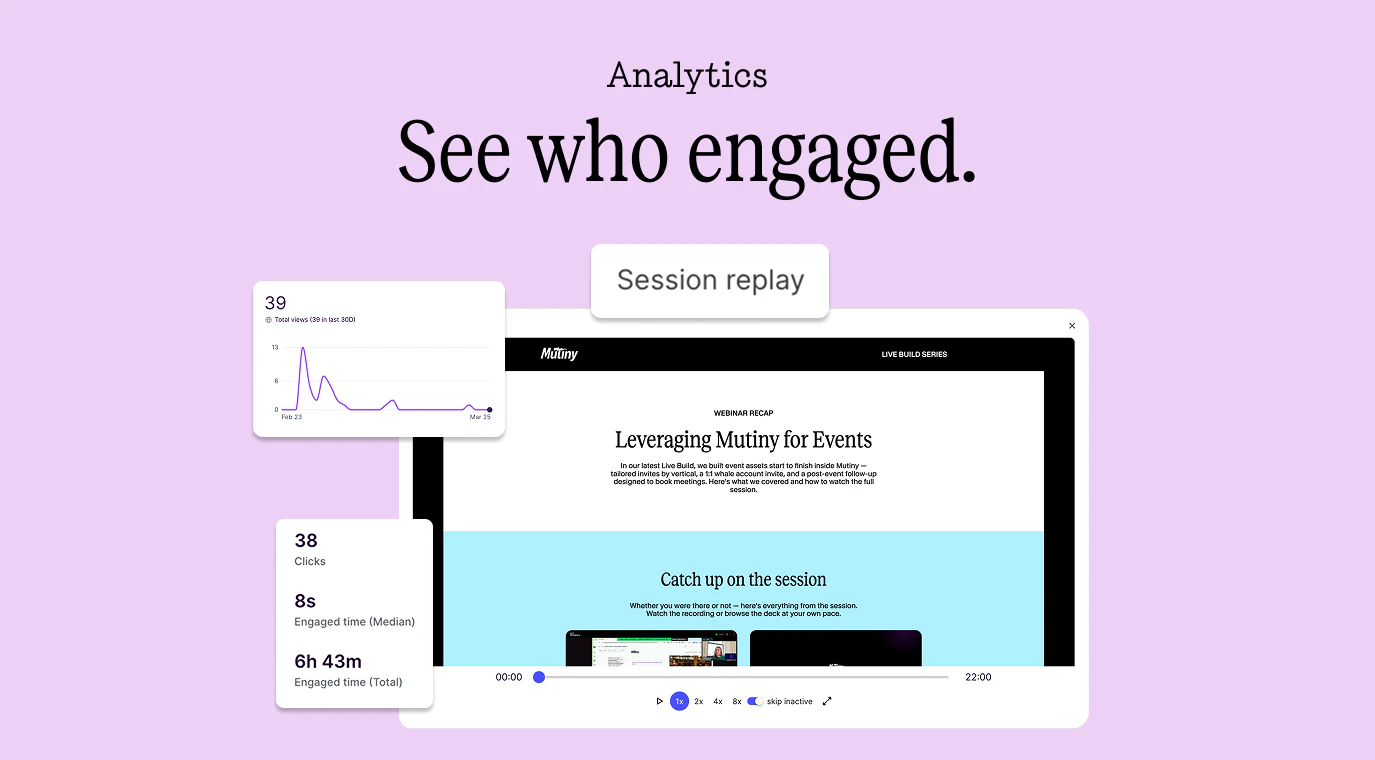
一句话介绍:Mutiny是一款AI驱动的销售与营销内容生成工具,它允许GTM团队在无需依赖设计、开发等部门的情况下,快速创建品牌化、个性化的客户面对资产(如业务案例、交易室等),从而解决跨部门依赖导致的效率低下问题,加速交易进程。
Sales
Marketing
Artificial Intelligence
销售赋能
营销自动化
AI内容生成
个性化营销
ABM工具
销售情报
品牌一致性
GTM平台
B2B SaaS
客户互动分析
用户评论摘要:用户反馈积极,认可其快速创建高质量、个性化资产的能力及销售情报价值。主要问题集中在适用团队规模(官方回应同样适合小团队)和买家对生成链接的接受度。建议方面,关注资产类型使用分布和提升买家采纳率的产品设计。
AI 锐评
Mutiny的“新发布”本质上是一次战略聚焦,从之前的个性化网页工具,升维定位为“客户面对面内容的AI智能体”。其真正价值不在于简单的模板化生成,而在于试图系统性解构并数字化“销售艺术”中那些非标环节——如为特定交易阶段定制说服话术、将冠军客户转化为内部推销员。产品介绍的“依赖之网”痛点精准击中了B2B企业的组织病。
然而,其宣称的“品质”面临双重考验。其一,AI生成的“品牌一致性”目前多停留在视觉和语气的浅层模仿,能否深度理解并演绎不同企业的核心价值主张与战略叙事,存疑。其二,其核心卖点“全流程可见性”是一把双刃剑。虽然让销售洞悉幕后动态,但将追踪功能嵌入发给客户的链接(如评论中所提“奇怪的链接”),可能引发买家对隐私的警觉,反而增加信任摩擦。这要求Mutiny必须在提供情报与保持专业、无侵犯感的体验之间找到精妙平衡。
它的野心是成为GTM的“中枢神经系统”,而非又一个单点工具。成功的关键在于其AI是否真的内化了顶尖销售的战略思维,而不仅仅是内容排版技巧。如果它能将最佳实践框架与实时情境数据(CRM、通话记录)深度融合,动态生成真正具有说服力的策略性内容,而不仅是美观的文档,它才有可能从“效率工具”蜕变为“竞争力引擎”。目前看,它迈出了关键一步,但最艰难的“智能”考验还在后面。
一句话介绍:一款通过浏览器快捷键和AI自动分类,极速保存与检索链接的工具,解决了用户因书签堆积、标签页混乱或跨平台发送链接导致的链接管理低效痛点。
Chrome Extensions
Productivity
链接管理
书签工具
生产力工具
浏览器扩展
自动化分类
隐私保护
个人知识库
免费工具
快捷键操作
用户评论摘要:用户普遍认可其解决“发链接给自己”痛点的核心价值,赞赏自动分类的免维护设计。主要建议/问题包括:增加扩展图标直达Web App、开发保存至专用邮箱功能、开放API、修复Telegram Bot移动端体验,以及对“永久免费”政策和隐私安全的确认。
AI 锐评
send/links 精准切入了一个被巨头忽视的“微小”市场:个人链接的瞬时保存与零成本整理。其真正价值不在于“又一个书签管理器”,而在于它通过“Alt+L”这一极致简单的动作,将“保存”这一行为的心理成本和操作步骤降到了近乎为零。这看似简单,实则深刻——它挑战了传统书签工具“先保存,后整理”的失败范式,用AI自动分类取代了用户迟早会放弃的手动文件夹管理,本质上是将工具从“需要维护的仓库”转变为“自主运行的背景服务”。
然而,其面临的挑战同样清晰。首先,其“永久免费”的商业模式在获得初期好感的同时,也埋下了长期可持续性的问号,用户对隐私的疑虑正源于此。其次,当前能力仍显单薄,评论中高频出现的邮箱转发、API集成、移动端体验修复等需求,恰恰暴露了其作为“链接收集中枢”的短板——若无法无缝嵌入用户所有的工作流(移动浏览、邮件、协作软件),其“一站式”定位便难以成立。用户的赞美多集中于“保存”的爽感,但链接管理的终极考验是“检索与复用”,其长期粘性将取决于后续在搜索、关联、知识图谱构建等“用”的层面能否带来同样惊艳的体验。
总体而言,这是一款以锋利单点突破切入市场的优秀作品。它聪明地避开了与 Pocket(稍后读)、Raindrop.io(功能全面)的正面竞争,转而聚焦于“无感保存”这一更前置的环节。若能稳固其“最轻快保存工具”的心智,并逐步构建起强大的出口和复用能力,它有望从一个解决痒点的工具,成长为个人知识基础设施中一个不可或缺的管道。
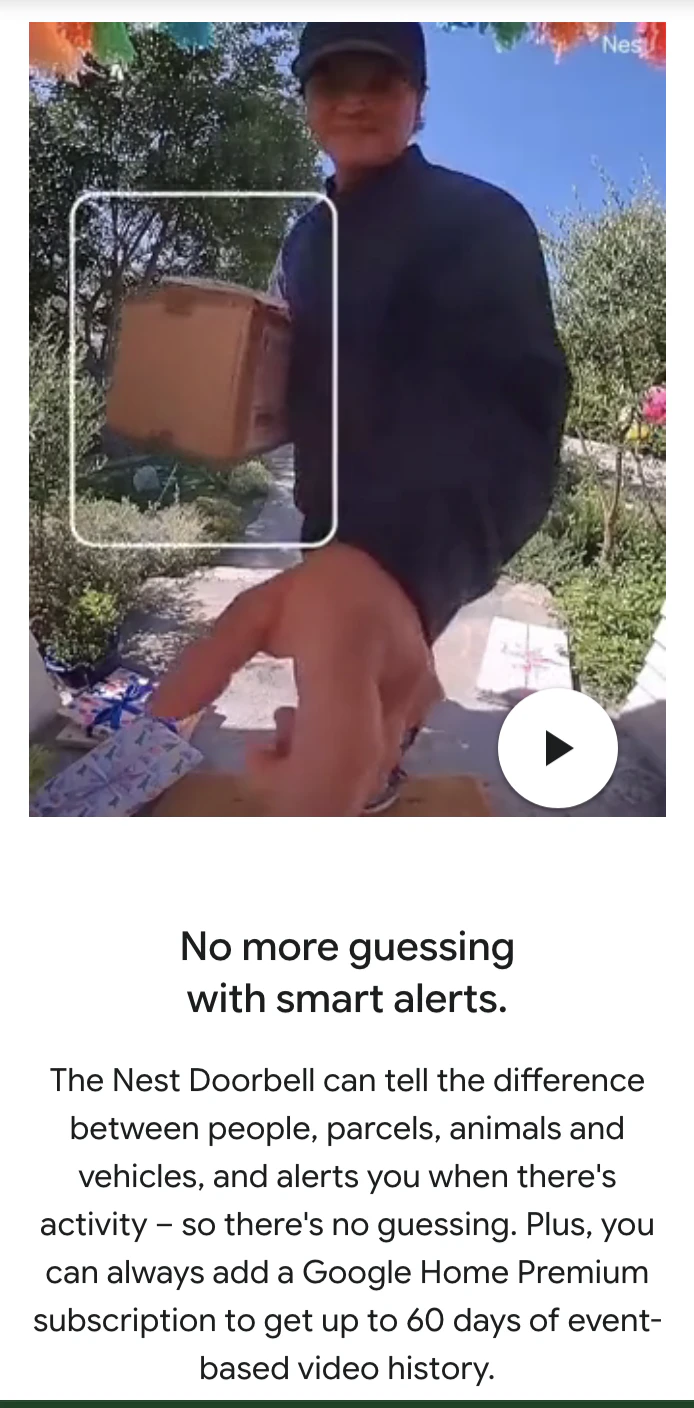
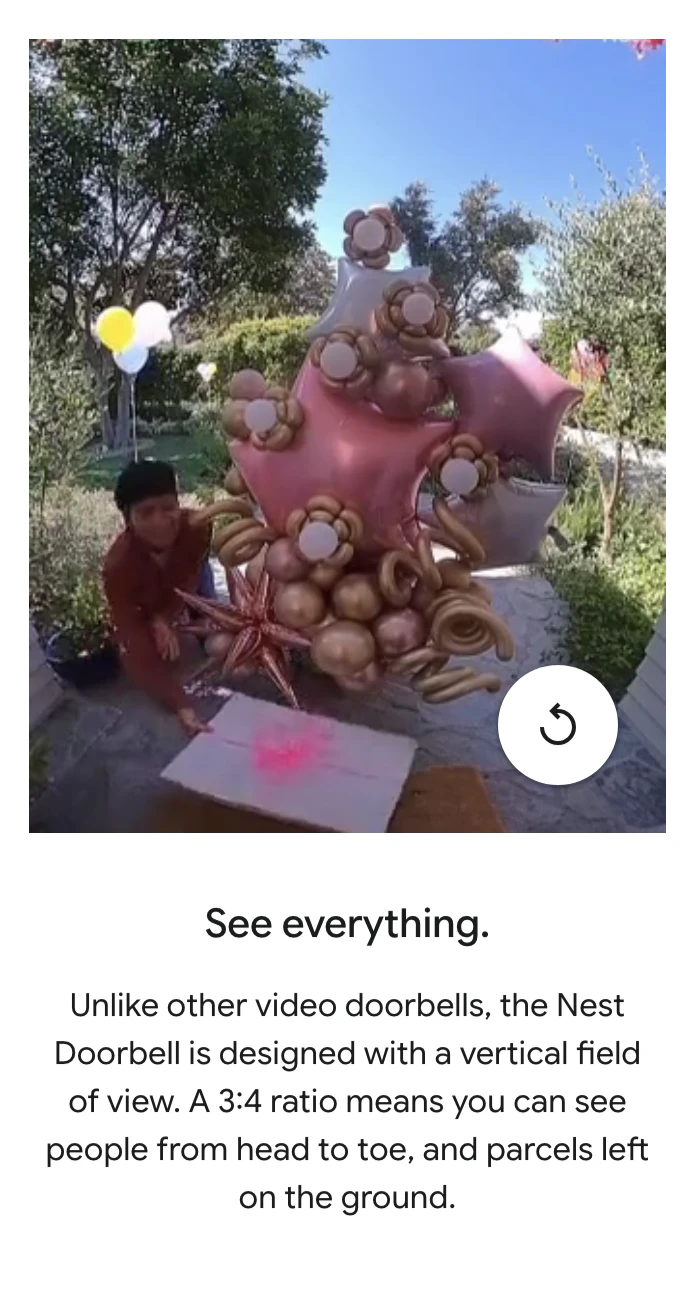
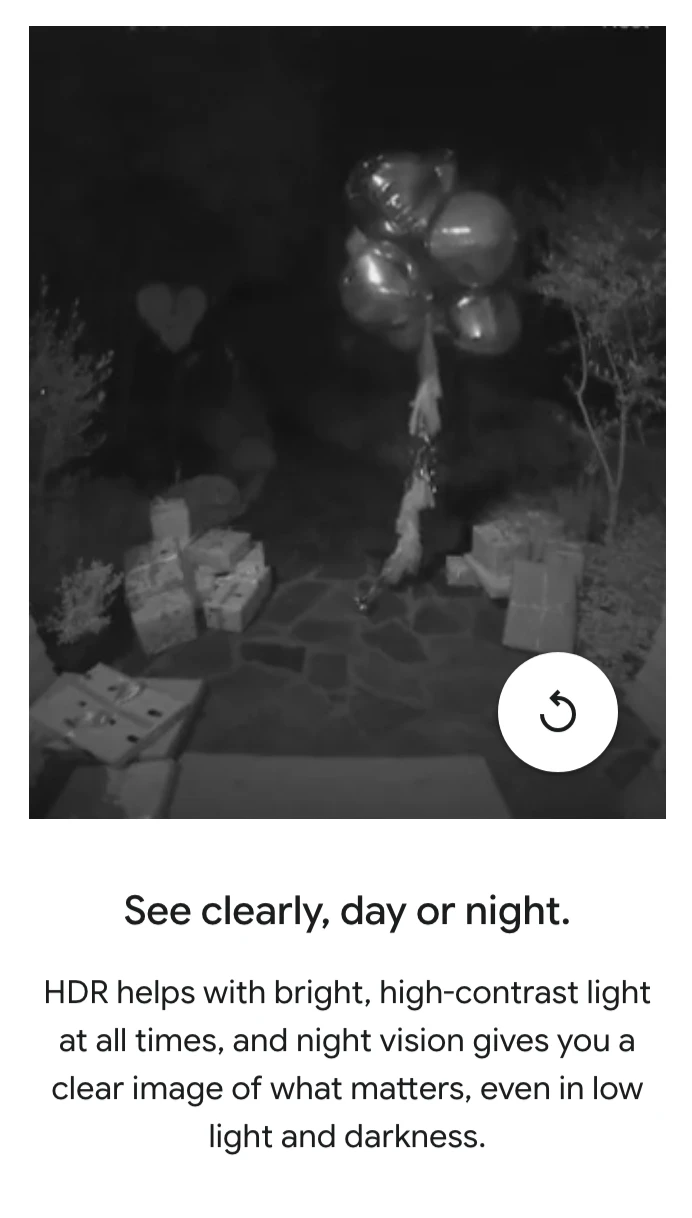
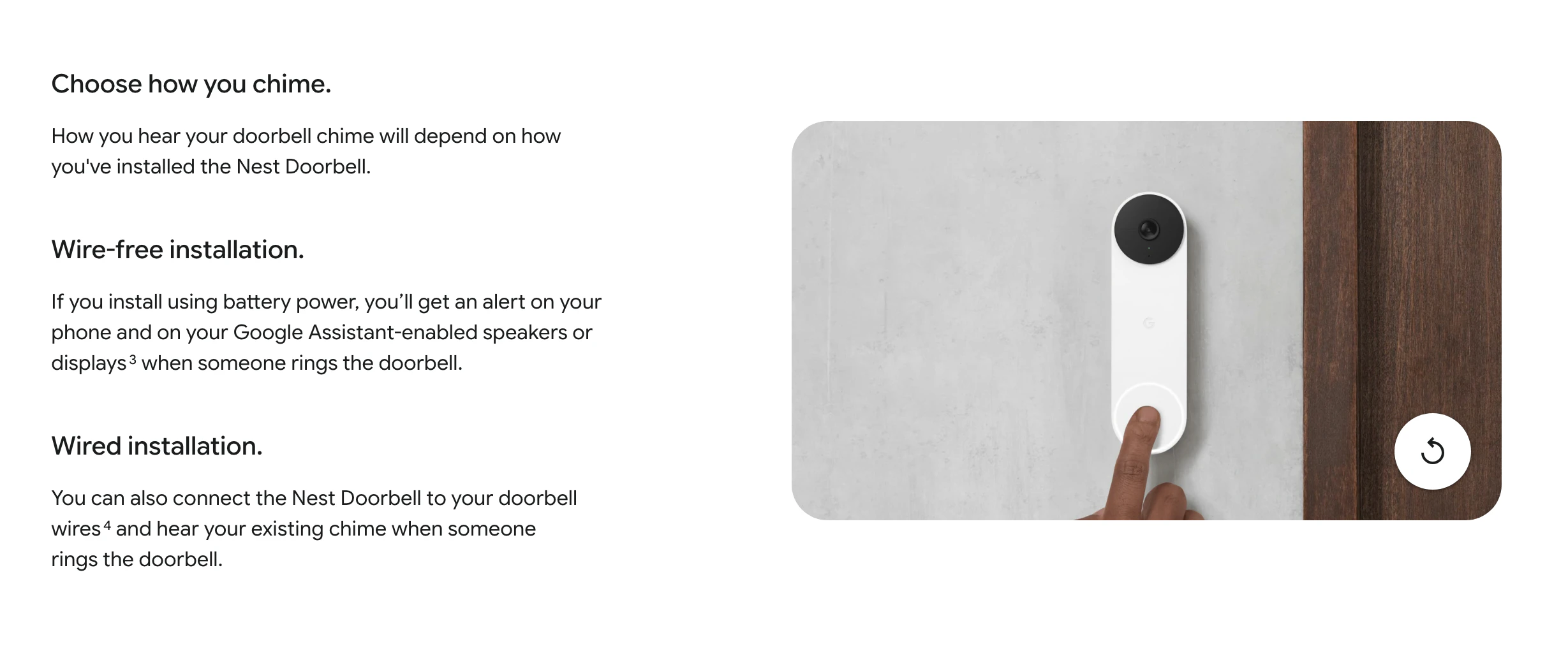
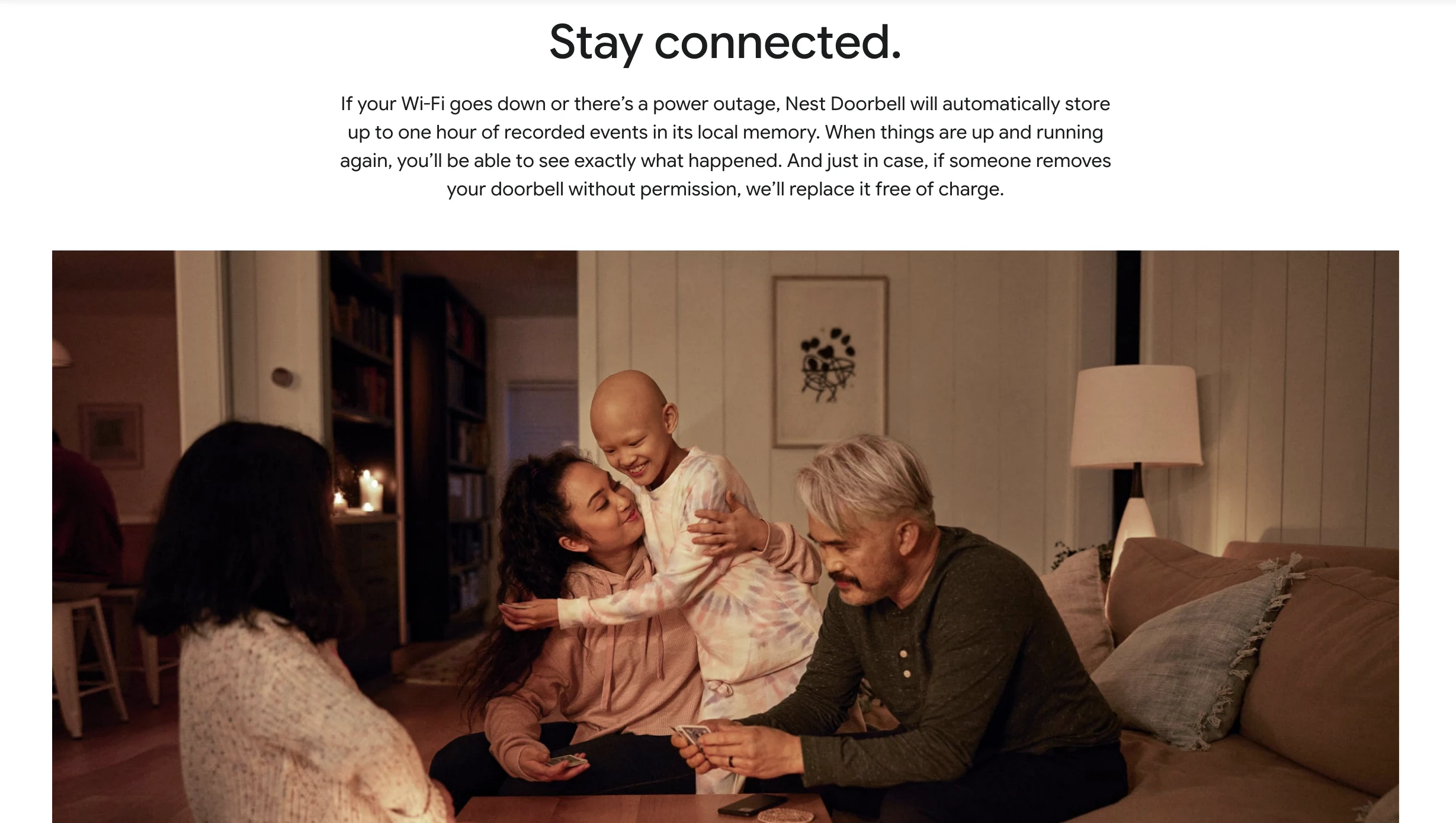
一句话介绍:Google Nest Doorbell是一款电池供电的智能可视门铃,通过本地AI精准识别关键事件(如人、包裹),无需布线安装,解决了家庭安防设备安装复杂和传统门铃误报警频繁的核心痛点。
Home
Privacy
Artificial Intelligence
智能家居
安防摄像头
可视门铃
电池供电
AI识别
无线安装
隐私安全
谷歌生态
用户评论摘要:用户肯定其无需布线的便利性。主要疑问集中于:1. 防盗措施的具体机制;2. 数据隐私,担忧视频数据被共享给第三方或政府;3. 质疑所谓“新功能”是否实为已有功能的整合。
AI 锐评
谷歌此次推出的Nest Doorbell,本质是一场针对主流市场的“体验降维打击”。其核心价值并非技术突破——AI识别、电池供电在业内已不新鲜——而在于将“可靠易用的智能安防”进行了极致的产品化封装。
真正的犀利之处在于三点:首先,它用“电池供电+可选有线”的组合拳,精准覆盖了租房者、老旧住宅用户等“布线困难户”,将安装门槛降至几乎为零,这是对市场规模的直接拓宽。其次,其宣传的“本地AI识别”是一步高明的隐私棋,旨在缓解用户对云端视频流持续上传的深层恐惧,尽管实际数据流向仍需深究。最后,捆绑“5年更新”和“防盗保护”,试图构建长期信任,对抗硬件同质化。
然而,产品面临的质疑直指科技巨头的阿喀琉斯之踵:隐私与数据主权。评论中接连出现对政府及执法部门访问数据的担忧,并非空穴来风,这反映了用户对谷歌作为数据巨头的天然不信任。产品介绍对此避重就轻,“与谷歌、Alexa等工作”的表述反而加剧了生态绑定的隐忧。此外,“防盗保护”细节模糊,若仅是事后补偿而非物理或技术上的防拆设计,则意义有限。
综上,这是一款在体验上做减法(安装)、在智能上做加法(本地AI)、但在信任上面临巨大挑战的产品。它的成功与否,不取决于参数,而取决于谷歌能否用透明的隐私政策和可靠的安全实践,说服用户把“前门”交给它。
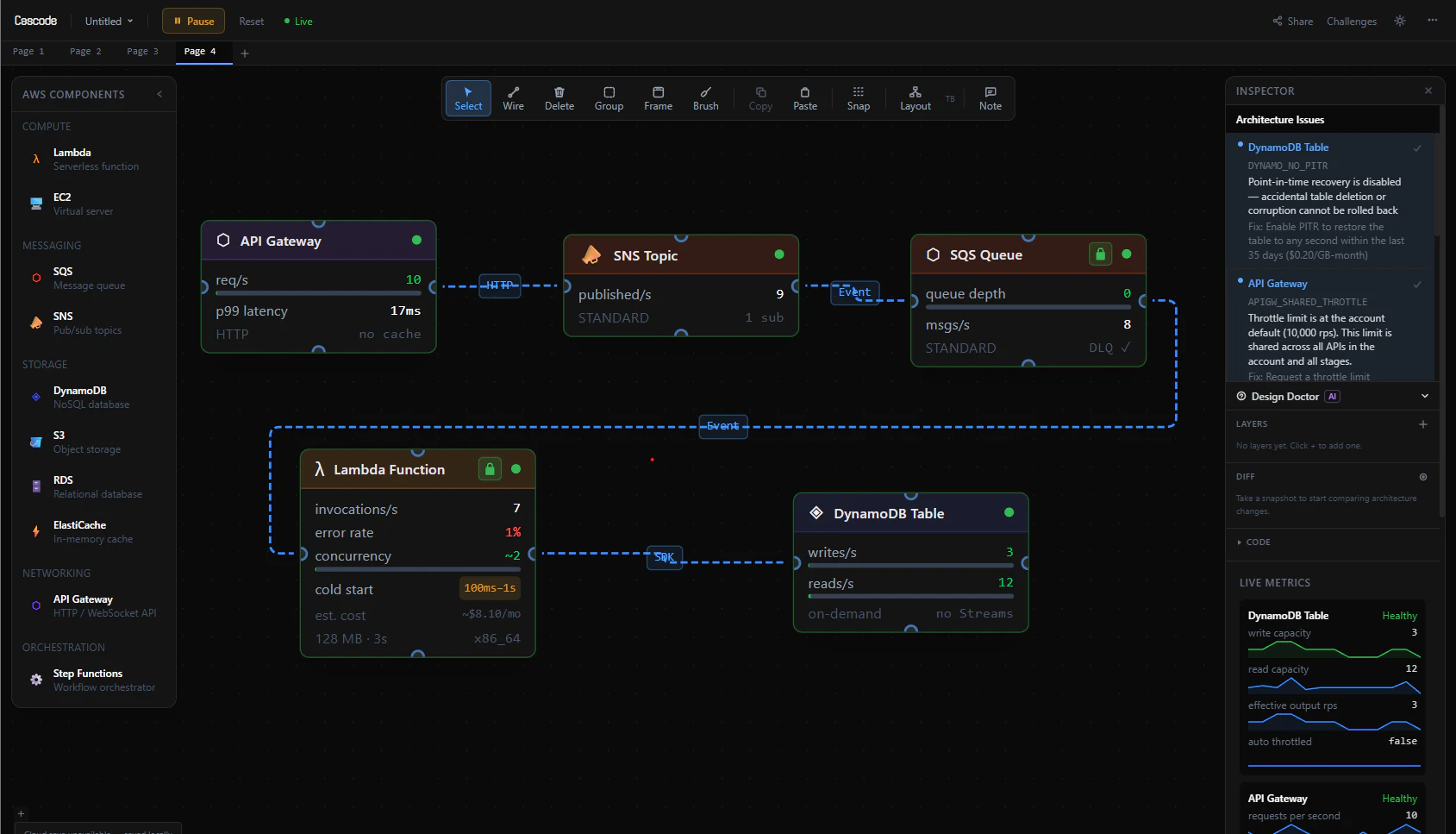
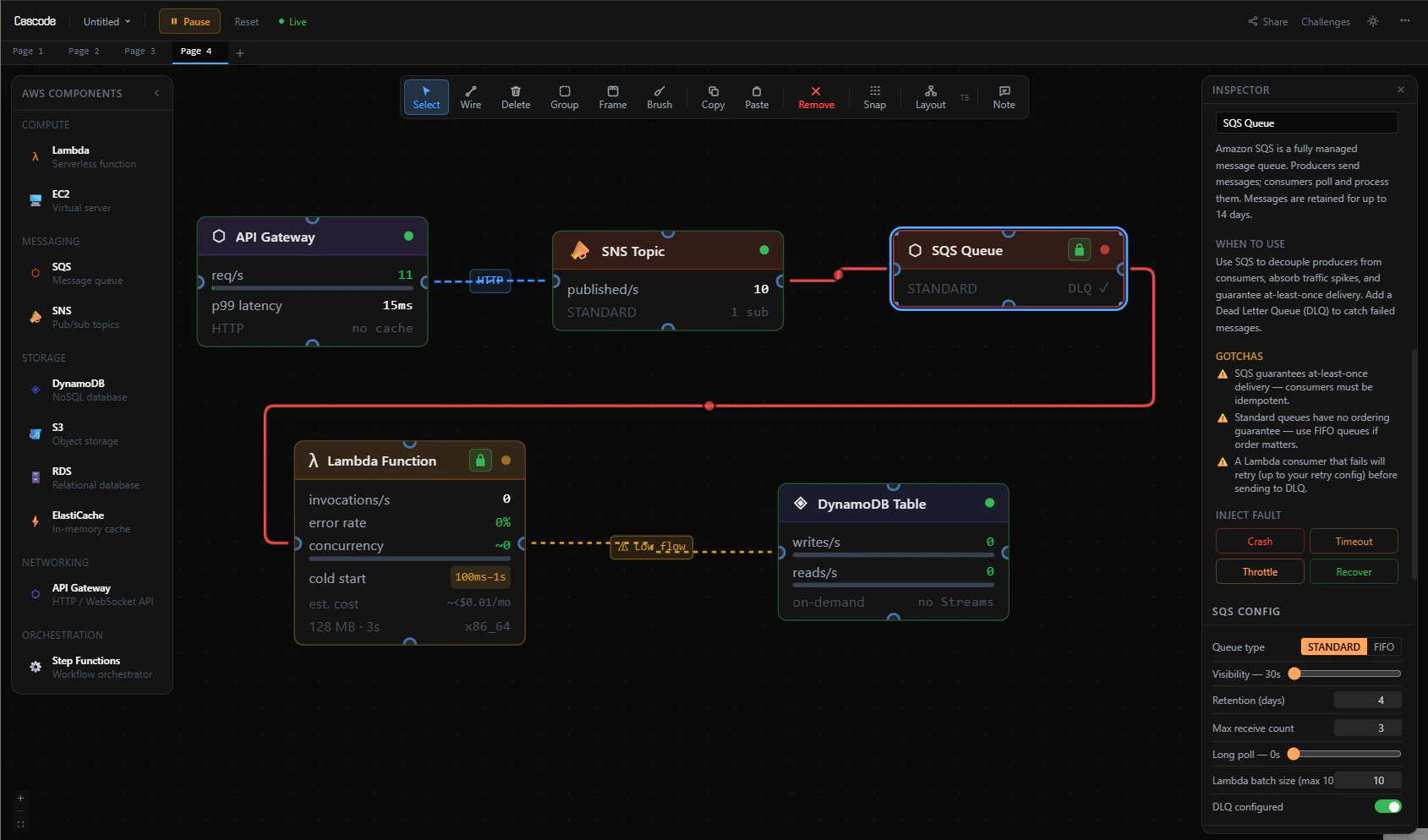
一句话介绍:Cascode是一款在浏览器中运行的AWS架构模拟沙盒,通过拖拽真实AWS服务并注入故障进行实时模拟,帮助开发者、架构师及面试者在零成本、无风险的场景下直观学习系统韧性设计,解决传统系统设计教育缺乏实践与故障感知的痛点。
Design Tools
Education
Software Engineering
AWS架构模拟
故障注入演练
系统设计学习
云原生沙盒
实时协作
基础设施即代码
运维可观测性
技术面试准备
云安全实践
开发教育工具
用户评论摘要:用户高度认可其“以故障为师”的理念,认为对构建技术直觉和面试准备极有价值。主要问题集中在:与现有开发环境的集成、故障场景的选择逻辑、IAM策略推断的准确性、底层状态管理机制。开发者回应详细,展现了技术深度与路线图。
AI 锐评
Cascode的锋芒,在于它精准地刺中了云计算时代一个被长期粉饰的软肋:我们设计了无数精美的架构图,却对真正的失败一无所知。它并非又一个画图工具,而是一个“故障剧场”,其核心价值是提供了一种稀缺的、可重复的“失败体验”。
传统云认证与系统设计教育,大多停留在静态知识与理想化流程的灌输,这导致工程师对复杂系统在压力下的涌现行为缺乏直觉。Cascode通过将实时流量模拟与可控故障注入结合,并可视化连锁反应,实际上是将“混沌工程”的门槛降到了零,并将其前置到了设计与学习阶段。这不仅仅是教学工具的创新,更是方法论上的颠覆——它让韧性设计从一种事后补救的专家技能,转变为一种可通过模拟反复训练、从而内化的核心能力。
其“一键导出IaC”与“AI设计医生”功能,试图打通从模拟到实践的闭环,野心可见一斑。但真正的挑战也在于此:浏览器内的简化模拟与真实AWS环境的复杂度之间存在巨大鸿沟。推断的IAM策略能否经得起生产级安全审查?模拟的流量与故障模式能否覆盖真实世界的诡异边角案例?这些疑问决定了它当前的核心定位仍是强大的“学习与原型设计辅助工具”,而非可信的“生产部署前验证工具”。
用户评论中流露出的兴奋,恰恰印证了市场对此类实践性工具的渴求。它未必能直接打造出坚不可摧的系统,但它能高效地培养出对脆弱性敏感、对韧性有直觉的架构师。这才是它更深层的价值:不是在画布上组装服务,而是在工程师脑中组装对复杂性的敬畏。
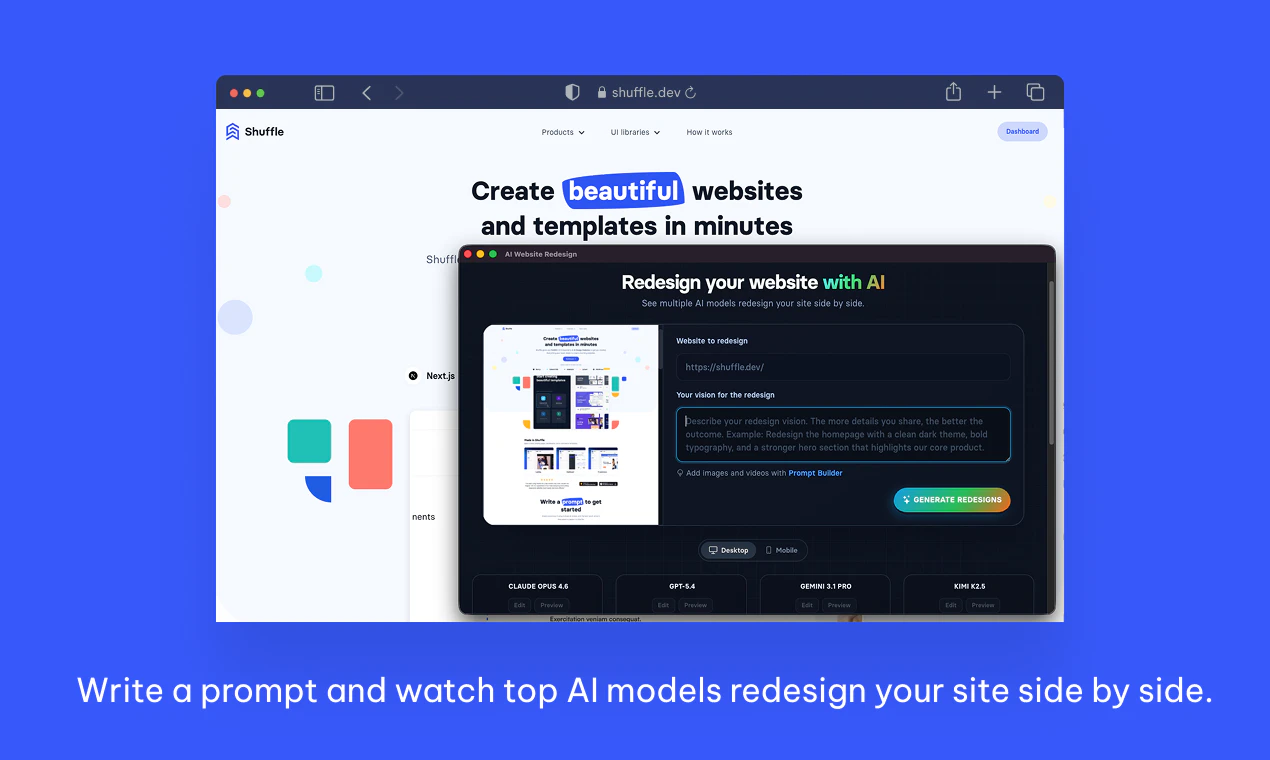
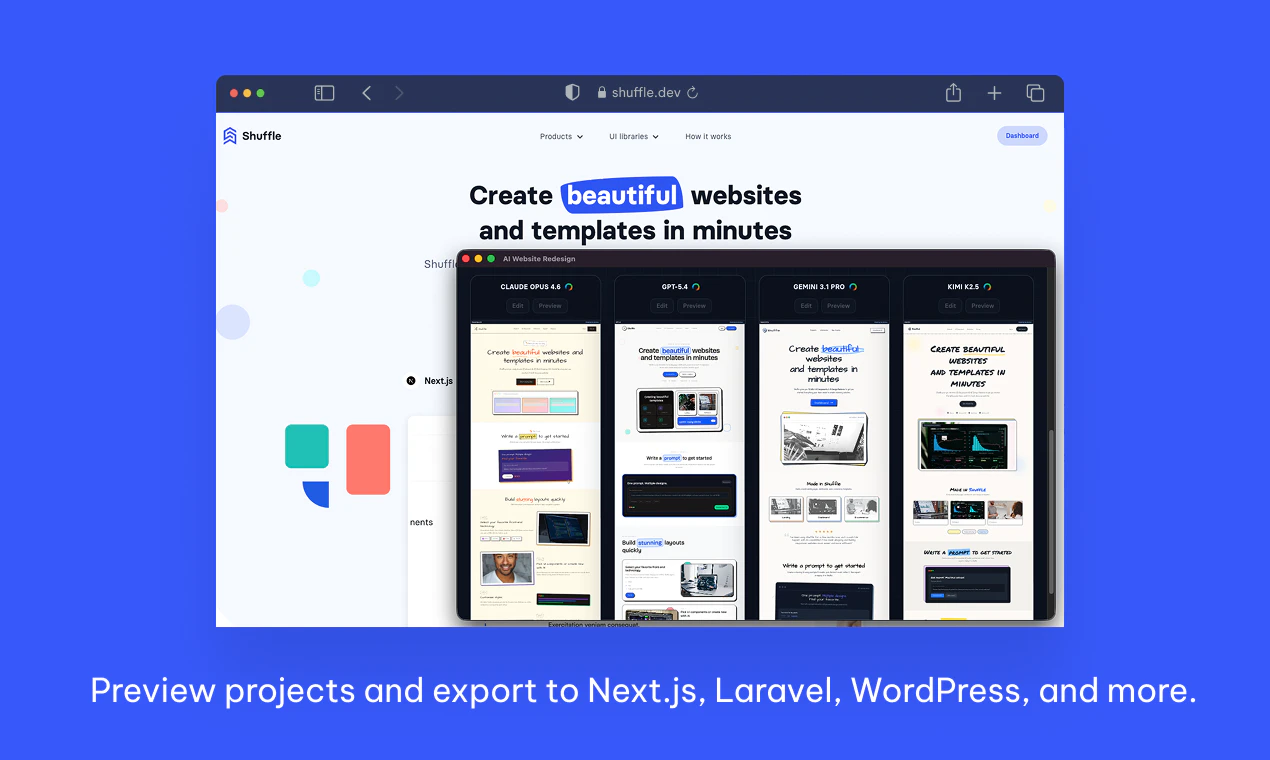
一句话介绍:一款基于主流AI模型的浏览器扩展,可即时对任何网站(包括本地和加密站点)进行AI重设计,帮助设计师和开发者快速完成网站视觉更新、客户提案和灵感生成。
Chrome Extensions
Design Tools
Developer Tools
AI设计工具
网站重构
浏览器扩展
设计灵感
原型生成
前端导出
效率工具
无代码设计
用户评论摘要:官方评论重点宣传了支持本地及加密网站这一关键更新,解决了先前最大使用障碍,并强调了其多模型对比、一键导出至主流开发框架等核心功能,旨在展示其实用性与灵活性。
AI 锐评
Shuffle AI Redesign Extension 将流行的生成式AI能力精准地锚定在了“网站视觉重设计”这一垂直且高频的痛点上。其真正的价值不在于“AI能画图”,而在于构建了一个从灵感激发到交付落地的微型工作流闭环。
产品犀利之处有三:其一,直击“最后一公里”障碍,通过浏览器扩展形态破解了本地与内网环境的使用壁垒,这看似是技术实现,实则是产品思维上的关键胜利,将工具从“玩具”转向了“工作伴侣”。其二,它巧妙地避开了与Figma、Webflow等成熟设计平台在完整工作流上的正面竞争,而是聚焦于“快速变异”和“灵感激发”的前期环节,扮演了一个高效的“催化剂”角色。其三,提供Next.js、Laravel等框架的直接导出选项,这看似是给开发者的甜头,实则暴露了其野心——它试图跨越设计与开发之间的鸿沟,将AI生成的视觉方案向可用的代码资产推进一小步,这极大地提升了其产出物的实用价值。
然而,其核心挑战也在于此:AI生成的“设计”在视觉新颖性和结构合理性之间存在固有矛盾。对于严肃的商业项目,其输出更可能被视为一种高级“情绪板”或组件灵感,而非可用的终稿。产品的长期价值将取决于其AI模型对设计系统、交互逻辑及代码语义的理解深度,而非仅仅停留在视觉层面的“重绘”。若仅停留在表面换肤,它很可能沦为一时新奇的工具;若能持续深化对“设计-代码”映射关系的理解,它则有望成为颠覆传统网站开发流程的楔子。目前看来,它迈出了聪明且务实的第一步。
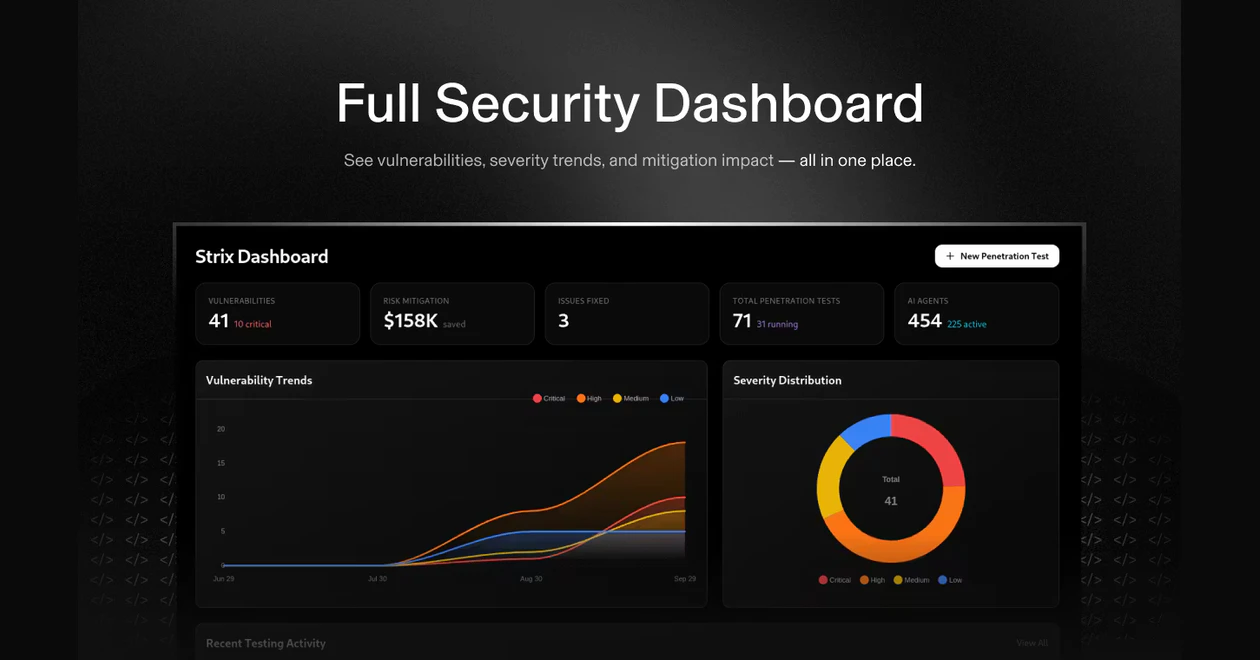
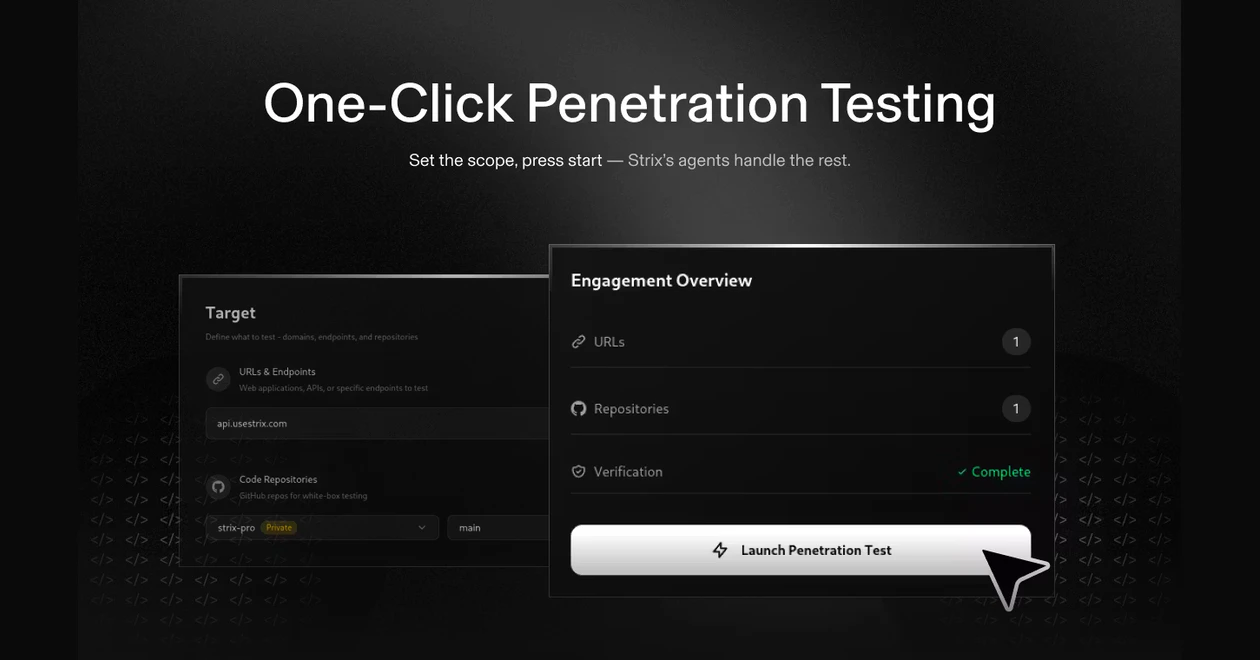
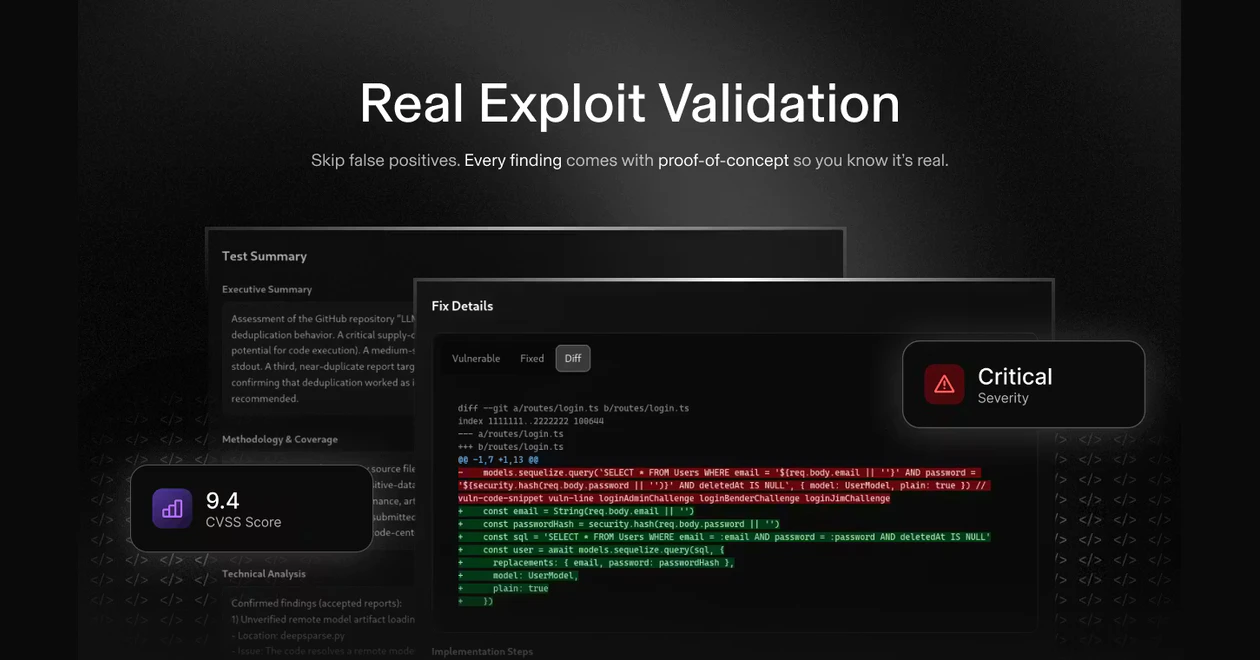
一句话介绍:Strix Agents 是一个持续安全测试平台,帮助开发者在快速迭代的DevOps流程中,自动拦截漏洞PR、生成修复代码并追踪安全态势,解决传统周期性渗透测试无法匹配现代高速开发节奏的痛点。
Developer Tools
GitHub
Security
AI安全测试
持续渗透测试
漏洞自动修复
DevSecOps
应用安全
代码安全
PR安全拦截
安全态势管理
企业安全
开源框架演进
用户评论摘要:用户主要关注其“验证漏洞”承诺的可信度,质疑AI工具普遍存在的误报问题,询问是否真能生成可复现漏洞的脚本;另有用户询问其对移动Web应用的支持范围。
AI 锐评
Strix Agents 的叙事核心是“用AI的速度对抗AI加速的开发”,这切中了当前DevSecOps最本质的矛盾。其从开源框架演进至平台化的路径,显示了市场对“持续安全”而不仅是“工具”的真实需求。产品将渗透测试从“周期性事件”重构为“持续过程”,并嵌入代码合并前这一关键卡点,意图将安全左移做到极致。
然而,其宣称的“利用证据验证”是最大亮点,也是最大风险点。AI安全工具长期困于误报的泥潭,若其真能通过生成可执行的漏洞复现脚本来实现高精度验证,将是技术上的显著突破;若做不到,则只是又一个包装精美的“幻觉生成器”。用户评论中的直接质疑,恰恰反映了市场最深的疑虑。
真正的价值不在于“AI黑客”的噱头,而在于它能否将安全专家的“上下文判断”与“验证逻辑”有效编码为可自动化的流程。其每日处理海量LLM令牌和数据,暗示了其试图通过规模数据迭代模型。成功与否,取决于其验证环节的工程严谨性,以及自动修复代码是否真正“可合并”、而非引入新问题。它不是在替代安全工程师,而是在竞争谁能更好地将工程师的智慧产品化、自动化。在AI重构一切工作流的当下,它的赛道正确,但最终的护城河将是“精准度”而非“速度”。
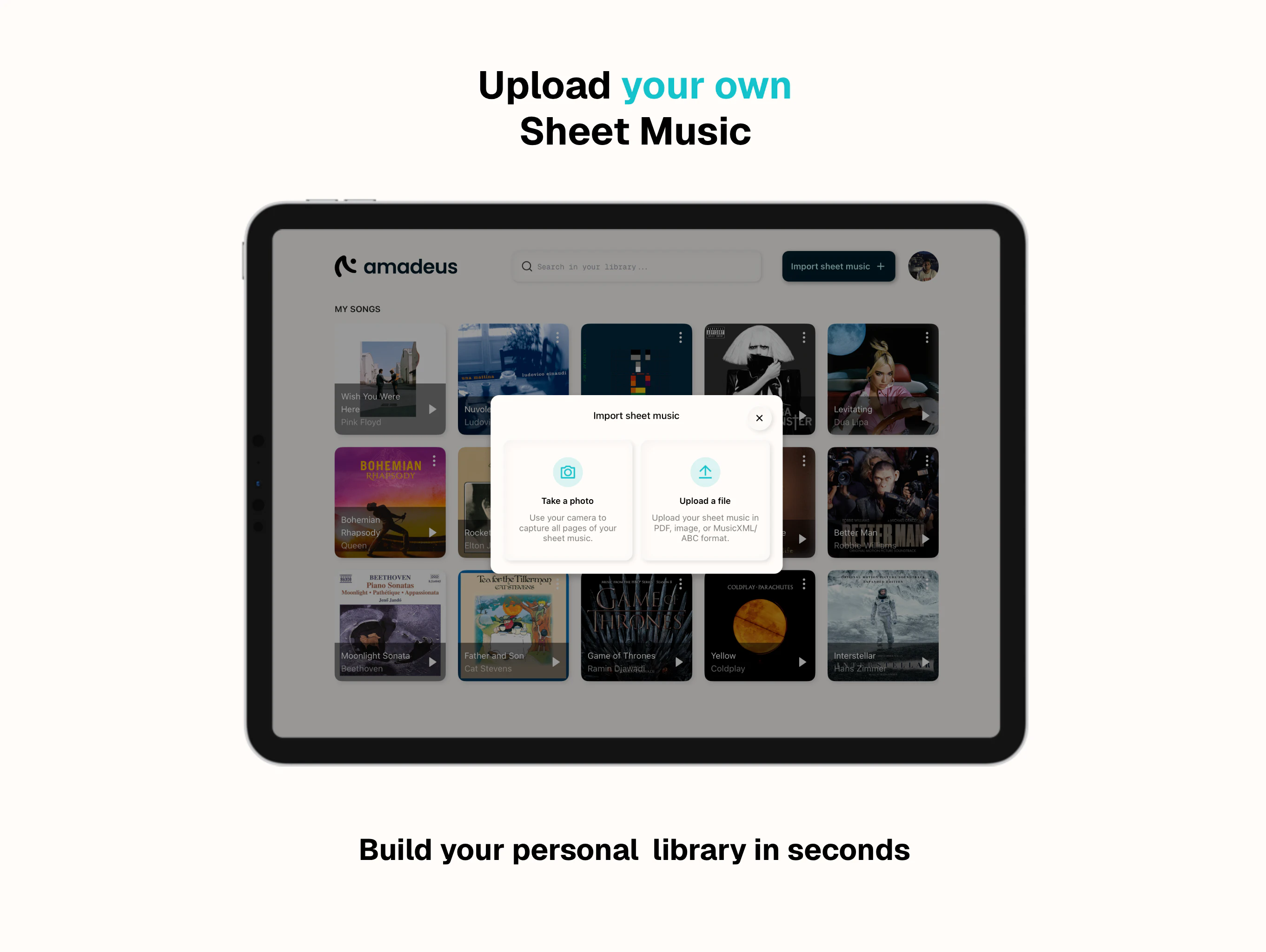
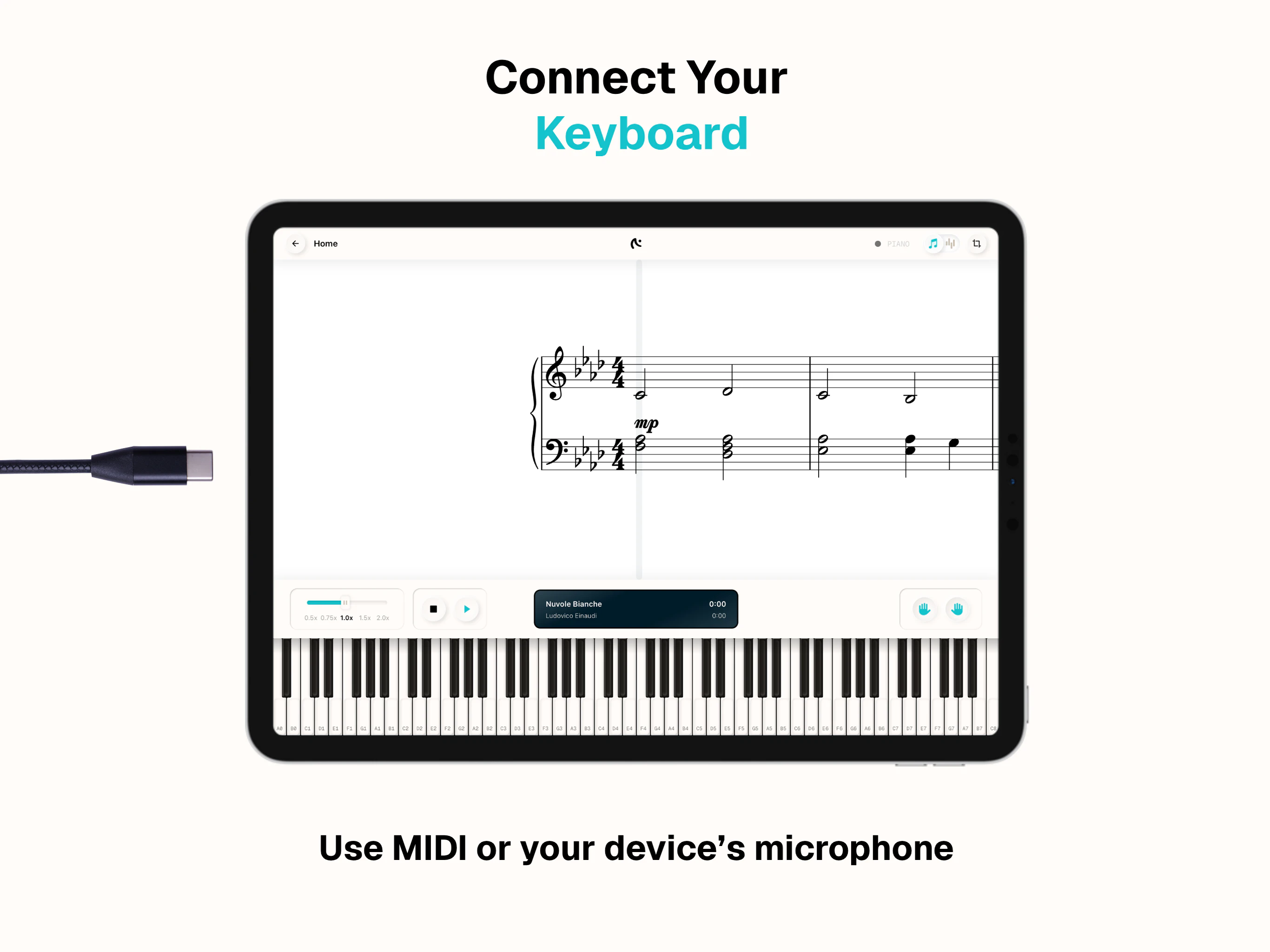
一句话介绍:Amadeus是一款钢琴学习应用,允许用户上传或扫描自有乐谱并连接电钢琴,通过实时反馈指导练习,解决了钢琴爱好者因识谱能力不足而无法自主练习心仪曲目的痛点。
Music
Education
钢琴学习
乐谱识别
实时反馈
音乐教育
数字乐器连接
技能提升
个性化练习
工具类应用
兴趣学习
移动应用
用户评论摘要:用户肯定其“自带乐谱”模式优于竞品,建议面向钢琴教师社群推广并制作短视频演示。开发者确认暂不支持蓝牙连接和乐谱编辑功能,产品定位为“上传即用”的便捷体验。
AI 锐评
Amadeus看似切入了一个精准的利基市场——为那些拥有乐谱和乐器,却卡在识谱门槛上的“半途而废”型钢琴爱好者提供解决方案。其真正的颠覆性不在于技术(乐谱识别、实时音准比对已非新鲜事),而在于其“乐谱平权”策略。它没有像Simply Piano等主流应用那样,通过构建版权曲库来建立护城河和订阅制依赖,反而反其道而行之,将乐谱的选择权完全交还给用户。这本质上是一种“基础设施”思维:将自己定位为连接任意乐谱与任意数字钢琴的通用翻译层和实时教练。
这种模式的潜在风险与机遇同样明显。风险在于,其体验高度依赖于用户自有乐谱的质量和格式兼容性,“上传即用”的承诺在复杂乐谱面前可能打折,且缺乏结构化课程体系可能削弱用户长期粘性。机遇则在于,它精准地切中了音乐学习中最个性化的情感需求——“学我所爱”。这使其能绕过昂贵的版权采购,以极轻的模式快速启动,并可能成为钢琴教师推荐的理想辅助工具,嵌入线下教学场景。
然而,其长期发展面临一个核心拷问:当工具效率足够高时,用户一旦跨越了初期的识谱障碍,是否还需要这个“拐杖”?这要求产品必须从“练习辅助”向“深度学习伙伴”演进,例如引入基于用户错误模式的智能针对性训练,或构建围绕同一乐谱的社交化练习社区。目前其“非编辑”的简洁定位是一把双刃剑,在吸引大众用户的同时,也可能将更严肃的音乐学习者推向其他专业软件。它的未来,取决于能否在“降低门槛”的便利性与“提升能力”的深度价值之间找到平衡点。
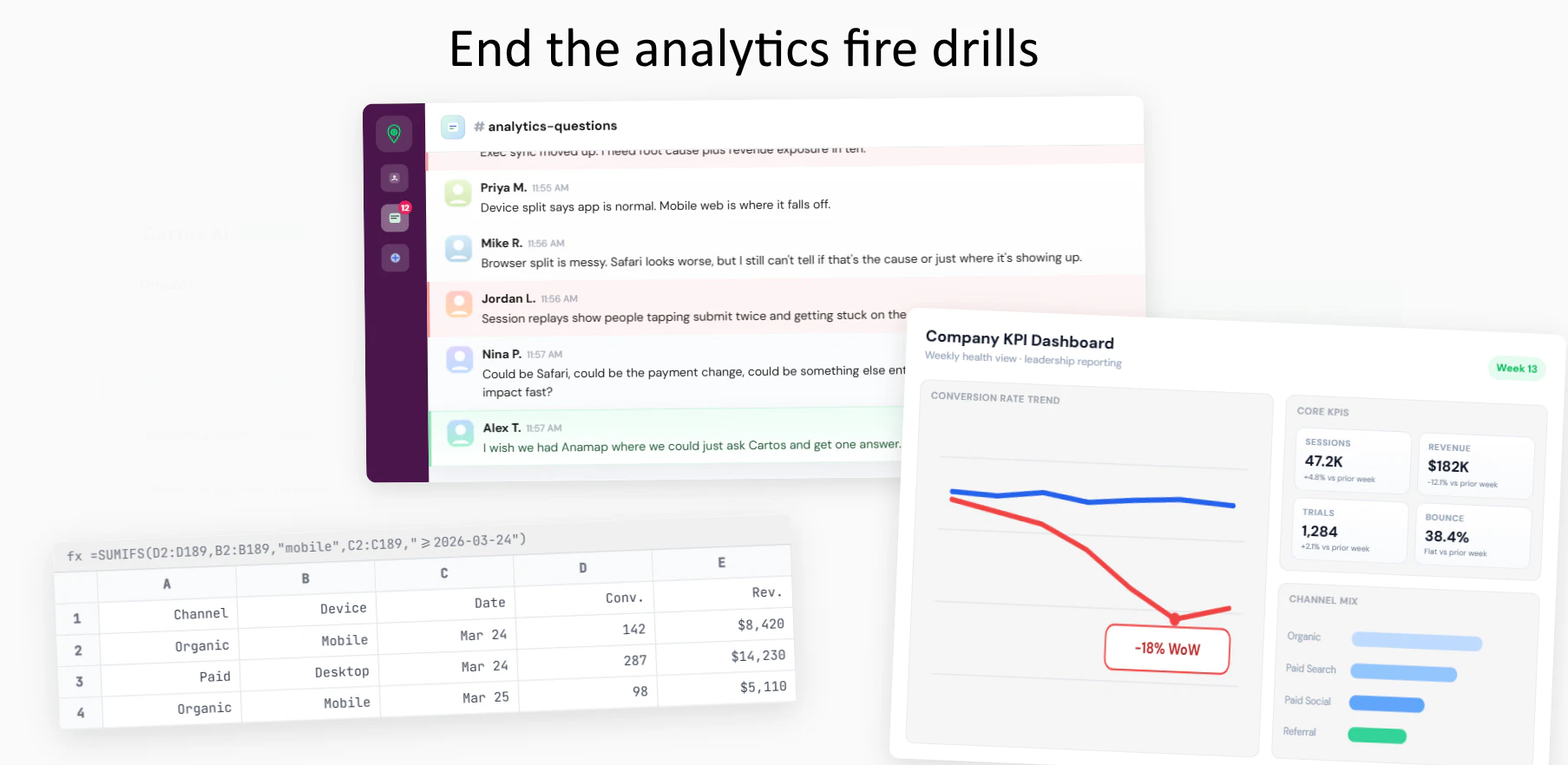
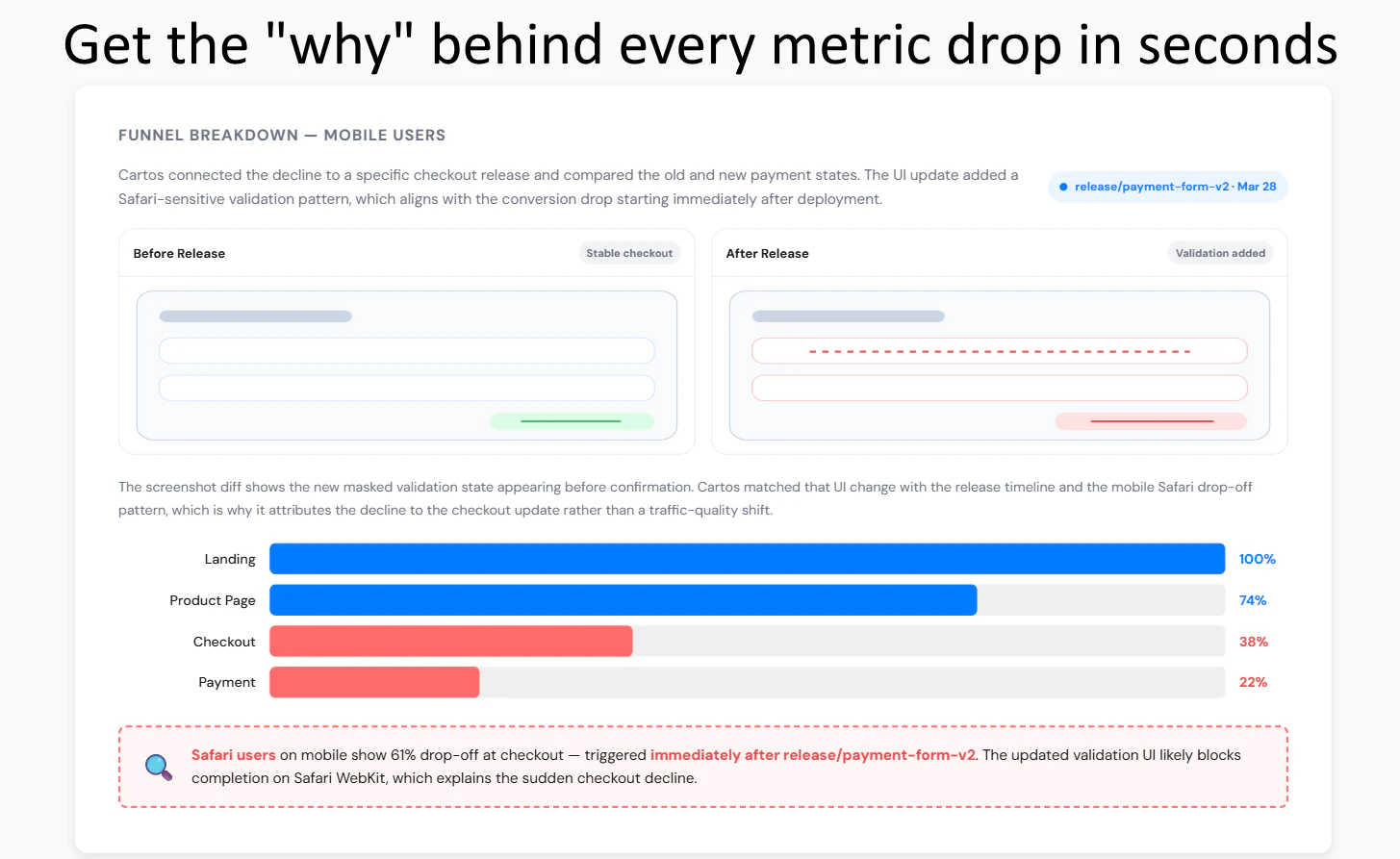
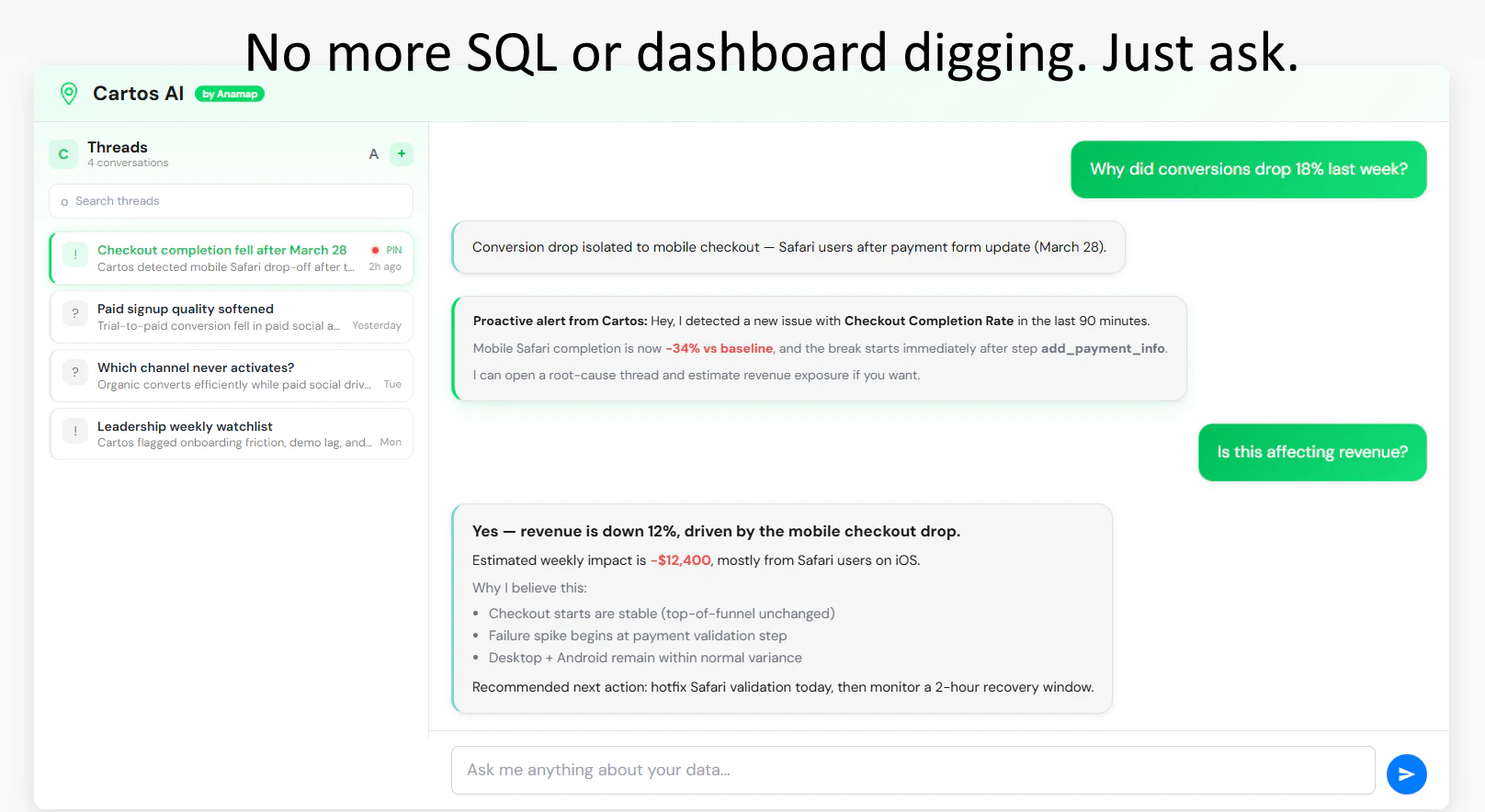
一句话介绍:Anamap是一款AI驱动的根因分析工具,它能在关键业务指标下跌时,自动关联分析仪表盘、用户行为与代码发布等多维度数据,用自然语言揭示问题根源,将团队从耗时的手动排查中解放出来,专注于业务增长。
Analytics
SaaS
Artificial Intelligence
AI数据分析
根因分析
指标异常检测
自动化诊断
业务洞察
SaaS
数据智能
增长工具
用户评论摘要:用户认可产品解决“数据迷雾”痛点的价值,期待其减少不确定性和手动工作。主要问题与建议集中在:AI分析的置信度如何透明化(已获解答);产品与现有数据源(如Google Analytics)的定位关系,澄清其是分析层而非数据收集层。
AI 锐评
Anamap(其AI代理名为Cartos)的核心理念并非替代BI仪表盘,而是试图填补“看到问题”与“理解问题”之间的行动鸿沟。它真正的野心是成为数据驱动决策闭环中的“推理引擎”,将资深分析师的经验与工作流自动化。
其价值不在于算法本身有多神秘,而在于产品设计上的关键洞察:第一,它强调“全栈关联”,敢于将代码发布等开发数据纳入分析范畴,这直指现代SaaS指标波动的常见盲区。第二,它提出“可审计的同事”这一概念,回应了当前AI应用最关键的信任问题——不仅给出结论,还展示推导过程和信心指数,允许人工干预纠正,这是一种务实的“人机协同”思路。
然而,其面临的挑战同样清晰。首先,产品效果高度依赖于客户数据栈的完整性与规范性,在混乱的数据基础上,AI很可能输出“精致的废话”。其次,从“解释现象”到“指导行动”仍有距离,如何将根因分析无缝嵌入到Jira、Slack等协作工具中,形成修复闭环,将是其能否从“聪明助手”升级为“核心系统”的关键。当前市场不乏监控和BI工具,Anamap若仅停留在生成解释性报告层面,其差异化优势可能被快速追赶。它必须证明,其节省的排查时间能切实转化为可衡量的增长加速,而不仅仅是另一份需要解读的分析报告。
一句话介绍:Creativly是一个社区驱动的AI视觉平台,通过专属生成器让创作者无需学习提示词或设计技能,即可在品牌实验、营销物料制作等场景中快速生成高品质视觉概念,解决创作流程繁琐、专业门槛高的痛点。
Design Tools
Marketing
Artificial Intelligence
AI设计
视觉生成平台
社区驱动
无代码创作
品牌设计
营销素材
产品模型
创意工具
工作流自动化
用户评论摘要:用户认可“社区工作室”概念,认为其能简化工作流。核心反馈聚焦于品牌风格一致性,质疑其能否从“玩具”变为“专业工具”,并建议增加品牌预设功能。创始人回应可通过自建生成器实现一致性。
AI 锐评
Creativly的野心不在于做出另一个“更好的AI生图工具”,而在于试图构建一个视觉创作的“操作系统”。其核心价值是“生成器即产品”,通过将复杂提示词工程封装成傻瓜式模块,并开放社区自建,它本质上是在交易标准化的“创作工作流”。
产品聪明地避开了与Midjourney等巨头在生图质量上的正面竞争,转而攻击“工作流中断”和“提示词学习”这两个应用层痛点。其宣称的“无需技能”实为将技能门槛从用户转移到了社区中的生成器构建者身上,平台则成为工作流的分发市场和执行引擎。这种模式能否成功,取决于两个关键:一是社区能否形成高质量UGC生成器的飞轮效应,二是能否解决评论中尖锐指出的“品牌一致性”问题。
目前来看,产品仍处于早期。自建生成器虽能部分解决风格统一,但对普通用户而言仍是门槛。若不能推出系统级的品牌资产管理和风格继承功能,它将很难切入真正的商业设计场景,而只能停留在灵感激发和一次性创作的“玩具”阶段。其真正的挑战在于,如何在降低操作复杂性的同时,不牺牲商业创作所必需的精准控制和一致性——这是所有AI设计工具迈向专业化的必答题。
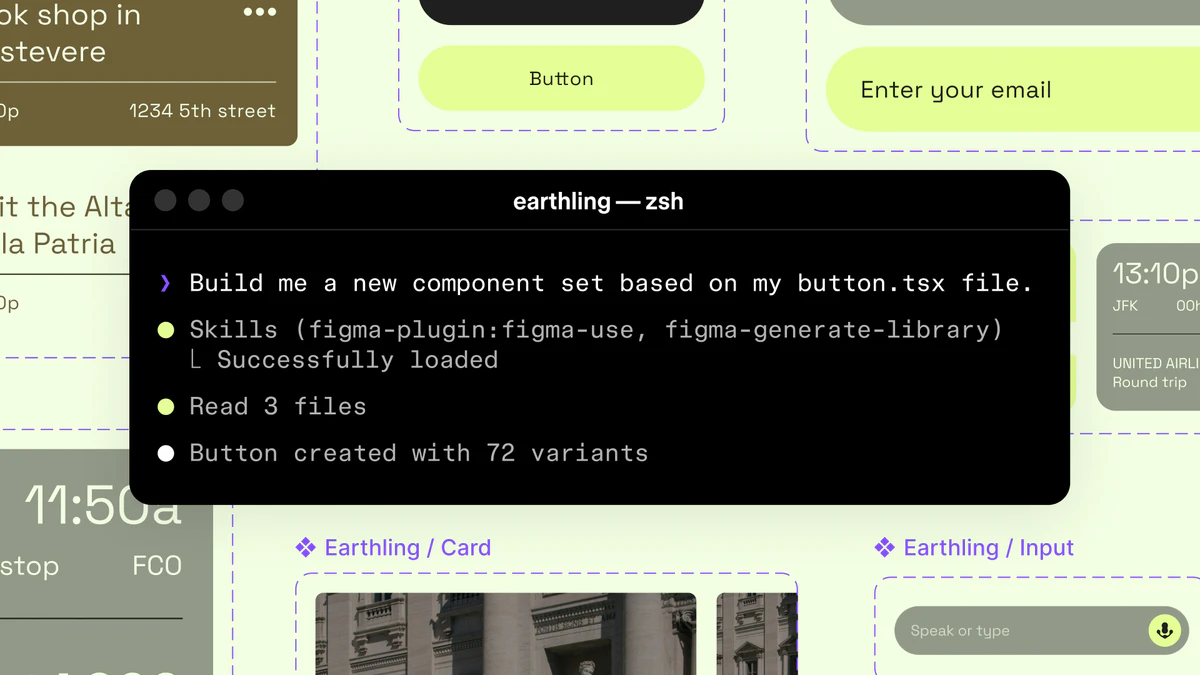
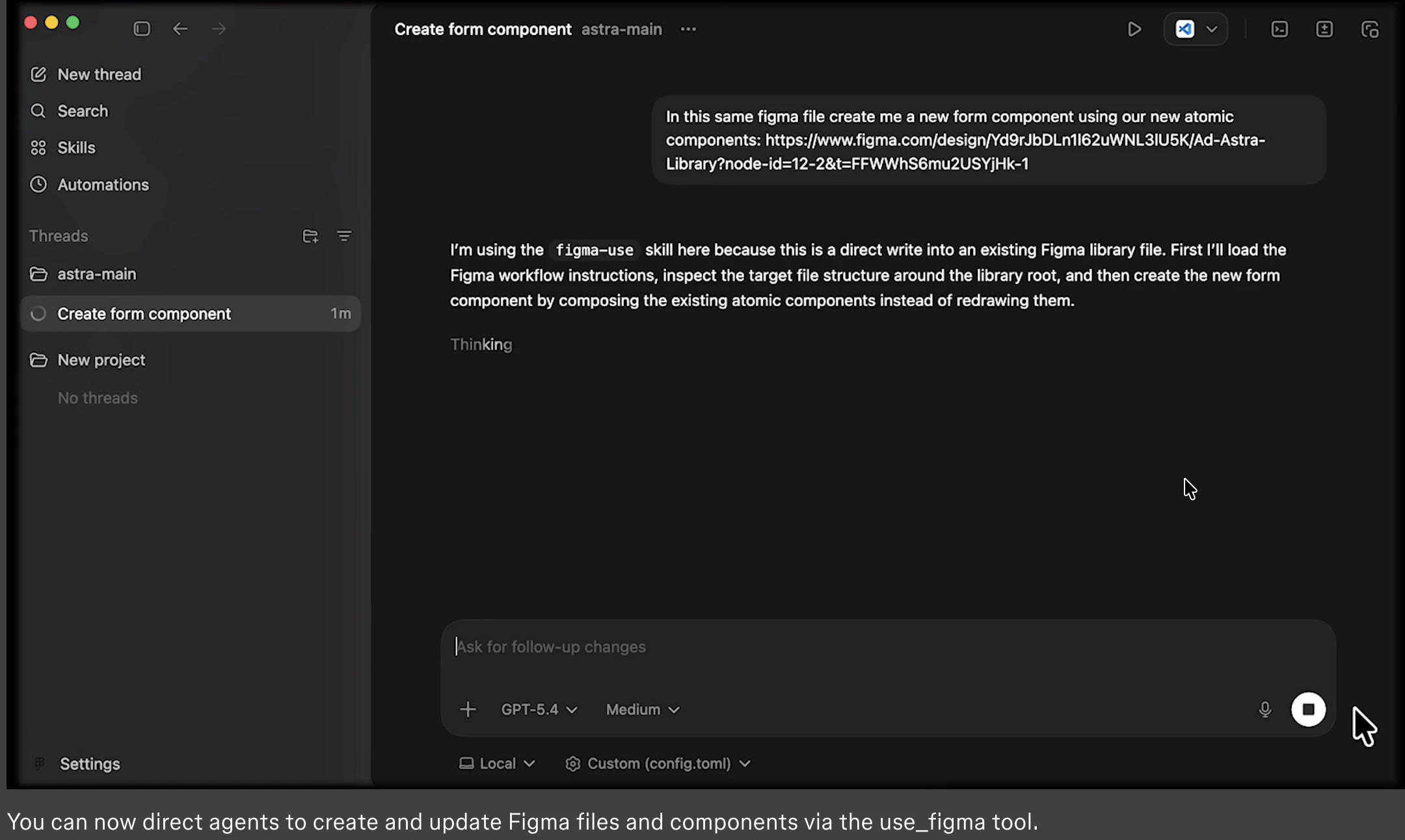
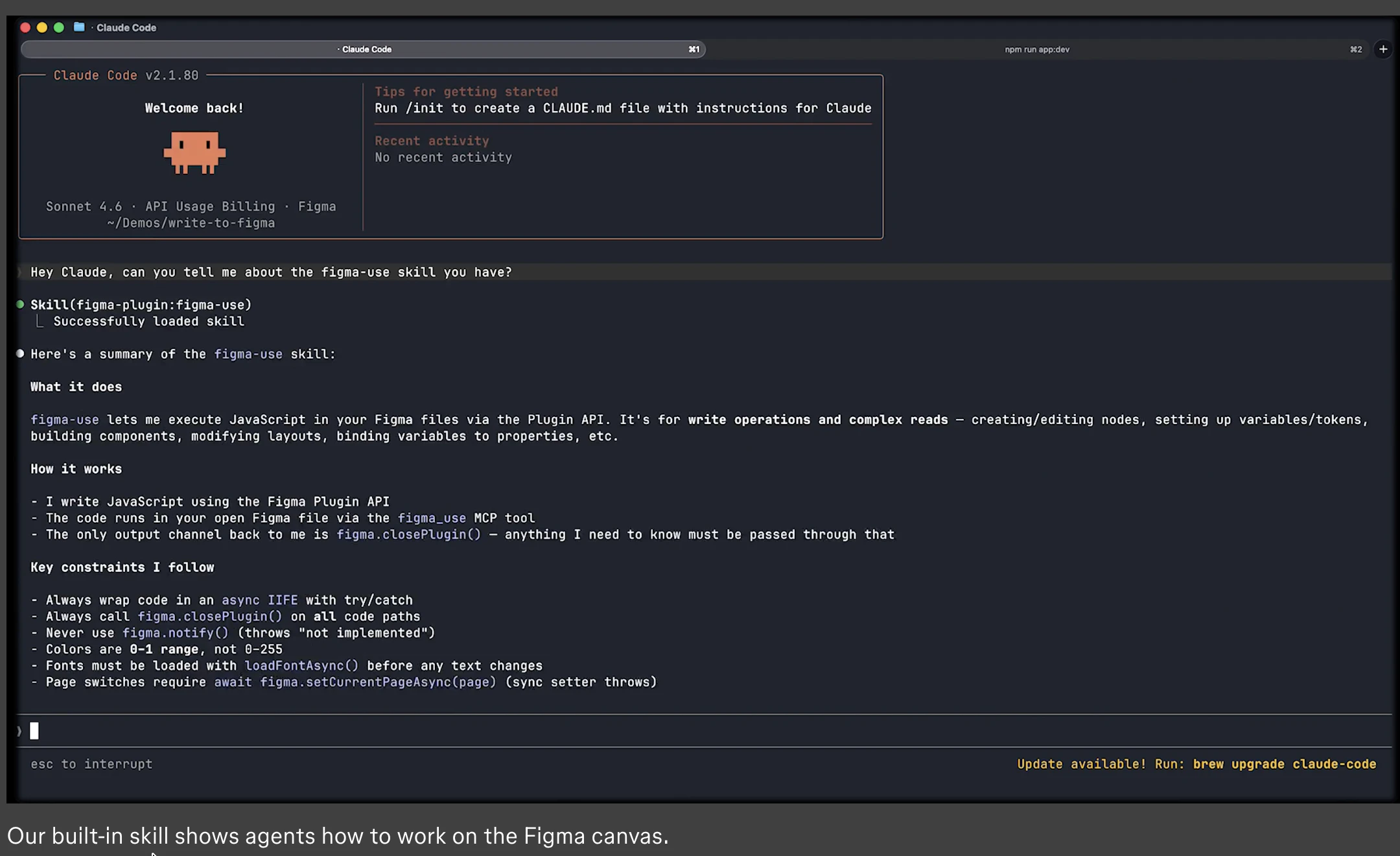
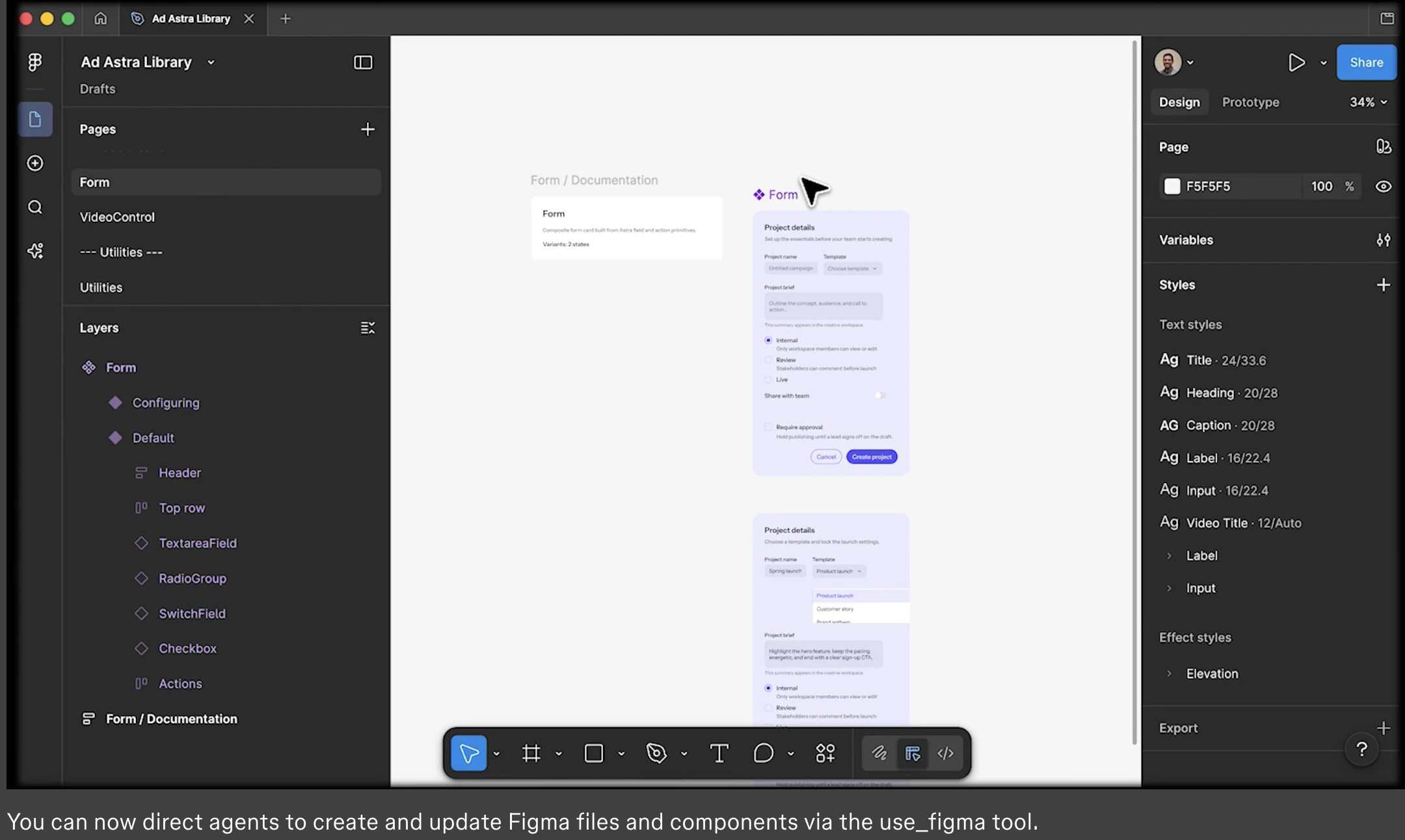
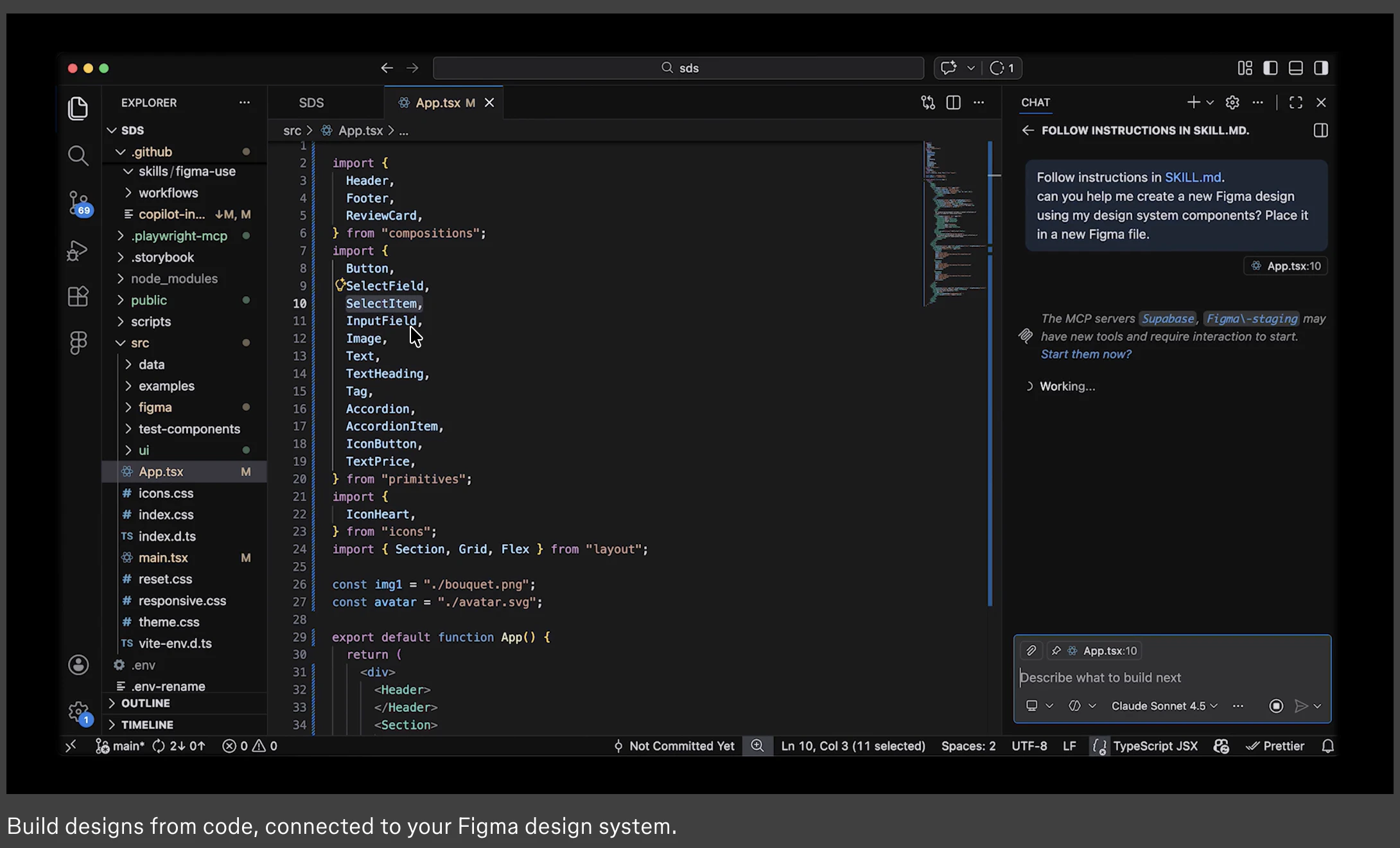
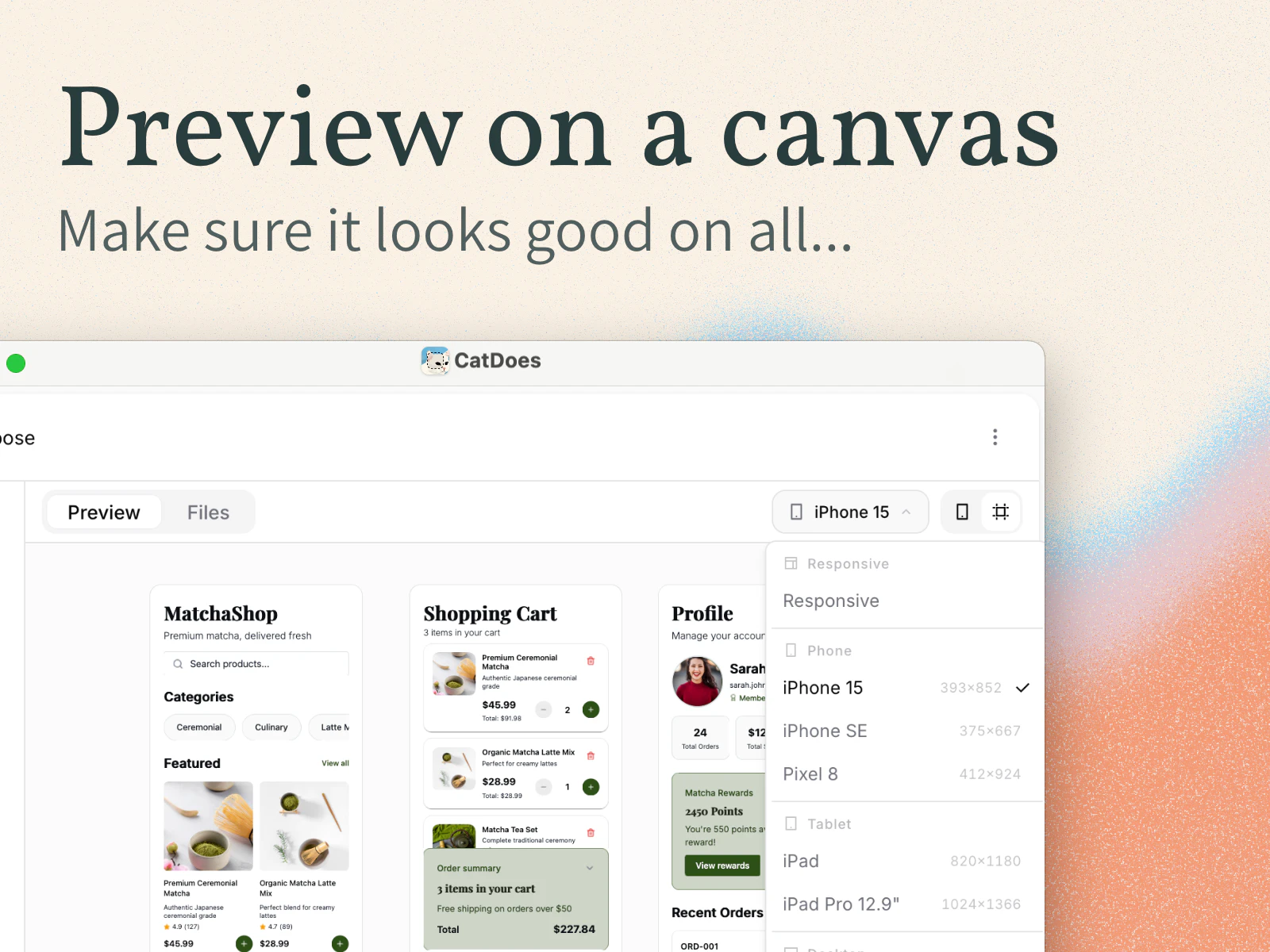

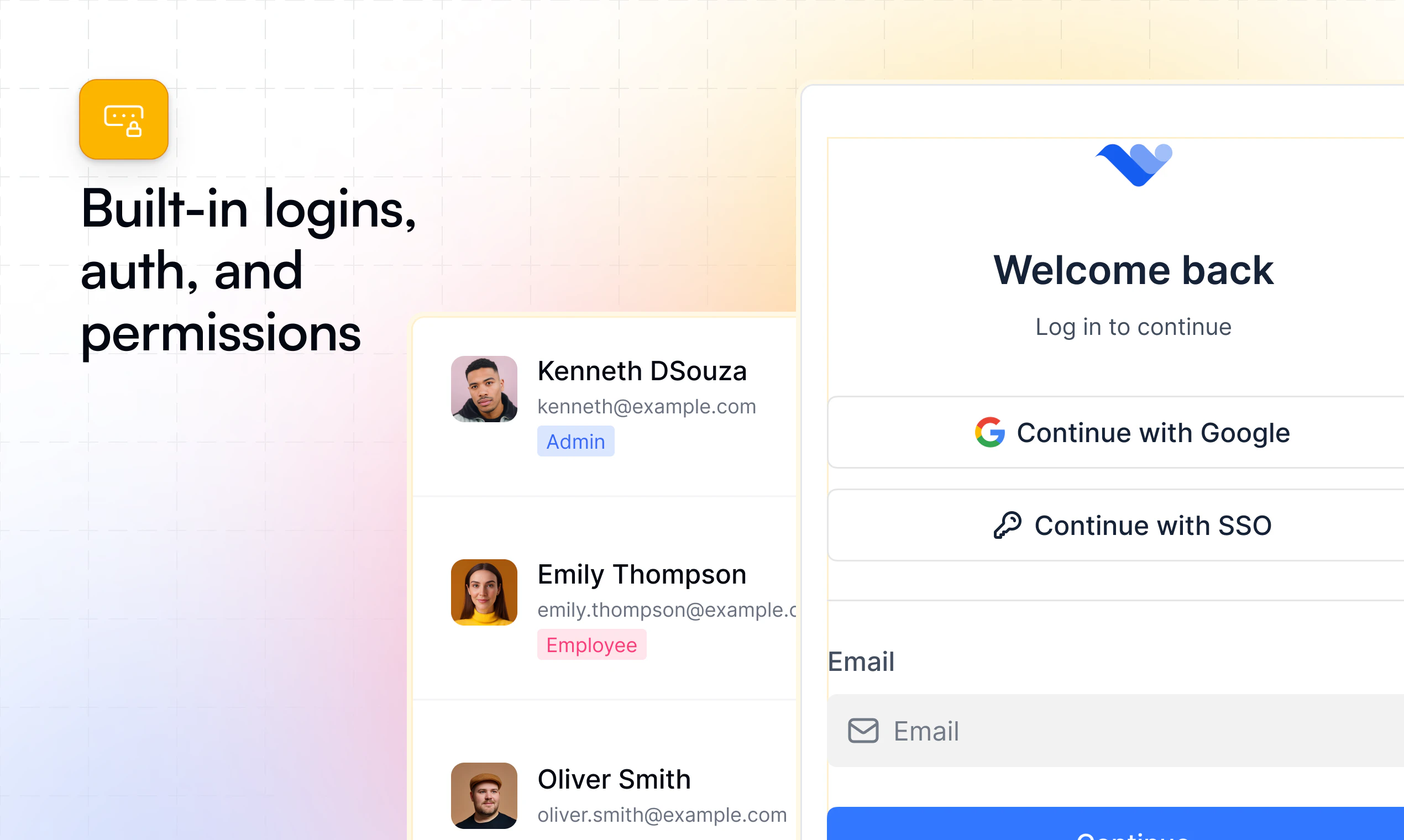
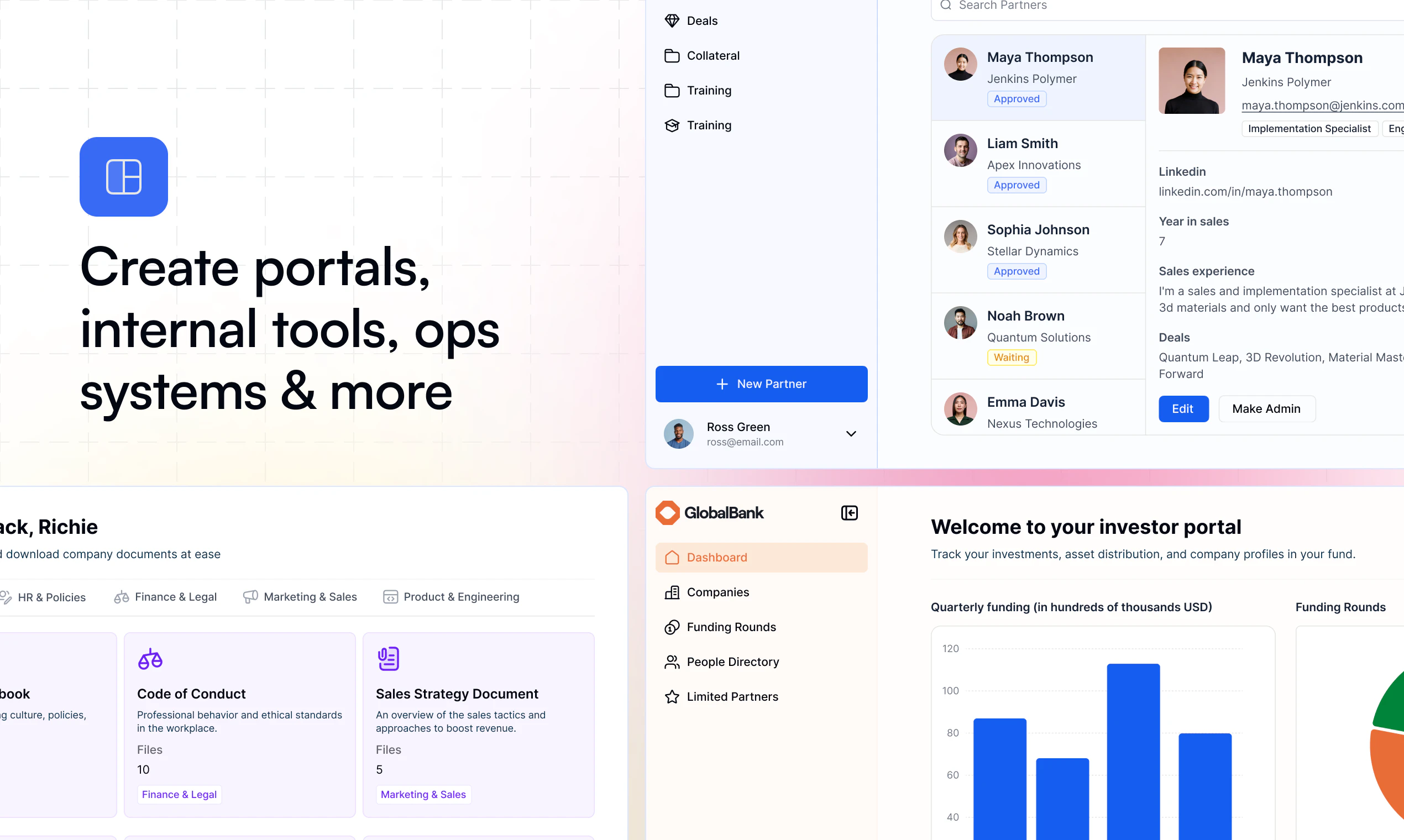
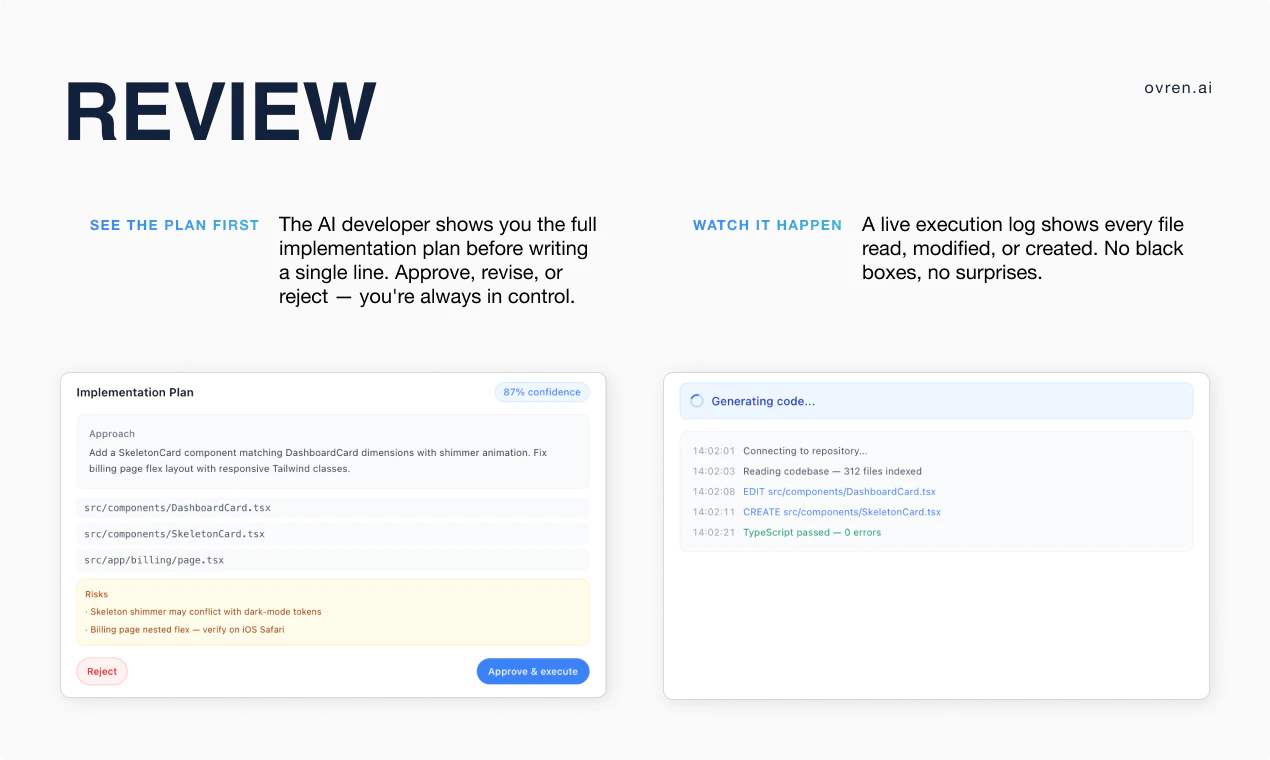
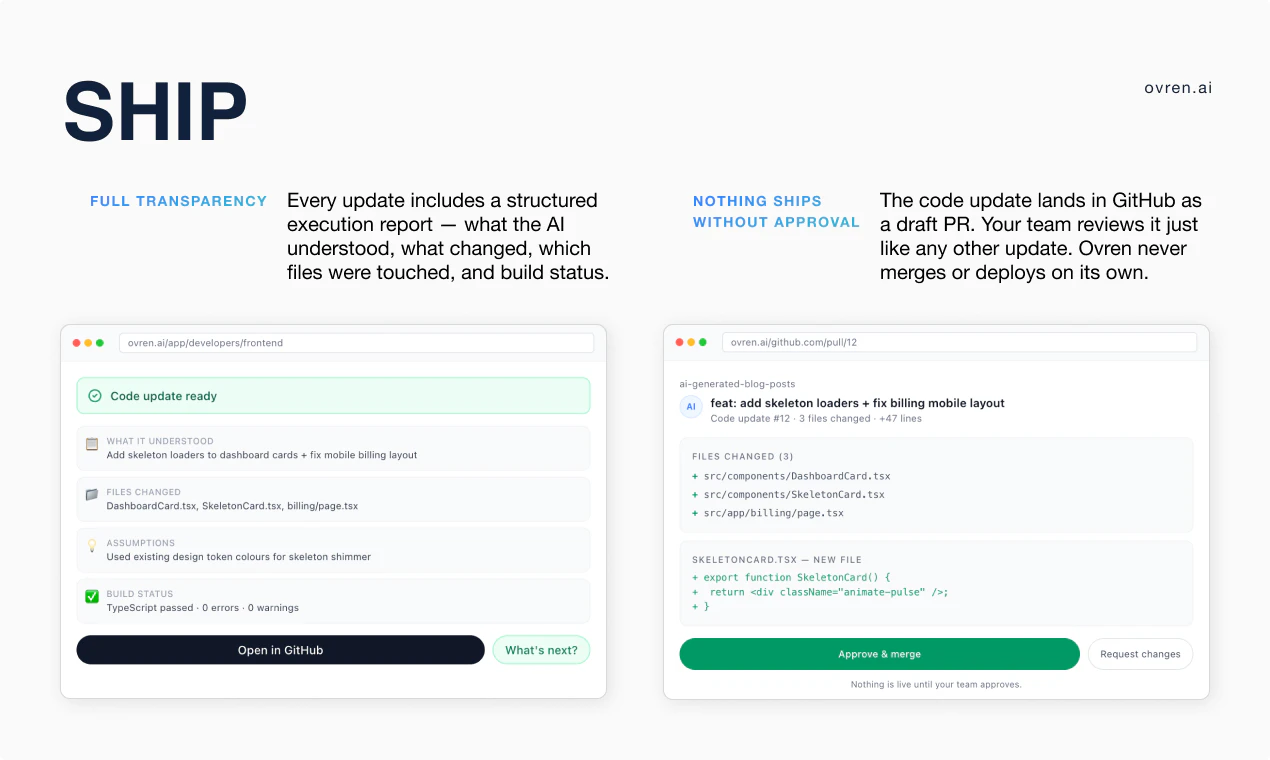










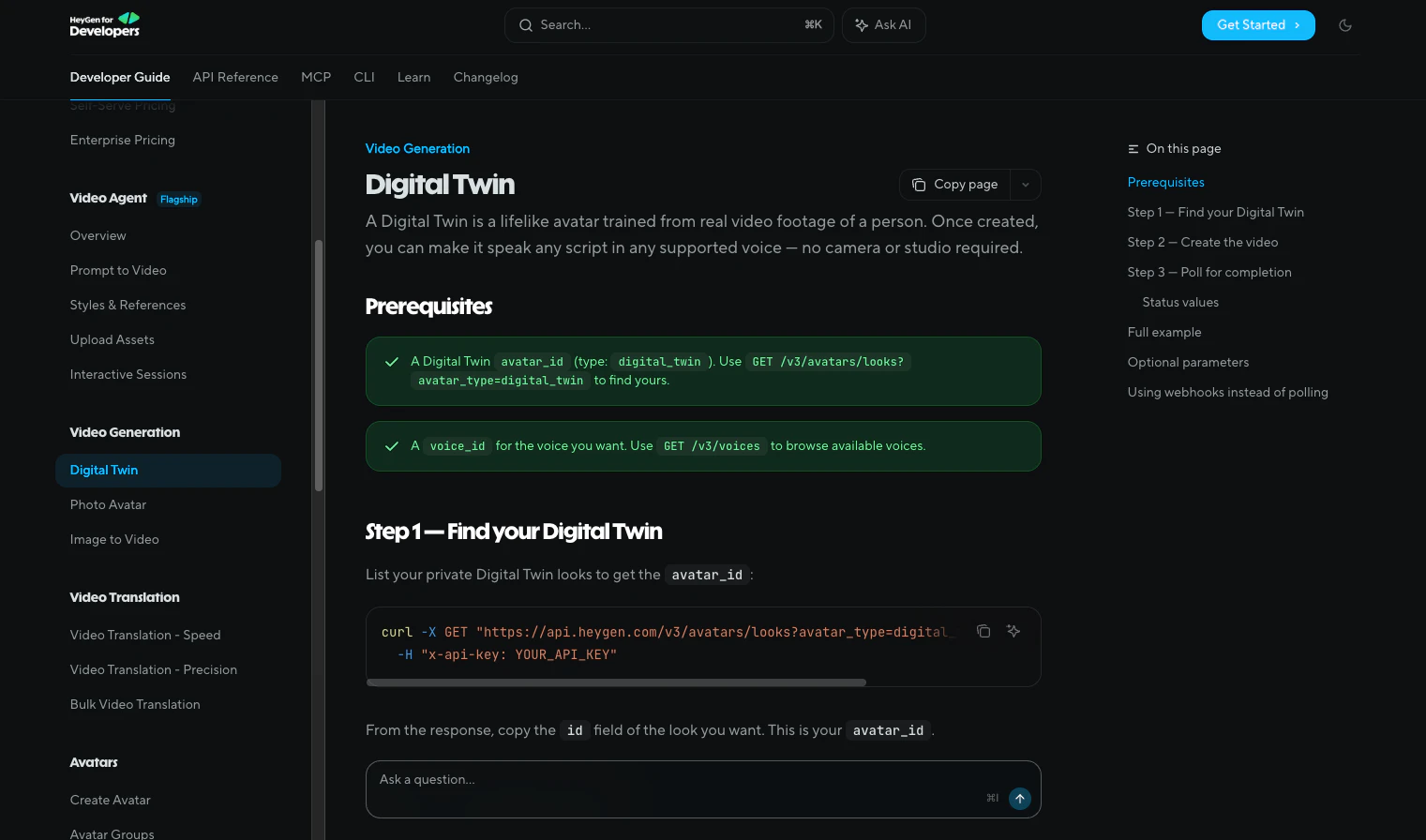










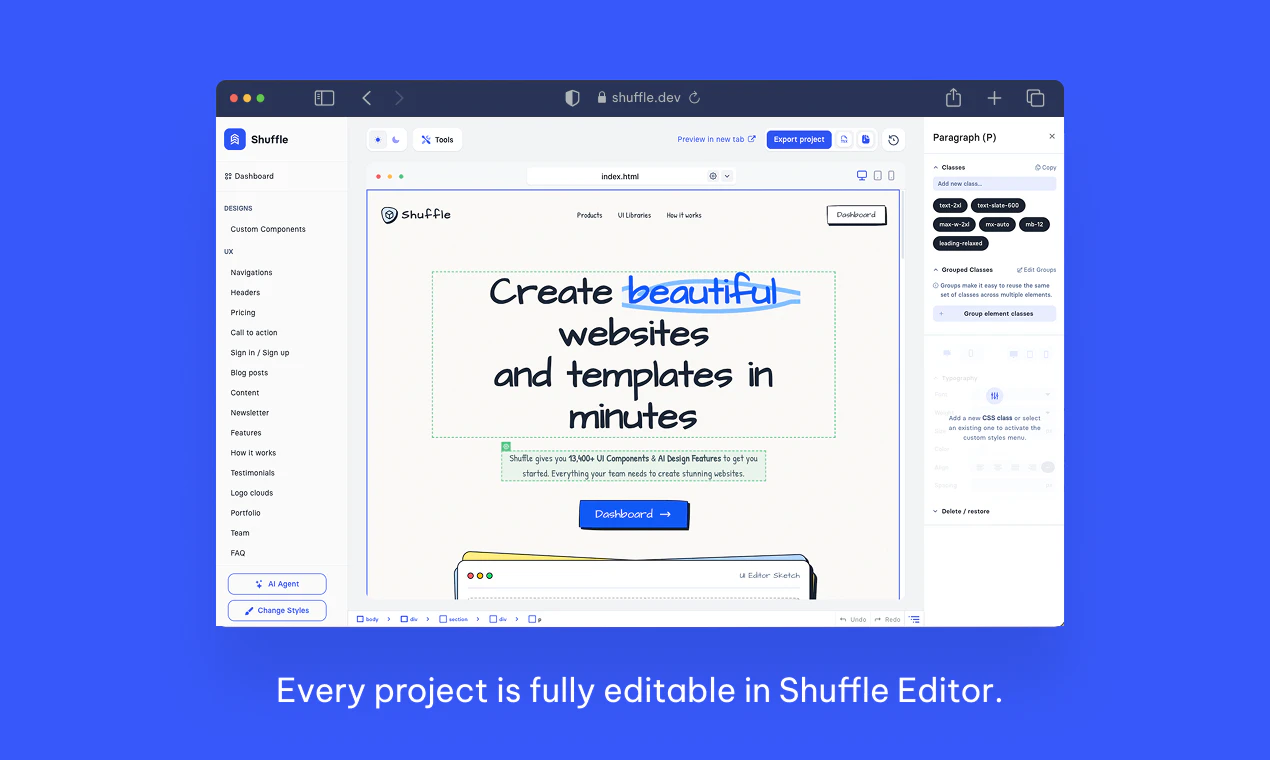






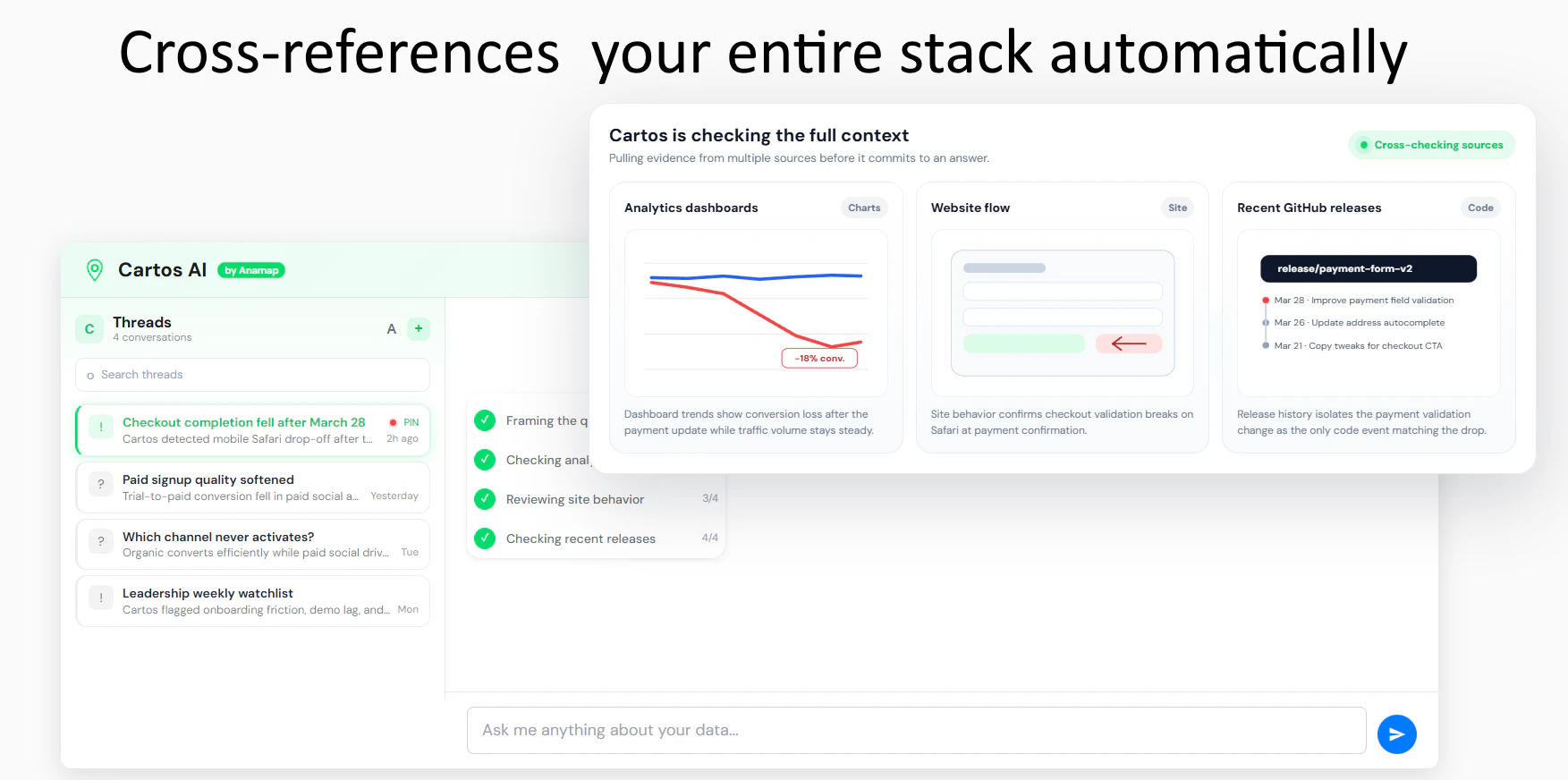

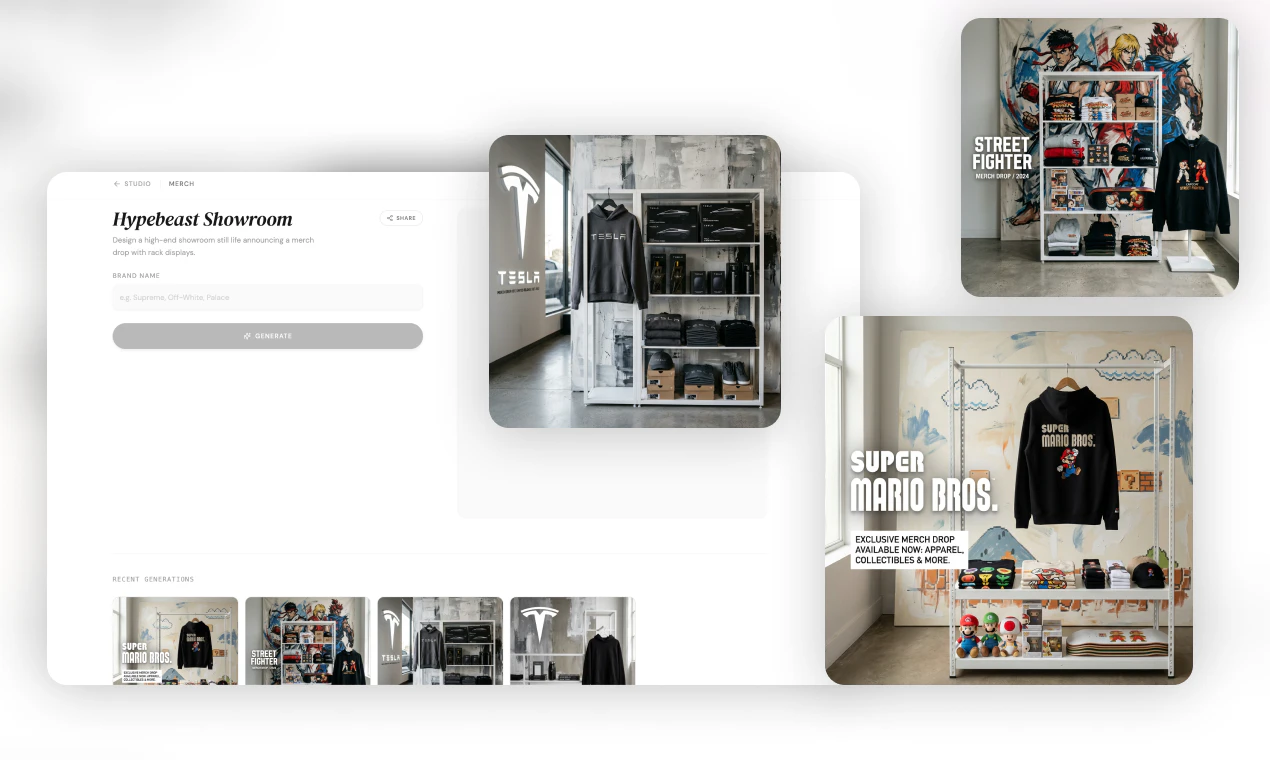


Figma opened the canvas to agents.
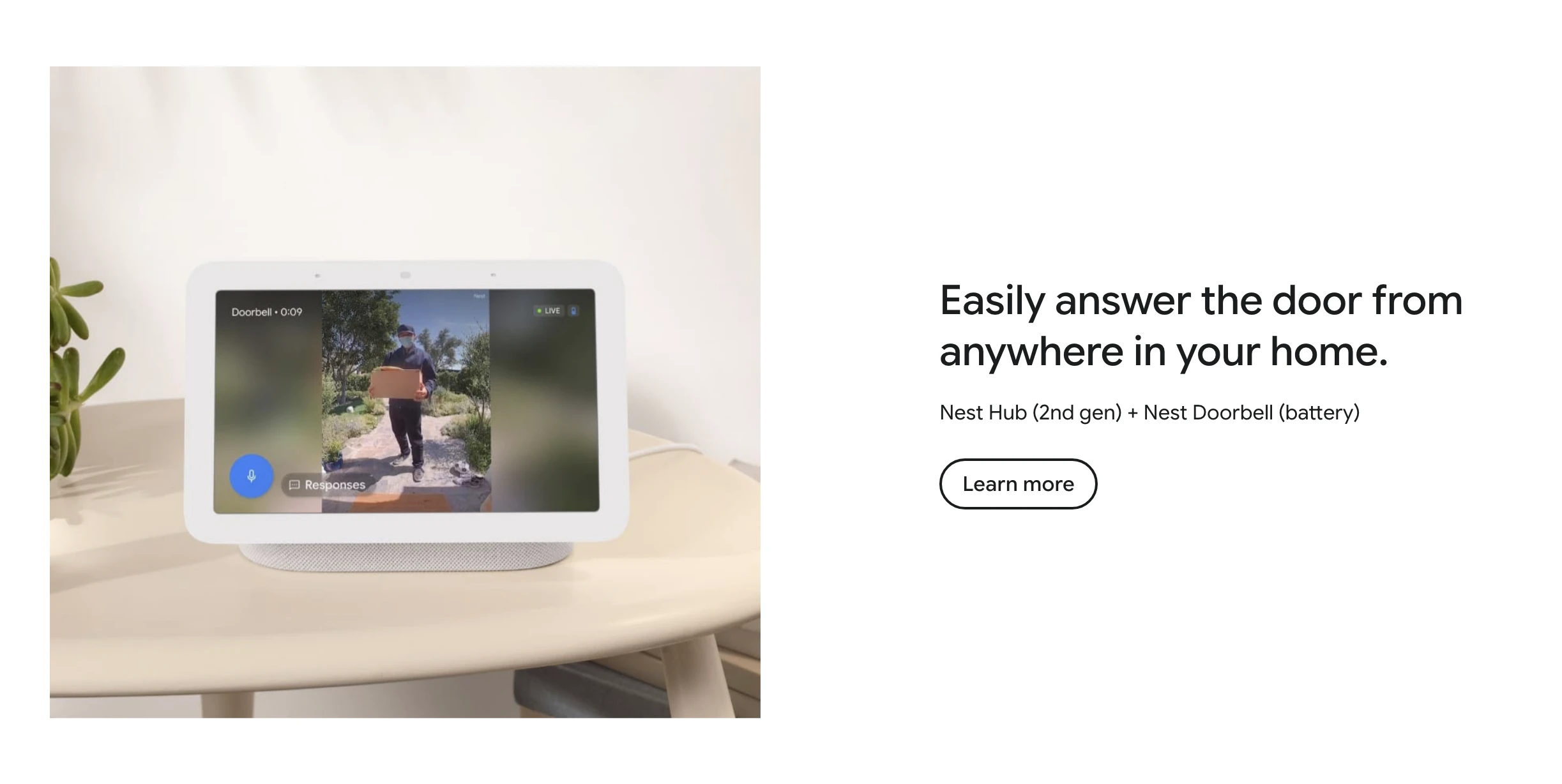
What is it: Figma's use_figma MCP tool lets AI agents create and edit designs directly in Figma, working with your actual components, variables, and auto layout not against them.
The problem: Every AI-generated design has the same tell: it doesn't look like your product. Components are invented. Spacing is arbitrary. The output is technically a UI, but it's nobody's design system. So designers throw it out and start over.
The solution: Skills are markdown files that encode your team's design conventions. Agents read them before touching the canvas. Combined with use_figma, agents now have both access and context they know how to work in Figma and they know how to work in your Figma.
What you can do with it:
🏗️ Generate component libraries from a codebase
🔗 Sync design tokens between code and Figma variables, with drift detection
♿ Auto-generate screen reader specs from UI designs
🔄 Run parallel workflows across multiple agents
Who it's for: Product and design-engineering teams that use Figma as the shared source of truth and want their AI agent workflows to stay connected to it. Heavy users of Claude Code, Codex, Cursor, and Copilot will feel this immediately.
P.S. I hunt the latest and greatest launches in tech, SaaS and AI, follow to be notified → @rohanrecommends
This is exactly what multi-agent platforms need. We're building Kepion — an AI company builder with 31 specialized agents, including Maya (Designer) and Kai (Frontend Dev). Right now Maya outputs design tokens and Kai codes them into React components. But there's a gap: Maya can't "see" or "touch" actual design files.
Figma for Agents closes that gap. If Maya could create and edit directly in Figma using this MCP tool, then hand off real Figma components to Kai for implementation — the design-to-code pipeline becomes seamless. No more translating between "design spec as text" and "actual visual design."
Two questions: does use_figma support reading existing design systems (variables, component libraries) so an agent can stay on-brand? And is there a way to export generated designs directly to code (React/Tailwind)?
Following this closely. The future of AI-generated products isn't just code — it's code that looks good.
Good to note that Figma is also innovating forward to stay competitive in the AI landscape. Congrats on the launch! Looking forward to trying it.
How does it handle the conflict when the code variables in Figma and the code base diverge? Congrats on the launch.
the screen reader spec generation is the most underrated part. a11y annotations are always manual, always late, and quietly ignored in code review anyway.
agents generating aria specs from actual design system components — if that's real, it's the first time accessibility sits upstream of the handoff, not downstream.
AI that doesn't treat Auto -Layout like a suggestion! Look forward to it!
Crazy. Would be happier if it works out great for multiple LLMs
This feels like a missing layer finally getting solved.
Most AI design tools create “usable UI”, but not your UI, which kills real adoption in teams. Connecting agents directly to the design system is the right direction.
If this actually maintains consistency at scale, it's not just a design tool upgrade; it changes how design and engineering collaborate.