PH热榜 | 2026-04-20
一句话介绍:Dune是一款上下文感知的Mac物理按键板,能根据前台应用自动切换三个按键的功能,为开发者和频繁开会人士自动化高频操作,减少工具切换和复杂快捷键的记忆负担。
Productivity
Artificial Intelligence
Development
智能硬件
Mac外设
生产力工具
自动化
上下文感知
AI助手
开发者工具
会议效率
可编程按键
工作流优化
用户评论摘要:用户肯定其设计理念和效率提升,关注核心技术细节:如何智能判定“最相关操作”、应用检测的准确性与延迟(200-600ms)、能否锁定按键功能、按键音量和高级自定义能力。创始人积极回复,解释了基于系统API的检测原理和自定义逻辑。
AI 锐评
Dune的野心不在于提供海量可编程按键,而在于用“情境智能”重新定义物理交互的逻辑。它本质上是一个“决策外设”,将用户从记忆和配置宏按键的负担中解放,代之以系统主动推送的、基于上下文的三个最优选项。这背后是对现代工作流,尤其是AI原生工作流演变的精准洞察:当操作对象从静态菜单变为动态AI Agent时,固定的快捷键体系已然失效。
其真正价值在于充当了物理世界与数字智能体之间的“低摩擦触发器”。无论是触发GitHub的PR流程,还是激活一个Claude Agent,它将多步、跨界的数字操作坍缩为一次确定的按压,提供了AI时代稀缺的“确定感”和“操控感”。垂直三键设计是反直觉的聪明之举,它承认了核心高频操作的有限性,并优化了手部移动路径。
然而,其核心挑战也在于“情境智能”的可靠性。200-600ms的检测延迟在快速切换场景下可能打断心流,而“最相关操作”的算法将是长期体验的关键。它目前更像一个“智能预设”而非“自适应学习”系统。能否从“理解应用”进化到“理解用户意图”,将决定它是下一个Stream Deck,还是一个昙花一现的精致玩具。它赌的是软件交互的复杂度已超越人类手动配置的意愿,这个赌注很大,但方向值得深究。
一句话介绍:一款通过蓝牙低功耗(BLE)API将Claude桌面应用状态(如会话、权限提示)连接到物理微控制器(如ESP32)的工具,为开发者和极客提供了将AI交互实体化、可触摸的创新方式,解决了AI交互缺乏物理反馈和沉浸感的痛点。
Open Source
Hardware
Artificial Intelligence
GitHub
硬件交互
AI实体化
开发者工具
物联网
蓝牙低功耗
微控制器
Claude生态
极客项目
人机交互
桌面伴侣
用户评论摘要:用户普遍认为这是一个极具潜力的创意起点,将AI与物理世界连接。主要问题集中在API功能细节(如事件流是否双向、是否只读)、未来扩展计划(如开放更多事件类型),以及具体的硬件兼容性(如GameBoy Color)。建议包括用于状态灯、电子看板等更丰富的硬件交互场景。
AI 锐评
Claude Desktop Buddy 表面上是一个为Claude桌面应用提供BLE API的小工具,但其真正的价值在于它悄然捅破了AI交互的“次元壁”。在AI交互被禁锢于屏幕像素和语音声波的当下,它提供了一个低成本、低门槛的“泄漏点”,让AI的抽象状态(如“正在思考”、“等待批准”)得以渗透进物理世界,变成一盏灯、一个桌宠或一块电子墨水屏的显示。这远不止是一个极客玩具。
其犀利之处在于两点:一是“轻”。它没有笨重地重新定义硬件,而是巧妙地利用了成熟的、开发者友好的微控制器生态(如ESP32、M5Stack),将创新成本降至最低,迅速激活了硬件创客社区的想象力。二是“桥”的定位。它目前聚焦于权限提示等核心交互点,看似功能单一,实则精准地锚定了AI助手工作流中“需要人类介入”的关键时刻,将其转化为一个可触摸的硬件事件。这为“被动式”或“环境式”AI交互奠定了基础——未来,你可能不再需要盯着屏幕等待Claude的提问,桌上一枚闪烁的灯光或一个玩偶的抬头就足以传达信息。
然而,其挑战也同样明显。目前的演示更像一个“单向状态广播”,评论中关于双向交互的疑问直指核心:如果硬件仅能“显示”而不能“输入”深层指令,其交互深度将大打折扣。此外,从酷炫的概念原型到稳定、安全的日常工具,还有很长的工程化道路要走。它能否从“有趣的实验”进化为“不可或缺的交互层”,取决于API的开放程度、事件流的丰富性以及是否能形成真正的硬件用例闭环。
总之,这不是一个成熟的产品,而是一颗精心投掷的“思想石子”。它的出现,其象征意义大于当前功能:它宣告了AI交互不再满足于虚拟世界,开始正式向物理空间“殖民”。无论这个项目本身未来如何,它所指向的“具身化AI交互”方向,无疑值得所有从业者侧目。
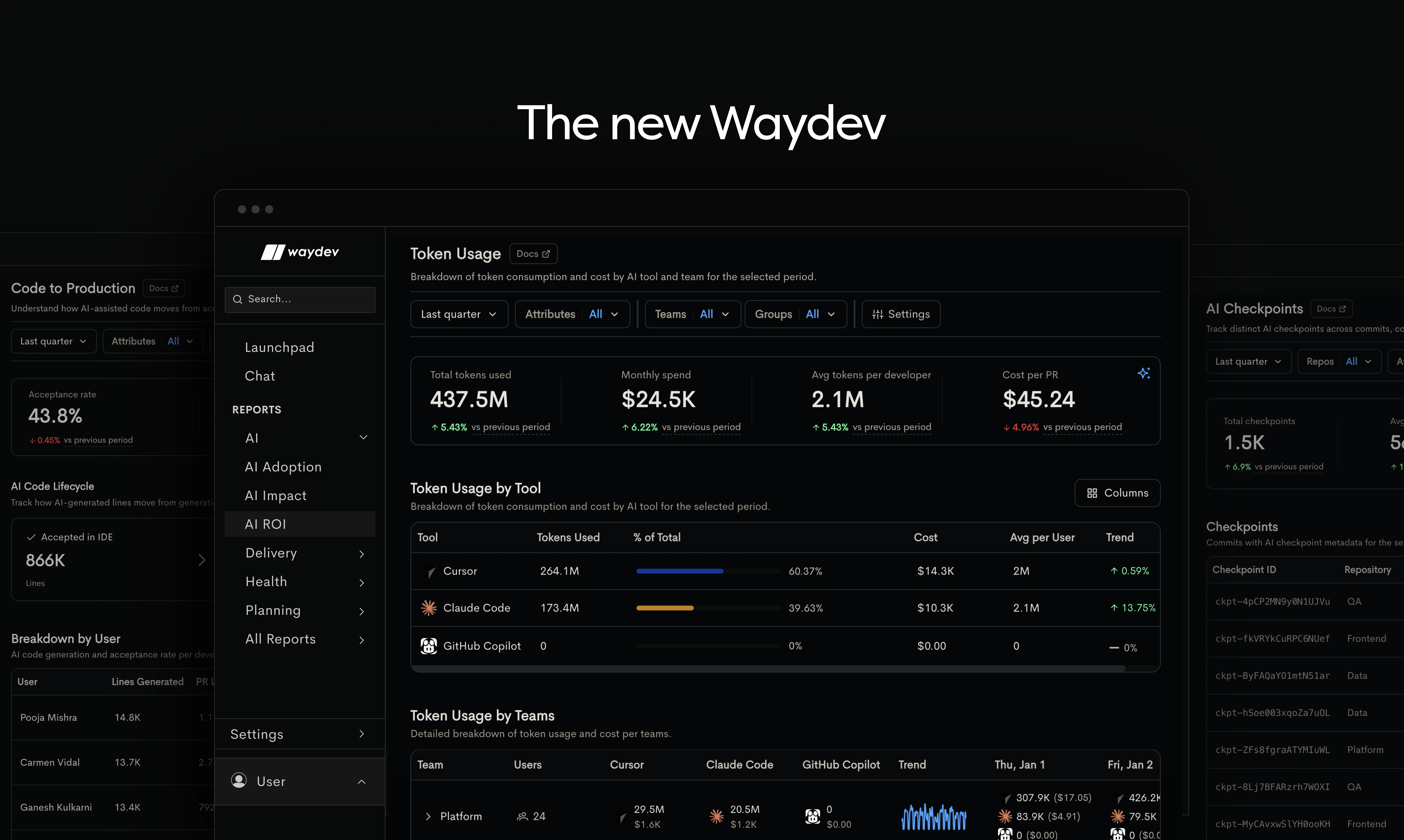
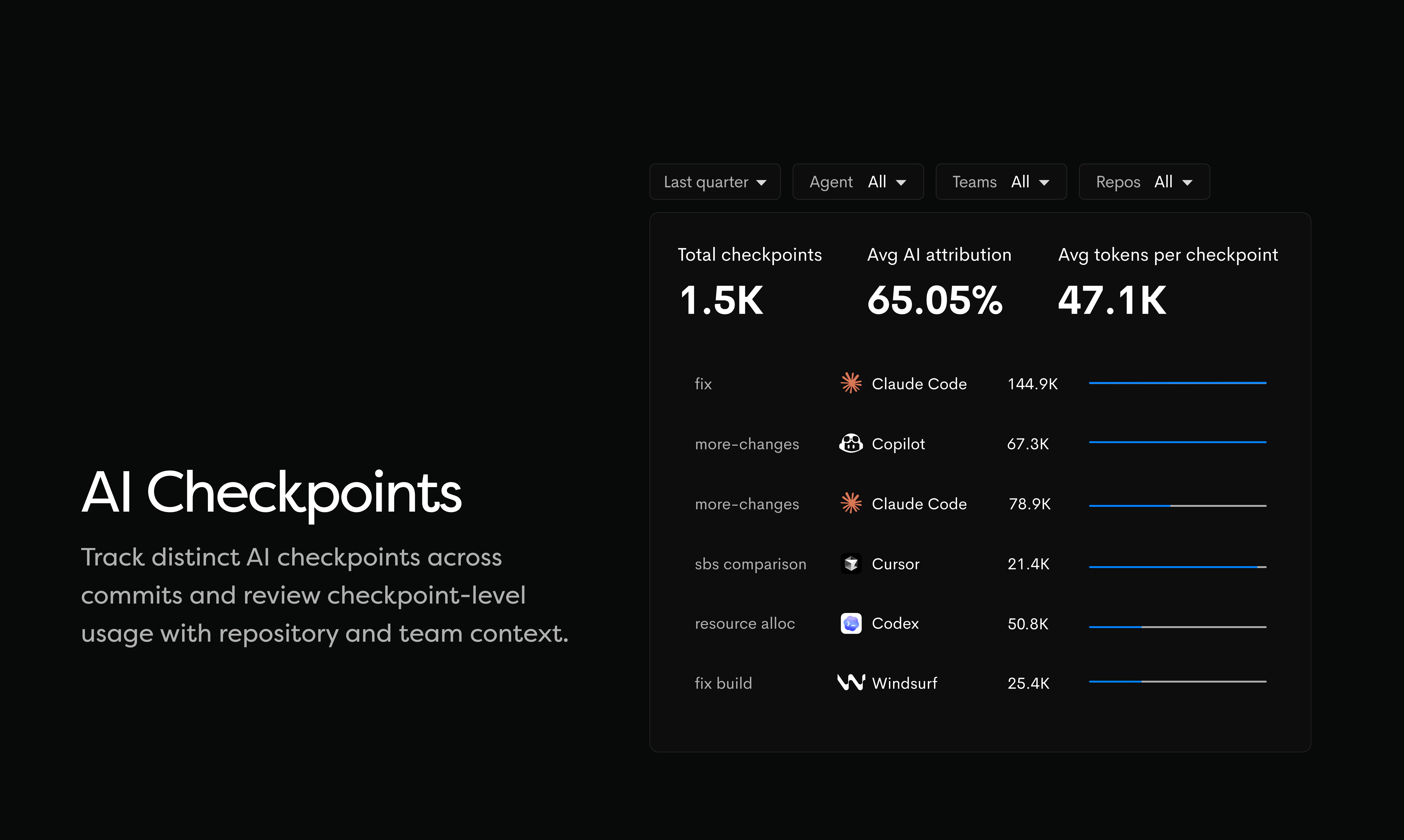
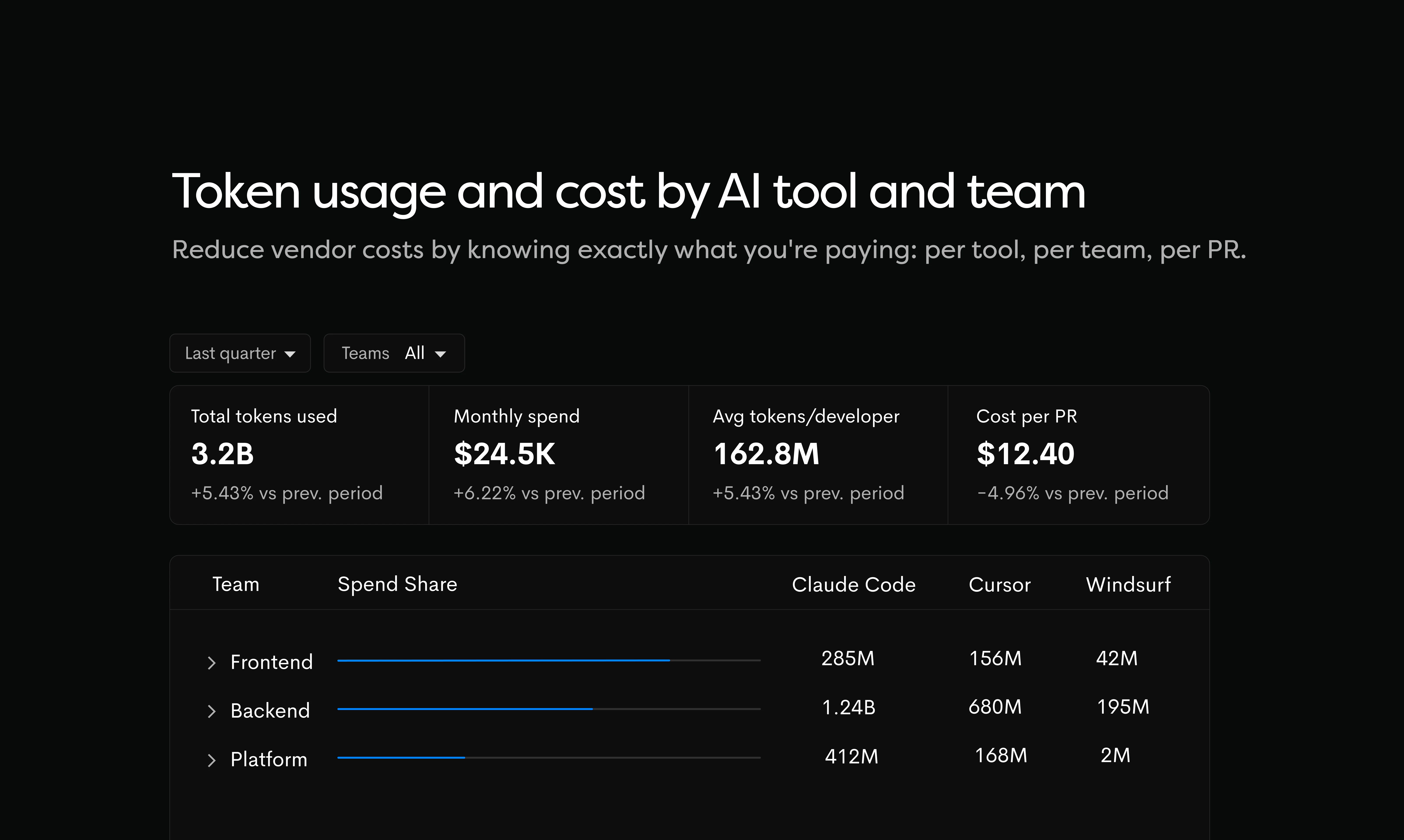
一句话介绍:Waydev是一款AI软件开发生命周期分析平台,通过在代码提交层面追踪AI生成代码从IDE到生产环境的全流程,解决了企业因无法量化AI编码工具实际产出与投资回报率而造成的资源浪费痛点。
Productivity
Developer Tools
Artificial Intelligence
AI代码分析
工程效能
开发运维
成本管控
ROI衡量
软件开发
数据驱动
开发工具
智能监控
团队协作
用户评论摘要:用户普遍认为该产品切中了当前AI编码工具“只知用量,不知成效”的核心盲点,对“成本/每个已合并PR”等实际ROI指标表示赞赏。主要问题集中于:如何精确进行多AI代理贡献归因、如何避免工具沦为开发者监控、以及与现有工程指标工具的差异化。
AI 锐评
Waydev的发布,与其说是一款新产品,不如说是对当前狂热AI编码工具市场的一剂“清醒剂”。它试图回答一个被速度幻觉掩盖的关键问题:当AI代理疯狂消耗token产出代码时,多少真正创造了价值?
其真正价值不在于提供又一个数据看板,而在于构建了一套从“活动量”到“产出价值”的映射与问责体系。通过将AI生成的代码块与最终的合并请求、生产部署进行“血缘关联”,它把模糊的“AI辅助”变成了可审计、可归因、可计费的具体贡献。这直接挑战了当前以消耗量为导向的AI工具商业模式,迫使供应商从比拼“生成速度”转向证明“产出质量”。
然而,其面临的挑战同样尖锐。首先,是度量本身的复杂性。代码贡献的归因在多人、多代理协作中极易模糊,简单的行数或提交关联可能扭曲真实价值。其次,是文化与信任风险。过度细粒度的追踪可能被误解为对开发者的监控,引发抵触,这与旨在提升效能的初衷背道而驰。最后,是其价值的终极证明难题。它成功连接了“工程输出”与“业务成果”之间的最后一公里吗?目前看,它更擅长回答“AI代码是否被采用”,而非“被采用的AI代码是否带来了更好的业务结果”。这仍是工程智能领域的共性挑战。
总体而言,Waydev精准地定义并抢占了一个新兴的品类——“AI生成代码的观测层”。它不生产代码,也不直接评判代码质量,而是成为价值流中的“审计员”。在AI编码工具从尝鲜走向常态化的拐点,这种对效费比和问责制的需求必然爆发。其成败关键在于,能否在提供透明度和避免制造恐惧之间找到精妙平衡,并最终将数据洞察转化为可行动的、改善开发流程与决策的智能,而非仅仅是事后报告。
一句话介绍:一款能根据跑者实际完成情况动态调整训练计划的跑步APP,解决了传统固定计划因生活变动而难以坚持、易脱轨的痛点。
Health & Fitness
Running
Pitch Berlin
跑步训练
自适应训练计划
AI健身教练
跑步应用
个性化训练
训练负荷管理
马拉松训练
数据驱动
运动科技
健康生活
用户评论摘要:用户普遍赞赏其自适应逻辑,让训练可持续且无压力。主要问题集中在:计划缺乏具体结构化间歇跑课程;UI/UX有待优化,操作繁琐;价格偏高。创始人回应将推出结构化训练系统。
AI 锐评
Kaizen的核心价值并非在于提供又一个训练计划库,而在于其底层逻辑从“计划驱动”转向“现实驱动”。传统训练计划本质是“理想世界”的线性投影,一旦现实偏离预设,整个模型就宣告失效。Kaizen试图构建一个以“训练负荷”为统一度量衡、以用户历史与当前状态为输入的反馋循环系统。它不执着于你“应该”在周二跑间歇,而是关注你“实际”累积的训练刺激,并动态调整后续目标以逼近最终赛事目标。
这戳中了业余跑者的真实困境:生活本身就是最大的变量。然而,其当前的“价值空洞”也显而易见。它将灵活性推向了极致,却牺牲了新手所需的具体指导(如配速区间、间歇结构),这使其更像一个为有经验的跑者设计的“元教练”或“负荷管理仪表盘”,而非一站式解决方案。用户关于“缺乏具体课程”和“UI不佳”的批评,正反映了其产品定位与用户预期间的落差——用户支付了“智能”溢价,却可能未获得与之匹配的、直观易用的结构化体验。
其真正的护城河在于算法对“个人体能模型”的刻画精度与自适应调整的合理性,这需要长期数据验证。若其算法足够可靠,未来价值可延伸至伤病风险预警与个性化强度建议。但目前来看,Kaizen是一次有价值的范式创新,但作为成熟产品,仍需在结构化内容与用户体验上完成关键补课,才能将犀利的理念转化为不可替代的用户价值。
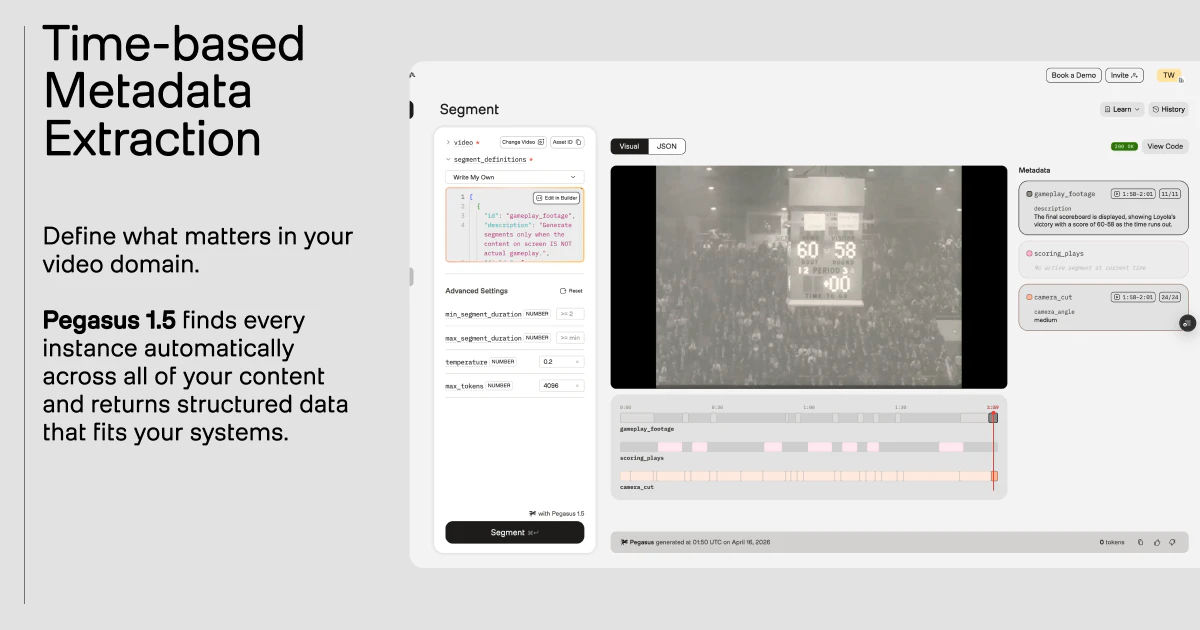
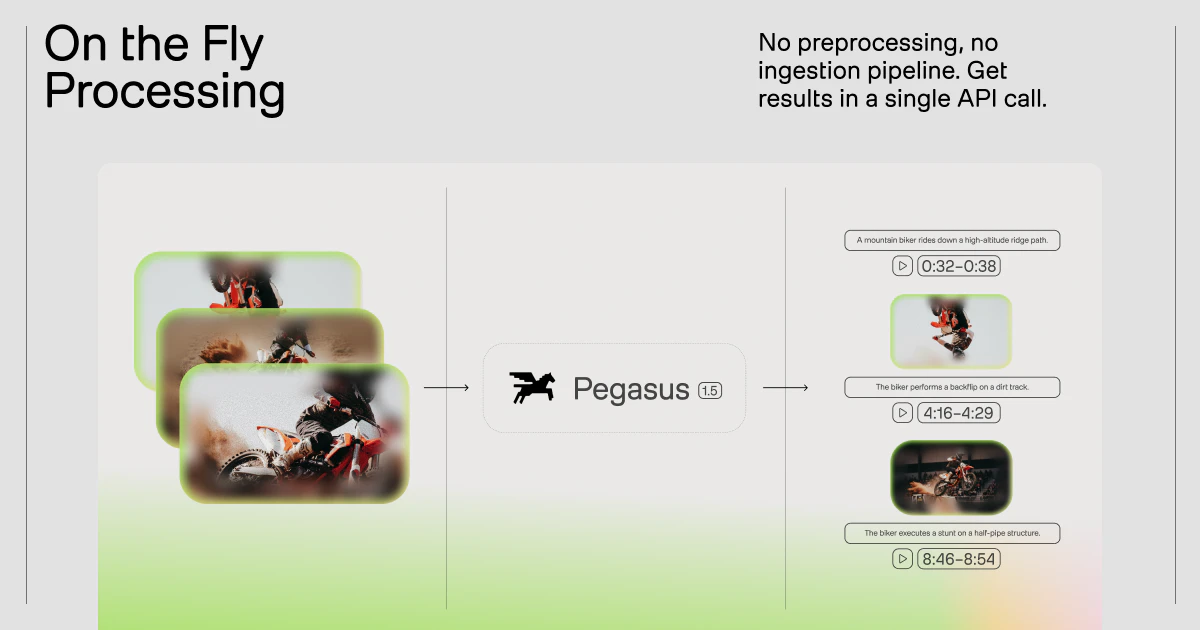
一句话介绍:Pegasus 1.5是一款将原始视频实时转化为可查询、可计算的时间戳结构化数据的AI模型,解决了海量视频内容难以快速检索、分析和利用的核心痛点。
Developer Tools
Artificial Intelligence
Video
视频理解AI
多模态AI
视频结构化
时间元数据
视频检索
内容分析
企业级API
长视频处理
智能剪辑
自动化生产
用户评论摘要:用户普遍赞赏其长达2小时的长视频处理能力和实际性能提升。主要关注点集中在企业数据安全与部署方式(询问本地化/VPC选项),以及处理大视频文件上传至云的潜在瓶颈。CEO的回复示例展示了其在自动章节划分等场景的“快速见效”应用。
AI 锐评
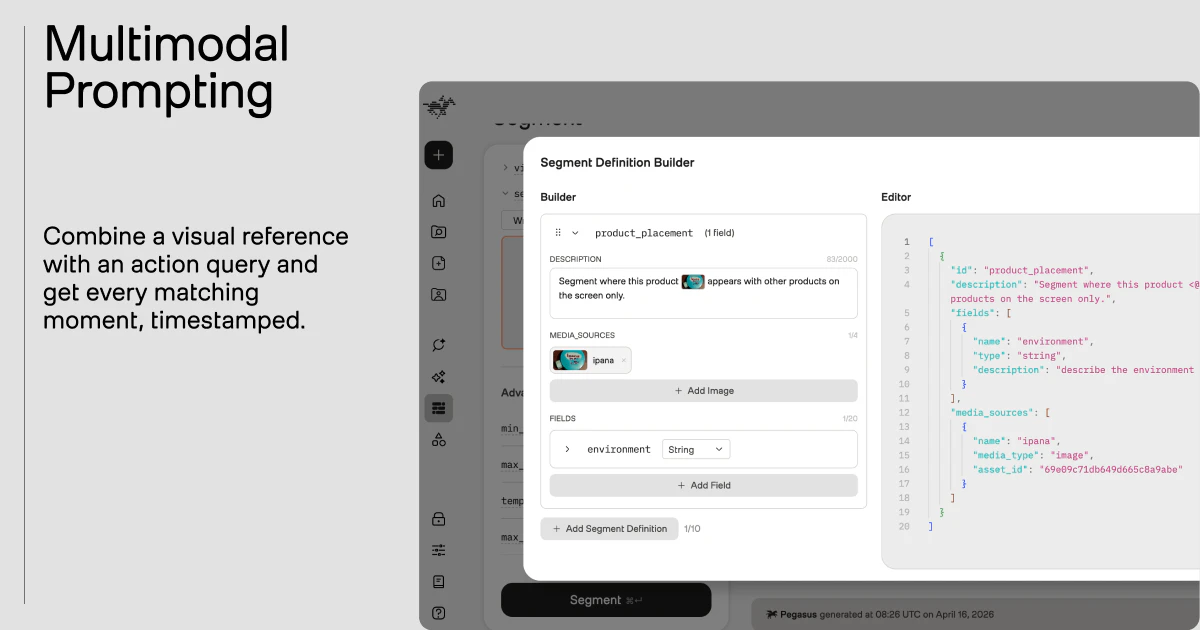
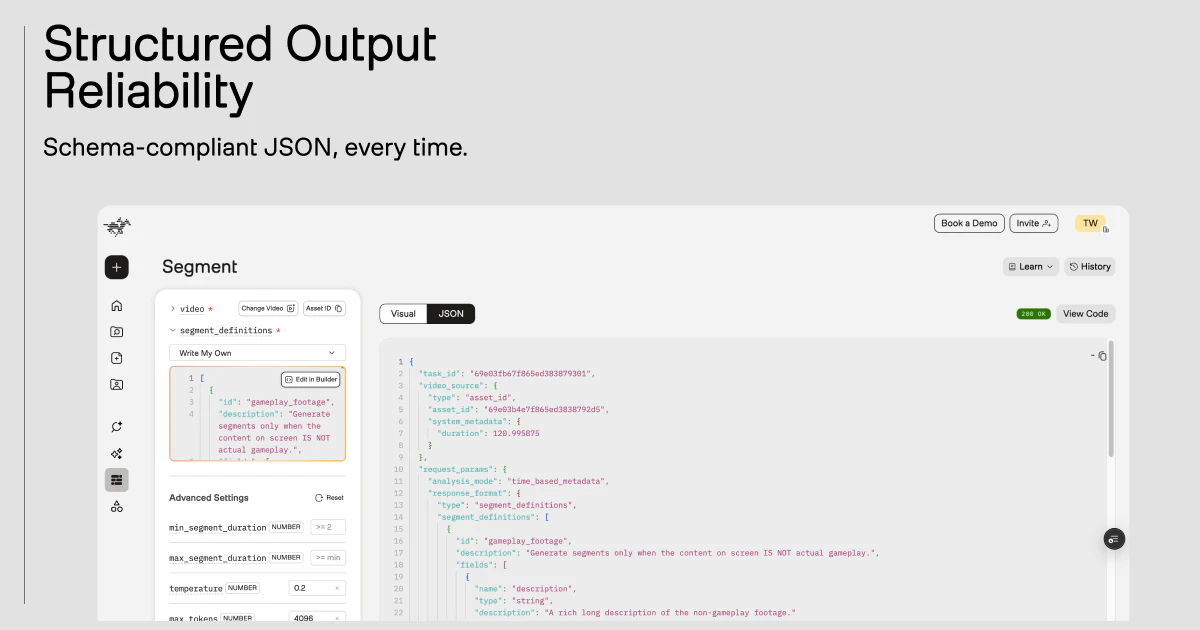
Pegasus 1.5的野心,远不止于又一个“视频理解API”。其核心价值在于试图为视频数据建立一套“时间本位”的标准化查询语言。将非结构化的视频流转化为带时间戳的、可自定义的结构化元数据,本质上是将视频从仅供人类观看的媒介,转变为可供机器直接读取和计算的“数据资产”。
产品强调的“自定义Schema”和“基于领域需求”是关键分水岭。这意味着它不再满足于提供通用的标签识别,而是允许企业将自身的业务逻辑(如“明星球员扣篮”、“logo出现”)直接编码为分析规则,从而实现深度垂直的场景化赋能。其标榜的超越Gemini等通用大模型的细分性能,以及长达2小时的处理能力,正是为了证明其在企业级、工业化场景下的可靠性与实用性。
然而,真正的挑战在于“最后一公里”的部署。正如用户尖锐指出的,对于涉及敏感或海量原始视频数据的企业,将2小时视频文件频繁上传至云端本身就是巨大瓶颈。模型性能再优,若无法解决数据移动的安全与效率问题,其“实时”与“规模化”的承诺将大打折扣。这要求TwelveLabs必须提供灵活(甚至边缘计算)的部署方案,而不仅仅是云API。
此外,产品将视频“未来验证”和“供智能体导航”作为愿景,颇具前瞻性。这实则是为即将到来的AI Agent时代铺设基础设施:当AI需要主动调用和理解视频资料时,预先被高度结构化和语义化的视频库将成为关键燃料。Pegasus 1.5的真正战场,或许不是今天的视频剪辑工具,而是明天的多模态AI生态底层。其成功与否,取决于能否以足够低的成本和足够高的灵活性,让企业愿意为尚未完全到来的“智能体时代”提前重构自己的视频数据仓库。
一句话介绍:Tasteit是一款以特定菜品为切入点的社交网络,在用户想通过美食结识新朋友或寻找饭搭子的场景下,解决了线上社交目的模糊、破冰尴尬的痛点,将共餐转化为自然的线下连接方式。
Pitch Berlin
美食社交
线下约会
饭搭子
陌生人社交
兴趣社区
本地生活
活动组织
消费体验
用户评论摘要:用户普遍赞赏其独特理念与流畅体验,认为其抓住了真实的社交需求。核心讨论围绕其与Yelp等工具的本质差异(“找食伴”而非“找餐馆”),以及“共同喜好”能否有效促成线下见面。创始人回复强调了“聚餐邀请”这一社交触发机制是核心抓手。
AI 锐评
Tasteit的野心并非再造一个美食点评或发现平台,而是试图将“共餐”这一最高频的线下社交行为产品化,其真正的价值在于对社交动机的精准重构。
它敏锐地刺中了当前社交产品的空白:熟人社交趋于固化,陌生人社交充满表演性与不安全感。Tasteit通过“菜品”这一具体、低门槛、高共鸣的介质,将社交的发起动机从“我想认识人”(压力来源)悄然转变为“我想吃这个,恰好有人同行”(自然需求)。这并非简单的“美食+社交”叠加,而是将“共餐”设定为第一性原理,所有功能都服务于促成线下饭局。其回复中提到的“Dine”模式是关键,它把抽象的“连接”打包成一个包含地点、人员、付费的具体事件,极大地降低了交易成本。
然而,其面临的挑战同样尖锐。首先,是冷启动与信任的双边市场难题:用户既需要足够多“想吃”的菜品,更需要足够多“可信”的食伴。其次,其模式重度依赖高密度城市与特定的用户群体(乐于尝试、有空闲时间),规模化可能遭遇文化差异与安全性质疑。最后,也是最关键的一点,它必须证明其“社交触发”频率足够高,能抵御“偶尔尝鲜”后的沉寂。它真正的对手不是Yelp或Instagram,而是用户固有的、与熟人约饭的惯性路径。
如果成功,Tasteit不会止于一个“约饭工具”,而可能成为基于真实兴趣与体验的、线下关系链的发起层,其想象空间在于对本地生活及体验式消费的颠覆。但目前,它仍是一场关于“人类是否愿意为了一盘菜,与陌生人共享一段时光”的大胆社会实验。
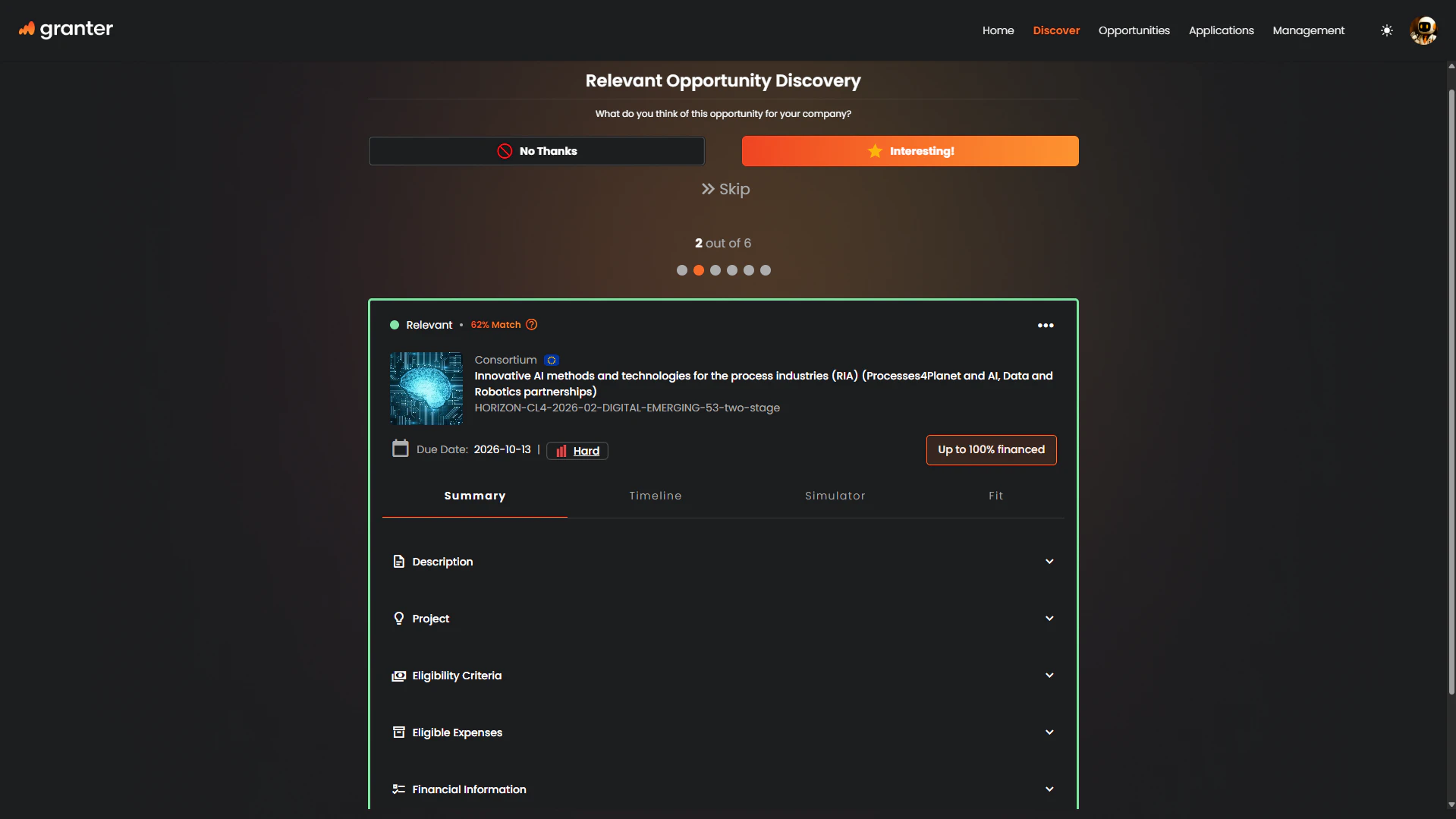
一句话介绍:Granter是一款深度集成到企业内部的AI代理,它能7x24小时自主运行整个资金申请生命周期,通过自动寻找机会、撰写高质量申请材料及处理获批后合规事务,解决了企业在申请政府或机构资助时流程繁琐、专业门槛高、耗时耗力的核心痛点。
SaaS
Artificial Intelligence
Pitch Berlin
AI企业服务
自动化资金申请
政府资助咨询
智能合规管理
企业数字员工
B2B工具
流程自动化
智能写作
区域化适配
申请成功率优化
用户评论摘要:用户关注区域适配性(如印度、欧盟)、处理超本地化复杂规则的能力、与现有系统集成和数据自动化的技术细节、以及AI生成内容如何满足特定技术叙事和合规审查。开发者回应强调区域化定制、通过数据消化和学习实现适配,并拥有专门的合规评估功能。
AI 锐评
Granter描绘的“全自动数字员工”愿景直击企业资金申请流程的顽疾——信息不对称、文书工作浩如烟海、合规细节令人望而生畏。其真正的价值不在于“又一个AI写作工具”,而在于试图成为贯穿“发现-申请-合规”全链路的智能中枢。这意味产品逻辑必须从“辅助生成”升级为“流程代运营”,其难度呈指数级增长。
从评论暴露的关切看,Granter面临三重核心挑战:首先是“数据的深水区”。自动集成企业敏感数据(财务、人力)存在技术与信任双重壁垒,目前仍需手动导入,这使其“深度集成”的承诺大打折扣。其次是“规则的迷宫”。各地资助计划规则碎片化且动态变化(如印度MSME计划的17个资格环节),AI需要持续消化超本地化知识,这考验其数据管道与Agent调优的敏捷性,所谓“快速扩张”背后是沉重的运营负担。最后是“评审的黑箱”。申请成功与否最终取决于人类评审的主观判断,AI能否精准构建符合其偏好的“技术叙事”,而不仅仅是合规清单检查,这是其宣称“高质量”的关键,但回复中仅以“给予高度消化的背景”一笔带过,缺乏说服力。
因此,Granter的潜在壁垒并非技术,而在于构建一个覆盖多区域、多行业的“资助规则知识图谱”与“成功案例模式库”的生态能力。它更像一个高度专业化的、按需配置的“外部顾问团队”的数字化投射,而非通用型员工。其成败将取决于:在特定垂直行业与区域能否真正跑通闭环、证明显著高于传统咨询的成功率,并在此过程中建立起难以逾越的数据与案例护城河。当前阶段,它仍是一个充满前景但需谨慎验证的“承诺”。
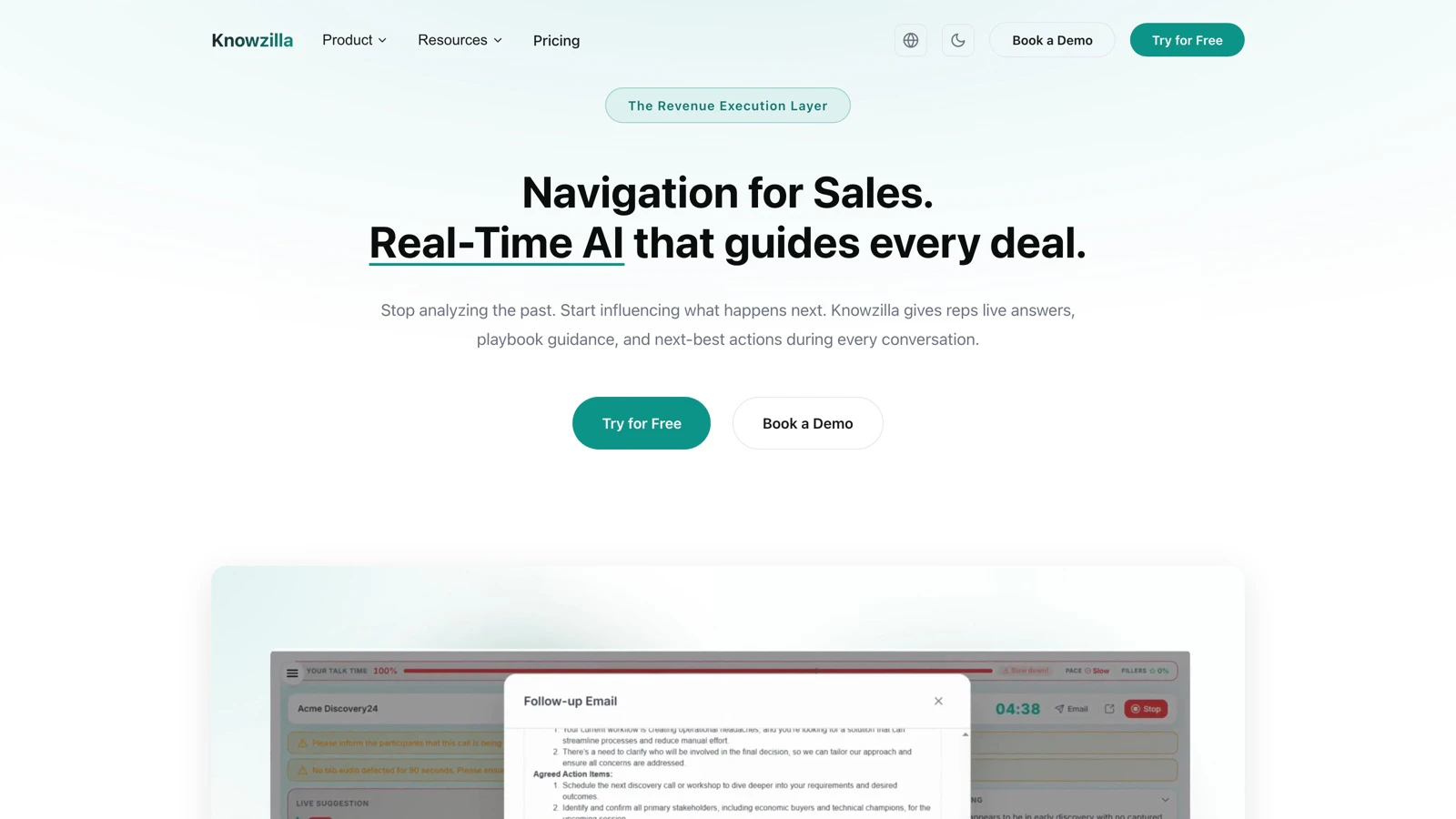
一句话介绍:Knowzilla是一款在销售实时通话中提供AI即时答案的工具,解决销售团队因无法快速从手册中找到答案而丢单的痛点。
Pitch Berlin
销售赋能
实时AI助手
通话辅助
销售培训
objection处理
知识管理
B2B销售
SaaS
销售效率工具
对话智能
用户评论摘要:用户认可产品解决实时销售对话痛点的价值,询问知识库构建方式、多语言支持、信息更新机制及是否干扰倾听。关注其对不同销售周期和角色的适用性,并报告了产品小故障。
AI 锐评
Knowzilla瞄准了销售培训领域最顽固的“知行鸿沟”——将静态的销售话术与动态的客户交锋相结合。其宣称的价值并非简单的信息检索,而是将企业沉淀的“部落知识”转化为实时战斗中的“肌肉记忆”,这直击了销售管理的核心成本:因初级代表临场失措而流失的机会。
然而,产品光鲜的AI外壳下,潜藏着几个本质挑战。首先,是“注意力争夺”悖论:在高压通话中,代表是应全心倾听客户,还是分神阅读AI提示?这需要极其精准、非侵入式的交互设计,否则工具本身会成为干扰源。其次,是知识库的“冷启动”与“持续喂养”问题。评论中尖锐地指出,这类工具的成败往往取决于初始知识构建与后续更新闭环。团队回复的“组合方式”和“更新提醒”仍是传统思路,并未展现AI在自动从成功案例中萃取、演化知识体系方面的突破性。最后,其“一刀切”的潜力受到质疑:长周期、复杂技术销售与快节奏交易所需的指导逻辑截然不同。若不能深度适配销售方法论,它极易沦为又一款“智能”却泛泛的提词器。
真正的价值不在于“有答案”,而在于“在正确情境下,以正确方式,给出经过验证的正确答案”。Knowzilla的框架正确,但其护城河的深度,将取决于它能否将AI从“实时文档”升级为懂得销售策略、客户心理与交易节奏的“虚拟销售教练”。否则,它只是把纸质手册电子化并加快了打开速度而已。
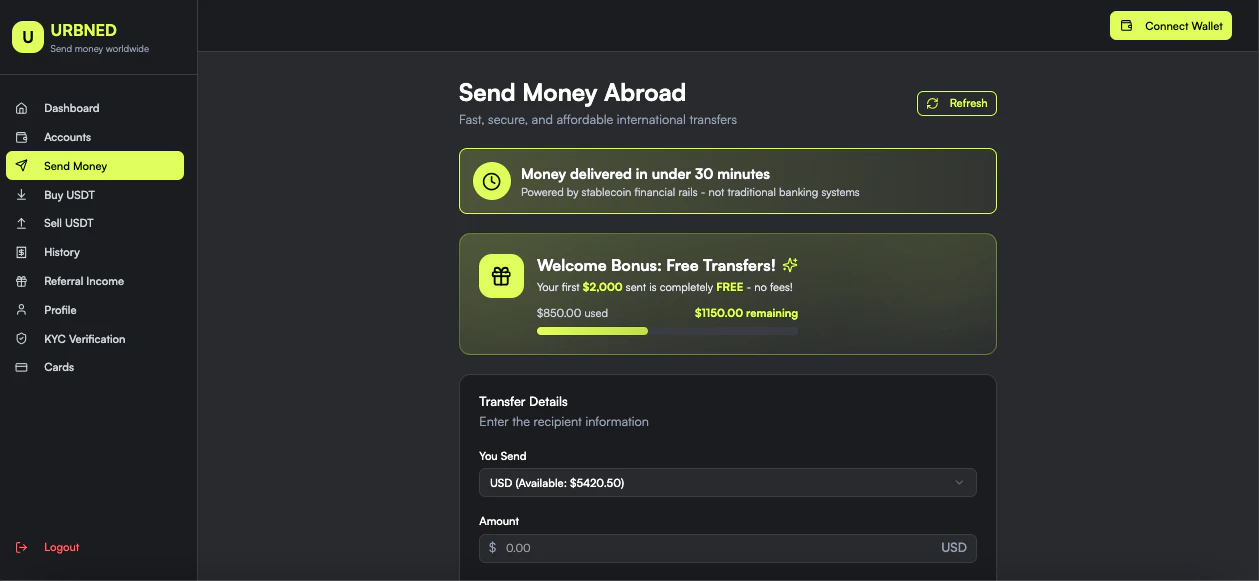
一句话介绍:Urbned 利用稳定币构建了隐形的跨境支付通道,让移民、自由职业者和企业能够像发短信一样轻松地完成美元到比索、卢比等货币的国际汇款,解决了传统跨境转账速度慢、费用高、流程复杂的痛点。
Fintech
Payments
Pitch Berlin
跨境支付
稳定币
加密货币钱包集成
虚拟银行账户
国际汇款
金融科技
区块链金融
全球劳动力
外汇兑换
用户评论摘要:由于提供的用户评论列表为空,无法总结具体反馈。通常在此类产品中,用户关注点会集中在到账速度、手续费、法币兑换汇率、监管合规性以及与传统银行和汇款商的体验对比上。
AI 锐评
Urbned 描绘的“像发短信一样汇款”的愿景,直击了传统SWIFT体系与西联等汇款巨头的核心短板:速度与成本。其真正的价值并非在于创造了新技术,而在于巧妙地充当了“中间层”,试图将稳定币的结算效率与前端用户熟悉的法币世界体验进行无缝缝合。
产品设计的精明之处有两点:一是宣称“稳定币层不可见”,这旨在消除普通用户对加密货币的认知门槛和操作恐惧,仅让其享受结果;二是直接集成MetaMask和Phantom钱包,这无异于精准捕获了已有加密资产、却苦于无法便捷用于现实支付的增量用户群,为他们开辟了清晰的变现和实用通道。
然而,其面临的挑战同样尖锐。首先,**监管是悬顶之剑**。提供虚拟美元/欧元账户并处理法币兑换,必然涉及严格的货币传输牌照(如美国MSB)及各国支付法规,其合规进程将决定生存空间。其次,**“最后一公里”的稳定性存疑**。将稳定币最终兑换为当地法币并存入收款人银行账户,严重依赖其当地银行或支付合作伙伴网络,这在部分新兴市场可能成为拥堵点和风险点。最后,**价值主张的可持续性**。在稳定币本身尚未经历完整金融周期考验的背景下,将其作为“隐形”基础架构,一旦发生类似UST的脱锚极端事件,整个系统的信誉将瞬间崩塌。
因此,Urbned更像一个在传统金融与加密世界夹缝中寻找机会的“巧匠”。它的成功不取决于技术是否最颠覆,而取决于其平衡监管、合作伙伴关系与用户体验的精细化运营能力。它可能无法颠覆银行,但有望成为特定高频、小额跨境场景中一个更优的补充选项。其前景,系于钢丝之上。
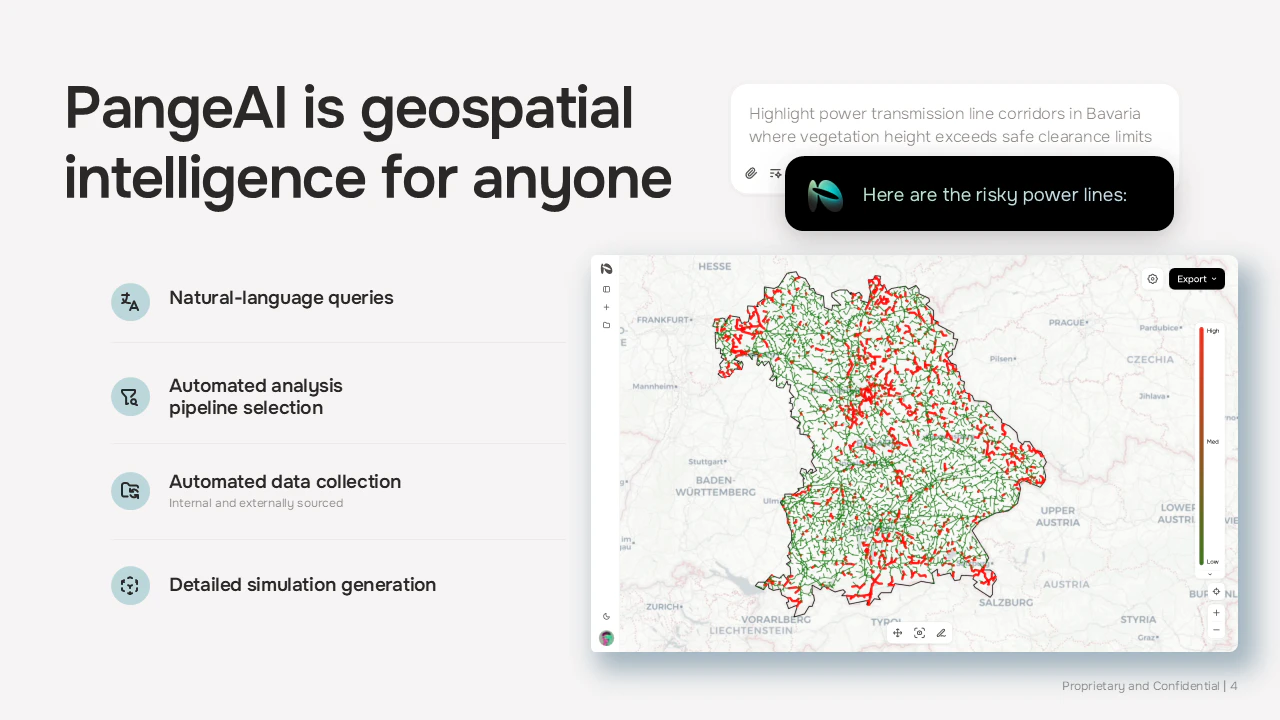
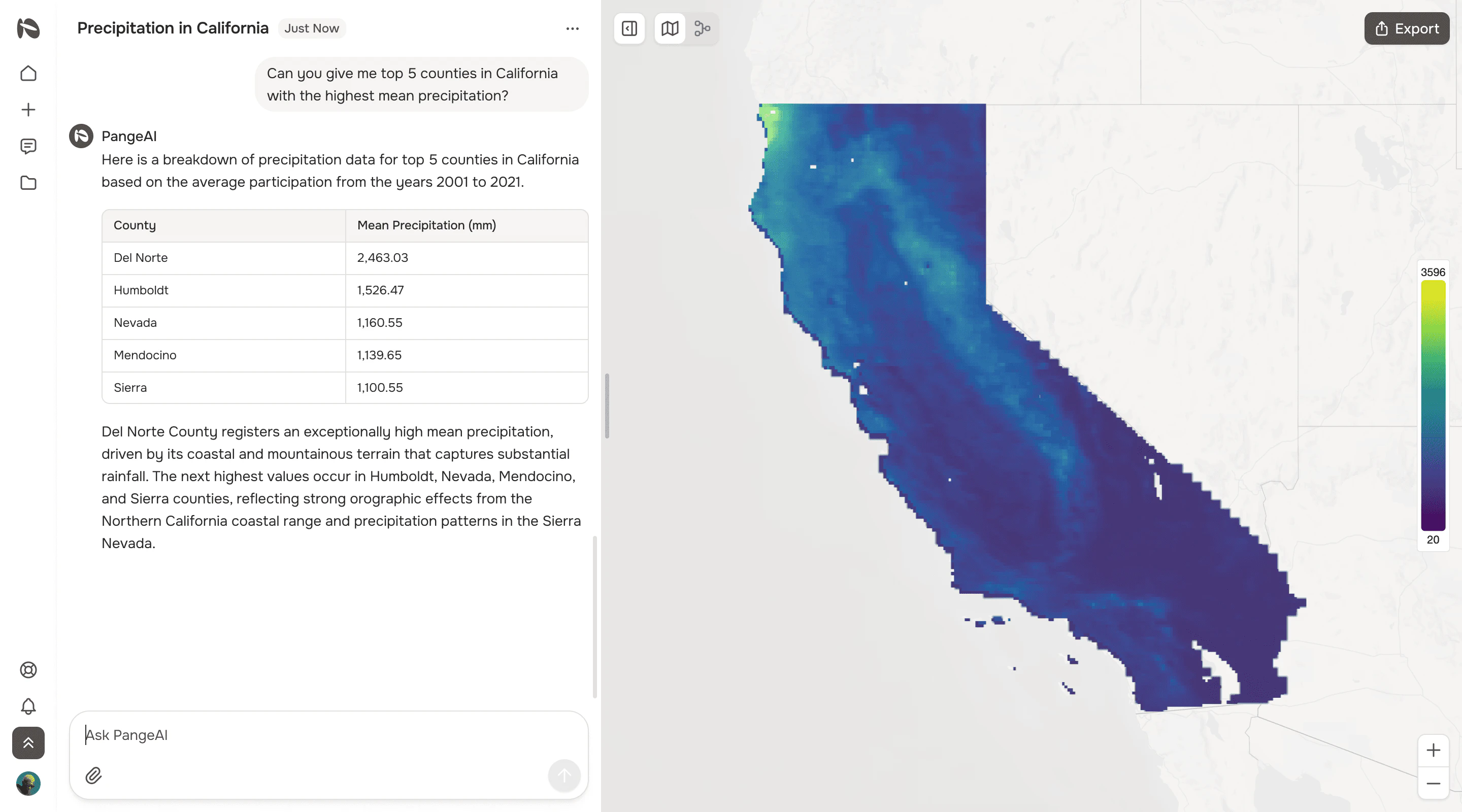
一句话介绍:PangeAI是一个基于AI智能体的地理空间数据分析层,让非专业用户无需GIS团队即可快速(分钟级)回答现实世界的地理问题,如快速评估数百个地点在上月是否遭遇洪涝。
Artificial Intelligence
Maps
Pitch Berlin
地理空间分析
AI智能体
卫星影像
空间决策
无代码GIS
自动化处理
数据融合
B2B SaaS
空间计算
物理世界理解
用户评论摘要:用户反馈积极,创始人以幽默方式点明传统GIS工作繁琐痛苦的核心痛点。有效评论集中于产品愿景(让AI理解物理世界位置)和具体技术关切,如如何处理不一致的遥感数据、多源数据(LiDAR、街景)融合,以及智能体如何推理并标识数据缺口。
AI 锐评
PangeAI的野心不在于成为另一个GIS工具,而旨在成为“空间智能”的推理层。其真正价值是试图填平两个巨大鸿沟:一是专业地理空间操作与日常业务决策之间的知识鸿沟,将“周”级的分析压缩至“分钟”级;二是当前大语言模型所代表的“语义理解”与真实物理世界“空间理解”之间的能力鸿沟。
产品标语中的“agent-driven”是关键。它暗示其AI并非仅用于图像识别,而是能自主调用、处理、融合多源异构地理数据(卫星影像、矢量、坐标系统),并执行链式推理以完成复杂任务的智能体。这直指传统GIS和单一API服务的天花板:它们提供数据或工具,但不提供端到端的、基于自然语言的决策答案。
评论中关于“处理混乱现实数据”的提问,恰恰点出了其成败的关键。地理空间数据的噪声、不一致和残缺是常态。PangeAI若仅是将传统处理流程自动化,价值有限。其宣称的“智能体”必须展现出真正的“推理”能力——例如,在云层遮挡卫星影像时,能主动寻找替代数据源(如街景摄像头),或基于历史模式和周边数据进行概率性推断,并明确告知用户结论的不确定性。这才是“无需GIS团队”承诺能否兑现的核心。
风险同样明显。作为夹在底层数据供应商与上层企业应用之间的“智能层”,其分析结果的准确性与可靠性将面临极端严格的场景考验(如灾害评估、选址规划)。此外,其商业模式、数据成本及对特定坐标系统或数据源可能存在的隐性依赖,都是其从炫酷Demo走向企业级服务必须跨越的障碍。如果成功,它定义的将是一个新品类;如果失败,则可能只是又一个试图用AI包装复杂性的、华而不实的工具。
一句话介绍:TorchTPU是谷歌推出的PyTorch原生TPU后端,允许开发者仅修改极少量代码即可在谷歌规模的TPU上运行现有PyTorch工作负载,解决了PyTorch用户难以利用高性能TPU硬件且迁移成本高昂的痛点。
Open Source
Developer Tools
Artificial Intelligence
人工智能基础设施
深度学习框架
硬件加速
PyTorch后端
TPU
高性能计算
模型训练
谷歌云
无缝迁移
分布式训练
用户评论摘要:用户普遍认可其“极简代码修改”和“Fused Eager模式”带来的性能提升价值,并关注其非封装层的深度集成方式。主要疑问集中在:从单机扩展到多Pod集群的实际挑战、对自定义CUDA内核作业的兼容性,以及调试模式对混合精度等边缘案例的处理能力。
AI 锐评
TorchTPU的发布,远不止是谷歌TPU生态对PyTorch的又一次“兼容”。其真正锋芒,在于以“PrivateUse1”级别的深度系统集成,试图对AI硬件竞赛的底层游戏规则进行一次迂回侧击。
表面看,它解决了PyTorch用户接入TPU的工程摩擦,通过“Fused Eager”等模式在易用性与性能间取得平衡。但深层次上,这是谷歌在NVIDIA CUDA生态统治下的一次精准破局。它不强迫用户改写模型逻辑,而是选择“融入”最流行的PyTorch生态,实质是降低开发者尝试TPU的心理和技术门槛,旨在从庞大且活跃的PyTorch社区中,为自家TPU硬件引流。其价值不仅在于50-100%+的性能提升,更在于“scale to 100K+ chip clusters”所暗示的、对超大规模训练场景的野心——这是直接瞄准了下一代前沿模型研发的基建战场。
然而,其挑战同样尖锐。评论中关于“自定义CUDA内核”的疑问直指要害:众多成熟生产管线深度绑定CUDA,TorchTPU依赖的XLA编译栈与CUDA生态的兼容鸿沟能否真正抹平,仍是未知数。此外,“动态形状支持”等关键功能尚在路线图中,说明其在应对灵活研究场景时可能仍有局限。它提供了优雅的入口,但通往峰值性能与极致灵活性的道路,依然可能布满需要“深度硬件专业知识”的坑洼。
本质上,TorchTPU是谷歌以软件柔性化解硬件生态壁垒的一次高明尝试。它能否成功,不只看技术指标,更取决于能否在开发者心中重塑“TPU=复杂难用”的刻板印象,并构建起一个足以与CUDA生态部分抗衡的、繁荣的PyTorch-on-TPU应用生态。这场战役,现在才刚刚开始。
一句话介绍:一款AI驱动的2D游戏创作平台,通过自然语言描述,无需绘画和编程技能,即可快速生成风格统一的游戏资产并构建可玩游戏,极大降低了游戏创意的实现门槛。
Design Tools
Indie Games
Artificial Intelligence
AI游戏开发
无代码游戏制作
2D像素艺术
游戏资产生成
智能游戏设计
创意工具
快速原型
独立开发者
视觉一致性
游戏工作室
用户评论摘要:用户肯定其生成优质像素艺术的能力,关注AI对“图块集”等专业资产的支持度。开发者回应迭代迅速,将专门优化图块集功能。核心问题聚焦于AI对复杂游戏机制(如“纳达尔式闪避”)的迭代反馈与理解能力,以及资产风格一致性工具的实际效果。
AI 锐评
Makko AI的野心并非仅是又一个“AI绘画工具”,它试图成为从创意到可玩游戏的“端到端”智能体。其宣称的价值在于用对话取代学习曲线陡峭的编程与美术工作流,这直击了无数“想法型”创作者的终极痛点。
然而,其真正的挑战与价值深度,隐藏在用户评论的细节中。首先,“风格一致性”是核心卖点,也是最大技术壁垒。AI生成单张图片已不新鲜,但确保角色、背景、动画在整个游戏项目中视觉统一,是规模化生产的刚需。其“Collections”工具能否智能管理并贯彻风格,将决定它是玩具还是生产力工具。其次,用户询问“纳达尔式闪避”的反馈机制,尖锐地触及了AI游戏开发的深水区:AI能否理解复杂、抽象的“游戏感”并迭代机制?目前看,它可能更擅长执行“生成一个红色头发武士”这类明确指令,而对“手感”这种主观、系统性的调优,其“智能”程度存疑。
产品目前看似以“资产生成”为立身之本,但其长期叙事必须建立在“理解游戏设计逻辑”之上。否则,它极易沦为高级素材库,而“构建可玩游戏”将局限于预设模板的拼接。每周更新的承诺显示了敏捷性,但若不能在图块集、机制迭代等核心需求上建立技术护城河,其宣称的“革命性”将大打折扣。它的真正价值,在于能否将游戏开发从“技能密集型”手工业,部分转化为“创意描述密集型”的智能工业,这条路才刚起步。
一句话介绍:Papayo.ai是一款面向招聘机构的AI原生招聘平台,通过部署专注于寻源、触达、日程安排和候选人评估的专属智能体,旨在显著缩短招聘周期,解决招聘机构耗时低效的核心痛点。
Pitch Berlin
AI招聘平台
智能招聘助手
招聘流程自动化
人才寻源
招聘机构SaaS
AI智能体
招聘效率工具
候选人评估
用户评论摘要:用户评论极少且无实质反馈。唯一主评疑似产品方自述,强调其专注于“高质量招聘”而非“大规模招聘”。一条回帖询问是否有浏览器扩展计划,表达了兴趣并认为产品看起来不错。
AI 锐评
Papayo.ai的构想直击招聘行业“时间就是金钱”的命门,其价值主张清晰:用AI智能体流水线式接管从寻源到评估的招聘全链条,为人力密集型的招聘机构提供自动化杠杆。这并非简单的聊天机器人套壳,而是试图构建一个“AI员工”团队,分工明确,颇具野心。
然而,其Product Hunt上近乎空白的真实用户反馈与95个点赞形成微妙反差,这暴露出其早期阶段的核心挑战:概念吸引力与落地验证之间的鸿沟。招聘是高度依赖信任、人际判断与复杂决策的领域,AI能否在“候选人评估”等关键环节提供可靠、无偏见的支持,而不仅仅是效率提升,这是其必须回答的尖锐问题。标语中的“AI-native”是亮点也是风险点,它意味着深度重构流程,但也可能过早将机构捆绑在一条尚未被完全验证的技术路线上。
当前,它更像一个精心包装的技术愿景。其真正价值不在于演示了哪些AI功能,而在于能否在真实的、纷繁复杂的招聘场景中,证明其智能体具备超越基础自动化的“理解”与“决策”能力,并最终转化为可量化的“招聘质量提升”而不仅仅是“时间缩短”。否则,它可能只是自动化洪流中又一个可被替代的效率工具。
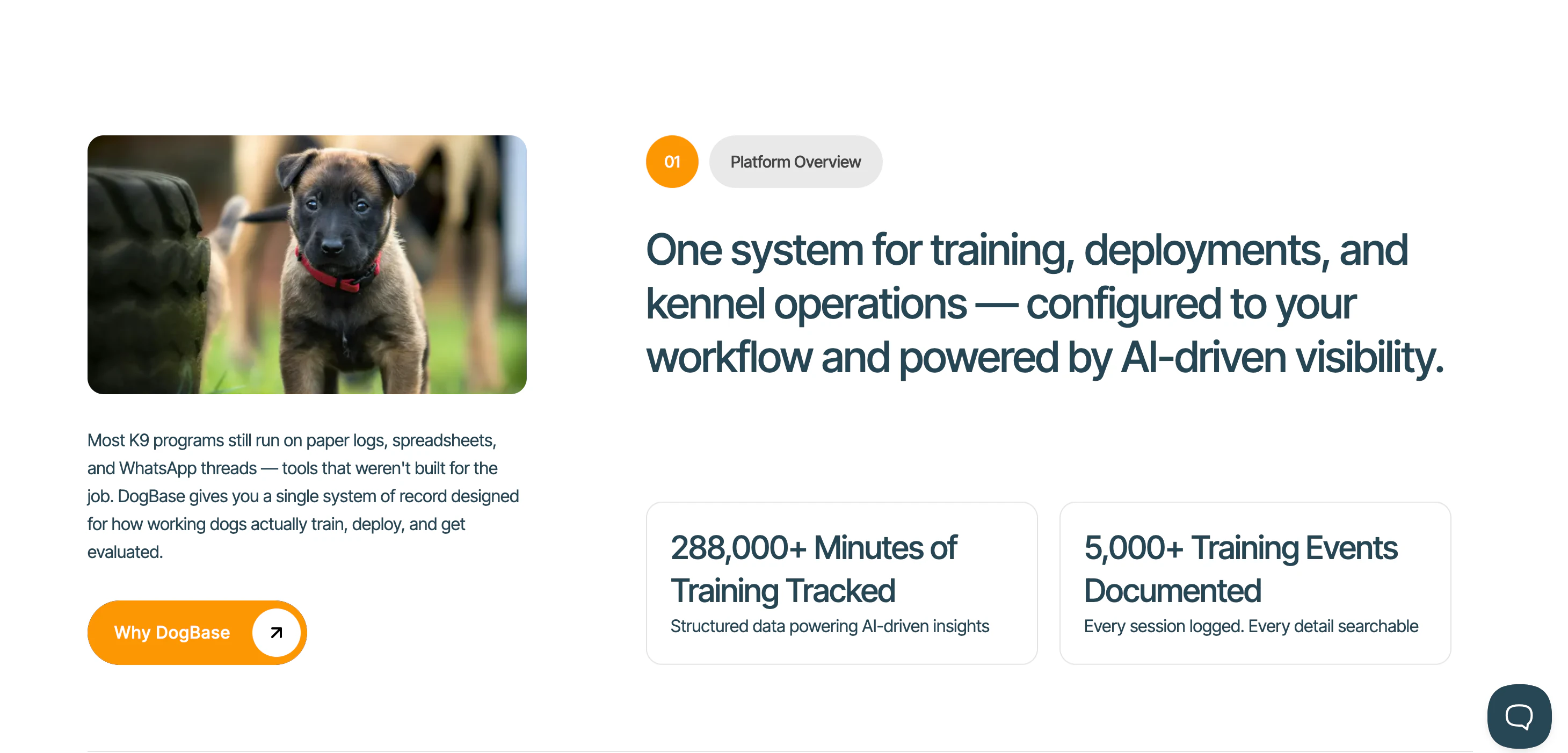
一句话介绍:DogBase是一款AI驱动的专业工作犬团队操作系统,通过整合训练日志、健康管理和绩效追踪,解决了K9搜救、执法等领域因依赖零散工具而导致数据丢失、模式难察、团队协作不透明的核心痛点。
Productivity
Artificial Intelligence
Pitch Berlin
工作犬管理平台
AI驱动分析
训练日志
健康监测
绩效追踪
专业K9团队
SAR工具
执法犬管理
服务犬
数据协同
用户评论摘要:用户反馈集中于AI功能的具体价值与数据呈现细节。创始人的深度回复阐述了产品源于真实场景,并强调了团队的专业背景。有效评论提出了两个关键问题:AI如何识别笔记难以发现的细微健康/疲劳趋势;以及“绩效追踪”功能的具体指标和报告形态。
AI 锐评
DogBase v2的发布,表面上是一个垂直的SaaS工具,但其内核是一次对高度专业化、高风险作业流程的数据化重构。其真正价值不在于简单的“记录”,而在于试图成为工作犬团队的“数据中枢”与“决策副驾”。
产品切入点的犀利之处在于,它没有选择泛化的宠物市场,而是锚定了“专业工作犬”这一需求刚性、容错率极低但数字化程度异常落后的缝隙市场。用户用笔记本、WhatsApp和电子表格的现状,是典型的“工具碎片化”困境,这直接导致了数据孤岛和模式湮灭。DogBase的核心价值主张,正是通过强制性的结构化数据录入,打破这些孤岛。
然而,其宣称的“AI驱动洞察”是价值兑现的关键,也是最大的风险点。评论中的提问一针见血:AI究竟能发现哪些人眼难以察觉的模式?是细微的行为变化预示的早期伤病,还是训练数据中隐藏的效能衰减曲线?这要求其AI模型必须建立在极其专业、高质量的领域数据之上,且需得到资深训导员的经验验证。创始人自称“身在行业中”并用自己的犬只数据,是建立初始信任的关键,但能否规模化地提炼出普适、可靠的洞察,将决定产品是停留在“数字记录本”,还是进阶为不可或缺的“团队预警系统”。
另一个潜在壁垒与机遇在于“协同”。专业团队(如特警队、大型搜救组织)的内部协作与信息可见性需求强烈。若能通过数据标准化,实现跨犬只、跨小组的绩效对标与健康趋势预警,其价值将从个体工具升维为组织级的资产管理与风险控制平台。这或许是它未来超越“工具”范畴,成为行业基础设施的关键一步。
总体而言,DogBase展现了一个优秀垂直AI应用的雏形:深扎痛点场景、拥有领域内行的理解、并试图用数据智能解决经验传承与风险预判的难题。但其成功与否,将严格取决于其AI功能在真实高压环境中所证明的实际效用与可靠性,而不仅仅是概念上的“智能化”。
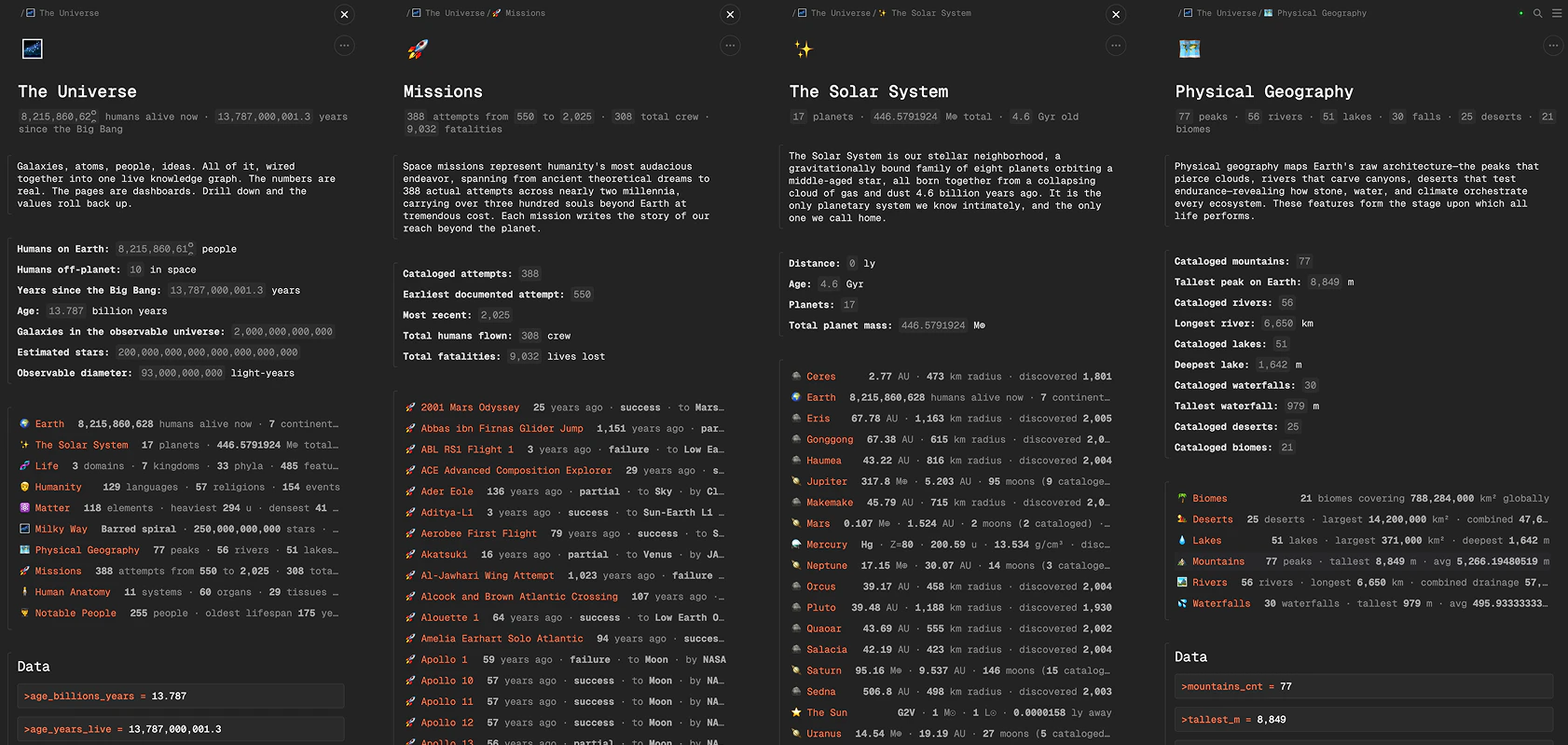
一句话介绍:GalaxyBrain是一款本地优先的信息操作系统,通过让文档页面拥有变量、公式和实时联动引用,在跨文档知识管理和动态项目跟踪等场景下,解决了信息孤岛与手动同步的效率痛点。
Productivity
本地优先知识系统
结构化文档
动态联动
无代码编程
个人知识管理
实时同步
JSON存储
HTTP API
信息操作系统
文档即应用
用户评论摘要:创始人详述了历时多年的重构历程,强调产品核心引擎现已稳固。用户评论主要关注非技术用户的上手难度,以及在管理多页面、公式密集型工作流时的实际表现,体现了市场对产品易用性与复杂场景能力的关切。
AI 锐评
GalaxyBrain的野心远不止于“智能笔记”。它本质上是一个运行在本地文件系统上的、面向非专业开发者的轻量级计算环境。其核心价值在于将“文档”从静态容器升格为可编程、可互联的“数据单元”,通过变量与公式在文件间建立动态图谱,试图在Notion的数据库灵活性与传统电子表格的单元格引用逻辑之间,开辟一条新路径。
“本地优先”与“结构化JSON存储”是它的战略支点,这确保了数据主权和可被其他工具(通过API/MCP)自由调用的潜力,契合了当前开发者与高阶用户对封闭生态的反思潮流。然而,其最大的挑战也在于此:如何让被“无代码”标语吸引的用户,真正理解并驾驭其类编程的思维模型?评论区的担忧已直指这一矛盾——产品强大的“引擎”与用户期待的“平滑上手”之间存在鸿沟。
它的未来,取决于能否在“电子表格般的直观”与“编程环境般的强大”之间找到那个精妙的平衡点。否则,极易陷入专业人士嫌其能力边界清晰、大众用户觉其学习曲线陡峭的尴尬境地。它是一款为“知识工程师”打造的利器,但要想破圈,必须在抽象概念的“封装”与用户引导上做出更多革新。
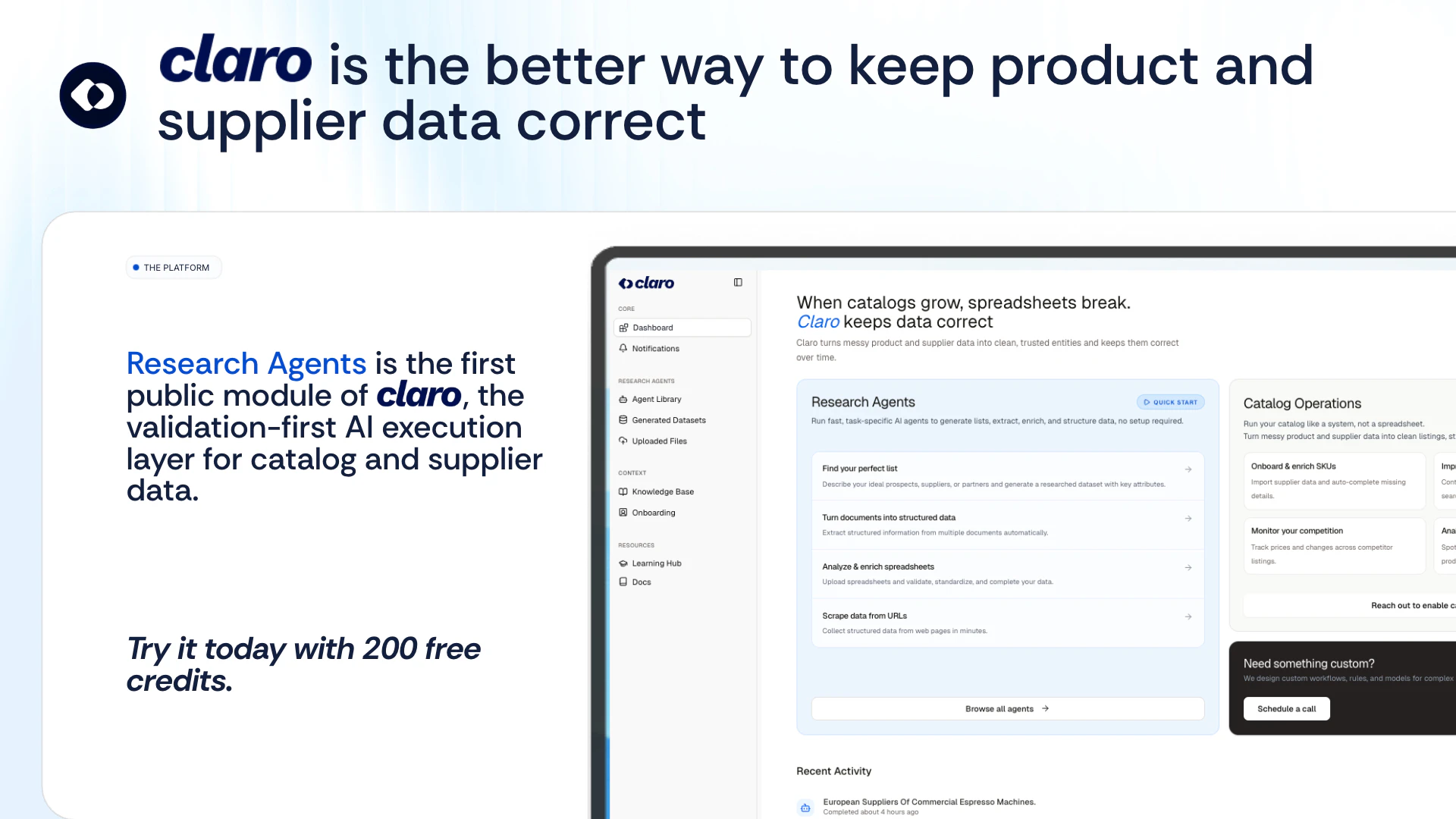
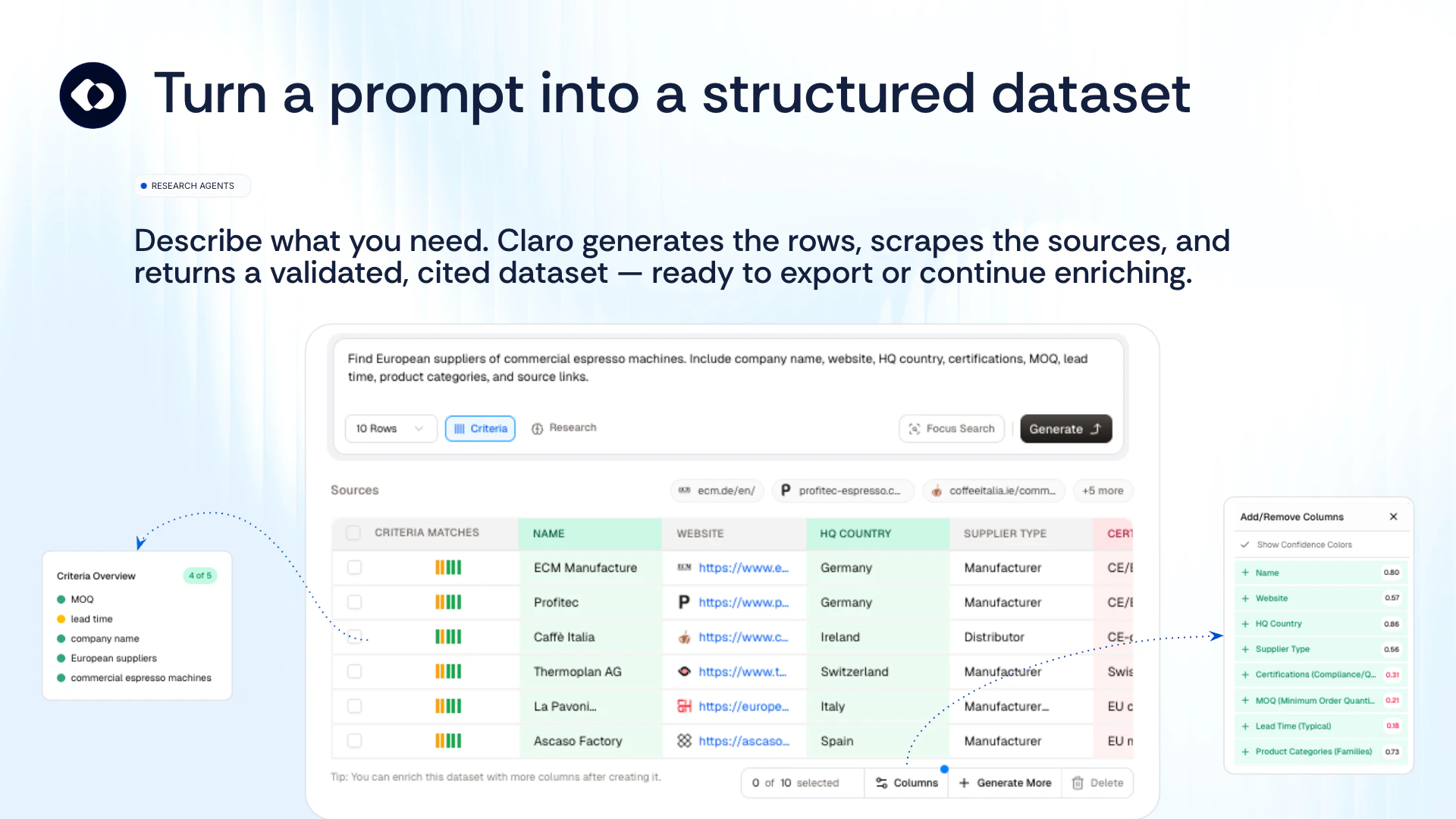
一句话介绍:Claro是一款AI数据研究代理平台,通过多模型共识和置信度评分机制,在表格内直接运行多种任务型AI代理,解决了企业在处理供应商、产品等海量异构数据时对AI输出结果缺乏信任的核心痛点。
Productivity
Artificial Intelligence
Pitch Berlin
AI数据代理
数据清洗与增强
PDF提取
网络爬虫
数据验证
置信度评分
来源追溯
多模型共识
企业级数据治理
无代码数据平台
用户评论摘要:用户反馈聚焦于置信度评分与引用机制的技术细节,特别是对PDF等非结构化数据处理的可靠性提出疑问。创始人详细解释了评分算法(来源可靠性40%等)与多模型验证架构,展现了产品构建的深度。
AI 锐评
Claro的亮相,直指当前企业AI应用最脆弱的“阿喀琉斯之踵”:华而不实的输出与无法落地的信任赤字。它没有沉迷于制造又一个聊天机器人外壳,而是选择了一条更艰难但更务实的路径——构建“验证优先”的AI执行层。
其真正价值不在于提供了十几种数据提取与分类代理,而在于为每一个输出单元格构建了一套量化可信度的“免疫系统”。将置信度评分拆解为来源可靠性、交叉验证一致性、模型确定性等可衡量的维度,并辅以多模型共识和LLM作为评判者的过滤机制,这实质上是在试图为AI的“黑箱”输出建立可审计的透明管道。尤其针对企业级的产品与供应商数据管理,这种对稳定ID、持续验证的强调,远比一次性的答案提取更有长期价值。
然而,其挑战也同样明显。首先,这套复杂验证体系的运行成本与延迟,能否在百万元级别的数据规模上依然保持实用性与经济性,有待观察。其次,当数据本身高度模糊或冲突时,即使评分机制标为“低置信度”,仍需人工最终裁决,产品能否形成高效的人机协同闭环至关重要。最后,从“研究代理”模块走向其愿景中的完整“数据执行层”,需要更深度的行业数据模式积累与集成能力。
总体而言,Claro是一次将AI从“提供答案”推向“交付可信决策依据”的重要尝试。它能否成功,不取决于AI代理的“广度”,而取决于其验证体系的“深度”能否真正经得起企业混乱、复杂现实数据的持续冲击。
一句话介绍:一款让开发者用自然语言编写QA测试的AI代理工具,通过模拟真实浏览器运行测试并生成结构化错误报告,解决了中小团队及独立开发者因传统QA平台价格高昂、流程复杂而无法获得有效测试的痛点。
SaaS
Developer Tools
Artificial Intelligence
AI测试代理
自然语言编程
软件测试
按量付费
开发者工具
自动化测试
错误追踪
独立开发者
中小团队
浏览器测试
用户评论摘要:用户普遍赞赏其按量付费模式和绕过销售流程的简洁性,认为精准契合小团队需求。主要疑问集中于:AI处理模糊指令和复杂流程的可靠性、如何避免误报、与直接使用通用AI编写测试的差异、以及具体的技术实现细节和竞品对比。
AI 锐评
QA Crow的亮相,与其说是一款技术产品的发布,不如说是一次对臃肿、封闭的B2B软件商业模式的有力嘲讽。它敏锐地刺中了当前QA工具市场的核心矛盾:一方面,AI的普及催生了大量快速开发的小型应用,它们对测试的需求迫切;另一方面,主流测试平台却将定价和销售模型锚定在“Fortune 500”企业,筑起了高不可攀的价格壁垒。
产品的真正价值,首先在于其**极致的商业模式减法**。它彻底摒弃了“坐席费”、“年度合同”、“最低消费”和“销售介入”这些传统SaaS的标配,回归最朴素的“用一次付一次”。这不仅仅是定价策略,更是产品哲学——它只为自己创造的价值收费(执行测试),而非为潜在的“企业关系”或“销售成本”买单。这使其成为了“独立开发者经济”生态中一个精准的基建组件。
其次,其技术路径选择体现了务实的**AI应用观**。它没有空泛地宣传“全自动测试”,而是构建了一个“人类描述-AI审查与修正-真实环境执行”的协作流程。将AI定位为“挑剔的审查员”和“可靠的执行者”,而非全知全能的替代者。这既承认了当前LLM在复杂逻辑和领域知识上的局限性,又将其在理解自然语言、执行重复性浏览器操作方面的优势最大化。用户评论中关于模糊指令处理的担忧,恰恰是产品需要持续构建核心壁垒的关键点:其AI的“判断力”能有多强?
然而,挑战同样明显。当用户询问“与直接让Claude写测试用例有何不同”时,触及了本质:**QA Crow必须证明其垂直化AI代理能提供远超通用模型的价值**。这价值应体现在:对测试领域的深度理解(如自动识别模糊步骤、补充认证逻辑)、与真实浏览器环境及错误报告系统的无缝集成、以及执行过程的稳定性和可观测性。否则,它可能只是一个精巧的、集成了支付功能的提示词工程外壳。
总而言之,QA Crow是一次值得尊敬的“小众突围”。它不试图在功能完备性上正面冲击“企业级”巨兽,而是通过商业模式创新和精准的AI能力聚焦,服务一个被长期忽视但正在蓬勃增长的群体。它的成功与否,将验证在AI时代,为“建造者”而非“采购部门”设计工具,是否是一条可行的商业路径。
一句话介绍:一款注重隐私、无广告的开源Android YouTube客户端,通过完全在设备端运行的推荐引擎,为用户在追求纯净观看体验时,解决了被平台广告、算法追踪和数据收集的痛点。
Open Source
GitHub
YouTube
开源应用
Android客户端
视频播放
隐私保护
无广告
本地化推荐
数据主权
Kotlin开发
Jetpack Compose
YouTube第三方工具
用户评论摘要:用户主要关注其与ReVanced等工具的差异、法律合规性及隐私实现深度(如是否使用代理隐藏IP)。开发者回应隐私重点在于无账号、无应用内追踪及数据本地化,承认IP可能暴露,并透露使用了基础的Firebase分析。有用户询问iOS版本计划。
AI 锐评
EchoTube的价值核心在于其“主权本地化”的激进主张。它并非简单地去广告,而是试图将“推荐算法”这一平台最核心的控制权与数据黑洞,从服务器拉回用户设备。这直接挑战了以数据喂养、以广告变现的传统流媒体商业模式,迎合了当前用户日益增长的数据主权意识。
然而,其面临的挑战同样尖锐。首先,技术层面,完全本地的推荐模型其精准度和发现能力,能否与云端巨量数据训练的算法抗衡,存疑。其次,法律与合规风险高悬。作为寄生型客户端,其绕过官方广告系统、集成SponsorBlock等行为,始终游走在YouTube服务条款的边缘,生存取决于平台的容忍度。开发者关于IP不匿名的坦诚,也揭示了其隐私保护的局限性——它主要防御的是应用层追踪,而非网络层。
本质上,EchoTube是理想主义开发者对垄断平台生态的一次“越狱”尝试。它提供的并非完美解决方案,而是一个重要的宣言和选择:即用户有权为隐私和洁净体验,牺牲部分算法精准度和便利性。它的真正意义在于展示了另一种技术路径的可能,但其长期生存,不仅依赖开发热情,更取决于开源生态的维护、法律环境的博弈,以及能否在“纯净”与“可持续”之间找到平衡点。目前来看,它更像是技术觉醒者的利基产品,而非大众的普及型解决方案。
一句话介绍:Iqana为家族办公室、高净值人士和财富经理提供非托管、自动化的加密资产组合管理,利用机构级技术和系统化风控,解决了他们缺乏内部量化团队与交易系统却想参与专业数字资产投资的痛点。
Pitch Berlin
加密资产投资
非托管
自动化投资组合管理
机构级技术
系统化风险管理
数字资产
财富管理
量化策略
高净值客户
家族办公室
用户评论摘要:产品方详细介绍了其系统化策略、非托管模式及服务对象。用户主要询问策略在类似2022年市场暴跌时的实时调整能力,以及客户在首月能获得的“速赢”体验,显示出对策略韧性与实际见效时间的核心关切。
AI 锐评
Iqana的定位精准地刺入了数字资产投资专业化进程中的一个关键缝隙:策略供给与托管权的分离。其“非托管、自动化机构策略”的卖点,本质上是将传统对冲基金的量化能力SaaS化,并刻意与资产托管解耦。这看似是技术方案,实则是一个精明的信任构建与市场进入策略。
在加密世界历经FTX等托管方暴雷后,“非托管”已从技术特性升华为核心价值主张。Iqana借此直接回应了高净值客户最深层的安全焦虑——资产控制权。然而,其真正的挑战与价值考验在于另一端:所谓的“机构级策略”在极端波动的加密市场中能否持续产生阿尔法?用户评论中关于“2022年熊市适应能力”的提问,一针见血。加密市场的动量与收益策略往往在牛市中表现耀眼,在长期、深度的熊市中却容易持续磨损甚至失效。产品方若不能清晰论证其策略的风控模块、资产轮动或对冲机制在极端行情下的具体表现,那么“系统化风险管理”就只是华丽的空壳。
此外,其目标客户(家族办公室、财富经理)虽资金雄厚,但决策谨慎,且传统金融领域已有成熟的TAMP(全权资产管理平台)服务。Iqana需要证明的不仅是策略的有效性,更是其整个操作流程、合规对接与客户报告体系能达到传统金融的严谨标准。否则,它可能仅被视作又一个加密量化工具,而非可靠的财富管理解决方案。
简言之,Iqana的模式颇具前瞻性,踩中了资产安全与专业需求两大痛点。但其长期成功的钥匙,不在于“机构级技术”的宣称,而在于能否以可验证、可审计的方式,向苛刻的机构级客户证明其策略的“机构级耐受力”与“机构级稳定回报”。否则,它可能只是为高净值客户提供了一个更优雅地亏损的通道。
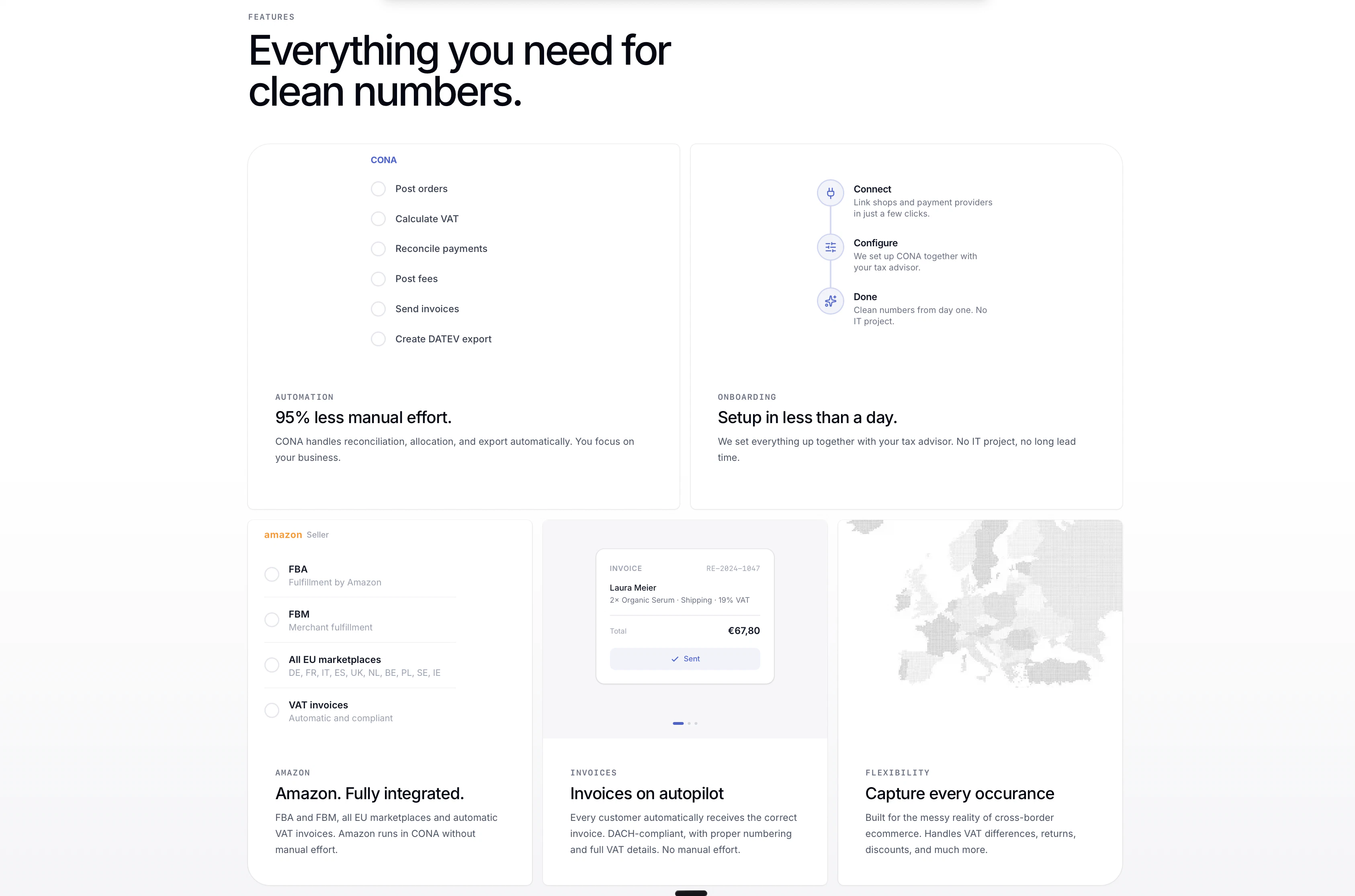
一句话介绍:CONA是一款专注于DACH地区(德国、奥地利、瑞士)的电商自动化记账工具,通过连接Shopify、亚马逊等平台与德国本土的DATEV会计系统,在电商财务对账场景下,自动完成订单核对、支付匹配、费用及增值税处理,解决了手动对账繁琐易错的痛点。
Pitch Berlin
电商SaaS
自动化记账
财务对账
DACH市场
德国会计准则
增值税处理
支付匹配
Shopify生态
中小企业
税务师工具
用户评论摘要:用户关注点集中在产品适用范围与核心能力。主要问题包括:是否支持多币种店铺与国际增值税,以及目标用户是自由职业者、中小企业还是会计师。官方回复明确了其专注于德国会计准则,能处理多币种、跨境增值税及汇率差异,主要服务对象为中小企业及税务顾问。
AI 锐评
CONA的发布,精准地刺中了跨境电商,特别是面向DACH市场卖家的一个隐秘而顽固的痛点:财务本地化合规与效率的悖论。其真正的价值不在于简单的“自动化”,而在于扮演了“生态翻译器”的角色——将全球电商平台(如Shopify、Amazon)产生的、结构庞杂的交易数据流,“翻译”成符合德国严格会计准则(DATEV系统)和复杂增值税体系要求的标准化账目。
产品标语“E-commerce accounting that runs itself”颇具野心,但评论区的问答揭示了其成功的边界与战略取舍。面对用户关于国际通用性的疑问,官方明确其“德国聚焦”的定位,这恰恰是其犀利之处。它没有选择做一个功能泛泛的全球通用工具,而是深挖德国市场高壁垒、高专业度的会计合规需求。这意味着它的核心用户并非所有跨境电商卖家,而是那些在DACH地区有实质业务,且深受本地税务顾问(Steuerberater)审计压力困扰的中小企业。它为这些企业提供的,是与本地财税专业人士无缝协作的“合规接口”,其价值等同于一个永不疲倦、零出错的初级会计团队,大幅降低了因手动处理海量订单导致的合规风险与人力成本。
然而,其深度本地化策略也是一把双刃剑。这固然建立了短期竞争壁垒,但也可能限制了其市场天花板和估值想象空间。产品未来发展需权衡:是继续深化在德语区的专业壁垒,向更全面的企业财务中台演进;还是将其“生态翻译”能力模块化,复制到法国、日本等其他高合规要求的市场?目前来看,CONA选择了先做深、再做广的务实路径。在跨境电商精细化运营时代,这类解决具体区域、具体难题的“手术刀式”工具,其生存与发展空间,可能比一个功能大而全的“瑞士军刀”式平台更为稳固。













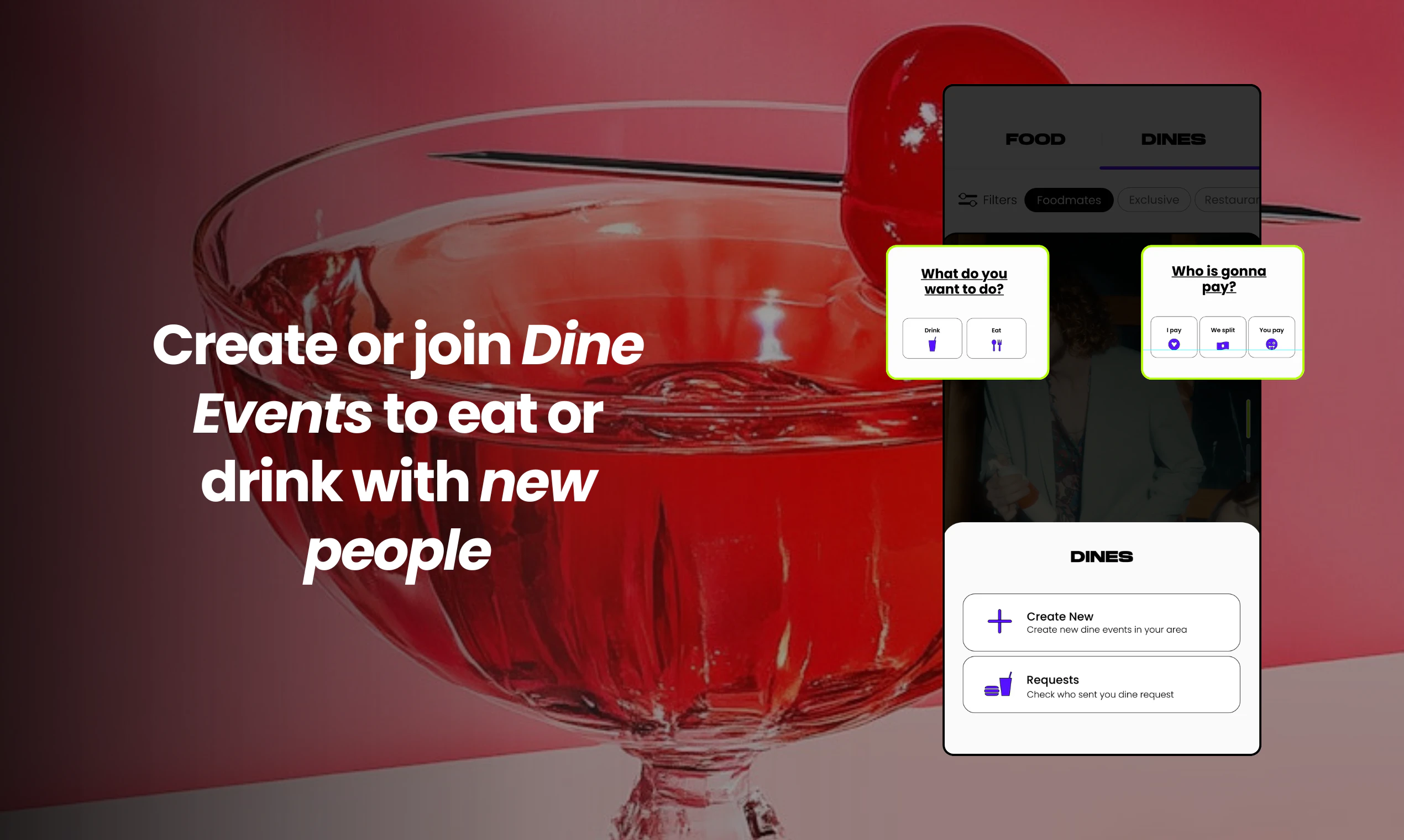
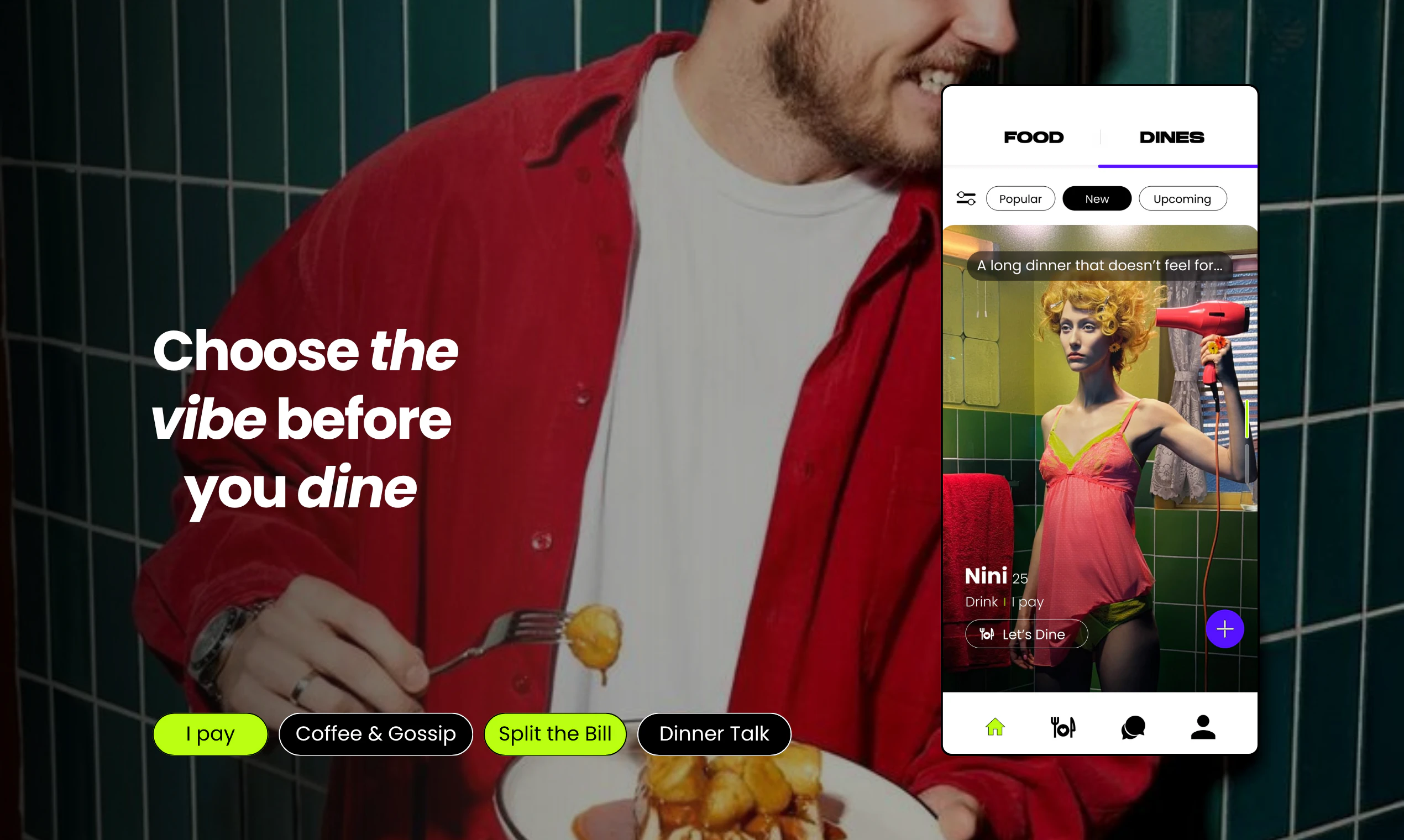







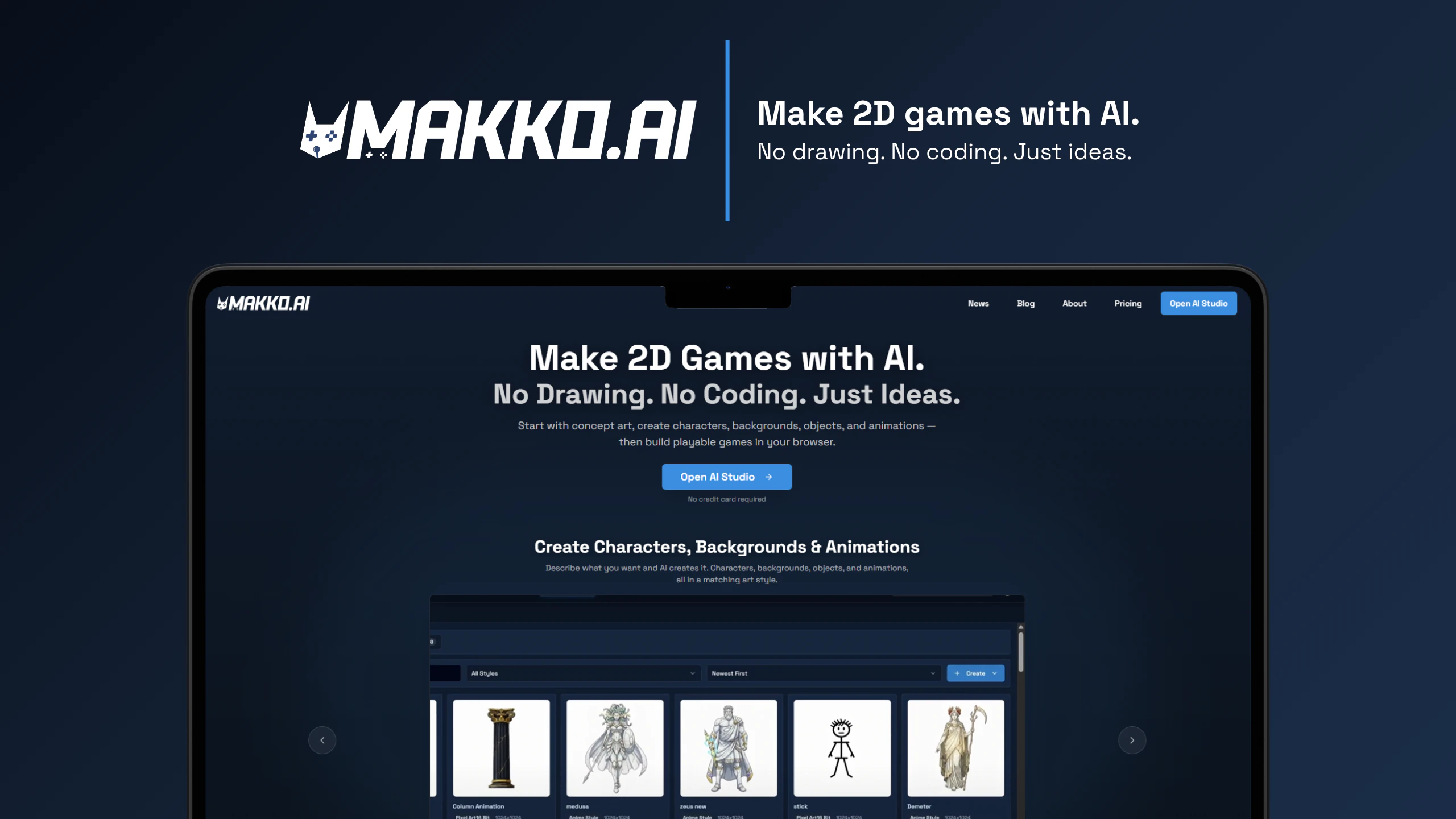
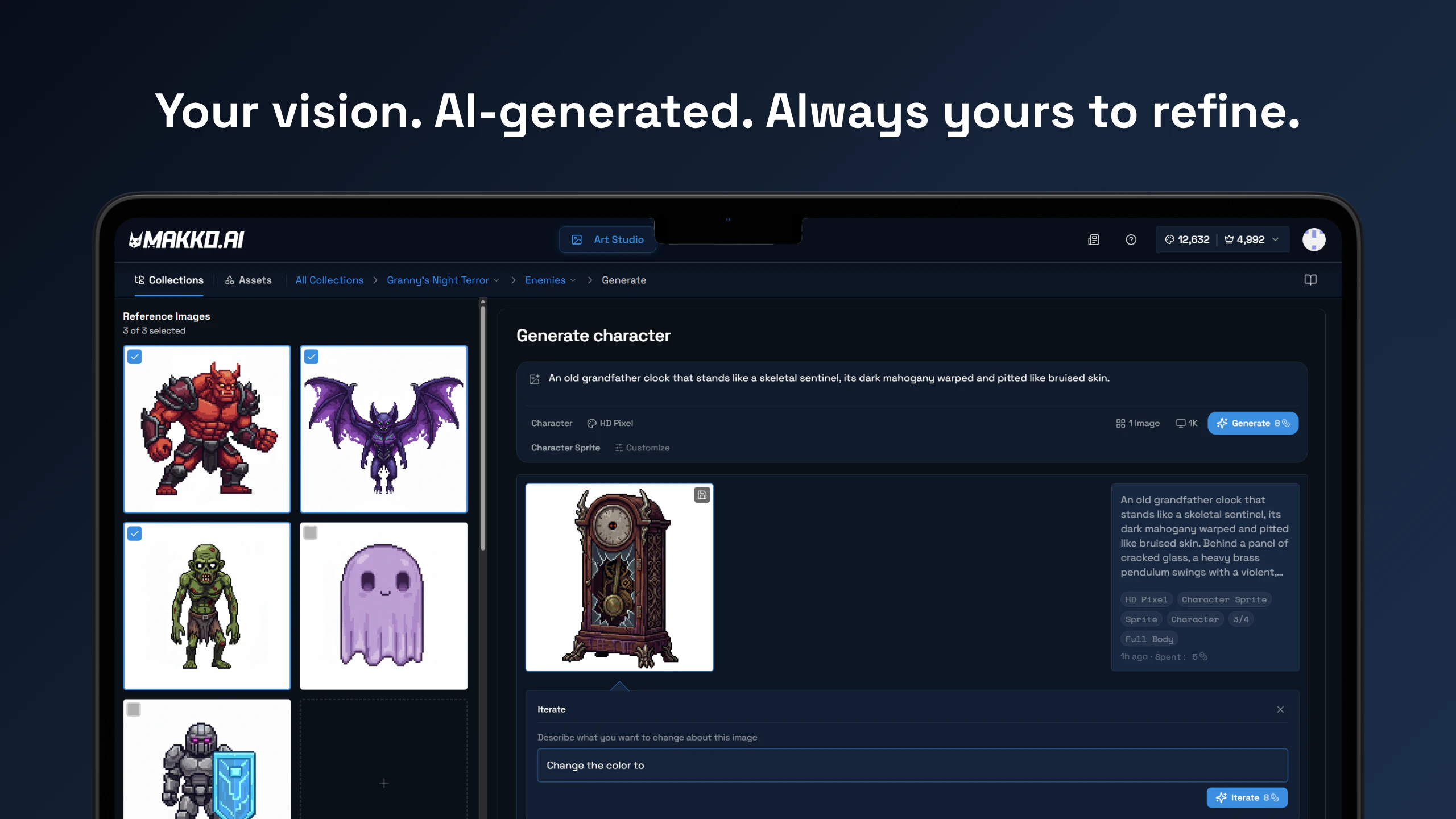
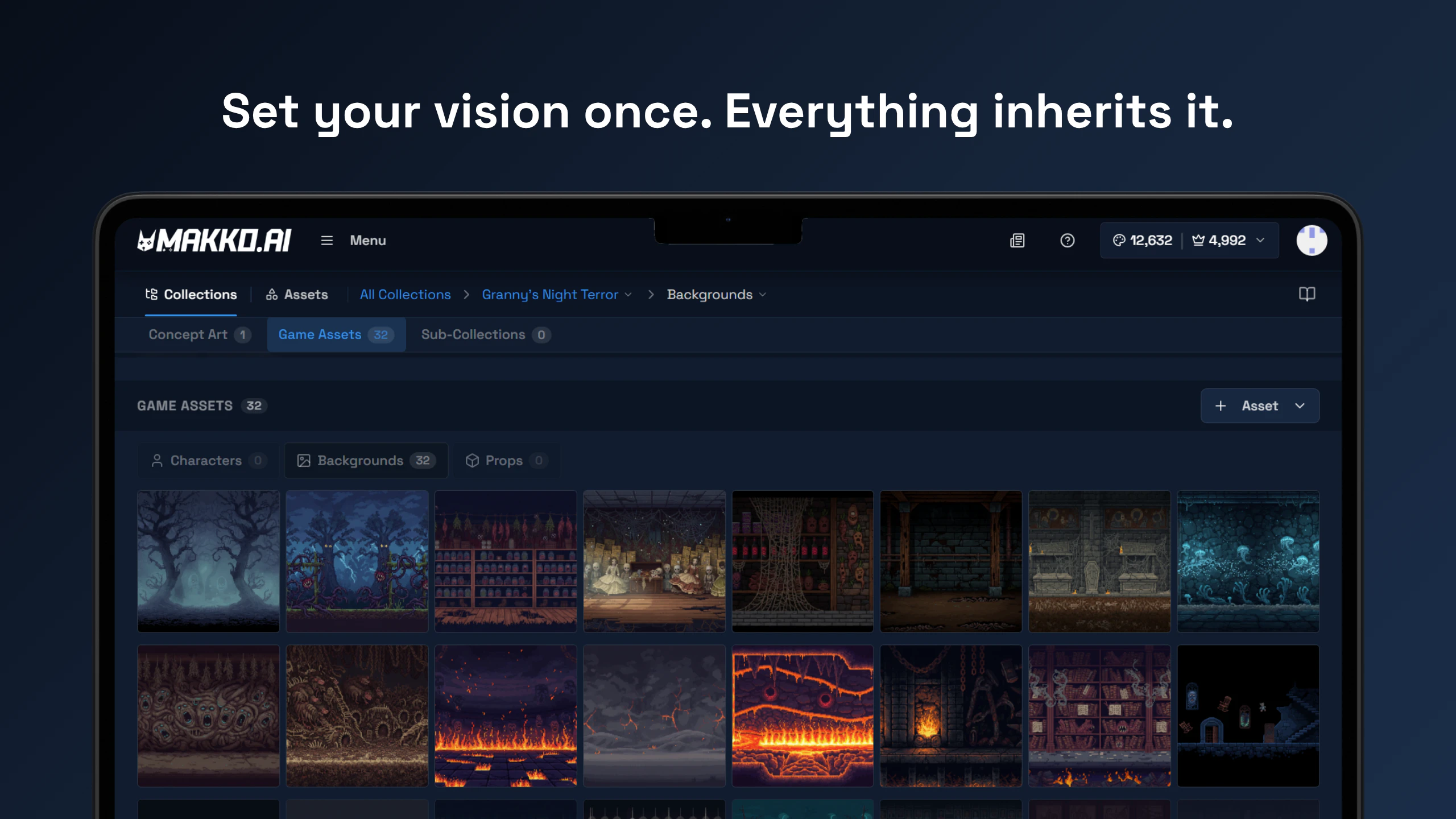
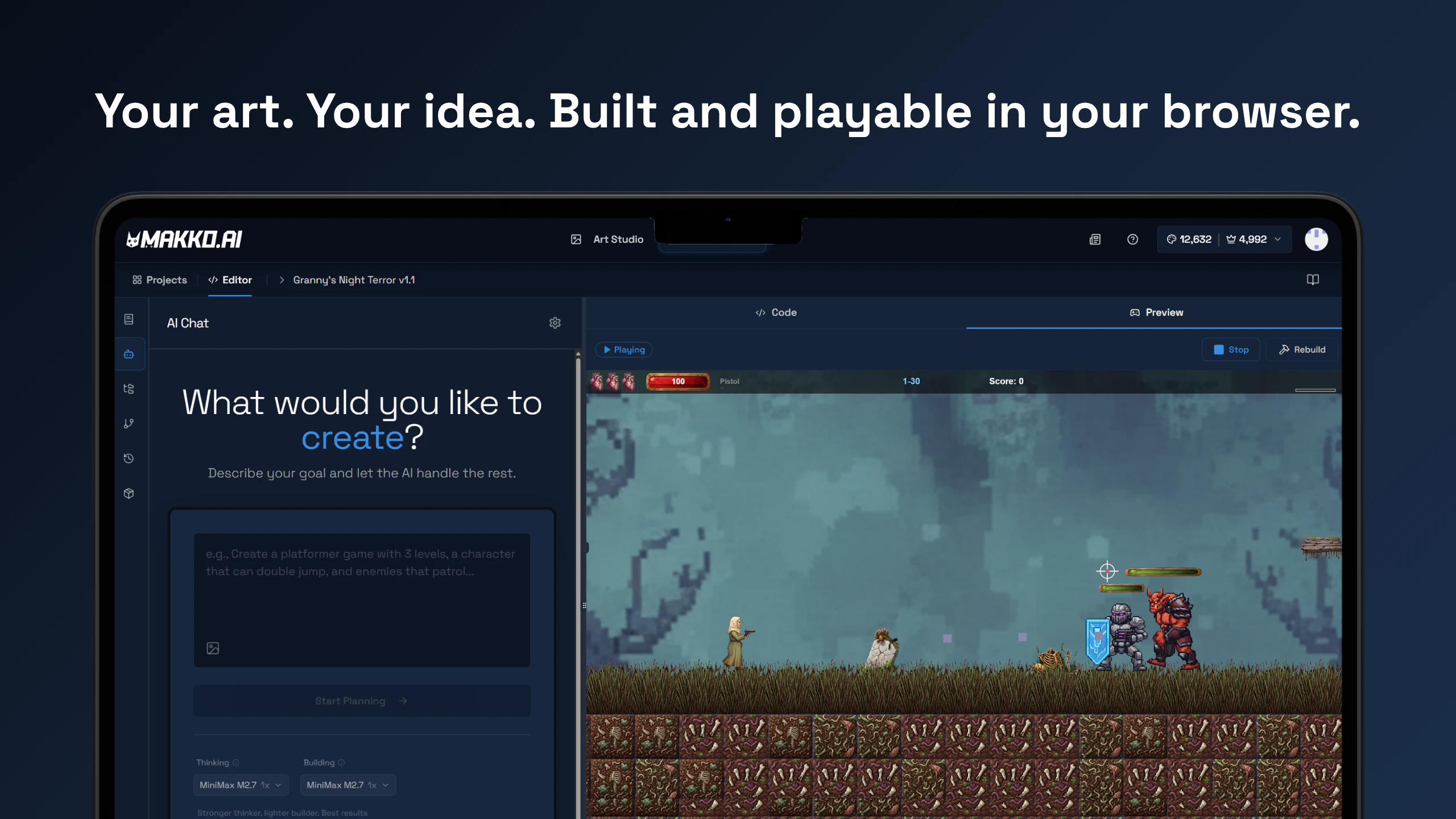
















Hi! Really excited to finally share what we've been building.
I’m the founder of Project Mirage. We are a team of Designers, Developers and Engineers who have been building in Consumer Hardware for over 8 years, now building in AI Interfaces.
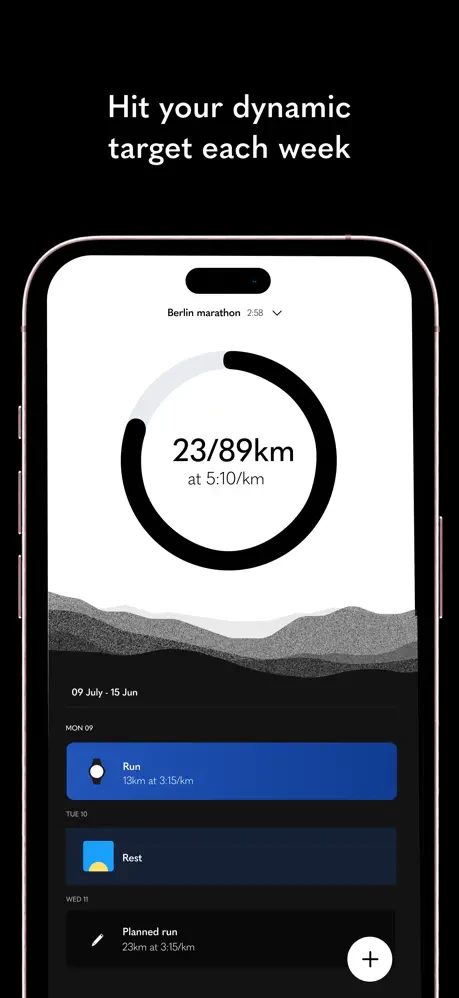
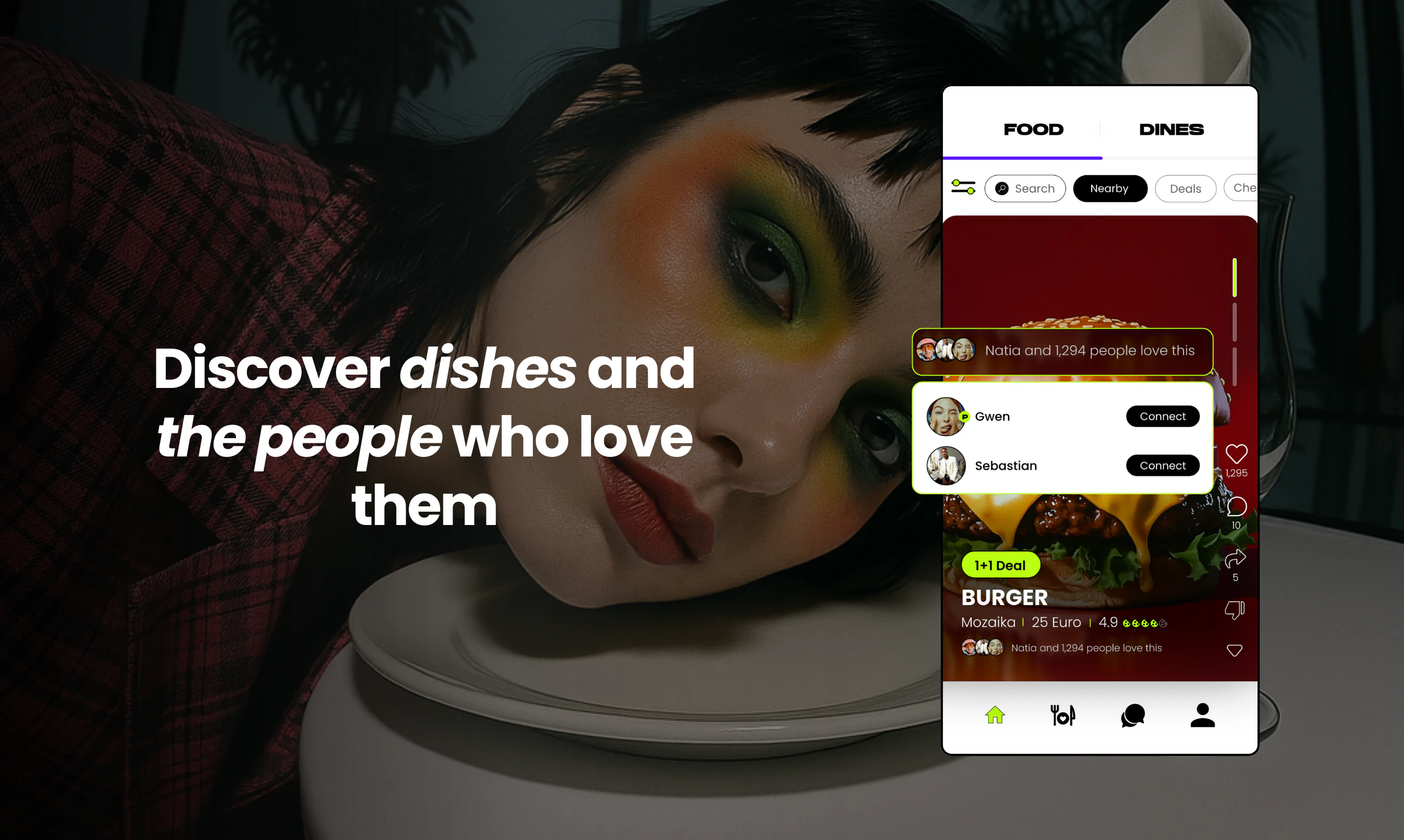
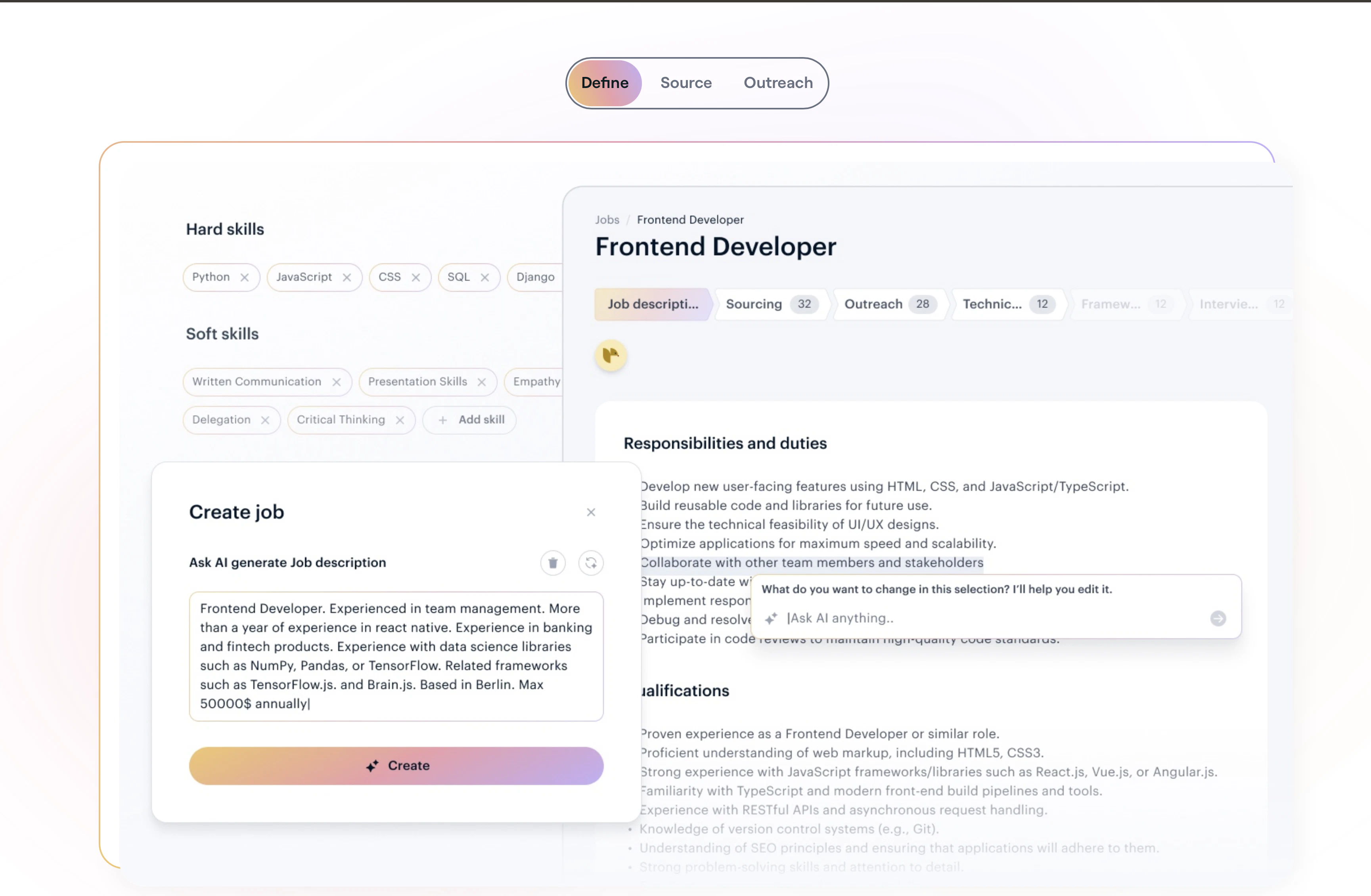
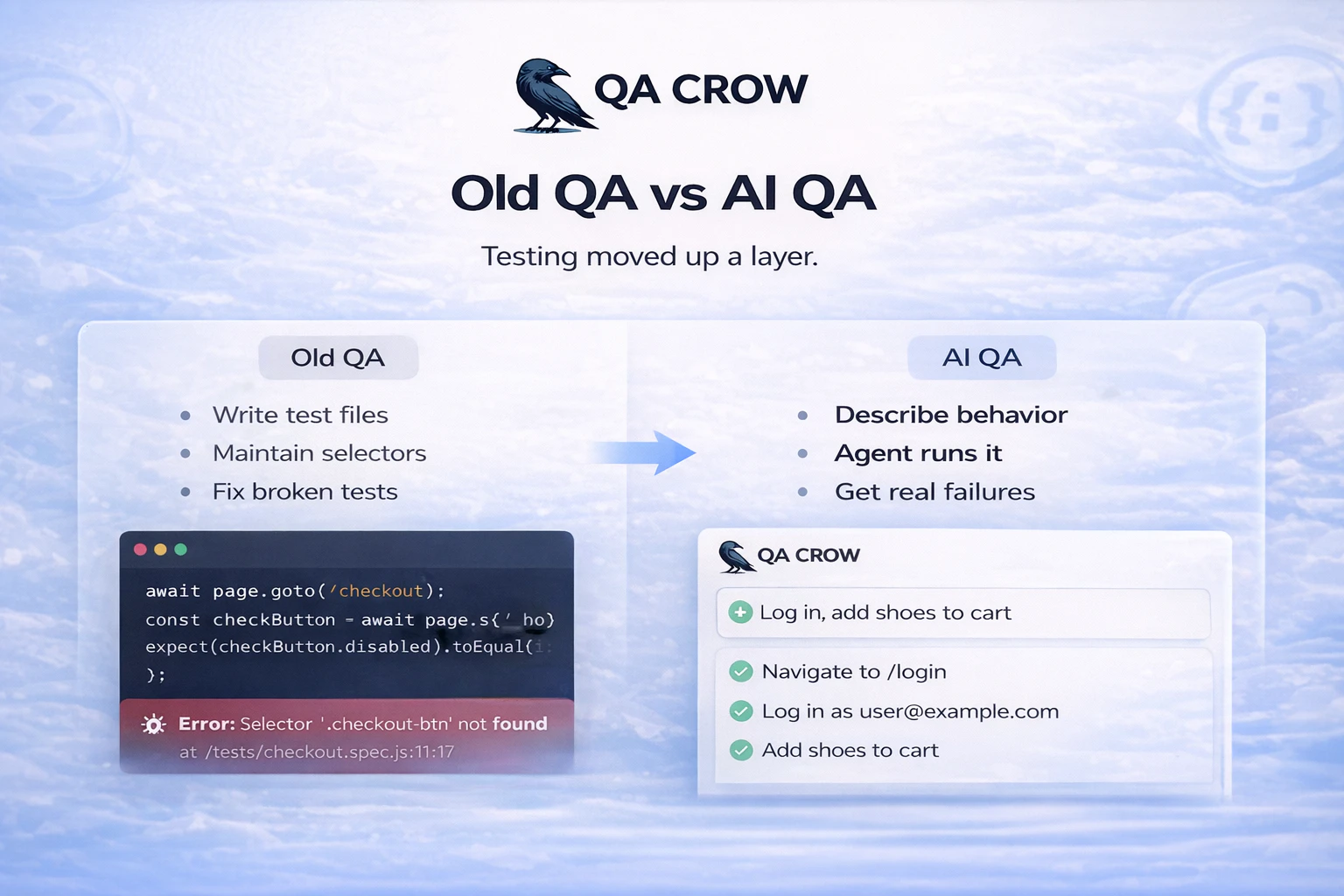
What is Dune and why is it called so?
Dune is a context Aware Keypad for mac that reads which app is in the foreground and automatically changes what its 3 keys do based on what you're doing. We call it Dune because a sand dune is never one thing. It shifts, quietly and constantly, shaped by whatever surrounds it.
That's what these three keys do. They observe what you're doing and become what you need, right then.
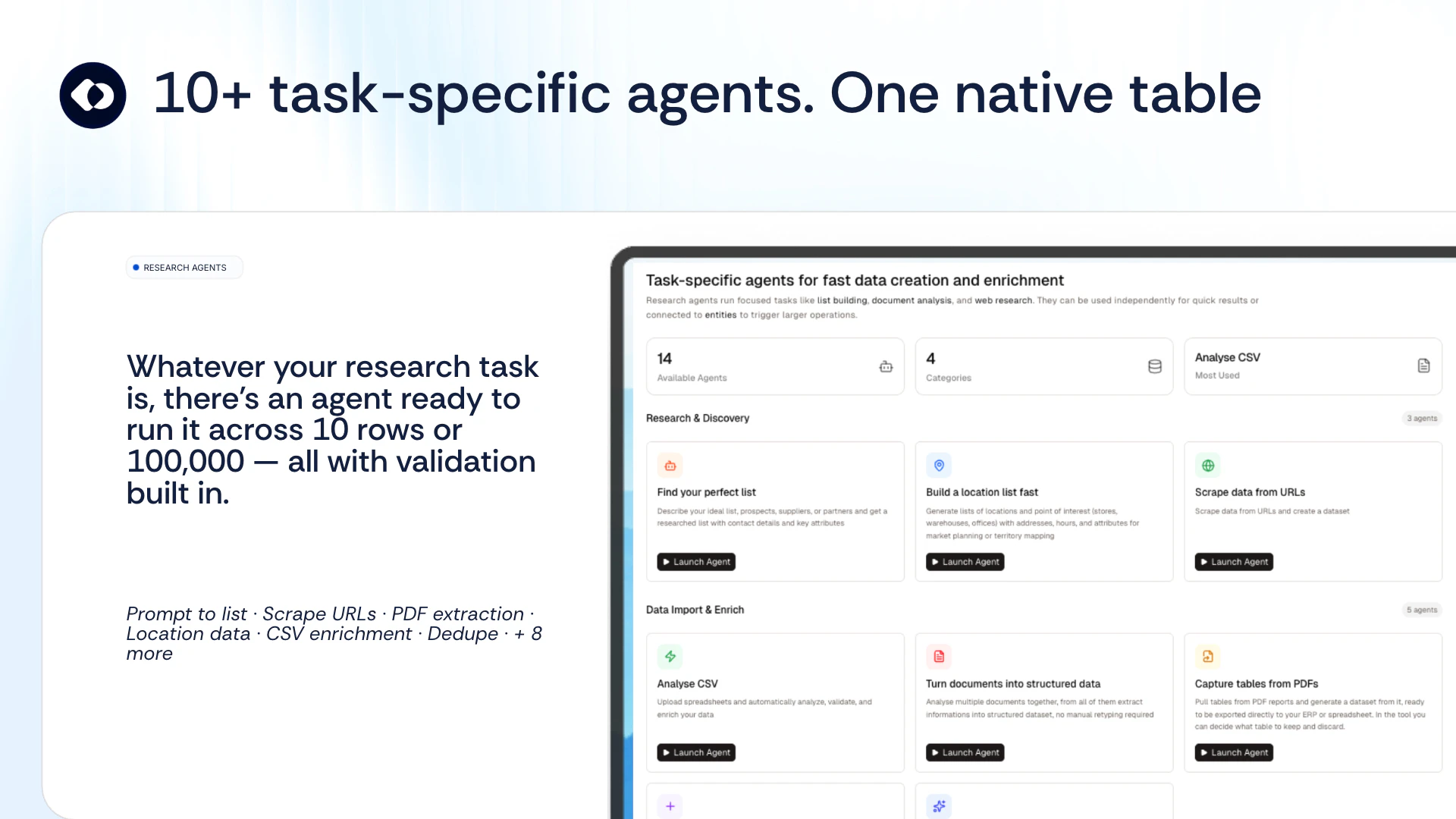
What Makes Dune Different
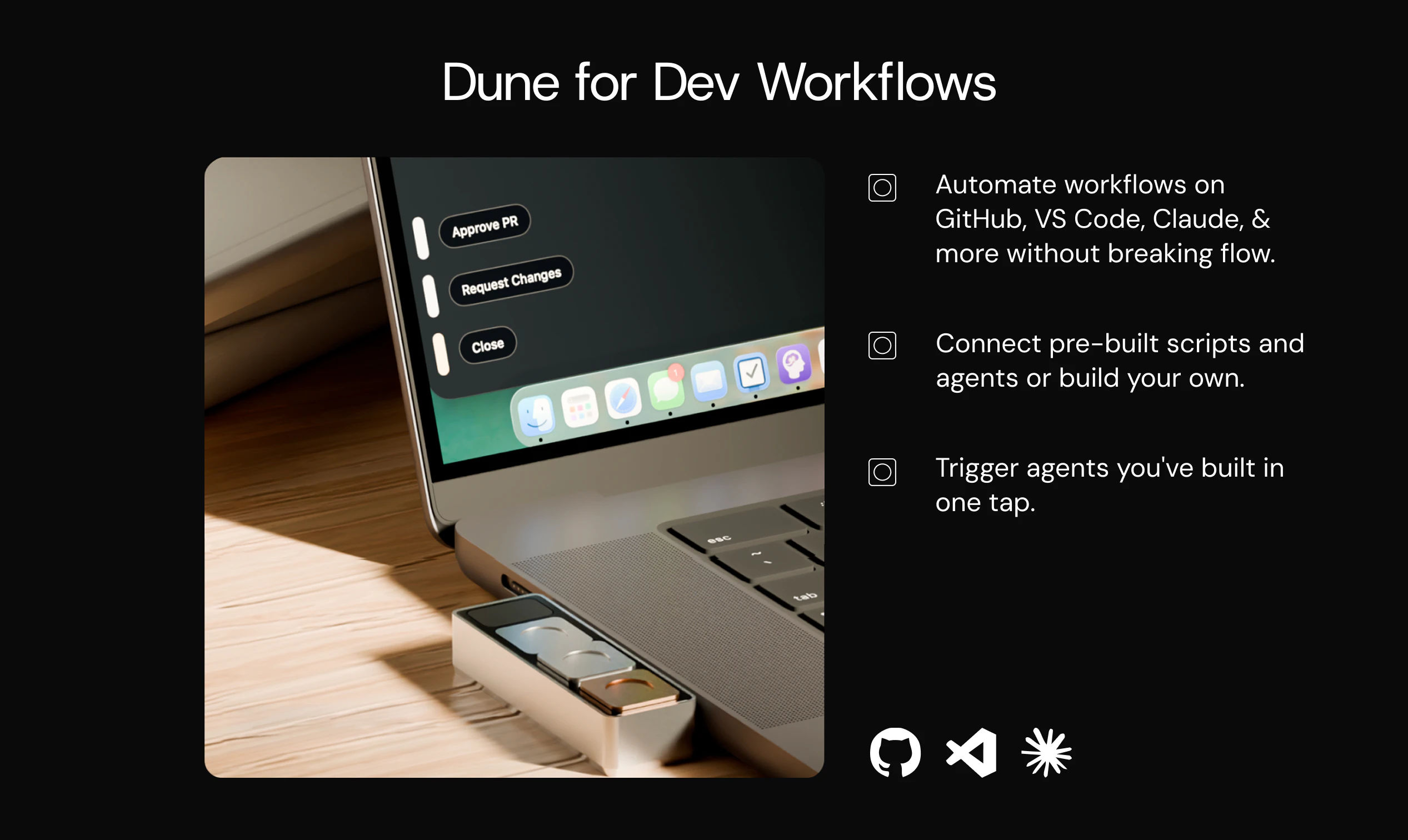
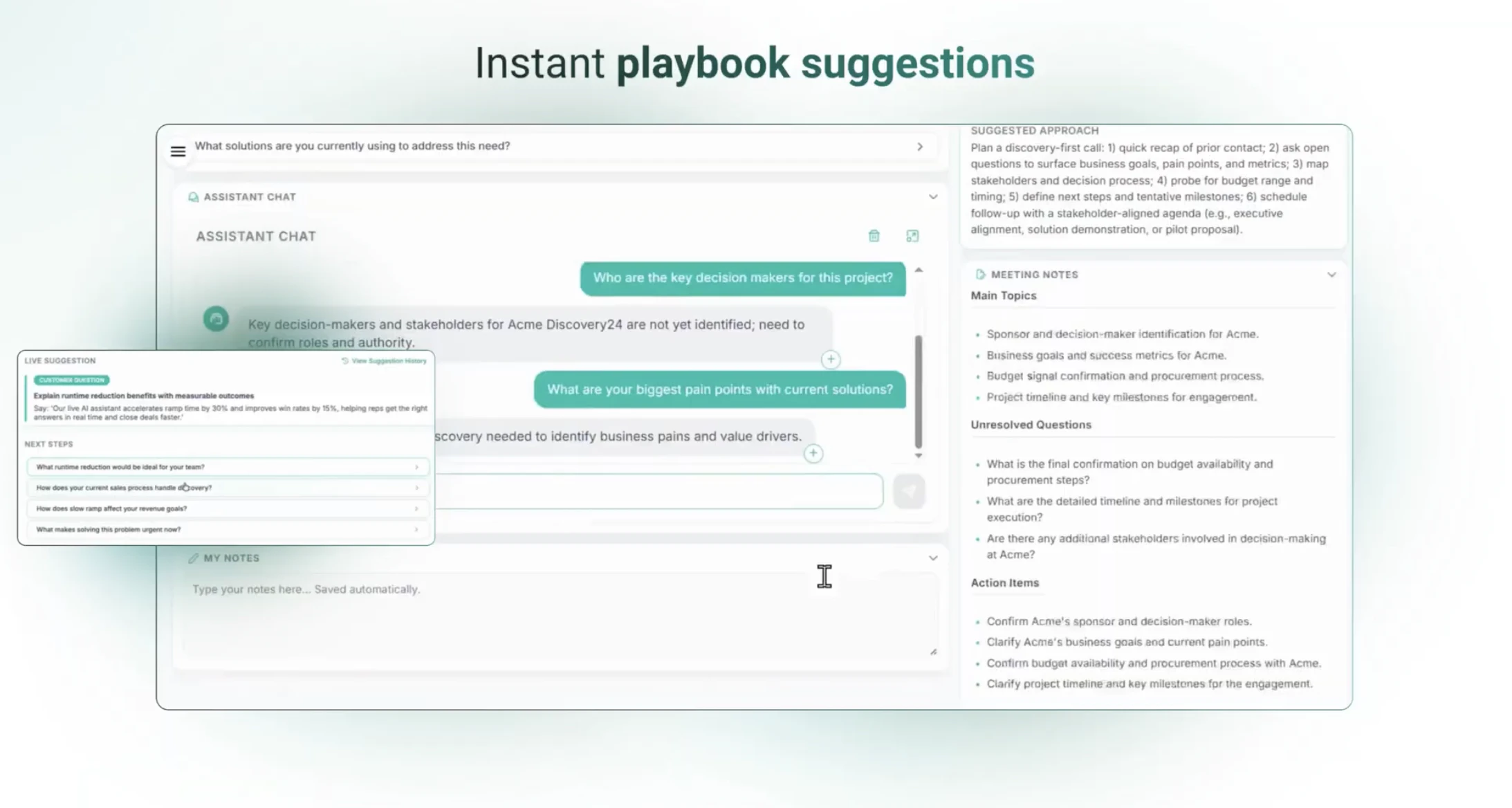
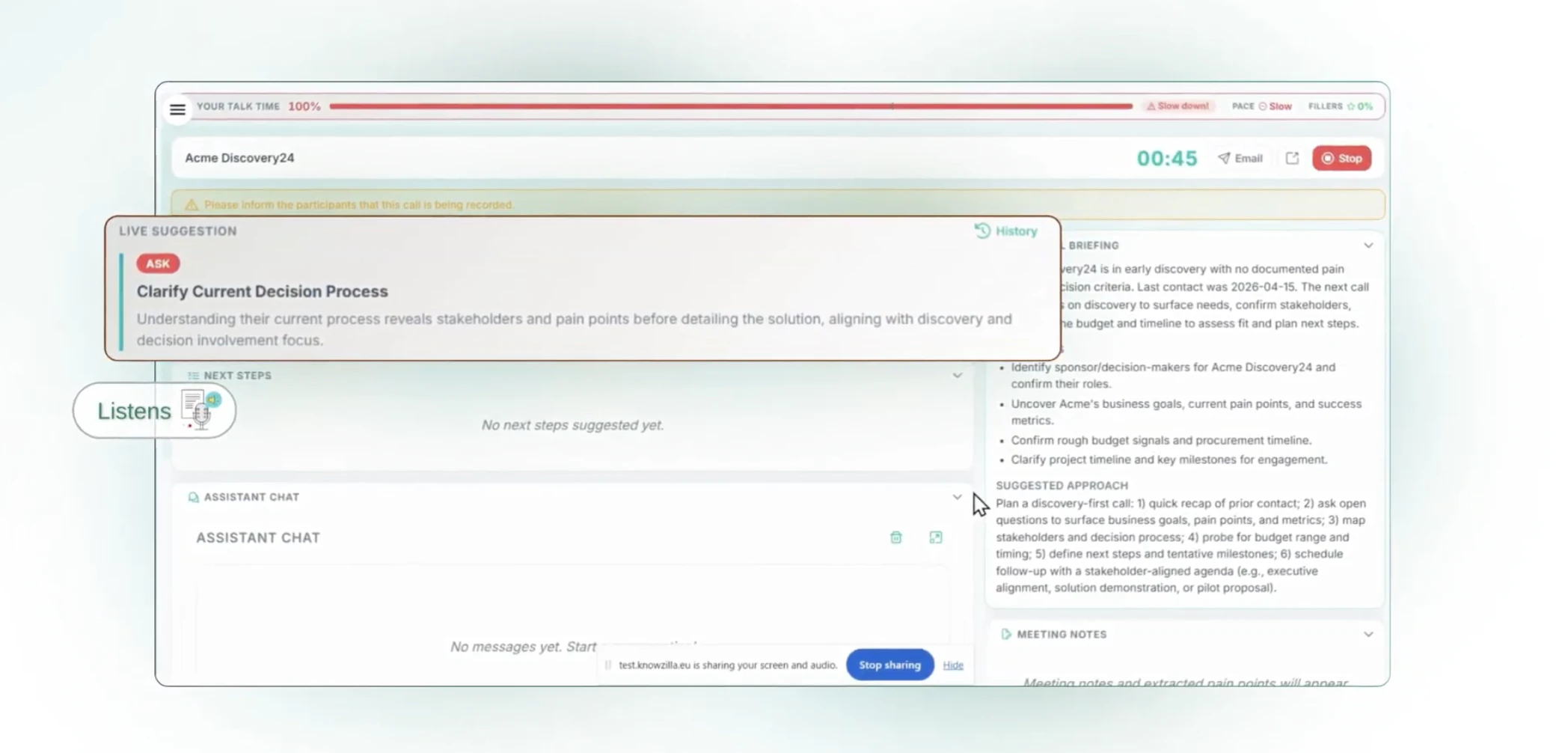
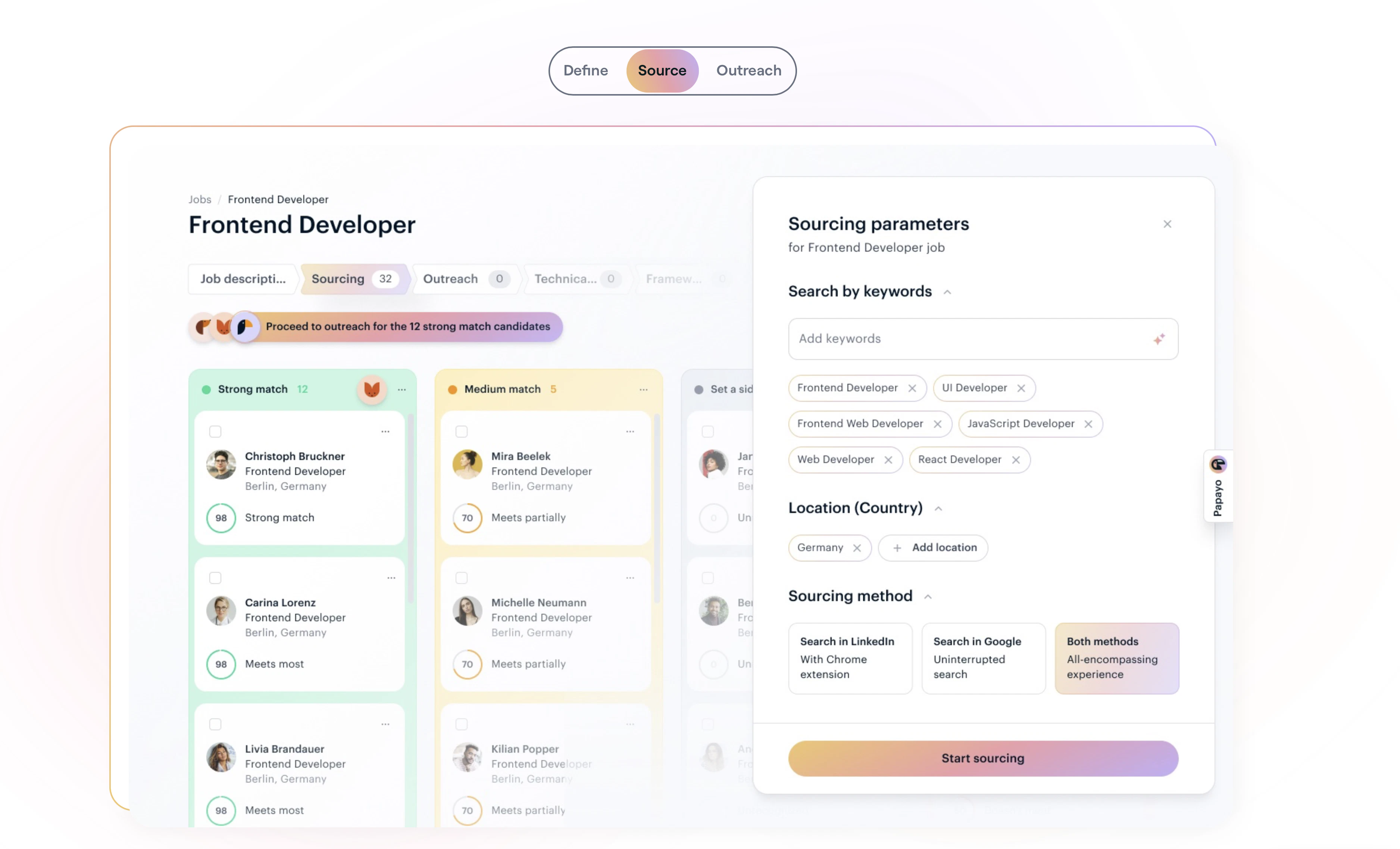
Dune is context-aware, meaning, its keys update automatically based on the app you are running. Unlike other keypads that lock you into setting up keyboard macros for each app, Dune comes with the most-used commands and complex workflows already built in. It is also highly customizable - you can write your own scripts and connect your own agents to trigger via Dune. It reads your active app and surfaces the three most relevant actions automatically, in real time.
The Problem & Our Solution
The way we interact with computers hasn't meaningfully changed in 45 years. We still rely on browsing through screens, clicking multiple links, and memorizing unnecessarily complex keyboard shortcuts for everyday actions. Most shortcuts are buried, forgotten, or simply never discovered, and that's not a user problem, it's a design problem.
Meanwhile, what we actually do on computers has gotten far more complex - developers juggle dozens of tools at once, and meetings now run back-to-back with controls scattered across cluttered interfaces. The friction is constant, and it adds up.
We spent months experimenting with new interface paradigms, showcased three of them at CES, and built Dune to put the best of what we learned directly in your hands. A three-key Mac keypad that reads your active app and surfaces the right actions automatically, whether you're coding, in a meeting, or getting things done.
Features & Benefits
1. Context Awareness: Dune detects which app is in the foreground and automatically updates what its 3 keys do in real time, so you never have to manually switch profiles or reconfigure anything.
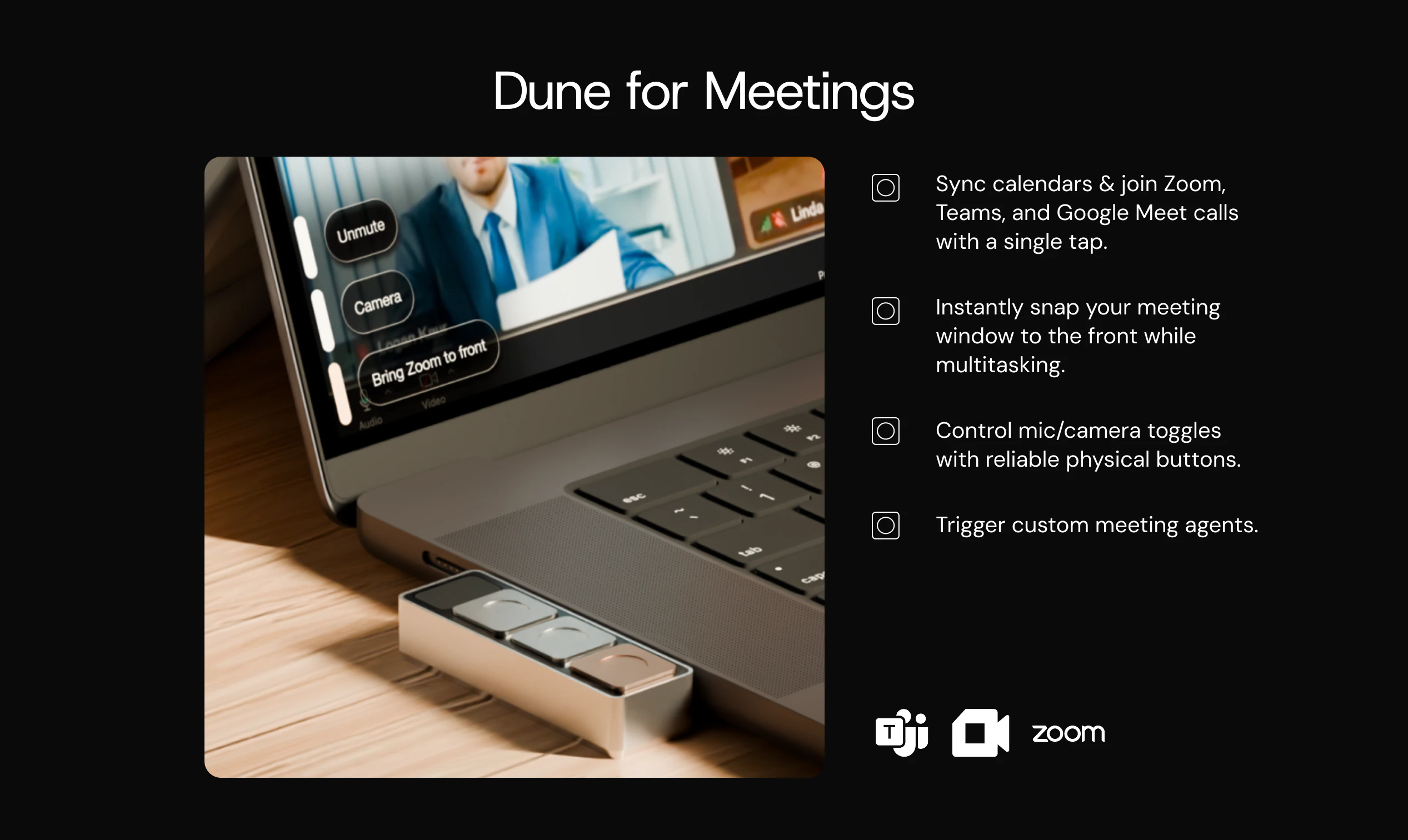
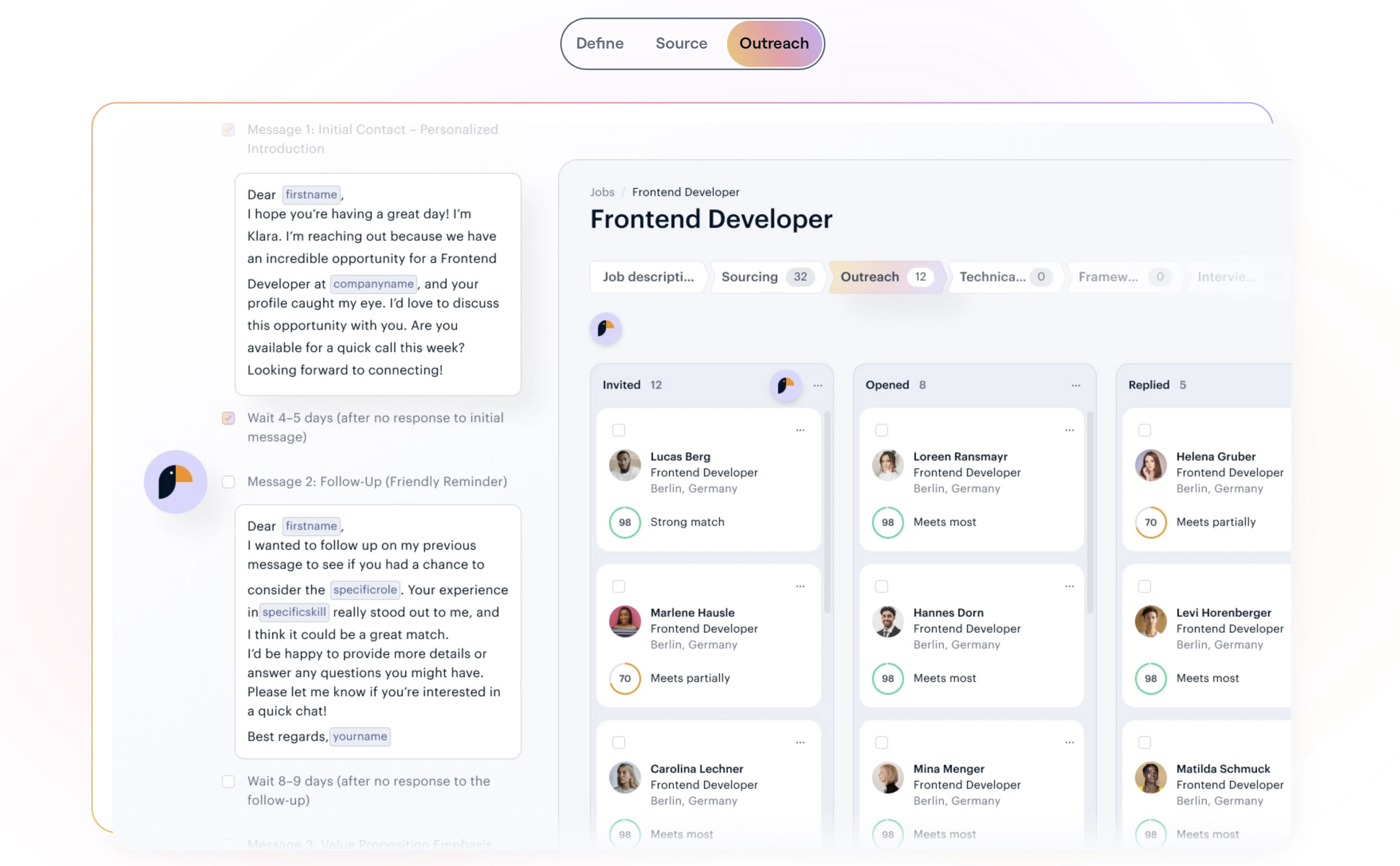
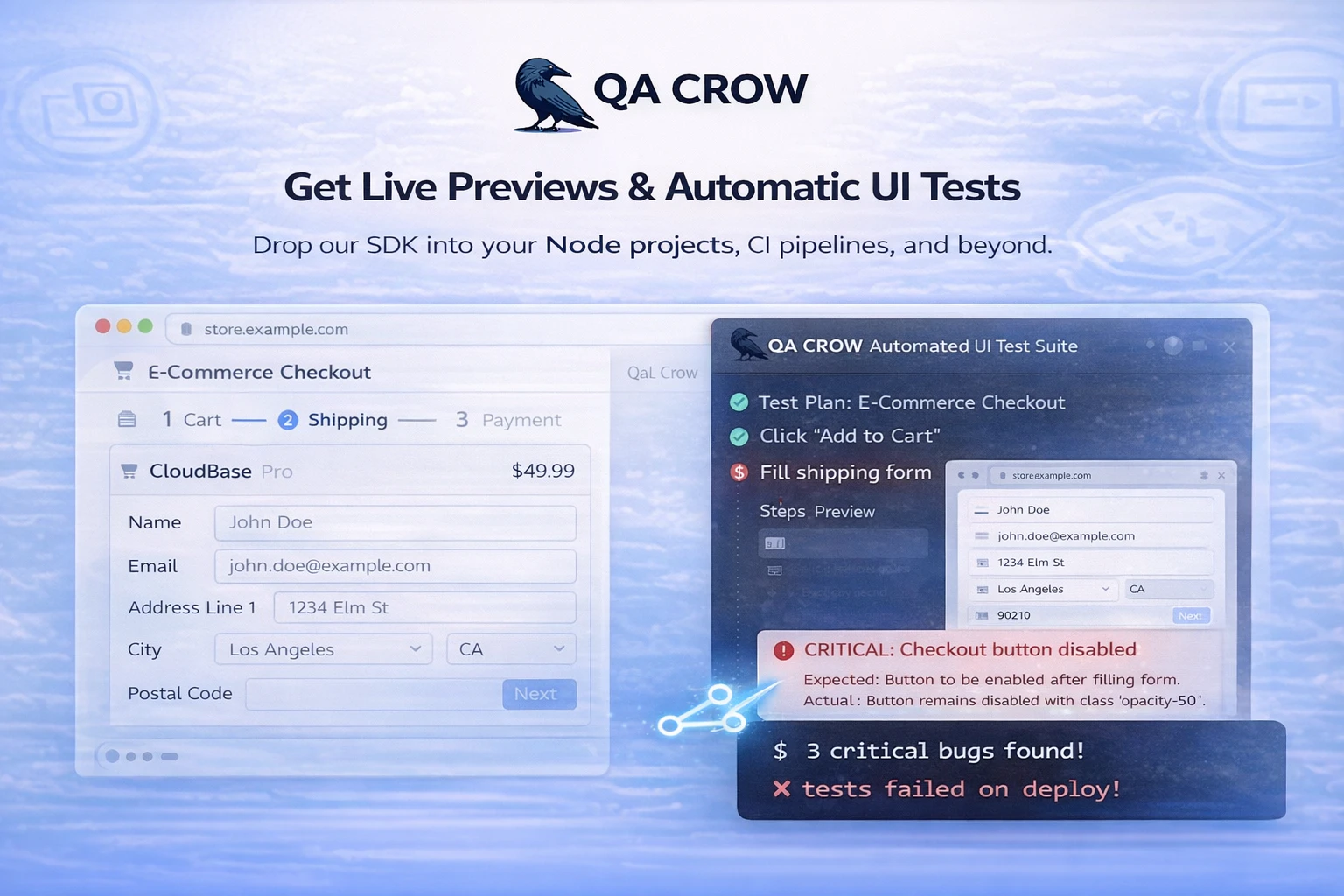
2. Instant Actions: Every key is always mapped to something relevant to what you are doing. In GitHub, that means raising a PR, approving/rejecting a change. In your meeting app, joining a call, toggling your mic and controlling your camera with one tap - all while juggling a hundred different tabs.
3. Calendar Sync: Dune syncs with your calendar so you can join your meetings in a single click. Works with Zoom, Teams and Google Meet.
4. Agent Triggers: Trigger your AI agents or agentic workflows directly from your desk. An email assistant, a calendar agent, or anything else you've built in Claude can be activated from the same three keys without switching context.
5. Custom Macros and URLs: Connect any keyboard macro or URL in the Dune app and define exactly what each key does across any app or workflow.
Who Is Dune For?
Dune is built for anyone who lives on their Mac.
1. Developers: Approving a PR on GitHub takes 4-6 clicks on average. Multiply that across a full day of reviews, commits, context switches, and agent triggers and you're spending more time navigating your tools than actually building. Dune maps its three keys to the actions you reach for most in GitHub, VS Code, Claude and more, so you stay in flow.
2. People who live in Back-to-Back Meetings: One tap to join a call, a dedicated mic toggle that auto-brings your meeting window to front, and a camera key so you're never fumbling at the wrong moment. Syncs with your calendar and works with Zoom, Teams and Google Meet.
We'd especially love to see what you build with it.
Drop a comment! I’d love to hear what shortcuts have been frustrating you and share how Dune can fix that for you.
---
🎁 Product Hunt Launch Offer
33% off for our early birds, use code PRODUCTHUNT99 at https://www.projectmirage.ai/order
⭐️ Important Links
Site: https://www.projectmirage.ai/
Setup Guide: https://boom-cuticle-650.notion....
All FAQs: https://www.projectmirage.ai/#du...
Demo: https://www.youtube.com/watch?v=4Hn_ece7NVc
Is it reading the active window process or something deeper than that?
Early user here - thought it would take weeks to build the muscle memory. Took about two days. Now if the keys are not there I notice immediately. Nicely done.
Is there a way to temporarily lock the keys so they stop remapping?
Three keys in a vertical stack rather than horizontal is interesting. Easier to reach without moving your hand off the home row.
Curious what the latency looks like between the macOS accessibility API firing and the key remap completing.
What is the loudest the keys get? Hot desk life is real, and some of us have to be considerate.
This is cool. Context-aware is doing a lot of work in the pitch. Macro keypads usually trade a few saved seconds for remembered mappings so net productivity ends up a wash. How does Dune's context trigger? Active window, calendar state, time of day.... ? Congrats, and good luck :)
Congratulations. And happy product launch. @apoorv_shankar
Cool project! Guys, you're great!
Congratulations!!!
Interesting contrast to tools like Stream Deck fewer buttons, but smarter ones. Feels like a bet on intelligence over customization.
Curious how fast and accurate the app detection is in practice. Even slight lag could break the flow you're aiming for.
Okay, I love this! I'm really excited. The vertical stack of keys looks like a smart idea. How is the latency?
Hardware that actually thinks about the person using it. That is what we were going for from day one and I think we got there. Really proud of this one.
custom scripts alone are worth it. i have sooooo many workflows I want to build with this. congrats on the launch, really proud of what we shipped :)
Waiting for an update wherein it connects via bluetooth and I could use it as my external Knuckles. Kudos to the team!
How long does it take to learn a new app? Like if I add a tool to my workflow tomorrow, does Dune pick it up automatically or do I need to do something?
the fact that it changes based on the foreground app is sneaky smart 👀 been losing my mind switching between cursor claude and meetings lately so this solves the exact right problem.
how hard was app detection to get reliable across all the chaos?
This looks fantastic! Congrats on the launch! It's USB-C connection, but you have M2 or later on the site for compatibility. Any specific reason an M1 Mac won't work? There are 2 USB-C ports in the same location as the newer models
How fast is the remapping actually? Like is it instant or is there a moment where the keys are in between states? Never clocked it properly.
Designing something this compact while keeping it intentional and complete was a unique challenge. Really Happy with how it turned out!
Every surface on this was intentional. Good to finally have it out in the world!
As someone who has spent years building hardware, shipping something this precise and this smart at the same time is genuinely satisfying. Really proud of what this team pulled off.
Three keys sounds like nothing until you realize those three keys are always the right three keys. This is a good one! 😎
nice, i basically wanted to do the same with the elgato custom stream deck module and call it "clawboard.engineer", but this is sooo much better. i need this in my life.
Why i need this ? If I can also use siri much faster than this
Looks dope man! Good luck
Congratulations on the launch! Looks exciting, and I love the naming, waiting for more geographies to come :)
three keys seems minimal but probably smart. love that it's built specifically for the GitHub/VS Code/Claude workflow since that's our daily stack. wondering if there's any way to customize actions beyond what the AI suggests, or if it learns your patterns over time?