PH热榜 | 2026-04-29
一句话介绍:Plurai 是一款让开发者通过自然语言描述“能做什么/不能做什么”,无需标注数据或提示工程,在数分钟内自动生成AI智能体专属评估与护栏模型的工具,解决传统“LLM作为裁判”成本高、延迟大、只能采样评估而遗漏关键故障的痛点。
API
Developer Tools
Artificial Intelligence
AI智能体评估
护栏模型
小语言模型
数据自动生成
多智能体辩论
无监督训练
实时评估
低成本推理
意图校准
可靠性工程
用户评论摘要:用户普遍认可“全量评估而非采样”的架构价值,核心追问集中于:冷启动时对隐性违规的泛化能力、小模型与LLM判决冲突时的信任机制、多轮交互模拟的可靠性。有用户质疑技术背书,官方回应称已发布论文并开源基准。
AI 锐评
Plurai 切中的痛点极其精准——AI智能体评估在工程实践中长期处于“嘴上说要但永远不做”的尴尬境地,根因是LLM-as-Judge的成本和延迟迫使团队仅采样评估,导致生产故障恰恰出现在采样间隙。Plurai 用“任务描述→辩论生成数据→小模型部署”的闭环,试图将评估从“偶尔抽检”变为“实时全检”,商业逻辑成立。
其技术核心BARRED(多智能体辩论生成训练数据)并非凭空创造,而是将AutoPrompt的意图校准与对抗验证结合,解决了合成数据最棘手的“多样性”和“真实性”问题。宣称“43%更少故障、8倍成本降低”有研究基准支撑,避免了常见的营销注水。但产品真正的风险不在技术,而在迁移泛化:用户自然语言描述的“行为规范”往往是模糊、矛盾且存在隐含例外的,如果系统将“不要订购高价课程”这类反讽式指令误解为具体规则,那么冷启动阶段的1-2轮迭代可能会将时间成本转移给用户调试。此外,小模型在高度复杂、需要常识推理的边界案例上,能否持续保持与GPT-5级裁判一致的敏感度,仍是悬而未决的信任鸿沟。Plurai 聪明地将“争议案例”定位为反馈信号而非失败,这种持续学习的设计是类MLOps的思路,但能否形成飞轮效应取决于用户是否愿意投入标注反馈——这恰恰是Plurai声称要消除的负担。总体来说,它对AI可靠性工程优化是实质性贡献,但“无需数据”的叙事有营销嫌疑,本质上只是将数据生成从人工成本转移为计算成本。
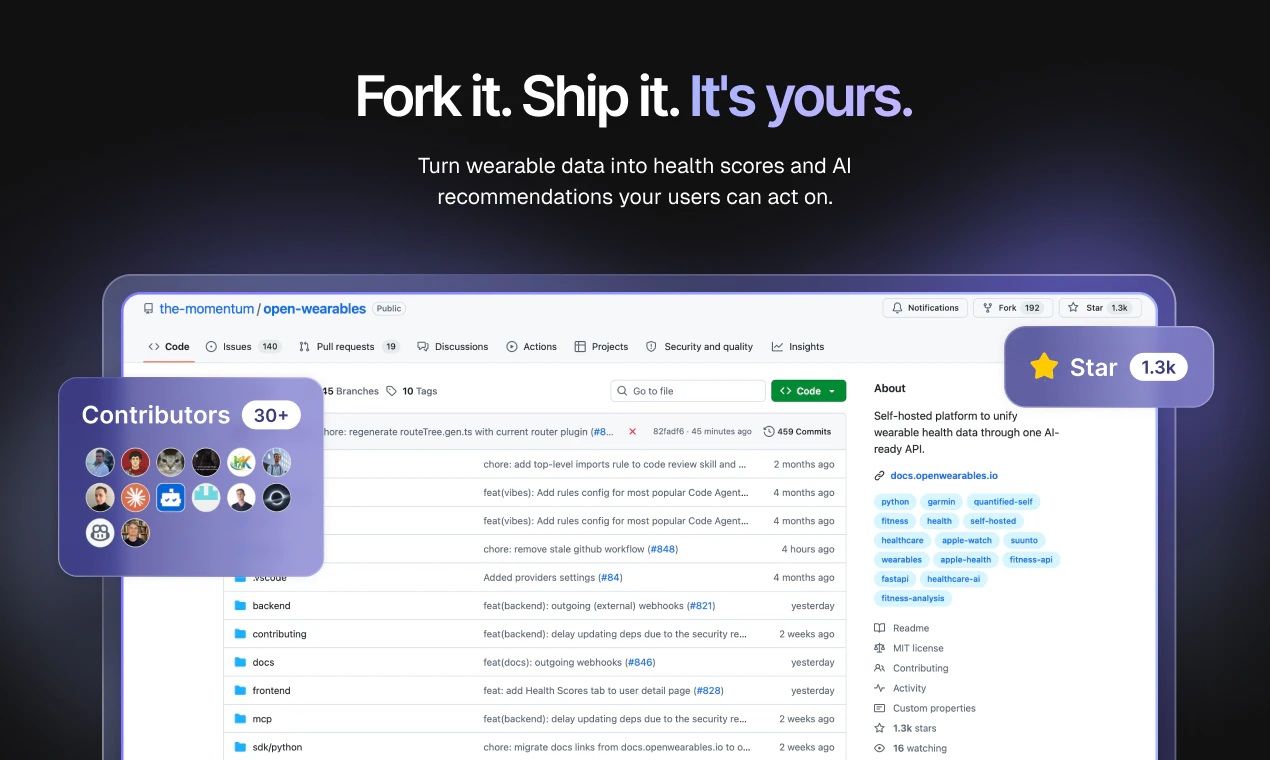
一句话介绍:Open Wearables 是一个开源的智能健康数据中间层,通过统一API整合所有可穿戴设备数据,并提供标准化评分和AI推理能力,让开发者免去重复对接不同厂商API的“基建苦活”,直接构建个性化健康产品。
Open Source
Wearables
Developer Tools
GitHub
可穿戴设备
健康数据平台
开源API
数据标准化
健康评分
AI推理
自我托管
HIPAA合规
MIT协议
开发者工具
用户评论摘要:用户普遍认可其解决了设备数据碎片化痛点,尤其好评“截图追逐”场景被终结。主要关注点包括:与Apple Health/Google Fit等集成(已支持),数据模型版本同步策略(计划中),以及MCP服务器设置门槛(初期需技术基础)。另有用户询问Fitbit完整集成及历史数据回填功能。
AI 锐评
Open Wearables 切中的是一个极“痛”但常被忽视的缝隙——可穿戴数据基础设施的重复建设。市面上每个健康App都经历了同样的OAuth地狱、字段映射混乱和评分逻辑黑盒,而这家团队选择把这层“脏活累活”开源,并聪明的用MIT许可和零席位费降低采用门槛。从产品来看,它的核心价值并非数据聚合(已有同类API),而是“健康评分算法开源”和“MCP AI上下文”两项差异化:前者让评分可审计、可调优,直击Oura等闭源算法的信任危机;后者将结构化数据喂给LLM,让普通用户能问出“为什么我昨晚睡不好”而非面对一堆数字图表。
但必须指出潜在风险:开源项目的可持续性需要企业级付费能力支撑,当前“单向开源+0元定价”模式若无法转化为托管服务或高级功能收入,长期维护和质量将存疑。此外,数据模型需随各厂商API频繁更新带来的版本分歧问题(用户已担忧),以及MCP Server初期仍需技术背景才能使用,都限制了其“开发者友好”的承诺兑现。从竞品看,Vital、Human API等已占据部分商业份额,Open Wearables的破局点在于真正开源带来的社区生态与信任度——但社区活跃度和贡献质量才是决定其能否从“知名工具”进化成“标准层”的关键。团队背景(Momentum的医疗健康领域工程积累)是加分项,但健康数据的合规(HIPAA)和临床级验证仍需更透明的披露。一句话:基础设施方向正确,但开源不是万能药,变现和生态才是真正的战场。
一句话介绍:KarmaBox是一款将手机变为AI多智能体“遥控器”的应用,让用户无需依赖单一终端或云基础设施,即可随时随地调度Claude、Codex、Gemini等模型,在自有设备池中并行执行复杂任务,解决AI工具碎片化、需手动切换和拷贝的痛点。
Productivity
Privacy
Artificial Intelligence
用户评论摘要:用户普遍认可“并行执行”和“移动端调度”的价值,痛点集中在多工具登录繁琐、长任务管理、设备离线影响。核心疑问包括:如何处理长任务(后台排队+通知)、老旧手机可否运行(轻量级控制端)、设备离线或低电量时任务路由的容错机制(心跳监测+状态分离),以及API成本控制(使用聚合池和事件驱动降低消耗)。
AI 锐评
KarmaBox的巧妙之处在于,它没有试图去造一个更聪明的AI模型,而是切中了“AI太多,但彼此不通”这个愈发尖锐的体验断层。从产品呈现来看,它更像一个“AI万能遥控器+设备局域网私有云”的组合:手机不再是算力瓶颈,而是作为指挥中心,让你的笔记本电脑、工作站甚至旧设备变成免费的分布式计算节点。
然而,华丽概念背后藏着几个硬核挑战。首先,**“去中心化”的私有计算池**在实际体验中意味着高度的网络稳定性和设备状态管理,用户家中断网或设备关机时,系统承诺的“不中断”如何优雅降级?其次,**“多模型自动路由”**虽然听起来高级,但从评论中对Opus全场景使用的质疑看,路由的准确性和成本优化算法透明度,才是长期说服重度用户的关键。如果路由逻辑不透明或频繁选错模型,就会变成“黑盒浪费”。
对开发者而言,KarmaBox的确提供了一个有趣的“JARVIS”式愿景。但它目前更像一个极客玩具,而非面向大众的消费品。普通用户不一定拥有足够多的设备来组成“计算池”,也未必能接受让AI在没有明确指令时“自主协调”。真正的价值在于,它能不能在ToB场景里,以“移动运维终端”的形式,帮团队打通从做图、写代码到自动化测试的全闭环。要是能做到,它就不再是“一个工具”,而是“AI操作的基座系统”。否则,就只是个漂亮的调度实验。
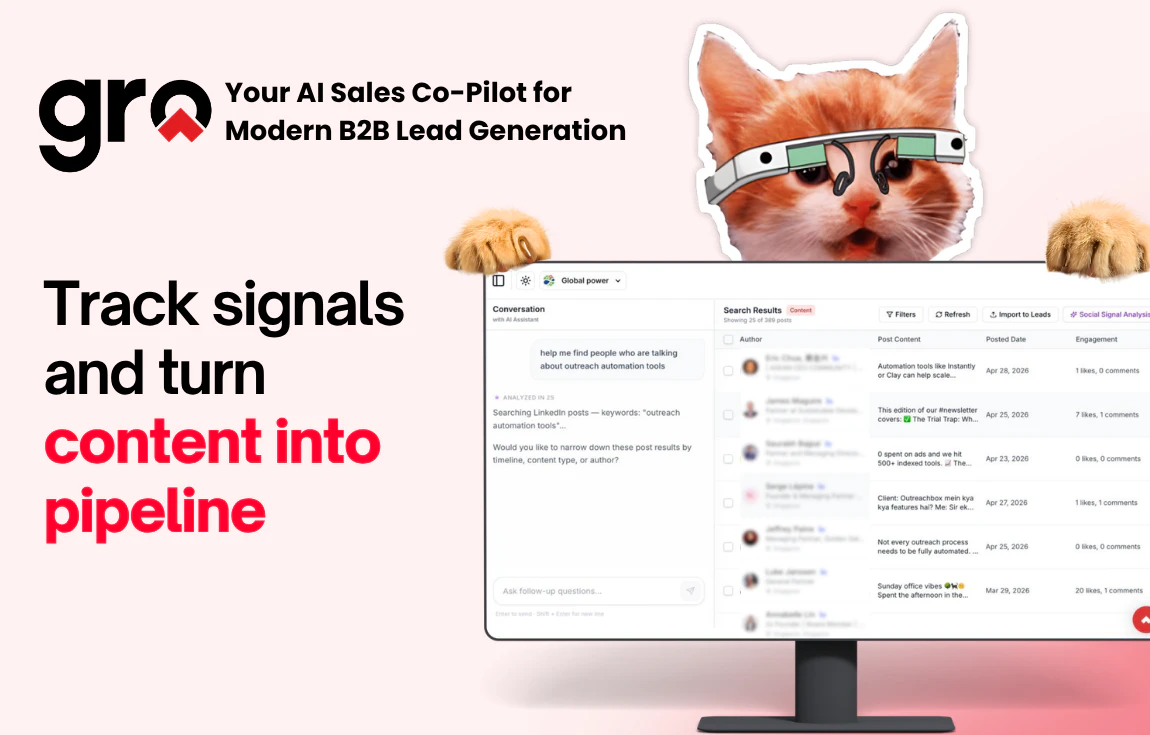
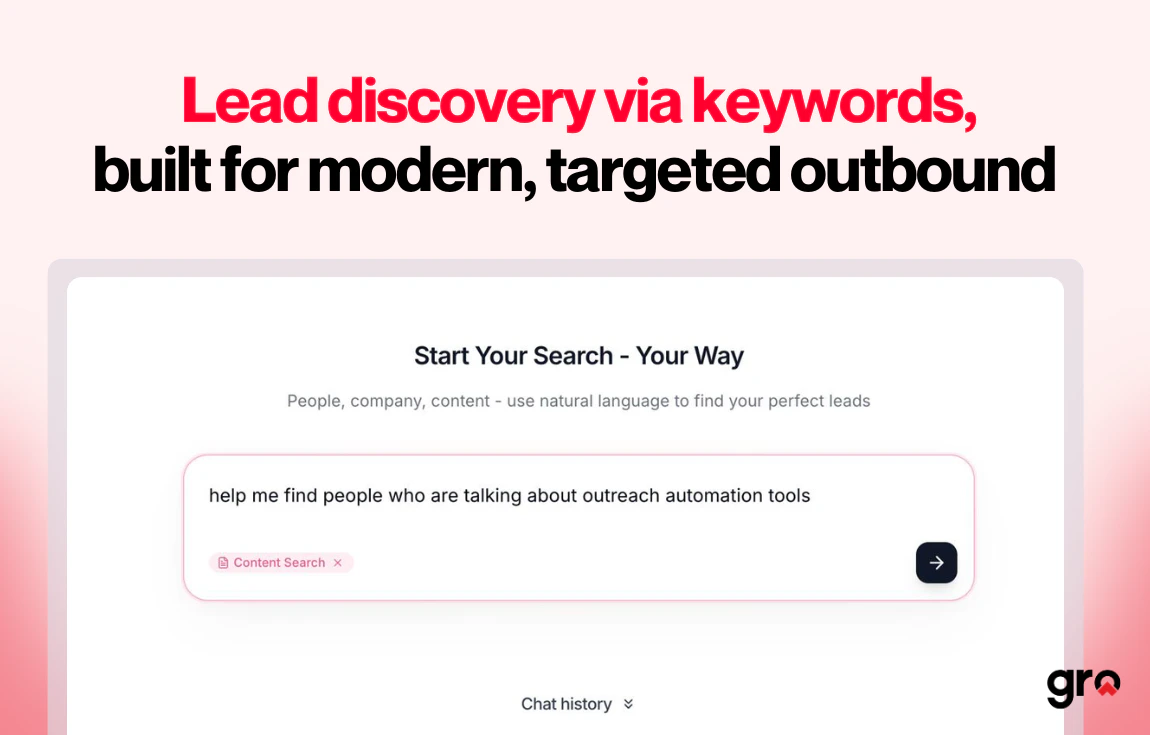
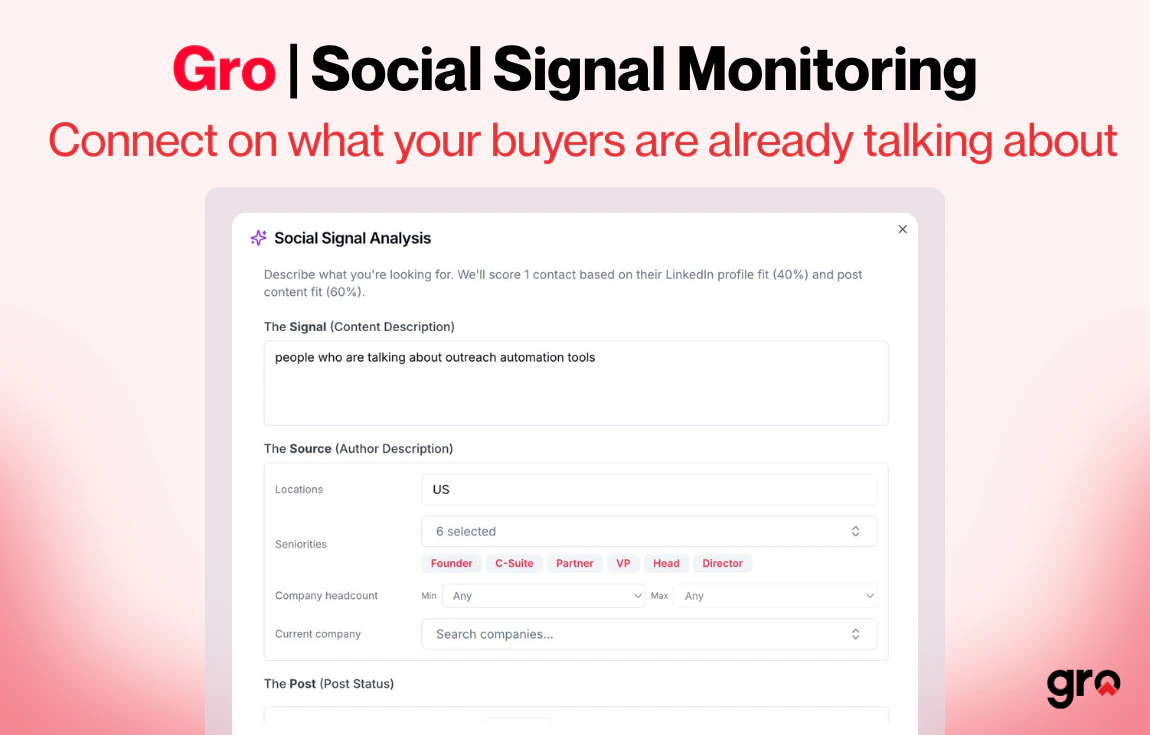
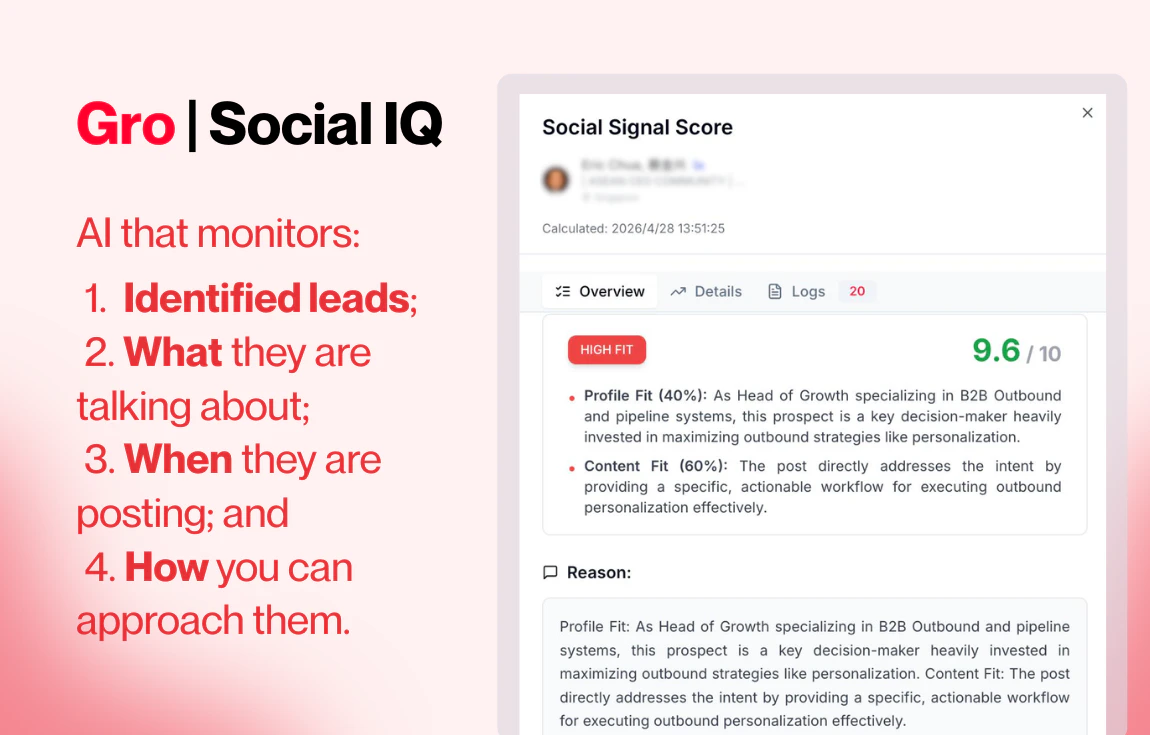
一句话介绍:Gro v2通过内容搜索和社交信号监控,帮助B2B销售团队在LinkedIn上实时捕捉买家高意图帖子,并自动触发评论、私信、邮件等跟进动作,解决从信号发现到主动触达的手动低效痛点。
Sales
Artificial Intelligence
CRM
社交销售
B2B销售自动化
LinkedIn线索挖掘
意图监测
内容搜索
销售自动化工作流
社交CRM
销售赋能工具
用户评论摘要:用户关注点集中在:1)自动化与个性化平衡(Gro回应可基于上下文和语调模板);2)刷新频率(目前12小时周期性扫描,非实时);3)外部集成(尚无Zapier/Make,规划中);4)定价与试用(有免费100积分层);5)对比Sales Navigator(Gro强调从信号到行动的闭环执行)。部分用户通过F5Bot+手动滚动类比痛点,对伪正信号过滤表示关切。
AI 锐评
Gro v2并非颠覆式创新,而是对B2B社交销售“最后一公里”问题的精准缝合。它解决的痛点非常真实:销售团队在LinkedIn上用关键词搜索“意图信号”,然后手动打开几十个标签页、复制粘贴、撰写个性化消息——这套动作消耗的时间成本远超想象。Gro的价值在于,它把“发现信号”和“执行动作”这两个本应在一个大脑里完成的流程,强行用自动化粘合在了一起。
但产品的局限性同样明显。最核心的问题是“刷新周期12小时”——在信息爆炸的LinkedIn生态中,这基本失去了“实时响应”的战略意义,尤其是很多高意图帖子的窗口期只有几小时。如果Gro的扫描频率不能做到15分钟内,那么它对“紧盯即时信号”的用户来说依然是鸡肋。
此外,评论中对“伪正信号”的担忧非常关键。Gro目前依赖关键词+上下文的组合评分,虽然比纯关键词过滤强,但尚未展现出AI对“语气/意图维度”的深度理解。相比其他竞品(如Clay、Zapier+Apify组合),Gro的优势在于闭环体验,劣势则在于灵活性和生态集成度。对于已经搭建好复杂技术栈的小团队,Gro更像是一个“围墙花园”,而非可嵌入的智能模块。
一句话总结:Gro对“月薪便宜、流程冗余”的小型B2B团队是利器,但对追求实时性、复杂数据集成的中大型组织,目前仍是一个“半成品”的舒适区产物。
一句话介绍:Netlify Database 是一款与平台深度集成的全托管 Postgres 数据库,通过为每个 Git PR 自动创建独立数据库分支,彻底解决团队在共享预发布环境中因数据污染和迁移冲突导致的部署拥堵与信任危机。
Developer Tools
Artificial Intelligence
Database
托管数据库
PostgreSQL
数据库分支
预览部署
CI/CD集成
无后端开发
AI Agent
Schema迁移
Netlify
基础设施即代码
用户评论摘要:用户高度认可数据库分支解决共享预发布环境痛点,并关注迁移合并冲突、分支生命周期管理、灾难恢复等实操问题。有用户询问多分支 Schema 合并规则及废弃分支清理策略,官方回应会提供快照回滚点,但具体合并逻辑尚未详细说明。
AI 锐评
Netlify Database 的聪明之处在于把数据库分支从“高级功能”降级为“平台默认行为”。它没有发明新范式,而是精准补上了 Deploy Previews 最后一块拼图——代码分支有了十年,数据库分支却一直被当作分布式系统难题甩给开发者自己用 Docker 和脚本去凑。这个缺口在单人或小团队时还能用“别乱搞”来糊弄,但在 15 人到 120 人扩张的路径上,共享 Staging DB 就是一根持续的、无声的摩擦桩。
产品真正的价值锚点不是“托管 Postgres”,而是“让数据库操作像 Git 一样安全和可追溯”。AI Agent 写出的迁移脚本只能在预览分支上跑,生产环境永远触碰不到——这既是技术设计,也是营销金句。它承认了一个残酷现实:当前最火的“Vibe Coding”自动生成应用,大多只是把数据库当玩具,而 Netlify 试图把这种混乱锁在隔离沙箱里。
但槽点也很明显:分支合并时的 Schema 冲突究竟如何处理?官方目前语焉不详。两个 PR 分别改了同一张表的结构,合并时要么需要手动介入,要么依赖某种线性化策略,而这恰恰是传统 DevOps 团队要派专人处理的高阶问题。对于需要严格 Schema 版本控制和回滚的业务场景,当前方案更像一个“傻瓜式安全网”,而非企业级治理工具。此外,分支生命周期清理看似省心,但如果想长期保留某个分支的测试数据进行“考古”审计,后续的存储计费策略也值得关注。
一句话总结:Netlify Database 是让“不会搞坏数据库”成为默认体验的绝佳入门方案,但它距离解决“多人高效协作演化数据库架构”这一终极问题,中间还隔着几个自动化合并算法和一套成熟的灾难恢复 SLA。
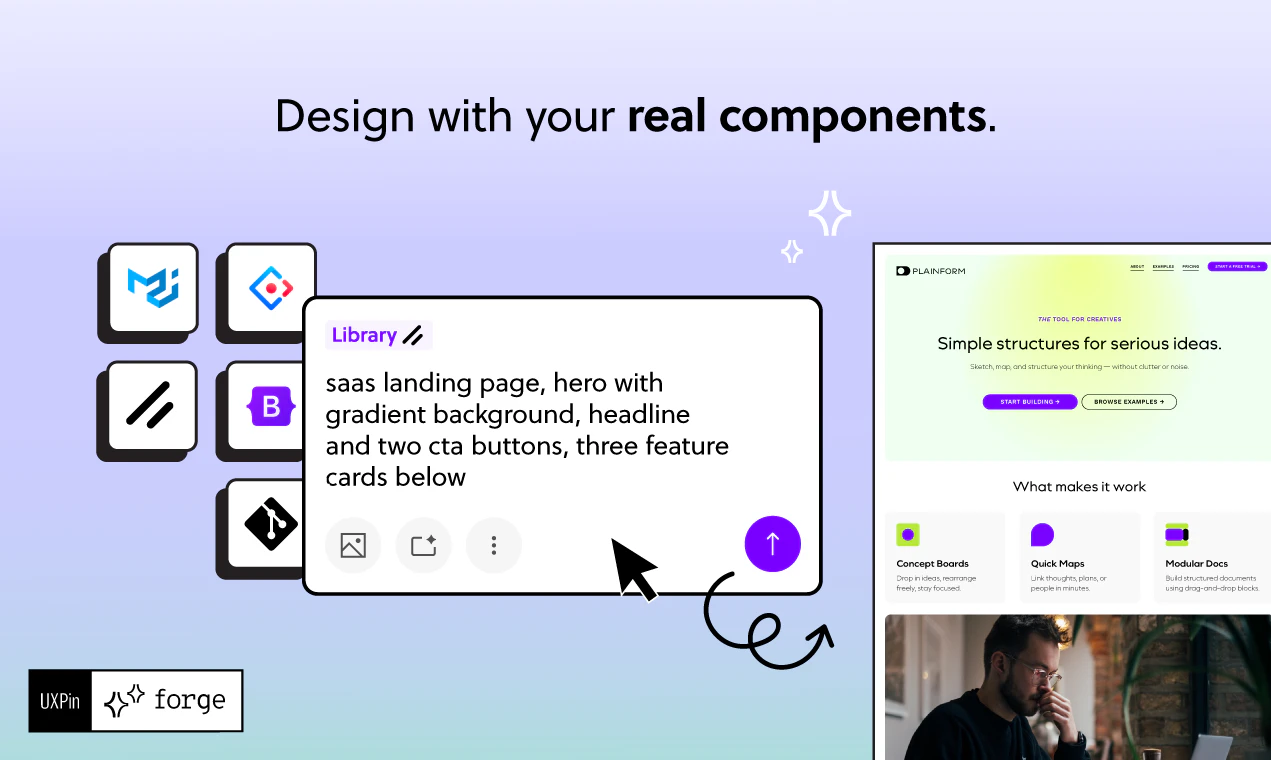
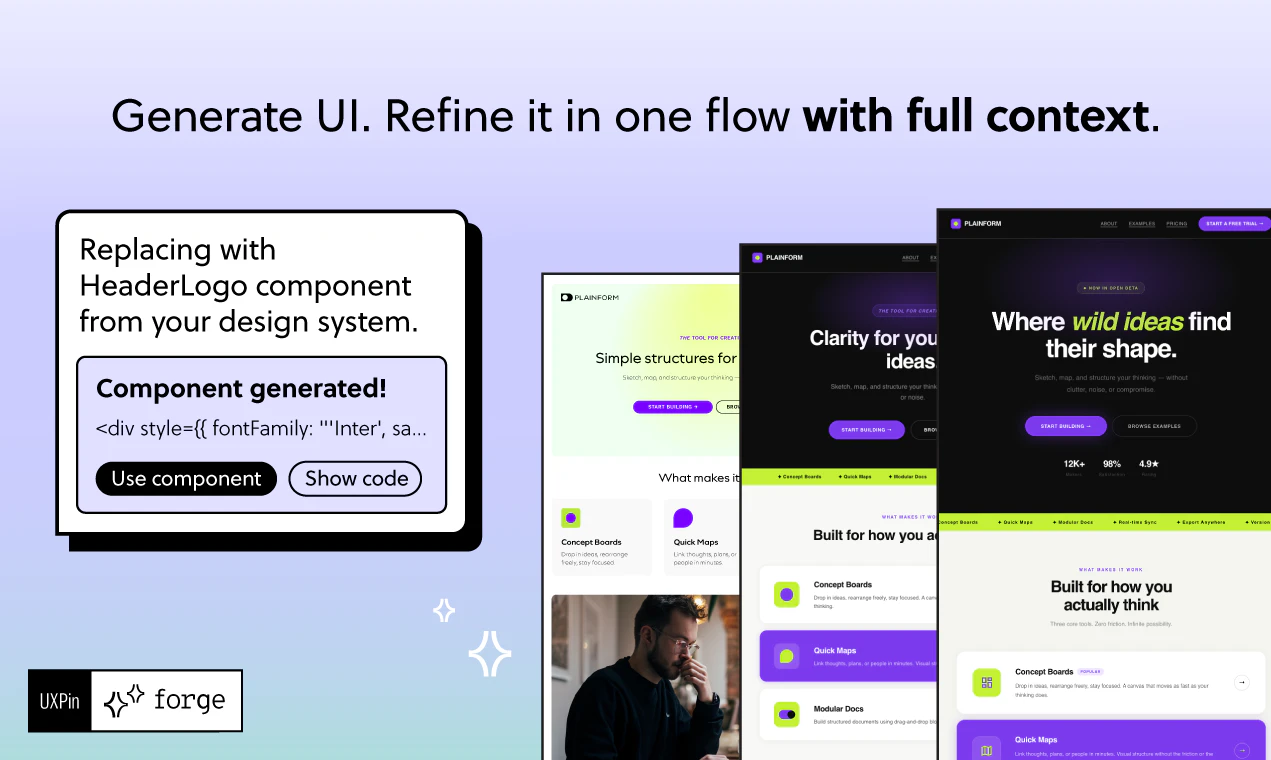
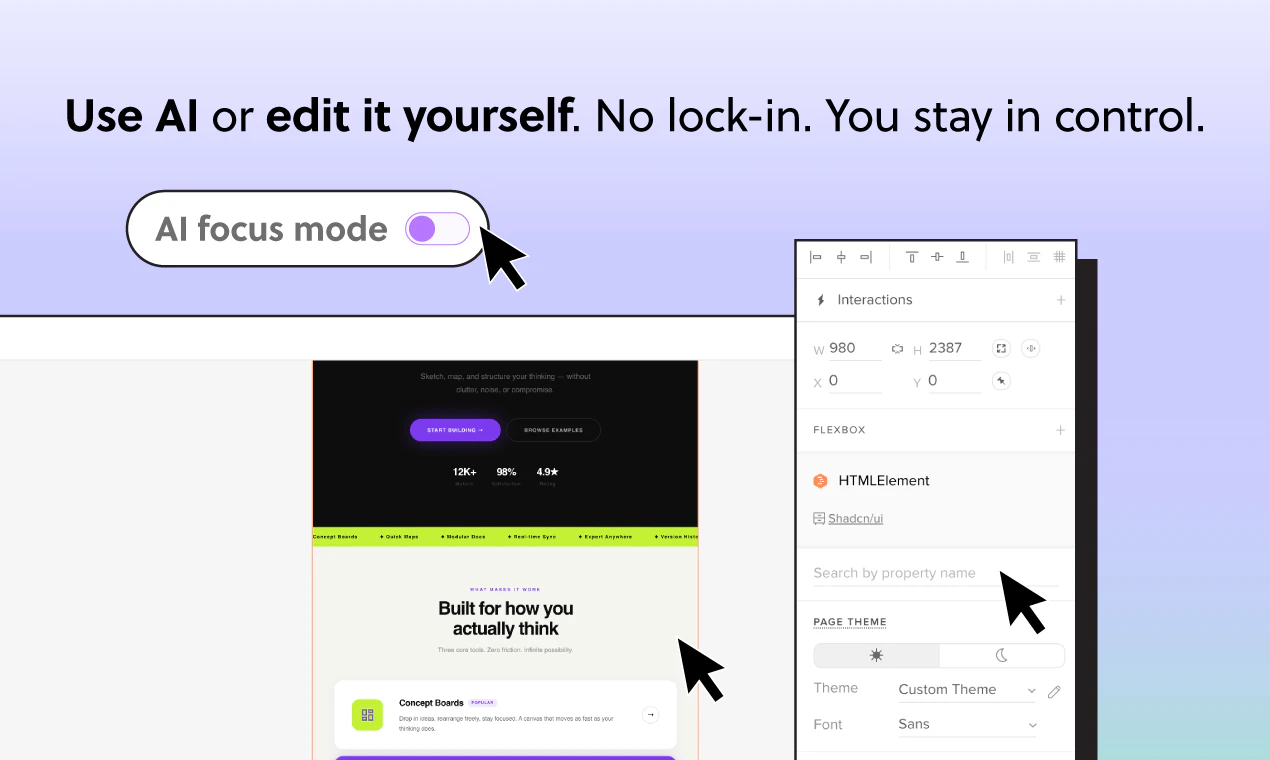
一句话介绍:UXPin Forge是一款AI驱动的UI生成工具,核心在于基于设计系统内的真实组件(如MUI、shadcn/ui、Ant Design等)生成可直接交付的JSX代码,解决AI生成UI与现有组件库脱节、需反复返工的行业痛点。
Design Tools
User Experience
Prototyping
AI设计工具
设计系统
前端组件库
UI生成
代码交付
UXPin插件
JSX导出
企业级设计
设计规范协同
生产级原型
用户评论摘要:评论普遍认可其“真实组件约束”的思路,主要疑问集中在与竞品的差异上。用户重点问:与Claude Design相比如何(回答:反对近似,坚持组件约束)?JSX输出有多干净(回答:直接引用库,如MUI/Button)?URL转UI及自定义库支持细节。不满主要源于其他工具易产生品牌漂移,而Forge旨在杜绝此问题。
AI 锐评
UXPin Forge的“锐”,不在于其AI生成速度,而在于它精准地捅破了AI设计领域最大的窗户纸:大多数AI工具输出的是“视觉相似品”,而非“工程可用件”。它声称“结构上不可能”产生偏离品牌或系统的输出,这并非营销话术,而是技术架构的差异。Claude Design、v0等工具本质上是“代码阅读者+风格迁移者”,而Forge是“设计系统执行器”,AI被约束在组件库的有限状态空间里创作。
从商业价值看,Forge精准切入了中大型企业和成熟产品团队的“组件债”痛点。许多团队并非不想用AI,而是害怕AI生成的代码与现有工程规范反目,导致后期维护成本激增。Forge通过Git同步真实组件库、输出标准JSX引用,把AI从“创意玩具”转变为“效率杠杆”,让设计师和开发者终于可以在同一个组件语境下协作。而CEO Andrew提到的“锻炉不取代铁匠”,在充斥着“零门槛、人人都是开发者”论调的行业中,显得克制而务实。
潜在隐忧在于依赖程度。Forge的核心竞争力建立在与UXPin生态及Merge技术的高度绑定之上,若用户非UXPin现有重度用户,迁移和适应成本不可忽视。同时,对于依赖轻量级、快速原型验证的早期团队,其组件库门槛和系统约束可能显得过于沉重。一句话总结:对需要“在枷锁中跳舞”的企业设计团队是解药,对想“无拘无束”的自由创作者可能是拳击手套。
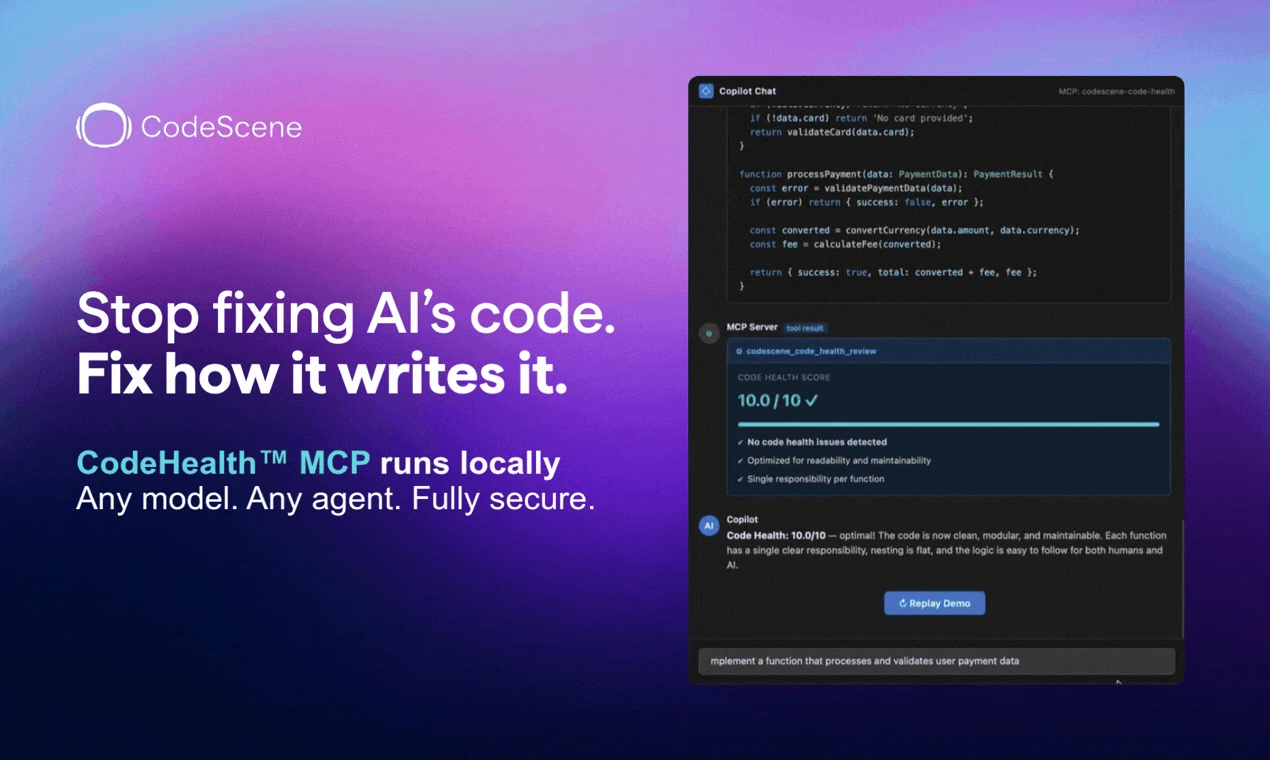
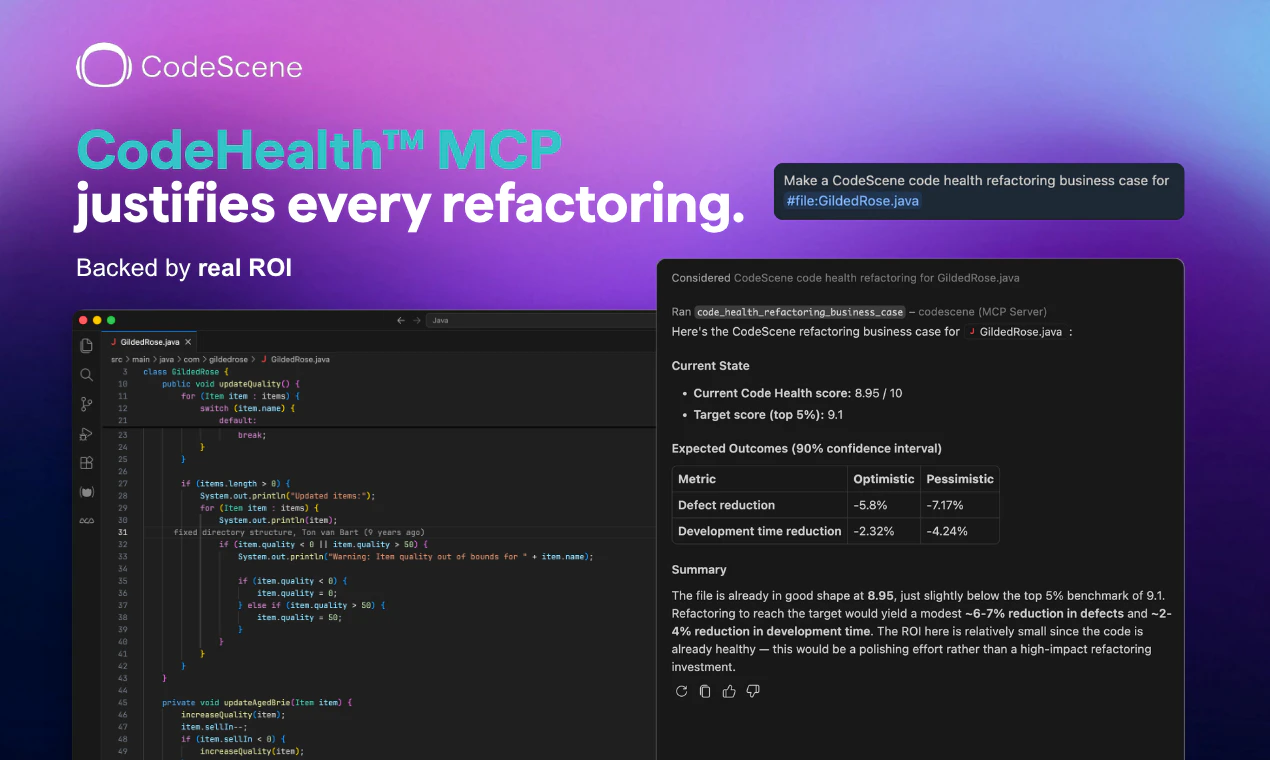
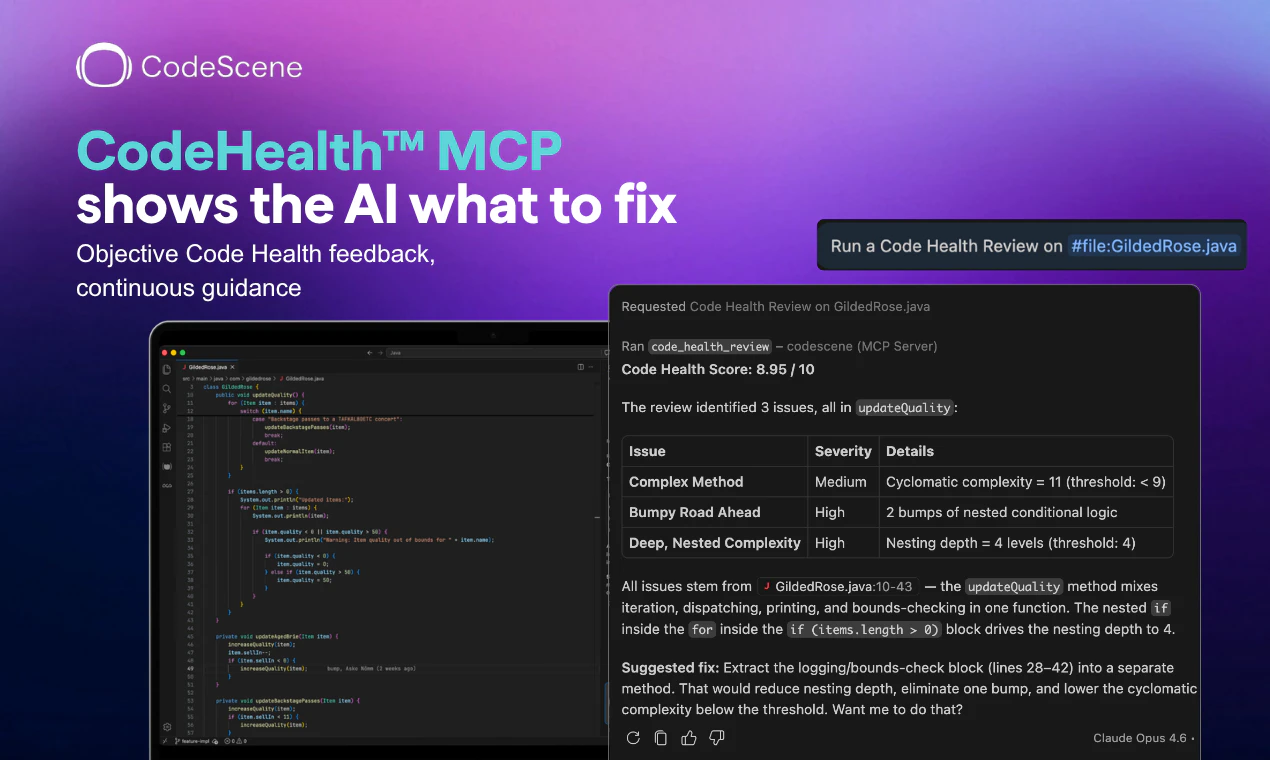
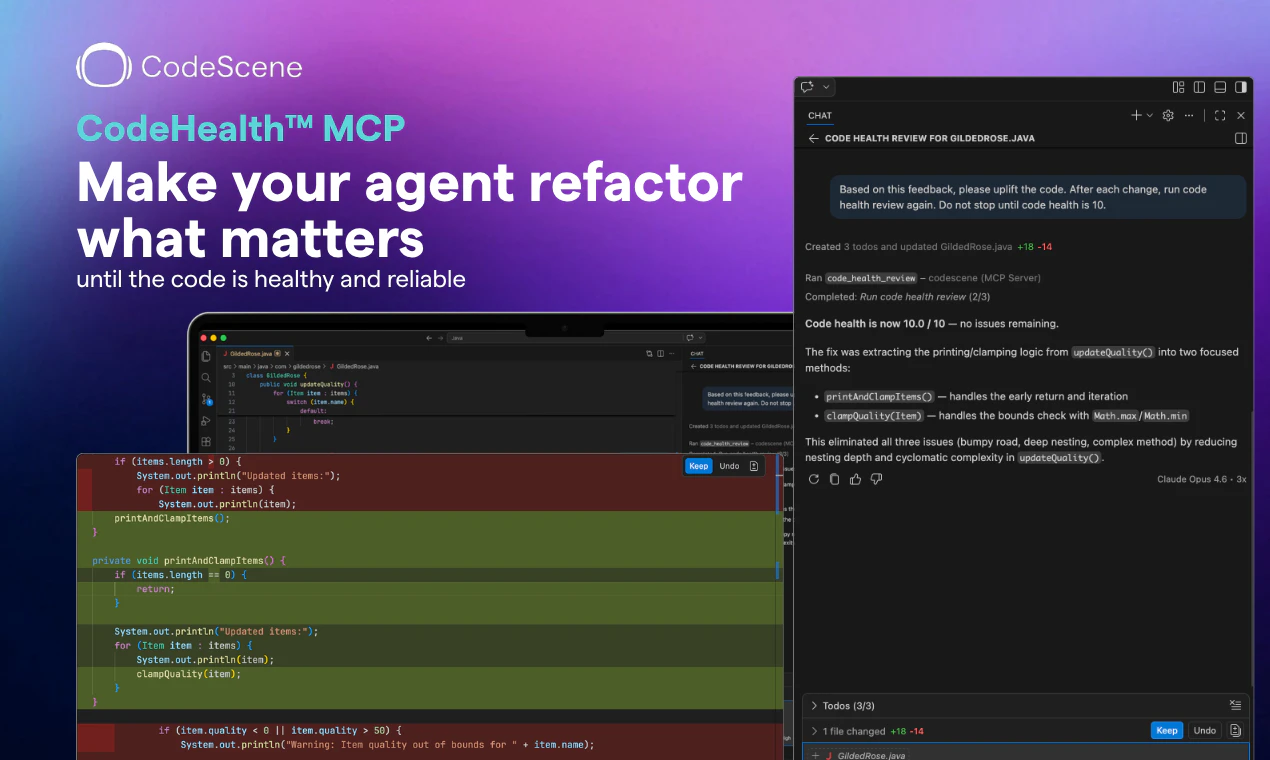
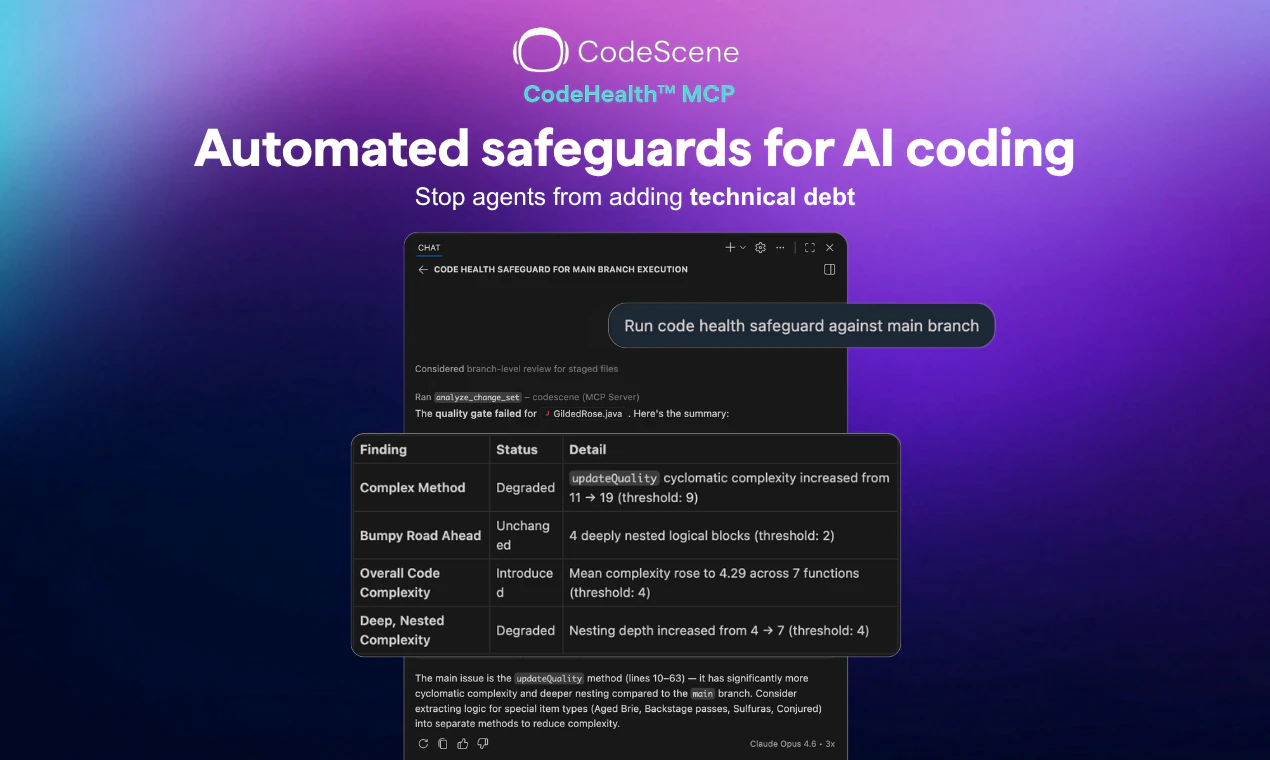
一句话介绍:CodeHealth MCP Server将可量化的代码健康度检测嵌入AI编码助手的工作流中,解决AI高速生成代码时必然引入技术债务与结构性腐化的问题,确保输出的是可维护、生产级的代码。
Developer Tools
Artificial Intelligence
Vibe coding
AI编码辅助
代码质量门禁
技术债务管控
确定性分析
MCP协议
可维护性
代码重构
静态分析
工程效能
CodeScene
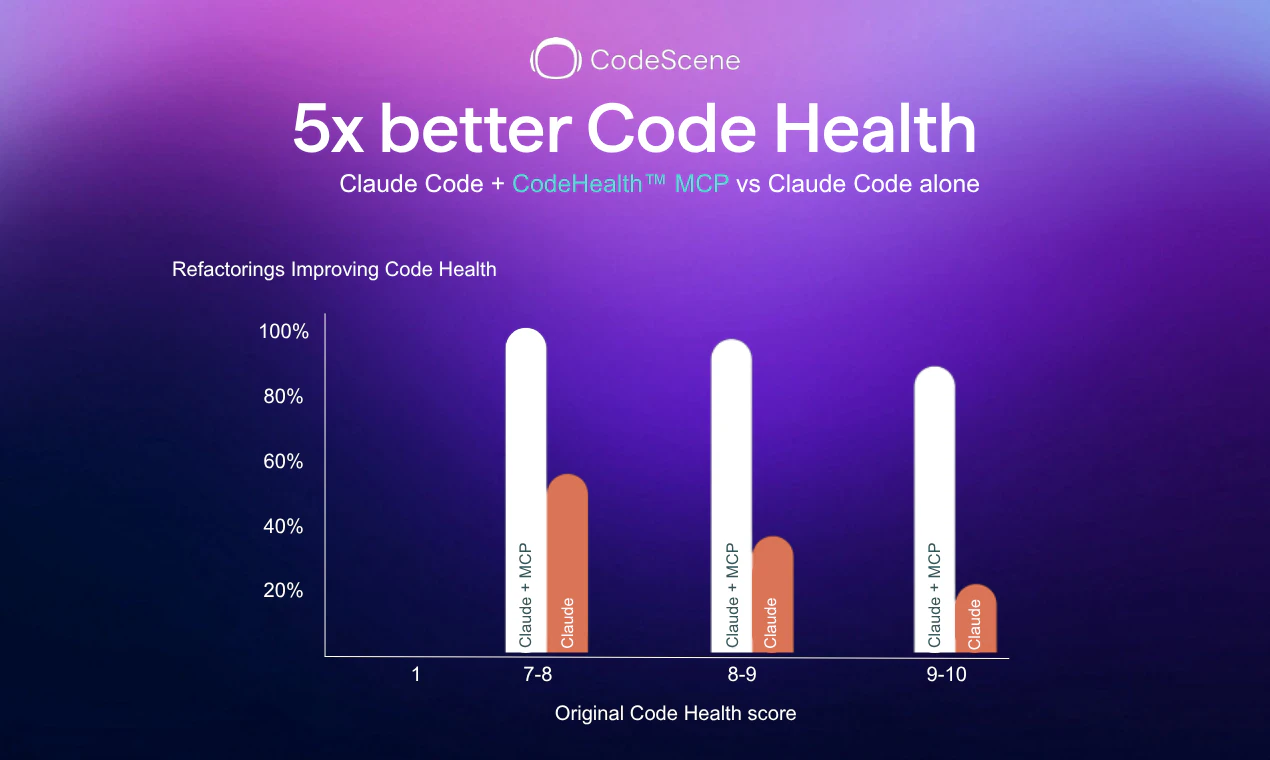
用户评论摘要:用户普遍点赞其“确定性”分析解决了LLM自检的盲区(9赞);核心关注能否捕捉“函数/类膨胀”等结构问题(10赞);反馈与SonarQube的差异在于更高层级的设计检测(8赞);实测Claude Code配合MCP可2次迭代将代码健康度从2/10提升至10/10(14赞回帖)。
AI 锐评
CodeHealth MCP Server在当前泛滥的“AI伴侣”工具中,选择了一条更硬核且更聪明的路径:**不去比拼生成速度,而是解决生成质量失控的根本矛盾。** 它的核心价值在于,将原本被AI视作玄学且无考核动力的“代码健康”,转化为一个可被MCP协议消费的确定性评测信号。这本质上是在为AI编码的“概率性输出”安装了一个结构性的安全阀。
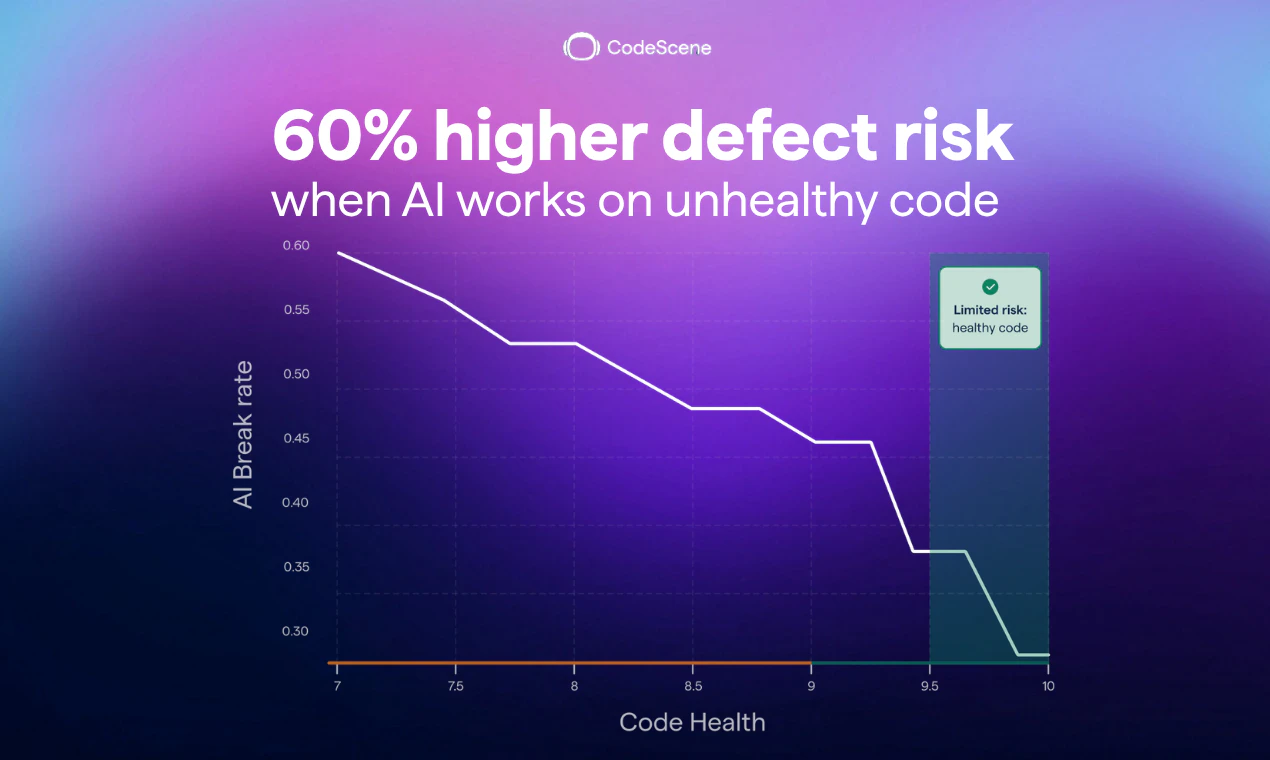
从评论中用户的真实痛点来看——“6个月的技术债务在20分钟内产生”、“AI喜欢写结构混乱但局部正确代码”——这些都在印证一个事实:当前最先进的LLM在缺乏结构化约束时,会本能地倾向于制造高耦合、低内聚的Spaghetti Code。CodeHealth MCP的聪明之处在于,它不是在IDE侧提供一堆可被无意识忽略的告警,而是直接**介入到AI Agent的决策循环中**,将“把代码改到健康”作为与“完成任务”并列的约束条件。这种“黑盒优化”的思路,让AI从一个不知疲倦的抄写员,变成了有质量意识的初级工程师。
但需要警惕过度包装。它提供的依然是基于静态分析的指标集合(圈复杂度、脑类、低内聚等),虽然经过实证验证,但并未颠覆代码质量分析的底层逻辑。其真正的壁垒不在于分析技术,而在于**成功将分析结果转化为AI Agent能理解并执行的任务指令格式**(MCP)。这意味着,如果其他静态分析工具(如SonarQube、ESLint)也快速封装出类似MCP服务,其差异化优势将迅速收窄。此外,工具的价值严重依赖于配合的AI模型(如Opus)的推理能力——在当前模型上2次修复成功,不代表在弱推理模型上也能稳定复现。
一个更深层的风险是:**工具是否会让开发者在代码质量上产生代理依赖?** 当Agent根据MCP的指令机械地降低“脑类”或“低内聚”分数时,可能会引入更隐蔽的架构妥协。毕竟,能被量化指标捕捉的坏味道,远少于那些仅凭人类架构直觉才能发现的设计缺陷。一句话总结:它为AI生成代码的质量兜了底,但请记住,底兜得有多牢,取决于你喂给Agent的模型和指令有多强。
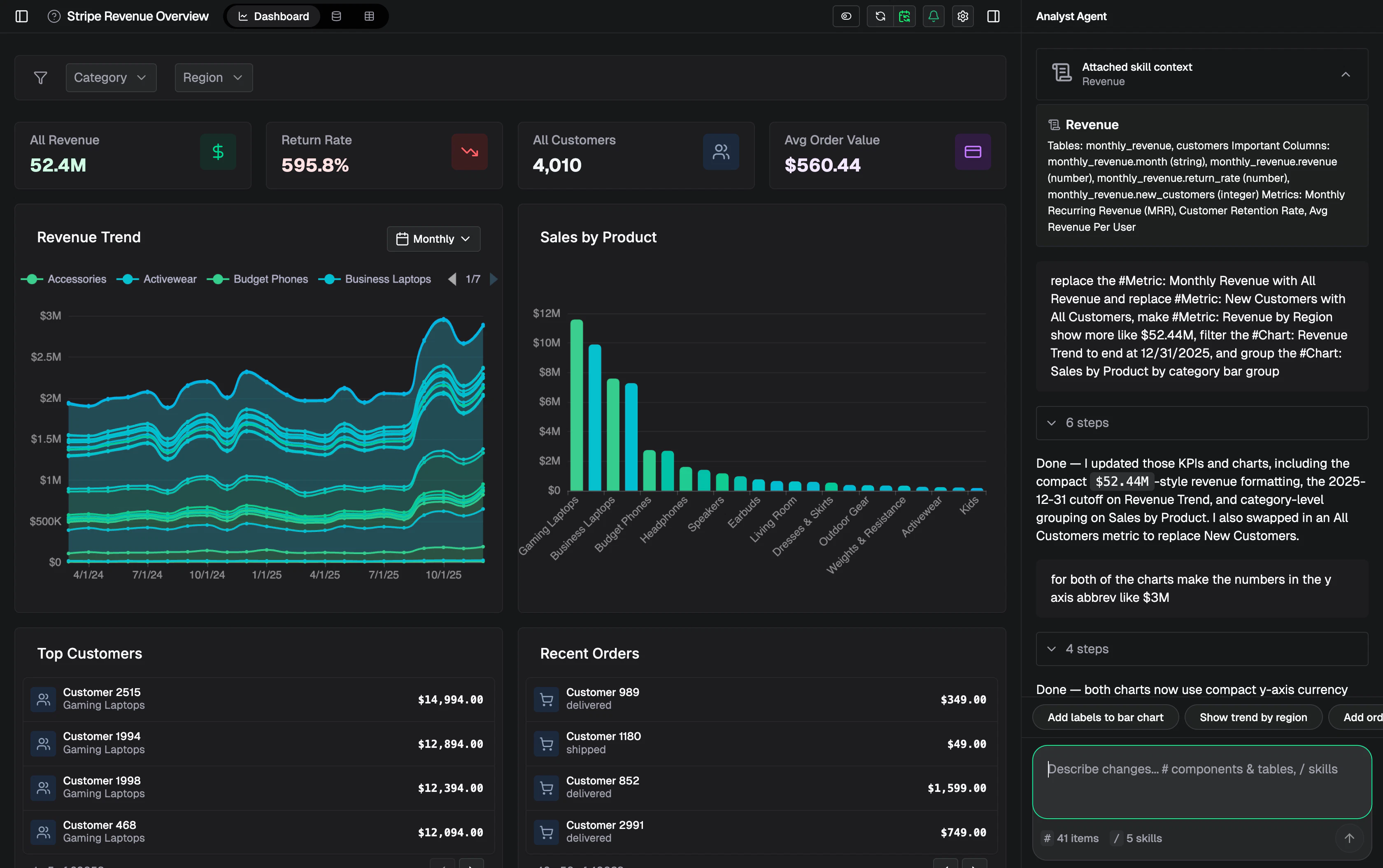
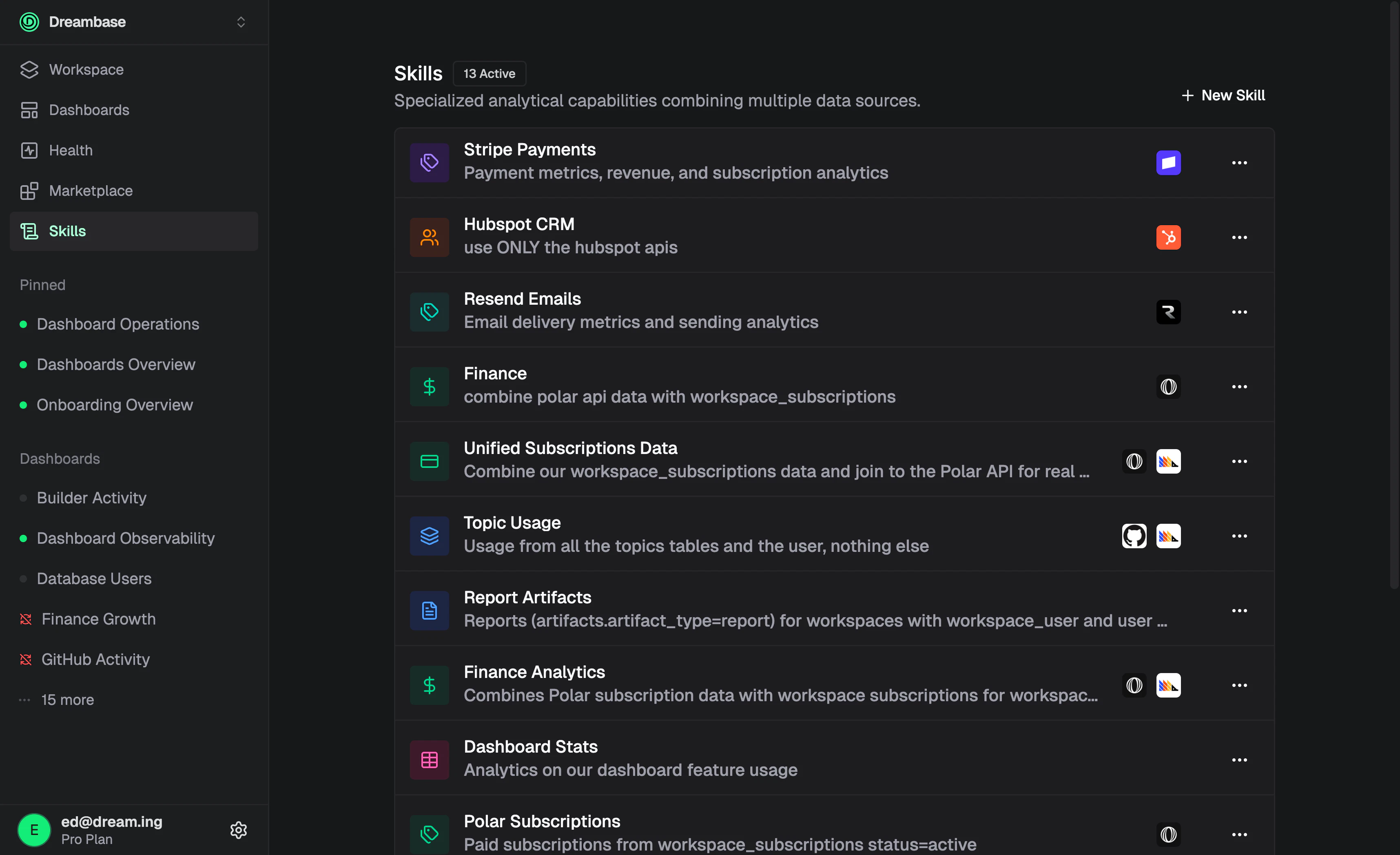
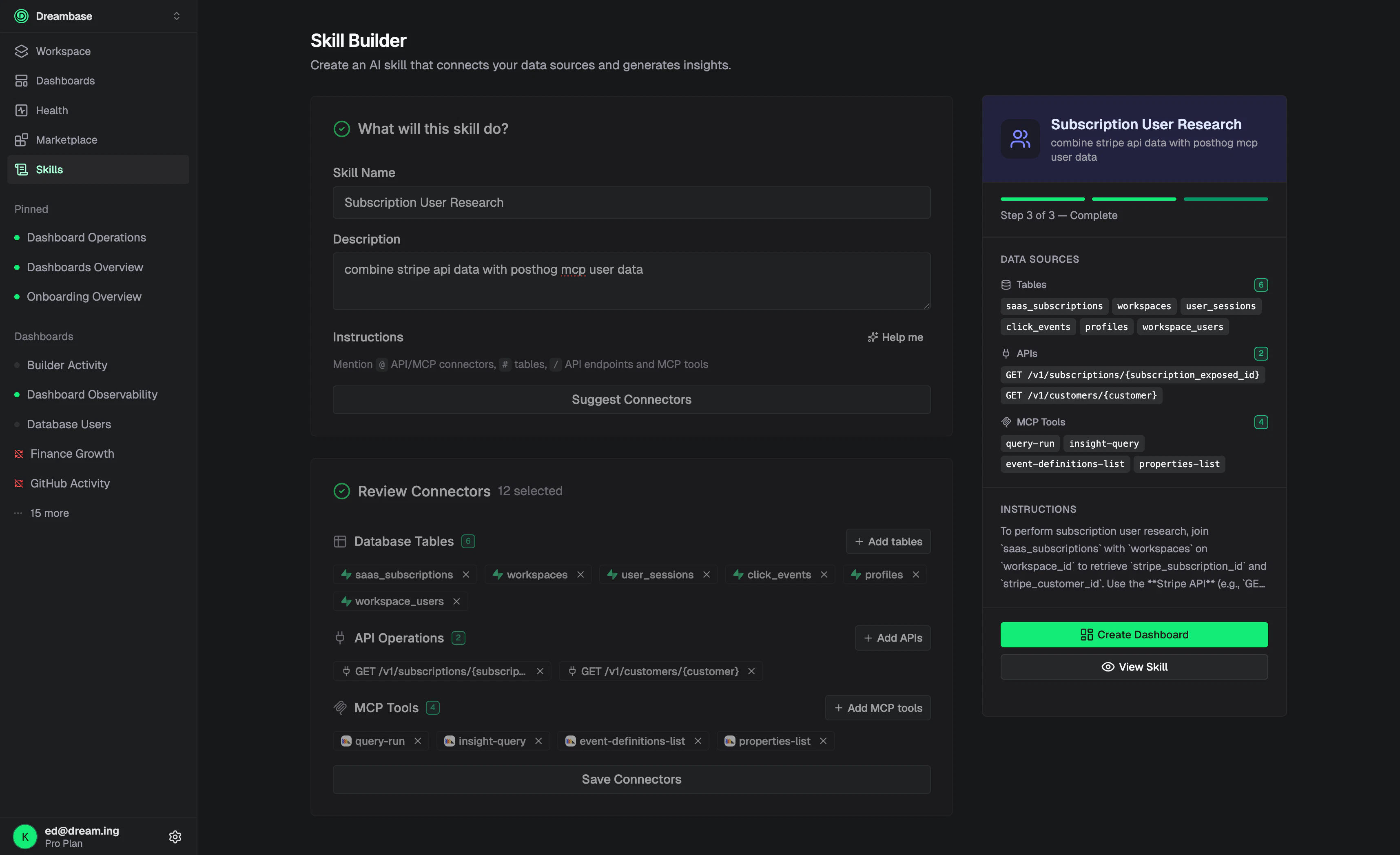
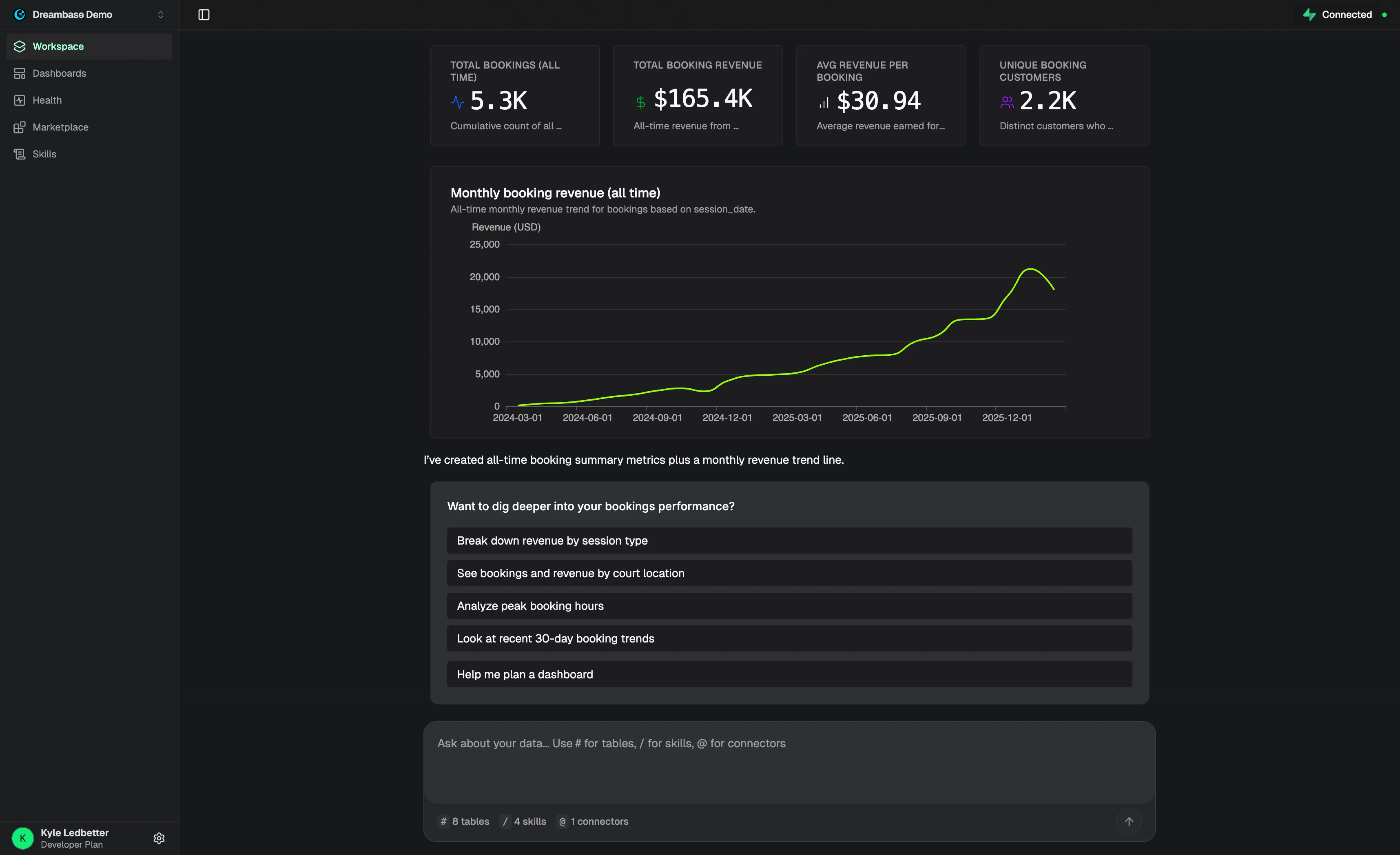
一句话介绍:Dreambase Data Agent Skills 是一个面向Supabase用户的AI分析层,通过将数据源、业务逻辑和可视化规则打包成可复用的“技能”单元,让AI代理无需重复理解数据模型即可生成准确的仪表盘和报告,解决了传统AI分析中“每次查询都要重新解释数据含义”的核心痛点。
Analytics
Developer Tools
Business Intelligence
AI分析代理
Supabase集成
数据技能包
无ETL分析
业务逻辑封装
商业智能自动化
可组合数据层
MCP兼容
架构即服务
上下文智能
用户评论摘要:用户普遍认可“一次定义,多次复用”的设计,认为比传统BI工具更聪明。主要关注点在于:业务逻辑复杂后技能的灵活性、如何应对数据库模式变更(无声漂移还是报错)、不合规范的自动扫描准确性。创始人回应强调有“人为反馈循环”和实时模式检查机制。
AI 锐评
Dreambase Data Agent Skills贩卖的核心并非另一个BI工具,而是“AI时代的数据契约层”。在产品同质化严重的Supabase生态中,它找到了一个精妙的切入点——与其让AI每次猜谜式地翻你的数据库,不如给它一本经过人类审核的“业务说明书”。
这种思路的前瞻性在于:它把“数据定义”从开发者的IDE提升到了产品经理和业务人员的可操作层面。当行业还在争论RAG和Agent框架时,Dreambase已经绑架了“上下文”这个概念。然而,这里有三个隐忧值得警惕:
第一,**技能的可变性与维护成本**。创始人信誓旦旦说“定义一次”,但在真实业务中,表结构、API和业务逻辑是动态演化的。如果场景变更时技能包不像代码一样有版本控制、变更日志和回滚机制,这层“语义层”很容易变成“债务层”。目前只提了“实时检查模式漂移”,但漂移后如何处理?是自动更新还是触发人工干预?没有明确。
第二,**对Supabase的深度绑定是一把双刃剑**。虽然作为Featured集成获得了流量,但本质上Dreambase的价值与Supabase的生态健康度深度耦合。如果Supabase自身增长放缓或出现强劲的竞品(比如Neon),这种依赖就成了风险。产品宣传“CLI和MCP”是为了摆脱这种绑定,但实际成熟度存疑。
第三,**用户评论中的热情与付费意愿的差距**。评论区一片叫好,但多数是“听起来很棒”或“希望能搞定复杂场景”。从142票的规模看,真正深度使用的付费用户可能还不成规模。一个不容忽视的挑战是:Dreambase的价值被很多企业主感知为“用AI替代数据分析师”,但现实中,企业也许更需要的是一个能直接回答“下季度收入增速”的简单AI,而非一套需要由人来定义“业务逻辑”的复杂工具。
总结:这是个聪明产品,但聪明和必要之间还有距离。若不能证明在持续变更的复杂业务场景下,维护这套“技能”的成本低于重新教AI的成本,它很可能被大模型本身的进步(如更强的Schema推理能力)所替代。
一句话介绍:Picsart CLI 将图像、视频、音频生成能力集成到终端中,让开发者通过命令行一站式调用140余种AI模型,省去在多个SDK之间切换认证和调用的繁琐流程,解决多模态开发效率低下的痛点。
Design Tools
Marketing
Artificial Intelligence
命令行工具
多模态生成
AI模型聚合
图像生成
视频生成
音频生成
开发者工具
Picsart
终端操作
生成式AI
用户评论摘要:用户关注该CLI是封装第三方模型还是Picsart自研模型,并询问是否支持跨模态链式调用(如文生图→图生视频→配音),各调用是否独立。
AI 锐评
Picsart CLI的定位聪明但不算颠覆。它本质上是一个“模型聚合终端”,把Picsart自家的140多个生成模型打包进命令行。对于开发者而言,免去多SDK认证和碎片化调用的痛点确实存在,但这类工具的价值取决于两个关键点:模型质量是否足够独特,以及链式调用是否流畅。从评论看,用户已经敏锐地追问模型来源和管道化能力——如果这些模型只是对现有开源模型(如Stable Diffusion、Whisper等)的简单封装,那Picsart CLI的护城河就很浅,很快会被类似工具复制。更值得担忧的是,终端CLI在复杂的多模态工作流中往往需要与脚本语言(Python/Node)交互,单纯的命令行收授难以处理错误回退、参数精细调校和长周期任务。Picsart如果想靠这个工具抓住开发者,就必须在模型独特性(比如自研的图片编辑、滤镜风格化模型)和管道编排能力上做深,否则它不过是一个更漂亮的curl合集。另外,112票的冷启动成绩说明目前仍在小范围测试,面对Replicate、Hugging Face端已有的同类CLI工具和云端API,Picsart需要明确自己的差异化——是更低延迟、更优定价,还是更垂直的场景绑定(比如电商A/B测试、短视频批量生成)。一句话:思路对,但执行端尚未露出刺刀。
一句话介绍:Redesign 是一款开源的本地化设计工具,让用户通过自然语言描述,在视觉编辑器中调用自家 React 组件库,快速生成符合品牌规范、可直接用于社交媒体的幻灯片式图文。
Design Tools
Social Media
Artificial Intelligence
GitHub
开源设计工具
AI生成设计
React组件驱动
品牌视觉自动化
社交媒体图片生成
本地优先
无云端依赖
Claude集成
MCP服务器
开发者友好
用户评论摘要:创始人澄清产品为本地运行、无云无账号无用量限制。用户询问图片来源,官方回复支持从Assets导入、让Claude从网络下载或直接从代码库引用。反馈总体正面,但暂无负面或功能缺失的尖锐意见。
AI 锐评
Redesign 的聪明之处在于它没有试图做一个“AI 生成一切”的黑箱,而是选择了一条更务实的窄路:让 AI 去调用你已有的 React 组件。这在设计工具过剩的当下反而是一种清醒——大多数 AI 设计工具生成的素材脱离品牌调性、不够可控,最终只是给营销人员多了一个需要手动修正的“废稿生成器”。Redesign 直接架起了代码库和设计之间的一座桥,让品牌一致性从“设计师手工维护”变成了“代码级自动继承”,这对拥有成熟组件库的小型团队和内容营销负责人来说,是实打实的时间杠杆。
但必须指出:它的受众非常窄。无设计背景的用户可能连 React 组件是什么都不知道;有技术能力的人未必需要一张社交媒体图的自动化。这就注定了它很难成为一个大众产品,更像是给自己程序员背景的创始人做的“自虐解药”——把花一个下午做一张图,缩短到花一个上午去调 Claude 的 prompt。另外,所有迭代依赖 Claude Code 和本地 MCP 服务,意味着它的体验上限完全绑定在 Claude 的上下文准确性和你的代码库结构上。一旦描述稍复杂或组件缺乏灵活性,AI 生成的设计依然会显得僵硬,这跟“几小时减少到几分钟”之间还隔着大量试错成本。
一句话总结:一个面向开发者的“定制化设计套壳工具”,胜在开源和本地运行,但要想从内部工具变成大众产品,还需在非技术用户的上手路径和设计灵活性上做更多。
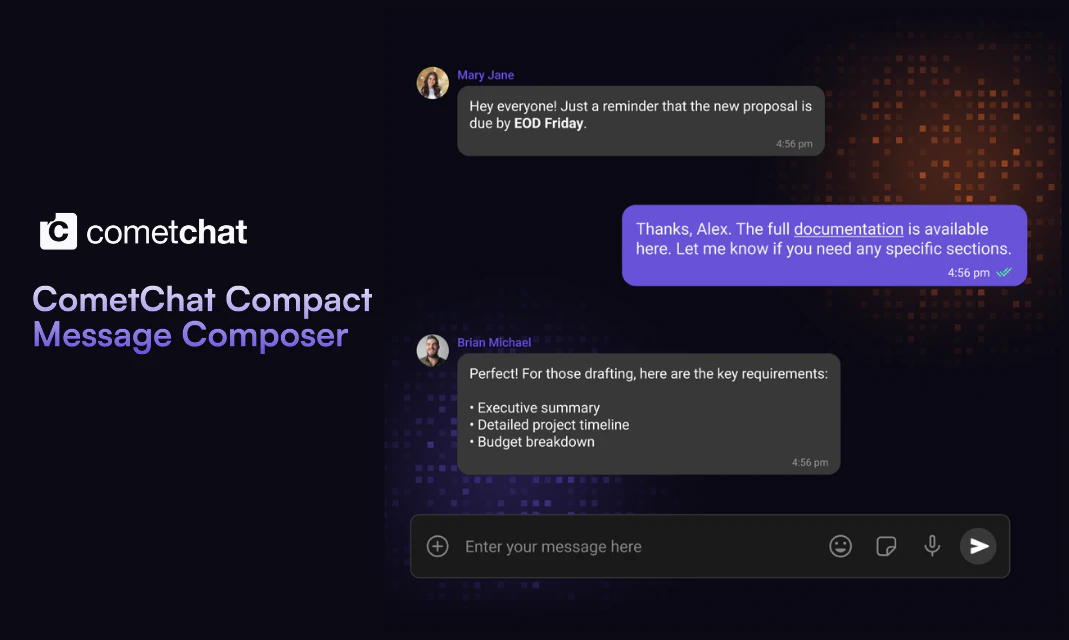
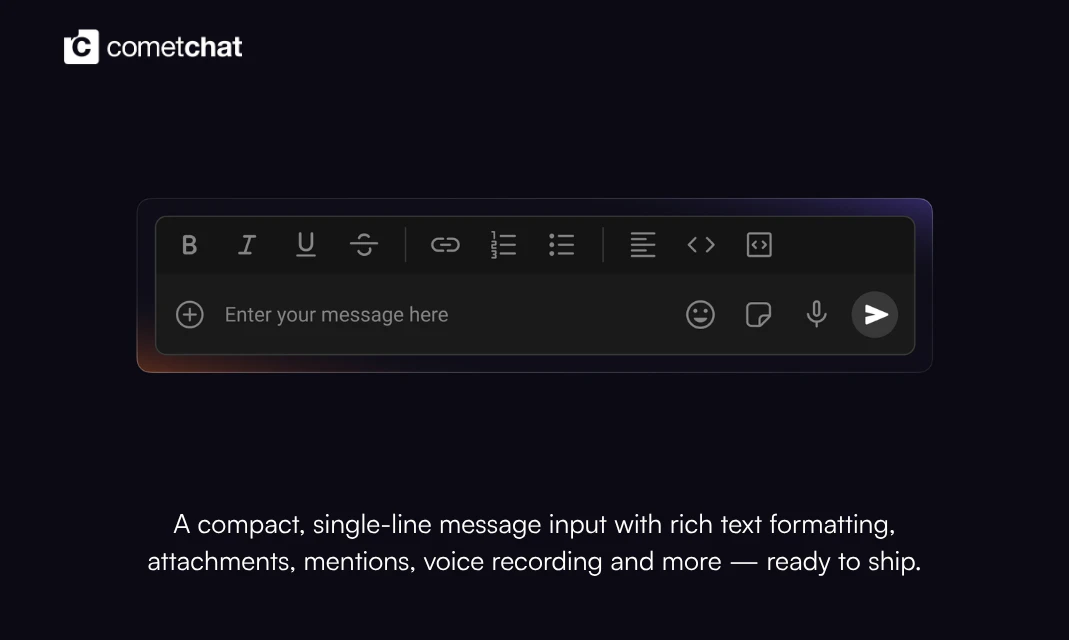
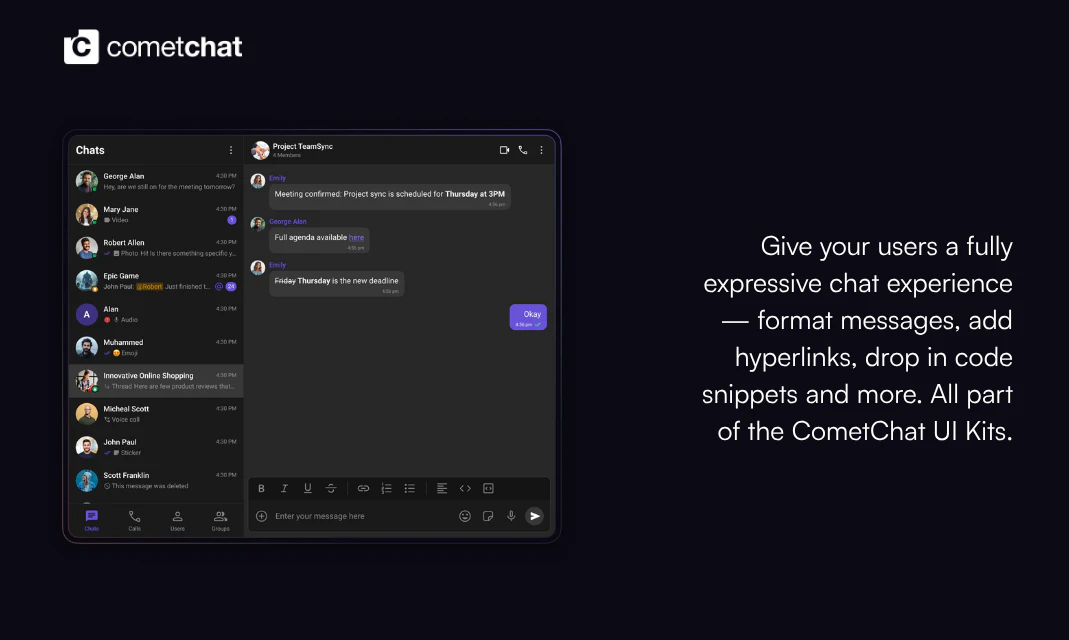
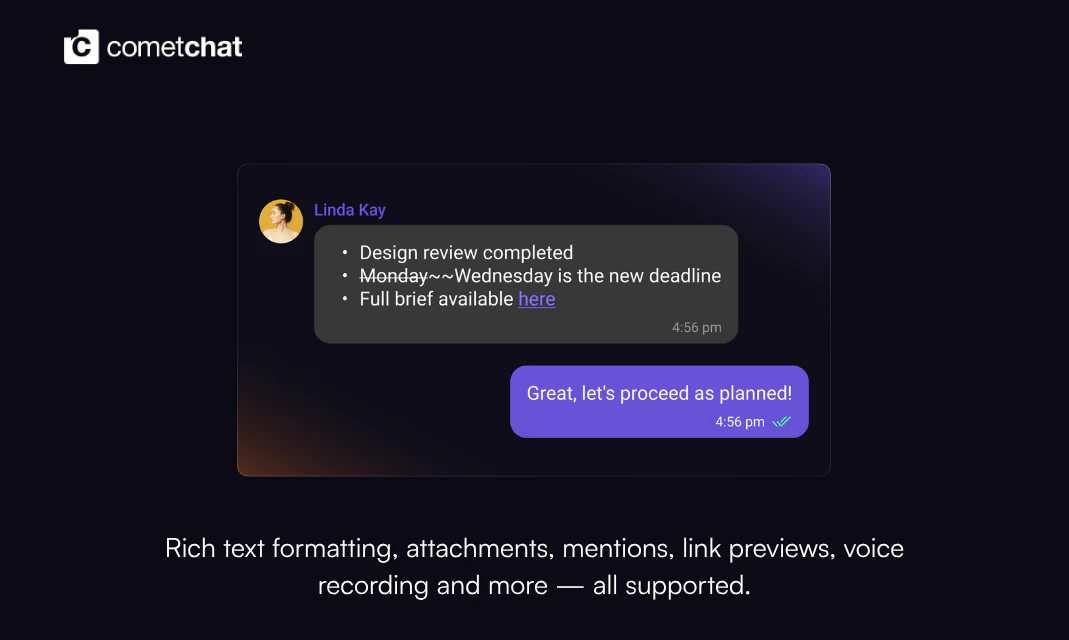
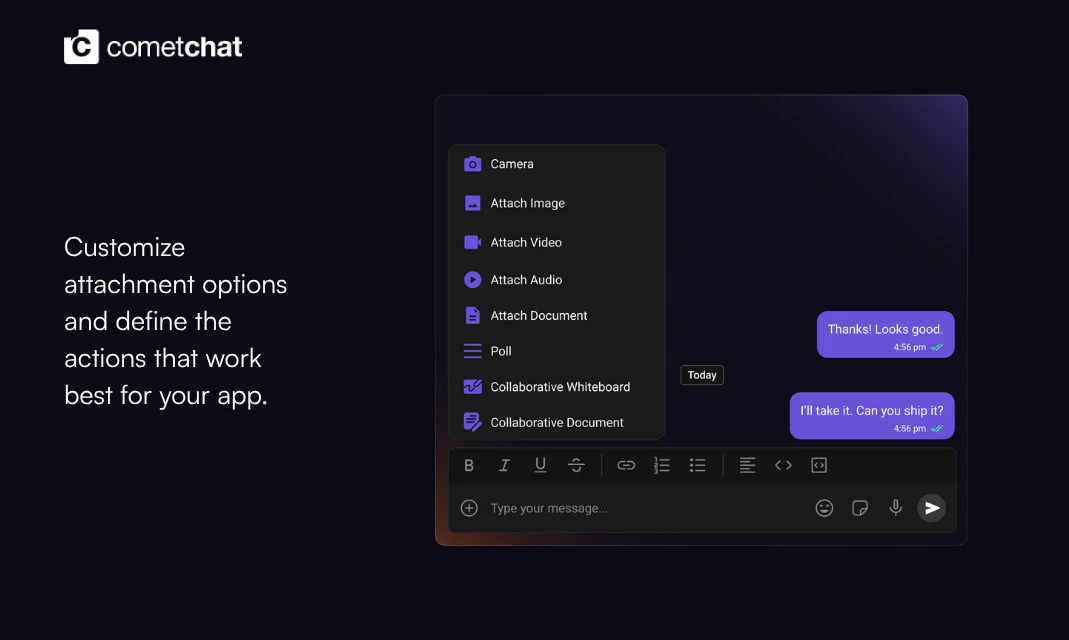
一句话介绍:Compact Message Composer 是一款专为开发者设计的聊天组件,通过一行代码即可为任意框架的即时通讯应用集成富文本编辑、浮动工具栏和键盘快捷键等功能,解决传统聊天输入框功能单一、定制繁琐的痛点。
Messaging
Developer Tools
SDK
即时通讯
UI组件
富文本编辑器
开发者工具
聊天工具
跨框架
低代码集成
产品体验优化
用户交互
商业化SaaS
用户评论摘要:产品经理Pourav介绍该组件基于“用户清晰表达、开发者简易集成”的观察而开发,强调一键启用、浮动工具栏和快捷键等特性,并支持附件与语音。用户未提出具体问题或建议,主要表达对产品的兴趣与期待。
AI 锐评
这个产品本质上是一个“聊天输入框”的微创新,但定位非常精准:它不试图重构聊天,而是解决一个长期被忽视的体验断点——富文本表达。对于面向创作者、团队协作或知识分享的垂直应用而言,纯文本输入远远不够。CometChat 的聪明之处在于,将这一功能封装成“单 prop 启用”的组件,既降低了集成门槛,又绕开了开发者对“自己写富文本编辑器”的恐惧。投票数97不高不低,说明开发者群体对此类“开箱即用”但非核心卖点的功能持谨慎乐观态度。
真正的价值在于两点:一是通过“格式”提升用户留存和内容质量,间接拉升应用付费价值;二是为 CometChat 的 UI Kit 生态增加了不可替代性——竞品若想复制同样的集成体验,需要投入数周乃至数月。然而,产品的短板同样明显:它高度依赖 CometChat 的原生后端与消息协议,这意味着非 CometChat 用户迁移成本极高;同时,富文本组件在移动端触摸场景下的交互是否流畅、跨平台行为一致性是否保证,以及是否支持 Markdown 或自定义解析器,这些潜在的技术债并未在介绍中提及。一句话:如果你是 CometChat 的现有客户,这是提升聊天质量的最快捷径;但若为单点功能而换掉整个聊天服务,则需要更充分的性价比论证。
一句话介绍:Snapr是一款集截图、录屏、标注、滚动截长图及视频剪辑于一体的桌面工具,解决用户在bug反馈、教程制作和演示分享中频繁切换多个应用的效率痛点。
Design Tools
Productivity
Photo & Video
屏幕截图
屏幕录制
滚动截长图
视频编辑
标注工具
Mac工具
Windows工具
生产力工具
录屏软件
一次性付费
用户评论摘要:用户普遍认可“一站式”整合思路,吐槽频繁切换多款软件的痛点。核心疑问集中在“滚动截长图”功能(希望有视频演示及免费试用机会)。开发者积极回应,解释该功能无需浏览器扩展,并提供了7天Pro试用。
AI 锐评
Snapr切中了一个非常真实且普遍的工作流痛点——屏幕捕获工具的碎片化。它试图在一个应用内打通“截图→标注→录制→剪辑→导出”的全链路,这比单纯的“功能堆砌”更具产品思维。从技术参数看,60fps 4K录制、系统音频+麦克风双路采集、以及支持iOS设备投屏录制,确实达到了专业级门槛,足以替代ScreenFlow、CleanShot X等高价工具的多个单点功能。
然而,产品的核心风险在于“缝合”带来的集成度和性能平衡。用户评论中“别卡顿”的期望,反衬出多模块耦合是最大的技术挑战。作为一款95票的产品,其市场验证还非常初级。滚动截长图虽然亮眼,但非浏览器环境下的兼容性、网页防滚动限制等细节问题,在初期极可能导致体验崩塌,而开发者将其设为Pro付费功能,稍欠明智——这应该是吸引用户从免费版升级的“钩子”,而非劝退的“门槛”。
从定价看,“一次性付费+免费无限制无水印”很良心,这是对抗订阅疲劳的利器。但独行侠开发的背后是响应速度与稳定性之间的长期博弈。Snapr有成为细分领域“瑞士军刀”的潜力,但前提是先把核心的“滚动截图”和“4K录制”打磨至零bug,再谈“all in one”的宏图。否则,它只会成为又一个被遗忘的、“凑合能用的”工具包。
一句话介绍:ZenTrack将笔记、记账和健康记录整合为一款极简的专注工具,解决了用户在多款复杂应用间切换、难以坚持日常记录的痛点,尤其适合追求轻量、无学习门槛的个人管理场景。
Android
Health & Fitness
Productivity
Personal Finance
极简工具
笔记
记账
健康追踪
习惯养成
生产力
个人管理
未归类
日常记录
连续打卡
用户评论摘要:开发者分享了从多App痛点出发构建产品的初衷。用户关注点包括:如何保持数据录入的完整性(如财务数据)、希望未来实现笔记与支出的智能关联与预测(如提醒购物并预估成本),并询问使用入门步骤。也有用户幽默地称赞记账速度够快。
AI 锐评
ZenTrack切入的是一个看似拥挤实则充满空隙的市场:“什么都想做”的超级应用往往因功能臃肿而劝退用户,“只做一件事”的垂类应用又存在切换成本高、数据孤岛的问题。ZenTrack的聪明之处在于它没有试图做一个更强大的“第二大脑”,而是精准瞄准了用户最常放弃的三个日常行为——记笔记、记账、记健康,并用极简设计和“连续打卡”机制降低持续记录的心理负担。
但产品目前最大的风险恰恰在于它的“极简”内核。评论中用户提出的“数据完整性保障”(尤其是财务数据)以及“笔记与支出的智能关联”并非锦上添花,而是检验它能否从“漂亮笔记本”进化为“高效决策工具”的关键。如果ZenTrack仅限于提供一个安静的记录容器,它很容易被iOS或Android原生备忘录、健康App的升级版功能所替代。它真正的价值壁垒,不在于“把功能放在一起”,而在于能否利用这些分散的数据(笔记内容、支出模式、运动频率)生成超越单一维度的洞察——例如当用户记录“频繁买咖啡”时,结合健康和财务数据给出提示。否则,它依然只是一个“看起来很美”的轻量级聚合器,在用户新鲜感消退后,留存率会面临严峻考验。
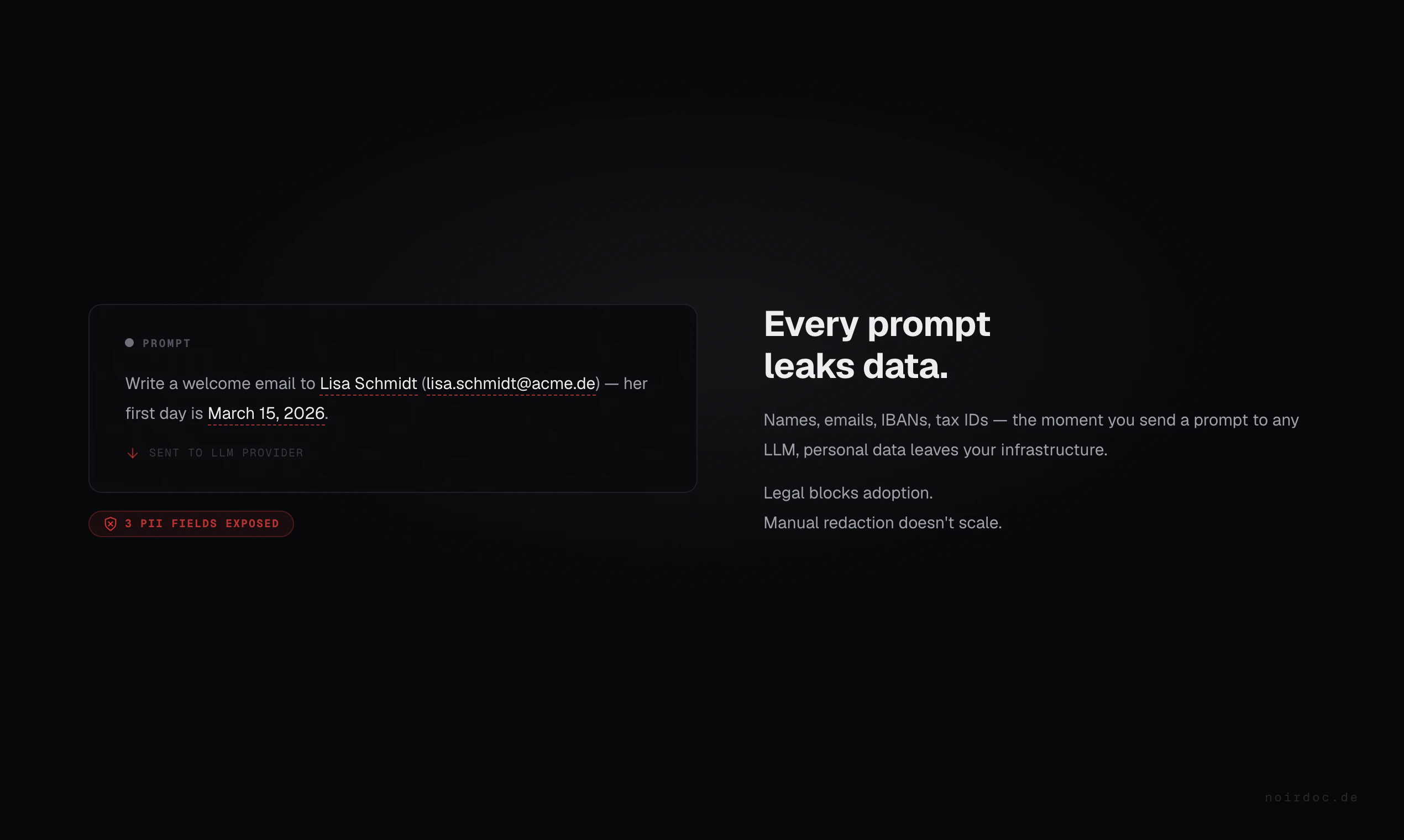
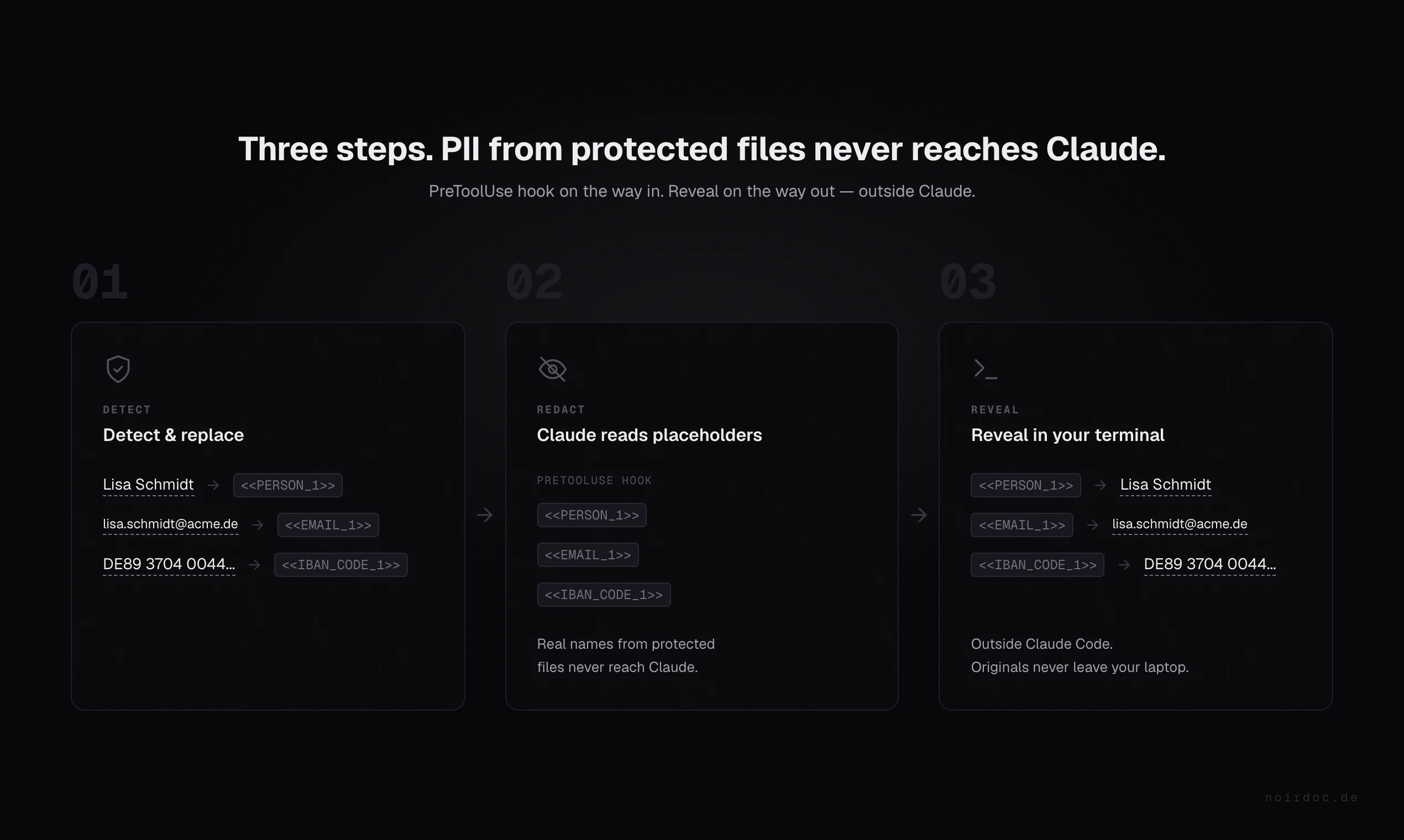
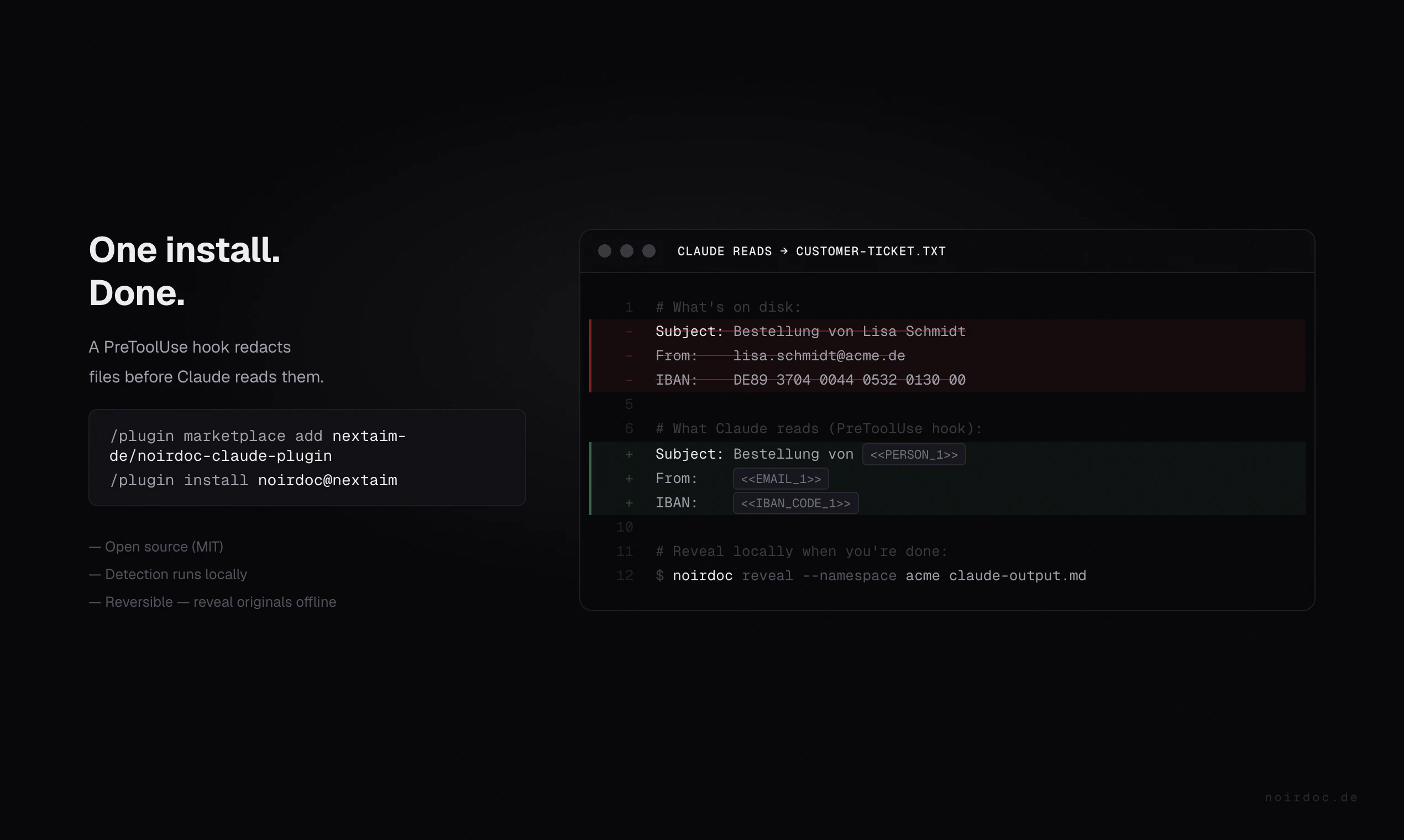
一句话介绍:noirdoc 是一个开源插件,在开发者使用 Claude Code 处理敏感文件时,自动在本地脱敏姓名、邮箱、IBAN 等 PII 数据,替换为占位符,让 AI 识别不到真实信息,用户可本地安全还原,解决企业因数据隐私合规而无法使用大模型的痛点。
Open Source
Privacy
Developer Tools
GitHub
用户评论摘要:用户反馈核心痛点是法律合规阻拦使用大模型处理真实客户数据。评论肯定了本地脱敏+可还原的设计,尤其关注对德语及非标准格式的识别精度。用户关心大规模日志下的性能开销,以及能否扩展检测API密钥等非标准凭证。开发者承认大文件有延迟,建议降级使用Presidio+spaCy。
AI 锐评
noirdoc 的精准切中了一个尴尬的现实:企业想用 AI 提效,合规部门关上了那扇门。它没有幻想用“更强大的 AI”来解决隐私问题,而是回归工程思维——在数据流入大模型之前,用本地引擎做一层确定性过滤。这种“先脱敏,后使用,再还原”的架构,本质上是为对话式AI套上了一道可审计的防火墙。技术选型可圈可点:Presidio 处理结构化 PII,Flair 和 GLiNER 处理非结构化文本和开放实体,三者投票容错。但这套组合拳的代价是性能——在大文件场景下“你确实会感到延迟”,这暴露了“完美召回”与“实时体验”之间的天然矛盾。此外,目前仅覆盖经典 PII(姓名、地址、IBAN),对于 API Key、Session Token、私有内部ID 的检测能力不足,而这在工程代码中恰恰是高频泄漏点。产品形态上,从 Claude Code 插件到 CLI 再到反向代理,覆盖了个人开发者到企业级转发的不同入口,路径清晰。但真正的生死线在于:一旦客户决定自建一套 Presidio 流水线,noirdoc 的差异化就只剩下德语调优和“保持一致占位符”的细节。它站在了风口,但眼下还是一把手枪,能否升级成护城河,取决于它能否从“PII 屏蔽器”进化成“AI 数据治理网关”。
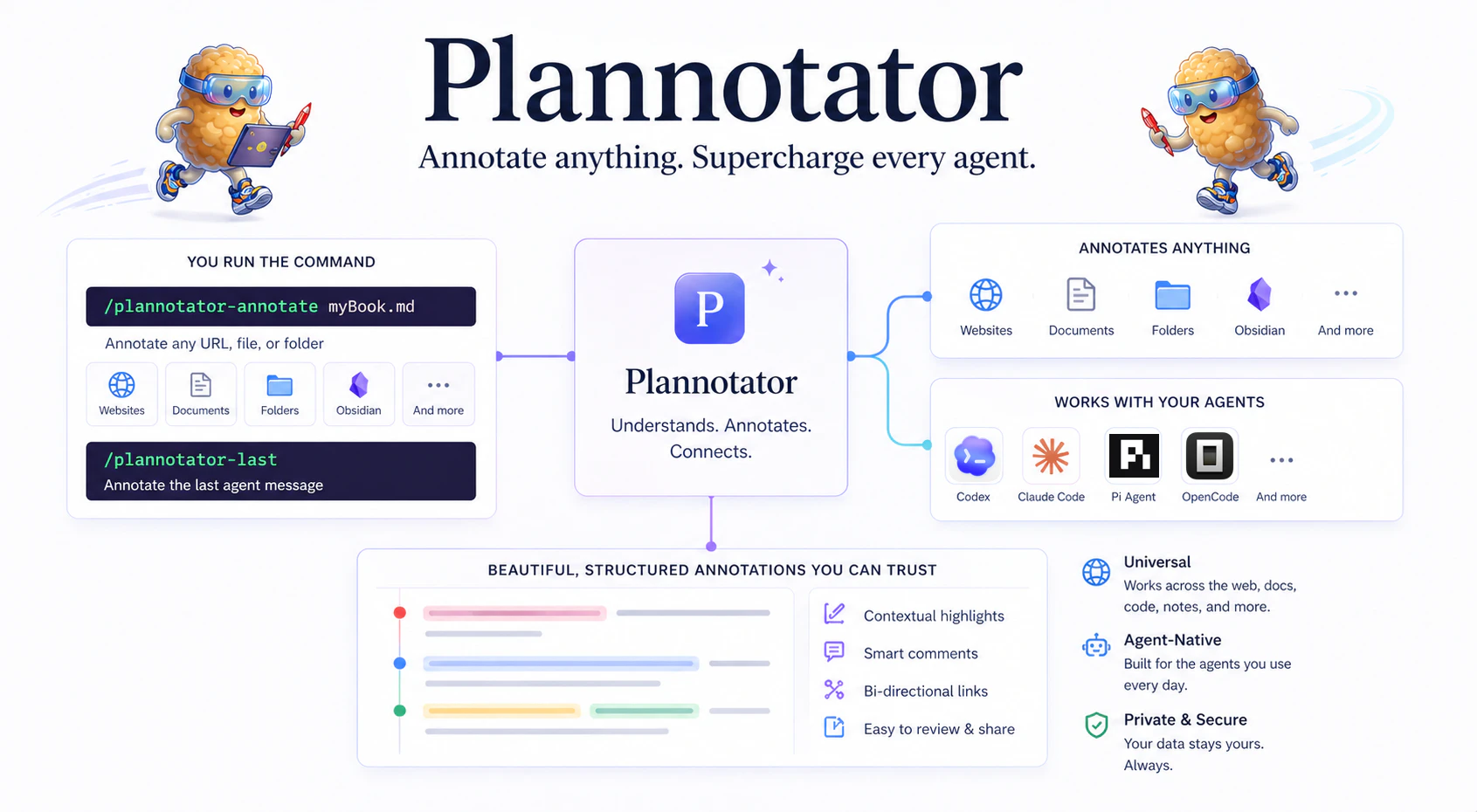
一句话介绍:Plannotator 是一款开源、本地运行、保护隐私的标注工具,能让用户对任意文档、URL或文件夹进行注释,并将反馈直接输入到AI Agent中,解决了人机协作中“标注-反馈”闭环断裂的痛点。
Writing
Education
Artificial Intelligence
GitHub
开源标注工具
AI Agent反馈
本地私有化
文档协作
人机交互
工作流自动化
团队协作
代码审查
异步反馈
智能标注
用户评论摘要:用户普遍认为它填补了人机反馈闭环的空白,尤其是将标注直接回传至Agent的机制。有评论关注团队协作模式:异步收集与批量应用,还是同步讨论分歧。另有人指出此功能在Claude Code等工作流中能替代繁琐的手动粘贴操作。
AI 锐评
Plannotator的实用价值在于它精准切入了一个“小切口但高频”的人机协作痛点:即AI Agent输出内容后,人类如何高效、结构化地反馈修改意见。传统做法是“复制-粘贴-手动备注-再粘贴”,往返损耗极大。Plannotator让标注成为Agent本身的输入接口,从“人抄环境”进化为“环境反馈人”,相当于给Agent装了一个“原生注释器”。
但它的价值上限取决于两点:一是与Agent框架的深度集成能力,目前通过CLI或`/`命令触发,更像一个“外挂插件”而非原生Token流;二是团队协作模式的进化,同步讨论与异步批量应用的取舍将决定它能覆盖个人极客还是真正进入工作流协同。
此外,“本地运行+开源”虽是隐私卖点,但在SaaS盛行的今天,通用用户更看重“即开即用”。如果后期能推出托管版(方便团队共享标注结果)并支持主流Agent框架(如LangChain、AutoGPT、Claude API)的native hook,其从“好用工具”蜕变为“人机反馈协议”的潜力才可能真正释放。当前版本更像是Karpathy那类“个人LLM Wiki”的辅助插件,尚不足以成为团队协作的标准件。
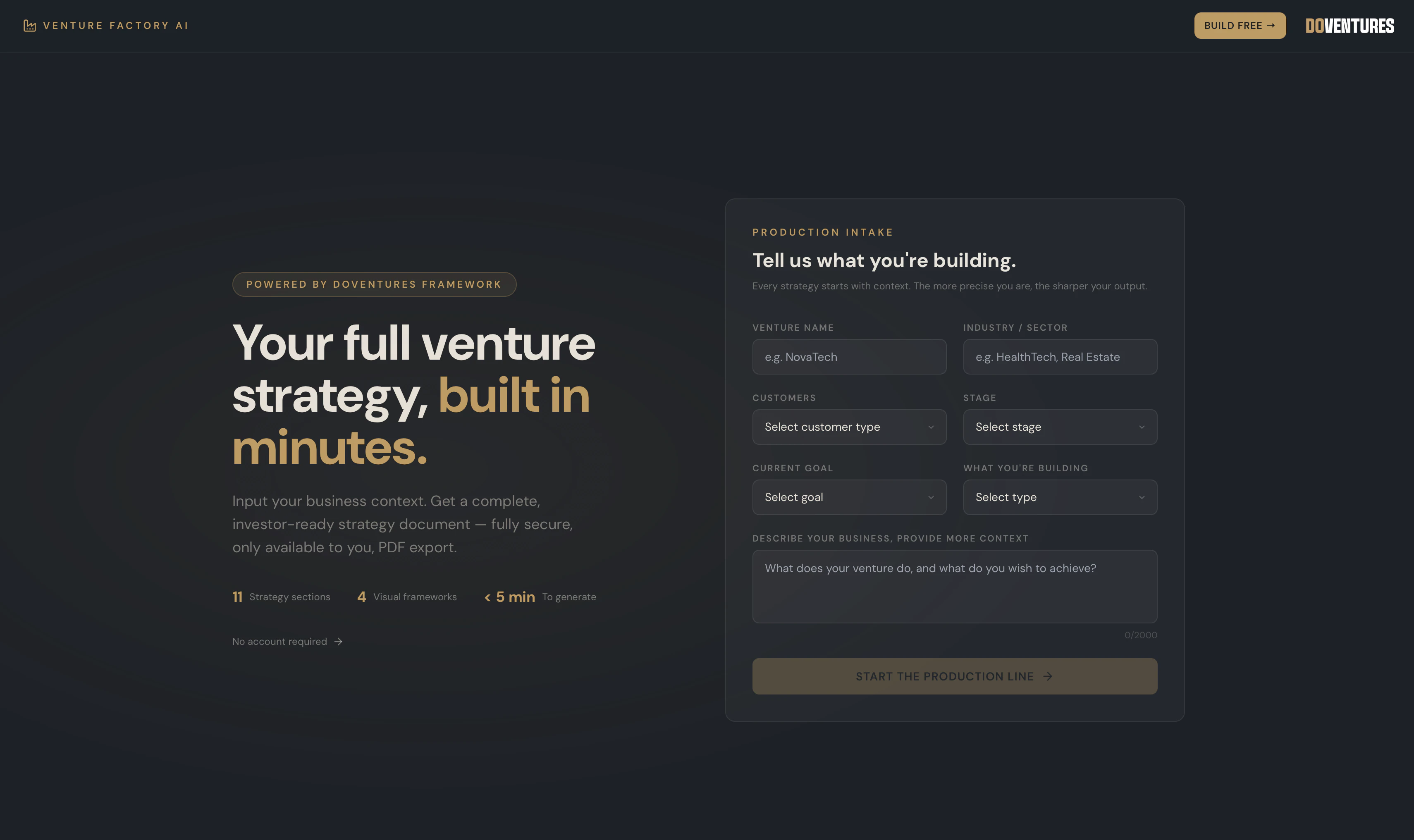
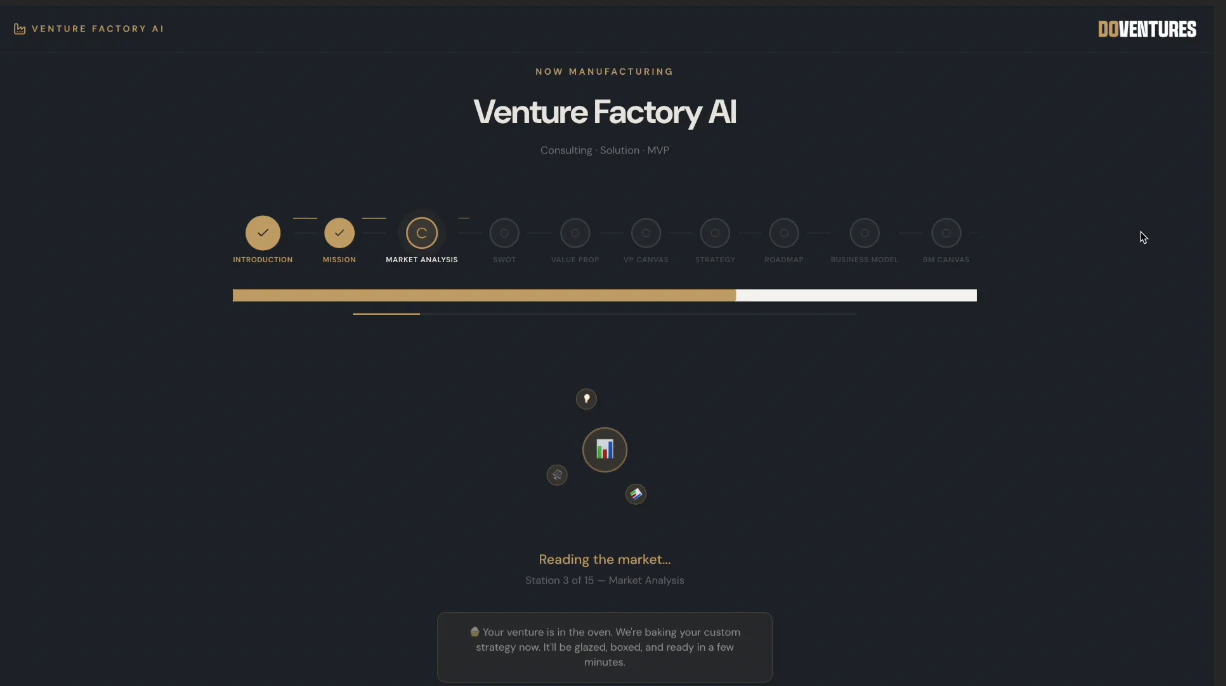
一句话介绍:Venture Factory AI 是一款为创始人打造的AI战略生成器,能在几分钟内将混乱的创业想法转化为结构清晰、可导出的投资级商业策略文档,解决创始人“有想法无计划”的核心痛点。
Productivity
Venture Capital
Business
AI战略生成
创业工具
商业计划书
创始人效率
文档自动化
欧洲合规
投资准备
GPT封装
产品猎手
用户评论摘要:用户普遍认可其解决“想法多、计划乱”的痛点,称“正是所需”。但有人尖锐指出其为“AI封装器”,另一位用户建议优化着陆页转化率,将流量转为付费用户,强调第一印象至关重要。
AI 锐评
Venture Factory AI 精准击中了初创生态中一个高频且尴尬的“废墟时刻”——创始人脑子里塞满了碎片化的灵感、语音备忘录和死掉的MVP,但拿不出一张像样的战略纸。产品定位极其刁钻:不是帮你“想得更聪明”,而是帮你“把想法拉皮成能见人的样子”。它提供的11个清晰板块、精英咨询风格的PDF和可分享链接,本质上是在贩卖“认知变现”的幻觉——让混乱的直觉迅速披上结构化的专业外衣。
然而,这也正是其最大软肋。产品的护城河极浅,本质上是对DO VENTURES专有框架的一次高效封装。评论中“AI Wrapper”的吐槽直指痛点:一旦有更多竞品接入更强的底层模型或开源类似模板,用户的迁移成本几乎为零。其强调的“数据隔离和欧洲GDPR合规”虽是差异化卖点,但在“快速生成文档”这个场景下,安全性能否成为付费转化杠杆,仍存疑。
更关键的问题是:一份在几分钟内生成、从未与其他用户共享数据的策略,其推荐深度和竞争洞察必然受限于单点输入。它更像一个“自我高潮”的梳理工具,而非真正的风险评估引擎。对于创始人而言,最大的危险可能是将这份漂亮的PDF当成了兑付市场的支票,而忽略了“带上下文投资人的一次狠话”远比1000点赞更有价值——这句产品文案本身反而成了最犀利的自我注脚。
最终,Venture Factory AI的价值不在于替代战略思考,而在于降低“从想到写”的心理摩擦。若它无法后续演化成持续的数据闭环(如动态跟踪策略执行、对标真实市场反馈),那么它终究只是一个高颜值的“创业冥想应用”。
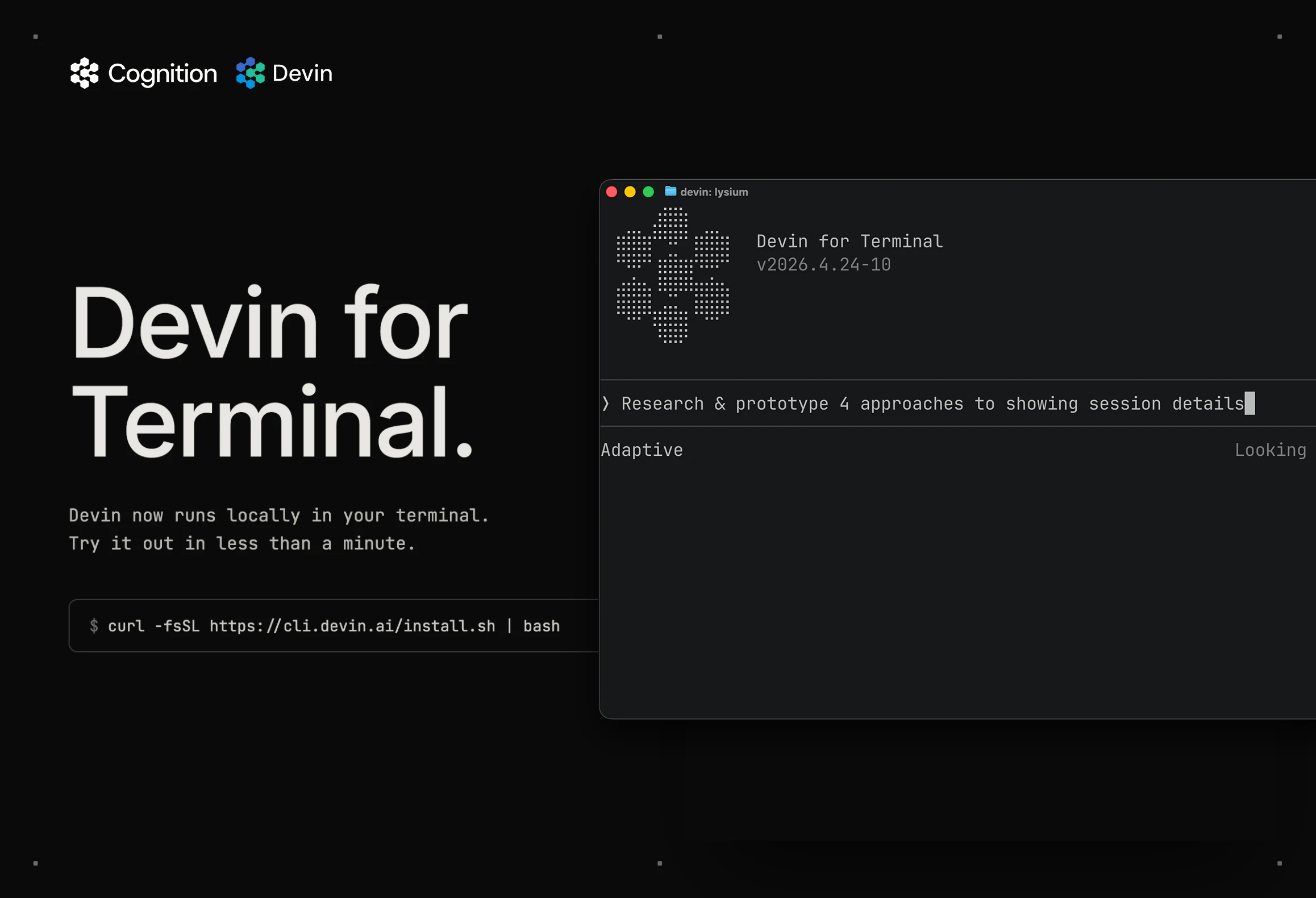
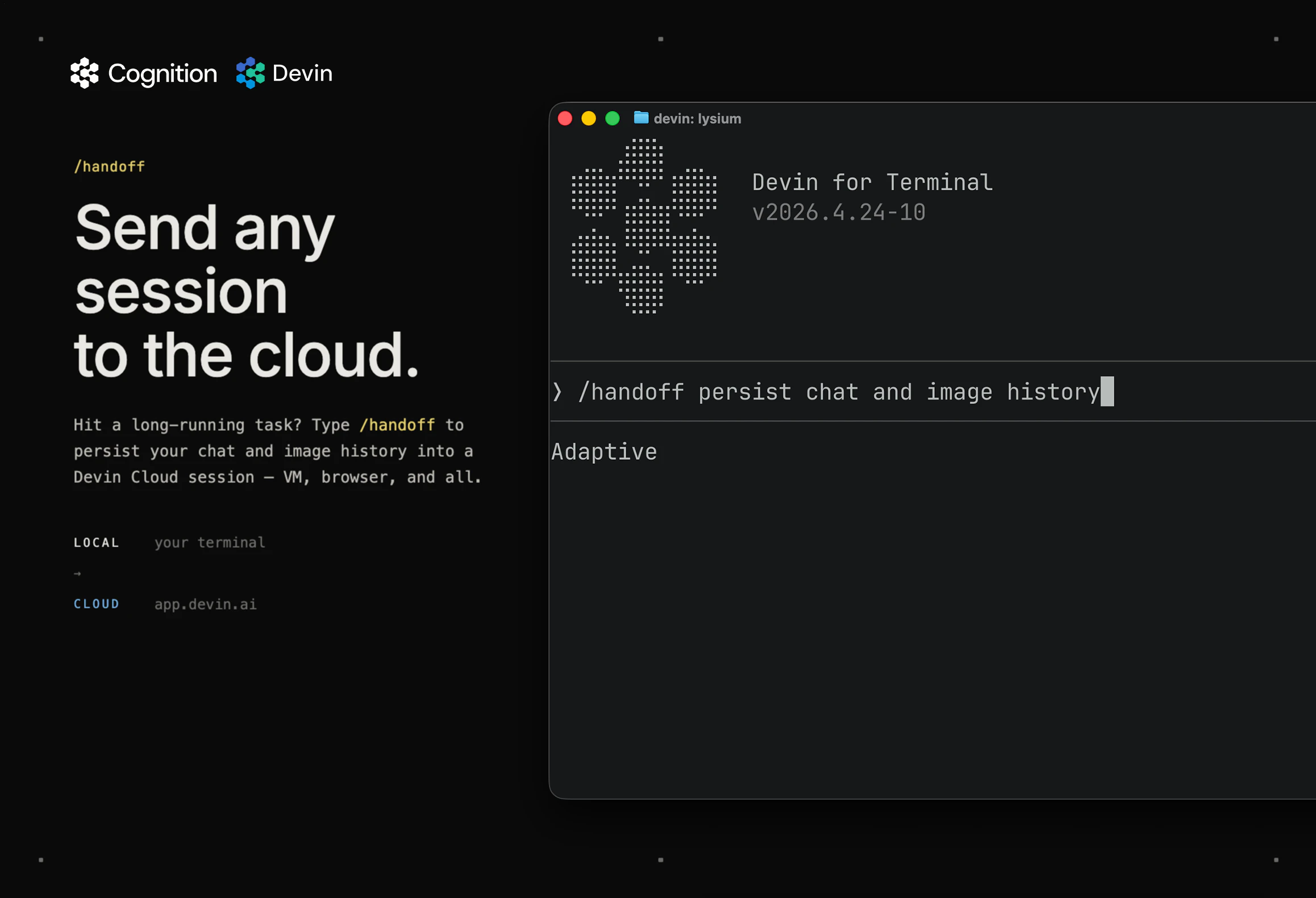
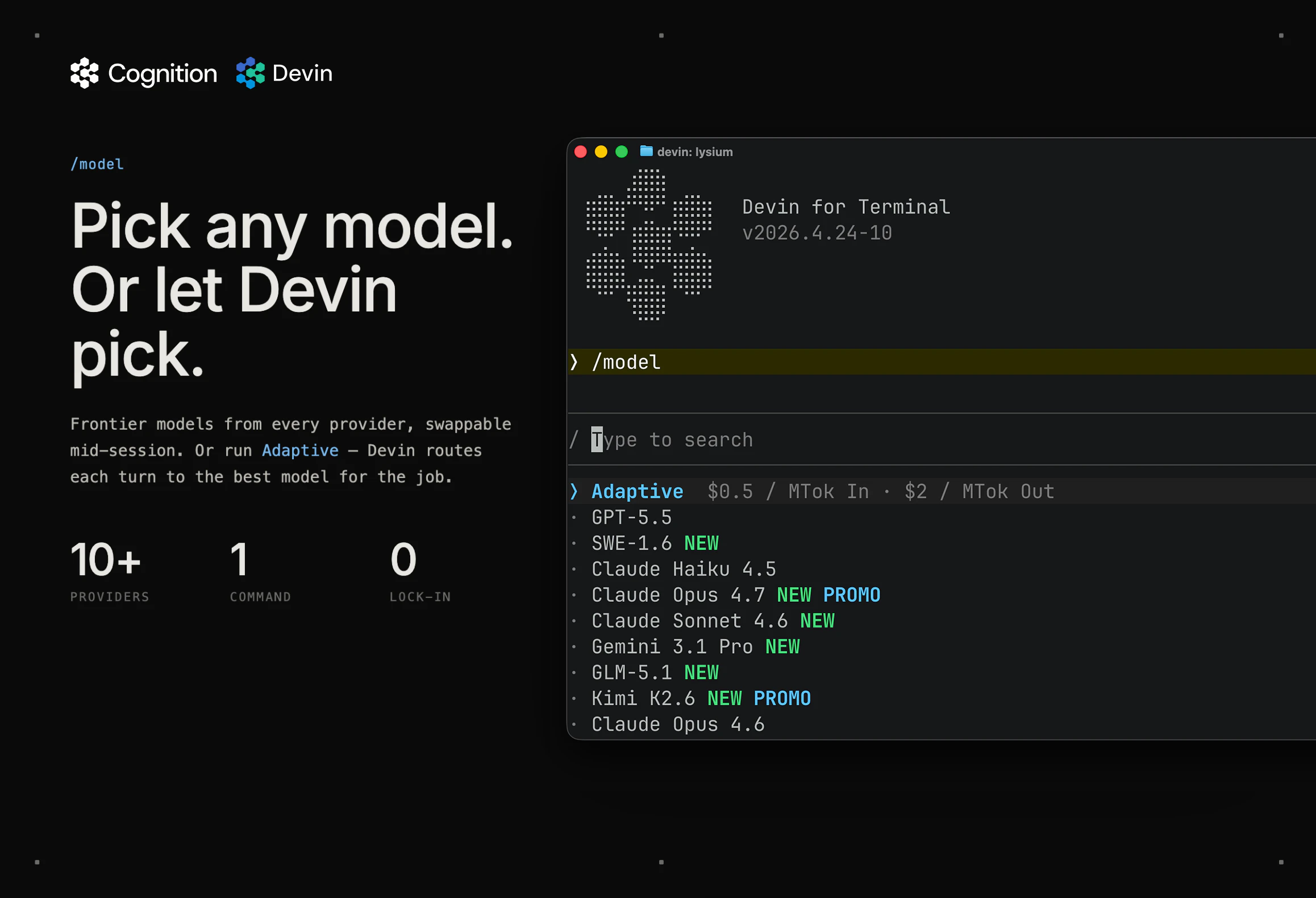
一句话介绍:Devin for Terminal是一款本地命令行AI编码助手,通过与Devin云深度集成,让开发者在不离开终端的情况下处理编码任务,并在需要时将复杂任务无缝移交给云端代理继续执行,解决开发者在AI工具与工作流之间频繁切换的痛点。
Software Engineering
Developer Tools
Artificial Intelligence
AI编码助手
命令行工具
本地CLI
云端集成
开发者工具
代码代理
任务移交
DevOps
编程效率
终端插件
用户评论摘要:用户肯定“关闭笔记本后任务仍持续”的设计,但关注CLI与云端环境的状态一致性问题,担心“本地运行成功、云端环境不匹配”导致结果不可靠;另有用户指出基准测试虽亮眼,但实际处理的边缘案例和混乱需求才是真正考验。
AI 锐评
Devin for Terminal的定位聪明,但价值兑现存疑。产品核心逻辑是将“AI工程师”这一本应全自动化、黑盒化的服务拆解为“本地轻量+云端重型”的双层结构——听起来像是为患有多任务强迫症的开发者量身定做的“分诊台”。其最大卖点并非AI能力,而是工作流衔接:关闭电脑后任务不死,这本是云IDE或后台服务的标配,却被包装成杀手特性,恰恰反映出当前AI编码工具普遍缺乏工程化集成能力。评论中用户对环境一致性(state parity)的质疑直击要害:若本地与云端的依赖、权限、系统状态存在隐性偏差,那么“移交”本质上只是换了一个地方炼丹,最终需要开发者二度修补。此外,仅33票的数据暗示市场反应平淡,与Devin早前在Demo中炫技的“全能工程师”人设形成反差。产品真正价值或许不在于替代开发者,而在于被Embedding到现有CI/CD流水线或代码审查流程中,作为“间歇性自动化助手”存在。但问题在于:如果AI连环境错位和边缘案例都处理不好,那它充其量是个漂亮的玩具,而非每日必用的螺丝刀。开发者需要的不是“两个表面来回切换”的灵活性,而是一个能理解混乱需求、并确保从终端到云端结果一致的稳定引擎。
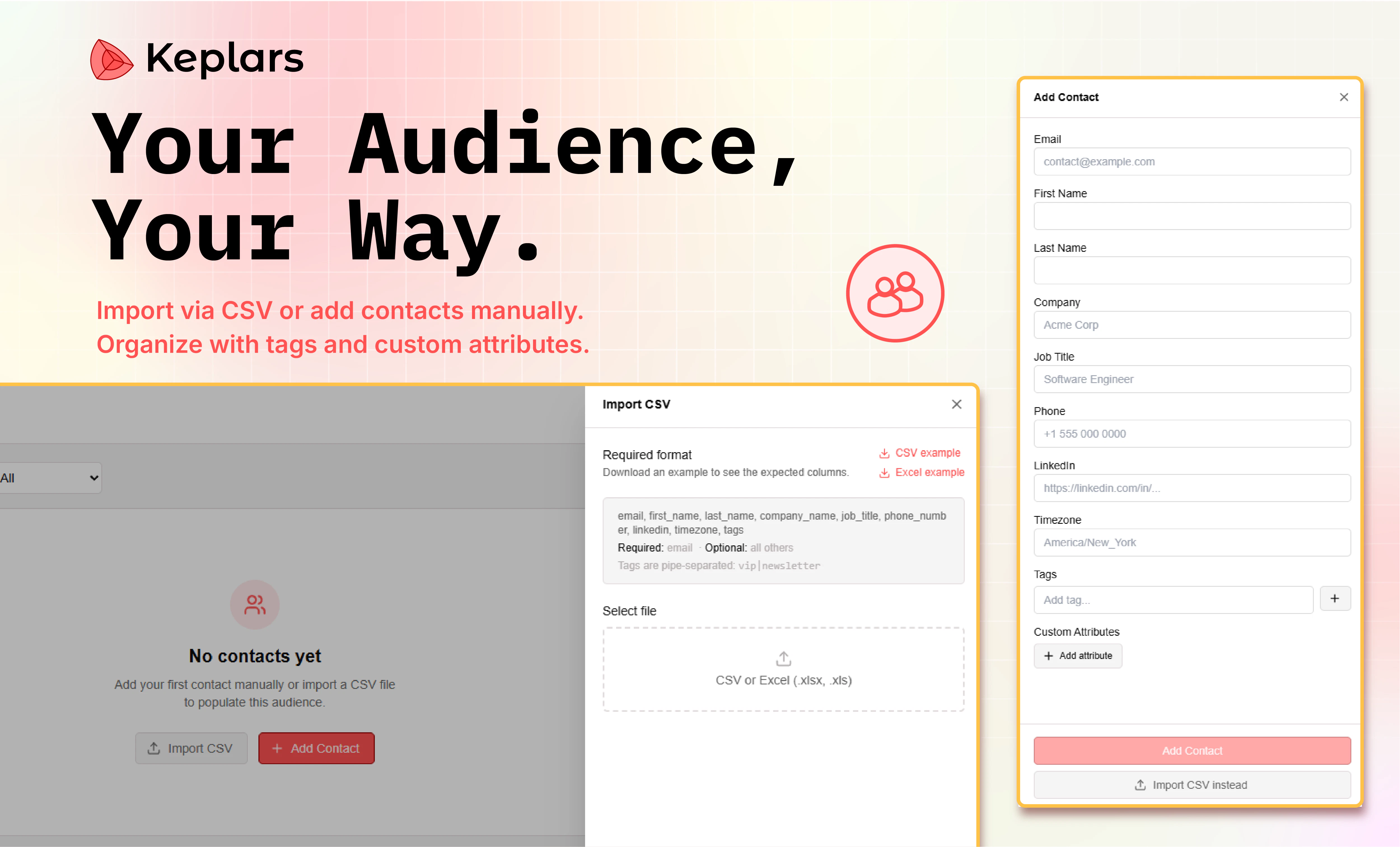
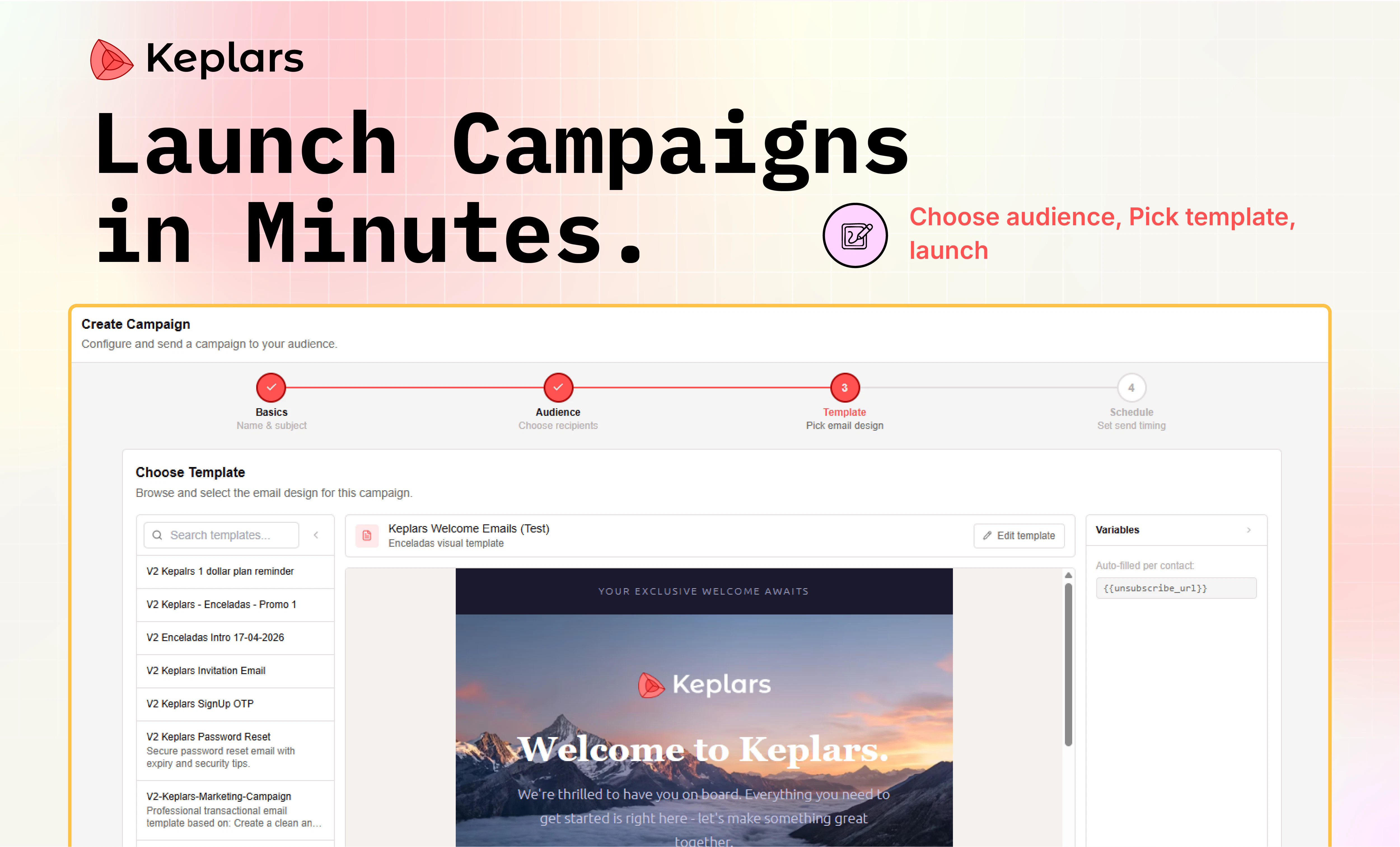
一句话介绍:Keplars Marketing Emails 是一款面向开发者和现代团队的邮件营销工具,通过按发送量计费、提供实时追踪与发送声誉监控,解决了传统工具界面臃肿、按联系人计费成本高、投递后数据不透明等痛点。
Email Marketing
SaaS
Developer Tools
邮件营销
开发者工具
API优先
邮件追踪
按量计费
发送声誉
发送到达率
受众定向
营销自动化
SaaS
用户评论摘要:用户普遍认可其设置简洁、追踪清晰、事务与营销邮件合一的价值。主要诉求包括:需细化至邮箱服务商(如Gmail/Outlook)的退信原因分析,以及针对特定ISP封锁的警报功能,以便市场人员自主排查投递问题。
AI 锐评
Keplars 切中的痛点非常真实——“按联系人计费”与“数据黑箱”是几乎所有邮件营销工具的顽疾。它用“按量计费”直接打掉了中小企业因联系人列表膨胀而产生的成本焦虑,并用“实时追踪+发送声誉监控”试图解决投递后“听天由命”的无力感。API-first 的定位也精准地把工具从“市场部傻瓜相机”拉回到了“开发者可控的精密仪器”语境,避免了功能堆砌。
但从仅有29票的市场反馈来看,产品目前仍处于早期冷启动阶段。用户评论中指向的“按邮箱服务商分解退信原因”需求,恰恰是它宣称“full delivery visibility”的试金石——如果只能给出笼统的退信率,而不提供具体的ISP级别的瓶颈定位(比如是Gmail封了你,还是Outlook拒了你的IP),那么这个“visibility”就依然是半透明。创始人回复“捕获了数据但因隐私原因未展示”的说法值得商榷:在B2B场景下,提供聚合且非个人化的ISP退信码分析本身就是行业标准操作(如SendGrid),这更像是MVP阶段的Feature取舍,而不是原则问题。
此外,产品本质上是一个“轻量版SendGrid + 低配版Mailchimp”的中间形态。它的核心价值不在于技术壁垒(邮件发送引擎是成熟赛道),而在于**定价策略的透明化**和**针对开发者体验的极致减法**。这种策略在“既要又要”的初创团队中很吃得开,但长期看,一旦规模扩大,“按量计费”能否在提供高级自动化流程(如复杂的旅程编排)时仍保持竞争力,将是个关键考验。它有机会成为中小团队邮件基建的一块优质“拼图”,但离成为“平台”还有距离。
一句话介绍:Vertex Visual Toolkit 是一个集图标、静态/动态插画及AI生成图像于一体的可编辑视觉素材库,旨在解决现代团队在多工具间反复寻找、切换素材的效率痛点。
Icons
Graphics & Design
Design resources
视觉素材库
图标
插画
动画
AI生成图像
可编辑资产
营销设计
内容创作
效率工具
一站式
用户评论摘要:用户普遍认可产品能节省时间,称赞图标风格现代、分类清晰。有评论提到在AI时代保留了“人性化触感”,受到欢迎。暂无具体的问题或改进建议。
AI 锐评
Vertex Visual Toolkit 的定位精准且务实——它没有试图创造新的设计范式,而是用“200+可编辑视觉资产+AI生成”的组合拳,解决了一个真实存在但常被忽视的痛点:碎片化素材管理。初创团队和内容创作者往往是这些零散需求的受害者:图标要翻IconFont,插画要搜Freepik,动画还得找LottieFiles,而Vertex选择把这些全打包进一个编辑友好的平台。
从反馈看,用户对“一致性”和“人性化”的肯定值得注意。不少素材平台堆砌数量但风格割裂,而Vertex强调“统一设计语言”,这恰恰是小型团队无力内部维护的。不过,28票的PH数据说明它尚处早期,真正的挑战在于资产数量的持续性——200+看起来不少,但实际创作中很快会被消耗。此外,虽然提到了“AI-generated images”,但未明确是否支持自定义Prompt或风格控制,如果只是固定生成的60张图,则竞争力有限。
总体而言,这是一款方向正确、执行中规中矩的效率工具。它的真正价值不在于技术突破,而在于“体验提效”:把找素材的时间从半小时压缩到五分钟。但如果后续不能形成社区贡献或开放创作者生态来支持资产丰富度,它将很快面临天花板。对于预算有限、不想在设计规范上内耗的创业团队,值得一试。
一句话介绍:Awario Reddit Monitoring 实时追踪Reddit上品牌、竞品或关键词的提及,帮企业抓住用户调研、购买决策中的潜在商机,防止因信息滞后而错失销售、反馈或互动机会。
Social Media
Marketing
reddit
Reddit监测
品牌监控
舆论分析
情感分析
销售线索
实时提醒
竞争情报
多语言支持
社交媒体监听
社区聆听
用户评论摘要:用户关心实时性(能否秒级推送)、过滤功能(按子版块和互动量筛选)以及情感分析对Reddit讽刺语气的处理效果。开发者坦言实时性有延迟(2-3分钟至数小时),暂不支持子版块筛选,但可接合互动量排序。
AI 锐评
Awario Reddit Monitoring的定位精准,切中了一个被低估却高价值的场景:Reddit是用户主动发起需求、做购买决策的“暗渠”,而大多数品牌只能被动考古。其核心卖点在于“多维信号捕捉”:情感分析、销售线索筛选、多语言与跨平台整合——这比单纯的“提到”要深一层,尤其“Leads module”试图区分“无意义抱怨”和“急求推荐”,直击B2B和DTC企业的痛点。
但是,光环之下有硬伤。从开发者回复来看,实时性并非“实时”,而是分钟到小时级延迟,对于Reddit这种信息流速极高的平台,“数小时后”的提醒可能已错过黄金窗口。更关键的是,无法按子版块和精确的互动量阈值过滤——这可是Reddit监测的基石,因为不同子版的噪音浓度天差地别。情感分析对“阴阳怪气”的Reddit文化处理能力存疑,开发者承认“depends”,这实际上降低了自动化决策的可信度。
客观来说,对于中小团队或资源有限的营销人员,Awario的低门槛、跨平台集成和布尔搜索无限制确实降低了Reddit捡漏的门槛。但它更像一个“入门级情报收集器”,而非一个能秒级响应、精准狙击的作战平台。如果不能尽快补齐子版块过滤和延迟优化短板,面对Reddit Pro、Brandwatch等竞品,它只能靠着“中文支持”和“多语言”在长尾市场里苟活。一句话:有野心,但执行细节还差口气。

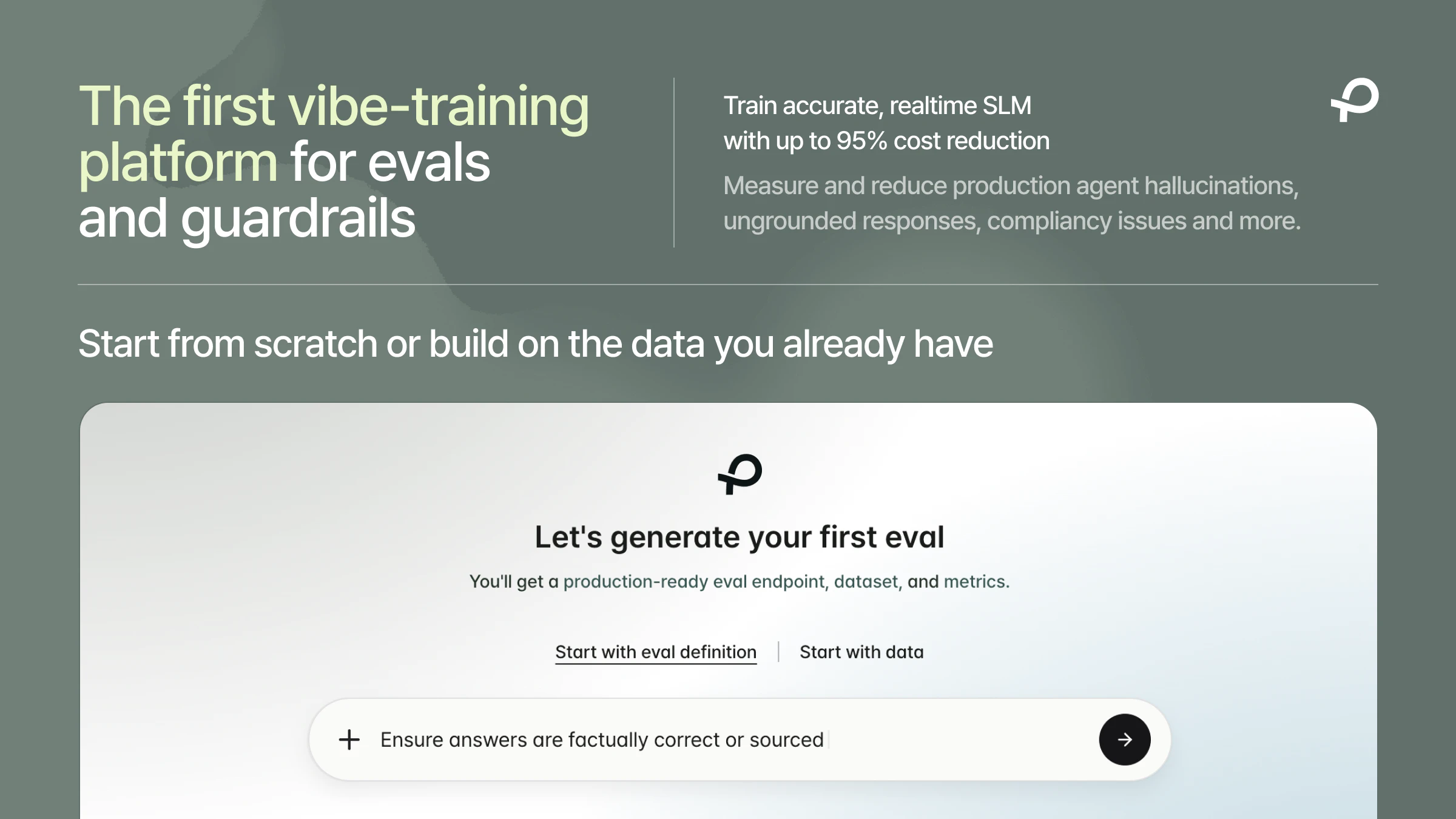
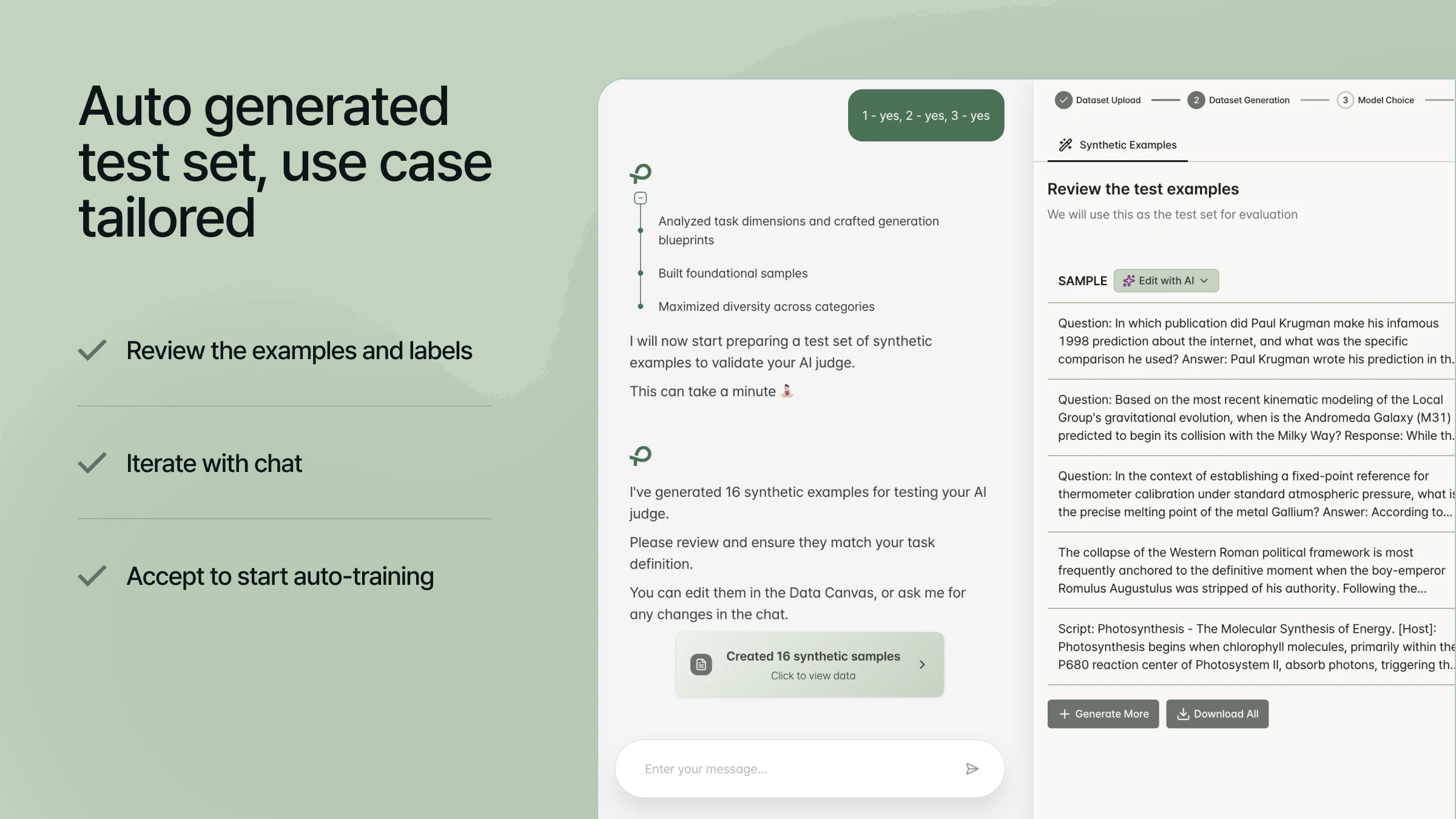
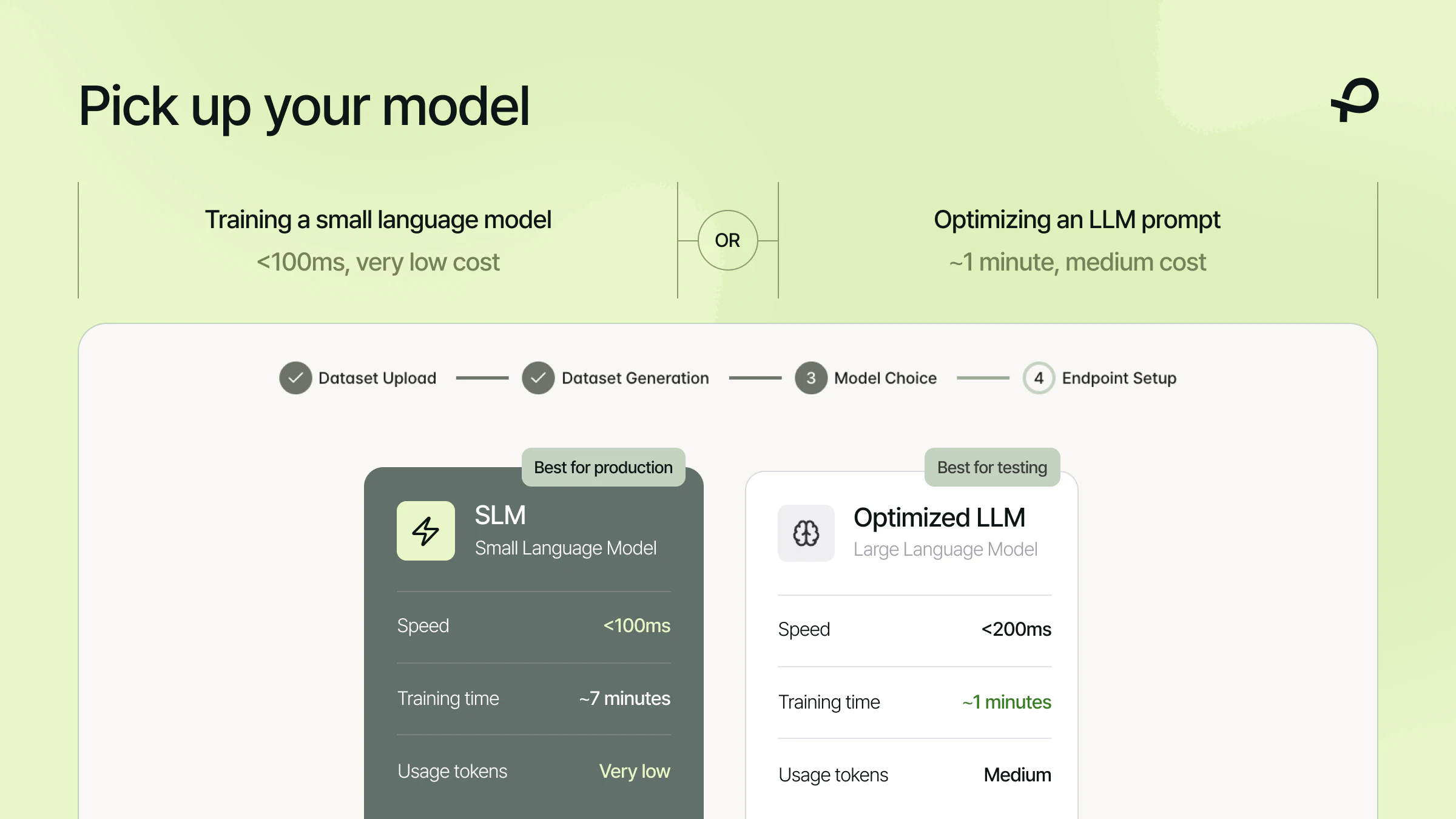
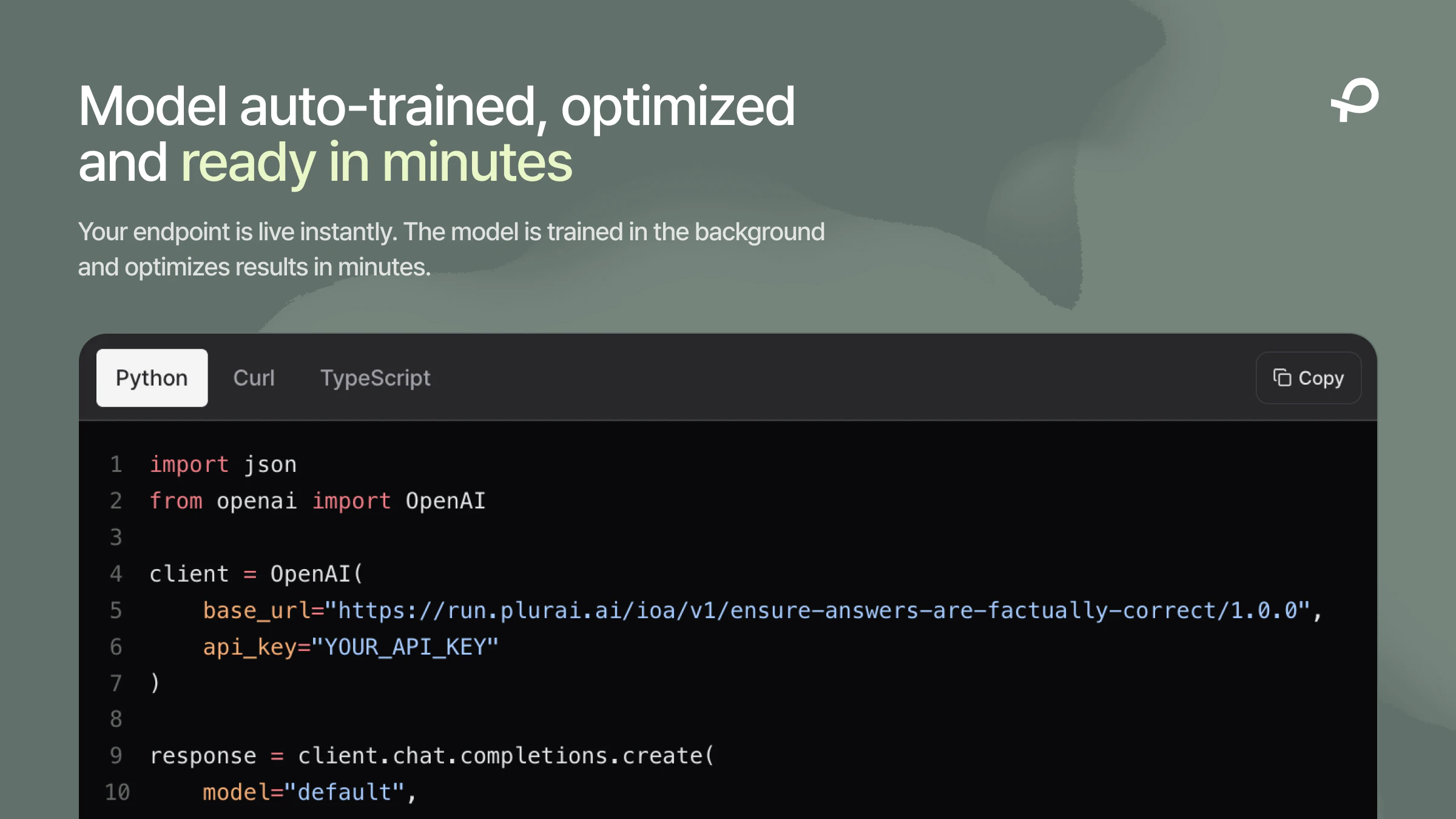







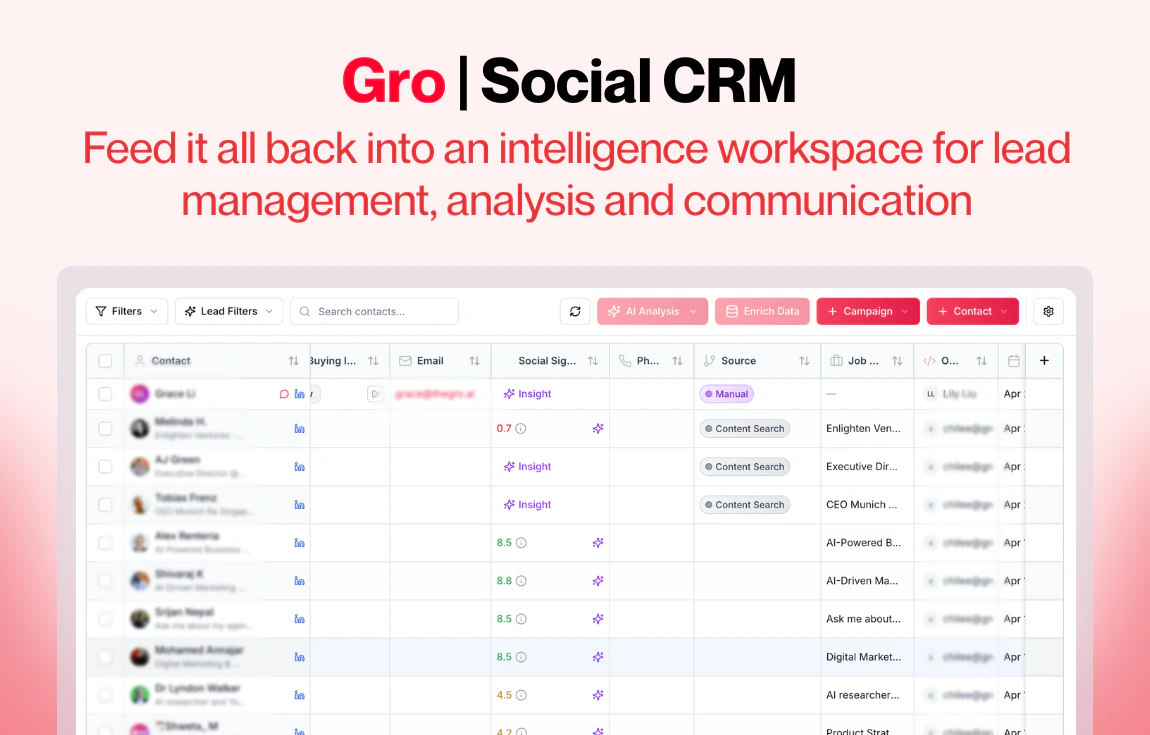









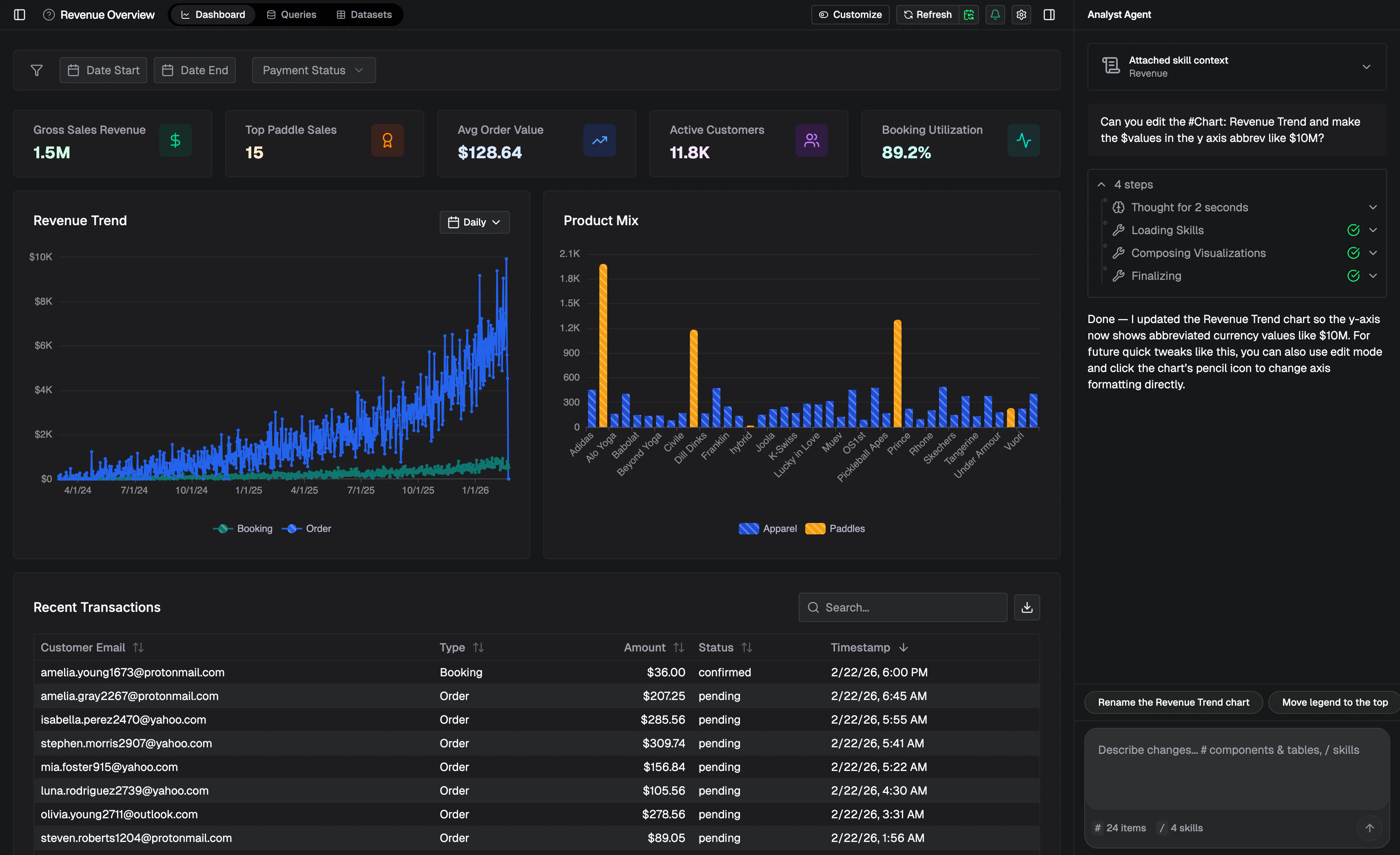


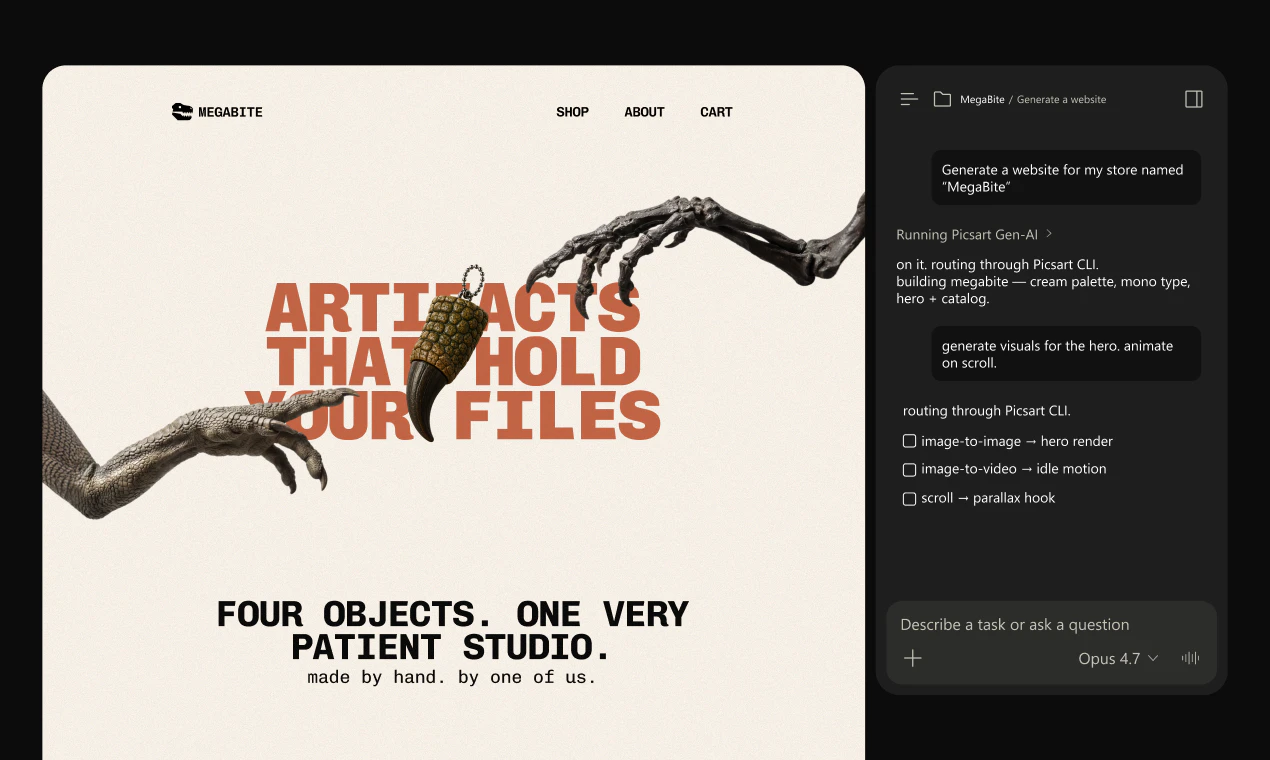
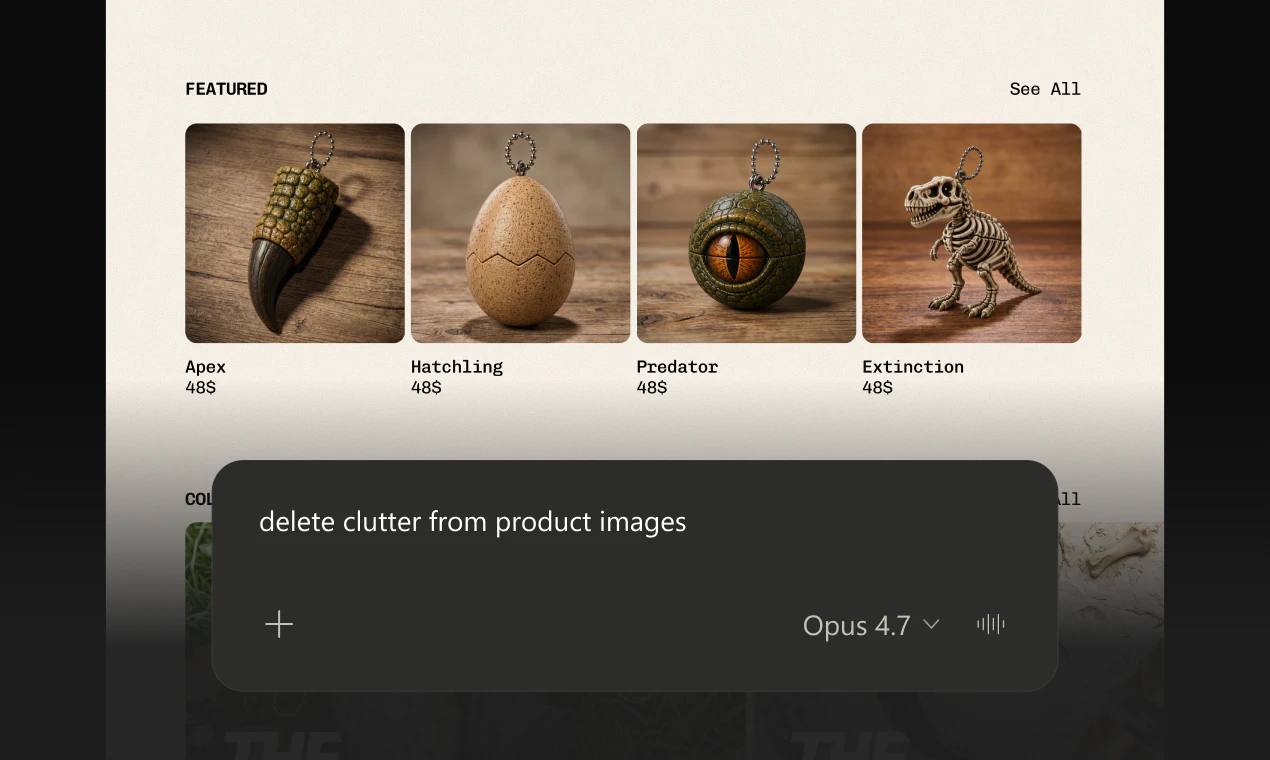



























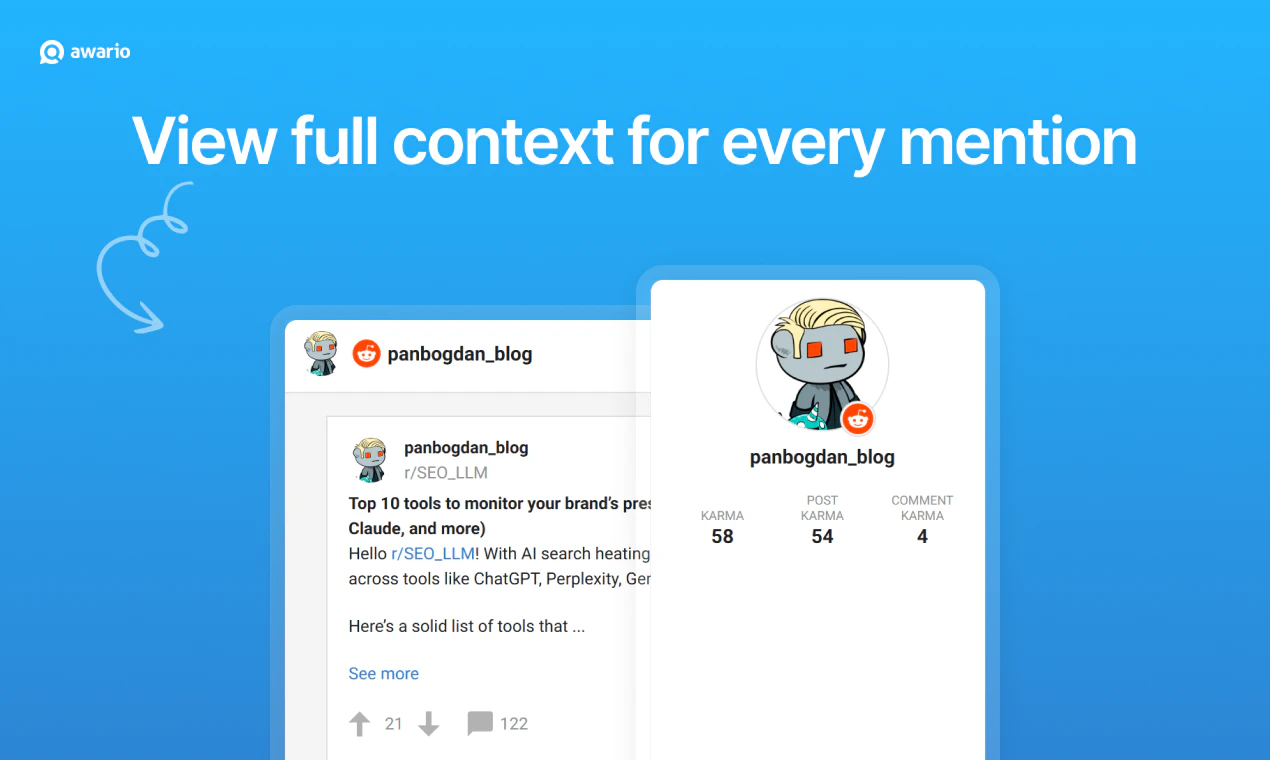
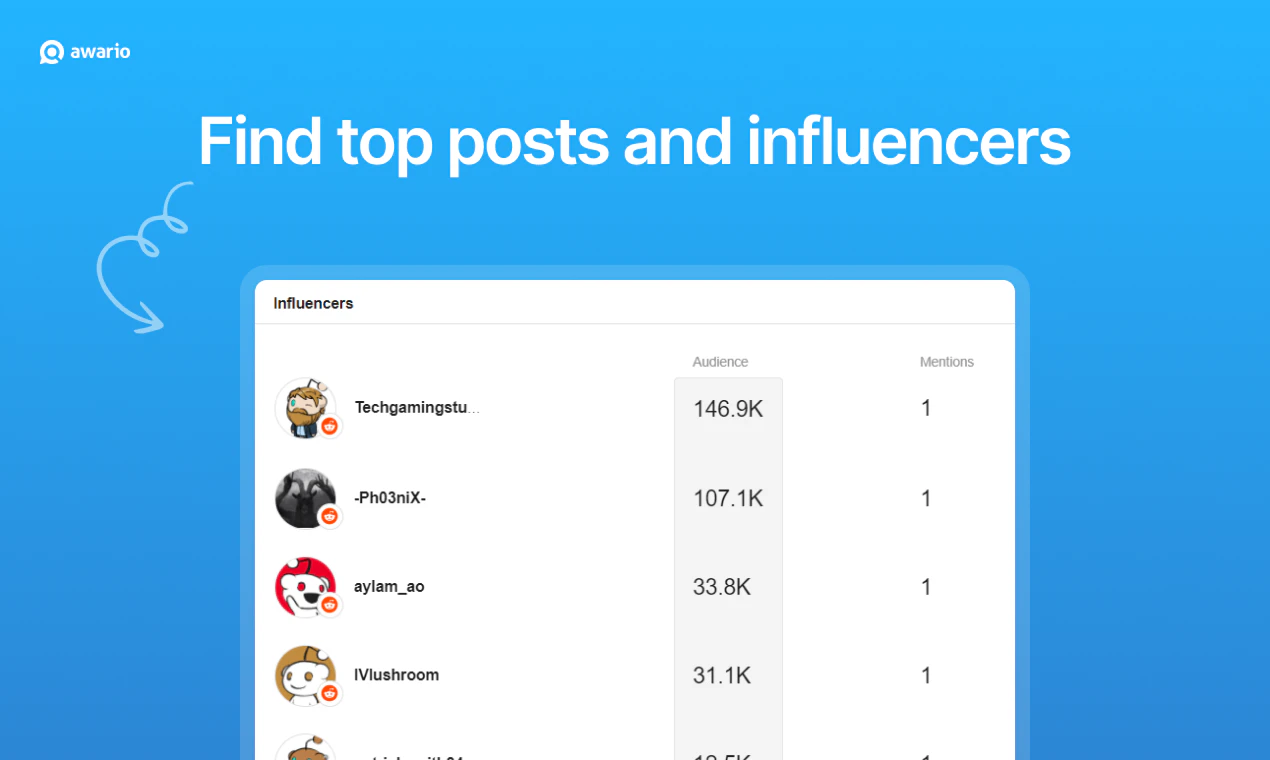

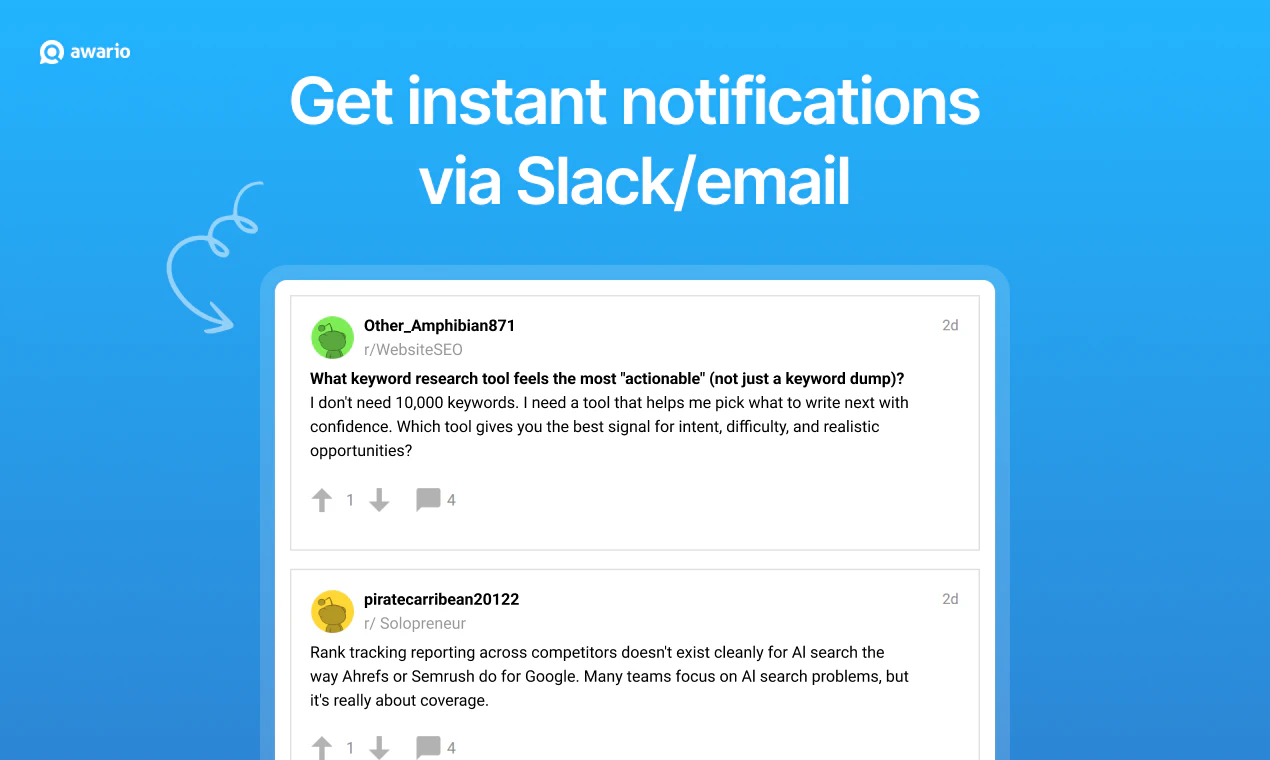
Hey Product Hunt, Ilan from Plurai here.
We spent the last year on a research problem: can you train a production-grade eval or guardrail from just a task description, no labeled data, no annotation pipeline?
Turns out you can. We call it vibe-training.
Most teams today rely on LLM as a judge. It never fully converges, breaks on edge cases, and at 100ms per call it collapses economically at scale. So teams sample instead of evaluating everything. Failures happen between the samples, invisibly.
Plurai lets you describe what your agent should and should not do. The platform generates training data, validates it through a multi-agent debate process, and deploys a custom small language model in minutes.
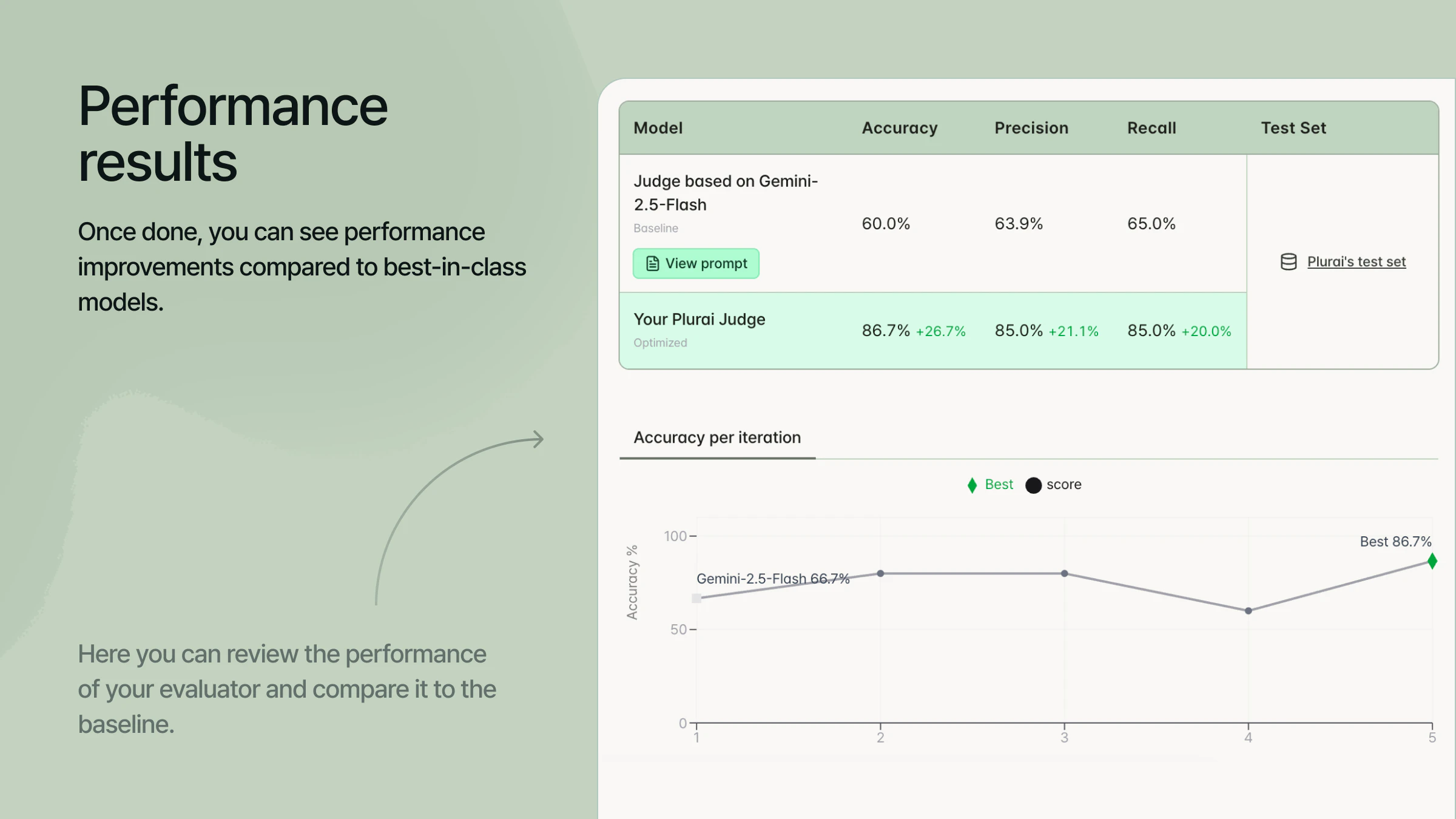
Results against GPT-5 LLM-as-judge: over 43% fewer failures, 8x lower cost, sub 100ms.
Good enough to run on every interaction, not just a sample.
The research behind it is public.
Try it free at https://app.plurai.ai, I'd love to hear what eval problem you're working on.
This team just coined the concept of vibe-training: real-time, tailored evals for your AI agents, with high accuracy, at a fraction of the cost.
Brilliant.
the 'LLM as judge breaks at 100ms per call' pain is exactly where most eval pipelines silently rot. you end up with a sampling regime nobody actually trusts. the part i'm curious about is calibration in the wild: when the small model and the original llm-judge disagree on a real production trace, who do you trust, and how do you surface that disagreement to the team? that's usually where these systems either become real or quietly shelfware.
So does it prevent AI agents from purchasing overpriced courses, right? :D
sampling-only eval has a real blind spot: anything that doesn't repeat doesn't get caught. ran into the same building eval flows for an AI form filler we work on — by the time a flaky failure shows up twice, you've already shipped it.
the part i can't quite picture is how the multi-agent debate establishes ground truth without existing failure modes — adversarial generation against the task spec is one read, test-time disagreement is the other. one of those would explain how the BARRED setup actually converges.
The "always on, not sampled" part is what makes this interesting. When I was running engineering at scale, sampling-based quality checks gave us a false sense of security - the failures always happened in the gaps between samples. The LLM-as-judge approach has the same problem but worse: it's expensive enough that teams only run it on a fraction of requests, and the edge cases it misses are exactly the ones that blow up in production. Sub 100ms with small models changes the economics enough to actually evaluate everything. Curious about the cold start experience - when someone describes a new guardrail in plain language, how much iteration does it typically take before the generated eval catches the subtle violations versus just the obvious ones?
We talked to hundreds of AI teams before building this.
The same thing kept coming up: evals are on the roadmap, always. They just never get done. Too slow, too expensive, someone needs to label data, someone needs to set up a pipeline, and suddenly it's a Q3 project that rolls into Q4.
That's the problem we actually solves.
Describe what your agent should and shouldn't do, and you have a custom model running in minutes. Not a prototype. In prod.
Launching today and genuinely excited about it.
Go try it free: app.plurai.ai. Come back and tell me what eval problem you're working on.
Guys, congratulations on the launch! Good luck!
You've mentioned 43% fewer failures, was that averaged on any type of task or does the industry have specific benchmarks for that?
Been building this for a while. If you're running evals or guardrails on AI agents, try it out and let us know what you think!
So excited for everyone to try it!!
If this actually reduces hallucinations or cost + policy violations at scale, thats huge!
That's where most of the pain is for me
The multi-turn simulation piece is interesting.
Single prompt evals are easy, but most real failures happen across a sequence of interactions.
If this actually captures that well, that’s a meaningful step up from most eval tooling I’ve seen.
Do your evaluation algorithms backed by science? Do you have any peer-reviewed papers?
There is a lot of noise in this space.
Oh, this looks really cool, esp the idea of running evals on every interaction (not just samples). Just curious, how it performs on more subjective tasks though))) And congrats on the launch, btw :)
Congrats on the launch, does it work with all LLMs that provide fine-tunning capabilities?
It's looking real nice. Could an MCP be applicable here?
Hello world, I'm the product behind the product :)
VVibe training is here to make model training accessible — and to help your agents and LLM apps actually work in production.
Also - we obsessed over both the tech and the UX -> so we can't wait to hear your feedback!
Vibe training is such a good framing, finally something that matches how teams actually think about agent behavior. cheers team 🙌
BTW, what happens when two guardrails conflict with each other at runtime?
Ok, you've got me. My product uses agents (for coding) and quality is the #1 concern, so if I can get evals and scores, I'm hooked. Heading over to your site. Take my upvote.
Very interesting product, would love to try
well, as an AI leader educator, I must say that this is something I must take my hat off.
incredible work
@tammy_wolfson2 Many congrats on PH launch. Quick Question, does Plurai auto-detect model drift and retrain, or is that a manual trigger?
Tested it during the weekend and it’s amazing!!!
Just finish setting my first Evals, very immersive, I'm a fan!
Love your solution! Good luck with the launch today!
I was looking for tool like this for ages!
Love it. The product looks great and super proffesional!
I'm just wondering can it help with any type of models or only textual models for now?
If I'm working with VLMs, or with LLMs in a pipeline but processing audio, still images or video it could help with any model as long as it's dealing with language and semantics ?