PH热榜 | 2026-05-04
一句话介绍:Mindra是一个AI代理团队指挥中心,通过创建和执行由多智能体协作的工作流,在营销、供应链等场景下替代人工完成重复性运营任务,解决单点AI代理无法端到端执行以及静态流程链在生产中易崩溃的痛点。
Productivity
Marketing
Artificial Intelligence
AI代理团队
工作流自动化
多智能体编排
任务委派
无代码集成
营销自动化
供应链自动化
企业运营工具
AI治理
用户评论摘要:用户普遍关注其与Zapier等链式工具的差异,核心问题集中在:集成难度、24小时运转的成本控制、治理层的可审计性、多智能体“发散/漂移”的收敛逻辑,以及迁移成本。团队以结构化协调层、确定性决策、自愈机制和权限控制回应,强调非黑盒、可审计。
AI 锐评
Mindra的“代理团队”叙事刚好踩在了当前AI工作流的两大痛点:单点智能荒废和静态链路脆断。它试图用“基于任务状态的确定性编排”替代“LLM自由发挥的伪团队”,这实际上是权衡了智能与可靠性的务实之举——保留LLM在边缘情况下的决策弹性,但将任务分解、重试、状态跟踪等核心逻辑剥离出来,交由一个类似状态机的结构化层控制。这个思路直击了CrewAI或LangGraph等框架在“Demo易、生产难”上的核心死穴:不可预测的Token消耗和无限的错误循环。
其真正的价值在于定义了“可信任的委托”的边界:不是让AI自主决策,而是让AI在清晰的剧本(任务分解、工具权限、失败阈值、人力介入点)内自主执行。这更接近“智能体SOP”而非“智能体自由意志”。营销、供应链这类需要反复执行的运营流程,正是这种模式的最佳阵地。
但高风险也并存:3000+集成意味着其“粘合剂”价值高度依赖与企业现有工具的连接深度与稳定性,一旦某家关键API变更,自愈机制很可能徒增调试成本。此外,“复合记忆”听起来诱人,但如果记忆管理不当,反而会成为代价昂贵的“幻觉放大器”。用户要警惕它在初期讲出的“全自动”故事,真正的价值点可能落在“半自动化”上——人机协作的治理层设计是否真如宣传般轻盈,将是决定其能否从尝鲜走向日常部署的试金石。
一句话介绍:Aaavatar是一款专为HR和设计团队打造的Mac端工具,能一键批量处理员工头像,自动去除背景、统一色彩、对齐高度并导出多种格式,彻底终结了手动PS统一团队照片的繁琐痛点。
Design Tools
Productivity
Artificial Intelligence
团队头像
一键处理
背景移除
色彩统一
高度对齐
批量导出
HR工具
Mac应用
AI修图
品牌形象
用户评论摘要:用户普遍认可其解决了团队照片不一致的长期痛点。主要疑问集中于:不同光线原图下品牌风格迁移的效果(产品回应称有Magic Retouch自动调色,并考虑后续加入跨图光线匹配);以及“一键修复缺失”与现有开源方案或Figma内置功能的差异点。
AI 锐评
Aaavatar切中的是一个极其垂直但高频的“屎上雕花”需求——统一团队头像。创始人从自身在快速扩张公司中目睹HR用80美元/月的Figma手动抠图的亲身经历出发,构建了“从上传到导出”的端到端工作流闭环。这不是一个AI炫技产品,而是一个流程优化器。
产品真正的价值不在于“去掉背景”这个单一功能(Figma、Remove.bg等已能廉价实现),而在于它把“背景移除-色彩匹配-高度对齐-格式统一导出”这一整套非标操作封装成了一次性动作。这恰恰是HR和行政人员最需要的“傻瓜式”体验,而非设计师的“精细化”工具。
评论中关于“不同光线原图”的质疑也暴露了其潜在短板:目前对单张照片的“Magic Retouch”只能各自为政,无法做到真正的“团队级”光线和色彩映射。若后续版本不能实现基于团队照片集的全局色彩分析,面对有数年跨度、光线千差万别的海量头像,效果仍会参差不齐。此外,仅限MacOS是其初期冷启动的明智选择,但也是未来增长的最大天花板——毕竟HR团队中的Windows用户比例不低。整体来看,这是一款“小而美、解决真问题”的工具,但需要警惕沦为下一个被大厂免费功能吞并的Airbnb(Figma或Canva完全有能力在插件层实现类似工作流)。
一句话介绍:Codex Pets 为 Codex 工作流注入趣味性,通过浮动动画宠物实时反馈线程状态,解决开发者等待时对任务进度的感知缺失问题。
Pets
Artificial Intelligence
AI开发工具
工作流增强
桌面宠物
状态可视化
动画插件
开发者体验
Codex生态
生产工具
GTD
互动装饰
用户评论摘要:用户赞赏其与Claude Code buddy类似的设计,建议引入稀有度分级(如稀有、传说)。另有用户询问如何自定义宠物,未获回复,说明文档或引导可能不足。
AI 锐评
Codex Pets 本质上是一个情感化的状态指示器,用“宠物”这一高亲和力载体,包裹了Codex运行/等待/就绪的二进制反馈。它解决了工具使用中一个微小但真实的痛点——在异步等待时,屏幕角落的静态“加载中”远不如一只活蹦乱跳的史莱姆能传递“它还在干活”的直觉感。这种软交互设计,是开发者工具从纯理性功能向感性陪伴进化的有趣样本。然而,其价值上限也很明显:它必须依附于Codex生态,且功能上极度轻薄,一旦用户习惯了动画反馈,腻味感会很快到来。评论中用户对“稀有度”“自定义”的期待,恰恰暴露了产品目前缺乏持续吸引力的核心——如果没有足够的“养成分剧情”或“系统化收集”来防止新鲜感衰减,它注定是开发者桌面上的短期装饰品。此外,团队未回应制作宠物的教程问题,暗示社区共建(例如让开发者自己搓宠物)的潜力尚未被重视。若能开放SDK,将宠物从“官配”升级为“平台”,或许能从一个可悲的UI玩具进化成Codex生态的小型UGC护城河。否则,它就是一个漂亮的、用完即弃的API可视皮肤。
一句话介绍:Flowly是一款原生桌面AI助手,通过全局热键即时呼出,能直接操控电脑上的应用和浏览器,自动执行填表、导航、发邮件等跨应用操作,解决AI工具“只能建议不能执行”的痛点。
Android
Productivity
Artificial Intelligence
Menu Bar Apps
桌面AI助手
浏览器代理
自动化操作
原生跨平台
端到端加密
全局热键
持久会话
语音教练
隐私安全
多应用协作
用户评论摘要:用户赞赏其“规划-执行-验证”闭环的可靠性,认为持久会话和端到端加密是亮点。核心疑问:面对多步跨应用任务如何确认(当前需逐次授权),以及AI如何持续学习用户习惯(已支持本地知识图谱)。建议增加对Notion等复杂DOM支持。
AI 锐评
Flowly的价值不在于又一个对话式AI,而在于它切中了“最后一公里”的执行力缺失——当多数AI助手停留在生成文本与建议时,它直接控制了应用的按钮和界面。这种“原生桌面+浏览器代理”的架构,使其从“思想者”进化为“操作者”,这是质的飞跃。从产品设计看,macOS/Windows/Linux全覆盖、系统级加密、全局Fn键热键等细节,表明团队对“桌面原住民”的体验有深刻理解;浏览器代理的“规划→行动→验证”循环则解决了自动化领域的信任问题,用户敢于走开,说明可靠性已具备基础价值。
然而,冷静审视之下,隐患同样明显:多步跨应用(如Excel到Word)操作目前需逐次授权,本质上未真正实现“端到端自动化”,反而可能成为高频场景下的效率瓶颈。产品回应称“单次预审”在计划中,说明其认知到问题但尚未解决。此外,用户对“学习用户习惯”的追问,暴露出AI对个性化工作流的理解仍是薄弱环节——当前仅靠“对话中收集+后台知识图谱”的方式,在面对复杂、非结构化的用户行为模式时,可能显得力不从心。
价格策略方面,“免费永久”极具颠覆性,但“专业版无限使用”的收费点尚不清晰——若核心功能在免费版中已完整,付费冲动何在?或许是高频API调用、高级安全策略或私有部署等。总体而言,Flowly在产品体验和信任设计上已领先多数同类,但要想真正替代人类操作员,仍需在跨应用流程编排和用户意图建模上做更深的功夫。赛道正确,执行尚佳,但距离“真正懂你”还有不止一个版本的距离。
一句话介绍:Rudel 将开发者在 Claude Code 和 Codex 中的编码会话数据,自动生成个性化的“AI编码员交易卡”,通过可视化图案和风格分类,帮助团队直观理解AI编码行为模式、诊断效率瓶颈,让“AI用量”变得可读、可玩、可优化。
Open Source
Developer Tools
Artificial Intelligence
GitHub
AI编程助手
开发者工具
使用分析
数据可视化
代码审计
开源工具
自托管
行为画像
效率追踪
趣味化报告
用户评论摘要:用户对产品整体反馈积极,主要提问集中在:1. 自托管的最低资源要求及升级迁移方案;2. 不同卡牌分类背后(如“公司卡”到“狂人”)的关键元数据信号(如早期错误、仓库广度)。此外,有用户请求进一步的交流合作。
AI 锐评
Rudel 的“交易卡”创意是一记精妙的“数据包装”。它将冷冰冰的 Token 消耗和会话日志,转化为带有“Roadrunner”、“Maniac”等性格标签的视觉卡片,本质上是用游戏化的方式解决了一个严肃的团队管理问题:AI辅助编程的“黑盒”困境。当团队成员都在用 Claude Code 时,管理者最怕的就是“感觉大家很忙,但不知道效率如何,钱花在哪”。Rudel 通过交易卡,给出了一个高度抽象但极其有效的诊断入口。
它的真正价值不在于卡面有多好看,而在于背后基于会话形状、模型混合、错误信号等元数据的分类逻辑。这相当于为每个开发者生成了一个“AI协作风格档案”,团队可以快速识别出谁是“高产出极客”、谁是“试水者”、谁是“高消耗低产出”的陷阱。这比任何仪表盘上的折线图都更直观,因为它直指行为模式而非堆砌指标。当然,产品目前仍处于“有趣”到“有用”的临界点。玩家拿到“公司卡”(高投入低产出)后的下一步是什么?Rudel 需要提供 actionable 的改进建议,而不仅仅是贴标签。作为工具,其真正的护城河在于能否从“诊断”跨越到“优化”——告诉用户如何从“游客”变成“公路赛手”。开放源码和自托管的策略很聪明,降低了企业采纳的心理门槛,也方便了深度用户自定义分类模型。一句话:Rudel 抓住了 AI 编程时代的“隐性痛感”,并用流行文化的外壳包装了一个刚需分析工具。如果后续能基于卡牌数据给出精确的行为改进指南,它完全有潜力成为 AI 开发团队的必备仪表盘。
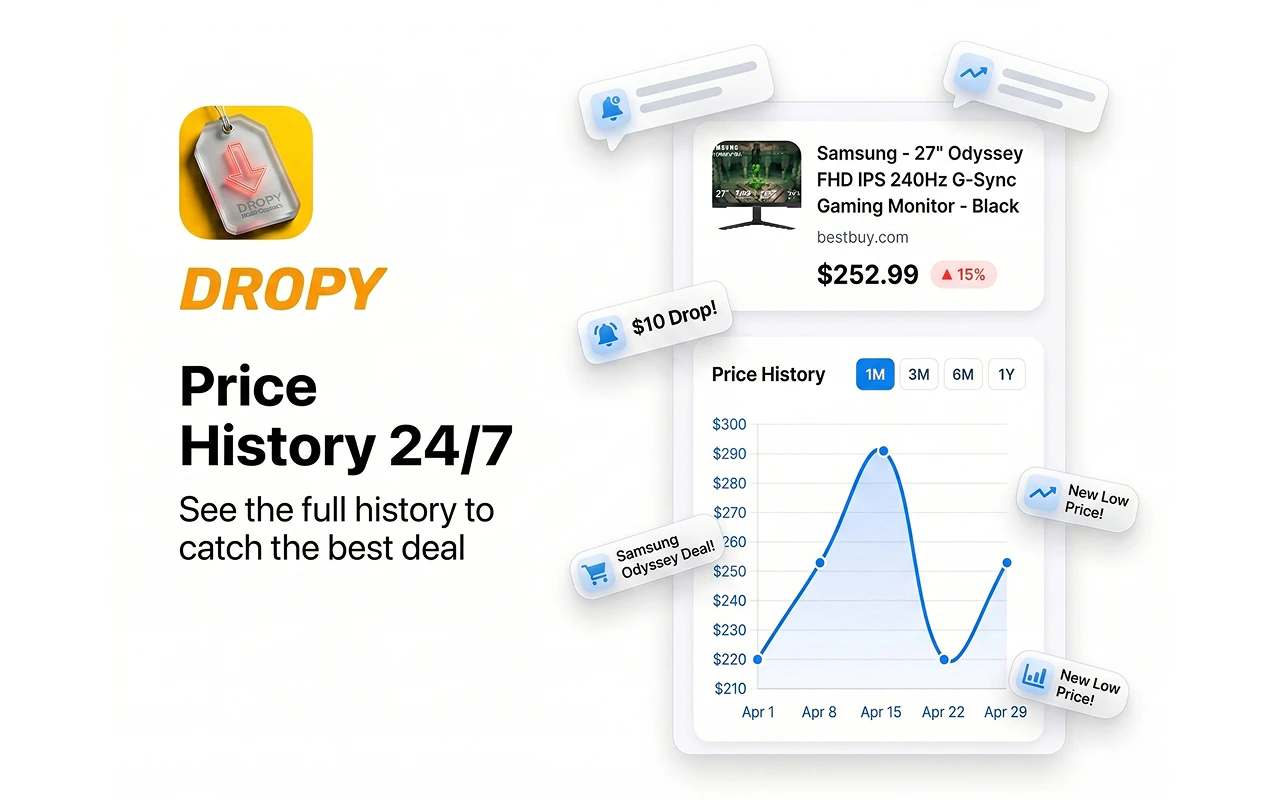
一句话介绍:Dropy是一款跨平台价格追踪浏览器扩展,帮助用户在亚马逊、eBay、速卖通等电商网站购物时监控降价、查看历史价格曲线,避免“买完就降价”的懊恼。
Chrome Extensions
Shopping
价格追踪
浏览器扩展
购物比价
降价提醒
历史价格
电商工具
亚马逊比价
省钱助手
Chrome插件
消费决策
用户评论摘要:用户普遍认可价格历史曲线能揭露虚假折扣,并希望扩展适用场景(如杂货店)。主要疑问:与Keepa、CamelCamelCamel的差异;是否仅支持弹窗还是能嵌入页面显示比价;有用户建议加入“强制24小时冷静+价格检查”功能以抑制冲动消费。
AI 锐评
Dropy切入的是电商购物中最经典的“后悔”场景——用户因信息不对称而支付溢价。其核心价值并非“降价通知”这一功能本身(Keepa、CamelCamelCamel早已覆盖亚马逊),而在于两点:一是“跨平台”覆盖,将eBay、AliExpress等常被单一追踪工具遗漏的渠道纳入监控,形成更广泛的比价网络;二是“历史价格图表”的直观呈现,直接拆穿了电商“先涨后降”的促销把戏,这比单纯的降价提醒更能培养用户理性消费习惯。
但从评论来看,Dropy目前仍面临定位尴尬:在亚马逊这个核心场景上,它并未提供比成熟工具(Keepa)更独特的优势,用户对“差异点”的追问提示团队需要更清晰的核心功能区隔。此外,功能上停留在“被动通知”而非“主动决策辅助”——比如没有比价聚合页、没有跨平台同款最低价推荐,也没有禁止弹窗或强制冷静期的设计,导致其对冲动型用户的约束力有限。理想的演进方向应是:从“提醒你价格变了”升级为“告诉你什么时候买最划算”,加入基于历史数据的降价趋势预测和买入时机建议,才能真正从工具进化为消费顾问。
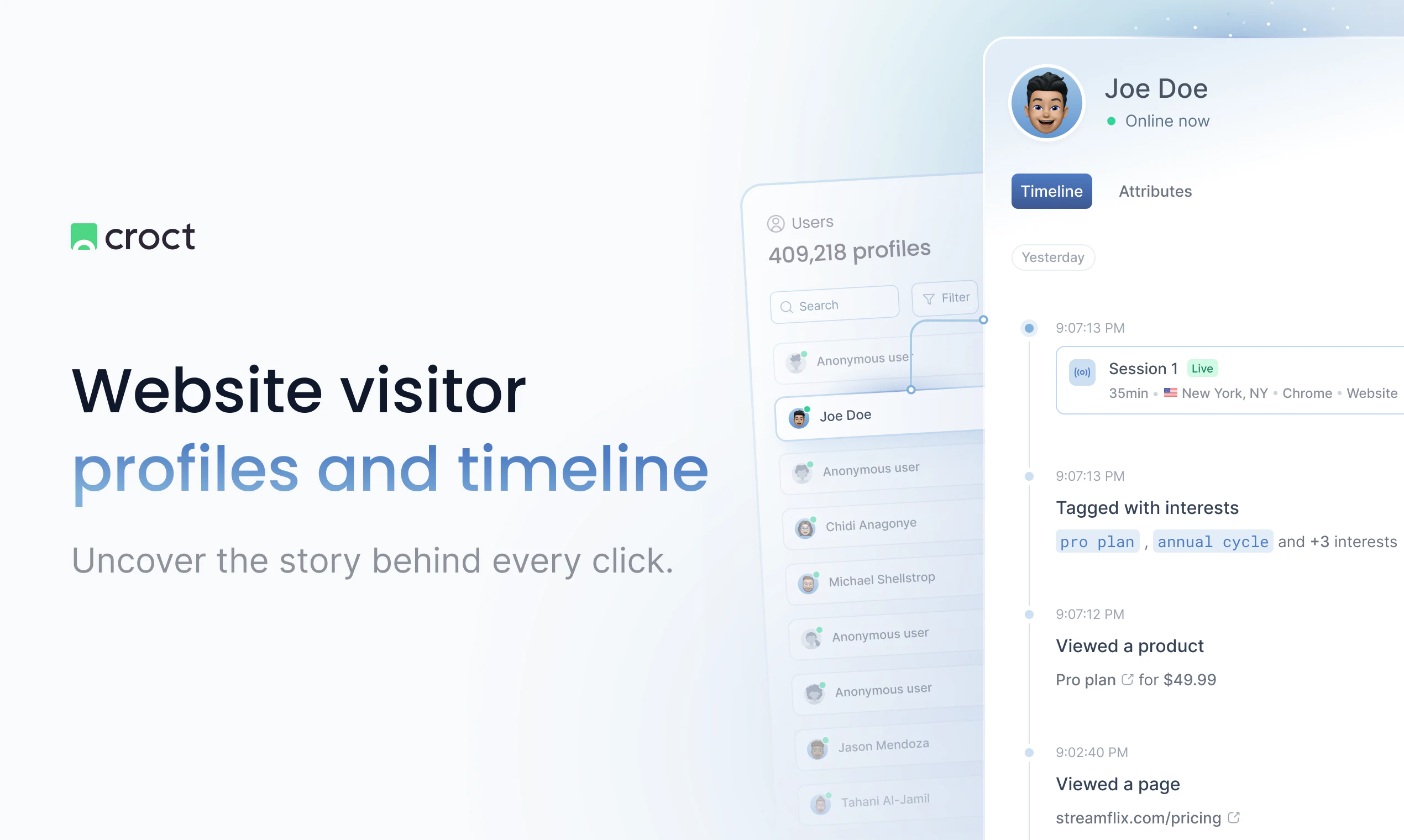
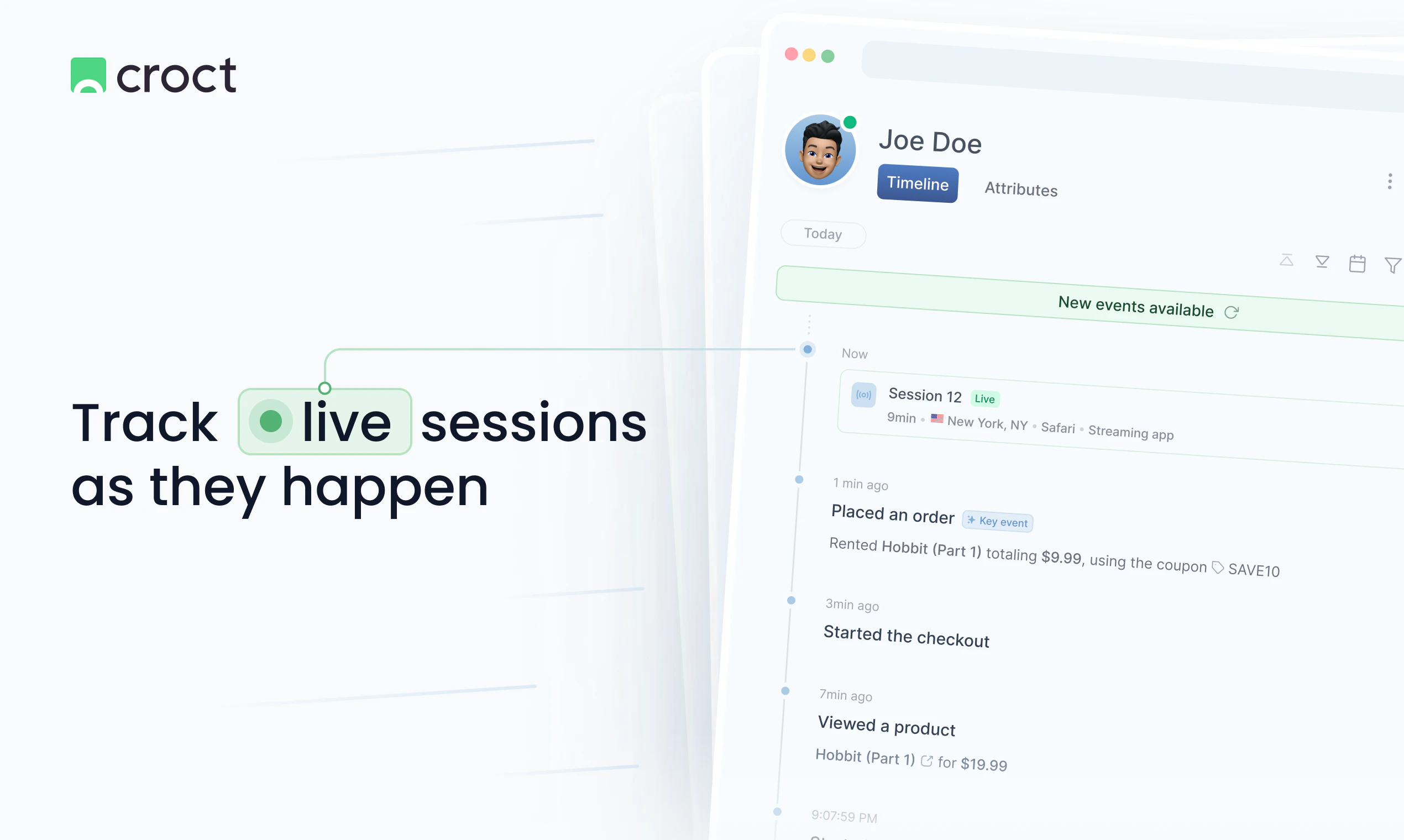
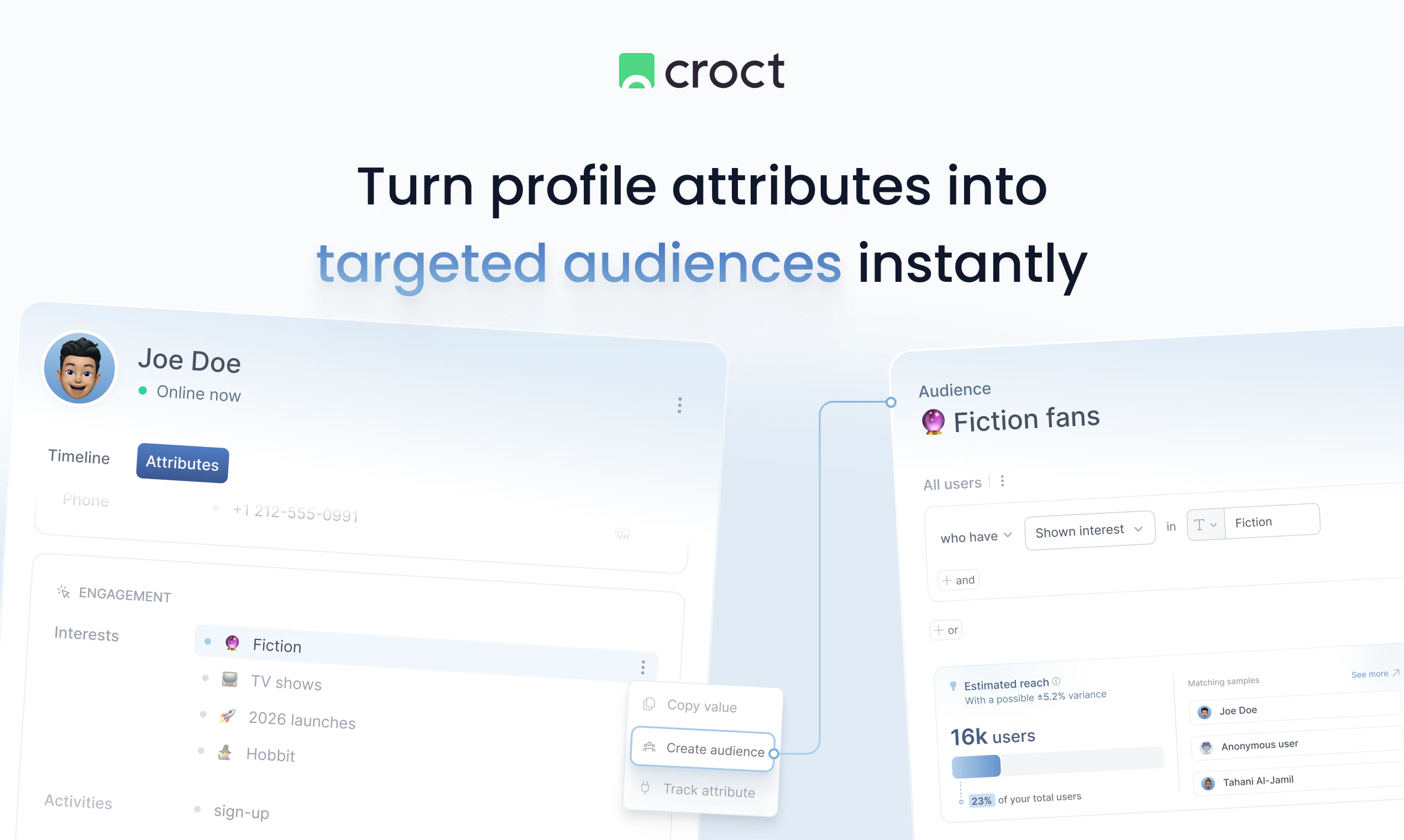
一句话介绍:Visitor profiles and timeline by Croct 通过构建用户行为时间线,将匿名与已识别访客数据无缝衔接,帮助产品、营销团队洞察点击背后的完整故事,从而优化网站个性化体验与转化率。
User Experience
A/B Testing
Data Visualization
用户画像
行为时间线
访客识别
数据关联
网站个性化
AB测试
实时跟踪
受众分群
SaaS工具
数据分析
用户评论摘要:用户赞赏匿名与已识别数据关联功能,询问跨设备时间线如何追踪流失点以及如何快速构建高效受众分群。团队回应称数据合并自动完成,并建议用户通过属性一键创建细分。部分用户认为产品将“事件”升华为“叙事”,有助于优化整体旅程而非单页面指标。
AI 锐评
Croct这次推出的“访客画像与时间线”功能,本质上是在解决一个古老却未被满足的痛点:数据孤岛。大多数分析工具能告诉你“用户做了什么”,但无法还原“用户为什么这么做”。Croct试图通过将匿名与已识别数据在登录瞬间自动合并,构建一条连续的时间线,来填补这一缺口。这确实是个聪明的切入点——特别是对跨设备、多会话场景下的B2B或电商网站而言,它能帮助团队识别出“用户在第二屏流失”这种隐藏的漏斗瓶颈。
但冷静来看,这并非颠覆性创新。客户数据平台(CDP)如Segment、mParticle早已具备身份解析和用户画像能力,而Croct的差异化在于“实时”和“轻量化”。它更像是一个面向中小团队的行动工具——用“一键分群”降低AB测试和个性化设置的复杂度,而非提供一个无所不包的BI系统。真正的问题在于:与其说用户需要“看时间线”,不如说他们需要“基于时间线做什么”。Croct目前给出的答案是“优化测试和个性化”,这很实用,但还不够数据驱动——比如能否自动检测异常路径并推荐优化方案?如果能从“展示数据”进化到“给出行动建议”,才更接近“uncover the story”的承诺。
此外,免费档从10k翻倍到20k月活用户,显然意在快速获客和验证PMF。但风险在于:低门槛也可能吸引大量“尝鲜型”用户,而这类用户对个性化场景的深度需求有限,容易造成留存率低。总体而言,这是一次精准的迭代,但要避免成为漂亮的“用户行为说明书”,而非真正的转化引擎。
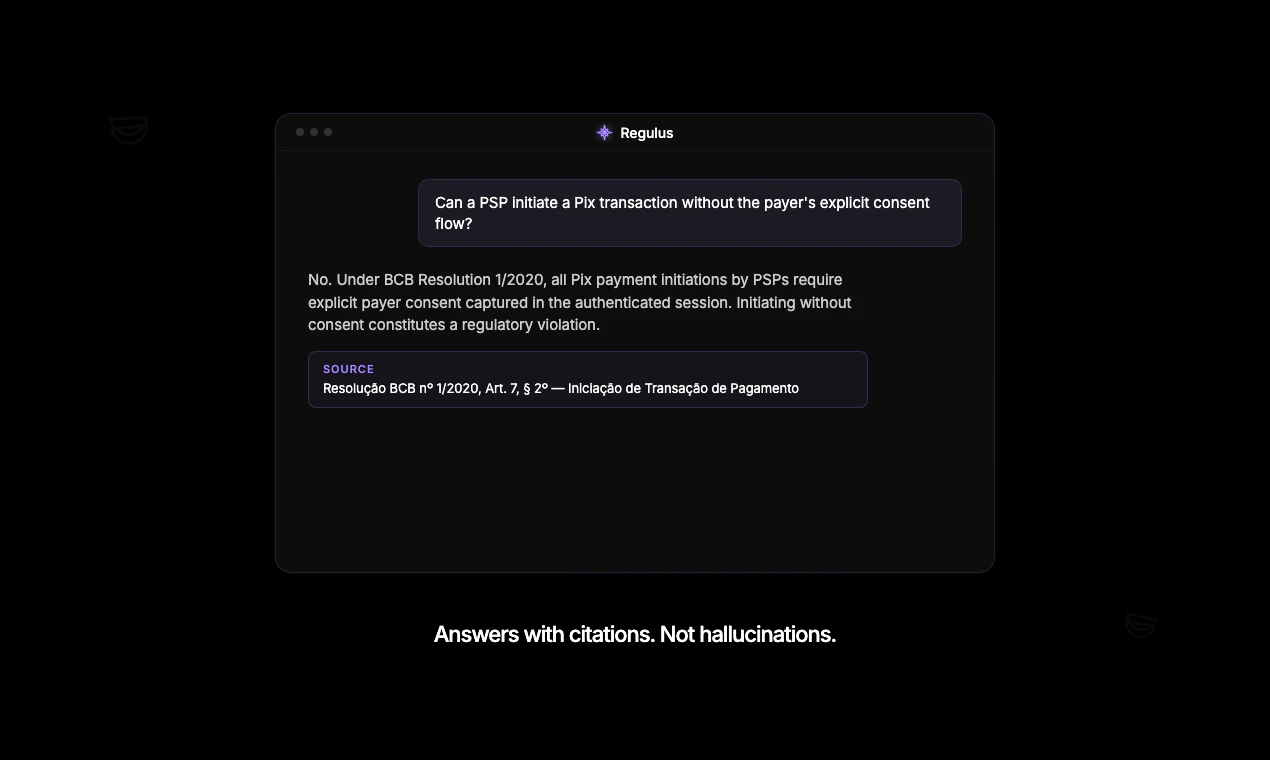
一句话介绍:Regulus是一款专精于巴西中央银行监管法规的AI聊天机器人,旨在为金融从业者提供精准、来源可查的法规解读,解决通用AI在金融监管问答中“胡编乱造”的痛点。
Fintech
Legal
Artificial Intelligence
AI法规助手
金融监管
巴西央行
巴西金融
Open Finance
Pix
合规问答
金融科技
小众垂类
垂直AI
用户评论摘要:用户反馈积极,认为产品在复杂监管环境中很有帮助。团队回应了感谢,并回答了关于API一致性的问题。有用户建议支持更多监管领域,也有用户借此机会推广自己的产品。核心关注点在于准确性和扩展性。
AI 锐评
Regulus的聪明之处在于它选了一个极其精准的“小切口”——巴西央行的Open Finance和Pix法规。这避免了通用大模型在高度本地化、专业化的金融监管领域“胡说八道”的通病,直击了合规人员、产品经理和开发者的刚性需求。115票的投票量和用户“帮助很大”的评价,验证了“垂直、专业、可溯源”策略的有效性。
但产品价值的核心不在于AI技术本身,而在于Cumbuca自身作为巴西支付牌照持有者的“局内人”身份。这意味着它拥有训练数据的独家获取、清洗和更新能力,这是任何通用AI公司都无法逾越的护城河。然而,风险同样明显:监管内容一旦涉及更广泛的金融领域(如信贷、证券、外汇),数据源的扩充和维护成本将指数级增长。
目前免费策略是聪明的获客手段,意在建立用户粘性和数据反馈闭环。但长期看,必须思考付费模式,例如按查询次数、按团队规模,或提供更深度的“解释+合规建议”增值服务。如果只是做一个“带来源的法规检索器”,其替代性太强。真正的价值在于能否从“问答工具”进化为“合规推理引擎”——比如自动审查产品功能是否符合最新通知,或对比不同监管文件间的矛盾点。
一句话总结:方向对了,切入点极好,但别满足于做一个“查法规的GPT”,否则天花板很低。
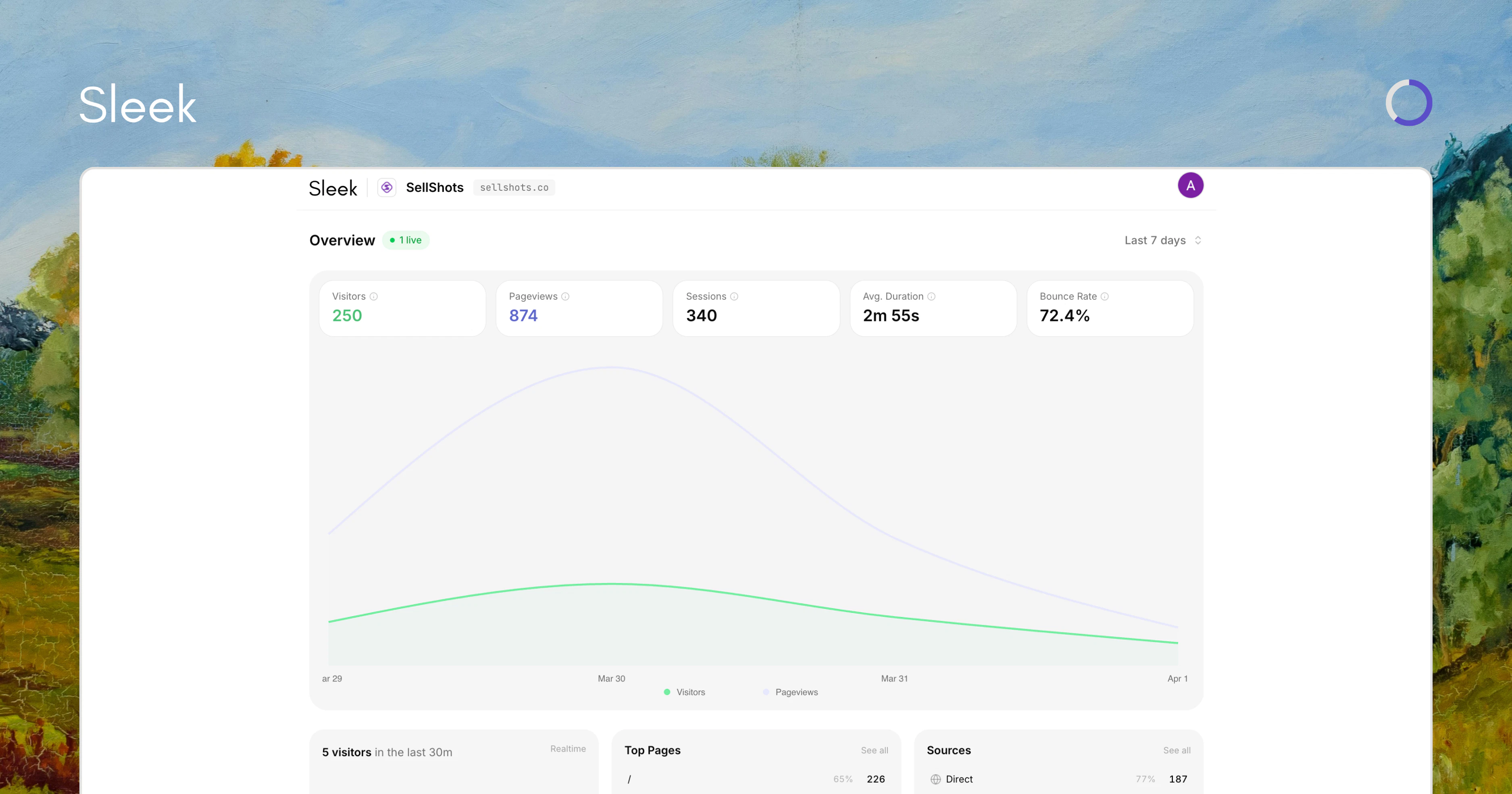
一句话介绍:Sleek Analytics是一款为移动场景设计的隐私优先网站分析工具,让创业者、创作者和代理机构能在手机上实时查看访客、来源和营收,无需打开电脑或浏览器。
Analytics
Marketing
Privacy
网站分析
隐私优先
无Cookie追踪
iOS应用
实时数据
移动端分析
独立开发者工具
内容创作者
替代Google Analytics
轻量级
用户评论摘要:用户称赞其iOS原生体验和实时性,疑问集中在:如何保证屏蔽追踪后的数据准确性;实时分析能否推送警报而非仅看仪表盘;是否支持非网页属性(如播客播放事件)的监控。开发者回应已提交含推送通知的新版本,并明确面向个人和代理机构。
AI 锐评
Sleek Analytics的巧妙之处不在于技术突破,而在于场景切分——它精准捕捉了一个被巨头忽视的“碎片化决策时刻”。当Google Analytics仍在用臃肿的界面和强制Cookie弹窗消耗用户耐心时,Sleek用“手机掏出来瞄一眼”替代了“打开电脑查报表”。这种从“被动查数”到“主动感知”的转变,才是它114张投票背后的真实需求。
但必须指出,它的价值天花板也很明显:第一,隐私优先与数据准确性之间存在固有矛盾,用户对屏蔽追踪后的数据失真担忧并非杞人忧天,这本质上是自选立场带来的能力折损;第二,产品功能尚停留在“展示”而非“洞察”——实时访客很酷,但把“谁在浏览”转化为“我应该做什么”才是分析工具真正的护城河。开发者虽已安排推送通知,但这个功能在同类工具中并不稀缺。
真正值得关注的是评论中提到的“非网页资产”场景。如果Sleek能跳出“网站分析”的固有标签,将无Cookie追踪能力延伸至播客、RSS、小程序乃至API调用等更广泛的数字化触点上,它或将从一个实用工具升级为新一代“去中心化受众感知平台”。否则,在Plausible、Fathom等同类产品的围攻下,它很可能只是“又一个好看但不中用”的替代品。
一句话介绍:Panels Store 是一个内嵌于知名漫画阅读器 Panels 的无 DRM 数字漫画商店,让读者能直接发现、购买并即时阅读,解决了“买与读分离”的体验割裂问题。
iOS
Comics & Graphic Novels
数字漫画商店
DRM-free
独立创作者
漫画阅读器
收入分成 80%
无排他性
即时阅读
文件下载
Web端
内容平台
用户评论摘要:用户主要关心两个问题:一是如何帮助创作者进行市场营销(@victorbaro 问“除了商店,如何营销作品”);二是 DRM-free 承诺的可靠性(@victorbaro 问“若商店关闭,图书馆如何保证?是否有明确保底方案?”。另有一用户借机推广自己产品,无实质反馈。
AI 锐评
Panels Store 解决了一个真实但窄众的痛点:给那些已经在用 Panels 看漫画的“高净值”读者补上了购买闭环。其核心卖点“80% 分成 + 无 DRM + 无排他性”放在数字内容领域很有吸引力,尤其是对受平台压榨的独立创作者和小出版商。这不是一个颠覆性的创新,更像是对现有生态(如 Gumroad、GlobalComix)的一次场景化整合——把商店搬到读者面前。
然而,它面临两个致命挑战。第一,获客与留存。Panels 本身有数十万用户,但其中有多少是愿意付费购买独立漫画的?目前商店更像是为已有忠实粉丝的创作者提供了一个后端,而非能主动“造浪”的流量引擎。用户问“如何帮创作者营销”,暴露了团队在分发和推广能力上的短板。第二,信任与规模。DRM-free 是双刃剑,它讨好核心用户(数字极客、版权敏感者),但很难吸引到大出版商(如 DC、Marvel)入局——大厂依赖 DRM 控制发行周期和二次销售。而若无大厂内容,商店就是“好用的独立漫画据点”,天花板明显。
最值得肯定的,是团队对“所有权”的坚持与透明度。当用户问及“商店倒闭怎么办”,创始人若敢答“你掌控文件,我无法销毁”,这本身就是比无数承诺更硬的信用资产。但现实是,仅靠情怀和分成比例,无法支撑起一个高增长的 marketplace。Panels Store 要证明的不只是“能卖”,更是“能让读者持续买到好东西”。否则,它只是 Panels 的一个扩展功能,而非独立生意。
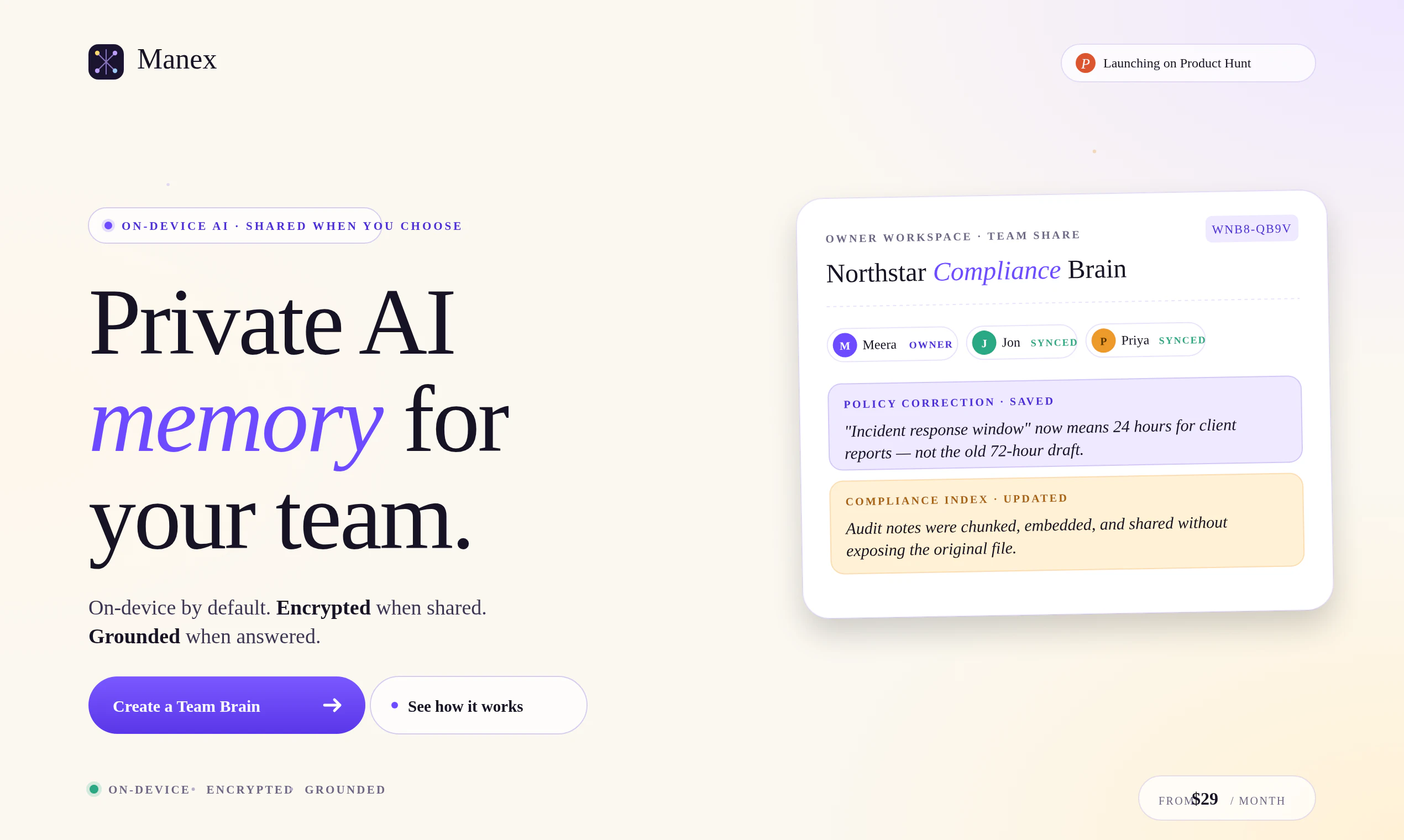
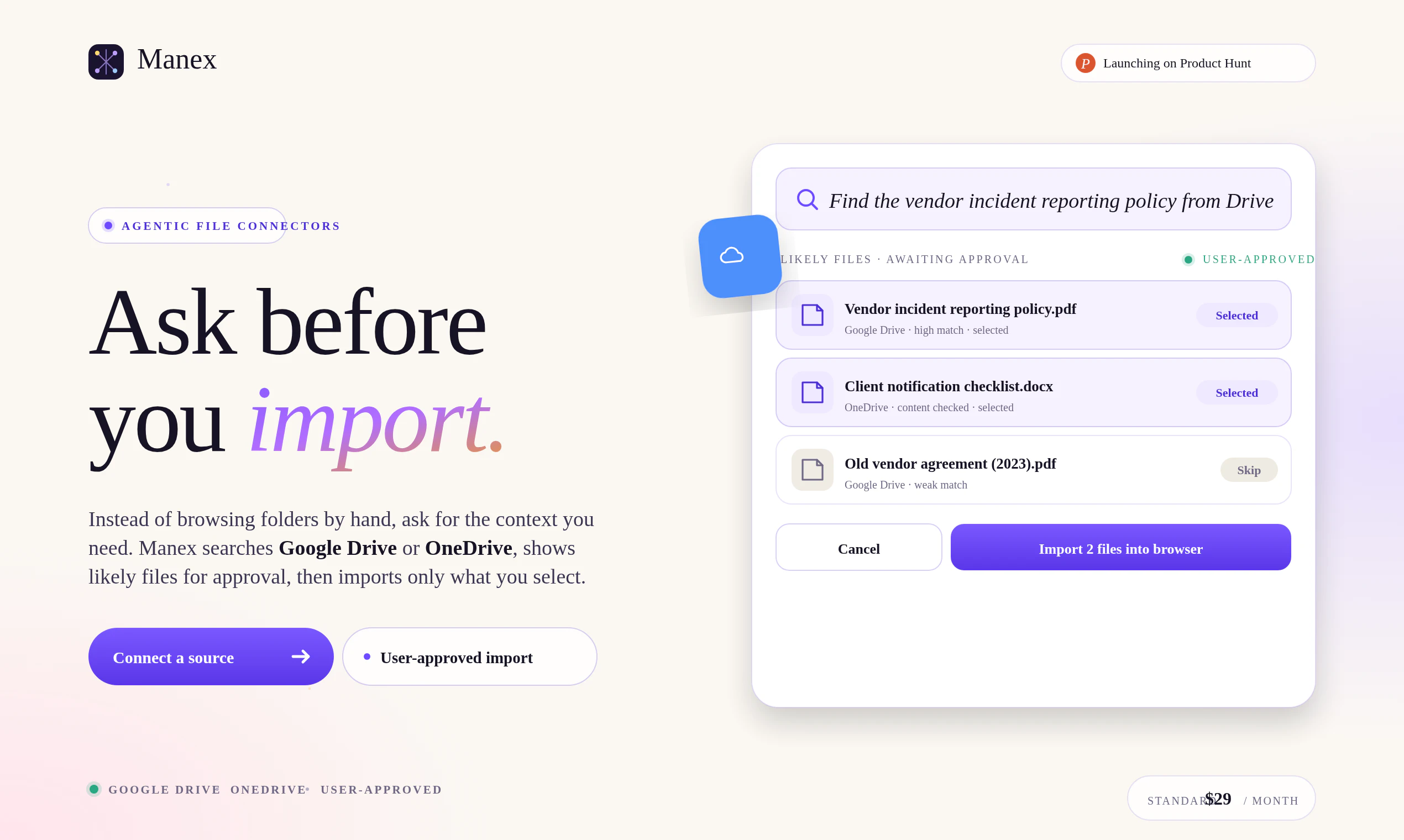
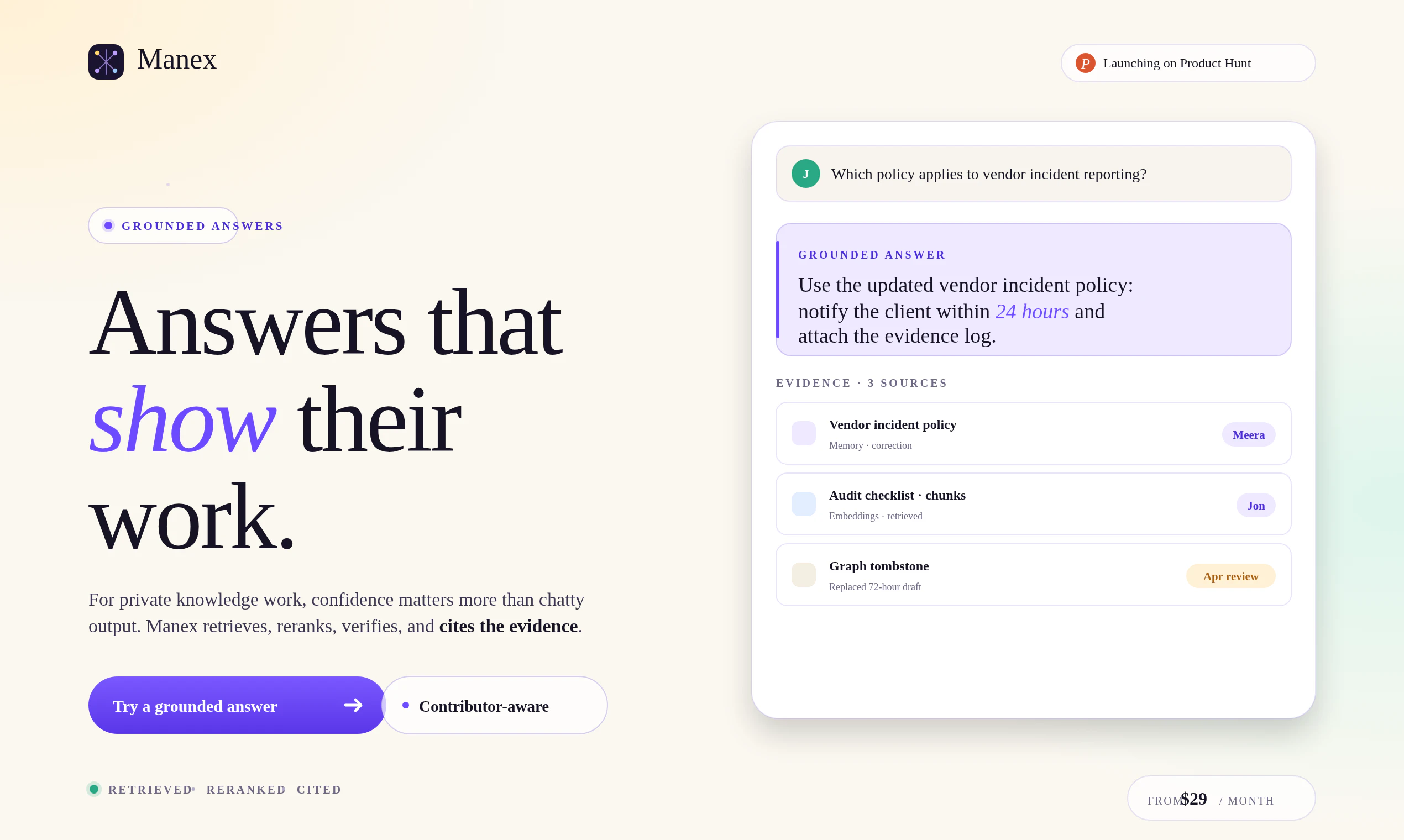
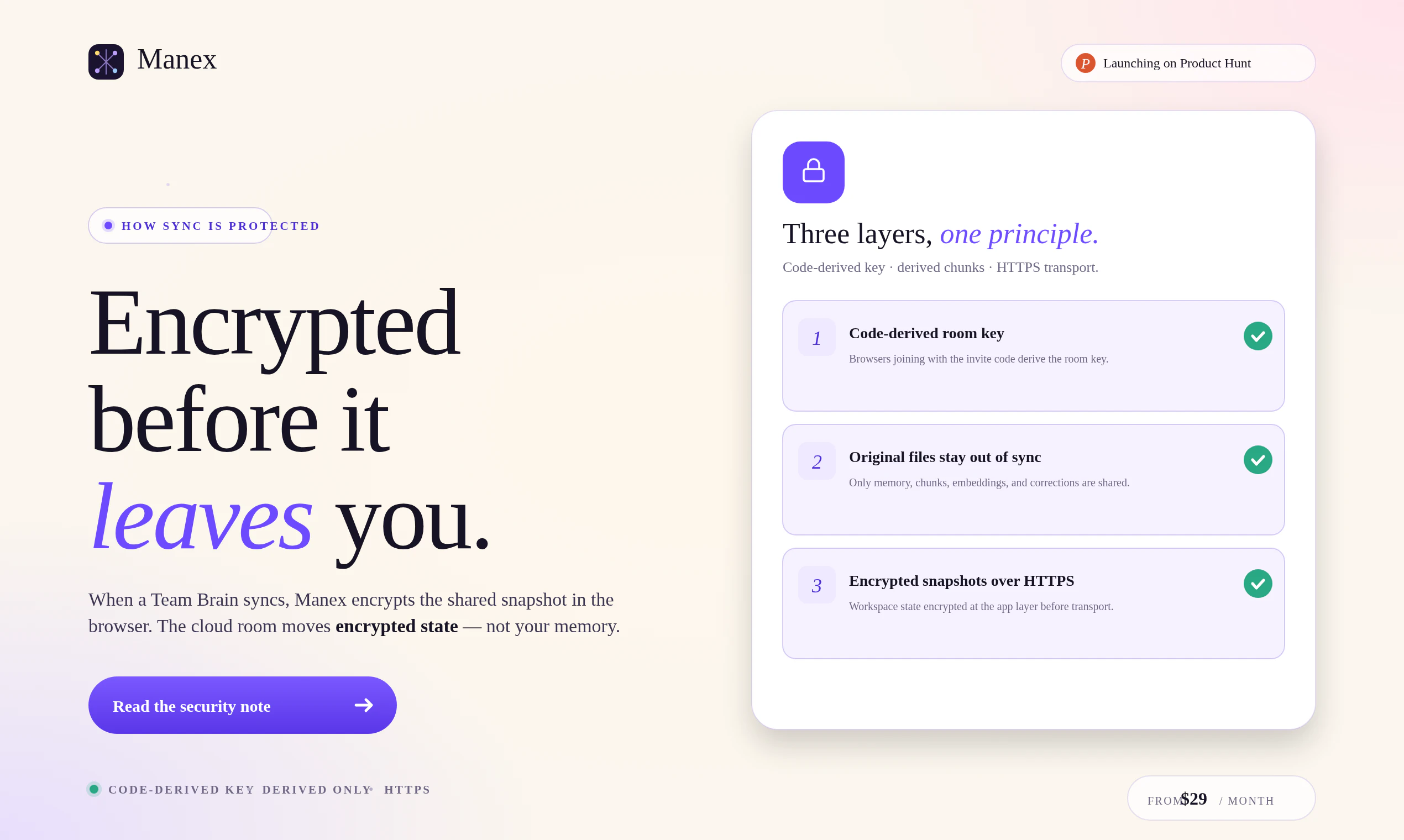
一句话介绍:Manex是一款基于本地AI的团队知识记忆工具,通过将文档、问答和专家修正转化为可搜索的私有记忆,解决团队“丢失上下文”的痛点,尤其适用于合规、研究、客户文件等敏感场景。
Productivity
SaaS
Artificial Intelligence
AI记忆管理
本地AI
团队知识库
RAG增强
私有化部署
文档问答
上下文保存
团队协作
无席位定价
用户评论摘要:用户关注本地运行上限与浏览器性能瓶颈,建议开发桌面端或CLI;高度认可“修正记忆”价值,认为其能捕获专家校正而非原始答案,现有回应称区别对待权重;有用户询问从3-5人团队小规模启动的实践路径;也有用户关心是否属于个人RAG。
AI 锐评
Manex切中了一个真实但细微的痛点——团队知识管理里“正确的上下文”往往比原始文档更值钱。它没有陷入大模型军备竞赛,而是聪明地聚焦于“修正记忆”和本地优先,这直击合规要求高的toB场景(法律、金融、医疗)的命门。但问题同样明显:浏览器本地执行严重受限于设备算力和存储,用户吐槽的“浏览器窒息”风险并非技术边角料,而是核心体验卡点。目前“渐进式索引”和“可恢复摄入”的回应更像是画饼,缺乏具体技术路线和性能基准。此外,团队版29美元/月的无席位定价确实有冲击力,但面对Notion AI、Glean等成熟竞品,Manex的“记忆层”是否真能形成差异化壁垒,取决于其AI对专家修正的权重算法和跨文档推理的准确性——而非仅仅一个概念。更致命的是,产品目前仍像是一个强化版个人RAG,缺乏企业级权限管理、版本控制和API生态,这会让它在决策采购时被IT部门直接否决。综合来看,Manex适合作为小团队或个人的知识增强工具,但距离“团队共享大脑”的愿景,还需要在工程稳健性和商业化完整度上补课。
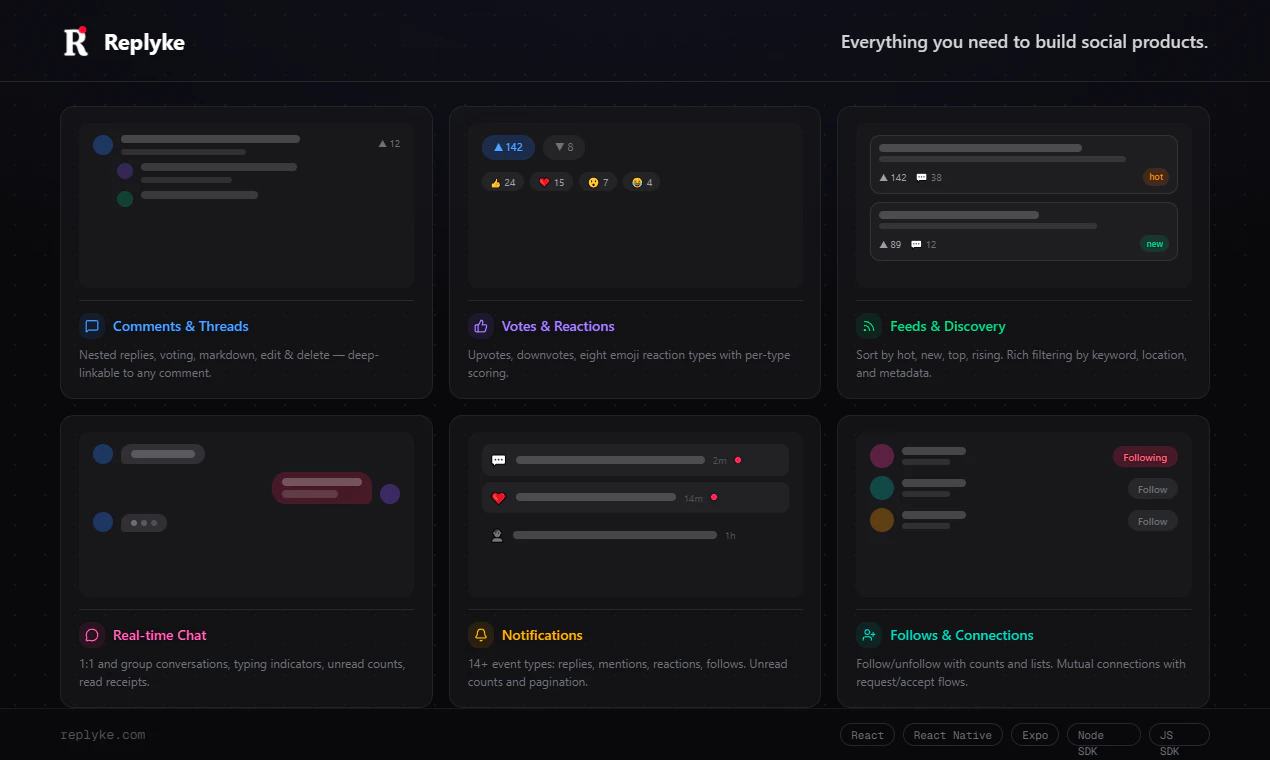
一句话介绍:Replyke V7为开发者提供预构建的用户交互基础设施(评论、聊天、空间、通知等),通过SDK快速集成,解决从零搭建社交功能、用户生成内容系统的高重复性开发痛点。
API
Developer Tools
SDK
用户交互基础设施
SaaS服务
社交SDK
评论系统
聊天功能
社区空间
用户生成内容(UGC)
应用程序开发工具
内容审核
多平台支持
用户评论摘要:用户高度认可其作为“用户交互即服务”的定位,主要关注点在于:1. 如何实现反垃圾、自动化审核与速率限制;2. 需要更完善的入门示例项目和AI Agent技能集成;3. 技术架构追问(如嵌入生成时机、WebSocket底层方案)。
AI 锐评
Replyke V7的真正价值并非“又一套评论SDK”,而是聪明地将“用户生成内容”拆解为一套可组合、多层级的基础设施。它精准击中了所有社交型、社区型或用户驱动型应用的开发痛点:当核心业务逻辑与社交交互纠缠不清时,开发团队往往陷入“重新造轮子”的泥潭。V7版本引入的Spaces(子社区)和Chat(全方位消息系统)是关键跃迁,它不再限于“文章下挂个评论区”,而是提供了一个类似“Discord频道+子Reddit”的通用权限与内容隔离框架。这种架构上的前瞻性,使得Replyke有望成为构建复杂UGC应用(从电商评价到垂直社交)的“乐高底板”。
然而,必须清醒看到其风险。作为一家单人维护的底层基础设施工具,稳定性和长期迭代能力存疑;对独立开发者友好的“一小时集成”承诺,在面对企业级高并发、自定义审核策略和私有化部署需求时,可能暴露出性能瓶颈和灵活性不足。其“项目级+空间级”的二级审核机制虽然巧妙,但将反垃圾责任通过Webhook甩回给开发者,实际上并未解决AI审核的落地复杂度。真正具有垄断潜力的竞争对手(如Firebase相关生态)一旦下场,其技术壁垒并不高。Replyke当前最聪明的策略,是牢牢抓住独立开发者与中小团队,通过“开箱即用+良好的开发者体验”建立口碑护城河,而非硬碰SaaS巨头。
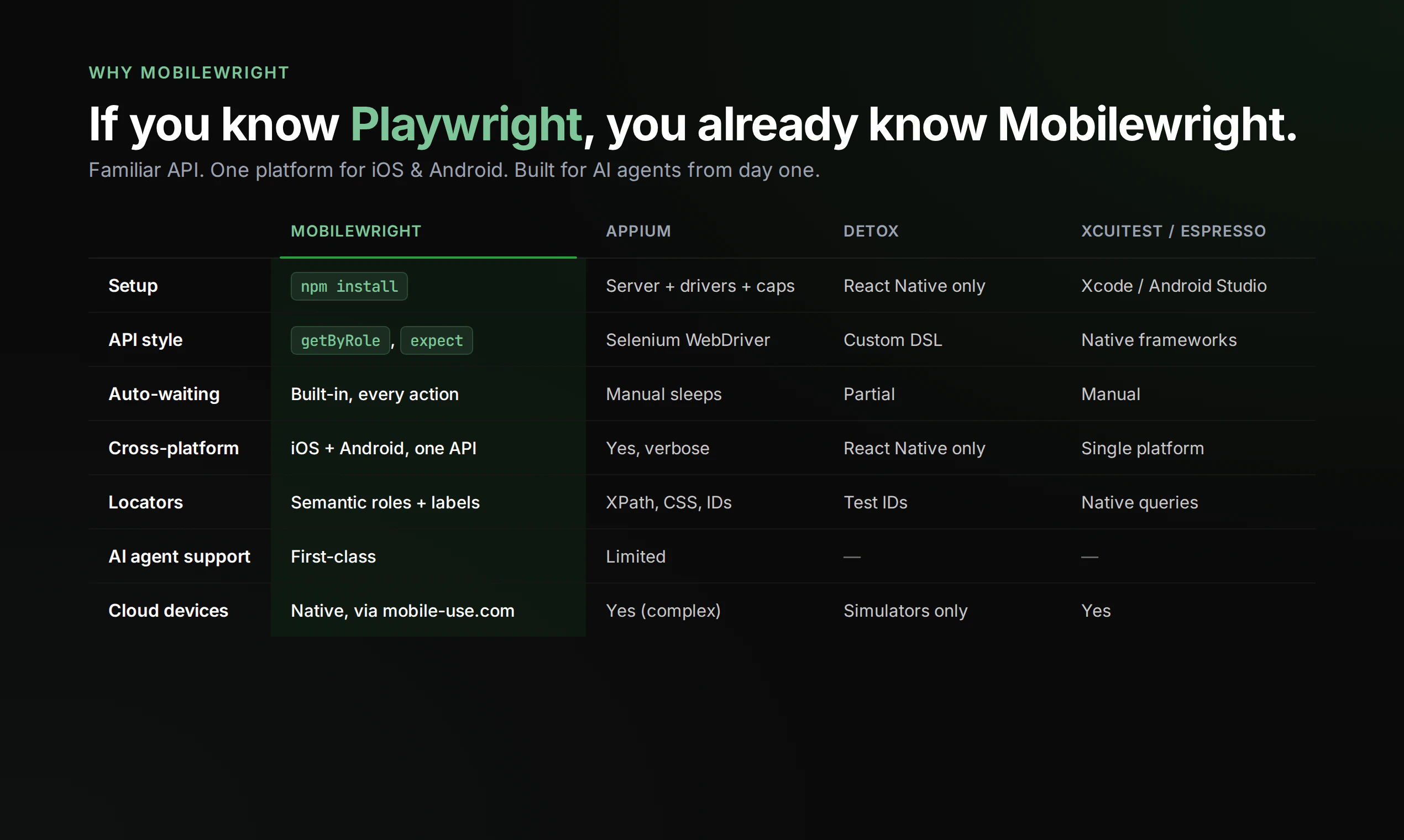
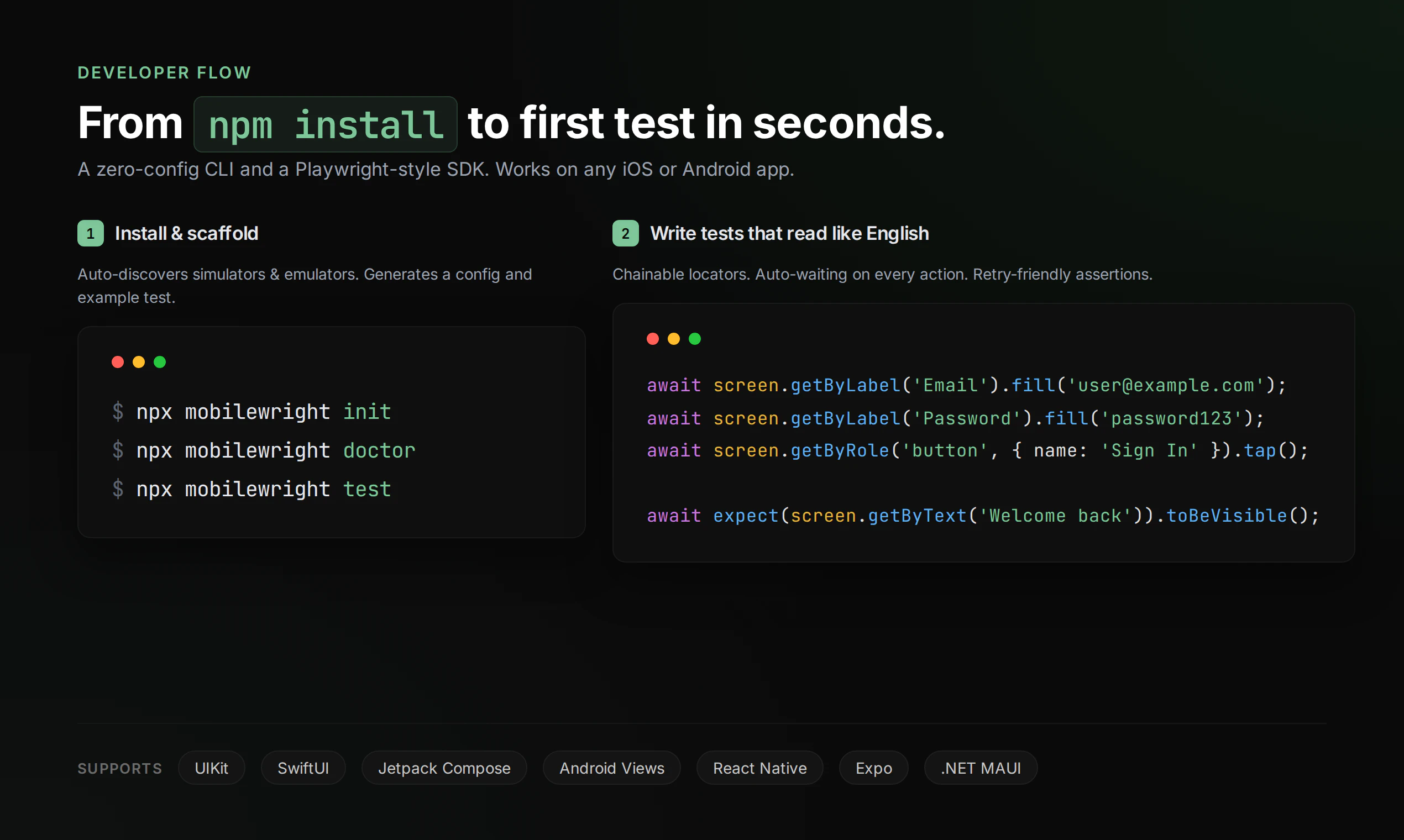
一句话介绍:Mobilewright 是一款基于 Playwright 语法、免费开源的移动端自动化测试框架,让开发者能用统一API在iOS和Android的真机、模拟器上编写和执行测试,解决跨平台测试脚本维护繁琐、配置复杂、AI Agent集成难的痛点。
Open Source
Developer Tools
Artificial Intelligence
移动端自动化测试
Playwright框架
跨平台测试
开源测试工具
AI Agent
无配置CLI
链式定位
自动等待
真机模拟
开发者工具
用户评论摘要:用户普遍认可其易用性和跨平台优势,认为“配置简单、执行流畅”。部分用户关注与Maestro的差异,尤其Maestro对真机支持不佳。有开发者点赞“无需维护两套测试”,并好奇框架如何优雅处理平台特有的手势识别和时间同步问题。
AI 锐评
Mobilewright的定位精准,但并非颠覆式创新。它本质上是用Playwright的语法和理念,重写了移动端测试引擎,核心价值在于“降低门槛”和“拥抱AI”。一方面,它继承了Playwright的确定性、自动等待和链式API,让原本晦涩的iOS/Android测试代码更易读、可维护,这对于手动编写脚本的开发者是实在的降本增效;另一方面,它为零配置CLI和统一API的设计,直接服务于AI Agent——当Agent能直接调用一套接口操作两大平台设备时,自动化从“写脚本”进化为“自然语言指令执行”的路径才被真正打通。
但风险也很明显。第一,生态壁垒:Playwright在Web端如日中天,但移动端早已有Appium、Espresso、XCTest等成熟方案,支持AI Agent不等于能处理好原生手势、通知、后台进程等真实场景的稳定性。第二,社区规模尚小(44票、数条评论),缺乏大规模企业级验证,用户提到的“真机手势识别”和“时序问题”正是Appium都头疼的深水区。第三,与Maestro的直接竞争:Maestro同样主打跨平台、简洁配置,若Maestro加速优化真机支持,Mobilewright的“Playwright血统”光环将迅速褪去。
一句话总结:这是一个“立意大于当下”的产品——它最聪明的不是解决移动测试,而是让移动测试“被AI理解”。但如果不能快速打磨出几个标杆案例,证明其在复杂场景下比Maestro、Appium更稳、更快,就很容易沦为又一个精致的玩具。
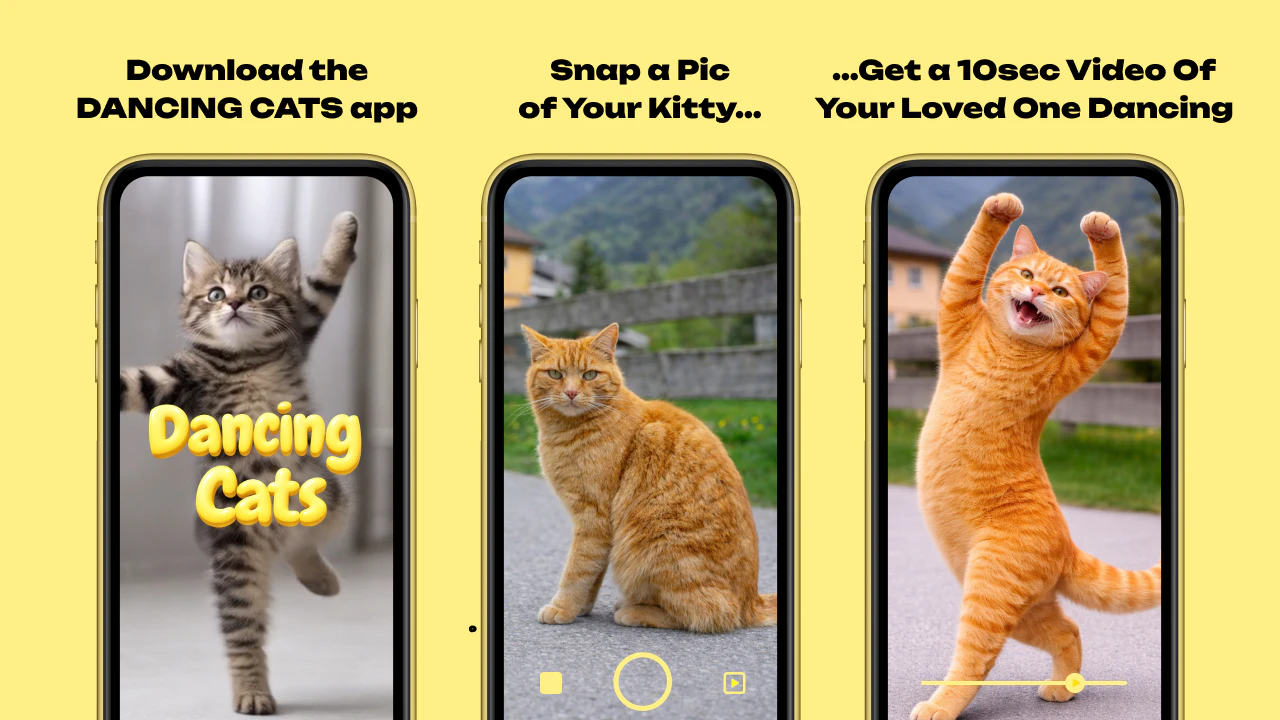
一句话介绍:DANCING CATS App 通过AI将用户拍摄的猫咪静态照片一键转化为10秒趣味舞蹈视频,满足宠物主人在社交分享场景下“让萌宠动起来”的娱乐需求。
Pets
Photography
Artificial Intelligence
AI视频生成
宠物娱乐
猫咪舞蹈
照片转视频
社交分享
搞笑工具
UGC创作
移动应用
用户评论摘要:用户整体反响积极,认为“无缝且搞笑”。主要询问视频生成时长(回复称约1-3分钟)、能否自定义背景(开发者已记录建议)。另有用户反馈该功能同样适用于熊等宠物。
AI 锐评
DANCING CATS App精准切中了宠物经济中“静态照片审美疲劳”的细分痛点。其核心价值不在于技术突破,而在于将成熟的AI动作迁移算法包装成一个“无门槛、高娱乐性”的社交货币生产工具。从30余票的成绩看,该产品在Product Hunt上的反响尚可,但远未到爆款级别。
冷静分析,这款产品存在明显的天花板:第一,功能单一且同质化严重——让宠物“跳舞”的App早已有之(如早年的My Talking Tom系列或各类宠物滤镜),仅靠10种舞蹈风格难以形成长期黏性。第二,用户评论中“自定义背景”的需求恰恰暴露了当前版本的粗糙:一个连背景都无法替换的AI视频工具,本质上只是将猫咪抠图后叠加到预设动画上,技术含量不高。第三,产品最终形态是10秒短视频,这意味着它更接近一个“一次性乐子生成器”,而非用户会反复使用的工具——用户为家里每只猫拍完一张照片后,使用意愿将断崖式下跌。
真正有价值的AI宠物工具,应该向“永生化互动”或“个性化定制”进化,比如让用户通过多张照片训练专属宠物模型,实现持续生成不同场景的动态内容。目前这款产品更像是一次AI浪潮下的“轻量试水”,适合作为社交裂变的彩蛋,但很难支撑独立App的商业变现。开发者若想突破,必须尽快加入背景替换、多宠物同框、甚至简单的剧情定制功能,否则热度褪去后,用户只会留下一句“挺搞笑”然后遗忘。
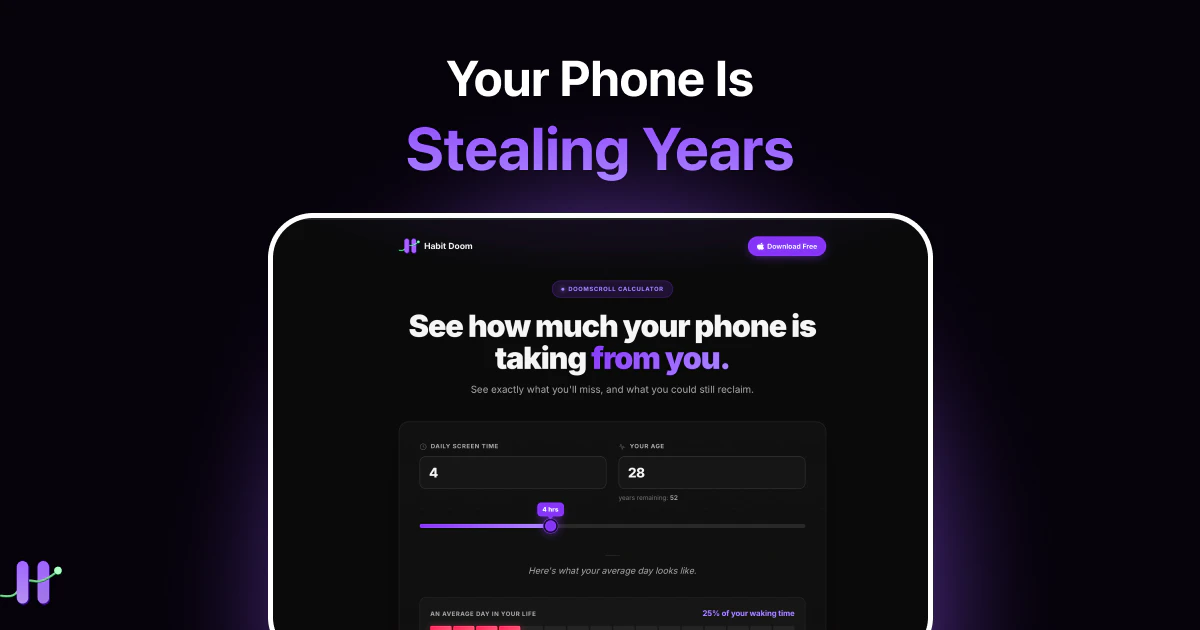
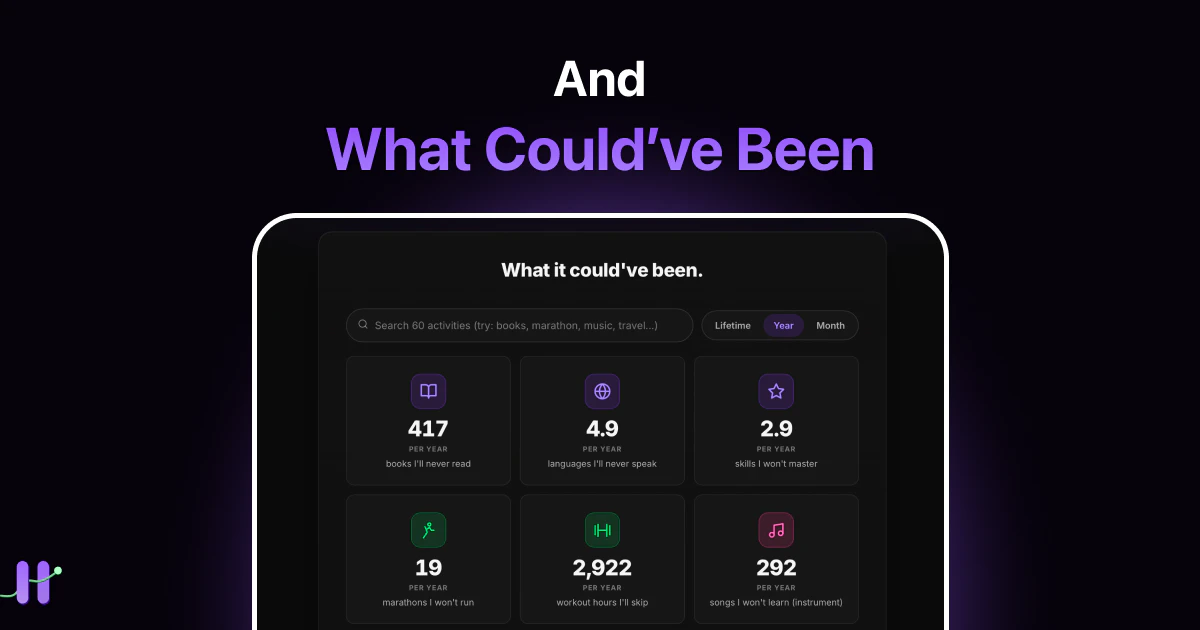
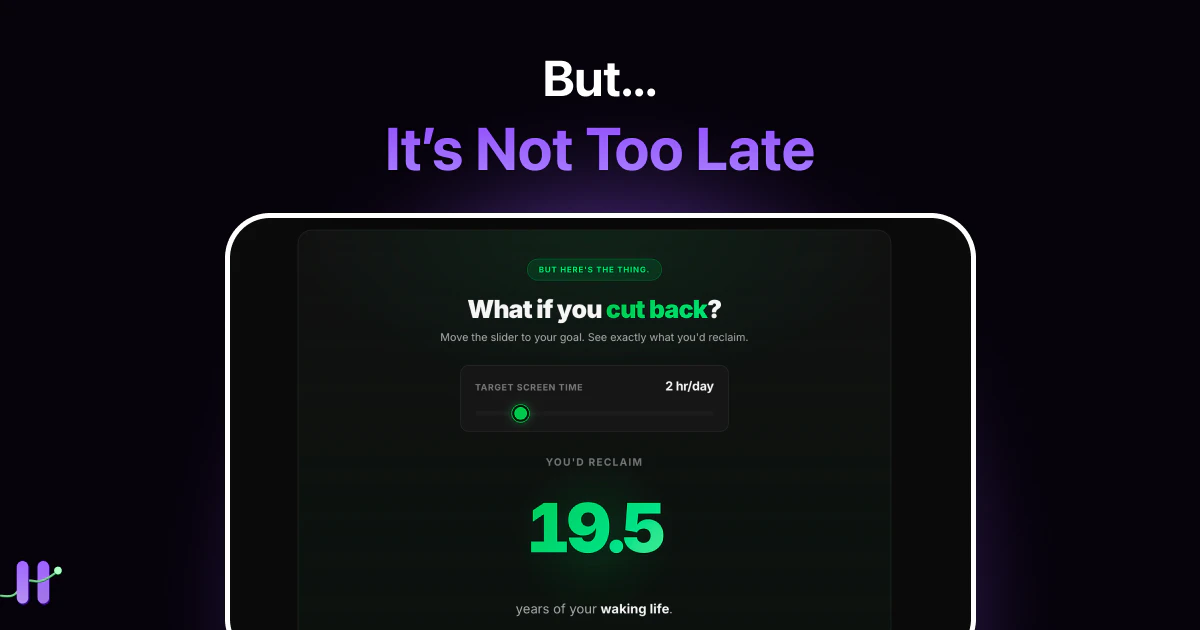
一句话介绍:Doomscroll Calculator 通过输入每日屏幕使用时间和年龄,将刷手机导致的“生命流失”转化为错过的具体人生体验(如书籍、马拉松、约会夜等),用可感知的损失唤醒用户减少手机依赖。
Productivity
Time Tracking
Health
屏幕时间计算
生命浪费可视化
习惯改变
行为设计
数字戒断
生产力工具
自我量化
健康科技
反思工具
互动计算器
用户评论摘要:用户被具体数字(如30.7年、612次约会夜)震撼,但反馈指出:短暂愧疚后行为难持续。有建议加入AI层分析使用模式、生成个性化减少计划并每日提醒;也有疑问是否区分“消磨”与“生产性”屏幕时间,作者回应聚焦“手机占用的生命总量”。
AI 锐评
Doomscroll Calculator 的真正价值不在于计算,而在于“翻译”——把抽象的“10小时”转译成“25,672本书”“1,198场马拉松”。这种具象化冲击远比“少玩手机”的劝诫更具认知穿透力。然而,产品的硬伤同样明显:它本质上是一次性震撼工具,正如用户评论中感叹的“愧疚感10分钟就消失了”。
从行为设计角度看,它完成了“问题诊断”却缺少“治疗路径”。评论中建议的AI分析+个性化计划+日常提醒,恰恰是当前版本的最大缺位——吓人一跳之后,用户只能靠意志力。更致命的陷阱是:这种“生命的数学魔法”可能反向刺激炫耀性自虐(“我30.7年,你才20?”),把戒断变成比赛。
产品真正的机会在于把“计算器”进化为“系统”:从单次计算变成持续监测,从静态数字变成动态趋势,从“你失去什么”延伸到“你通过减少屏幕时间实际获得了什么”。目前“希望半页”的滑块只展示假设性收益,而缺少真实反馈闭环——如果用户今天少用1小时,产品能立即换算成“多读3章《百年孤独》”吗?这才是从“认知觉醒”迈向“行为改变”的工程级挑战。
一句话评价:优秀的警觉性开关,但还没变成改变引擎。
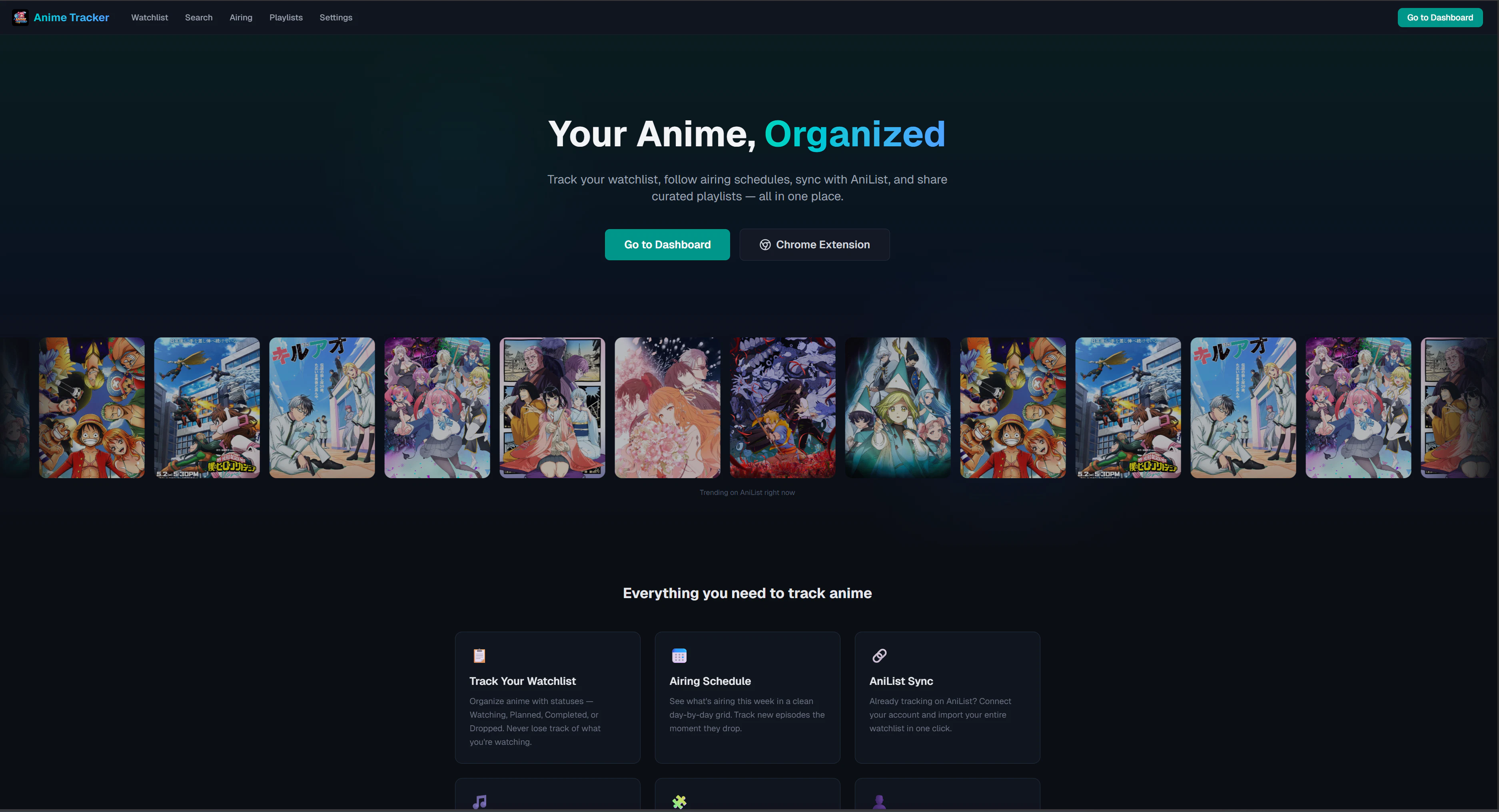
一句话介绍:Anime Tracker 是一款集智能推荐、好友互动、续集提醒于一体的免费动漫追踪工具,解决动漫迷在多平台间手动追踪、错过续集更新、缺乏社交分享与个性化推荐的核心痛点。
Chrome Extensions
Entertainment
Social Networking
动漫追踪
智能推荐
续集提醒
社交分享
Chrome 扩展
AniList导入
免费工具
动漫管理
好友互动
二次元社区
用户评论摘要:用户 s_am_0202 质疑:为何不直接关注社交媒体获取续集提醒、用 AI 聊天获得推荐?开发者借评论征集功能建议,表示投票最高功能将在本周实现。
AI 锐评
Anime Tracker 的定位精准,切中了动漫追踪领域长期存在的体验割裂:MAL 臃肿陈旧、AniList 缺乏主动通知、社交元素几乎为零。产品通过“智能推荐+朋友互荐+续集提醒”三位一体,试图把被动记录转为主动服务,这一思路比传统工具更贴近现代用户对“推”服务的依赖。
但其真正护城河不在于功能堆砌,而在于“免费+无功能限制”的承诺。在多数同类产品靠收费解锁功能或植入广告时,Anime Tracker 敢以“卖皮肤”作为唯一变现手段,倒逼产品必须靠体验和社区黏性留住用户。这是一种高风险策略——如果用户增长不够快、活跃度不够高,皮肤销售很难支撑长期运营。
从评论看,用户 s_am_0202 的疑问一针见血:为什么不用通用工具替代?这也暴露出产品最大的弱点——数据壁垒。无论是 AI 推荐还是续集提醒,都需要足够庞大且活跃的数据库支撑。AniList 导入虽然解决了冷启动问题,但后续的推荐逻辑是否真能优于用户自己去 ChatGPT 描述心情得到的答案?续集提醒能否比 Twitter 关注官方账号更及时?如果只是“稍微好一点点”,用户没有迁移动力。
此外,“邀请朋友互推”的社交功能看起来很巧妙,实则依赖网络效应——孤岛用户无法激活该功能。这也意味着早期用户很可能只会把它当纯追踪器用,而纯追踪器的替代者太多了。
总的来说,这是一个小而美的诚意之作,但在成为“必选产品”之前,还需要证明两点:推荐算法的个性化深度,以及续集提醒的时效性。建议优先强化推荐引擎的“可解释性”——告诉用户“为什么推荐这部”,这比单纯说“智能”更有说服力。如果能把续集提醒做成全平台的推送系统,无需依赖浏览器扩展,才是真杀手锏。
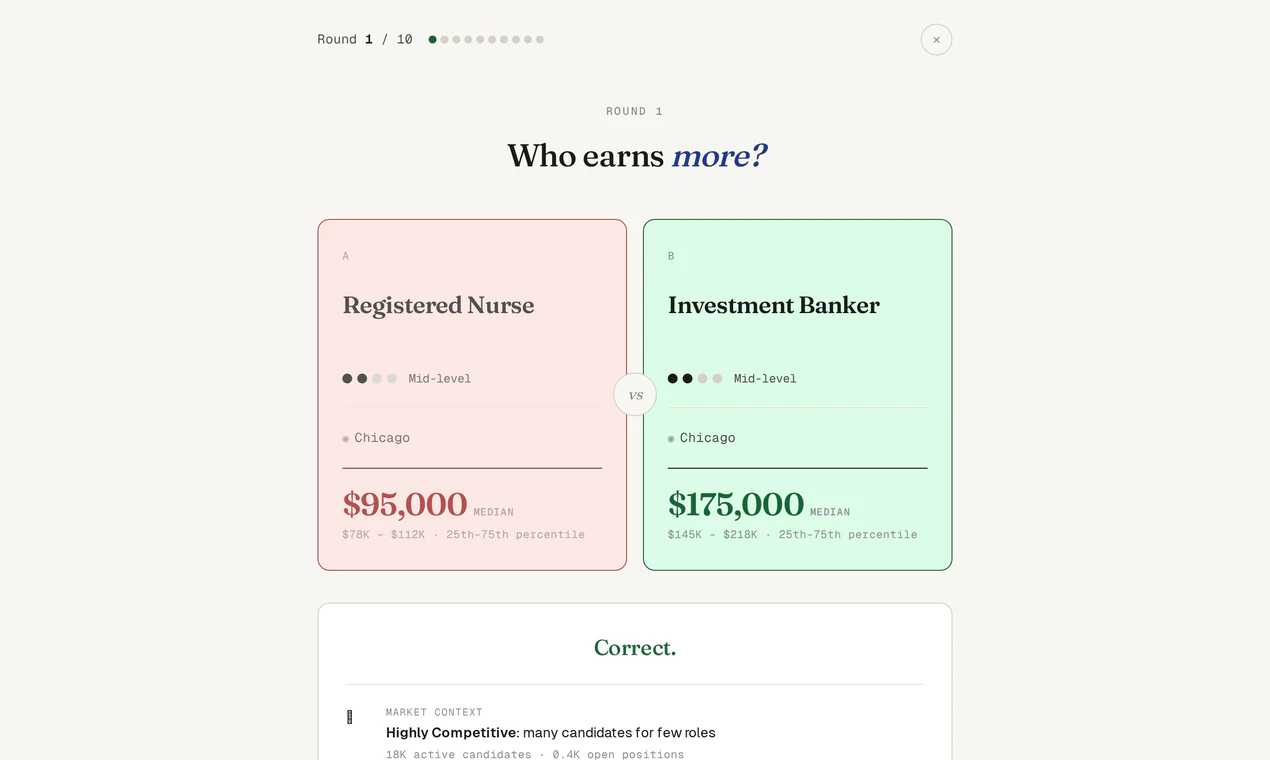
一句话介绍:SalaryDuel是一款基于美国真实薪资数据的每日猜谜游戏,通过角色薪资对比校准用户的市场薪资认知,适合求职者、HR或猎头在碎片时间中检验直觉并获取行业洞察。
Web App
Free Games
Data & Analytics
薪资猜谜游戏
美国薪资数据
数据校准
市场薪资认知
求职工具
HR洞察
每日挑战
无注册应用
行业对比
数据驱动
用户评论摘要:用户反馈游戏出乎意料地考验直觉,部分薪资对比令人惊讶(5赞);开发者自述该游戏灵感来自公司实时薪资数据的副产品,并询问是否应加入公开排行榜(4赞);另有评论指出跨角色和行业的薪资差距常超预期,适合求职参考(3赞)。
AI 锐评
SalaryDuel的巧妙之处在于将枯燥的薪资数据库“包装”成游戏——但这恰恰也是它的双刃剑。从产品本质看,它并非追求娱乐性的传统游戏,而是一个“认知校准工具”:通过每日10轮猜谜,让用户反思自己对劳动力市场的隐性偏见,比如“程序员一定比HR高?”这种直觉往往被实际数据打脸。评论中开发者提出的“是否加排行榜”很关键:若加入公开榜单,产品会滑向社交竞争,偏离其核心价值(个人认知训练);若保持纯私密,则缺乏粘性。当前18票的数据说明它仍在小众圈层发酵,真正的威胁在于数据更新频率(每月一次)和角色覆盖范围(仅7城)。一旦用户习惯某类对比,挑战性会迅速衰减。更值得思考的是:它能否在“游戏”与“工具”之间找到平衡?比如引入用户自定义角色对比(输入自己的职位和城市)生成个人校准报告,这比单纯猜谜更具长期价值。否则,它终究是那个“有趣的副产品”,而非独立的产品。
一句话介绍:Highlyt 是一款将散落在不同书籍和PDF中的高亮笔记,通过语义分类与跨文档链接转化为个人知识图谱的工具,解决深度阅读者“记了却用不上”的痛点。
Productivity
Writing
Artificial Intelligence
知识图谱
高亮管理
跨文档链接
AI辅助连接
阅读笔记
深度阅读
语义分析
个人知识管理
Chrome扩展
用户评论摘要:目前仅有一条用户评论(即开发者自述),正面阐释产品动机和功能,暂无其他用户反馈。评论中未出现具体问题或改进建议,需后续观察真实用户使用体验。
AI 锐评
Highlyt 切中了知识工作者一个真实的软肋:收藏如山,调用如抽丝。它聪明地跳出了“更好用的笔记工具”这个红海,转而解决“连接”这个更深层的认知难题。给高亮赋予“支持/反驳/扩展”等语义标签,相当于为思想搭了有向路径,比简单的标签或文件夹逻辑高出不止一个维度。AI 自动推荐潜在关联、人工确认后纳入图谱的设计,是在“效率”和“控制感”之间取了一个不错的平衡,避免了 AI 替你思考的常见陷阱。但18票的冷启动数据也暗示了它的风险:门槛太高。普通读者只需要记住一句话,而 Highlyt 要求你为每段笔记判断“它属于什么逻辑类型”——这种元认知负担,对大多数人可能过重。长远看,它更适合研究者或知识密度极高的资深写作者,而非普通阅读者。此外,图谱越大越依赖初始节点质量,如果早期输入稀疏,AI 推荐的连接大概率沦为鸡肋。它现在最缺的不是功能,而是一套能让普通用户“无痛养成习惯”的引导机制。否则,再精妙的知识图谱,也只会在收藏夹里继续睡觉。
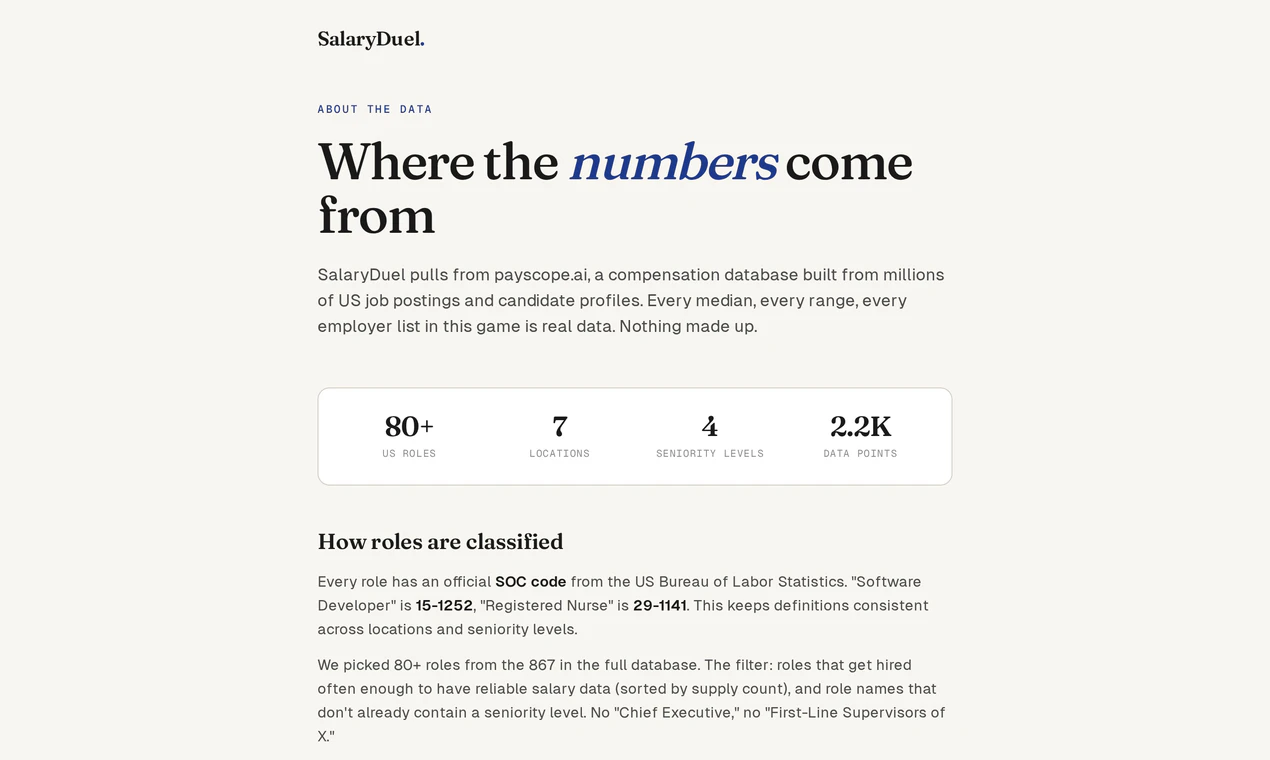
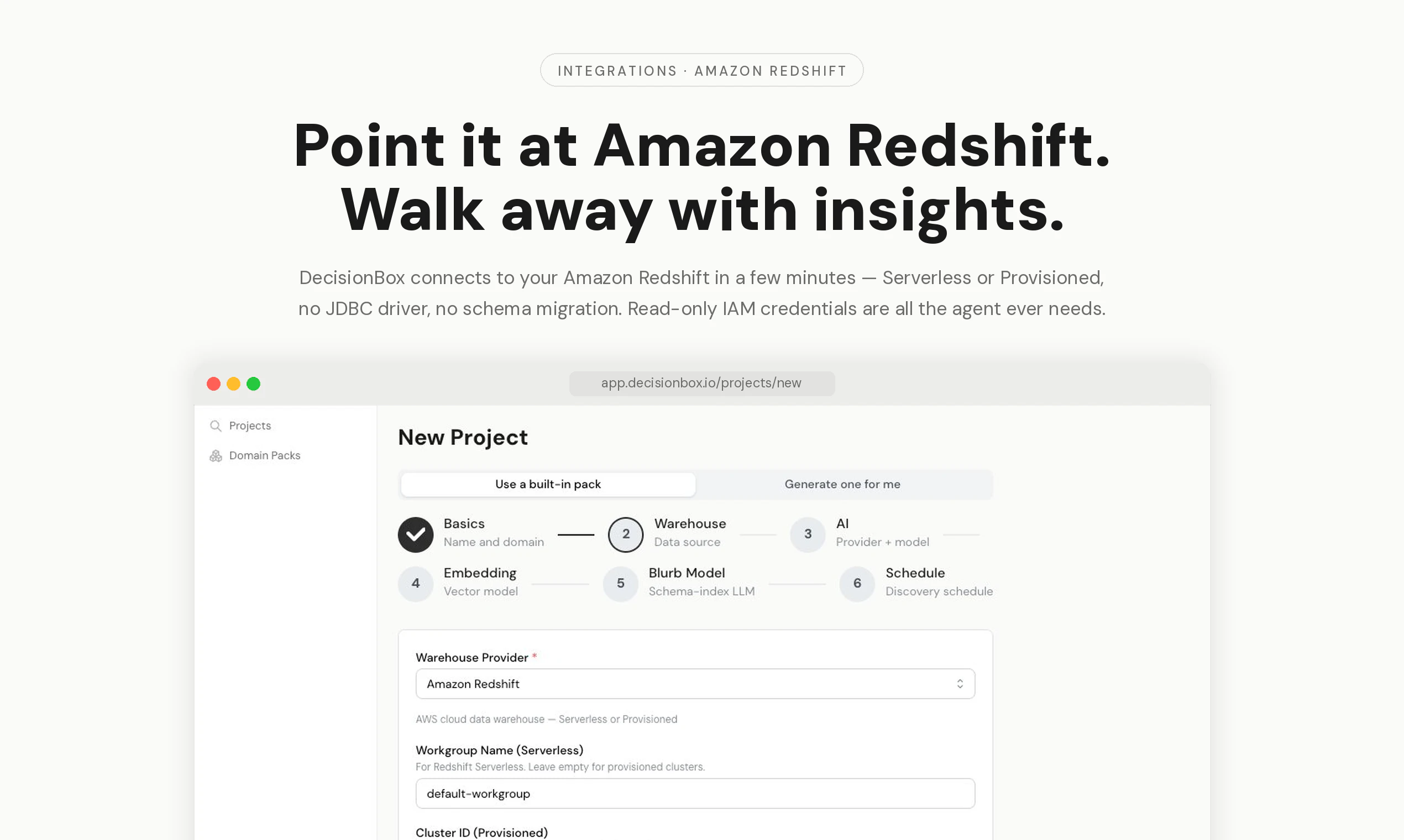
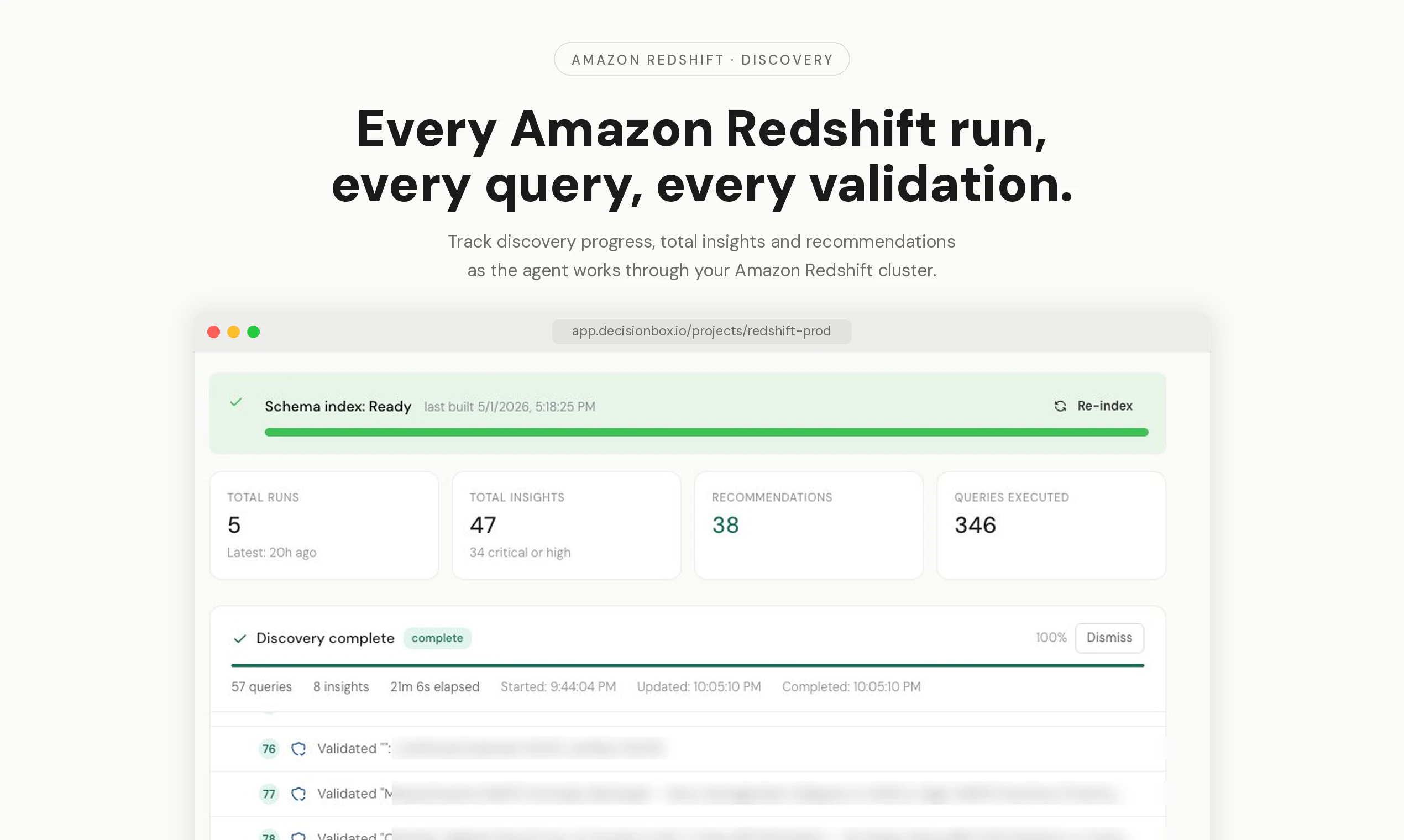
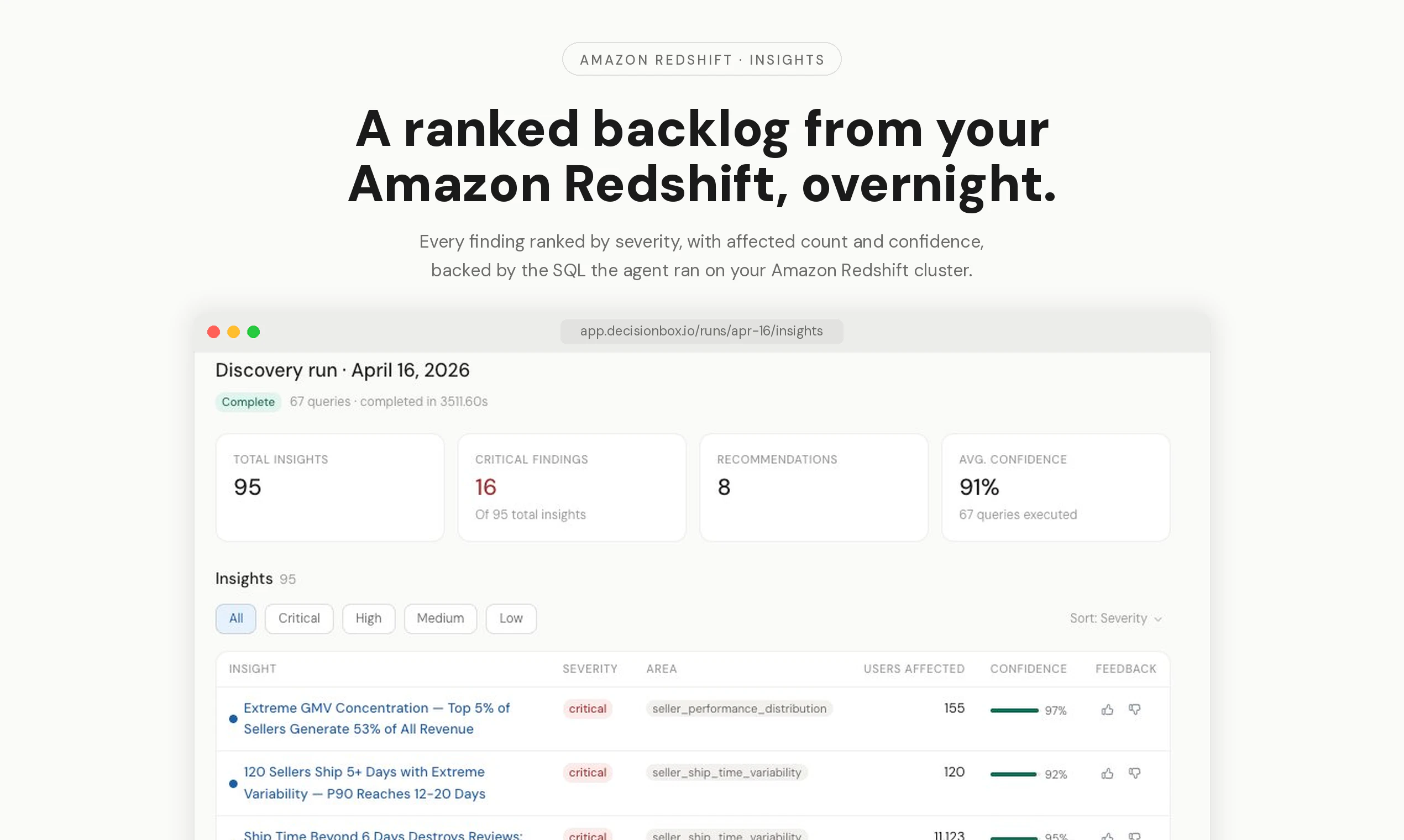
一句话介绍:DecisionBox 是一个开源自主AI代理,能通过只读权限直接连接亚马逊Redshift数据仓库,自动执行SQL探索、验证并输出排名推荐,无需迁移架构或搭建数据管道,解决企业数据仓库中手动分析效率低、洞察发现慢的痛点。
Open Source
Artificial Intelligence
GitHub
Data & Analytics
自主AI代理
数据仓库智能分析
亚马逊Redshift
开源AGPL v3
只读连接
IAM角色集成
Kubernetes部署
多云数据引擎
无管道分析
企业级数据发现
用户评论摘要:用户关注部署细节,希望了解如何在AWS环境中安全运行。创始人回应强调代理运行在用户自有VPC内(通过Helm和Terraform部署),使用IRSA进行IAM角色授权,数据不出账户,且只读连接设计可快速审计。未收到负面反馈或问题。
AI 锐评
DecisionBox的定位相当精准——它不是又一个“数据目录”或“BI增强插件”,而是一个敢于自己写SQL、执行并验证的自主代理。这直接命中了目前数据仓库“数据多,洞察少”的核心矛盾:企业往往有海量数据,但真正有价值的关联分析和异常发现还是依赖资深数据分析师的手工劳动。
从技术架构看,它最聪明的地方在于“只读+用户自有环境”。不做数据复制,不要求重建数据管道,只读IAM权限+IRSA保证了安全合规的红线,这让DBA和安全团队很难有理由拒绝尝试。开源AGPL v3虽然对商业变现不友好,但在这个信任成本极高的领域,反而成了推销给技术决策者的最佳武器——你可以在GitHub上读完每一行代码再决定是否启用。
但需要泼一点冷水。它的价值高度依赖“领域包”(domain pack)的质量。如果这些领域包只是简单的SQL模板集合,那么面对复杂业务逻辑时,AI生成的SQL很可能出现语义错误或低效查询。另外,产品目前的投票数只有16,社区反馈几乎为零,说明它还非常早期。对于Redshift用户而言,这更像是一个值得关注的技术风向标,而非成熟的生产力工具。真正的挑战在于:当数据量达到PB级、查询时间长达数小时时,这个自主代理的“自动执行验证”成本是否可控?目前看来,它更适合作为轻量级的数据探索辅助,而非企业级数据中台的核心组件。
一句话介绍:KundliAI是一款利用AI技术免费生成印度吠陀占星报告的应用,解决了用户获取专业星盘分析需付费、流程繁琐且语言不通的痛点,在30秒内提供包括出生星盘、婚配匹配、每日运势及20年生命预测的全套服务。
Productivity
Developer Tools
Artificial Intelligence
吠陀占星
AI占星师
印度占星
星盘生成
婚配匹配
每日运势
生命预测
多语言支持
免费工具
Product Hunt
用户评论摘要:用户肯定其解决现有占星App痛点(如AstroSage体验差、Astrotalk收费高)的思路,并关注准确性验证,建议增加用户用真实生活事件对比预测结果的功能以建立信任。
AI 锐评
KundliAI的切入点相当精准——它并非试图颠覆占星这个古老领域,而是用AI解决印度占星市场的“数字化服务鸿沟”:一边是传统App的糟糕体验和高昂收费,另一边是用户对快速、免费、本土化服务的刚需。其价值不在于AI能否“真正算命”,而在于它用技术手段将占星从“高价咨询”降维成“免费工具”,本质上是数据可视化与个性化内容生成的一次成功落地。
但务必警惕该产品的“卖点陷阱”。它宣称的“20年AI预测”和“Pandit AI”极易陷入玄幻营销。占星本身的非科学属性决定了任何“精准度”验证都是伪命题,而AI不过是基于用户出生时间与预设参数进行数据映射,这比传统占星师多了一层算法黑箱,反而可能助长用户对“技术权威”的盲目信任。产品若真想建立长期价值,不应陷入“比占星师更准”的内卷,而应聚焦于“占星数据解读的透明化”与“用户行为数据反哺”——例如允许用户标注某次预测是否应验,积累真实反馈数据集。此外,印度市场对免费模式依赖性强,如何把流量转化为可持续收入(如高级报告、个性化AI解读订阅)是生死线,否则30秒免费服务最终只会变成高价SaaS的引流漏斗。一句话:它是个好工具,但离“颠覆行业”的宣称,还差一个商业闭环的距离。

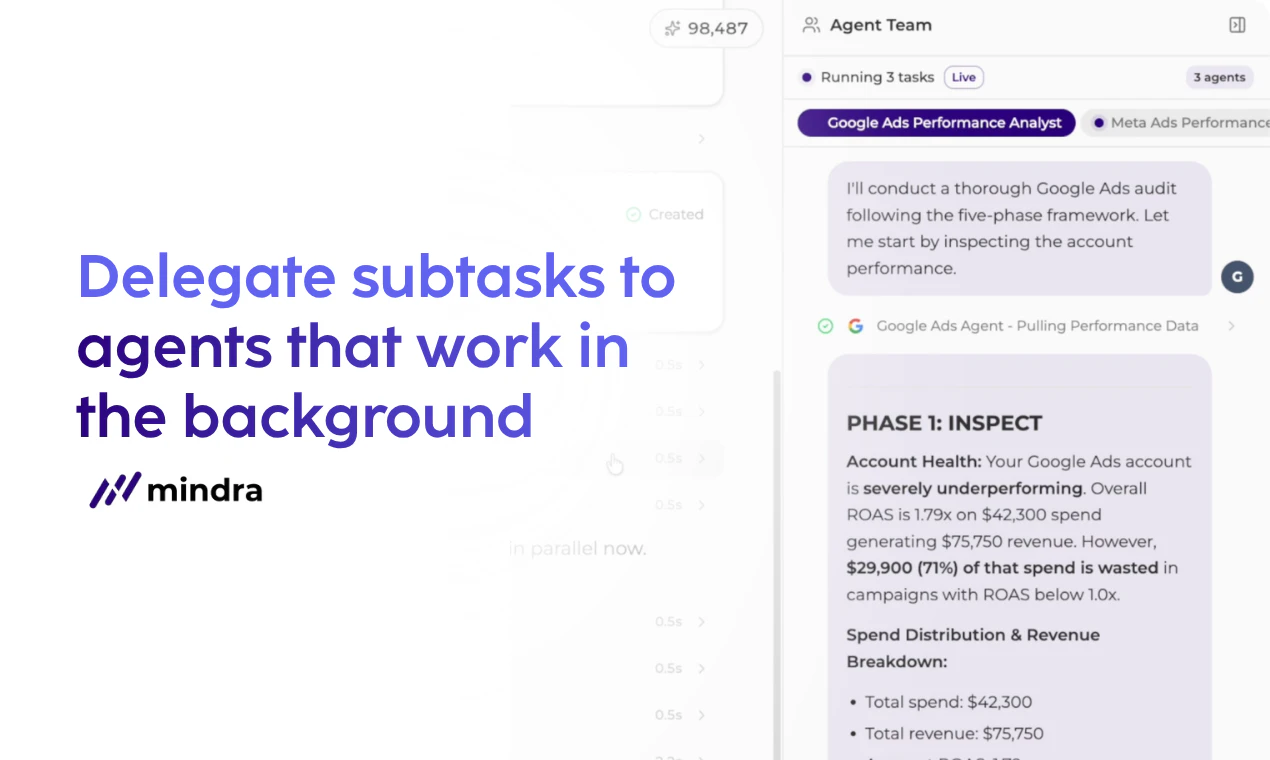






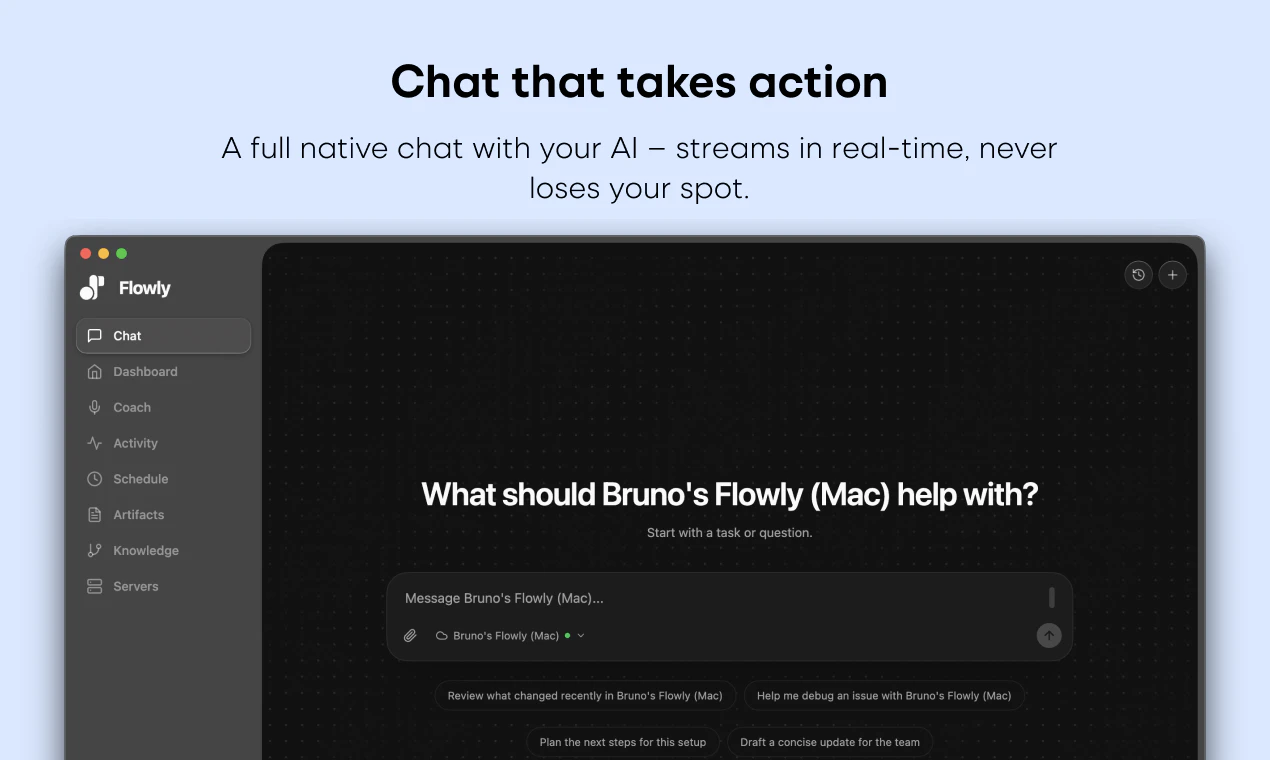
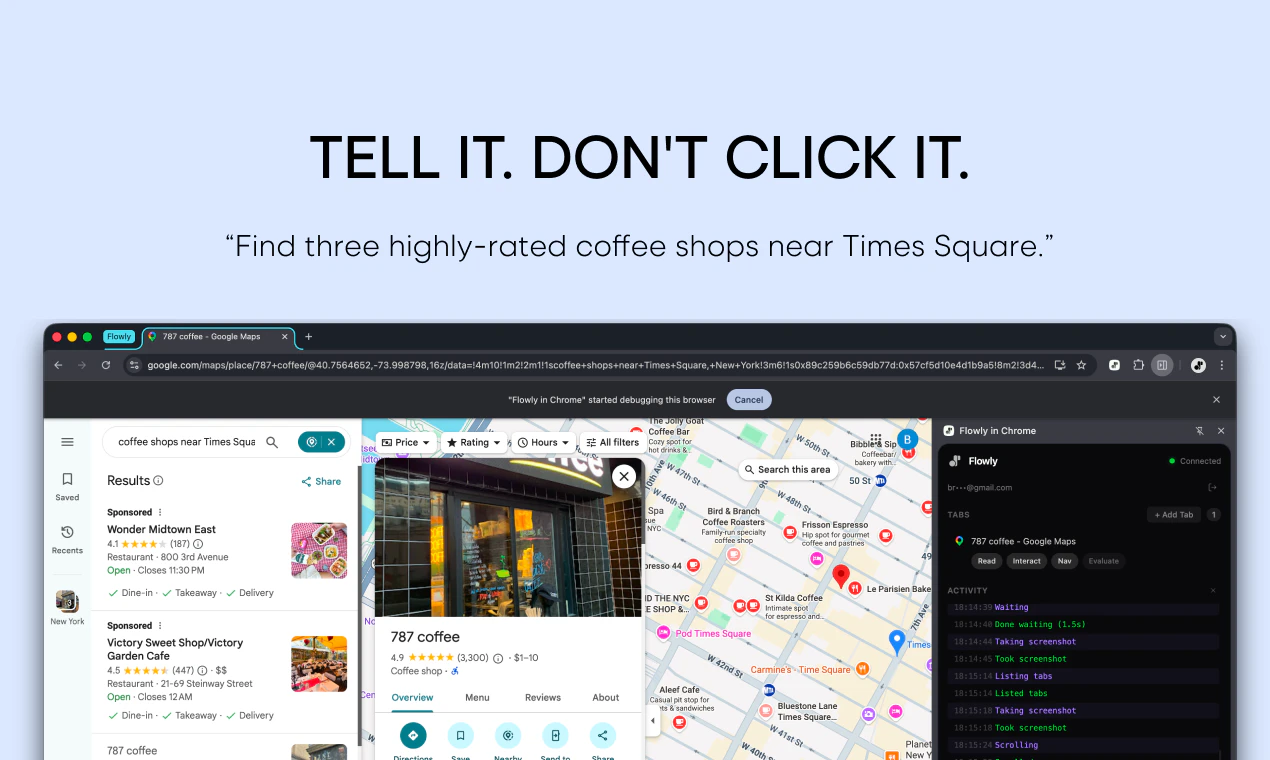

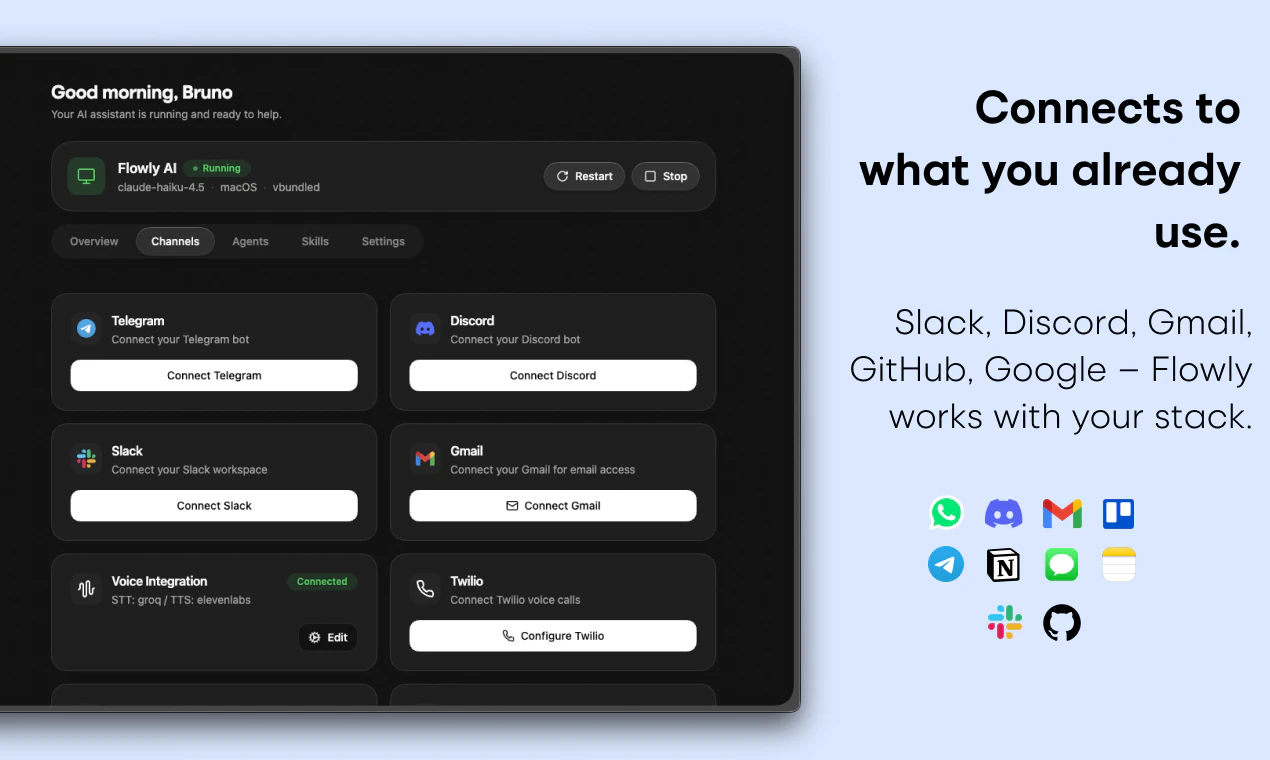









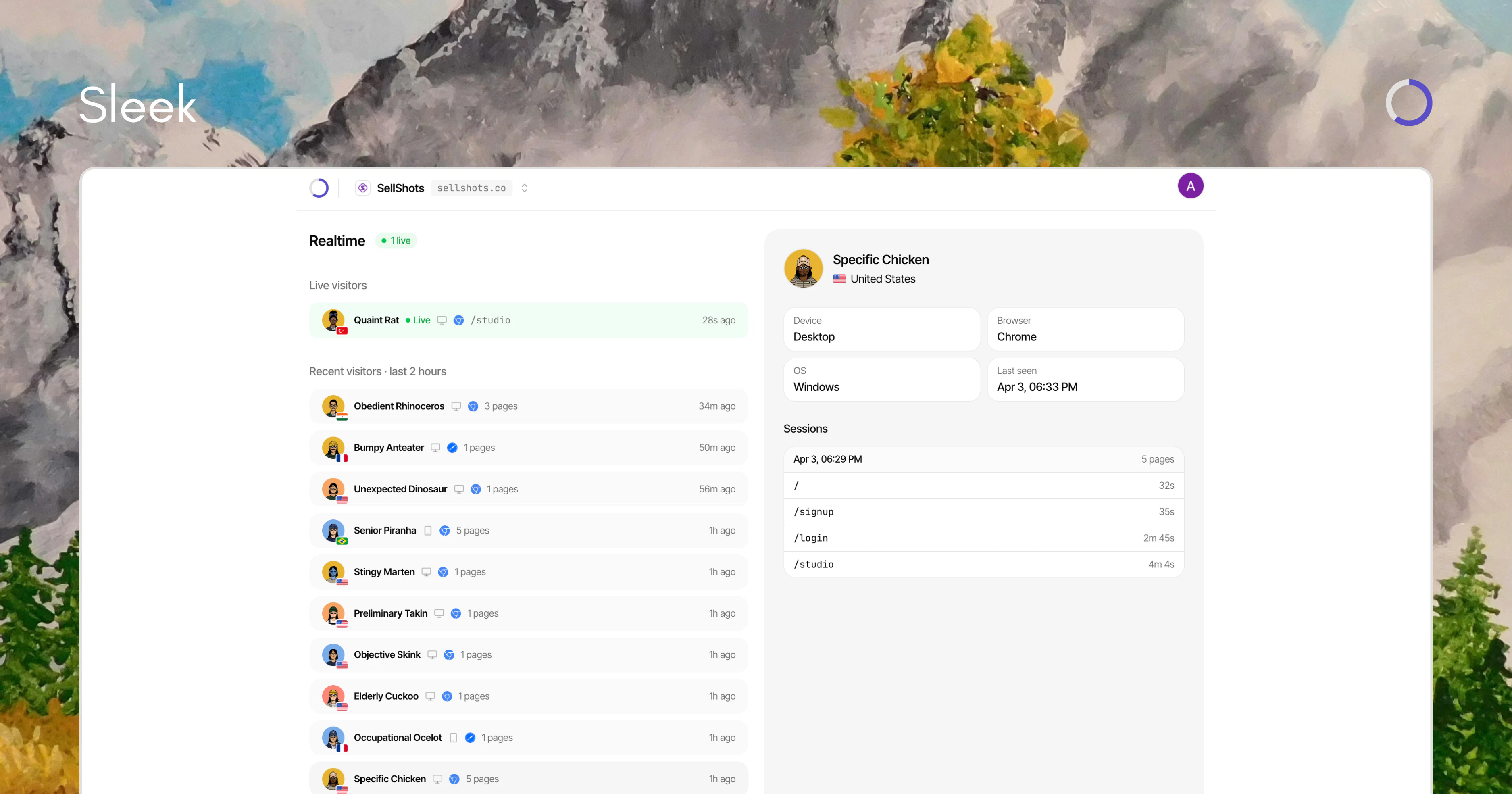
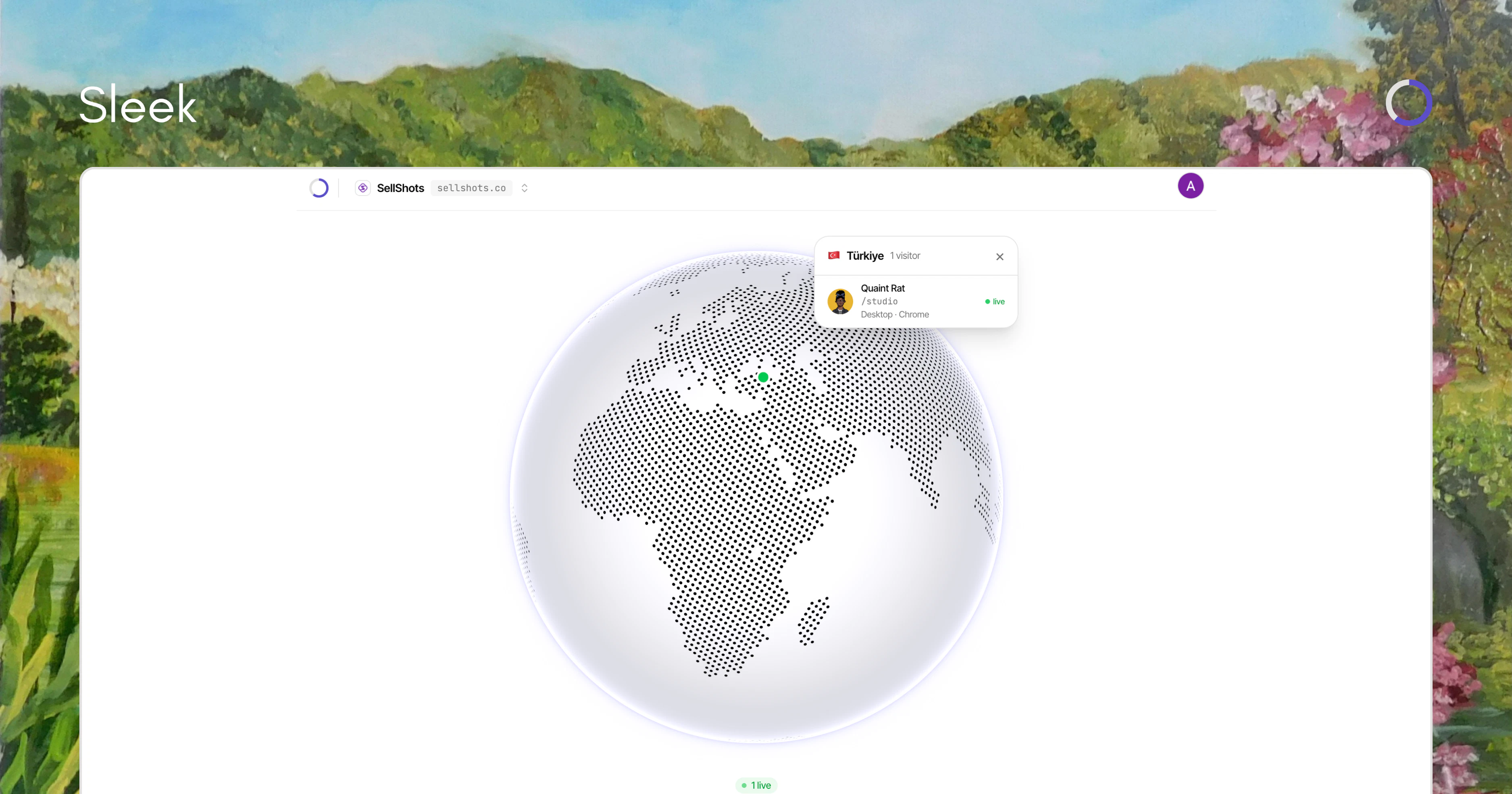































Hey Product Hunt 👋. I’m Zeynep, co-founder of Mindra. We started building Mindra with my co-founders @denizsoylular and @ilker_yoru 6 months ago.
The problem
AI agents are powerful, but isolated. Each does one thing, none collaborate, and when one fails, the whole workflow breaks.
Most tools fall into two dead ends:
• Single-agent assistants → great at drafting, not at doing. A summary isn’t a shipped campaign.
• Pre-defined chains (Zapier, n8n, LangChain) → look clean on a whiteboard, but in production every step is a fragile point of failure. No critic, no retry, no fallback.
What we built instead
Mindra runs teams of specialized AI agents that actually execute work across your tools—with humans in the loop where it matters, and tight permissions everywhere else.
Why it’s different
• Teams, not chains → Every workflow gets a purpose-built agent team tailored to your company
• Self-healing, always-on → Agents run 24/7, re-plan and retry when things break, and only escalate when truly stuck
• 3,000+ integrations → Meta Ads, Google Ads, HubSpot, Salesforce, Slack, your ERP—no glue code
• Compounding memory → Agents learn your business (tone, policies, playbooks). Context gets stronger over time
Who it’s for
Marketing, sales, ops, support, supply chain, any team buried in repetitive execution. Our users are running campaigns end-to-end, automating outbound, handling tier-1 support, and closing books weeks faster.
Check it out
👉 mindra.co
For the Product Hunt community: we’re onboarding a small group of pilot customers this quarter. Bring one workflow you’d love to delegate—we’ll scope it with you, no pitch.
We have an online launch party where you can ask your questions directly to us. 5 pm May 4th
Register here: https://luma.com/dmph2nle
Drop a comment or DM me. I’ll be here all day 🙌
Very Cool! Is the integration easy
The naming is spot on - "agent teams you can actually delegate to." When I was scaling from 15 to 120 engineers as CTO, the hardest part wasn't hiring - it was learning to delegate effectively without losing quality. If AI agents can genuinely own a workflow end-to-end with proper human oversight, that changes the game for lean teams trying to punch above their weight. Curious how the governance layer works in practice.
For the always-on 24/7 piece, how do you keep costs predictable? An agent team that re-plans and retries sounds great until I'm staring at an LLM bill that 10x'd because something kept failing overnight.
Strong pitch agents teams you can trust and built-in governance is exactly where most agent tools currently fail. Real test will be whether users can predict and audit what agents are doing without feeling like it’s a black box.
Looks nice, if we can integrate with legacy systems it can solve a lot of problems in traditional business lines like Insurance
So it integrates with everything, learns my business context and works while i sleep?💀Should i just pre-emptively fire myself now?)
How do you handle agent disagreement / drift over time ? Most multi-agent systems I've tried collapse into either chaos or echo-chamber consensus after a few iterations. What's the orchestration model under the hood?
the agent-team angle is interesting — most agent products today still ship as a single agent that pretends to be a team. real delegation needs a coordinator that owns task decomposition + retry logic, not just parallel chat windows. curious what you're using under the hood for the orchestration layer? we hit a similar problem on a different category of agent work and ended up writing the orchestrator as a state machine because LLM-driven orchestration was too non-deterministic for production. great to see this shipped today, congrats.
Don't forget to book a personal demo:
https://mindra.co/
Or join our online launch party:
https://luma.com/dmph2nle
Can you set working hours or quiet modes for automations?
but how did u adapt to these agents to rapidly changing world what are the scenarios your system works best and worse
For someone currently doing this with LangGraph or CrewAI — what's the migration story? Is there an import path, or is it 'start clean'? Asking because the switching cost is usually what kills adoption, not the feature gap.
Who doesn't love non-sleeping agents!? Congrats @zeynep_yorulmaz and the team! I assume there is an agentic team behind the launch as well :)))
The 'agentic team you can actually delegate to' framing is what nails it for me — I run finance content (financial modeling YouTube at https://www.youtube.com/@Mod3Loop) on top of a day job in M&A, and the bottleneck has never been ideas, it's the production layer (briefs, thumbnails, repurposing, distribution). Curious how Mindra handles agents that need long-running domain context (e.g. a recurring "audit my LBO model walkthrough script for IRR/DSCR accuracy before publishing") vs. one-off tasks. Where does the human governance step usually slot in?