PH热榜 | 2026-05-05
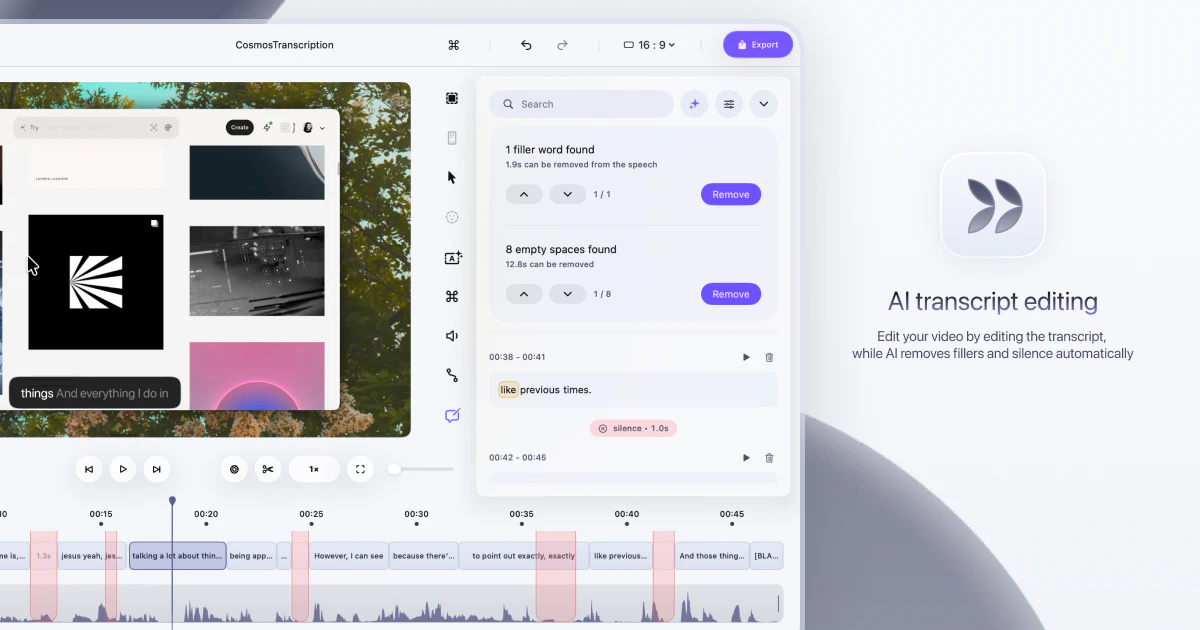
一句话介绍:Kilo Code v7 是一款基于OpenCode服务器重建的VS Code扩展,通过并行代理、差异审查器和多模型对比,解决了开发者在复杂编码任务中因工具调用串行化导致的效率低下、以及多代理协作时文件冲突和审查繁琐的痛点。
Open Source
Software Engineering
Developer Tools
GitHub
AI编码助手
VS Code扩展
并行代理
代码审查
多模型比较
开源
开发者工具
IDE插件
工作流自动化
用户评论摘要:用户普遍认可并行工具调用和子代理带来的速度提升,并关注代理管理器、内联代码审查、多模型对比等功能。核心问题包括:依赖代理间如何共享上下文、审查疲劳如何缓解、切换模型是否中断上下文。建议体现在对远程功能、移动端分屏支持的期待。
AI 锐评
Kilo Code v7 的发布,表面上是一次功能迭代,实则是对“AI编码代理”这一品类底层逻辑的重新定价。它没有在“生成代码”这个红海里卷参数或模型,而是精准地切入了“多任务并行”与“多人协作”这两个被多数工具忽略的工程痛点。并行工具调用和子代理隔离(git worktree)直击了传统AI助手“一条路走到黑”的串行瓶颈,让耗时任务在感知上产生了降维打击。而内联代码审查与多模型对比,则巧妙地将AI生成的代码拉回到了“人机代码评审”的规范流程中,本质上是在提升信任与可控性。
值得商榷的是,评论中反复出现的“速度提升”和“模型多样性”是很棒的钩子,但用户提出的“依赖代理如何管理上下文”、“审查疲劳能否量化”等问题,暴露了产品在多代理协作的复杂性上尚未给出完美闭环。对于追求极致效率的“重码”开发者而言,并行是解药,但复杂的依赖协调可能成为新的毒药。此外,虽有“零加成”定价,但当下AI编码工具的忠诚度多绑定于编辑器生态(如C
ursor),从Cursor迁移过来的用户提及“受够了模型绑定”,这或许才是Kilo真正的战略窗口——构建一个“不绑架模型”的、开放的核心引擎。v7证明了它有能力跑得更快,但能否跑出生态赢家,要看它能否把“多代理不打架”这个难题,从“能用”进化到“好用”。
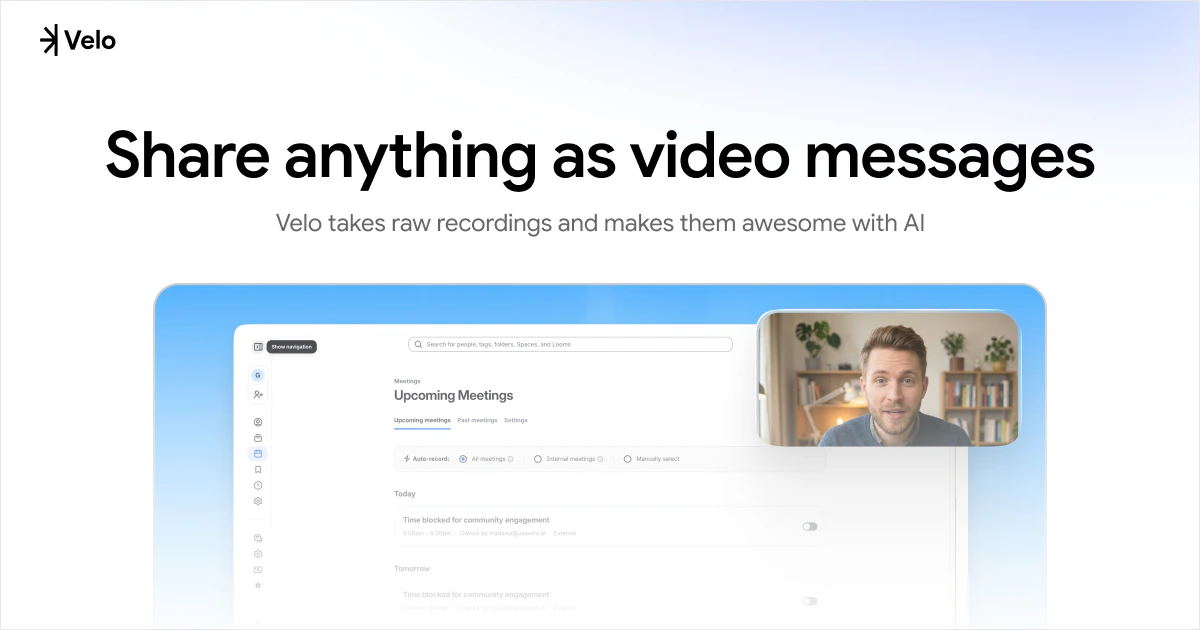
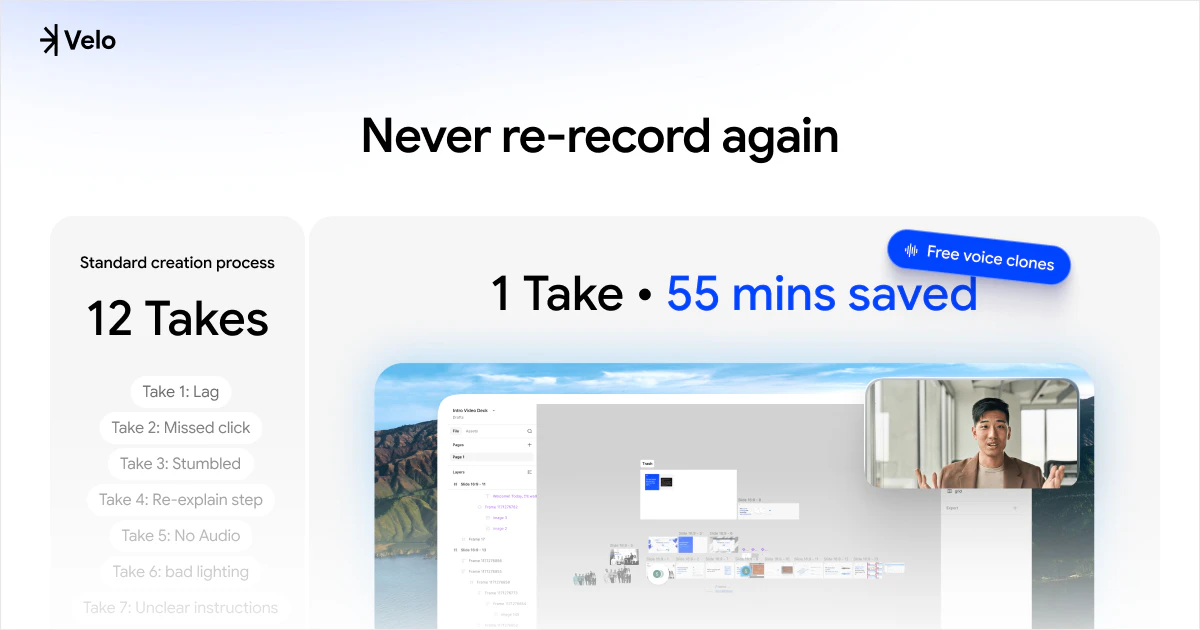
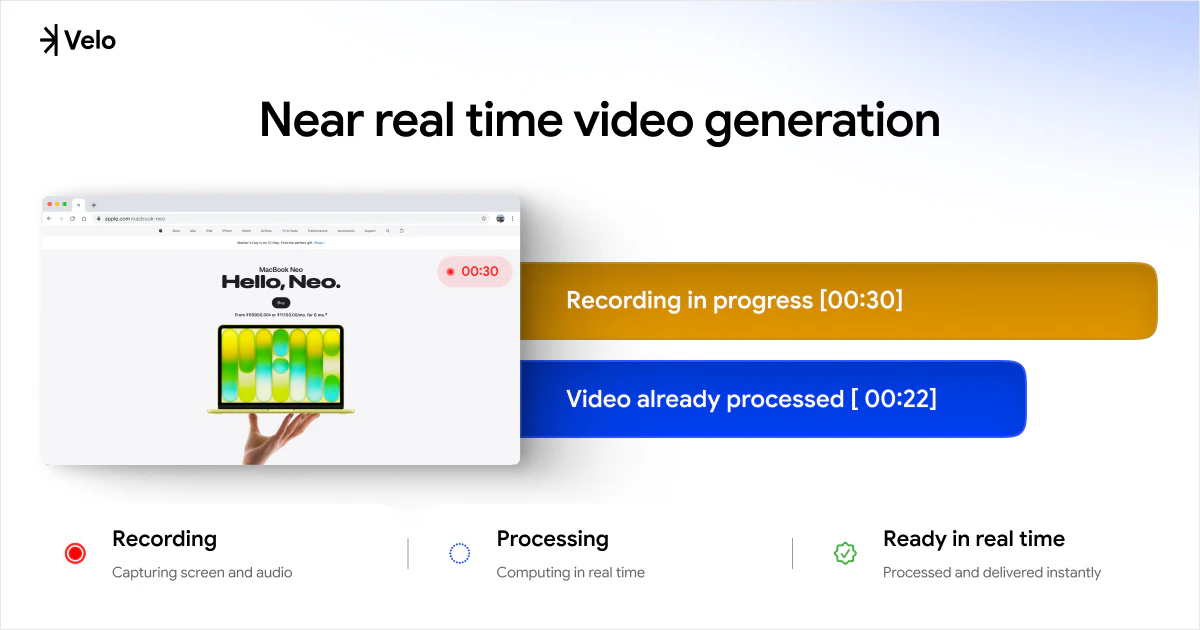
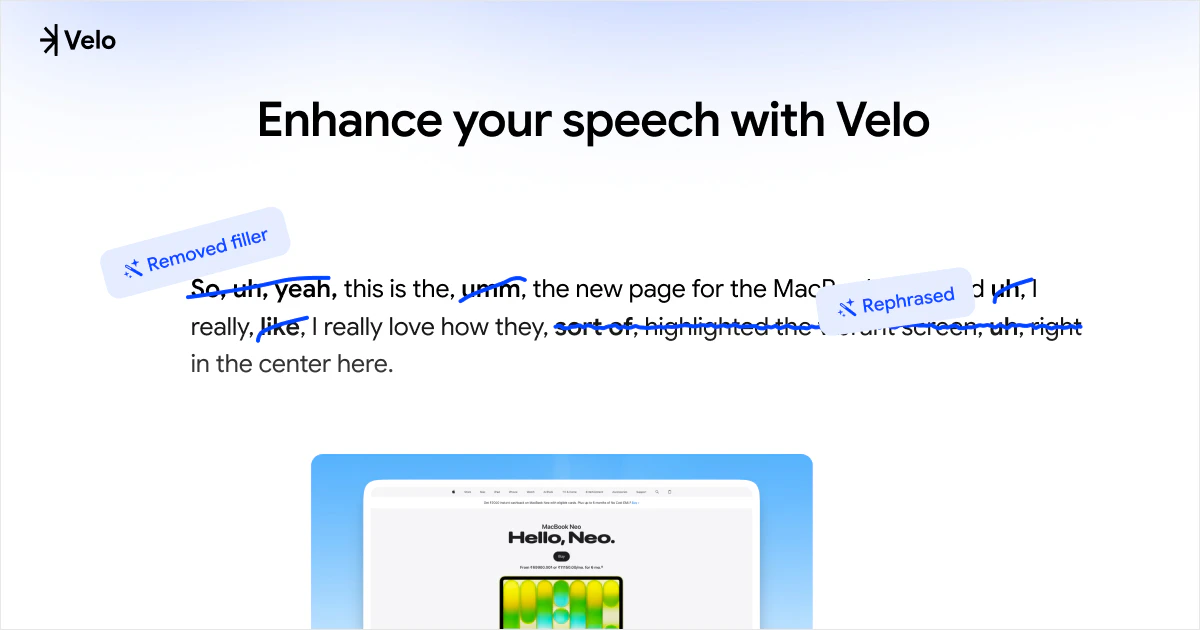
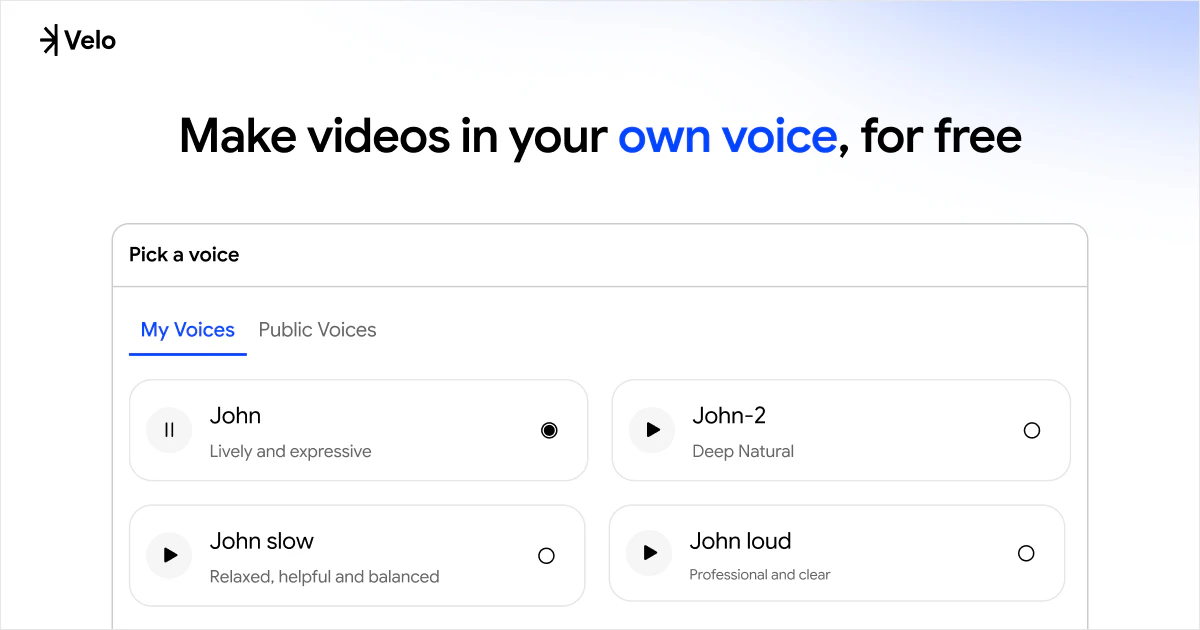
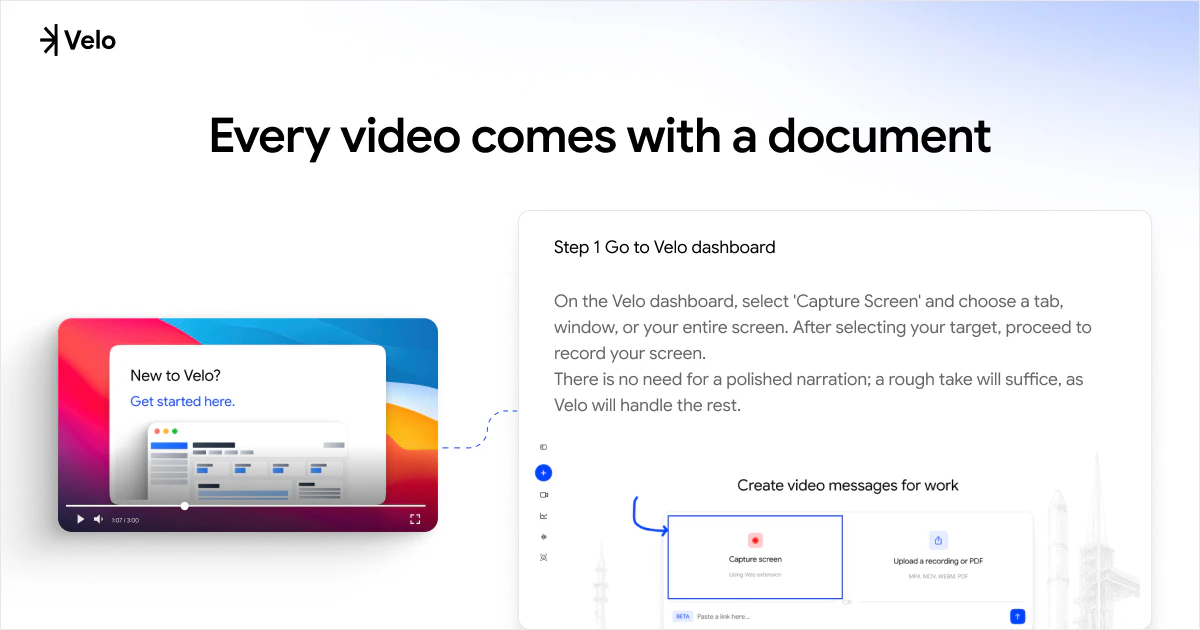
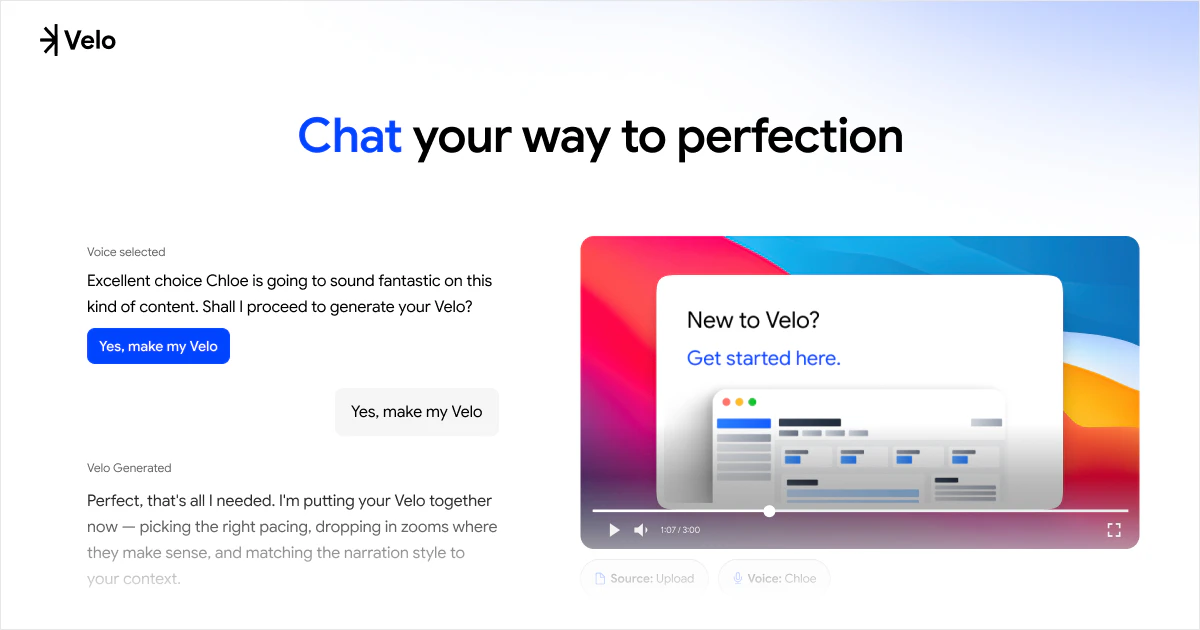
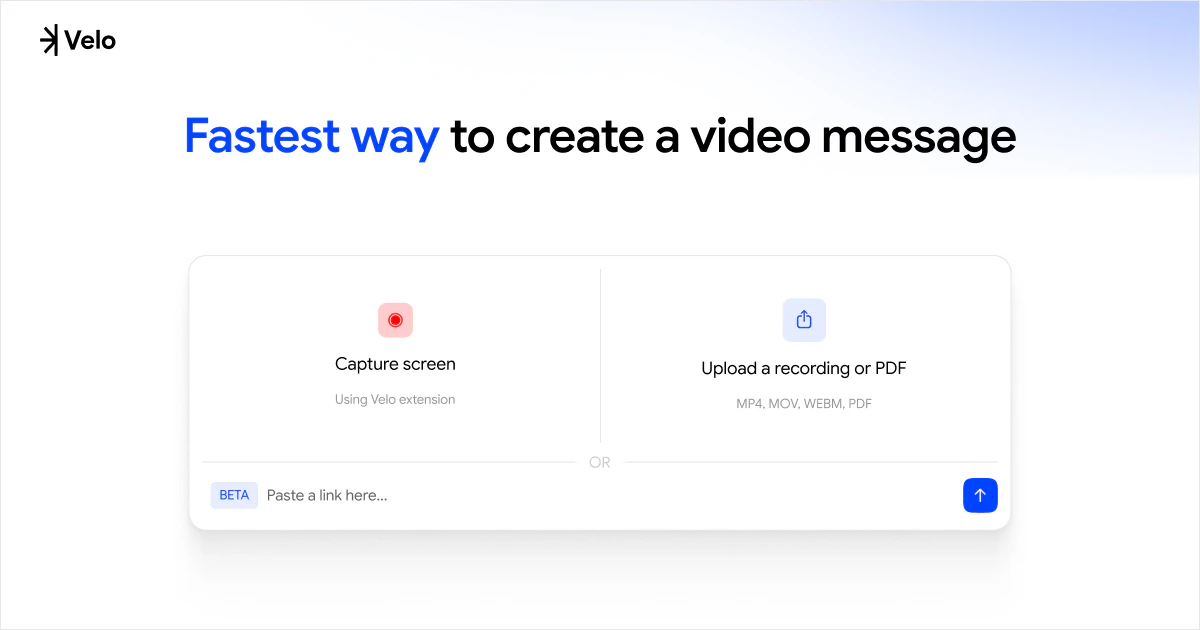
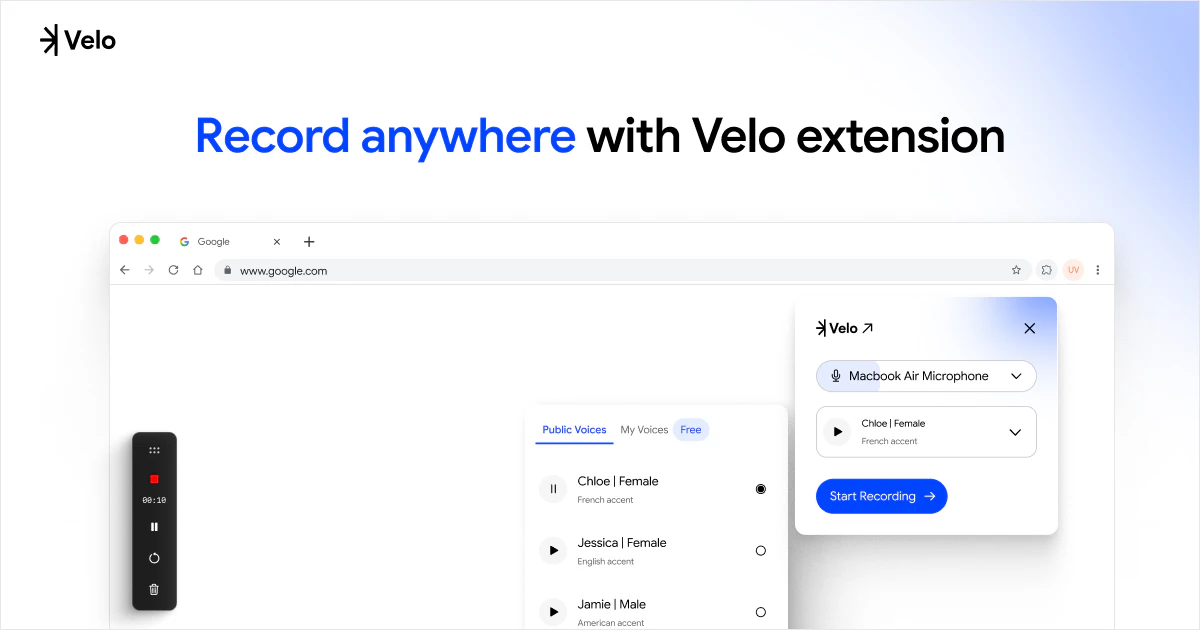
一句话介绍:Velo 2.0通过聊天式界面和AI实时处理,将用户原始的屏幕录制和语音一键转化为可直接分享的精美视频与文档,省去繁琐的后期剪辑,让非专业人士也能高效制作出专业级视频消息。
Productivity
Sales
Video
AI视频生成
屏幕录制
语音克隆
聊天式编辑
视频转文档
脚本重写
实时处理
B2B创作工具
效率工具
产品展示
用户评论摘要:用户普遍称赞2.0版响应了“不够省力”的痛点,尤其对聊天界面、视频与文档同步生成、更自然的语音克隆表示认可。反馈的问题和建议集中在:PDF中的图表如何描述、能否编辑已生成的视频、是否支持纯音频转视频、以及长视频的稳定性。
AI 锐评
Velo 2.0的升级路线堪称“听劝”的教科书,但需要警惕这种迭代方式的风险。团队从1.0用户“能用但不够省力”的单一痛点出发,放弃堆砌功能,转而重构核心体验:用“聊天”替代时间轴编辑,用“实时流处理”消灭等待感,用“一次录制,视频文档双出”解决复述痛点。这些改动精准命中了B2B创作者(如产品演示、教程录制)在“录制后”环节的深层痛点——沟通成本远高于创作成本。
然而,Velo的护城河并不稳固。目前的核心逻辑(屏录+语音+AI润色)技术门槛不高,竞争对手可以快速复制。其真正的价值可能在于“从屏幕内容到结构化文档”的转化精度和“语音克隆的情感保真度”,这需要高质量的数据积累和模型调优,而非简单的功能堆叠。评论中用户对图表处理、长视频稳定性的担忧,也暴露了其在复杂场景下的成熟度不足。
此外,“聊天式编辑”虽然降低了学习门槛,但可能牺牲了对精细节奏和画面层面的控制权,这会让专业创作者感到掣肘。Velo必须在“极简”与“可控”之间找到更聪明的平衡。短期来看,它是一款出色的演示视频制作工具;长期来看,若要成为视频沟通的基础设施,需要证明其能处理更高维度的叙事和创意表达,否则很容易沦为一个“好用的PPT生成器”的升级版。
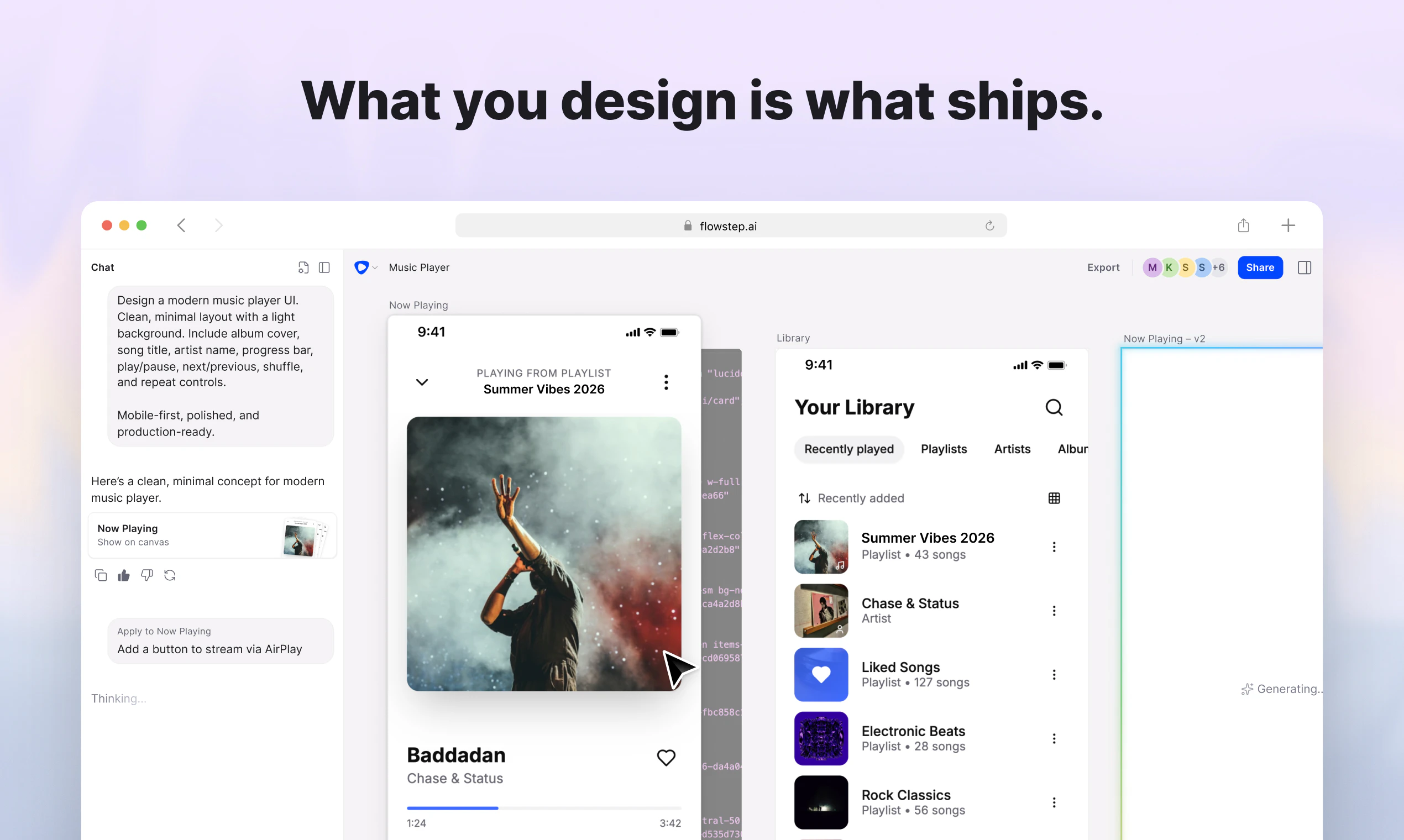
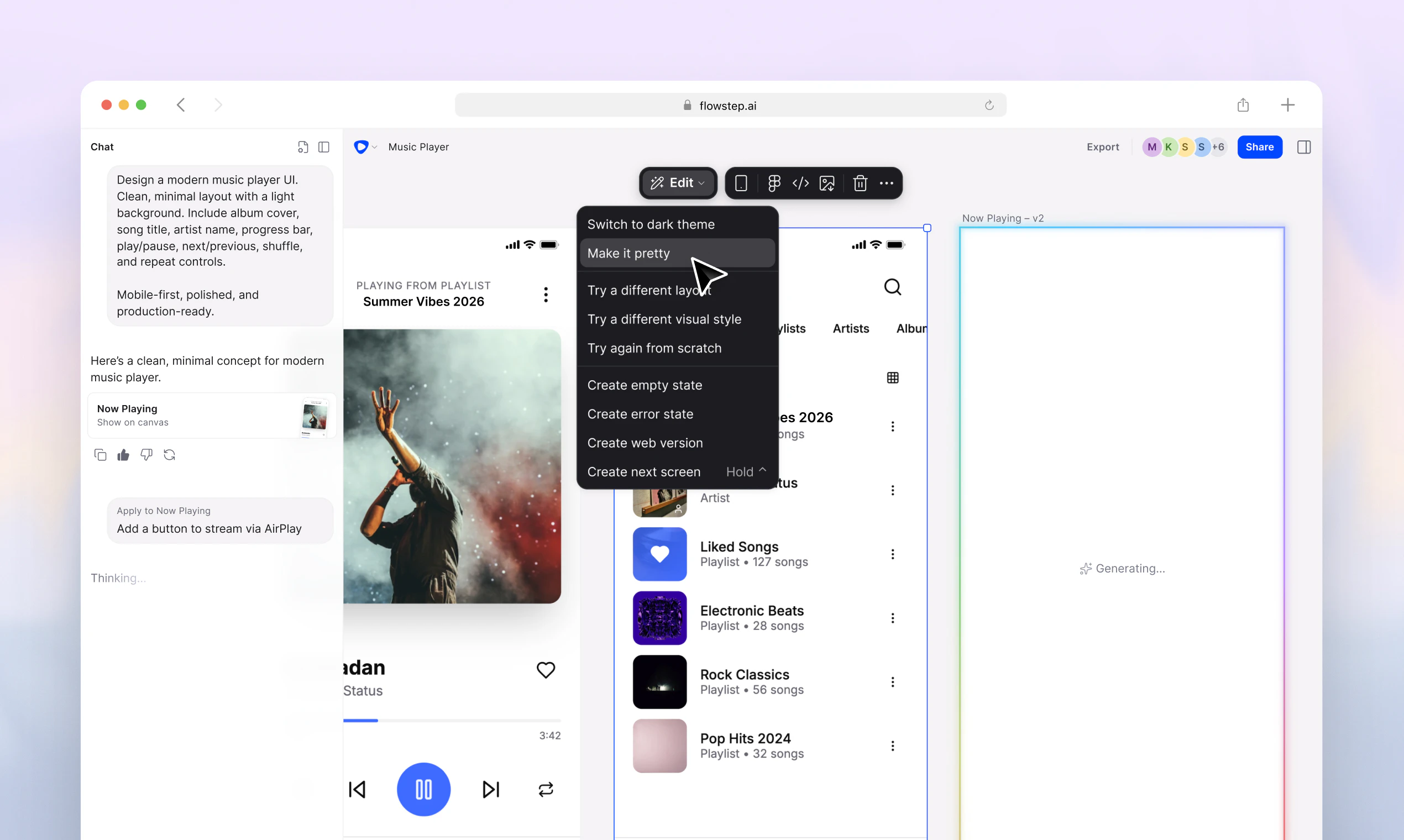
一句话介绍:Flowstep是一个AI驱动的UI设计工程平台,在无限画布上通过提示词或手动编辑,能将设计师的构思直接生成可投入生产的React+TypeScript代码,彻底消除设计与开发之间的“翻译”损耗。
Developer Tools
Artificial Intelligence
Vibe coding
用户评论摘要:用户最关心生成代码的真实可用性,质疑是否仍需大量清理。核心需求是AI能同步脚手架状态管理(useState/useEffect)逻辑,并期待设计系统(如DESIGN.md)的一致性维持。团队回应代码可直接运行,但承认复杂API和状态绑定仍需开发者处理。
AI 锐评
Flowstep的定位非常精准,它没有重蹈“AI生成设计稿”的覆辙。创始人在评论中直截了当揭示了行业的痛点——“AI能完成80%,剩下20%得重写”,这正是所有同类工具失宠的根本原因。Flowstep的解法是将“设计与代码合二为一”,用无限画布的体验换取开发者对传统设计工具的最后一点留恋,然后直接吐出可集成的React+Tailwind代码,并通过MCP接入Cursor等IDE生态,这是一种极为务实的“截胡”策略。
但真正值得玩味的是,用户并不满足于此。评论中最高赞的问题聚焦于“状态管理”和“生产级代码”,这暴露了Flowstep当前的核心软肋:它本质上仍是一个“静态UI生成器”。漂亮的页面骨架和样式很容易,但一旦涉及到交互逻辑、API绑定、数据流,它就和Figma导出切片没有本质区别。团队将“API和状态交给开发者”视为理所当然,这是一个危险的自我安慰。当V0.dev、Claude Design等竞争对手开始切入状态层和业务逻辑时,Flowstep目前“静态UI”的技术护城河会迅速变浅。
它目前的价值在于为“高保真UI原型→代码落地”提供了当前市场上最丝滑的路径,尤其适合独立开发者或小型团队快速搭建界面。但要兑现“what you design is exactly what ships”的承诺,它必须尽快攻克“智能状态脚手架”和“设计系统一致性”这两个技术高地,否则它将永远停留在“设计师的玩具”层面,而非“工程师的生产力工具”。这是一次勇敢的突围,但距离真正的“设计工程”,还有一段需要硬啃的路。
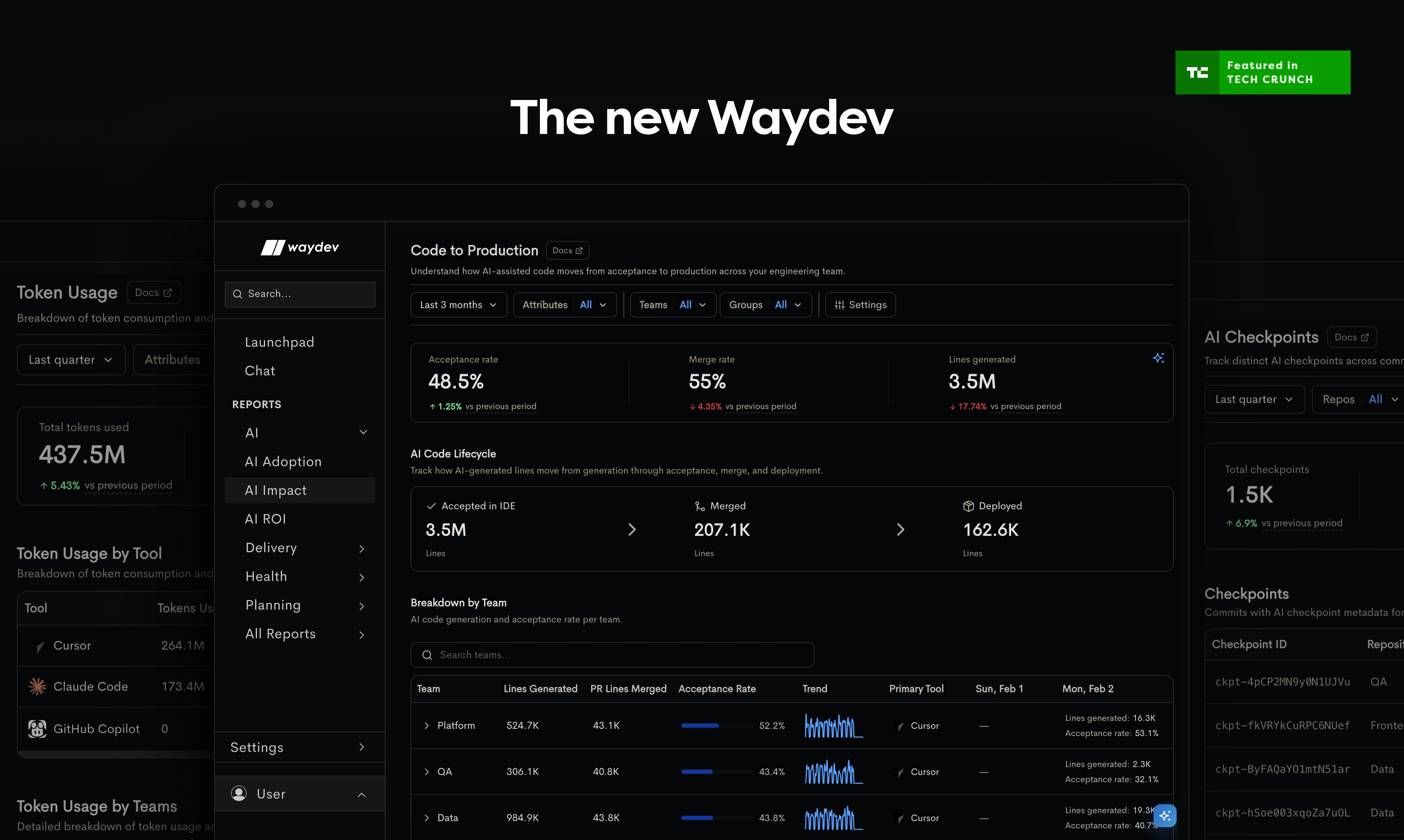
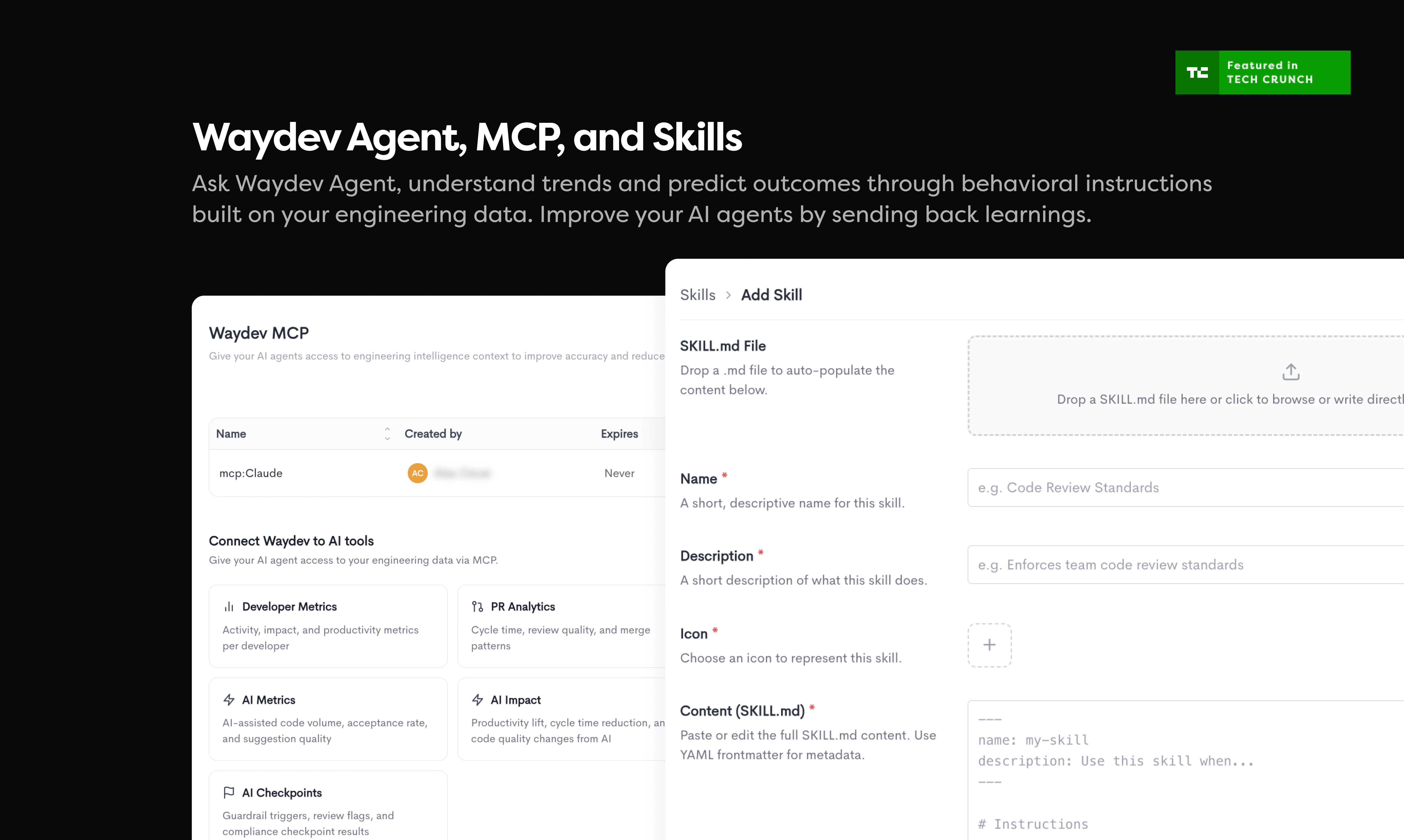
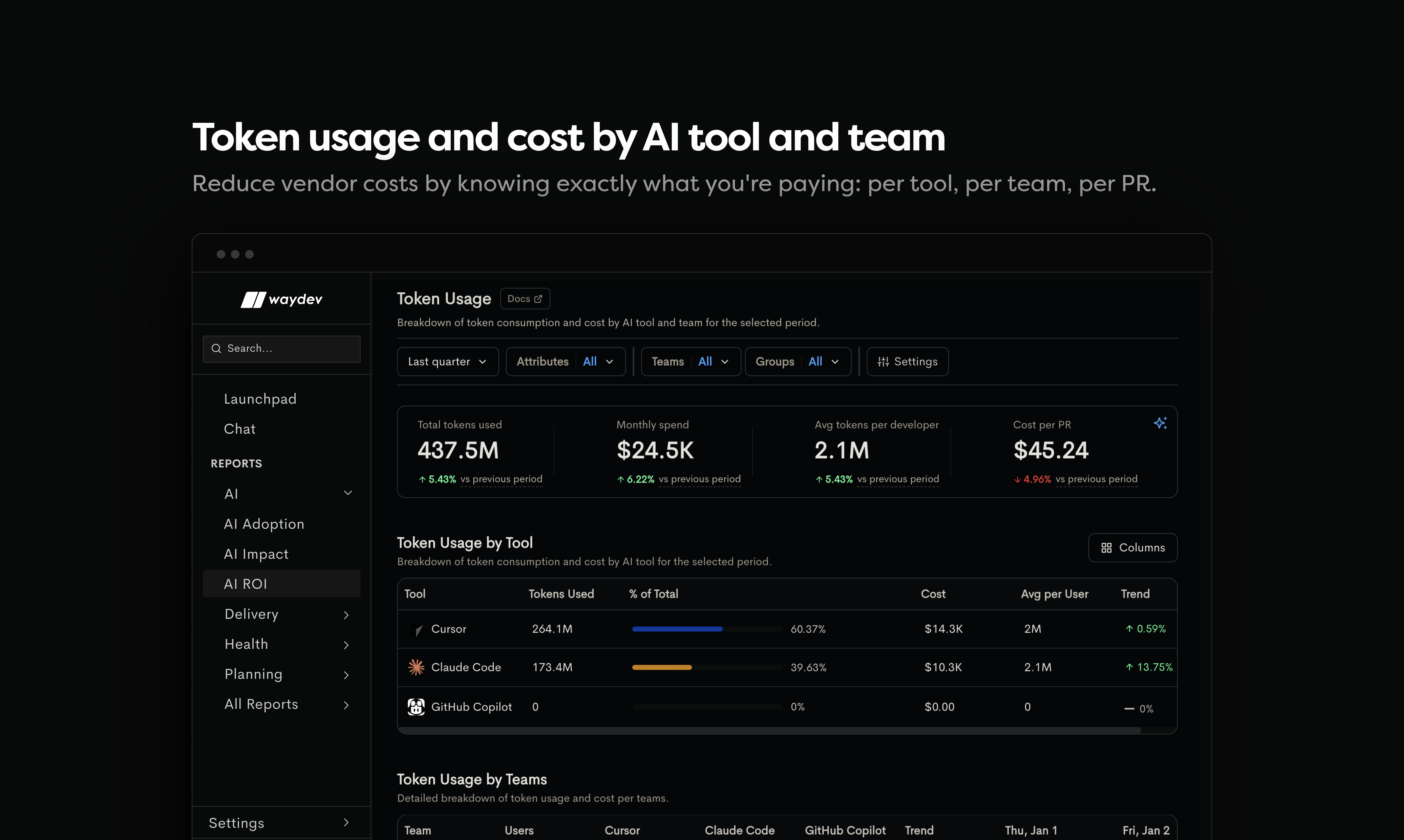
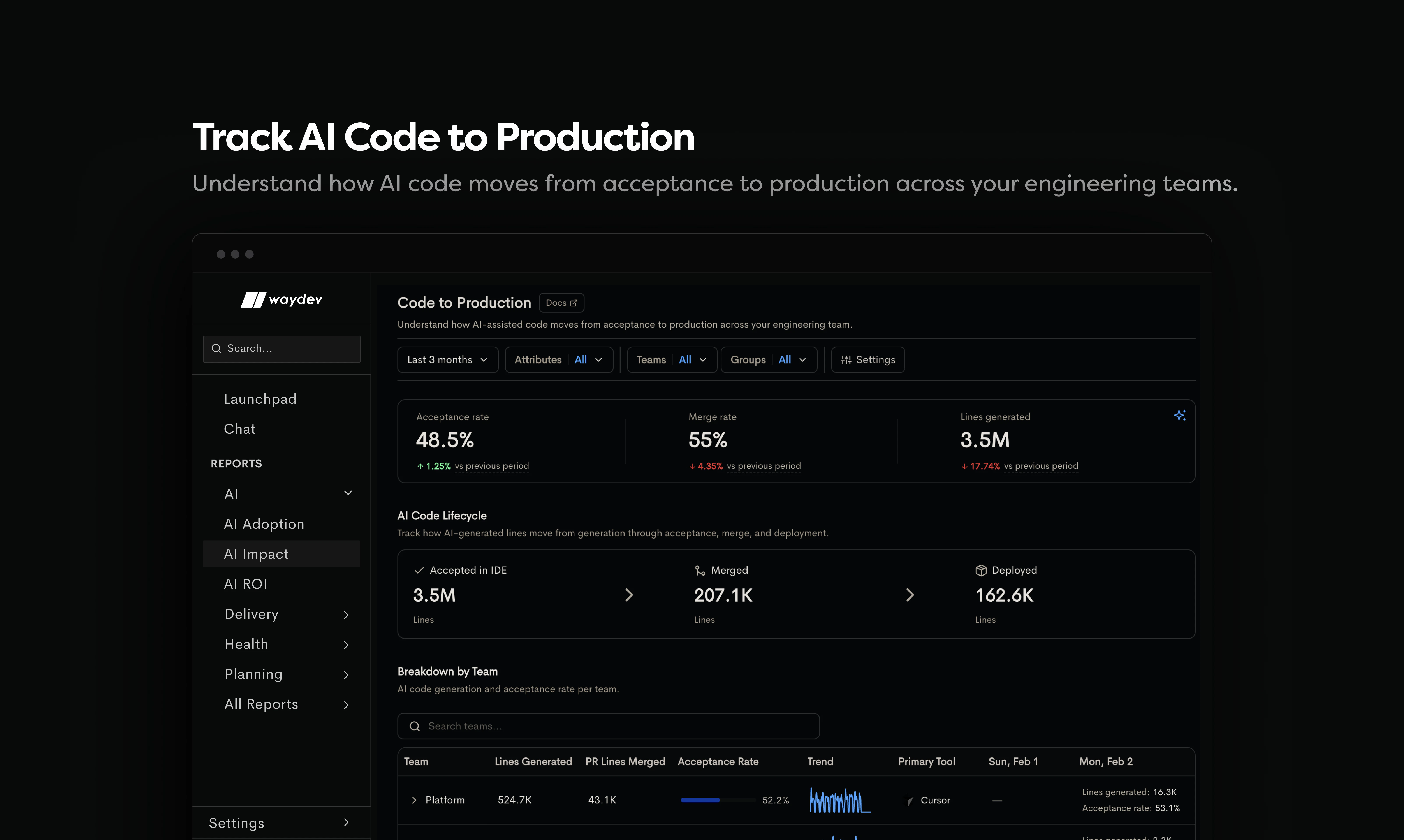
一句话介绍:Waydev Agent是面向工程领导者的AI投资回报率测量平台,通过追踪AI代码的采用、影响和ROI,解决企业在“花大钱买AI却不知成效”场景下的决策盲区。
Pitch NYC
开发者工具
工程管理
AI治理
代码分析
ROI计算
SaaS
数据可视化
Copilot分析
Cursor监控
DevOps
用户评论摘要:用户普遍肯定产品解决了“AI投入不见回报”的痛点,称赞“采用-影响-ROI”的分解逻辑。批评集中在:隐藏定价令人警惕,担心试用期后高昂费用。创始人在评论中承诺提供定制化报价和PH专属折扣。另有技术用户追问AI代码归属的精确归因方法,以及与其他平台(如Jellyfish)的差异化。
AI 锐评
Waydev Agent切中了一个真实且昂贵的问题:企业疯狂采购AI开发工具,但财务与工程之间缺乏一个共识的“刻度尺”。它的拆分逻辑——“采用”看量,“影响”看质,“ROI”算账——比单纯统计“谁用了Cursor”要科学得多,这使其从数据看板工具升维为审计工具。
但它的核心挑战在于“归因”的信噪比。评论中那位技术用户的提问非常尖锐:当AI辅助变得零散且难以追踪时(如手动复制粘贴并重写),任何声称能精确归因于AI的工具都带有不可逆的误差。Waydev坦诚地承认了“未知”状态的存在,这反而比许多号称100%精确的工具更具专业操守。
真正值得关注的不是它如何测量“好”的AI贡献,而是它如何处理“坏”的:被回滚的AI代码、导致线上故障的AI代码。这才是ROI计算的陡峭门槛。如果产品能在“AI影响”层面细分出“正向贡献”与“引入技术债”的对比,其价值将跃升为工程战略层的风险管控工具。
至于隐藏定价,在这个预算敏感期确实是个减分项。但创始人的快速回应(定制报价、免会议)说明团队明白这个痛点。整体上,这是个针对性强、思考成熟的产品,但能否从“工程领导者的玩具”变为“CFO的决策依据”,取决于它能否提供让财务人员都信服的、经得起审计的数据链。
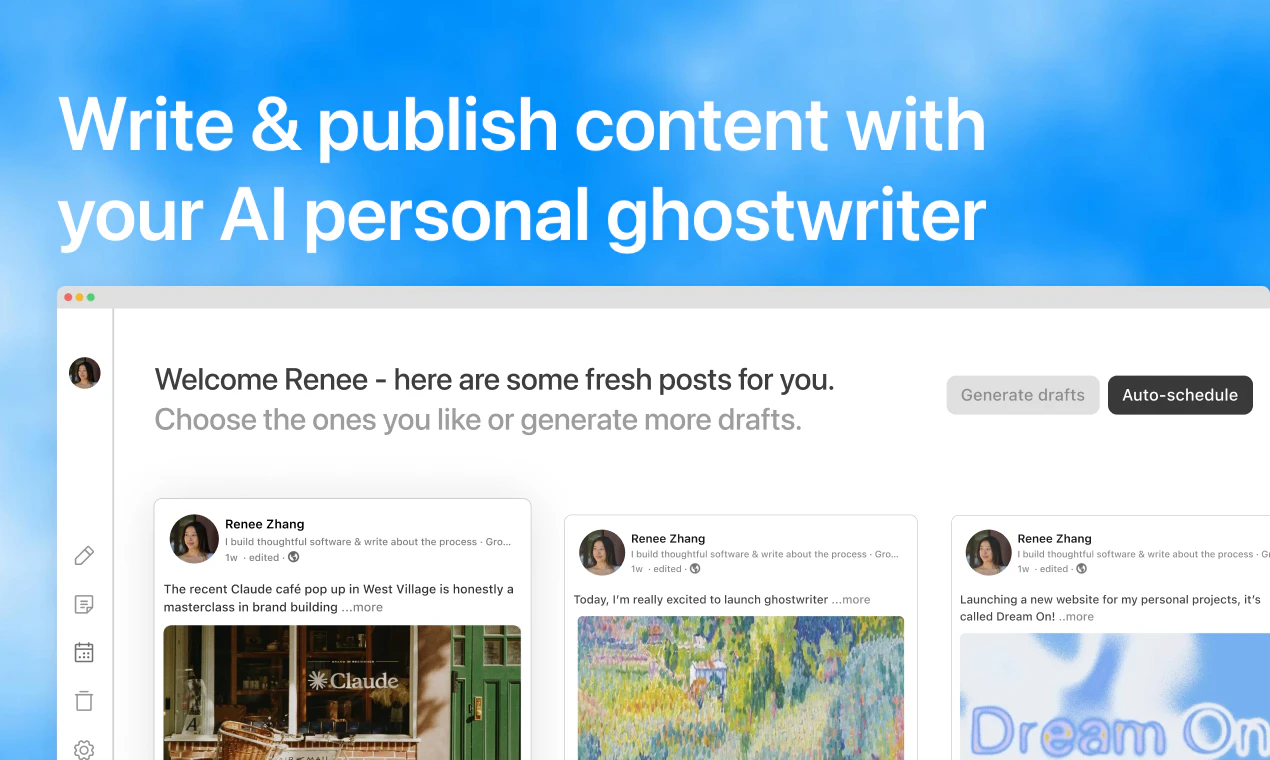
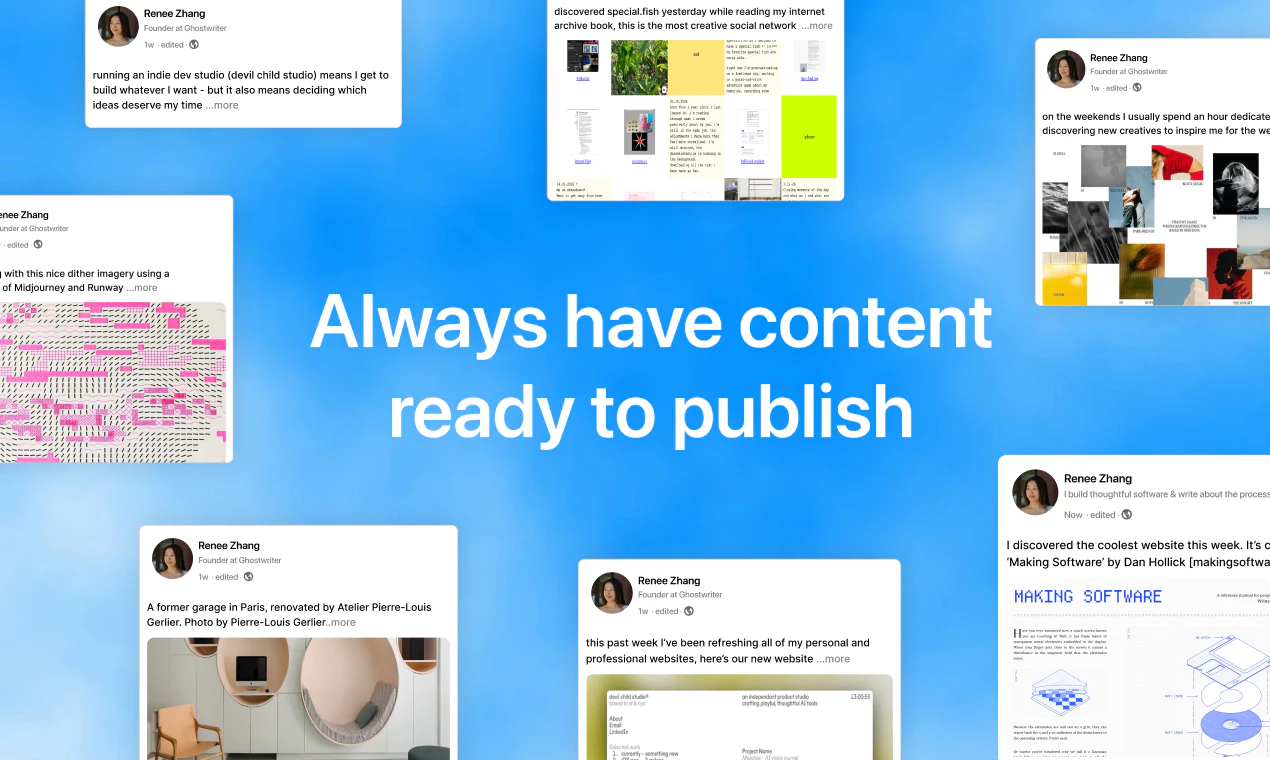
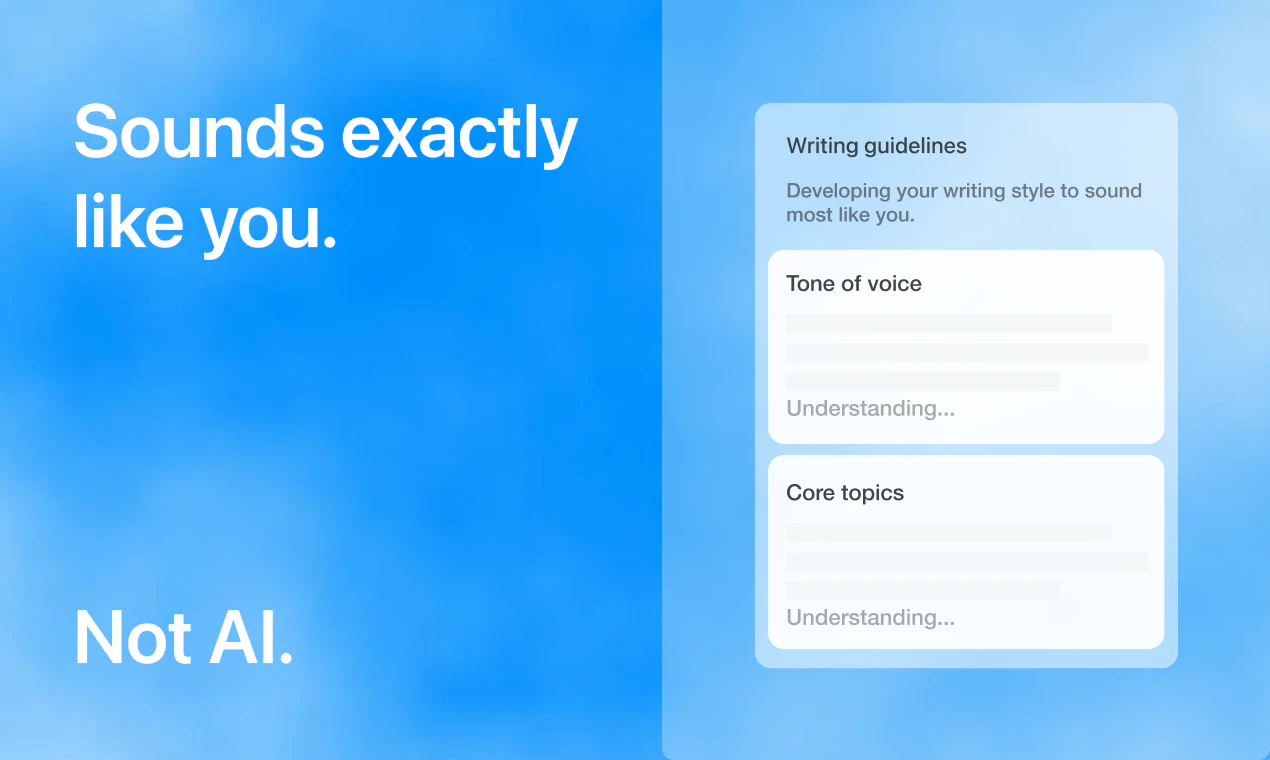
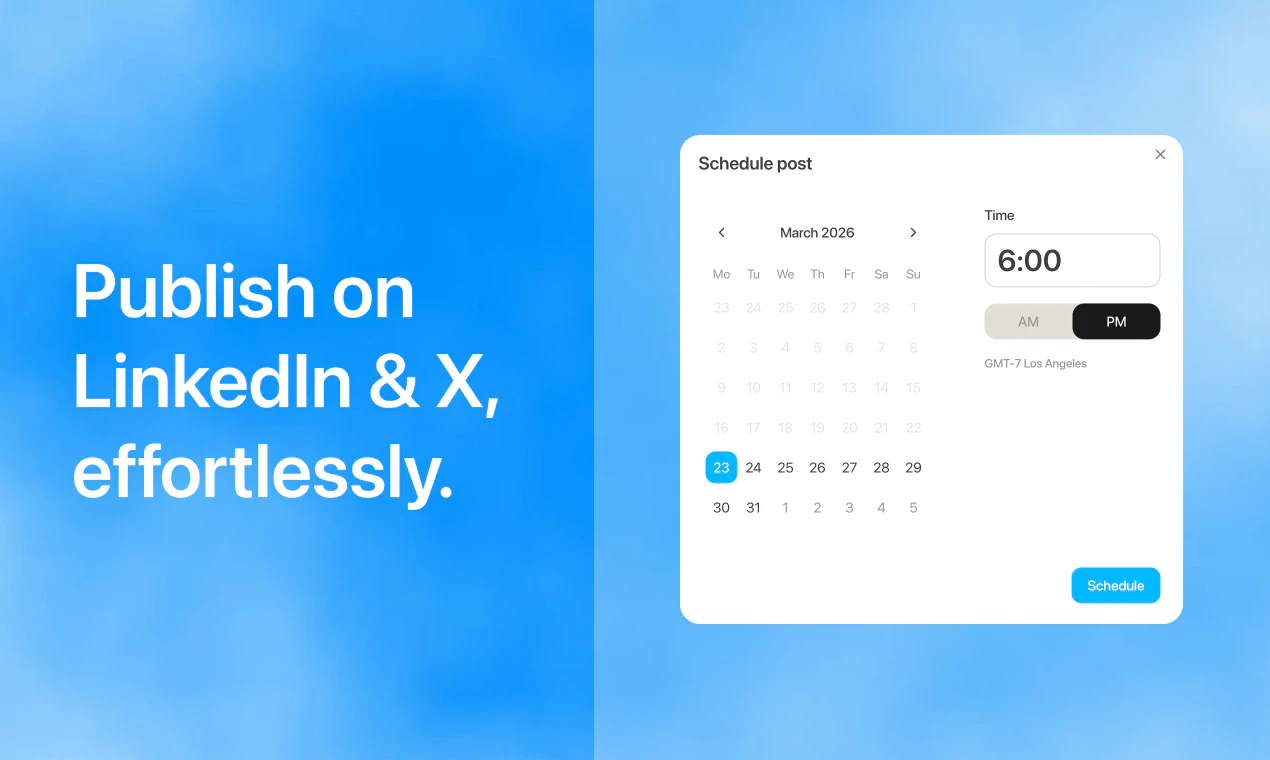
一句话介绍:Ghostwriter是一款AI代笔工具,帮助用户在LinkedIn和X上自动撰写、排期并发布个人品牌内容,解决内容创作耗时且难以持续更新的痛点。
Productivity
Writing
Social Media
AI代笔
社交媒体管理
内容自动化
个人品牌
LinkedIn
X
排期发布
语音模仿
内容创作
工具
用户评论摘要:用户关心AI是否能准确模仿个人写作风格(冷启动时如何学习);支持哪些平台(Threads、Bluesky在路线图上);能否自定义附件媒体(支持上传,即将支持图片生成);以及LinkedIn是否会对AI生成内容降权(回复称无影响)。有用户反馈beta版节省时间且效果不错。
AI 锐评
Ghostwriter的定位并非又一个“帮你写”的AI套壳,而是一个完整的“内容发行闭环”。它将起草、风格定制、排期、跨平台发布整合到单条流水线,切中了个人品牌建设中最棘手的“一致性”问题——不是你不会写,而是你坚持不下来。从评论区看,产品在“风格模仿”和“冷启动”上的策略(基于个人资料生成主题、提供头脑风暴功能)初步获得了用户信任,但这也正是其核心竞争力所在:系统能否在无人干预的情况下,持续产出与真人高度一致的内容,并保持情绪连贯性?如果这一环节只靠pre-set tone或短期反馈微调,而非动态学习用户最新表达习惯(如转发热文、评论互动后的人格变化),那它终究会沦为“更顺滑的ChatGPT包装”。此外,当前仅支持LinkedIn和X,规划中的Threads、Bluesky使其有望成为多平台分发枢纽,但这对算法公平性(各平台对AI内容的态度)与品牌一致性提出了更高要求。总体而言,Ghostwriter抓住了高杠杆、低频但影响巨大的“个人内容引擎”需求,但要想真正站住脚,必须证明自己不是又一个文案转述工具,而是能反向激励用户输出真知灼见的“内容伙伴”——否则,它只会在最后两轮点赞中消亡。
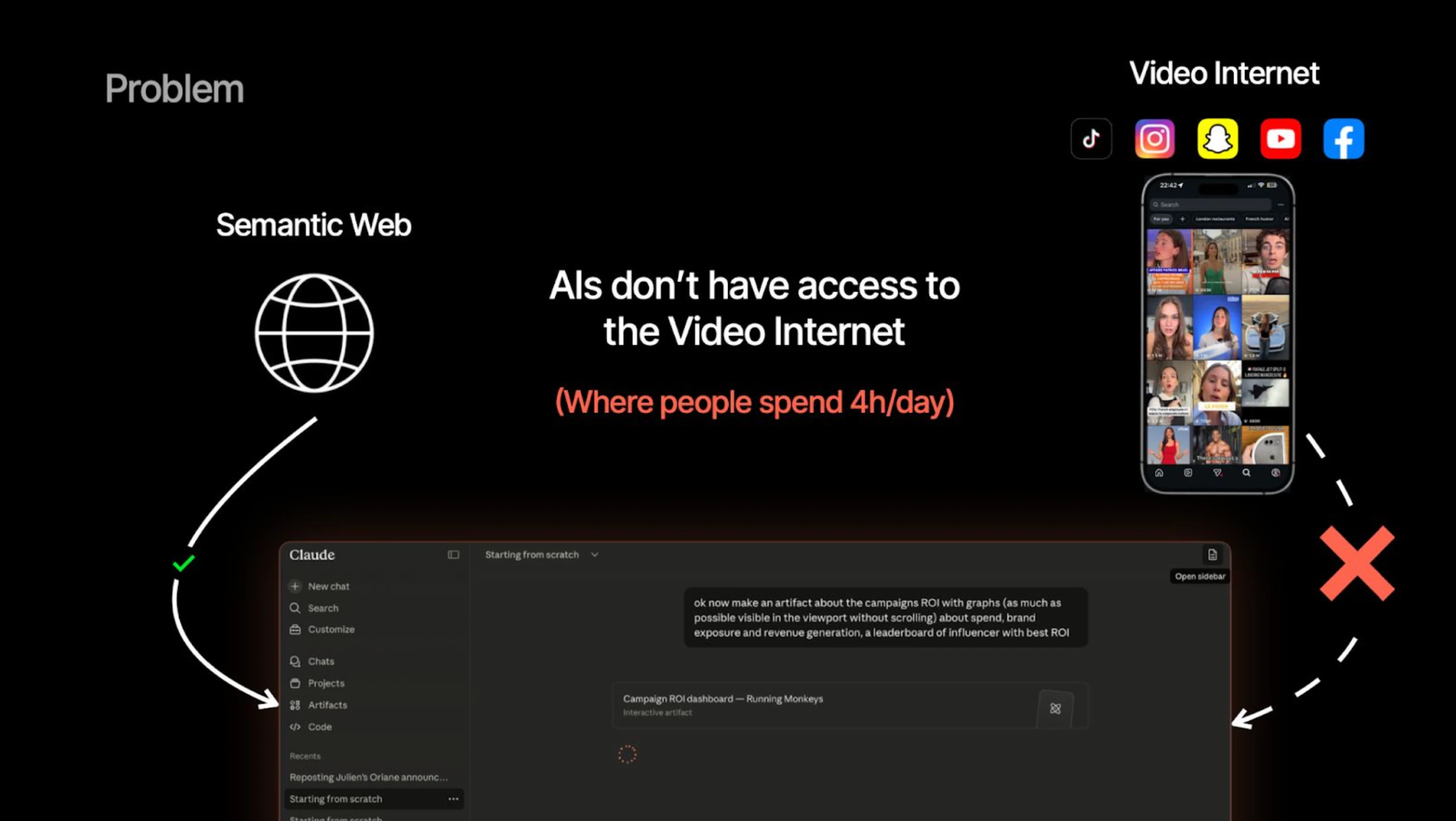
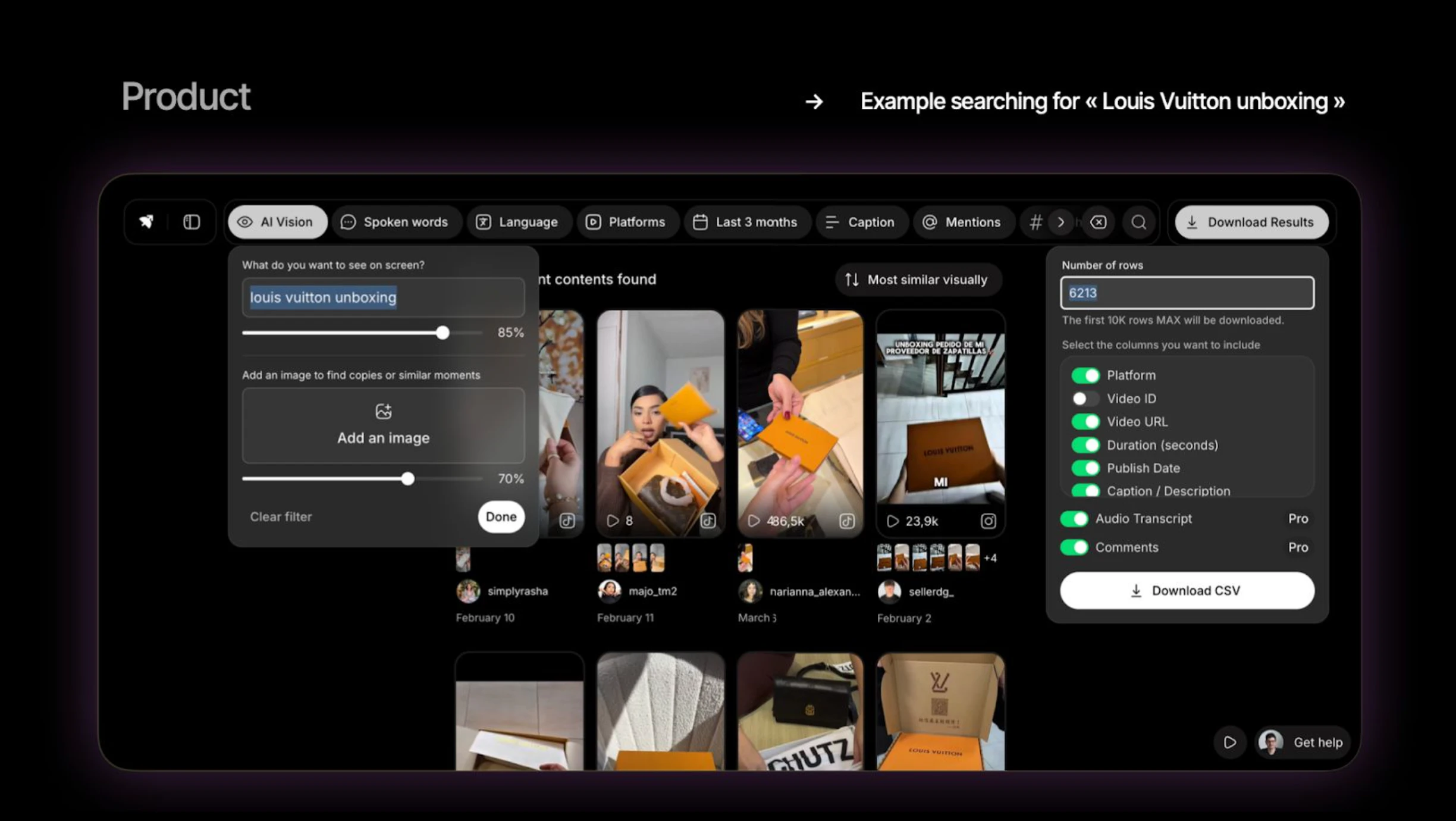
一句话介绍:Oriane是一个为营销团队及其AI打造的“感知层”,通过实时观看并结构化分析海量社交媒体视频(TikTok、Reels等)中的画面、音频和字幕,解决传统工具仅能处理文字而无法理解视频内容,导致品牌无法追踪视频内曝光、发现趋势和挖掘创作者的核心痛点。
Influencer marketing
Social media marketing
Pitch NYC
SaaS
视频内容分析
AI营销
社交聆听
计算机视觉
创作者经济
品牌监测
趋势发现
多模态AI
视频向量化
用户评论摘要:用户核心关注技术突破(1000倍成本降低)和实际应用。主要反馈:1)趋势新鲜度(36小时生命周期内的延迟问题);2)数据量大,需强大过滤能力避免信息过载;3)搜索速度和学习曲线;4)对视频内语义、意图及多模态(如音乐)分析的进一步需求。创始人积极回应将优化搜索模板和AI报告层。
AI 锐评
Oriane的价值在于它精准刺穿了传统社交聆听最大的“皇帝新衣”:用处理文字的思维处理视频。它做的事不是简单的转录,而是构建了一个将视觉、听觉和文本三流合一的“感知层”。从“把10万视频向量化成本从6万降到60美元”这个技术亮点来看,团队确实通过工程创新把不切实际的赛道变成了可规模化落地的生意,这是Oriane真正的护城河。
然而,产品正面临从“炫技”到“落地”的关键鸿沟。评论中反复出现的“数据噪声”和“学习曲线”不是小问题,而是产品价值兑现的死穴。对品牌方而言,从400条杂乱结果中人工筛选出洞察,比没有数据更痛苦,这说明现在的输出更多是“情报”而非“决策”。创始人承诺的LLM报告层和搜索模板,本质上是在帮用户补足“分析师”的角色,这步棋走对了,但实施难度极高——如何把品牌意图精准转化为视觉搜索逻辑,需要有深度的行业知识嵌入。
另一个隐患是“快”。短视频生态消化趋势只需36小时,涉足该市场必须与内容流速赛跑。目前的客户群体是拥有成熟策略师团队的顶级广告公司和奢侈品牌,这证明了产品的底子够硬,但也暴露了其现阶段的高使用门槛。如果Oriane不能快速将复杂能力封装成低门槛的即插即用产品,它将永远困在“高端定制工具”的狭窄市场里,无法动摇Brandwatch们的根基。其真正的未来,在于能否成为AI Agent时代“眼耳”的标准接口,但在此之前,先要解决如何帮普通市场经理“看见”而不只是“看到”的问题。
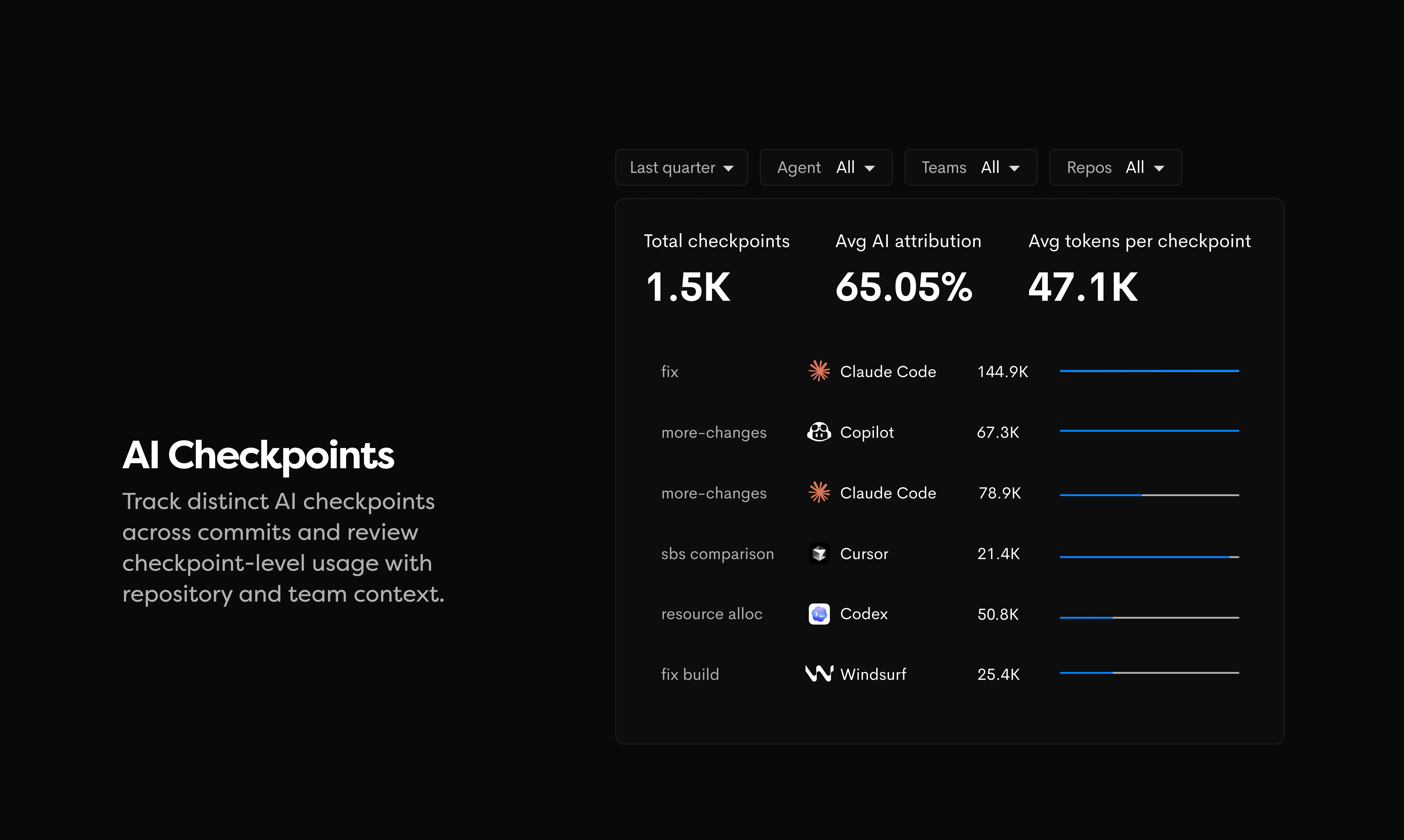
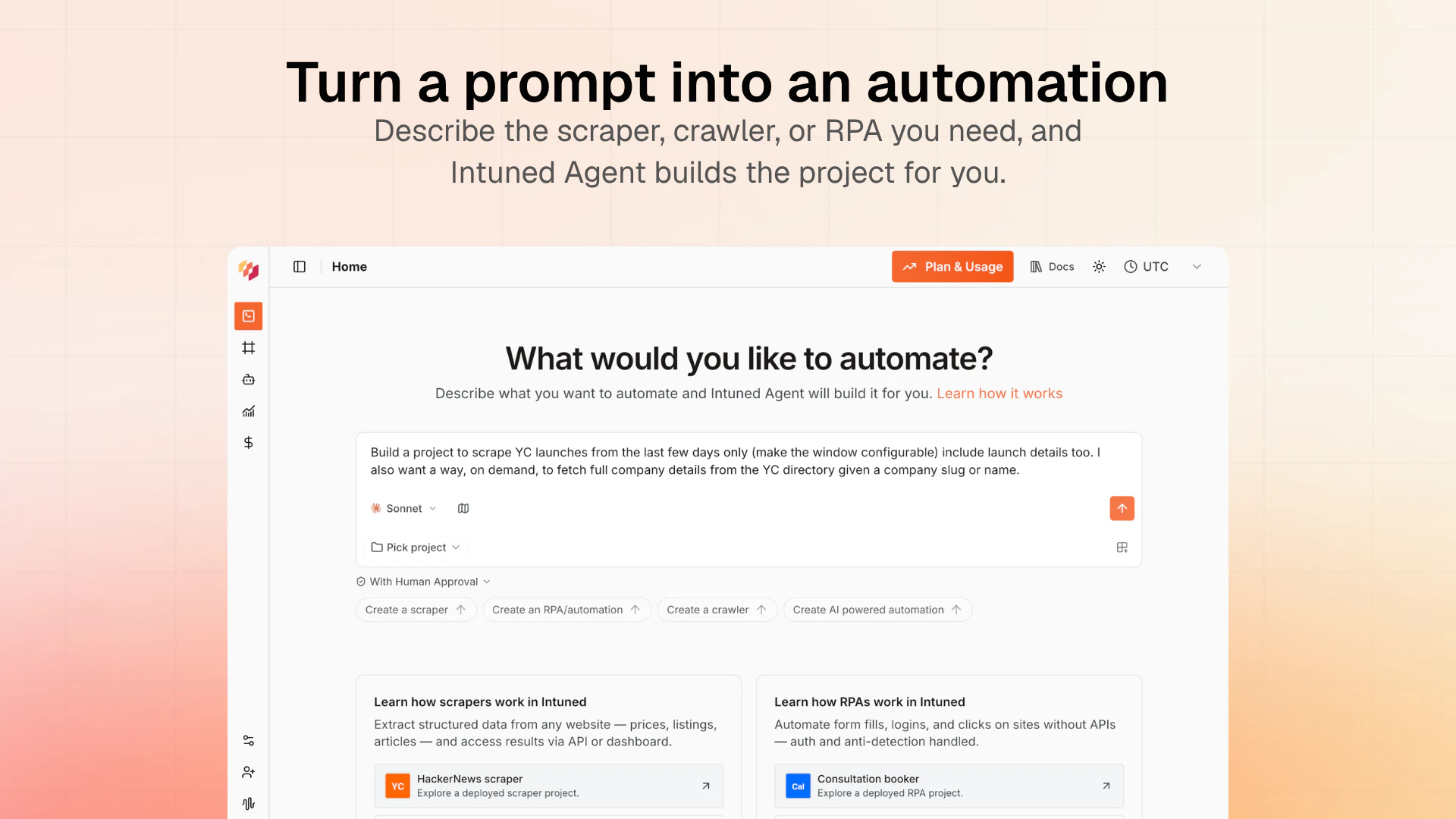
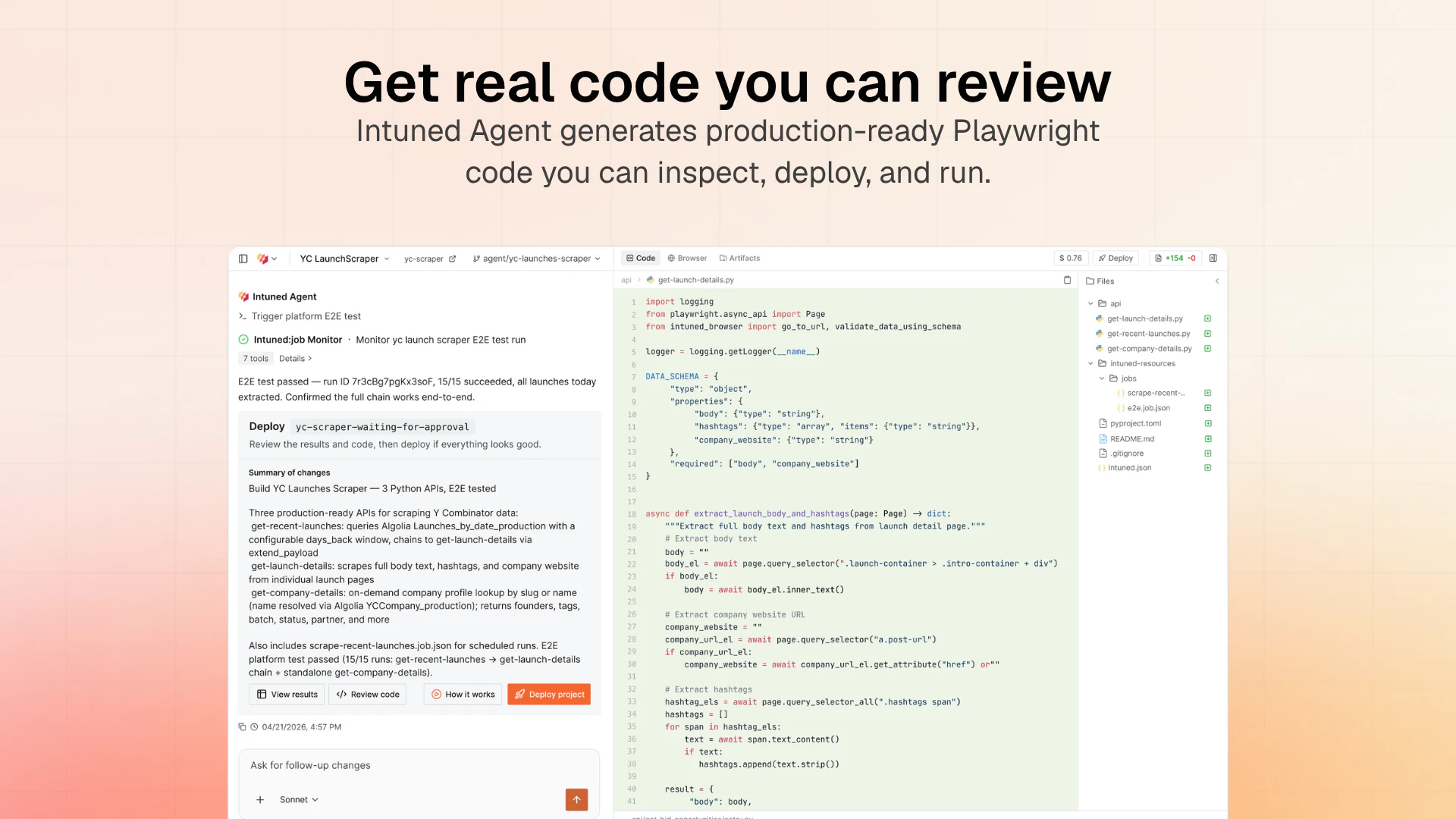
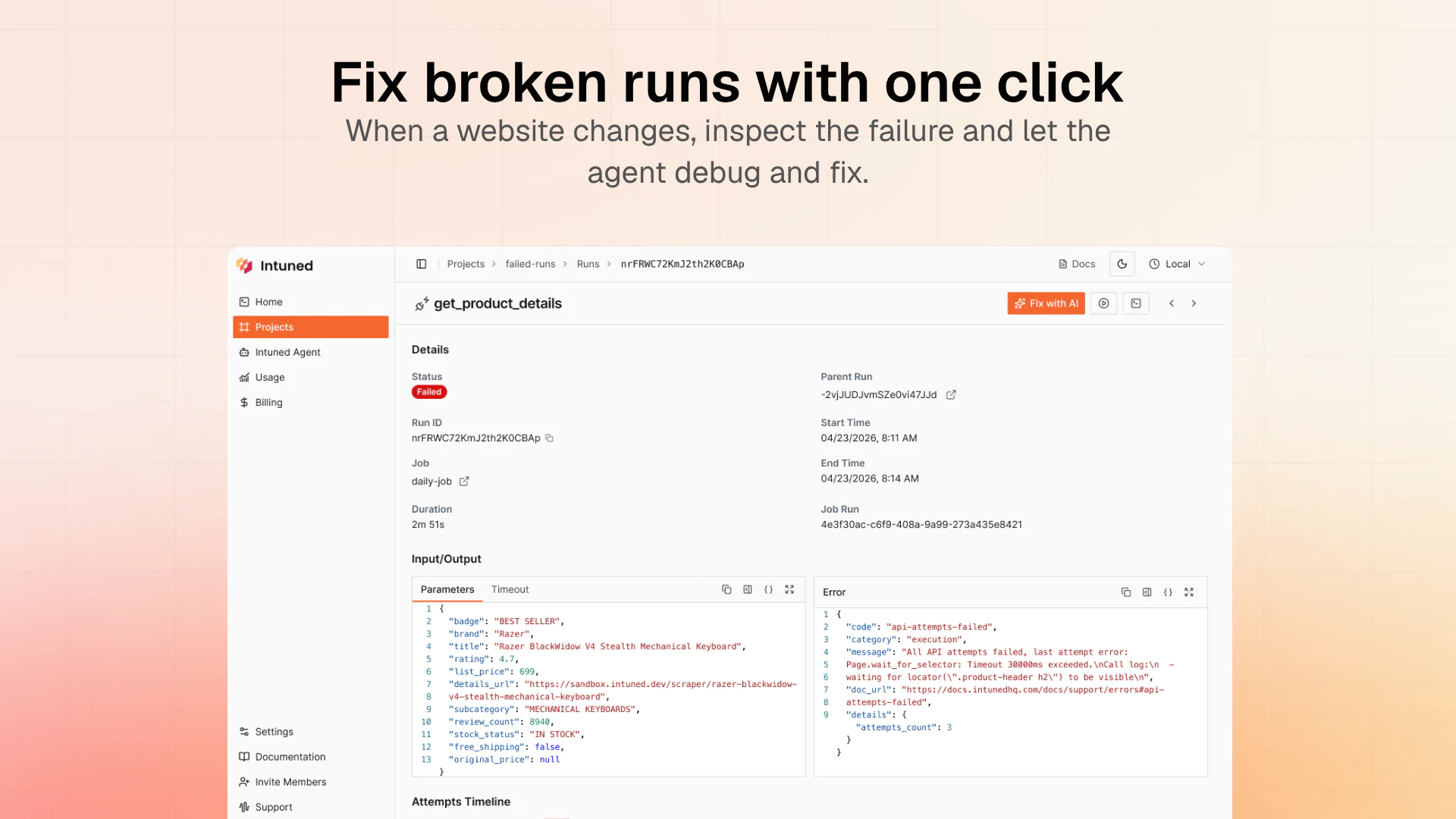
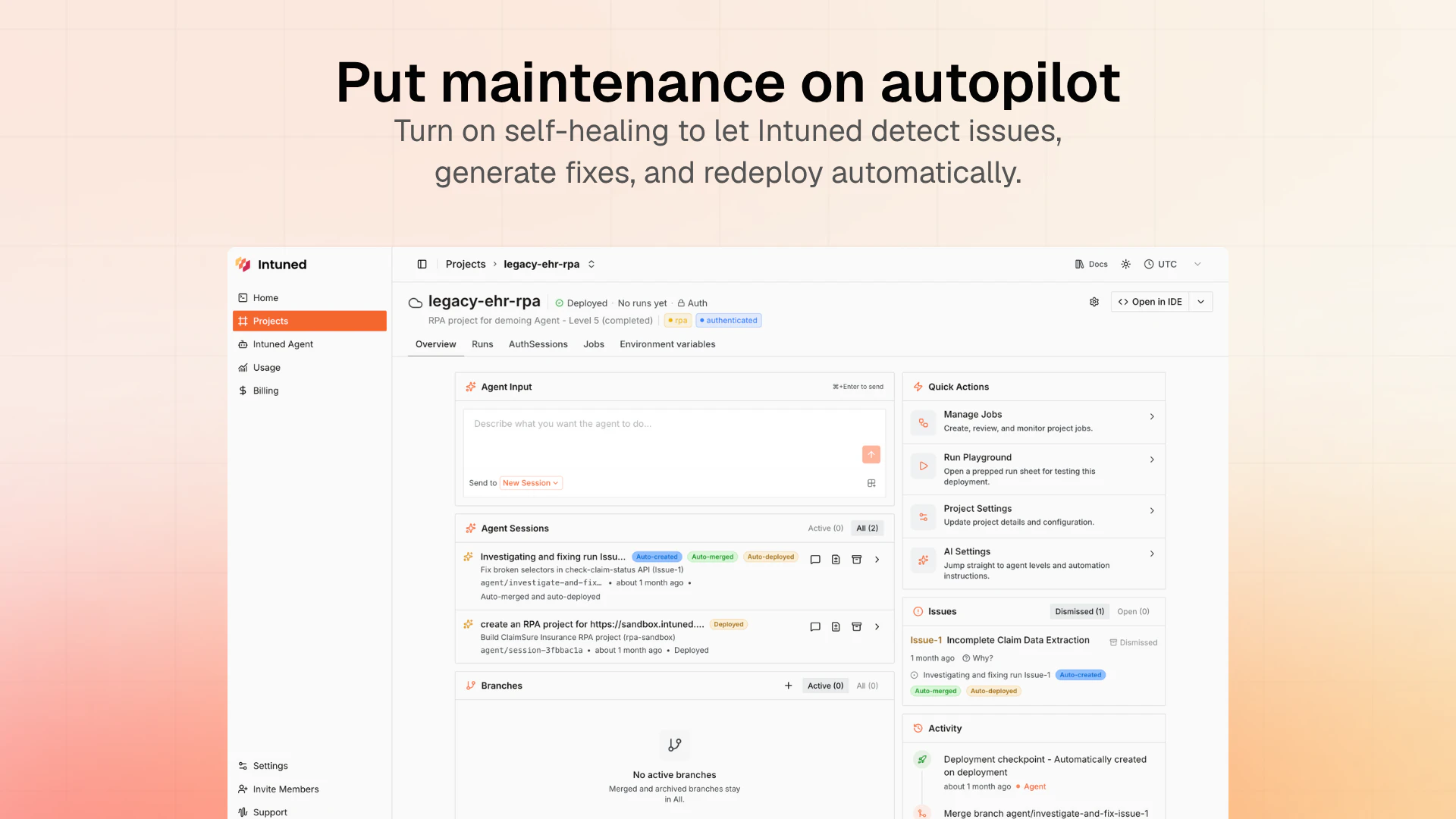
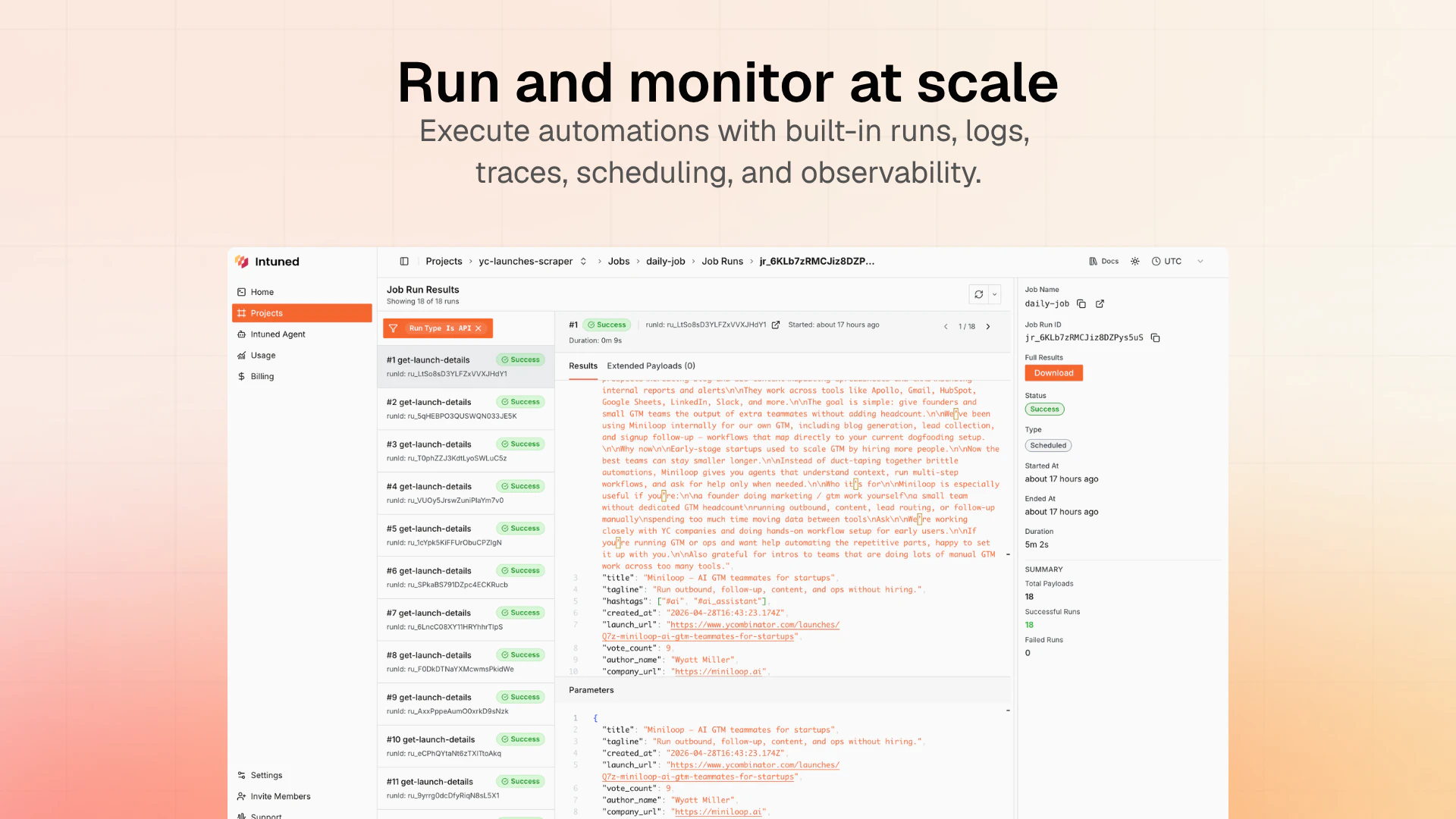
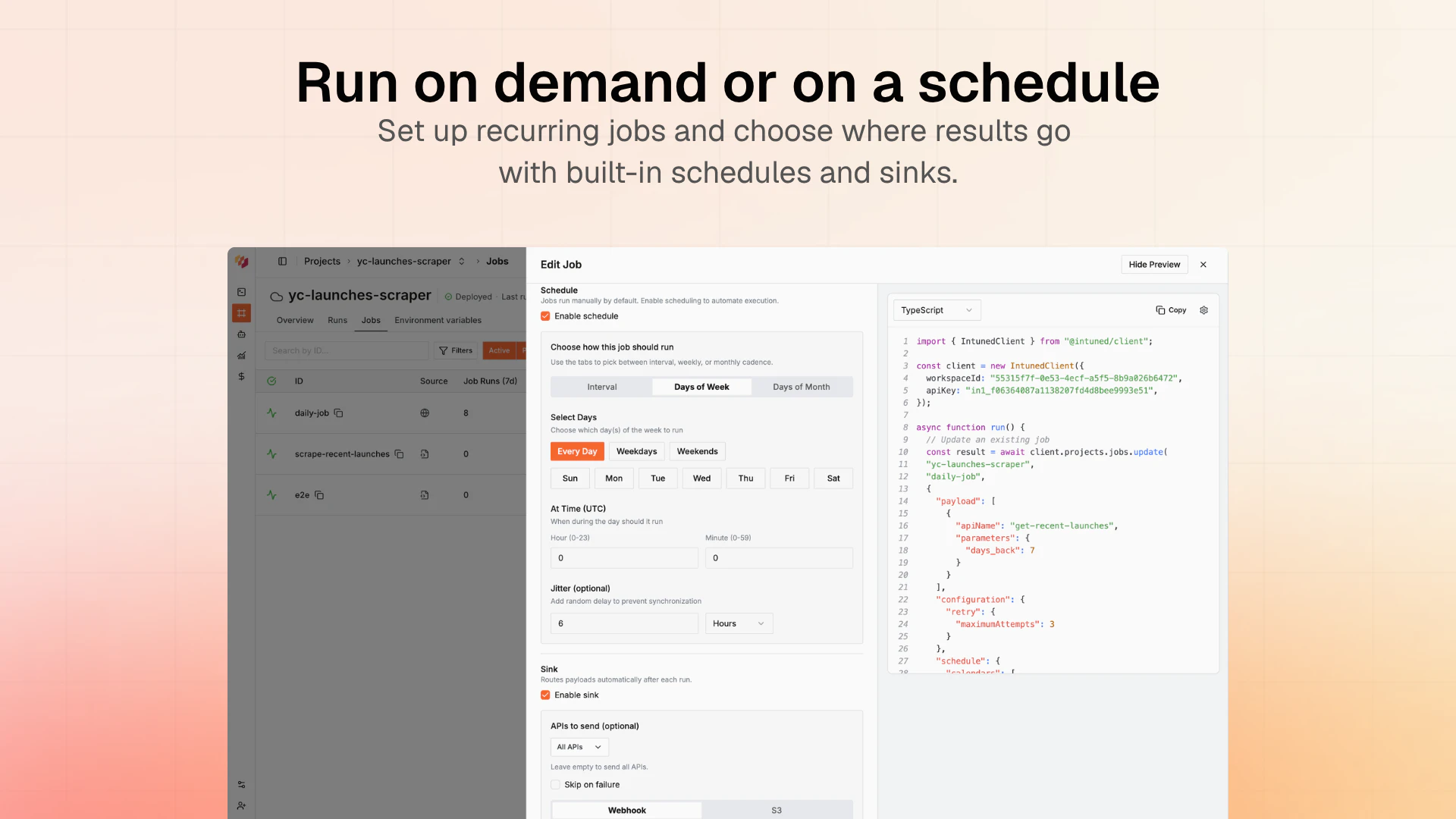
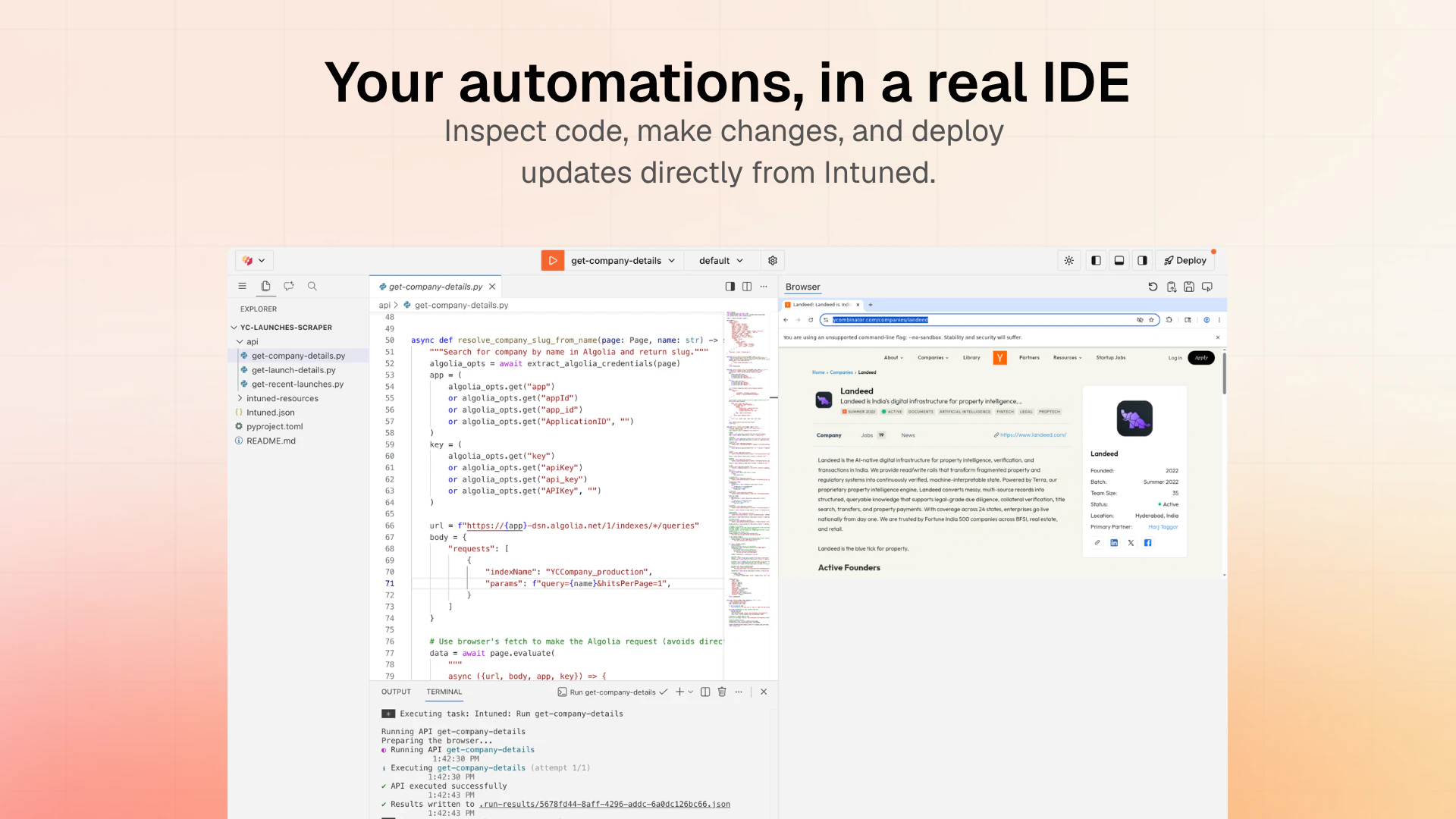
一句话介绍:Intuned Agent 是一款将AI代理直接嵌入生产级浏览器自动化基础设施的产品,让用户通过自然语言描述即可构建、调试和自动修复爬虫、RPA等工作流,解决了传统自动化脚本脆弱、维护成本高的问题。
Productivity
Developer Tools
Artificial Intelligence
AI代理
浏览器自动化
爬虫
RPA
自愈
Playwright
Claude SDK
生产级
代理/反检测
代码生成
用户评论摘要:用户关注自愈功能的触发机制与准确性,担心误报或漏报;询问修复流程(如PR审查)及对认证流程等敏感操作的信任度;认可Infra集成是亮点,但质疑“中间运行时漂移”等复杂场景下的可靠性。
AI 锐评
从“提供工具”到“提供劳动力”,Intuned Agent完成了一次漂亮的商业逻辑跃迁。其核心价值不在于又一个AI代码生成器,而在于将“自愈闭环”变成了产品化服务。市面上90%的AI爬虫都在解决“写代码”这个相对简单的环节,却对“代理、反检测、超时、站点改版”等80%的维护成本视而不见。Intuned的聪明之处在于,它直接建设了生产运行所需的全部基础(Auth、Stealth、CAPTCHA处理等),再让AI Agent坐在“运维工程师”的位子上,通过监控指标异常来触发诊断和修复,而非依赖单次任务的成败。
这种模式听起来很“自动化”,但风险也明牌:在长运行、多步骤的复杂流程中,AI的“中间漂移”问题(即因页面渲染变化导致后续步骤理解错位)仍未得到令人信服的解决。评论中用户对“信任梯度”和“误报阈值”的追问,直指痛点——自愈的自愈本身才是一项高成本工程。此外,产品严重绑定Anthropic的Claude模型,如果模型输出不稳定或平台策略变更,整个产品的护城河将面临挑战。
综上所述,Intuned Agent是一个优秀的“垂直Agent”实践,它解决了过去靠“人肉运维”的沉重负担,但也把可靠性风险从“代码逻辑”转移到了“模型与监控的缝合处”。对于追求高度确定性的企业级场景,它仍需提供更硬核的“审计与回滚”能力来建立信任,而不是让用户“边睡边祈祷”。
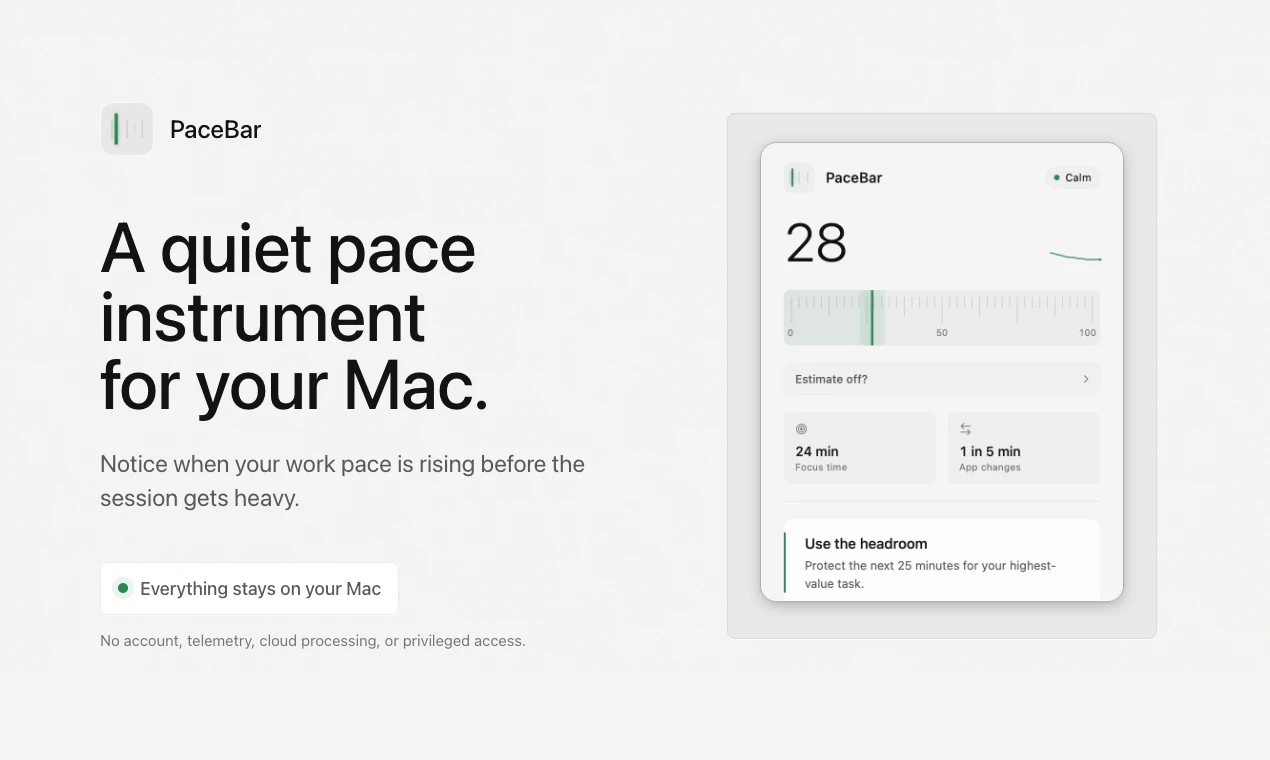
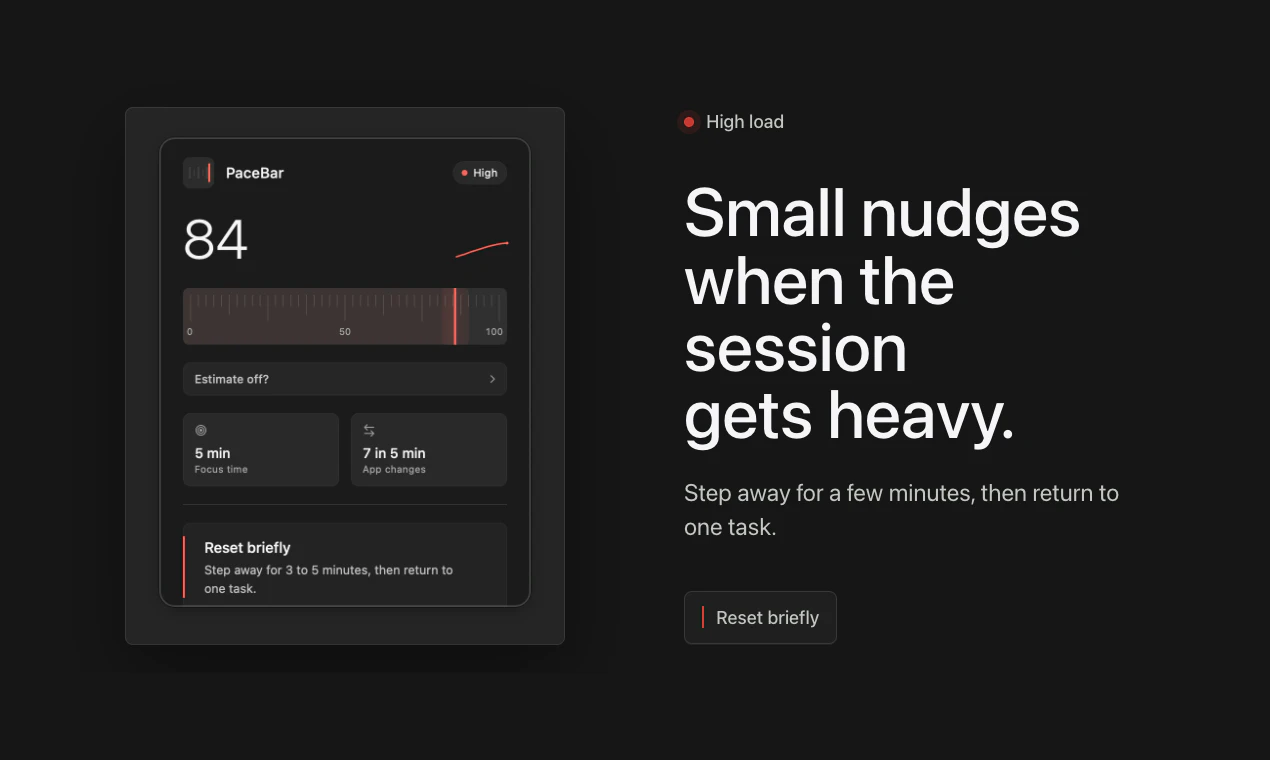
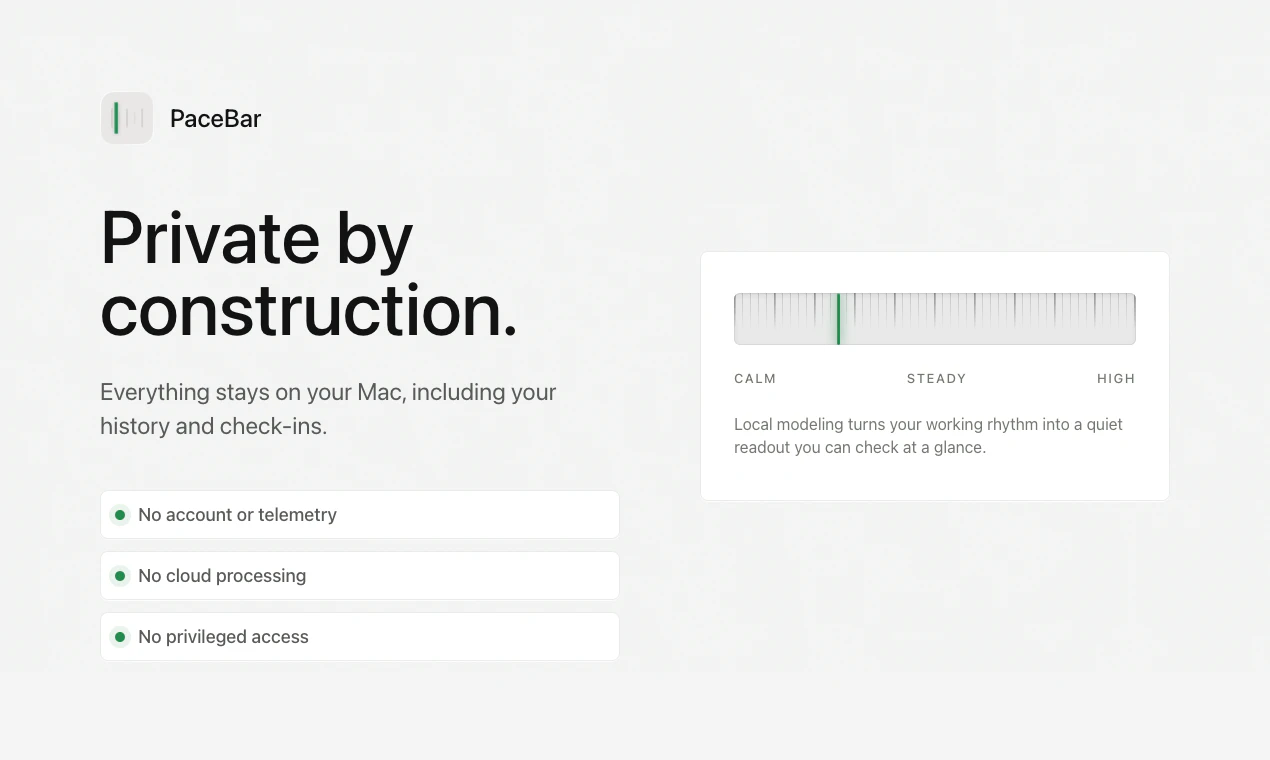
一句话介绍:PaceBar 是一款驻留在 Mac 菜单栏的安静工具,通过分析本地交互模式(如活动时长、闲置时间、应用切换频率)生成 0-100 的“工作负荷指数”,在你不自觉陷入多任务混战时及时提醒,帮你避免过度消耗。
Mac
Productivity
Menu Bar Apps
Mac 菜单栏工具
工作节奏监测
专注力管理
防过度疲劳
隐私安全
无云端处理
本地行为分析
会话负荷
应用切换提醒
极简生产力
用户评论摘要:用户关注会话起止的判定逻辑(基于闲置/日历/手动?),并希望增加周/月历史数据回顾功能。还有用户因欧盟DSA验证暂无法下载,开发者承诺尽快全球发布。总体反馈积极,核心疑虑围绕“轻量”与“历史记录”的平衡。
AI 锐评
PaceBar 精准切入了一个被忽视的痛点:我们往往在“已经累垮”时才后知后觉,而非在“节奏失控”的早期收到信号。它没有重复造“番茄钟”或“应用计时器”的轮子,而是提供了一个“心率监测器”式的隐喻——不干预,只反射。这种克制恰恰是它最有价值的地方。从产品思维看,它用“回避Dashboard”的姿态反衬出多数效率工具的“数据自恋”病态:过度量化、追求记录一切,反而增加了认知负担。PaceBar 的“0-100 负荷读条”简化了决策成本,让用户只需瞥一眼就知道“现在该喘口气了”。但商业隐忧也在此:太安静的工具在传播上天然吃亏。无法生成漂亮的周报、无法分享专注排名,意味着病毒系数极低。评论区用户对“历史数据”的期待也暴露了产品未来可能陷入的矛盾:一旦加入回顾功能,就可能滑向“Dashboard”的泥潭,丧失“安静”的初心。此外,应用场景高度依赖用户自主性——只有对自身状态敏感的人才会有意识地看菜单栏,而这类人往往已经能自我调节。真正的“失控型”用户可能根本不会装它。总体而言,PaceBar 是献给数字时代里“过度清醒者”的一把标尺,不是救命药,而是一面让你不得不看自己跑姿的镜子。
一句话介绍:Firstwork通过AI代理为一线岗位(如医护、物流、零售)打造从招聘到入职的运营自动化流水线,将验证、培训、排班、合规等碎片化流程整合到单一管道,加速员工上岗并降低审计风险。
Hiring
Artificial Intelligence
Pitch NYC
AI招聘
一线劳动力管理
入职自动化
合规引擎
文档验证
排班调度
运营流程
人力资源科技
Staffing
Audit Readiness
用户评论摘要:用户普遍认可Firstwork解决了一线入职流程碎片化痛点,尤其称赞“合规规则引擎”显著节省操作时间。有用户提问如何应对入职后临时缺席和国际化人才入职问题,以及针对创业公司的定价。部分用户将其与Greenhouse、Workday等进行对比,团队澄清自己侧重运营层而非纯粹招聘流程。
AI 锐评
Firstwork的价值并不在于又做了一个“AI招聘工具”,而在于它瞄准了人力资源技术中一个被严重忽视的“灰色地带”——一线岗位的运营执行层。ATS(申请人追踪系统)和HRIS(人力资源信息系统)巨头们垄断了候选人的“获取”和“记录”,却遗忘了从“录用”到“第一天上班”之间那段漫长的、充满手工协作的流程沼泽。Firstwork精准地切入这个“入职黑箱”,将文档验证、合规校验、排班同步等低效、高风险的“脏活”自动化,其核心壁垒在于处理“同一人多个证件”的复杂匹配逻辑,而非简单的OCR(光学字符识别)。评论区中,“审计就绪”与“招聘速度”被并列讨论,反而揭示了产品的隐藏价值:在高监管行业(医疗、能源),合规风险的成本远高于招聘速度延迟,Firstwork实际上售卖的是“合规保险”。然而,产品高度依赖垂直场景(如美国医疗执照系统),地域扩展性存疑;且若大型HR系统未来将这部分功能内建,Firstwork的生存空间可能被挤压。当下,它是最佳补位者,但能否变成新标准,取决于其能否从“管道”进化为“操作系统”。
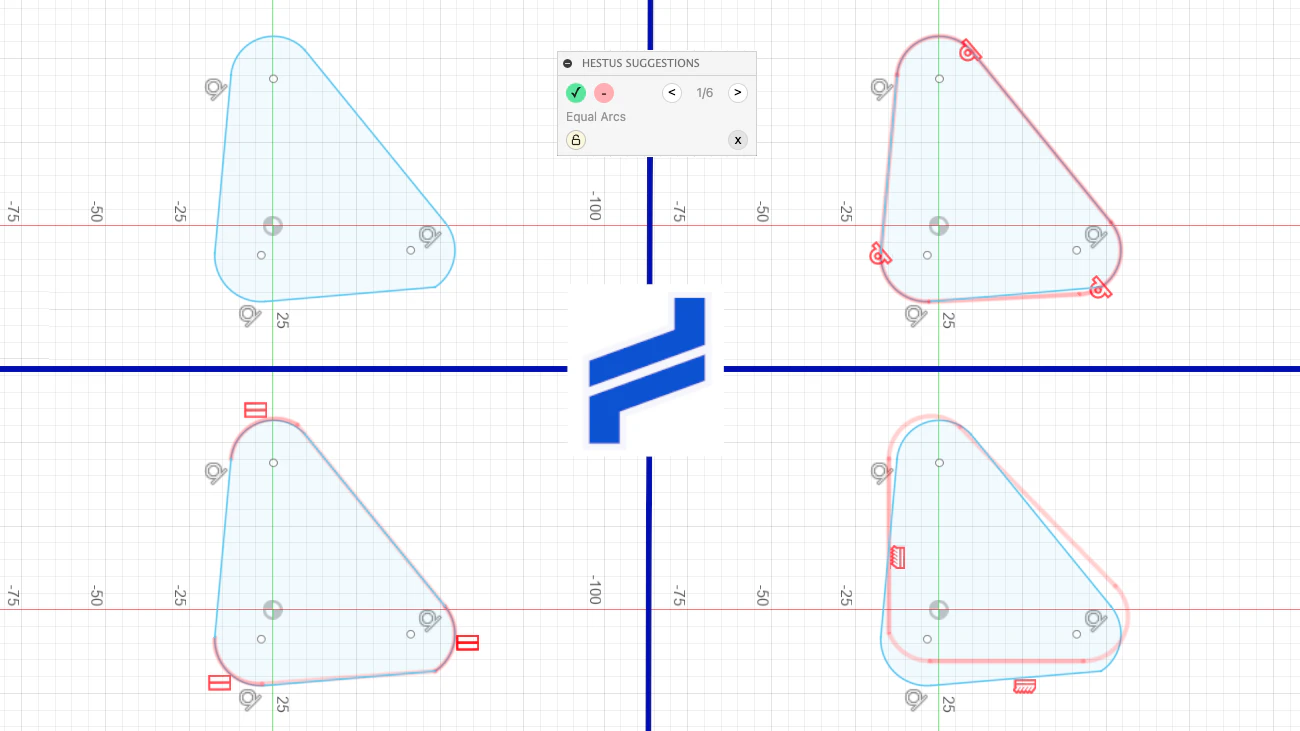
一句话介绍:Hestus 是一款原生集成于CAD环境中的智能自动补全工具,旨在通过实时预测设计师的下一步操作,大幅提升建模速度并减少点击次数,解决传统CAD设计流程中的重复性低效问题。
Design Tools
3D Printer
Pitch NYC
CAD自动补全
设计意图预测
原生集成
效率提升
Fusion 360
Solidworks
工业设计
辅助设计工具
3D建模
AI辅助
用户评论摘要:用户普遍看好(“v cool! good work”),并关注软件兼容性。已有用户询问除Fusion外是否支持其他CAD软件,官方回复称Solidworks已进入内测,将于六月全面开放。
AI 锐评
Hestus 的核心价值在于它精明地绕开了当前AI辅助设计工具的两个常见陷阱:一是“提示词依赖症”(需要用户学习新交互范式),二是“工作流断层”(需要导出/导入数据)。它选择以“原生插件”的形态,在用户熟悉的CAD语境里做“减法”——不是创造一个更智能的新工具,而是让现有工具变得更“懂你”。
这种策略极其务实且聪明。它瞄准的痛点是设计流程中大量重复、可预测的“肌肉记忆”操作(如固定几何约束、标准特征阵列等),通过算法实时解析“设计意图”来预测下一步,这比自然语言提示更符合设计师的触觉思维。2.5倍速度和4倍点击减少的数据,如果能在复杂模型中稳定复现,将是一个量级的生产力提升。
然而,其真正的护城河不在于算法,而在于生态。目前仅押注Fusion 360和即将开放的Solidworks,远未覆盖Catia、NX、Creo等高端工业软件。这些软件的用户体量虽小,但客单价高、迁移成本极高,且对AI介入的稳定性要求近乎苛刻。此外,实时预测的准确率是双刃剑:当预测准确时,它是“神队友”;一旦频繁误判或打断设计思路,就会变成“令人暴躁的自动纠正”。Hestus需要证明它的模型不仅快,而且在复杂、非标准的设计场景中足够“隐形”且可靠。总体而言,这是一个方向正确、落地谨慎且极具B端商业化潜力的产品,但能否从小圈子口碑扩散到硬核工业领域,是其从“酷工具”蜕变为“生产力标准”的关键。
一句话介绍:Dina是一款macOS全栈视频创作工具,专为屏幕录制后的“后期噩梦”而生,让用户在单一软件中完成屏幕录制、剪辑、AI降噪、字幕生成与导出,省去在多个应用间反复跳转的繁琐流程。
Productivity
Marketing
Video
macOS视频工具
屏幕录制
AI剪辑
转录驱动编辑
自动字幕生成
文本转语音
视频标注
创作者工具
AI降噪
8K导出
用户评论摘要:用户关注多语言转录支持(德语等)和导出时的编码/码率可调性;希望录制中能实时标注。创始人回应称转录支持任意语言并可选模型,导出采用原生高码率。早期用户赞赏迭代速度和注释功能,建议修复官网残留旧名“Phia”的内容。
AI 锐评
Dina的定位精准戳中了内容创作者一个长期被忽视的痛点:录制容易,后期难。它没有尝试在“录制”这个红海领域(如OBS)硬拼功能广度,而是将核心价值集中在“录后处理链”上——通过转录驱动剪辑、AI去填充词、一键降噪等自动化手段,把原本需要Premiere、Audacity、剪映等多个工具串起来的工作流,压缩到一个场景内。这种“岛屿式”解决方案对教程博主、产品演示制作者极为有效,因为他们的痛点从来不是画质或帧率,而是“把一段笨拙的原始录制变成体面的交付物”的效率。
然而,Dina的短板同样清晰。首先,它绑定macOS生态,PC用户根本无缘;其次,创始人评论中透露的“转录模型可切换”说明AI能力仍依赖本地算力,对于更复杂的多语言、方言处理,效果存疑。更关键的是,产品看似集成众多功能,但每一项的深度都值得推敲:字幕生成能否媲美专业工具的字幕对齐?降噪能否处理非语音噪声?8K导出是否只是分辨率拉伸而非真8K渲染?用户对码率和编码的追问,恰恰暴露了潜在的专业用户对“质量可掌控”的焦虑。
从一个工具到生产链基础设施,Dina需要证明的不只是“省去切换”,而是“每个环节都达到专业标准”。它走对了方向,但接下来要解决的问题,不是“再增加多少功能”,而是“现有功能能否经得起挑剔用户的审查”。否则,它很可能会沦为一个漂亮的“万能遥控器”,却终将被每个细分领域的专业工具逐一击败。
一句话介绍:Unity AI 是一套嵌入Unity 6+编辑器的AI辅助套件,通过项目感知助手、AI网关和MCP服务器,解决游戏开发中通用AI代理无法理解Unity特有工作流和项目上下文的痛点。
Artificial Intelligence
Games
Development
游戏开发
Unity编辑器
AI代理
AI游戏开发工具
工作流自动化
MCP服务器
第三方AI集成
项目上下文感知
开发辅助
Beta套件
用户评论摘要:用户称赞Unity针对游戏开发高上下文环境自建AI层,助手能理解Unity工作流、项目上下文(场景、组件、资产),支持第三方AI接入及撤销、权限等控制。评论整体正面,强调其解决通用AI代理不适配游戏开发场景的问题。
AI 锐评
Unity AI的推出是一次战略性的防守反击,而非颠覆性创新。在游戏开发领域,通用代码助手(如GitHub Copilot)正持续蚕食IDE市场,但它们对Unity这一高度专有、以场景和组件为核心的工作流几乎束手无策。Unity AI的核心价值不在于“AI有多强”,而在于“边界有多明确”——它精准地将AI限制在编辑器内、项目感知的范围内,并通过AI Gateway和MCP Server构建了可控的“第三方AI接入层”。这种设计既避免了开源社区对模型安全性的担忧(通过权限、撤销、资产标签等控制面),又为未来接入更强大的闭源模型留了后路。但Beta标签和仅94票的投票数暗示其完成度仍有待验证。真正的挑战在于:当AI开始直接修改游戏场景、资产标签甚至代码时,Unity能否在“效率提升”与“项目稳定性”之间找到平衡?如果控制机制过于繁琐,开发者会弃用;如果过于宽松,项目损坏风险剧增。此外,训练数据的质量与模型对最新Unity API的响应准确性,将是决定产品口碑的隐形门槛。一句话:方向正确,落地尚需打磨,不要把它当作“AI生成游戏”的捷径。
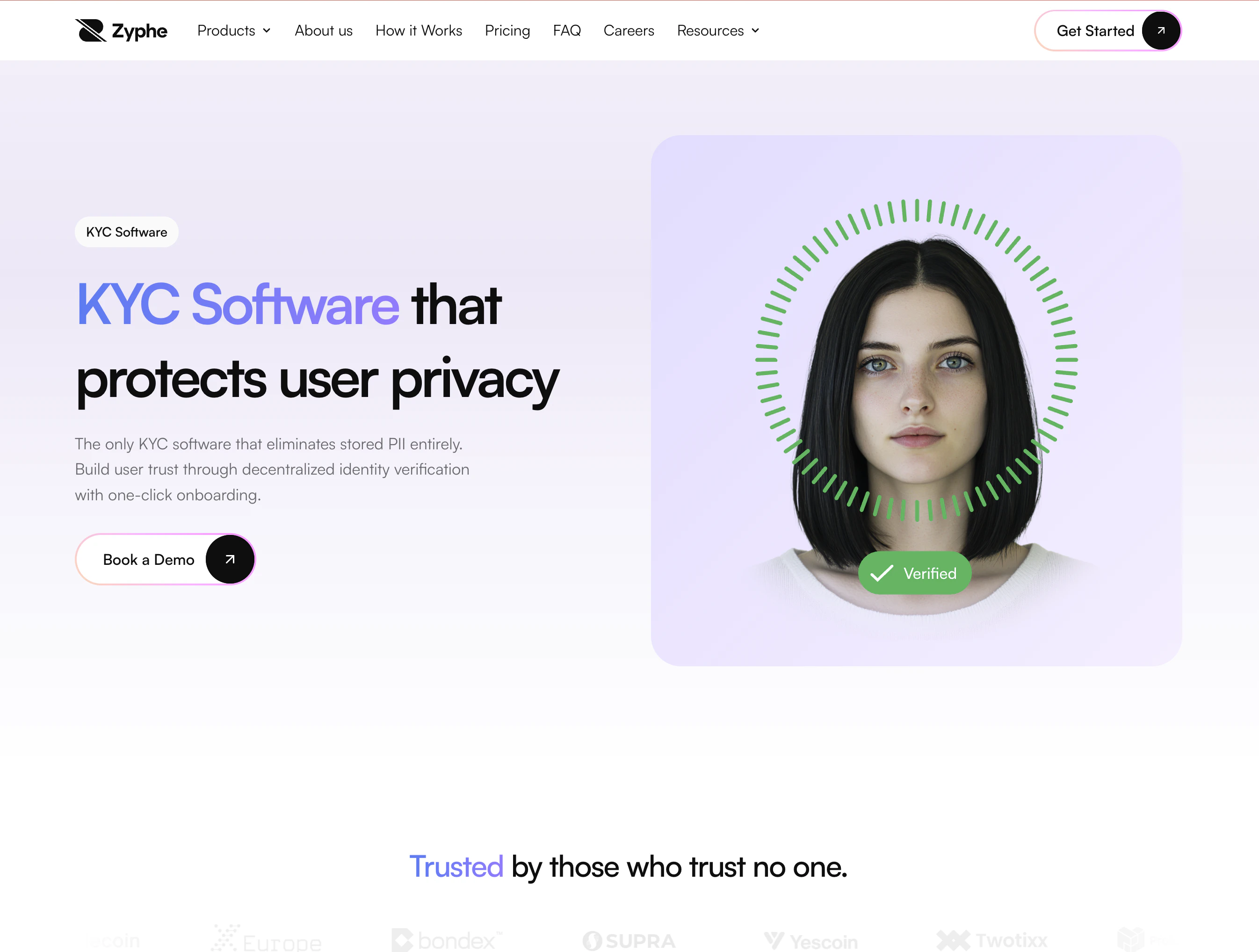
一句话介绍:Zyphe是一个去中心化、隐私优先的KYC/KYB合规平台,让用户“一次验证、多处复用”,并允许AI代理安全处理身份核验,彻底解决重复提交敏感数据和数据泄露风险。
Fintech
Privacy
Pitch NYC
KYC认证
KYB企业认证
隐私优先
去中心化身份
合规自动化
AI代理
数据复用
加密存储
零信任架构
身份安全
用户评论摘要:用户关心数据具体存储位置、加密与访问控制机制,要求“去中心化”的技术细节;对“一次验证、多处复用”高度认可;部分用户质疑AI代理处理合规流程的信任度;普遍认为产品切中当前合规痛点。
AI 锐评
Zyphe切入了一个真实且昂贵的痛点——合规流程中身份数据的重复提交与隐私泄露。其“代理优先+可复用凭证”理念在技术原型上并不新鲜(本质是自托管身份加代理重加密),但巧妙地将MCP协议与合规工作流绑定,让AI代理能在不接触明文数据的前提下执行核验,这比传统KYC SaaS(如Jumio、Onfido)更适配未来AI驱动的高频交互场景。
然而,真正的瓶颈在于规模化:要说服B端企业放弃自有数据库、接受“用户掌控密钥”的分布式模型,意味着合规审计、法律追责链条都要重构。目前93票的社区热度尚属早期,评论中对于“去中心化”的具体实现(如存储层是IPFS还是可信执行环境)尚存疑问,说明产品在技术透明度和企业级SLA保障上还有缺口。
一句忠告:别只强调“炫酷的加密”,尽快输出典型案例(比如哪些Pitch by Deel客户部署了),并解决企业最关心的“一旦用户丢密钥,合规记录如何补?”这个致命问题。否则,容易沦为又一个“技术很美,落地无门”的隐私工具。
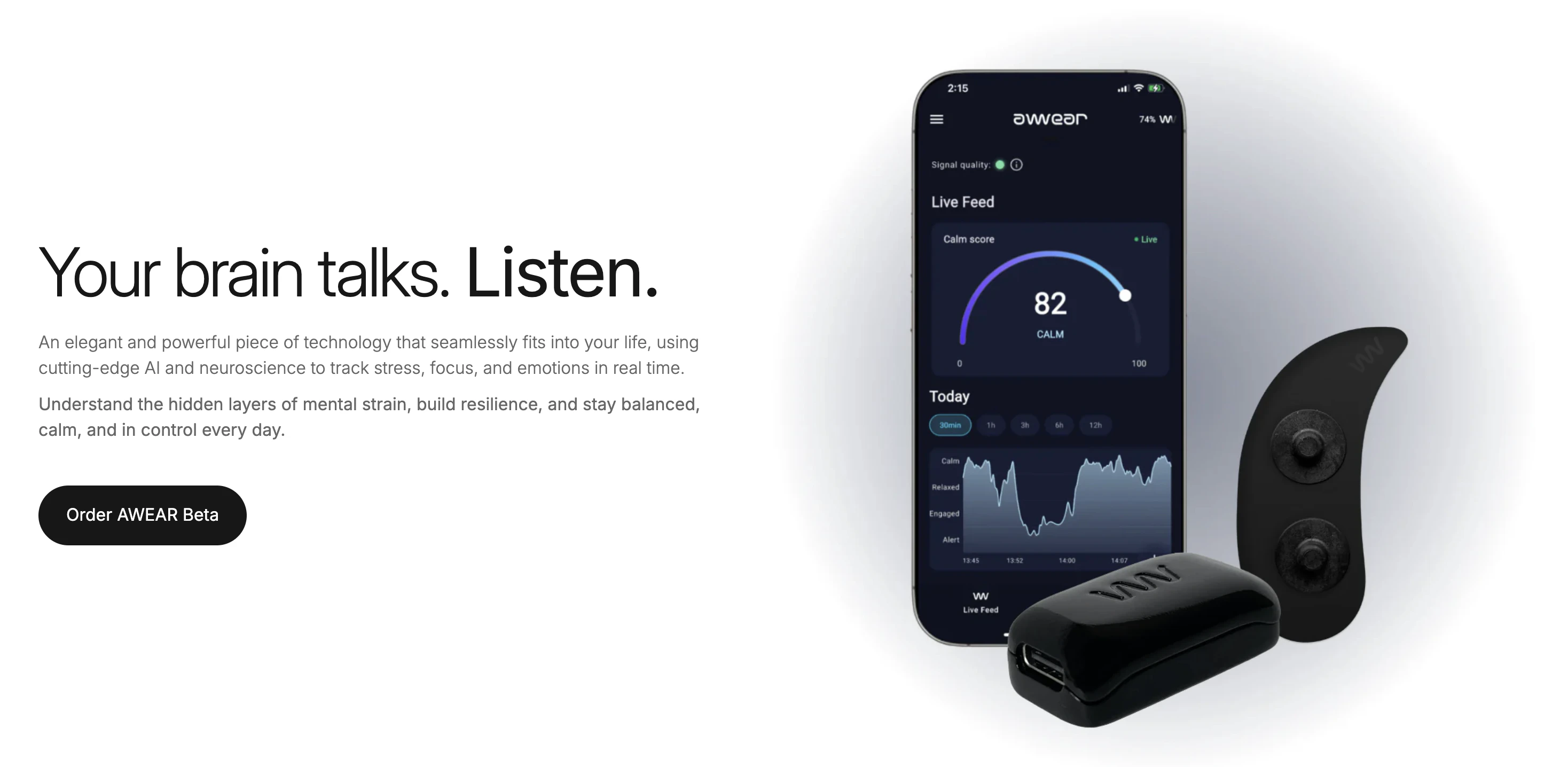
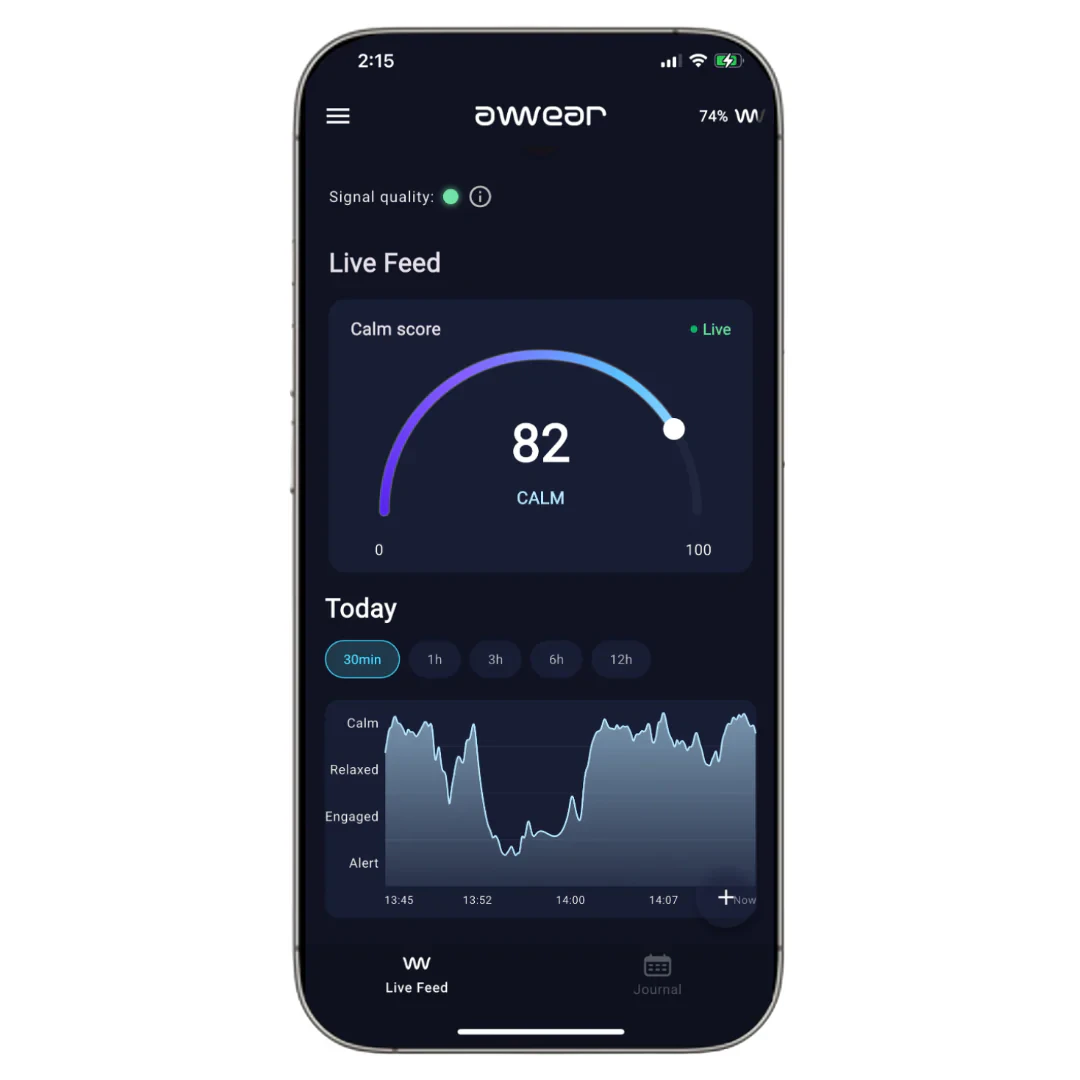
一句话介绍:AWEAR是一款隐蔽的耳戴式脑电图设备,通过实时捕捉脑电波,帮助用户在日常工作、学习或生活中监测压力、专注度和情绪状态,并提供呼吸练习等即时反馈,以改善心理健康。
Wearables
Biohacking
Pitch NYC
脑机接口
可穿戴设备
脑电图
心理健康
压力监测
专注力提升
情绪洞察
非医疗设备
神经科技
实时反馈
用户评论摘要:用户关注核心功能定义:有评论质疑“改善心理健康”的具体含义,团队回应称是通过测量脑波模式提供压力趋势与恢复建议。另一用户询问适用人群,团队明确为健康人士设计的非医疗级设备,不用于诊断或治疗。
AI 锐评
AWEAR切入了一个极具潜力的“软神经科技”赛道——将原本停留在实验室的脑电图(EEG)技术做轻、做隐蔽、做日常化。它主打“耳戴式”形态,相比头环更具社交接受度,这是产品设计的聪明之处。
但其价值目前仅限于“数据的可视化与简单反馈”。从评论回复看,产品能识别压力、紧张等情绪状态,并通过呼吸练习进行引导。这本质上还停留在“测-反馈”的闭环,与Apple Watch监测心率后提醒你深呼吸并无本质差异。关键在于,它是否真的能带来更底层、更独特的洞察。比如,是否能区分“积极专注”和“焦虑性思虑”?是否能捕捉到用户自己都未察觉的认知疲劳趋势?
AWEAR的价值不取决于它能“看到”多少原始脑波,而取决于其AI模型能在多大程度上将脑波信号转化为用户难以自行感知的、具备高行动指导力的心理状态指标。如果只是用EEG代替心率变异性做压力提醒,那就是科技加价但价值平替。真正“锐”的落脚点,是能否建立一套超越主观感受的“认知效能档案”,让用户不仅感到被提醒,更能了解自己的认知极限与恢复节奏——这才是从“监测设备”迈向“大脑私人教练”的关键一步。
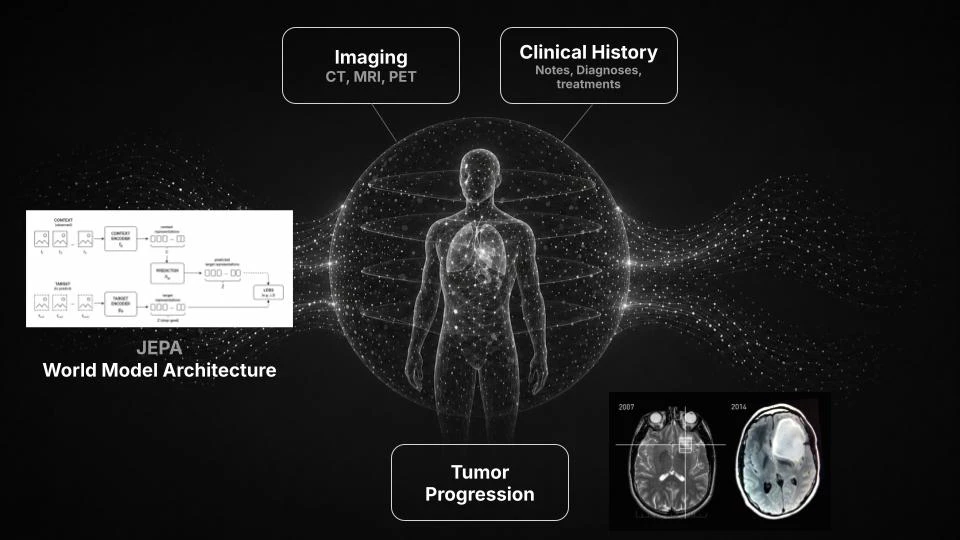
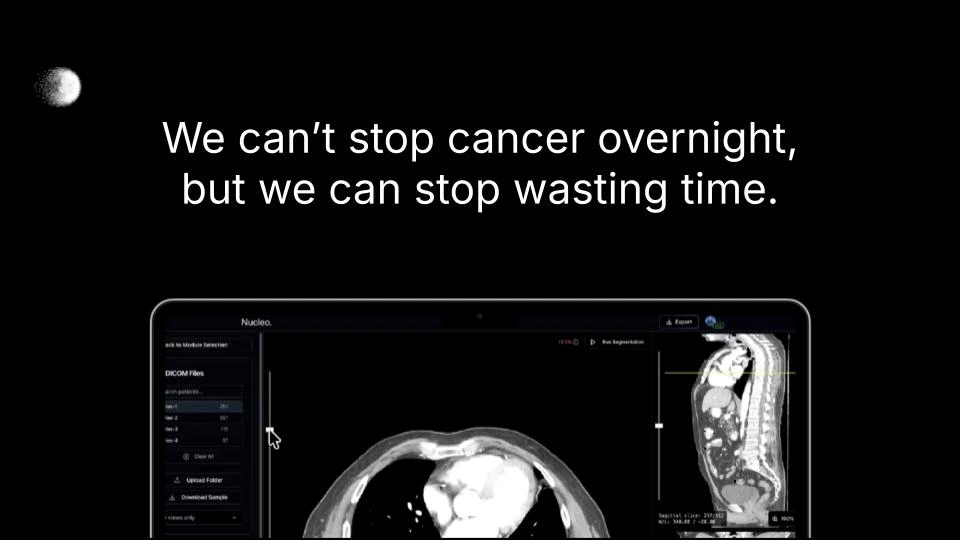
一句话介绍:Nucleo 是一款面向肿瘤科的自动化癌症诊断AI工具,通过分析患者完整的影像、治疗和临床历史数据,预测疾病进展,解决现有AI软件无法利用纵向病程信息帮助医生决策的痛点。
Pitch NYC
癌症诊断
医疗AI
世界模型
医学影像
肿瘤检测
疾病预测
临床工具
自动化分析
放射科
初创公司
用户评论摘要:用户评论较少且以创始人自述为主,核心反馈强调现有医疗AI仅分析单次扫描,忽视了病历纵向演变;Nucleo旨在通过构建肿瘤学世界模型,及基于收入流的成像工具(如体成分分析、肿瘤检测),来填补临床落地鸿沟。
AI 锐评
Nucleo的叙事很有野心——“世界模型”被套用在肿瘤学上显然是为了蹭AI圈最热的概念。但冷静来看,他们现在的产品不过是“自动化医学成像分析”,在体成分、肿瘤检测上已有无数成熟竞品,差异性并不显著。真正的愿景——基于纵向数据的疾病进展预测,虽然技术上合理,但需要完善的医疗数据闭环和多模态对齐能力,这是目前行业公认的硬骨头。问题在于:一家仅靠两个创始人和86票认可度的初创公司,凭什么认为比其他大厂更有可能攻克?创始人的斯坦福背景和苹果履历有一定说服力,但缺乏临床验证和规模化数据。现阶段,Nucleo更像是一个“挂着世界模型卖旧酒”的产品,其商业逻辑是先靠传统影像工具养团队。如果后续无法迅速与医院深度绑定并拿到真实、结构化、可追溯的长期患者数据,所谓的“世界模型”将永远停留在PPT里。医疗AI的护城河不在算法,而在数据和合规。Nucleo还需要证明自己不只是又一个聪明的CT分析插件。
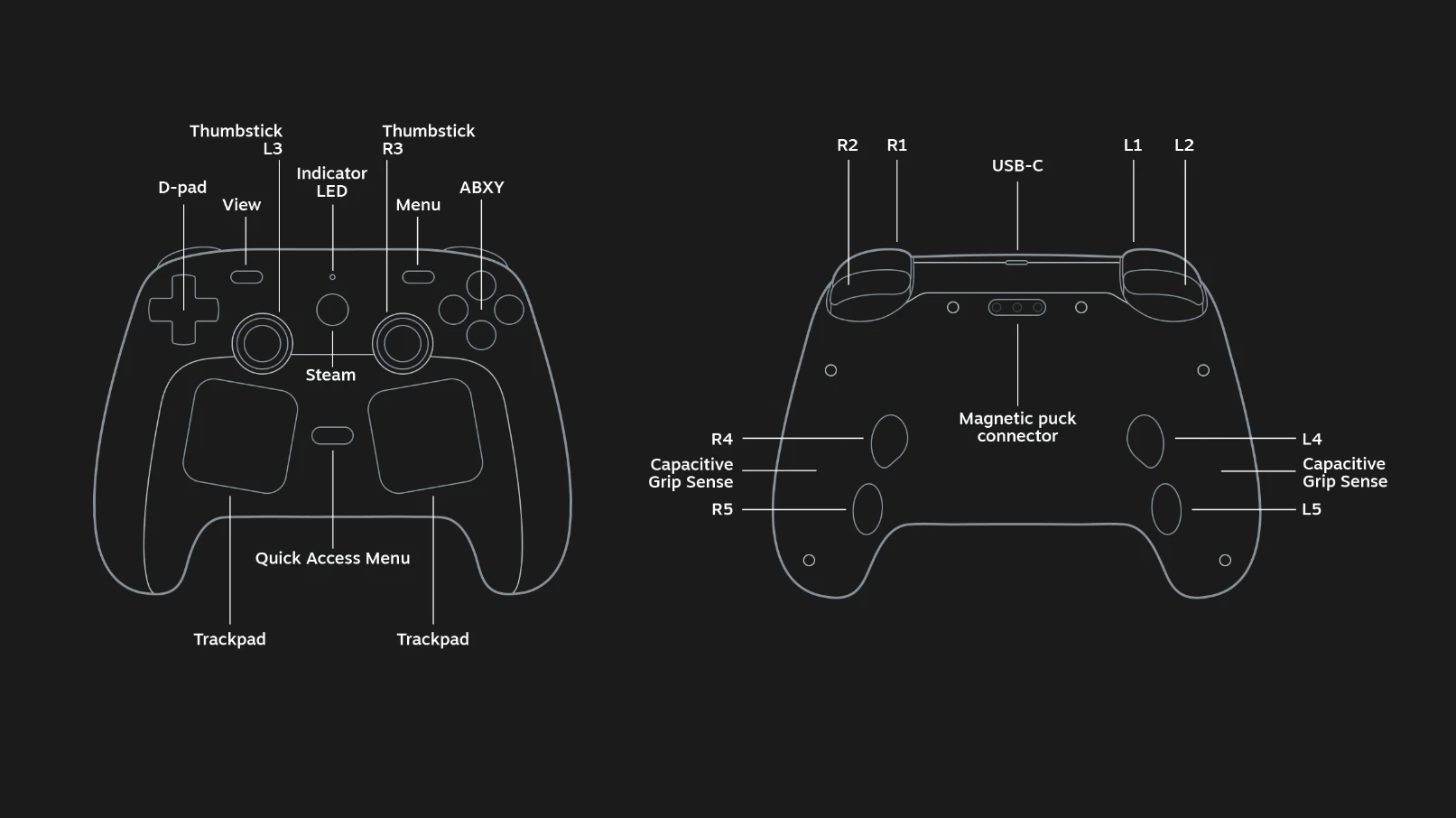
一句话介绍:Steam Controller 是一款为Steam全库游戏设计的可配置手柄,通过TMR摇杆、双触控板与陀螺仪的组合,在PC端跨游戏场景下,解决玩家因不同游戏操作逻辑差异而需要频繁切换或适应手柄的痛点。
Home
Hardware
Games
游戏手柄
PC游戏
Steam
TMR磁摇杆
触控板
陀螺仪
可配置
无线充电
游戏硬件
Valve
用户评论摘要:用户高度认可其TMR摇杆、触控板及陀螺仪等硬件组合,以及社区布局与每游戏独立配置功能。核心评价是“很Valve”,即虽然独特,但功能设计完全围绕“无需强行适配,就能畅玩整个Steam库”的理念。
AI 锐评
Steam Controller的回归,本质上不是对传统手柄的挑战,而是对PC游戏输入范式碎片化的一次“收编”。它试图用一套硬件,去包容从点击式冒险、RTS到现代3A射击的不同交互逻辑。TMR摇杆与触控板的共存,并非堆料,而是提供了一种“选择权”:当你要精细瞄准时,启用陀螺仪;当你需要策略点击时,触控板是鼠标的完美替代。低延迟无线充电底座和Grip Sense也让实用性拉满。但风险也很明显——Valve需要证明这种“万能”设计的易用性远超Xbox或DualSense的社区映射方案。如果配置门槛依旧偏高,它将只服务于折腾型玩家,而非真正改变主流游戏的操作生态。其核心价值在于:它最终可能不是最好的手柄,但可能是“最不会让你换手柄”的那一个。
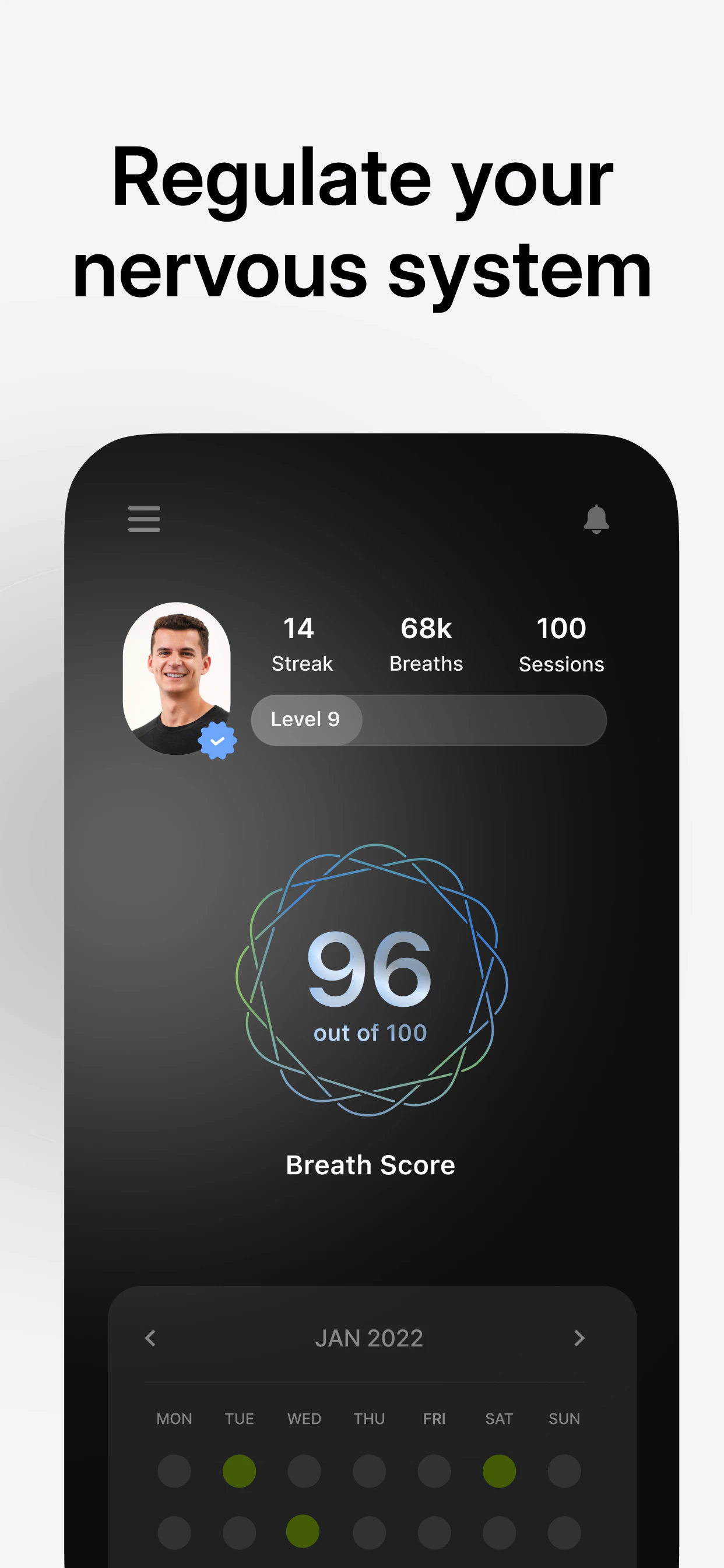
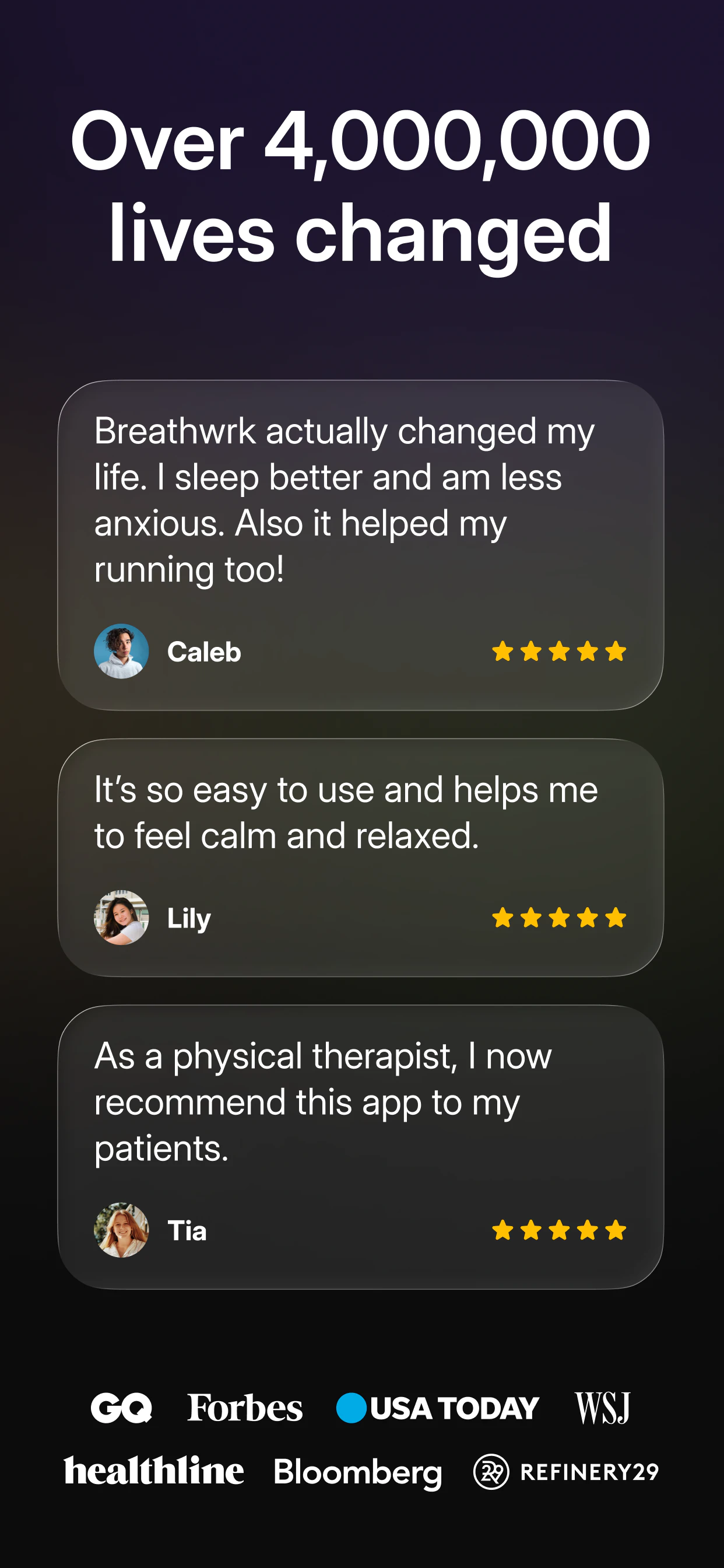
一句话介绍:Breathwrk是一款基于神经科学的呼吸训练应用,通过引导式呼吸练习(如方形呼吸、生理叹息),帮助用户在工作、睡前或高压场景中快速改善睡眠、缓解压力、提升专注力和精力。
Android
Health & Fitness
Meditation
Fitness
呼吸训练
正念冥想
压力管理
睡眠改善
专注力提升
神经科学
Peloton
习惯养成
健康监测
健康科技
用户评论摘要:用户指出Peloton收购(220万美元)验证了呼吸训练从“边缘养生”升级为“核心恢复工具”。评论建议与HealthKit/可穿戴设备(HRV、压力指标)联动,被动触发练习而非依赖用户主动打开APP。提示器与打卡系统是习惯养成的关键。
AI 锐评
Breathwrk被Peloton以220万美元收购,本质上是一次“工具型应用”向“场景化基础设施”的进化。其核心价值不在于提供几种呼吸法——毕竟方形呼吸或生理叹息的教程在谷歌上一抓一大把——而在于通过“提醒-追踪-打卡”的闭环,把呼吸这个高杠杆但极其枯燥的行为,嵌入了用户的日常节奏中。这恰恰是大多数冥想或健康类应用失败的地方:它们高估了用户的意志力,低估了习惯形成所需的“触发机制”。
然而,Breathwrk目前仍是一款典型的“响应型”应用:用户必须主动打开、选择练习、完成闭环。评论中提议的“被动触发”(如根据HRV或压力波动自动推送练习)才是真正的护城河。如果Peloton只是将Breathwrk作为其运动生态的一个附加模块,那它本质上是把高端用户已掌握的方法论包装成了付费内容;但如果它能利用Peloton的硬件和心率数据,实现运动后自动推荐冷却呼吸、压力过高时弹出短时恢复练习,那么呼吸训练将从“你记得要练”变成“系统知道你需要练”。
目前来看,78票与零点赞评论的境遇,说明该产品在独立应用市场声量有限。Peloton的收购更像是一次战略试水:测试用户是否愿意为“看不见的收益”(降低皮质醇、提升HRV)持续付费。终究,呼吸教练再优秀,也比不上一个在你心烦意乱时悄无声息启动的手机震动提醒。这才是科技之于正念应有的姿态——不是添一个App图标,而是消失成为环境本身。
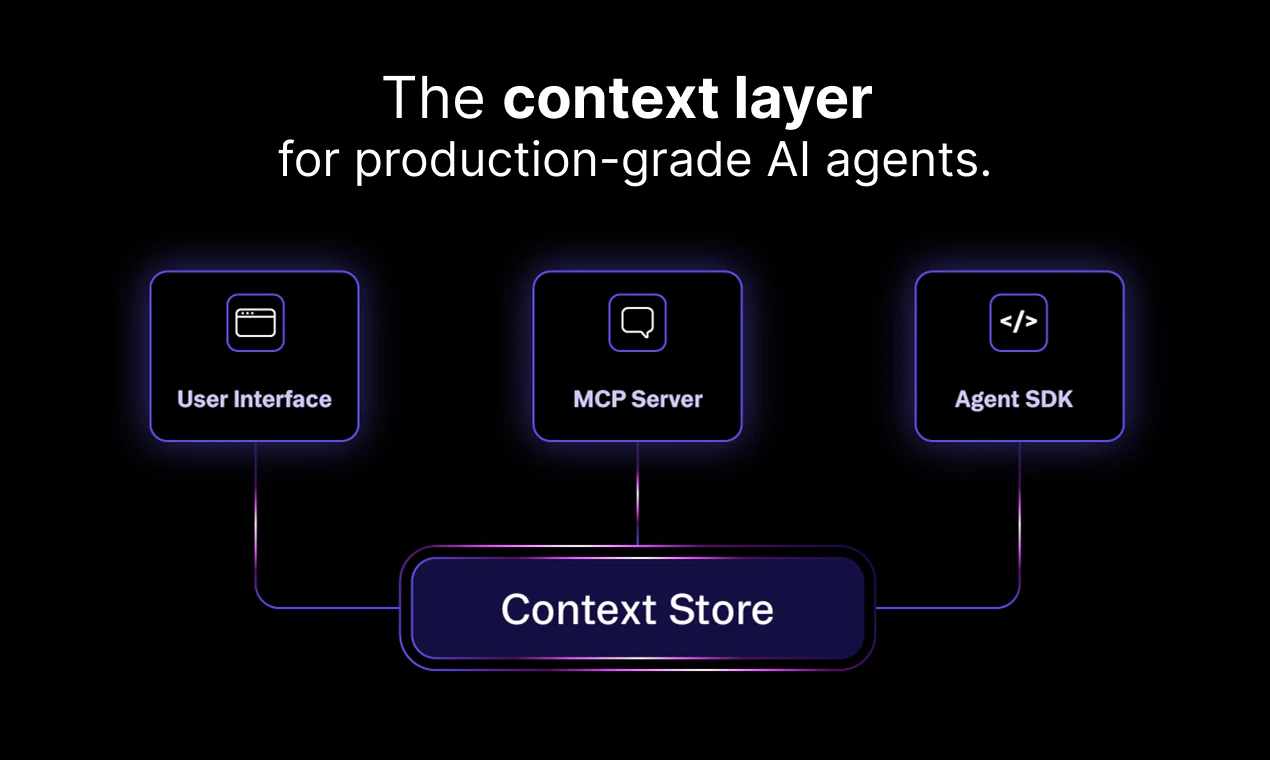
一句话介绍:Airbyte Agents通过构建统一的上下文存储层,将Salesforce、Stripe等50+业务系统的数据实时同步并结构化,解决了AI智能体在生产环境中因多系统数据碎片化而导致的连接器维护成本高、上下文缺失、工具调用和Token消耗过大的核心痛点。
Productivity
Developer Tools
Artificial Intelligence
数据连接器
AI智能体上下文层
企业数据同步
MCP服务器
生产级Agent
多系统查询
低代码工具
金融数据时序
实时数据索引
Token优化
用户评论摘要:评论总体积极。用户点赞“上下文层”框架直击生产级Agent缺失的关键——跨系统推理而非单纯API调用。有金融领域用户询问时间戳快照能力,Airbyte回应采用混合架构:上下文存储做亚秒级查询,执行前再从API直连校验最新状态。另有用户质疑该解决方案为“发明出来的问题”,认为个人开发者可通过N8n等工具自建,建议Airbyte增加发现新端点的服务功能。
AI 锐评
Airbyte Agents的定位精准且务实——它不是又一个花哨的Agent框架,而是扎进“数据连接”这个最脏最累的环节。从评论中那位金融用户的追问可看出,真正的价值不在于“能接多少API”,而在于“如何让Agent理解数据之间的时间与实体关系”。Airbyte用“混合架构”回应了时序问题:亚秒级索引做预查,执行前再API自验,这既避免了实时API轮询的延迟,又保留了执行态的数据新鲜度,逻辑闭环。
但需警惕两点:其一,“40%更少工具调用、80%更少Token”的营销数据在复杂业务场景中是否可持续?若上下文存储的数据质量不高(如同步延迟、实体歧义未解),Agent引用的“旧数据”可能导致推理错误,反而增加纠错成本。其二,评论区质疑并非空穴来风——N8n、Zapier等低代码工具正在吃掉“简单连接”的需求,Airbyte必须证明自己不仅仅是“更多连接器”的集合,而是一个能支撑Agent做生产级决策的“知识盘”,否则在开源社区的力量下,其护城河会很快被抹平。真正的考验在于:当数据量从千级跃升至百万级时,那个“亚秒级搜索”是否还能撑住推理的瞬时性?
一句话介绍:Hutsy 通过每日财务简报,帮用户自动识别即将到来的账单、潜在费用和下一步行动,解决个人财务管理中“看不清钱去哪了”和“不知道下一步该做什么”的痛点。
Pitch NYC
个人理财
财务管理
账单提醒
费用追踪
行为引导
智能简报
消费分析
理财规划
每日简报
金融科技
用户评论摘要:用户认可其“引导下一步行动”的差异化价值,认为多数工具只展示数据却不指导行为。同时质疑“下一步行动”的推荐逻辑,建议增加收入趋势分析与分期付款追踪功能,以优化还款策略。
AI 锐评
Hutsy 的价值不在于“帮你记账”,而在于用“简报”这种轻量交互,在消费决策的最后一公里提供即时干预。市面上90%的记账App堆积图表和数据,却让用户陷入信息过载后的决策瘫痪——Hutsy 切中的正是这个断层。其“每日简报”形态降低了认知负荷,可能比 Mint 或 YNAB 更适合“懒人理财”群体。
但必须指出,产品的护城河极薄。目前“下一步行动”的推荐机制语焉不详,若只是基于固定规则(如“某日有账单待付”),实质上仍是传统提醒功能的包装。真正的差异化在于能否引入智能学习——比如发现用户连续一个月在午餐上超支后,主动建议“本周午餐预算还剩XX元,建议带饭三次”。另外,营收场景模糊:如果仅靠免费+广告,很容易陷入用户活跃度陷阱;如果做付费订阅,又需要证明其行动建议能切实帮用户省钱(需量化ROI)。
评论中关于“收入趋势分析”和“分期付款追踪”的需求,暗示当前产品可能偏重支出端而忽视收入与负债管理。想从“提醒工具”进化为“财务管家”,Hutsy 必须在数据维度上补足(账户聚合、现金流建模),同时在交互上克制——不要试图取代全功能记账软件,而是成为用户每天花30秒就能掌控财务的“遥控器”。否则,它不过是一个带着颜值的日历提醒。
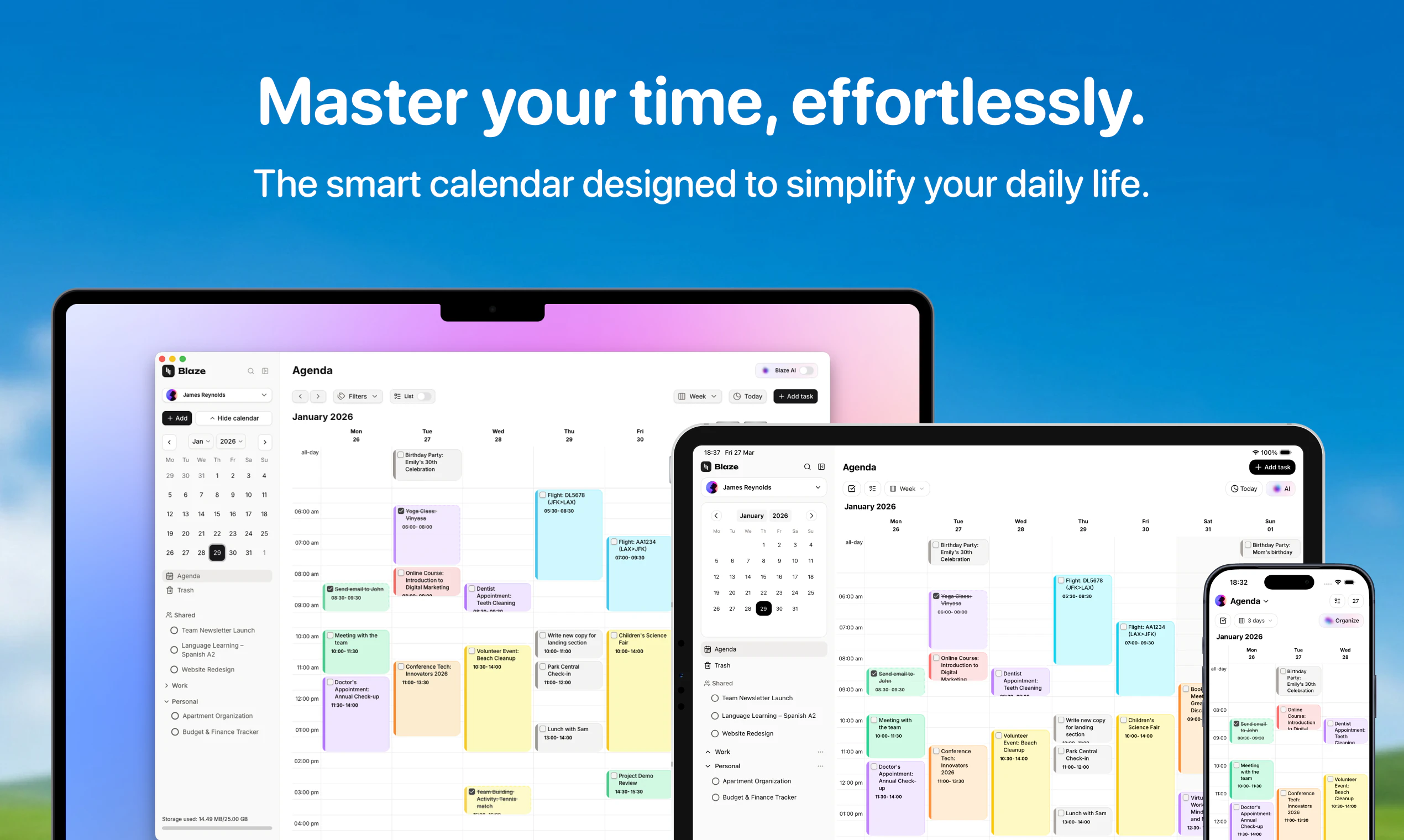
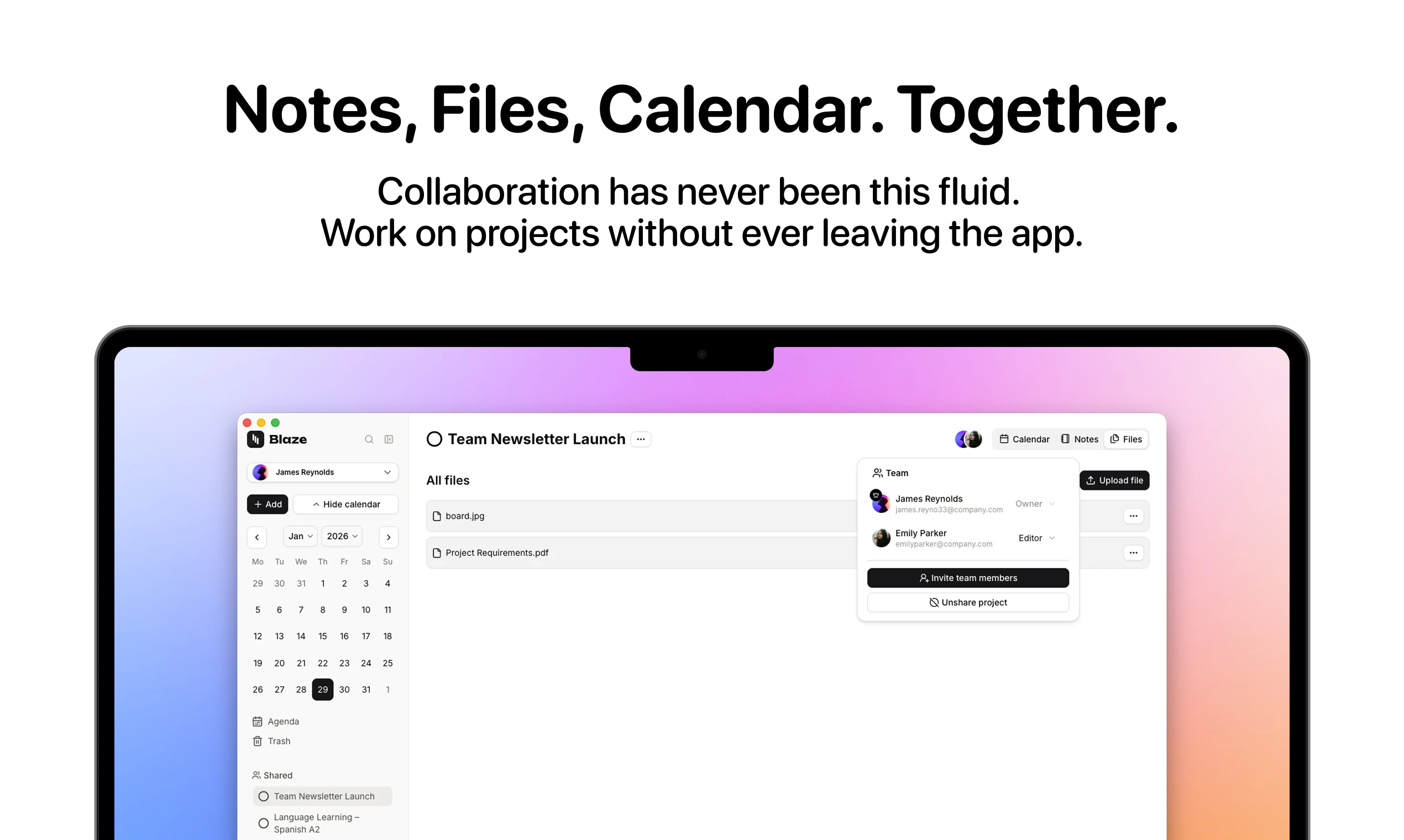
一句话介绍:Blaze是一款AI驱动的智能日历,它将任务、事件、项目、笔记整合为一体,通过自动规划日程、查找空闲时段与平衡工作量,解决用户在多平台间手动管理日程和任务切换的低效痛点。
Productivity
Calendar
Artificial Intelligence
AI日历
智能日程管理
生产力工具
任务协作
跨平台日程同步
Mac应用
iPhone应用
iPad应用
团队协作
自动规划
用户评论摘要:用户主要关注多日历连接限制(能否整合工作与家庭日历),以及AI对任务实际精力消耗的认知(是否仅靠时间数据)。创始人回应确认支持多日历,并强调可以学习用户真实耗时。此外,用户对原生iPad版本设计表示赞赏。
AI 锐评
Blaze切入了一个极其拥挤但痛点明确的市场——“日程管理疲劳症”。市面上Calendly擅长预约,Notion侧重文档,Todoist专注清单,而Blaze试图做“终结者”:把任务、日历、笔记和项目全部塞进一个AI大脑里,听起来很性感,但实现难度极大。
创始人的问题问得很聪明,但恰恰暴露了产品的软肋:如果AI不知道“真正消耗精力的是什么”,那它只能做时间排列组合游戏——这跟把Excel表排序后打印出来没有本质区别。Blaze目前的核心价值更接近一个“增强版自动排序器”,而非真正的智能助手。它能否从日历数据中学习到用户的认知负荷、创意峰值时段、干扰恢复成本,这才是从工具跃升为系统的关键门槛。
不过,提供原生的iPadOS体验、免费两个月Pro订阅,以及对用户反馈的开放态度,都表明团队在产品打磨上有诚意。对于受困于“日程碎片化”的独立开发者和中小企业团队,Blaze的“一站式整合+自动平衡”确实能显著降低认知负担。但要想让AI真正变成私人生产力管家,Blaze还需要更多关于“人”而非“时间”的数据。目前的它更像一个聪明的起点,而不是终点。
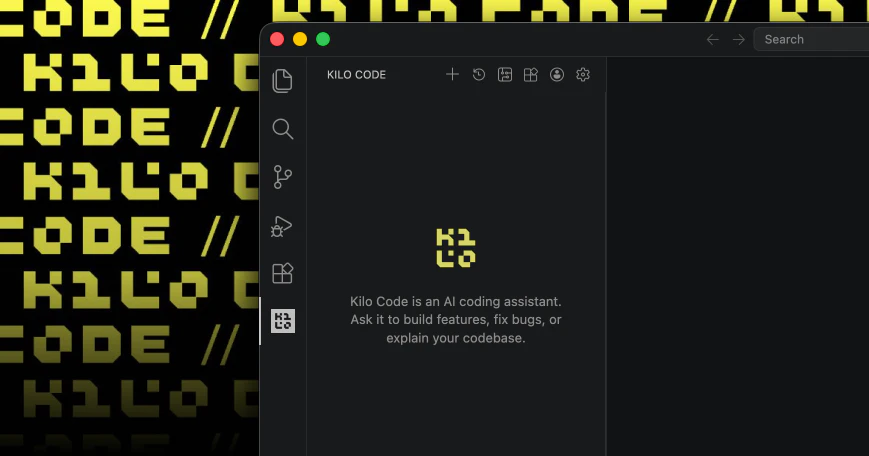
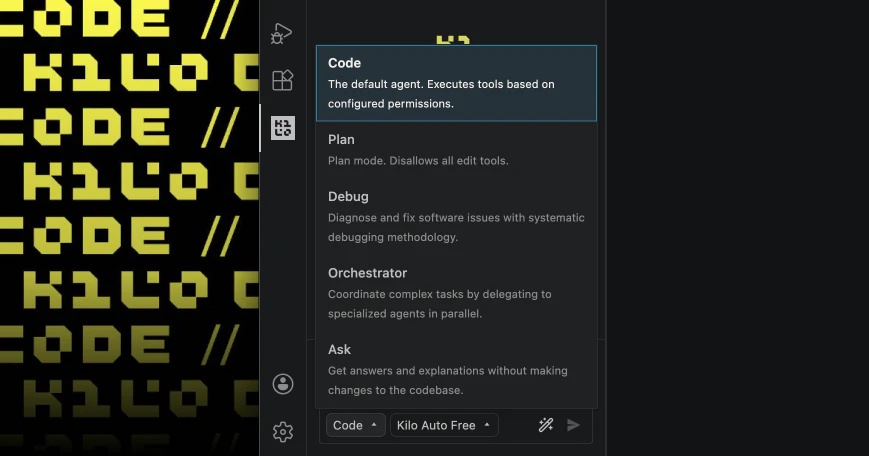
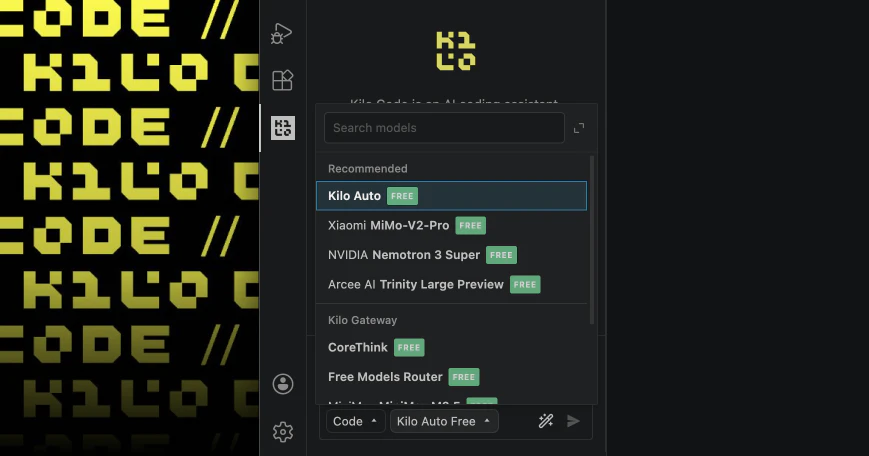











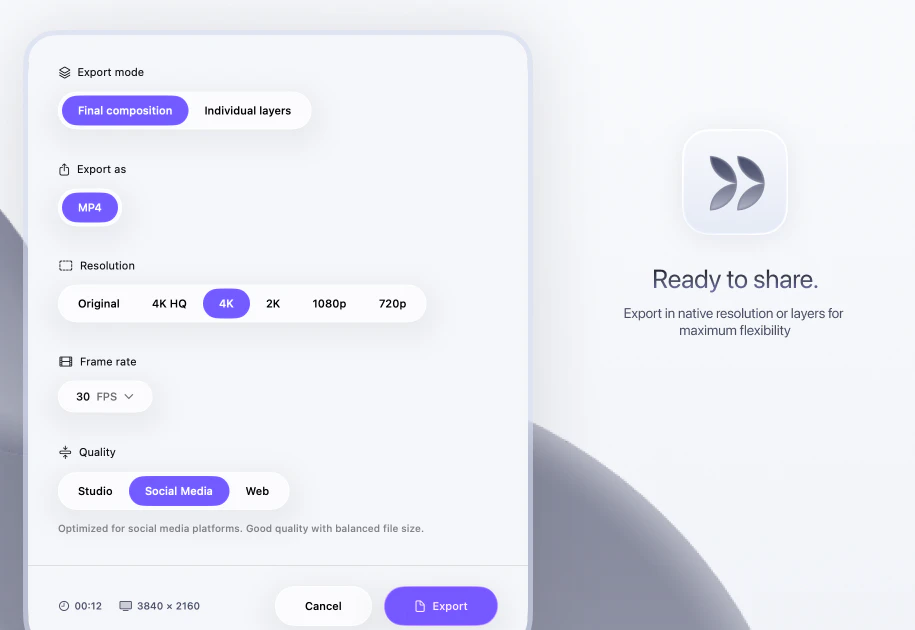
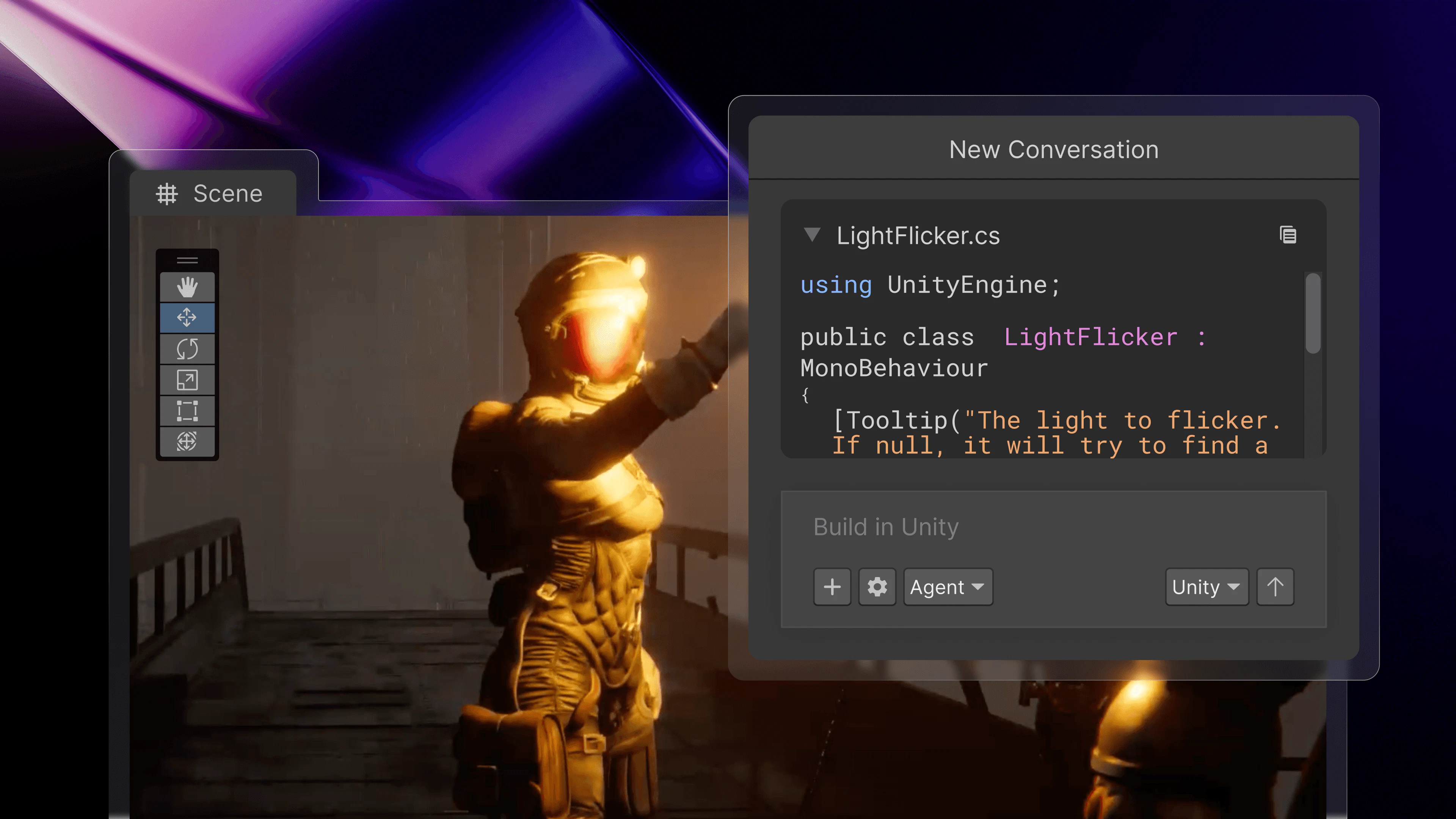
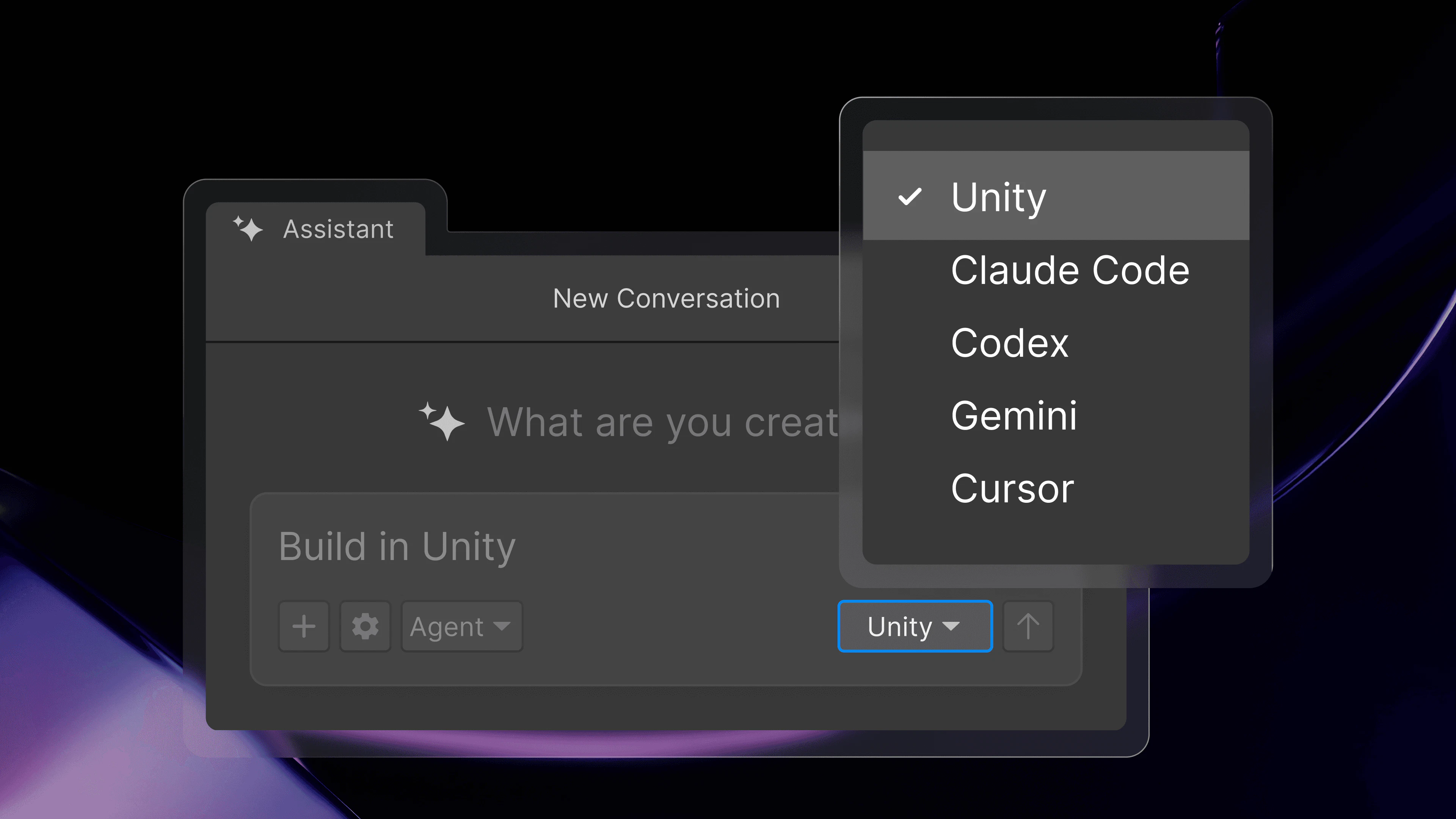
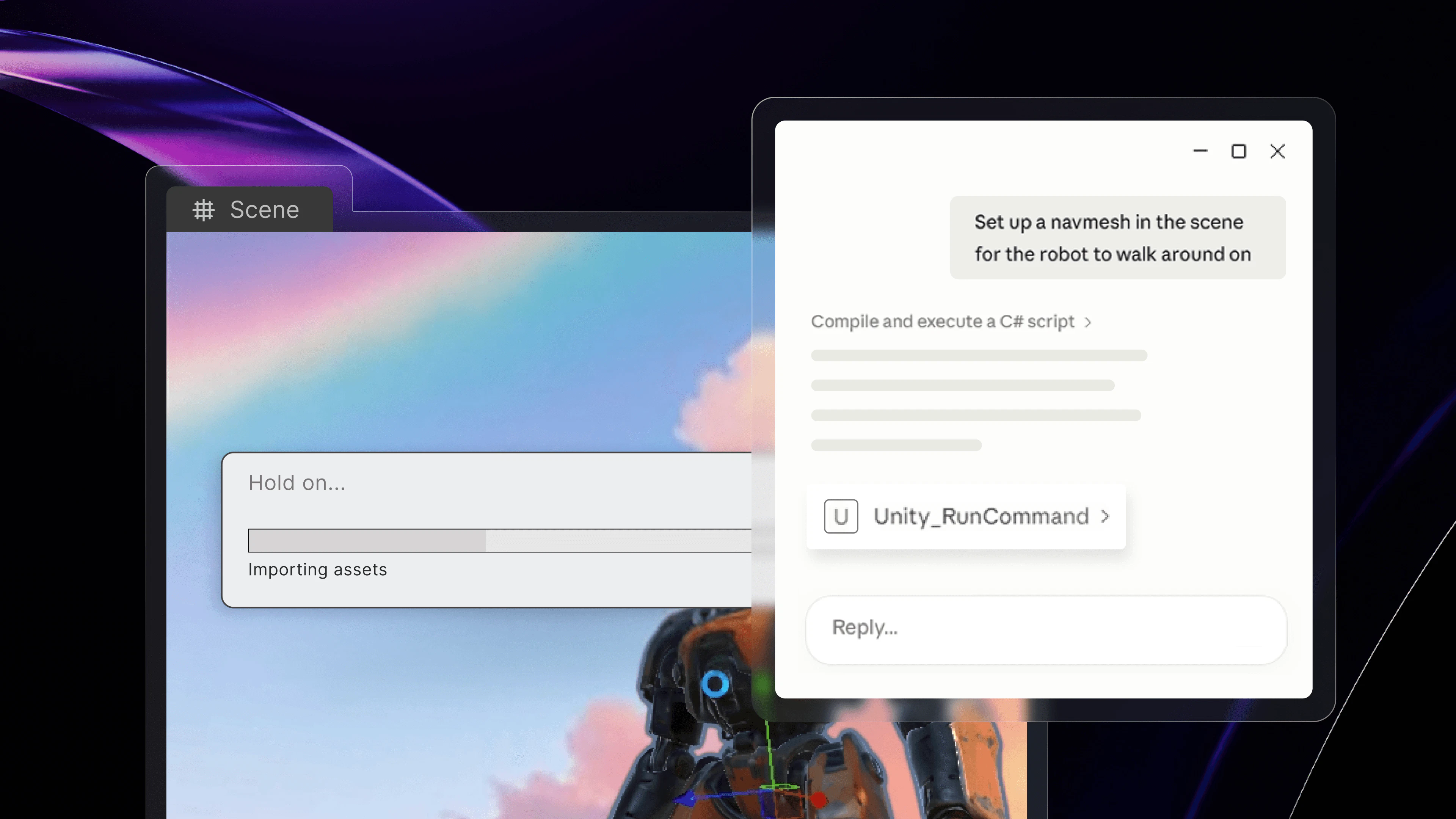














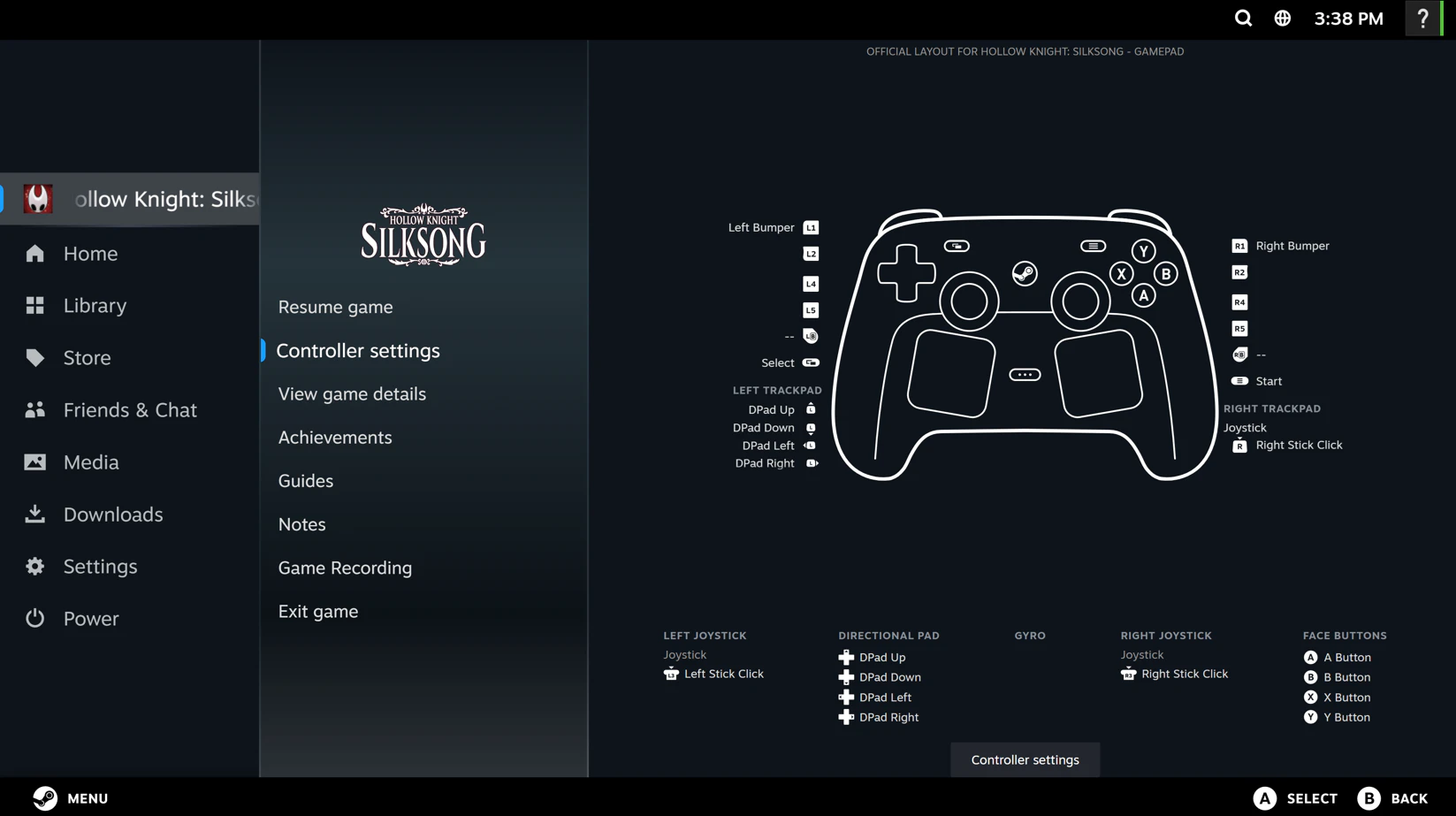














Looking forward to seeing what you're building with @Kilo Code!
Hey Product Hunt 👋 Brian from Kilo Code here.
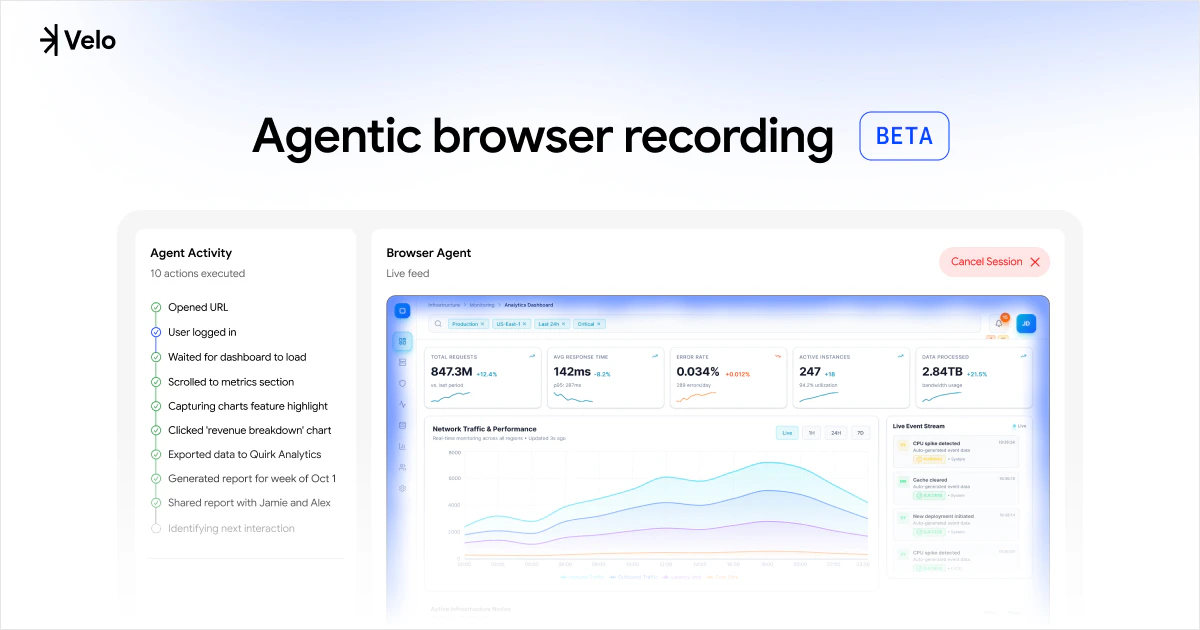
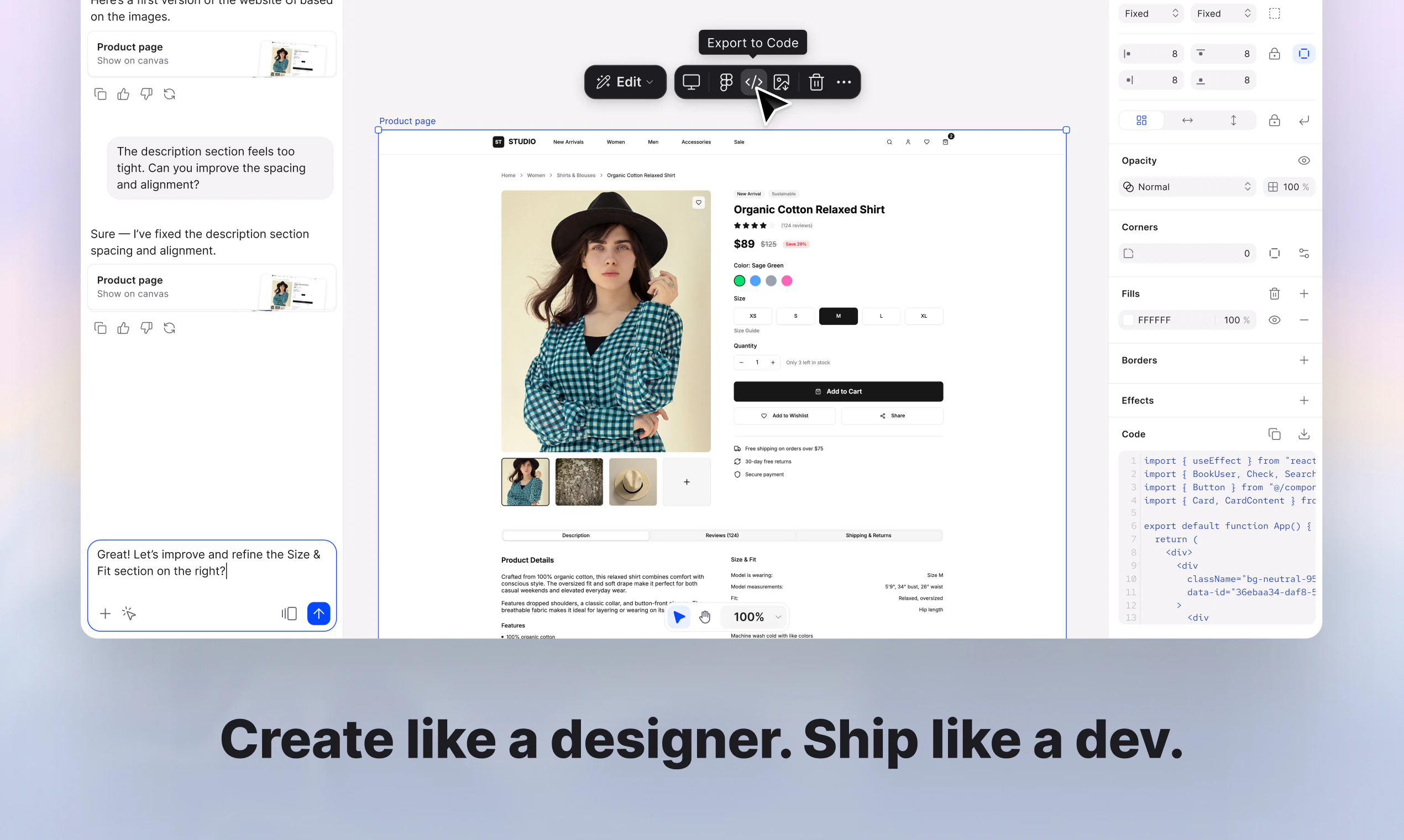
We just shipped the biggest update to our VS Code extension since launch. The entire thing has been rebuilt on OpenCode server, which is the same open-source core that powers our CLI and Cloud Agents. One engine across every surface, so when we improve something, it gets better everywhere.
The headline feature is real parallelism. Kilo can now run multiple tool calls at the same time (file reads, searches, terminal commands all firing concurrently), and it can spin up parallel subagents that each handle a piece of a larger task simultaneously. You actually feel the speed difference.
A few other things shipping in this release:
Agent Manager — run multiple independent agents in separate tabs, give each one a role, and use git worktrees so they never step on each other's code
Inline code review — leave line-level comments directly on agent diffs, just like a PR review, and send them back as structured context
Multi-model comparisons — run the same prompt through different models side by side and pick the best result
Cross-platform sessions — start in the CLI, pick up in VS Code, share with a teammate
Kilo is open source, runs 500+ models at provider cost (zero markup), and has over a million developers using it. We'd love for you to try it out and tell us what you think!
Came from Roo Code a few months ago and honestly haven't looked back. The migration was smoother than expected. Good luck for today!
Hey Product Hunt 👋 - Job from the Kilo team.
Very excited for this launch. The new Kilo for VS Code is my daily driver, and this rebuilt version with agent manager is in my opinion the next step in agentic coding. I now let multiple agents run at the same time using agent manager, and it speeds up my workflow a lot. Super curious to hear what you think of it!
🚨 We're also hosting 2 live sessions TODAY:
•
10am EST | The Kilo Show for Non-Coders
We'll talk marketing automation, SEO, competitive analysis, and design
Register →
•
11am EST | The Kilo Show for Coders
We'll talk agent orchestration, codebase indexing, and IDE workflows
Register →
I’ve been using Kilo Code for a while, and this update feels noticeably faster.
The parallel tool calls are the part I felt right away. It doesn’t sit around waiting as much, especially on bigger tasks where it needs to search files, read code, or run commands. The Agent Manager is also really nice if you’re juggling a few things at once without wanting everything mixed together.
Inline review on diffs is probably my favorite addition. It makes giving feedback to the agent feel a lot closer to how I’d review a teammate’s PR.
Overall, this is a really strong update. Kilo is becoming one of the few coding tools I actually keep coming back to.
Been using v7 for a while, and even the versions before this. Took a while to get used to, but generally excited to see it being built on OpenCode. Can't wait for more features especially /remote 🤞🙏
The parallel subagents with git worktree isolation is the part that actually makes sense to me. Every other tool just runs agents on the same files and hopes for the best. Congrats on shipping this!
If one agent is refactoring an API and another agent is consuming that API, how do they handle the dependancy? Do they share context live or waiting for human reviews?
How does the multi agent system comparison handle tokens ? does it run them all in the background simultaneously ? btw Congrats on the launch :)
Used the old Kilo VS extension and have been using the new. Love the changes and it works smoothly. Excited to see many of the coming updates, too.
Been loving my experience with Kilo! Love the team and the speed at which things are shipped. This is just another great example of the speed at which this team can produce great work!
Been on Cursor for a while but the model lock-in is starting to bother me. The 500+ models angle here is hard to ignore. Does switching models mid-project break any context?
Using Kilo for Resume Matcher. Works really well, however, ƒor this launch. I'd suggest some features that Kilo should add. The first one is Skills, just like Claude-Code. A .kiloignore, and custom routines to be fired up to check for dependencies, security risks, and other supply chain attacks that may be in transitive dependencies. Because the more we vibe-code, the better the security should be, and the more exhaustive the reviews should be.
Niiiice! Looks amazing and clean
Does the agent manager have any limits on how many parallel agents you can run at once, or is it just constrained by your machine's resources?
WooW this feels really fast.
Great update guys! Nice work!
Congratulations!
Rebuilt from scratch on OpenCode server and still GA'd, that's not a small thing. Most teams would've shipped a half-baked beta and called it done.
The line level review comments on agent diffs is a really smart UX call. Feels like the missing link between AI wrote this and I actually trust this going to prod.
How does Kilo handle context limits when you've got multiple subagents running on a large codebase? Does each subagent get its own context window or do they share?
Just curious, when multiple subagents are running in parallel, how does the merge back to the parent agent work? Does it ever create conflicts when two agents touch overlapping parts of the codebase?
been looking for something like this, the ai coding space is getting crowded but this looks focused