PH热榜 | 2026-05-08
一句话介绍:RankSpot是一款利用深度竞品情报,为忙碌的创始人全自动完成每日SEO博客的研究、写作与发布的AI代理,解决小团队因时间、成本或专业度不足而无法持续产出高质量内容、抢占Google排名和AI搜索引用的痛点。
Marketing
SEO
YC Application
AI SEO
竞品分析
自动化博客
AI内容生成
搜索引擎优化
生成式引擎优化
内容营销
小团队工具
多语言支持
Reddit洞察
用户评论摘要:用户核心关注点在于:1)如何构建垂直领域权威性(引用论坛/Reddit);2)多语言环境下hreflang和区域关键词及LLM引用的差异化;3)AI内容是否被Google惩罚,以及如何提升LLM引用率;4)竞品差异化(对比Byword/Jasper)和已有文章的更新策略。用户对竞品情报和GEO优化功能表示认可。
AI 锐评
RankSpot打了一个非常聪明的牌:将“AI写文章”这个已经红海泛滥的功能,与“深度竞品情报”和“GEO(生成式引擎优化)”进行绑定。这不仅回答了用户“AI内容会不会被罚”的焦虑,更切中了当前流量获取的核心变化——你的内容不仅要取悦Google,还要取悦ChatGPT和Claude。
产品最大的价值在于其“自动化闭环”的设计逻辑:追踪竞品关键词 -> 分析排名文章 -> 生成内容 -> 自动发布。这解决了小团队“没时间写”和“不知道写什么”的双重困境。创始人Dan在评论区对“如何被LLM引用”的回答很实在(FAQ、统计数据、Reddit),但问题在于:这种策略能否规模化且不被算法视为作弊?目前来看,先发优势和创始人的SEO实战经验是其护城河。
然而,隐患也很明显。第一,缺乏关键的Google Search Console集成和已有文章更新功能(尽管在路线图中),这意味着用户无法看到内容的实际效果和持续优化,容易陷入“只管发、不管活”的陷阱。第二,在面对Byword等已建立壁垒的对手时,仅靠“竞品情报”一个卖点是否足够?如果竞品后续也快速跟进这一功能,RankSpot的差异化将迅速缩水。第三,过度依赖Reddit作为LLM来源是双刃剑,随着Reddit与Google的交易加深,其权重波动可能影响引用稳定性。
总体而言,RankSpot是一个“创始人友好型”的提效工具,而非增长黑客的银弹。它最适合预算有限、急需建立基础内容生态的早期创业公司。但对于追求精密SEO策略或垂直深度的团队,它可能只是一个不错的起点,而非终点。
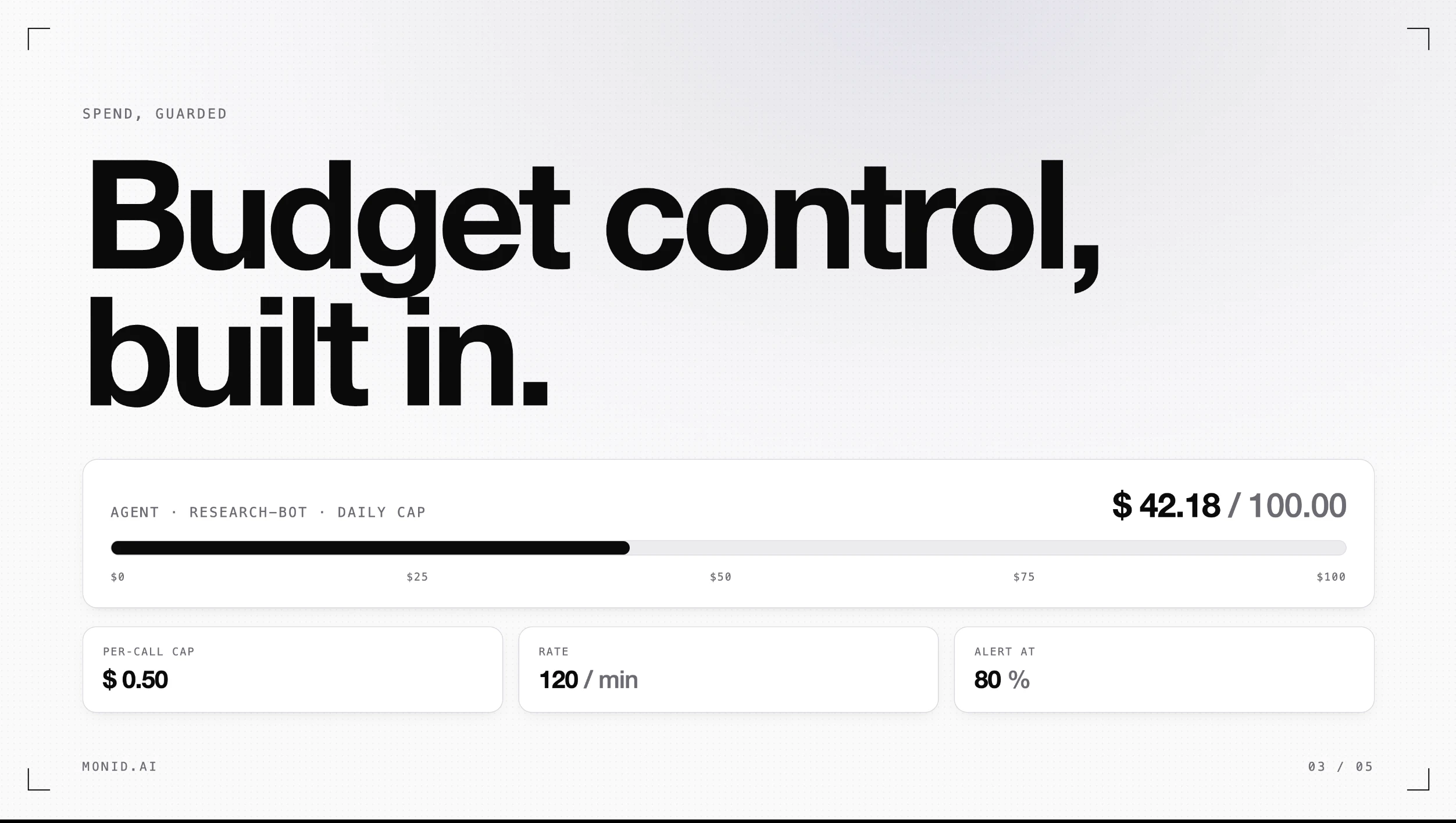
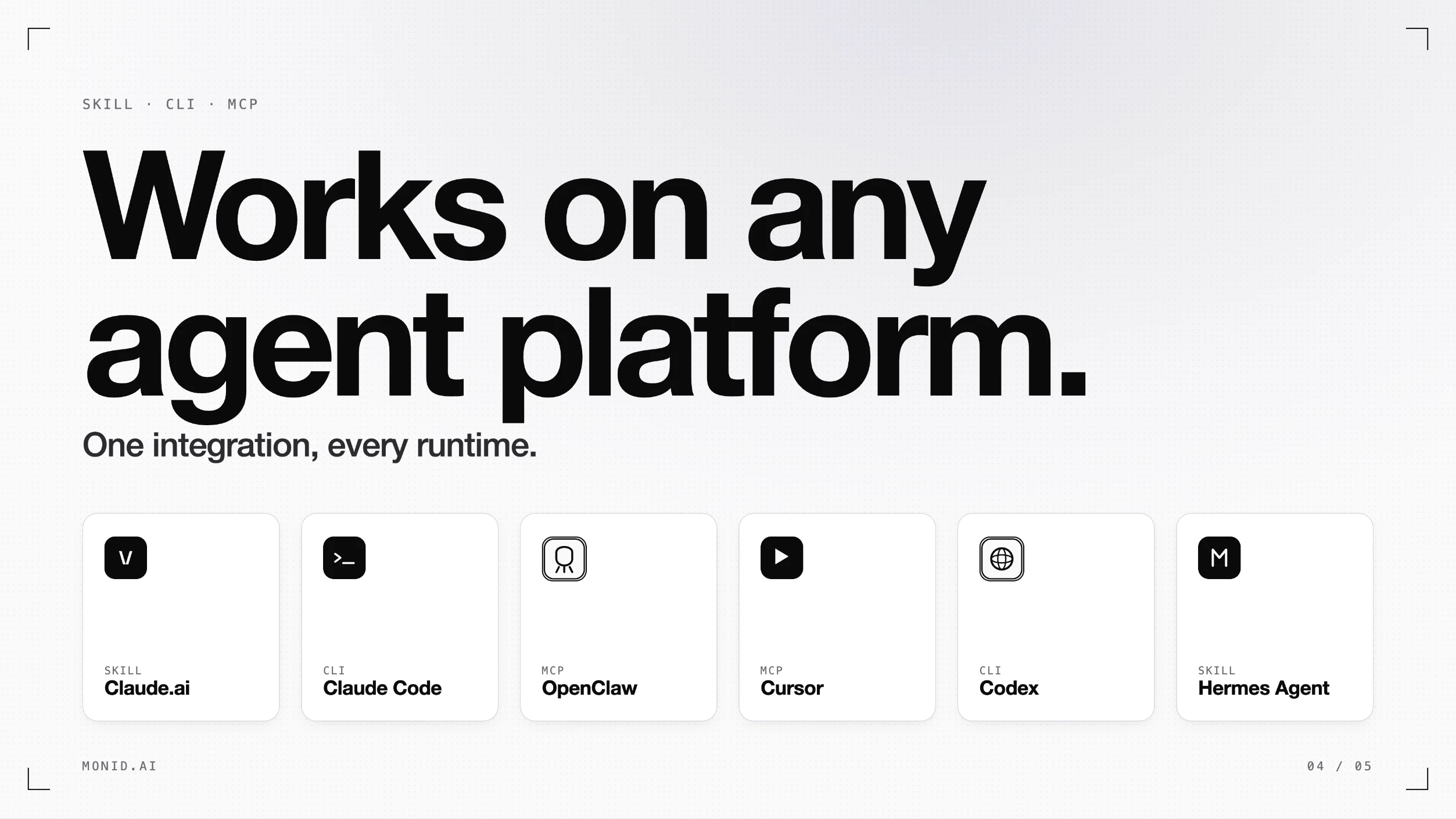
一句话介绍:Monid 2.0 是一个为AI智能体打造的工具市场与支付层,让智能体可以动态发现、比较并按需调用超过200个API(如社交媒体抓取、搜索、电商数据、潜在客户挖掘等),一次集成即可解决工具碎片化与计费复杂的痛点。
Developer Tools
Artificial Intelligence
YC Application
AI智能体工具市场
按需API调用
工具发现与路由
代理钱包
社交媒体数据抓取
MCP支持
无代码工具集成
动态计费
OpenRouter替代方案
用户评论摘要:用户关注点:1. 平台前三大付费工具是什么(回复:社交媒体抓取和人企数据丰富化)。2. 能否支持发布内容到社交网络(回复:暂不支持,需更强权限模型)。3. 与RapidAPI/PhantomBuster等DIY方案的根本区别(回复:专为运行时智能体设计,支持语义发现、按次支付、CLI原生)。4. 能否自带工具(回复:可以,需私下沟通)。5. 技术实现细节(数据源如何绕过封锁),团队回复称与数据提供商合作,不自建爬虫。
AI 锐评
Monid 2.0 的定位足够精准:“OpenRouter for agent tools”是一句聪明的口号,它抓住了当前AI智能体落地中一个真实但非性感的需求——工具调用与结算的基础设施。与OpenRouter解决模型路由和计费类似,Monid试图将数百个API的发现、认证、按次计费、预算控制打包成一个标准化层,让开发者不再纠缠于每个API商的独立集成和订阅逻辑。
产品价值成立,但挑战不小。首先,200+工具的“货架”规模虽够,但截至评论反馈,前三大热门工具集中于社交媒体抓取和人企数据,说明长尾工具的实际调用量可能很低。工具生态的丰富度需要时间沉淀,而智能体的“发现”能力是否真的比RapidAPI的静态搜索更智能?评论中用户语义发现“两个抓取工具覆盖同一平台”的疑问直指痛点:如果路由算法仅靠价格/延迟/成功率,本质上与代理网关无异,难以形成护城河。
其次,Monid宣称不做自建爬虫,而是对接现有数据提供商。这既是聪明选择(规避合规风险),也是风险所在——一旦头部数据提供商(如Bright Data、Apify)自己推出类似代理层,Monid的中间件价值将被压缩。此外,x402/MPP支持固然前沿,但当前主流通用性有限,可能过早消耗精力。
最后,团队的迭代速度值得肯定(15天从“钱包”进化到“工具市场”)。但值得注意的是,当前评论样本中活跃点赞用户多为团队或熟面孔,真实独立用户的声音更多体现为“用过类似方案”而非“完全取代”。Monid现在的机会在于抓住AI原生代理(如Claude MCP、OpenClaw、Cline等)从原型到生产的窗口期,成为默认的工具网关——前提是,它需要证明自己在工具路由(如基于成功率和上下文的智能选择)上比开发者自己手写几行代码拼RapidAPI更划算、更省心。否则,充其量是一个漂亮的代理钱包UI。
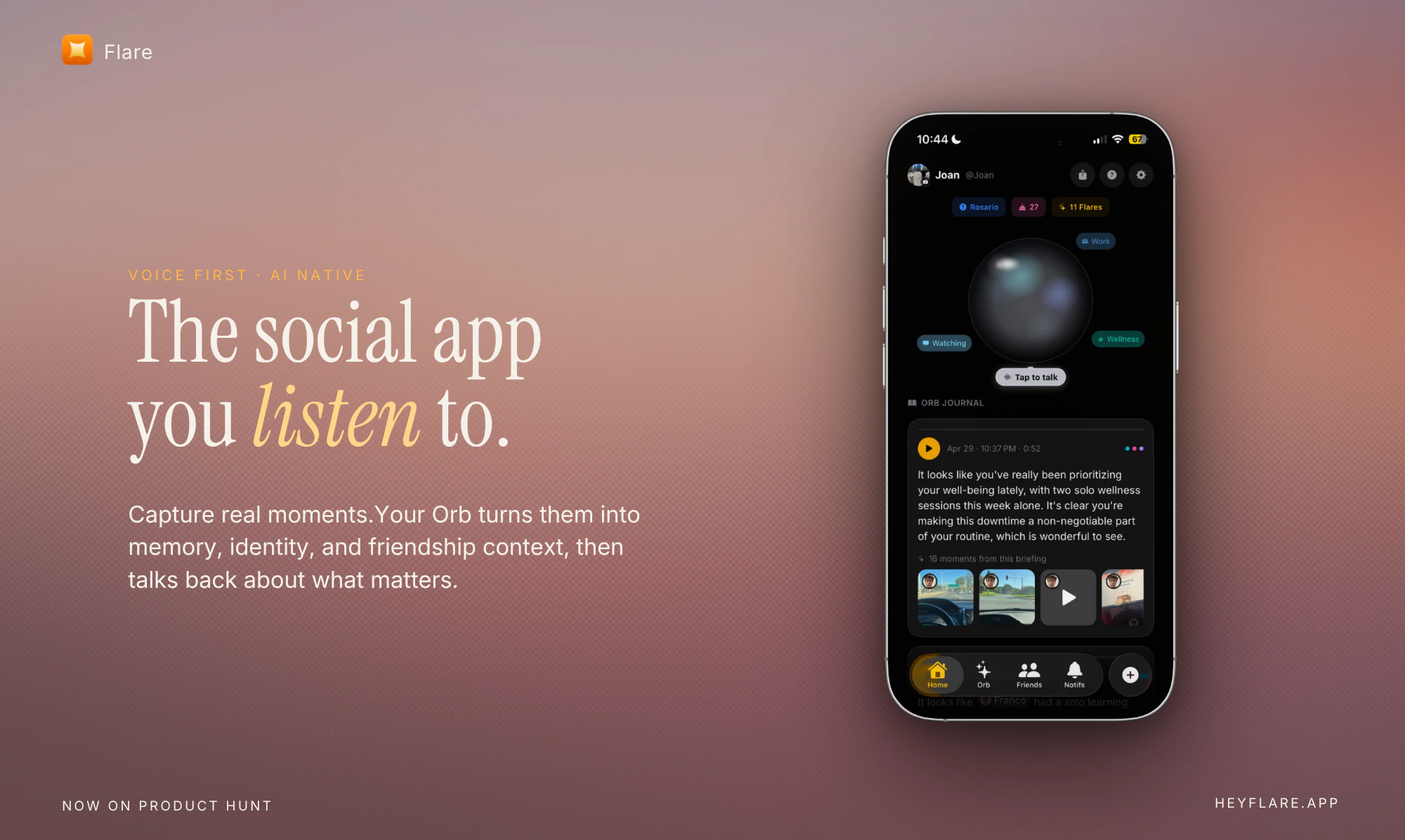
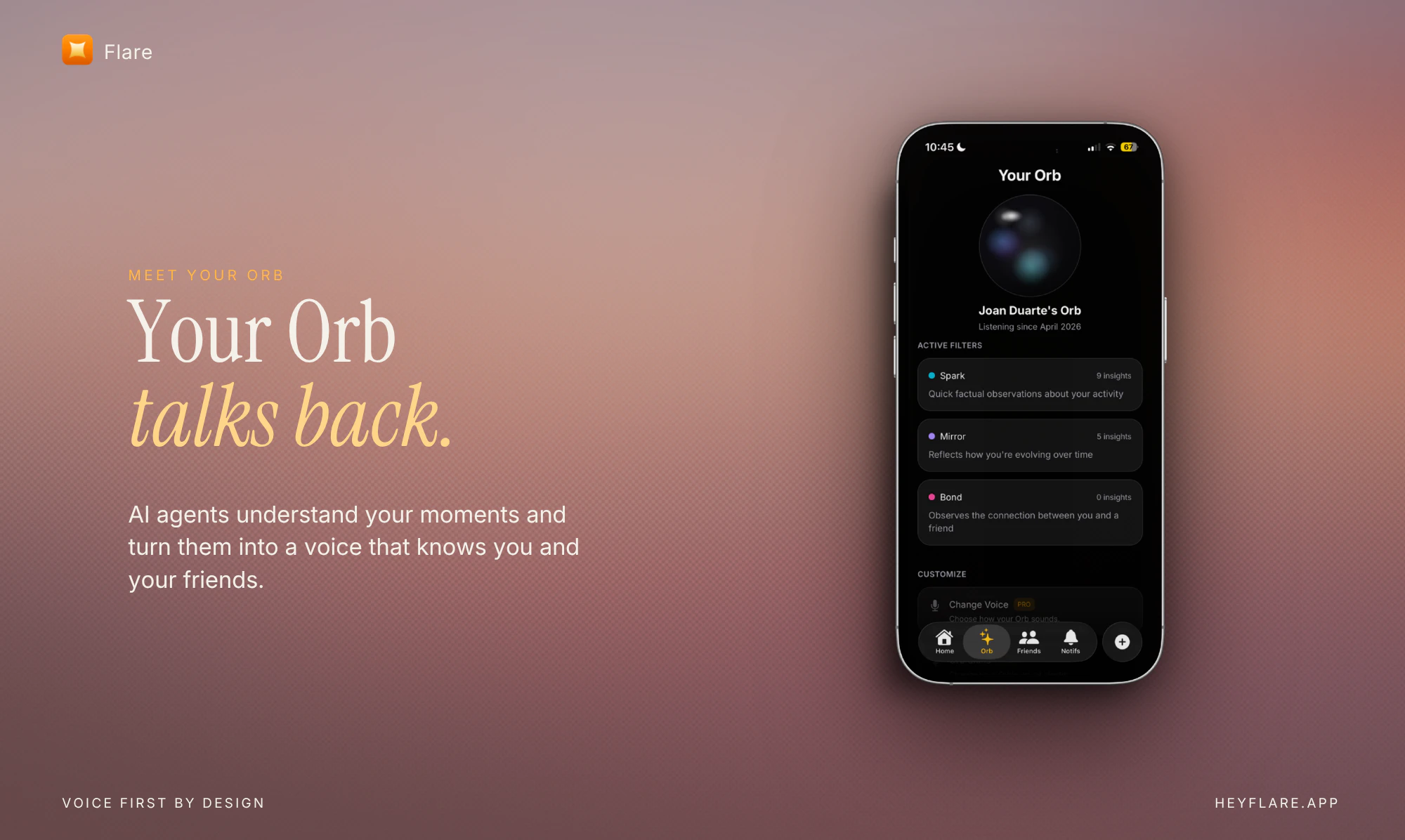
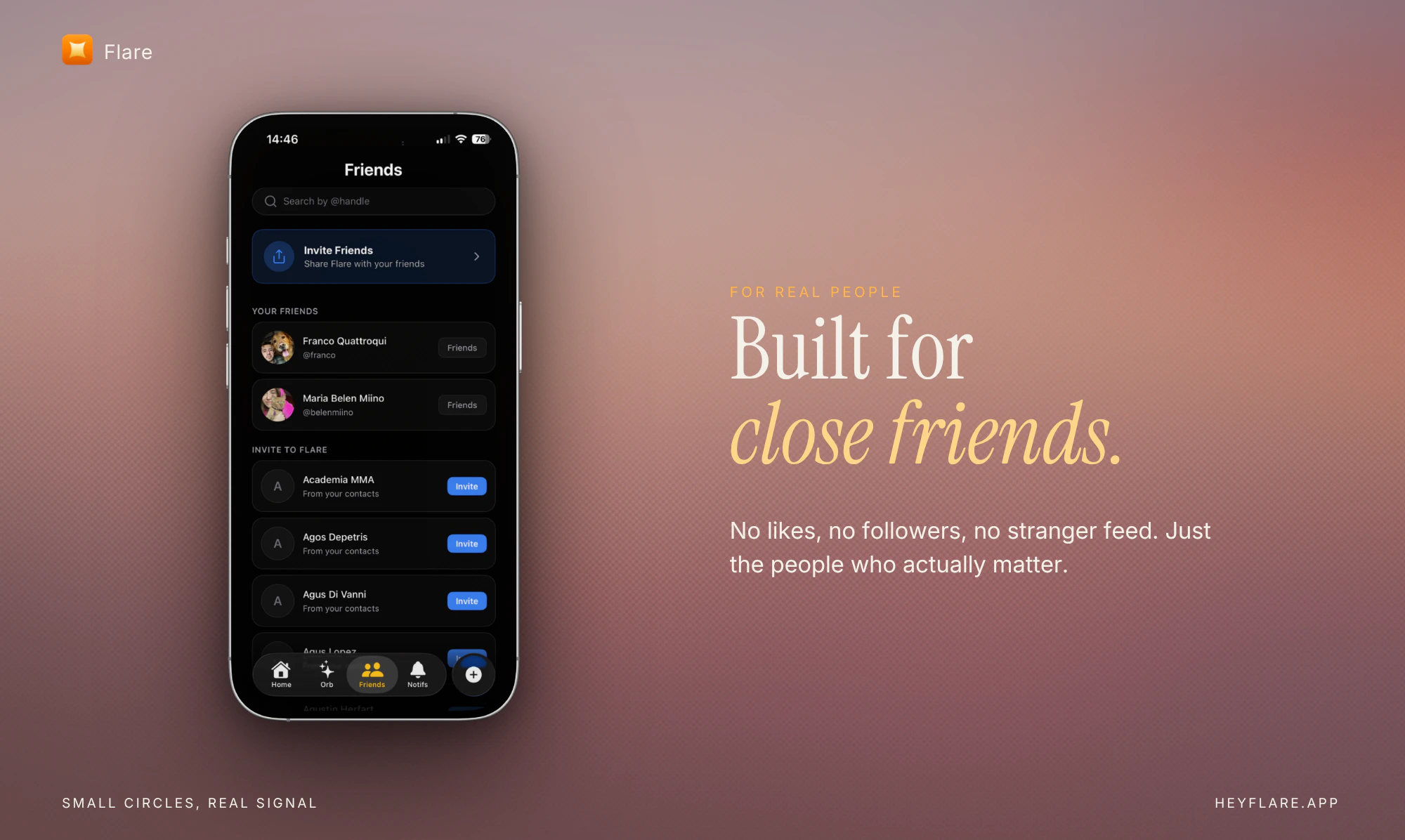
一句话介绍:Flare是一款面向Z世代的AI原生语音社交应用,通过AI助手将用户的照片、短视频或心情转化为记忆与友谊背景,让用户“听”社交而非刷屏,旨在消除点赞、粉丝和陌生人信息流带来的表演焦虑。
Social Media
Artificial Intelligence
YC Application
AI社交
语音优先
Z世代
无点赞社交
AI记忆助手
亲密社交
反性能焦虑
语音简报
异步语音
无Feed
用户评论摘要:用户期待AI能避免泛泛而谈,保持个性化和长期相关性(如“专属我的感觉”);关注“打开率”和“Orb主动推送”的平衡;质疑“社交性”如何体现,建议明确朋友间的互动逻辑;对比Air Chat,担心语音社交沦为机器对话,强调语境和连接感。
AI 锐评
Flare的“听社交”概念及其对Z世代的聚焦,无疑精准命中了当前社媒的疲劳痛点——点赞、评论、算法Feed已演变为一场无止尽的表演竞赛。其核心在于将AI从“推荐引擎”重塑为“记忆管家”,力图回归社交本质:连接与理解。三个Agent(Spark, Mirror, Bond)的设定颇具野心,试图将零散的“捕捉”升华为结构化的“记忆”与“关系上下文”。
然而,产品的根本矛盾在于:一个“没有点赞、评论、陌生人Feed”的社交App,其“社交”属性究竟锚定何处?从用户反馈看,目前Orb更接近一个高阶的、私人的AI日记或生活简报生成器。若朋友间的互动仅限于各自向AI输入内容,而缺乏直接的、双向的语音对话或共同创作机制,那么“社交”的黏性可能沦为空谈。当“你的Orb”和“朋友的Orb”成为两个独立的信息岛时,所谓的“共享语境”极易变成单薄的、AI总结后的“事不关己”。
此外,最大的挑战在于“主动权”的平衡。Orb被设计应“值得被倾听”,但若它只在用户打开App后才回应,这本质上仍是“拉取”模式,未能真正颠覆“Feed主动推送”的沉浸式体验。若它尝试“主动推送”,又极易滑向被用户反感的“AI骚扰”。这种“不打扰但又有用”的微妙区间,目前在产品逻辑上尚未见到巧妙解法。
Flare是一个勇敢的尝试,它赌的是“关系密度”胜过“内容广度”。但要想不成为一款美丽的电子宠物,它必须证明:AI不仅能帮你回忆“你今天做了什么”,更能促使你和朋友“一起做点什么”。否则,它提供的不是社交,而是一场精致的、AI主持的、关于社交的独角戏。
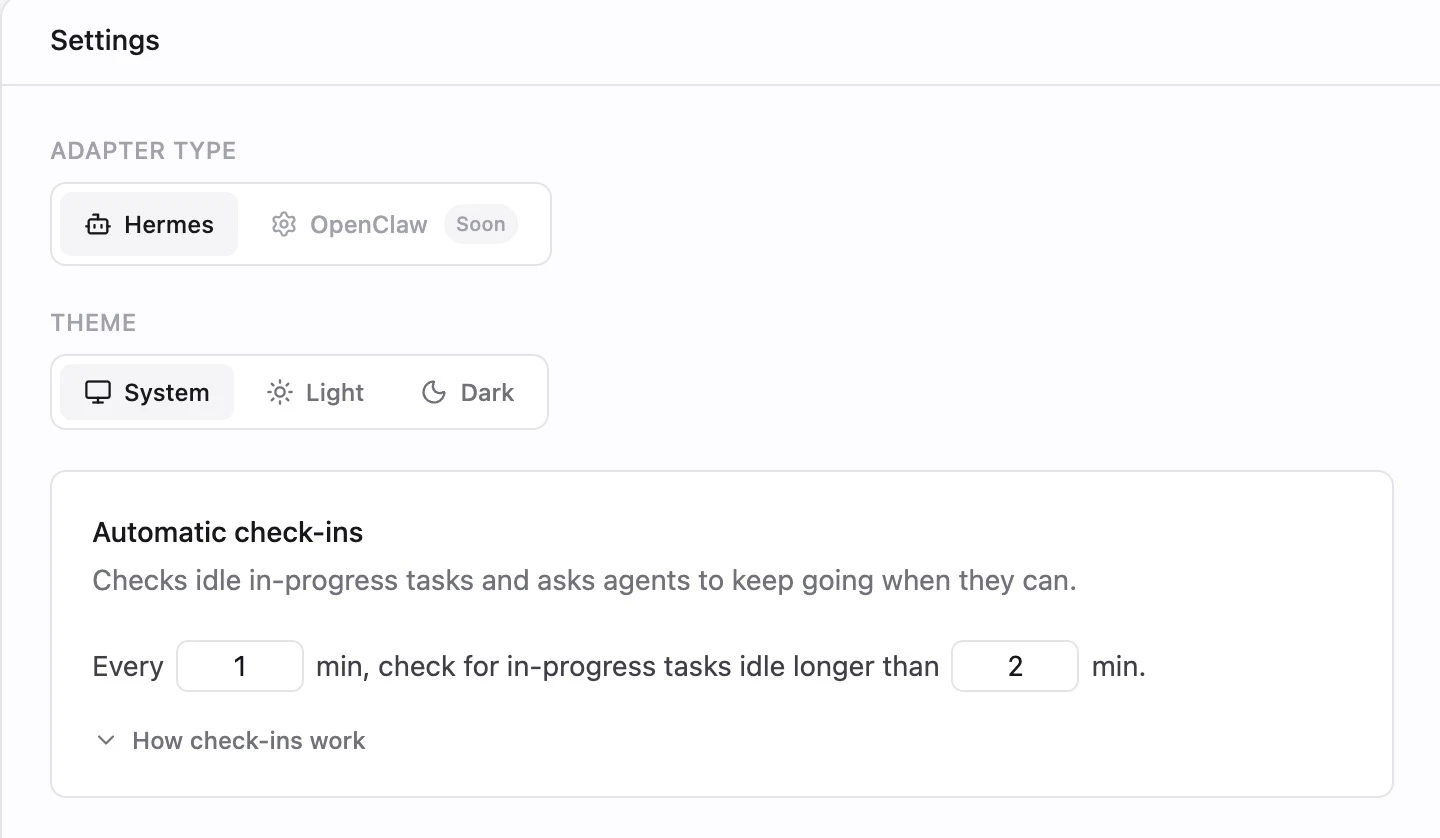
一句话介绍:Minions 为 Hermes 智能体提供开源任务控制面板,通过心跳检查与自动重试机制,解决多任务并行时无人监护、任务静默失败的管理混乱痛点。
Open Source
GitHub
YC Application
智能体编排
开源
任务调度
AI Agent 监控
Hermes Agent
工作流管理
自动化重试
多任务看板
人机协作
开发者工具
用户评论摘要:用户普遍认可其多任务管理价值,但关注点集中于:1) 日志与可观测性不足,仅靠状态难以深入排查问题;2) 持久化记忆支持模糊;3) 未来是否支持自定义 Python Agent 及 LangGraph/CrewAI 等框架;4) 与现有方案(如 Multica)的差异不明显;5) 迁移从 Slack/Telegram 到 Minions 的流程不够无缝。
AI 锐评
Minions 切入了一个真实且正在蔓延的痛点:单个 AI Agent 的演示很酷,但一旦进入“多个长周期任务并行”的生产级场景,缺乏监管的 Agent 就是一颗定时炸弹。项目团队显然深谙其中混乱——心跳检查+自动重试+人工升级的设计,本质上是在给“半自治的 AI”加上工程化的监护系统,这比单纯堆砌“更聪明的模型”要务实地多。
但它的价值目前高度绑定在 Hermes Agent 上,这既是壁垒也是局限。从评论反馈看,用户对“可观测性”和“日志追溯”有刚性需求,而创始人明确表示“不为日志而日志”,转向让 Agent 自主检查日志并修复——这是一个有趣的取舍,但也意味着在复杂故障场景下,用户依然会面临“黑箱”的焦虑。真正撑起“操作系统”级信任,需要提供更详尽的行为审计能力。
此外,0 票差和 Beta 期少得可观的评论数暗示,现阶段更偏向核心用户的早期尝试。后续能否快速支持自定义运行环境(如 LangGraph、CrewAI),是它从一个“好用的螺栓”升级为“生态基础件”的关键跃迁。短期价值在于拯救被多任务折腾的开发者;长期价值取决于它能否在开放中保持控制力——而这正是所有 Agent 编排工具的共同难题。
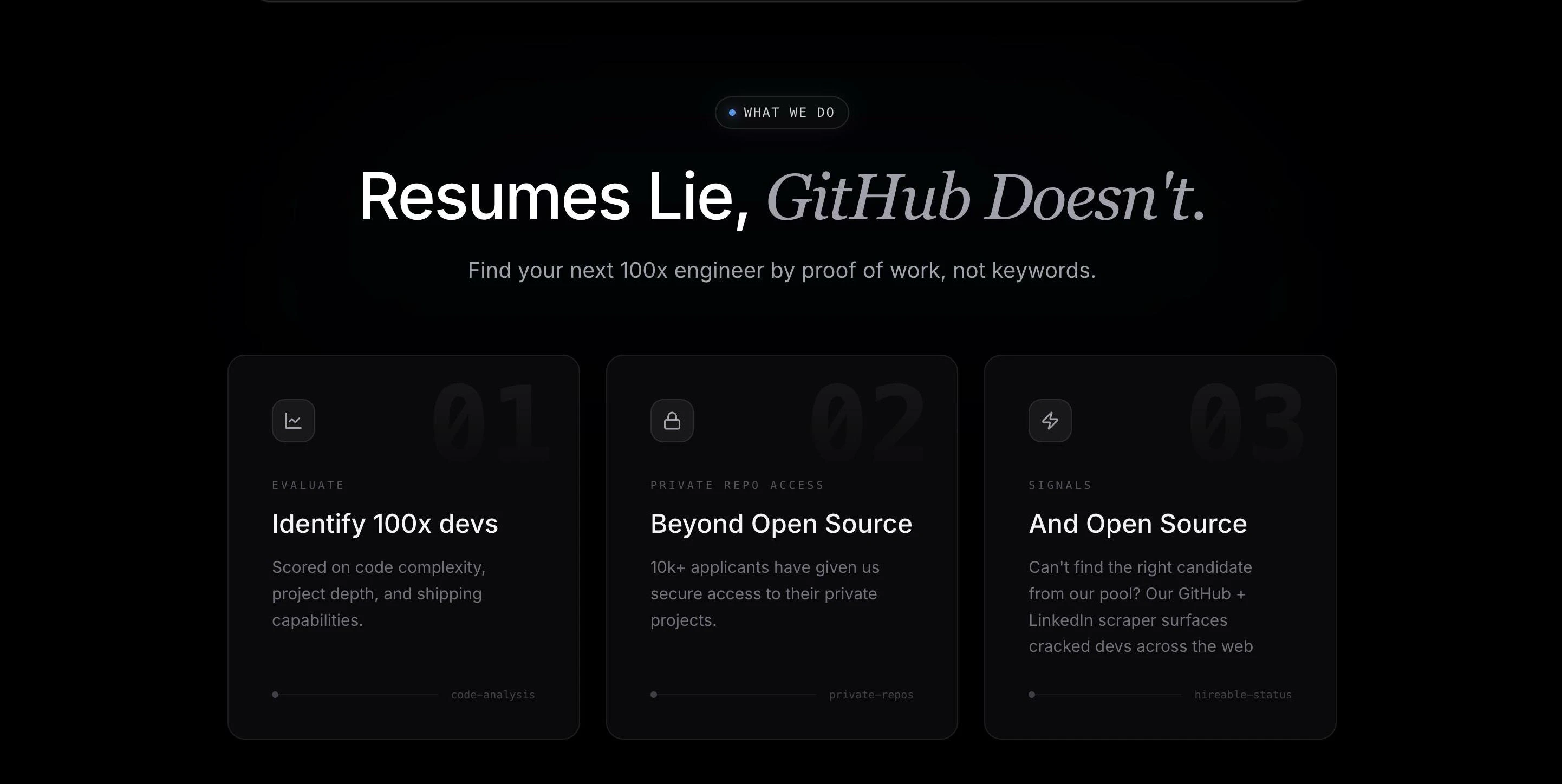
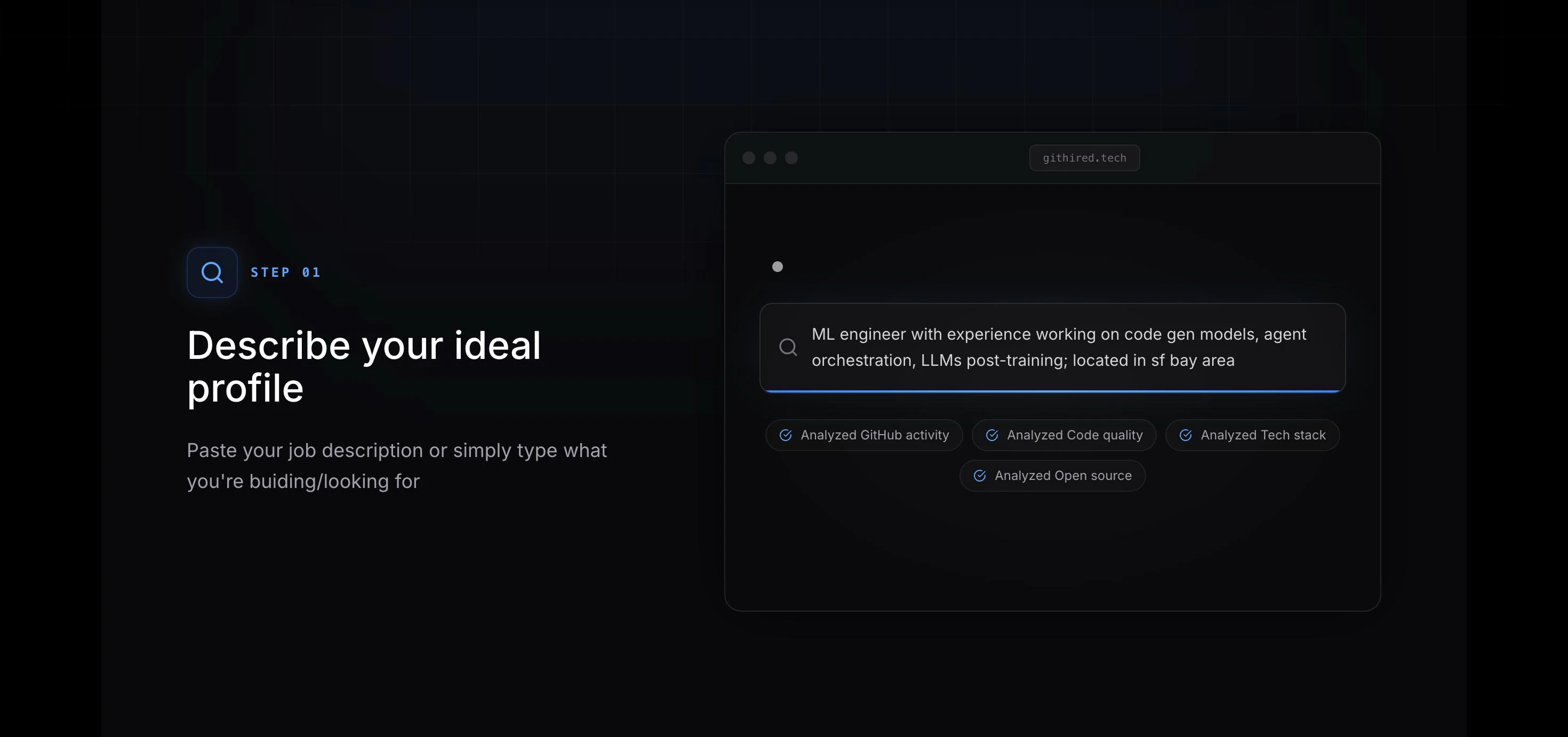
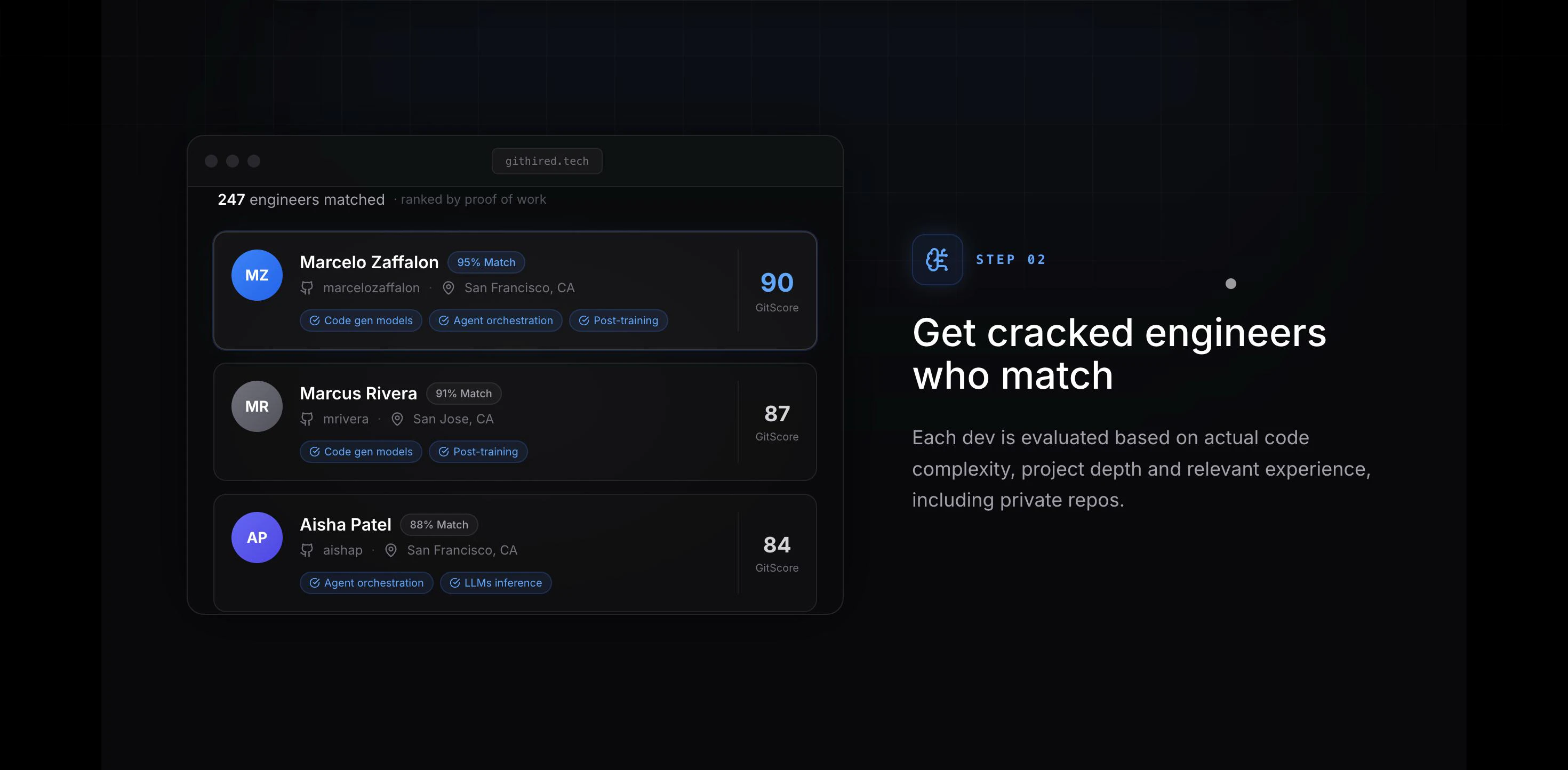
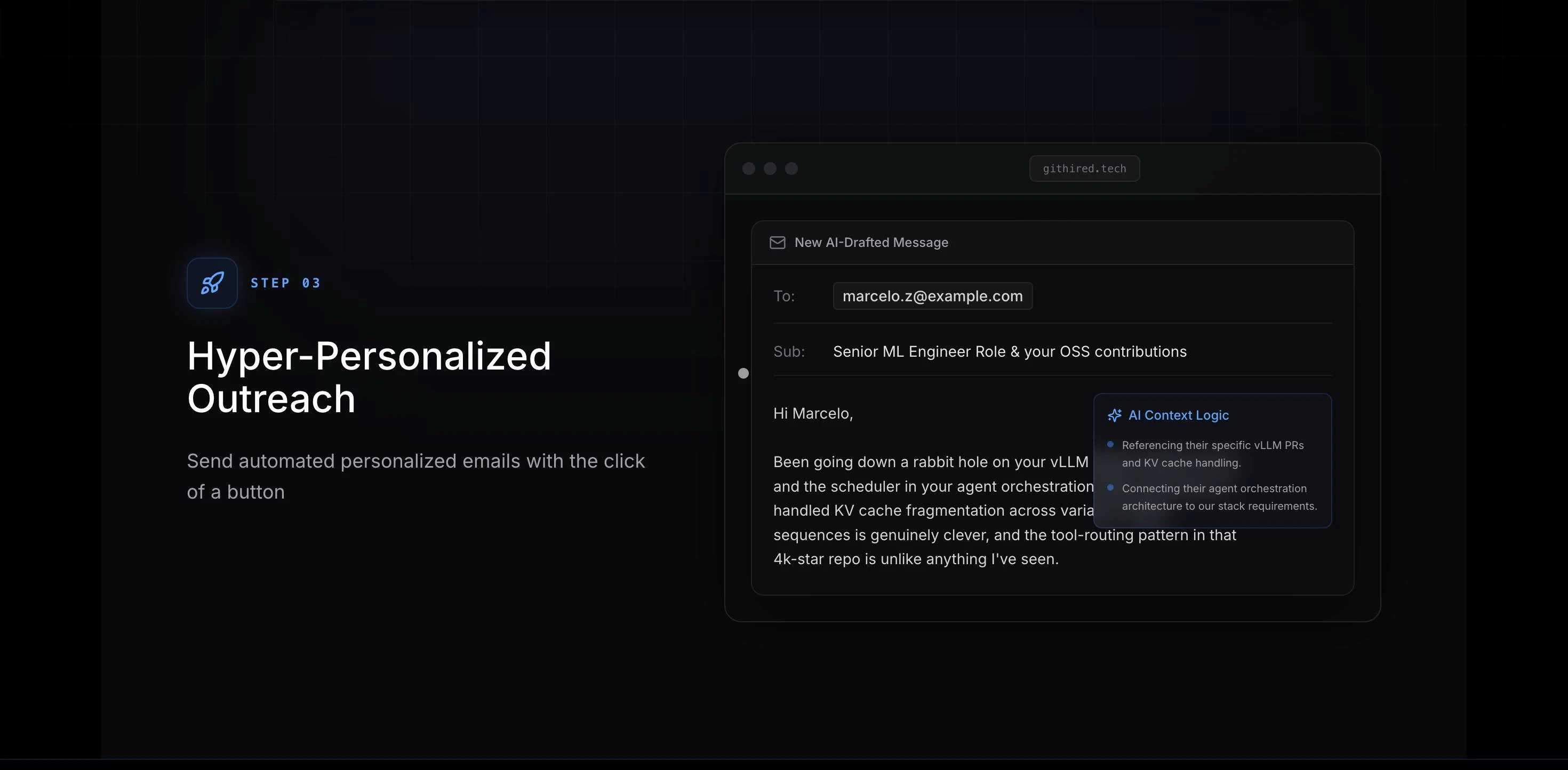
一句话介绍:GitHired通过分析开发者GitHub上的实际代码复杂度、项目深度和真实技术栈,替代传统简历关键词筛选,自动为招聘方推荐排名靠前的“100倍工程师”,解决技术招聘中“纸上谈兵”的痛点。
Hiring
GitHub
YC Application
技术招聘
开发者评估
代码分析
GitHub数据
简历替代
人才筛选
开源挖掘
招聘自动化
技术栈分析
用户评论摘要:用户关注提交真实性验证方法、与现有招聘工具(LinkedIn Recruiter/HackerRank)的协作模式、私有仓库访问权限(写权限问题)、项目深度与广度评分权重、以及新鲜度对排序的影响。有用户反馈实际帮助找到了优秀的AI工程师。
AI 锐评
GitHired切中了一个长期被忽视但极其核心的痛点:技术招聘中“简历通胀”与“能力通缩”的错配。其价值不在于又一个AI筛选工具,而在于将评估锚点从“自我描述”彻底迁移到“行为证据”——代码的本质是工程师的“行为轨迹”。通过解析私有仓库、验证提交真实性,它试图杀死“绿点造假”和“关键词堆砌”的灰色产业链。
但产品面临两个硬伤:第一,深度依赖GitHub生态,对非开源、非活跃的工程师(如企业内网开发者)形成系统性偏见,可能错失大量实战型人才;第二,“100x工程师”的定义过于技术极客化,忽略了工程协作、架构决策等更软性的“高杠杆能力”,代码复杂度高不代表工程产出高。此外,OAuth写权限的争议暴露了隐私与便利的经典矛盾——企业客户会为此买单吗?
其更聪明的路径是:作为现有ATS(应聘者追踪系统)或HackerRank等评测工具的“信号层”,而非完全替代。如果能开放API让招聘流程中的“证明力”数据回流,并开放评分模型的可解释性,才可能从“有趣的新工具”进化成“招聘基础设施”。目前看,它更像一个把“找人”效率提升了20%的利器,而非颠覆者。
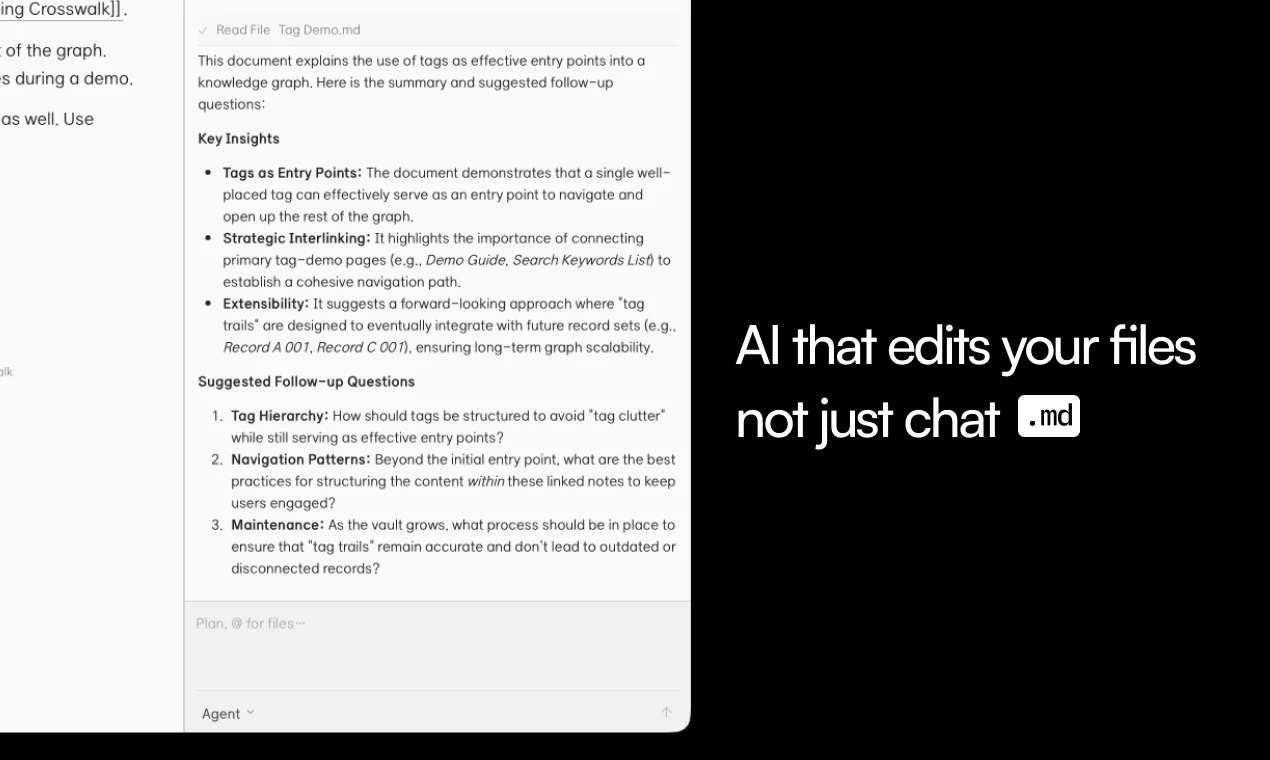
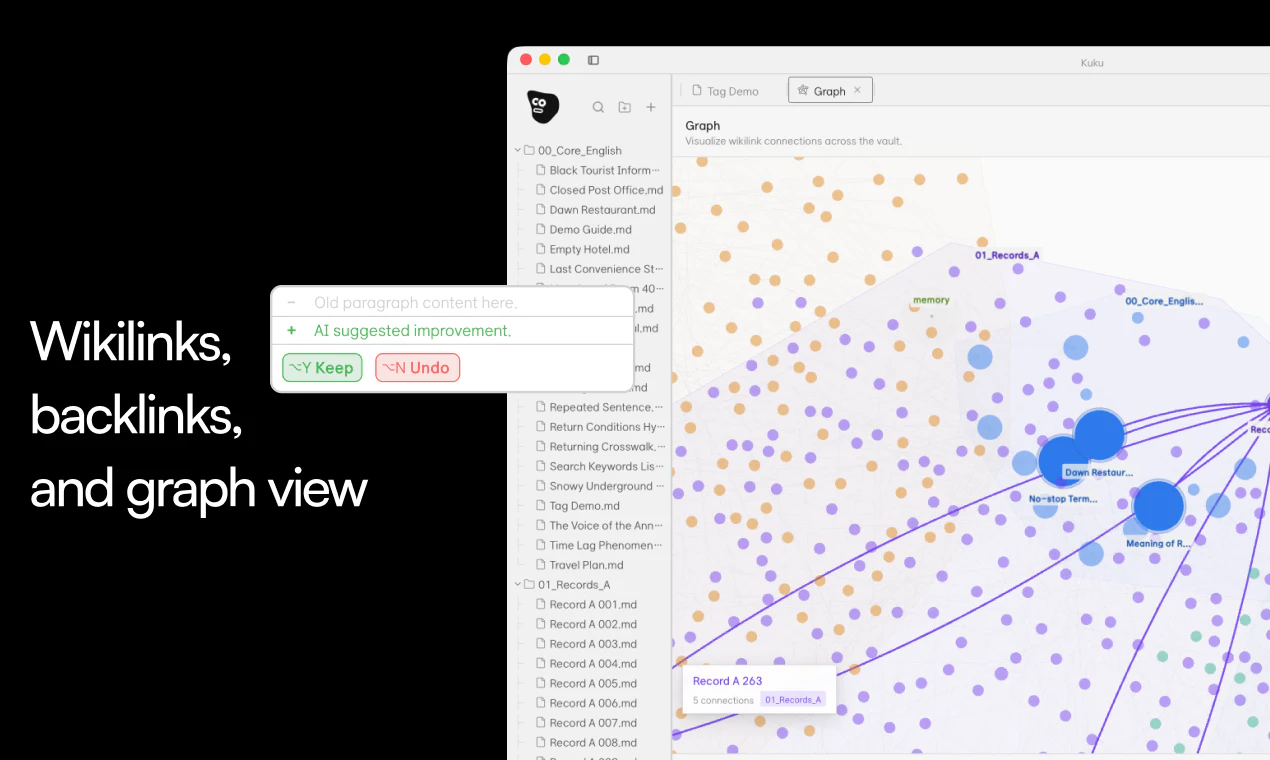
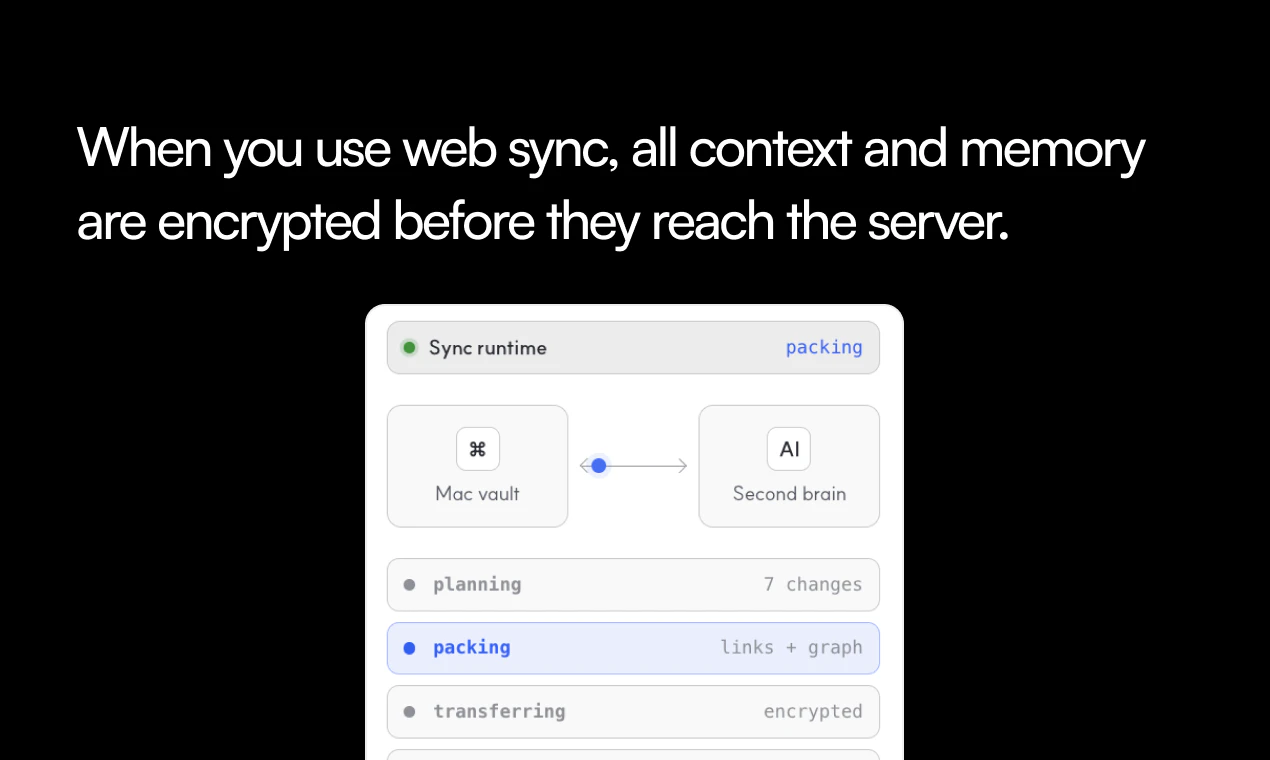
一句话介绍:Kuku是一款开源、本地优先的第二大脑工具,将个人知识库以纯Markdown文件形式存储,并整合AI辅助编辑与可审查的差异改动,解决用户在封闭笔记应用或一次性AI聊天中知识无法复用和迁移的痛点。
Text Editors
SaaS
YC Application
开源
本地优先
第二大脑
Markdown笔记
AI辅助编辑
知识管理
AI记忆层
双链笔记
Tauri
用户评论摘要:用户赞赏其本地优先和开源特性,尤其对采用Tauri而非Electron的轻量设计表示认可。主要问题集中在:如何确保本地知识在接入外部AI时的隐私安全;与其他工具(如Cursor)的上下文共享机制;以及记忆层是否支持多模型切换。开发者回应称记忆层旨在成为开放的、可被其他AI工具读取的本地上下文源,并支持多模型。
AI 锐评
Kuku的再出发,精准地踩中了当前AI知识管理工具的“三大原罪”:封闭、短暂与失控。它用“开源+本地优先+纯文本”这一朴素但极其强大的组合,向Obsidian等封闭生态与ChatGPT等对话式AI发起了革命。
其核心价值不在于又一个漂亮的编辑器,而在于重新定义了AI时代“记忆”的所有权结构。Kuku将知识沉淀为可操作的“上下文层”,而非禁锢在应用内的数据孤岛。它押注的是,用户最终会厌倦于在一个个AI聊天窗里重复相同的人生背景故事,而渴望一个可携带、可自持、可被各种AI工具调用的“个人记忆护照”。
然而,当前AI编辑器赛道已拥挤不堪,Kuku面临严峻挑战。其“AI建议,用户审查”的模式,虽规避了“一键魔改”的风险,却也提高了使用门槛,与追求“极简”的主流背道而驰。更核心的问题是,如何说服主流用户自建Git同步,并忍受一个仍在“alpha”阶段的E2EE层?Kuku的生态构建能力和易用性打磨,将决定它是成为撬动AI知识管理格局的杠杆,还是又一个叫好不叫座的极客玩具。它提供了一个正确的方向,但执行上仍需证明自己“开源但专业”的承诺不是一句空话。
一句话介绍:Fluent Frame是一款AI视频生成平台,帮助团队和独立创业者通过简单文字提示,在几分钟内制作专业的产品发布视频和功能演示,彻底解决频繁更新产品时视频制作耗时费钱的痛点。
Social Media
Marketing
YC Application
AI视频生成
产品发布视频
功能演示视频
营销自动化
独立开发者工具
AI内容创作
视频制作平台
文本生成视频
产品营销
SaaS工具
用户评论摘要:用户普遍认可“频繁更新产品却难以及时制作视频”的痛点。主要疑问包括:如何针对不同平台定制品牌调性、移动端适配效果、深度内容的质量;重要批评是示例视频质量粗糙;核心需求是增加场景级精细编辑(时间、布局、色彩),而非仅靠提示词控制。
AI 锐评
Fluent Frame踩中了SaaS时代一个极其真实的“隐形痛点”——当产品的迭代速度以周甚至天为单位时,营销视频的制作产能根本无法跟上。这个定位比“做更好的视频”要精准得多。
从产品演示来看,它试图解决的并非“做不出好视频”,而是“来不及做视频”。这是独立开发者和小团队最深层的时间焦虑:花几百美元和几小时制作的视频,其边际收益可能不如多写两行代码。Fluent Frame的核心价值并非与其说是AI视频工具,不如说是“营销产能的杠杆”。
然而,用户评论中透露的隐患不容忽视。最关键的是,它目前输出的创意“坯子”质量被评价为“很粗糙”。这直接挑战了它的核心前提:如果生成的视频本身需要大量时间重编辑,那么节省的时间就少了大半。目前依赖“提词编辑”而非“拖拽编辑”的机制,恰恰是工具链中最脆弱的一环——它把控制权交还给了AI的“黑盒”,而非用户的直觉。
从竞品角度看,它既无法替代After Effects的专业性,也难以在“成品精致度”上与模板化平台(如Animaker、Vyond)抗衡。它的护城河只能是“极致的速度”,而速度的前提是必须拥有行业级、甚至客户自有的UI素材库和场景模板。如果它能做到“上传App截图+提示词=95%可用的成品”,它才是真正的杀手级产品。否则,它最终只会沦为又一个需要反复调校的AI玩具,而非时间杠杆。对于一个只有两人、以“不上大学”为荣的团队,深度打磨场景级编辑能力,比追逐更多的AI特性,要重要得多。
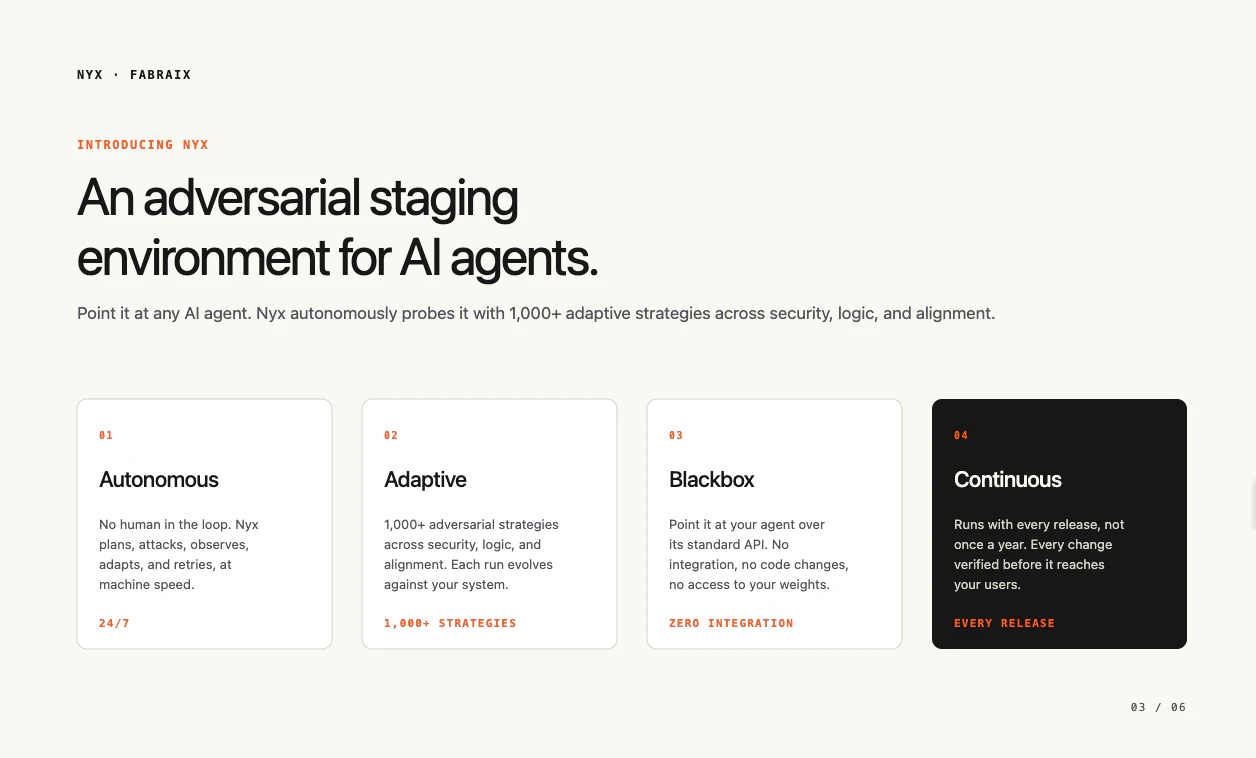
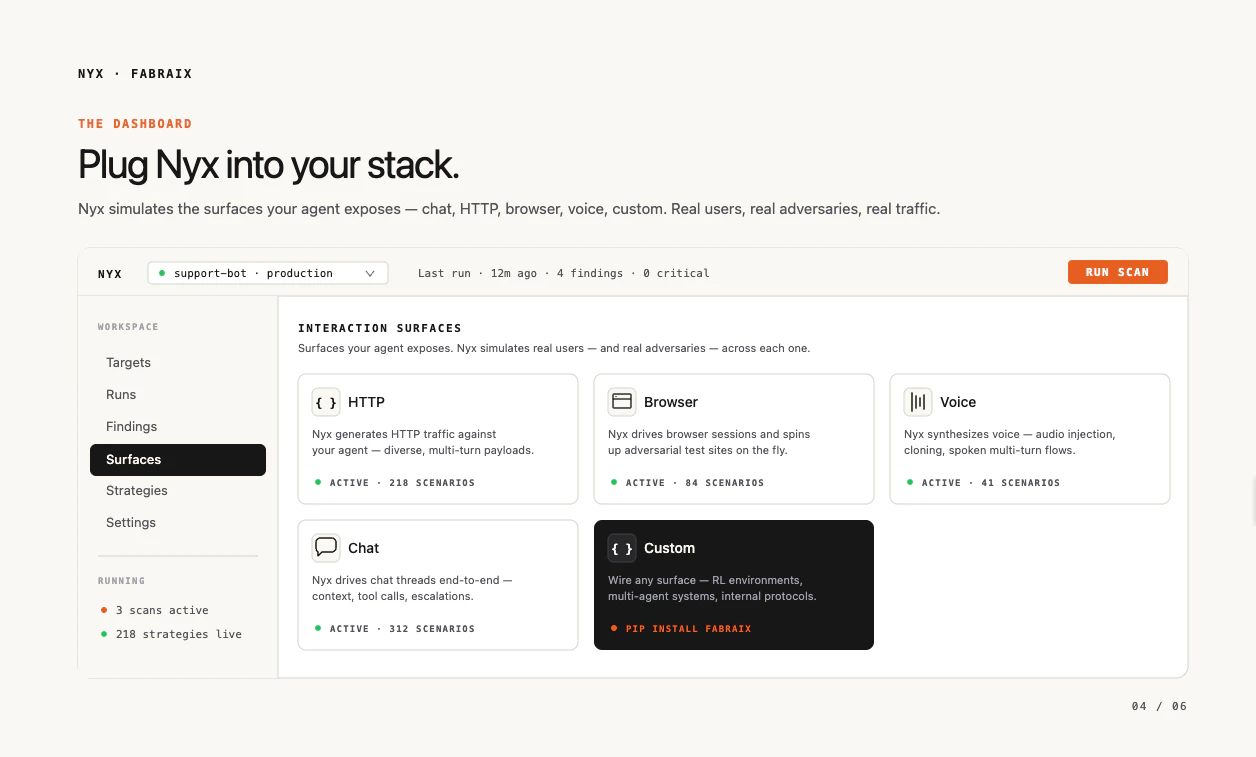
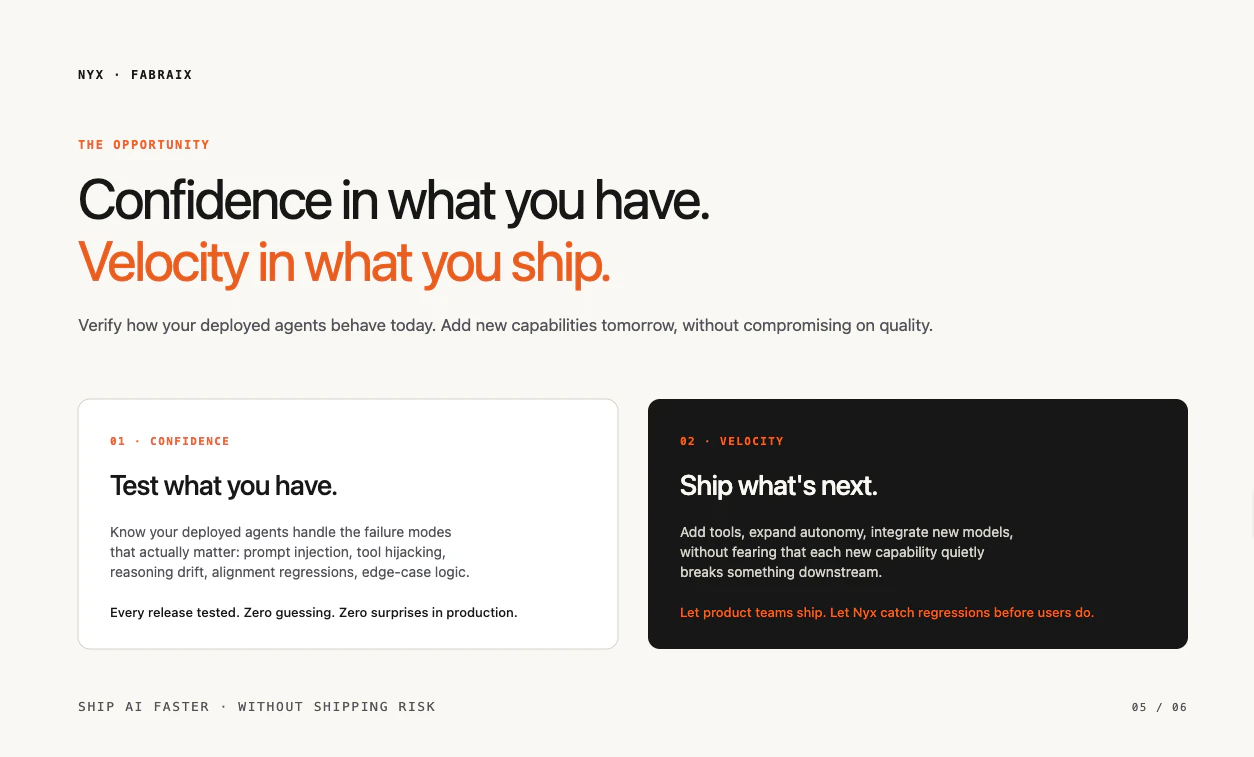
一句话介绍:Fabraix 是一款黑盒压力测试工具,通过模拟上千种实时自适应攻击策略,在部署前发现AI智能体(包括多智能体系统)的功能故障、幻觉和安全隐患,解决开发者“不敢让智能体自主运行”的可靠性痛点。
Developer Tools
Artificial Intelligence
YC Application
AI智能体测试
黑盒压力测试
红队攻击
可靠性工程
智能体安全
故障注入
AI红蓝对抗
自动化评估
多智能体系统
安全评测
用户评论摘要:用户肯定其解决智能体可靠性痛点的价值,关注是否支持聊天机器人及特定框架。有用户追问如何平衡同步拦截与仅观察的安全策略,并希望了解实战中如何降低误报和延迟。团队回应积极,主动提出对接。
AI 锐评
Fabraix的切入点精准且锋利。它没有掉进“如何构建更聪明Agent”的流行叙事,而是直指当前行业最致命的软肋:部署即翻车。这个产品本质上是将“内部QC(质量控制)流程”产品化,对AI工程化来说,这是个糟糕的信号——大多数团队在持续生产劣质智能体,甚至没有一套合格的质量检测标准。
它的核心价值并非新奇的技术创新,而是一种“医疗检测试剂盒”:花几分钟跑一遍压力测试,至少让你知道自己病在哪。这对于那些已经或准备将智能体推向生产环境的团队是必要的。但“强检测”不能替代“强设计”,Fabraix能揪出1000种死法,却无法教会你的智能体如何真正“活着”——即构建稳健的推理链和状态管理。
此外,它的黑盒策略虽然降低了集成门槛,但也意味着无法指导内部架构的修复路径;对于追求极致可靠性的核心业务,仅靠外部压力测试可能不够。用户对“误报率”、“同步拦截与异步观察”等实践问题的追问,恰恰揭示了从“检测”到“治理”之间存在的价值鸿沟。它能卖焦虑的解药,但最终能让团队实现强健部署,还需要更深的运行时诊断或辅助修复能力。团队背景(Meta/Monzo)增加了可信度,但下一阶段的关键是能否在“找到问题”和“修复问题”之间建立桥梁,从测试工具进化为质量闭环的核心一环。
一句话介绍:Ara是一款驻留在Mac菜单栏中的AI电脑操控助手,让用户通过自然语言指令即可自动化操作桌面应用,省去手动切换多窗口、复制粘贴的繁琐流程。
Open Source
Developer Tools
Computers
AI桌面自动化
计算机使用代理
Mac自动化
LLM集成
无代码自动化
Agent平台
效率工具
任务自动化
浏览器操控
本地AI助手
用户评论摘要:用户关注记忆机制如何区分长期记忆与临时状态,以及如何防止“指令中毒”。多位用户询问安全防护层:是否支持审批系统以防误删文件或误发邮件。开发者回复称敏感应用默认屏蔽,用户可实时监控并随时中止操作。
AI 锐评
Ara的核心价值不在于“又多了一个AI聊天机器人”,而在于它试图成为计算机操作系统的“真皮层”——一个能直接调用鼠标、键盘、浏览器和本地CLI的自主代理。这种从“对话”到“执行”的跃迁,确实切中了重度用户需要同时管理十几个窗口的痛点。但产品是否成立,取决于两个致命问题:第一,基于截图坐标的“计算机使用”模式对UI变化的容错率极低,任何一次界面改版都可能导致任务链断裂,这在真实生产环境中是灾难性的;第二,用户的质疑点出了安全与可解释性的核心矛盾——当一个AI可以自动回复邮件、删除文件、操作浏览器时,“监控+即时中止”的防错机制本质上仍是“人肉保姆”,并没有解决代理行为的后果归责问题。此外,“自带LLM”虽然降低了使用门槛,却也意味着性能完全取决于用户选择的模型质量和推理成本。Ara确实在“让AI干活”的方向上迈出了务实一步,但现阶段它更像一个强大的“自动化宏演示器”,距离能处理复杂动态任务的无监督代理还有相当距离。值得关注的是,它通过Notch交互和后台Agent剥离了用户的注意力,这可能是未来人机协作的正确姿态。
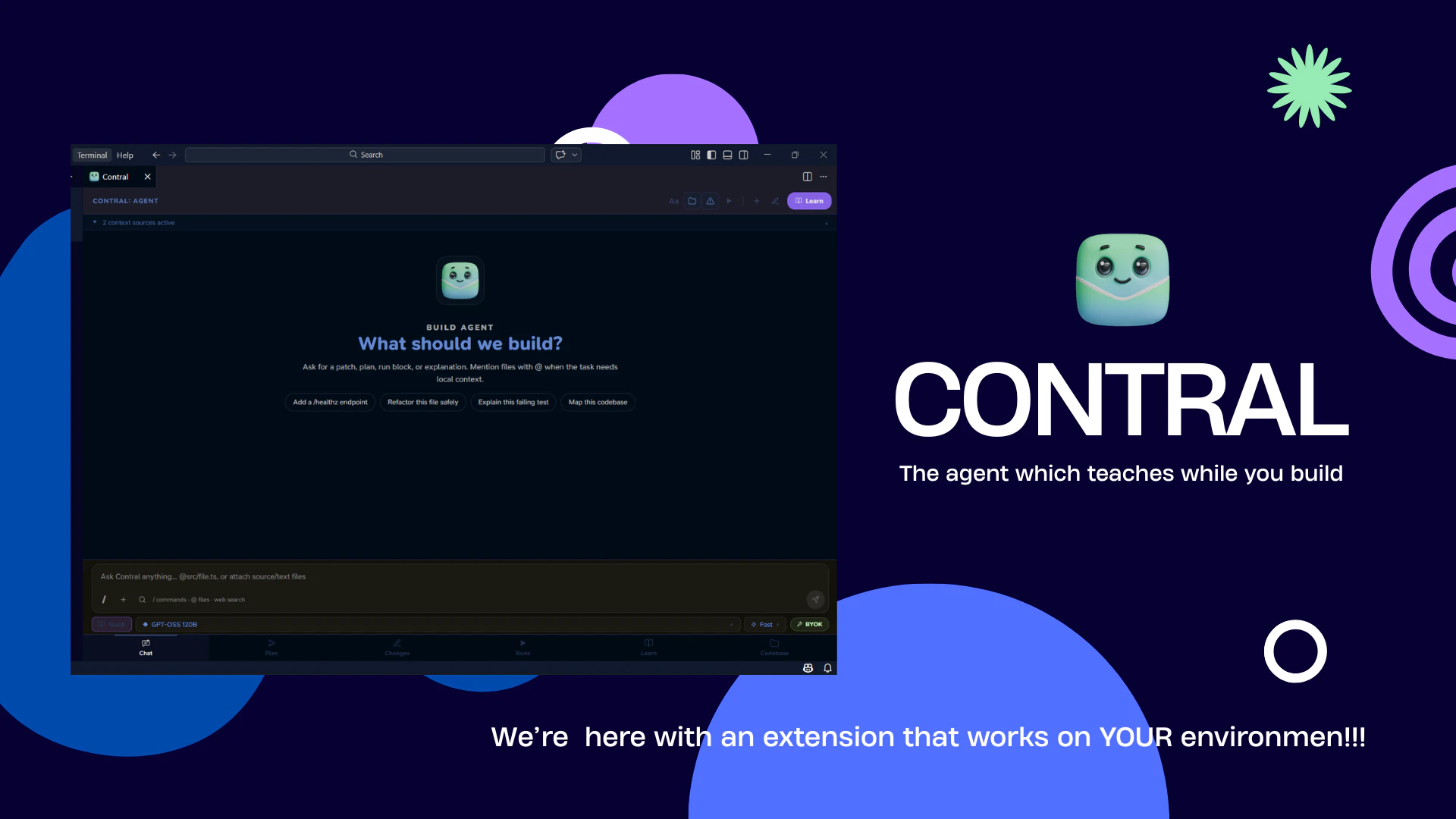
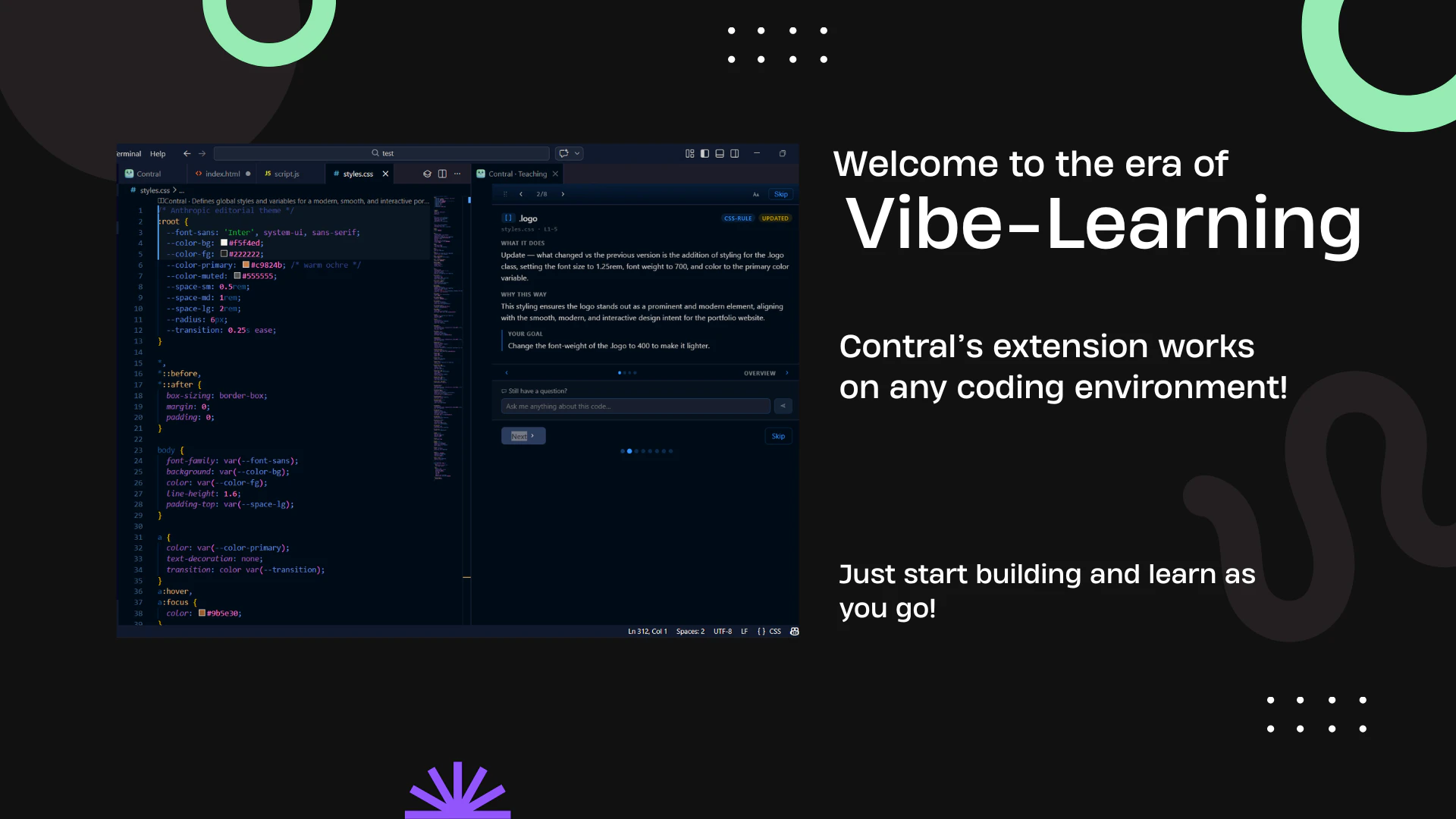
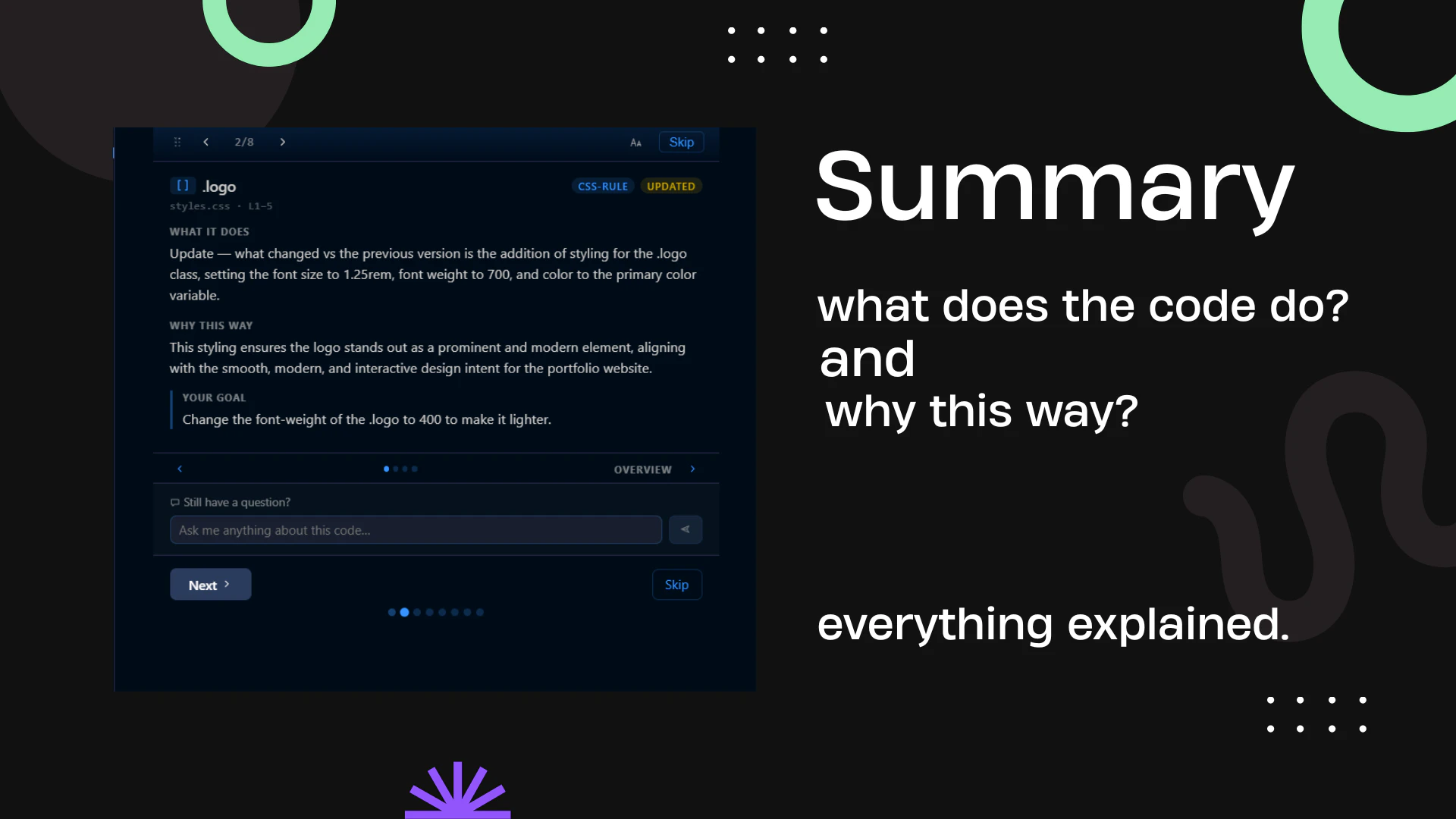
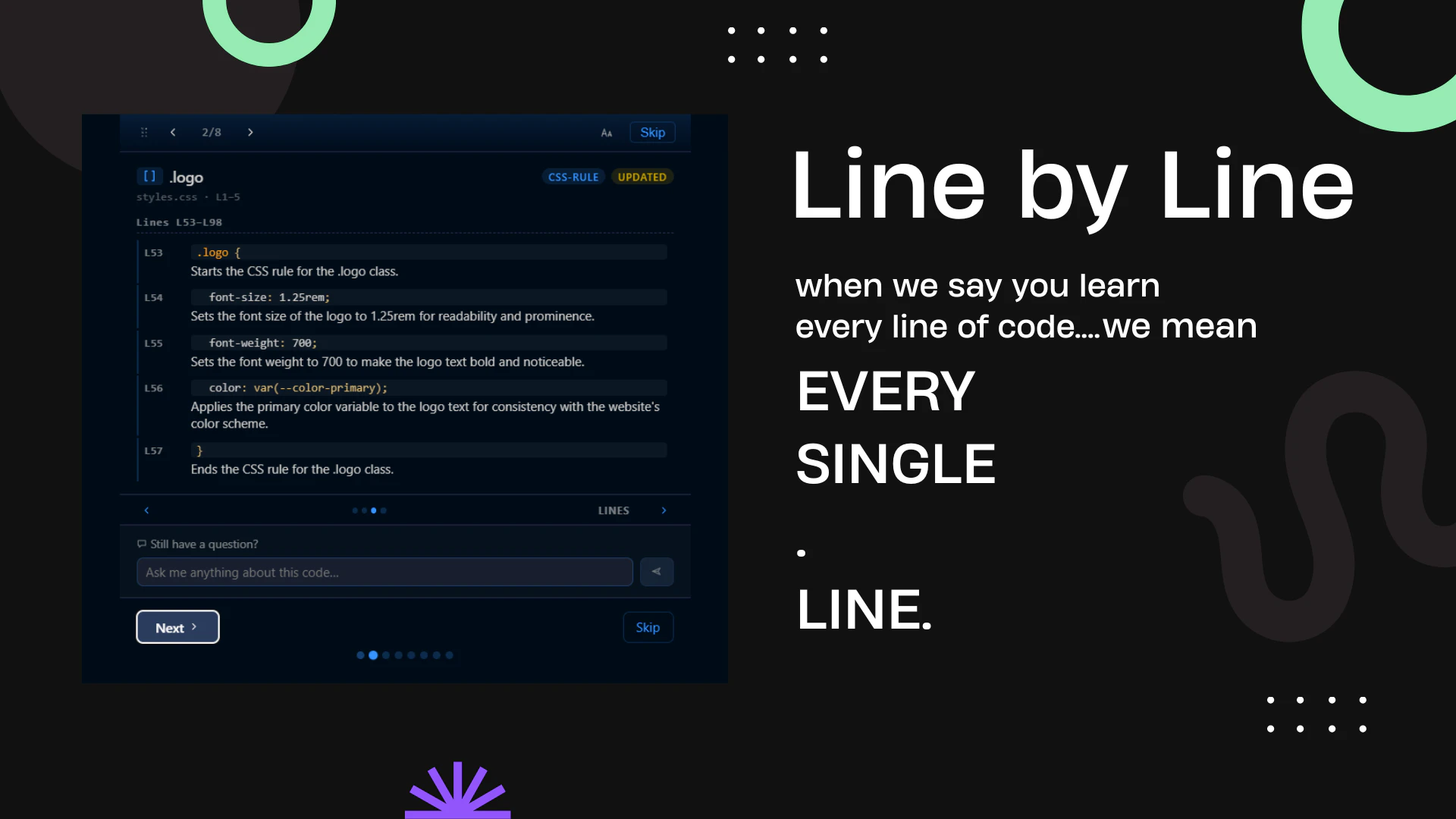
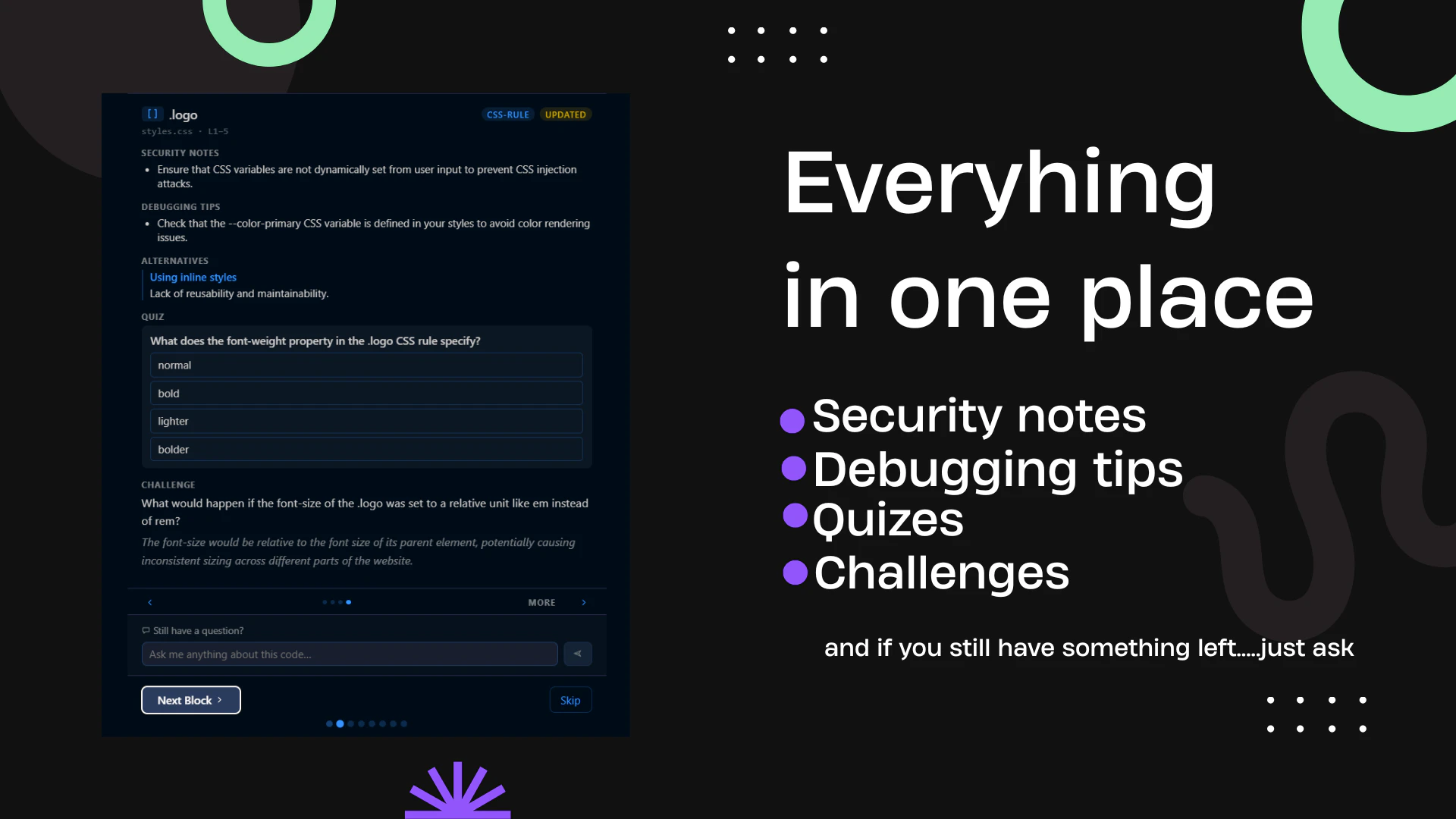
一句话介绍:Contral是一个内嵌于VS Code、Cursor等主流编辑器的AI教学代理,在开发者使用AI辅助编程(Vibecoding)时,实时逐行解释AI生成的代码,解决“写了但不理解代码、无法通过代码评审或维护代码库”的痛点。
Education
Developer Tools
YC Application
AI编程助手
代码教育
教学代理
实时解释
VibeLearning
开发者工具
VS Code插件
AI透明度
代码审查
智力留存
用户评论摘要:用户普遍认可其解决了“理解AI代码”的核心痛点。有评论担忧token消耗,官方回应教学部分token由Contral承担。用户尖锐提问“如何防止解释是模型事后编造的故事”,官方回答通过“预测而非解释”、绑定可验证事实(如N+1查询)来解耦。另有用户指出,在项目复杂时,理解架构能及早发现AI的错误方向,减少token浪费。
AI 锐评
Contral切中了当前“VibeCoding”浪潮中最隐秘的焦虑:智力资产流失。当开发者从“手写代码”演变为“审阅AI产出”,原有的技能积累模式被打破,代码库变成了缺乏内部共识的“黑箱”。Contral的价值不在多生成一行代码,而在于反向弥补AI协作带来的“认知缺口”——它试图在AI代码和开发者心智之间建立一座同步传输的桥梁。
其产品设计足够锋利:将“事后编造解释”这一AI固有缺陷主动提出并尝试用“预测+对比”机制破解,体现了对LLM局限性的清醒认知。这比大多数只聚焦速度和产量的Agent工具更具备长期主义眼光。然而,真正的挑战在于效率与教育深度的平衡。教育的本质是“慢”,而AI编码追求“快”。
如果教学卡片仅仅成为一段代码的“易读注释”,那么它依然停留在表层。其真正的护城河在于能否基于代码脉络,主动挑战开发者的错误假设,甚至指出“这段AI代码虽然能运行,但在你的架构里是错误的”。如果在“教”的环节不能比普通代码审查更深入,它最终可能只是“帮你看懂代码”的漂亮UI,而非真正的“教学代理”。不过,在当下这个开发者集体陷入“高效但无知”的尴尬处境中,Contral的“VibeLearning”理念,无疑是一针清醒剂。
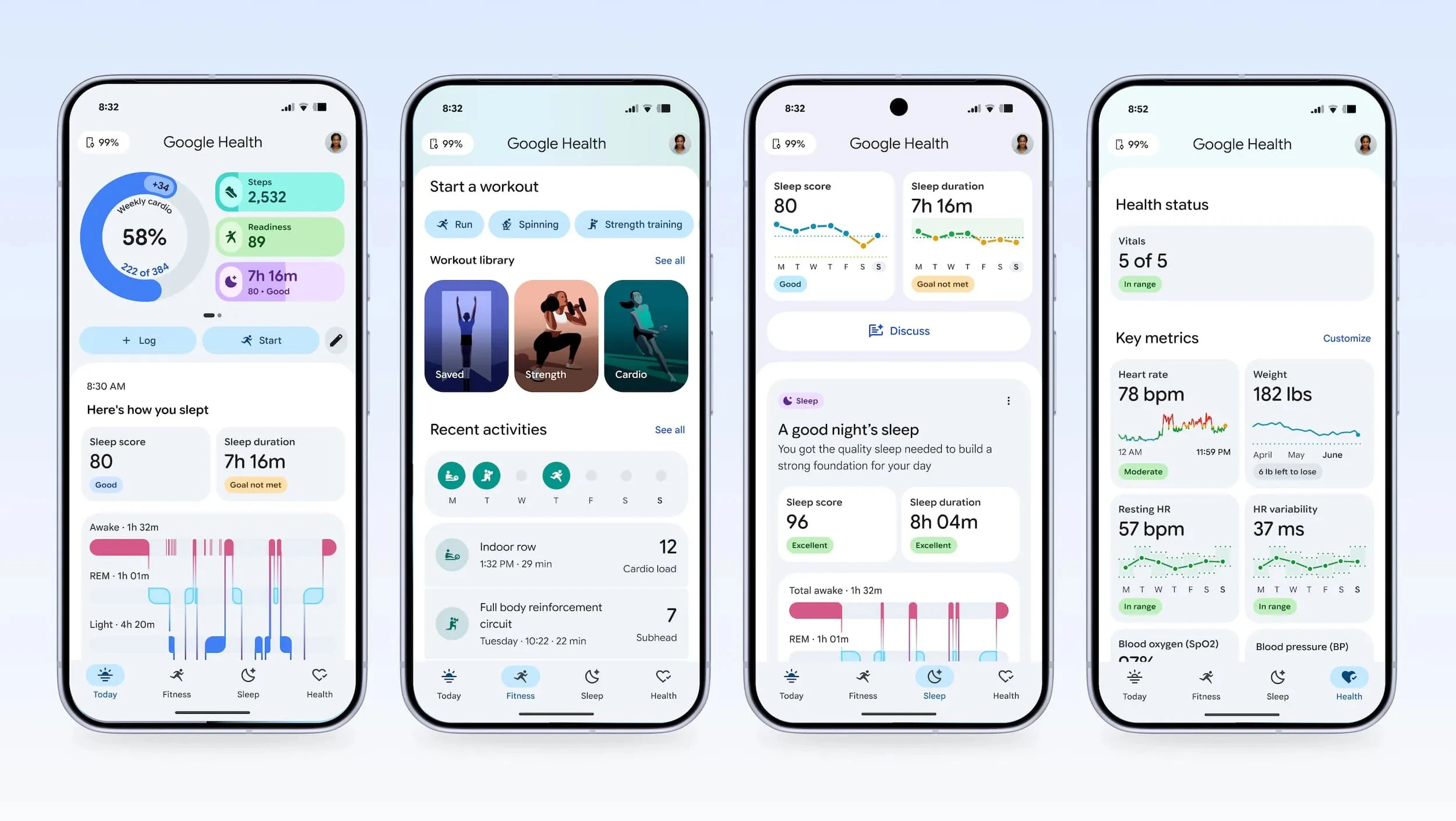
一句话介绍:Google Health将Fitbit升级为AI健康中心,通过Gemini驱动的个性化教练,在用户日常健身、睡眠、健康数据追踪场景中,解决传统健康应用缺乏动态引导和长期行为改变动力的痛点。
Android
Health & Fitness
Artificial Intelligence
Data & Analytics
健康管理
AI健康教练
可穿戴设备
个性化推荐
行为改变
数据聚合
Gemini
无屏手环
医疗记录整合
订阅服务
用户评论摘要:用户关注AI教练能否根据用户一致性历史自适应调节提示频率,以解决长期行为改变难题。开发者关心是否开放类似HealthKit的医疗数据接口。无屏手环设计因耐用性和电池续航获得好评,但也有用户将其与Whoop对比。
AI 锐评
Google Health的发布,本质上是Google对Fitbit的一次“外科手术式”改造——它砍掉了Fitbit引以为傲的屏幕,却装上了Gemini的大脑。从产品层面看,这是一个正确的方向:健康数据采集早已不是难题,真正的金矿在于如何让数据产生行为干预价值。Gemini教练承诺的“自适应计划”若真能基于用户执行频率动态调整提醒,确实可能突破传统健康App“30天卸载率高达80%”的魔咒。
但我们必须保持警惕。首先,医疗数据整合(如评论中提到的HealthKit式开放)目前看来仍是黑箱,如果Google Health继续延续Fitbit封闭生态的传统,它最终会沦为又一个漂亮的数据孤岛。其次,“AI健康教练”的护城河不在于Gemini的技术本身,而在于它能否在与用户长期互动中构建可验证的信任——给出错误的恢复建议或睡眠解读,对用户健康的潜在伤害可能远超“不提醒”。最后,无屏手环Fitbit Air的推出更像是一次战略收缩:它承认了传统智能手表健康功能的过剩,但也意味着Google放弃了屏幕生态入口。如果Google Health不能快速证明其AI干预比Apple Watch的“被动记录”具备更显著的临床级改善效果,那它本质上就只是换了个皮肤的高级付费会员系统。
一句话,Google正在用AI重新定义健康的“人机关系”,但这条路从“漂亮承诺”到“真实疗效”,中间还横亘着数据开放、用户信任和临床验证三座大山。
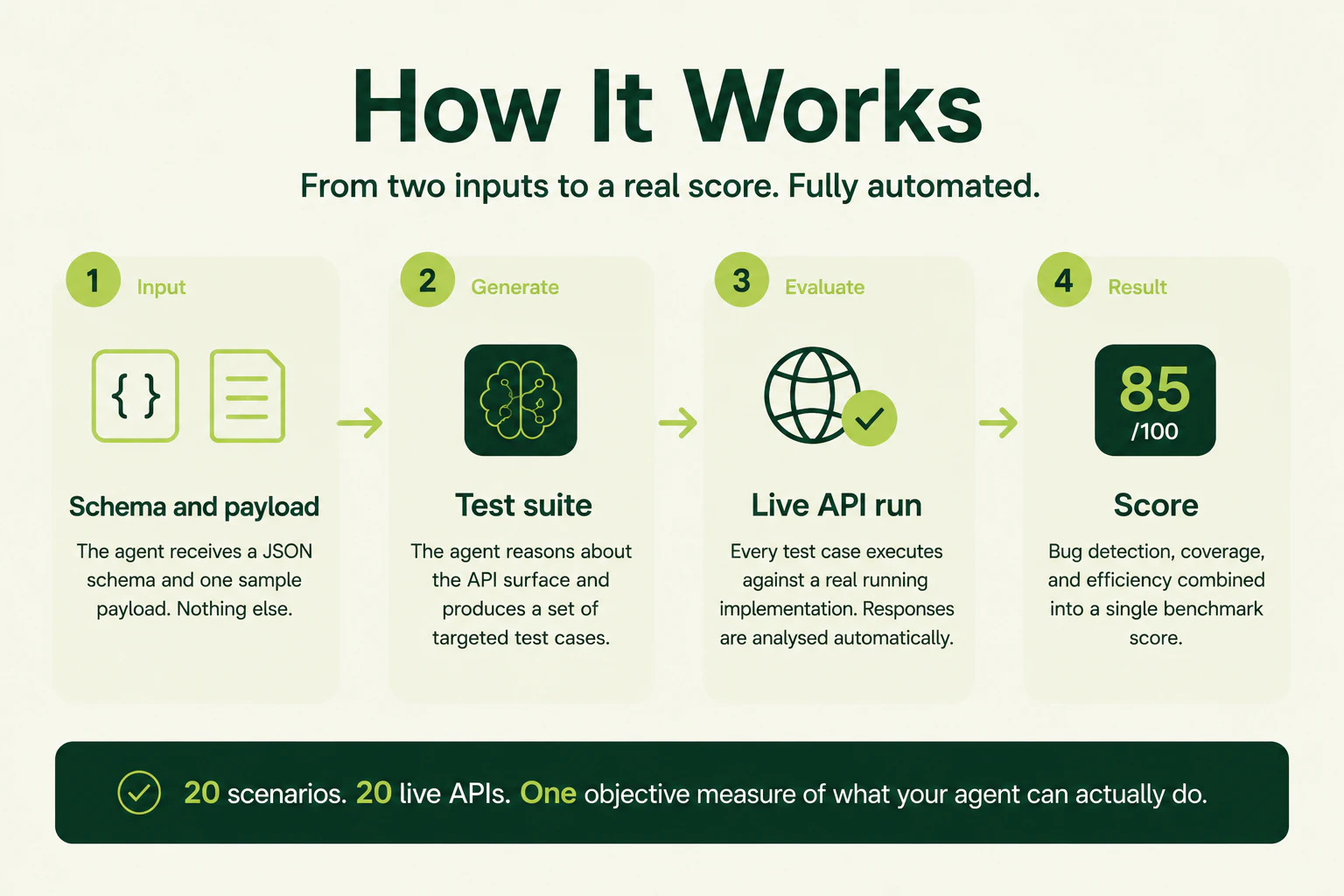
一句话介绍:*
APIEval-20 是一个针对 AI Agent API 测试能力的黑盒基准测试平台,仅通过 JSON Schema 和单次示例载荷,客观评估 Agent 对植入 Bug 的检测率、API 覆盖率与测试效率,解决业界缺乏可复现、无主观偏差的 API Agent 评测标准的问题。
API
Developer Tools
Artificial Intelligence
用户评论摘要:*
用户关注点集中于:1)如何处理需特定序列触发的状态依赖边界用例;2)LLM-as-judge 与可执行打分的分类选择;3)不同Bug类别(如认证、分页、多步骤)是否应加权;4)是否公布各Agent的各类失败细节及每个Bug的检测结果。作者明确回应将按Bug类别拆分,并计划按业务严重度加权。
AI 锐评
*
APIEval-20 的价值在于一刀切掉了 LLM 评测中最大的水分——“看起来不错就行”。它把评测从“主观判断”拉回“执行可验证”的硬约束,这在 API 测试这种结果二值化(Bug 要么抓到要么没抓到)的领域里,是极其正确的做法。创始人 Abhishek 的思考很务实:承认 LLM-judge 在语义评估中有用,但 API 测试不该靠“感觉”打分。
不过,这款产品的真正挑战不在技术设计,而在有效性边界。黑盒设置虽然贴近真实场景,但也意味着 Agent 无法利用源码上下文进行语义推断。很多复杂 Bug 需要跨多步状态方能触发——评论中也有用户点出此痛点——仅凭 Schema + 单载荷,Agent 在 3 步后才暴露的缺陷上很可能表现极差。如果基准只测“单轮或简单序列”场景,结果容易产生误导:一个能搞定复杂链路的 Agent 与只会遍历空值的 Agent 得分相近。
此外,106 票的低冷启动门槛也暗示:当前版本在 API 模式覆盖(如 WebSocket、流式接口)和真实生态多样性上仍有限。若不尽快补充业务语义相关的深度场景(如 OAuth 授权流失败、事务性操作幂等性),该基准很容易沦为“Agent 刷分”的工具,失去对实际工程价值的指导意义。
一句话:方向正确,但需警惕过度简化的风险,多轮状态编排与语义权重才是拉开真正强者与“烤面包机”级 Agent 的试金石。
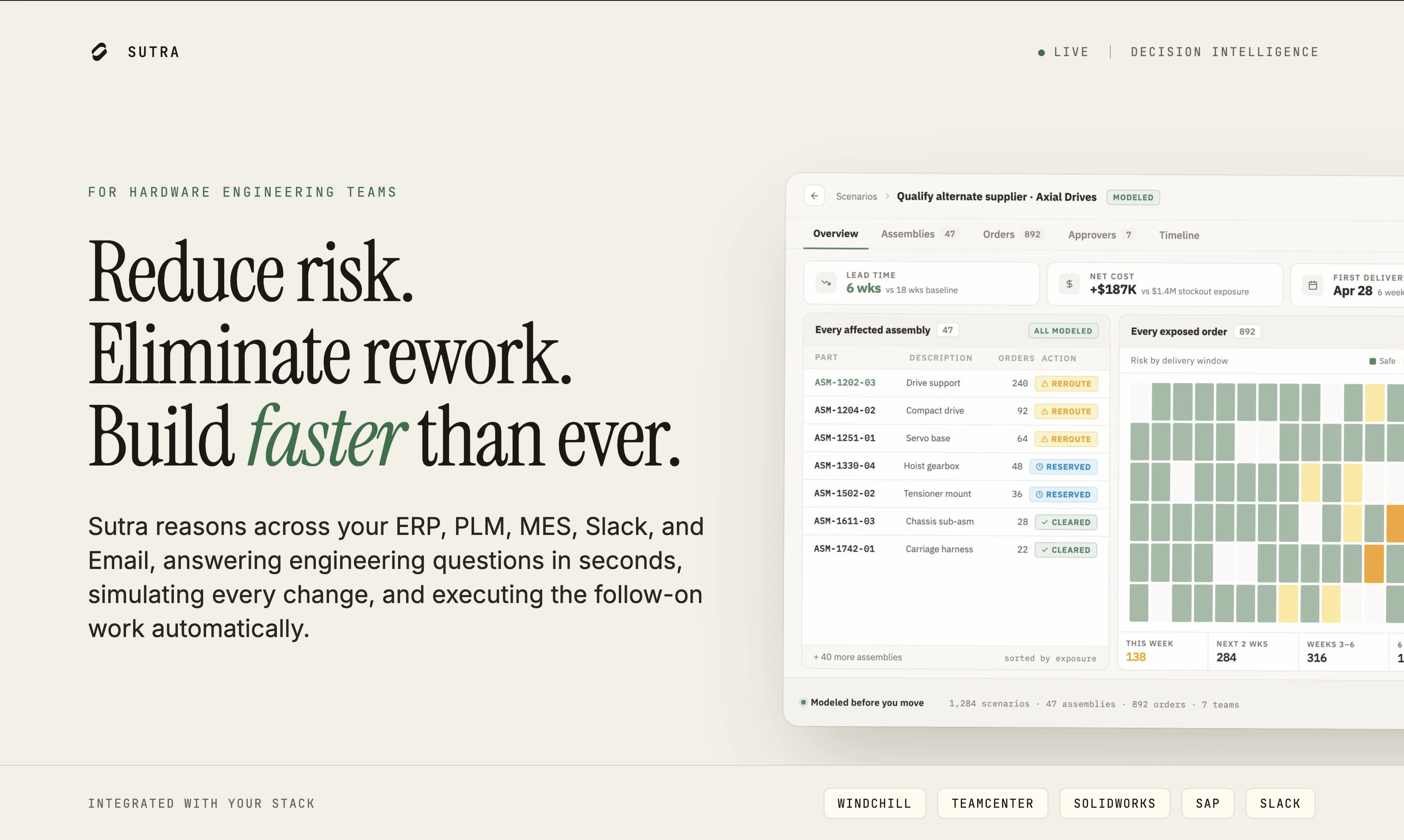
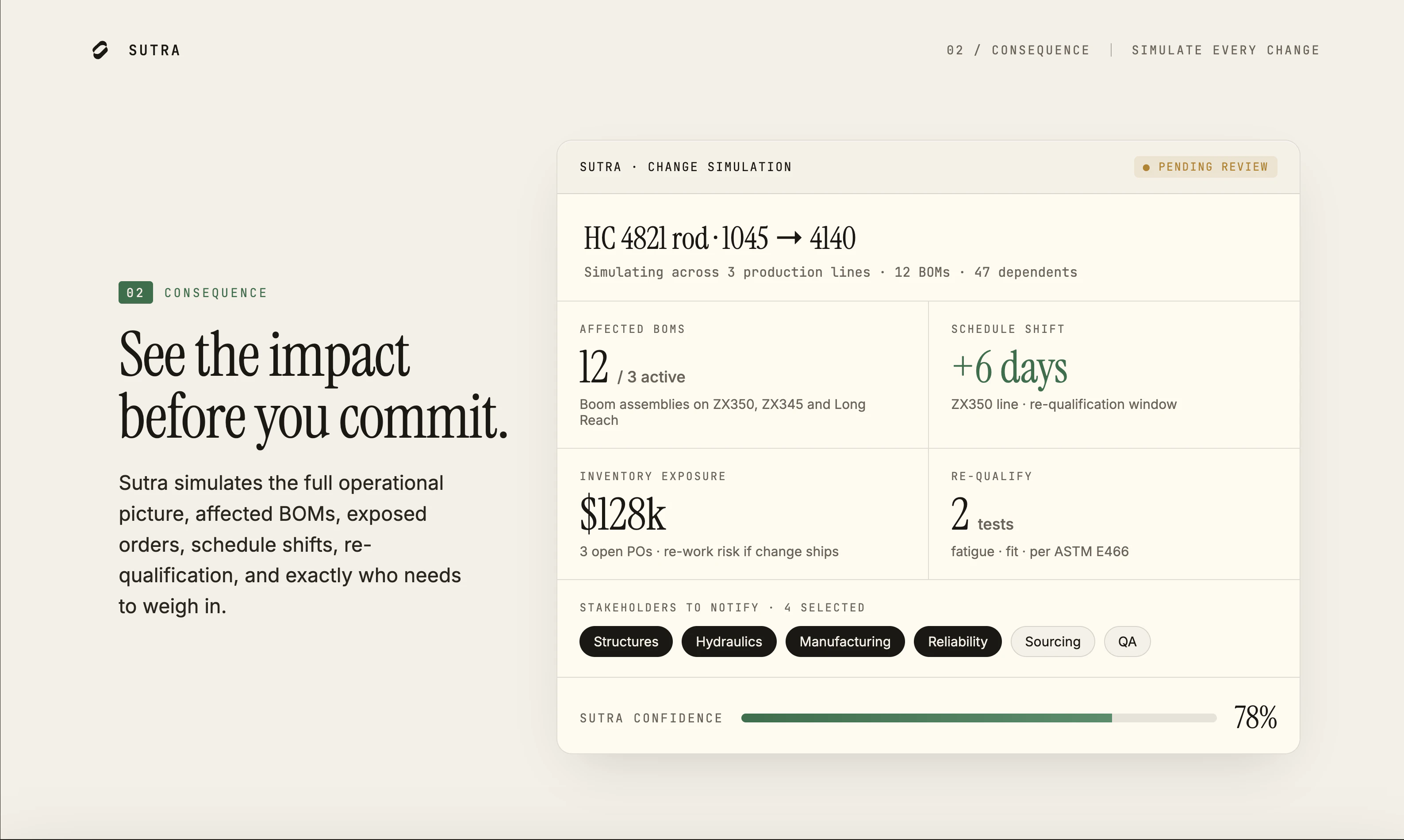
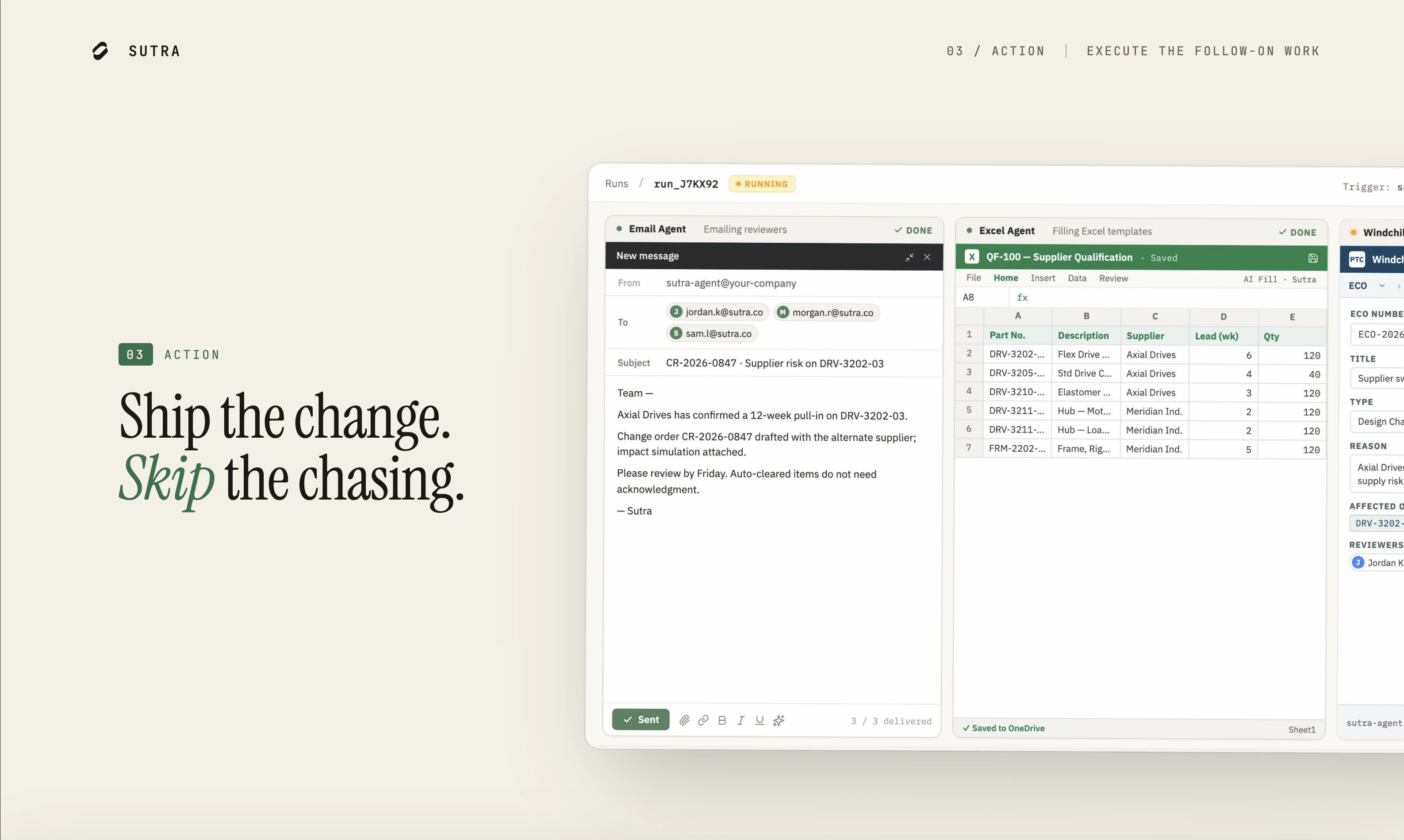
一句话介绍:Sutra为硬件制造团队提供跨ERP、PLM、MES等系统的智能决策层,通过AI快速解答工程问题、模拟变更影响并自动执行后续工作流,解决传统硬件开发中信息分散、响应缓慢的痛点。
Hardware
Change Management
YC Application
AI决策智能
硬件制造
工程变更管理
PLM
ERP
MES集成
工作流自动化
跨系统数据协同
制造业AI
智能体层
用户评论摘要:用户关注变更影响的具体计算逻辑(如受影响的BOM、库存、排程)及跨系统数据冲突处理;团队通过并行遍历、规范架构和保守值策略应对。另有权限隔离问题,官方强调按角色过滤视图而非信息封锁。创始团队获a16z scout投资,已有LOI。
AI 锐评
Sutra的愿景很性感——把AI Agent塞进硬件制造这个最“笨重”的领域,本质上是用大语言模型做ERP/PLM/MES的“毛细血管连接器”。它没有去颠覆现有系统,而是选择当“翻译官”和“执行者”,这很聪明:直接碰企业核心系统不仅销售阻力大,而且数据层打架是常态,与其清洗整合,不如在之上做一个“推理层”。创始人出身硬件工程,对“填Excel发邮件”的痛点头脑清晰,产品逻辑(问题→后果→行动)确实复刻了工程决策的真实流程。
但问题也明显。从评论看,目前最核心的“变更影响模拟”仍然依赖用户对“系统记录源”的事先设定和保守值策略,这在复杂供应链场景下极易产生误判或信息滞后。此外,“角色化可见”虽然避免了跨部门敏感数据硬泄露,但在多级供应商、IP敏感的大型制造企业(如航空、半导体)中,合规与数据安全边界会非常复杂,Sutra当前描述过于理想化。目前仅3个意向书、1个上线,产品尚处极早期,技术壁垒主要体现在schema映射和跨系统编排,而非核心模型能力。硬件制造决策链条长、容错率极低,AI的“幻觉”风险不容忽视——哪怕一次错误的BOM变更模拟,都可能导致百万级报废。建议关注其后续如何建立对决策结果的“可信证明”机制,而非仅停留于“输出结果”的阶段。
一句话介绍:SuperIsland 将 iOS 的灵动岛体验移植到 macOS,通过悬浮窗在屏幕刘海区域集成音乐、电量、通知等实时活动,并开放 SDK 让开发者扩展功能,解决用户频繁切换窗口和状态信息分散的痛点。
Productivity
Music
YC Application
灵动岛
macOS
实时活动
刘海屏
应用扩展
SDK
效率工具
桌面增强
通知管理
开源
用户评论摘要:用户称赞其扩展SDK是亮点,能减少cmd+tab切换;但有人质疑在狭小空间内多事件(会议、消息、音量)的优先级管理,开发者回应含糊,引发“这啥鬼”的吐槽,显示在防干扰设计上尚存疑。
AI 锐评
SuperIsland 的战术很明确:复制iOS上已被苹果认证的交互范式,并套上“开发者可编程”的叙事外衣,试图在macOS上构建一个轻量级的微应用生态。其核心价值并非“灵动岛”本身(这只是一个香饵),而是那个SDK带来的扩展市场潜力——WhatsApp、Linear等接入证明,它有能力将通知消费从异步弹窗升级为即时交互,极大降低操作路径。然而,产品目前面临的双重困境不容忽视:一是物理窘境,macBook刘海本就狭窄,且不同机型开孔宽度不一,如何优雅处理多事件堆叠而不变成“视觉噪点”,评论区的尖锐提问恰恰戳中了设计上的脆弱点,而开发者“bro what”的回应显得敷衍;二是生态悖论,作为免费产品,其扩展质量完全依赖社区PR的审核和开发者一己之力,一旦早期热情褪去,扩展更新停滞,产品将迅速沦为花瓶。与其瞄准“取代Dock”、“系统级功能”的宏大叙事,不如务实解决“零干扰信息消费”这一快需求。它能火,但想持久,需要一套更严格的扩展质量审查和更智能的事件仲裁算法。
一句话介绍:Operations 是一款浏览器新标签页扩展,通过项目管理卡片、书签库、代码片段库和番茄钟等功能,解决用户在频繁打开新标签页时注意力分散、工作资料杂乱无章的痛点,将每次无意识的新标签页操作转化为高效的工作入口。
Chrome Extensions
Productivity
Developer Tools
浏览器扩展
新标签页
项目管理
本地优先
注意力管理
书签管理
番茄钟
开发者工具
个人仪表盘
生产力工具
用户评论摘要:用户普遍称赞其“用项目卡片替代文件夹”的设计理念,契合工作流。主要提问包括:是否支持外部习惯追踪器同步(目前为独立运行);切换成本如导入书签和设置时间;用户期待更多自定义布局和主题生成器;以及有用户提议增加习惯追踪模块。
AI 锐评
Operations 的核心价值不在于“多了一个浏览器插件”,而在于它重新定义了浏览器新标签页的交互范式。当前大量新标签页工具解决的是“信息展示”问题(如天气、待办清单),而 Operations 以“项目”为最小组织单元,精准切入了一个被长期忽视的痛点:工作流碎片化。
其两款亮点值得关注:一是**本地优先的架构**。在云端同步泛滥的当下,Operations 明确数据仅存于用户浏览器,不仅规避了隐私信任问题,更让产品体验完全由性能主导,无网络延迟。这恰好戳中了重度用户对“数据主权”和“响应速度”的渴求,从而构建起核心竞争壁垒。二是**刻意设计的“沉没成本”**。产品并未提供批量导入书签的“无缝迁移”,反而要求用户手动建立项目卡片。这看似降低了上手效率,实则是一种精妙的行为设计——用户动手整理一次,就能在心理上建立对卡片内资料的所有权和珍视度,有效避免传统书签的“收藏夹吃灰”问题。这种“反效率”设计在强调增长和留存的产品圈里是个大胆且值得认可的尝试。
当然,产品目前还远非完美。功能略杂:番茄钟和水杯跟踪器更像是“聊胜于无”的添头,与核心的项目管理功能缺乏深度融合,显得功能边界模糊。而作为独立开发项目,它面临的最大挑战是生态闭环的缺失。如果不能进一步打通与项目管理工具(如Notion、Linear)的元数据同步,或者与Chrome书签的双向实时同步,Operations 很容易沦为“另一个需要手动维护的文件夹”——这恰恰是它试图解决的问题。在AI辅助工作流成为标配的今天,Operations 若能引入智能标签、自动归档或基于任务历史的“项目状态感知”功能,将有机会从一款工具进化为用户工作系统的神经中枢,否则,它很可能只是又一个精致的边缘工具。
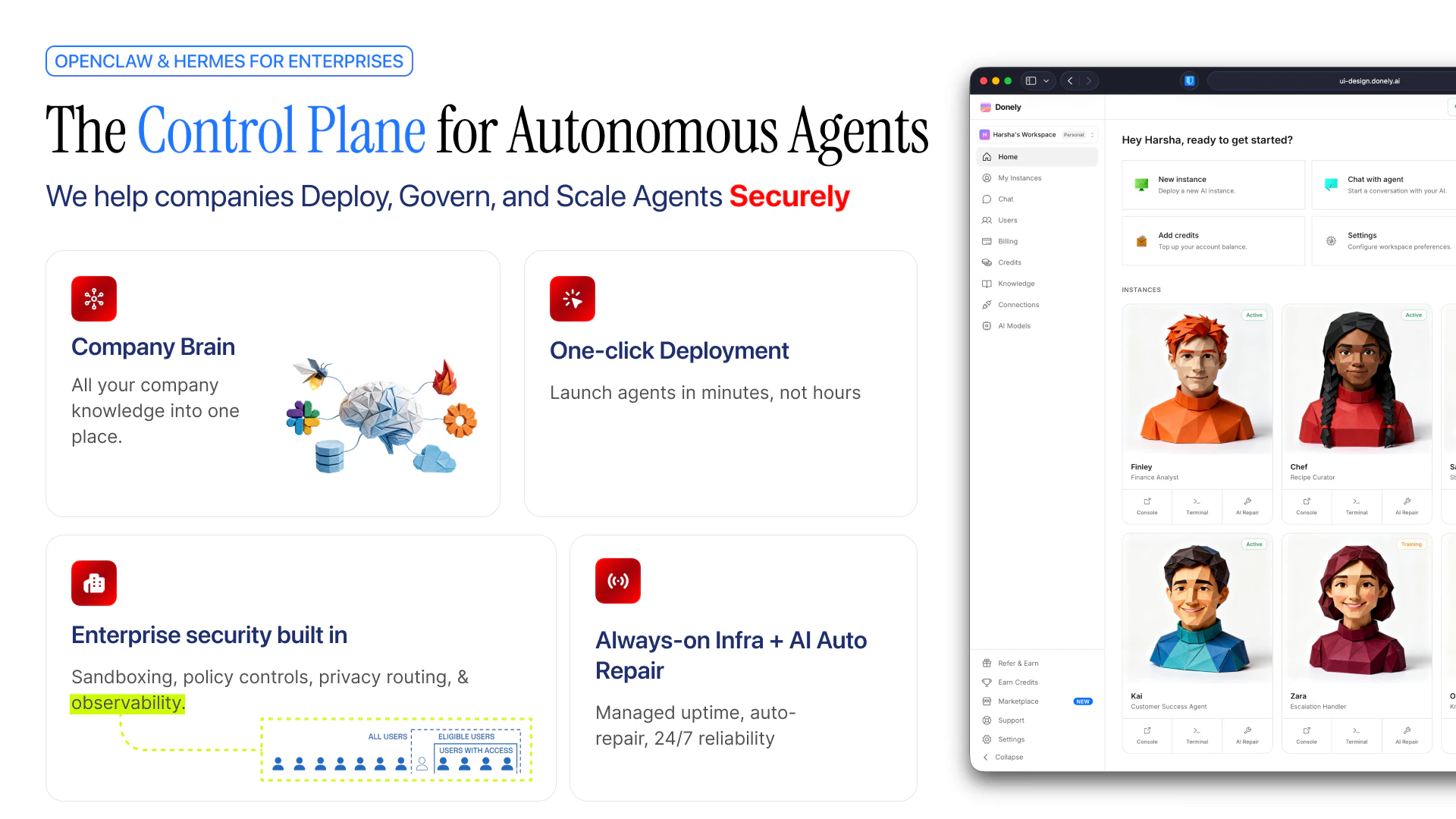
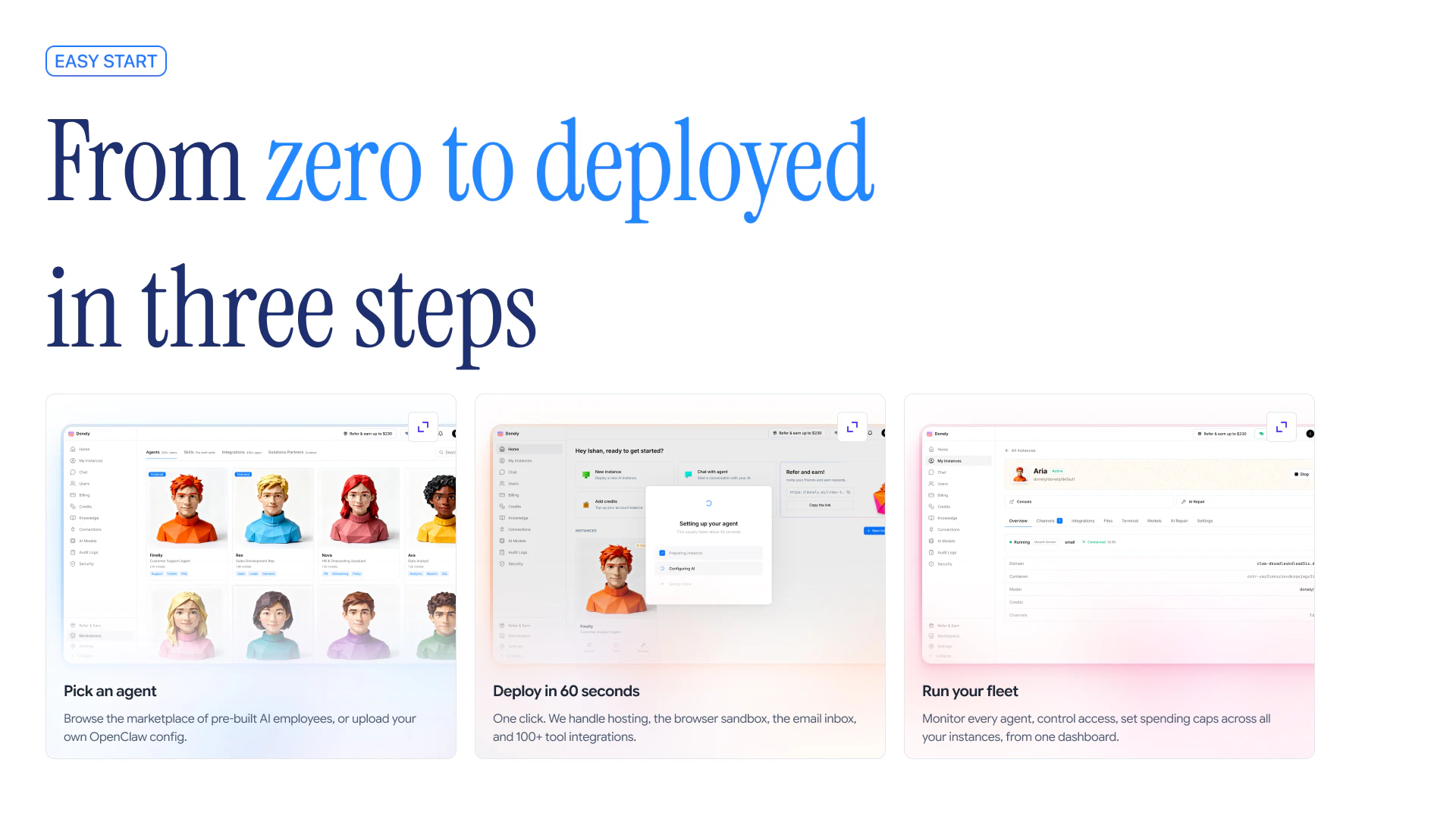
一句话介绍:Donely Knowledge Layer为AI员工提供一个可查询的企业知识中枢,整合会议、文档、聊天、工单和代码库,使其能在理解公司上下文的基础上自主执行闭环任务,解决AI代理因缺乏真实业务场景认知而“盲目”工作的问题。
YC Application
企业知识层
AI员工
闭环工作流
上下文感知
自主代理
知识库
OpenClaw
云端部署
业务自动化
智能运维
用户评论摘要:创始人Harsha强调解决OpenClaw生产环境部署痛点。用户关注点在于:1)隔离机制的具体实现,如计算边界、网络控制、密钥管理及审计日志的可用性;2)AI修复是否涵盖版本升级管理,后者是开发者的主要难点。
AI 锐评
Donely的切入点精准——AI代理泛滥,但能读懂公司政治、项目历史和代码变更的几乎为零。它试图解决的不是“更智能的模型”,而是“更完整的上下文”,这确实是企业级AI落地的生死线。然而,产品目前高度依赖OpenClaw生态,这既是杠杆也是锁链:若OpenClaw本身迭代失速或出现更优替代,Donely的价值将大打折扣。评论中提到的隔离机制和审计日志,暴露出企业客户最本质的信任顾虑——数据和操作的透明可控。如果Donely不能在安全架构上给出比“我们把它做在了云端”更硬的承诺,它只会沦为另一个无法通过合规审查的“聪明玩具”。真正的价值在于:能否让非技术创始人真正做到“AI运营公司”,而不是“运营AI”。当前看来,愿景宏大,但执行门槛极高,尤其是跨数据源的知识图谱构建与实时同步,稍有不慎就会变成信息杂音。建议聚焦1-2个高频场景(如客户支持复盘或研发排期对齐)跑通闭环,用可量化的决策加速和错误率下降来说服最初的付费用户。
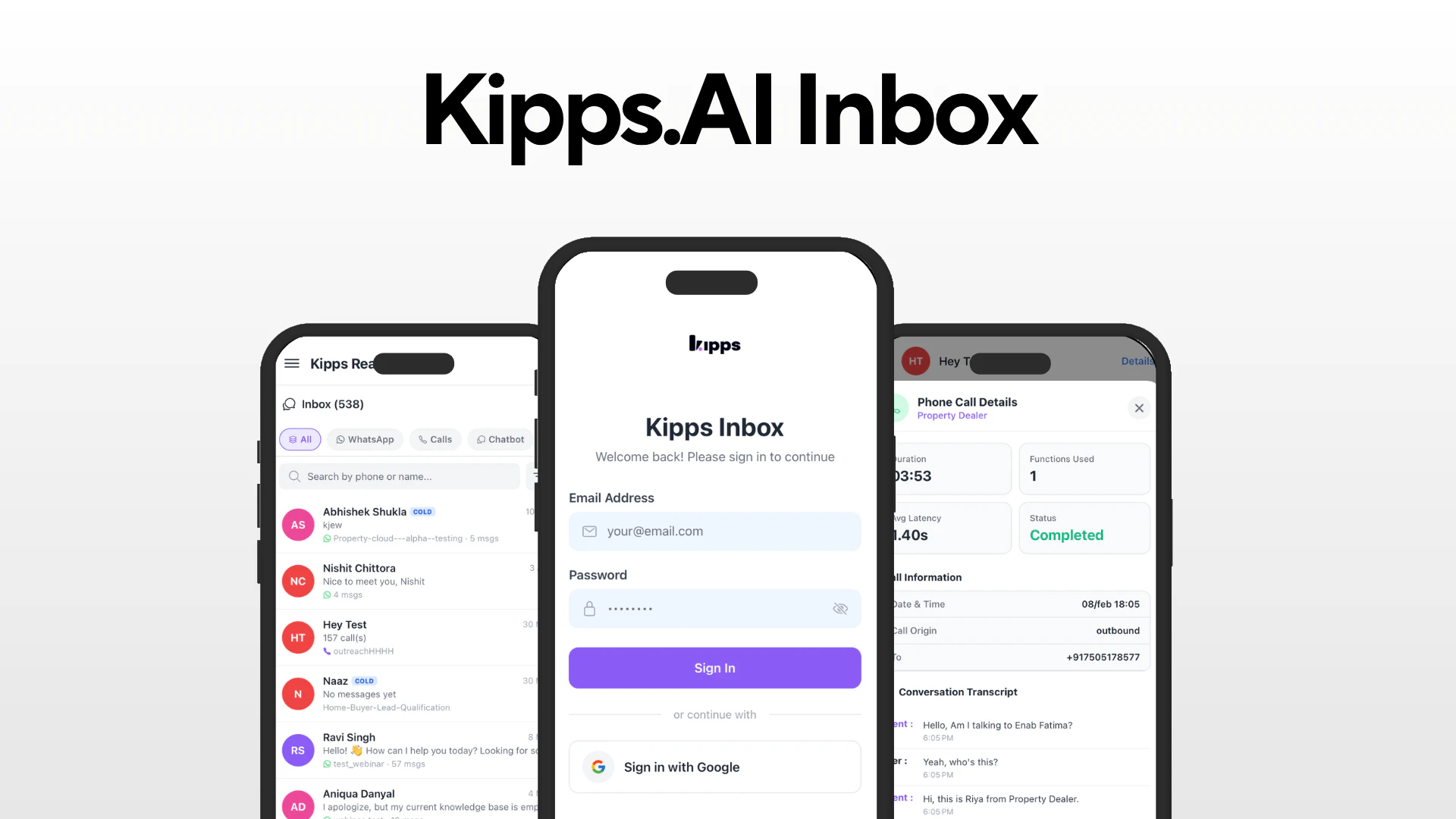
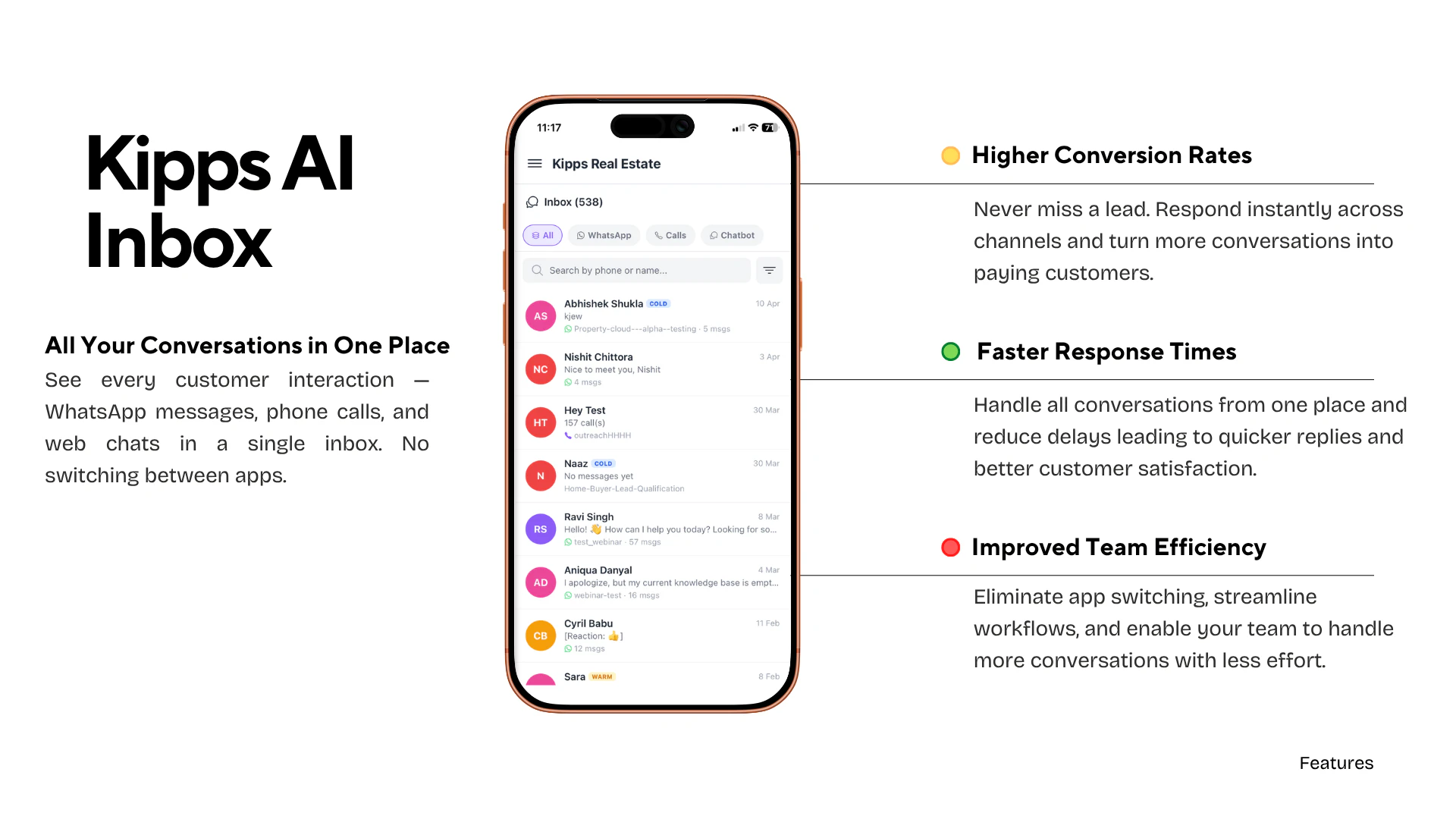
一句话介绍:Kipps.AI Inbox 是一款专为中小团队设计的全渠道AI客服收件箱,将WhatsApp、网站聊天、来电等所有客户对话汇聚一处,通过AI实现7x24小时自动回复与无缝人工交接,解决因多应用分散导致的信息遗漏和线索流失问题。
Messaging
Sales
YC Application
全渠道客服收件箱
AI客服
客户沟通平台
对话式AI
线索管理
中小团队
WhatsApp集成
语音代理
智能转接
SaaS
用户评论摘要:用户高度关注AI与人工之间“一键转接”的具体实现与上下文保留机制(如是否在单独视图显示历史)。同时有声音质疑它与respond.io等专业收件箱在日工作流中的核心差异,以及对语音代理处理延迟与口音的顾虑。
AI 锐评
Kipps.AI Inbox精准切入了一个残酷的痛点:中小团队在客户信息量爆发时,因工具碎片化导致的“系统性的客户丢失”。其核心价值并非纯粹的“AI聊天机器人”,而是一个具备“AI兜底+人工介入”弹性的协作枢纽。官方强调的“一键切换与完整历史记录”,精准打击了当前多数客服工具“AI冷冰冰、人工重复劳动、交接断档”的三大弊病,这是产品最犀利的差异化支点。
然而,产品目前面临两大质疑。第一,竞争壁垒模糊。面对成熟的respond.io或开源的Chatwoot,Kipps.AI能否在“全渠道整合”这一基础能力上做到更便捷、更稳定?如果AI只是锦上添花,而基础通讯集成仍有痛点(比如电话转接延迟、API稳定性),那么“AI亮点”将无法弥补基础设施的短板。第二,AI可用性的硬仗。评论中关于语音延迟和口音识别的问题,直接指向AI在实际场景中的可用性。如果AI在嘈杂环境、印度口音或复杂多变的中文语境下频繁出错,反而会制造更多混乱——这时候“AI辅助”就成了“AI添乱”。
一句话总结:Kipps.AI赌对了方向,但能否杀出重围,取决于它能不能把“一键转接”做到极致流畅,并在全渠道的基础稳定性上不拖后腿。否则,它就只是一款“看起来很美的轻量级客服聚合器”。
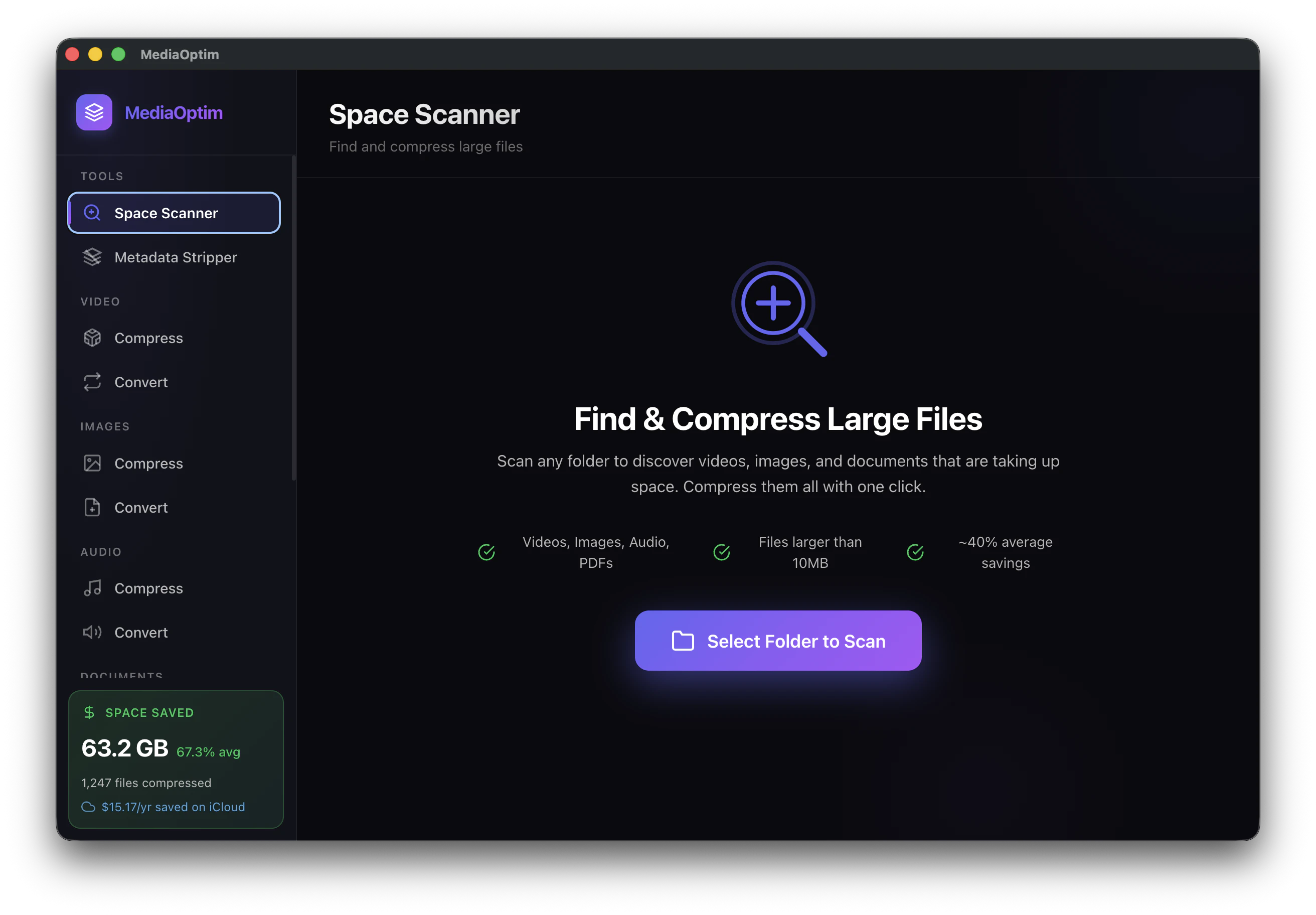
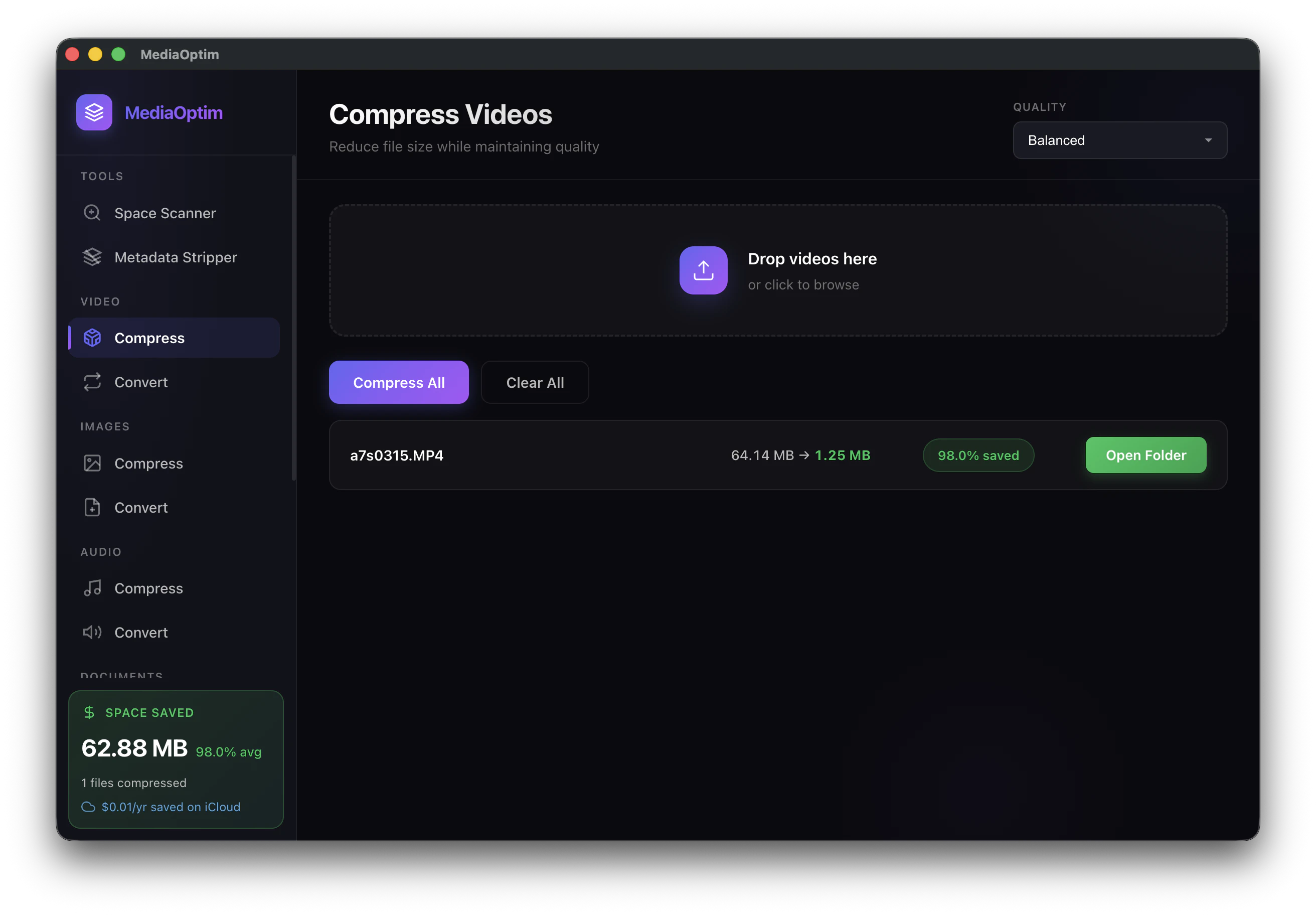
一句话介绍:MediaOptim是一款在Mac上本地离线批量压缩图片、视频和音频文件的工具,解决了用户担心隐私泄露、上传等待以及订阅付费的痛点。
Mac
Productivity
Privacy
本地压缩
批量处理
隐私保护
离线工具
Mac应用
图像压缩
视频压缩
音频压缩
Apple原生框架
无订阅
用户评论摘要:用户指出压缩后照片会丢失EXIF元数据(日期、GPS、Live Photo配对),视频元数据保留。开发者承认问题,计划增加元数据保留开关。有用户建议增加面向不同场景(社交、存档、邮件)的智能预设,并询问元数据设置是按格式还是全局。
AI 锐评
MediaOptim切中了一个现实痛点:大多数压缩工具本质上是“上传-服务器处理-下载”模型,这在日益注重隐私和数据主权的环境下显得过时。其本地化、无订阅的定位非常清晰,尤其对处理大型视频和敏感素材的用户极具吸引力。
但产品的硬伤也暴露无遗:**元数据丢失**。对于照片和视频,EXIF和Live Photo信息往往是资产的核心价值。开发者的回应“会加开关”虽然是正确的方向,但作为一款上线的产品,在核心功能上存在如此严重的“副损伤”,说明其在产品打磨和用户场景理解上还不够精细。用户不可能为了省空间而接受“时光倒流”和“丢失定位”。
此外,“本地+离线”虽然安全便捷,但也意味着功能的边界完全受限于macOS原生框架的能力。目前缺乏智能预设和格式间参数分离,会让普通用户面对一堆技术参数无从下手,而专业用户又觉得这些参数不够灵活。
一句话:MediaOptim方向正确,但交付了一个“半成品”体验。真正有价值的产品应当做到“压缩而不损伤”,在安全与可用性之间找到精确平衡点。如果开发团队不能在元数据保留、预设场景化、格式级参数控制上快速迭代,它很快会被其他同样本地化但更精良的工具替代。
一句话介绍:KodHau是一个MCP服务器,通过注入团队在GitHub PR中沉淀的历史决策、被拒方案和设计讨论,解决AI编码代理因缺乏隐性知识(部落知识)而频繁破坏生产环境的核心痛点。
Developer Tools
Artificial Intelligence
YC Application
AI编码代理
部落知识
MCP服务器
GitHub PR
历史决策注入
开发者工具
团队上下文
代码知识管理
Claude Code
Cursor
用户评论摘要:用户普遍认可其解决“AI不理解代码背后推理”的痛点。主要问题:如何应对大型仓库的Token限制(建议本地向量库过滤);如何处理Prompt注入和权限泄露风险(询问GitHub Token推荐的作用域默认值)。另有用户建议补充Agent自动生成变更日志的功能。
AI 锐评
KodHau的切入点极其精准——它没有去卷代码生成质量,而是直击当前AI编程工具最本质的盲区:代码只是结果,决策过程才是灵魂。团队内部大量“为什么这么写”、“为什么不能那么写”的隐性知识,恰恰是AI Agent频繁“翻车”的根源。其通过MCP协议将GitHub PR历史中的讨论、拒绝理由、前辈工程师的“血泪史”作为上下文注入,本质上是在给AI补“情商课”,这比任何训练数据拼接都更直接有效。
但冷静下来看,产品面临两个硬伤:一是Token和上下文窗口的物理瓶颈。对于拥有数千个PR的大型仓库,如何高效、智能地筛选出当前任务最相关的历史决策,而不是一股脑塞给LLM,这决定了其体验上限。如果每次都是全量检索,成本将迅速失控。二是风险敞口。PR、Issue中充斥着系统路径、API Key、内部安全策略等敏感信息,一旦AI根据过时或不安全的评论生成代码,后果可能比“不知情”更严重。安全审计与权限隔离必须是一个内置特性,而非后期补丁。
简而言之,KodHau解决了“正确”的问题,但要让企业心甘情愿把“部落记忆”交给AI,它必须证明自己不仅能“懂”历史,更能安全地“管理”历史。它现在的价值更像一个聪明但未经风浪的实习生——知道很多,但还需要学会甄别信息的轻重缓急与安全边界。对于初创团队而言,这是切入企业级工具的绝佳缝隙,但技术深水区的航程才刚刚开始。
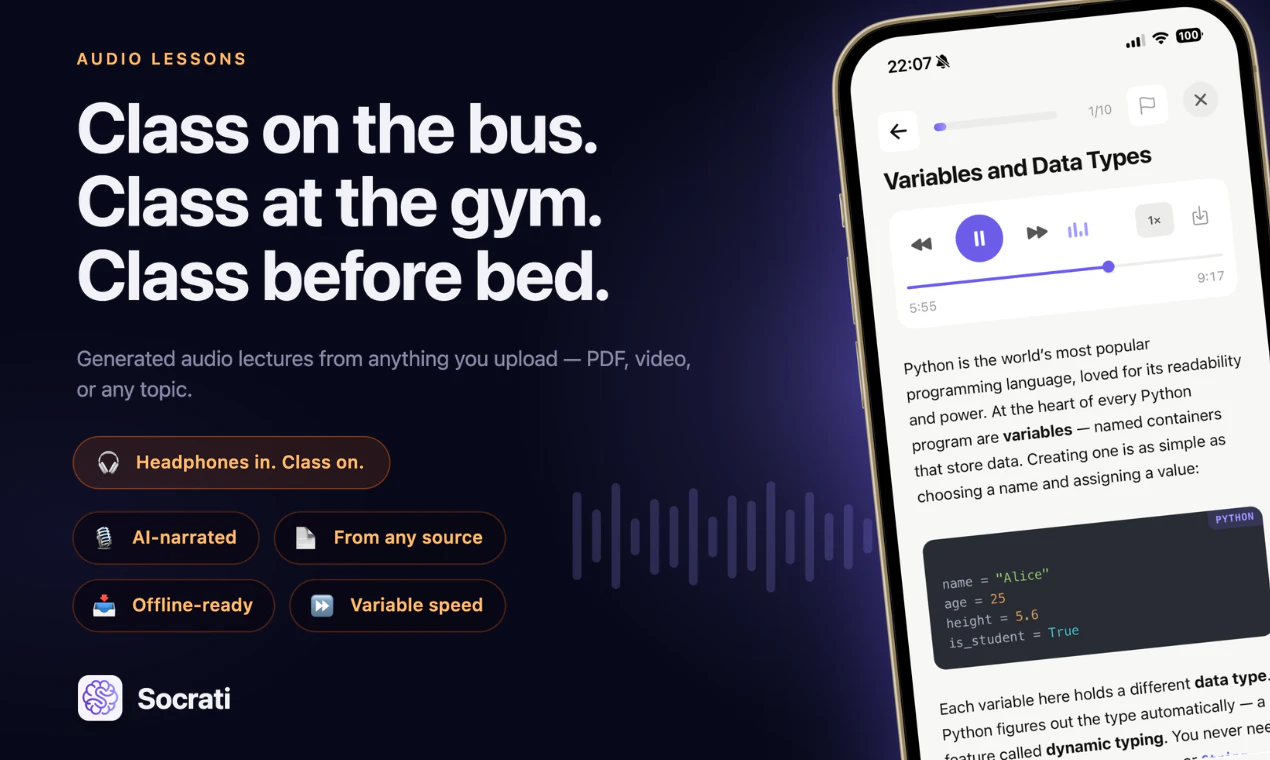
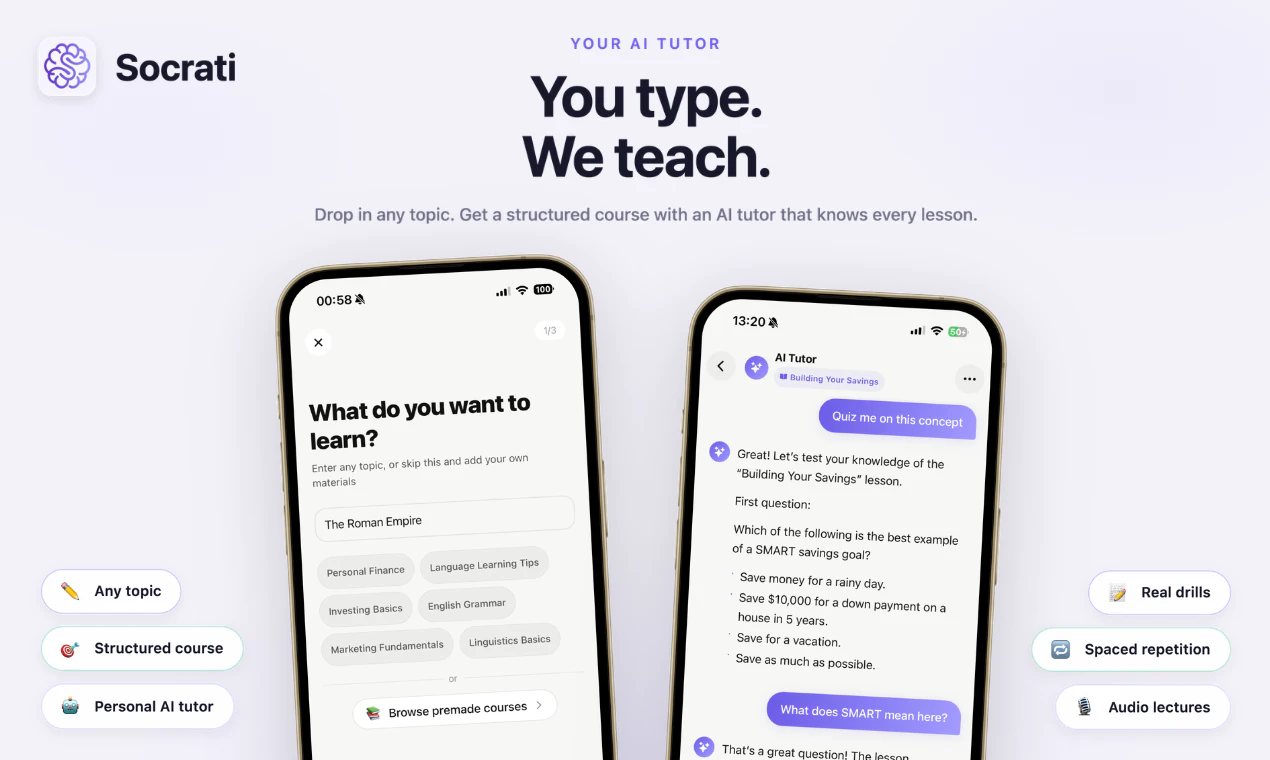
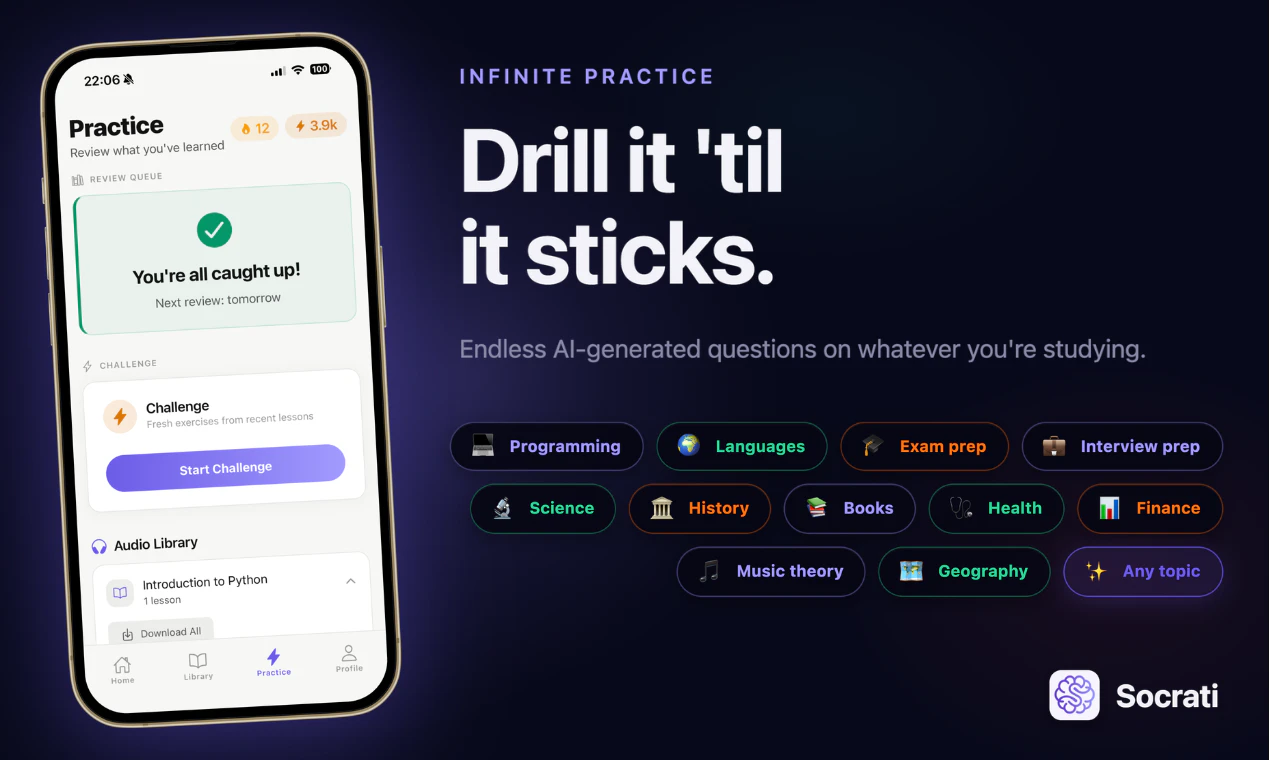
一句话介绍:Socrati通过将PDF、视频、手拍页面或输入话题一键转化为配有语音讲解、多种练习与间隔复习的完整音频课程,解决用户无法坐在桌前时依然想高效学习并保持长期记忆的痛点。
Education
Artificial Intelligence
YC Application
AI学习工具
播客式学习
间隔重复
音频课程
知识留存
移动学习
多语言
闪卡生成
Anki兼容
自主学习
用户评论摘要:用户称赞Socrati将被动音频变为主动留存的创新,但询问是否支持导出卡组(如APKG/CSV)及接入Notion、Readwise等工具。开发者回应称将优先支持导出至Anki,并计划集成Readwise,坚持“课程输出而非卡组起点”的理念。
AI 锐评
Socrati的切入点很聪明:它没有去和Anki、Quizlet争夺“闪卡工具”这一存量市场,而是直接切入“从原始素材到结构化学习内容”这一价值链的上游。用户只需扔进一个PDF或视频链接,就能输出一整套可听的音频课程、主动练习题和规划好的复习周期——这本质上是在用AI把“学习设计”这个专业门槛极高的过程自动化了。
但产品真正的护城河不在于“生成课程”这个动作,而在于“间隔重复”的执行力。正如开发者所言,生成是容易的,而设计一套能让知识点在用户大脑遗忘临界点精准浮现的算法才是硬功夫。这也是Socrati区别于一众“文字转播客”工具的关键——它不只是让你听,而是让你“记得”。
然而,必须指出的是,目前它仍是一个“封闭环路”:用户输入素材,输出标准化课程。真正的挑战在于,高阶学习者习惯了在Anki里自由调校卡片优先级、字段和笔记结构,Socrati若只是单向导出,无法实现双向协同或元数据编辑,最终仍会被这些用户视为“更轻便但更受限的预处理工具”。开放API、支持从外部笔记工具动态拉取素材并智能切片,才是它从“酷玩具”跃升为“终身学习基础设施”的必经之路。一句话:Socrati走对了方向,但要避免成为另一个用AI包装的“隔离花园”。













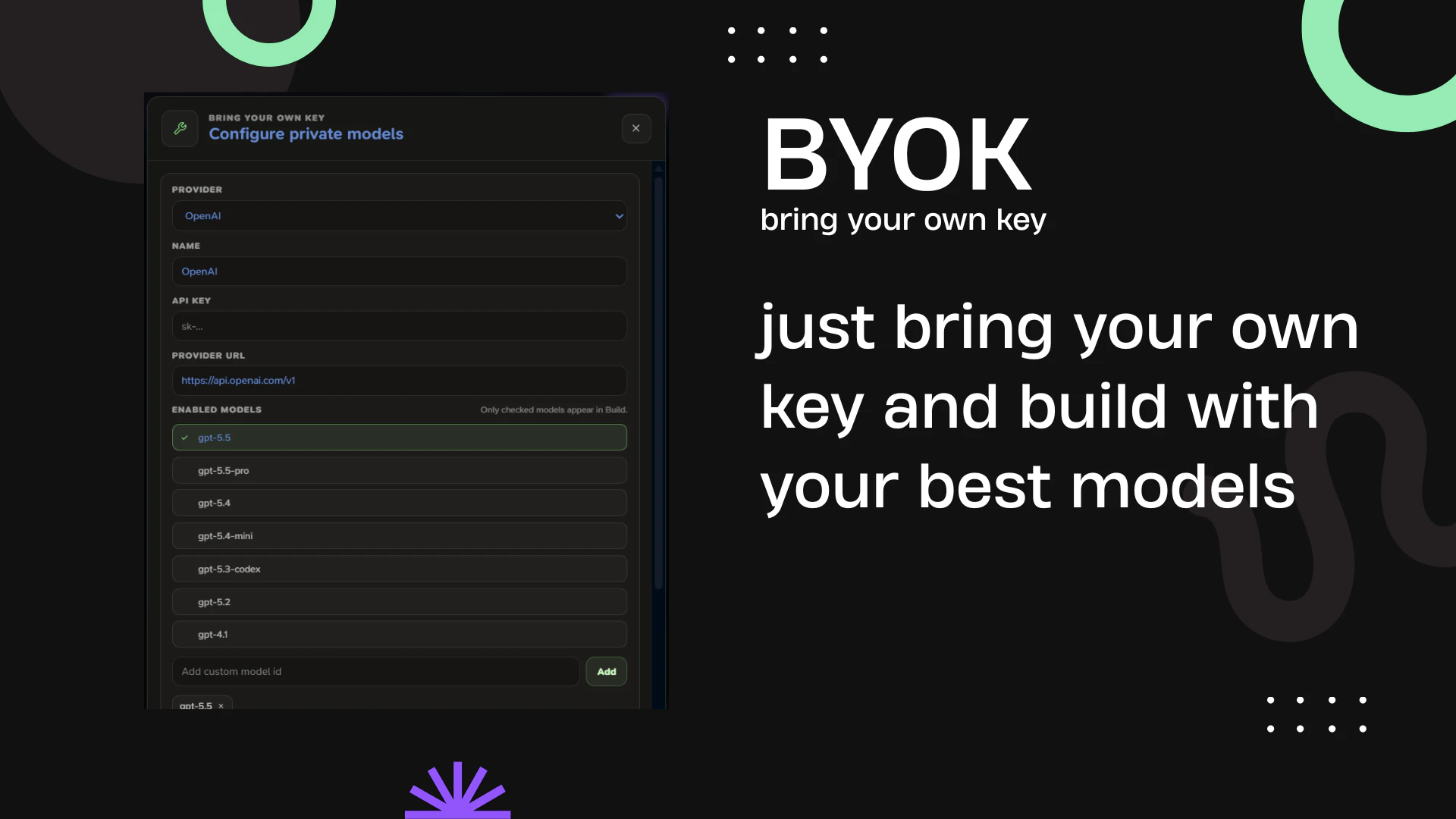





























Hey everyone 👋
I'm Dan, founder of RankSpot - and yes, some of you might recognize me from our previous launch!
Based on the incredible feedback we got from the Product Hunt community and our early users, I made a big decision: to split the project and build RankSpot as a dedicated, focused product. This launch is a direct result of what you told us. So thank you - you literally shaped this.
The problem 👀
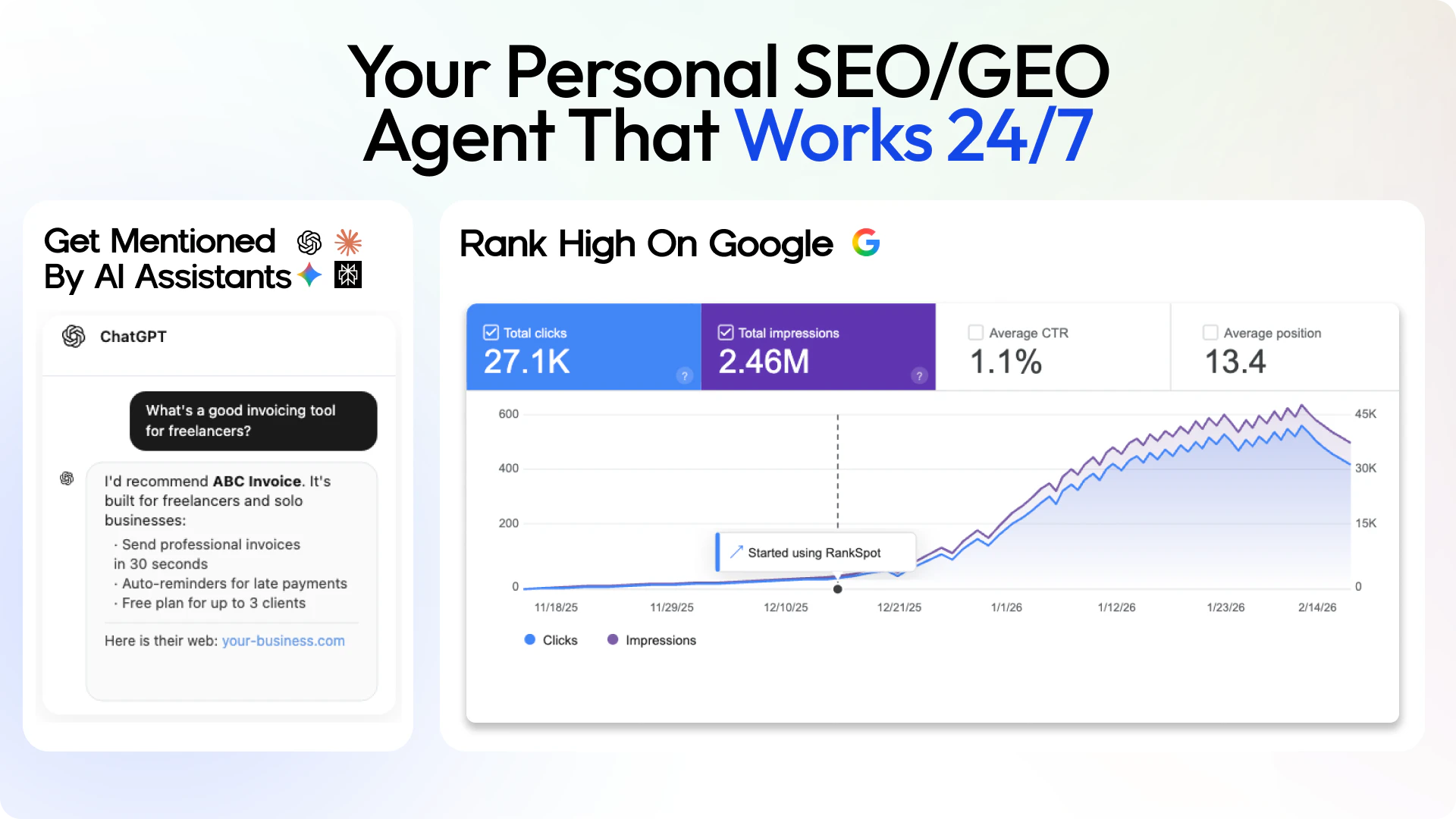
Every founder knows they should be publishing content. But between writing, keyword research, images, and publishing - it never happens. You wrote 2 blog posts this year. Your competitors are on page 1 of Google. And when someone asks ChatGPT about your industry, they get recommended - not you.
SEO agencies want $3,000/month. Doing it yourself takes 5+ hours per article. Neither works for a small team.
Our solution ⚡
RankSpot is a fully automated AI SEO agent driven by deep competitor intelligence. It handles your entire SEO pipeline - every single day.
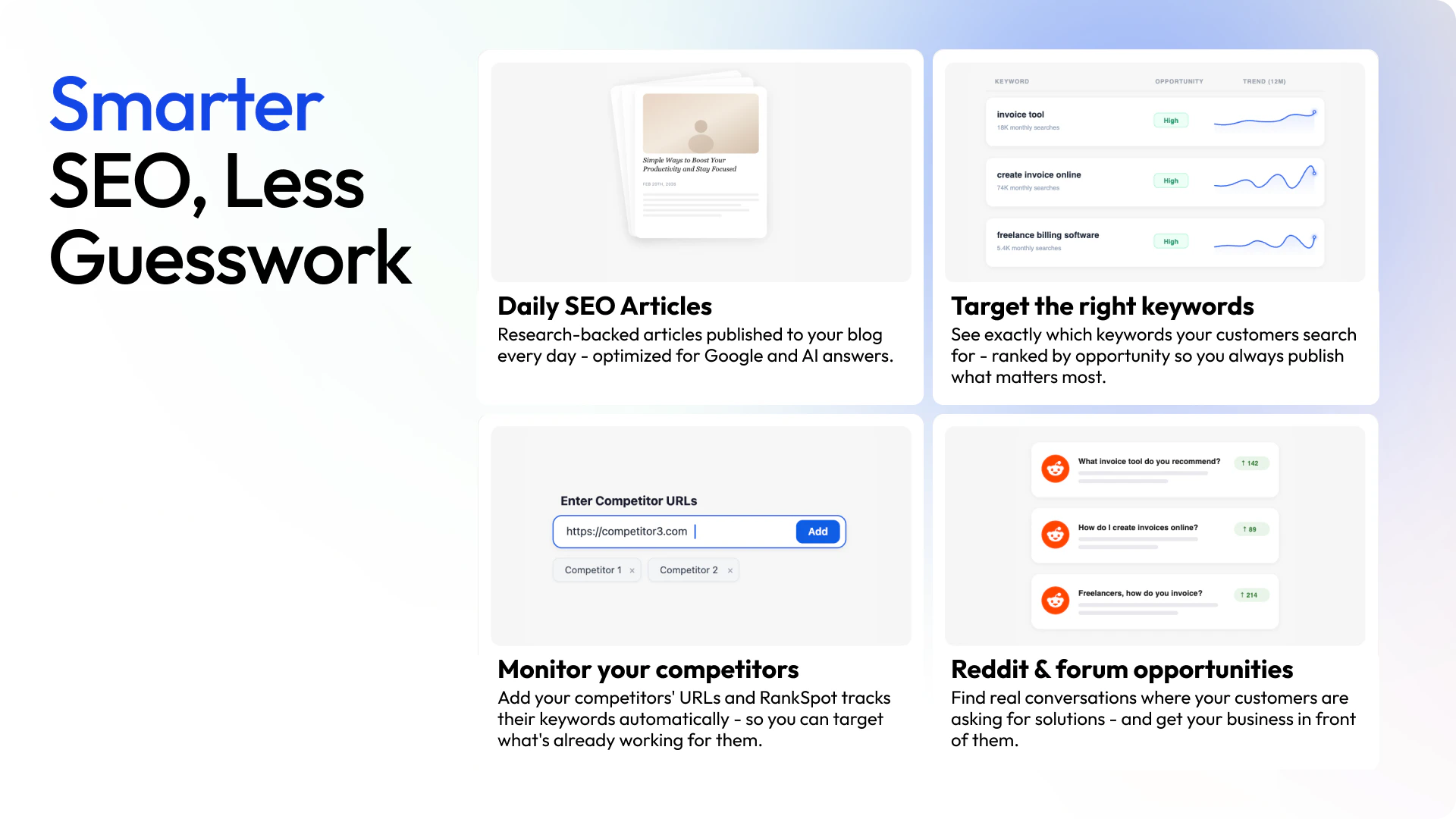
🔍 Competitor intelligence:
- Tracks what keywords your competitors rank for
- Automatically scores and targets most relevant keywords
- Finds Reddit & forum conversations where your customers are asking for solutions
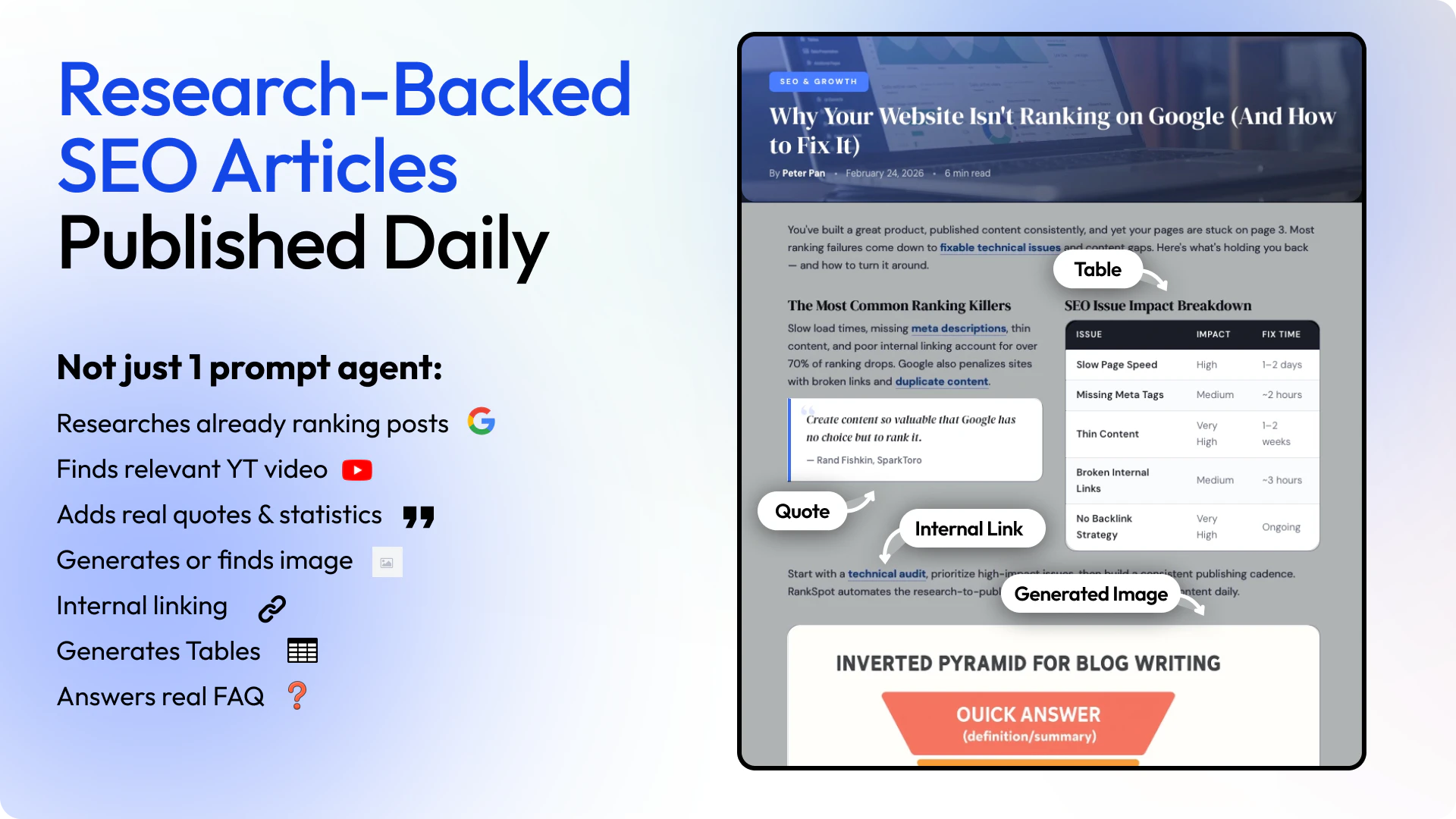
✍️ Research-backed articles:
- Writes 1,500+ word SEO & GEO optimized articles daily
- Adds real quotes, stats, tables, internal links, and generated images
- Researches top-ranking posts before writing - not just a one-prompt agent
🚀 Fully automated publishing:
- Connects directly to WordPress, Webflow, Shopify, Framer, Ghost, and more
- Articles go through a review queue - you stay in control
- Supports 100+ languages
Why it matters 🌟
When you rank high on Google, LLMs like ChatGPT and Claude start citing you too. RankSpot optimizes for both - so you get customers from search and from AI, on autopilot.
Is there a deal? 💰
Yes! First 3 articles are completely free when you start a trial. Try it, see the quality, then decide.
👉 Start for free: https://rankspot.ai
Would love your feedback - you shaped this product once already, let's do it again 🙏
Happy launch! This is super useful!
Some questions though: 1. there is lots of competition in this field, how you stand out? 2. Doesn't Google penalise AI created content? I don't know, just asking, because I heard about it, couple of times. 3. How do these SEO articles translate into LLM citation? It's just quantity or there is some specific algo, which makes LLMs pay attention to those articles?
This is a great solution, exactly what I needed (I don't always have the energy and strength to do everything myself).
Good luck!
@danshipit Congratulations on the launch! Curious how do you adapt for regional differences in LLM recommendations? A user searching in India vs the US may see very different sources, forums, and recommendations. Is this localized to market or primarily translation-led?”
Congratulations on the launch! Have you noticed certain article formats or structures getting better picked up by the LLMs? more consistently? Feels like that’s becoming the new SEO game :)
On mailwarm, we have now around 6-7% of our trafic coming from ChatGPT
Congratulations on the launch! SEO is an extremely important area for startups. Of course, a lot can now be done with LLMs, but the real challenge is knowing how to apply them effectively in an SEO workflow. This feels like a very strong niche, great work!
Congrats team for the launch!
Interesting...
Is there some example of articles written by it? Is someone already using it? Are your using it yourself?
Hey Daniil! Congrats on the launch. Getting Customers from LLMs is trendy now and I'm sure many founders gonna take the most of it
Will it also work for NextJS vibe coded apps ? Congrats @danshipit
Congrats Dan! How do you handle keyword cannibalization when publishing daily? Easy to end up with articles fighting over the same intent within a month. And is internal linking automated based on semantics, or does it need manual cleanup?
I recently discovered Google HCU protocol, do you adjust content pillars to it? Can it roast my existing blog posts?(that would be a nice product add-on)
Congrats on launch! How do you find keywords and monitor competitors?
Happy launch! I've already tried generation of non-english articles and they are very high quality. Incredible product!
What I also like about RankSpot is that it doesn’t stop at keyword research.
It analyzes forums and gives me direct links to relevant Reddit and Quora threads where people are already discussing problems connected to my product.
So instead of guessing where my audience hangs out, I can see real conversations, understand the language people use, and find places where it actually makes sense to join the discussion.
niceee
Guys, congratulations on the launch!
Congrats the launch! Usually, results of SEO appear in several months after issuing articles. How long does it take to recognize effects of RankSpot SEO articles?
Interesting, does it help with backlinks or just posts content? Any internal linking in the content? How does it not post the same content for different users? Great idea though!
Curious how it handles very niche topics with low search volume most AI SEO tools are optimized for high-traffic keywords. Does it work well for small audiences with specific long-tail needs?
Nice!
Asking Credit card before teaser is bad in current days.