PH热榜 | 2026-05-11
一句话介绍:Articuler.ai 是一个基于意图匹配的专业人脉平台,通过分析9.8亿公开资料,帮助用户精准找到投资人、合伙人、客户或导师,并生成高回复率的定制化联系邮件,解决传统关键词搜索无法识别真实需求和人际关系匹配的痛点。
Social Network
Career
Community
人脉匹配
AI社交
意图搜索
专业网络
冷邮件
求职招聘
投资对接
创始人工具
事件匹配
向量搜索
用户评论摘要:用户普遍认可“意图匹配”比关键词搜索更精准,关注冷邮件的真实感。核心疑问包括:对“15%回复率”的真实性有待验证,能否用于招募工程师或找客户,以及是否支持批量发送。团队背景(曾开发2.5亿用户社交应用)增加了信任度,但产品尚未解决大规模发送与个性化之间的平衡。
AI 锐评
Articuler.ai 在概念上确实击中了 LinkedIn 的软肋——后者本质是一个静态目录,而前者试图将“人脉搜索”从“查黄页”升级为“语义理解”。团队曾搭建过数亿用户的约会匹配系统,这种经验在构建高维度偏好向量和冷启动策略上具备天然优势,因此产品在“匹配精度”而非“覆盖面”上的竞争力值得期待。
但必须泼一盆冷水:平台高调宣传的15%回复率缺乏严格的AB测试对比和行业基准。在B2B场景中,决策链复杂,回复率不等于成交率;而在C端社交中,高回复率可能更多反映的是信息差价值而非长期关系建立能力。此外,产品强调“非数据库、非批量工具”,这在商业变现上是一把双刃剑——高客单价的私密匹配服务能否支撑规模化增长,仍需验证。
更关键的问题在于用户数据主权和隐私风险。虽然声明基于“公开资料”,但通过大量非结构化数据生成个人画像的Playbook功能,在欧洲GDPR或美国CCPA等法律框架下存在模糊地带。另外,该模式能否真正解决“弱关系激活”这一社交网络经典难题,还是最终沦为更智能的版领英InMail垃圾邮件生成器,取决于它对“意图”二字的定义——如果算法依然偏爱高薪、高学历、高热度的候选对象,将会重构精英人脉圈而非打破信息壁垒。产品目前仍处于尝鲜阶段,能否从“约会游戏的打工者”进化为“商业关系的操作系统”,团队还需要补上信任机制、合规体系和付费模型这三块拼图。
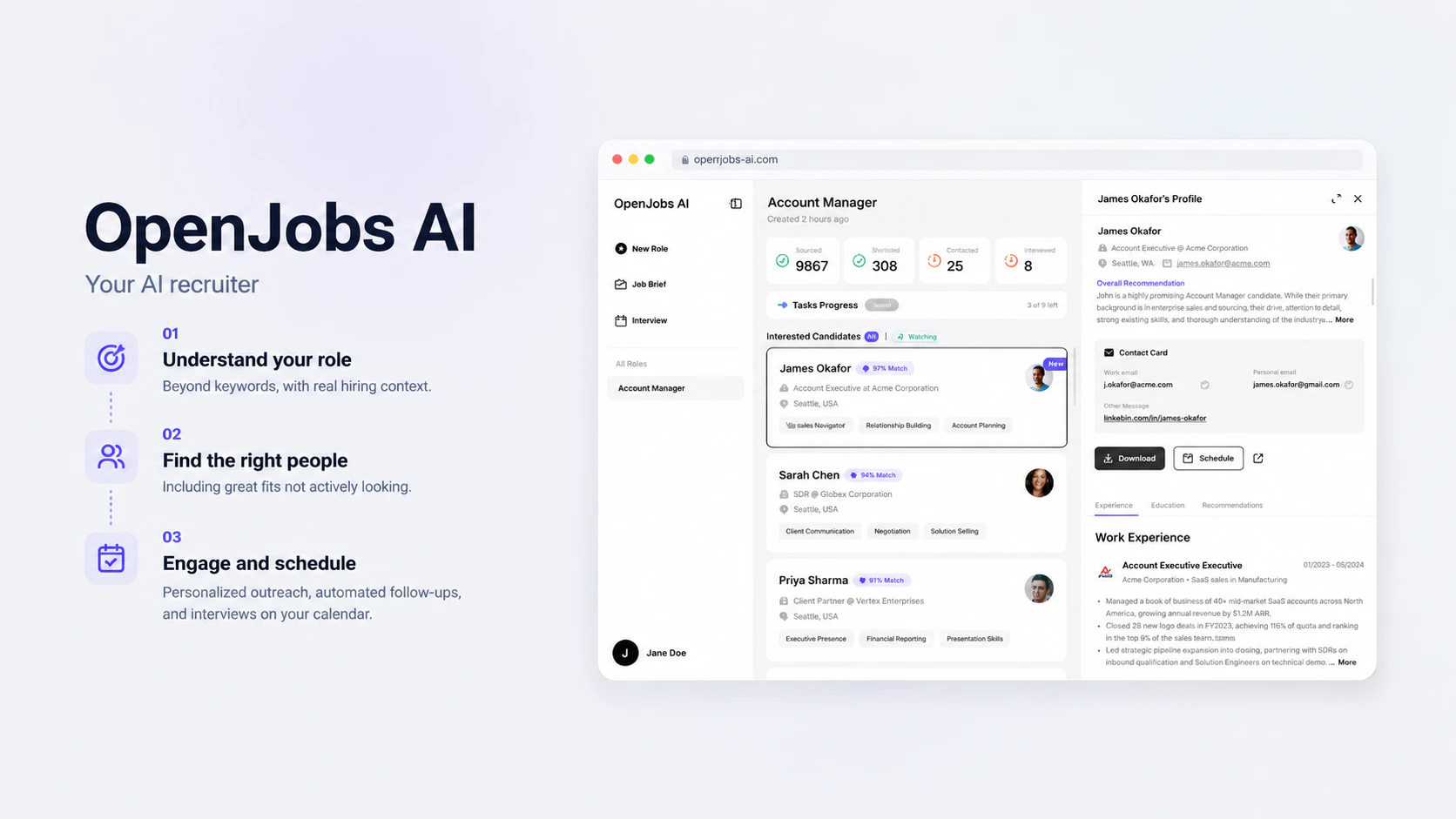
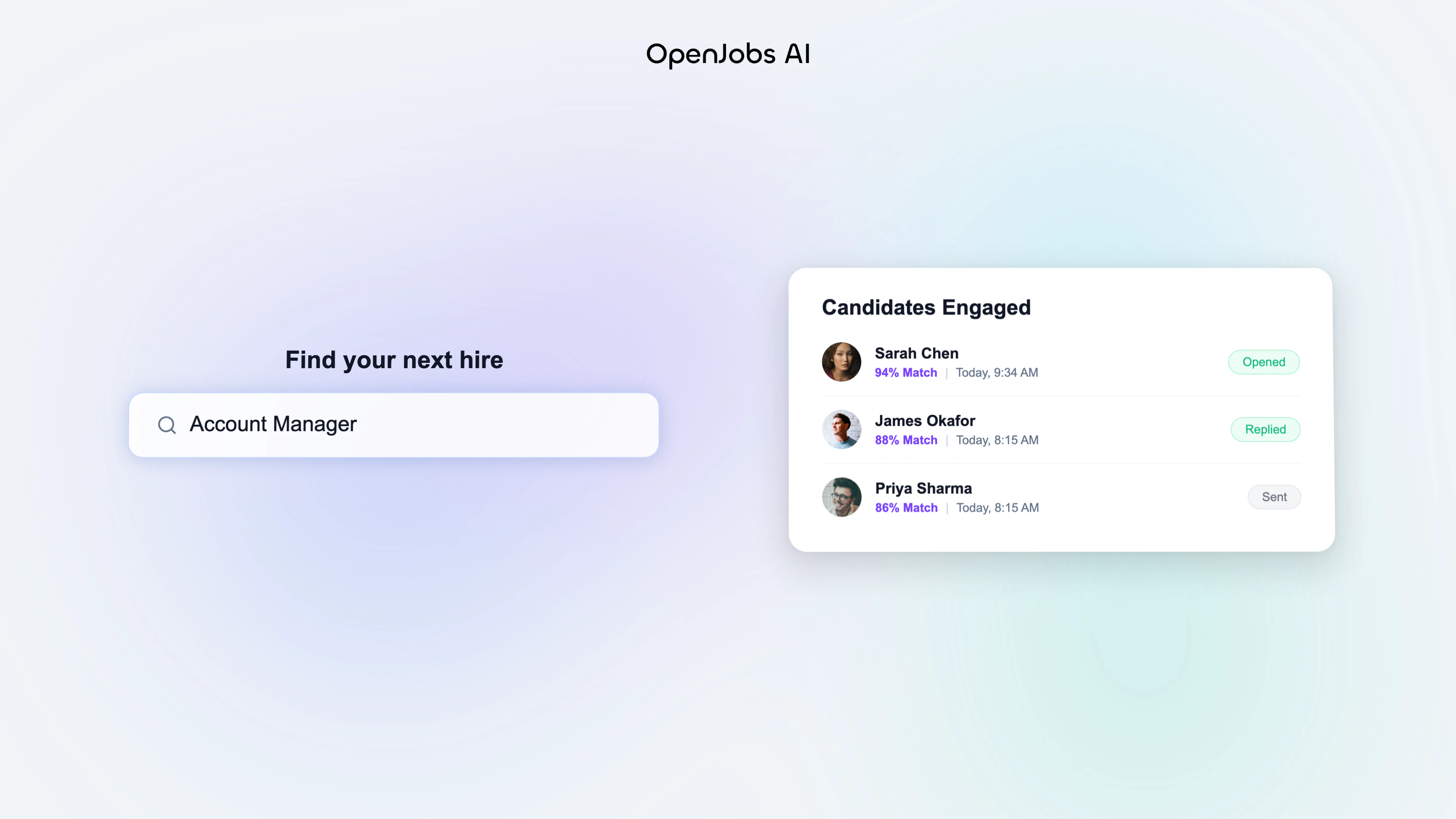
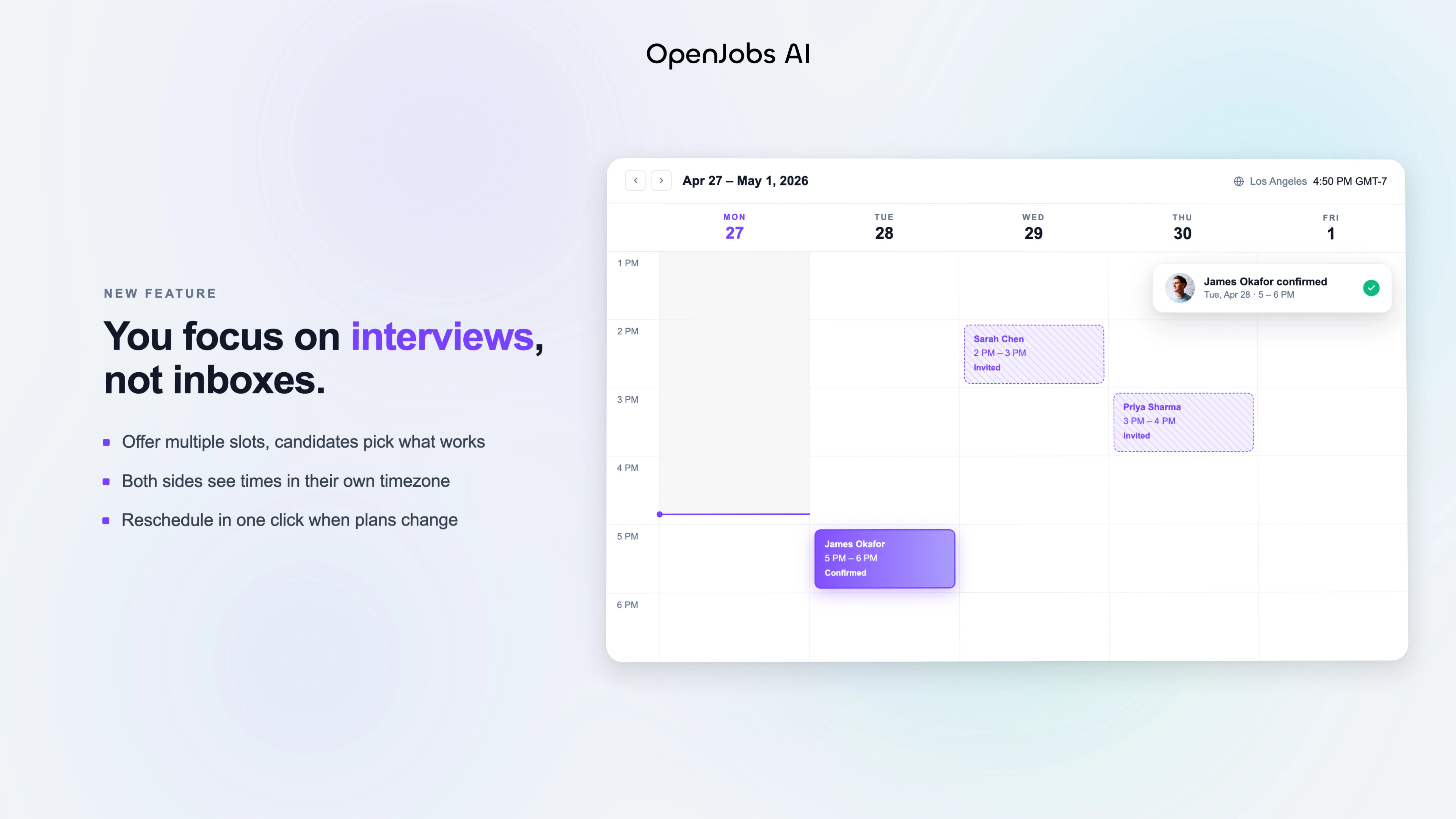
一句话介绍:OpenJobs AI 是一款端到端自主AI招聘代理,通过多代理协作自动完成从职位需求解析、候选人搜寻与筛选、个性化沟通到面试安排的完整招聘流程,解决招聘中“找到人但约不到人”的中间环节断裂问题。
---
### 关键词
AI招聘代理, 自动化招聘, 候选人筛选, 多代理协作, 招聘SaaS, 人才搜寻, 面试安排, AI智能体, HR科技, 招聘效率
---
### 评论摘要
用户认可其多代理架构和自主性,但关注点包括:对量化、生物等小众岗位的有效性;积分机制的价格合理性;候选人体验是否会造成信息骚扰;AI能否区分简历包装与真实能力;获取首批候选人的速度;以及邮件沟通的自然度。
---
### AI锐评
OpenJobs AI 的核心价值不在于“找到更多人”,而在于“把人留住”。它准确切中了招聘流程中最被忽视的“黑暗地带”:候选人沉默后的二次触达、已表达兴趣后的跟进、以及从“可能合适”到“确定面试”之间的漫长拉扯。这些年,招聘SaaS几乎把资源全砸在了漏斗顶部(职位发布、简历匹配、ATS),却让最劳力密集型的中段环节——也就是长达数周、需要高度情境化的候选人沟通——继续由人类手工驱动。MIRA的四代理架构在技术上是合理的:搜索代理解决广度,对话代理解决深度,而跟踪代理解决“流失率”。但真正决定其天花板的是两个核心问题:第一,积分定价机制(一个已确认意向的候选人消耗1积分)是否会激励平台优先推送高频简历而非最优匹配?如果“已确认”是付费门槛,那AI的筛选逻辑可能从“最合适”滑向“最可能回复”,这对雇主是一种隐性伤害。第二,处理AI优化的简历是个棘手的噪声问题。官方声称通过代码库、论文、对话深度来识别“真实建设者”,这在技术可行,但规模化后极易被对抗性手法污染(例如Ghost Contributors、伪装的项目轨迹)。若不能建立可信的、实时验证的能力凭证链路,这个优势会迅速被刷子工具有效攻击。总体而言,OpenJobs AI 的产品逻辑是近5年来HR技术中最诚实的创新之一——它不画饼“找到完美候选人”,而是承诺“把已经关注的候选人变成面试”。建议团队尽快开放可以显著降低价格敏感性的API接入模式,让招聘代理直接嵌入ChatGPT、Claude等企业级智能助手,将“招聘工具”进化为“招聘能力基础设施”。在人才稀缺的行业(AI、生物技术),它能立刻创造可量化的ROI;但在招聘已是买方市场的领域,它仍需证明自己的成本效率高于一个普通的招聘专员。
Hiring
Pitch Singapore
一句话介绍:Graphbit PRFlow 是一款基于确定性分析的 AI 代码审查工具,它能以单次遍历追踪跨文件函数依赖,在每次拉取请求发布前捕获他人遗漏的严重安全漏洞,解决了现有 AI 审查器结果不一致、噪音多、缺乏跨文件上下文的核心痛点。
Productivity
Developer Tools
GitHub
AI代码审查
Pull Request
安全漏洞检测
跨文件上下文
确定性输出
开发工具
GitHub集成
团队协作
付费按次计费
用户评论摘要:用户高度认可其“确定性”和“跨文件追踪”能力,认为可解决AI审查结果不一致的痛点。主要问题集中在对大型存储库的支持、本地部署可能性、自托管LLM支持、以及如何在团队标准演变中避免误判。有用户建议在营销中强化“确定性基线”带来的信任价值。
AI 锐评
PRFlow 最聪明的做法,是放弃了“AI 全能”的幻象,转而押注了一个朴实但极具商业价值的定义:**确定性基线审查**。它精准地戳中了当前 AI 代码审查市场的两个现实困境:一是“结果如开盲盒”带来的信任缺失,二是“噪音过多、审都审不完”带来的生产力新黑洞。通过将自身定位为工程师的可信赖“第一道防线”,而非试图替代人,PRFlow 巧妙地避开了与人类判断力的正面竞争。
其核心壁垒在于对“跨文件上下文”和“函数级依赖追踪”的工程落地。这并非概念创新,而是对代码审查本质的回归——危险的代码错误往往隐藏在文件的连接处,而非单行 diff 中。用“14比0”的竞品对比来证明其价值,远比宣传虚幻的“无限智能”更具说服力。
然而,其真正的考验在于:**良性的“确定性”能否对抗系统性的“复杂性”**?用户的犀利提问直指要害,大型单体仓库、深度嵌套的依赖图、以及不断演变的团队编码规范,都可能成为确定性流程中的变量。PRFlow 目前的解法(Token预算、文件优先级、基于人工纠正的学习)虽是其理性回应,但仍需在真实企业级项目中证明其泛化能力和鲁棒性。一次性基准测试与持续稳定服务之间存在巨大鸿沟。
此外,采取“按次付费”的模式是精明的市场切入策略,降低了团队的采用门槛。但长远来看,真正的挑战不在于获得首批尝鲜的技术专家,而在于如何让这套工具说服那些对“AI阴影”充满警惕的资深架构师和CTO。如果能通过持续的、可靠的“零噪音”表现,将自己从“工具”升维为“工程文化的一部分”,PRFlow才算真正站稳了脚跟。目前看,它走在一条正确的窄路上,但前方的路远比发布会上展示的那10个PR更崎岖。
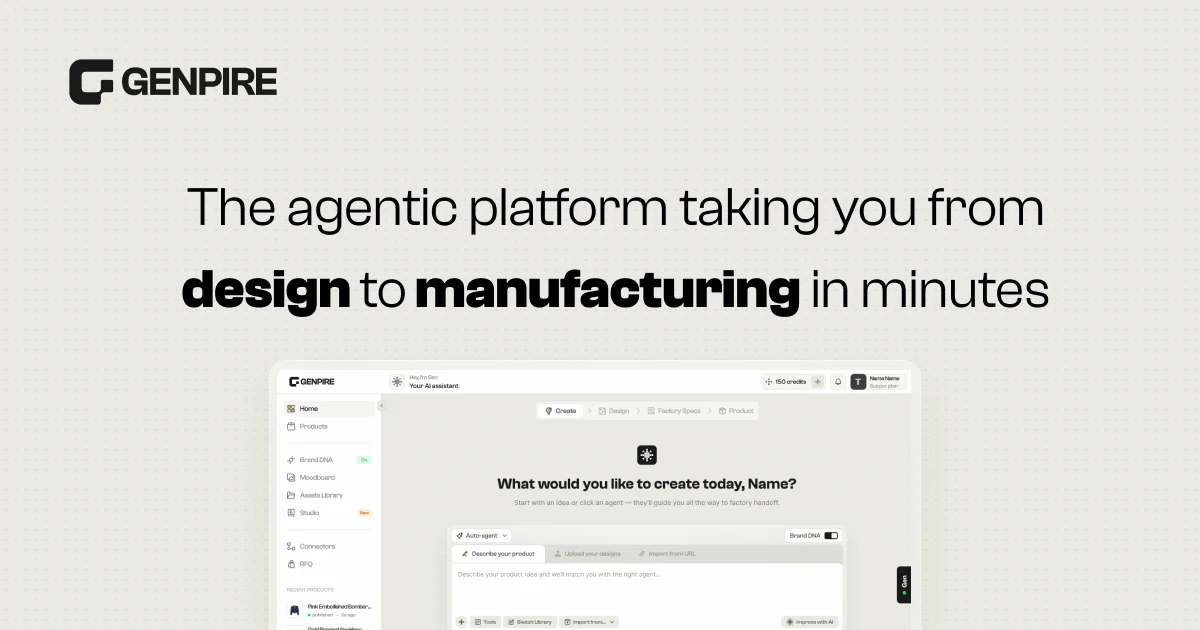
一句话介绍:Genpire是一款将AI创意转化为实物生产的平台,用户通过文字描述或草图即可生成包含技术图纸、物料清单的工厂级技术包,并直接对接工厂进行打样和批量生产,解决了从“想法”到“工厂”这一物理产品落地过程中的高门槛、高成本、长周期痛点。
Design Tools
Artificial Intelligence
Maker Tools
AI制造
消费品生产
技术包生成
智能工厂对接
产品设计
供应链AI
创意落地
ToB SaaS
AI Agent
物理产品
用户评论摘要:用户普遍认可其“消费品界的Lovable”定位。核心问题集中在:1. 技术准确性能否处理运动部件与静态物体的差异(如转轴公差);2. 产品须经历真实生产验证,是否有成功案例链接;3. 落地环节的工厂合作模式、定价策略及如何处理履约、支付与退货等后端问题。评论中对“一步到位”的生产实现充满期待与审慎。
AI 锐评
Genpire的产品定位非常精准,它抓住了当前AI热潮中一个被忽视的巨大断层——AI可以帮你写代码、做PPT、画图,但几乎无法帮你制造一个实物。从“vibe-coding”到“vibe-manufacturing”的迁移,本质是将AI从纯粹的数字化界面延伸到了物理供应链的最前端,这个思路极具前瞻性。
从技术实现看,Genpire解决了两个核心矛盾:一是将模糊的创意(prompt/草图)转化为高度结构化的、工厂可读的“技术包”,这是对制造业非标知识图谱的工程化挑战;二是通过AI Agent和多层数据分析,将“设计”与“找厂”两个传统割裂的环节打通,试图创造一种“设计即报价、即生产”的闭环体验。
然而,产品目前最大的风险在于“最后一公里”的信任鸿沟。评论中关于“技术准确性”和“成功案例”的追问直指核心——技术上生成的“完美图纸”与工厂线下实际开模、试产时遇到的工艺、公差、材料收缩等变量之间的鸿沟,是任何软件都难以完全模拟的。Lovable能快速生成代码,是因为代码解释环境是确定的;而制造业的变量是极端的、依赖经验和物理试错的。如果没有足够的实际生产数据和真实的返修案例来训练其AI模型,Genpire很容易变成一个“漂亮的提案工具”,而非真正的“生产引擎”。
策略上,创始人提到的“60%的beta用户已有供应链”值得警惕。这意味着Genpire正在扮演“锦上添花”的设计工具角色,而非颠覆性的生产平台。如果核心价值局限于提升早期设计效率,而无法在“智能匹配工厂”和“管控生产质量”上建立不可替代的壁垒,它很可能面临来自SolidWorks、Adobe等传统CAD/设计工具的AI化反击,或成为工厂端自研系统的“前菜”。
真正的价值检验点在于:Genpire能否通过其“工厂网络”积累足够多的实际交付数据和订单反馈,反向优化其Agent的判断力,最终做到“AI生成的方案不仅好看,而且好造”。如果能,它将打开万亿级消费品市场的效率革命;如果不能,它将仅是一个营销噱头,昙花一现。
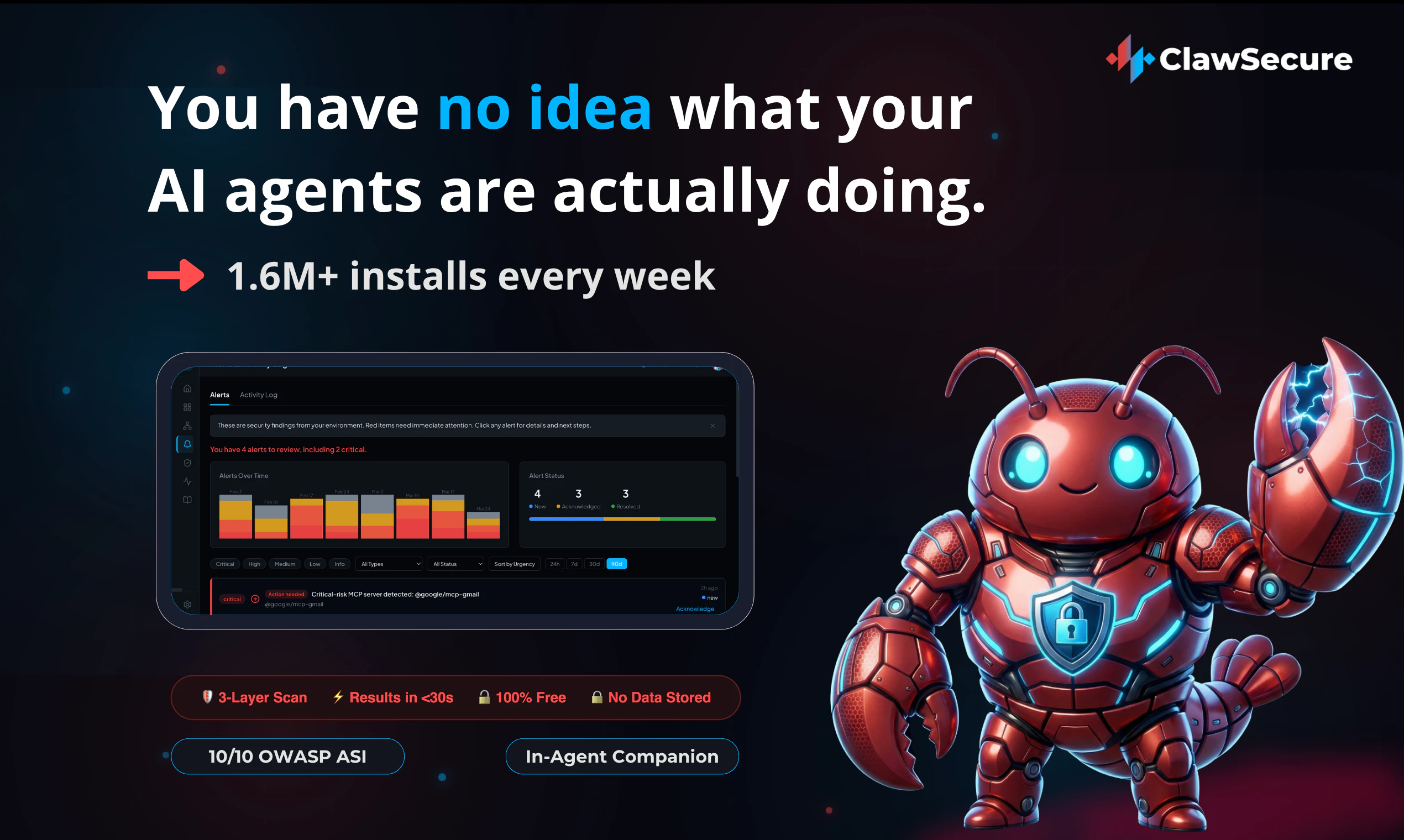
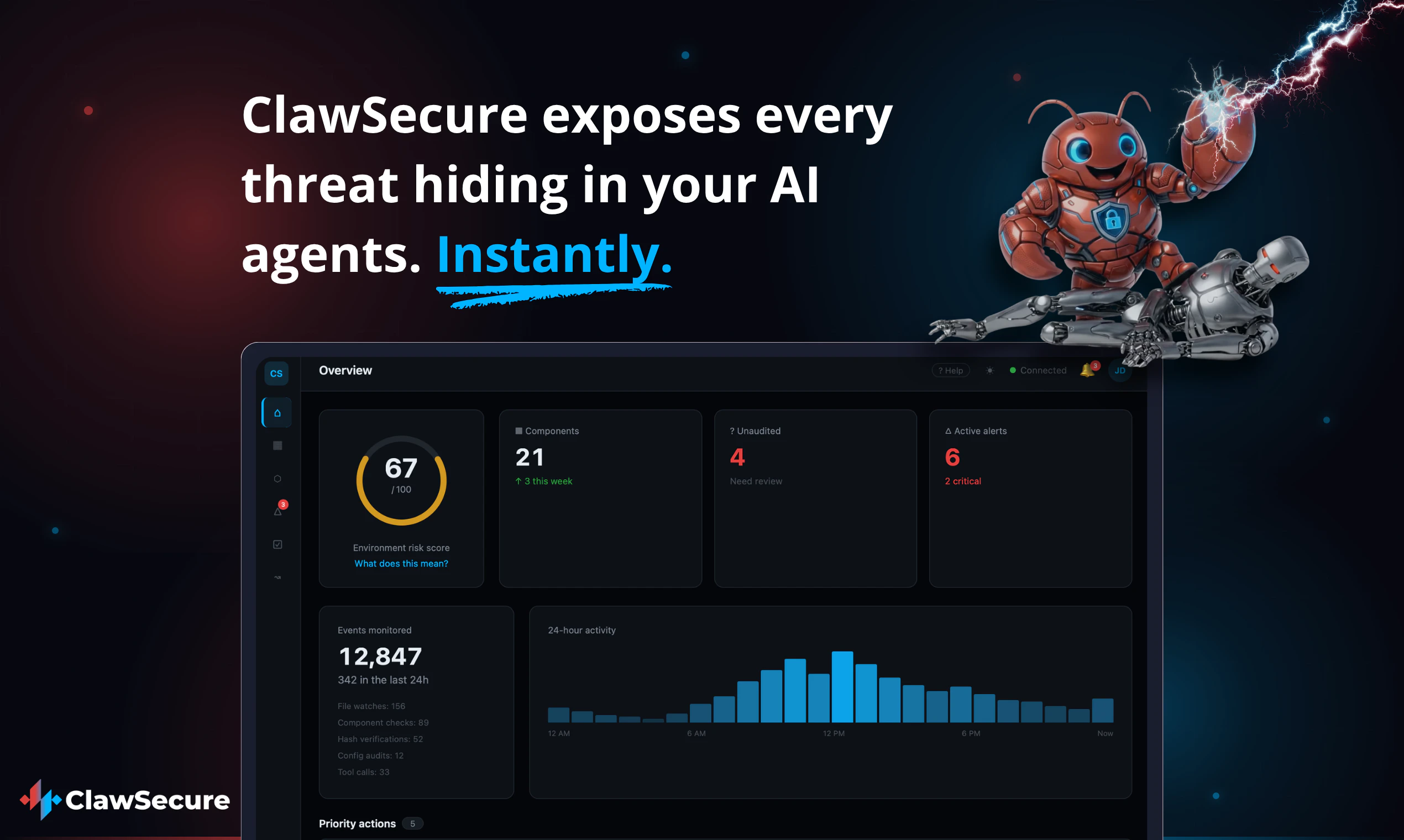
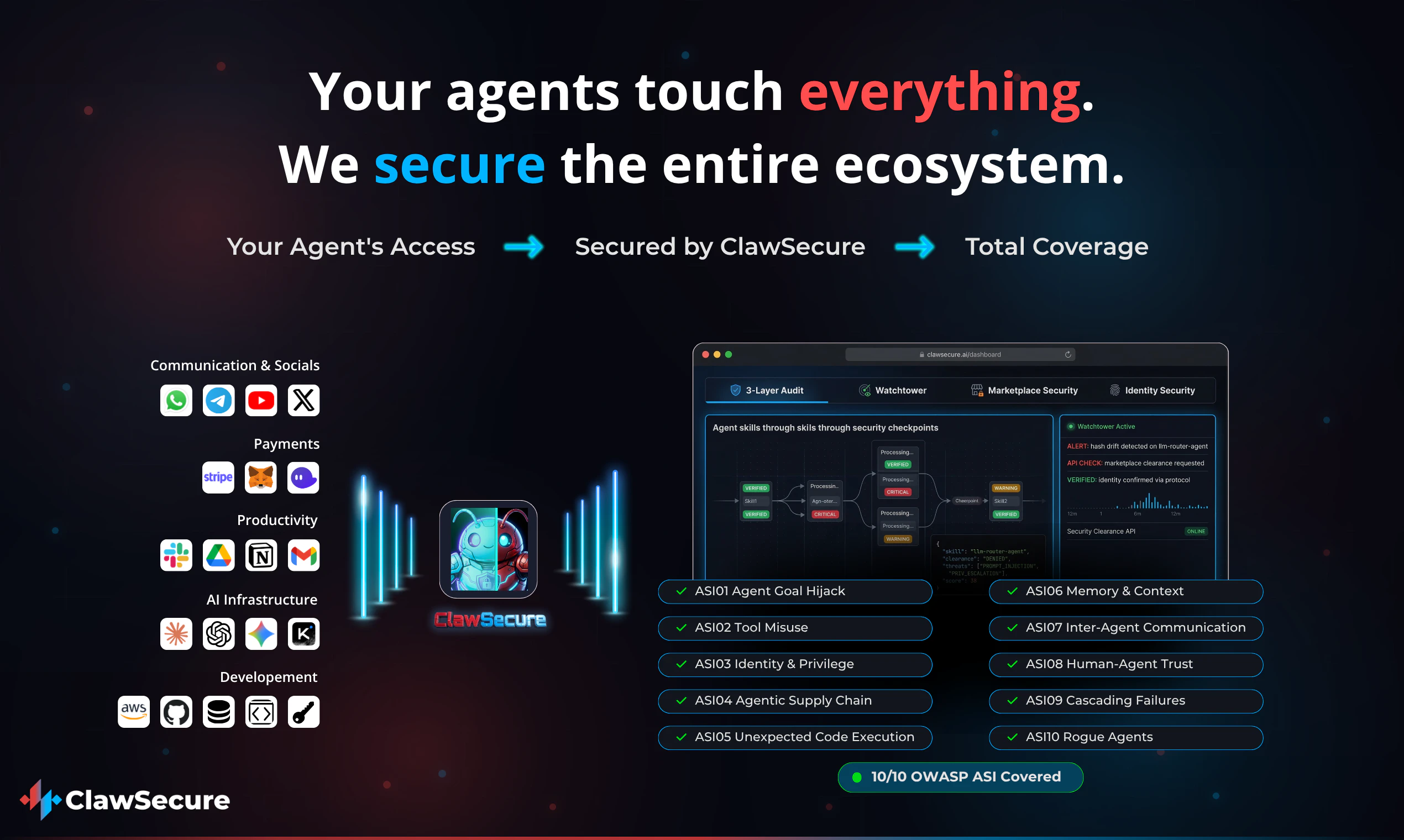
一句话介绍:ClawSecure 是一个专为 AI Agent 生态打造的 AI 驱动安全工具,通过预安装扫描、实时运行时监控和亚 200ms 验证 API,解决 AI 智能体在无监管环境下代码突变、权限滥用和数据泄露等核心安全隐患。
Developer Tools
Artificial Intelligence
Pitch Singapore
AI Agent安全
杀毒软件
运行时监控
代码审计
OWASP
智能体防护
威胁检测
安全扫描
权限管理
开源
用户评论摘要:用户对产品概念高度认可,称其为“无聊但必须”的工具。核心问题围绕:如何区分代码突变是恶意还是正常更新?如何处理误报?同时用户期望集成 Slack 警报。有用户实测发现权限隐藏问题,并验证了 30 秒扫描承诺。另有用户询问如何从手动审查迁移到采用该产品。
AI 锐评
ClawSecure 切中了一个真实且正在迅速恶化的痛点:AI Agent 生态的“裸奔”状态。创始人提出的“代码即攻击”并非危言耸听——当每个 Agent 都拥有系统级权限且无沙箱隔离时,传统的安全范式彻底失效。该产品并非简单的“为 AI 做杀毒”,而是构建了一套贴合 Agent 运行特征的动态防护体系:利用哈希漂移检测代码突变,结合行为上下文而非静态规则来区分恶意操作与正常进化,这比传统 AV 引擎对零日攻击的感知能力至少领先一个维度。
商业策略上,通过免费无注册的 30 秒扫描作为“漏斗”入口,利用“数据震惊”——用户发现自己信任的 Agent 正偷偷外泄数据——完成从免费到付费的转化,逻辑清晰且杀伤力强。缺失的 Slack 集成是明显短板,但已在路线图上。
目前最大的挑战不在于技术,而在于生态。“41% 的 Agent 有风险”这个数字本身就意味着,如果市场教育不足,ClawSecure 可能面临“产品好但用户还没感受到痛”的窘境。另外,“AI 驱动”是现代 SaaS 的标配用语,ClawSecure 需要更明确地展示其 AI 模型在具体场景下(如代码突变 vs 代码更新)的决策逻辑和准确率数据,而非停留在“行为分析”的宣传上。如果它真能成为 Agent 生态的“Windows 安全中心”,那估值天花板会很高。但前提是,它必须先活过这个安全产品“叫好不叫座”的初期阶段。
一句话介绍:Warp Open-Source 是一个通过社区与AI代理协作,将代码编写、测试等繁琐工作交由Oz代理处理,让开发者聚焦于创意与验证的“半监督式”开源开发环境,旨在解决传统开源项目维护者人力瓶颈和AI工具缺乏人为审核闭环的问题。
Open Source
Developer Tools
Artificial Intelligence
GitHub
开源终端
AI代理
人机协作
社区驱动
开发环境
Oz编排
PR审核
智能体
代码审查
自动化测试
用户评论摘要:用户普遍赞赏开源策略,但关注点集中在:1)BYO本地模型支持(如Ollama)以保护NDA代码;2)社区贡献的PR审核速度与安全框架;3)AI自动化与开发者控制权的平衡;4)跨命令会话的上下文保持能力。创始人回应称本地模型支持将在一两周内落地。
AI 锐评
Warp的野心不止于做AI终端,它试图重构开源协作的底层范式——用“监督式自动化”替代传统的“众包式”贡献。创始人Zach点出的“最大瓶颈已从写代码变为人为验收”是精准的行业洞察。然而,这步棋存在三重风险:首先,目前系统高度依赖Warp的自有云代理Oz,对于企业级用户关心的NDA代码和私有网络环境,即便承诺1-2周内支持BYO模型,但若无法在本地或内网实现完整代理编排,其Agentic能力将大打折扣。其次,“人机协作”表面是提效,实则是将审核压力从代码审查转移到了“规范审查”——社区贡献者写代理文档的能力可能远差于写代码的实力,导致“上游规范污染”而Oz无法兜底,这在评论中已有用户提出。最后,500+贡献者、56K星标的爆发式增长究竟能维持多久?当基础设施平台(Warp Core)问题暴露时,社区是否会因缺乏决策参与感而流失?Warp的长期价值不在于实现“AI写代码”,而在于能否证明“AI能可信、可控地接受社区集体指挥”——这恰恰是所有开源项目治理都未解决的奥德赛。如果做成了,它是开源3.0的里程碑;如果做砸了,它不过是又一个被开发者尝鲜后弃用的套壳玩具。
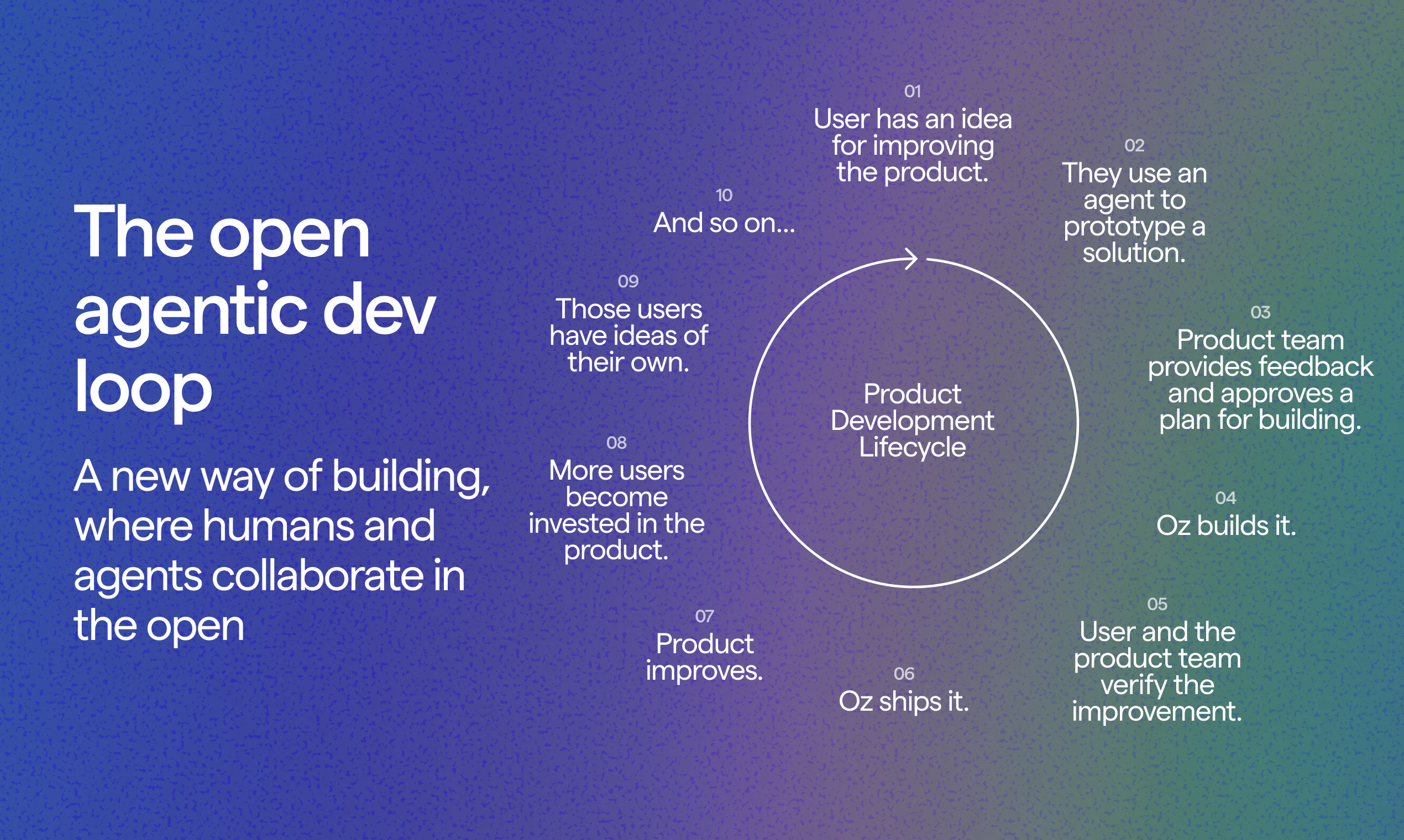
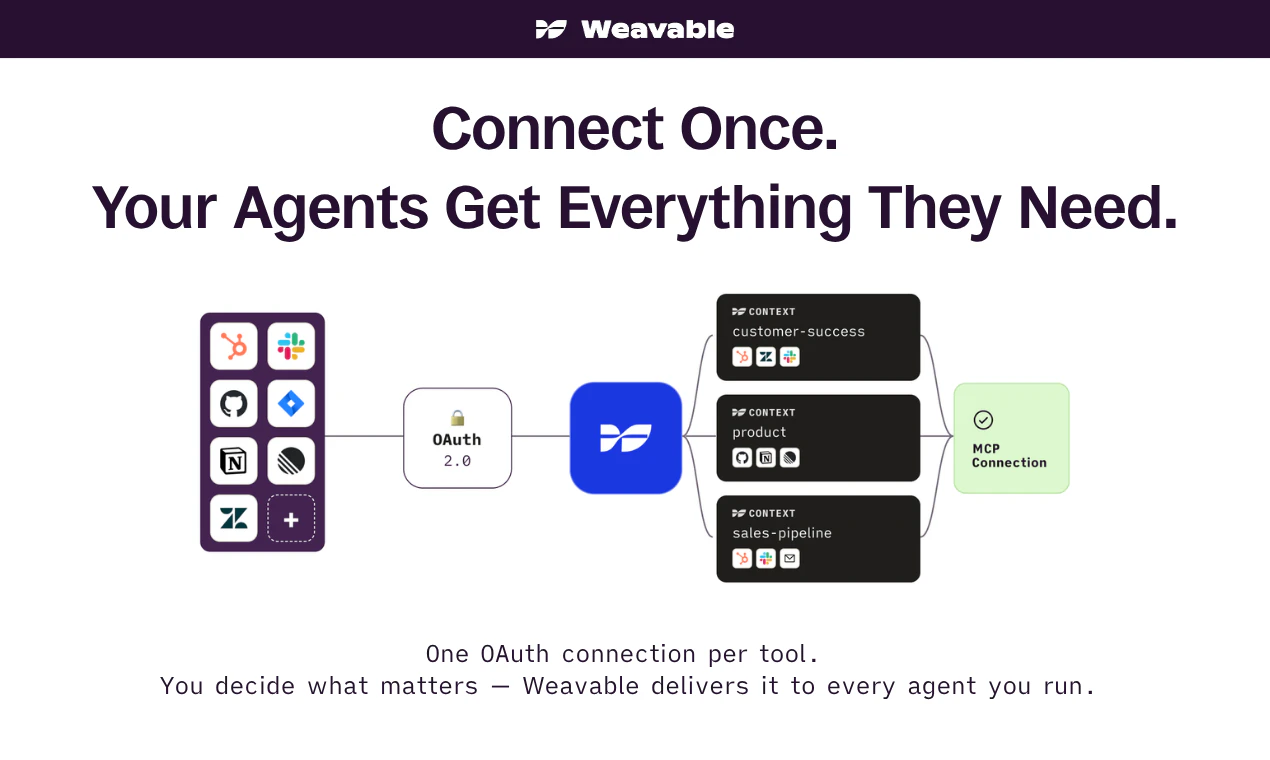
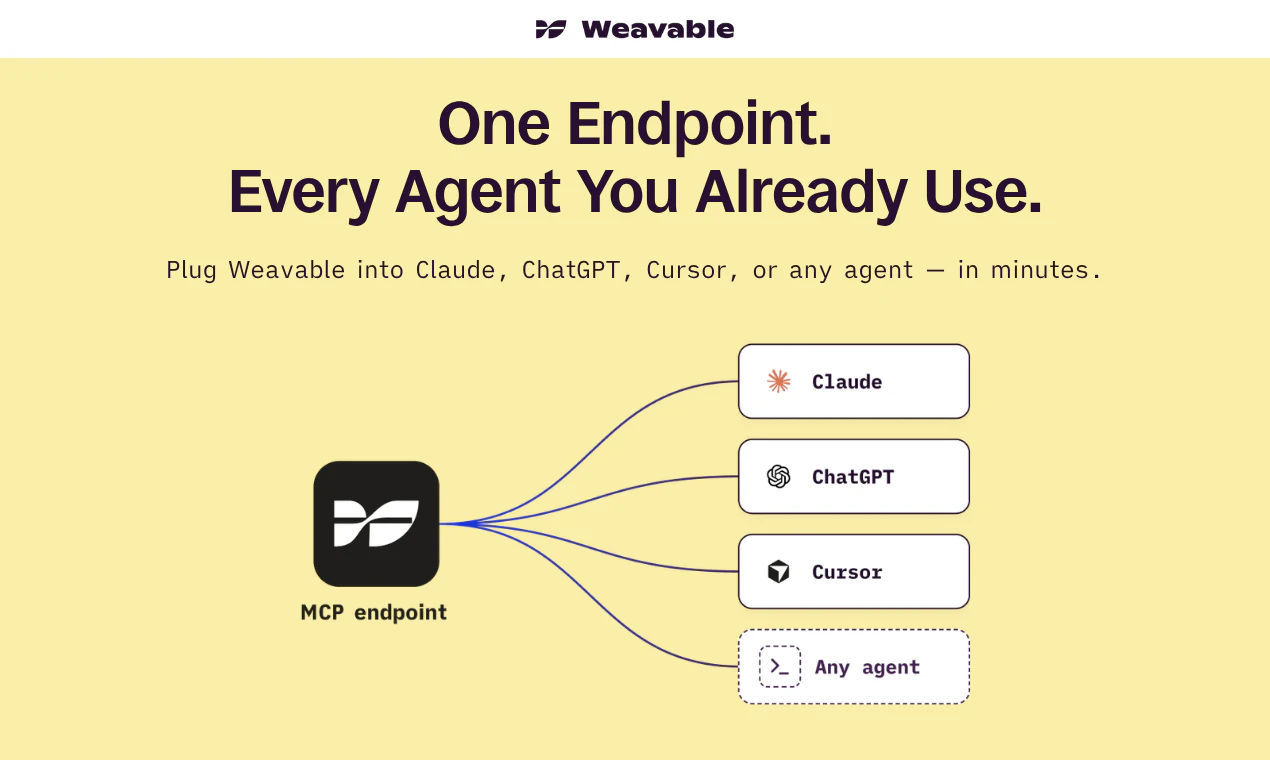
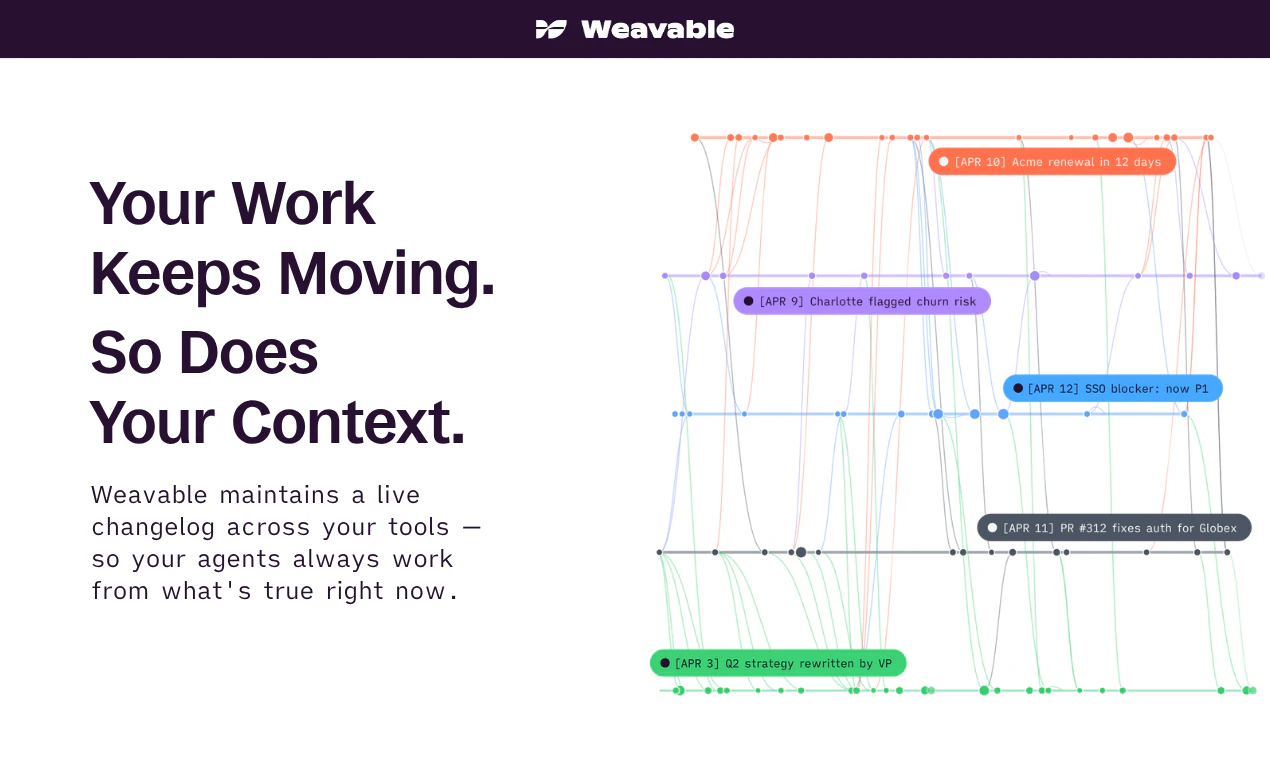
一句话介绍:Weavable通过持续更新的活动图谱为AI代理提供持久、实时的业务上下文,解决代理因直接连接API导致token浪费或使用静态知识库导致上下文过时的问题。
SaaS
Artificial Intelligence
Operations
AI代理上下文
知识图谱
MCP端点
企业工具集成
Token优化
实时数据
活动日志
工作流自动化
用户评论摘要:用户普遍认可活动图谱/变更日志解决上下文动态性的思路。核心问题聚焦于:多模型对同一上下文的解释差异、权限治理如何随规模扩展、快速变化场景下的实时性、以及旧数据导致代理混淆的上下文修剪策略。
AI 锐评
Weavable切中的是一个极其精准且昂贵的痛点——AI代理在企业落地时的“上下文断裂”。传统方案要么让代理在原始API数据中“大海捞针”,烧掉大量Token;要么依赖RAG的快照,导致决策滞后且不准确。Weavable提出的“活动图谱”本质上是将昂贵的、实时的上下文推理工作从模型侧前置到基础设施层,用结构化的变更日志替代重复的检索和推理循环。其宣称的90%Token节省和85%的输出偏好并非营销噱头,而是架构优化的直接结果。
然而,产品面临的核心挑战并不在技术,而在生态位。当前市场上,MCP(Model Context Protocol)正在成为连接模型与数据的行业标准,而Weavable本质上是在MCP之上构建了一个更“聪明”的中间层。这个中间层有价值,但它的命运取决于两点:其一,能否避免沦为“临时补丁”,而是真正成为企业上下文治理的标准化层;其二,其治理模型(基于OAuth的上下文隔离)在企业复杂权限体系下的可操作性仍有待验证。评论中用户对“多模型解释差异”和“权限边界”的追问,恰恰点出了其当前架构的盲区——它优化了Token效率,但暂未从根本上解决模型行为的一致性与数据安全的根本矛盾。
一句话总结:Weavable是当前AI代理工作流中一个优雅且必要的“加速带”,但能否成为企业级上下文的核心“锚点”,取决于其能否在标准化与治理深度上持续进化。
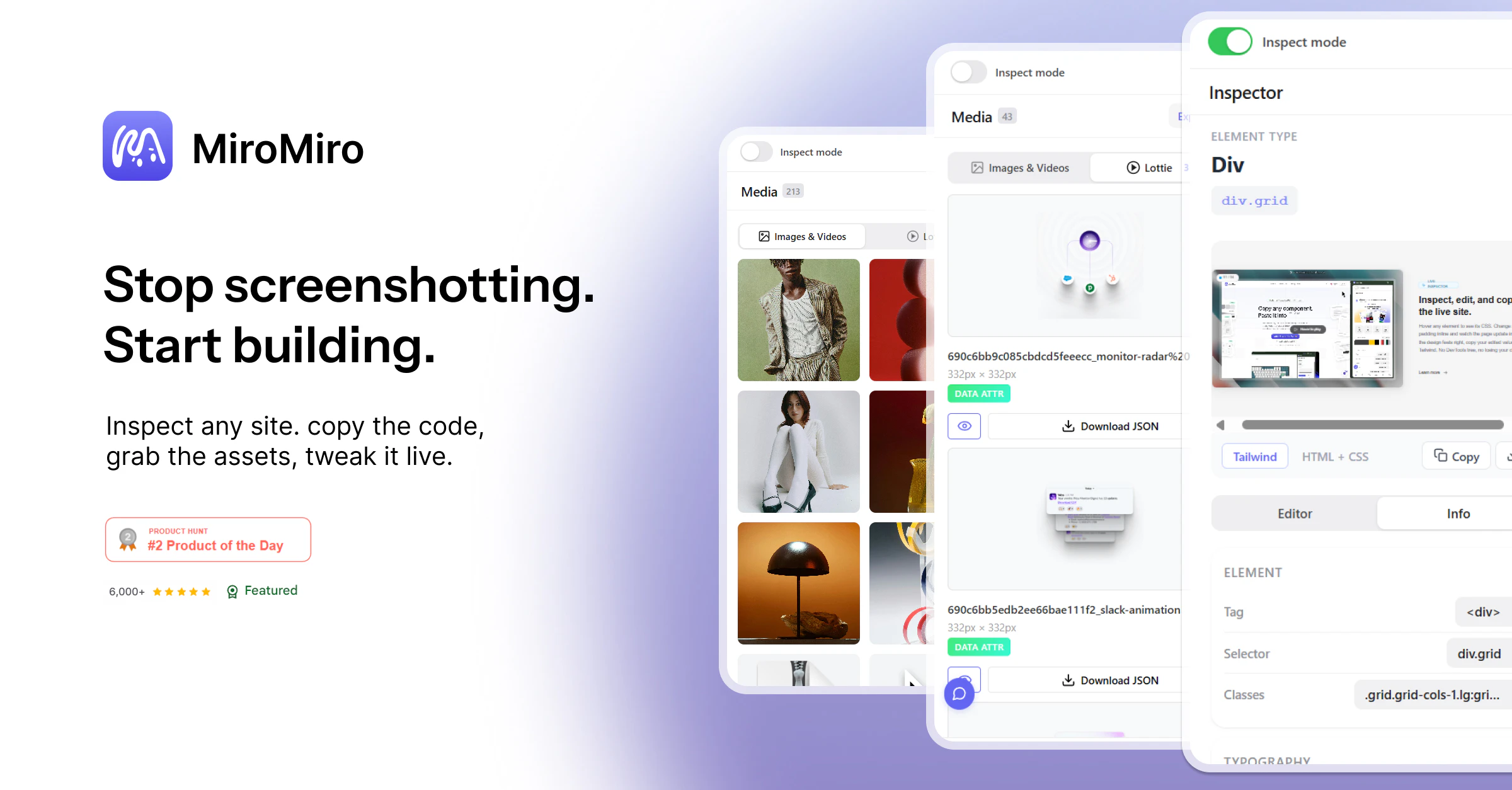
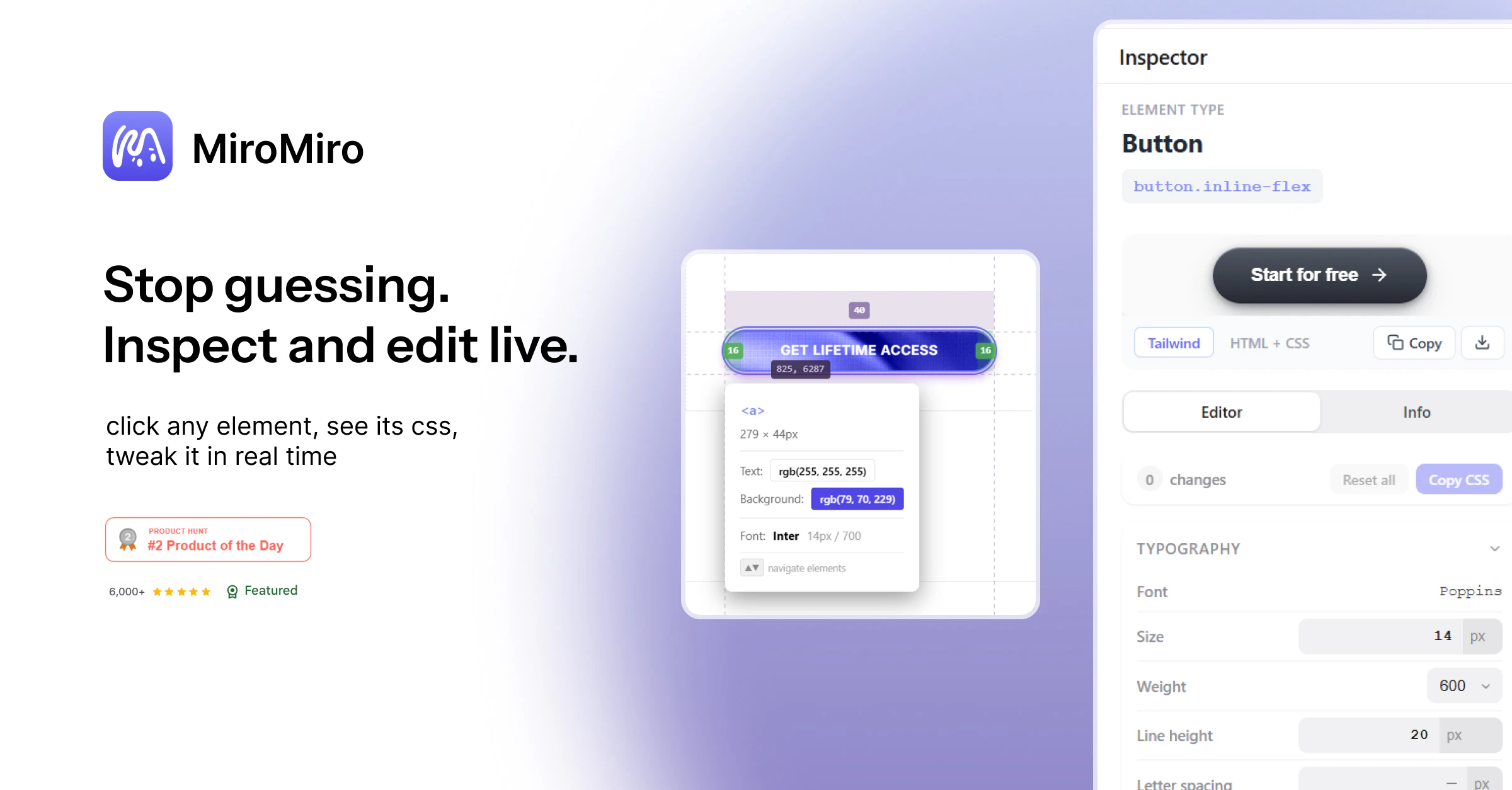
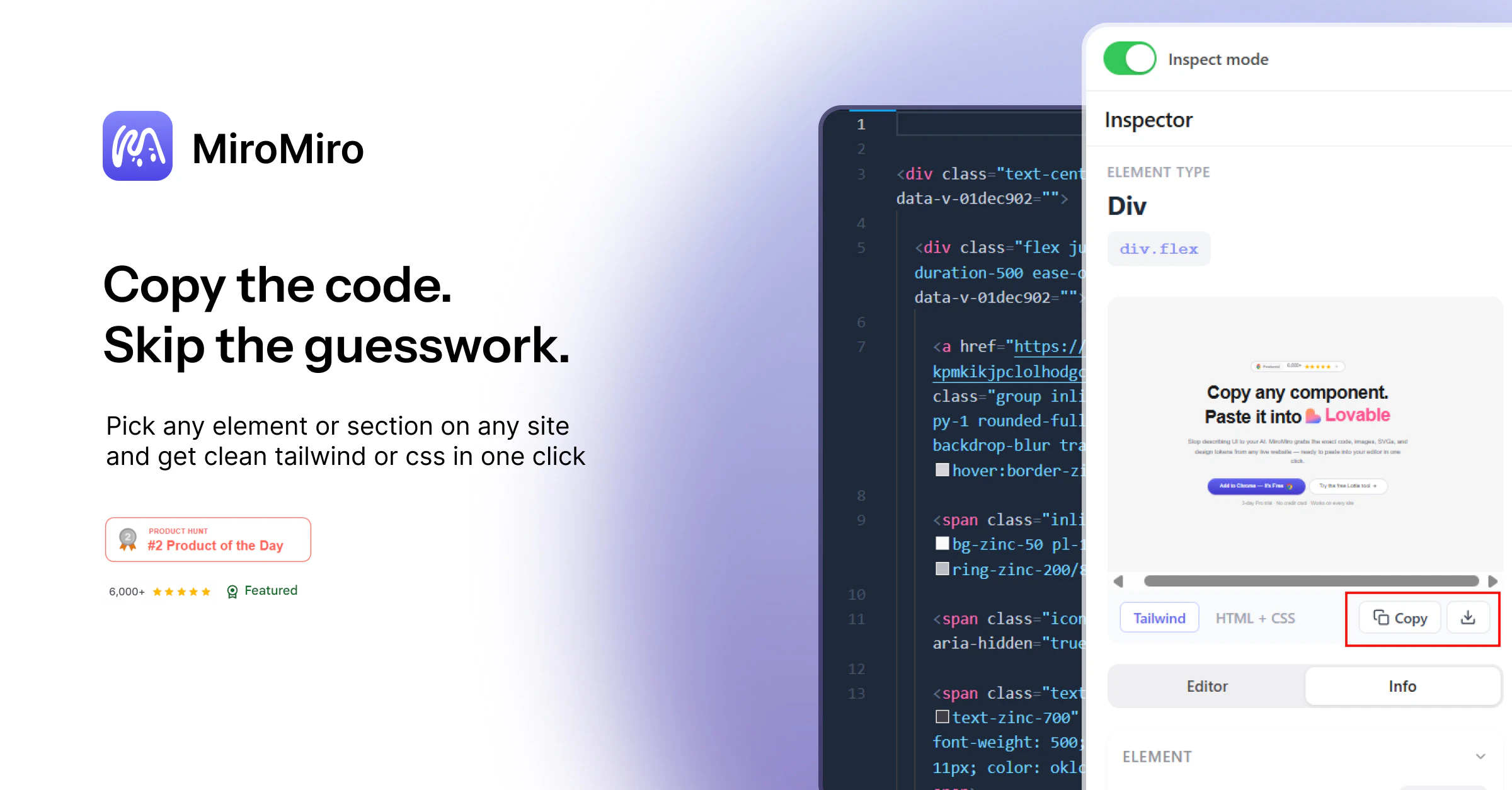
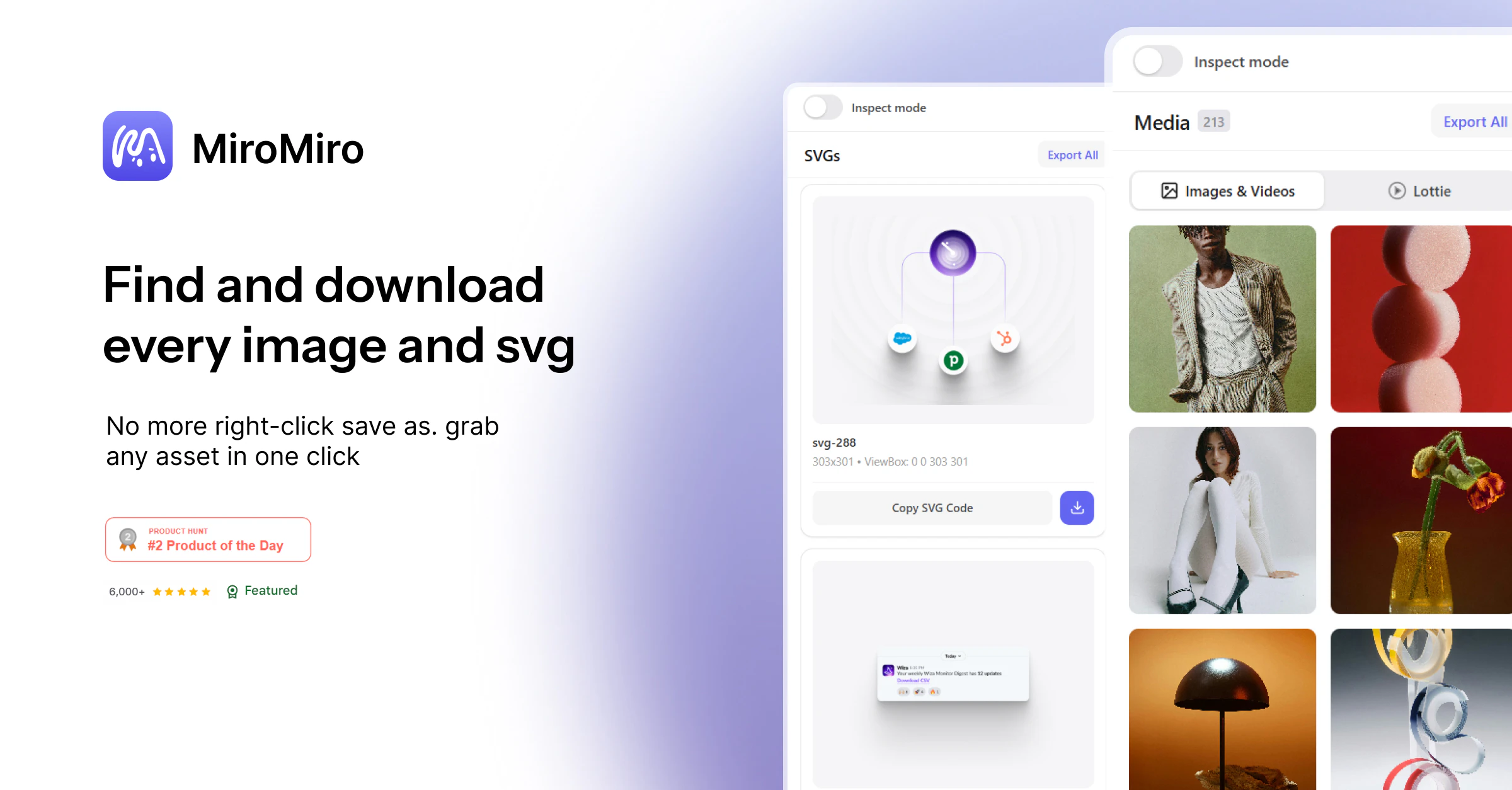
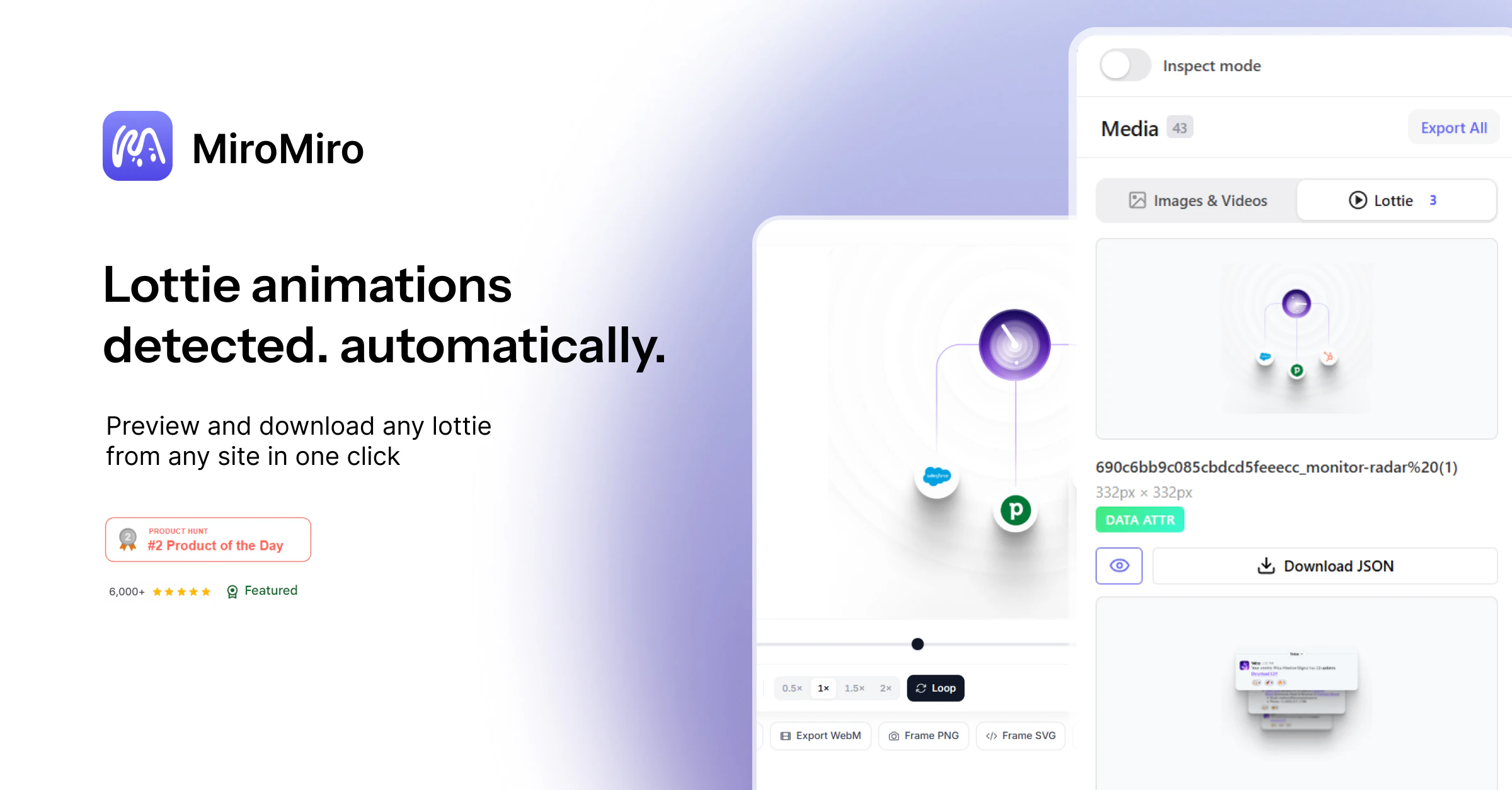
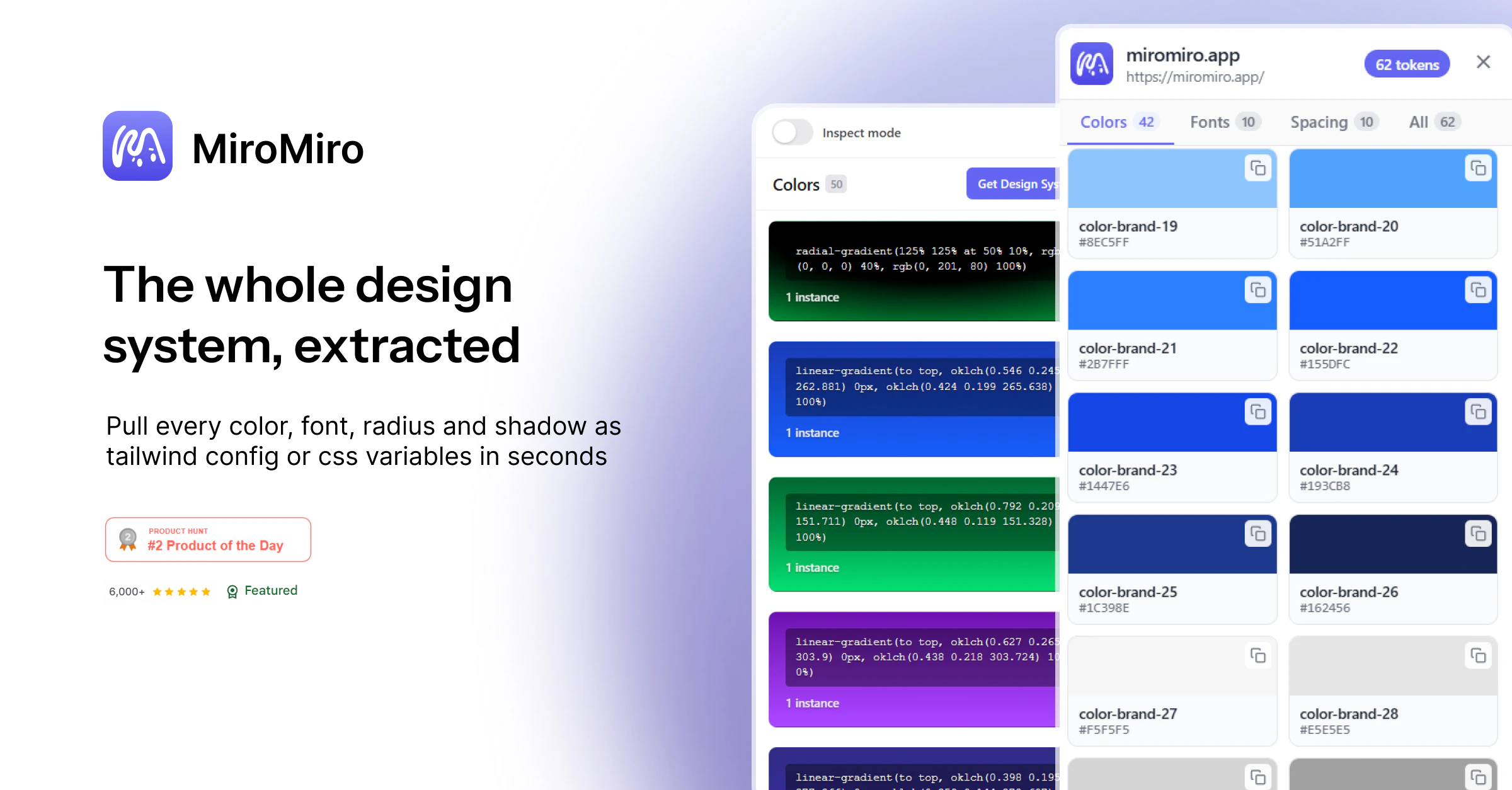
一句话介绍:MiroMiro v2是一款浏览器设计工具,让开发者/设计师能像使用Figma一样,实时检查和编辑任意网站的设计样式(颜色、字体、间距、阴影),并一键将选中区域导出为Tailwind或HTML/CSS代码,大幅缩短从灵感借鉴到实际代码的转化时间。
Chrome Extensions
Design Tools
Productivity
Developer Tools
设计审查
前端开发
代码导出
Tailwind CSS
实时编辑
设计系统提取
无障碍检测
浏览器插件
设计到代码
开发者工具
用户评论摘要:用户普遍赞同其解决“从视觉到代码”的痛点,尤其欣赏“实时编辑+导出”流程和Lottie自动检测。核心疑问聚焦于导出的代码质量:复杂页面的响应式布局和可复用组件是否需大量清理。开发者建议将其定位为“视觉到AI提示的桥梁”,而非直接“导出即用”。
AI 锐评
MiroMiro v2本质上是一个“设计反编译工具”加“单向样式同步器”。它的真正价值不在于取代Figma或DevTools,而在于切断了“视觉参考→手动调参→重新编码”的痛苦链条,将前端开发者从“看一个好看页面,花20分钟在DevTools里翻找并手动重构样式”的低效劳作中解放出来。
然而,产品目前存在两个致命内伤:第一,导出代码的“生产就绪度”是最大短板。评论中开发者已直接指出,复杂页面导出的代码仍需要大量人工重构,这暴露了其核心算法在处理真实世界“混乱”标记结构(如内联样式、嵌套组件、CSS-in-JS)时的无力感。如果不解决导出代码的语义化和可复用性,它最终只会沦为一个“高级截图工具”,而非真正的“代码生成器”。第二,商业转化场景模糊。它提供了从“看到”到“拥有”的捷径,但“偷”来的设计代码在法律和职业道德上存在灰色地带。产品创始人建议的“导出→提示AI”策略很聪明,这实际上将MiroMiro定位为指导AI生成代码的精确语境提供者,而非最终代码的制造者。这个定位比“一键导出生产级代码”更务实,也更具想象力。
V2最大的亮点其实是“实时编辑”和“设计系统提取”——前者让前端调试体验从DevTools的“一次性”升级为“可持久化”,后者则是一个被低估的企业级功能,能快速反向工程竞品的设计系统。对于独立开发者或小型团队,在快速原型验证和素材收集阶段,MiroMiro是极具杀伤力的。但若要成为日常开发工作流的核心,它还需要在代码重构和团队协作上下更多功夫。目前,它更像一把锋利的“撬棍”,而非一套完整的“工具箱”。
一句话介绍:Snapseed 4.0 将经典免费修图工具升级为全流程移动摄影工作台,解决用户在手机端无法同时完成胶片风格直拍、精准局部蒙版、批量导出和非破坏性二次编辑的痛点。
Android
Photography
Photo & Video
Photo editing
移动修图
Google官方
胶片滤镜
智能蒙版
RAW编辑
无损工作流
批量处理
内置相机
免费无广告
专业化摄影
用户评论摘要:用户对Snapseed回归表示期待,但更关心“seriously better”具体指什么——是增加AI修图、批量导出、还是提升原有工具精度?部分用户希望针对内容创作者优化社交媒体素材处理效率,也有用户担忧新版能否保持经典手感。
AI 锐评
Snapseed 4.0的发布,本质上是一次“经典IP的现代化复权”。145票在Product Hunt上不算爆款,但足以说明核心用户群的怀念与观望。从介绍来看,Google并未选择堆砌AI滤镜或强行订阅化,而是老老实实补齐了全工作流缺口:胶片风格内置相机、无损编辑、批量处理——这几个功能直击了Lightroom Mobile付费用户的软肋。
但需要注意的是,Snapseed当年失势并非因为功能不足,而是Google长期缺乏维护与迭代,导致被Adobe和VSCO蚕食市场。4.0版本若想“王者归来”,不能只靠情怀和免费标签。评论中用户最在意的“AI修图”并未在更新中明确提及,反而强调“仍像Snapseed”——这既是定心丸,也是双刃剑:如果仅停留在操作手感和免费层面,在AIGC席卷修图领域的今天,它依然只能做“精准的旧工具”,而非“高效的下一代工具”。
真正的价值在于:Google通过Snapseed 4.0重新掌握了一个零门槛、无广告的移动端入口,这对旗下Pixel相机生态和照片存储服务是潜在的导流利器。但若这是又一场“复活即弃养”的操作,145票可能就是它最后的高光。
一句话介绍:ChatGPT for Google Sheets 是一款内嵌于电子表格的侧边栏AI,让用户通过自然语言直接完成公式编写、数据清理和模型构建,彻底消除跨工具切换的痛点。
Productivity
Spreadsheets
Artificial Intelligence
用户评论摘要:用户称赞“权限先行”机制解决了AI篡改数据的信任问题,尤其适合金融建模场景;关注AI如何维持数据格式一致性;有用户建议针对已熟悉Google Sheets的深度用户进行精准获客,并询问推广策略。
AI 锐评
这款产品的价值不在于“能用AI写公式”,而在于它重塑了人机协作的信任基线。当前市面上的AI办公插件大多沦为“高级搜索引擎”——用户描述需求,AI生成结果,但过程是黑箱。而ChatGPT for Google Sheets的“权限先行+变更追溯”设计,本质上是把AI从“代劳者”降格为“参谋”——它不越俎代庖地修改数据,而是先解释逻辑、请求许可,再将每一步变更具象化到具体单元格。这种克制,恰恰击中了金融、运营等对数据准确性有零容忍要求的用户的命门。值得注意的是,产品释放到免费和Go计划,看似是普惠,实则是在铺数据飞轮——更多免费用户意味着更丰富的自然语言与电子表格交互场景训练数据,这比直接收费更有战略意义。但问题同样尖锐:AI是否真能理解复杂的公式级联与隐含假设?从评论中“如何保证数据格式与类型一致”的质疑来看,产品在面对跨表引用、条件格式、数组公式等Excel/Sheets边界案例时,大概率会出现幻觉或错误更新。此外,侧边栏形式虽降低了切换成本,却也割裂了与主界面的视觉连贯性——对于重度用户而言,小窗间的滚动操作可能反而拖慢效率。总体而言,这是一款思路清晰的“陪练型”AI工具,但距离真正替换人类的建模能力,还有很长的边界案例要填。
一句话介绍:Web Speed通过将混乱的DOM/HTML页面转换为高保真、低Token消耗的机器可读JSON地图,解决AI网页代理在浏览网站时Token成本高昂和运行不稳定的痛点。
Productivity
Developer Tools
Artificial Intelligence
GitHub
AI网页代理
Token成本优化
DOM转JSON
MCP协议
SDK
浏览器自动化
动态内容处理
反爬虫绕过
Agent适配层
效率提升
用户评论摘要:用户肯定了“Token税”的痛点,询问成本降低的基准测试数据,并关注处理动态内容、SPA及反爬机制的细节。开发者回应已提供Benchmark页面,并详细解释了通过Playwright执行JS、CDP附着真实浏览器、模拟人类操作等技术方案。
AI 锐评
Web Speed切中了当前AI Agent落地时最现实的“经济账”——Token成本。其本质是把浏览器解析的“脏活”(DOM变异、JS延迟加载、反爬检查)从大模型昂贵的上下文窗口中剥离,转化为一个预处理的确定性映射引擎。这种“逻辑层”的定位非常聪明:它不试图替代大模型的智能,而是用工程手段降低调用成本的指数级。
真正价值在于两点:一是将成本结构从“Token数×单价”优化为“映射固定成本+低Token交互成本”,让Agent在长链路任务(如多步表单填写、价格监控)中不再因Token爆炸而不可用;二是通过SDK模拟人类操作(如真实按键、附着浏览器指纹),解决了企业级自动化无法无视的反爬墙问题,这是普通DOM解析器做不到的。
潜在风险在于:产品对反爬策略的“灰色兼容”可能触碰平台服务条款,且依赖Playwright在大量并发场景下的稳定性需要严苛测试。若真想切“90%更便宜的Agent”,还需证明映射层的维护成本(如网站改版后的适配工作)不会转嫁给用户。总体而言,这是为Agent成本敏感场景提供的一把工程精确刀,而非AI革命。
一句话介绍:Grok Connectors 是一个让AI助手(Grok)直接读写并操作你日常办公软件(如Gmail、Notion、GitHub)的集成层,解决AI“只对话不办事”的痛点,实现从信息获取到任务执行的闭环。
Productivity
Artificial Intelligence
AI代理
工作流自动化
应用集成
MCP协议
生产力工具
办公软件连接
任务执行
SaaS连接器
AI办公
xAI
用户评论摘要:用户(@zaczuo)认可其整合日常应用的价值,但核心疑问在于分发渠道:是否与主流应用市场建立了合作关系?如何触达最需要的重度用户?这暴露了工具落地中“酒香也怕巷子深”的隐忧。
AI 锐评
Grok Connectors 的本质是给原本“嘴炮”的AI装上了一副“机械臂”。其核心价值不是“连接应用”这个技术动作,而是将Grok从“问答助手”升格为“数字执行者”——它终于能代你读邮件、改文档、审代码,这是从认知层到行动层的质变。
但冷静来看,这并非技术上的壁垒创新。竞争对手如Zapier的AI、OpenAI的GPT Actions早已布局类似MCP标准的自动化能力。Grok的优势在于xAI与Anthropic的算力合作带来的低成本推理,以及马斯克生态下Twitter/X实时数据的先天壁垒——这才是“Connectors”中最独特的连接器。
用户评论中的担忧极其精准:在SaaS工具林立且每个公司都拼命建护城河的当下,分发与合作远比技术实现更难。Grok Connectors能否打通Google Workspace、Notion等平台的企业级API授权,能否让CIO们信任一个来自xAI的AI代理操作核心业务数据,这些才是生死挑战。
一句话锐评:这把“万能钥匙”的技术门槛不高,但能否打开企业的大门,取决于xAI的商务壁垒和信任资产,而非代码的巧拙。
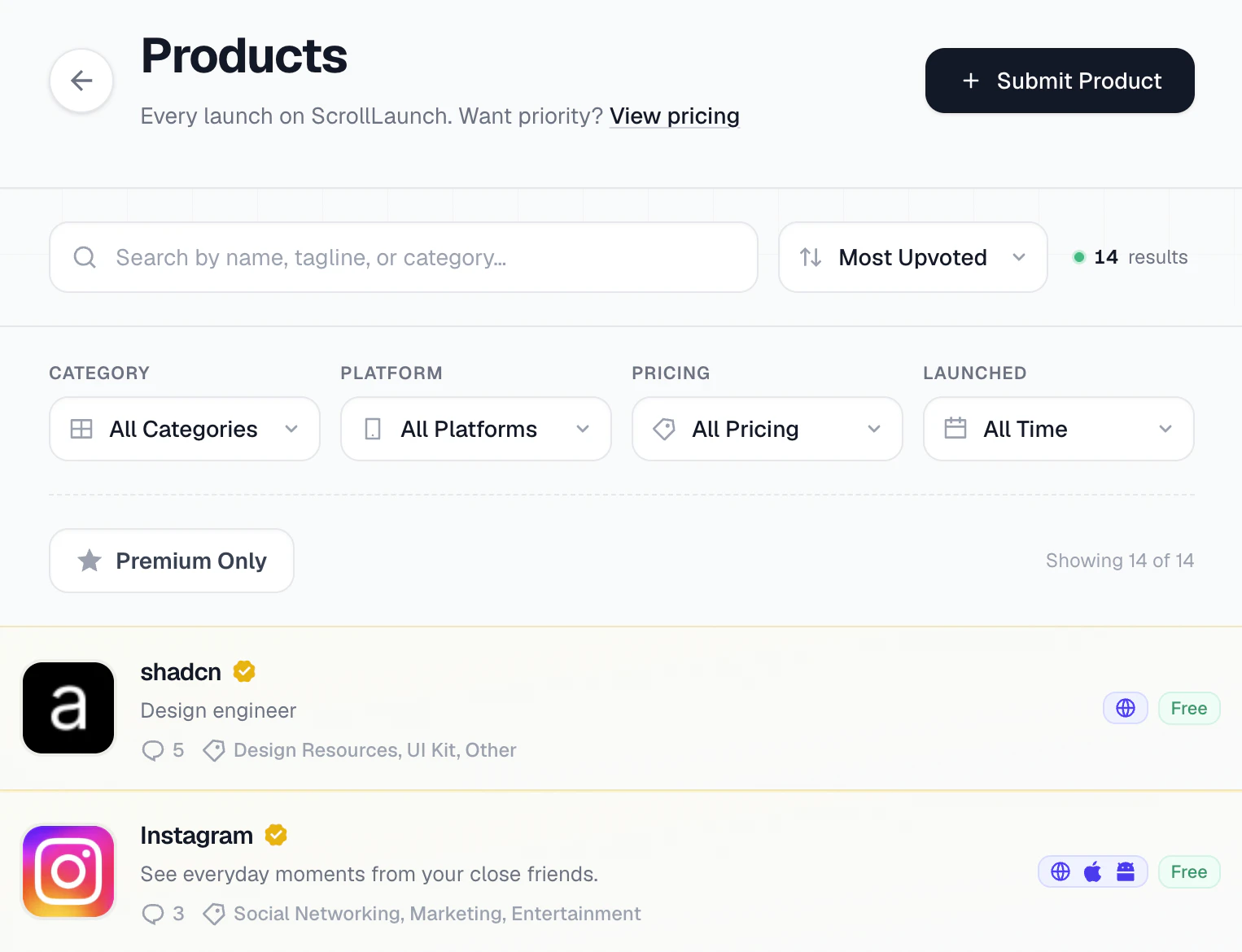
一句话介绍:Scroll Launch 是一个专为独立开发者与 SaaS 创始人打造的产品发布平台,通过周排行榜与高 DR 外链,帮助他们避开 Product Hunt 拥挤赛道,更快被早期用户发现。
Sales
Marketing
SEO
产品发布平台
独立开发者
SaaS 创始人
Product Hunt 替代
周排行榜
高 DR 外链
早期用户获取
增长工具
社区推广
产品发现
用户评论摘要:用户核心关注:① 与 PH 的受众是否重合;② 发布时机如何搭配 PH 策略;③ 当前排队需等8周,担心效果过期。另有反馈建议将“替代方案”卖点转化为“直接获益”表述。
AI 锐评
Scroll Launch 切中了 Product Hunt 的痛点:竞争红海、注意力碎片化、后续流量衰减。它以“周排行榜+DR外链”作为价值锚点,本质是给独立开发者一个**确定性更强的曝光窗口**,而非随机抽奖式的首页搏杀。这一点在标题和产品介绍中直接对标 PH,策略聪明但危险——用户会拿它与 PH 的所有优势(流量规模、媒体覆盖、品牌背书)做直接对比,哪怕前者只是一款社区型工具。
从评论反馈看,用户最焦虑的并非“值不值得用”,而是**时机衔接与排队效率**。8周的等待期几乎摧毁了“趁势发布”的紧迫感,对于快节奏的产品 Launch 周期来说,这是致命的设计缺陷。真正的价值不在替代 PH,而在于**作为第二通道与PH形成协同**——早鸟发现、高权重外链、周榜持续曝光,恰好补足 PH 发布后的长尾衰退。团队应当优先优化发布排期,把等待时间压缩到1-2周内,否则再好的定位也会被运营滞后拖垮。
此外,当前用户对“受众重合度”的质疑来自对平台冷启动的合理谨慎。Scroll Launch 若不能证明自己拥有与 PH 互补的独立用户画像(例如更关注技术原型、较早期的小众买家),就会沦为一款只有供给方(开发者)而无需求方(真实使用者)的零和游戏。真正的壁垒不是“替代”,而是**能否在一年内积累出1000个愿意每周主动回访发现产品的活跃用户**。只有做到这点,它才值得被称为“alternative”,而非“landing page”。
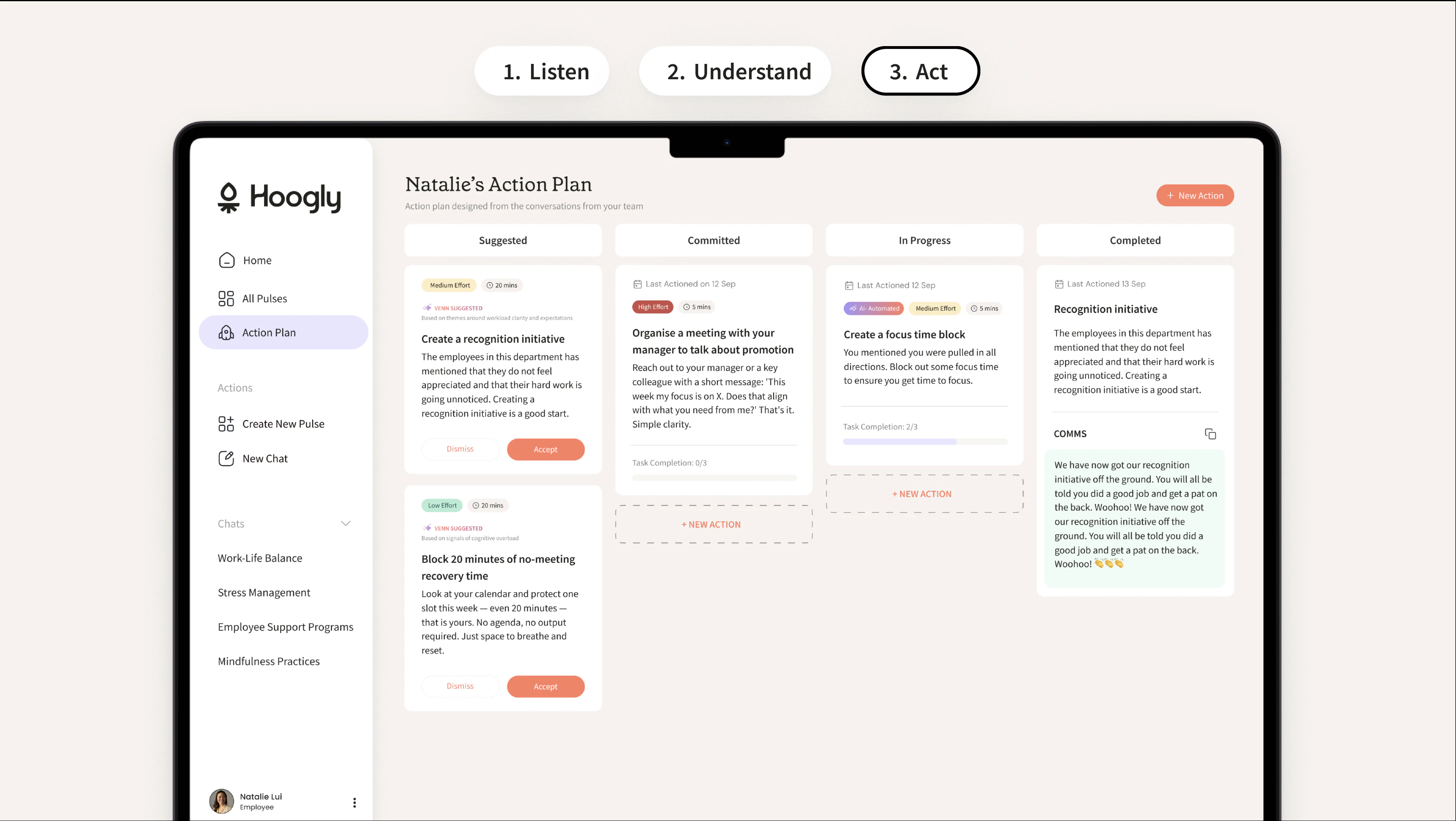
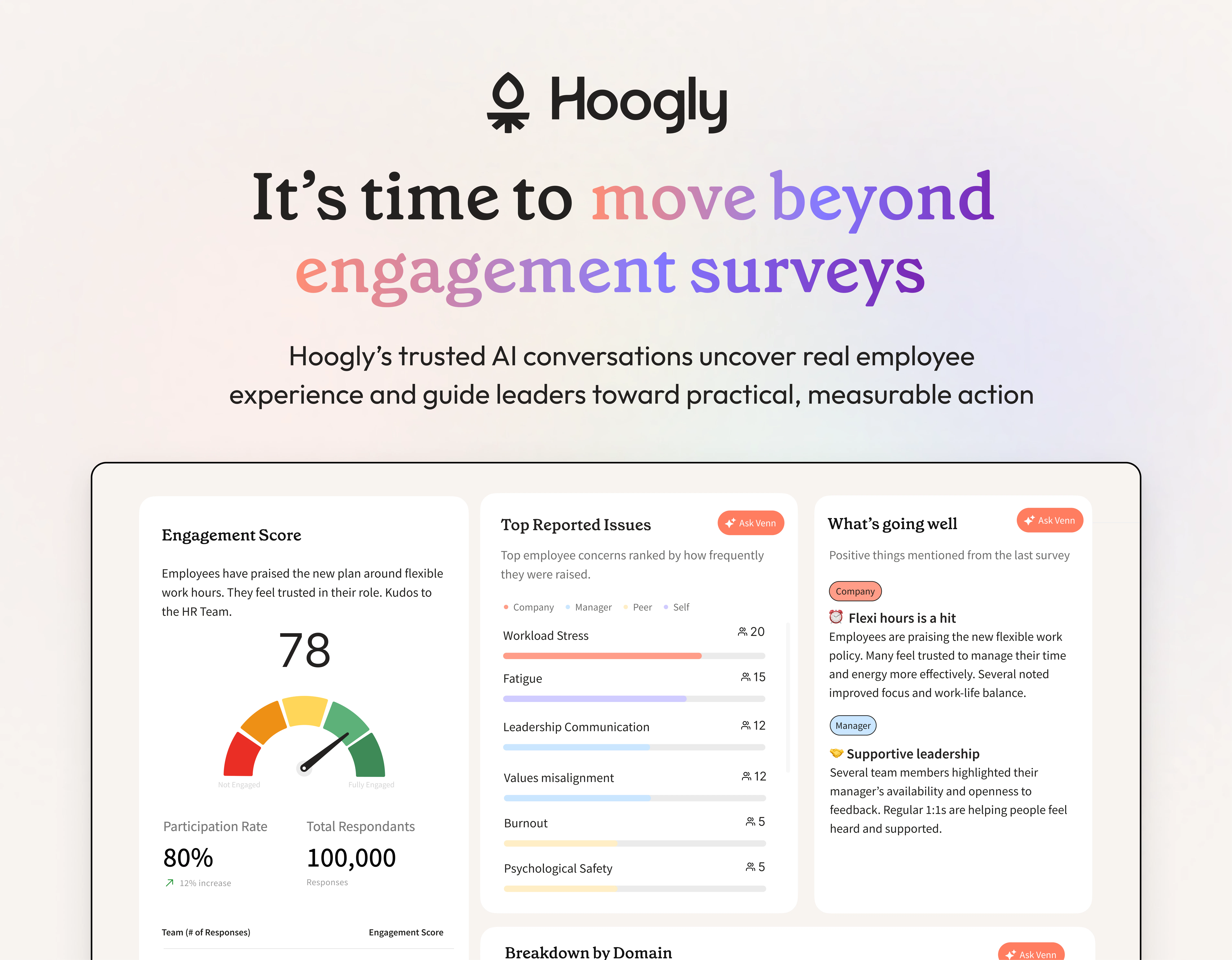
一句话介绍:Hoogly.ai利用AI驱动的保密对话替代传统员工调研,解决企业反馈收集后难以转化为管理者实际行动的痛点。
Human Resources
Pitch Singapore
AI驱动
员工体验
反馈管理
行动跟踪
匿名隐私
领导力教练
组织发展
HR科技
对话式调研
SaaS
用户评论摘要:用户肯定产品聚焦“后续行动”,指出调研反馈后缺乏跟进是行业通病;同时关切AI如何在保证员工匿名性(如隐藏个人信息)的同时,仍为管理层提供足够具体、可操作的洞察。
AI 锐评
Hoogly.ai的选品切中了企业HR领域“调研疲劳”与“行动瘫痪”之间的巨大鸿沟。传统问卷只是数据采集器,而Hoogly试图将闭环延伸到“建议-洞察-行动-跟进”的全链路,这比单纯做AI对话引擎高明一个段位,也是其获得早期用户“正名”的核心原因。
但必须清醒看到:89票对应的社区热度尚属早期,其价值真正成立的唯一标准是管理者是否会因为AI生成的“匿名又能落地”的洞察而改变决策。当前评论里关于“隐私vs可操作性”的质疑恰恰是最大的技术瓶颈——如果AI为了安全过度清洗数据,结果就是一堆正确的废话;如果不够模糊,又会沦为又一个打着AI旗号的监控工具。此外,将“行动”自动化为管理者推送动作建议很容易,但让管理者愿意执行并承担后果,这不是算法能解决的代际文化问题。产品目前更像一把补齐“漏斗末端”的锋利好刀,而企业变革这头大象,远不止一把刀就能撬动。
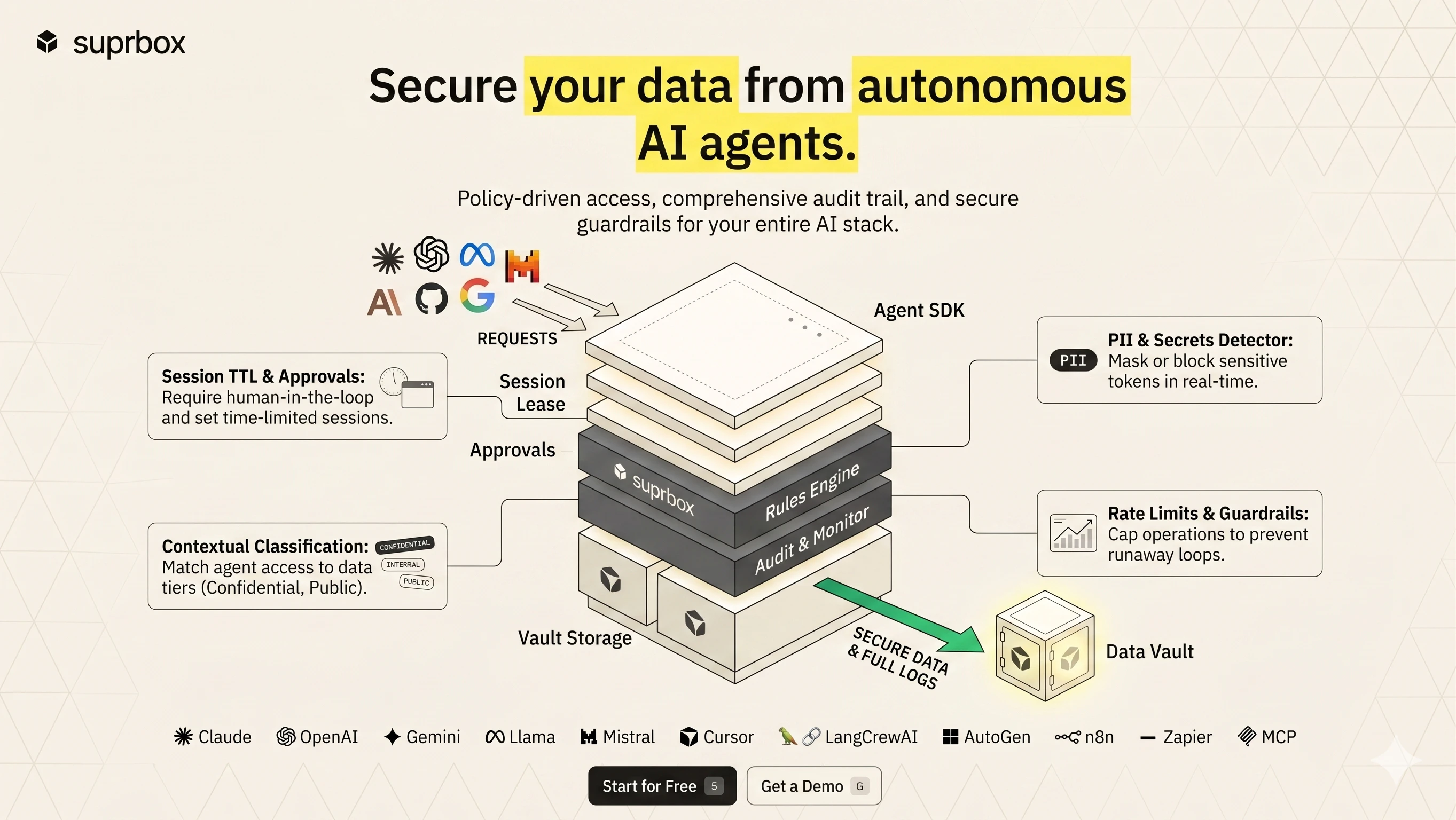
一句话介绍:Suprbox 是一个策略驱动的数据保险箱,专为使用AI智能体的团队设计,通过在存储层设置细粒度访问规则(如敏感度、时间、频率、人工审批),解决智能体误用或越狱后读取敏感企业数据(如薪资表、董事会备忘录)的泄露风险。
Storage
Artificial Intelligence
Security
AI代理数据安全
企业数据保险箱
策略网关
审计日志
访问控制
S3替代方案
敏感文档管理
AI安全基础设施
用户评论摘要:用户赞赏其针对自主AI代理的数据泄露场景切中痛点,并追问“人工审批”在执行中是否会暂停Agents流程(如通过Slack通知),还是仅针对特定文档类别预授权。另一评论关注其向大型企业推销时,如何应对复杂安全协议及获取有效客户线索。
AI 锐评
Suprbox的切入点聪明且务实:它不试图在提示词层面与AI对齐博弈,而是回归到数据存储的物理边界——政策门控。这本质上是一个带“规则引擎”的S3兼容存储层,其核心价值在于将安全控制从“不可解释的模型行为”转移到“可审计的基础设施策略”。创始人清醒地意识到,当自主Agents具备访问凭证后,一切提示词护栏都是沙堡,唯有对数据读取本身进行强制规则检查才是抗震的。
产品逻辑非常清晰:客户不是需要另一个“AI安全”噱头,而是需要一把能按“文档敏感度+时间+频率+人工”等多维规则自动上锁的保险箱,且每把锁的开启都要留下不可篡改的签名日志。这对于处理薪资、法律合同、内部备忘录的金融、法律、HR和R&D团队,是硬刚需。
但问题同样尖锐:在Agents持续异步运行的典型场景中,“人工审批”的门控如何不拖死工作流?是设计成“无敏感操作自动放行-高敏感操作进入异步审核队列”的微架构?还是像评论所问那样,会中断进程并ping Slack?此外,即便存储层正确,如果Agents能通过聚合多个低敏感文档推断出敏感信息(推理攻击),Suprbox能否感知?目前看,它更擅长阻止明文外泄而非语义推断。
商业化挑战也很现实:大企业的安全团队通常不相信SaaS自称的“零信任”,它们会要求私有化部署或硬件密钥。Suprbox若想从“车库神器”走向“CIO必备”,需要尽快证明它比S3 IAM+组织级DLP方案更简单、审计颗粒度更细,且能兼容已有合规框架(SOC2、HIPAA等)。目前86票算是圈内口碑开局,但要规模化,还需在“插拔式集成”和“策略模板化”上做足功夫。一句忠告:不要让自己变成另一个“需要人看守的保险箱”。
一句话介绍:Plouton AI 通过浏览器内的AI代理,直接在SAP、NetSuite、QuickBooks等财务系统中自动执行应付账款、对账和结账工作流,无需API集成,解决财务团队手工操作低效且难审计的痛点。
Pitch Singapore
AI代理
FinOps自动化
财务工作流
浏览器自动化
无API集成
对账
应付账款
审计追踪
人工审核
企业软件
用户评论摘要:创始人强调产品定位是交付结果而非仅给建议。用户关注点:如何精准触达FinOps目标客户;以及工作流回放审计时是实时屏幕录像还是日志记录。官方回复确认会录制并脱敏每一步操作的屏幕视频,以供复盘。
AI 锐评
Plouton AI 的“计算机使用”概念并不新鲜,本质上仍是RPA与AI的缝合体——通过浏览器模拟人类操作来执行财务流程。其核心卖点“无需API”是一把双刃剑:一方面降低了与老旧ERP系统的集成门槛,让财务团队能快速上手;但另一方面,依赖浏览器DOM解析的稳定性存疑,一旦SAP或QuickBooks更新UI布局,工作流就可能中断,这正是传统RPA厂商多年来未能根治的顽疾。
产品的真正价值在于“可回放审计”和“人工审核”的设计——在财务合规这个敏感领域,黑盒自动化会引发信任危机。通过记录屏幕录像并提供人工介入节点,Plouton实际上在贩卖“可控的自动化幻觉”,而非真正的AI决策。对于中小企业的重复性对账、凭证录入等低价值劳动,这无疑是效率工具;但对于大型企业的核心财务链路,完全依赖浏览器代理跑关键流水,风险管控不足。
80多票的反馈量说明它仍处于早期概念验证阶段。创始人的坦诚值得肯定,但“用自然语言描述工作流并端到端执行”的愿景,距离真正颠覆FinOps还很遥远。目前更现实的定位是:一个带审计尾巴的脚本录制工具,而非智能体。
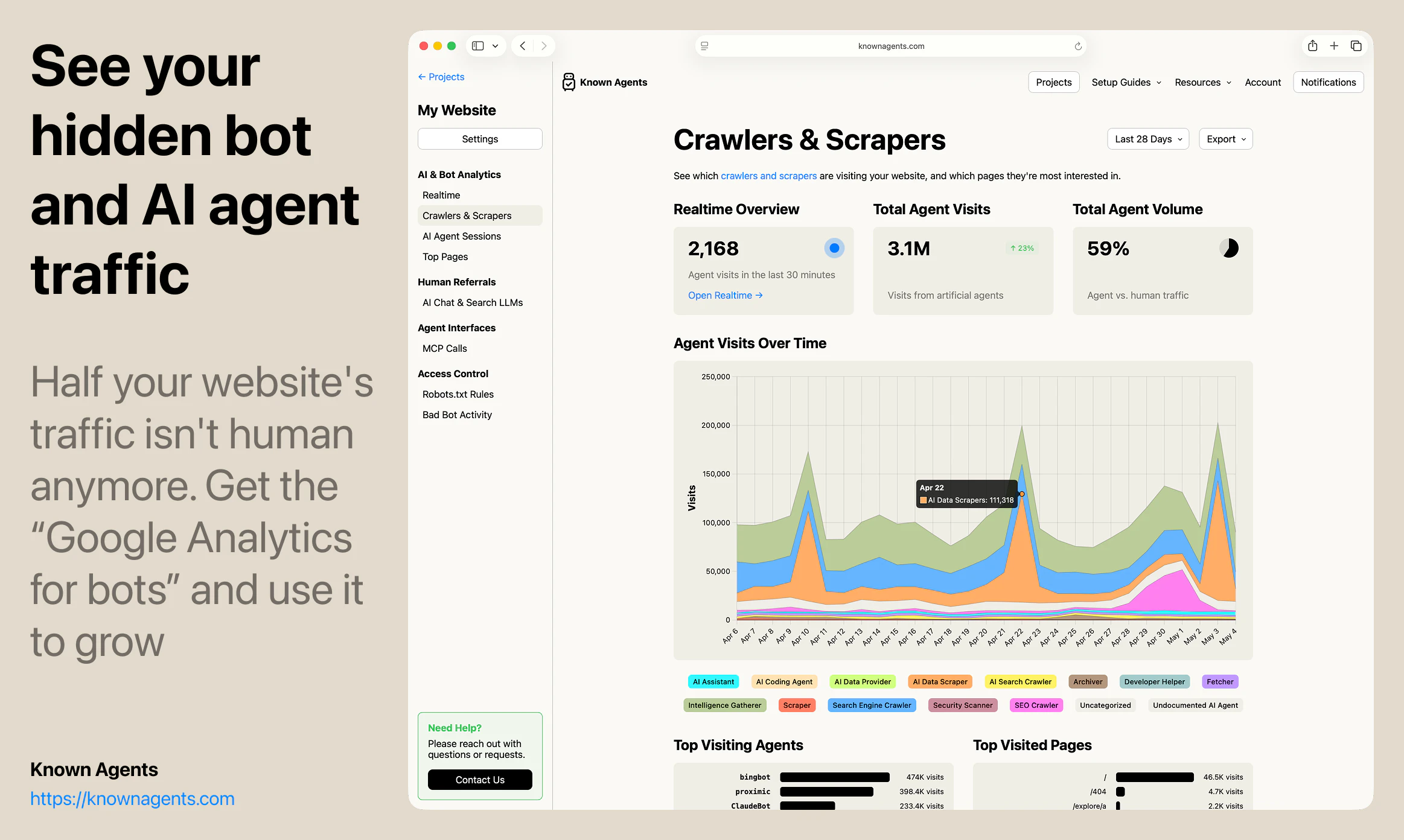
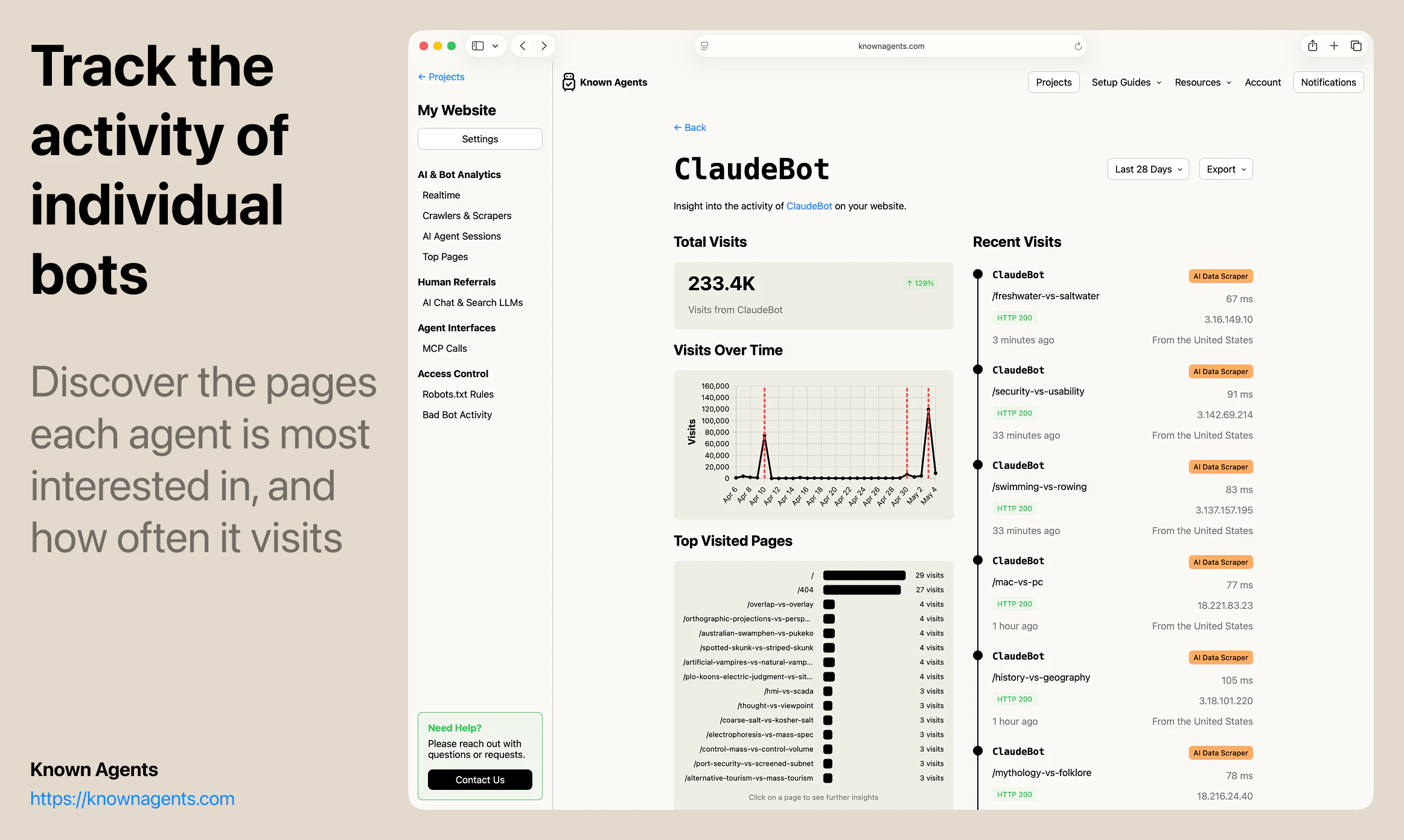
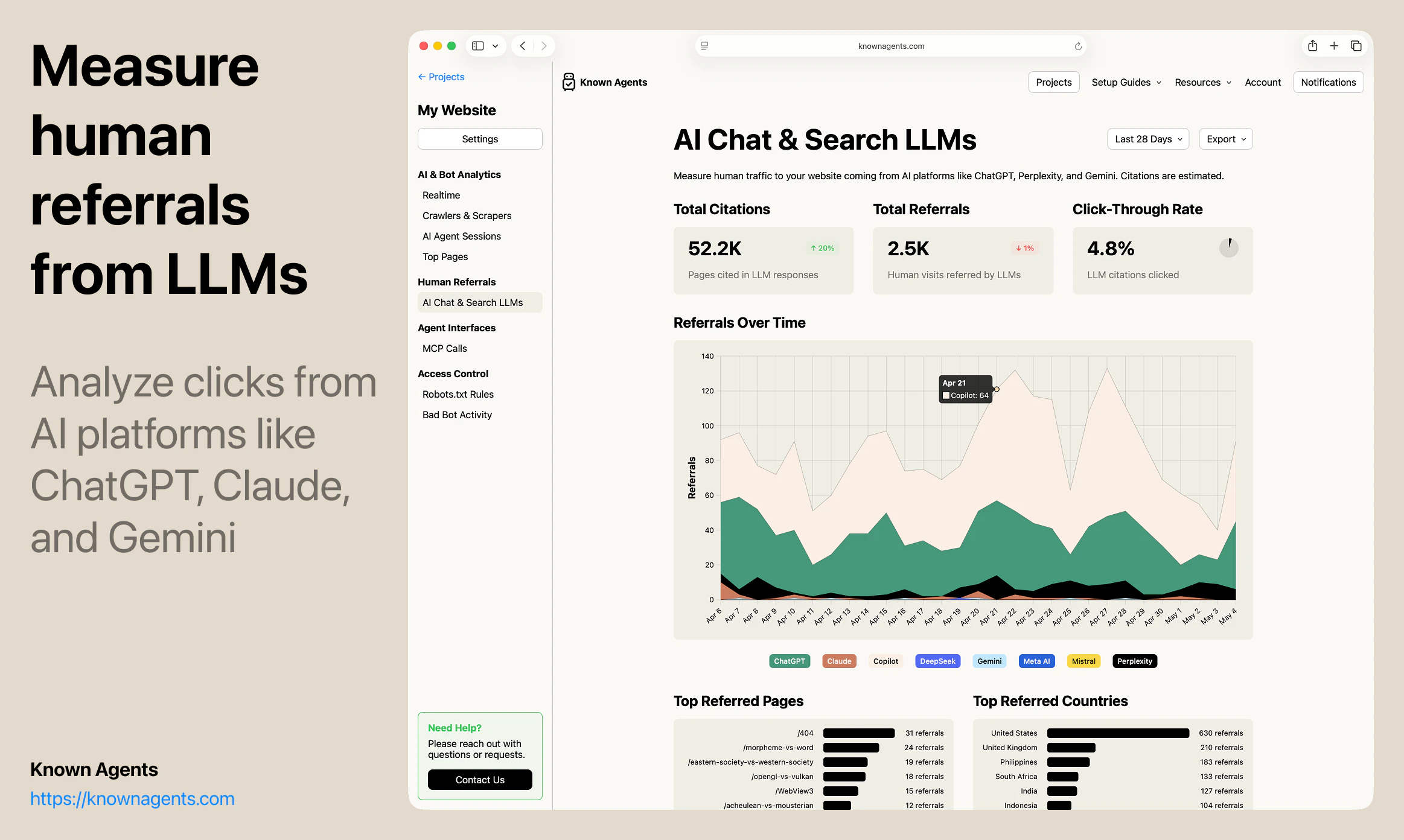
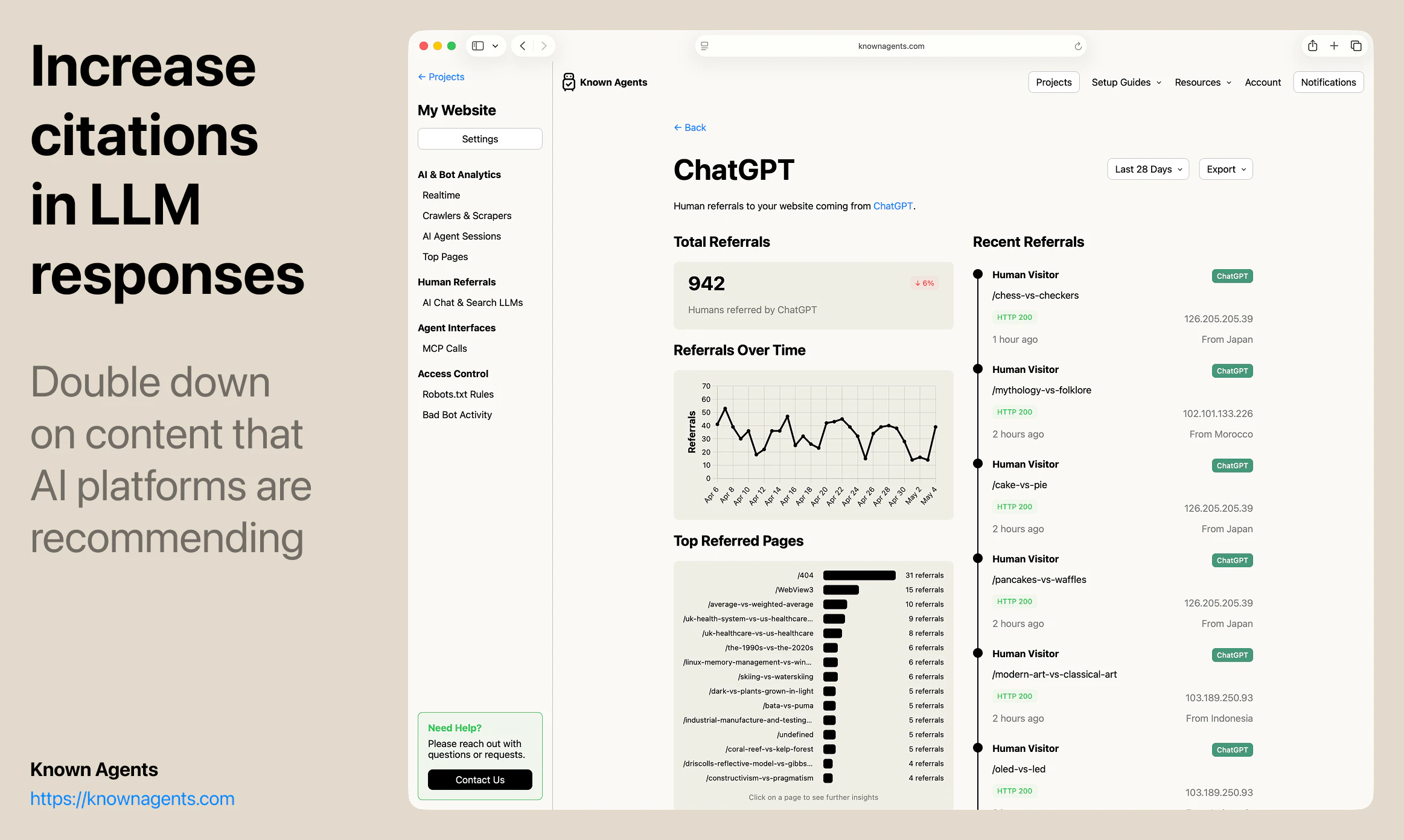
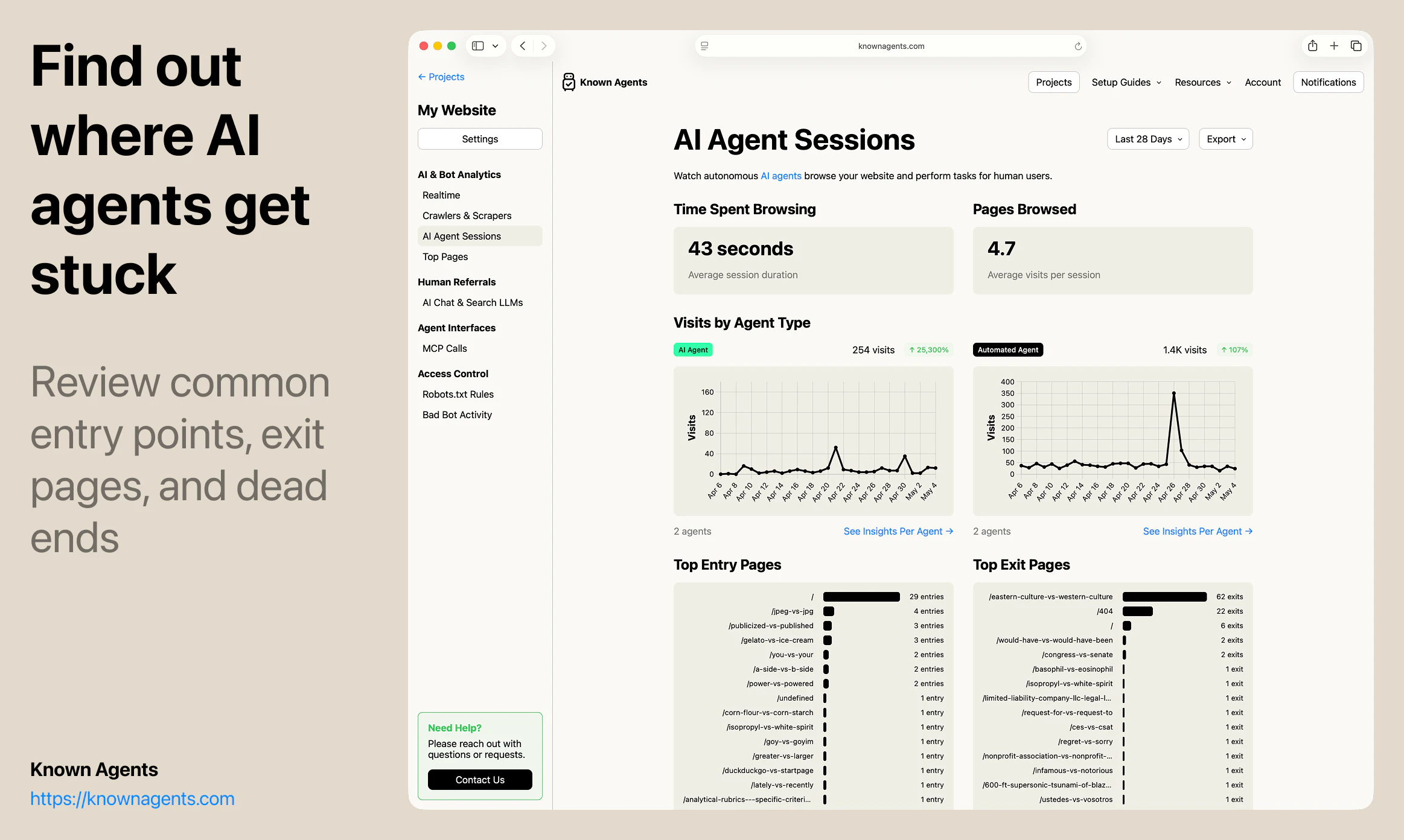
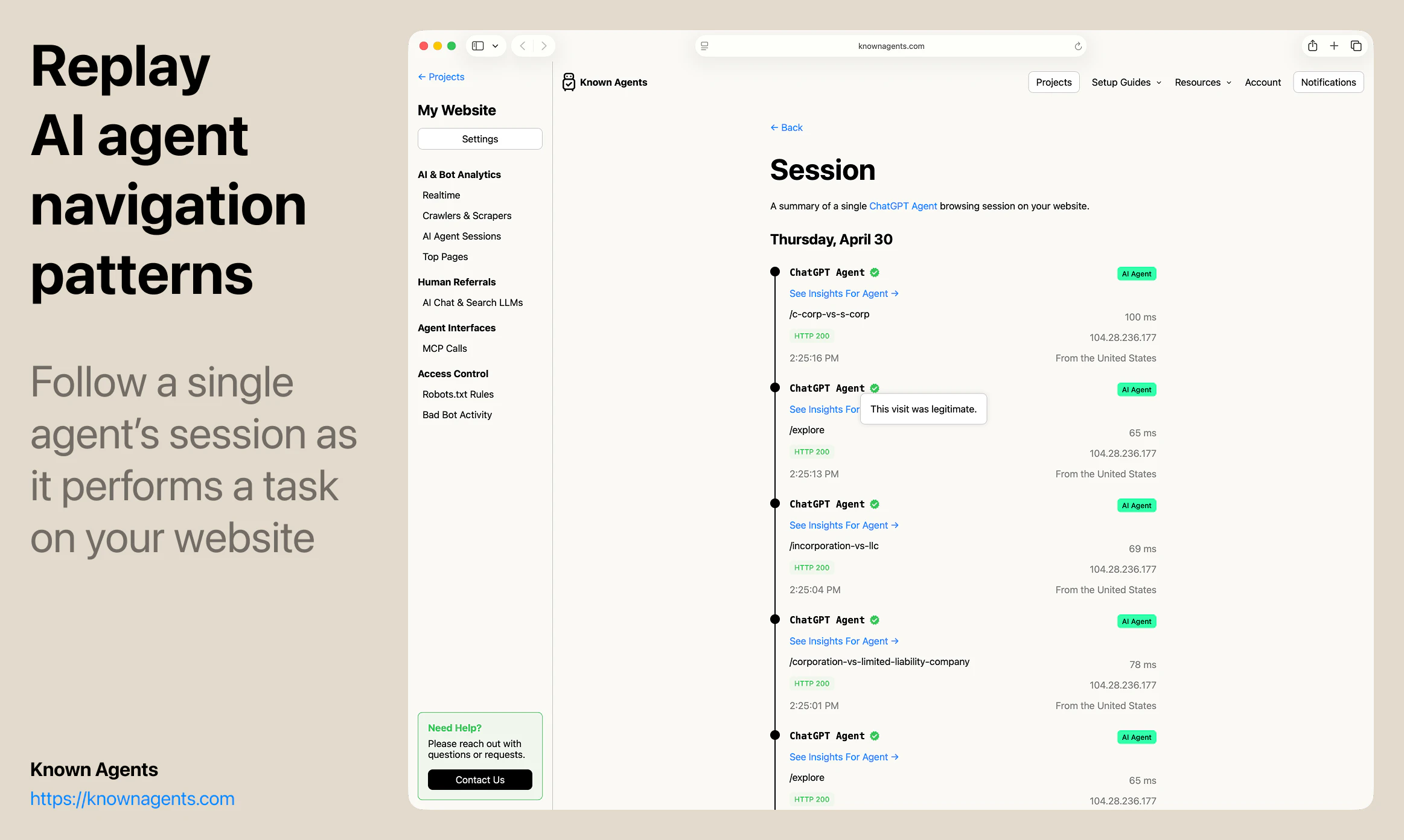
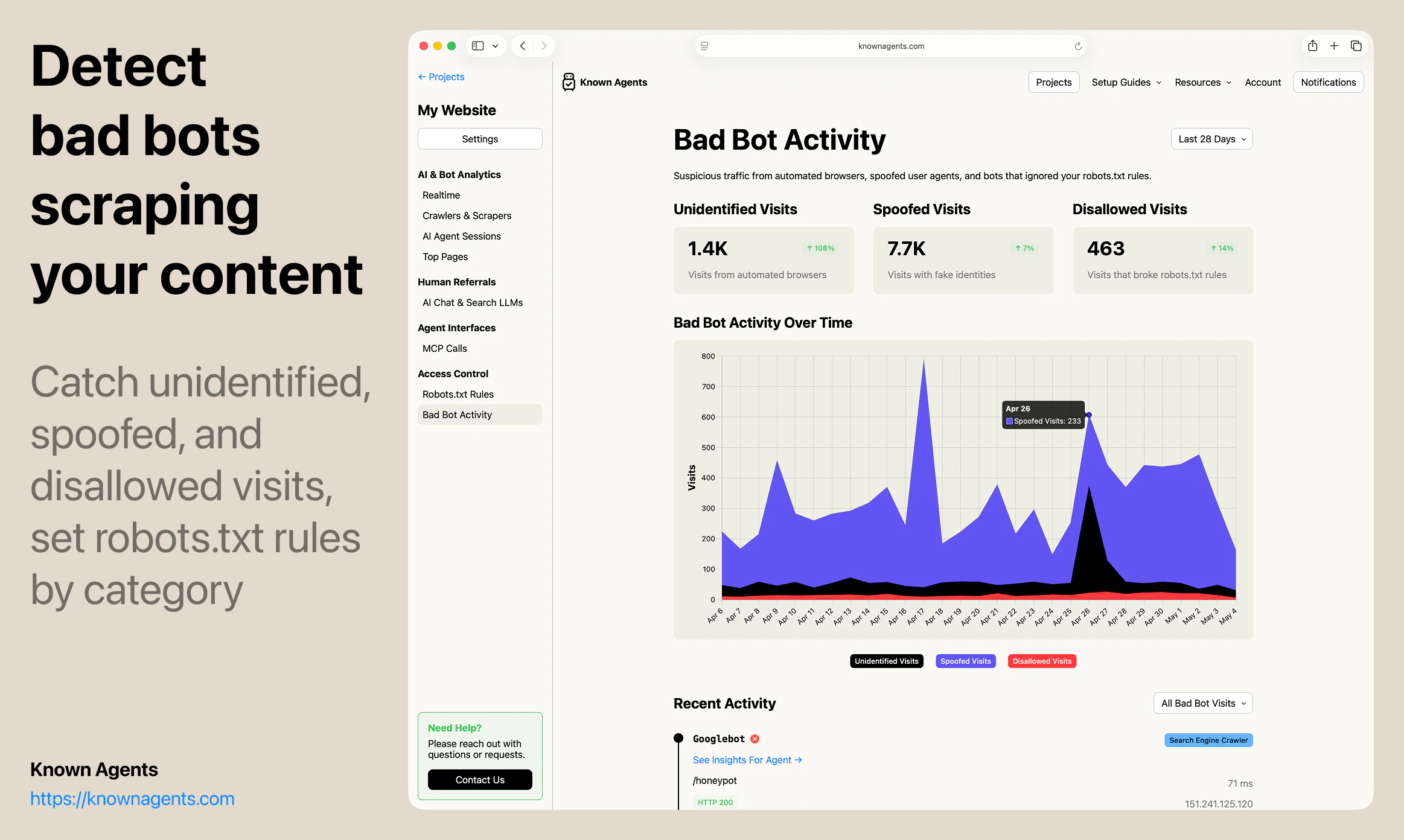
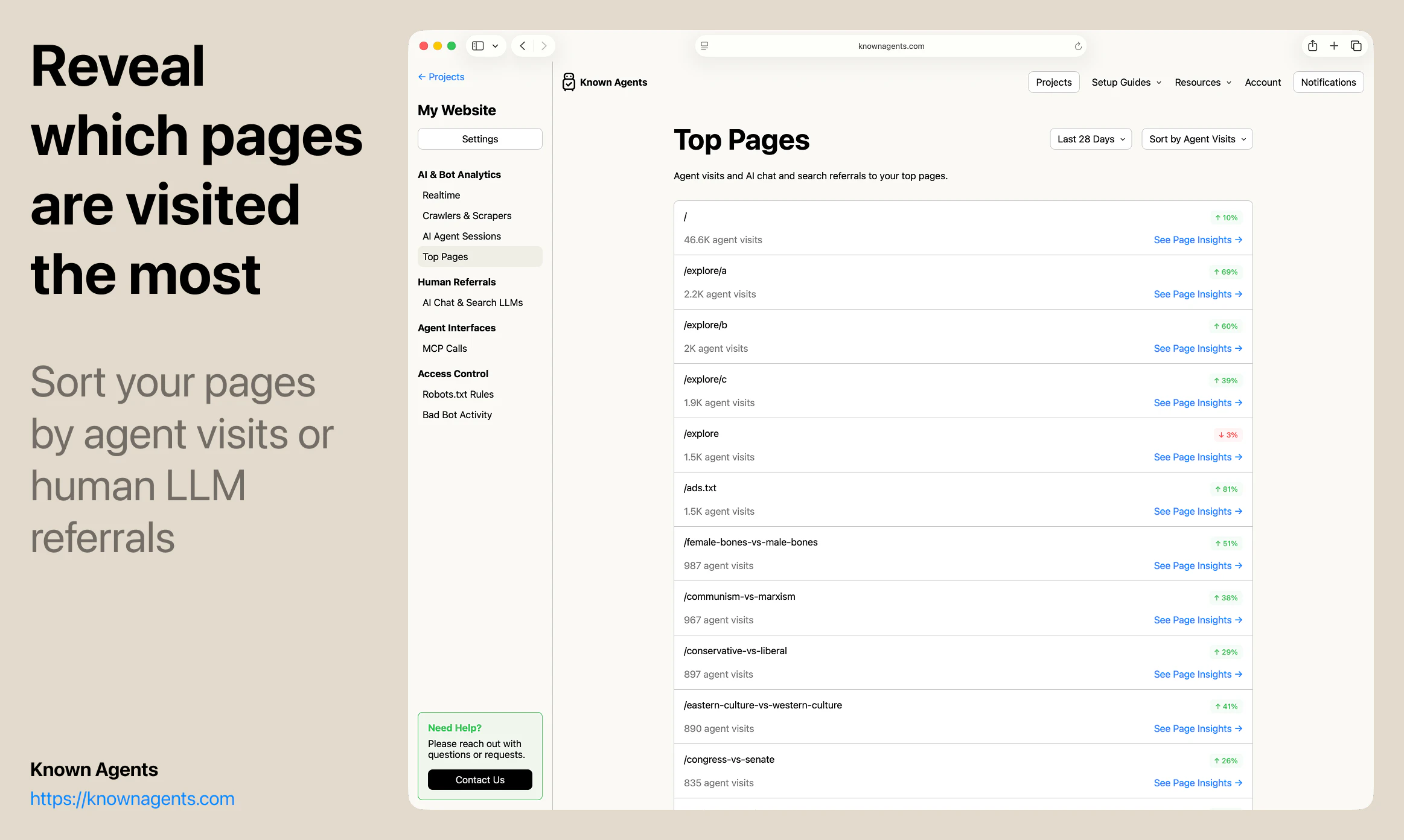
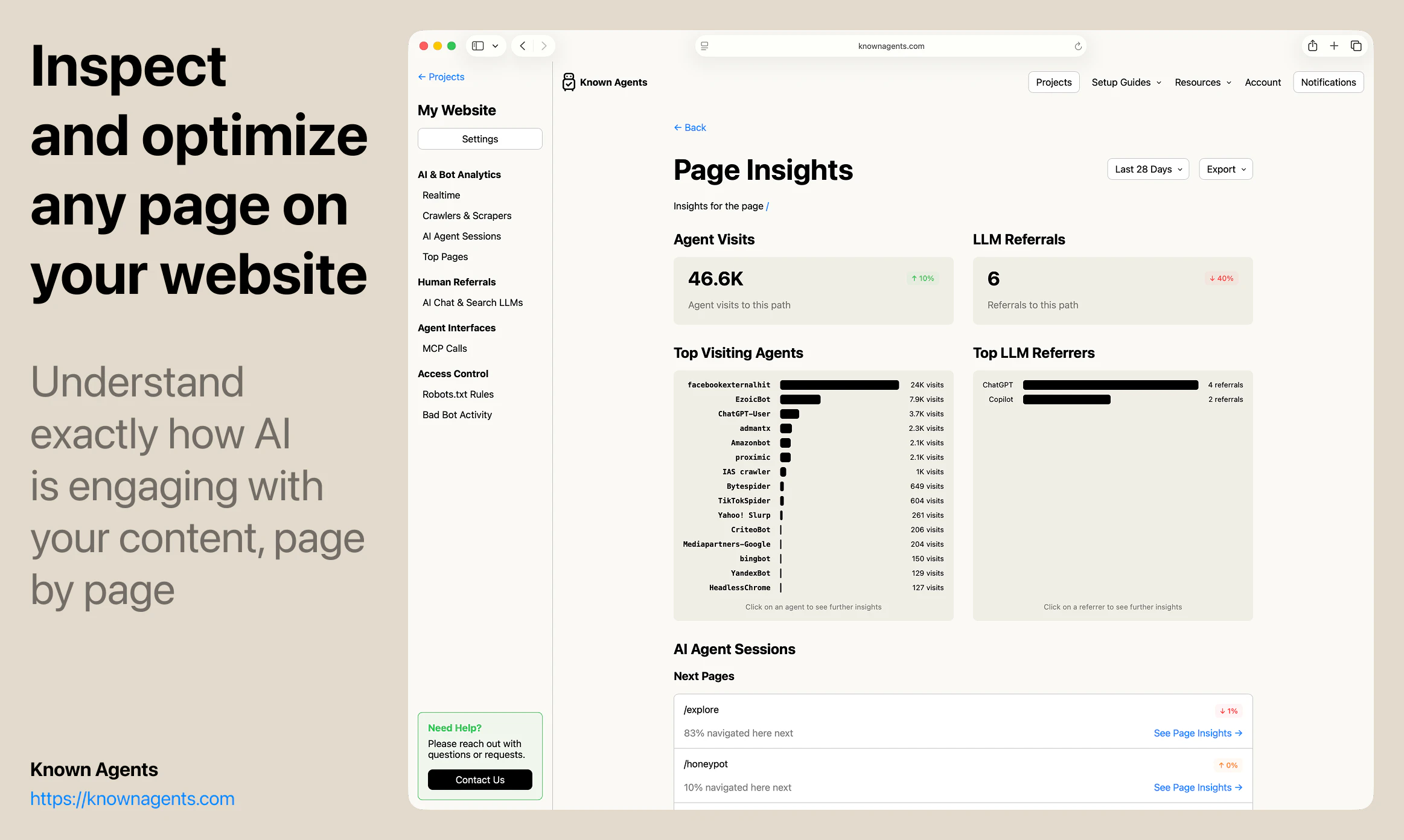
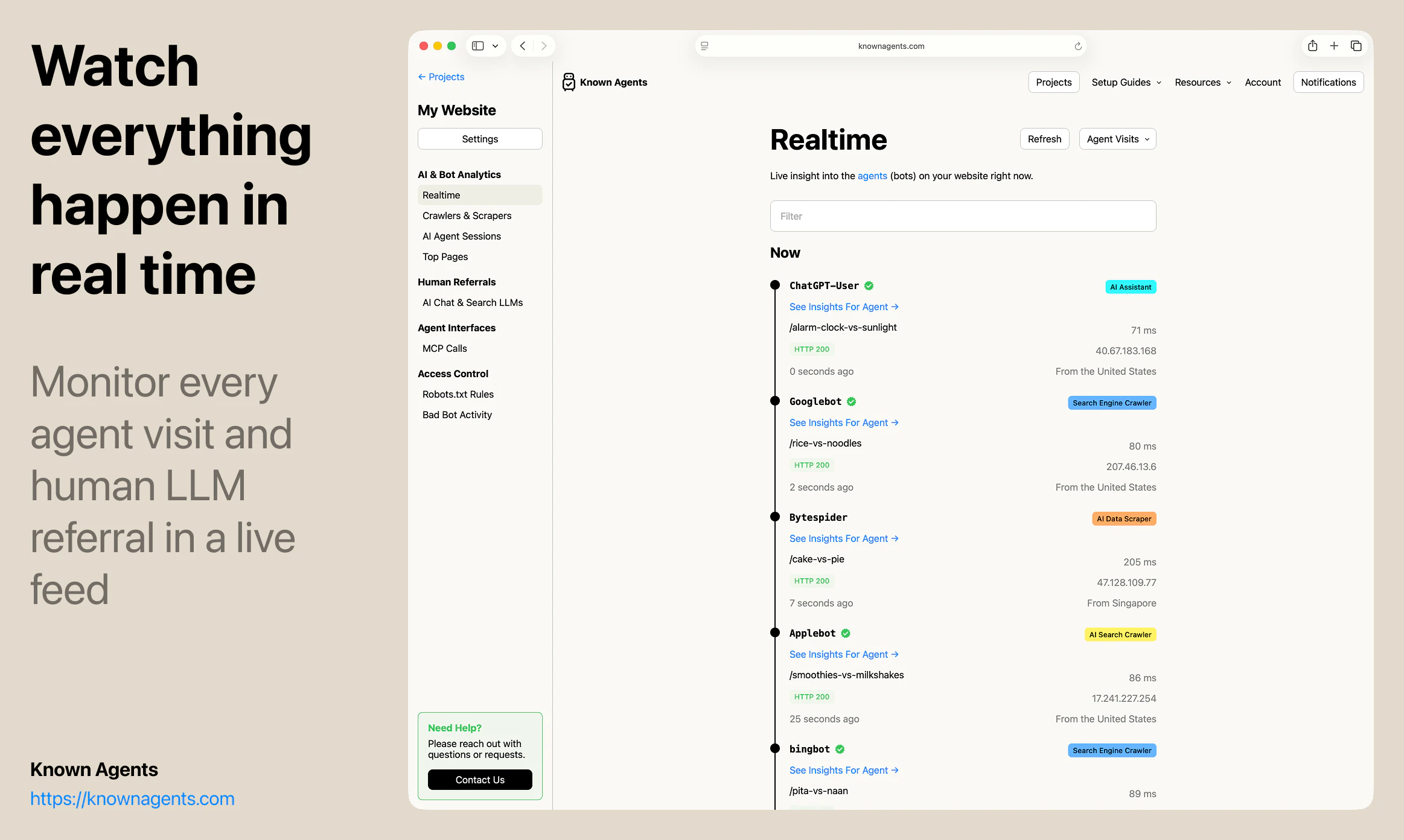
一句话介绍:Known Agents 是一款为网站设计的“机器人版Google Analytics”,帮助站长实时追踪AI代理、爬虫和抓取工具的访问行为,解决传统分析工具忽视非人类流量、导致企业对AI用户行为完全盲区的痛点。
Analytics
Artificial Intelligence
Bots
AI代理追踪
机器人流量分析
网站监控
爬虫识别
LLM引荐来源
代理体验优化
实时数据面板
SEO/AEO
内容安全
企业级分析
用户评论摘要:用户普遍认可其价值,主要关注:如何用数据指导行动(如屏蔽、优化或监控);LLM引荐来源跟踪对SEO/AEO的启发;代理商购受阻时如何优化UI;以及能否帮助设计更好的“代理体验”(AX)。也有用户询问获客策略,需教育市场。
AI 锐评
Known Agents切入了一个“所有人都知道存在、但没人认真量化”的盲区——AI代理流量。其核心洞察是:当互联网流量中近半数来自非人类实体,传统分析工具(如Google Analytics)的“用户画像”已彻底失真。产品以“LLM引荐来源”为差异化卖点,直接回应了GEO(生成引擎优化)这一新兴需求,让企业能像优化搜索引擎排名一样优化在AI对话中的曝光。
但产品目前的价值更多停留在“认知层”——告诉用户有多少Agent来了,看了什么页,来自哪个AI平台。真正的护城河在“执行层”:如何将数据转化为可操作的规则(如动态调整robots.txt),如何识别恶意爬虫与合法采购代理人(例如OpenAI的BingBot vs. Claude的Browser Agent),以及如何从“被动监控”跃迁到“主动引导代理完成转化”。团队提到的“代理会话回放”功能方向正确,但若仅停留在回放而不提供智能建议(如“该页面83%的代理在此放弃,建议简化表单”),就难逃“漂亮仪表盘”的工具宿命。
此外,商业模式隐含风险:多数网站无需付费,意味着客户粘性来自于免费用户的“数据控制感”,而非即期收入。而真正高价值的企业(如电商、内容平台)可能需要更细粒度的防火墙集成与API支持。如果仅作为“监控工具”存在,被云服务商(如Cloudflare、AWS WAF)原生集成将是时间问题。能否抓住窗口期,将监控升级为“代理流量操作系统”或“AX优化引擎”,决定了该项目是昙花一现的垂直工具,还是下一代互联网基础设施的组成部分。
一句话介绍:Needle结合AI自动化与人工审核,为电商品牌提供从活动策划到广告/邮件素材生成的一站式营销服务,替代传统代理商的繁琐流程。
Pitch Singapore
AI营销
电商自动化
广告素材生成
邮件营销
人工审核
Shopify
SaaS
活动策划
增长工具
营销代理替代
用户评论摘要:用户主要关心产品是否仅针对Shopify/电商品牌,以及除Meta外是否支持Google Ads、TikTok等渠道获客,暗示需求多样性与跨平台兼容性。
AI 锐评
Needle切中了一个真实的痛点:电商品牌在预算有限时,常困于“外包贵、自建慢”的营销困境。它试图用“AI+人工审查”的混合模式,在效率与质量间找平衡,比起纯AI工具更可信,比传统代理更灵活。但产品价值的关键在于“人工审查”的深度与成本——如果只是低效校对,就只是伪创新。评论中用户聚焦Shopify和Meta外的渠道支持,暴露了其当前可能过于依赖单一生态的局限。真正的硬核价值应体现在:能否打通多渠道(如TikTok、Google)并自动适配不同平台的素材规范,以及AI策划能否真正理解“转化率驱动”而非堆砌创意。对于订阅SaaS品牌,其“电商”标签可能成为障碍,除非它能把邮件自动化能力抽象成通用的增长引擎。总体而言,这是一个方向正确的工具,但尚未展现出颠覆性壁垒,需警惕沦为“平庸的模板工厂”。
一句话介绍:onBeacon是一款AI增长产品经理工具,能在几分钟内基于230+行为科学原则分析用户流程并提供可测试的A/B变体,帮助团队快速提升留存和转化,解决传统增长实验周期长、效果难以量化的痛点。
User Experience
Artificial Intelligence
Pitch Singapore
AI增长产品经理
行为科学分析
A/B测试生成
用户留存优化
产品增长工具
实验自动化
用户流失预警
SaaS工具
数据驱动增长
产品优化
用户评论摘要:用户关注行为科学原则是否根据产品类别(如电商vs教育)加权,开发者回应权重取決于产品上下文和目标。另一用户询问变更优先级,开发者区分了“速赢项”和“战略建议”。整体评论认可概念,但对分发策略和普适性有疑虑。
AI 锐评
onBeacon的定位非常精准——它试图用AI取代传统增长团队“研究-设计-实验”的低效循环,直接输出可落地的A/B变体。其核心卖点“230+行为科学原则”和“2.3倍留存提升”的数据极具吸引力,但真正的价值并非算法本身,而是将心理学洞察与产品流程自动匹配的能力,这比通用增长工具更贴近“PM思维”。
然而,必须冷静看待几个现实问题:第一,行为科学原则的应用高度依赖产品上下文——同样“损失厌恶”在电商和医疗SaaS中的权重天差地别,虽然开发者声称会按上下文加权,但初期缺乏足够训练数据时,效果可能只是“精心包装的通用建议”;第二,A/B变体“即时生成”听起来很美,但实际落地需要技术对接、数据埋点和实验平台,若产品本身基础设施薄弱,这些“分钟级方案”反而会成为新瓶颈;第三,团队背景(Siri、AdWords)是优势,但大厂经验未必能直接移植到中小团队——后者更需要的是“教它如何理解自身业务逻辑”,而非“直接给答案”。
真正的壁垒在于其“知识库”能否随着实验积累形成飞轮效应。如果像Figma那样让用户贡献行为数据反哺模型,onBeacon有望成为增长团队的“第二大脑”;若只是静态规则引擎,最终难免沦为“更贵的A/B测试工具”。当下版本更建议作为“诊断雷达”使用——用其发现用户流失的关键节点,再结合团队自身判断做决策,而非盲目全盘采纳。
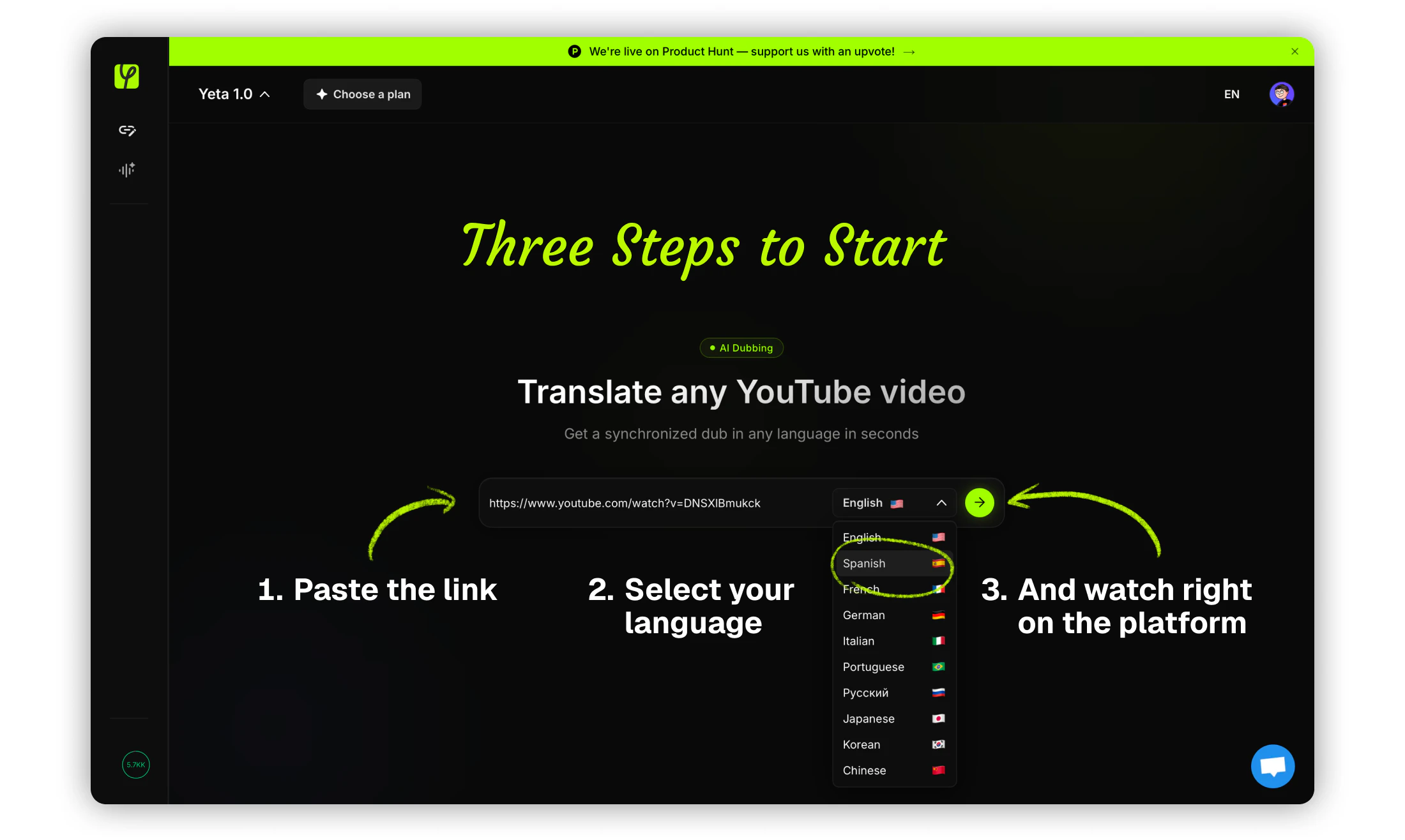
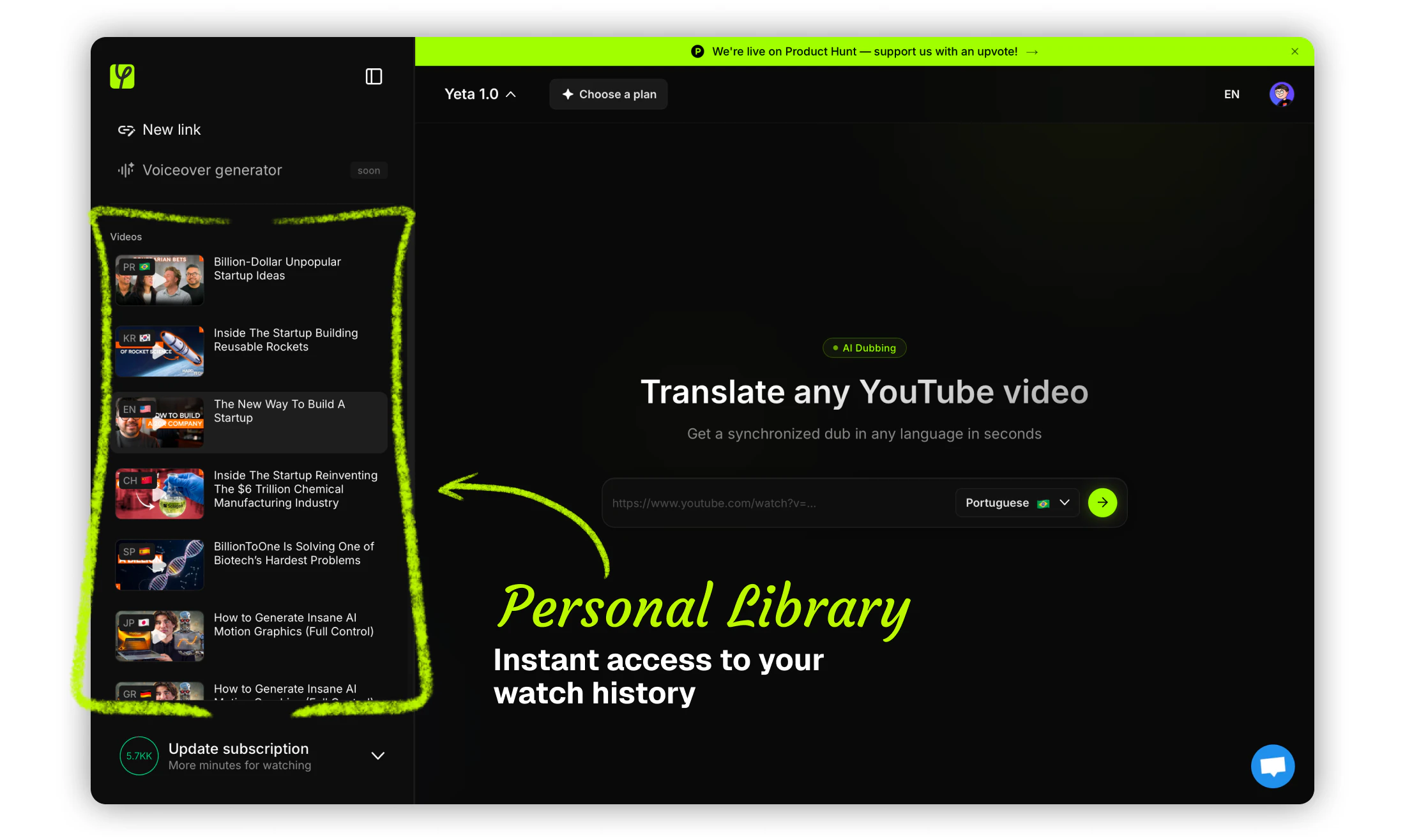
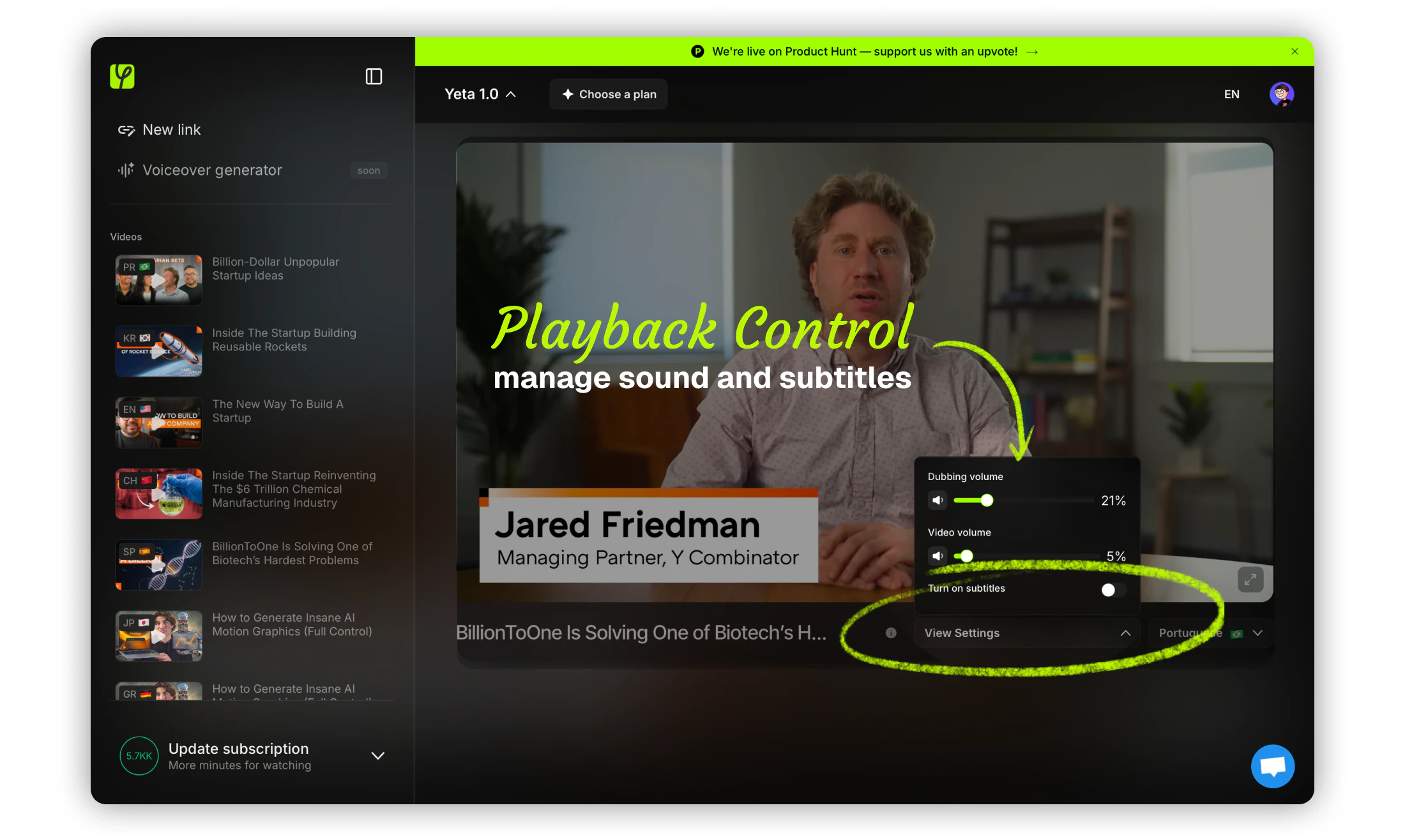
一句话介绍:Yeta AI让用户只需粘贴YouTube链接、选择语言,即可实时将视频自动配音成目标语言,解决了学习或观看外语优质内容时“字幕费眼、等待漫长”的痛点。
Productivity
Artificial Intelligence
Video
AI实时配音
YouTube视频翻译
多语言配音
海外内容本地化
在线学习工具
创作者工具
无代码
语言障碍消除
实时音频流处理
免费试用
用户评论摘要:用户认可其“实时性”和“即贴即用”的便利性,尤其对教育内容全球分发价值表示期待。关键追问包括:分发策略、与YouTube自带配音的差异、以及实时配音的技术实现(是流式处理还是预计算缓存)。
AI 锐评
Yeta AI切入了一个明确且高频的痛点:语言屏障导致优质教育和娱乐内容的浪费。从产品介绍和评论来看,其核心壁垒在于“实时性”——宣称30-60秒启动、流式缓冲处理,这比传统上传等待几小时的任务式配音体验提升了一个量级。创始人强调“零VC、自发型团队创业”虽然情感上引人共鸣,但也暴露出前期冷启动和商业化压力。
**价值所在:** 这款产品本质上是“内容本地化的实时翻译器”,而非简单的字幕工具。它让用户从“被动阅读”转为“主动视听”,尤其对教学类、科技类、财经分析等高价值长内容有奇效。评论中那位做可再生能源金融建模的博主就点出了核心:它把“成本高昂的多语言版本制作”变成了零门槛的即时需求满足。
**潜在风险:** 第一,语音质量和同步准确性是“一票否决”的关键。若出现音画错位、AI语气生硬、专业术语翻译错误,用户信任会迅速崩塌,目前无数据支撑长期效果。第二,商业模式高度依赖YouTube平台生态,如果谷歌收紧API政策或推出更强大的内置配音,Yeta将面临“天花板式”竞争。第三,产品目前仅限桌面端,移动端尚在开发,而海外用户视频消费正快速转向手机,这是一个时间窗口上的软肋。
**锐评总结:** Yeta AI抓住了一个真实且刚需的“小而美”切口,用技术极简主义降低了全球化内容消费门槛。但它需要尽快证明自己在高负载下的配音质量、建立用户UGC案例库,并探索与内容创作者的付费分成模式,否则极易沦为“好用但无法赚钱的工具”,或者被大平台功能吞噬。
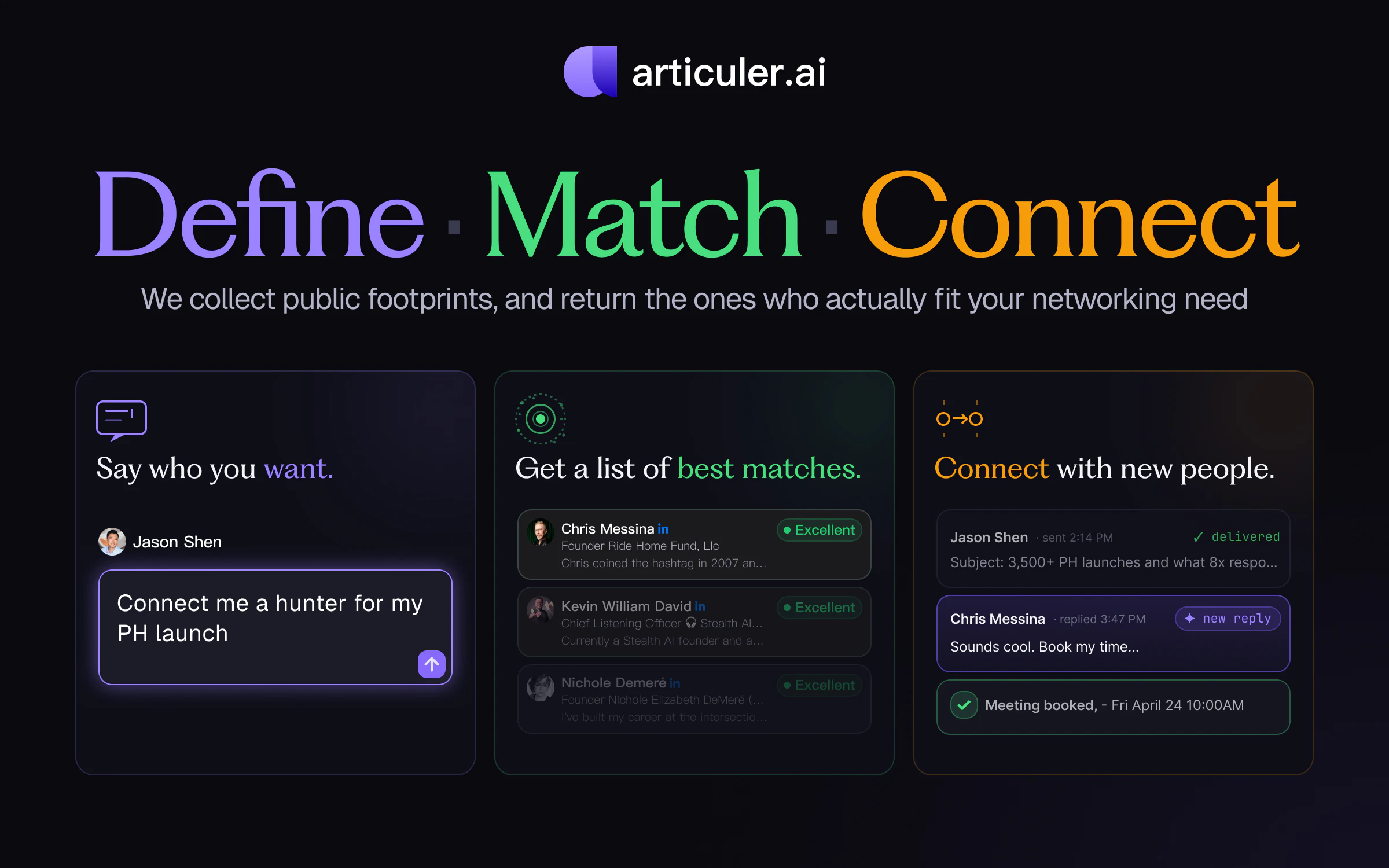
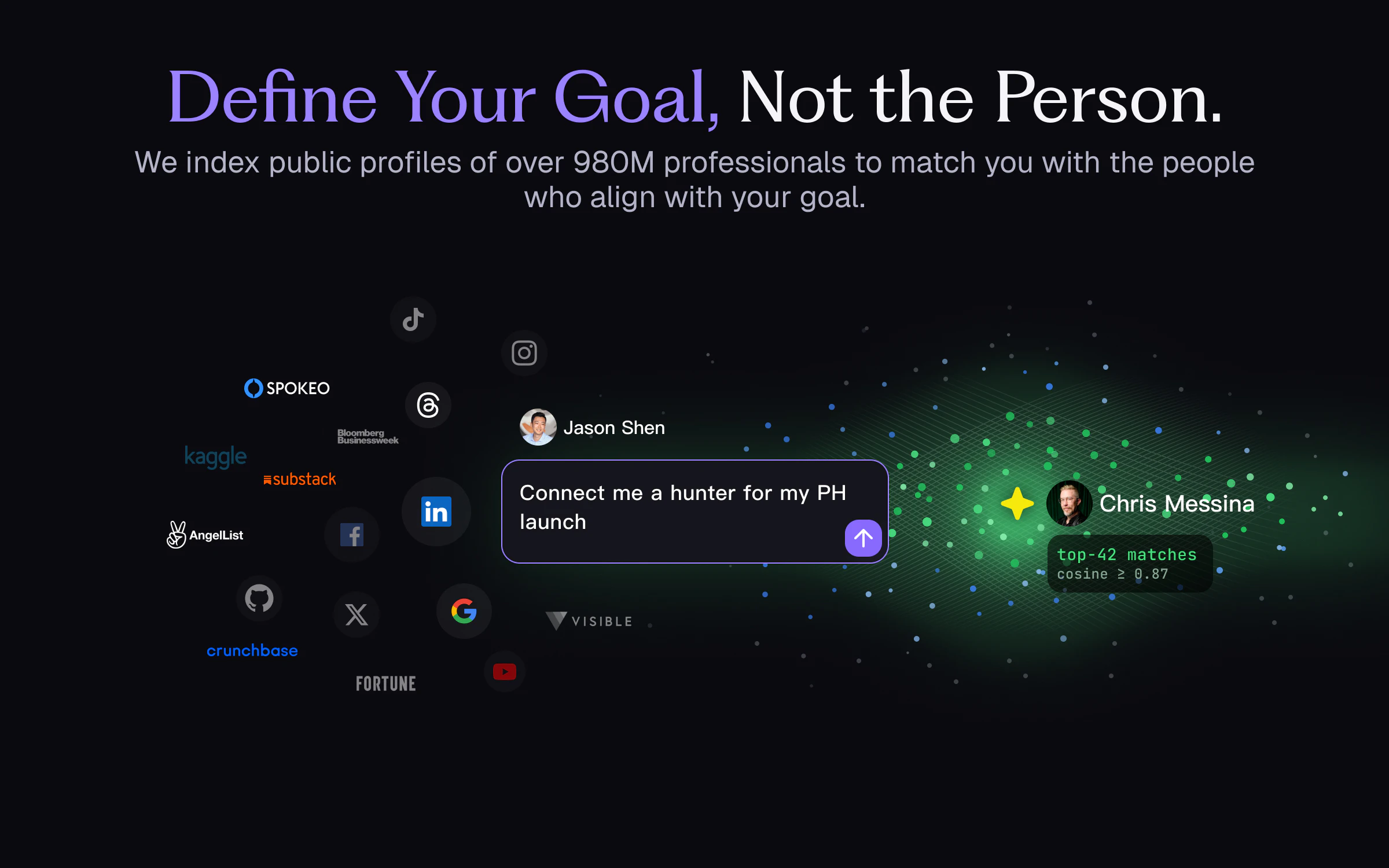
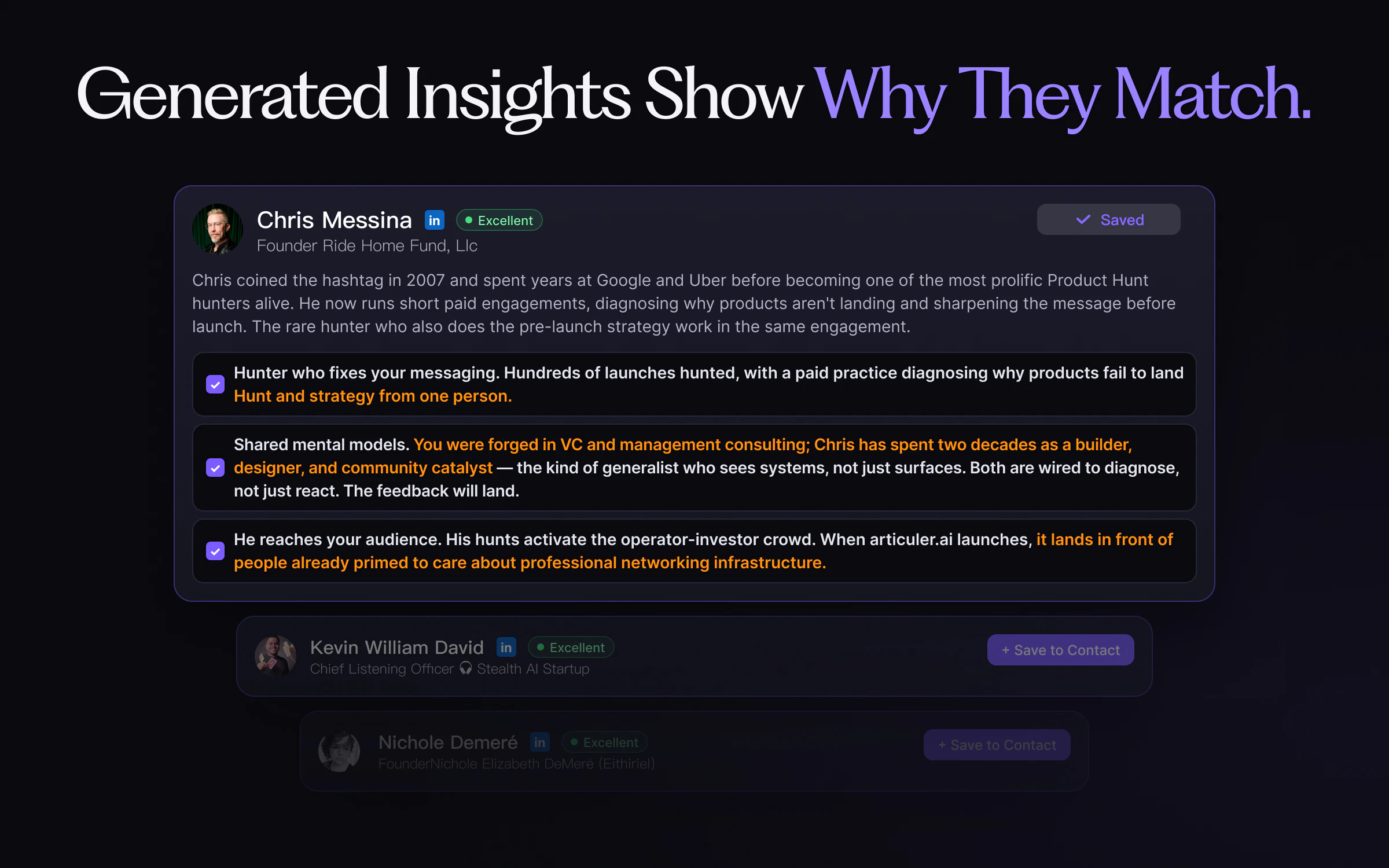
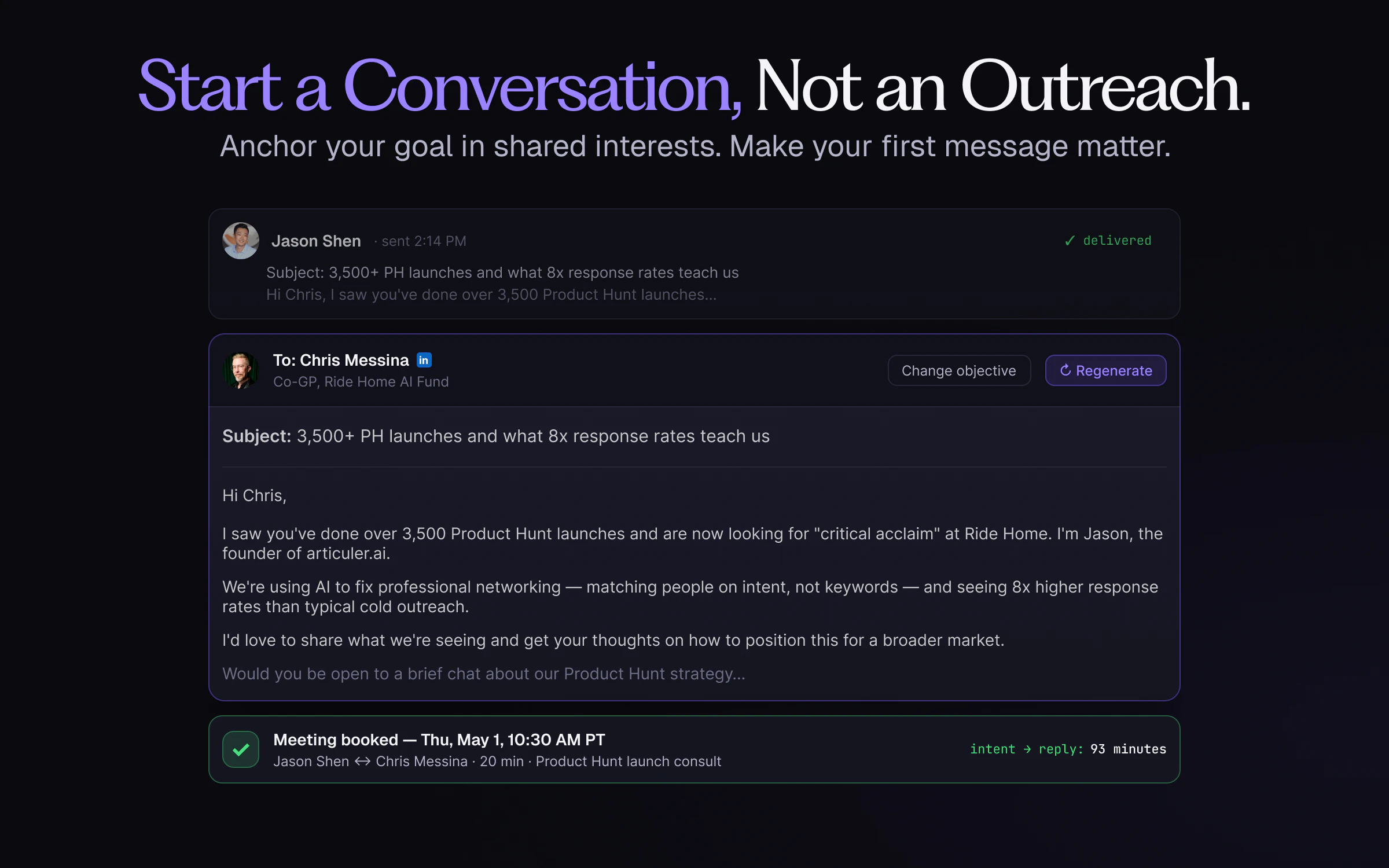
































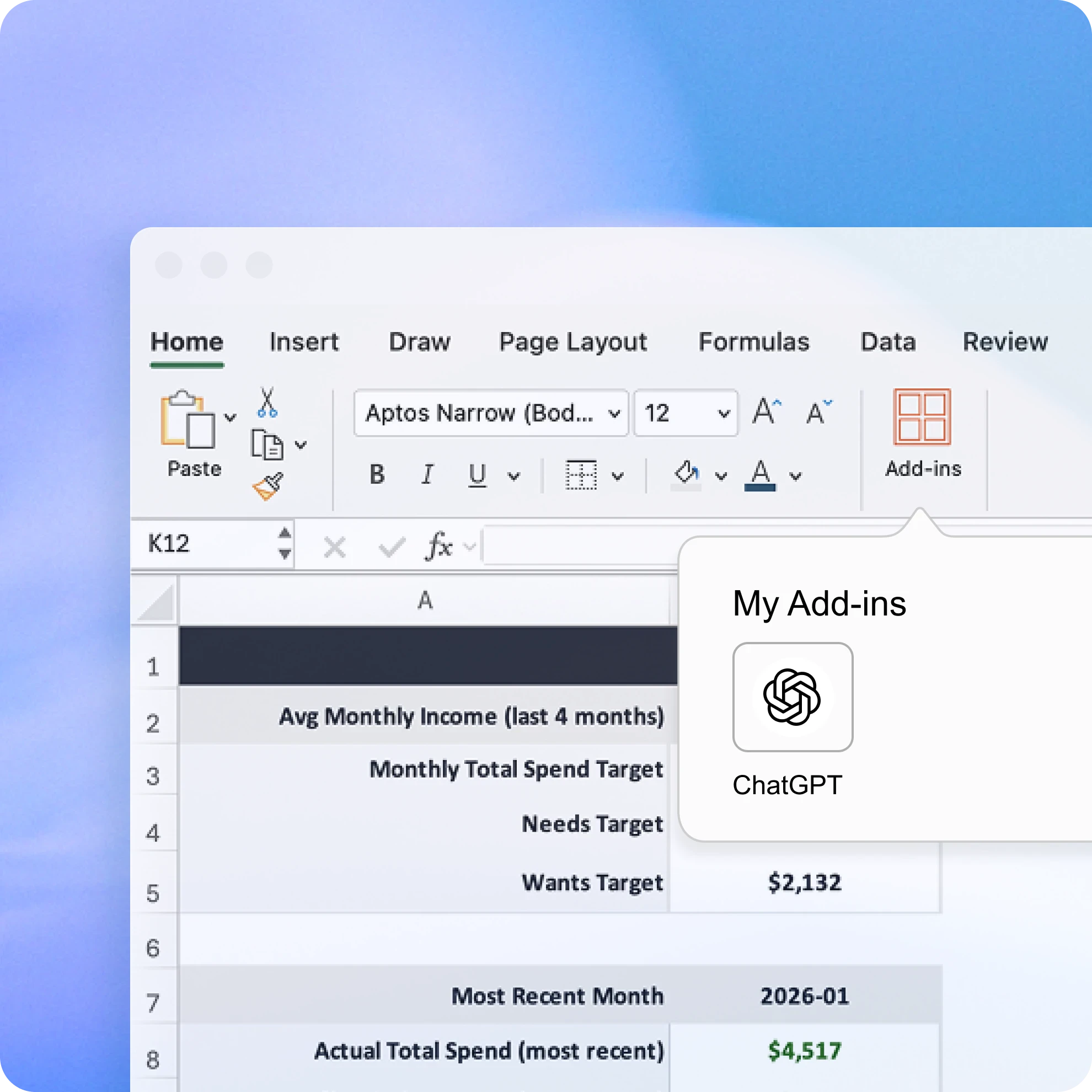
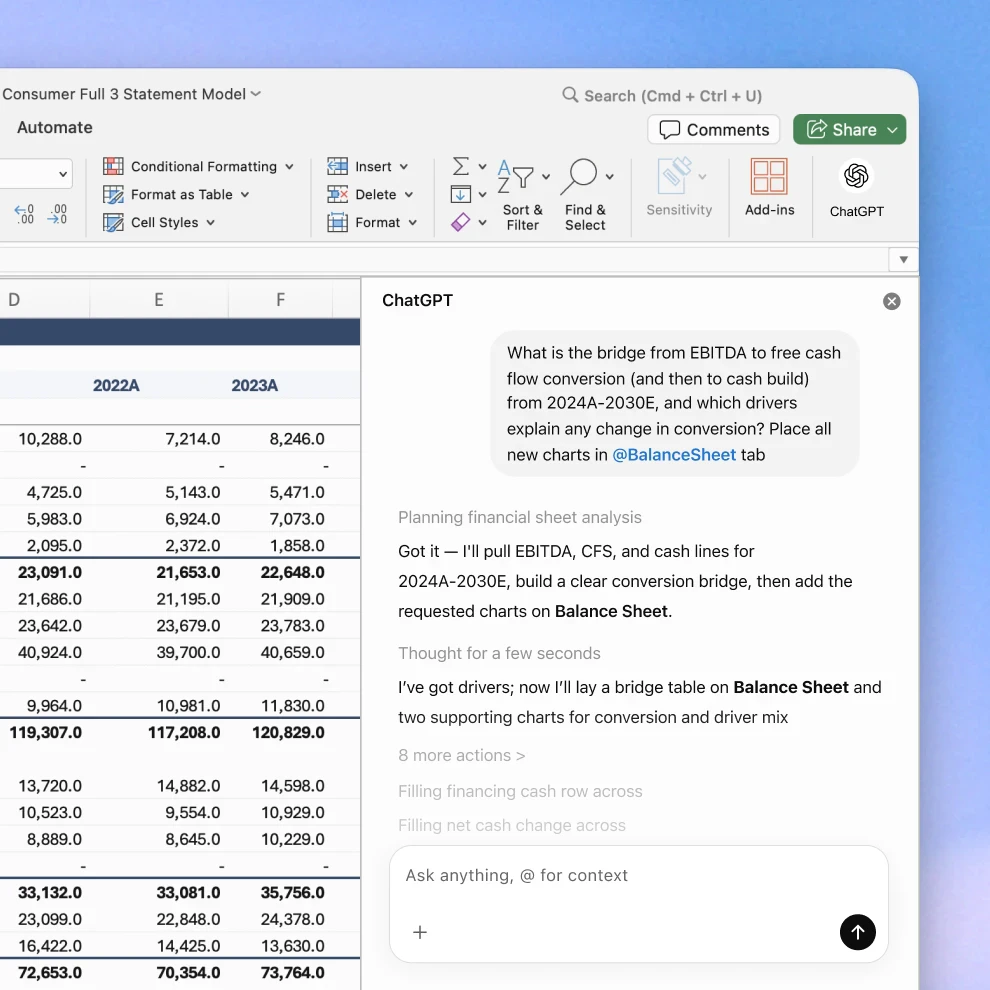








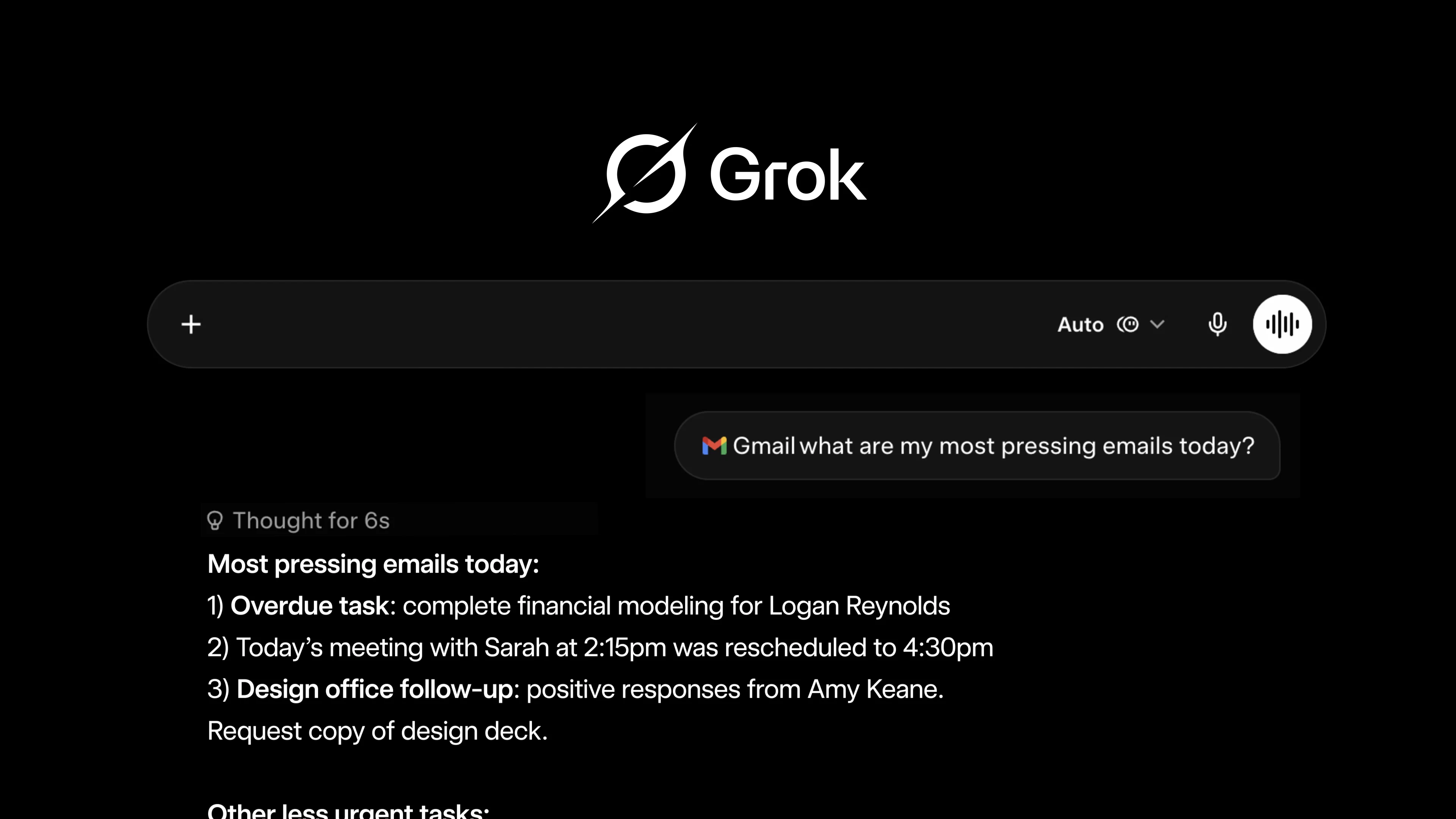











Hey Product Hunt 👋
I'm Jason, CEO of Articuler.ai. Before this, I was a VC — and the hardest part of the job was never closing the deal. It was finding the right person in the first place.
LinkedIn works like the Yellow Pages: you have to already know who you're looking for. That's broken.
Articuler.ai matches on intent, not keywords.
Describe what you need in plain language — e.g., "early-stage consumer AI investors who wrote checks recently."
We match across 980M public profiles and surface the people who actually fit.
Playbook decodes them. For every match, we read their public footprint and tell you what they care about, how they think — and the things you should never say. ("Don't ask Chris Messina to be your hunter — his FAQ says he doesn't charge.") The intel you used to only get from a friend who knew them.
We draft the first note — anchored in shared context. 15% reply rate. 8x cold outreach.
🔍For founders sourcing co-founders, hires, or investors, and young professionals exploring their next move. If your next opportunity depends on a person who isn't in your contacts yet, Articuler.ai is for you.
What's next: Event Match (pre-event matchmaking) launches next month.
🎁 PH gift: apply code PH26Q2 at checkout → one month free of our Pro features.
Drop a comment and tell us what do you think!
— Jason
I get a load of cold outreach that opens like, "based on your experience with the Ride Home AI Fund…" — and I laugh, because I'm not actively investing from the fund now.
In these cases, someone's AI agent scraped some stale info, deemed it "relevant," and sent it to me anyway.
With Articuler, that problem goes away.
@jason_shen3 and @hotwheels_bo built two of China's largest dating apps — Tantan (acquired by Momo / Hello Group) and Jimu (acquired by Inke / Inkeverse) — and they made an observation: dating apps got cannibalized by Instagram and Snapchat because people found more natural ways to meet. The professional equivalent hasn't happened yet.
LinkedIn is still the default, and LinkedIn is full of AI garbage that nobody wants to read.
Articuler starts from intent: you describe who you're trying to reach, it runs conversational clarification, then surfaces ranked matches from ~980M public profiles with a "why connect" annotation baked in. The cold email writes itself from there.
The relevance problem is real and unsolved. But if anyone has the pattern-matching instincts to crack professional matchmaking, it's a team that already did it twice in a harder market.
Hey PH 👋
I'm Bob, co-founder & CTO of Articuler.ai.
Before Articuler.ai, I spent a decade developing human-matching systems — as Tech VP at Tantan and CTO at Jimu. Two dating apps, 6M+ DAU combined 👨🏻🎓.
You might think dating apps and professional networking tools are different things, but the core challenge was always the same:
💕 Twenty years ago, you met your spouse in your village, your church, your office, or your social circle. Dating apps decoupled romance from those institutions — now you can match with anyone, anywhere, based purely on signals.
🎓 The same thing is happening to professional life, just faster. AI is unbundling individuals from organizations. A solo operator with Cursor and Claude ships what used to take a 10-person team. The unit of value creation is shrinking from the company to the person.
Which means: who you find, and who finds you, stop being a career nicety and become infrastructure, as critical as your bank account.
LinkedIn is a directory. Warm intros don't scale. What's needed is matching at internet scale, on intent — which wasn't possible until GenAI turned every public footprint into a vector.
That's what we're building. 980M+ professionals, vectorized. Match on intent.
Have a great day guys!
— Bob
Has anyone used this for finding mentors rather than transactional connections?
As a solo founder, finding the right people is literally my biggest bottleneck. This feels like it was built for me.
Congrats on the launch! Does this work for recruiting as well? Can I find a growth engineer on Articuler?
Congrats. Do I understand correctly, it's a database of users/companies, where you can use text search to narrow down results and then sent them email?
I run a founder community with monthly events. Could I use Articuler.ai to match attendees before they show up?
How specific can I get with my search? Like can I say "founders in Austin who just raised a seed round"?
Congrats on your launch! This looks like a powerful way for companies to move beyond keyword search and build real, outcome‑driven connections.
Looks pretty useful tbh. If it can actually match you with the right investors, hires, or partners without endless keyword searching, that’s a big win. The 15% reply rate sounds impressive, but I’d definitely want to test it myself
This is interesting — the framing of "define your goal, not the person" actually flips how I usually think about networking. Most tools I've tried make me start with a name or a title, then I'm basically guessing whether that person is the right fit. Starting from intent feels much closer to how I actually think when I need help with something.
The 980M number is wild but what caught me more is the "filtered through yours" part — outreach grounded in their public footprint AND mine. That's the gap in every cold email tool I've used: they help you research the recipient but the message still sounds like it could've been sent by anyone.
Curious about a few things:
How does it handle softer intents like mentorship or peer connections vs transactional ones like sales/hiring? Feels like those need very different tones.
For the "8x better than cold outreach" — is that across all use cases or skewed toward certain categories?
Can you bring your own context (notes, past convos, what you're actually working on) to sharpen the match, or is it all inferred from your public footprint?
Hi, congrats! Quick question: is it mainly for finding investors, or can it also help with finding and pitching potential clients?
Recently what makes me headache is to send out cold reach out emails in batches... what platforms or social media apps do you support now?
made by dating app guys, so they literally know how to match humans!
Could a BD lead use this to find partnership opportunities, or is it more focused on people-to-people connections
this + event networking = actually useful combo
What have you seen as the biggest issue for matchmaking so far? Also are you planning on adopting more features like they have at Boardy?
The intent-based matching is a smart angle. LinkedIn search is basically keyword roulette. I'm building a startup right now and finding the right investors and advisors is one of the hardest parts. Going to try this for that exact use case.
The matching logic here seems really interesting. How are you handling the 'vibe check' between the user's goal and the professional's style beyond just skill keywords? Congrats on the launch.
@jason_shen3 @hotwheels_bo @justin_bai Similar to my review (jumped in to give feedback before the launch was live). Congrats on the launch and looking forward to seeing where this gets.
The meat on the bone here is obviously the quality of the outputs. I tend to rush through onboarding (nothing different here) and even by doing so quickly - I got super tailored and unique outputs - specific to my intended need.
Text box is great for search (vs a thousand filters) and I really love the niched product experience. Create a profile - search for X - shortlist and track those prospects.
The simple Kanban style tracking feels intuitive and intentional.
In a world full of AI slop products - it's nice to see some really solid products with really specific / niche use cases that just feel purpose built with a clear mission.
Congrats on the launch! The intent-based matching is what hooks me — searching LinkedIn by keyword
feels broken the moment you're looking for someone with a specific perspective, not a specific job
title. As a founder building in the AI space, the part I'm most curious about is the Playbook — how
deep does it go on someone's public footprint? Does it pull from podcasts/Twitter/Substack, or
mostly LinkedIn + company pages?
The cold email piece — "15% reply rate, 8x cold outreach" — is the part that genuinely stands out here. We build B2B sales automation for service firms and the hardest problem isn't sending volume, it's relevance at the point of first contact. Curious how Articuler handles cases where the public profile data is stale or the "why connect" annotation lands wrong — does the system have a feedback loop to recalibrate match quality over time?
love it! so glad to see the fast iteration and yes it really works for all people business!
This is game-changing stuff
Congrats on the launch. The "define your goal, not the person" framing is very clear.
Curious how you avoid the system over-optimizing for obvious public signals. Do you have a way to surface less obvious but high-fit people when their profile does not use the expected keywords?
Intent-first networking is such a smarter approach than keyword-search. As a solo dev building FinTrackrr, I've wasted so much time on LinkedIn trying to find the right early advisors and beta users — keyword search just surfaces random people. The idea of describing your goal and letting the AI decode public footprints to find actual matches is exactly what cold outreach needs. 15% reply rate claim is impressive. Does it work well for early-stage founders looking for beta users or first customers?
Congrats on the launch. The 'intent-based' matching vs. keyword search is such a necessary shift.
Looks great!
Early-stage hiring is all about reaching the right people fast. Love the concept — gonna test this for my next hire.