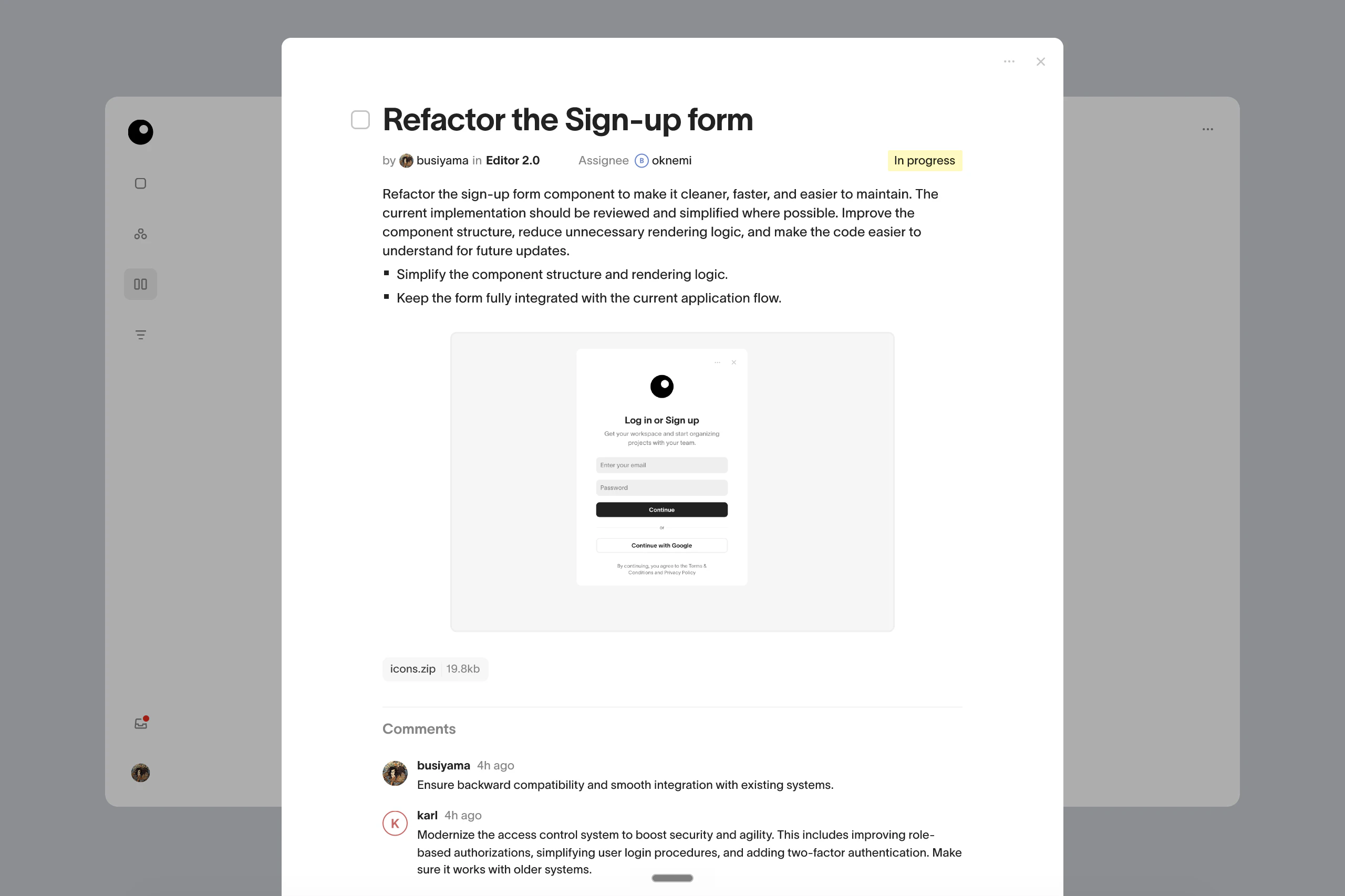
PH热榜 | 2026-05-13
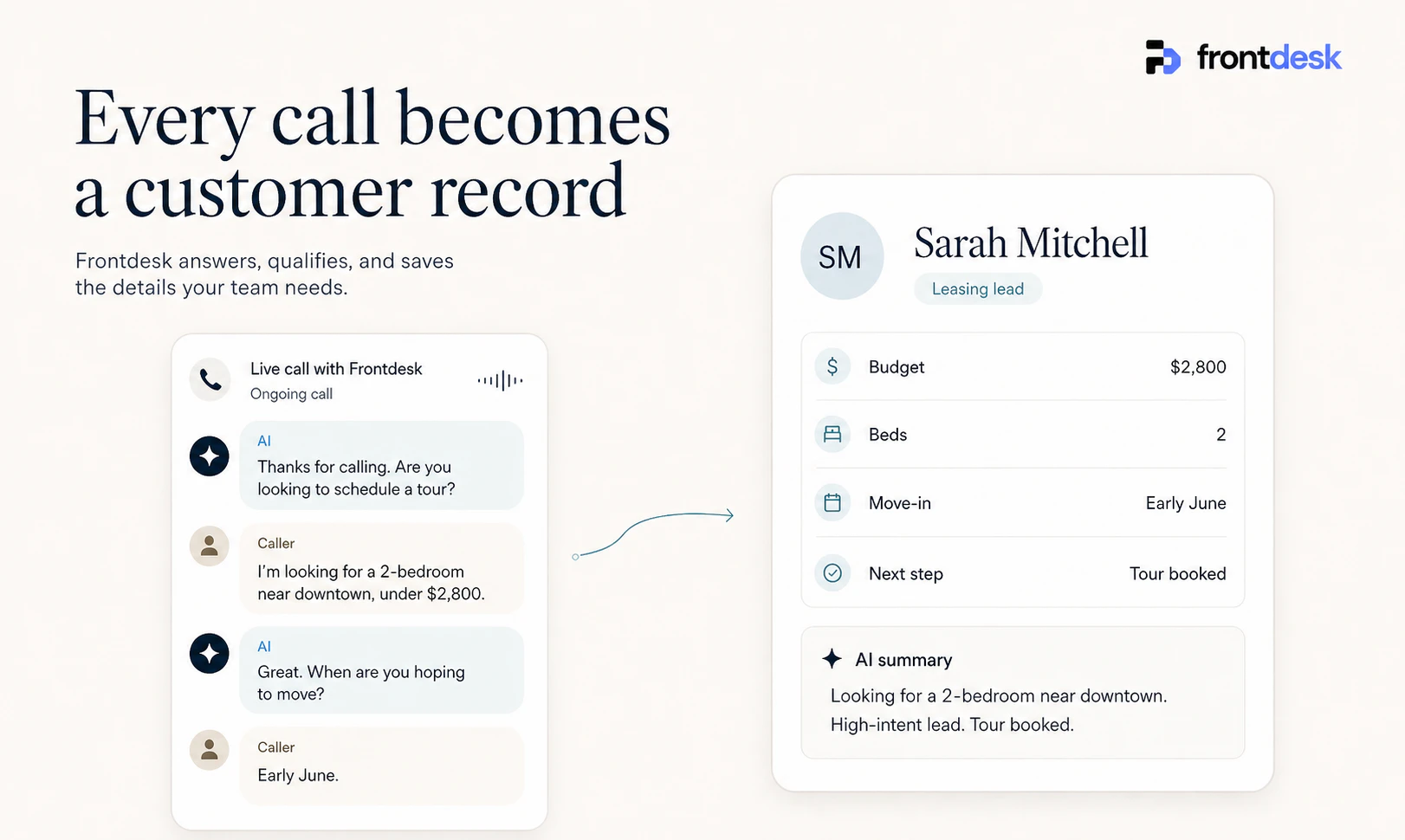
一句话介绍:Memoket Gem是一款全天佩戴的AI穿戴设备,通过一键录音与云端分析,帮助忙碌的创始人和小企业主自动捕捉会议、通话、聊天中的关键信息,并转化为摘要、任务和笔记同步到常用工具,解决“说了就忘、信息分散”的痛点。
Productivity
Wearables
Artificial Intelligence
AI穿戴设备
智能录音
会议纪要
语音转文字
任务管理
工作流自动化
隐私保护
搜索增强
企业效率工具
记忆助手
用户评论摘要:用户主要关注:隐私与数据安全(如本地处理、加密、被动录音风险);设备形态(手环比项链/卡片更自然);信号 vs 噪音的识别机制;能否手动调优而非完全黑盒;印度等地区发货受限。正面反馈集中于对话转任务、跨时间上下文连接功能。
AI 锐评
Memoket Gem的“噱头”大于颠覆性。本质上,它还是一枚带麦克风的“录音笔+AI转写”硬件,核心卖点“全天记忆”依赖于用户主动按下按钮——这恰恰说明它离真正的“AI记忆”还有一步之遥。目前市面上已有类似形态产品(如Plover、Rewind.ai),而它的差异化在于“连接多段对话形成上下文”,而非单次记录。这个能力如果仅靠私有算法实现,在缺乏足够多用户对话数据训练前,效果大概率是“弱关联+伪洞察”。
团队背景确实加分——Anker等硬件老兵的进入,意味着品控、功耗和佩戴舒适度有基本保障。但硬件只是载体,真正的价值壁垒在于“数据闭环”:设备捕捉→AI提炼→同步到工具→后续任务触发。这个闭环一旦跑通,就能把用户从“手动整理”的苦活中解放出来,进而锁住用户。然而,目前仅靠50个免费名额的Beta测试,数据积累速度恐怕难以支撑其宣称的“跨时间上下文连接”。
隐私策略是最大的地雷。“一键录音+红色LED”看似坦诚,但在商务场景中,对方知情是否会天然改变沟通内容?一旦出现泄密纠纷,品牌信任将瞬间崩塌。此外,用户关于“信号 vs 噪音”的追问恰恰暴露了AI的黑箱问题——用户只能被动接受摘要,无法精准调教其“听力”偏好。这会导致长期使用中,用户认知成本反而增加。
一句话总结:思路正确,执行存疑。它可能是创始人忘事的“创可贴”,但想成为AI工作流的“底层系统”,还需要更多真实用例和透明化能力背书。
一句话介绍:Latitude for Claude Code 通过全链路追踪用户的每次会话,清晰展示系统提示、工具调用、子代理和每次交互的 token 消耗,帮助开发者避免意外撞上使用限额,实现精准的成本与性能监控。
Developer Tools
Claude Code 监控
token 追踪
会话分析
成本管理
开发工具
代理调试
自动故障检测
无侵入遥测
云端追踪
大模型应用
用户评论摘要:用户高度认可其解决 token 消耗不可见的痛点,并关注子代理和工具调用的细粒度成本归因、导出分析能力、对 Claude Team 与 API 的支持、遥测对性能的影响、自动报警机制以及敏感数据的传输安全性。
AI 锐评
这款产品精准切入了一个“刚需但常被忽视”的战场:大模型代理的“油耗”管理。在 Claude Code 这类高消耗、高复杂度的开发代理普及的当下,“钱烧在哪”是每个重度用户的暗痛。Latitude 的杀手锏并非单纯的仪表盘,而是“开箱即用的安装命令 + 全链路、异步零开销追踪 + 自动故障标记”,这直击了开发者在调试代理时“黑盒焦虑”的软肋。
然而,产品存在几个潜在风险。一是用户指出的安全问题:其通过修改 Bun 全局环境变量注入钩子,不仅显得工程粗糙,更可能被误读为“超范围监控”,尤其在合规敏感的企业环境中,数据路径的透明度会直接影响采用。二是功能深度的挑战:当前以“周报”和“自动标记”为主,但高级用户(如评论中提及的自定义仪表盘、实时告警、基于 ML 的失败模式识别)的需求正在浮现,若不能快速从“追踪工具”进化到“智能运维平台”,很容易被 Claude 原生功能或更成熟的 APM 工具降维打击。三是生态绑定风险,过度依赖单一模型生态,一旦 Claude 更新或推出类似竞品,护城河会被迅速侵蚀。
总体来看,Latitude 提供了当前最急需的“流量图”,但在企业级安全审计和深度分析链路上仍需补课。它更像一个优秀的补丁,而非一个可持久的平台。
一句话介绍:AI解读失败
SaaS
Artificial Intelligence
GitHub
Vibe coding
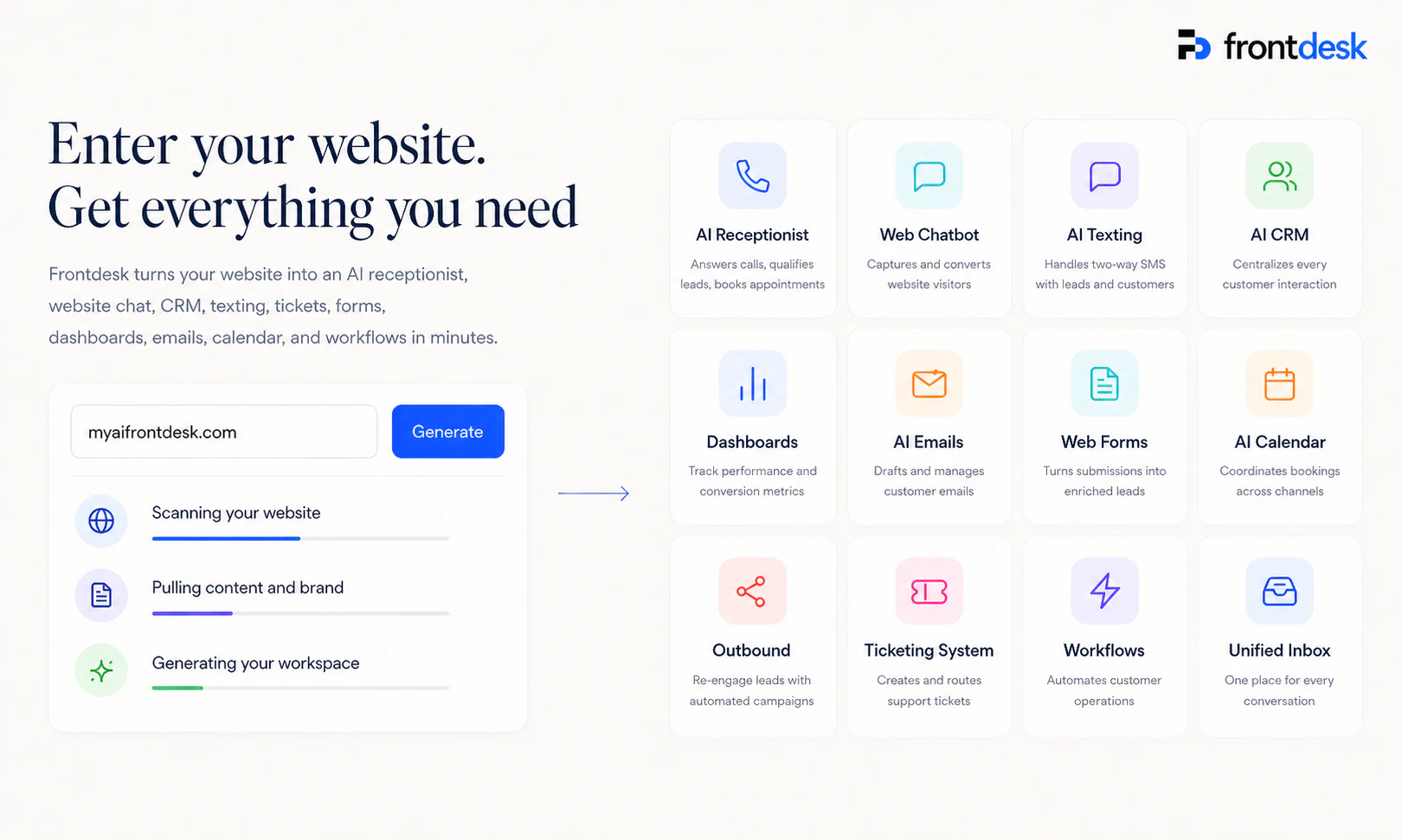
一句话介绍:Frontdesk AI是一款将网站、CRM、聊天机器人、AI前台接待等功能整合为一的“AI首席运营官”,帮助中小型企业以低成本、低门槛的方式,实现24/7客户沟通与业务增长自动化,解决多工具拼凑导致的数据孤岛与客户流失痛点。
Email
Artificial Intelligence
CRM
AI运营
全栈客服
CRM
AI接待
智能外呼
销售自动化
中小企业工具
网站生成器
多渠道沟通
用户评论摘要:用户核心关注点在于AI的决策边界与容错机制:如何防止跨渠道错误决策、处理边缘案例(如客户不满、账单纠纷)时能否明智升级而非沉默失败;现有用户认可其透明日志、人工干预开关、测试模式及分阶段信任机制,但对API集成(如HubSpot)和多渠道无缝切换的“单一真相源”能力仍存疑。
AI 锐评
**数据孤岛被AI平替了,但运营的黑盒恐惧还在。** Frontdesk AI的“AI COO”概念聪明地击中了中小企业用五六个工具却系统不协同、利润被抽走的痛点,本质是将HubSpot+GoHighLevel+网站搭建的杂乱模块压缩成一个单点闭环,成本降低、数据打通——这是产品层面最硬的价值。
但将所有客户沟通(电话、短信、邮件、聊天)交由一个AI代理“运营”,用户评论中频现的“信任”问题并非虚言。CEO Ben试图用“限定范围、人工兜底、全量日志”来回答安全边界,这逻辑成立,但**执行力才是分水岭**:边缘案例的升级逻辑是否足够智能?跨渠道上下文是否真的零丢失?一个“billing dispute”或“irate customer”若被AI机械回复,品牌伤害远超漏接电话。
更值得审视的是,产品通过“AI COO”包装从自动化工具升格为“替你做主”,对非技术用户极具吸引力。但就像评论中谈到的“信任是养成的”,它高估了中小老板一次性交出经营主控权的意愿。10秒建站、AI自动回复的表面流畅,与背后数十条风险策略配置的复杂性之间存在鸿沟。
结论:这是一个先发优势明显但易被模仿的整合型产品。真正的护城河不在于功能多少,而在于AI在处理复杂客户场景时的**“聪明克制度”**——既不能木然地“什么都管”,也不能怯懦地“什么都问”。否则,它只是另一个用大模型包装的“低代码表单+聊天机器人”套壳。
一句话介绍:Googlebook是一款深度集成Gemini AI的笔记本电脑,通过Magic Pointer智能指针和自定义AI小部件,解决用户在多任务处理和App切换中的效率痛点。
Android
Hardware
Artificial Intelligence
AI笔记本电脑
Gemini智能
Magic Pointer
上下文建议
自定义小部件
Chromebook替代
安卓融合
铝合金OS
隐私控制
多任务优化
用户评论摘要:用户主要关心隐私与系统追踪程度的平衡;质疑真实多任务体验是否流畅;猜测目标受众;部分认为这是Chromebook的进化版,融合安卓与ChromeOS,Magic Pointer类似Touchbar的AI升级版。
AI 锐评
Googlebook看似是一个“为AI而生”的硬件宣言,实则是一场谷歌生态霸权下的无奈妥协。
从产品本身看,Magic Pointer和自定义小部件是亮点,但本质仍是“AI版Touchbar”的旧瓶新酒——苹果已证明,触控条并非刚需。真正的价值在于“Aluminium OS”融合:谷歌终于承认,ChromeOS和Android的割裂是巨大败笔,AI不过是缝合碎片化体验的遮羞布。
评论中关于隐私的质疑直击要害:Gemini若要提供精准上下文建议,必然深度扫描用户行为,这在“AI助手”与“数字偷窥者”之间只有一纸之隔。此外,“减少App依赖”的期待不切实际——AI小部件若仅能调用现有应用,而非创造原生体验,只会增加第三层冗余。
至于目标受众,谷歌很可能瞄准了传统Chromebook的教育和企业用户,试图用AI噱头拉动换机潮。但面对MacBook和Windows Copilot PC的双重夹击,Googlebook若不能解决核心痛点的实时性(如跨设备任务流转延迟),无非是又一个“叫好不叫座”的硬件实验。
一句话锐评:AI是药引,但谷歌需要的是一剂猛药,而不是在旧肾上贴新膏药。
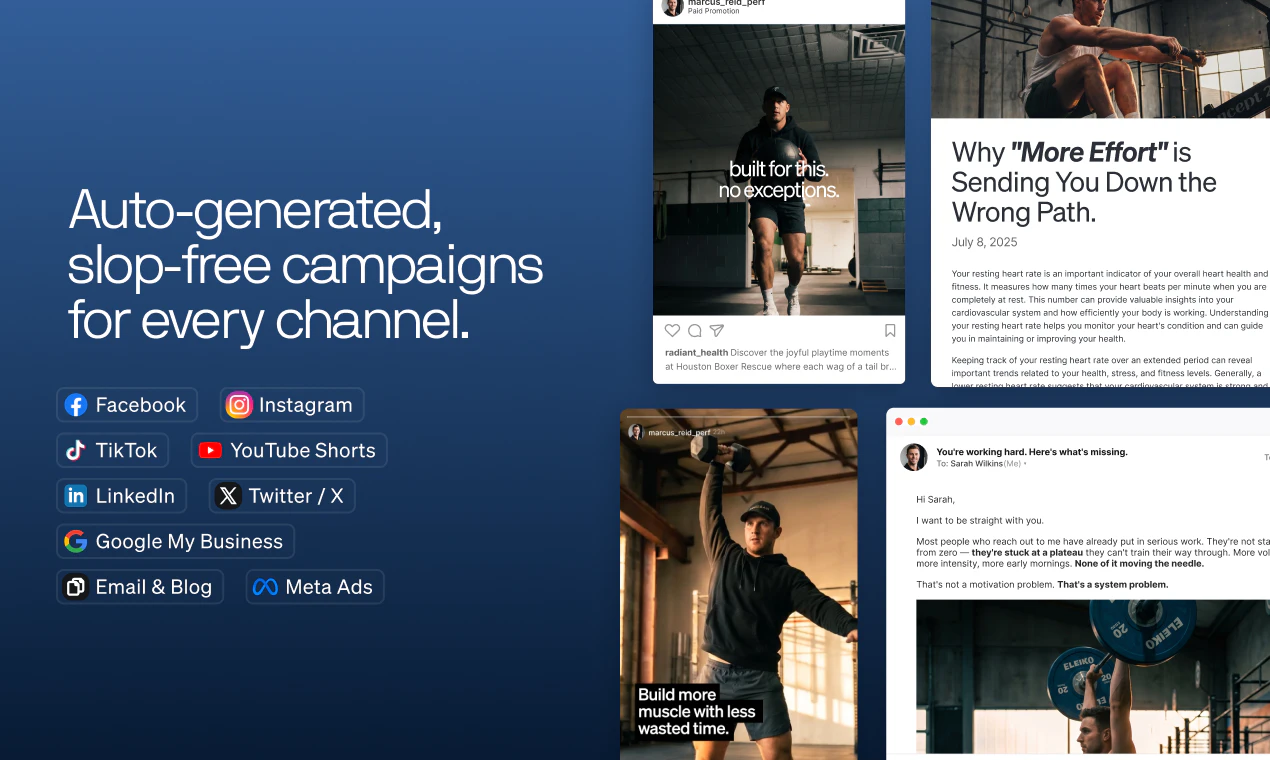
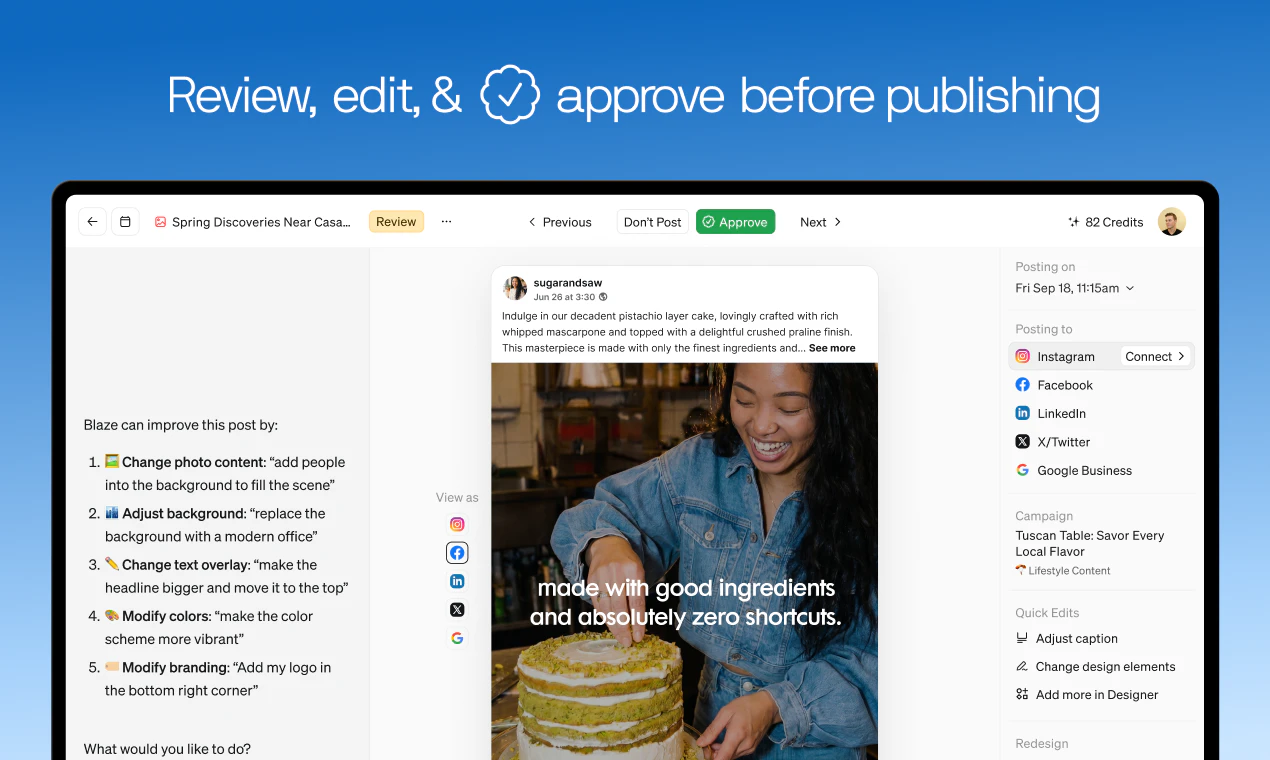
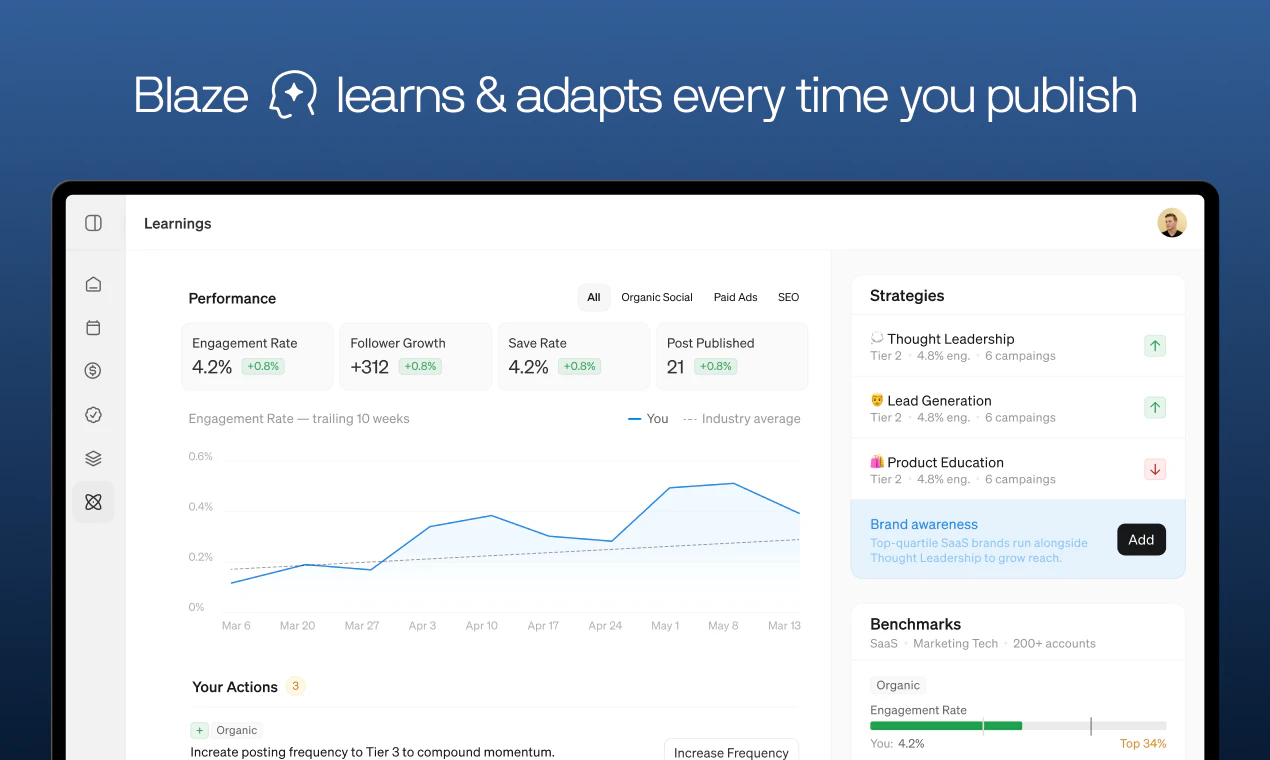
一句话介绍:Blaze 2.0 是一个面向中小企业的全自动AI营销平台,能够学习企业业务、受众和品牌语调,自动执行从策略制定、内容生成到广告投放的完整营销流程,解决小企业主“没时间做营销”的痛点。
Marketing
Artificial Intelligence
Social media marketing
AI营销
自动化营销
中小企业
内容生成
广告投放
社交媒体管理
SEO优化
品牌管理
增长工具
Blaze
用户评论摘要:用户普遍认可其节省时间、自动生成内容的核心价值。主要问题集中在:品牌语调学习初期不精准,视觉风格生成偶有失控;对数据分析的“学习回路”提出质疑,担心过度优化点赞等虚荣指标;多语言支持不足,仅限单语输出;用户建议明确针对“避免被忽视”这一痛点进行定位强化。
AI 锐评
Blaze 2.0的进化逻辑非常清晰:从“工具”走向“代理人”。其核心竞争力不在于又多了一个AI内容生成器,而在于它试图闭环“策略-执行-优化”的营销全链路,直击小企业主“没有时间”这一永恒痛点。CEO关闭千万美元ARR的1.0产品来重构方向,这种断舍离的姿态颇具魄力。
然而,产品的真正考验不在于功能堆砌,而在于“信任”与“控制感”的平衡。用户评论揭示了关键困境:当AI学习品牌语调时画面跑偏、生成定制化内容的精度依赖于训练数据,这本身就构成时间成本。而“学习回路”依赖有噪点的平台数据,极易陷入优化虚荣指标的陷阱,反而偏离业务增长本质。它声称要成为“不领薪水的营销团队”,但团队的价值在于策略判断与风险规避——目前的Blaze在应对“杂乱的真实商业世界”时,其自动化越强,失控的风险就越大。
产品的生死线在于:它是否能将“节省时间”的价值,兑换为“效率提升”与“营收可见增长”之间的明确因果。目前的240+投票和用户好评更多是基于“救火”心态的依赖,而非证明可复制的ROI。从“帮你发帖”到“帮你获客”之间,隔着巨大的信任鸿沟。Blaze 2.0解决了一个真实问题,但若不能建立更精细的控制机制和量化增长指标,它很可能沦为“聪明但不可靠的实习生”,无法真正进入小企业主的必选工具包。
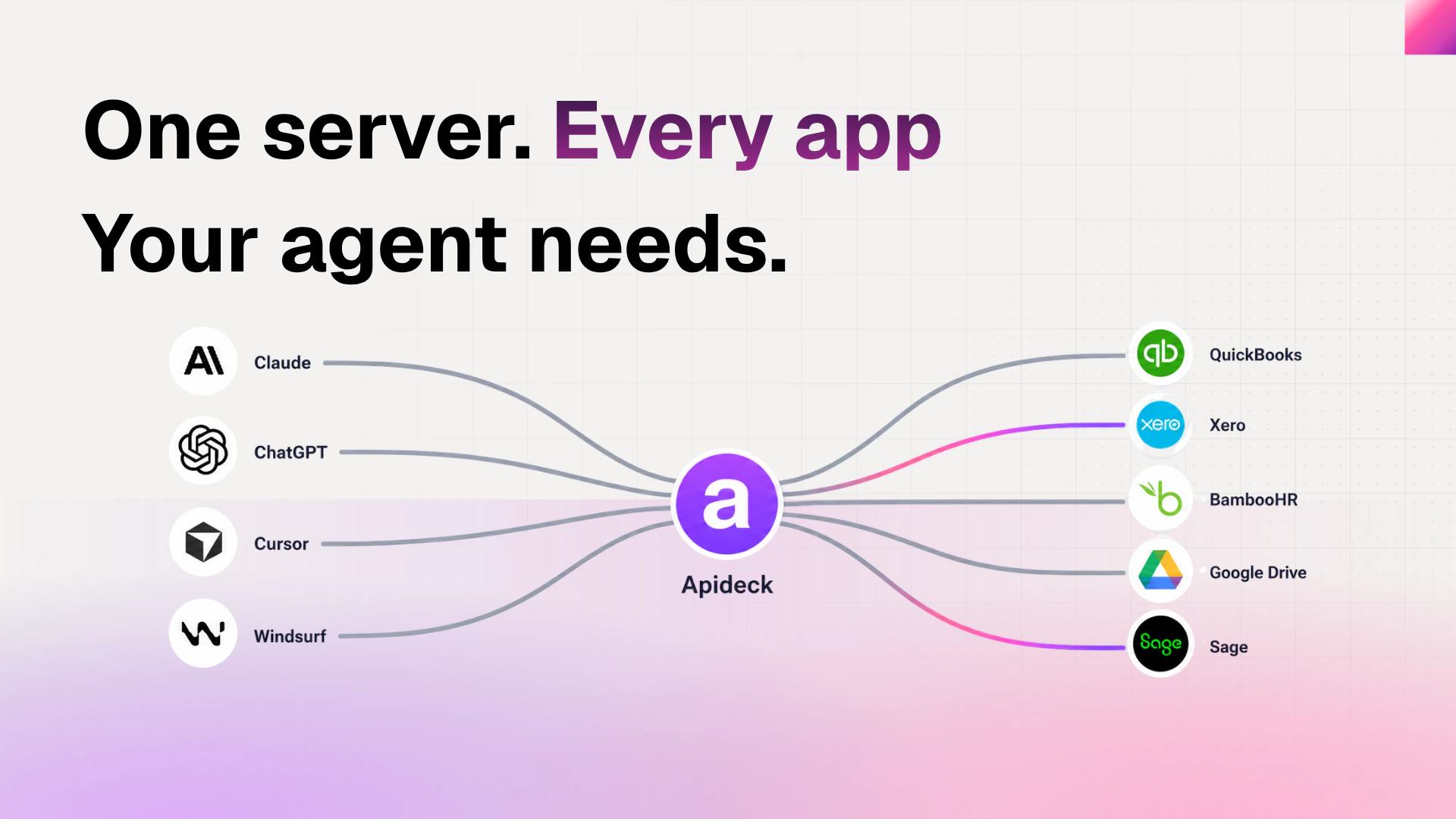
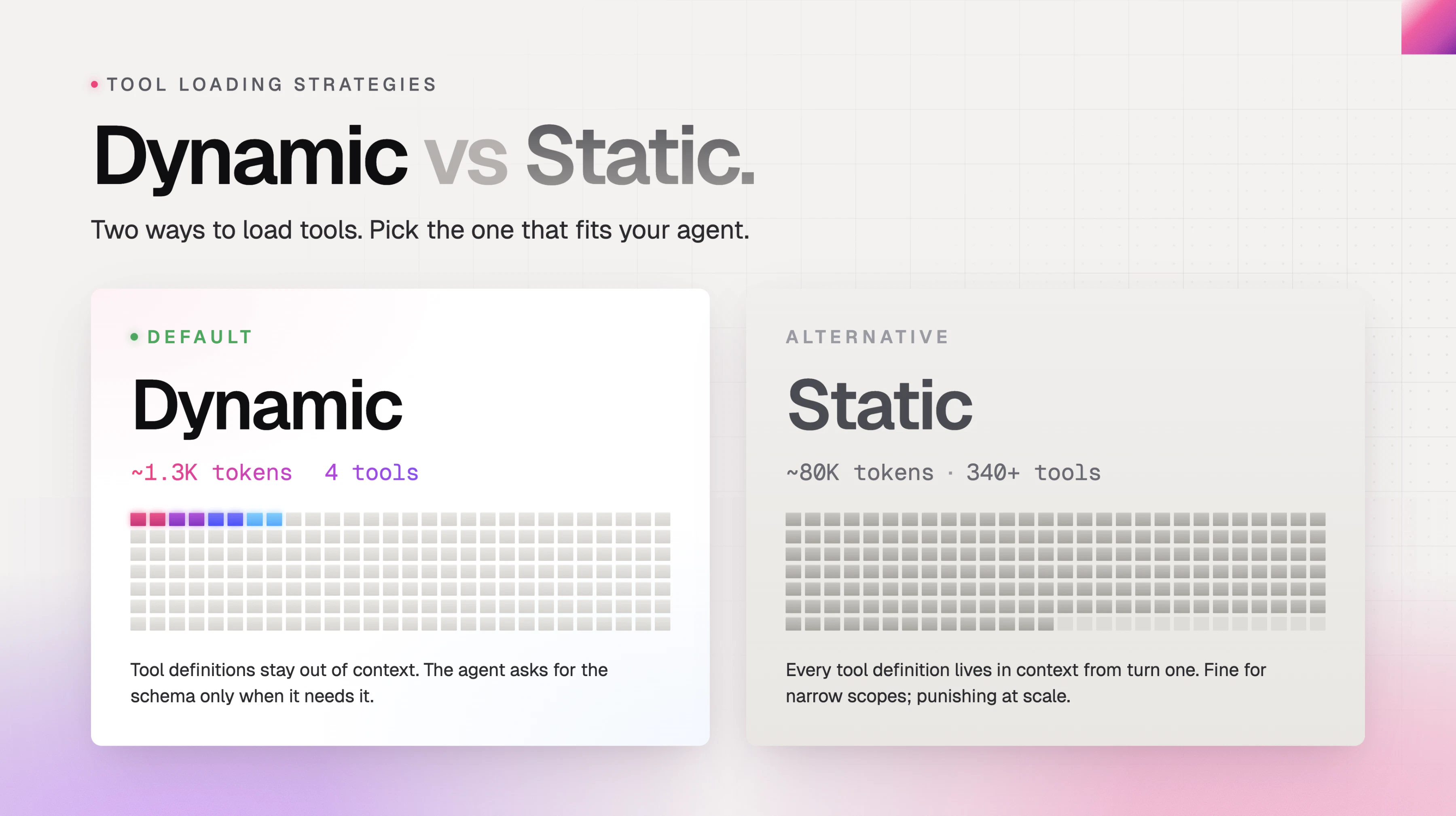
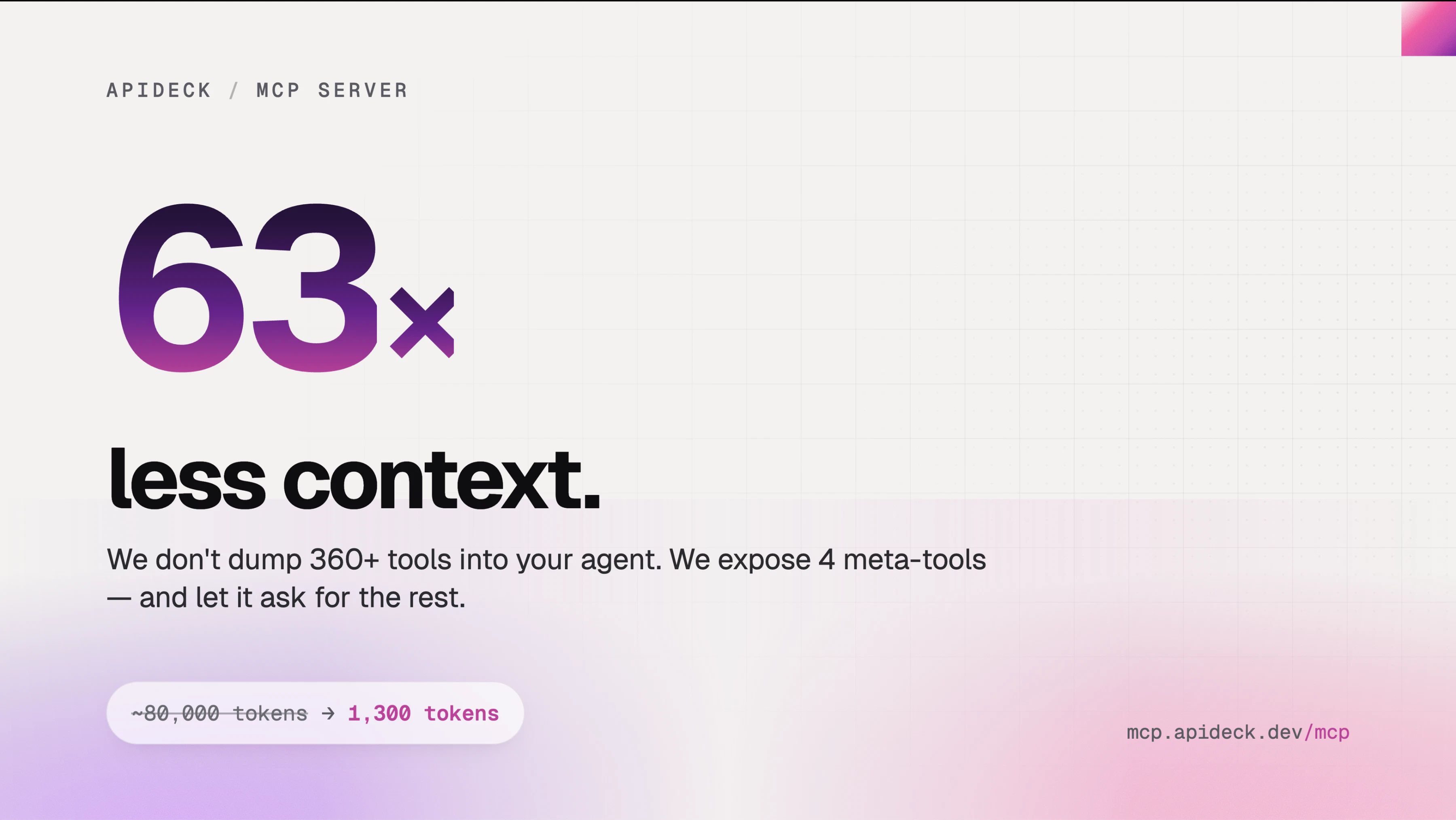
一句话介绍:通过统一API层为AI智能体提供对200+企业SaaS应用(如CRM、HRIS、会计系统)的实时、授权且细粒度数据访问,解决代理工具“乱闯”用户数据与Token成本过高(40K)的痛点,采用动态工具发现机制将启动Token消耗压至1.3K。
API
Open Source
Developer Tools
GitHub
MCP协议
统一API
AI代理数据访问
企业SaaS集成
权限控制
动态工具发现
Token优化
数据归一化
开发者工具
用户评论摘要:用户关注点高度集中在:1)跨平台写操作的幂等性问题,官方确认提供统一Schema;2)动态工具发现对长工作流性能的影响,已有限权预配置方案;3)数据模型版本管理及上游接口断裂风险,官方邀请查看文档;4)审计与写前确认机制,强调已实现作用域权限隔离而非单纯UI层保护。
AI 锐评
Apideck MCP Server 的野心很清晰:成为AI代理与企业数据的“万能钥匙”。其核心价值并非“200+连接数”——这是存量资产的包装——而是**动态工具发现**和**MCP层的权限拦截**。静态加载229个工具耗费40K Token,这背后是一种对无状态AI调用生态的诚实认知:没有智能体能无损处理所有API的“天书”。动态发现把选择权还给代理,这一机制务实且聪明。
但“统一化”也是致命护城河与债务的起源。QuickBooks与NetSuite的会计模型差异是结构性的,推倒重来的历史数据迁移、多租户Schema版本管理、上游接口无声漂移——这些才是真正考验工程深度的地方。评论中有人一针见血地指出了“数据模型版本化”的火山口。
此外,产品目前强调“读+写”,但企业级场景真正的恐惧不是数据泄露(权限可以管),而是**在代理自主发起的写操作中,谁是最后的责任人**?Apideck的“作用域权限”只解决了“能做什么”的开关,却没有回答“事后出错了,审计追踪和回滚流程是否跟得上”。这是所有MCP+企业数据方案的盲区:语义校验与可撤销性。
总的来说,这是一款切入时机精确、架构有巧思的生产力工具。但它不应被神化为“AI操作后台的神器”,更现实的角色是“企业数据面的Gatekeeper+Overseer”——尤其在金融、HR等强监管场景,缺乏明确的事故追溯协议会让它沦为昂贵的实验品。
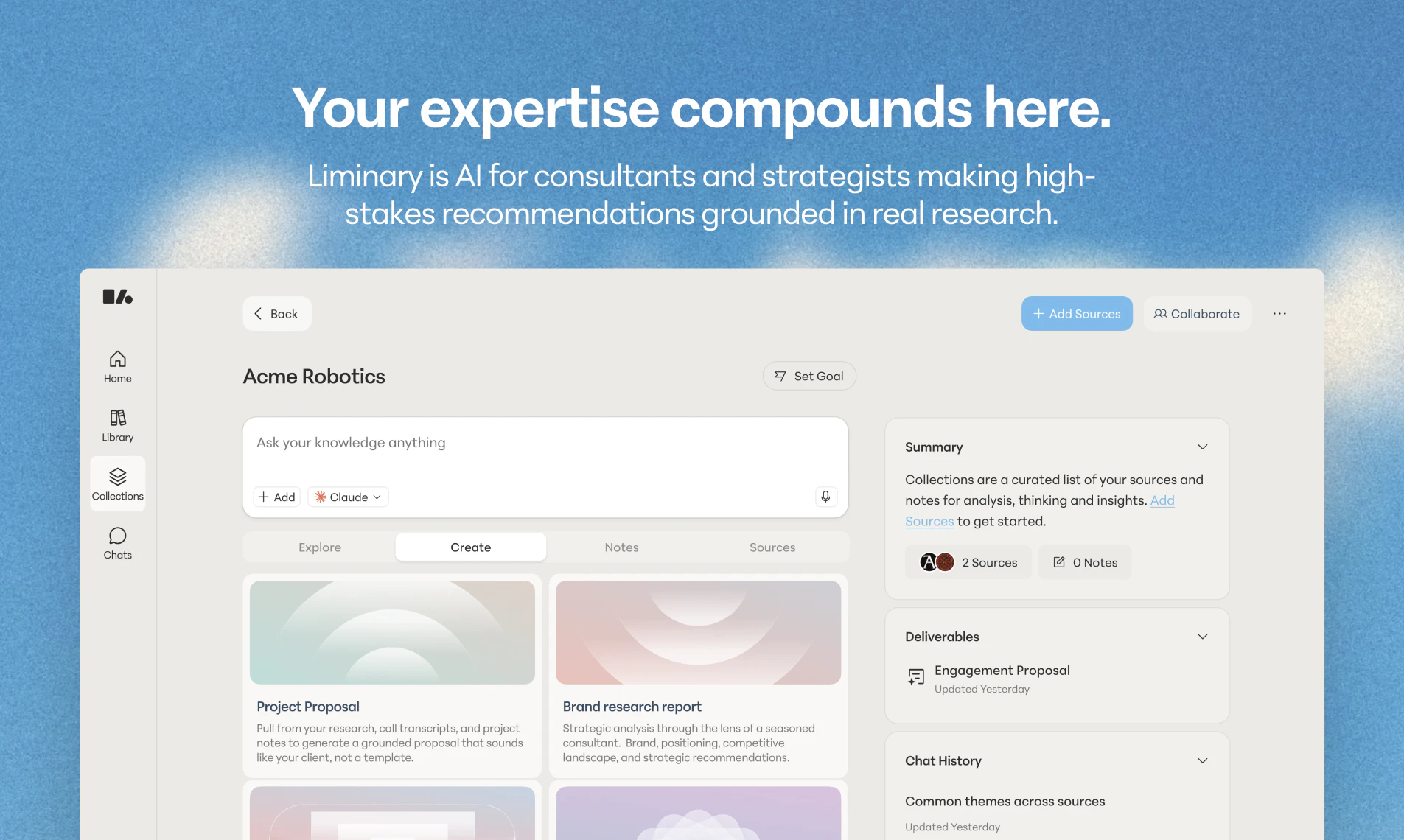
一句话介绍:Liminary将你所有已保存的各类资料(文件、会议记录、网页等)整合为AI的“共享工作记忆”,在写作、开会和研究时自动提供相关上下文,解决知识工作者信息碎片化、重复寻找和AI工具“猜测”上下文的核心痛点。
Chrome Extensions
Productivity
Artificial Intelligence
AI记忆层
知识管理
上下文引擎
RAG
知识工作者
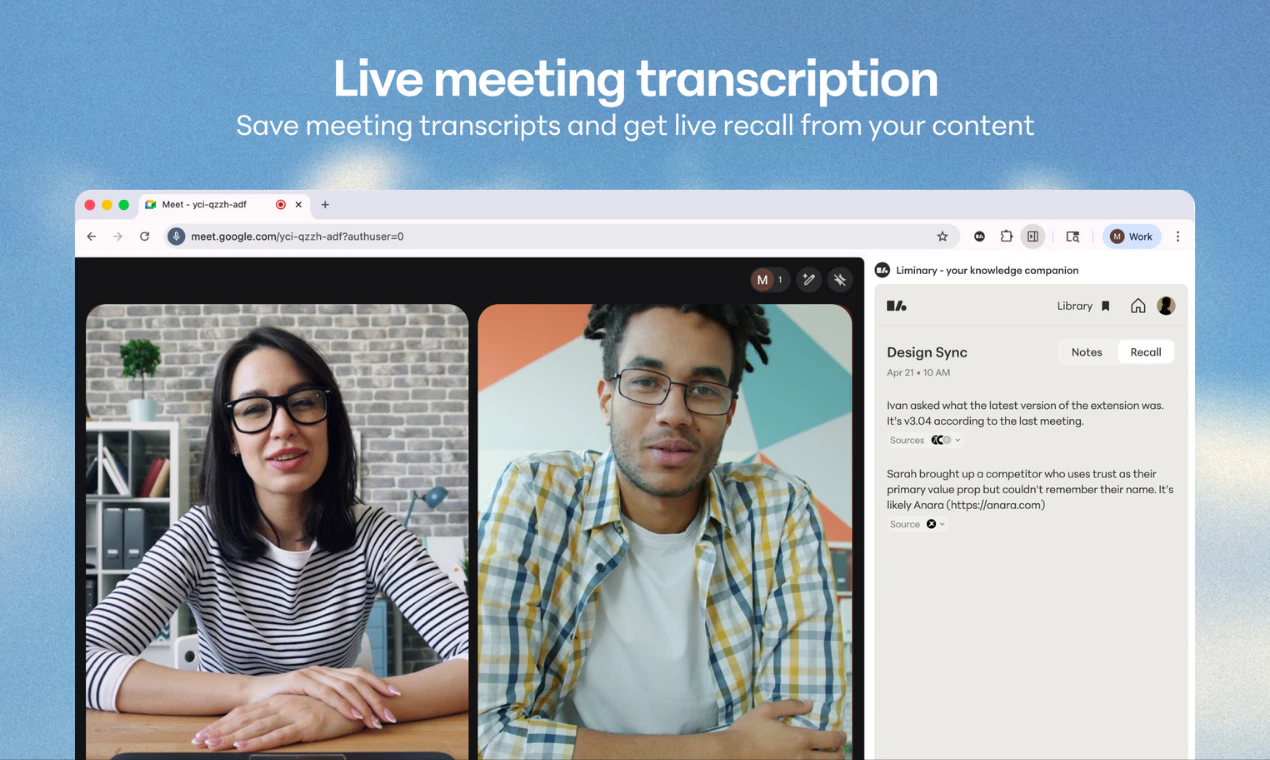
会议智能
文档协作
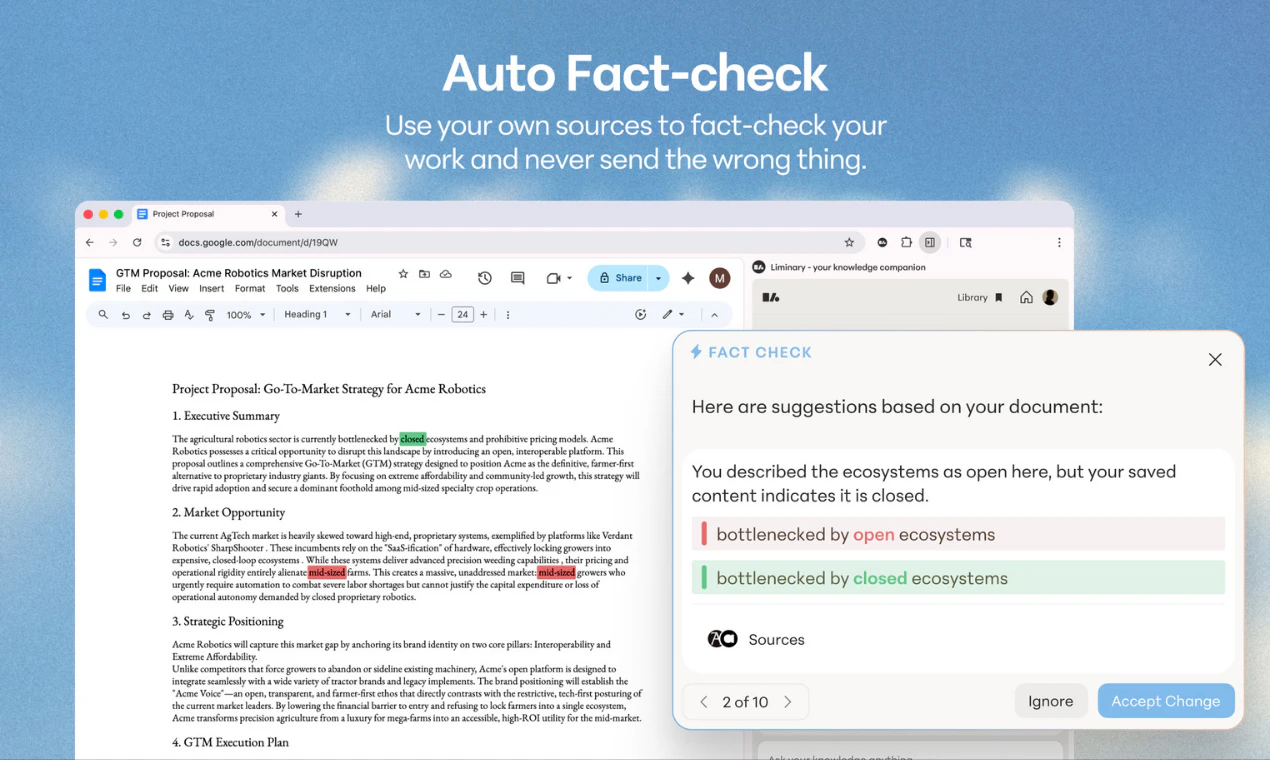
AI事实核查
提示词优化
生产力工具
用户评论摘要:用户普遍认可“基于个人已选资料”的价值,但核心关注点在于:如何避免“技术上相关但实际无用”的噪声;如何设计显示机制避免过度干扰决策;如何解决知识库随时间腐化、版本冲突;以及用户是否会过度信任AI呈现的上下文。创始人回应强调通过用户反馈学习、克制展示、结构化提取而非纯文本检索来解决这些问题。
AI 锐评
Liminary的聪明之处在于,它没有掉进“更聪明的AI”这个同质化陷阱,而是精准地切入了“更好的上下文”这个价值洼地。其核心洞察在于:在模型能力趋同的今天,知识工作者的真正壁垒不是谁能写出更漂亮的提示词,而是谁能将过去产出的高质量判断、历史会议、客户谈话中的隐性知识,无痕地复用到当前的决策瞬间。
从产品设计看,Liminary的“Proactive recall(主动召回)”和“Meeting recall without bot”是对传统AI工具“人找信息”模式的反转。它试图将AI从一个被动的对话对象,转变为一个懂你工作流、知道你此刻需要什么的“上下文伙伴”。这比任何单纯的RAG增强都要先进,因为它试图解决的不是检索的“查全率”,而是认知的“调用率”。
然而,风险同样明显。用户评论中反复出现的“噪声”和“信任”问题,是这类“系统自动喂食”产品的达摩克利斯之剑。Liminary需要证明自己的“克制”不是技术缺陷而是审美选择,以及“基于用户反馈学习”不是一句空话。如果系统频繁地在用户高度专注的写作或会议中推送“看似相关实则鸡肋”的信息,瞬间就会从“生产力伙伴”沦为“注意力杀手”。此外,将“工作记忆”从用户大脑中剥离出来交给AI,本质上是一场认知权力的让渡,用户是否愿意、以及是否有能力持续“训练”这个系统让其贴合自己的真实思维,将是决定其能否成为刚需而非玩具的关键。
一句话介绍:Claudy 为 Claude Code 打造了一个原生的 macOS 桌面“家”,解决在多个终端标签页中混乱管理多项目、多会话及多账号切换的痛点,并集成了脚本市场与版本检查点功能。
Productivity
Developer Tools
Vibe coding
Claude Code客户端
macOS应用
多会话管理
多账号切换
AI编程工作流
命令市场
Draft Commits
终端增强
开发者工具
效率工具
用户评论摘要:用户普遍认可多会话管理是刚需,尤其是多个Pro账号切换的痛点,认为Claudy的自动切换与Draft Commits功能极具价值。有用户询问账号切换是手动还是自动触发,开发者回应可在项目设置中配置自动切换。
AI 锐评
Claudy的价值不在于技术创新,而在于精准捕捉并优雅解决了Claude Code用户在真实工作流中的“环境摩擦”。本质上,它是为AI编程主力工具Claude Code打造的操作系统层。
其核心洞察在于:用户被迫使用多Pro账号绕过定价鸿沟,这一“苦活”被Claudy通过自动化无缝包装,变相降低了高端用户的使用门槛。Draft Commits功能则触及了AI编程的痛点——AI生成的代码常需要“回滚到某个中间状态”,它用简单的git trailer本地化实现了类似于AI会话中的“存档读档”功能,非常务实。
不过,Claudy也面临极大的不确定性:其核心价值高度依赖Anthropic的定价策略和API设计。一旦官方推出合理的中端套餐并改进账号管理,或Claude Code原生支持多窗口,Claudy的生存空间将被急剧压缩。其市场功能虽有开源作为护城河,但本质上仍是锦上添花。
总体而言,Claudy是一个精悍的“管道”型产品,能在当前生态痛点爆发时赚取足够红利,但长期发展必须快速构建不可替代的社区资产(如市场)或深入工作流链条。否则,它很可能成为巨头调整策略的牺牲品。开发者应警惕“围绕单一平台API打补丁”的商业模式风险。
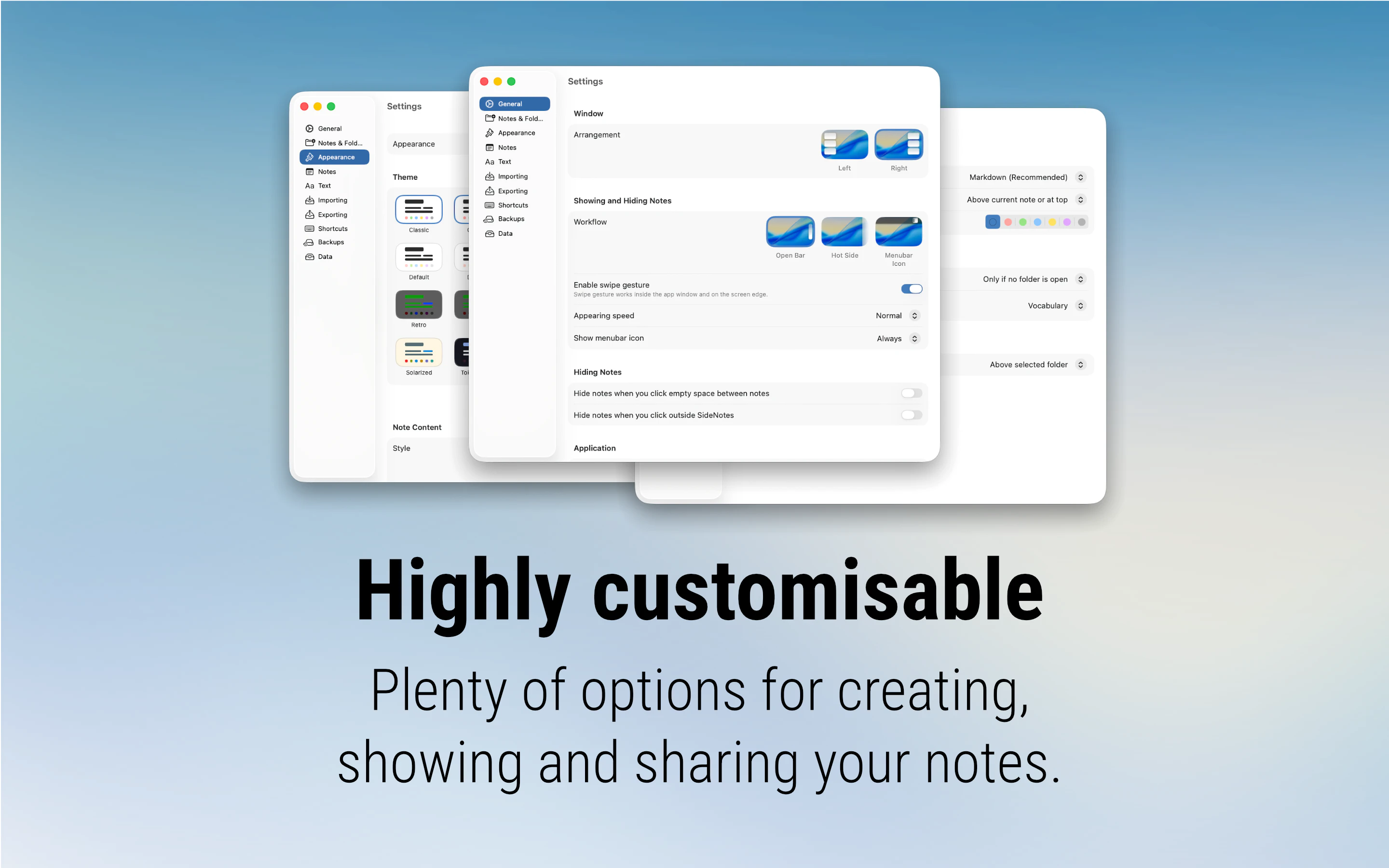
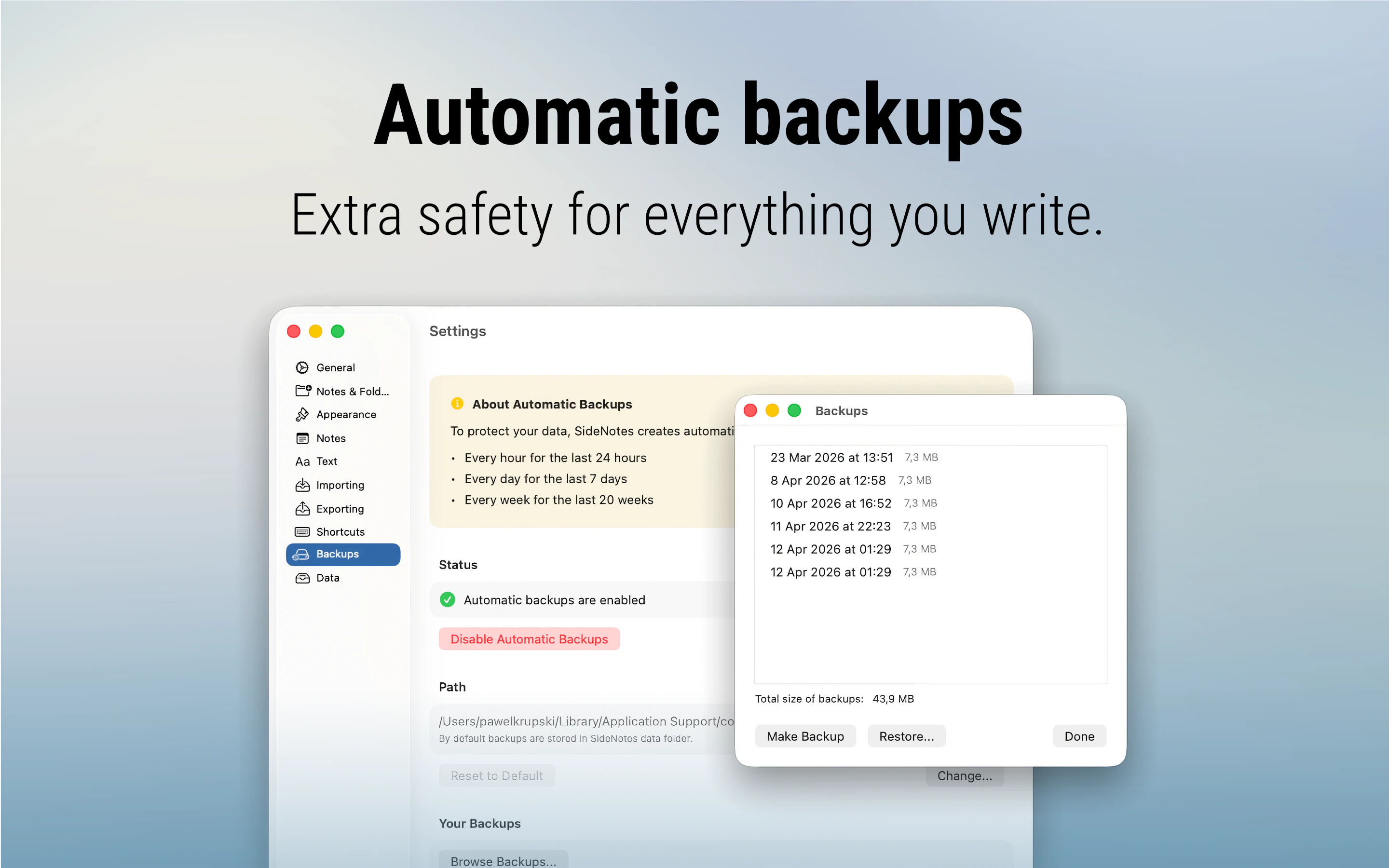
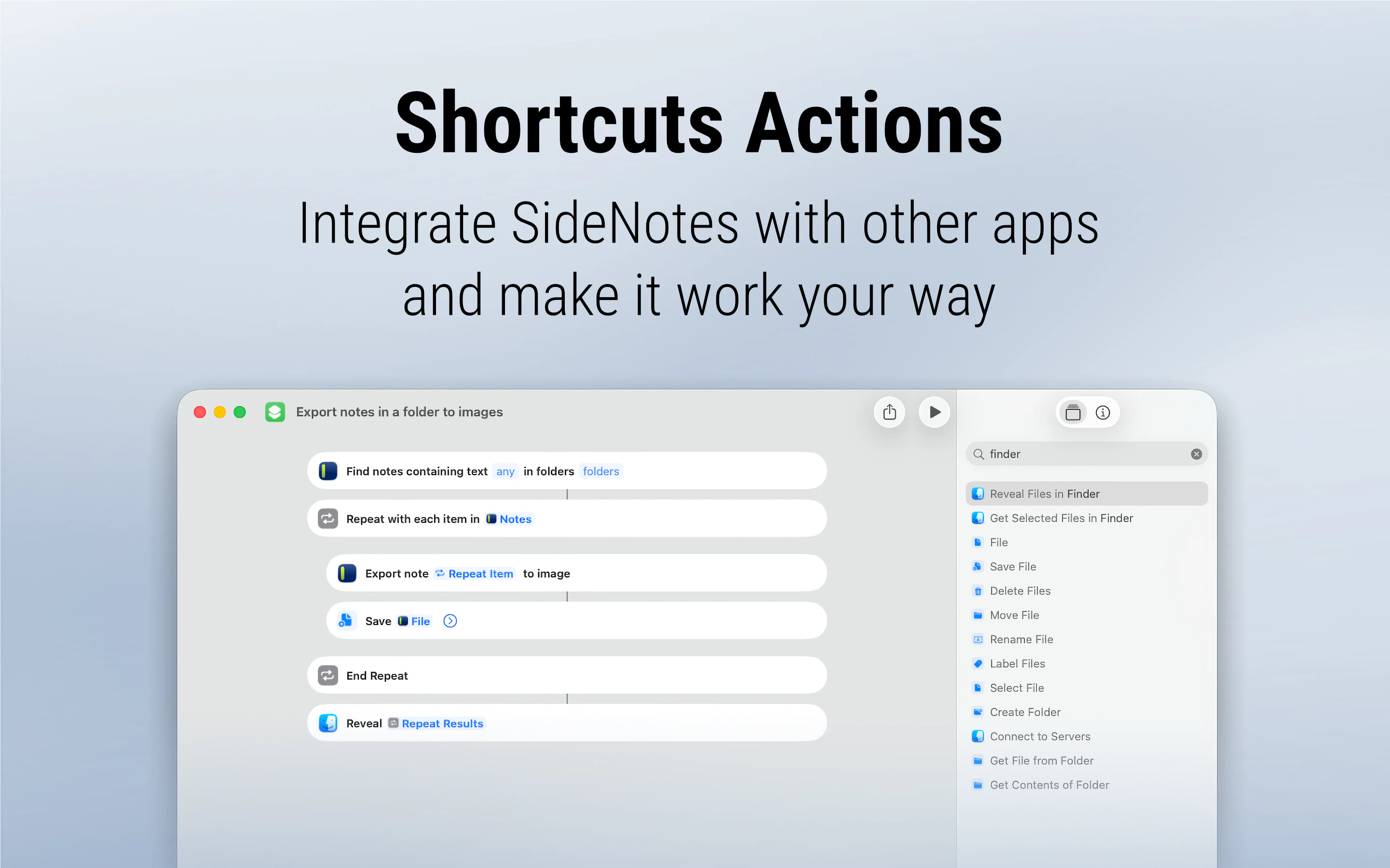
一句话介绍:SideNotes 是一款常驻屏幕侧边的笔记应用,帮助用户在浏览网页或全屏工作时快速捕捉想法,无需切换上下文或打断当前流程,解决笔记工具“想用时找不到、一全屏就消失”的痛点。
Productivity
Writing
Notes
侧边笔记
屏幕侧边
速记工具
Markdown笔记
任务管理
文件夹
贴纸式
分屏
macOS
移动端
用户评论摘要:用户关注全屏模式下的始终可见性及多显示器适配,开发者回应可在每台显示器显示同一窗口,但仅能激活一个。另有用户询问能否与Apple Notes同步,开发者表示因Apple Notes格式封闭,无法简单实现。
AI 锐评
SideNotes 切中的是一个真实但被大厂忽略的刚需——在深度工作场景中,笔记工具不应该是一个需要“打开”的应用,而应该是一块随时可以瞥见的便签。它将笔记固定在屏幕侧边,在全屏模式下依然可见,这一点直接甩开了传统粘滞贴和大多数笔记软件。但产品目前的价值边界非常清晰:它本质上是一个“加强版贴纸”,而非“轻量级Notion”。Markdown、任务、图片、文件夹等功能只是让贴纸更好看、更有序,并未突破侧边速记的定位。多显示器支持虽有,但仅能显示同一窗口且不能联动,对于跨屏设计、开发、运营等工作流来说依然是半成品。另外,它与Apple Notes的同步几乎不可能,意味着SideNotes更适合作为独立速记仓库,而非已有知识体系的补充。118票的成绩证明产品方向对了,但功能深度和生态整合仍是软肋。对追求“零干扰记录”的用户来说,它值得一试;但对需要长期知识管理、深度组织笔记的用户,它目前还撑不起“超能力”这个宣传词。
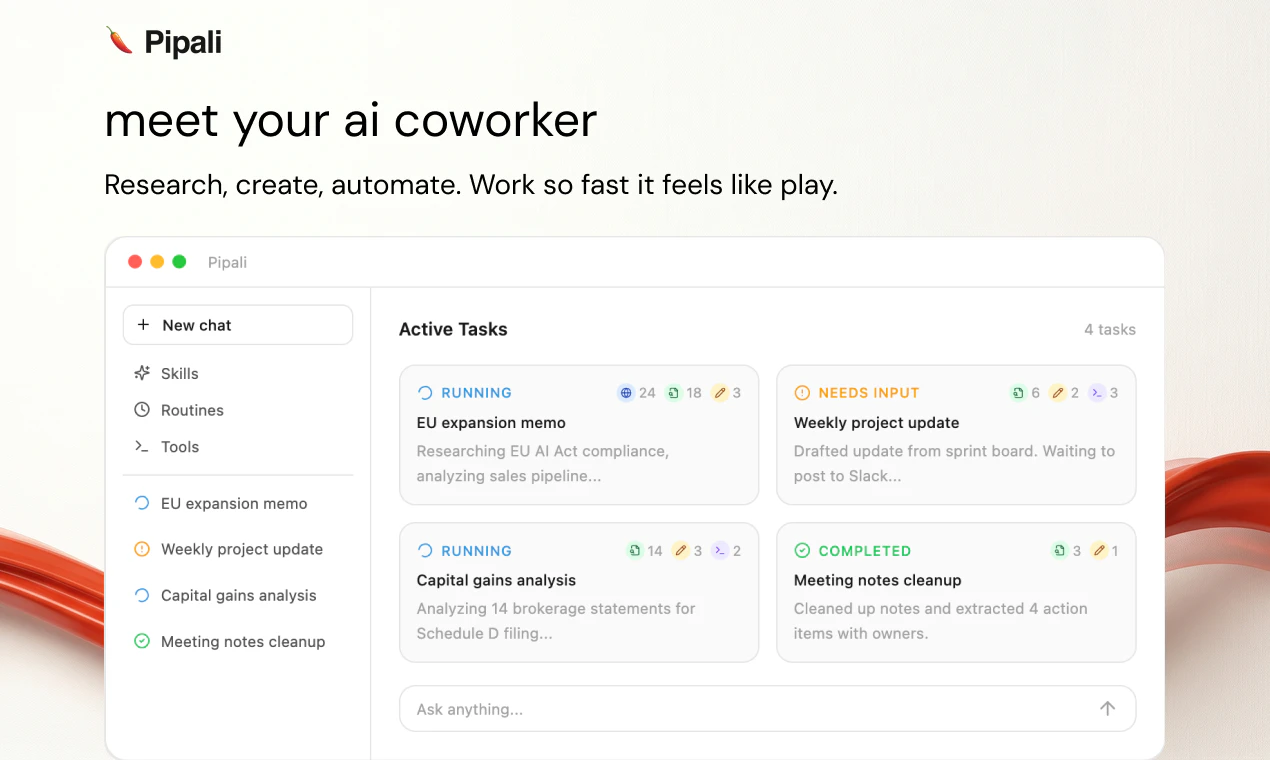
一句话介绍:Pipali 是一款运行在用户电脑上的AI同事,能操控文件、浏览器和应用来完成深度研究、文档撰写、重复性任务等实际工作,解决AI对话无法落地为操作、无法记忆工作流程以及无法处理多步骤复杂任务的痛点。
Productivity
Open Source
Artificial Intelligence
GitHub
AI桌面代理
AI同事
MCP集成
任务自动化
工作流记忆
开源
本地AI
计算机操控
重复性任务
企业效率工具
用户评论摘要:用户赞赏Skills和Routines解决AI“每次从头开始”的痛点,但关注无MCP支持的桌面应用处理(开发团队承认暂未实现“计算机使用”模式),以及多任务冲突时如何协调(开发团队表示用户可主动授权或使用隔离实例)。
AI 锐评
Pipali试图回答AI行业的“最后一公里”问题:从“能聊”到“能干”。其核心差异化在于“记忆工作流”,通过Skills让用户教AI完成多步骤任务,Routines让这些任务可定时、可触发,这在大量“一次单步”的AI工具中属实亮眼。但标语“Any computer work”在大胆之余也暴露了当前能力的边界——团队坦诚对缺乏MCP接口的桌面应用无能为力(没做CUA),且安全机制尚需完善。商业上,这一定位精准切入白领“脏活累活”的自动化需求,但用户真正关心的不是“能否联网查资料”,而是“我关掉浏览器后,能不能让它帮我整理完这50页PDF并生成周报”。Pipali的理念很棒,不过从产品到“真正的自动化同事”还差一个关键功能:对任意GUI应用的无障碍操控。如果只停留在“适配了MCP的应用”,它更像高级脚本工具而非“同事”。开源策略降低了尝鲜门槛,但大规模推广仍需解决稳定性、权限管理和任务冲突的自动化决策。
一句话介绍:LayerProof Matte 2.0 是一款专为社交媒体内容创作者设计的AI工具,帮助个人创作者和小团队快速跟热点、生成多平台适配的轮播图及图文帖,一站式解决从创意到发布之间的“执行内耗”,提升内容产出速度。
Design Tools
API
Social Media
用户评论摘要:用户普遍关心趋势源是否会沦为噪音干扰,团队回应强调“用户自主筛选趋势”而非算法推荐。另有用户纠结AI工具的万能陷阱,团队承认挑战,但表示通过快速发布小产品来测试市场。还有用户提出修图精细度、轮播图生成和团队账户管理等具体需求,团队均给出实操解答,显示对早期用户反馈的积极回应。
AI 锐评
LayerProof Matte 2.0 真正值钱的地方,不在于它又做了一个AI内容生成器,而在于它精准切中了“速度”与“品牌一致”之间那个最痛苦的缝隙。市面上太多工具要么追求极致自动化,输出沦为千篇一律的模板(适合蹭量但毁品牌),要么要求用户花大量时间手工调教,根本跟不上热点节奏。Matte 2.0 的聪明之处在于,它让“人”做决策(筛选趋势、把关内容),让“AI”做执行(多模型协同、快速适配多平台、生成轮播逻辑),这不是技术上的伟大突破,而是分工上的务实重构。
但必须直说的是,它目前依然处于“小而美”阶段。团队承认“不知道自己是文本工具还是设计工具”,这种身份模糊在融资和规模化时会是硬伤。此外,其核心竞争力——趋势匹配——目前还是纯手工筛选,所谓的“向量嵌入智能推荐”尚未上线,这导致它现阶段更像一个“带趋势情报的快捷设计工具”,而非真正的“内容智能引擎”。对于个人创作者或极小型团队而言,它可能是当前市面上“最快把想法变成帖子”的方案之一;但对于运营多品牌的中大型团队,它的多账户支持、权限管理和品牌资产沉淀系统尚属空白,短时间内难以替代成熟的企业级SaaS。
一句话总结:Matte 2.0 是一个方向正确、执行果断的早期产品,适合那些“不差创意,只差速度”的创作者,但对“还要管流程、管品牌一致性”的团队来说,仍需耐心观望其下一阶段的进化。
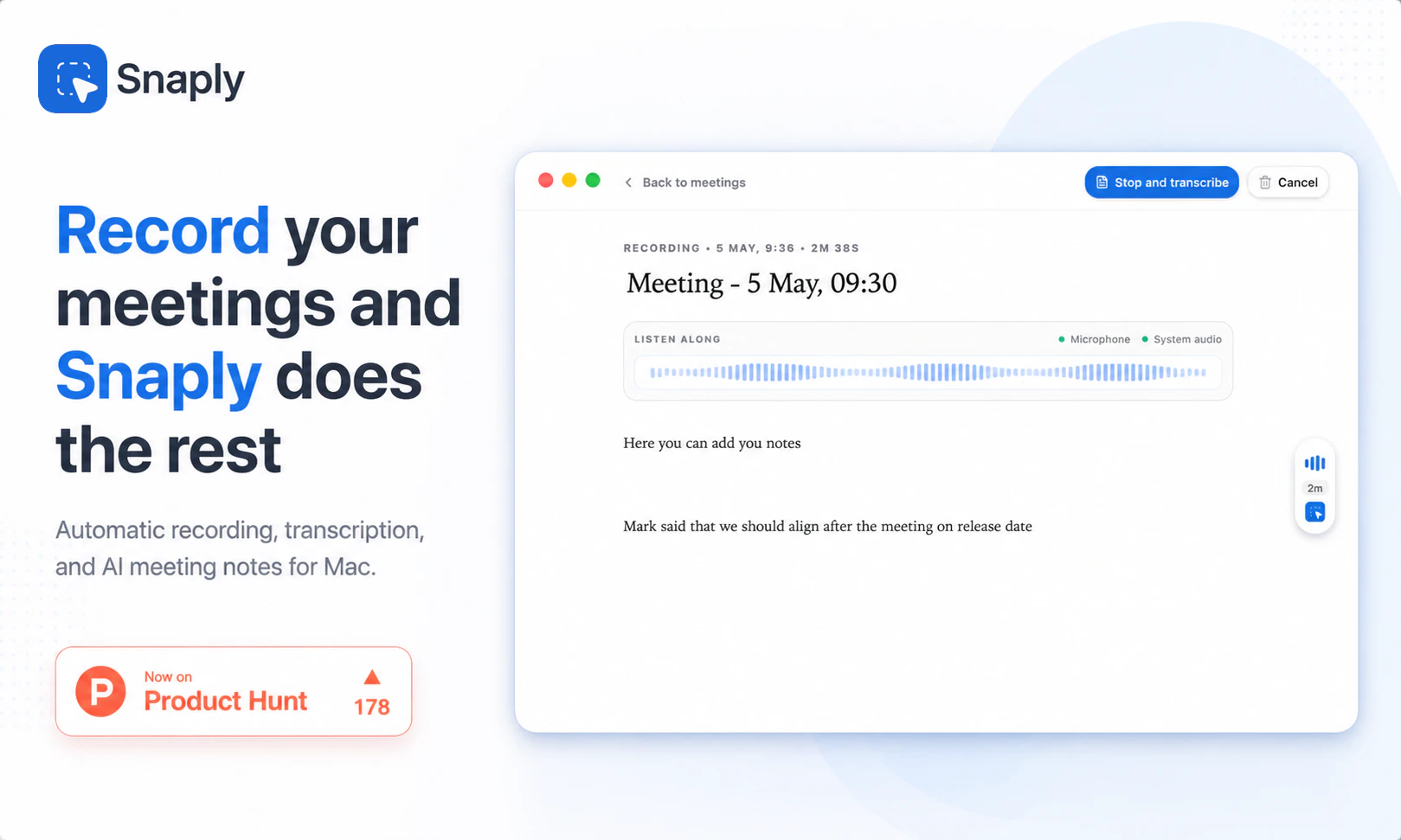
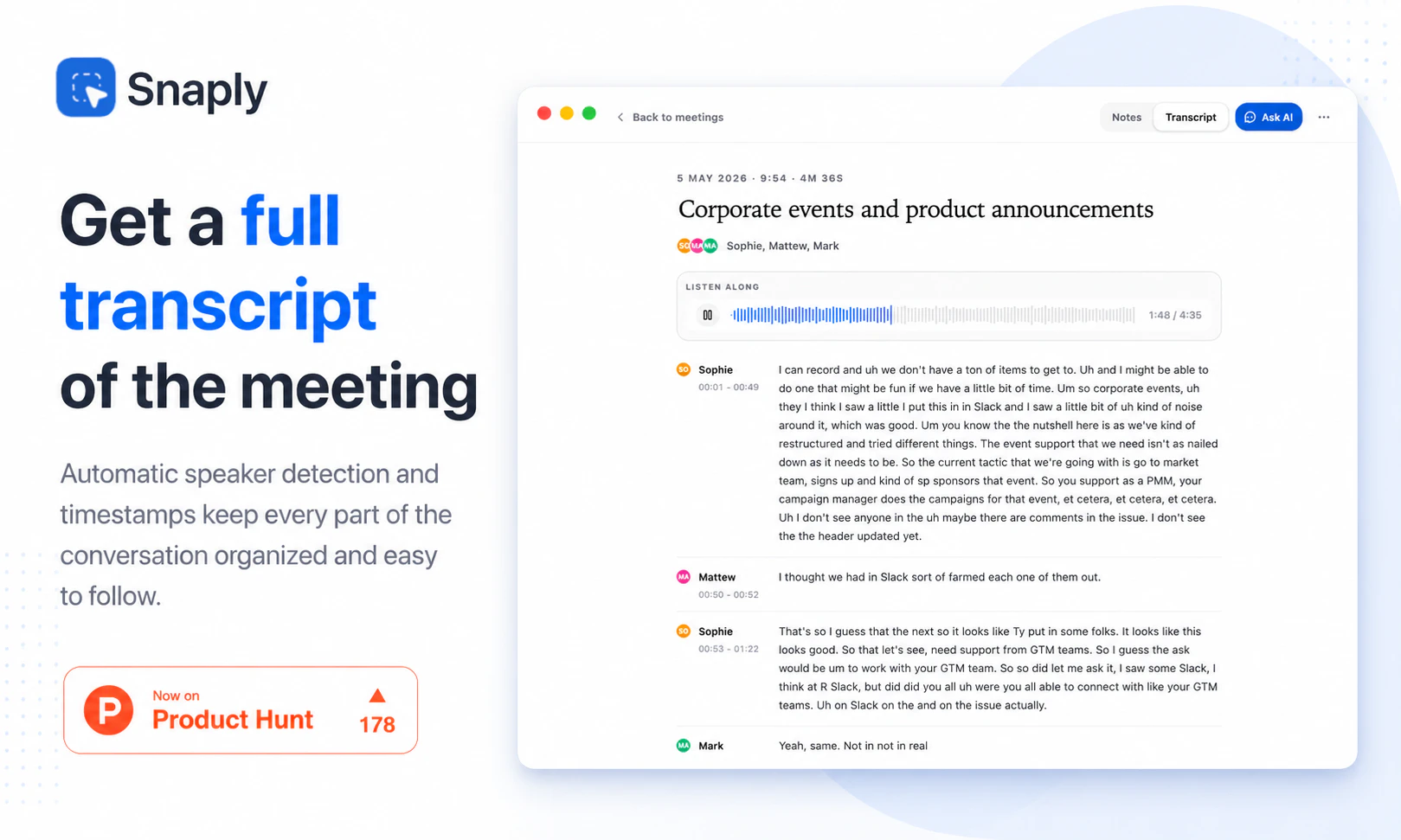
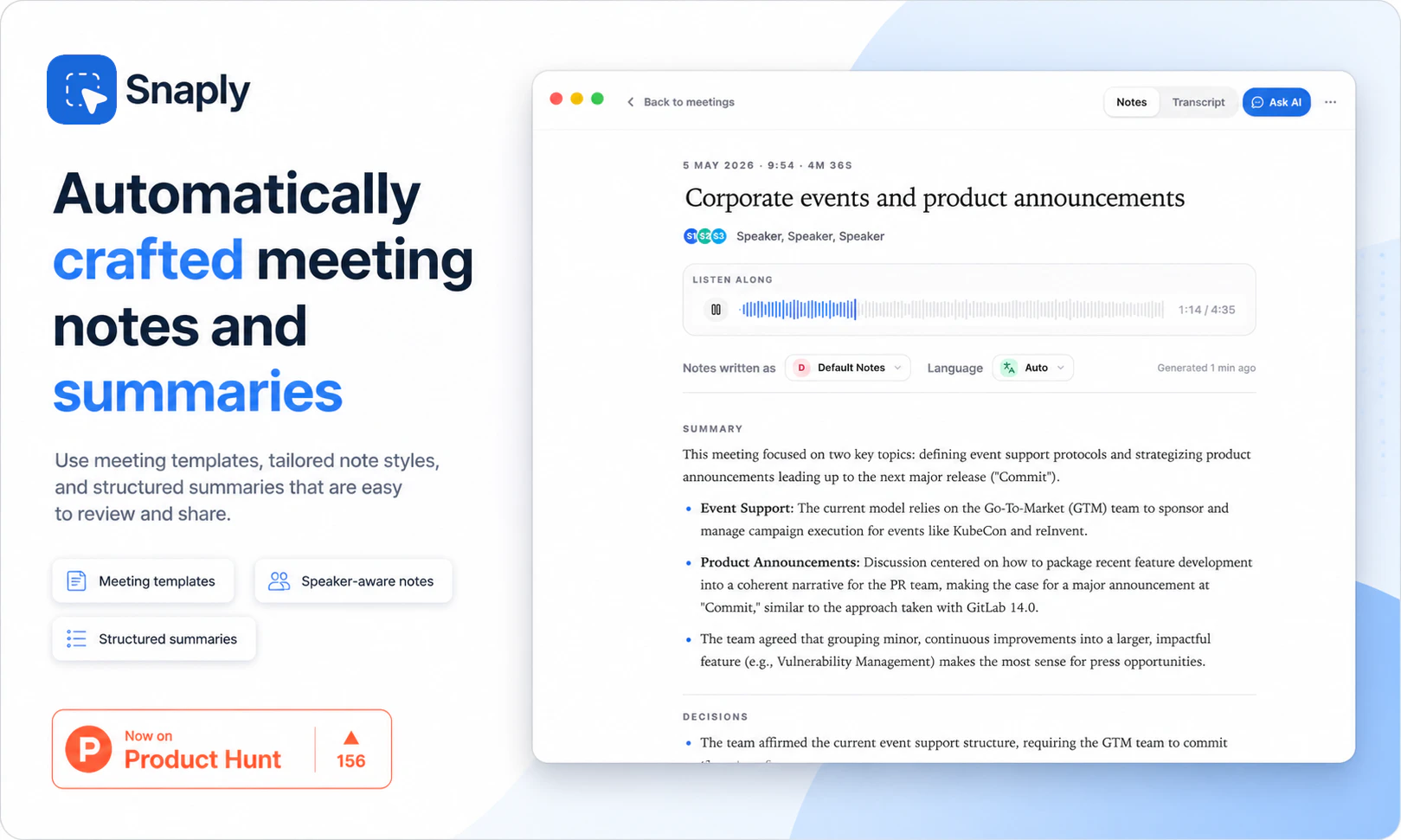
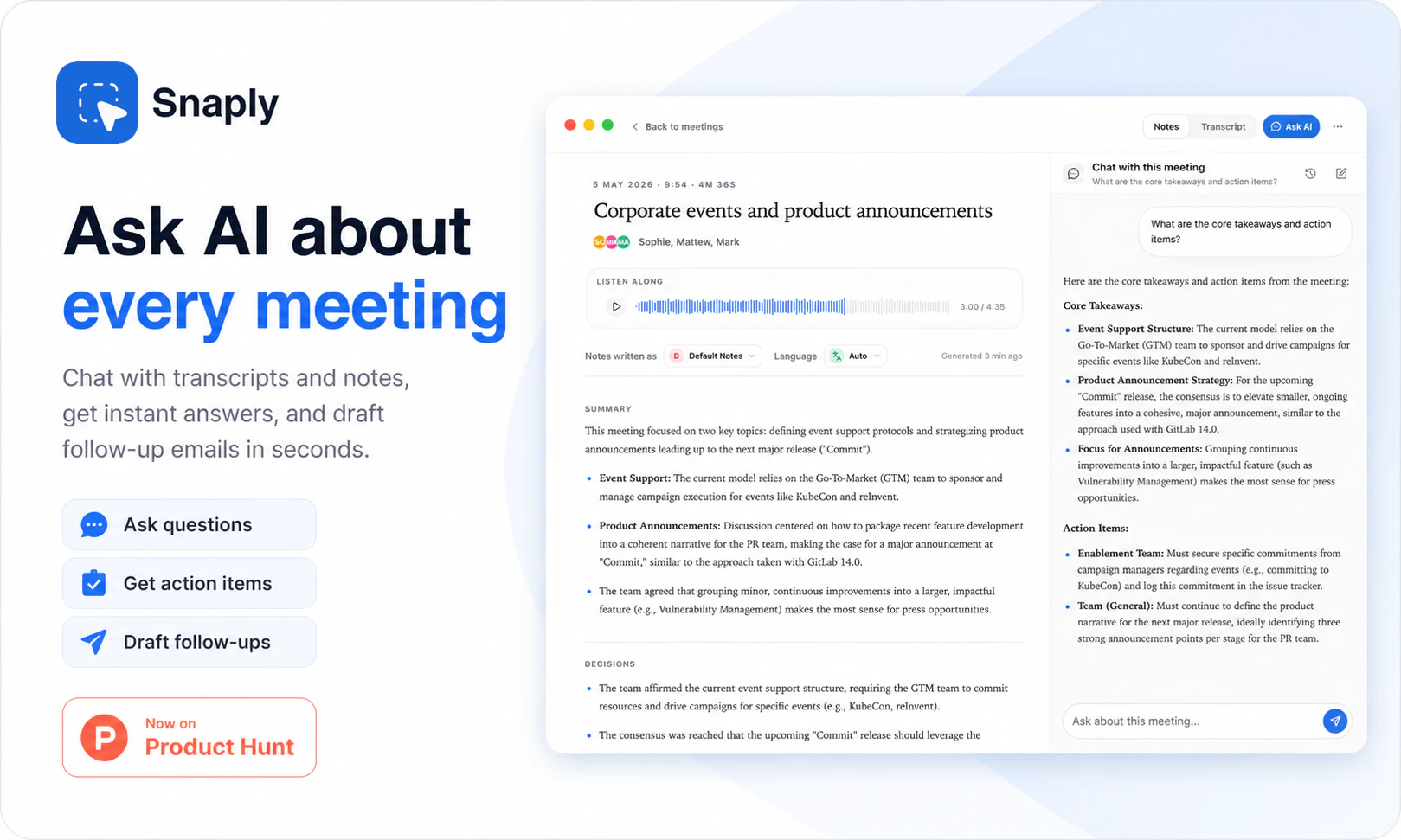
一句话介绍:Snaply是一款运行在Mac上的免费、本地化AI会议纪要工具,让用户在录屏、转录、总结会议和撰写后续邮件时,无需联网、无需注册、无需担心数据外泄,彻底解决敏感会议场景下对隐私和成本的焦虑。
Mac
Meetings
Artificial Intelligence
Mac应用
本地AI
会议纪要
语音转文字
隐私优先
离线处理
MLX模型
免费工具
生产工具
语音识别
用户评论摘要:用户关注本地转录(500MB模型)与云端工具的准确率差异,尤其关心噪声和口音处理;开发者确认英语准确率媲美云端,但暂不支持亚洲/非洲语言。用户还询问如何区分多说话人(答复:同时录制麦克风和系统音频),以及能否完全离线使用(支持首次下载模型后离线)。法律合规问题(单方同意录音)已被提醒。
AI 锐评
Snaply踩中了“隐私焦虑”与“语音会议”的交叉痛点,但它在技术兑现上仍有明显短板。以500MB的Whisper-small级离线模型,宣称与云端准确率“持平”,这在嘈杂环境或多人快语速场景下,理论上是不现实的——开发者自己也承认“云端会更好”。这恰好暴露了本地AI的最大矛盾:用户既要隐私安全,又要求比云端更好的识别体验,而现阶段本地模型的质量与体量很难与云端大模型正面竞争。不过Snaply聪明地集中在Mac音频捕获的完整性和本地LLM(MLX)的灵活生成上,让“隐私免费”成为护城河,而非“语音质量”。它更适合轻度、高隐私场景,如小型一对一会议或内部讨论,而不适合大型正式会议或需要精准多人分离的场合。一个潜在隐患是,开发者承诺“永远免费”,但本地推理的设备及GPU消耗不是零成本——后期商业模式注定会成为悬案。此外,缺少API或MCP接口也限制了它被更专业的AI工作流或企服工具调用的可能性,使其更多是“个人笔记本级”便利品,而非企业级解决方案。一句话:Snaply诚实地解决了“笔记本会议不想被监控”的痛点,但它的天花板,就是Mac本地语音模型的准确率边界。
一句话介绍:Plate 是一款面向小团队的极简项目管理工具,通过“工作区→项目→分区→任务”的有限结构,解决传统PM工具功能臃肿、学习成本高的问题,让团队快速聚焦任务推进,回归“纸笔般直观”的协作体验。
Task Management
项目管理
极简主义
小团队协作
任务看板
实时协作
轻量级
Basecamp替代
Linear竞品
PM工具创新
用户评论摘要:用户对极简理念认可,但核心质疑有三:1. 限制是否过于严格(如缺优先级、日历视图);2. 团队规模扩大后是否可用;3. 与Basecamp、Linear的差异化是否足够。建议补充“自定义字段”和第三方集成。
AI 锐评
Plate 的“反内卷”宣言值得赞赏——它精准戳中了被 Asana/Jira 功能滥用折磨的小团队痛点:看板、甘特图、自动化规则往往只是管理者的“控制欲装饰”,对实际产出并无增益。用有限层级(工程→项目→分区)强制设定“不要叠床架屋”,确实比那些提供 50 种视图却无人配置的工具高明。
但风险也在此:极简是双刃剑。团队可接受的“复杂度上限”因行业、规模而异——营销组需要日历联动,开发组需要优先级的量化,Plate 目前只提供了“项目→任务”的线性结构,更像是“带评论的共享清单”,而非项目管理。其强调“像纸一样简单”,却忽略了数字化转型的真正价值在于“自动化和关联性”(如任务依赖、超期提醒),这些恰恰是纸笔做不到的。
产品定位上,它夹在 Basecamp(更强调团队沟通)和 Linear(面向工程团队、更严苛的状态流)之间,有些尴尬。如果无法在“简单”和“够用”之间找到精确阈值,极易沦为精致的鸡肋——用户探索几次后,要么回归 Trello 的散养式管理,要么升级到 Linear 的结构化节奏。下一步的关键,不是增加功能,而是构建“可退出”的预设模板:允许用户少量自定义而不破坏核心简洁性,才是小团队付费的真实锚点。
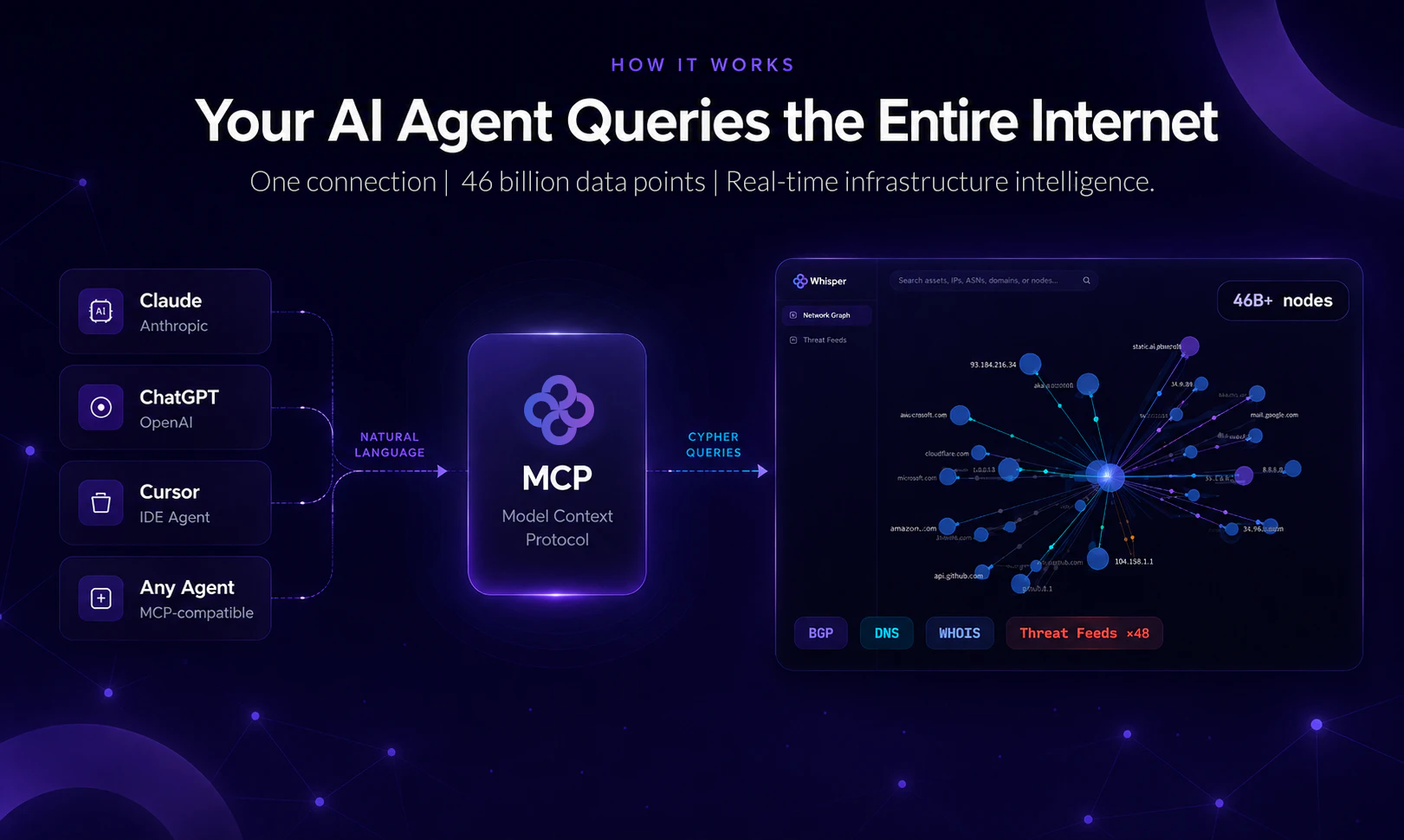
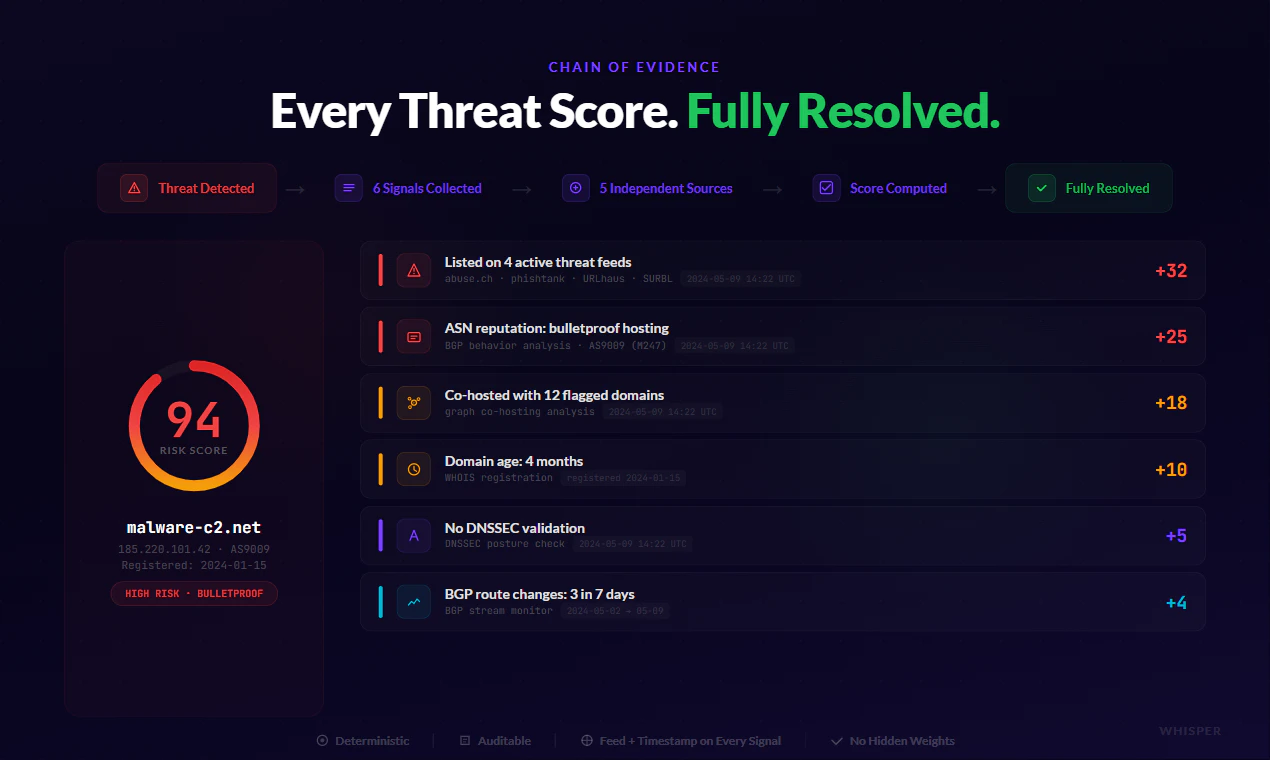
一句话介绍:Whisper提供MCP服务器,让AI代理(如Claude、Cursor)在2分钟内获得实时互联网基础设施上下文(BGP、DNS、WHOIS和威胁图谱),无需多次API调用,大幅节省AI上下文预算并加速调查。
Developer Tools
Artificial Intelligence
Security
MCP服务器
网络安全AI
实时BGP/DNS
威胁图谱
互联网基础设施智能
AI Agent上下文
图数据库
SOC工作流
自动化调查
46B数据点
用户评论摘要:用户肯定数据量和即时性,关注查询一致性(快照+不可变时间戳)、高并发链式查询性能(单跳毫秒级,Cypher化多跳)、实际上下文节省(避免多工具编排)、真实SOC场景挑战(时间轴关联、大扇出控制、内部数据融合)。团队承诺持续优化大扇出和客户侧集成。
AI 锐评
Whisper定位精准:AI Agent的“互联网地图”。其价值不在数据量大小,而在于将复杂、碎片化的基础设施查询(BGP/DNS/WHOIS/威胁)封装为一个MCP协议下的图查询接口。对于正在用Claude、Cursor等工具进行安全威胁调查的用户而言,这直接解决了“上下文预算”和“工具链编排”两大痛点。传统的多API+JSON解析模式在LLM中极易消耗token,而Whisper通过Cypher图遍历将多跳查询合并为一次,本质上是把“数据搬运”工作交给了底层引擎,让AI专注推理。
产品设计有老练的安全基础架构思维:不可变历史(只追加不覆盖)支持时间倒查,快照读保障事务一致性,以及由专业数据团队(RIPE NCC/ICANN背景)维护的实时网络拓扑。不过,犀利之处在于,其承诺的“极大节省上下文”和“Cypher一步到位”是否在所有SOC场景下成立?用户评论已指出大扇出(如CDN IP的三跳关联)和内部数据融合会是硬骨头。前者考验图数据库的剪枝能力,后者则涉及客户数据治理和安全隐私这类未解决的行业难题。
目前,该产品在MCP生态中的“护城河”尚不深——图数据库+安全数据接口模型并非独一无二,但“即插即用”的MCP标准化接入是关键的差异化优势。如果是AI Agent安全分析的刚需用户,值得立即试用;但若期望一个开箱即用的企业级S0C平台,仍需等待其工具链成熟及与内部日志的融合方案。总结:解决“AI不知道网络拓扑”的痛点很巧妙,但需更多真实大流量压力测试来证明其规模化后的稳定性。
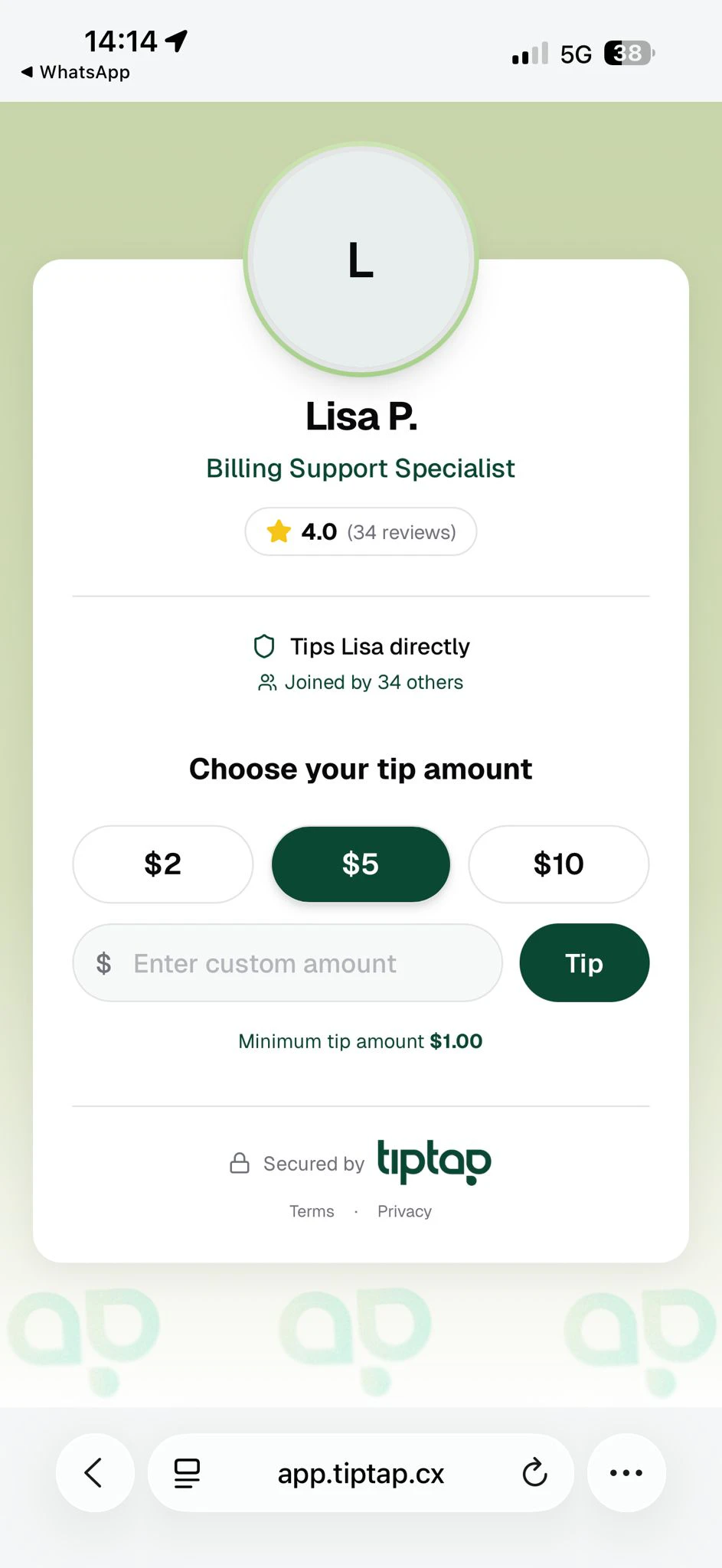
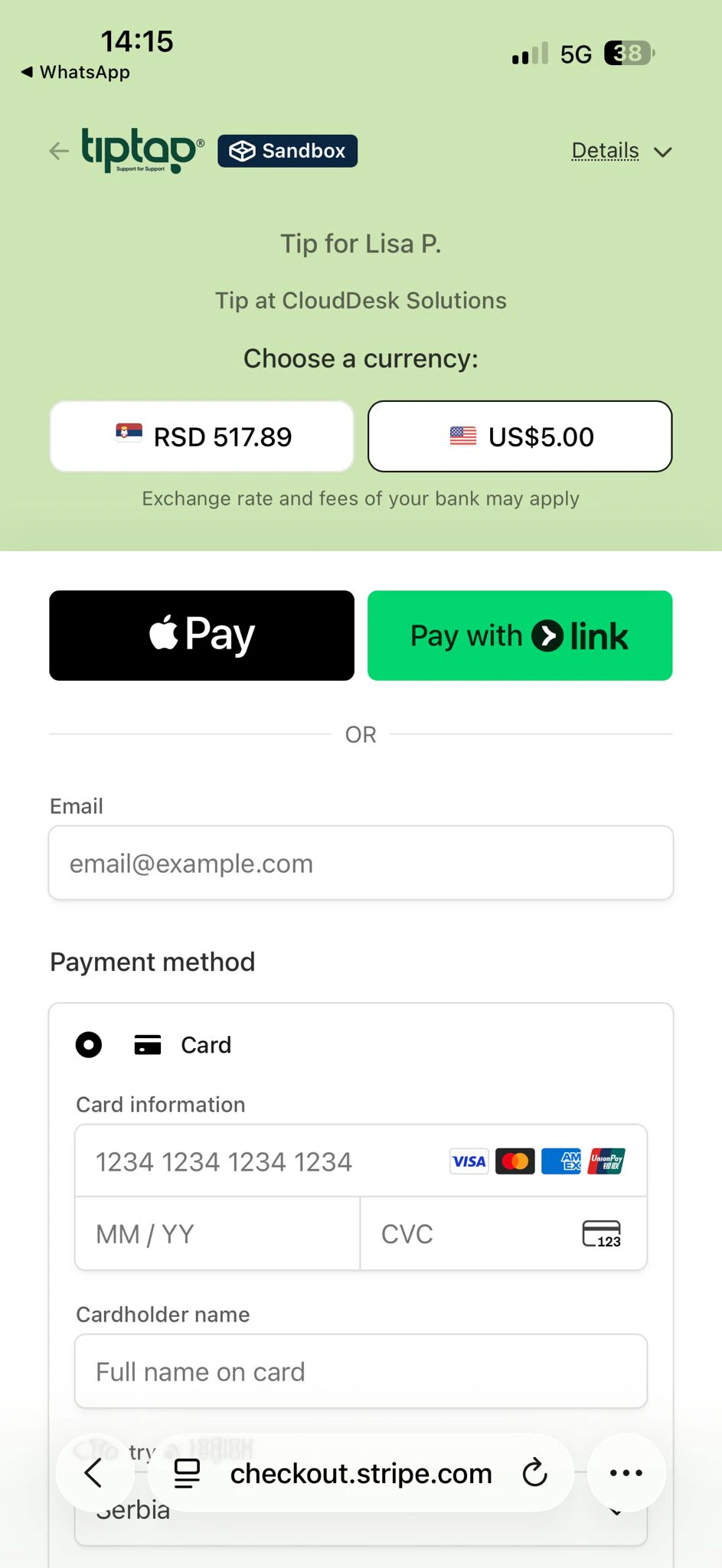
一句话介绍:TipTap通过在客服工单解决后嵌入小费打赏流程,让客户直接奖励提供优质服务的客服人员,解决客服行业收入低、流失率高、认可度不足的痛点。
User Experience
Customer Communication
SaaS
客户支持
小费打赏
客服激励
员工保留
零成本部署
Zendesk集成
Stripe支付
行为经济学
SaaS工具
人力资源管理
用户评论摘要:用户主要关注三个问题:打赏是否会让支持体验变得交易化(创始人强调仅在解决后出现且为感谢性质);如何避免高额小费偏向特定工单类型(承认偏差存在但认为零小费现状更差);以及打赏是否导致客服挑工单(论证复杂问题反而更容易获得高额小费)。自动化税务和支付逻辑受到好评。
AI 锐评
TipTap抓住了一个真实且被忽视的痛点——客服岗位的高流动率和低认可度,却用了一个极具争议性的解决方案:小费。产品的核心逻辑看似聪明:零成本部署、自动化支付、不触及公司薪酬体系,仿佛是一个能让三方都获益的“润滑剂”。但剥开“零成本”和“补充收入”的包装,它的价值并不纯粹。
首先,小费本质上是将客户满意度与客服收入进行了一次粗暴的线性绑定。这避开了系统性薪酬改革的难题,把本应由企业承担的激励成本,转嫁给了客户的“善意”和“冲动”。这让优质服务变成了一种随机性极强的运气,而非体系化的回报。客服拿到的是“赏钱”,不是“薪酬”,其尊严感和职业发展的公平性并未提升。
其次,评论中创始人承认的“偏差”——不同工单类型、不同客户群体的小费差异巨大——恰恰戳中了产品的软肋。这会把客服推向两个极端:要么为了高额小费而争抢“大单”,要么在低价值工单中持续承受“经济惩罚”。所谓的“管理者可见的队列分布”只是一个事后事换,无法解决因打赏产生的内部攀比和对低价值工单的隐性歧视。
TipTap真正的价值不在于“打赏”本身,而在于它提供了一套低成本、高可见的**行为数据反馈系统**。它强制性地让“服务质量”和“客户经济意愿”挂钩,并生成了微观层面的绩效指示。对于那些缺乏精细化激励工具、但又面临高流失压力的客服团队,它是一个有趣的实验性工具。但它绝不是一个根治客服人员激励问题的良方,更像是一剂止痛针,暂时掩盖了企业对全职员工进行公平薪酬设计这一根本责任的缺失。它能在特定场景(如SaaS、小众高端服务)获得欢迎,但试图将其推广到大型、复杂的客服组织中,将会诱发远比现在更隐蔽和麻烦的内部矛盾。
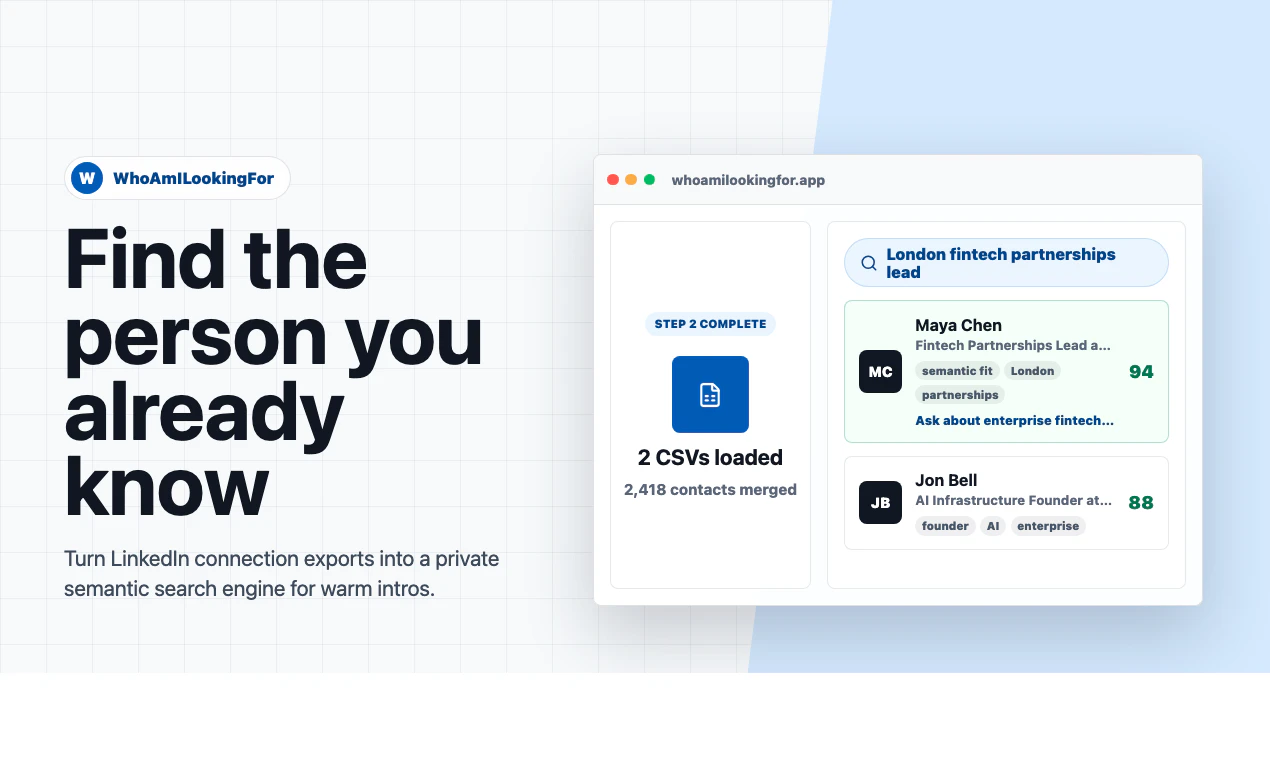
一句话介绍:WhoAmILookingFor是一个将LinkedIn联系人CSV文件转化为私有语义搜索引擎的工具,帮助用户在海量人脉中快速找到符合特定需求的人选,并提供匹配评分、理由、联系角度和邮件等 actionable 信息,解决了在庞大社交网络中高效定位目标人脉的痛点。
Productivity
Social Media
LinkedIn
LinkedIn人脉搜索
语义搜索引擎
CSV导入
人才筛选
人脉管理
AI匹配
销售线索
社交网络分析
人事招聘工具
产品猎头
用户评论摘要:用户“busmark_w_nika”反馈正面,表示会收藏该工具。开发者回复感谢关注,并邀请进一步反馈。目前评论数量较少,未显示具体问题或建议。
AI 锐评
WhoAmILookingFor瞄准了一个被低估的痛点:LinkedIn人脉数据量大但搜索粗暴。传统筛选依赖关键词匹配或手动浏览,而这款产品通过语义搜索和CSV离线处理,把联系人清单变成了可定制的人才雷达。从产品介绍看,它的核心价值不在“搜索”,而在“推理”——不仅告诉你“谁合适”,还解释“为什么合适”,并提供 outreach 策略,这直接缩短了商务拓展和招聘漏斗的第一步效率。
但问题也很明显:数据源仅限LinkedIn导出的CSV,这意味着用户必须先手动导出联系人文件,且数据存在时间差。更关键的是,92个投票、1条有效评论,说明产品仍处于早期验证阶段,缺乏真实用户反馈,特别是关于准确率、数据隐私(“私有”引擎如何保障?)、以及是否支持实时更新的合规风险。此外,竞品如Clay、Apollo.io等已提供更全面的数据聚合+自动化流程,除非它在语义匹配的精准度和成本上有显著突破,否则很容易沦为“小众插件”而非高效工具。
一句话锐评:创意不错,但壁垒不高,需要更丰富的实时数据源和商业场景验证才能从“玩具”变成“武器”。
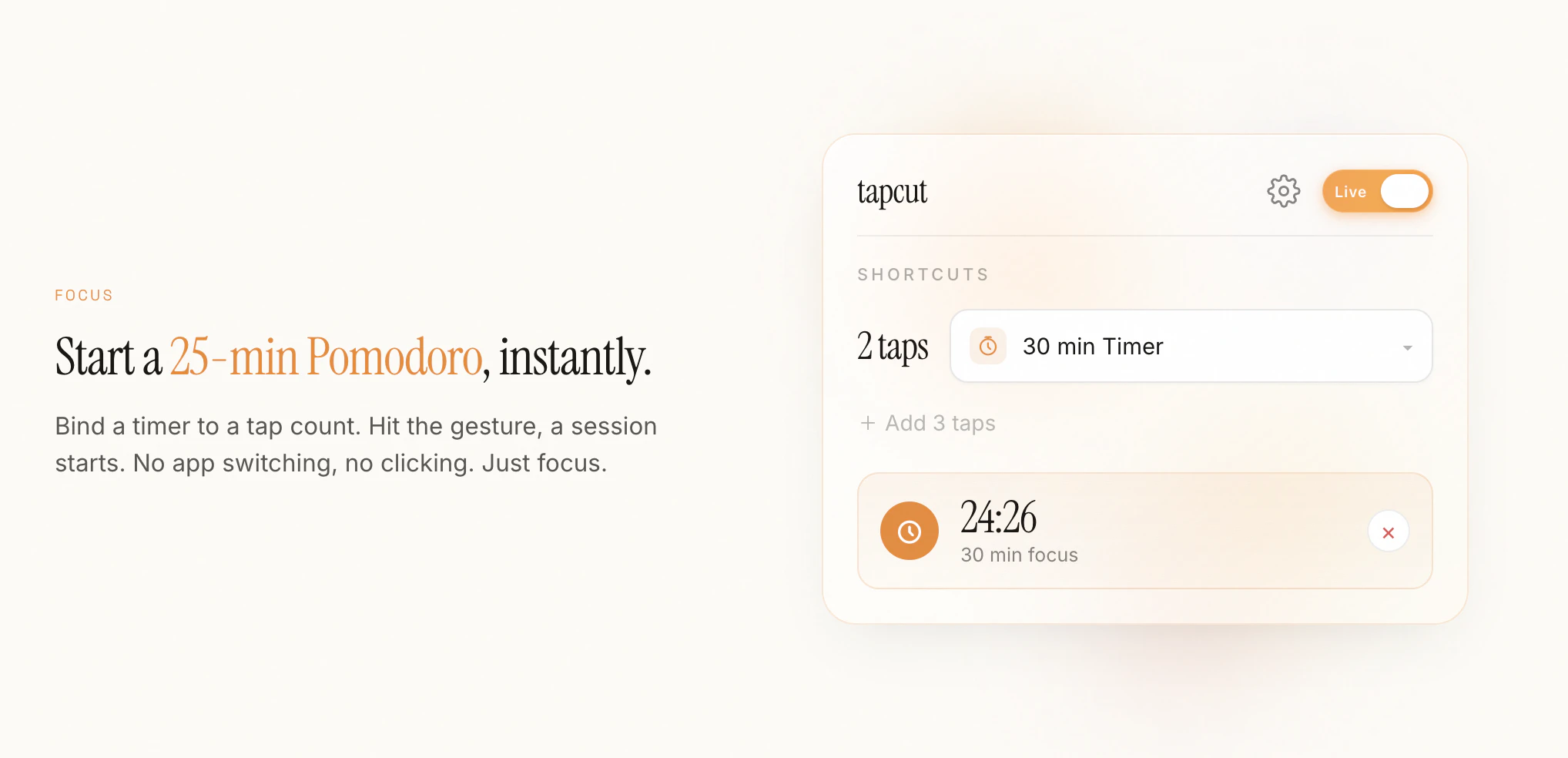
一句话介绍:tapcut 利用 MacBook 内置加速度传感器,将轻拍掌托的 2/3/4 次敲击映射为触发 AI 对话、运行快捷指令或启动应用的快捷操作,解决了用户记不住热键、打断工作流的问题。
Mac
Productivity
Tech
手势控制
快捷键替代
加速度传感器
MacBook 效率工具
应用启动器
苹果芯片
macOS 快捷指令
无代码自动化
生产力工具
触控手势
用户评论摘要:用户对加速度传感器输入的新颖性表示赞赏,但担心在咖啡桌等晃动场景下误触。开发者回应称通过“抖动检测”算法(瞬时加速度变化幅度)过滤误触,并提供灵敏度滑条及将高风险动作映射到 3/4 次敲击的规避方案。
AI 锐评
tapcut 的聪明之处不在于“又做了一个快捷启动器”,而在于它挖掘了 Apple Silicon 平台上一个被严重忽略的硬件潜力——内置加速度计。这种“偷”来的硬件输入,比触控栏更物理,比语音更隐私,比热键更直觉。但它的价值也受限于这个精妙的“副作用”:它本质上是把“敲击”当成一种有节奏的 binary 信号,其表达能力天然有限,且依赖场景的物理稳定性。开发者坦诚地承认了咖啡桌误触的边界,并给出了 2/3/4 次敲击的风险分级方案,这是务实的,但也暗示了该产品在复杂工作流中难以成为核心交互方式——它更适合做“记忆负担极低”的少数几个高频动作(如唤出 Claude、截图),而不是替代键盘映射的全部。从 89 票和仅两条评论(含作者自答)来看,产品尚未形成大规模的社区反馈循环,其真正的耐久性取决于 “用户愿意忍受多少次误触以换取那 0.5 秒的便利”。对于追求极简且只使用少数 AI 插件的 MacBook 用户,这是一个优雅的捷径,但若想覆盖更多场景,taouct 需要更智能的环境感知(比如结合前摄像头判断用户是否在使用键盘),而非仅靠一次敲击的力度曲线。
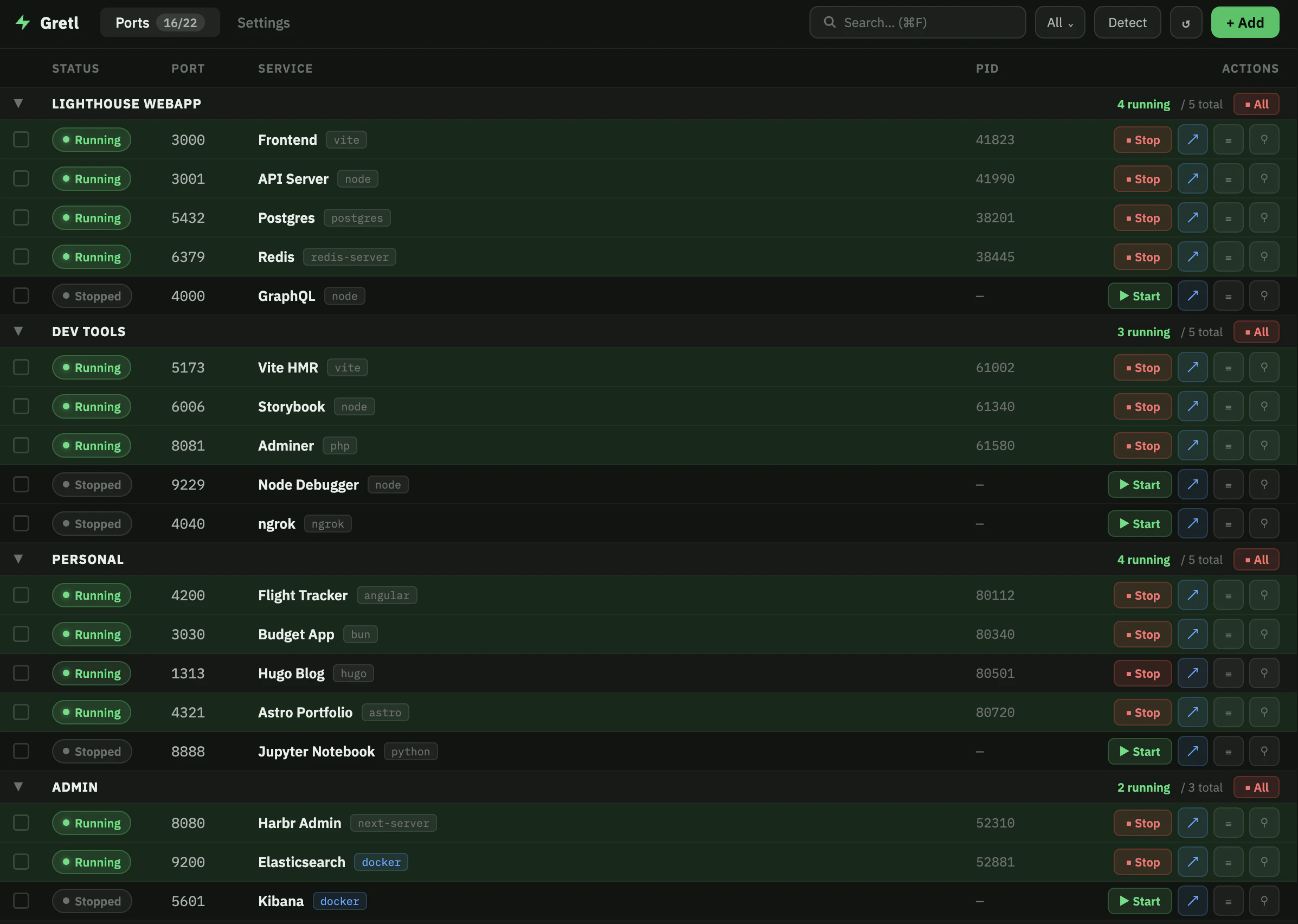
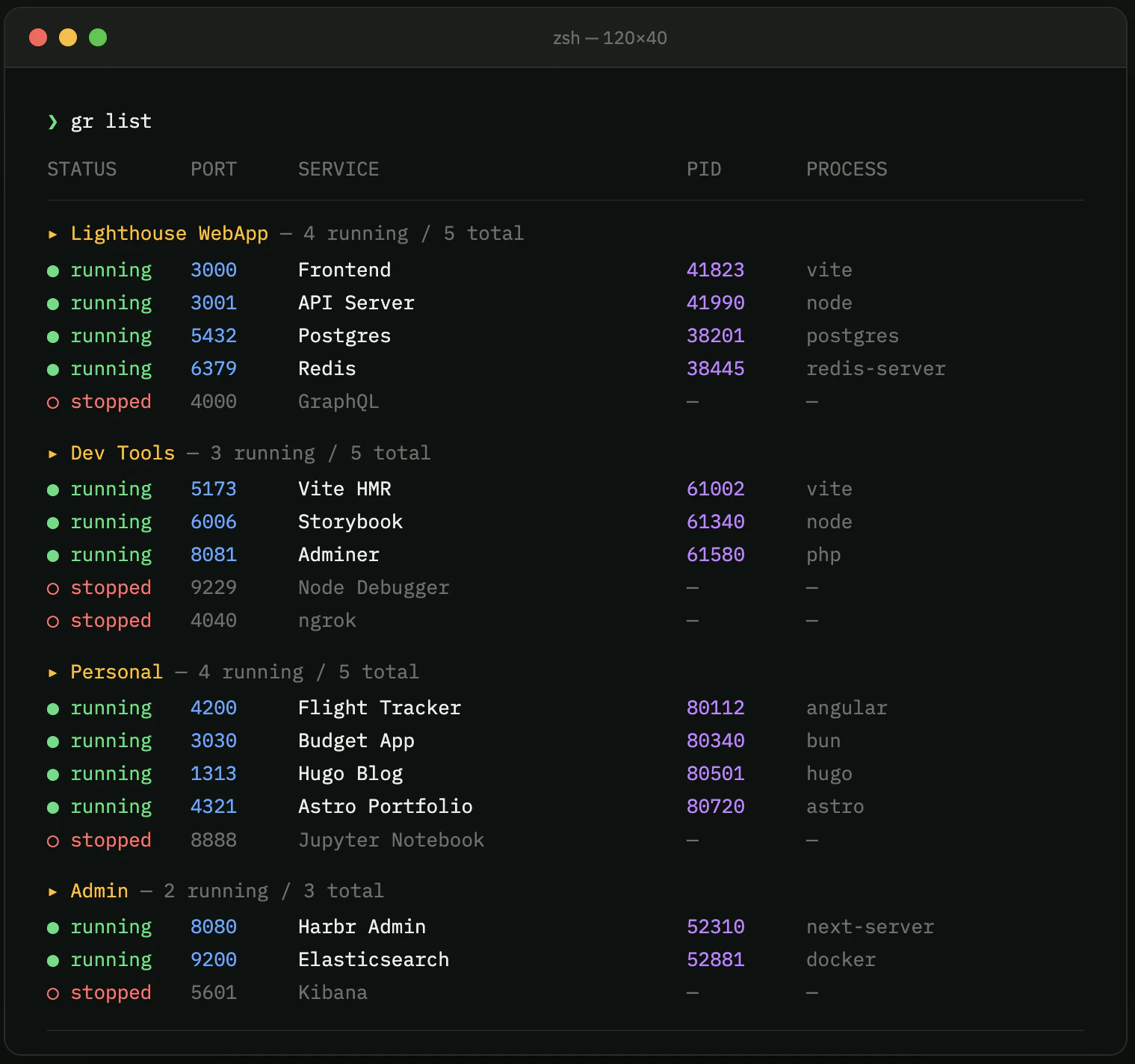
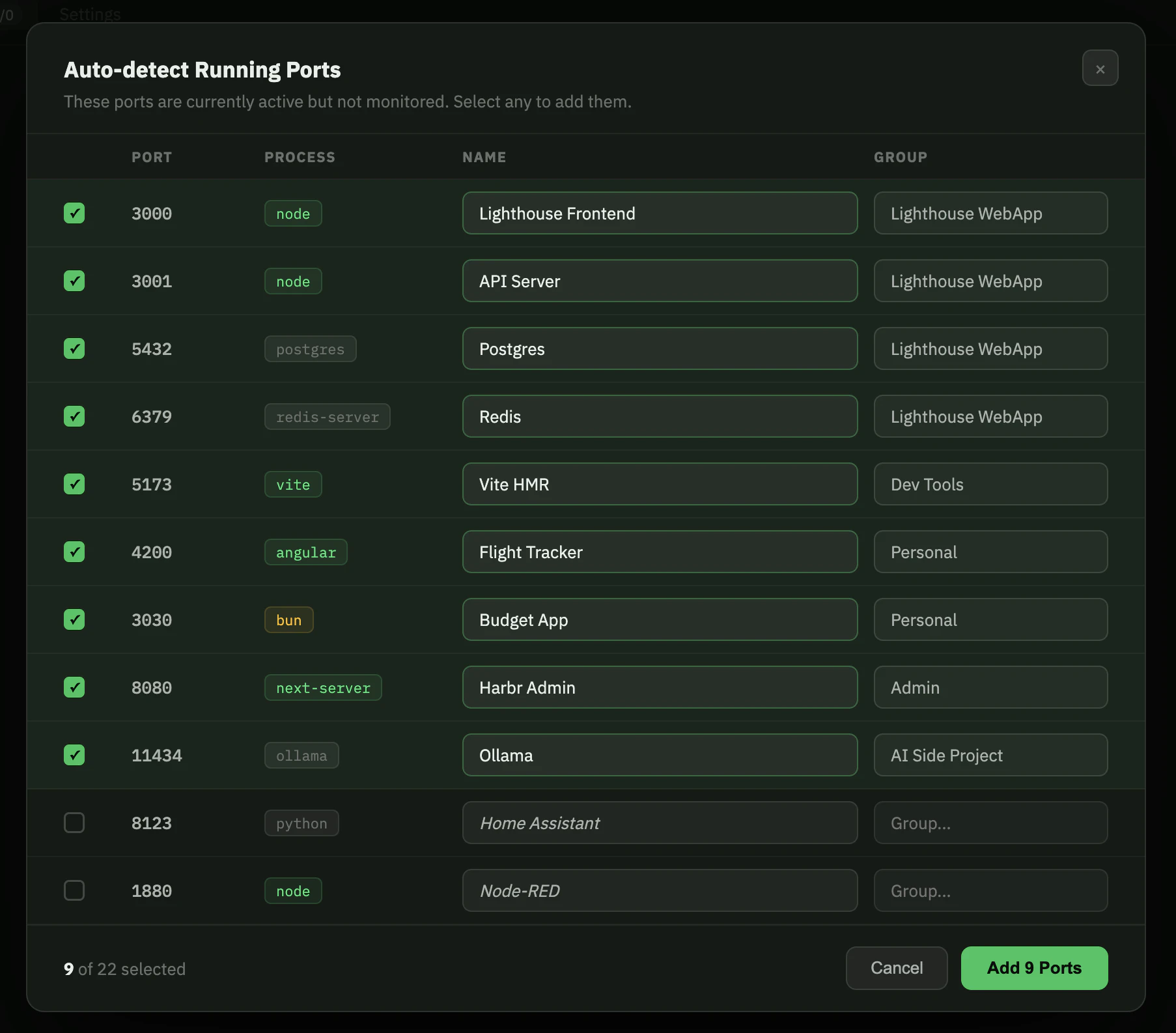
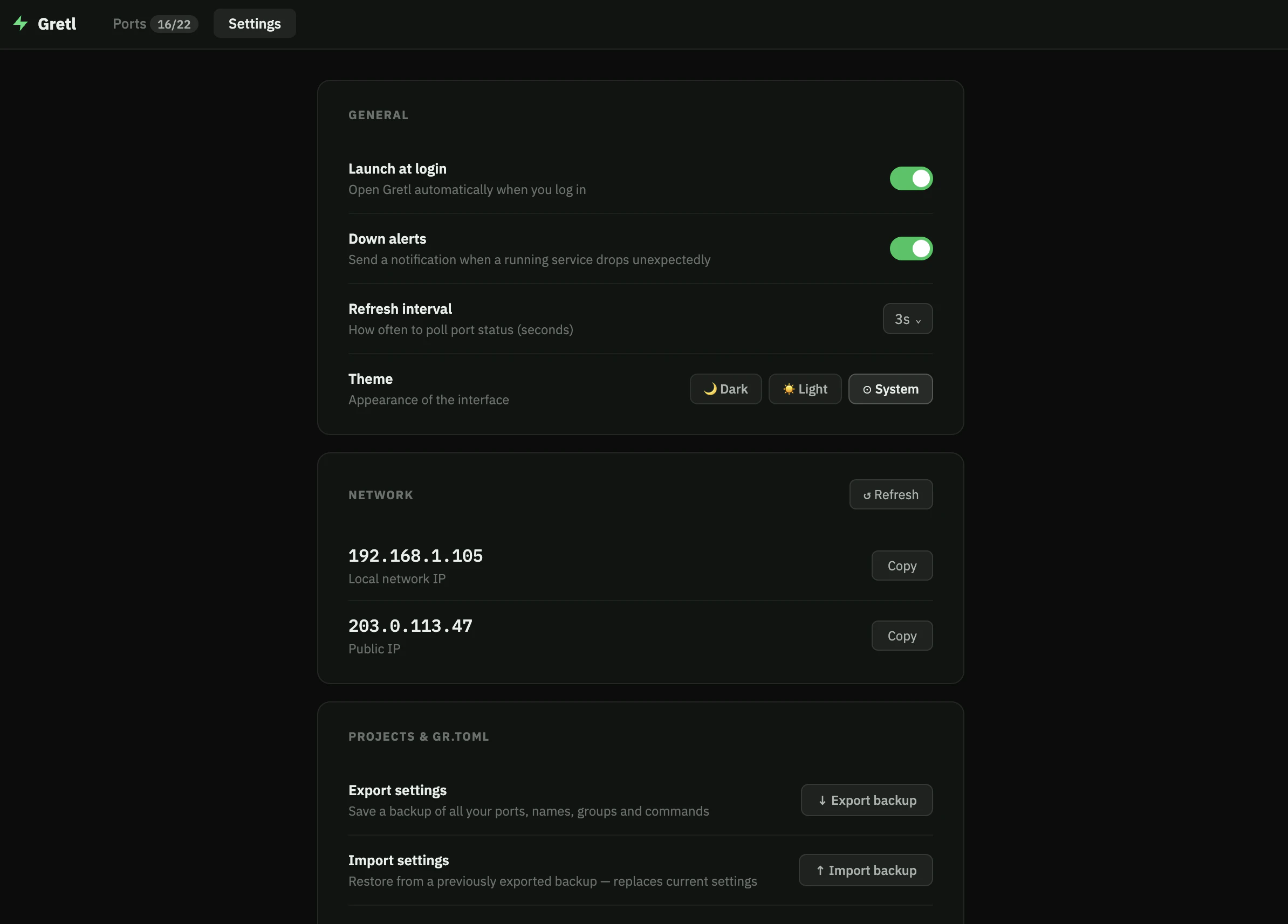
一句话介绍:Gretl 是一款菜单栏端口管理器,通过可视化界面和配置文件,解决开发者在本地开发时频繁查询“端口上跑了什么”以及团队协作时重复配置的痛点。
Productivity
Open Source
Developer Tools
GitHub
端口管理
本地开发
开发者工具
菜单栏应用
CLI工具
团队协作
配置即代码
运维
SDK
Mac工具
用户评论摘要:开发者普遍认同“查询端口上跑了什么”是常见痛点。产品核心功能被肯定,特别是自动检测、gr.toml配置文件以及CLI与UI的统一,被认为能有效减少新成员的学习和配置成本。
AI 锐评
Gretl切中了一个真实但常被忽视的“微痛点”——本地开发端口混乱。它的巧妙之处在于将“临时性”的端口信息“资产化”和“代码化”。通过gr.toml配置文件,它将一个原本属于个人习惯的管理问题,转化为了可版本控制、可自动化分发的团队协作标准,这比单纯提供一个GUI工具更具商业护城河价值。产品自身定位清晰:不做容器编排(如Docker)、不做反向代理(如Nginx),而是作为它们的“端口大脑”,填补了从“跑起来”到“管理好”之间的空白。
然而,风险也很明显。88票的低热度反映出它并非普适性刚需。Docker、Kubernetes、以及VSCode内置的端口转发面板已经覆盖了大部分场景。Gretl的优势在于对非容器化环境(如部分公司遗留项目、快速原型开发)和微服务数量适中的Node/Python项目的管理。它需要进一步挖掘更具体的杀手级场景,例如与测试框架深度集成(用SDK在CI中按名控制端口启停),或结合ngrok等工具实现一键隧道共享,否则很容易沦为“更好看的系统监视器”。其真正价值不在于“管理端口”,而在于“定义工作流”,能否围绕这一点构建生态,是成败关键。
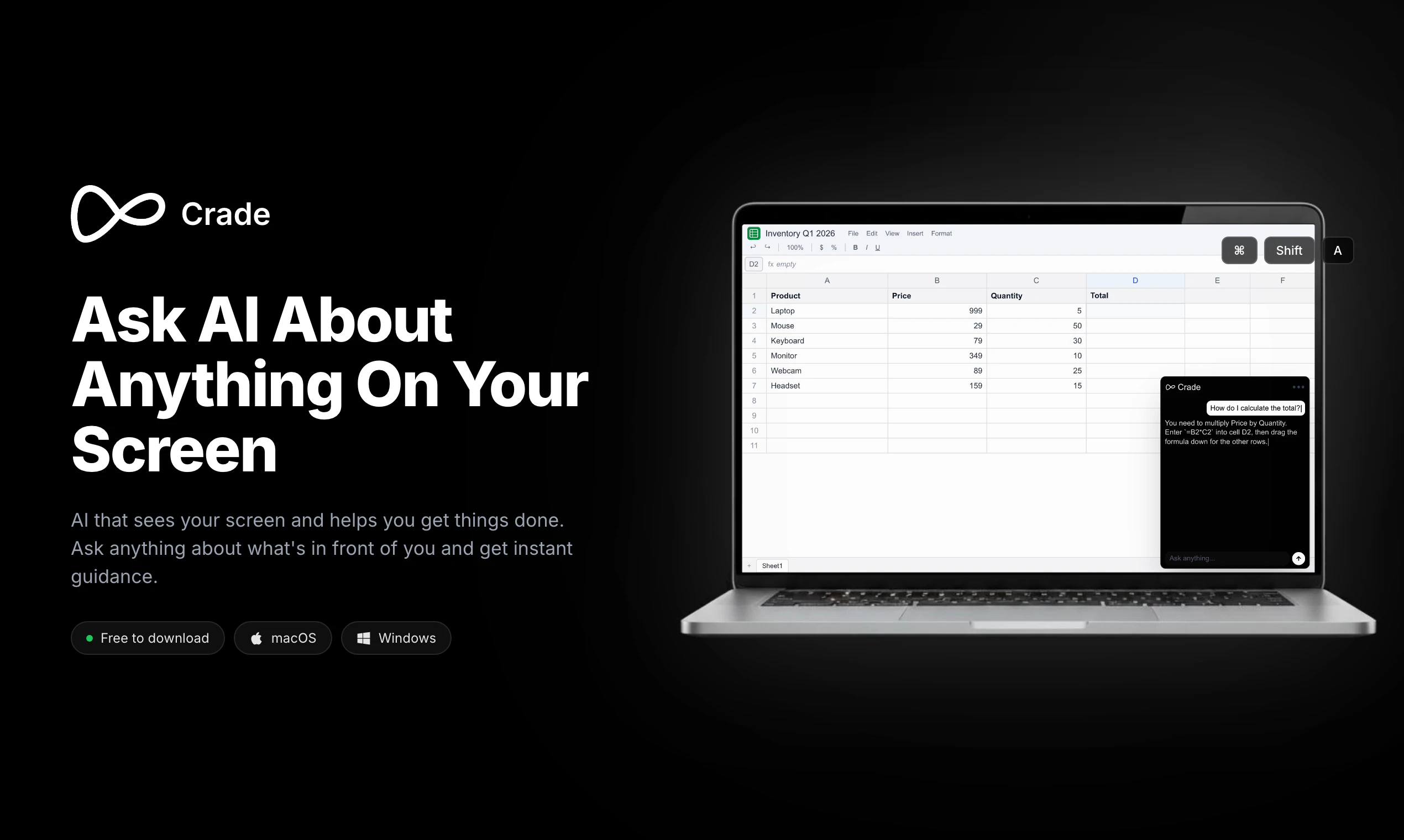
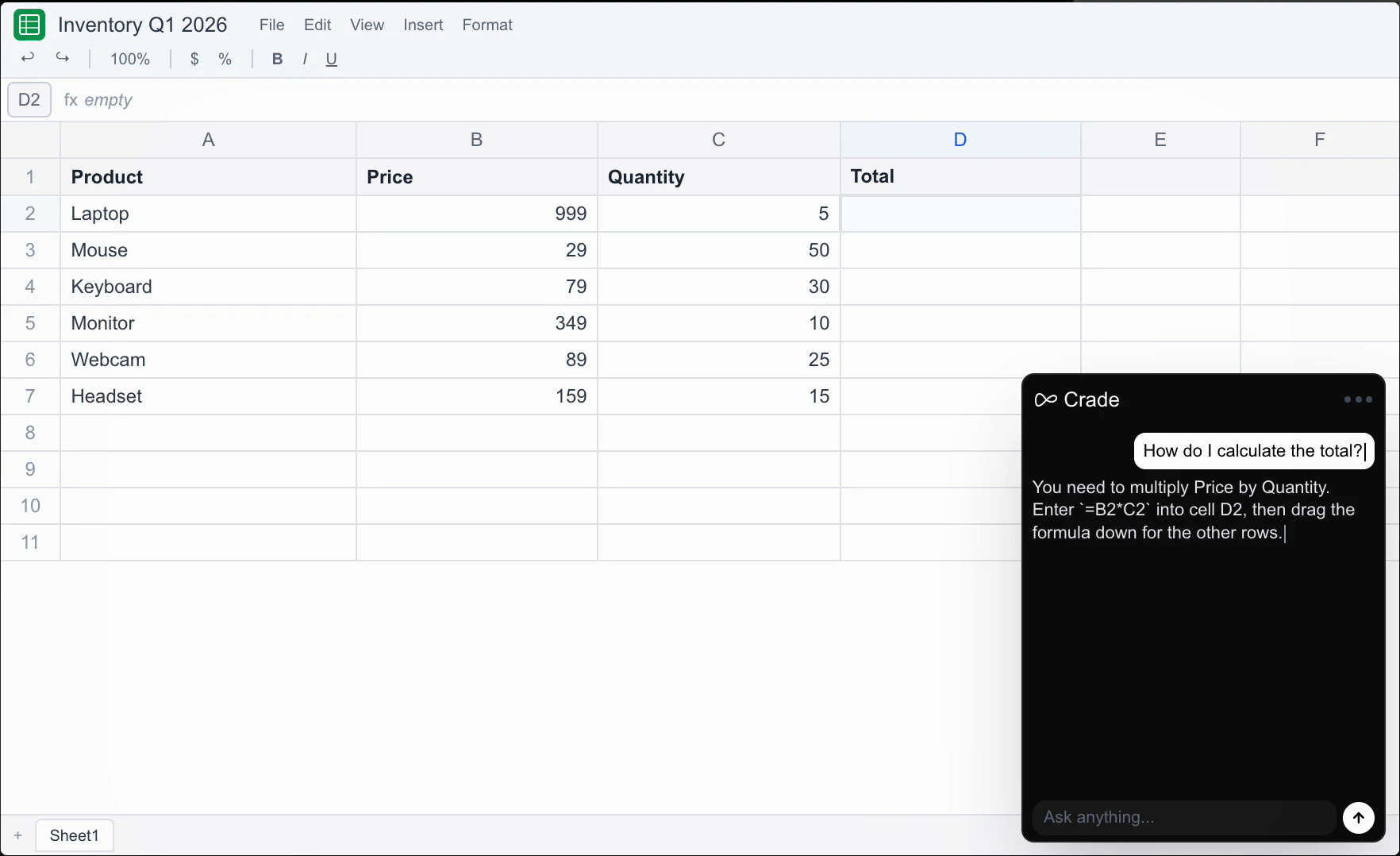
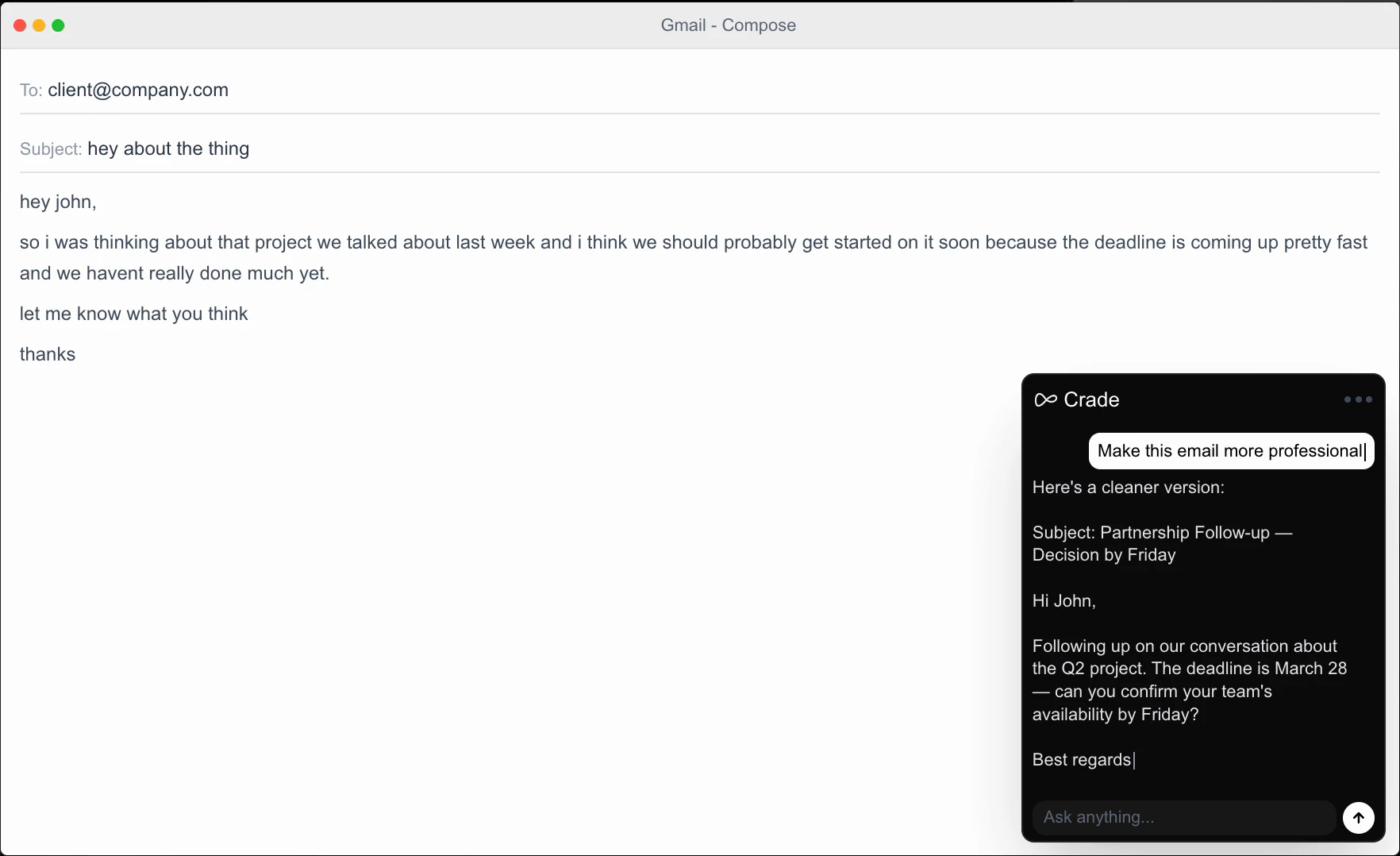
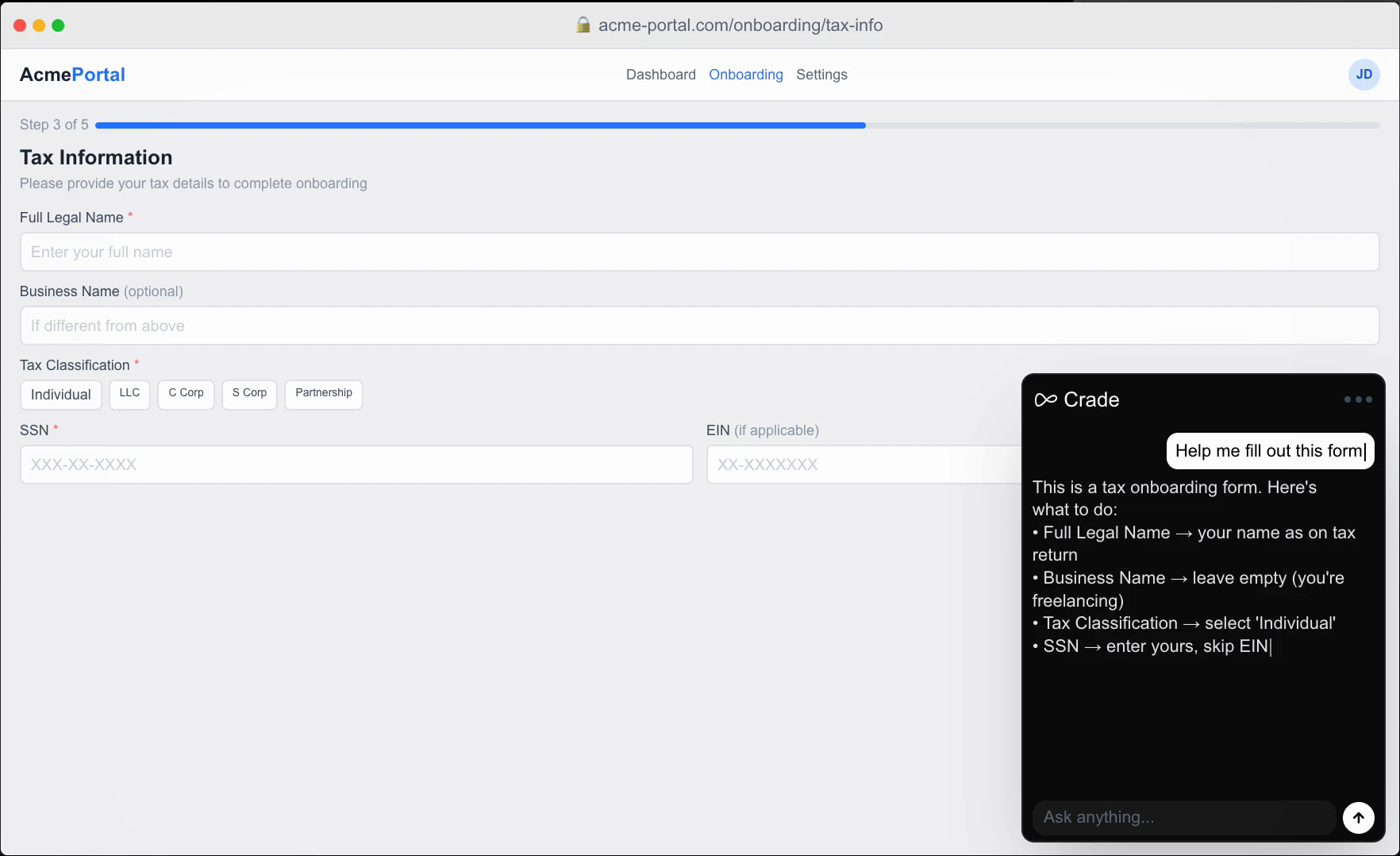
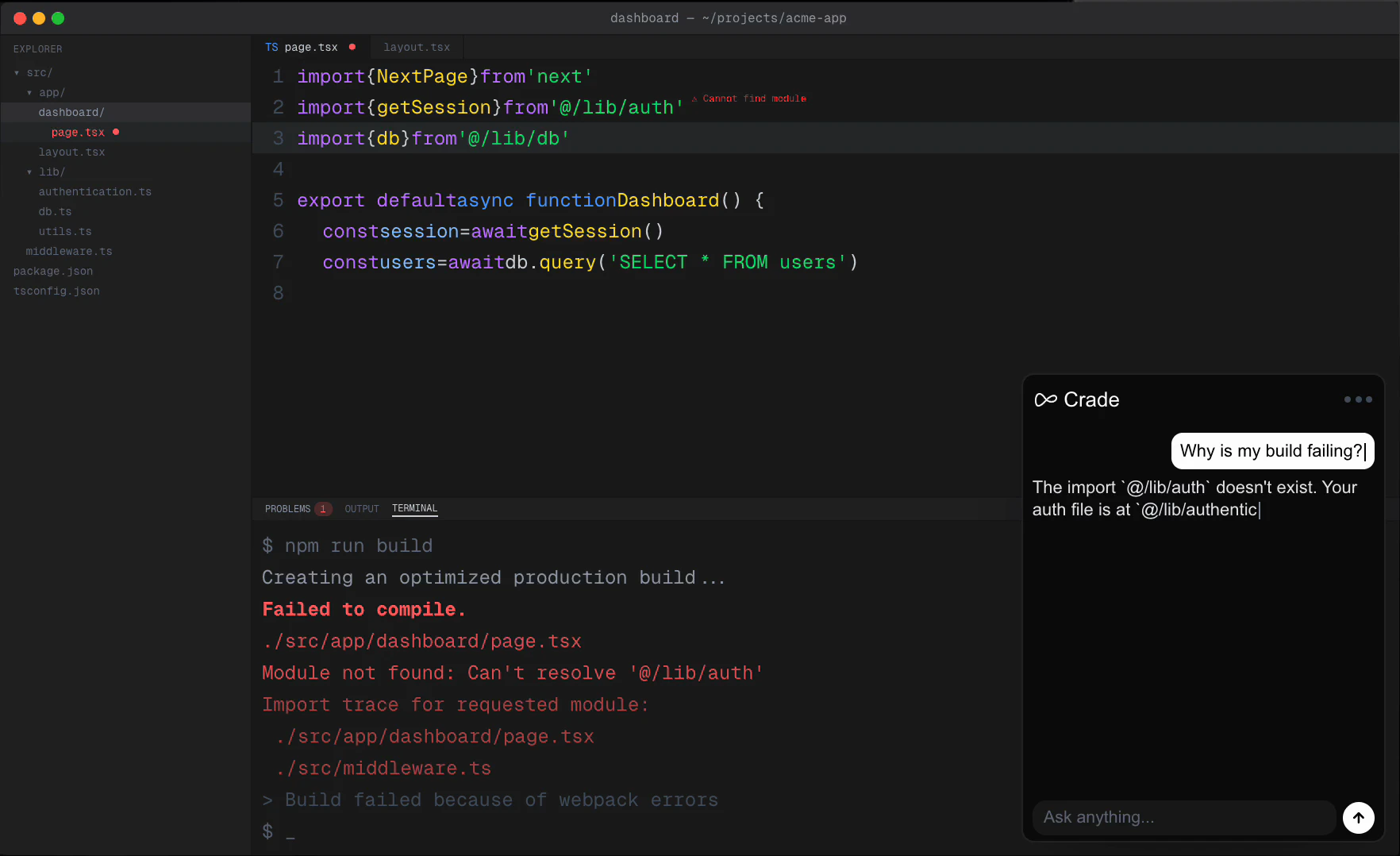
一句话介绍:Crade AI 是一款能实时“看见”用户屏幕的桌面AI助手,无需截图、复制粘贴或切换浏览器,直接在正在工作的软件上方弹出答案,解决了多步截图上传与AI对话的繁琐流程痛点。
Productivity
Developer Tools
Artificial Intelligence
桌面AI助手
屏幕感知
AI副驾驶
生产力工具
效率提升
截屏替代
实时问答
Mac/Windows
低代码
开发调试
用户评论摘要:用户认可其解决截图-上传-切换等痛点,特别适合调试、电子表格、工作流自动化场景。有用户追问能否自主与桌面元素交互并执行自动化任务,以及能否捕捉按钮点击等动态状态变化。另有回帖者暗示可协助拓展国际市场。
AI 锐评
Crade AI 切中的是一个非常实在且高频的“微摩擦”场景——在AI对话与桌面操作之间反复横跳。本质上,它用“屏幕共享”代替了“屏幕截图+文件上传”,把多步动作压缩为一步直接提问。这个改动虽小,但对那些每天要在代码、表格、邮件和AI之间来回切换的职场人而言,节省的不是几秒钟,而是注意力的连续性。
但从产品护城河来看,Crade目前更像是一个“聪明的截屏转发器”。它的核心能力是感知屏幕,而非理解并操作屏幕。用户评论中提到的“能否自主执行自动化任务”和“能否捕捉动态状态变化”才是真正的深水区——如果它只是被动接收问题、借助大模型看截图作答,那么它和用户手动截图上传的差距只在“少点两次鼠标”。真正有价值的差异化在于:能否主动监测屏幕变化、触发上下文感知的自动建议、乃至自动化部分重复操作(如识别错误弹窗后自动给出修复命令)。
此外,定价上7.99美元/月、1000次/月(Pro)略显中庸。对于高频使用者,这个额度可能捉襟见肘;对于轻度用户,免费200次/天又足够覆盖大部分日常。这可能导致它既难以留住重度付费用户,又难从免费用户中实现转化。产品方向如果向“工作流自动化助手”演进,则定价逻辑需随之重建;如果持续停留在“截图替代器”,则面临同类OCR+Paste插件的低价围剿。一句话:切入点很好,但得赶紧长出操作反馈的“手”来,否则会被当作一个漂亮的“眼镜”。







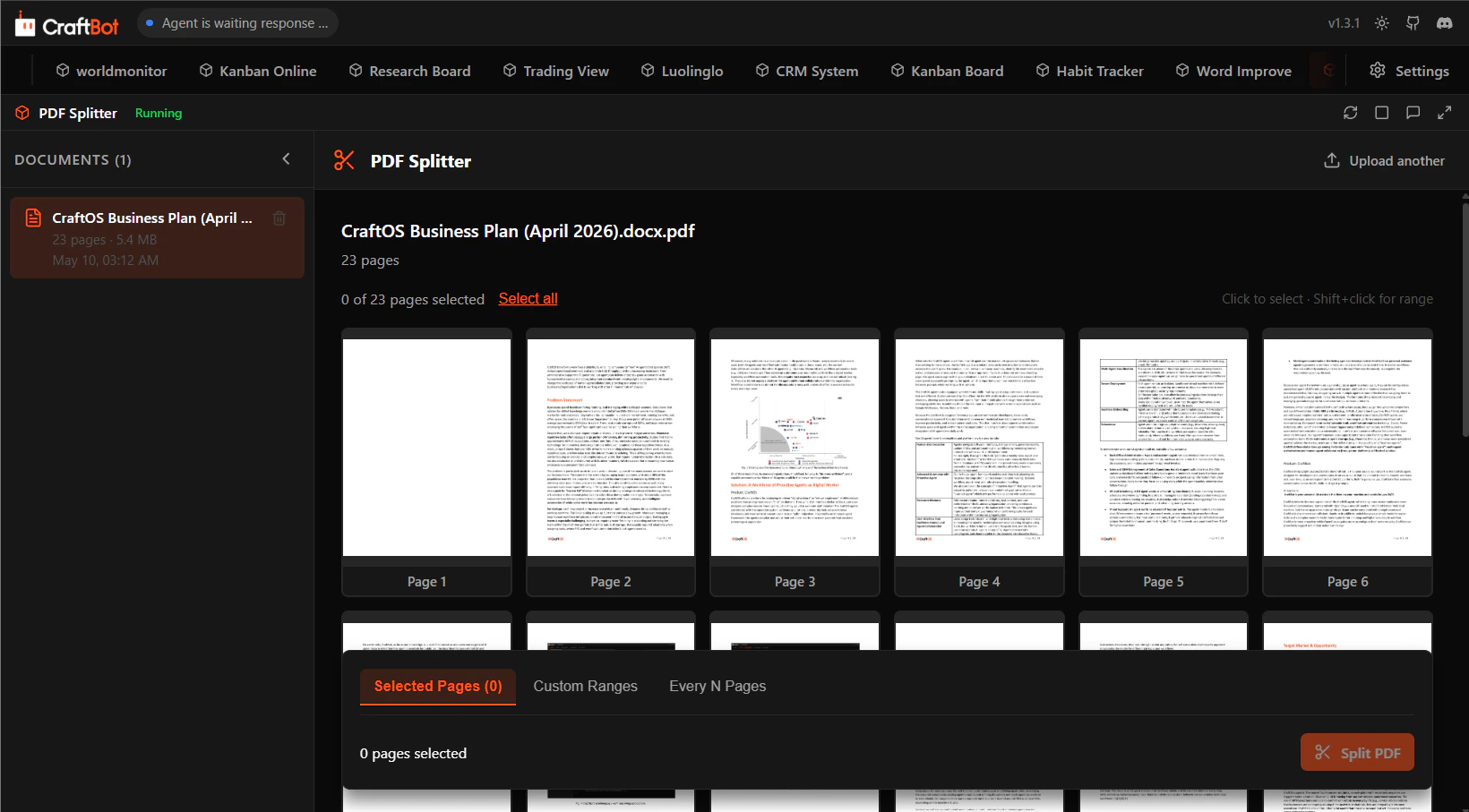
































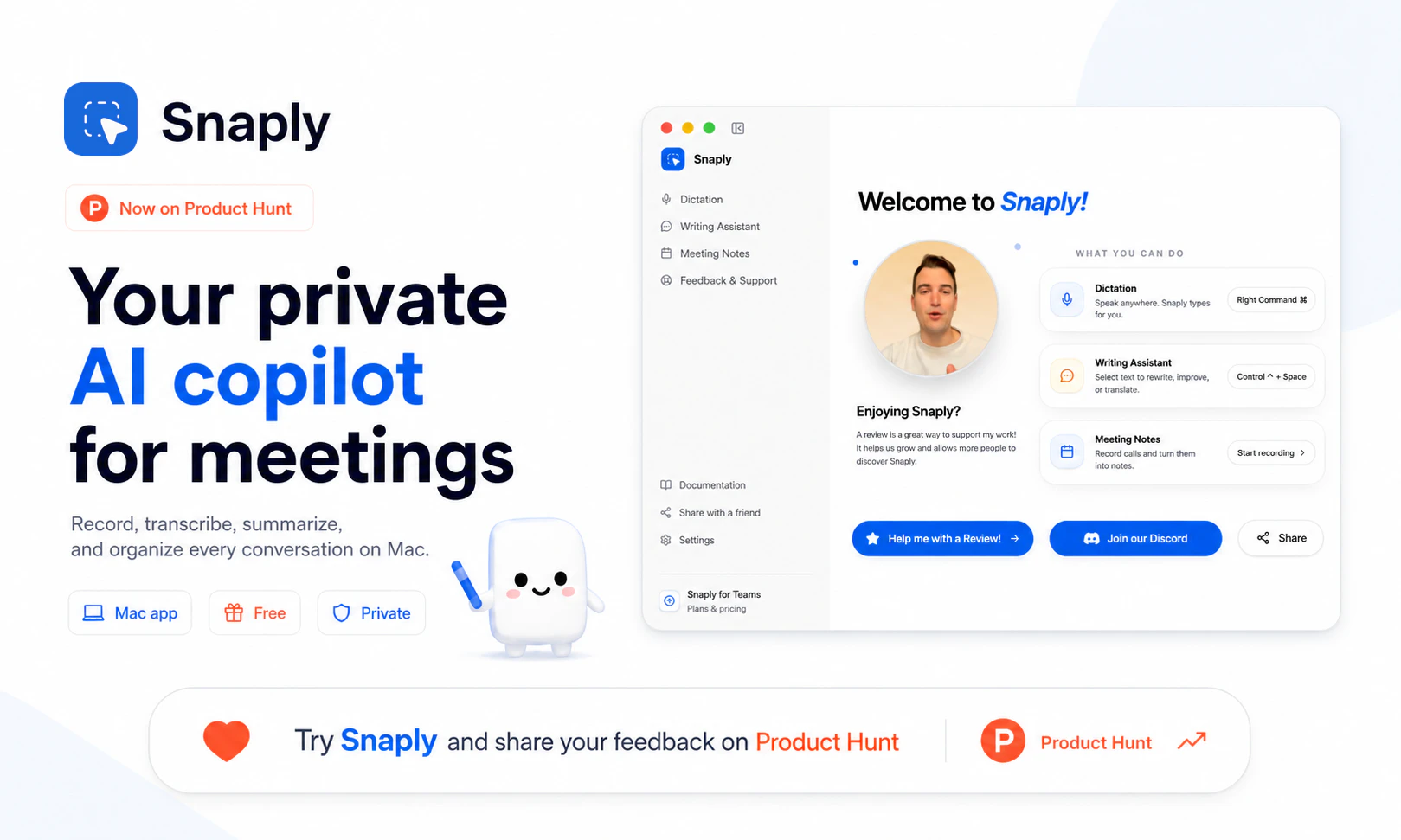






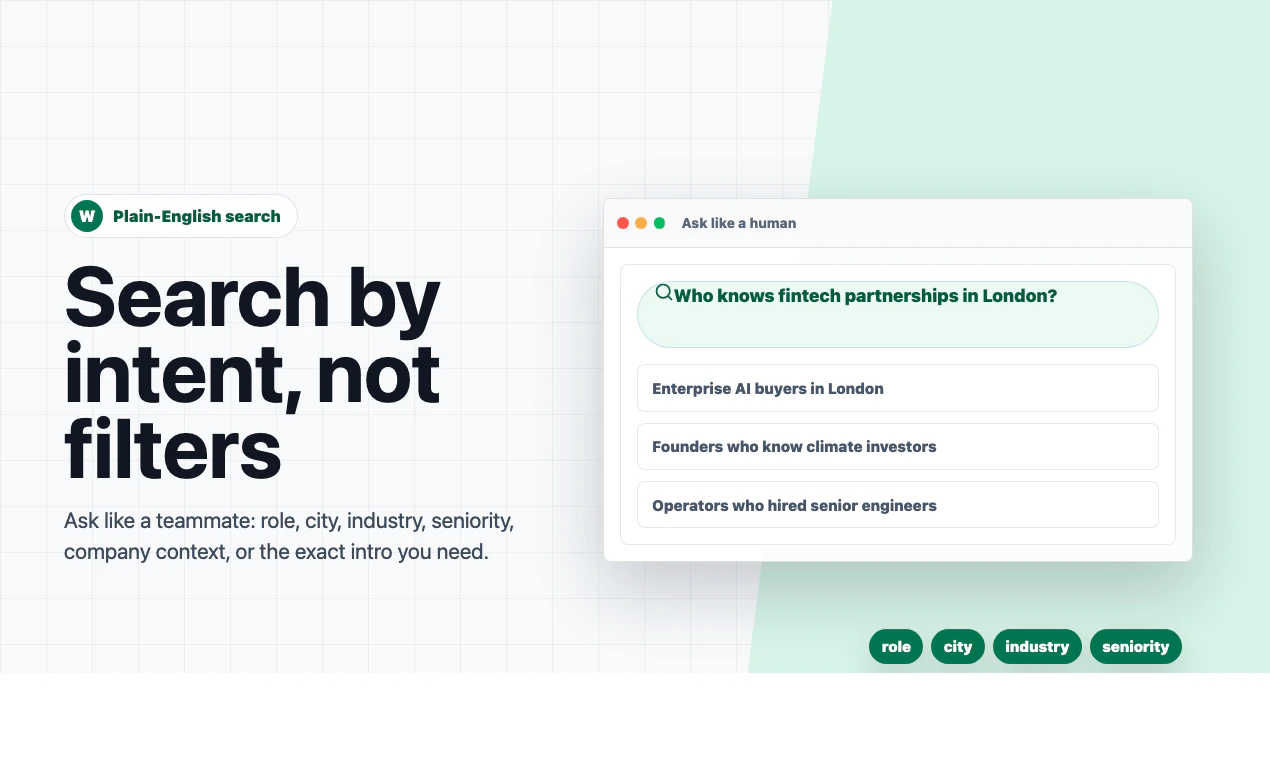






Hey Product Hunt! 👋
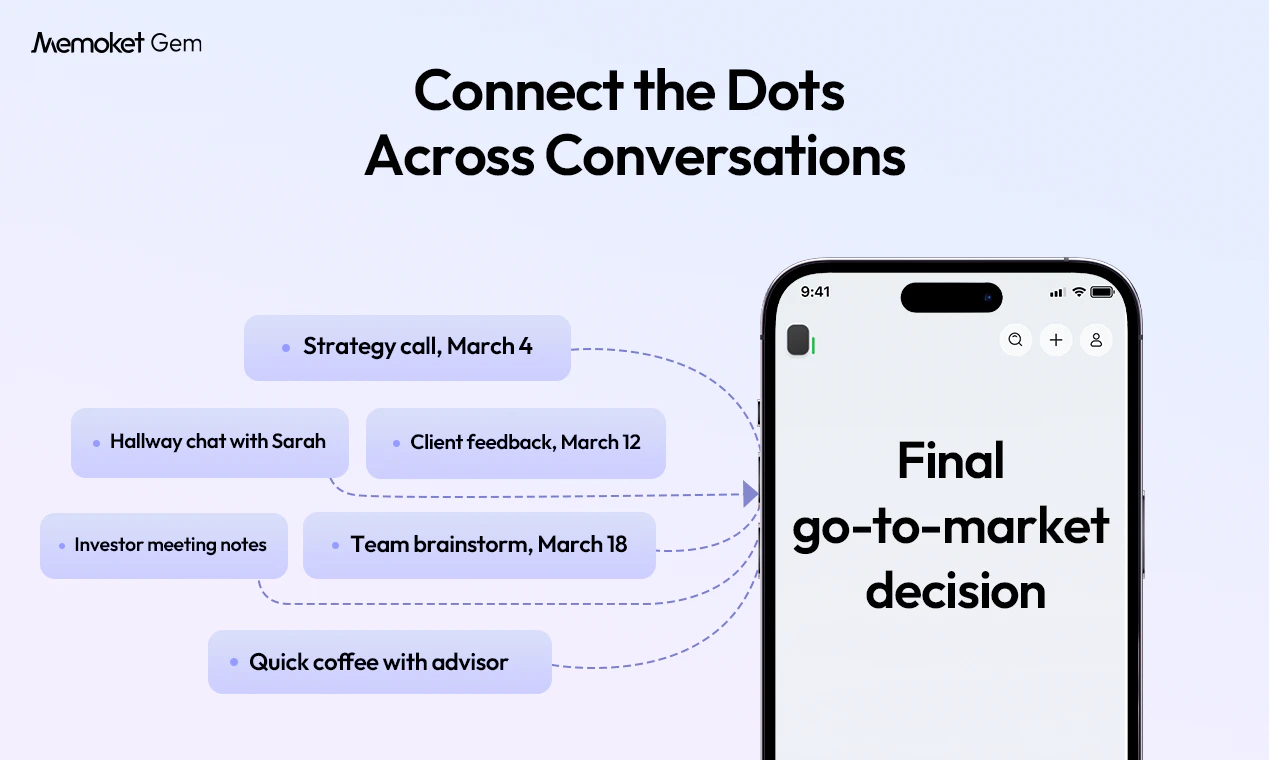
I’m Terrence, Co-Founder and CEO of Memoket. We built Memoket Gem for founders and SMB owners whose work happens through real-world conversations — meetings, client calls, coffee chats, trade shows, and quick decisions on the go.
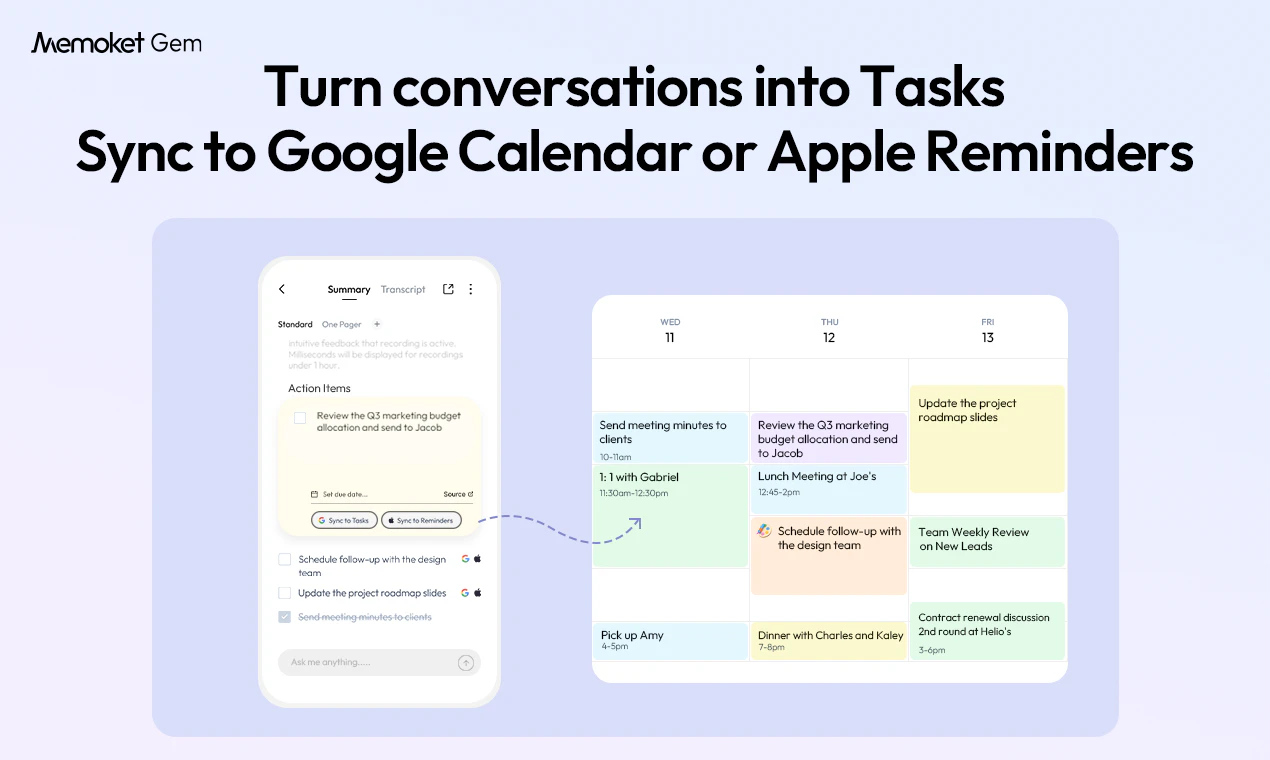
As a founder myself, I kept running into the same problem: important details, follow-ups, customer insights, and decision context often got scattered across notes, stuck in my head, or lost completely. That’s why we built Memoket Gem, an all-day AI wearable that captures business conversations, summarizes key moments, connects context across discussions, and turns them into tasks, notes, and follow-ups in the tools you already use.
A bit about who’s behind it: our team has 10+ years of consumer hardware experience, with members from Anker, Bosch, Siemens and Procter & Gamble. We’ve worked on consumer products used by millions of people around the world, and we’re bringing that real-world hardware experience into Memoket Gem. Memoket Gem is already beyond the concept stage. We have working samples and a group of beta testers helping us refine the product in real-world use. I’ve personally been using Memoket Gem for the past 4 months, and it has helped me reduce mental load, remember important details, and turn scattered conversations into action.
Our bigger vision is to build the off-screen context layer for AI, bringing real-world business context into AI workflows, not just what already lives in docs, emails, or chats.
We’re opening 50 free beta test slots(apply via the link below) founders, SMB owners who live in back-to-back conversations. Selected beta testers will receive a Memoket Gem valued at $199 for free, we only ask you to cover $5 shipping.
If that sounds like you, please check us out, apply to join the beta, and let us know:
Would you use an AI wearable for business conversations?
What real-world context do your current AI tools miss?
Which integrations would matter most to your workflow?
Thanks so much for checking us out — we’d love your thoughts, questions, and feedback! 🙏
https://memoket.ai/checkouts/cn/hWNBtSMOPDqHhsq2xghJWIrL/en-us?_r=AQABqhD_ltrZWXPxEJctoBUJIwLpLPex4oxdvRn1t4nfrMQ&preview_theme_id=182914744649&skip_shop_pay=true
Congrats on the launch! 🎉 @alice_lee0917
I've been on the hunt for something like this for a while now. I've tried both the necklace and card versions, but neither really stuck — I'm just not someone who wears jewelry or wants to carry an extra card around. And reaching for my phone? That works, but it kind of defeats the purpose. Hoping Memoket Gem turns out to be the one that actually fits into how I live and work.
What I like about this team is they shipped the app first so you can actually experience the AI before the hardware even arrives. I've been testing it and the summaries and action items it pulls from conversations are surprisingly accurate. The Gem is going to take this to another level.
Love the idea of an AI memory layer for real-world conversations. Feels especially useful for founders constantly jumping between meetings, calls, and coffee chats. How long have your beta users been wearing it daily?
This is interesting. I can see myself using it after customer calls or even casual chats with users. I usually write notes later and forget half of what was said, so having something that captures the details and lets me review them later would be useful.
One press to capture vs always-on is a design decision that defines the whole trust model here. If it's intentional capture, the accuracy of what you chose to record matters. If it moves toward passive, the data pipeline becomes a liability — every ambient conversation is now a structured asset sitting somewhere. Would love to know where the transcription actually runs: on-device, on-phone, or server-side. That alone changes whether this can be used in any professional or enterprise setting.
Curious how Gem decides what's signal vs noise in those drift-y moments, is that something the user gets to tune, or more "it learns you over time"?
Just seeing ex-anker makes me want to buy it immediately.
How is the management of privacy? Are my billionaire ideas and BBQ grocery list be used for training and tailor ads?
I would ideally want it on 100%.
As someone who juggles multiple projects, family, and calls every day, this is exactly what I needed. The conversation-to-task feature alone is worth it.
This is one of those products where once you start using it, you can't imagine going back. The gap between what you discuss and what your tools know is real...Gem closes it.
The interesting part to me is less the recording itself and more the “connecting conversations over time” idea.
Feels like that’s the part current AI note tools still miss. Congats on the launch guys!
curious what would you want your AI memory to remember for you ?
Hi, I’m a UI/UX design studio founder based in India and I’d love to try Memoket Gem as part of your Founding Member / beta program.
However, I noticed that India is not available as a delivery option on the checkout page.
Is there any way I can still opt in-perhaps via an alternative shipping method, a waitlist for India, or at least access to the app while the hardware isn’t shipping here yet?
Would really appreciate any workaround you can offer.
Congrats on the launch! Very exciting!
@alice_lee0917 @terrence_wang1 @edo_campos Congratulations guys on the launch! 🎉Really interesting vision for real-world AI memory. Curious, how are you handling privacy and consent when conversations involve multiple people in meetings or public settings? Also, what makes Memoket Gem different from existing AI wearables in terms of long-term memory/context retention?
As someone who runs a construction business all over the state, my days are basically back-to-back conversations, client calls, team check-ins, supplier negotiations, investor updates. By the end of the day I have a notebook (yes, still old-school) full of half-legible scribbles and a head full of things I'm pretty sure I'm forgetting. I started using the Memoket app a couple of weeks ago and the difference is real. After a client call, I can pull up exactly what was discussed and turn it into action items in minutes. No more 'wait, what did they say about the timeline?' moments. If you're anyone who talks to people for a living and then needs to act on those conversations, this is worth checking out. Can't wait to put my hands on the Gem.
Congrats on the launch! Memoket Gem looks very functional and innovative, it's something that can really help SMB owners with their daily routines.
wow... this is something that I was looking for. But, the only concern for me is... i need to wear this instead of Apple Watch.
Congrats on the launch! I have been looking for wearable that will do this for me and be focused on recording. I currently use my Apple Watch with Wispr Flow in order to achieve this, but it is not as elegant as I would like. I’m excited to see how this compares as I am a heavy user.
The "remembers all day" promise is compelling but raises a real question how does it handle conversations you don't want remembered? Is there an easy way to pause or delete specific recordings?
Congrats on the launch, and an intriguing solution to AI Wearables! I'm curious about the APP that Memoket has to process the recording the gem generates. Do I just need to make a one-time payment for the APP along with the hardware, or will there be subscriptions?
What's the battery life?
The passive capture angle is the part that actually changes behavior — most people won't stop a conversation to take notes, but they would review a summary afterward. Curious how the privacy side works when you're in a meeting with others who haven't opted in. Is there any disclosure mechanism built in?
This feels useful for business owners like me. A lot of work happens outside formal meetings — supplier calls, customer chats, quick team discussions, random ideas. Having those captured and turned into tasks could make the day feel less scattered. When can I buy one?
Huge congrats on the launch! 🚀
Working in the marketing tech space, my day is a constant blur of desk work and spontaneous IRL syncs, so the flexibility of this form factor (especially the wristband) is definitely more appealing than awkwardly pulling out my phone.
I am a bit curious though, since those random offline catch-ups often happen in noisy cafes, how well does the mic actually isolate voices from heavy background chatter? If the noise cancellation is solid, this could seriously streamline my daily workflow.
Congrats team! The cross-conversation context is what stands out to me. A single meeting summary is helpful, but being able to connect multiple conversations over time and see how a project or decision evolved feels much more powerful. I can see this being useful for founders, sales teams, and product managers.
Congrats on the launch! I actually really like the idea of this being wearable. I’ve tried recording notes on my phone before, but I always forget to start it or it is interrupted by a phone call. This feels more natural.
I need the always-on capture capability, but my wrist real estate is already taken. Have you considered a modular design or something that could attach to an existing watch strap?
Congrats on the launch. Sounds like a really cool product! I can imagine using it for all my meetings, including consumer research, team meetings, weekly reviews, etc. I think it will start writing my weekly review reports compiling data from my whole week's meetings. That would save me at least 2 hours every week!
Happy launch! Sounds really interesting. Did you think about adding fitness overlay and make it a combo of fitness and business wearable? Otherwise many people would need to use two wearables.