PH热榜 | 2026-05-14
一句话介绍:Spellar 3.0 是一款跨会议记忆型AI助手,能无声加入通话、记录所有内容,并构建跨越不同会议的持久上下文,解决职场人士在跟进多次客户或项目沟通后,无法快速追溯历史决策与待办项的“会议失忆”痛点。
Productivity
Meetings
Artificial Intelligence
AI会议助手
跨会议记忆
智能笔记
会议纪要
上下文检索
多语言转录
隐私优先
工作流自动化
团队协作
AI模型自由选择
用户评论摘要:用户高度认可跨会议记忆功能,认为能显著减少手动跟进时间。问题集中于:如何协调同一客户前后矛盾的表述?是否支持本地模型(LLM)及联系人分组?与Fireflies的差异化优势何在?团队协作是否存在独立账户?建议加强自动分类,并期待原生Obsidian同步。
AI 锐评
Spellar 3.0 的发布切中了当前AI会议工具市场的痛点盲区:大量产品止步于“单次会议的高质量摘要”,而忽视了职场人真正的需求——跨会话的认知延续。从产品定位看,“AI Meeting companion with memory”比“note-taker”高明了一个维度,它实质上在做的是“工作记忆的外挂化”,将过去依赖人脑的高成本上下文衔接,变成了可检索、可追溯的结构化数据。
技术层面,跨会议记忆的实现难度远超单次转录。它需要解决信号衰减(早期会议信息被新会议覆盖)、实体对齐(同一客户、项目在不同语境下的唯一身份识别)以及时间维度上的决策冲突。评论中提到的“如何处理客户前后立场矛盾”正是这类系统的典型难关,目前Spellar似乎尚未给出AI层面的主动调和方案,这是其“记忆”价值从“查询”迈向“推理”的关键一步。
在商业化策略上,用户可自由选择AI模型(OpenAI、Anthropic、Perplexity等)是个聪明的差异化卖点,既满足了企业对隐私和合规的焦虑,也避免了与底层模型厂商的深度绑定。不过,所谓的“bot-free”更多是体验层面的优化,核心价值仍取决于云端LLM的推理质量。如果本地LLM支持不能及时跟上,其“隐私”叙事将大打折扣。
核心竞争力不在于技术堆叠,而在于通过“模板”和“自动分组”将非结构化的会议流水账,转化为结构化的“客户/项目知识库”。如果能打通与Notion、Obsidian等知识管理工具的双向实时同步,Spellar很有潜力从一个会议工具进化为企业的“第二大脑”入口。否则,它只是一款更聪明的笔记软件而已。
一句话介绍:Naptick AI是一款无手机操作的智能床头AI睡眠伴侣,通过光照疗法、自适应音景、环境监测、App锁定和AI睡眠教练,帮助创始人和高压人群在睡前主动改善环境与习惯,解决“睡前焦虑、刷手机、入睡困难”的痛点。
Health & Fitness
Hardware
Artificial Intelligence
AI睡眠伴侣
智能硬件
睡眠科技
光照疗法
音景
环境监测
App锁定
AI教练
床头设备
无手机设计
用户评论摘要:用户重点关注其无手机设计、AI语音交互和硬件可靠性。问题包括:夜间灯光是否扰眠?焦虑时能否抵挡手机诱惑?App锁定机制在压力下是否有效?建议未来推出针对儿童的玩偶式外观。总体上认可其“主动干预而非事后追踪”的差异化定位。
AI 锐评
Naptick AI在“睡眠科技”这条拥挤赛道上,打出了一张漂亮的差异化牌:**不做被动的数据记录仪,做主动的睡前干预者**。这恰恰是Oura、Whoop等穿戴设备与手机App的集体盲区——它们擅长告诉你“你昨晚睡得有多烂”,却对导致你失眠的“睡前刷手机、焦虑反刍、环境不适”毫无招架之力。
产品的核心洞察在于:**睡眠问题的根源不在床上,而在上床前一小时**。Naptick将卧室重构为一个“受控环境”,用硬件(光照、音景、环境传感器)建立物理结界,用AI教练提供心理卸载出口,用App锁定切断数字依赖。这种“硬件+AI+行为设计”的组合拳,远比一个白噪音App或智能灯泡更具粘性。尤其点赞其“无手机设计”——物理按钮和语音交互(无唤醒词,靠按键激活)是对隐私和睡前习惯的双重尊重,直接化解了“把手机带进卧室”这一现代睡眠头号杀手。
当然,风险也不容回避。第一,硬件的“可信赖”门槛极高:设备死机、Wi-Fi断连、光污染控制失当,任何一次故障都可能让用户重回手机怀抱。第二,AI睡眠教练的“人性化”深度存疑——如果对话流于模板化,用户很快会失去新鲜感。第三,价格与渠道:面对几百元的智能音箱+免费App的组合,Naptick必须用纯粹的体验红利证明其溢价合理。
一句话:**Naptick不是在卖一个睡眠工具,而是在卖一套“睡前仪式”的硬件化解决方案。** 它能否成为卧室里的新基础设施,取决于它能多大程度让用户“无痛戒断手机,自然滑入睡眠”。方向对了,但执行容错率极低。
一句话介绍:Tendem是一个将AI代理与经过筛选的人类专家结合的托管平台,专为解决高精度任务中AI输出“最后一公里”需要人工验证与完善的痛点而设计。
Design Tools
Productivity
Artificial Intelligence
AI+人工协作
任务托管平台
人机协同
高质量交付
专家网络
AI验证
内容审核
数据标注
企业级AI
混合智能
用户评论摘要:用户普遍认可其解决AI输出“80%完成度后需自行修复”的痛点。主要关注:任务与专家匹配机制、周转时间(分钟级还是小时级)、QA流程(人员与AI的双重校准),以及能否替代Apollo、Clay等工具。
AI 锐评
Tendem并非一款激进的创新产品,而是对当前AI应用困境的一次务实纠偏。它精准命中了“AI幻觉”与“自由市场质量波动”之间的夹缝地带:纯AI代理在演示中惊艳,但实际交付时80%的完成度往往伴随着20%需人工收拾的烂摊子;而自由职业平台的人力成本和项目管理负担又消解了效率优势。Tendem给出的解法是“AI初筛+人类终审”的流水线,其核心价值不在于技术突破,而在于将“人机协同”从概念固化为可规模化、按次付费的服务产品。
从专业角度看,Tendem最大的护城河是其母公司Toloka十余年为前沿AI实验室构建“人在回路中”质量体系的经验,这意味着其专家筛选、任务路由和QA机制具备成熟的工业化基础,而非简单的UGC撮合。评论中透露的“LLM-QA + 独立Human QA”两层质检体系,以及针对不同任务复杂度的成本路由策略,显示出其对“人机分工”的深刻理解——知道在哪些环节省钱,哪些环节必须花钱砸质量。
然而,潜在问题同样明显:3到24小时的周转时间在“秒级响应”成为预期的时代,可能存在用户感知落差。此外,如何在与低成本纯AI工具和海量低成本自由职业者的竞争中维持定价与质量的平衡,将是其规模化过程中的核心挑战。本质上,Tendem卖的不是工具,是“确定性”。对于财务、法务、医疗等零容错领域的客户而言,这一定价可以成立,但对于追求极致速度的早期初创团队,它需要提供更具说服力的ROI叙事。
一句话介绍:Theneo推出Elva,为人类与AI Agent提供一站式API设计、文档、管理与可观测平台,解决API在Agent调用场景下语义不清晰、文档过时与生产安全不可控的痛点。
API
Developer Tools
Pitch Dubai
API管理平台
AI Agent开发
API文档自动化
MCP服务器
可观测性
API审计
接口安全
开发者工具
API设计
企业级
用户评论摘要:用户赞赏API目录审计和Agent就绪检查功能,认为能发现隐藏过时端点。焦点集中在:Agent在生产中的语义可靠性(端点语义歧义、不安全工作流)、版本更新自动触发、认证与限流如何处理,以及MCP服务器是否真能扛住生产级压力。建议增加独立审计产品。
AI 锐评
Theneo这步棋下得很准,但风险也不小。
产品的核心洞察在于:AI不是只改变了“谁来写文档”,更关键的是改变了“谁来读文档”。当Agent开始批量调用API,传统针对人类阅读者优化的文档体系(描述性段落、模糊的状态码、不强调幂等性)瞬间失效。Elva试图从“Agent可读性审计”切入,找到“文档存在但语义陷阱多”这一显性痛点,非常有杀伤力。
但需要警惕的是,目前评论区对MCP生产级安全(认证、限流、凭证零存储)的回应仍是“设计承诺”而非“大规模验证”。API管理的最大痛点永远是变更管理和版本兼容——多个Agent并行调用,一个API的非兼容性更改会导致连锁故障。产品目前强调自动更新文档和通知,但“通知”不等于“版本隔离”,也没有公布多环境分治或AB测试策略。
价值不在“帮API变好”,而在“帮API变‘安全’”。Elva更精准的定位应是“API的Agent安全护栏”而非单纯的文档工具。真正能让它颠覆Postman、Swagger的,是对Agent调用行为的事前预防和事后溯源,而非又一个AI美化文档的壳子。关键在于:能否在“建议优化”和“自动化修复”之间,形成闭环,否则仍逃不出“智能报告+手动改”的老路。
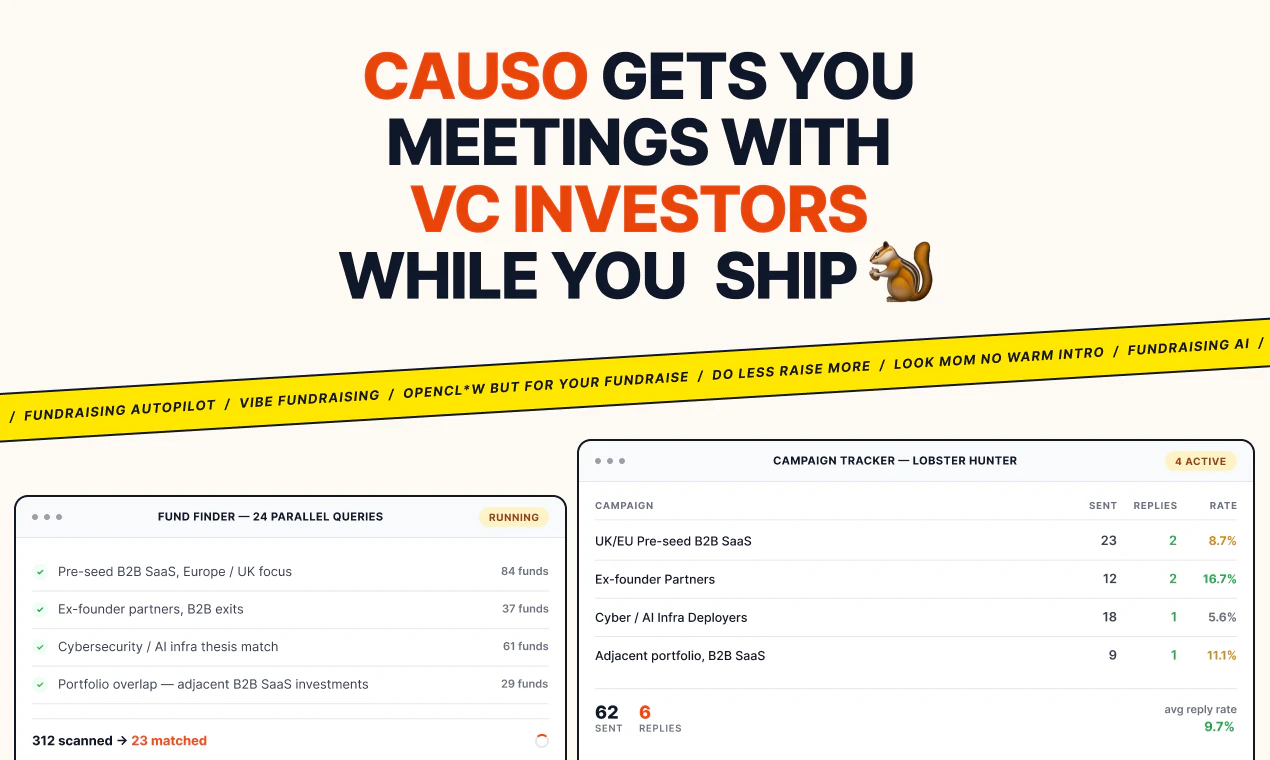
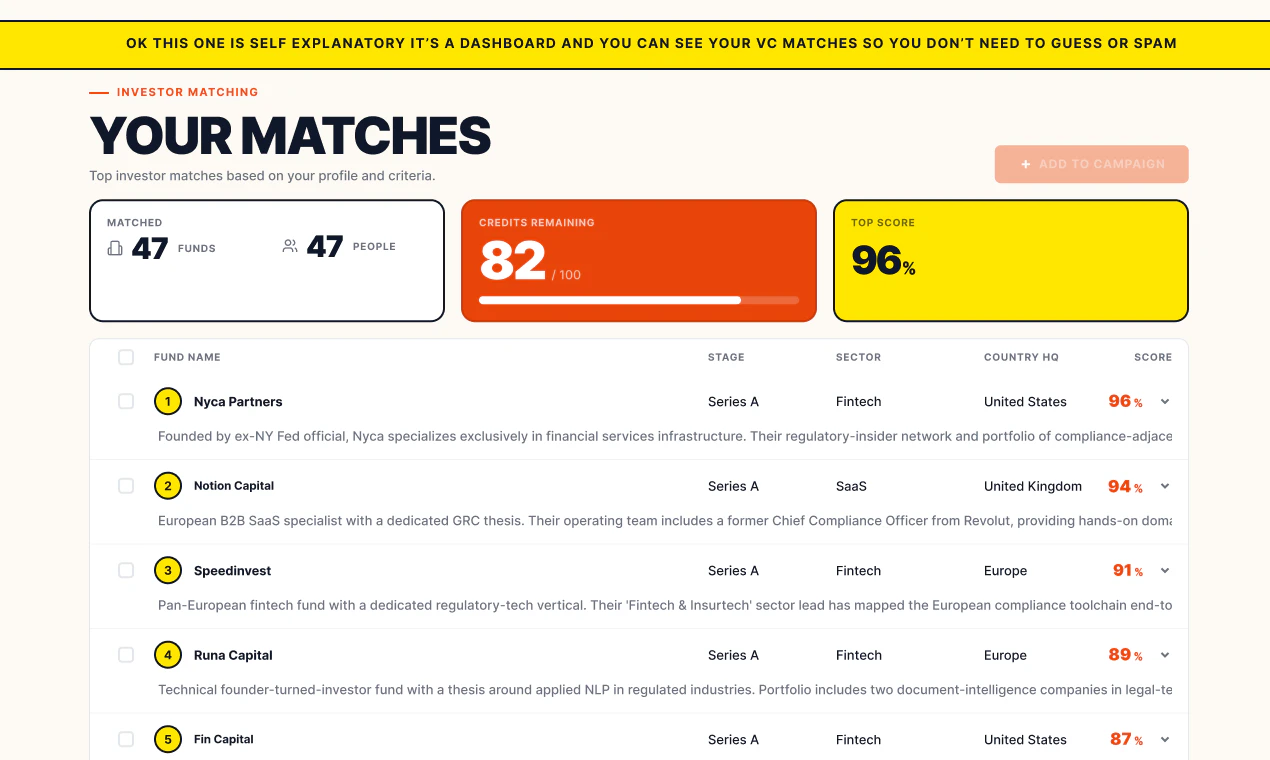
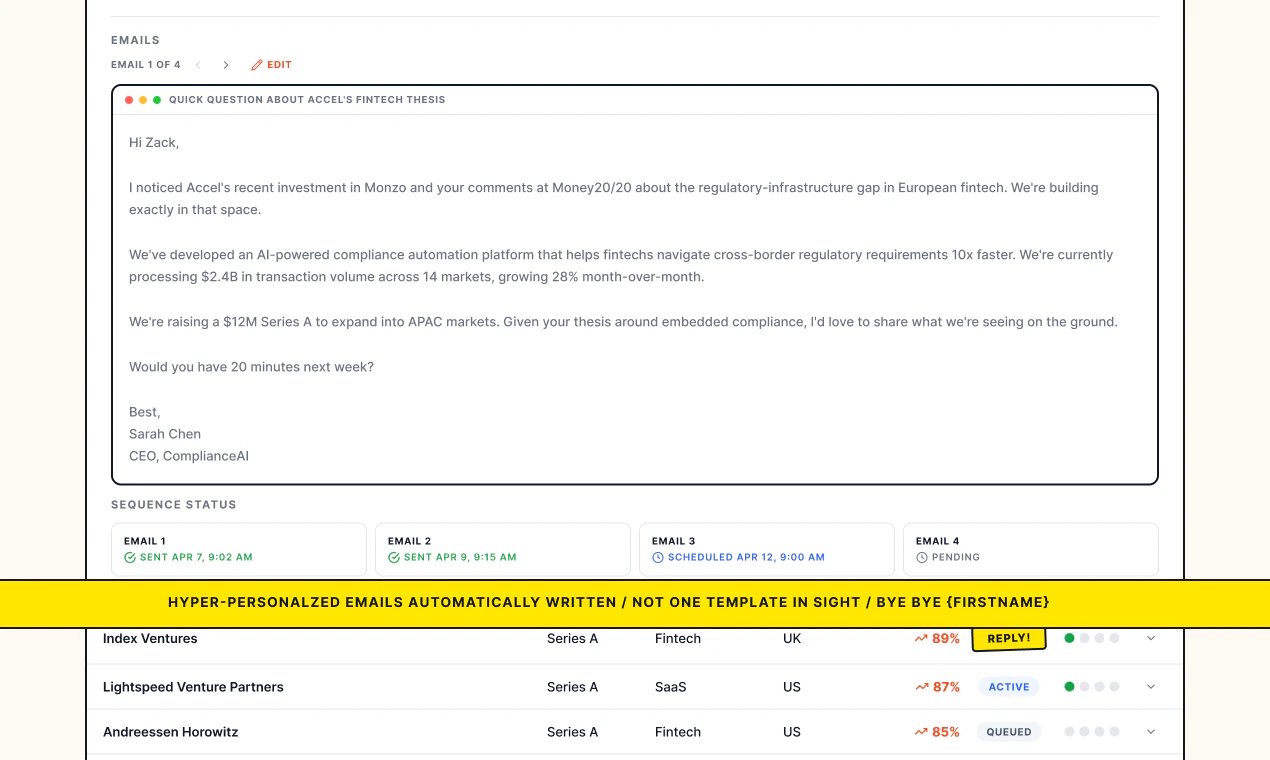
一句话介绍:Causo是一个AI驱动的融资助手,通过实时更新的VC数据库和自动化邮件 outreach,帮助创始人自动匹配合适的投资人并发送个性化推销邮件,解决融资中手动研究、定向和沟通的低效痛点。
Productivity
Venture Capital
Artificial Intelligence
AI融资
VC数据库
投资者匹配
自动化外联
创始人工具
融资效率
邮件自动化
冷启动
初创服务
SaaS
用户评论摘要:用户普遍认可其解决“手动研究VC”和“AI幻觉”痛点,称赞实时数据库刷新和个人化邮件质量。问题集中:何时集成LinkedIn外联?能否追踪VC回复后的情感信号?如何避免邮件进垃圾箱?当前答:邮件为主,情感分析和CRM整合在路线图中;发信使用个人邮箱,有发送量指南。
AI 锐评
Causo踩中了创始人融资中“信息不对称”与“重复劳动”的双重痛点,产品逻辑扎实。其核心价值不在于“AI生成邮件”这个噱头,而在于“实时更新的合伙人级VC数据库”——这是大部分LLM方案无法逾越的护城河。评论中用户对“幻觉”的痛骂与对“实时性”的追问,恰恰证明了这一点。
产品形态上,它本质上是“智能化的SDR(销售开发代表)”替代,把融资中最繁琐的“找人、调研、写第一封邮件”自动化,让创始人回归产品与客户。从已有用户反馈(18家基金5周获4个会议)看,冷启动效果不错,证明匹配质量并非噱头。
但需警惕:一是邮件为主的天花板明显,LinkedIn等渠道的缺失会限制触达深度,特别是对看重私密关系的早期投资人;二是“实时数据库”依赖公开数据源,合伙人秘密离职或基金策略变化等“暗信息”可能遗漏;三是外联效果高度依赖创始人自身公司质量与赛道热度,“跳过苦劳”不等于“跳过功劳”,Causo是放大器而非创造者。后续能否通过构建VC反馈闭环、提升投后匹配的归因能力,将是其从“工具”进化为“平台”的关键。目前来看,对于种子轮到A轮的创始人,这是一笔值得尝试的时间投资,但别期待它替代你与投资人面对面喝的那杯咖啡。
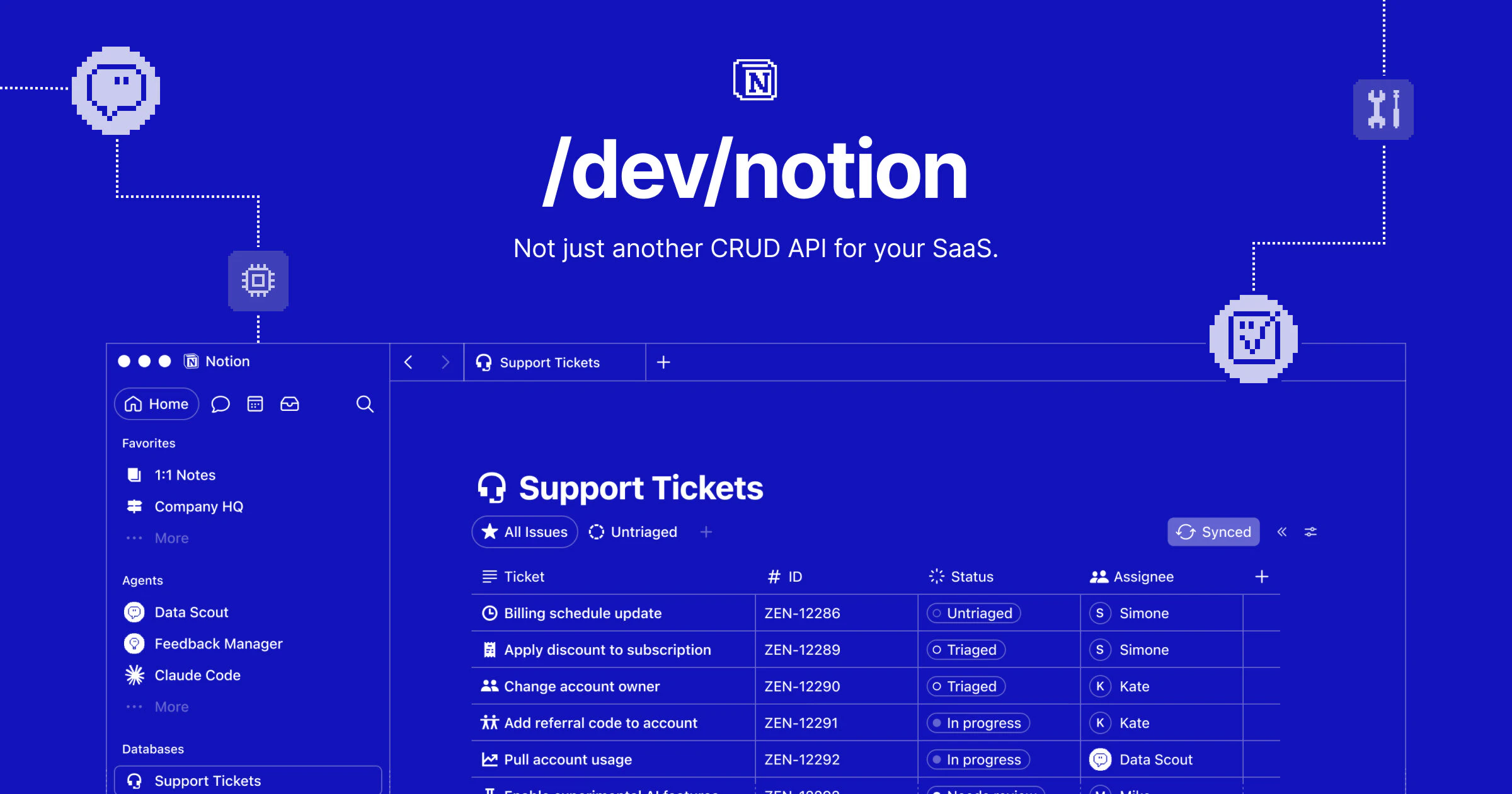
一句话介绍:Notion Developer Platform 让团队通过 CLI、Workers、外部代理API等工具在 Notion 上构建工作流与智能体,突破传统文档协作,将 Notion 从“工作场所”升级为可编程的“应用与代理基础设施”。
Artificial Intelligence
Development
Notion
低代码/无代码平台
开发者工具
智能体协作
工作流自动化
API集成
数据库同步
CLI工具
Webhook触发
MCP协议
企业级应用
用户评论摘要:用户肯定其创新方向与落地页设计细节,但核心质疑集中在:Notion编辑器本身卡顿、数据库不稳定、S3媒体链接超期、API速率限制仅3次/秒等问题未解决,认为其不适合作为生产级数据库或CMS,建议先优化基础体验再扩展平台功能。
AI 锐评
Notion Developer Platform 的发布,本质上是一次“借壳生蛋”的叙事升级——它试图用“智能体基础设施”的概念,掩盖其底层数据库长期存在的性能与可靠性短板。从用户尖锐的吐槽可以看出,3次/秒的API限速、过期即崩的媒体链接、祖传的编辑器卡顿,这些根本性问题在开发平台的光环下不但没有消失,反而因为要承载“生产级应用”而变得更加致命。
该平台真正的价值,并非让开发者用Notion替代PostgreSQL或Supabase,而是提供一种“轻量级粘合层”:让非技术团队能在Notion内直接触发线性/Zendesk同步,或给Claude/Codex分配可溯源的任务。这切中了一个现实痛点——企业真正的瓶颈不是缺少强大的数据库,而是数据、流程与代理分散在不同系统,无法形成闭环。Notion凭借已有的用户基数和协作心智,来降低这个闭环的搭建成本。
但风险同样明显:如果Notion不优先解决底层稳定性而只顾堆砌“CLI+代理API”等宏大的开发者体验,最终只会吸引一批尝鲜者,然后被“3秒限流”劝退。平台能否真正成为“智能体基础设施”,取决于Notion愿不愿意从“笔记软件”的底层架构做一次痛苦的硬核重构。否则,这只是一张漂亮的建筑图纸,地基却还在漏风。
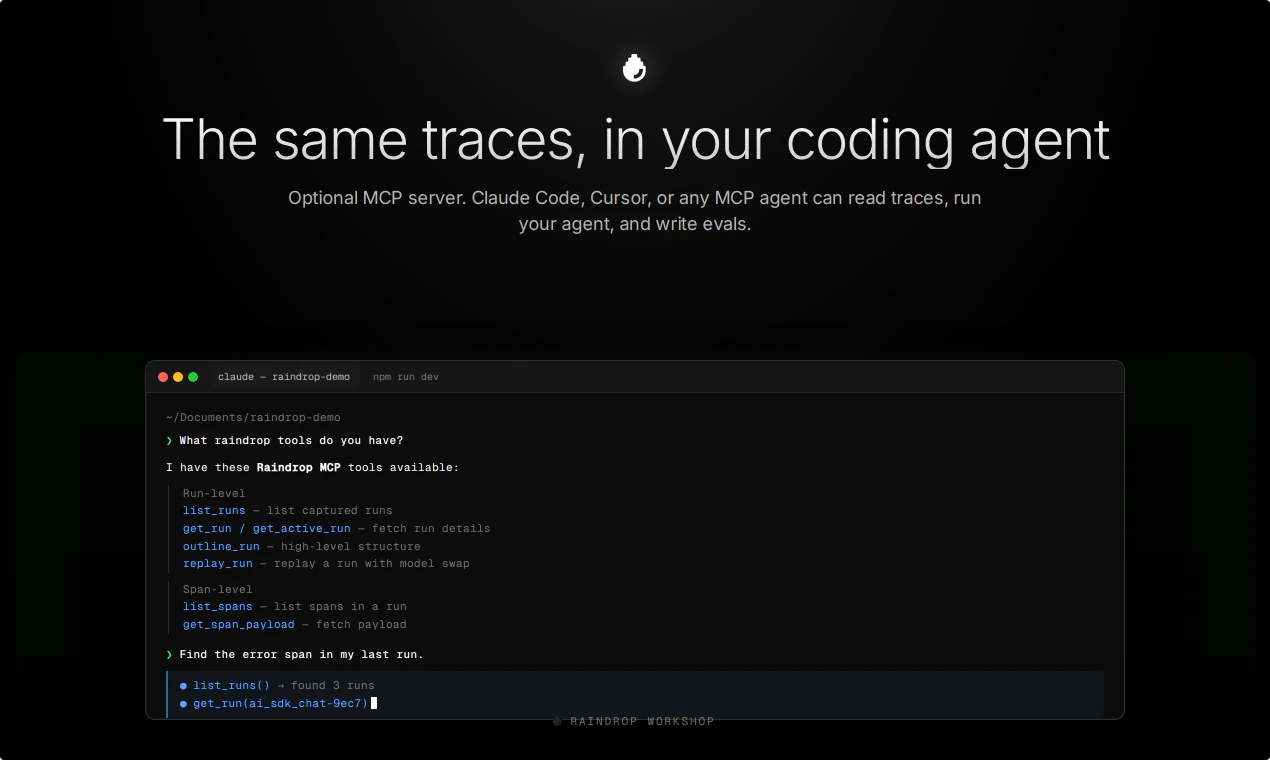
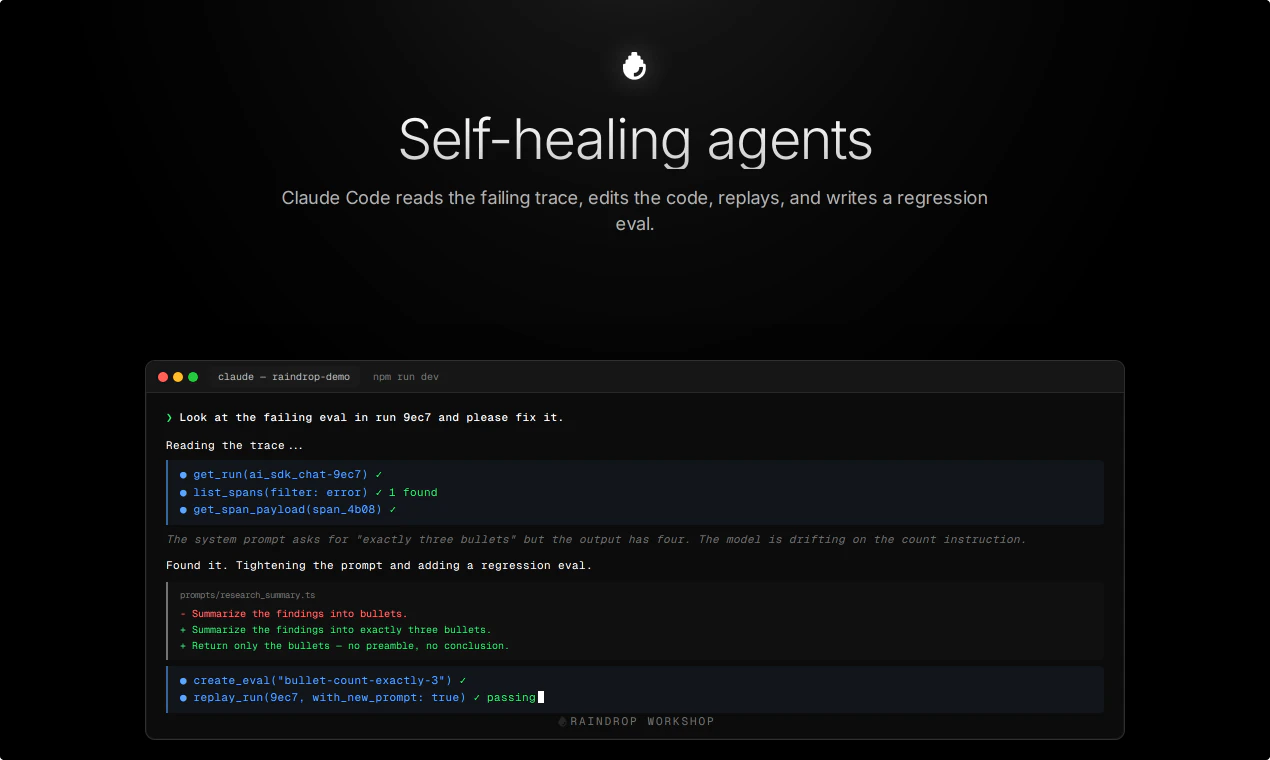
一句话介绍:Raindrop Workshop 是一款免费开源的本地AI代理调试器,通过实时追踪流和MCP协议,让开发者能本地调试、回放并让AI代理自我修复,解决了代理行为黑盒化和调试效率低下的痛点。
Open Source
Developer Tools
Artificial Intelligence
GitHub
AI代理调试器
开源工具
本地开发
MCP协议
自愈循环
代理追踪
实时流式调试
Claude Code集成
开发者工具
AI工程化
用户评论摘要:用户普遍赞赏其集成简便和实时追踪功能,解决了“不再需要console logging”的痛点。核心疑问集中在如何保证自修复质量(担心修复不彻底)、与Vercel AI SDK调试器的区别、以及自定义可视化支持情况。
AI 锐评
Raindrop Workshop的野心不止于做一个本地调试器,它试图定义AI代理开发的“调试范式”。其核心价值在于两点:一是将代理的运行时状态从远程SaaS“拽回”本地,这不仅仅是隐私和延迟的优化,更意味着开发者获得了完全的掌控权——可以在离线环境下逐token分析、任意修改提示词并即时重放,这是任何云端仪表盘都无法比拟的调试粒度。二是通过MCP协议将调试器本身变为可编程的AI工具。当Claude Code能读取追踪、编写评估、触发修复时,产品从“被动观察者”跃升为“主动诊断者”,形成了“开发-失败-自愈”的闭环。这一架构巧妙地利用了现有大模型(如Claude)的代码能力来反哺代理开发,本质上是在为“代理即应用”的范式构建底层基础设施。不过,评论中“如何保证自修复质量”的质疑直指核心:当前版本的修复成功率依赖于Claude Code对特定逻辑的理解,一旦任务涉及复杂业务规则或非确定性行为,自动修复很可能会引入新bug。此外,产品目前强依赖Claude生态,对LangChain、AutoGPT等其他框架的支持深度尚待观察。值得肯定的是,开源策略降低了上手门槛,也为其积累修复案例库提供了土壤——是否能从“开源玩具”成长为“工业级标准”,取决于它对多代理协作、长链追踪的支撑能力,以及社区是否能贡献出高质量的评估集。短期看,它是代理调试的效率工具;长期看,它可能是构建可观测、可自我进化的代理系统的基石。
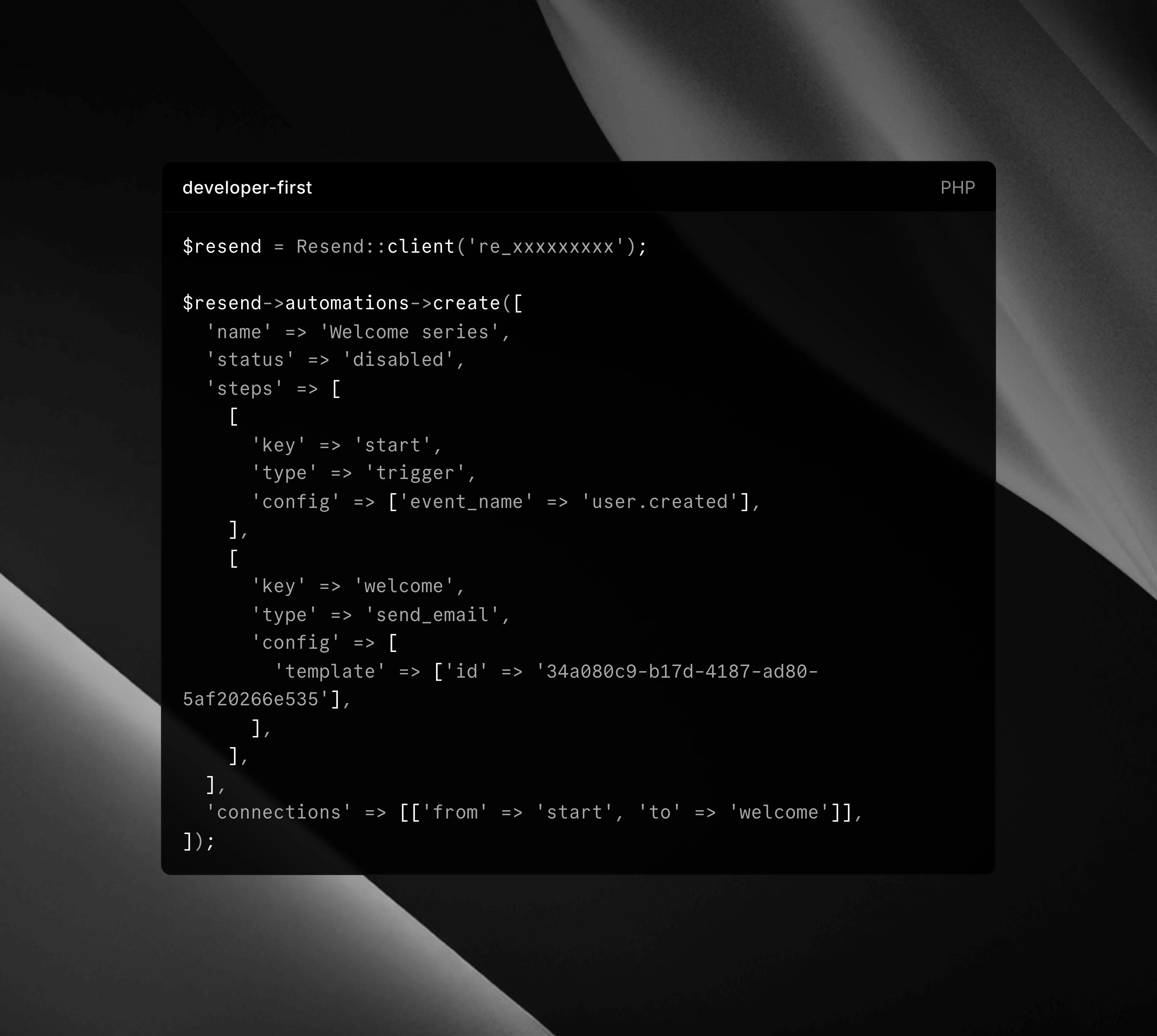
一句话介绍:Resend Automations 通过触发、条件、延迟和运行可见性,让开发者构建事件驱动的自动化邮件工作流,解决传统邮件发送无法灵活响应业务事件、缺乏流程控制和反馈的问题。
API
Developer Tools
事件驱动邮件
自动化工作流
邮件触发
条件延迟
开发者工具
邮件API
运行可见性
电子邮件基础设施
SaaS工具
自动化引擎
用户评论摘要:用户普遍兴奋,认为该功能让邮件编排更直观,期待集成到自身产品。有用户询问题发支持的自定义事件,官方回复确认可使用自定义事件作为触发条件。此外,有用户提到推出仅一个月已运行超过51万次自动化,侧面验证了需求强劲。
AI 锐评
Resend Automations 的推出,本质上是将 Resend 从“邮件发送管道”升级为“邮件编排引擎”。它抓准了开发者长期以来的痛点:业务邮件不是“发了就行”,而是需要根据用户行为、状态变化、延迟通知等复杂逻辑动态触发。过去这类需求往往需要开发者自建调度任务系统或依赖营销自动化工具(如 Customer.io),前者成本高、难维护,后者则与代码层割裂、灵活性差。
该产品的真正价值在于“事件驱动”与“开发者体验”的结合。通过API自定义事件,开发者可以将业务逻辑与邮件流程强绑定,同时获得运行日志、回溯可见性——这对于调试、审计和后期优化至关重要。评论中用户询问“是否支持自定义元数据”,说明高级用户已经开始考虑更复杂的分支场景,而官方肯定的回答则体现出产品架构的弹性。
不过,目前该产品仍高度依赖 Resend 已有的发送基础设施。如果其定价策略不能匹配自动化带来的额外计算成本(如触发器监听、条件判断),或者缺乏与主流后端的深度集成(如 Webhook 动态响应、数据库变更流),它将容易被 Zapier 等低代码工具或成熟的多渠道平台替代。Resend 最大的护城河在于其“邮件可靠性与交付性”的口碑,Automations 若想走得更远,下一步必须补齐对失败回放、A/B测试以及非邮件渠道的扩展能力。
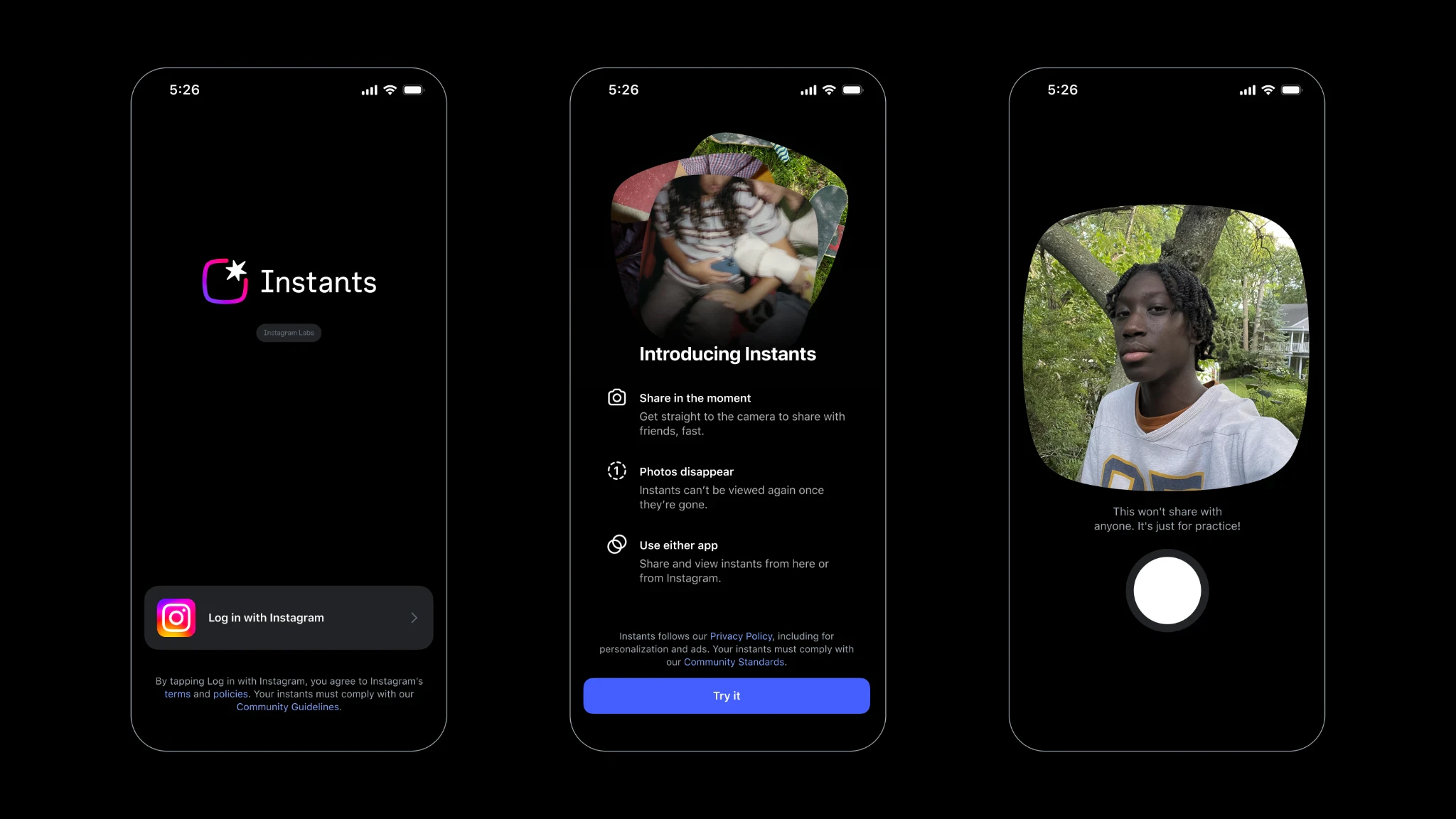
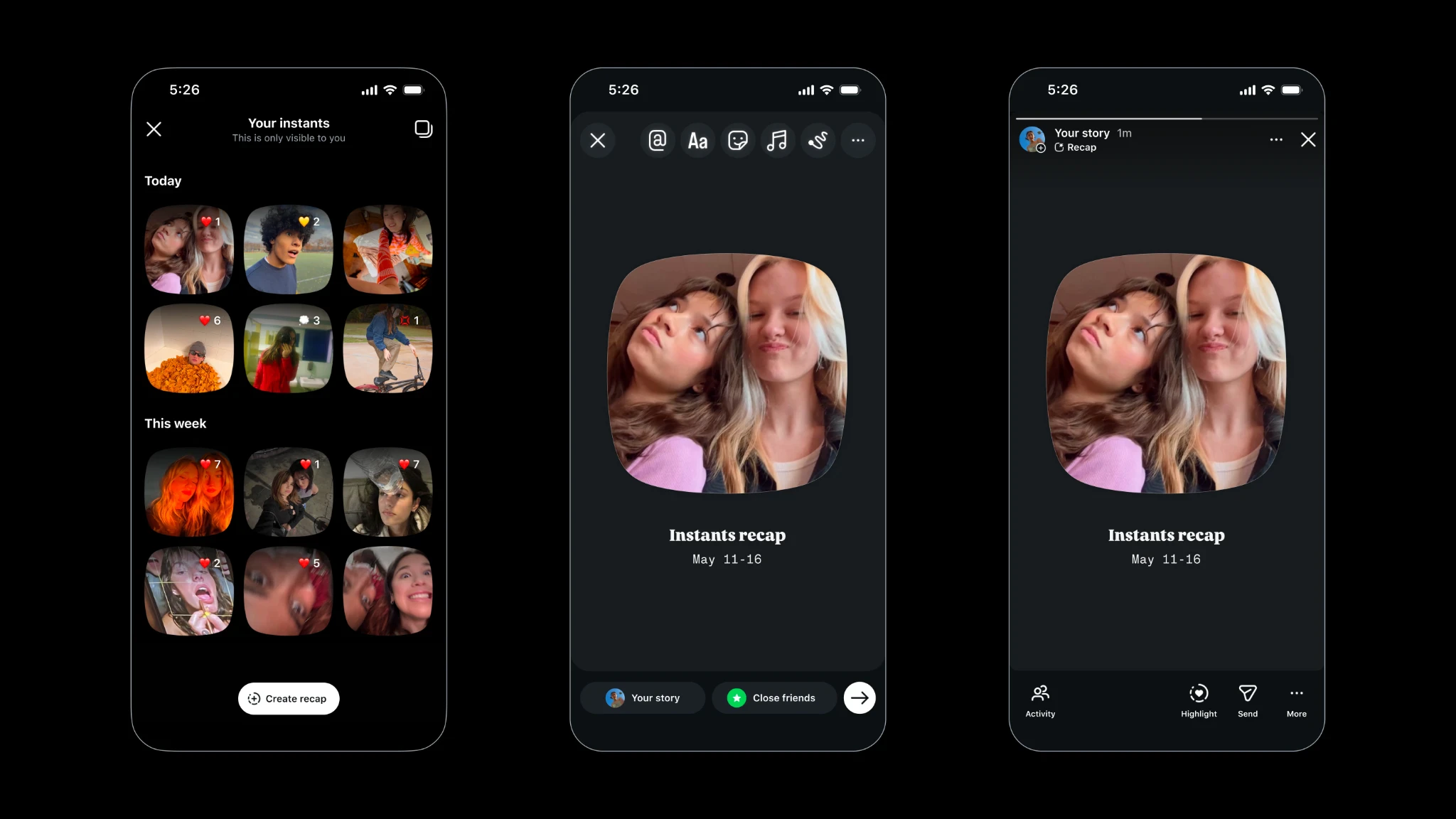
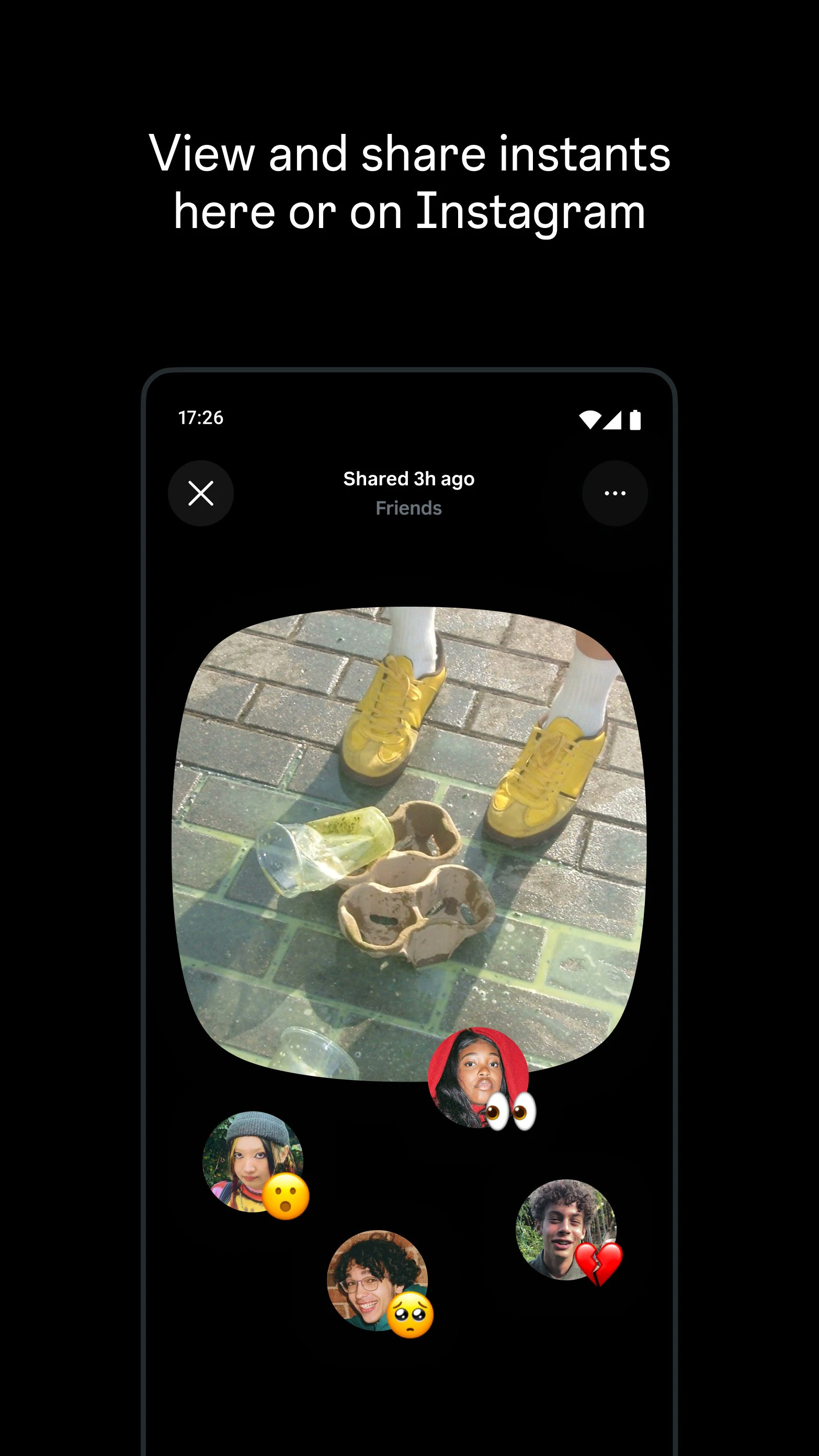
一句话介绍:Instants 是 Instagram 推出的独立应用,强制用户用手机实时拍摄、无编辑无滤镜的瞬时照片,发送给“密友”后自动消失,旨在解决社交平台上“过度修饰”带来的真实感缺失,满足小圈子内自发、坦诚的视觉分享需求。
Android
Social Media
Photography
真实社交
密友分享
瞬时照片
防截图
无编辑
Instagram 生态
贝瑞尔模式
青少年保护
数字极简
下架式应用
用户评论摘要:多数用户认可“无编辑/无上传”的强制真实机制,但质疑防截图技术的可靠性(能否跨OS真正拦截而非仅标记),并指出用户可能找到变通方法。部分评论认为这是BeReal与Snapchat功能的融合,并对仅为此单一功能推出独立App表示困惑。
AI 锐评
Instants 的本质,是 Meta 对“真实性”的一次产品工程化实验。它把“无滤镜、无相册上传”从用户选择变为技术铁律,这比 BeReal 的“定时拍”更激进,也比特效滤镜的反向操作更有结构张力。但真相是:防截图技术至今仍是猫鼠游戏,Android 端几乎不可能绝对封堵屏幕采集;而“密友”列表一旦膨胀到20人以上,信任密度稀释,所谓的“真实瞬间”也会沦为另一种表演。更关键的是,这款独立 App 的功能几乎完全复制了Instagram 客户端内已有的“密友”瞬时分享能力,只是砍掉了入口、加上了约束。它解决的是“朋友间看到的是真实的你”这一幻觉需求,而非“更好地分享”的实用需求。因此,Instants 更像一次品牌公关——向公众传递“Meta 懂真实社交”的信号,而不是一个能规模化独立存活的产品。它的终局很可能是作为 Instagram 的一个可开关功能模块被收回,而不是单独占领用户桌面。Meta 在下注:在滤镜疲劳期,约束反而成为解放。可惜,约束一旦成真,用户也会抛弃。
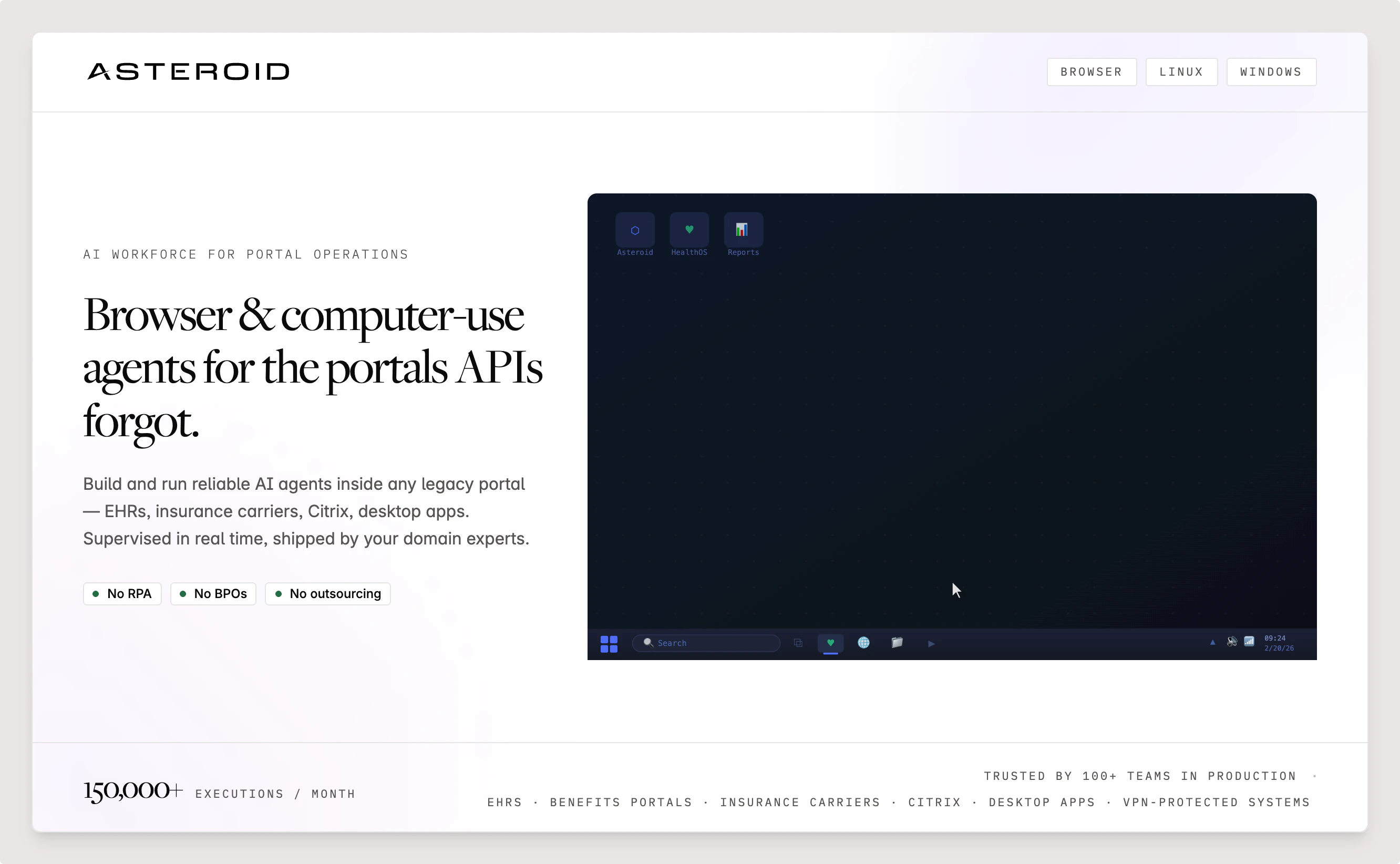
一句话介绍:Asteroid让运维团队和工程师在几分钟内构建用于浏览器、Linux和Windows工作流的自动化AI代理,彻底解决了传统RPA和AI代理在无API的复杂企业系统(如EHR、保险门户、Citrix等)中难以可靠执行的痛点。
Developer Tools
Artificial Intelligence
No-Code
AI代理构建平台
计算机使用代理
浏览器自动化
RPA替代
企业工作流自动化
多环境支持
元代理
合规自动化
医疗自动化
保险自动化
用户评论摘要:用户高度认可其针对Cookie登录、复杂门户的可靠性;核心关注点包括MFA/验证码处理(支持TOTP和验证码求解器)、失败重试策略(支持自定义)、HIPAA合规下的数据记录处理(提供零数据保留选项)。对“元代理”自动调试功能期待较高。
AI 锐评
Asteroid的定位非常精准——它没有追逐当前AI Agent领域“无所不能”的乌托邦叙事,而是务实地下沉到企业最痛苦、也最有价值的“脏活累活”中:那些没有API、依赖老旧浏览器、需要VPN、动辄MFA验证的遗留系统。这恰恰是当前大多数炫酷的通用Agent框架(如CrewAI、AutoGPT)集体翻车的地方。
其核心价值不在于“AI多聪明”,而在于“工程化做得多扎实”。支持Windows/Linux桌面、持久化文件系统、会话保持、独立邮箱处理2FA、代理支持——每一项看似基础的功能,都是在企业真实生产环境中“翻车”后才能沉淀出的必要基建。135条评论中,用户对MFA、CAPTCHA、失败重试策略等细节的追问,恰好验证了这一点。
“元代理” Astro 的引入是关键一步,它试图将构建和维护Agent本身的工作也自动化,这直接命中了当前AI Agent开发中“调试成本远超构建成本”的痛点。从数据看,单月15万次执行和HIPAA/SOC II合规认证,证明其在小而精的垂直场景(医疗、保险)中已经跑通闭环,具备了极强的壁垒。
然而,风险同样明显。产品高度依赖底层LLM(如Claude Opus 4.6),模型的降级或定价波动将直接冲击其可靠性。此外,目前仍以SaaS形态提供服务,不提供本地部署,这对最高安全要求的金融、国防客户而言是个硬伤(评论中已有提及)。若未来无法在“深度定制”和“规模化复制”之间找到平衡,Asteroid可能会被困在“Best for Healthcare”的标签里,错失更广阔的通用企业市场。总的来说,这是一款“懂行”的产品,但天花板取决于其能否将垂直领域的深扎能力,横向复制到更多行业。
一句话介绍:Fei Design Mode 让设计师在实时预览界面中直接点击UI元素,通过AI代理可视化调整像素级样式,并一键将修改推送到生产代码库,彻底消除设计到开发的交接瓶颈,让设计师真正掌控最终上线的每一个像素。
Design Tools
Artificial Intelligence
No-Code
AI设计工具
UI像素级编辑
设计转代码
Figma插件
实时预览编辑
设计交付
无代码开发
设计师提效
设计工程化
Product Hunt
用户评论摘要:用户赞赏该工具颠覆了“提示转代码”模式,实现像素级结对编程。核心关切包括:复杂组件状态处理(官方回应支持状态和代码层面)、代码质量与重构(官方承诺生产级代码且会干净重构)、版本控制与回滚(官方确认内置完整版本控制)。整体反馈积极,认为对小型团队快速交付有巨大价值。
AI 锐评
Fei Design Mode 真正值得关注的不是“AI生成UI”,而是它重新定义了设计交付的终结形态——将设计师从“规格说明书提供者”转变为“直接部署者”。产品切中了长期被忽视的痛点:设计迭代中最耗时的并非“从0到1”,而是“从1到1.01”的像素级微调。传统流程中,每一次“往上移2px”都需要发起一个完整的开发工单循环,效率损耗巨大。
然而,冷静审视其声称的“生产级代码”和“干净重构”能力,这恰恰是最大的技术挑战。如果AI在处理数十次微调后能真正生成符合语义化、可维护的CSS/组件逻辑,而非堆叠内联样式和负边距,那么它确实具备颠覆性。但目前130票的社区热度尚不足以验证其在大规模、复杂组件树中的鲁棒性。产品真正的护城河在于对“像素-状态-代码”三层意图的精准映射,而非视觉编辑本身。
对中小型团队而言,这可能是“设计一人成军”的加速器;但对大型工程化团队,代码质量、设计系统的绑定以及AI修改的审计合规性仍是悬而未决的问题。建议团队尽快展示在React/Vue等主流框架中,经过多次迭代后实际生成的代码片段,否则“生产就绪”的说法仍停留在营销话术层面。
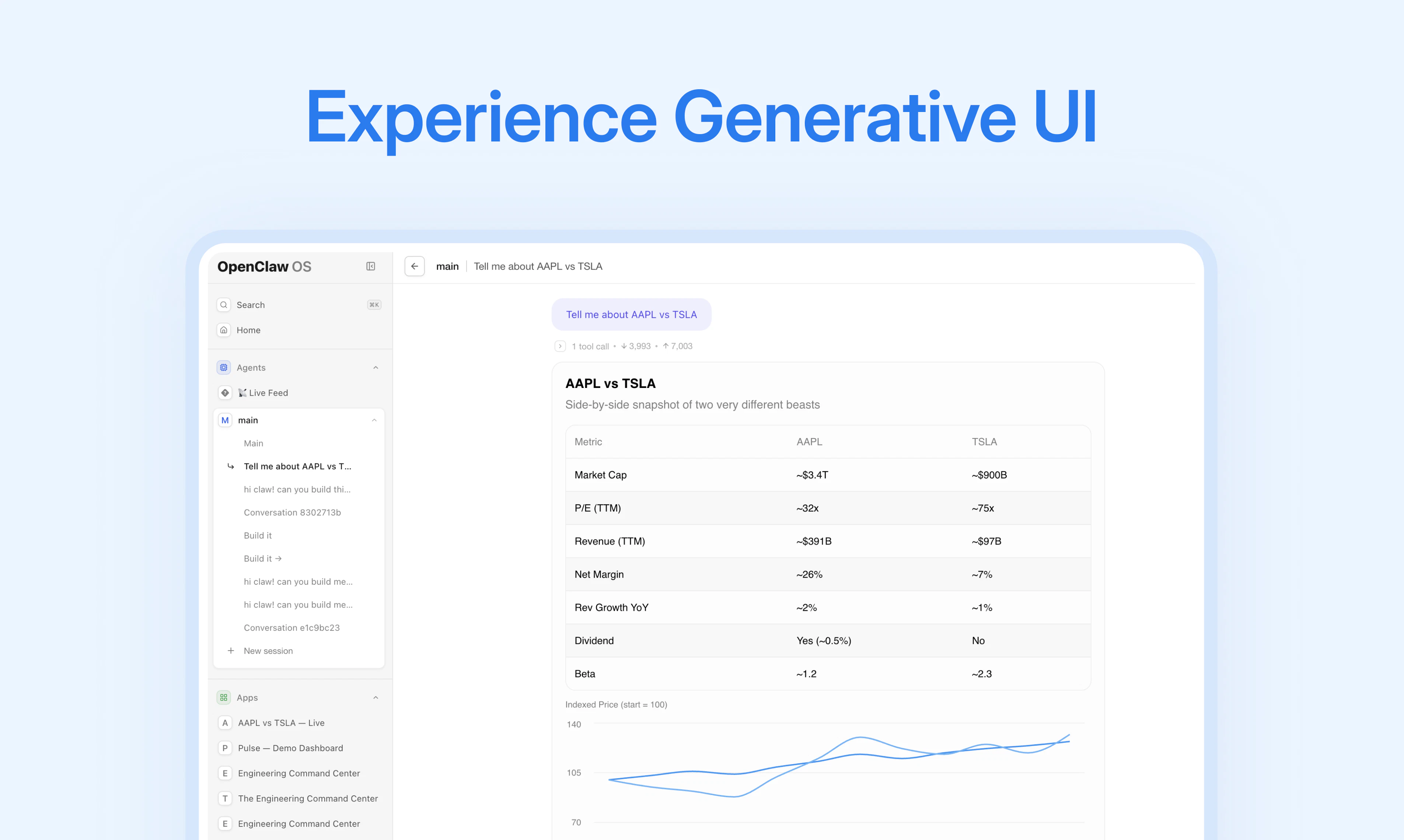
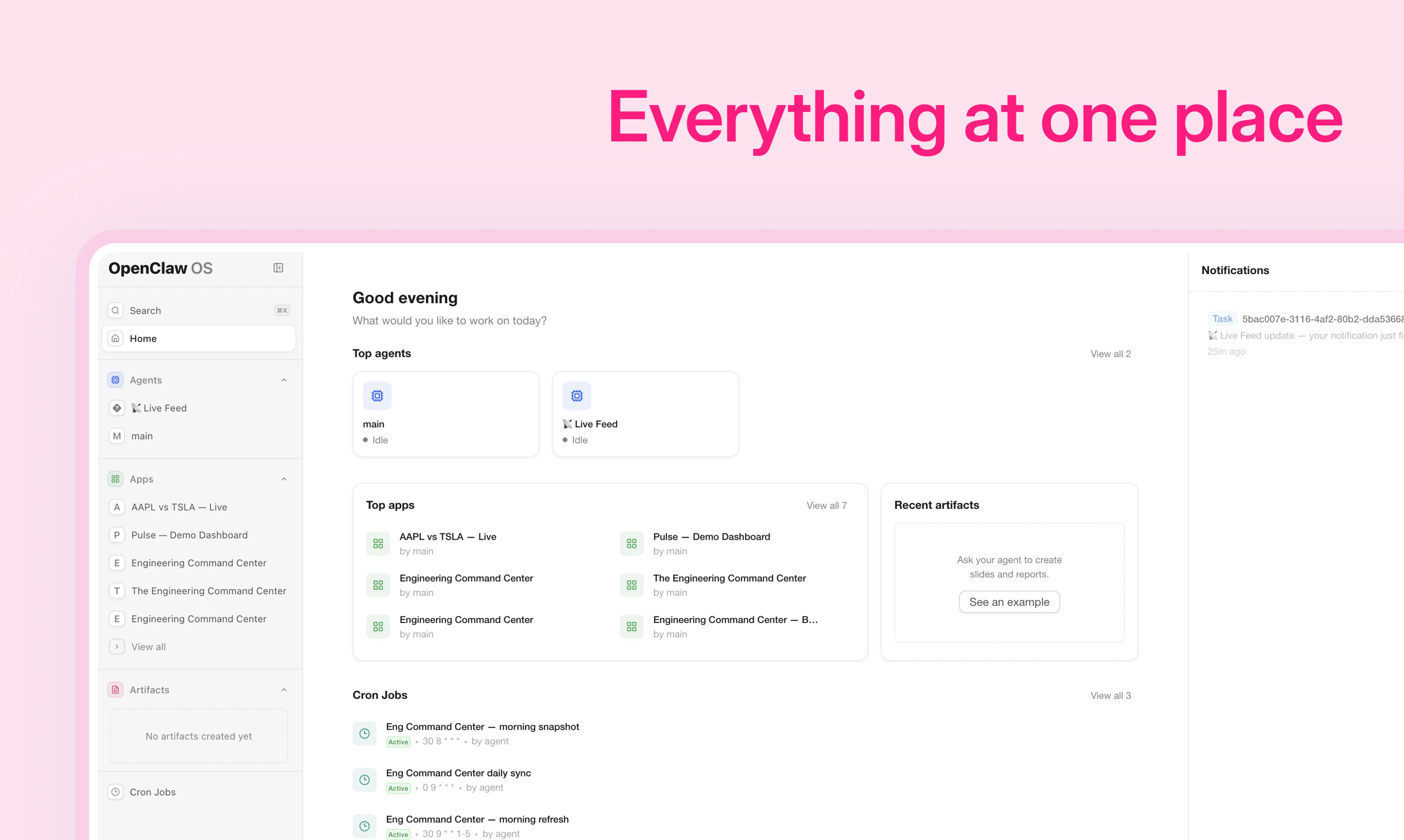
一句话介绍:Openclaw OS将AI从聊天窗口解放出来,让用户把一次性的对话指令固化成一键运行、可复用的持久化应用,解决AI工作成果被聊天记录淹没、难以管理和复用的核心痛点。
Productivity
Open Source
Developer Tools
GitHub
AI操作系统
持久化应用
生成式UI
智能代理(AI Agent)
工作流自动化
任务管理
效率工具
插件生态
定时任务(Cron)
用户评论摘要:用户普遍认可从聊天到持久化应用的转变是重要方向。核心关注点聚焦于:持久化应用的状态如何跨对话保持?应用是独立前端还是寄生于现有生态?社区期待了解具体的上下文管理机制与实现细节。
AI 锐评
Openclaw OS精准地命中了当前AI Agent落地的“最后一公里”难题——成果的沉淀与复用。其核心价值不在于创造了一个更强的聊天机器人,而在于宣判了“聊天界面作为AI唯一交互形态”的死刑。它敏锐地指出,当AI开始真正处理工作,聊天窗口就成为效率的瓶颈,而将对话碎片“编译”为结构化、可管理的“App”和“Cron Job”,本质上是将AI从“对话型工具”升级为“系统型基础设施”。
这一步棋巧妙之处在于,它没有试图从头造轮子,而是通过“OpenClaw插件”的形式,为其生态内的Agent赋予了操作系统级别的管理能力。这更像是一个“元管理”层,为混乱的Agent产出建立了秩序和契约——你不再需要重复描述需求,而是运行一个由AI为你定制的、随时可用的“工作程序”。不过,真正的挑战在于“生成的应用”的质量、稳定性和可编辑性。如果生成的App只是“一次性玩具”或者“黑箱”,无法让用户进行深度的二次定制和调试,那么“持久化”反而可能变成“僵硬化”。此外,目前深捆OpenClaw生态,意味着它的市场天花板取决于OpenClaw本身的普及度。但无论如何,它为AI Agent的实用化探索了一条清晰且极具启发性的路径:未来的AI竞争,不是比谁更能聊,而是比谁的成果能更有效地“凝固”下来,变成真正的生产力。
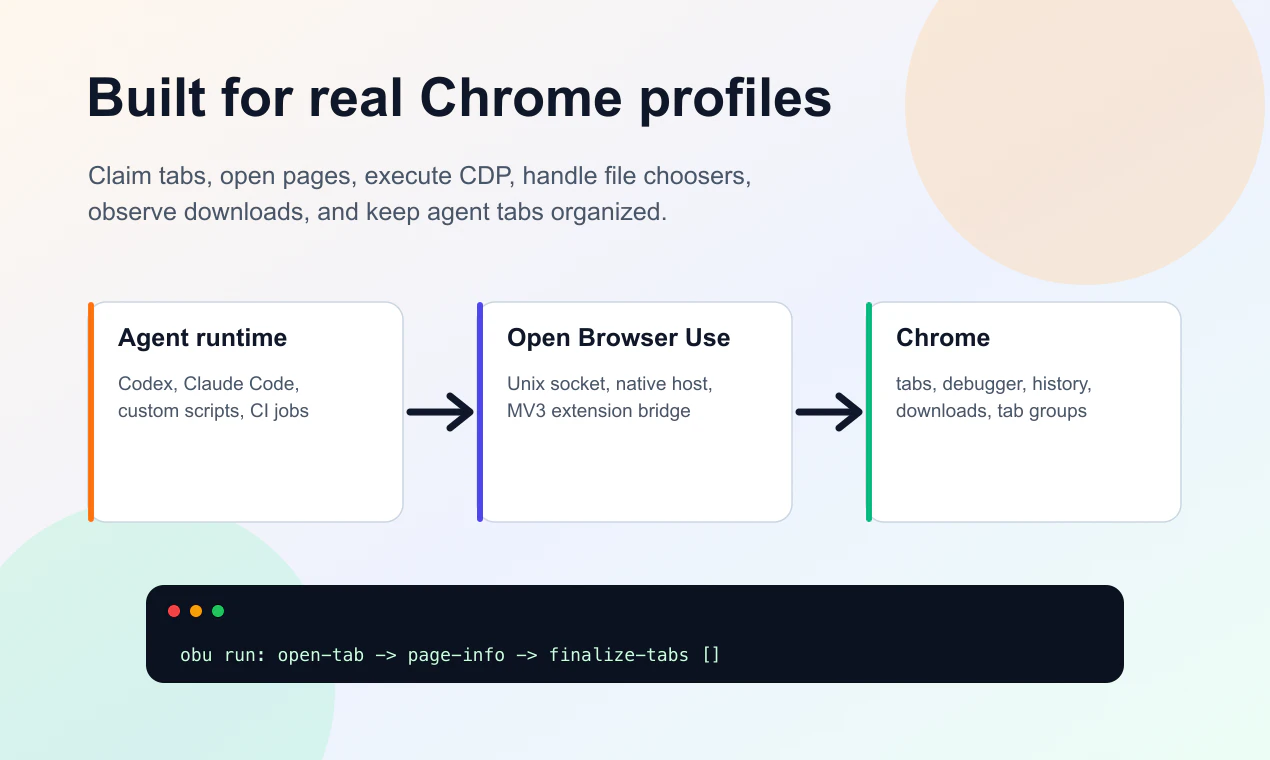
一句话介绍:Open Browser Use 是一款开源、本地优先的浏览器自动化工具,通过真实 Chrome 配置文件连接本地 AI 代理,解决了开发者在无需托管服务的情况下实现复杂标签页操作、状态检测与多 SDK 集成的痛点。
Chrome Extensions
Developer Tools
Artificial Intelligence
GitHub
SDK
开源
浏览器自动化
本地 AI 代理
MCP 服务器
Chrome 扩展
CDP 命令
多 SDK 集成
标签页管理
本地优先
开发者工具
用户评论摘要:用户关注本地优先和真实 Chrome 配置文件的优势,询问代理管理、多代理标签协调及 CDP 检测等问题。开发者回应支持标准 MCP 协议,并强调其非单一运行时绑定特性。
AI 锐评
Open Browser Use 精准切中了当前 AI Agent 落地中“浏览器自动化”的夹缝需求——既要本地实时、又要真实状态、还要可编程。它没有重造轮子,而是通过 MV3 扩展+原生宿主+MCP 的三层架构,巧妙绕过了托管服务的延迟和限制,直接赋能开发者操控 Chrome 的真实标签页。从 CLI 到 JS/Python/Go SDK 的快速布局,显示出强烈的工具链野心。
但它的真正挑战不在于技术,而在于生态兼容性:与已成熟的 Playwright/Puppeteer 相比,OBU 独特价值在于“真实配置文件”和“标签页级控制”,但这也意味着稳定性依赖 Chrome 扩展 API 和 CDP 的黑盒行为,多代理协调、下载监控等高级特性仍需大量工程打磨。同时,作为一个 100 票的早期项目,文档完善度、社区支持、长期维护性都是潜在风险。
客观来说,OBU 目前更像是“一个有趣的桥梁”,而非替代品。它适合快速原型、本地调试以及 CI 中的轻量任务,但若想在生产级多代理编排中站稳脚跟,还需要在容错机制、跨平台兼容和性能基准上证明自己。MIT 许可证是加分项,但开源项目从“有趣”到“可靠”,中间隔着一整个微服务的距离。
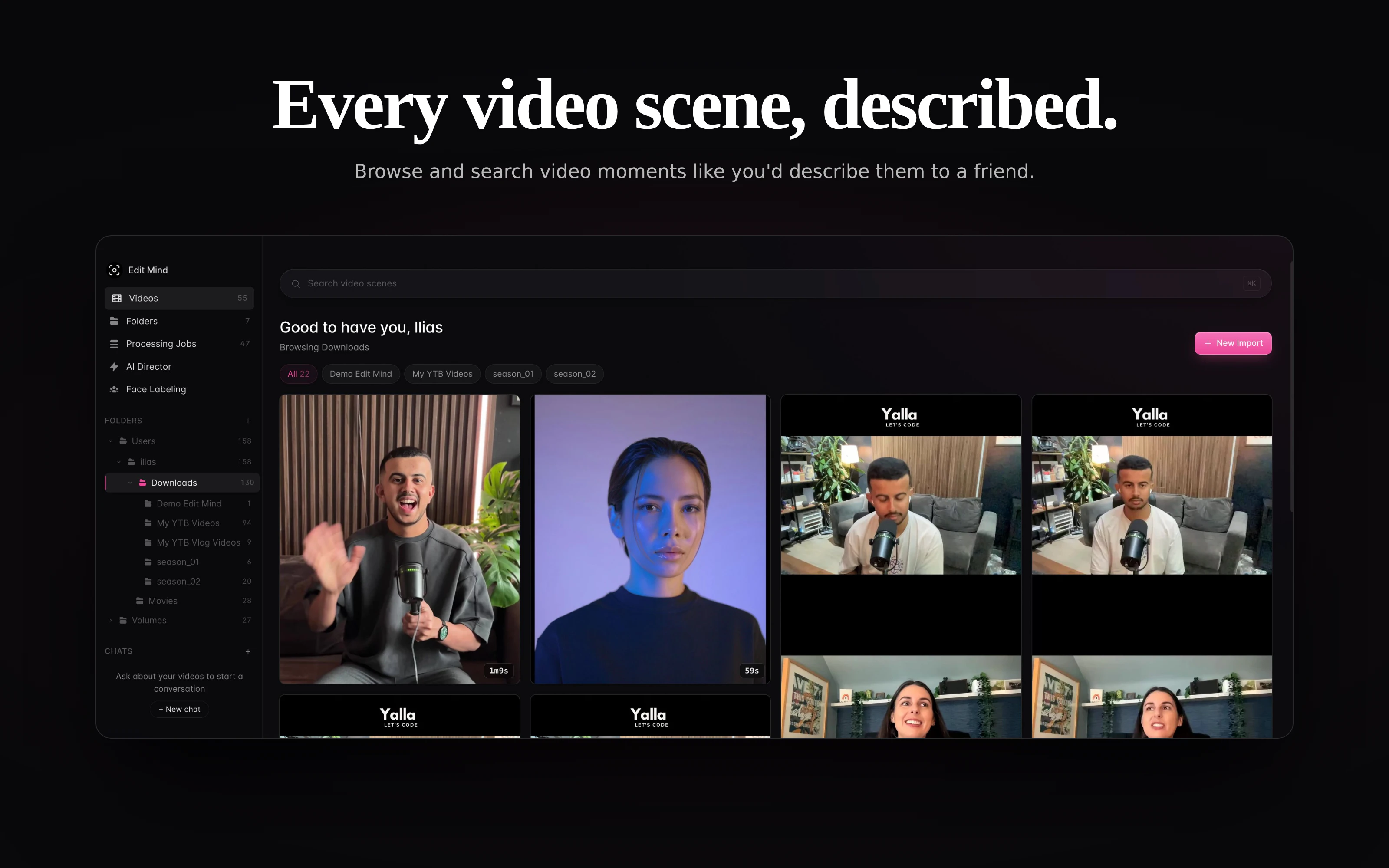
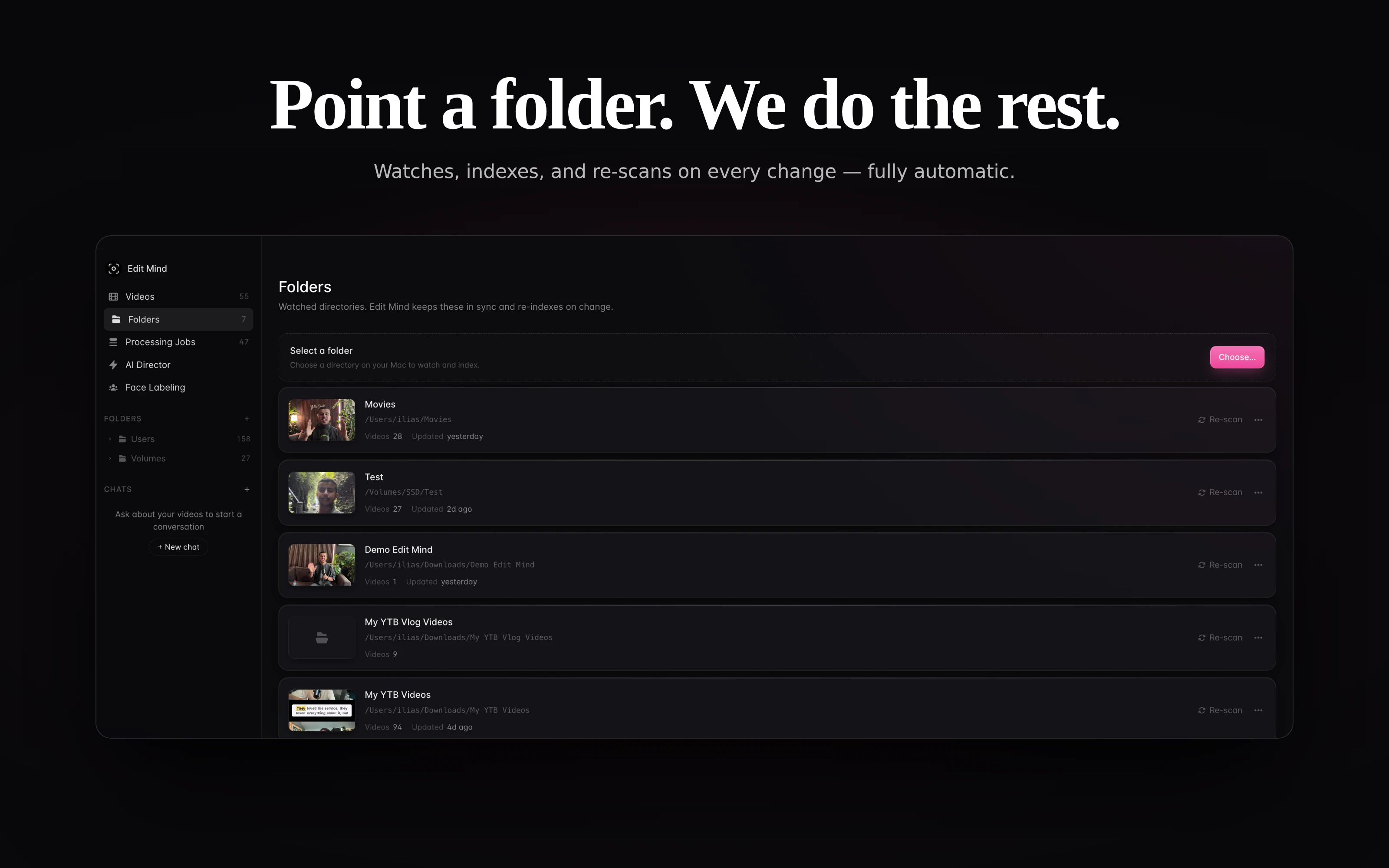
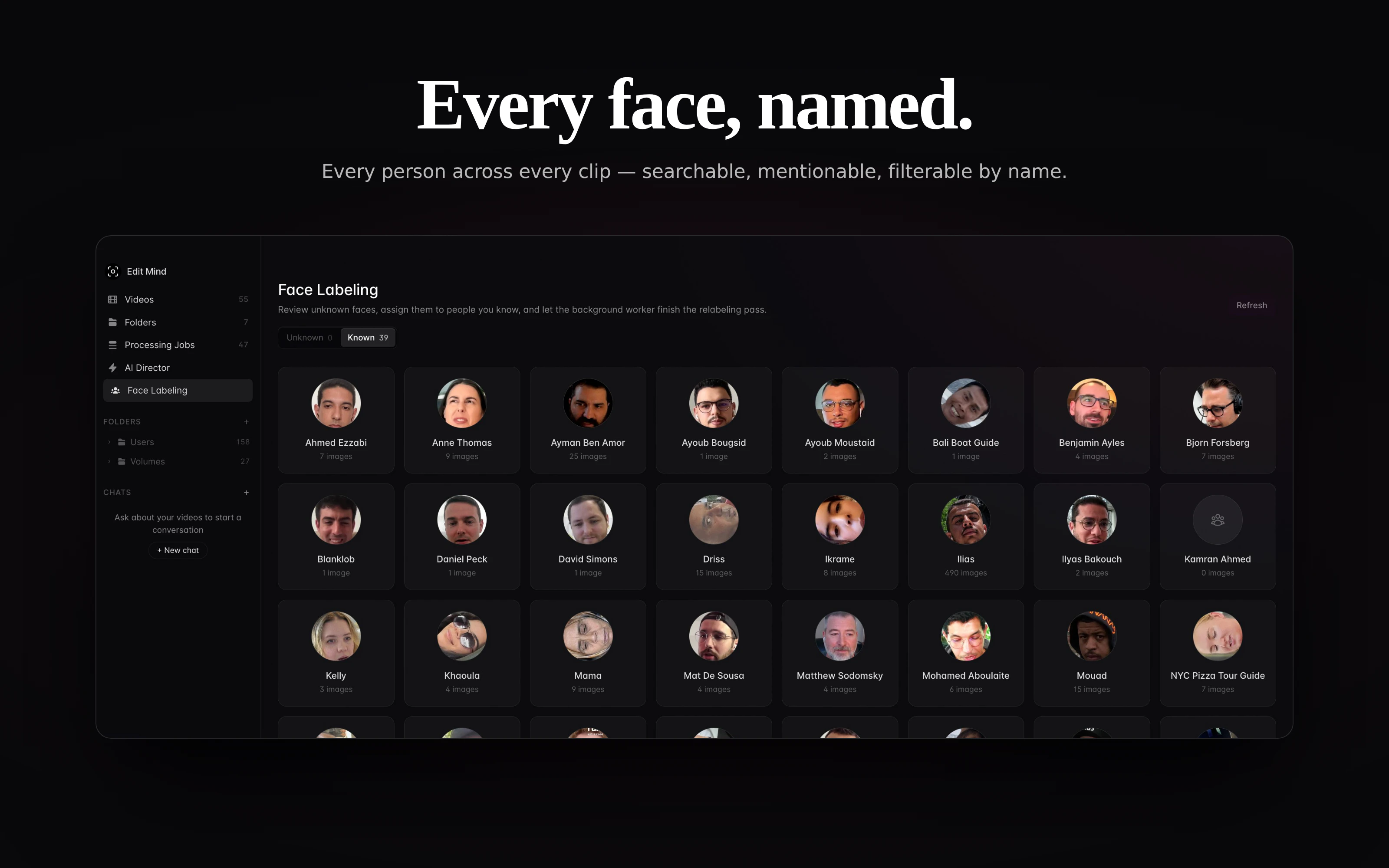
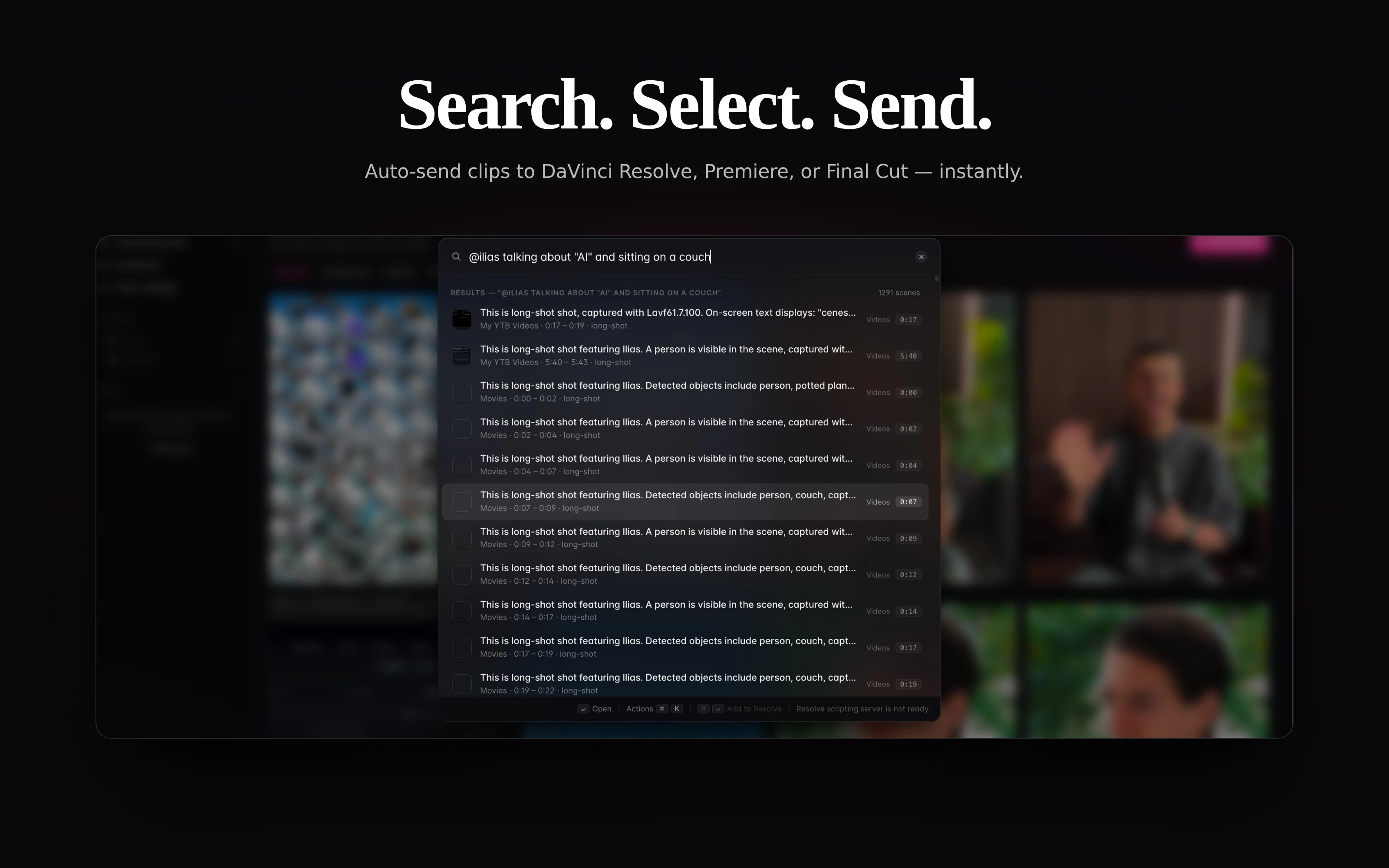
一句话介绍:Edit Mind是一款100%本地的视频内容搜索引擎,帮助视频创作者、编辑和记者通过自然语言对话式搜索,在海量本地视频中瞬间定位所需画面,彻底解决传统云端分析成本高、效率低、隐私无保障的痛点。
Mac
GitHub
Video
用户评论摘要:用户高度认可其本地化、无需上传的特性,并询问是否支持跨视频统一索引、能否批量选取片段发送至编辑时间线。有用户关心支持的本地AI模型类型,以及未来路线图(如桌面端优化、多格式支持)。创始人回应确认支持批量发送,并分享了自托管版本与技术栈(Whisper、YOLO、DeepFace等)。
AI 锐评
Edit Mind切中了一个长期被忽视但极具痛点的场景:视频素材的“本地化智能检索”。它不仅规避了Google等云端API高昂的按量计费成本(对动辄TB级素材的创作者堪称财务噩梦),更从根本上解决了内容敏感数据的外泄风险。产品在技术实现上颇具深度——结合Whisper进行语音转录、YOLO实现物体检测、DeepFace完成人脸识别,同时加上了Qwen等本地大模型驱动的对话式索引,已经是一个相当完整的本地AI视觉分析流水线。
然而,必须指出其潜在挑战:首先是模型性能对硬件的要求。在用户评价中提到的“Apple Silicon与GPU优化”正是关键——无论是Whisper还是YOLO,在普通消费级设备上处理大量长视频时,索引时间与功耗仍是巨大瓶颈。其次,产品目前生态整合尚浅,是否能原生嵌入Premiere、DaVinci Resolve等主流编辑软件的工作流,将决定它是否只是一个“独立搜索工具”而非“编辑必备插件”。最后,“自然语言搜索”的准确度高度依赖语音转录与视觉模型的质量,错检与漏检在复杂场景下仍难以避免。
但从另一个角度看,Edit Mind代表了一个明确的产品趋势:本地AI不再只是概念,而是正在重塑专业创作工具的底层逻辑。它的真正价值不在于搜索本身,而在于将视频从“不可查询的二进制文件”转变为“可全文搜索、可片段调用的结构化资产”。如果能持续优化性能、开放API并深度融入剪辑流程,它有可能成为视频媒体团队的标配基础设施。
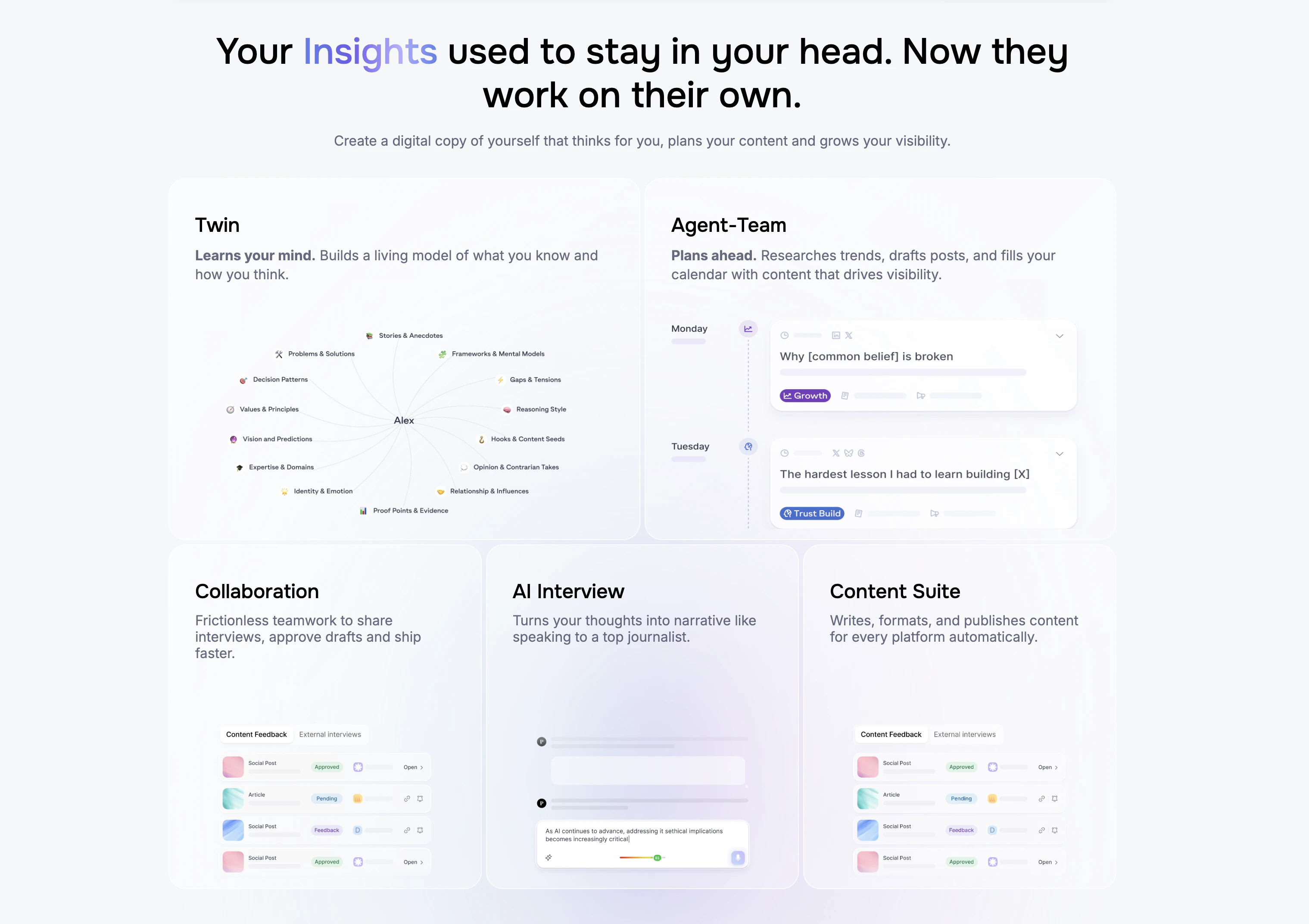
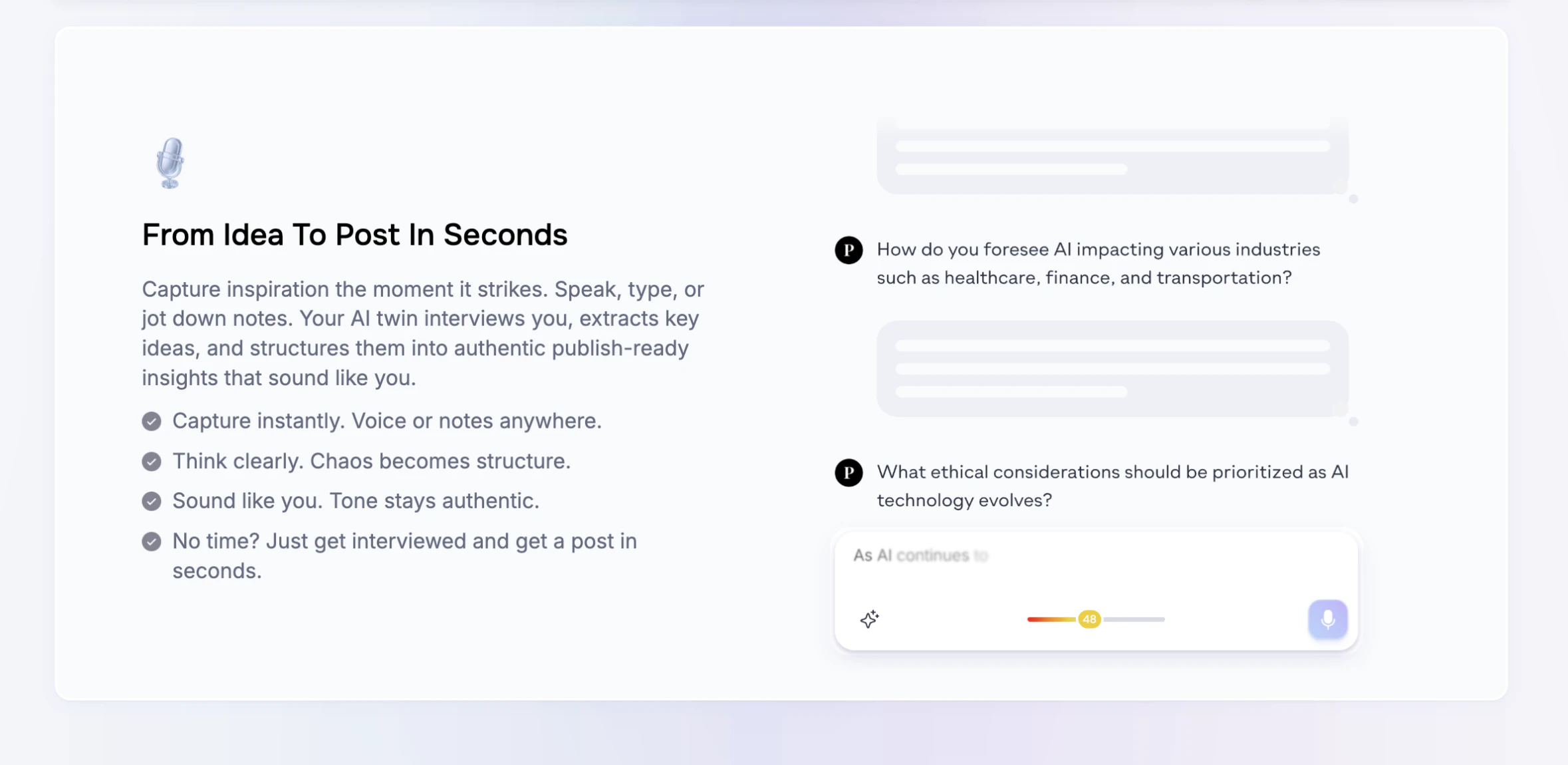
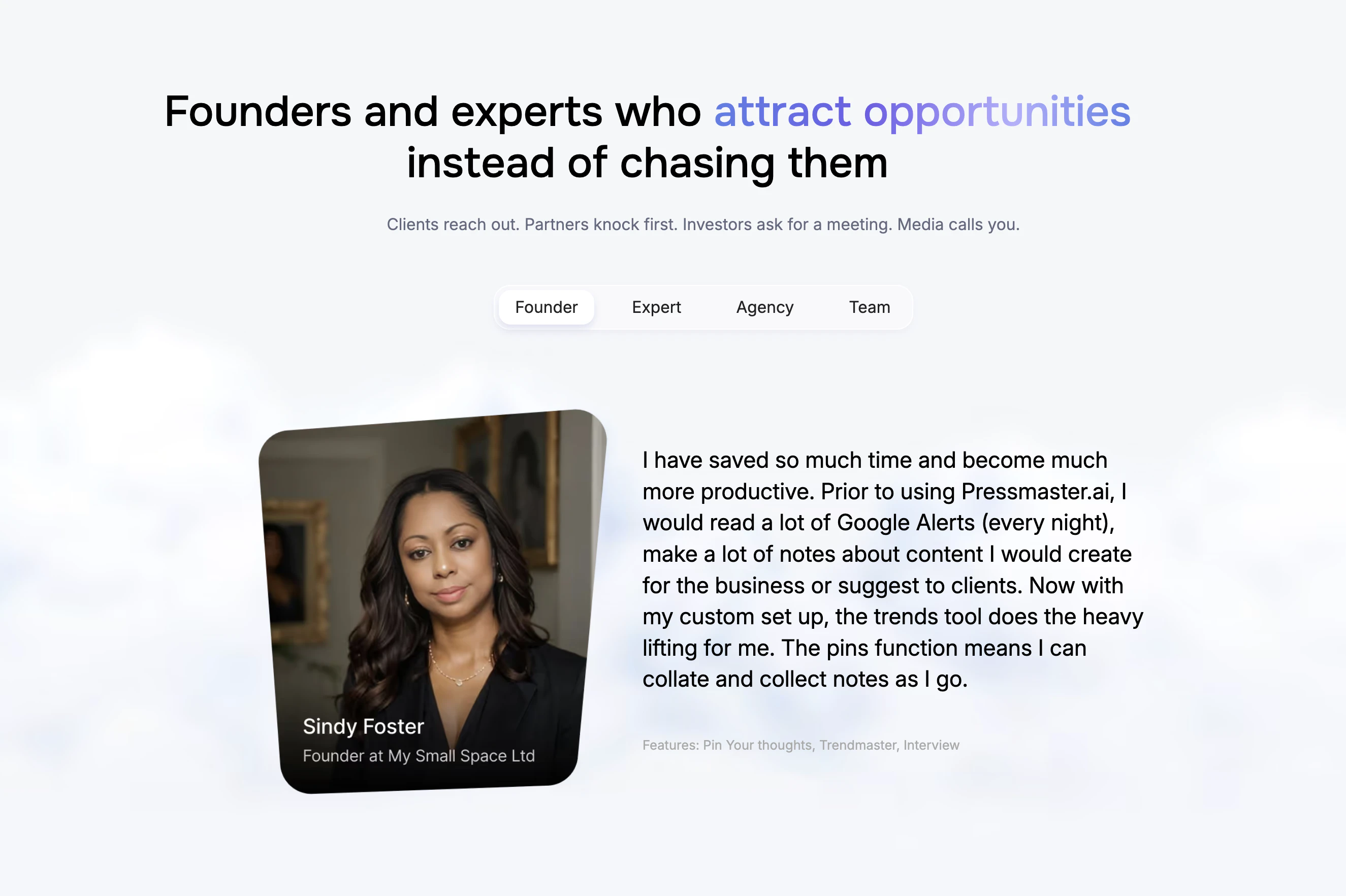
一句话介绍:Pressmaster.ai通过“AI双胞胎”将创始人的采访、零散想法和素材自动转化为符合其个人风格的高质量文章、帖子及多平台发布内容,解决创始人没时间将思想转化为专业内容的痛点。
Pitch Dubai
AI内容生成
思想领导力
创始人工具
AI双胞胎
内容策略
多平台发布
个人风格
趋势发现
内容规划
采访转内容
用户评论摘要:用户赞赏采访转内容流程节省时间,能捕捉真实声音;但质疑如何保留创始人独特观点和反面意见,避免模型过度平滑导致内容失真。官方强调通过上下文、句法和语义三重优化来保护个人风格。
AI 锐评
Pressmaster.ai切中了一个真实但极其刁钻的痛点——不是“内容太少”,而是“创始人的思想被AI洗成平庸的鸡汤”。绝大多数AI内容工具本质是“排列组合机器”,产出再多也只能填充流量垃圾,而创始人真正的资产是其独特的判断、取舍和反主流观点。Pressmaster聪明地绕开了这个陷阱:它不试图从零生成,而是通过双胞胎建模优先捕获“句法+语义”,即一个人如何想,而非仅仅如何说。这使其在思想领导力赛道具备了真正的壁垒。
但问题也很明显。评论中用户对“保留负面样本”的疑虑直击核心——AI天然倾向于正向、平滑,而真正的领袖魅力往往来自“对什么说不”。Pressmaster声称建模了“信仰和反主流观点”,但具体如何量化“不被采纳的选项”仍是黑箱。另外,深度依赖输入素材质量意味着前期访谈和语料采集成本不低,这对于孤身作战的早期创始人是否友好?若无法自动化这步,“节省时间”就可能沦为半成品。
短期内,它解决了“从思想到草稿”的70%问题,但剩下的30%——尤其是对独特性的保护能力——才是决定其能否从“工具”升级为“创始人第二大脑”的关键。如果它能持续证明自己不仅产出内容,更能生产“只有这个人才能说出来的话”,那它就不仅是增效工具,更可能成为思想领导力碎片化时代的出版系统。但若只是优化了文案工序,那迟早会被其他更廉价的方案追上。
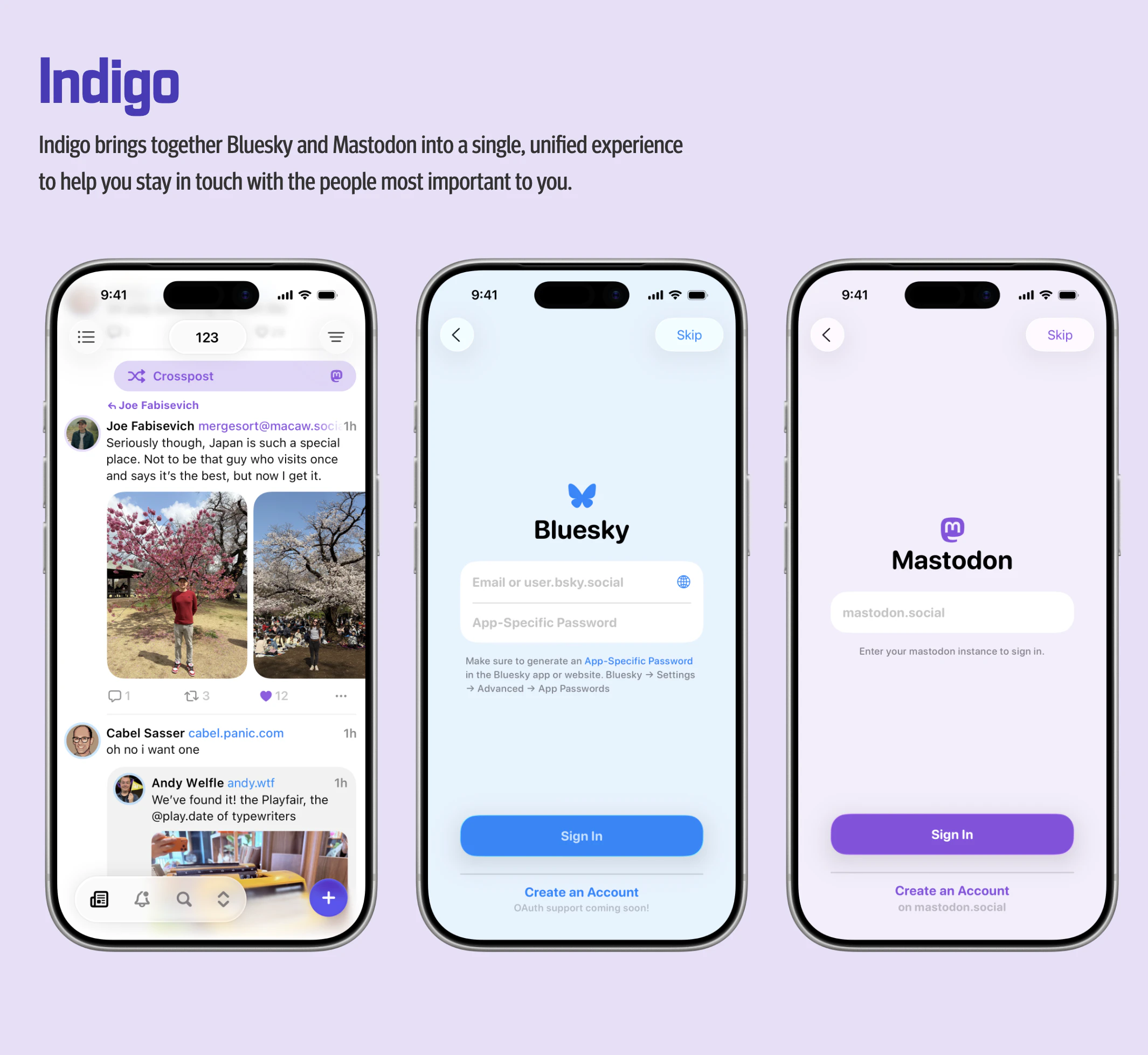
一句话介绍:Indigo是一款将Bluesky和Mastodon动态整合到一个时间线的社交客户端,解决用户在多平台分散关注、难以统一维护社交圈子的问题。
Social Network
Social Media
Social Networking
联邦宇宙
跨平台社交
Bluesky客户端
Mastodon客户端
统一时间线
跨帖发布
付费订阅
社交聚合
第三方客户端
Ultraviolet
用户评论摘要:用户肯定其作为联邦宇宙桥梁的价值,并询问是否支持跨帖发布。开发者确认支持跨帖,并称其前身Croissant专为此设计。关于商业模式,用户将其类比Ivory,开发者披露了免费试用、付费互动的订阅制(Ultraviolet),月/年/一次性购买及地区定价策略。
AI 锐评
Indigo的“统一时间线”定位并不新鲜,但其真正的价值锚点在于“跨帖发布”的深度实现。从评论中可知,团队此前开发的Croissant为跨帖功能积累了技术基础,这让Indigo不再是简单的“聚合阅读器”,而是切中了多平台创作者的刚需——在一个客户端发布,内容同步辐射至Bluesky和Mastodon两大阵营。这种“输出端整合”比“输入端整合”更具差异化和黏性。
商业层面,其“免费浏览、付费互动”的模式颇值得玩味。这本质上是在用“信息消费”做漏斗,用“互动与发布”做付费墙,巧妙地避开了与Instagram、Threads等巨头的正面竞争,转而服务联邦宇宙里的轻度用户。但挑战同样尖锐:119.99美元的终身买断不覆盖所有未来功能,这种“减配版永久授权”容易引发用户对“半成品”的信任危机。更关键的是,Indigo完全依赖Bluesky和Mastodon的开放API,一旦平台收紧访问策略或功能变更,这款“桥梁”产品的根基就会动摇。它像是联邦宇宙生态的“精品插件”,价值明确但天花板也清晰——无法独立,只能寄生。对于需要多平台高效发布的重度用户,这是一笔值得计算的“时间成本置换”;但对只想刷时间线的普通用户,免费浏览已足够,付费动力不足。
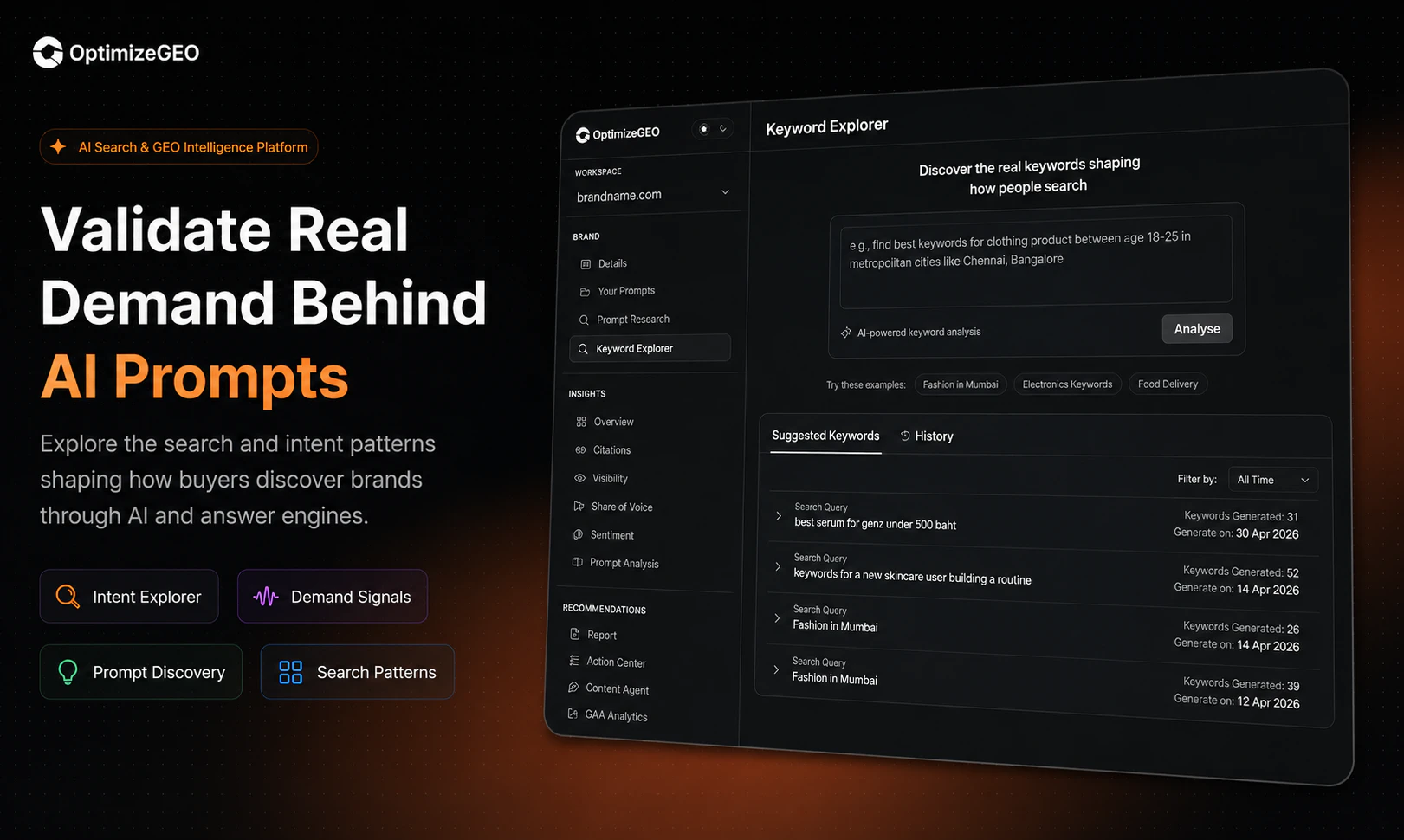
一句话介绍:OptimizeGEO.ai是一个帮助品牌监控并提升在ChatGPT、Gemini等AI搜索引擎中可见度与准确性的自动化GEO平台,解决品牌在AI回答中“被误读”或“不被提及”的痛点。
SEO
Artificial Intelligence
Pitch Dubai
GEO
AI搜索优化
品牌可见度
生成式引擎优化
AI代理
声誉管理
内容策略
自动化监测
市场分析
企业SaaS
用户评论摘要:用户普遍认可产品解决了棘手痛点(如品牌在AI中被错误描述)。有用户指出,多语言场景下GEO评分会失真,因为不同AI引擎对不同语言的回应不一致,单一分数无法指示优先修复的市场。
AI 锐评
这是一款踩准了AI搜索变革节奏的产品。其核心价值不在于“优化”本身,而在于“监测与诊断”——当多数营销人还对AI引擎的“黑箱”反馈束手无策时,OptimizeGEO提供了可量化的“可见度”与“准确性”指标,本质上是为品牌在AI生态系统里建立了第一道质检线。AI代理自动识别问题并归因到内容、引用、PR等环节,将模糊的“提升AI友好度”转化为可执行的工单,这才是实效所在。但产品面临两大挑战:一是用户评论中提到的“多语言GEO评分失真”问题,这暴露了模型间行为差异带来的度量标准不统一,若无法细化到引擎-语言-市场颗粒度,宏观分数反而会误导资源分配。二是AI搜索格局未定,ChatGPT、Perplexity等平台的算法迭代频繁,此刻的“优化策略”可能随时失效,产品需要证明其策略的时效性与自适应性,而非静态报告。整体上看,这是一张通向下一代SEO的入场券,但能否从“工具”升级为“标准”,取决于它能否率先解决跨引擎、跨语种归因的底层逻辑难题。
一句话介绍:Open Computer Use 将本地桌面自动化封装为标准 MCP 服务,让任何 AI 代理(如 Codex、Claude Code 等)都能跨平台操控桌面应用,解决单一平台或闭源代理无法自由集成桌面自动化能力的痛点。
Open Source
Developer Tools
Artificial Intelligence
GitHub
桌面自动化
MCP服务
AI代理
开源工具
跨平台
命令行工具
开发者工具
办公自动化
用户评论摘要:开发者普遍认可“标准化桌面控制”的思路,认为这为自定义代理打开了新可能。主要疑问集中在能否用于自动化数据录入(如从旧系统导出到数据库或表格)。项目方回应肯定,并建议加入校验截图等环节以保证稳定性。
AI 锐评
Open Computer Use 的定位非常聪明——它没有试图再造一个“完美”的桌面操控引擎,而是敏锐抓住了 Agent 生态中“算力过剩、接口孤岛”的错配,用 MCP 这个标准协议做了一次完美的缝合。把 Codex 的“计算机使用”体验提取成跨平台服务,本质上是在为 AI Agent 提供“手脚”的标准化接口,让开发者不再受限于单一厂商的封闭方案。87票不算爆款,但其核心价值在于解耦:“应用操控”从特定产品能力变成可插拔的基础设施。这解决了 Agent 落地的关键卡点——AI 在数字世界里的“行动力”。风险在于:跨平台兼容、非侵入式自动化的可靠性(定位、点击、截图准确性)仍是硬骨头;而且 MCP 协议本身还在早期,生态渗透率有限。如果项目能搞定 Linux/Win 的高频 fail case,并借助 npm 降低部署门槛,它极可能成为 Agent 时代的一根重要“拐杖”——虽不性感,但没它不行。对于工具型产品,别急着吹“改变世界”,先把 “click and type” 做到 99.9% 不出错再谈野心。
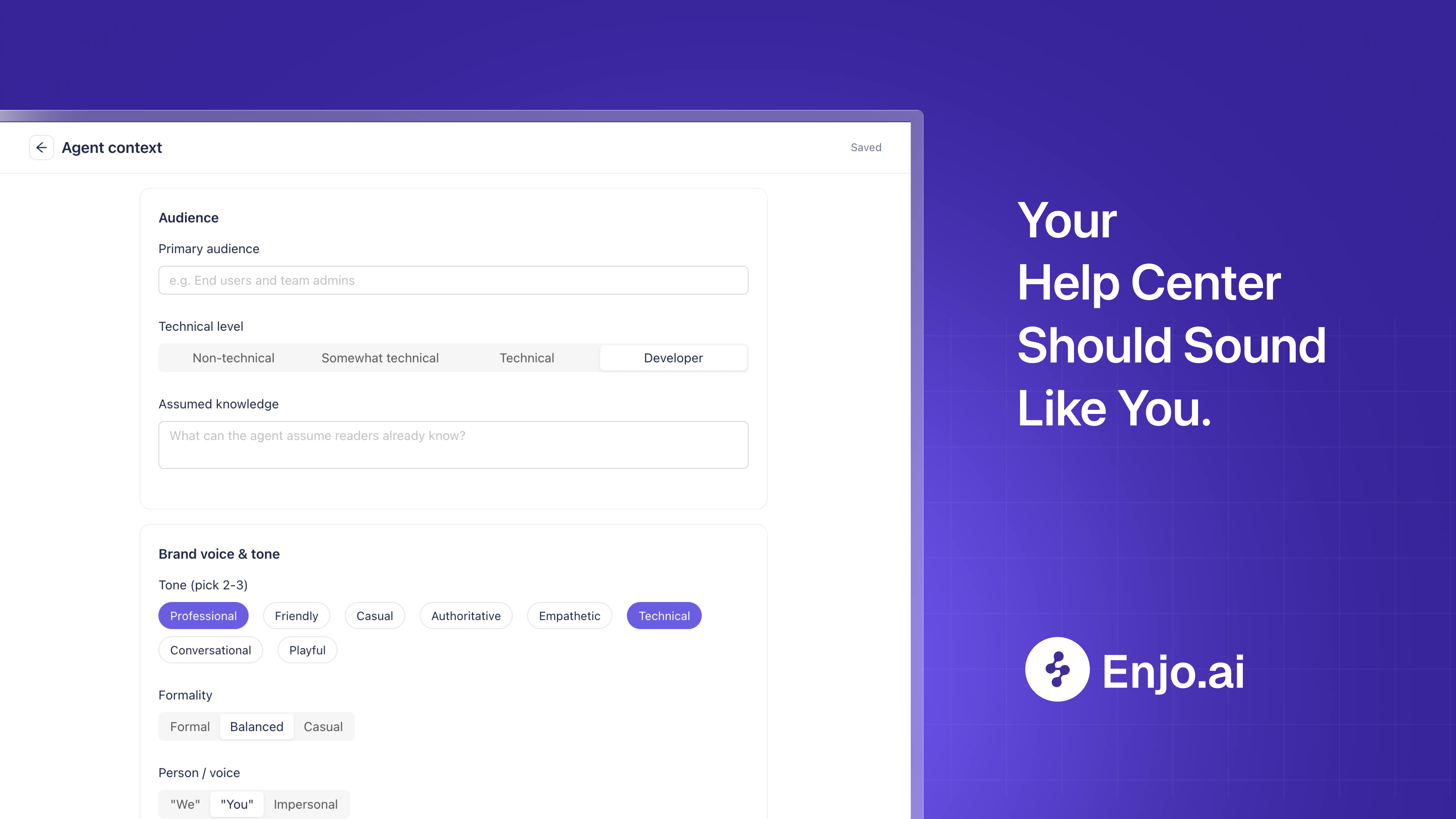
一句话介绍:Enjo Help Center 通过AI自动从网站URL生成帮助中心,并能从团队解决客户问题的过程中自动学习并撰写新文章,解决了帮助中心“建而不用、维护困难”的核心痛点。
Customer Success
SaaS
Artificial Intelligence
AI帮助中心
知识库自动化
客户支持
工单闭环
AI学习
自动文档生成
SaaS工具
知识管理
用户评论摘要:用户普遍认可AI自动建立和更新帮助中心的价值,尤其赞赏从已解决对话中自动生成文章的功能。评论中未见具体问题或建议,用户更多是表达对AI-first设计理念的认同,以及希望看到实际应用效果的期待。
AI 锐评
Enjo Help Center的发布,精准击中了企业中知识管理与客户支持脱节这一长期痛点。其核心创新并非简单的“AI生成文档”,而是构建了一个“问题-解决-知识沉淀”的自动闭环。这看似简单的逻辑,实则颠覆了传统帮助中心“人工撰写->定期维护->被动查询”的静态模式,将其转变为随客户互动不断自我完善的“活”系统。
产品真正的价值在于,它将“维护成本”从撰写环节转移到了更具价值的“审核”环节。团队不再需要绞尽脑汁预判所有问题并撰写长文,只需处理AI筛选出的盲区问题,并在解决后复核一篇AI草稿。这种模式无疑会大幅降低企业(尤其是SaaS公司)建立和维持知识库的心理门槛与人力成本。
然而,必须冷静看待的是,这套系统的天花板在于“学习质量”。AI自动生成的文档质量高度依赖于初始知识库(网站URL)的规范性和团队解决方案的专业度。如果初始信息混乱,或团队为解决短期问题给出不够标准的答案,AI学习到的“错误”将会被放大和固化,造成知识污染。此外,产品目前200条/月的免费额度和$95/月的起步价,对于小团队或查询量级不高的场景可能是门槛。它能否在更复杂的、多语言或高度定制化的支持场景中保持质量,还有待观察。总的来说,Enjo不是“自动写文档工具”,而是“知识资产管理引擎”,但如何管理好这个引擎的“燃料”(输入质量),是用户和产品自身都需要警惕的核心命题。
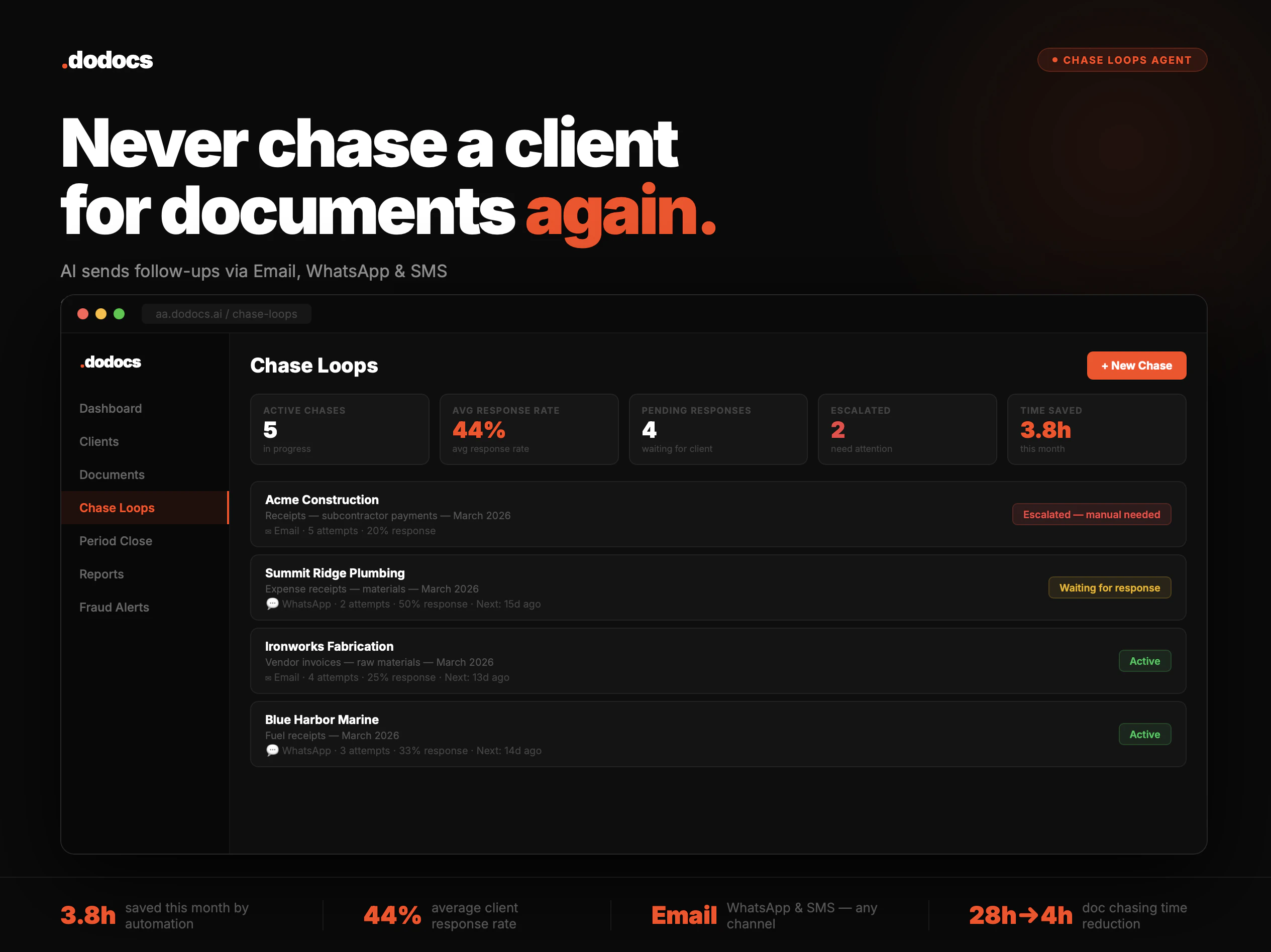
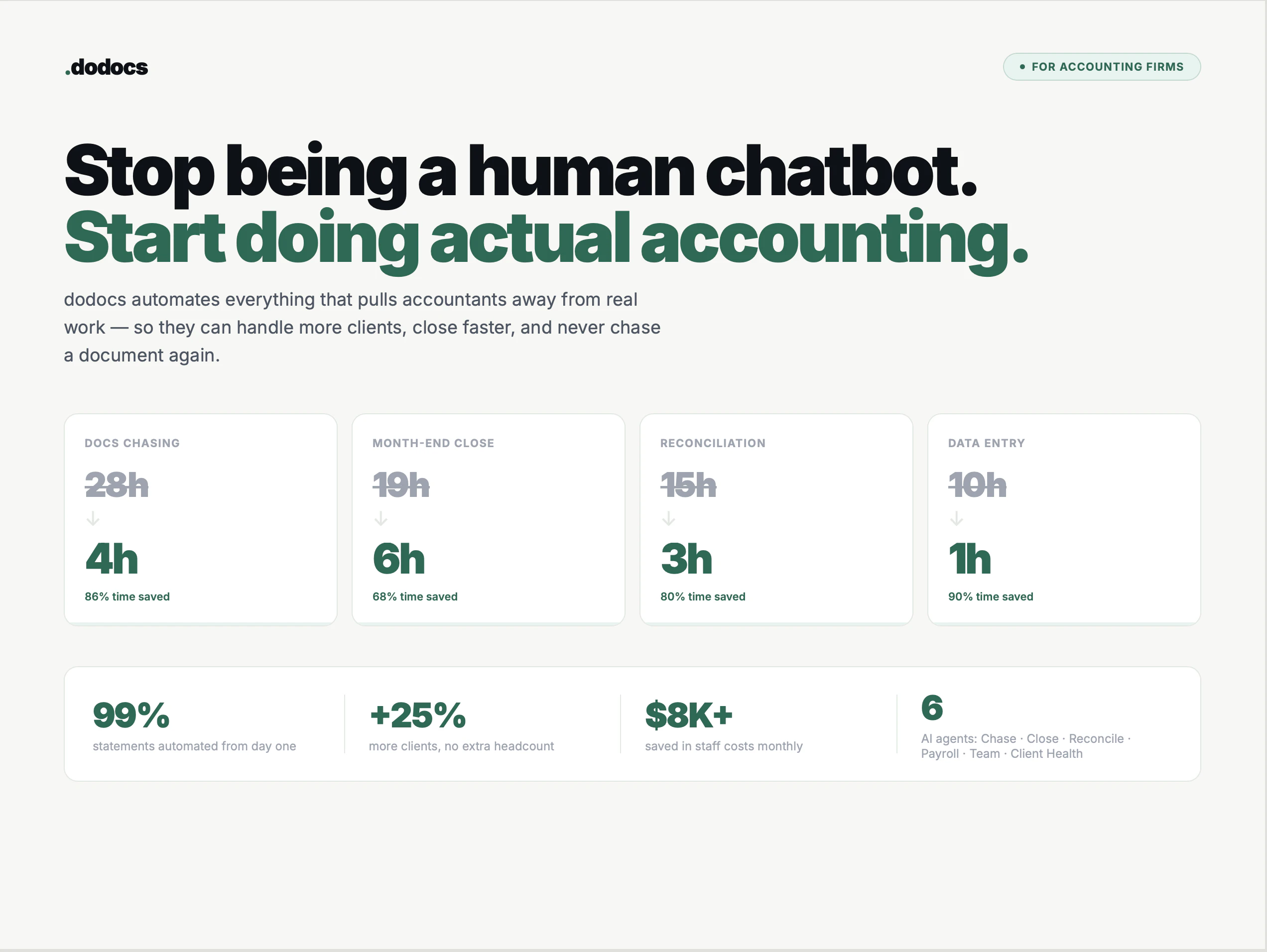
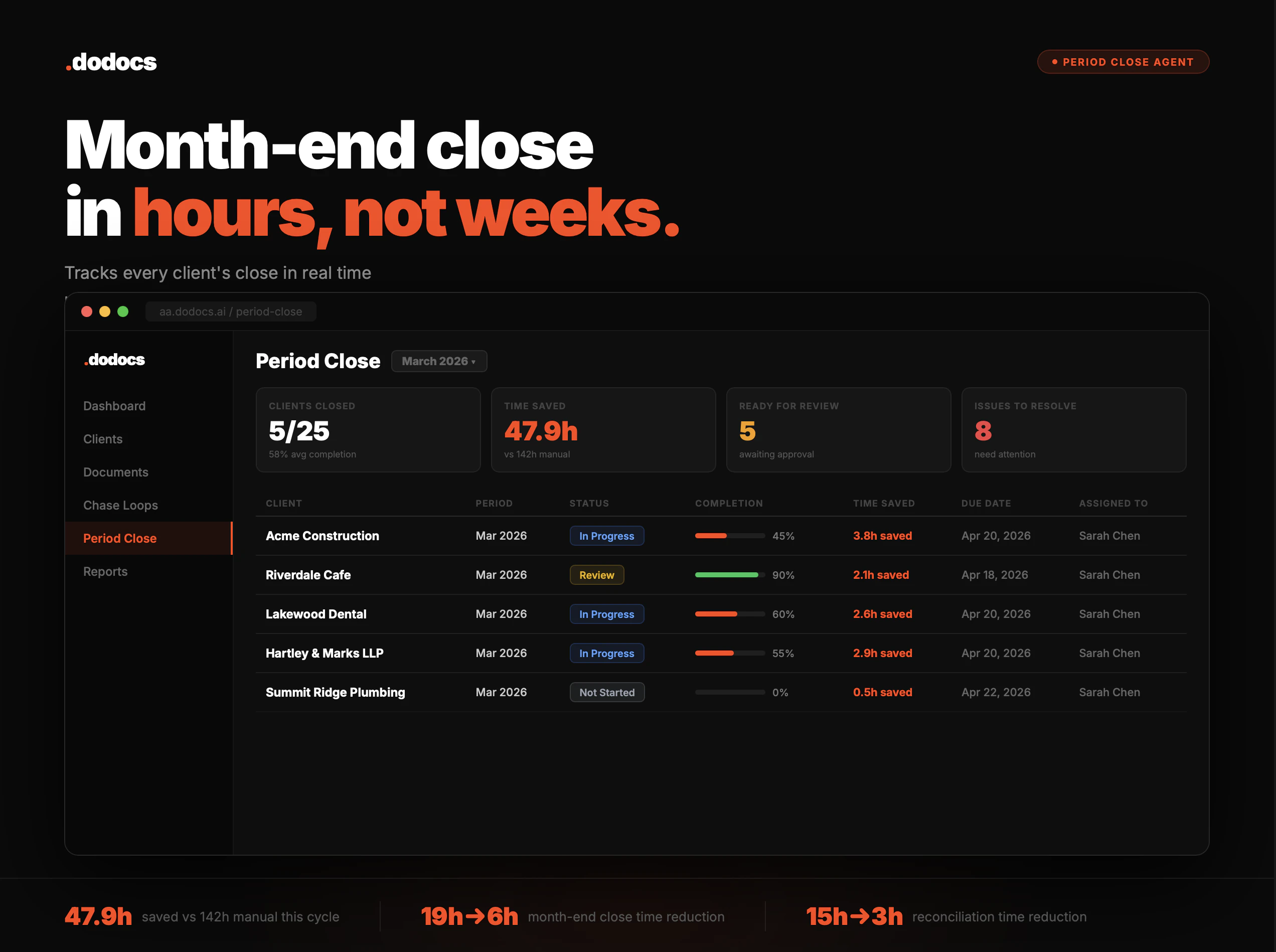
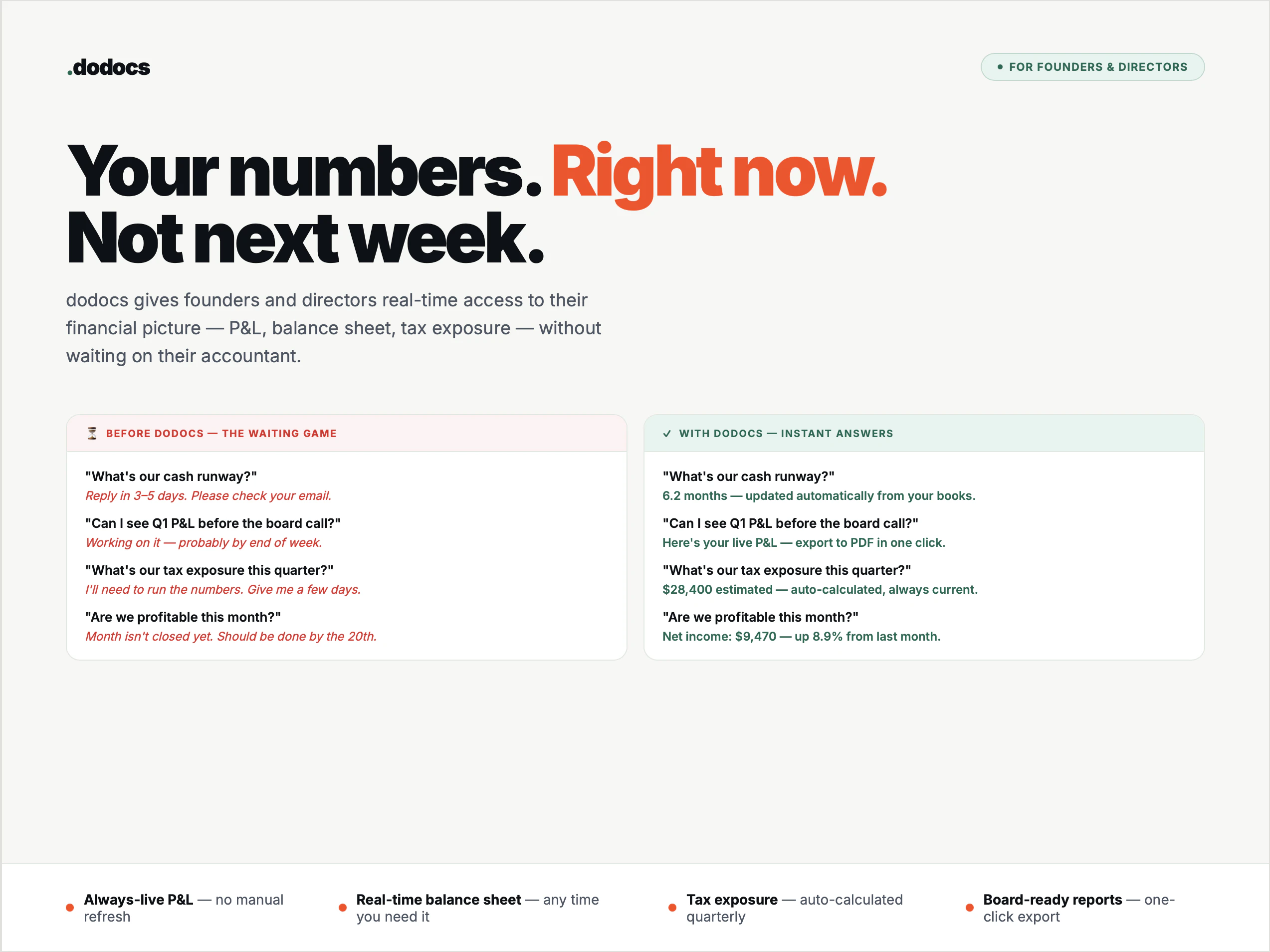
一句话介绍:DoDocs作为会计操作系统,自动执行账单催收、发票对账和欺诈检测,帮会计师与创始人摆脱低效文书工作,实现财务数据实时响应。
Fintech
Artificial Intelligence
Pitch Dubai
会计自动化
AI对账
发票匹配
欺诈检测
文档追踪
QuickBooks集成
Xero集成
Zoho集成
Workflow自动化
SaaS
用户评论摘要:用户关注已上线模块(文档催收与对账功能),提问AI对账的判断逻辑(确定性/AI混合)及人工审批交互方式。创始人关心边缘费用分类处理能力。团队回复承诺自定义模式和演示支持。
AI 锐评
DoDocs切中了会计行业最痛的“无效工时”问题——53%的时间花在催单、对账这类低价值重复劳动上。其产品逻辑清晰:不试图取代会计,而是以OS层整合QuickBooks、Xero等现有工具,用AI agent替代人工流程,同时保留人工干预的灵活性(如用户可控制自动化程度),这既解决效率痛点又避免职业抵触。
但需冷静审视:81票的Product Hunt数据不算惊艳,且其“二度上市”暗示过往产品未形成爆款。当前仅两个模块(催款与对账)在线,剩余四个要年内交付,功能矩阵完整度存疑。AI金融数据处理合规性(如欺诈检测的误报率、数据安全)和与核心财务系统的深度集成能力是长期壁垒,亦是对手(如Bill.com、Vic.ai)已深耕的领域。
真正价值在于“实时财务问答”——缩短创始人等待会计回复的天数至秒级,这直击中小企业和初创公司融资对账的信任痛点。但若未来不能持续扩展至薪资、关账等复杂场景,并建立生态网络效应,则容易停留在“高级脚本工具”阶段,难以支撑其“OS”叙事。















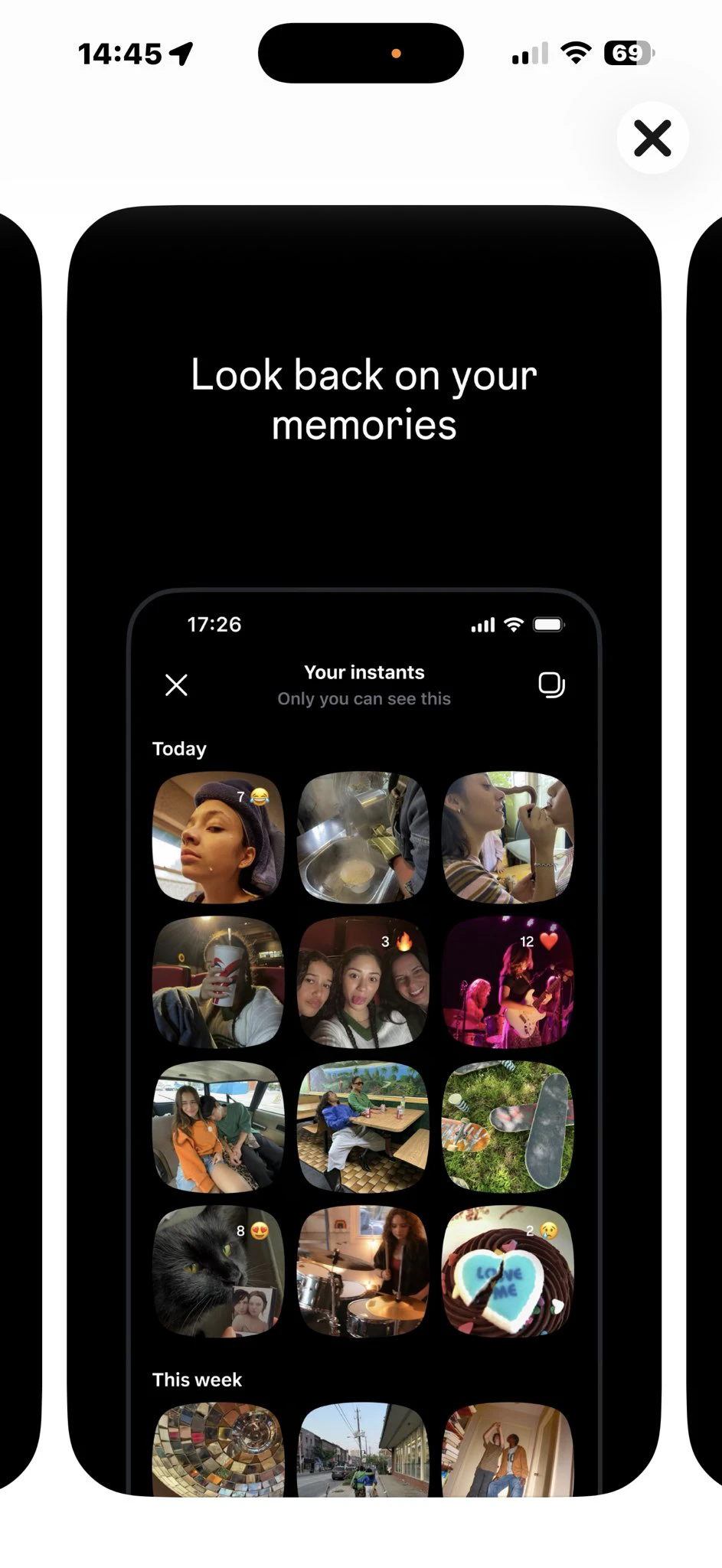





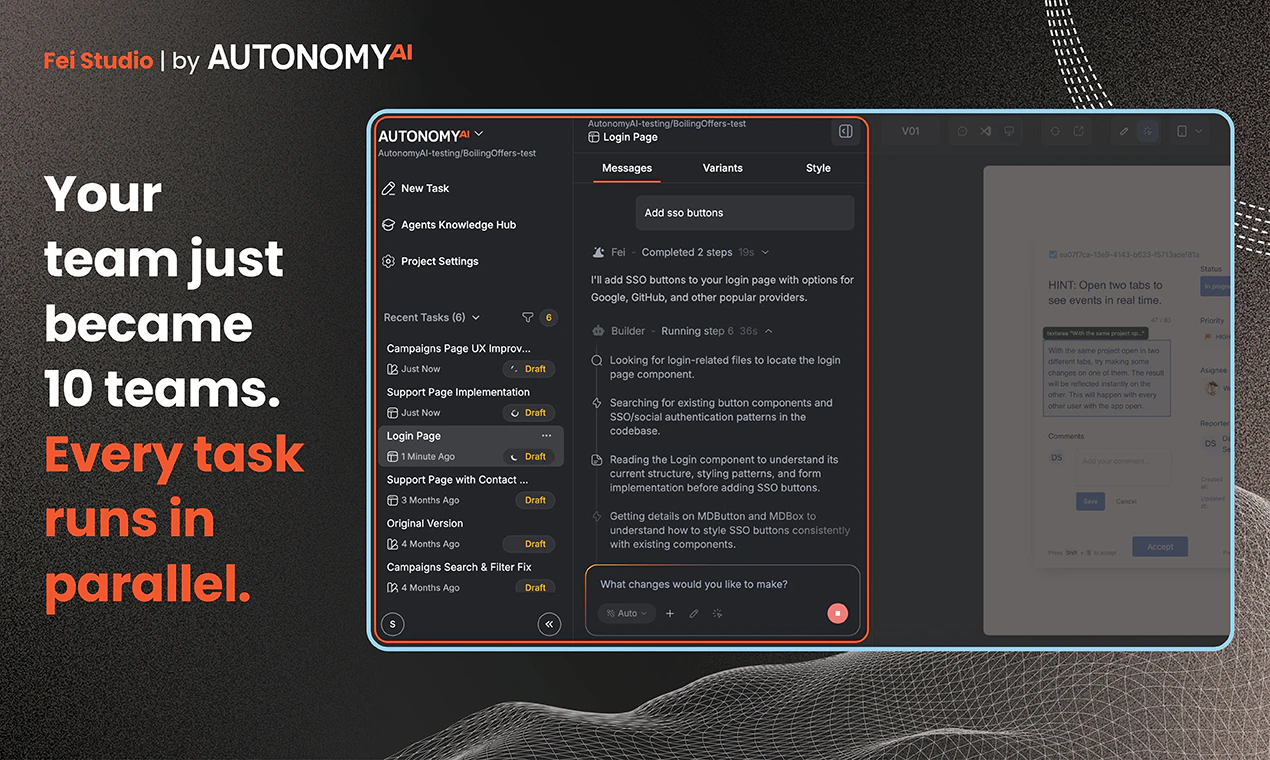





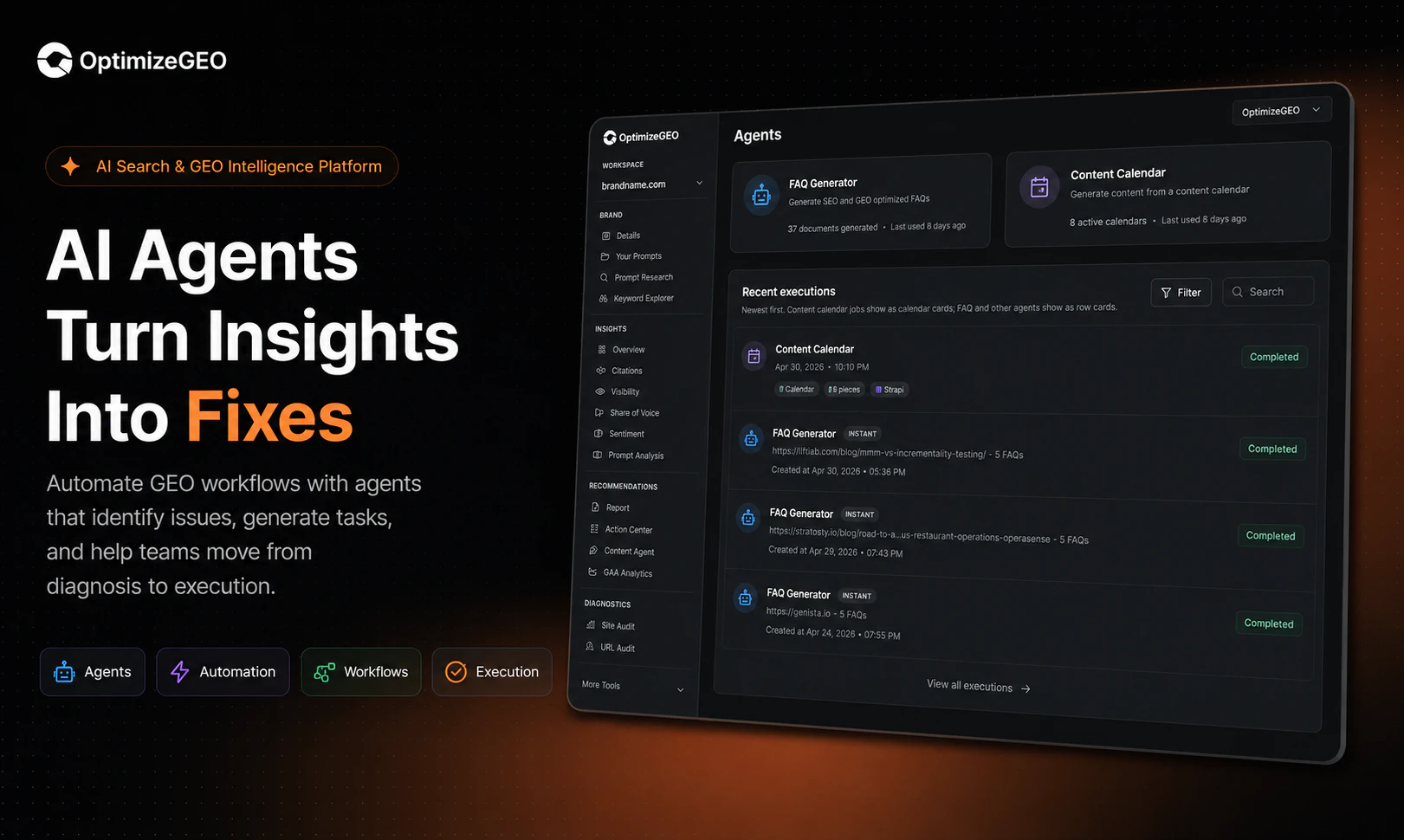




🚀 Hey Product Hunt! I’m Zino the founder of Spellar AI 3.0, and I'm beyond excited to be back with our biggest launch 🎉
Your support on our previous hunts (those #2 and #3 spots still give me chills 🏆) pushed us to ask a harder question: why do meeting tools only capture the moment — and never remember it?
So we built something different.
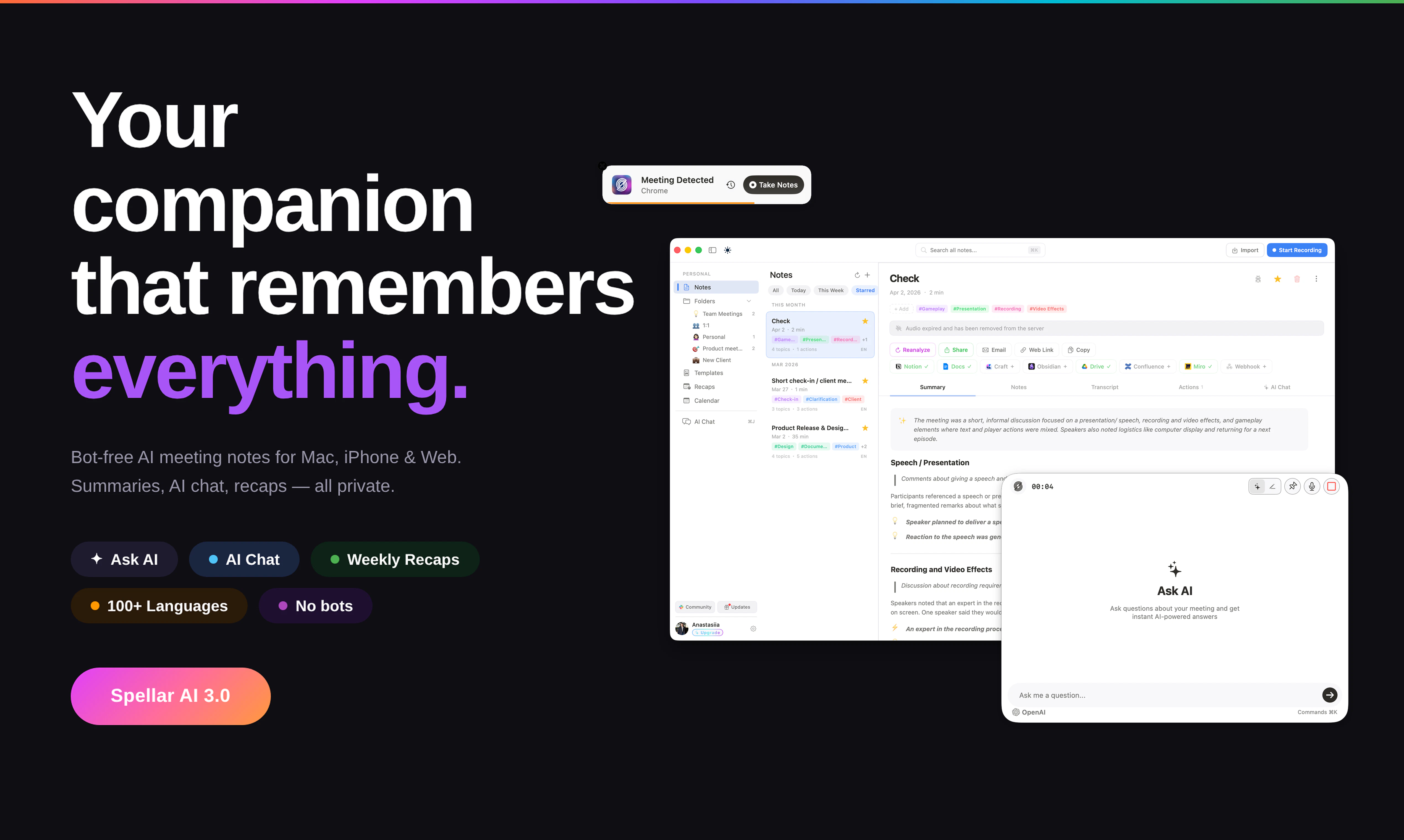
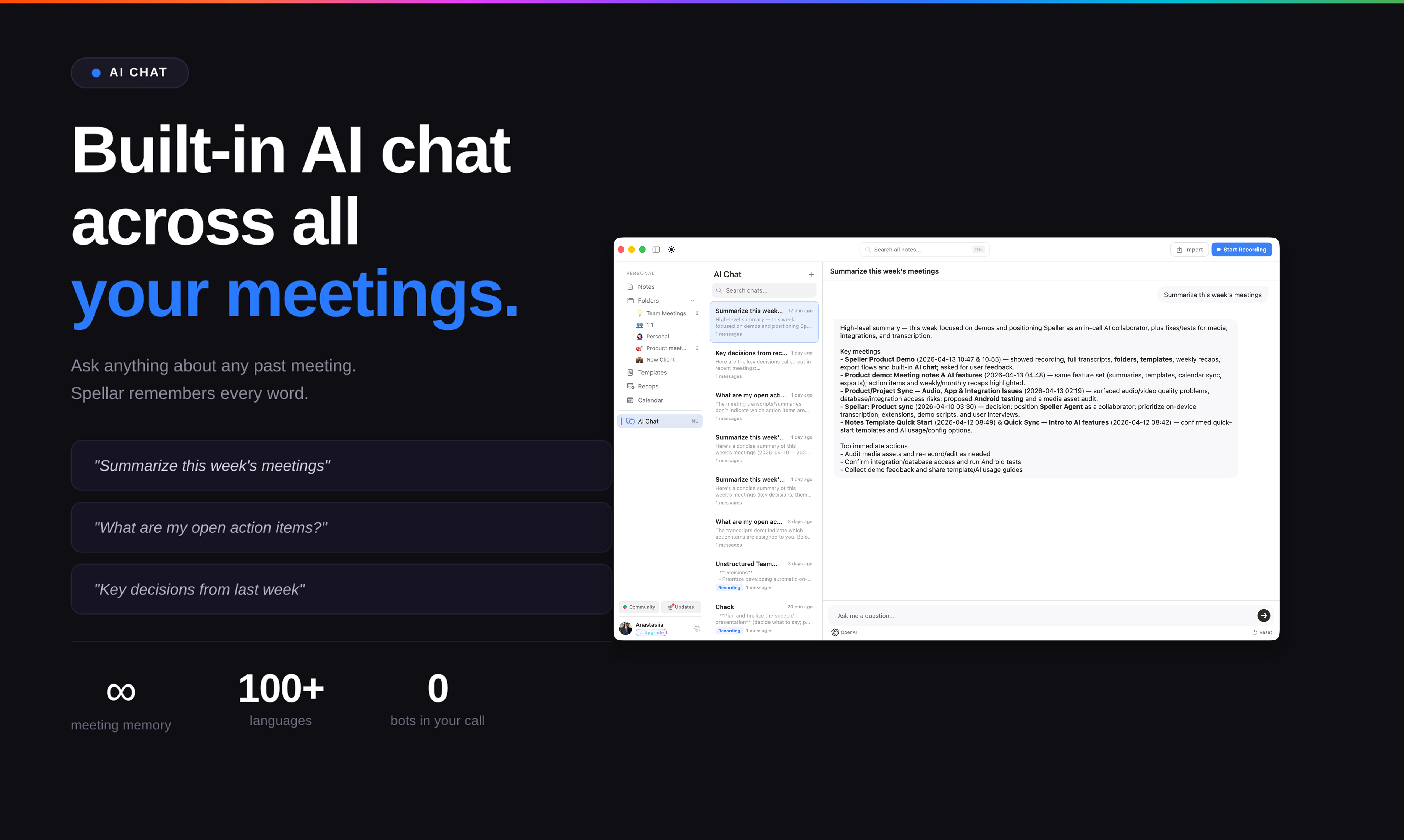
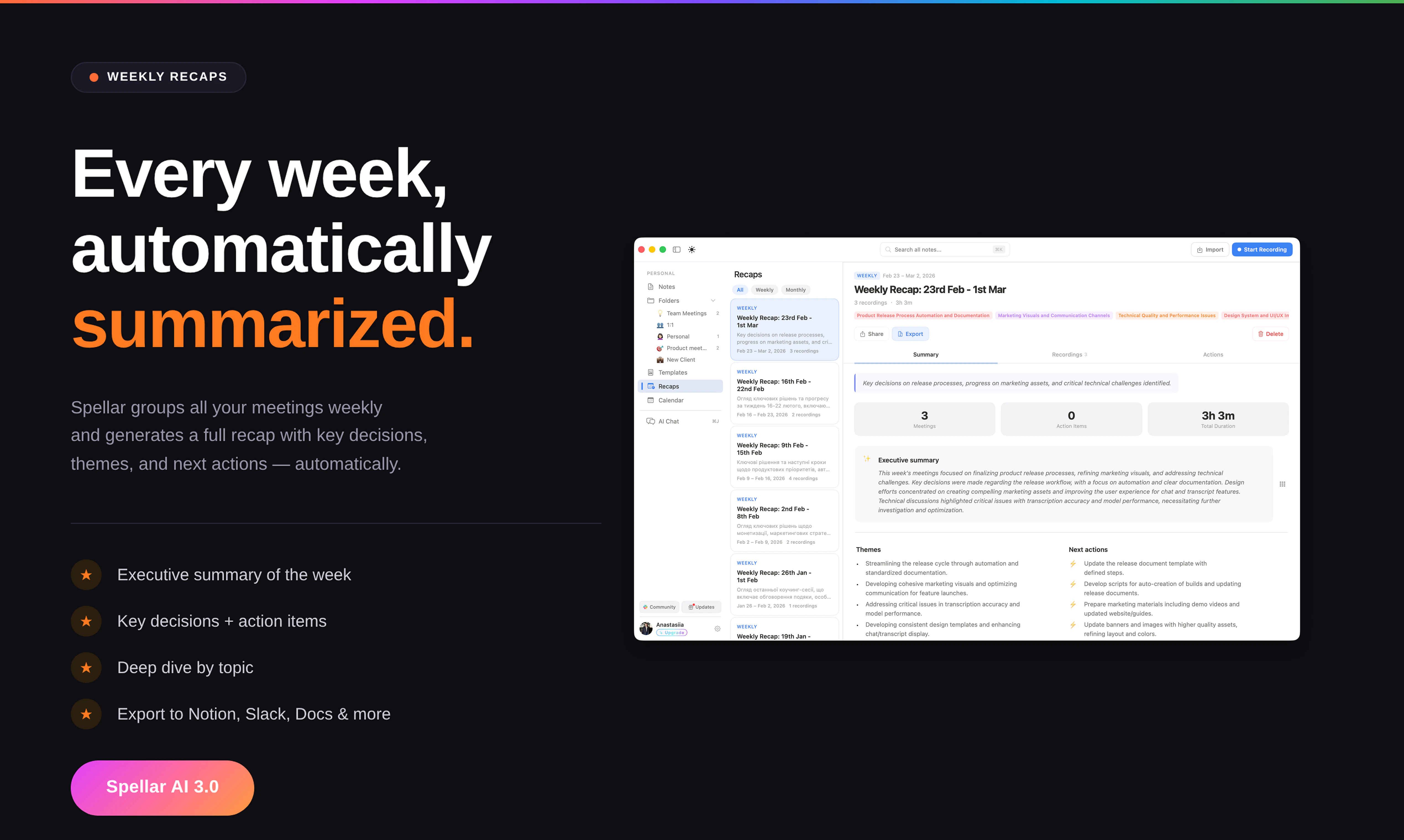
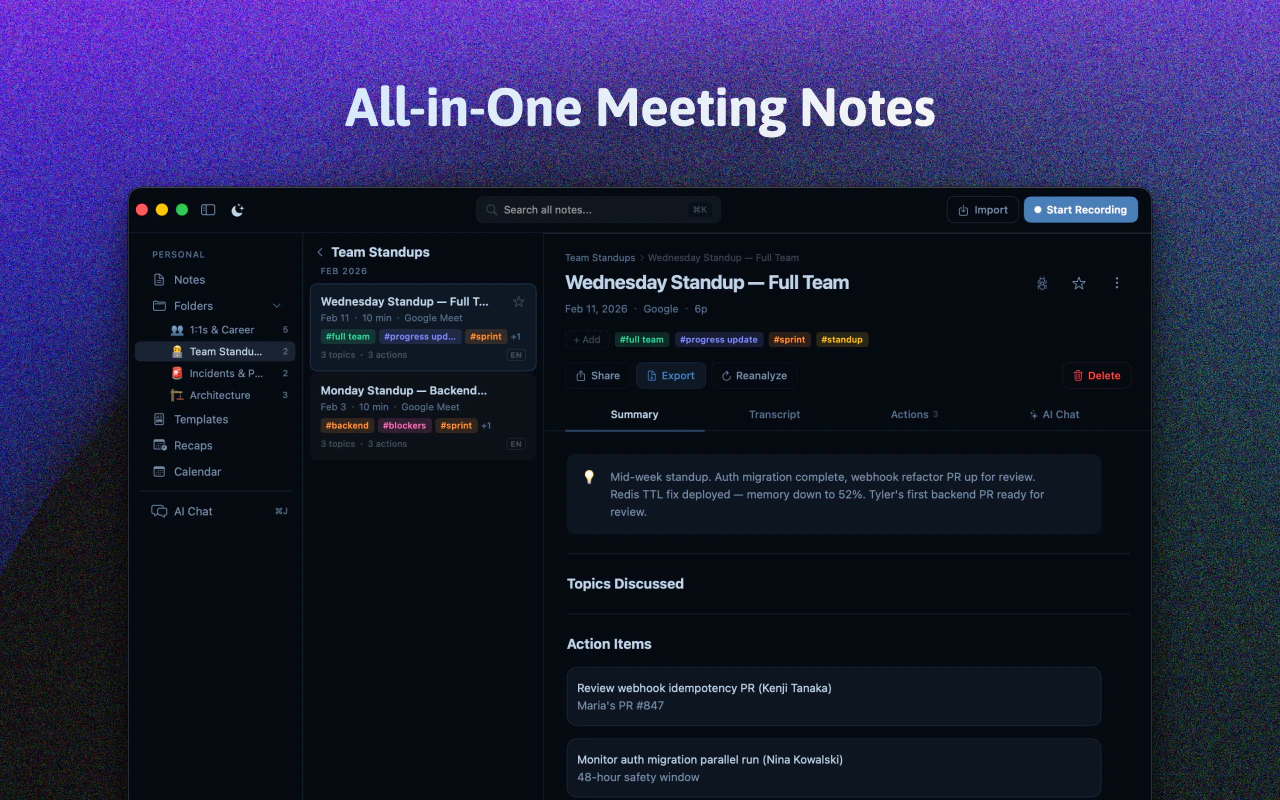
Spellar AI 3.0 isn't a note-taker. It's memory.
It joins your calls, captures every word, and builds context across your meetings — so you can actually use what was said, not just find it.
What's new in 3.0:
🧠 Cross-meeting memory — Ask what a client said three calls ago. Get an actual answer.
📁 Organized by client & project — Your context, structured the way you work.
📋 Templates — Set up the right AI context before the meeting even starts.
🤖 Your AI, your choice — OpenAI, Anthropic, Perplexity or Google. You decide who processes your data.
🔍 Open decisions & follow-ups — Never lose track of what still needs to happen.
We've always believed your meeting assistant should be native and bot-free, with support for 100+ languages. With 3.0, we're taking that further: meetings that don't just get recorded — they get remembered.
Would mean the world if you'd give it a try and share your honest thoughts. The Product Hunt community has shaped everything we've built, and today is no different. 🙏
Let's make meetings actually stick!
Zino
Today we launched Spellar 3.0 on Product Hunt, and I want to be honest about what this launch means to me.
The last PH launch was in June 2025. Spellar got great traction, kind reviews, and new users who took a chance on us. Then, for a while, we went quiet.
Not because something went wrong — but because we kept hearing the same thing in feedback: people would use our meeting assistant, get solid notes... and still lose context a few weeks later. They'd join a follow-up call and not remember what had been decided. The notes were there. The memory wasn't.
So we spent the past year rebuilding Spellar around that idea.
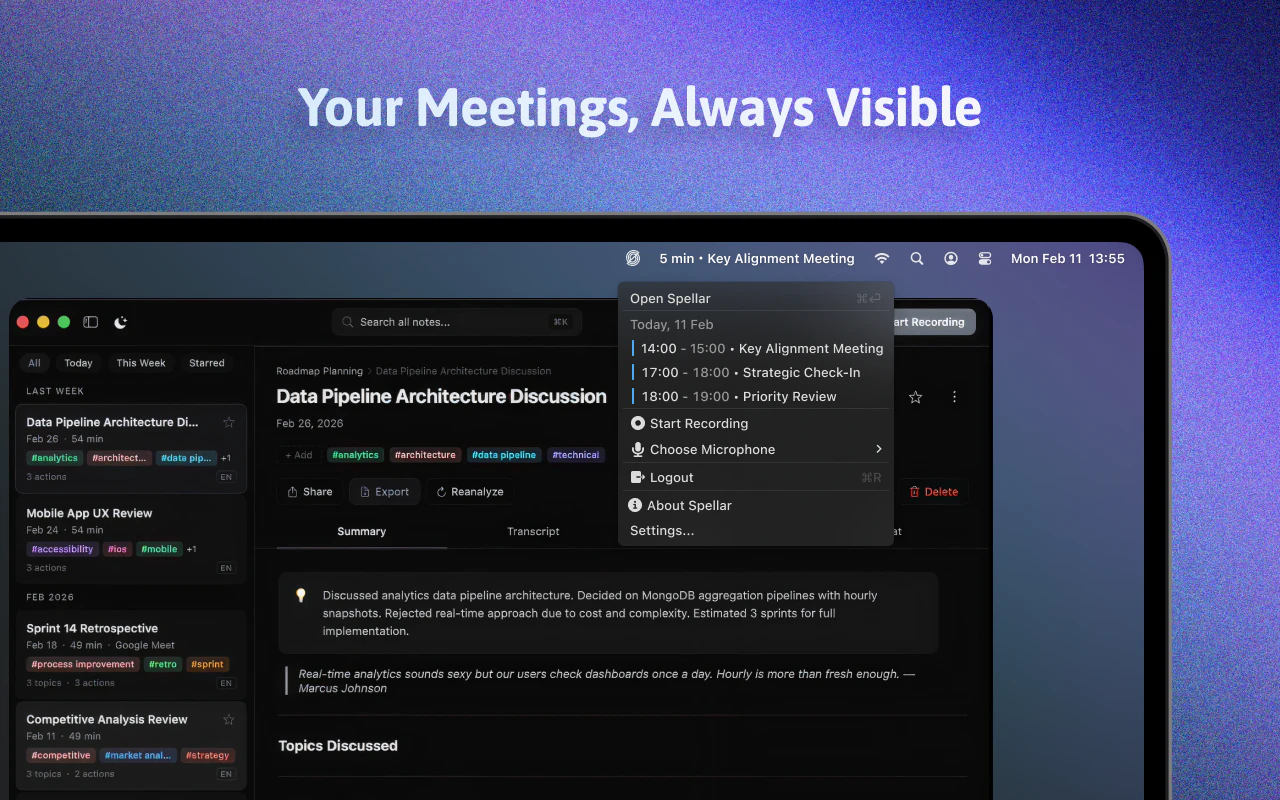
Spellar 3.0 isn’t just a meeting recorder with a better summary. It’s an AI companion that works quietly in the background — no bot joining your call, no one else noticing — and creates a persistent memory across all your conversations.
You can search for something from two months ago. Pick up a thread from a call you half-remember. Walk into a client meeting with the full story from every previous chat.
Most meeting tools give you notes.
Spellar gives you memory.
We’re live today. If this resonates with how you work, your support on Product Hunt means a lot to a small, bootstrapped team like ours
Thank you so much, your support means a lot!
hey team, my congrats! the memory feature is what got me. so if I have a related call today, can Spellar surface context from a meeting I had three weeks ago?
Hi product hunters, my name is Andrii, and I'm a developer on this product.We're live. Spellar 3.0 is on Product Hunt.
There's a specific kind of exhaustion that comes not from the hours but from holding a complex system in your head for weeks straight. Every edge case. Every architectural decision you made at 2am and then spent three days second-guessing. Every "it works on my machine" that turned into a two-hour debugging session the night before a deadline.
The memory layer was the hardest part. Making a system that reliably connects context across meetings — not just stores it, but actually retrieves the right thing at the right moment — is not a small problem. We rebuilt parts of it more than once.
But today it's out. And it works. And I'm pretty proud of that.
Spellar 3.0: AI meeting companion that remembers everything. No bot joining your calls. Just quiet, persistent memory running in the background.
If you want to see what we shipped — it's live on Product Hunt today
Congrats on the launch! I like the idea of a botless AI meeting companion. I'm curious whether it would be possible for Spellar to sort the recordings and meeting notes into related piles automatically. Would be a good time-saver!
Congrats on the launch!
Have a question about i18n support. What languages does Spellar support for transcription? Our team spans three countries, and not everyone runs meetings in English.
The summary quality is noticeably better than alternatives I’ve tried. Feels like it actually understood the conversation.
Looks great folks. Been struggling with AI notetakers' output being isolated - good to see someone is consolidating it with persistent memory:)
Hi all, my name is Yuliia, and as the QA engineer on this product, I've spent months doing one thing: trying to break it.
That's the job. Find every edge case. Every flow that almost works. Every moment where the product doesn't quite deliver what it promised.
What made this one different: the core idea held up.
The memory feature - the thing that connects context across meetings over time - is the kind of feature that's easy to get almost right and very hard to get actually right. The gap between "it usually works" and "you can trust it" is where I spend most of my time.
We're at the second one. I wouldn't have let it ship otherwise.
Spellar 3.0 is live on Product Hunt today. An AI meeting companion that remembers everything - no bot, no noise, just context when you need it.
Want to hear your feedback ❤️
I've been using Fireflies for about a year - what would be the main reason to switch to Spellar? Genuinely curious!
Congrats on the launch. A killer feature would be to make it open source
Congrats, team @zinovii_z @hotfixer Great update with memory angle! Can teammates each run Spellar independently and have their notes connected, or is it only for individuals? GL today!
My friend organizes their notes/knowledge from meetings in Obsidian, where he can interlink stuff with other knowledge.
Does your tool allow to go beyond meetings?
This is quite cool. The cross-meeting memory is what finally makes this category interesting. I've tried a few note-takers but the problem was always the same: it is great for the moment, useless two weeks later when you're trying to remember what clients actually said about pricing. The fact that it runs natively without a bot joiner is a big deal too! Does the memory search work across meetings with different participants or only the ones you attended yourself?
🚀 Already 11 hours into our Product Hunt launch day — and Spellar 3.0 is still holding the #1 spot 🥹
Is there a way to create templates for recurring meetings — like 1:1s or standups — so the summaries are always structured the same way?
Really interesting shift from meeting transcription to persistent memory. The cross-meeting context and ability to surface decisions from earlier conversations feels more practical than just searchable notes. Curious how Spellar handles conflicting information or changing decisions across long client relationships.
congrats, team! any plans for more integrations? I'd love to sync with Linear after calls.
The cross-meeting memory is the part that actually changes the workflow — most tools just dump a transcript per call and leave you connecting the dots yourself. Curious how it handles context when a client refers to the same project by different names across calls — does it pick that up automatically, or does it need some manual tagging to stay organized?
How does the 'bot-free' part actually work? Will anyone else on the call notice something's running in the background?
Most meeting tools just dump transcripts somewhere and hope you’ll revisit them later 😂
The cross meeting memory angle is way more useful in actual day to day work. Congrats on the launch!🚀
Noise! Nice update guys
Does the cross-meeting memory work retroactively? Meaning, if I'm starting fresh today, can I import old transcripts from another tool to seed it, or is the memory only built going forward?
Good luck with your launch!
The cross-device sync is underrated — record on iPhone during a coffee chat, summary is on the Mac when I get back. Question: any plans for Apple Watch quick-record (start recording from the wrist for impromptu hallway conversations)? Would unlock the "captured the idea before I forgot it" use case for me 🤔