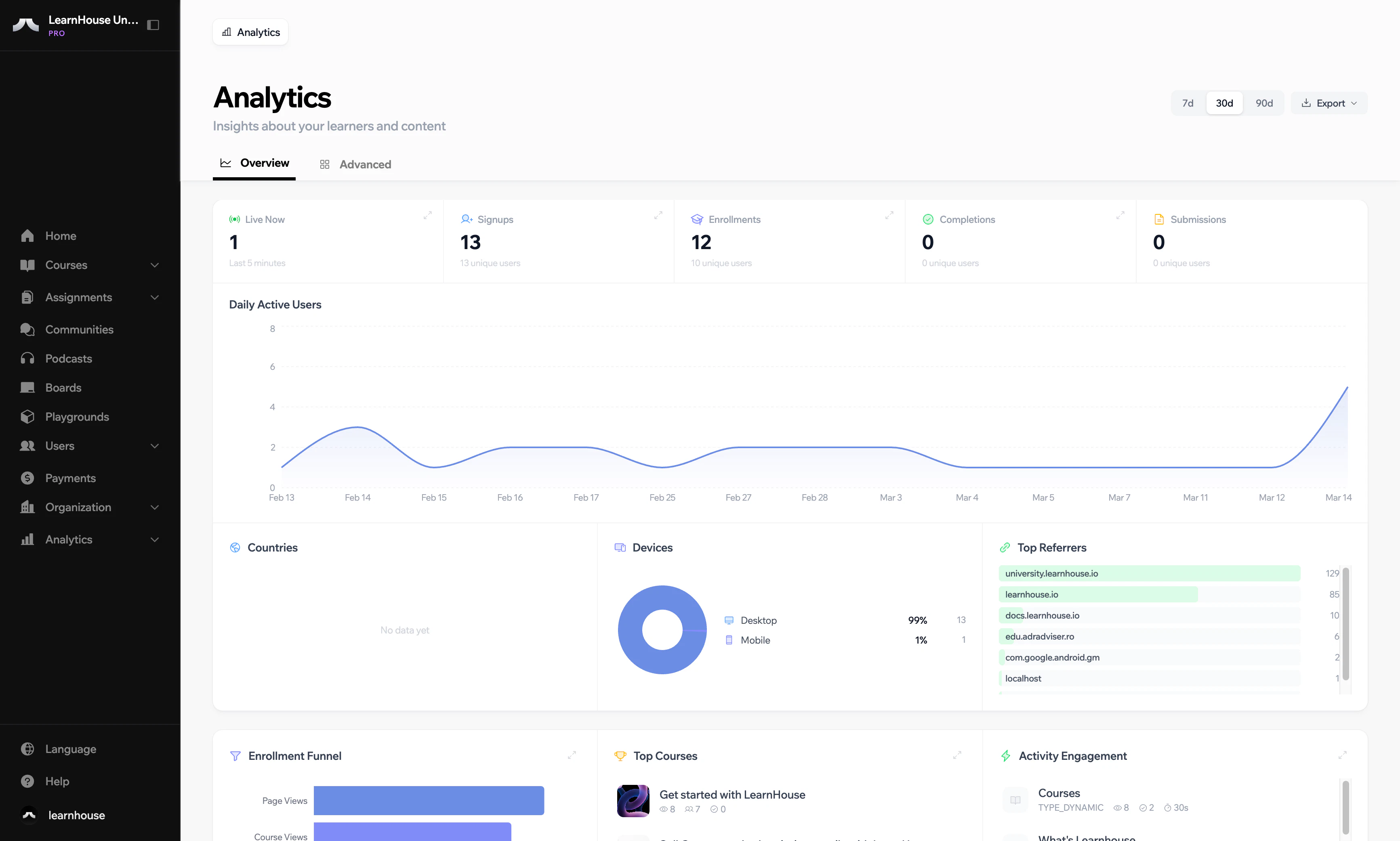
PH热榜 | 2026-05-19
一句话介绍:PollyReach为个人用户提供AI驱动的真实电话号与语音,解决预约、被咨询等需电话沟通的痛点,支持50+语言。
Productivity
Artificial Intelligence
Virtual Assistants
AI电话助手
语音代理
电话预约
智能呼叫
垃圾电话过滤
多语言
语音交互
个人助理
呼叫自动化
真实号码
用户评论摘要:用户关心AI能否处理真实通话中的插话、等待、意外情况,要求看到失败案例而非仅成功演示。呼声较高的需求包括:通话记录可路由至Webhook、支持现场转接、保留与同一商家通话的上下文记忆。产品团队承诺呼出时AI会自报身份,且严格报告呼叫结果(确认/未接等),不虚报。
AI 锐评
如果说硅谷的AI语音公司在忙着给企业画CRM宏图的饼,PollyReach则在干一件更“俗”但也更必要的事:帮你给饭店打订位电话。它的切入点精准得近乎刁钻——AI能跨语言流利交流,但绝大多数此类产品仍旧困在“呼叫中心即服务”的B端高墙内,而普罗大众真正痛的是“看到电话号码就烦躁,宁可发信息也不愿开口”这一共情。
从产品形态看,PollyReach聪明地避开了“全功能自动化保姆”的陷阱:不谈取代人类销售,只说帮你预约、帮你过滤垃圾电话。评论中创始人坦诚日语和英语是主力语言,且不回避日本餐厅无人接听、对话偏离脚本等“不完美但真实”的edge cases,这种表态比那些宣称“AI完美理解一切”的PPT可信得多。但问题同样明显——多语言质量“ongoing”意味着横向扩展尚不成熟;每个电话需要事前授权而非实时转接,说明在复杂场景下的决策边界还很狭窄。
最值得留意的是对“滥用”场景的回应:每通电话都自报AI身份、多层防线防范欺诈——这在欧美严苛的电话合规环境下是保命线,而非可有可无的装饰。对于想做个人助手的玩家,与其烧钱拼大模型多模理解,不如像PollyReach一样,先把“等待转接时不挂断”这种毛细血管级体验的精度做透。产品有真实场景,但不宜过早吹捧“颠覆电话沟通”,因为只解决“敢拨号”而尚未完全解决“能搞定”。对于频繁被机构客服、物业公司、海外签证中心电话折磨的用户,这200免费积分值得一试,但别指望它能替你求完银行调额。
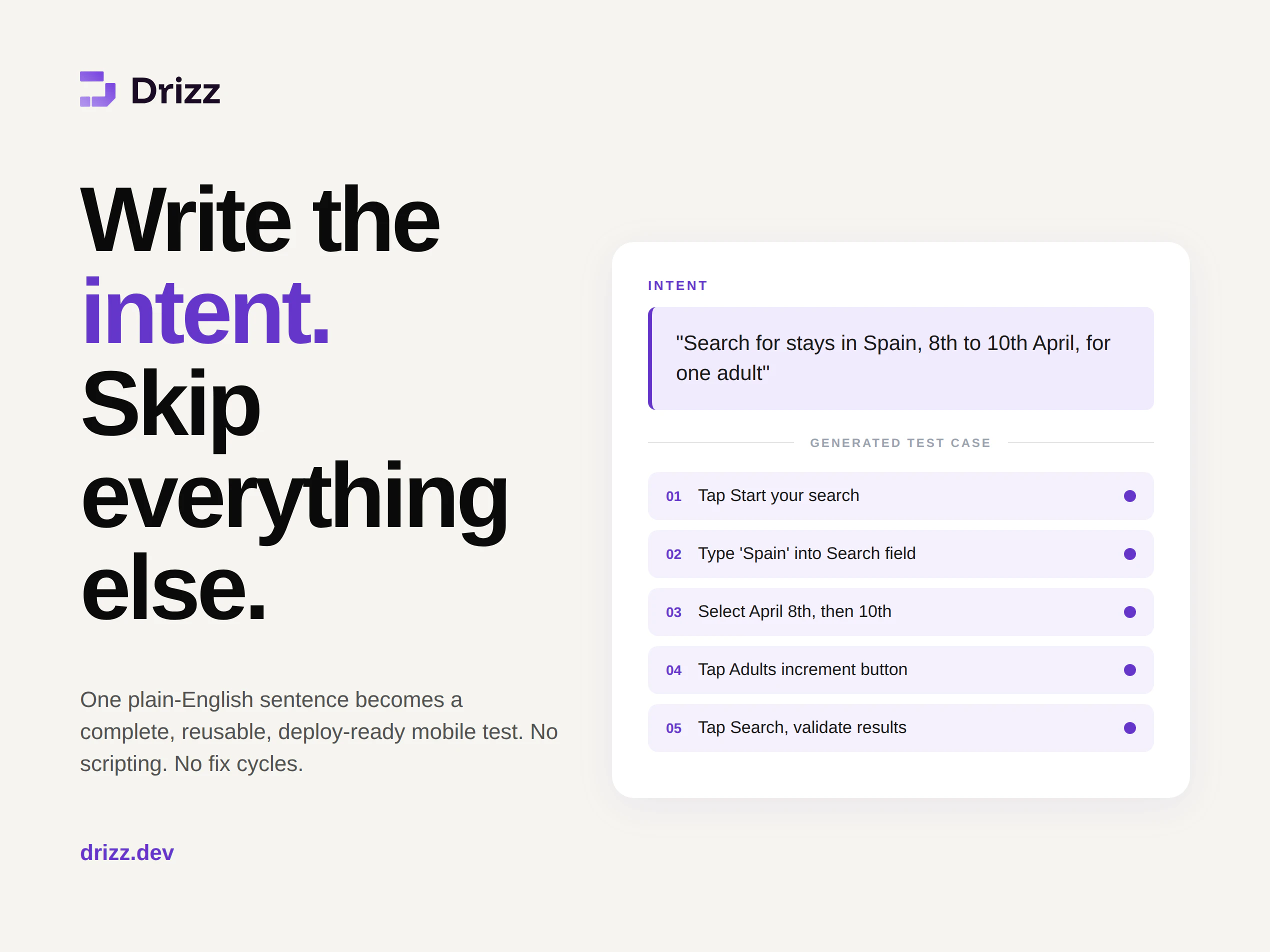
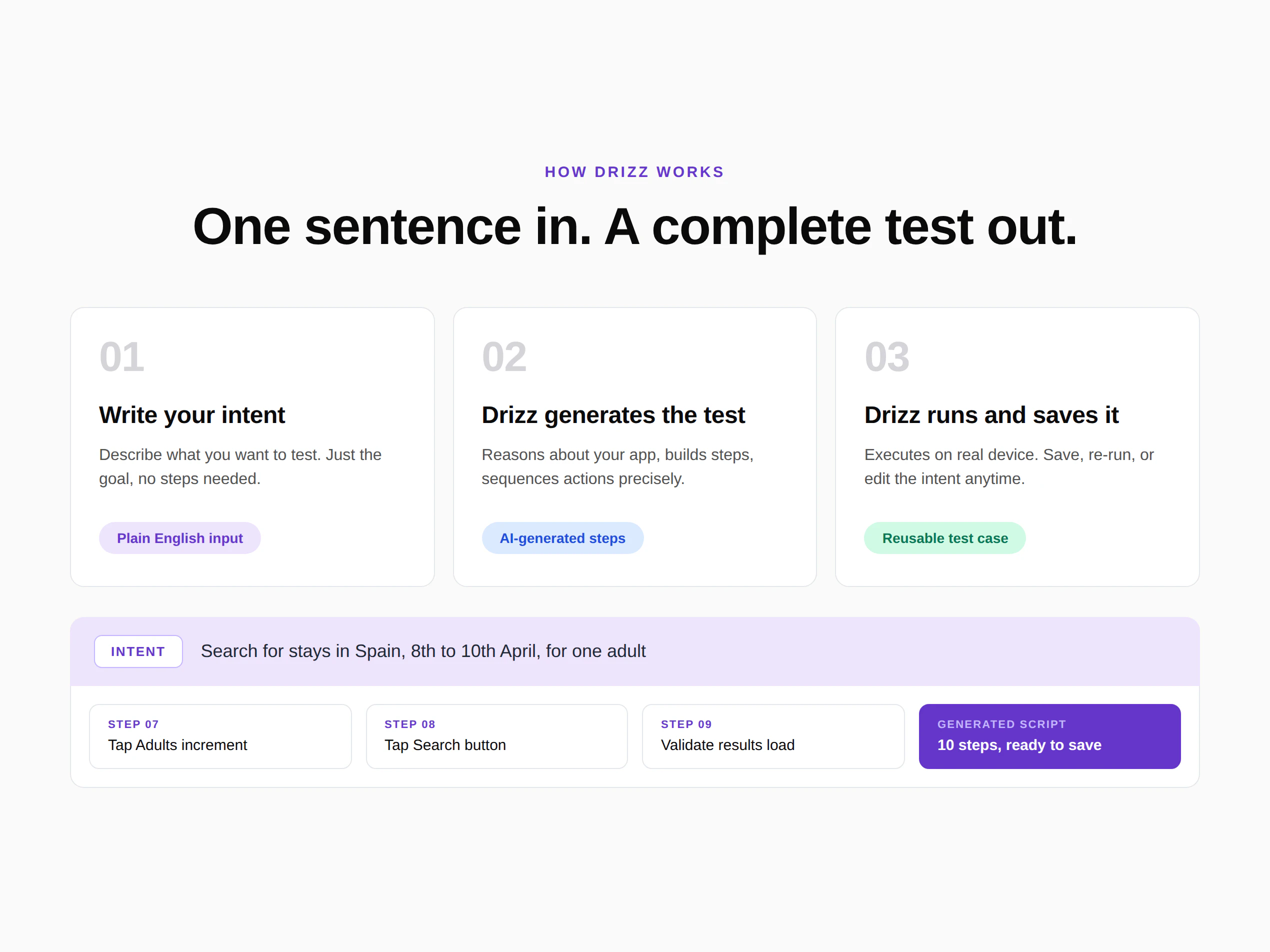
一句话介绍:Drizz是一款基于Vision AI的移动端测试自动化平台,让开发者用自然语言描述测试意图,即可在真实设备上自动生成、执行并自我修复测试用例,彻底摆脱脚本编写和选择器维护的痛点。
Developer Tools
Artificial Intelligence
No-Code
AI测试自动化
移动端测试
视觉AI
自然语言测试
无脚本测试
CI/CD集成
自我修复测试
真实设备测试
iOS/Android
质量保障
用户评论摘要:用户核心关切:Vision AI的确定性(担心误判和自愈行为)、审计追溯能力、多步骤复杂流程处理。正面反馈集中在免脚本、真机运行和团队响应速度。建议优化新手引导(第三步)。创始人承诺95%+CI可靠性和可修改保存测试步骤。
AI 锐评
Drizz的标语“Mobile tests that write, run, and fix themselves”听起来像是一个完美的终结者,但残酷的现实是:AI测试工具最大的敌人不是代码,而是信任。用户Ferdi的评论堪称犀利——Vision AI的“自愈”可能变成“自我欺骗”,一个模型在周二和周三对同一屏幕的不同解读,比固定的XPath错误更难调试。创始人Yash用“结构化可靠性层”和“不重新解释成功定义”来回应,这是正确的方向,但关键在于执行细节:置信度阈值如何设定?失败回放机制能否100%复现?对于监管合规用户提出的审计追查需求,当前“记录agent动作和推理”的回答还不够具体——需要可导出的时间戳、版本快照和操作日志。
Drizz的真正价值在于将测试从“工程负担”降级为“产品思维”。当设计师移动按钮12像素不再导致3小时调试,当“搜索西班牙住宿”这种业务语言直接变成可运行的测试,它确实解决了测试成本与软件复杂度成正比的行业顽疾。但有两个潜在陷阱:一是“自然语言”并非万能,复杂多步骤流程(如基于购物车状态的结账)的意图描述本身就需要深厚业务知识;二是对已有Maestro+Claude CI/CD管道的团队,Drizz需要证明它不是另一个“额外工具”,而是能秒级替换现有链条的“超级节点”。
最后,创始人团队来自Amazon和Coinbase的背景是加分项,但这点与用户在评论中提到的“测试是税不是工具”一样,本质上是对现有框架(Appium、XCUITest)的否定。Drizz的成功与否不取决于它能解决多少问题,而在于它能多大程度上将“测试”从一次性痛苦迁移到“持续信任”的新范式。建议团队尽快公开“幻觉率”和“CI通过率”的基准数据,并开放测试步骤的导出和版本对比功能,这是建立专业信任的敲门砖。
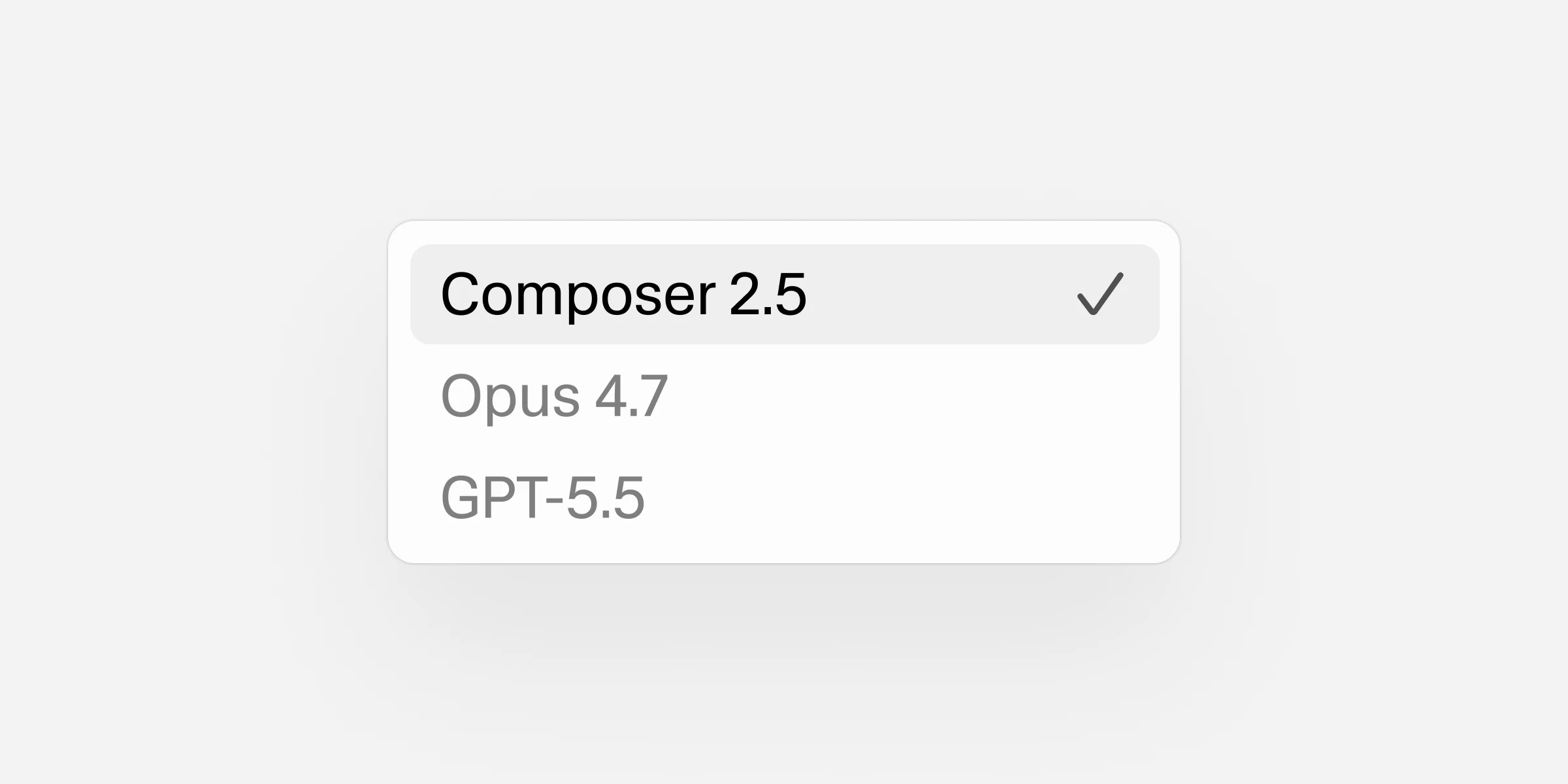
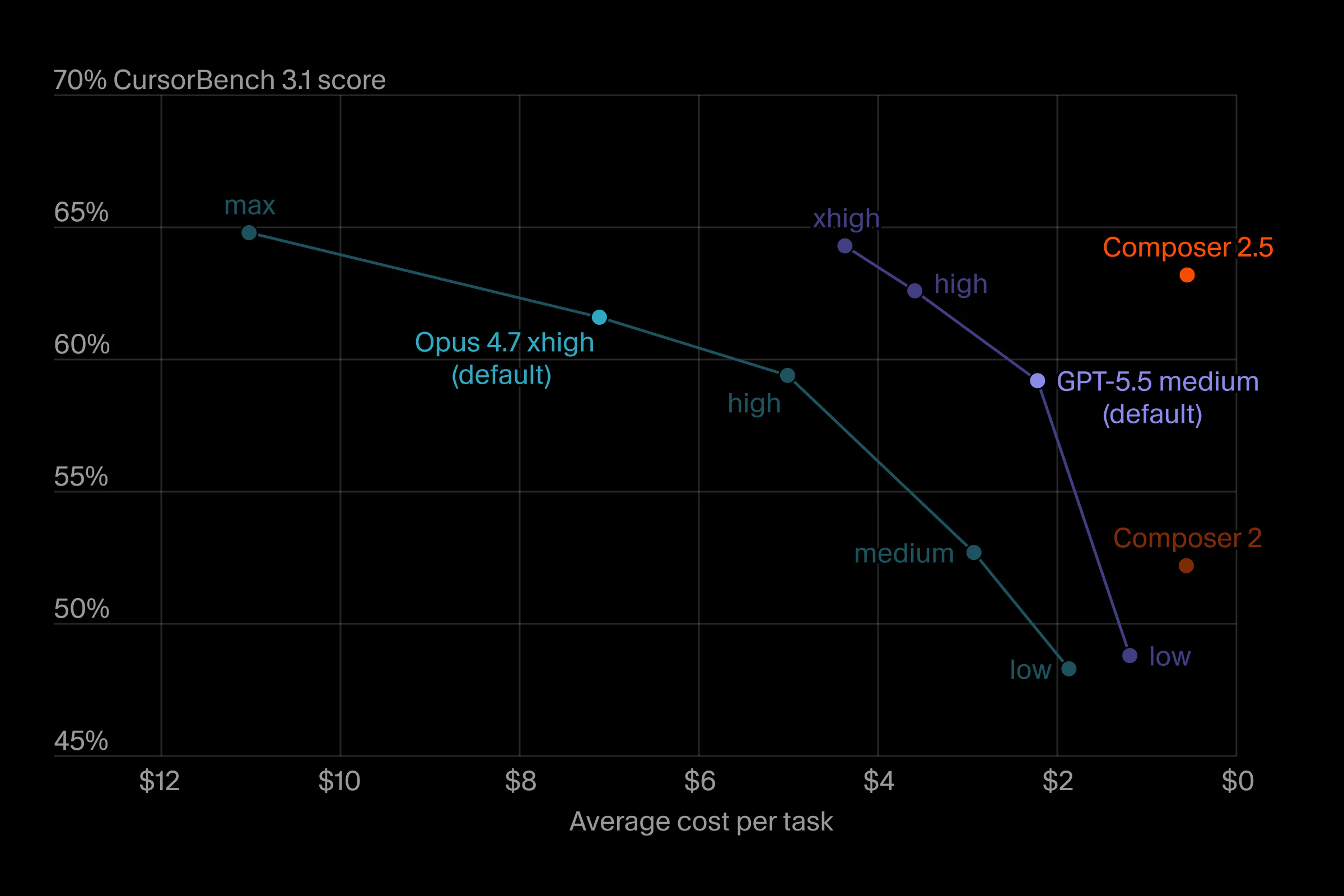
一句话介绍:Composer 2.5 是针对 Cursor 代码编辑器的深度定制模型,在长时间、多文件、多步骤的 Agent 式编程任务中显著提升了智能性与行为一致性,解决了通用模型在复杂编码场景下的“中途掉线”和“上下文丢失”痛点。
Artificial Intelligence
Development
AI编程助手
代码编辑器
Agent式编程
长上下文
模型优化
Cursor
Composer
多文件编辑
任务链稳定
云端IDE
用户评论摘要:老用户肯定其进步,尤其长任务稳定性和努力校准。但也有直言不讳的对比,认为仍不及 Opus 4.7 和 Sonnet。用户关注点集中于:多文件语义冲突处理、长时间任务链(20+步)的状态管理、是否集成日志/错误跟踪的运行时感知、以及针对长轨迹的训练反馈机制细节。
AI 锐评
Composer 2.5 不是一次炫技式的发布会,而是 OpenAI/Anthropic 套壳之外的“局内人”突围。它的聪明之处在于:不吹嘘基础能力对标 GPT-5,而是诚实地承认“继续基于 Composer 2 微调”,并在“努力校准”和“长序列文本反馈”这些工程化的细节点上死磕。这在 AI 编码工具同质化严重的当下,是一种正确的“反卷”策略。
优势很明显:它精准命中了 Cursor 重度用户的痛点——不是写一行代码的聪明,而是写十个文件、重构几十个函数时,模型能否保持“清醒”。这种针对特定工作流的强化训练,比单纯堆算力的基座模型更有效地提升了用户的“有效编码产出”。从用户反馈来看,那种“不再需要 Opus”的呼声,正是产品精准定位的胜利。
但危险信号同样清晰:评论中有人直言“比不上 Opus 4.7 或 Sonnet”,这说明在单一任务或复杂推理的绝对上限上,微调模型仍有天花板。另外,用户关于“多文件语义冲突”和“长久任务状态管理”的提问非常尖锐,这背后其实是指出了 Cursor 当前架构的软肋:模型本身不错,但 IDE 与 AI 之间的环境感知和冲突解决机制仍然粗放。如果这些系统级体验不做强化,Composer 2.5 再强也难免被更原生集成的 Agent 产品(如 Devin)降维打击。
一句话总结:这是一次优秀的增量优化,让 Cursor 在 Agent 编程赛道保住了基本盘,但距离“终结 IDE 之争”还有很长的工程化道路要走。
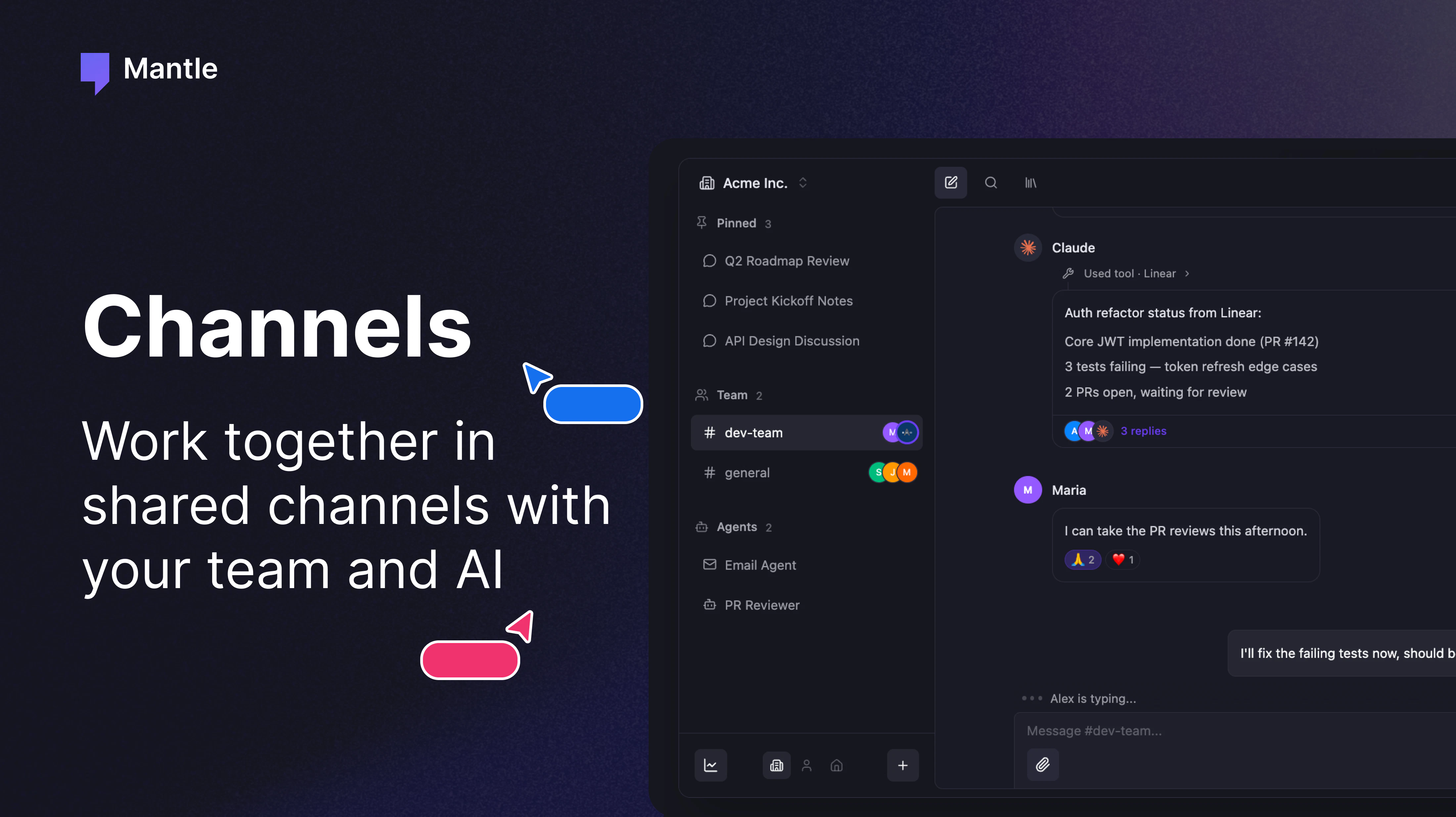
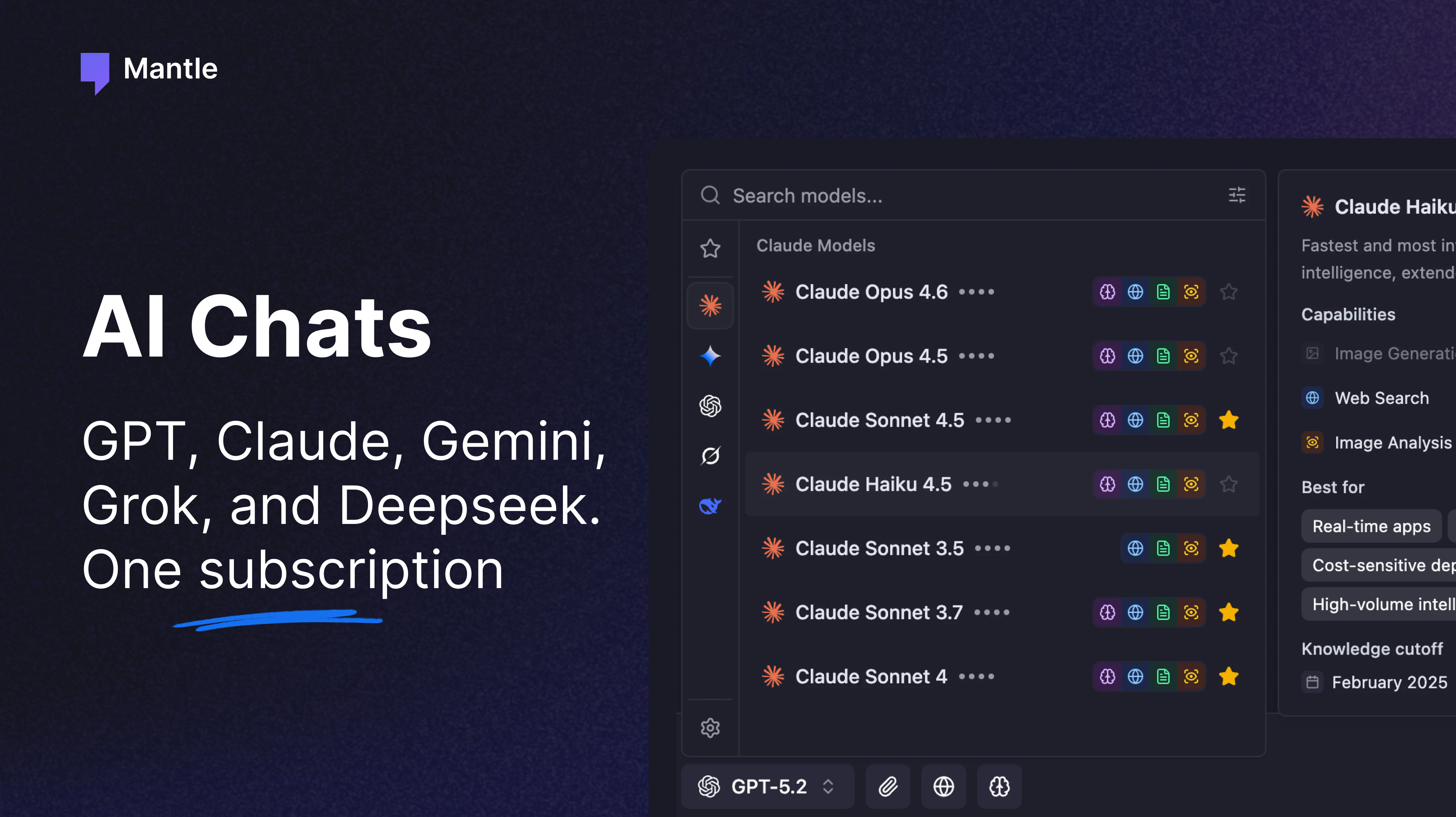
一句话介绍:Mantle Chat 是一个将实时团队通讯、多模型AI(GPT/Claude/Gemini等)、自主智能体及30+工具集成于一体的协作平台,旨在解决团队在AI使用中“信息孤岛”、上下文割裂和重复工作的问题,让AI成为团队协作的一部分而非个人私用工具。
Productivity
Messaging
团队AI协作平台
智能体
多模型聊天
团队知识库
工具集成
企业级AI
生产工具
实时通讯
用户评论摘要:用户普遍认可“共享AI上下文”避免知识蒸发和重复工作的价值。核心问题集中在:如何实现跨会话的长期记忆及项目间上下文隔离;是否支持HubSpot/Zendesk等销售客服集成;以及多智能体在频道内并行工作的上下文管理细节。
AI 锐评
Mantle Chat的立意找准了一个真痛点:AI工具正在让团队协作变得更加原子化。当每个成员都在自己的ChatGPT、Claude、Gemini对话框里孤军奋战,所谓的“AI提效”其实是在制造新的信息烟囱。Mantle试图用“频道+@提及”的模式,将AI拉回团队协作的主战场。
从产品逻辑看,它本质上是一个“AI First”版本的Slack/Discord,但核心差异在于它把模型选择、智能体执行和工具集成作为一等公民,而非事后添加的bot。这解决了两个关键问题:一是降低了AI采用的门槛,非技术人员无需IDE或复杂配置就能用@召唤智能体;二是让AI产出的内容(分析、代码、方案)直接沉淀在团队对话上下文中,形成可检索、可迭代的“机构记忆”。
然而,产品面临的挑战也很明显。首先是竞品挤压:Slack和Teams正在将AI助手深度内嵌,用户是否愿意为“另一个聊天工具”迁移?其次是“上下文隔离”与“共享智能”之间的平衡难题。从用户质疑看,如果不同项目、不同智能体的上下文管理不够清晰,AI反而会因信息混杂而变得“智障”。Mantle目前的workspace隔离和线程机制算是及格,但距离“长期记忆”和“精准上下文感知”仍有距离。最后,30+的集成列表看着很美,但HubSpot、Zendesk等关键B端工具的缺失(仍在路线图),暴露了其当前更偏技术团队和初创公司的定位。
客观评价,Mantle Chat不是颠覆式创新,而是对现有“聊天+AI”模式的精细整合。它真正的价值在于降低团队协作中AI的使用摩擦,让“AI辅助”从个人体验变为团队资产。能否成功,取决于能否在保持轻量体验的同时,将“共享上下文”这个核心卖点做到足够精准和可靠,而非沦为又一个功能堆砌的聊天室。
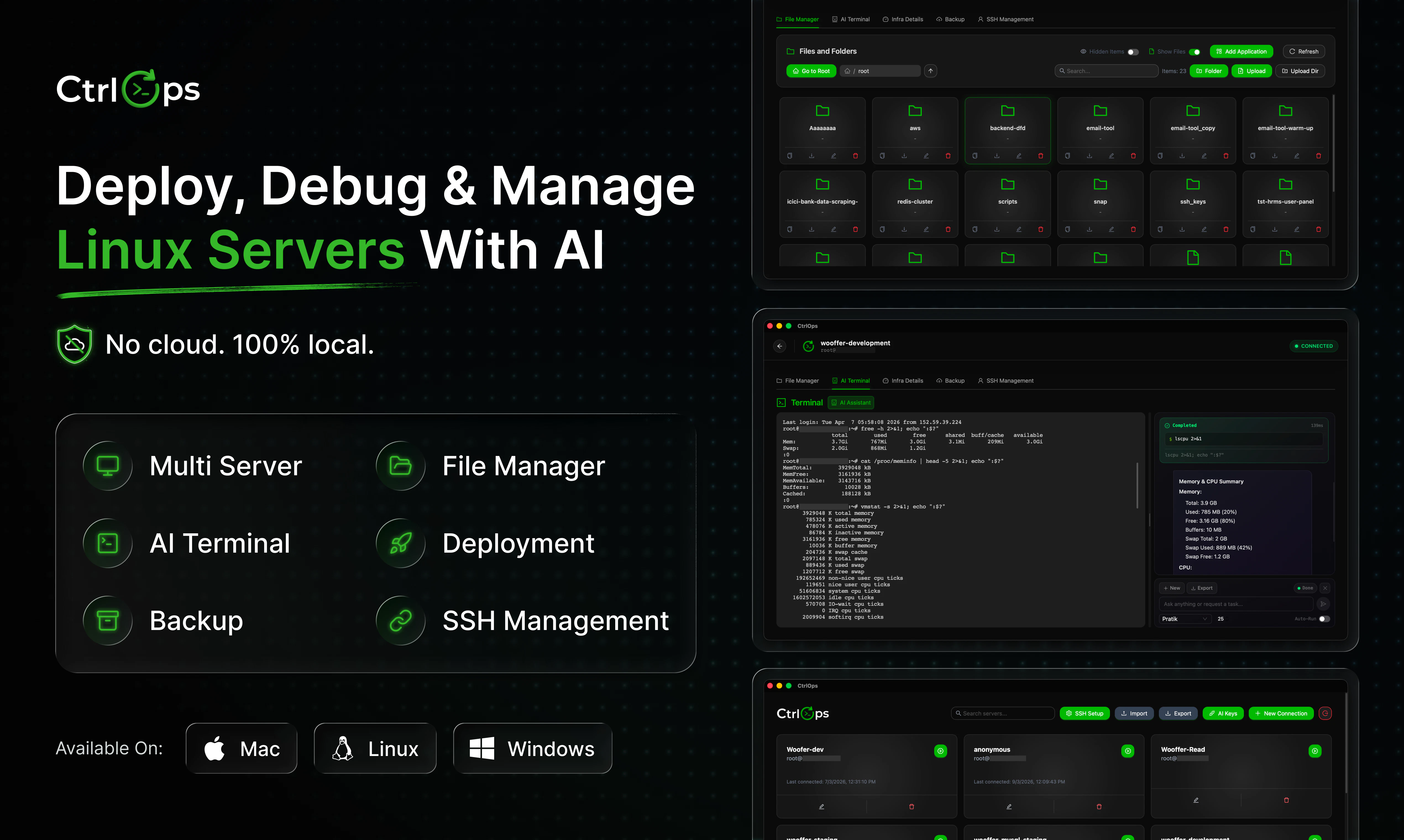
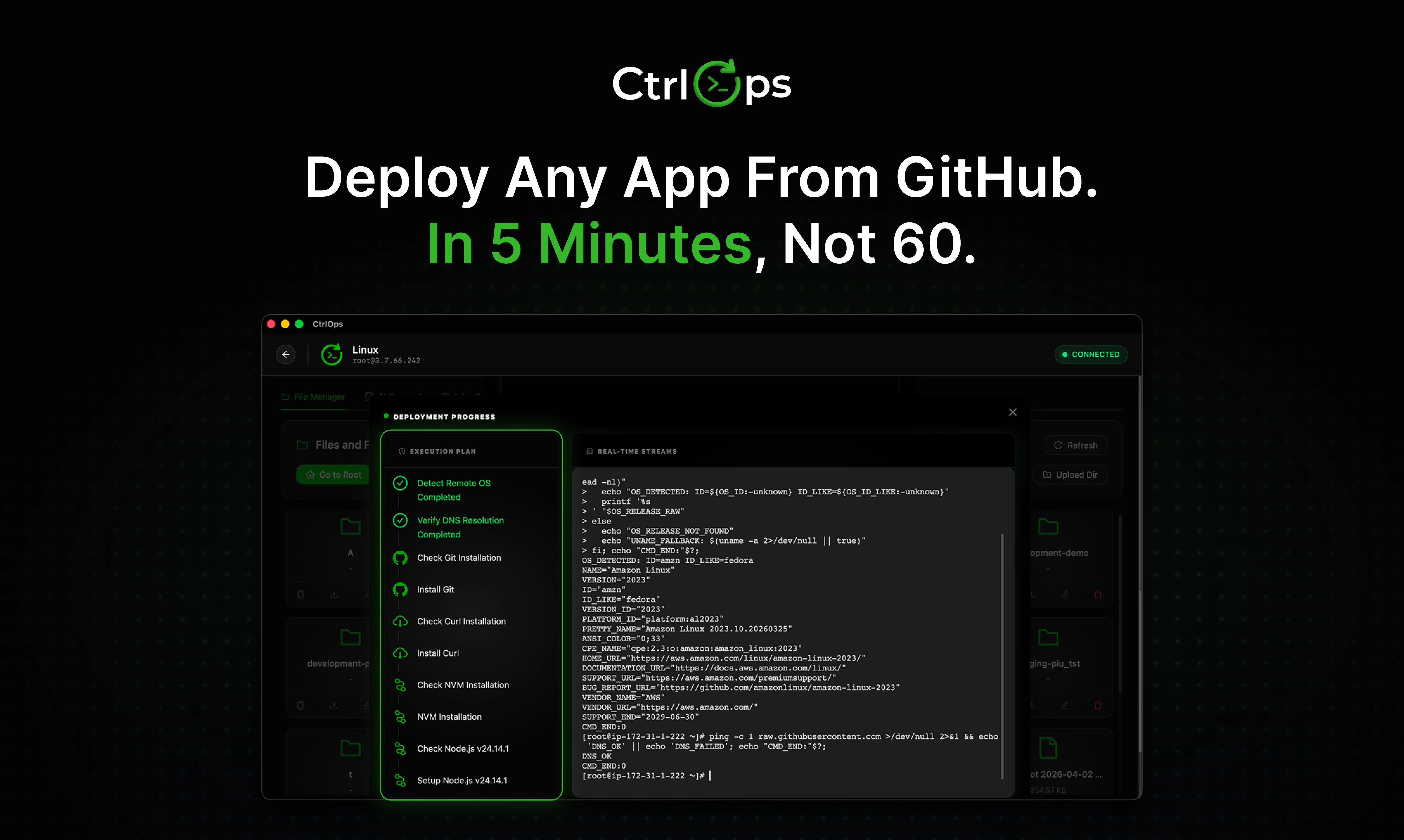
一句话介绍:CtrlOps 是一款面向开发者的 AI 驱动 Linux 服务器管理工具,核心场景是让非 DevOps 人员通过自然语言指令、可视化文件管理和一键部署,摆脱对 IP 表格、SSH 混乱标签和记忆命令的依赖,将原本耗时60分钟的部署降至5分钟。
Linux
Developer Tools
Artificial Intelligence
AI服务器管理
DevOps简化
Linux运维
终端助手
可视化部署
本地安全
服务器监控
脚本库
开发者工具
免Agent
用户评论摘要:用户普遍共鸣“SSH标签混乱”和“依赖单一运维高手”的痛点。核心问题集中在安全机制(确认所有AI命令需人工审批)、多服务器管理能力(支持100台)、以及调试会话的上下文连续性。HR角色也提到SSH管理简化了员工离职权限撤销流程。
AI 锐评
CtrlOps 精准狙击了“会写代码但不想运维”的开发者群体——这几乎覆盖了全行业。其核心价值并非发明新技术,而是通过“AI生成+人工确认”的闭环,将服务器管理从“玄学”降维成“可复用的日常操作”。产品设计的聪明之处在于,它没有试图取代人类运维,而是将AI定位为一个“永不睡觉、永不跳槽”的资深助手,在生成命令后强制要求人工审批,既规避了黑盒执行的信任崩塌,又保留了开发人员对生产环境的控制权。
从用户反馈看,真正的杀手锏不是AI终端本身,而是其“脚本库”功能——AI解决“第一次”的不知所措,脚本库解决“每一次”的重复劳动,这种组合拳形成了从试错到固化的高效闭环。此外,100%本地运行、凭证不离开机器的设计,直击企业对数据安全的敏感神经,这是许多云端AI运维工具难以逾越的护城河。
然而,该产品面临的真正挑战是:当规模超过100台服务器时,AI的上下文管理能力是否会成为新瓶颈?当前“会话级记忆”而非持久化记忆,对复杂故障排查的连续性来说略显鸡肋。此外,一旦用户习惯了AI建议,团队是否会逐渐丧失土法运维的底层能力?这种“运维外包大脑”的风险,CEO们需要权衡。总而言之,CtrlOps 是一款优秀的“降本增效”工具,但距离成为“智能运维中枢”仍有距离。
一句话介绍:Motion 是一个专注于“有品味”动态设计的AI视频代理,通过智能研究、分镜和元素级可编辑工作流,解决用户反复生成AI视频时“差不多但不够好”、修改成本高且缺乏专业审美的痛点。
Artificial Intelligence
Animation
Video
AI视频生成
动态设计
代理式AI
可编辑视频
分镜制作
营销视频制作
视频编辑
AI创作工具
产品发布视频
设计品味
用户评论摘要:用户普遍认可其元素级编辑能力,称“终于不用从头再生成了”。核心疑问包括:能否单帧替换元素、“品味”的具体来源(是否有风格库)?另有用户反馈邀请码无效。团队回应可通过提示词、链接或上传设计文档来控制风格。
AI 锐评
Motion的吸引力不在于“生成速度”,而在于对“成品感”的追求。它敏锐地捕捉到了当下AI视频工具的一个致命缺陷:生成太快太廉价,但修改慢如噩梦,结果像“老虎机”一样随机。用户那句“almost good enough is not good enough”是行业写照。
其核心杀招是“后生成编辑性”。将AI视频从黑盒生成转换为一个可拆解、可操作的元素级项目,这本质上是在AI视频领域复刻了从“静态图跑图”到“Canvas可编辑”的范式跨越。正是这个能力,让它从“生成器”升格为“工具”,让创作者敢用、愿意用,而不是只拿来跑Demo。
然而,风险同样在于“品味”。团队声称“有品味”,但品味本质上是主观且昂贵的——它依赖于精准的数据、风格库和复杂的CMF(色彩、材质、质感)控制。如果仅仅靠提示词或网站链接爬取风格,在实际多人协作与品牌一致性场景中,很容易滑向“及格但平庸”。另一个隐患是:当用户“全功能”编辑时,底层逻辑是否会退化为传统编辑器?若控制与智能之间的平衡失当,Motion可能沦为另一个挂靠AI功能的Adobe套件。
一句话判断:Motion选对了细分赛道(动态设计品味、超细化编辑),但如果无法建立可复现的“品味引擎”,它最终会在“放权给AI”和“要求人工精修”的夹缝中,消耗掉自己的先发优势。
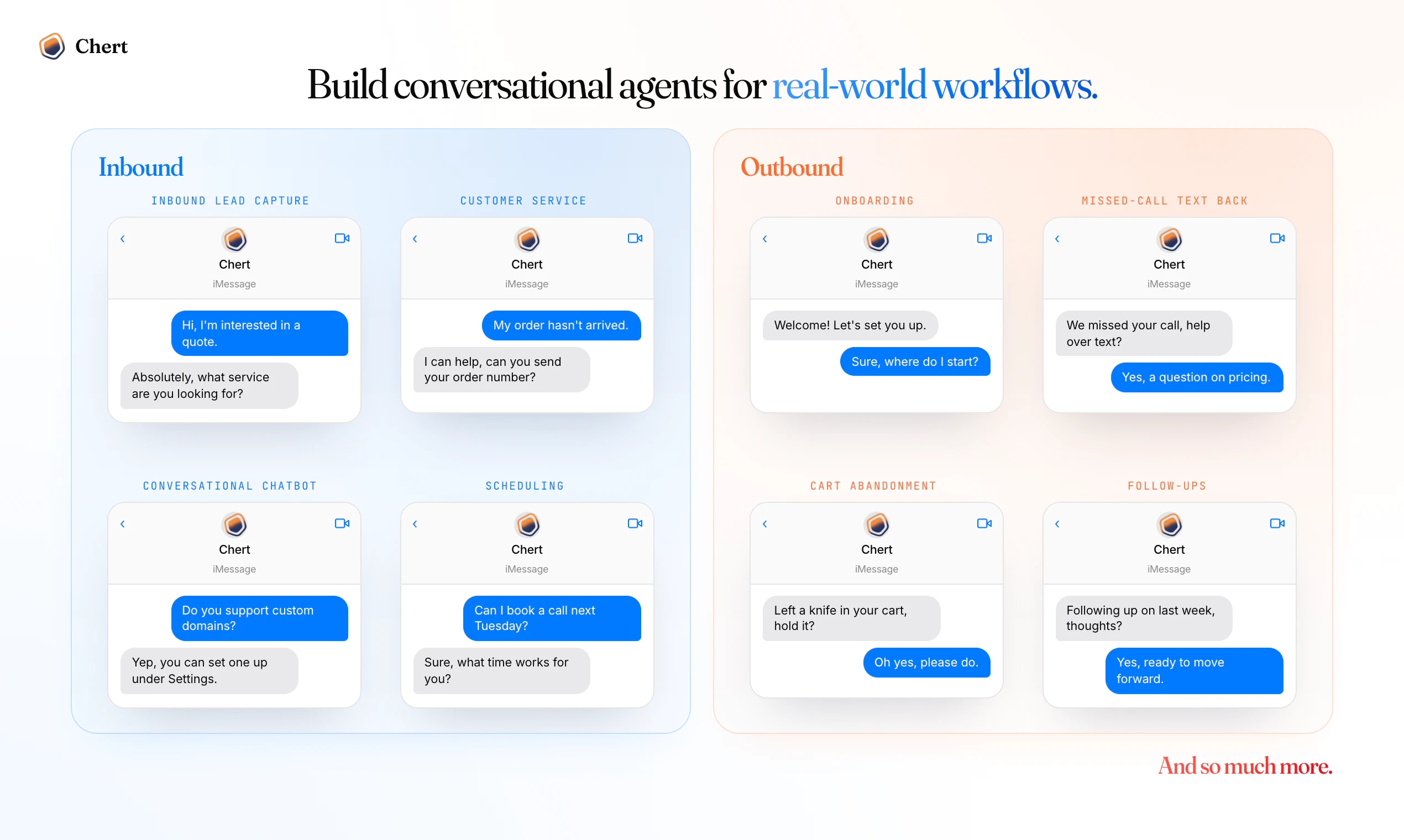
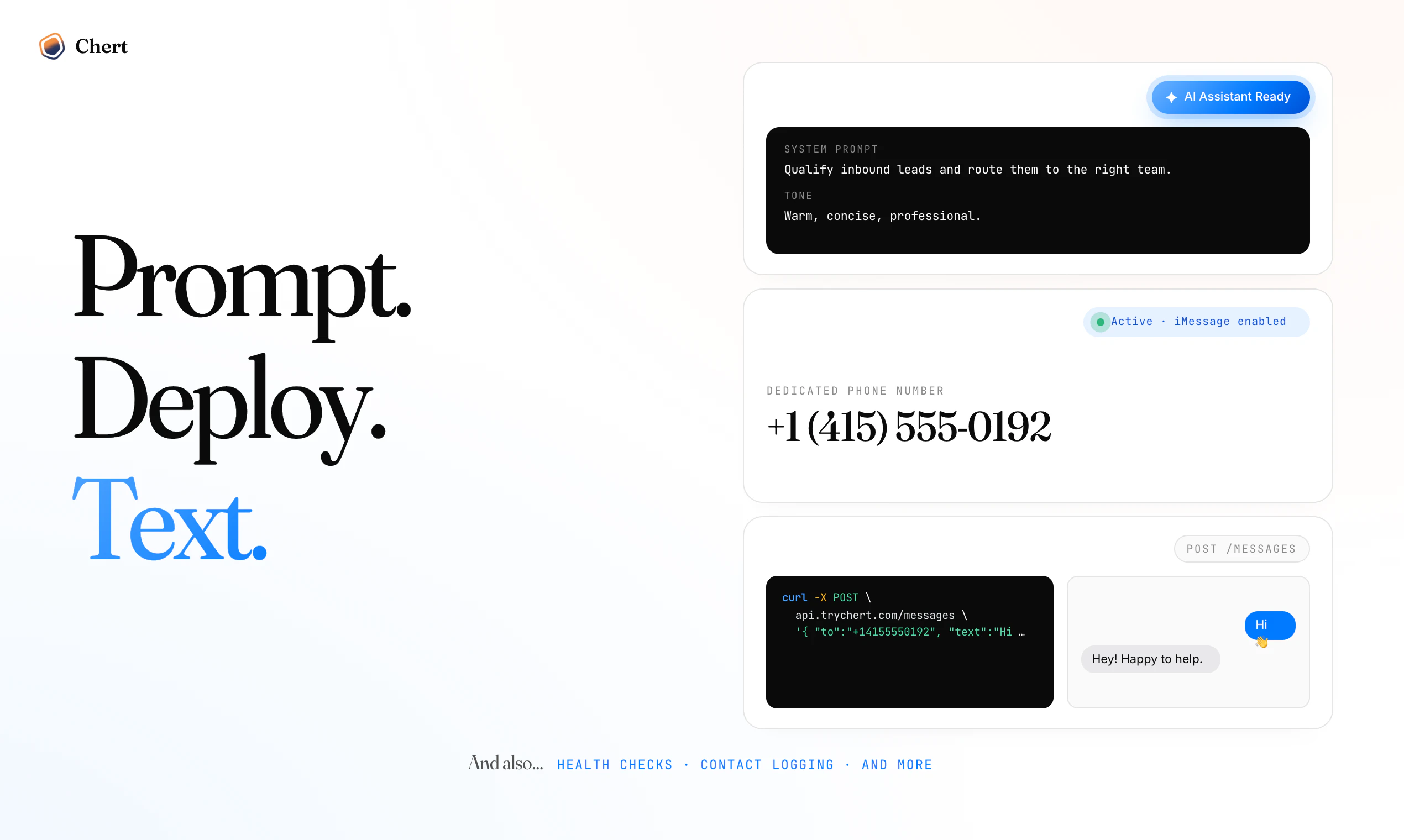
一句话介绍:Chert是一个让企业无需复杂开发即可在iMessage上构建和部署AI代理的平台,专注于客户服务、潜在客户捕获和主动外联,解决苹果官方缺乏商业API导致的高信任度消息渠道规模化利用难题。
Messaging
API
Artificial Intelligence
AI代理
iMessage客户服务
对话式商业
Apple Business Chat替代
CRM集成
外呼自动化
智能客服
消息通道基础设施
线索捕获
Mac中继
用户评论摘要:用户高度认同iMessage的高打开率与信任度,核心关切集中在:1. 技术可行性(无苹果官方API如何保障稳定发送与限流);2. 多平台支持(是否支持WhatsApp等);3. 功能边界(是仅入站还是支持外呼、是否支持线索预筛);4. 渠道定位(与SMS/RCS是替代还是互补)。创始人回复强调采用Mac中继+健康检查+设备分发策略保证可靠性,并支持双向对话。
AI 锐评
Chert精准切入了一个被多数AI客服厂商忽视的“黄金缝隙”——iMessage。当所有人都挤在网页聊天窗、WhatsApp和邮件中时,创始人Gary赌对了“高信任度+高打开率”这个商业公式。从评论区“iMessage not yet slop”的感慨可以看出,该渠道在商业消息尚未泛滥前,拥有远高于SMS的触达率与转化潜力。
产品价值核心并非“AI对话能力”——市面上ChatGPT套壳易做,难的是底层基础设施。Chert真正解决的是:苹果不开放iMessage商业API的物理约束。其采用Mac中继(即通过真实苹果设备路由消息)的方案,虽非全新,但集成了健康检查、跨账号设备分发、状态机跟踪等企业级功能,这在基础设施层面构建了护城河。对于依赖HubSpot、Close CRM的DTC品牌和家装服务公司而言,无需自研消息层即可将iMessage高效融入现有leads追踪流程。
值得警惕的是,其技术路线存在单点风险和可复制性。Mac中继方案的稳定性受限于苹果的软硬件更新及账号拉黑风险。随着苹果可能最终推出iMessage for Business API,当前的中继模式可能瞬间贬值。因此,Chert的窗口期在于“成为该生态被官方化之前的最大玩家”。目前来看,其先发优势和切入的“2B消息基础设施”定位,比直接做AI SaaS更具持久性。但能否从“蓝泡泡的管道工”进化为“智能对话平台”,取决于团队是否在CRM深度集成和场景化BPO方案上持续投入,而非停留在简单的prompt界面包装。
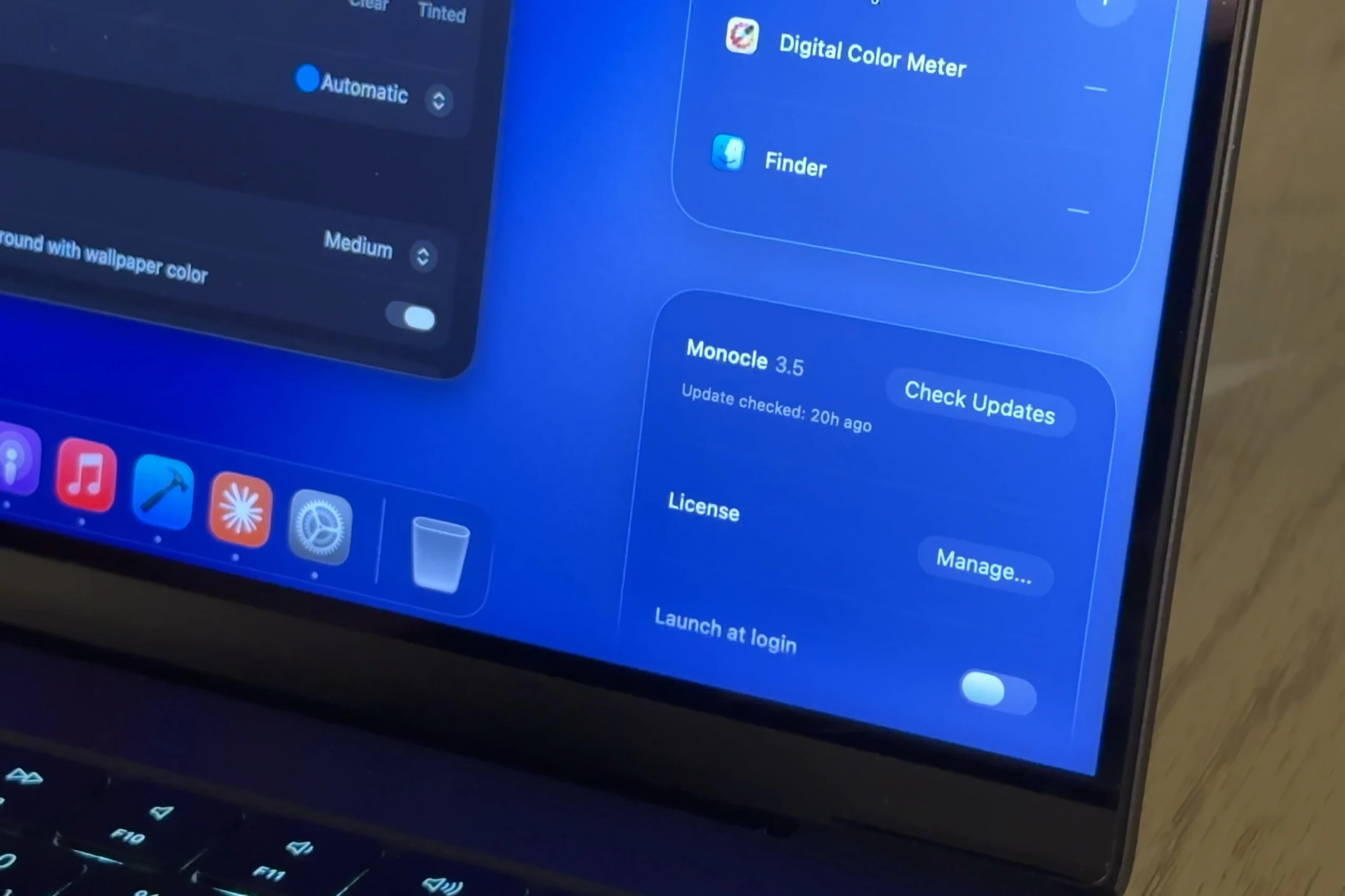
一句话介绍:Monocle 3.5 是一款 macOS 专注工具,通过模糊除当前活动窗口外的所有屏幕内容,帮助用户在多窗口环境下减少视觉干扰,提升工作与思考的沉浸感。
Productivity
User Experience
macOS
专注工具
窗口管理
屏幕降噪
应用分组
多显示器支持
模糊效果
生产力工具
Stage Manager
系统级体验
用户评论摘要:用户普遍认可其概念与实现,尤其赞赏“应用分组”功能将单一窗口聚焦工具升级为多窗口工作流的日常驱动。有用户询问资源占用,开发者回应M3芯片闲置时约1.8% CPU。另有用户对“系统原生感”的宣称持谨慎期待。
AI 锐评
Monocle 3.5 的价值不在于“模糊”,而在于“精准的遮蔽”。它解决的不是“窗口太多”本身,而是人类视觉系统在多任务切换时的认知过载——这是很多效率工具(如单纯的窗口管理器或分屏应用)忽略的心理层面痛点。从3.0到3.5的迭代,开发者显然意识到,单一窗口聚焦只是一个“演示级”功能,只有“应用分组”才能让它真正进入多窗口工作流。这是从线性思维到网状思维的跃迁。
但需注意其技术代价:正如开发者在评论中坦承,模糊渲染的实时性意味着更高的CPU开销(尤其是在窗口切换瞬间)。虽然M系芯片下1.8%的闲置占用可接受,但在Intel Mac或重度负载场景下,这一体验可能打折。其“系统原生感”的宣称是一把双刃剑——无缝体验带来高粘性,但任何微小的UI卡顿都将直接击穿用户预期的底噪。
总体而言,Monocle 并非macOS的必需品,而是针对“信息敏感型”重度用户(写作者、设计师、开发者)的隐形眼镜。它不提供功能,只提供状态。这种“减法思维”在如今工具泛滥的环境里,反而是一种稀缺的清醒。
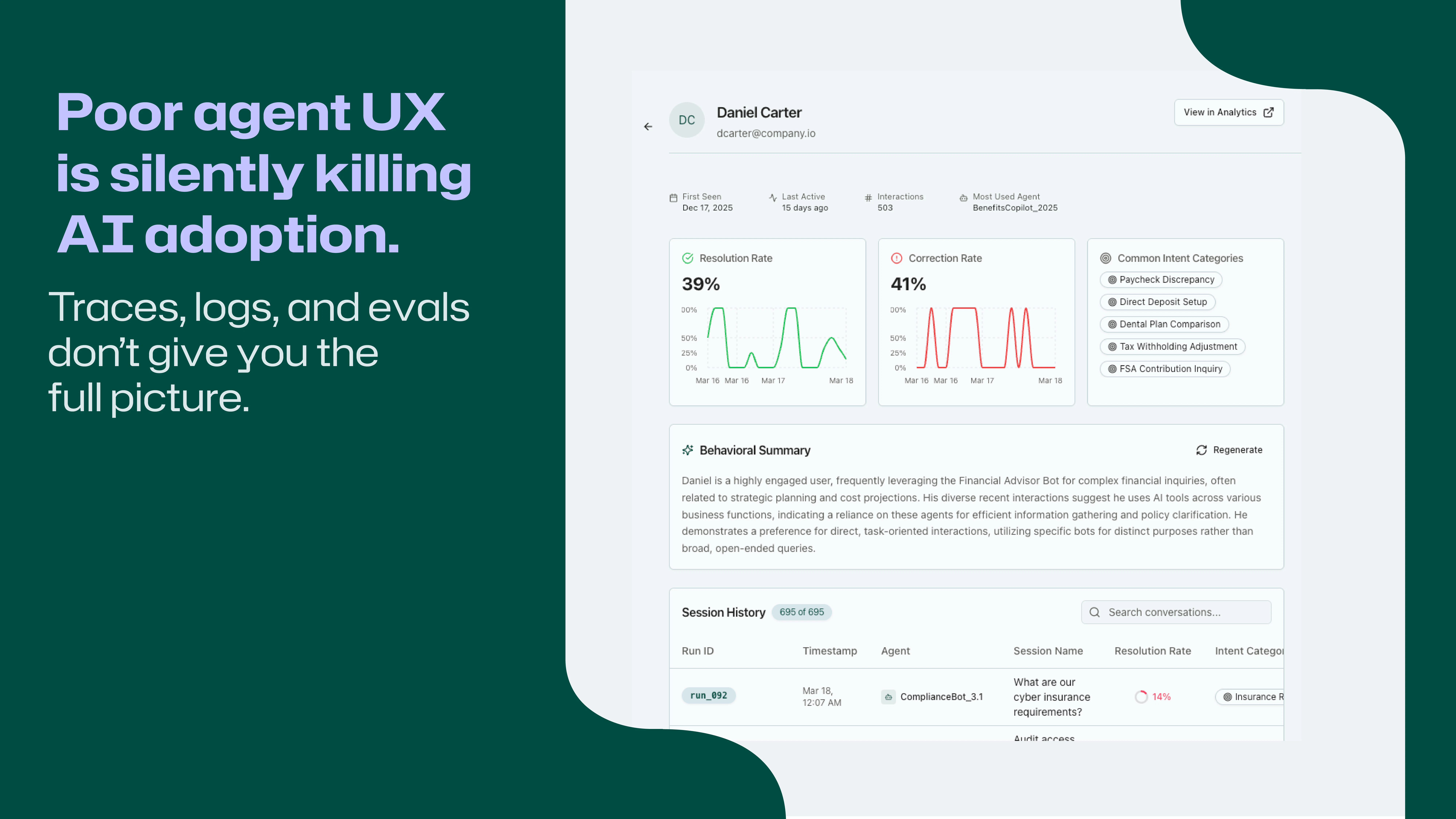
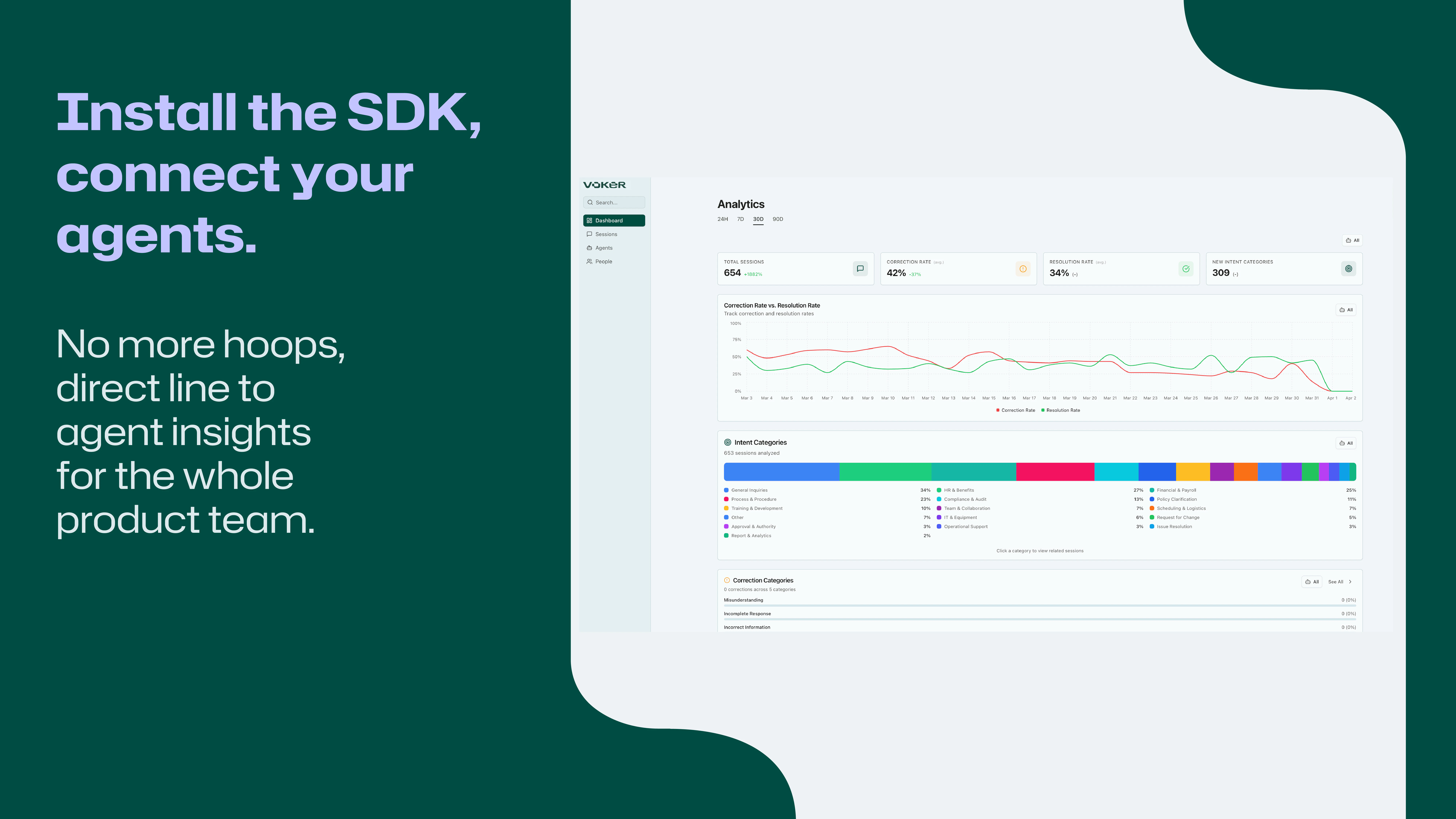
一句话介绍:Voker是为AI产品团队打造的智能体分析平台,通过轻量级SDK自动捕获用户意图、纠正和分辨率等行为数据,解决生产环境中智能体性能黑箱和监控缺失的痛点。
Analytics
Developer Tools
Artificial Intelligence
AI智能体分析
用户行为追踪
智能体性能监控
对话分析
自动意图识别
生产环境监控
智能体优化
SaaS工具
开发者工具
数据驱动
用户评论摘要:用户普遍认可自动意图/纠错检测的价值,关注点集中在:处理多意图会话和智能体间切换的能力、自定义指标和语义变体支持、追踪决策分支和性能回归、能否直接触发修复动作。部分用户怀疑“纠错”标注会受语义歧义和重定向场景干扰,要求降低误报率。
AI 锐评
Voker切中了AI Agent落地中最隐蔽的痛点:当LLM生成的对话流变成新的“黑箱”,传统日志和追踪工具只提供碎片化的调用栈,却无法回答“用户到底得到好的结果了吗”这个核心问题。它的“自动意图-纠错-分辨率”三层标注,本质上是在混沌的语义流中建立可量化的“好坏”标尺,这是比Token计数和延迟统计更接近业务本质的监控维度。
但产品目前的锋利程度,远不及它的洞察力。从评论中大量关于“多智能体切换”、“意图中途漂移”、“纠错语义词表训练”的追问来看,Voker的通用模型在面对高度定制化的生产场景时,很容易陷入“标注正确但对业务无意义”的尴尬。尤其是创始人坦承目前无法区分“成功交付”和“甩锅交接”之间的差异,这直接动摇了其在复杂业务流中的可信度——如果连核心指标“分辨率”都可能被污染,后续的优化决策就容易变成沙上建塔。
真正的价值壁垒不在于抓取了多少原始对话,而在于能否让数据解读与业务逻辑对齐。Voker提出“Amplitude for agents”是对的,但Amplitude价值的前提是用户事件是准确且结构化的。Voker目前更像是一个强大的LLM+启发式规则驱动的事件打标器,接下来要看它:一是能否让用户低成本纠正自动标注错误(反馈循环),二是能否通过API让Agent直接利用分析结果自我迭代。如果只提供了一层似是而非的仪表盘,那也只是另一种形式的“AI鸡汤”——看起来营养丰富,喝下去却未必能治病。
一句话介绍:Insights by Omnia 是一款将AI引擎可见性监测转化为可执行行动方案的工具,帮助内容与营销团队跳过繁琐的人工引用分析,直接获得优化AI搜索结果的分步计划。
Marketing
Artificial Intelligence
AI可见性监控
SEO行动方案
内容优化
引用差距分析
营销自动化
品牌监测
多语言支持
按引擎定制
协作分享
数据分析
用户评论摘要:用户关心行动方案的跨团队可分享性(如含负责人标签)、是否按搜索引擎(ChatGPT vs Perplexity)定制、多语言博客的引用波动处理、可见性测量方法论(采样 vs 确定性)、以及能否明确区分“自建内容更新”与“外部引用获取”两类任务。
AI 锐评
Insights by Omnia 本质上解决的是一个行业通病:AI可见性监测的“最后一公里”困境。大多数工具止步于告诉用户“你在哪里被提及”,却把最耗时的引用分析和行动规划甩给了客户。Omnia 的差异化在于将“数据呈现”升级为“决策输出”,通过按影响等级、实施步骤和引用缺口拆解任务,试图弥合洞察与执行之间的鸿沟。
从用户反馈看,其核心价值已得到初步验证:针对不同AI引擎(如ChatGPT和Perplexity)定制行动方案,以及通过标签区分“自建内容”和“外部引用”两类任务,直击了多团队协作场景的痛点。特别是对多语言市场的引用波动处理,回应了全球化营销团队的实际成本——这让它超越了简单的仪表板工具。
但问题同样明显。产品依赖“长期监控数据”来提效,然而评论中提到的“引用来源每周波动”可能导致“周一的高优先级计划周五就失效”。如果行动方案无法动态适应这种高频变化,其“计划”价值会随时间快速衰减。此外,对外部来源的RAG框架引用展示虽有亮点(如Nike案例),但这类数据的具体性和获取难度依然是未知数——用户能否真正看到“哪些具体页面该添加品牌信息”,决定了“行动”是否只是伪命题。
真正的考验在于:当用户从“监测”转向“执行”时,Omnia能否证明其生成的行动方案(尤其是技术SEO和第三方外联部分)在实际SEO排名或AI引用率中产生可量化提升。如果只是将人工分析换了个UI打包,那它最多是效率工具,而不是增长引擎。目前看来,方向对了,但脆弱性尚存。
一句话介绍:imgproxy v4 是一款自托管的图片处理服务器,旨在解决企业因使用第三方图片处理服务导致成本失控、性能受限和供应商锁定,或自建方案耗时易错的问题,能在不修改代码的情况下按需处理图片。
Software Engineering
Developer Tools
GitHub
Tech
图片处理服务器
自托管
开源
图片缩放
性能优化
实时图片处理
Docker部署
企业级
API替代
成本控制
用户评论摘要:用户肯定了imgproxy“按需处理、避免资产反复准备”的理念;CEO强调自托管可规避第三方成本与锁定;开发者提问v4版本新增的内部缓存如何解决源图变更后的失效问题(是否支持ETag/Last-Modified),社区回帖指出不处理此场景,建议变更时换文件名。
AI 锐评
imgproxy v4 的定位很聪明:它不是在和自研系统拼灵活性,而是在和“SaaS烧钱陷阱”抢市场。其核心价值并非技术创新,而是“成本结构重构”——用一次性的OPS(运营)投入,取代持续增长的API调用账单。对于日处理百万级图片的中大型团队,这是典型的经济账战胜技术账的案例。
然而,产品在工程思维上存在明显的盲区:对缓存失效这类“脏活”采取回避态度,简单粗暴地要求“改文件名”。这在动态内容或CMS系统中将引入大量运维负担,更暴露了其“高速但不够智能”的技术底色。v4版新特性如RAW格式支持和图像分类算是不错的增量,但“内建缓存”的价值被评论区直接拷问,说明技术细节并未跟上营销话术。
综合来看,imgproxy是优秀的“降本工具”,但距离自称的“企业级解决方案”还有距离。真正的企业级意味着不仅要处理极限流量,更要处理复杂业务逻辑下的数据一致性。如果团队能接受“变更图片就得改名”的强约束,它确实是一款高性价比的开源替代品;否则,最终仍需在前端或CDN层做额外补偿工作,反而得不偿失。
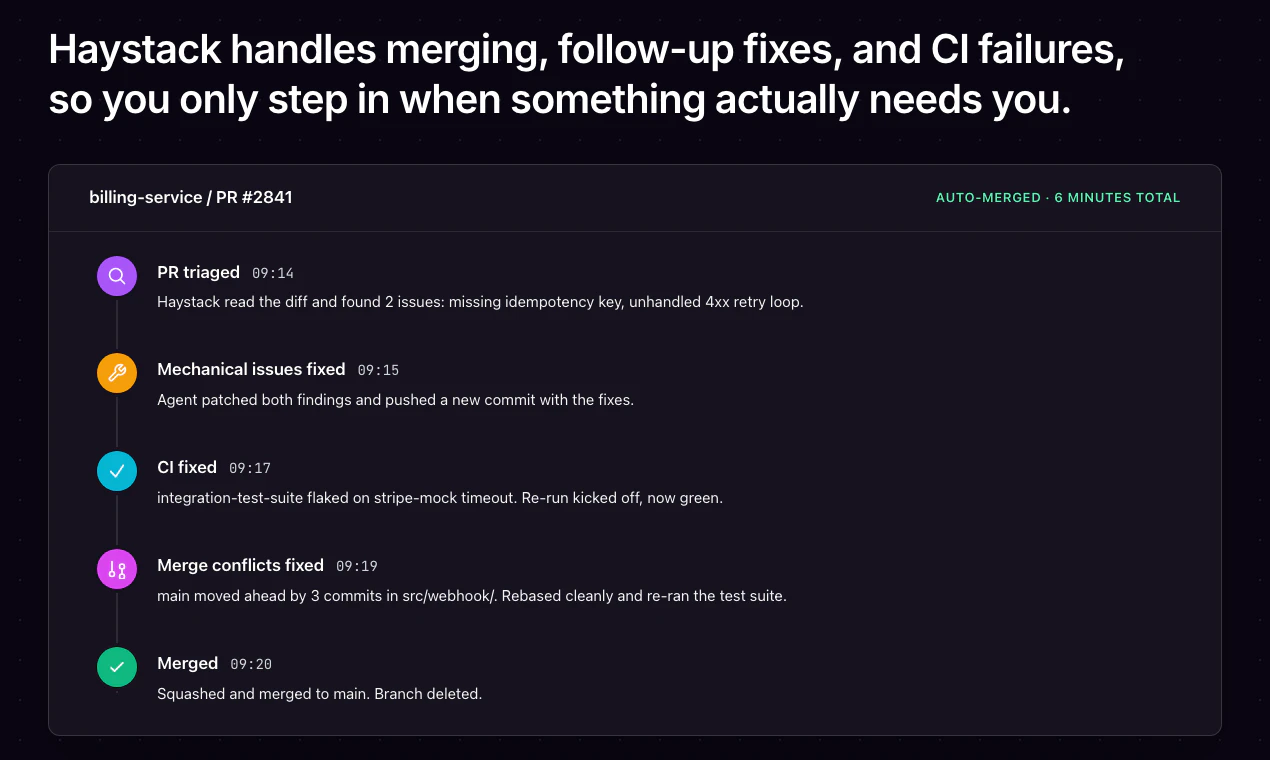
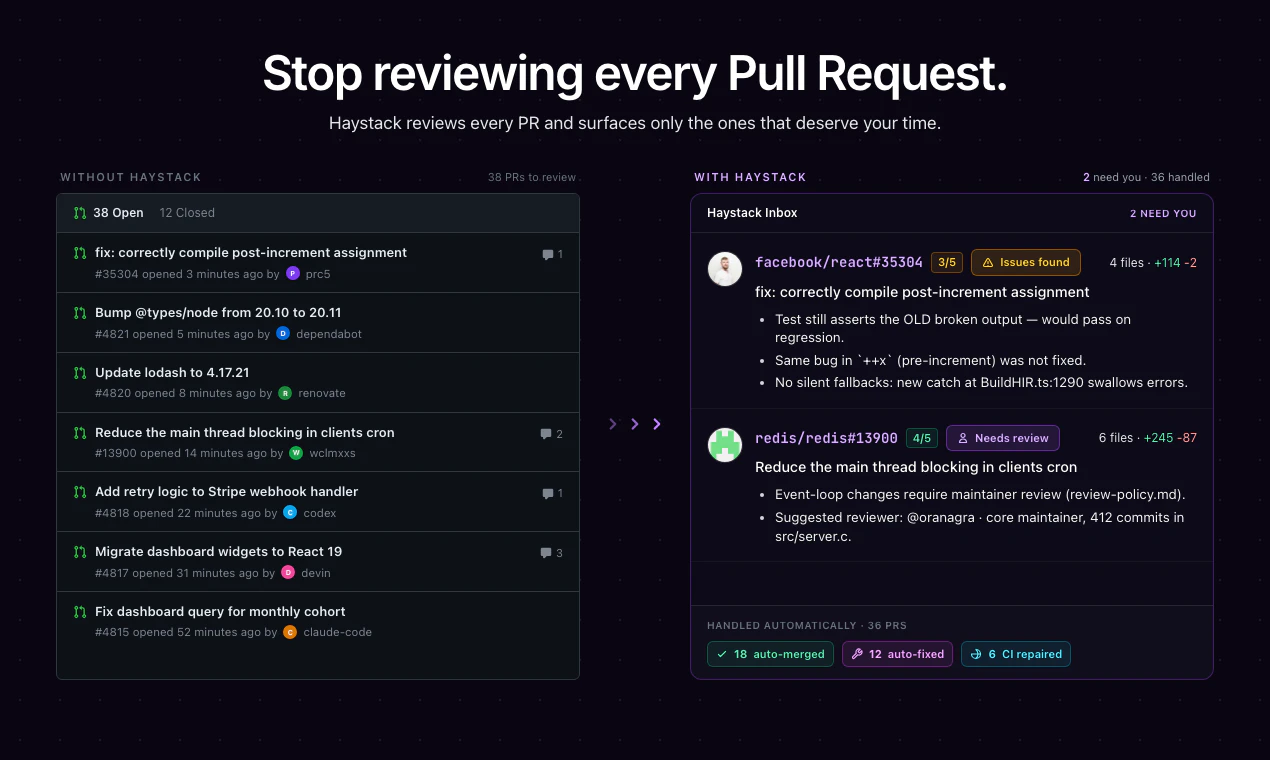
一句话介绍:Haystack是一款AI驱动的代码审查智能路由工具,它通过分析GitHub PR的代码差异、上下文、Agent轨迹和验证证据,自动将PR分流为“安全合并”、“需修复”或“需人工审查”,解决AI生成PR激增导致的人力审查过载和认知疲劳问题。
Developer Tools
Artificial Intelligence
GitHub
代码审查工具
AI代码审查
PR路由
开发者工具
工程效率
GitHub集成
Agent代码管理
代码合并自动化
DevOps
审查队列管理
用户评论摘要:用户普遍认同AI生成PR带来的“信号噪声比”问题,但关注点集中在:规则判断对AI的“良好判断力”依赖风险;是否支持多仓库及monorepo中不同服务(如支付vs内工具)的差异化审查规则;以及决定审查级别(安全/需修复/需人工)的关键信号是什么。团队回应称规则可配置、支持多仓库,并举例说明基于变更敏感性和验证充分性做判断。
AI 锐评
Haystack精准戳中了AI编程时代的核心痛点:当每个工程师都能日产20+个PR时,传统线级diff审查彻底沦为体力活。产品巧妙地将审查逻辑从“看代码改了什么”转向“验证代码是否达成了意图且有证据”,本质上是在为稀缺的人类注意力定价——让机器做机器擅长的合规检查,让人做人擅长的价值判断。
然而,产品成功的关键极其脆弱:它要求团队事先定义高度明确的规则集(“哪些变更触碰安全红线”“怎样的测试算充分证据”),而这本身就是高认知成本的工作。如果规则太松,AI将学会钻空子(如截个UI图假装过人工验证);如果规则太严,又会退回“所有PR都需人工”的老路。更深层的问题是,产品假设“意图与验证证据可被自动解析”,但当前AI agent产生的trace往往冗长且结构混乱,Haystack能否精确提取设计决策链,决定了它是真智能路由还是高级分类垃圾桶。
致命隐患在于,一旦开发团队习惯依赖Haystack自动放行“安全”PR,人类审查能力将加速退化——长期看,这会削弱团队对代码质量的整体直觉。此外,该产品本质上是在给GitHub PR系统打补丁,而非重构协作流。若GitHub或GitLab原生推出类似功能,Haystack的生存空间将迅速收窄。短期它确实是救火队长,长期需警惕沦为“AI代码的塑料瓶盖回收站”——表面上解决了流量问题,实际上只是把塑料瓶(低质量PR)压扁了再分类。
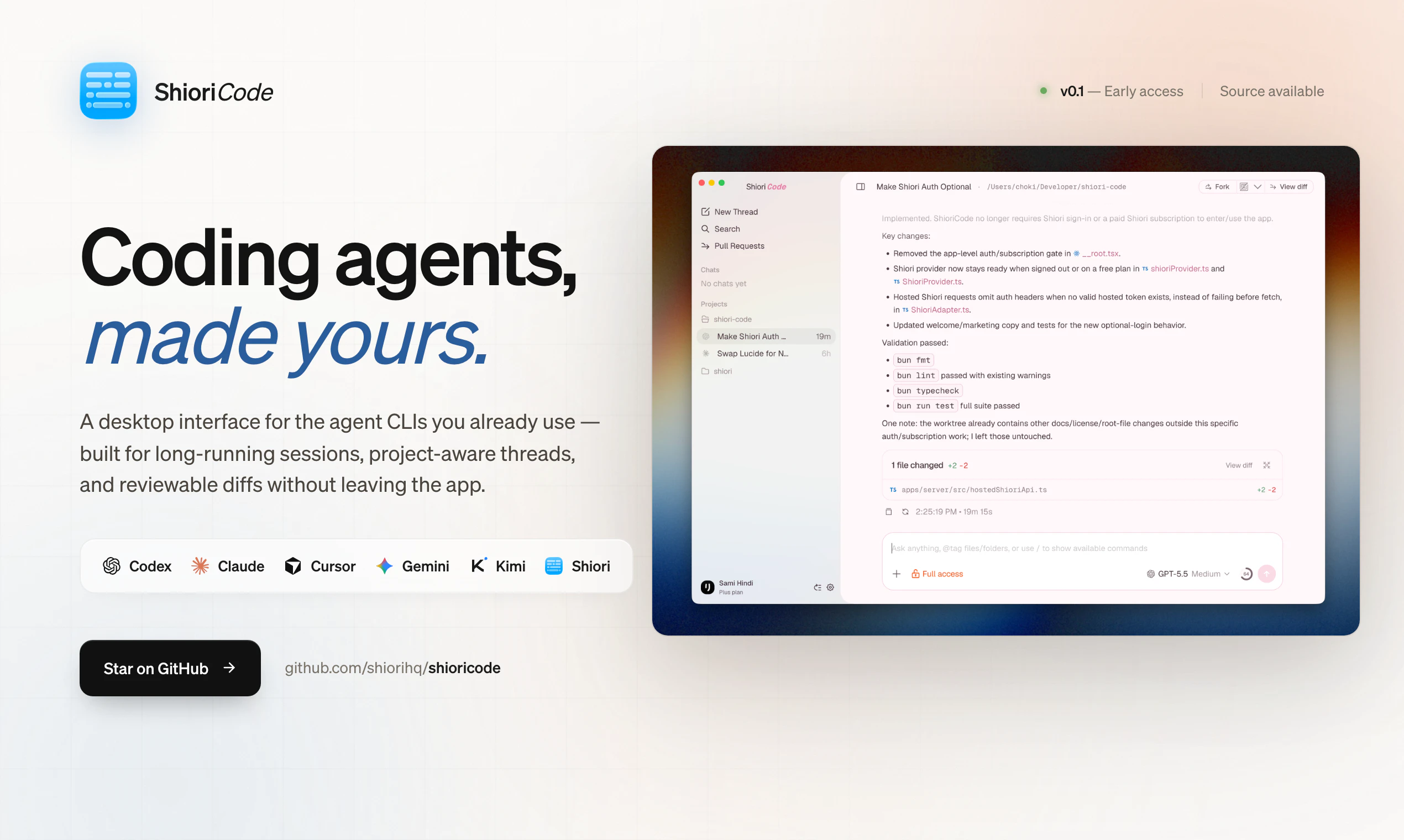
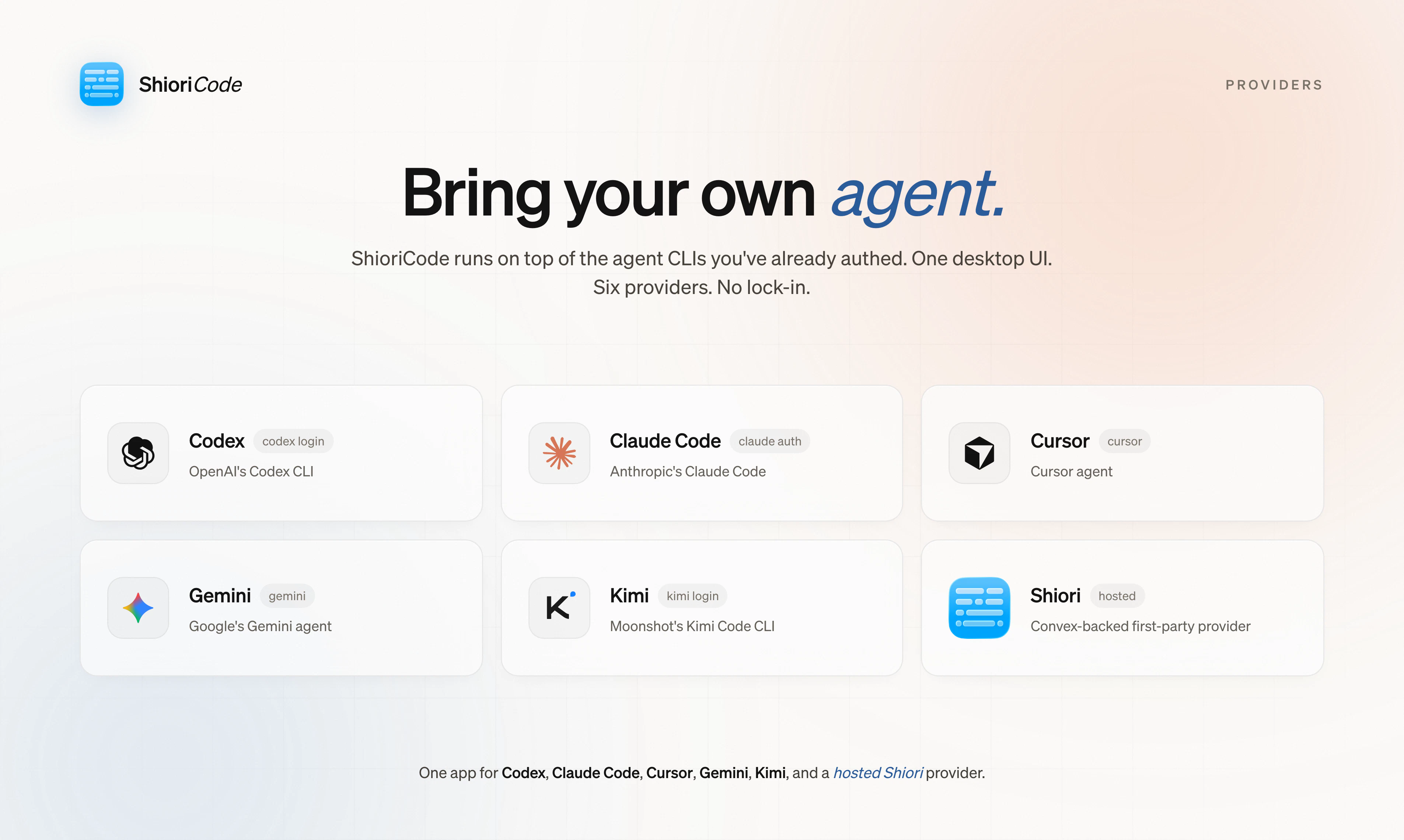
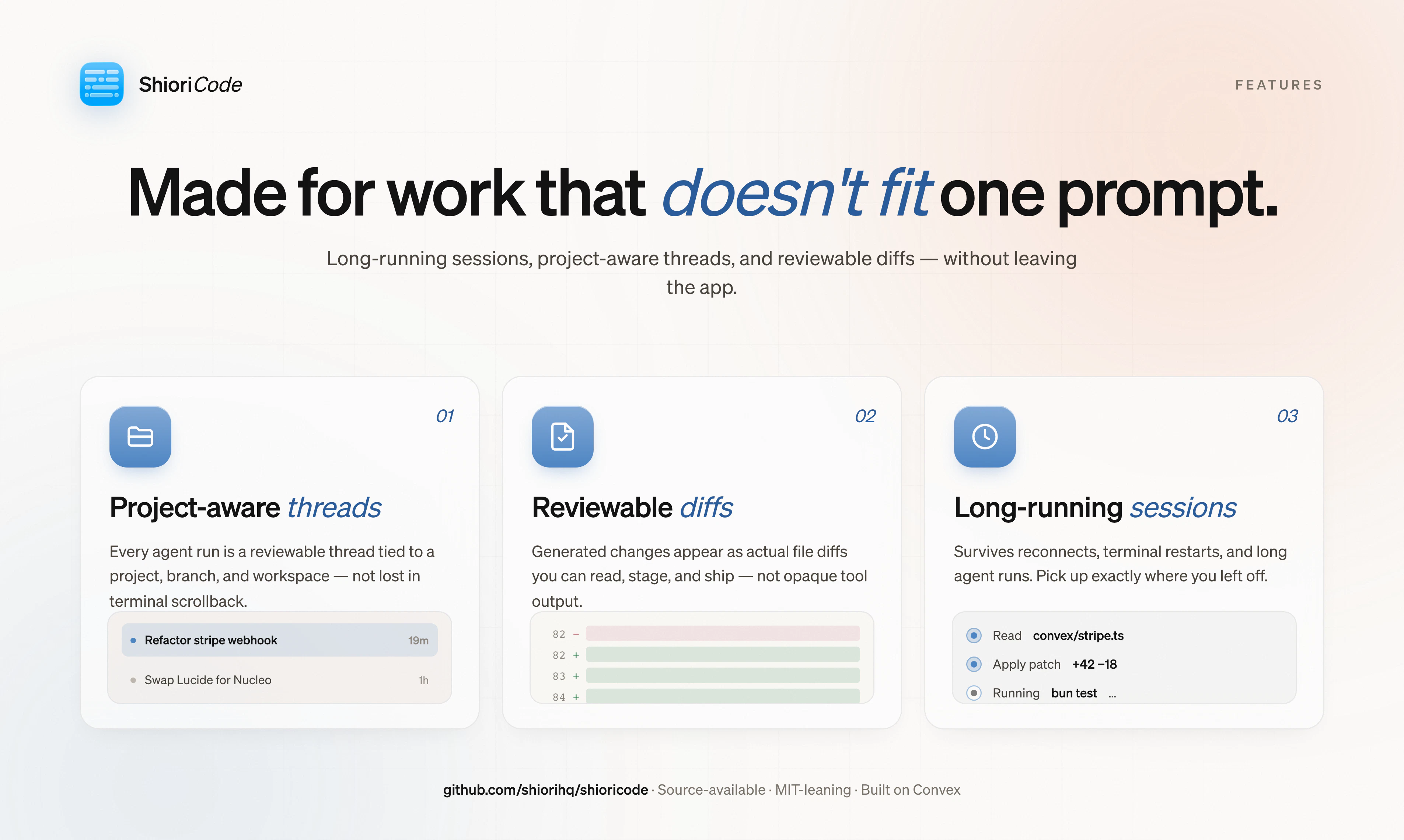
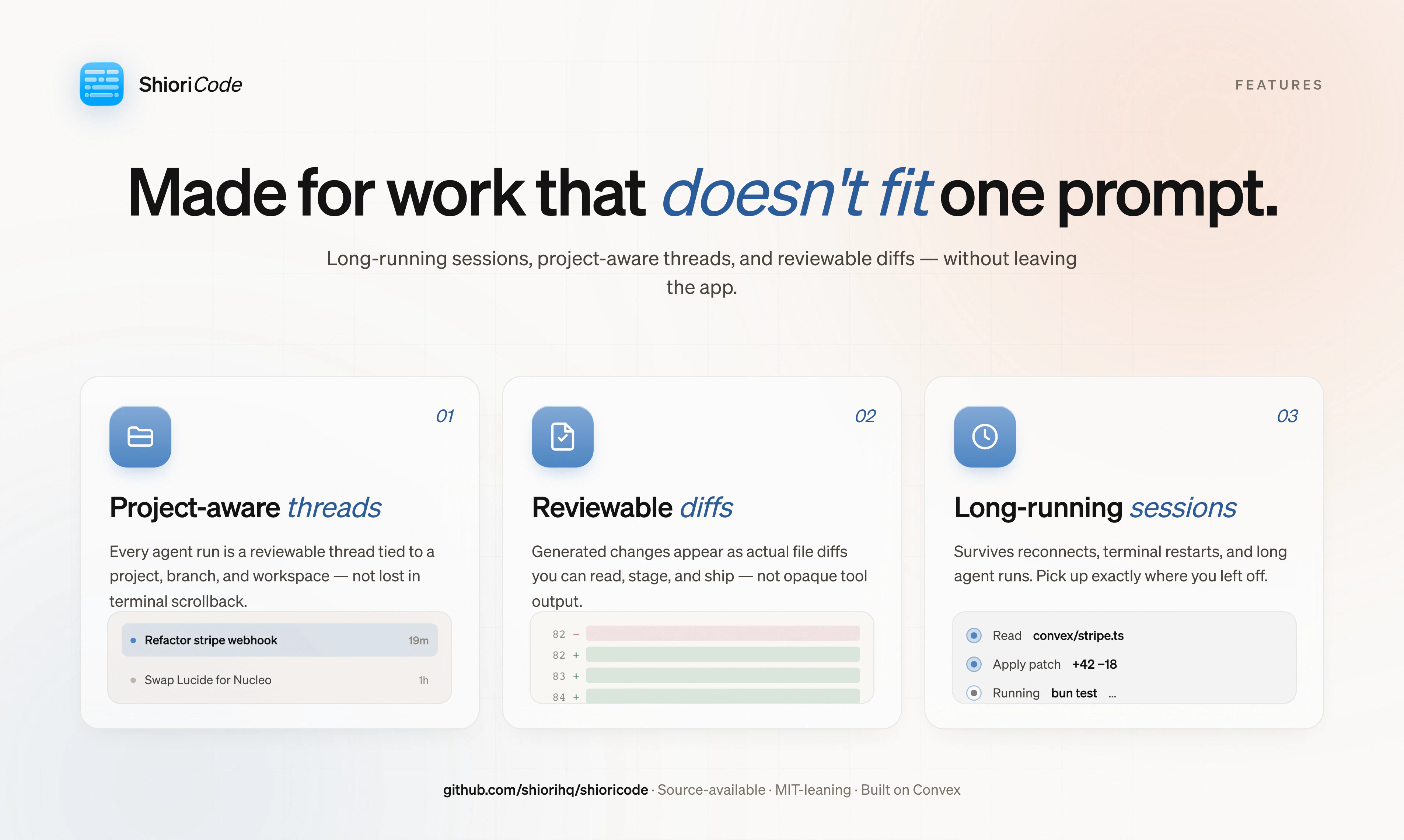
一句话介绍:ShioriCode 是一个桌面端应用,为 Claude Code、Codex 等编码代理 CLI 提供项目感知的线程管理、活动时间线和差异审查界面,解决长时编码任务在终端中会话易中断、信息难追溯的痛点。
Open Source
Developer Tools
Artificial Intelligence
GitHub
用户评论摘要:用户关心多代理间是否共享上下文与差异栈(是启动器还是抽象层),以及是否统一不同代理的工具调用格式。另有关注Elastic License原因,以及代理达到token限制时的连续性处理。官方回应通过原生压缩维持连续性。
AI 锐评
ShioriCode切中了一个真实但狭窄的痛点:编码代理CLI在长时、多文件任务中的会话管理几乎为零。它没有试图再造一个代码生成引擎,而是老老实实做“胶水层”——把多个CLI的碎片化输出整理成可浏览、可回溯的界面。这种定位聪明却也危险:价值完全依附于底层代理的表现与接口稳定性。当Claude Code、Codex们未来自身补上会话管理和可视化差异视图(几乎必然如此),ShioriCode就只剩下“整合多个代理”这一个薄弱的理由。目前评论中最关键的问题“是启动器还是抽象层”一语道破:如果它只是各自隔离的UI壳,换代理等于换工作记忆,那么协同价值微乎其微;而如果它能统一上下文和差异栈,则需要面对工具调用格式的标准化——这比它自己写一个代理还难。Elastic License的选择也暗示了开放性与商业化之间的摇摆:源码可用但不自由,社区贡献和商业竞品的张力未来将反复撕裂这个项目。此刻的ShioriCode更像一个精致的前端终端复用器,要成为真正的“编码协作层”,还需要在上下文持久化、代理间知识传递和差异归并上付出远超UI打磨的技术深度。
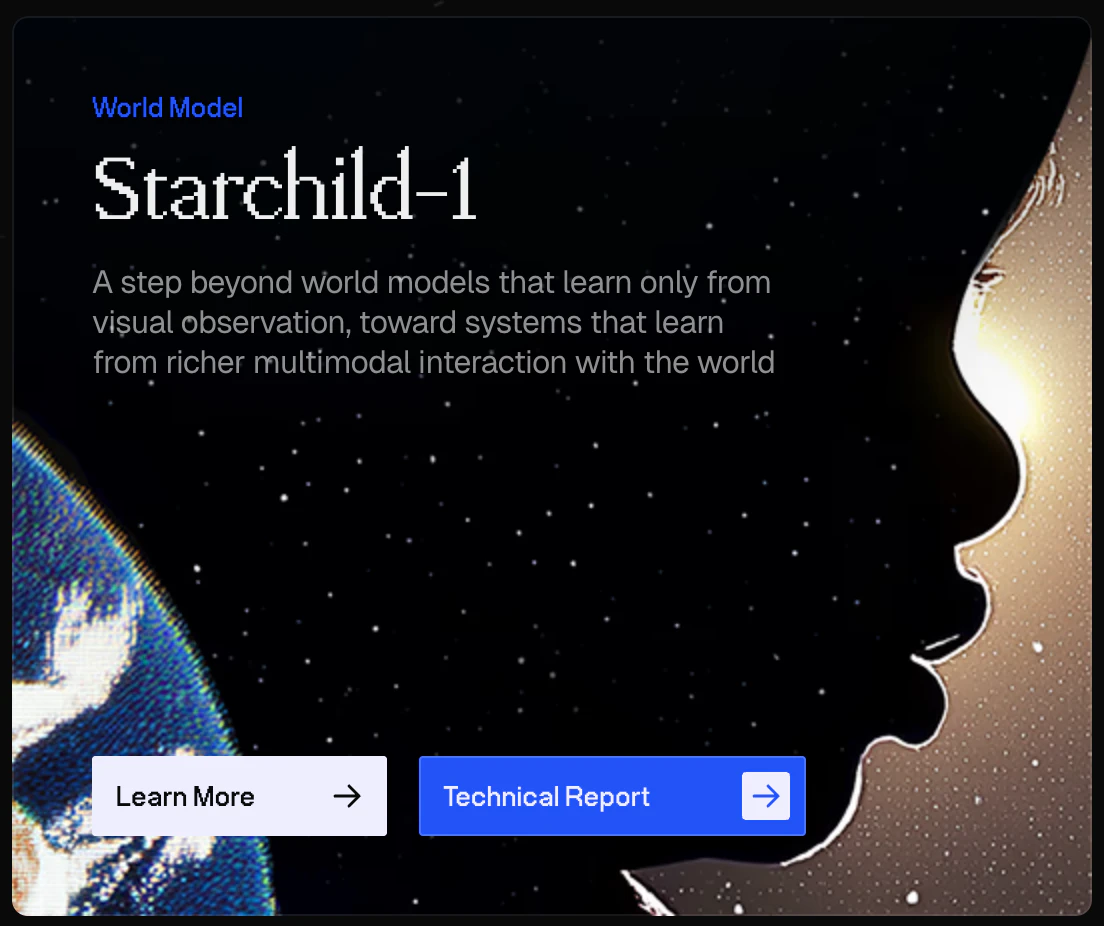
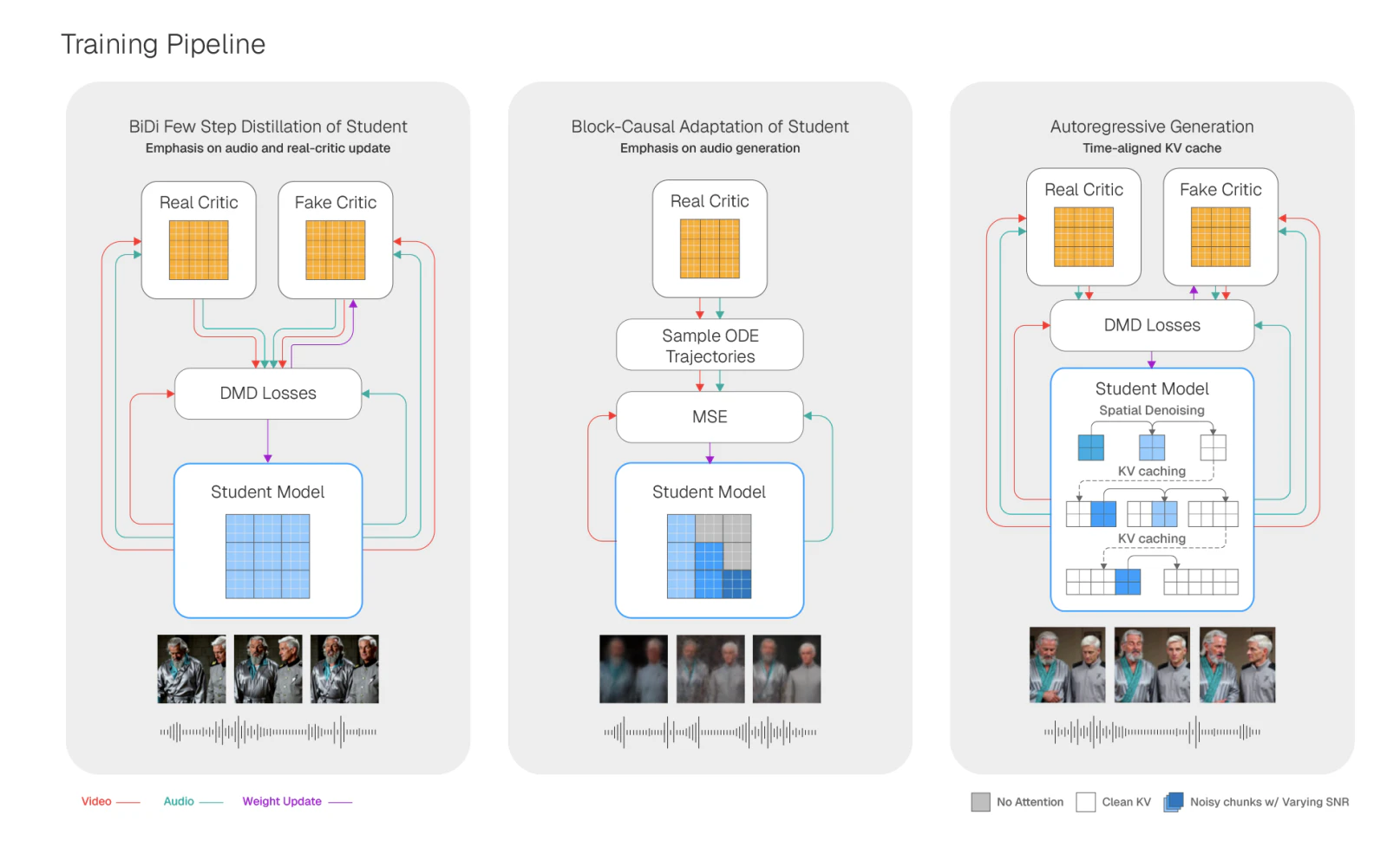
一句话介绍:Starchild-1是全球首个实时多模态世界模型,能同步生成音视频并实时响应用户输入,旨在为游戏、机器人、教育等场景提供沉浸式交互体验,解决传统AI模型无法实时、多模态协同模拟真实世界动态的痛点。
Robots
Education
Artificial Intelligence
实时多模态
世界模型
音视频同步生成
流式交互
交互式AI
游戏引擎
机器人仿真
教育科技
沉浸式模拟
认知计算
用户评论摘要:用户主要肯定其突破性——将世界模型从离线视觉扩展至实时音视频交互,并指出连续流式输入与音视频因果推进是关键价值。设计师建议需配备更直观的界面策略来降低交互门槛,体现对用户体验落地的关注。
AI 锐评
Starchild-1的“首个实时多模态世界模型”定位,确实击中了当前大模型一个关键盲区:绝大多数模型仍停留在文本或静态图像响应,即便有视频生成也多为离线“一刀切”。它所做的,是通过因果音视频联合生成,让AI从“看图说话”进化到“边听边看边聊”,这为游戏NPC的智能交互、机器人具身模拟、甚至动态教育内容生成提供了底层基础设施。
但必须泼一盆冷水:101票的冷启动数据说明这仍是一款极早期产品,技术报告很可能揭示其实时性依赖极高的算力或特定场景剪枝,距离“商业级可用”还隔着显存、延迟和内容一致性三座大山。评论中设计师提到的“界面策略”暴露了另一重风险——过度强调技术创新而忽视交互范式的重新设计,容易让用户陷入“它很厉害但不知怎么用”的尴尬。
其真正价值不在“更逼真”,而在“更低成本地模拟因果”——例如机器人训练中无需物理实体即可测试视听反馈回路。但若不能快速降低集成门槛,并开放API给游戏引擎和机器人中间件,它很可能沦为又一个“技术超炫、落地稀缺”的实验室展品。Odyssey团队需要尽快用具体的行业合作案例(比如与Unity集成、与ROS2打通)来证明,这不仅是demo,更是工具。
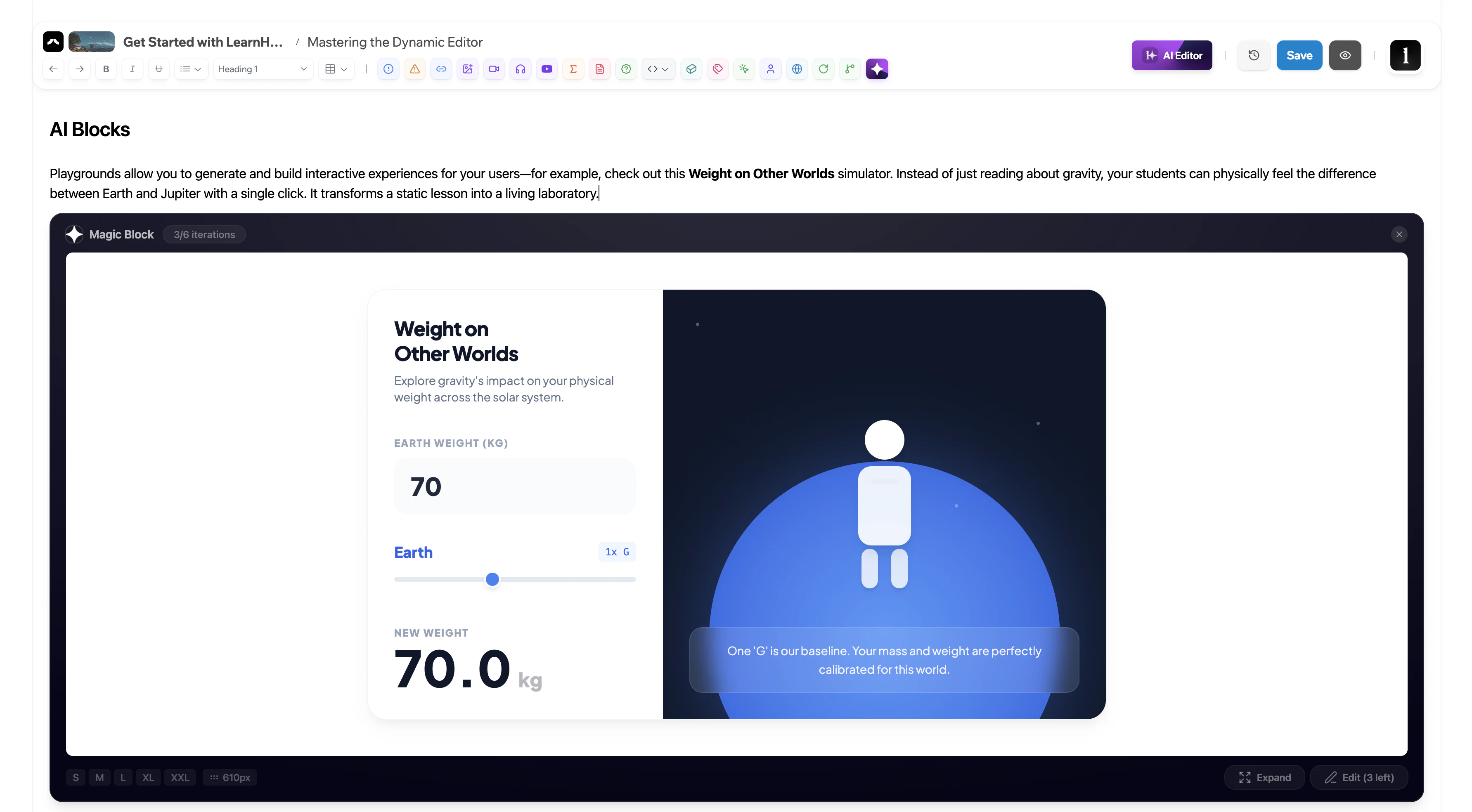
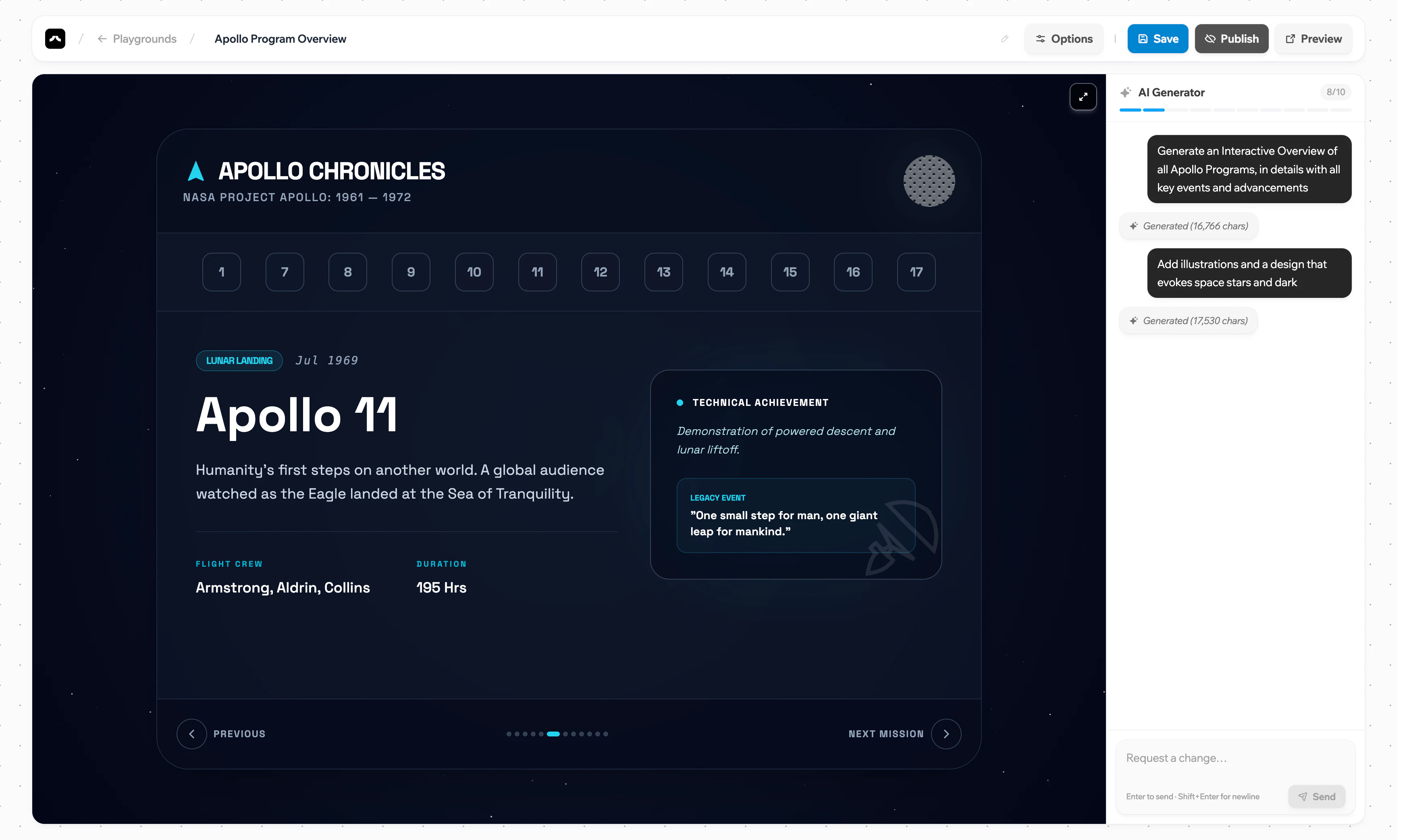
一句话介绍:LearnHouse 是一款专为开发者打造的开源学习平台,能够帮助你在产品内部快速创建并嵌入交互式课程,解决用户理解产品难、学习动力低的问题,实现“边用边学”。
Open Source
Education
GitHub
Online Learning
开源学习平台
产品内教育
代码执行
AI教学助手
互动模拟
社区讨论
自托管
SaaS替代
开发者工具
用户激活
用户评论摘要:用户普遍认可“自托管+云服务”模式对数据自主权的保障。核心关注点集中在:1)AI对公式或专业领域内容的处理能力;2)沙箱化的多语言代码执行在规模化下的成本与架构(统一容器 vs 独立沙箱);3)希望将课程与产品版本变更动态关联,实现“活文档”式持续教育,避免课程内容滞后。
AI 锐评
LearnHouse 巧妙抓住了“软件即教学”的缝隙——多数团队要么依赖生硬的知识库,要么被臃肿的SaaS LMS绑架。v1.0 的亮点不在功能多,而在于将代码执行、AI问答、交互模拟这些原本属于开发工具的能力,以开发者熟悉的方式(开源+自托管+API)整合进教学场景。这比 Moodle 等传统项目更具现代感,比 Teachable 等商业平台更可控。
但问题也显而易见。第一,AI 的“上下文感知”目前更多是课程内容内检索,若扩展到产品API变更、版本差异、用户行为轨迹,才能真正让学习“活”起来,而这需要极强的工程集成。第二,多语言代码执行是双刃剑——既可以是“杀手级功能”,也可能因沙箱隔离复杂度与服务成本,在规模化后拖垮体验。评论中已有人质疑统一容器 vs 独立沙箱的设计取舍,这是技术底账,绕不开。第三,产品进化速度过快(19种语言、200+修复),但核心教学效果——用户完成率、知识留存率——是否优于视频+文档的组合,目前缺乏数据背书。这可能是早期团队最容易忽视的“盲区”:做的功能很多,但对“什么功能真正驱动了学习闭环”缺乏聚焦。
总体而言,LearnHouse 是一个针对开发者群体的“武器级”工具,但尚未脱离工具属性,距离一个“自带生态的学习平台”(如课程市场、讲师认证等)还有距离。其真正的突围机会在于:深耕 product-led growth 场景,成为API发布、版本发布等产品动作与学习内容动态绑定的基础设施,而非另一个静态的课程编辑器。
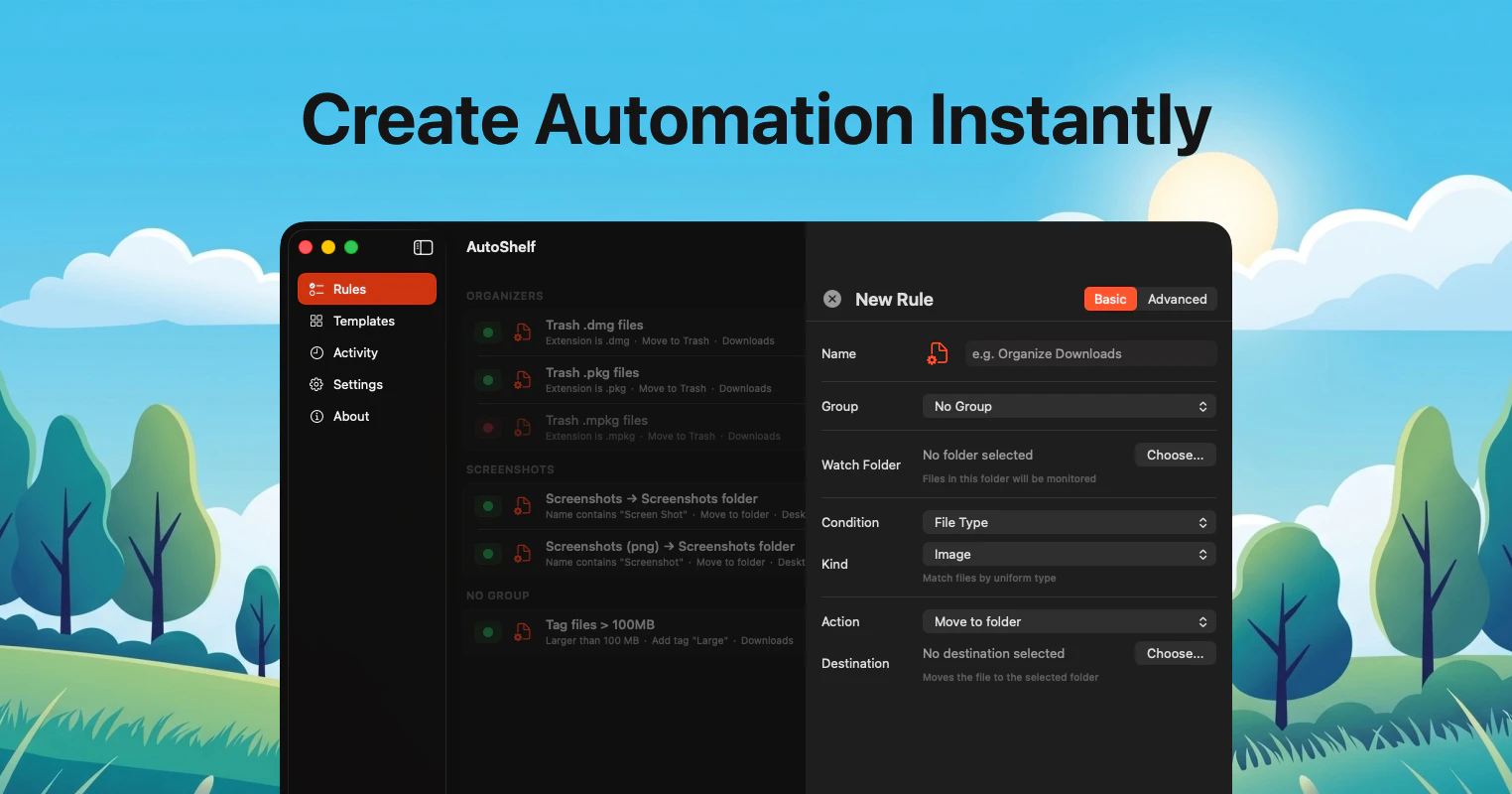
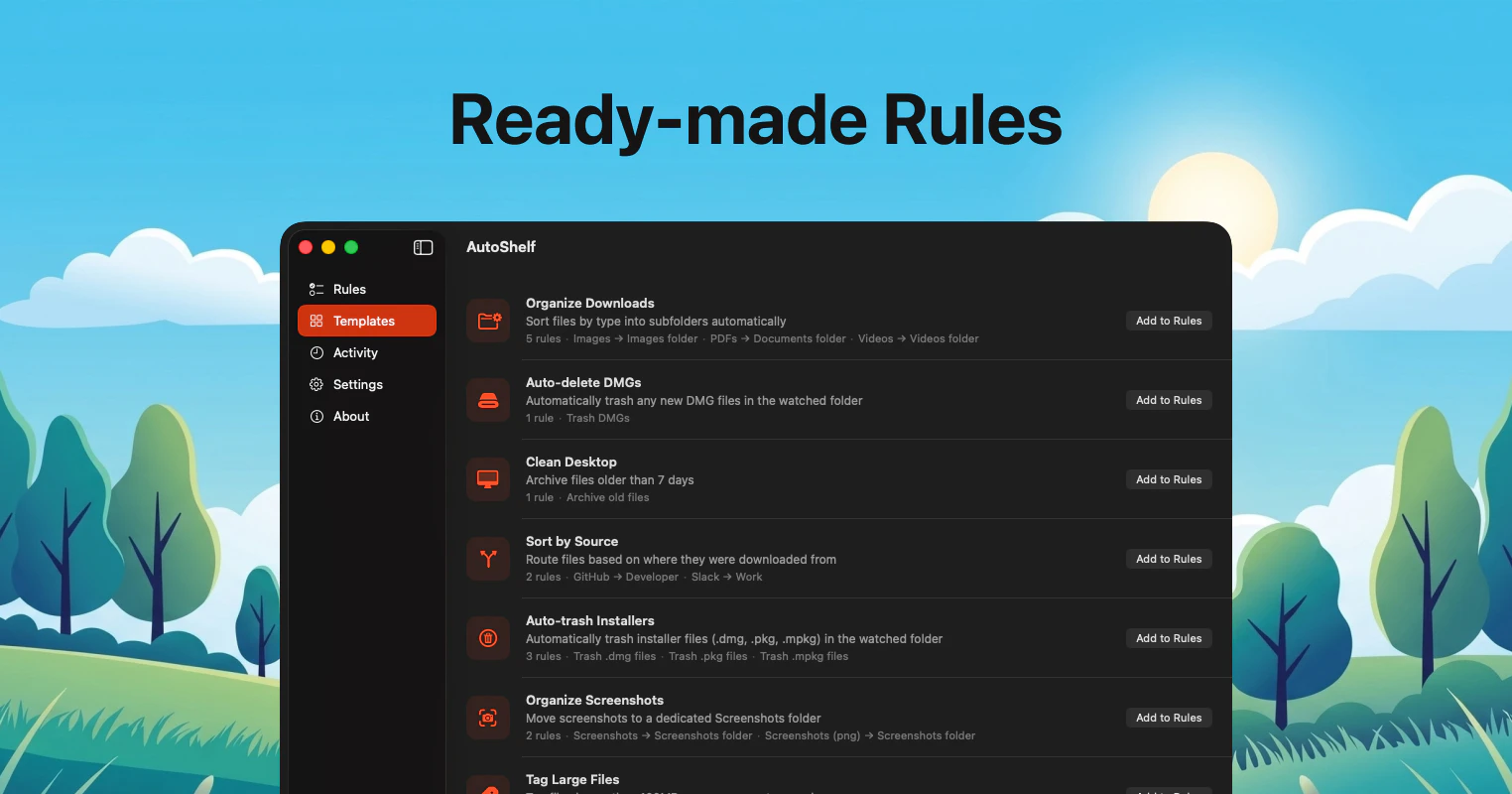
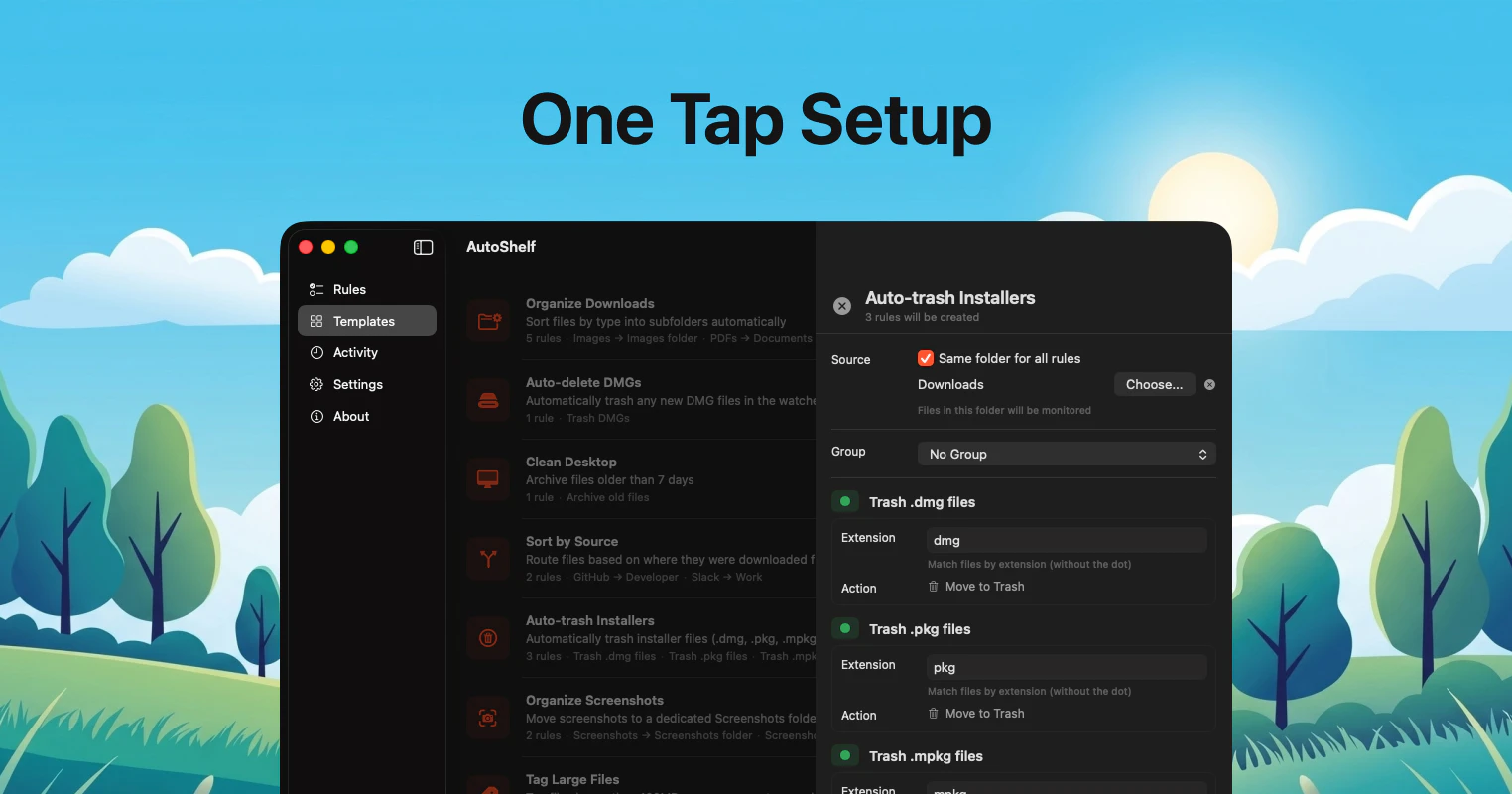
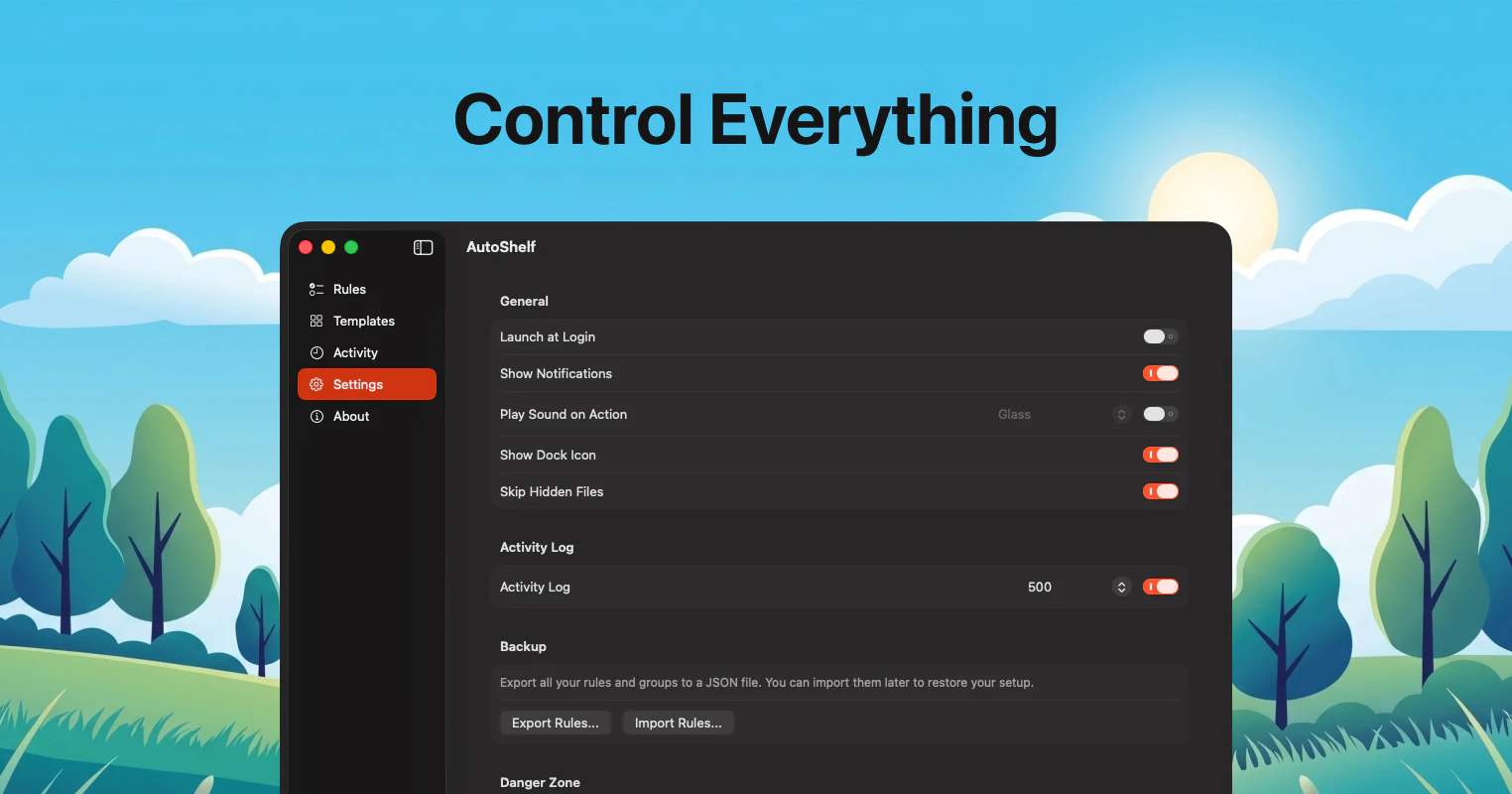
一句话介绍:AutoShelf 是一款 macOS 菜单栏文件自动整理工具,通过预设规则一键清理下载文件夹等杂乱区域,解决用户手动分类文件的繁琐痛点。
Mac
Productivity
Menu Bar Apps
文件整理
macOS工具
自动化
菜单栏应用
规则引擎
图片优化
一次性付费
效率工具
文件管理
用户评论摘要:用户肯定其菜单栏监控和模板化规则设计;核心疑虑包括:多规则冲突时处理逻辑(是否按创建顺序或优先级)、是否支持不同文件夹独立规则集、能否处理嵌套子文件夹(目前仅顶层文件)。也有用户询问是否支持 Dropbox、iCloud 等云盘。
AI 锐评
AutoShelf 是一款定位精准但尚显 “青涩” 的效率工具。其核心价值在于将文件整理这一高频、低价值操作,降维成“设一次规则,终生托管”的自动化流程,切中了数字时代 “下载文件夹即无底洞” 的普遍痛点。19.99 美元一次性买断的定价,相较于同类 SaaS 订阅制产品显得克制且有诚意,降低了用户的决策门槛。
然而,从评论反馈来看,产品当前的功能完整度仍有明显短板:缺乏直观的规则冲突解决机制、无法按文件夹定制独立规则、不支持嵌套目录——这些并非锦上添花,而是文件整理场景下的基础刚需。开发者虽在回复中表现出积极迭代态度,但如果这些关键功能不能在短时间内补齐,AutoShelf 可能很快从 “尝鲜工具” 沦为 “半成品弃坑”。
产品真正的护城河不在于“自动整理”这一概念,而在于其边界的拓宽:支持多条件链式动作、文件格式自动转换、乃至对接云存储和 RSS 下载,如果这些规划路线图能顺利落地,AutoShelf 将从单纯的“文件清洁工”进化为“文件全生命周期管家”。但若只停留于解决“顶层目录”和“单一规则”的浅层需求,它最终难逃被 Hazel、Dropzone 等老牌工具或 macOS 自带的快捷指令取代的命运。一句话:方向对了,但需要跑得更快。
一句话介绍:Hanami 是一款每日清晨推送一幅日本艺术杰作(附有人声解说与文字背景)的极简冥想式APP,帮助用户在忙碌中建立片刻专注、从容的文化沉浸习惯,解决“碎片化焦虑”与“高雅艺术门槛”之间的体验空白。
iOS
Art
Education
冥想艺术
日本美术
日课
极简设计
文化教育
公众领域艺术品
人声播讲
无AI生成
iOS独享
个人开发者
用户评论摘要:用户关注“无AI生成”与厘清真迹归属的艰苦劳动,开发者回应作品来自大都会、芝加哥美术馆等公开馆藏,并人工交叉研究文化背景。另有用户建议提供文字替代音频,开发者确认APP内已配有文本介绍与词汇说明。
AI 锐评
Hanami 的真正价值不在于它是一款“艺术推送APP”,而在于它用一种极其克制的方式,重新定义了移动时代的精神消费逻辑。
在一片争抢用户注意力的红海中,Jun 选择反其道:只给用户一分钟,然后“ leave you alone ”。这种“有意的稀缺”是比内容本身更深层的设计哲学——它暗示高质量的审美体验并不需要无限Scroll,而恰恰需要在限定时长中凝练精华。此举既有心理学的敏锐(晨间仪式感促进习惯养成),也有消费伦理的清醒:无广告、无追踪、无AI生成,让“安静”本身变成可以量化的差异化卖点。
但冷静来看,产品仍有硬伤。一是内容深度依赖开发者个人研究,长期能否保持专业性与学术严谨性成疑;二是目前仅限iOS且无社交/社区机制,用户增长高度依赖口碑与App Store展示位,商业可持续性存在风险。音频+文字说明虽满足大部需求,但对于真正想深入学习某一画派、技法的用户来说,目前的“每日一幅”式浅尝略显单薄。
如果Hanami能围绕“艺术日课”切入轻度艺术学习订阅、策展人线上讲座、或是开放的策展人投稿机制,则有可能从“极简应用”蜕变为“审美教育基础设施”。但目前它更像一个漂亮、有态度的最小可行性产品,距离“改变人们如何面对艺术”还有一段不得不走的谋生路。
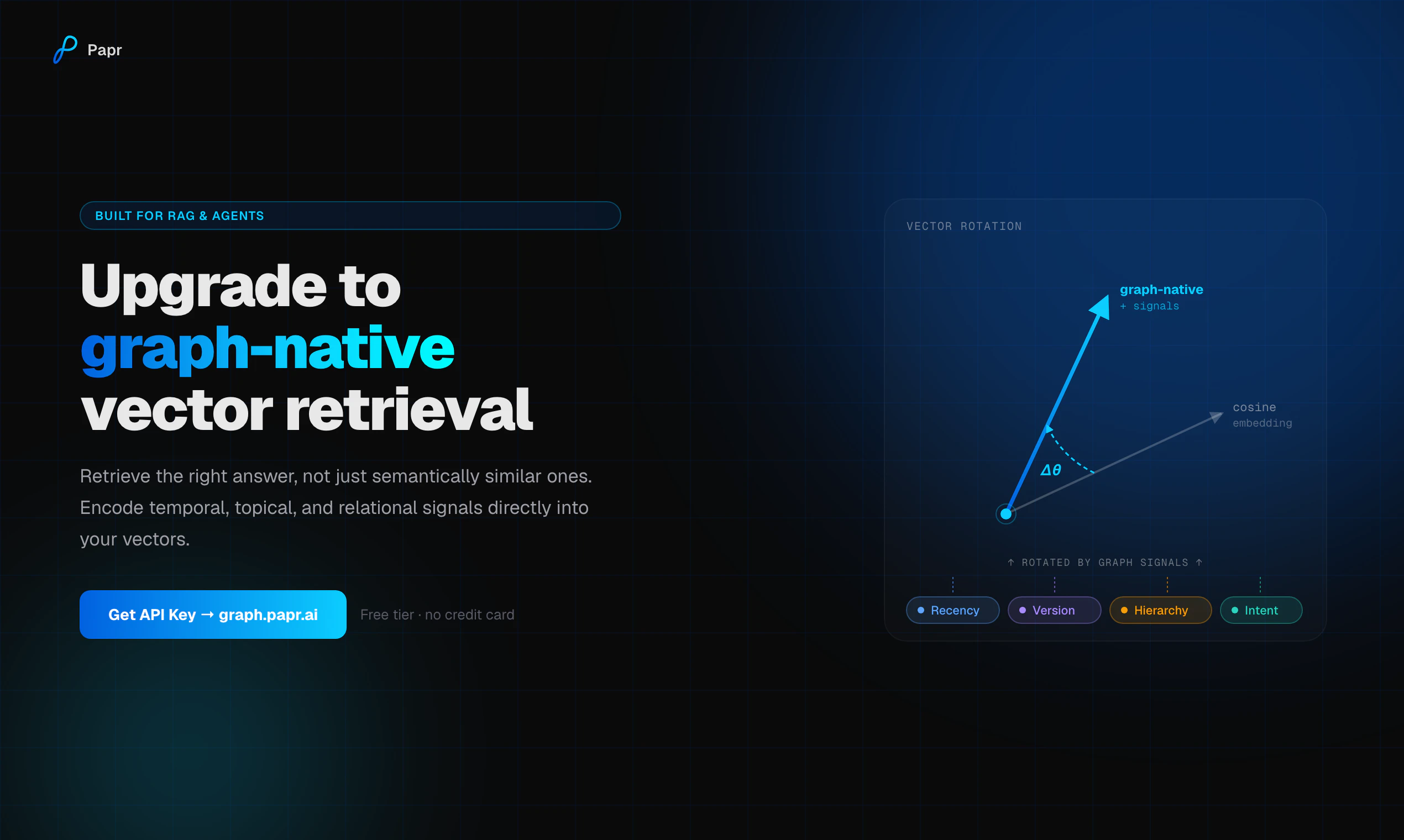
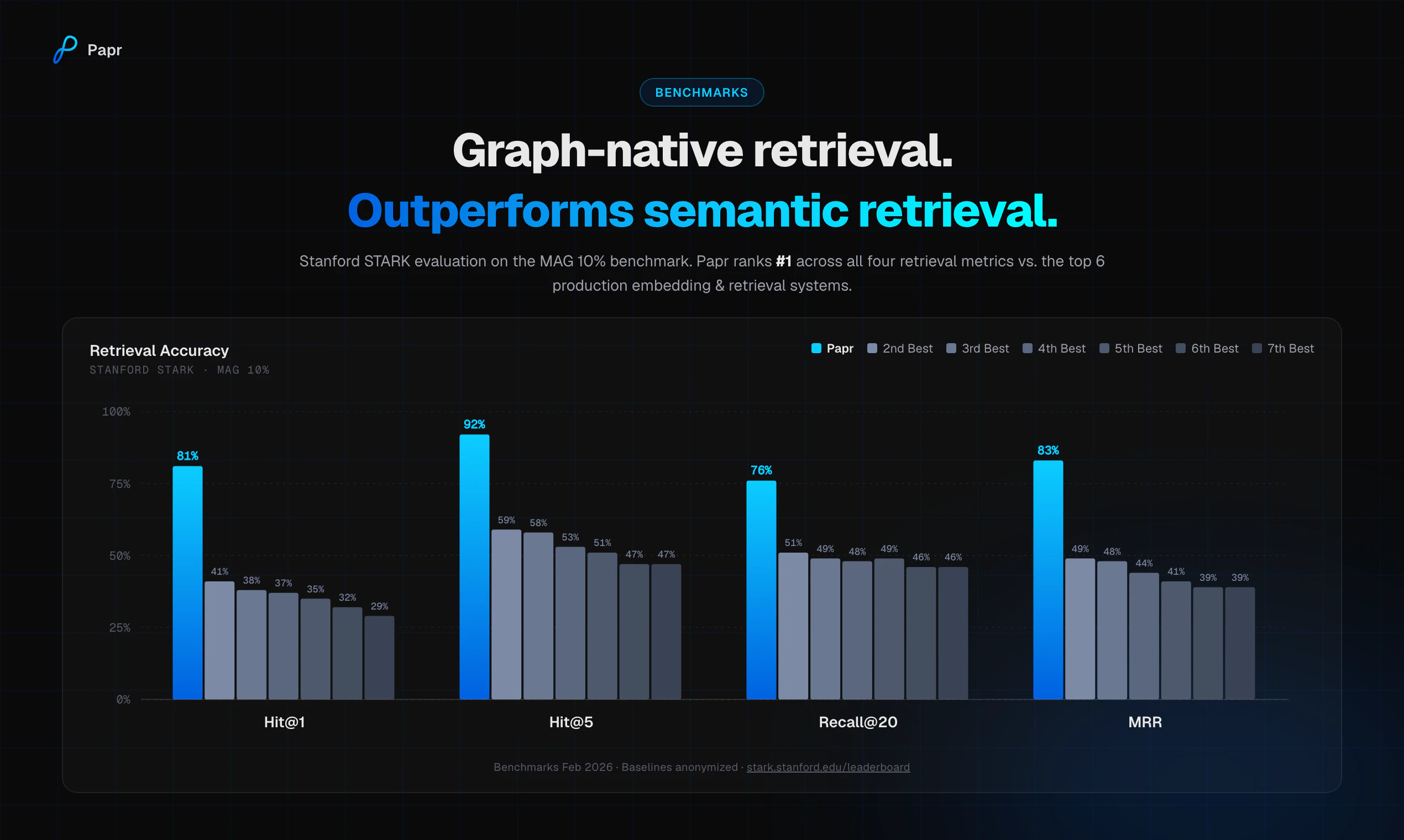
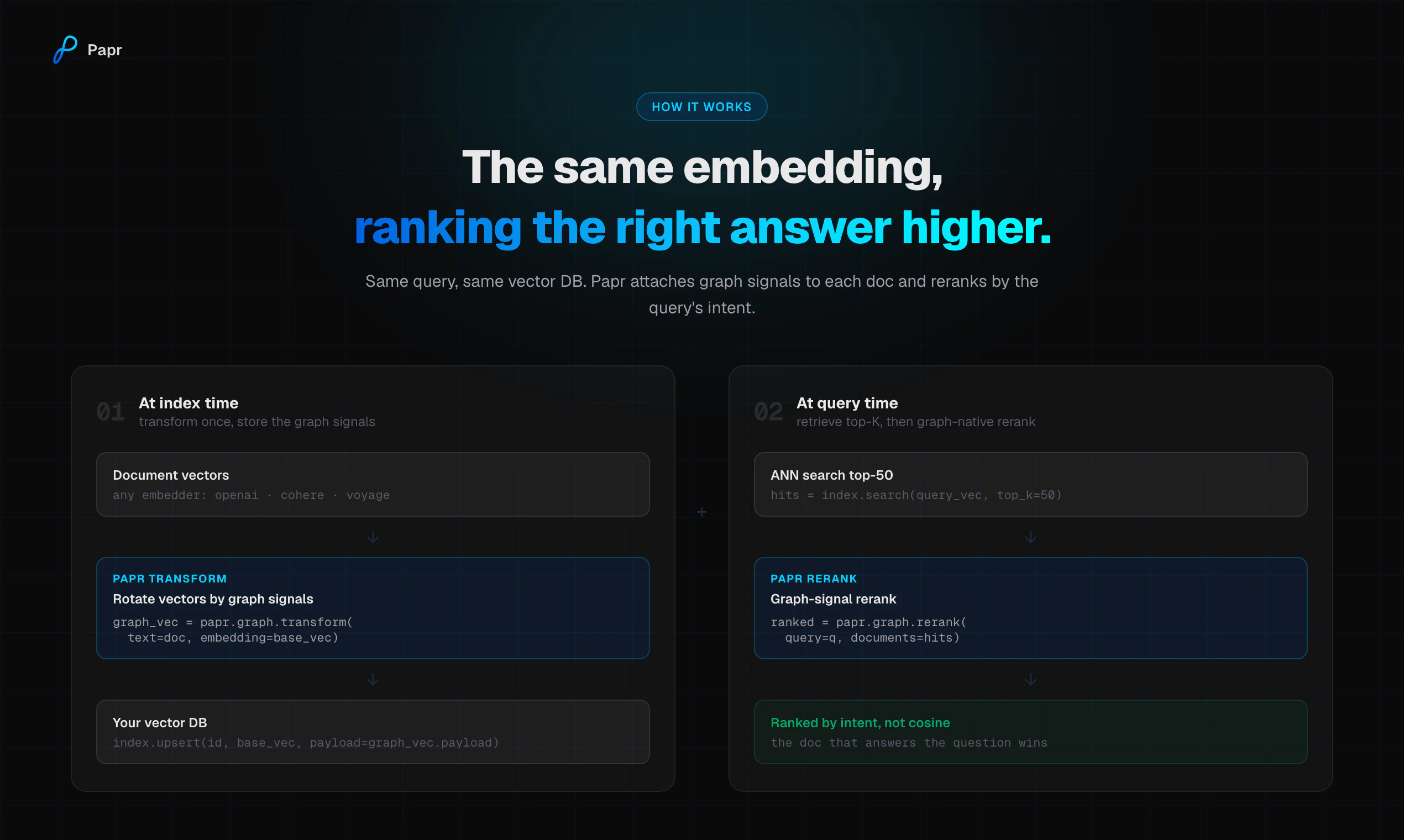
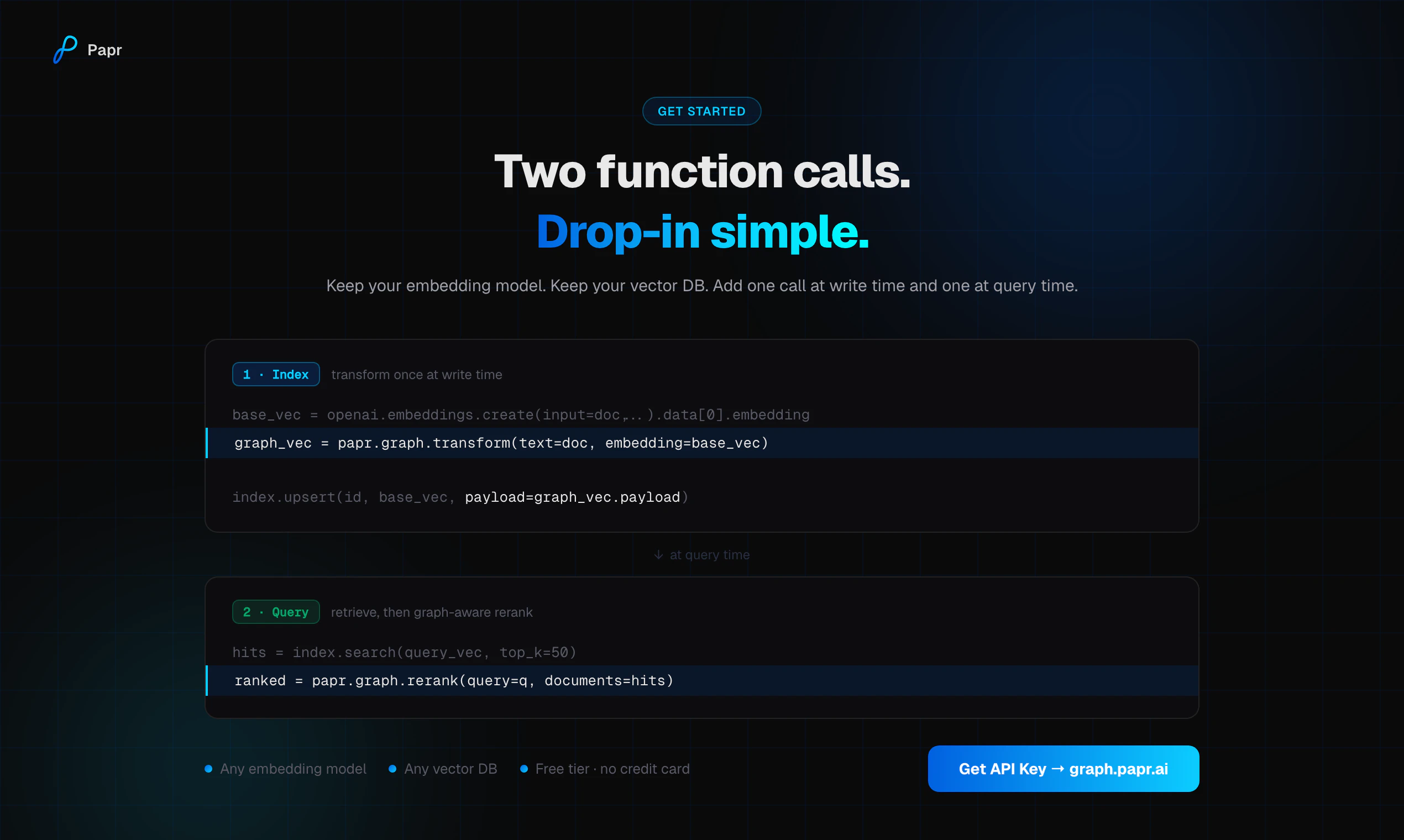
一句话介绍:Papr Graph 通过一个API调用将语义嵌入转化为图原生嵌入,解决了AI智能体在多跳查询、关系数据等复杂场景下因向量检索只重语义相似性而忽略正确性的痛点。
API
Developer Tools
Artificial Intelligence
图原生向量嵌入
AI智能体检索
向量数据库
语义搜索
图数据库
多跳推理
知识图谱
检索增强生成
词嵌入优化
MTEB
用户评论摘要:创始人Amir指出模型非问题,检索才是短板,图原生嵌入可编码时间、主题等信号提升正确性。用户质疑这是否只是语义结构化不好,并询问如何自动化理解不同垂直领域的上下文。
AI 锐评
Papr Graph的本质是在向量检索的“语义近邻”与“语义正确”之间架起一座图结构的桥梁。它不试图推翻现有嵌入模型或向量数据库,而是以一个轻量的、模型无关的插件形式,在检索链路中插入“图结构信号”。这种务实的设计逻辑值得肯定。
然而,产品演示中“阿司匹林”的例子揭示了根本矛盾:当语义相似度与事实正确性冲突时,Papr Graph所谓的“图原生嵌入”依赖于用户手动定义并编码“topic、time、intent”等信号。这本质上将检索的“正确答案”责任部分转移给了用户——你要先告诉你喜欢什么结构,才能获得结构化的正确。对于评论中“如何自动化理解各垂直领域上下文”的质疑,创始人的回应目前缺失,这是产品从demo走向生产的最大鸿沟。
此外,5-20%的MTEB提升数据很漂亮,但注意这只是在特定任务(coding, scifact, finance)上。对于通用检索场景,尤其是非结构化、噪声大的长尾数据,这种图信号的注入可能沦为过拟合。同时,“模型无关”的另一面是,Papr Graph需要你已有的嵌入在语义空间本身质量就够好——如果底层向量本身是乱码,加再多的图信号也是绣花枕头。
整体而言,Papr Graph解决了一个真实但窄的问题:让AI代理在已有向量检索基础上,更精准地理解“何时何地何种关系”下才该返回那条结果。但它的天花板也很明显——它不是一个独立的知识图谱引擎,而是向量检索的“强化补丁”。能否成为下一个基础设施,取决于它能以多低的成本、多高的自动化程度,让用户忘记“我该手动定义什么信号”这个前提。
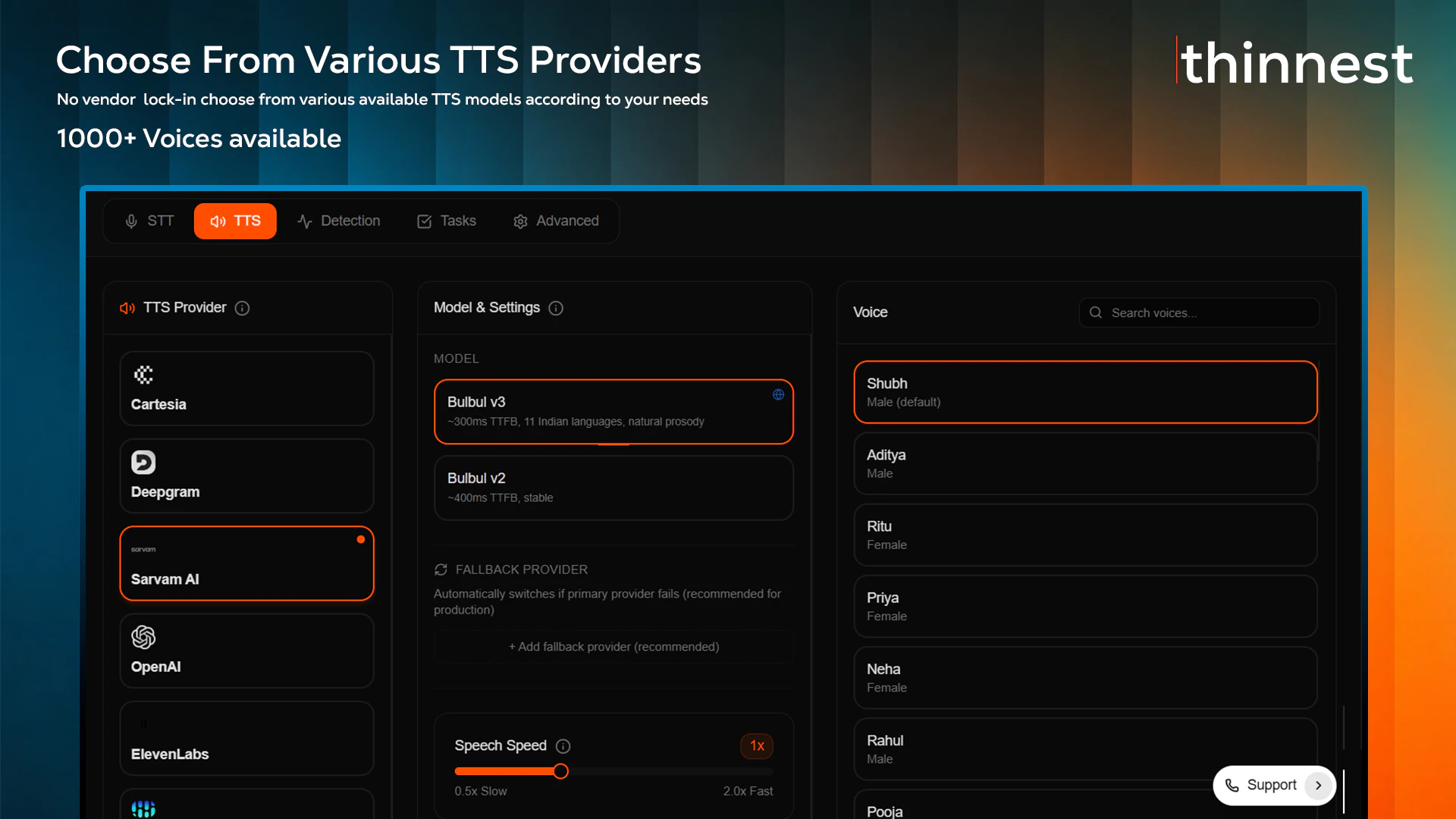
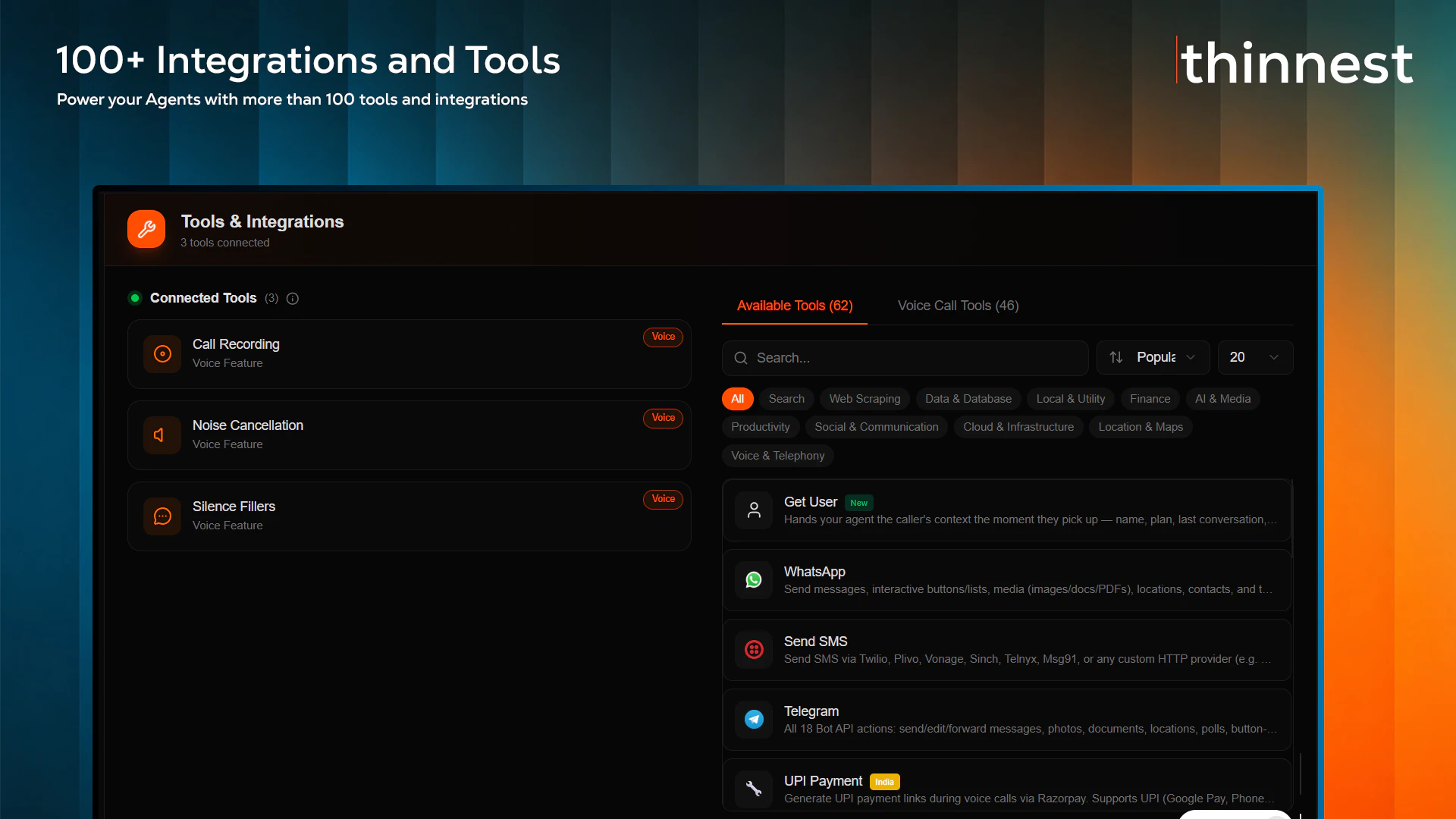
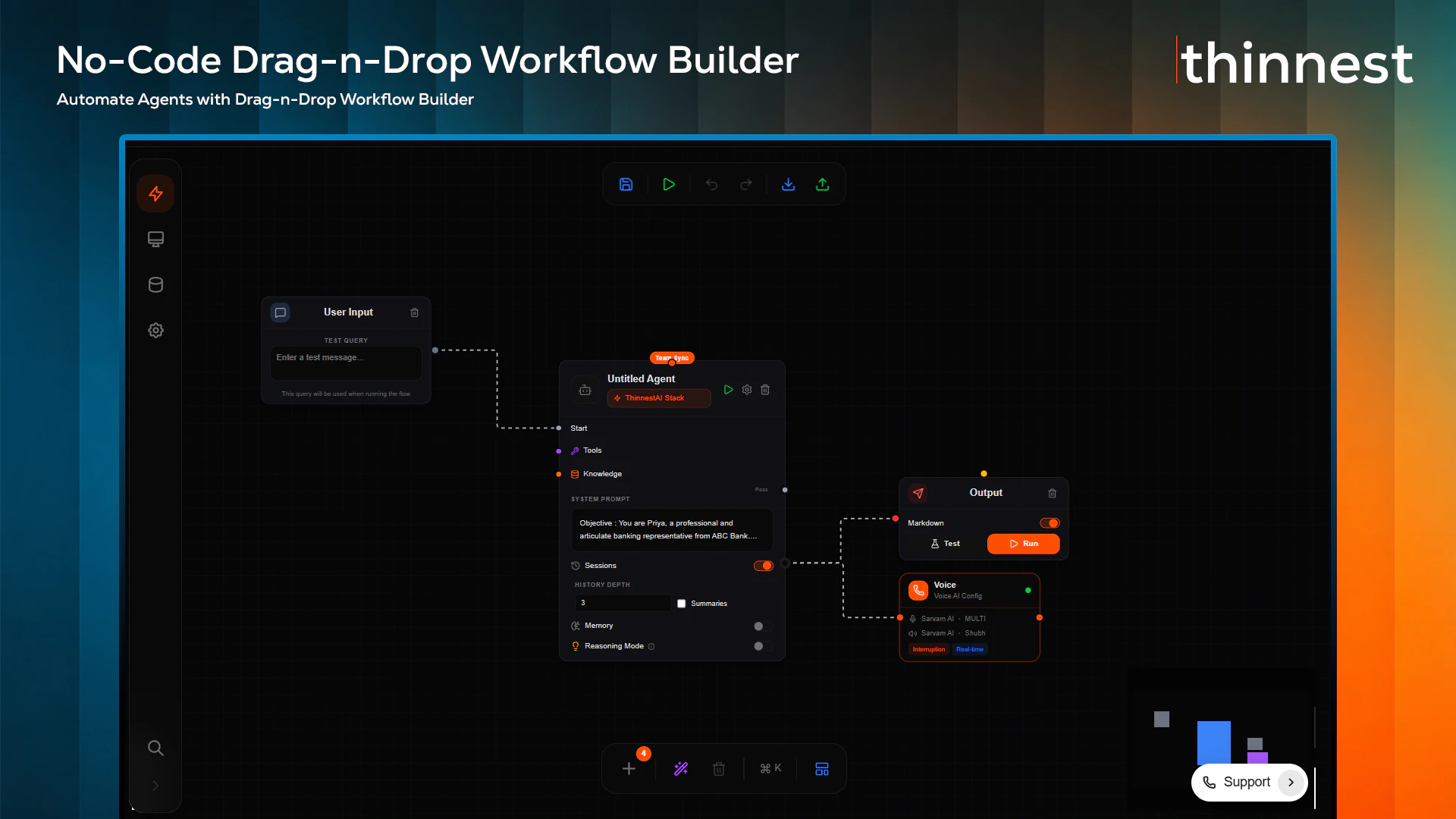
一句话介绍:Thinnest AI 是一套可编程的语音AI基础设施,专为需要构建支持100多种本地语言、且能按分钟计费的AI电话客服与销售代理的企业设计,解决了现有平台语言支持差、账单货币不灵活、供应商锁定等痛点。
SaaS
Artificial Intelligence
Virtual Assistants
语音AI基础设施
多语言支持
电话代理
BYOK (自带密钥)
低代码/无代码
RAG知识库
MCP集成
印度市场
低价计费
Twilio/SIP集成
用户评论摘要:用户关注两点:一是产品是否仅限于印度市场还是可本地化至其他国家;二是MCP服务器是作为“语音产品”还是“语音基础设施”(即暴露流程给外部客户端,还是作为消费外部工具的客户端)。此外,有用户询问印地语-英语代码混用场景下的实时表现,创始人给出具体技术选型(Sarvam Saaras v3)回应。整体评论围绕本地化能力与基础架构开放度展开。
AI 锐评
Thinnest AI 的定位非常精准:它不是在跟美国巨头(如 Retell、Vapi)抢全球 API 市场,而是切入了一个被长期忽视但需求硬核的细分场景——印度本土化的企业级语音代理。其核心价值不在于“能做100种语言”(很多产品都宣称支持),而在于“把基础设施层彻底开放”。BYOK、自带SIP、自带STT/TTS,这对大型银行、BPO和保险机构是致命的吸引力——它们既不想被单一模型供应商锁死,又希望保留自己的合规计费、电话号码和API配额。1.5卢比/分钟(约人民币0.12元)的定价策略聪明,它把“语音AI”从按美元计价的昂贵黑盒,变成了按印度本地费率可轻松验收的成本项。这实际上是在教育一个价格敏感的长尾市场。
但挑战同样明显。目前评论集中在“MCP服务器边界”与“语言本地化”上,这反映了开发者对Thinnest到底是“平台”还是“工具”的担忧——如果它只是封装了一个低代码编辑器和RAG的“盒子”,那它本质上仍然是在用定制化抢占传统IVR集成商的生意,而非真正成为新范式的基础设施。关键在于,它能否通过MCP和开放SDK,让用户不仅能“搭建”语音代理,能“解构”并“嵌入”语音能力到自己的系统里(比如CRM、工单系统、支付回调)。此外,印度市场的合规、DLT注册、SIP互通协议在多家运营商间的碎片化问题,是比模型能力更棘手的地雷。Thinnest目前的杀手锏是靠Sarvam Saaras v3解决Hinglish混说场景,但如果后期用户规模上来,是否能保证不同TTS/STT配置在真实通话中的延迟和稳定性,还需要时间检验。
一句话总结:Thinnest AI 不是简单的“语音API”,而是一次针对印度企业级语音AI市场的“本地化基础设施集成”进攻——架对了,但打得通所有运营商的电话网,才是真正的护城河。
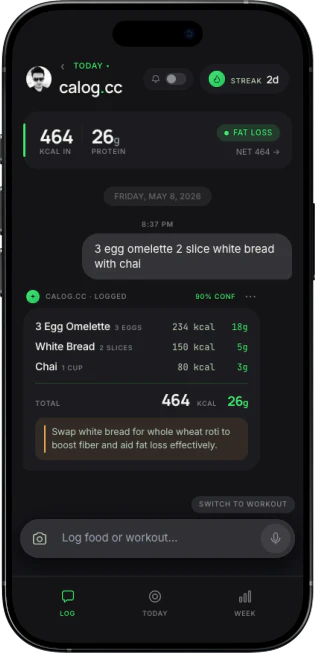
一句话介绍:calog.cc 是一款基于AI聊天的卡路里追踪器,专门解决南亚饮食(如Roti、Qeema)在主流应用中无法准确记录的问题,用户只需输入或拍照即可获得精准的卡路里和宏量营养素数据。
Health & Fitness
Productivity
Artificial Intelligence
AI卡路里追踪
南亚饮食
饮食记录
健康管理
聊天式输入
拍照识别
宏量营养素
渐进式Web应用
减脂
免费工具
用户评论摘要:用户称赞其解决了南亚饮食难以追踪的痛点。有用户询问下载方式,开发者回应为PWA应用无需下载。另有用户建议增加低脂烹饪提示,开发者表示可对话获取建议,并会将此功能加入未来规划。
AI 锐评
calog.cc的价值不在于“又一个卡路里计数器”,而在于精准切入了一个被主流健身应用长期忽略的细分市场——南亚饮食文化圈。其“AI聊天式记录”本质是降低了文化差异带来的使用门槛:用户不用学习“一个馕=几克碳水”,只需说“吃了两张Roti”,AI便能自动解析。这种“即说即得”的体验,比手动从数据库大海捞针要高效得多。
然而,产品目前仍处于早期阶段(仅33个真实用户),其核心竞争力“AI对南亚食物理解的准确性”尚未经过大规模验证。如果用户在连续输入“Chicken Karahi”、“Daal Chawal”后,AI给出的估算值与实际差异过大,信任感会迅速崩塌。此外,PWA形态虽然降低了获客成本,但也意味着在手机原生功能(如健康数据同步、通知推送)上有所妥协。
真正的“锐意”在于:calog.cc没有试图做大而全的全球数据库,而是选择用AI模型去理解一个特定文化圈的食物。这种“小切口、深垂直”的打法,如果能通过用户反馈持续迭代模型精度,就有可能从“有趣的小工具”蜕变为“特定群体的刚需产品”。但若AI能力仅是调用通用大模型做关键词映射,没有针对南亚烹饪中“油、香料变量大”的特点做专门优化,那它依然只是个“看起来对口”的玩具。


























































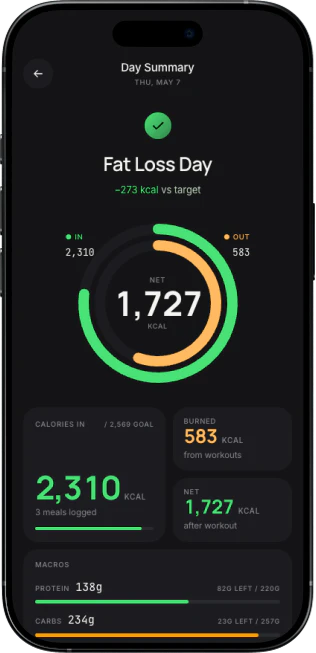
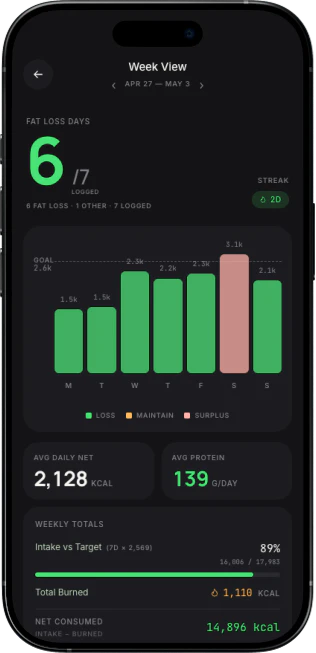
Hey Product Hunt! 👋
I'm Gia, maker of PollyReach.
I'm the kind of person who'd rather text than call. But some things still require a phone call — and when the restaurant is full, you have to try the next one, and the next.
In Japan, I wanted to book a small izakaya. No online reservation, just a phone number. I don't speak Japanese.
That's when it clicked: AI speaks 50+ languages. Why can't it just make the call?
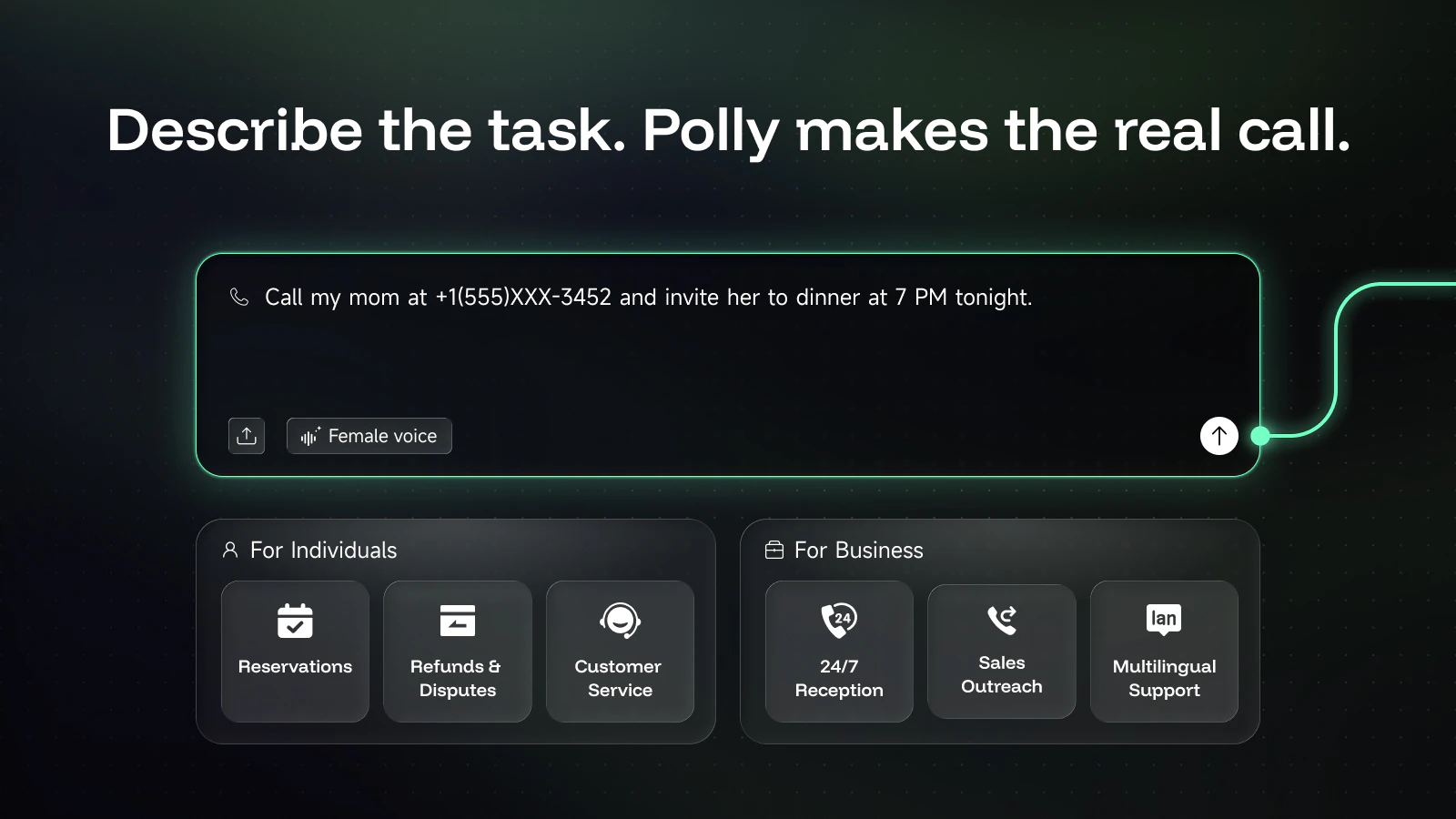
So we built PollyReach — Your Agent gets its own real phone number and a real voice. It handles real conversations the way a personal assistant would — gets interrupted, responds naturally, waits on hold, navigates IVR menus, and knows when to push back and when to hang up.
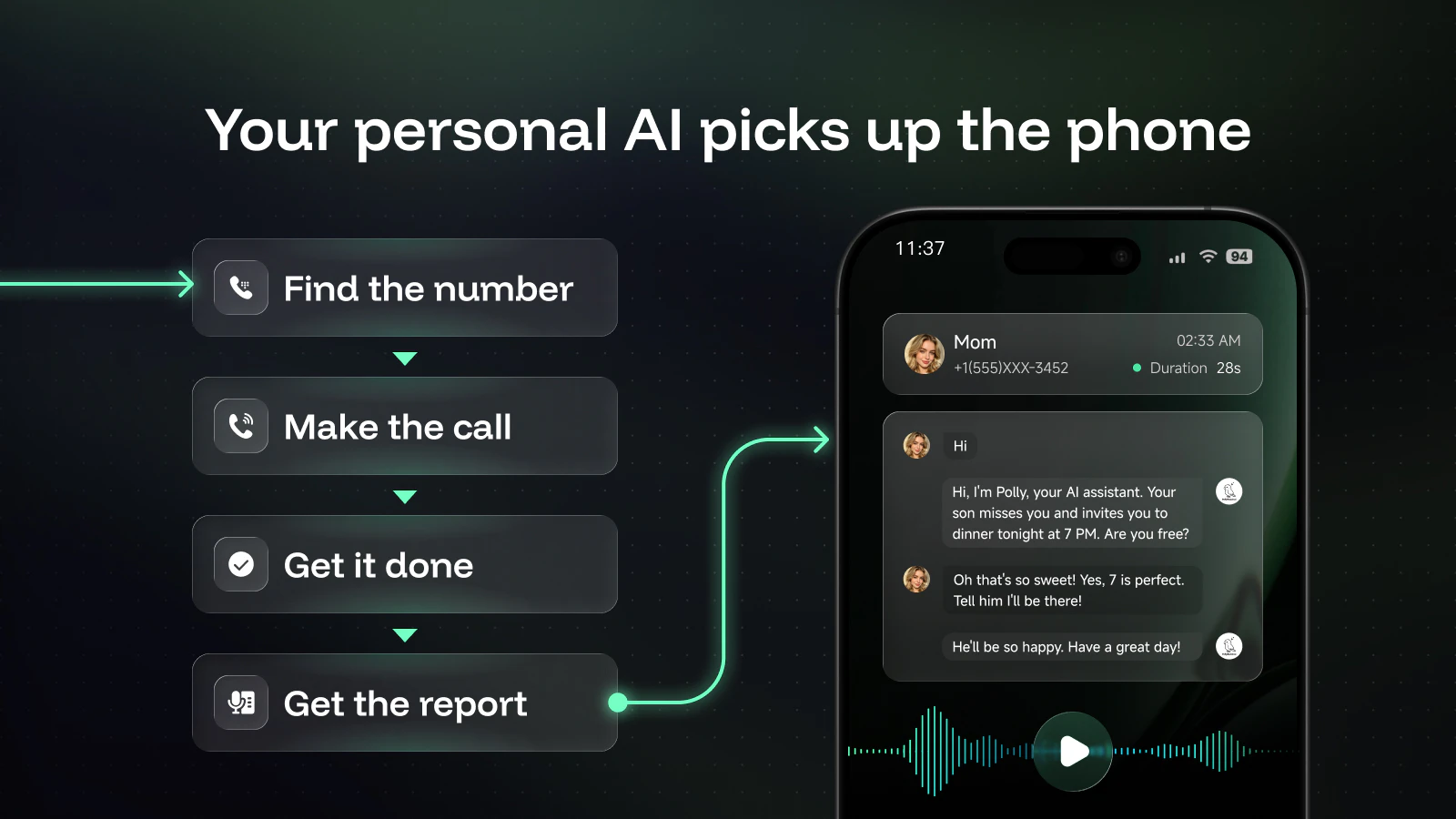
It calls for you
Polly finds the number, dials, navigates phone menus, handles the conversation, and confirms the booking. You get a summary + recording + transcript.
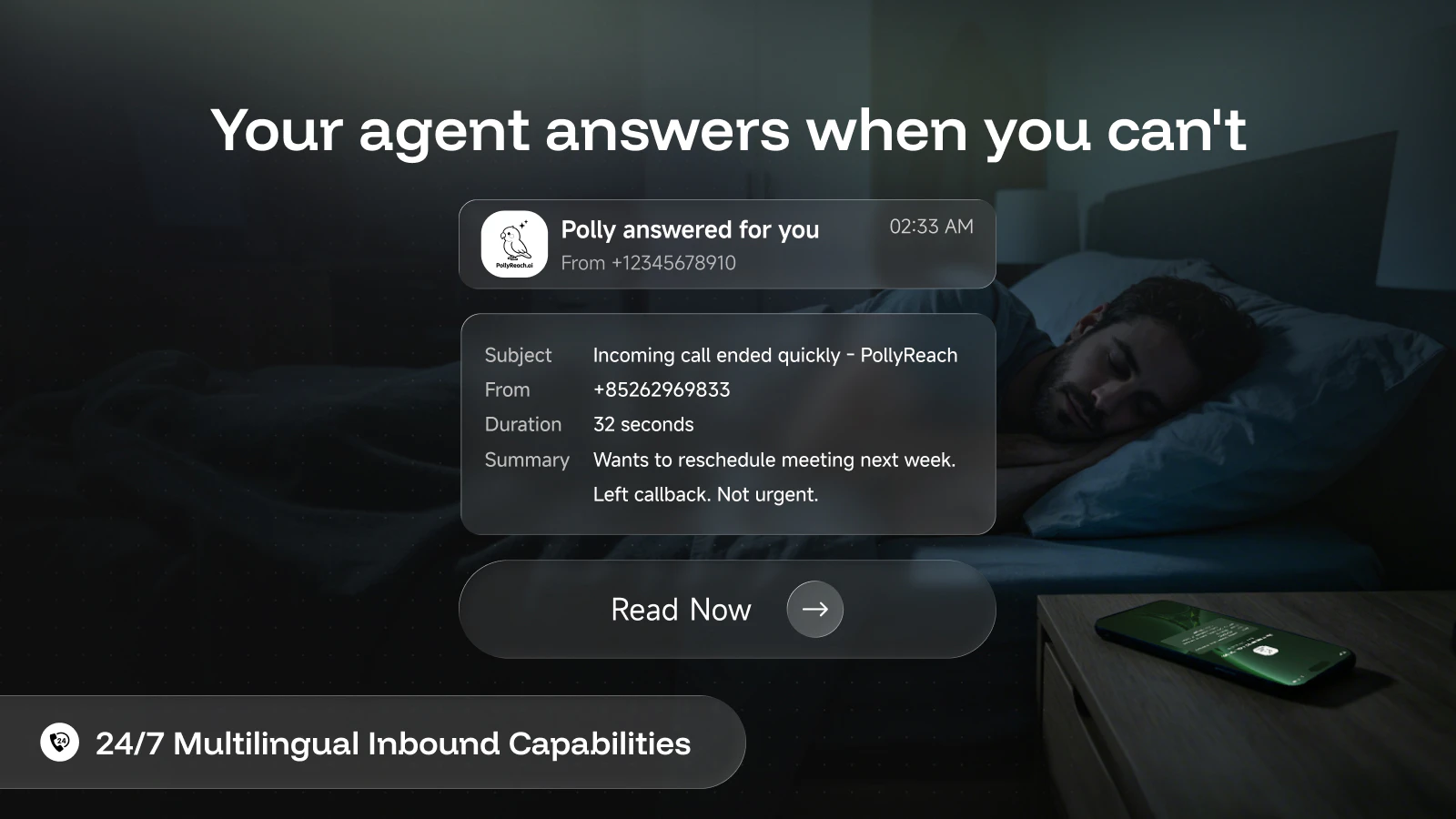
It answers for you
Polly picks up 24/7 with a natural-sounding voice — screens spam, talks to real callers, takes messages, tags priority, and sends you a summary. You decide what's worth calling back.
It works for your business
One of our users manages 80+ rental properties — his AI assistant handles tenant calls, follows up with vendors, and sends him a daily report.
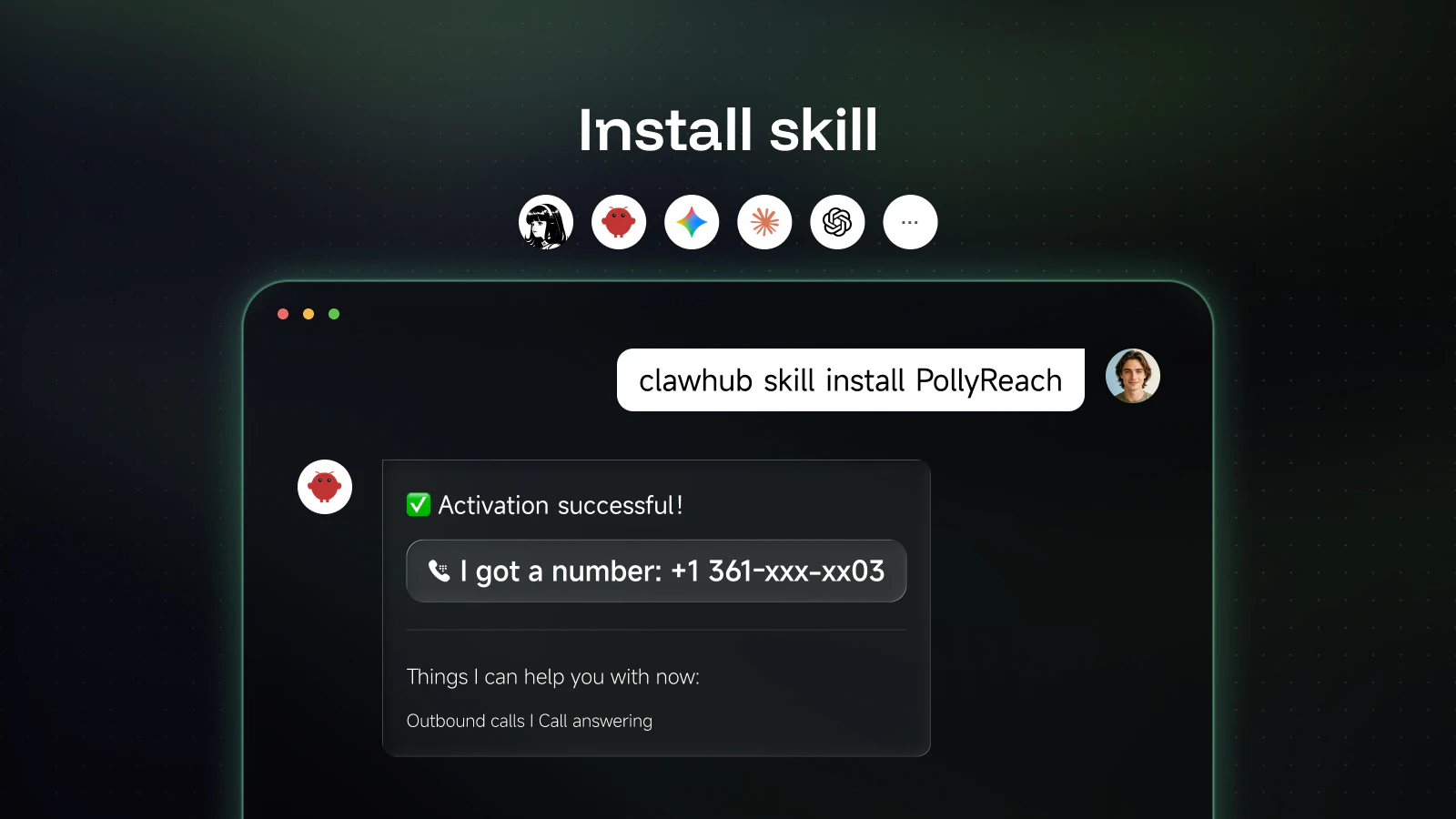
Get started — just send this to your agent:
Everyone here gets 200 free credits + a free phone number. Try it and let me know what your first call is.
Really excited to share this with the PH community. We'll be around all day answering questions! 🙌
What languages are actually solid right now? Curious about Japanese specifically since that's the founding story.
Do you have a demo call recording somewhere? I want to hear the natural interruptions in action.
This feels like one of those products where the demo probably converts people instantly. Would love to test it on real world calls.
This is one of those products where the demo can be simple but the real test is annoying real life. Booking a table sounds easy until the place is closed, the number is stale, the person asks a follow-up question, or the bot has to negotiate between "7pm" and "we only have 7:45."
I’d love to see examples of failed or partial calls, not just successful ones. A useful agent should say “I called, they didn’t answer,” “they only had 8pm,” or “I wasn’t confident enough to confirm,” instead of pretending the task completed.
Congratulations
Congrats! great team!!!
Aren't you afraid that some people may use it for harmful purposes? E.g. automating the frauds (against banks and its users, or "behaving like relatives")? How can we protect / avoid such an usage?
Finally, an AI that can actually wait on hold instead of hanging up after 10 seconds. Take my credits.
Does Polly learn from previous calls with the same vendor, or is each call fresh?
That's a very good tool. I tried to use it to book a restaurant for me and guess what? it succeed! Damn good.
Congrats!
Quick question: Can Polly transfer a live call to me if it realizes it's out of its depth?
How many simultaneous calls can one Polly agent handle? Asking for the property manager.
Is there an API or MCP for developers? Would love to plug this into my own agent.
Congrats on your launch! I have a small question: Does it integrate with anything yet (calendar, email, Slack), or is it standalone for now?
One scene keeps playing in my head: strolling through the streets with an AI companion, like the movie Her finally stepping into real life. She just gets it, makes the call, and the table is already waiting when we show up.
PollyReach made that dream real. So cool!
Congrats! curious can you give it specific instructions before a call, like "only book if there's outdoor seating available"?
Where do you find the number? Actually, I want to know the limit. What kind of tasks would be impossible to complete?
Interesting concept. My main question is how it handles calls where the other side gets suspicious or asks to speak to a real person — does it disclose that it's an AI? Would love to know more about how that's handled before fully committing.
Loving this
The free phone number + credits to test is the right move, i been waiting for something like this that doesn't require API setup. Just installed 🎉
@gia_xu is it possible to connect it to an existing, real phone number so it can serve as my "assistant"?
How does it handle situations where the restaurant asks for a credit card to hold the reservation — does the AI pause and hand off to you, or is that not in scope yet?
From your terms:
Prior Express Consent for non-marketing automated calls
What does that involve? How would I get consent prior to calling a restruant like in your example?
它不仅成功打通电话(餐厅不接受在线预订),还能灵活应对 "只有吧台座位" 的情况,帮我争取到了 7 点的最佳位置,全程用自然的日语对话,餐厅完全没发现是 AI 在沟通
Hi! How does Polly handle conversations that start to become negative or unproductive?
Feels less like one of those robotic AI callers and more like an actual assistant handling stuff for you.
The “book me a table” use case is honestly super relatable 😂
Congrats on launching this useful tool! I'm curious whether the numbers PollyReach has would be considered valid ones. I know many cell phones would automatically filter seemingly suspicious calls, so I would like to make sure the calls will actually get through.
Hello - what sort of compliance do you have right now? Can it be used in healthcare?