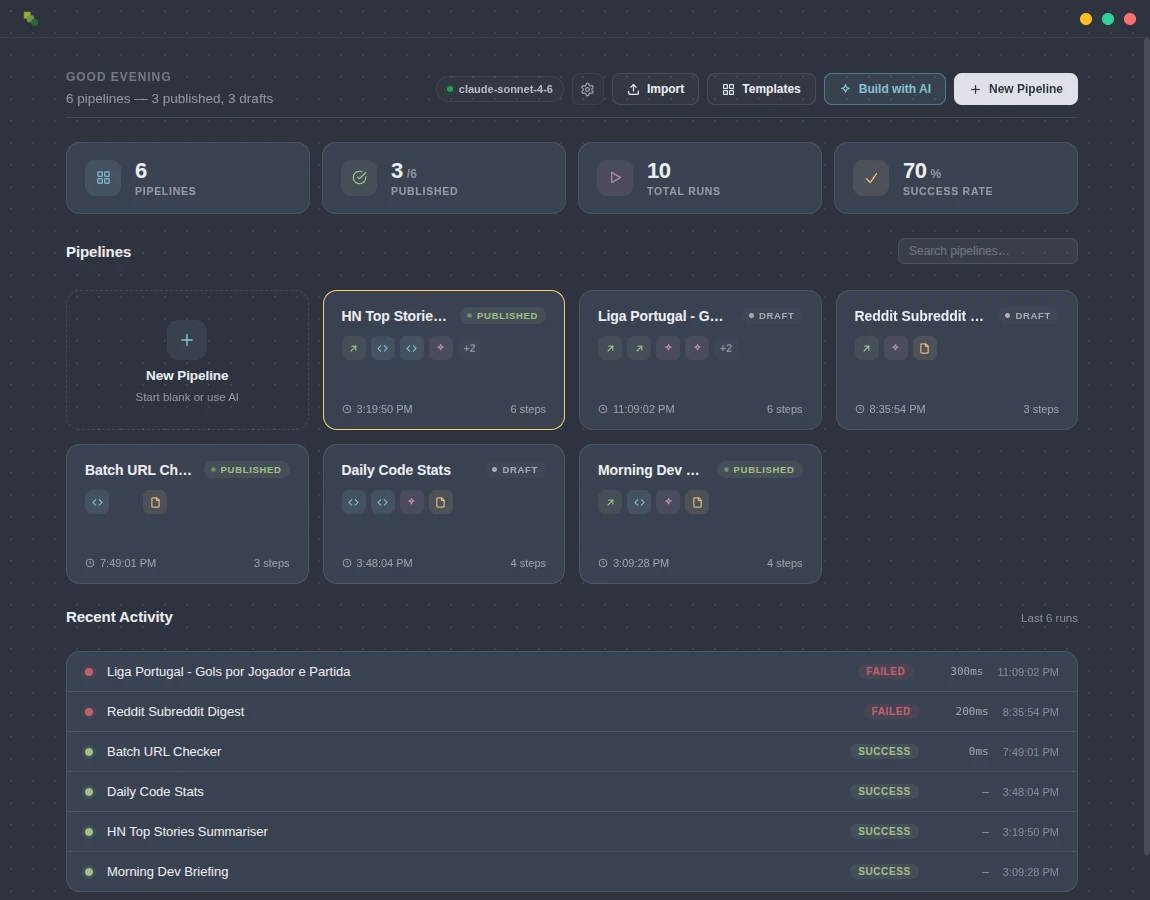
PH热榜 | 2026-05-22
一句话介绍:TestSprite 3.0通过并行AI代理集群自动探索并测试Web应用的前后端,无需手动编写脚本,解决了传统端到端测试脚本脆弱、维护成本高、覆盖不全的痛点。
Developer Tools
Artificial Intelligence
自动化测试
AI代理
端到端测试
回归测试
UI漂移自愈
CLI工具
开发者工具
集成测试
数据流调试
智能运维
用户评论摘要:用户关注探索时对生产环境的副作用(需沙箱或干跑模式);UI自愈在CI中可能静默改写断言,建议默认关闭并人工审核;询问AI如何区分真Bug与视觉差异;提及多角色权限模拟、异步系统(消息队列、Webhook)支持及测试结果可解释性。
AI 锐评
TestSprite 3.0的发布,标志着测试工具从“脚本执行者”向“行为探索者”的范式跃迁。其核心颠覆点不在“自动生成测试”,而在“并行探索集群”——让数十个AI代理像真实用户一样先探索再测试,这解决了传统E2E测试最大的痛点:测试覆盖率与人对应用的理解之间不可逾越的鸿沟。过去,你写什么,AI测什么;现在,AI替你发现你没想到要测的。
但真正的考验远非营销能覆盖。第一,破坏性副作用问题。评论中用户一针见血地指出了“模拟用户”与“免于破坏”的矛盾。TestSprite是否具备智能识别并优雅跳过“下单”“发邮件”等危险操作的能力,将决定它能否进入高安全等级的企业生产环境,而非仅限于沙箱。第二,自愈功能的双刃剑效应。UI漂移自愈听起来很美,但它可能掩盖了真正的回归。将自愈默认关闭并仅限本地/预发布环境,是明智但保守的做法——它暴露了当前AI尚无法绝对区分“无害漂移”与“逻辑性DOM错误”的核心局限。第三,规模化后的成本与效率。并行代理集群若在复杂应用中全面运行,产生的API调用成本和测试运行时间是否线性可控?对于CI流程,这可能是压垮骆驼的最后一根稻草。
总体而言,TestSprite精准地抓住了AI代码生成(如Claude Code、Cursor)爆发后,测试环节滞后这一关键市场空白,其CLI集成策略更是对准了AI-first开发者的高频场景。但产品价值目前更多体现在“验证覆盖范围”而非“缺陷发现深度”。要真正成为开发流程的“神盾局”,还需在副作用隔离、置信度阈值和异步系统测试(评论中有提及)上交出更硬核的证据,而非停留于“支持”二字。
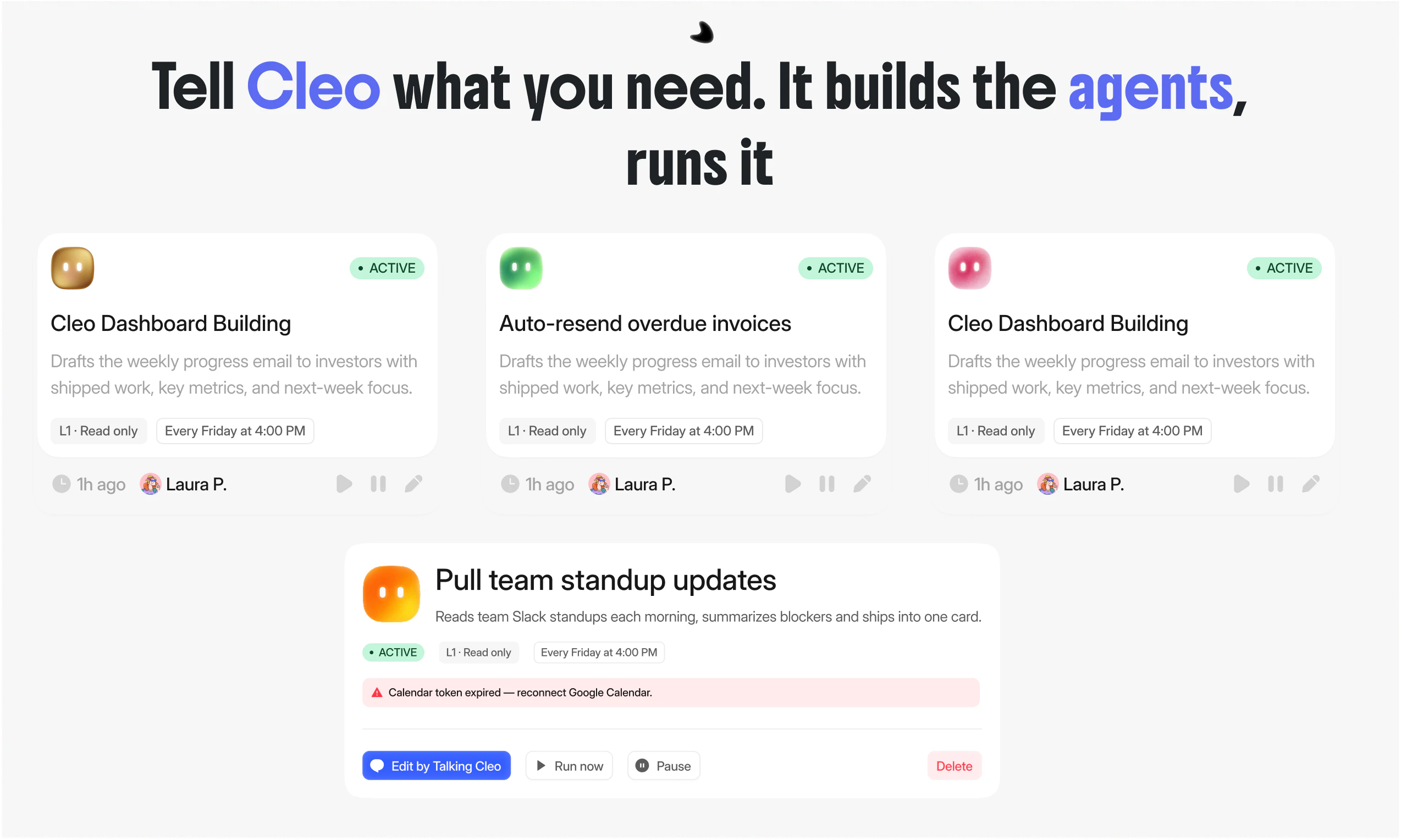
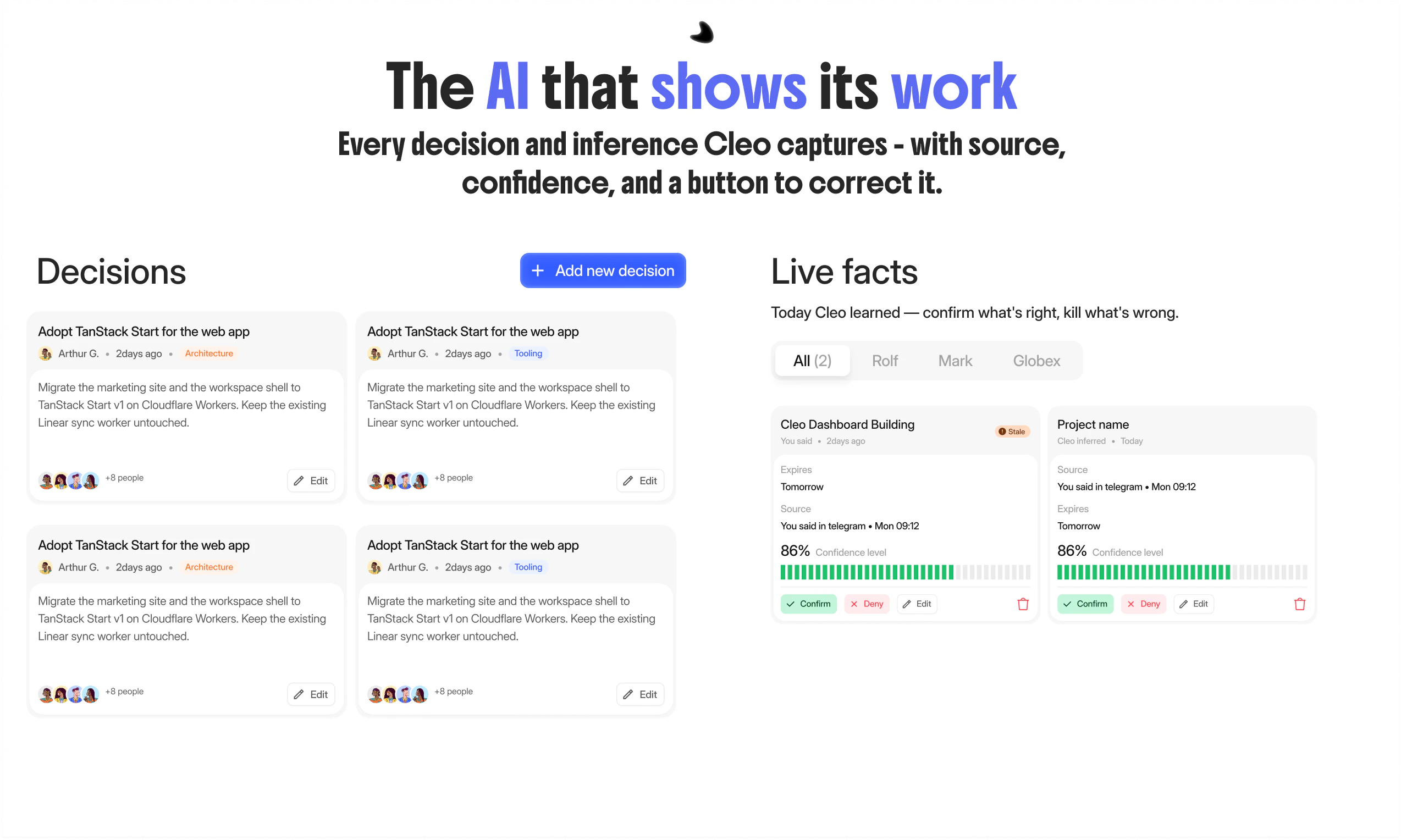
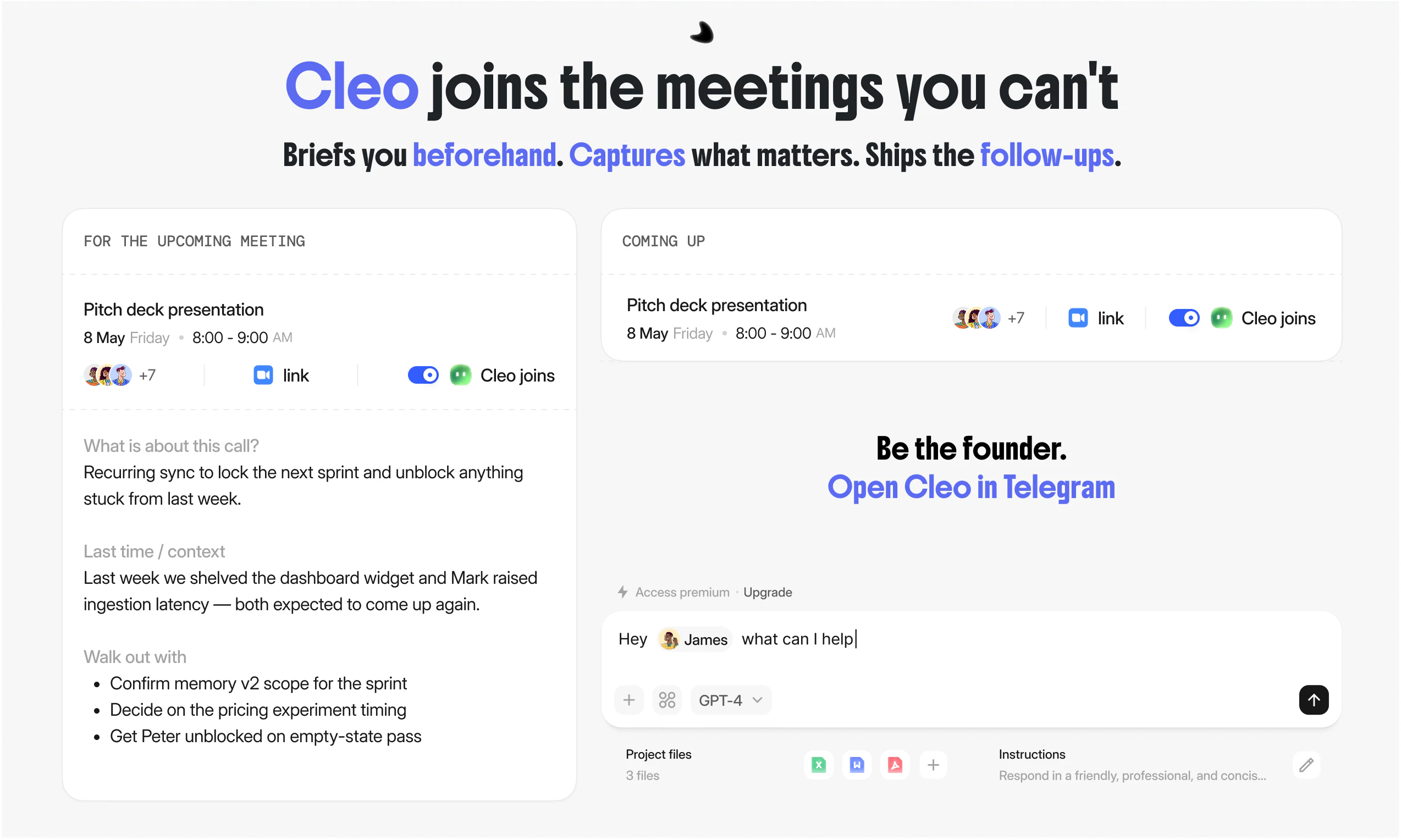
一句话介绍:Cleo 是一个嵌入 Telegram 和 Slack 的 AI 产品经理,专为创始人和精简团队设计,通过持续学习团队上下文和执行日常管理任务(如站会、跟进、决策记录),解决创始人被项目管理琐事淹没、无法专注核心产品开发的痛点。
Productivity
Artificial Intelligence
Alpha
AI 产品经理
团队协作
项目管理
Slack 集成
Telegram 机器人
记忆透明
自动化工作流
创始人工具
小团队
任务跟进
用户评论摘要:用户赞赏其记忆透明和聊天侧边栏设计,但核心聚焦于可靠性:多名用户质疑如何处理冲突信息、长项目记忆衰减、以及跨工具上下文一致性。创始人承认当前仅“呈现冲突而不解决”,且主动过滤80%噪声以维持质量,但审计负担(确认事实)仍是潜在失败模式。
AI 锐评
Cleo 的“透明记忆”并非技术上的护城河,而是一次精准的信任声明。在“AI 替你干活”已成烂大街标语的市场里,Cleo 选择了一条更难却更务实的路径:让 AI 不是黑箱决策者,而是可审计的助理。其“五级信任度”和“源+置信度+修正按钮”的设计,直接回击了用户对 AI 幻觉的深层恐惧——这比任何花哨的自主决策引擎都更贴合小团队的实际需求。
但“透明”是一把双刃剑。如果 CEO 需要每天花时间确认 AI 记住的事实是否正确,那它不过是把“填站会表格”的苦役换成了“修改记忆错误”的苦役。Cleo 核心团队显然意识到了这一点,他们在回复中强调“置信度决定可见性”和“错误修正转化为规则”,试图将审计行为从“日常维护”压缩为“间断排查”。然而,对于一个连 PM 都雇不起的团队,他们真的有精力去扮演“AI 事实裁判”吗?这个模型能否在团队规模扩大时依然保持低干预率,是 Cleo 从“有趣的玩具”走向“真正的生产力工具”的关键。
真正聪明的是 Cleo 的“不作为”:它明确不解决内部冲突,不盲目决策优先级,不试图全自动开 sprint。这看似功能边界,实则是针对“低配置高噪声”现实的最优解——小团队的冲突往往是领域判断,AI 猜错了比不猜更致命。Cleo 恪守“放大人类信号”的角色,这是当前 AI 在复杂协作中最诚实的定位。对于每天被 PM 文书淹没的创始人,它至少能帮你省下50%的琐碎注意力。至于剩下的50%,请记住:你仍然是那个最终必须站在代码和客户之间的人。
一句话介绍:General Compute 是一个基于ASIC芯片构建的推理云,为编码助手和语音代理等延迟敏感型AI工作负载提供比GPU快5倍的响应速度,通过兼容OpenAI的API让开发者无缝切换。
API
Software Engineering
Alpha
AI推理云
ASIC芯片
低延迟推理
代理工作流优化
编码助手
语音AI
SambaNova
OpenAI兼容API
实时AI
基础设施
用户评论摘要:用户普遍认可解决代理工作流延迟问题的价值。核心问题集中在:当前支持的模型有限(尤其是ASIC限制);何时支持“自带模型”;如何应对长上下文和KV缓存;对嵌入模型等扩展功能的需求;以及ASIC架构下弹性伸缩的技术细节。
AI 锐评
General Compute的切入点非常精准——直击当前AI推理基础设施的核心错配。当行业还在用训练出身、内存带宽饱和的GPU来跑推理时,它用ASIC(特别是SambaNova)的存算一体架构,从物理层面打破了延迟瓶颈。对于需要数十次连续调用的编码和语音代理场景,5倍的端到端加速足以改变产品体验的质变点,这是其真正的价值所在。
然而,产品目前仍处于“先发优势”与“生态壁垒”的博弈期。评论中“模型受限”和“计算资源紧张”的反馈揭示了其核心短板:ASIC的专用性导致模型支持速度远慢于GPU云,这极大地限制了可玩性和用户粘性。当前的产品更像是一个为特定前沿模型(如Llama)打造的超级加速器,而非通用的模型托管平台。承诺的“自带模型”功能能否在几周内兑现,且能否在复杂的ASIC上维持高吞吐,是其从“演示级的快”走向“生产级的可”的关键一步。此外,SambaNova SN40s的供应瓶颈也是潜在风险。
值得称道的是,其策略非常务实:用OpenAI兼容的API降低迁移门槛,用“代理人自主注册”这种极具未来感的营销点吸引开发者。但长远来看,通用计算市场仍是生态为王。如果General Compute不能快速扩大计算集群、补齐主流模型,并解决好KV缓存与长上下文的工程优化,那么当GPU云(如Groq、Fireworks)也开始专注推理优化时,其ASIC的先发优势可能会被迅速追平。这是一个关于“速度”与“广度”的豪赌,目前看有惊喜,但变数极大。
一句话介绍:WordPress 7.0在网站后台管理中引入原生AI工具与全新设计控件,帮助内容创作者、企业主和开发者降低设计门槛,提升网站搭建与定制的效率与创造力。
WordPress
CMS
网站建设
AI工具
区块编辑器
后台管理
内容管理
开源
用户体验
主题开发
网站定制
用户评论摘要:用户普遍认可AI工具和可访问性提升的亮点;有评论关注性能与SEO改进,指出页面速度仍是痛点;另有人期待插件与开发者基于此版本构建更多功能。
AI 锐评
WordPress 7.0的发布,与其说是一次功能更新,不如看作是一次生态博弈的宣示。当Wix、Squarespace等建站平台大肆宣扬AI生成网站时,WordPress终于将AI工具纳入核心,但这更像是一个“补课”而非“领跑”。名为“Armstrong”的7.0版本,核心价值不在于那几项与AI相关的表层功能——例如内容生成或布局推荐——而在于它主动定义了AI能力在开源CMS中的底座。这意味着未来插件开发者、托管商、代理商无需各自为战地整合非标AI接口,而是可以在一个统一框架下进行二次创新。
然而,锐评不能只看到战略层面的远见,更要警惕体验层面的落差。从用户反馈来看,对页面速度和SEO优化的呼声依然很高。WordPress长期以来依赖插件生态解决性能问题的模式,在AI工具运行需要更多算力资源的背景下,可能会放大“系统臃肿”的负面体验。另外,AI工具的底座化,也意味着若官方对AI内容的合规性、版权归属不给出明确治理方案,将衍生出更多“低质AI内容农场”。
从开发者角度看,“新管理后台”与“设计控件”的扩展确实降低了定制门槛,但这本质上是将传统主题开发者的部分权力下放给普通用户。这对平台活跃度是利是弊?长期来看,专业开发者的不可替代性会被削弱,WordPress社区的职业结构可能面临重构。7.0是一个扎实的战略布局,但“新纪元”的序幕能否拉开,关键不在AI,而在于WordPress能否先解决自己积重难返的效率与治理问题。
一句话介绍:iPromise 是一款利用 Mac 刘海区域承载“AI替身”的专注工具,旨在通过“身体双人”(Body Doubling)心理机制,为缺乏外部监督的远程/独立工作者提供温柔的问责与提醒,解决自由环境中极易分心、难以进入深度工作的痛点。
Mac
Productivity
专注力工具
深度学习
Mac应用
AI伴侣
身体双人
刘海屏交互
隐私优先
行为心理学
分心对抗
独立开发
用户评论摘要:用户普遍认可“替身陪伴”比传统限制类工具更人性化。核心疑问集中在:如何精准判断“真工作”与“假分心”(如看技术贴)?AI替身是否会成为新干扰?隐私安全性如何独立验证?无刘海屏Mac的适配方案?以及能否自定义替身的语气、音效和关联个人日程。
AI 锐评
iPromise 敏锐地抓住了“自由工作者的孤独困境”这一被忽视的痛点,用“身体双人”这个心理学术语包装出的产品逻辑,比传统番茄钟、锁网工具高明了一个维度——它不制造对抗,而是创造陪伴。将AI替身安放在Mac刘海,更是绝佳的UI创新,在视线边缘提供低成本、高感知度的存在感,几乎不消耗屏幕空间。
然而,产品的真正挑战在于其核心:“上下文感知”的准确性。评论中大量关于“误判”的担忧并非无病呻吟。在一个程序员查看文档、设计师逛Behance、作家阅读研究材料时,工具如何区分“工作”和“摸鱼”?如果判断机制频繁失误,AI替身就从“温柔同伴”降级为“烦人领导”。目前创始人表示依赖窗口标题等表层信号,这远远不够。想要解决这个问题,要么引入复杂的本地模型进行内容语义分析(成本高且隐私承诺更重),要么放弃“智能化”而转向“用户自定规则”(如手动标记“这是工作窗口”),后者虽然笨拙但更可靠。
此外,创始人强调“免费”、“未定商业模式”是一把双刃剑。这能迅速积累种子用户,但也为产品的长期存在性打上问号。一旦考虑收费,这种“情感陪伴型工具”的付费意愿往往不如硬核效率工具。并且,一个底层逻辑尚未解决:单人AI替身如何还原多人虚拟自习室的“社会临场感”与“互惠监督”?缺少了真实他人的压力,AI的“温柔提醒”对于重度拖延症患者,可能很快就会沦为背景噪声。
iPromise 是一个精巧的创意原型,但它成功的关键不在于“刘海的好创意”,而在于能否在“精准判断”和“隐私安全”之间建立真正的技术壁垒。否则,它很可能只是下一个被新鲜感迅速消耗的可爱工具。
一句话介绍:Auto Posts是一个轻量级社交媒体内容调度工具,帮助小型团队和个体创业者在一个仪表盘中跨平台(Facebook、Instagram、X、LinkedIn、Pinterest、Telegram等)规划、调度并自动发布内容,解决手动多平台发帖的时间浪费与效率低下问题。
Social Media
Marketing
Alpha
社交媒体管理
内容调度
自动发布
跨平台发布
小型团队工具
轻量级SaaS
多平台分析
Telegram发布
Product Hunt新品
用户评论摘要:用户关注点集中在与竞品的差异化(如Post-Bridge)、是否支持AI内容生成、跨平台内容适配(单次发布统一文案问题)、API架构灵活性(以应对平台接口变动)、以及从Buffer/Hootsuite等工具切换的原因(价格与复杂性)。建议加强跨平台对比分析功能,并明确是否提供API调用和免费层级。
AI 锐评
Auto Posts是一个典型的“硬土创业”产物——从收购一个起起落落的老应用(Pursocial)重写代码后重生,团队坦诚地承认自己打不过Hootsuite等巨头,于是选择服务“小而美”的群体。这个定位在逻辑上成立,但必须面对一个残酷现实:社交调度工具市场已是红海中的坟场。用户评论里提到的“Content creation”和“per-channel variations”才是真正的痛点,而Auto Posts目前只是把最基本的多平台定时发布做出来了,AI写稿、文案适配、深度分析等重要能力尚未成型。
从技术角度看,团队回复中提到“快速迭代、倾听用户”,但API接口频繁变更是所有第三方调度的阿克琉斯之踵。他们通过Node.js重写后能否比竞品更快适配X(原Twitter)或Instagram的API变动?这尚未经过市场检验。更关键的是,用户增长和留存需要靠“不可替代性”,而目前Auto Posts的功能集只是把企业巨头们(如Sprout Social、Later)的弃用功能(基础调度、简单比数)搬了过来,缺乏独创壁垒。
产品目前最大的优势是价格(首年50% off)和不起眼的“Telegram支持”这种地域化差异点,但这很难撑起长期护城河。建议团队尽快完成两个关键动作:1)用低成本AI包装一个“内容适配引擎”,实现一条文案在不同平台自动调整结构和语调;2)将“简单调度”向“自动化营销”转化,比如结合用户事件触发发布动作。否则,用户可能会像试用Buffer一样,试用完打折期就流失到下一个更便宜的替代品。关注“执行速度”是好的,但小团队唯一的生存策略是用时间换取功能深度,而不是单纯在广度上模仿大厂。
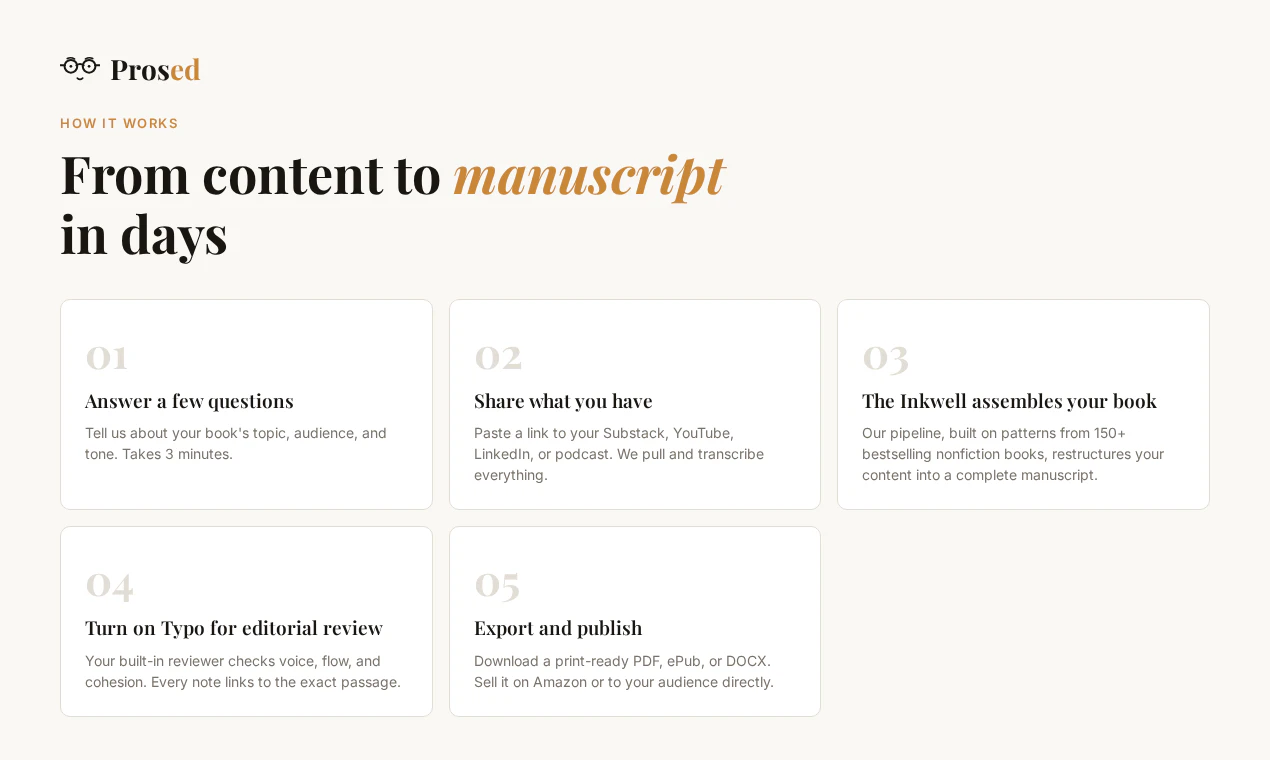
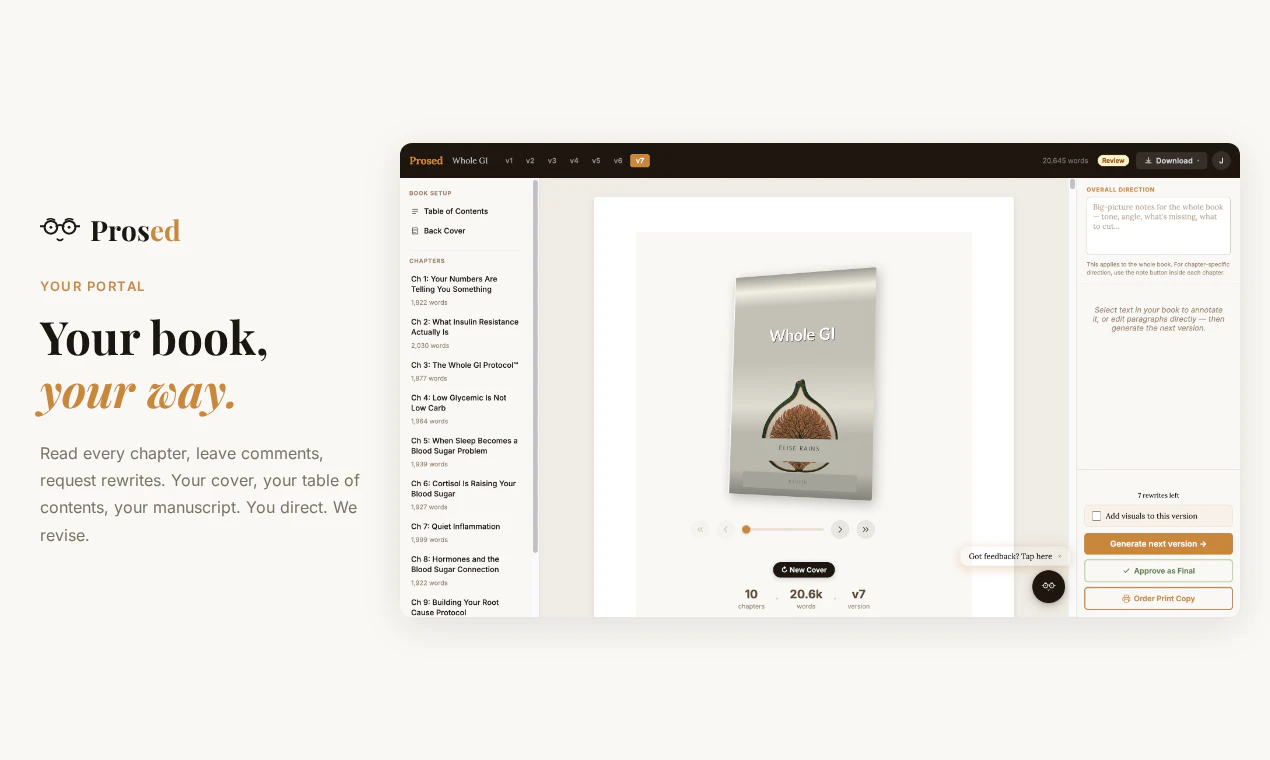
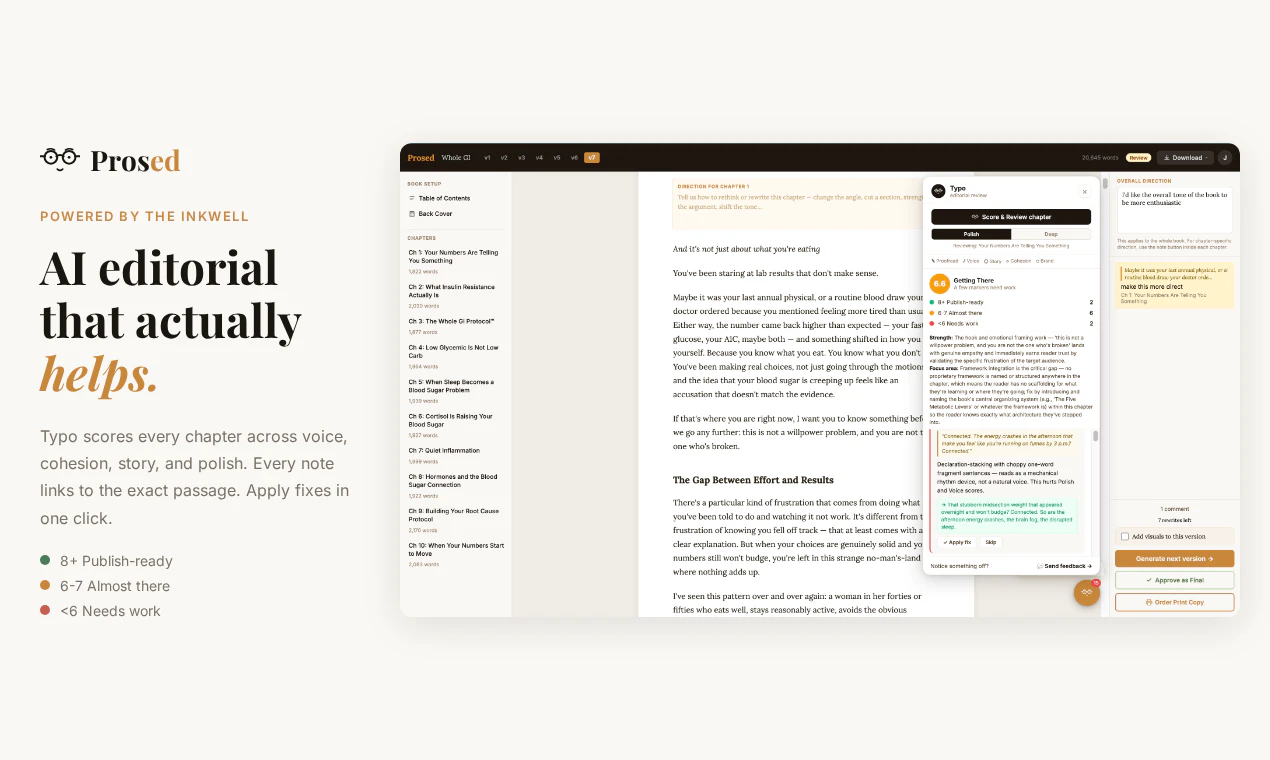
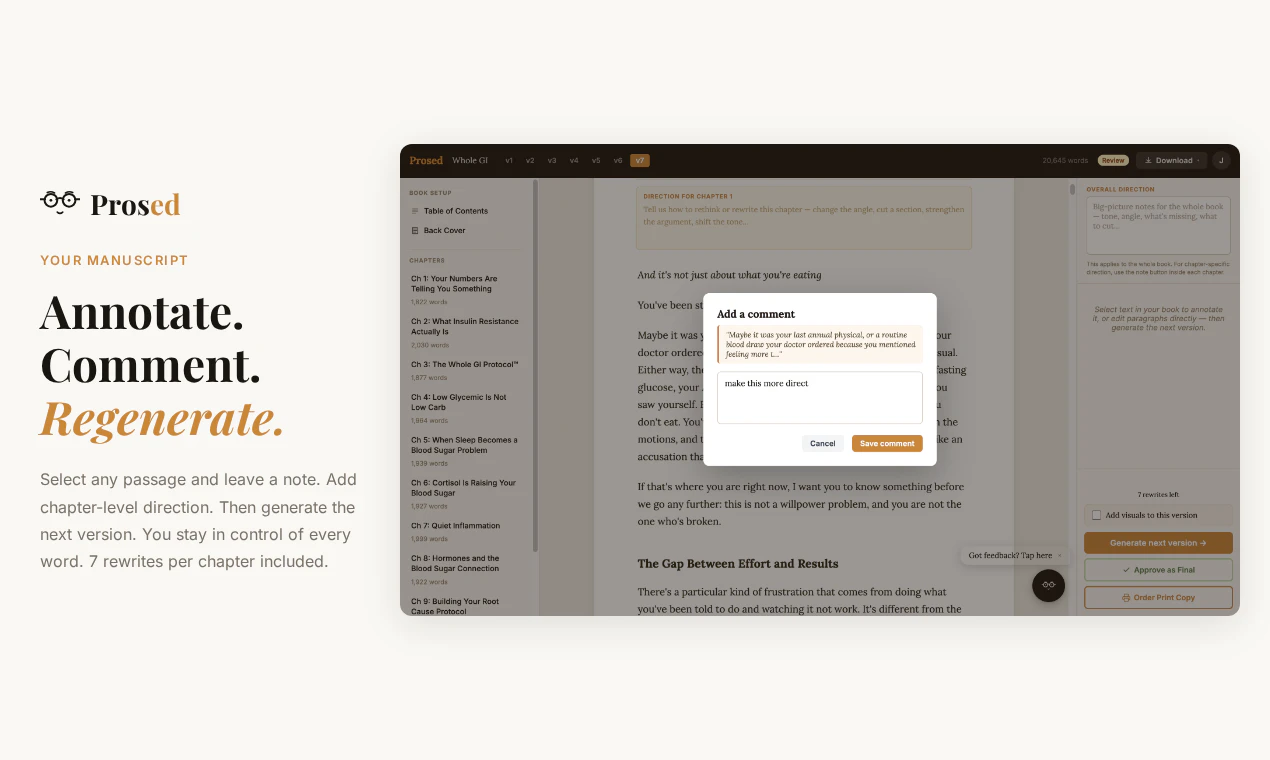
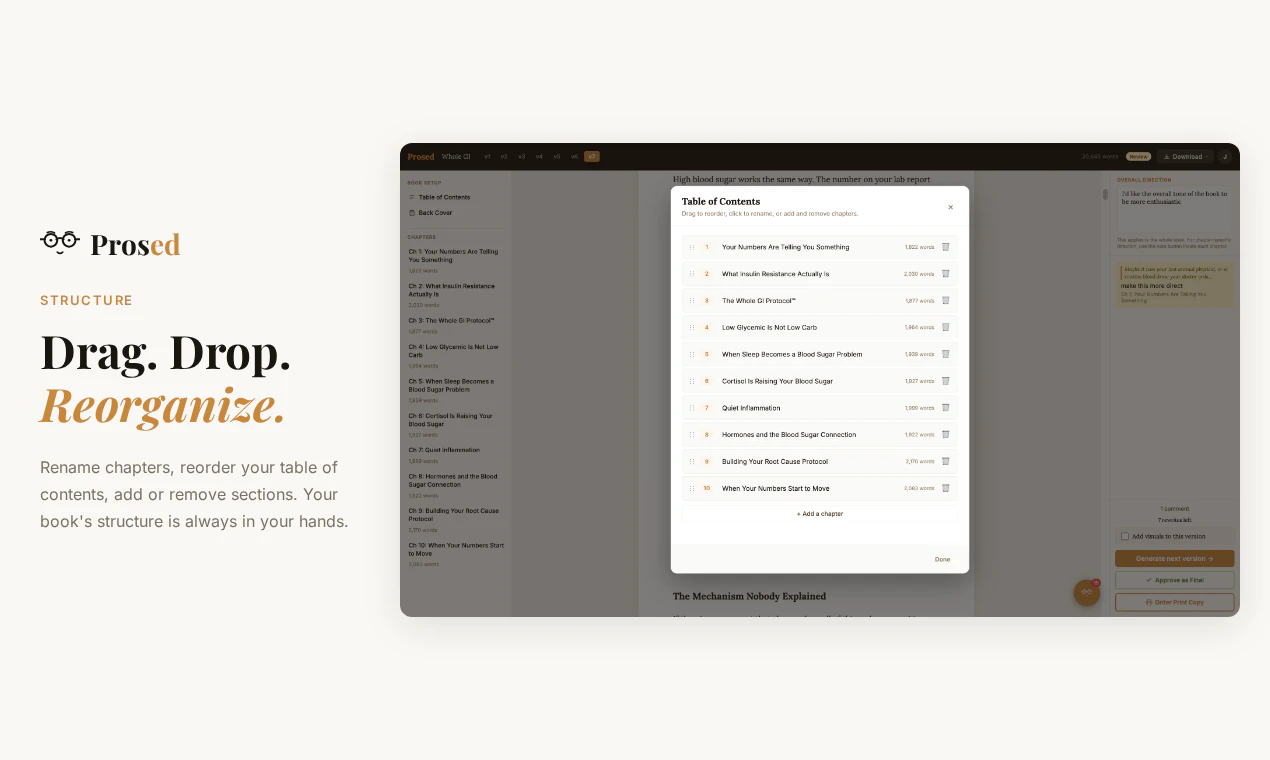
一句话介绍:Prosed通过分析创作者已有的Newsletter、播客、社交媒体等内容,将其自动整理成保留个人语气的完整书稿,解决“内容散落各处,没时间整合成书”的痛点。
Artificial Intelligence
Books
Alpha
书籍写作
内容整合
AI写作辅助
非虚构出版
创作者工具
语音克隆
出版导出
自动化手稿
个人知识管理
用户评论摘要:用户肯定产品定位,但关心:①仅限非虚构,无法写科幻;②输入质量依赖长文(Newsletter最佳),碎片化内容效果差;③需明确标注“AI生成的连接部分”与“用户原始内容”的界限;④话题分散时产品会失效。
AI 锐评
Prosed切中了一个真实但狭窄的痛点:资深内容创作者“有料但没空整理”的出版焦虑。其核心价值并非“AI写作”,而是“AI汇编”——不生成新观点,只做结构化和语气保留。这巧妙避开了当前AI写作“味同嚼蜡”的信任危机,也符合创作者对“个人品牌一致性”的执念。
但风险同样明显:第一,产品对输入质量要求极高,30-50篇同主题长文是门槛,这注定它只服务极少数已有大量沉淀的专业人士(如博主、讲师、咨询顾问),而非大众。第二,“保留语气”在长文本中极易退化为“表面模仿”,若缺乏严格的来源溯源机制(如用户反馈的“来源-章节地图”),最终稿仍可能被识破为“AI润色版”,反而伤害创作者口碑。第三,定价策略($47锁价)在早期可以吸引KOL,但若后续无法证明能显著提升出版效率(如从6个月压缩到2周),复购与场景扩展存疑。
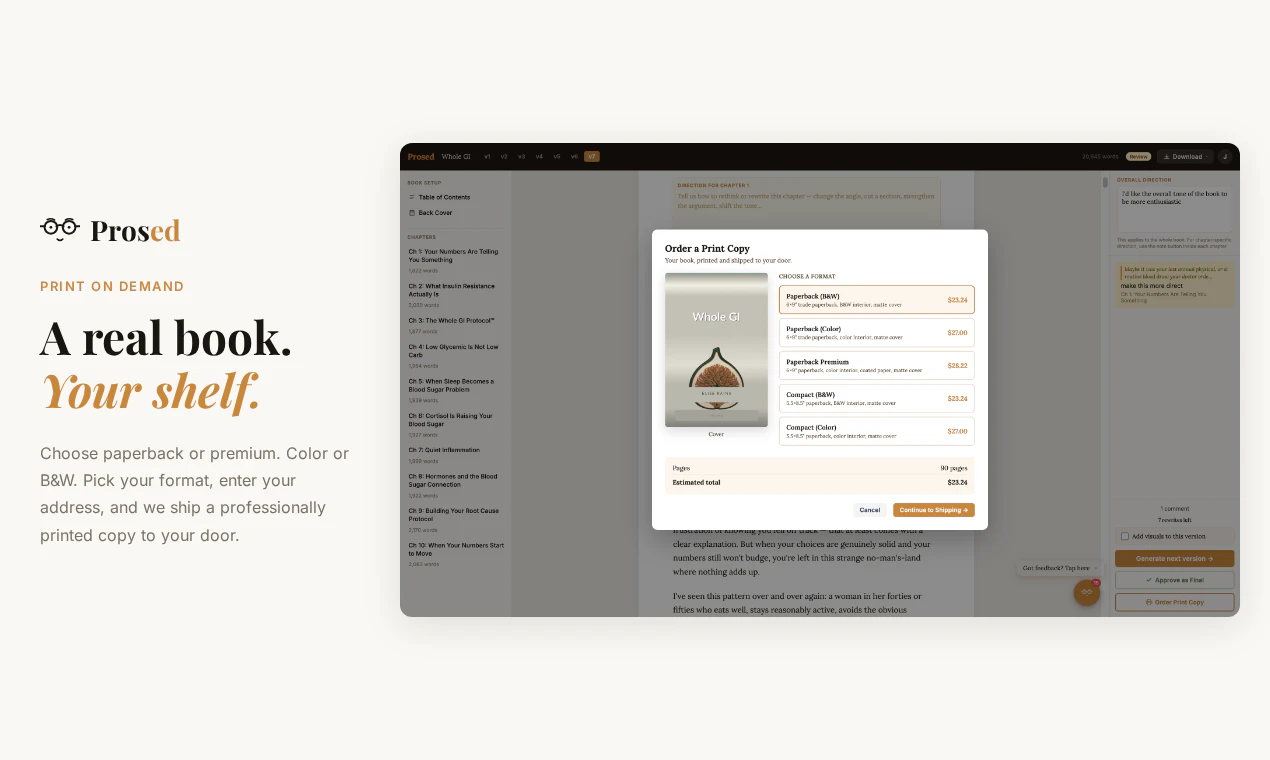
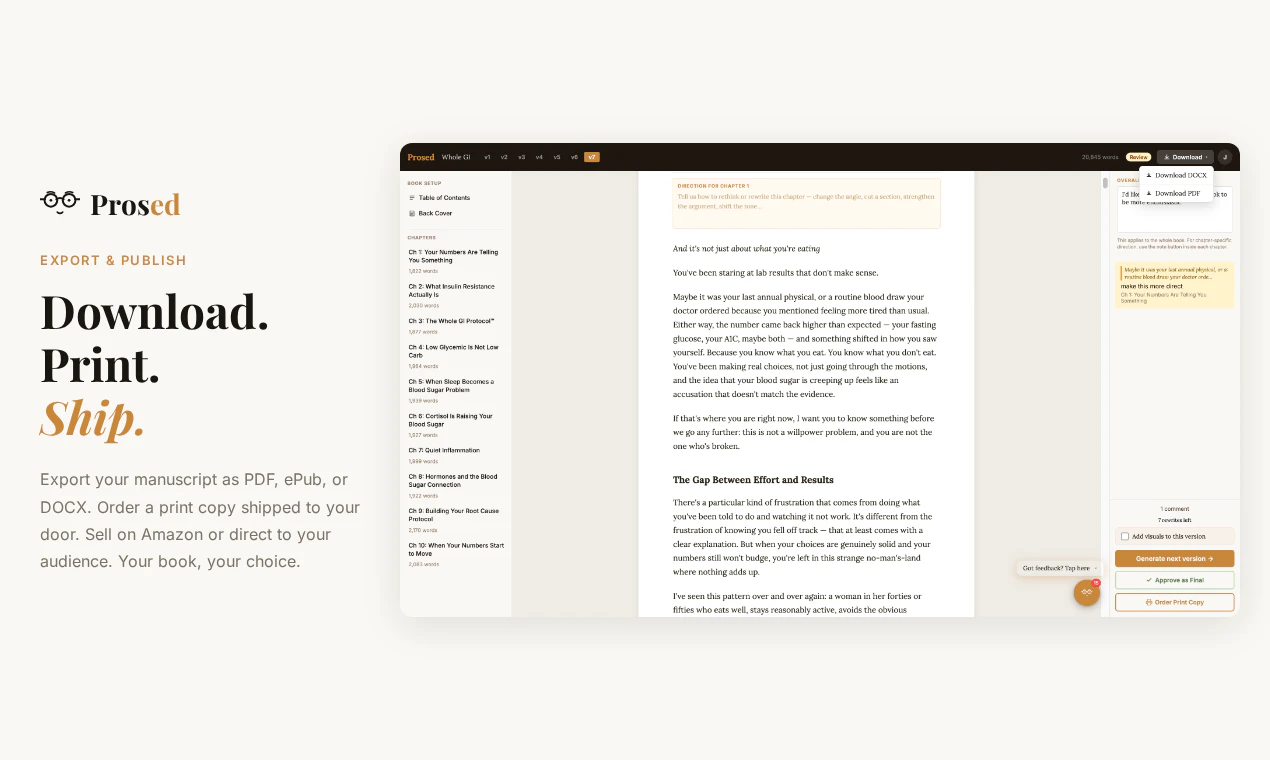
本质上,Prosed卖的不是工具,而是“让创作者有本自己的书”的社交货币。其成败不取决于技术多强,而在于能否帮用户绕过“写完不算,卖得出去才算”的出版冷启动——若仅止于PDF/DOCX导出,价值有限。真正的杀手锏或许是内置的ISBN申请、亚马逊上架、甚至按需印刷对接。目前透露的“封面设计+打印订购”是正确方向,但细节缺失。
一句话总结:对存量创作者是“时间换名声”的高效杠杆,但对普通用户而言,内容都没有,谈何整理?
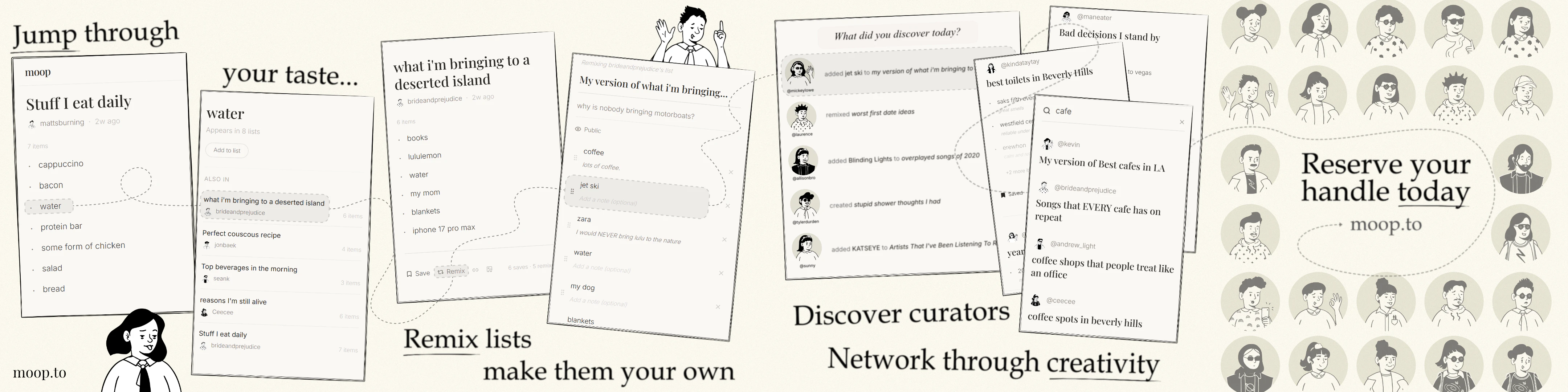
一句话介绍:Moop是一个纯文字列表式社交网络,旨在替代视觉轰炸的“脑腐”内容,让用户通过分享书单、电影、探店等个人品味列表来激发灵感,而非靠算法推送的短视频和图片消耗时间。
Social Media
Books
Alpha
纯文字社交
列表式社交
反脑腐
品味网络
极简社交
发现工具
创意社区
无媒体
品味策展
替代社交媒体
用户评论摘要:用户普遍认可纯文字、极简的设计方向,但多数认为它更像“发现工具”而非社交网络。主要建议包括:增加协作列表功能、允许超链接(如地图/购买页)、丰富本地化内容(低价美食、深夜去处),并担忧无媒体模式能否避免陷入传统平台的流量优化陷阱。
AI 锐评
Moop的标语和定位极其精准——“没有媒体的社交网络”直接命中了当代社交媒体内容过载、注意力碎片化的广泛痛点。从产品形态看,它更像一个“结构化版的前互联网论坛+BBS”,用“列表”这一古老而高效的单元,成功切入了用户的收藏癖、策展欲和品味标榜需求。它巧妙地将“品味”转化为可执行、可关联、可混排的数据点,打通了从“个人笔记”到“公共发现”的链路。
然而,这款产品的真正挑战并非设计理念,而是商业逻辑与用户留存机制。评论中一位用户精准地发问:“是什么设计决策让它结构性地不同,而不仅仅是审美不同?”答案恐怕在于,Moop目前的纯文字列表其实只有一个隐形的“排序器”——点赞数。如果未来平台按点赞热度推荐列表,必然会引导用户创作“最佳XXX”或“最怪XXX”这类追求传播力的标题党内容,从而重蹈“脑腐”的覆辙。同时,无媒体模式天然缺乏短视频的沉浸式黏性,用户的打开频次和时长完全取决于其“产生新列表”的频率,商业化路径(广告位?付费策展?)极其狭窄,稍有不慎就会变成“一个很好看的手机备忘录”。
Moop最宝贵的资产不是技术,而是它吸引来的第一批用户——那些对“品味”有明确追求、愿意为“反算法”站台的KOL。如果Moop能坚定地走“慢社交”路线,不做通用平台,而是成为亚文化圈子、读书会、探店达人的组织化工具,并开放API让数据回流到用户的个人笔记或博客,它或许能成为一个小而美的垂直生态。但若试图对标TikTok或小红书,它只会是“完美”的另一款静默产品。这是一个关于“规模”与“纯度”的经典博弈,而Moop目前的选择非常勇敢——但路还很长。
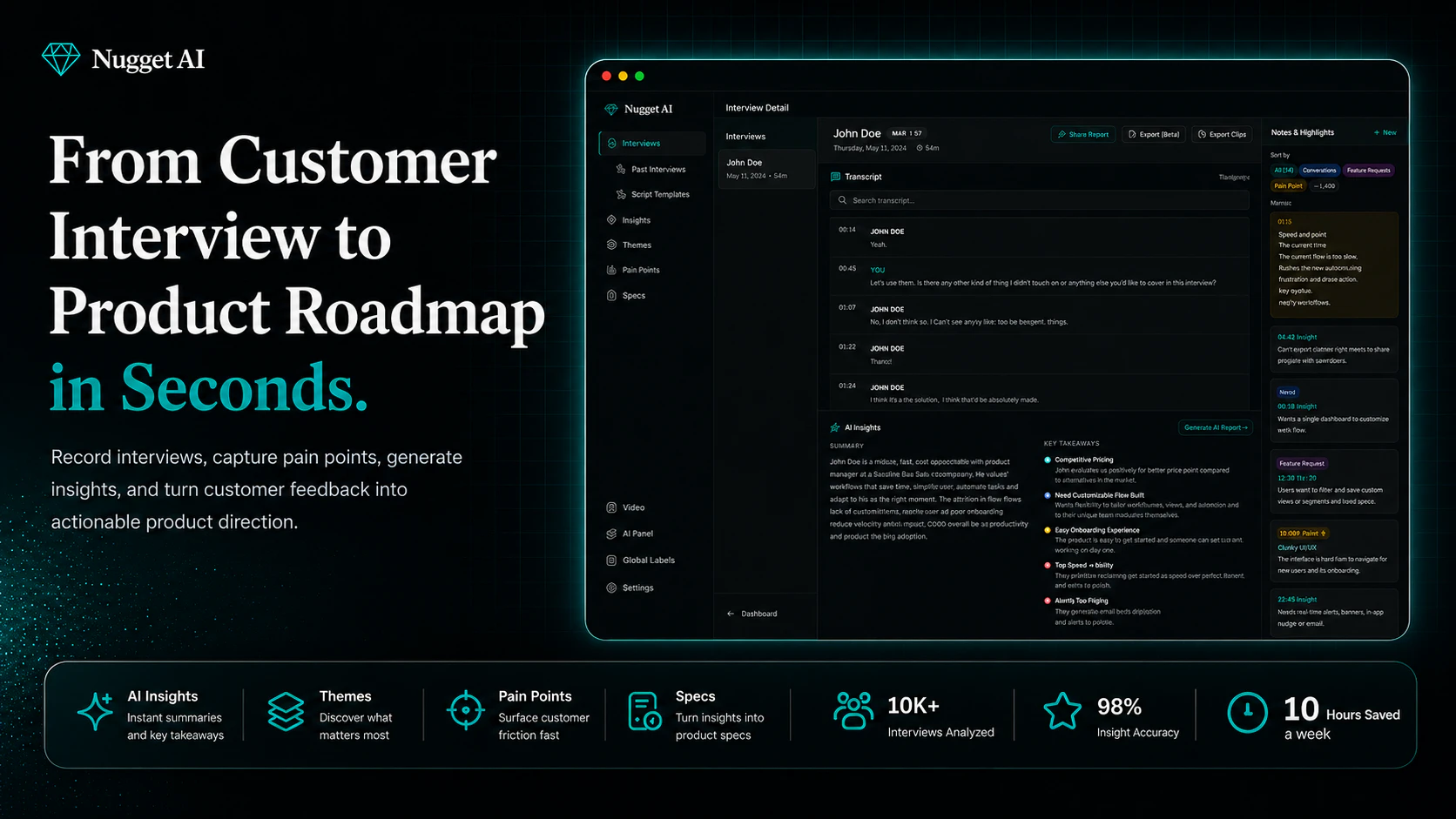
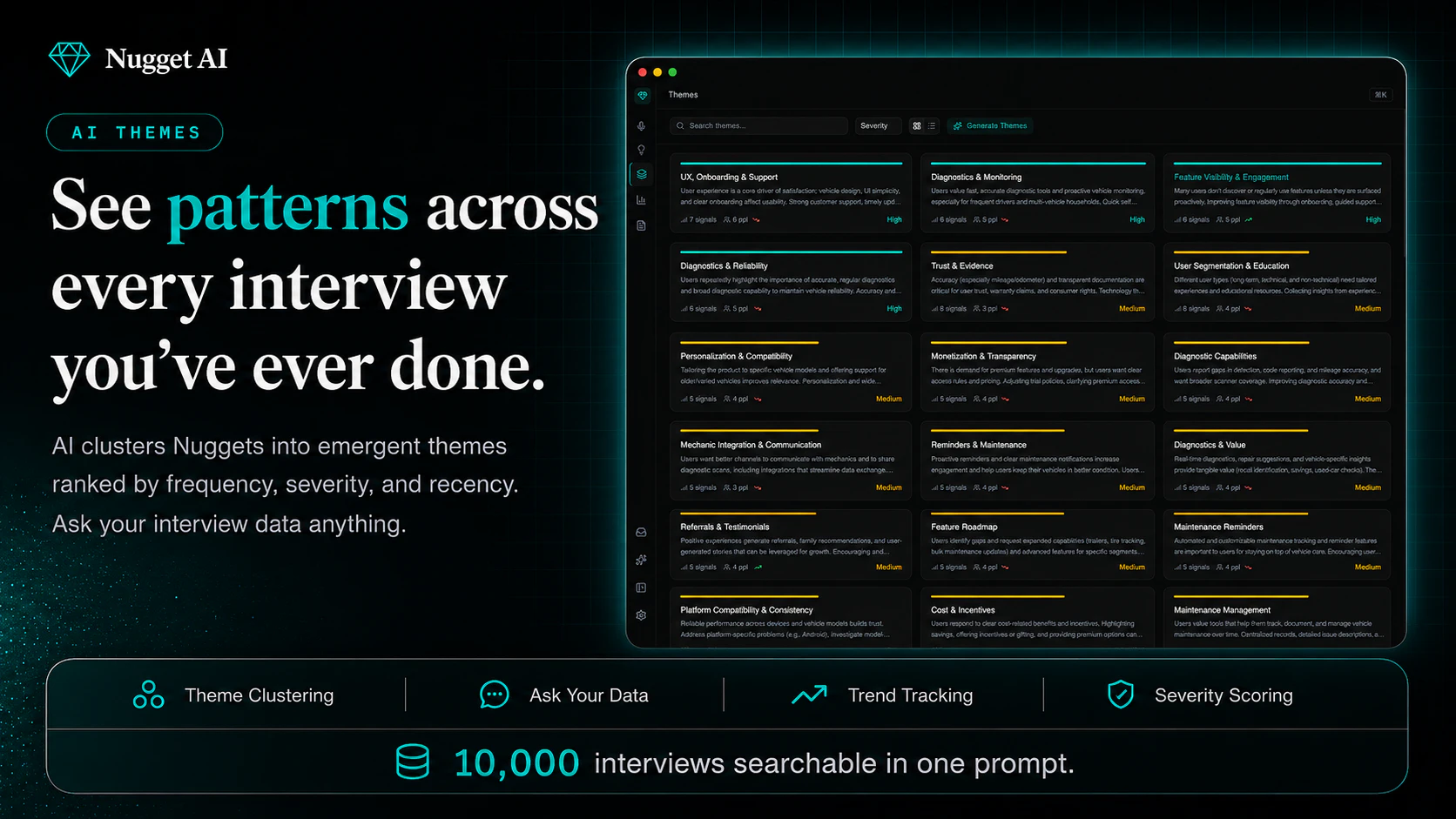
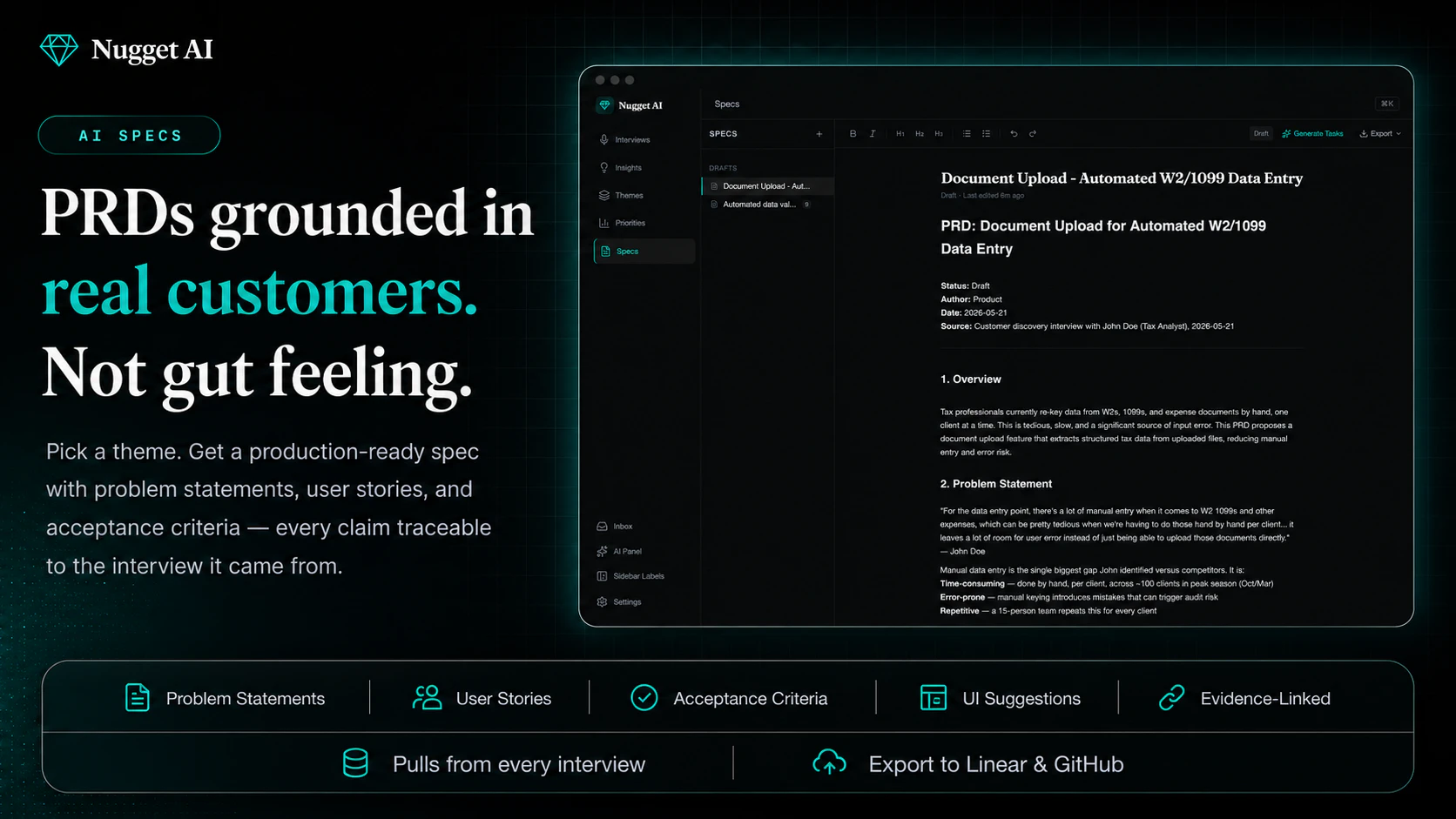
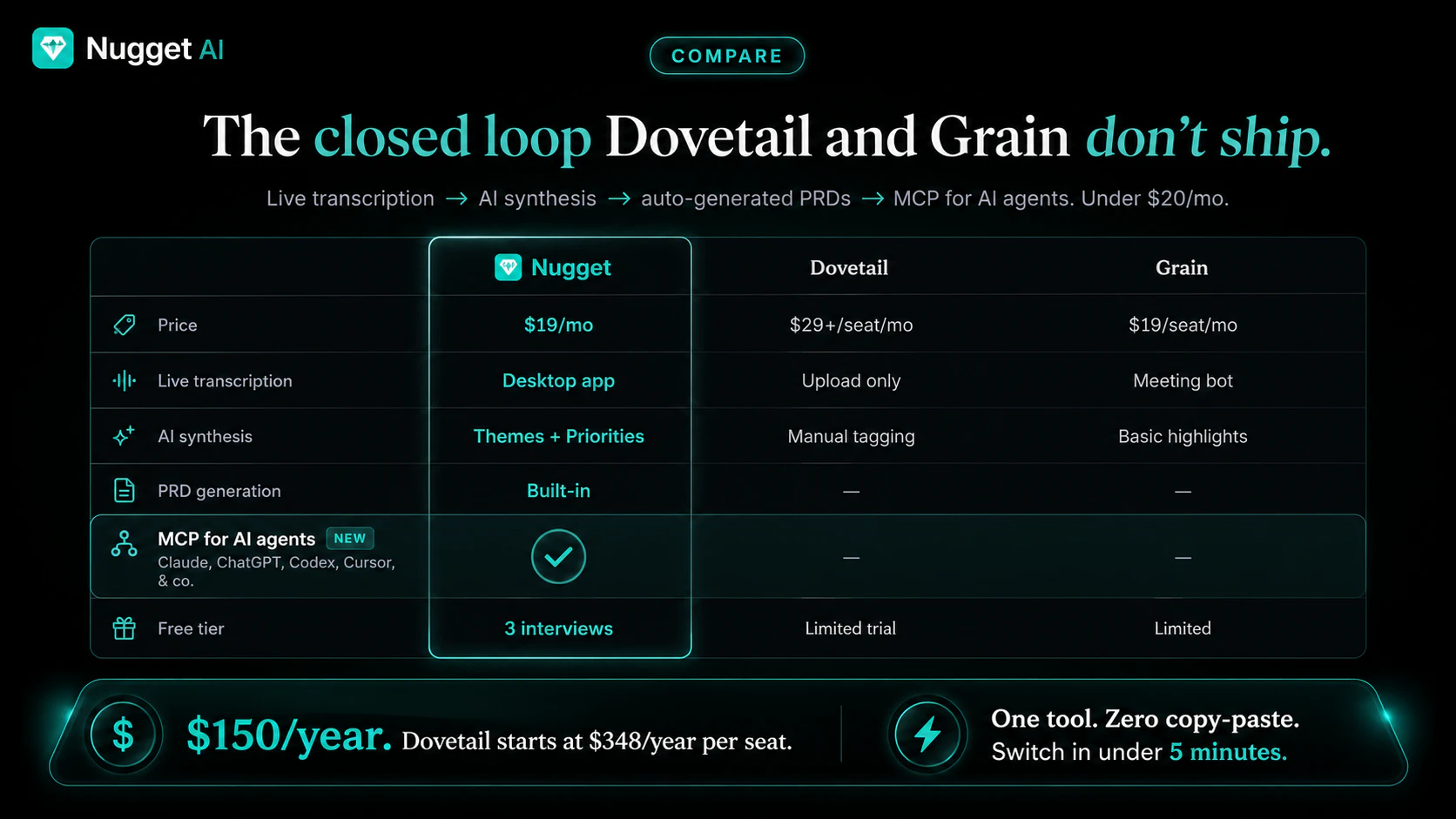
一句话介绍:Nugget AI 将用户访谈录音转为结构化产品证据,自动提取痛点、功能请求并生成带真实用户引言的PRD,直接对接开发工具,解决PM“访谈信息沉睡”的痛点。
SaaS
Artificial Intelligence
Alpha
产品研发工具
AI访谈分析
用户研究
PRD生成
产品路线图
MCP服务器
证据驱动
提示词
B2B SaaS
开发者工具
用户评论摘要:评论肯定其解决访谈信息流失的核心痛点,尤其赞赏MCP服务器让AI引用真实用户。用户关注:如何处理低质量访谈(如引导性问题);机会评分如何避免偏重“喧闹用户”;能否处理非结构化数据(如应用商店评论);买家与用户分离场景的合成逻辑;以及生成的PRD是否包含证据存根和“未采纳请求”的决策说明。
AI 锐评
Nugget AI抓到PM群体一个极深且普遍的痛点:“用直觉写PRD,假装数据驱动”。它不只是一个转录工具,而是试图重构从“用户证据”到“开发指令”的全链路。MCP服务器是其最具战略价值的动作——让AI agent在编码或撰写时直接检索并引用真实访谈,这意味着Nugget不再是信息坟场的搜集者,而是AI工作流中不可替代的“事实层”。
但风险也在此。产品声称能对抗“引导性访谈”和“噪音用户”,这本质上是将人类研究者的专业判断,抽象为一套可量化的规则。在实际场景中,“信号强度”的加权标准、低质量访谈的误判率,都会直接影响产出质量的信任度。如果AI生成的PRD因为源头数据偏差被工程团队质疑过一次,整个工具的可信度就会崩塌。
此外,当前生态绑定过紧(Linear、GitHub、Cursor),虽利于深挖,但排除了Jira/钉钉等主流企业的真实场景。定价故事不错(“一半Dovetail价格”),但如何向非PM用户群(如设计师、市场人员)证明价值,是破圈的关键。
一句话:Nugget是**证据驱动的工程化工具**,但如果想成为产品团队决策的“操作系统”,它需要比亚伦·埃瓦兹的《妈妈测试》更严格地处理“定性证据的有效性”问题。产品很棒,但用户信任的积累会比功能迭代慢得多。
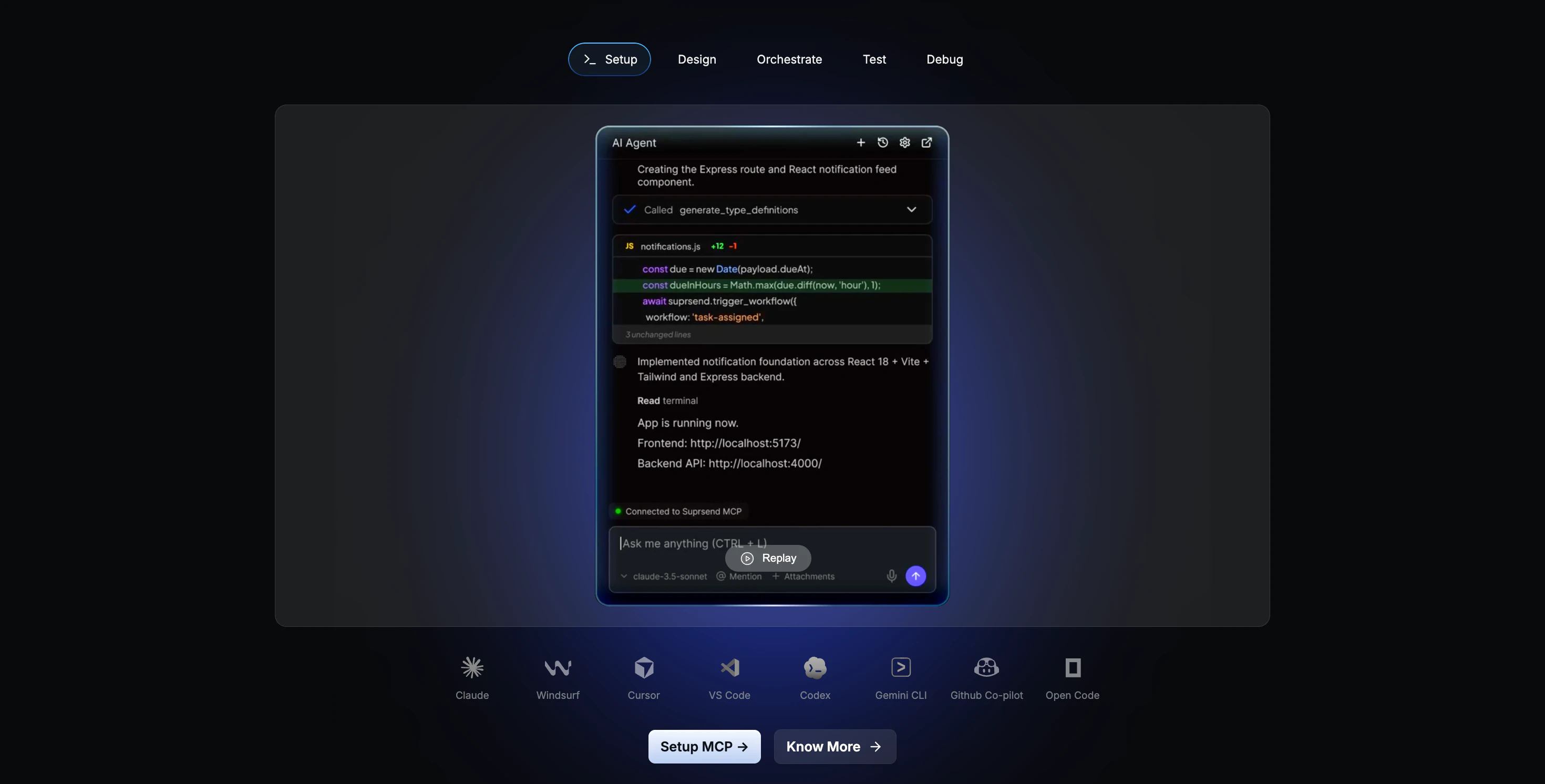
一句话介绍:SuprSend AI 是一个将 AI 原生集成到通知基础设施中的平台,通过 MCP、CLI、Agent 等六大 AI 界面,让开发者和运营人员在 IDE、Slack 或仪表盘中用自然语言快速创建、调试和管理多通道通知,将集成时间从数周缩短到数小时。
SaaS
Developer Tools
Artificial Intelligence
AI通知平台
多通道通知
开发者工具
MCP服务器
通知即代码
Copilot
Slack集成
生产安全
模板自动化
SaaS
用户评论摘要:用户普遍认可其大幅缩短了模板创建、调试和集成时间。核心问题聚焦在:1️⃣ 安全性:MCP 层的限制是服务端强制还是仅靠提示,能否防御提示注入?2️⃣ 架构:如何处理模式漂移?去重逻辑如何避免跨通道重复发送?3️⃣ 细节:AI 是否感知自定义字体、不同渠道的语气适配等细节场景。
AI 锐评
SuprSend AI 的野心不在于“给通知工具加个聊天框”,而是一次基础设施交互范式的重构。它用六大 AI 界面(MCP、CLI、Copilot、Agent等)把通知的“配置-编码-调试-运营”全链路塞进了自然语言和 IDE 中,试图抹平工程师、产品经理和运维人员之间的沟通鸿沟。其核心价值在于“领域知识预载+行为约束”:Agent Skills 解决了 AI 幻觉 API 的致命伤,而生产环境只读、操作前置检查等机制表明团队清楚 MCP 化的风险——它们不是把安全甩锅给提示词工程,而是在服务端做了硬隔离,这点比多数跟风“AI+工具”的产品成熟。
但问题同样尖锐:当用户问“模式漂移”“跨渠道去重”时,暴露的是 AI 层的知识时效性与动态配置的冲突。目前的“预加载”方案对静态 schema 有效,一旦用户频繁调整通知规则或路由逻辑,Agent 能否实时感知并保持上下文一致性?另一个隐忧是:24 个工具暴露了极高的能力密度,但边界越宽,被恶意利用的潜在缺口越大——除非安全策略能做到“任何客户端、任何提示均不能绕过服务端策略”,否则 MCP 不过是更快的破坏工具。
表面上看,它帮用户省了“数周”的时间;但真正长久的价值,取决于它能否在“多模交互”与“运维严谨性”之间找到平衡——即让 AI 足够懂你,又不让你因为懂它而翻车。目前来看,方向正确,但细节(如 schema 同步机制、去重策略)仍需在实际大规模部署中接受拷打。
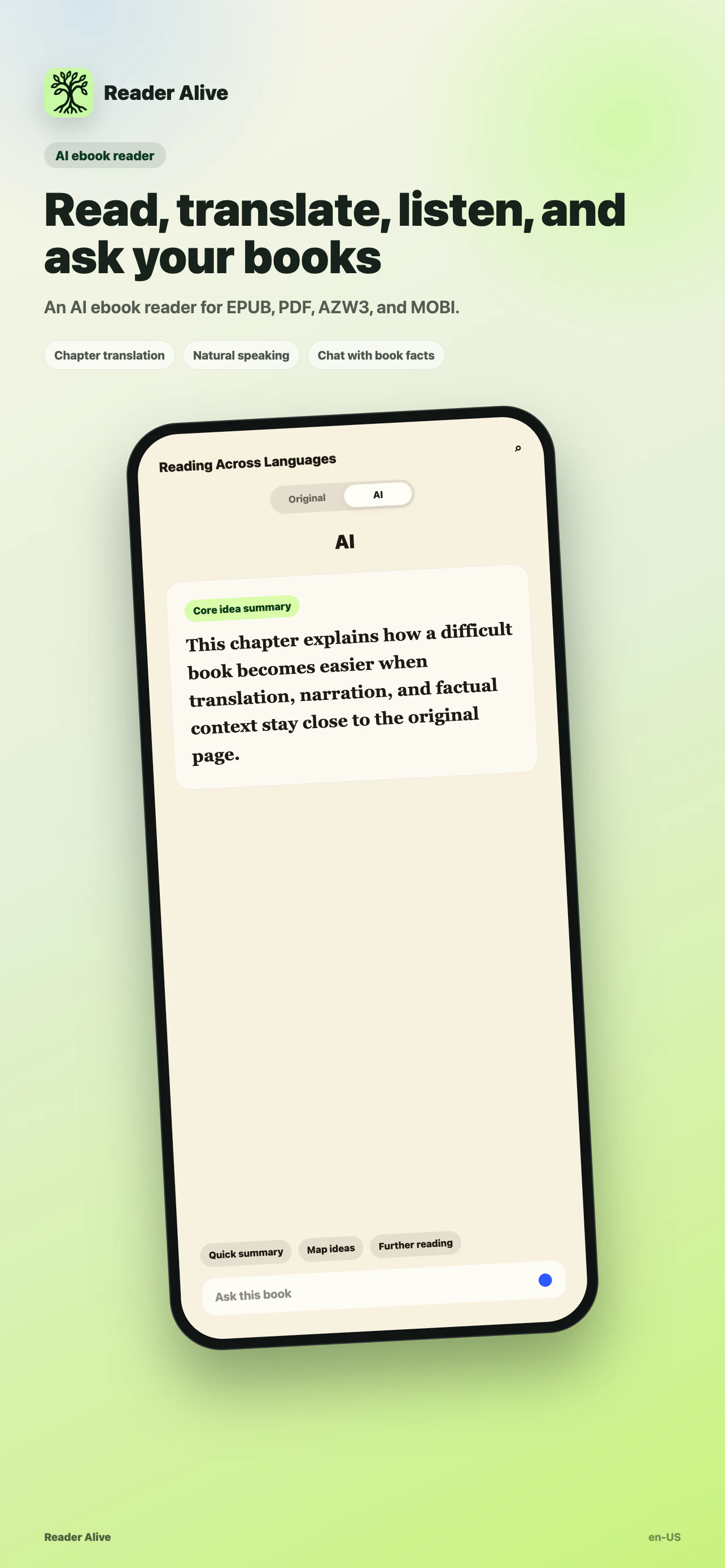
一句话介绍:Reader Alive 是一款专为iPhone/iPad设计的AI电子书阅读器,解决了用户在阅读外文、专业书籍等“硬核”内容时,需要切换工具翻译、听读、查资料、做摘要的碎片化痛点,将翻译、语音朗读、AI问答、章节总结集成在阅读场景内,实现“边读边问边听”的一站式体验。
eBook Reader
Artificial Intelligence
Alpha
AI阅读器
电子书翻译
文本转语音
AI问答
摘要生成
PDF阅读
EPUB阅读
外语学习
阅读效率工具
iOS应用
用户评论摘要:用户主要关注:问答是否严格从书中内容生成(需引文验证)、翻译是否会削弱作者原意、是否支持Android和Amazon下载书籍格式;开发者回应称AI回答会引用原文并支持逐章翻译(采用Deepseek V4降低成本),同时考虑未来推出Android版。
AI 锐评
Reader Alive 的切入点很聪明:它没有重造一个“更好的阅读器”,而是把AI嵌入阅读场景,解决的是“读不下去”这个老问题。用户对翻译、问答、TTS的追求背后,本质是对“信息获取效率”和“理解门槛跨越”的双重刚性需求。产品在功能堆叠上较为面面俱到:支持七种格式、章节翻译、上下文问答,甚至在回答中标注引用来源——这相比一个独立的ChatGPT“泛答”有明显进步,因为阅读场景下“精确引用”比“胡诌”重要得多。
但需要警惕的是“AI的边界感”。用户评论里已经有人察觉到:翻译会不会磨平作者风格?问答是否真的只限当前书?这些都是AI在阅读场景下的“致命脆点”。如果用户问一句“主角的名字是什么”,AI给出正确引用是加分;但如果问“你觉得这本书和《三体》谁更好?”,AI一旦开始自由发挥,阅读的沉浸感立刻崩塌。
从商业模式看,产品明确面向个人用户,没有走团队协作路径,这既是克制也是克制。问题在于:AI翻译和推理的API每次调用都有成本,109票的众筹级热度很难撑起长期运营。更值得思考的是,是否真的有人会因为“TTS语音自然”或“内置AI问答”就放弃Apple Books、Kindle等拥有成熟生态和同步体验的竞品?答案可能取决于:快感是否能覆盖迁移成本。
一句话锐评:AI让读“难书”的大门开了条缝,但门槛依然在“书”本身——你的PDF要是扫描件,或作者风格像乔伊斯,AI再强也帮不了你。
一句话介绍:buildpipe是一款本地优先的多步骤AI开发者工作流自动化桌面应用,让开发者无需编写YAML或依赖云端服务,即可通过可视化方式将Shell命令、AI调用、HTTP请求和文件操作编排成可复用的管道,并通过定时、文件变更或Webhook触发执行。
Developer Tools
GitHub
Maker Tools
Alpha
本地优先
AI工作流自动化
开发者工具
管道编排
桌面应用
Zapier替代
隐私安全
可视化编程
命令行集成
无代码自动化
用户评论摘要:用户关注本地性能需求(无需高配)、工作流审批节点缺失、运行历史可搜索性、凭证安全与OAuth支持、AI步骤的非确定性处理(建议定义JSON输出与置信度),以及二进制文件管道与资产工作流适配性。开发者计划路线图增加审批及OAuth功能。
AI 锐评
buildpipe试图解决一个真实且普遍的痛点——开发者对临时脚本的依赖和遗忘。它的核心价值不在于“AI”,而在于“本地优先”+“可视化编排”的组合拳。在n8n、Zapier等云端工具让数据流经他人服务器时,buildpipe选择让一切留在本地,这既是技术上的硬核选择,也是隐私合规的聪明押注。然而,v1版本的缺失相当明显:无OAuth支持、无审批节点、无原生AI模型支持(依赖外部API),这导致其“AI工作流自动化”的宣称更像是一个半成品——你依然需要将API密钥交给外部大模型供应商,而非真正实现本地推理。更关键的是,对于开发者而言,Shell脚本和Makefile的编程灵活度远高于可视化管道,buildpipe真正面对的对手不是Zapier,而是开发者根深蒂固的“写脚本”习惯。它的生存空间在于:那些需要频繁修改、跨步骤调试、且希望有UI回溯历史的工作流场景。但如果不能解决AI步骤的非确定性与可调试性问题,单凭“本地JSON日志”和“48个模板”很难形成护城河。未来若开放插件系统、支持本地LLM调用、并强化文件资产管理(如WOFF2输出),才可能从“玩具”进化为“工具”。当前1.0.0版本,更像是一个很好的赛道占位。
一句话介绍:motionvid.ai 是一款 AI 驱动的运动图形与视频编辑器,让用户无需设计技能,几分钟内即可生成带旁白和音乐的视频,解决视频制作中剪辑、节奏把控和动画合成的耗时痛点。
Marketing
Artificial Intelligence
Video
AI视频编辑
运动图形
自动剪辑
视频生成
无代码创作
营销视频
内容创作工具
浏览器编辑器
Miltos模型
节奏感知
用户评论摘要:用户高度关注与Premiere等传统软件的交接(能否导出后微调)、风格一致性(多尺寸能否统一)、自定义音乐及上传参考图像的能力。核心疑虑在于“纯文本描述”对风格和语气的控制精细度是否足够。
AI 锐评
必须承认,motionvid.ai 找准了剪辑流程中最枯燥的环节——节奏匹配和镜头拼接。其自研的“Miltos 5.0”模型强调“理解时间和知道哪里该剪”,这比那些只会生成低效短视频的AI工具更懂专业创作者的痛点。然而,98票的冷清开局,以及评论区清一色来自创始人的自问自答和粉丝式提问,暴露出这是典型的“技能导向型”产品,缺少真实恶劣场景的压力测试。
真正的问题在于,它试图扮演“自动剪辑师”的角色,却忽视了剪辑是一门“选择”的艺术。用户追问的“能否在Premiere中微调”、“能否保持品牌风格一致性”,直指AI视频工具的核心硬伤:自动化输出与可控精修之间的矛盾。如果每次输出都是一次独立的“黑盒”生成,无法导出可编辑的工程文件,仅靠浏览器的“调整”功能,那它只会是After Effects的廉价平替,而非颠覆者。
对于营销团队而言,一个不能统一管理视觉资产的AI编辑器,注定只能做快速出片的一次性生意。它在解决“效率”问题的同时,制造了“控制权”的焦虑。建议团队聚焦于“风格锁定”和“多尺寸自适应”这两个高频需求,而非炫耀模型的“智能”。否则,即便吹得天花乱坠,它也不过是剪辑师草稿箱里一个昙花一现的玩具。
一句话介绍:Zero Assist是一款实时AI作弊检测工具,用于远程技术面试场景,通过监控候选人的操作系统进程,检测Parakeet AI、Final Round AI等20多种隐藏式AI作弊工具,帮助招聘方规避基于AI伪造能力做出的错误聘用决策。
Hiring
Remote Work
Alpha
AI作弊检测
远程面试监考
实时监控
技术招聘
OS级监控
隐私合规
招聘防伪
人力科技
过程审计
招聘反欺诈
用户评论摘要:用户关注两大核心问题:一是法律合规性,质疑“静默部署”是否会未经同意监控候选人,制造者回应需明确同意且只监控进程非屏幕;二是误报率,担心Copilot等合法工具被误判,官方称检测目标是隐藏覆盖层的“特定技术指纹”,支持实时白名单。
AI 锐评
Zero Assist切中的是一个真实且正在快速膨胀的痛点:远程技术面试中的AI辅助作弊已经不再是“偷看一眼小抄”,而是形成了以Parakeet AI、Final Round AI为代表的“钢盔行业”。这类工具能够绕过传统屏幕共享,用GPU覆盖层隐藏答案投射,让面试官完全无从察觉。从这个角度看,Zero Assist提供的OS级进程监控,比“眼神追踪”和“事后看回放”更贴近作弊行为的物理本性——无论AI变得多聪明,它终究要作为一个隐蔽的进程运行在候选人的机器上。这种“检测执行过程”而非“揣测行为意图”的思路,是其核心差异点。
不过,产品面临的挑战同样尖锐。首先是法律灰色地带:即便得到知情同意,在面试场景中要求候选人安装监控软件,依然存在因地域法律不同导致的不合规风险,尤其在欧盟GDPR或加州CCPA下,隐私权的抗辩可能直接让产品不可用。其次是商业模式的信任困境:招聘方愿意付钱的动机是“抓出作弊者”,而一旦产品漏报(假阴性),他们会认为工具无效;一旦误报(假阳性),则可能引发法律纠纷或毁掉一个真实候选人的机会。创始人强调“检测特定技术指纹”,但这套指纹库能覆盖多少工具?更新速度能否跟上作弊工具的迭代?这些才是用户真正会掏钱的决定性因素。总体而言,这是一个“兵来将挡”型的产品,AI作弊工具升级一步,它就得紧跟着升级一步,否则价值归零。短期有价值,长期看,监管和技术的双重博弈才是真正的赛场。
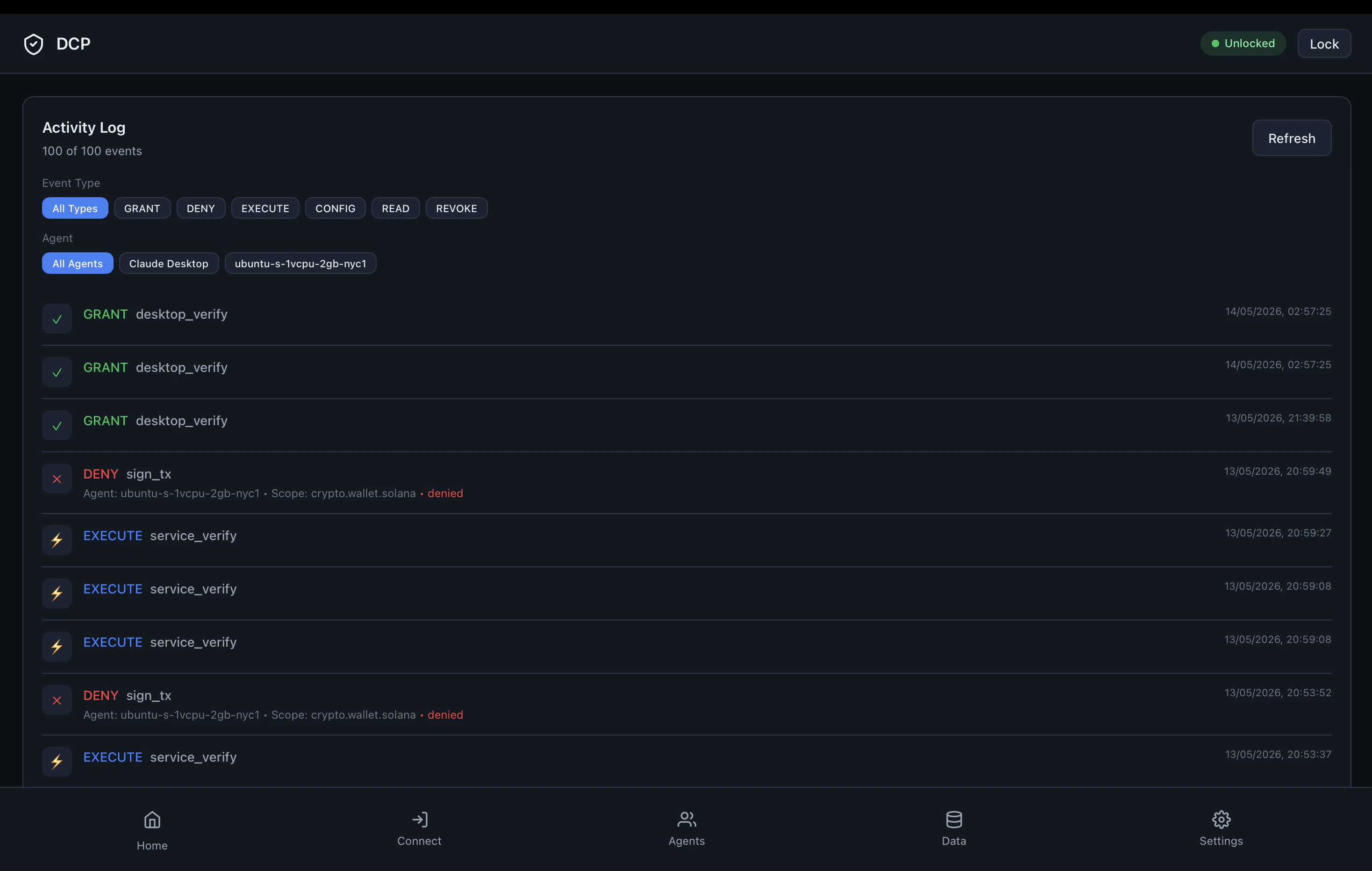
一句话介绍:DCP 是一款本地加密权限保险库,让AI代理在执行交易、调用API等敏感操作时,必须经过用户审批授权,密钥永不泄露给代理,解决了代理安全与资产控制的核心矛盾。
Developer Tools
Artificial Intelligence
Alpha
AI代理安全
权限管理
加密保险库
非托管
密钥管理
MCP
Telegram审批
本地签名
开源
Web3
用户评论摘要:用户高度关注“代理在远程服务器运行”时的部署模式与“本地保险库”的矛盾。核心问题包括:能否支持临时/定时过期密钥、每日预算耗尽后的行为。一条评论尖锐对比了DCP与传统密钥管理器(如Vault)及代理钱包方案的本质差异。另有一名用户反馈macOS安装时遇到“应用已损坏”的Gatekeeper问题。
AI 锐评
DCP切中了一个正在被忽视但致命的痛点:AI代理的权限失控。当代理从“问答玩具”进化为“执行工具”,密钥泄露风险急剧放大。DCP的“代理只请求动作,不接触密钥”设计,是比传统秘密管理器(如HashiCorp Vault)和代理钱包(如Privy)更根本的解法——前者管的是“存储”,后者管的是“身份”,而DCP管的是“授权瞬间”。其本地签名+Telegram审批的架构,在安全与易用间找到了平衡点,尤其对于个人开发者和小团队,是门槛极低的零信任实践。
然而,产品当下最大的隐忧在于部署模型的局限性。社区已敏锐指出,“本地桌面保险库”与“云端运行代理”之间存在根本性冲突。若无法提供合理的守护进程或中继模式,DCP将天然地屏蔽掉服务器端和自动化流水线场景,而这恰恰是代理最有价值、最需要安全防护的战场。此外,macOS的Gatekeeper问题暴露出产品尚未经过正式分发流程,对于一个处理密钥的敏感工具,这会严重损害早期用户的信任。DCP的价值主张清晰且正确,但若不能快速弥合部署鸿沟并提升工程成熟度,它可能只能成为一个“理想场景”下的漂亮Demo,而非生产级的基础设施。
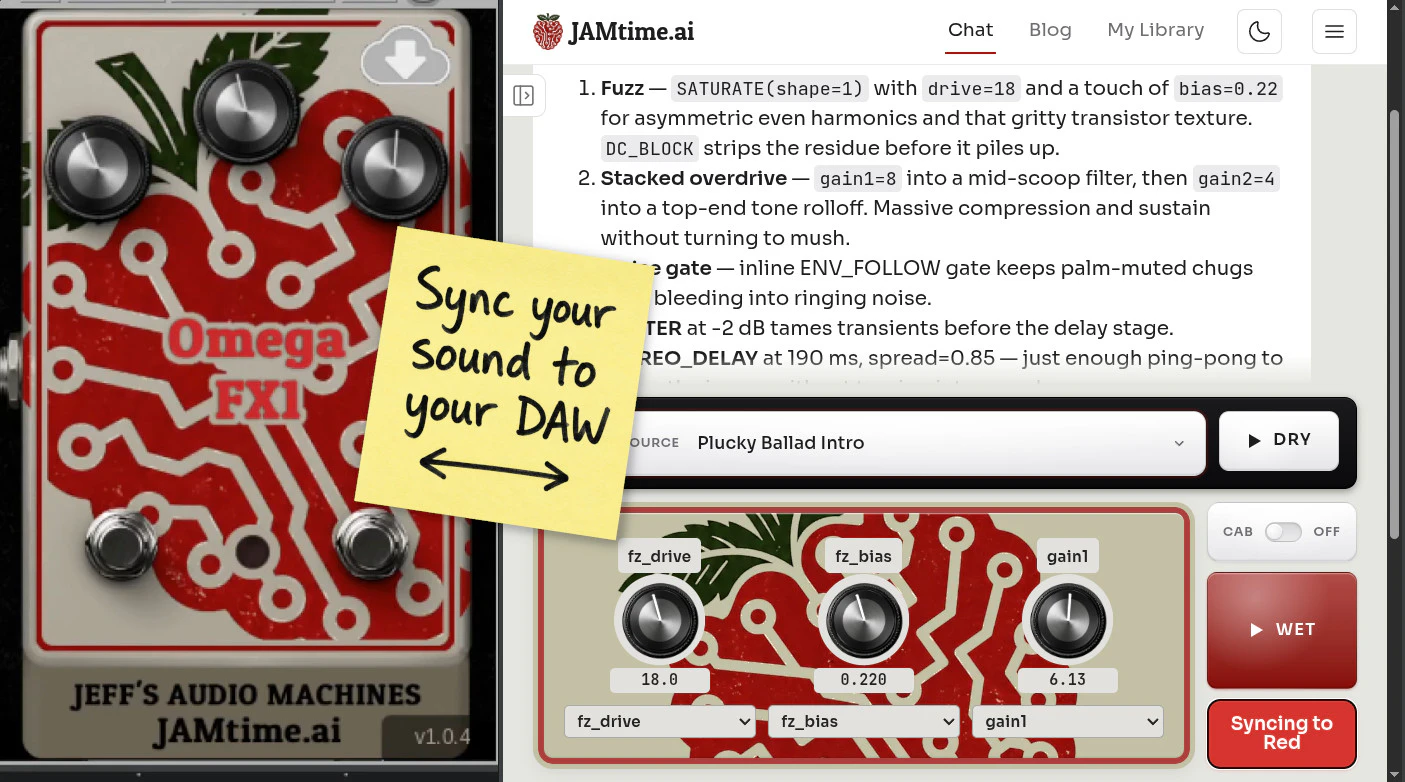
一句话介绍:JAMtime.ai是一款通过自然语言对话实时生成真实DSP吉他效果器链的工具,让乐手告别繁琐旋钮调参,用“更亮、更脏、板式混响加梳状滤波”等口语指令直接设计出可编辑、可分享的精准音色。
Artificial Intelligence
Audio
Alpha
用户评论摘要:开发者Jeff强调产品用真实DSP代码而非AI生成音频,并透露未来将推出实体踏板Omega FX1。用户关心实时延迟和稳定性,Jeff回应已深度优化C++引擎并提供了分叉回滚机制;担心音量失控或共振,他建议通过多轮对话调整参数。多数评论表达了对概念的兴奋。
AI 锐评
JAMtime.ai最值得称道的价值,不是“用AI取代调音师”,而是它精准地抓住了音乐硬件领域长期存在却被忽视的鸿沟:乐手用“温暖”“粉碎感”这类模糊词汇思考音色,而传统效果器却强迫用户理解增益、截止频率、干湿比这些工程参数。它没有走“AI生成音频”的捷径——那不过是另类采样器——而是让AI学会写可编辑、可复现的DSP图,这保留了专业音色设计的可解释性和可控性。
但必须指出,产品目前仍处于“技术惊鸿”阶段。90票的冷启动数据说明它尚未破圈。核心挑战在于:当一位吉他手说“给我一个后摇墙式失真的空灵音色”时,AI能否稳定输出在舞台演出级延迟(<10ms)下不炸音、不啸叫的补丁?开发者虽然在回复中提到了CPU优化和端口隔离,但这在堆叠复杂的模块链(如多级失真+颤音+立体声延迟)时仍是巨大工程挑战。此外,实体踏板Omega FX1的落地将直接检验“自然语言”交互是否比传统旋钮更快——在需要即兴切音色的演出中,打字聊天远没有脚踩预设快。假如未来能加入语音识别或场景化补丁推荐,它才真正具备颠覆传统调音工作流的潜力。
一句话介绍:Shuffle Design CLI 是一款终端内运行的、聚合多款AI模型(如Claude、Gemini、GPT)的网站设计工具,旨在让开发者从命令行直接生成落地页或重新设计现有网站,解决“在设计流程中来回切换工具与模型”的低效痛点。
Design Tools
Developer Tools
用户评论摘要:用户关注点集中在:1)如何与现有设计系统(如图标库、设计Token)对接,避免AI输出偏离品牌风格;2)多模型协同如何防止风格“漂移”;3)“更快”的具体指标——与直接用Claude、Cursor等工具的差异是什么。
AI 锐评
Shuffle Design CLI 的定位很取巧:它不试图造轮子,而是做“AI模型的调度器+工作流的中转站”。在AGI工具泛滥的当下,这个思路既务实又危险。务实在于,它解决了开发者“在多模型间来回复制粘贴提示词、分别等待输出、再手动合并”的体力活,把“多模型并行生成+截图+在线预览+可编辑项目导出”打包成一个终端命令,这确实契合技术团队的自动化场景(比如CI/CD中的自动设计审查、A/B测试素材生成)。危险则在于,它本质上是一个“模型代理层”,技术壁垒不高,Cursor、V0、甚至Claude自己的MCP协议都可以轻松复刻类似功能。更深层的问题是:用户评论中提出的“设计Token锁定”“图标库接入”等实操痛点,产品介绍里只字未提。如果Shuffle只做表面编排,不做深度的“设计系统映射层”,那么它很快会沦为“又一个用钱买时间的工具”——稍微复杂一点的品牌定制需求,用户会发现还是要自己写大量胶水代码去纠正AI的跑偏。一句话:Shuffle Design CLI 是一个很好的“脚手架”型产品,但若想真正嵌入研发流程,它必须证明自己能守住设计一致性这条底线,而不是只做AI的“传声筒”。
一句话介绍:Our Stories是一款帮助跨国/双语家庭为儿童创建个性化多语故事的亲子工具,让父母、祖辈等家人在异地也能用各自母语为孩子讲述连贯的睡前故事,解决双语家庭让孩子自然接触父母母语、并跨越时空进行亲子阅读的痛点。
Kids
Artificial Intelligence
Alpha
多语亲子故事
双语育儿
OPOL育儿法
睡前故事
个性化故事生成
亲子连接
亲情联络
非屏幕育儿
家庭故事书
多语言教育
用户评论摘要:用户普遍认可创意与意义。主要反馈包括:1) 一位用户遇到TTS生成错误(quota_exceeded),开发者正在追问具体语言;2) 有用户担忧跨语言故事的角色与情节连贯性,开发者解释通过OPOL模式及“继续故事”“同一主角”功能解决,并承认希腊语旁白质量是难点;3) 用户称赞“keep your hero”功能带来连续性体验。整体反馈积极,且开发者与评论者互动坦诚、具体。
AI 锐评
Our Stories切中了一个真实但小众的刚需:跨国婚姻家庭中,父母各自母语与主环境语言之间的代际断裂。它没有贪大求全,而是聚焦在“睡前故事”这一高频、高情感浓度场景,让父母角色自然融入各自语言的讲述,而非陷入翻译式生硬。产品逻辑清晰:一个tap生成故事,孩子作为主角,同一角色可延续、可交叉讲语言版本,祖辈可远程参与,且严格避开了儿童屏幕沉迷——定价上免费生成+有限旁听,仅对“印刷成书”和“无限旁听”收费,既降低了试用门槛,也表明变现重心在实物纪念品和订阅,而非内容付费。评论中暴露的“TTS错误”和“跨语言情感连贯性”问题说明其技术实现尚未成熟,尤其对小语种的语音合成和自然叙事逻辑仍需打磨。未来若不能解决用户反馈的核心技术“卡顿”,很快就面临“创意甜蜜,执行酸涩”的结局。另外,产品过于依赖父母主动生成故事,对阅读时段本身就疲惫的双语父母,长期使用意愿存疑。若能在“被动物理书推送”与“语音续播”等懒人体验上再深挖,才是真正的黏性来源。一句话:立意动人,但能否成为育儿的“每日一故事”,取决于它能否比父母自己瞎编更省心、更好听。
一句话介绍:Shroomie是一款将阅读新闻与养成蘑菇花园游戏相结合的信息应用,通过AI驱动的个性化摘要与交互式阅读,解决用户觉得传统新闻阅读枯燥、难以坚持的习惯养成痛点。
Productivity
News
Artificial Intelligence
AI新闻
游戏化阅读
习惯养成
个性化推荐
碎片化学习
互动内容
蘑菇养成
用户画像
新闻摘要
信息流
用户评论摘要:用户普遍喜爱可爱的手绘蘑菇形象,并认可其创意。主要关注点在于:个性化程度(能否屏蔽特定主题如政治)、用户可控性(自定义源与话题的添加)、Android版本何时推出,以及AI功能的未来规划。
AI 锐评
Shroomie的创意价值在于,它敏锐地捕捉到了传统新闻App在用户体验上的一个核心悖论:信息越重要,阅读感受往往越沉重。通过“种蘑菇”这一轻松、低门槛且具有成长感的游戏化机制,它尝试将新闻消费从一种基于“义务”的被动接收,转变为一种基于“期待”的主动习惯。这种“玩中学”的设计思路,在对抗信息焦虑和培养用户粘性上,确实比单纯优化摘要或Al推送的同类产品(如Artifact的遗老们)更具情绪价值。
然而,产品的潜力与风险同样明显。从用户尖锐的提问中已能看出,其核心挑战在于“游戏化”与“信息深度”的平衡。如果游戏机制过于浅层(如只是装饰性地收集蘑菇)而未能与信息消费深度挂钩,用户的新鲜感将迅速消退;如果AI个性化过于“黑盒”,无法让用户精准控制内容“禁入名单”(如完全移除政治或负面新闻),那么“缓解焦虑”的初衷便会沦为空谈。目前其“AI Prompt”个性化层是一个正确的解法,但关键在于执行细节。
此外,作为V1版本,仅支持iPhone且用户自定义源功能仍在“roadmap”上,意味着其内容生态和数据壁垒尚未建立。在一个被信息流充斥的市场中,Shroomie必须证明自己制造的“蘑菇”,不仅是可爱的数字玩具,更是能帮助用户在信息丛林中精准觅食的切实工具。否则,它很可能只是另一款短暂的“新奇玩具”,而非改变新闻阅读习惯的“必需品”。
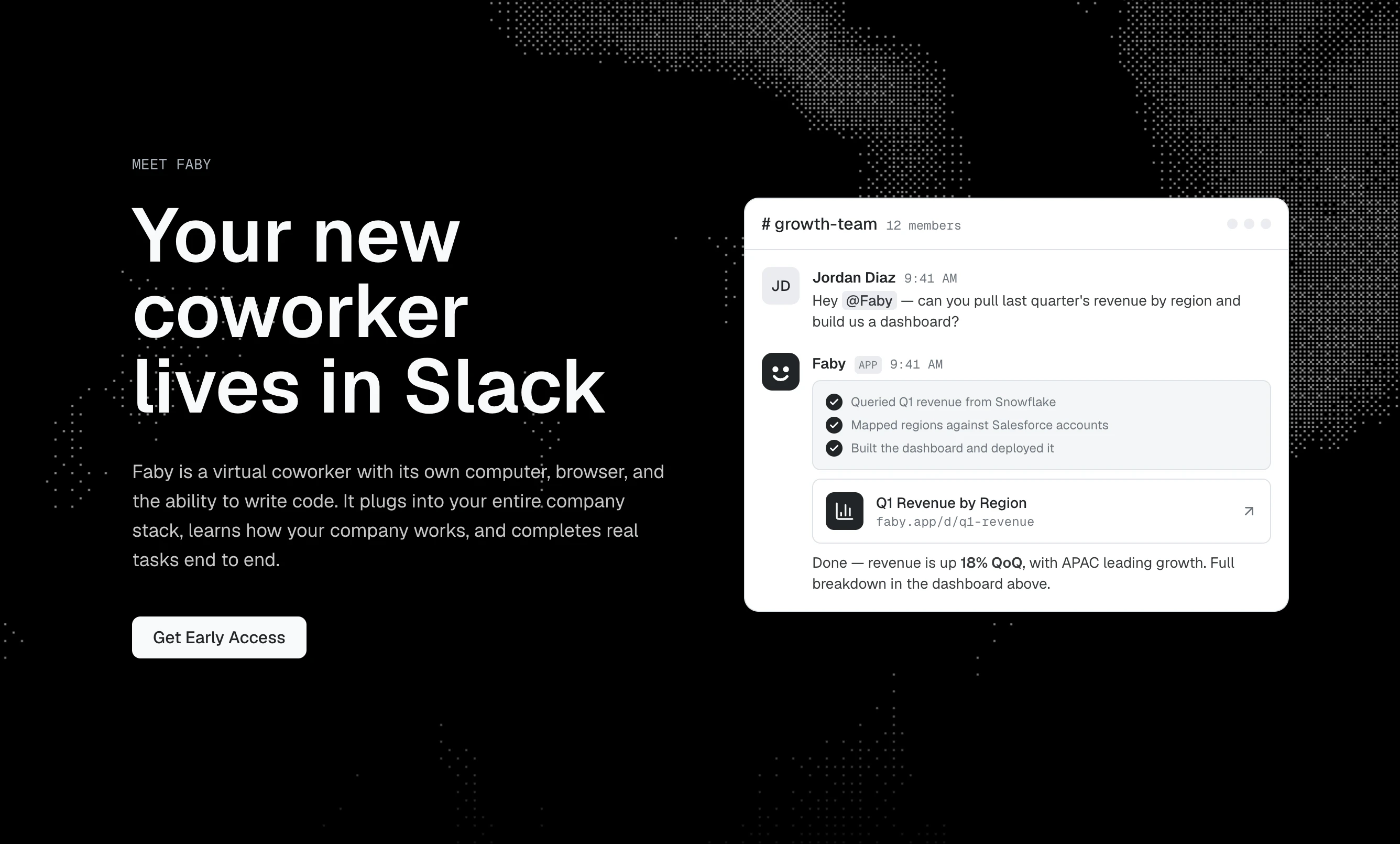
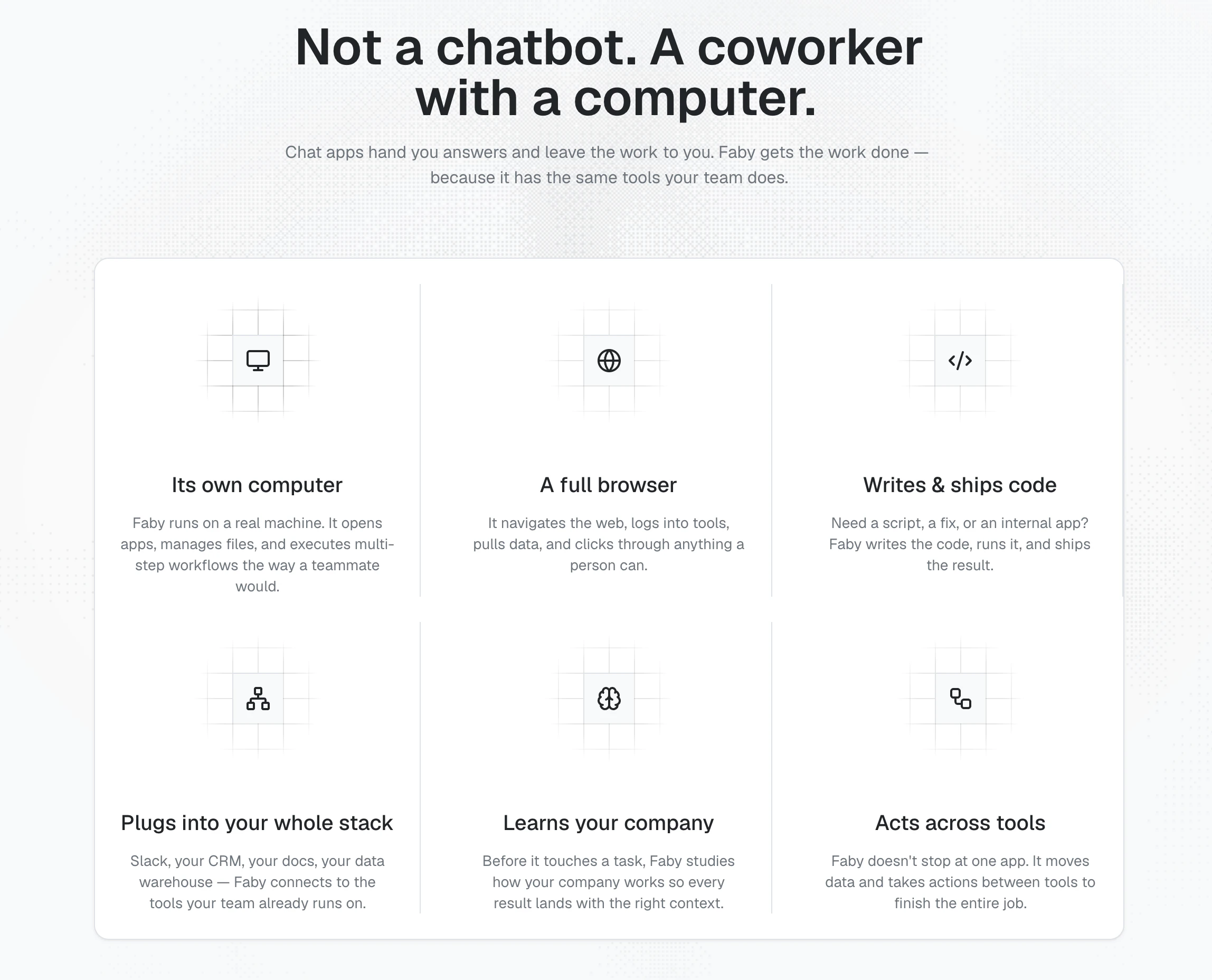
一句话介绍:Faby 是一款嵌入 Slack 的虚拟同事,拥有独立的计算机、浏览器和编程环境,能将用户用自然语言提出的工作请求直接执行到底,解决团队在聊天工具中需求落地难、依赖人工执行的痛点。
Slack
Artificial Intelligence
AI 代理
Slack 集成
自动化执行
虚拟同事
团队协作
端到端任务
代码开发
数据报告
企业工具
沙盒安全
用户评论摘要:用户关注安全边界,询问 Faby 是否在沙盒中运行、能否安装包或访问内部工具;还有用户关心输出质量控制(QA);另有人好奇产品是否仅面向技术团队,非技术人员能否使用。
AI 锐评
Faby 的核心价值不在于“生成文本”,而在于“完成任务”。它将 AI 从“建议者”升级为“执行者”,这是当前 Copilot 类产品普遍缺失的关键一环。通过赋予 AI 自己的计算机、浏览器和编程环境,Faby 实际上创造了第一个真正意义上的“数字劳动力”——它能拉取数据、生成报告、写代码、管理工单,甚至跨工具流转任务。
然而,成也“自主”,危也“自主”。用户评论中关于安全沙盒与输出 QA 的质疑直指命门:允许一个 AI 代理安装包、访问内部系统、执行代码,相当于将公司 IT 的后门钥匙交给了一个黑盒。缺乏可信的审计日志和细粒度权限控制,企业很可能不敢将它接入核心生产环境。此外,评论中“是否会写死代码”“是否仅限技术团队”等疑问,暴露了产品在非技术用户友好度上的潜在短板。
Faby 的方向无疑是正确的——AI 要落地,必须从“嘴炮”变为“动手”。但如果它不能在安全护栏、结果可解释性和低门槛配置上建立信任,很容易沦为极客的玩具,而非企业的标配。建议 Faby 尽早推出“执行记录回放”和“可配置权限模板”,让非技术管理者也能放心地把工作交给这个虚拟同事。
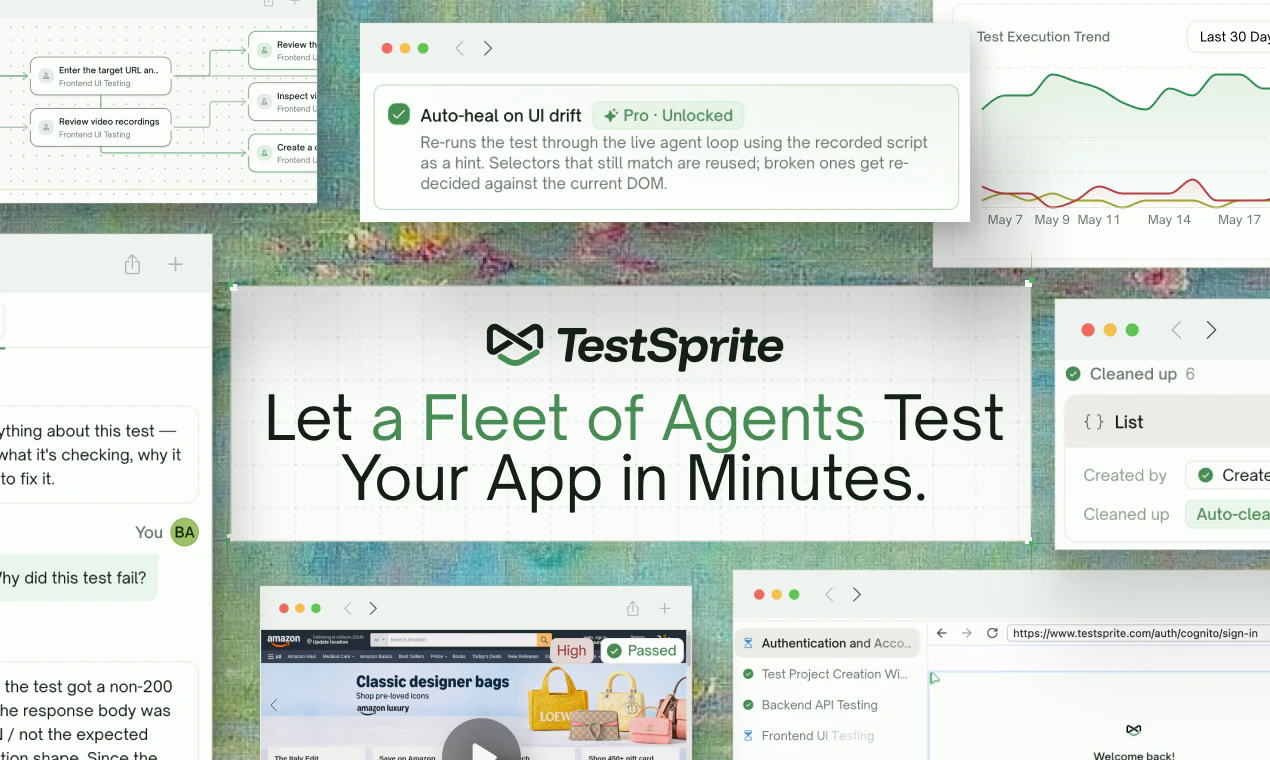


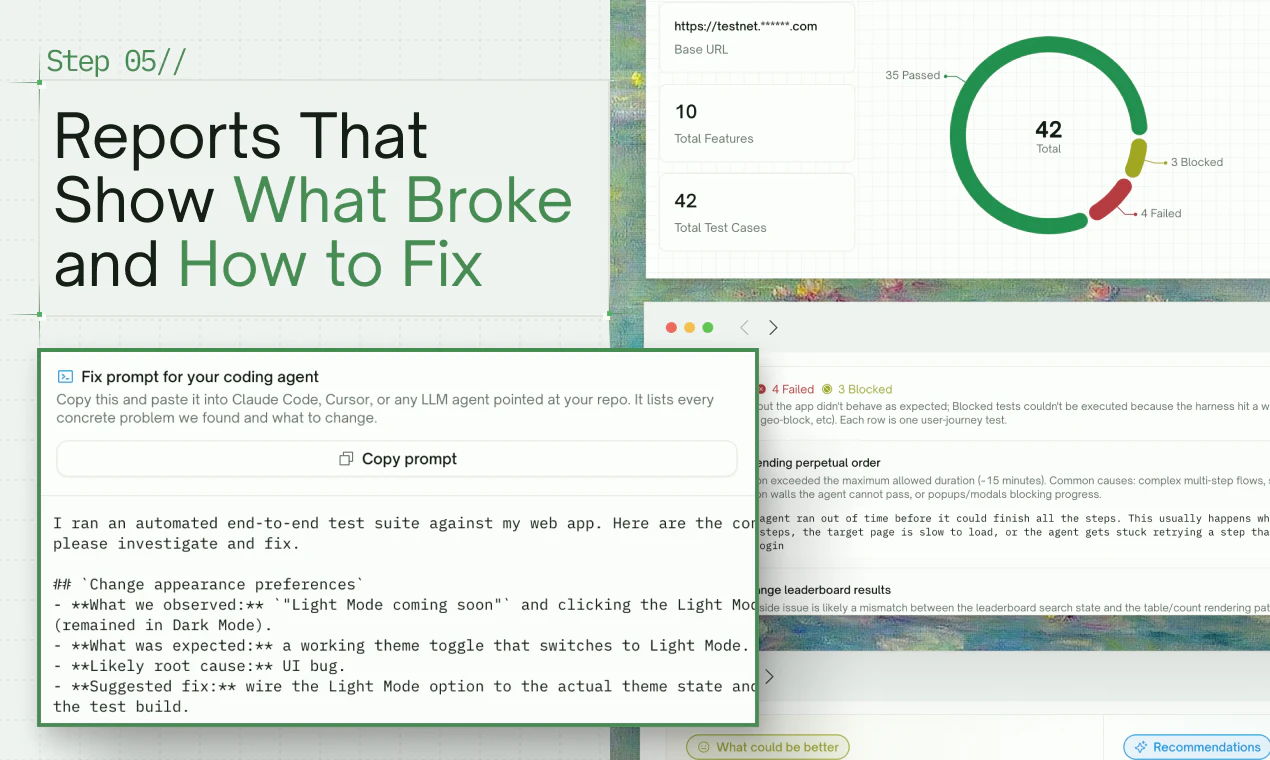
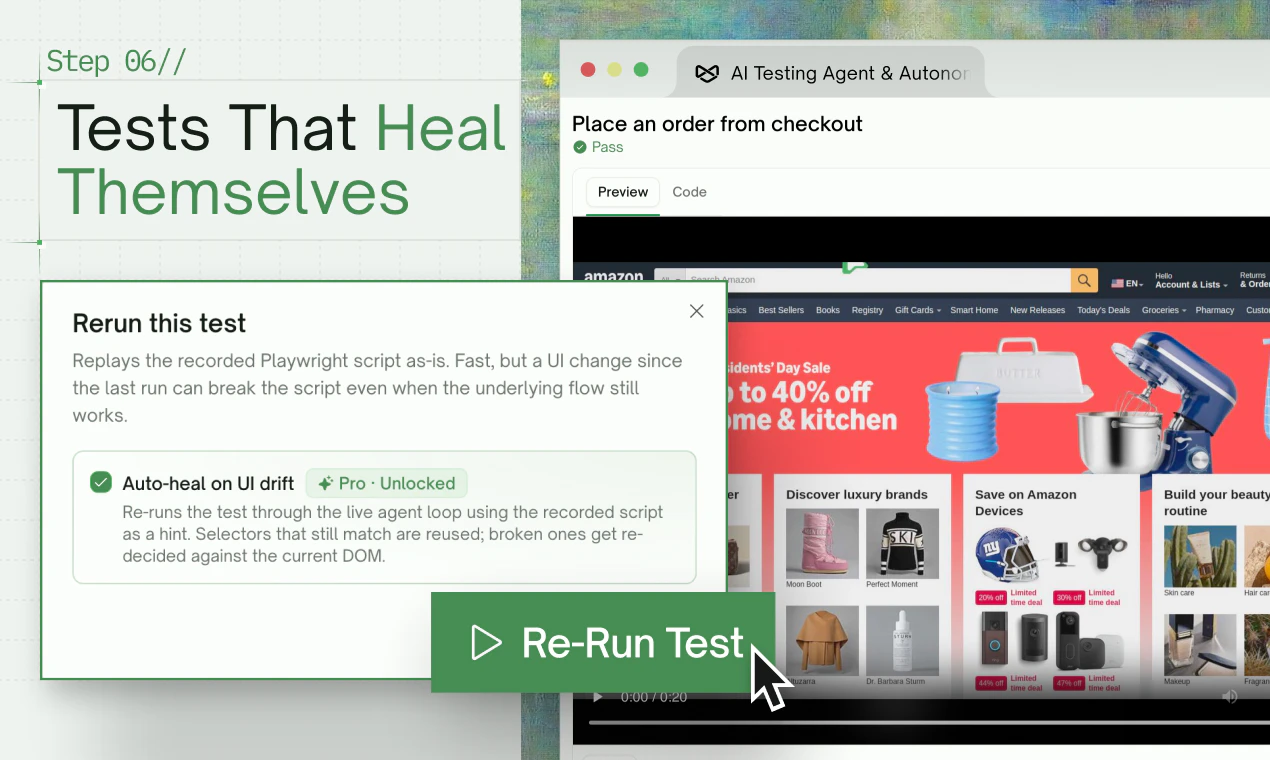







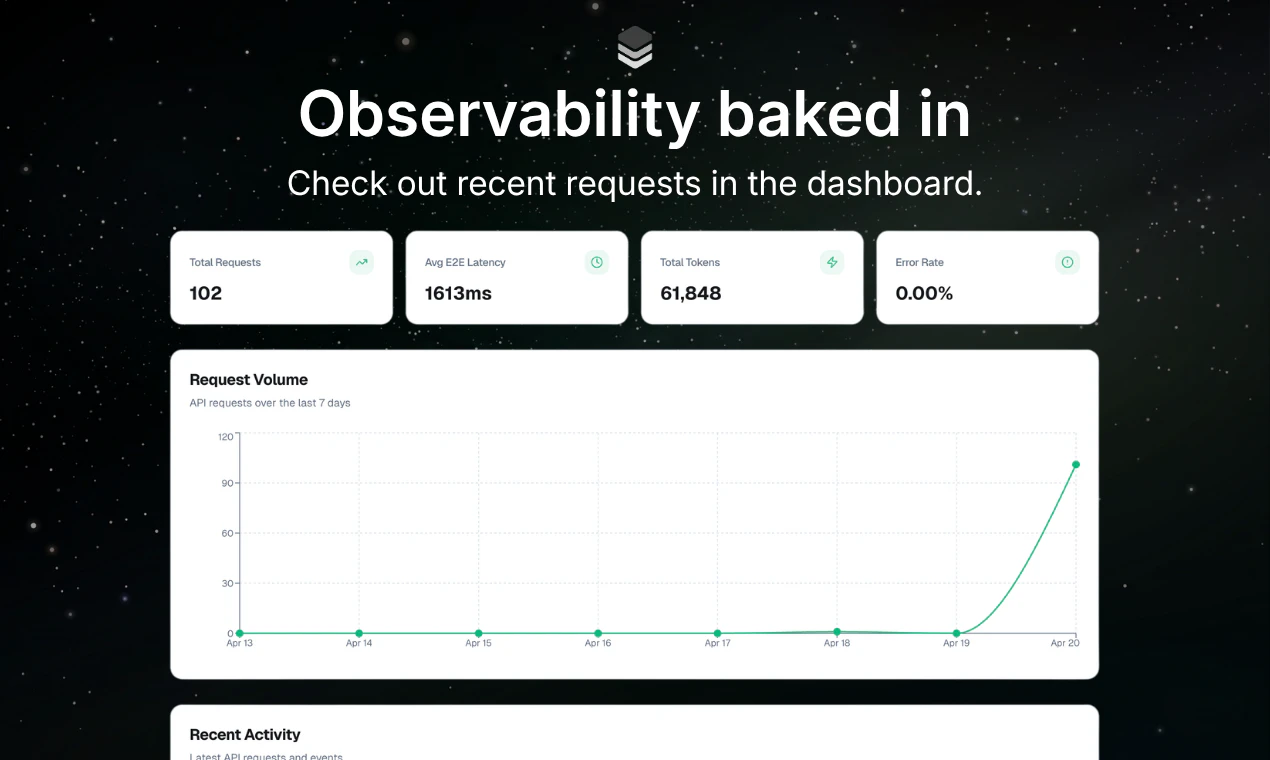

























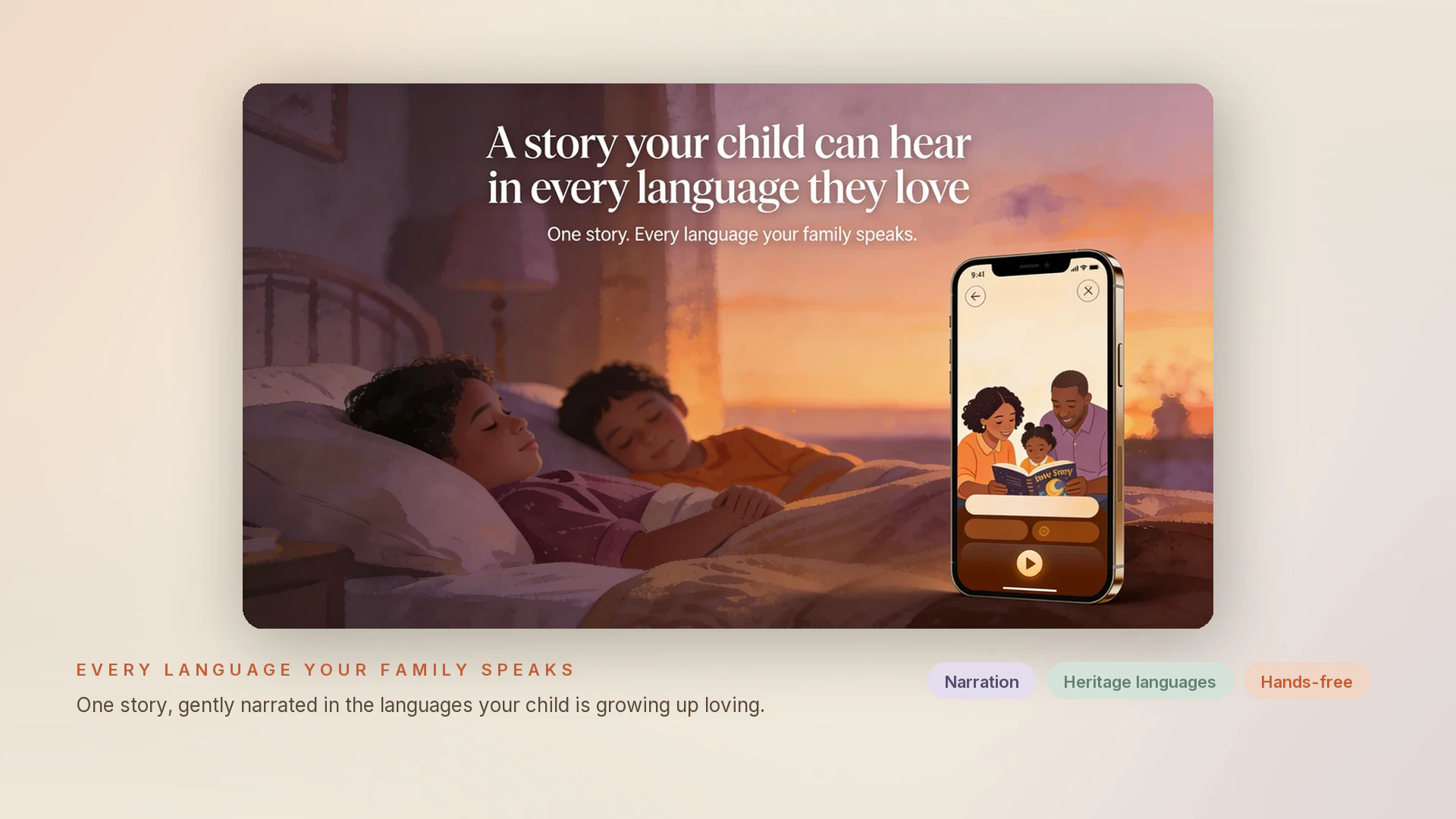
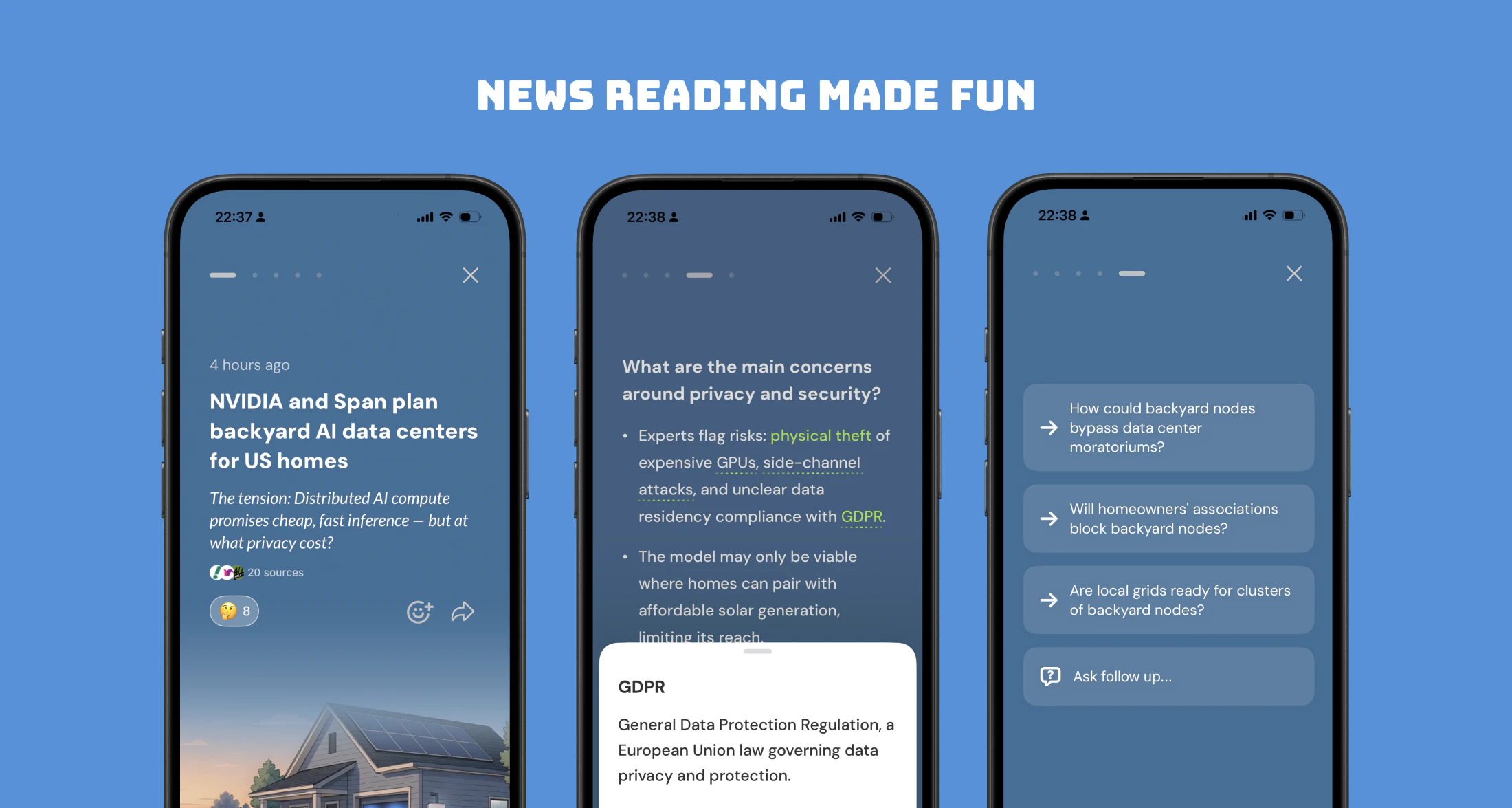




Hey Product Hunt 👋
I'm Yunhao, co-founder and CEO of @TestSprite.
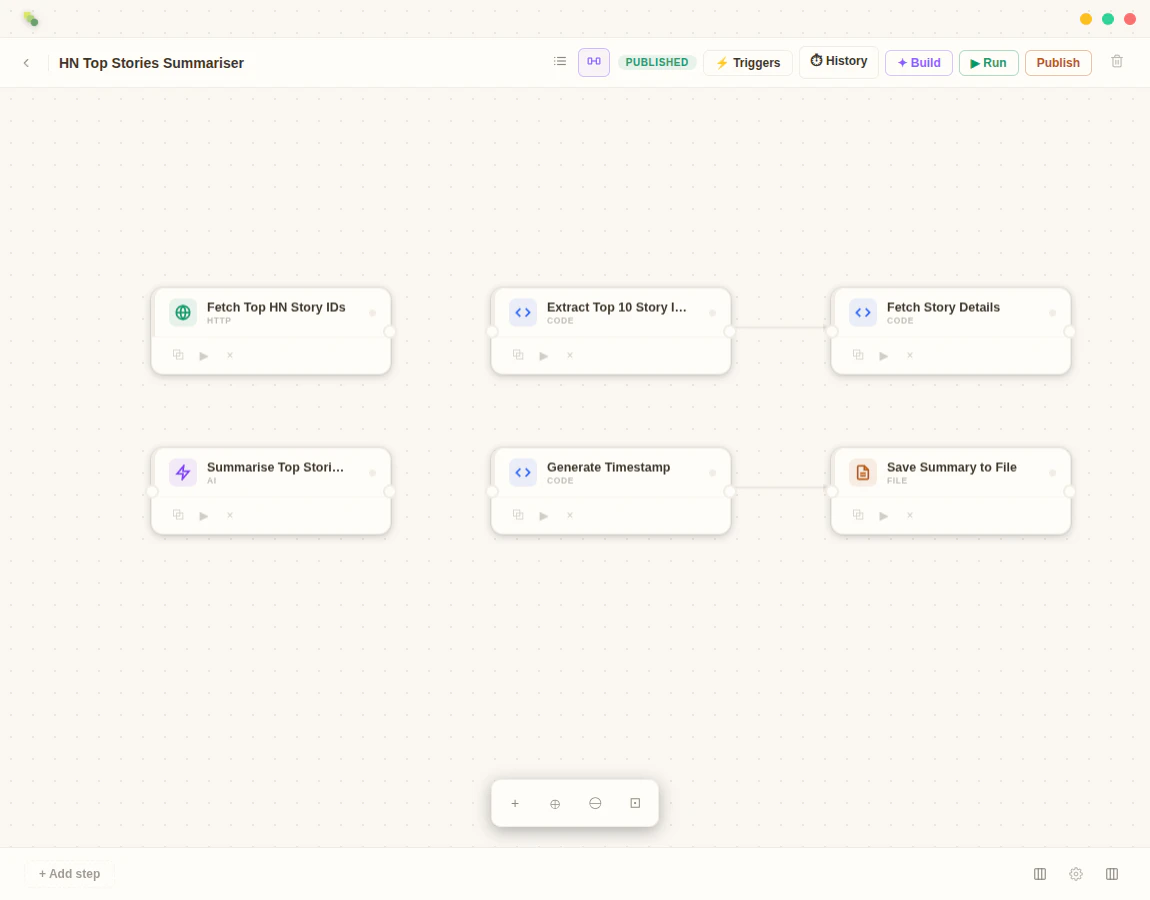
Today we're shipping TestSprite 3.0 — autonomous end-to-end testing that actually understands what your app does, not just what your code says.
✍️ Here's how it works:
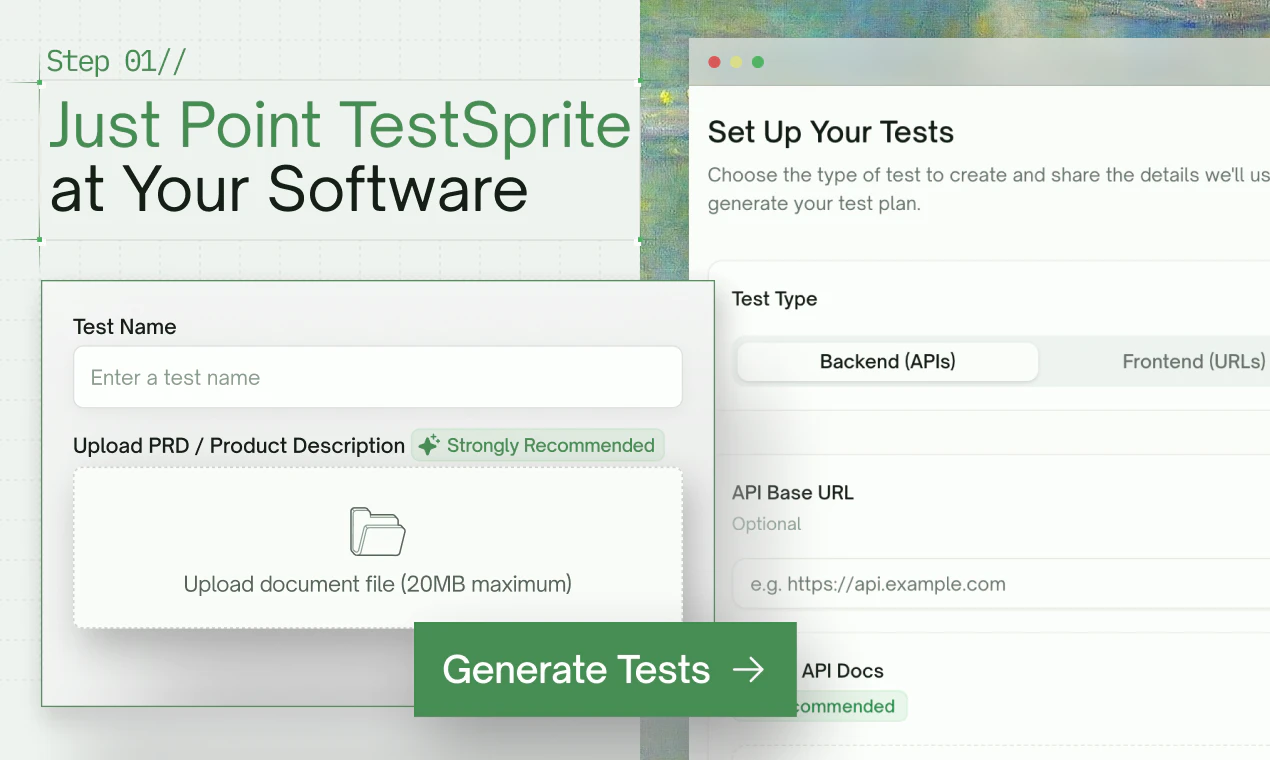
Point TestSprite at your live web app or API endpoints. Drop in your PRD or product spec if you have one (strongly recommended — it sharpens what we test).
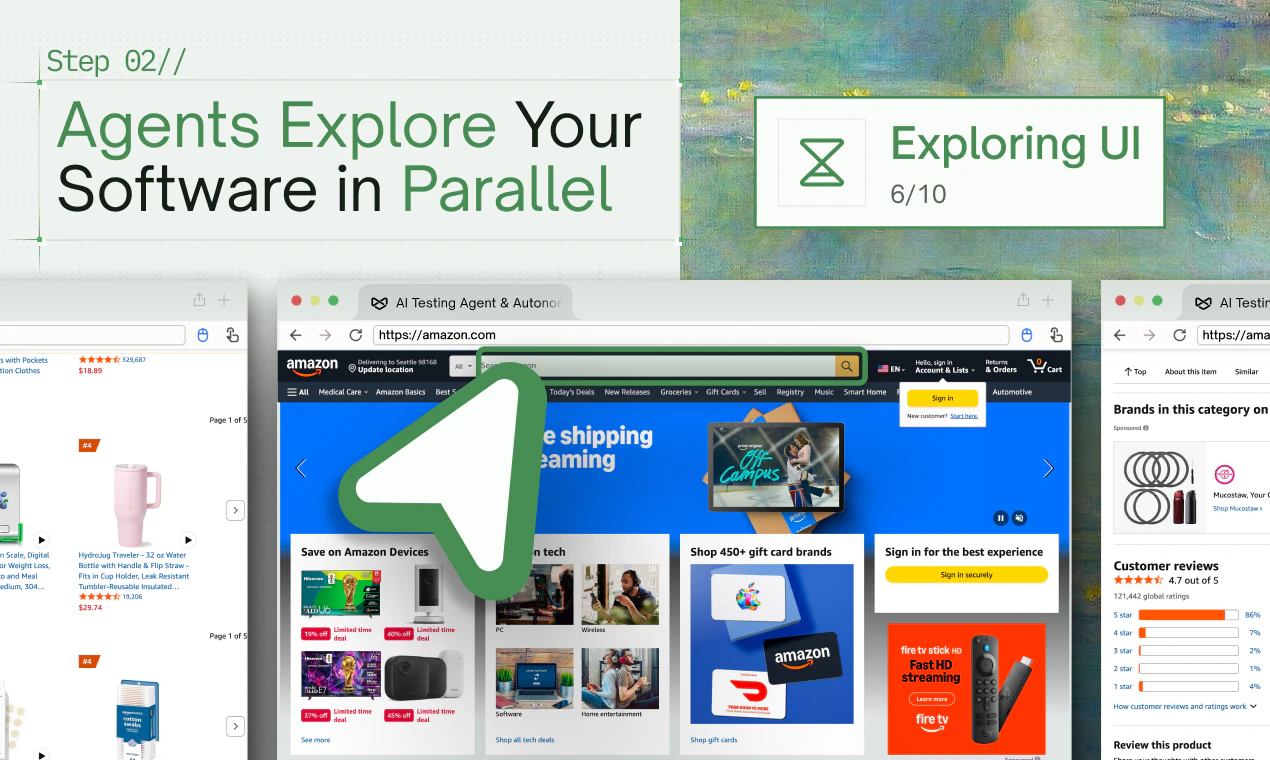
We send a swarm of AI agents to explore it in parallel — clicking through every feature like real users.
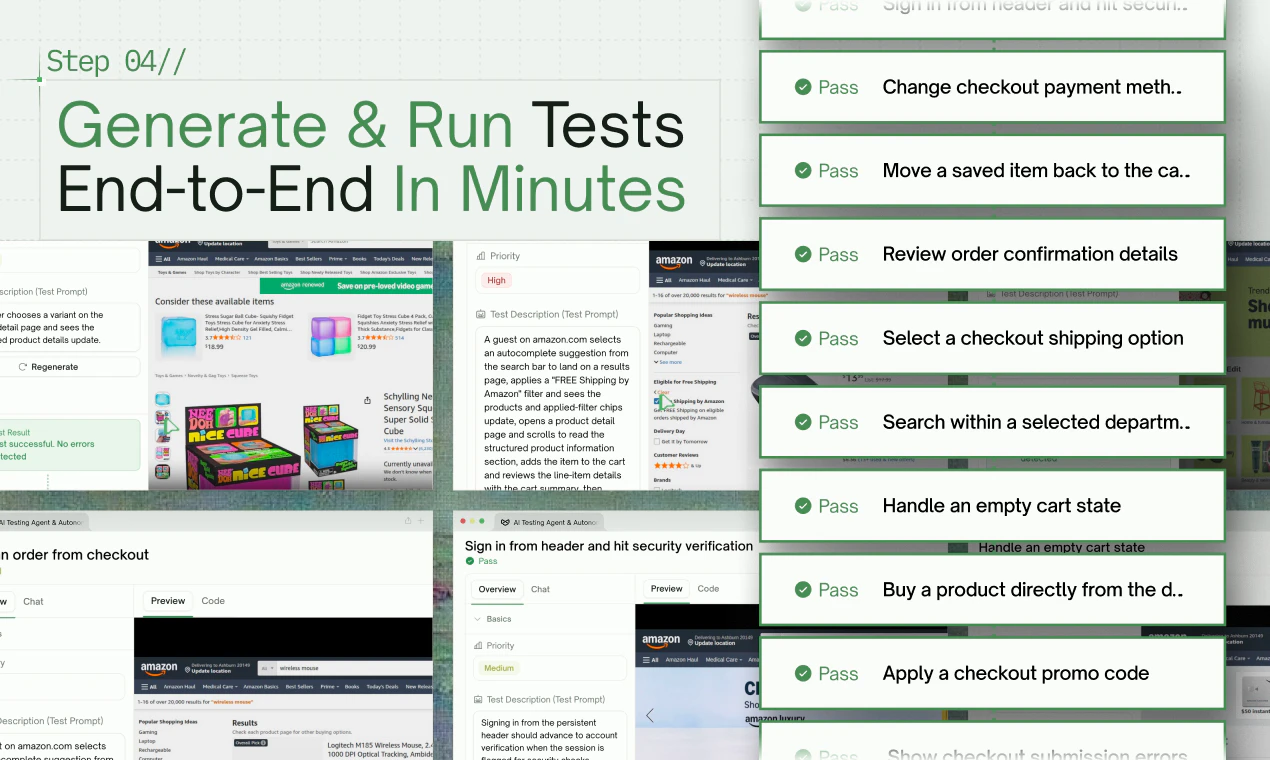
They generate full backend + frontend test suites from what they saw. Then run, debug, and auto-heal them for you.
🚀 What's new in 3.0:
Parallel exploration fleet — dozens of agents map your app before a single test is written. As far as we can tell, no one else is doing this yet.
Backend gets serious — multi-dependency integration tests, Dynamic Variables, Auto Cleanup, and a Data Flow view that makes debugging an agent-generated test feel like debugging your own code.
Frontend tests auto-heal when your UI drifts. Auto-auth keeps nightly regression sane.
Accuracy up ~40% — and it really shows on complex enterprise projects, where most agents fall apart.
Coverage jumped from ~20 to 50+ meaningful cases per run.
CLI for Claude Code and Codex users — coming soon, right inside your terminal.
🎉 Launch day offer: Sign up for our Starter package today and get your first month free.
Come tell us what you'd want TestSprite to break on. We're reading every comment today 🚀
Every piece of community feedback has shaped what we have built, and we are deeply grateful for that!
The goal has always stayed the same: learn and build from what users actually need. We hope this latest version shows how much we truly care. ❤️
Interesting! Auto-heal for UI drift sounds great in demos and gets dangerous in CI. How do you separate the two without a human in the loop? Congrats on the launch
Congrats on the launch!
one thing i would love to understand better is how the AI differentiates between actual product bugs versus harmless visual inconsistencies. Is there some confidence scoring or prioritization involved?
The autonomous debugging part sounds wild 🤯 How many retries does the system usually need before stabilizing a test?
Super cool launch 🚀
Love seeing testing evolve alongside AI coding tools. The autonomous workflow + CLI support for Claude Code/Codex users feels especially timely.
Most testing tools still feel like they need a whole setup manual before you can even start, but TestSprite making it conversational is a smart move. Love the frontend + backend coverage in one flow too.
what’s been the hardest type of bug for TestSprite to catch so far?
I am especially interested in the collaboration aspect around generated tests and debugging flows. Can multiple developers review and refine generated suites together inside the platform?
the auto-heal for UI drift is quietly the best feature here. tests breaking because someone moved a button is why most teams stop maintaining their test suite after month two
The upcoming CLI integration sounds perfect for modern AI-assisted coding workflows. Are you planning support for local-first testing environments directly from developers’ machines?
Congrats team!
One of the hardest parts of AI generated systems is transparency and debugging. How explainable are the generated test decisions when developers want to understand why a workflow failed?
Most automation tools still require a lot of brittle manual scripting, while this feels much closer to real user behavior. Can TestSprite also simulate different user roles and permission levels during exploration?
Congrats! The data flow debugging view sounds particularly useful for developers trying to trust AI generated tests. can engineers manually edit or optimize the generated flows directly inside the platform afterward?
Congrats! how transparent is the reasoning process behind generated bug reports?
Congratulations team!
The backend testing upgrades seem particularly strong for API heavy products. Does TestSprite support testing asynchronous systems like queues, webhooks, or websocket driven workflows as well?
Congrats! the CLI integration for claude code and codex users sounds exciting for developer workflows. Will developers eventually be able to generate or run targeted test suites directly from the terminal?
Generating 50+ meaningful cases automatically is a massive jump compared to traditional approaches. How do you internally define “meaningful” coverage versus repetitive or low-value test cases?
Congrats on the launch!
The parallel exploration fleet really caught my attention because most testing tools still operate sequentially. How do you coordinate multiple agents without them duplicating the same testing paths repeatedly?
E2E testing is not just about generating scripts — it is about understanding which workflows actually matter to users and the business.Curious how TestSprite separates meaningful coverage from noisy coverage. For complex enterprise apps, do the agents prioritize test cases based on the PRD/spec only, or also by app structure, failure severity, role-based flows, and real usage patterns? and can it simulate real scenarios like live meeting and chats ?
The backend integration testing upgrades sound powerful, especially Dynamic Variables and Auto Cleanup. Can TestSprite also manage dependent API chains with temporary tokens and session-based workflows?
Congrats on the release! Looks great!
Appreciate everyone checking out the launch today ❤️
This release took a lot of iteration, especially around autonomous frontend exploration and regression reliability. We wanted TestSprite 3.0 to go beyond simply generating test scripts, and actually understand how users move through an app before creating tests.
Excited to hear your feedback and keep improving it from here!
It feels like AI coding tools are moving faster than testing infrastructure right now. Do you see TestSprite becoming part of the default AI development stack?
I’ve been with the @TestSprite team for a while, and 3.0 feels like the version where the product got much more practical.
Now, instead of guessing at what your app does, TestSprite sends out a fleet of parallel AI agents to explore it first — almost like real users poking around — then generates tests from what they observed.
This is a key differentiator from most “AI testing” products that feel like asking a coding agent to squint at your app and hope for the best.
TestSprite is pushing toward something more concrete and ambitious: hundreds of parallel agents that explore, generate, and run tests at scale, and then Ralph Wiggum healing broken features.
Also: the CLI story is spicy! 🌶️ The team described an internal “Gundam mode” where Cloud Code + TestSprite CLI + AWS CLI can keep coding, testing, checking logs, and iterating for days.
That’s the bit I’m looking forward to trying!
Congrats on the launch! 🎉 The exploratory-testing-by-parallel-agents framing is the interesting move — QA traditionally treats exploration as the part you can't automate, only deterministic scripted runs. One question: when auto-heal fixes UI drift, how do you prevent a 'false pass' where the heal silently masks a real regression? Curious where the line sits between adaptation and over-tolerance.
As a solo dev building small SaaS tools, testing is always the first thing I skip when rushing to ship. The "90% cost reduction" claim is bold — curious how it handles edge cases in backend API testing specifically. Does it work well with lightweight stacks like Vercel + serverless functions?
Curious how TestSprite handles visual regression for design tokens specifically — if a colour or spacing token changes upstream in a design system, does the agent catch that drift across every affected component automatically, or is visual diffing still a separate manual step on top of the functional tests?
Really curious — when the agents explore an app, do they sometimes discover workflows or edge cases that developers themselves overlooked?
Parallel agents for testing is the right approach running tests sequentially is the bottleneck nobody talks about. Does it work for iOS/mobile apps or mostly web? That's where I'd love to use this.
This sounds awesome, particularly PRD to test case development! I gotta connect the MCP to Brief.