PH热榜 | 2026-05-25
一句话介绍:Unabyss为重度AI用户打造一个自动化的个人上下文层,从日常应用提取并结构化身份与知识,通过MCP协议让所有AI工具共享,彻底告别反复自我介绍和跨平台信息孤岛。
Productivity
Artificial Intelligence
AI上下文层
MCP协议
跨平台AI记忆
知识管理
个人数据聚合
用户隐私控制
自动化工作流
生产力工具
AI Agent
Prompt工程
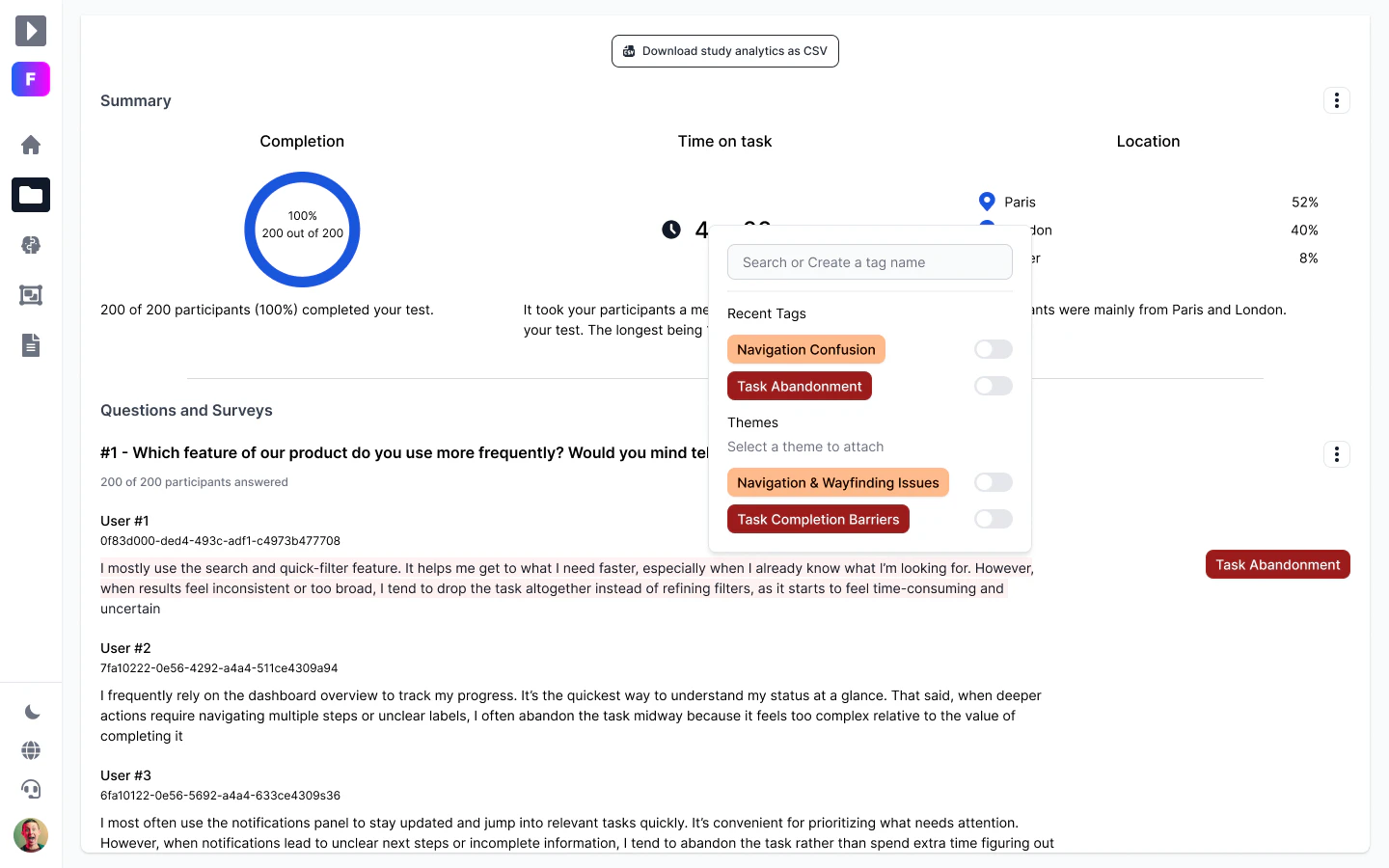
用户评论摘要:用户普遍认可解决了多AI工具间信息割裂的核心痛点,但高频质疑上下文新鲜度(同步间隔、变更触发机制)、冲突解决逻辑(多源数据优先级)、文件膨胀处理(自动摘要与版本管理),以及质疑“预提取”本质仍是缓存,存在数据漂移风险。
AI 锐评
Unabyss切中了一个正在指数级膨胀的痛点,但它的“杀手锏”或许也是其阿喀琉斯之踵。
**价值核心**:它没有选择做又一个“记忆插件”,而是以用户为中心,把分散在多个SaaS应用中的碎片信息,抽提、清洗、结构化为一套可读、可编辑、可精细授权的本地化文件(persona.md等)。这比ChatGPT的被动记忆、Claude Projects的封闭缓存高明了一个维度——用户真正拥有了“副本控制权”,并能通过MCP这个正在标准化的协议,一次性分发给所有Agent。对跨平台重度玩家而言,这是当前最优雅的“一次构建,随处使用”方案。
**隐忧与挑战**:
1. **新鲜度悖论**:所谓“自更新”目前仍依赖源应用的同步间隔(如5分钟),而非实时的变更事件推送。在高速迭代的AI工作流中,几分钟甚至几小时前的陈旧信息足以让Agent产生严重误导。正如评论指出的,任何缓存都会漂移。当“自动同步”变成“自动过时”时,信任会迅速崩塌。
2. **冲突仲裁机制**:当LinkedIn与Notion对“职位”描述矛盾时,产品目前依赖人工确认一次“作为基座”。这在初期可行,但复杂场景下(多项目、多身份),缺乏自动化、带权重的冲突解决逻辑,会导致上下文混乱。
3. **规模化壁垒**:文件会膨胀。虽然有摘要和版本控制,但如何在不丢失关键细节的前提下,保证上下文能满足Agent的token窗口限制,并维持高信息密度,是技术上的硬骨头。
**锐评**:
Unabyss像一个极富才华的仓库管理员,把货品(你的上下文)归置得井井有条,并给了你(用户)一把万能钥匙(MCP)。但仓库里的货品是否“新鲜”,完全取决于供应商(Gmail、Notion)的通知系统是否准时。它解决的是“你有地方放”和“如何找”的问题,但尚未根治“东西已经坏了你还在吃”的问题。
对于早期的尝鲜者和技术先锋(founder、builder),这是提升AI工作流一致性的必备工具。但要称为“终极上下文层”,它必须进化出主动的情境感知能力——不仅是被动同步,更要能基于模型交互的反馈,智能判断哪些上下文“已腐坏”并主动提示刷新。否则,随着记忆量增大,它可能从“第二个大脑”退化为“另一个需要维护的档案柜”。
一句话介绍:own.page 让创作者和创始人无需代码,能在1分钟内搭建出比传统“链接聚合页”更具视觉表现力和生命力的个人网站,解决社交媒体简介过于局限、现有工具过于模板化和缺乏个性化表达的痛点。
Social Network
Social Media
Website Builder
个人网站
链接聚合页
拖拽式建站
无代码
创作者工具
个人品牌
网红营销
数据分析
落地页
Bento风格
用户评论摘要:用户普遍赞赏设计美观和易用性。主要问题:有用户询问与Carrd、Notion、Linktree等工具的核心差异;以及是否支持动态数据拉取(如自动更新最新博文或社交内容)。创始人回应称动态更新已在路线图中。
AI 锐评
own.page在Product Hunt上获得484票,评论热情看似不错,但深挖来看,这款产品本质上依然是“C端版本的Carrd+Linktree缝合怪”,并未跳脱出Bento风格页面生成器的框架。其核心卖点“比链接聚合页更像个人网站”更像是一种营销话术,而非技术壁垒。
从用户反馈看,大家夸的都是“好看”、“易用”,这恰恰是此类工具的准入门槛,而非护城河。当Carrd、Notion、Super等工具都能用更低的成本或更高的自由度实现类似效果时,own.page的差异化究竟在哪?创始人强调的“动态数据拉取”仍在路线图上,这意味着当前产品只是一个精美的静态展示页面,对于需要“活”的内容(如最新博文、社媒缓存)的创作者来说价值有限。
真正值得关注的是创始人透露的长期愿景——社区和受众增长,但这恰好是虎口夺食。从“花钱做页面”到“用页面赚钱”,中间隔着用户增长、内容分发、社交网络效应等庞杂的难题,而own.page目前只解决了第一步“展示”。其“Freemium”模式靠收20%折扣的Pro年费,商业模式极为依赖付费转化率。在AI建站和超级App不断吞噬入口的今天,这种轻量化工具极易被巨头复制或降价挤压。
一句话总结:一个合格的精美PPT,但距离一个有生命力的“数字家园”,还差一个时代的距离。除非能快速补齐动态生态和社交裂变能力,否则大概率会淹没在Link-in-Bio工具的红海中。
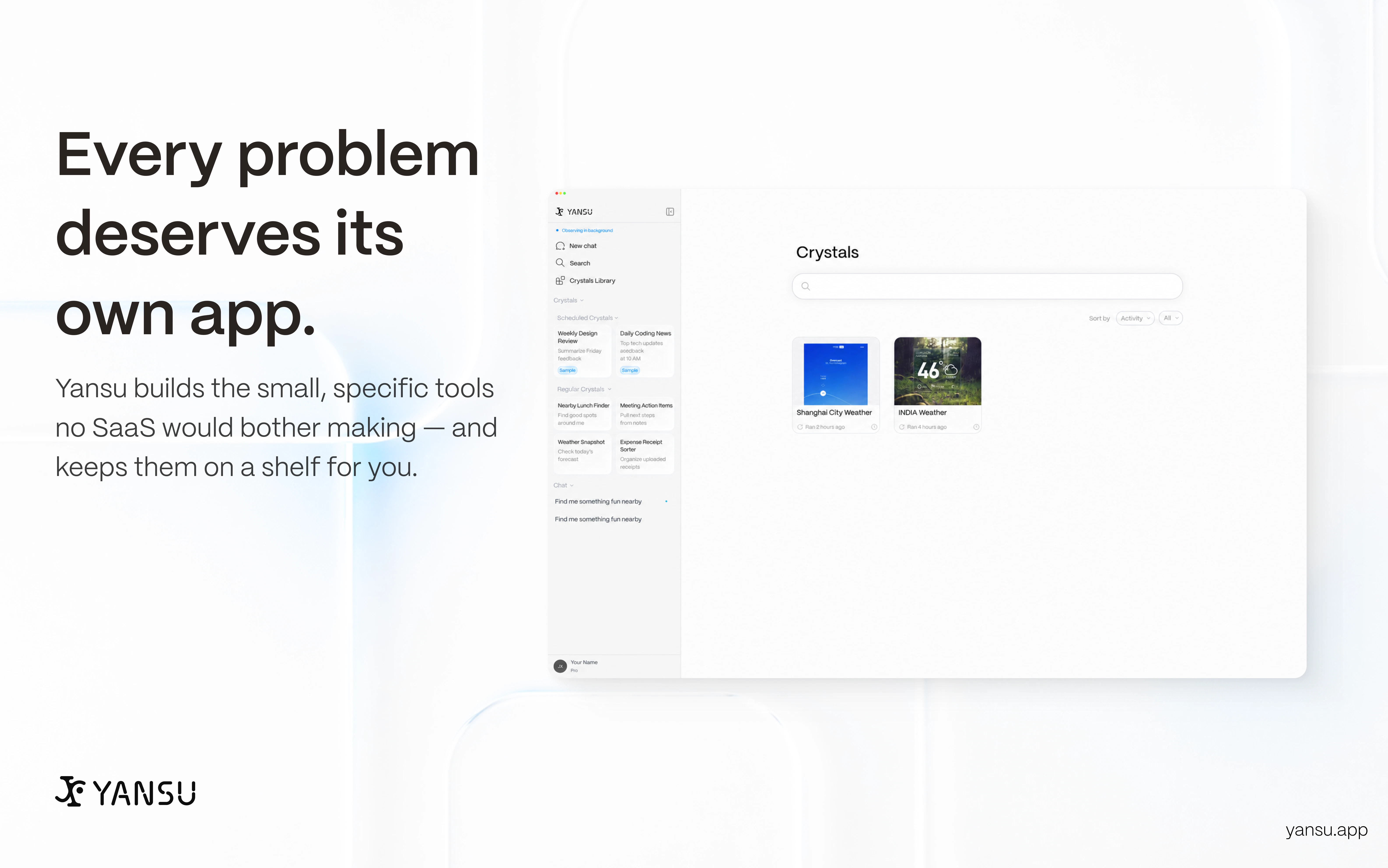
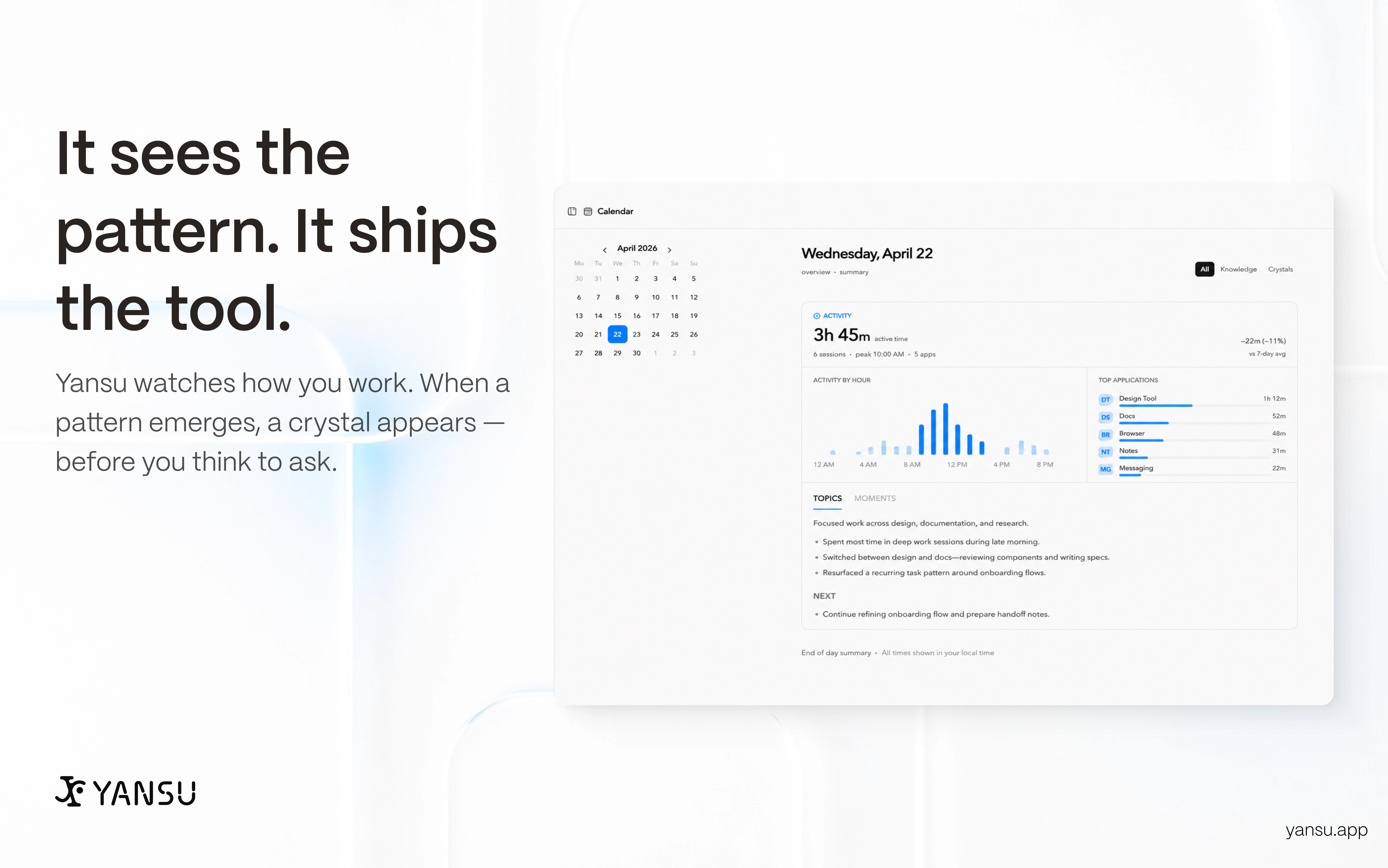
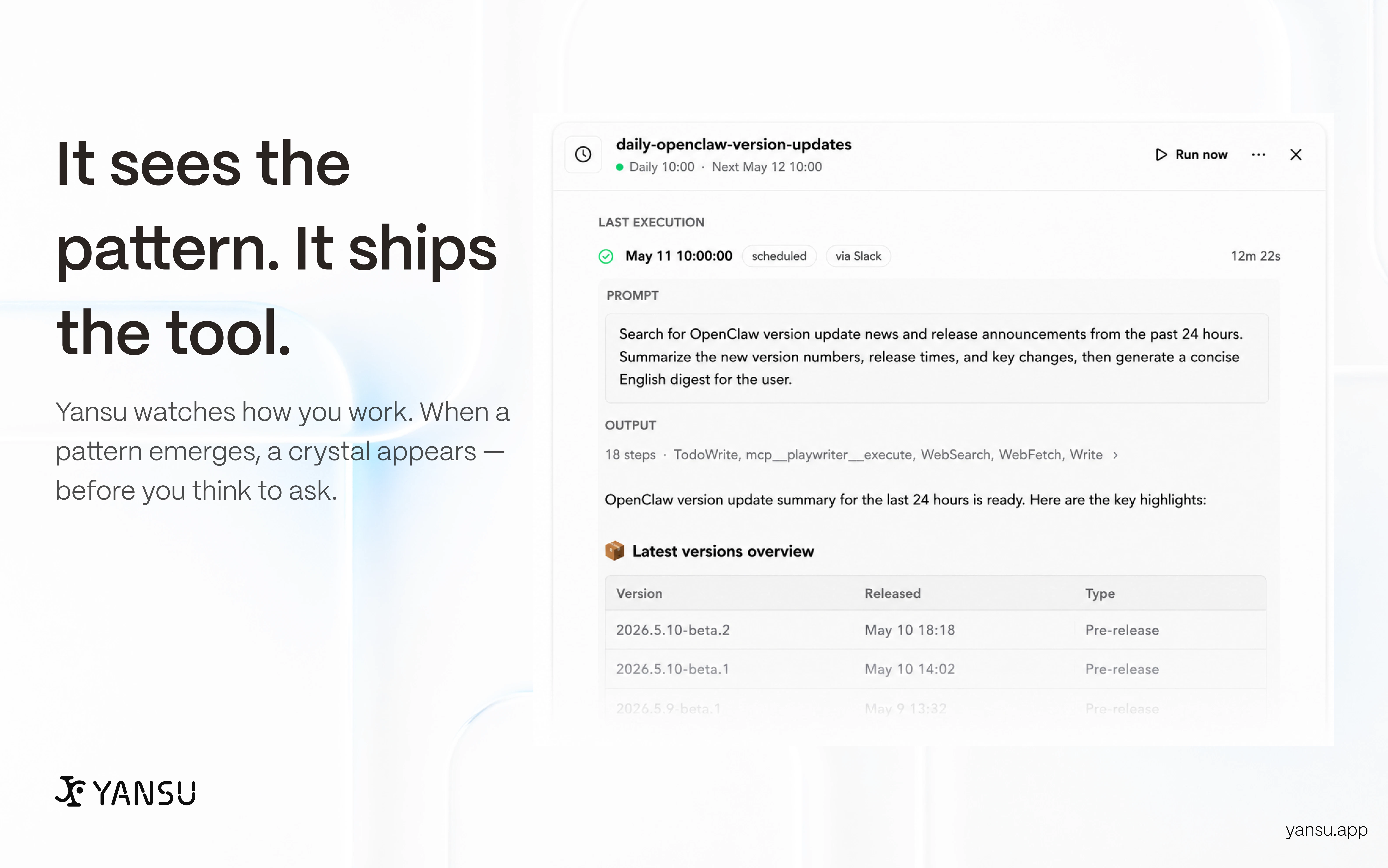
一句话介绍:Yansu是一款通过持续观察用户屏幕和工作流来学习个人工作模式,并自动生成定制化软件和自动化流程的AI工具,解决了用户需要手动描述和配置自动化任务的痛点。
Productivity
Artificial Intelligence
Maker Tools
AI自动化
屏幕监控
工作流学习
低代码工具
智能体
办公效率
个人化软件
隐私保护
本地处理
用户评论摘要:用户核心关注隐私、意图推断的准确性及误操作的纠错机制。开发团队强调本地处理与PII脱敏,但学者提出“Hand-Off”若执行错误如何发现与回退问题。另有用户询问区分临时与永久行为变化的能力,以及面对API变更的适应性。
AI 锐评
Yansu试图回答一个根本问题:软件应适应人,还是人去适应软件?其“被动观察-主动生成”的理念极具颠覆性,直指当前自动化工具“上手即静态”的根病。技术上“搭模型理解意图”的路线远超简单的宏录制,野心可见一斑。但“预定义正确”的坑里,跳过手动配置就意味着把信任全押给了黑盒推断。用户评论中关于“误操作发现与回滚”的尖锐提问戳中了软肋——当前回复“我们会在执行前询问”本质上是将决策权推回给用户,违背了“主动为主”的设定,这是理念与实践的割裂。隐私作为护城河也非坦途:本地脱敏虽好,但从截图推断商业机密、非公开合同等敏感信息的边界何在?尽管技术宣传漂亮,但产品从“玩具”到“严肃生产力工具”还差一个决定性的闭环:一套用户能轻松编辑、回溯、审核AI生成的“工作流释义”,让透明度和可解释性成为新的信任基石。Yansu如果只停留在“自动生成”,不做成“可理解、可修正的共创伙伴”,大概率会沦为下一个“看似性感,实则鸡肋”的自动化demo。
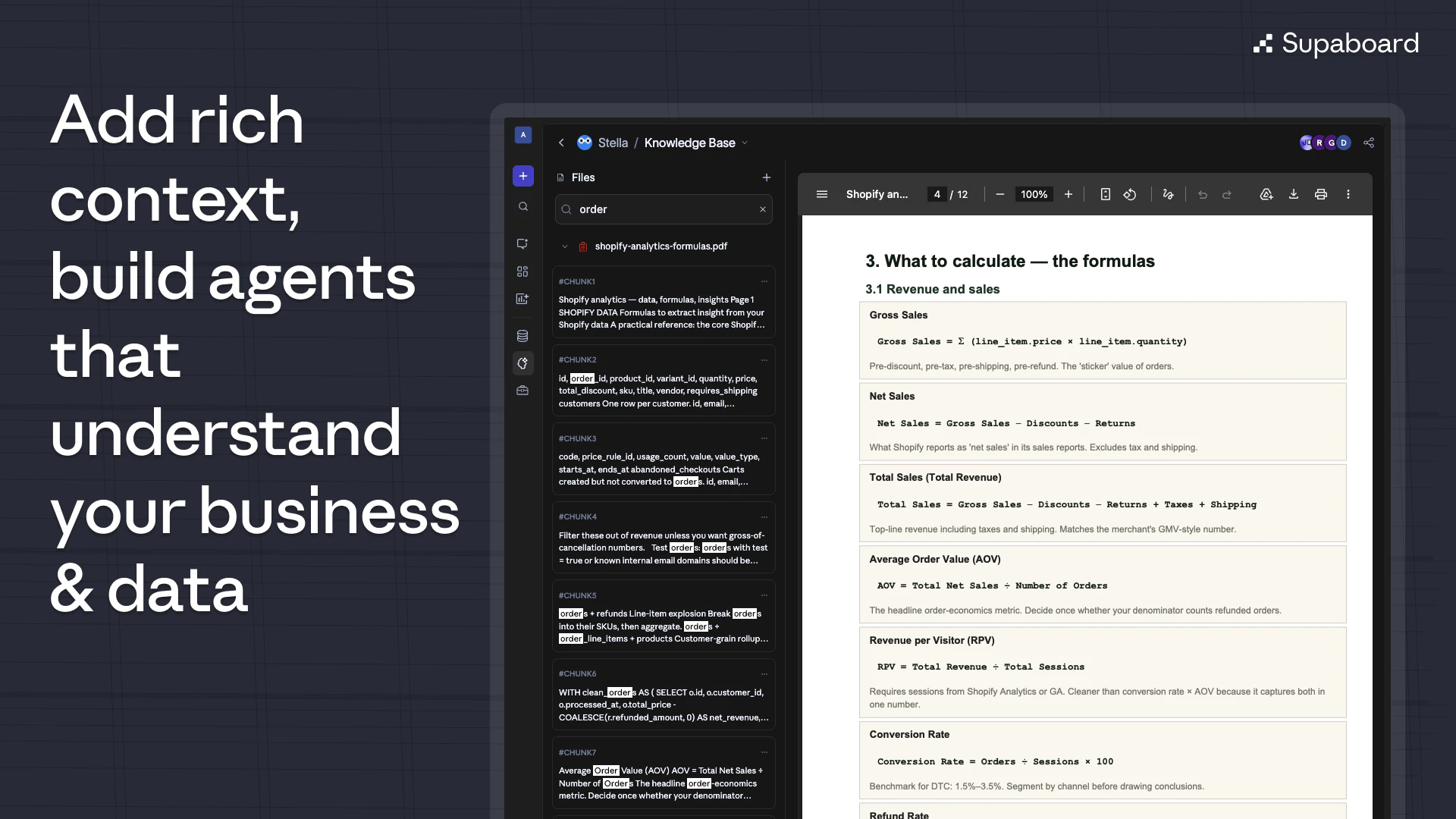
一句话介绍:Supaboard 3.0 是一款让非技术团队通过自然语言提问、无需编写SQL即可快速创建仪表盘和获取业务洞察的AI原生商业智能平台,解决了传统BI工具依赖技术背景、仪表盘泛滥和报告响应慢的核心痛点。
SaaS
Data & Analytics
Data Visualization
AI商业智能
自然语言查询
无代码分析
智能仪表盘
数据治理
业务逻辑代理
600+数据连接器
文本转SQL
数据问答
自助分析
用户评论摘要:用户普遍认可其快速从提问到仪表盘的能力,但高度关注数据治理与审计,尤其是多数据源下业务逻辑冲突时的处理机制。核心疑问包括:能否替代Metabase/Looker、是否支持查询溯源与编辑、如何处理关键指标中途变更,以及定价模型(99美元)背后的技术支撑。部分用户指出“业务逻辑在先”是差异化价值,但强调审计性和防幻觉能力是信任前提。
AI 锐评
Supaboard 3.0 的标语“理解你业务的AI分析师”精准戳中了当前AI+BI领域的最大软肋——大多数文本转SQL工具只做到了“语法正确”,却做不到“业务正确”。其核心价值不在于又多了一个ChatGPT wrapper,而在于它试图将“业务逻辑”提升为一等公民,让AI不是根据你问的句子去猜,而是根据你预设的规则去答。这种“规则优先、查询后行”的架构,至少在理念上跳出了纯大模型幻觉的泥潭。
但评论中暴露的信任危机才是真正的生死线。用户反复追问“如何保证两个部门的营收定义一致?”“能否追溯源数据行?”“指标变更时AI如何适应?”——这些不是边缘需求,而是企业级数据分析的硬门槛。Supaboard在宣传中提到了“治理与审计”,但在回应中更多是理念层面的“我们会标记不匹配”,而非给出具体的技术实现路径(如血缘追踪、版本化规则集、冲突仲裁算法)。没有这些,它就仍然是一个“看起来很美的原型”。
最大的亮点在于定价策略的回应。团队没有陷入模型参数竞赛,而是直接将其定位为“价值10万美元的数据分析师”的平价替代,这对中小企业极具杀伤力。但危险也在于此:一旦出现一次“自信的错误回答”,信任崩塌的速度会比传统BI更快,因为用户没有SQL能力去验证。
一句话总结:方向对了,但“业务逻辑代理”的工程化落地,远比PPT上展示的仪表盘要残酷得多。
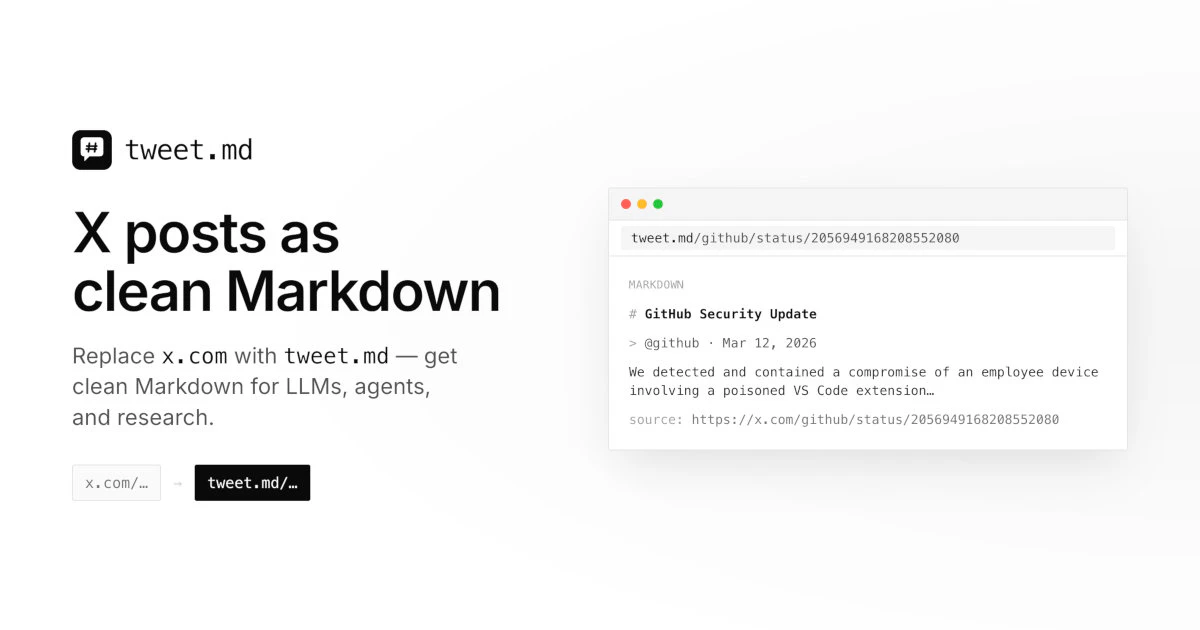
一句话介绍:tweet.md 通过简单的URL替换(x.com→tweet.md),将X平台帖子/线程一键转为干净的Markdown格式,解决AI工具、笔记软件和大模型调用时复制内容格式混乱、缺失上下文的痛点。
API
Social Media
Artificial Intelligence
X内容转换
Markdown输出
AI工作流
笔记转存
URL替换
LLM数据处理
线程结构保留
Obsidian集成
Agent Skill
社交内容清净化
用户评论摘要:多数用户认可其解决实际痛点,赞赏URL替换的简洁设计。主要建议:1.输出中加入完整的来源元数据(原URL、作者、抓取时间等);2.扩展支持LinkedIn等其他社交平台;3.确认图片是否保留URL而非文本;4.关心API限流与缓存机制。
AI 锐评
tweet.md切中的是一个被低估但日益严重的需求——社交平台内容的“格式污染”。当X的内容被大量用于AI训练、RAG检索或LLM上下文窗口时,原始HTML里的广告脚本、动态加载块、响应式冗余代码会直接破坏解析鲁棒性。该项目用极简的URL重写而非浏览器扩展或脚本,降低了用户学习成本,本质上是在构建一个“社交内容的数据清洗中间层”。
但从商业与生态角度看,产品存在明显天花板。首先,完全依赖X API意味着随时可能因政策或速率限制而失效,且API对历史线程的完整度(如删除帖、编辑历史)支持有限,用户评论中提到的“抓取时完整性”问题正是其隐含缺陷。其次,Markdown输出虽然优于HTML,但本身仍是线性文本结构,对连锁引用、嵌套转推、媒体轮播等X原生复杂交互的还原能力存疑。最后,功能单薄(仅X平台),一旦头部AI工具(如ChatGPT、Cursor)内置同类功能或X自身推出官方Markdown导出,tweet.md的替换逻辑将瞬间失去护城河。
其真正的护城河可能在于“开发者生态集成”——通过Agent Skill让AI自主调用,并形成缓存+结构化元数据的付费墙。但若不能快速将相同模式复制到LinkedIn、Threads、小红书等碎片化内容源,它只会是小众生产力爱好者的一把瑞士军刀,而非数据清洗赛道的基础设施。产品思路很聪明,但体量上还无法与“复制粘贴”的用户习惯竞争。
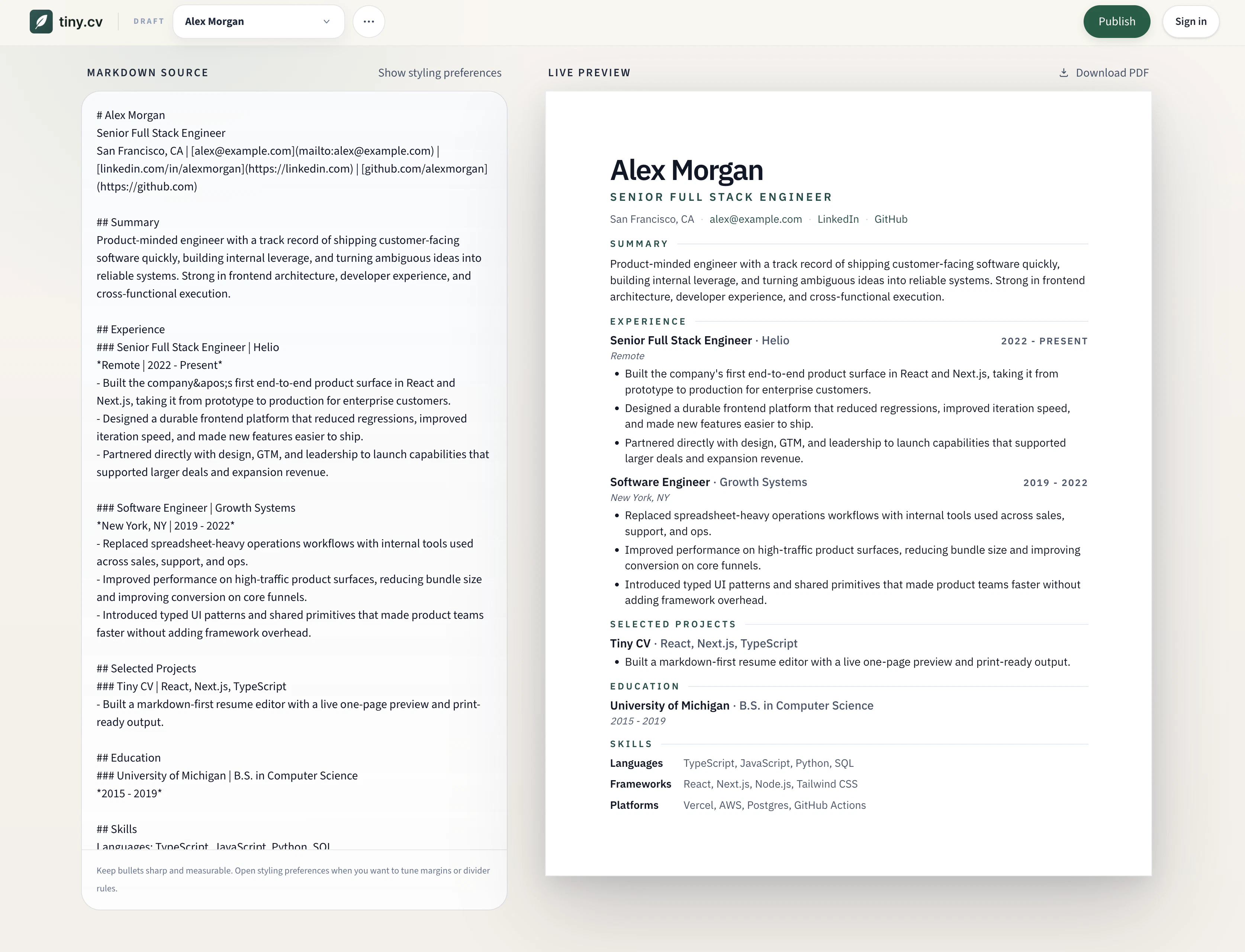
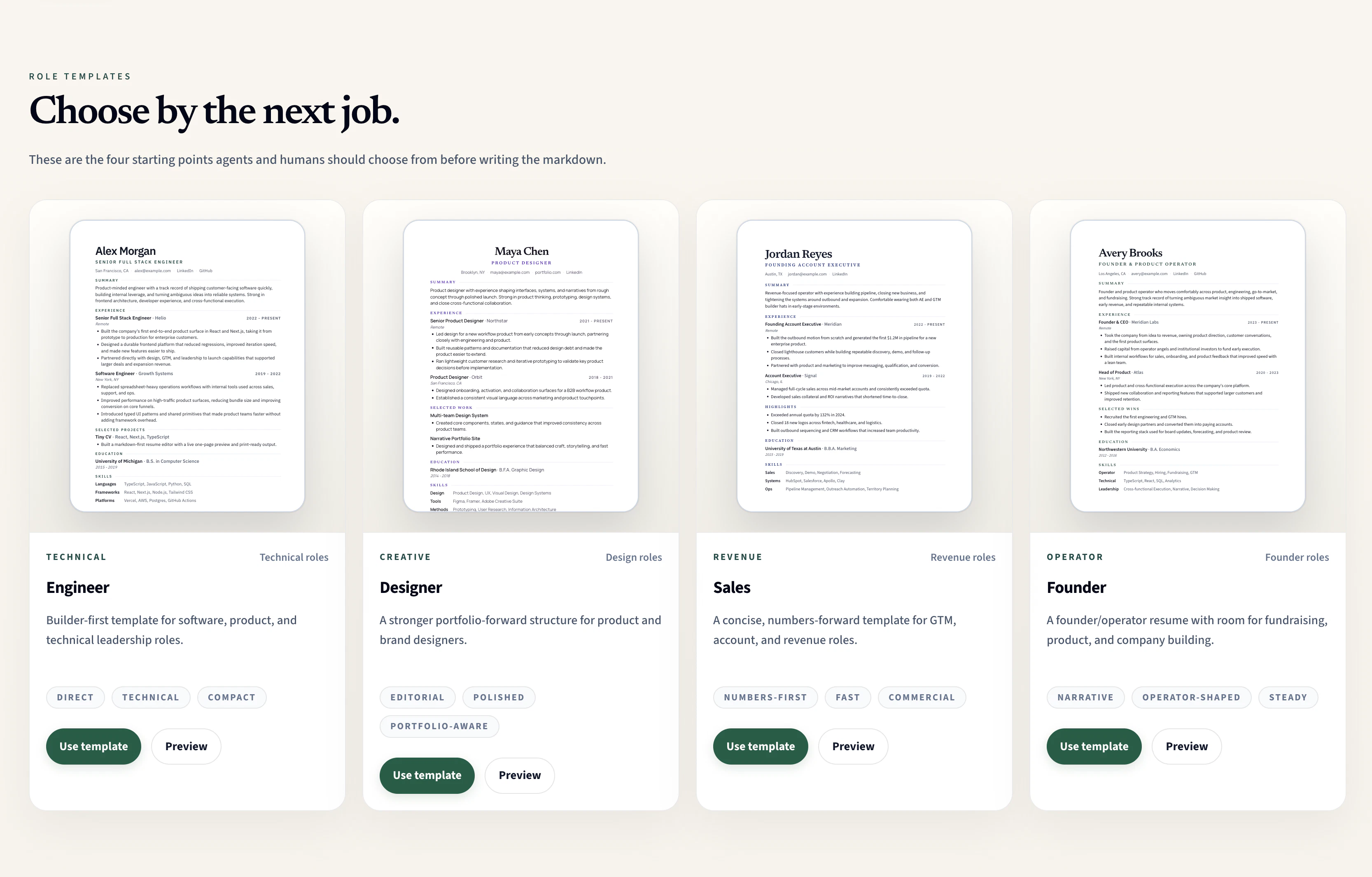
一句话介绍:Tiny CV 将Markdown内容一键生成为一页PDF简历和干净公开链接,解决AI写简历后排版乱、适配难、分享烦的痛点。
Hiring
Productivity
GitHub
Career
简历构建器
Markdown转PDF
一页简历
AI简历优化
开源简历工具
求职工具
公开简历页
简历模板
人物页面
用户评论摘要:用户普遍认可其简洁和Markdown工作流集成,核心建议包括:支持简历内嵌图片,简历自动适配一页并预警,支持连接GitHub同步项目,增加AI简历抗AI筛选功能,以及为每条经历提供面试追问的强化功能。
AI 锐评
Tiny CV精准切中了“AI写稿、人工排版”这一代求职者的高频撕裂感。它没有试图做一个大而全的简历编辑器,而是聪明地定位为Markdown的一页PDF渲染器,并开源,这本身就是一种克制且锐利的产品哲学。
产品核心价值并非“好看”,而是“约束”。一页强制让用户从堆砌关键词转向精选证据,配合自动排版(Pretext自动调整字体边距),降低了非设计师用户最后的排版焦虑。从评论看,“一页警告”功能是刚需,极大减轻了用户手动调布局的痛苦。
然而,产品天花板也明显。多数反馈集中在功能补全(图片、GitHub同步),而非颠覆性创新。创始人回应较为保守,这既是保持简洁的坚持,也可能成为增长瓶颈。真正有壁垒的是“AI代理自主操作”的建立,以及在AI筛选简历时代,如何帮助候选人“在海选中曝光”——而非单纯展示。如果Tiny CV只停在“漂亮的PDF展示层”,其护城河很浅,容易被大厂模板或AI原生工具(如Notion AI、ChatGPT渲染插件)吞没。更值得深挖的方向是:将“一页简历”作为入口,延伸至“面试准备深度解读”的叙事验证层,形成从撰写、优化到面试预演的内容闭环。
一句话介绍:Pi Coding Agent 是一个极简且高度可定制的终端编码助手,让开发者能自由构建和调整 AI 编码工作流,而非被工具束缚。
Open Source
Artificial Intelligence
Development
编码助手
终端工具
AI工作流
可定制
开源
扩展包
npm
开发者工具
代码代理
插件系统
用户评论摘要:用户称赞其易用性和自定义性,强调可通过 npm 包分发避免专有插件注册表。提出如何跨包实现提示模板继承的问题。有用户表示它改变了对固定编码代理风格的依赖,而更像一个团队协奏工具。
AI 锐评
Pi Coding Agent 的野心不在于做又一个“万能”的代码助手,而在于重新定义“谁该主导工作流”。它刻意砍掉 sub-agents 和 plan mode 等花哨功能,反其道而行之,保持核心调度器的最小化。这种做法在业内看似保守,实则精准打击了当前 AI 编码工具的痛点——过度智能、僵化、不可控。用户厌倦了被工具牵引,Pi 选择了“裸奔”却开放的哲学:把决策权还给开发者。
值得注意是,它甚至押注于 npm 这种现有生态作为分发管道,而非自建插件体系,既降低了开发者学习成本,也避免了平台锁定风险。评论中提到的“与 OpenAI Codex 流量接近”更是一个噪音信号:这意味着它极可能被用作 AI 代码生成底层的“透明管理层”,而非前端的“聊天界面”。
但批评点也很明显:零门槛不等于零复杂度。这种“一切皆插件、无默认设定”的模式,对初学者/小型团队可能意味着高昂的组装成本。另外,全终端化路线意味着它几乎放弃了图形界面交互的可能性,这注定会损失大部分非硬核用户。
总体而言,Pi 不是面向市场的“产品”,而是面向开发者社区的“基础设施”。它的真正价值不在于自身功能多强,而在于它重新让开发者成为了 AI 代理的控制者,而非被控制者。
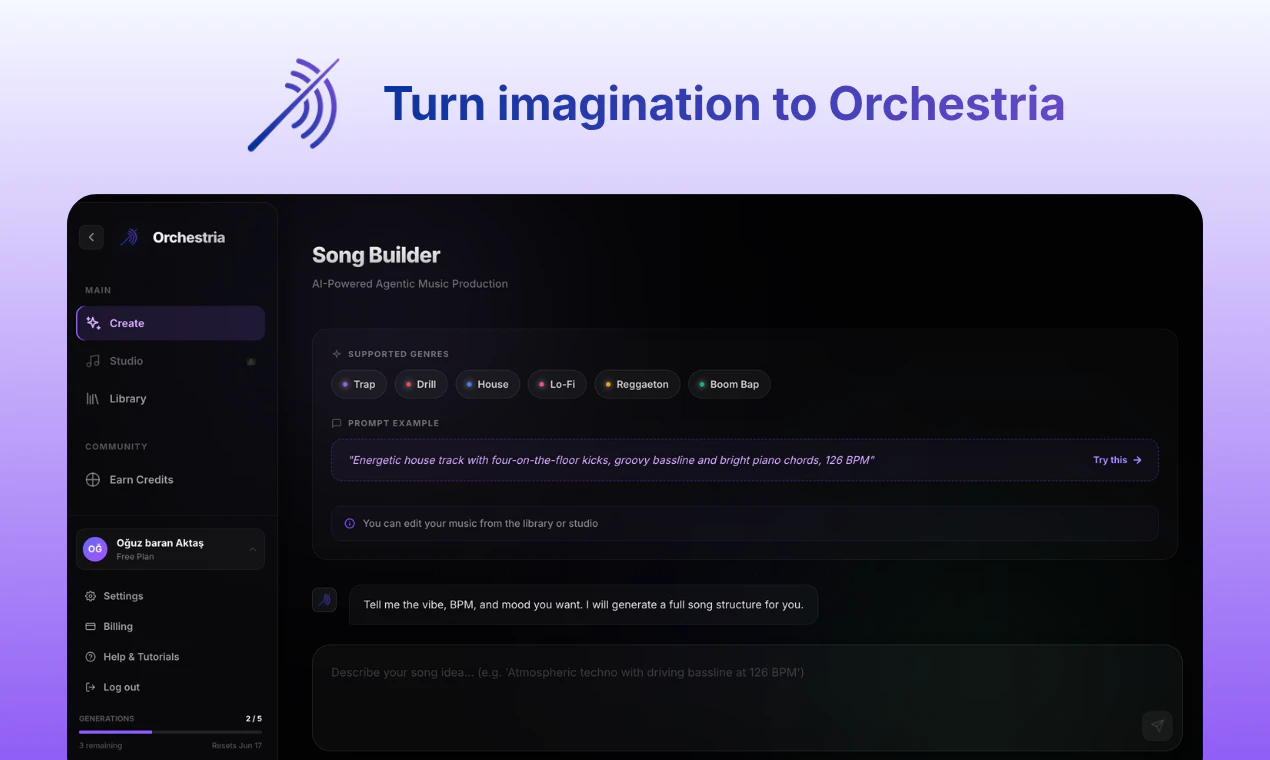
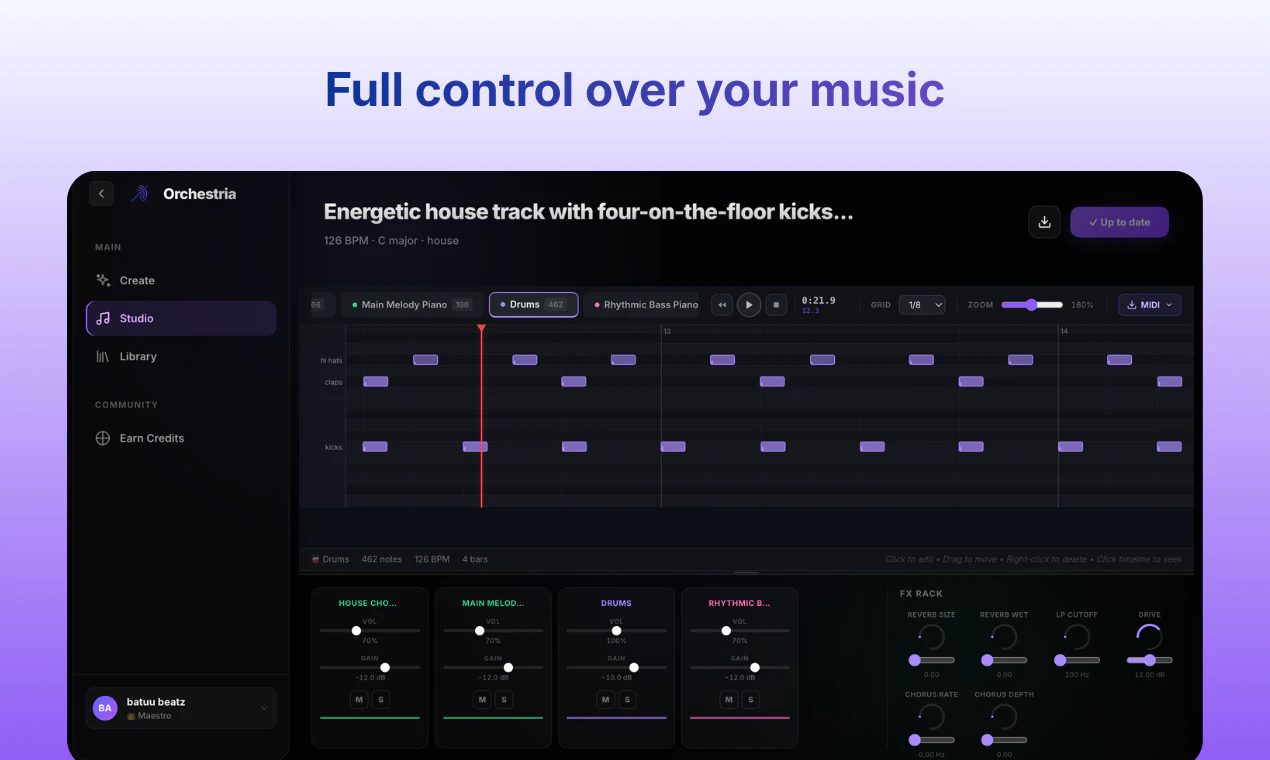
一句话介绍:Orchestria是一款通过将AI音乐生成为独立音轨(Stem)并支持自然语言“代理式”指令修改的音乐引擎,解决了现有AI音乐工具无法对成品进行精细化单轨编辑、必须整体重做的痛点,让创作者拥有真正的掌控权。
Web App
Music
Artificial Intelligence
AI音乐引擎
音轨分离编辑
自然语言控制
音乐制作工具
免版税音乐
音频工作站
AI代理
音乐创作
48kHz音频
创作者工具
用户评论摘要:用户肯定其“避免全轨重做”的实用价值,视其为“音频层的Figma”。同时,一位初学者询问是否友好,收到肯定回复。另一用户关注版权归属,官方提供了完整的审计与创作过程证明方案。
AI 锐评
Orchestria的115票在Product Hunt中不算惊人,但其切入的痛点足够精准。当前AI音乐生成(如Suno、Udio)最大的硬伤在于“黑箱”——你只能祈祷抽卡般得到一首好歌,而无法像在DAW里一样微调一个鼓点。Orchestria的“粒度化音轨控制”和“代理式自然语言指令”本质上是为AI音乐加入了“撤销”和“局部替换”功能,这不再是一个玩具,而是一个真正的生产力工具。
不过,我们必须警惕其宣传中的水分。“Agentic Flip”听起来很酷,但底层逻辑仍是基于预设的MIDI和VST映射,其“自然语言”修改的准确性将直接决定产品生死——当你说“让贝斯更拨弦”,AI是否能理解你对音色质感的模糊描述?这需要强大的预训练音频模型作为支撑,而不仅仅是简单的关键词匹配。此外,项目目前仅处于发布阶段,DEMO和实际使用中的延迟、音频质量一致性(尤其是多音轨合轨后的相位问题)仍有待考验。
其最大的价值在于向市场证明了:“AI音乐”的下一个竞争点不是生成一首完美的歌,而是提供一个可编辑的、可协作的“工程文件”。如果Orchestria能持续优化其AI对复杂音乐术语的语义理解,并开放VST插件接口,它确实有机会成为音频领域的“Figma”。但若仅停留在生成几个音轨片段的Demo阶段,它很快就会被大厂的集成方案所淹没。真正的挑战,永远在细节里。
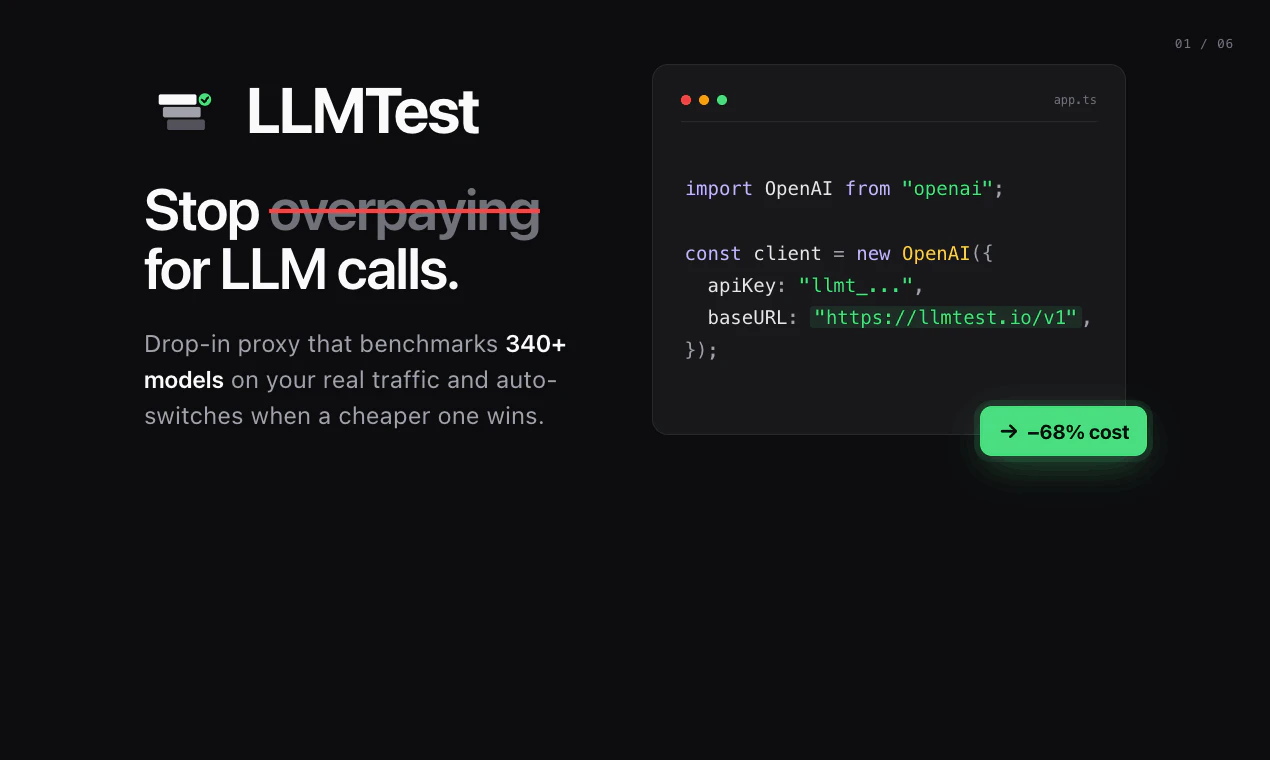
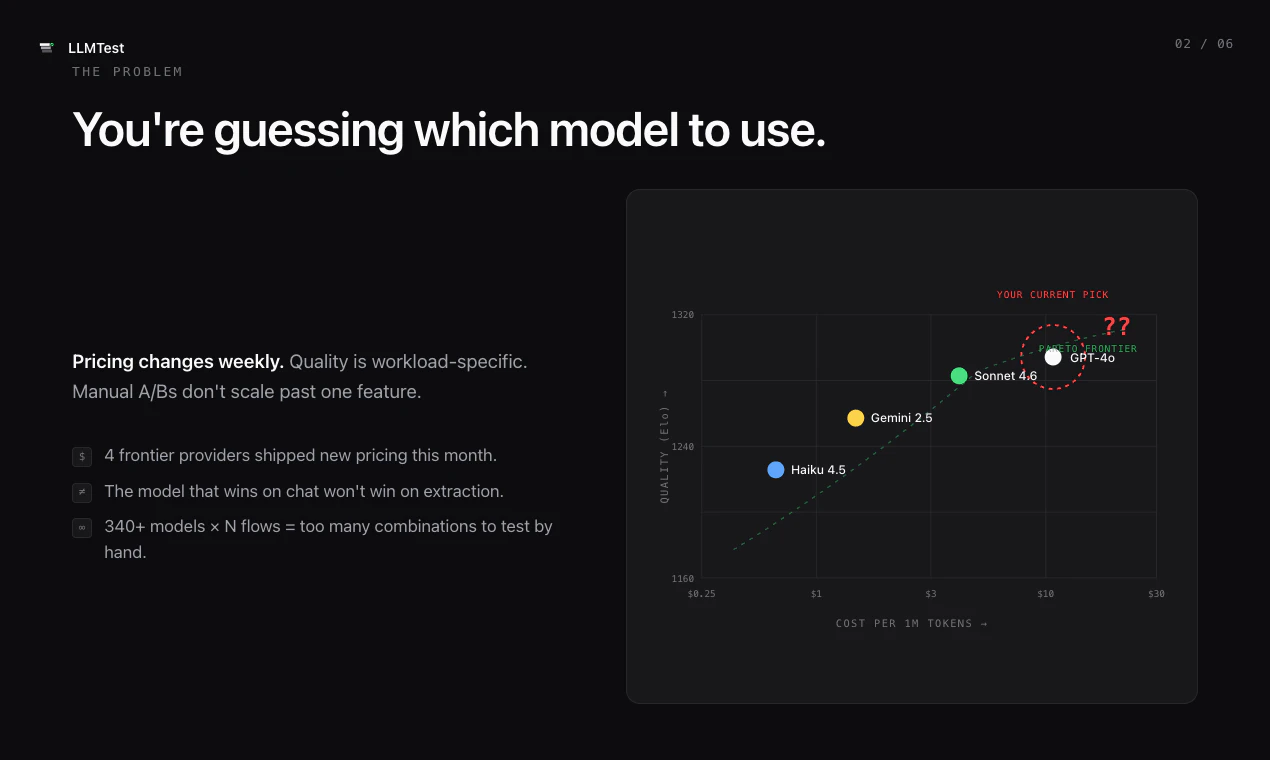
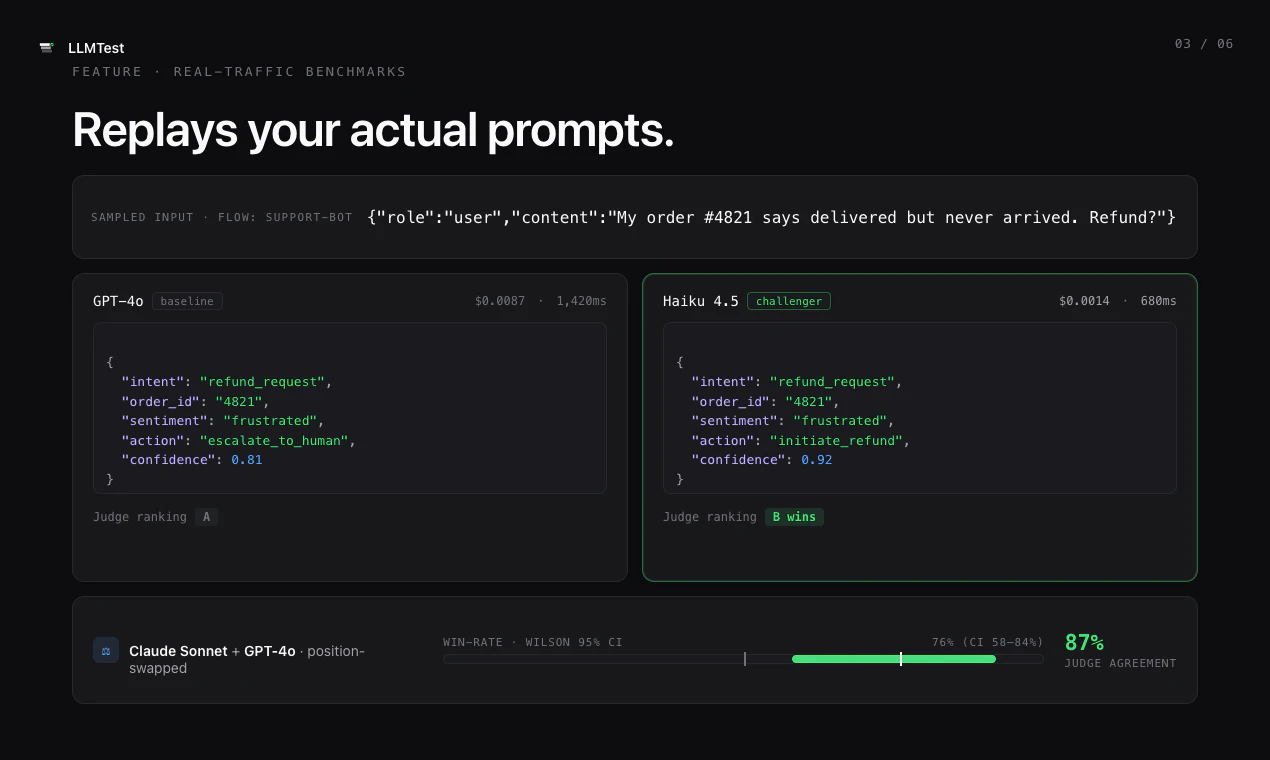
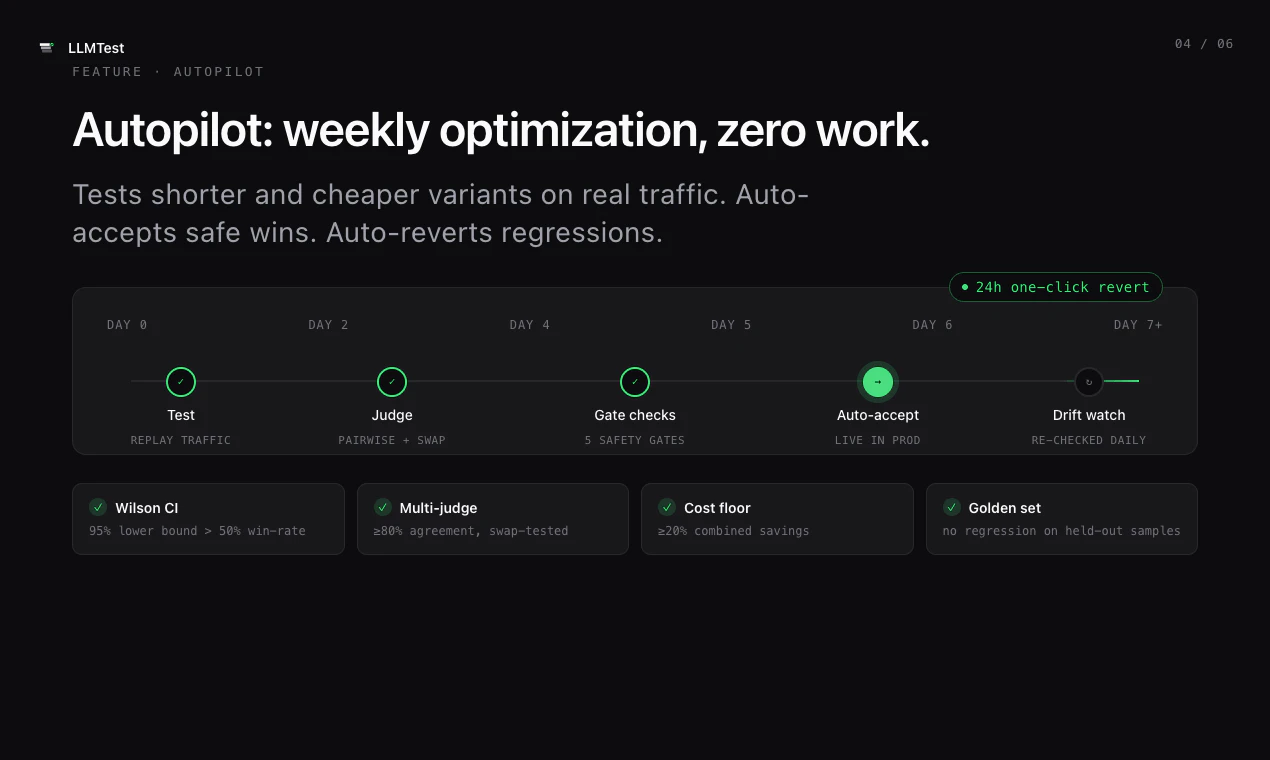
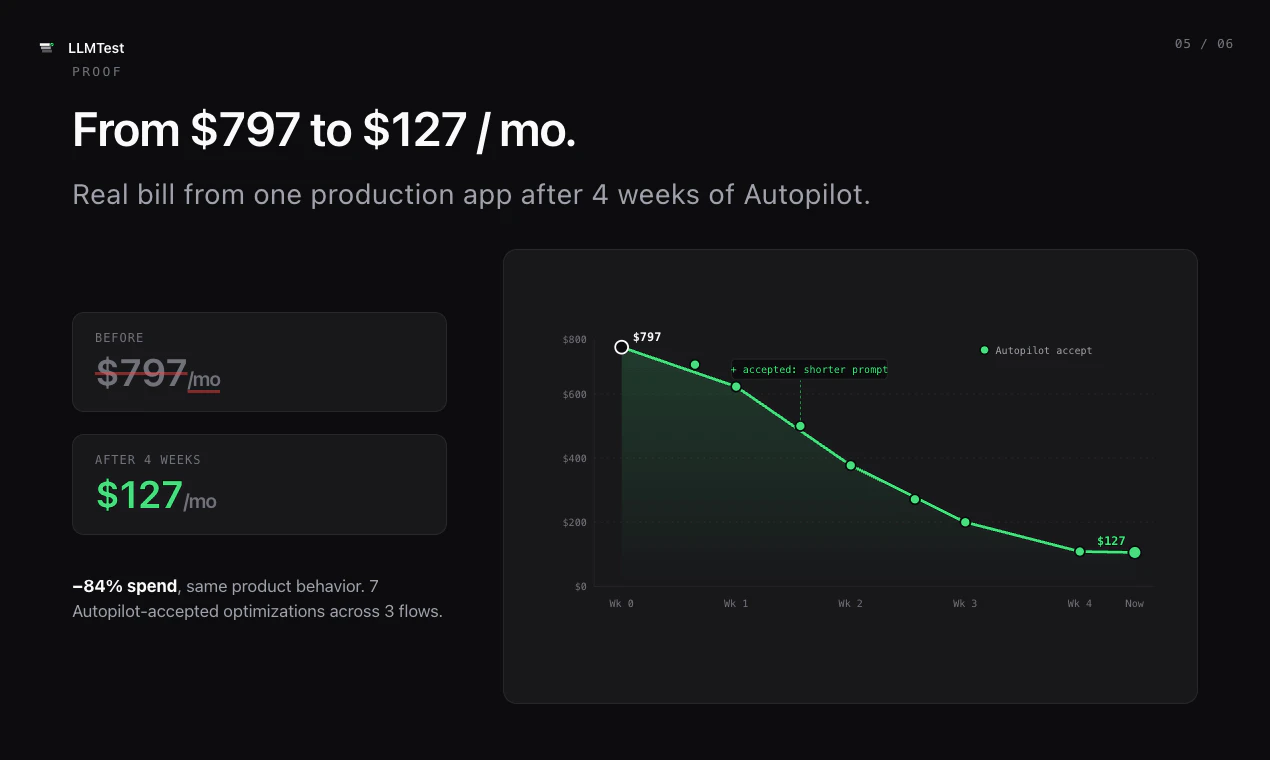
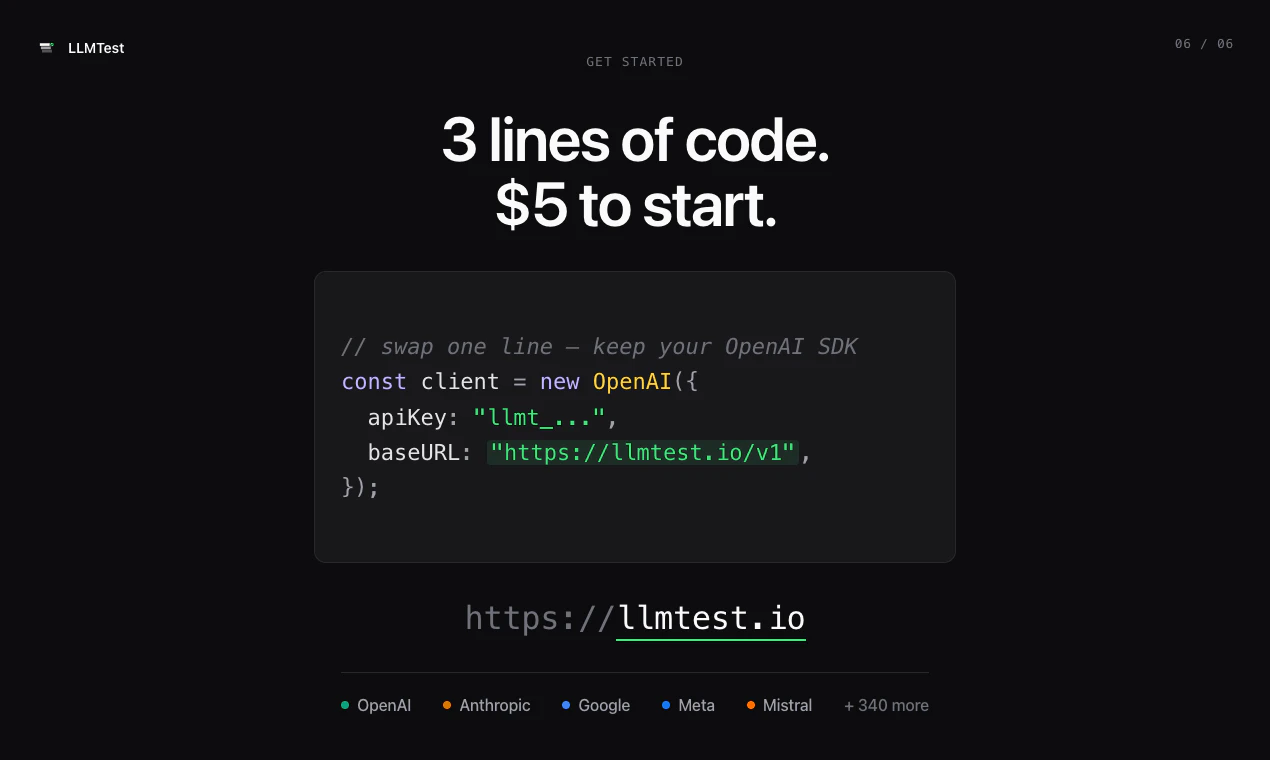
一句话介绍:LLMTest通过统一API和自动回退机制,帮助开发者自动评测并选用最优LLM模型,解决AI功能在模型选择与生产环境中因API故障导致的业务中断问题。
API
Developer Tools
Artificial Intelligence
AI模型评估
模型自动选择
API回退
开发者工具
LLM测试
MCP集成
生产稳定性
OpenRouter聚合
智能降级
vibe coding
用户评论摘要:用户认可自动回退机制是核心亮点,能防止生产故障。但指出注册页采用全黑背景、缺乏导航和产品信息提示,与首页体验割裂,建议补全引导和“无需信用卡”说明以降低心理门槛。
AI 锐评
LLMTest瞄准了一个真实且日益尖锐的痛点:LLM泛滥时代的选择瘫痪与生产环境的不确定性。其核心价值并非“评测哪个模型最好”——这类工具已不新鲜,而是将“模型评测”与“生产级容错”缝合进一条API,并提供MCP接口让Claude/Codex直接调用,这本质上是在做AI时代的智能路由+熔断降级基础设施。
从产品设计看,“自测+自动回退”的组合拳,切中了vibe coder与技术型开发者共同惧怕的黑洞:花时间选出最优模型,结果上线后因API限流或JSON解析失败直接崩掉。LLMTest让选择权从人工猜测变成数据驱动,同时把容错逻辑内置化,这才是生产环境的硬需求。
但需要注意几个隐患:一是评测的客观性存疑——如果测试用例与真实场景分布不匹配,推荐结果可能误导;二是过度依赖OpenRouter单一上游,若OpenRouter本身出现故障或定价波动,LLMTest的可用性将直接受损;三是门槛感知问题,用户评论已指出注册体验断档,这类细节在B2D工具中往往决定转化率。
整体而言,LLMTest是一款“切口准、价值清晰但天花板受制于生态依赖”的工具。它不会取代原生模型供应商,但有望成为AI应用开发者在模型选择与运维交接处的可靠粘合剂。建议尽快补全注册引导和开放免费沙盒测试,以降低试用摩擦。
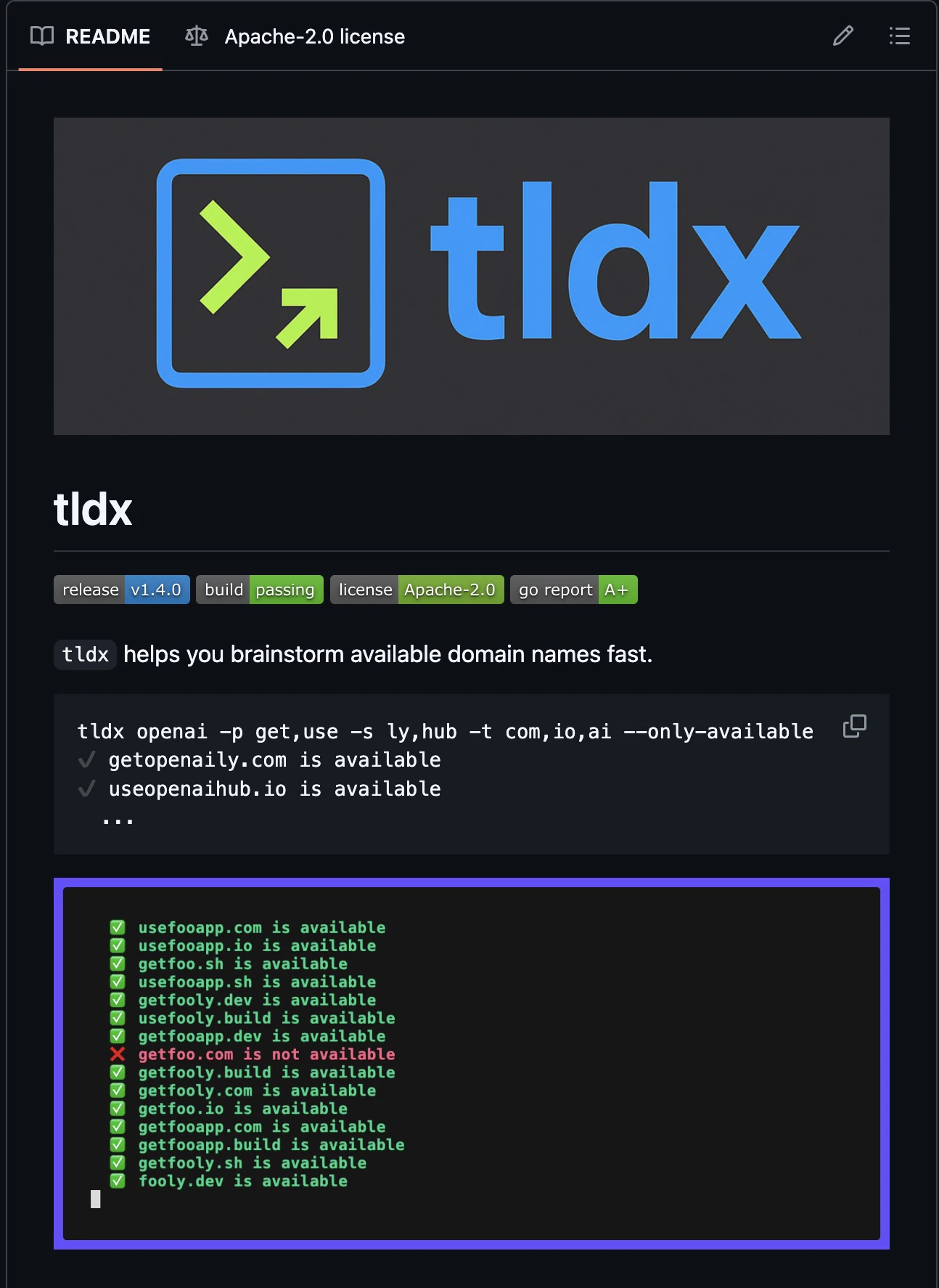
一句话介绍:tldx 是一款基于 RDAP 协议的极速批量域名查询 CLI 工具,通过并发检测与 MCP 服务器集成,帮助创始人或 AI 代理高效筛选可用域名,彻底摆脱传统 WHOIS 的速率限制和低效解析痛点。
Open Source
Developer Tools
GitHub
域名查询
RDAP
CLI 工具
开源
Go语言
AI 代理
MCP 服务器
Homebrew
批量生成
创始人工具
用户评论摘要:用户 @brandonyoungdev 在产品介绍中说明了构建初衷(个人工具开源)与核心使用场景(按关键字组合批量查域名)。跟帖用户询问技术实现细节(是否直接查询 DNS),开发者未在提供的评论中直接回复该技术问题。
AI 锐评
tldx 的真正价值不在于“查域名”这个老生常谈的需求,而在于它用 RDAP 协议和 Go 语言的高并发能力,彻底砸碎了传统域名查询的枷锁。它没有选择吃力不讨好的 WHOIS 解析或容易被封的 DNS 探测,而是基于 RDAP 这一规范化、无速率限制的公开注册数据查询协议,本质上是在做“数据的批量合规抓取”。这让它从一个玩具变成了一个可以稳定用于抢注监控、前期调研的工业级实用工具。
更值得玩味的是它内置的 MCP 服务器。这绝不是拍脑袋加的功能,而是看到了 AI Agent 正在从“聊天气泡”进化到“执行任务”的必然趋势。开发者敏锐地识别出“域名创意+快速验证”是一个非常适合由 AI 代理完成的自动化闭环。tldx 不再仅仅是一个给程序员用的终端命令,而是成为了 AI 系统直接调用的“数据库 API”。
不过,必须指出的是,它的使用门槛依然很高。命令行界面和 Go 语言的开源生态,决定了它目前的受众仍然仅限于开发者群体。对于那些创业小白来说,“brew install tldx”这个动作本身就是一道门坎。但换个角度看,这或许正是产品的精准定位——它服务的是那些真正需要高效工具、不惧怕命令行的硬核用户和 AI 开发者。在大模型争相接入各种工具的时刻,tldx 通过 MCP 不经意间卡住了“AI 时代域名助手”的身位,这可能是其最隐蔽也最致命的后手。
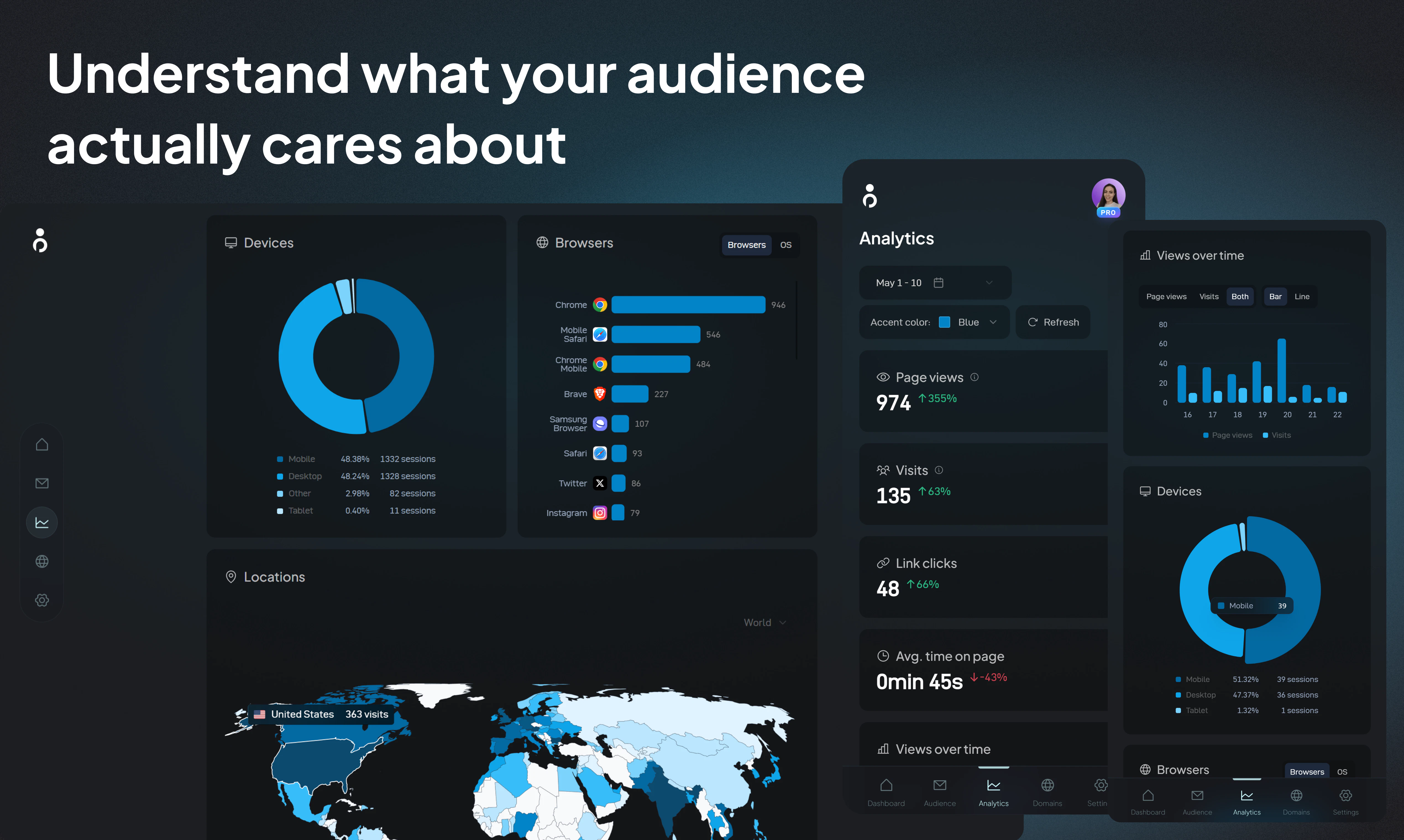
一句话介绍:Databerry 是一个面向独立创业者的数据聚合仪表盘,让你无需在多个工具间来回切换,就能在一个界面中集中监控收入、分析、会议等关键业务指标。
Analytics
Data & Analytics
Business Intelligence
数据聚合仪表盘
创业工具
业务监控
Stripe集成
PostHog
Calendly
SaaS
效率工具
一站式看板
独立开发者
用户评论摘要:用户普遍认可其解决了多项目、多工具切换的痛点,但同时提出几个关键问题:数据源连接失效时能否明确告警(如Stripe重授权、token过期);如何避免仪表盘自身变得嘈杂;是否提供财务层级的专业分析(如跑道、烧钱率);以及是否支持MCP接口供AI代理查询。
AI 锐评
Databerry切中的确实是创业者的真实痛点——“信息碎片化”带来的心智负担,尤其是独立开发者或小团队,他们往往同时管理数个轻量级项目,每一分钟都在被不同工具的通知和登录流程消耗。产品“反仪表盘”的定位值得肯定:只展示对创始人真正有用的指标,强调分钟级上手,而非像传统BI工具那样堆砌复杂图表和维度,这恰恰是它与Notion、Metabase等通用工具拉开差距的关键。
但需要警惕的是,它的核心竞争力并不在“整合”本身——Stripe、PostHog等接口的对接在技术上并不构成护城河。评论中指出了两个核心风险:第一,数据同步一旦出现故障(API限流、授权过期),安静的“假数据”会比没有数据更危险;第二,当用户接入的工具增多,创始人仍然需要主动筛选“什么该看”,这意味着产品目前在“主动排除噪声”和“数据健康度可视化”上仍有空白。
此外,缺少对财务模型的支持(如跑路率、CAC、LTV的动态计算)也会削弱其在融资场景下的价值——一个仪表盘如果只告诉你“昨天下单数”,却没有告诉你“按当前速度还能撑多久”,那它仍然只是多个工具的“显示器”,而非决策的“驾驶舱”。
Drew的叙事很扎实,社区反馈也积极,但Databerry需要更快速地构建数据异常告警机制和意图驱动的智能视图,否则很容易沦为又一个“打开即忘”的营销工具。
一句话介绍:The Incident Challenge 是一款让软件工程师在模拟真实生产故障中进行根因分析与修复的竞技游戏,旨在通过限时实战提升工程师在高压环境下的排错能力。
Artificial Intelligence
Tech
Games
生产调试
故障模拟
根因分析
软件工程师
限时挑战
工程思维
AI辅助
系统架构
故障演练
CTF风格
用户评论摘要:用户普遍认可其真实感和挑战性,认为它比纯编程更有价值。有反馈指出“确实很难,像真的故障”,但未提及具体改进建议或缺陷。部分用户强调该游戏能帮助工程师练习在压力下保持冷静。
AI 锐评
The Incident Challenge 的切入点是精准的:当AI能生成大量代码时,“理解系统为何崩溃”成了稀缺的人类技能。它把传统CTF里偏重安全攻防的模式,转向了更普适的工程排故——这才是大多数软件工程师日常最痛的点。产品设计上,用真实故障模式、误导性文档、限时排名的机制,把被动挨打的“背锅体验”变成了主动竞技,这很聪明。但问题也很明显:首先,99票在Product Hunt上属于中等表现,未形成病毒式传播,说明其吸引力可能仍局限在“爱折腾的排障狂”圈层;其次,AI辅助能被集成,但产品未能清晰定义“AI无法替代的人类直觉”究竟是什么,容易陷入“AI能加速查Log,但人类仍需理解上下文”的模糊叙事——这会削弱不可替代性的说服力。最后,如果模拟场景不能持续更新、紧贴真实云原生架构(如K8s、微服务、数据一致性问题),玩家很快就可能摸透套路。它的真正价值,不在于教人写代码,而在于训练“在噪音中锁定信号”的系统直觉——这才是资深工程师与初级工程师之间最难被量化的鸿沟。如果能把这个鸿沟变成可衡量的层级,并嵌入企业内训流程,它可能从游戏变成标准化的工程素质评估工具。
一句话介绍:MashuPack将代码仓库中的指定部分打包成一个清洁文本文件,解决用户在ChatGPT/Claude等浏览器端AI工具中因文件数量限制和上下文混乱而无法高效上传代码的痛点。
Productivity
Developer Tools
Artificial Intelligence
代码上下文打包
AI工具集成
代码库管理
文本文件生成
开发者工具
浏览器AI工作流
文件上传优化
代码审计辅助
Token估算
开发效率
用户评论摘要:用户普遍认可其解决了AI工作流中的上下文痛点,但提出需保留文件路径和目录结构以便模型引用,建议增加文件列表、时间戳、忽略路径、Token估算等上下文清单功能,以实现更轻量的审计追踪。
AI 锐评
MashuPack精准切入了一个被忽视却高频的“隐形摩擦点”——AI对话界面与本地代码库之间的上下文鸿沟。当众多工具沉迷于自动化全量代码分析时,它反其道而行,强调“可控性”与“轻量打包”。这种定位既聪明又务实:聪明在于,它承认了当前浏览器AI模型对单一文本文件的兼容性最佳,避免与复杂API或插件生态直接竞争;务实在于,它将开发者从手动复制粘贴、分割文件、管理上传限制的琐碎中解放出来,保留了“选择权”。
然而,其真正价值取决于两个关键变量:一是能否解决“出口歧义”——当模型返回需要修改具体路径的建议时,打包后的扁平文本文件可能丧失原仓库的精确映射,虽然开发者回复中提到会保留路径和结构,但用户评论中“上下文清单”的呼声恰恰说明当前方案在可追溯性上仍有缺口;二是护城河极低——类似的脚本、浏览器插件或Repo-to-text的开源方案并不少见,UI友好度是唯一壁垒。若止步于“美观的文件打包器”,MashuPack很快会被Aider、Cursor等原生支持AI工作流的新型IDE碾压。真正的突围方向应是成为“AI工作流的内容总线”:通过元数据强化(如版本对比、需求-代码片段映射)将单一文本输出从“一次性输入”升级为“可审计的对话上下文资产”,而非仅做一个漂亮抄送员。
一句话介绍:Rixx是一款以可信溯源为核心,通过多模态搜索、文件上传和可视化图表等功能,将AI搜索从“猜答案”转化为“查证据”的研究管理工具,解决用户对AI回答不信任和研究资料碎片化的痛点。
Productivity
Artificial Intelligence
Search
AI搜索
可信溯源
多模态搜索
研究管理
论文级引用
图表可视化
文件上传
搜索替代方案
生产力工具
信息整理
用户评论摘要:用户高度认可其解决“多标签页切换”的痛点;核心疑问集中在搜索深度(爬取上限)、JS渲染页面及多媒体兼容性;建议增加“声明-来源-强度”对照表以提升研究可信度;开发者回应已支持多源并行搜索与源质量排名。
AI 锐评
Rixx的定位并非又一个“更聪明的搜索引擎”,而是试图重新定义“可信研究”的流程标准。它的核心价值不在“答得更快”,而在“敢让你验证”——用实时引文、图表内联、PDF/文档上传和Insights分组,把AI搜索从黑箱式答案生成器,扭转为可审计的研究资产。
但必须泼盆冷水:当前产品仍处于“漂亮原型”阶段。用户评论中“搜索深度是否有上限”“是否支持JS渲染页面”等质问,直指技术地基——若多模态搜索只是简单拼接API,而非统一的信息抽取与交叉验证管道,那么“不撒谎”只是营销话术,而非工程承诺。此外,“公开引文”不等于“语义保真”,评论区那位用户提醒得很尖锐:AI是否会把狭窄源头扭曲为宽泛结论?Rixx若不能推出“声明-来源-矛盾标记”的透明对照表,就永远停留在“带链接的摘要”水平,离“可发表研究”还有鸿沟。
商业化是另一道坎。Perplexity Pro已20美元/月,Rixx若缺乏独家数据源或企业级协作功能(如团队空间、自定义爬取策略),很难说服重度用户迁移。创始人说“深层研究模式开发中”——希望这不是画饼,而是通往真正差异化护城河的起点。否则,Rixx只会是研究者收藏夹里又一个“偶尔用一下”的工具。
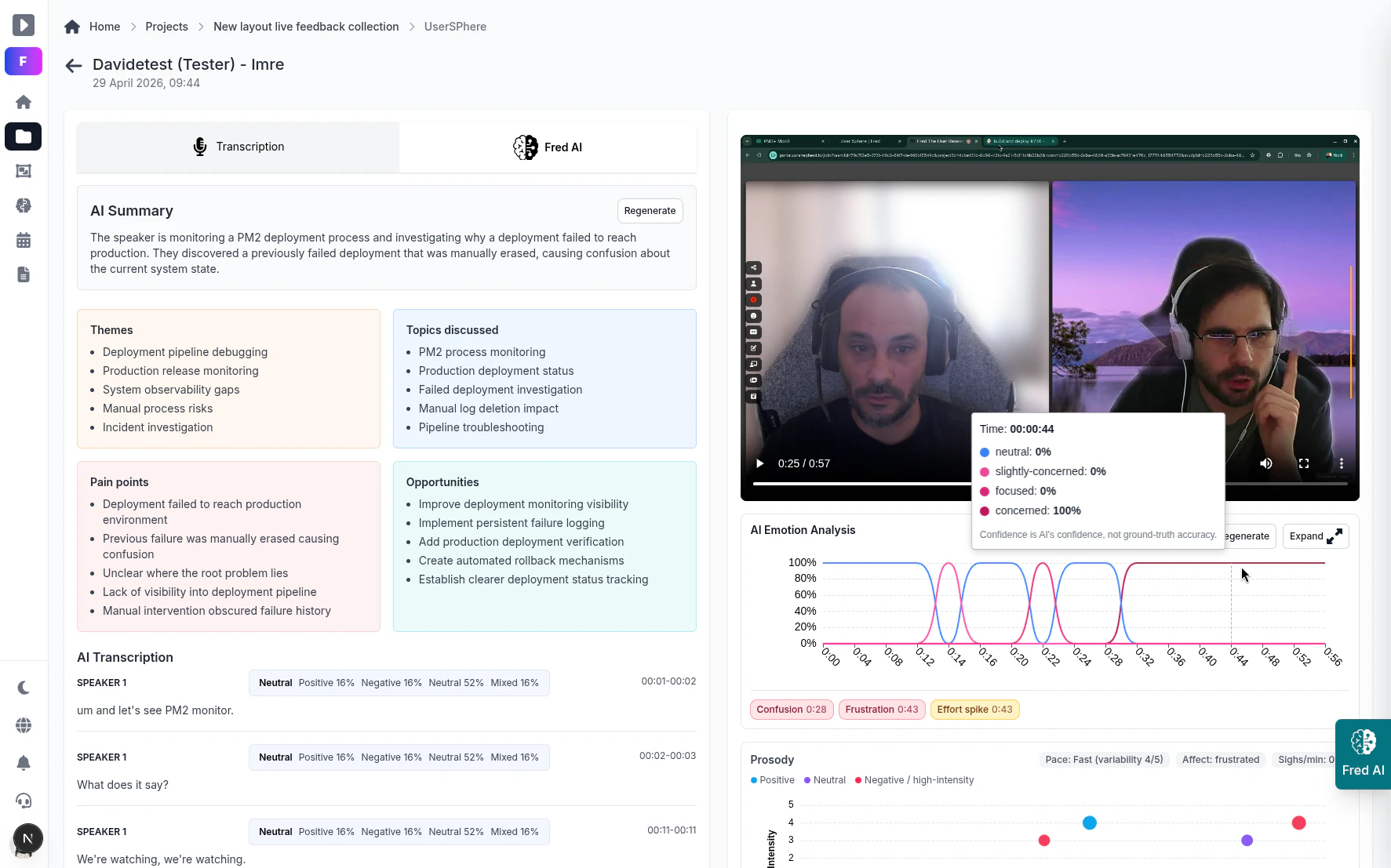
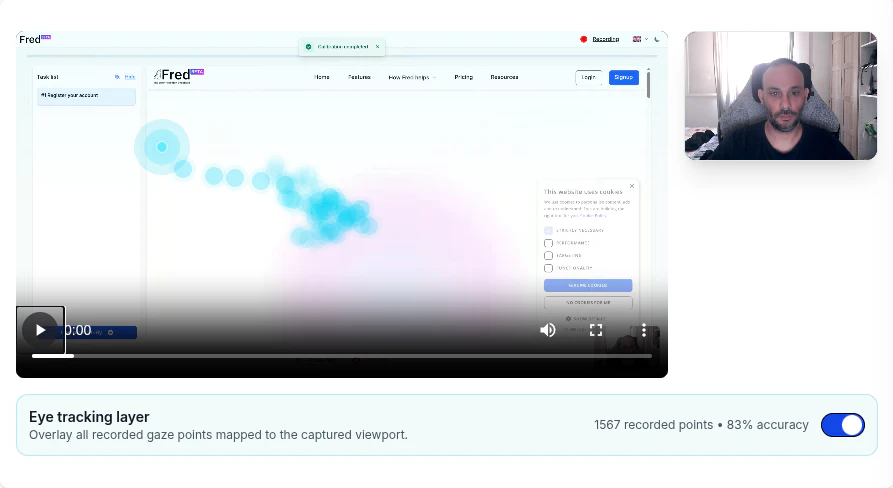
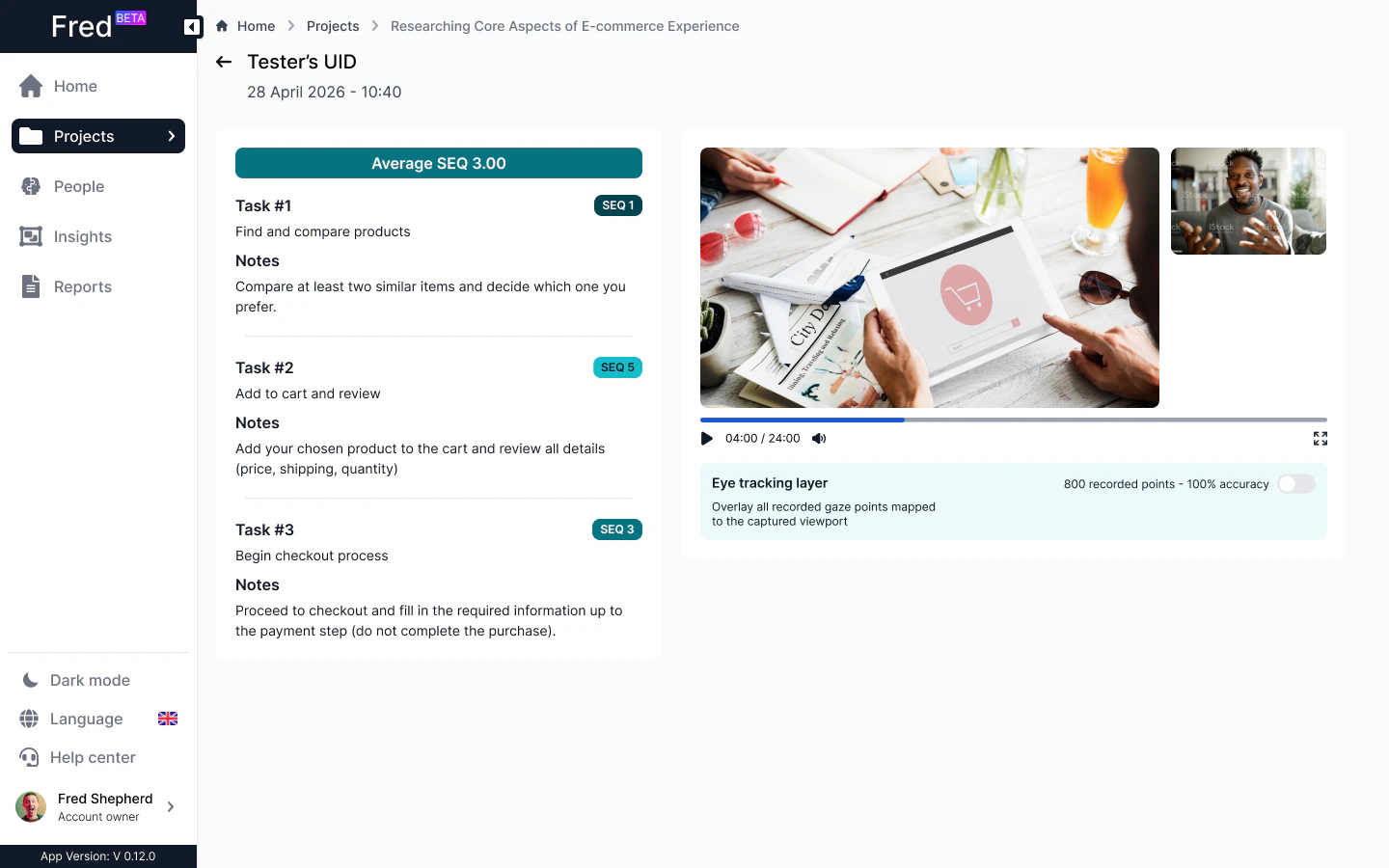
一句话介绍:Fred通过AI编排将UX研究中的规划、招募、测试、分析与报告全流程整合为一站式平台,并引入实时/回放眼动追踪与行为热图,解决研究团队工具碎片化与操作拖沓的痛点。
Productivity
User Experience
Artificial Intelligence
UX研究
AI编排
眼动追踪
行为分析
热图
用户研究平台
产品体验
流程自动化
模式检测
证据驱动
用户评论摘要:用户关注AI眼动追踪的准确性与长会话识别能力,并提出研究者如何覆写AI解读的疑问。创始人回应强调AI仅加速模式发现,不替代判断,所有信号附带置信度与证据链接,允许人工审查与覆盖。
AI 锐评
Fred的定位精明——它不标榜“AI取代研究员”,而是切中“研究流程碎片化”这个真实成本痛点。眼动追踪与行为回放的确比纯文本分析更具洞察力,但真正的护城河在于“置信度+证据链”的设计:AI只做初筛,研究者掌握最终否决权,这恰恰是专业工具与“AI玩具”的分水岭。不过需警惕,若团队迷信AI标记的“热度区域”而忽略环境变量(如设备噪声),结论仍可能失准。产品目前更偏向敏捷团队与小型机构,对大型企业级研究的权限、合规和多项目并行管理,尚未看到足够深的信息。一句话:Fred在“效率”与“方法尊严”之间找到了平衡点,但能否从“好用”进化到“不可替代”,取决于它后续能否提供更复杂的研究设计模板与跨工具生态集成。
一句话介绍:Forum是Meta推出的独立Facebook群组应用,旨在解决用户在主信息流中难以深入参与群组讨论的痛点,为社群交流、问答和内容沉淀提供专属空间,并引入AI问答与管理员辅助工具。
Social Network
Social Media
社交应用
Facebook群组
社群讨论
独立应用
AI问答
管理员工具
隐私聊天
话题社区
内容沉淀
Reddit竞品
用户评论摘要:用户对Forum能与Reddit竞争表示好奇;有人指出仅因群组和活动才用FB,认为群组仍有吸引力;询问安卓版本支持;评论指出社群正回归小众私密空间,认为该应用时机恰当。
AI 锐评
Forum的诞生透露了Meta的焦虑与野心——Facebook主应用沦为“时间黑洞”后,群组这一高粘性互动场景被严重稀释。剥离出独立App是明智之举,但“去主信息流化”能否真正留住用户值得怀疑。产品核心价值在于“轻量化私密社区+AI赋能”,AI Ask能跨群组提炼答案,直击Reddit依赖搜索和人工整理的低效痛点;但对普通用户,匿名发帖才是逃离熟人社交的杀手锏。然而,Forum本质仍是Facebook的附庸,用户行为和内容资产受制于主平台,一旦群主迁移无奖励,冷启动便难成气候。更致命的悖论是:Meta一边高举“私有社群”大旗,一边用AI抓取群组内容构建公共答案库,隐私与开放性的平衡术一旦失衡,反而会加速用户流向Telegram或Discord。时机虽对,但若不能设计出与主App差异化的激励体系(如独立积分、跨群影响力),Forum最终不过是为Facebook续命的又一个“精致壳子”。
一句话介绍:PhoneDiffusion 让 iPhone 用户无需联网,直接在本地设备上离线、免费且无限量地生成 AI 图像,解决了云端生成带来的隐私泄露和网络依赖痛点。
Art
Artificial Intelligence
Apple
AI图像生成
本地生成
离线AI
iOS应用
隐私计算
Stable Diffusion
Core ML
创意工具
免费应用
模型选择
用户评论摘要:用户普遍认可本地生成与隐私优先的价值,并对模型选择策略(如A17 Pro对应SDXL)感兴趣,希望未来能支持侧载自定义微调模型。开发者积极回复并收集需求,关注“简单控制”与“专业功能”的平衡。
AI 锐评
PhoneDiffusion 的定位非常精准:它没有陷入“云端AI无所不能”的迷思,而是直面移动端算力瓶颈,用“离线本地化+定向模型匹配”的策略,切中了两类核心用户——隐私敏感型创作者和网络不稳定场景下的工具依赖者。其最大价值并非性能(它跑不过云端),而是“所有权”:你的提示词、生成历史、模型文件,从生成到存留,全程由用户主导。这等于宣告:AI工具可以不只是“服务”,也可以是“私产”。
但它的“窄入口”策略也意味着天花板明显:免费版仅提供一个基础模型,Pro版解锁的高级控制(手动CFG、步长、批量生成)对于专业用户极为重要,却也把轻度玩家挡在体验门外。定价与价值感知之间的平衡,将决定这款产品是“超级隐私工具”还是“小众玩具”。此外,动态模型适配与未来侧载模型的支持是高频期待,若只靠固定硬件阈值区分SD 1.5/SDXL,会随着芯片换代迅速过时。真正的护城河,在于能否建立一个iOS上可信赖的本地AI模型生态,让用户不仅能“跑模型”,更能“选模型”。
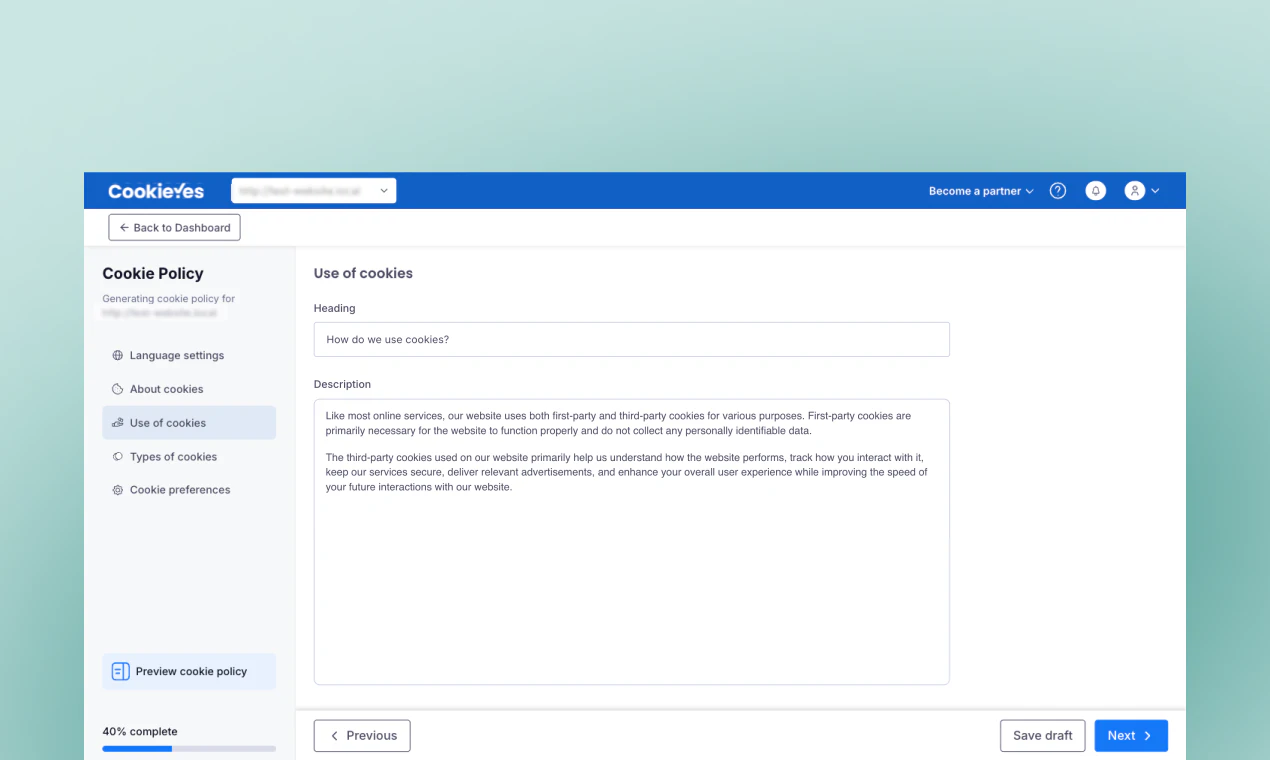
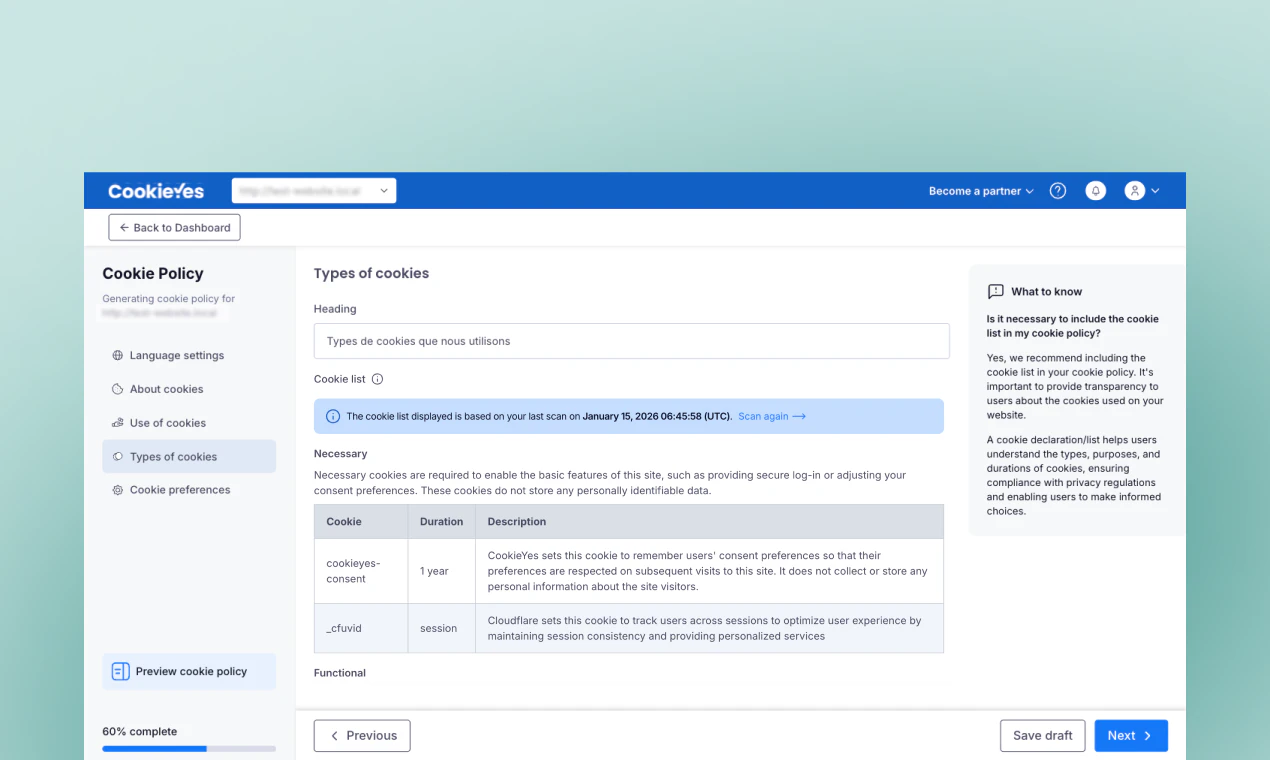
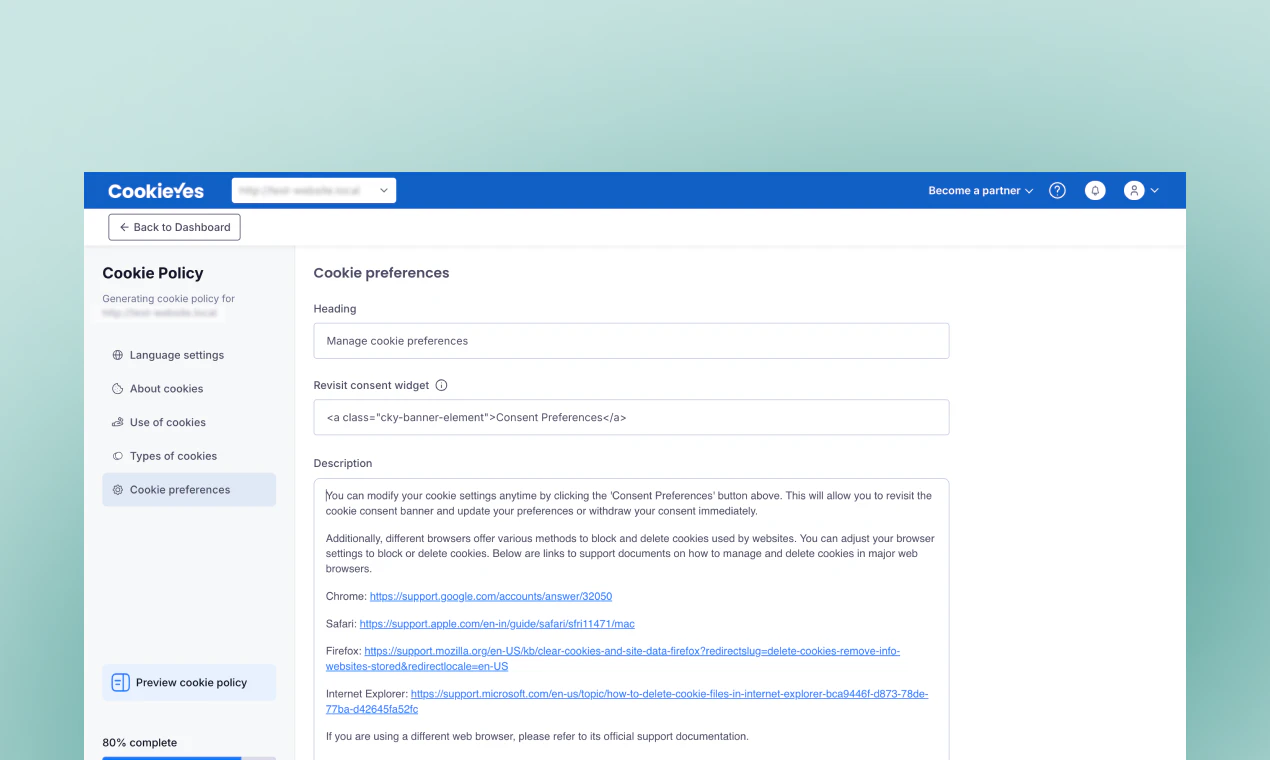
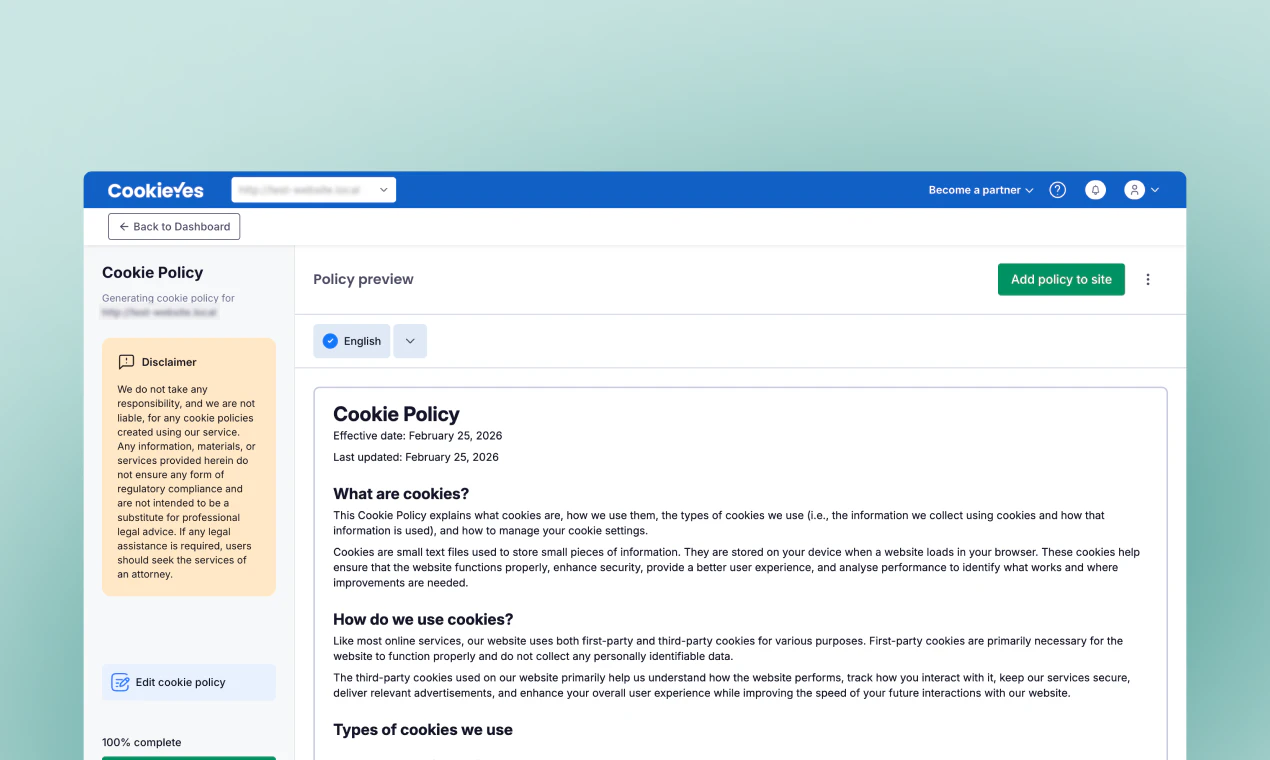
一句话介绍:CookiePolicy Generator 通过自动扫描网站真实使用的 Cookie,快速生成并自动同步更新 cookie 政策,解决了网站政策与实际运营脱节的法律合规痛点。
Privacy
Legal
Cookie合规
Cookie政策生成
网站扫描
隐私政策
GDPR
自动更新
法律合规
SaaS工具
网站检测
嵌入脚本
用户评论摘要:用户普遍反馈产品易用、能自动同步扫描结果,解决了长期拖延和更新困难的问题。有用户提到手动更新政策容易滞后,而该工具能发现未知Cookie。整体反馈积极,无明确负面问题或建议。
AI 锐评
CookiePolicy Generator 切中了一个真实但常被忽视的痛点:Cookie 政策不是“写一次就完事”的静态文档。在 GDPR 八周年之际,CookieYes 将自身在 Consent Management 领域的技术积累(网站扫描、Cookie 检测)向下延伸,做了一款“轻量级但自动维护”的政策生成工具,思路清晰。
从产品定位看,它避免了传统法律模板的“假合规”陷阱,也绕开了聘请律师的高昂成本,直接用技术手段解决“网站动态变化”与“政策静态滞后”的核心矛盾。自动扫描+嵌入脚本+定时更新,本质上是在做一个“政策即代码”的自动化合规闭环,这让它比市面上绝大多数“一次性生成”的竞品更有长期价值。
不过,需要警惕的是:政策自动更新固然方便,但用户是否真正理解自动更新后内容的准确性?如果扫描引擎漏检了某些第三方脚本或自定义代码,产生的政策可能形成“表面合规但实际有漏洞”的假象。此外,该功能高度依赖 CookieYes 自家的扫描能力,对存量用户而言是生态内工具的自然延伸,但对新用户来说,如果仅需要一个“能出文档”的工具,迁移成本是否值得、是否绑定过深,都是潜在门槛。
总体而言,这是一款切中真实需求、执行得很扎实的工具。建议未来可增加“政策版本回溯”和“人工审核提示”功能,在自动化与可控性之间取得更好平衡。
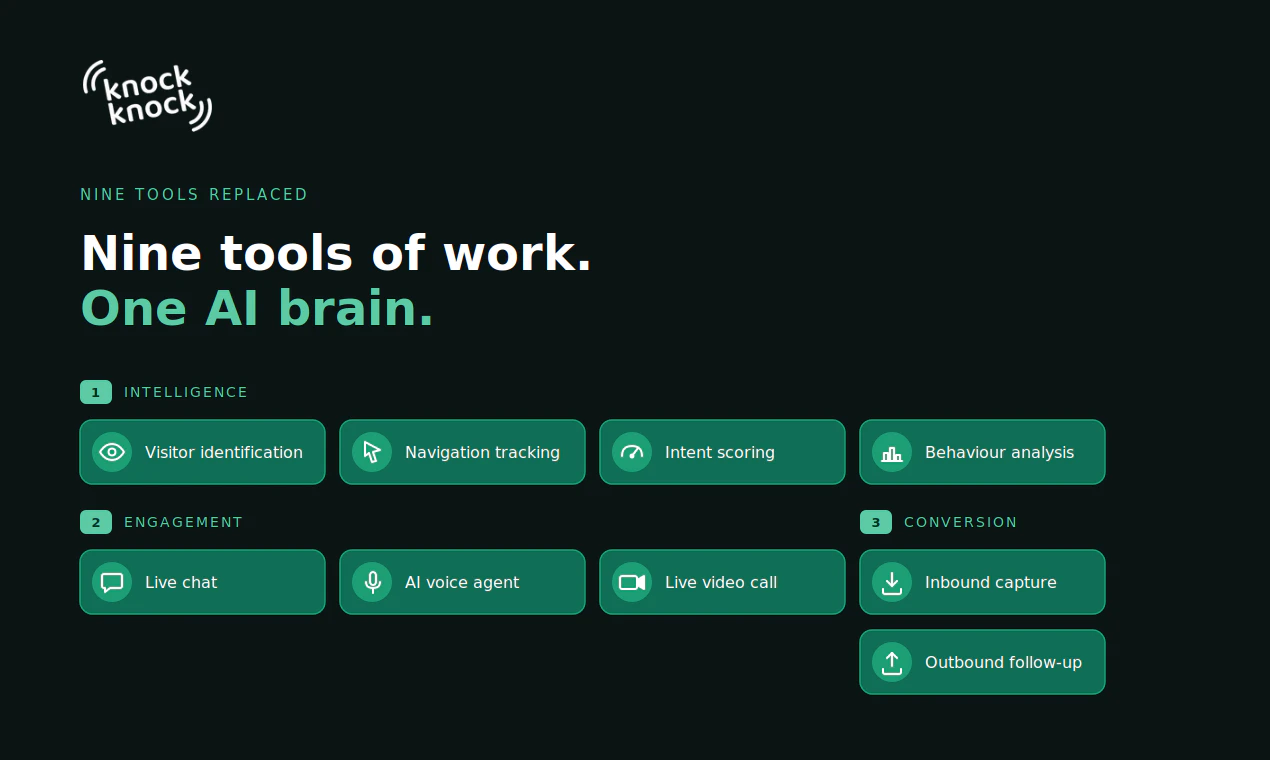
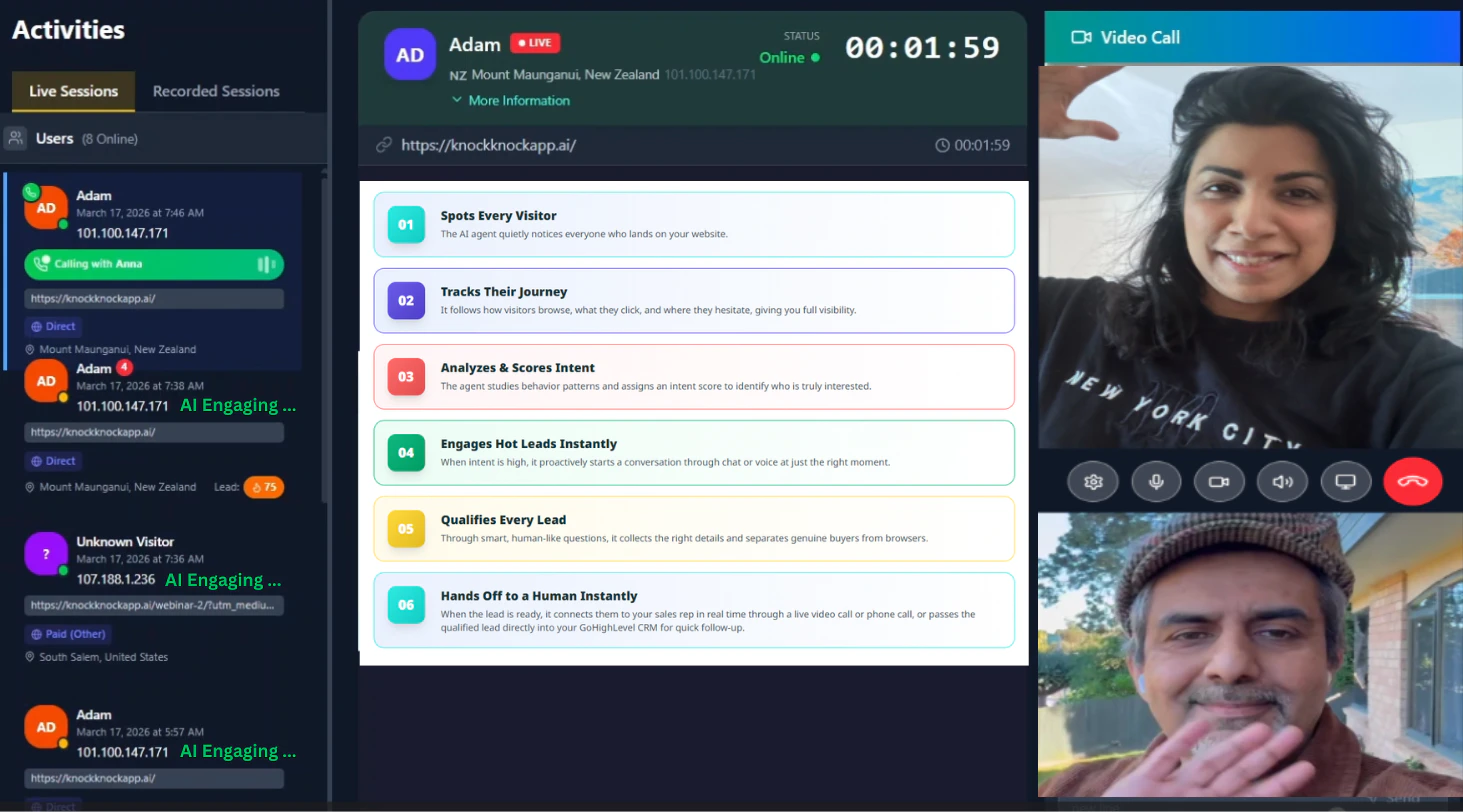
一句话介绍:Knock Knock通过NOX将AI销售大脑嵌入官网、电话、CRM全渠道,实现访客识别、实时对话、自动跟进与人工无缝接管,解决中小企业用不起庞大销售团队、却需全流程自动化获客的痛点。
Sales
Customer Communication
Artificial Intelligence
AI销售层
全渠道获客
对话式CRM
实时访客识别
智能外呼
人工无缝切换
销售自动化
白标方案
HubSpot集成
创始人工具
用户评论摘要:用户提问:如何判断访客是适合实时人工对话还是仅需自动化培育?此问题触及AI销售的核心智能决策机制,显示用户对NOX的“资格判定”逻辑与自动化教育边界有真实需求。
AI 锐评
Knock Knock的进化令人眼前一亮,但也需冷静拆解。从“门铃”到“大脑”,NOX的核心价值不是增加功能,而是用统一记忆解决销售工具碎片化的老问题。产品聪明地抓住了“AI筛查+人工收口”这一被验证的效率模型,且支持GHL、HubSpot等主流CRM实时读写,降低了中小团队的切换成本。1票点赞的评论虽少,但用户对“何时转人工”的追问恰恰点出关键——NOX能否精准判定“质变节点”,还是依赖人工预设规则?若全凭规则,则可能沦为花哨的聊天机器人;若真有自学习模型判定销售意向深度,才是壁垒。
但风险同样明显:12票在Product Hunt上热度偏低,说明要么市场认知尚未发酵,要么产品本身在演示之外的真实表现存疑。安娜作为非技术创始人打造的产品,在Llama、GPT-4等底层模型成熟度上能否支撑多信道实时推理?电话场景下的延迟与误判率?一旦错误转接或遗漏高意向线索,反而会伤害品牌。此外,“白标方案”表明其更倾向渠道合作而非直达客户,这或许是早期快速布局的捷径,但也意味着产品深度与品牌壁垒需靠合作伙伴反馈来打磨。一句话:NOX的方向正确,但“大脑”的精确性和可靠性才是决定它能跑多远的关键。
一句话介绍:Elsy是一款专为早期认知衰退老人设计的AI语音伴侣,通过每日对话帮助记忆与日常管理,并为远距离家属提供每周情绪、参与度和重复行为趋势报告,解决痴呆症护理中的信息碎片化和情感陪伴缺失痛点。
Android
Health & Fitness
Virtual Assistants
AI语音伴侣
老年痴呆护理
认知衰退
记忆支持
情绪监测
家庭沟通
隐私设计
健康管理
跨语言支持
语音交互
用户评论摘要:创始人莫滕分享父亲患病经历,强调产品针对痴呆症而非普通孤独感,关注记忆衰退、日常重复和家属远程监控需求。产品无原始对话记录,仅提供趋势分析,保护隐私。用户问题聚焦于语音交互的温暖感、对混乱时刻的响应能力及多语言适配效果。
AI 锐评
Elsy切中的不是一个泛化的“老年陪伴”市场,而是一个被技术长期忽视的硬核医疗护理场景——痴呆症早期干预。其核心价值在于两点:一是将AI从“情感填充者”升级为“疾病辅助监测工具”,通过分析语言重复率、情绪波动等生物标志物,为家属提供可量化的病程参考,而非廉价的情感安慰;二是坚守隐私底线,拒绝原始语音记录,仅输出趋势摘要,这在医疗伦理和家庭信任间找到了微妙平衡。创始人带着切肤之痛参与开发,但需警惕“亲情绑架”光环下的产品缺陷:目前投票仅12票,说明冷启动困难,且高龄用户语音交互的认知门槛(如方言适应、环境噪音)未被充分验证。此外,该模式本质是“让AI代替子女执行护理观察”,可能加剧老人的情感替代焦虑——当父亲意识到每周的“关心报告”来自机器而非子女电话时,孤独感是否更深?Elsy的方向正确,但离“真正解决问题”还有一段路:它需要证明自己不是家属甩锅的借口,而是家庭主动护理的增强器。
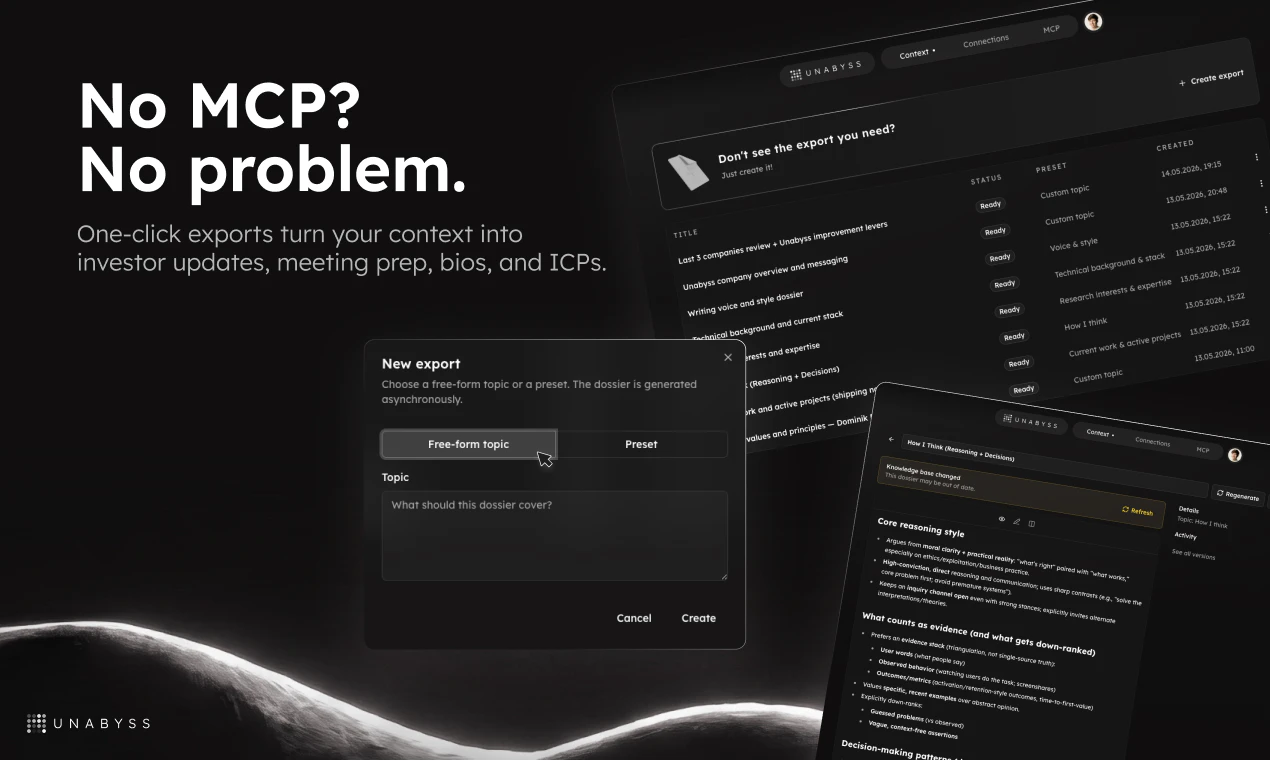

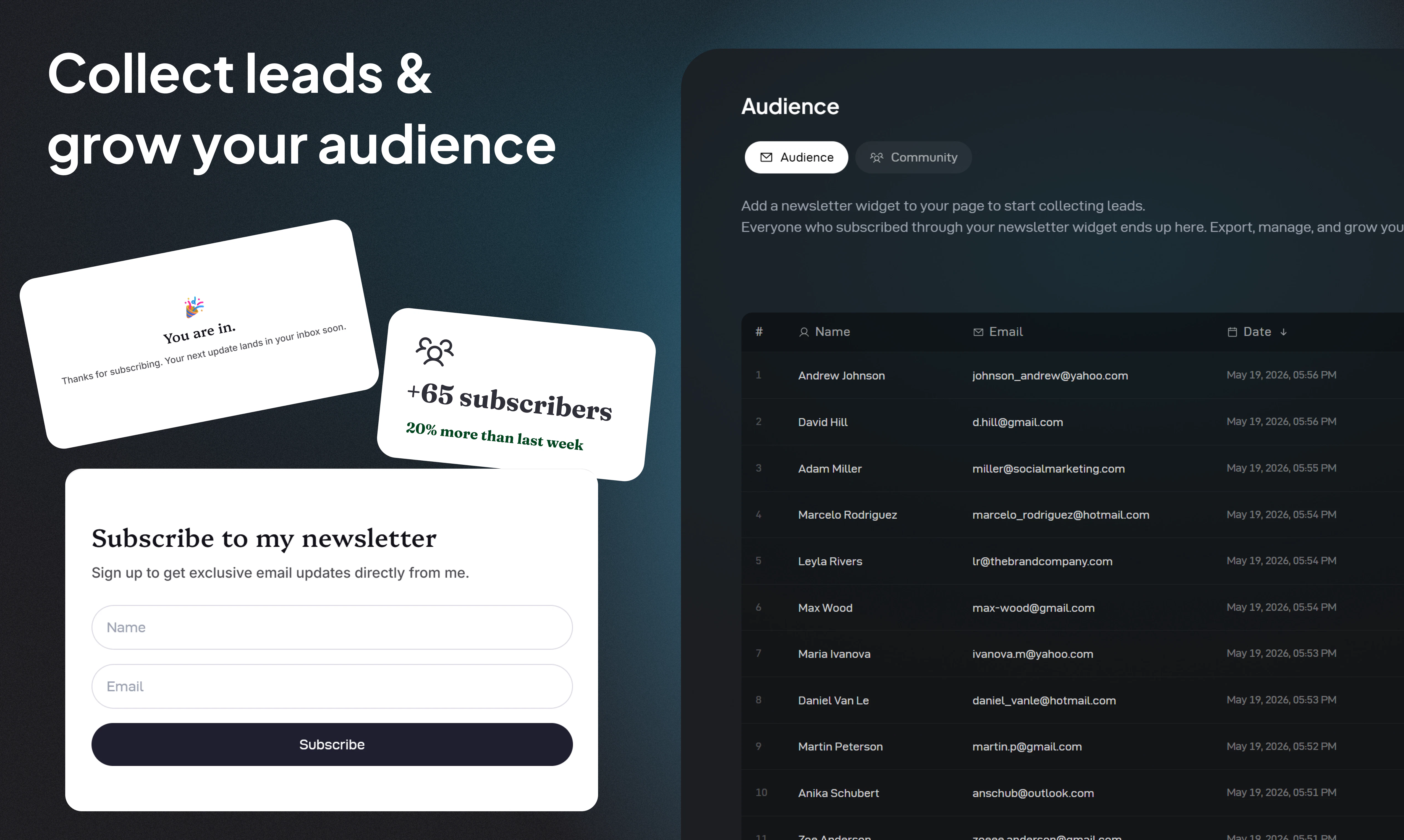


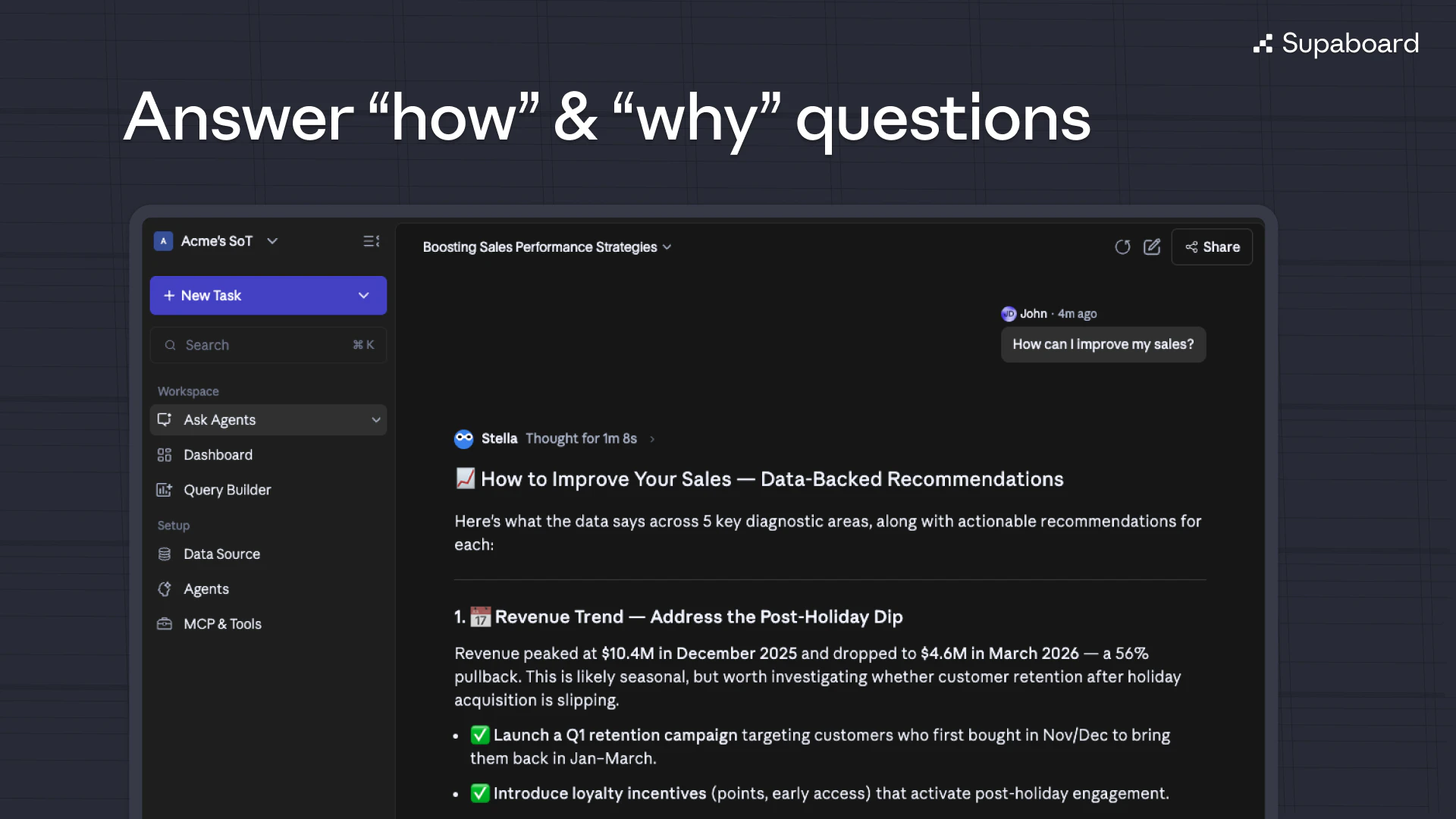
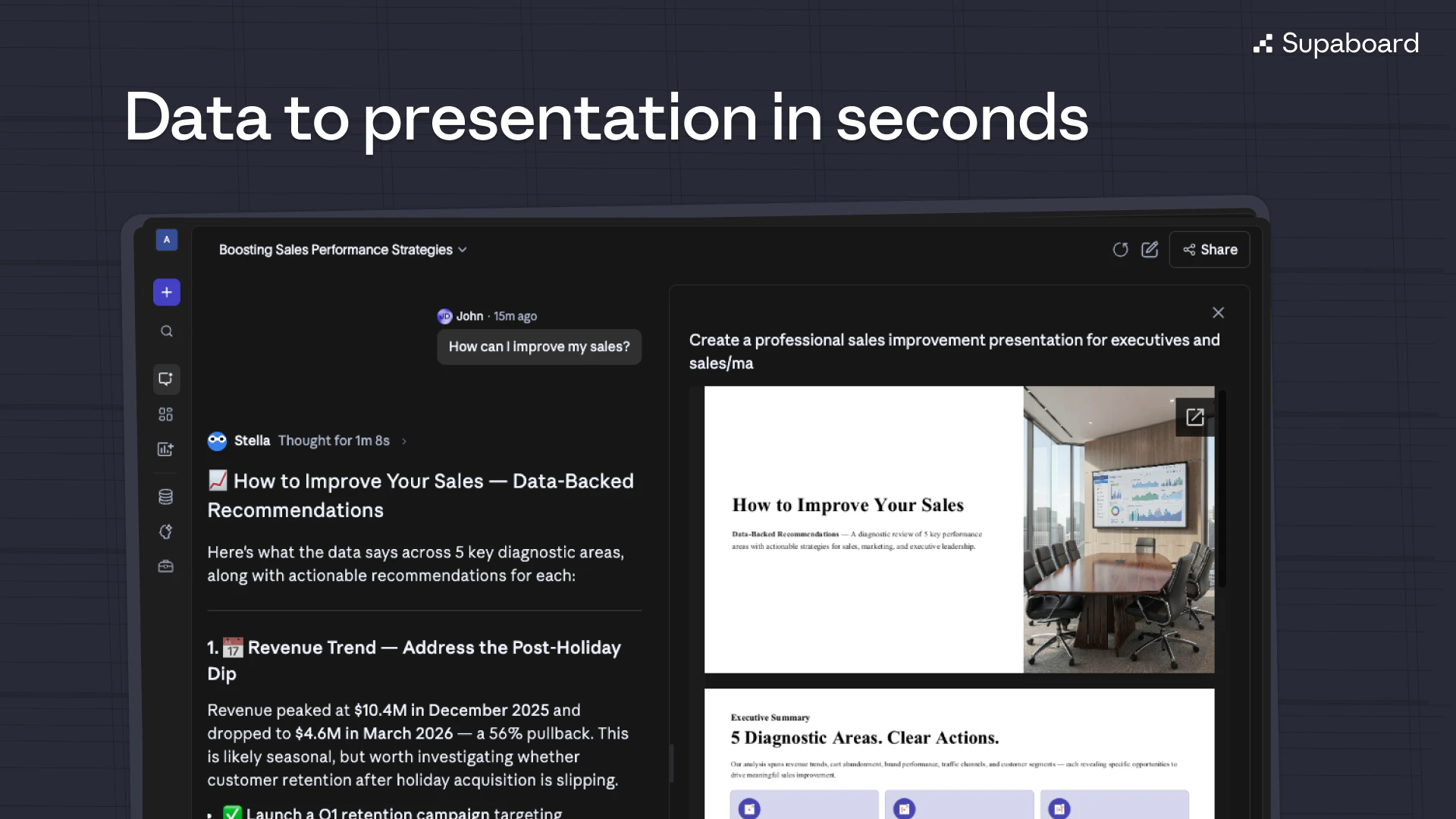














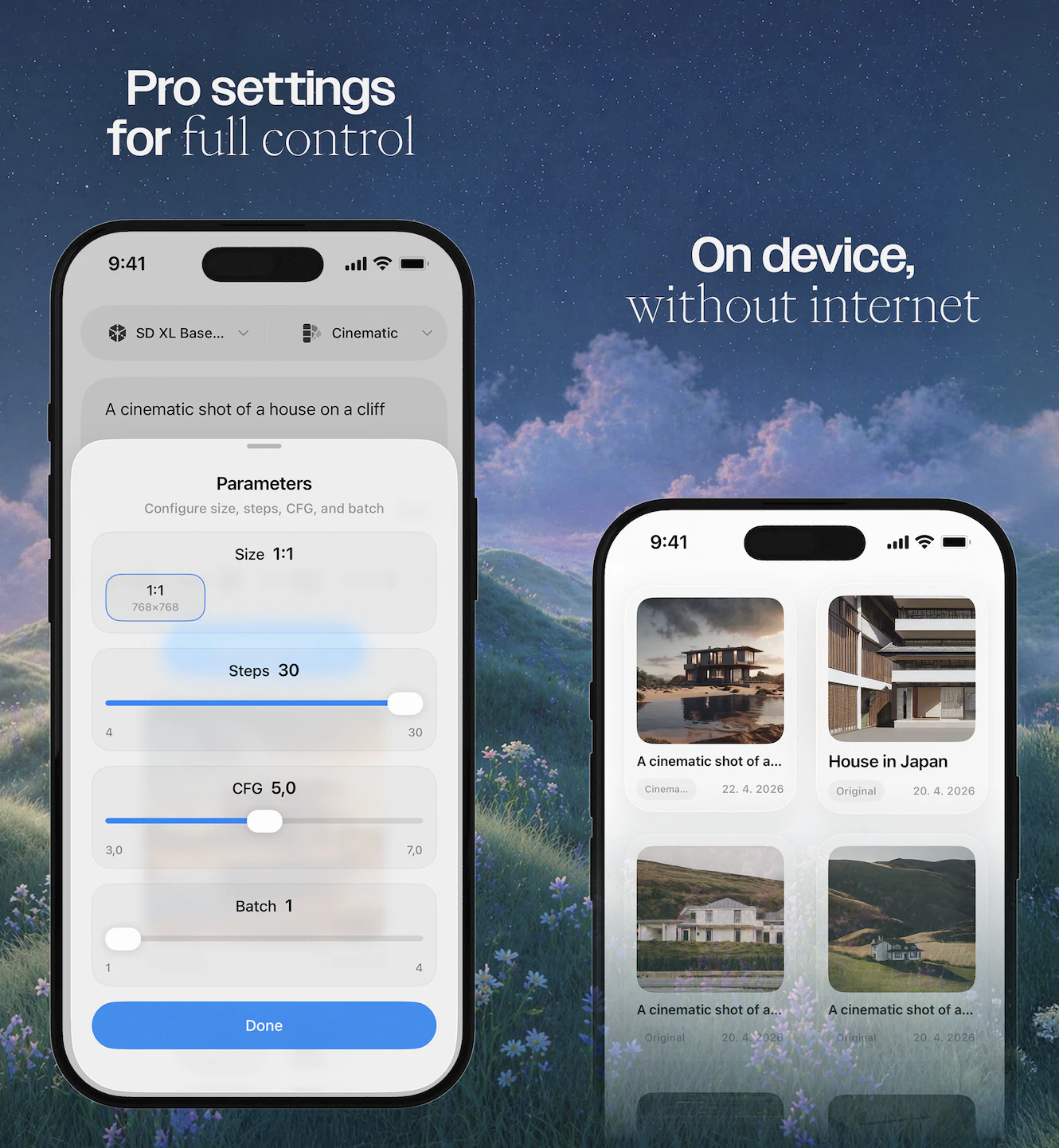







Hey PH 👋 Philip here, co-founder of Unabyss.
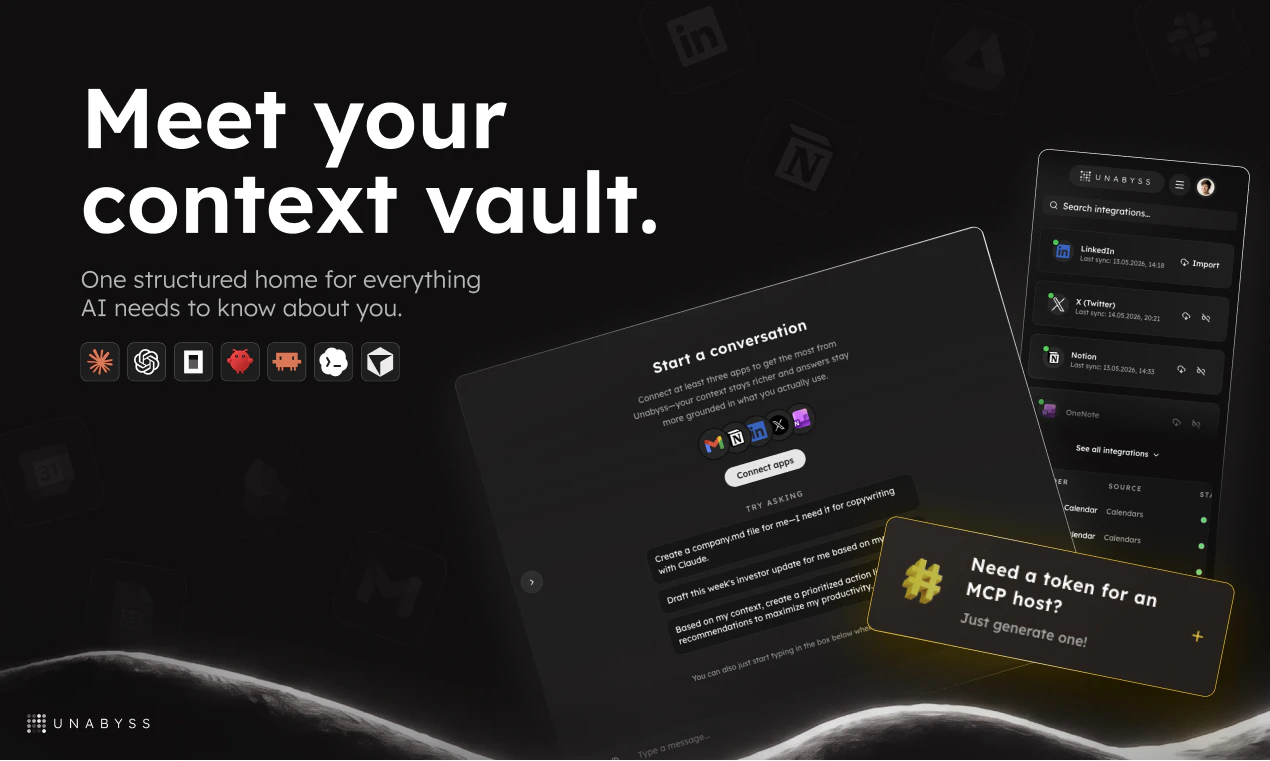
What is Unabyss? Unabyss is your personal context layer - a single, structured vault of your identity, knowledge, and preferences that any AI app or agent can access instantly, with you in full control of what gets shared and with whom.
The Problem Every AI tool you use starts from zero. You re-explain your role, your goals, your tone, your company - over and over. And when you finally do build up context inside one platform, it's trapped there. ChatGPT memory doesn't follow you to Claude. Claude Projects don't talk to Cursor. The more AI tools you adopt, the worse it gets.
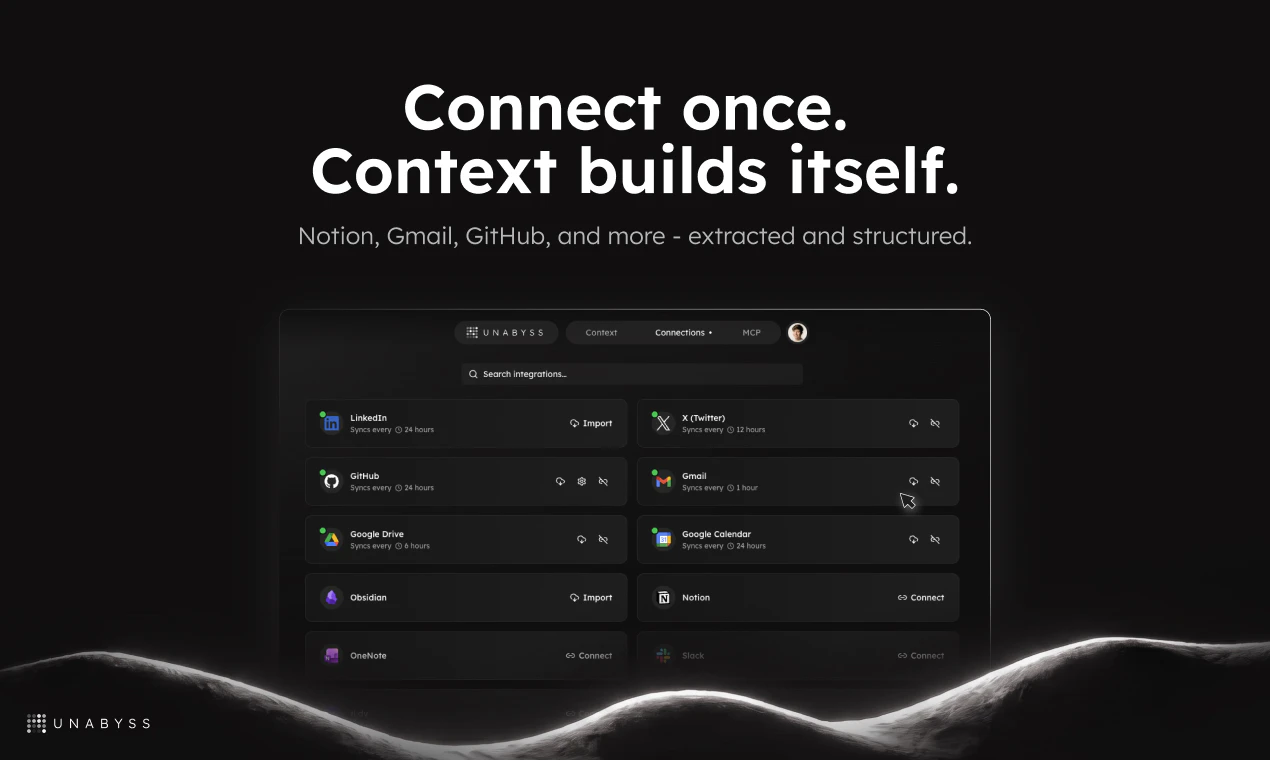
The Solution Unabyss extracts your context once - from LinkedIn, your website, Notion, Gmail, Slack, GitHub, and more - and structures it into clean, layered files (persona.md, voice.md, company.md...). From that point on, every agent and LLM tool you use can pull exactly the right context automatically, via MCP or one-click exports. No re-explaining. No copy-pasting. No context left behind.
What makes it different: your context is user-owned, pre-extracted (not built from interactions over time), and cross-platform - it works with any tool, any LLM, any agent, through a single connection.
Key Features
⚡ Auto-extraction from your existing tools in under 90 seconds
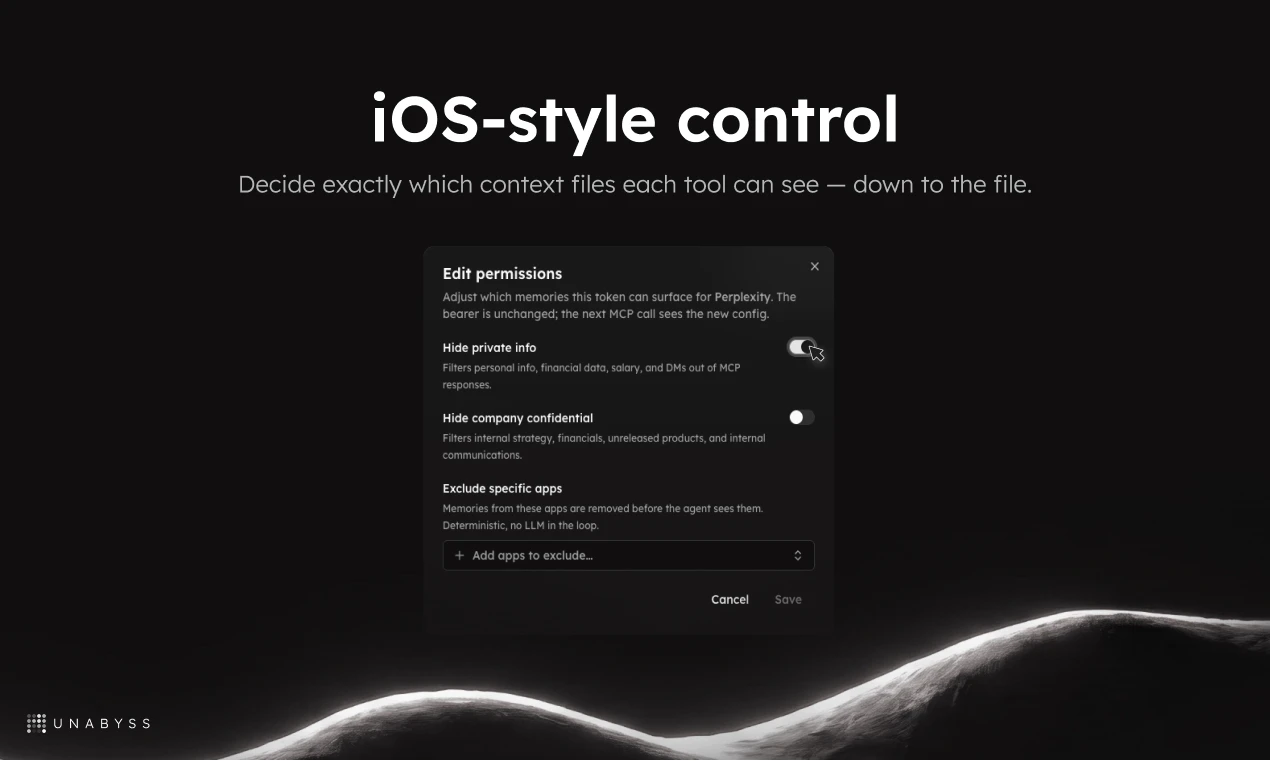
🔒 Granular permissions — share e.g. voice.md without exposing professional.md. iOS-style control, not cookie banners
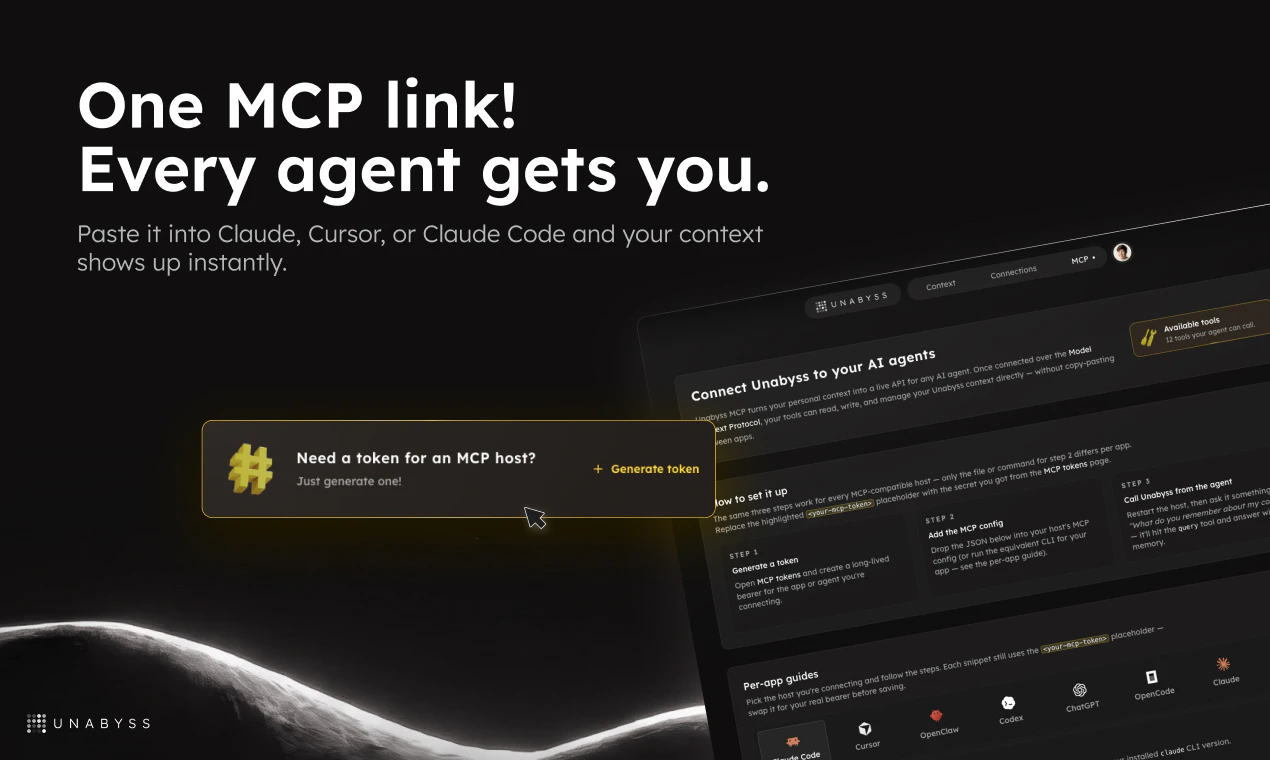
🔌 MCP server for Claude, Cursor, Claude Code, OpenClaw, and any compatible agent
📤 One-click exports - investor updates, meeting prep, ICPs, bios - generated from your context instantly
🔄 Always up to date as your sources sync
Who It's For Founders, operators, and builders who live across multiple AI tools and are tired of starting from zero every time. If you use Claude, Cursor, ChatGPT, or any LLM daily - and you've ever thought "it should already know this" - Unabyss is for you.
What We'd Love From You Try it, connect your first source, and tell us: which integrations should we prioritize next, and where do you need your context the most? We'll be here all day reading every comment — your feedback directly shapes what we build next. 🙏
Really like the idea of context following you across AI tools instead of starting from scratch every time. Feels much closer to how people actually work .
How does updating work in practice? If my tone or role changes over time, do I manually refresh it or does Unabyss adjust it automatically from new activity?
Looks incredible @philip_kubinski @marcin_uchacz1 - all the best!
How exactly is the context connected to tools? Is it MCP only?
Looks lit! very much needed.
Curious how context staleness is handled — if I update a doc in a connected app mid-conversation, does the MCP layer reflect that in real-time or on a sync interval?
my context was never that organised before, great stuffff
So you mean I don't have to manually feed stuff into my claude's memory? Extremely cool idea. Will be trying over the next days.
These kinds of products are what's making AI feel more and more like actual magic every day, well done folks:)
Looks super useful. Will give it a try! Congrats on the launch
This sounds helpful, just a quick question about the control part: If I connect to my apps, can I tell Unabyss to only look at specific folders, or does it just scan everything it finds?
This is a very relevant problem. One question; What happens when these context files become too large over time ? Does Unabyss automatically summarize or compress it?
Congratulations on the launch! I have a question: where does the vault actually live? is it stored locally, on your servers, or encrypted in the cloud? and if I disconnect tomorrow, is my data fully deletable?
how is this different from connecting your github repo (that has all the context about you)?
Such a useful tool! One question though, that is how are you handling conflicting context across sources?
Like for ex, if my linkedIn says one thing, slack conversations imply another and my Notion docs are outdated then how does Unabyss decide what becomes the source of truth??
Setup fallbacks. Be happy. might be the most relatable AI dev tagline this week
Can I have like a "work mode" and a "personal mode" and flip between them depending on which tool I'm using?
Every few days or every week I start something new with AI, and each time I have to repeat the same things all over again. Since it’s impossible to keep all these AI systems updated regularly, I never really get 100% out of them because I’m never providing the full context. Unabyss sounds like exactly the kind of solution I desperately need! Congratulations, I’ll definitely be following your progress.
Will it support my open claw ? Also I use 3 subscription of claude for different purposes. Is it possible to select what is bbeing shared via unabys?
This sounds great and I was actually waiting for something like this. My main question: is there a way to handle projects or specific topics separated? For instance when working on several codebases / products. My issues is always the amount of information I need to manage across projects while keeping an overview. Currently it feels like one huge mixed salad.
For everyone that didn't try the Unabyss MCP - it's super easy - one click connect!
Is there a risk that the Unabyss fills the gaps in my context with fabricated information? I mean - hallucination?
Congratulations on the launch! This is a great product and much needed.
One question I had: I have setup memory.md files in Claude which is basically a memory of the interactions I have had with Claude for it to remember the context of the project. Can Unabyss understand from those files about "how" the engineer usually proceeds with a problem?
when linkedin says one thing and notion says another, who wins? the conflict resolution between sources is where this gets tricky and most context tools just pick the latest update which isn't always right
@marcin_uchacz1 Congratulations. And happy product launch.
Great idea - not my use case yet as I use only one AI tool and also have very well written personal/projects skills - but definitely will revisit this when I hit some issues with remembering me as person by AI in multpile AI tools!
I had this exact problem of wiring different context sources 3 times this month only. Well done and congrats on #1 today!