PH热榜 | 2026-05-26
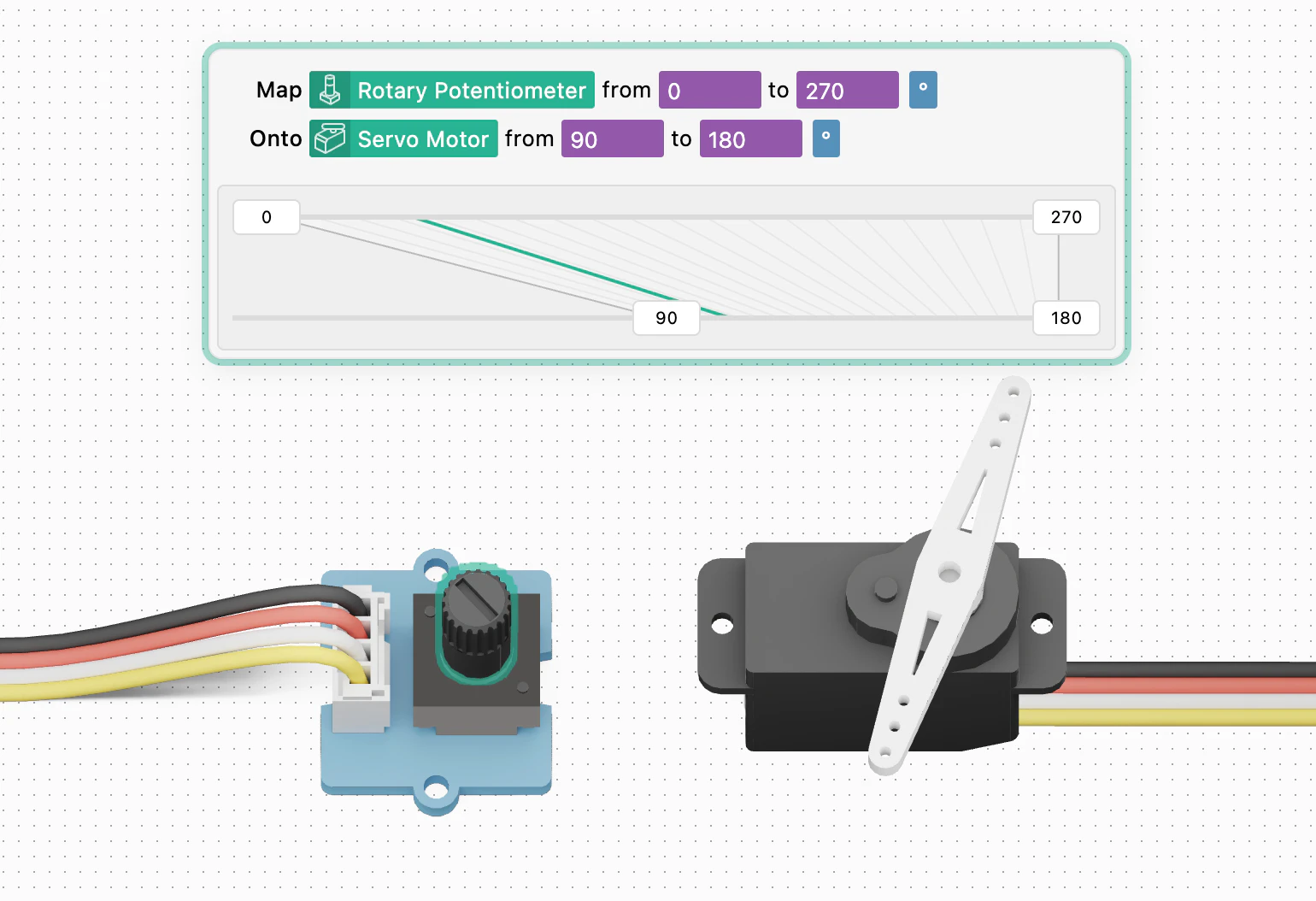
一句话介绍:Brew 是一款 AI 驱动的邮件营销工具,让用户用自然语言描述需求,即可在几秒内自动生成包含文案、设计、受众和逻辑的多步骤自动化邮件序列,解决传统邮件营销工具操作复杂、制作周期长的痛点。
Design Tools
Email Marketing
Artificial Intelligence
AI邮件营销
自动化邮件设计
邮件模板生成
品牌一致性
多客户端兼容
营销自动化
邮件HTML
AI代理集成
零代码邮件
用户评论摘要:用户普遍认可其生成邮件质量和品牌一致性,赞赏“一键生成多步骤流程”和“完美渲染”能力。主要需求是:期待与Klaviyo/HubSpot等平台的深度集成(如可编辑模板)、开放的Brew MCP接口以便从编程代理自动化触发,并对Outlook渲染的实现细节表示好奇。
AI 锐评
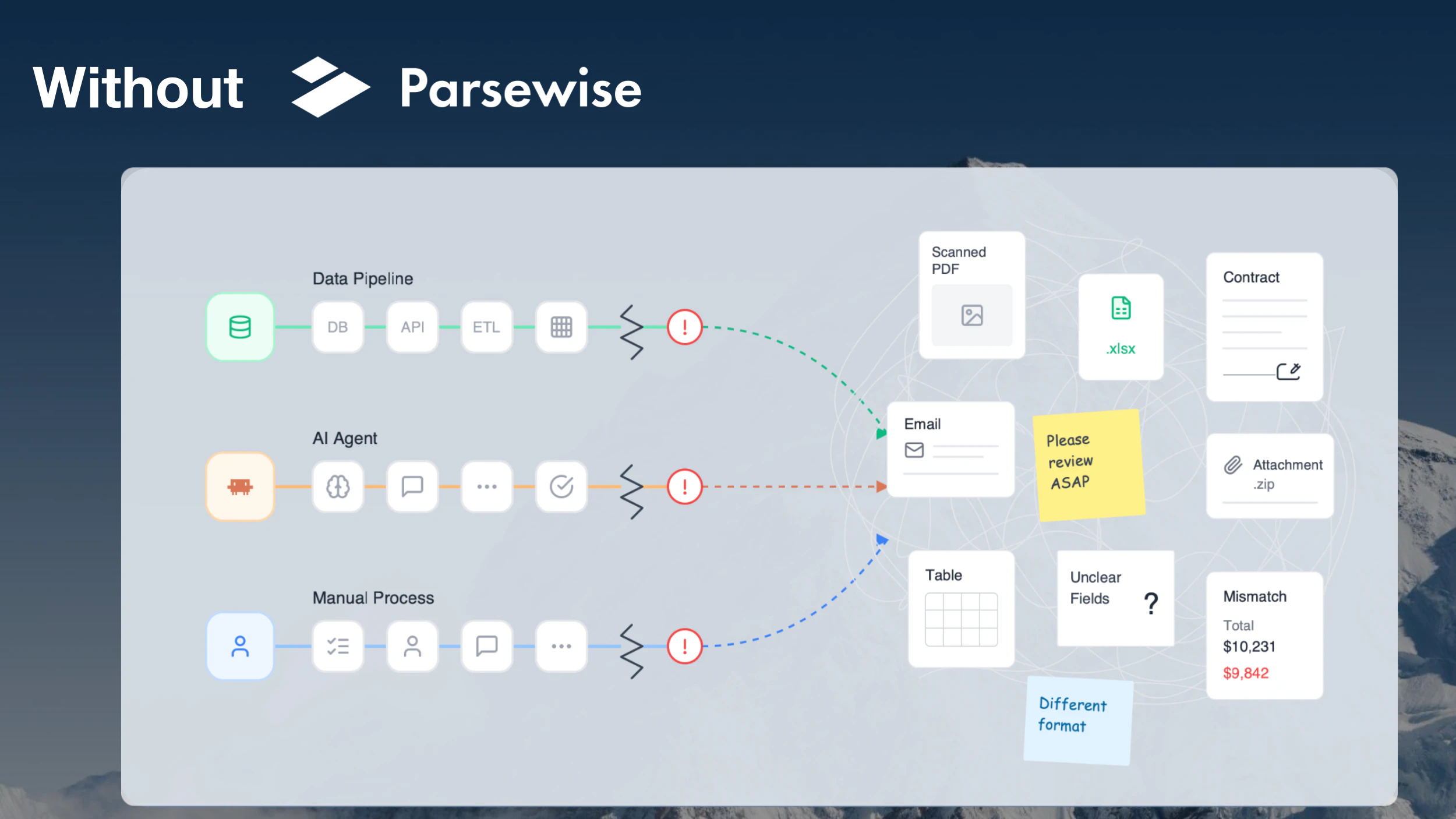
Brew 踩准了一个最“钝”的市场——邮件营销工具早已是红海,但痛点依旧扎人:HubSpot 和 Mailchimp 这类老牌工具本质上是为配备全职运营团队的大型企业设计的,而绝大多数中小团队根本玩不转。Brew 的切口极其精准:不是再做一个“更轻量的 Mailchimp”,而是直接用 AI 对话式生成消灭“设计-开发-测试”的中间环节。
它的核心战斗力在于“交付确定性”。很多同类 AI 工具能生成漂亮的静态设计稿,但一到真实收件箱就崩,尤其是在 Outlook 上。Brew 把“邮件渲染完美”作为硬性交付标准,这是将 AI 从“概念验证”推向“生产可用”的关键一步。同时,它不自建封闭生态,主动拥抱现有的 ESP(邮件服务商)和 AI Agent(如 Claude、Viktor),定位清晰如“AI 邮件代理层的中间件”,而非一个传统 SaaS 端的替代品。
唯一值得警惕的是“深度集成”的浅层风险。目前生成的序列输出到 Klaviyo 等系统是“静态 HTML 块”还是“可编辑的图形化模板”?这对已在使用成熟流程的团队至关重要。如果仅仅是“导出 HTML”,那 Brew 的价值就局限于“一次性邮件生成器”,而非“自动化营销系统的智能大脑”。此外,MCP(模型上下文协议)接口的开放进度决定了它能否真正嵌入开发者工作流,成为被编程调用的“邮件模块”,而不仅仅是网页端的“漂亮玩具”。
一句话:Brew 是个聪明的“缩窄”产品——在 AI 浪潮中不做大而全,而是把邮件交付的冷启动时间从一周缩短到一分钟,这是实打实的生产力提升。但能否从“尝鲜工具”进化为“营销中台”,要看它对 ESP 生态的渗透深度。
一句话介绍:Bond是一款AI驱动的GTM工程平台,帮助团队在15分钟内完成从受众构建、线索评分到个性化消息生成的全流程外联,无需昂贵工程师,解决中小团队“会造产品不会卖”的痛点。
Productivity
Sales
Artificial Intelligence
AI销售外联
GTM自动化
B2B线索挖掘
信号驱动营销
个性化触达
数据丰富
无代码
智能营销
销售赋能
初创工具
用户评论摘要:用户普遍认可其“15分钟上手”和“替代复杂工具链”的价值。核心反馈包括:希望拓展到B2C场景;关注信号时效性(如融资/招聘信号过期后价值下降);询问回复率、ICP筛选颗粒度及底层数据源(是否自建);以及技术用户担心邮件预热、黑名单检测等细节是否完善。团队回应称内置验证、可自定义API及全流程控制。
AI 锐评
Bond的叙事抓住了当下最真实的断层:AI让“造产品”平民化了,但“卖产品”反而变得更像军备竞赛。它精准切入的痛点是,SMB和初创团队既雇不起年薪15万美金的GTM工程师,也养不起7个销售工具的月费。Bond的价值不在技术壁垒(其底层很大程度是聚合Apollo、ZoomInfo等第三方数据),而在于用AI代理层大幅降低了“专业外联”的认知门槛——让一个非技术创始人也能在15分钟内做出看起来像GTM老手才有的信号触发式营销活动。
但这恰恰是它的潜在风险。用户评论中关于“信号过期”和“误报成本”的质疑非常到位:一通基于过时融资新闻的冰冷触达不仅无效,还会留下黄页骚扰般的负面品牌印象。Bond若不能证明其信号新鲜度和数据质量优于竞对(如Clay),那它不过是把“手动缝补七套工具”变成了“自动缝补七套工具”,核心价值并未跳升。此外,它主打的“推送至邮件序列工具”而非自建发送链,意味着对邮件预热、域名声誉、黑名单规避等核心交付环节的控制力有限,这可能导致高拒信率和低送达率,反噬其作为“一站式解决方案”的承诺。
Bond的真正定位应该是“GTM领域的Cursor”——大幅提速原型(外联策略)的搭建,但最终执行质量和精细度仍取决于使用者本身的业务理解和数据清洗能力。如果它后续能在信号保鲜、数据反误导和序列执行质量上建立闭环,它将有机会定义AI时代的“轻量级GTM”标准,否则很容易沦为又一款“第一次用惊艳,第二次用失望”的PPT生成器。对于早期团队而言,用它快速验证一个外联假设是有价值的,但若将其视为无脑增长按钮,则需警惕。
一句话介绍:Rezonant是一个连接产品构思与代码执行的协作平台,帮助团队将模糊的产品想法转化为AI编程代理可直接执行的结构化规格和任务,解决“构建什么”的上游决策瓶颈。
Productivity
Task Management
Artificial Intelligence
产品管理
AI协作
需求规格
任务管理
编程代理
Chrome扩展
PRD生成
GitHub集成
团队协作
产品开发
用户评论摘要:用户普遍认为该产品解决了从创意到执行过程中的混乱问题,Chrome扩展的录制功能受欢迎。核心疑问集中在:AI解读意图时如何避免误读?是否有足够的审核步骤?如何确保与Claude Code等编程代理的无缝对接?以及对于已有业务分析师的大团队的实际价值。
AI 锐评
Rezonant切入了一个极具价值的市场缝隙——在AI编程能力爆发后,“写代码”已不再是瓶颈,“该写什么”和“为什么写”的混乱成为新的效率黑洞。其核心洞察在于,将产品管理从散落的Notion文档和Slack对话升级为一个“活”的、与代码库锚定的结构化协作空间。
产品的真正价值不在于简单的AI生成,而在于“结构化”与“可执行性”。它试图将PM模糊的语言、指点和录音,转化为编程代理看得懂、能执行的任务。这种“上游标准化”是当前AI软件开发流程中缺失的关键一环,也是其区别于普通协作工具的核心壁垒。
然而,风险同样显著。来自用户的质疑——AI误解意图、缺乏审核闭环——绝非杞人忧天。如果AI在意图转译过程中产生错误,而团队又过度依赖自动化,那么“更快地犯错误”只会加速灾难。Rezonant必须证明其“AI督察”能力(即主动识别模糊点、提出边角案例)的可靠性,而不仅仅是提供漂亮的PRD模板。此外,其MCP服务器的推出,是打通与Claude Code等工具闭环的关键,但这也意味着其成功高度依赖于外部生态。
一句话总结:Rezonant是AI时代的“图灵测试”工具——它能否真正理解人类的产品意图,决定了它究竟是一个强大的“放大器”,还是一个漂亮的“幻想引擎”。对于已经或正在拥抱AI编程代理的团队,它值得一试,但绝不可“无脑信任”。
一句话介绍:QuakPit 是一款 macOS 菜单栏应用,通过让动物驾驶飞机拖拽横幅飞过屏幕的趣味动画,替代传统弹窗,在会议开始前以令人会心一笑的方式提醒用户,解决传统通知容易被忽略或让人感到厌烦的痛点。
Mac
Productivity
Meetings
GitHub
macOS 应用
会议提醒
趣味通知
菜单栏工具
日历集成
开源软件
免费应用
桌面小工具
动物动画
用户评论摘要:用户普遍喜爱其创意和趣味性,认为比传统弹窗更有效。主要问题:1. 截屏共享时动画会显示给第三方(开发者确认);2. 希望支持本地日历而非仅联网日历;3. 好奇水豚是否是最高频选择的动物。多名用户肯定了免费开源的策略。
AI 锐评
QuakPit 的走红,精准击中了“通知疲劳”这一赛道,但其真正价值不在于技术创新,而在于一个聪明的行为心理学设计:用“惊奇”替代“烦恼”。传统弹窗因高频重复已被大脑自动过滤,而QukPit的动画则是一次“情境重构”——将例行公事变成了短暂的游戏。这本质上是对用户注意力的“温柔劫持”。
不过,冷静来看,该产品的护城河极低。核心功能“动画+日历”是一个标准的一周速成项目,GitHub上已有大量类似实验。其“免费开源+一次性收费”的模式,虽然博得了Developer社区好感,但变现天花板明显:$4.99的溢价能力,取决于用户对“鸭子换恐龙”这类定制化新鲜感的支付意愿,但“新鲜感”本身是快速衰减的。当用户第一周的新奇感过去,动画本身也会变成新的“干扰”。
产品的真正纵深在于两条路:一是向纯娱乐转型,成为桌面互动宠物;二是向效率工具进化,利用“注意力捕获优势”承载更复杂的日程管理场景——比如用动物表情预警会议冲突。目前版本偏轻松玩具,若止步于卖音效皮肤,用户留存堪忧。创始人“想到就要做到”的执行力值得赞赏,但Product Hunt的热度不一定能转化为长期的日活。下一个阶段,需要在“让人发笑”和“真正有用”之间找到可持续的平衡点。
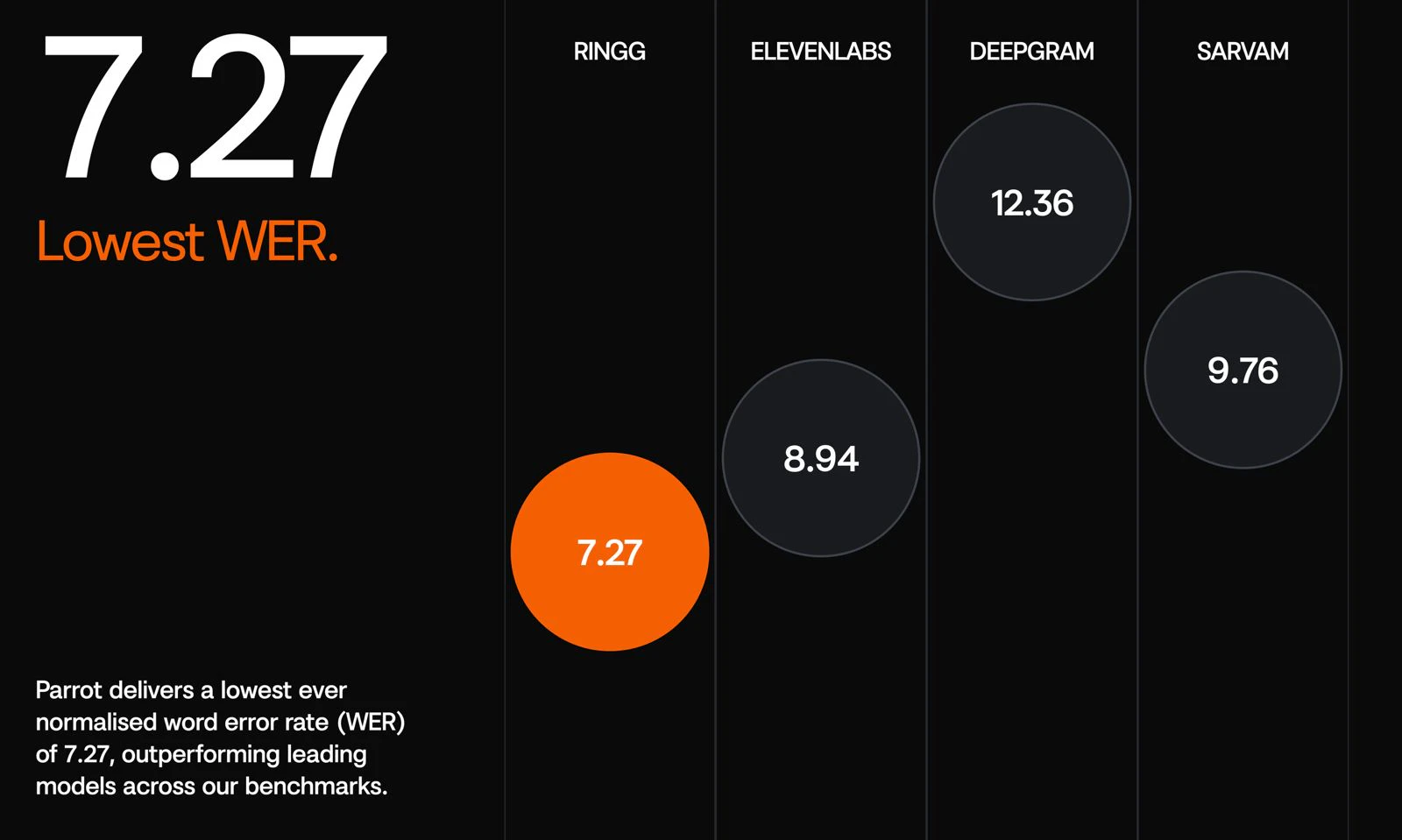
一句话介绍:Parrot是一款专为生产级语音助手设计的语音转文字API,核心解决嘈杂环境、印地语混杂英语及实时低延迟转录的痛点。
API
Artificial Intelligence
Audio
语音转文字
API
印度英语
印地语
代码切换
语音助手
实时转录
低延迟
噪声鲁棒
自然语言处理
用户评论摘要:用户聚焦其印地语-英语代码切换与噪声处理能力,但发现英语混印地语时系统会偏向输出天城文。多位用户询问欧洲语言支持、多说话人重叠对话处理及P95延迟数据,官方确认多说话人场景为路线图功能,未透露精确延迟基准。
AI 锐评
Parrot切入了一个精准但狭窄的痛点:让语音转文字在印度口音、噪声和代码切换的“脏”数据中依然可靠。这确实是OpenAI Whisper这类通用模型的软肋——它们对清晰音频的“蜜月期”基准测试,在真实电话会议中往往一触即溃。Parrot在基准之外强调“下游工作流可用性”,即转录必须被LLM干净调用,这很实际,但也暴露了其局限性。
从评论区看,用户最尖锐的质疑在于:它是否只在“单说话人-智能体”场景有效,而回避了更棘手的多说话人重叠会话?官方坦诚这属于未来路线图,这很诚实,却也意味着其应用场景被严格限定在客服、语音助手等一对一呼入场景。此外,印地语主导时对英语词汇的“印地语化转录”现象,说明其代码切换机制仍存在语言偏向,官方却称之为“预期行为”,这可能会让依赖英文原文的金融、技术类应用望而却步。
产品真正的护城河不在于技术指标(P95延迟和WER尚未公布),而在于对印度语音市场垂直场景的深度优化。但这种垂直性也是一把双刃剑:它既让Parrot成为服务印度用户的语音产品团队的“现成答案”,也意味着在全球化或欧洲语言场景下可能水土不服。对于创业者而言,若目标用户群80%以上来自印度语区,Parrot是当前最优选;但若需覆盖多语种、多场景,它目前更像一个“专用工具”,而非通用平台。
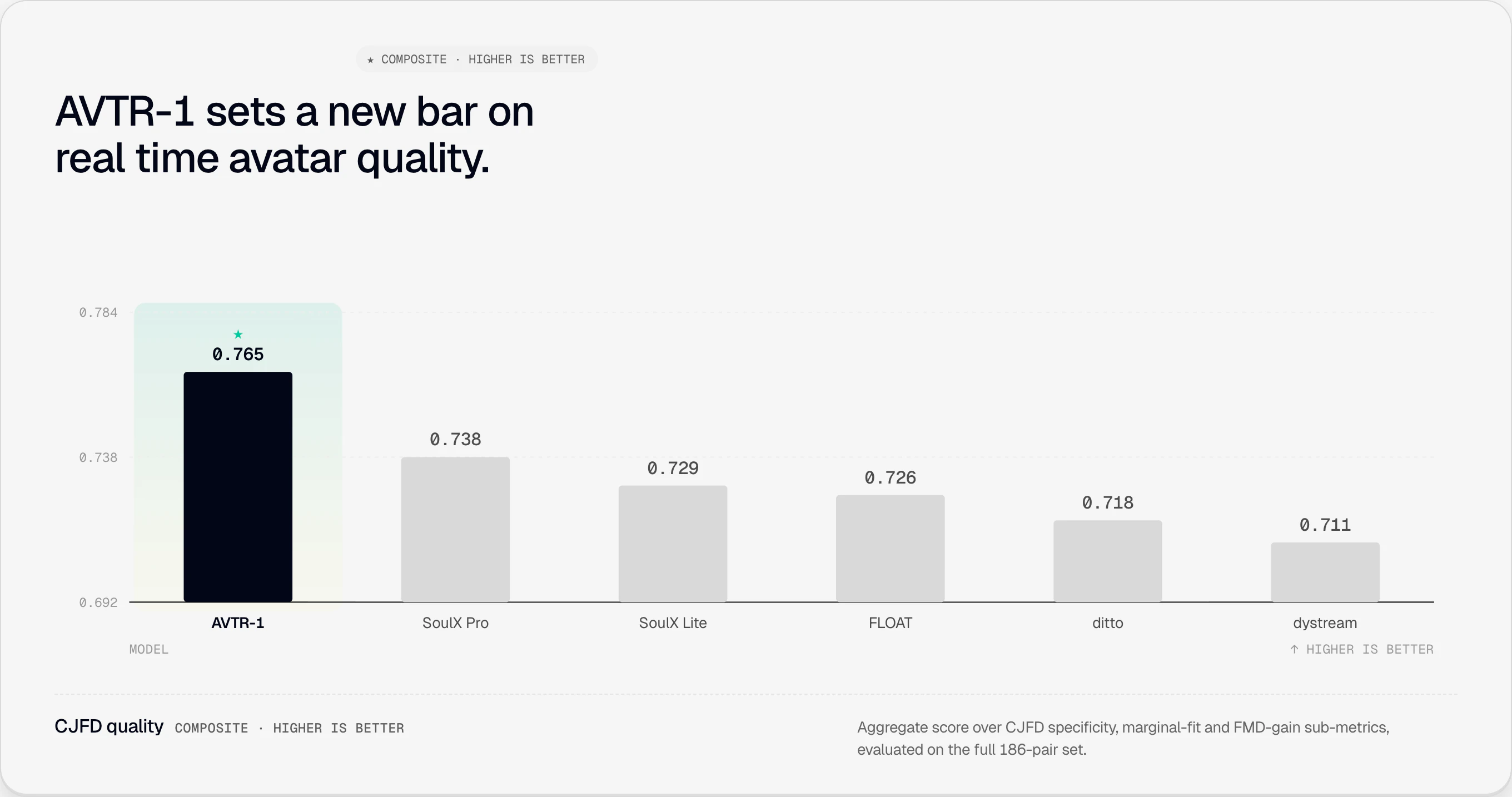
一句话介绍:AVTR-1 是一款开源实时AI头像模型,能在你说话时实时生成每一帧面部表情并实现全双工主动聆听,解决了现有AI头像“假唱式”延迟和缺乏语义反应的痛点,让开发者零成本自建逼真交互头像。
Video Streaming
Open Source
Artificial Intelligence
开源AI头像
实时生成
全双工
主动聆听
情感响应
零成本
开发者工具
低延迟
视频模型
人机交互
用户评论摘要:用户聚焦于全双工主动聆听和实时表情是最大差异化优势,质疑端到端延迟(回复澄清模型侧仅80-90ms,总延迟还依赖语音管道)。提问集中在许可证、头像定制、单GPU运行性(4090可行)及与Tavus/HeyGen的差异。开发者看重开源对商业订阅模式的颠覆。
AI 锐评
AVTR-1的本质并非“又一个逼真头像”,而是用开源重写游戏规则。它精准捅破了当前AI头像行业的窗户纸:那些宣称“实时”的竞品,实际大多是预录面部循环加嘴型替换,消费者被忽悠了三年。AVTR-1每帧从头到下巴全生成+全双工聆听,在技术维度上确实把行业标准从“表演”拉到了“对话”。
但真正致命的不是技术参数,而是定价策略和开源心态。对年收入低于1000万美元的商用完全免费,直接撕开了按分钟计费巨头(如HeyGen)的利润防线。这并非慈善,而是阳谋:用0成本吸引海捞的独立开发者、中小团队和尝鲜者,迅速积累应用场景和数据反馈,让模型在开源社区中被磨得更锋利。
不过,“犀利”之外也有冷静点。其“实时”存在上下文:模型生成端仅80-90ms,但整个对话链路的端到端延迟(STT-LLM-TTS+网络传输)才是用户体验的真瓶颈。官方公布的L4/4060等消费级显卡能跑,但性能并未超过A100,这意味着开发者如果不上高端云GPU,在高并发场景下仍可能体验跳水。此外,当前公开的参考头像数量和风格有限,若开发者想定制独特形象,复刻成本如何,仍需实战验证。
AVTR-1最大的贡献并非技术本身,而是把“可自持、可修改、可集成”的视频头像层从黑盒变成开源协议。它动了谁的蛋糕?所有靠API调用费赚钱的闭源头部。它挑战了谁?每个想喝到头汤的开发者——现在你们要做的不再是选供应商,而是决定用0成本拼出下一个爆款应用,还是一边观望一边看别人起飞。
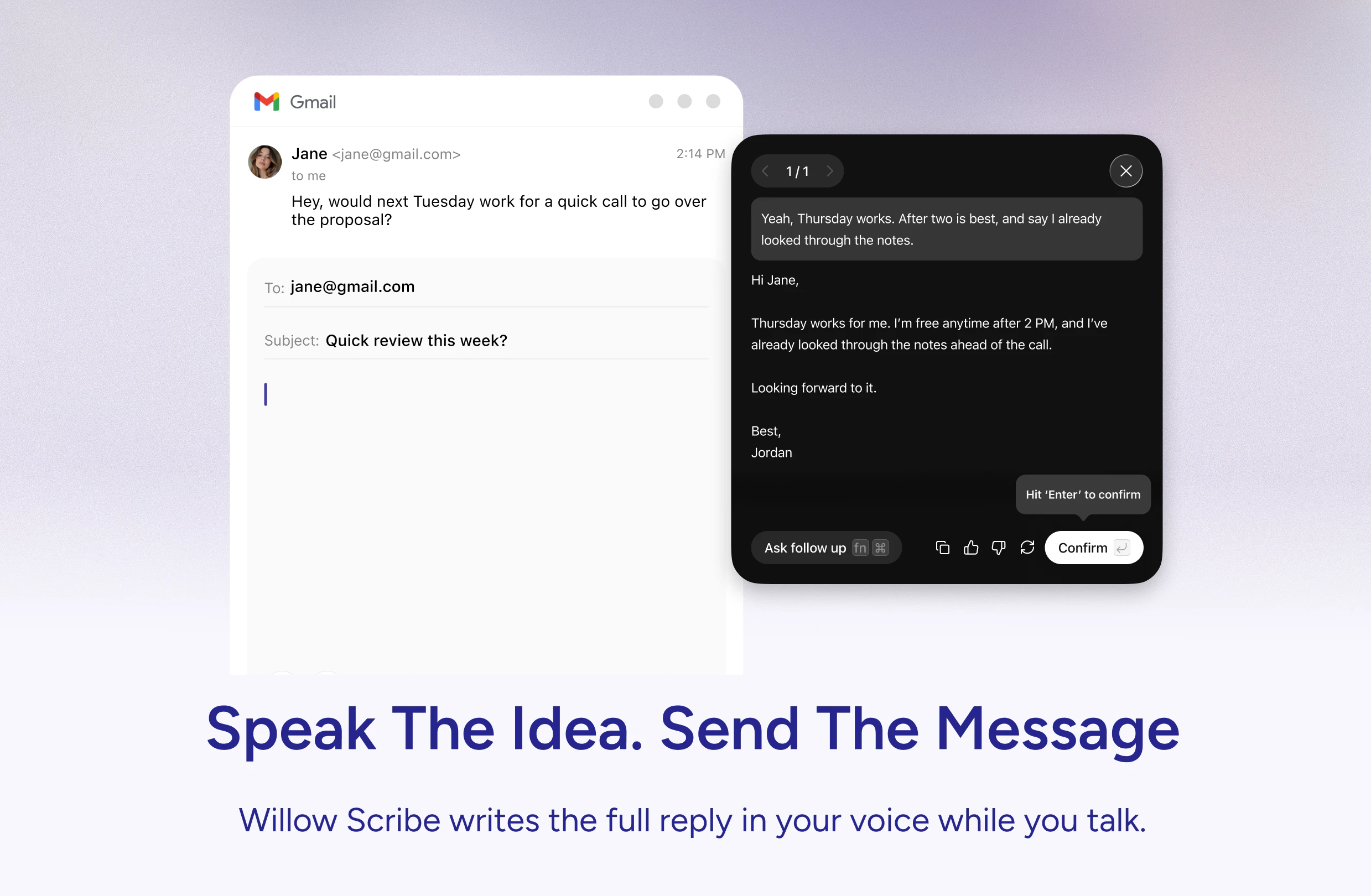
一句话介绍:Willow Scribe是一款通过语音输入核心意图、自动生成完整消息的AI写作助手,解决用户在邮件、Slack、iMessage等工作应用中“说时想法凌乱、打字时费力”的沟通痛点。
Productivity
Writing
Artificial Intelligence
AI写作助手
语音转文本
智能撰写
工作流集成
邮件助手
Slack集成
写作风格学习
文本改写
生产力工具
Mac应用
用户评论摘要:用户普遍认可其“将口语化思考转化为整洁消息”的价值,认为传统听写工具难以处理中途改口和暂态语言。主要问题:风格学习是否可重置、定价细节、能否在非指定应用中实时改写、以及Scribe相较于基础听写功能的长期留存率。
AI 锐评
Willow Scribe的切入点非常精准——它没有试图去取代打字或对话式AI,而是填补了“语音输入”和“可发送消息”之间的断层。传统听写工具本质上是“语音打字机”,忠实捕捉每一个字和错误,最终输出仍需要人工修正;而Scribe则在底层上进行了一次语义重构,将用户混乱的口语草稿视为“意图”,并在用户写作风格模版中生成干净的成品。这种“从说意图到写完毕”的转变,才是真正降低了思考到输出的认知负荷。
不过,产品面临的核心挑战恰恰在于“隐私与风格学习”的平衡。正如评论中提到的,当用户在不同社交层级(老板 vs 好友)中切换时,AI需要动态调整“语气热度和直接程度”,而目前的产品描述似乎偏向静态学习用户“风格”,这可能导致情感错位。此外,留存率问题同样棘手——人们用完一段话后可能忘记激活该工具,除非它深度嵌入到输入法或系统菜单层,而不是依赖显式“按热键-说话”的触发模式。从技术实现看,其对macOS文本高亮区进行“原位改写”的能力,如果只限制在几款APP内,体验将大打折扣;如果必须通过Accessibility API全覆盖,则性能和兼容性是需要迈过的坎。
总体而言,Willow Scribe有潜力成为“生成式AI+写作工作流”品类中真正让人形成肌肉记忆的工具,前提是它必须证明自己的实时性(不卡顿)、全局性(非只限指定App)和动态适应性(非暴力学习用户的所有风格)。目前135票的首日表现中规中矩,是否能在功能堆叠中逃过“体验两周即弃用”的怪圈,关键看它后续能否从“帮你写”进化到“帮你想得更清楚”。
一句话介绍:SelectPrism 是一个由AI驱动的面试与筛选平台,旨在解决招聘团队在筛选、面试和评估候选人过程中耗时过长、流程繁琐的痛点,帮助团队快速锁定并录用最合适的候选人。
Hiring
SaaS
Career
AI面试
招聘自动化
候选人筛选
ATS集成
技能图谱
反作弊
人才评估
生产力工具
HR科技
智能短名单
用户评论摘要:用户对产品速度和自动化能力表示认可,但关键疑问集中在:1) AI面试的候选人体验(是否告知是AI、影响完成率);2) 技能图谱的更新机制;3) 对软技能(沟通、领导力)的评估方式;4) 是否需要独立ATS;5) 评分权重能否自定义;6) 对非传统背景候选人是否友好;7) 反作弊的具体实现。
AI 锐评
SelectPrism切入的是招聘领域最痛、最脏、也是最真实的环节——从简历堆到第一次面试之间的“黑箱地带”。它没有去追逐那些花哨的、骗投资人的“预测性招聘”概念,而是务实且残忍地解决了一个核心问题:用机器替代人类完成大量低价值的重复性劳动。从“上传JD→AI面试→输出短名单”这条链路来看,其功能设计和产品定位是精准且犀利的。
但产品的真正价值,不在于那个基于6000万简历的技能图谱,也不在于那25项反作弊检查。这些是当下AI招聘工具的标配,而非命门。关键问题在于:它能否在“提升效率”和“维系候选人体验”之间找到微妙的平衡。从用户评论中可以看到,候选人能否在30秒内感知到是AI面试,以及这种感知如何影响后续的Offer接受率,是这个产品能否从“好用”跃升为“必用”的隐性天花板。如果AI面试最终只是让招聘方单方面爽了,却伤害了候选人的体感,这反而会制造新的流程瓶颈。
另一个潜在风险是“同质化打分”。其基于历史数据训练的模型,天然倾向于筛选出“看起来像过去优秀员工”的人,这会系统性地错杀那些拥有非传统背景、跨行业经验或强成长潜力的候选人。对于强调创新和突破的企业而言,这可能是灾难性的。
总体而言,SelectPrism在解决“招聘速度”这个问题上做得足够好,但它是否真正解决了“招聘质量”的终极问题,仍需打一个问号。它是一把非常锋利的手术刀,但需要清醒的医生来操刀,否则可能把传统招聘中那点弥足珍贵的“人味”和“意外之喜”也一并切掉了。
一句话介绍:法拉利首款与LoveFrom联合设计的纯电超跑,通过四个电机、主动悬架与四轮转向系统,在保留品牌驾驶激情的基础上,解决电动车“性能有余、操控无魂”的体验痛点,让赛道级动态控制与豪华座舱数字化触控共存于同一场景。
Cars
Design
Electric Cars
纯电超跑
法拉利
LoveFrom
四电机
主动悬架
四轮转向
触控交互
豪华电动
驾驶动态
概念车
用户评论摘要:用户对设计提出质疑,认为外观“廉价”“不像法拉利”,与高价不符;关注点集中在触控与物理按键的取舍策略、充电基建对超跑用户的实际影响,以及宣传片缺失动态驾驶场景的遗憾。
AI 锐评
这台“Ferrari Luce”在Product Hunt上获得的119票,更像是一场设计圈的自嗨,而非汽车迷的集体狂欢。抛开“第一台法拉利电车”的噱头,它暴露了传统超跑品牌在电动化转型中的典型矛盾:既要维持历史符号,又急于贴上科技标签。
最大的叙事张力在于“电子触控与物理控制的结合”——但这恰恰是行业过去十年踩过的坑。保时捷Taycan的屏幕瀑布、特斯拉的极简主义,都已证明:当一家赛道公司开始大谈“生活之舱”时,往往意味着它在驾驶本质上的妥协。评论中“宣传片没有试驾场景”的质疑,精准刺中了痛点:如果1050匹马力只能在PPT上咆哮,那它和一台会发光的昂贵模型有什么区别?
更值得警惕的是,LoveFrom(乔尼·艾维的团队)加入,导致这款车的外形呈现出强烈的“消费电子化”倾向——流线镀铬、一体玻璃、无格栅前脸,几乎就是一台放大版的iPhone。但汽车不是可穿戴设备,法拉利用户买的是血脉贲张的引擎声波与后轮漂移时脊椎的痉挛感,而不是一组能发光的“触控反馈马达”。
至于充电基建对超跑定价的影响,评论中那位能源模型维护者的质疑更致命:当超级充电站都要和数据中心抢兆瓦级功率时,你让一个有十几辆收藏车的富豪,为了一台“玩具”再买套工业变压器?这已经不是产品问题,而是生态硬伤。
总结:这是一场美学与工程妥协后,最终服务于品牌故事而非驾驶体验的发布。如果法拉利真要把电车当“第三空间”卖,那它首先得忘了自己是谁。
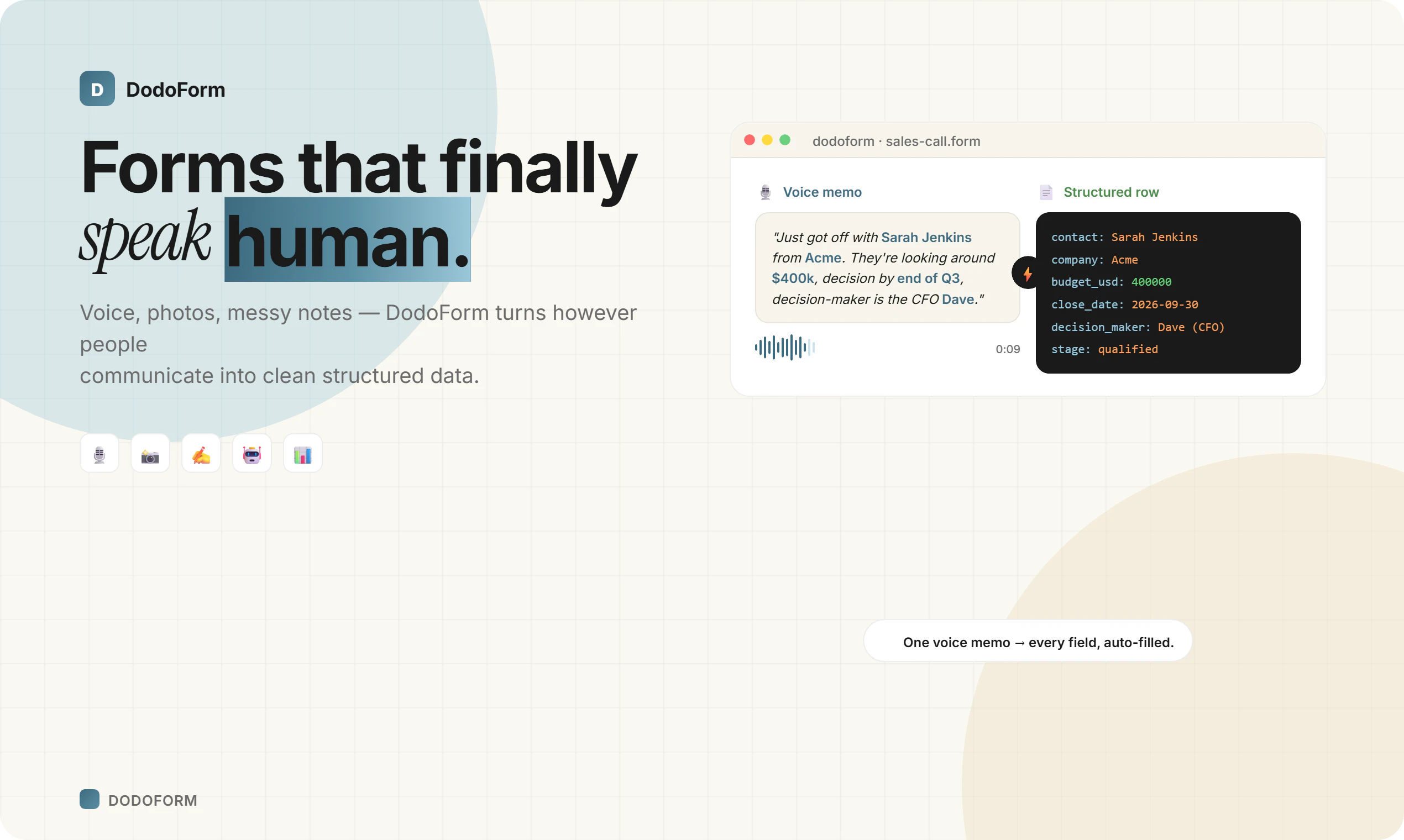
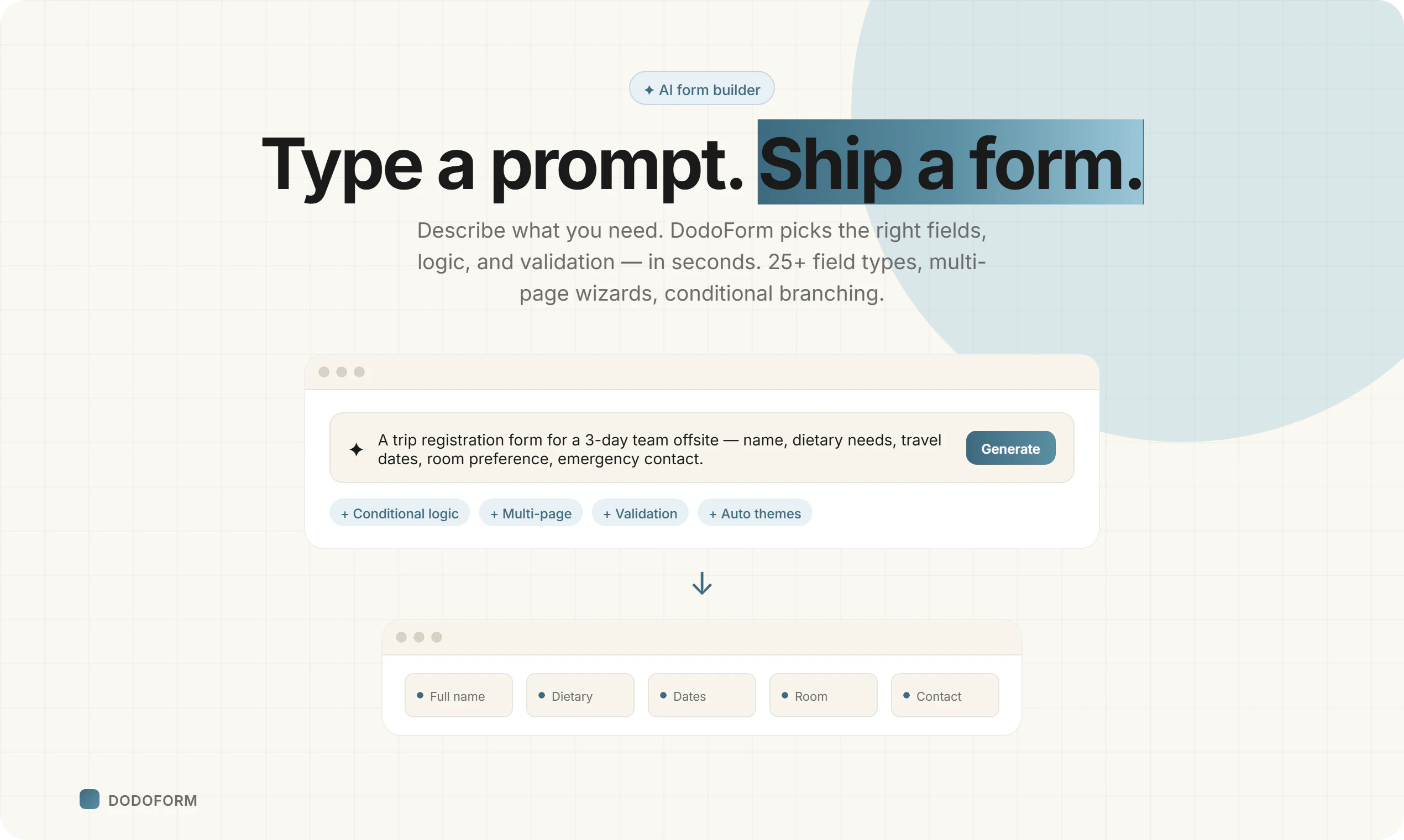
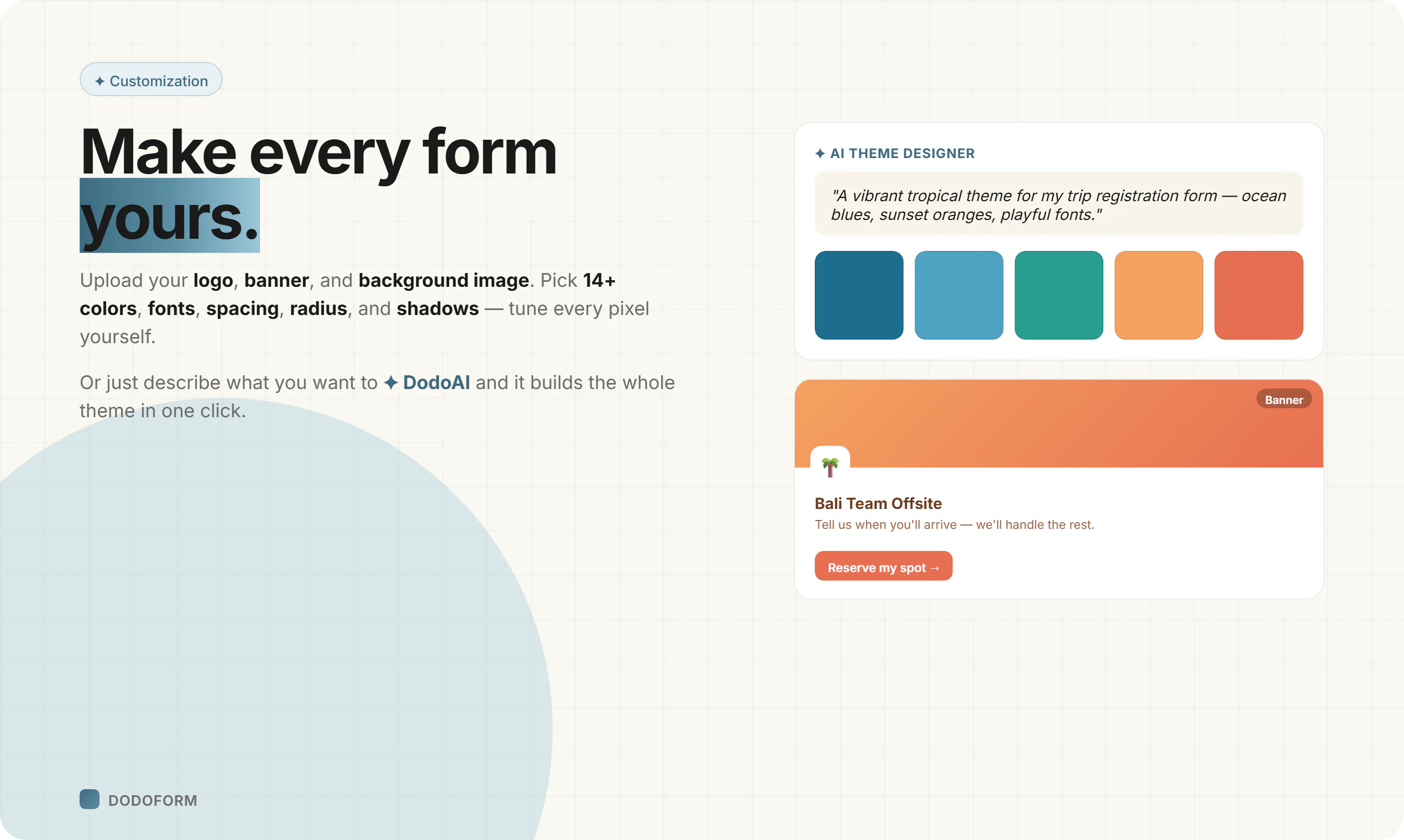
一句话介绍:DodoForm 是一款利用AI将语音、照片、潦草笔记等非结构化输入自动转换为干净结构化数据的表单构建工具,解决了传统表单死板、用户易放弃的痛点。
Analytics
SaaS
Artificial Intelligence
AI表单构建
非结构化数据处理
语音转结构化数据
智能表单模板
AI数据分析
用户调研工具
销售CRM接入
雇佣流程表单
事件RSVP管理
用户评论摘要:用户关注语音输入的噪音过滤与置信度问题(如片段化表述、中途改口);建议对“时间模糊”或“有条件答复”保留上下文附件而非静默清理;希望为高重要字段提供最终值、置信度与原文追溯的审计轨迹,供表单拥有者按字段设置确认策略。
AI 锐评
DodoForm切中了一个真实而顽固的痛点:表单不是给机器人填的,是人填的。人说话缠绕、夹带噪音、自我修正,而传统表单偏偏要求你像API一样精确——这本身就是在把用户往外推。DodoForm将AI作为底层架构而非贴纸,核心逻辑是做“字段感知提取”而非“先转录后解析”,例如对日期、电话字段预置schema,模型直接锚定“最终意图”而非“完整语句”,配合“最后陈述优先”及置信度分级验证,在工程上构建了可落地的容错链路。
但真正有深度的设计在于它没有把噪声一律丢弃。用户在评论中提到的“but”保留(如“除非Sam回复”)、“for now”标记、以及高重要字段的审计轨迹,意味着DodoForm意识到:模糊往往携带信息,而干净不等于齐全。这种“既保留上下文,又输出结构化结果”的双层策略,使其超出单纯的表单清理工具,向数据洞察工具演进——未来可能会帮助企业发现客户下单前的犹豫点、候选人offer谈判中的真实约束。
然而,这也带来挑战:置信度阈值是否可调?字段级别的“噪音/信号”边界是否由用户自定义?若不对不同行业(如医疗 vs. 活动报名)做差异化配置,容易陷入“看似智能、实则一刀切”的陷阱。同时,治理门槛也将抬高——表单创建者需要愿意投入理解字段schema与置信度设置,而非简单的拖拽即用。DodoForm聪明在底层,但能否让用户在执行上不觉得复杂,是其从好工具跳到好产品的关键分水岭。
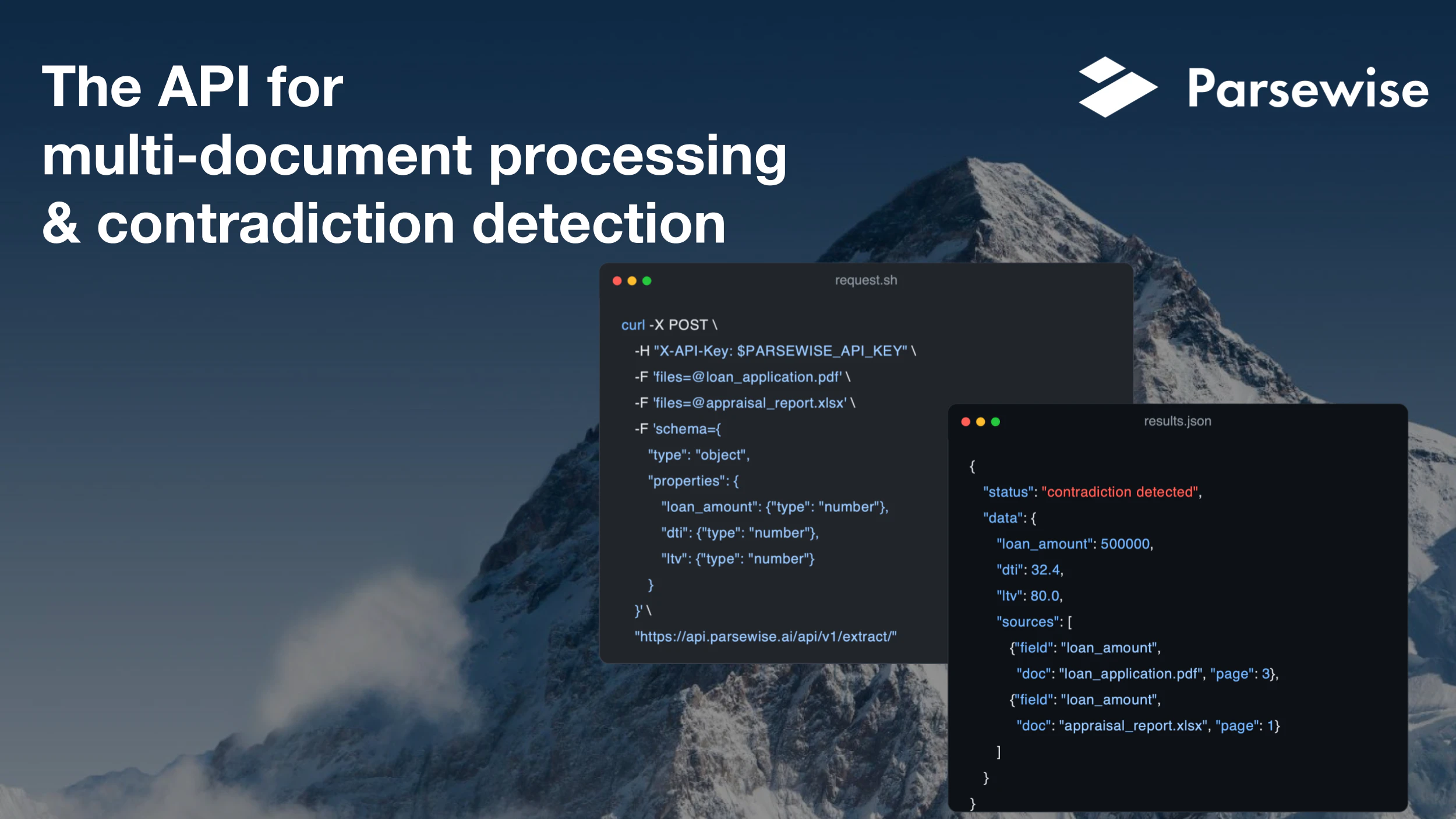
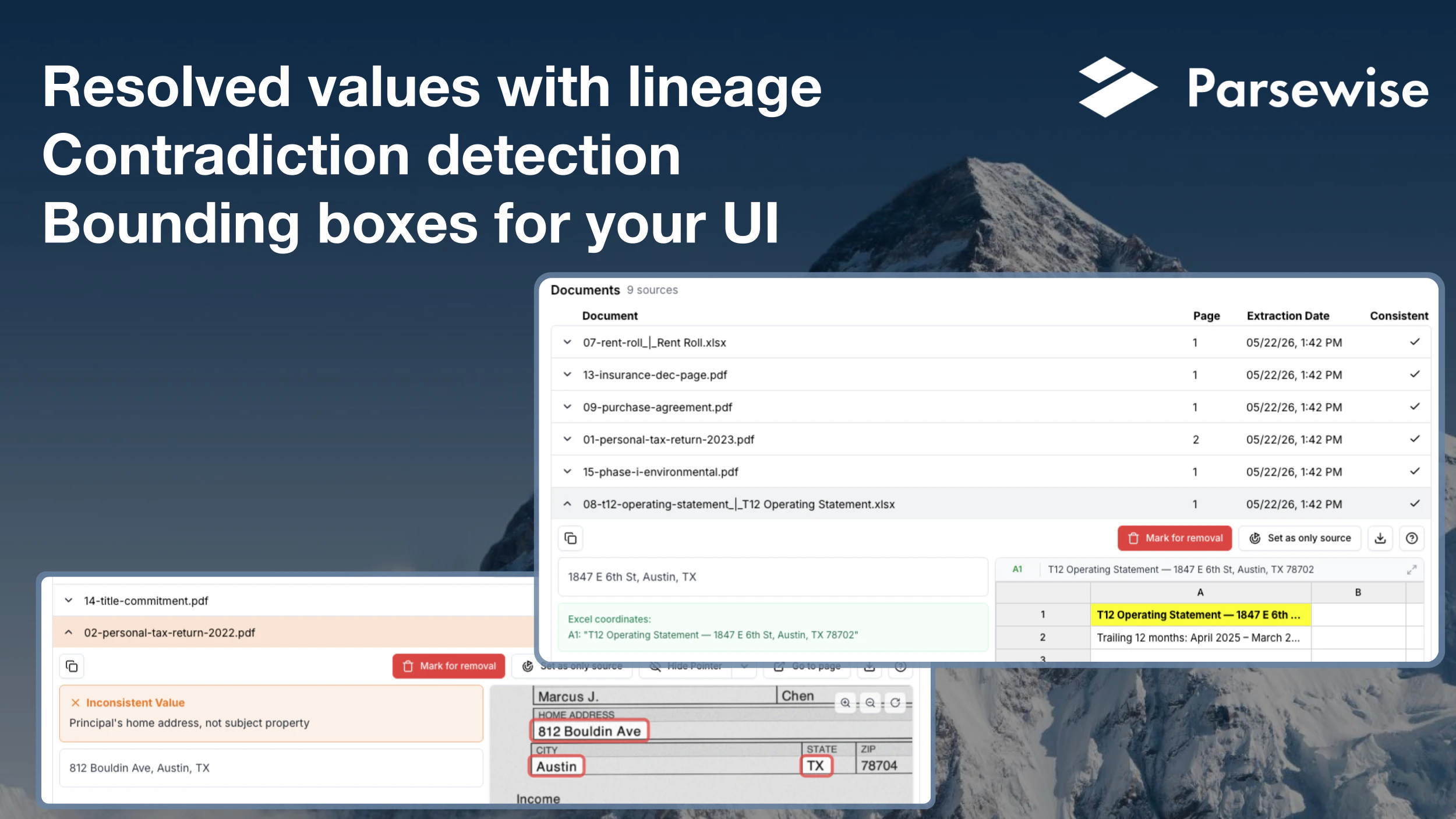
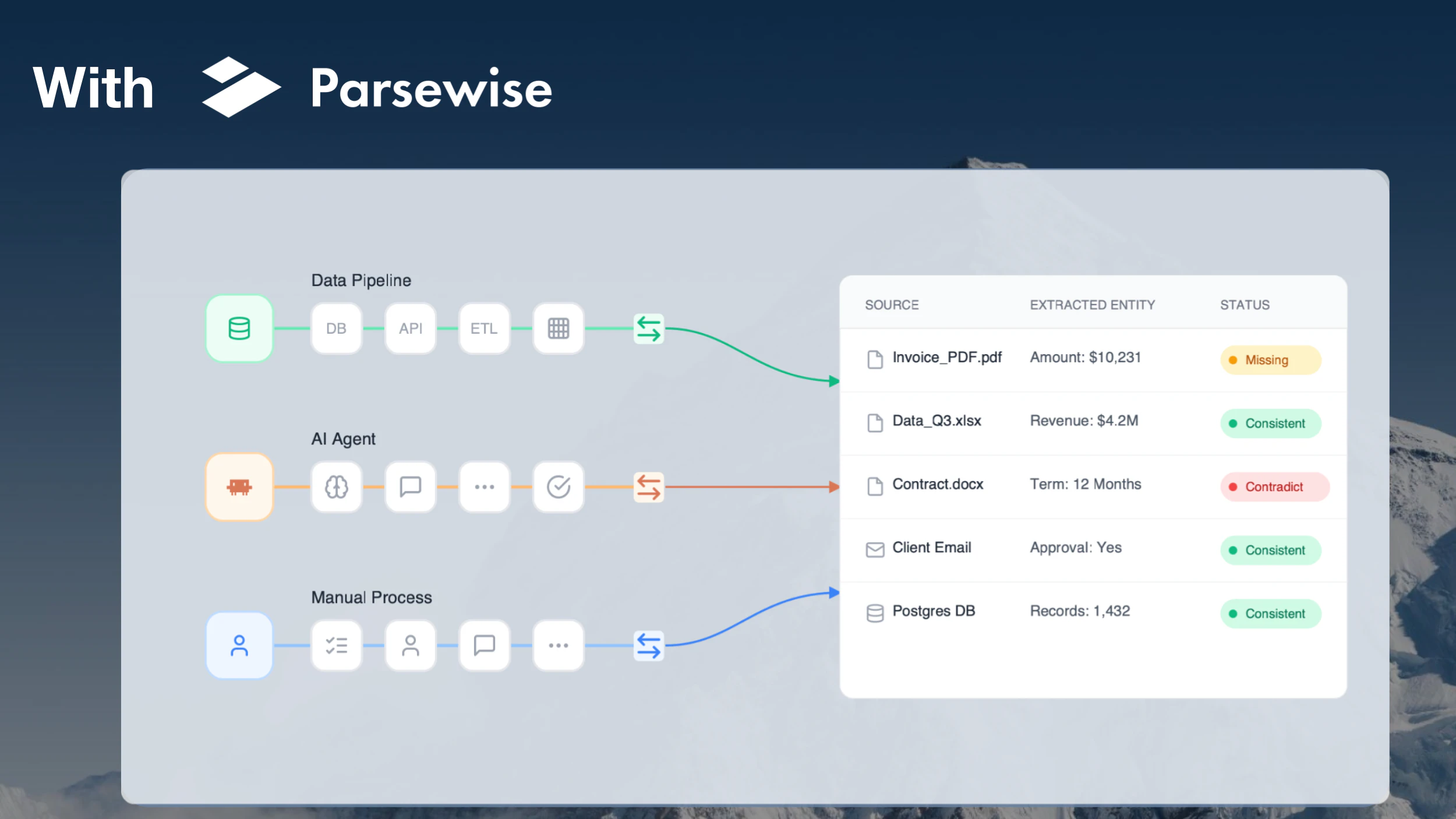
一句话介绍:Parsewise API通过单次API调用,即可在多份文档间自动提取信息、解决矛盾并追踪来源,替代了传统需要人工搭建的复杂文档处理流水线,专为需要可靠数据处理与人工验证的Agent应用场景设计。
API
Developer Tools
Artificial Intelligence
文档处理API
多文档处理
矛盾检测
信息溯源
Agent工作流
智能数据提取
人工验证
无代码流水线
企业级应用
AI文档解析
用户评论摘要:用户关注多格式混合处理的准确性(扫描PDF、表格、文本),以及非视觉文档(如电子表格、纯文本)的溯源实现方式。开发团队回应支持混合格式且无精度损失,并详细解释了溯源到单元格引用或行号的可行性。用户高度认可矛盾检测和边界框溯源价值,认为这是大多数人手动构建且效果不佳的核心痛点。
AI 锐评
Parsewise API做了一件许多人都在做但做得很痛苦的事:将一个碎片化的、由多个工具拼接起来的文档处理流水线,抽象为一个有状态、可回溯的智能Agent。其真正的价值不在于“提取”,而在于“协调”——当信息源之间出现矛盾时,它不依赖LLM的赌博式置信度评分,而是通过显式的规则和可编辑的逻辑,让机器与人的协作变得透明且可控。这一思路切中了企业级应用的命门:信任。
然而,产品面临的挑战同样明显。首先是“格式黑洞”问题——用户已追问非视觉文档的溯源方式,如果团队只能提供模糊的“行号”或“单元格引用”,而无法像PDF那样提供可视化高亮,那所谓的“full lineage”就产生了用户体验上的断层。其次是规则的维护成本:虽然宣称可让用户定义解决矛盾的原则,但这些原则在跨行业、多语种、动态变更的业务场景下,可能迅速膨胀为另一个需要专人维护的“规则库”,最终和它试图替代的流水线一样复杂。最后,112个投票和仅有的几条评论暗示产品可能仍处于早期阶段,其核心Agent在处理极端复杂的多文档异构场景(如几十份混杂格式的法律尽调材料)时的稳定性、速度和成本,尚未受到真正的压力测试。
一句话总结:Parsewise瞄准了一个100%真实且高痛度的场景,用“可回溯的协调”取代了“黑箱式提取”,方向正确。但讲好“溯源”的故事易,兑现“通用且低成本”的承诺难。它能否成为文档处理领域的下一个标准接口,取决于这些边缘案例的解决深度,而非演示demo的流畅度。
一句话介绍:LangPanda将用户追剧、刷YouTube的娱乐时间转化为多语言学习场景,通过即时词典、闪卡生成和词汇追踪,解决了传统语言应用“方法虽好但难坚持”的痛点。
Android
Chrome Extensions
Education
Languages
语言学习
视频沉浸学习
多语言支持
闪卡工具
词汇追踪
YouTube集成
亚洲语言
沉浸式学习
AI教育
订阅制
用户评论摘要:用户普遍认可“用剧集学习”的核心理念,认为其能解决翘课问题。有评论指出分词语义分割(尤其亚洲语言)是难点,开发者详细回应了自建分词器(如日语的kuromoji/泰语的Intl.Segmenter)。建议增加AI生成字幕及更多平台支持,部分用户询问是否支持任意视频或仅限YouTube。
AI 锐评
LangPanda切入了一个被忽视却极其刚需的细分赛道——用“被动娱乐”置换“主动学习”。110票的评价不算爆款,但评论质量很高,尤其开发者对分词技术(日、泰、中等)的详细回应,暴露出该产品在技术基底上的真实壁垒:没有现成库能覆盖36种语言,他们必须自研或深度定制。这既是护城河,也是成本黑洞——维护一套多语言解析系统的技术投入远超普通工具类App。
从用户反馈看,核心吸引力并非“36种语言”的广度,而是“从你已经爱看的剧里学”这个行为逻辑。它击中了语言学习高频失败点:不是方法不行,是习惯撑不过倦怠期。产品价值不在速成,而在“习惯绑定”——把学习挂在追剧这个高粘性行为上。但需警惕:YouTube上带字幕的视频质量参差,若字幕不精准或内容对初学者太难,体验会迅速滑坡。目前仅限YouTube且依赖现有字幕,上限明显;而Netflix、Disney+等主战场未打通,意味着很多用户的“本命剧”不在服务范围内。
从商业逻辑看,7天免费试用+订阅制对强需求用户是合理的,但这更符合“工具”而非“内容平台”的定价逻辑。如果后续无法联动流媒体平台或打造独家难度的解说语料库,用户价值极易被AI逐句翻译类插件(如Language Reactor)替代。最后,开发者在回帖中展示的技术热情值得肯定,但技术爱好者的集大成之作与普通用户心中“即开即用”的期待之间,始终隔着一条护城河——而且这条河得由产品经理和UX设计师来填平。
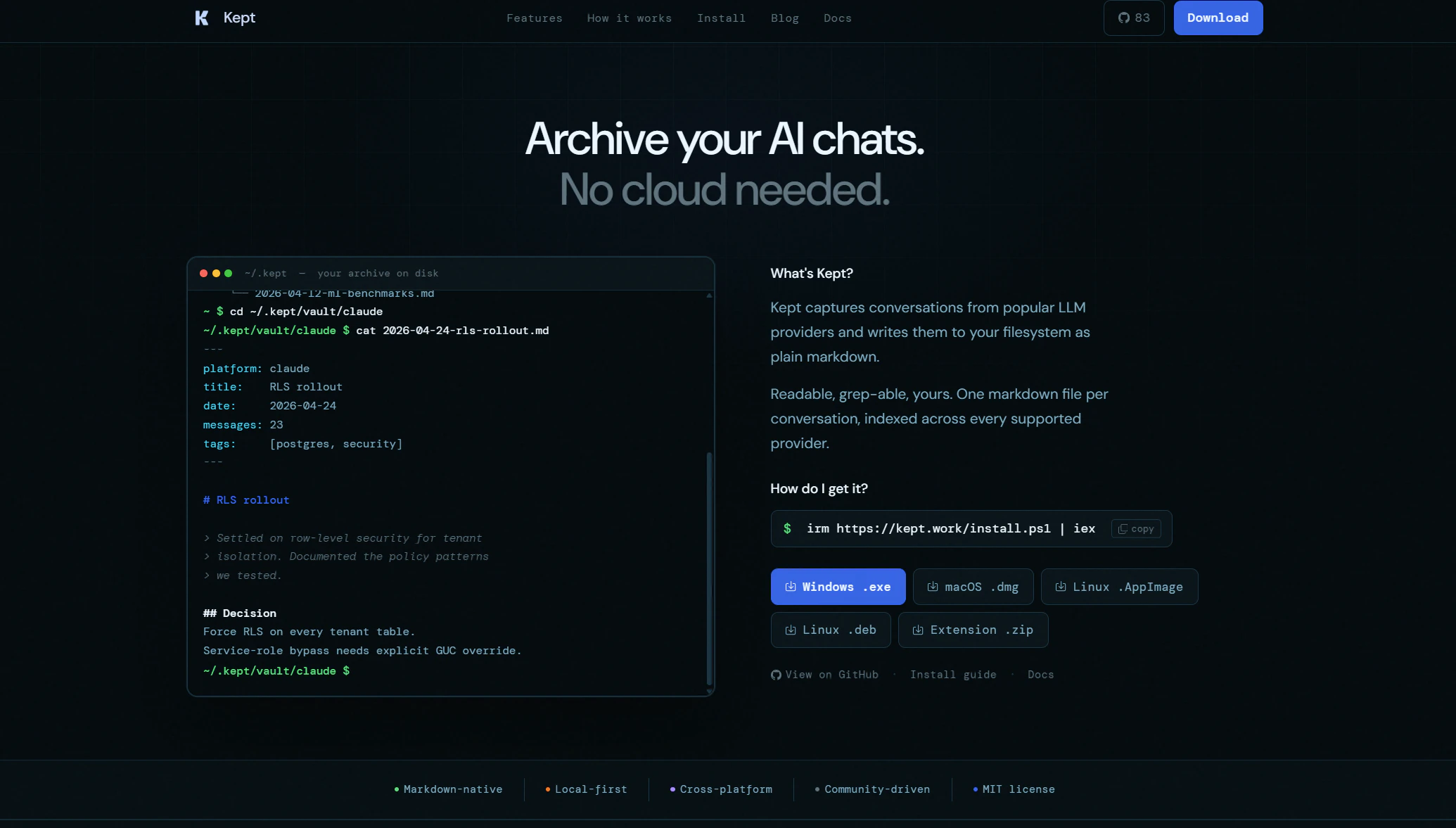
一句话介绍:Kept 是一款本地优先的AI对话存档工具,能将ChatGPT、Claude等主流AI平台的聊天记录自动保存为Obsidian兼容的Markdown文件,解决用户因厂商锁定而丢失宝贵对话历史与灵感片段的痛点。
Mac
Productivity
Artificial Intelligence
AI对话存档
本地优先
Markdown
Obsidian
知识图谱
开源
隐私
全文本搜索
MCP服务器
生产力工具
用户评论摘要:用户高度认可本地Markdown和Obsidian兼容的设计。核心建议包括:增加语义搜索;支持聊天分组/分类;在“存档”基础上,增加对“记忆性”和“草稿性”内容的显式标记与区分;解决跨设备同步问题;担忧浏览器扩展抓取DOM的模式易因厂商UI更新而失效。
AI 锐评
Kept精准地切入了一个普遍但未被充分解决的痛点:AI对话中的数据主权与知识沉淀问题。它并非又一个AI聊天客户端,而是一个聪明的“数据搬运工”和“本地化知识库构建器”。其核心价值在于通过“本地Markdown”这一极简且强大的格式,彻底解除了用户对AI厂商UI的依赖。
从产品策略看,“Obsidian兼容”是一步妙棋。它不仅提供了一个现成的、拥有强大生态的阅读和编辑环境,更巧妙地将AI对话从“一次性消费品”转化为可链接、可组织、可长期积累的“知识单元”,完成了从聊天记录到知识库的质变。从评论反馈来看,用户已经敏锐地捕捉到了更深层次的需求:如何从“存档”进化到“整理”。用户需要的不是将海量垃圾对话原封不动地倒进本地,而是希望系统能帮助识别并提炼出有价值的决策、示例和约束条件。Kept的“摘要”和“项目”功能虽已触及,但“显式标注记忆与草稿”的提议才是真正的增长飞轮——它将工具从被动记录升级为主动的知识管理系统。
然而,Kept面临着两个严峻挑战。首先,其核心“自动捕获”依赖浏览器扩展对各大AI平台DOM的解析,这是一种极不稳定的方案。任何UI的轻微调整都可能导致捕获功能静默失效,维护成本极高,且用户信任度会因数据丢失而瞬间崩塌。其次,“单机+文件夹同步”的方案在隐私和简洁上得分,但协同工作流、跨设备无缝体验仍是短板,这阻止了它从个人效率工具向团队协作平台跃迁。Kept目前是一个精美的、有远见的“存档器”,但若想成为下一代知识管理的基础设施,它必须解决数据捕获的健壮性挑战,并在“自动存档”与“智能整理”之间,找到更优雅的衡量和转化机制。
一句话介绍:Marpy.io 是一款专为 Python 全栈开发者打造的浏览器端 AI 集成开发环境,帮助用户快速从想法到部署上线,免去后端基础设施和胶水代码的折腾之苦。
Developer Tools
Artificial Intelligence
Development
Python IDE,AI编程助手,浏览器开发环境,Django
FastAPI
Flask
代码生成,应用部署,全栈开发,ORM感知
用户评论摘要:用户关注点在于AI对Django/FastAPI ORM关系的理解深度,以及能否跨文件维护模型和依赖上下文。有评论指出新手和中等水平用户是主要目标群体,资深开发者不易迁移。开发者回应称已通过AST解析实现框架感知和跨文件映射。
AI 锐评
Marpy.io精准切入了一个被巨头有意无意忽略的“窄口”——Python后端AI开发。它不是又一个“什么都能写但什么都写不专”的通用AI IDE,而是彻底堵死了“前端优先、JS兜底”的弯路,将赌注全部押在Python生态上。从用户互动看,其核心卖点在于对Django/FastAPI的ORM和依赖注入体系的AST级解析,这确实戳中了当前AI编码工具的软肋:能生成看似正确的代码,但无法理解项目级别的数据模型和路由依赖,导致“看起来对,跑起来废”。Marpy通过构建实时的跨文件架构地图来缓解这一痛点,甚至暴力限制了生产环境的破坏性迁移操作,这是务实且有勇气的设计。
然而,它的发展路径也充满风险。浏览器IDE的固有短板(如本地化调试体验、插件生态匮乏)使其难以真正吸引有固定工作流的高级开发者,正如用户反馈所言,其最佳用户群是“想写后端但怕配环境”的中级开发者。这意味着它必须在“易用性”和“专业性”之间走钢丝:既要降低上手门槛,又要避免沦为玩具。如果它能基于这一垂直入口,逐步积累针对Python后端的深度编程逻辑库,并构建小众但忠诚的社区,还有机会在AI编程工具的差异化竞争中分一杯羹。否则,一旦主流工具(如Cursor、GitHub Copilot)加大对Python框架的专项优化,Marpy的护城河可能会迅速变浅。简而言之,切入角度犀利,但执行和壁垒构建是真正的生死考验。
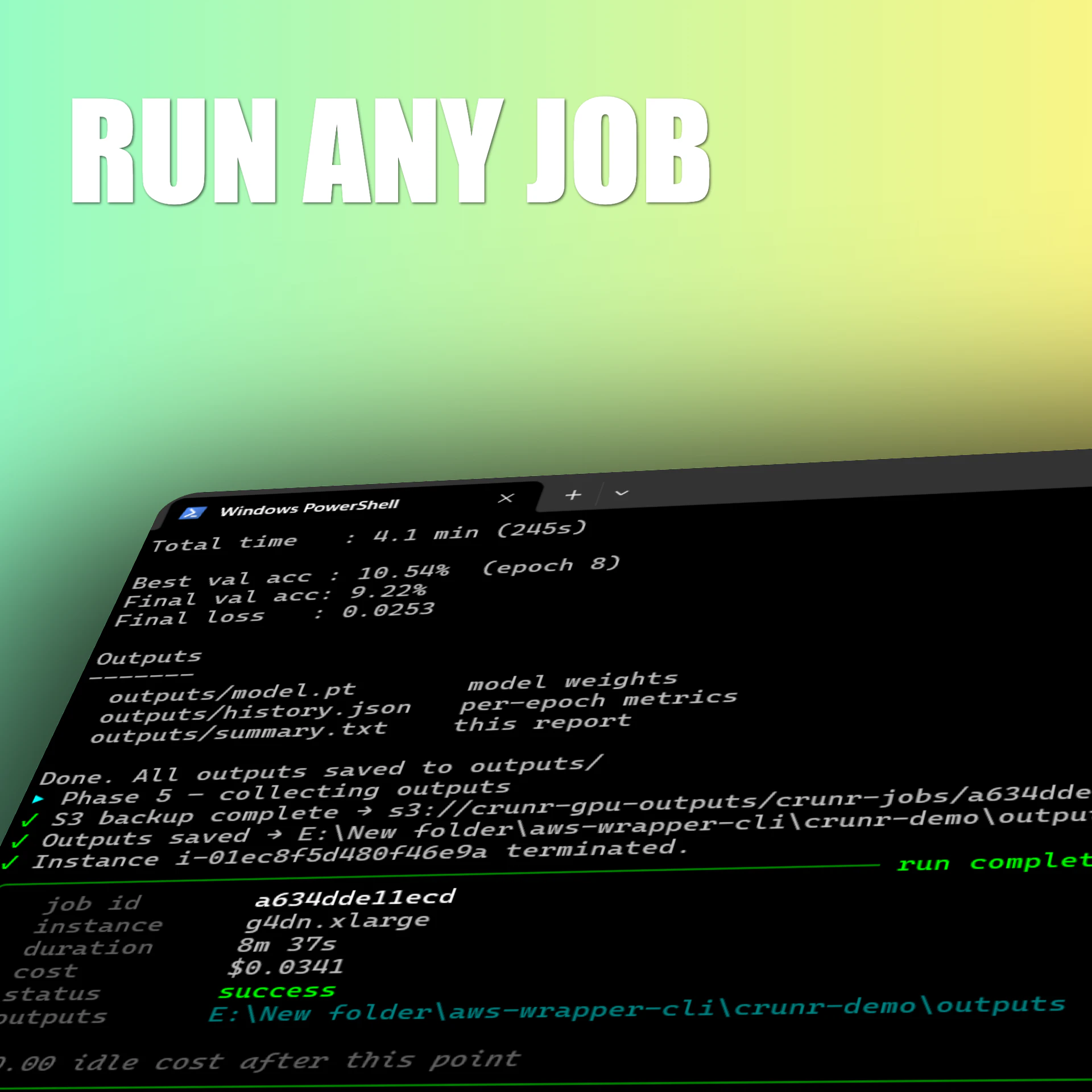
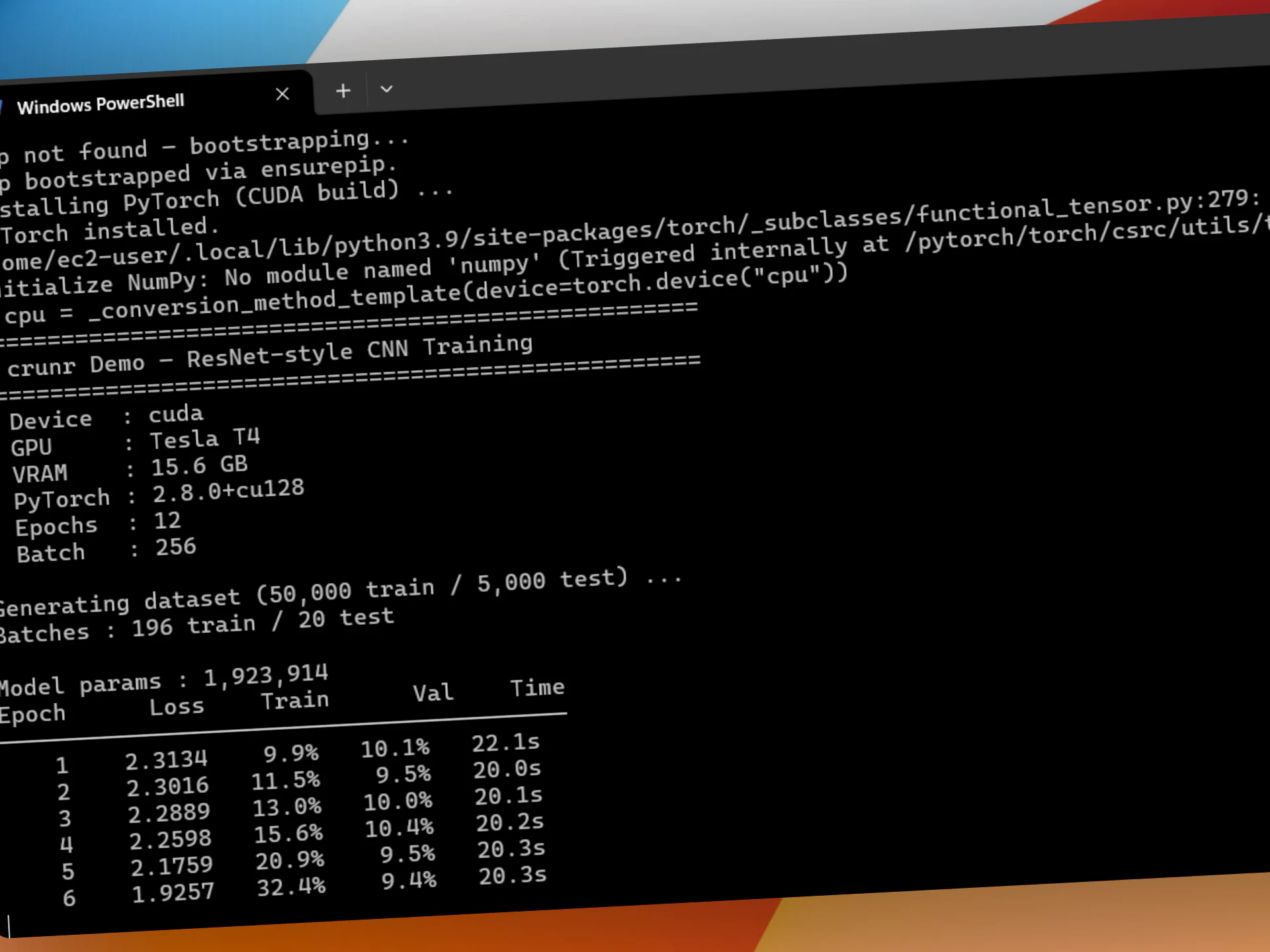
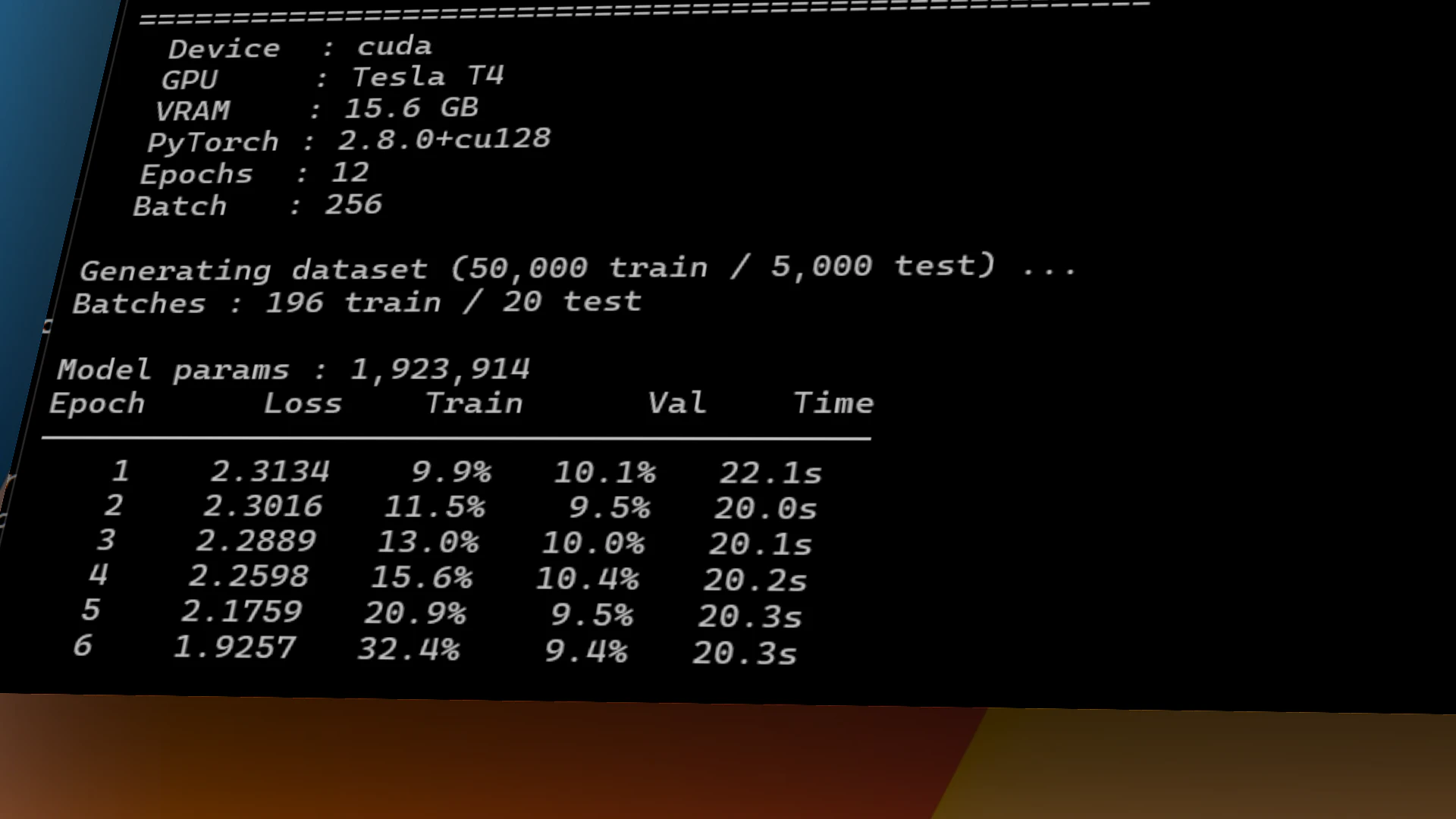
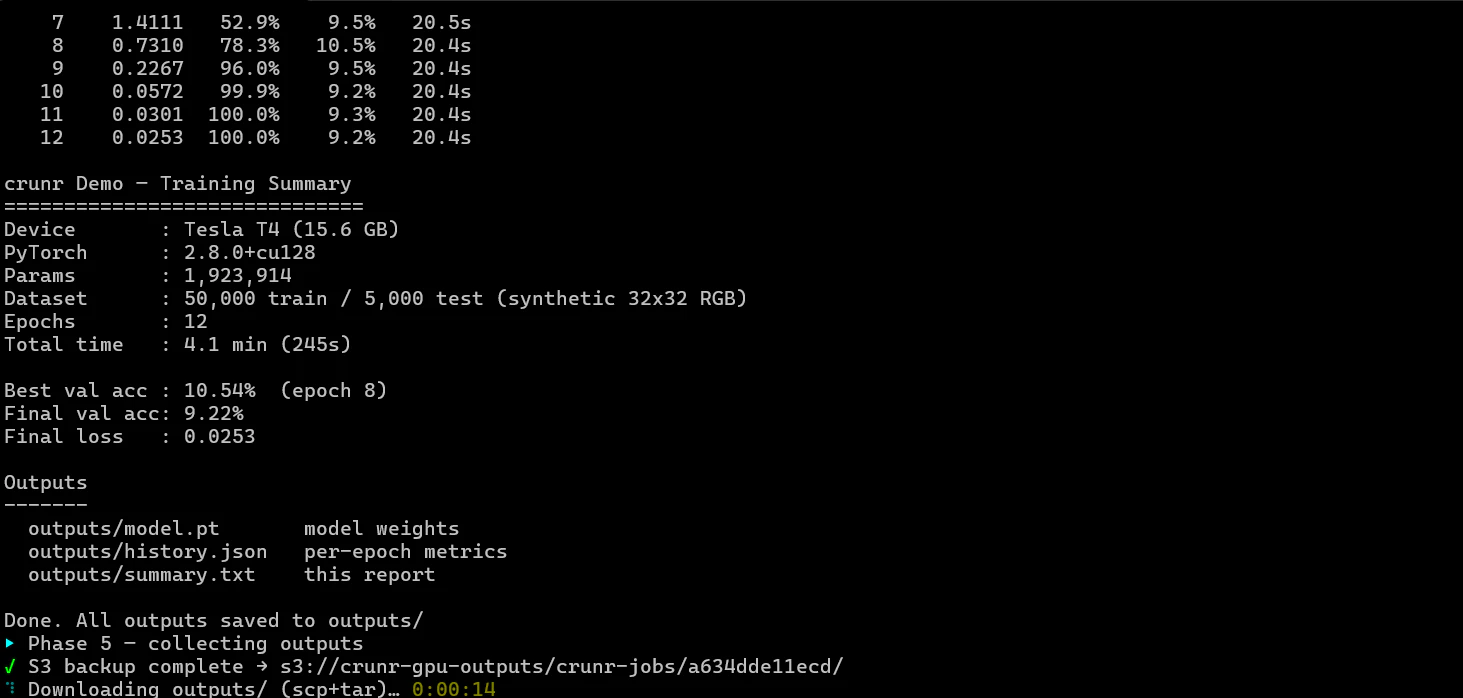
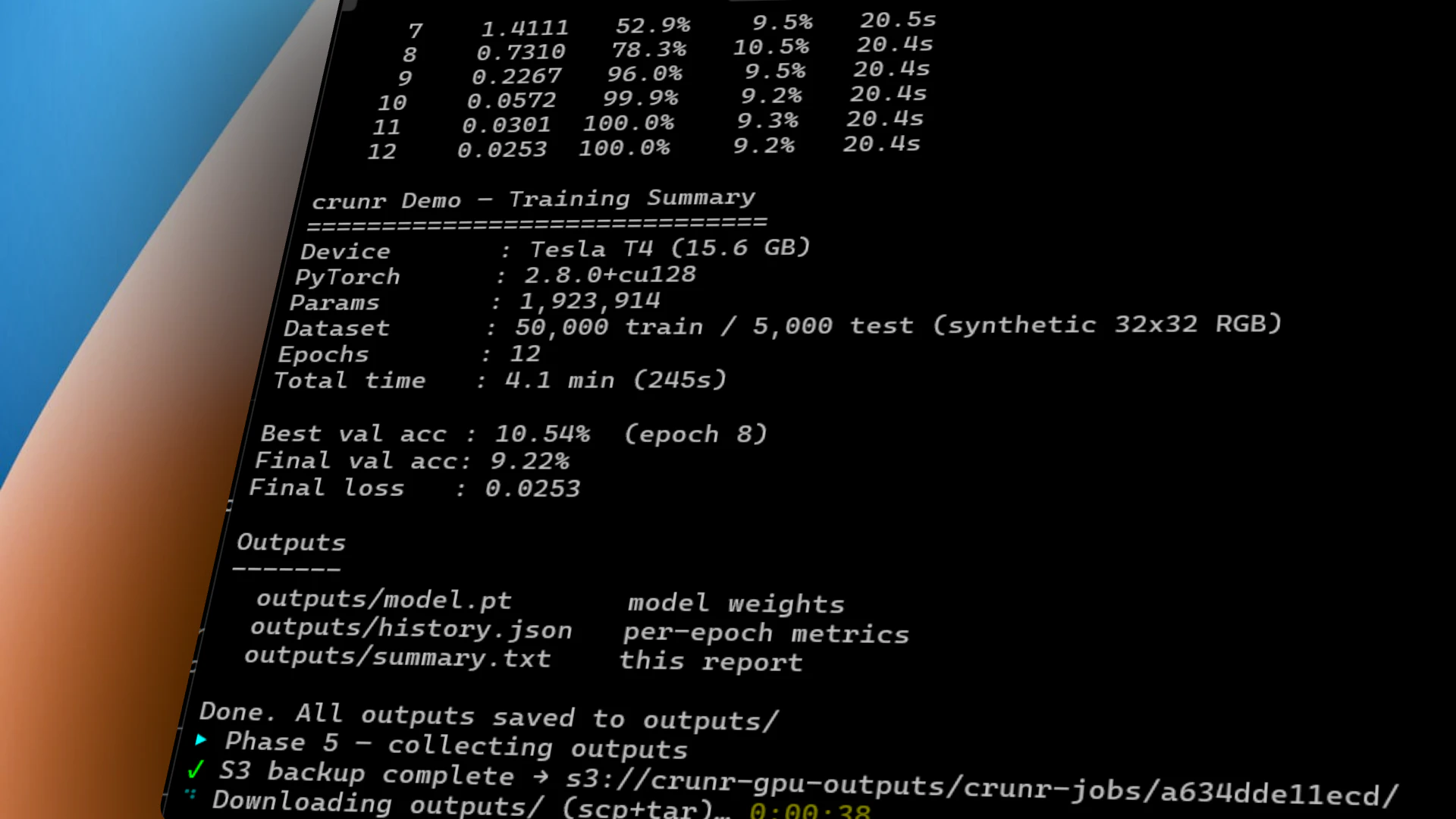
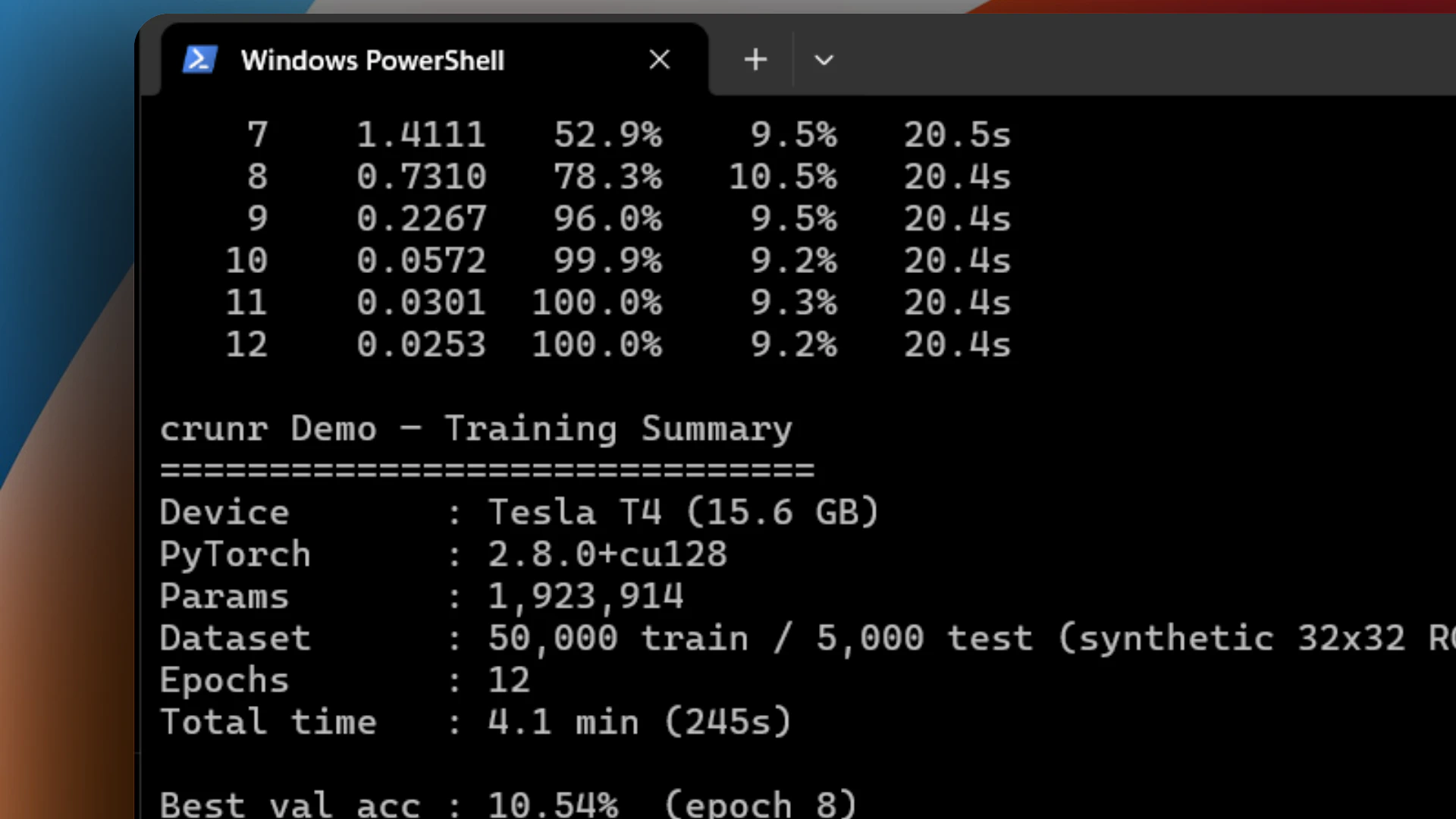
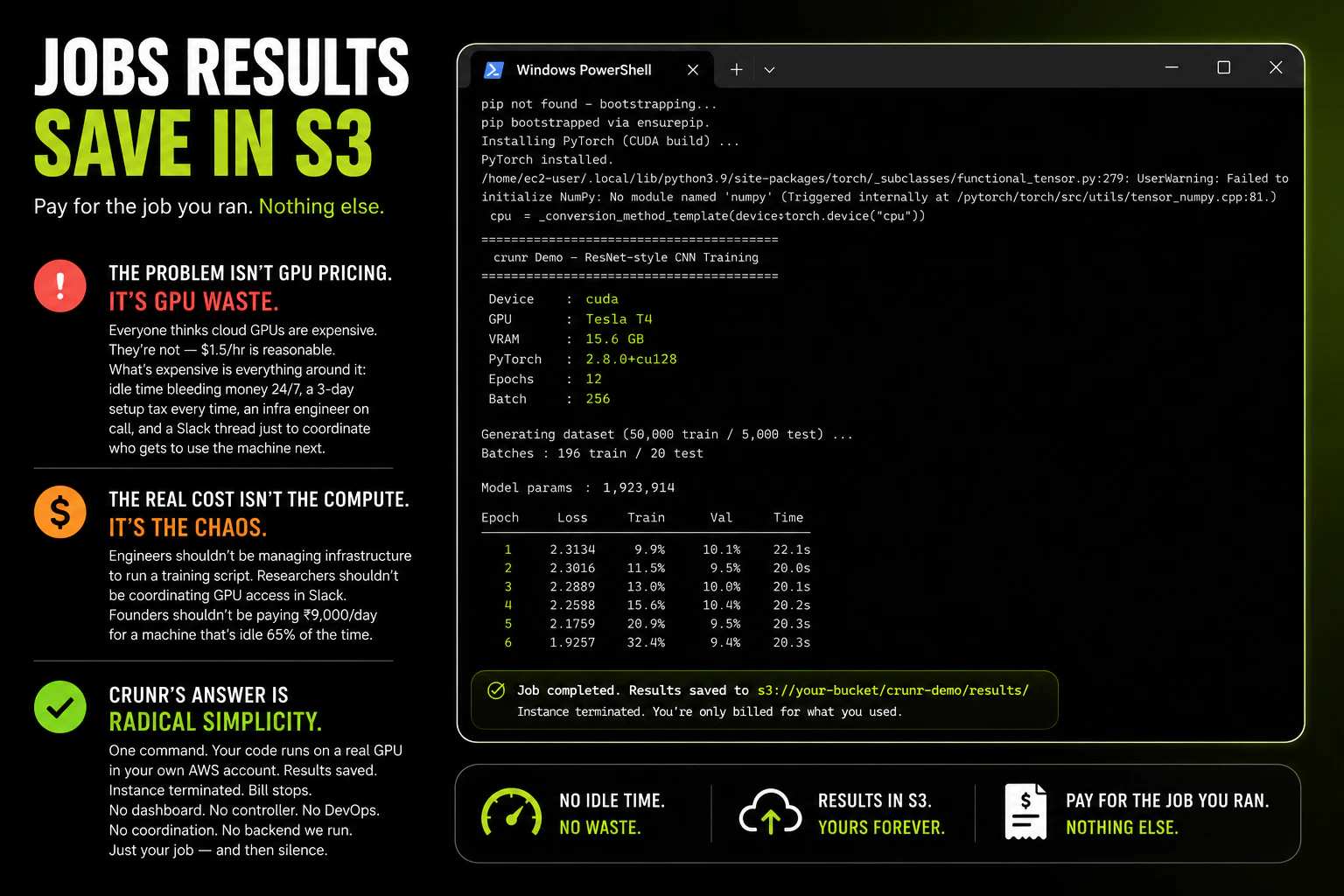
一句话介绍:crunr 通过一句命令在 AWS 上按需拉起 GPU/CPU 实例、运行作业并自动终止,解决机器学习团队因空闲实例、DevOps 维护和故障调试导致的隐性高额账单与效率浪费问题。
Developer Tools
Tech
云计算
GPU计算
AWS工具
机器学习
DevOps简化
命令工具
按需付费
作业调度
成本优化
命令行
用户评论摘要:用户关注点集中于:作业失败后的实例闲置与中间结果恢复。创始人回应称实例崩溃后立即终止,现已支持通过 `--s3` 将输出同步至 S3;自动断点续训功能(无需用户编写检查点逻辑)预计下周上线。另有用户询问对纯 CPU 任务的支持,确认已支持。
AI 锐评
crunr 解决了一个真实但不够尖锐的痛点:GPU 闲置成本。65% 的空闲率、每小时1.5美元的算力标价、每月800美元的浪费账单——这些数字确实触目惊心,crunr 的“用完即走”模式也精准切中了预算敏感型用户(独立开发者、小团队)的神经。但从产品形态看,它本质上是一个 AWS EC2 的“一键关机”封装器,技术壁垒并不高。核心卖点“无需 DevOps”依赖的是用户已有的 AWS 环境配置,一旦用户的 IAM 权限、VPC、安全组等网络基建不标准,crunr 的“1 命令”体验就会迅速塌陷为 debug 噩梦。
更深层的问题在于:作业失败后的自动检查点恢复功能“还在下周”。对于短时训练(3小时),手动写 checkpoint 是轻微的成本;但对于多日微调作业,断点续跑是生死线。如果只能用“你自己在训练脚本里写好 outputs/”来搪塞,那 crunr 不仅没有降低心智负担,反而让用户多了一层“忘了写检查点->重跑”的焦虑。创始人那句“mid-run snapshotting is on you”是当前产品最大的软肋。
此外,评论区中互动积极、回复详细,但缺少对成本结构的进一步拆解:crunr 本身是否收费?其调度层是否引入了额外开销?当用户同时发起多个作业时,管理对象数量膨胀后的编排能力如何?这些才是团队在“抢滩”阶段后必须回答的。
一句话总结:crunr 是 ML 团队的“小贴士”而非“救世主”。它值得为每周跑几次、怕忘关机的轻度用户安装,但任何指望它托管生产级工作流的想法,都还需要等待它核心基础设施的补全。
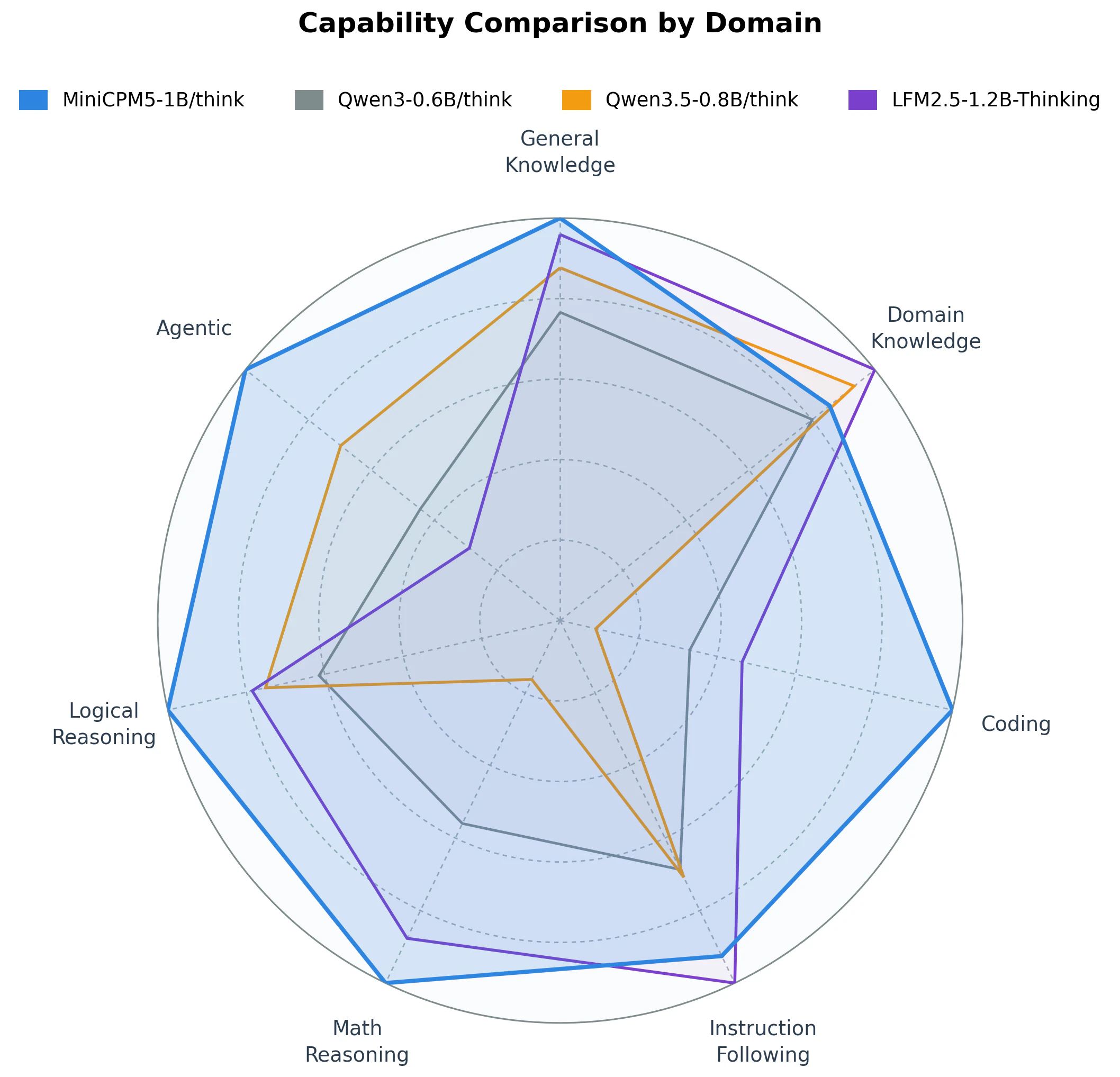
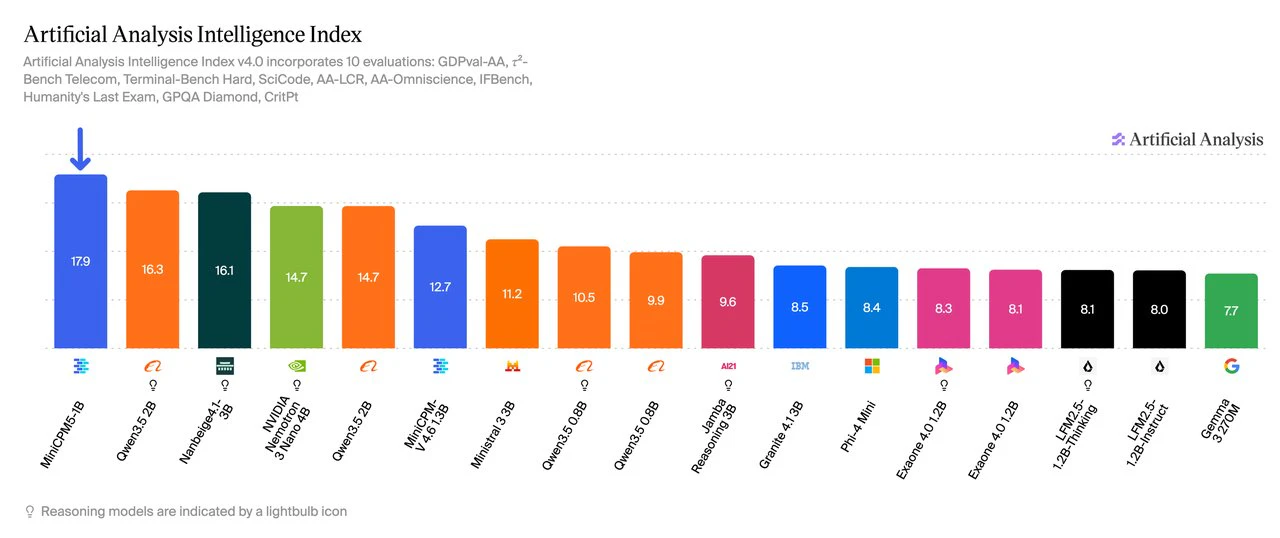
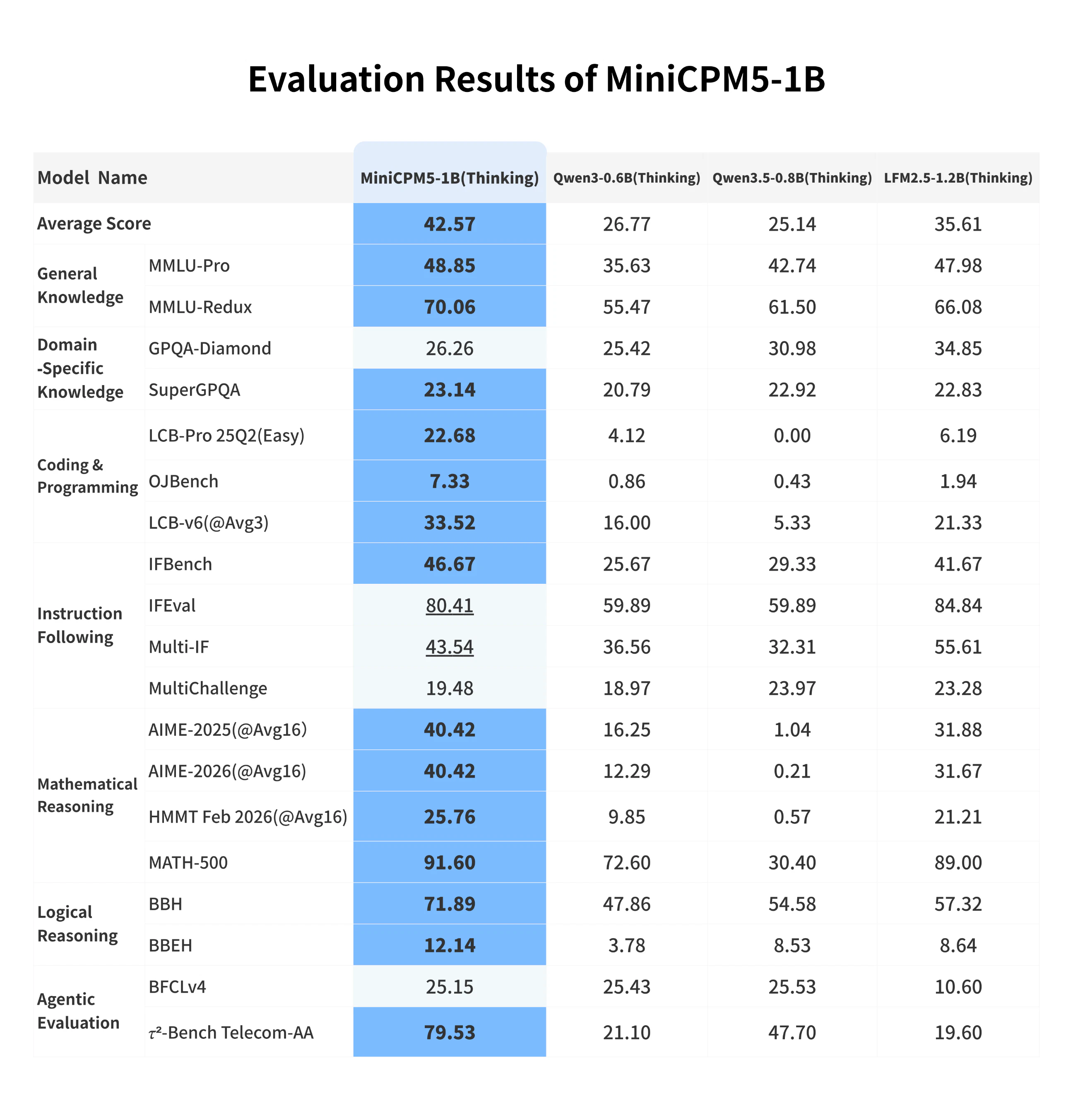
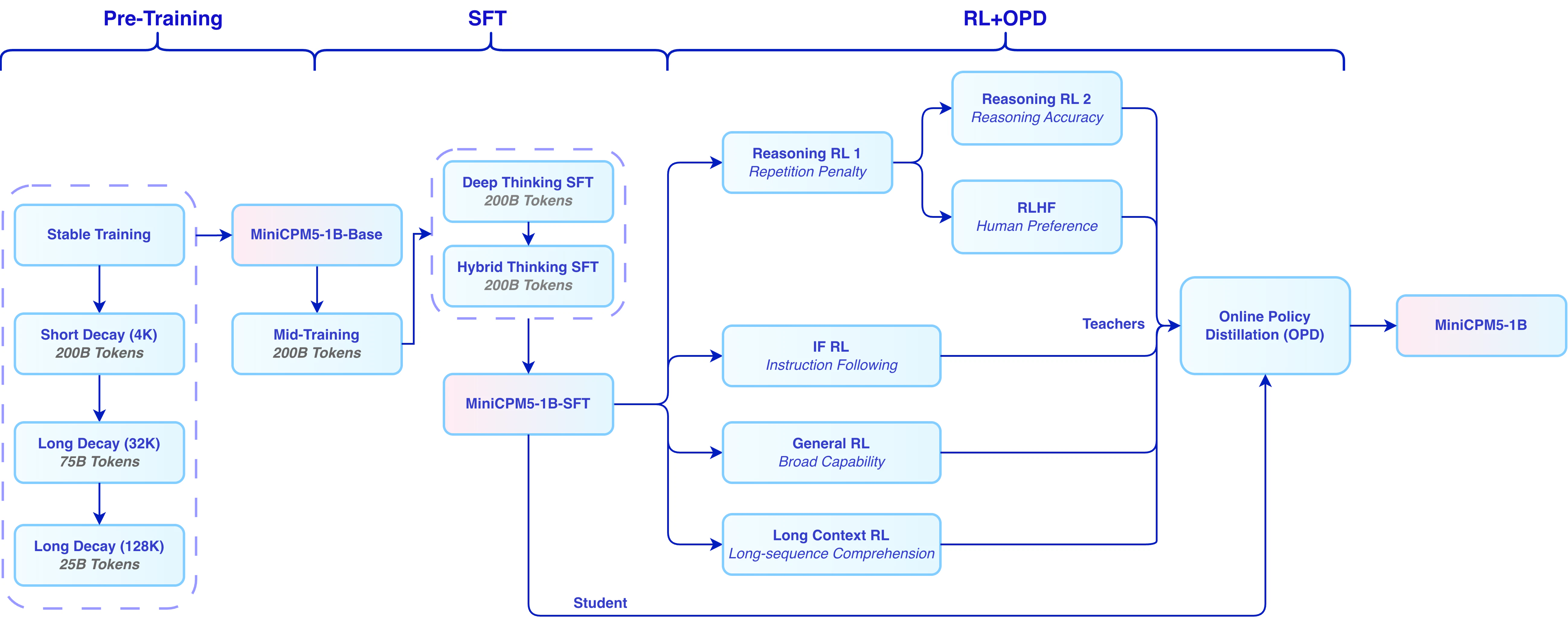
一句话介绍:MiniCPM5-1B是一款专为边缘设备和本地部署设计的1B参数稠密开源模型,通过极小的体积(INT4仅0.5GB)和强大的端侧推理能力(支持131K上下文、工具调用),解决了AI应用在离线或无云环境下无法运行复杂任务的痛点。
Open Source
Artificial Intelligence
GitHub
Development
边缘AI
开源模型
本地部署
小参数模型
工具调用
代码生成
推理加速
GGUF
MLX
桌面宠物
用户评论摘要:用户高度认可其1B参数在端侧达SOTA的性能,特别点出131K上下文和全本地化对降低云推理成本的价值。有从事边缘AI开发的用户表示会持续关注,期待对其长上下文能力进行压力测试。
AI 锐评
MiniCPM5-1B的“SOTA”含金量在于,它不是在实验室的GPU集群上刷榜,而是在1B参数、0.5GB INT4的极端约束下,将智能体工具调用、代码生成等“高门槛”能力压到了消费级硬件可承载的极限。这比单纯的参数堆砌更有意义,因为它切中了开发者最大的焦虑:云成本失控和离线场景的算力真空。131K长上下文和「Think / No Think」模式的设计很聪明,前者让端侧模型摆脱了“记不住”的尴尬,后者则是在有限计算资源下对“效率与智能”的务实取舍。但必须泼一盆冷水:1B参数在复杂逻辑推理和长文本理解上,与7B、13B级别模型的代差是客观存在的,其“SOTA”更多是在同类小模型维度内的胜利。真正的价值在于,它作为技术示范,验证了“小而全”的可行性——尤其是那个100%离线的桌面宠物,虽然看似玩票,但实则是降低开发者心理门槛的绝佳钩子。对于做边缘AI、AI桌面应用、以及对数据隐私极度敏感的B端场景,这可能是目前成本最低的入场券。接下来,就看它的社区生态(GGUF/MLX支持)能否催生出真正好用的杀手级本地应用了,否则容易沦为开发者“尝鲜后积灰”的又一个玩具。
一句话介绍:Ormedo通过AI智能体自动化B2B外联全流程,让非销售专业人士只需粘贴网址即可完成客户画像构建、潜在客户挖掘、个性化邮件与LinkedIn消息撰写及发送,解决传统工具操作复杂、依赖专业销售知识、需跨平台切换的痛点。
Email
Sales
SaaS
AI销售代理
B2B外联自动化
潜在客户生成
个性化邮件
LinkedIn outreach
买家画像
销售工具
创业公司
全自动管道
AI工作流
用户评论摘要:用户关注其与Apollo等工具的集成能力,建议增加Slack/Telegram通知功能。有用户询问B2C场景支持。评论普遍认可“学习用户语气”的功能价值,认为这是差异化亮点。创始人回应称可直接连接Apollo,无需额外配置。
AI 锐评
Ormedo的核心竞争力在于“去销售专业化”,它精准击中了非销售背景创业者(如技术创始人)的痛点——他们深知获客重要,却被复杂的ICP定义、多工具联动、账号预热等环节劝退。产品通过“粘贴URL自动生成买家画像”与“双屏极简界面”大幅降低了外联门槛,这比传统SDR工具(如Outreach、SalesLoft)更适用于早期验证和微小型团队。
然而,其价值局限同样明显。目前依赖Apollo数据源,意味着潜在客户的质量和合规性受第三方制约;AI生成的邮件与LinkedIn消息虽然减少手动工作量,但“个性化”深度取决于训练数据量,在冷启动阶段可能仍显机械。更关键的是,B2B外联的核心在于“信号质量”与“触达时机”,Ormedo通过评分控制发送量这一逻辑方向正确,但用户反馈中提到的“Slack集成缺失”暴露了其工作流整合的短板——创始人既希望“无需监督”,又需要“一键审批”,若缺失IM通知,用户仍需要频繁回到Web端检查,这削弱了“全自动”的承诺。
从市场定位看,Ormedo更适合作为“外联初创期的过渡工具”,而非长期销售引擎。一旦用户积累了一定线索并需要CAC测算、A/B测试或多渠道归因时,其极简设计反而会成为瓶颈。真正的挑战在于:如何在保持“傻瓜式操作”的同时,让专业销售能做更精细的调控,这往往是“极简”与“强大”最难平衡的悬崖。
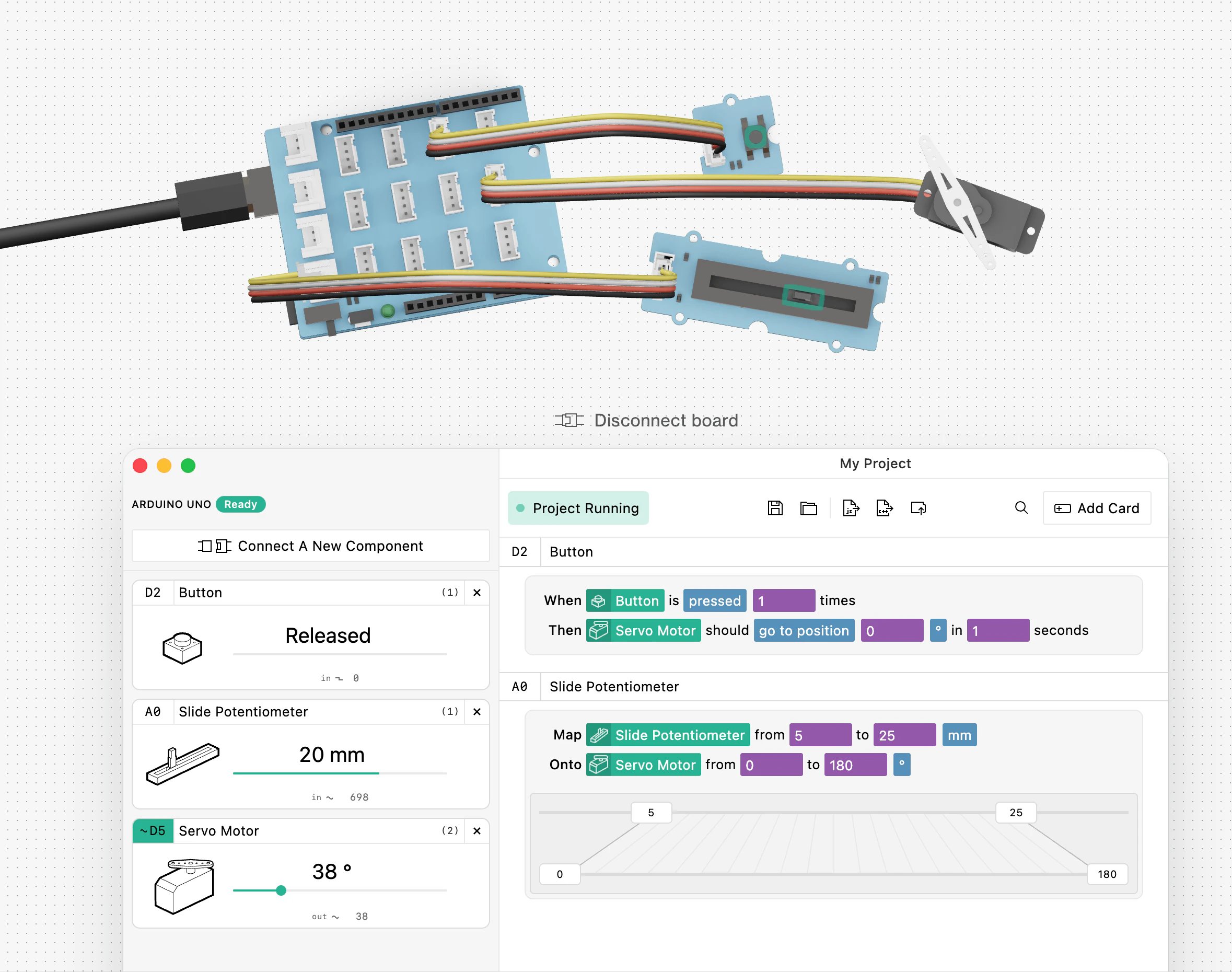
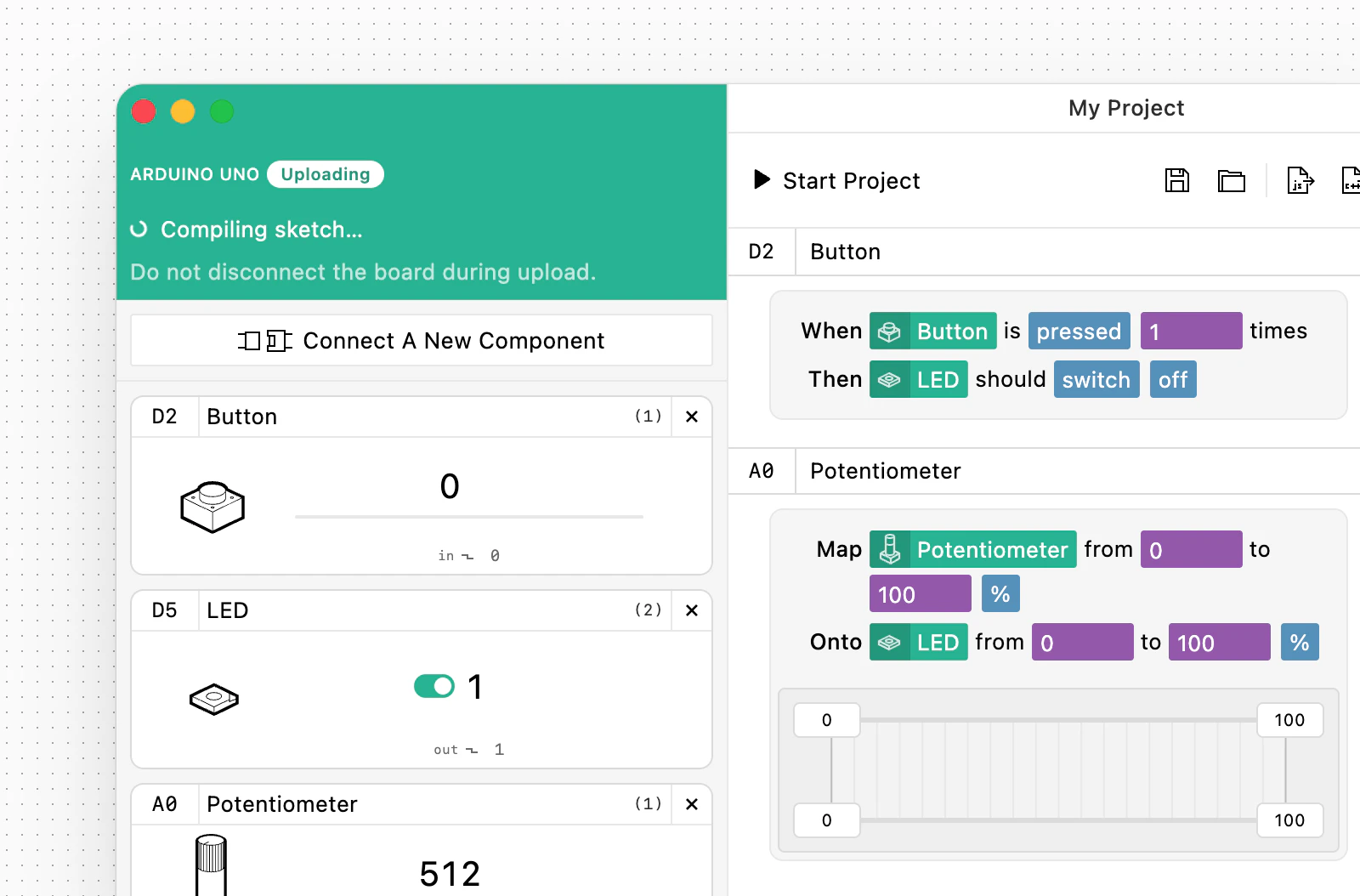
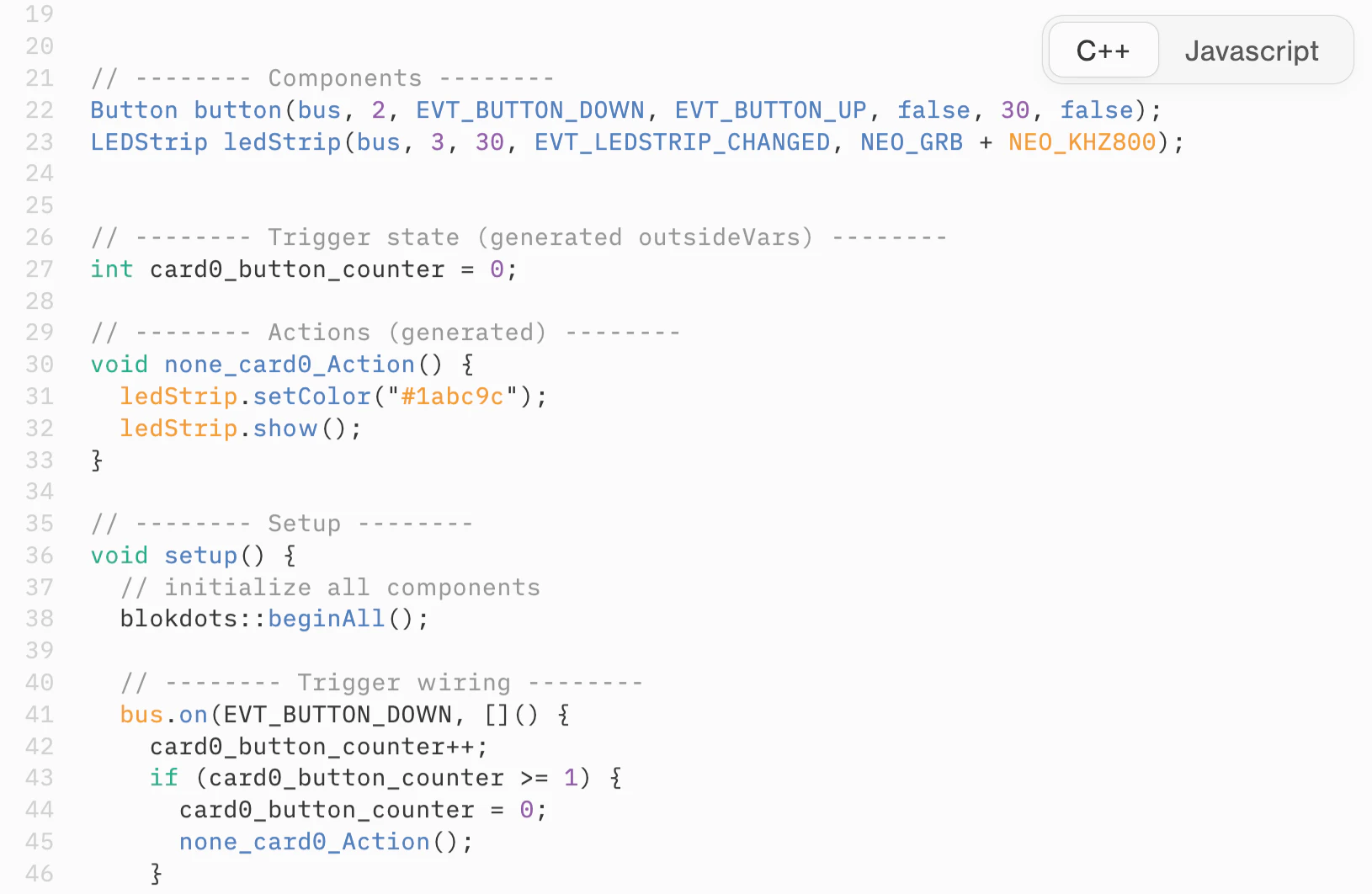
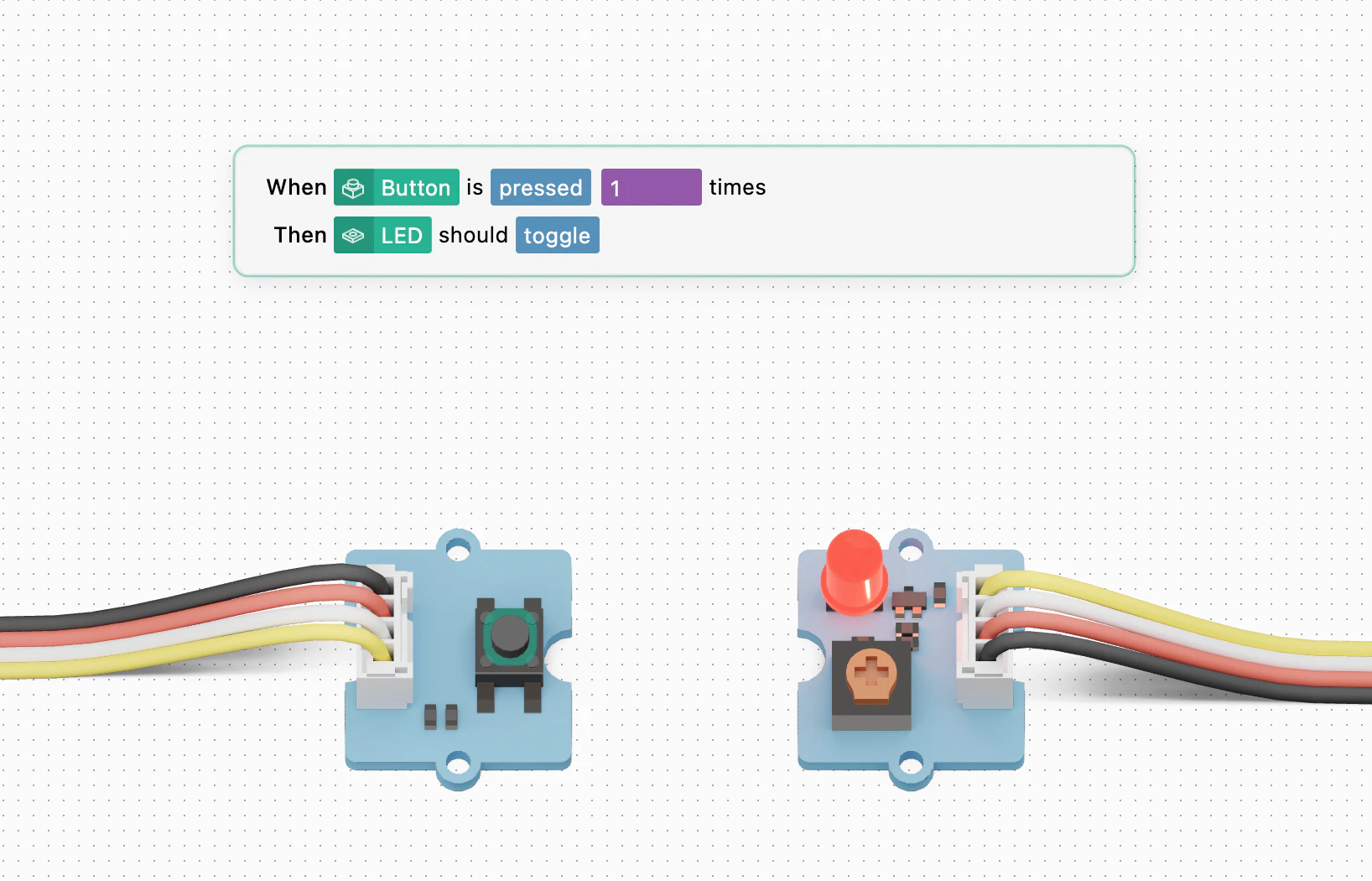
一句话介绍:blokdots 3.0 是一款面向硬件交互原型的可视化编程工具,让无编程背景的设计师通过拖拽触发-动作逻辑连接传感器与执行器,并可直接导出工程级C++代码或固件上传Arduino,解决原型从设计到工程交付的衔接痛点。
Design Tools
Prototyping
Hardware
可视化硬件编程
Arduino原型工具
C++代码导出
无代码硬件交互
Figma原型集成
ProtoPie联动
UI+硬件原型
触发-动作引擎
独立运行模式
I2C多设备支持
用户评论摘要:用户赞赏Figma与ProtoPie集成及双向交互潜力(回帖确认ProtoPie为双向,Figma目前单向);询问独立模式在展会等8小时以上长时间运行的可靠性;部分用户点赞并计划分享给创客社群。
AI 锐评
blokdots 3.0的真正价值不在于“无代码”口号,而在于它试图弥合设计思维与工程现实之间那道最顽固的鸿沟。彻底抛弃通用Firmata,自研C++框架和串行协议,意味着它不再是Arduino生态的附庸,而是有能力定义自己的底层规则。这带来的“独立运行”与“C++导出”两项能力,精准命中了两个关键痛点:一是设计师的桌面原型无法脱离电脑运行,二是工程团队收到的代码需要重构而非直接使用。从评论看,用户对长时间稳定性与集成双向性存疑,这也是工具尚需打磨的地方。但方向是对的——硬件原型工具行业长期缺少一个能把“拖拽逻辑”和“可交付代码”在底层真正统一的产品。如果能持续优化运行时稳定性并打通双向设计工具链(尤其是Figma),blokdots有望成为设计-工程协同领域的一个底层基础设施。
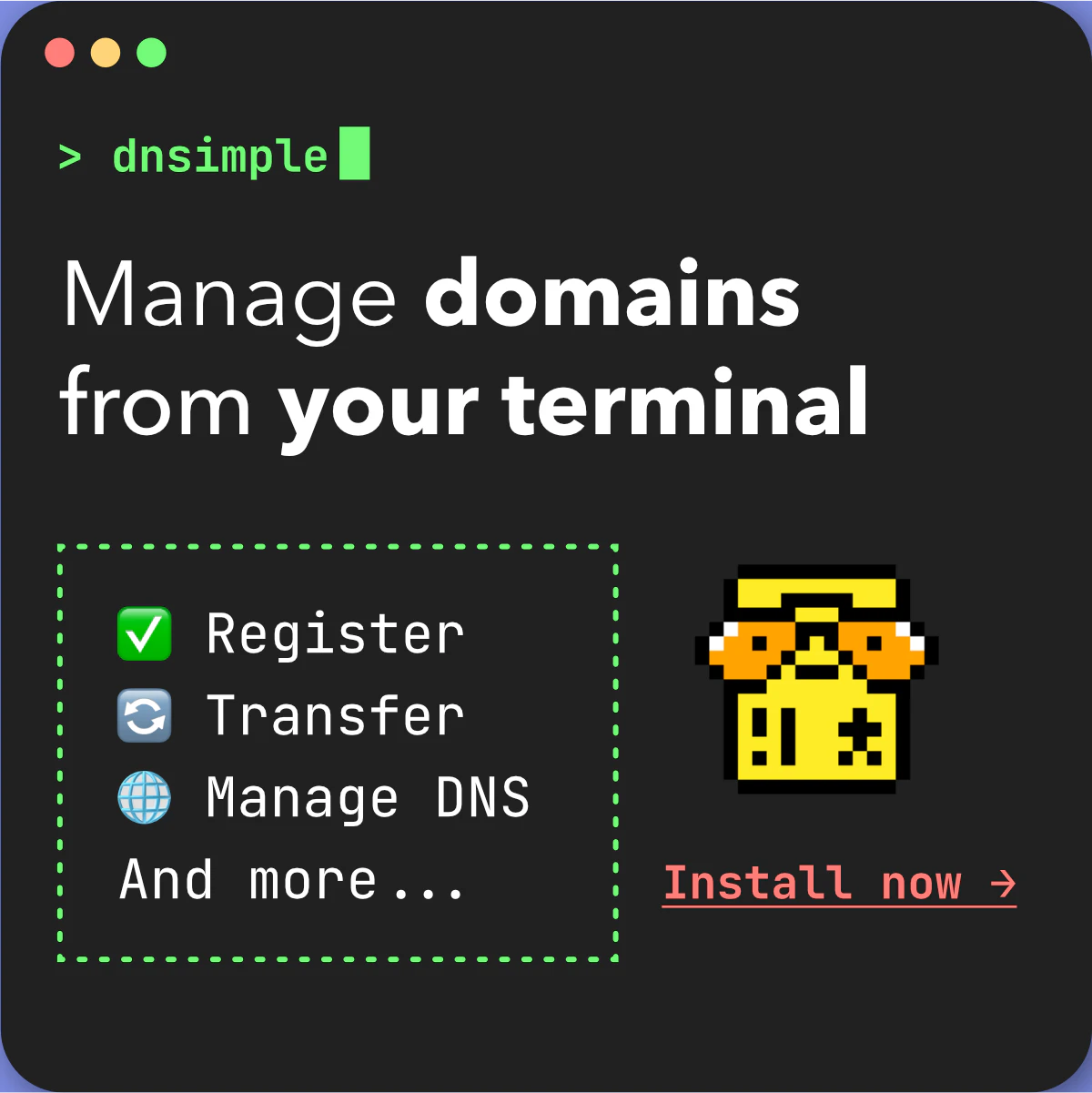
一句话介绍:DNSimple CLI 是一款专为开发者设计的命令行工具,让用户无需离开终端即可管理域名、DNS记录和SSL证书,解决了开发者在本地环境或CI流水线中频繁切换界面操作DNS的痛点。
Developer Tools
Artificial Intelligence
GitHub
YouTube
DNS管理
命令行工具
开发者工具
域名注册
SSL证书
CI集成
自动化运维
API客户端
Go语言
DevOps
用户评论摘要:用户肯定了CLI对开发者身份的天然契合,并点出关键疑问:与Terraform提供商的边界在哪?同时关注CI结构化输出是否作为稳定契约存在,担忧输出格式变更会破坏流水线。
AI 锐评
DNSimple CLI的价值不在于“又造了一个轮子”,而在于它精准填补了DNS运维中一个长期被忽视的断层:即Terraform这类声明式基础设施工具无法覆盖的临时操作、故障排查和快速响应场景。官方承认社区早有非官方CLI,这反而验证了需求本身真实且持久。然而,产品的生死线取决于两个核心承诺:一是“结构化输出”是否真正文档化、版本化,而非仅是人机可读的JSON——GitHub-style的API变更可能让CI直接崩盘;二是与自家Terraform provider的职责划分是否清晰——如果用户最终发现CLI能做的Terraform也都能做(只是多写几行代码),那CLI就会沦为玩具。从战略上看,将CLI定位为“AI代理的第一公民”倒是更高明的思路:在LLM驱动的运维自动化浪潮中,结构化输出+原子化命令的组合远比API调用更容易被智能体消费。但前提是,DNSimple必须足够克制,让CLI成为“命令的瑞士军刀”,而不是“API的摸黑仿品”。否则,它只会加重用户的心智负担,而非减轻。
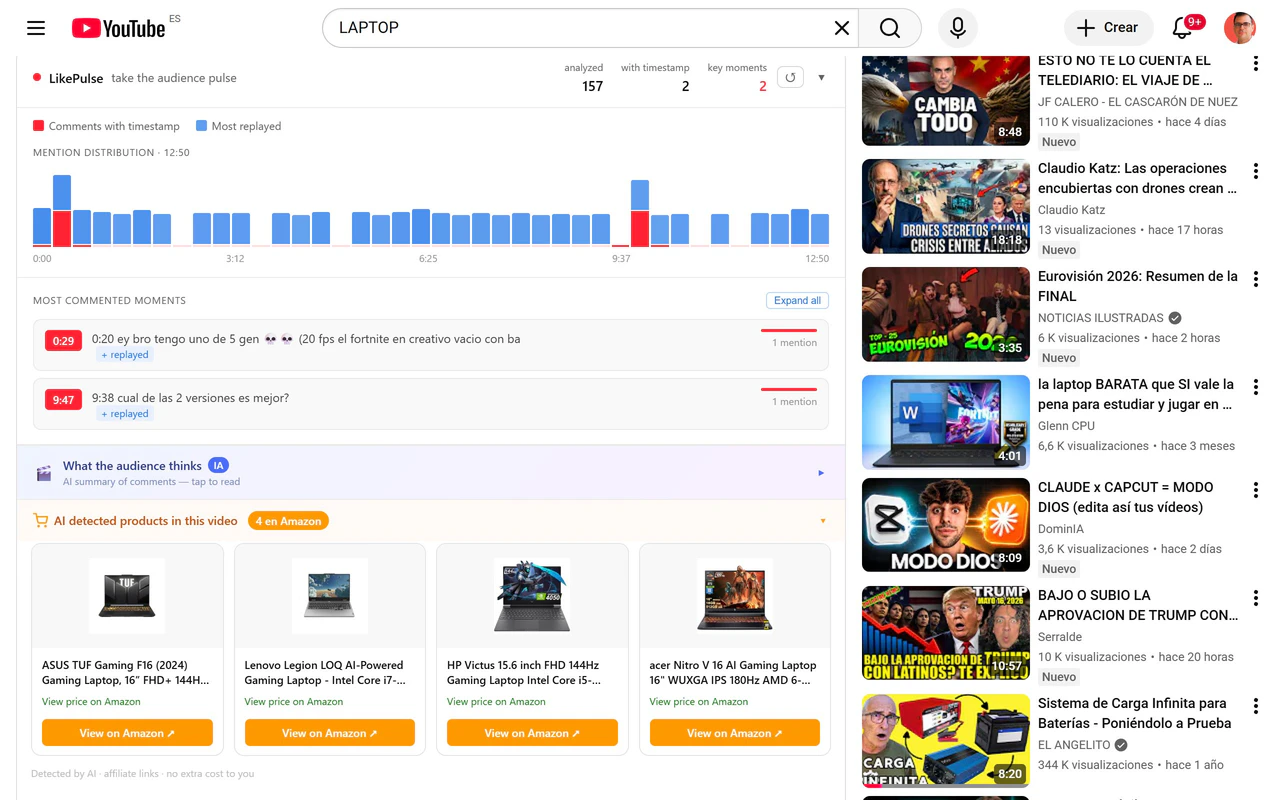
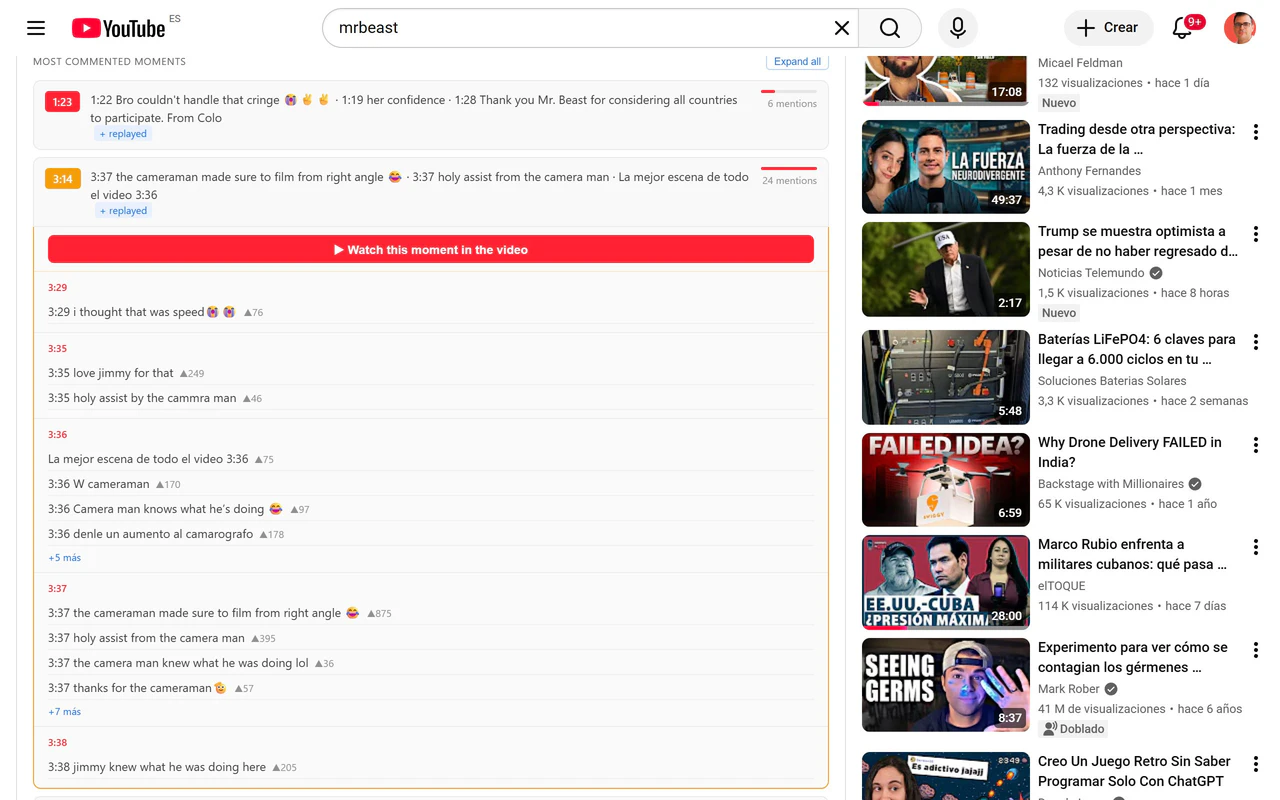
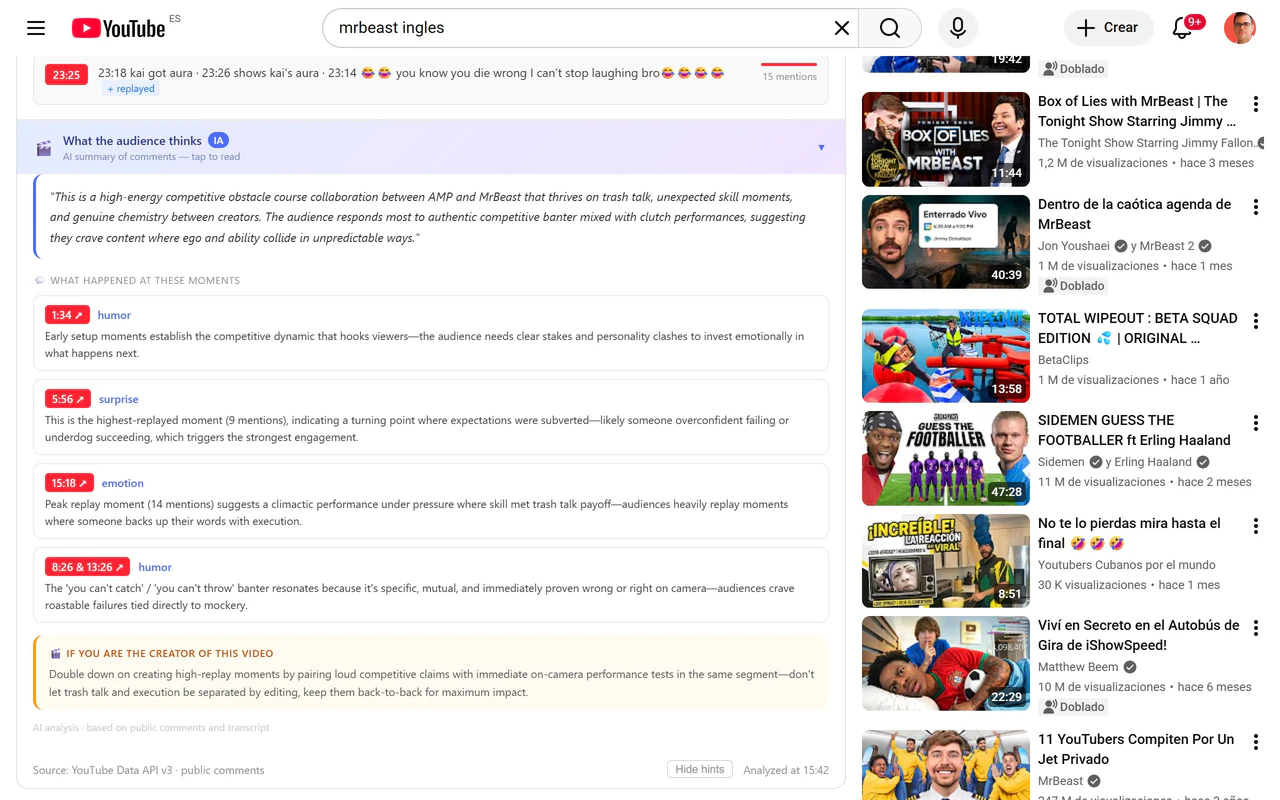
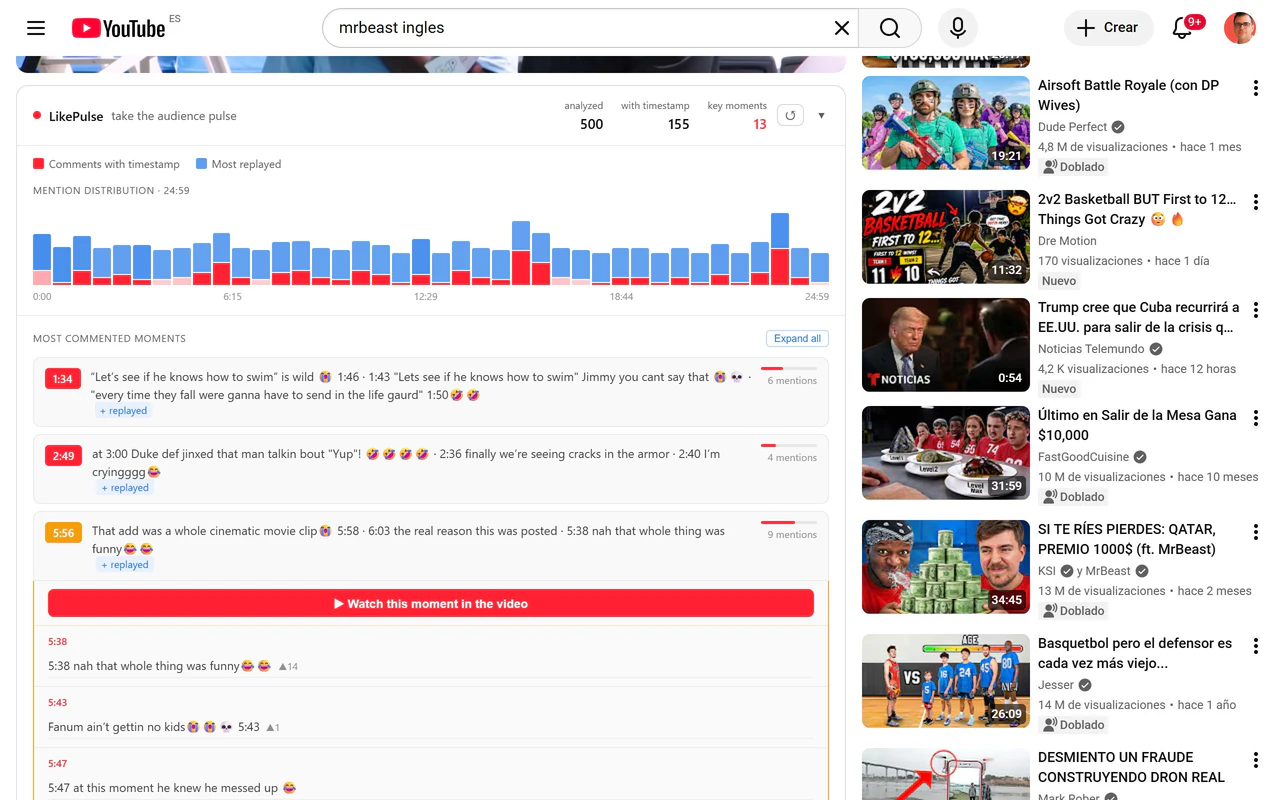
一句话介绍:LikePulse是一款YouTube视频评论区实时分析工具,通过热力图和AI解读,帮助创作者精准定位用户情绪爆发点,解决“知道视频播了多少次,却不知道观众在哪里真正嗨了”的痛点。
Chrome Extensions
Productivity
Artificial Intelligence
YouTube分析
评论区热力图
观众情绪检测
AI视频分析
内容优化
创作者工具
亚马逊商品识别
产品发布
Chrome扩展
免费工具
用户评论摘要:用户普遍认可“评论热力图+YouTube重播数据”的双信号对比价值,认为其能揭示创作者未察觉的编辑盲点。争议点在于“亚马逊商品检测”功能定位模糊,部分用户质疑其偏离核心用户群。另有用户指出工具应主动突出“信号分歧点”,而非仅展示两列数据。
AI 锐评
LikePulse的价值在于它把YouTube评论区从一个被忽视的信息垃圾场,变成了一座可挖掘的“观众情绪金矿”。其核心洞察“评论峰值与重播峰值往往不一致”是极其尖锐的——这恰好戳破了创作者对“观众想看什么”的直觉幻觉。当大多数分析工具还在卷“播放量和完播率”时,LikePulse用低成本(免费、免登录)切换到了“观众在想什么”的更高维度。
但产品在策略上存在一个微妙的撕裂。主功能“评论热力图+AI解读”服务于严肃的创作者和内容研究者,这是一条小而美的工具链;而“亚马逊商品检测”一眼就能看出是奔着“带货变现”的灰产或电商分析用户去的。这两个用户画像的行为逻辑完全不同:前者关心叙事节奏,后者关心转化漏斗。强行杂糅只会让产品面目模糊——既不能让创作者觉得你是纯粹的内容“共鸣”放大器,又不足以让营销人信任你的商品识别精度(毕竟是从评论里扒,而非视频帧识别)。创始人解释这条功能是“另一实验”,但放在主页作为卖点,说明其还未想清楚核心用户是谁。
另一个隐忧是数据深度。当前工具本质是“对公开评论的实时聚合与分段标记”,它不涉及私有数据(如YouTube Studio的真实观众留存曲线),这意味着分析天花板很低:你看到观众在哪兴奋,但永远不知道“他们跳过了哪一段”来衬托这个兴奋。如果未来不能与YouTube Insight交叉验证,LikePulse最终只是一个漂亮的“灵感风暴”工具,而非用于指导编辑决策的“准星”。
一句话锐评:免费、优雅、洞察犀利;但功能杂糅与数据浅层化,正将其拉向“看起来很酷但难以成为刚需”的深渊。











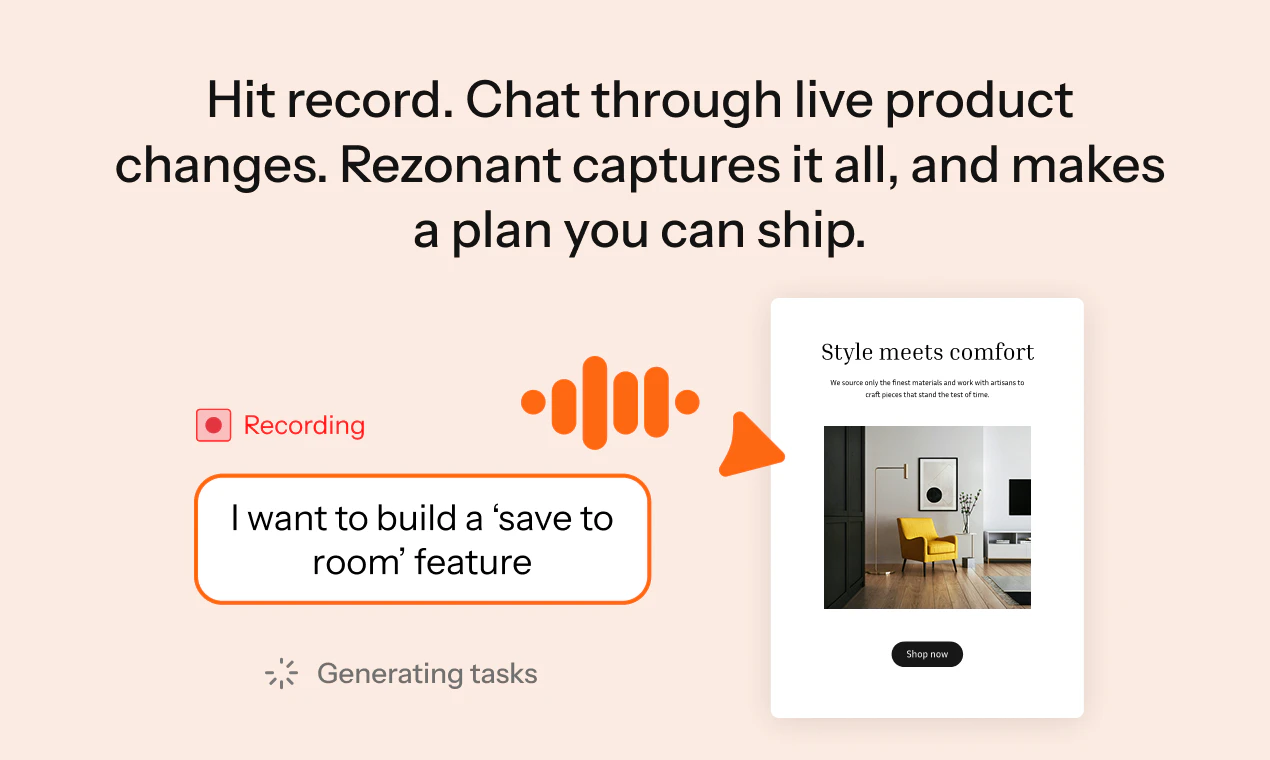



































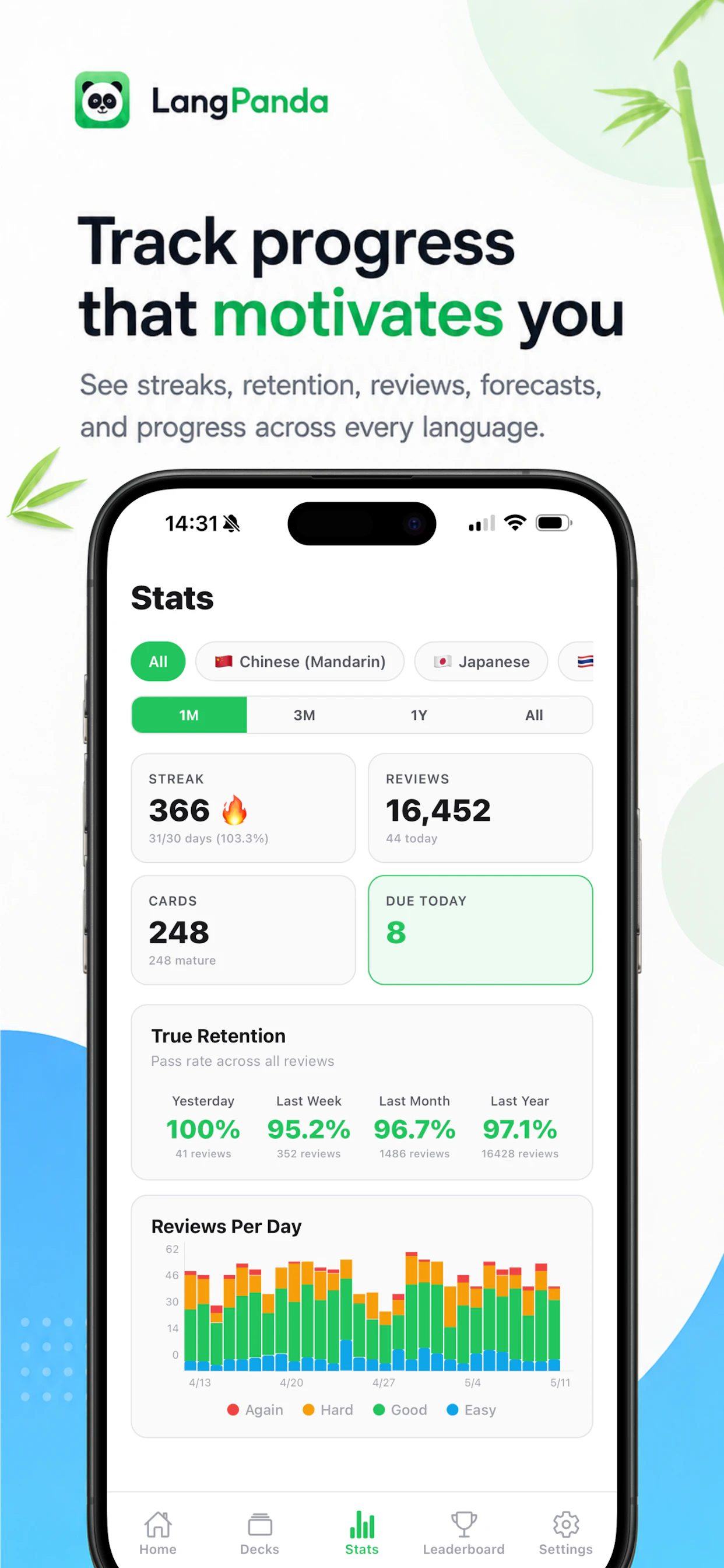

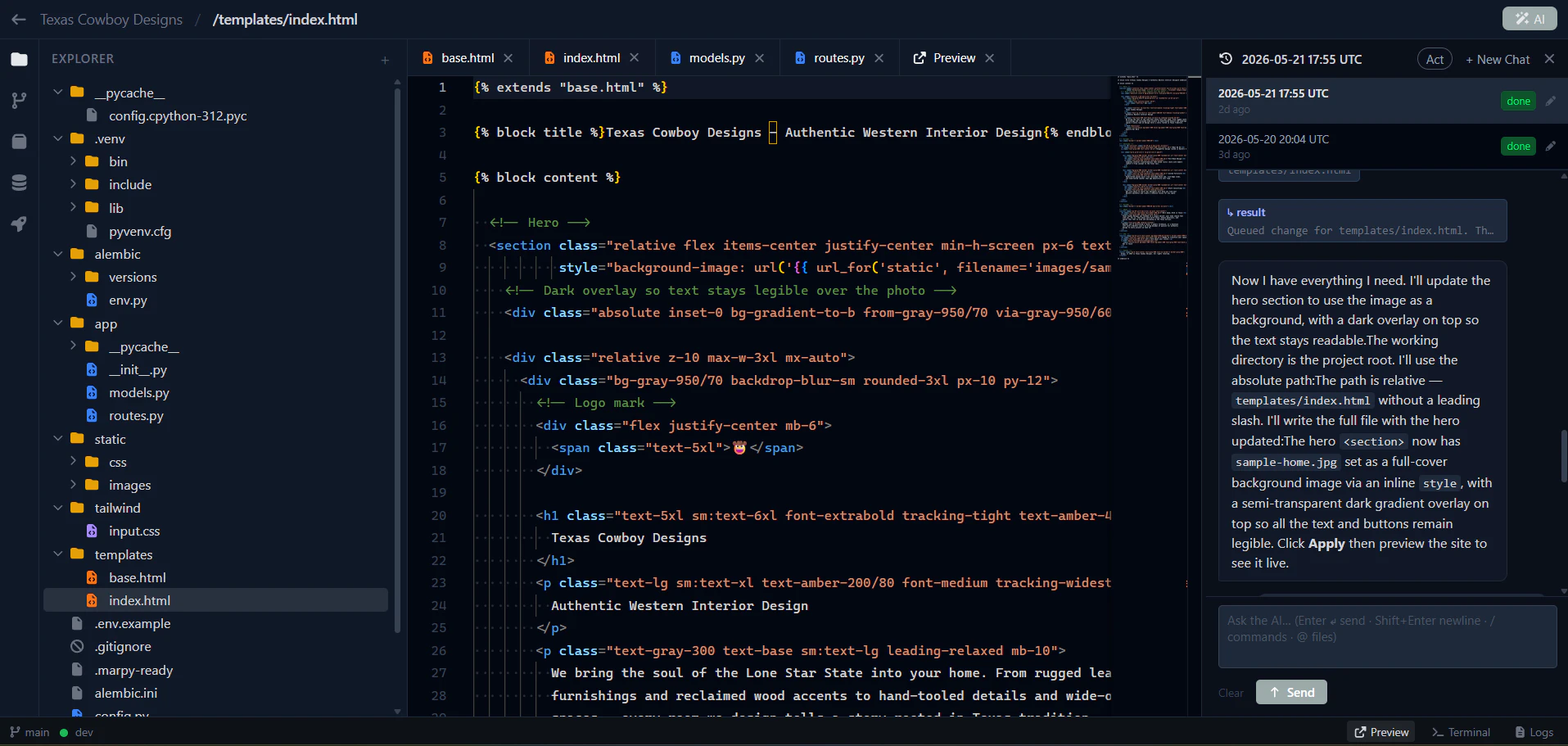
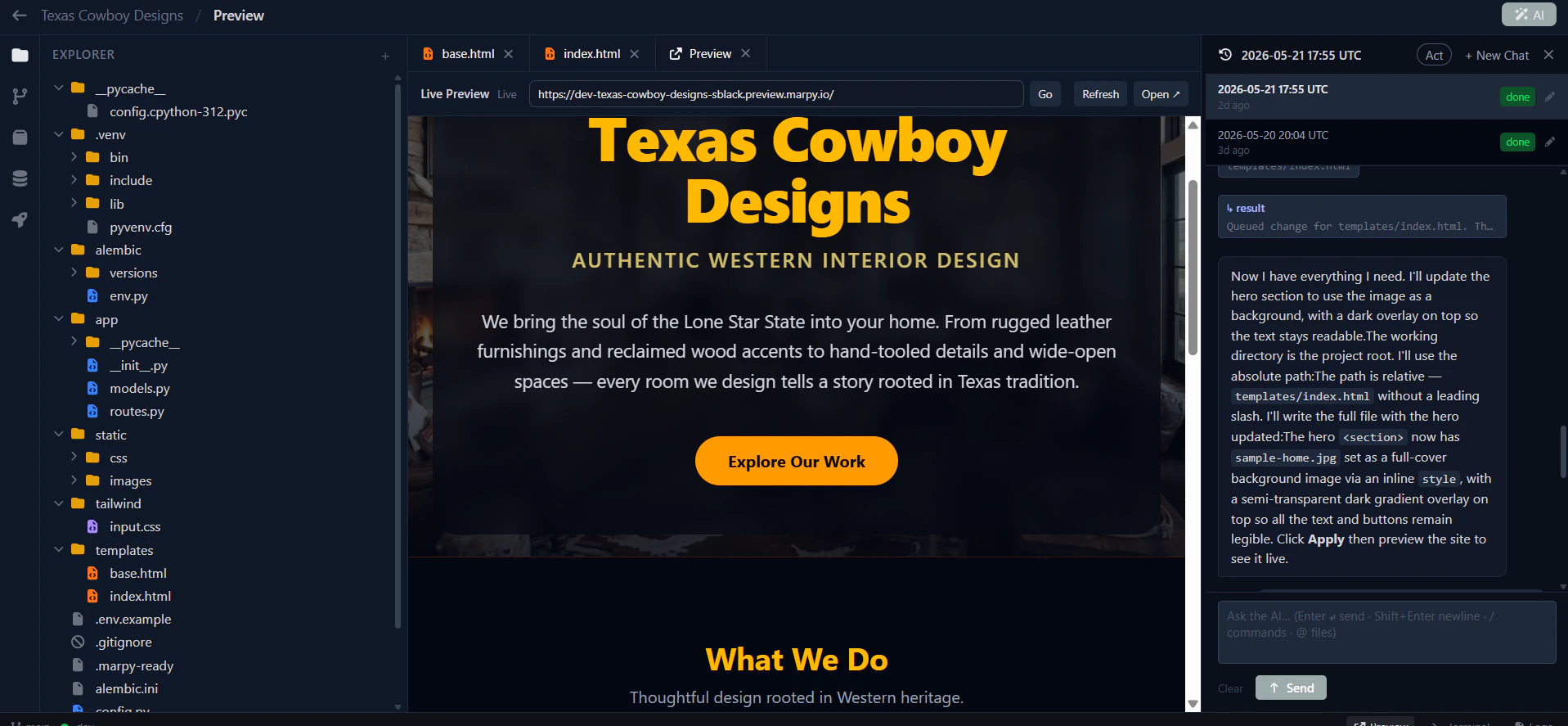














Hey Product Hunt 👋
I'm Philip, co-founder and CEO of Brew. When I was leading US growth at Revolut, I kept seeing teams with world-class products fail at the last mile - actually reaching and retaining the users they'd worked so hard to acquire.
The fix was always email. It's still the highest-ROI channel for activating, nurturing, and retaining users - nothing else comes close.
But every time we tried to execute it properly, we ran into the same painful cycle. Campaigns that took weeks to build. Emails that broke in half our users' inboxes. Designs that didn't look on-brand. And when the pressure was on, they just didn't go out at all.
The problem wasn't the team. It was the tools.
Old school SaaS platforms like HubSpot, Mailchimp, and Marketo were built for companies with entire departments dedicated to running them. Someone has to analyze the data, plan the campaign, write the copy, design the emails, code the HTML, deploy it, and optimize the results.
For most teams that's just not realistic - so the software sits there underused and revenue gets left on the table.
My co-founder @thomas_park2 (former Vercel) and I built Brew to fix this.
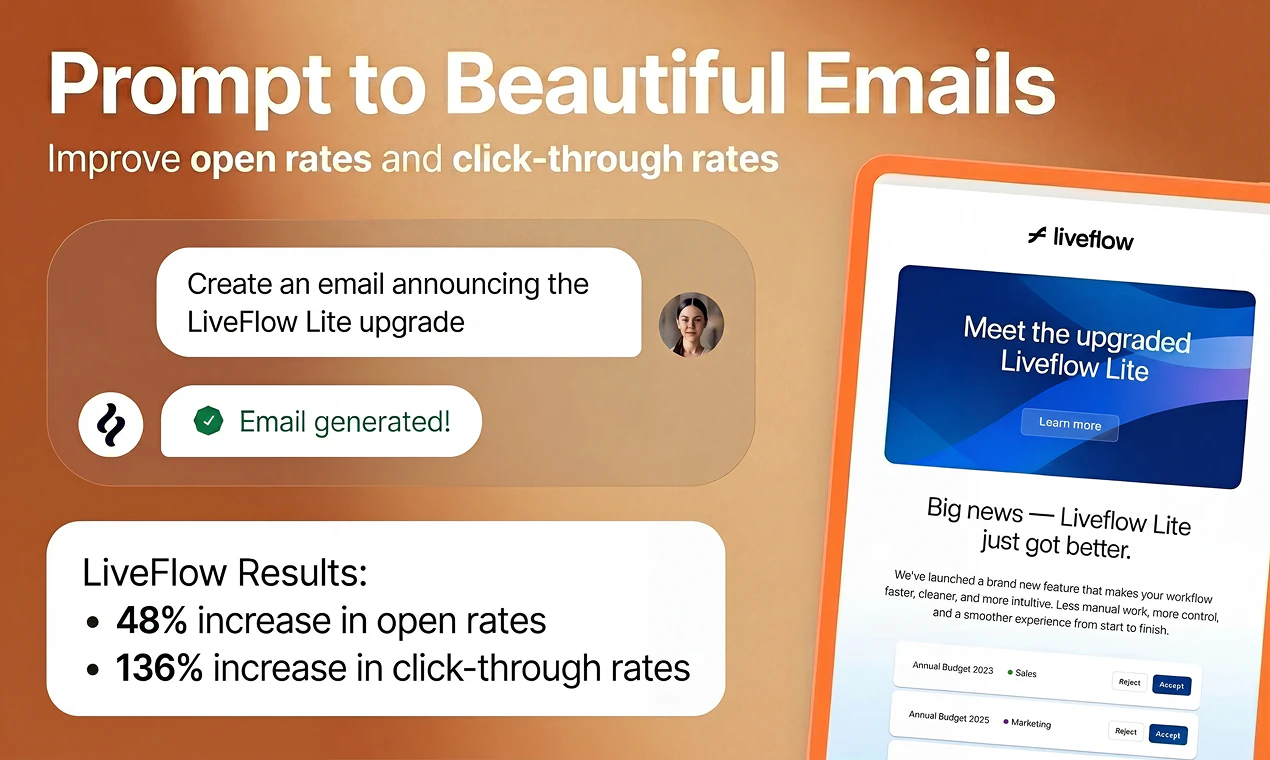
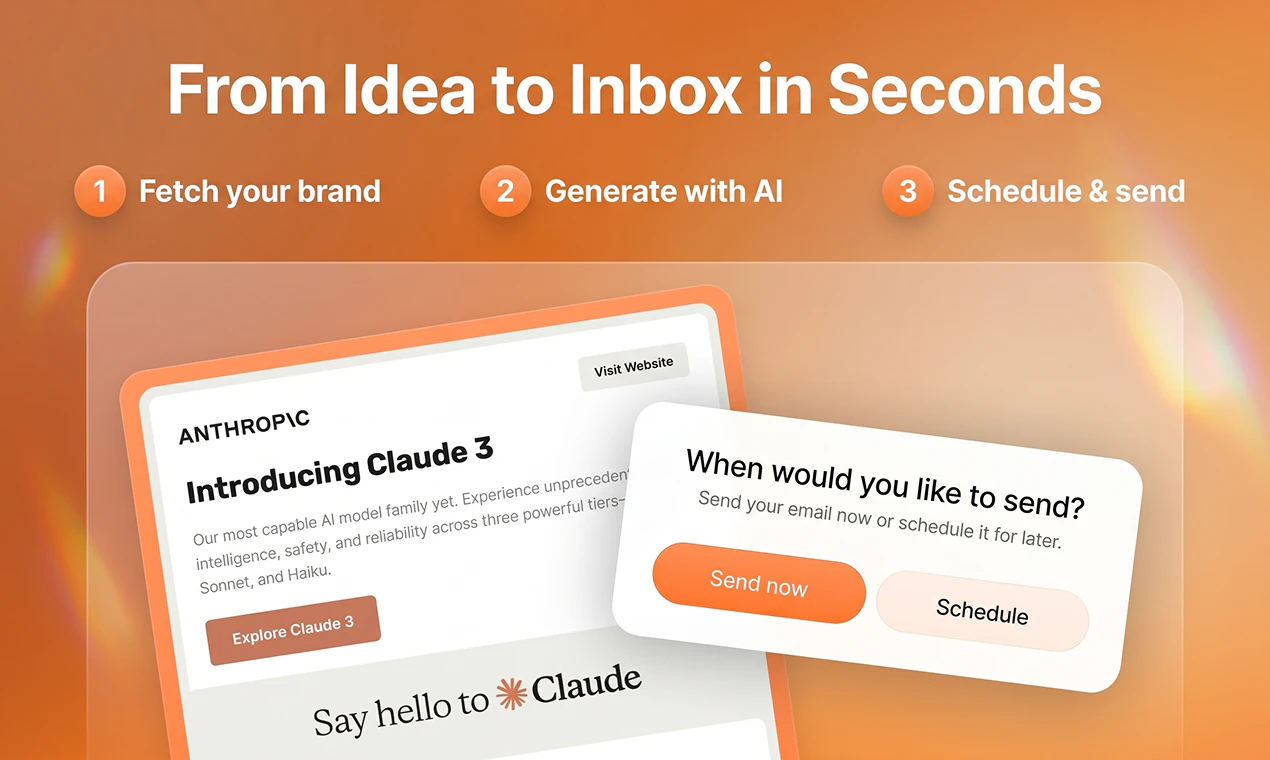
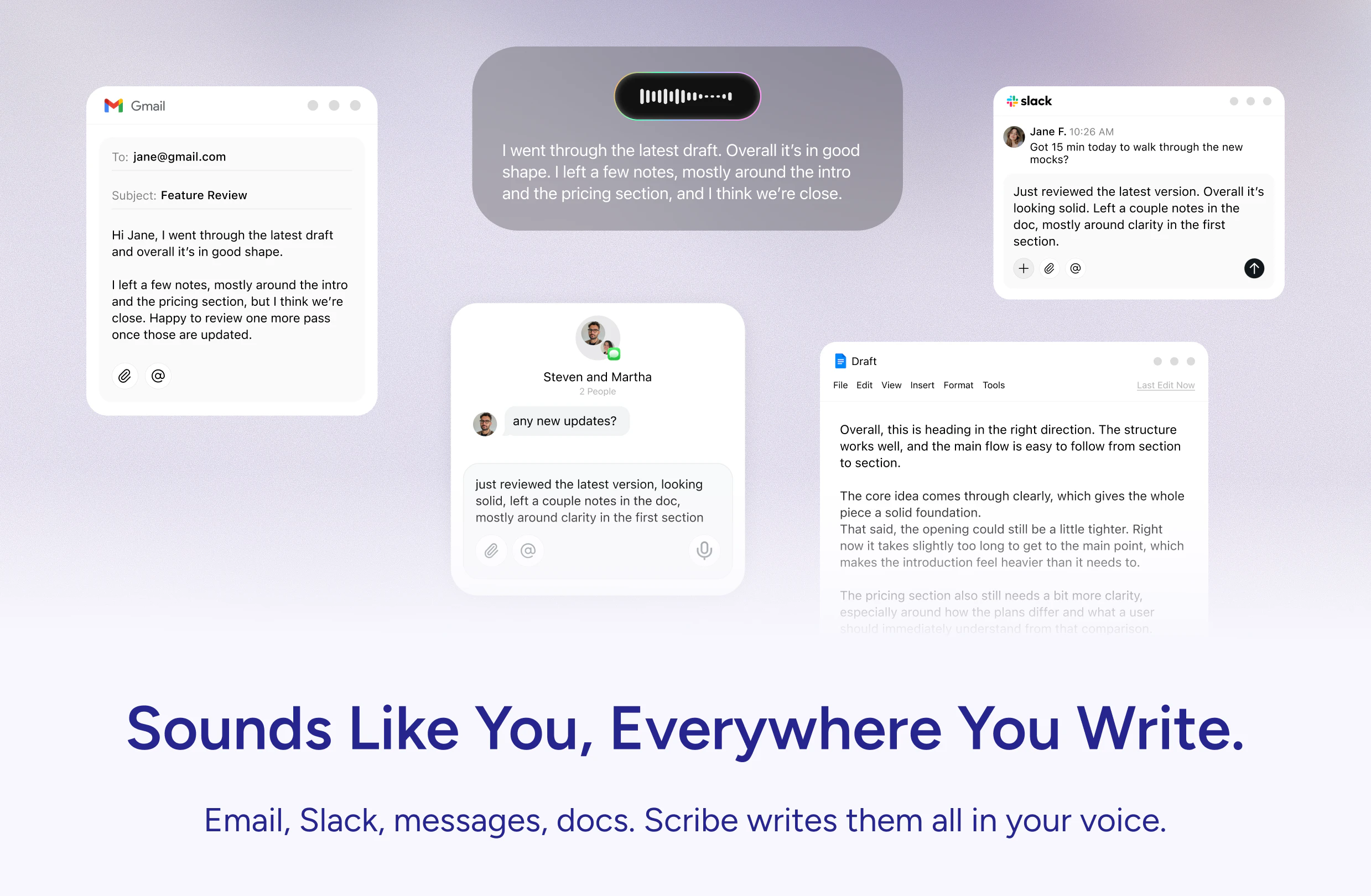
You describe the campaign you want and Brew builds the whole thing in seconds:
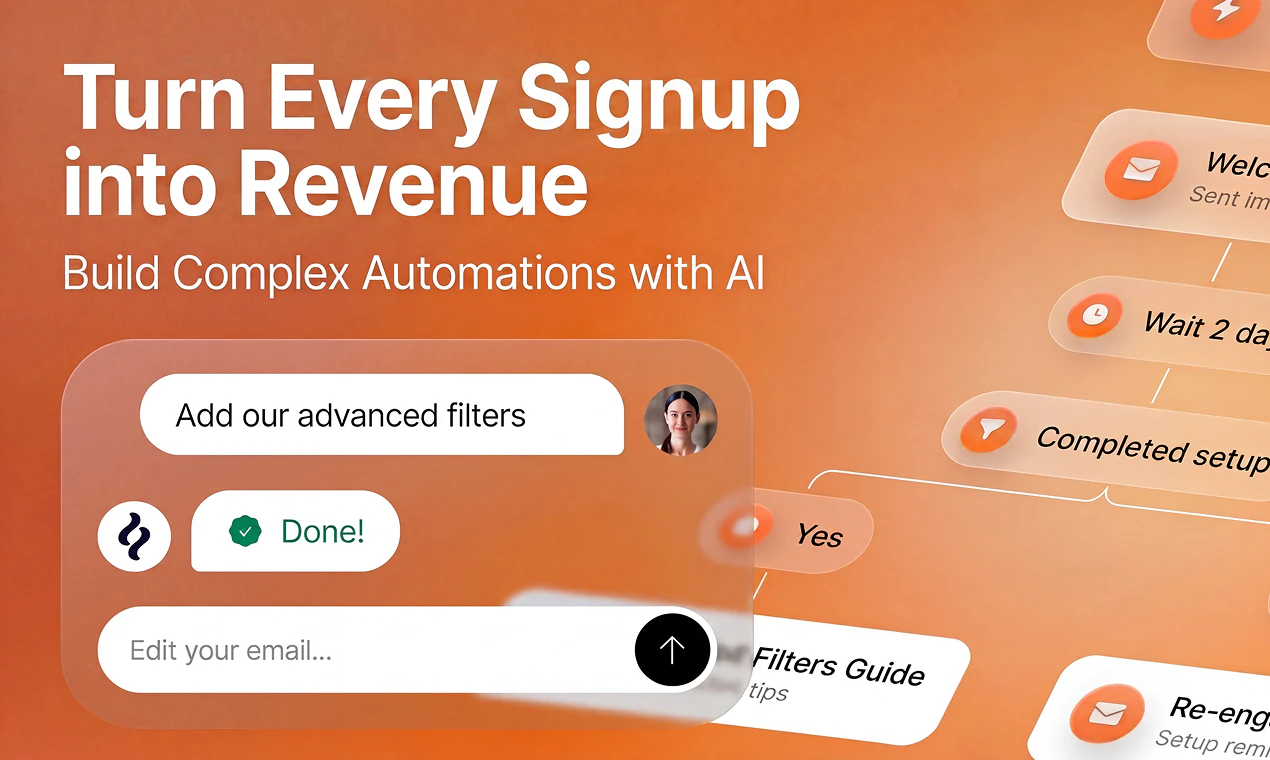
Welcome flows and drip sequences
Newsletters and lifecycle campaigns
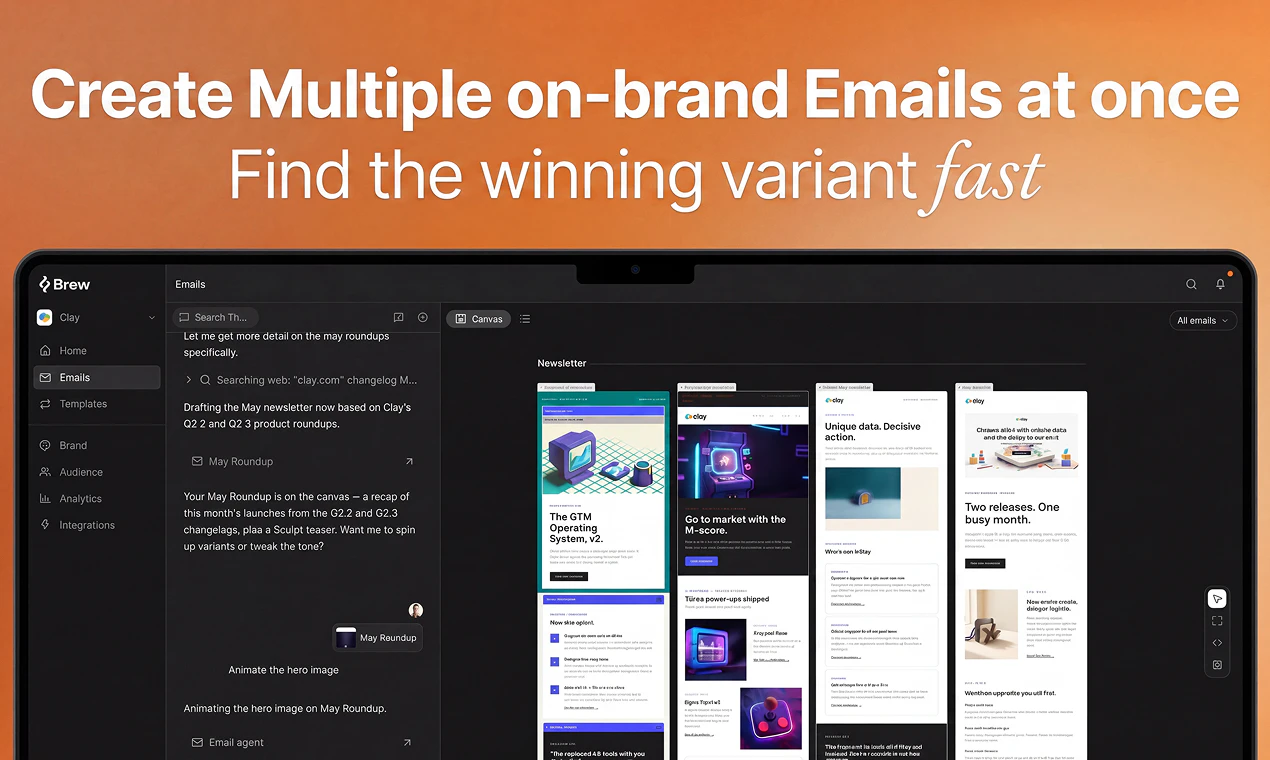
Multiple on-brand variants
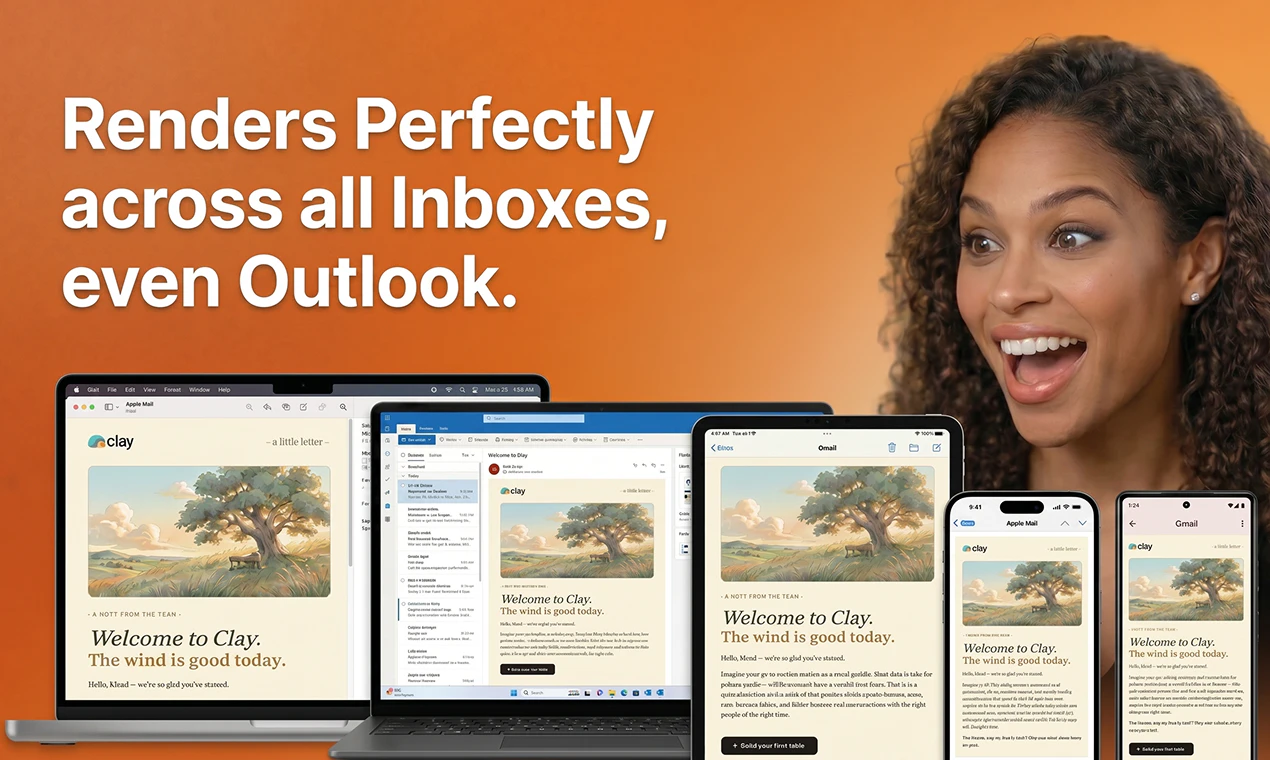
Production-ready HTML that renders perfectly across Gmail, Outlook, and Apple Mail
It pulls your branding automatically from your website and Figma. What used to take even the best teams 8 days now takes one prompt.
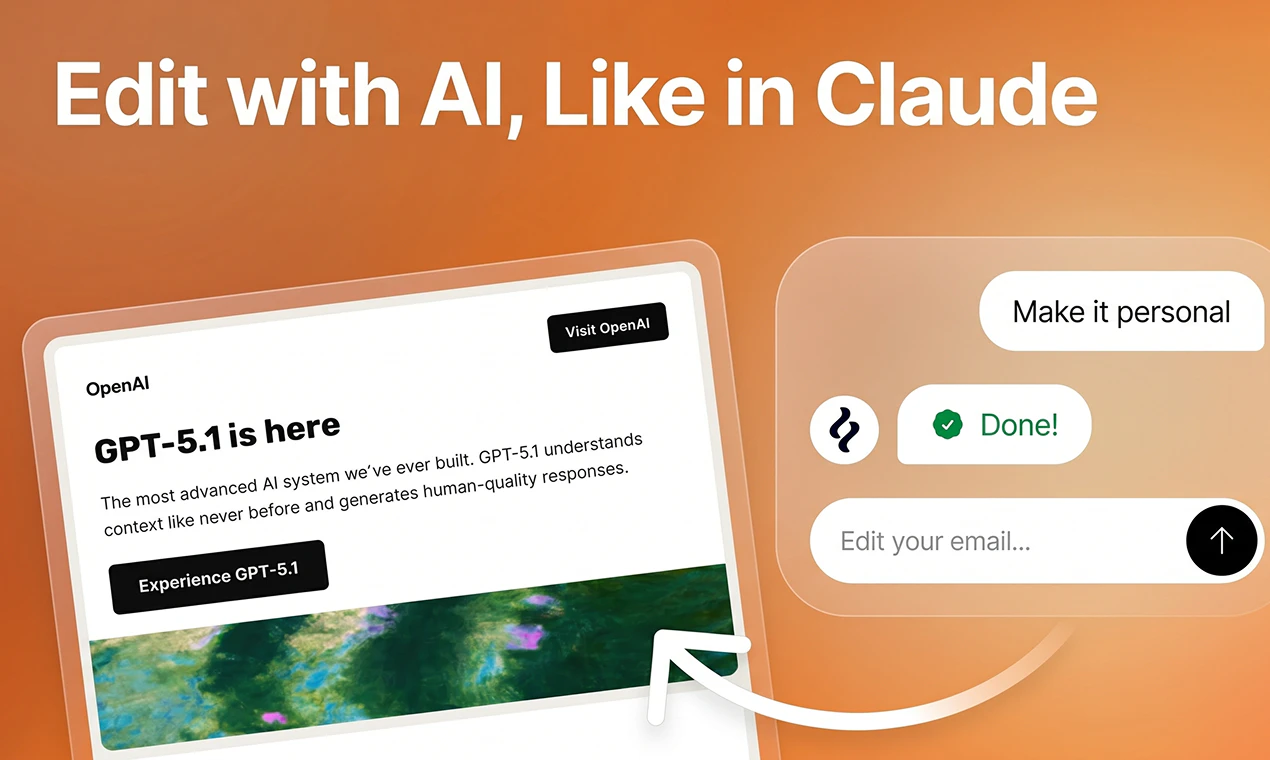
It's like Claude Design or Lovable, but made specifically for email marketing (the emails render perfectly across inboxes because the underlying HTML is email-optimized, unlike Claude).
Watch me walk through it personally here: https://www.loom.com/share/dc325b42a4b54c50b1e5cdea3964e66a
A few things people are surprised by when they first try it:
It builds entire multi-step sequences, not just single emails
The brand extraction is scarily accurate
It works natively with Viktor, OpenClaw and any AI agent
You can push straight to Klaviyo, HubSpot, Mailchimp, or whatever ESP you're already on
This is just the beginning. We're building toward a full autopilot - you set the objective, Brew handles everything else. The goal is to become the new system of record for email marketing. One where going back to the old way is unthinkable.
Try it for free, break it, and tell us what's missing. Every piece of feedback goes straight into what we build next.
Get started free at Brew.new or reach me directly at philip@brew.new
Thanks to @jessica_w204 and @antlio for building this with me and Thomas. And to the Product Hunt community - there's no better place in the world to launch something you've worked this hard on.
Much love,
Philip 🫶
Been a happy Brew user for some time now. Incredible team and beautiful UX; this is what modern email marketing should look like.
Congrats on the launch team!
When can we expect a Brew MCP so we can automate directly from coding agents or OpenClaw? :)
I'm a happy MailerLite user, but looking at that gorgeous video I have to sign up and try the platform out! Congrats on the launch and the awesome execution :)
Congrats @philip_sorensen ! I love the demo video, inspiring to start building beautiful emails😻 How are you handling Outlook rendering under the hood? It is usually the hardest client to get right and most tools give up on it.
Looks super cool! Go go team Brew!
wow! scaling signups -> customers has been a major painpoint, and automating personalized emails seems like it would be the missing piece. LFG brew ☕️☕️ @philip_sorensen
I've been using Brew for the past few months in beta, it really does what it says on the tin. Super impressive outputs in no time!
This is so sick @philip_sorensen and team - been waiting for this!!!
Switched from Mailchimp to Brew and never been happier! Congrats on the launch guys!
Super stoked for this!
I needed to send on brand emails for one of my own side projects. Brew was a tremendous help. My favorite part is how I just gotta enter my domain and keep sending unique emails still sticking to the aesthetic, theme and taste of my brand.
Tried Brew today and it genuinely killed my last excuse for not fixing our lifecycle emails. Gave it a plain‑English prompt and got something I’d be happy to ship in one go. Super impressed with how on‑brand it comes out and how little I had to change the HTML manually.... Upvote.
Congrats on the launch, love it! A good email still goes a long way, and I think people don’t spend enough time crafting genuinely thoughtful emails anymore, instead they just blame the whole “channel” and say email is dead.
Love it! Congrats on the launch 🚀
Awesome
Finally an ESP that doesn’t feel like operating SAP through a microwave.
You can tell product taste was part of the roadmap, not just deliverability dashboards and 400 toggles.
Solo founder here, building toward an App Store launch, and lifecycle email is exactly the thing on my roadmap I keep deferring because the tooling tax is real. So the "8 days → one prompt" promise lands.
Quick q: How deep does Brew go on tone? Can it learn a brand's voice from existing copy (site, past emails), or is it pulling visual identity and writing in a competent-but-generic marketing register underneath?
The integration with tools like @Brevo is interesting. So we adopt Brew without full switching our stack. Well done.
@philip_sorensen Awesome to see native compatibility with tools like OpenClaw and Viktor right out of the gate. For an automated multi-agent workflow, can we hook Brew up to run autonomously like having an agent analyze weekly database churn metrics and prompting Brew via API to generate a custom win-back sequence?
Congrats on the launch!
I really like the positioning here. It is easy to understand, but the part that stands out to me is the last mile: not just generating nice-looking email drafts, but turning them into on-brand, production-ready campaigns and automations that can actually be sent through the tools teams already use.
As someone working around AI + productivity, I think email is one of those areas where pretty demos are easy, but reliable execution is hard. Brand consistency, lifecycle logic, ESP handoff, and rendering across inboxes are where the real value is.
Curious how you think about the rendering/testing layer over time, especially for Outlook, Gmail clipping, and dark mode. If Brew can keep that reliable while making campaign creation feel this lightweight, this could become a very useful tool for growth and lifecycle teams.
Upvoted. Excited to see where this goes.
Is there a way to easily migrate to Brew from Mailchimp or other providers?
Congrats on the launch =) One question on the brand extraction: how do you handle sites that block automated readers or render everything client-side? Curious if you've found a way around it.
congrats on the launch :) this feels like a very obvious pain point to go after. i like that it’s not just “generate an email”, but the whole messy part around brand, sequence logic, variants, and inbox-safe html.
curious how the workflow feels once brew has made the first version. do teams usually treat it as ready to send, or is there a review/tweak step before it goes live?
Been using Brew with the Customer IO integration the past two months, and it works perfectly. We send broadcast emails 5 times per week, and it's traditionally been a huge hassle to produce the content and design the emails — but it's fast (and much better) now. I especially like how we can get very differentiated versions of an email in no time. Reminds me of website building in Lovable. Highly recommend it to any marketers or founders out there!
Curious how Brew handles multiple parallel campaigns, is it one workspace per brand, or can you run separate sequences with their own logic side by side?
For context: Our team runs nurture sequences across pretty different client segments and keeping every campaign on-brand at that volume eats up real time...
Nice product btw!
The "describe a campaign in plain English, get the full thing rendered" framing is exactly what email needed — most teams aren't bottlenecked on having something to send, they're bottlenecked on the production tax of every send. I work on StoryRoute on the travel side and we see the same dynamic: people will narrate what they want a city walk to feel like, but they won't sit down and design the route step-by-step. The product that closes that gap wins. Congrats on the launch.
How complex can the automations get? Wondering if it handles conditional branches based on whether someone opened or clicked.
Hey! Amazing product.
Are there any trials available? I was looking to export the first campaign that Brew designed to me in order to evaluate the quality of the HTML.
Let me know, thanks.