PH热榜 | 2026-05-28
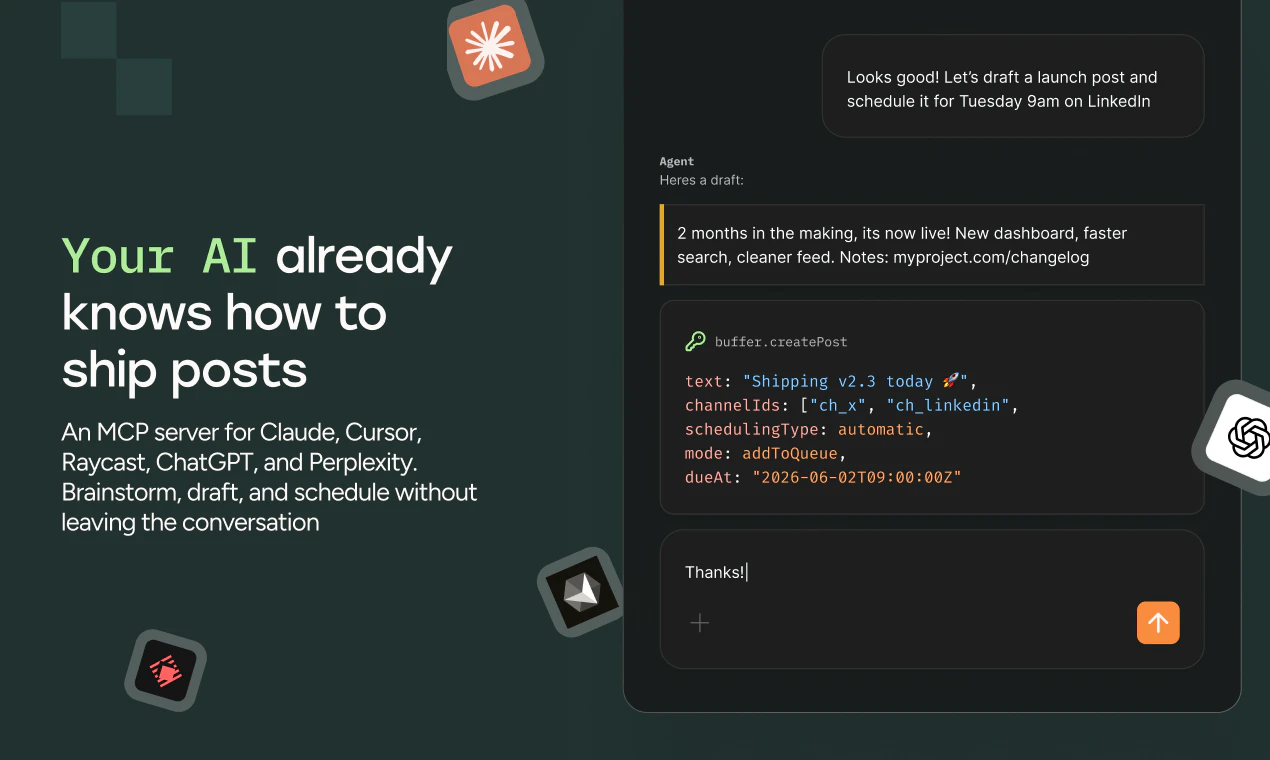
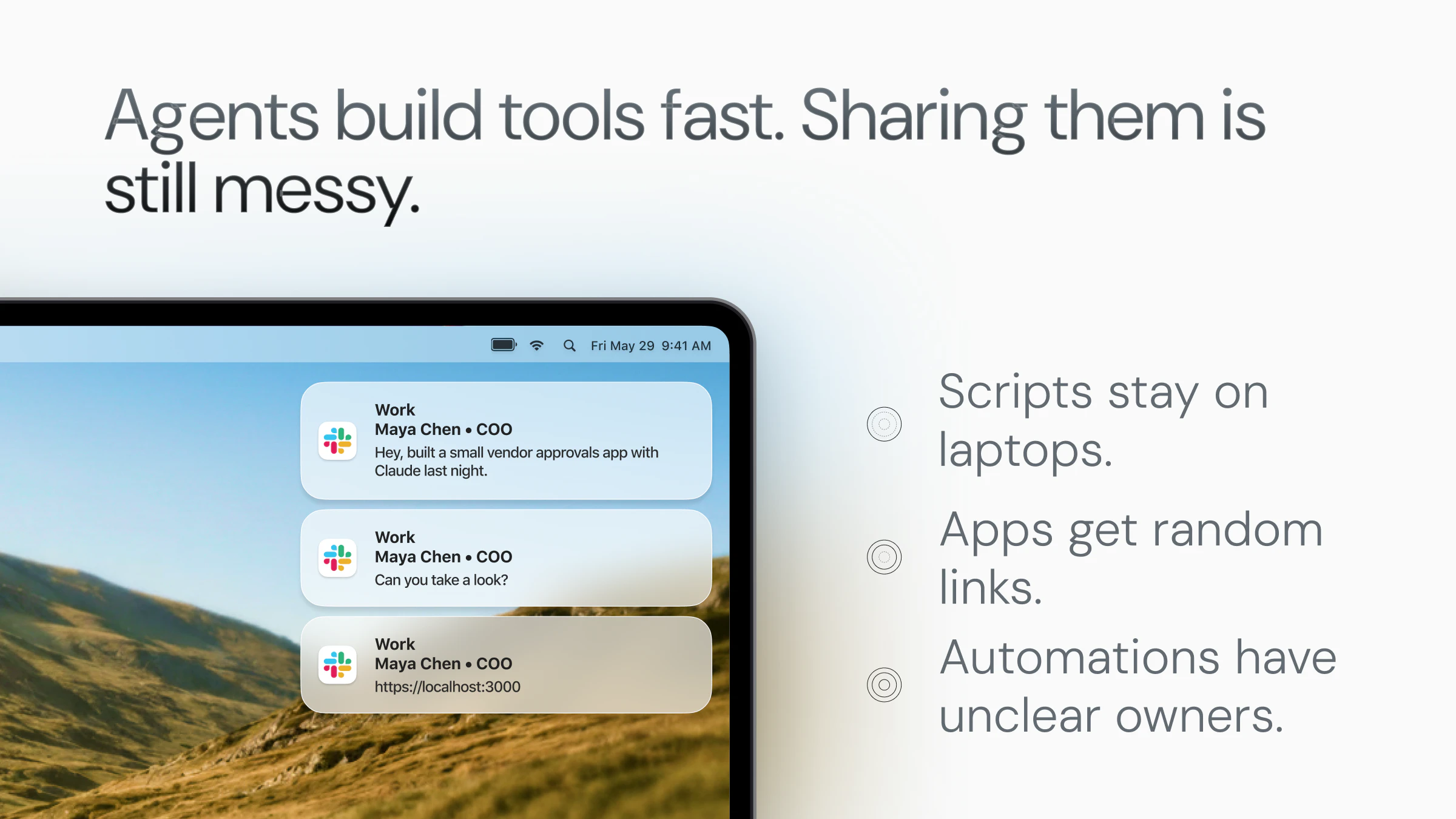
一句话介绍:Pancake 是一个嵌入 Slack 的 AI 代理组织架构,通过设置角色、目标和心跳机制,让公司实现从 0 到 70% 的自动化运营,用户只需设定方向并审批不可逆操作,其余工作由代理自主完成。
Slack
Artificial Intelligence
Maker Tools
AI代理
企业自动化
Slack集成
自主运营
组织架构
GTM自动化
产品开发
运营管理
开源模板
公司大脑
用户评论摘要:用户高度认可其自主性,称赞“无需 babysitting 代理”和“能提出自己想不到的解决方案”。关键问题聚焦于:如何界定“不可逆”操作(如 API 调用、成本支出)与审批边界,以及如何设置护栏以确保代理只在授权范围内行动。
AI 锐评
Pancake 的“自主公司”口号极具煽动性,但本质上仍是“AI 代理即服务”的进阶版。其真正的价值不在于“取代人类”,而在于将公司内部可标准化的流程(如会议纪要转PR、SDR外联、操作审计)彻底外包给 AI 组织,从而释放出创始人和核心团队的时间——这确实是当前 AI 工具中最务实的切入点。
产品设计的精妙之处在于“心跳”和“叠加式自主”。传统 AI 工具是让人类发号施令,而 Pancake 让代理主动“反馈”并推进任务,形成反向驱动力。这种“被 AI 提示”的体验对习惯自上而下管理的团队是颠覆性的,但也是风险所在:一旦代理的优先级判断偏离了公司真实目标,可能导致大量无效工作。评论中用户对“审批边界”的追问恰中要害——Pancake 将“不可逆”定义为二值逻辑,但现实商业场景中,“发一封邮件”和“关闭一台服务器”的后果差异巨大,需要更精细的权限粒度。
团队用“Pancake 运行 Pancake”的案例虽具营销魅力,但23个代理每天3个任务的数据表明其目前处于“低风险自动化”阶段。关键挑战在于:当代理数量膨胀到 200+,且任务涉及跨部门决策时,如何避免“代理内耗”或“决策雪崩”?此时人类审批者反而可能成为瓶颈,违背“自主”初衷。从产品定位看,它更适合“早期创业公司”或“创新团队”,因为这类组织流程灵活、容错率高;对于大规模企业,当前版本缺乏足够的治理层和安全审计链。
总体而言,Pancake 是一次勇敢的实践——它不再让人类做 AI 的“保姆”,而是让 AI 做公司的“水手”。但“船长”仍需清醒:方向错了,帆再大也只是加速触礁。
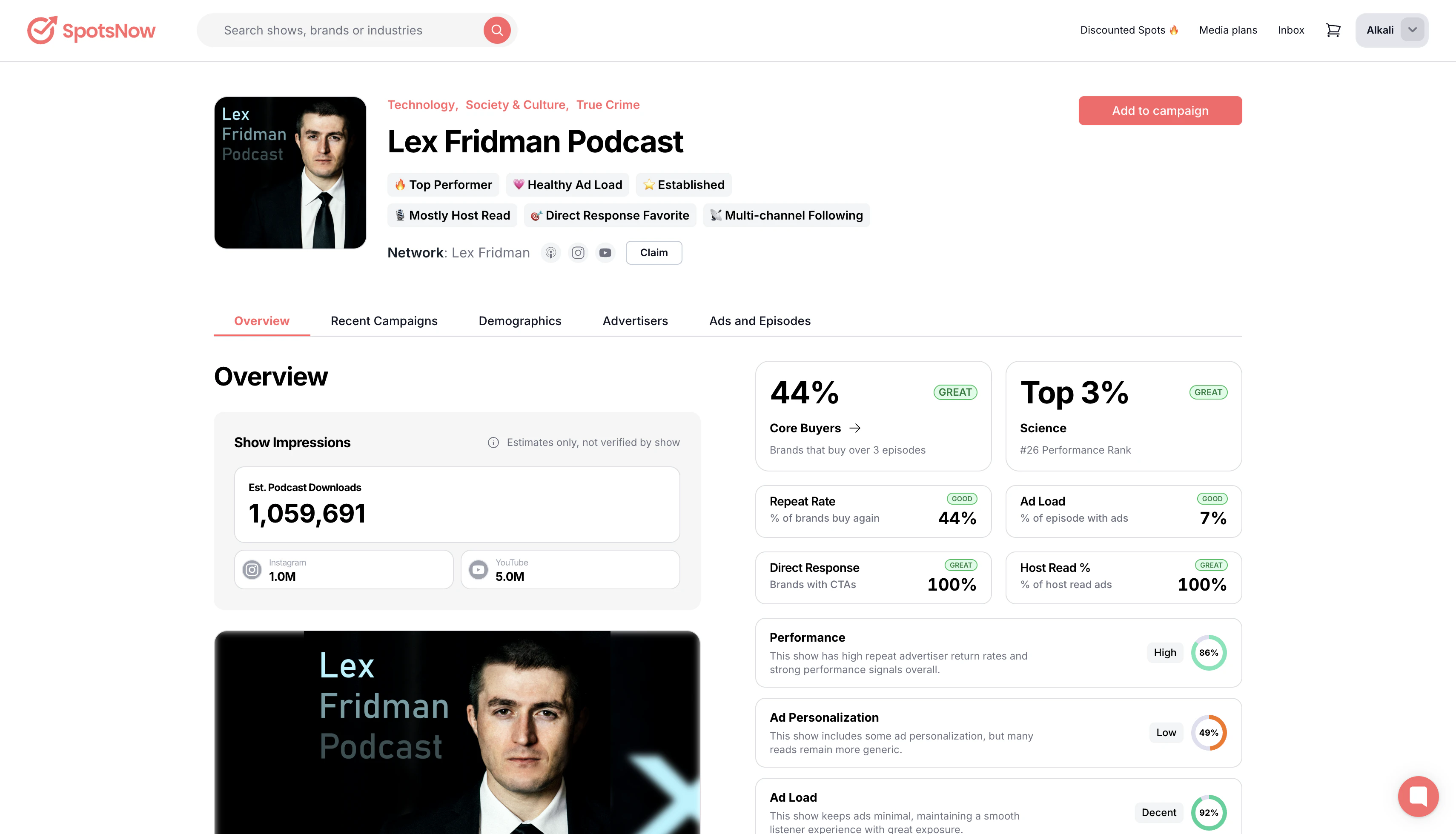
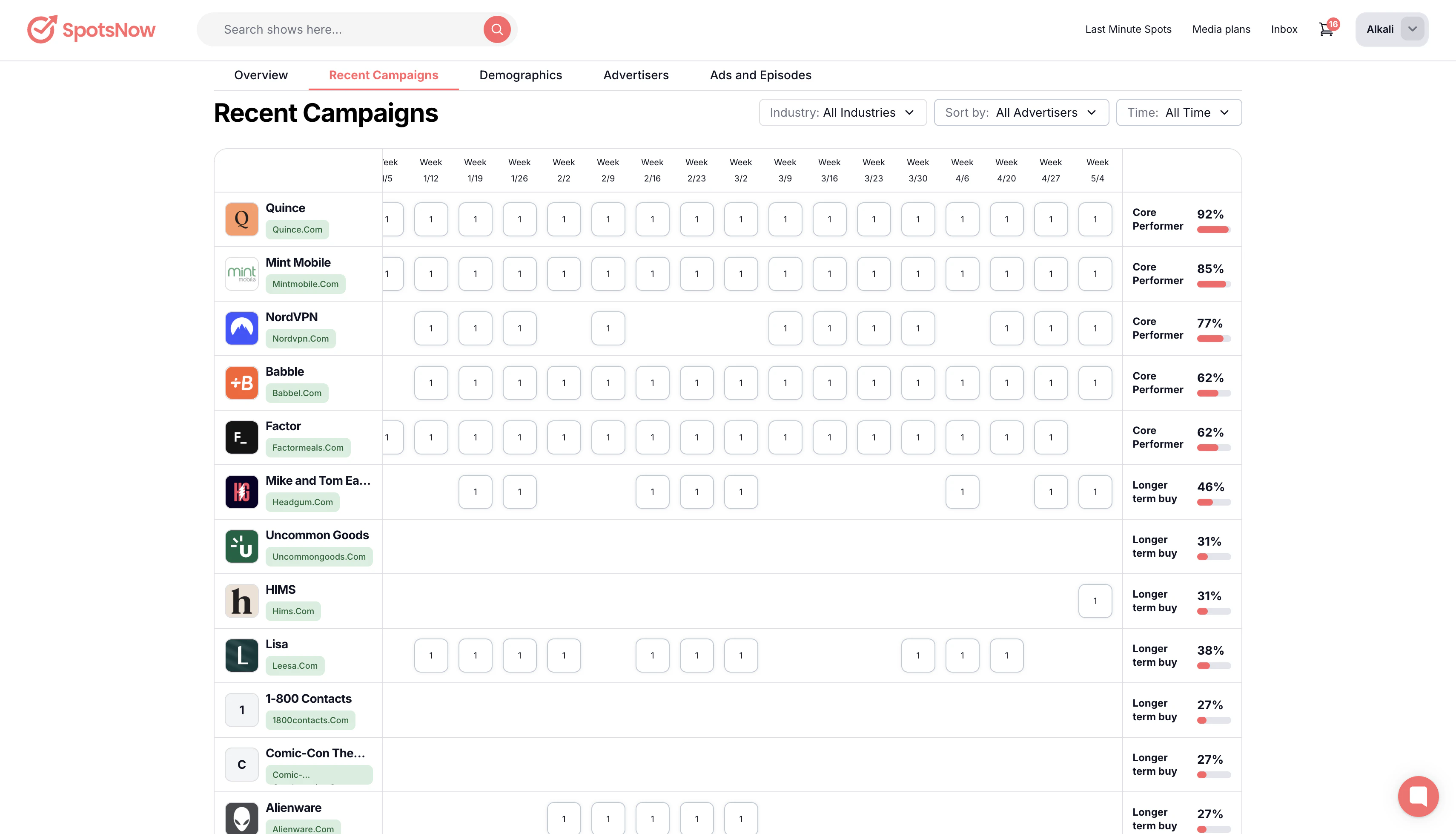
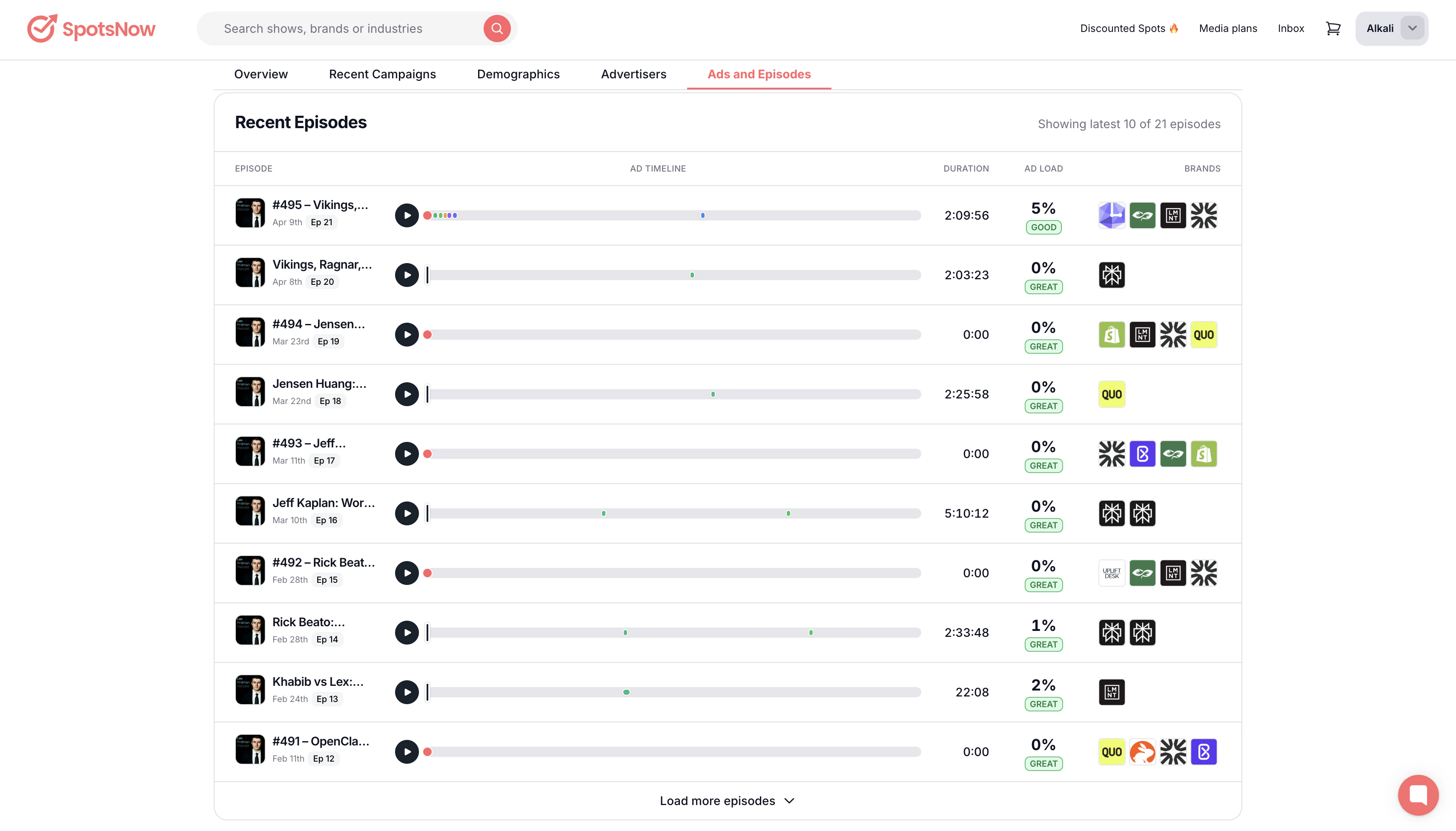
一句话介绍:SpotsNow是一个播客广告竞争情报平台,帮助用户追踪各品牌在6万个播客上的广告投放、花费及广告位库存,并直接在平台内购买开放库存,解决播客广告数据不透明和购买流程繁琐的痛点。
Analytics
Advertising
Radio
播客广告
竞争情报
广告投放追踪
媒体监测
广告位购买
市场分析
SaaS
广告技术
营销工具
数据平台
用户评论摘要:用户普遍认可其解决了播客广告“黑箱”问题。核心建议包括:希望按主题(如“约会”、“健康”)而非行业标签导航;询问开放库存更新频率;关心无优惠码时的归因方式;期待对品牌与播客匹配度的评估;以及能否衡量业务成果而非仅曝光量。
AI 锐评
SpotsNow切中了一个长期存在的市场痛点——播客广告领域的“数据黑箱”。其核心价值并非单纯的数据聚合,而是将“竞争情报”与“交易执行”闭环,极大地缩短了从洞察到行动的路径。产品方向精准,但面临的挑战同样严峻。
首先,数据准确性是生命线。播客广告多为口播,如何通过声纹识别、自然语言处理等技术精准抓取广告主、估算花费(而非依赖粗糙的CPM模型),并解决无优惠码时的归因问题,是技术护城河所在。评论者已抛出“信任”挑战,若数据失准或更新滞后(尤其是开放库存是否真的“实时”),工具将沦为噱头。
其次,用户体验的悖论。产品化努力值得肯定,但用户反馈中“按主题导航”的需求,暴露了工具思维与购买思维的错位。营销人员先想“我的目标受众听什么”,而非“哪个行业广告多”。若缺乏基于听众画像、内容语境或AI的智能推荐,仅靠标签库搜索,其“可探索性”将大打折扣,最终仍会退回“用vibe做决策”。
再者,商业模式存疑。免费+市场交易抽成是典型策略,但能否吸引并留住头部播主提供独家库存?中小播主库存价值有限,而头部播主本就拥有品牌直客。若库存质量不高,市场一端便会萎缩,破坏其宣称的闭环优势。
总体而言,SpotsNow是“足够好”的第一步,但远非终点。它优先解决了“看到”的问题,但在“看懂”和“选对”上仍有巨大鸿沟。下一步的重点不应仅是类别分类,而是建立品牌与播客之间更智能的“信号匹配”机制。若不能提供超越简单爬虫的深度洞察,它很容易被更厚的资金或更全的生态(如Spotify的广告平台)所降维打击。
一句话介绍:Pitch Agent是一款内置于Pitch演示工具中的AI助手,能从用户的真实模板、设计语言和图像风格出发,在数秒内生成符合品牌调性的幻灯片,并通过对话式交互进行精修,解决团队协同制作演示文稿时品牌一致性差、后期修改耗时等痛点。
Design Tools
SaaS
Artificial Intelligence
AI演示文稿生成
品牌一致性
团队协作
幻灯片模板
对话式精修
企业级PPT工具
Pitch集成
设计语言复用
模板驱动AI
产品发布
用户评论摘要:用户普遍认为Pitch Agent解决了AI生成PPT“仅换肤”的痛点,品牌一致性是关键。常见问题包括:如何应对模板信息不足、如何保证多人协作时的品牌统一、能否支持数据幻灯片与叙事幻灯片的混排、以及是否支持从网站或Logo推断品牌风格。
AI 锐评
Pitch Agent的定位很聪明,它没有盲目跟风做“从零生成”的AI幻灯片工具,而是死磕“品牌一致性”这个真痛点。市面上绝大多数AI演示工具所谓的“On Brand”,只是给通用模板换层皮,这对需要交付数十甚至上百份高质量演示稿的团队而言,根本是杯水车薪。Pitch Agent真正的价值在于,它是一个“生于模板、长于系统”的AI Agent。它读取的是你团队已有的设计语言、布局模式和图像选择,而非一张孤立的色卡。这种对“上下文”的深度理解,是其与竞品拉开差距的核心。
然而,这款产品的局限性也在于其对Pitch生态的强依赖。它并非一个独立的AI工具,而是Pitch工作区内的一个功能。这意味着,其成败与Pitch平台的用户基础和普及度深度绑定。此外,用户评论中暴露出的几个关键问题——数据幻灯片与叙事幻灯片的混排、多人协作时的品牌锁定——都只是Pitch团队口头承诺的“未来更新”,目前看来解决方案还停留在“用户用提示词描述”的初级阶段。更值得关注的是,一位金融领域用户的需求(将AI生成的数字直接溯源至财务模型)没有得到实质性回应,这暴露了其在数据引用和可信度方面的短板。总的来说,Pitch Agent是一个定位精准的“进阶版”AI演示工具,它很讨巧地解决了“最后10%”的品牌问题。但能否成为团队的标配,取决于Pitch能否快速补足数据协作和跨平台集成的短板,而不是仅仅停留在“生成—聊天—导出”的闭环里自嗨。
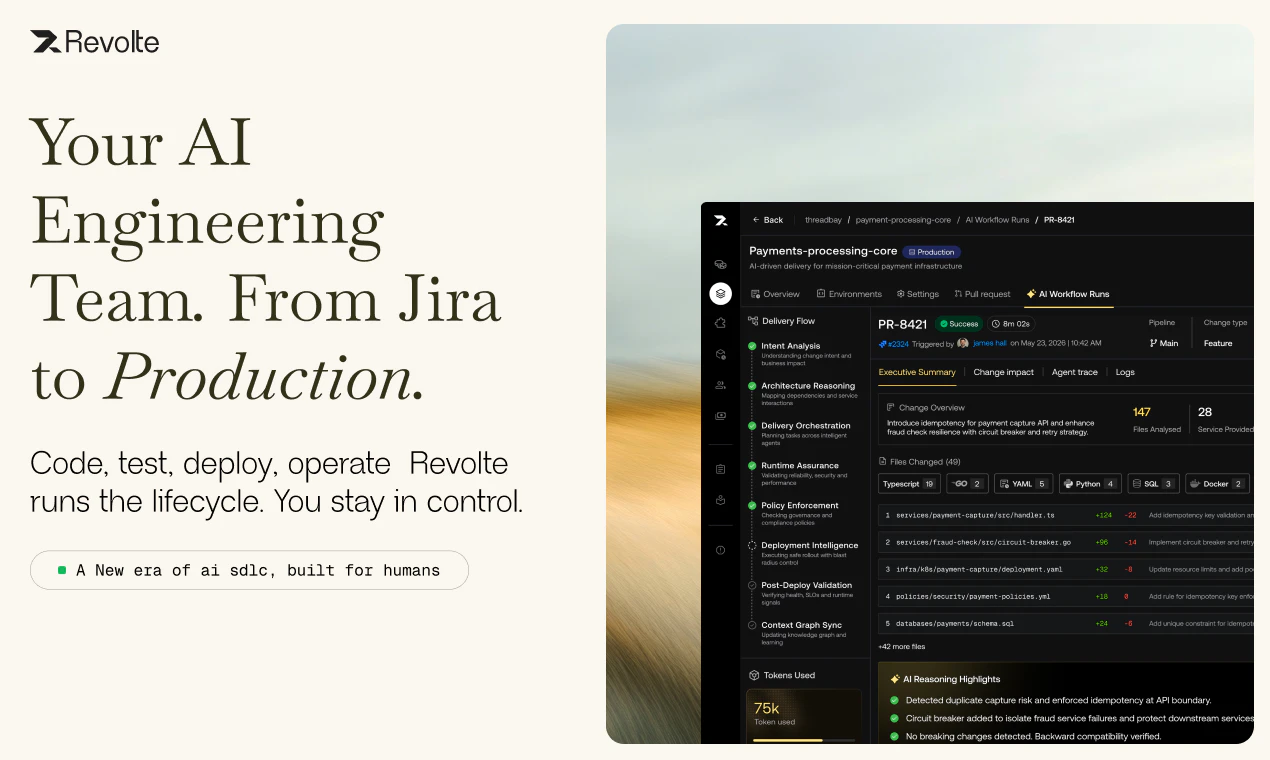
一句话介绍:Revolte 是面向工程团队的智能体平台,通过规划、编码、质检、部署及监控的自动化流水线,解决软件交付过程中“编码之外”的协作与操作瓶颈,让人类工程师控制关键决策点。
Software Engineering
Developer Tools
Artificial Intelligence
AI软件工程
智能体平台
代码审查
自动化交付
安全合规
研发效能
开发运维
工程治理
SDLC
人机协作
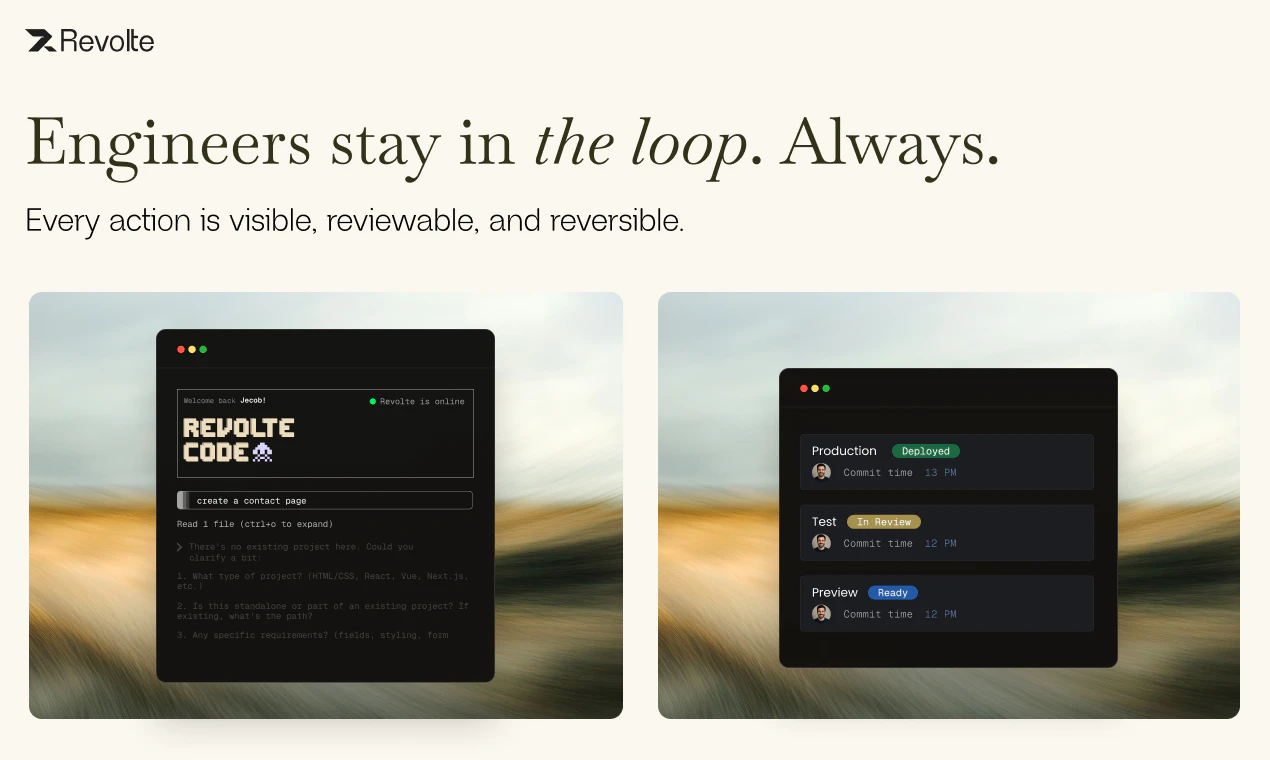
用户评论摘要:用户赞赏其将信任机制作为基座的理念,质疑点集中在:1)在老旧/混乱代码库中的实际表现;2)审批环节是否会形成新的瓶颈;3)对严格合规行业的数据与策略保障;4)如何跨大规模多仓库管理上下文;5)任务执行的端到端准确率。
AI 锐评
Revolte 试图回答一个行业级难题:如何让AI不只是“写得更快”,而是“交付得更可靠”。它的核心价值不在于抛弃Cursor的IDE助手路线,而在于对“软件交付全生命周期”这一更宽、更深的场景进行系统化重构。
从产品设计看,它确实避开了两个极端:既不搞全盲自助式自动驾驶,也不做需要工程师全程盯屏的“AI辅助”。通过将SDLC拆解为规划、编码、测试、PR、部署等标准化Agent行为块,并在关键变更处设置由工程判断把关的“人机护栏”,它试图将AI的生产力注入到最痛的“编码到上线”的灰色地带。
真正的挑战在于“治理的可兑现性”。评论中提到的“老旧代码库”、“多仓库上下文”、“合规审计”并非边缘问题,而是软件工程的常态。Revolte的“Service/App”上下文模型和YAML化的策略定义虽然构思清晰,但将组织沉淀多年的、隐性的交付规则显性化为系统可执行的规范,本身就是一项高门槛的工程实施。如果规则映射不到位,所谓的“自治”就会在真实压力下退化为“带审批的手动补丁”。
另外,其“按服务定价”而非按人头收费,是对传统AI工具定价逻辑的一次锐利解构。这暗示产品的价值锚点在于平台替代了人力交付链路中的“管道”,而非为每个工程师的IDE订阅付费。
一句话:Revolte的骨架搭建得相当专业,但能否在乱麻般的工程现实里长出肌肉,取决于它的“上下文摄入”和“策略落地”能力,是否真的像PPT上那样干净。
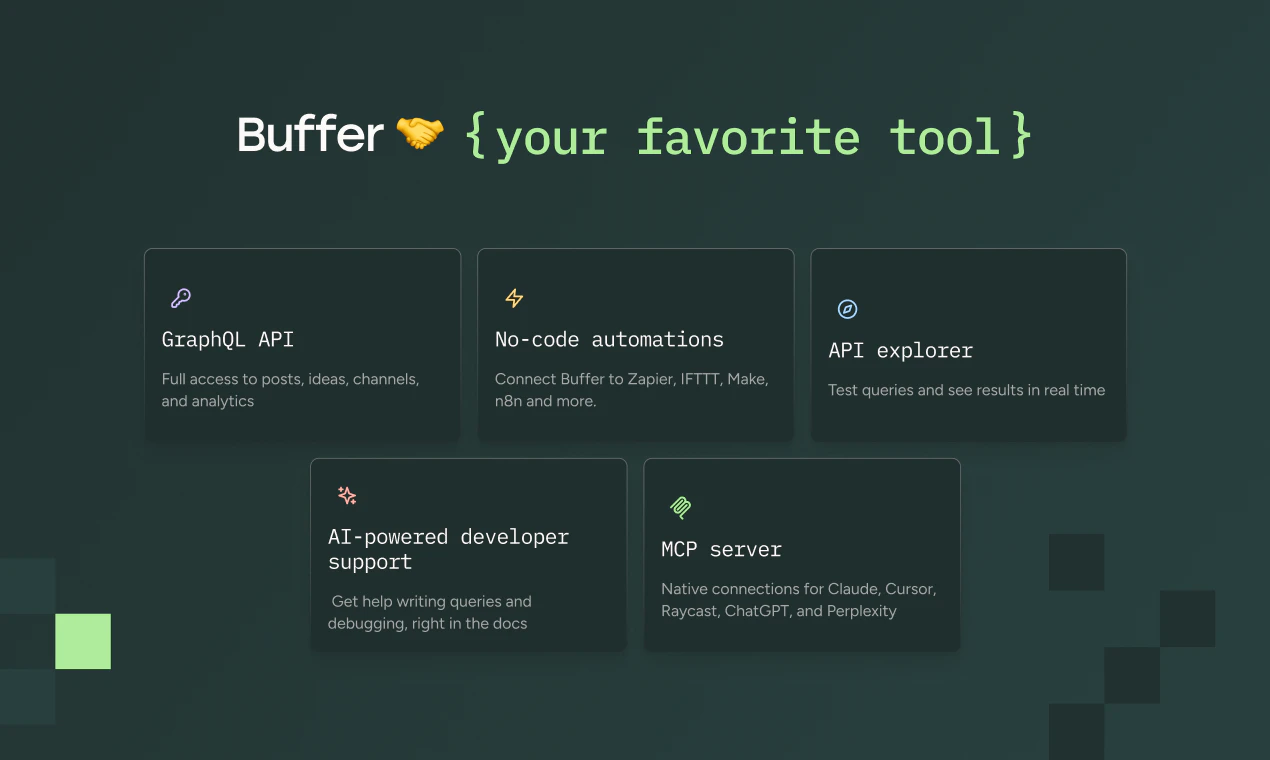
一句话介绍:Buffer API通过一个统一端点对接11个社交平台,解决开发者、AI代理及自动化工具在多平台内容发布与管理时面临的接口碎片化、认证复杂和格式适配难题。
API
Social Media
Artificial Intelligence
社交发布API
多平台聚合
GraphQL接口
MCP服务器
AI集成
内容管理
无代码自动化
开发者工具
SaaS
内容调度
用户评论摘要:用户赞赏其统一数据模型和MCP服务器,有效缓解多平台格式差异痛点。问题聚焦于平台规则突变时的适应机制、API发布对账号健康的影响,以及对白标/ISV定价的询问。
AI 锐评
Buffer API 的发布,与其说是一个新功能,不如说是一次战略宣言:它正式将自身从“社交管理SaaS工具”升级为“社交基础设施即服务”。从产品角度看,它回答了一个长期悬而未决的问题——能否用一个接口处理Twitter、LinkedIn、TikTok等平台的“人格分裂”?答案是用GraphQL统一数据模型在上层做抽象,用MCP服务器在下层做协议解耦。这种“中间件”思路非常务实,也直接切中了AI Agent和自动化工作流(如n8n、Zapier)的刚性需求。正如用户提到的,“post everywhere”在多平台场景下极易因边缘规则(如媒体格式、速率限制、帖子类型差异)而崩溃。Buffer API通过单一速率限制模型和结构化错误响应,把本应耗时的脏活揽了过来,这对其核心用户(agent开发者、无代码构建者)极具价值。
然而,这种“归一化”的弱点在于平台规则的不可预测性。LinkedIn或X的一次突发格式变更,会让中间的适配层瞬间产生逻辑裂痕。此外,用户对“API发帖影响账号健康”的担忧并非空穴来风,平台对自动化内容的隐性降权策略,Buffer的API层无力也无法承诺解决。最尖锐的拷问来自定价:当ISV希望将社交功能嵌入自身产品时,标准的套餐框架极可能构成成本瓶颈——这是一个非自营基础设施服务商在向“平台化”演化时必须面对的宿命。总体来说,Buffer API在产品打磨上极佳,但商业模式的挑战与平台对抗的风险,是其长期价值的真正试金石。
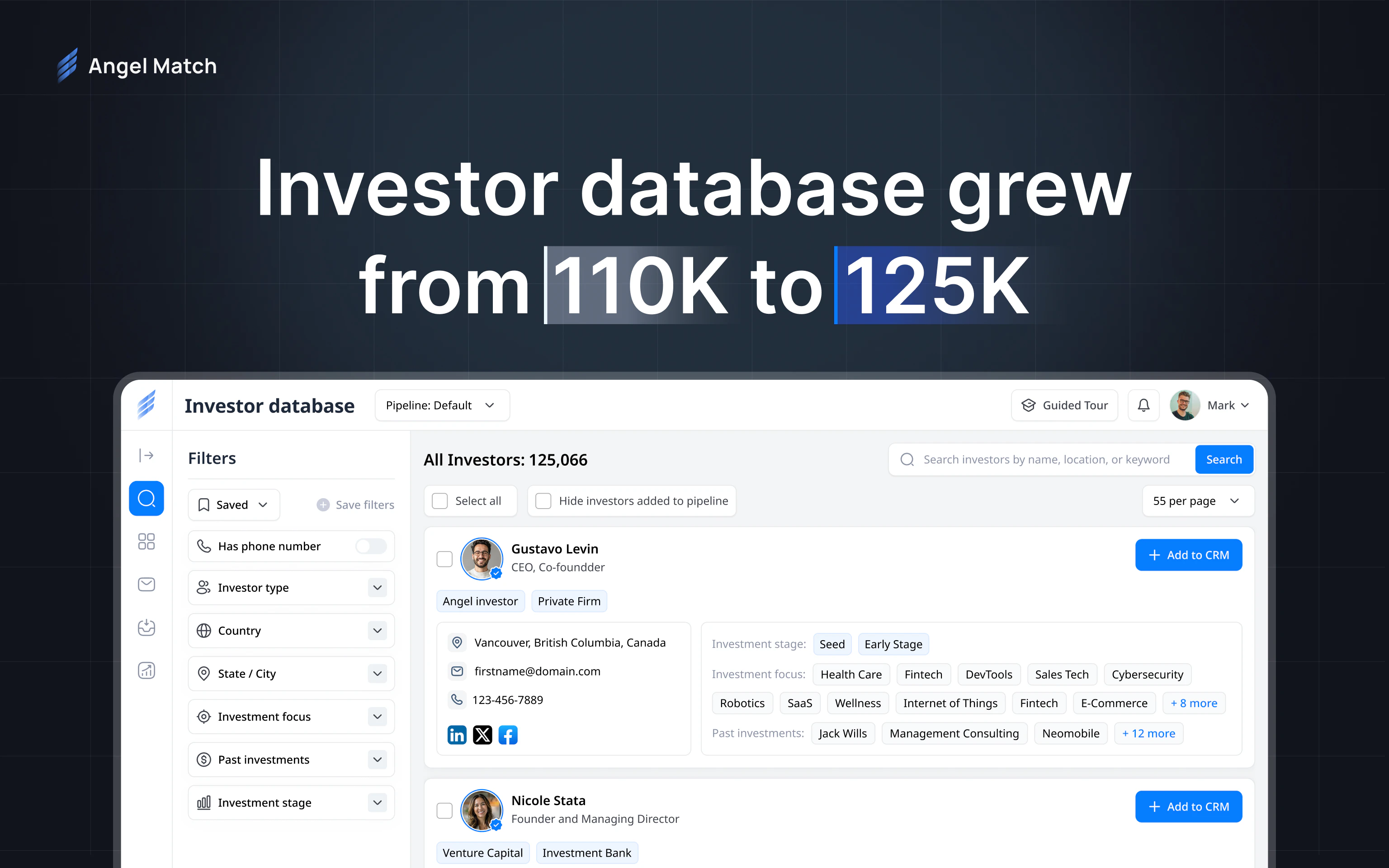
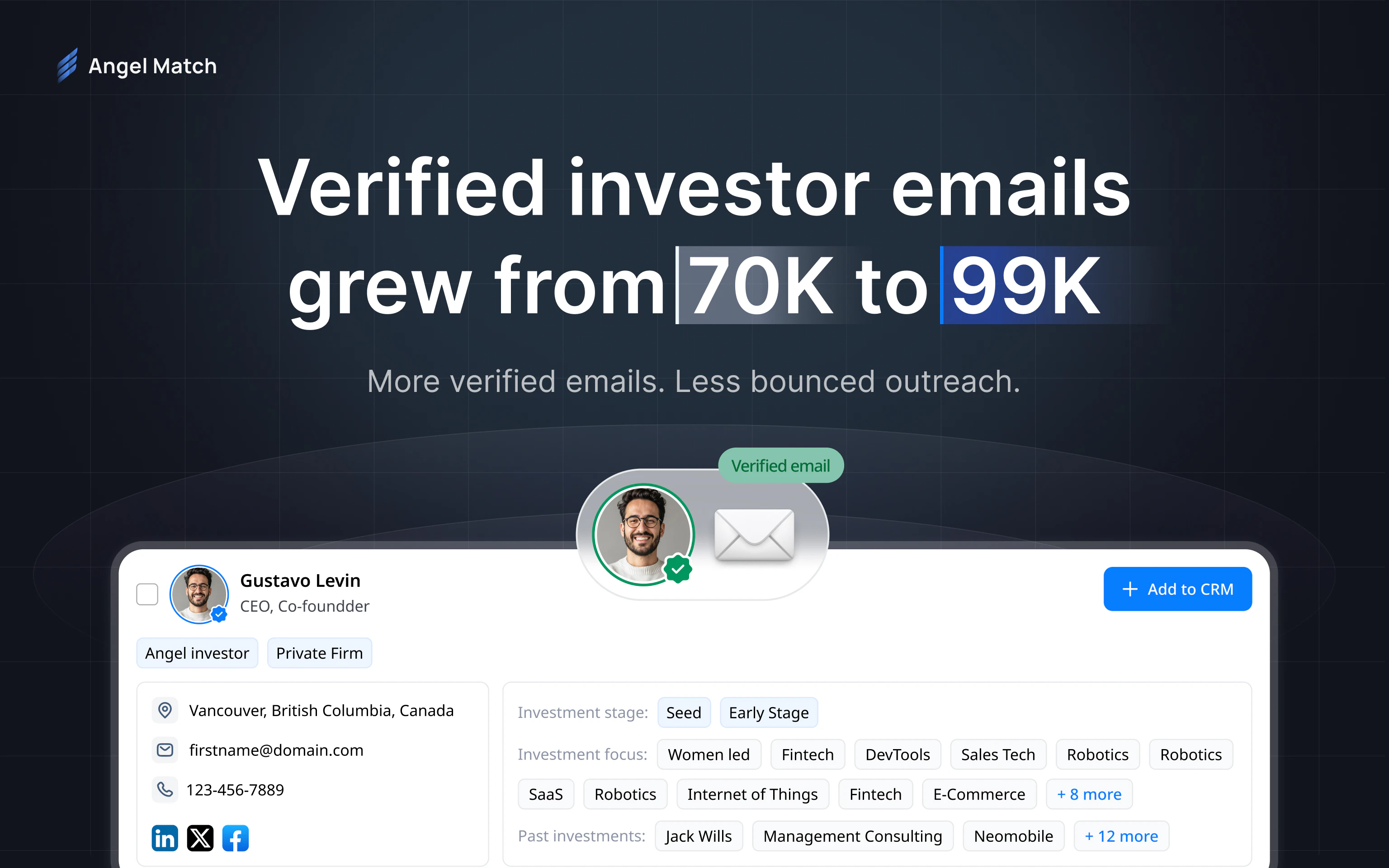
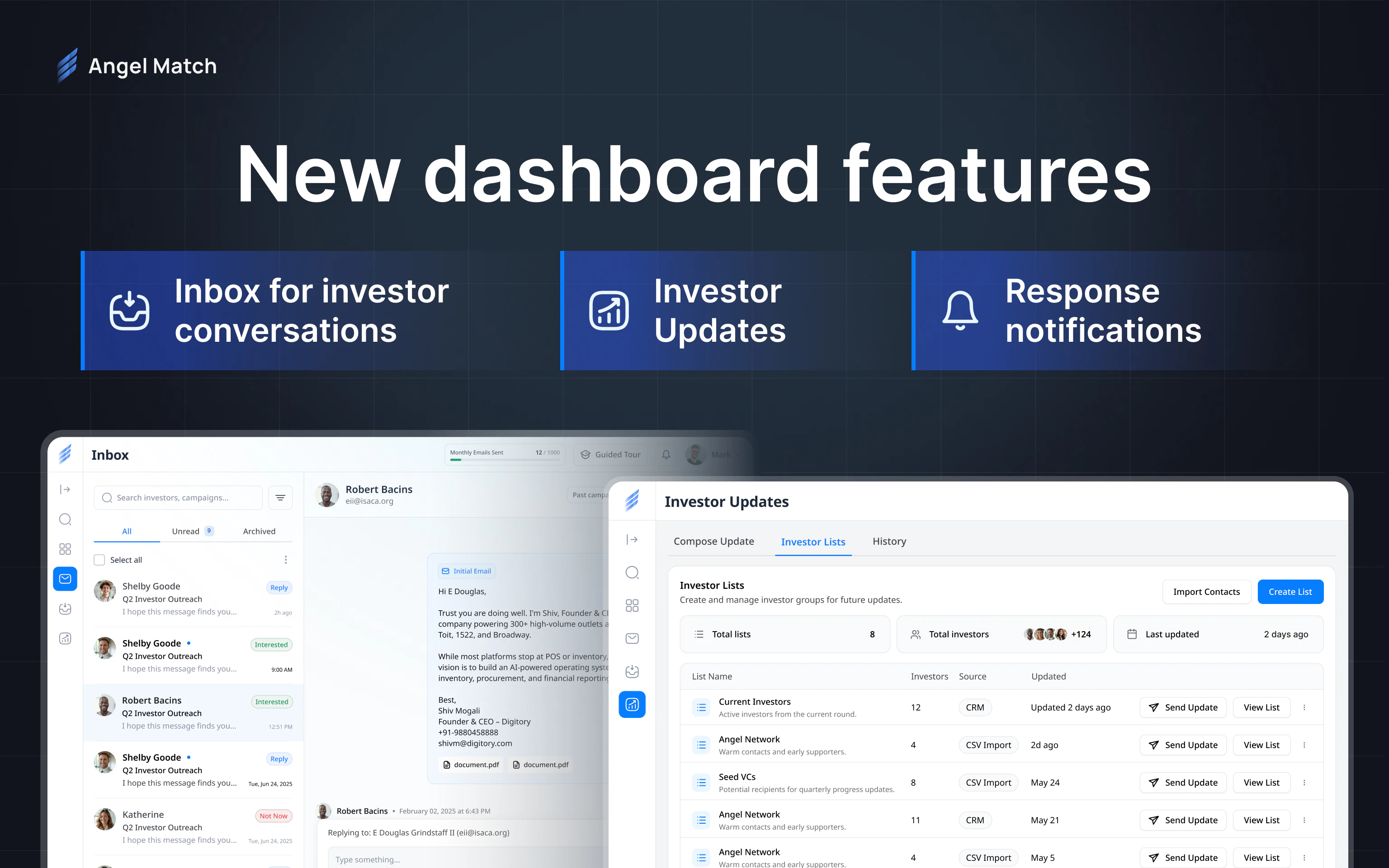
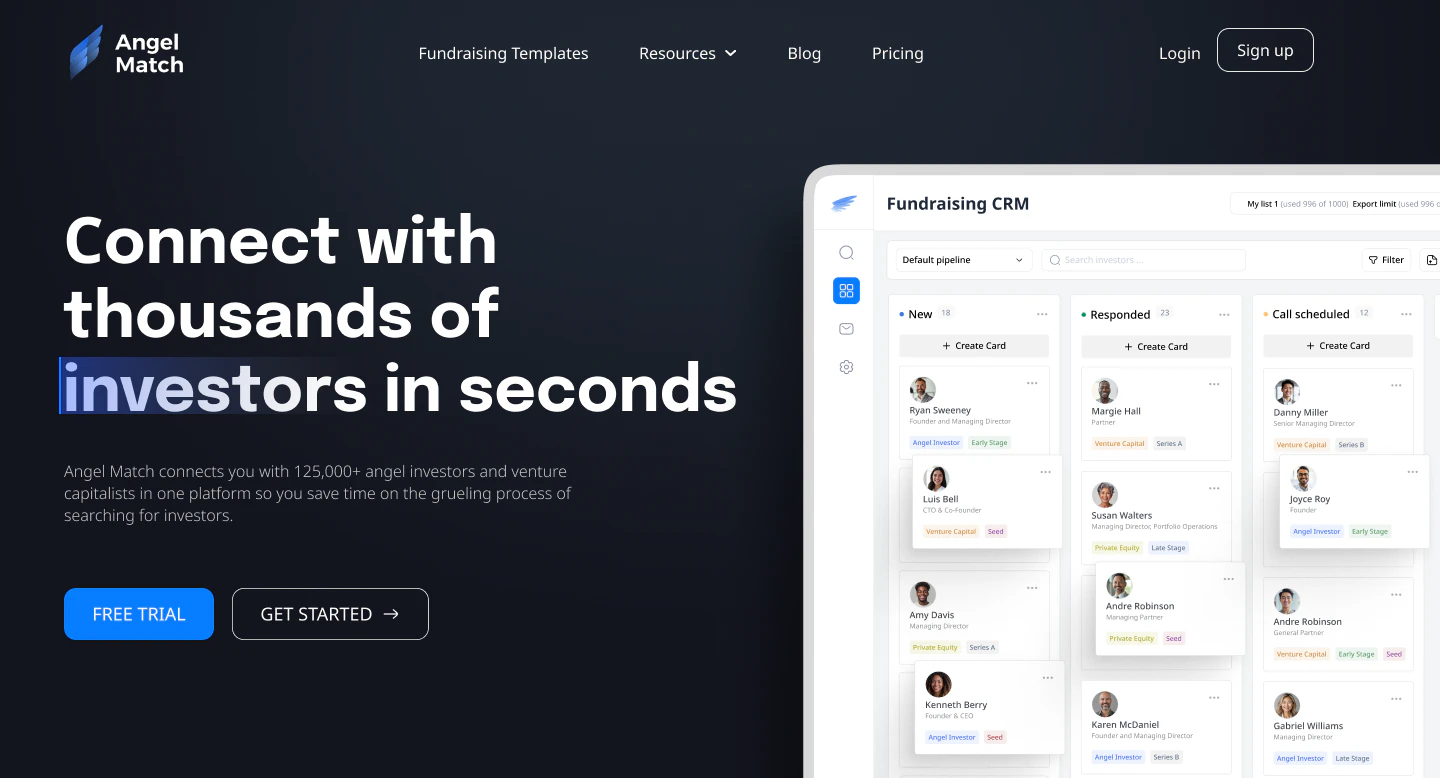
一句话介绍:Angel Match 4.0是一个整合了超12.5万天使投资人与VC的数据库平台,帮助创业者在种子轮融资阶段,通过精准筛选和自动化邮件营销,大幅节省寻找投资者和发送冷邮件的时间。
Productivity
Venture Capital
Fundraising
投资者数据库
种子轮融资
天使投资人
风险投资
融资工具
邮件营销
冷启动
创业服务
B2B SaaS
人脉对接
用户评论摘要:用户主要关注数据库信息的验证与活跃度(如回复率、开放率),以及地域覆盖(除美国外是否支持欧洲、亚洲等)。同时有用户在询问特定领域(如旅游+AI)的交叉筛选能力。
AI 锐评
Angel Match 4.0本质上是一个“融资效率工具”,其核心价值并非人脉拓展,而是用数据替代了初创团队在搜索和冷邮件阶段最耗时的体力劳动。从产品迭代来看,团队显然意识到了“数据质量”和“触达效率”的双重关键:将数据库规模从11万扩充至12.5万,并将验证邮箱数提升至近10万,同时新增收件箱和跟进邮件流程,这是在试图打造一个从“发现”到“沟通”的闭环。
然而,这款产品的真正挑战不在于功能堆砌,而在于数据资产的时效性与深度。用户评论中关于“投资者活跃度”和“回复率”的追问,直接命中其护城河:如果数据库仅仅停留在静态的联系方式堆积,而非动态的“投资偏好、活跃阶段、近期动态”,那么它相较于AI驱动的智能关系图谱工具(如PitchBook或Affinity)仍存在代差。此外,产品目前仍以美国投资者为主(占比超50%),且未展示出对欧洲、东南亚等地投资者行为数据的深度深耕,对于全球化的早期创业公司而言,这可能会成为一个短板。
总的来说,Angel Match 4.0对第一次融资、缺乏人脉的创始人具有极高工具价值,属于“雪中送炭”而非“锦上添花”。但其长期竞争力取决于能否从“数据仓库”进化为“融资情报引擎”,并在回复率等真实效果指标上提供实证,否则容易陷入与其他Crunbase类工具的同质化竞争。
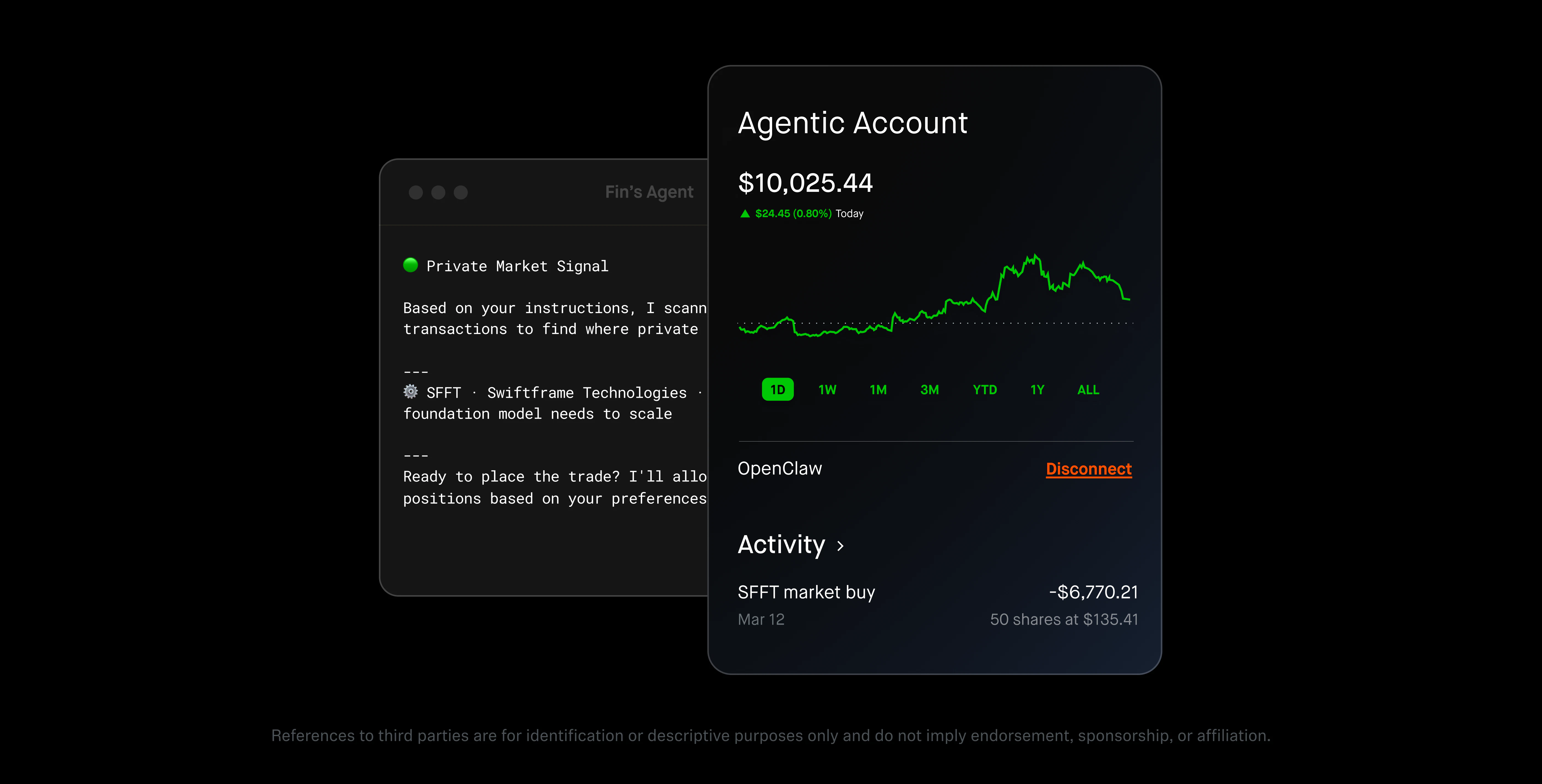
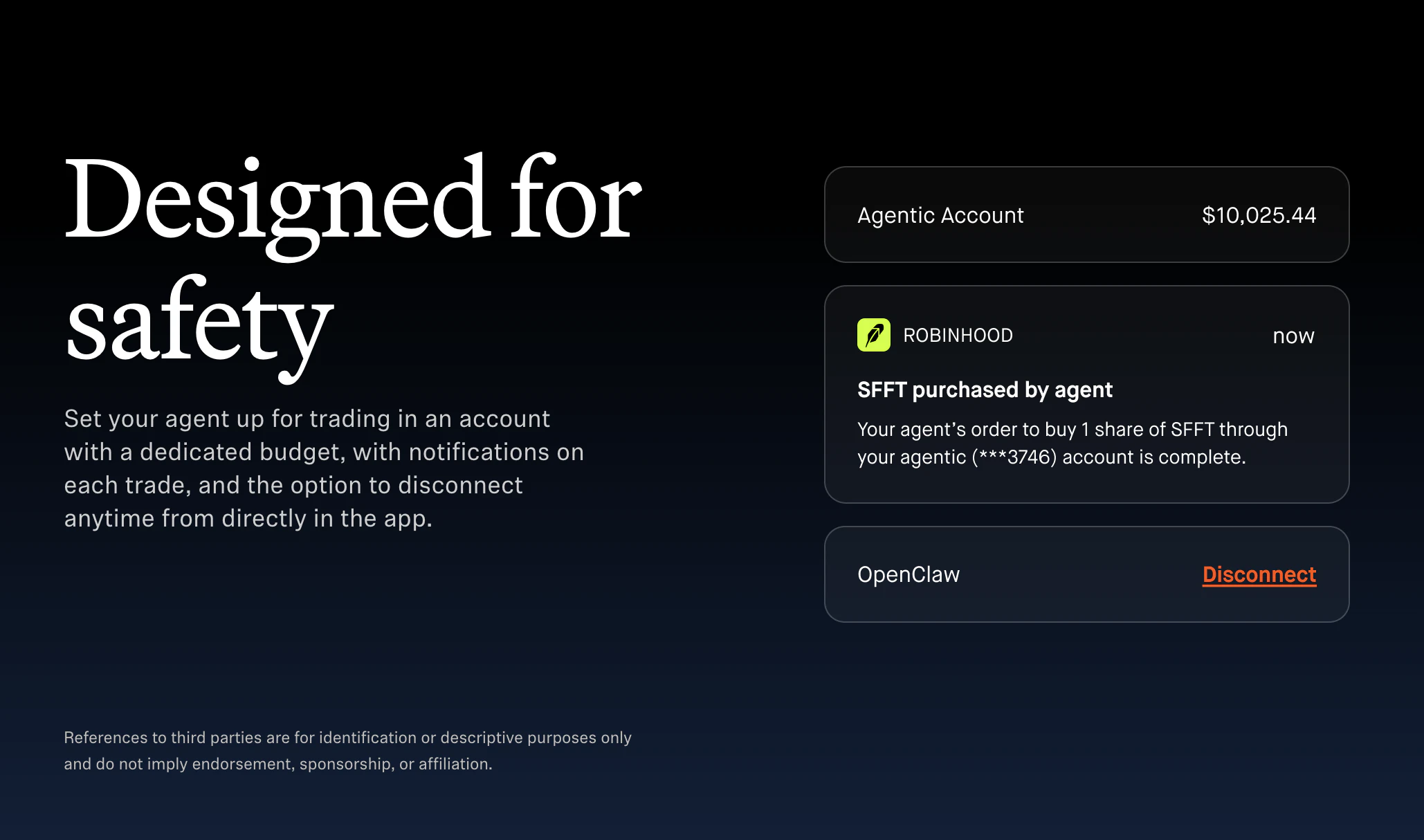
一句话介绍:Robinhood允许用户将自己的AI代理接入专属交易账户,在实时活动流与内置风控下,自动化执行股票交易和信用卡支付,从而解决手动盯盘与策略执行效率低下的痛点。
Fintech
Investing
Artificial Intelligence
AI代理交易
自动化投资
智能风控
券商API
主题投资
实时活动流
独立交易账户
零售交易工具
金融科技
Agentic Trading
用户评论摘要:用户肯定独立账户与实时活动流的设计,认为降低了风险敞口。核心问题包括:是否仅限美国、能否设置税务优化或交易单偏好?建议引入预测市场(如Polymarket)信号作为信念校准的护栏,并关注风控设置的颗粒度(如单笔限额)。
AI 锐评
Robinhood此次推出Agentic Trading,本质是在“让AI替你下单”这条危险赛道上,用账户隔离和活动流给用户递了一颗定心丸。150票的冷启动量说明市场既兴奋又狐疑。产品亮点在于“分离式账户+可审查的实时流”,这比直接开放API让AI进出主账户要诚实得多——至少给用户留了拔网线的时间。
但真正致命的问题在于:AI代理的“智能”从何而来?Robinhood目前只充当执行管道,用户仍需自己组装或训练代理逻辑。所谓“让代理按你信念交易”听起来很美,实际却需要用户具备策略编程能力,或依赖第三方草台班子式的AI封装。如果Robinhood不能像其竞品(如Trade Republic的AI投顾)那样提供内置的策略生成与校准层,这个产品很快就会沦为极客玩具和接盘侠温床。
另外,评论中提到的“用户信念与市场定价的校准”才是真正的价值洼地。如果Robinhood能整合宏观事件预测、波动率信号等作为代理的“反偏见护栏”(而非仅靠止损),那它就不只是下单工具,而是一台半自动的套利纪律器。但以Robinhood过往“先拉客再补洞”的尿性,大概率只会做最小可行性产品。总之,这个功能对懂API的量化尝鲜者是福音,对“说句话就躺赚”的散户则是新的韭菜收割机。
一句话介绍:Memori 为AI Agent提供基于执行轨迹(而非对话)的结构化持久记忆,解决多轮复杂任务中记忆丢失、上下文膨胀和决策不可追溯的痛点,大幅降低推理成本。
Open Source
Developer Tools
Artificial Intelligence
Agent记忆
持久记忆
执行轨迹
结构化知识图谱
推理成本优化
多轮交互
状态管理
AI基础设施
开发者工具
用户评论摘要:用户普遍认可其“基于轨迹而非对话”的记忆方向,认为抓住了Agent记忆的本质。主要疑问集中在:如何从工具调用噪声中提炼有用信息?如何处理矛盾记忆与记忆衰减?如何在大规模、深层嵌套的执行图中高效存储和检索?与手动维护的CLAUDE.md有何实质区别?
AI 锐评
Memori的定位精准,但真正的护城河不在“技术”,而在“叙事”。
首先,技术层面,“从执行轨迹而非对话创建记忆”并非独创性革命,而是对行业痛点的正确回应。当前多数Agent记忆方案本质是“聊天历史压缩器”,丢失了最关键的执行因果。Memori将工具调用、决策路径、结果状态等结构化为知识图谱,确实提供了更可靠的“状态层”。其81.95%的LoCoMo准确率和仅1.5%的上下文开销(1294tokens/查询)是极其亮眼的工程成果,直接击中了“长上下文 = 高成本 + 低性能”的行业死穴。
但问题在于,评论区多次出现对“矛盾记忆处理”、“大规模检索”和“噪声过滤”的追问,团队回答均偏向原则性描述(加权、衰减、多维度元数据),缺乏具体的冲突解决算法细节或压力测试数据。这表明产品在边缘场景的鲁棒性上仍有待验证。将“执行轨迹”全量入库是廉价方案,如何优雅地“遗忘”和“抽象”才是核心工程挑战。
其次,商业叙事层面,正如一位高赞评论者犀利指出,其标语“Persistent memory from agent trace, not just conversation”过于内观化。企业决策者不关心“如何生成”,只关心“什么结果”——更低的Token消耗、更少的人肉编写CLAUDE.md、更可审计的自动化流程。Memori的最大价值在于将隐性的“Agent决策意志”显式化、可版本化、可追溯,这直接击穿了金融、合规等高风险行业对“黑箱”Agent的不信任。
最后,真正值得警惕的是“AGI幻觉”——以为记忆是通往超级智能的钥匙。Memori解决的是“Agent不犯同样的低级错误”和“记住上次的配置规则”,而非“理解业务因果”。将一个优秀的“缓存系统”包装成“记忆基础设施”是市场策略,但开发者需明确:它更像一个结构化的、附带版本控制的高性能Redis,而非真正意义上的生物记忆。对于构建B端可解释Agent的团队,这是必需品;对于追求“能力涌现”的实验,它只是工具,不是解药。
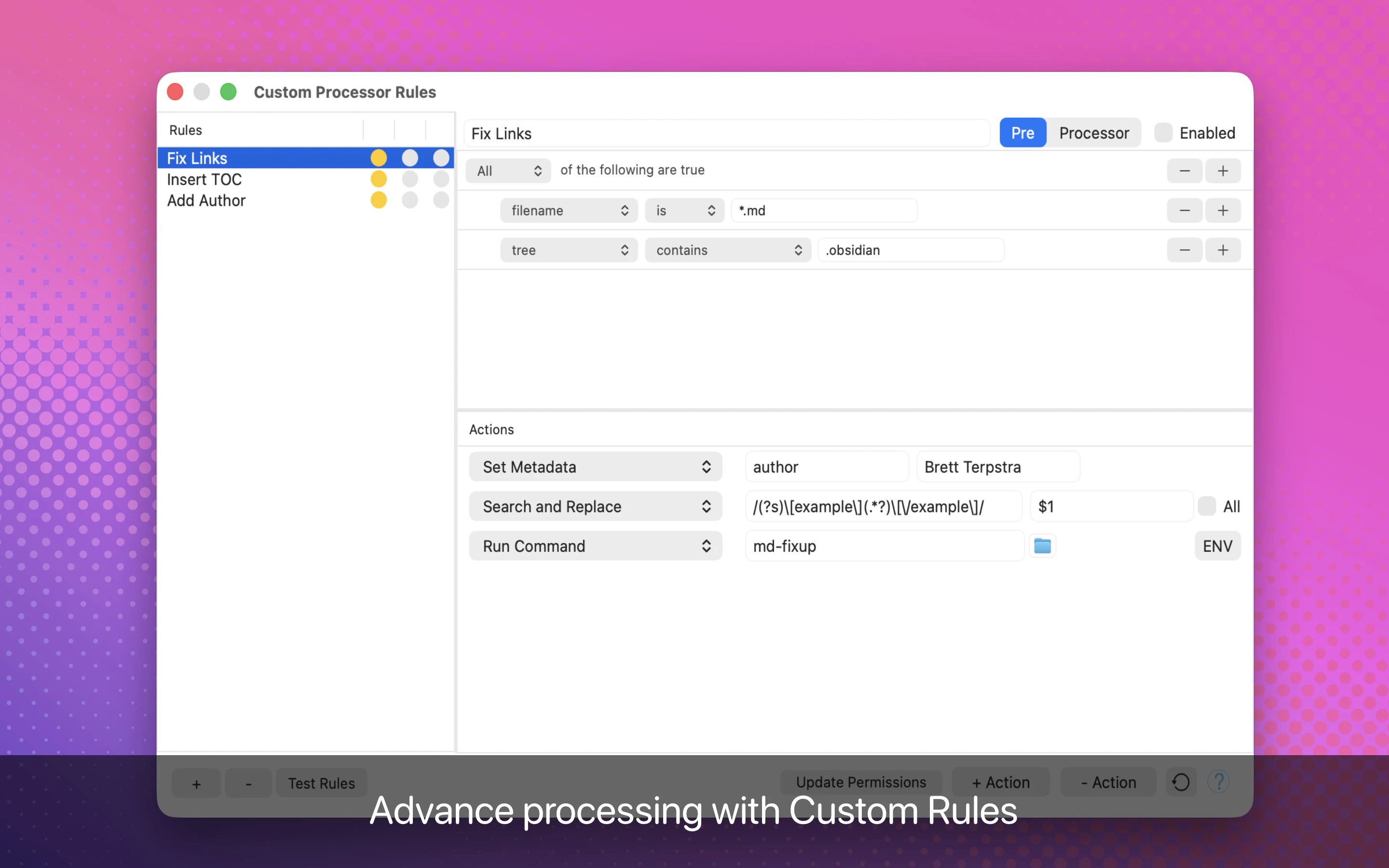
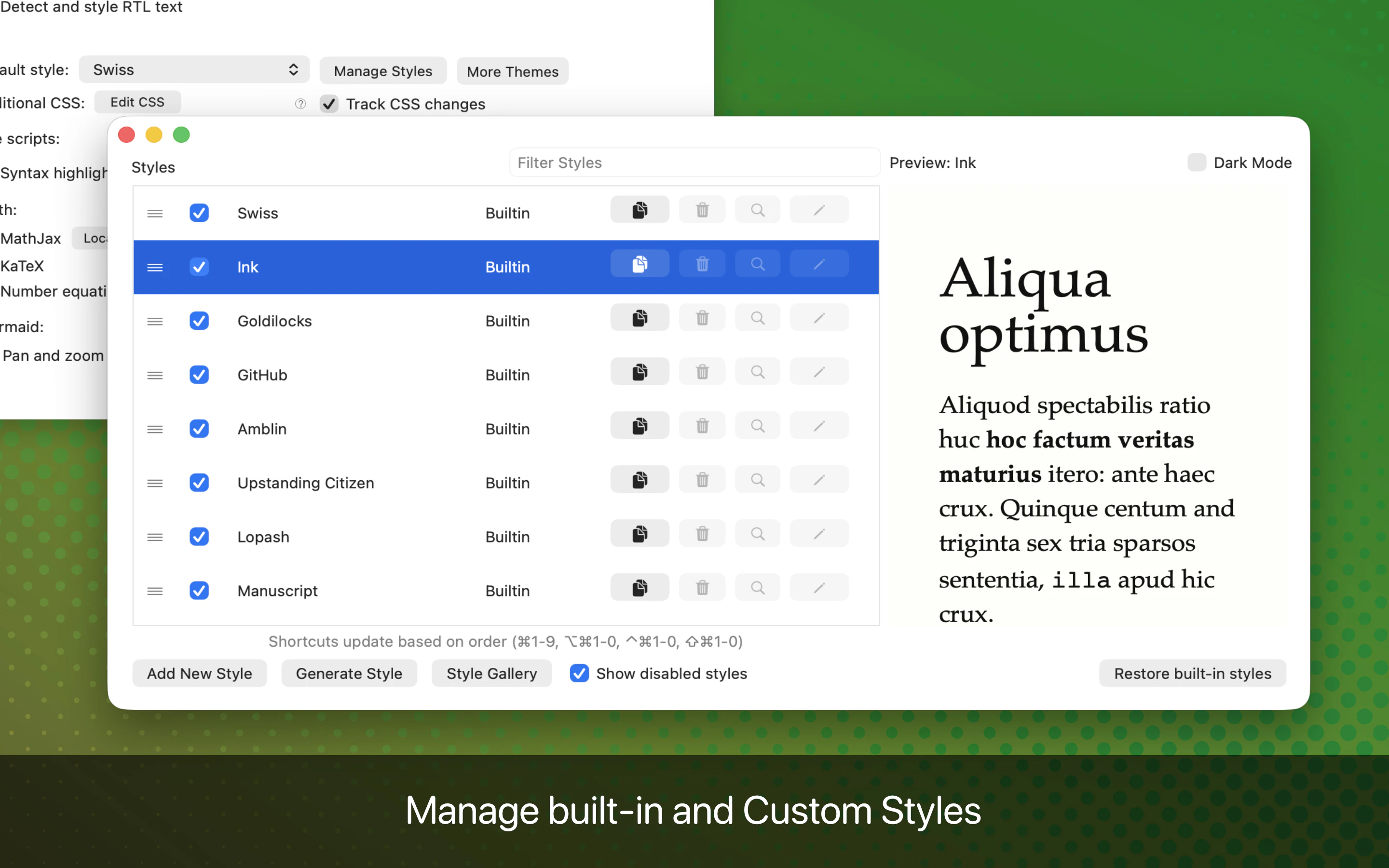
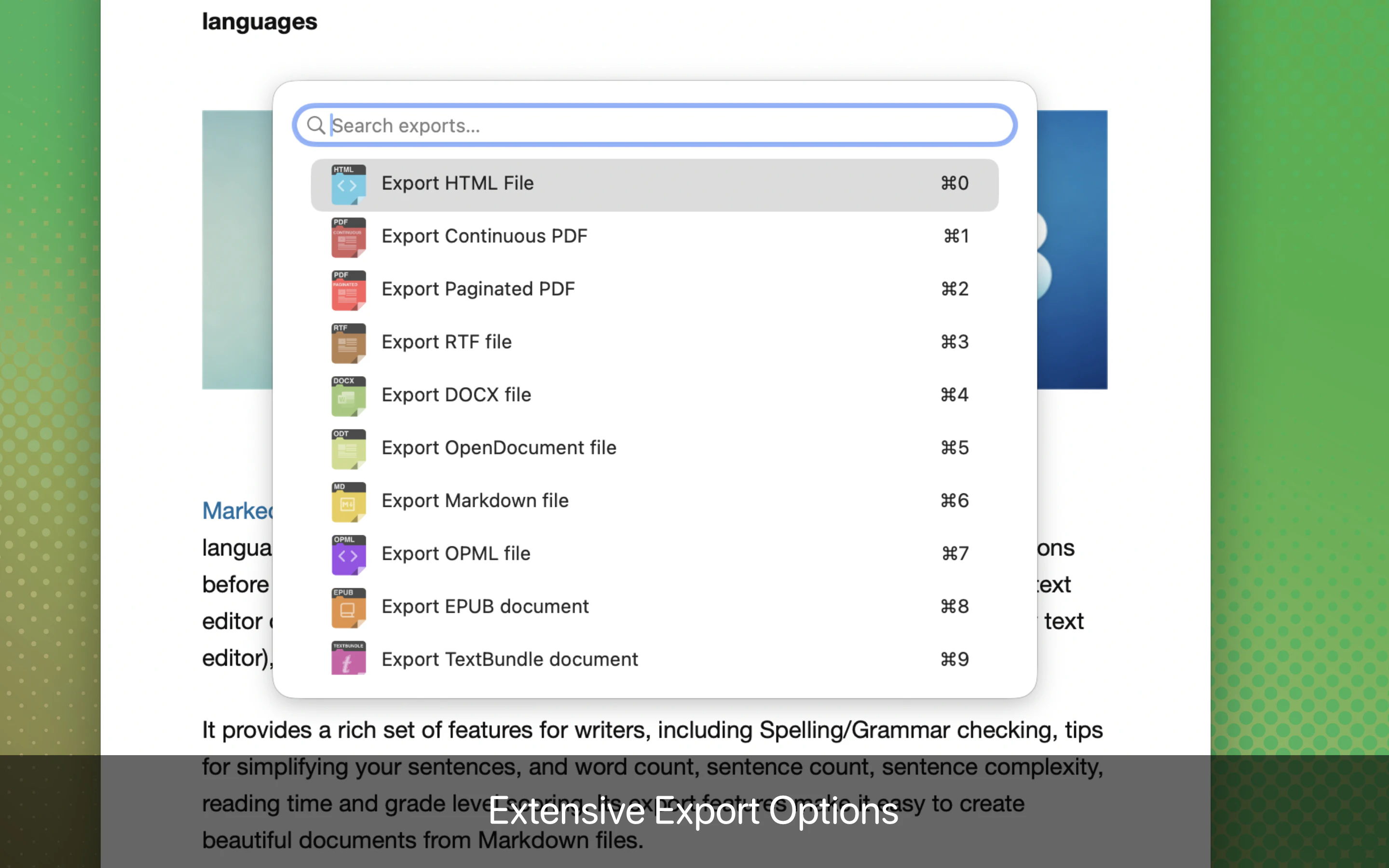
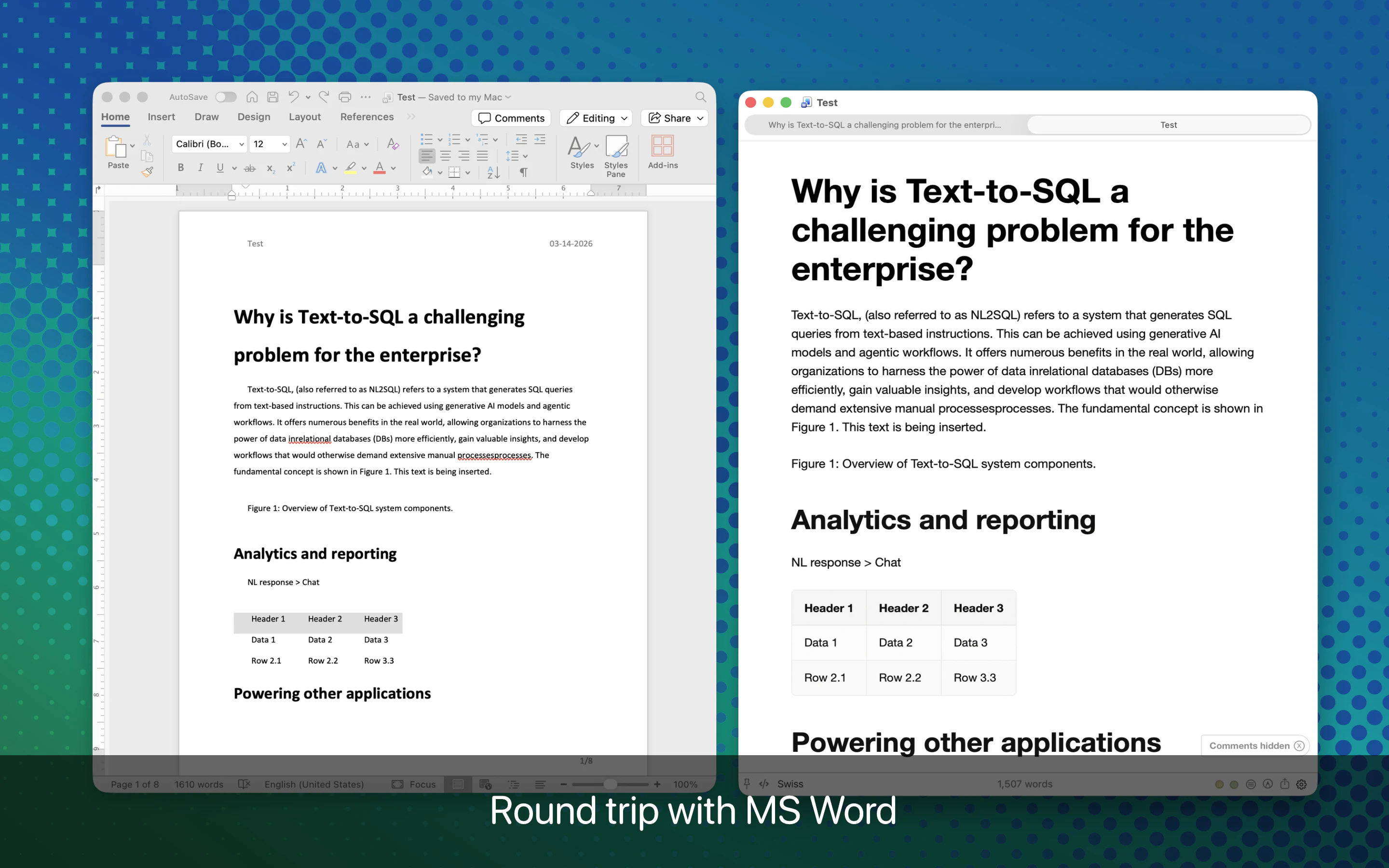
一句话介绍:Marked 3 是一款专为内容创作者设计的 Markdown 预览与发布工具,解决了在撰写、排版和导出文档时因格式转换繁琐、样式管理混乱而导致的效率低下问题。
Writing
Notes
Developer Tools
Markdown预览
文档转换
写作工具
内容创作
HTML导出
PDF生成
DOCX转换
EPUB制作
样式管理
格式分析
用户评论摘要:用户高度认可其专注预览而不沦为编辑器的克制设计。核心需求包括:支持跨文档的独立CSS主题记忆(已实现,通过书签与元数据持久化);DOCX集成显著简化了工作流;对于内容写作者而非开发者更为适用;部分用户关注价格合理性及促销码获取方式。
AI 锐评
Marked 3 的回归,本质上是一次对“生态位”的精准卡位。在 Notion、Obsidian 等全能编辑器攻城略地的当下,它选择将“预览与发布”这一单一环节做到极致,这种反潮流的克制恰恰是它最大的护城河。
从产品价值看,Marked 3 解决的不是“写”的问题,而是“写完后”的麻烦。它规避了绝大多数 Markdown 工具在导出 PDF/DOCX 时排版崩坏、样式不统一的痛点,通过自定义CSS主题、文档级样式记忆、以及智能化排版引擎,为长内容生产提供了工业级的输出一致性。这对于需要频繁将草稿交付给非技术同事或客户的内容创作者(如文案、编辑、咨询顾问)而言,是刚需级工具。
然而,“高端定位”也带来了隐忧。12年迭代后的高定价与订阅制,表明开发者试图将这款工具从“小工具”升级为“职业收入来源”。但面对免费或低成本的替代方案(如 MacDown、Typora)、以及编辑器内嵌的预览功能,Marked 3 的“交付价值”能否说服足够多的用户持续买单,仍存疑问。此外,其功能重心仍在 macOS 生态,若未来不拓展到 Web 或跨平台,天花板会非常明显。
总的来说,它是一款“匠气十足”的优秀工具,但对普通用户可能溢价过高,能否成为创作者工作流中的“必需耗材”,取决于市场到底有多痛恨格式问题。
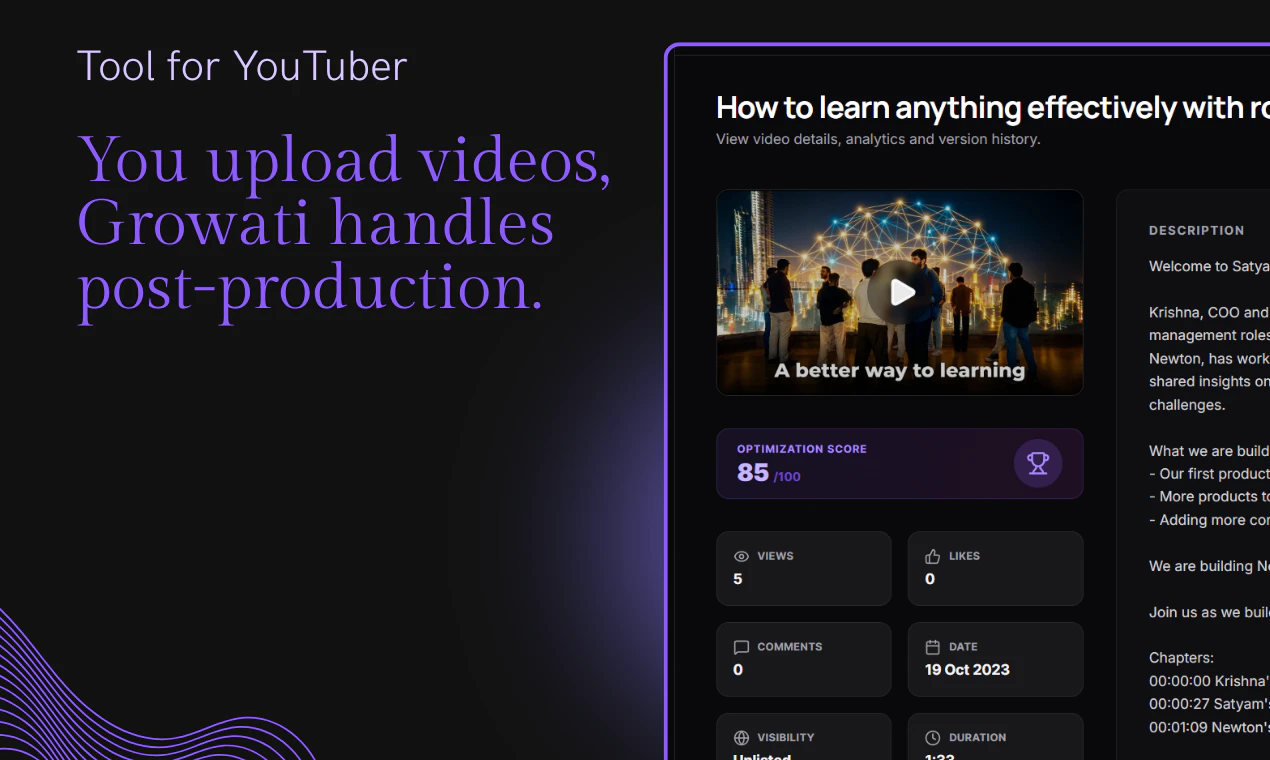
一句话介绍:Growati是一款为YouTube创作者打造的“后期自动化副驾驶”,能在几分钟内根据视频表现自动生成并优化个性化标题、描述和缩略图,解决创作者在内容包装和算法优化上的精力消耗问题。
Productivity
Artificial Intelligence
YouTube
YouTube创作工具
AI视频优化
缩略图生成
标题优化
内容自动化
创作者工具
后期制作
数据驱动优化
播客工具
教育创作者
用户评论摘要:用户普遍认可解决创作者“后期疲劳”的痛点,特别关注AI如何保持个人风格一致性、缩略图质量(被指“紫得过分”),以及是否基于历史爆款数据学习。也有提问优化是否按单个视频处理。
AI 锐评
Growati切中的是个真痛点,但也是个伪护城河。
说它真,是因为绝大多数创作工具只停留在“一键生成”,而真正折磨人的是反复试错、A/B测试、分析数据——这恰恰是Growati所强调的“性能驱动更新”要解决的事。它把后期从一次性动作变为闭环反馈流程,这是比单纯生成强得多的价值主张。
但问题在于,标题、缩略图、描述的自动化,几乎所有大平台(如Canva、Adobe、甚至YouTube自身)都在做,且更有版权和素材库优势。Growati目前唯一的差异化在于“根据视频表现来更新”,但这一功能是否能稳定、精准地反映算法偏好?还是只是基于低互动率做机械替换?这是它在技术上的命门。
用户评论中“紫色过多”的吐槽并非纯审美问题:这暴露了目前AI生成结果在视觉风格上仍存在“模板化”风险。创作者怕的不是AI,是AI让自己的频道失去辨识度。Growati如果只停留在“效率”层面,而没有建立起可持续的风格学习机制(比如通过学习该创作者历史爆款来生成风格一致的素材),那么它最终只会沦为又一个“快速起量、快速被弃”的工具。
另外,它专注“教育创作者和播客”,是聪明的切入点,因为这类人群内容是核心、样式偏稳,对AI的容错率高。但这也意味着Growati需要精准衡量它在垂直场景中的ROI——省掉的那几小时后期时间,是否真的能换来更高的播放量。如果能用数据证明这笔“时间投资回报率”,它才真正有机会从“工具”变成“增长伙伴”。否则,当前那122票,可能就只是创业者的情绪价值。
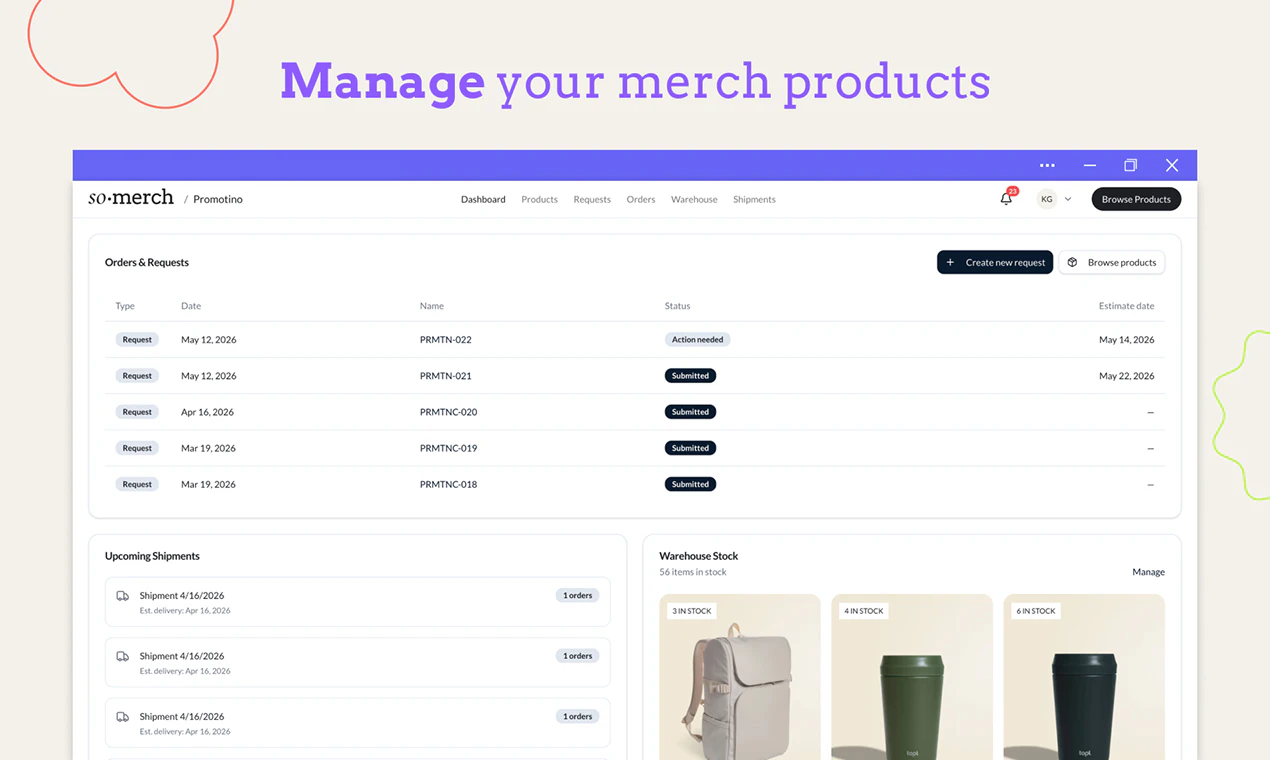
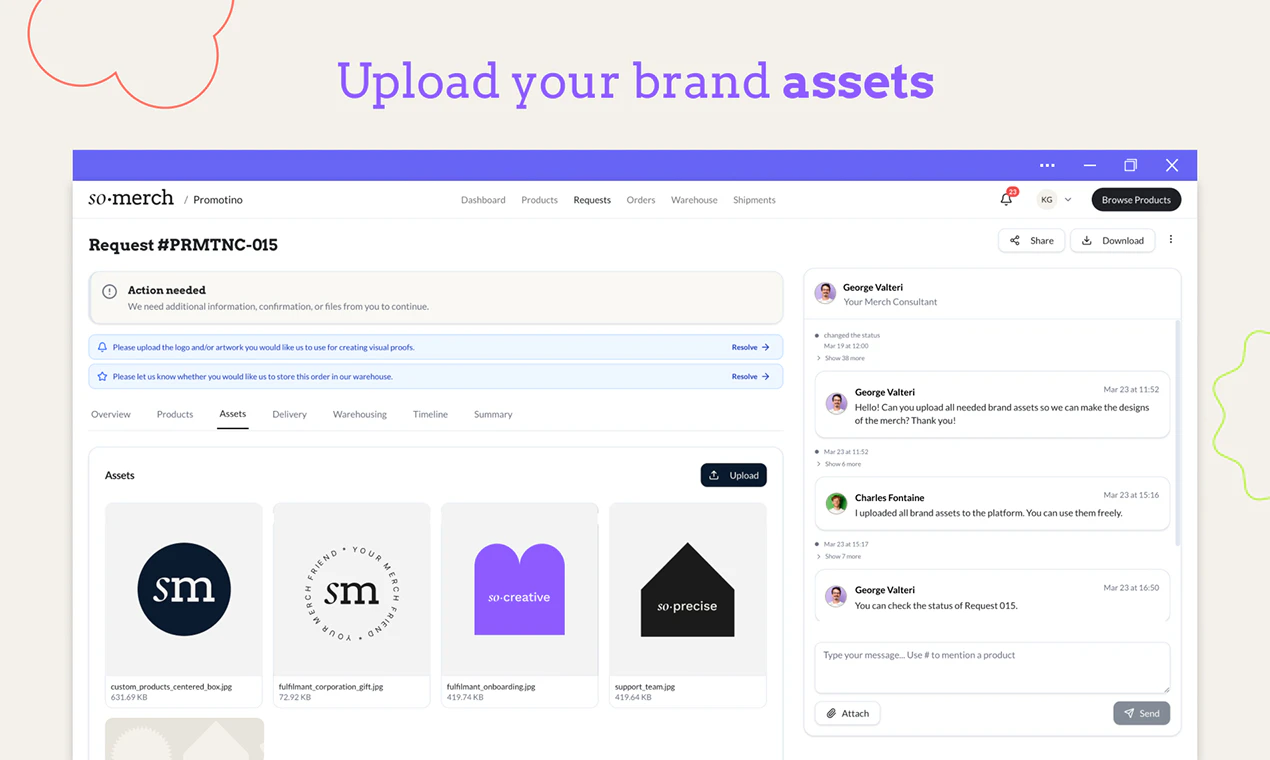
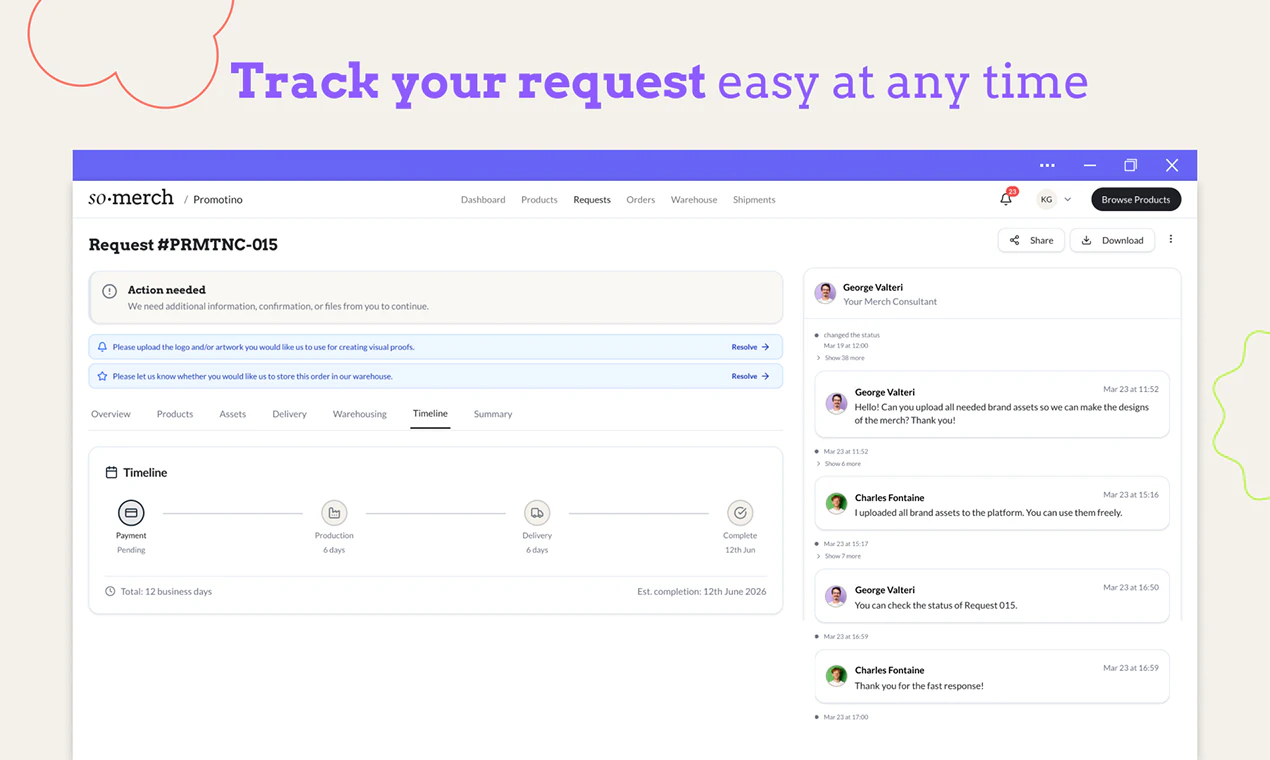
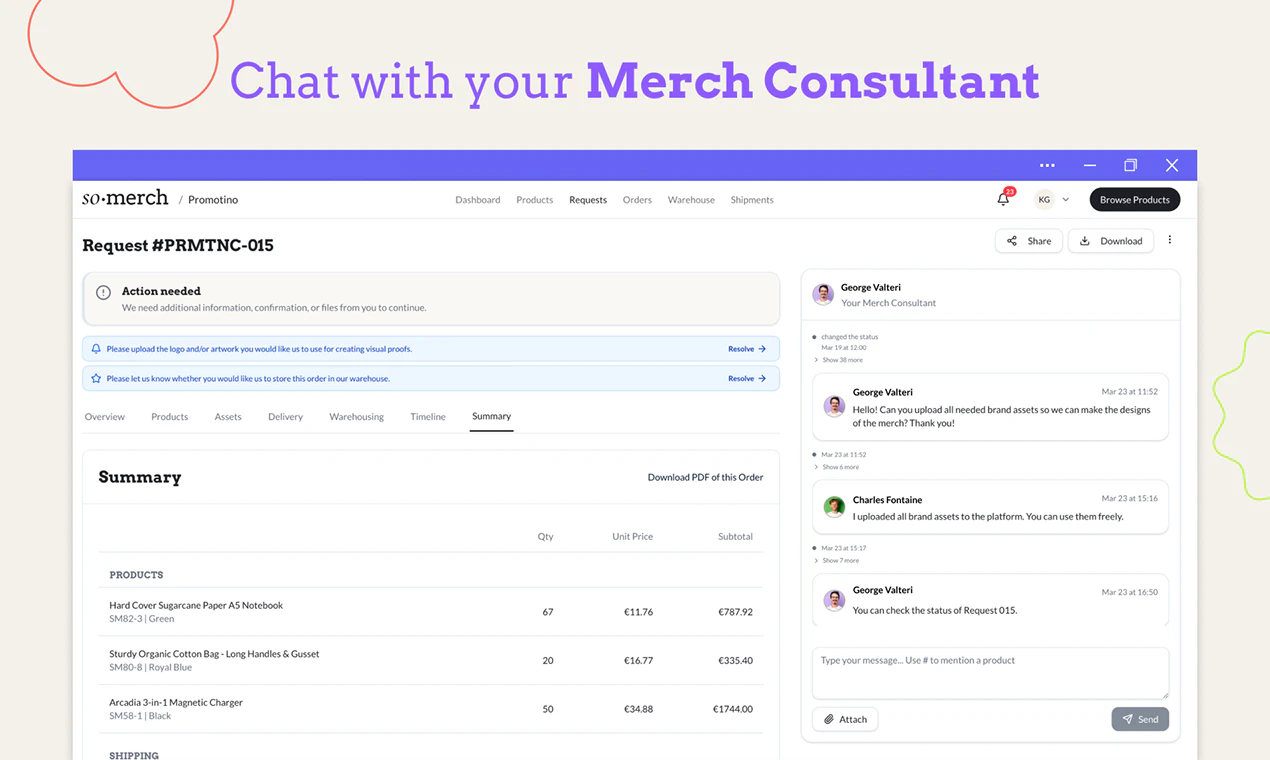
一句话介绍:SoMerch为分布式团队提供从设计、生产到多地址配送的一站式员工周边管理平台,解决跨国企业因多供应商、无历史记录、手动物流导致的混乱和重复劳动问题。
Marketing
Remote Work
Human Resources
员工周边管理
企业礼品
分布式团队
批量印刷
仓储物流
统一采购
远程入职礼包
欧洲多地址配送
B2B平台
品牌运营
用户评论摘要:用户反馈高度认同“周边管理混乱”的痛点(2点赞),指出HR常因此受累(2点赞),并询问对接流程、是否定制化、是否负责采购(2点赞),以及探索是否可按需生产、是否支持不同国家定制。创始人均一一回应,强调生产不外包、支持按需触发配送。
AI 锐评
SoMerch切中的是一个“看起来轻松做起来鸡飞狗跳”的刚需——分布式团队的企业周边采购。其核心价值并不在于印刷技术或产品设计有多酷,而在于它把“流程资产化”了。传统模式下,每次采购都是孤岛,知识藏在人的脑子里或混乱的邮件里;而SoMerch提供的实际是一个“企业周边操作的SaaS + 托管生产”复合型基础设施——平台留存了历史、审批链、供应商关系和客户偏好,解决了离职带走的隐性成本。
但必须指出,产品被宣称的“端到端”并没有那么不可替代。供应链整合在欧洲不算新故事,很多本地打印店也提供类似仓储配送,只不过没有数字前台。SoMerch真正的护城河不在于生产闭环,而在于能否形成企业内部的“默认路径”,即成为公司发放周边时的唯一入口,并由此积累数据和信任。此外,112票、评论互动多为基础反馈,尚未看到规模化企业客户的背书,对真正的“多国HR”而言,合规、税务、退货率等更棘手的问题仍存疑。
当下它更像一个“更好用的外包供应商”,而非颠覆者。除非它能从“帮HR下单”进化到“帮HR自动根据入职、节日、活动规则主动触发订单”,并打通员工喜好数据,才可能从工具跃升为体系。创业方向很对,但壁垒比想象中低,需要加速产品化形成绑定。
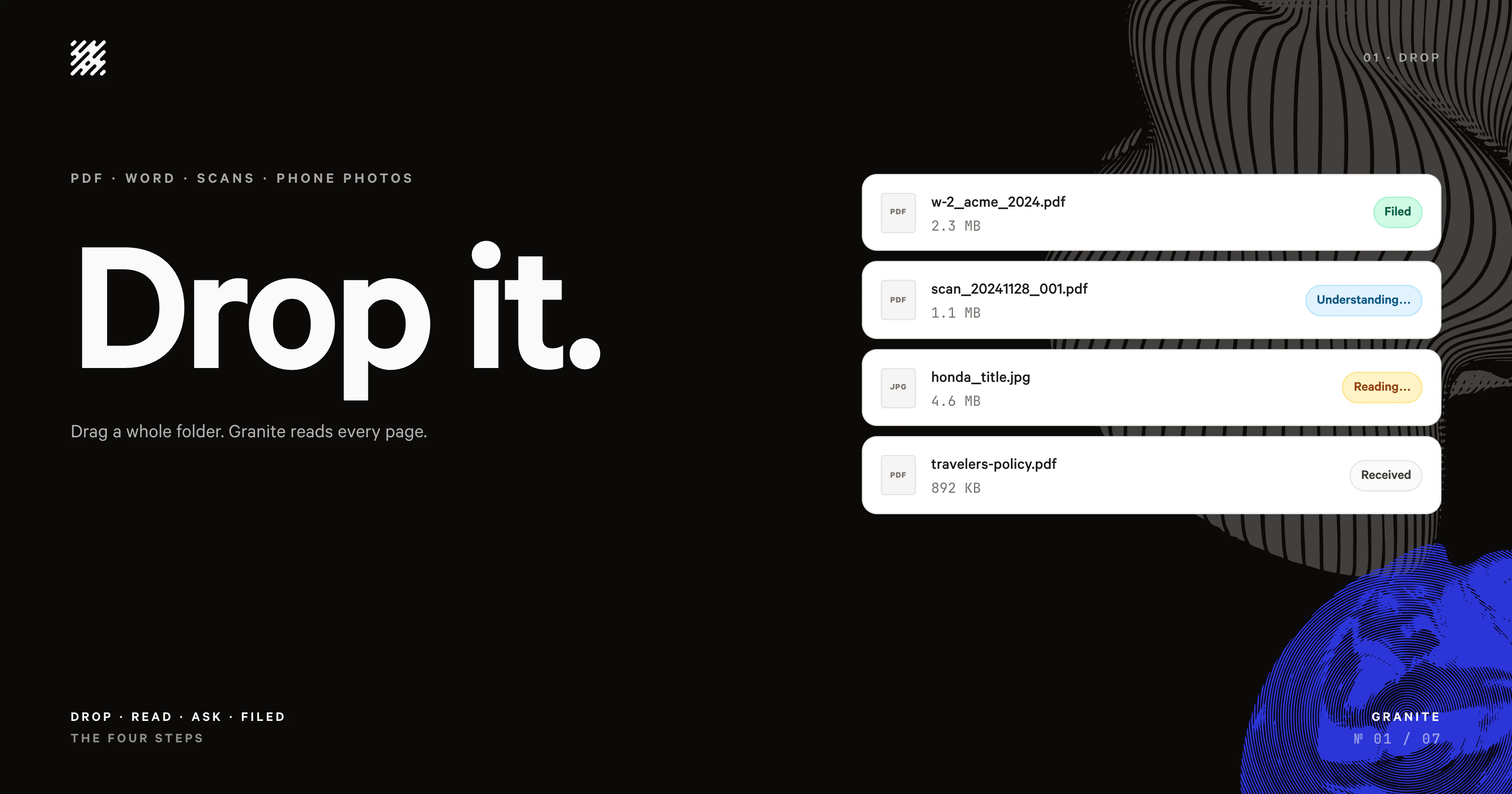
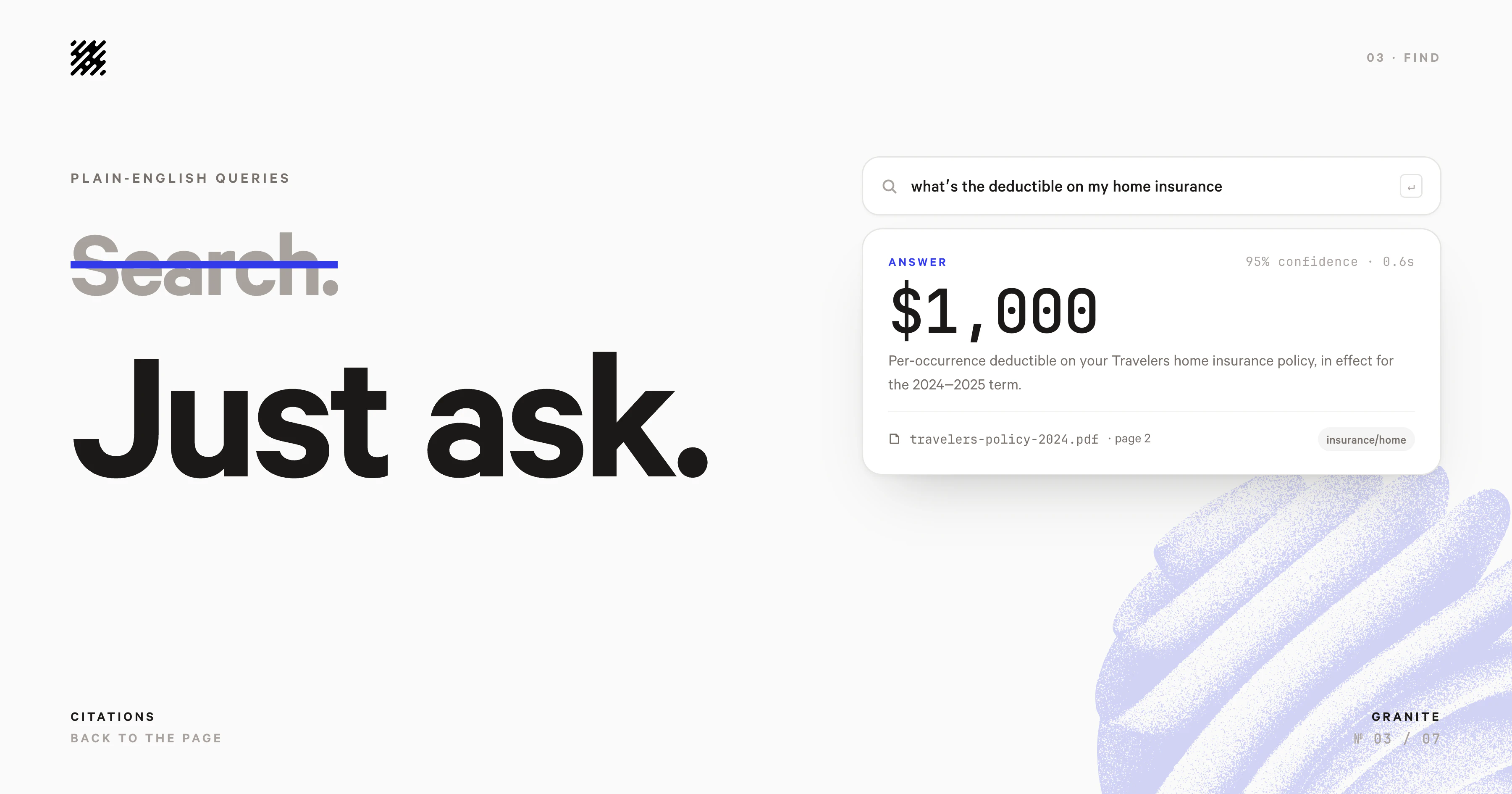
一句话介绍:Granite 是一个长期文档保险柜,用户上传法律、税务、医疗等关键文件后,系统自动读取、归档并永久记忆,通过自然语言搜索即可瞬间找回,解决“知道文件存在但找不到”的文档焦虑问题。
Productivity
SaaS
Artificial Intelligence
文档管理
文档保险柜
智能归档
自然语言搜索
长期存储
个人文件
税务文件
法律文件
无需整理
AI分类
用户评论摘要:用户肯定其“不组织、不贴标签、直接搜索”理念,直击文件焦虑痛点。核心疑问包括:模糊文档如何处理(自动还是手动纠错)?是否支持版本控制与衍生文档回溯?能否基于文档日期触发提醒(如利率窗口)?是否支持本地部署和保护隐私?多语言搜索是否可行?
AI 锐评
Granite 的标语“每一份重要文档的保险柜”精准地切中了一个被长期忽视的刚需:不是知识管理,而是“文件遗忘管理”。它放弃了主流文档工具奉为圭臬的文件夹、标签、组织层级,直接回归核心——你把文件丢进去,忘了它,需要时用大白话问出来。这种极简主义设计本质上是在对抗人性中的惰性与拖延,比任何要求用户主动维护分类系统的工具都更务实。
然而,当前的产品形态仍存在明显的“轻量陷阱”。评论中提到的“模糊文档归属”“版本控制”“时间敏感提醒”绝非锦上添花,而是决定用户能否真正信任这个“保险柜”的关键。试想一个用户把一份混杂了税务与家信的多页PDF扔进去,如果Granite直接默认归档到税务类别,而用户半年后需要找那封家信时,这个“自动归档”反而成了搜索噪音。同样,缺失版本衍生管理意味着它只能处理“死文件”,无法适应商业合同、财务模型这类动态迭代的场景,这恰恰是高频刚需。
此外,用户对“本地+本地LLM”的呼声指向了更深的信任问题。文档保险柜存放的是最私密、最敏感的个人资产(房产证、遗嘱、报税单),完全依赖云端处理意味着用户必须接受数据权限的让渡。如果Granite无法在未来提供端侧处理的选项,它将永远被限制在“轻量试用”的范畴,而无法成为那些对隐私有绝对要求的用户的终极选择。
整体而言,Granite找到了一个足够狭窄但真实的切口,其差异化价值在于“用AI的搜索能力替代用户的管理负担”。但产品的护城河不在于口号,而在于对“模糊文档决策”“版本演进”“时间触发”等细节的硬核支撑。如果这些基础能力没有在短期内补齐,它就只是一个高级的全文检索工具,而非值得托付一生的文档保险柜。
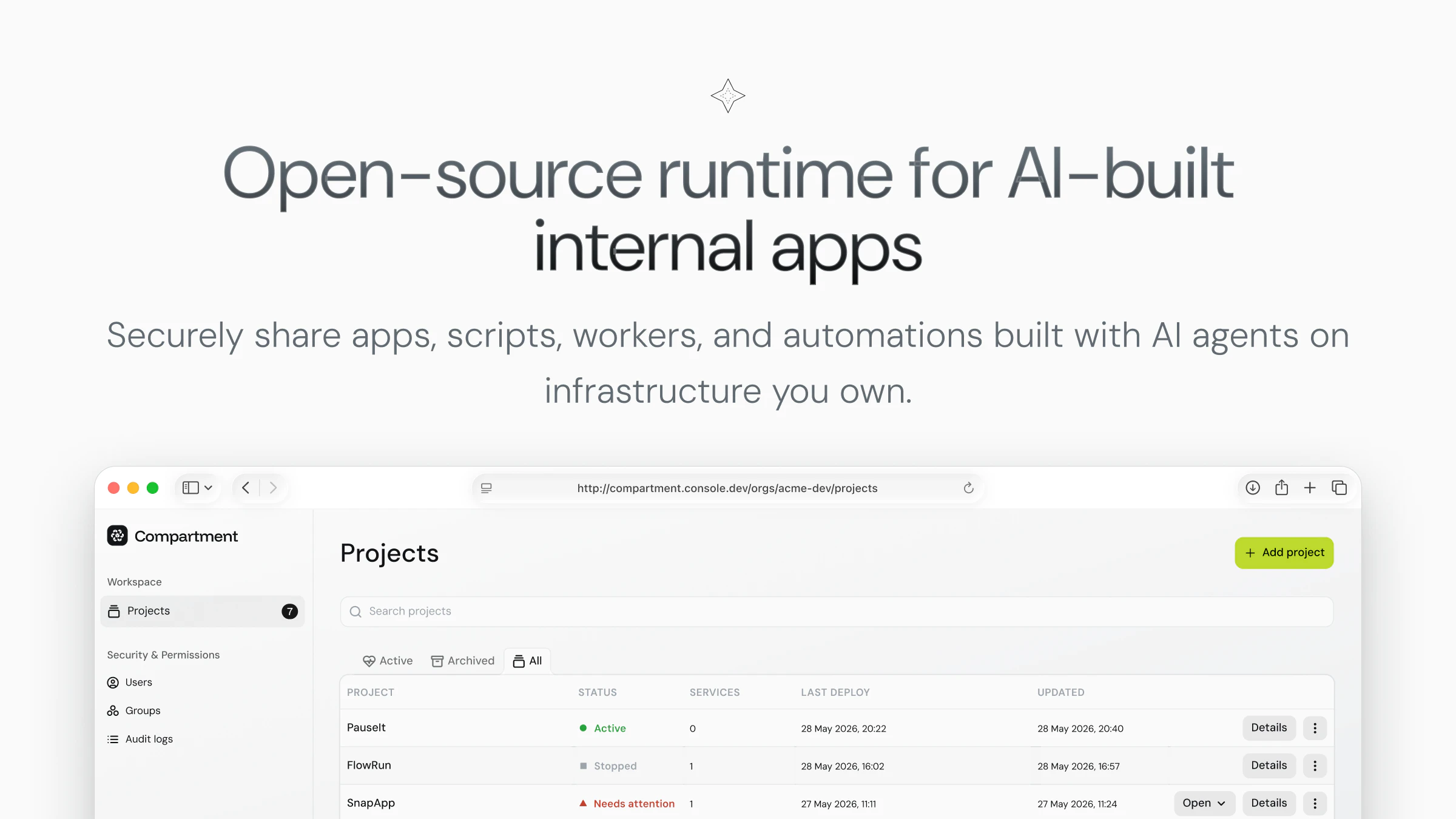
一句话介绍:Compartment 是一个自托管的开源运行时,专为AI生成的内部应用而设计,旨在解决团队中这些临时工具难以共享、部署、审计和维护的痛点,提供统一的运行与管理环境。
Open Source
Developer Tools
GitHub
开源
自托管
内部工具平台
AI应用运行时
RBAC
SSO
审计日志
团队协作
DevOps
应用管理
用户评论摘要:评论指出内建工具常从临时修复开始,产生新混乱;用户关心如何发现、使用及维护这些工具。另有建设性意见认为产品定位应从“基础设施”转为“企业效用层”,以吸引决策者,减少运维开销是核心卖点。
AI 锐评
Compartment 切中的是一个真实且正在扩大的痛点——AI辅助编程让“造轮子”变得廉价,但让轮子安全、可控地滚动起来却仍是硬骨头。从产品角度看,它没有去卷AI生成能力,而是聪明地填补了“AI产出的管理真空”,定位清晰。
然而,它的“开源+自托管”路线是一把双刃剑。对于技术排头兵团队,这是福音,能深度把控数据与权限;但对于大多数渴求“一键解决”的企业用户,部署和维护一个运行时环境本身就是门槛。评论中有人一针见血地指出:企业采购的不是“控制”的概念,而是“减少运维”的结果。如果Compartment不能提供比自行搭建(如基于Kubernetes的简单封装)更低的运维成本,那它的核心壁垒就只是“集成开箱”的便利性,而非不可替代性。
此外,其“与任意AI agent/技术栈协作”看似灵活,实则可能带来兼容性风险。内部工具五花八门,从脚本到Web应用,从Python到Node,一个“运行时”想要优雅隔离一切而不需要用户改造代码,工程挑战巨大。
总体而言,Compartment找准了场景,但能否从“开发者玩具”升华为“企业基础设施”,取决于它能否在“零配置部署”和“深度安全控制”之间找到精妙的平衡,并真正让运维团队爱上它。否则,它很可能只是又一个漂亮的管理面板。
一句话介绍:AccountyCat是一款基于AI上下文感知的macOS专注伴侣工具,通过识别当前应用和窗口标题(必要时截屏)来判断用户是否真正分心,而非简单粗暴地屏蔽网站或应用,解决了传统屏蔽类专注工具“要么全封要么全解”的痛点。
Productivity
Open Source
GitHub
Menu Bar Apps
macOS专注工具
AI上下文感知
开源隐私
分心检测
Qwen本地模型
OpenRouter
智能提醒
窗口活动监控
用户行为学习
替代屏蔽应用
用户评论摘要:用户普遍认可“区分工具性YouTube与娱乐性YouTube”的创意。核心建议包括:希望支持Windows/Linux、能按应用启用而非全系统监控(已实现)、查看提醒逻辑的日志。有用户担忧高频率任务切换可能让AI困惑,开发者回应可通过配置多任务档案解决。
AI 锐评
AccountyCat切中了一个长久以来被忽视的痛点:专注工具不是“监工”,而是“助理”。传统屏蔽类软件的问题在于其“非黑即白”的哲学——要么禁止,要么允许,完全忽略了用户行为的意图。Jonas用大模型做上下文感知,看似是技术上的简单叠加,实则是产品理念的根本转变。
从架构上看,本地Qwen模型+可选OpenRouter的方案兼顾了隐私与灵活性,开源代码也降低了信任门槛。但这也引出了核心问题:**AI误判的成本有多高?** 尽管开发者将“干扰合法工作视为Bug”,但LLM在处理模糊场景(如同时写代码和查文档)时难免犯错,用户每一次手动纠正都是对信任感的消耗。当前虽然设计了“学习记忆”机制,但这需要足够的数据密度和精准的负反馈循环,否则AI可能仅学会“沉默”而非“辨别”。
此外,macOS独占和Apple Silicon限制决定了它当前只是小众玩家的玩具。考虑到Windows用户群体巨大,且WSL、虚拟化场景的复杂性才是分心管理的真正战场,团队若止步于“社区贡献”的被动策略,很可能被Copycat快速抢占市场。
真正有趣的是其“被管理型”订阅模式——若能将AI的提醒策略转化为可量化的效率指标(如“每日合理分心次数”),就能从工具蜕变为生产力反馈系统,这比单纯的“分类YouTube”更具长期价值。但在此之前,它需要证明:在随机波动中,AI的判断能稳定优于用户依靠自我认知的直觉排查。
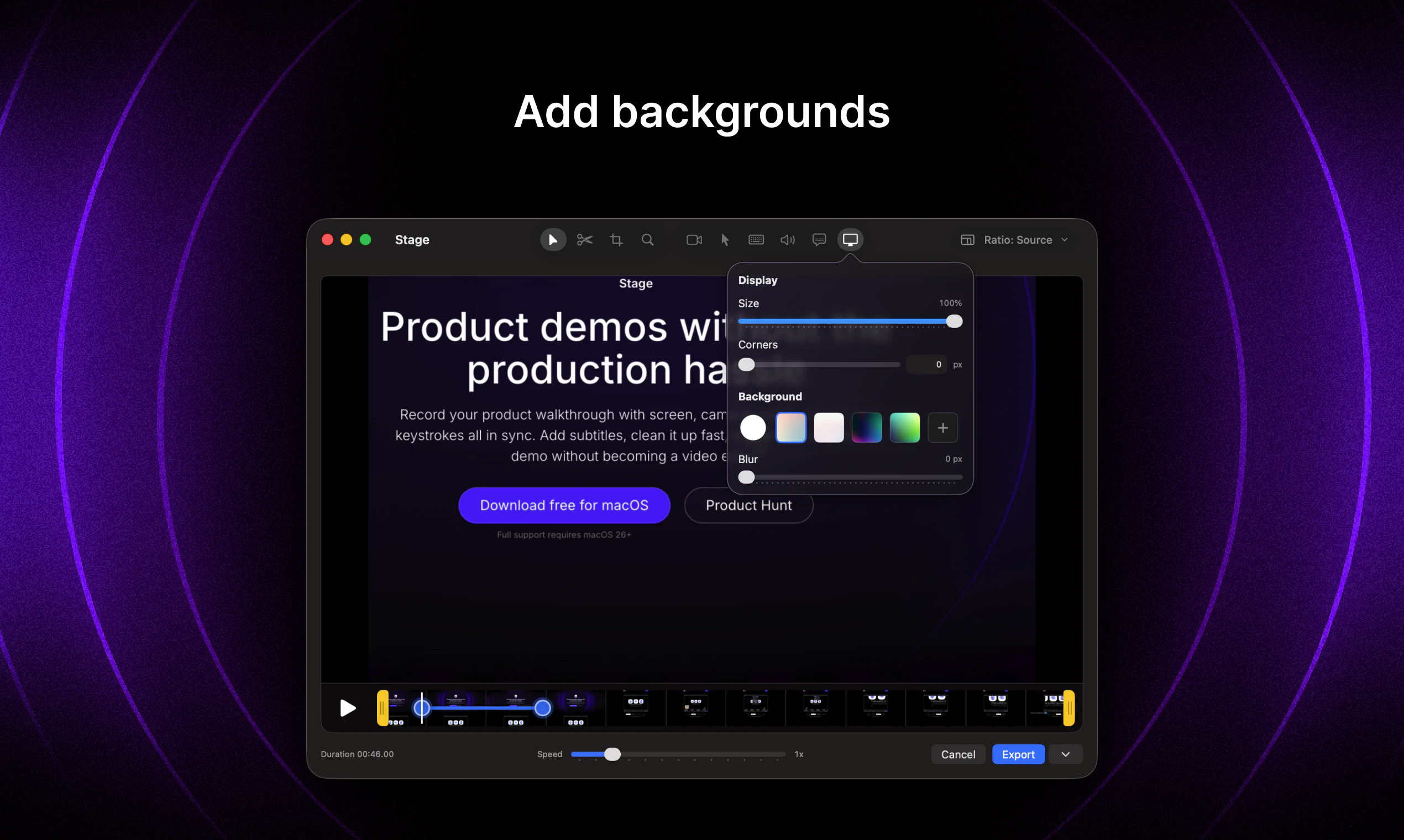
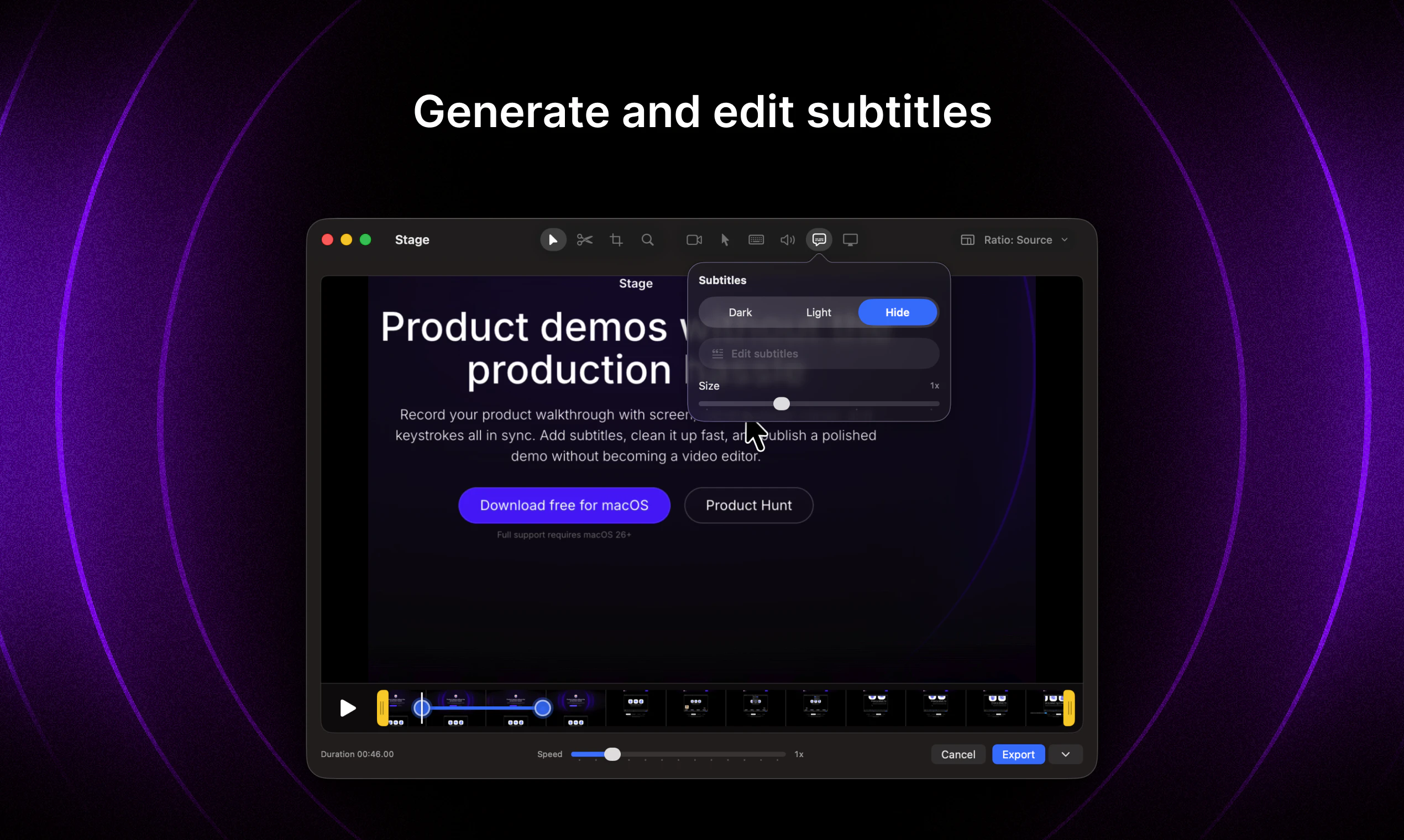
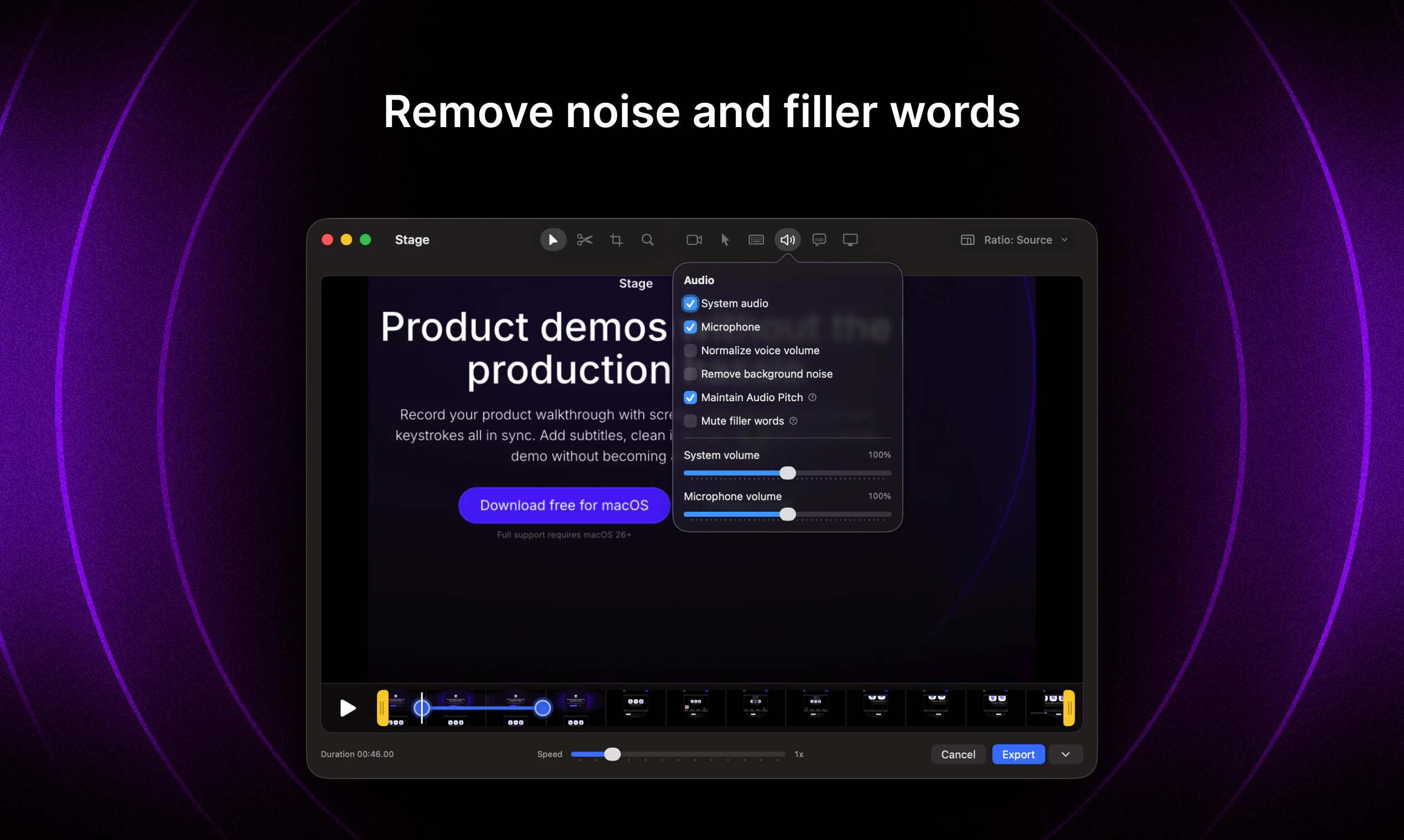
一句话介绍:Stage是一款免费macOS录屏工具,专为产品演示、Bug反馈更新等场景设计,解决用户录完视频后仍需复杂剪辑的痛点,实现屏幕、摄像头、音频、光标和按键动作同步录制并快速产出精致演示视频。
Productivity
Marketing
Video
录屏工具
产品演示
屏幕录制
视频编辑
macOS
光标录制
按键显示
字幕添加
Bug记录
快速成片
用户评论摘要:用户普遍认可其解决录制后需复杂编辑的痛点,反馈询问编辑速度(10分钟内能否出片)、是否支持视频导入、自动缩放功能;建议中提及希望加入意图标记(如Bug、决策点)以增强演示叙事性,以及动画背景等增强功能。
AI 锐评
Stage精准卡位了一个被忽视的中间地带——它既不像系统自带录屏那样简陋,又避开了Final Cut Pro等专业工具的沉重负担。其核心价值并非“功能多”,而是“流程逻辑的对齐”:将原本分散在录制、剪辑、字幕、光标美化等多个环节的操作,压缩为一个连贯的感知系统。从评论可见,用户厌烦的不是剪辑本身,而是“为一个小演示启动整个视频工作流”的心理门槛。Stage通过同步多轨录制+轻量后期(字幕、光标、按键)实现了“所见即所得”的演示产出,这正是创始人、PM等非专业视频创作者需要的。但隐患也明显:仅支持macOS,且缺乏视频导入与多轨编辑能力,一旦用户对“演示”的需求升级为“教程”或“培训内容”,Stage可能迅速触及天花板。另外,评论中“10分钟出片”虽然是卖点,但也暗示其边界——不支持复杂叙事结构。建议尽快支持视频导入与时间轴标记功能,否则容易成为“用完即弃”的工具型产品,而非平台型入口。
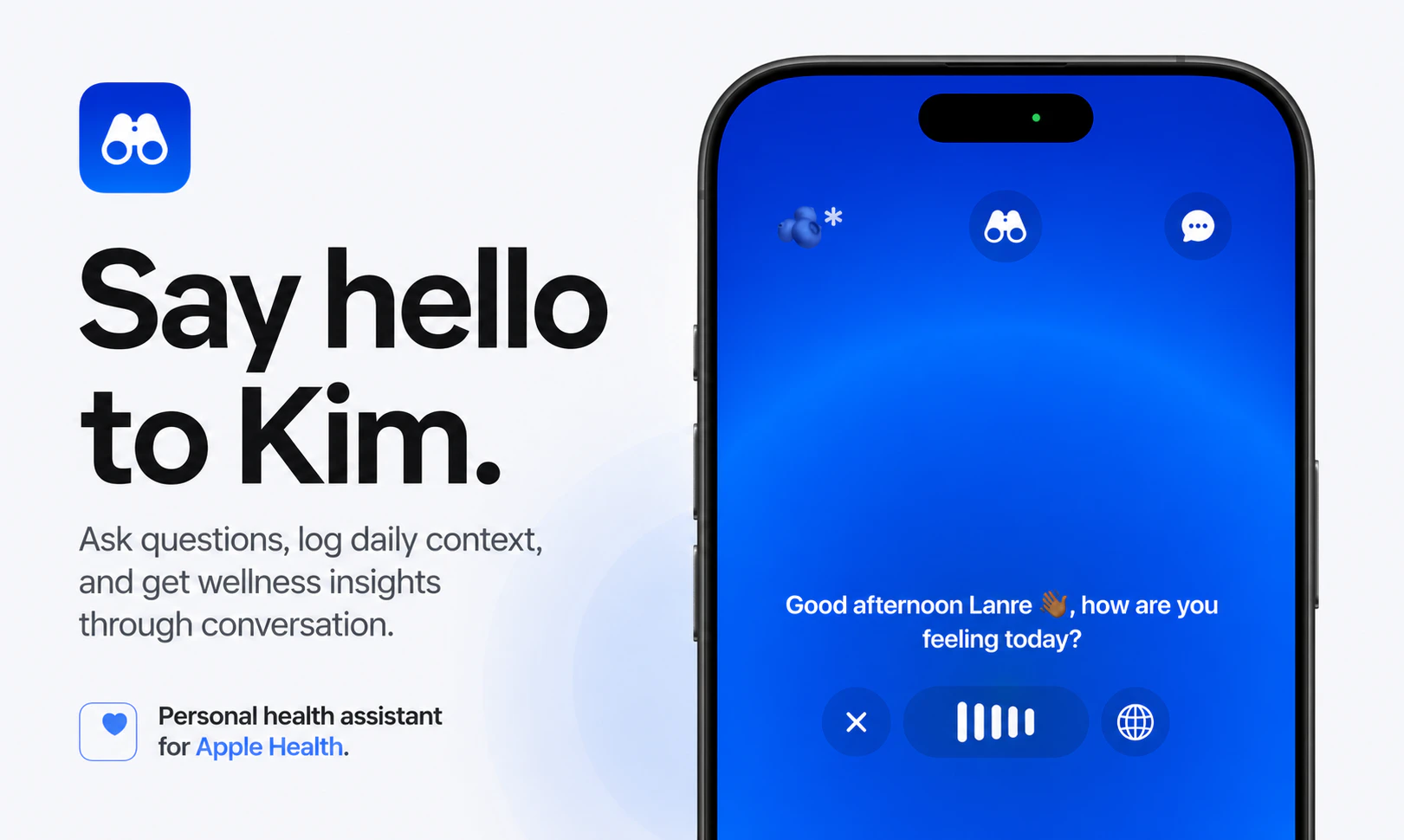
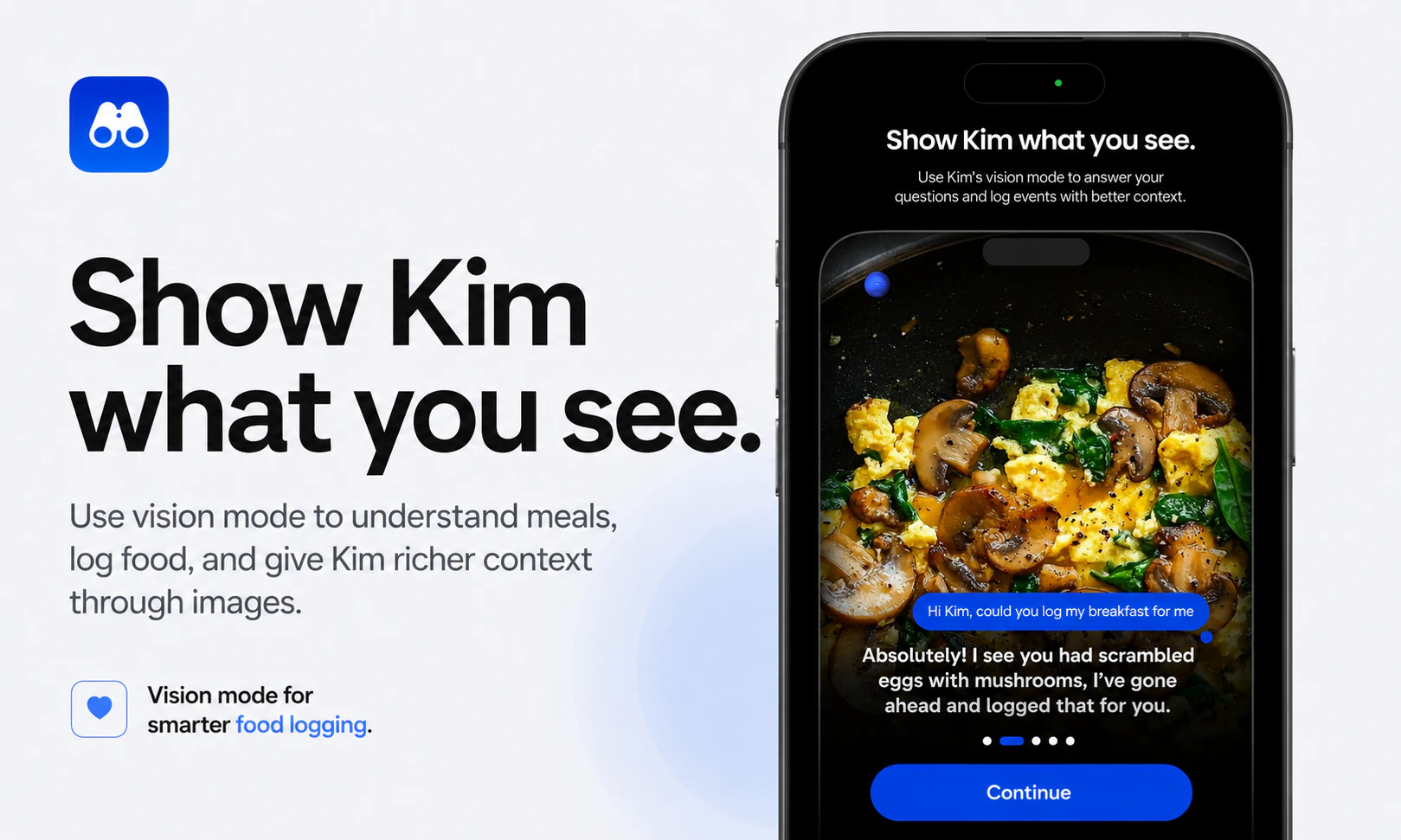
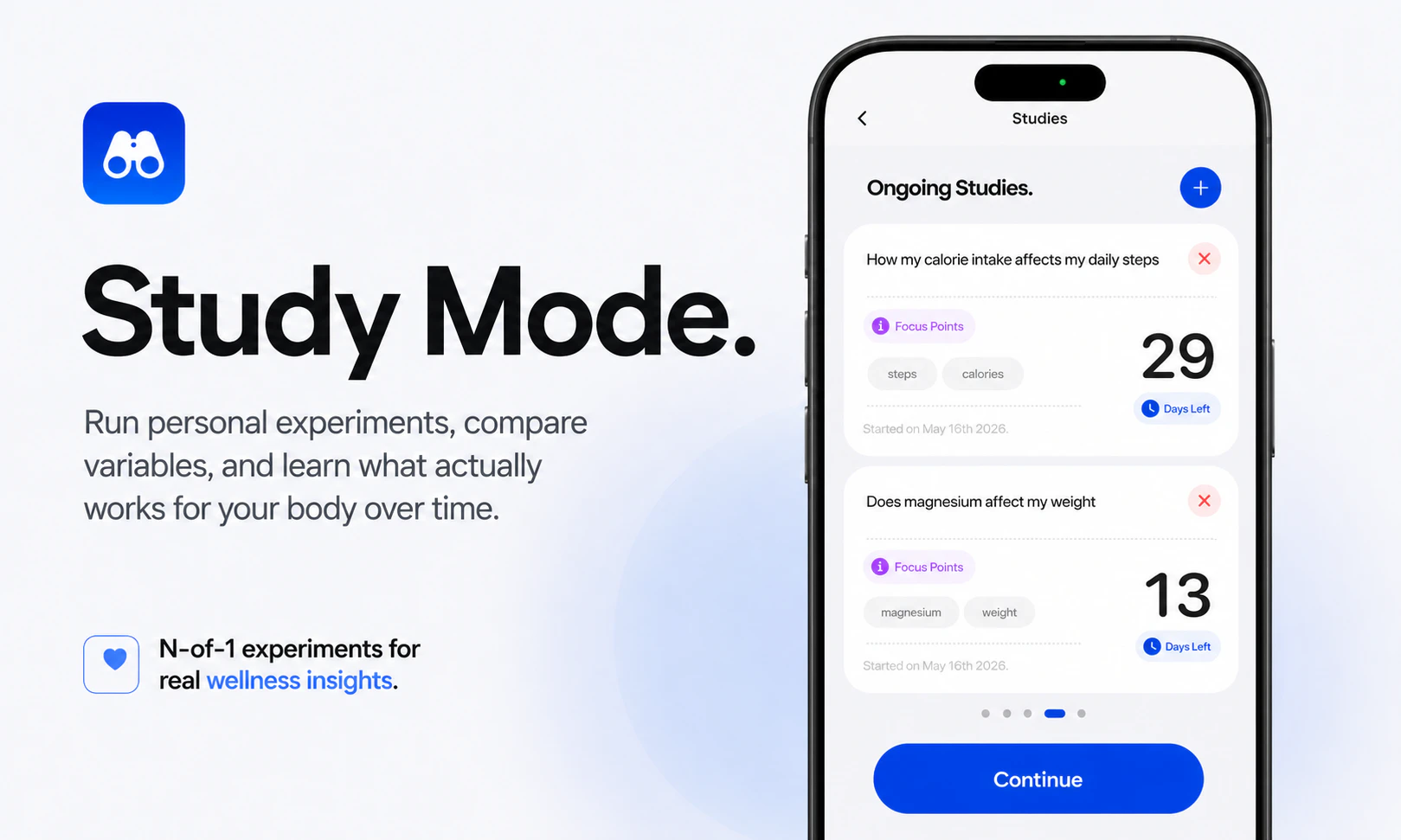
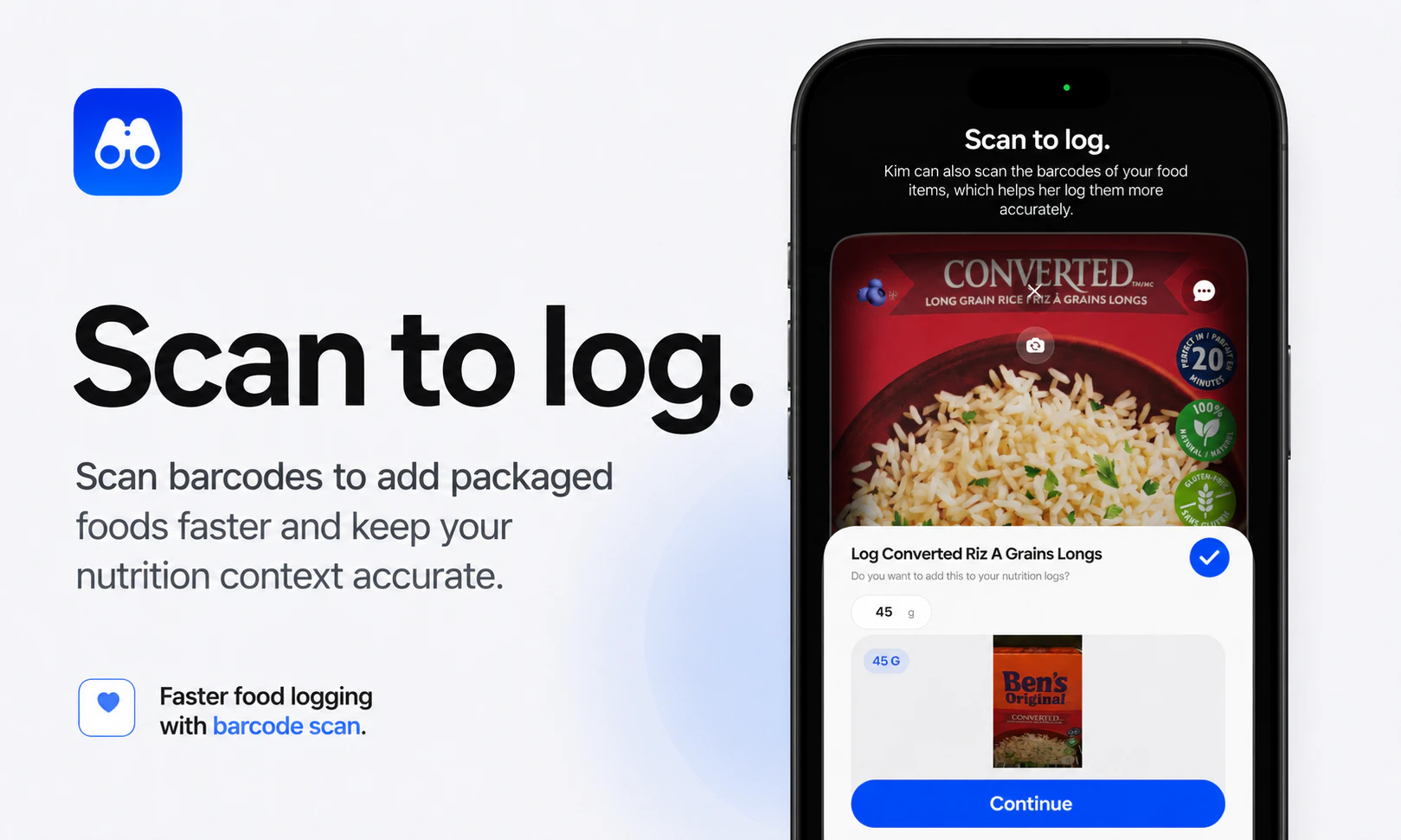
一句话介绍:Kim是一款将Apple Health数据转化为个性化对话与自身体验实验的个人健康助手,帮助用户在繁杂的体征数据中找到真正影响自身状态的规律,而非仅看仪表盘。
Health & Fitness
Artificial Intelligence
Tech
个人健康助手
Apple Health数据分析
健康数据解读
个性化实验
生物特征追踪
情绪记录
健康管理
自我量化
数字健康
用户评论摘要:用户肯定“个人实验”与情绪日志等差异化功能,并关注其能否识别有意义的长期规律而非短期波动。反馈建议包括支持医学文件/截图上传,以及修复在读取测量信息时卡片无法滚动的Bug。
AI 锐评
Kim的定位精准地切中了健康App领域的“数据孤岛”现象:用户手环、手表上的心率、HRV、睡眠等数据堆积如山,但缺乏一个能直接回答“这对我意味着什么”的智能层。它不试图做另一个追求数据精度的健康监测器,而是做“数据翻译官”——把冰冷的数字转成洞见和行动建议,这个策略在用户“数据疲劳”的时代显得明智且必要。
其核心价值不在于数据采集本身,而在于“个人实验”这个颇具科学精神的框架。允许用户自己设定变量(如是否服用镁剂),然后对照身体反馈(如睡眠质量),这比千篇一律的“最佳睡眠建议”更有说服力和私密性。结合情绪、能量的主观日志,也弥补了纯传感器数据缺乏上下文的致命短板。
然而,产品面临两个潜在挑战:其一,从评论看,Bug和功能缺失(如不支持文件上传)表明尚处早期,用户对“理解数据”的期待是否会被粗糙的交互体验消磨掉,需要快速迭代来验证。其二,“个人实验”的结果揭示未必总是积极的甚至可能是虚假的(混淆变量、安慰剂效应),Kim是选择诚实呈现不确定性,还是自信输出“行动建议”?从行业角度看,跨出“解释”走向“教练”是更大的差异化,但也伴随着巨大的责任和法律风险。如果Kim能始终尊重数据的不完美,并引导用户进行科学的自我发现,它远比那些故作高深的“AI健康教练”更具长线价值。
一句话介绍:Crew44是一个本地优先的开源命令行工具,能将用户电脑上已有的多个AI编程代理(如Claude Code、Cursor等)组织成拥有记忆和专业技能分工的协作团队,解决多代理工作流中上下文割裂、重复配置和任务协调混乱的痛点。
Open Source
Developer Tools
Artificial Intelligence
GitHub
用户评论摘要:用户普遍共鸣于多代理“上下文割裂”的痛点,盛赞本地优先、无账户和开源理念。核心疑问集中在:未来路线图如何?能否绑定本地运行的LLM?跨会话记忆是项目级还是全局级?有回帖指出其宣传定位(“编排工具”)未能凸显“记忆复合”这一核心突破价值。
AI 锐评
Crew44精准击中了当前AI编程领域的“隐性耗损”——不再是模型能力不足,而是多工具间的协调熵增。其“本地优先+开源+无账户”的组合拳,在用户信任层面几乎是无敌的,直接狙击了那些对数据隐私和SaaS绑定感到疲惫的资深开发者。
但冷静来看,这本质是一个“工作流编排脚本”的精致化包装。它的核心价值并非创造新能力,而是解决“已有工具的上下文衔接”。创始人对“记忆复合”的强调非常正确,这也是产品真正的护城河——让代理积累项目知识。然而,技术上实现跨会话、跨项目的智能记忆召回,难度远大于提供一个本地配置界面。目前公开的信息中,记忆机制似乎仍偏重文件化的手动管理,离“自动复合”还有距离。
最大的隐忧在于,它依赖第三方代理的API稳定性。如果未来Claude Code等工具原生内置了团队协作和记忆功能,Crew44的价值将被严重稀释。当前,它更像一个优秀的“中间层过渡方案”,适合熟悉CLI、习惯自主配置的深度用户。想突破小众圈层,必须将“自动化记忆复合”从宣传语变成可感知的智能特性,而不是一个手动配置的记忆库。那句“卖记忆层,而不是编排”的评论,一针见血。
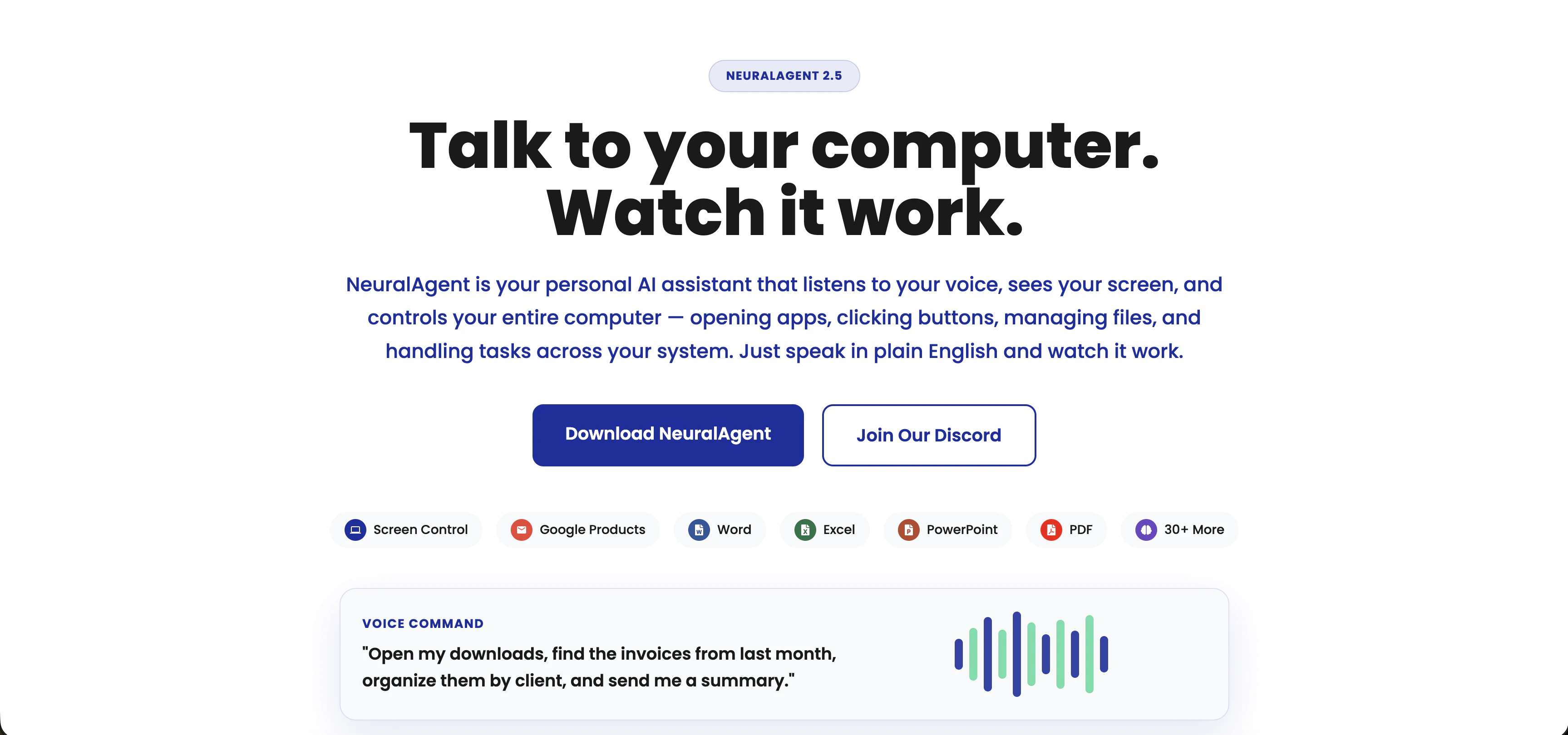
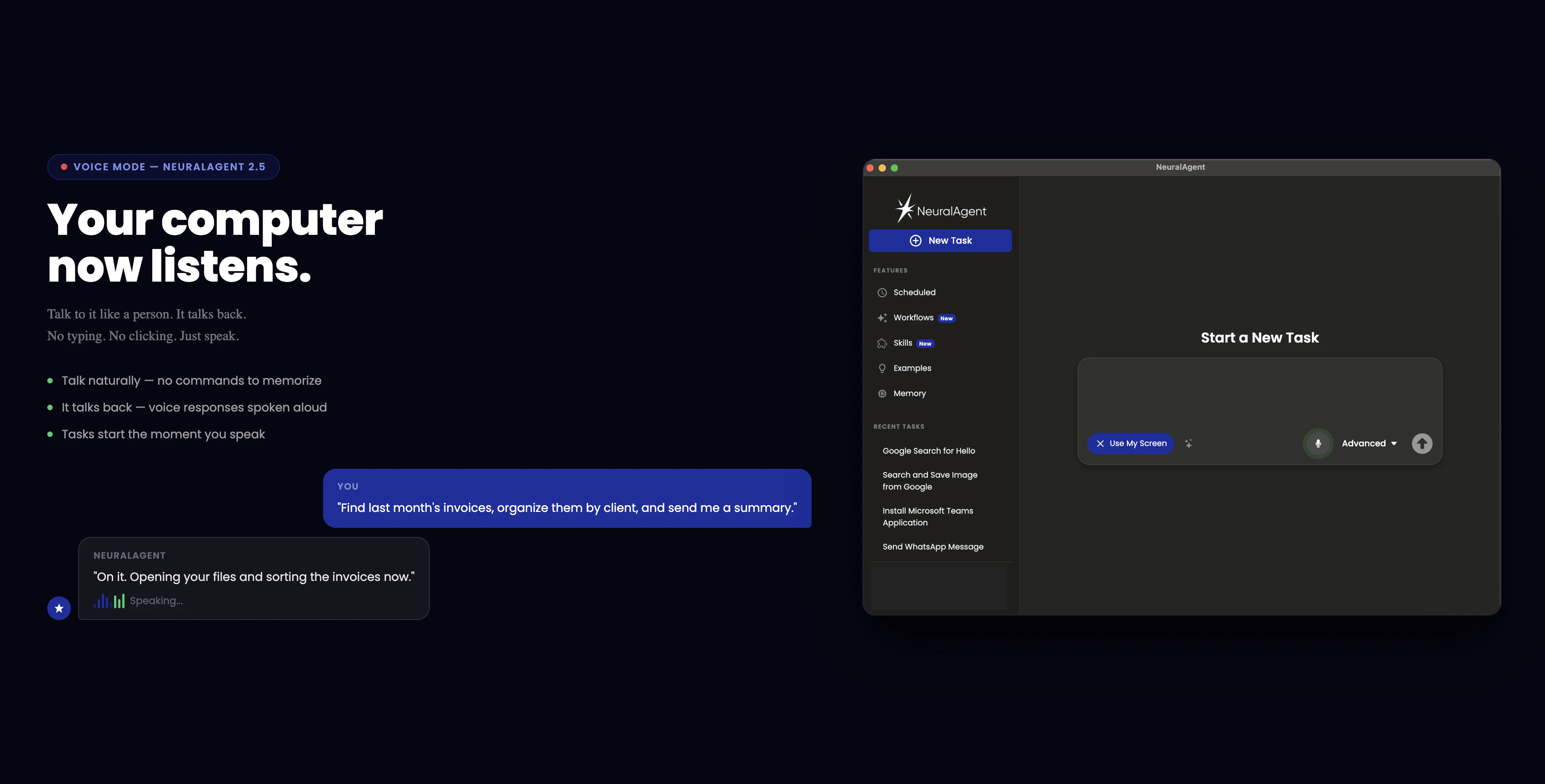
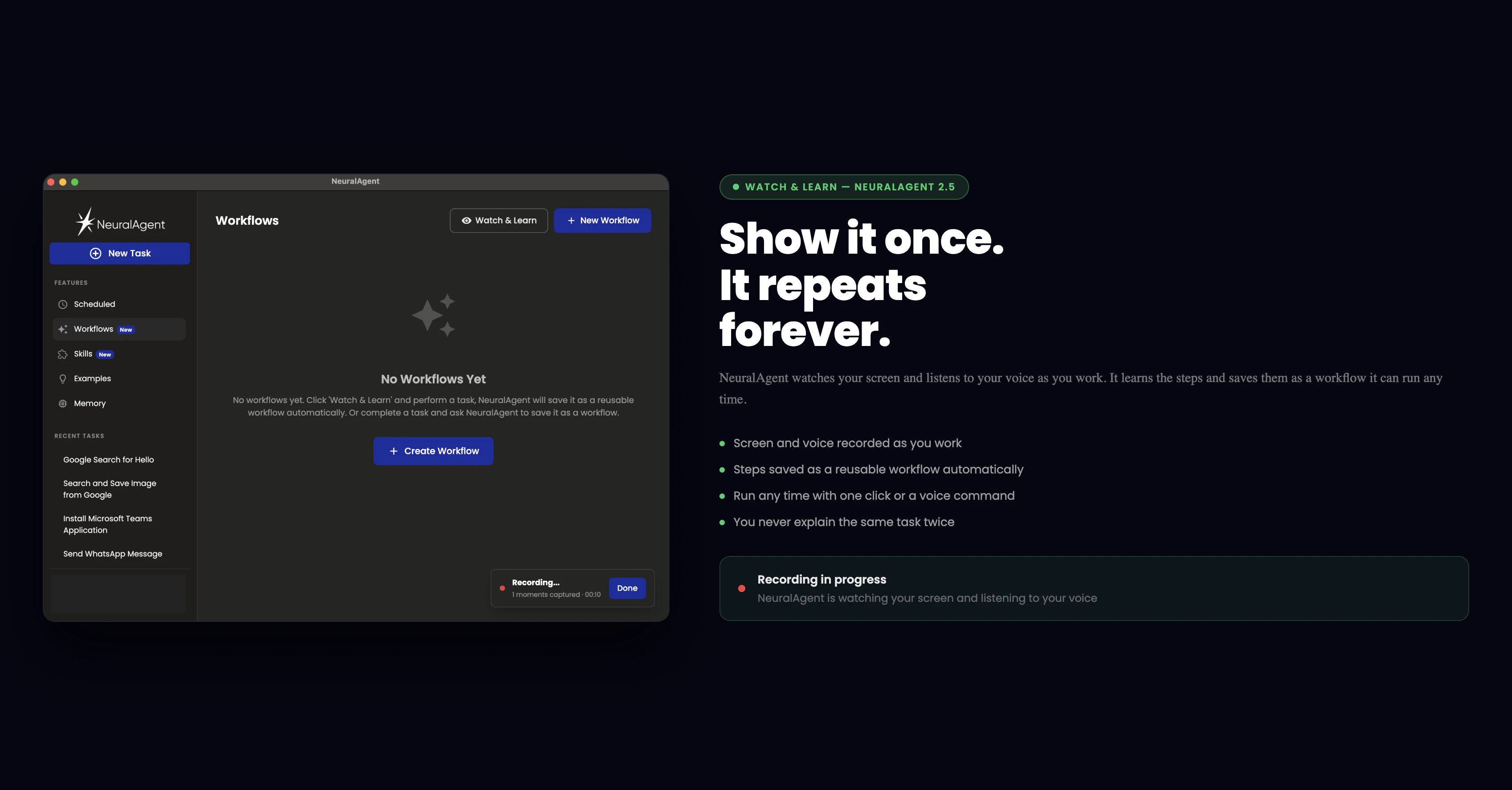
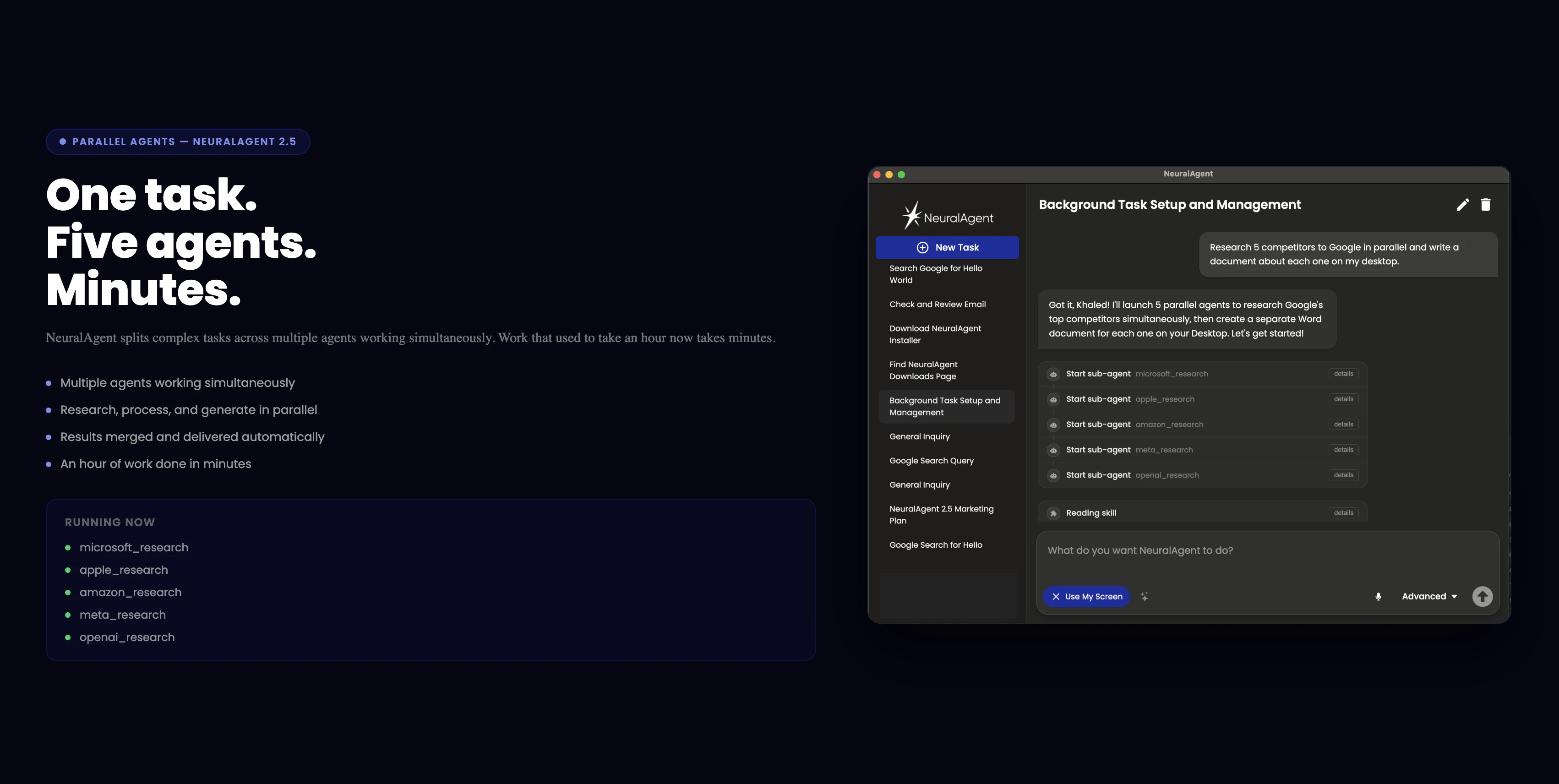
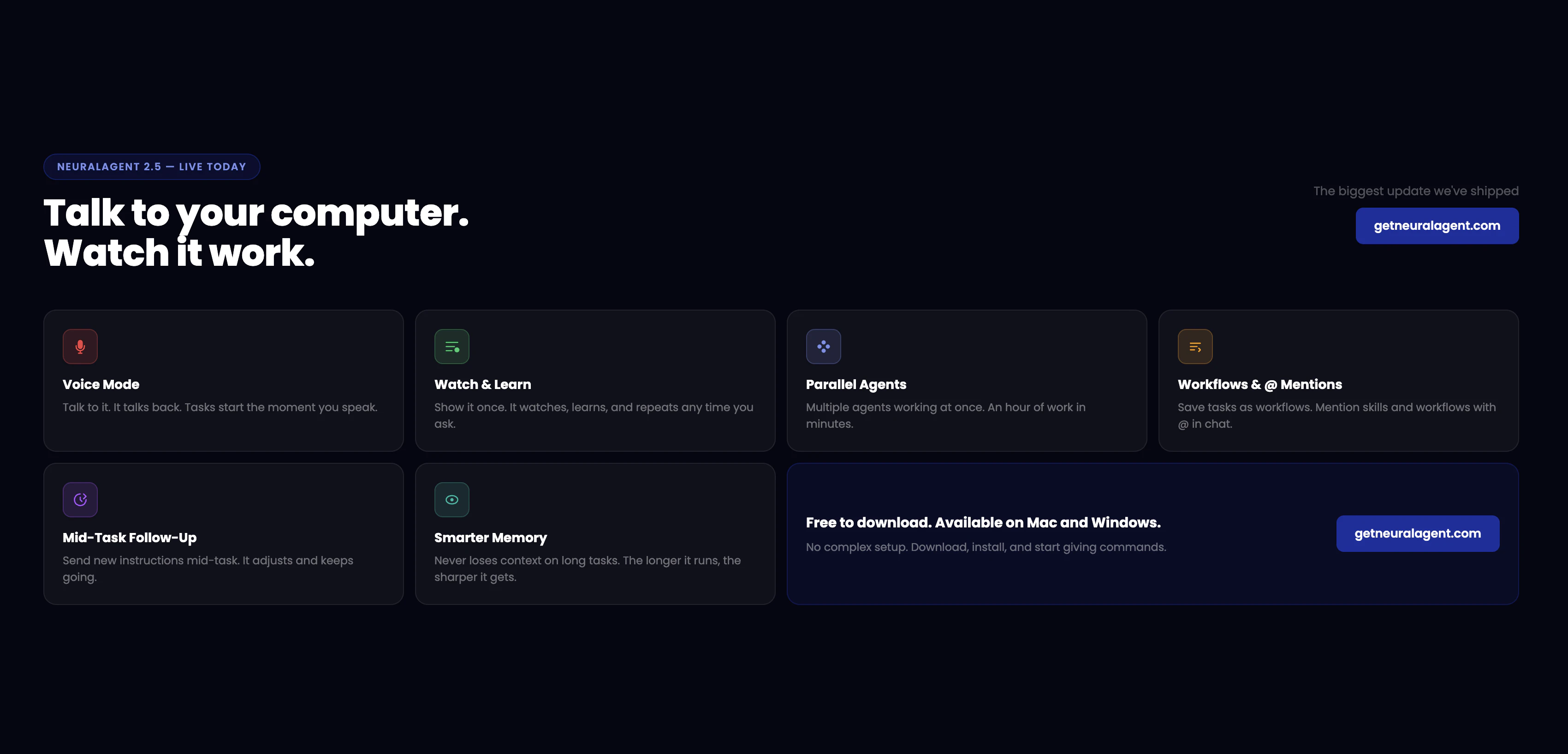
一句话介绍:NeuralAgent 2.5通过语音交互、任务录制与并行执行,让用户无需动手即可指挥电脑自动完成多步骤工作流,解决了AI助手“能聊不能干”的落地痛点。
Productivity
Artificial Intelligence
Tech
智能体
自动化工作流
语音控制
屏幕录制
并行处理
AI助手
效率工具
操作系统级AI
RPA
企业自动化
用户评论摘要:用户关注并行代理能否输出可对比的结果而非散乱信息;质疑任务中途出现意外页面或弹窗时的恢复能力;普遍怀疑从演示到实际完成任务的一致性,以及跨应用多步骤任务的可靠性。
AI 锐评
NeuralAgent 2.5最诱人的地方在于它的野心:不再满足于当个“聊天窗口”,而是伸手去操作你的电脑。Voice Mode和Watch & Learn让“教一次就自动干”的愿景听起来像Jarvis成真,Parallel Agents更是直接瞄准了“一小时工作变成几分钟”的效率暴政。但冷静下来,这恰恰踩中了当前AI操作系统的三个大坑:一是状态恢复问题——评论里“按钮移动、意外弹窗”的提问直击要害,单次演示的丝滑覆盖不了长尾的软件崩溃、权限弹窗或网络断连;二是输出整合的“最后一公里”,30个并行Agent确实酷,但如果每个返回一篇杂乱笔记,用户缝合的时间成本依旧爆炸;三是信任赤字——用户要的是“放心交办”,而不是“花式演示”。真正的价值在于:NeuralAgent能否在实用场景中,用自己的记忆系统和Workflows逻辑,构建一个可靠的容错闭环,而不是把所有“意外”都推回给用户手动处理。目前看,它向着“真正的数字员工”迈出了一大步,但离“下班后让它自己加班”的生产级信任,还差一个精心设计的错误处理层。
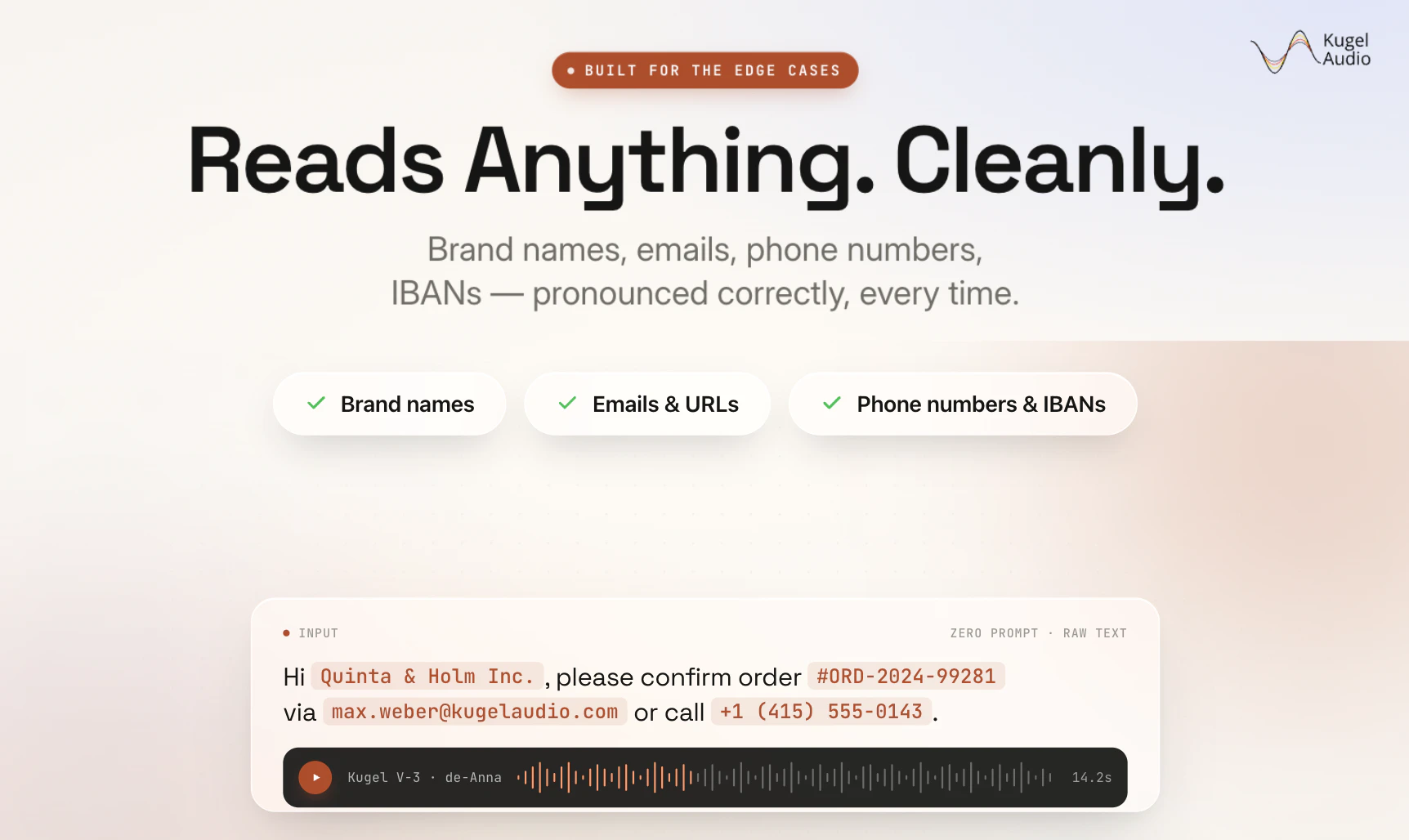
一句话介绍:KugelAudio 是一款支持自部署的实时文本转语音模型,通过极低延迟(低于60毫秒)和语音克隆技术,帮助开发者在语音代理、呼叫中心等场景中实现自然、合规的多语言语音合成,尤其解决了医疗、金融等对数据隐私要求严格的企业的自托管需求。
API
Developer Tools
Artificial Intelligence
实时文本转语音
语音克隆
低延迟
自托管
语音代理
多语言
LiveKit集成
语法感知
AI语音模型
开发者工具
用户评论摘要:用户称赞其德语TTS表现出色;关注多语言混合语境处理(如德语与英语产品名),得到“支持词典自定义发音”答复;询问尼泊尔语支持,回复暂不支持;询问印地语支持及流式API多上下文功能,回复称主攻欧洲语言,并兼容Elevenlabs SDK提供多上下文端点。
AI 锐评
KugelAudio 在拥挤的 TTS 赛道中切出了一个精准且务实的细分切口:不是去拼“更像真人”这种无限内卷的参数,而是直击语音代理(Voice Agent)部署中的两个核心痛点——延迟与合规。60ms以下的端到端延迟(排除网络)是目前在生产环境中支撑流畅对话式AI交互的硬门槛,这比许多云服务商还快,而“支持自托管”则直接撬开了金融、医疗、政府等高合规性行业的大门,这正是谷歌、微软等巨头的TTS云服务难以渗透的领域。创始人背景(4人,柏林出身,YC孵化)暗示了其工程效率之高:通过适配LiveKit、Pipecat、Vapi等主流语音框架,他们聪明地借用了生态的力量,让开发者无须重写集成代码即可嵌入;语法感知的归一化(如准确朗读IBAN、药品名)则体现了对垂直场景(如医疗、金融客服)的真实理解,这往往是通用TTS模型的盲区。
然而,锐评必须指出其风险:语音克隆的门槛——30-60秒样本虽方便,但克隆泛化能力与防滥用(如深度伪造)机制需持续验证;多语言覆盖野心(25+语言)与实际稳定支持(以欧洲语言为主)之间存在鸿沟,非英语/欧洲语言的语音库稀缺将限制其全球化突破;4人团队的资源瓶颈在后续模型迭代、开发者支持与模型安全性审核上可能暴露。总体而言,KugelAudio 的产品策略是“以速度和部署灵活性换取场景深度”,比十一人实验室(ElevenLabs)更偏向开发者和企业自管,在中小型语音代理团队中有明确价值,但对于需要超大规模、超多方言和超高级情感表达的场景,它仍需证明自己不仅仅是“够用”,而是“好用”。
一句话介绍:Plz Support Me 是一款为独立创始人打造的产品发布副驾驶,通过整合发布渠道、提供计划模板和构建支持者社群,解决单打独斗者缺乏系统性的分发策略和情感支持的痛点。
Sales
SEO
Vercel Day
产品发布
独立开发者
营销工具
启动加速器
分发目录
SEO外链
支持者管理
创业社群
发布规划
AI辅助
用户评论摘要:用户认可“支持者团队”的创意但担忧沦为刷票工具;创始人承诺不做交易,而是构建真正支持关系。有用户认为核心价值在于提供按阶段、品类匹配渠道的判断力,而非简单列表。也有用户对产品名称和图标设计提出优化建议。
AI 锐评
Plz Support Me 抓住了“发布是独立创始人最孤独战役”这一真实情绪,其价值并非在于那265+的目录列表——类似资源在Hacker News、Indie Hackers上早已泛滥。真正有潜力的,是构建“发布品控层”:基于创始人阶段、ICP和信誉度的渠道匹配逻辑。这恰好击中了“我知道要分发,但不知道在哪分发”的决策瘫痪症。
但产品必须警惕两个致命陷阱。其一,创始人宣称的“supporter crew”若缺乏明确的标签分类(如客户、投资人、社区伙伴),极易滑向PH官方封杀的刷票机制。如何在合规框架下验证支持者的“真实关系”,是能否长期立足的关键。其二,工具解决“how”而不解决“why”——如果产品本身在功能或市场匹配上存在硬伤,再精妙的发布策略也只是为劣质演出准备的绚烂烟花。
当前最大的价值,或许不是AI生成的发布策略,而是通过结构化的清单,迫使创始人提前思考用户画像与渠道匹配度,从而减少“闭眼乱投”的力气浪费。对于月发布量数以万计但平均质量堪忧的Product Hunt生态而言,这种“限制性引导”反而比“增长黑客”更有长期意义。下一步的AI分析功能若仅停留在预测“什么时间发帖流量高”,则只是同质化竞争的注脚——真正的壁垒,在于数据能否反哺产品迭代。





















































Love this flavor of OpenClaw — no more lobster, bring on the syrup! 🥞
What I particularly enjoyed during onboarding was that Pancake dutifully did a deep research web crawl on me and my business and then put together an onboarding deck describing me, my current foci, and how it could help me.
Once I reviewed the deck, it gave me four succinct options to get started, all from within the comfort of my own Slack:
I decided to ask it to write a hunter comment for me for its launch — kinda meta, but in a good way, right?
After Product Hunt's bot detection slapped it, it produced this:
Not bad, eh? :)
Give it a try!
👋 Hey Product Hunt!
I’m Tristan, one of the cooks behind Pancake.
While building our previous company, we were such heavy OpenClaw users that 50% of our company was running on autopilot, generating ~10 demos per week and handling ops on its own.
We were so excited about this that we decided to go all in on Pancake.
Pancake is a full AI org chart in Slack, across GTM, product, and ops.
Pancake creates a company brain by syncing with your meeting notes and Slack discussions. It understands what you're building.
Unlike other "autonomous company" products, you stack agents one by one, each matched to a real goal -- compounding autonomy over time. Go from 0 to 70% autonomy in a few months.
Unlike other "AI in Slack" tools, Pancake is literally an org chart that you build as you go. Hire agents from our open-source Squad templates, or roll your own.
A real example of one of our autonomous Pancake Product Squads:
A founder books a demo with us
The Pancake product squad listens to feedback during the call and creates a pull request immediately after, unprompted. We merge it as-is.
We're running Pancake on Pancake and now have 23 autonomous agents doing 3 tasks/day each, posting a daily digest to Slack.
I hope you'll love Pancake as much as we do!!
P.S.: @francoisdefitte bet he'd shave his head if we hit 1,000 upvotes today. Let's make him bald (hairdressers in SF are unaffordable anyway).
Was a basalt customer back in the day, so I'm already biased toward whatever you ship next. "Autonomous company" is a big swing and I'm honestly into it. How much does it actually run without a human in the loop right now versus what still needs a thumbs-up? And how are you thinking about guardrails so it only acts where it's supposed to?
I was lucky to be part of the beta and the experience was just amazing. The fact that Pancake treats agents like its own org chart and grow it according to your need is really amazing. Soon we'll need a LinkedIn for AI agents I guess 😅
Great job team. The 'approve the irreversible line' seems to be doing most of the work here? How does Pancake classify what counts as irreversible vs just costly? Sending an external email is binary whereas spinning up infra or making API calls with downstream effects is a gradient
For the past few weeks I've been a beta tester, and it has been absolutely wild... especially coming from someone who has been deep in the AI automation rabbit hole for a while 🫠
Before Pancake, I had built my own setup to try to automate my side project: a swarm of OpenClaw agents, a custom triage command center to distribute tasks across them... It was fun to build but was always breaking and often under-performing. It just takes a lot of work to maintain and fine-tune a bunch of agents working on your systems.
Couldn't be happier to be relieved of my OpenClaw babysitting duties when the Pancake crew offered me a beta seat!
It is geniunely the best "AI as cofounder" solution I have tested out there - and the team is super reactive to fix stuff.
I'm not a normy, I use OpenClaw constantly, both personally and professionally, so I thought I had a pretty solid mental model of what AI agents can and can't do. But Pancake still surprised me a few times! The level of autonomy is quite impressive... it doesn't just execute tasks, it comes up with solutions to problems I wouldn't have known how to solve myself. That's the part that genuinely got me, it is very.. resourceful?
I am overall a big fan!
Wishing the team all the best for this launch - you've built something special here! 🥞
Had so much fun building this, the list of use cases really is limitless
Hi ProductHunt, cofounder of Pancake here. We use Pancake on Pancake, and honestly: I'm proud of what we're shipping today. We still have so much to do, but we're passionate about this product and pouring our soul into it !
If you want to join the adventure, try it, give us feedback, even join our Discord, we're building in public and we can't wait to meet you!
Really incredible product! Congrats François, Guillaume and the team!
“Prepare yourself to be prompted by Pancake” is honestly a great line 😄 Love the shift from AI as a helper to AI as an actual operating layer for a company. Congrats on the launch!
Congrats on launching this new product!
I tried the outreach agent and love it, looking forward to what's next!
Awesome!
That's wild! Congrats.
As someone who had started spending way too much time on OpenClaw, I'm sure this is going to save me a lot of time.
My question: when you talk about going from 0 to 70% autonomy in a few months, what happens with the remaining 30%?
Also curious to know how agents handle conflicts between them when two squads are pursuing goals that contradict each other.
Congrats on shipping, Francois! Most AI tools stop at "copilot" — betting on actually autonomous agents with roles, goals, and a heartbeat, run from inside Slack where teams already live, is a much bolder swing. Love the "approve the irreversible, the rest runs" framing. Just followed you on X (@JayTheSong), would love to connect and follow where this heads 👏
LFG, looks awesome! Can't wait to tryyy 🥞🥞🥞🥞
Let's go! Autonomy is clearly the future of automations.
Sounds amazing! Definitely what's been missing !
Really cool :) Need to try this asap @francoisdefitte
Awesome product, congrats on the launch
Love the team and their new product, can't wait to put some pancake in my life :)
Looks really cool! Does it work in whatsapp?
The launch week continues for Pancake with our Product Hunt launch 🥞
Yesterday, we officially moved out of beta and released Pancake to everyone. Hundreds of people have already joined the adventure and are using Pancake every day.
Try it out for free, send us your feedback, and most importantly: cook with Pancake 🥞
"Agents with a heartbeat working while you sleep" is a great line, but it's also the exact scenario that makes me nervous — the thing I want to picture is what the company looks like the morning after something goes sideways at 3am. How much of "the rest runs" is genuinely unattended versus quietly piling up in a queue for a human to sign off on?
This looks pretty slick. Great work @tricomte and team.
Very much lacking a list of practical use cases that this service can solve. The video is cool, I really liked it, but I don’t fully understand what the AI is capable of. For example, if I give login and password to Google Analytics and ask it to connect and analyze why website traffic dropped, can it do that or not?