PH热榜 | 2025-12-26
一句话介绍:Thordata为AI团队和数据驱动型企业提供住宅、移动和数据中心代理基础设施,解决其在全球网络数据收集中遇到的稳定性差、难以扩展及合规风险高等核心痛点,专注于构建可持续、生产就绪的长期数据管道。
SaaS
Artificial Intelligence
Data & Analytics
数据采集基础设施
AI训练数据
代理服务
网络爬虫
合规数据访问
数据管道
住宅代理
市场情报
数据收集
企业级工具
用户评论摘要:用户普遍认可其解决规模化数据采集痛点的价值,尤其赞赏其稳定性和合规设计。主要建议包括:提供更细粒度的区域IP覆盖和成功率仪表板、增强对动态反爬网站的应对能力。团队积极回应,透露已在规划相关功能。
AI 锐评
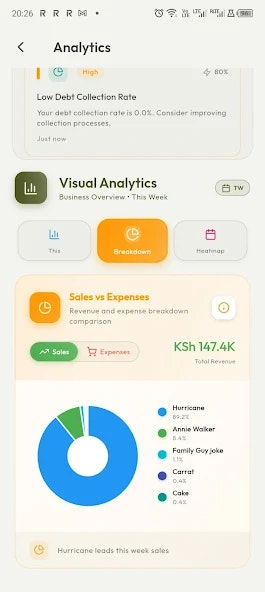
Thordata的亮相,精准刺中了AI浪潮下一个隐秘而关键的瓶颈:高质量训练数据的可持续供给。它并非又一个简单的代理服务,其野心在于成为AI数据管道的“基础设施”。这一定位使其与众多“数据抓取工具”划清了界限。
其真正价值在于将“合规”和“生产就绪”从营销话术提升为设计原则。创始人反复强调此点,回应了企业级客户最深的恐惧——数据源的法律风险与管道脆弱性足以摧毁整个AI系统。从评论看,用户(尤其是来自竞争情报和AI产品领域)的共鸣点恰恰在于“从DIY维护中解脱”和“成功率从40%跃升至98%”这类可靠性叙事,这验证了其核心价值主张:提供确定性的数据访问能力,让团队专注于模型与应用,而非与变幻莫测的反爬机制缠斗。
然而,挑战同样清晰。作为基础设施,其面临的将是极端苛刻的稳定性和规模性考验。评论中关于“动态网站反爬”和“更细粒度监控”的建议,正是从“能用”到“好用且可信赖”的关键跃升点。此外,其企业级定位虽清晰,但如何平衡性能、合规性与成本,并在巨头环伺的代理市场中建立足够深的护城河,将是后续发展的观察重点。本质上,Thordata售卖的不是IP地址,而是AI时代数据供应链的“保险”与“效率”,这条路走通了便是刚需,走偏了则易沦为同质化竞争中的一员。
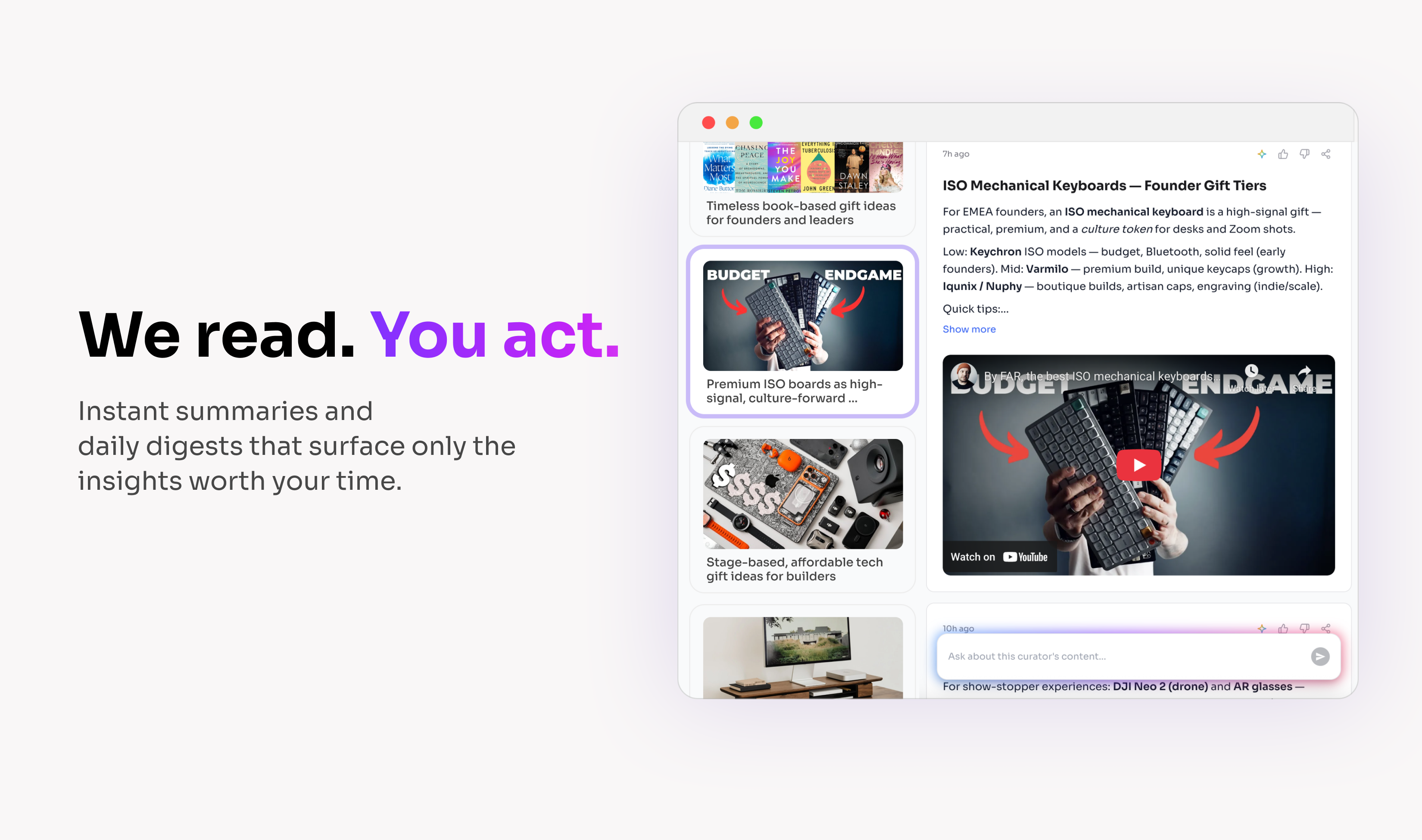
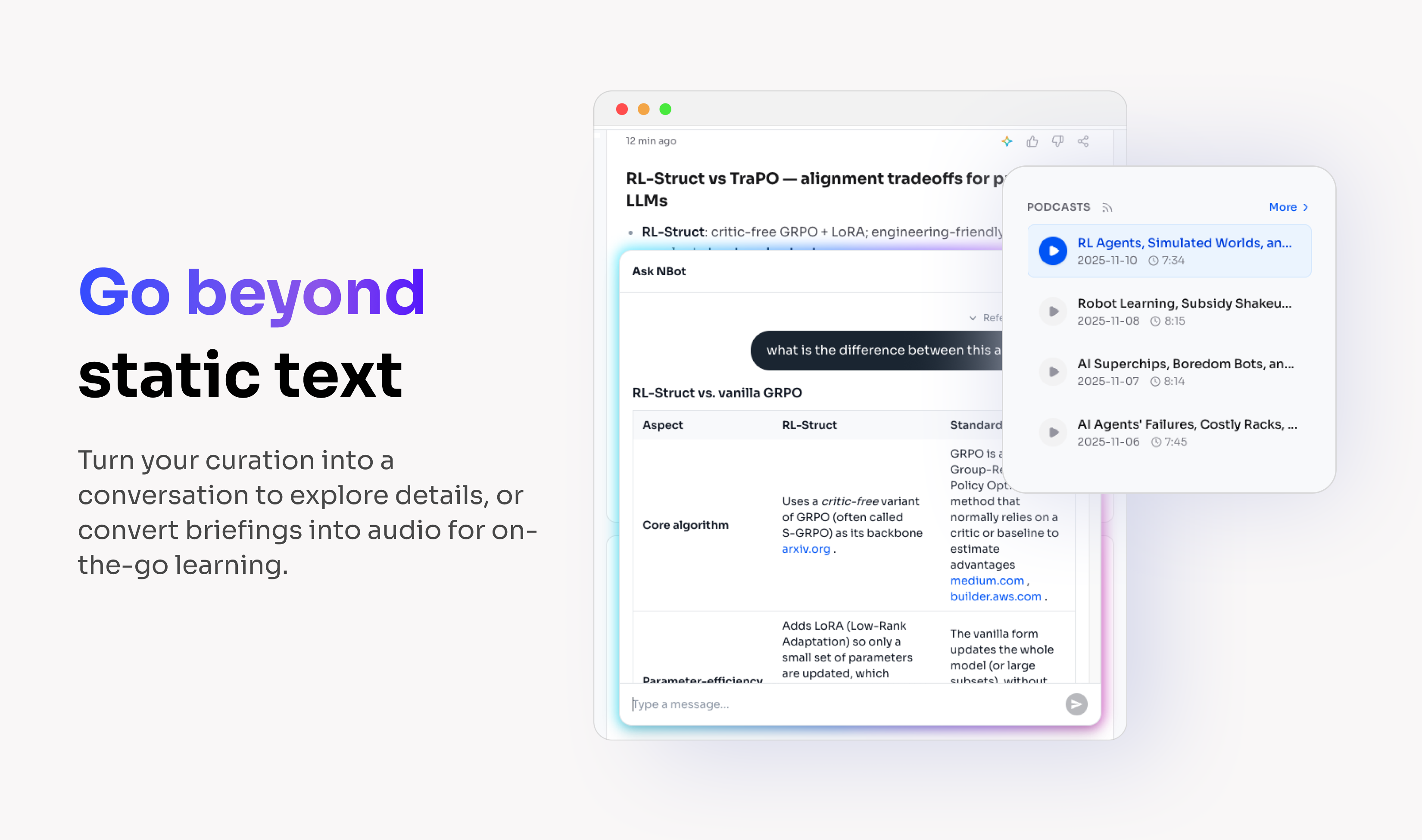
一句话介绍:NBot是一款个人AI信息雷达,通过创建个性化主题追踪器,在信息过载的背景下,自动扫描全网多源内容,滤除99%的噪音,为用户精准呈现其真正关心的1%核心信息,解决了专业人士和兴趣爱好者高效获取、消化碎片化信息的痛点。
Productivity
News
Artificial Intelligence
AI信息过滤
个性化内容推荐
信息聚合
智能简报
知识管理
生产力工具
多源追踪
播客简报
意图驱动
信息过载解决方案
用户评论摘要:用户普遍认可产品解决信息过载的核心价值,赞赏其多源追踪、播客简报等特色功能。主要问题与建议集中在:如何避免信息茧房、增加过滤过程透明度与可控性、开发浏览器扩展以快速保存内容、优化长文阅读体验。
AI 锐评
NBot的亮相,与其说是一款新产品,不如说是对当前主流推荐系统的一次“叛离宣言”。它敏锐地戳中了一个行业悖论:即便拥有强大的算法和百万日活,用户依然因接收不到“对自己真正有价值”的信息而抱怨。这揭示了推荐系统从“猜你喜欢”到“懂你所需”的进化断层。
其真正价值在于将信息获取的主动权从“平台推荐”重新交还给“用户意图”。通过创建专属“Curator”,NBot试图构建一个围绕用户长期、深度兴趣的、具有记忆的AI代理。这不再是简单的关键词订阅,而是一个能理解上下文、积累认知、并进行对话式交互的私人知识库。播客简报功能更是将“信息消费”无缝嵌入碎片化时间,体现了场景化设计的巧思。
然而,其面临的挑战与潜力一样巨大。首当其冲的是“透明性与可控性”的平衡难题。如何让用户信任AI过滤掉的99%确实是噪音,而非关键信号?这要求产品必须在算法黑箱上开一扇窗,提供过滤日志和手动校正机制,否则“避免回声壁”的承诺将难以自证。其次,从“个人雷达”走向“团队协作”的路径虽已显现,但如何管理多人意图下的信息流,将是更复杂的工程。本质上,NBot的终极考验是能否将“个性化”做到极致,同时避免陷入狭隘,这需要AI不仅理解用户的显性指令,更能洞察其潜在的信息需求边界。它的探索,正指向下一代信息获取范式的核心。
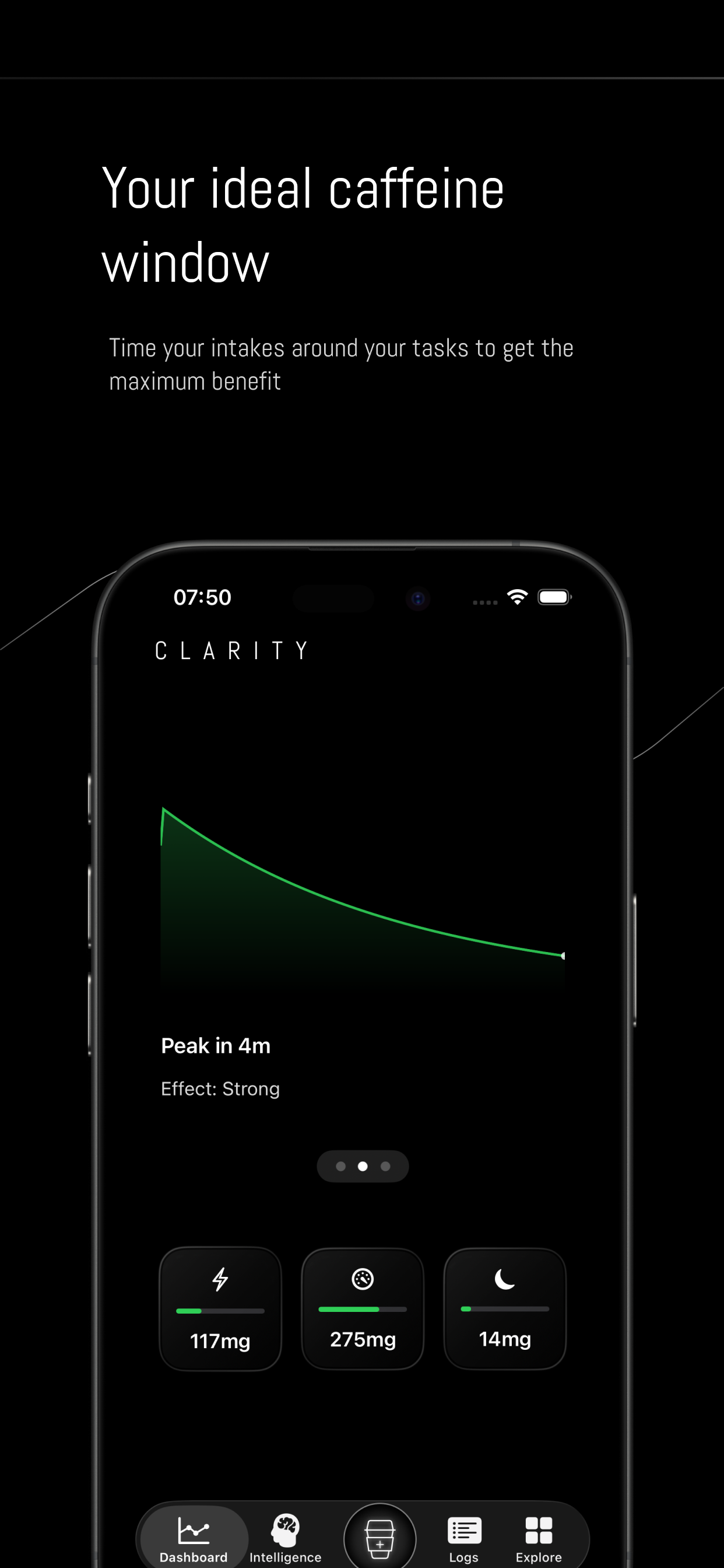
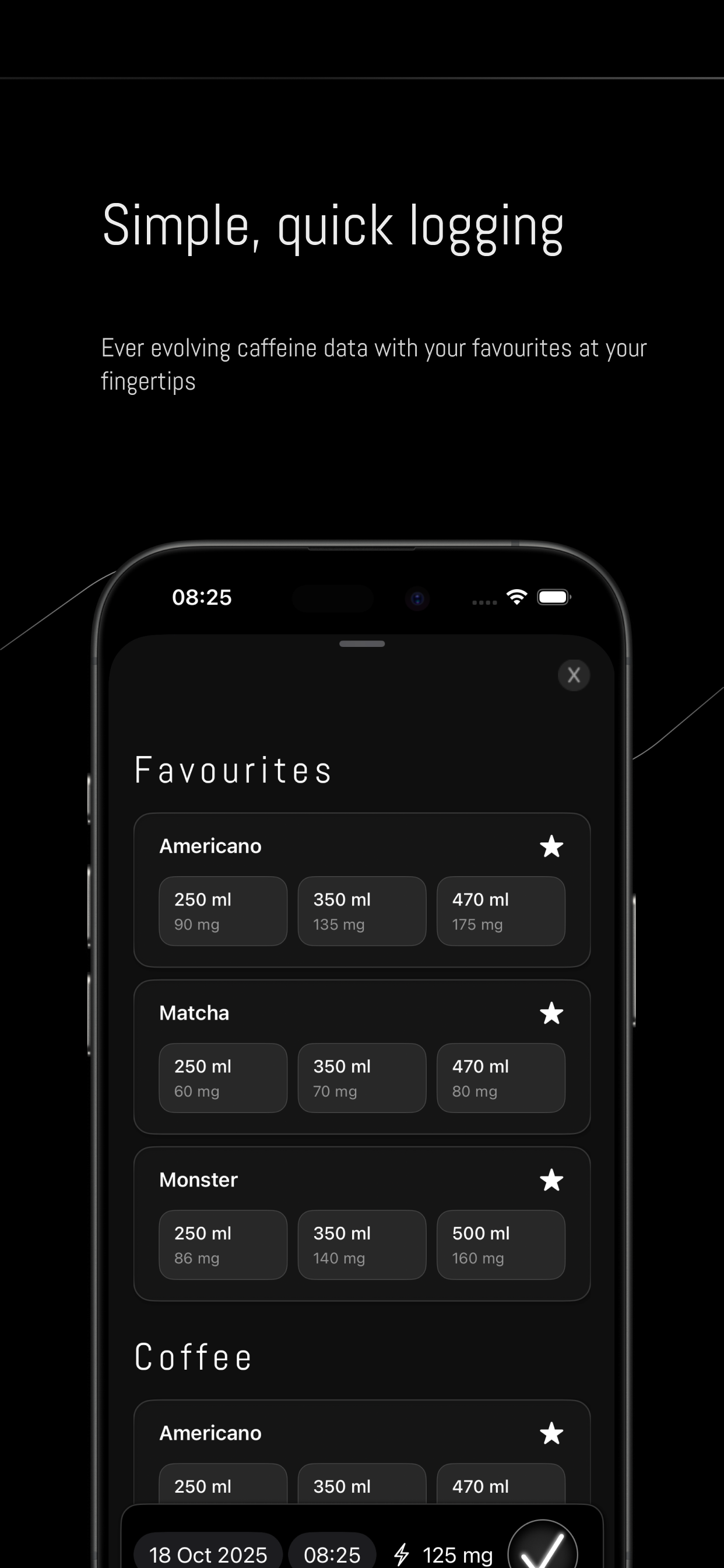
一句话介绍:一款利用设备端AI提供个性化洞察的咖啡因追踪应用,帮助用户在追求工作效率或运动表现等场景下,科学优化咖啡因摄入,避免过量影响睡眠,解决盲目摄入的痛点。
Health & Fitness
Coffee
Apple
健康科技
咖啡因追踪
个性化健康
设备端AI
性能优化
睡眠管理
习惯养成
量化自我
用户评论摘要:用户普遍认可其核心价值:直观可视化咖啡因效果曲线、饮品数据库详实。创始人透露企业合作、个性化模型升级(V2开发中)及“咖啡因重置”等未来路线图。有用户询问模型是否会基于个人敏感性进化,得到肯定答复。
AI 锐评
Clarity的野心远不止于记录。它试图将咖啡因从一种模糊的“提神饮品”成分,解构为一种可量化、可策略性使用的“生物黑客”工具,这是其核心价值跃迁。通过设备端AI分析摄入数据,可视化半衰期与效果曲线,它直接回应了高端用户对“精准优化”的诉求——不是为了少喝,而是为了“喝对”。
然而,其面临的挑战同样尖锐。首先,科学壁垒:咖啡因代谢受基因、耐受度、饮食等多重变量影响,现有模型能否提供足够个性化的“洞察”而非通用结论,是其专业性的试金石。创始人提及的“个体敏感性”模型是正确方向,但需严谨科学背书。其次,场景延伸:从个人工具向企业健康解决方案拓展(如评论中暗示的办公室场景)是聪明的增长策略,但这要求产品从“建议”转向可能的“干预”,涉及更复杂的责任与数据伦理问题。
当前版本更像一个精美的“教育工具”,用于建立认知。其真正的护城河在于,能否将“Clarity Intelligence”迭代为具有预测与主动干预能力的“咖啡因导航系统”,并与穿戴设备、日程深度集成。用户评论中的“合作伙伴”若指向连锁咖啡品牌或健康平台,将极大丰富数据输入维度。总之,它卡位了一个细分但高潜力的需求点,但要从“令人惊艳”到“不可或缺”,仍需在科学严谨性与生态整合上证明自己。
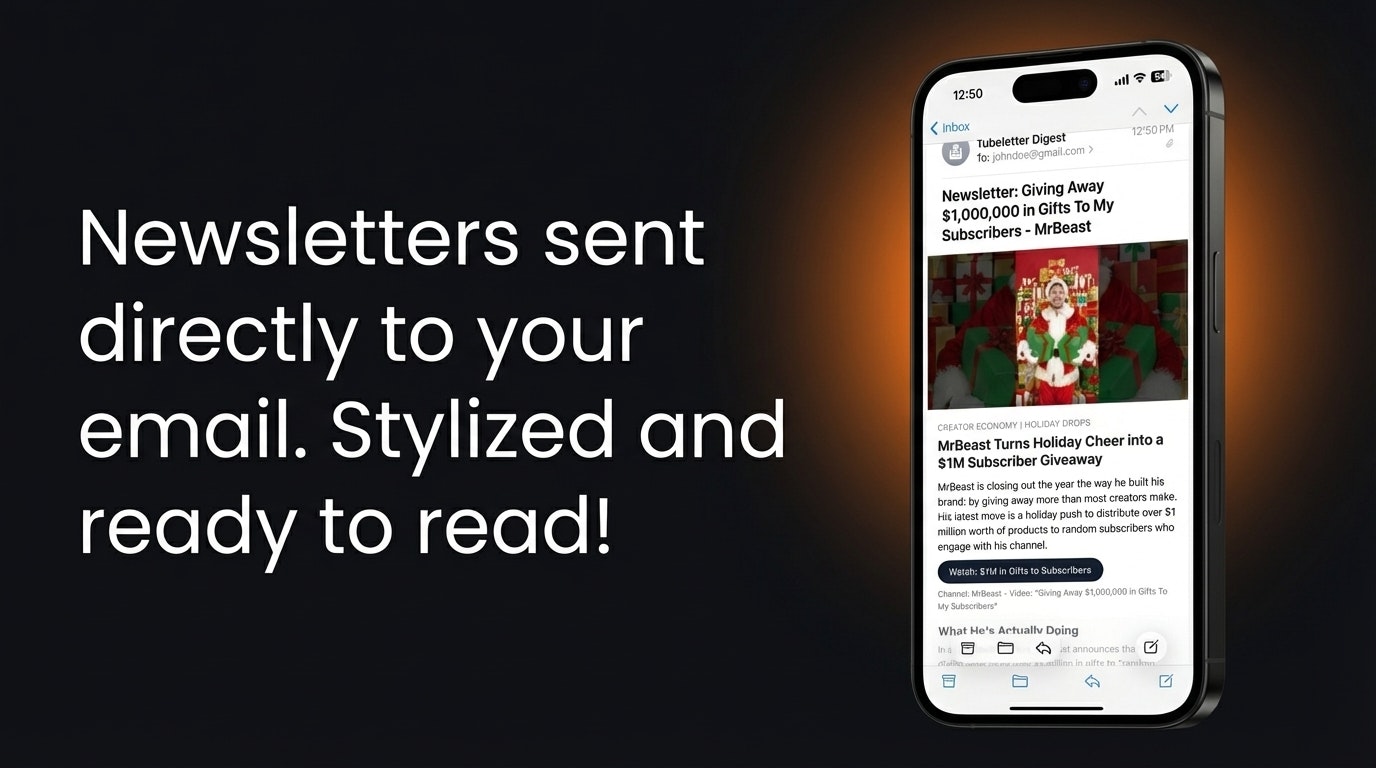
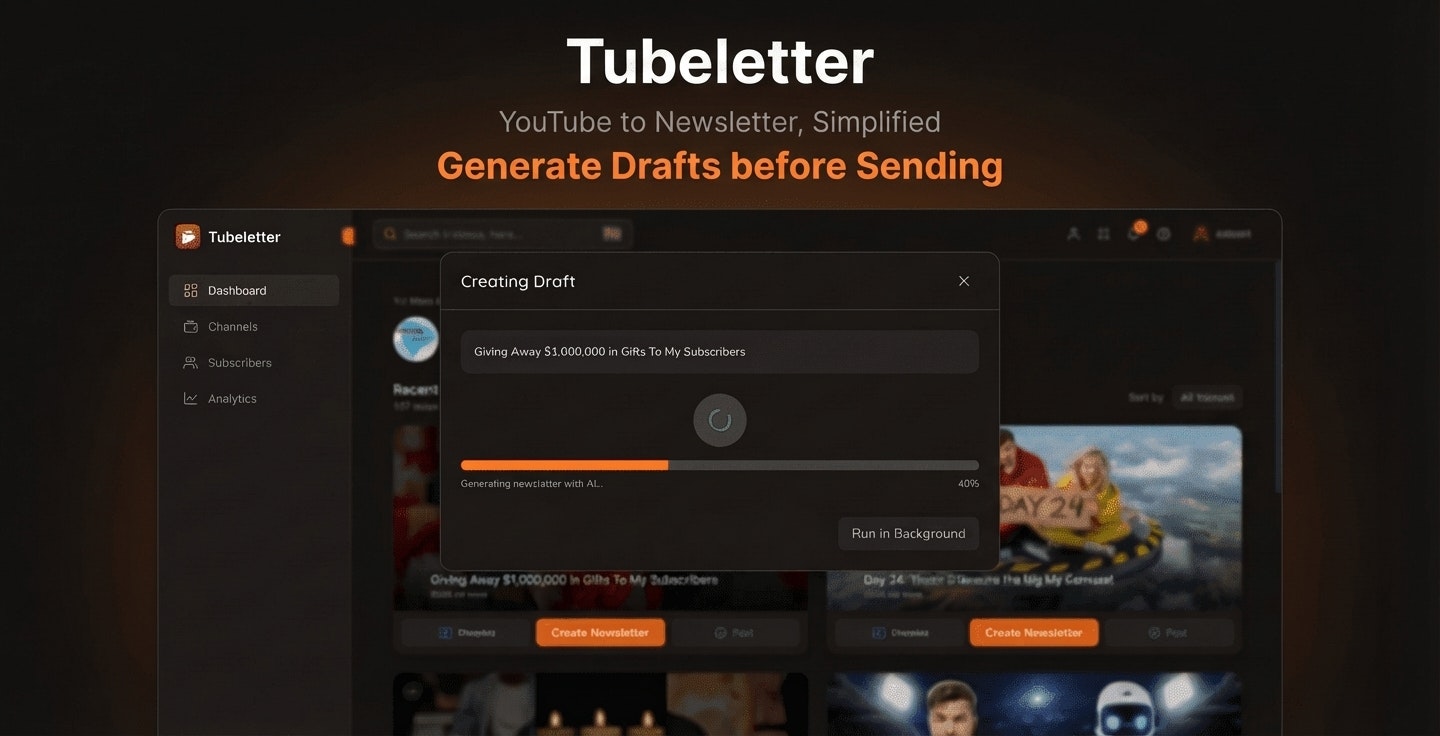
一句话介绍:Tubeletter利用AI将YouTube长视频转化为可订阅的电子邮件简报,帮助内容创作者拓展分发渠道,同时为观众提供无需观看全程的视频信息摘要,解决了信息过载与时间有限的痛点。
Newsletters
Artificial Intelligence
YouTube
AI内容摘要
视频转文字
新闻简报工具
创作者经济
电子邮件营销
内容再生产
信息消化
自动化工具
YouTube生态
SaaS
用户评论摘要:用户肯定其核心价值,认为适合忙碌的内容消费者。主要反馈包括:关心简报可读性与排版格式;询问产品定位(服务创作者还是观众);建议探索Telegram等推送渠道;开发者自述源于个人需求。
AI 锐评
Tubeletter看似是又一个“AI+内容再生产”工具,但其真正价值在于精准切入了一个被忽视的中间层市场:非文本原生创作者的内容文本化需求。它并非简单做视频转录,而是试图成为连接视频内容与邮件订阅习惯的“格式转换器”。
产品巧妙地扮演了双重角色:对观众,它是“时间压缩器”,将动辄一小时的长视频榨取出核心信息,迎合了当代人碎片化吸收深度内容的需求;对创作者,它则是“渠道拓展器”,将视频平台的订阅关系低成本迁移至邮件列表,这实则是为创作者构建了抗平台算法波动的私有化触点。开发者自述源于个人投资视频摘要需求,这揭示了产品的真实起点——它解决的是信息效率问题,而非创作问题。
然而,其深层挑战也在于此。首先,从视频到文本的“损耗”不可避免,AI摘要能否保留原作的叙事魅力与细微观点存疑,这可能让简报沦为干瘪的要点罗列。其次,评论中关于排版和可读性的担忧直击要害:产品若仅提供通用模板,其体验将难以匹敌专业编辑的精品邮件,价值大打折扣。最后,其商业模式存在隐忧:作为中间件,它既依赖YouTube的API稳定性,又受制于邮件送达率等传统问题,且在推送渠道上已被用户建议拓展至Telegram,这反衬出电子邮件作为承载媒介可能并非最优选。
总体而言,Tubeletter的价值不在于技术突破,而在于场景定位。它能否成功,不取决于AI摘要的准确度,而取决于它能否成为视频创作者“观众关系管理”工作流中不可或缺的一环,并提供足够优雅、可定制的邮件体验。否则,它很可能只是一个有趣但可被替代的自动化小工具。
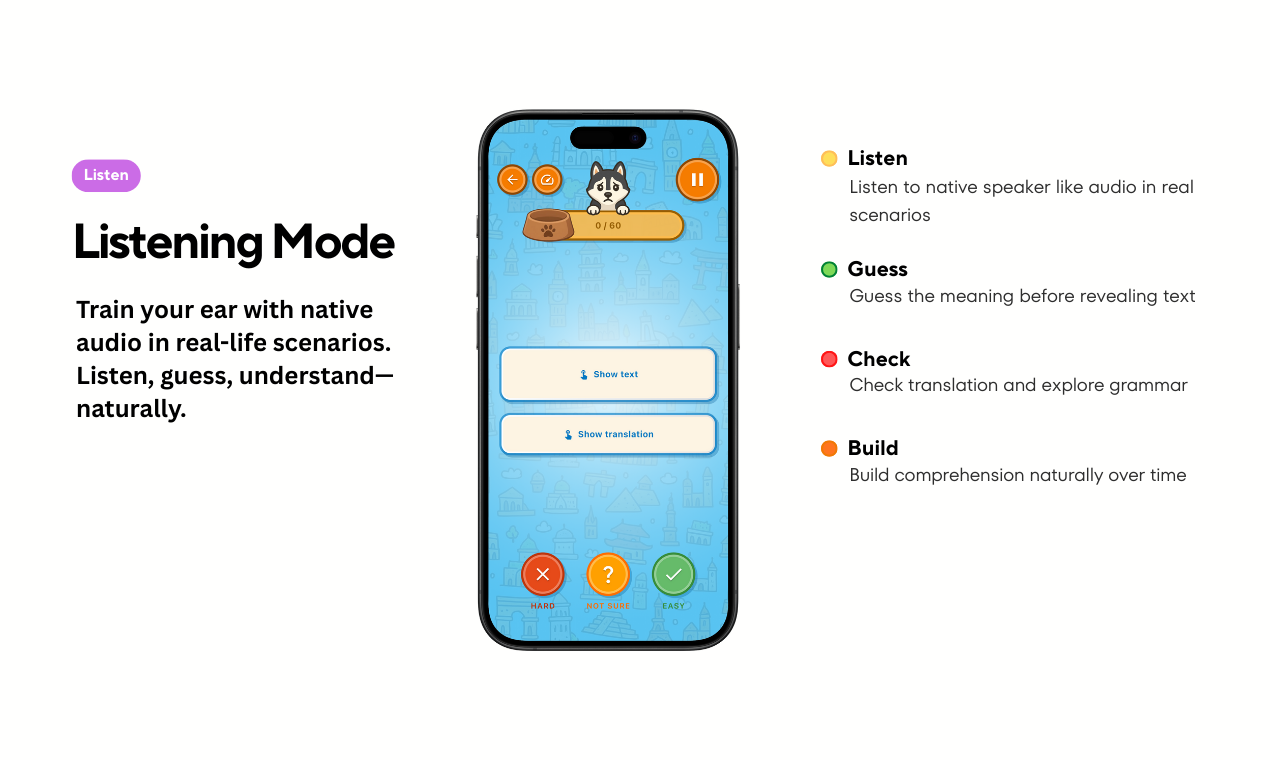
一句话介绍:Erla是一款AI驱动的语言学习APP,通过5-10分钟的短课程、真实场景音频和交互式阅读,解决学习者在实际对话中因听不懂而“卡住”的核心痛点,强调理解先行。
Education
Languages
语言学习
AI教育
理解优先
真实场景
短时课程
交互式阅读
去游戏化
多语言支持
独立开发
效率工具
用户评论摘要:创始人自述产品源于自身学习挫败感,强调“理解优先”理念获共鸣。用户认可其解决真实痛点的初衷。主要建议是推出网页版以拓展至教学场景,创始人已回应正在开发。
AI 锐评
Erla的“理解优先”理念,直击了当前主流语言学习APP的核心软肋:用游戏化机制和碎片化练习制造“进步幻觉”,却牺牲了真实的、可迁移的听力与阅读理解能力。其产品设计——真实场景音频、可点击解析的短篇阅读——本质上是将“可理解性输入”理论进行了标准化、数字化的封装,路径正确。
然而,其真正的颠覆性可能不在前端教学法,而在后端近乎“粗暴”的规模化策略。为22种语言生成独立APP,以矩阵形式覆盖市场,这并非简单的本地化,而是对传统“一个平台承载多语种”模式的解构。这揭示了独立开发者的一种生存智慧:在巨头林立的赛道,通过技术自动化(自动生成与发布)将边际成本降至极低,用数量博取概率,在细分市场和长尾语言中寻找巨头无暇顾及或模式不兼容的缝隙机会。这是一种产品策略与增长策略的深度捆绑。
风险同样明显。产品体验的深度与一致性将面临巨大挑战,AI生成内容的质控是关键命门。其“去游戏化”的纯粹性是一把双刃剑,在获取深度用户的同时,可能牺牲了大众市场的留存钩子。创始人将“1万美元月经常性收入”视为人生改变,也坦诚了其作为副项目的规模边界。Erla更像一个精心设计的“特洛伊木马”,其内核是对语言学习本质的回归,但其外壳(22个APP矩阵)则是一场关于注意力与流量的精益实验。它能否成功,不在于理念是否先进,而在于这套“小而多”的自动化体系,能否在特定语言的学习者社群中形成足够深的口碑穿透。
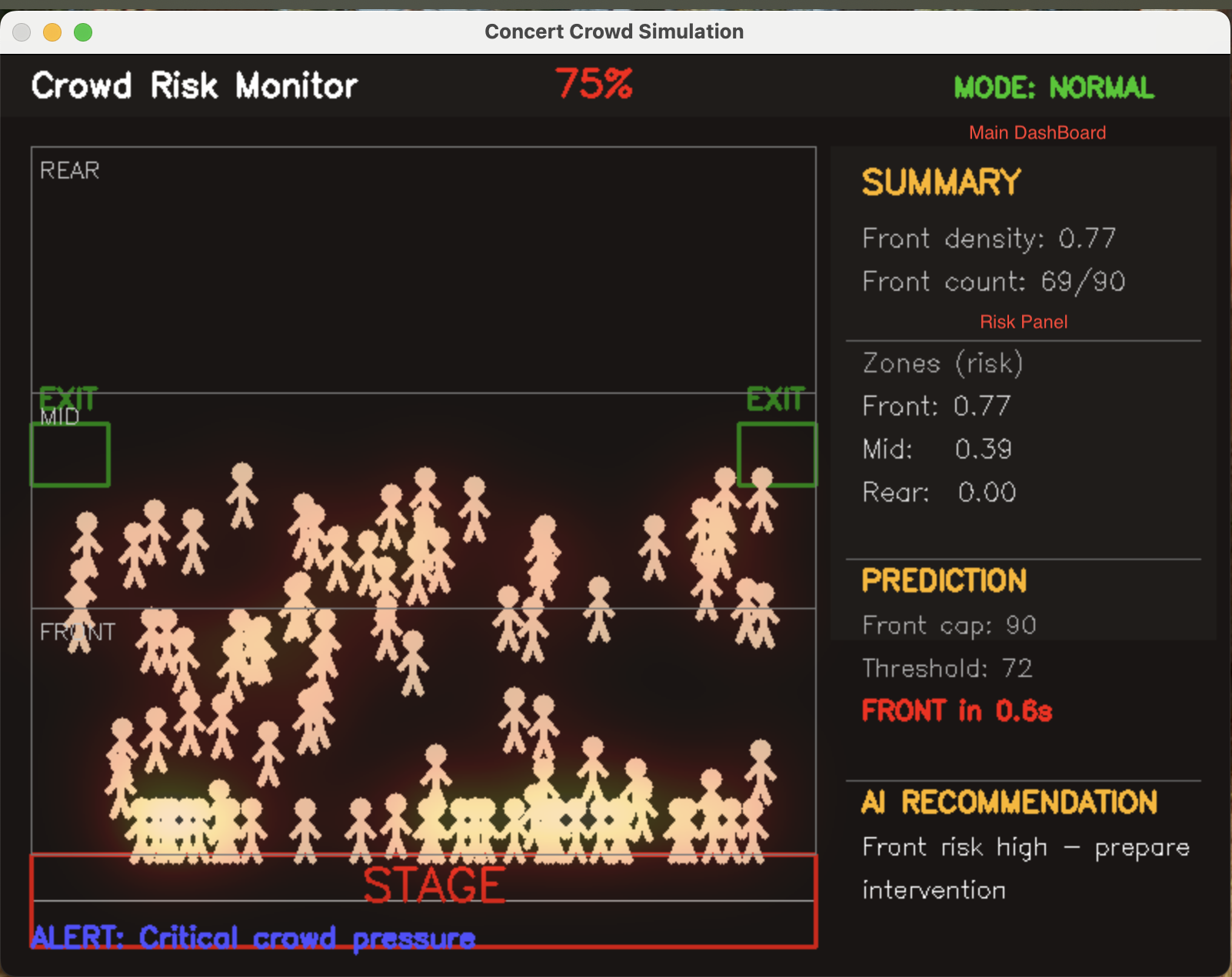
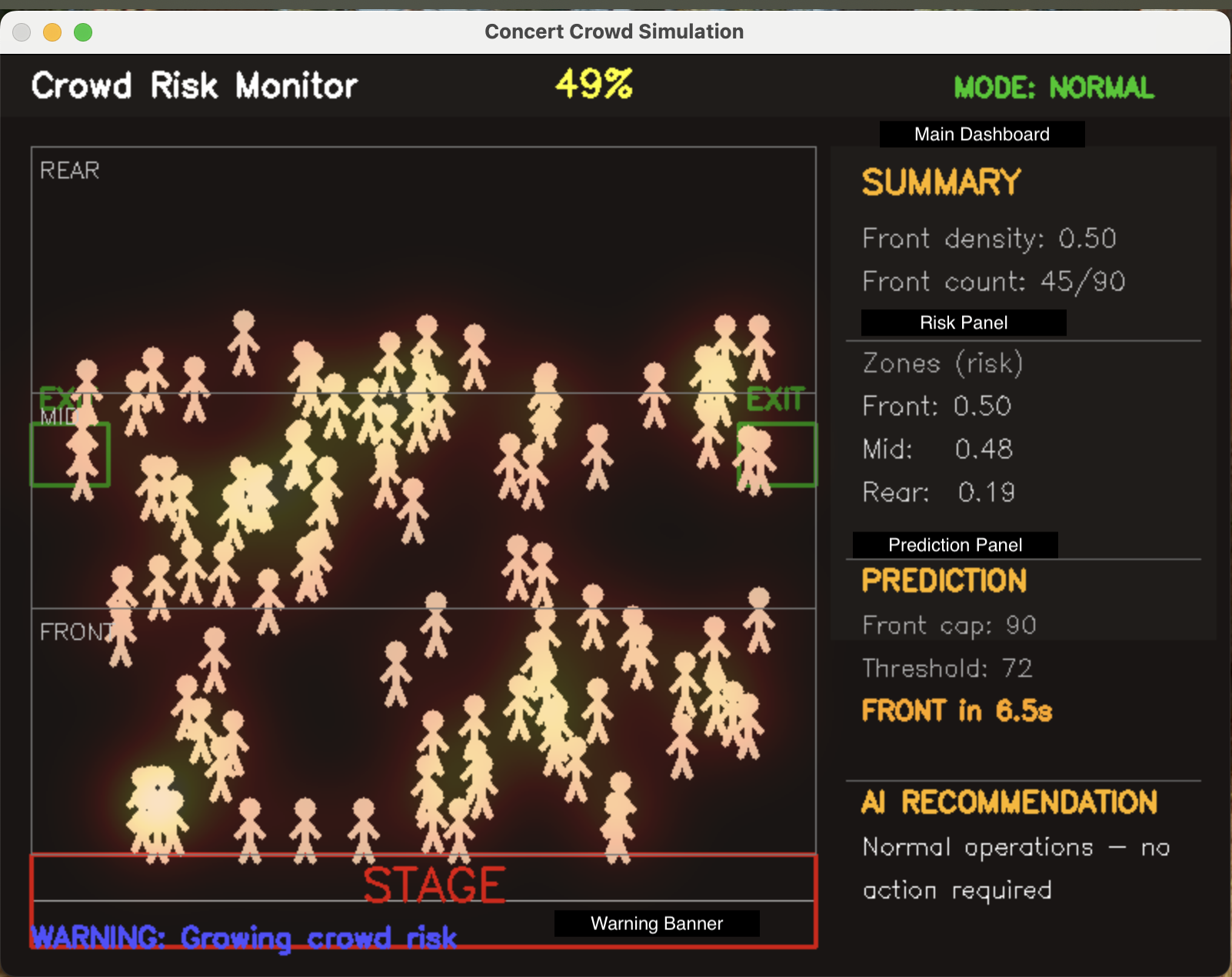
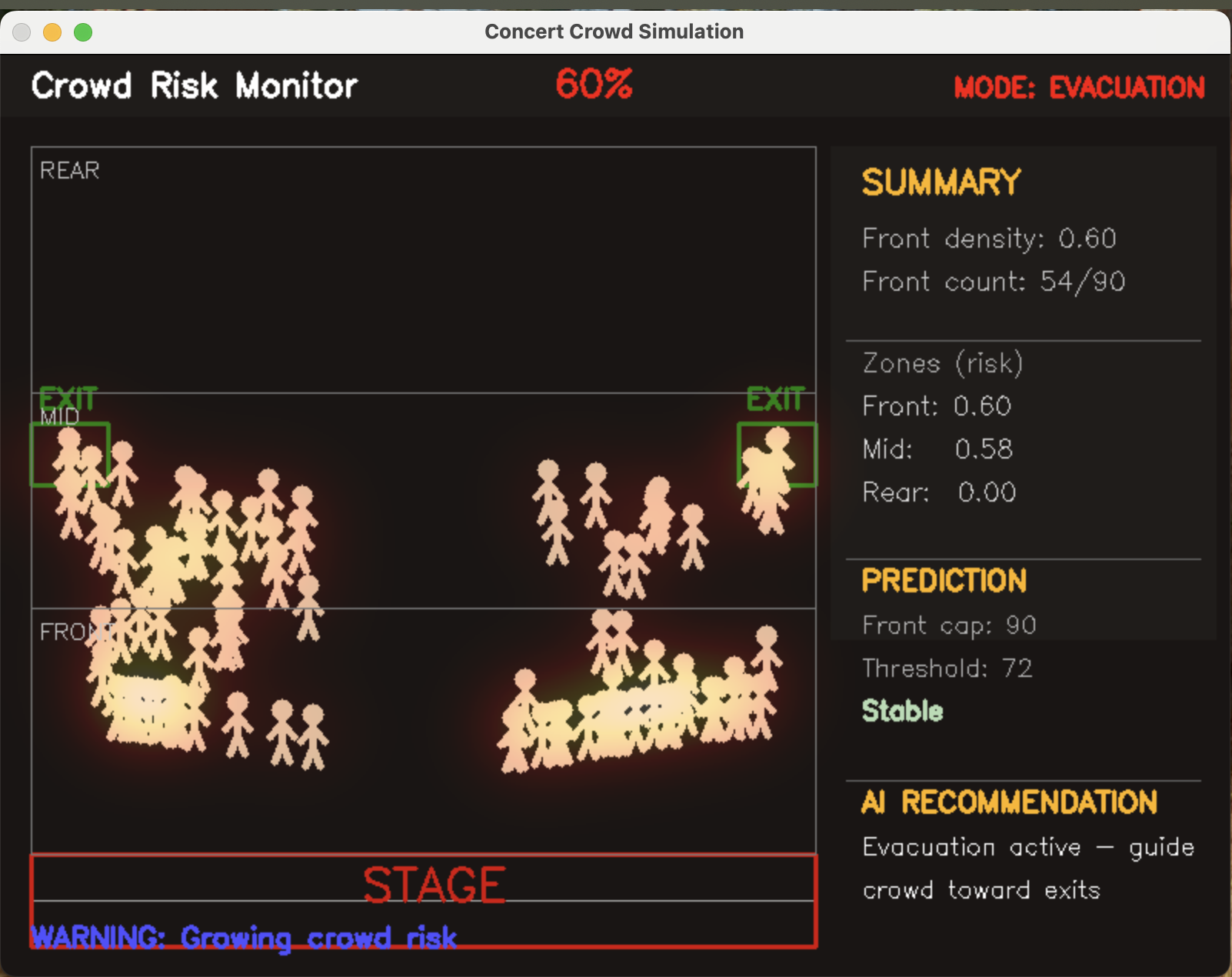
一句话介绍:CrowdSynthetic是一款开源AI人群安全模拟器,通过在演唱会、体育赛事等大型活动前预测和可视化人群拥堵,帮助组织者主动预防踩踏等安全事故,从被动应对转向主动风险管理。
Open Source
Simulation Games
Artificial Intelligence
GitHub
人群安全
AI模拟
开源软件
实时热图
风险评估
疏散逻辑
活动管理
公共安全
预测分析
本地部署
用户评论摘要:开发者阐述了产品初衷是变被动安全为主动预测。有用户从访客视角提出,该工具可像谷歌拥挤度功能一样帮助个人规划出行,避免过度拥挤。开发者回应称此视角拓展了产品价值,使其兼具服务组织者与公众的双重潜力。
AI 锐评
CrowdSynthetic切入了一个高社会价值但技术渗透率低的领域——公共聚集性活动的人群安全管理。其核心价值并非简单的“预测拥堵”,而在于将安全管理的范式从“事后应急响应”前置为“事前模拟推演”。通过开源、本地部署的方式,它试图解决此类敏感数据上云的信任与合规门槛,这是其切入市场的明智策略。
然而,其真正的挑战与价值深度并存。第一层价值是工具性的,即通过热图和风险评分提升组织者的态势感知能力。但更深层的价值应在于其“自动化疏散逻辑”——这意味系统需与物理基础设施(闸机、广播、指示灯)深度集成,从“驾驶舱仪表盘”升级为“自动驾驶系统”,这对产品的工程化、可靠性及责任界定提出了极高要求。
评论中透露的消费者端需求(如个人规划)是一个有趣的岔路,但可能分散其核心焦点。To B的安全工具与To C的便利服务在数据精度、实时性要求和商业模式上截然不同。产品目前最大的优势是开源带来的透明性与可定制性,适合在特定垂直场景(如寺庙、音乐节)深耕,建立可信案例。但若想成为行业标准,则需构建经过大量真实数据验证的、远超经验判断的预测模型,这将是其面临的最严峻技术考验。它不是一个能快速盈利的“爆款”,而是一个需要长期投入、建立生态的“基础设施型”产品。
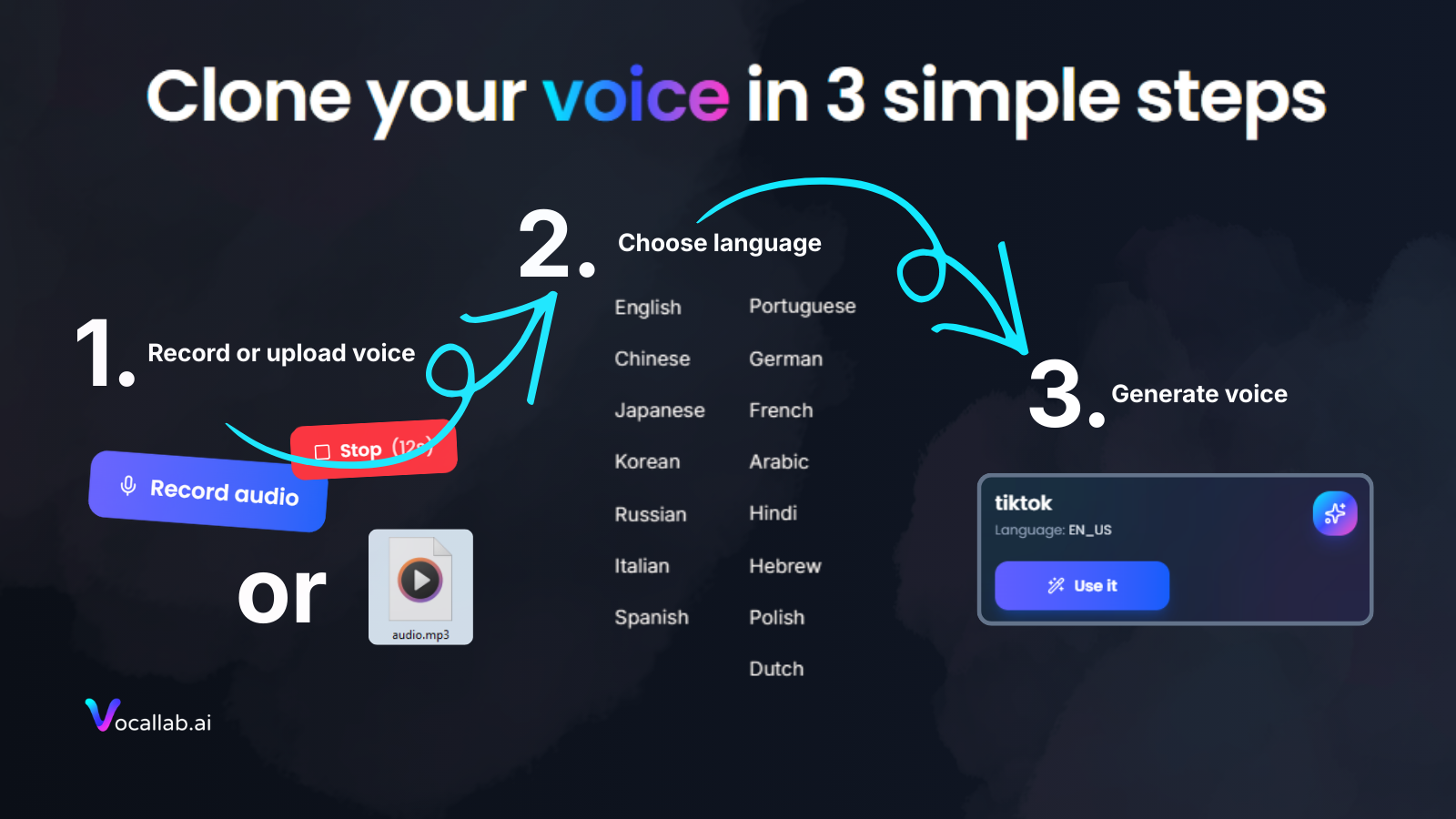
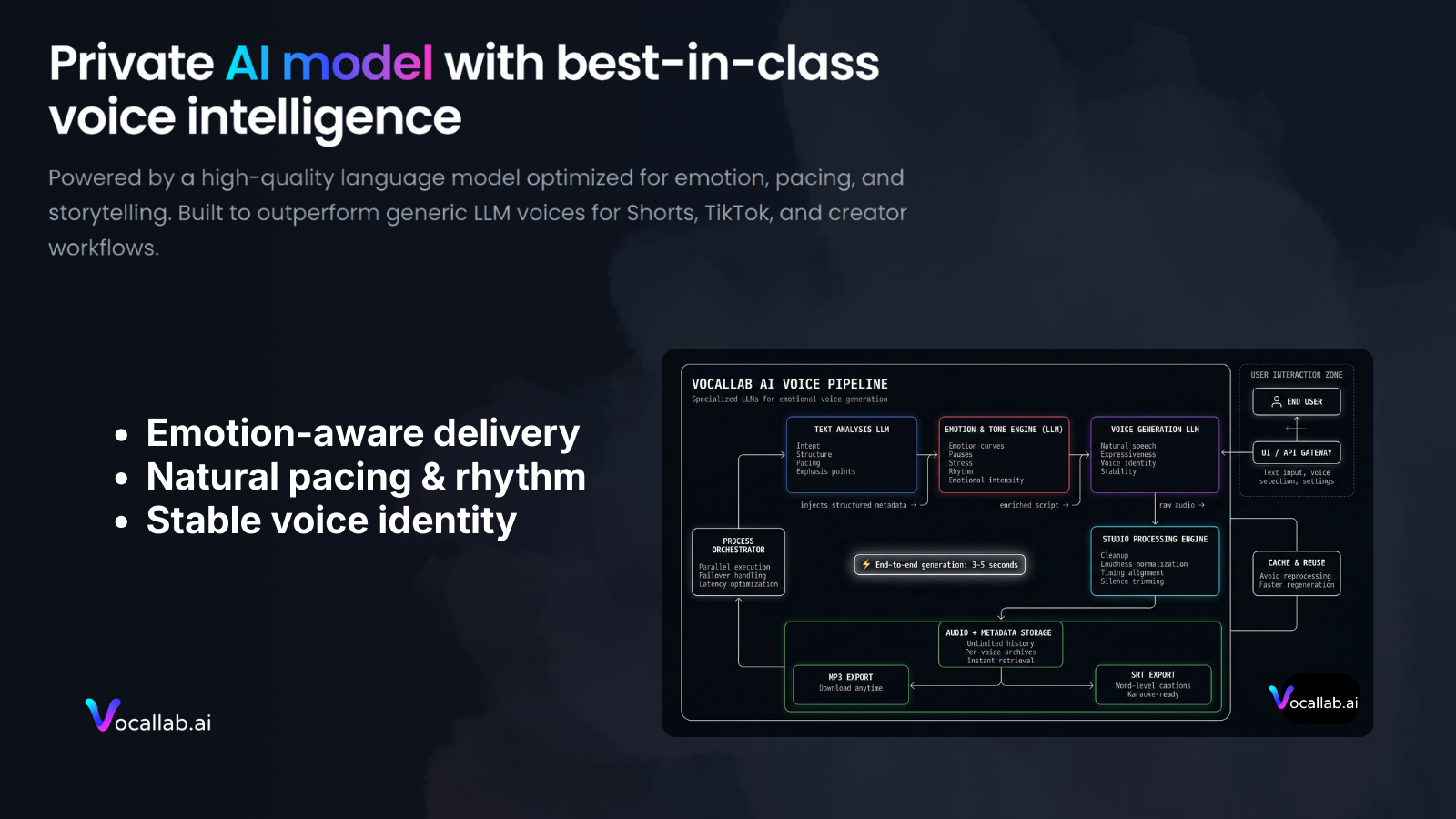
一句话介绍:VocalLab.ai 是一款为短视频创作者打造的AI语音克隆与合成工具,通过提供无限免费克隆、一键导出音轨及字幕,解决了短内容创作中音频制作耗时、流程繁琐的核心痛点。
Social Media
Artificial Intelligence
Audio
AI语音克隆
文本转语音
短视频创作
内容创作者工具
音频处理
字幕生成
免费增值
效率工具
社交媒体内容制作
用户评论摘要:用户普遍认可其操作简便、对短视频工作流友好,尤其赞赏一键导出MP3和SRT字幕的功能。主要建议是未来能增加针对短视频的语速、语调等预设模板,以进一步提升效率。
AI 锐评
VocalLab.ai 精准切入了一个喧嚣赛道中一个被忽视的缝隙:为海量的、追求极致效率的短视频创作者提供“免费无限量”的AI语音基础设施。其真正的颠覆性不在于语音克隆技术本身(这已是红海),而在于其激进的产品策略和精准的场景化封装。
它将“免费、无限、无水印”作为核心卖点,直击中小创作者的成本敏感和版权焦虑痛点,本质上是以近乎基础设施的方式快速获取用户,构建壁垒。一键导出MP3+SRT的设计,更是将“音频生产”与“字幕生产”两个割裂的流程强行耦合,直接输出内容生产的半成品,大幅缩短了从文案到成片的路径。这看似微小的创新,实则是深刻理解短视频工业化生产流水线后的精准手术。
然而,其商业模式与长期价值存疑。在昂贵的AI算力成本下,“无限免费”犹如悬顶之剑,要么依赖烧钱换增长,后续通过高级功能或增值服务变现,要么可能在数据隐私或语音版权上留有后手。此外,其功能高度聚焦于“短内容”,场景单一,护城河并不深。一旦巨头旗下的剪辑工具(如CapCut、Premiere Pro)将类似功能以模块化形式集成,其独立工具的价值将迅速被稀释。
当前的成功,是产品定位与市场时机结合的产物。它能否从“锋利的功能点”成长为“可持续的平台”,取决于其能否在耗尽初始红利前,快速迭代出更深的工作流整合能力,或构建独特的语音资产生态,否则很可能只是又一个叫好但难以叫座的流星式产品。
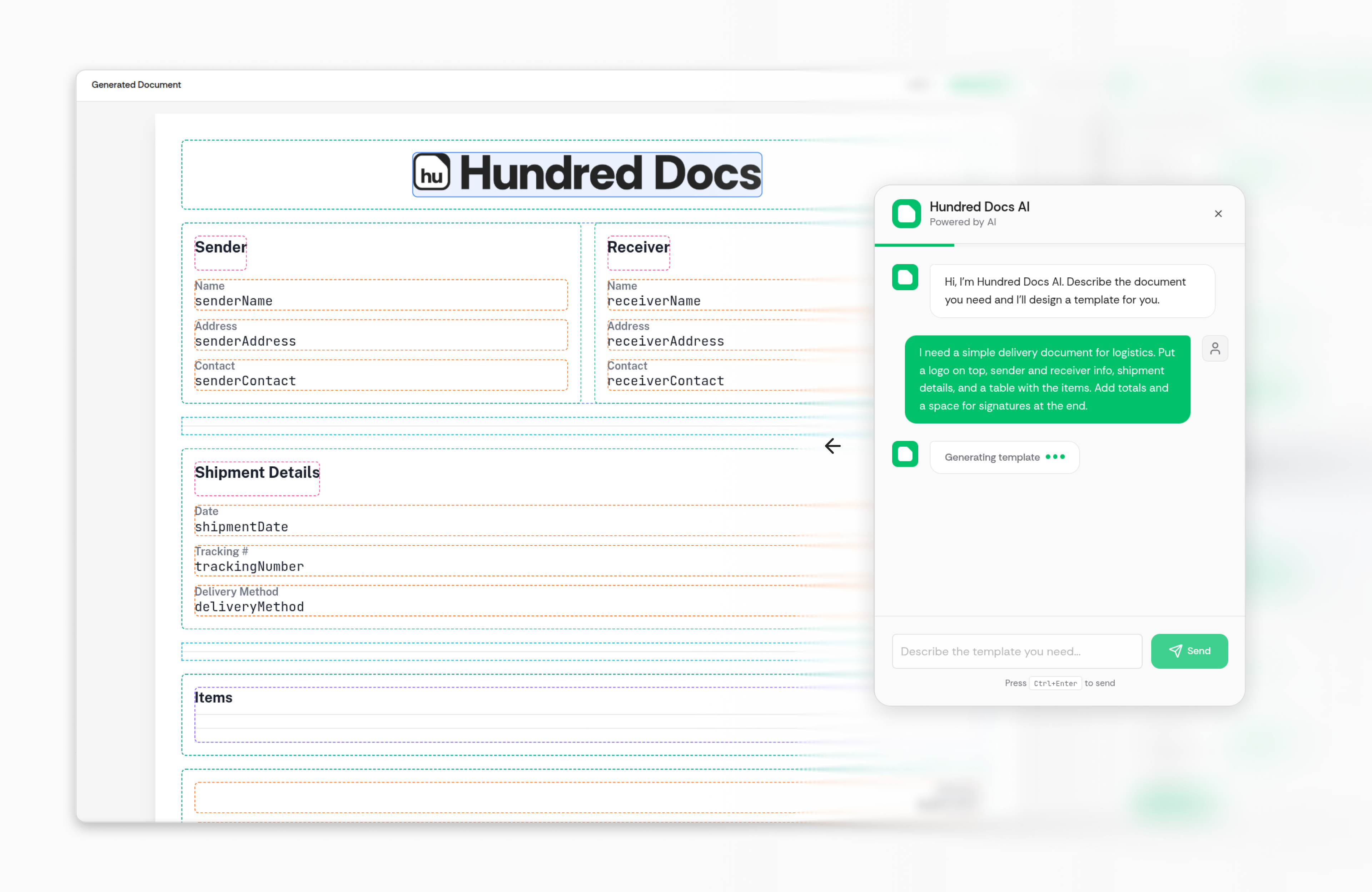
一句话介绍:一款AI驱动、API集成的文档模板设计工具,通过分离文档设计与数据填充,解决了开发者在处理复杂PDF生成时集成困难、与非技术团队协作效率低下的痛点。
API
SaaS
Artificial Intelligence
AI文档设计
PDF生成API
无代码编辑
开发效率工具
技术非技术协作
文档模板引擎
云原生
SaaS
自动化工作流
用户评论摘要:用户反馈高度认可其“分离关注点”的设计理念,开发者赞赏其能避免纠缠于PDF库和布局,专注于业务逻辑;非技术用户则看重其可视化编辑能力。核心价值被普遍认为是提升了协作效率与系统可扩展性。
AI 锐评
Hundred Docs 精准地切入了一个细分但顽固的痛点:企业级PDF文档的自动化生成与协作。其真正的价值并非简单的“AI生成模板”,而在于构建了一个清晰的权责分离架构——将易变的、审美驱动的文档布局交给非技术团队通过可视化界面维护,而将稳定的、逻辑驱动的数据填充交给开发者通过API完成。这本质上是一个“协作中间件”。
产品聪明地利用了AI作为降低模板创建门槛的入口和营销亮点,但其核心壁垒和长期价值可能在于其设计的API抽象层与数据模型。它让开发者从iText、PDFKit等重型库的集成噩梦中解脱,其宣称的“避免痛苦集成”直击开发者要害。然而,其面临的挑战也同样明显:作为一款面向B端的产品,其场景的深度和复杂性(如法律合同、动态表格、高性能批量生成)能否经得起考验?与现有工作流(如CRM、ERP)的集成生态是否完善?其AI模板生成的精准度和可控性在复杂文档中能保持多少实用性?
当前评论呈现出一边倒的早期采纳者好评,这验证了产品概念的市场需求,但缺乏对实际使用中边界案例的质疑。它更像是一个“开发者体验优先”的工具,其成功将取决于能否在保持API简洁性的同时,覆盖足够多的企业级文档场景,并构建起非技术用户真正爱用的设计器。如果它能做到,其价值将远超一个工具,而成为企业文档流水线中不可或缺的标准化层。
一句话介绍:LyftMyApp是一个开发者协作测试平台,通过“以测试换测试”的模式,解决了独立或小型开发者在产品早期难以获取真实、快速、可执行反馈的痛点。
SaaS
Developer Tools
开发者协作
应用测试
SaaS测试
用户体验反馈
产品验证
互助平台
同行评审
产品迭代
用户评论摘要:创始人阐述了解决开发者获取真实反馈难的初衷。用户普遍认可其“互助激励”模式对缺乏用户基础的小开发者的价值,认为这是刚需。同时,有评论提出了核心挑战:如何确保参与者提供深入、非敷衍的反馈质量。
AI 锐评
LyftMyApp试图构建一个“开发者乌托邦”——一个纯粹由建设者为建设者提供高质量反馈的闭环社区。其核心价值主张犀利地切中了现代应用开发,尤其是独立开发领域的最大软肋:在冷启动和早期迭代阶段,真实用户反馈的稀缺与低效。传统的“有机获取”或向朋友征集反馈的方式,要么缓慢且不可控,要么因人情关系而失真。
平台“交换劳动”的互惠模式设计是聪明的,它试图用内在的、对等的利益驱动(你想获得反馈,就必须付出反馈)来替代金钱激励或道德呼吁,以此保障社区的活跃与供给。这比单纯的论坛或征集帖更具结构性。
然而,这正是其最大的阿喀琉斯之踵。该模式的成功完全依赖于一个脆弱的前提:所有参与者都具备高度的专业自觉,并愿意为他人投入与自己期望等价的、认真的测试精力。一条用户评论“Could work if people give real effort and not rushed feedback”直接刺破了这层理想面纱。在缺乏强约束和评价体系的情况下,平台极易滑向“敷衍互刷”的陷阱,导致反馈质量稀释,最终沦为另一种形式的“噪声”。当高质量贡献者发现所得反馈浅薄无用后,他们会迅速离开,引发社区质量的螺旋式下降。
因此,LyftMyApp的真正战场并非功能开发,而是社区治理与机制设计。它需要构建一套能识别、奖励深度反馈,筛除敷衍行为的信用或质量评估体系。其最终提供的真正产品,不是一个功能平台,而是一个可持续、高信任度的“专业同行评审网络”。若能攻克此关,它将从一个简单的工具升级为极具价值的开发者基础设施;若不能,则可能只是又一个充满美好愿景却难以逃脱人性博弈的实验场。
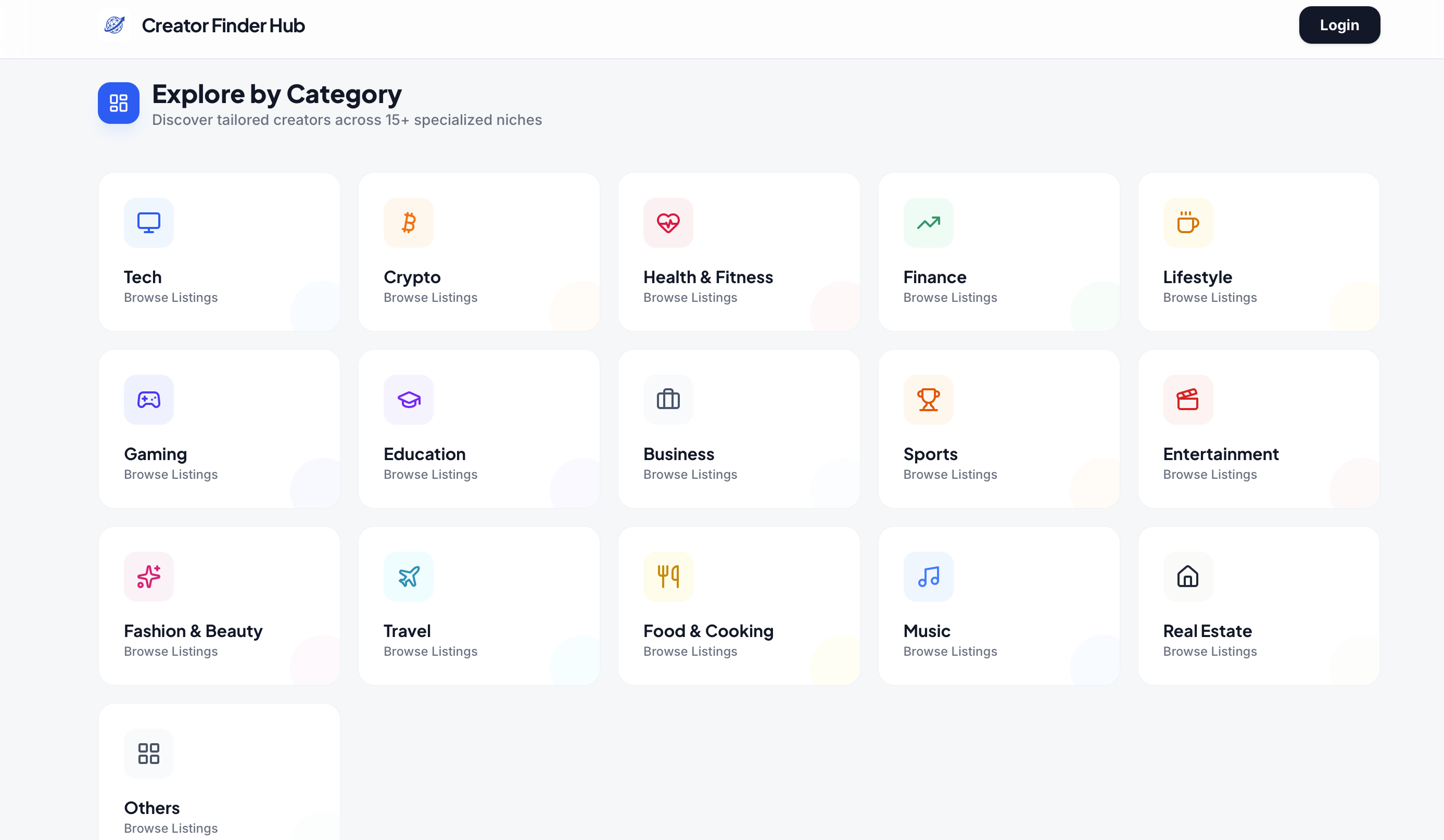
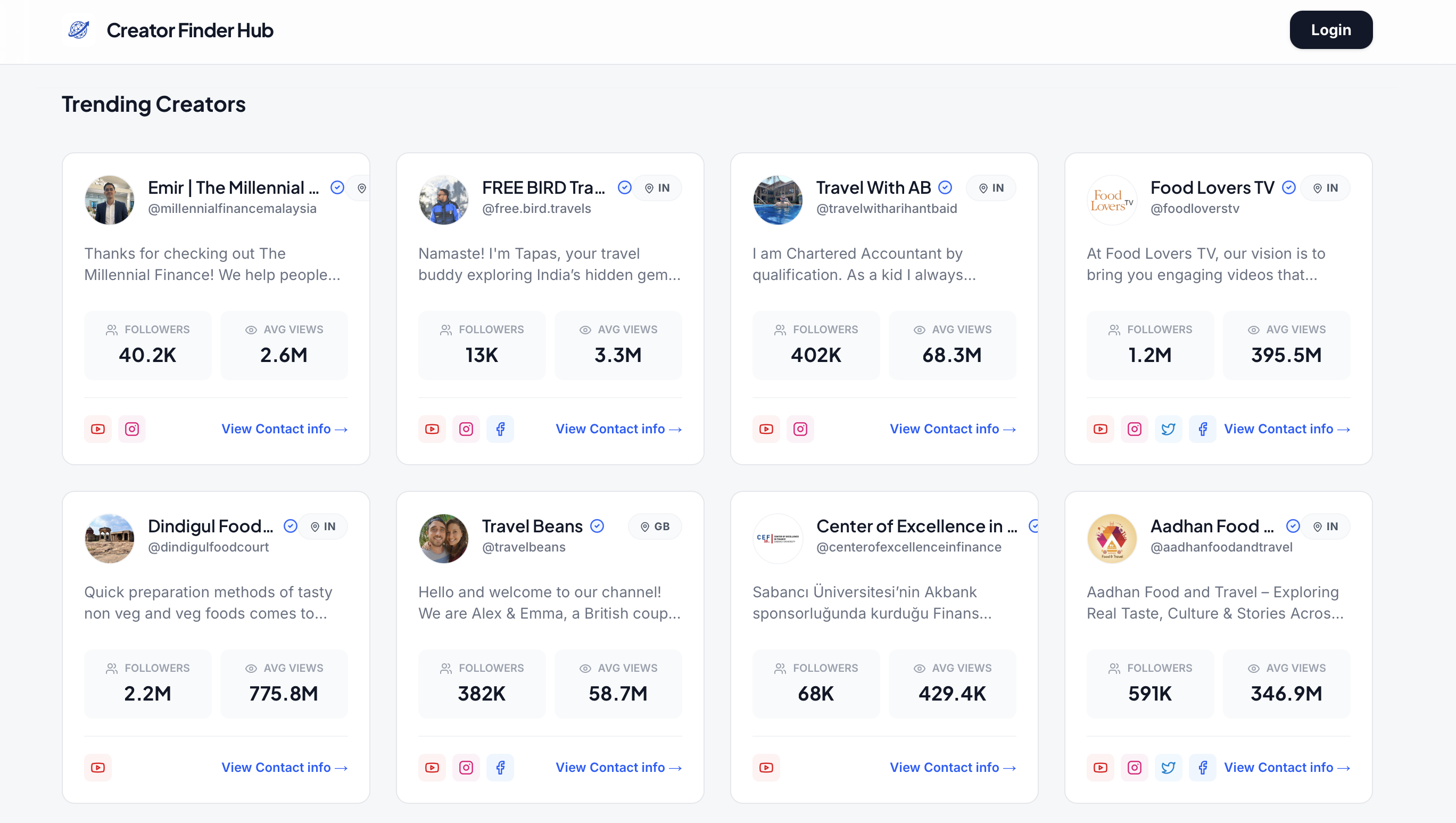
一句话介绍:一款集创作者发现、数据查看与联系功能于一体的平台,为营销人员、创始人和机构解决了跨多个垂直领域寻找合适内容创作者时,信息分散、筛选耗时费力的核心痛点。
Marketing
Influencer marketing
创作者发现平台
网红营销
影响力者目录
营销工具
创作者数据库
垂直领域搜索
营销数据分析
联系人管理
营销自动化
B2B SaaS
用户评论摘要:用户认可产品概念的价值,认为能解决过往手动寻找的低效痛点。主要反馈集中在数据新鲜度的疑问、对更多筛选功能的期待,以及希望了解其重点覆盖的细分领域。
AI 锐评
Creator Finder Hub 瞄准的是网红营销中“发现”环节的标准化与效率化需求,其本质是一个试图将非标信息(创作者)进行结构化、数据化处理的B2B目录工具。它的真正价值并非技术创新,而在于对“脏活累活”的整合——将散落在社交媒体、个人主页和电子表格中的碎片信息聚合,并提供基础的筛选维度。
然而,其面临的挑战同样尖锐。首先,数据的“质”与“鲜”是生命线。评论中关于数据新鲜度的疑问直击要害。创作者数据(粉丝量、互动率、联系方式)变动频繁,维持高更新频率意味着高昂的运营或数据采购成本,这对初创产品是巨大考验。其次,产品的护城河较浅。其功能框架易于复制,且严重依赖于上游平台(如Instagram, YouTube, TikTok)的公开数据接口政策,存在外部风险。最后,从“发现”到“合作”的链条很长。提供联系方式仅是第一步,更关键的定价、案例、合作意愿、效果评估等深度信息,才是决定营销人员决策的核心,目前产品尚未触及这些高价值环节。
因此,该产品在当前阶段更像是一个“功能型工具”,而非“解决方案型平台”。它的短期价值在于为特定垂直领域(如Tech, Crypto)的营销人员提供一个快捷的起点,但若不能快速构建起数据动态更新能力、向交易撮合或效果分析等环节延伸,或建立起活跃的创作者社区生态,将很容易陷入同质化竞争,或被更大型的营销云平台以功能模块的形式覆盖。其成功与否,取决于执行深度与资源速度,而非创意本身。
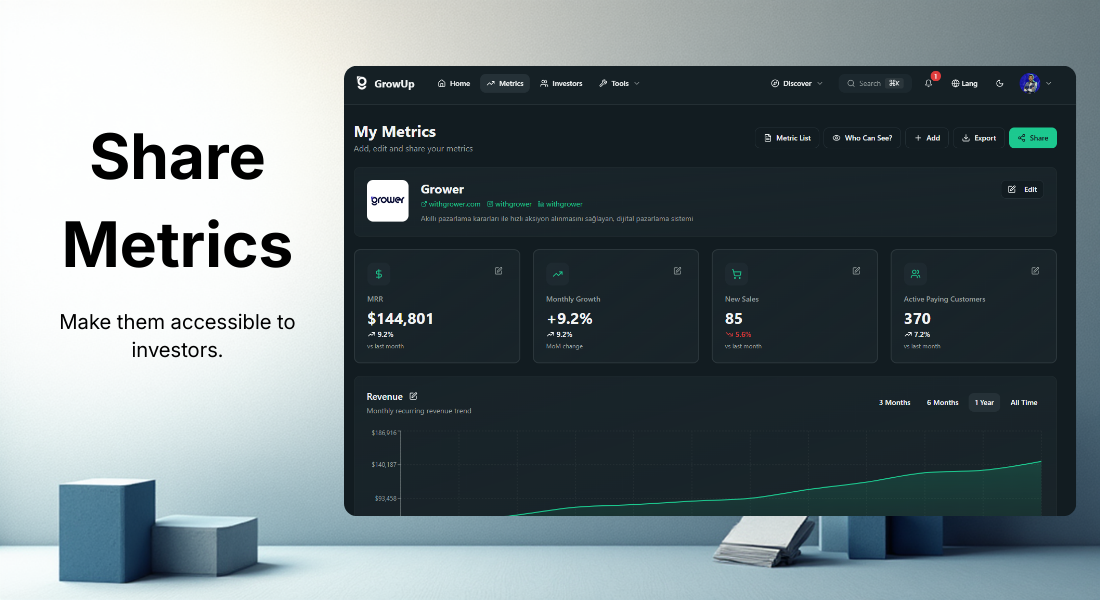
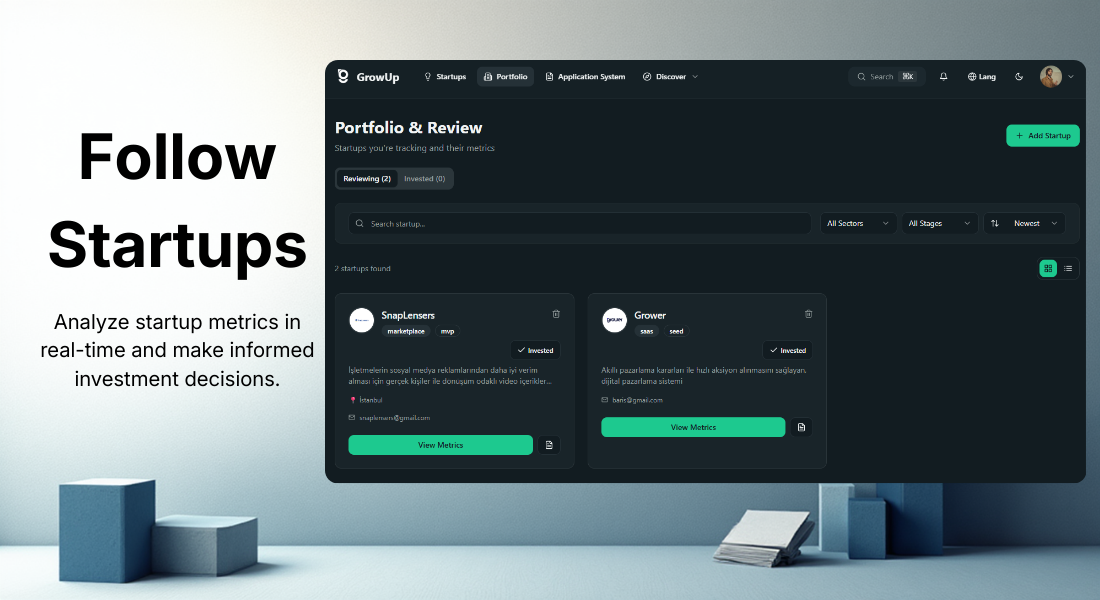
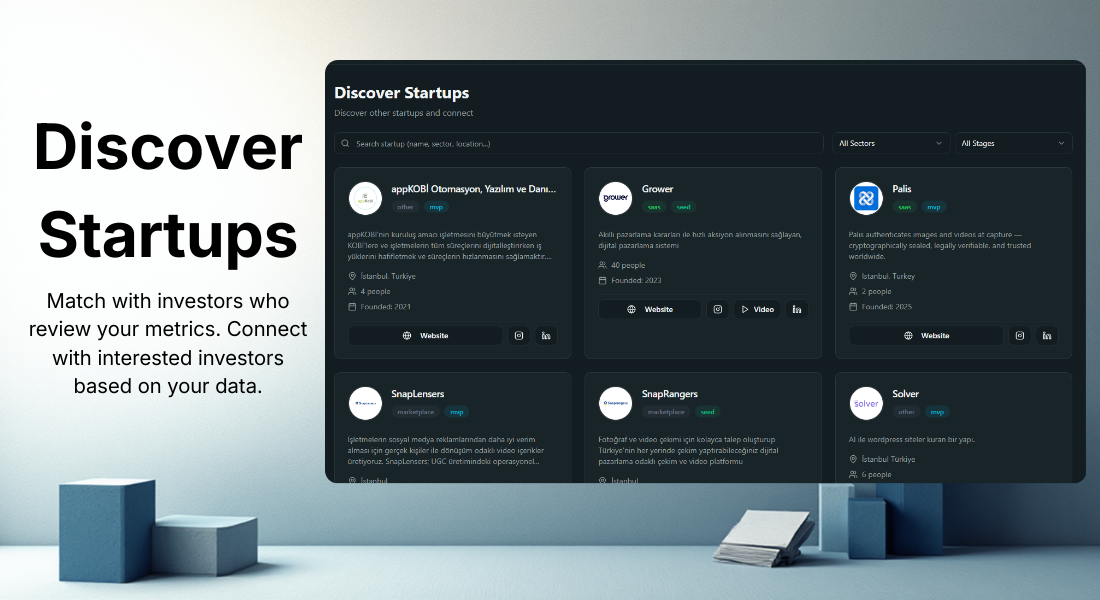
一句话介绍:GrowUp是一个初创企业数据透明化平台,通过让创业者实时分享财务指标,帮助投资者发现和分析早期项目,解决双方信息不对称与对接效率低下的痛点。
Analytics
Investing
Crowdfunding
初创企业服务
投融资平台
数据透明化
财务指标展示
投资者对接
早期项目发现
创投生态
增长工具
SaaS
用户评论摘要:用户普遍认可其解决创业者与投资者沟通痛点的价值,强调平台能提升生态透明度和对接效率。反馈集中于产品简化数据展示、便于早期项目被发现等优势,无具体功能建议或问题指摘。
AI 锐评
GrowUp试图以“数据透明”为楔子切入创投对接市场,但其核心逻辑存在深层矛盾。产品将“分享指标”等同于“建立信任”,却忽视了早期投资中非量化因素(团队背景、市场直觉、技术壁垒)的关键权重。真正的风险投资者并非缺乏数据渠道,而是疲于甄别数据的真实性与上下文——一个自愿披露的指标库,反而可能成为精装修的“数据橱窗”,加剧信息博弈而非缓解。
平台看似同时服务双方,实则更偏向创业者侧的展示需求,这可能导致投资者端沦为低效浏览工具。早期项目筛选本质是高接触、低频率的决策,标准化指标面板难以替代深度尽调与关系构建。更尖锐的问题是:优质项目往往在非公开渠道已完成融资,而急于公开数据的项目是否隐含“逆向选择”风险?
其真正机会或许不在通用平台,而在垂直领域(如深科技、ESG)建立结构化评估体系,或与孵化器、会计师事务所合作嵌入工作流。当前模式若不能形成闭环验证机制(如后续融资数据回溯),恐将停留于创业者的自我展示墙,而非投资者的决策仪表盘。在创投这个人脉与信任驱动的行业,纯数据中间件的生存空间,远比想象中狭窄。
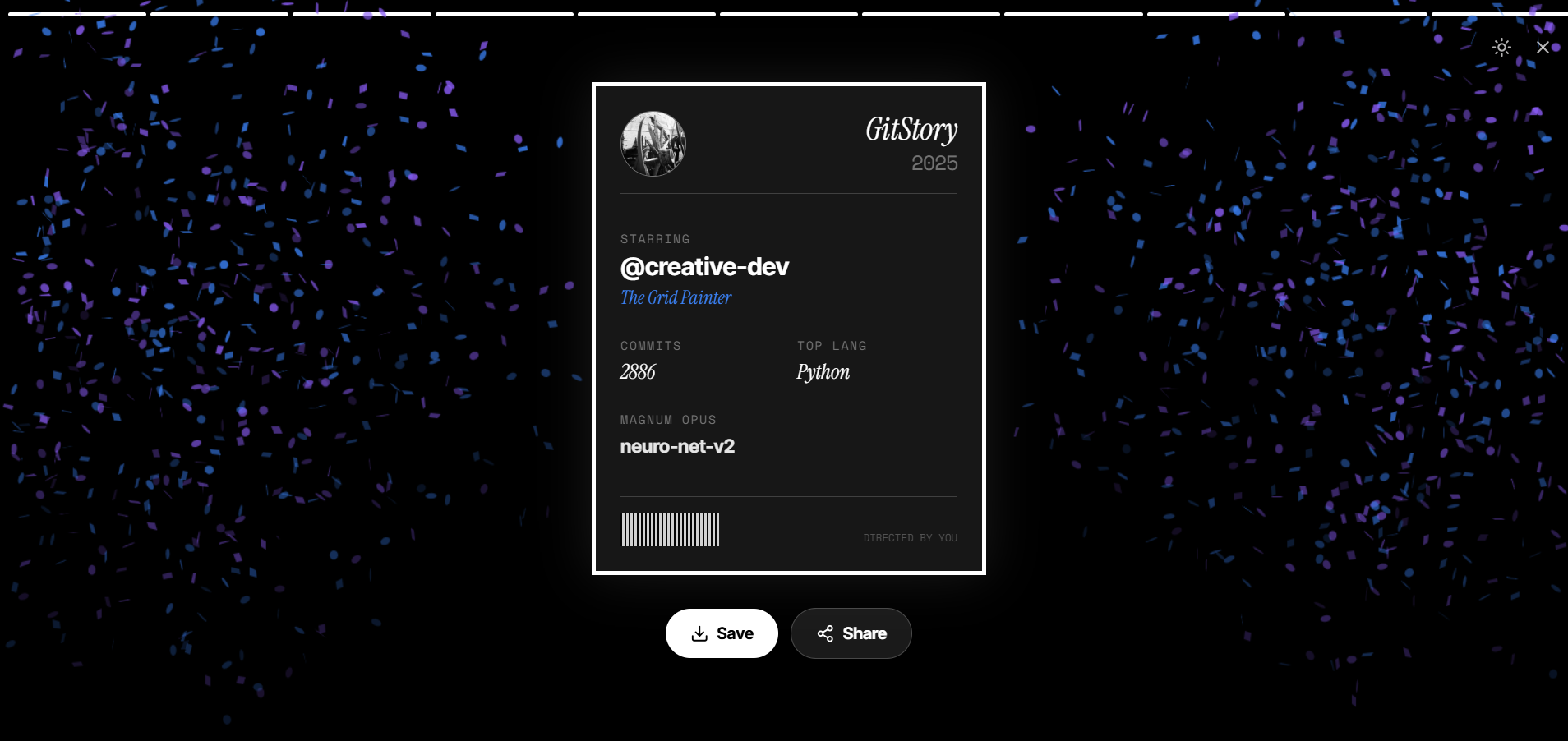
一句话介绍:GitStory将用户枯燥的GitHub贡献记录转化为精美的年度视频总结,在个人复盘或社交分享时,为用户提供了直观、富有成就感的数字化编程旅程回顾。
Open Source
GitHub
Tech
开发者工具
年度总结
GitHub可视化
个人复盘
社交分享
代码生涯
数据动画
Wrapped模式
情感化设计
用户评论摘要:评论以正面为主,用户肯定其良好的UX设计和个人数据回顾价值。主要反馈包括:产品能有效激励编码习惯、整体评价很高。开发者积极与用户互动,收集反馈。
AI 锐评
GitStory本质上是将“Spotify Wrapped”这一成熟的年度情感化复盘模式,成功移植到了开发者领域。它的核心价值并非技术突破,而在于精准抓住了程序员群体的情感需求——将日复一日、冰冷抽象的Git提交方块,转化为具象、流动且充满个人叙事感的“电影”。
产品巧妙地利用了“成就展示”与“社交货币”的双重驱动力。对于个体开发者,它提供了仪式化的年度里程碑,满足自我认同与激励需求;在社交层面,生成的精美视频极易在技术社区传播,满足了用户的展示与归属感。这正是其虽功能简单却能获得好评的关键。
然而,其模式的天花板也显而易见。首先,其数据维度和叙事深度严重依赖GitHub贡献图这一单一、且可能被“刷提交”行为污染的数据源,洞察的个性化与真实性存疑。其次,作为轻量级工具,其用户粘性和长期价值有限,很可能沦为“年抛型”产品,每年仅被使用一两次。最后,其商业模式模糊,目前看来更像是开发者的一次趣味实验或个人品牌项目。
长远来看,若想突破工具属性,它需要向更深度的“开发者数字身份”平台演进。例如,整合多平台(GitLab、Bitbucket)数据,引入代码质量、项目影响力等更复杂的分析维度,甚至与招聘档案或技术社区声望系统联动。否则,它很可能只是下一个昙花一现的“年度爆款”,难以形成持续影响力。当前版本是一个出色的MVP,证明了市场需求,但通往“必用工具”的道路仍漫长。
一句话介绍:一款专注于精准截图与尺寸可重复性的Chrome浏览器插件,解决了分析师等专业人士在制作周期性报告时,难以获取像素级精准、尺寸一致的可比性截图的痛点。
Chrome Extensions
Productivity
Developer Tools
浏览器截图插件
像素级精准
元素选择
尺寸可重复性
本地处理
无账户
无云端上传
效率工具
数据分析辅助
用户评论摘要:目前仅有一条开发者自述评论,阐述了其作为分析师,为解决周期性报告截图尺寸不一致的痛点而开发此工具的个人背景与开发初衷,并表达了根据用户反馈持续改进的意愿。
AI 锐评
Lliben的出现,看似是拥挤的截图工具市场中的一个简单变体,实则精准地刺中了一个被通用工具长期忽视的专业化缝隙:可重复的、具备严格可比性的视觉信息采集。
其核心价值并非“截图”,而是“测量”与“记录”。大多数截图工具追求功能的广度(滚动、标注、分享),而Lliben则追求结果的“一致性”这一深度。这对于需要定期监测网页数据看板、广告素材、竞品UI变化或社交媒体动态的分析师、运营、产品经理而言,是刚需。它试图将截图从一次性的“拍照”行为,转变为可编程的、标准化的“数据采集”流程。
然而,其挑战也显而易见。首先,作为Chrome插件,其能力边界受浏览器沙盒限制,在复杂网页(如重度依赖WebGL或动态加载)上的元素精准捕获可能面临技术挑战。其次,“单人开发”与“年轻产品”的状态,意味着其长期维护性、与Chrome版本更新的兼容性,以及面对更复杂需求(如自动定时截图、批量处理)时的进化能力,都存在不确定性。最后,其“无云端”的隐私卖点,在需要协作的场景下可能反而成为短板。
当前8票的关注度,反映了其高度垂直的属性。它未必能成为大众爆款,但若能牢牢抓住“专业分析工作流”这一核心,持续深化其精准度与自动化能力(例如,允许保存并重复调用元素选择器脚本),它完全有可能成为特定领域从业者不可或缺的“瑞士军刀”。它的成功之路,在于做深而非做广。
一句话介绍:DocBuilder是一款通过AI对话深度挖掘需求,自动生成完整产品需求文档的工具,旨在解决“氛围编码”时代开发者因需求模糊导致AI代码生成受阻的核心痛点。
Developer Tools
AI需求生成
产品文档自动化
氛围编码
敏捷开发
AI编程助手
产品规格
Markdown文档
需求梳理
智能问答
原型设计
用户评论摘要:仅有一条创始人自述评论,属于产品介绍而非用户反馈。目前缺乏真实用户的使用评价、问题反馈或改进建议。
AI 锐评
DocBuilder试图切入“AI编码”流程的上游空白点,其宣称的价值在于充当“严格的AI产品经理”,通过结构化对话将模糊想法转化为精准需求文档。这一逻辑直击当前AI辅助开发(如Cursor使用)的核心矛盾:Garbage in, garbage out。AI编码工具的能力边界严重依赖于输入指令的精确度,而人类开发者往往疏于或拙于进行严谨的前期定义。
然而,产品呈现出一个关键悖论:它声称要替代与“原始ChatGPT”的散漫聊天,但其核心交互模式本质上仍是聊天对话,只是预设了更结构化的问卷流程。其真正的技术护城河可能在于对产品管理知识的深度编码——它是否内化了优秀PM的思维框架,能否提出真正触及要害的“深度问题”,这决定了它产出的是真正可执行的蓝图,还是另一份精美的废话文学。
从市场角度看,它将自己定位为Cursor等工具的“前道工序”,这个定位巧妙但场景略显狭窄。其成功不仅取决于自身对话质量,更依赖于下游AI编码工具生态的稳定与发展。目前产品缺乏公开的用户验证数据(仅有7票且无真实用户评论),其“严格拷问”的用户体验是否流畅,是否会因过程繁琐而被抛弃,仍是未知数。它解决了一个真实痛点,但解法是否优雅高效,仍需观察。真正的考验在于:最需要清晰规格的严肃项目,是否敢将此关键环节托付给一个AI访谈器。
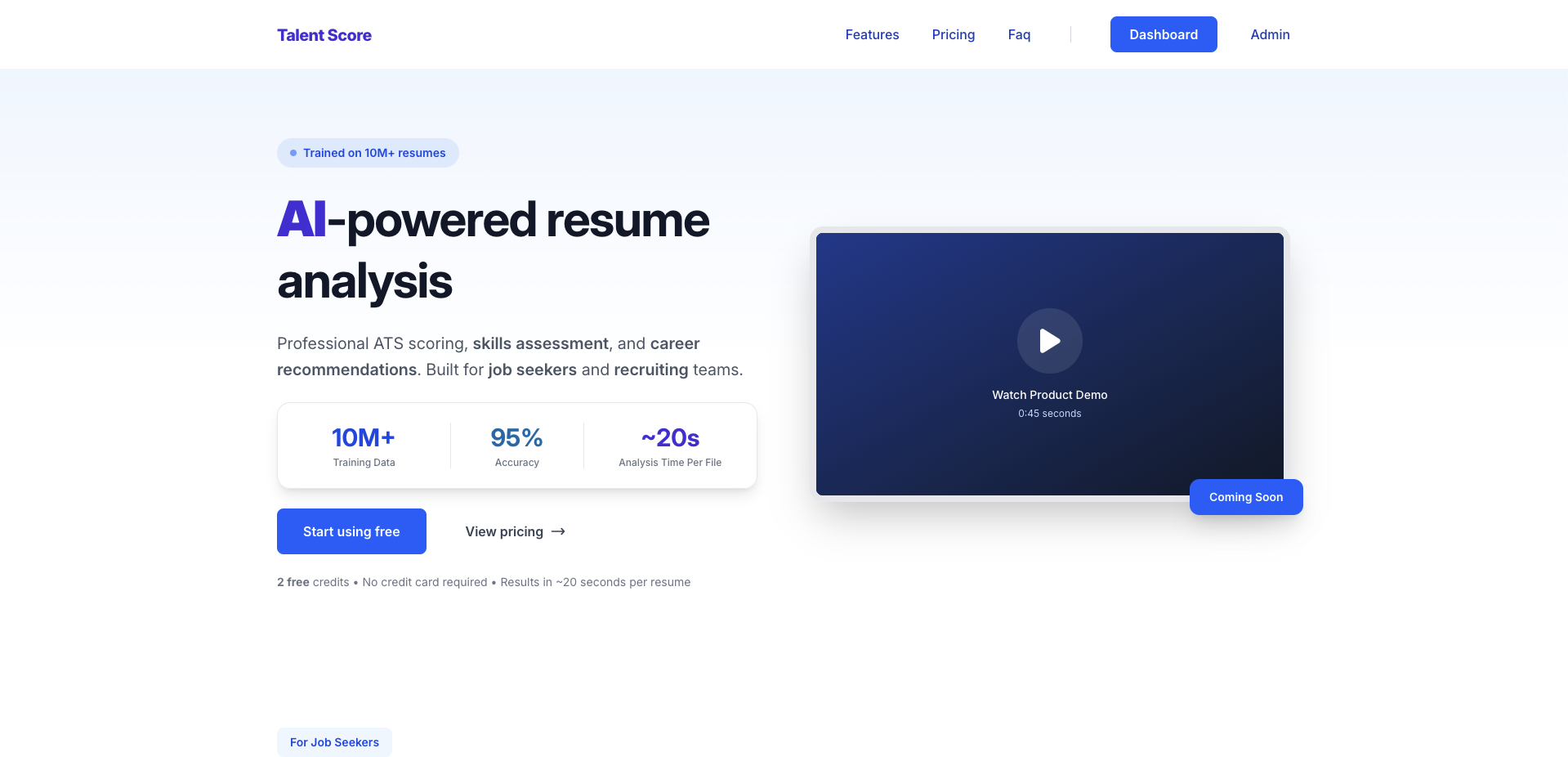
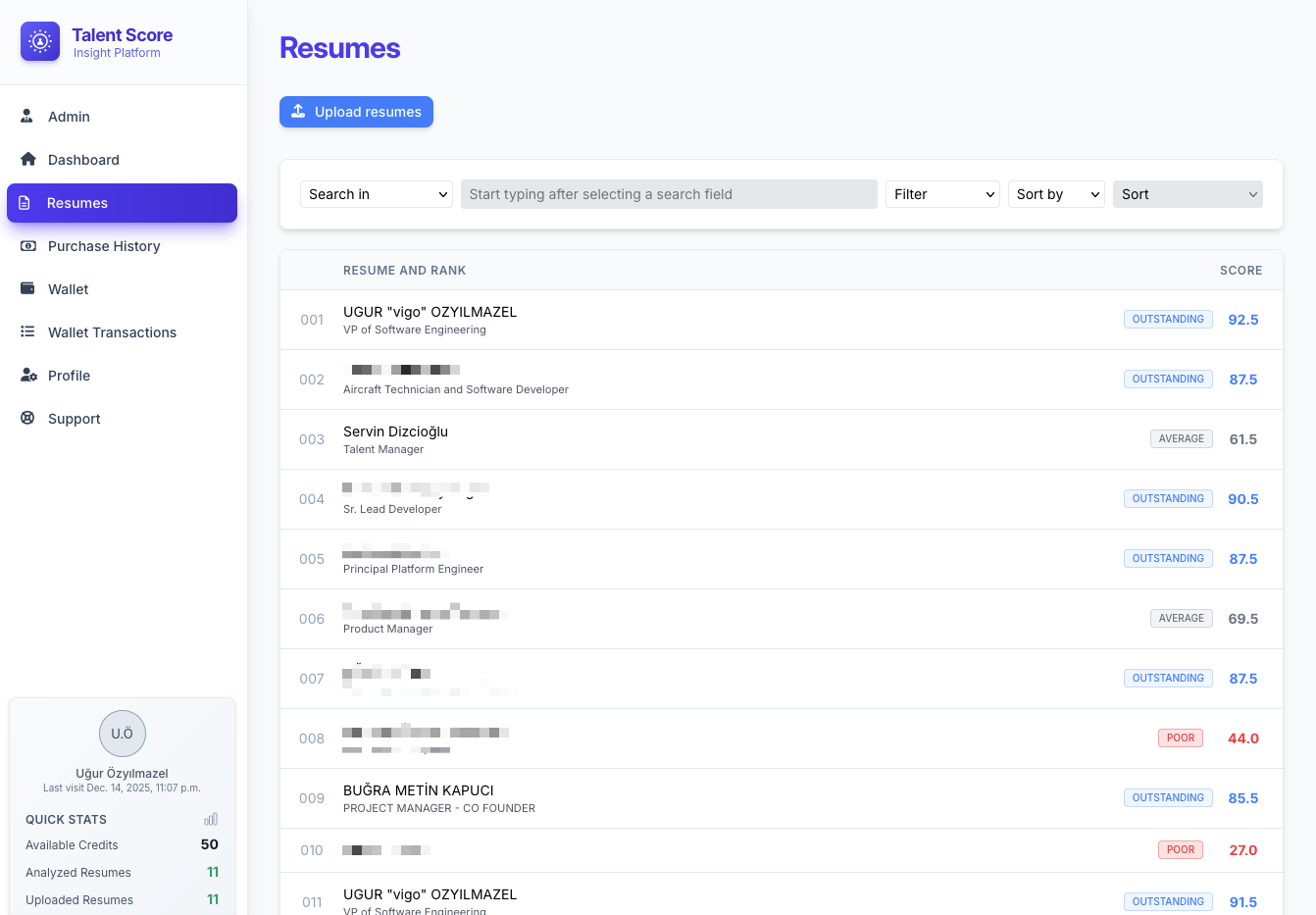
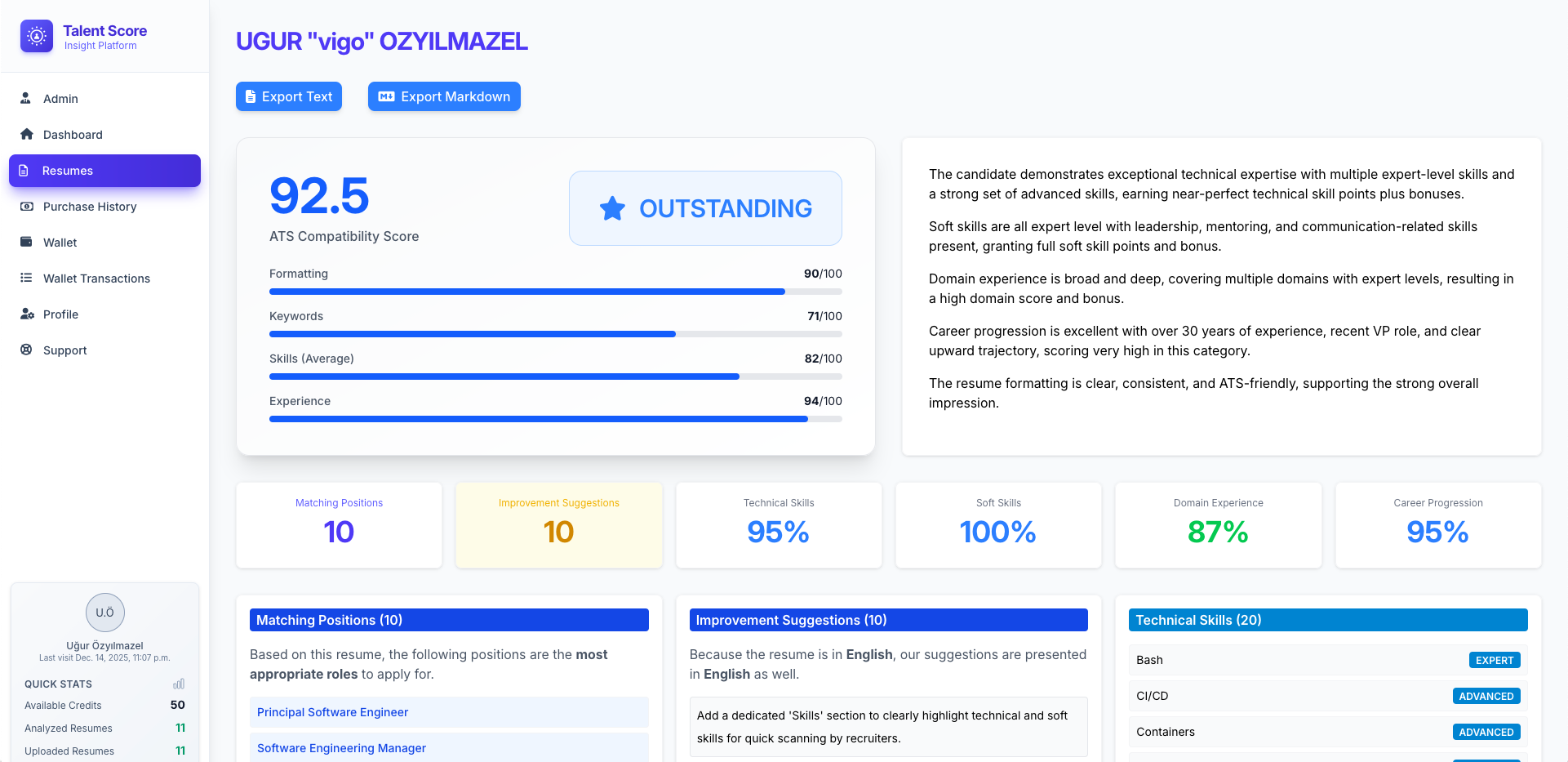
一句话介绍:Talent Score是一款AI驱动的简历分析平台,通过提供ATS分数评估、技能分析等功能,帮助求职者优化简历以提升面试机会,并辅助招聘团队高效、一致地预筛大量申请,解决简历筛选主观耗时与求职者简历优化无门的双向痛点。
Hiring
Artificial Intelligence
Career
AI简历分析
ATS优化
求职工具
招聘筛选
技能评估
简历优化
HR科技
人才评估
SaaS
公平招聘
用户评论摘要:用户反馈揭示了产品源于内部面试平台的“简历网关”需求,验证了其解决简历预筛痛点的初衷。评论者认可其在处理海量申请、实现客观一致筛选方面的价值,并认为市场存在需求。未出现具体功能改进建议。
AI 锐评
Talent Score的叙事呈现了一个经典的“工具产品化”路径——从解决自身工程痛点(为AI面试平台构建简历过滤器)到发现普适性市场机会。这既是其优势,也暗含风险。
其宣称的核心价值在于双向赋能:对求职者是“简历优化器”,对招聘方是“自动化筛子”。然而,这两类用户的核心诉求存在本质张力。求职者追求高分与通过率,倾向于美化与迎合;招聘方追求精准匹配与风险规避,需要去伪存真。平台试图用同一套AI模型服务对立双方,其“公平性”承诺将面临严峻考验。ATS分数分析已是红海功能,其差异化优势或许在于其出身所积累的、对“面试环节”所需技能的更深理解,但现有信息未体现此独特洞察。
评论中提及的“高量申请预筛”场景是更清晰、更刚性的价值点。产品若能证明其AI在降低误筛(尤其错失优秀候选人)率上优于传统关键词筛选,并为招聘团队节省可观时间,其B端商业化逻辑将比C端简历优化订阅更为坚实。当前数据(低投票数)显示市场热度不足,产品需尽快明确其首要客群与核心价值主张:究竟是成为求职者的私人家教,还是招聘团队的守门机器人?试图两者通吃,可能两者皆失。
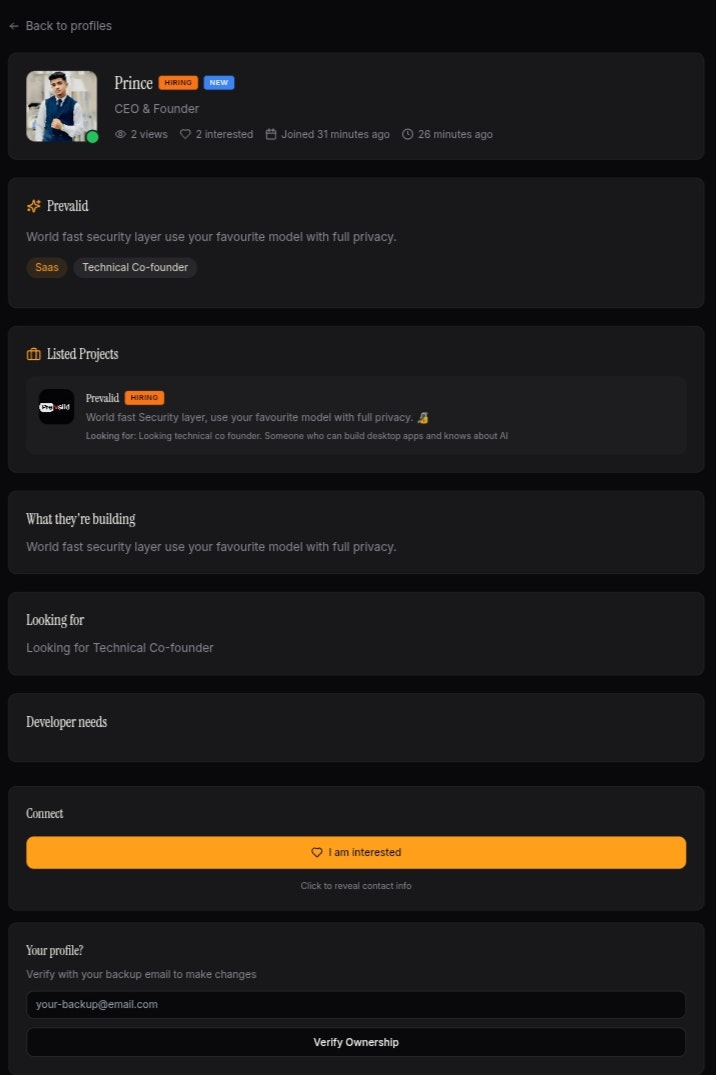
一句话介绍:Co-finder是一个为创业者和开发者精准匹配联合创始人的平台,通过验证资料和意向连接,在早期创业团队组建场景中,解决了“有想法找不到技术伙伴,有技术找不到好项目”的核心痛点。
Marketing
SaaS
Startup Lessons
创业者平台
联合创始人匹配
技术合伙招募
初创团队组建
人才对接
产品验证
早期创业服务
社交网络
用户评论摘要:用户反馈积极,认可其解决了真实痛点。评论者多为主动寻找技术合伙人的创业者,对产品表示支持和期待。创始人积极寻求反馈,询问产品的不足、困惑之处及实用改进建议。
AI 锐评
Co-finder切入的是一个古老而棘手的市场——联合创始人匹配。其价值主张清晰:用“验证”和“意向”来过滤噪音,试图将随机性社交转化为确定性连接。这直指现有渠道(如LinkedIn、Twitter)的核心缺陷:信息泛滥而信任缺失,社交广泛却意图模糊。
然而,其面临的挑战远比产品介绍中描述的更为深刻。首先,**“验证”的尺度与公信力**是首要难题。验证资料是否足以评估一个潜在合伙人的技术能力、抗压性格与长期承诺?早期项目的成败极度依赖于人的契合度,这远非资料验证所能涵盖。其次,**平台的双边网络效应启动**异常艰难。它需要同时聚集大量高质量的“有想法的创始人”和“有技术的建造者”,任何一方的缺失都会导致另一方迅速流失。目前个位数的投票数也侧面反映了冷启动的艰巨。
创始人的坦诚(“早期”、“不完美”、“独自建造”)是优点,但也凸显了资源的匮乏。评论中的支持声音多来自“寻找者”而非“建造者”,这或许是一个危险信号——平台可能更容易吸引需求更迫切的非技术创始人,而稀缺的优质技术人才是否愿意入驻,仍是未知数。
其真正的机会在于,如果能通过精细的运营(例如,深度筛选、成功案例打造、社区文化构建),打造出一个以“严肃建造”为核心的高信任度小社群,它或许能成为一个有价值的筛选层。否则,它极易沦为另一个信息布告栏,无法解决匹配中最关键的“质量判断”与“关系促成”问题。它的成败不在于功能,而在于能否定义并捍卫一个高质量的“俱乐部”标准。
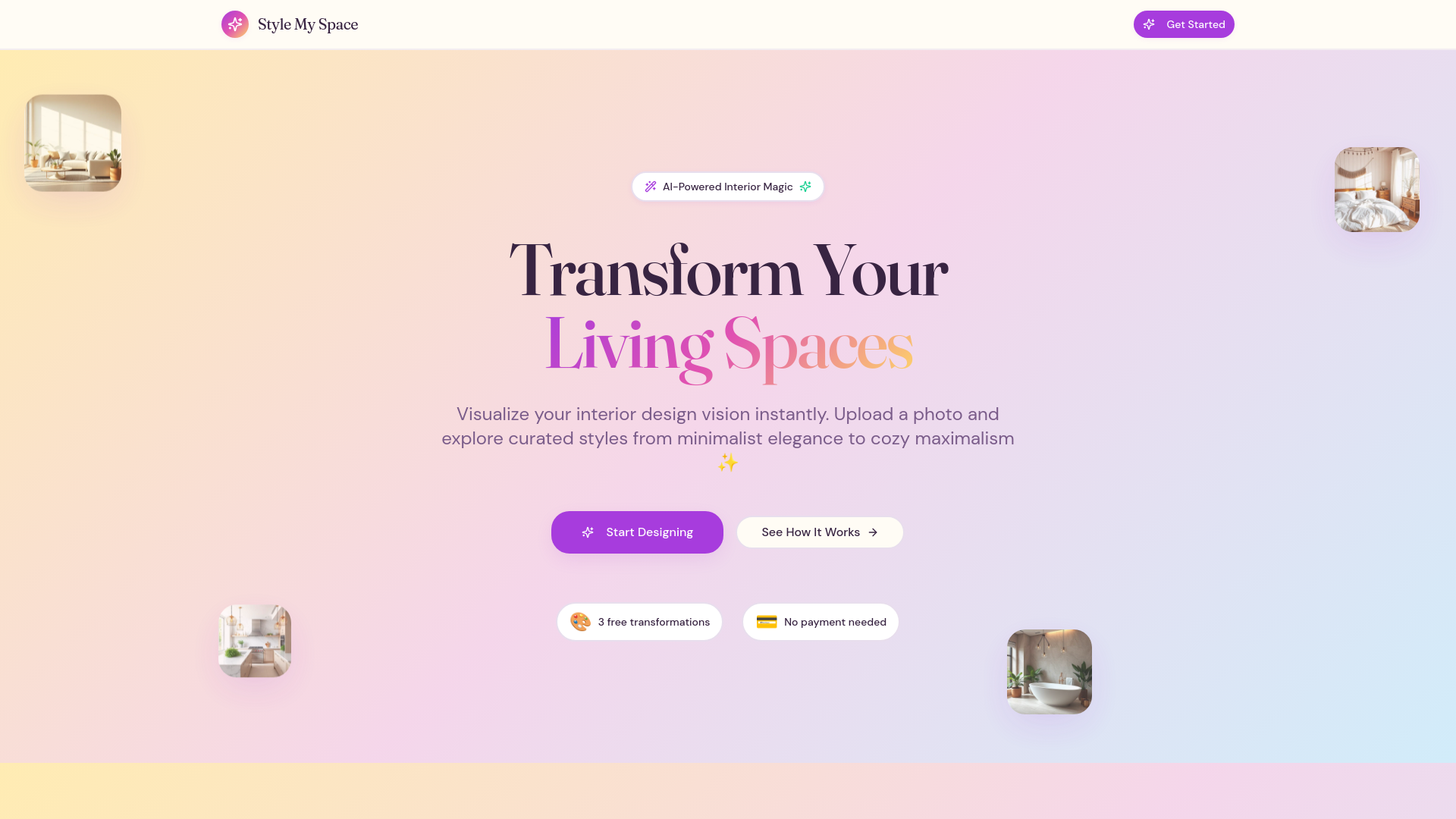
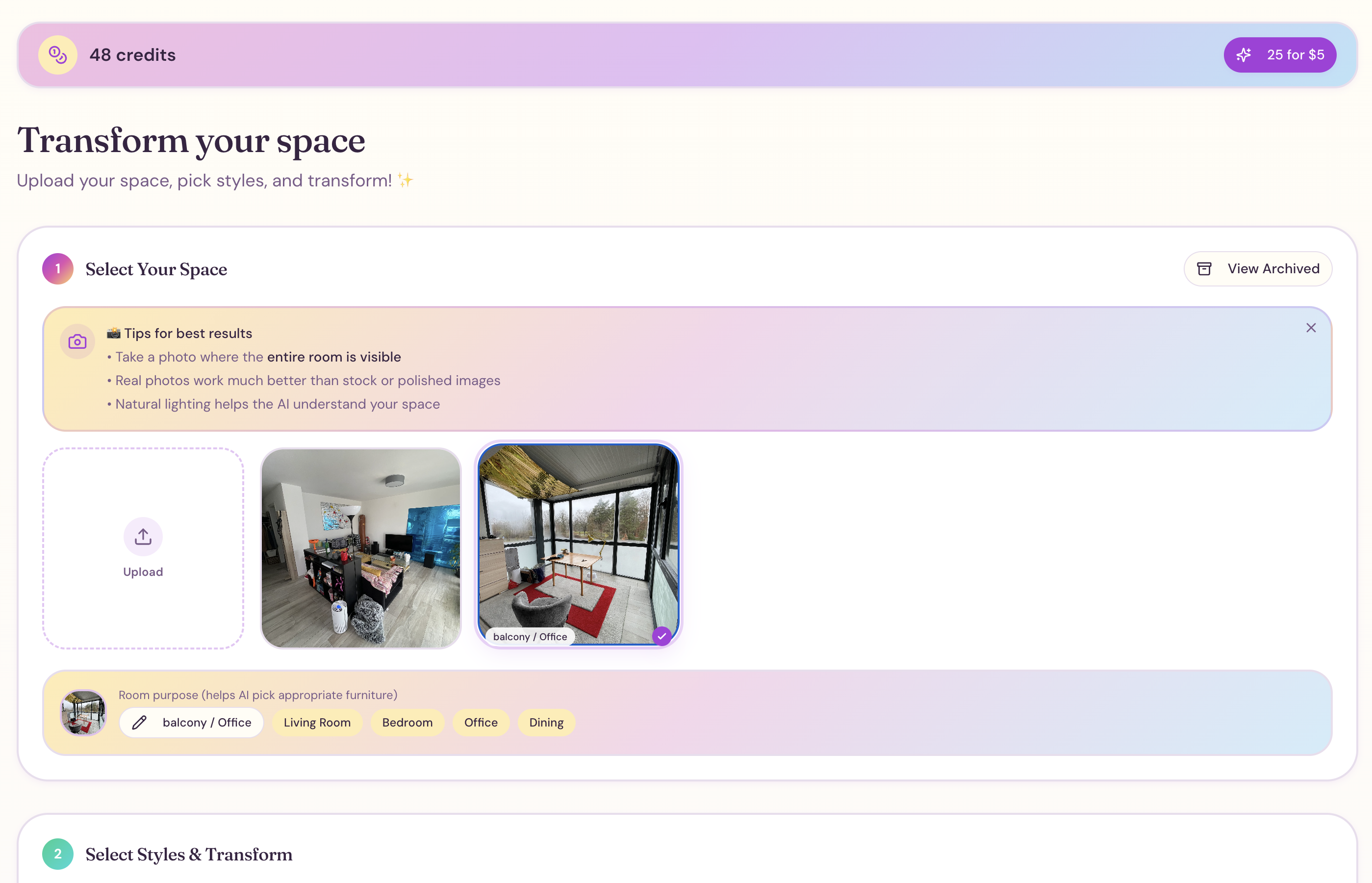
一句话介绍:一款利用AI技术,让用户通过上传房间照片即可重新构想并可视化多种装修风格,解决家居改造前期风格选择和搭配难题的应用。
Design Tools
Home
Interior design
AI室内设计
家居改造
风格可视化
空间设计
装修灵感
AI图像生成
家居装饰
消费级AI应用
用户评论摘要:用户结合自身经历,高度评价AI在可视化风格和发现未曾想到的家具方面的巨大帮助。有效评论指出,该产品核心价值在于“消除摩擦”而非“增加新奇”,通过基于真实空间的个性化推荐,改变了抽象的决策过程,能主动拓展用户品味,发现用户未曾主动搜索的选项。
AI 锐评
Style My Space切入了一个古老且高决策成本的领域——家居装饰。其宣称的价值并非简单的“Pinterest式”灵感收集,而是试图将AI从“信息过滤器”升级为“品味拓展器”。从有限的用户反馈中,我们得以窥见其可能成功的核心:它并非替代设计师,而是解决普通人在启动改造项目时最根本的“想象力匮乏”和“词汇量不足”问题。
用户不知道“法式乡村风”的沙发具体在自己灰暗的客厅里是何效果,更不知道自己可能更适合“带有中古元素的现代折衷主义”。传统解决方案是依赖大量图片浏览和模糊的脑补,过程抽象且耗时。该应用将决策起点从“无限网络图库”拉回至“有限自家空间”,通过AI生成将抽象风格与具体场景强绑定,极大地降低了构思阶段的认知负荷。评论中“发现你从未有意搜索的家具”这一点尤为犀利,这揭示了其潜在优势:通过跨风格、跨品类的生成推荐,进行创造性的“信息偶遇”,可能打破用户固有的信息茧房和风格定式。
然而,其面临的挑战同样清晰。首先,技术层面,AI生成的家具在比例、材质、光影的真实性上能否经得起推敲,关乎用户信任。其次,商业层面,从“灵感可视化”到“商品可购买”之间存在巨大鸿沟,如何将生成的虚拟物品与实体供应链对接,是决定其能否商业闭环的关键。最后,模式层面,它必须证明自己不仅仅是“一次性的新奇玩具”,而是能融入用户持续迭代的“生活设计流程”中的工具。
当前市场不缺AI图像生成器,缺的是深度绑定垂直场景、真正理解行业决策链条的应用。Style My Space的初步反馈显示它击中了真实痛点,但其长期价值将取决于它能否从“风格模拟器”进化为连接灵感、设计、采购乃至项目管理的“家居改造智能中枢”。这条路很长,但起点值得关注。
一句话介绍:Likii是一款通过AI将简短文字记录自动转化为蜡笔风格插画的日记应用,在用户希望以轻松、艺术化方式捕捉和重温日常幸福瞬间的场景下,解决了传统日记枯燥或需要用户具备绘画技能才能进行视觉化记录的痛点。
Health & Fitness
User Experience
Artificial Intelligence
日记应用
AI绘画
情绪记录
视觉化日记
艺术创作
心理健康
日常记录
蜡笔风格
记忆管理
幸福感收集
用户评论摘要:有效评论认为产品概念“迷人”,将日常快乐转化为温暖、有形之物。核心好评在于其交互简单(“一个想法输入,一个插画记忆输出”),形成了个人仪式感,而非工具感。评论者将其与注重“精心呈现”的内容产品类比,看好其构建“幸福档案馆”的长期价值。未发现具体功能问题或改进建议。
AI 锐评
Likii所切入的,并非功能性的笔记赛道,而是情绪价值与数字疗愈的交叉口。其真正的产品内核,是提供了一个极低门槛的“积极心理学”实践工具——通过“记录-视觉化-回顾”的闭环,将用户无意识的、转瞬即逝的积极情绪(POSITIVE AFFECT)进行外化与固化,本质上是在售卖一种“可触摸的幸福感”。
产品设计的精明之处在于“降维打击”。它没有与专业插画AI比拼精度和可控性,而是主动拥抱“蜡笔风格”的稚拙与温暖。这种风格选择是战略性的:其一,它大幅降低了用户的心理预期,任何不完美都可被解读为“人情味”;其二,蜡笔质感天然关联童年、安全与纯粹情感,强化了产品的情绪定位。其交互的极度简化(一句话生成一幅画)进一步将使用过程仪式化,使其从“生产力工具”范畴剥离,进入“数字珍品柜”的范畴。
然而,其面临的挑战同样清晰。首先是新鲜感褪去后的留存难题。当用户积累了几十幅风格雷同的蜡笔插画后,这种形式的情绪价值是否会边际效应递减?产品目前缺乏更深层的互动或叙事结构(如时间线、情绪图谱、故事串联),记忆库可能沦为静态的陈列馆。其次,其商业模式的想象力受限。作为情感记录载体,用户付费购买“幸福感”的意愿存在,但天花板明显;而若向社交或内容平台转型,又会破坏其私密、纯粹的初心,与核心价值产生冲突。
当前版本像一个精美的“最小可行性情感产品”(MVEP)。它的成功与否,不取决于AI画得有多好,而取决于能否围绕“构建个人幸福博物馆”这一核心,设计出可持续的情感互动循环。下一步的关键,或许在于如何让这些孤立的“幸福瞬间”产生化学反应,让回顾与再体验的过程,本身就能生成新的价值与感动。
一句话介绍:ShopFlow是一款面向小型零售商和贸易商的一体化管理应用,核心功能整合库存、销售与员工管理,在单一平台上解决日常运营中多系统切换、数据分散的效率痛点。
Android
Sales
SaaS
Business
小企业管理软件
零售业解决方案
库存管理
销售跟踪
员工管理
一体化运营
效率工具
SaaS
数字化转型
用户评论摘要:目前仅有一条官方介绍性评论,无真实用户反馈。缺乏有效评论来识别实际使用中的问题或建议。
AI 锐评
ShopFlow切入的是一个拥挤且认知门槛高的市场——小微企业管理软件。其“all-in-one”的定位看似直击痛点,但恰恰是最大的风险所在。对于小本经营的店主而言,其真实需求往往是“够用就好”,而非功能大杂烩。一个试图同时解决库存、销售、人力管理的应用,很可能在每一个垂直功能上都难以媲美单点解决方案,最终沦为“什么都不精”的尴尬产品。
当前零真实用户评论的状态,更揭示了其核心困境:获客与建立信任。小企业主对运营数据极为敏感,迁移成本高,他们更倾向于使用已被市场验证或极度轻量的工具。ShopFlow需要回答的关键问题不是“功能有多少”,而是“为什么是你”?是凭借极致的用户体验、难以置信的低价,还是与特定硬件/支付渠道的深度集成?缺乏清晰的、难以复制的独特价值主张,仅靠功能堆砌,在SaaS红海中很难激起水花。
其真正的机会或许不在于“通用管理”,而在于深入某个极其细分的零售业态(如独立咖啡馆、精品服装店),做透该业态的专属工作流,形成壁垒。否则,它很可能只是又一个在概念阶段看起来合理,却难以跨越早期采用者鸿沟的产品。
一句话介绍:Foodshare是一款基于地图的邻里食物共享应用,通过连接有剩余食物的家庭与附近需要食物的邻居,在日常生活场景中解决家庭食物浪费与社区饥饿并存的痛点。
Health & Fitness
Food & Drink
Social Networking
食物共享
邻里社交
零浪费
可持续生活
社区互助
地图发现
实时聊天
iOS应用
SwiftUI
公益科技
用户评论摘要:开发者主动介绍了v3.0的技术栈(Swift 6, SwiftUI, Supabase)与核心更新(玻璃态UI、地图发现、实时聊天),并积极寻求反馈和Beta测试者。目前暂无其他用户评论,主要反馈渠道为开发者引导的产品方向探讨与功能建议征集。
AI 锐评
Foodshare 3.0呈现了一个典型的“善意科技”悖论:其愿景直击美国40%食物浪费的社会顽疾,但产品形态却陷入了“邻里社交”与“实用工具”的定位模糊地带。
产品核心逻辑看似清晰——将家庭余粮对接给社区需求者,但其真正的挑战远非技术重建所能解决。开发者热衷于展示Swift 6、SwiftUI、玻璃美学等现代技术栈,这固然提升了应用体验,但v3.0的本质仍是优化信息匹配(地图、聊天),并未触及食物共享最棘手的信任、安全与动机问题。用户为何要费心拍照、上传、协调交接,只为送出几颗番茄或半条面包?而接收方又是否愿意为不确定的、非标准化的剩余食物承担社交成本甚至安全风险?这比“Too Good To Go”的标准化商户余量处理复杂得多。
评论区的冷清(仅开发者自述)与较低的投票数,或许已折射出市场最真实的早期反馈:概念获赞易,建立可持续的用户行为与社区网络极难。产品若仅作为“技术演示”或“情怀项目”,其社会价值将止步于小众实验。要突破瓶颈,它或许需要更深入的思考:是强化工具属性(如集成食物保存指南、取货标准化流程),还是深化社区构建(如建立信誉系统、与社区组织合作),或是彻底转向更轻量的信息平台角色。
真正的“锐评”在于:解决食物浪费,App只是一个可能入口;若没有对人性动机、社区动力学及线下履约复杂性的深刻设计,再优雅的代码与界面,也可能只是数字时代的乌托邦样板间。


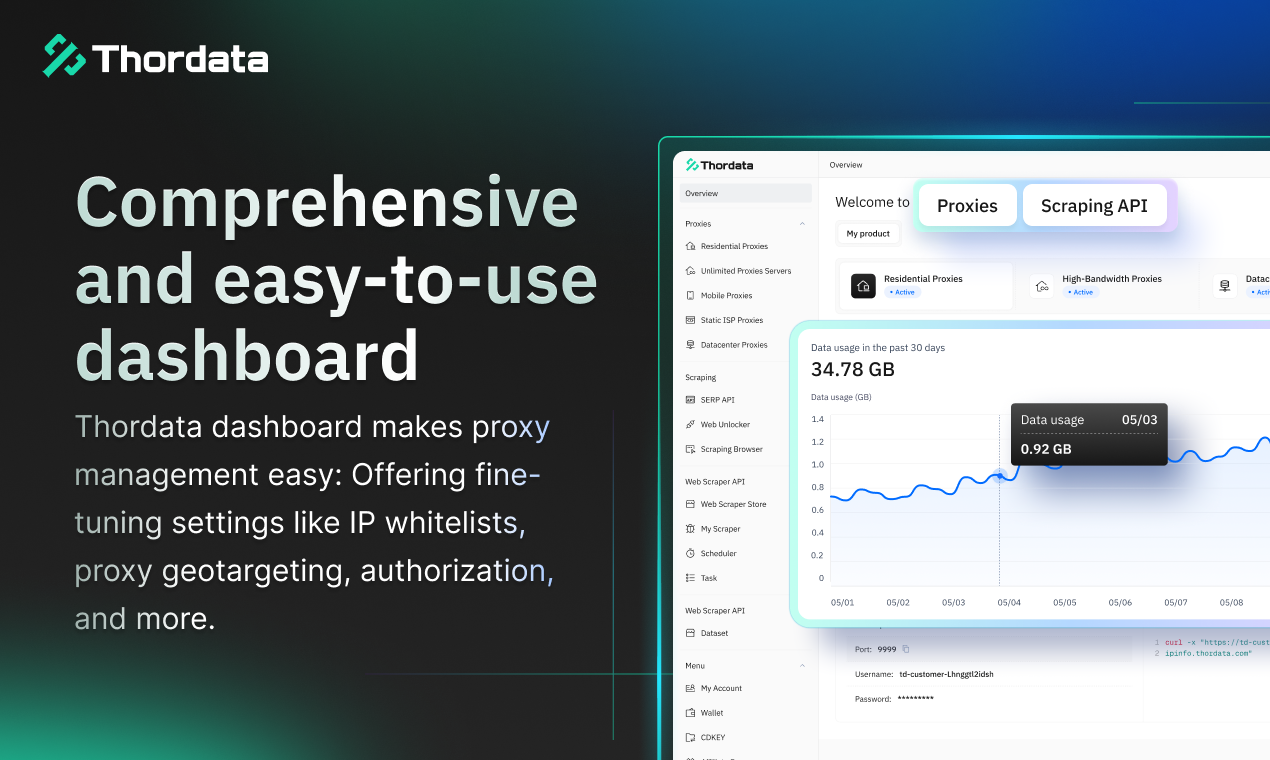
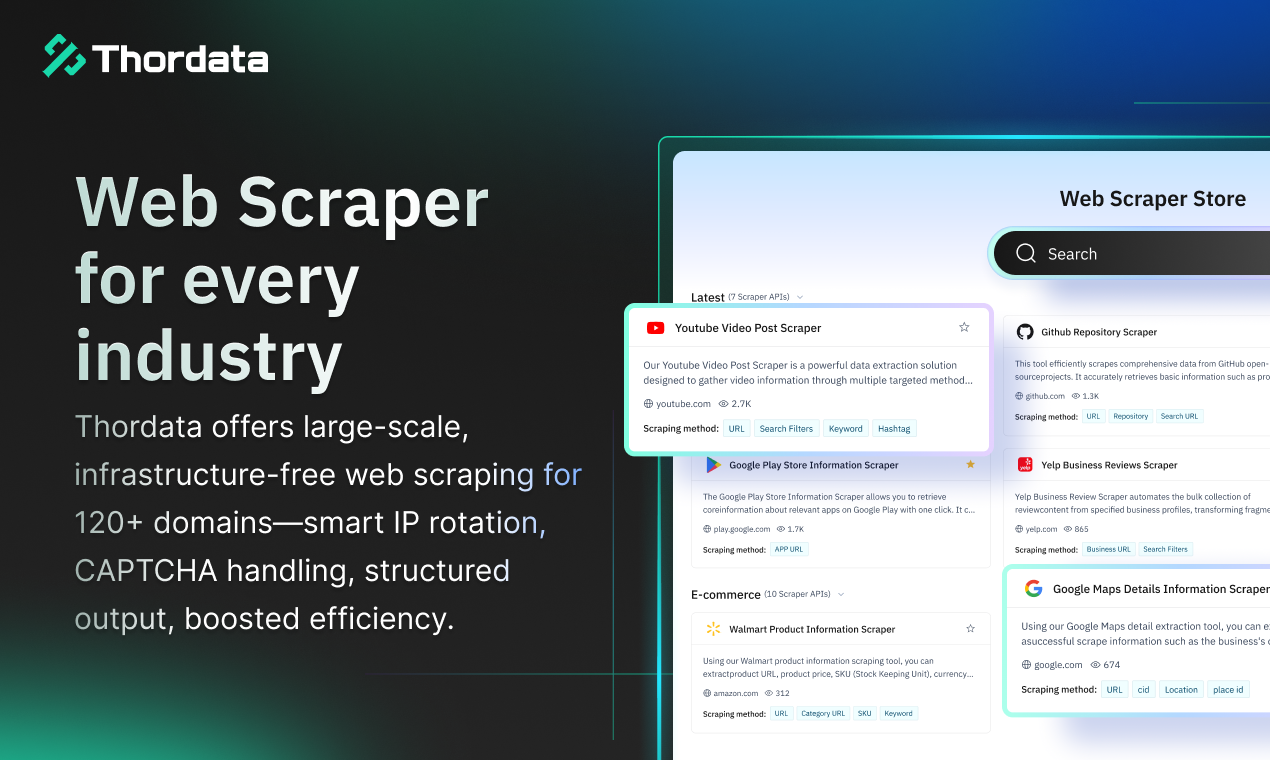




















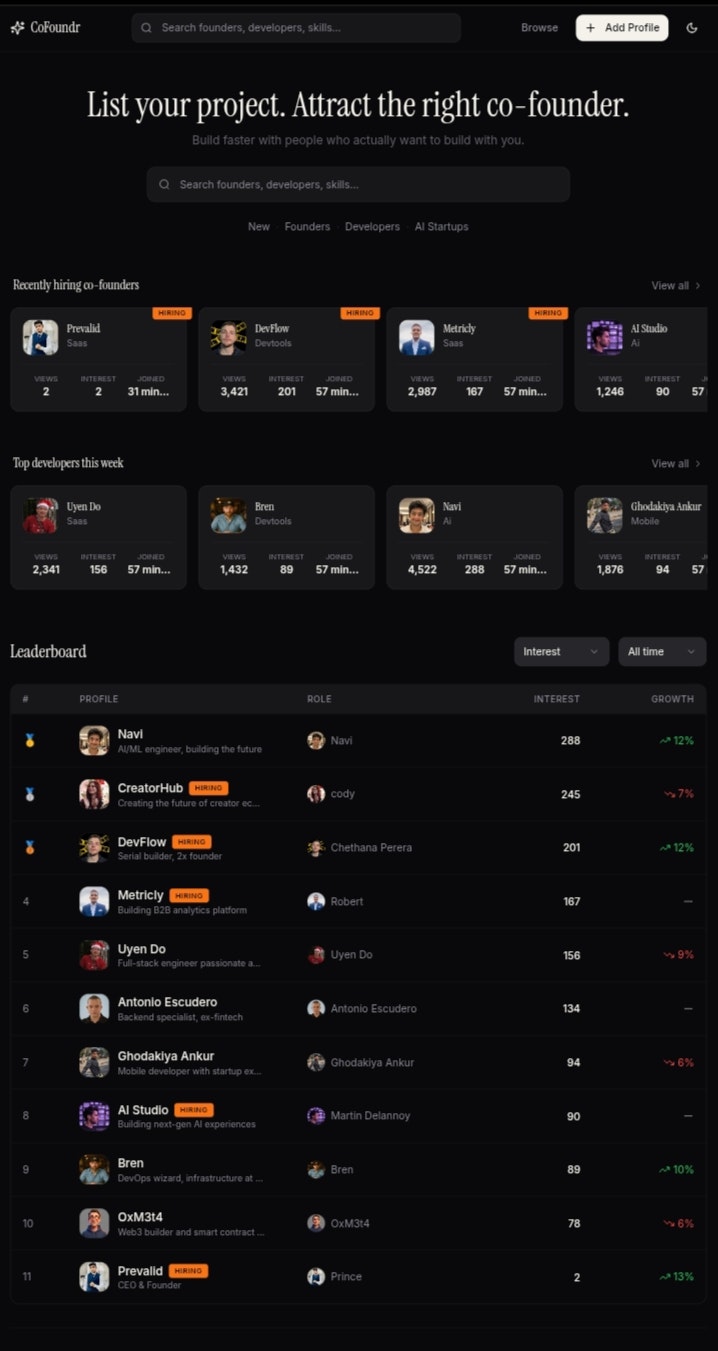




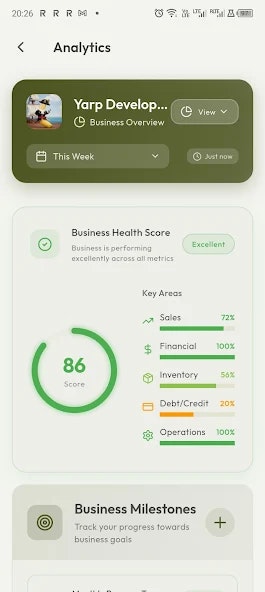
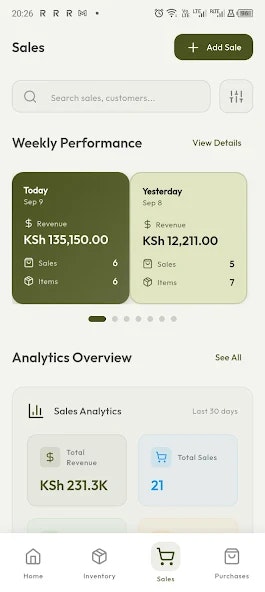
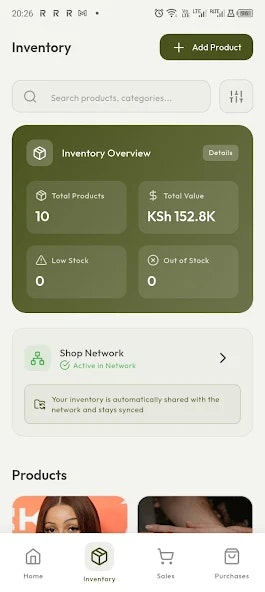
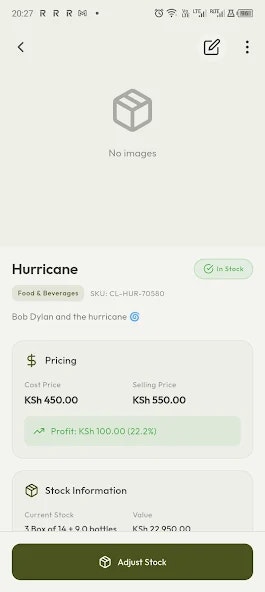

Hi everyone, I’m Kevin, one of the founders of Thordata.
We’re in a moment where AI models and applications are moving fast -- but high-quality, usable web data hasn’t kept up. Many teams can technically scrape data, but quickly run into instability, scale limits, or trust issues.
For AI teams, data isn’t just about access. It has to be sustainable, commercial-ready, and reliable over time. If your data pipeline breaks every few weeks, or creates compliance risks, the whole system fails.
Thordata provides proxy infrastructure designed for real AI and developer workflows -- from global data collection to long-running pipelines that need consistency, speed, and control.
Today, our users include:
AI companies that need to build training datasets.
Data teams running global market intelligence.
Developers maintaining large-scale web data pipelines.
One thing we care deeply about:
Compliance isn’t a feature for us -- it’s a design principle. From how our IP resources are sourced to how traffic is managed, responsible and compliant data access has been built into Thordata from the very beginning.
We’re excited to share Thordata with the PH community and would love your feedback.
Try it here:https://www.thordata.com
Congrats on the launch!
Web data collection at scale is never trivial, and it’s great to see a solution built specifically for AI training and production use cases rather than generic scraping needs.
🎉 Congrats on the launch, Kevin @cao_kevin & Thordata team! As an AI product lead, I’ve seen so many teams struggle with messy, unstable web data pipelines — Thordata looks like a much-needed solution, especially with compliance built into the design from day one. Love the focus on sustainable, production-ready data for AI workflows.
⚡ The proxy infrastructure for long-running pipelines sounds promising!
One small suggestion: maybe consider adding more detailed visibility into regional IP coverage and success rates per domain (via a dashboard or API metrics). That would help data teams fine-tune collection strategies faster.
Excited to see where this goes! How do you handle dynamic sites with heavy anti-bot protections? 🙌
This looks perfect for our use case! Does it offer sticky sessions for multi‑step workflows like checkout simulations?
I need this!
Can the service auto‑extract specific data points (prices, titles, ratings) and return JSON, not just HTML?
Hey everyone,
While my work is more about textures and floor plans than AI training, the underlying principle here makes perfect sense. For any tool that needs to source real-time product data, pricing, or material availability from around the web—especially from region-specific vendors—having reliable, compliant access to that information is crucial. A service that provides stable, scalable infrastructure for this kind of data collection would be a powerful enabler for building smarter, more informed design and sourcing applications. It addresses a fundamental need for any data-dependent service, creative or otherwise. Solid foundation.
Congrats on the launch! Do I understand right that your product is more for enterprises?
The service respects our time. No more manual IP whitelisting or daily password resets.
If the data breaks, everything breaks. I'm happy to see a tool built for long-term use, not just quick wins.
Daily user here for competitive intelligence work. I used to build custom proxy solutions myself, but this service delivers far better value for the price. Highly recommended.
Been using Thordata for a month now. The residential proxy pool is incredibly reliable—our scraper success rate went from 40% to 98% overnight.
I use it for daily competitive intelligence. Speaking as a former “DIY proxy” person—this is worth every penny.
The combination of global coverage, scalability, and compliance makes this especially compelling for teams planning long-term data pipelines, not just one-off projects.
Great job on the launch. AI teams need infrastructure they can trust as they grow, and Thordata seems well thought out for that journey. Excited to see how this evolves!