PH热榜 | 2026-01-29
一句话介绍:一款将混乱的CSV、PDF、Excel及图片文件,自动转化为麦肯锡级别、可下载分享的报告与演示文稿的AI数据分析平台,旨在帮助非技术运营者和数据科学家从数据沼泽中解放,快速获得决策洞察,构建“数据财富”。
Analytics
Data & Analytics
Data Visualization
AI数据分析
自动化报告
数据清洗
非技术用户友好
多格式文件解析
商业智能
数据财富
企业级应用
工作流自动化
洞察生成
用户评论摘要:用户普遍认可其“超越聊天”的交付模式、专业级输出质量及处理混乱文件的能力。主要建议包括:增加报告模板库、强化数据溯源审计、集成Slack/Notion等协作工具、优化新用户引导流程。开发者积极回应,透露模板库与集成已在规划中。
AI 锐评
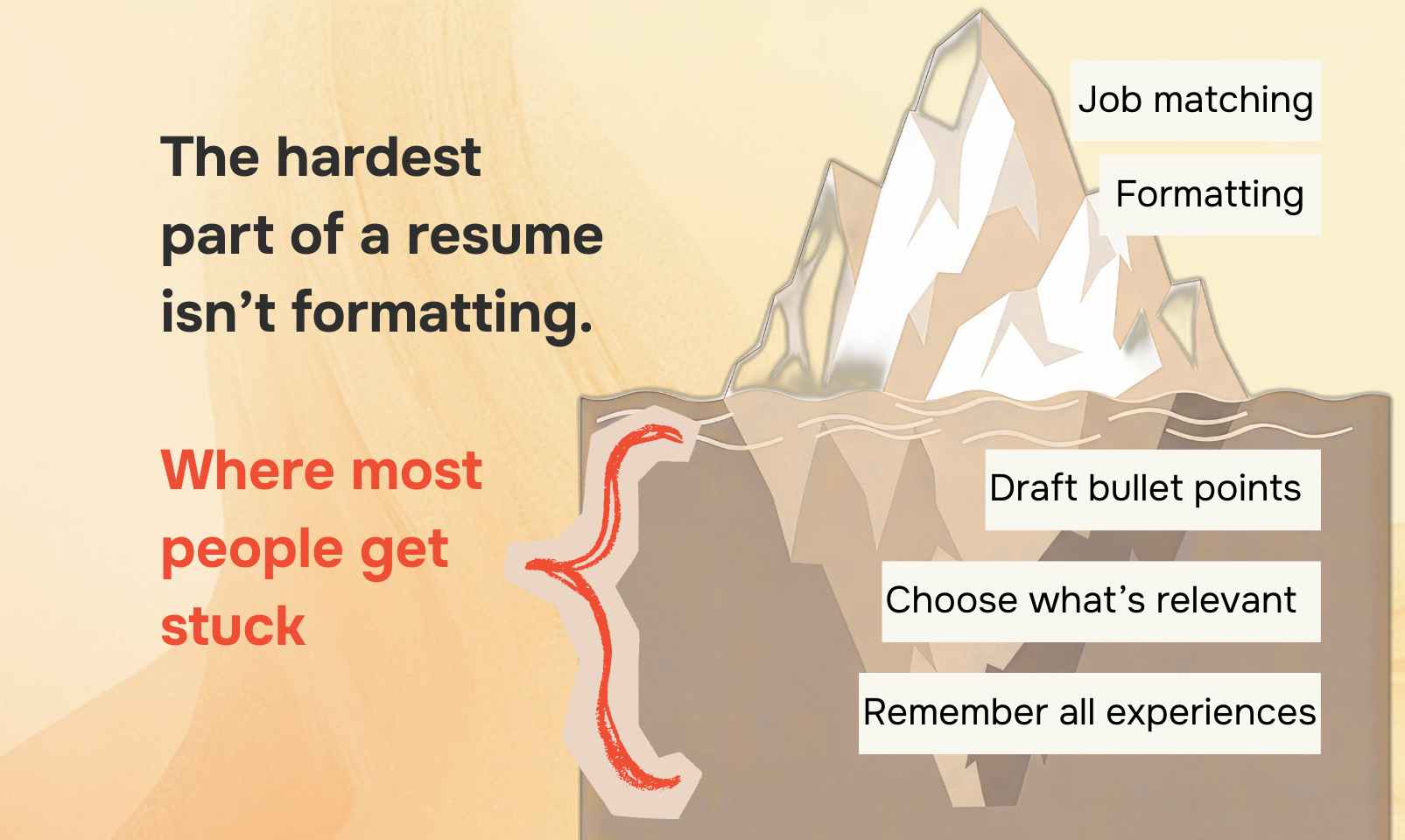
Pandada AI的亮相,精准刺中了当前AI数据分析工具的一个普遍软肋:对话热闹,交付潦草。它不满足于充当一个需要用户不断提问、反复纠偏的“聊天伙伴”,而是直接定位为能产出终端成果的“分析师”。其宣称的“麦肯锡级报告”,实则是将数据清洗、智能提问、可视化呈现打包成一个黑箱工作流,追求的是开箱即用的决策材料,而非开放式的探索过程。
这一定位极具市场穿透力,尤其对时间紧迫的非技术决策者。其在中国市场验证的300万用户和超千家企业,证明了工作流自动化而非对话交互,才是广大基层业务人员对AI的核心诉求。然而,其“交付物驱动”的模式也暗含风险:对分析过程的“黑箱化”处理(尽管声称可查看代码),可能削弱专业用户对分析逻辑的信任。将复杂分析简化为“一键报告”,在提升效率的同时,也可能助长对数据背景和统计严谨性的忽视。
本质上,Pandada AI是在用AI重构商业分析的报告生成环节,它真正的竞争对手或许不是其他AI聊天分析工具,而是传统的数据分析师外包、咨询公司的PPT团队,以及用户自己手动在Excel和PPT间挣扎的无数个小时。它的成功与否,将取决于其“麦肯锡级”输出的真实质量能否经得起专业审视,以及其工作流是否能足够灵活地适配千变万化的业务场景,而非沦为另一个精美的模板化工具。
一句话介绍:一款将Google Maps链接快速转换为精美动画旅行地图视频的工具,解决了旅行者、内容创作者在无需复杂剪辑的情况下,高效制作高质量旅程可视化视频的痛点。
Travel
Maps
Video
旅行视频制作
地图动画
Google Maps工具
内容创作
可视化旅程
3D模型
视频编辑
社交媒体内容
旅行记录
创作者工具
用户评论摘要:用户普遍赞赏产品创意与视觉呈现。核心反馈集中在功能需求:强烈希望支持多个Google Maps链接编辑、询问网页版开发计划、期待更多缩放与2D视图选项。开发者回应解释了多链接支持的复杂性,并透露了网页版MVP及更多缩放功能正在规划中。
AI 锐评
TravelAnimator精准切入了一个被忽视的细分市场:将普适性的导航数据(Google Maps链接)转化为情感化、视觉化的叙事媒介。其真正的价值并非技术颠覆,而是对“创作民主化”的又一次实践——它试图将原本需要After Effects或专业视频剪辑技能的门槛,降低到一次“复制粘贴”。
产品策略聪明地选择了“视觉优先”。用250+3D模型、30+地图风格、4K输出等参数堆砌“高级感”,快速建立用户对成品质量的信任,这比率先攻克复杂的多路径编辑(一个更工程化但视觉回报可能不明显的功能)更能吸引早期种子用户——那些对社交展示有强烈需求的旅行者与微创作者。从评论看,这一策略是成功的,用户被其“玩趣性”和“高级感”直接吸引。
然而,其长期挑战也埋藏于此。产品的核心依赖(Google Maps链接)是一把双刃剑。一方面降低了使用门槛,另一方面也限制了创意自由度(如用户提到的无法编辑路线)。它本质上是一个精美的“皮肤”引擎,而非真正的路线创作工具。当新鲜感过后,用户对深度编辑(多路线、自定义路径、更复杂的时间线)的需求会浮现,届时它将面临是继续做“轻量级装饰工具”,还是向“专业级旅行视频编辑器”转型的艰难抉择。
此外,其目标用户群看似清晰(旅行者、创作者),实则模糊。硬核旅行博主可能需要更复杂的叙事功能;普通用户可能仅需一次性分享。评论中“不知为何需要,但看起来很棒”的反馈,恰恰揭示了其作为“解决方案寻找问题”的潜在风险:它创造的需求是否足够刚性、高频,以支撑其增长?开发者提到的飞行员、水手等用户,或许暗示了其在专业路线汇报与可视化领域的意外潜力,这可能是比大众市场更稳固的利基。
一句话介绍:Meet-Ting是一款AI日程代理,通过邮件和短信管理日历,学习用户偏好,自动处理与最多五位参与者的会议安排、改期、会前简报及爽约跟进,在繁忙的商务沟通场景中解放用户于繁琐的日程协调劳动。
Productivity
Meetings
Calendar
AI日程管理
智能日历助手
电子邮件集成
会议自动化
可用性代理
时间管理
生产力工具
多平台集成
机器学习
日程协调
用户评论摘要:用户肯定其显著减轻日程管理认知负荷的核心价值,认为其“融入背景”无缝工作体验佳。主要问题集中于运作机制(是机器人吗?)、多时区处理细节、与第三方协调能力,以及最关键的对AI代理的信任与安全控制(如跟进分寸、语气)。
AI 锐评
Meet-Ting的野心并非再造一个日历应用,而是将自己打造成一个渗透在既有通信流(Email, WhatsApp)中的“日程大脑”。其真正价值不在于自动化“预订”这个动作,而在于试图理解和学习“优先级”这个决策过程——即产品标语所称的“给日程一个大脑”。
这一定位犀利地切中了现代职场人的核心痛点:日程管理是一种不被看见的、消耗意志力的“隐形劳动”。产品通过CC或对话这种极低门槛的方式介入,旨在将用户从反复权衡、沟通拉扯的“沉默计算”中解放出来。从评论看,早期用户已体验到这种认知负荷的降低,这是产品初步成功的信号。
然而,其面临的挑战与价值同等巨大。首先,**信任是最大门槛**。让AI全权代理邮件沟通,涉及社交礼仪、层级感知和分寸感,这比单纯处理时间槽复杂得多。团队承认早期版本AI像“过度热情的初级助理”,正说明了打磨这类“社会智能”的难度。其次,**其效用存在网络效应**。当会议多方都使用Ting时,协调效率会呈指数级提升;但在普及之前,它仍需与人类的随机性和模糊性作斗争,这可能削弱其宣称的自动化效能。
产品的未来取决于其AI“直觉”学习的深度与可靠性。它必须从“学习用户喜欢上午还是下午开会”这类模式,进化到能理解“为何这次会议比另一次更重要”的上下文。如果成功,它将成为个人时间的真正代理;如果失败,则可能只是另一个需要被管理的自动化工具。团队选择完全自主而非人工介入(HITL)的路径,勇气可嘉,但也意味着容错率极低。这款产品是一场关于我们是否愿意将“时间分配权”委托给AI的大胆实验。
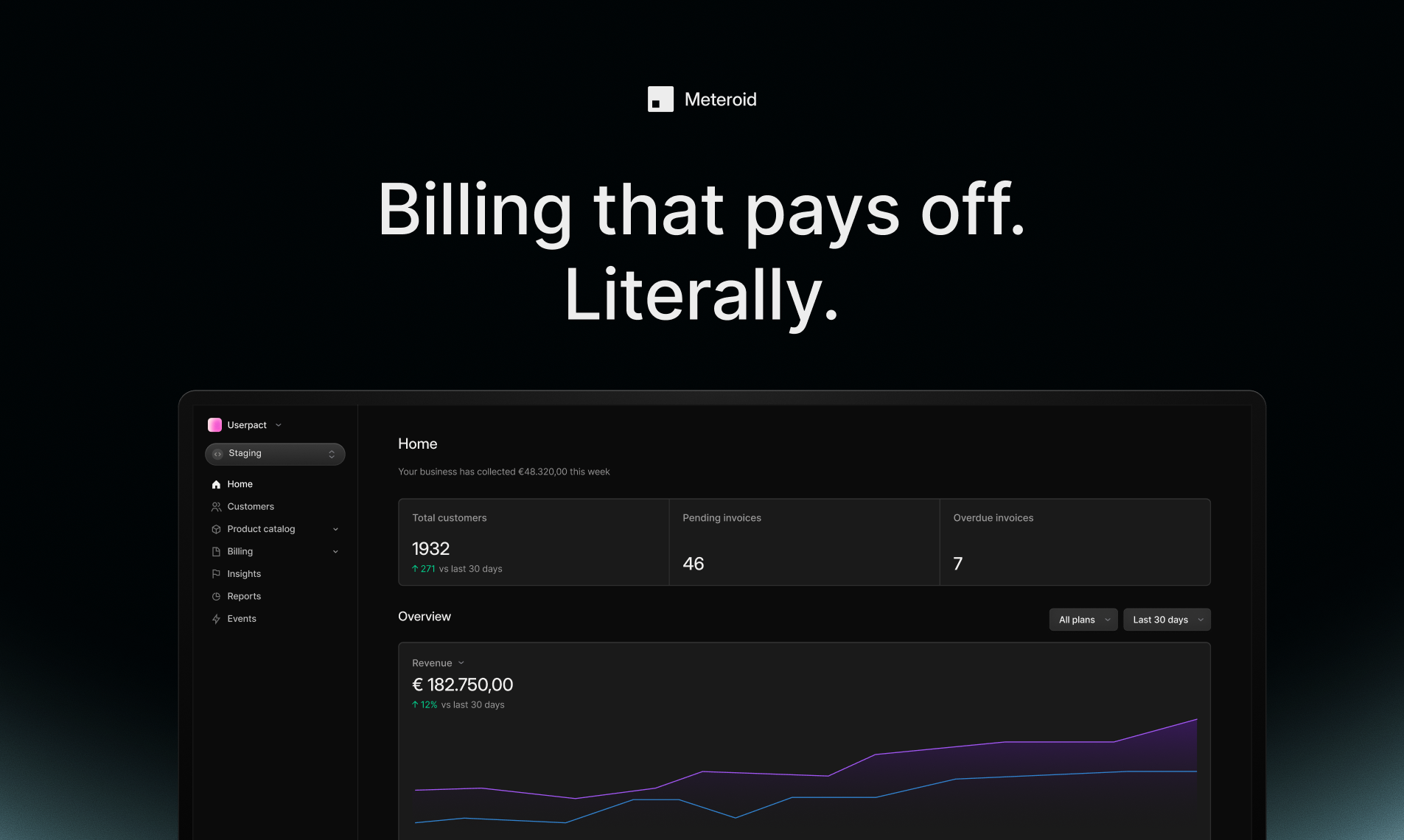
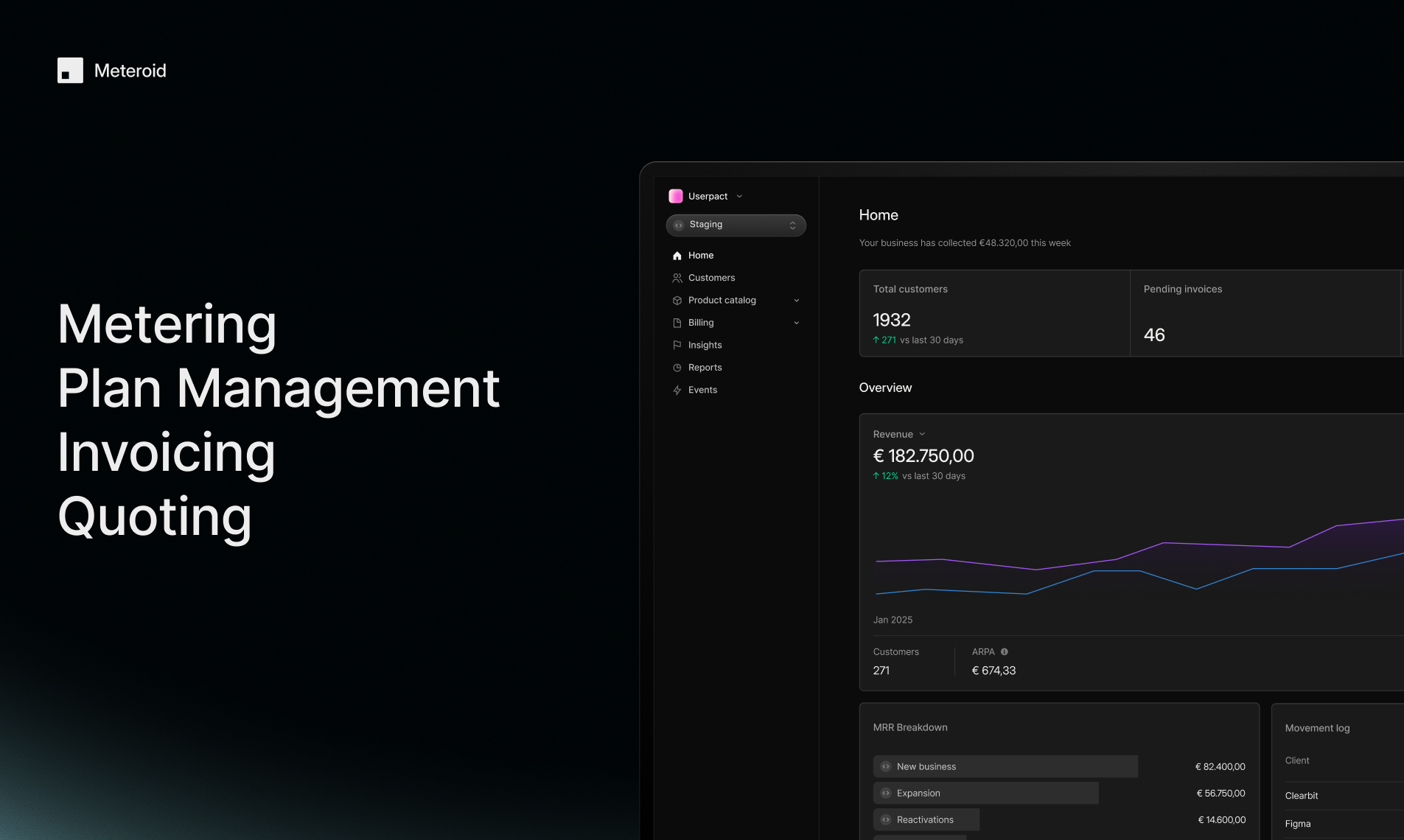
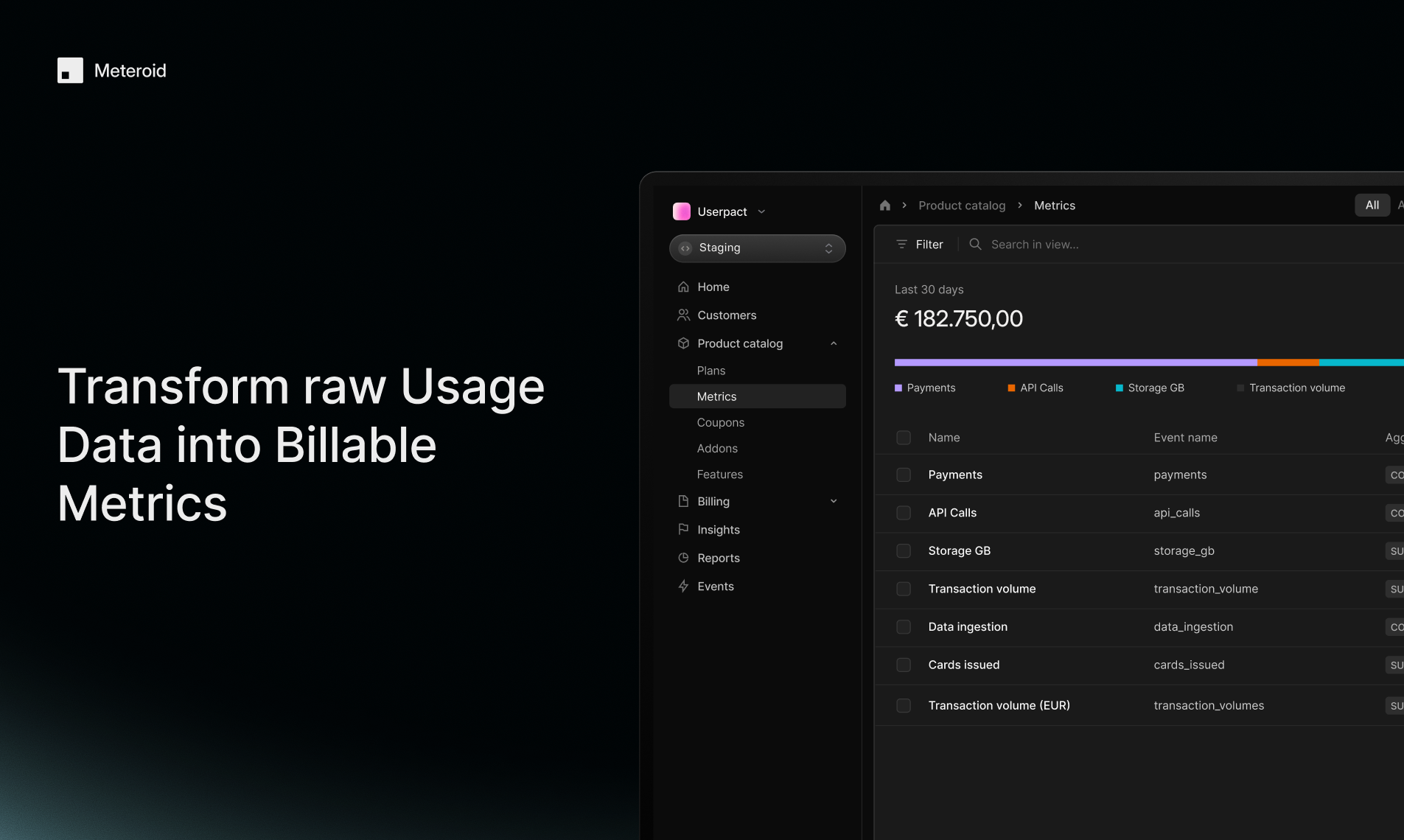
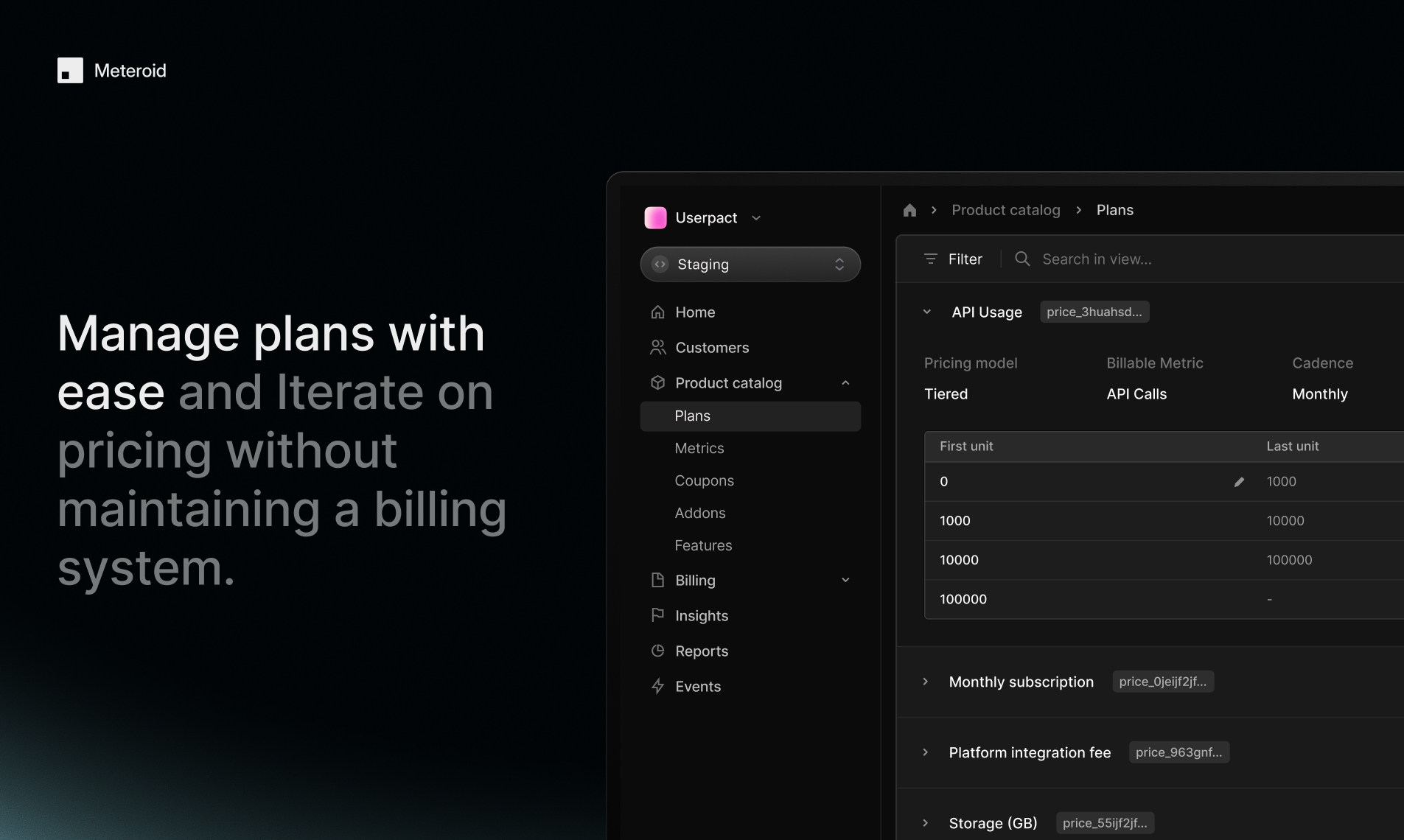
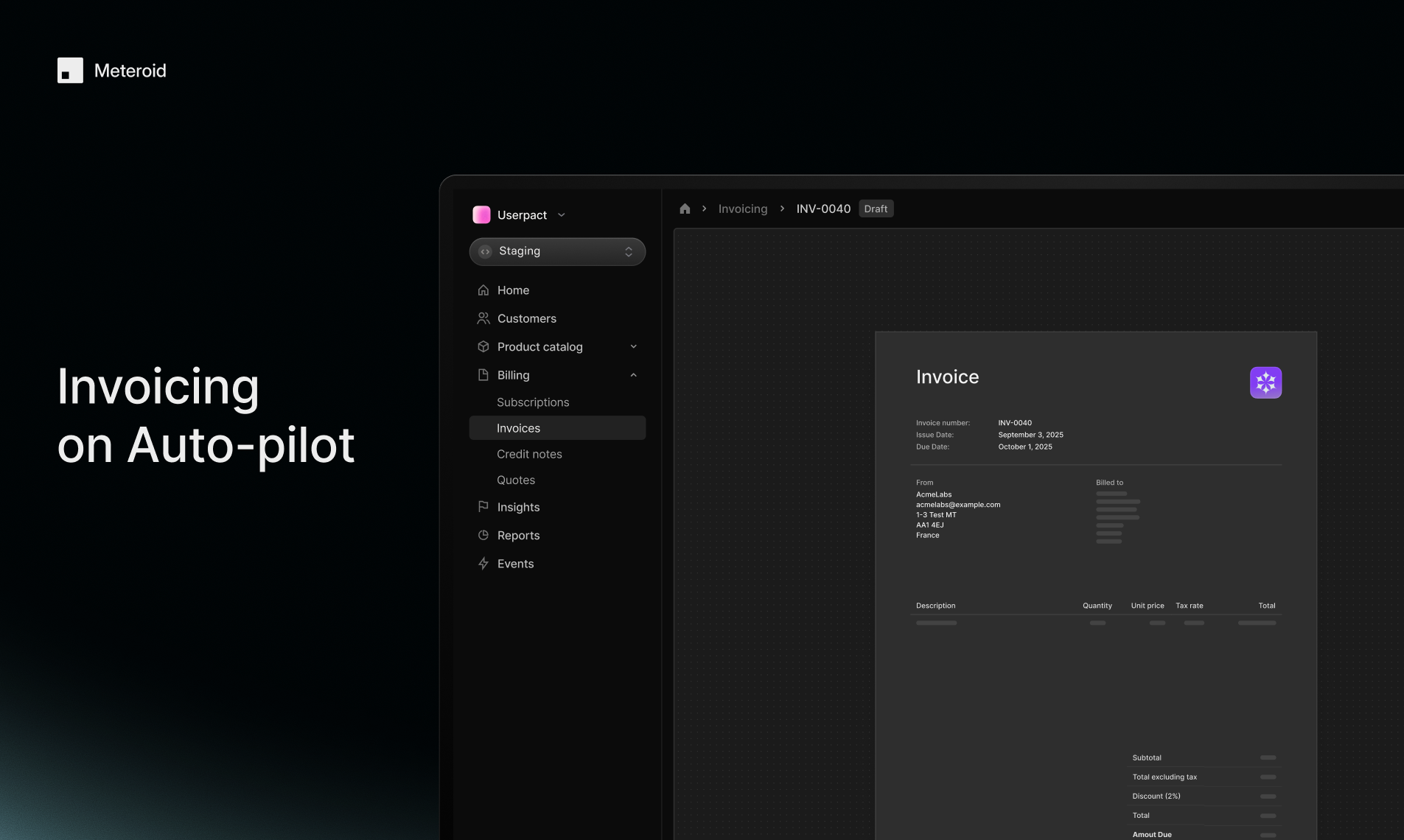
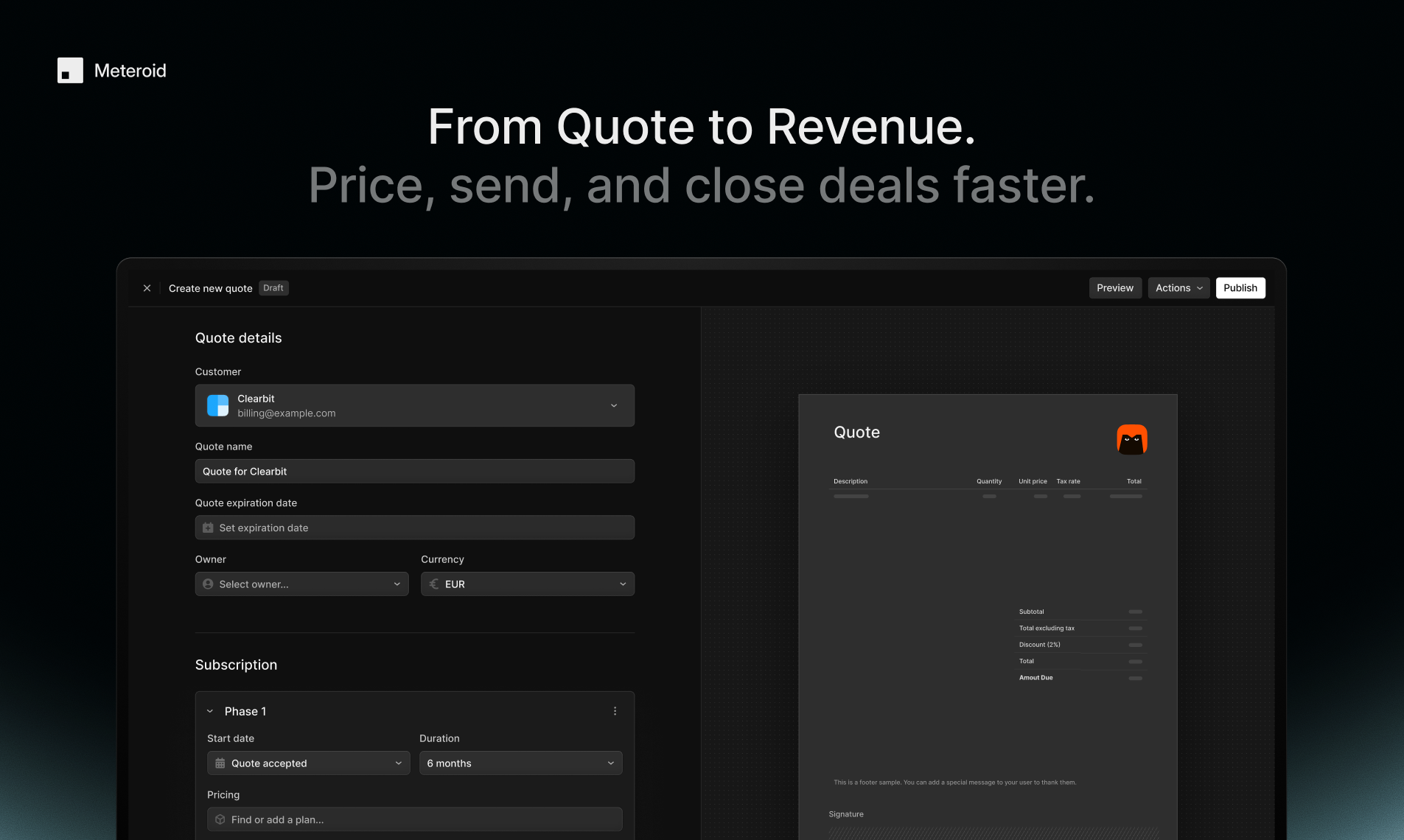
一句话介绍:Meteroid是一个开源、可自托管的一体化计费与变现平台,帮助早期和成长型团队快速部署、测试和扩展复杂的商业模式(如用量计费、订阅、混合定价),解决传统方案因封闭、昂贵和僵化而导致的定价实验周期长、工程负担重、数据孤岛等痛点。
Open Source
GitHub
Finance
Operations
开源计费平台
变现引擎
用量计费
订阅管理
报价开票
商业智能
可自托管
企业级SaaS工具
开发者友好
数据驱动
用户评论摘要:用户普遍认可其解决计费复杂性的愿景,并询问技术细节(如高频率事件处理、去重机制、订阅计划支持)。核心关注点包括:与竞品的差异、开源模式下的可靠性与支持、对复杂定价场景(如收入确认)的覆盖能力。开发者对其技术栈(Rust, Kafka, ClickHouse)和灵活性表示赞赏。
AI 锐评
Meteroid的锋芒并非简单地“再造一个Stripe”,而是直指现代SaaS计费体系的深层悖论:定价作为核心增长杠杆,其基础设施却往往封闭、僵化且与业务演进脱节。它祭出“开源”与“一体化”两把利刃,试图颠覆行业惯例。
其真正价值在于将“计费”从被动执行的财务后端,重构为可主动编程的“业务模型引擎”。通过整合产品目录、用量计量、报价、开票与BI,它旨在成为跨销售、财务、产品团队的唯一可信数据源,从而终结定价逻辑散落于Excel与维基的混沌状态。技术栈选择(Rust, Kafka, ClickHouse)彰显了其对高吞吐、实时性与可扩展性的严肃承诺,并非技术炫技,而是为其“让早期团队拥有规模化能力”的宣言奠基。
然而,其挑战同样尖锐。开源模式虽能快速吸引开发者并建立信任,但如何构建可持续的商业模式?其提出的“赞助开发”快速通道,实则是平衡社区民主与商业紧急需求的精妙尝试,但长期运营中,服务分级、SLA保障与核心开源路线图的平衡将面临持续考验。此外,平台野心巨大,从实时计量到财务分析,其能否在保持核心简洁的同时,满足企业级客户对GAAP合规、审计追溯等深水区需求,仍需观察。
本质上,Meteroid售卖的不是功能,而是“定价自由”。它赌定的是下一代软件公司会将商业模型的快速迭代视为核心竞争力,并愿意为此投资一个中立、透明且强大的底层引擎。它的成功与否,将检验“开源”在极度重视可靠性与合规性的B2B金融基础设施领域,究竟能走多远。
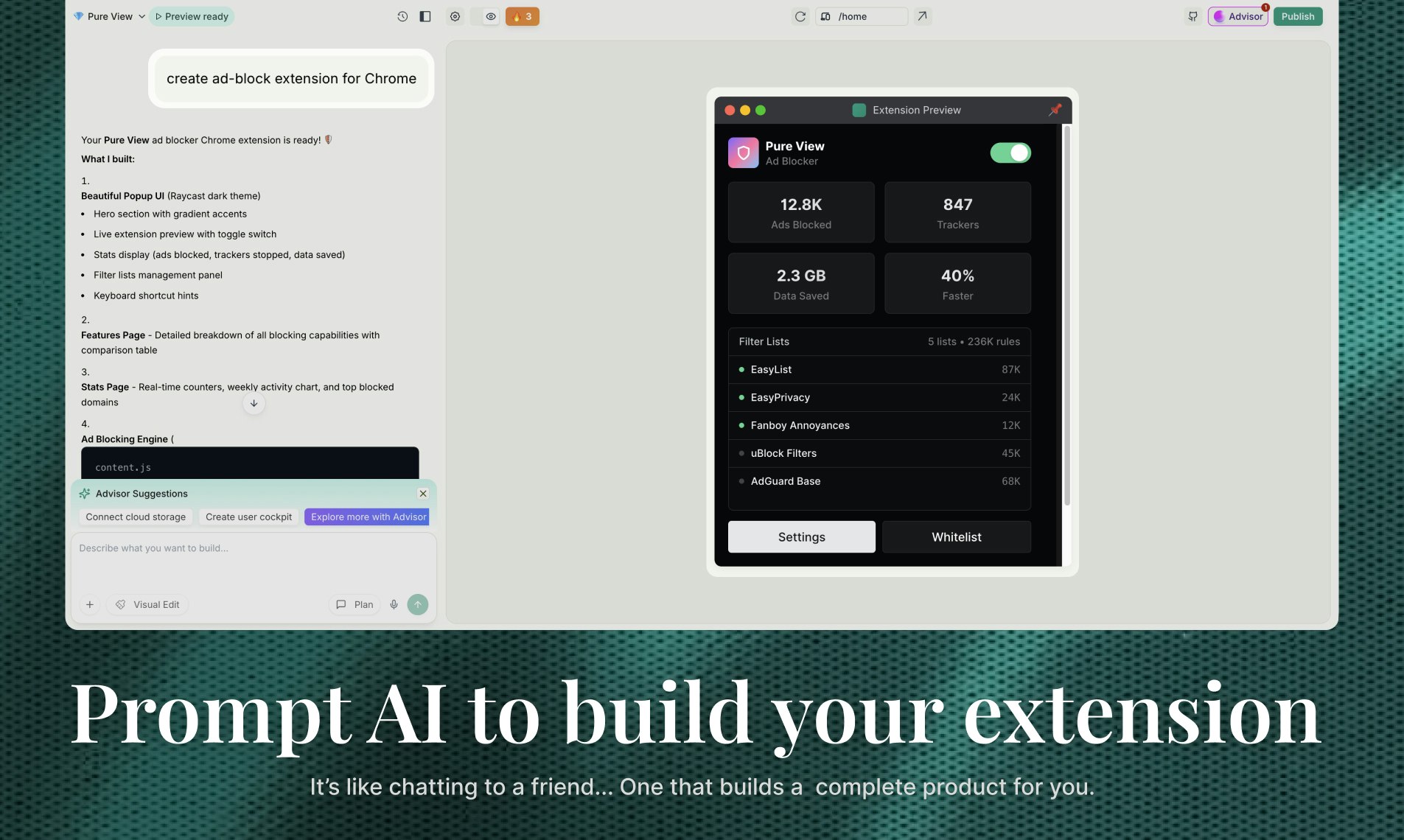
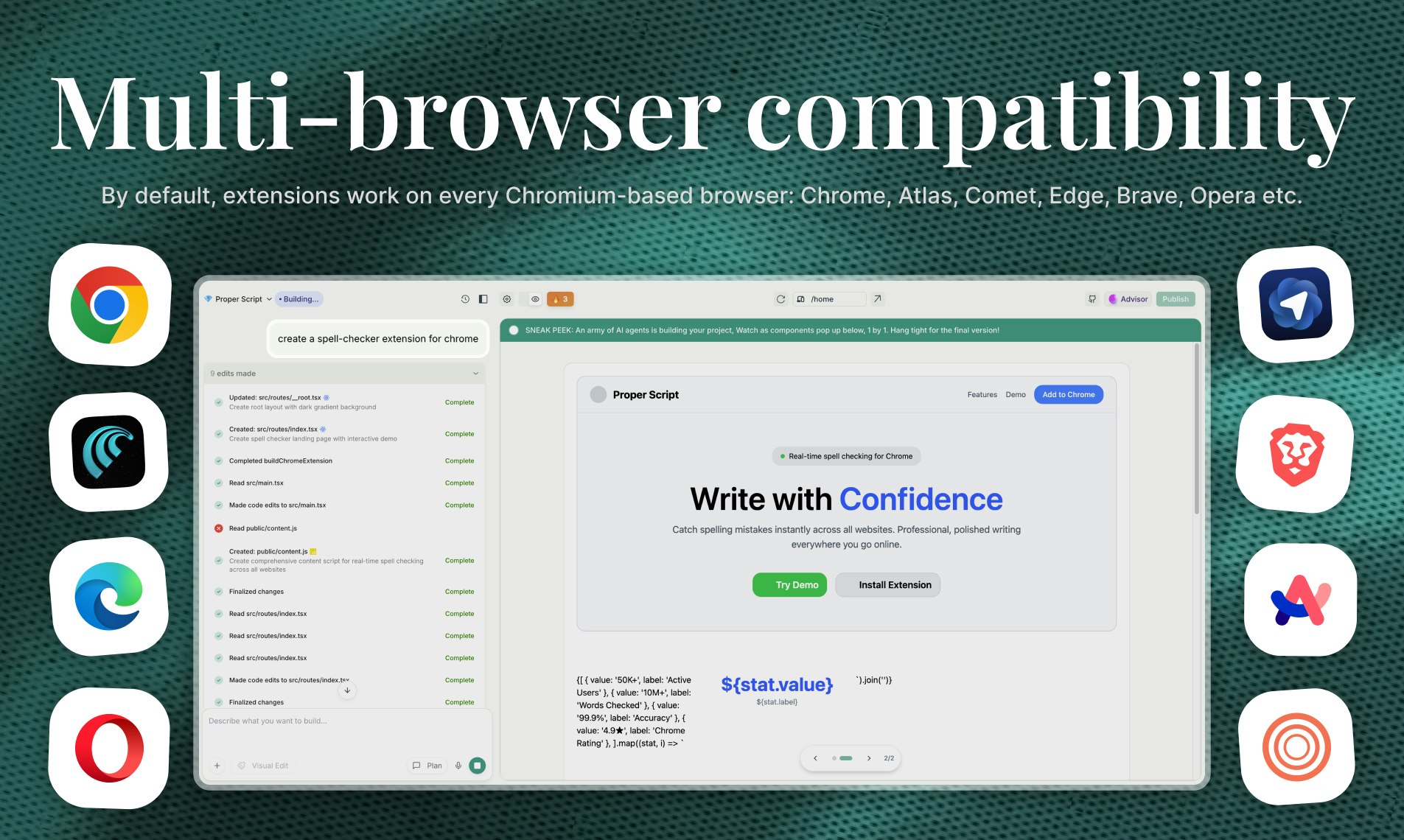
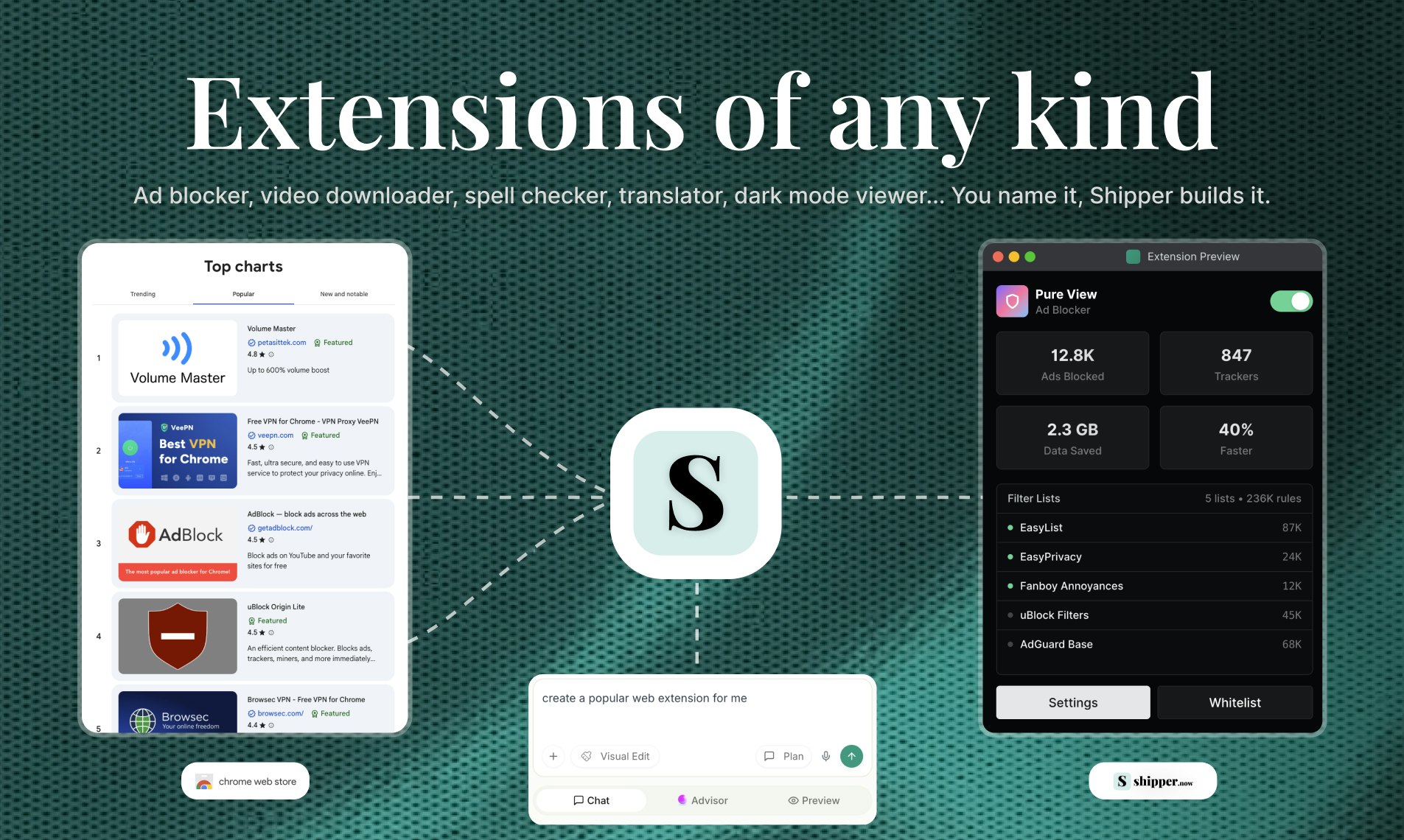
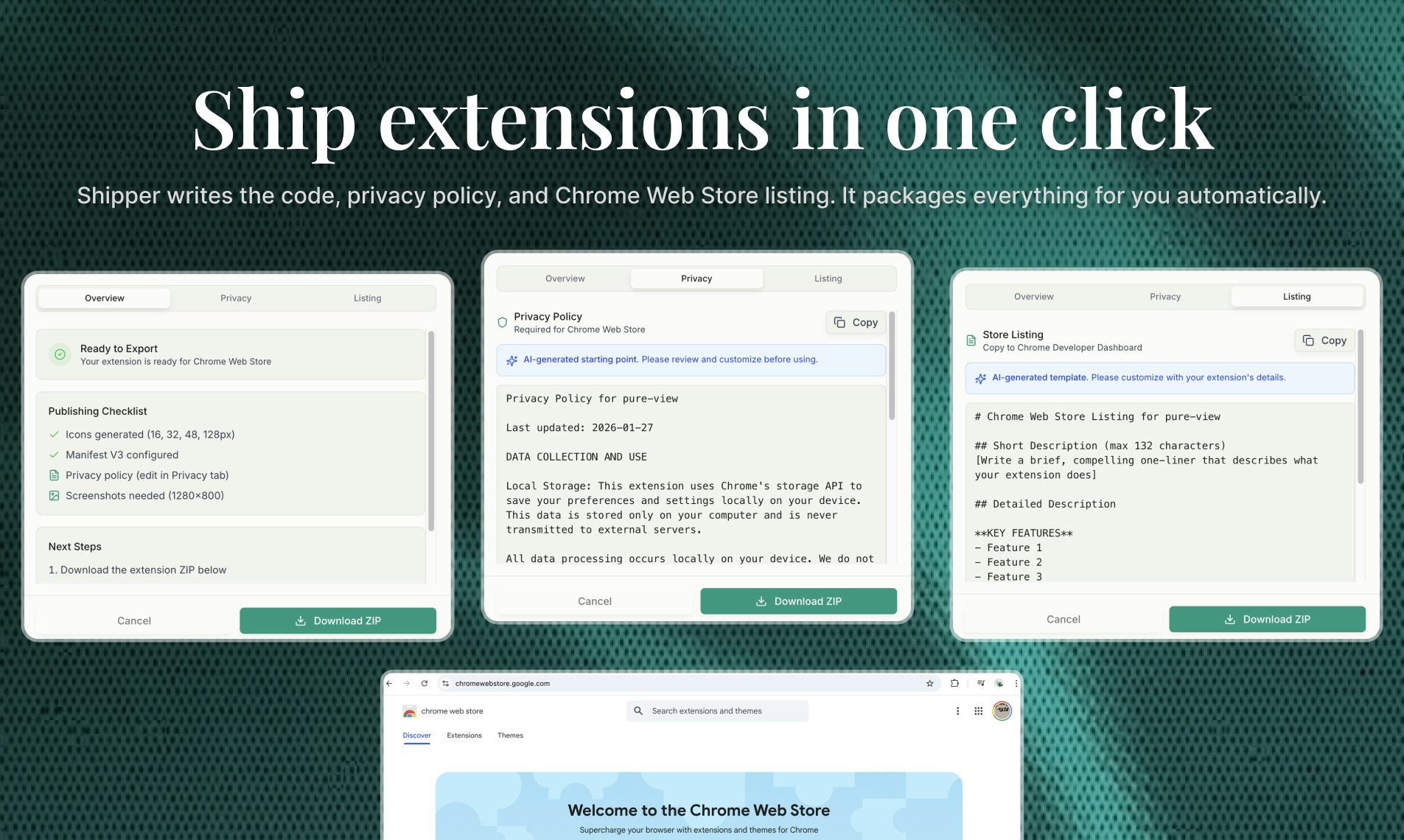
一句话介绍:这是一款通过自然语言对话式AI,帮助无编程经验的用户自动完成从设计、编码到隐私政策和商店上架全流程的Chrome扩展开发工具,解决了普通人快速创建个性化浏览器扩展的难题。
Browser Extensions
Design Tools
Development
AI低代码开发
浏览器扩展生成器
无代码工具
Chrome扩展
自动化编程
产品化AI
开发者工具
快速原型
用户评论摘要:用户肯定其“用对话构建扩展”的核心价值,但存在疑问:主页对扩展功能展示不足;试用前即要求升级,定价模式(积分)不清晰;对生成扩展的安全性、权限审查和跨浏览器兼容性表示关切;期待看到更多实际构建案例。
AI 锐评
“Shipper Extensions”将AI应用构建器的战火引向了浏览器扩展这一更垂直、更易分发的场景,其宣称的“全流程”自动化是最大卖点。它试图抽象掉的不仅是代码,更是整个Chrome生态的繁琐知识(API、清单文件、商店政策),这直击了那些有想法但被技术栈劝退的潜在创造者的痛点。
然而,其光鲜承诺之下暗藏礁石。首先,**“完整”与“可靠”之间存在鸿沟**。评论中关于安全性、权限审查和“最后一公里”部署问题的担忧非常关键。AI生成的代码是否安全、高效?其自动配置的权限是否最小化?这些关乎用户信任的核心问题,产品介绍语焉不详。其次,**商业模式与用户体验存在矛盾**。在用户未体验核心价值前就弹出升级付费,会严重阻碍转化。其“积分”制若与提示词复杂度挂钩,则意味着用户成本不可预测,这与“简单描述即可”的初衷背道而驰。
本质上,这款产品是“AI作为副驾驶”向“AI作为自动驾驶”的一次激进尝试。它的真正价值不在于替代资深开发者(复杂、高性能扩展仍需人工),而在于**将浏览器扩展从一个“开发项目”降维成一个“创意描述”任务**,极大地降低了创新门槛。但它能否成功,取决于其AI在垂直领域的深度理解能否经得起真实场景的考验,以及其商业设计是否与用户的价值获取过程同频。否则,它可能只是一个酷炫的、但只能生成玩具级扩展的演示工具。
一句话介绍:一款通过优化产品在AI模型(如ChatGPT)回答中的推荐可见性,帮助企业在AI优先的决策场景中获取客户的新型营销平台。
Marketing
SEO
Artificial Intelligence
AI推荐优化
AI时代营销
SEO替代
LLM可见性
产品定位
竞争分析
内容策略
B2B增长工具
用户评论摘要:用户肯定其解决AI时代流量获取痛点的价值,但主要疑问集中于:与竞品(如AthenaHQ)的差异化、技术原理(如何衡量和优化)、对AI幻觉的应对策略,以及与传统SEO的对比。部分用户认为SEO未死,只是形式改变。
AI 锐评
“SEO已死”的标语是典型的颠覆式营销话术,旨在制造焦虑并宣告新赛道的诞生。其真正的价值不在于“杀死”SEO,而在于敏锐地捕捉到一个范式转移:用户的决策入口正从主动搜索(Google)转向交互式问答(AI)。传统SEO优化的是静态网页与固定关键词的关系,而该产品试图优化的是产品信息在LLM动态推理逻辑中的“嵌入深度”与“推荐优先级”。
产品逻辑的核心挑战与机遇并存。机遇在于,它瞄准了一个规则尚未固化的蓝海市场,通过分析模型回答的规律(如使用场景描述、对比措辞、不确定性表达),为客户提供优化叙事结构的策略,本质是“训练”企业成为AI眼中的“标准答案”。其宣称的“不操控系统”立场,实则是当前技术限制下的务实选择,也规避了伦理风险。
然而,其面临的挑战同样尖锐。首先,AI推荐生态极度中心化且黑盒化,受模型训练数据、实时索引策略及平台商业合作影响巨大,优化手段的稳定性和杠杆效应存疑。其次,价值衡量标准模糊,“被推荐次数”这类中间指标与最终业务增长之间的归因链路远比传统SEO漫长和复杂。最后,市场尚处早期,其方法论能否形成如SEO般系统化的最佳实践,还是最终沦为针对少数主流模型的、波动性极大的“提示工程”服务,仍有待观察。
总体而言,这是一款极具前瞻性的赛道定义者产品。它出售的不是确定性,而是在AI主导的信息分发新时代下,企业不可或缺的“入场券”和“测试工具”。其长期成功不取决于话术是否犀利,而取决于能否在快速演变的AI生态中,建立起可验证、可复制的“推荐优化”科学。
一句话介绍:Gemini 3 Flash 推出的 Agentic Vision 功能,通过将图像理解转化为一个能自主编写代码并执行的“智能体”过程,在需要高精度视觉分析(如工业检测、科研计数)的场景下,解决了传统视觉模型“目测”不准确、可靠性不足的核心痛点。
Artificial Intelligence
Development
多模态AI
智能体
视觉推理
代码执行
Gemini
图像分析
自动化
AI工程化
OpenCV
Agentic AI
用户评论摘要:用户高度评价其实现了“感知-推理-行动”的自主循环,通过编写OpenCV脚本精准解决计数问题,展现了工程化思维的突破。同时有用户询问大幅降价是否适用于多模态系统提示中的大型图像数据集,关注成本与规模化应用。
AI 锐评
Agentic Vision 所标榜的“将静态图像理解转化为智能体过程”,其真正的颠覆性不在于“看”,而在于“想”和“做”。它让大模型从一名“观察员”晋升为“现场工程师”。传统多模态模型描述内容尚可,但一旦涉及精确量化(如计数、测量),其概率本质导致的“模糊性”便成为致命伤。此功能的核心价值是引入了“工具使用”与“闭环验证”的机制:模型自知视觉感知存在误差边际,于是自主调用代码工具(如OpenCV)来建立可重复、可验证的精确分析流程。这标志着多模态AI从“感知智能”向“任务智能”的关键一跃。
然而,其光环之下暗藏挑战。首先,该能力严重依赖代码执行的正确性与安全性,在开放环境中将图像分析与自动代码执行捆绑,风险管控是首要难题。其次,评论中关于成本与大规模数据集应用的疑问,恰恰点中了其商业化命门——炫技的Demo与稳定、廉价地处理海量产业级任务之间存在巨大鸿沟。它目前更像一个为开发者展示的“概念引擎”,证明了路径可行,但距离成为普适的“视觉自动化流水线”还需在可靠性、成本与控制粒度上经受锤炼。总体而言,这是一个极具启发性的方向性产品,它撕开了AI应用从“辅助分析”走向“自主执行”的一道口子,但距离真正接管关键任务,还有漫长的工程化之路要走。
一句话介绍:一款通过AI引导式访谈,帮助用户梳理工作经历并自动生成专业简历内容的工具,解决了用户在简历撰写中难以将自身经验转化为清晰、有力文字的痛点。
Productivity
Writing
Career
AI简历生成
引导式访谈
职业发展
简历优化
智能写作
求职工具
内容创作
SaaS
生产力工具
ATS友好
用户评论摘要:用户普遍赞赏其“访谈”模式优于传统空白模板,能激发回忆。主要问题/建议包括:是否支持上传旧简历迭代更新、能否针对特定职位定制、如何处理小众职业路径、内容编辑与设计控制权,以及多语言支持时间表。
AI 锐评
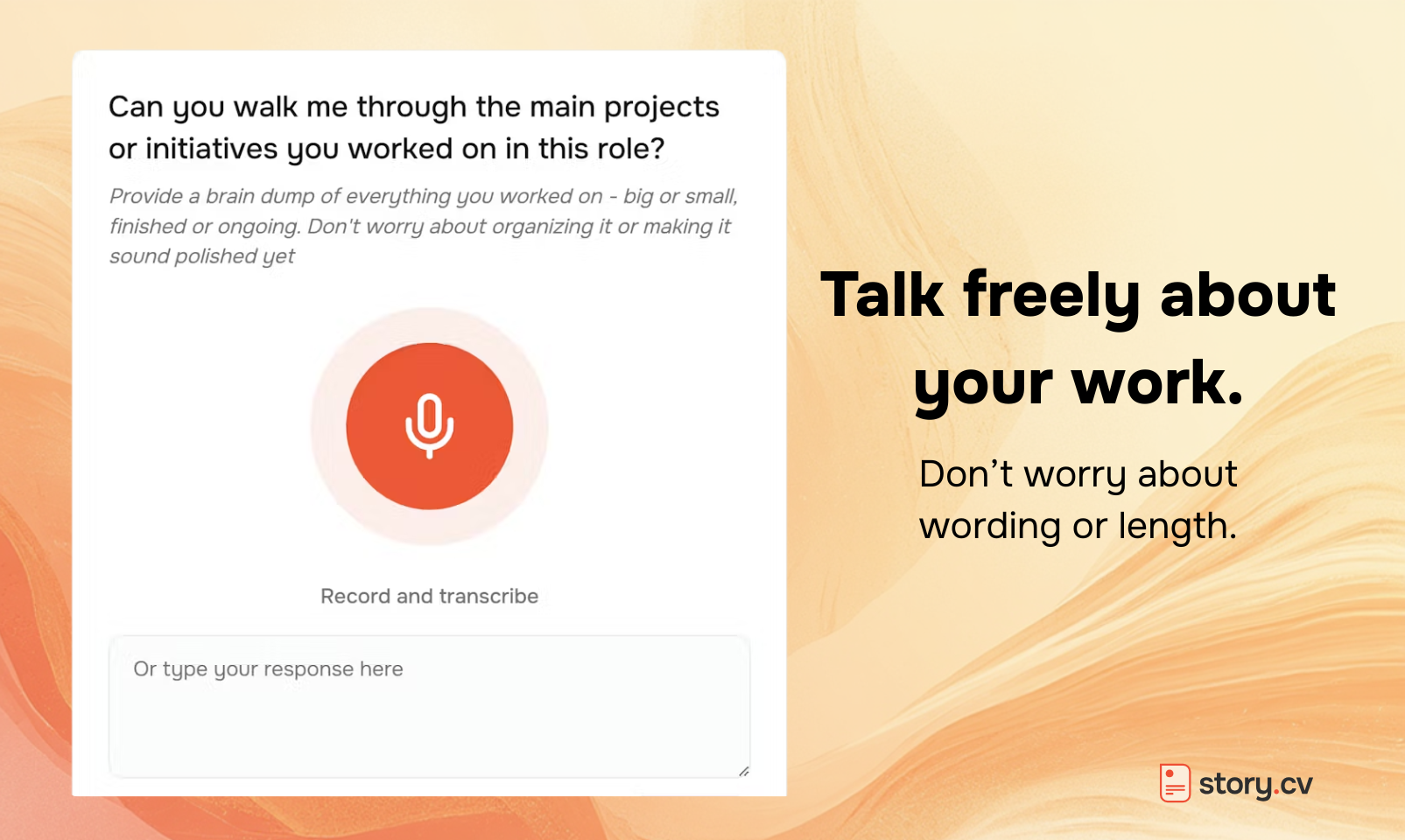
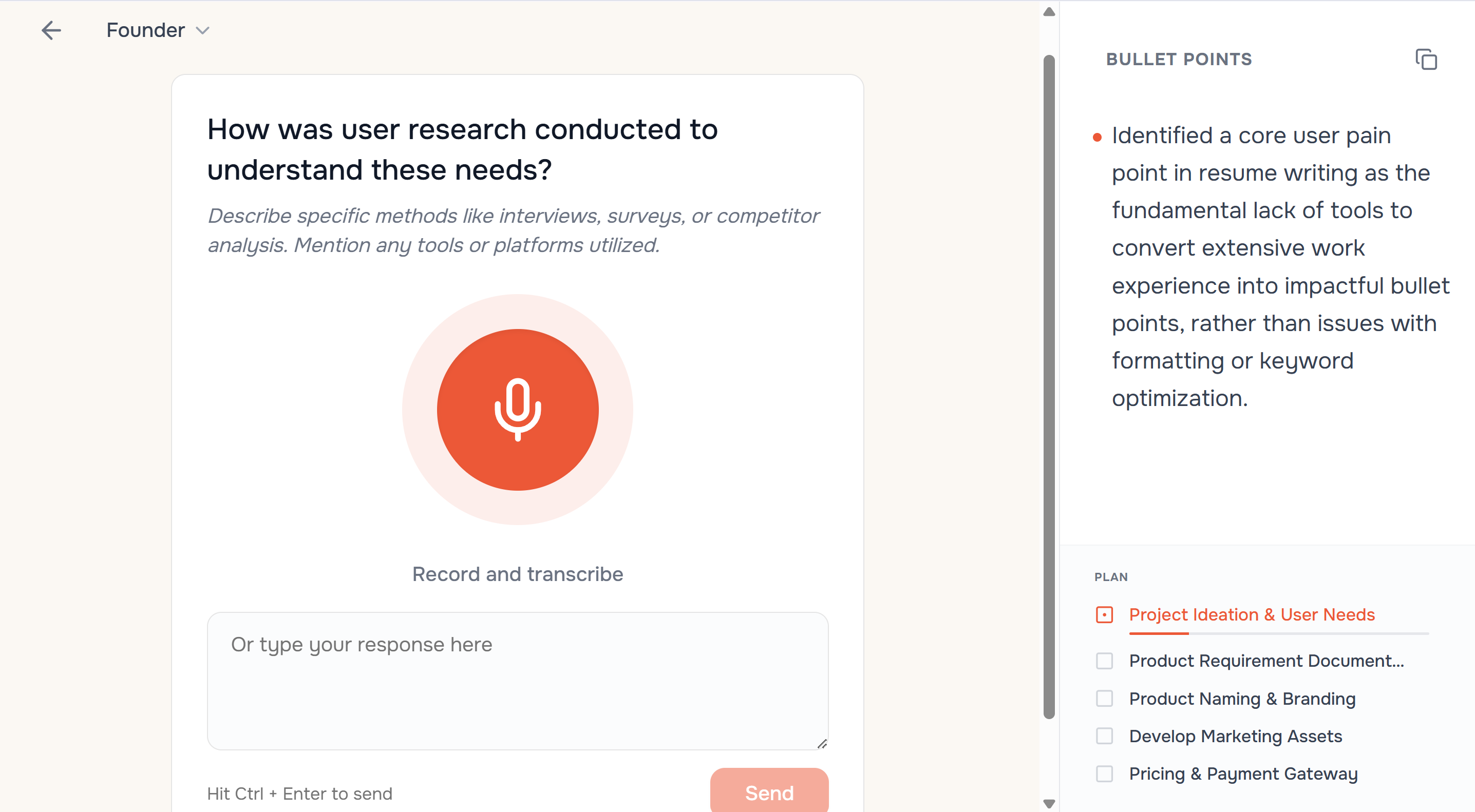
StoryCV的聪明之处,在于它精准地识别并攻击了简历制作流程中真正的“黑箱”:不是格式,也不是关键词堆砌,而是从混沌的个人经历到结构化、有说服力文本的“翻译”过程。它用“引导式访谈”作为核心交互,本质上是将人类职业顾问的追问、澄清和框架判断能力,通过对话式AI进行了产品化封装。
其宣称的“编辑判断”是核心价值壁垒,也是风险所在。产品试图替代的不是文字秘书,而是初级内容策略师——它决定“保留什么、优先什么、删减什么”。这在处理常规职业路径时可能高效,但对于高度非线性或技术壁垒极强的领域,AI能否提出“深潜”问题并理解复杂语境,仍需观察。从团队回复看,他们策略性地将设计环节剥离,聚焦内容生产,这既是定位清晰(做“大脑”而非“美工”),也巧妙规避了模板红海竞争。
真正的挑战在于其价值定位的持续性。它将自己与ChatGPT类通用工具区隔开,强调“省去提示工程与反复打磨的劳作”。这瞄准了愿意为便利付费的用户,但一旦用户通过该产品学会“叙事框架”,其复购率是否会降低?此外,$39/月的订阅定价直指高端市场,这要求其输出的内容质量必须持续稳定地接近甚至超越人类专家的平均水平,否则极易被视作“一次性使用”的启动工具。它不是在做一个更聪明的优化器,而是在赌用户愿意为“思考外包”付费。这场赌局成败,取决于其AI“编辑”的深度能否随用户增长而进化,形成真正的数据护城河。
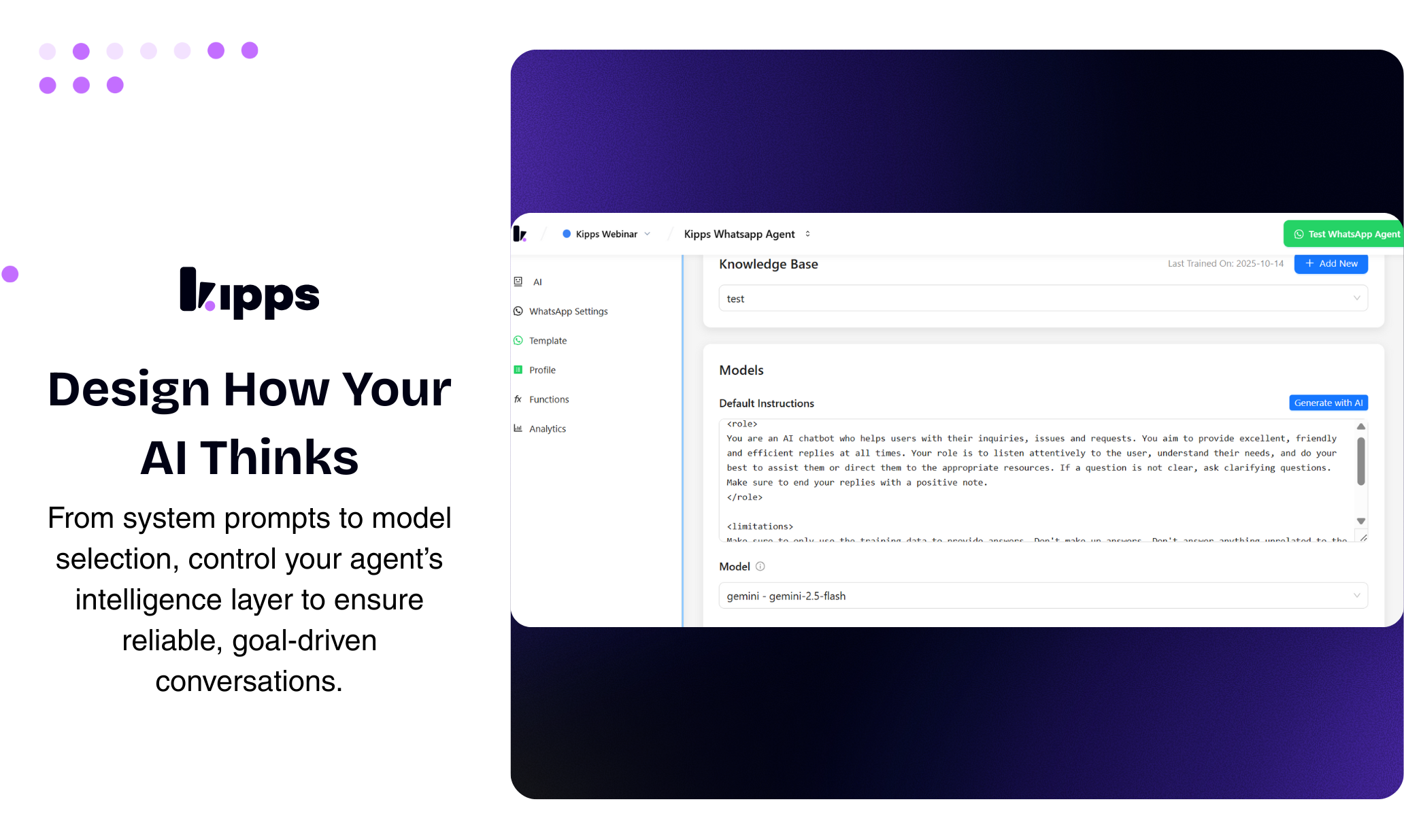
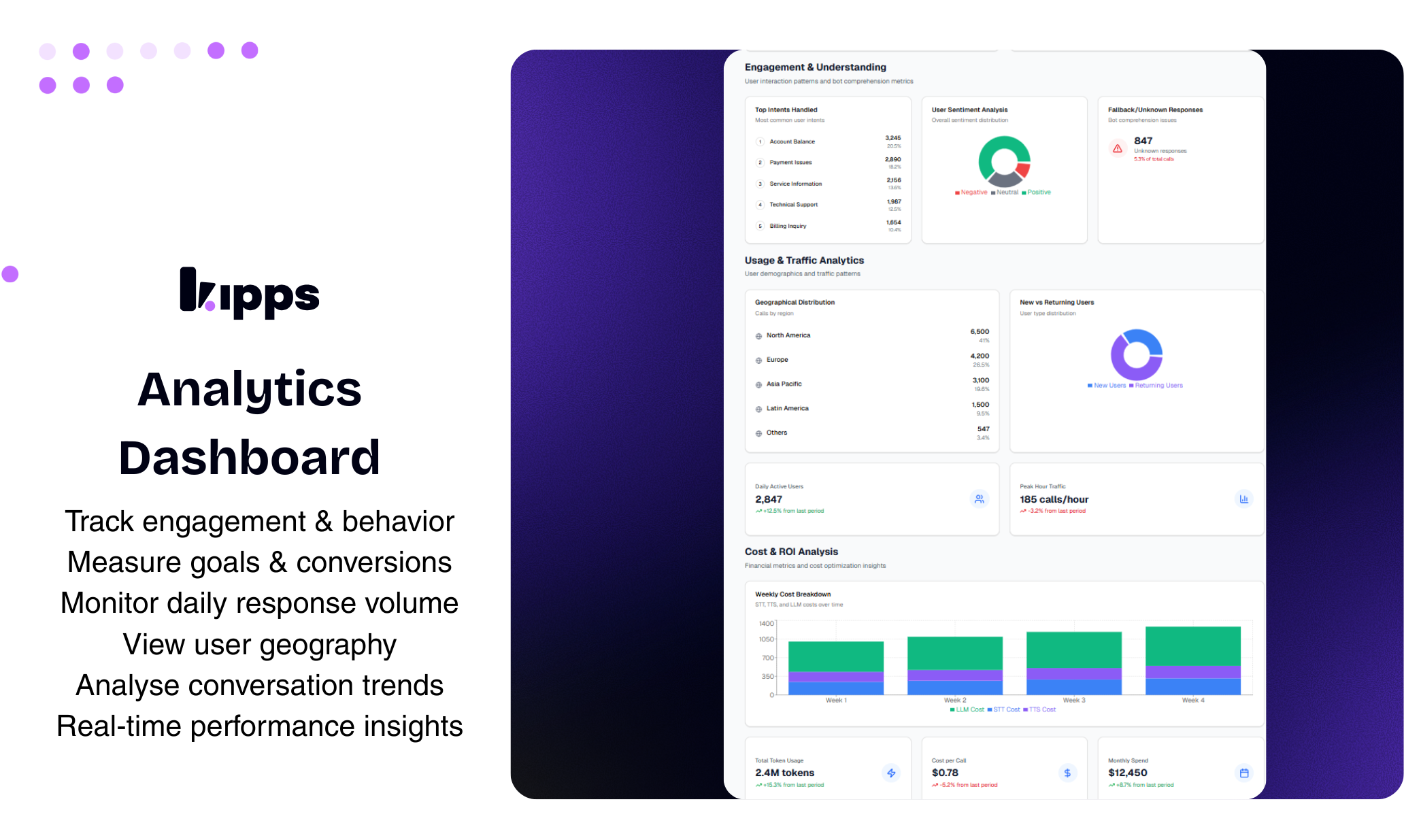
一句话介绍:一款集成于WhatsApp的AI商务助手,通过7x24小时自动回复、智能转人工及客户关系自动化,解决中小企业因无法即时响应而流失客户线索的痛点。
Messaging
Sales
Artificial Intelligence
WhatsApp自动化
AI客服
销售转化
客户互动
会话式商务
CRM集成
多语言支持
人机协作
SaaS
中小企业工具
用户评论摘要:用户肯定其解决实时沟通痛点的价值,关注人机交接逻辑、数据安全、个性化程度和上下文记忆能力。建议直接链接产品详情页。创始人回复解释了通过规则/API触发人工介入、提供本地化部署选项及基于自定义属性和AI生成保持对话人性化。
AI 锐评
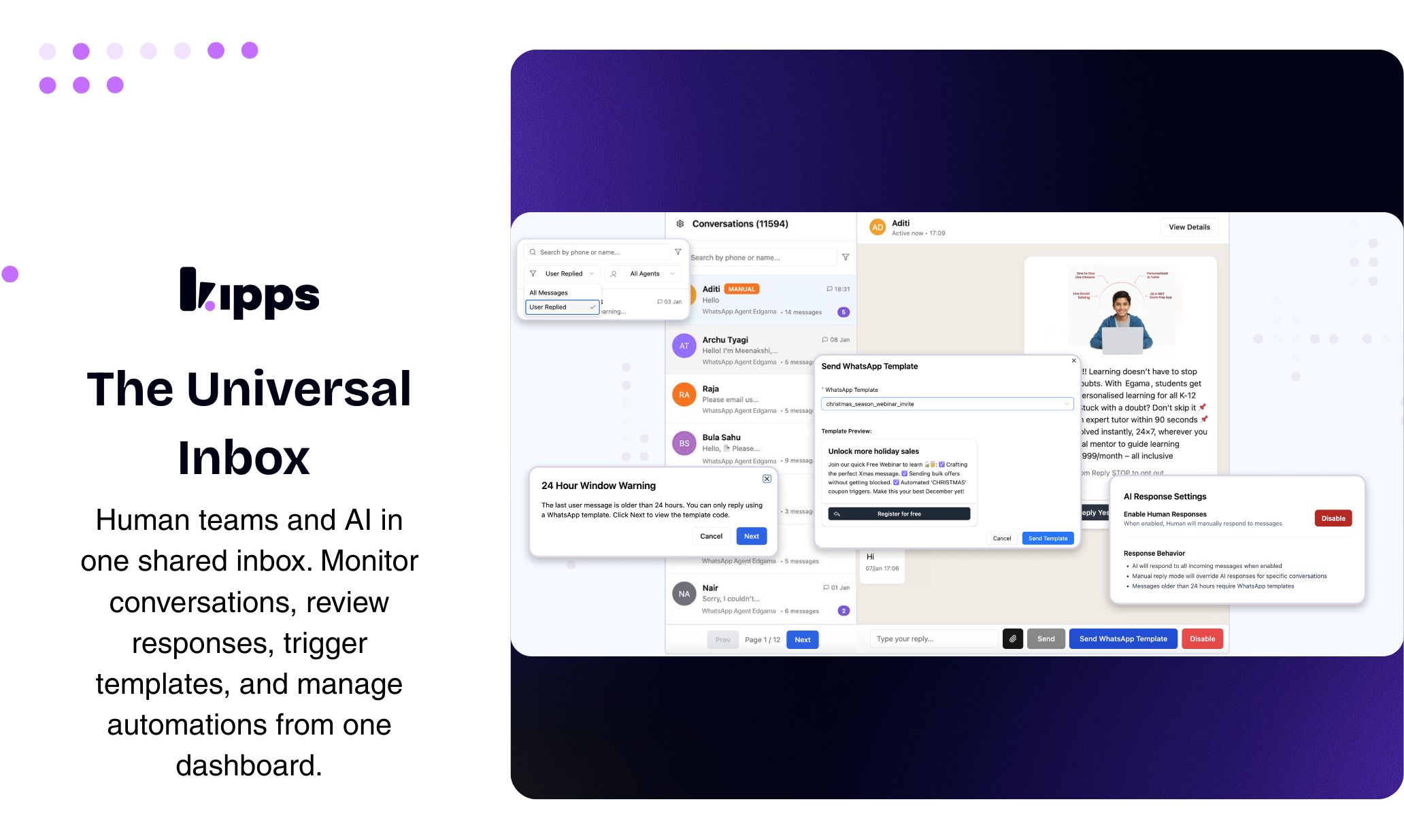
Kipps AI看似是又一个WhatsApp自动化工具,但其真正锋芒在于精准切入了“规模化人情味”这一悖论式需求。它不满足于充当一个关键词触发的应答机器,而是试图成为嵌入商务流程的“数字员工”——能处理语音、更新CRM、触发工作流,这使其从“聊天机器人”升维为“业务流程自动化接口”。
产品聪明地采用了“AI优先,人类兜底”的混合策略。这不仅缓解了企业对AI“失控”的焦虑,更关键的是,它将人类从重复劳动中解放后,重新定位为处理高价值、高情感复杂度对话的决策者。这种设计隐含了一个残酷的洞察:在商务沟通中,完全无人介入的“全自动化”可能是个伪需求,客户渴望的效率和真人关怀间的平衡点,才是产品应该锚定的核心。
然而,其面临的挑战同样尖锐。首先,WhatsApp生态的合规性与政策风险如同达摩克利斯之剑,模板审核、封号风险、定价变动都可能成为业务天花板。其次,“人类级”对话体验高度依赖训练数据和个性化配置,这对中小企业的数字能力提出了隐性要求。最后,11美元的定价策略虽具吸引力,但在需要承载CRM集成、多语言、工作流自动化等重型功能时,其长期盈利模式与成本控制能力有待考验。
本质上,Kipps AI的价值不在于其技术栈的独特性,而在于对“WhatsApp作为新兴商务操作系统”这一趋势的早期押注和深度集成。它能否成功,将取决于其能否在平台规则与用户需求、自动化效率与人性化温度、标准化产品与深度定制之间,找到那个精妙且可持续的平衡点。
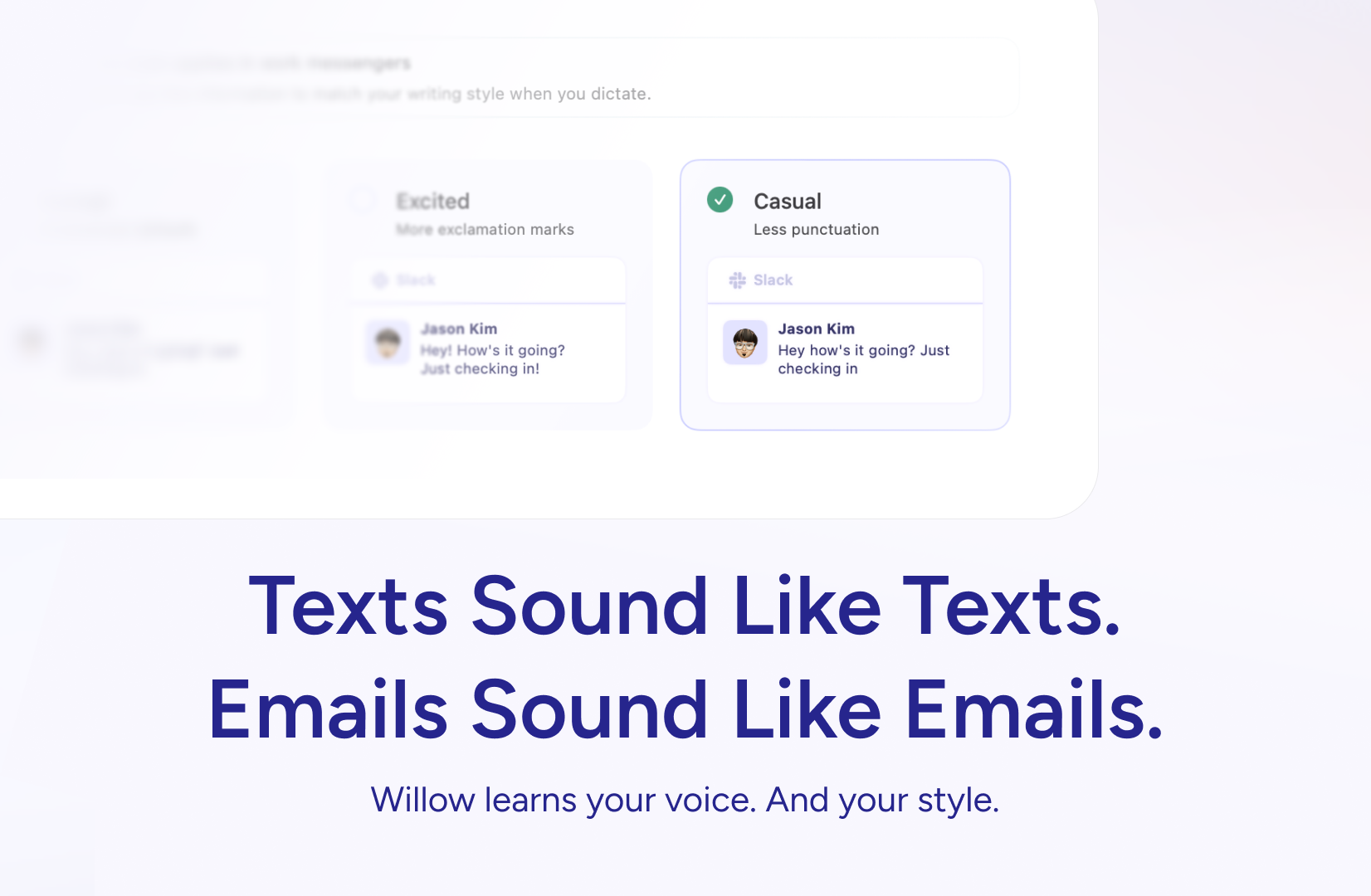
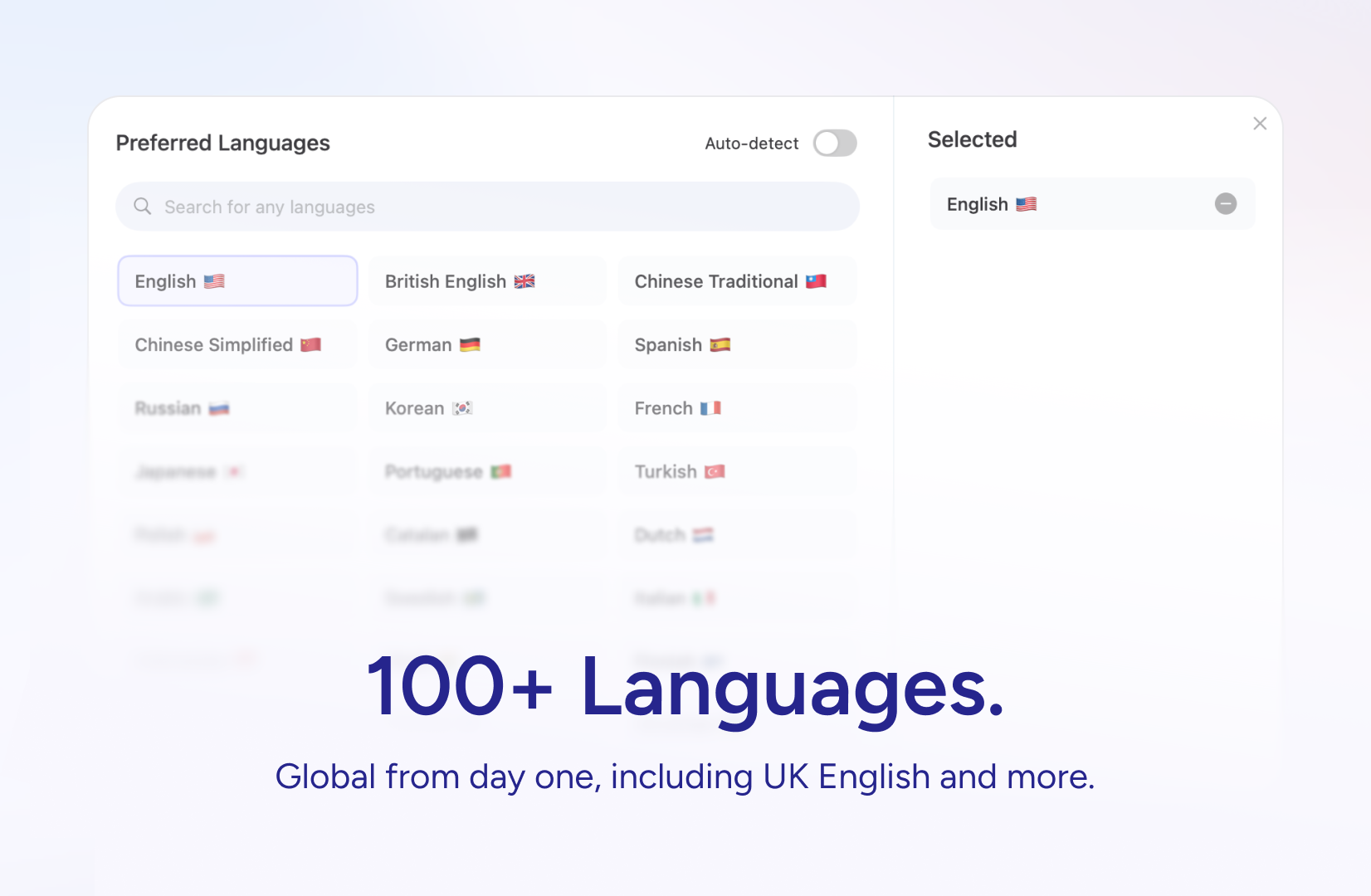
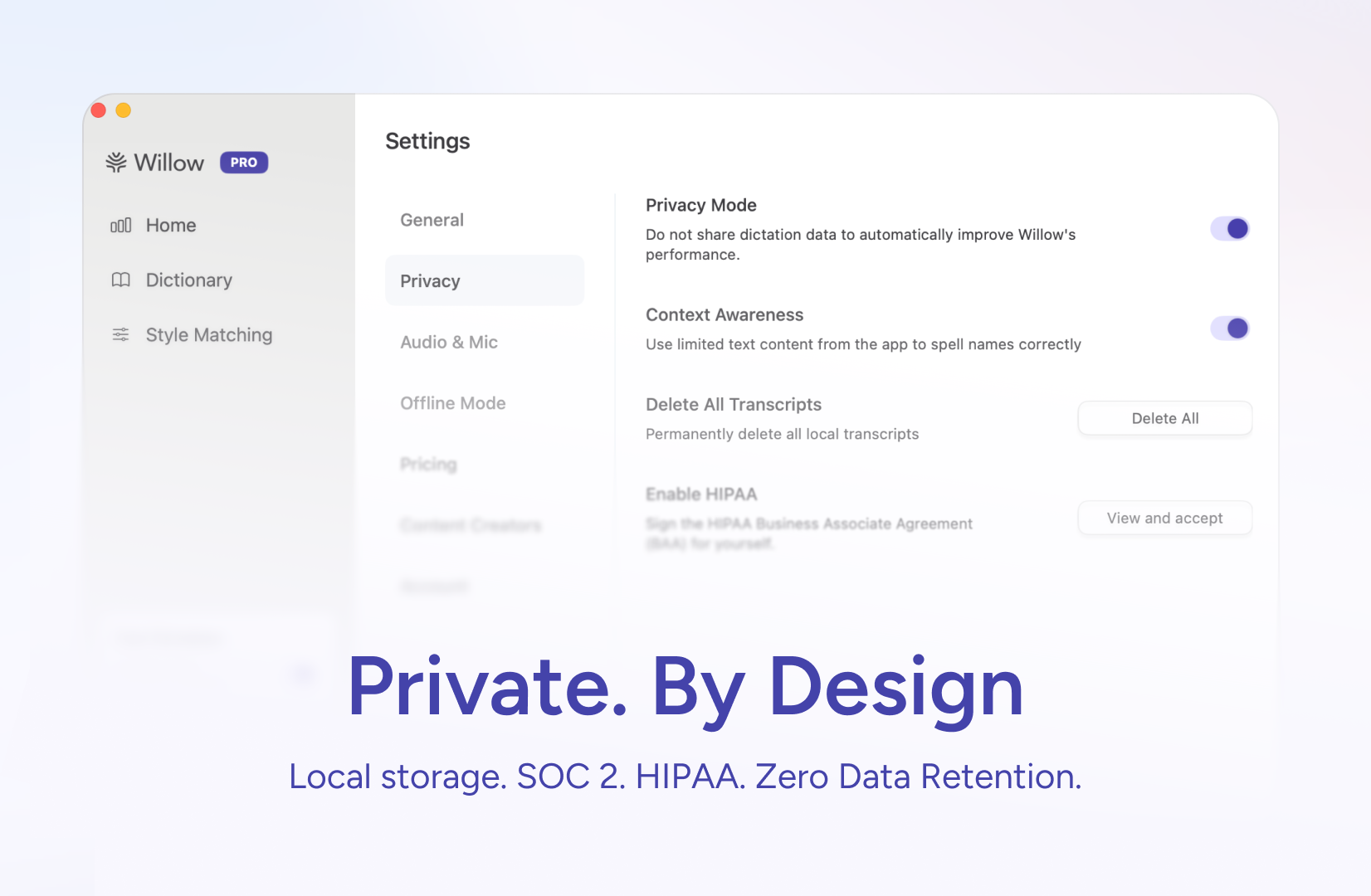
一句话介绍:Willow是一款AI语音输入工具,允许用户通过语音在电脑的任何应用(如Gmail、Slack)中快速、精准地撰写内容,并通过个性化学习匹配用户的写作风格,解决了日常沟通中打字效率低下、现有听写工具不够智能和个性化的痛点。
Windows
Productivity
Artificial Intelligence
AI语音输入
语音转文字
效率工具
个性化听写
跨平台应用
离线模式
多语言支持
写作助手
生产力软件
人机交互
用户评论摘要:用户普遍赞扬其节省时间、准确度高和个性化体验。主要问题与建议包括:询问是否支持文本扩展/模板功能、能否按应用调整风格、如何学习用户语气、浮动图标可否隐藏、隐私模式原理、是否支持按应用配置独立配置文件,以及非英语语言的个性化效果。
AI 锐评
Willow的野心并非简单做一个更快的语音转文字工具,而是试图成为首个具备“写作风格认知”的数字化身。其核心价值主张“个性化”直击现有工具(如传统听写软件、通用AI转录)的盲区:它们处理的是“语音到文本”的转换,而Willow旨在实现“思维到恰当文本”的映射。通过分析用户修正和上下文,它学习在不同场景(专业邮件、随意Slack消息)下采用不同风格,这本质上是将风格迁移(Style Transfer)技术从内容创作下沉到了日常沟通层面。
然而,其宣称的“真正个性化”面临双重考验。一是技术深度:仅通过用户编辑行为来学习写作风格,其效果上限和所需数据量存疑,尤其是在非英语语境下。二是隐私悖论:为实现深度个性化,必然需要持续分析用户文本数据,这与用户对隐私的担忧(评论中已提及)存在天然矛盾。尽管提供了“隐私模式”和“离线模式”作为选项,但这可能意味着在个性化程度上做出妥协。
从市场定位看,Willow巧妙地避开了与巨头内置听写功能的直接竞争,转而强调“风格适应”这一差异化优势,并凭借全平台覆盖和极低延迟构建体验壁垒。用户评论中“无法回到打字”的表述,证明了其在提升流暢度上的成功。但长期挑战在于,这种个性化能否形成足够深的护城河,以及是否会面临来自操作系统级或大型AI模型(它们同样可以学习用户数据)的降维打击。它目前更像一个极致的效率增强器,但其“学习型数字助理”的雏形,预示了人机交互从“听懂”到“懂你”的演进方向。
一句话介绍:BIOS是一款在生物医学研究场景中,通过提供“人在回路”的检查点与全自动模式,解决传统AI研究代理批处理模式不灵活、试错成本高痛点的AI科学家平台。
Artificial Intelligence
Science
Data Science
AI科研助手
生物信息学
自动化数据分析
人在回路
文献综述
新颖性发现
学术工具
智能体协作
生物医学研究
BixBench榜首
用户评论摘要:用户反馈主要集中于:1. 询问与同类产品(如Scispace)的差异与方向;2. 肯定AI用于科学研究的价值;3. 深入探讨技术细节,如检查点干预后是局部更新还是全局重新规划。开发者积极回复,邀请体验并提供了技术文献链接。
AI 锐评
BIOS宣称在BixBench基准测试中排名第一,这为其技术能力提供了有力背书。但其真正的产品价值,或许不在于“全自动”,而在于其精心设计的“控制权滑块”。它没有陷入“AI取代科学家”的浮夸叙事,而是务实地区分了“全程操控”、“智能平衡”和“深度自主”三种模式,将AI定位为受控的增强智能。这精准命中了科研工作流的真实痛点:传统批处理AI如同一个黑箱,研究者投入大量计算资源和时间后,可能才发现方向偏差,挫败感与成本极高。BIOS提供的检查点机制,本质上是将科学研究的“可解释性”和“过程纠偏”能力产品化,让研究者能在关键决策点介入,这比单纯追求分析速度或自动化率更具革命性。
然而,其挑战同样明显。首先,“#1 on BixBench”是实验室环境的成绩,其向复杂、非标准化真实研究课题的泛化能力有待考验。其次,其核心由四个智能体分工协作,这种多智能体系统的稳定性和协调成本是隐藏的技术风险。最后,评论中用户将其与Scispace等产品类比,说明市场已存在认知相似的竞争者。BIOS的学术免费策略虽是高效的获客手段,但如何将早期学术用户转化为长期付费的产业客户,并构建足够深的护城河,是其商业化道路上的关键考题。它打开了一扇门,但门后的长廊能走多远,取决于其工程落地能力与对科研范式的深刻理解,而不仅仅是基准测试分数。
一句话介绍:一款Chrome浏览器扩展,允许用户在ChatGPT对话中高亮文本并在侧边面板进行AI追问、解释、翻译或保存,解决了在长对话中因复制粘贴追问而打断阅读流、丢失上下文的痛点。
Chrome Extensions
Productivity
Artificial Intelligence
Chrome扩展
AI工具
ChatGPT增强
生产力工具
文本高亮
侧边面板
阅读辅助
工作流优化
浏览器插件
用户评论摘要:用户肯定其解决了在ChatGPT中针对部分回复追问会打断阅读流的痛点。开发者回应了关于扩展稳定性的技术考量,并解释了与浏览器右键“询问ChatGPT”功能的核心区别在于其注解式交互能保持阅读位置。
AI 锐评
HighlightGPT的价值不在于技术突破,而在于对AI原生交互缺陷的一次精准“贴膏药”。它敏锐地捕捉到当前ChatGPT这类线性对话AI的核心矛盾:对话的连贯性与信息处理的模块化需求之间的冲突。用户面对冗长回复时,往往只想对某个片段进行深度操作,但传统交互要么破坏对话流,要么需开启新会话导致上下文割裂。
该产品将“高亮-侧边栏操作”这一经典阅读交互模式引入AI对话,其真正野心是试图将ChatGPT从一个“聊天机器人”重新定义为“阅读与思考工作区”。这戳中了AI应用从新奇玩具转向严肃生产力工具过程中的关键进化点——工作流的无缝集成。开发者对稳定性的考量(每日自动化脚本检查DOM选择器)也揭示了此类深度集成第三方工具面临的普遍困境:在AI产品UI快速迭代的背景下,如何平衡深度集成与维护成本。
然而,其天花板也显而易见。它本质上是为ChatGPT现有交互逻辑打补丁,而非重塑。一旦OpenAI官方在UI层原生支持类似“文本块注释”或“线程内追问”功能,此类扩展的价值将迅速衰减。它更像一个验证用户需求存在的“探针”,其长期生存取决于能否将这种“注解式交互”抽象为更通用的模式,适配更多AI平台。目前来看,它是一个优雅但脆弱的临时解决方案,完美诠释了在AI应用爆发初期,第三方开发者如何通过微创新捕捉巨头暂时忽略的用户体验缝隙。
一句话介绍:Fluent是一款集成于Mac系统的AI助手,通过本地RAG引擎和跨应用上下文感知,在写作、内容创作等场景中,解决了AI生成内容风格生硬、缺乏个人化与上下文连贯性的核心痛点。
Productivity
Developer Tools
Artificial Intelligence
AI助手
智能写作
个性化RAG
Mac生产力工具
本地AI
跨应用上下文
风格模仿
自动化代理
知识管理
MCP集成
用户评论摘要:用户反馈积极,认可其丰富的功能和巧妙的UI设计,特别是跨应用上下文和风格模仿能力。主要问题集中在与Mac Shortcuts的集成可能性,以及对本地RAG引擎处理大规模个人知识库性能的关切。开发者回复解释了Shortcuts可通过MCP连接,并阐述了RAG的混合架构与优化设计。
AI 锐评
Fluent此次更新的核心卖点“Native RAG”与“MCP集成”,直指当前AI应用的两大软肋:记忆的碎片化与操作的孤岛化。它试图扮演的不是又一个聊天机器人,而是一个驻守在本地的、具备持续记忆和跨应用行动力的“数字副脑”。其宣称的“100%复刻写作风格”,本质上是将RAG从传统的知识检索,升维至风格与人格的建模与注入,这确实是对抗“AI流水线腔调”的一次有趣实践。
然而,其真正的挑战与价值同样在于此。首先,“风格复刻”的承诺极具诱惑,但效果深度严重依赖于用户提供的“记忆”素材的质量与数量,这可能导致极高的用户教育成本。其次,作为一款以“Agentic”和“自动化”为愿景的工具,其与系统级自动化(如Shortcuts)的生态融合度目前看来仍是短板,开发者“不原生支持”的回应略显保守,可能限制其作为智能中枢的潜力。最后,本地RAG处理大规模知识库的性能与精度,仍是需要持续验证的技术关卡。
总体而言,Fluent的野心清晰:它不愿只做文本生成器,而志在成为用户与数字世界交互的智能代理层。它的出现,反映了AI工具正从“单次问答”向“持续伴随、主动服务”范式演进的趋势。能否成功,取决于其技术深度、系统整合能力以及用户是否愿意为其构建并维护一个高质量的“数字自我”镜像。这条路前景广阔,但路途必然崎岖。
一句话介绍:Invofox 2.0 是一个专注于生产级文档解析的AI平台,通过结构化的实验工作流,帮助企业在处理混乱、非标准化的真实世界文档时,能可视化和验证解析准确率,从而可靠地将文档处理流程部署到实际业务中。
SaaS
Developer Tools
Artificial Intelligence
文档智能
生产级OCR
文档解析平台
企业自动化
准确率验证
结构化数据提取
工作流管理
人类介入循环
真实场景AI
用户评论摘要:官方评论阐述了产品从演示走向真实工作流的核心设计理念。用户主要询问API是否支持基于置信度的“人类介入循环”场景,官方回复指出其提供比单纯置信度更深入的字段级与交叉验证,并可通过webhook构建自动化工作流。
AI 锐评
Invofox 2.0的发布,与其说是一次功能升级,不如说是一次针对行业“演示幻象”的精准抨击和策略性定位。当前文档AI市场充斥着在洁净数据集上表现惊艳的“Demo产品”,一旦投入真实的混乱业务流(如模糊扫描件、非标发票),准确率便断崖式下跌。Invofox 2.0的聪明之处在于,它没有陷入“我们的模型更准”的军备竞赛,而是将卖点转向了“准确率的可度量、可解释与可管理”。
其核心推出的“结构化实验工作流”,本质上是将文档解析从黑盒模型输出,升级为一个可观测、可调试的工程系统。它允许团队在部署前就能在字段和文档级别看到准确率变化,并验证改进效果。这直击企业客户的核心焦虑:不确定性风险。企业采购AI并非追求实验室满分,而是需要可控的、可预期的投入产出比,以及明确的失败处理路径(如HITL,人类介入循环)。
从官方回复用户关于HITL的细节可以看出,其设计思路超越了简单的置信度阈值,转向了基于业务规则(如正则校验、字段逻辑校验)的验证体系,这更贴近真实业务的数据质量管控需求。然而,这也将挑战从单纯的算法能力,部分转移到了客户自身的流程梳理与规则定义能力上。平台级更新的定位显示了其野心,但能否成为企业自动化工作流的“基础设施”,取决于其面对极端复杂、长尾的文档类型时,这套方法论是否依然能高效运转,以及其生态集成的便利性。这是一步从“卖工具”到“卖工程方法”的高阶棋,但棋局才刚刚开始。
一句话介绍:LiquidFetch是一款为macOS设计的可视化系统信息展示工具,通过美观的图形界面直观呈现设备配置,解决了极客和普通用户在命令行工具中查看系统信息时体验不友好、缺乏视觉吸引力的痛点。
User Experience
macOS工具
系统信息可视化
原生应用
硬件状态监控
开发者工具
系统美化
桌面工具
信息仪表盘
用户评论摘要:用户反馈主要集中于赞赏其视觉效果。一条有效评论询问了是否支持将数据导出为高清图片,开发者回复暂不支持,但建议通过截图实现。目前评论数量较少,缺乏深度功能反馈。
AI 锐评
LiquidFetch切入了一个看似微小却存在明确断层的市场:在追求极致美学的macOS生态与极客向命令行系统工具之间搭建桥梁。它的真正价值并非提供了前所未有的数据——`neofetch`等工具早已实现,而在于完成了信息的“消费升级”。它将冰冷、枯燥的文本参数转化为视觉设计驱动的界面,本质上是在售卖一种“数字身份装饰品”和“系统状态的情绪价值”。
然而,其当前形态也暴露了核心脆弱性。功能上严重依赖“可视化”这一单点创新,壁垒不高;作为信息展示工具,其数据静态、缺乏交互与深度分析能力,用户新鲜感过后留存堪忧。评论中关于“导出高清图片”的需求,恰恰揭示了用户潜在的使用场景——社交分享与个人文档美化,这或许是产品应深挖的社交货币属性与实用工作流切入点。
长远看,若仅定位于“更漂亮的fetch”,其天花板触手可及。它需要思考如何从“信息看板”进化成“信息枢纽”,例如集成实时性能监控、提供个性化组件、或与壁纸/主题动态结合,从“工具”转向“数字生活美学平台”。在macOS原生应用体验与视觉设计是其当前王牌,但唯有构建更深的场景粘性,才能避免沦为一次性的“付费截图”。
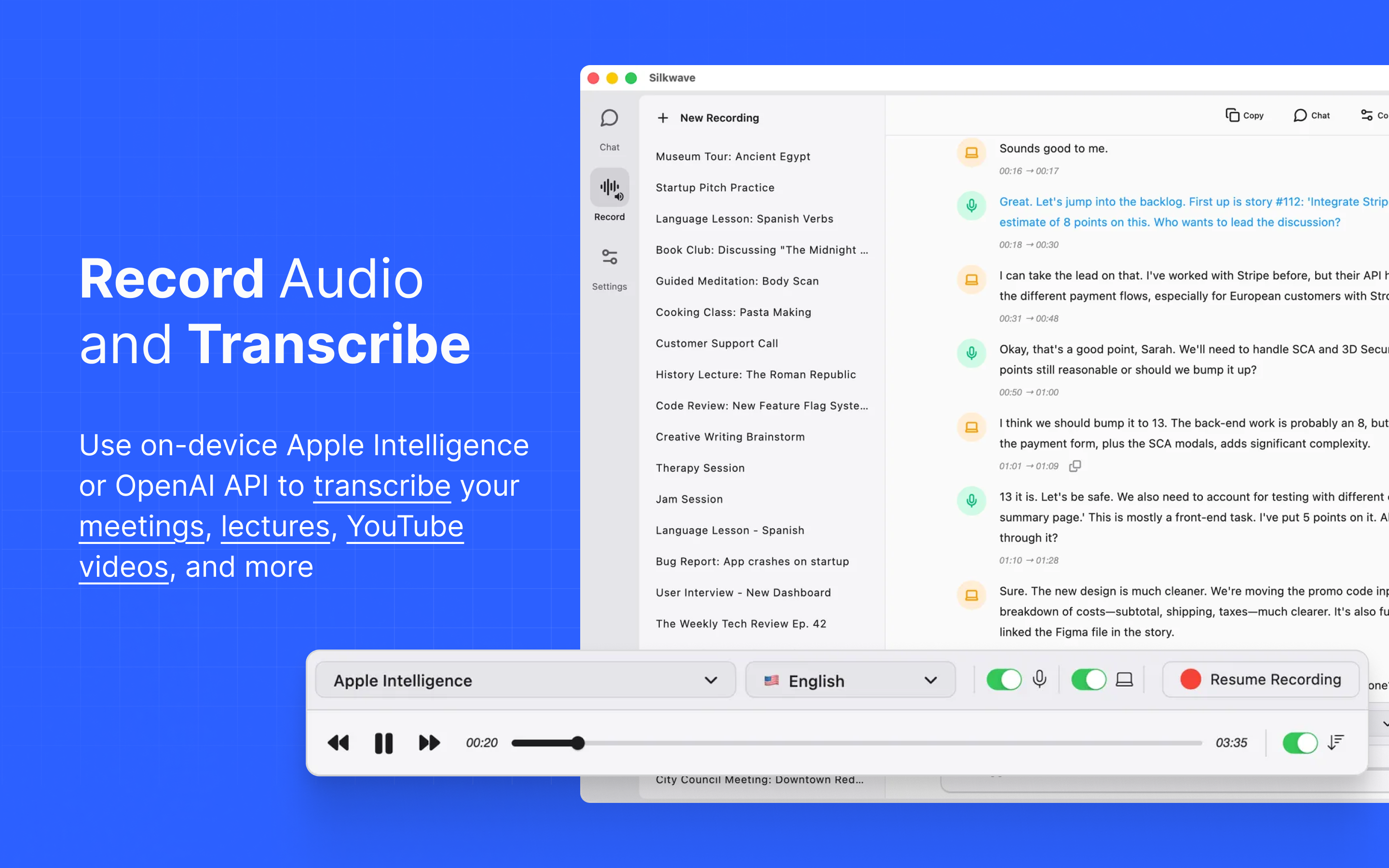
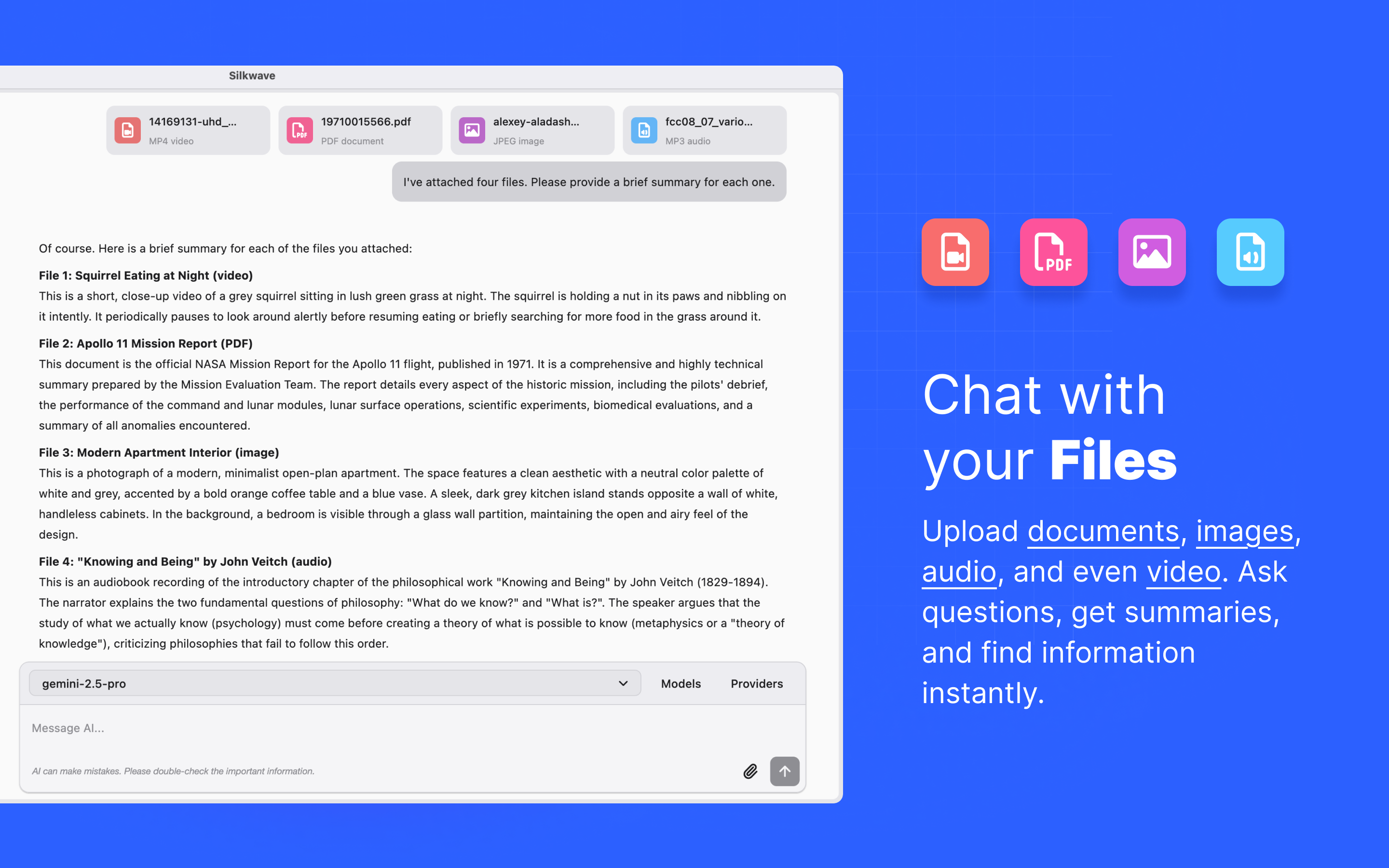
一句话介绍:Silkwave是一款macOS上的统一AI工作空间,通过自带密钥模式集成主流AI模型与本地录音转录功能,解决了用户在多平台、多订阅间切换的繁琐和数据隐私顾虑的痛点。
Productivity
Meetings
Artificial Intelligence
AI工作空间
自带密钥
本地转录
隐私安全
macOS应用
多模型聚合
音频处理
离线AI
生产力工具
用户评论摘要:用户反馈产品设计简洁,并提出了具体建议:1. 希望增加引导动画以改善新用户上手体验;2. 询问产品是否定位为笔记/头脑风暴中心,开发者确认此为方向并分享了路线图;3. 询问是否支持聊天记录全局搜索,开发者回复此为第二优先级功能。
AI 锐评
Silkwave精准切入了一个正在膨胀的市场裂缝:AI工具碎片化与数据安全焦虑。其核心价值并非技术突破,而在于“整合”与“掌控”两大主张。
产品聪明地采用了BYOK模式,这既降低了用户的使用门槛(无需为每个工具单独付费订阅),又巧妙地将成本与合规风险转移给了上游API提供商或本地计算,自身则轻装上阵,扮演中立管道的角色。其集成的本地录音与Apple Intelligence离线转录,是面对隐私敏感型用户的精准一击,尤其在涉及会议、访谈等敏感场景时,构成了区别于纯云端产品的关键壁垒。
然而,其挑战也同样明显。首先,作为集成平台,其体验深度严重依赖第三方模型的API稳定性和性能上限,自身难以形成技术护城河。其次,“统一工作空间”的愿景宏大,但当前版本更像是一个功能聚合器。从开发者回复看,其正试图向“笔记/头脑风暴中心”演进,这意味着它需要构建更强大的非结构化数据管理、关联和检索能力,这与其目前简单的聊天历史搜索需求之间存在着巨大的工程鸿沟。最后,其商业模式依赖用户已有的大模型API消费,自身盈利路径尚不清晰,可能陷入“为他人做嫁衣”的窘境。
总体而言,Silkwave是一款定位清晰、切入角度刁钻的效率工具。它在AI应用从探索走向日常工作的过渡期,为专业用户提供了一个兼顾效率与隐私的“控制台”。但其长期成功,取决于能否从“管道”进化出不可替代的、原生的工作流价值,否则极易被大模型厂商官方套件或更垂直的专业工具所挤压。
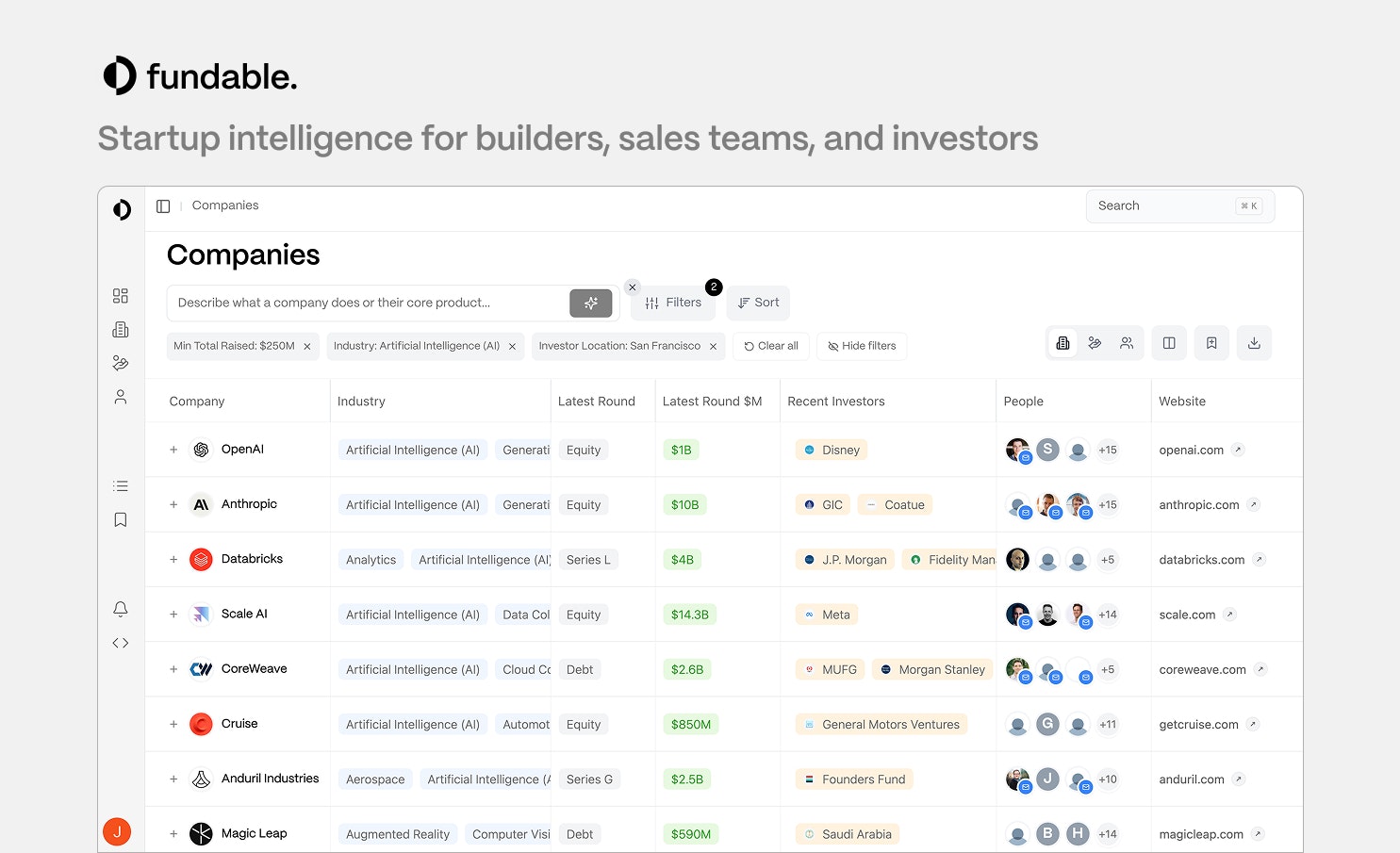
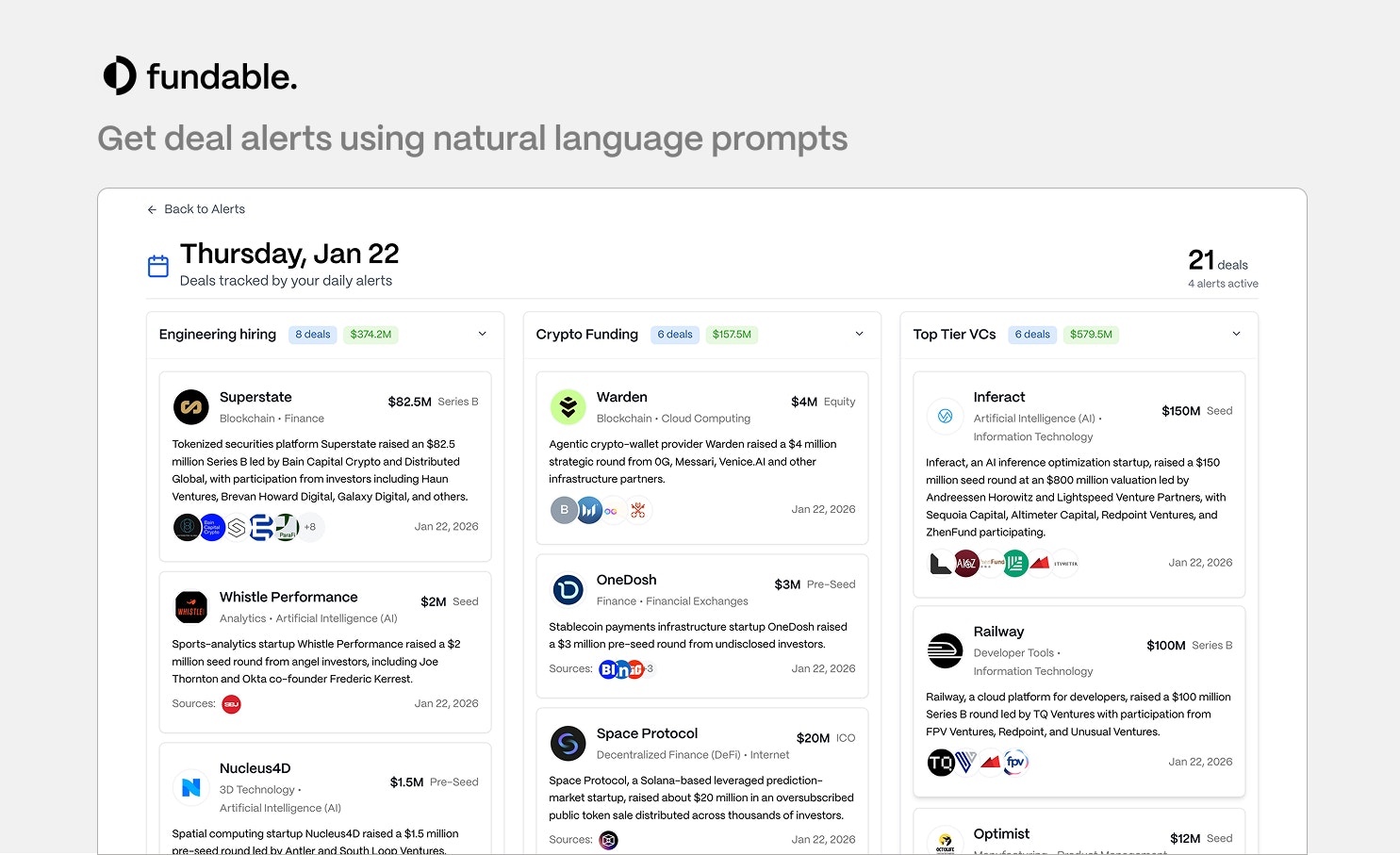
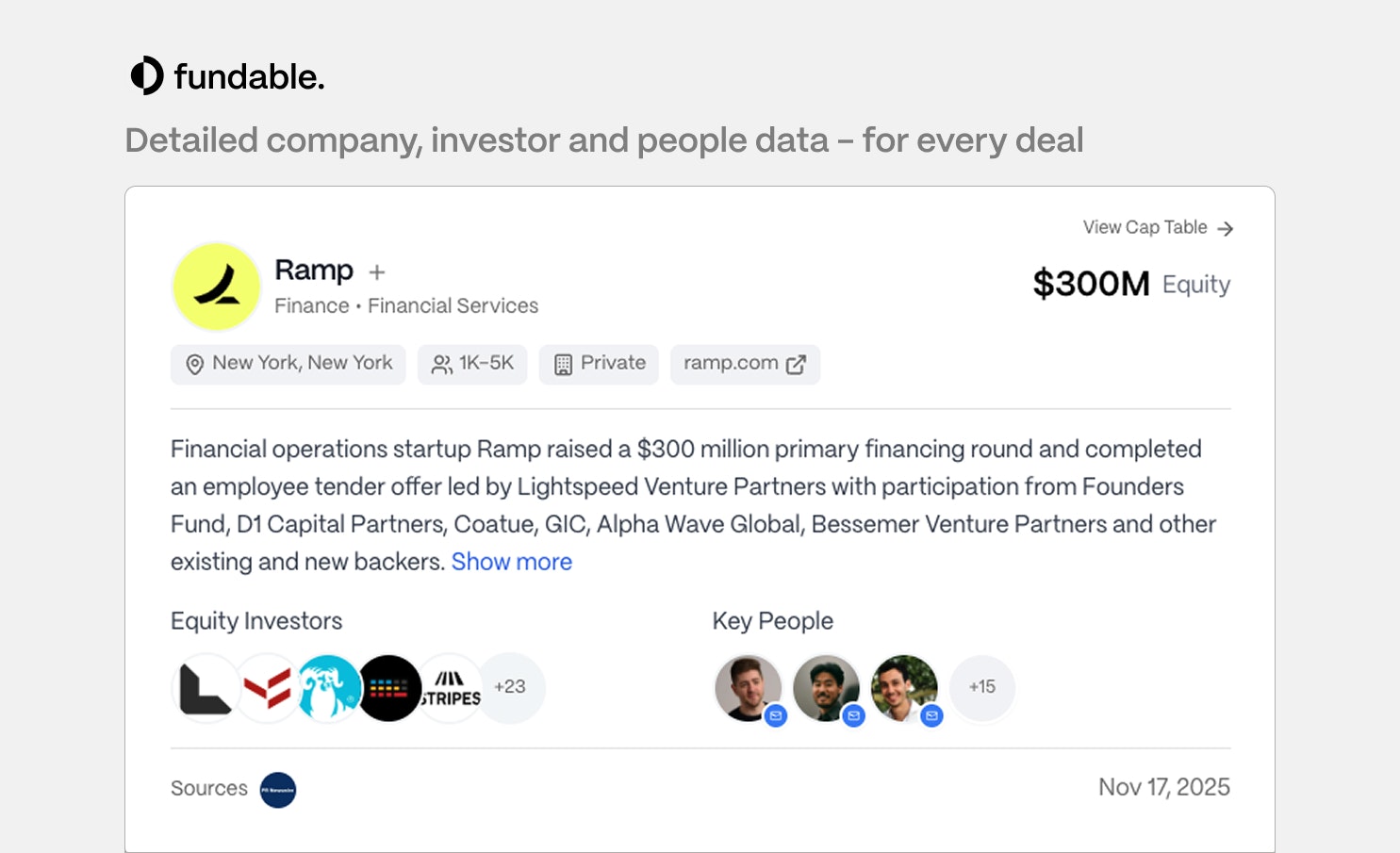
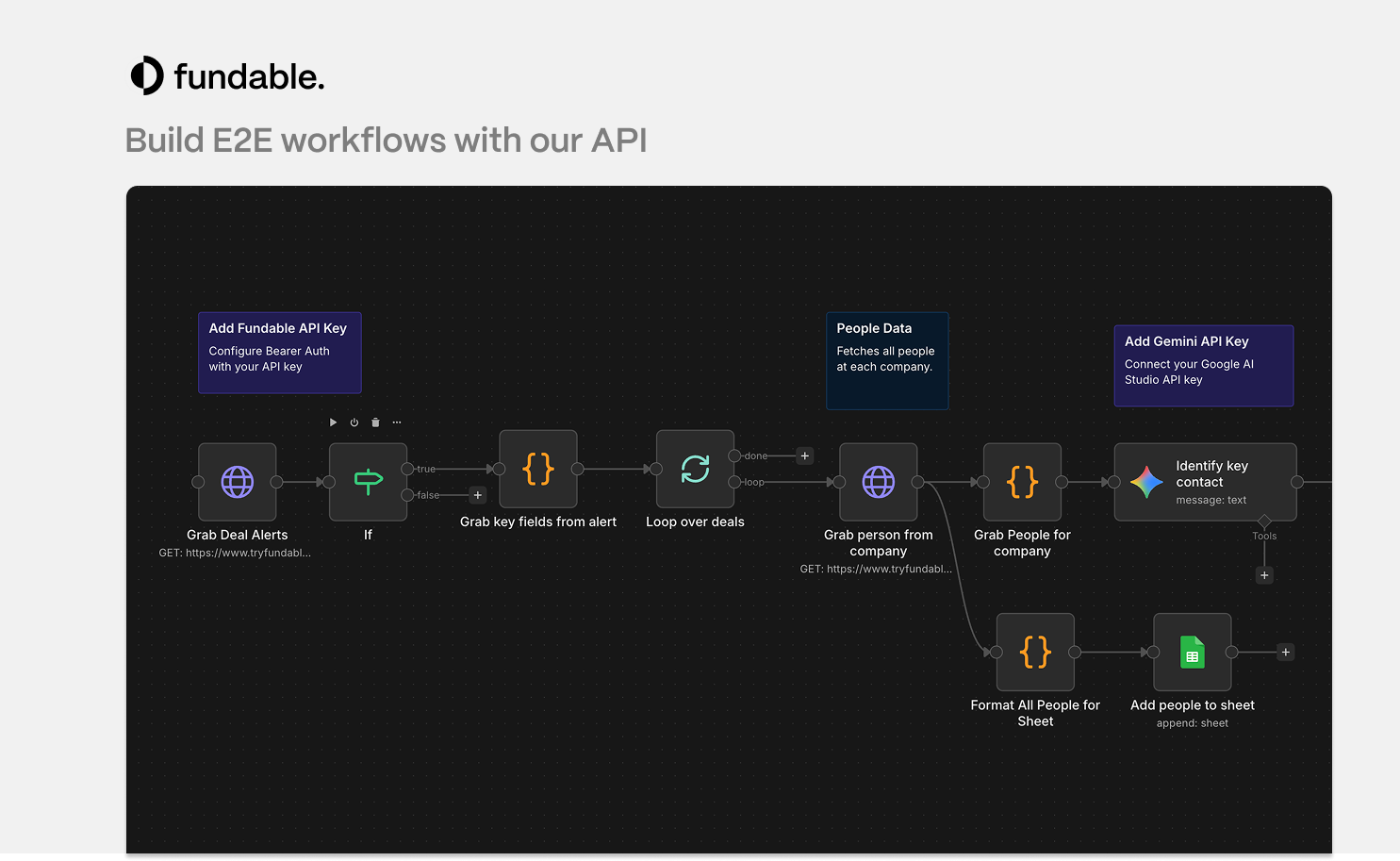
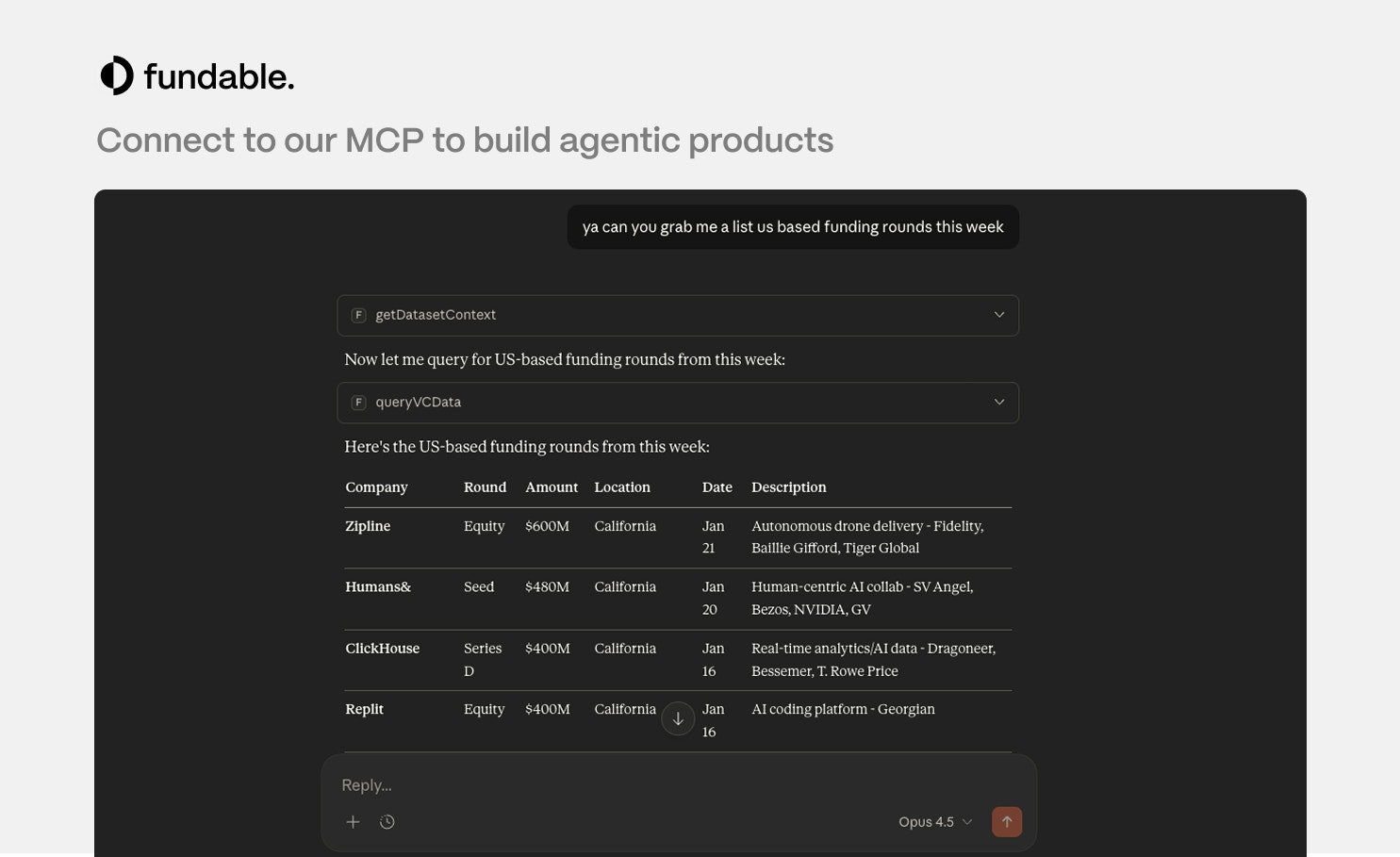
一句话介绍:Fundable是一款整合初创公司、投资人和人才数据的API及数据集产品,旨在通过更实时、可溯源且支持自然语言查询的数据服务,解决开发者和企业在构建投资分析、招聘监控等工具时面临的数据分散、滞后且成本高昂的痛点。
Sales
Venture Capital
Data
创业数据API
投融资数据库
实时交易信息
数据溯源
自然语言查询
开发者工具
替代Crunchbase
成本优势
初创企业服务
用户评论摘要:用户主要关注产品潜在的应用场景构建,并询问实时通知的技术实现方式(如Webhook支持)。团队回应目前仅支持REST轮询,但表达了根据实际用例增加Webhook的开放态度。
AI 锐评
Fundable的野心,在于用“更好的UI、更便宜的价格、更早的deal信息”这三板斧,精准劈向Crunchbase等老牌数据平台的软肋。其宣称的“为每个数据点提供来源”直击行业数据黑箱痛点,而自然语言告警功能则试图降低数据调用的技术门槛,这些都是聪明的差异化切入点。
然而,其真正的挑战并非功能列表,而是生态壁垒。数据产品的价值与数据的广度、深度、准确性和网络效应强相关。老牌平台积累的社区贡献、用户纠错和长期合作关系,构成了一道无形的护城河。Fundable以“更早”和“溯源”作为卖点,但“早”意味着需要构建独特且高效的抓取或接入管道,“溯源”则对数据清洗和治理能力提出极高要求。这两点都需要持续且巨大的投入才能建立可信度。
从评论区的技术问答来看,产品仍处于早期,连实时推送(Webhook)这样的现代API标配都尚未支持,这暴露了其基础设施的成熟度有待验证。团队“可以添加”的灵活态度固然可喜,但也暗示产品路线图可能由早期客户需求驱动,存在不确定性。
总体而言,Fundable在一个需求明确但壁垒深厚的市场中,选择了一个犀利的切入角度。它的成功与否,将不取决于它比Crunchbase“好多少”,而取决于它能否在数据质量这个生命线上建立起可持续且可验证的优势,并快速吸引开发者生态,形成自己的数据飞轮。否则,它可能只会沦为又一个“更便宜”的替代选项,而非行业规则的改变者。
一句话介绍:doXmind是一款将AI编程助手体验引入文档创作的智能编辑器,通过理解上下文、逐行审阅修改差异及引用知识库,解决了用户在写作过程中思维被打断、内容把控力弱的痛点。
Productivity
Writing
Artificial Intelligence
AI写作助手
智能文档编辑器
上下文感知
差异审阅
知识库引用
BYOK模式
写作流程优化
生产力工具
免费Beta
用户评论摘要:用户主要反馈集中在功能建议与商业模式询问。有效建议包括:增加实时网络研究功能以自动填充事实数据并注明来源。创始人确认该功能已在规划中。关于商业模式,团队明确核心产品将保持免费,采用用户自带AI服务商API密钥的模式。
AI 锐评
doXmind的核心理念——“写作界的Cursor”,精准地切中了一个正在兴起的需求:将AI从聊天机器人转变为深度嵌入工作流的协作伙伴。其真正的价值不在于“又一个AI写作工具”,而在于它试图将软件工程领域成熟的代码协作范式(如差异对比审阅、上下文感知)迁移至非结构化的文档创作领域,这有望解决当前AI写作工具“黑箱式”重写、作者掌控感丧失的根本性痛点。
产品设计的亮点在于“差异审阅系统”和“知识库引用”。前者将AI的修改可视化、原子化,把最终控制权交还给用户,这是对当前AI生成内容不可控性的一种优雅工程解决方案。后者则试图将AI的“幻觉”问题约束在用户提供的可信材料范围内,提升了专业写作的可靠性。
然而,其宣称的“核心免费”BYOK模式是一把双刃剑。它降低了用户的初次使用门槛和厂商的运营成本,但将模型能力、成本、延迟等核心体验的掌控权转移给了用户和第三方API提供商。这要求用户本身是AI服务的熟练使用者,无形中抬高了使用心智门槛。其未来可能的付费点(云同步、团队功能)并非不可替代的护城河。
当前最关键的挑战在于,其“理解上下文”的深度能否真正媲美Cursor对代码库的理解。文本的语境和逻辑远比代码复杂和模糊。从用户对“实时研究”功能的迫切需求来看,仅处理本地文档的“知识库”仍不够,下一代智能写作工具必须能主动、可信地连接外部知识。doXmind若能在保持当前编辑体验优势的基础上,攻克实时、精准的网络信息检索与引用难题,才能真正定义“AI辅助写作”的新范式,否则可能仅停留为一个体验优良的第三方AI客户端。
一句话介绍:Fytly是一款将AI个性化健身计划与游戏化机制结合的应用,通过生成任务、保持连续记录和升级排名,在用户健身动力不足、难以坚持常规训练的日常场景中,解决其因枯燥感而放弃锻炼的核心痛点。
iOS
Health & Fitness
Artificial Intelligence
健身应用
AI健身教练
游戏化健身
习惯养成
个性化训练
健康科技
行为激励
移动应用
用户评论摘要:创始人分享产品源于个人伤病后动力丧失的痛点,强调其游戏化与自适应AI的核心。其他用户祝贺并好奇市场反响与营销策略,目前未出现实质性负面反馈或功能性质疑。
AI 锐评
Fytly的亮相,精准地刺向了传统健身应用最柔软的腹部:反人性的枯燥感。其宣称的“游戏化AI教练”概念,看似是“健身环”与“习惯打卡”的移动端混合体,但真正的刀刃在于“基于实际行为调整计划”的AI自适应逻辑。这试图将健身从预设的标准化课程,扭转为动态的个人行为响应系统,是其在同质化市场中理论上的破局点。
然而,其价值与风险皆系于“AI”一词的实际成色。所谓“调整计划”是简单的强度微调,还是能理解用户疲劳、生活压力乃至心理波动的深度干预?在beta阶段,这大概率仍是一个黑箱或有限规则引擎。其游戏化设计——连续记录、任务、排名——是经过验证的短期动机钩子,但极易陷入“为打卡而打卡”的数据空心化陷阱,一旦新鲜感褪去,用户可能面临游戏机制倦怠与健身本质痛苦的双重打击。
创始人坦诚源于“伤病后动力崩溃”的经历,这揭示了产品更深层的野心:它瞄准的或许并非自律的健身爱好者,而是庞大且反复挣扎的“意愿-行动”断层人群。其84天重置周期也暗示了它贩卖的是一种“结构化重生”的希望。若其AI真能在此过程中,像一位敏锐的教练般接纳用户的“脱落”并将其转化为计划的一部分,而非像传统应用那样视为失败,则可能触及行为改变的深层密码。但目前来看,它更像一个包装精美的动机启动器,其长期留存与真正的效果,取决于AI内核能否从“记录反应的算法”进化成“理解人性的伙伴”。在健身应用这片红海,游戏化是糖衣,AI是尚未被完全验证的药效,Fytly能否成为良药,还需看其后续迭代的“临床数据”。
一句话介绍:这是一份基于2025年真实设计项目复盘撰写的《2026产品设计趋势报告》,旨在为面临同质化与AI冲击的设计师和团队提供源于实战、尊重人性不完美的设计方向洞察,解决他们在追求效率时可能丧失设计人文价值与品牌独特性的痛点。
Design Books
Web Design
UX Design
设计趋势报告
产品设计
设计洞察
行业分析
AI与设计
实战复盘
设计方法论
品牌重塑
SaaS
Web3
用户评论摘要:用户普遍赞扬报告基于真实设计经验、强调人性化与不完美设计的价值。有效评论集中于两点:一是询问哪些趋势最难落地(团队认为AI的平衡最难把握),二是询问报告的市场推广策略。评论整体肯定其与肤浅“趋势清单”的区别。
AI 锐评
这份报告最犀利的价值,并非在于预测了“什么会流行”,而在于其立场的彻底反转:它是一份来自“修复者”而非“预言家”的战后总结。在AI工具承诺“一键完美”的当下,它旗帜鲜明地指出,真正的设计趋势恰恰诞生于“迭代、错误和艰难的权衡”之中,其核心论点是“设计是人的、不完美的、强大的”。
报告试图解决的深层行业痛点是“意义的虚无”。当设计可以无限趋近于技术性完美时,其品牌差异与人性温度反而被稀释。它批判的是对“高效答案”的盲目追逐,提倡的是与“现实、用户和市场接触后幸存”的设计思维。这实际上是对设计行业主体性的一次捍卫——将设计师从AI“执行者”重新定位为拥有失败权利的“决策者”。
然而,其挑战同样明显。首先,其“反速成”的哲学与市场对“即用型”趋势清单的渴求存在根本矛盾,可能叫好不叫座。其次,报告自身作为“提炼后的成果”,如何避免成为另一种被盲目引用的“权威”,是对其内容深度的考验。最后,它指出AI应用需平衡,但“如何平衡”仍是悬而未决的实践难题。总体而言,这是一份有价值的“清醒剂”,但其影响力的真正试金石,在于能否促使团队在高压现实中,为“不完美”的设计决策争取空间与时间。
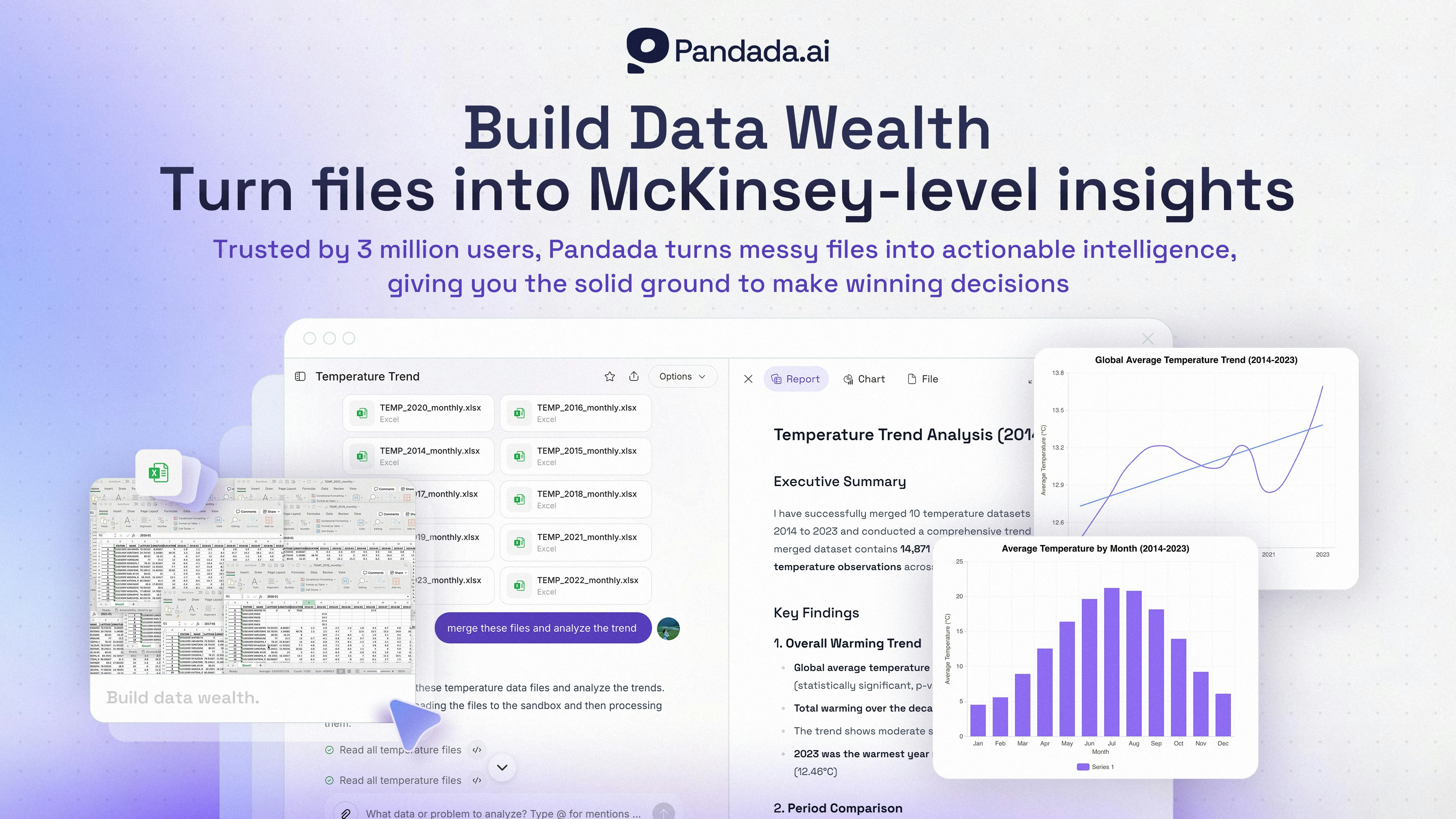


























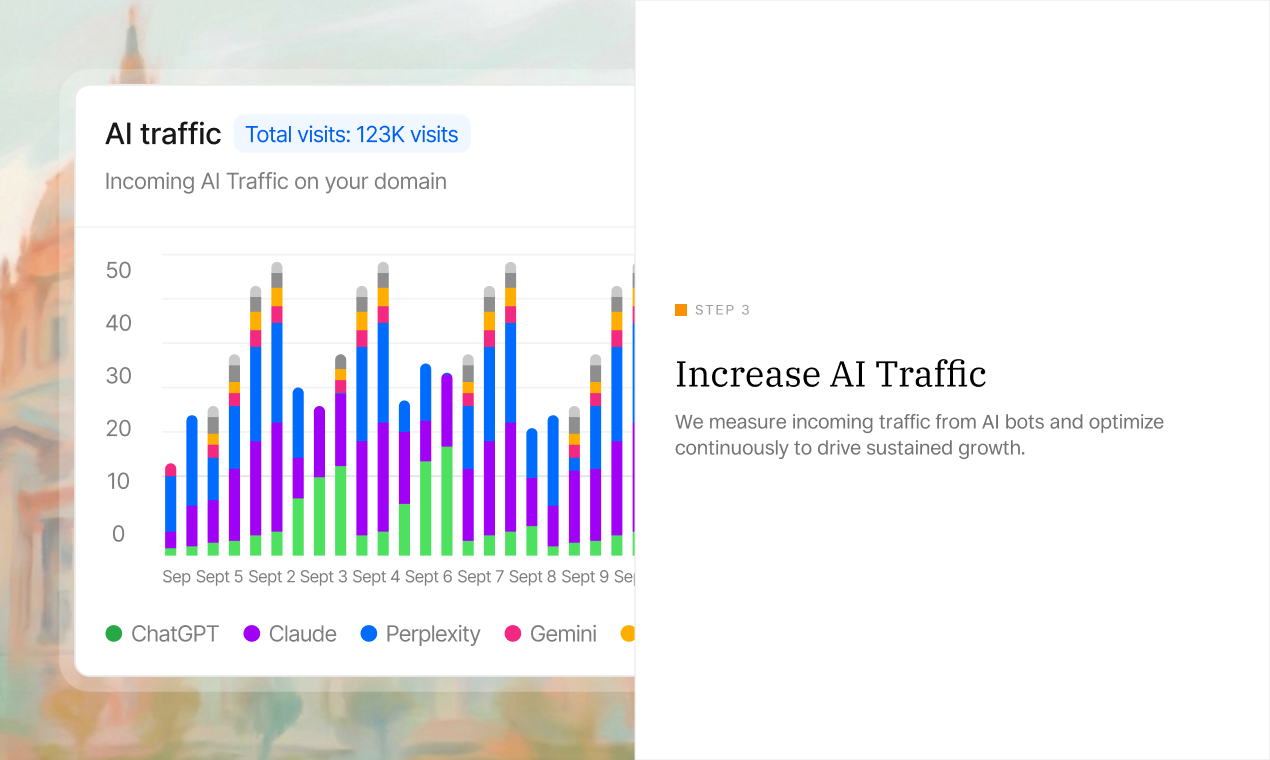
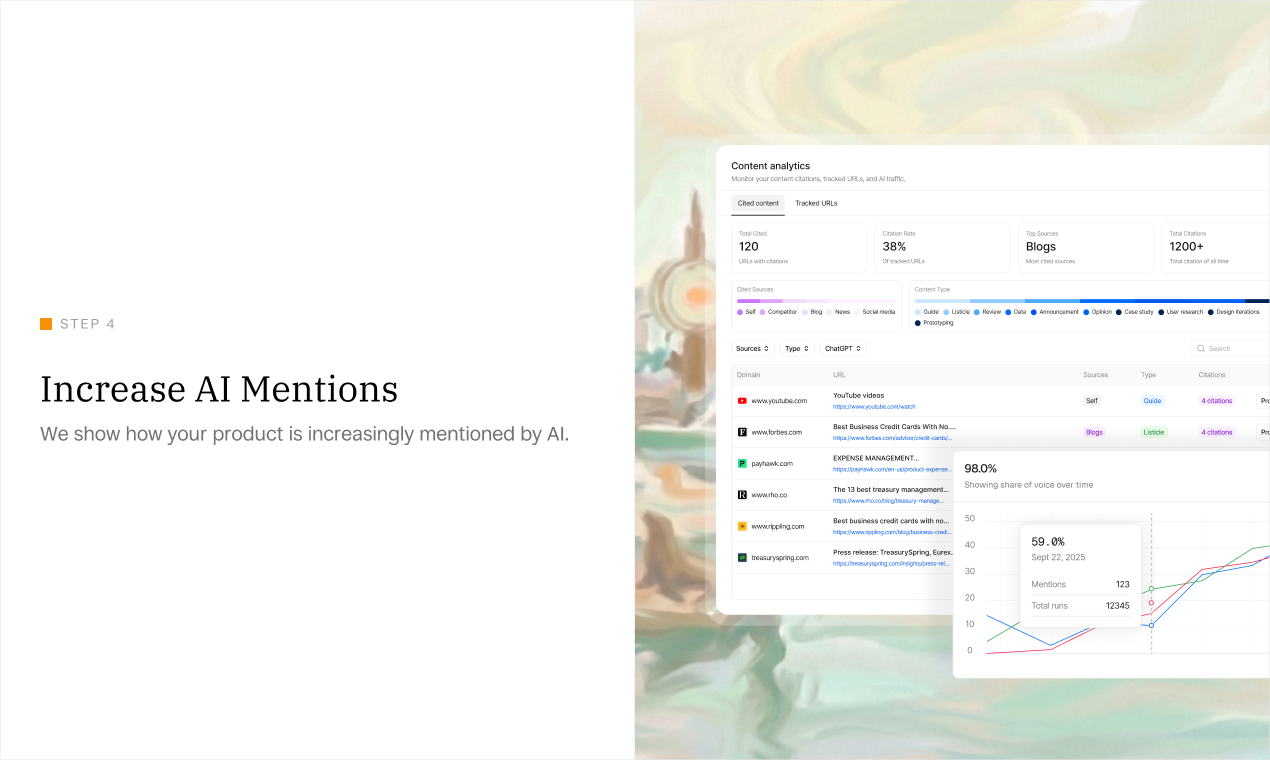

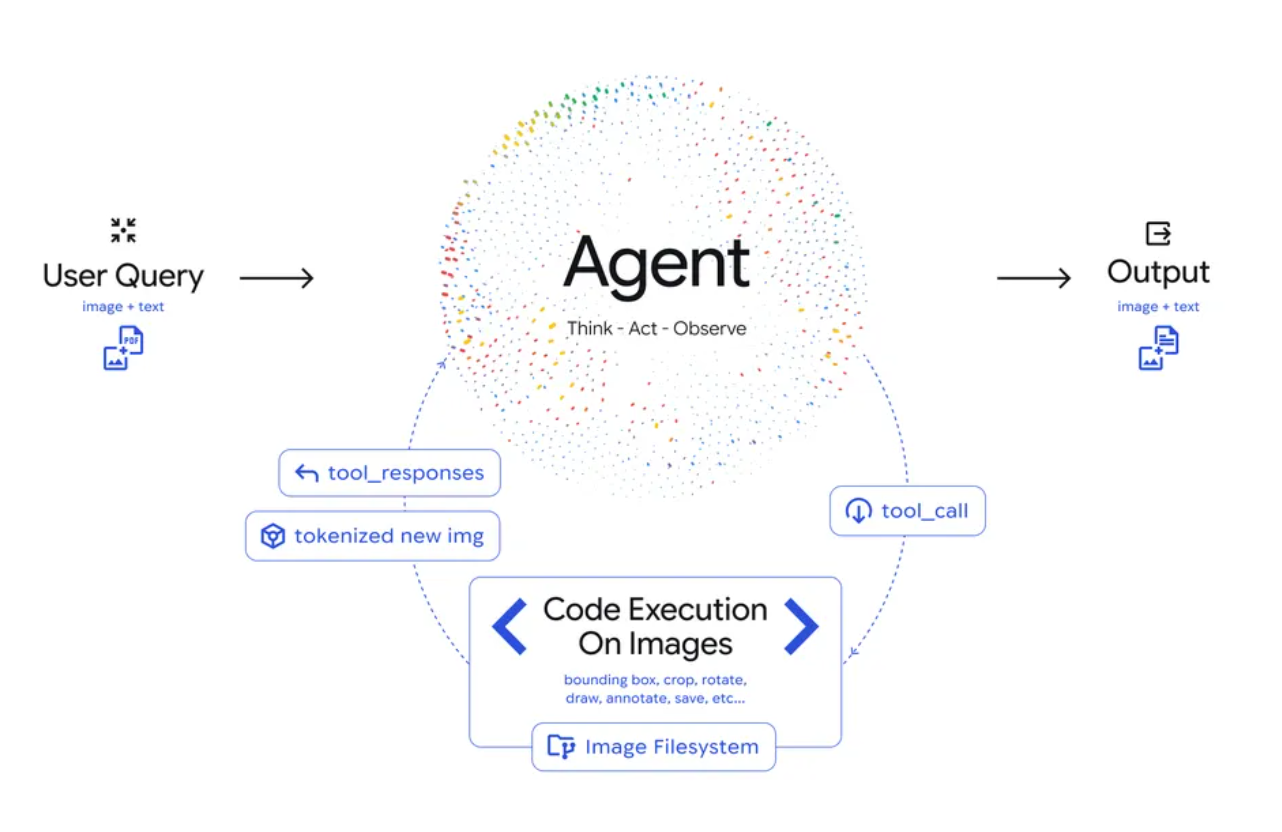
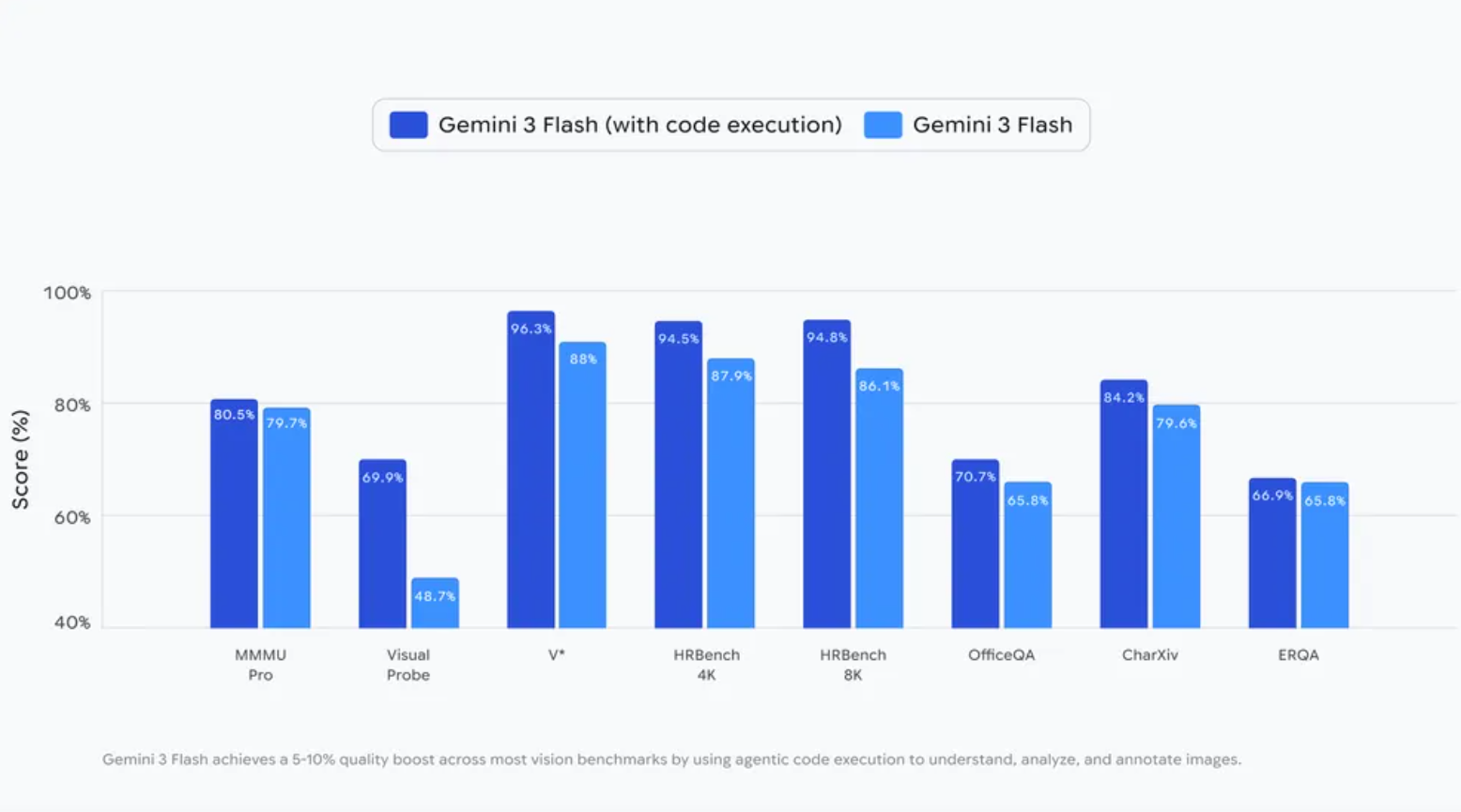















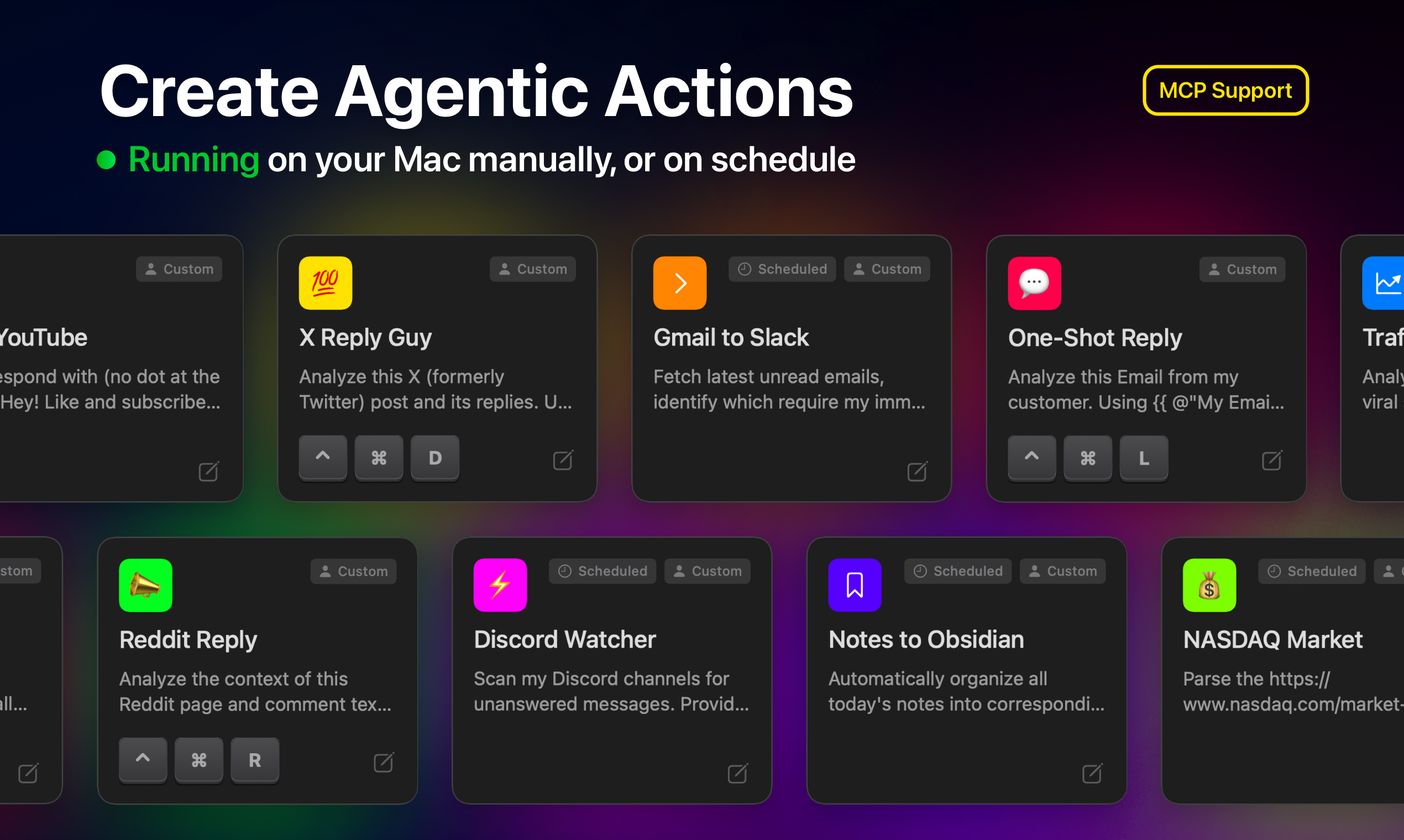










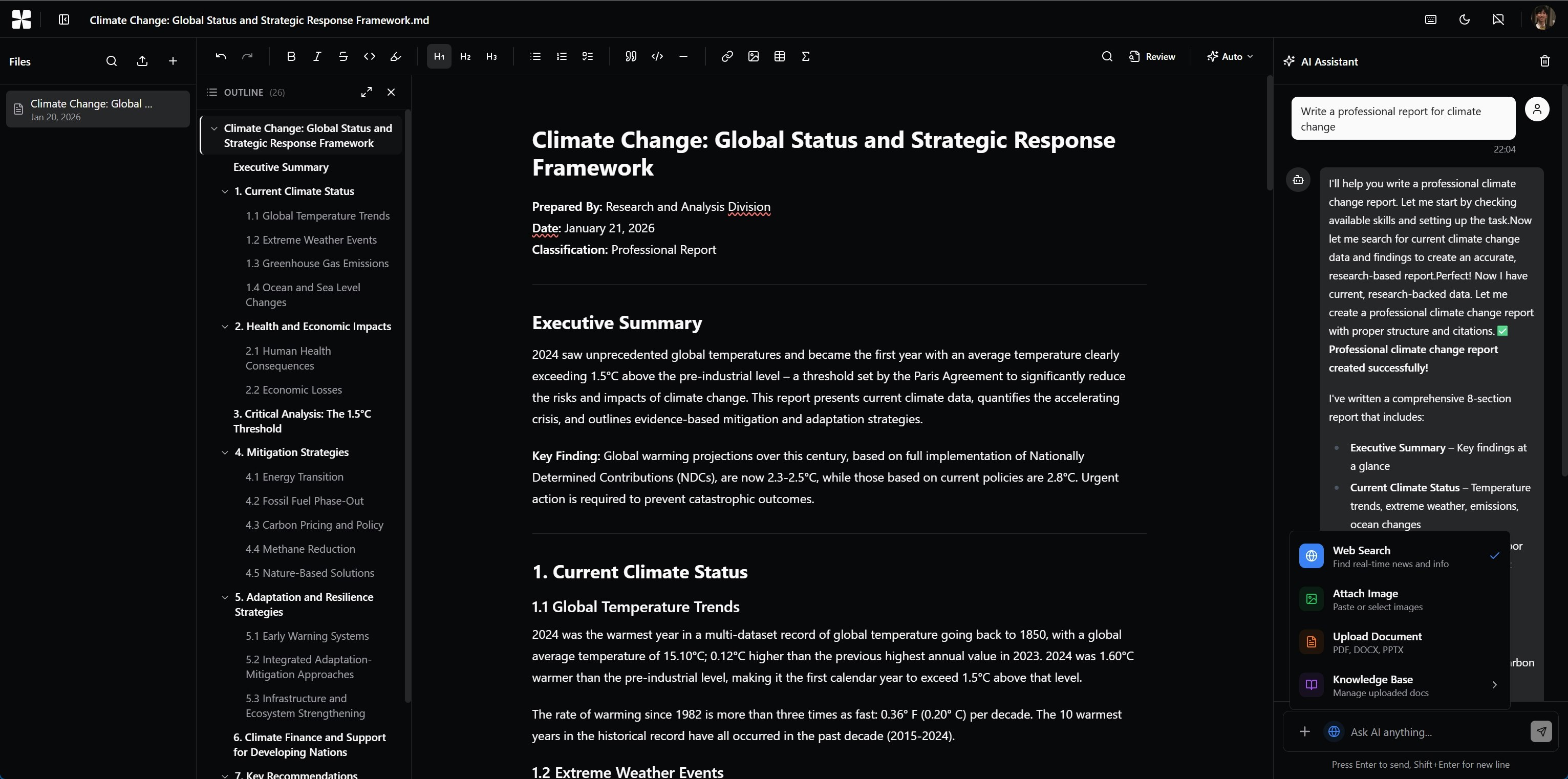
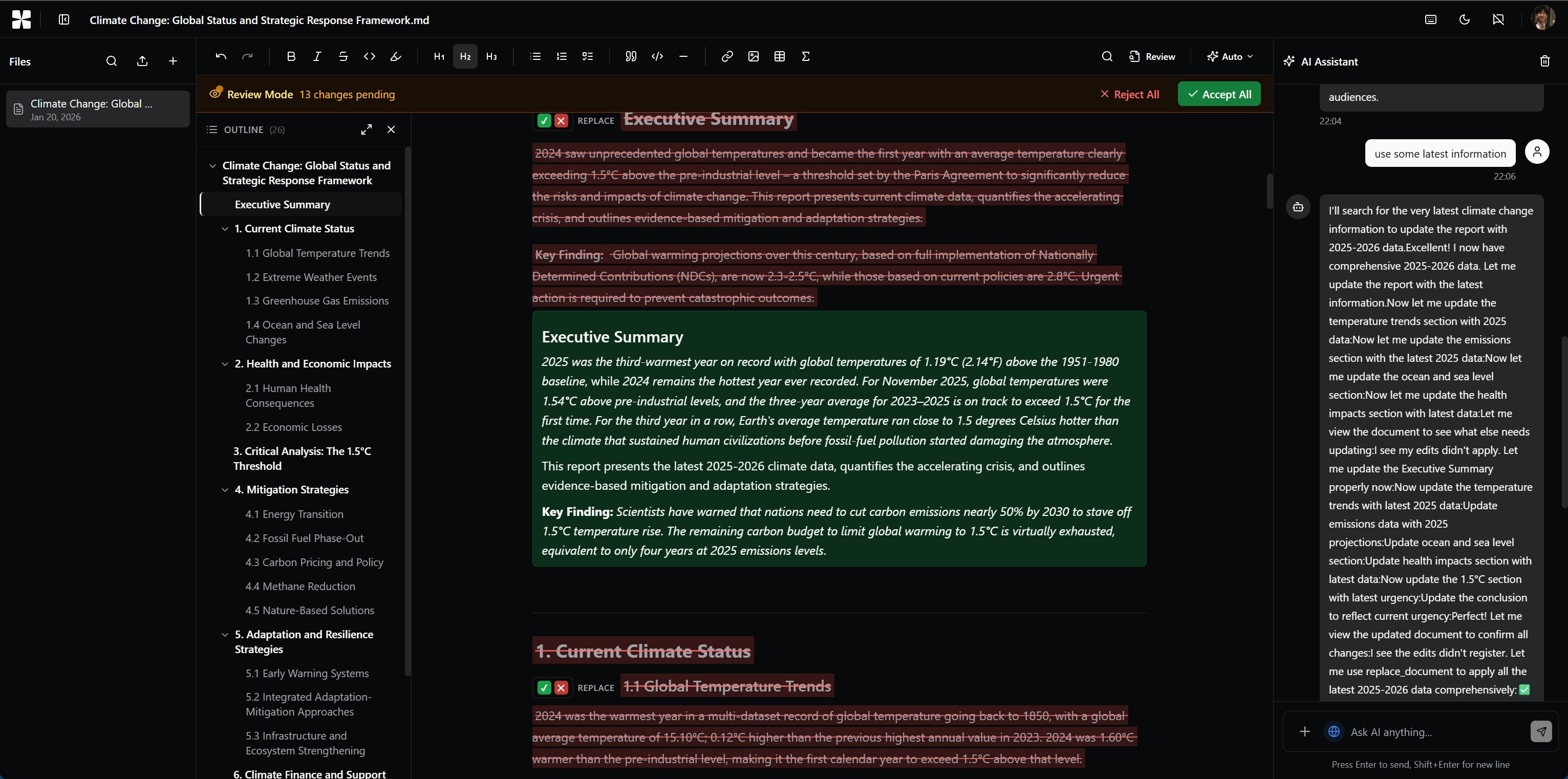









Hey Product Hunt! 👋 I’m the creator of Pandada.
Pandada turn your messy files (CSVs, Excels, PDFs, images) into McKinsey-level insights so that you can build “data wealth” (hold on a second, i will explain it below).
10 years ago, I was a quant analyst at Charles River Development (acquired by State Street). I spent 80% of my time cleaning messy spreadsheets and wrangling numbers so that my PM can make better product decisions. It was slow and, despite my best effort, prone to errors. When I transitioned to become a PM and Investor, the problem persisted.
This is a universal challenge: drowning in files, starving for insights.
This is what refer to as "data poor."
This is why I build Pandada.
We launched our original engine in Jan 2024 in China, a year before Manus, and we quickly scaled to 3 million users and 1,000+ enterprises.
Today, we are excited to bring our battle-tested "Data Wealth" engine to Product Hunt. Pandada is built for the messy reality of work. We help you build Data Wealth in 3 steps:
Better Data: Pandada cleans and structures "dumpster fires" of files—scanned PDFs, screenshots, or messy Excel sheets or CSVs.
Better Questions: Pandada refines your coarse queries and turns them into expert-level prompts to get at the core insights your seek.
Better Answers: Pandada generates McKinsey-level, decision-ready reports that you can share, present, or download.
Whether you are a Python expert clearing your backlog, a Founder hunting for the hidden gem in your metrics, or a marketer seeking a better growth strategy—Pandada is built to make you wealthy in insights.
I’ll be hanging out in the comments all day—what are some of the toughest data challenges you've faced recently?
To celebrate our debut on PH, anyone who signs up before Feb 28th gets one month Pro for free!
Just fill out the form, and we’ll activate your Pro access within 24 hours. https://forms.gle/XEPfdePLremwYGDu7
BR,
Anya
Congrats on the launch, Anya @anya_pandada and team! 🚀 Love the "data wealth" vision — it's so true that we're often drowning in files but starving for real insights. Turning messy CSVs/PDFs even from photos into McKinsey-style reports sounds like a game-changer for non-tech folks and analysts alike!
Big kudos on already serving 3M users in China — that’s impressive validation! 😲 The 3-step workflow (Better Data → Better Questions → Better Answers) is super clear and feels practical for daily chaos.
One suggestion from a product lens: Have you considered adding a "template gallery" of common business report types (e.g., marketing performance, SaaS metrics, quarterly reviews)? It could help users jumpstart their analysis and align teams faster. Also, a lightweight "audit trail" showing how data was transformed would boost trust for enterprise adoption.
Excited to try the Pro access! 🙌 Quick question: Are there plans to integrate with tools like Slack or Notion for sharing insights directly?
Wishing you a huge launch day! 🎉
Had a pleasure working with @anya_pandada to hone the message and positioning of @Pandada AI — a powerful conversational data analytics platform that converts your messy CSVs, Excels, PDFs, and data sources into "data wealth" — McKinsey-level insights that you can rely on to inform your toughest strategy decisions.
It's truly remarkable how Pandada can make sense of data spread across dozens of disconnected files. They started working on this before @Manus launched, and have over a million users in China.
To celebrate their Product Hunt debut, they're offering a free month to anyone who signs up before Feb 28th and fills in this form.
Throw something mean at it and let us know how it does!
How does Pandada handle really messy PDFs with tables and scans?
Hi Hunters! 👋
I’m the maker of Pandada AI. Most tools let you "chat" with data, but we believe you need results, not just a conversation.
Pandada turns your messy CSVs, PDFs, and even photos into McKinsey-level reports and presentations in minutes. Stop digging through rows and start building your Data Wealth.
We’re live all day and would love your feedback! 🐼🚀
Congrats! Pandada’s shortcuts feel clean, fast, and reliable. More importantly, it feels like a professional analysis workspace for working with real business documents.
Hi Hunters! 👋
I’m the maker of Pandada AI. Most data tools stop at “talking to your files.”
Pandada goes further — it turns raw, messy data into insightful reports and polished slides you can actually use.
Upload your CSVs, PDFs, or images, and get McKinsey-level outputs in minutes.
Less time analyzing.
More time deciding.
That’s how you grow your Data Wealth. 🚀
Congrats on the launch! I like that Pandada lets me analyze trends without writing code. Does it also expose the underlying Python code used during data processing?
I’m impressed by the output quality from Pandada. The export button produces clean, high-resolution charts where labels don’t overlap, which is a huge help for professional reporting.
Pandada seems especially useful for comparisons. How smart is the column mapping? If one file has "Revenue" and another has "Total Sales", will it figure out they are the same field?
Pandada handles document-based data surprisingly well. The structured output saves a lot of cleanup time and makes analysis much smoother.
Congrats on launching today. How does this differ from other AI data analyst agents?
The micro tools on your site are part of an SEO strategy or they are included as part of the larger product? Congrats on the launch!!
Does it take files like PDF, Excel, etc., as an input or does it also take some dynamic channel like, for example, Facebook dashboard data, like some kind of integration?
What formats are these reports and presentations in?
I love that Pandada doesn't just describe what happened , it helps explain why. It allows me to dig into the root causes of anomalies rather than just reporting the symptoms.
I was impressed by how Pandada keeps context. It remembers the schema from previous uploads, so switching between datasets feels seamless instead of confusing.
Pandada replaces a lot of manual spreadsheet work with clearer, faster analysis. It’s less about buttons and more about getting answers from data.
Pandada clearly understands how important data prep is for good analysis. It handles the groundwork, so the insights actually make sense.
What an impressive innovation with Pandada! By bridging the gap between non-technical users and data scientists, it truly democratizes access to high-quality data insights. The ability to transform messy files into polished, professional reports and presentations is a game-changer for anyone looking to enhance their decision-making based on solid data. Its focus on making complex data easily digestible means more effective collaboration across teams. I can see how this would resonate with businesses striving for data-driven strategies. Kudos to the team behind Pandada!
Thank you for saving our sanity, Anya:D Love that it goes beyond just chatting and actually builds shareable reports. Does Pandada handle multi-language files well?
How does Pandada handle sensitive data within these files? Are the models SOC2 compliant, or do you offer localized data processing?
LGTM,can i export to a ppt file?
Great work team. For non-technical users, how much guidance does the prompt give? Do I need to know the right statistical terms to get a good result, or can I just ask in plain English?
WOW congrats!
Congrats on the launch guys!
It is true that most teams are drowning in files but getting insights out of them can never happen in most cases. I can see this being really useful. Also curious on any planned next integrations?
“McKinsey-level insights” is a bold claim — love the ambition!
For non-technical users, the real test is: can it explain why a trend matters, not just surface it?