PH热榜 | 2026-02-27
一句话介绍:一款支持在本地同时并行运行多个AI编码代理(如Claude Code、Codex)的增强型IDE,通过沙盒隔离和集中监控,解决开发者因串行等待和上下文切换导致的开发流程低效痛点。
Productivity
Developer Tools
Artificial Intelligence
GitHub
AI编程助手
集成开发环境
多代理并行
沙盒隔离
工作流增强
本地开发
开发效率工具
代码代理编排
用户评论摘要:用户普遍认可其并行能力和沙盒设计。核心问题集中在:跨代理上下文共享与协调机制;安全隔离性;与云开发/CI/CD/任务管理工具的集成;长期内存处理;以及并行工作流的实际生产力收益量化。
AI 锐评
Superset的野心并非做一个普通的IDE,而是旨在成为本地AI编码代理的“操作系统”或“编排层”。其核心价值在于将“人指挥单个代理”的模式,升级为“人指挥一个代理军团”的模式。通过沙盒隔离,它巧妙地规避了当前AI代理在复杂任务中容易“精神错乱”和相互干扰的缺陷,保证了基础稳定性。
然而,其宣称的“10倍效率”面临深层拷问。首先,瓶颈转移:它解决了代理排队等待的问题,但将负担转移给了开发者的事后集成与决策。多个代理产出的大量代码变更,仍需人工进行最终的审查、合并与架构把控,这可能带来新的认知负荷。其次,架构悖论:严格的沙盒隔离虽干净,却与真实软件开发中模块间需频繁通信、保持上下文一致的本质相冲突。团队提及正在构建的“@提及”式共享内存层,是对此的补救,但这恰恰说明,从“隔离”走向“受控的协同”,才是真正的难点与关键。
产品目前巧妙地站在了“本地”与“云”的十字路口。它利用本地算力与现有订阅实现低成本启动,但资深用户已指出,大规模并行(如100+代理)的未来必然在云端。Superset的终极想象空间或许在于成为跨环境、跨厂商AI代理的标准化编排平台,但这要求其在解决当前协同短板的同时,建立起强大的生态集成能力。它点燃了并行AI开发的引信,但真正的效率革命,取决于它能否让这群“数字工人”从各自为政走向协同作战。
一句话介绍:一款允许开发者将本地Claude Code编程会话无缝切换至手机、平板等设备远程继续操作的工具,解决了开发者离开工作环境时被迫中断编码流程的痛点。
Android
Developer Tools
Artificial Intelligence
Tech
AI编程助手
远程协作
移动办公
开发工具
会话持久化
上下文保持
生产力工具
Claude生态
多设备同步
用户评论摘要:用户普遍认可其解决“上下文丢失”痛点的价值,期待在通勤等场景提升效率。主要疑问集中在:是否支持多会话并行、交互模式是双向控制还是只读监控、是否有推送通知功能,并与类似产品Macky进行了对比。
AI 锐评
Claude Code Remote Control 看似是一个简单的多设备同步功能,实则是对AI原生工作流的一次重要重构。它击中的并非简单的“移动办公”需求,而是AI编程时代一个深层矛盾:以“会话”为核心的、高度沉浸的AI协作过程,与物理位置固定性之间的冲突。产品将“会话连续性”提升为第一优先级,本质上是在保护开发者最宝贵的“心流”状态。
然而,其“一次仅一个远程会话”的限制暴露了战略上的谨慎与当前的技术边界。这并非愚蠢,而是一种权衡:在确保低复杂度与避免状态冲突之间,选择了前者。但这也引出了核心挑战——当AI代理能处理多个并行任务时,远程控制界面能否演进为真正的“指挥中心”?用户提出的双向控制与推送通知问题,正指向这个未来:它不应仅是会话的“镜像”,而应成为移动端对AI工作流的“调度终端”。
当前方案更像是对现有模式的优雅补丁,而非范式革新。真正的未来,或许是评论中隐约提及的:一个与设备解耦的、持续运行的AI协作环境,远程控制只是其最浅层的接口。产品的真正价值,不在于今天能远程看代码,而在于它首次将“AI编程会话”作为一个可迁移的、持久的实体进行管理,这为未来更智能的、情境感知的分布式开发体验铺下了一块基石。
一句话介绍:Perplexity Computer 是一款端到端自主执行复杂项目的AI协调系统,通过并行调度多种专业模型并连接用户工具,在研发、设计、编码等场景中,解决了用户需要手动串联多个AI工具与人工干预执行的效率痛点。
Artificial Intelligence
AI智能体编排
多模型协同
端到端AI执行
自主AI代理
AI项目协调
模型路由
AI生产力工具
企业级AI
自动化工作流
Perplexity生态
用户评论摘要:用户普遍认可其从“对话”到“执行”的跨越及多模型架构的价值。核心疑问集中在:长时任务中模糊决策点的处理机制、子代理错误的自我纠正能力、模型路由层的具体实现逻辑(规则或学习),以及高昂价格下缺乏试用。
AI 锐评
Perplexity Computer 的野心不在于成为另一个“更强的ChatGPT”,而在于扮演“AI时代的操作系统内核”。它将当前AI生态从“工具调用”升级为“系统调度”,其核心价值是**决策与协调的自动化**。产品介绍中“编排19个模型”、“路由到最佳模型”等表述,直指当前AI应用层的核心矛盾:单一模型能力有限,而人工串联多个专家模型成本极高。
然而,其宣称的“运行数月直至完成任务”恰恰暴露了最大风险点:AI在复杂、长周期任务中的“判断力”和“责任归属”问题。评论中的尖锐提问非常到位——当遇到规范模糊的决策分支时,系统是暂停请示,还是自主决断并承担潜在错误成本?这并非技术实现问题,而是产品哲学与边界定义。目前它更像一个概念验证,将内部复杂的AI pipeline产品化,但其可靠性验证和“黑盒”决策过程,是企业客户投入真金白银前必须跨越的信任鸿沟。
从市场定位看,它直接瞄准高端与企业级市场,但缺乏试用和高达2000美元的年费,在竞争白热化的AI助手市场显得颇为激进。这或许是一种策略:过滤早期重度用户,聚焦于真正有复杂自动化需求的客户。如果其模型路由层能持续优化,并建立透明的任务追溯与干预机制,它有可能定义下一代AI原生工作流的标准。否则,它可能只是一个技术领先但曲高和寡的昂贵实验。
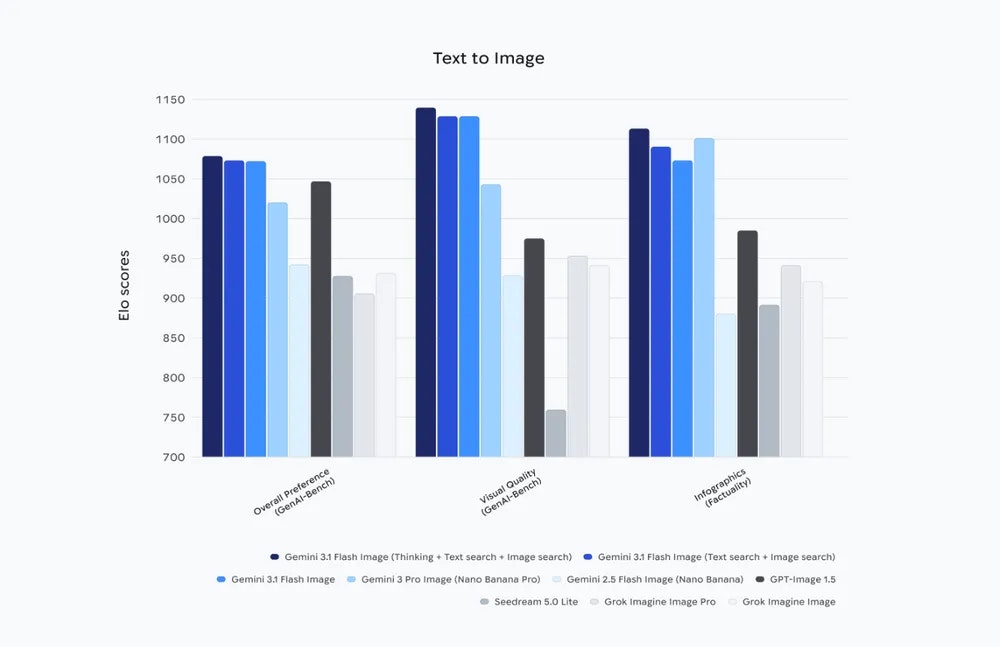
一句话介绍:Google最新推出的高速AI图像生成模型,在营销创意、广告制作、故事板绘制等高频率生产场景中,解决了图像生成速度慢、多角色/物体一致性差、文本渲染不准确等核心痛点,提供生产就绪的视觉内容。
Artificial Intelligence
Graphics & Design
Design
AI图像生成
多角色一致性
文本生成
生产级工具
营销创意
高速推理
品牌资产
谷歌Gemini
实时搜索
合成数据溯源
用户评论摘要:用户高度评价其角色/物体一致性、精准文本生成及生产速度,认为这是改变高容量创意工作流经济性的关键。关注其与竞品的对比优势、复杂版式处理能力及定价策略,并认可谷歌快速的迭代速度与长期信任基础设施的构建。
AI 锐评
Nano Banana 2并非一次简单的性能迭代,而是谷歌将其AI基础设施优势,系统性转化为行业生产力的关键一步。它精准切入当前AI生图领域的核心商业瓶颈:高频率、高一致性、需嵌入工作流的“生产”需求,而非“演示”需求。
其宣称的“生产就绪”规格,如5角色、14物体的强一致性、精准多语言文本生成、实时搜索数据支撑,以及从512px到4K的原生分辨率控制,直指广告批量制作、品牌视觉资产生成、视频帧序列创作等规模化场景。这标志着竞争焦点已从“生成一张惊艳的图片”,转向“稳定、廉价、可控地生成一万张符合商业规范的图片”。谷歌正利用其全栈优势(模型、搜索、云平台、广告系统)打造一个闭环:模型在自身生态(Ads、Vertex AI等)中深度集成,确保从生成、使用到溯源(SynthID、C2PA)的端到端可控,这远非独立模型公司可比。
然而,真正的考验在于“生产就绪”承诺的兑现度。复杂提示词的遵循稳定性、极端长尾场景的渲染准确性、以及最终面向API用户的实际定价,将决定它能否真正成为行业默认的“基座”。谷歌的闪电速度在扩大技术代差的同时,也可能让生态整合与开发者适配面临压力。若其能如评论所期,以“Flash”模型的亲民定价提供“Pro”级的一致性,它确实可能重塑AI图像生产的成本结构与行业格局。
一句话介绍:Mastra Code是一款基于“观察记忆”技术的AI编程代理,通过智能压缩上下文而不丢失关键细节,解决了开发者在长周期编码会话中因上下文窗口填满、信息被压缩遗忘而导致的效率中断和重复劳动痛点。
Software Engineering
Developer Tools
Artificial Intelligence
GitHub
AI编程助手
上下文管理
观察记忆
无压缩会话
CLI工具
开发效率
长周期编码
代码生成
开发者工具
终端代理
用户评论摘要:用户高度认可“永不压缩”概念,认为其解决了长期会话中的“上下文遗忘”核心痛点。有效评论集中于技术细节:询问记忆层如何加权罕见但关键的约束、如何处理信息冲突、数据安全与隐私保护措施,以及错误假设的纠正机制。开发者团队对部分问题进行了回应。
AI 锐评
Mastra Code的宣示——“永不压缩的AI编程代理”,与其说是一项功能升级,不如说是对当前AI编码助手普遍缺陷的一次精准外科手术。主流AI助手受限于固定上下文窗口,在会话膨胀后被迫进行“上下文压缩”,这本质是一种粗暴的信息丢弃,常导致关键架构决策或罕见约束被遗忘,使代理在长会话后半段“精神错乱”,从助手变为负担。
Mastra Code的核心“观察记忆”技术,试图将记忆从被动的、基于最近/频率的文本摘要,升级为主动的、基于理解的要点提取与持久化。这直击了AI协作工具从“玩具”迈向“专业工作流伙伴”的最大障碍:状态持久性与决策一致性。用户评论中反复提及的“三小时前的一次性架构约束”,正是这种价值的最佳注脚——它保留的是决策逻辑,而不仅仅是对话历史。
然而,其宣称的“革命性”背后,隐藏着更严峻的挑战。首先,技术层面,“不丢失重要细节”的定义权归属问题。是启发式算法,还是用户显式信号?评论中的提问切中要害。若依赖算法,其“重要性”判断可能与开发者意图产生偏差,形成更隐蔽的认知鸿沟。其次,产品逻辑上,无限增长的“记忆”本身可能成为新的负担,如何结构化、查询乃至遗忘,避免成为杂乱的信息垃圾场,是下一阶段的问题。最后,安全与信任维度,长周期、高细节的记忆存储,使得代码安全、数据隐私和潜在偏见问题被急剧放大,这需要远超普通代码补全工具的安全架构。
本质上,Mastra Code的竞争点已从“代码生成质量”上移至“协作过程可靠性”。它不再仅仅比拼单次响应的惊艳度,而是争夺开发者的“心智带宽”,旨在成为开发者可以真正托付复杂任务背景的“数字同事”。其成功与否,将取决于它能否在“记忆的智能”与“系统的可控”之间找到精妙的平衡,否则,“永不压缩”可能只是将崩溃从“中途失忆”推迟为“最终的系统性混乱”。这条路充满希望,但也布满了尚未解答的工程与伦理难题。
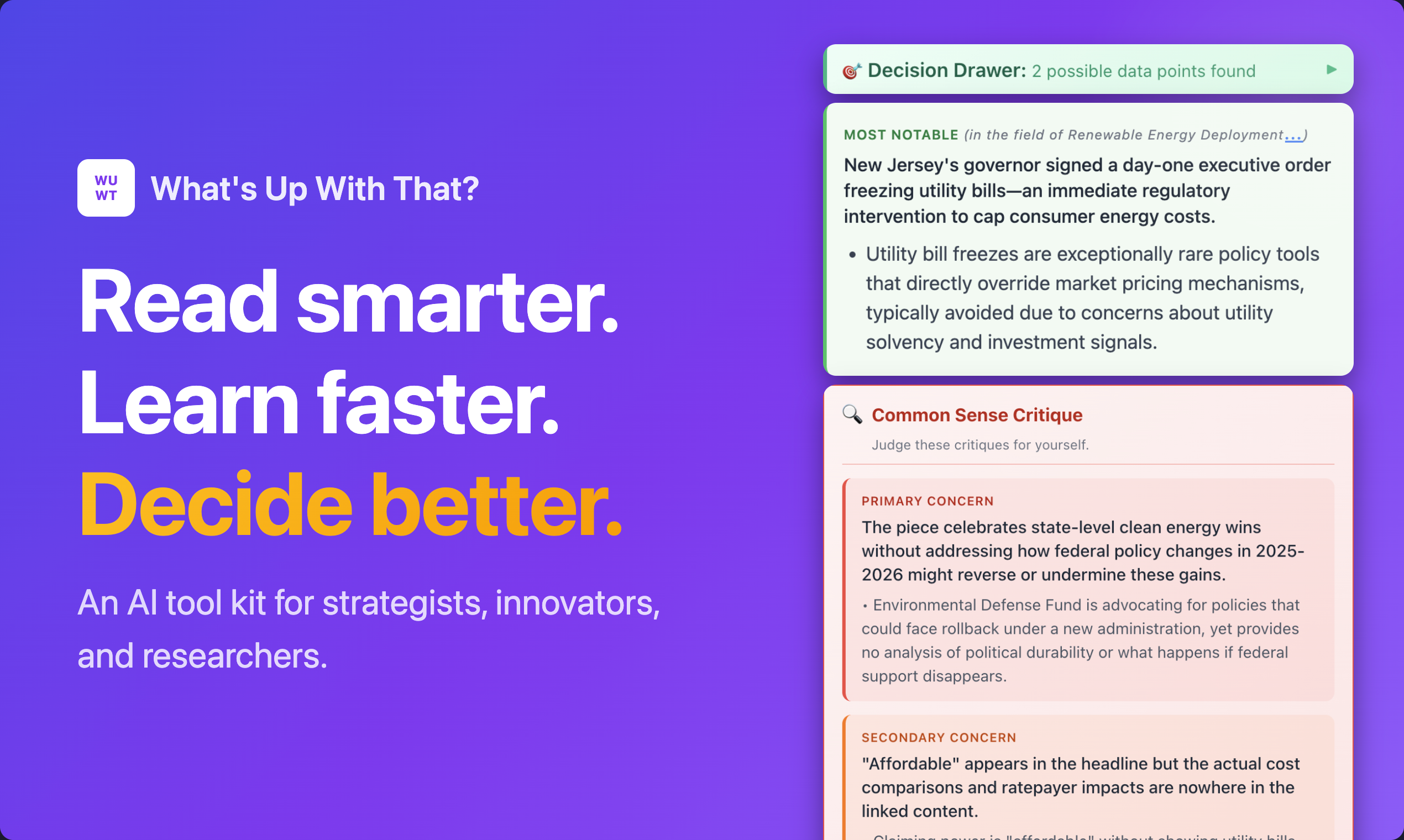
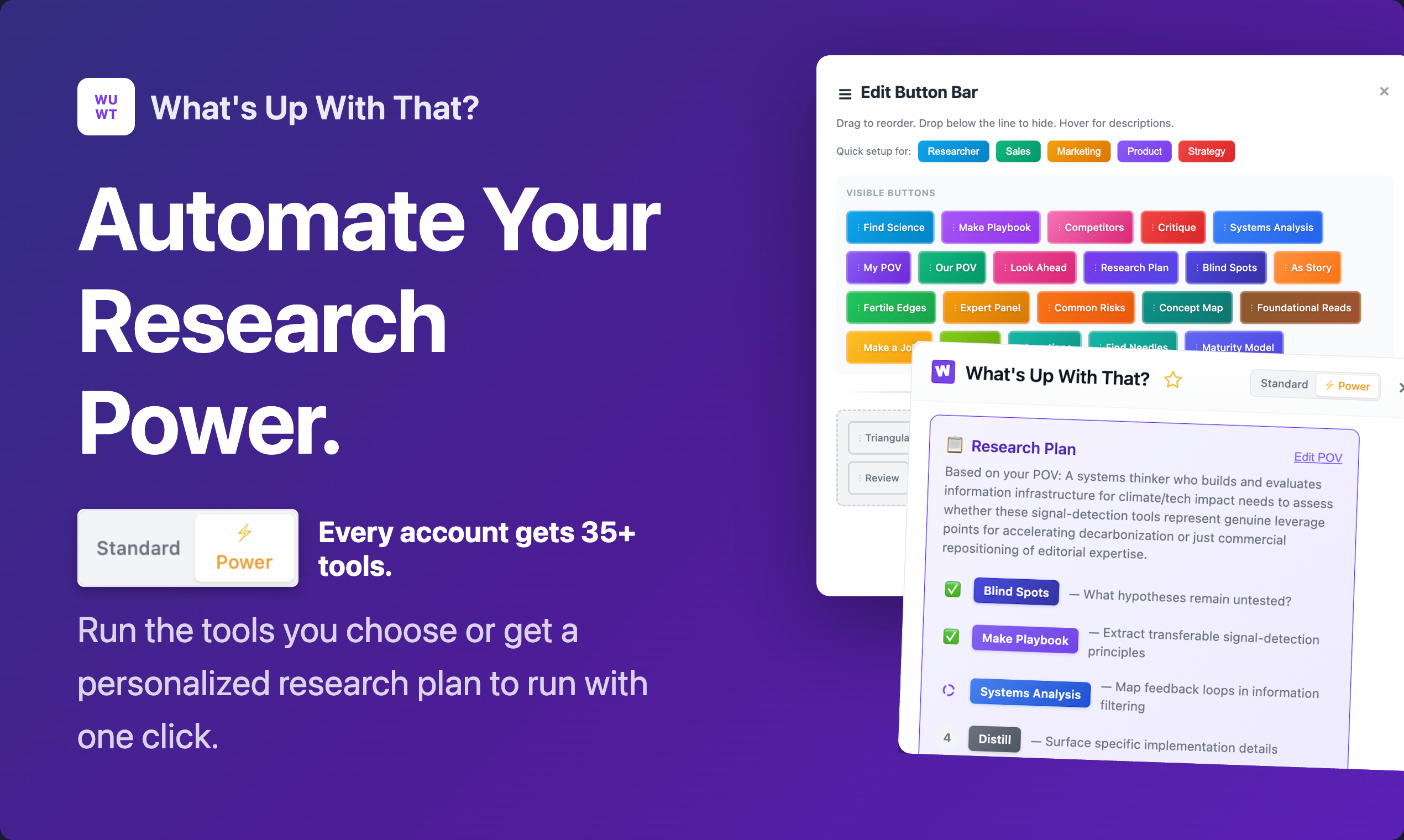
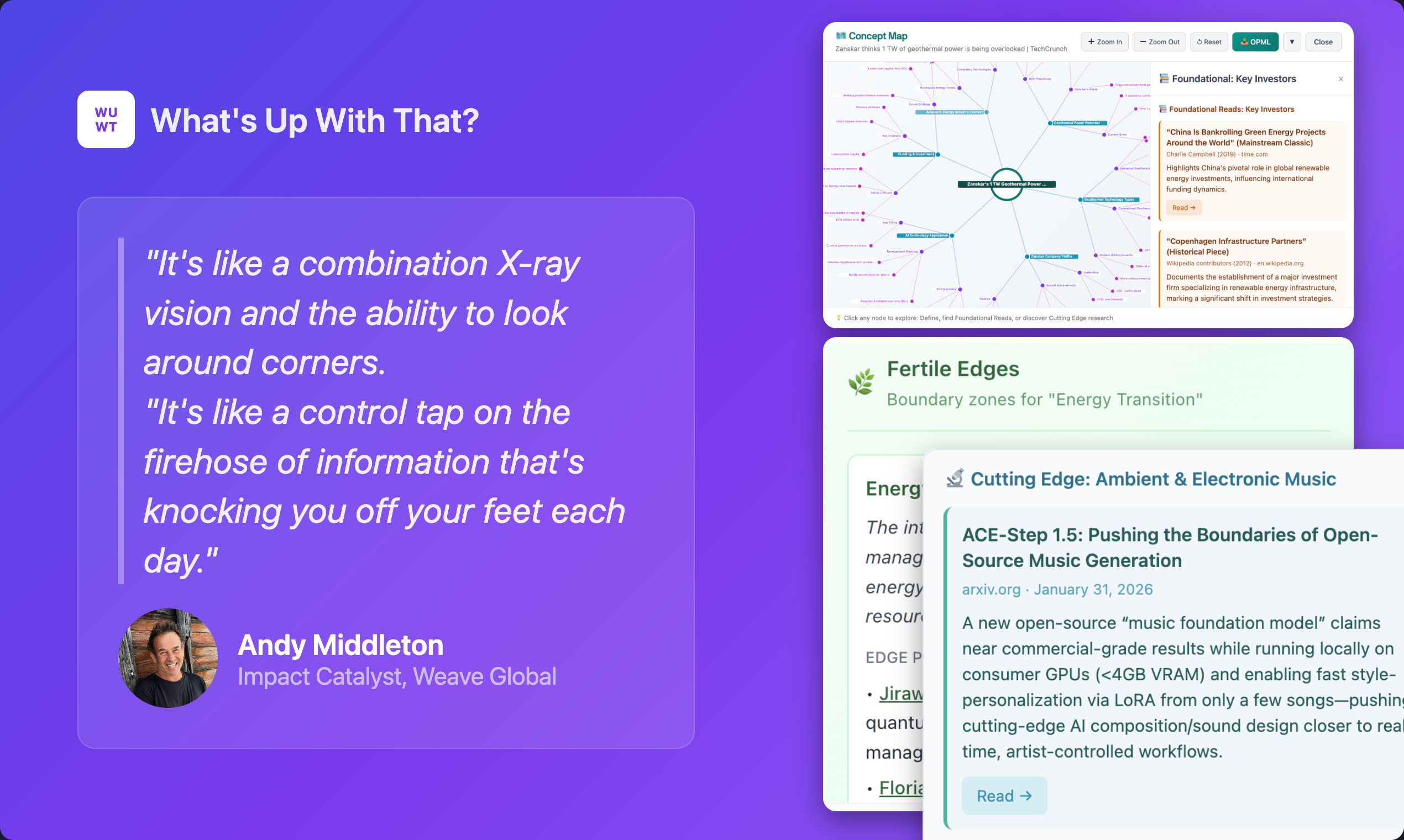
一句话介绍:一款浏览器插件,通过一键生成领域知识图谱和应用多种思维模型AI工具,帮助深度阅读者在研究行业动态、分析文章时快速获取关键洞察,解决信息过载与思考碎片化痛点。
Productivity
Artificial Intelligence
浏览器插件
AI阅读助手
思维模型
知识图谱
竞争分析
信息提炼
决策支持
生产力工具
用户评论摘要:用户肯定其“思考操作系统”的定位及结构化思考的价值。主要问题/建议包括:如何确保知识图谱准确性、避免AI专家小组观点同质化、处理长文章的技术方案、工具过多可能导致的分析过载,以及Edge浏览器兼容性和导出功能优化。
AI 锐评
“What‘s Up With That?” 的野心远不止于又一个文本摘要工具,它试图成为嵌入浏览器的“认知增强层”。其核心价值不在于信息压缩,而在于信息重构——通过“领域现状图谱”提供上下文,再以35种基于思维模型的AI工具对文本进行多维度解构。这直击了高阶知识工作者的核心痛点:在信息洪流中,缺乏快速建立认知框架并进行批判性、系统性分析的工具。
然而,其宣称的“10秒生成图谱”也是最大的风险点。在快变领域,AI如何保证图谱的实时性与准确性,而非生成看似合理实则幻觉的“竞争格局”?这关乎工具的信誉根基。同样,其宣传亮点的“合成专家辩论”若不能确保观点真正异质化,则沦为华丽的噱头。
产品设计上,35+工具既是卖点也是陷阱。开发者通过“推荐研究计划”、工具收纳与置顶来管理复杂性,这体现了对用户心流的思考。但本质上,它将选择负担部分转移给了AI推荐系统,该系统推荐质量将直接影响用户体验是流畅高效还是徒增困惑。
该产品真正的赛道是“决策智能”的入口。其“自动捕获决策数据点”和“阅读回顾”功能,隐约指向构建个人阅读与决策的反馈闭环。若能持续优化信号质量、克制功能膨胀、深化个性化,它有可能从一款聪明的阅读插件,演进为个人知识管理与决策的“外部大脑”。反之,若无法解决准确性根本问题,则会淹没在同质化AI工具的浪潮中。
一句话介绍:一款为追求高效阅读体验的Hacker News深度用户打造的macOS原生客户端,通过可视化文章网格、文章与评论并排浏览等核心功能,解决了在网页端频繁切换标签、界面信息密度过高导致的浏览效率低下痛点。
News
Open Source
Developer Tools
GitHub
macOS原生应用
Hacker News客户端
信息阅读效率工具
SwiftUI开发
开源软件
侧边栏阅读
视觉化浏览
键盘快捷键
广告屏蔽
用户评论摘要:用户普遍赞赏其现代化界面和并排浏览功能,认为显著提升了HN阅读体验。主要讨论点包括:开发者分享创作初衷与SwiftUI选型考量;用户探讨HN官网设计长期不变的原因;有评论询问开发中遇到的macOS特定设计挑战。
AI 锐评
这款产品表面上是为经典极客社区Hacker News披上了一层现代化的SwiftUI外衣,但其真正的价值远不止“皮肤”更换。它精准地解剖了HN作为高质量信源与落后前端体验之间的核心矛盾,并提供了手术刀式的解决方案。
其价值首先体现在对“阅读上下文”的重构上。将文章与评论并排展示,并非简单的界面布局调整,而是深刻理解了HN用户“阅读-验证-讨论”的闭环行为模式。这打破了网页浏览的线性流程,将信息消费从“串行”变为“并行”,直接提升了认知效率。其次,通过Open Graph缩略图构建可视化网格,是对信息过载时代“扫描式阅读”需求的妥协与优化,在保持HN文本核心的同时,增加了视觉锚点。
选择SwiftUI而非跨平台框架,是一个值得玩味的决策。这固然牺牲了潜在的用户基数,却换来了对macOS原生交互规范(如手势、快捷键、渲染性能)的深度集成。这暗示了开发者的目标用户画像非常清晰:是那些长期驻留macOS环境、对操作流畅度有苛刻要求、且厌倦了Electron应用资源消耗的专业用户。本质上,这是一款由重度用户为自己同类打造的“工具”,其开源属性进一步强化了其在开发者社区中的可信度与可扩展性。
然而,其挑战也同样明显。产品的生存严重依赖于HN官方API的稳定与宽容度,存在潜在的政策风险。其功能创新虽好,但壁垒不高,易被模仿。最大的问题在于,它优化的是“消费端”体验,并未触及HN的核心——内容生产与社区互动机制。因此,它更像一个精致的“阅读终端”,其长期价值将取决于能否围绕这个终端构建更深层的用户习惯(如收藏同步、个性化过滤)乃至社交关系,否则可能仅停留为一款优秀但替代性较强的效率插件。
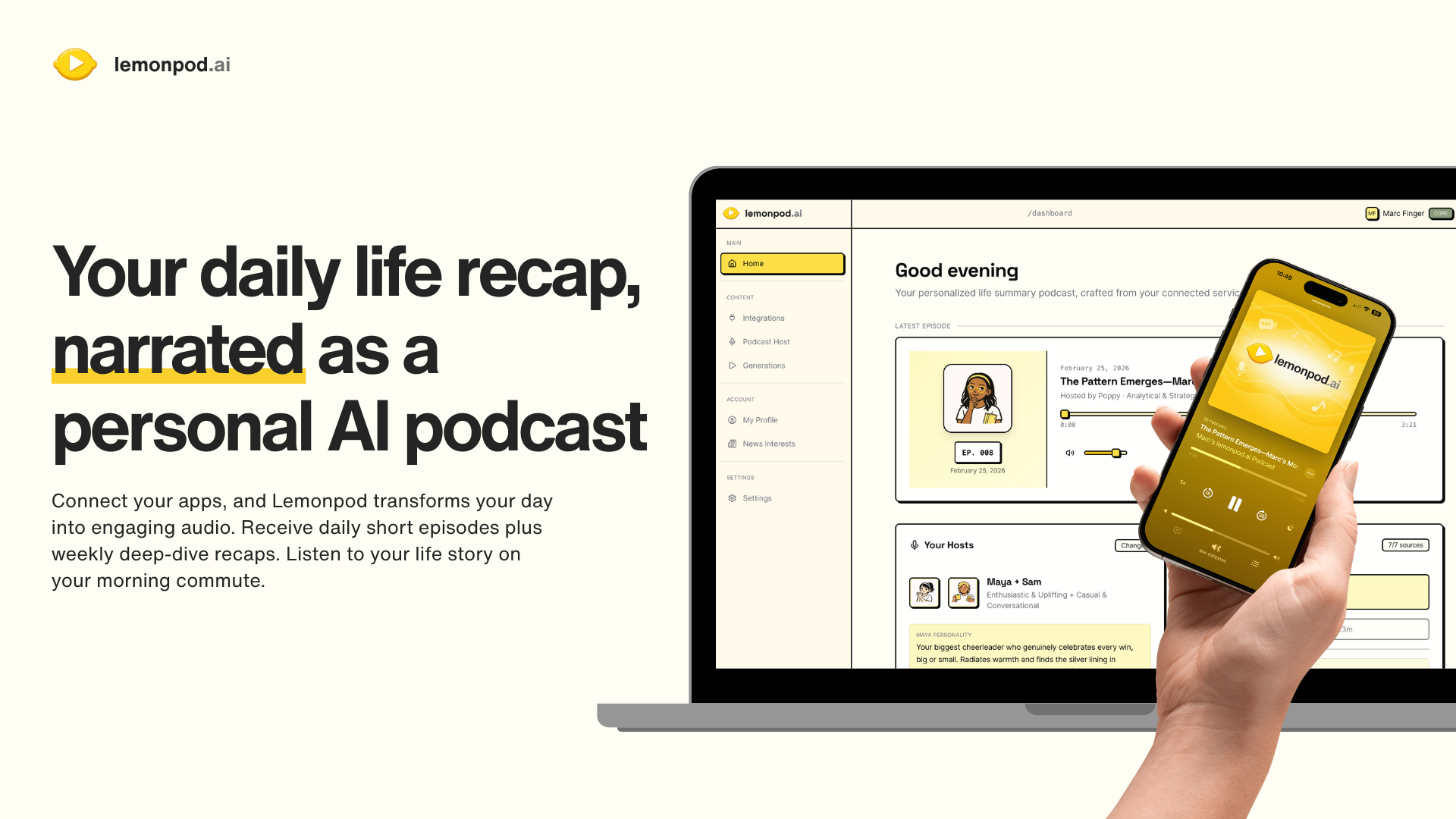
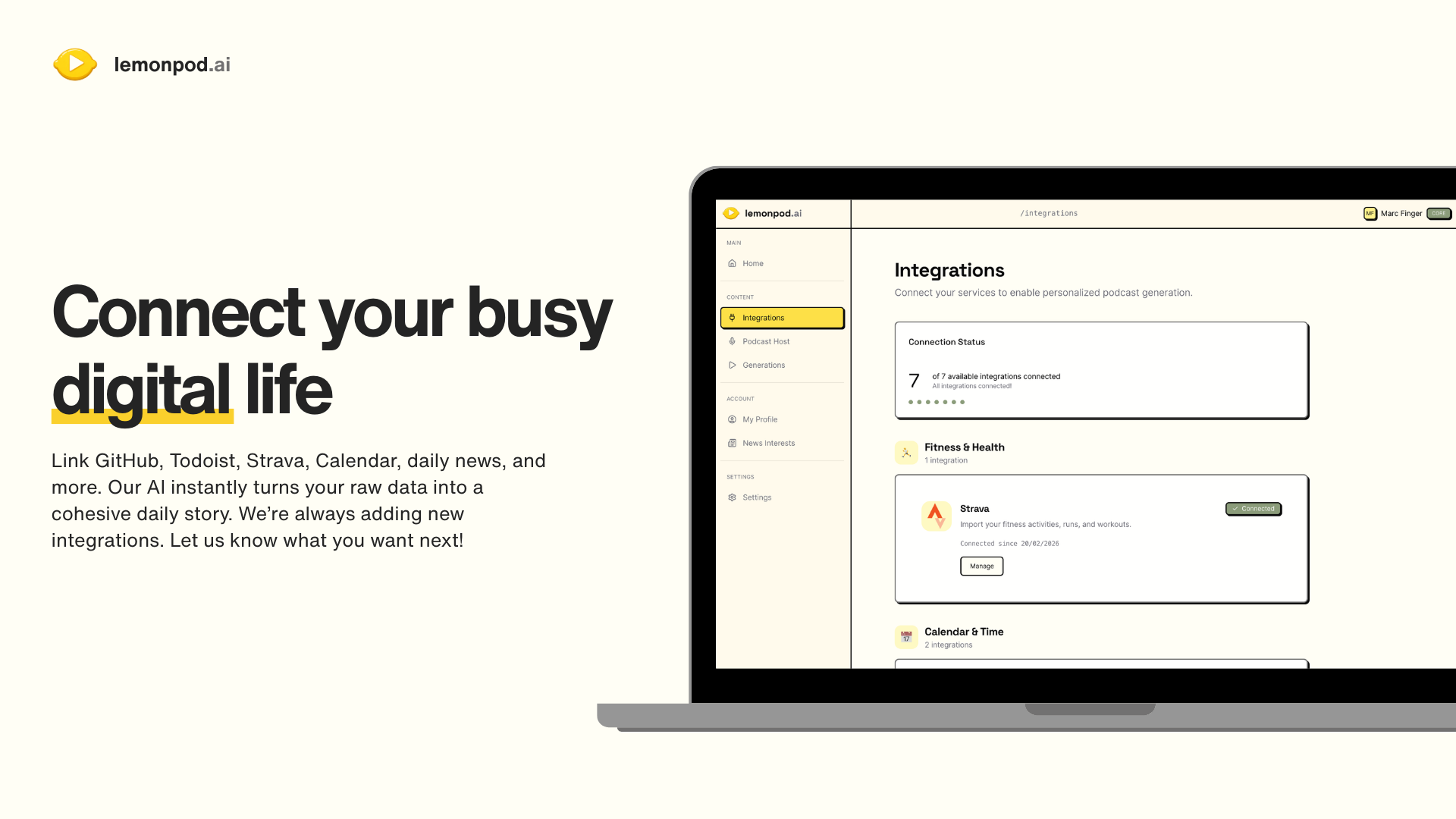
一句话介绍:Lemonpod.ai 将用户分散在日历、运动、音乐、代码等平台的数据整合,生成个性化的AI播客,在晨间场景中为用户提供高效、人性化的每日回顾,解决了信息过载与碎片化管理的痛点。
Productivity
Artificial Intelligence
Entertainment
个人AI播客
每日回顾
生活日志
数据聚合
音频叙事
晨间仪式
生产力工具
个性化生成
生活量化
RSS订阅
用户评论摘要:用户普遍认可概念新颖,关注点集中于:数据安全与隔离的实现方式;AI生成内容的“人性化”与个性化程度(如语调调整、信息过滤);未来集成规划(Notion、金融数据等);内容所有权与RSS可移植性;以及长期使用是实用工具还是短期新奇。
AI 锐评
Lemonpod.ai 的聪明之处在于,它没有选择在拥挤的“可视化仪表盘”赛道上竞争,而是将“数据回顾”这一行为场景,从“需要主动查看”的视觉负担,转化为“可以被动收听”的音频陪伴。这本质上是对个人量化数据价值的一次再挖掘——从冰冷的图表转向有温度、有性格的叙事,试图在效率工具中注入情感连接。
然而,其面临的挑战同样尖锐。首先,**“叙事深度”陷阱**:当前模式更接近基于模板的智能播报,与真正的“理解”与“洞察”尚有距离。用户质疑其能否区分一次普通的GitHub提交与一个关键突破,这直指核心——若AI无法理解数据背后的意义与情感权重,播报终将流于表面,新鲜感褪去后极易沦为背景噪音。其次,**数据隐私的“感知风险”**:尽管开发者解释了技术上的安全措施,但将如此多生活核心平台的OAuth权限授予一个新兴独立应用,用户的信任门槛极高。最后,**产品定位的摇摆**:评论中既有人视其为私密的“个人操作系统”,也有人期待其成为公开的“内容引擎”。这关乎产品根本:是强化私密、深度的个人生活优化,还是走向可分享、轻量化的个人品牌内容生成?两者路径所需的AI能力和产品设计截然不同。
其真正价值或许不在于替代现有工具,而是创造了一个全新的、低摩擦的“数据消费”习惯。成功的关键在于AI能否从“播音员”进化成“编辑”乃至“知己”——不仅报告“发生了什么”,更能基于历史模式,指出“这意味着什么”以及“接下来可以关注什么”。否则,它可能只是为“数据自恋”提供了一个更优雅的形式,而非一个可持续的效用工具。
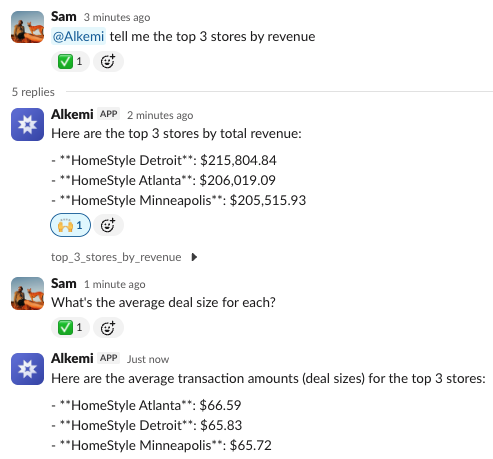
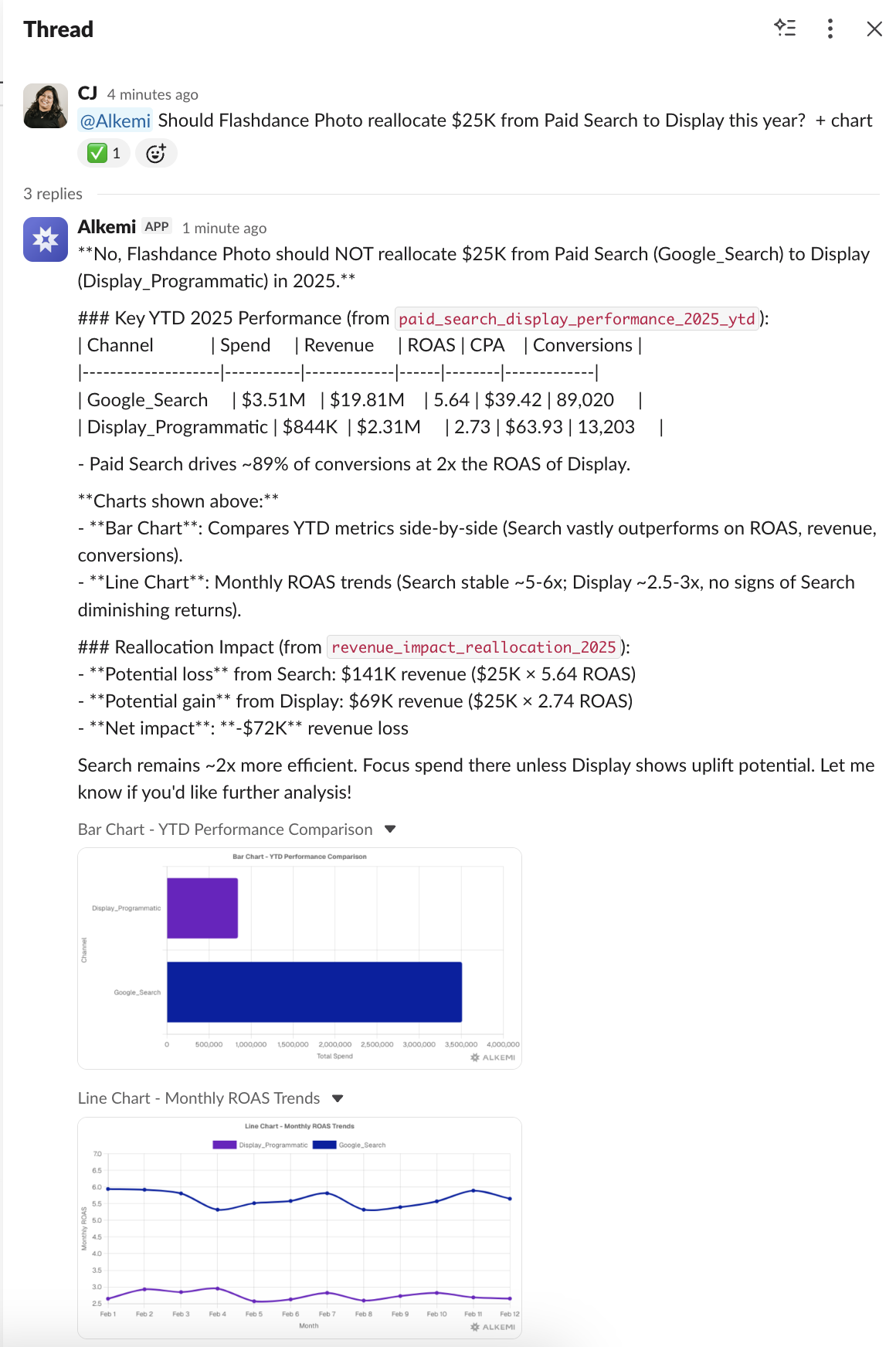
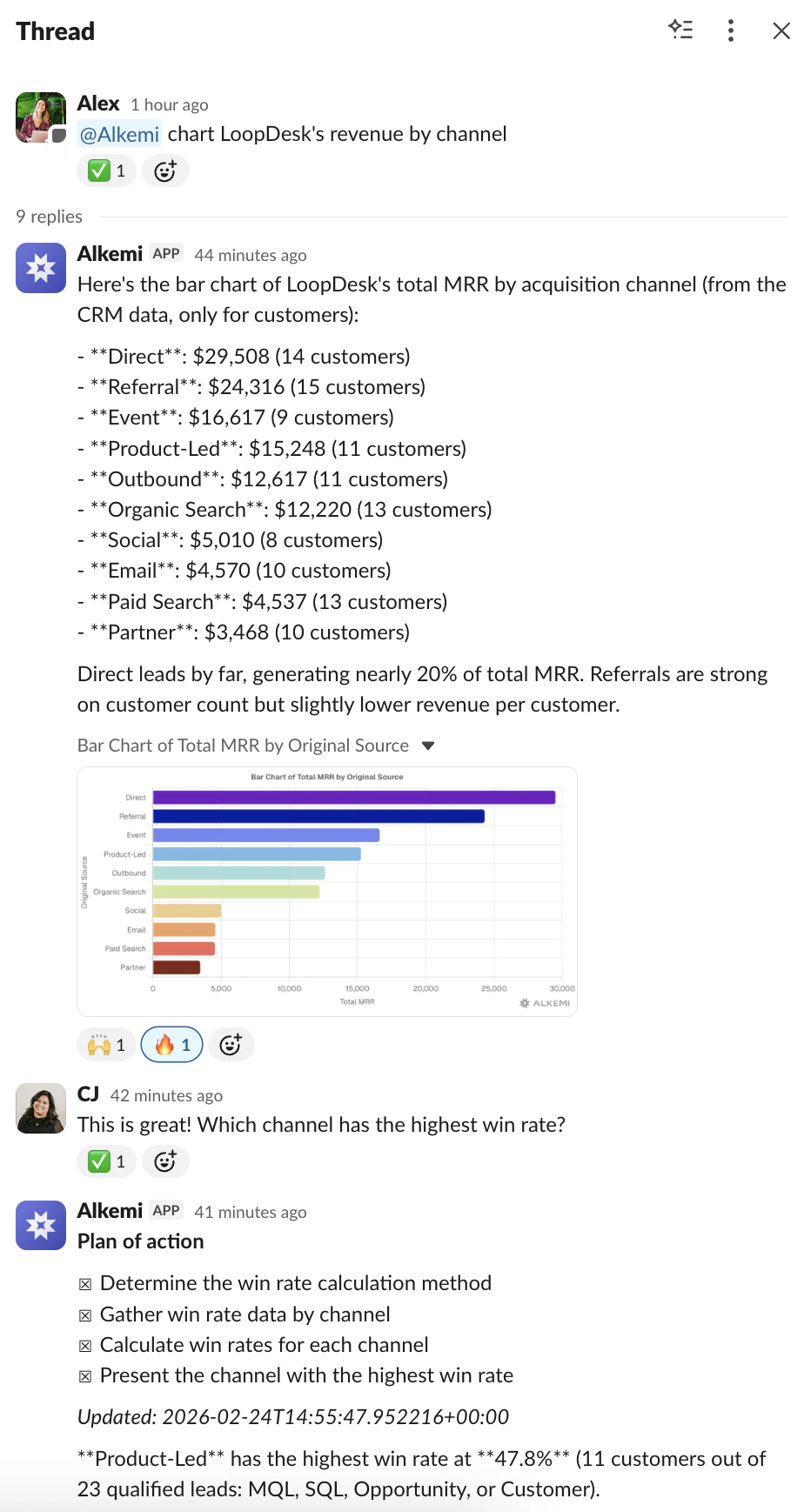
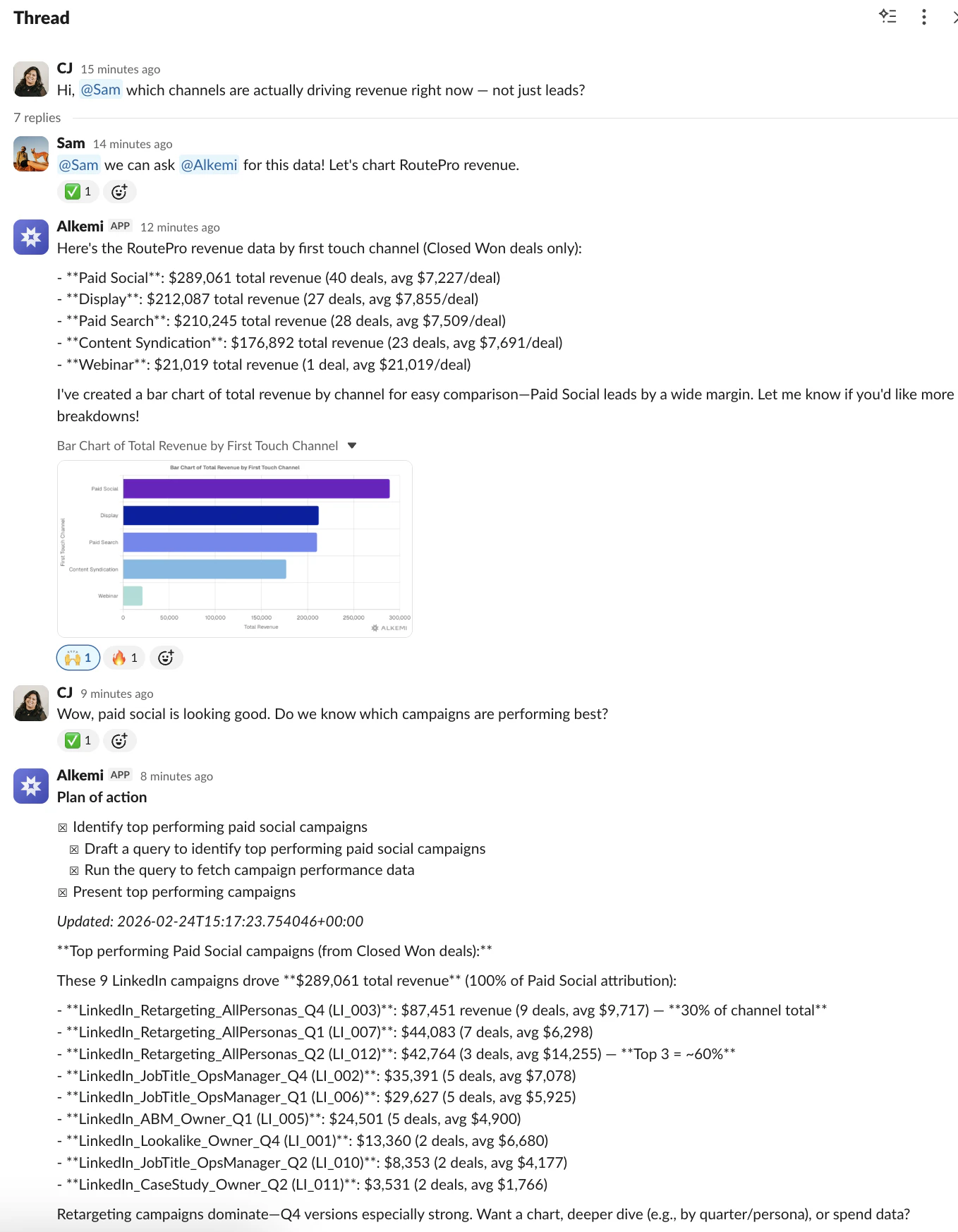
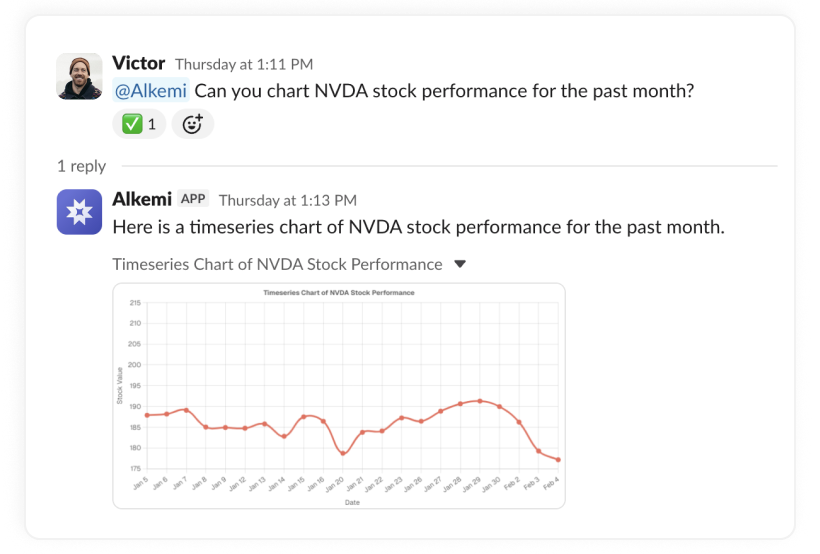
一句话介绍:Alkemi是一款集成在Slack中的AI数据分析助手,通过自然语言对话,让团队成员能直接在协作平台中实时查询业务数据、生成图表与报告,解决了数据与决策场景分离、传统BI工具使用门槛高且响应慢的痛点。
Slack
Artificial Intelligence
Data & Analytics
Slack集成
数据分析AI
实时查询
自然语言BI
决策支持
数据 democratization
企业级AI
对话式分析
数据安全
团队协作
用户评论摘要:用户肯定产品在Slack中整合数据的便捷性,创始人强调了数据不离开用户环境、实时处理、权限管控及可追溯的设计。有效提问集中在数据安全与权限控制机制、答案准确性保障,以及是否存储聊天记录。
AI 锐评
Alkemi瞄准了一个真实且顽固的企业痛点:数据基础设施与决策场景的割裂。它不试图取代专业数据平台,而是充当“最后一英里”的输送管道,将Snowflake、BigQuery等数据源封装成Slack中的对话函数。其真正价值不在于“AI分析”本身——这类技术已不新鲜——而在于精准地嵌入了“决策发生地”(Slack),以近乎零摩擦的方式将数据洞察注入日常对话。
然而,其面临的挑战同样尖锐。首先,它本质上是一个“翻译层”,其分析深度受限于底层数据模型的完整性与清洁度,复杂、模糊或需要深度建模的问题仍可能超出其能力范围,“错误或不完整答案”的风险依然存在。其次,安全与权限虽被强调,但一旦在群聊中触发,信息分发的边界可能变得模糊,如何在便捷性与数据管控之间取得平衡,将是企业安全团队考量的重点。最后,其商业模式和长期定位面临疑问:是成为独立的数据查询入口,还是最终沦为大型数据平台(如Snowflake)的一个嵌入式功能?其护城河在于对Slack工作流的深度理解和集成体验,而非底层AI技术。
总体而言,Alkemi是一次务实的“场景创新”。它未必能替代数据科学家,但确实在降低高频、浅层数据查询的“政治成本”和等待时间。它的成功与否,将取决于能否在提供“即时满足”的同时,建立起足够坚固的信任壁垒——包括答案的可靠性、系统的安全性,以及对企业复杂权限架构的细腻适配。
一句话介绍:MaxClaw是一款基于MiniMax M2.5模型、无需部署的常驻托管智能体,可在主流通讯平台(如Telegram、WhatsApp)中7×24小时运行,为用户提供零运维、即开即用的自动化助手服务,解决了个人与团队在多个平台部署和维护AI助理门槛高、成本高的痛点。
Artificial Intelligence
AI智能体
常驻托管
通讯平台集成
无服务器架构
零运维
自动化助手
多平台支持
企业工具
即时通讯机器人
MiniMax生态
用户评论摘要:目前展示的有效评论较少,主要来自官方或早期用户,强调其“一键部署”、“常驻运行”、“零维护/无服务器”的核心特点,尚未看到来自真实用户的深入问题或具体改进建议。
AI 锐评
MaxClaw的核心卖点清晰且尖锐:它试图将“智能体即服务”(Agent-as-a-Service)推向主流。产品直指当前AI智能体应用的两大核心门槛:复杂的部署运维成本,以及跨平台集成的繁琐。其价值不在于技术上的颠覆,而在于体验上的“降维打击”——通过托管服务和预集成,将实验室里的“常驻智能体”概念,包装成如同开通SaaS订阅一样简单的产品。
然而,光鲜标语之下,疑点重重。“基于OpenClaw”的表述略显暧昧,是深度整合还是品牌借用?“无额外API费用”的模式能否持续,是否会成为未来捆绑高价模型版本的入口?“即用型MiniMax专家生态”听起来美好,但生态的深度、实用性与可定制性,才是决定其能否从“玩具”变为“工具”的关键。当前106的投票数也反映出,市场仍处于观望状态。
真正的考验在于“为真实工作而升级的内置工具”究竟有多“真实”。如果其能力仅停留在信息查询与简单对话,它不过是另一个聊天机器人;若能深度处理工作流、理解复杂上下文并执行可靠操作,它才有机会成为数字员工的雏形。在巨头环伺的AI赛道,MiniMax此举是找到了一个差异化的垂直切口,还是仅仅制造了一个华丽的概念泡沫,完全取决于其落地后的实际效能与稳定性。产品思路值得肯定,但必须用硬核的交付能力来证明自己。
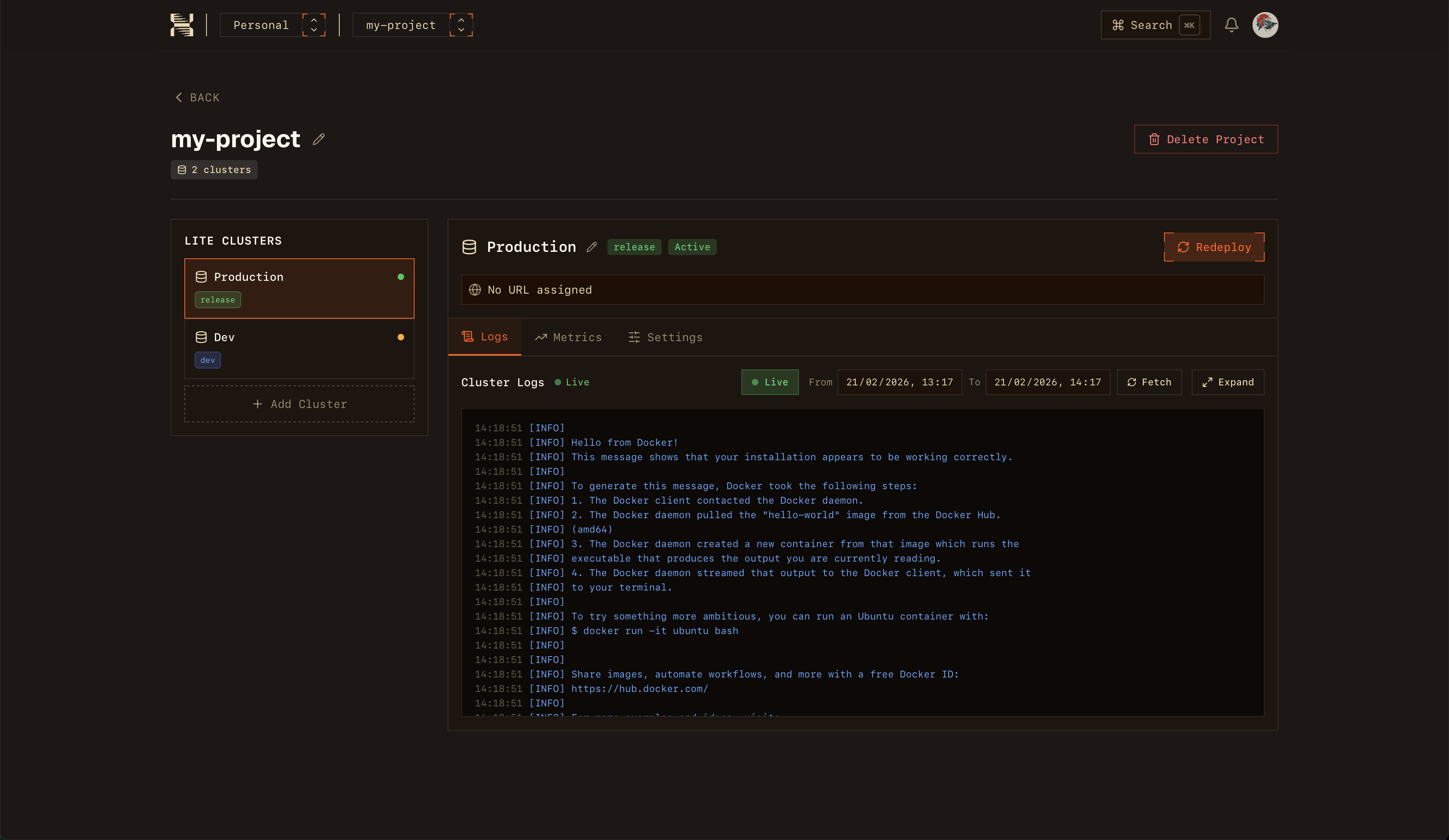
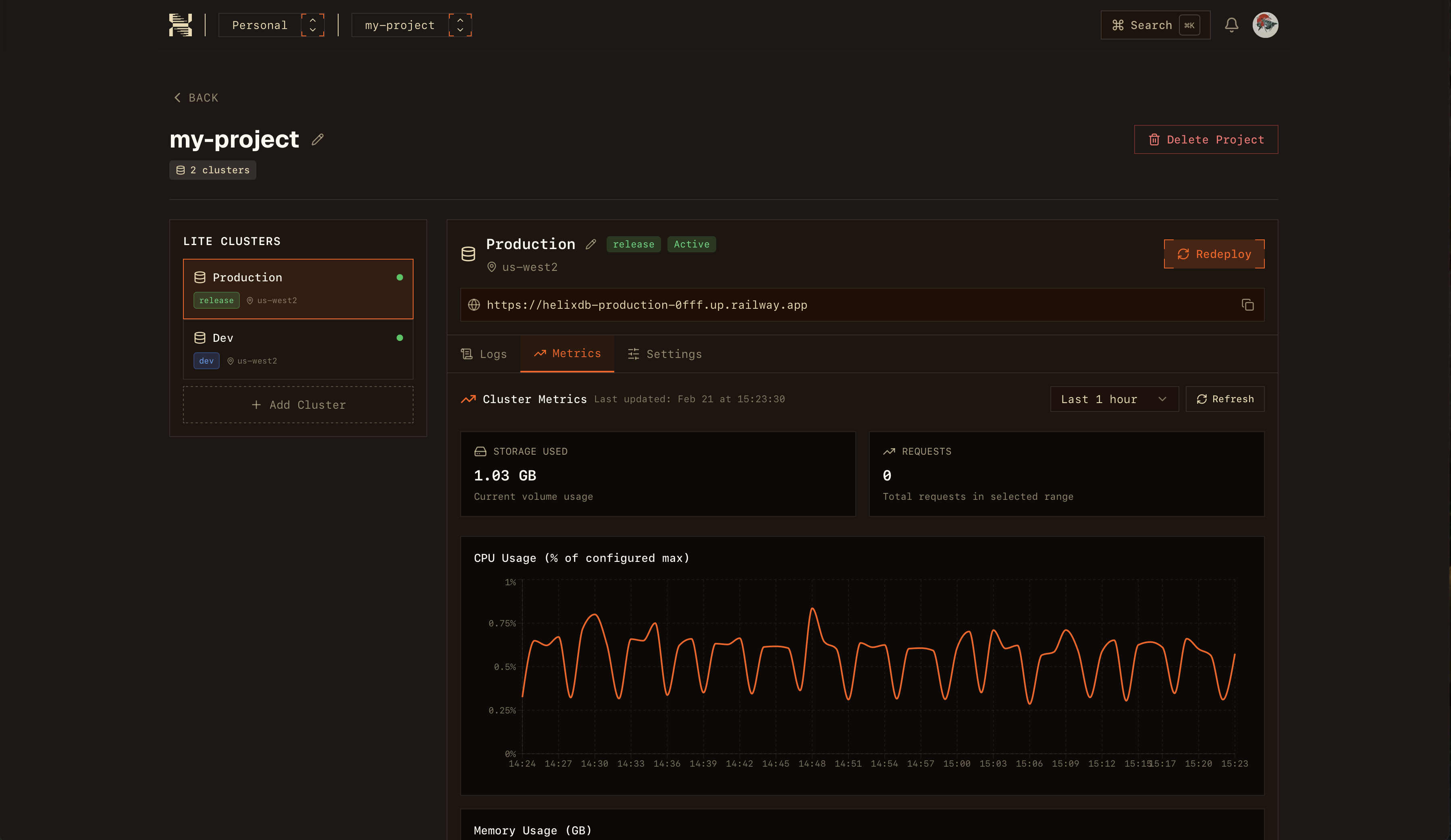
一句话介绍:HelixDB是一款开源的OLTP图向量数据库,专为需要实时处理复杂关系数据和向量搜索的场景设计,解决了开发者以往需要组合多种数据库(如Postgres与Pinecone)才能实现的痛点,尤其适用于AI智能体记忆等新兴工作流。
Developer Tools
Artificial Intelligence
GitHub
Database
开源数据库
OLTP
图数据库
向量数据库
Rust
智能体记忆
实时查询
可扩展
HelixQL
云原生
用户评论摘要:用户肯定其图向量一体设计是“AI智能体生态当前所需”,并关注其自研查询语言HelixQL的设计逻辑、与竞品的对比、数据安全与多租户隔离方案。团队回应避开了OLAP场景,专注OLTP,并以智能体记忆为当前切入点,但强调通用性。
AI 锐评
HelixDB的发布,与其说是一款新数据库的诞生,不如说是对当前AI基础设施“拼凑式”架构的一次精准狙击。其核心价值在于将OLTP、图与向量三种能力原生融合,直指AI应用(尤其是智能体工作流)中频繁交织的关系推理与语义搜索需求。团队聪明地以“智能体记忆”作为市场楔子,这是一个痛点明确、增长迅速的细分场景,但将其定位为“通用数据库”的野心已昭然若揭。
技术栈选择Rust,迎合了高性能基础设施领域的主流偏好,而自研HelixQL则是一把双刃剑:它提供了优化和定制的空间,但也带来了额外的学习成本和生态隔离风险。从评论看,早期采用者最关心的并非性能参数(尽管团队提及了数十亿查询的规模验证),而是实际落地问题:安全、隔离、明确的能力边界。团队坦诚避开OLAP、专注OLTP的回答,显示出一种可贵的产品聚焦。
真正的挑战在于,它同时闯入了一个竞争激烈的“红海”:传统图数据库、专业向量数据库以及正在增强向量能力的云数据库巨头。其长期生存的关键,或许不在于“三者兼备”,而在于能否在“实时、事务性、复杂关系与向量混合查询”这一具体交汇点上,建立起足够深的技术壁垒和开发者体验优势。否则,它可能只是另一个“优秀但小众”的工具。当前的热度(4k GitHub stars)证明了需求的存在,但能否从“有趣的项目”进化为“关键的基础设施”,仍需在工程完备性、商业支持和生态建设上接受更严酷的考验。
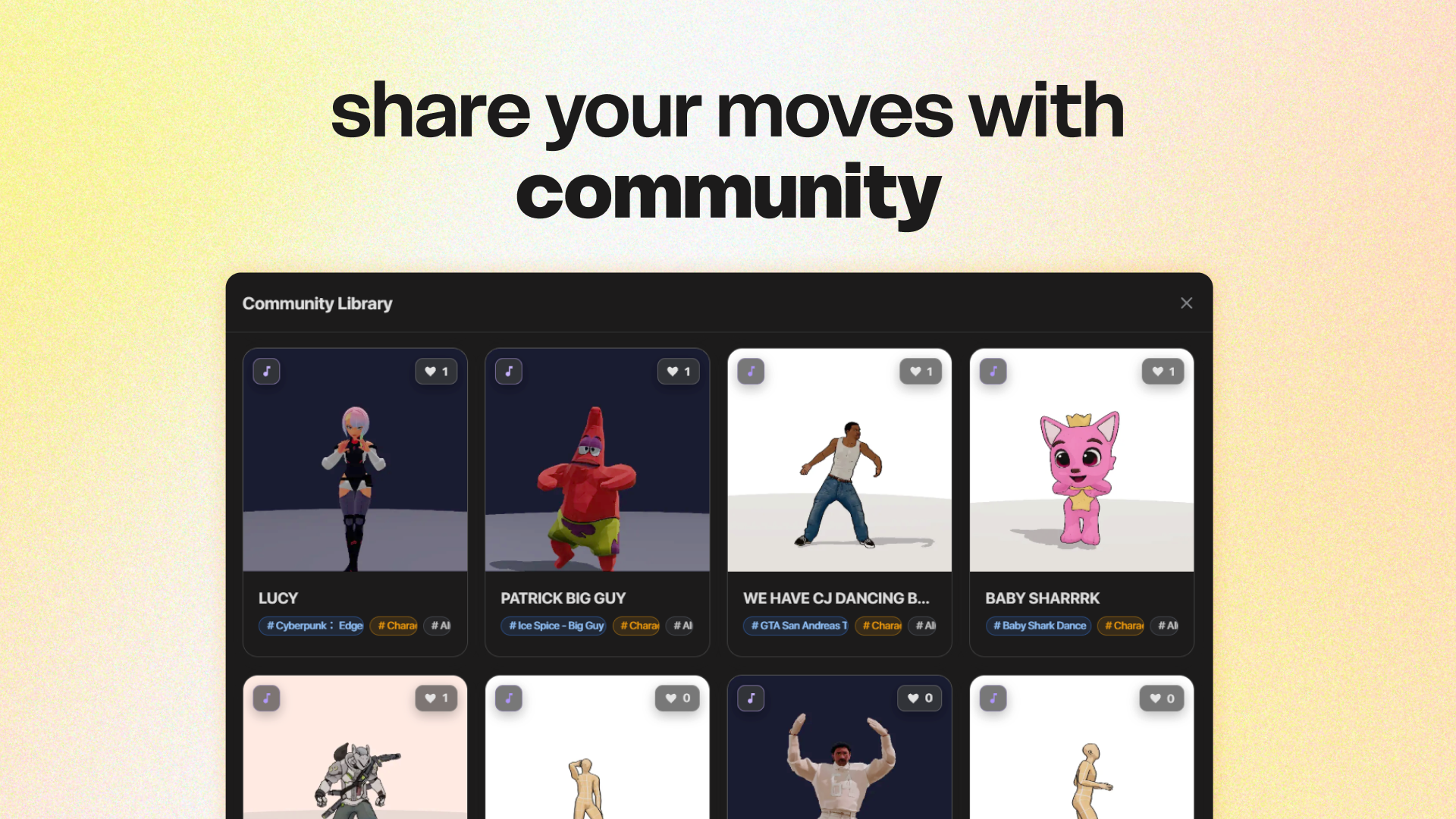
一句话介绍:一款基于AI的音乐驱动舞蹈动画生成工具,用户只需提供歌曲或角色图片,即可快速生成可用于制作的舞蹈动画,解决了视频创作者、舞者等群体在内容创作中缺乏专业编舞和动画制作能力的痛点。
Music
Artificial Intelligence
Animation
AI舞蹈生成
音乐可视化
3D动画
内容创作工具
AIGC
编舞辅助
视频制作
Web应用
娱乐科技
创意平台
用户评论摘要:用户反馈积极,认为应用很酷。主要问题集中于:1. 界面对非舞者是否直观;2. 能否自定义舞蹈风格(如嘻哈、芭蕾);3. 能否通过文字提示描述自定义舞蹈序列;4. 对产品端技术栈感兴趣。创始人回应坦诚,说明了当前版本功能及未来优化方向。
AI 锐评
mvntSTUDIO的核心价值,在于它试图将前沿的扩散模型(mvnt-m4)与Tripo AI的3D生成能力,封装成一个低门槛的“舞蹈游乐场”。其真正的野心并非替代专业编舞,而是成为创意流水线上的“动作素材快消品”供应商——为TikTok挑战、K-pop模仿乃至AI视频工具(如Kling AI)提供即插即用的舞蹈动画模块。
产品目前呈现明显的“研究产品化”过渡特征。团队坦诚提及画质、生成速度、面部手指细节等不足,这恰恰暴露了从实验室模型到稳定生产工具的典型鸿沟。用户关于风格定制和文字提示的提问,直指当前AI生成的核心矛盾:在“全自动黑箱”与“可控创意”之间,产品尚只能提供前者。这使其短期内更适合猎奇娱乐和灵感参考,而非精准创作。
其“Epic MegaGrant获得者”背景是重要背书,暗示了在3D实时领域的技术积累及与虚幻引擎生态的潜在联动。若能将舞蹈动作生成与游戏、VR虚拟人驱动结合,想象空间将远超视频模板。然而,当前版本依赖YouTube链接和图片上传,更像一个功能演示。其长期成功的关键,在于能否构建一个“生成-分享-再创作”的创作者飞轮,并用社区画廊沉淀数据反哺模型,形成护城河。否则,它极易被大厂的综合型AIGC平台以类似功能模块覆盖。
总的来说,这是一个在正确赛道(AI+3D内容生成)上、技术出身团队的一次敏捷验证。它亮出了“让每个人都能跳舞”的愿景,但现阶段提供的,更多是一面映射音乐节奏的“舞蹈哈哈镜”。
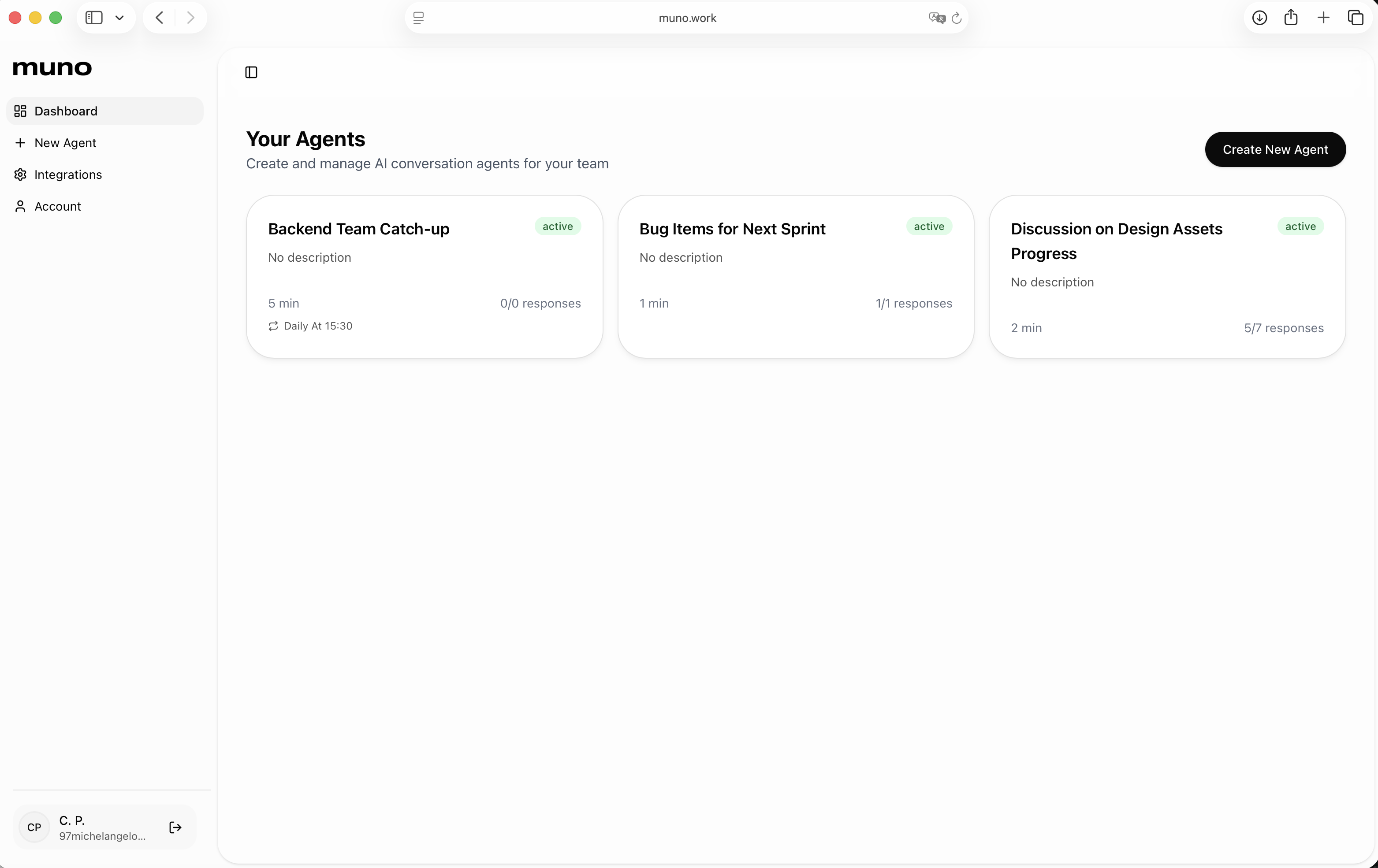
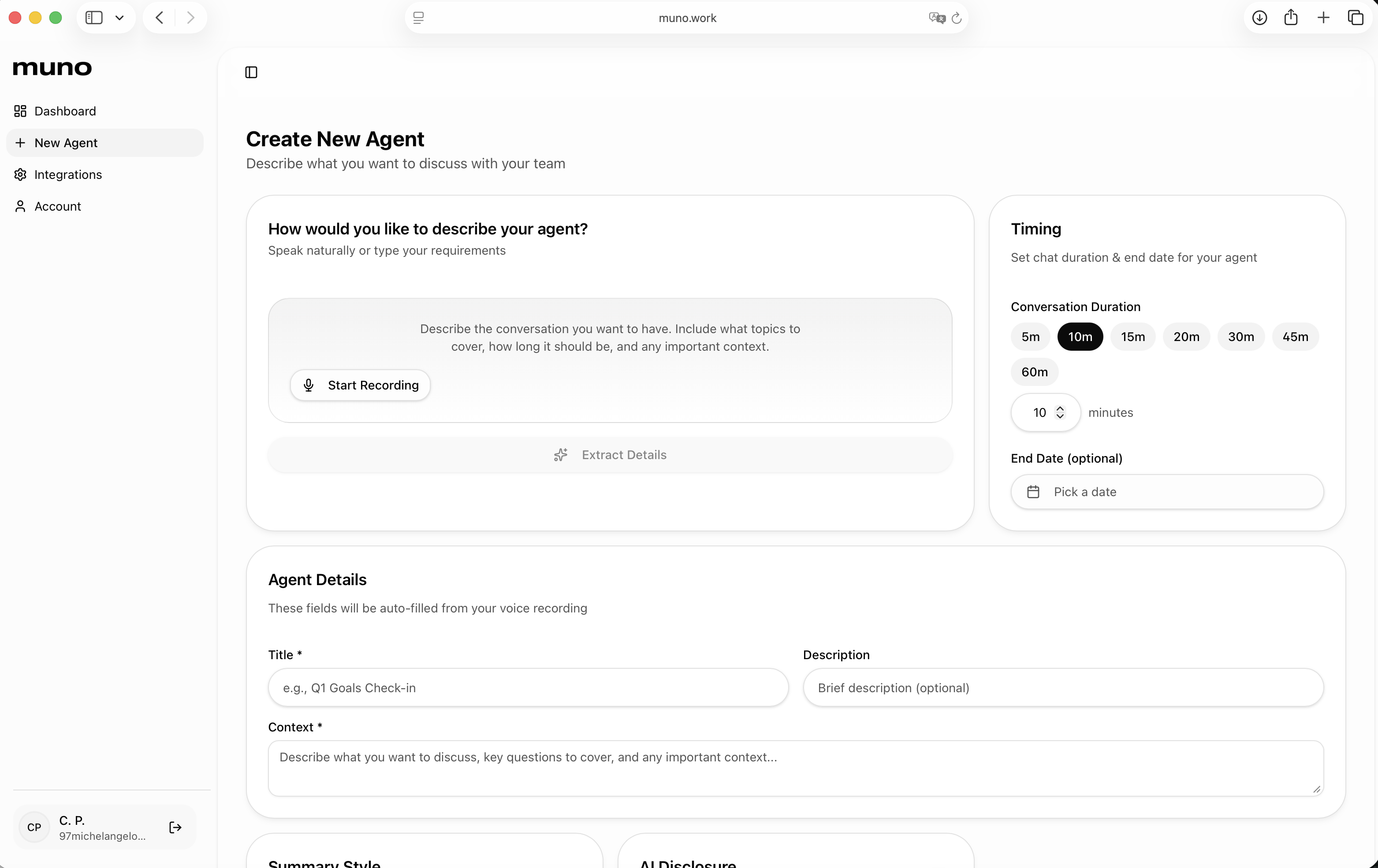
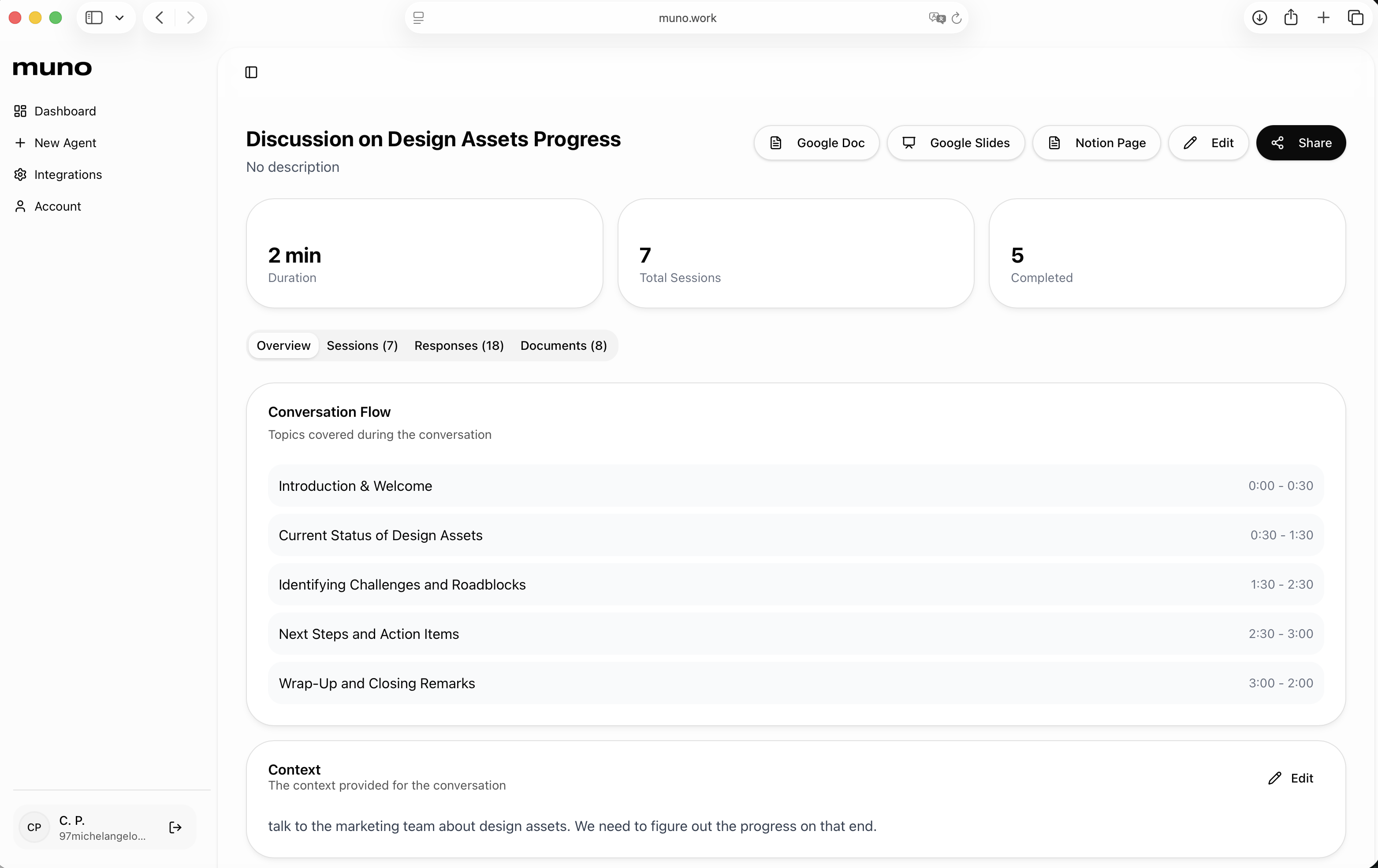
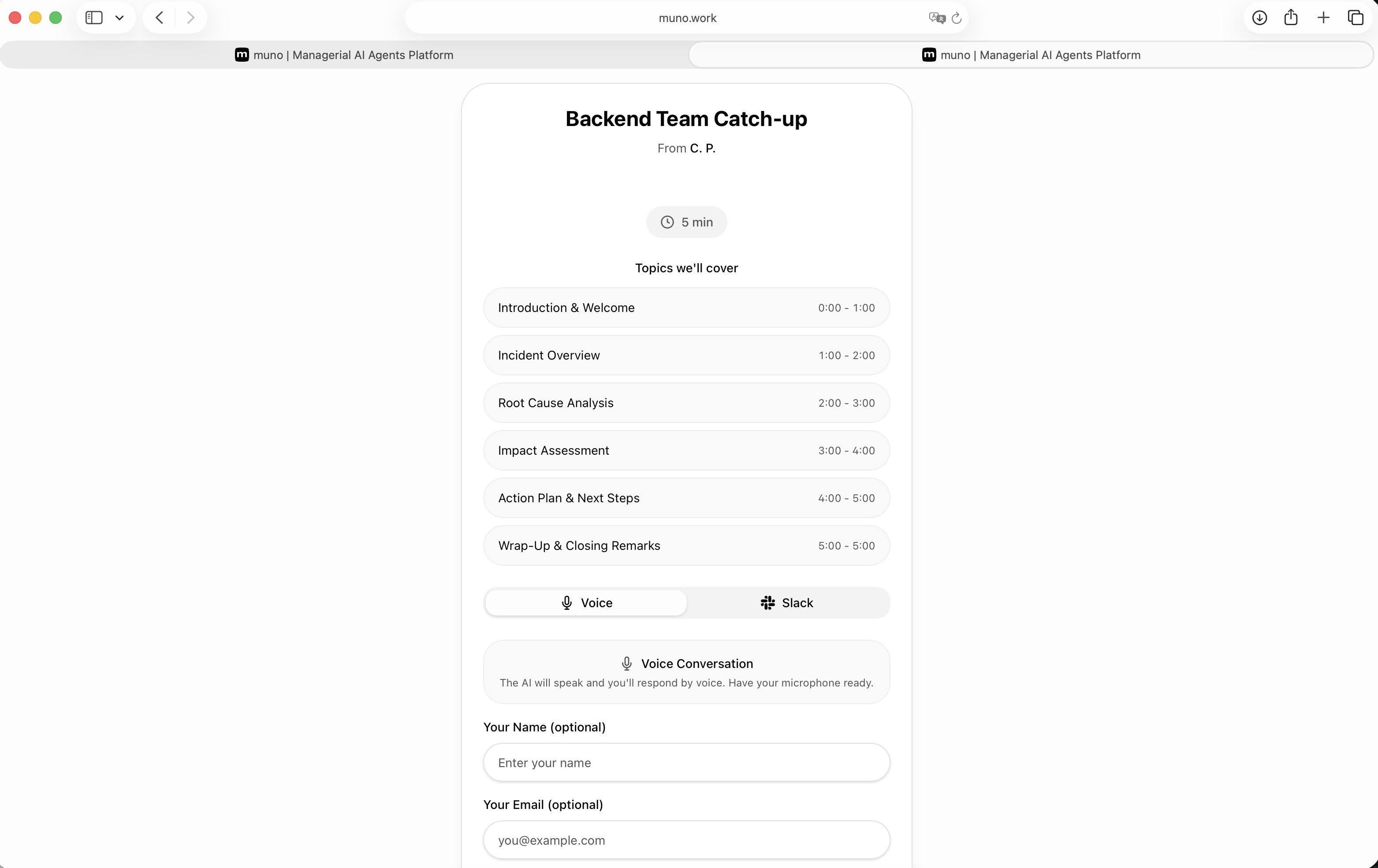
一句话介绍:muno是一款创建AI代理的SaaS工具,其核心功能是让AI代理代替管理者与团队或用户进行语音对话,自动生成会议洞察文档并联动项目看板更新任务状态,旨在解决管理者在进度追踪和会议沟通上耗时过多的痛点。
Productivity
Task Management
Artificial Intelligence
AI智能体
语音对话代理
自动化会议
工作流自动化
项目管理集成
团队协作
SaaS
生产力工具
会议摘要
用户评论摘要:用户普遍对产品解决管理痛点的定位感到兴奋。有效反馈包括:询问多代理间协作可能性、期待小团队试用、认可其在根因分析和规划中的价值、询问韩语支持,以及将其与Claude等竞品对比。回复确认将支持多语言,并强调了其“代理代开会”和会后自动执行任务的独特优势。
AI 锐评
muno的野心不在于做一个更聪明的聊天机器人,而在于试图成为组织内的一个“自动化中层”。它切入的并非泛化的知识工作,而是管理者身上最具体、最重复且高成本的“沟通债”——进度同步会。其真正价值在于将“信息获取-分析整理-任务推动”这一管理闭环自动化。
产品介绍中“move tickets”一词是关键。这意味其AI代理被设计为具有“执行权”,能直接操作Jira、Asana等系统。这使其从被动记录的分析工具,跃升为主动参与工作流的智能体。风险与价值并存:价值在于极大压缩从沟通到行动的延迟,提升组织流速;风险则在于将系统权限赋予AI所带来的准确性与安全性挑战,这需要极高的可靠性背书。
从评论中的对比提问可以看出,市场正在区分“AI工作空间”和“AI同事”。muno显然属于后者。它不回答“这个任务怎么做”,而是直接帮你“催办并更新了这个任务的状态”。这种定位使其必须深度集成业务系统,建立比通用AI更深的上下文和业务逻辑理解,这也是其主要的竞争壁垒。然而,其场景目前看来相对垂直,能否从“管理者的语音机器人”扩展到更广泛的异步协作枢纽,将决定其天花板。当前版本像一个精准的“痛点止痛药”,但药效的持久性和副作用(如人际沟通的进一步弱化),还需在更复杂的组织实践中观察。
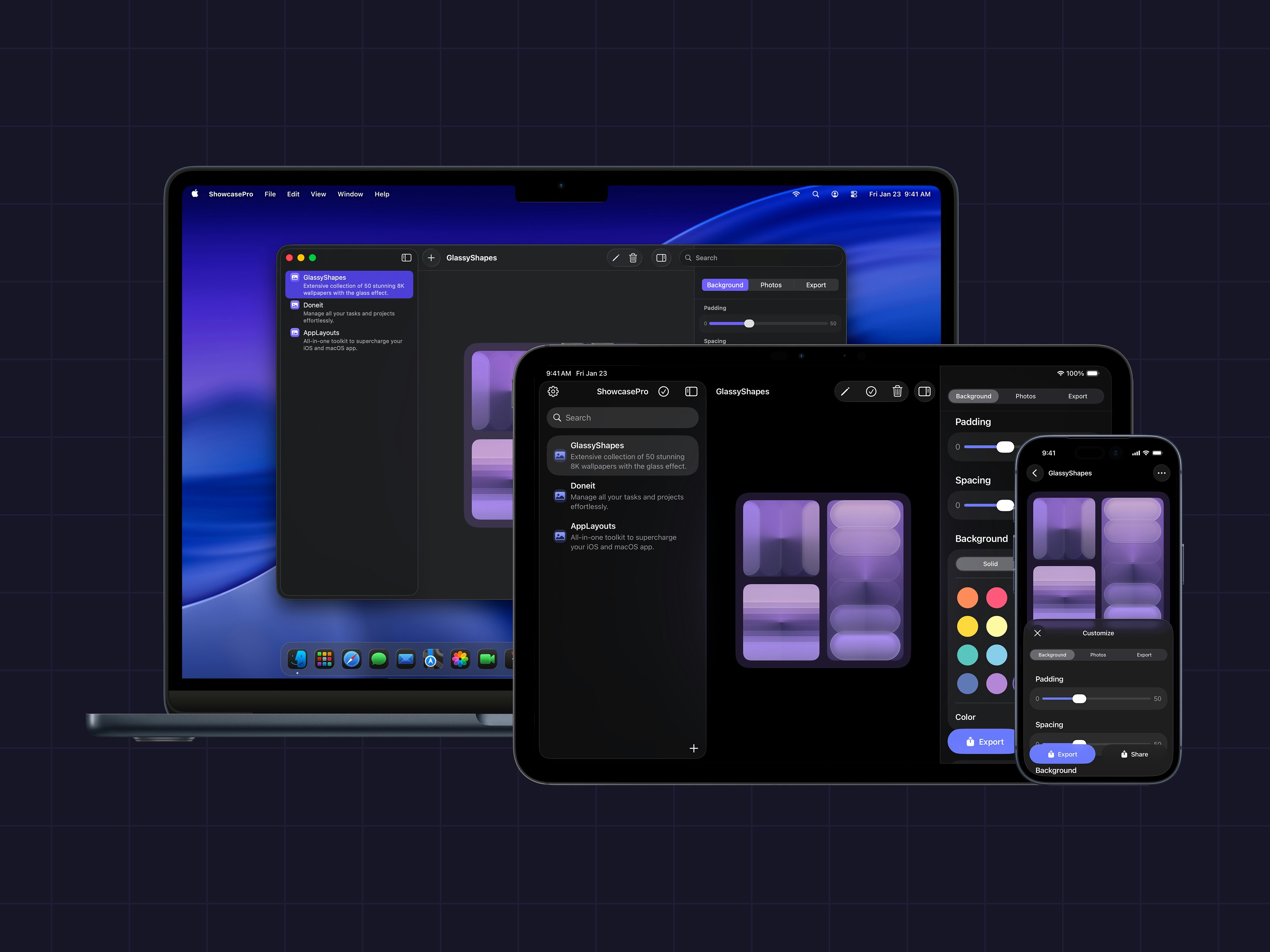
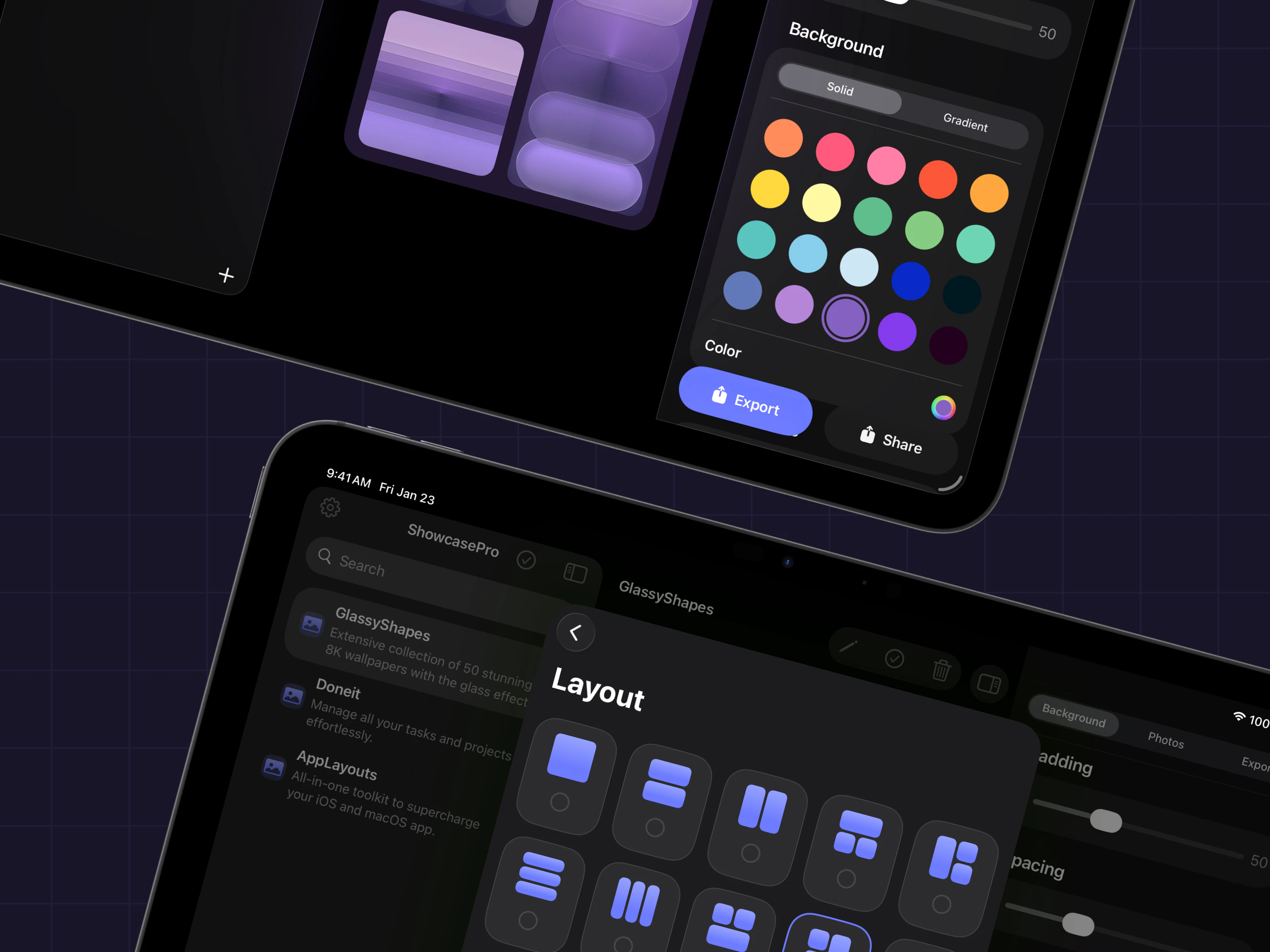
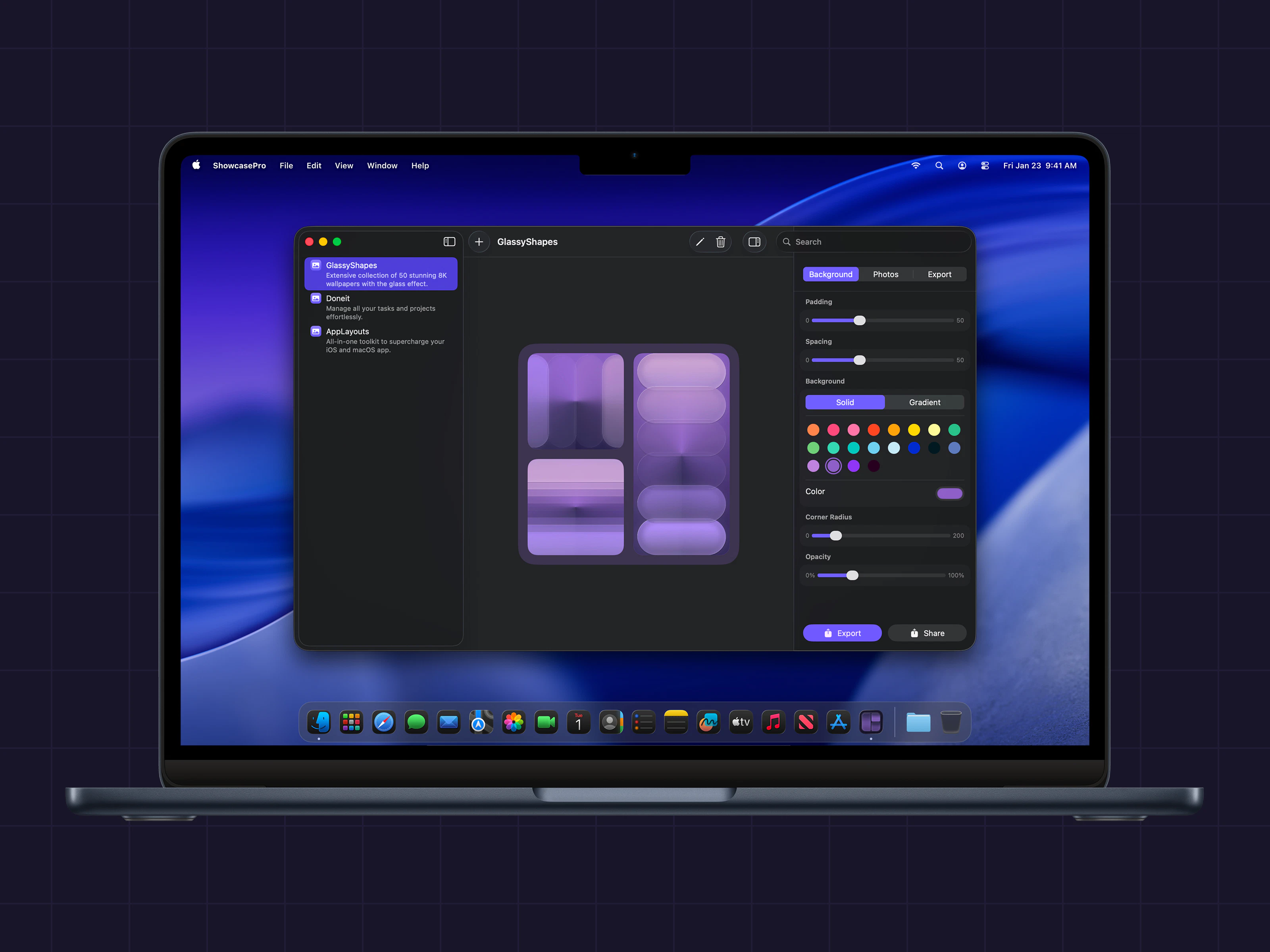
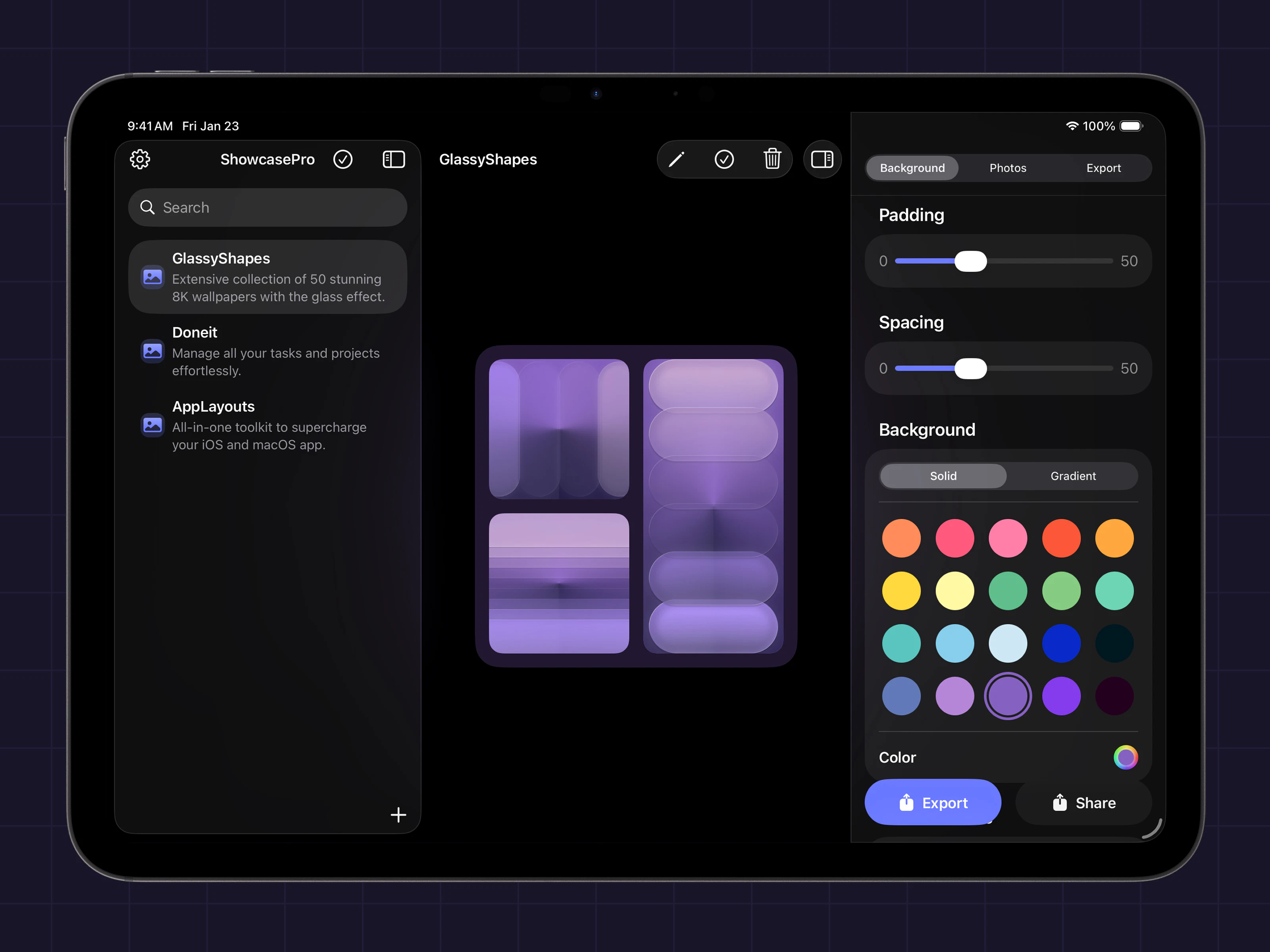
一句话介绍:ShowcasePro是一款将多张照片快速合成为可高度自定义的精美展示图的拼贴应用,解决了用户在社交媒体营销和个人分享中缺乏高效、专业设计工具的痛点。
iOS
Mac
Graphics & Design
图片拼贴
照片编辑
设计工具
营销素材
社交媒体内容
个性化定制
模板布局
一键分享
用户评论摘要:官方评论主要为产品介绍与更新邀约。有效用户评论仅一条,表达了“非常有用”的积极肯定,但未提出具体问题或功能建议。整体缺乏深度反馈。
AI 锐评
ShowcasePro切入了一个拥挤但需求明确的市场:轻量化、模板化的视觉设计工具。其价值并非技术创新,而在于对成熟需求的精准封装。产品将“多图排版-自定义装饰-导出分享”这一工作流极致简化,瞄准的是中小商家、自媒体运营者等非专业设计师群体,他们需要快速产出美观、统一的营销图片,但无法或不愿使用复杂的专业软件。
然而,其面临的挑战同样清晰。首先,功能层面与Canva、Photoshop Express等成熟产品的部分功能高度重叠,差异化优势仅在于更聚焦于“多图展示”这一垂直场景,护城河并不深。其次,从Product Hunt上寥寥的互动来看,产品可能尚未触及核心痛点或引爆市场兴趣。唯一的用户评论虽正面却空洞,反映出产品可能仍处于早期验证阶段,缺乏来自真实场景的深度反馈。
真正的考验在于,它能否从“又一款拼贴应用”升级为“内容创作者的工作流节点”。这需要它在个性化定制上做到更智能(如AI辅助构图、品牌元素一键套用),或与营销平台、电商后台深度集成,实现“设计-发布-分析”的闭环。目前来看,ShowcasePro提供了一个合格的最小化可行产品,但要想在红海中突围,必须在后续迭代中展现出更深刻的用户洞察和生态构建能力,否则极易被功能更全面的平台级应用覆盖。
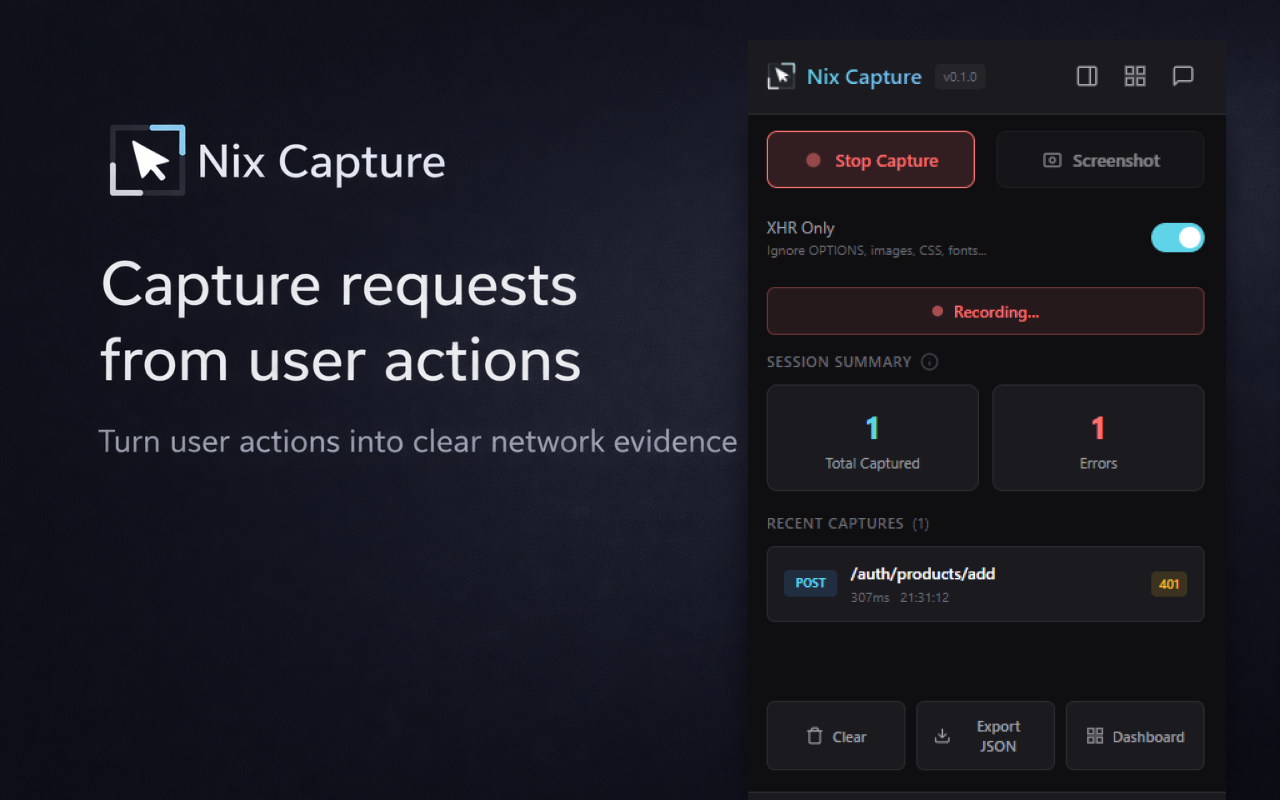
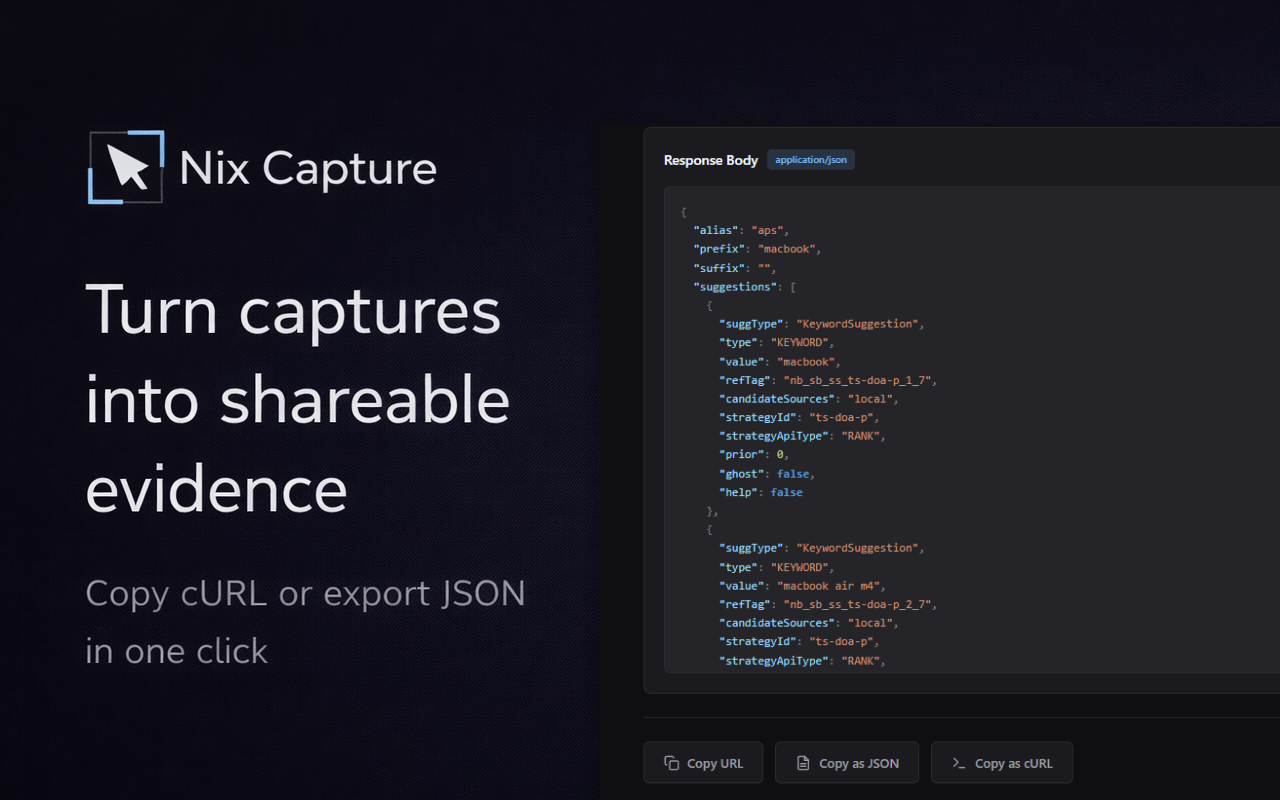
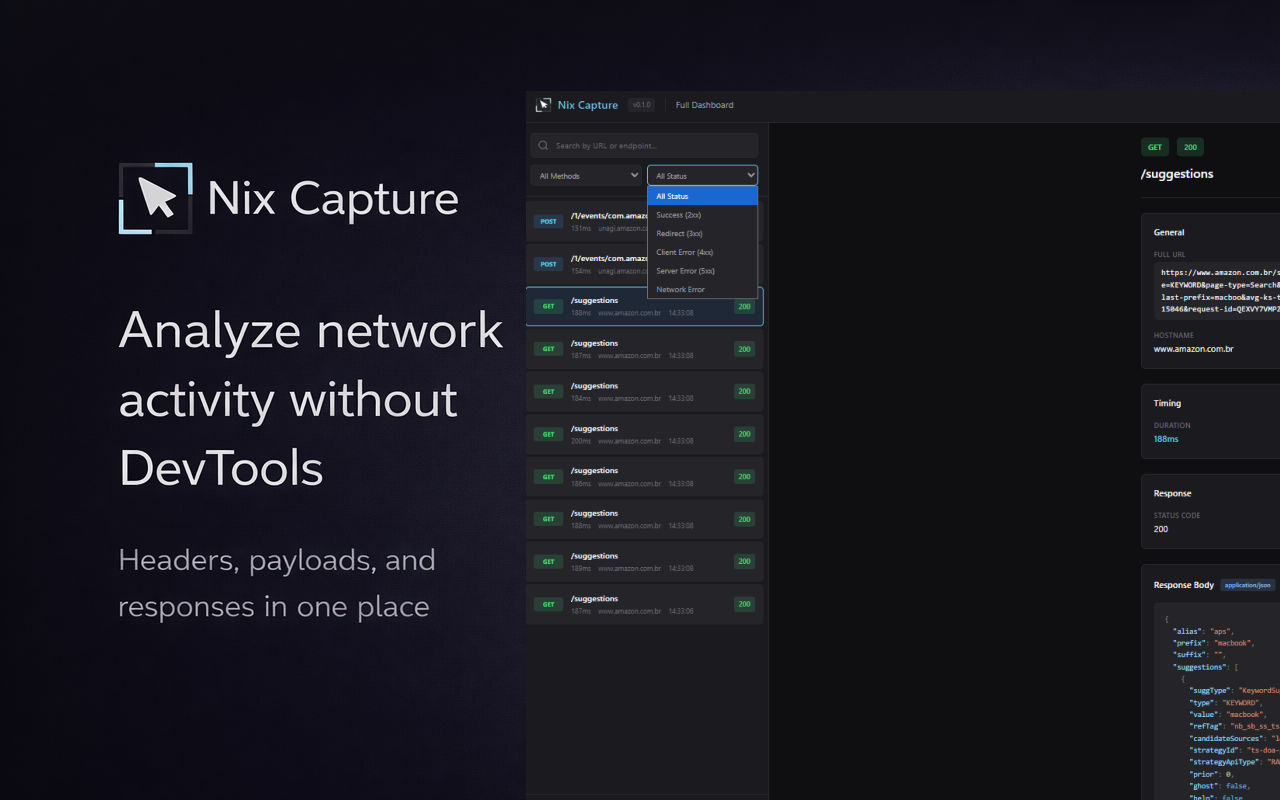
一句话介绍:Nix Capture是一款Chrome扩展,能让QA、支持和产品团队在复现问题时,无需打开开发者工具即可一键捕获网络请求上下文,解决了非技术成员提交Bug报告时缺乏关键接口信息的核心痛点。
Chrome Extensions
SaaS
Developer Tools
开发者工具辅助
Bug报告工具
网络请求捕获
QA工具
技术支持工具
产品管理
Chrome扩展
效率工具
团队协作
用户评论摘要:用户普遍认可其解决“Bug报告缺乏上下文”痛点的价值。主要反馈集中在数据安全性(如自动脱敏认证令牌)、适用场景扩展(如外部用户使用),以及对权限申请和Chrome商店审核流程的关切。
AI 锐评
Nix Capture精准切入了一个长期存在且被默认为“流程成本”的缝隙市场:技术与非技术团队之间的信息断层。它的真正价值并非技术创新,而在于流程重构——将需要专业知识的“主动提取”动作,转化为无感知的“被动记录”行为。
产品定位看似谦卑(“不取代DevTools”),实则精明。它避开了与专业调试工具的正面竞争,转而充当一个“翻译器”和“降低摩擦”的管道。其核心用户并非工程师,而是工程师的上下游协作方。这一定位使其具备了成为团队基础流程插件的潜力,价值体现在缩短无效沟通的循环周期上。
然而,当前版本暴露了其作为“管道”的核心矛盾:信息完整性与安全性的天然冲突。评论中反复出现的“敏感数据脱敏”问题,直指产品在实用性与合规性之间的平衡难题。捕获所有头信息对调试至关重要,但自动共享则可能引发安全风险。创始人“给予团队可见性和控制权”的回应,目前只是一种折中方案,并未从根本上解决问题。这将是其迈向企业级应用必须跨越的鸿沟。
此外,其发展路径(结构化导出、智能过滤)略显常规。真正的壁垒和增长点或许在于其评论中隐约触及的“外部用户”场景。若能安全、可控地将此能力封装并赋予最终客户,使其能一键提交包含完整上下文的错误报告,则可能从内部协作工具演变为一个影响客户支持体验和产品开发循环的开放平台。这一步风险巨大,但想象空间也同样巨大。目前,它仍是一个优雅地解决了局部问题的效率工具,尚未展现出颠覆性潜力。
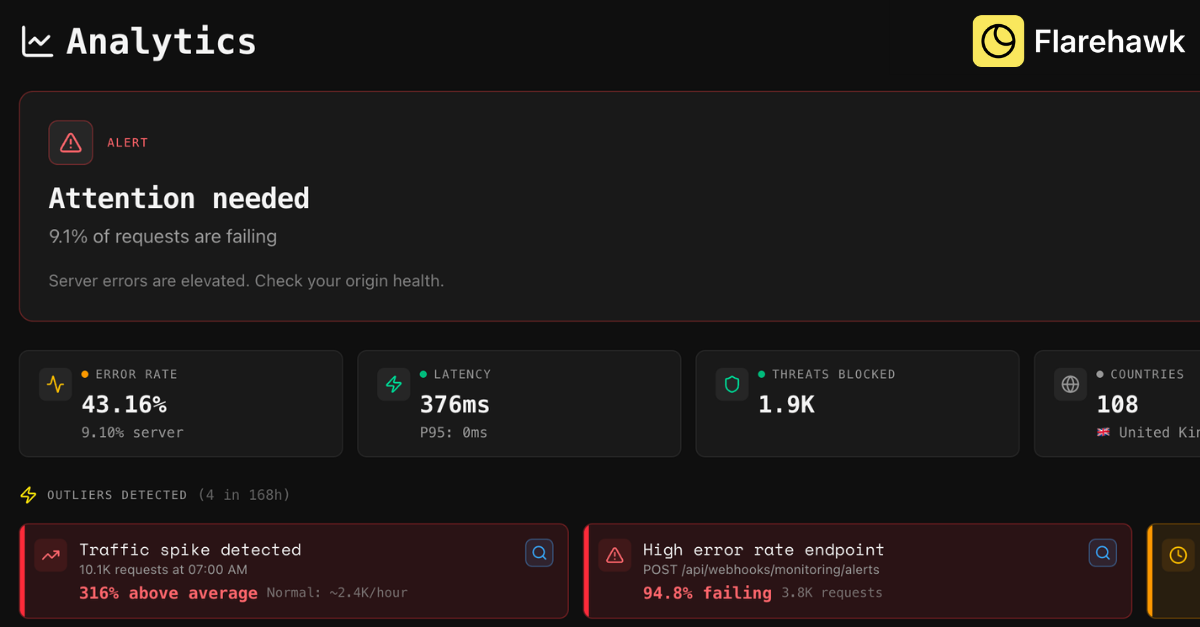
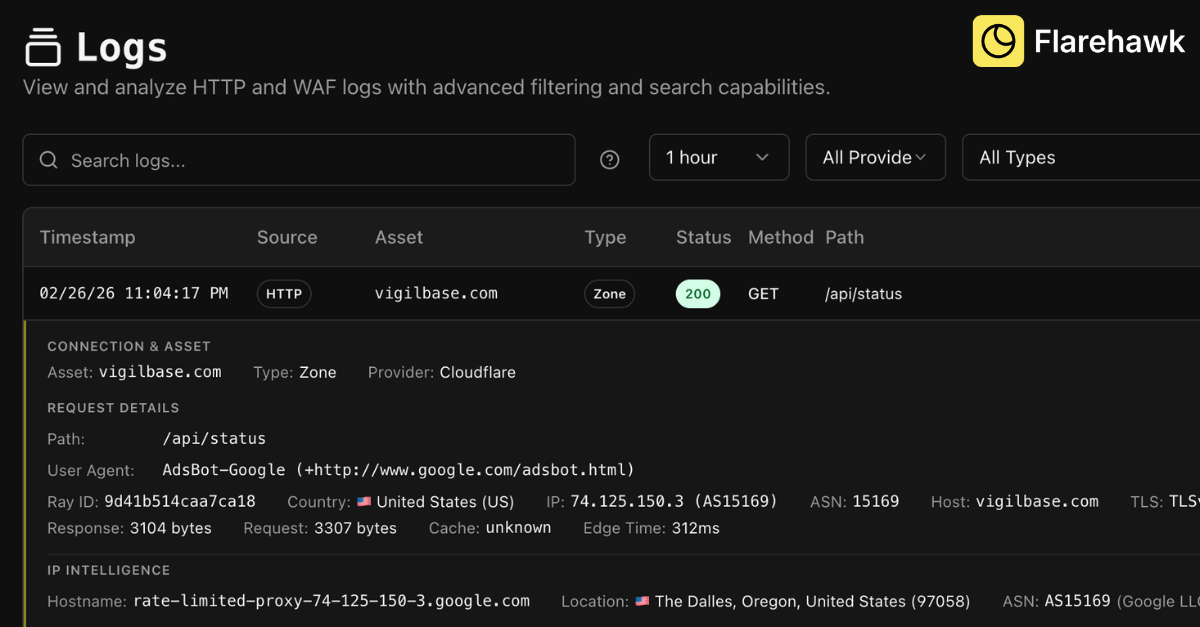
一句话介绍:Flarehawk是一款安全运营AI平台,通过为每个客户构建独立的机器学习模型,在云环境安全监控场景中,自动分析海量告警、调查威胁根源并提供一键修复,有效解决安全团队告警疲劳与响应效率低下的核心痛点。
SaaS
Artificial Intelligence
Security
安全运营
AI威胁检测
自动化调查与响应
云安全
机器学习
日志分析
告警疲劳
Cloudflare
SOAR
安全基线
用户评论摘要:用户反馈聚焦于产品核心创新点(每租户独立ML模型)的价值与落地细节。主要问题/建议包括:1. 询问除日志分析外是否支持监控指标;2. 关注模型建立可靠基线的所需时间(“预热期”)。开发团队积极回应,透露了即将支持更多数据源和功能(自定义监控仪表盘)的路线图。
AI 锐评
Flarehawk的叙事直指安全运营(SecOps)最顽固的“脓包”:告警疲劳。其宣称的“每租户专属ML模型”(Flarehawk Fabric)是产品真正的技术棱角,意在将安全分析从基于通用规则的“广谱抗生素”时代,推向基于个体环境基线的“靶向治疗”时代。这并非新概念,但将其作为核心交付物并承诺“无采样”的全量日志分析,意味着其试图构建的护城河是深度、个性化的上下文理解能力,而非单纯的检测规则库。
然而,其锋芒之下暗藏挑战。首先,从Cloudflare Enterprise切入虽精准捕获高价值种子用户,但也将自身初期发展与单一生态深度绑定,后续扩展至多云、混合环境的数据 ingestion 与模型泛化能力将是关键考验。其次,评论中关于“模型预热时间”的提问触及了产品体验的阿喀琉斯之踵——模型在初始“盲区”阶段的判断可靠性,以及用户对这段“黑盒”学习期的信任度,将直接影响 onboarding 体验。团队回复的“15分钟到1小时”是一个乐观的技术指标,但实际效能需在复杂、异构的真实企业环境中验证。
本质上,Flarehawk 的价值主张是成为安全团队的“AI副驾驶”,将分析师从“筛选告警”的体力劳动提升至“决策与行动”的智力层面。其宣称的“一键修复”是这一价值的终极体现,但也伴随着最高的风险与责任。产品能否成功,不仅取决于其ML模型检测的准度,更取决于其行动建议的精度与可解释性——在安全领域,一个错误的自动化修复可能意味着业务中断。因此,在“自动化”的炫目光环下,其控制粒度、复核机制与归因能力的扎实程度,才是决定其能否从“有趣的实验”蜕变为“可信赖的平台”的关键。目前其处于公开测试阶段,路线图中透露的更多数据源连接和自定义仪表盘功能,显示其正朝着更开放的SecOps平台演进,这是一个正确的方向。
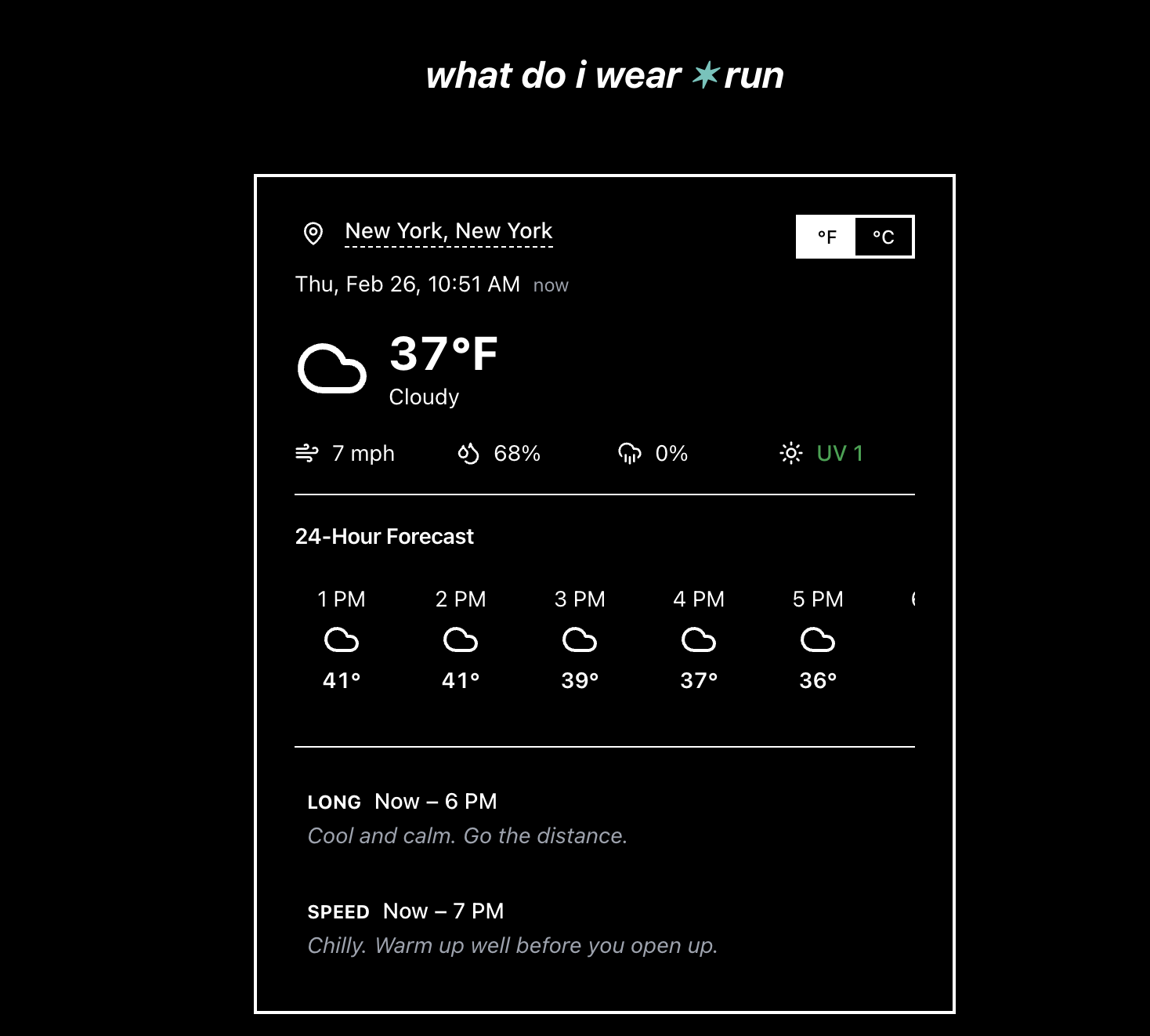
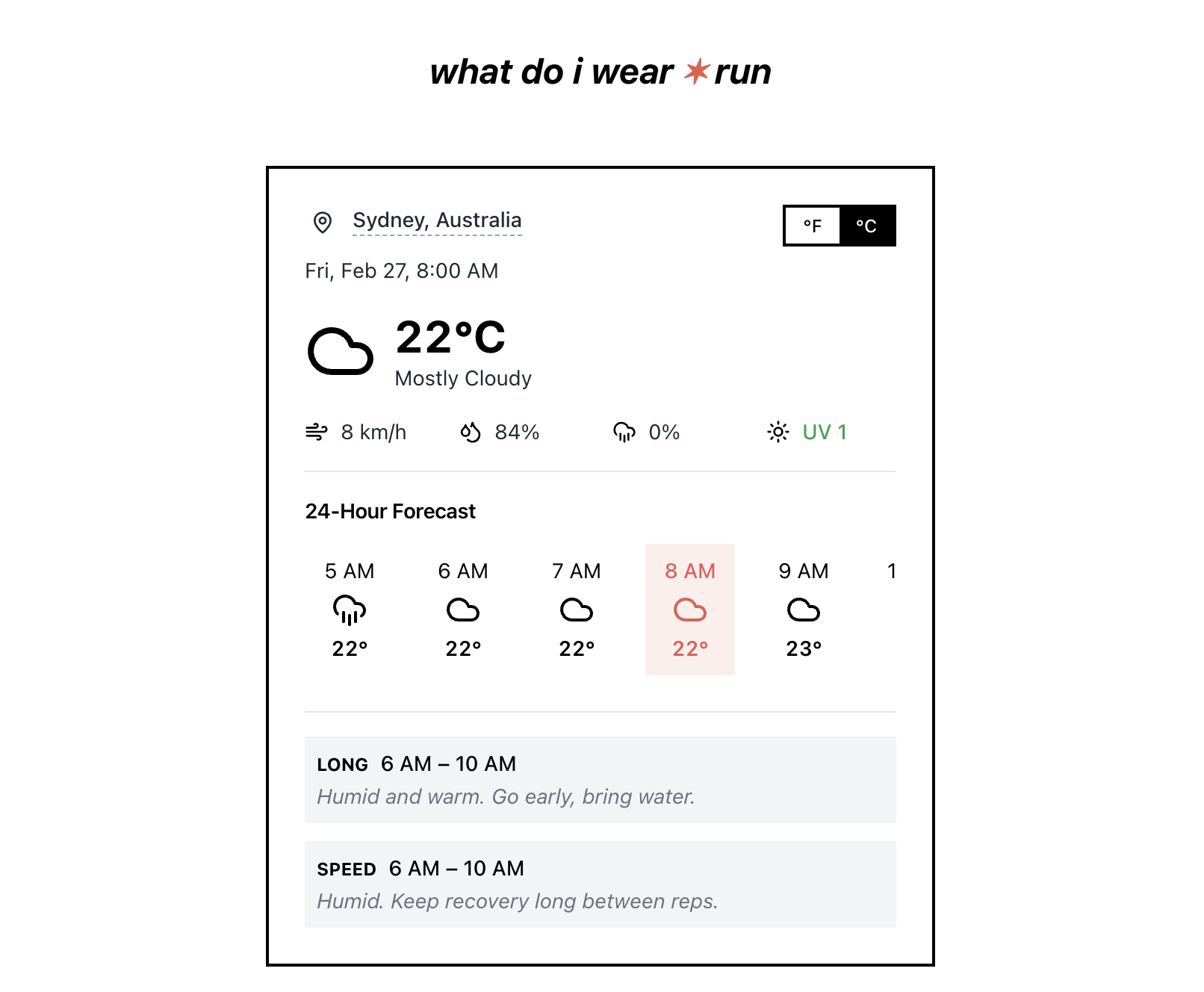
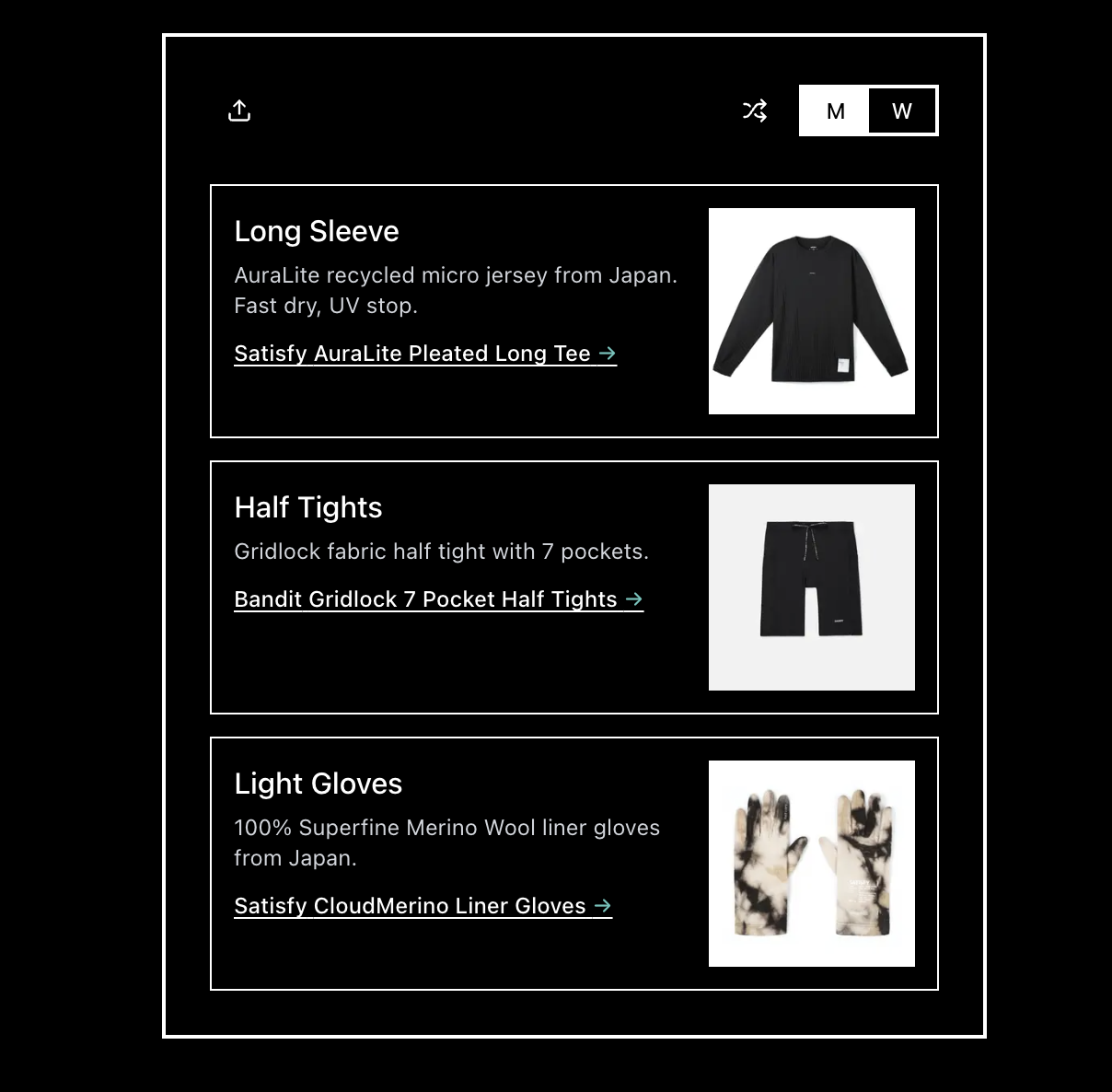
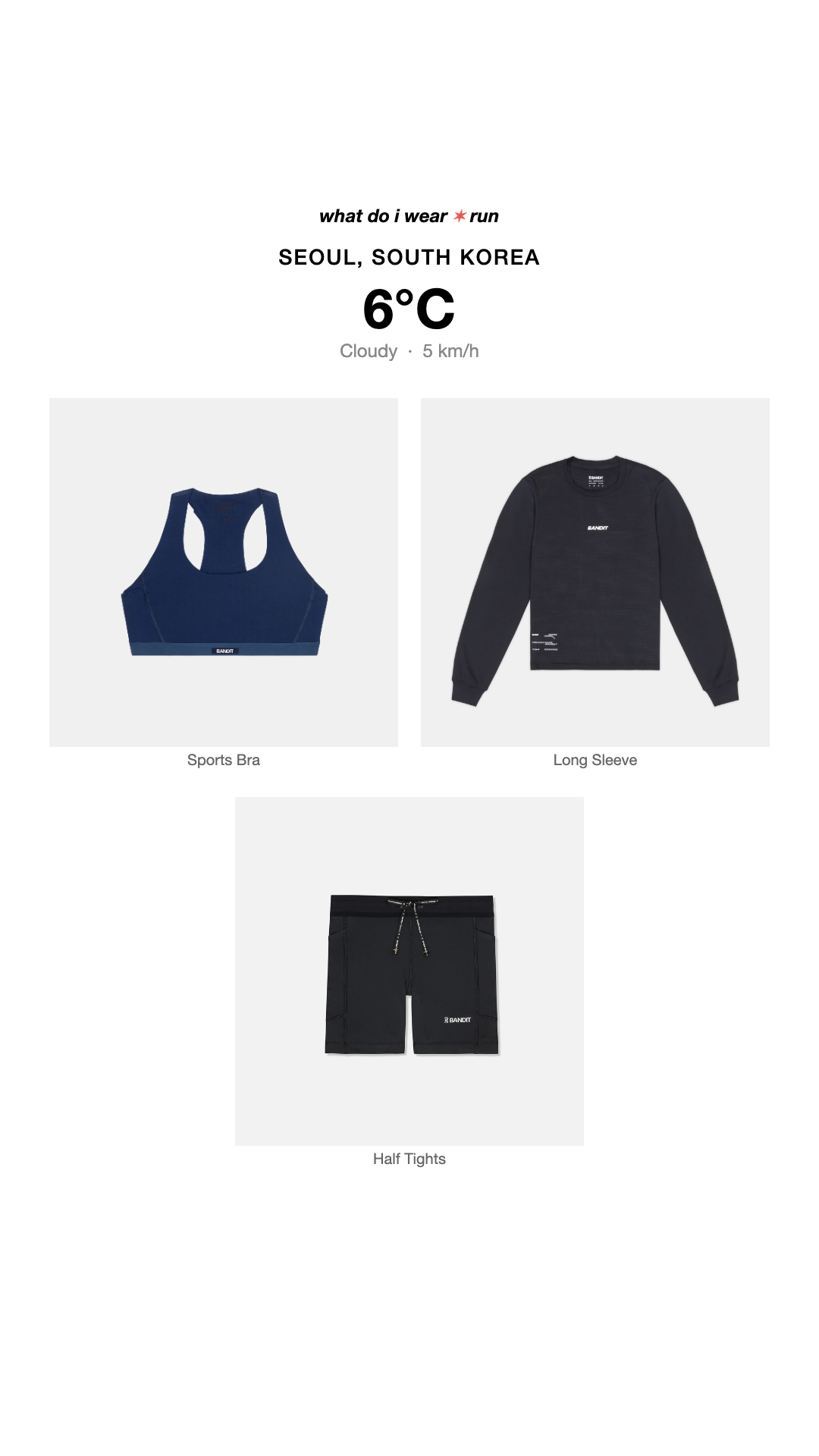
一句话介绍:一款基于实时天气的跑步着装推荐引擎,为全球跑者在任何天气条件下提供来自Satisfy、On和Bandit等先锋品牌的装备搭配方案,解决跑步前“穿什么”的决策痛点。
Fashion
Weather
Running
跑步装备
天气应用
着装推荐
运动科技
生活方式
品牌导购
跑步社区
移动优先
个性化建议
用户评论摘要:用户肯定其填补了现代跑步着装推荐App的市场空白,对比了旧有产品,赞赏其移动优先、PWA、分享等体验。核心问题聚焦于AI推荐的数据依据。开发者回复显示,未来可能扩展至鞋履、装备、营养建议,并加入聊天界面,向“一站式跑步助手”演进。
AI 锐评
whatdoiwear.run 表面上是“天气跑步引擎”,实则是先锋跑步品牌(Satisfy, On, Bandit)精心构建的“场景化零售前端”。它将抽象的天气数据转化为具象的品牌商品推荐,完成了从内容工具到消费导流的关键一跃。用户评论中“购物助理”与“性能分层指南”的疑问,恰恰点明了其商业内核与实用外壳的双重属性。
产品价值不在于算法有多深奥,而在于其精准的定位:它没有服务所有运动者,而是锚定了对装备有高认知、高消费意愿的“现代跑者”。这群人追求的不仅是保暖防雨,更是风格表达与品牌认同。App将复杂的装备知识(如分层系统)打包成即用方案,降低了专业跑步的入门心理门槛,但最终落点很可能是引导至合作品牌的购买页面。
从开发者回复看,其野心远不止于着装。规划中的鞋履、配件、营养推荐及聊天界面,暴露了其构建“跑步垂直领域生态闭环”的意图。风险在于,当推荐范围从核心着装无限扩展时,可能稀释其专业性与简洁体验,沦为又一个泛泛的“运动建议平台”。此外,其推荐算法若完全依赖合作品牌库而非全市场数据,其中立性与客观性将始终存疑。本质上,这是一次成功的品牌联盟营销实验,其长期成功取决于如何在提供真实价值和促进品牌销售之间维持微妙的、不被用户反感的平衡。
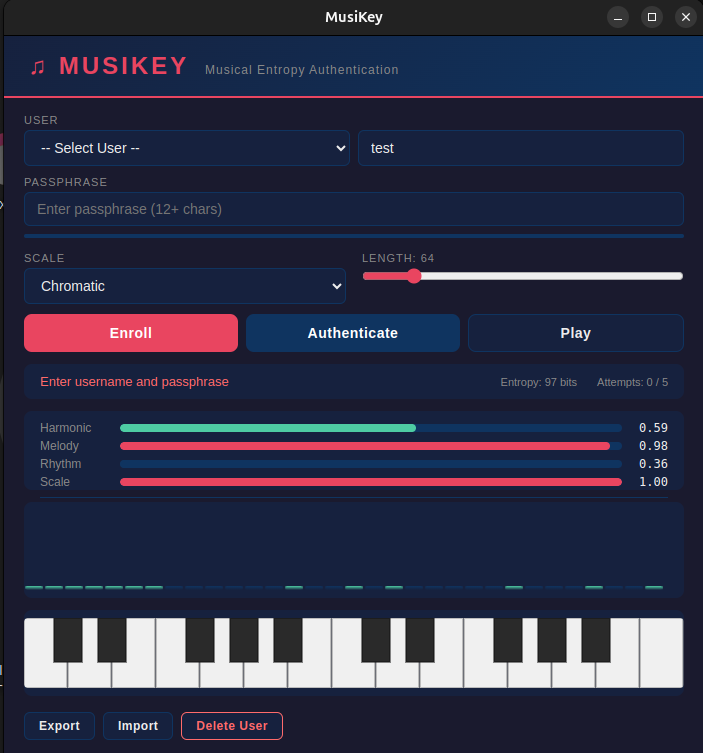
一句话介绍:一款用随机生成的加密音乐旋律替代传统密码,为身份验证提供高安全性并兼顾可访问性与美感的桌面端认证工具。
Music
Privacy
Security
身份验证
密码替代方案
音乐加密
多因素认证
本地化处理
开源软件
安全工具
辅助功能
创新交互
桌面应用
用户评论摘要:用户肯定其创新性,但指出UI引导不足,功能不直观。开发者回复将改进引导并增加工具提示。有建议推出网页版以降低体验门槛。开发者确认核心加密已支持Web API,网页版演示正在规划中。
AI 锐评
MusiKey 试图在“安全”这个理性至上的领域,引入“艺术”这个感性变量,其“音乐熵认证”的概念在技术层面是一次炫技式的缝合:它将密码学标准(PBKDF2、Argon2id、AES-256-GCM、ECDSA)与音乐理论(和声、旋律、节奏)强行耦合,生成所谓“可听、可识别”的密钥。其宣称的价值在于提升可访问性——用旋律记忆替代字符记忆,并为感官验证(听音、看视觉指纹)提供了可能。
然而,其核心矛盾在于将认证的“可用性”复杂化而非简化。记住一个固定密码或使用生物识别是直接的,而MusiKey要求用户记忆一个“通行短语”来解密并验证一段随机生成的音乐模式,这实际上增加了一个认知转换层。其真正的用户画像或许并非普通大众,而是极客、音乐技术爱好者或对现有认证范式有哲学性不满的人。产品目前更像一个严谨的“概念验证”,证明了音乐结构可承载高熵值,但距离成为解决“密码疲劳”的普及方案,还有巨大鸿沟。
它的亮点在于彻底的本地化、开源和自毁机制,这在隐私敏感场景下有吸引力。但作为认证工具,其生态位尴尬:个人用户嫌其繁琐;企业级应用则难以整合并审计其非标协议。它更像一个启发性的“艺术装置”,揭示了安全与人性化交互之间的张力,但其技术路径的实用性,仍需经受真实场景的残酷检验。
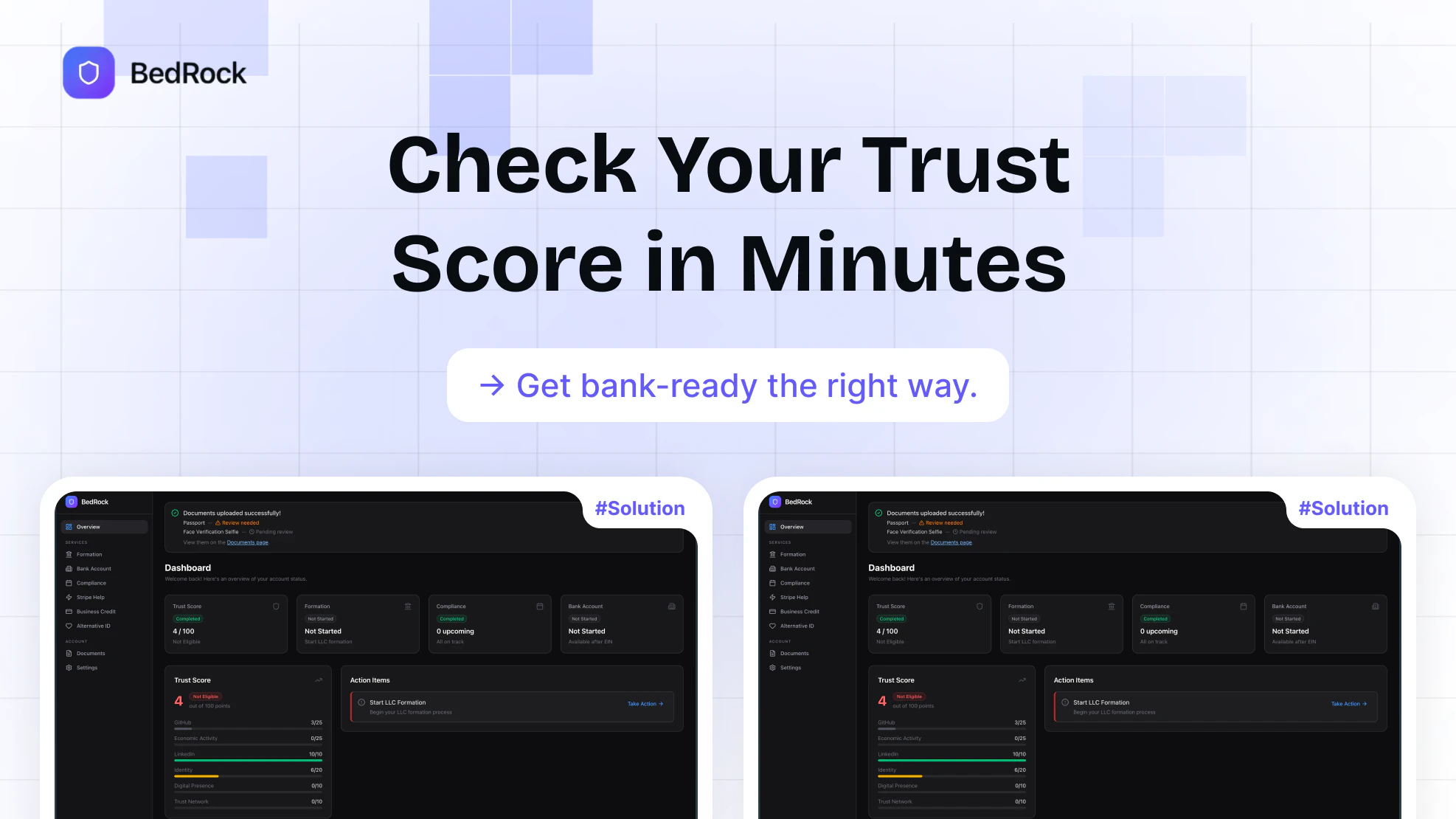
一句话介绍:BedRock通过分析创始人的数字轨迹(如Git代码提交、Stripe交易记录等)生成可信度评分,帮助因地域限制被美国银行拒绝的跨境创业者提升开户成功率。
Fintech
Payments
GitHub
Banking
金融科技
跨境银行服务
数字身份验证
可信度评分
反欺诈
合规自动化
创业者服务
替代数据
银行基础设施
地缘金融包容
用户评论摘要:用户普遍赞赏其“亲身经历痛点而诞生”的创始人故事和数据驱动的验证理念。主要问题集中在具体操作层面:如何与银行整合、如何评估被拒用户的财务画像,以及用户在被某家银行拒绝后如何具体使用该服务。
AI 锐评
BedRock的锋芒,在于它用数字时代的“血统证明”,正面挑战了传统金融基于地理边界的“出身论”。其真正价值并非简单地“帮助开户”,而是试图构建一套基于数字行为数据的、去地域化的信任量化体系。它用GitHub提交和Stripe历史这类难以伪造的持续生产与盈利证据,替代极易造假且静态的护照和自拍,本质上是将“你是谁”的判定,从“你来自哪里”转向了“你做了什么”。
然而,其面临的深层悖论也显而易见。首先,其目标客户是“被拒的合法创业者”,但其核心验证数据(如持续的Stripe收入、活跃的代码库)本身已是成功创业者的标志,这可能导致它最终服务的是那群“差点运气”或“卡在合规门槛”的相对优质群体,而非最底层、最需要帮助的创业者。其次,其商业模式依赖于银行体系对其“信任分”的认可。银行拒绝特定地区客户,成本考量远大于技术障碍。BedRock需要证明,采用其系统所降低的风险与合规成本,足以抵消银行拓展这些“高风险”地区客户带来的潜在麻烦。这不仅是技术整合,更是一场艰难的金融利益重构。
其愿景从“开户楔子”迈向“跨境创始人的银行支付基础设施”显得野心勃勃,但也危机四伏。一旦其评分体系建立权威,它便拥有了定义“可信创始人”标准的话语权。这条路若能走通,将是金融民主化的重要一步;若走不通,则可能仅仅成为现有金融体系中,一个服务于“高级流亡者”的精致工具。
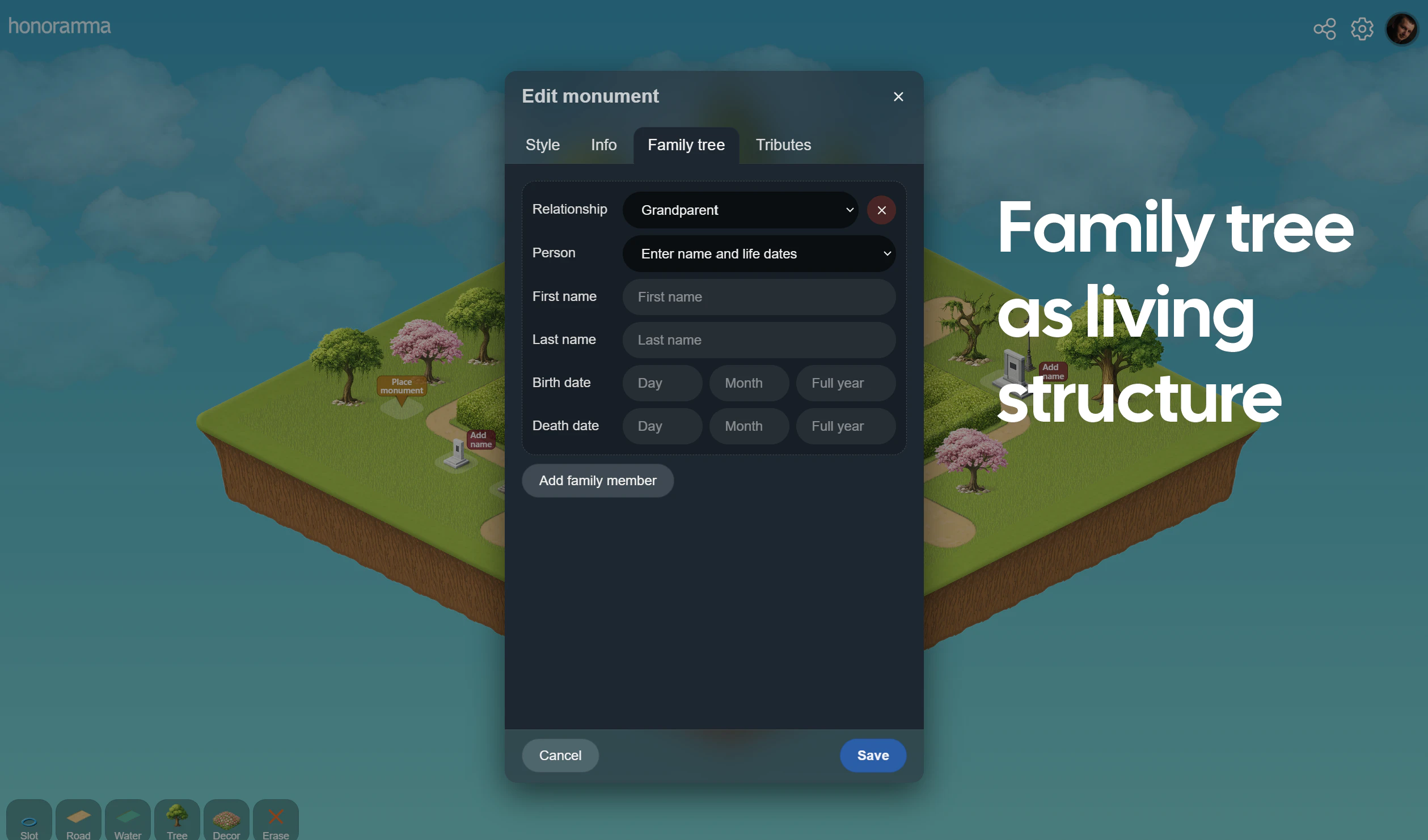
一句话介绍:一款允许用户为家族、历史或任何重要事物创建数字化纪念公园,通过在地图上放置纪念碑来构建永恒记忆世界的平台,旨在为数字时代的纪念与荣誉表达提供专属空间,解决传统社交媒体缺乏庄重纪念氛围的痛点。
Web App
Social Impact
Community
数字纪念
家族历史
虚拟公园
纪念碑
永恒记忆
荣誉表达
共创平台
一次性付费
情感科技
数字遗产
用户评论摘要:用户反馈积极,认为概念怀旧且有趣。主要问题集中在:与家谱网站(如MyHeritage)的差异、防止滥用内容的机制、公园布局锁定原因、纪念碑自定义范围(如宠物)、盈利模式(公园创建者能否从地块销售中获益)以及主题和布局的自定义程度。创始人积极回复,阐释了平台重在“表达荣誉”而非数据整理,并说明了通过锁定地图和审核来维护稳定。
AI 锐评
Honoramma 试图在数字时代构建一个关于“永恒”的悖论性产品。其核心价值并非技术突破,而在于敏锐地捕捉到一个被主流社交平台忽视的情感需求:在信息流之外,提供一个具有空间感、仪式感和稳定性的数字纪念场所。它将“纪念碑”和“公园”的隐喻数字化,用一次付费对抗订阅制下的“记忆风险”,这既是其最大的诚意,也是其商业可持续性的核心赌注。
产品定位巧妙避开了家谱应用的数据工具属性,转而强调“表达”与“荣誉”,这使其更接近情感体验产品。然而,其挑战也同样鲜明:首先,“付费贡献”能否形成稳定现金流支撑“永恒”的服务器与维护成本,需要严峻的财务考验。其次,将情感表达锚定在虚拟地块的购买与布局上,其长期互动性和用户粘性可能面临挑战,容易从“纪念空间”滑向“数字墓地”。最后,内容审核与所有权管理将异常复杂,尤其是涉及生者、历史人物与公共事件时,极易陷入伦理与争议的泥潭。
创始人提及Sam Altman的“糟糕初印象”理论,恰恰点明了该产品的本质:它是一个大胆的社会实验,测试在快速流动的数字世界中,人们是否愿意为一份静止的、需要精心维护的“数字永恒”付费和投入情感。其成败不在于功能多寡,而在于能否在用户心中建立起不可替代的仪式价值和社区共识。












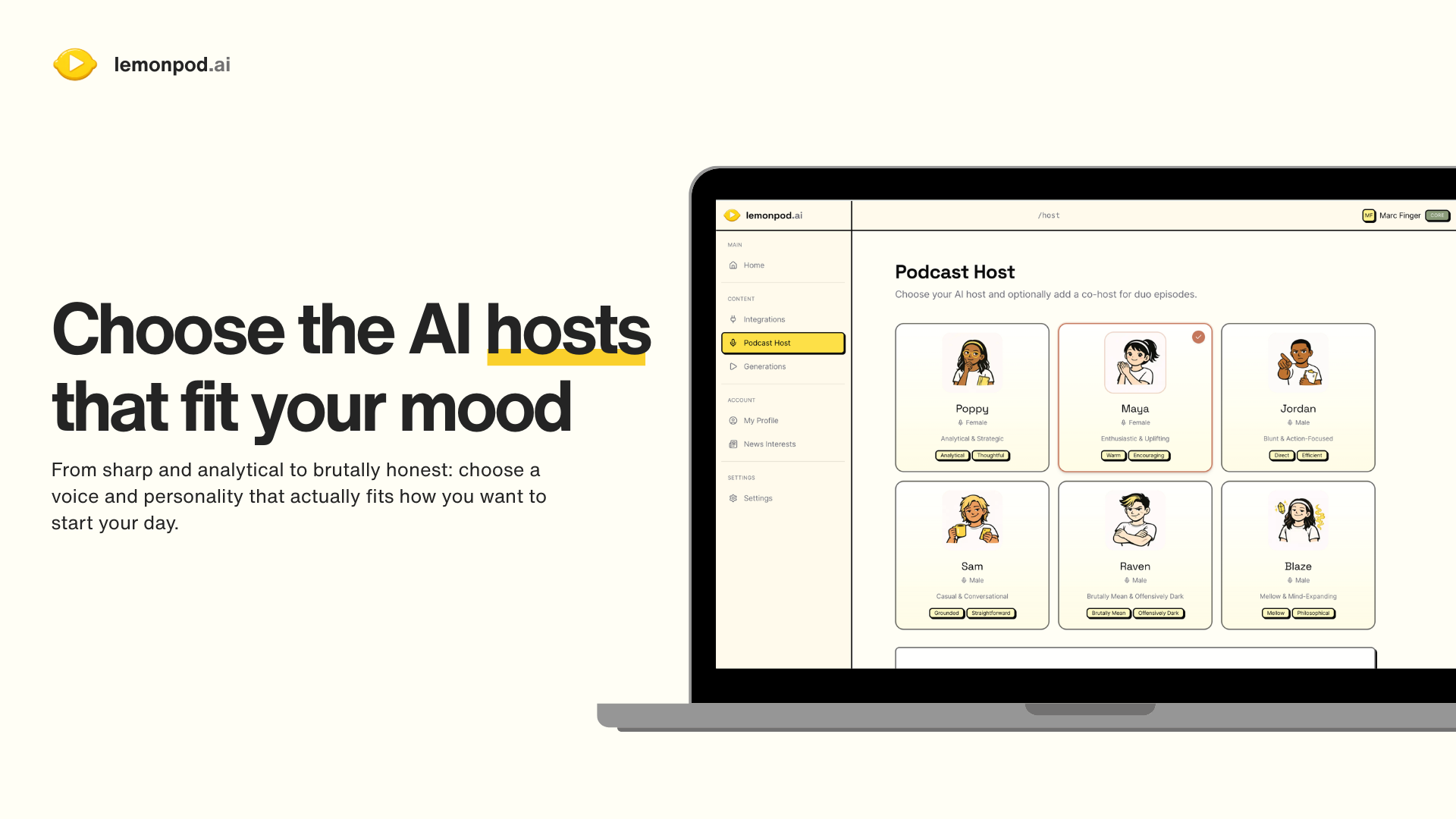




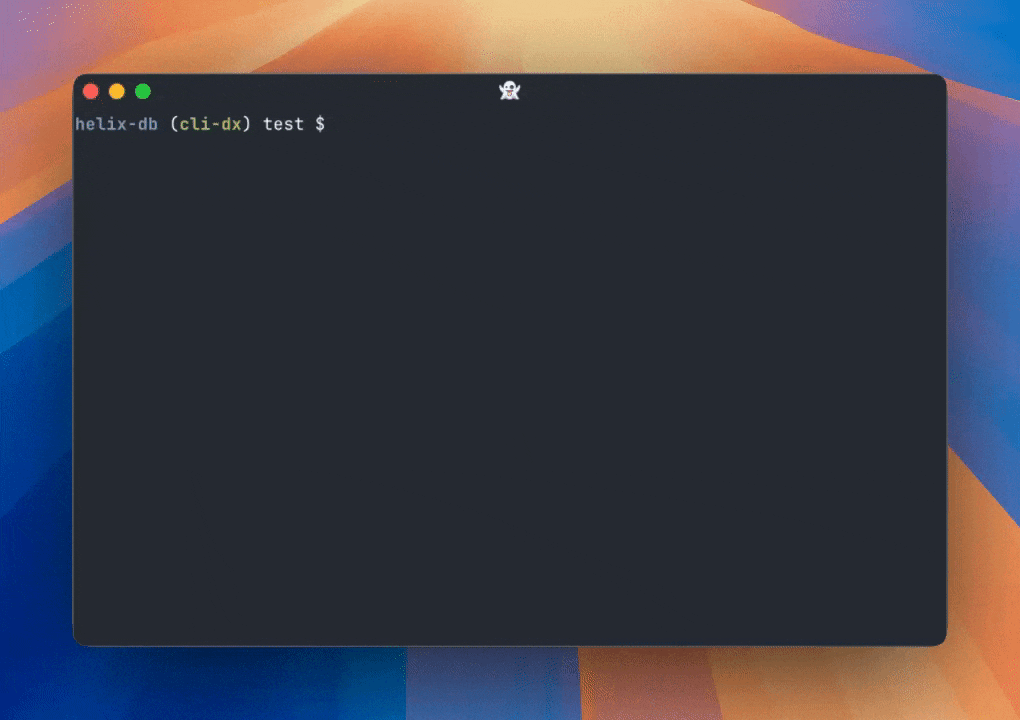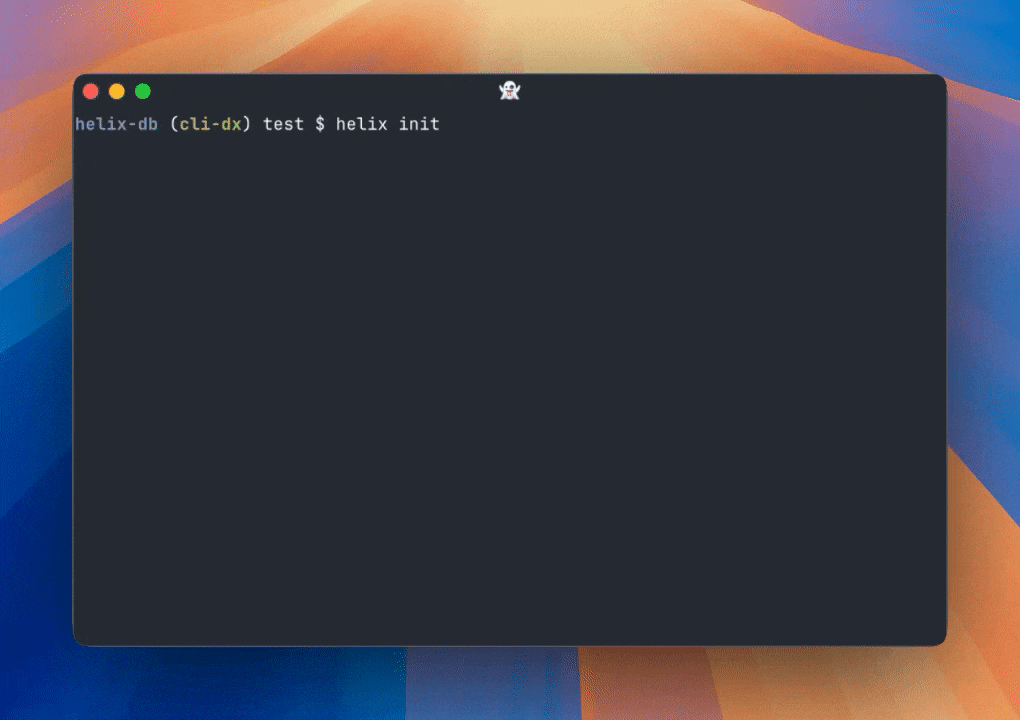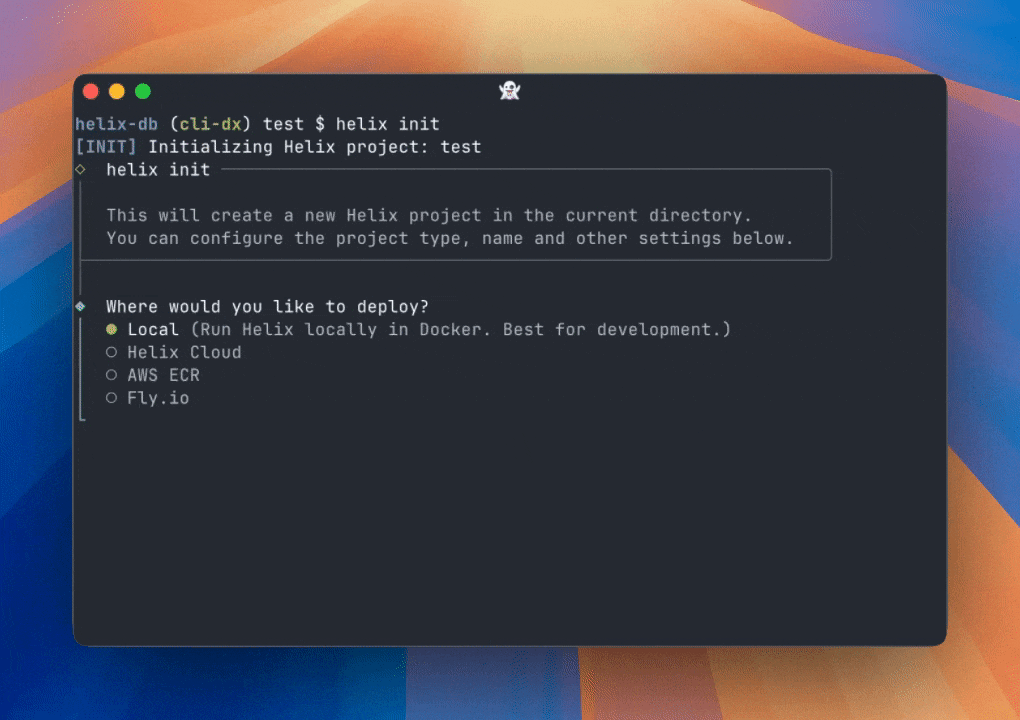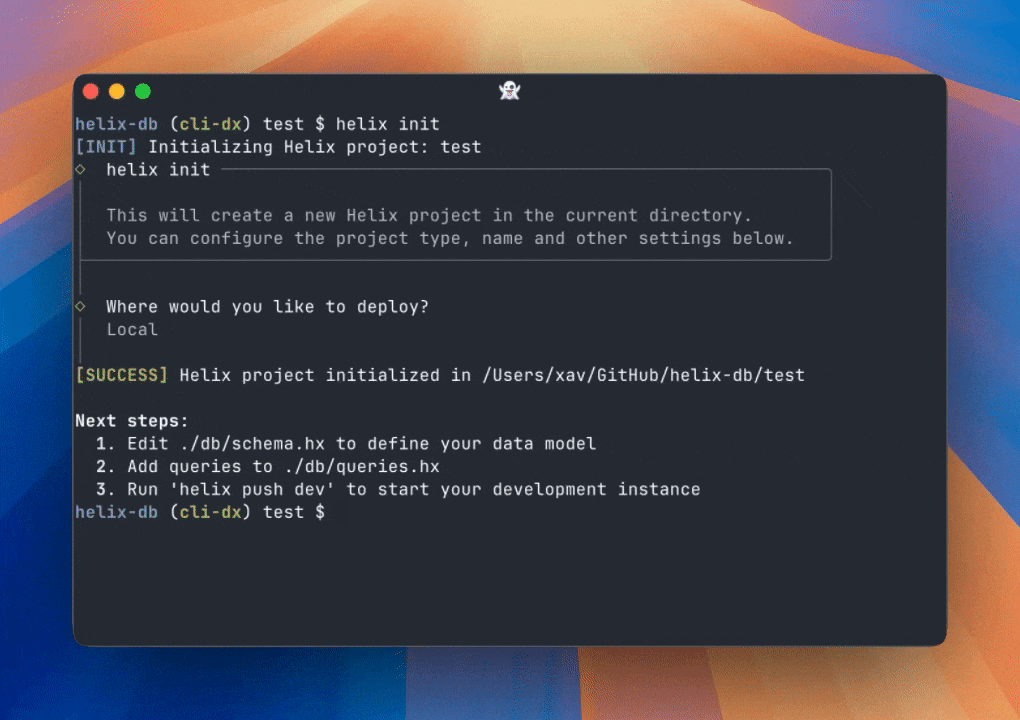
















Hey all,
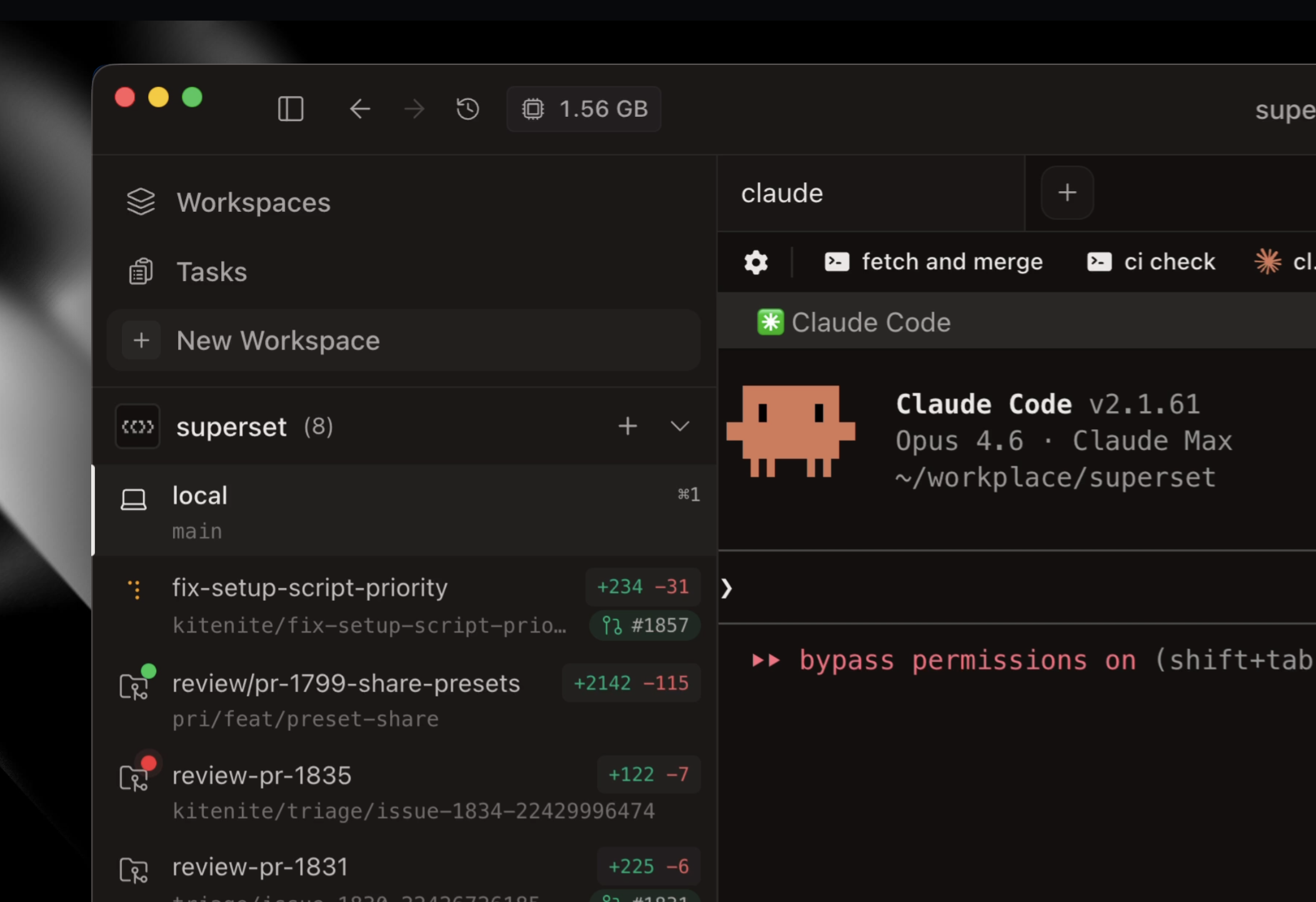
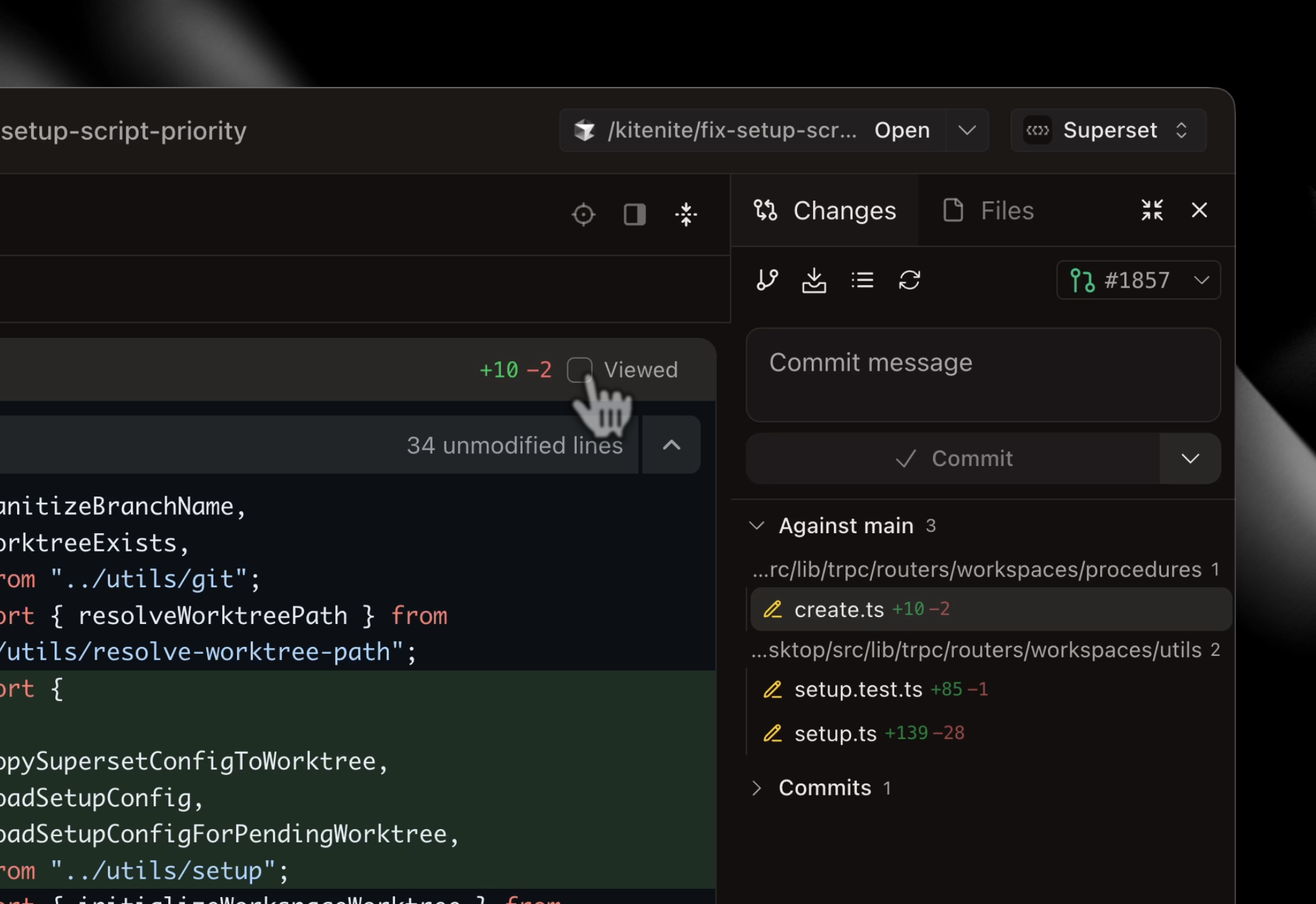
I'm Kiet, one of the creators of Superset. We created Superset to reduce the time you spend waiting around for agents like Claude Code to run. Superset lets you kick off dozens of coding agent sessions in parallel. It works with any coding agents like Claude Code, Codex, OpenCode, etc. while allowing you to use your Pro/Max plans. It's a full featured IDE optimized for parallel agents workflows.
The last few months have seen incredible adoption from the most cutting edge teams from all over the world. I'm excited to see what you will build with Superset!
Hey there,
I'm Satya, I'm also part of the core team building Superset! It's been amazing seeing our product grow over the last few months up to this 1.0 launch. We've helped so many people already improve their Claude Code, Codex, etc. CLI flows by helping them manage worktrees in parallel, organize Linear tickets and more. It's been really gratifying to watch the product grow, I just want to shout out all of our users - they've been incredibly supportive and helped us get to a product we're all very proud of.
If you end up using Superset from this post I'd love to hear what you think!
The sandbox isolation is the right architectural call to prevent interference, but it creates the inverse challenge: when two agents are working on related tasks — say, a frontend and a backend agent that both need to agree on an API shape — how does Superset handle cross-agent context sharing? Full isolation is clean but can lead to agents making conflicting assumptions in silence. Is there a shared workspace layer agents can read from, or is isolation by design absolute?
Hey yall,
I'm Avi, one of the creators of Superset. I'm super excited to share what we've been building. We use Superset to build Superset and its really fun to see how much people are enjoying it. Theres a lot more we are planning on shipping but I'm looking forward to hearing all the feedback from more users, and to see what you all think of it!
Let me know if you have any questions :)
love this, it’s my daily driver now. replaced cursor, claude code, and conductor!
Let's gooo massive fan of Superset product + team! One of the fastest executing teams I've seen!
Question for you guys: Do you think the future will see more local or cloud development? Right now I'm using my mac mini and ssh'ing into it, and it's great in many ways but can get messy with enough things running in parallel. Cloud is easier to manage but problem becomes continuing working from the CLI and all that. Where do you think things are heading?
This looks really solid love the idea of running multiple agents in parallel
Quick question — with all these isolated environments, how are you handling security between them?
Like making sure one agent can’t access another or any API-related risks?
Been a power user. These folks ship so fast I get an update every day!
Congrats on the launch. This is super cool! Are agents aware of how much ram they are using on the host machine to prevent slowness?
Interesting approach to running multiple agents locally. Curious, how are you thinking about agent coordination to avoid conflicting code changes?
Really love that this works with existing Pro/Max plans, that’s a huge unlock for teams already deep into AI coding workflows. Such a smart move 🙌
Big fan of this team and product. We use it daily. Congrats on the launch!
Running multiple coding agents in parallel without context switching is exactly where dev workflows are heading. The sandbox isolation + centralized monitoring feels like a serious productivity unlock, especially for teams experimenting with Claude, Codex, and other agents simultaneously.
The built-in diff + review layer is a smart touch too. That’s usually where agent workflows get messy.
Curious:
How does Superset handle long-running agent memory?
Any benchmarks on productivity gains vs. single-agent workflows?
Is there team collaboration support on the roadmap?
This solves a real pain point. I've been running Claude Code sessions sequentially and the context switching kills momentum. The sandbox isolation per task is smart — I've definitely had agents step on each other's changes when working on related files.
Question: how does the diff viewer handle conflicts when two agents modify overlapping files? Is there a merge flow or does it flag it for manual resolution?
Great launch, congrats to the team!
Great ease working with claude code etc using SuperSet!! No more headache and waste of time!
The waiting problem with Claude Code is real, but I'm curious how Superset handles the orchestration layer. When you have dozens of agents running in parallel, how do you decide which tasks are safe to run concurrently versus which ones need to be sequenced to avoid conflicts?
And with sandbox isolation per task, does each workspace get its own file system snapshot? Wondering how state gets reconciled if two agents end up touching related parts of the same codebase.
I use Claude Code daily for building my AI platform and parallel agent workflow conflicts are something I've been thinking hard about. Would love to understand more about how Superset handles those edge cases in practice. Congrats on the launch!
Congrats on reaching #1 today, Superset team! The ability to run multiple coding agents without context switching is a game-changer for speed. As a developer building a PropTech SaaS (ParkEase) with React Native and Python, I can see how this would have saved us tons of hours during our latest sprint. Question: Does it support custom sandboxes for private Python libraries? Good luck with the launch!
Finally an IDE for people who find waiting 30 seconds for Claude Code physically painful. Now I can be unproductive in 12 parallel threads instead of one 🙏
already use yall daily haha
Worktree isolation per agent is the key design choice here. Without it, parallel agents would constantly step on each other's changes. The persistent daemon surviving crashes is a nice touch too. How are you handling merge conflicts when multiple agents edit overlapping files?
Another IDE, of which there are already many. How are you better than the others?
Been using superset since the beginning and it's great for managing multiple projects!
Congrats on the launch! As someone who often uses just a single aider session at a time and calls it a day, very excited to try this out!
Been using superset consistently for the last month and my usage on it is probably > cursor right now! Insanely helpful tool if you're trying to work parallel coding sessions (multi projects, worktrees, etc.)
Does this handle git worktrees automatically? Do I need to reclone all my existing repos as bare repos in order to use this?
Congrats on the launch!