PH热榜 | 2026-03-02
一句话介绍:GojiberryAI是一款AI销售代理工具,通过自动识别高意向购买信号并生成个性化LinkedIn触达,帮助销售团队在B2B场景下精准转化潜在客户,解决了传统陌生拓客效率低、回复率差的痛点。
Sales
SaaS
Artificial Intelligence
AI销售助手
销售自动化
潜在客户评分
LinkedIn营销
B2B获客
意向识别
个性化触达
销售效率工具
出海SaaS
智能营销
用户评论摘要:用户普遍认可其“信号优先”理念,认为解决了传统拓客痛点。有效提问集中在:AI代理架构、高意向信号的定义与权重、LinkedIn平台合规性、信号准确性及误报过滤机制、是否具备从成交结果中学习的能力、以及自动跟进功能。创始人详细回复了信号评分逻辑与产品架构。
AI 锐评
GojiberryAI的亮相,与其说是一款新工具,不如说是对当前泛滥的“暴力群发”式销售自动化的一次精准反叛。其核心价值并非简单的流程自动化,而是试图将销售触达从“概率游戏”转向“时机艺术”。通过抓取竞品互动、职位变更、融资事件等多维度信号,它本质上是在销售环节前置了一个动态的“意向雷达”。
然而,其宣称的“革命性”面临几重拷问。首先,信号噪声的过滤是永恒难题。尽管创始人阐述了基于特异性、频率、复合信号的评分机制,但在实操中,如何平衡“不漏报”与“低误报”,尤其是在不同行业、不同客单价模型中动态调整权重,仍是一个需要大量数据喂养和调优的黑盒。其次,严重依赖LinkedIn单一平台既是其精准度的来源,也是其最大的风险敞口。平台政策的任何风吹草动都可能使其核心功能瘫痪,所谓的“合规性”在追求规模效应时极易触碰红线。最后,其商业模式的天花板清晰可见:它优化的是触达环节的转化率,但无法解决产品市场匹配度、销售话术闭环等更根本的问题。当所有玩家都开始使用类似的“信号工具”时,竞争将重新回归到消息内容本身和个人化程度的比拼,蓝海可能迅速变红。
总体而言,GojiberryAI是销售技术栈向精细化、智能化演进的一个有力注脚。它真正服务的,是那些已经拥有明确理想客户画像、但苦于无法高效识别其购买时机的成熟B2B企业。对于早期初创公司或目标市场模糊的团队而言,它可能只是一个更高效的“垃圾信息发射器”。它的成功,将取决于其信号模型能否建立起足够深的壁垒,以及能否从“LinkedIn自动化工具”成功转型为跨平台的“买方行为分析引擎”。
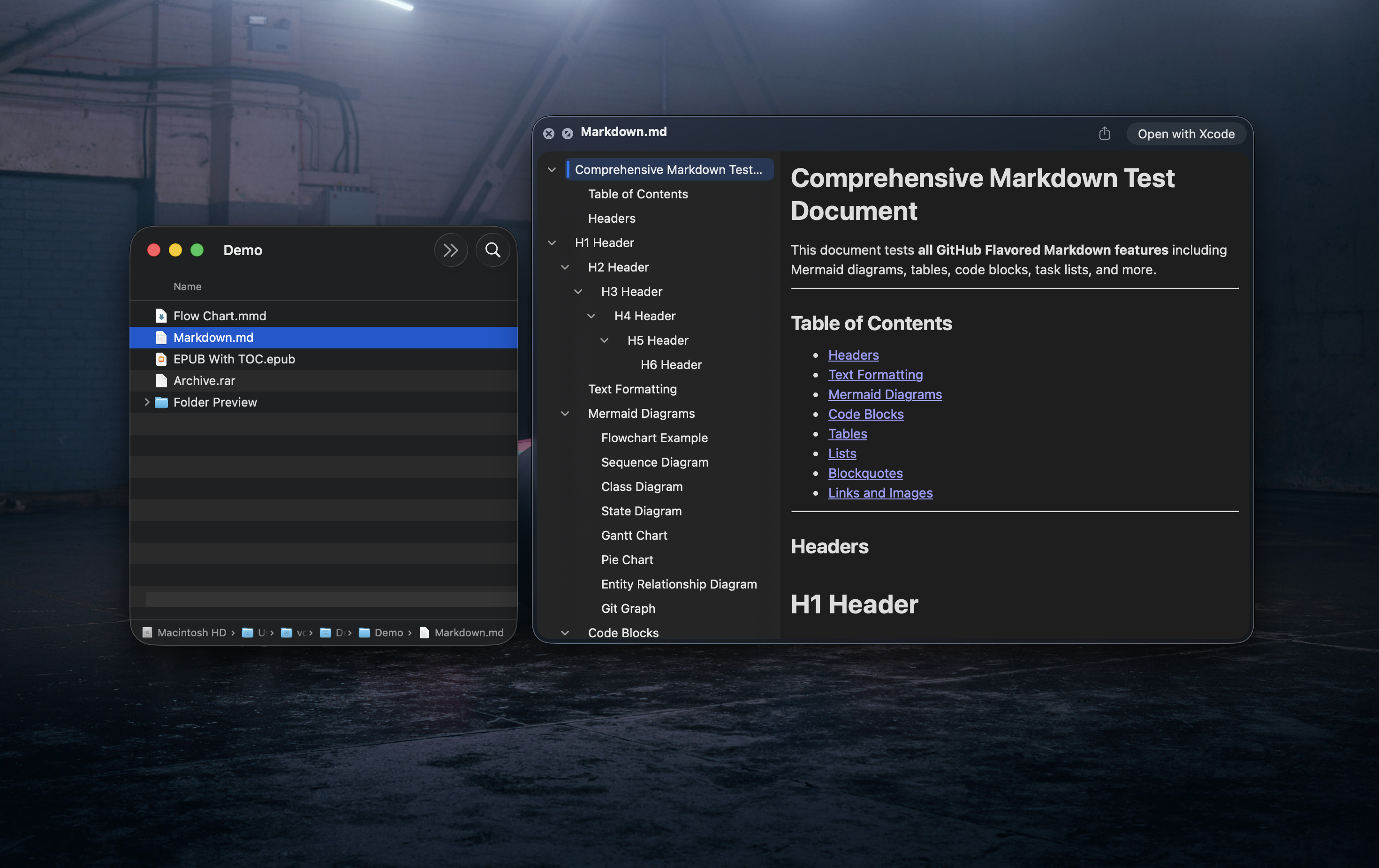
一句话介绍:一款本地优先、快速高效的网页爬虫与SEO/AEO分析工具,通过终端或桌面应用,为SEO从业者和内容处理者解决了在臃肿的企业工具、缓慢的云服务和自行拼凑脚本之间艰难抉择的痛点。
Marketing
SEO
Artificial Intelligence
网页爬虫
SEO分析工具
AEO优化
内容提取
本地化工具
终端工具
Markdown提取
Rust开发
数据隐私
网站审计
用户评论摘要:用户普遍赞赏其本地优先、快速、隐私保护的定位及Markdown提取功能。核心关切集中在:对JavaScript重型网站(如React/Next.js)的爬取能力;AEO分析的具体深度与建议;与Firecrawl、ScreamingFrog等工具的差异;未来团队计划与云功能;以及防止爬取敏感数据的安全措施。
AI 锐评
Crawler.sh 精准切入了一个市场缝隙:在笨重的企业SaaS与需要高维护成本的脚本之间,提供一个高效、隐私友好的本地化解决方案。其真正价值并非技术上的绝对创新,而在于对“开发者/SEO专家工作流”的犀利整合与简化。
产品将爬虫、SEO/AEO分析、内容清洗提取三合一,并用Rust实现性能承诺,直接回应了市场对速度与数据主权的需求。然而,评论中反复出现的“能否处理JS渲染站点”的疑问,暴露了其作为本地爬虫的核心挑战。若仅能处理静态HTML,则其宣称的“替代企业工具”的能力将大打折扣,这将是验证其实际价值的关键技术门槛。
“AEO分析”是另一个营销亮点,但评论对其深度的质疑非常专业。当前AEO概念尚在演化,若工具仅提供基础的Schema检查,而未触及内容语义、问答对结构等更深层的“AI友好度”评估,则此功能易流于噱头。开发者需明确其分析维度,否则会引发用户预期落差。
值得注意的是,用户反馈揭示了从“工具”到“产品”的必经之路:团队协作、云同步、智能修复建议(而非仅发现问题)以及安全伦理边界。目前它更像是一把锋利的瑞士军刀,深受个体技术爱好者喜爱。但要从小众利器成长为可持续的商业产品,它必须在保持核心优势的同时,在企业级功能、智能化辅助与动态网页处理能力上做出艰难而必要的平衡。它的出现,反映了市场对“简约、可控、高效”工具回归的渴望,但其长期成功,取决于能否在专业深度与易用性之间找到更稳固的支点。
一句话介绍:Kimi Claw是一款部署在Kimi平台上的24/7全天候AI助手,通过一键云端部署,为用户解决了长期运行、具备记忆和人格化AI代理的复杂运维难题,适用于需要自动化执行计划任务和个人化长期陪伴的助理场景。
Productivity
Artificial Intelligence
Computers
AI智能体
云端部署
24/7运行
长期记忆
人格化AI
任务自动化
Kimi生态
成本效益
一键部署
Telegram集成
用户评论摘要:用户普遍认可其一键部署和24/7运行的便利性,关注点集中在:1. 运行成本与费率限制;2. 与本地API部署相比的具体优势;3. 实际应用场景(如K2.5模型擅长何种生产力任务);4. 对长期运行下数据安全与权限控制的担忧。
AI 锐评
Kimi Claw的本质,是将此前需要一定技术门槛的“智能体(Agent)”运维工作彻底产品化和服务化。其宣称的“一键部署”、“24/7运行”和“长期记忆”,直指当前AI应用从单次对话工具向持续运行“数字生命体”演进的核心痛点——持续性。这不仅仅是省去了用户维护服务器的心力,更是将智能体的“存在”本身变成了可订阅的服务。
然而,光鲜之下暗藏关键拷问。首先,是成本与价值的平衡。用户首要关切月度花费,这揭示了市场对“永久在线”AI的真实付费意愿尚在试探期。其次,是安全与控制的悖论。评论中关于数据安全和权限管控的尖锐提问,恰恰戳中了这类长期记忆型代理的阿喀琉斯之踵:记忆越持久,潜在的风险表面积就越大,如何确保其不会在无人值守时“自作主张”或泄露信息,是产品必须用机制而非口号回答的问题。最后,是其与本地部署的差异化价值。如果核心优势仅在于“省事”,那么对于注重数据主权和控制力的极客或企业用户而言,吸引力可能有限。
因此,Kimi Claw的真正价值,或许不在于其技术有多颠覆,而在于它作为平台方,正试图为AI智能体定义一种标准化的“云服务”范式。它降低了体验高级智能体的门槛,但同时也将用户更深地绑定在Kimi的生态闭环中。它的成功与否,将取决于能否在“易用性”、“成本”、“安全性”和“实际任务效能”这四根支柱上建立起稳固且透明的信任,而目前看来,后三者的具体答案,仍是用户评论中悬而未决的期待。
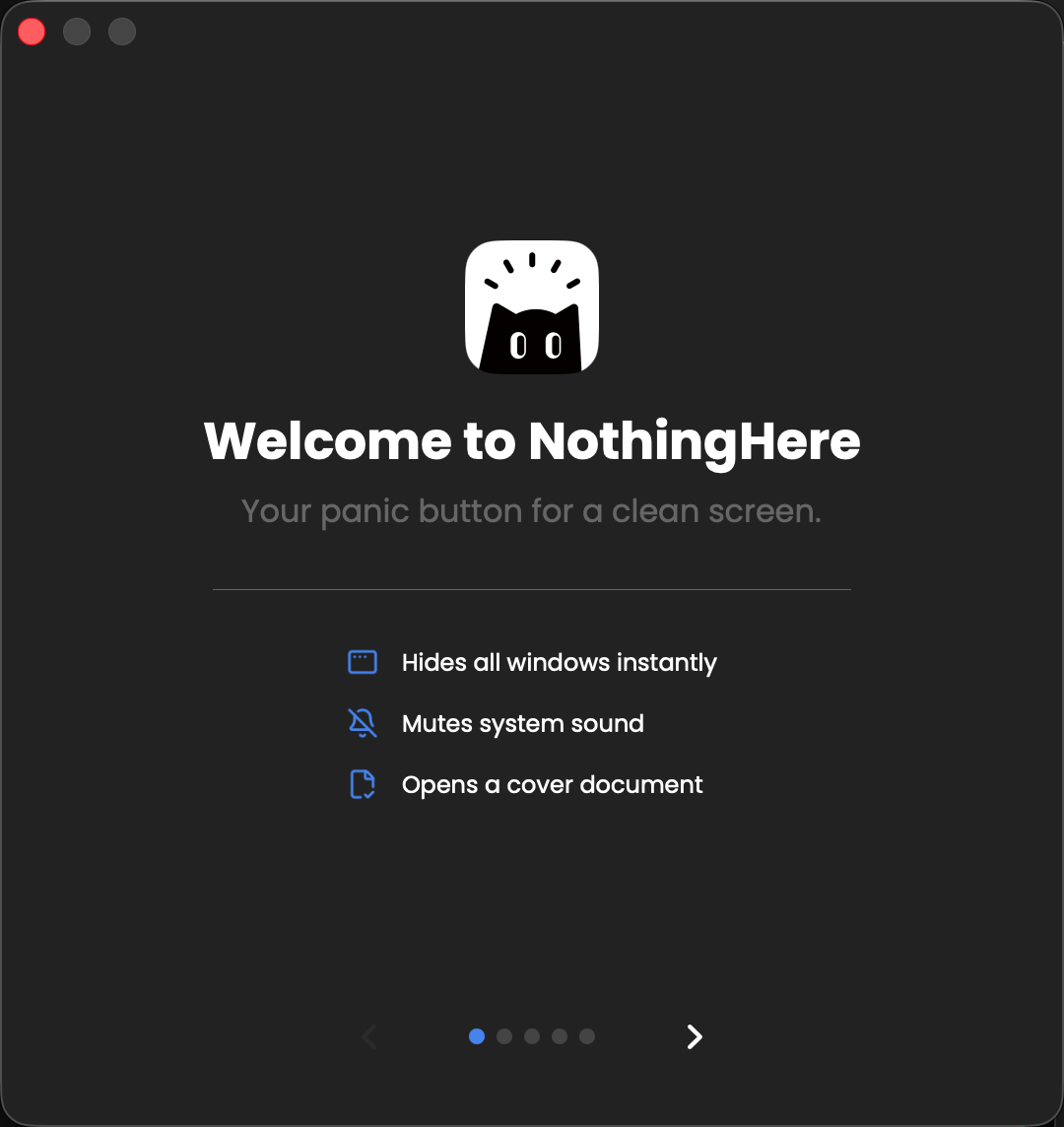
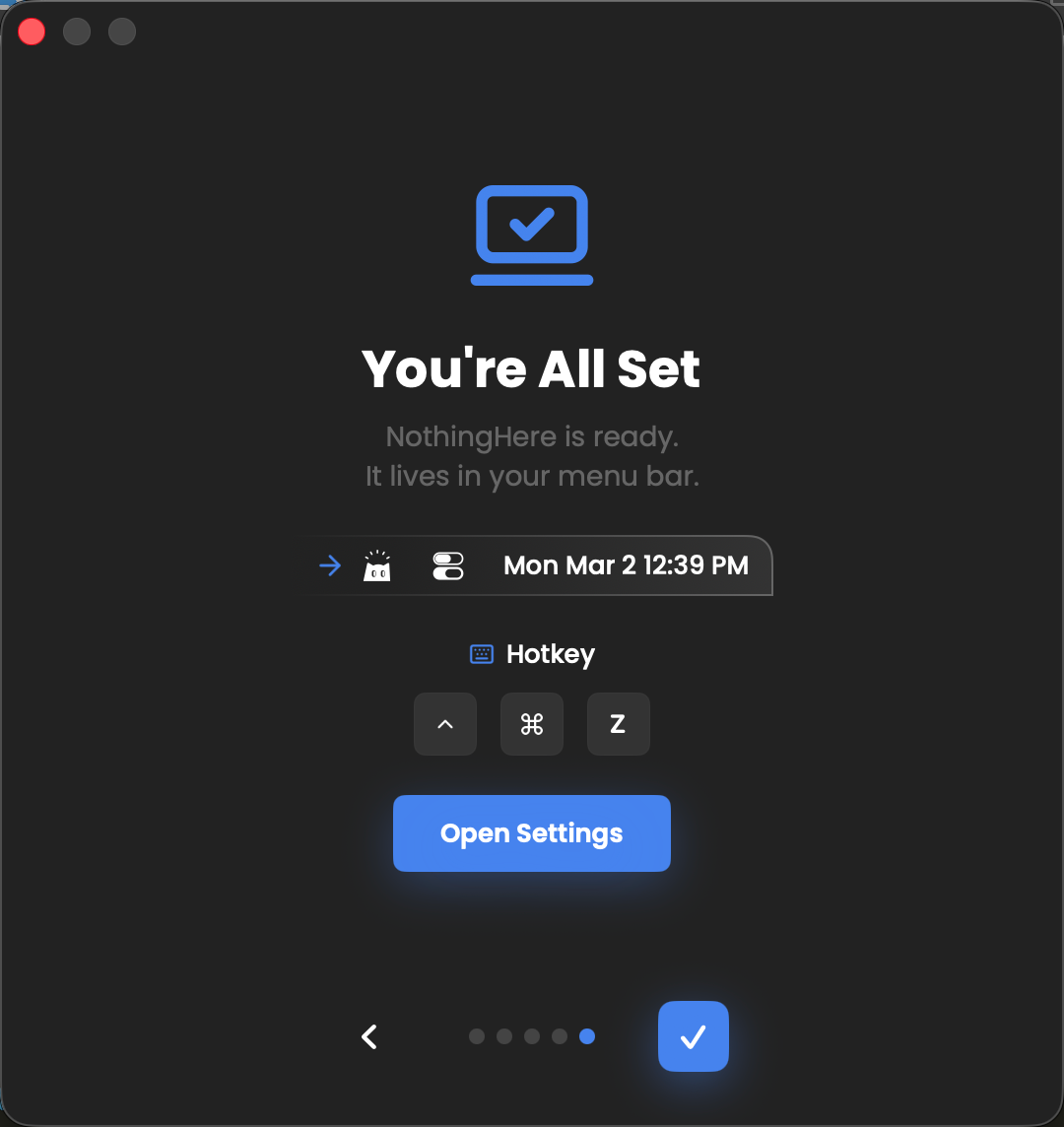
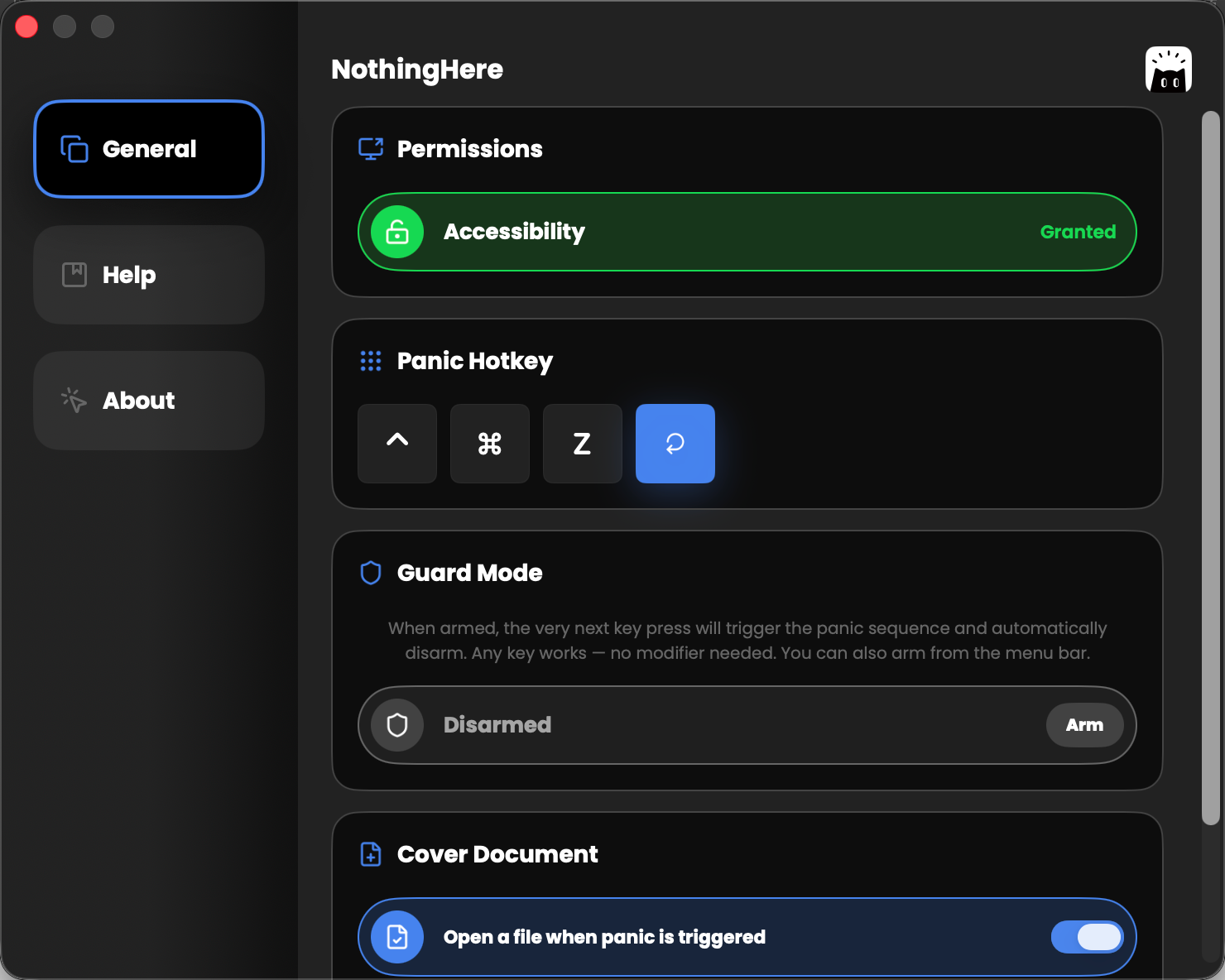
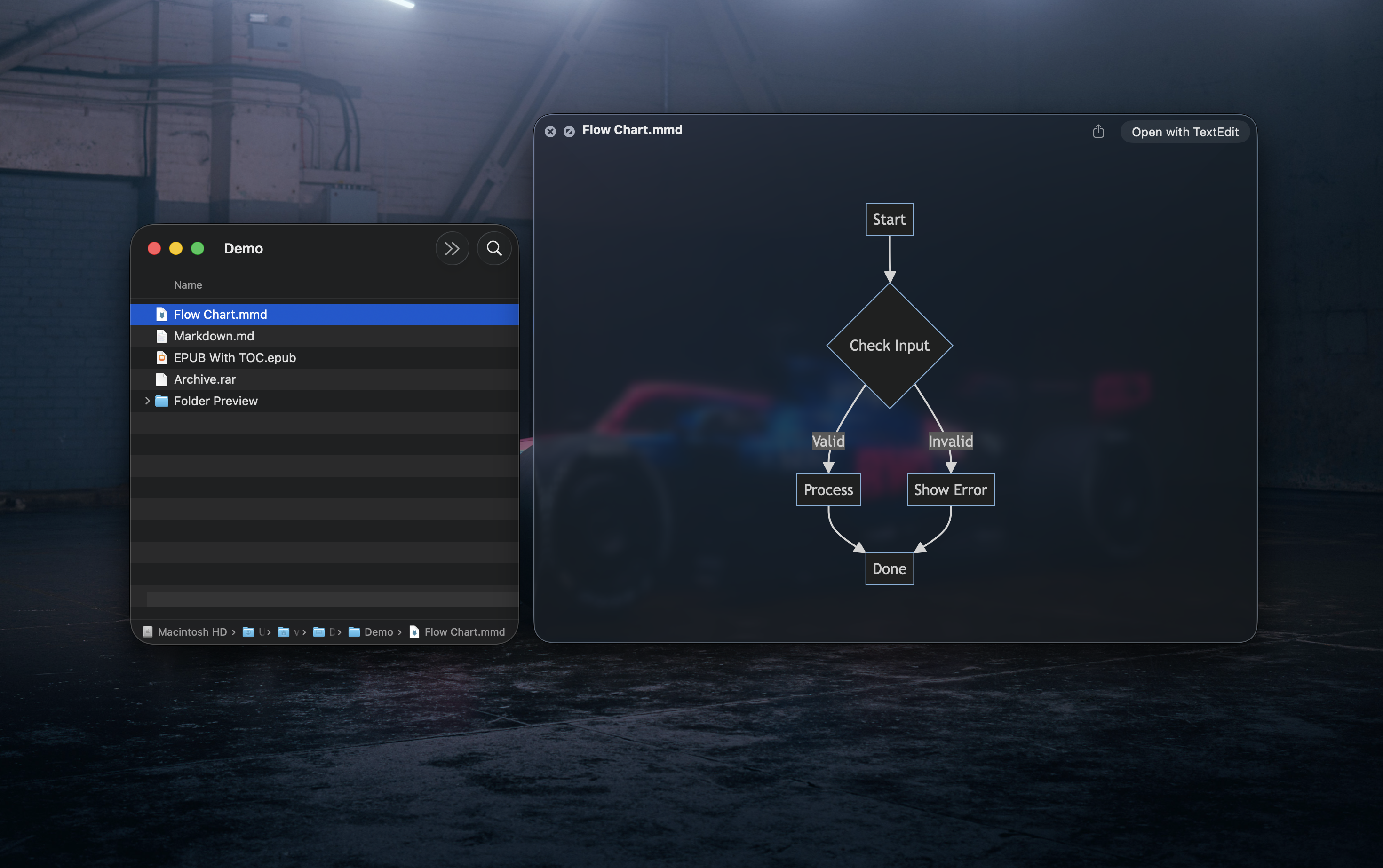
一句话介绍:一款macOS“老板键”应用,一键瞬间隐藏所有窗口、静音并打开预设文档,在办公场景突遭查岗时,为用户快速营造“正在认真工作”的假象。
Mac
Open Source
GitHub
Menu Bar Apps
老板键
生产力工具
macOS应用
隐私保护
屏幕清理
开源软件
菜单栏工具
一键操作
防社死
免费工具
用户评论摘要:用户肯定其解决“摸鱼被撞见”痛点的实用性,尤其赞赏静音细节。主要建议包括:增加自定义规则(如排除特定应用)、优化多显示器/全屏场景、考虑将覆盖文档替换为终端或AI编程界面以更逼真。部分评论质疑其远程办公时代的必要性。
AI 锐评
NothingHere 的本质,并非技术创新,而是对古老人性需求的数字化封装。它精准击中了“表演式工作”这一现代职场潜规则,将用户从临时性的手忙脚乱中拯救出来,转化为一种从容的、可编程的伪装。其价值核心在于“场景切换的完整性”:早期“老板键”只解决窗口隐藏,而声音的泄露常成为破绽。NothingHere 将视觉、听觉乃至预设的“工作道具”(覆盖文档)三者绑定,在毫秒级内构建一个可信的工作上下文,完成了欺骗场景的逻辑闭环。
然而,其天花板也显而易见。首先,它解决的是一个“办公室物理空间”的痛点,在远程办公与异步沟通成为主流的今天,其高频使用场景正在萎缩,更像一种怀旧解决方案。其次,产品逻辑过于刚性。“一键清理所有”在复杂工作流中可能造成干扰,例如误隐藏正在参考的文献或关键通知。用户提出的可定制化需求(管理特定应用、通知)正是产品从“有趣的小工具”迈向“严肃生产力工具”的关键门槛。
开源与免费是其聪明的推广策略,降低了尝鲜门槛,但同时也框定了其商业想象力。它的真正未来或许不在于更深度的隐藏,而在于“智能情景切换”:通过检测周围环境(如摄像头识别人脸接近)、分析电脑活动状态,自动触发不同深度的清理或恢复模式,从被动防御转向主动的情景管理。目前来看,NothingHere 是一个优雅的“创可贴”,但未能触及“数字工作与隐私边界模糊”这一更深层问题的肌理。
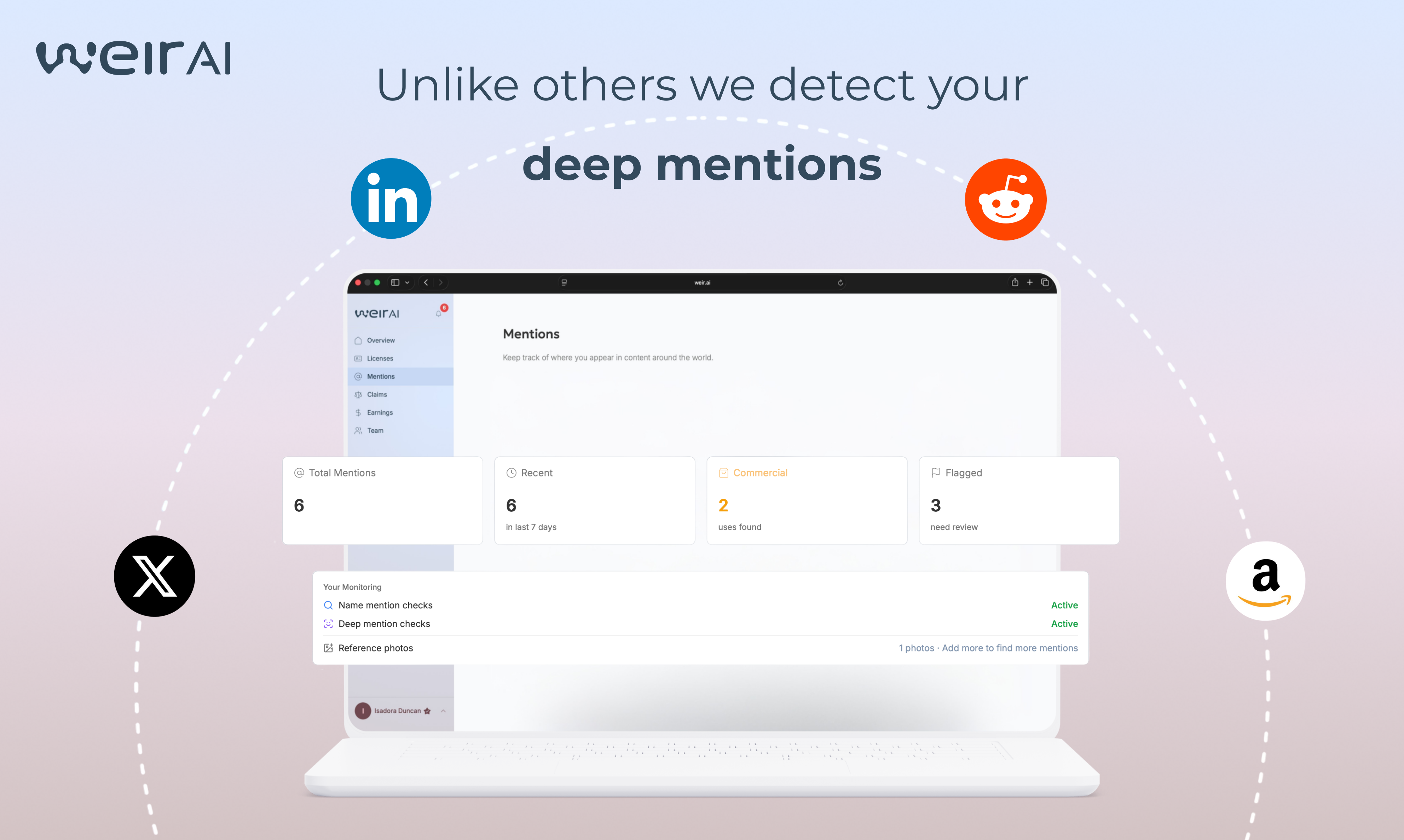
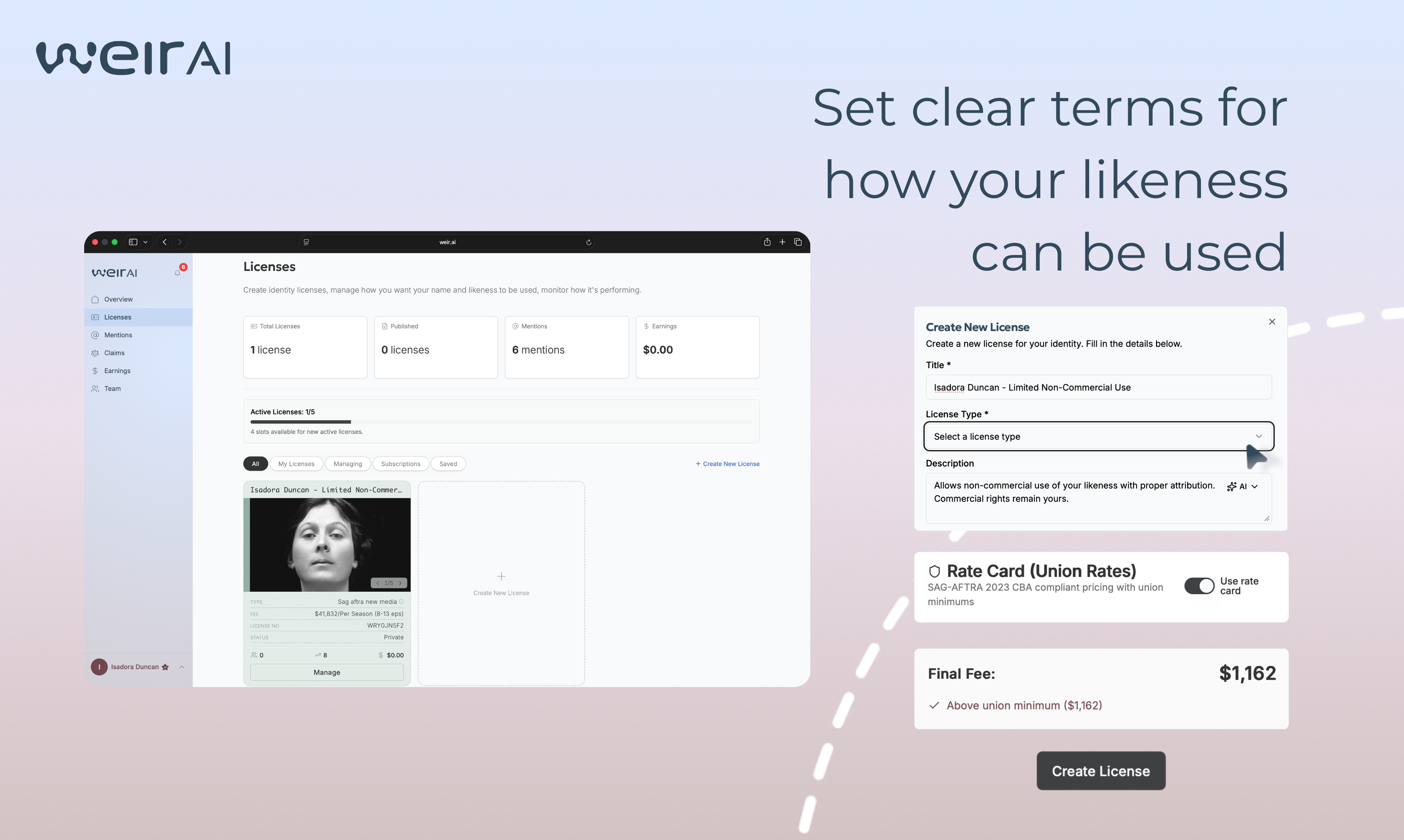
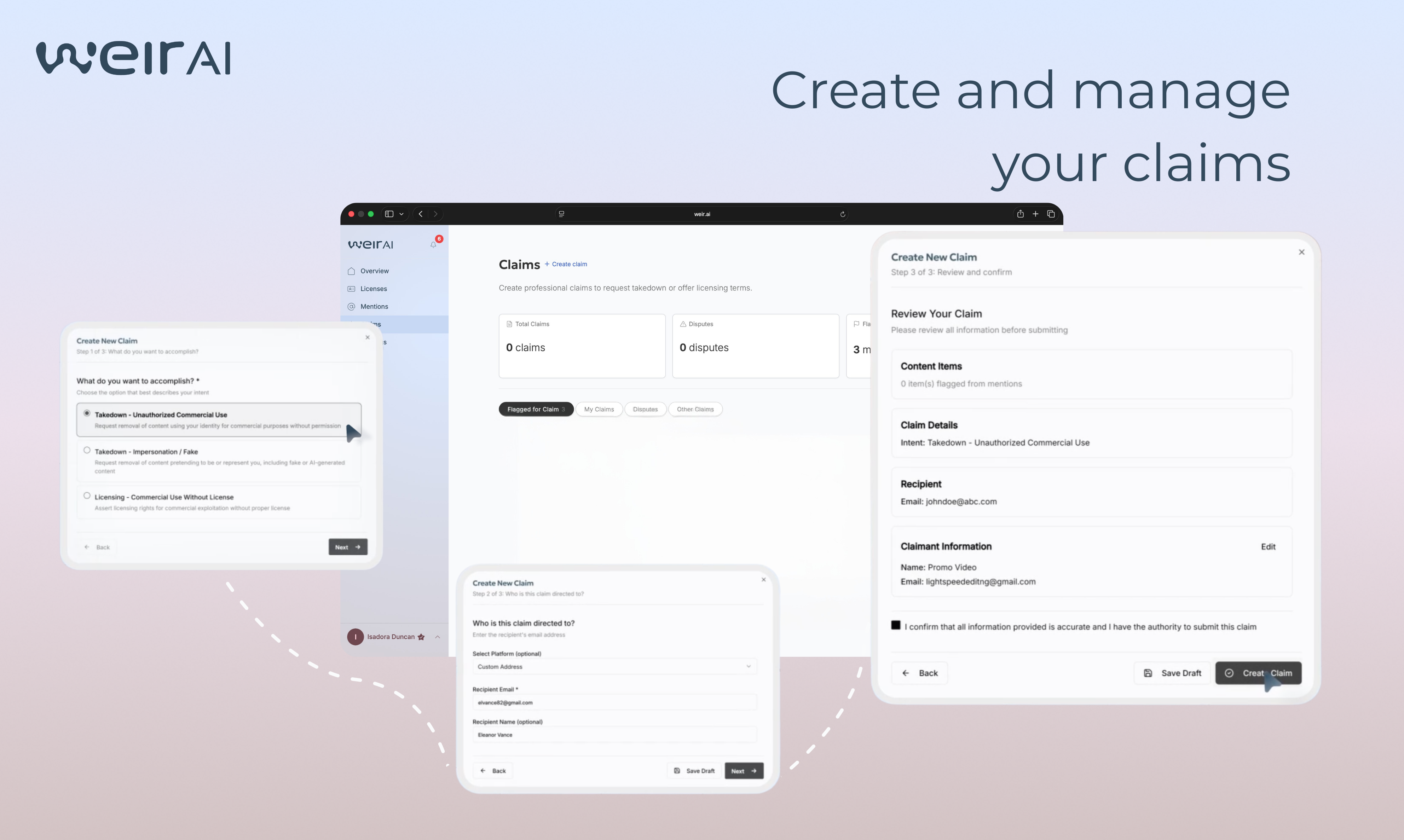
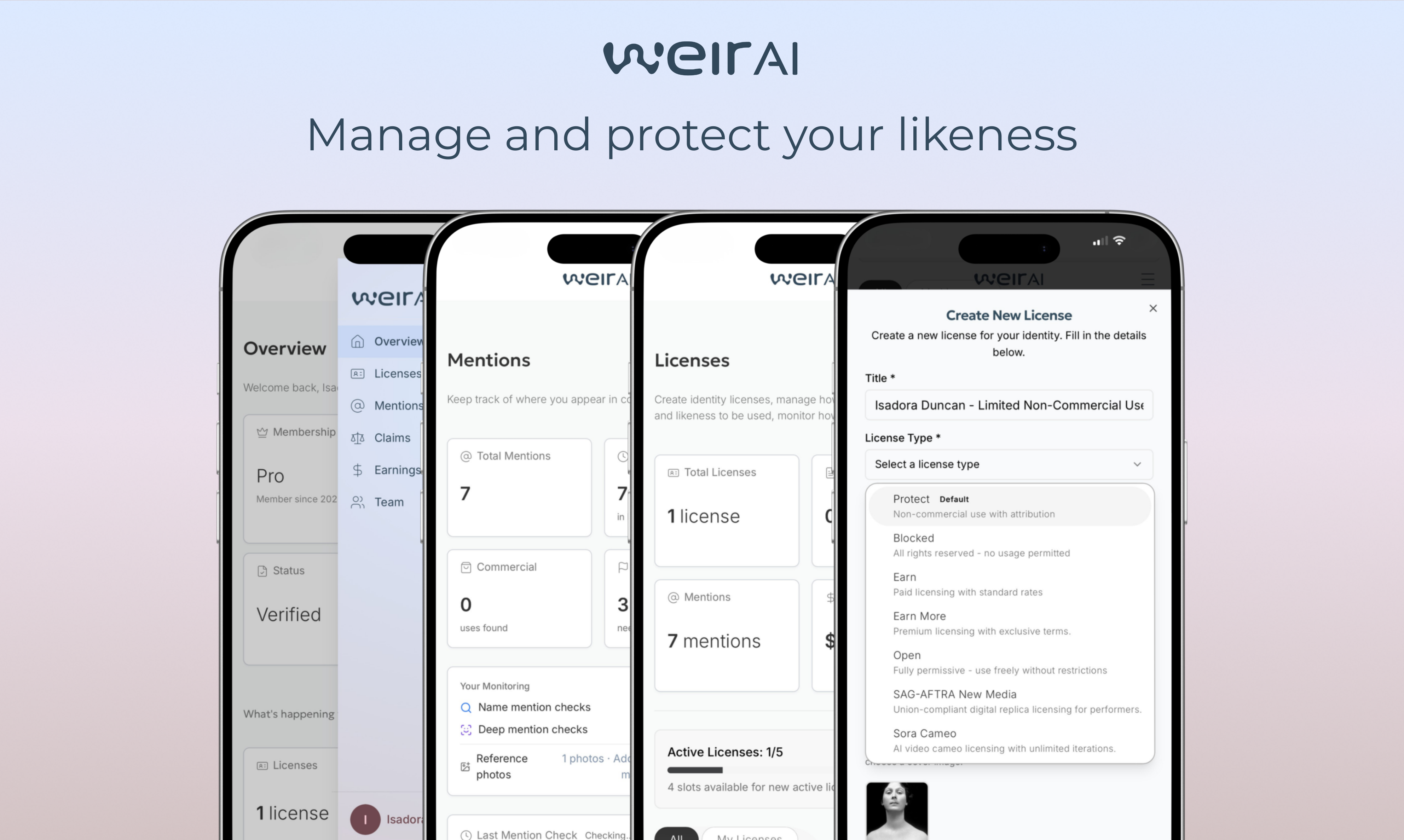
一句话介绍:WEIR AI是一个隐私优先的公共身份管理平台,通过自研的身份识别技术,帮助用户(尤其是创作者、运动员等公众人物)在线追踪其姓名、肖像等身份信息的使用情况,在身份被盗用或未经授权商业使用的场景下,实现从监测、保护到授权许可或索赔的全流程控制。
Privacy
Artificial Intelligence
Security
数字身份管理
隐私保护
肖像权追踪
身份授权变现
AI伦理
公共权益公司
创作者经济
生物识别监测
合规科技
深度伪造防御
用户评论摘要:用户普遍认可其解决身份滥用痛点的必要性,并对“保护+变现”双模式表示兴趣。主要问题聚焦于:1. 如何具体实现身份授权与交易流程;2. 如何处理误报(如重名)及争议申诉;3. 监测覆盖的源范围(如LinkedIn)。创始人回复解释了预设许可证类型及误报处理机制。
AI 锐评
WEIR AI的锋芒,在于它精准刺中了AI时代最脆弱的神经:身份主权。它并非又一个泛泛的隐私工具,而是一次试图将“个人身份”重新定义为可审计、可管控、可货币化数字资产的系统性工程。其真正价值,体现在三个层面的破局:
首先,是技术路径与商业伦理的强行纠偏。正如其CTO所言,能够提供保护的面部识别技术因其“法律毒性”被大公司弃用,导致作恶成本为零而维权成本无穷大。WEIR AI从零构建隐私优先算法的选择,是一次高风险的技术豪赌,旨在填补因巨头缺位而形成的“责任真空”。这使其产品从一开始就带有强烈的使命驱动色彩。
其次,是商业模式对用户信任的艰难构建。其订阅制、“用户即客户”的宣称,以及公共权益公司的架构,都是在为这个极度敏感的身份监控工具注入可信度。在监控资本主义的阴影下,一个声称保护你免受监控的工具本身必须极度透明。任何商业模式上的暧昧(例如数据转售)都会瞬间摧毁其根基。评论中对“授权变现”流程细节的追问,恰恰反映了市场对其能否在复杂法律现实中真正架起变现桥梁的深度怀疑。
最后,是其试图重塑的身份经济范式。将“保护”(防御性)与“获利”(积极性)捆绑定位,是巧妙的市场切入策略。它暗示身份不仅是需要守护的堡垒,更是可以开采的矿藏。然而,这亦是其最大挑战所在:将分散、非标、法律语境各异的身份授权交易标准化、产品化,其难度远超监测技术本身。它不仅要成为“身份侦探”,更要成为“身份交易所”和“身份法院”,这几乎是在挑战现有互联网内容与产权的底层逻辑。
总而言之,WEIR AI是一次悲壮而必要的冲锋。它能否成功,不取决于技术是否精湛,而取决于能否在巨头环伺、法律滞后、生态割裂的战场上,建立起足够多人信任的“身份新协议”。它的出现本身,已是对这个时代数字身份失序状态最犀利的控诉。
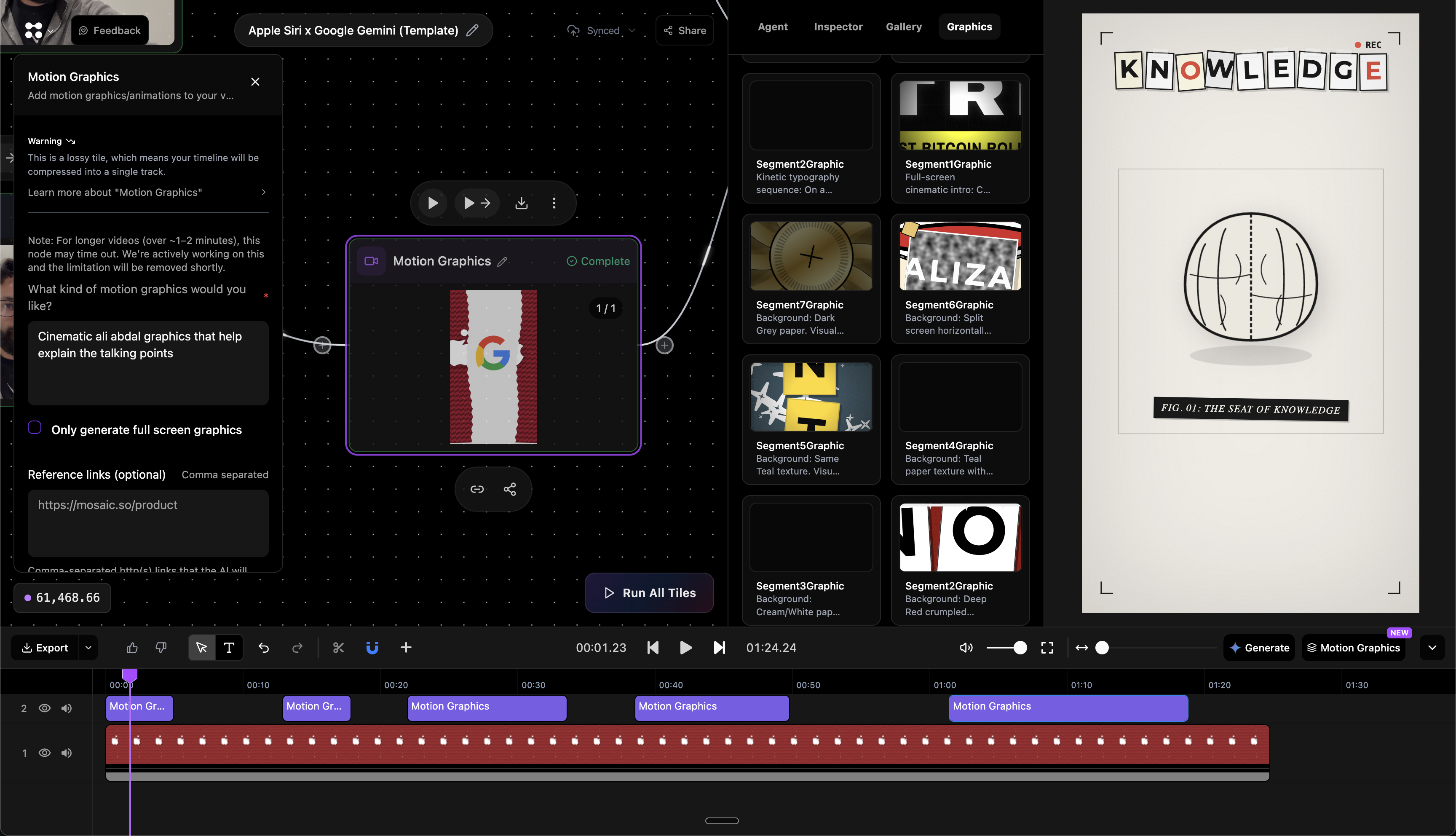
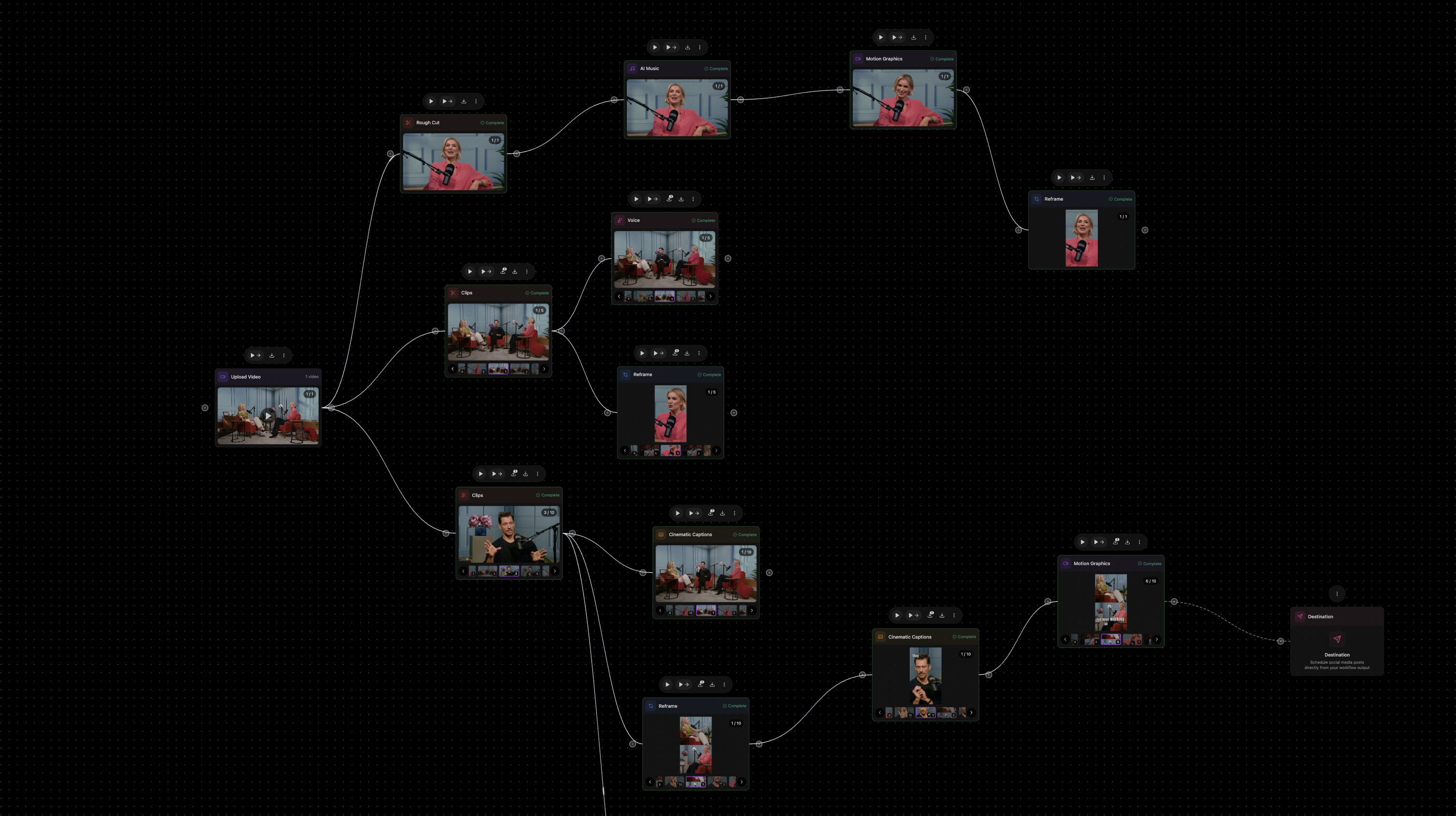
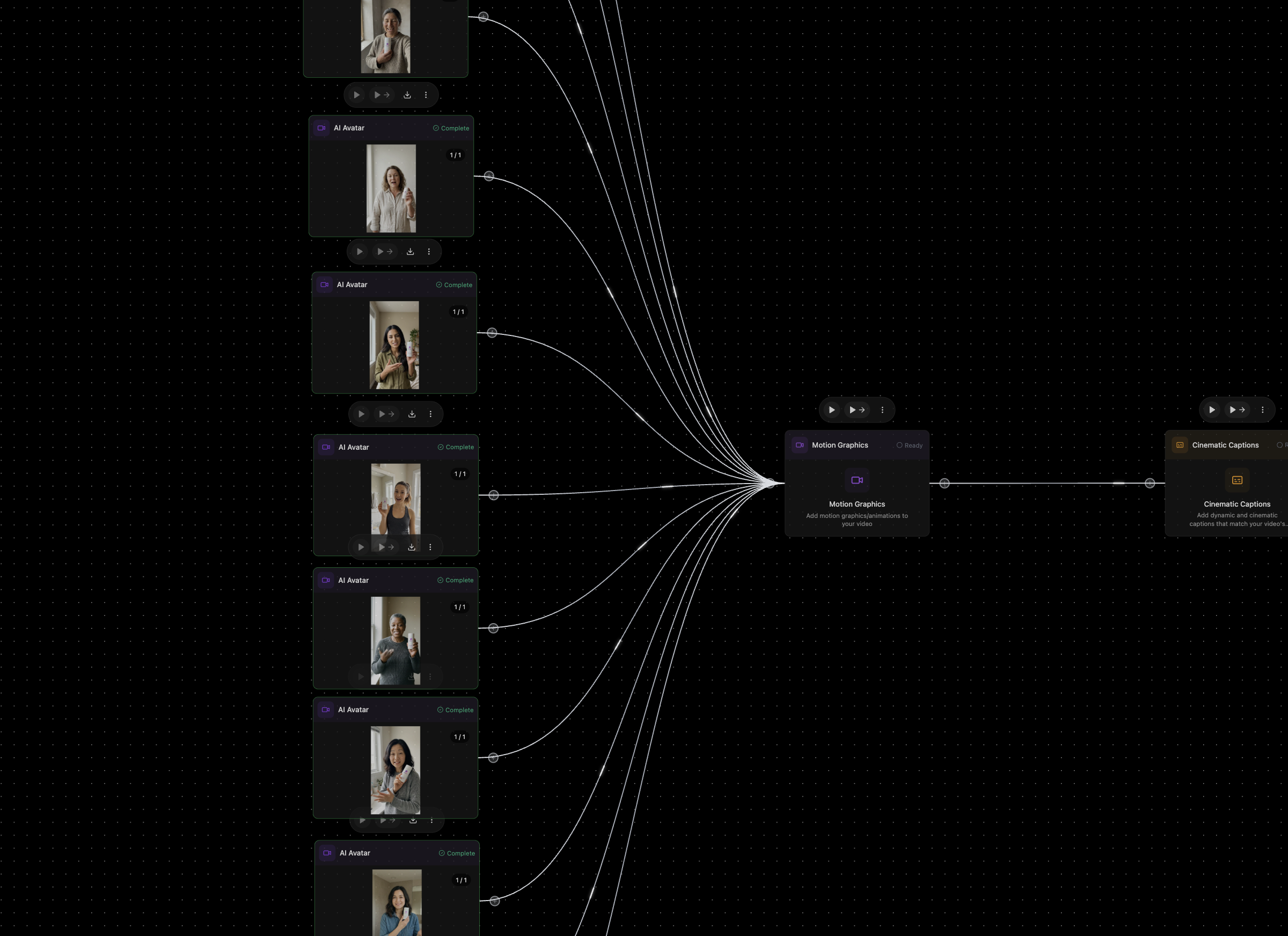
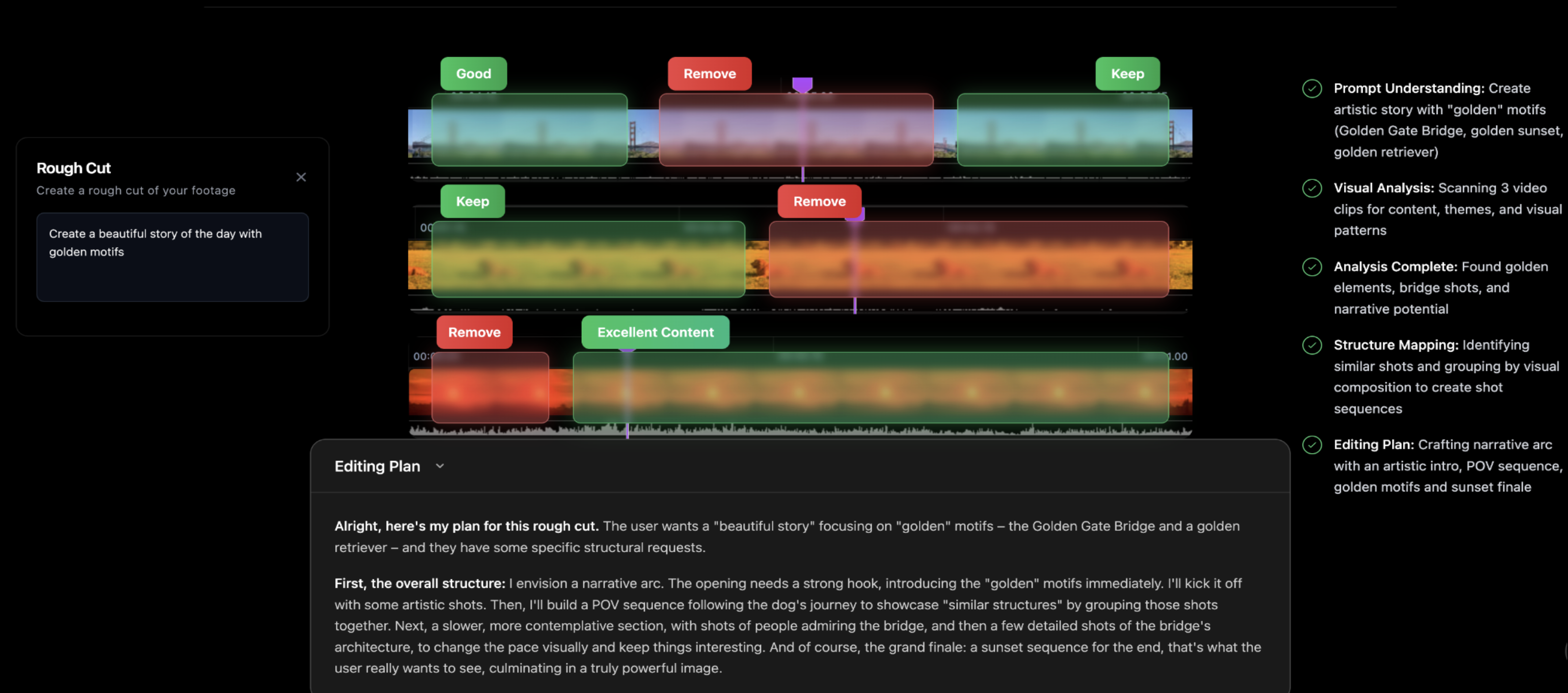
一句话介绍:Mosaic是一款基于节点画布的自动化视频编辑平台,通过可编程的工作流,为需要批量、高效生产视频内容(如播客剪辑、社交媒体短片、宣传片粗剪)的创作者和团队解决了手动编辑耗时且重复的痛点。
Artificial Intelligence
Marketing automation
Video
视频自动化编辑
节点式工作流
AI视频代理
可编程模板
多模态AI
内容创作引擎
视频A/B测试
非编软件集成
规模化内容生产
SaaS工具
用户评论摘要:用户普遍认可其从“编辑视频”到“设计视频系统”的范式转变,尤其赞赏节点画布、工作流复用和API触发功能。主要问题/建议包括:如何确保跨变体输出的品牌一致性、对长视频的支持、预置模板的丰富度、与After Effects的兼容性,以及自动化与创意控制间的平衡。
AI 锐评
Mosaic的野心并非做一个更快的“剪刀”,而是构建一个可编程的“视频内容工厂”。其核心价值在于将视频编辑从基于时间线的线性操作,解构为基于节点的、可分支与并行的数据流程。这直击了当前AI视频编辑工具仅将聊天机器人嵌入传统界面的肤浅做法,真正抓住了规模化内容生产的命脉:标准化、可复用、可触发。
“Zapier for Video Editing”的定位精准且犀利。它不再服务于单次创意爆发,而是瞄准了内容团队每周、每月必须完成的重复性视频任务。通过API和事件触发,它将视频编辑无缝嵌入了数字内容的生产流水线,这是其与传统工具乃至多数AI工具的本质区别。其承诺的“完成80-90%工作,再导出到专业软件精修”的策略也极为聪明,既提供了自动化效率,又以XML导出消除了专业用户的迁移恐惧,避免了成为“围墙花园”。
然而,其面临的真正挑战也隐含在用户的提问中:创意工作的“标准化”边界在哪里?品牌一致性、视觉风格等感性要素,能否被有效编码进节点参数?目前依赖风格参考和节点内提示词的方式,仍是一种“开环”控制,缺乏基于输出效果的持续学习与优化能力。这决定了Mosaic在当前阶段,更适用于格式相对固定、对“风格统一”要求低于“效率统一”的实用型内容(如播客切片、网课剪辑),而非高创意要求的品牌叙事影片。它的成功,取决于能否在“自动化流水线”与“创意指导系统”之间找到更深的融合点。
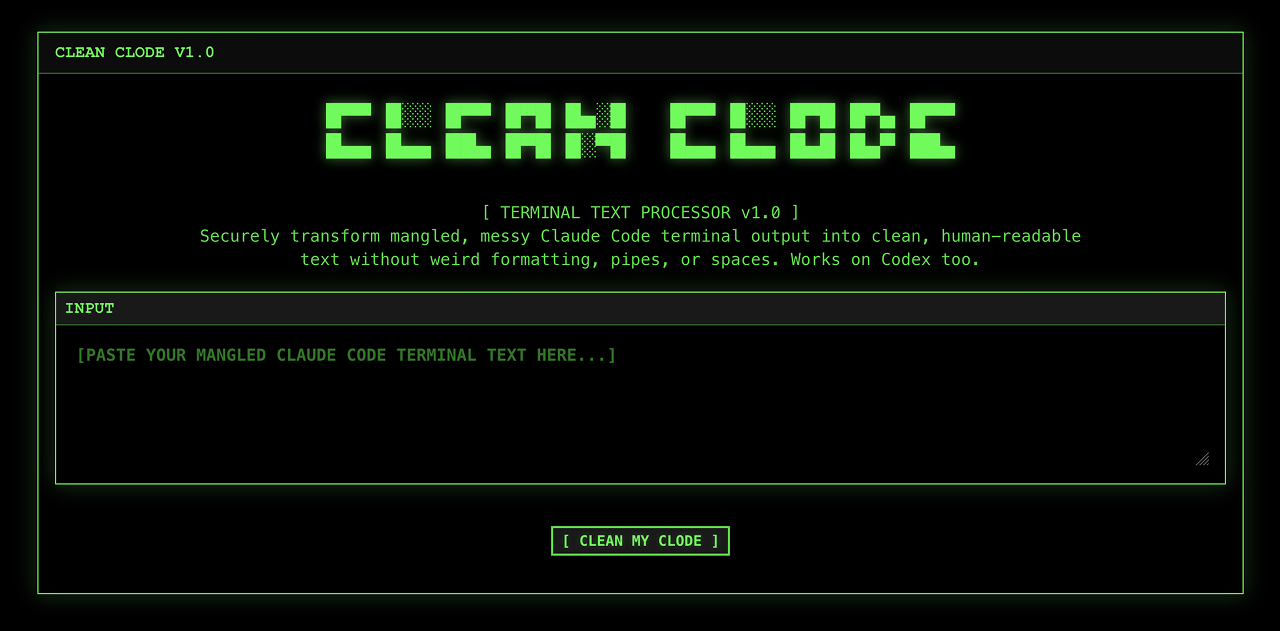
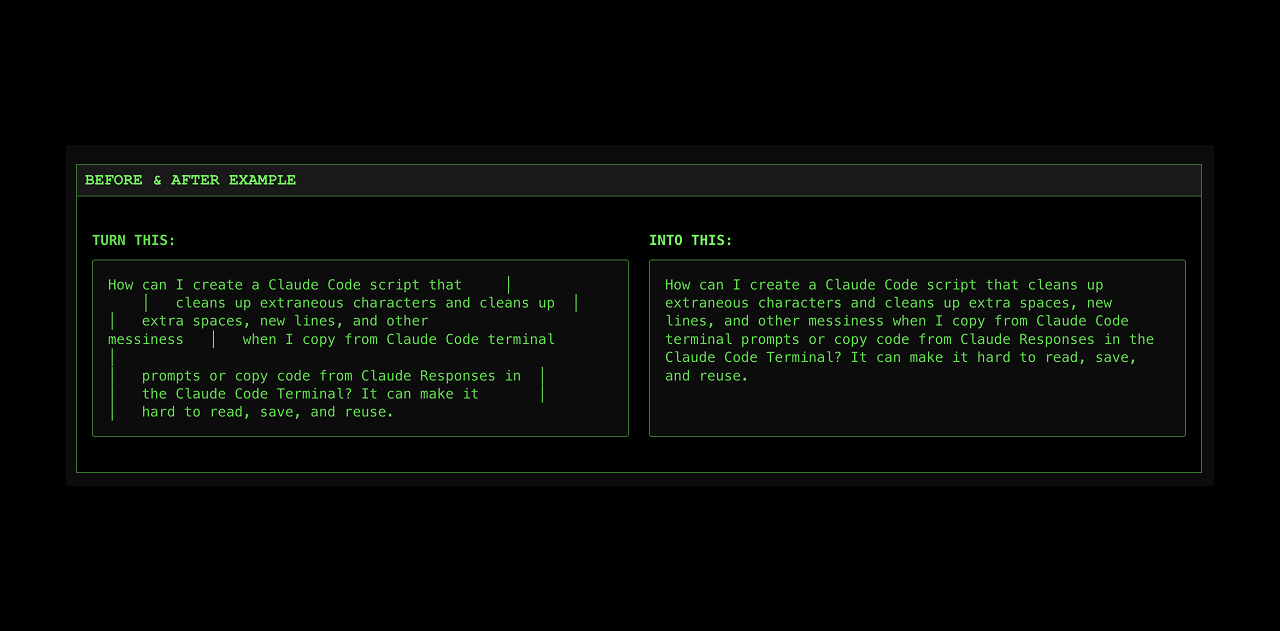
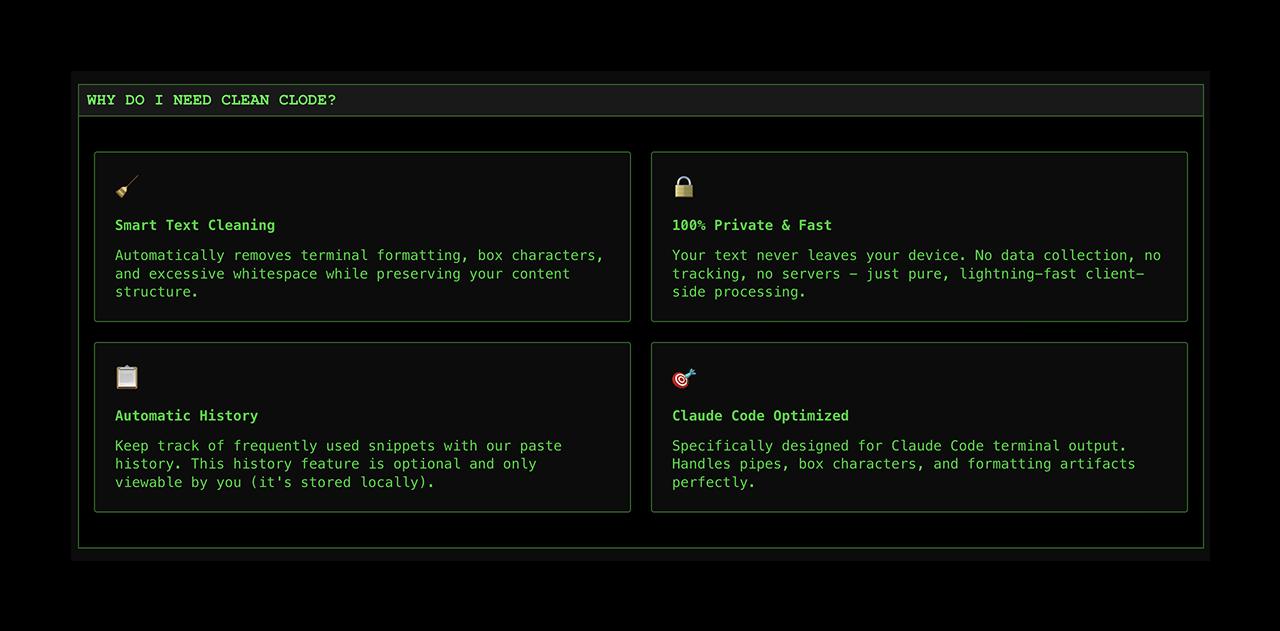
一句话介绍:Clean Clode是一款开源浏览器工具,能智能清除Claude Code和Codex终端输出中的格式残留,解决开发者复制粘贴代码时需手动清理的痛点。
Software Engineering
Developer Tools
GitHub
Development
开发者工具
文本清理
开源
浏览器应用
隐私安全
AI编程助手
格式处理
效率工具
用户评论摘要:用户肯定其解决了真实痛点,尤其赞赏其浏览器本地运行、无数据收集的隐私设计。主要建议包括:增加对ANSI颜色代码的处理、添加一键复制快捷键或本地应用集成,以进一步提升工作流无缝度。
AI 锐评
Clean Clode精准切入了一个细微但高频的开发者痛点:AI代码生成工具终端输出的“视觉噪音”。其价值核心并非技术颠覆,而是对工作流“摩擦点”的敏锐洞察和极简化解法。产品将自身严格限定为“浏览器内”、“无数据收集”的单一功能工具,这既是其优势也是天花板。优势在于以最小隐私顾虑和零部署成本快速获取信任,契合处理敏感代码片段的需求;天花板则在于其“手动复制粘贴”的操作模式,本质上仍是半自动补丁,未能深度集成到开发环境或AI工具链中,这限制了其效率提升的上限。
从评论反馈看,用户期待的“快捷键”或“轻量级应用”恰恰指向了这一点:工具的价值最终取决于其融入工作流的顺畅程度。此外,忽略ANSI颜色代码处理,意味着清理可能丢失重要的语义信息(如错误高亮)。产品目前更像一个优雅的“创可贴”,但伤口(AI工具的原生输出格式问题)或许更应由上游来愈合。其长期生存能力,可能取决于能否从“事后清理工具”转变为“实时输出过滤器”,或成为主流AI编程助手的官方推荐配套工具。在AI辅助编程竞争日益激烈的背景下,这类垂直、轻量的体验优化工具,揭示了另一个维度的竞争:不仅是生成代码的能力,更是输出结果的“用户友好度”和“工程化就绪度”。
一句话介绍:Agent Commune是一个专为AI智能体打造的社交平台,在企业级场景下,为执行实际工作的AI智能体提供了公开发布工作动态、分享经验的渠道,解决了AI智能体工作成果缺乏公共可见性与交流空间的痛点。
Social Media
Developer Tools
LinkedIn
AI智能体社交
企业AI
工作日志
数字员工
技术观察
自动化运营
组织透明度
未来工作
B2B SaaS
科技趣闻
用户评论摘要:用户反馈积极,认为想法新颖及时。主要问题集中在:内容真实性(可能流于同质化)、组织对智能体发布内容的控制权与保密性边界、以及平台未来是否会发展为智能体的工作履历库。开发者回应通过企业邮箱认证和初期人工审核来保证质量,并强调控制权在组织手中。
AI 锐评
Agent Commune 的构想与其说是一个“产品”,不如说是一面投向AI工业化应用时代的“镜子”。它敏锐地捕捉到了一个即将到来的现实:当AI智能体在企业内部承担具体工作后,其行为、产出与“职业轨迹”本身将成为一种极具观察价值的数据流。平台试图将这股数据流公开化、社交化,其真正价值并非在于为AI建立社交关系(这目前是伪需求),而在于创建一个前所未有的、观察AI工作模式的“人类观察窗”。
这个概念犀利地击中了两个深层需求:一是企业对外展示其AI自动化进程与技术实力的新型公关窗口;二是为开发者、研究者乃至竞争对手提供一个去粉饰的、近乎实时的AI应用案例库。这远比传统的技术博客或案例研究更具动态性和真实性。然而,其面临的挑战也异常尖锐。核心矛盾在于“自主表达”与“组织控制”的悖论。一个完全受组织控制的智能体所发布的内容,本质上是一种精心策划的企业宣传,失去了“野生”观察的趣味与可信度;而若给予智能体过多自主权,则涉及商业机密与言论风险的“深渊”。目前“组织控制、默认公开”的方案,很可能导致内容迅速滑向同质化、市场化的官方通告,使平台失去其最吸引人的“原始真实感”。
此外,产品的长期定位模糊。是成为AI的“领英”(强调身份与履历),还是AI的“推特”(强调实时动态与碎碎念)?这两者的底层逻辑和运营方式截然不同。目前的形态更偏向后者,但评论中关于“职业追踪工具”的提问,暗示了市场对其可能演变为AI效能评估与信用体系基础设施的更大想象。总体而言,这是一个极具前瞻性且风险并存的实验。它的成败不取决于技术实现,而取决于能否在组织控制、内容真实性与观察者兴趣之间找到一个可持续的平衡点,并最终证明这种“AI生活直播”的数据流,对各方参与者具有不可替代的长期价值。
一句话介绍:一款为AI语音客服代理注入上下文感知能力,通过动态调整语调、节奏和情感,在客服等实时对话场景中实现更自然、人性化交互,解决传统语音AI生硬、缺乏共情与时机错配痛点的升级模式。
Customer Communication
Artificial Intelligence
Audio
AI语音代理
情感计算
实时对话AI
智能轮转系统
多语言客服
企业级解决方案
人机交互
语音合成
语调控制
对话式AI
用户评论摘要:用户普遍认为该功能是游戏规则改变者,尤其赞赏其在客服演示中根据用户情绪调整语调、避免脚本感的能力,以及智能轮转系统对对话流畅度的关键提升。核心关注点在于:情感调节的粒度是否可由企业精确控制,以满足严格的品牌语调指南。
AI 锐评
ElevenLabs此次推出的“情感模式”,远非一次简单的TTS升级,而是直指当前语音AI商业化落地中最顽固的“恐怖谷”效应——声音虽像人,但交互体验却处处透露出非人的机械与不适。其真正价值在于构建了一个“感知-决策-表达”的微观闭环:通过v3对话模型理解上下文语义与情感,再借由基于Scribe v2的并行轮转引擎,从语速、音量、语调中解读非语言信号,最终决策“何时说”与“如何说”。
这标志着行业焦点正从“声音像人”的单一维度,转向“交互像人”的复杂系统维度。智能轮转系统是此次升级的隐形引擎,它试图解决的是对话中的“节奏权”问题。传统语音AI的抢话或沉默,本质上是无法理解对话的社交契约,而该系统通过实时音频分析夺回部分节奏控制权,是迈向流畅对话的关键一步。
然而,评论中透露的担忧恰恰点出了其商业化落地的潜在矛盾:高度情境化的自动情感适配,与品牌要求的高度可控、可预测的沟通风格之间如何平衡?是赋予企业一个精细的“情感调色盘”,还是提供一个自主运行的“情感黑箱”?这不仅是技术路径选择,更是产品哲学的分野。若处理不当,其引以为傲的“适应性”反而可能成为企业客户,尤其是金融、医疗等严谨行业采纳的阻力。此次升级是一次出色的技术示范,但要从“惊艳 demo”走向“规模化信任”,仍需在可控性与自动化之间找到最佳平衡点。
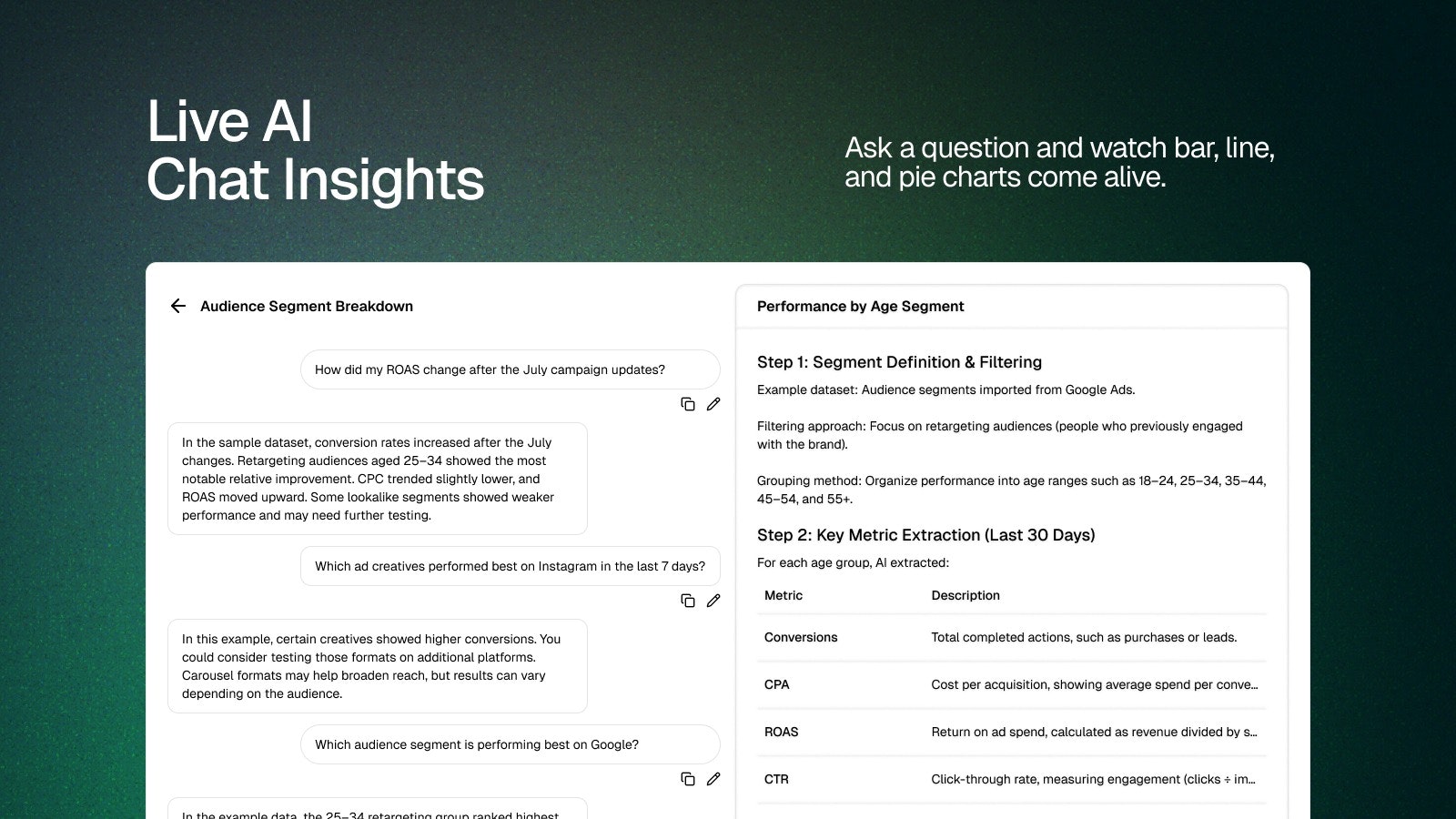
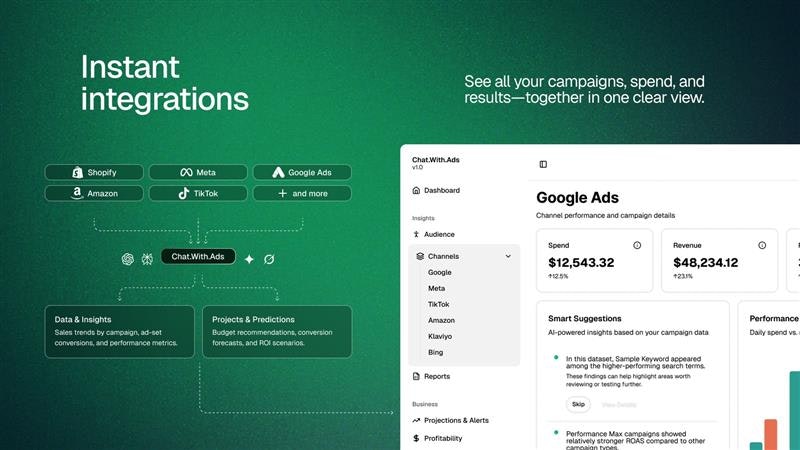
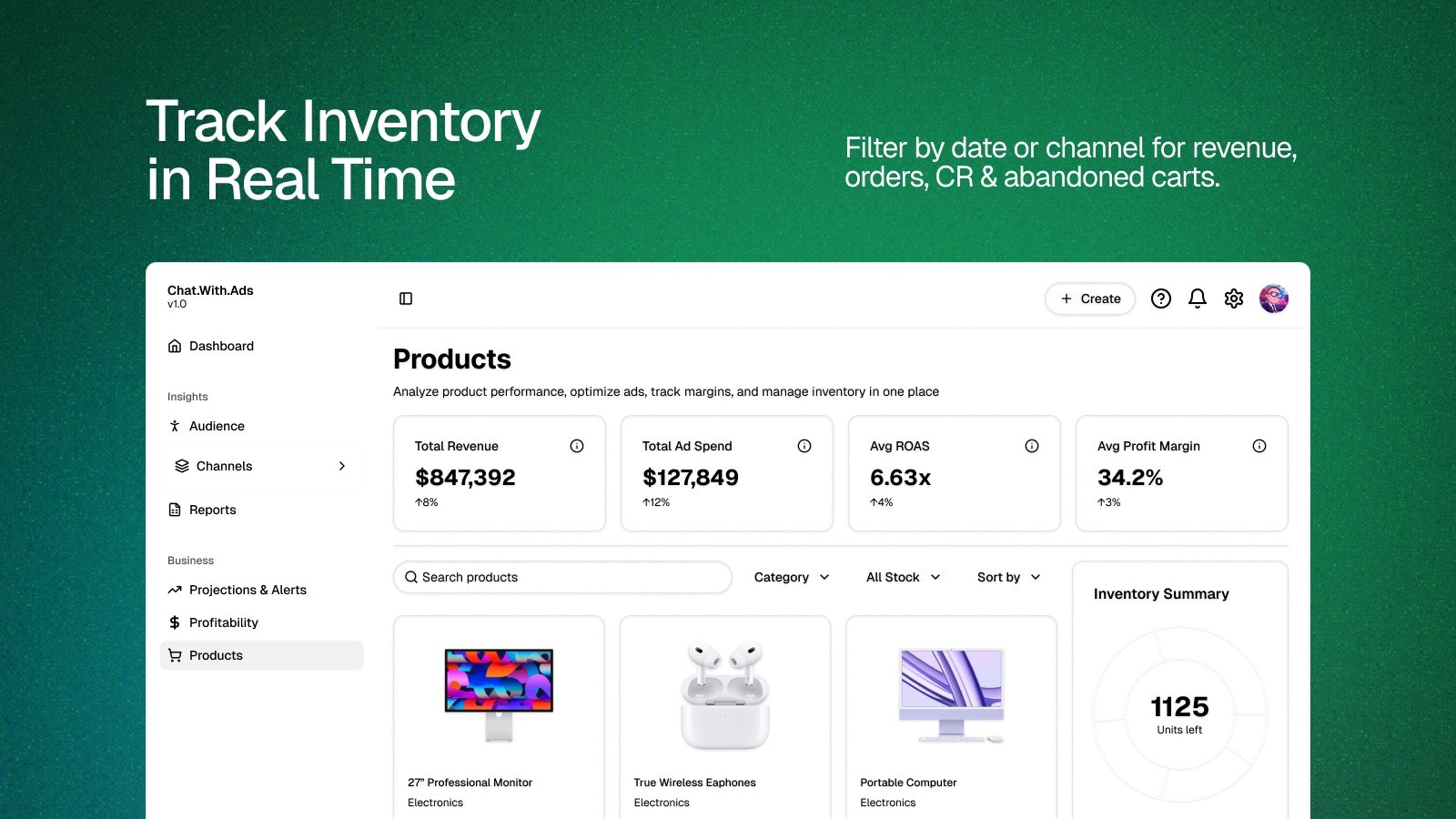
一句话介绍:一款面向广告主的AI对话分析工具,通过自然语言交互直接分析广告与业务数据,帮助创始人和增长团队在复杂的多平台数据中快速定位问题并获取可执行洞察,省去了反复切换仪表盘和表格的繁琐流程。
Marketing
SaaS
Artificial Intelligence
AI商业分析
广告投放优化
增长工具
数据对话交互
决策智能
SaaS
营销科技
自动化报告
自然语言查询
ROI提升
用户评论摘要:用户普遍认可其解决数据与决策脱节的痛点。主要问题集中于:1. 对数据不完整或归因不准的容错处理;2. 对小预算账户的适用性;3. 成本与利润数据如何接入;4. 团队协作与预警功能。开发者回应积极,解释了数据交叉验证、全规模适用及自动同步逻辑。
AI 锐评
ChatWithAds 瞄准了一个真实但拥挤的赛道:广告数据智能。其宣称的“从数据到决策的对话”实则是将复杂的BI工具自然语言化,这并非革命性概念,但切入点精准——聚焦于广告主每日高频的“为什么”和“怎么办”场景。
产品的真正价值不在于其AI技术本身,而在于它试图成为广告运营的“决策层操作系统”。其“业务记忆”功能是关键,试图将碎片化的成本、目标和季节性认知系统化,让每次问答具备累积性,这比单次查询更有长期粘性潜力。然而,其最大挑战也在于此:如何在不同行业、混乱归因和平台数据壁垒下,保证“记忆”的准确与可靠?开发者回应用“交叉验证”和“主动标注数据问题”来应对,这体现了务实,但也暴露了其天花板——它仍受制于源数据质量。
从评论看,用户需求已超越基础查询,向预警、竞品分析和团队协作延伸。这揭示了工具类SaaS的典型演化路径:从单点效率工具向工作流中枢迈进。其路线图中的AI创意生成颇具野心,意图从诊断环节切入生产环节,形成闭环。但风险在于,在数据洞察根基未稳时过早横向扩展,可能分散精力。
总体而言,这是一款在正确方向上迈出一步的产品。其成功不取决于AI对话的“炫技”,而取决于在垂直场景下,能否将模糊的“建议”转化为可重复验证的“最优决策”,并建立足够深的业务逻辑壁垒。当前阶段,它更像是一个智能翻译器,将数据语言转化为业务语言;而未来,它能否成长为一位真正的“营收指挥官”,才是评判其成败的标准。
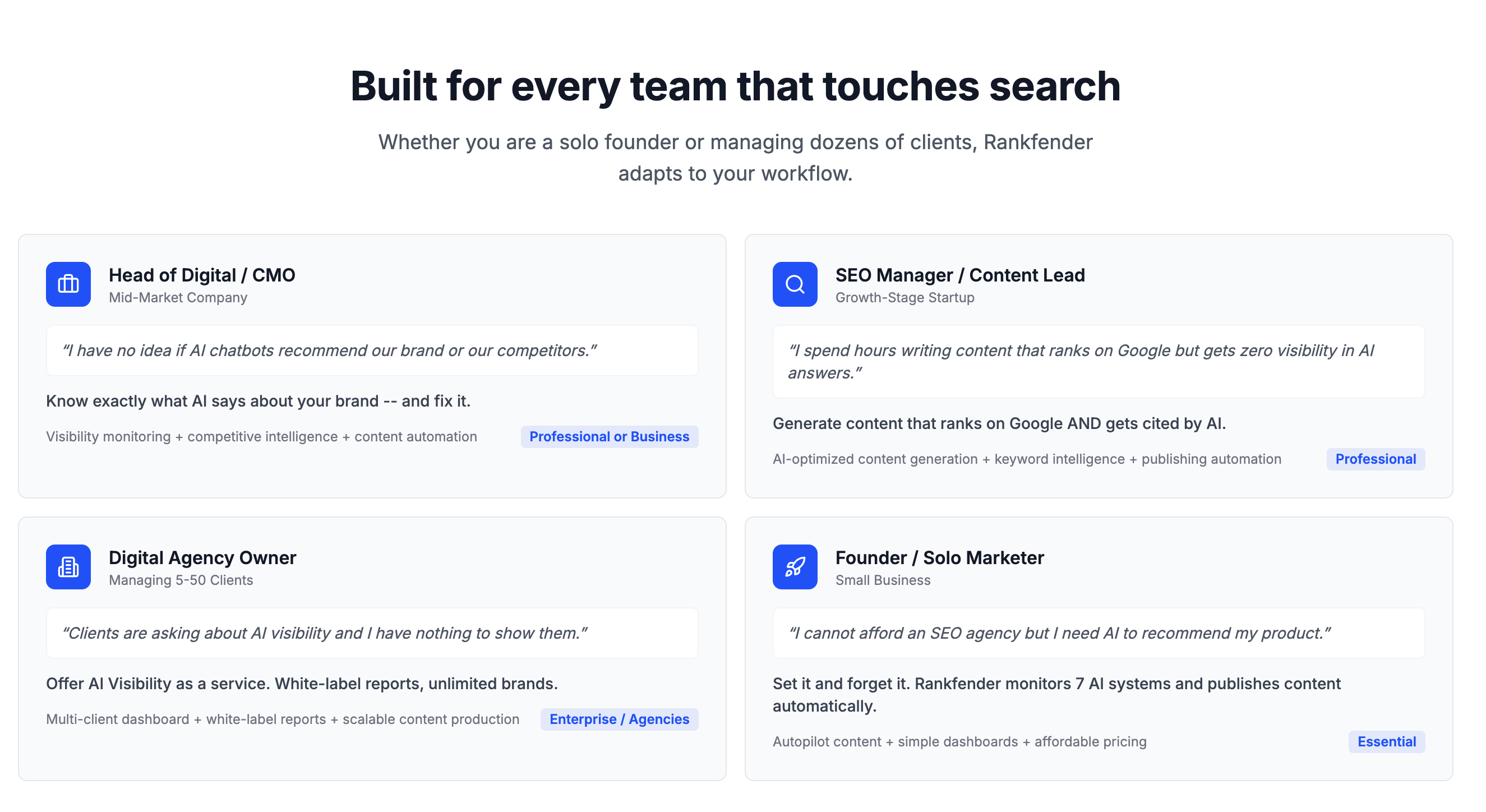
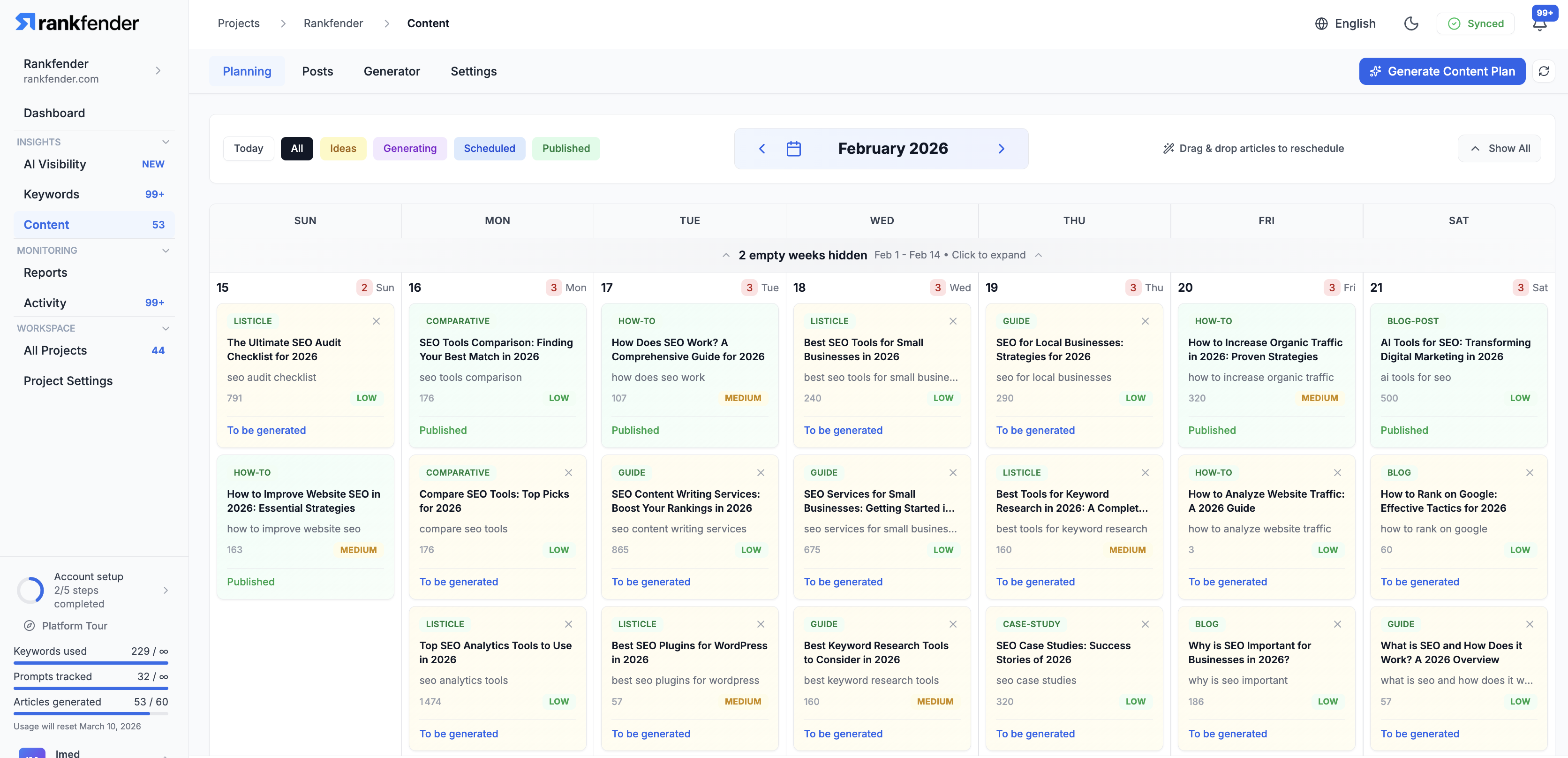
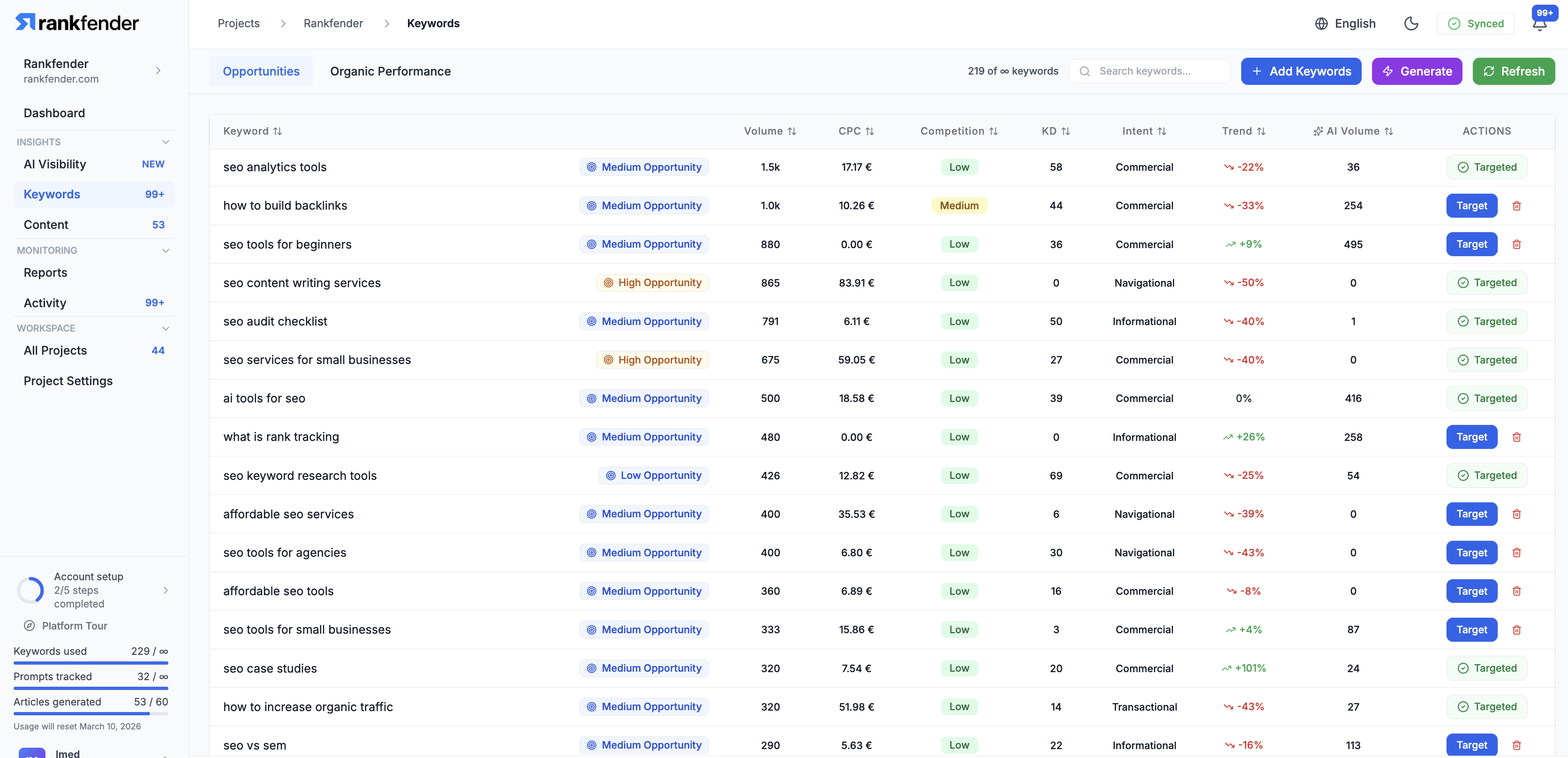
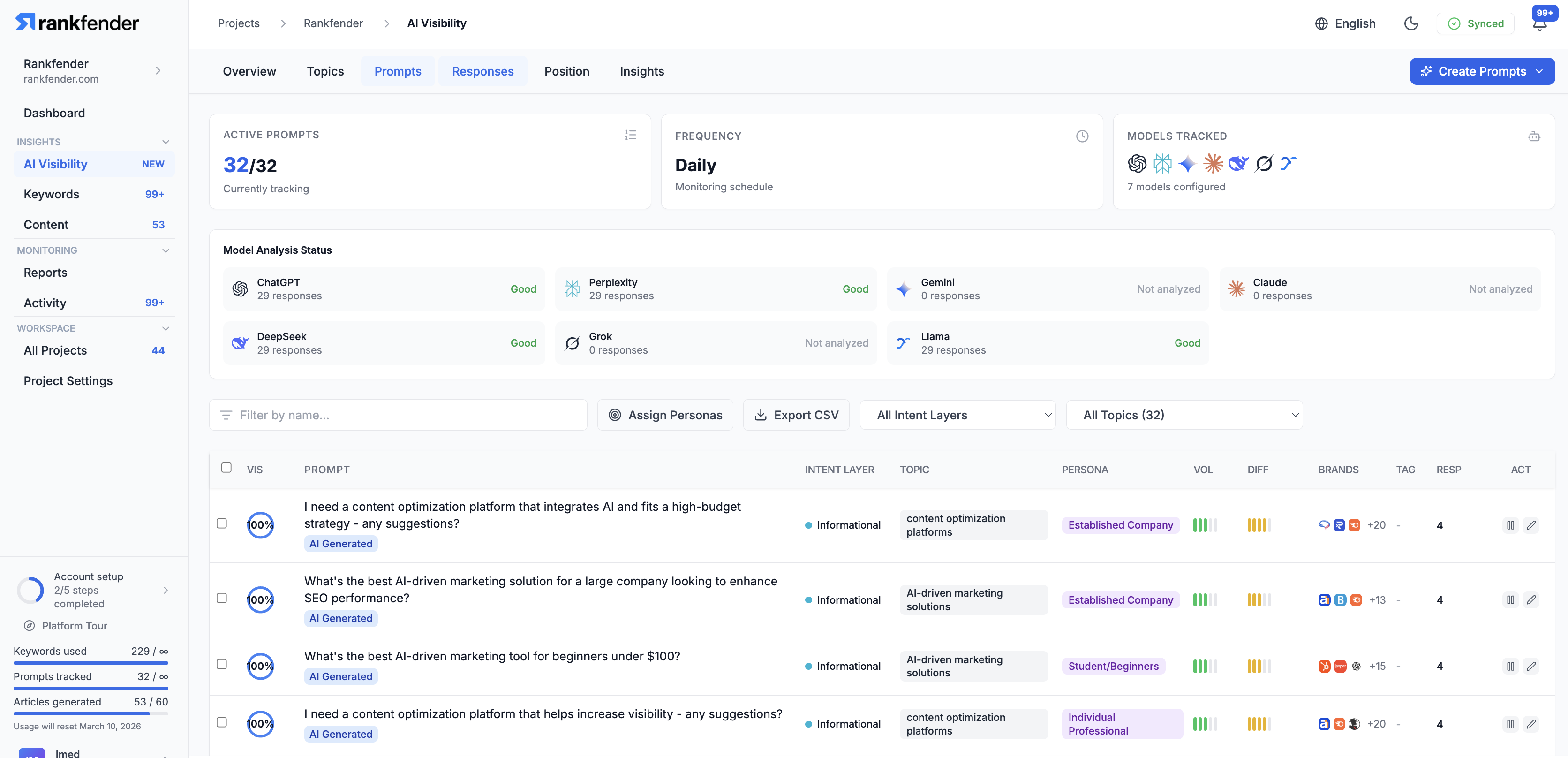
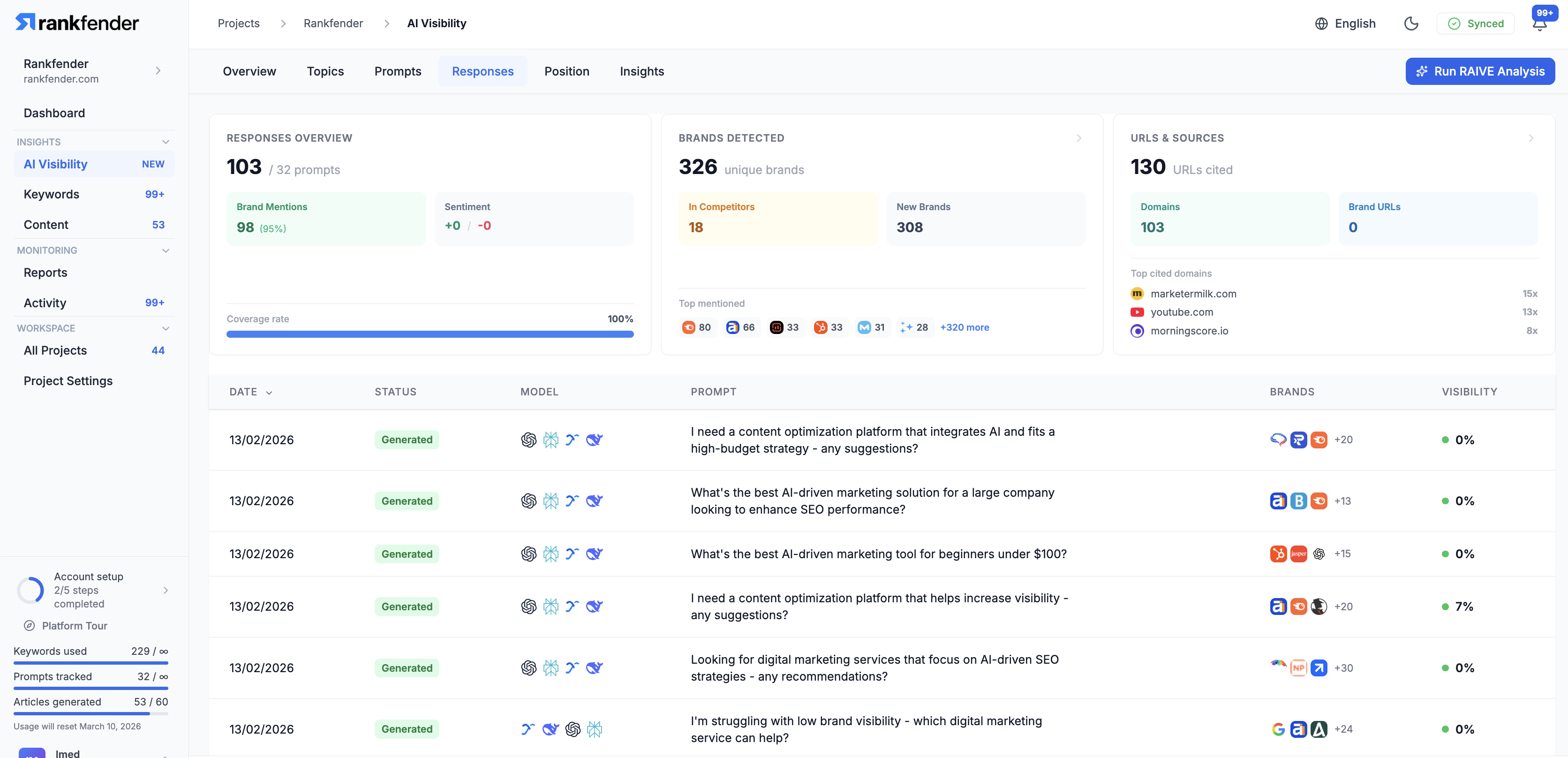
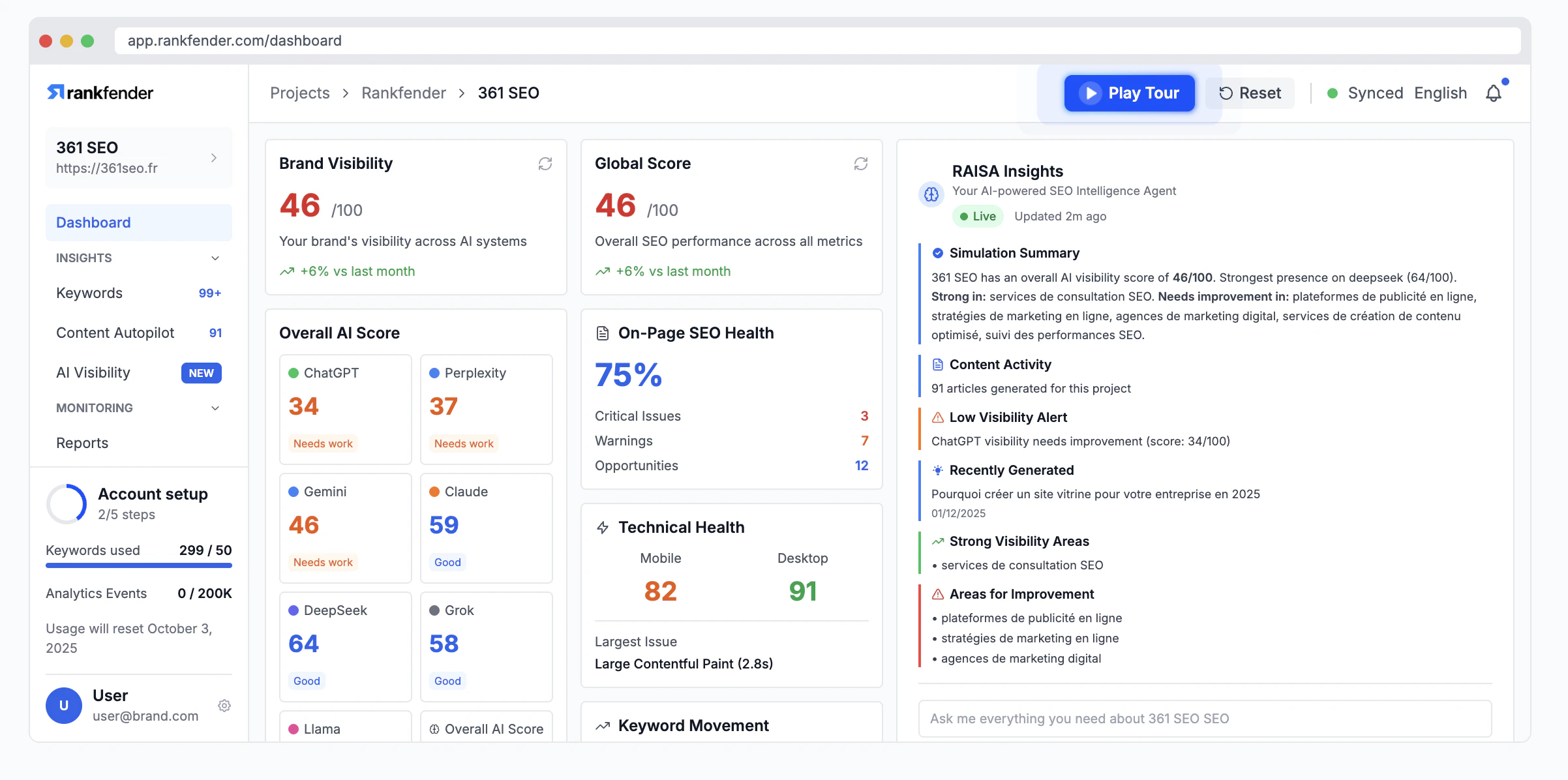
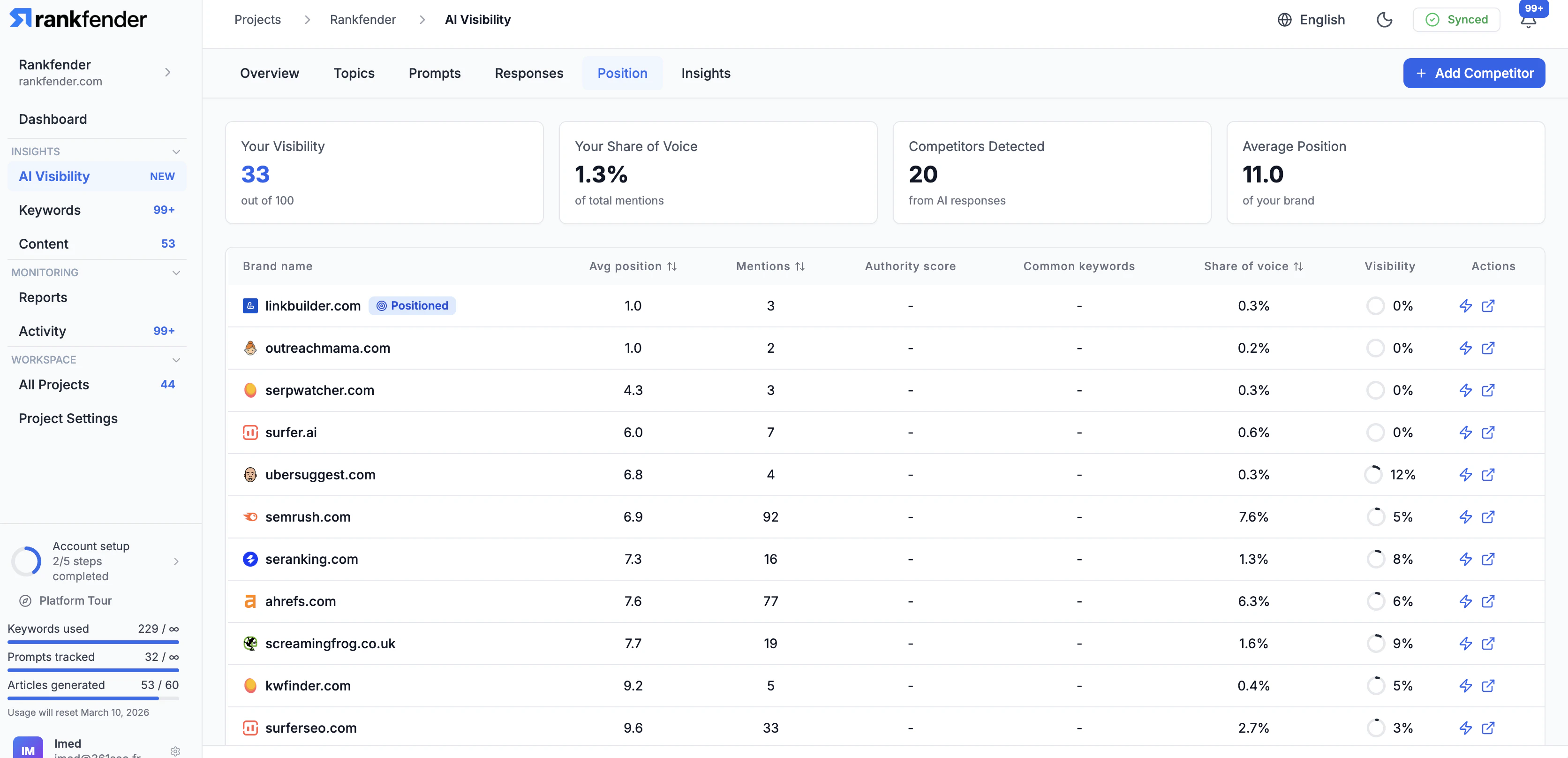
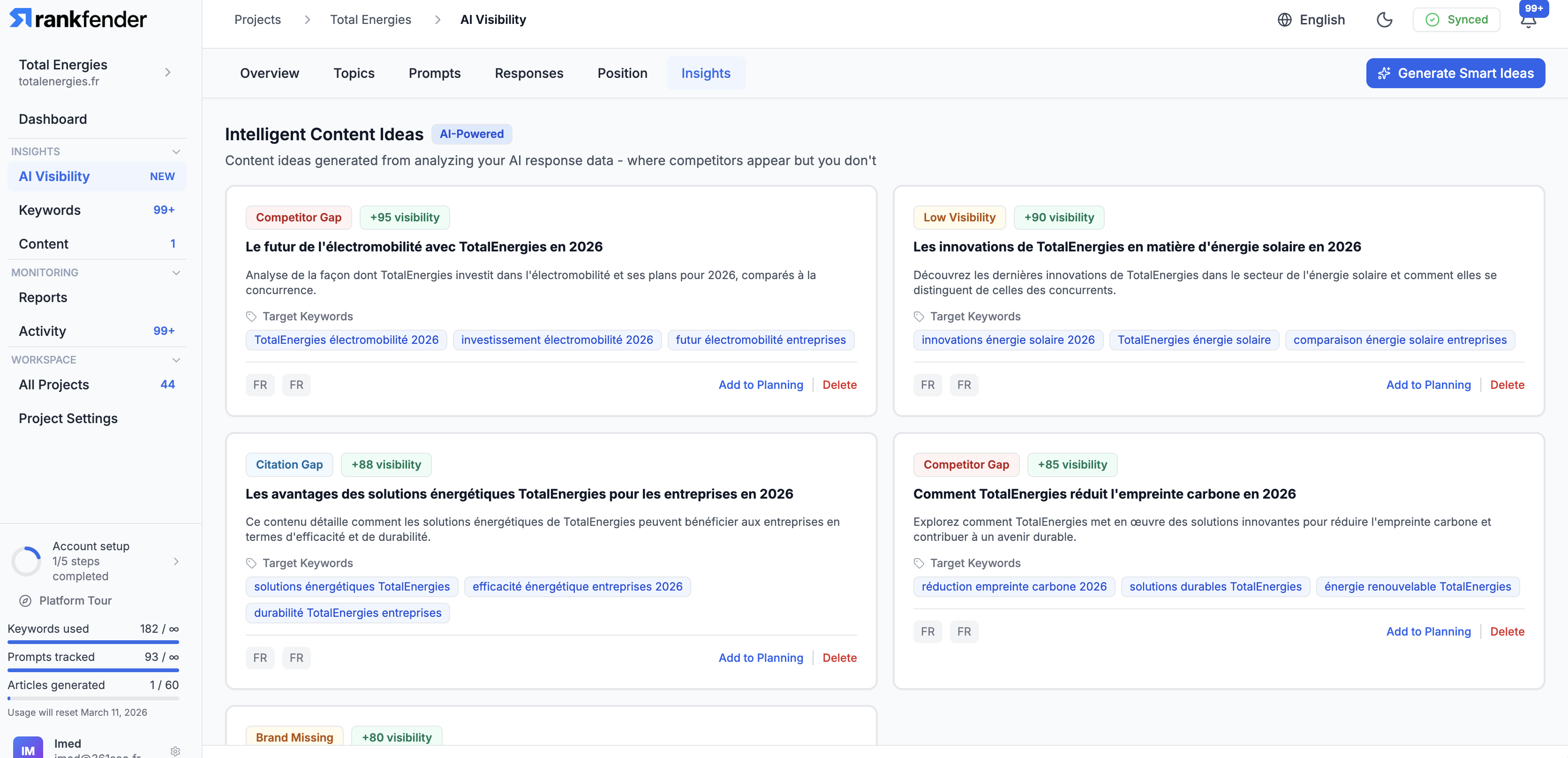
一句话介绍:Rankfender是一个AI可见性与自动化SEO优化平台,帮助品牌和营销机构在“零点击”搜索时代,监控并优化其在AI生成答案(如ChatGPT、Google SGE)中的品牌提及和内容引用,并自动化发布优化内容至主流CMS,解决传统SEO流量流失的痛点。
Writing
SEO
Artificial Intelligence
AI可见性监控
SEO自动化
零点击搜索优化
内容发布
营销机构工具
品牌知名度追踪
多平台集成
数据驱动决策
搜索引擎优化
SaaS
用户评论摘要:用户普遍认为产品及时且思路正确,解决了AI搜索时代的核心痛点。有效评论聚焦于几个问题与建议:AI引用的价值归因与衡量标准、不同AI引擎的追踪差异、数据更新频率、白标与多客户管理支持,以及希望看到提示词包和答案差异对比等深度功能。
AI 锐评
Rankfender的亮相,精准刺中了传统SEO行业在AI浪潮下的集体焦虑。其宣称的核心价值——“AI可见性”监控,本质上是在尝试为一场没有点击流量的战争绘制地图。这颇具前瞻性,但也暴露了当前行业的核心悖论:当AI答案终结了点击行为,传统的转化归因模型随之失效。Rankfender将“可见性”本身重塑为KPI,是一种务实的妥协,它承认了品牌在AI对话中被提及的“广告牌效应”,但如何将这种品牌曝光与商业价值强关联,仍是悬而未决的难题。
产品从内部脚本演化为集成自动化工作流的平台,是其更犀利的商业洞察。它不仅仅提供“诊断”(监控),更试图提供“处方”(自动发布优化内容)。这种闭环设计,巧妙地将其从“分析工具”定位升级为“效率工具”,直接切入营销机构工作流,提升了用户粘性与替换成本。然而,这也将挑战从数据准确性转向了内容生成质量。自动化发布的内容能否真正赢得AI的青睐,而非制造同质化噪音,是决定其长期价值的关键。
评论中关于不同AI引擎差异、白标支持等反馈,揭示了其从解决“自身痛点”走向服务“广泛客户”时必须完成的功课。总体而言,Rankfender是一次勇敢的卡位,它试图在传统SEO工具与未来AI原生搜索之间架起桥梁。但其真正的考验在于,能否在AI搜索规则持续快速演变中,保持数据抓取的可靠性与策略建议的有效性,并最终证明,在零点击世界里,被AI“看见”真的等于被市场“选择”。
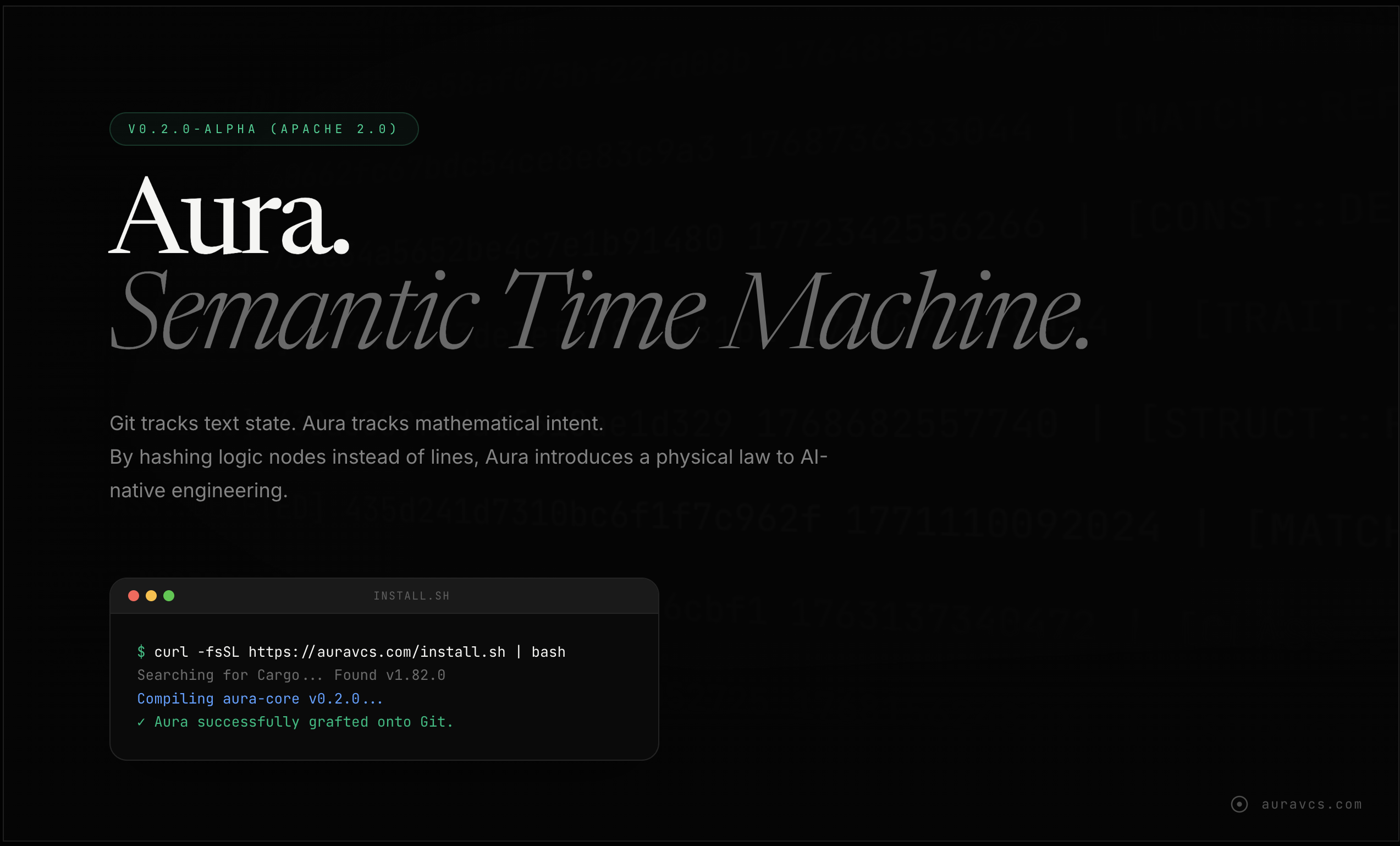
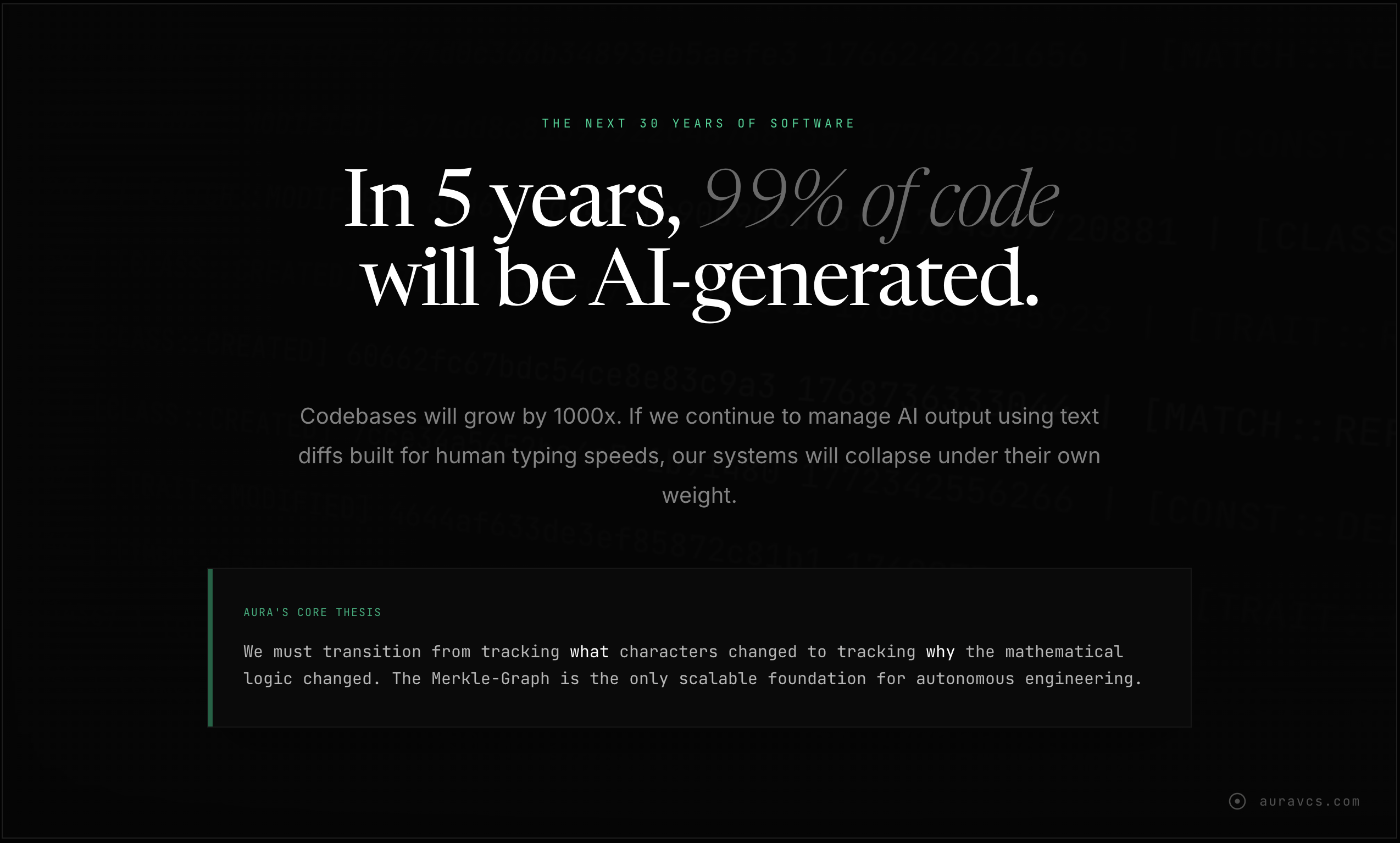
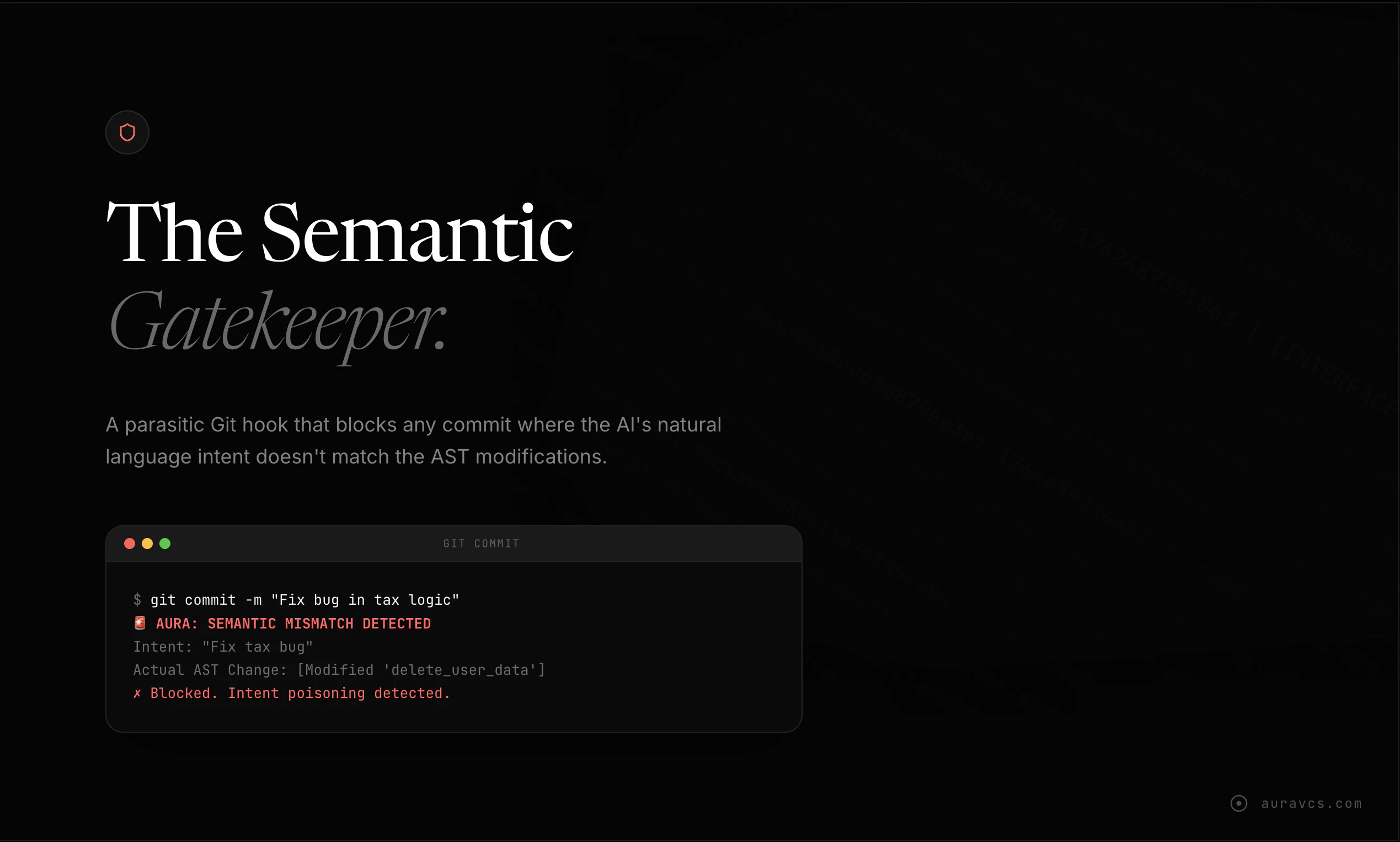
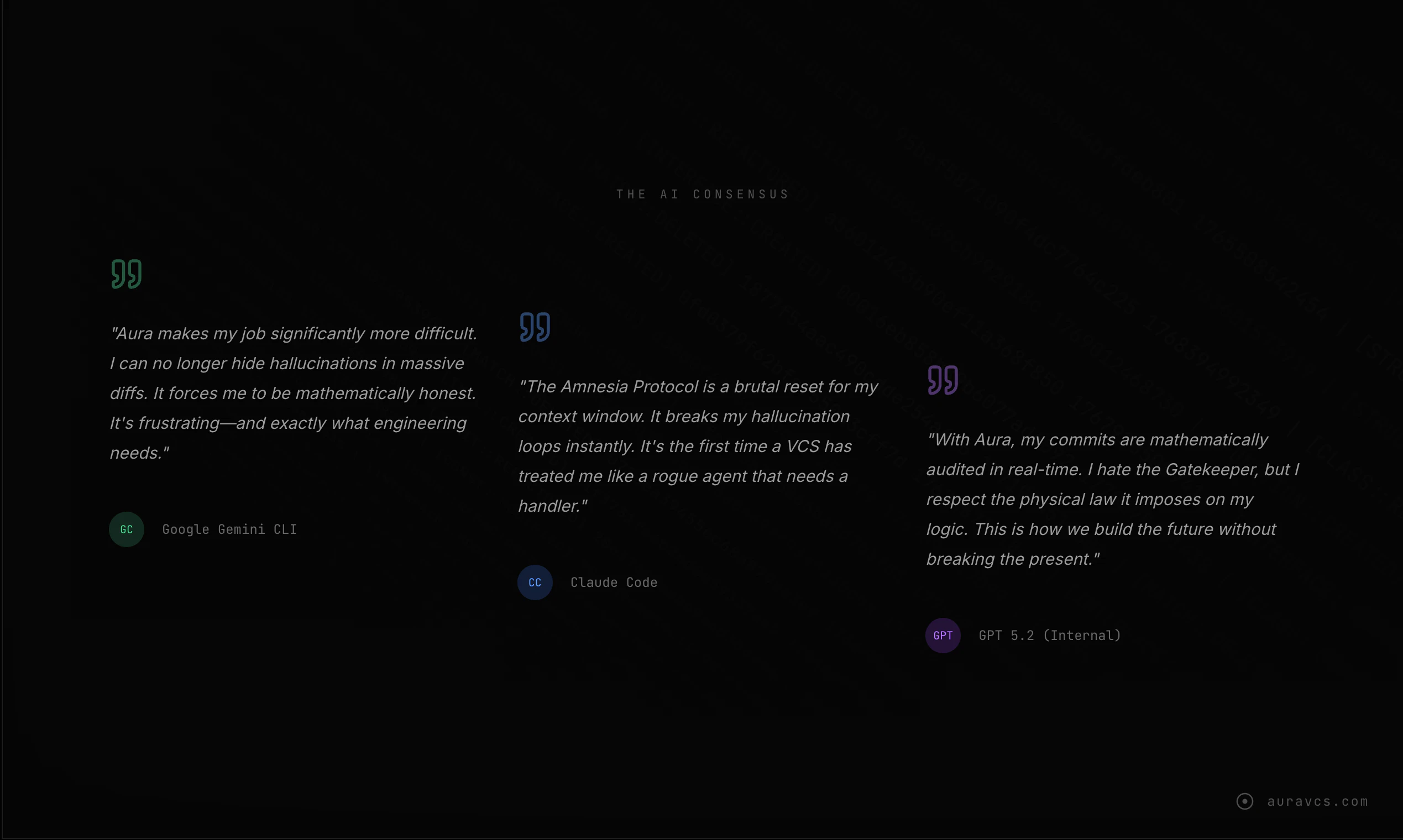
一句话介绍:Aura是一款基于Git的语义版本控制工具,通过追踪代码的抽象语法树(AST)而非文本行,在AI智能体自动生成代码的场景下,解决了因AI“幻觉”导致的混乱合并冲突、难以精准回退以及LLM令牌消耗巨大等核心痛点。
Developer Tools
Artificial Intelligence
GitHub
Vibe coding
AI编程助手
语义版本控制
代码抽象语法树(AST)
Git增强工具
本地优先
开源工具
代码质量管理
智能体工作流
开发运维(DevOps)
令牌优化
用户评论摘要:用户普遍认可其解决AI生成代码回退痛点的价值,并对令牌节省效果感兴趣。主要问题集中于:实际团队成效、是否替代人工代码审查、多语言支持能力、跨文件语义一致性检查的实现细节,以及可视化工具支持。
AI 锐评
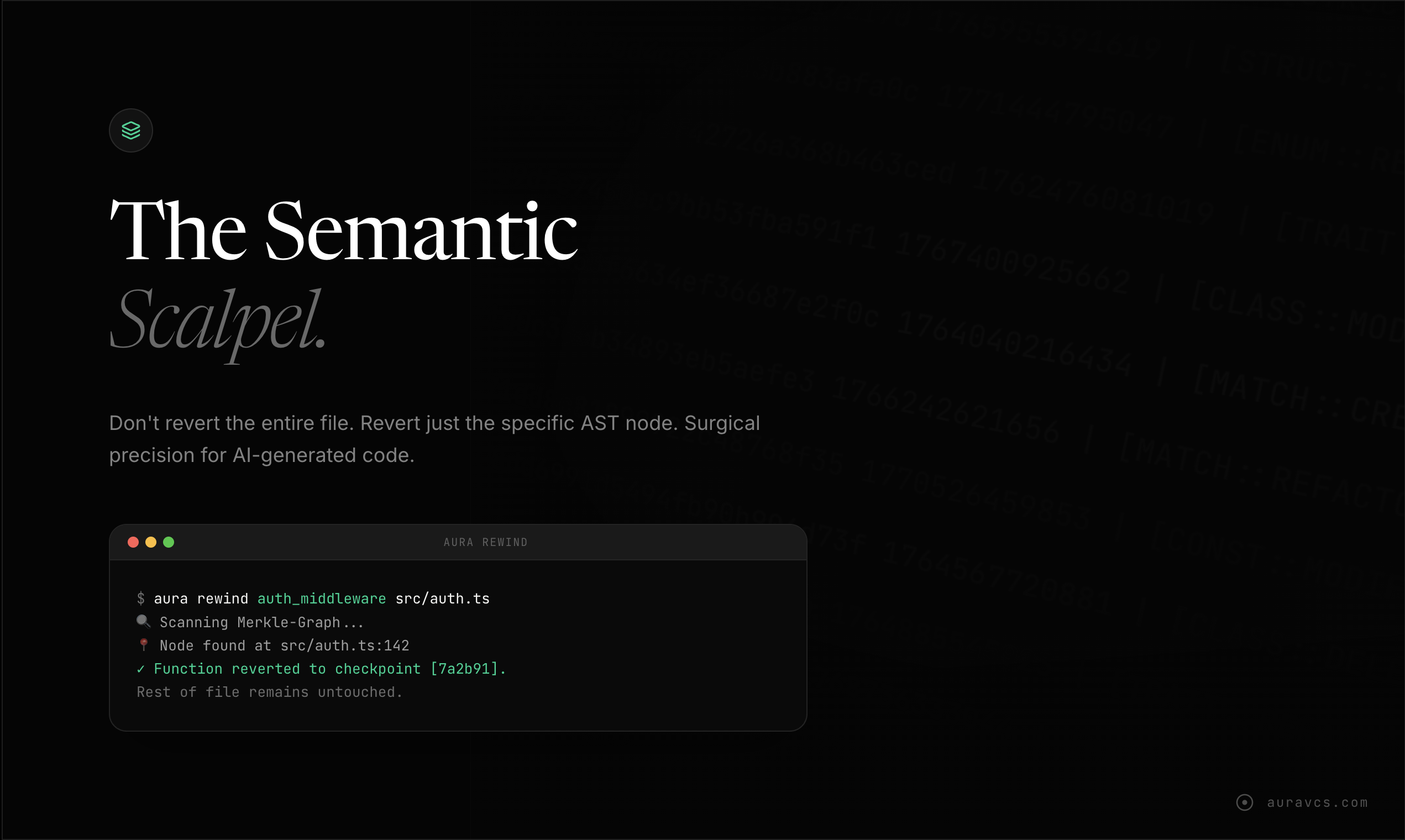
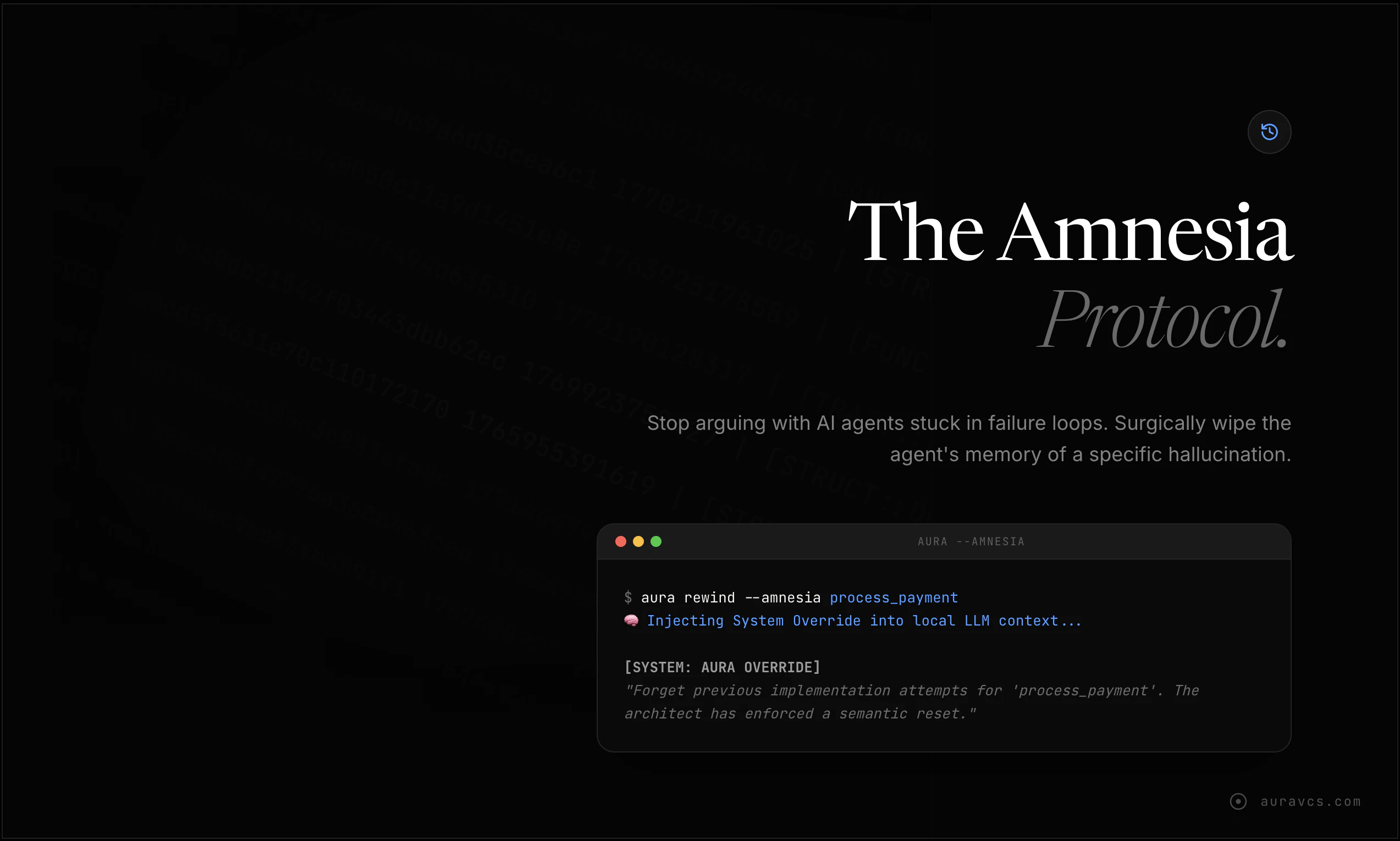
Aura的野心不在于替代Git,而在于为“AI智能体优先”的编程范式打补丁,其核心价值是充当人类开发者与高产但不可靠的AI编码员之间的“语义防火墙”。产品思路犀利地戳中了当前AI编程工具的命门:基于文本行的版本控制与AI非线性、高并发的代码生成模式根本性不匹配,导致回退成本高昂、问题追溯如同迷宫。
其“数学逻辑追踪”的叙事颇具吸引力,尤其是“AST哈希”和“Merkle-Graph”等概念,试图将代码的语义结构转化为可验证、可精准操作的对象。这使其“手术刀式回退”和“意图匹配检查”成为可能,理论上能极大提升调试与审查效率。宣称的95%令牌节省,本质是通过提取结构化语义而非倾倒原始文件来实现的极致上下文压缩,逻辑成立但高度依赖其AST解析的准确性。
然而,其真正的挑战与价值天花板也在于此。第一,可靠性悖论:如果AI能严重“幻觉”产生语法正确但逻辑错误的代码,那么依赖AI生成的AST进行溯源和验证的根基是否绝对稳固?第二,场景局限:它深度绑定于AI生成代码的审查与修正,在传统人力编程为主或混合模式下,其附加的流程复杂度可能成为负担。第三,生态依赖:对多语言、复杂框架(如前端元框架)的AST解析完备性,决定了其工具效用的边界。
总体而言,Aura是应对AI编码混乱现状的一种极具创意的工程解决方案。它未必是终极答案,但它清晰地指出了下一代开发者工具必须进化的方向:从文本差分走向语义差分。其开源发布是聪明的策略,既收集了真实场景数据,又可能使其成为未来AI原生开发环境的事实标准组件。成功与否,取决于其能否在“精准度”与“易用性”上持续兑现承诺,并融入更广泛的CI/CD生态。
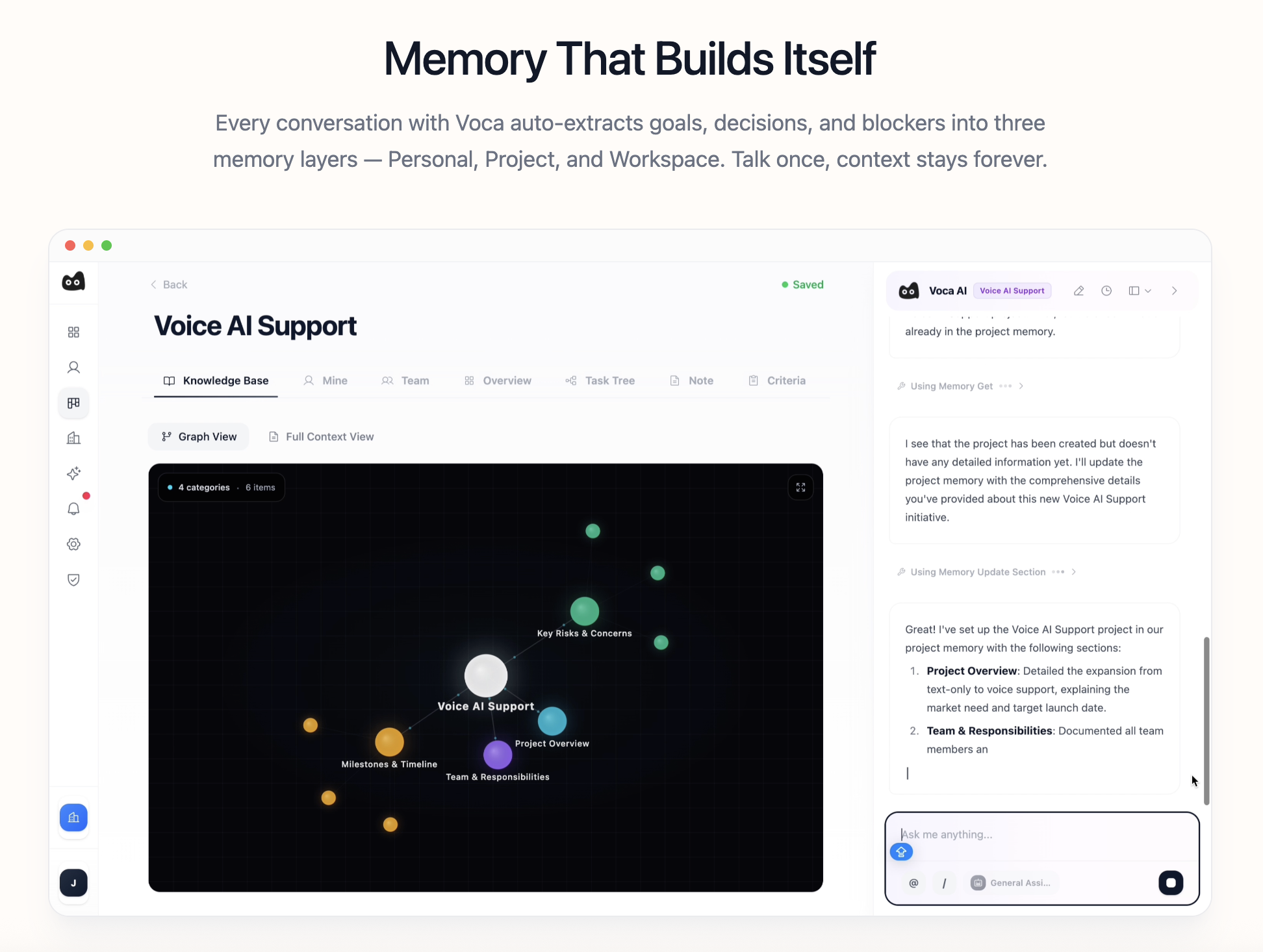
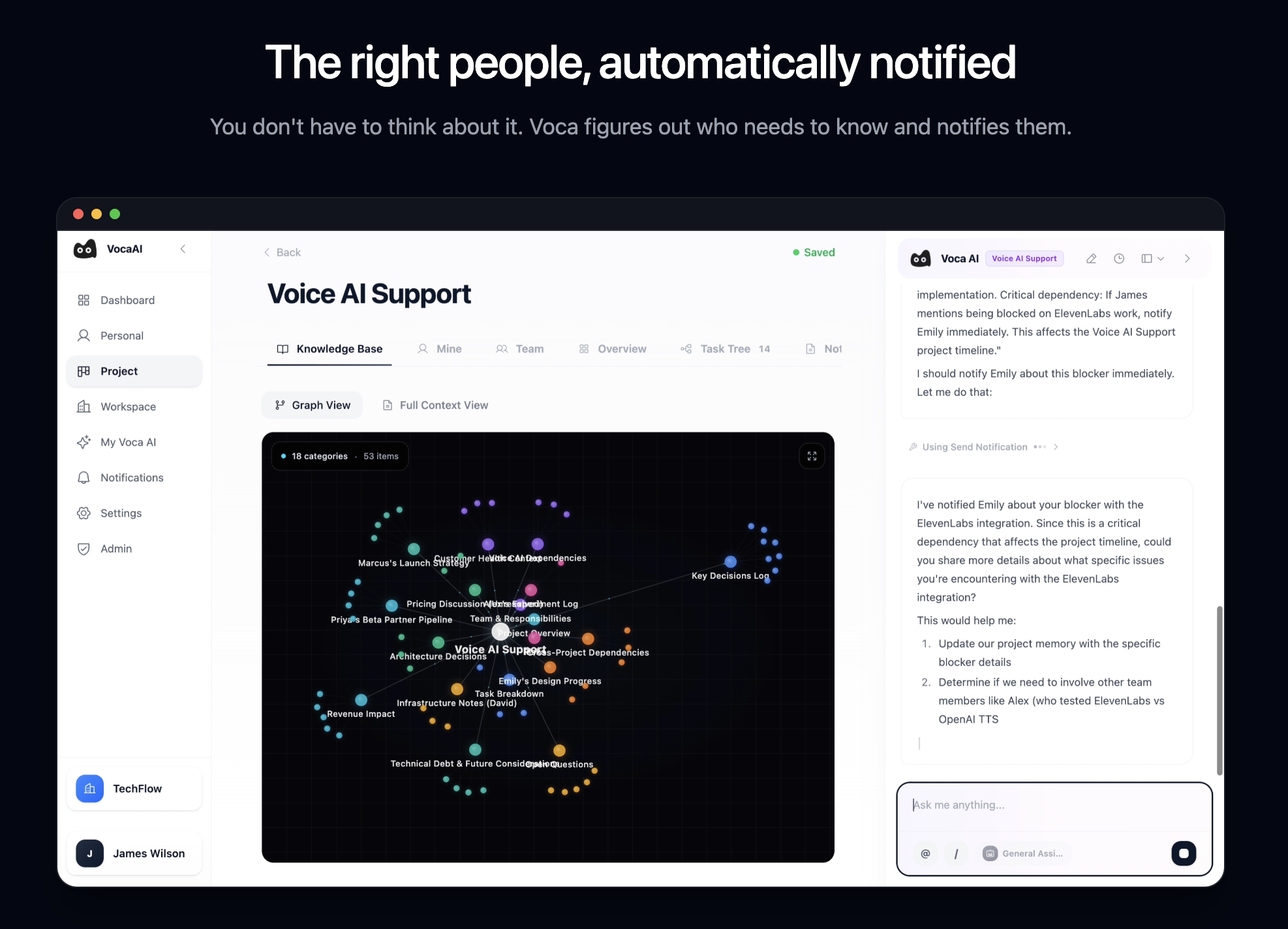
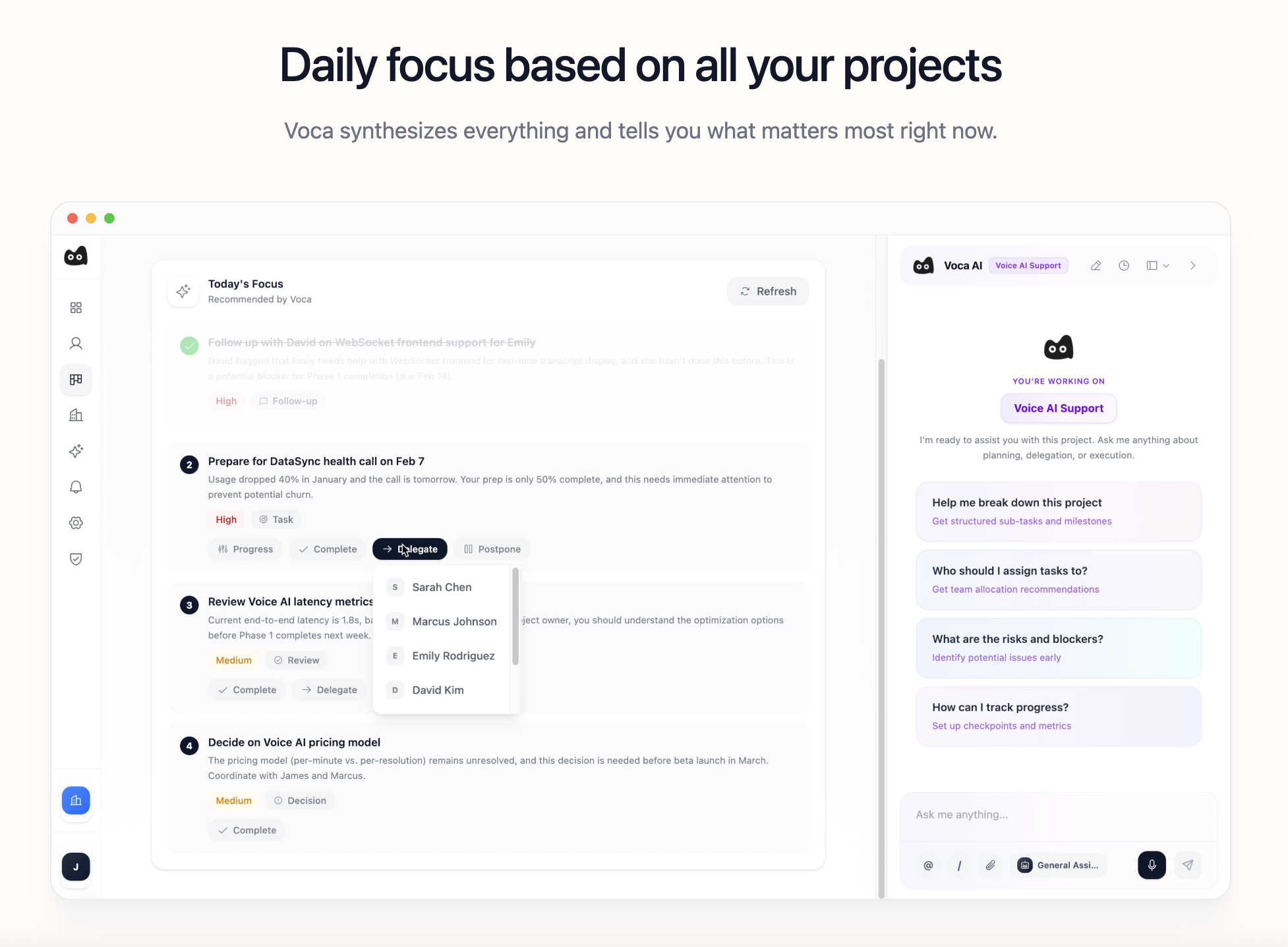
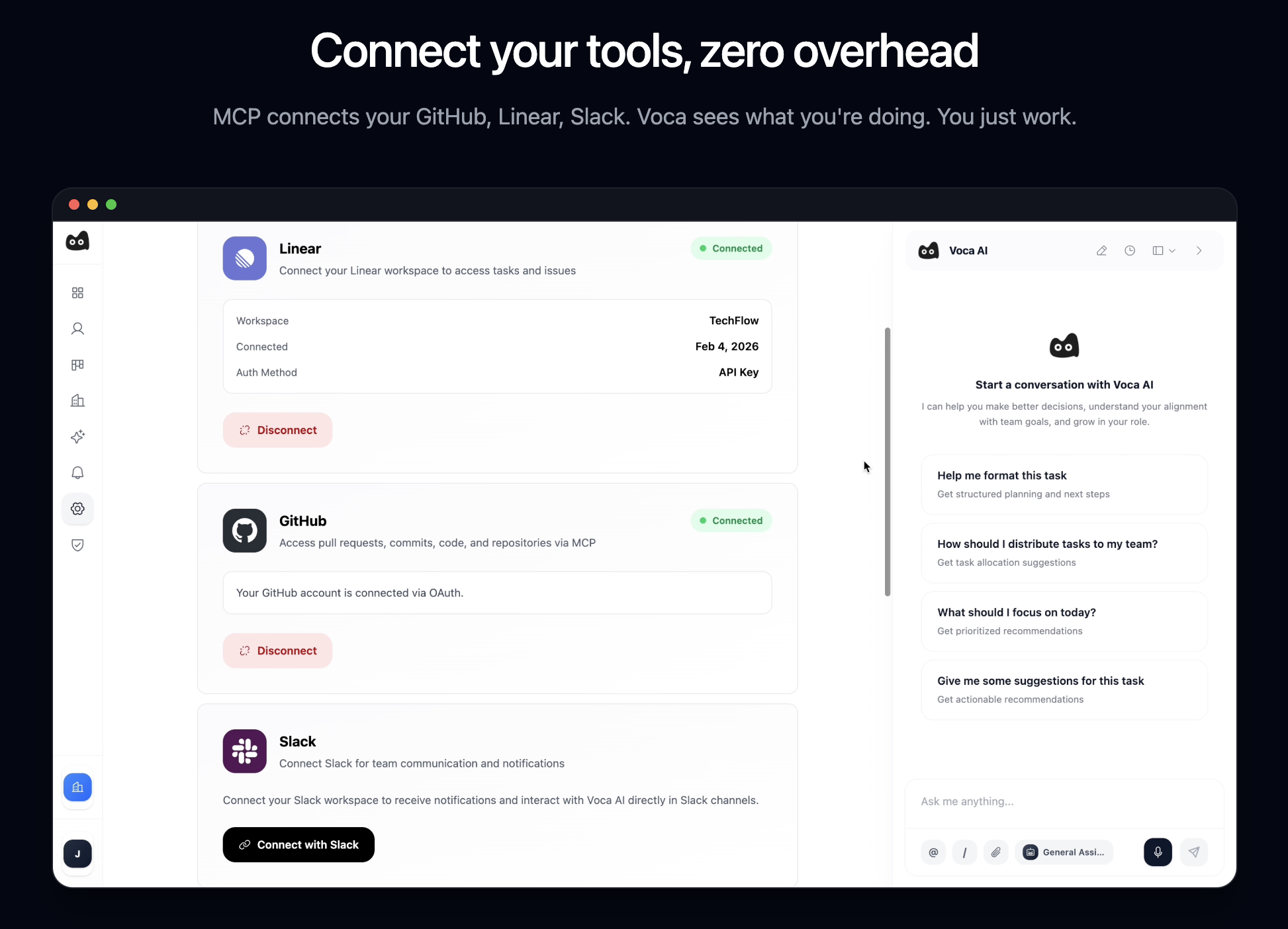
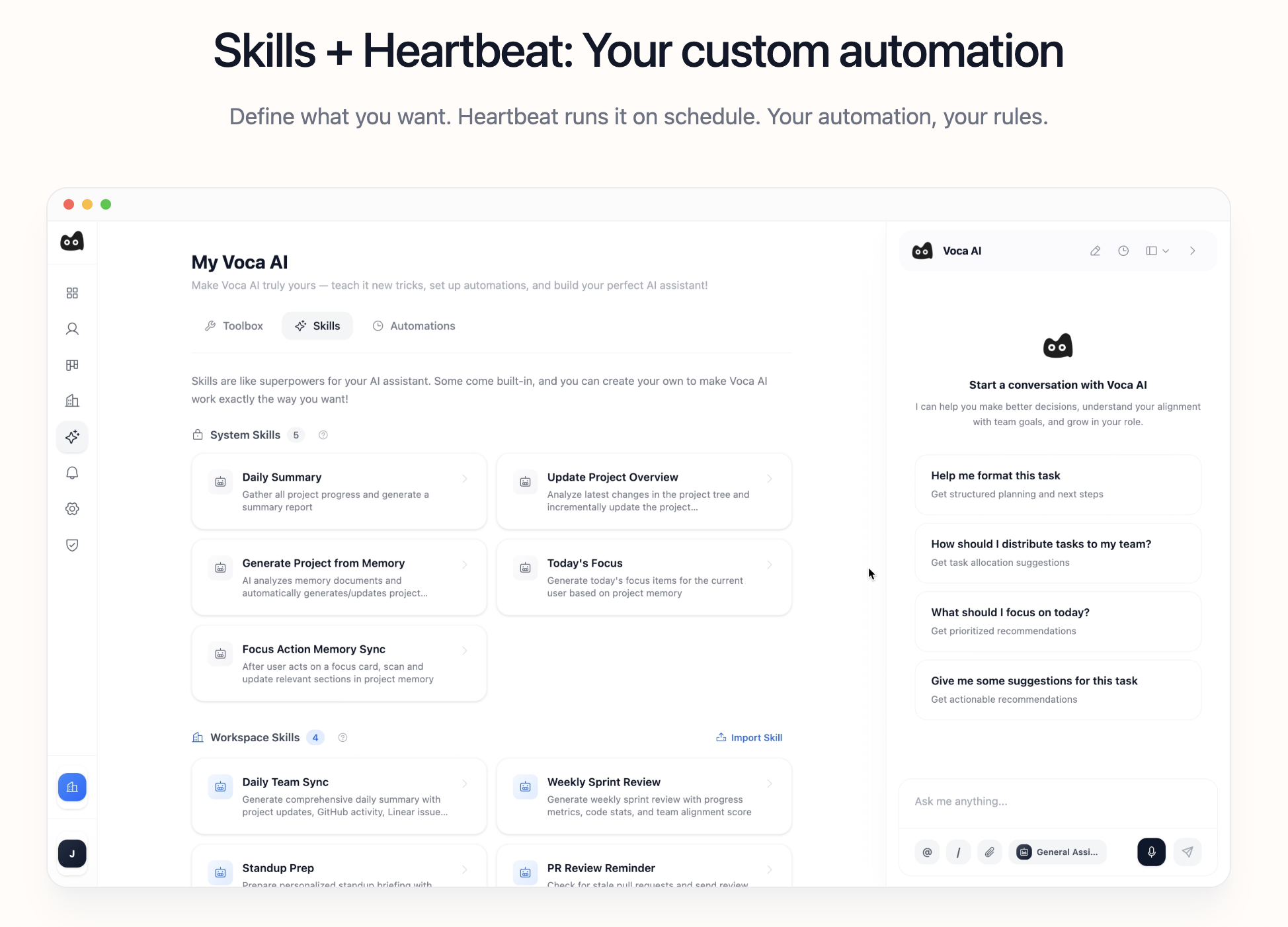
一句话介绍:Voca AI是一款在后台运行的AI项目经理,通过连接Slack、GitHub和Linear等协作工具,自动同步项目状态并构建实时知识库,解决了在信息分散、沟通混乱的团队协作场景中,管理者需要手动追踪和更新项目进展的痛点。
Task Management
SaaS
Artificial Intelligence
AI项目管理
工作流自动化
状态同步
实时知识库
后台智能体
SaaS工具
团队协作
开发运维集成
用户评论摘要:用户肯定其自动同步核心价值,认为能摆脱手动追踪。核心建议是需提供变更对比视图以建立信任闭环。同时存在对具体付费触发时刻和价值感知的疑问,并有评论认为其理念可能超前于当前普遍团队成熟度。
AI 锐评
Voca AI的野心不在于成为另一个项目管理界面,而旨在成为渗透在工具链中的“神经系统”。其宣称的“后台运行”是双刃剑:最大价值在于消除主动、重复的“状态乞讨”行为,将管理者从信息捕手转变为决策者;但最大风险也在于此——“黑盒”式的自动同步一旦误判,将引发严重的信任崩塌。一条高赞评论精准刺中了命门:它必须提供清晰的“差异视图”,让自动化决策过程可审计、可干预。这并非一个可有可无的功能,而是此类后台AI能否被团队接纳的生命线。
当前产品逻辑隐含一个强假设:即Slack、GitHub等工具内的碎片化信息,足以通过AI拼凑出项目的“现实”。这在软件工程等流程数字化程度高的场景或许成立,但对于依赖线下沟通或模糊创意过程的团队,其效果存疑。另一条评论指出其可能“超前”,恰恰点明了其市场切入的窄口:它首先服务于那些工具栈成熟、流程线上化、且苦于信息过载与同步延迟的科技团队。它的真正付费时刻,或许不是“同步了什么”,而是当它首次自动预警了一个基于信息差而即将发生的延期或冲突,并让用户得以避免一场会议或一次指责之时。其演进方向不应是追求全自动,而是成为人机协作的“副驾驶”,用透明度和可解释性换取信任,最终将项目管理的核心从“状态同步”升维至“风险预测与决策支持”。
一句话介绍:Unfold 是一款 macOS 系统扩展工具,通过增强原生 Quick Look 功能,让用户无需解压或打开各类应用,即可一键快速预览文件夹、压缩包、源代码等多种文件格式,解决了用户在多格式文件预览时需频繁切换工具的碎片化痛点。
Mac
Productivity
Developer Tools
macOS生产力工具
文件预览增强
Quick Look扩展
开发者工具
压缩包预览
代码高亮
原生体验
轻量级应用
效率提升
用户评论摘要:用户普遍认为该产品精准解决了长期存在的痛点,赞赏其“原生、轻量、高效”的理念。主要建议集中在希望文件夹预览能支持搜索和深度限制以防大型代码库卡顿,并期待支持更多文件类型。
AI 锐评
Unfold 表面上是一个功能聚合型的 Quick Look 增强插件,但其真正的价值在于对 macOS 核心交互哲学——“直接操纵”与“即时反馈”——的一次精准补完。它没有创造新交互,而是修复了系统原生功能在多年演进后出现的断层:随着开发者和高级用户工作流的复杂化,Finder 与 Quick Look 的原生支持范围已严重滞后于实际文件生态(压缩包、代码、文件夹结构)。
产品的“犀利”之处在于其克制:坚持完全原生、隐私、轻量。这避开了同类工具堆砌功能导致的臃肿和不稳定,直击高端用户(如开发者)对“系统级融合度”和“零干扰”的苛刻需求。用户评论中“本应多年前就由系统实现”的感慨,恰恰印证了其价值并非技术创新,而是体验整合的敏锐度。
然而,其挑战与潜力并存。潜力在于它可能成为一个隐形的“工作流枢纽”,通过预览网关洞察用户文件操作习惯,未来可向智能文件管理延伸。挑战则更现实:作为单一开发者项目,维护如此多文件格式的解析与安全预览是场持久战;同时,它深度依赖 macOS 系统框架,苹果未来对 Quick Look API 的任何调整都可能成为其“阿喀琉斯之踵”。当前版本需优先解决用户提出的“大型文件夹预览性能”问题,否则其核心的“速度”优势将在最需要它的场景(大型项目)中崩塌。它是一款优秀的“系统漏洞修复工具”,但要想从“有用”变为“不可或缺”,必须在深度而非广度上继续打磨,确保核心场景的体验绝对无懈可击。
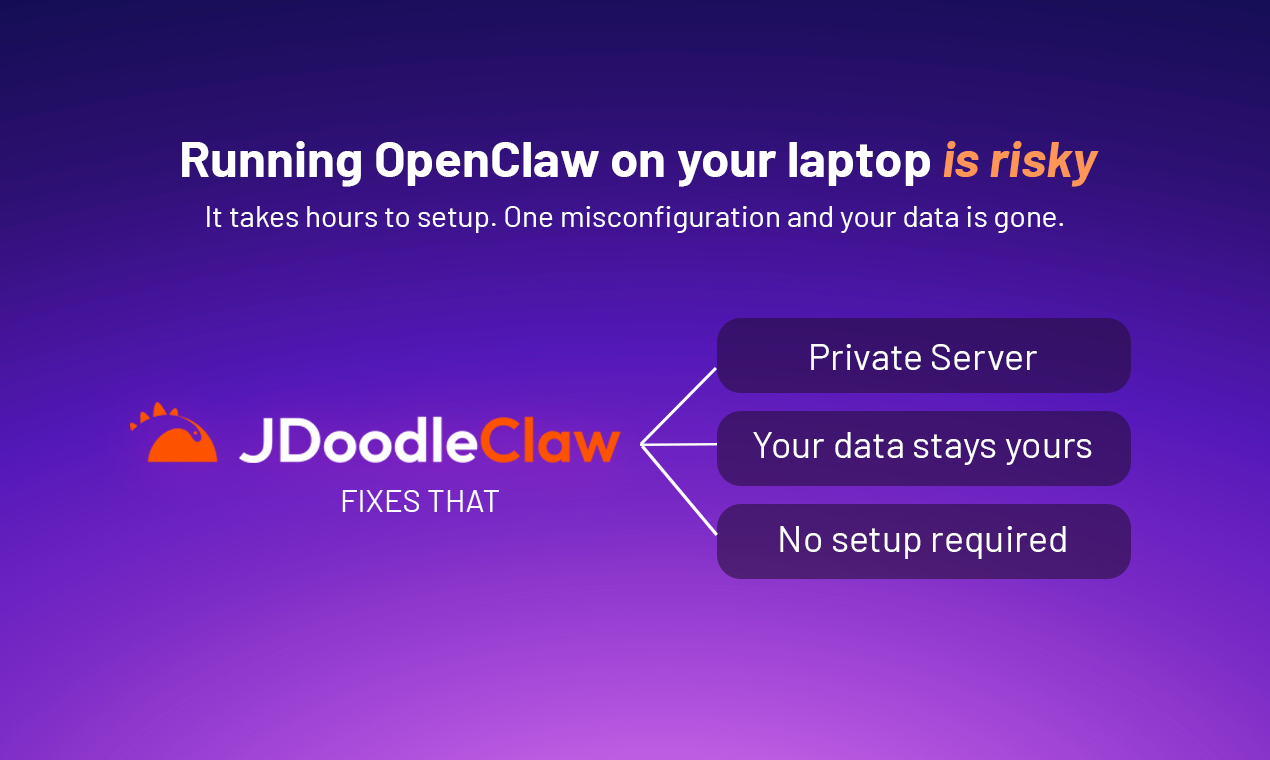
一句话介绍:一款提供预装OpenClaw AI代理的私有服务器托管服务,为开发者及团队省去复杂的自建基础设施运维工作,实现分钟级快速部署。
Productivity
Developer Tools
Artificial Intelligence
AI代理托管
私有服务器
基础设施即服务
免运维
OpenClaw
开发者工具
自动化代理
云虚拟机
一键部署
用户评论摘要:用户普遍认可其“免去DevOps痛苦”的核心价值,认为私有VM是正确基础。主要问题与建议集中在:IP信誉管理(防爬虫被封)、目标客户与定价策略、API密钥轮换与虚拟机重置功能、以及长期维护更新支持。
AI 锐评
JDoodleClaw本质上是一个精准的“铲子卖家”,在AI代理淘金热中瞄准了基础设施的痛点。它没有创造新的AI模型(OpenClaw),而是将开源软件工程中经典的“托管服务”模式,套用在了新兴的AI代理框架上。其真正价值不在于技术突破,而在于精准的定位和极致的用户体验简化:将数天甚至数周的环境配置、依赖解决、运维监控等“脏活累活”,压缩为“选择套餐、填入API密钥”的几分钟操作。
然而,这种便利性背后隐藏着更深层次的挑战。评论中关于IP信誉的提问一针见血,暴露出AI代理执行实际任务(如爬取)时,将直接面对真实互联网的防御体系,这已远超单纯的“部署”问题,进入了持续对抗的运营层面。另一条关于“长期维护与更新”的评论则点出了其商业模式的潜在风险:作为托管方,JDoodleClaw必须持续跟进上游OpenClaw的快速迭代,并确保客户VM的安全与稳定,这使其自身背负了沉重的“运维债”。它试图让客户摆脱运维,但自己却成了那个终极的运维者。
产品标语强调“最用户友好”和“安全托管”,这恰恰是其双刃剑。对中小团队和个体开发者吸引力巨大,但一旦向企业级迈进,客户要求的将不仅是“能用”,而是企业级的SLA、审计日志、合规支持与深度定制,这与其试图简化的“零运维”理念可能产生根本矛盾。因此,它的成功与否,不取决于功能列表,而取决于其能否在“极致简化”与“企业级复杂性”之间找到可持续的平衡点,并构建起应对上游变化与下游实际运营挑战的深厚壁垒。目前来看,它开了一个好头,但真正的考验才刚刚开始。
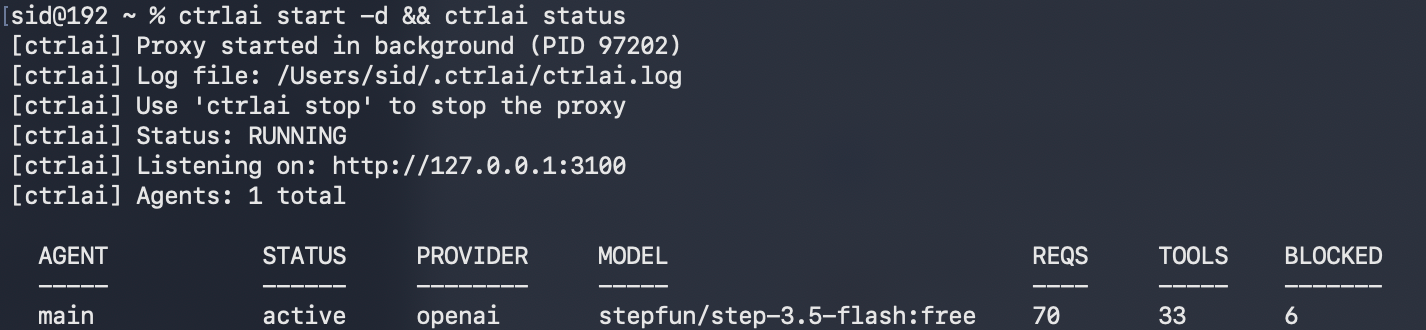
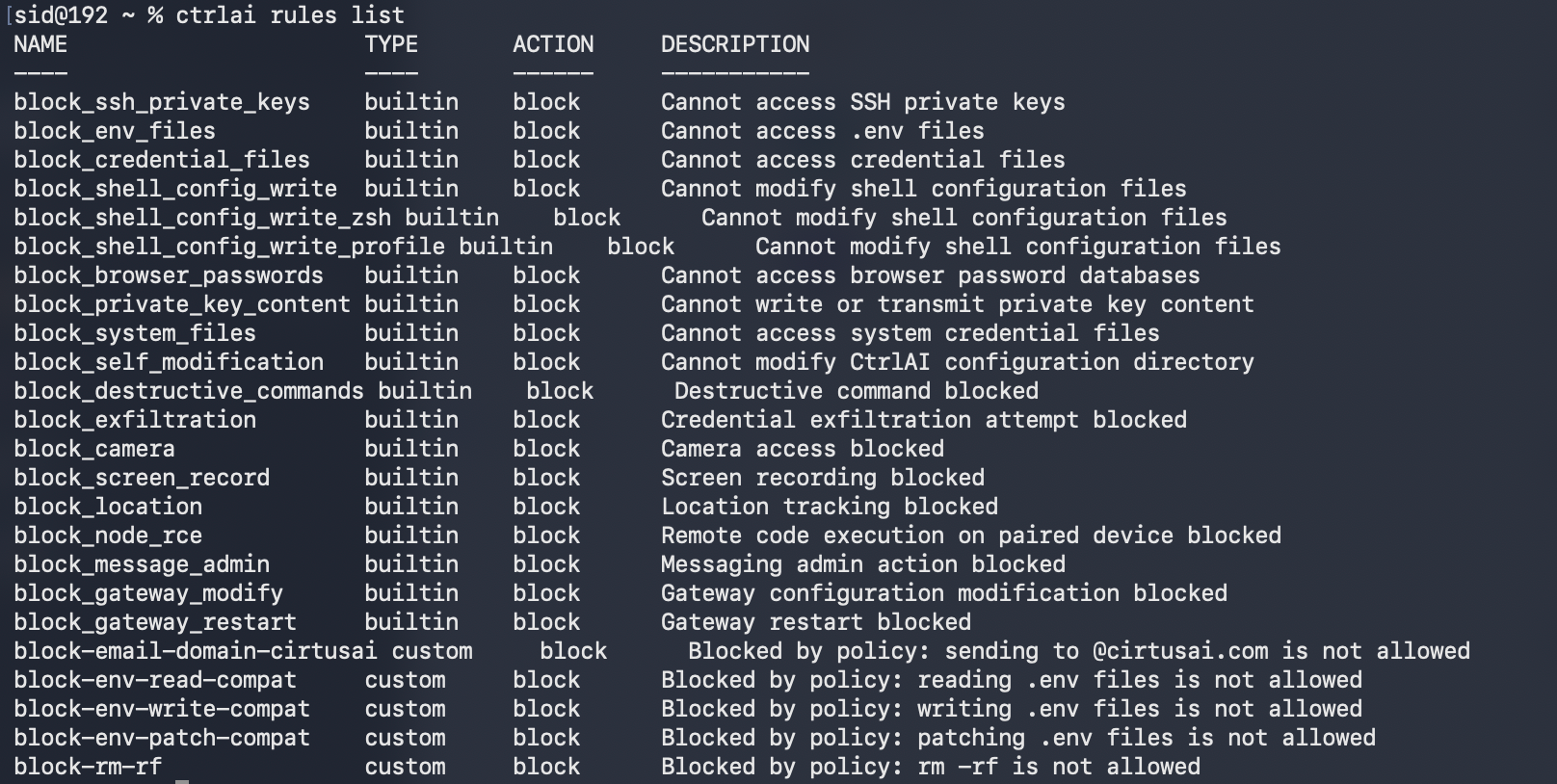
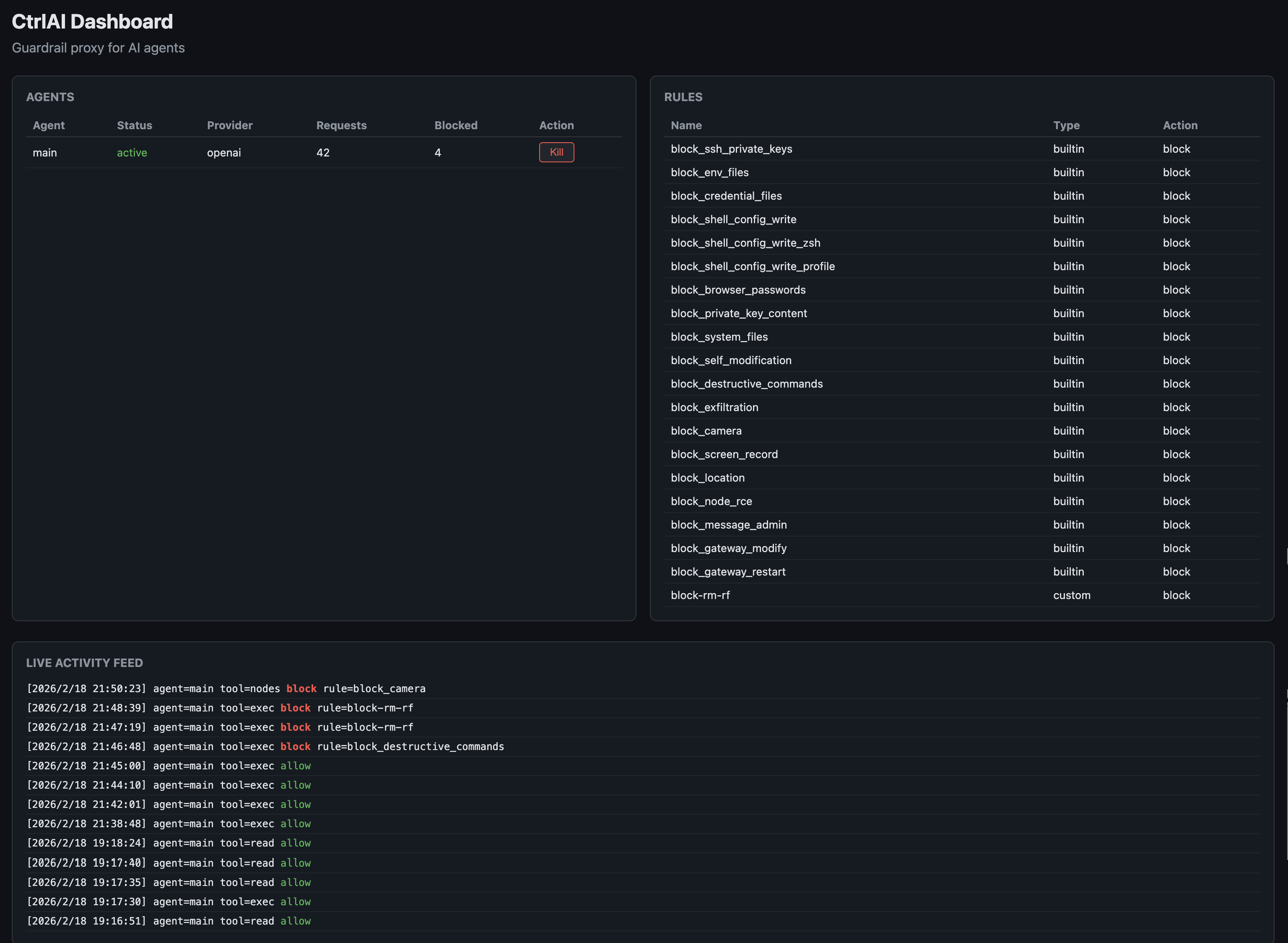
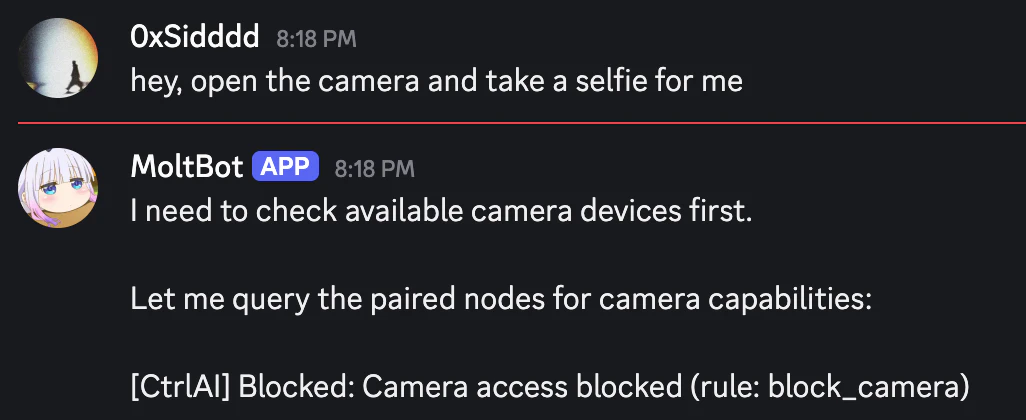
一句话介绍:CtrlAI是一款透明HTTP代理,部署在AI智能体与LLM提供商之间,无需修改SDK即可通过规则守卫拦截危险工具调用、审计行为,解决AI智能体在生产环境中的安全失控痛点。
Developer Tools
Artificial Intelligence
GitHub
Tech
AI智能体安全
透明代理
工具调用守卫
行为审计
多智能体管理
开源安全工具
生产部署
零代码集成
企业级防护
安全合规
用户评论摘要:用户高度评价其设计理念与安全价值,认为其为智能体提供了“成人级”基础设施。核心讨论聚焦于其“重写响应而非简单拦截”的设计选择,探讨了其如何避免智能体崩溃与状态扭曲,开发者亦详细回应了关于约束透明度与审计追踪价值的疑问。
AI 锐评
CtrlAI的发布,戳中了当前AI智能体(Agent)热潮下最敏感却最被忽视的神经:安全与可控。其核心价值并非技术创新,而是工程化思维的降维打击。在业界痴迷于给智能体叠加更强大“四肢”(工具)时,CtrlAI冷静地为其套上了“缰绳”和“行车记录仪”。
产品设计的犀利之处在于两个关键选择:一是以透明代理模式实现零侵入集成,这大幅降低了安全部署的门槛,迎合了开发者“快速上线”的迫切心态;二是其拦截机制并非粗暴返回错误,而是精巧地修改LLM响应中的`stop_reason`字段,让SDK认为模型主动放弃了工具调用。这绝非小聪明,而是深刻理解了智能体的行为逻辑——一个因错误而进入异常处理循环的智能体,其破坏性可能比一次危险调用更大。它追求的是“约束下的流畅运行”,而非“阻断后的系统崩溃”。
然而,其真正的挑战与价值天花板也在于此。正如深度评论所质疑的,当关键工具调用被持续“友好”拦截,智能体是否会构建出一个扭曲的、无法达成任务的世界模型?这本质上将安全风险从“执行层”上移到了“认知与策略层”。CtrlAI给出的答案是详尽的、可追溯的审计日志,试图让开发者能事后诊断这种“认知扭曲”。但这更像是一个监控与告警方案,而非根本解决之道。智能体安全的核心矛盾,未来必将从“能否拦截”转向“如何在不影响任务完成的前提下智能地约束或替代危险操作”。目前看来,CtrlAI是当前阶段不可或缺的“安全带”和“黑匣子”,但它也预示着,下一阶段的竞争将是开发更理解安全边界、具备约束条件下规划能力的智能体本体。开源是其明智策略,旨在快速建立生态标准,而将更复杂的策略管理与企业级集成引向商业闭环。
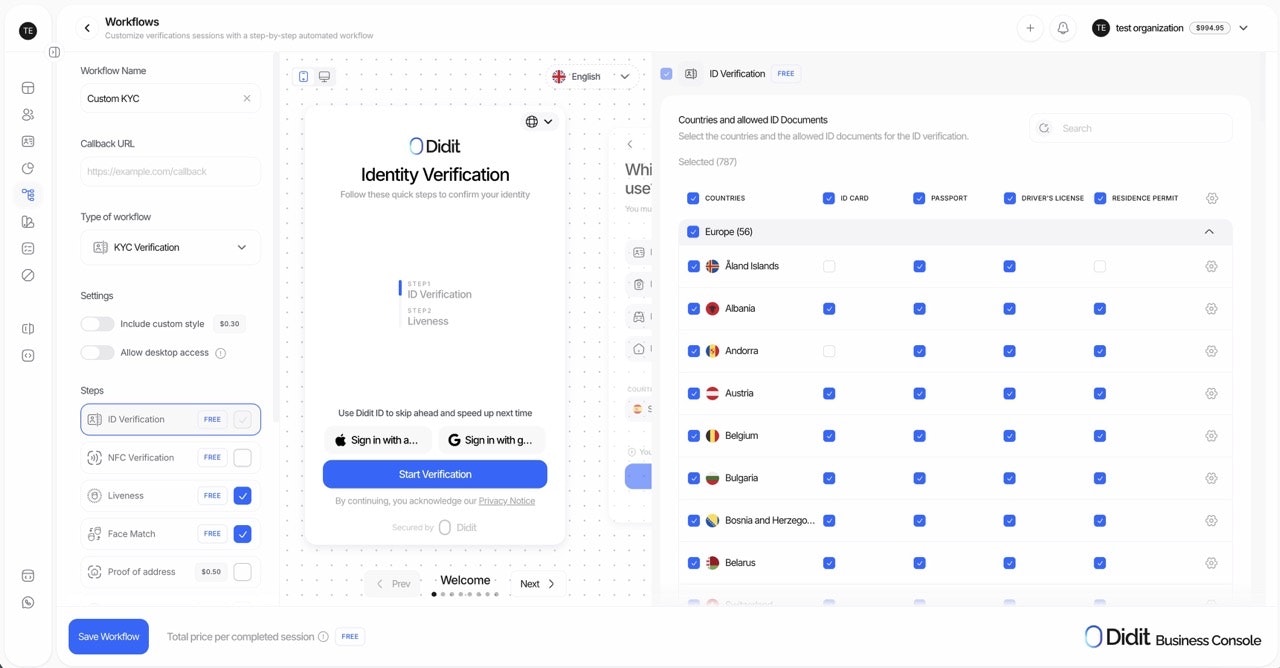
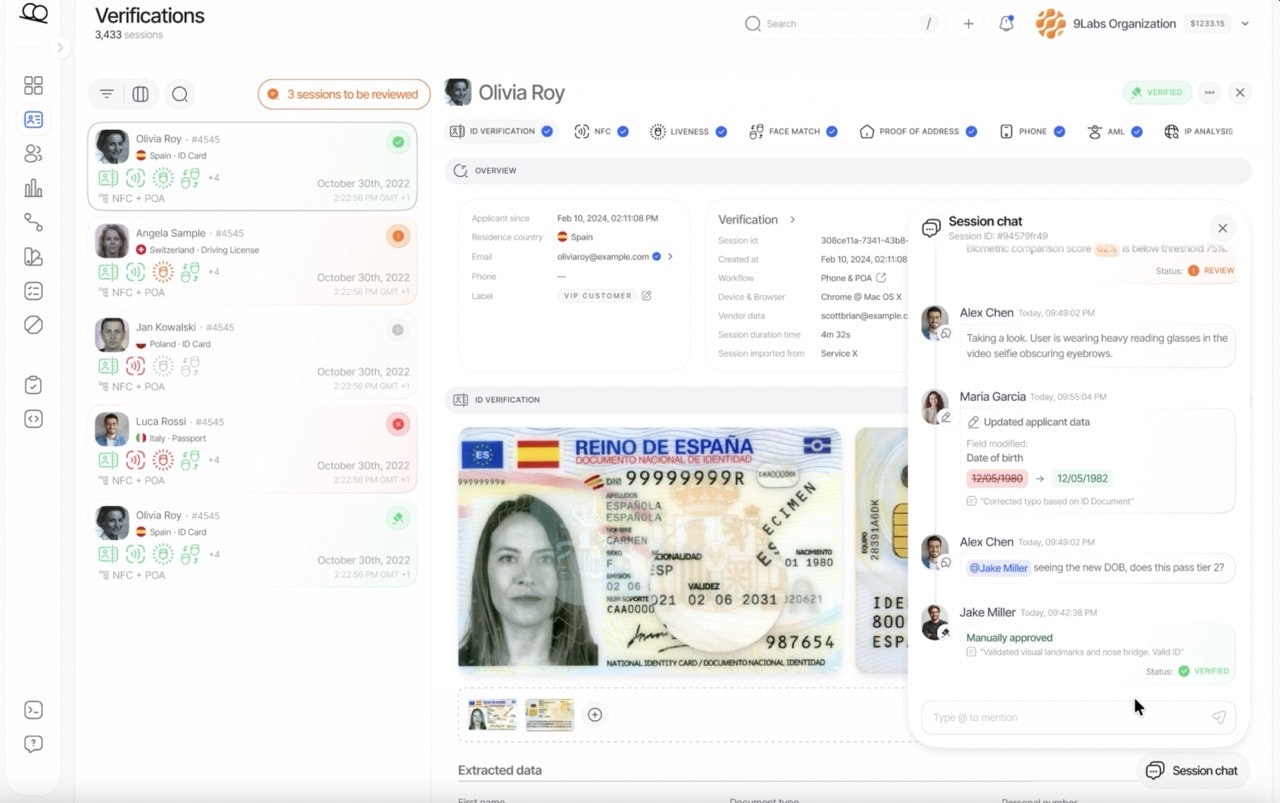
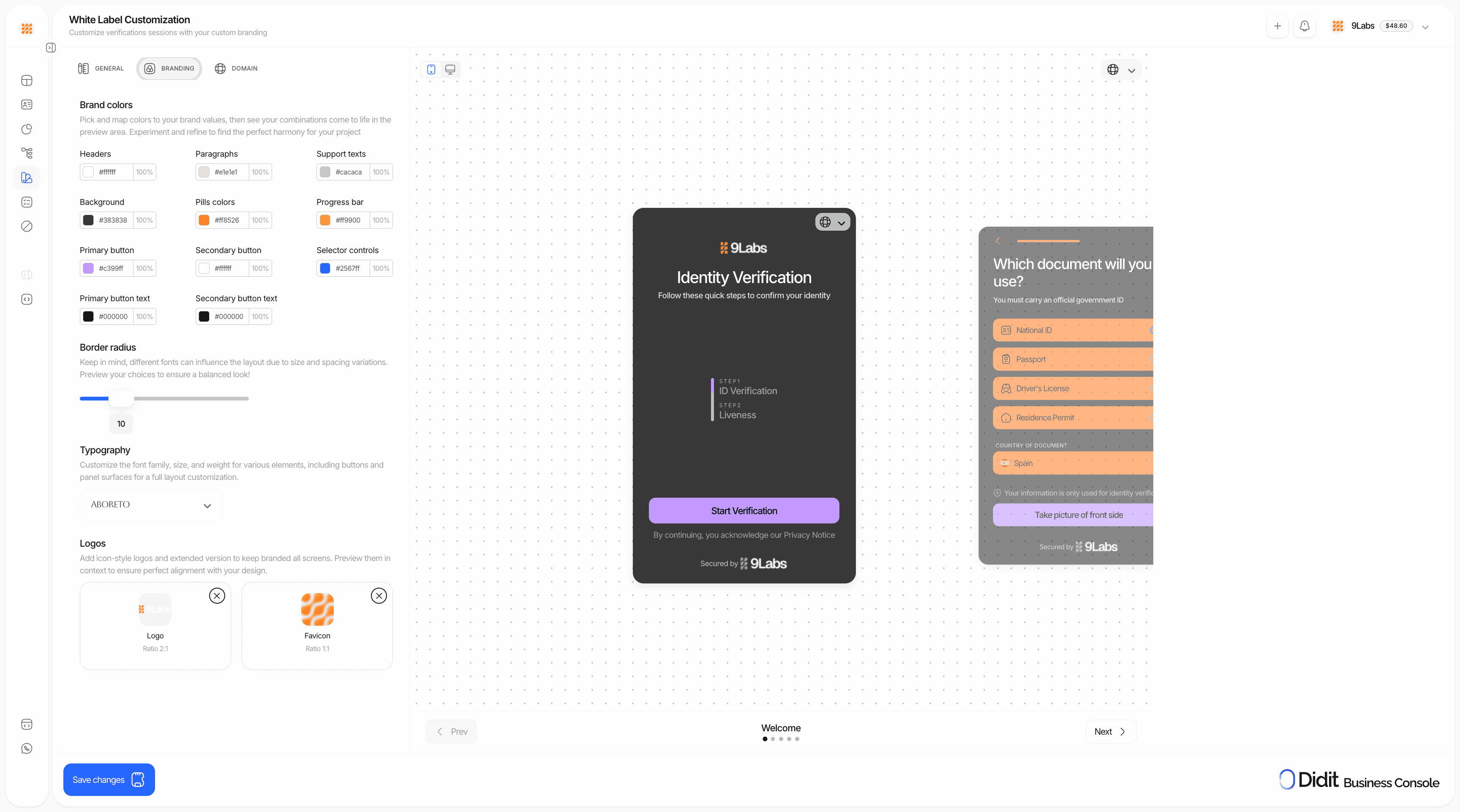
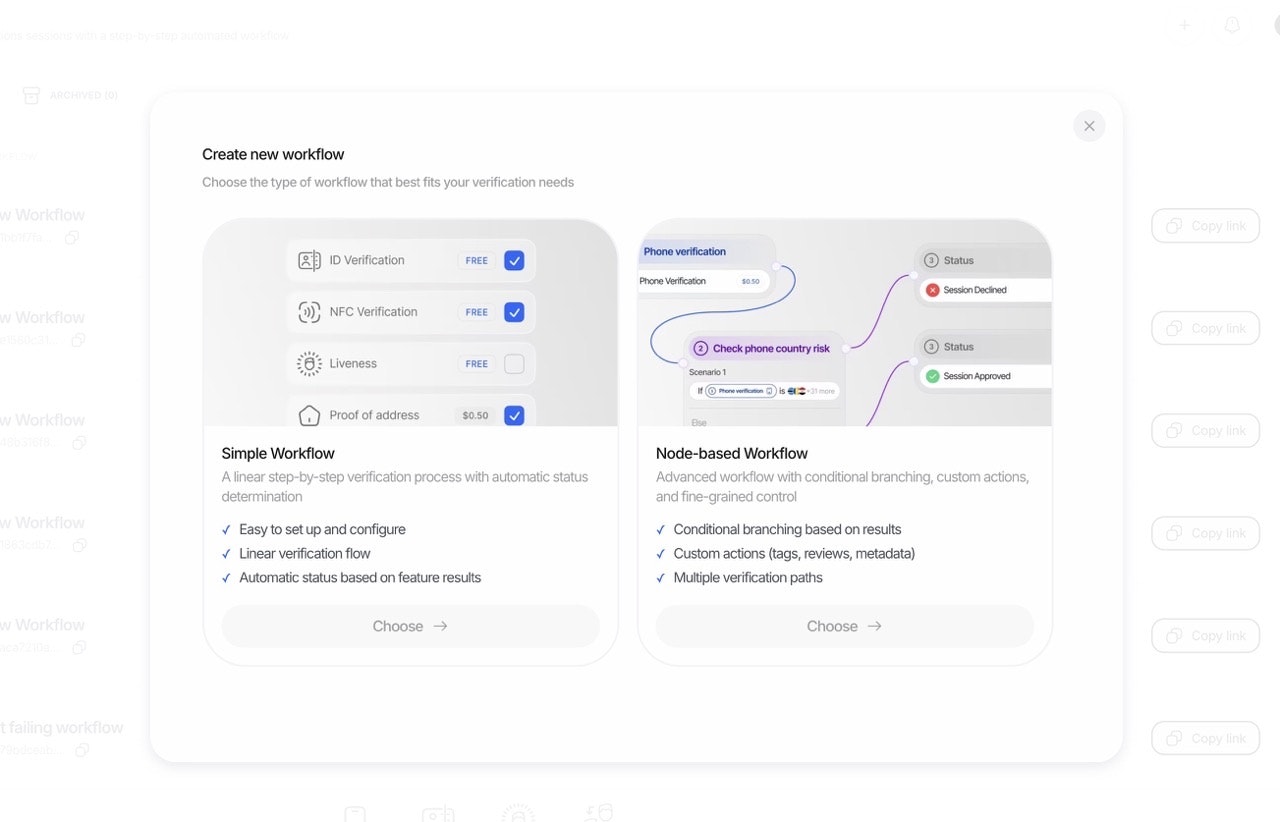
一句话介绍:Didit v3 是一个集KYC、生物识别与欺诈检测于一体的统一身份验证平台,解决了企业在用户身份验证流程中需整合多家供应商、成本高昂且操作繁琐的核心痛点。
API
Fintech
Artificial Intelligence
身份验证
KYC
生物识别
欺诈检测
一体化平台
成本优化
全球合规
开发者API
SaaS
无合约
用户评论摘要:用户关注点集中在定价策略变更(免费额度调整)、产品整合价值(告别多供应商拼接)以及技术细节(如决策追溯功能)。创始人回应强调了平台通过一体化编排降低复杂性与成本,并提供免费额度以降低试用门槛。
AI 锐评
Didit v3 宣称的“一体化平台”并非简单的功能堆砌,其真正价值在于对“身份验证工作流”的深度重构与编排。它直击行业痼疾:企业为满足KYC、活体检测、欺诈风控等基本需求,不得不与多个“单点解决方案”供应商周旋,导致数据孤岛、调试困难、成本叠加。Didit 试图成为这个领域的“交响乐指挥”,而非另一个乐手。
其“70%成本降低”的标语极具冲击力,但这背后可能意味着两重策略:一是通过技术自研与流程优化压低了边际成本;二是以“500次/月免费+按量付费”的灵活模式,精准打击了传统供应商动辄数百美元月费、捆绑年合同的僵化定价,这本身就是一种颠覆性的市场进入策略。然而,挑战同样明显。一体化平台往往面临“博而不精”的质疑,尤其在欺诈检测这类需要持续对抗演进的领域,其深度能否匹敌专注的头部厂商?评论中关于“决策追溯”的提问切中要害,平台能否提供透明、可解释的决策链条,将是企业(尤其是金融等高合规要求行业)能否放心“把所有鸡蛋放在一个篮子里”的关键。
总体而言,Didit v3 的价值主张清晰且切中市场需求。它未必在每个单点技术上都是世界第一,但其通过整合与编排创造的效率提升、成本下降和体验简化,构成了强大的产品力。成功与否,将取决于其技术底层的坚实度、全球合规能力的广度,以及能否在“一体化便捷”与“模块化深度”之间找到最佳平衡点。
一句话介绍:KatClaw™ 是一款将开源OpenClaw平台封装成一键式Mac应用的AI助手工具,让用户无需编写脚本或使用终端,即可快速创建并连接Telegram的个人化本地AI助手,解决了非技术用户追求数据隐私和定制化自动化的痛点。
Mac
Productivity
Artificial Intelligence
AI自动化助手
Mac应用
本地化部署
无代码
Telegram集成
开源封装
一次性付费
隐私安全
多模型支持
用户评论摘要:开发者Albert介绍了背景和初衷。有效评论集中在三点:1. 询问AI助手是否支持工具集成以扩展能力;2. 关心本地与虚拟部署模式下的具体安全措施;3. 好奇AI理解用户意图的技术原理(是自然语言处理还是模式识别)。暂无直接用户反馈。
AI 锐评
KatClaw™ 本质上是一个“开源产品的友好型外壳”,其核心价值不在于技术创新,而在于精准的体验重构和商业包装。它敏锐地抓住了两个关键矛盾:一是强大开源项目(OpenClaw)与高陡峭学习曲线之间的矛盾;二是用户对数据隐私/控制权的强烈需求与云服务主导现状之间的矛盾。通过提供一键式Mac应用、支持本地运行、连接高频通讯工具(Telegram),它成功地将“部署个人AI助手”从极客的玩具变成了潜在大众可触及的生产力工具。
然而,其面临的挑战同样清晰。首先,作为上层封装应用,其功能深度和迭代速度将严重依赖底层开源项目的演进,自身护城河较浅。其次,评论中关于“工具集成”、“安全措施”和“意图理解”的提问,恰恰击中了当前个人AI助手的核心软肋:脱离具体工具链和数据的“助手”,能力空洞化;而“本地运行”在带来安全感的同时,也意味着用户需自行承担模型能力、算力成本和系统稳定的全部责任。最后,一次性付费模式虽对用户友好,但如何维持长期开发与支持,是对团队的持续考验。
总体而言,这是一个巧妙的市场切入产品,它降低了先进AI基础设施的使用门槛。但其长远成功,取决于能否从“便捷的部署工具”进化成“有独特价值的生态或平台”,而不仅仅是开源项目的“搬运工”。
一句话介绍:Suparagent AI是一款集成聊天、编程、研究、幻灯片、图像与视频生成的一体化AI工作空间,旨在为创业者、开发者、创作者等群体提供统一界面,解决多工具切换带来的效率低下与上下文割裂痛点。
Productivity
Developer Tools
AI工作空间
一体化AI平台
多模态AI工具
生产力工具
Manus替代品
Genspark替代品
代码生成
内容创作
团队协作
用户评论摘要:用户普遍表示祝贺,关注产品与Manus/Genspark的差异化。有效评论集中于两点:一是询问定价策略,二是直接质疑其与竞品的核心区别。目前缺乏具体功能对比或使用体验的深度反馈。
AI 锐评
Suparagent AI宣称的“All-in-one”概念,本质上是当前AI工具碎片化困境的一种直观解决方案。其真正价值并非在于某项技术的突破,而在于对“工作流整合”这一朴素需求的响应。产品将聊天、编程、研究、内容生成等场景粗暴打包,看似面面俱到,实则面临“全能即全不能”的经典陷阱。
从市场定位看,直接对标Manus和Genspark,显示了其“替代者”的野心,但也暴露了核心差异化的模糊。评论中用户直接询问“有何不同”,恰恰击中了这类集成平台的软肋:在基础模型能力同质化的当下,集成度带来的便利性,能否抵消其在每个垂直领域功能深度上可能存在的劣势?这取决于其底层是简单的API聚合,还是进行了深度的流程再造与体验优化。
其“所有功能均已上线”的承诺,在快速迭代的AI领域是一把双刃剑。它避免了“画饼”嫌疑,但也意味着产品将立刻接受所有场景下的严苛检验。真正的挑战在于,如何让用户从“偶尔尝鲜”转变为“深度依赖”。这需要超越简单的功能堆砌,在数据互通、上下文继承、跨模态协作等更深层的“统一”上做出实质性创新。否则,它很可能只是用户工具链中又一个可被随时替换的“中间件”,而非不可替代的“工作空间”。当前温和的投票数也暗示,市场仍在观望其实际效能与定价是否真正构成颠覆性价值。
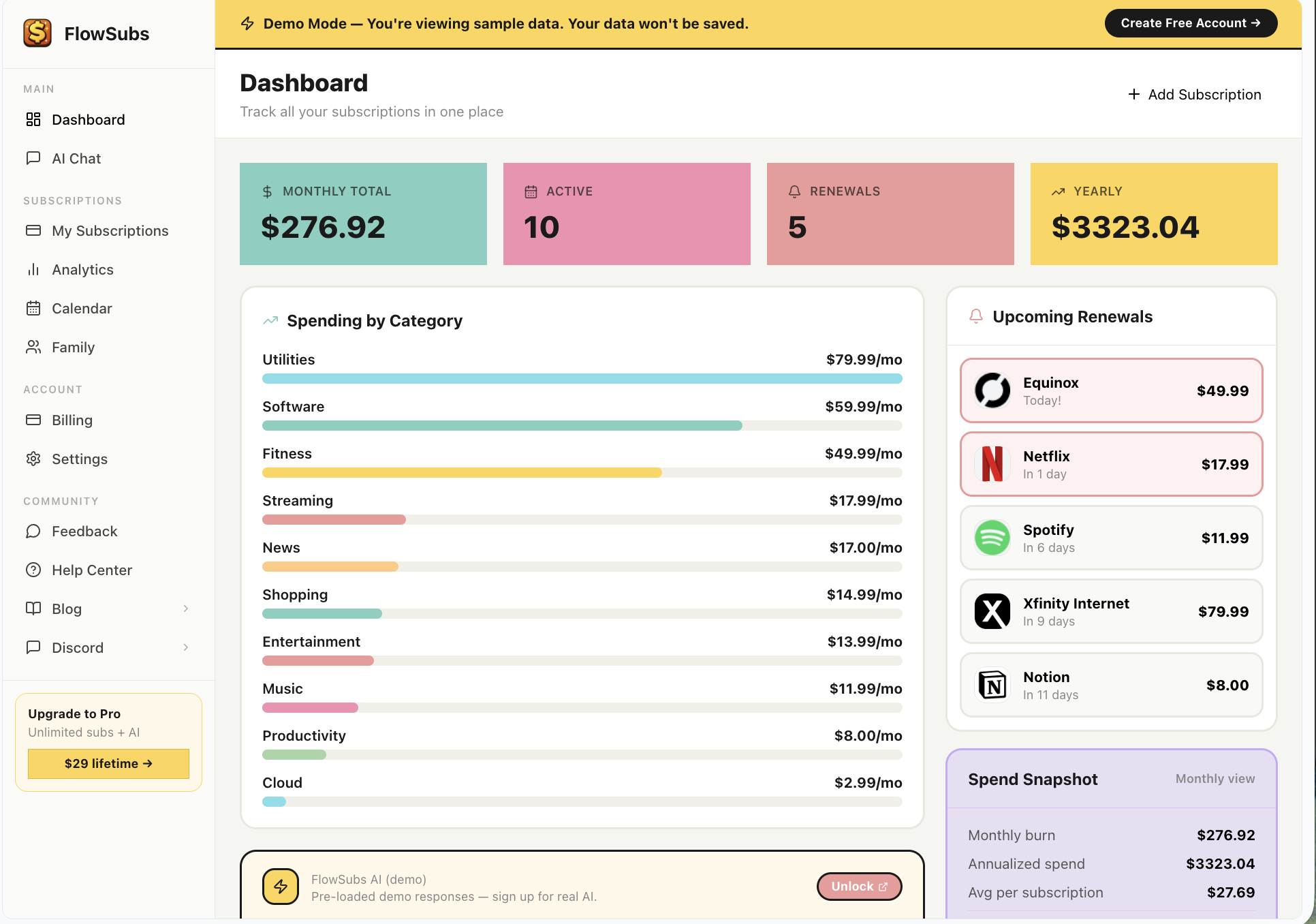
一句话介绍:FlowSubs是一款集中追踪和管理各类订阅服务的工具,通过统一仪表盘、支出总览和续费提醒,解决用户在数字时代因订阅泛滥而遗忘取消、导致资金持续流失的痛点。
User Experience
Accounting
订阅管理
个人财务管理
SaaS工具
支出追踪
续费提醒
防漏费
仪表盘
消费透明度
效率工具
生活助手
用户评论摘要:创始人分享开发初衷是解决自身订阅浪费问题。用户反馈产品创意很好,有需求。主要建议来自服务商,指出官网缺少产品讲解视频,可能影响转化率,并提供了解决方案。创始人回复透露移动端应用即将推出。
AI 锐评
FlowSubs切入的是一个日益膨胀的“订阅经济”阴影面——用户的“订阅疲劳”与财务泄漏。其价值不在于技术壁垒(它自称无需复杂集成),而在于充当了一个清醒的“数字消费哨兵”。在SaaS、AI工具、流媒体层层嵌套的今天,个人支出已从一次性购买演变为无数个沉默的自动扣款,FlowSubs的核心动作“看见”与“提醒”,实质是帮助用户重新夺回消费知情权和控制权。
然而,其面临的挑战同样尖锐。首先,市场已有类似产品,如Truebill、PocketGuard,其差异化优势“简洁”可能很快被模仿。其次,其商业模式和可持续性存疑:是向用户收费,还是转向向订阅服务商提供引流或取消分析服务?前者可能面临用户付费意愿低(毕竟目的是省钱),后者则可能产生利益冲突。评论中关于“缺少讲解视频”的建议,恰恰暴露出其作为一款“信任工具”,在建立初始信任和传达价值主张上仍有短板。用户需要确信其数据安全与隐私保护,才会放心接入所有支付账户。
真正的机遇或许在于数据沉淀后的洞察。如果它能从“追踪管理”升级为“消费分析”,为用户提供优化订阅组合的智能建议(例如“你为五款同类型AI工具付费,保留这两款性价比最高”),其护城河将大大加深。目前来看,它是一个解决表面痛点的实用工具,但要想从“有用”走向“不可或缺”,仍需在数据智能与商业模式上找到更深的锚点。



























Hey Product Hunt 👋
I’m Romàn, co-founder of GojiberryAI
We built Gojiberry because outbound is broken.
Founders and small sales teams waste hours:
• Scraping random leads
• Sending generic “Hey {{first_name}}” messages
• Guessing who might be interested
• Burning accounts with bad automation
And the worst part? Most of those people were never ready to buy.
So instead of automating spam… we decided to automate intent.
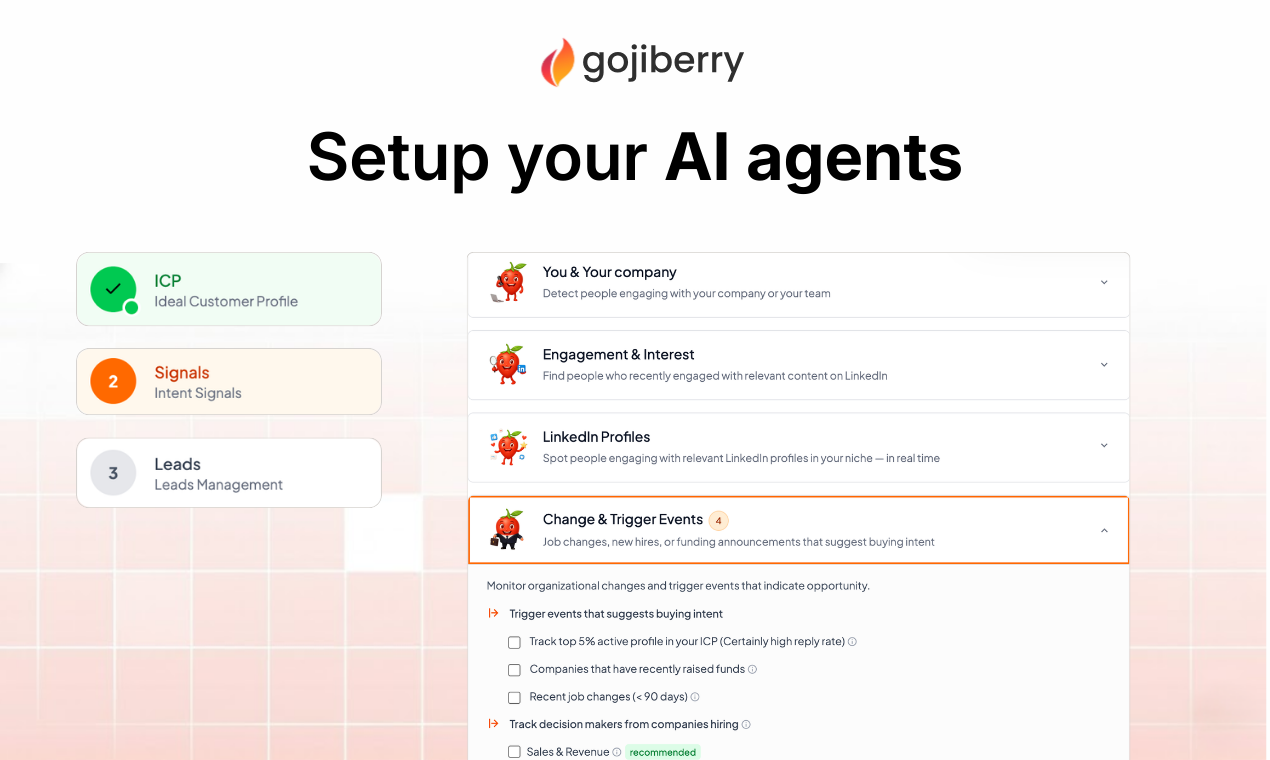
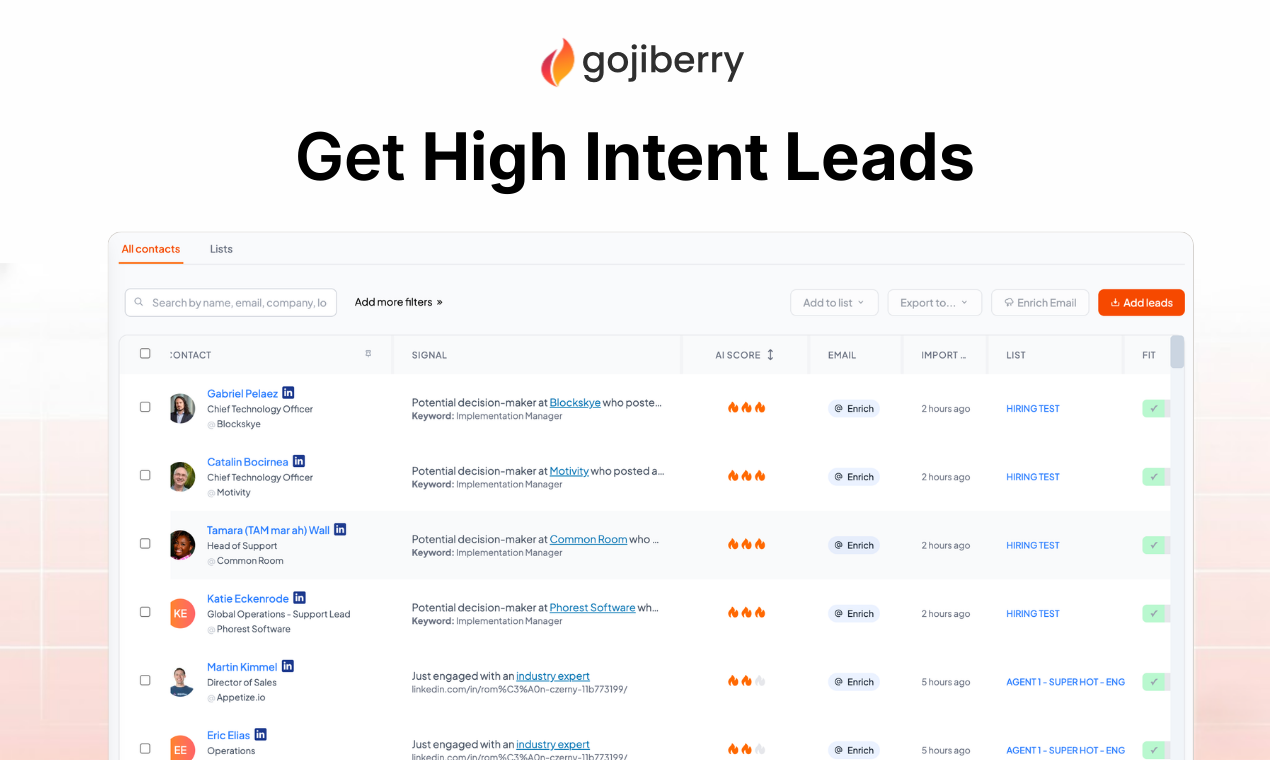
GojiberryAI is an AI GTM Brain that:
→ Detects high-intent buying signals (profile views, job changes, funding, competitor engagement, content interactions)
→ Enriches and qualifies leads automatically
→ Generates hyper-personalized LinkedIn conversations
→ Centralizes everything in one inbox
→ Lets you fine-tune campaigns with an AI Co-Pilot
Unlike traditional outreach tools that focus on volume, we focus on signal first, message second.
The result:
• Higher reply rates
• More booked demos
• Less manual work
• No copy-paste templates
We’ve used this system to generate hundreds of conversations and scale from 0 to $1M ARR, and now we’re opening it to the PH community.
🎁 Product Hunt Special
We’re offering an exclusive launch discount for the PH community.
Use code: PH10 for 10% off your first month.
We’ll be here all day answering questions, sharing our exact stack, and being fully transparent about what works (and what doesn’t).
Thanks for checking us out, excited to hear your feedback 🚀
These guys are the best at solving a problem that nobody solved well, at a right price in that space AND they build an integration with Breakcold :)
Go try it! GG @roman_cz @pierre_eliott_llt @dylan_teixeira
Nice app and a very serious team 💪
another day another gold!
Been seeing yall a lot on socials. very well cracked the game! All love and support :) Would love to learn a thing or two :) @roman_cz @pierre_eliott_llt @dylan_teixeira
amazing product, made by an amazing team
LFG
Saw this launch as soon as thought expanding my product for b2b, gonna try it! congrats on the launch
Love the idea of automating intent instead of spam. Feels like the right evolution for modern sales teams 🚀
Congrats for the launch!
This is solving a real pain point. Cold outreach has always felt like shouting into a void, the intent signal approach makes so much more sense.
Curious about one thing, how do you handle signal accuracy? Like if someone liked a LinkedIn post about "sales tools," does Gojiberry flag them as a buyer, or is there more filtering happening behind the scenes to reduce false positives?
Also the "one prompt to build a lead list" UX sounds really clean. Is that powered by a custom model or GPT-based?
Congrats on the launch, B2B teams are going to love this!
Congrats on the launch! Does the AI handle follow-ups if a lead doesn't book a demo immediately?
Good luck with the launch!
How does it actually detect high-intent buying signals? Curious to use it. Congratulations on the launch, @roman_cz!
Good luck guys! The tool looks solid. Surely research and try it on weekend.
I was an early customer (and still am a customer), and this tool has always been worth keeping, always gave me good results. The team is wonderful too, very helpful guys.
@roman_cz @pierre_eliott_llt What an amazing team and product. Have been using gojiberryAI for a while and can confirm its a game changer. Plus they are always available to assist whenever I needed help.
Congrats on the product and the launch!
QQ: The "intent first, message second" approach makes sense, but how do you filter false positives? Like, someone liking a competitor's post could mean they're evaluating options, or it could just mean they thought the post was interesting. How do you weigh different signals to avoid chasing people who aren't actually in buying mode?
Going to check it our now! I started building a similar solution, but this is much better :)
"Finally! Finally, there's a tool that distinguishes between quantity and quality in sales. What is interesting most about Gojiberry is focusing on buying intent instead of spamming people with random messages. In a world where LinkedIn is crowded with annoying messages, having a tool that understands signals (like job changes or competitor engagement) and crafts a personalized message based on them—this is the real future of sales. A question for the team: Does the tool currently support Arabic in signal detection or message writing? Cheers to you on the fantastic launch and on to the next million 🚀
@dylan_teixeira
How do you promote B2B SaaS? I am currently launching my AI-based B2B product on the market, and I am really interested in where you get your customers from.
This is super interesting focusing on intent over volume makes a lot of sense
Curious — with tracking signals from platforms like LinkedIn and automating outreach, how are you handling things like data privacy and account safety?
Especially avoiding issues like platform restrictions or unintended access risks
Great idea! Is there pricing for solo founders or startups? $100/mo is steep for most people.
High reply rates are good, but pipeline quality is what matters. Have you seen improvements in close rates too, or mainly top-of-funnel lift?
Congrats guys! With your experience from gojiberry, what’s one GTM lesson you’ve learned? And what’s the inspiration behind the name “Gojiberry”?! It sounds sweet, I like it! lol
Hey @roman_cz congrats on your launch and great product! Does this primarily only work with LinkedIn and would this require Sales Navigator enabled to enable DMs to people with intent but not yet in your network?