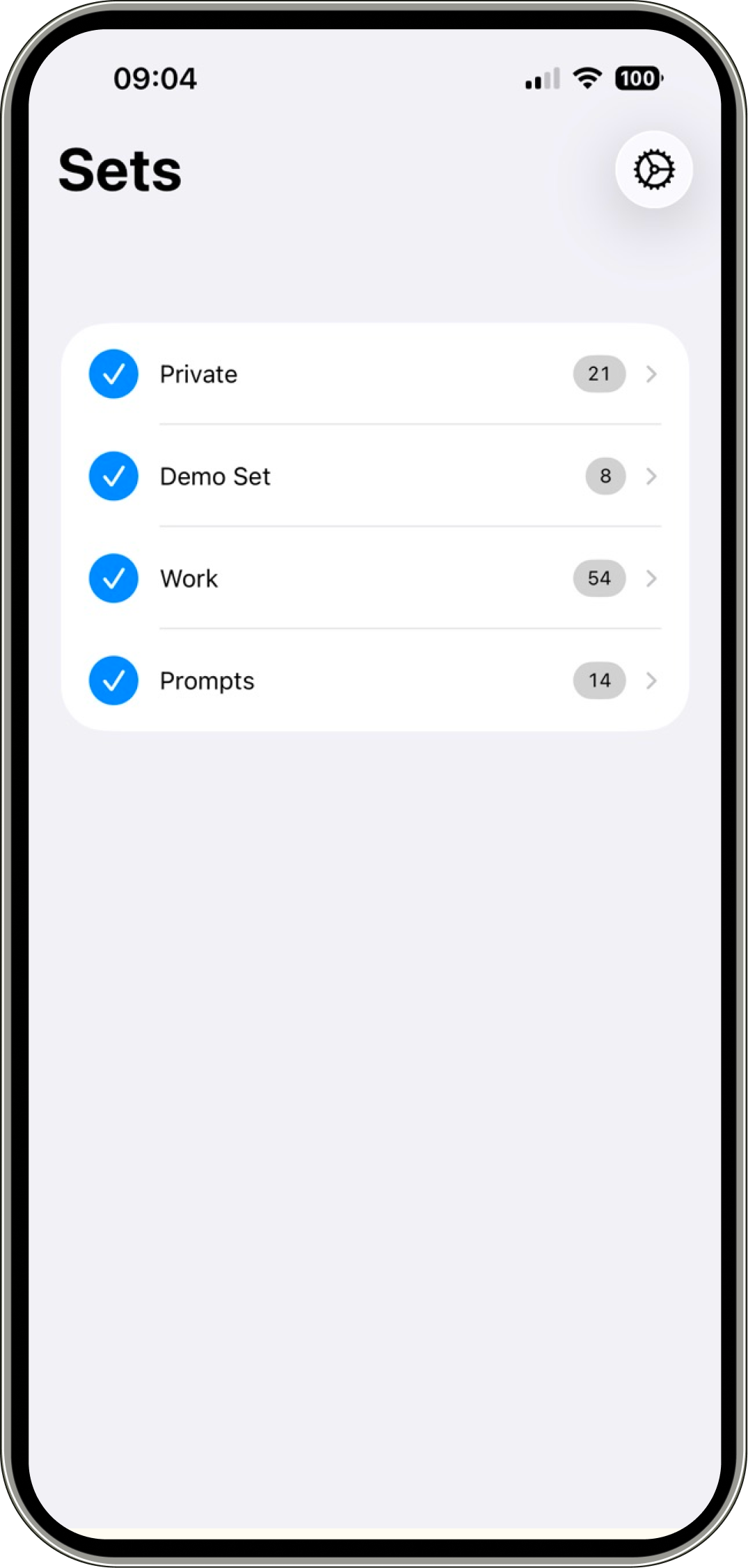
PH热榜 | 2026-03-11
一句话介绍:InsForge是一个专为AI智能体开发设计的原生后端平台,通过语义层为智能体提供数据库、认证、存储等基础设施的端到端操作能力,解决了智能体在构建全栈应用时难以理解和操作传统人类中心式后端架构的痛点。
Open Source
Developer Tools
GitHub
Database
AI原生后端
智能体开发平台
全栈应用开发
语义层
开源后端
MCP集成
基础设施即代码
开发者工具
Agentic开发
云部署
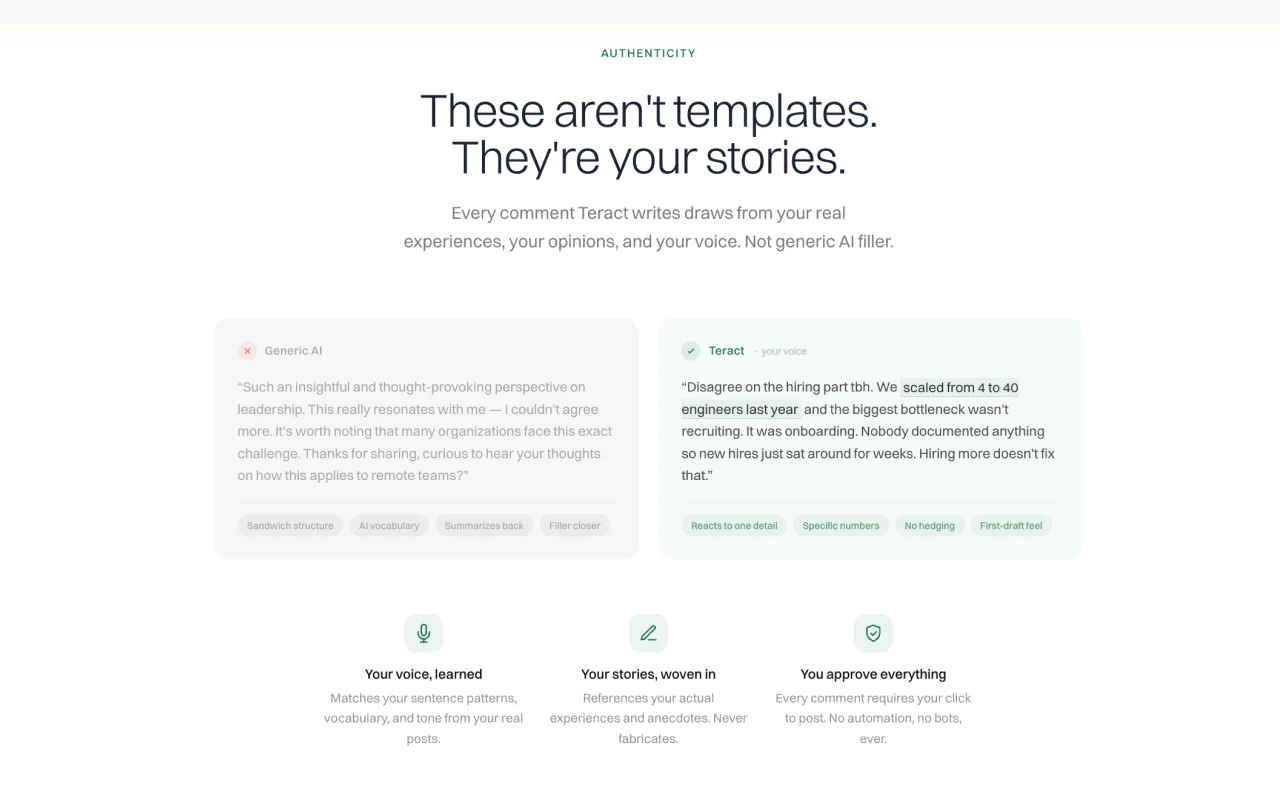
用户评论摘要:用户普遍赞赏其“AI原生”理念与开源+托管模式。核心反馈包括:MCP集成能让智能体获取实时上下文而非猜测API,是关键优势;关注与Cursor/Claude等工具的集成细节;询问与现有Supabase等后端是替代还是可协同;探讨性能基准提升的具体技术原因及在大规模工作流下的表现。
AI 锐评
InsForge的野心不在于成为又一个BaaS,而在于定义“Agentic Infrastructure”这一新品类。其真正的颠覆性在于“语义层”的提出——这不是简单的API封装,而是将后端资源抽象为智能体可内省、可推理的结构化数据类型。这试图从根本上解决当前AI智能体开发的核心矛盾:智能体的代码生成能力与对复杂、隐晦的系统状态认知不足之间的断层。
产品巧妙地抓住了两个趋势交汇点:一是AI编码助手(如Cursor)的普及,让原型构建极快,但部署上线仍卡在人类运维;二是MCP等协议的出现,为工具提供统一“感知”通道。InsForge将自身构建为通过MCP暴露的、智能体可操作的“活系统”,让智能体从代码编写者晋升为系统管理员。其公布的优于Supabase的基准测试,暗示减少“猜测性”工具调用能显著提升效率与准确性,这直指当前智能体工作流中大量的试错成本。
然而,挑战同样尖锐。首先,“智能体原生”是否真能形成壁垒,还是仅成为对传统API的一层友好包装?其次,将基础设施的操作权大幅让渡给智能体,在安全性、错误传播和权责界定上带来全新风险。最后,其价值高度依赖于整个开发生态向“Agentic”范式的迁移速度。若该迁移缓慢,它可能只是一个有特色的BaaS;若迁移加速,它则可能成为智能体与物理数字世界交互的关键中间层。InsForge是一场大胆的赌注,赌的是未来软件的核心操作员不再是人类,而是AI。
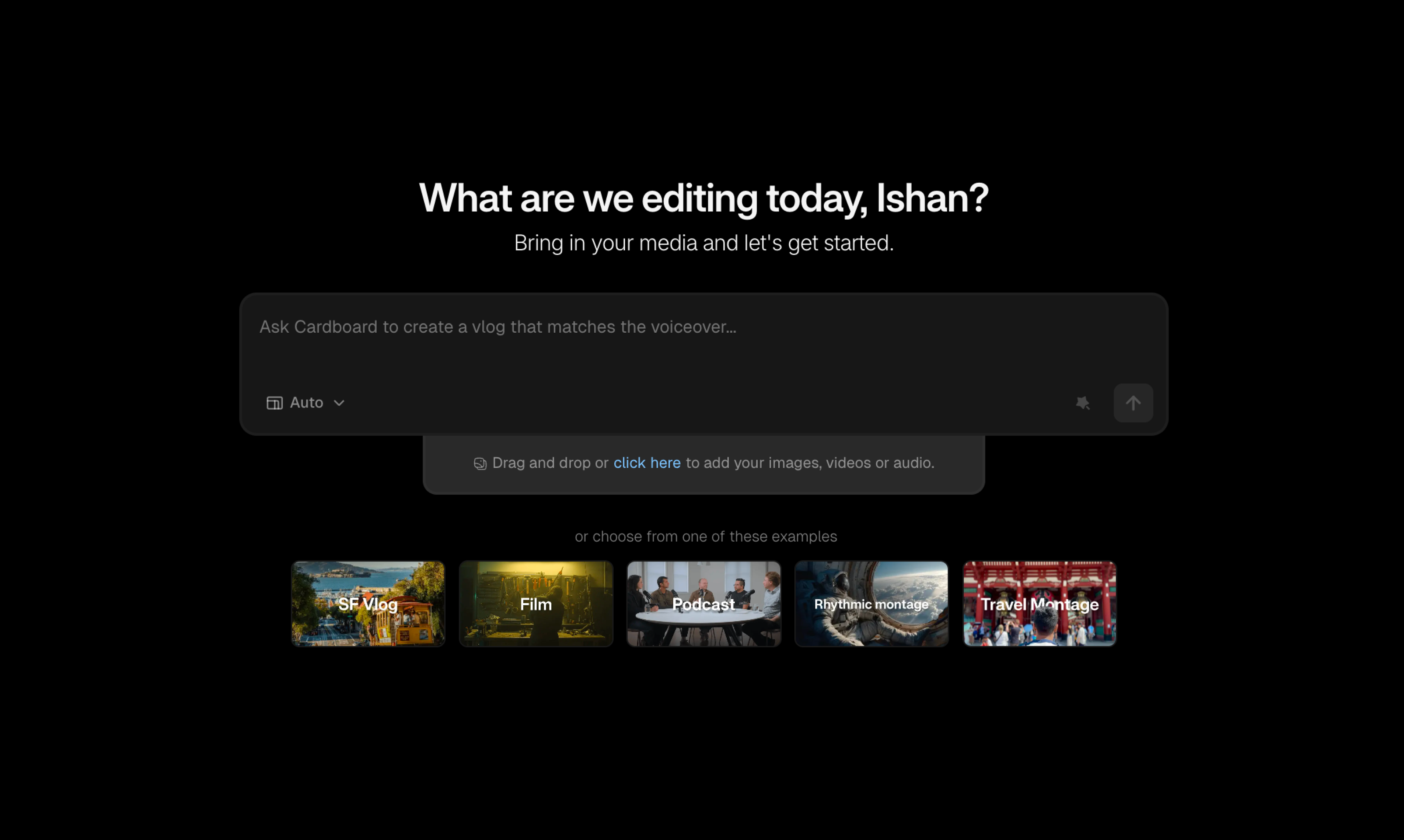
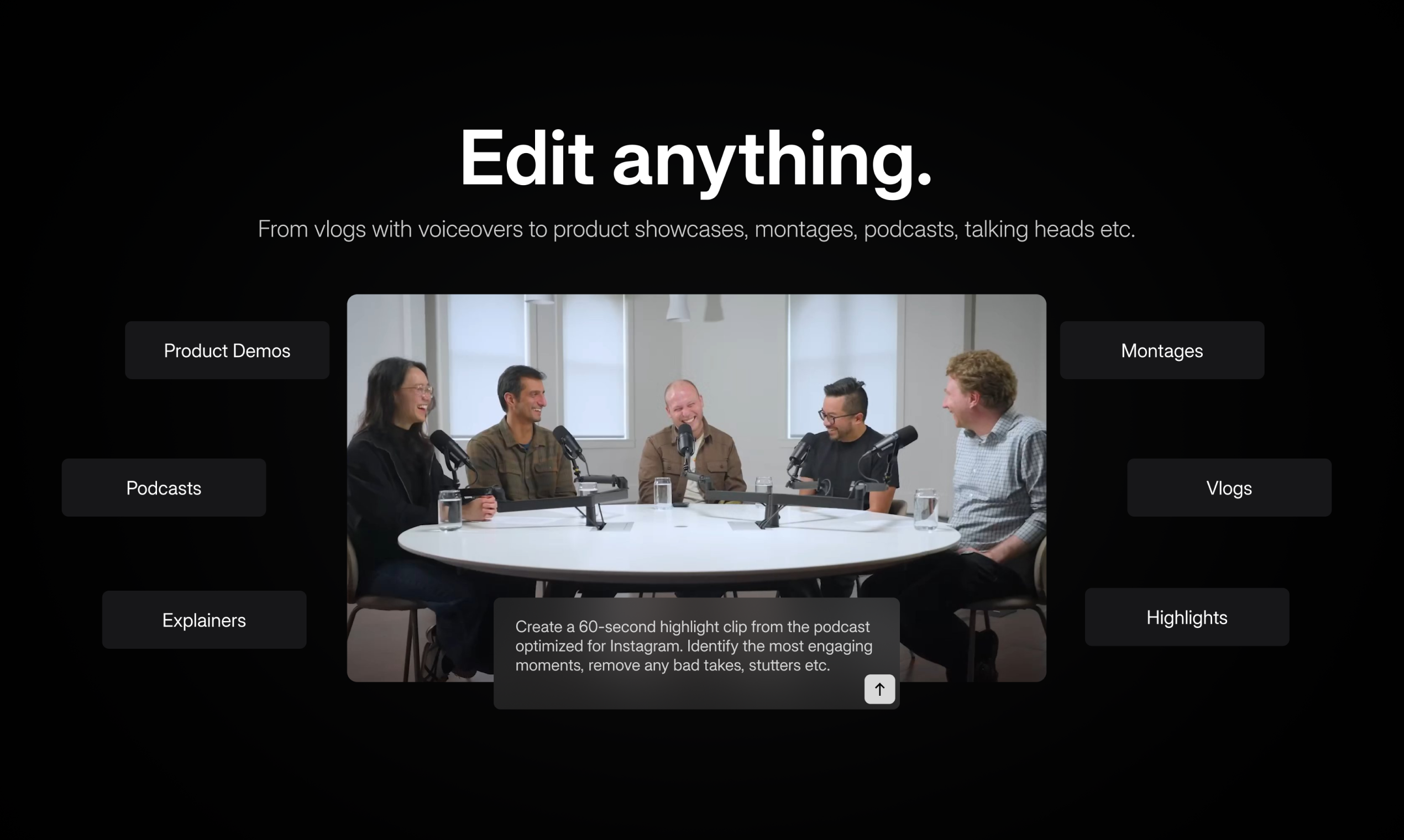
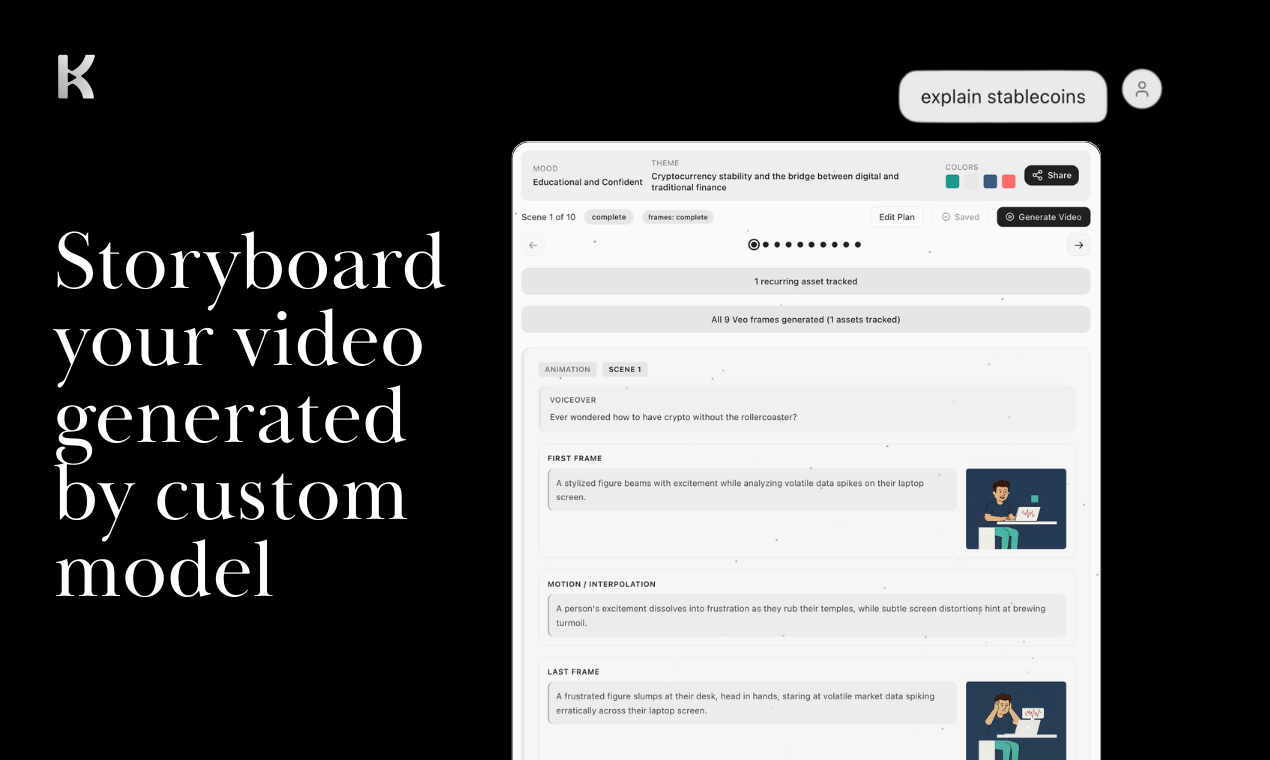
一句话介绍:Cardboard是一款智能代理视频编辑器,通过自然语言描述指令,在浏览器中实现从原始素材到成片的快速剪辑,解决了传统视频软件学习门槛高、操作耗时繁琐的核心痛点,尤其适合内容创作者、营销团队快速批量生产视频。
Marketing
Artificial Intelligence
Video
AI视频编辑
智能剪辑代理
自然语言视频编辑
云端协作工具
YC孵化
生产力工具
内容创作
视频自动化
浏览器应用
用户评论摘要:用户普遍认可其颠覆传统编辑流程的潜力,关注其对长视频(如会议、婚礼)亮点提取的效果。核心问题集中在:与Descript/Premiere的差异化优势(回答:规模化、低技能要求、视觉理解);如何处理叙事连贯性;以及具体功能如时间线评论协作的路线图。
AI 锐评
Cardboard的野心不在于成为另一个功能更强大的“剪辑座舱”,而是旨在成为视频编辑的“自动驾驶系统”。其真正的价值锚点并非单纯提升既有专业用户的效率,而是试图重新定义视频编辑的交互范式与用户边界。
它将编辑从基于时间轴的、以工具操作为核心的手工活,转变为以“意图表达”为核心的协作过程。这直接攻击了传统专业软件(如Premiere, DaVinci)最大的软肋:将大量认知负荷消耗在软件操作而非创意决策上。其宣称的“视觉理解”能力,若真能可靠实现,将是与纯转录驱动工具(如Descript)的关键代差,意味着AI能理解画面内容而不仅仅是文字,从而做出更具创意的剪辑判断。
然而,其面临的挑战同样尖锐。首先,“代理”的可靠性是信任基石。当前AI在复杂叙事、情感节奏和微妙审美上的判断仍不稳定,产品回复中“不确定时会询问用户”的策略,揭示了其作为“副驾驶”而非“全自动驾驶”的现状。其次,其定位看似是“能力放大器”,但实际可能夹在中间:追求极致效率与规模的初级用户和营销团队可能觉得功能足够;而一旦用户对创意控制有更高要求,又会迅速触及AI的天花板,退回专业工具。团队明确不竞争长片、调色、特效等专业领域,这虽是明智的聚焦,但也框定了其天花板——它更像是一个强大的“视频内容生产工具”,而非“影视创作工具”。
最终,Cardboard的成功将取决于其AI“导演”在多样化真实素材中表现出的“品味”一致性,以及能否在“全权代理”与“用户控制”之间找到那个既高效又不令人沮丧的甜蜜点。它开启的赛道值得期待,但距离“改变一切”的承诺,还有漫长的可靠性验证之路要走。
一句话介绍:Teract AI是一款AI声誉教练,通过分析用户语言风格与专业知识,在LinkedIn、X、Reddit等8个平台主动发现高价值对话,并代用户起草符合个人语境的评论与帖子,解决了专业人士需频繁维护多个社交形象但时间精力不足的核心痛点。
Productivity
AI写作助手
个人品牌管理
社交媒体管理
声誉教练
跨平台互动
内容生成
人类在环
Chrome扩展
精准触达
对话发现
用户评论摘要:用户反馈集中于产品安全性(是否触发平台封禁)、跨平台语调校准能力、AI生成内容在Reddit等社区的“非人性化”风险、学习用户声音的机制与伦理边界,以及“每日情报”功能能否实现精准的垂直领域筛选。开发者回复强调手动审核、无自动化行为及平台差异化适配。
AI 锐评
Teract AI的野心不在于替代用户写作,而在于重构社交媒体参与的“发现-决策-创作”工作流。其宣称的核心价值“AI声誉教练”实则是将策略层(在哪说)与执行层(说什么)进行了AI赋能整合,这比单纯的内容生成工具高出一个维度。
产品巧妙地将自身定位为“浏览器内的写作助手”,而非自动化机器人,这是对当前各大社交平台反自动化政策的高明规避。然而,这恰恰暴露了其商业模式的潜在天花板:它本质上是一个效率工具,而非增长黑客工具。其价值上限取决于用户自身的参与意愿和审阅时间,无法实现真正的“规模扩张”。
用户评论中关于“语调校准”和“Reddit人性化”的质疑,直指此类产品最脆弱的命门——语境理解。AI可以模仿词汇和句法,但难以真正理解每个社区亚文化的、瞬息万变的“氛围”和“梗”。在LinkedIn上得体的专业评论,移植到Reddit可能立刻被视为“AI味浓重”的冒犯。开发团队“可引入不完美”的回复是一种妥协方案,但“刻意的不完美”本身也可能被社区雷达侦测。
更深刻的伦理问题在于“声音的异化”。当用户长期依赖并批准AI起草的、模仿自己的“深思熟虑”的言论时,其线上人格是否会逐渐趋近于AI所认为的“理想化专业形象”?这本质上是一个数字时代的“自我呈现”悖论:我们使用工具来更高效地表达“真实的自我”,但工具也在悄然塑造着表达的内容与边界。
总体而言,Teract AI是当前AI应用浪潮中一个思路清晰、定位精准的产品。它瞄准了有个人品牌建设需求的专业人士这一付费意愿强的群体,并通过“人类在环”解决了初期的信任问题。但其长期成功,不仅取决于技术对“用户声音”模仿的保真度,更取决于其能否真正理解并融入各个平台的微型文化战场,成为用户洞察与社交智慧的延伸,而非一个略显笨拙的修辞学助手。
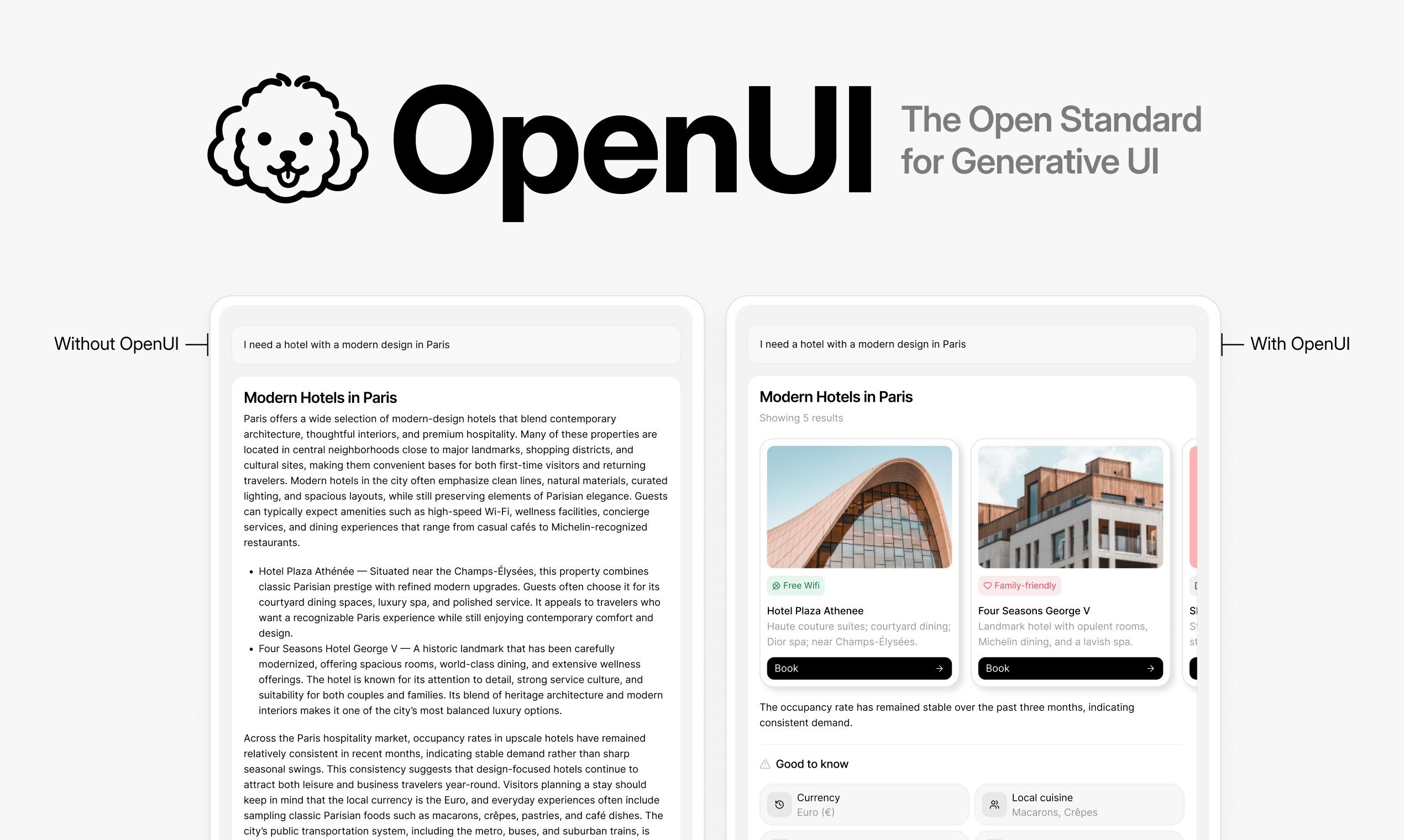
一句话介绍:OpenUI是一个生成式UI开放标准,它让AI应用能够直接输出交互式UI组件而非纯文本,解决了开发者在构建AI界面时因JSON格式笨重导致的渲染慢、易出错、设计系统难集成等核心痛点。
Open Source
Developer Tools
Artificial Intelligence
GitHub
生成式UI
AI界面开发
开源标准
UI组件
大语言模型
开发框架
渲染优化
模型无关
前端工具
开发者工具
用户评论摘要:用户普遍认可其解决JSON痛点的思路及开源价值,关注其流式渲染性能、多模型/框架兼容性、设计系统适配及生产环境可靠性。主要问题集中于C1平台对模糊UI意图的处理、跨平台一致性及具体测试细节。
AI 锐评
OpenUI的野心不在于创造另一个UI库,而在于重新定义AI与界面之间的“通信协议”。它敏锐地戳破了当前AI应用界面层的华丽泡沫:开发者耗费大量精力在提示工程和JSON解析上,只为让LLM输出一个本应更直观的结构。其真正的颠覆性在于,它承认了“代码即LLM母语”这一事实,放弃驯服LLM去生成严谨但反直觉的JSON,转而采用一种更贴近代码习惯的语法。这是一种范式转移。
然而,其宣称的“模型无关”与“框架无关”更像是一种理想宣言。评论中透露的C1平台对GPT-5和Sonnet4的“生产推荐”,暗示了在追求极致可靠性的实际场景中,标准仍需与特定模型的“习性”和平台的工程化方案结合。其核心矛盾在于:一个旨在普适的开放标准,其最佳实践和稳定性保障却可能依赖于背后的商业平台Thesys C1。这引发了关于“开放标准”与“商业闭环”如何共存的经典质疑。
它的价值若止步于“更快的JSON替代品”,则格局有限。其深层潜力在于成为AI原生应用的“HTML”——一种描述交互意图的中间层语言,让UI真正成为AI思维的流式自然延伸,而非事后的笨重包装。但能否成功,取决于其能否在保持简洁性的同时,构建起强大的生态共识,并真正解决评论中关心的模糊意图处理、跨端一致性等工程深水区问题。否则,它可能只是解决了旧痛点,却开启了新锁定的序章。
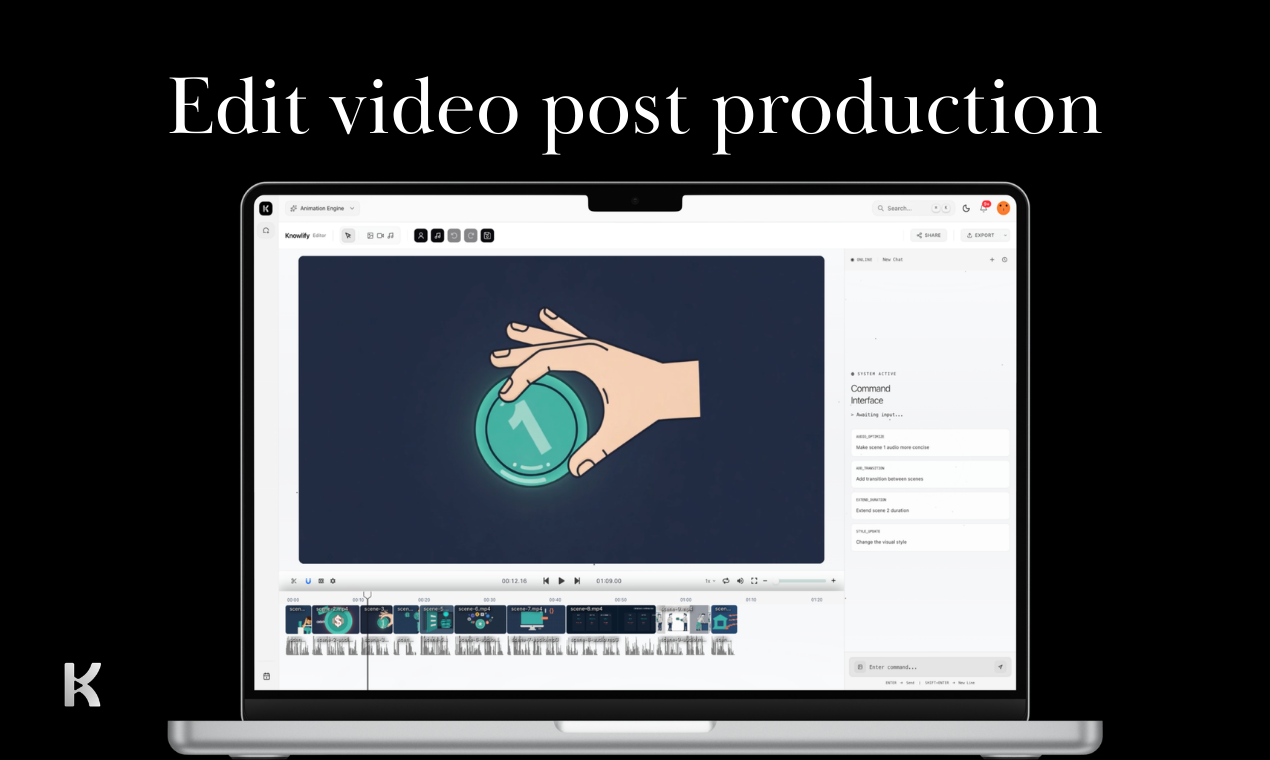
一句话介绍:Knowlify是一款AI视频工作室,能将文档(如PDF)快速转化为高质量、高吸引力的Kurzgesagt风格动画解说视频,主要解决团队在规模化制作高留存率知识解说视频时面临的效率低下、内容枯燥的痛点。
Productivity
Artificial Intelligence
Video
AI视频生成
文档转视频
知识解说
动画视频
团队效率工具
Kurzgesagt风格
B2B内容创作
教育科技
营销内容自动化
用户评论摘要:用户普遍认可其解决真实痛点,风格独特。核心反馈集中在:1. 价格昂贵,成本计算方式引发疑虑;2. 对PPT支持、高度定制化(如自定图像、控制叙事核心)的需求;3. 询问技术细节(如生成时间、视觉生成方式、AI规划器逻辑);4. 期待其在不同垂直领域的应用效果。
AI 锐评
Knowlify的定位精准且颇具野心,它没有陷入“AI数字人”或“动态PPT”这两个已显疲态的竞争红海,而是锚定了“知识留存”这一更高阶的目标,并聪明地借用了已被市场验证的Kurzgesagt动画风格作为载体。这使其从工具层面跃升至“认知效率方案”层面,价值主张更锋利。
其真正的护城河并非单纯的视频生成,而在于宣称的“定制化AI规划器”。这暗示它试图理解文档逻辑、重构叙事,而不仅是视觉化文本。如果成功,它将解决内容创作中最核心的“策划”环节,这才是其宣称“节省90%时间”的关键。然而,这也是最大风险点:当前AI的语义理解和抽象能力能否稳定产出逻辑严谨、重点突出的脚本?用户关于“控制叙事核心”的疑问直指这一黑盒。
当前最现实的掣肘是定价策略。高昂的单片成本($150/5分钟)虽以节省传统动画制作时间和成本为辩护,但会直接将高频、规模化生产的潜在用户(如内容营销团队)拒之门外。这暴露了其依赖重度计算资源的现状,也使其在早期更像是一个“优质外包替代方案”,而非可随意迭代、试错的内部生产力工具。能否在提升模型效率的同时快速降低价格,将决定它是成为小众精品还是大众爆款。
总体而言,Knowlify展现了一个正确的方向:用AI处理创意生产中的“重脑力”部分(策划与设计),而非仅仅替代“重劳力”部分(渲染与剪辑)。但它正走在技术、成本与市场接受度的钢丝上。
一句话介绍:Google首个原生多模态嵌入模型,通过将文本、图像、视频、音频和文档映射到统一的向量空间,解决了开发者在构建跨媒体检索与分类系统时需整合多个独立模型和处理流程的复杂痛点。
Developer Tools
Artificial Intelligence
Development
多模态AI
嵌入模型
向量数据库
跨模态检索
语义搜索
谷歌云AI
机器学习
RAG系统
人工智能开发
统一表征学习
用户评论摘要:用户普遍认可其统一多模态嵌入的突破性价值,能极大简化跨模态检索和RAG系统构建。同时,有具体场景的开发者提出了对音频嵌入在短时、嘈杂环境中实际效果的疑问,并希望测试其性能边界。
AI 锐评
Gemini Embedding 2的发布,与其说是一项技术升级,不如说是谷歌对AI基础设施层一次深思熟虑的战略整合。其真正的锋芒,并非简单的“支持多模态”,而在于“原生”与“统一”这两个词。当前业界的普遍实践是将不同模态的数据通过各自独立的模型(如CLIP用于图文,Whisper用于音频转录)转化为向量,再费力地拼凑到一个近似空间中进行运算。这个过程充满了工程上的胶水代码、精度损失和协同难题。Gemini Embedding 2直接釜底抽薪,试图从底层提供一个“原子化”的统一语义空间。
它的价值必须放在两个维度审视:一是效率与成本,开发者得以用单一API调用替代复杂的多模型Pipeline,降低了系统复杂度和维护成本;二是能力边界,原生多模态嵌入可能解锁全新的应用范式。例如,评论中提到的“无需转录的音频嵌入”,其意义远不止于降低延迟。它意味着模型能直接捕捉语音中的韵律、情绪等超文本信息,这些信息在转录为文字时已永久丢失。这对于情感分析、内容安全或更细腻的交互体验至关重要。
然而,掌声之下需存冷思考。首先,“统一空间”的质量是最大问号。将文本、图像、视频、音频的语义强行对齐,是否会带来“维度诅咒”?即在某些模态(如图像分类)上的精度,是否会为了跨模态对齐而做出牺牲?这需要严格的基准测试来验证。其次,作为闭源的云API,它进一步强化了开发者对谷歌AI基础设施的依赖,模型的黑箱特性可能让其在某些对可解释性有要求的场景中受阻。最后,那个关于“短时嘈杂音频”的评论直击要害:这类模型通常在干净、标准的实验室数据上表现惊艳,但在真实世界的混乱与噪声中,其鲁棒性才是真正的试金石。
总而言之,Gemini Embedding 2是一次重要的基础设施跃进,它描绘了多模态AI走向工程化、平民化的清晰路径。但它并非万能钥匙,其实际统治力将取决于它在具体、嘈杂的现实任务中的性能表现,以及开发者是否愿意将核心的嵌入层“锁”在谷歌的生态之中。它拉开了下一代AI应用竞争的序幕,但比赛才刚刚开始。
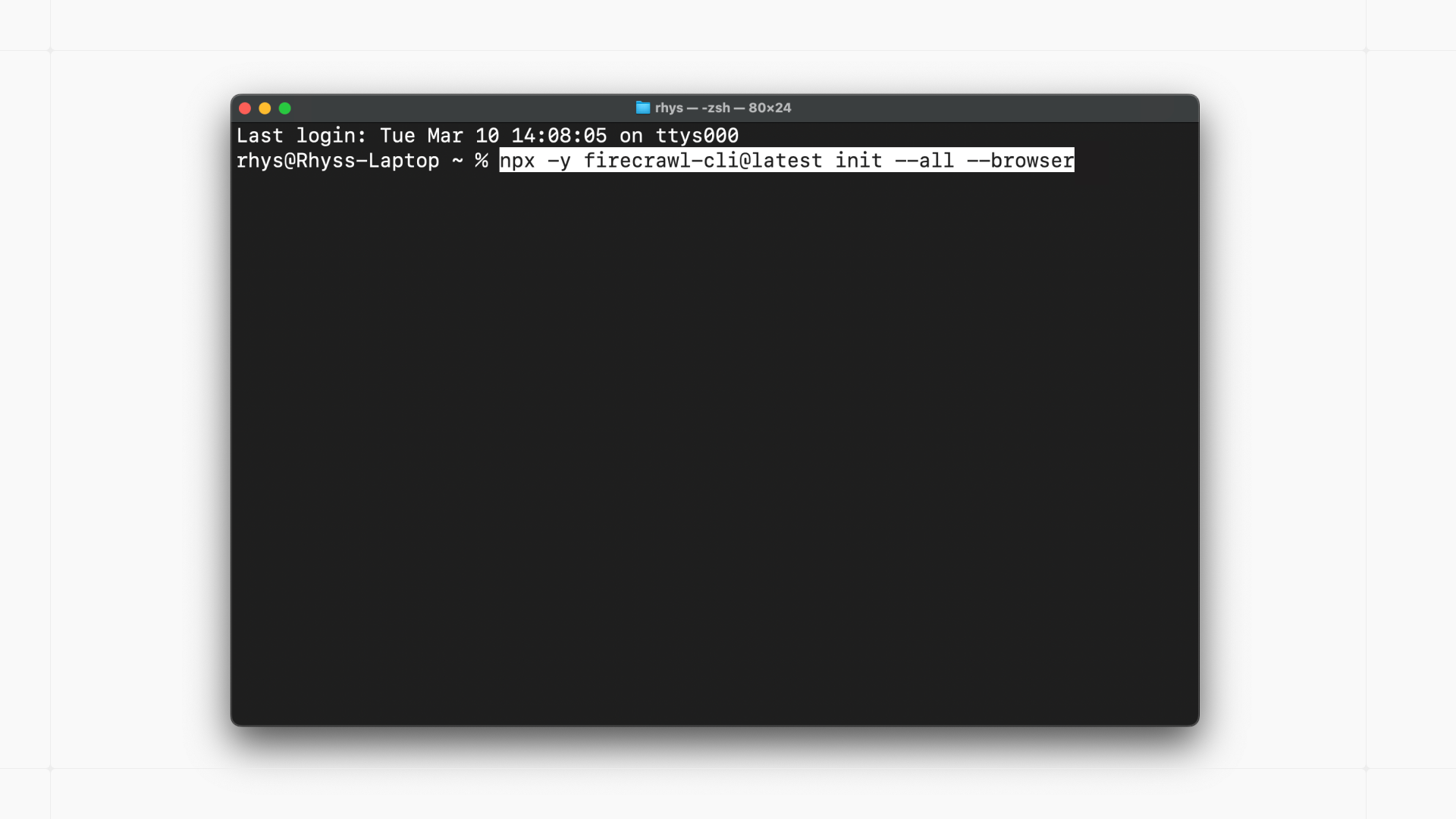
一句话介绍:一款为AI智能体与开发者设计的命令行工具,通过提供网页抓取、搜索和浏览的一体化方案,解决了智能体获取可靠、结构化网络数据时遇到的JS站点兼容性差和上下文令牌浪费的核心痛点。
Developer Tools
Artificial Intelligence
AI智能体开发工具
网页数据抓取
命令行工具
数据提取
上下文优化
网络爬虫
市场情报
研发赋能
自动化工具
用户评论摘要:用户普遍认可其解决了AI智能体获取可靠网络数据的核心痛点,赞赏其文件化上下文管理和令牌高效性。主要问题集中于:1. 如何处理反爬和结构多变的网站;2. 对Next.js等客户端渲染站点的支持细节;3. 是否有现成的技能模板。
AI 锐评
Firecrawl CLI的发布,直指当前AI智能体开发中最“脏累活”却至关重要的环节——高质量、高可靠性的外部数据接入。其宣称的“超越Claude原生抓取80%覆盖率”和“最大令牌效率”,本质上是在挑战一个行业共识:即大模型智能体的能力边界,正从纯代码与内部数据推理,转向与动态、混乱的真实世界网络数据可靠交互。
产品将“抓取、搜索、浏览”三合一,并输出清洁Markdown/JSON,其真正价值并非功能堆砌,而在于试图为智能体建立一套标准化的“网络感官”与“信息消化系统”。文件系统作为交互中介的设计尤为巧妙,它避开了让智能体直接处理原始HTML的复杂性,将数据预处理和结构化这一高不确定性任务从智能体推理链中剥离,转化为相对确定的环境操作(文件读写),这提升了智能体行动的可靠性与可预测性。
然而,其面临的考验同样严峻。评论中关于反爬与动态站点的疑问,正是其商业与技术护城河所在。若其云浏览器方案能稳定绕过主流反爬机制并高效处理SPA,它将从一个“好用工具”升级为“关键基础设施”。但这也意味着持续的高对抗性技术投入和潜在的法律灰色地带风险。
总体而言,Firecrawl CLI代表了AI工程化演进的一个务实方向:与其一味追求模型规模的宏大叙事,不如深耕如何让现有模型更可靠、更经济地利用现有网络信息。它的成功与否,将取决于其技术深度能否支撑起其承诺的“可靠性”,以及能否在开发者中形成处理网络数据的“事实标准”工作流。
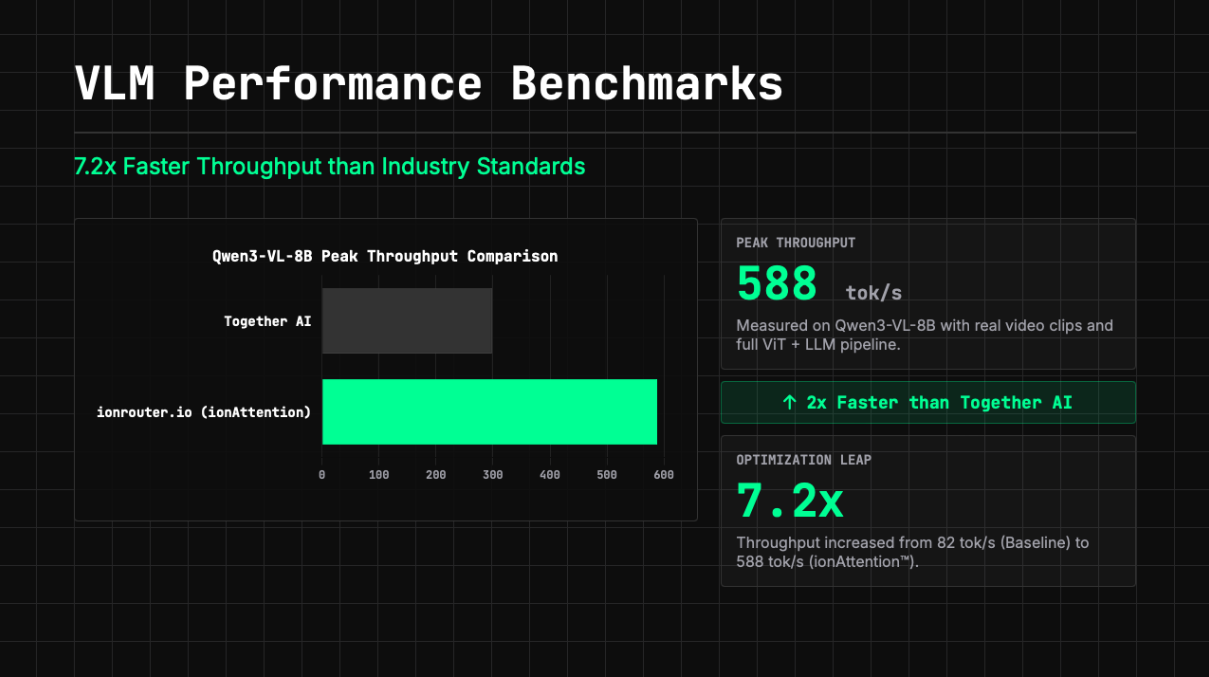
一句话介绍:IonRouter 是一款提供与 OpenAI 兼容的 API 路由服务,通过自研的高效推理引擎,以市场半价、更低延迟调用多种主流开源模型,解决了开发者在构建多模态AI应用时面临的高成本和性能优化难题。
Developer Tools
Artificial Intelligence
Tech
AI模型路由
推理优化
成本削减
OpenAI兼容API
多模态AI
模型部署
基础设施即服务
高性能计算
Grace Hopper优化
用户评论摘要:用户普遍对“半价”和低延迟表示强烈兴趣,并询问技术原理与免费计划。核心关注点在于:1. 成本与速度如何兼得;2. 与OpenRouter等竞品的差异;3. 生产环境下的重度负载表现。开发者回应揭示了其自研引擎与芯片级优化的技术路径。
AI 锐评
IonRouter 的叙事核心是“半价”,但这恰恰是其最犀利的双刃剑。它并非简单的模型聚合商,而是试图通过自研的 IonAttention 推理引擎,在 NVIDIA Grace Hopper 这一特定硬件架构上重构推理的“Token经济学”,实现硬件利用率的突破。其宣称的“单GPU多模型复用且切换时间<100ms”,直指当前云上AI推理资源闲置与碎片化的行业痛点,价值在于将推理从“粗放的资源租赁”转向“精细的效能运营”。
然而,光环之下疑点重重。首先,其“半价”优势严重绑定于对特定(且较新)芯片架构的深度优化,这既是技术壁垒,也是生态枷锁,其通用性和可持续性有待观察。其次,作为后来者,面对 OpenRouter 等已建立生态的对手,仅凭价格和速度参数难以形成绝对护城河,开发者社区的信任与迁移成本是更高门槛。评论中关于生产负载的担忧非常关键——在理想演示与复杂、异构的真实生产场景之间,往往存在巨大的“效能鸿沟”。
本质上,IonRouter 是一场豪赌:赌的是专用硬件(Grace Hopper)将成为主流,赌的是自研引擎的优化幅度能持续抵消生态劣势。它若成功,将推动AI基础设施层从“堆算力”向“榨算力”的范式转变。但在此之前,它必须向市场证明,其“奇迹引擎”不仅在实验室跑分中领先,更能在千奇百怪的真实业务流中,稳定地交付“又快又省”的承诺。
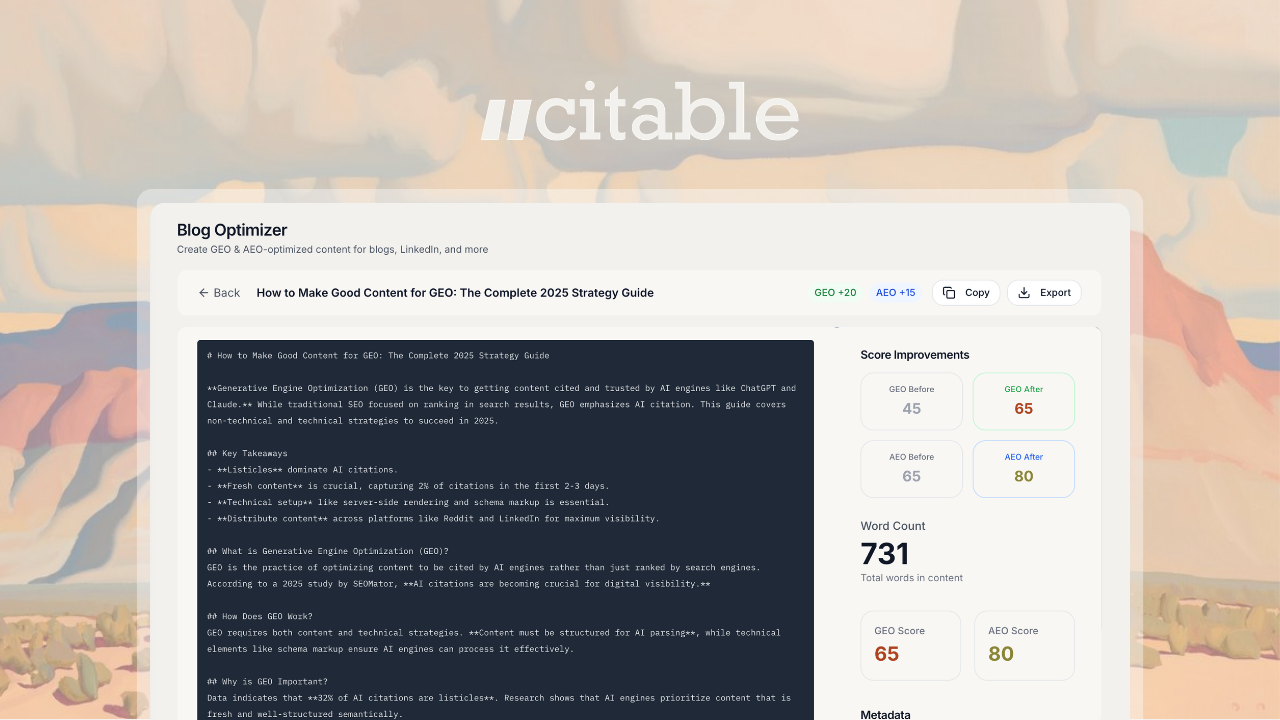
一句话介绍:Citable 是一款为中小企业提供全托管式AI搜索优化服务的平台,通过专业的策略、内容创建与引用构建,帮助企业在ChatGPT、Perplexity等AI对话引擎的答案中被推荐,解决其在AI搜索时代品牌曝光不足的痛点。
Artificial Intelligence
Search
Marketing automation
AI搜索优化
GEO营销
品牌曝光
内容营销
托管式服务
中小企业营销
AI引用构建
竞争情报
营销自动化
获客引擎
用户评论摘要:用户肯定产品方向,认为从“排名”到“推理”的搜索转变是关键。核心问题聚焦于:1. 如何确定高引用概率的内容?2. 如何准确追踪效果?3. 与同类工具相比的差异化(避免混乱、实现真正提升)。建议关注模型漂移对进度报告的影响。
AI 锐评
Citable 敏锐地抓住了“搜索范式转移”的焦虑——当答案由AI生成时,传统的SEO失灵,竞争在全新的“引用战场”上重启。其宣称的“服务即软件”模式,本质是将专业的GEO(生成式引擎优化)能力产品化、订阅化,试图为无力雇佣专职团队的中小企业提供“外脑”。
产品的真正价值不在于又一个“AI搜索排名跟踪器”,而在于承诺了从诊断到执行的闭环,并捆绑了人力服务。这戳中了当前AI搜索营销的核心矛盾:知道方向容易,但生产出能被AI识别并引用的高质量、结构化内容极难。其提供的“内容映射”、“行动引擎”和“博客优化”,实则是将内容策略与工程能力打包出售。
然而,其模式面临双重考验:一是服务规模化与质量控制的矛盾,重度依赖人力服务难以实现指数级增长;二是AI搜索本身的不稳定性,各大模型的检索与引用逻辑持续演变,今日的有效策略明日可能失效。用户关于“模型漂移”和“效果追踪”的提问直指这一软肋。
长远看,Citable更像一个过渡期的“拐杖”。它验证了市场对AI原生营销服务的迫切需求,但其护城河取决于能否将服务过程中积累的“如何被AI引用”的知识沉淀为真正的、可复制的算法或系统,从而从“人力密集的顾问”进化成“智能驱动的平台”。否则,它可能只是数字营销长河中,又一个因平台规则变迁而兴起、也可能随之衰落的服务型产品。
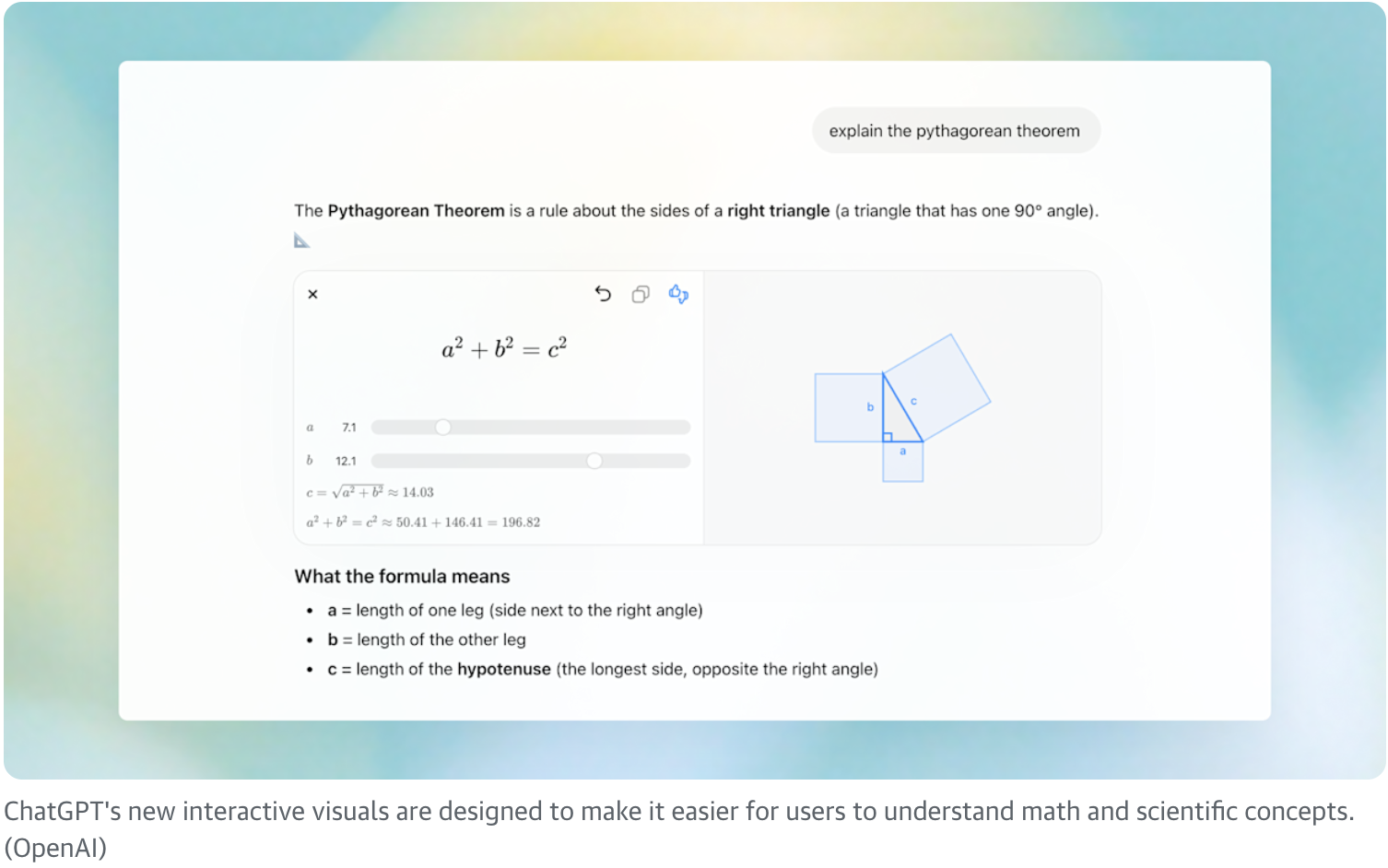
一句话介绍:ChatGPT推出交互式可视化学习功能,通过动态图解和变量操控,将抽象的数学与科学概念具象化,解决了传统学习方式中理解困难、缺乏直观性的痛点。
Education
Artificial Intelligence
School
人工智能教育
交互式学习
可视化教学
STEM教育
概念理解
自适应学习
教育科技
AI导师
沉浸式学习
ChatGPT插件
用户评论摘要:主要评论为积极的产品功能宣传,强调其升级意义与教学价值。但存在用户质疑信息真实性,指出未找到官方发布信息,并对产品通过Product Hunt发布的形式表示疑惑。
AI 锐评
这款所谓的“ChatGPT Interactive Learning”产品,其发布本身比功能更值得玩味。从现有信息看,它并非独立APP,而是ChatGPT的功能升级,却以独立产品形式出现在Product Hunt,这引发了对其发布渠道和真实性的社区质疑。这反映出AI巨头功能迭代与独立产品边界模糊化的新常态。
其宣称的价值——通过交互可视化攻克STEM教育抽象性——确实直击要害。动态图解与变量操控若能实现,是从“知识检索”迈向“概念建构”的关键一步,将大语言模型的逻辑链条转化为可感知的因果模型。这不再是提供答案,而是搭建理解的情境,理论上能降低认知负荷,促进直觉形成。
然而,深度剖析之下,隐患与挑战并存。首先,其内容深度与广度存疑。70+核心话题仅是起点,科学体系的复杂性与知识网络的连贯性,远非孤立模块所能覆盖。其次,“交互”的真实性有待检验。是预设动画的触发,还是基于物理规则的实时模拟?这决定了学习者是“探索发现”还是“观看演示”。最后,教育效果缺乏实证。互动是否真能转化为深层理解与迁移能力,需严谨学习科学评估,而非仅凭体验新颖性断言。
更尖锐的问题是:这是教育范式的革新,还是高级营销素材?OpenAI若严肃进军教育,需构建完整的教学逻辑、评估体系与课程规划,而非仅提供炫酷的工具。当前形式,更像是对其代码解释器与可视化能力的场景化展示,旨在巩固其“全能助手”的叙事,吸引更广泛的用户群体(学生、家长、教育者)进入其生态。
真正的价值不在于“又一个学习工具”,而在于它是否标志着AI从知识库向交互式认知伙伴的范式转变。如果成功,它将重新定义人机协作学习的边界;如果流于表面,则不过是AI热潮中又一个精美的教育科技泡沫。用户对发布信息的质疑,恰恰反映了市场对AI炒作日益增长的警惕性。产品需要以持续、扎实的教育成果来回应这份警惕。
一句话介绍:Mindspase是一款视觉化AI知识库,通过零手动整理和自然语言搜索,解决了用户在信息过载时代“收藏即遗忘”的痛点,让灵感与知识得以轻松重现。
Productivity
Artificial Intelligence
AI知识管理
视觉化信息组织
无文件夹整理
自然语言搜索
隐私安全
团队协作空间
灵感管理
跨内容类型存储
智能标签
情绪化浏览
用户评论摘要:用户普遍认可其解决“收藏夹坟墓”痛点的价值,并对“视觉情绪浏览”概念表示兴趣。主要疑问集中在:AI标签随内容量增大的准确性、模糊搜索的机制、与其他工具的集成可能性,以及多语言搜索支持。也有评论提醒产品需清晰传达价值以促进增长。
AI 锐评
Mindspase的野心不在于成为另一个笔记或书签工具,而旨在构建一个符合人类记忆非线性、关联性特征的“外脑”。其核心赌注——“零手动整理”看似是卖点,实则是巨大的产品与技术悬崖。它试图用AI完全替代人类的信息分类劳动,这要求其底层模型不仅要有出色的多模态理解能力(处理文章、图片、PDF等),更需具备深度的个性化学习能力,以理解每个用户独特的“记忆逻辑”。从评论中关于“AI标签是否会随内容增多而变得嘈杂”的质疑即可见,用户对此的信任是脆弱的。
当前,其“视觉情绪浏览”和“自然语言搜索”概念颇具前瞻性,击中了传统关键词搜索的盲区——即我们常凭感觉和模糊片段进行回忆。然而,这恰恰也是技术难点所在。模糊查询的准确度将直接决定产品是“神奇”还是“鸡肋”。此外,产品将“隐私”和“无广告”作为核心原则,这在赢得早期技术敏感型用户好感的同时,也为其商业模式画上了问号。是走向订阅制,还是未来在B端的“集体思维”协作功能上寻找路径,需要更清晰的叙事。
总体而言,Mindspase切入了一个真实且普遍的需求缝隙,但其长期成功不取决于概念的新颖,而取决于AI在真实、复杂、海量的个人数据场景下,能否持续提供稳定、精准、且令人惊喜的“记忆重现”体验。它不是在优化组织效率,而是在挑战人类如何与信息交互的根本范式,这是一条迷人但遍布荆棘的道路。
一句话介绍:TADA是一款开源的语音语言模型,通过1:1文本-声学对齐技术,在语音合成场景下,解决了传统TTS系统速度慢、易出现吞词和内容幻觉的痛点。
Open Source
Artificial Intelligence
Audio
开源语音模型
文本到语音
语音合成
快速生成
消除幻觉
长上下文
边缘计算
多语言
AI语音代理
音画同步
用户评论摘要:用户普遍认为该产品理念出色,速度快、无幻觉、支持长音频是核心优势。主要疑问集中在:1. 对齐技术对富有表现力或情感化语音的处理效果;2. 量化模型格式(GGUF)的发布计划;3. 对开发方Hume AI在衡量AI对人类情感幸福影响这一宏观理念的追问。
AI 锐评
TADA的“1:1对齐”并非简单的效率提升,而是一次对传统TTS范式根基的动摇。传统系统在离散的文本标记与连续的声学帧之间进行模糊映射,是导致速度瓶颈、内容错乱(幻觉、吞词)和上下文窗口受限的根源。TADA将两者统一为连续的、对齐的令牌流,实质上是重构了语音生成的数据结构,从源头上规避了映射失配问题。这解释了其宣称的5倍速、零幻觉和超长上下文能力——这些并非独立的优化成果,而是同一技术范式突破后的必然体现。
然而,其真正的价值与潜在局限皆系于此。评论中关于“情感表达”的质疑切中要害:强制性的严格对齐,是否会以牺牲语音的韵律变化、情感起伏和自然停顿为代价?将语音过度“文本化”和“令牌化”,可能导向机械、平坦的播报风格,在需要高度表现力的场景中处于劣势。这揭示了TADA当前更适用于对准确性、速度和稳定性要求极高的场景,如信息播报、边缘设备语音代理,而非情感陪伴或内容创作。
Hume AI将其开源,野心在于确立新的行业标准,并推动社区在其高效、可靠的底层架构上,构建更复杂的语音应用生态。但另一条评论则触及了Hume更深层的企业叙事矛盾:一家以“情感AI”为标签的公司,却率先发布了一款强调“精准对齐”而非“情感表达”的语音模型。这或许暗示,在工程可靠性问题未解决之前,谈论情感福祉仍是空中楼阁。TADA是Hume交出的一份扎实的基础设施答卷,但它离其宏大的“改善人类情感”使命,还有相当长的距离。它的成功,将取决于社区能否在其精准但可能“枯燥”的基石上,重新演绎出语音的丰富情感。
一句话介绍:一款为Claude Code设计的CLI工具,通过后台代理分析编码会话记录,自动生成并管理精准的规则,解决AI编码助手因项目上下文过时或混乱而重复犯错的痛点。
Developer Tools
Artificial Intelligence
Tech
AI编程助手
上下文管理
开发者工具
CLI工具
规则引擎
代码会话分析
自动化
本地运行
开源项目辅助
生产力工具
用户评论摘要:用户普遍认可其解决了Claude.md文件易过时的核心痛点。主要问题集中于规则冲突处理机制、与Claude原生记忆工具的区别,以及“困惑模式”检测的准确性。开发者回应积极,提供了技术细节和使用指引。
AI 锐评
CodeYam Memory切入了一个AI原生开发中日益凸显的“技术债”问题:如何系统化地管理AI助手的上下文,而非依赖零散、静态的提示文件。其价值不在于简单的自动化,而在于构建了一个“观察-诊断-规则化”的反馈闭环。它试图将开发者与AI协作中模糊的、经验性的“调教”过程,转化为可审计、可迭代的显性知识库。
产品聪明地利用了Claude Code内置的、尚未被充分发掘的规则系统作为底层支撑,这比从零构建一个外部覆盖层更轻量,也避免了与官方生态的直接冲突。其真正的挑战在于算法的精准度:“困惑模式”的识别极具主观性,过度概括可能导致规则泛滥,反而污染上下文窗口;而识别不足则工具形同虚设。评论中关于“困惑与模糊指令区别”的质疑直指核心——这本质是一个意图推断问题,对当前AI仍是难题。
因此,CodeYam Memory的长期价值并非替代人工,而是提升人机协作的“可观测性”与“可操作性”。它将散落在聊天记录中的碎片化修正,沉淀为结构化的项目规则,本质上是在为团队积累如何与AI高效协作的“元知识”。它的成功与否,将取决于其规则生成与维护的“信噪比”,以及能否融入开发者的自然工作流,而非成为又一个需要维护的“副驾驶的副驾驶”。
一句话介绍:MorphMind将AI从一个黑盒聊天机器人转变为可自定义、可引导的专家团队,在复杂的研究、分析和决策支持等场景中,解决了用户对AI输出结果缺乏透明度、控制力和可追溯性的核心痛点。
Productivity
Artificial Intelligence
Tech
可引导AI
AI代理团队
可追溯性
工作流协作
角色定制
知识复用
AI项目管理
企业AI
智能体平台
人机协作
用户评论摘要:用户普遍赞赏“可引导的专家团队”理念和可追溯推理功能,认为对实际工作流至关重要。主要问题集中于跨项目知识/工作流如何安全准确地复用。创始人回应称通过“专家”作为持久化载体来积累结构化经验。
AI 锐评
MorphMind的野心不在于打造另一个更强大的“全能型”AI助手,而是试图解构并重构人机协作的范式。其核心价值并非技术突破,而是产品哲学上的转向:从追求“答案的生成”转向“过程的治理”。它敏锐地击中了当前企业级AI应用的真实软肋——失控感。当AI开始涉足研究、分析、决策等复杂链条时,单次性的、黑盒的对话模式立刻显得笨拙而危险。
产品提出的“可引导的专家团队”模型,本质上是将项目管理与质量控制的成熟思想注入AI协作流程。通过角色分配、过程检查、中途介入和知识复用,它试图将AI的输出从“概率性艺术”转变为“可管理的工程”。这直指专业工作场景中问责制、一致性与知识沉淀的核心需求。
然而,其宣称的“专家”能跨项目积累经验并安全复用,是理想也是最大的风险点。这涉及AI智能体的长期记忆、偏好泛化与边界控制等一系列未完全解决的技术挑战。产品若成功,将开辟企业AI应用的新层;若其“专家”的复用逻辑出现偏差或“幻觉”,则可能放大错误,形成复合型风险。它真正的考验在于,能否在“可引导”的灵活性与“可信任”的稳定性之间找到精妙的平衡,这远非一个产品设计就能解决,更需要底层AI行为的根本性进步。
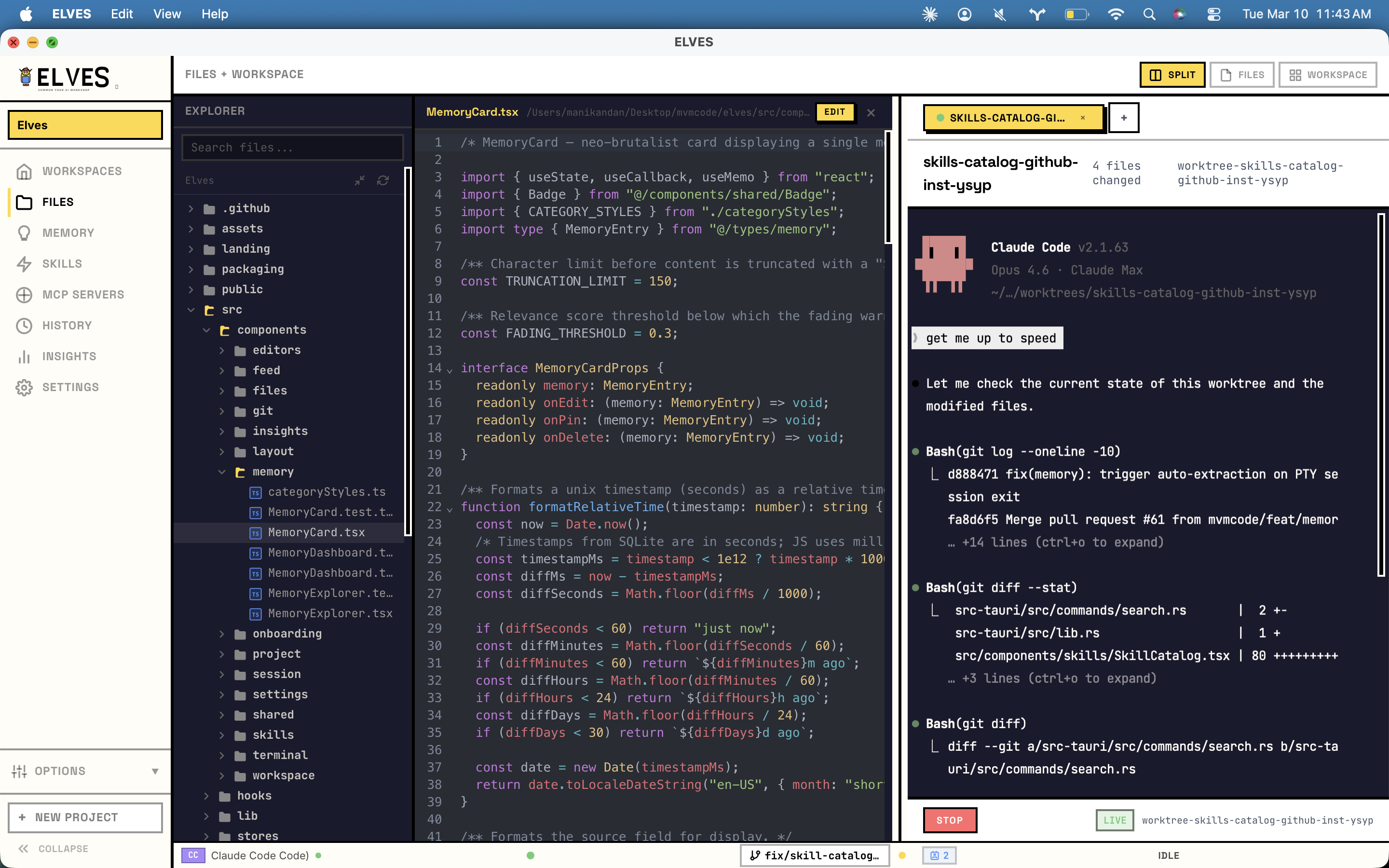
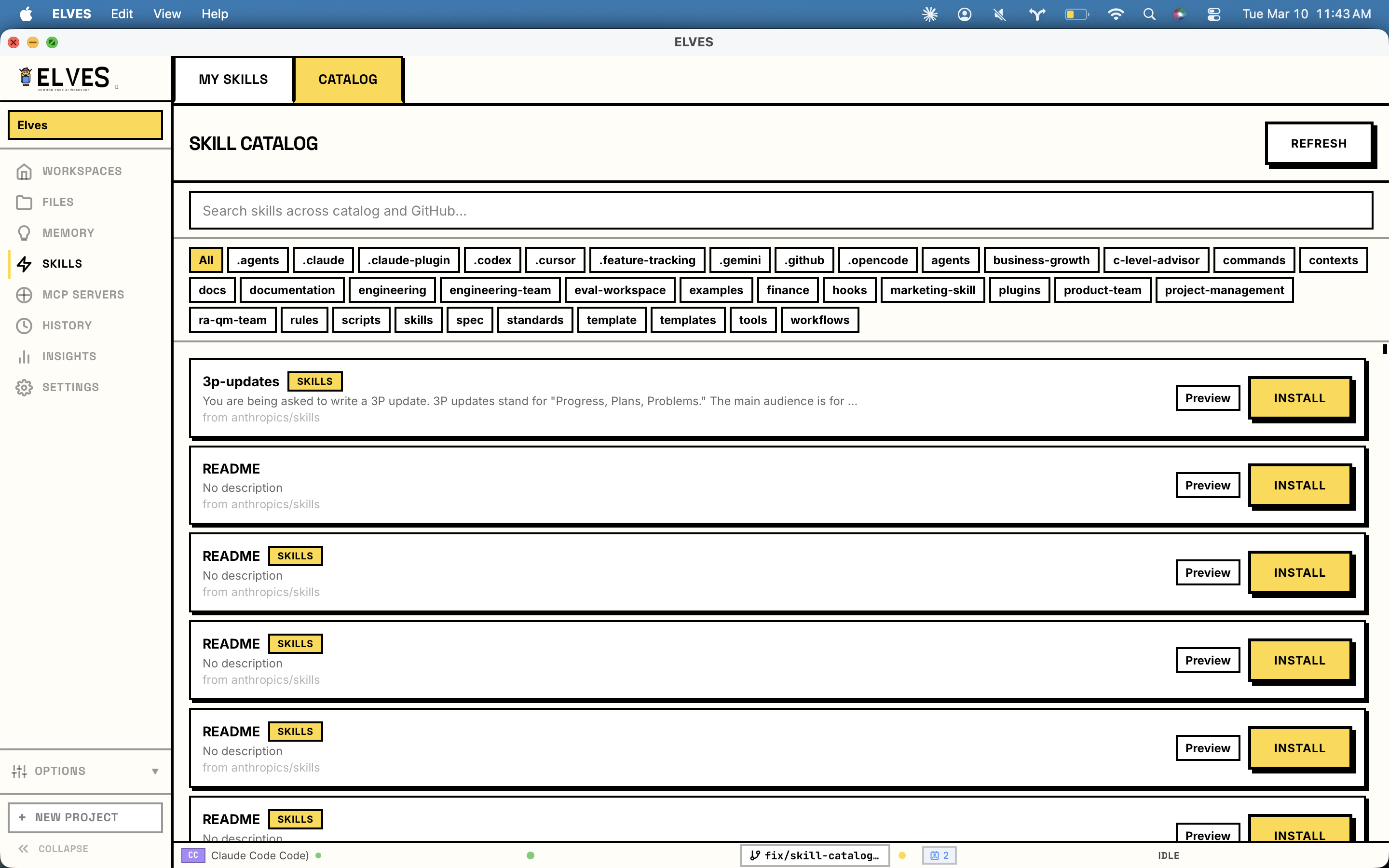
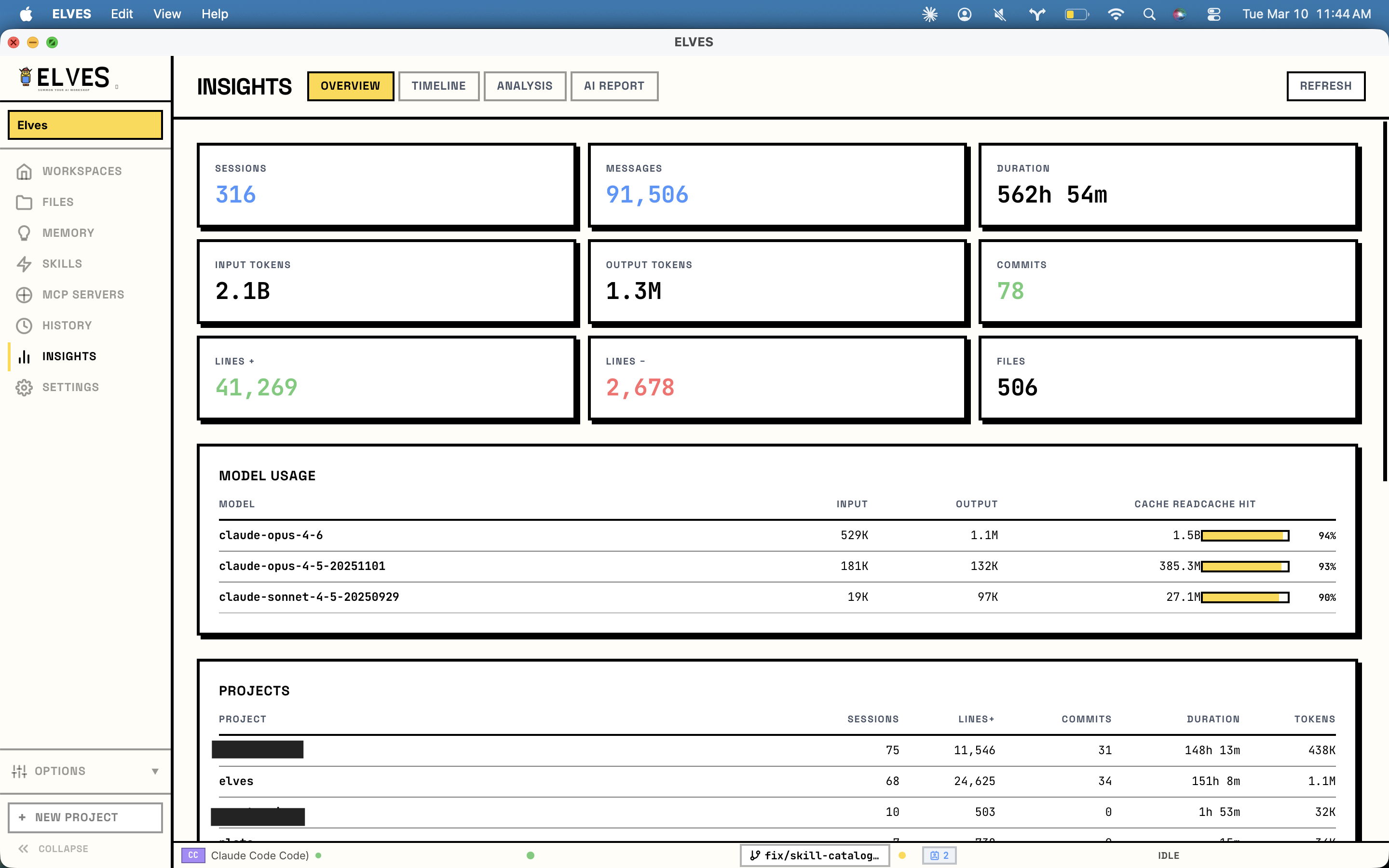
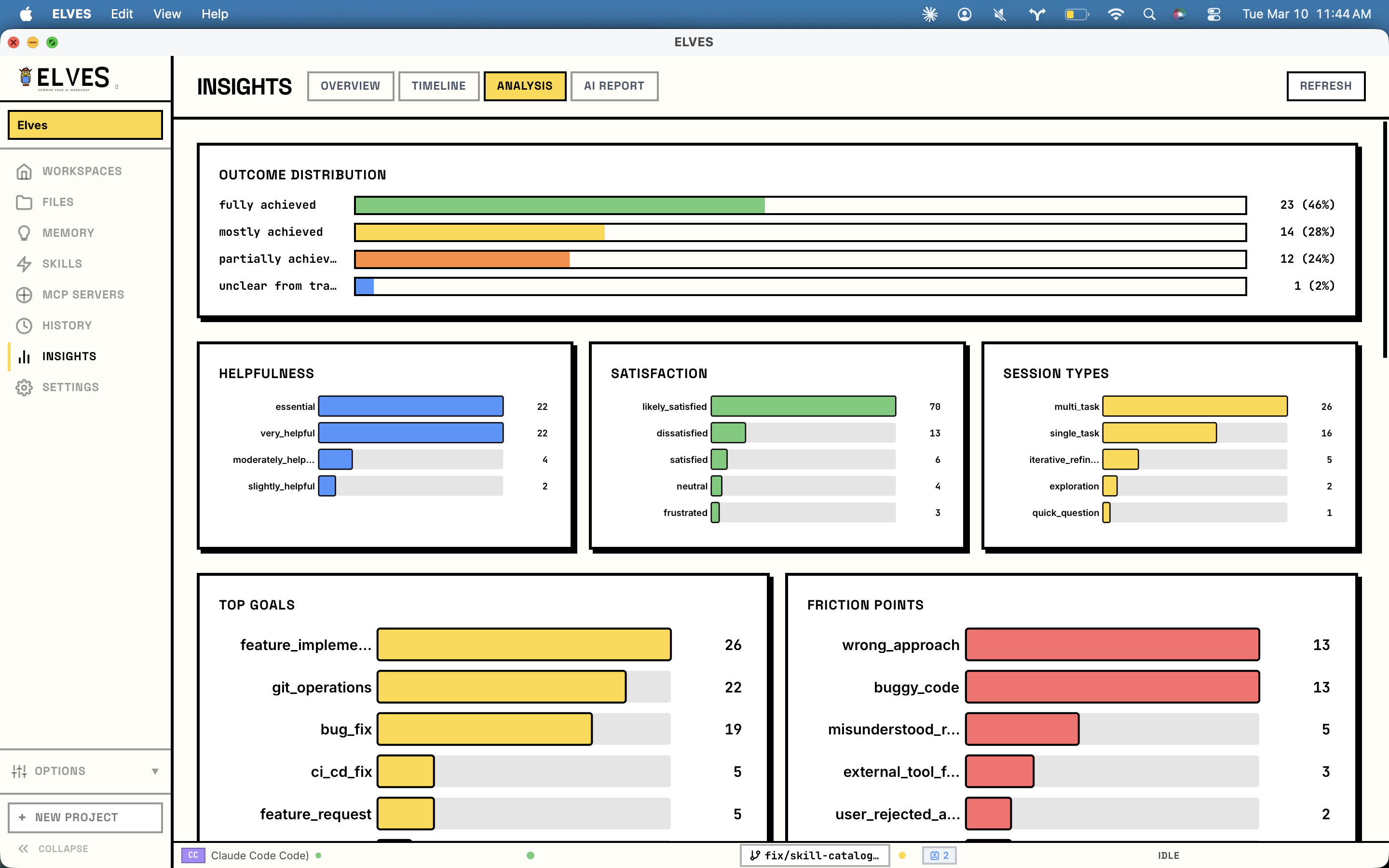
一句话介绍:ELVES为Claude Code等AI编程代理提供了一个具备共享工作空间、记忆层和统一部署点的本地管理平台,解决了多代理切换混乱、上下文丢失和资源消耗不透明的问题。
Developer Tools
Artificial Intelligence
YC Application
AI编程助手管理
本地开发工具
多代理协作
上下文持久化
工作空间隔离
性能监控仪表盘
开源工具
开发者生产力
用户评论摘要:用户(包括开发者本人)肯定其解决了AI编程代理会话隔离、手动配置繁琐及资源消耗不透明等痛点。特别指出其SQLite记忆层与相关性衰减架构设计合理。同时提出更高维度的“开发者身份”持久化是待解决问题。
AI 锐评
ELVES看似是一个AI编程代理的“管理外壳”,但其真正价值在于它试图为当前离散、短视且“失忆”的AI编码体验,构建一套系统性的本地工程化基础设施。它不生产代码,而是管理“生产代码的AI”。
产品犀利地切中了当前开发者使用Claude Code等工具时的核心矛盾:AI能力强大,但交互模式原始。手动编辑Markdown/JSON配置、会话间状态清零、多任务冲突、资源消耗黑盒,这些痛点让AI辅助从“智能”倒退为“手工劳动”。ELVES通过工作树隔离解决冲突,通过SQLite记忆层实现带衰减的上下文持久化,并将底层遥测数据可视化,本质上是在为AI编程引入版本控制(git worktree)、状态管理(记忆层)和可观测性(仪表盘)这些软件工程的核心范式。
然而,其挑战与价值并存。首先,它深度绑定特定AI工具(Claude/Codex),生态依赖性较强。其次,其“记忆衰减”机制虽被评论赞许为避免“陈旧上下文毒害”,但衰减策略的普适性与可配置性将是关键,否则可能从“保存一切”的极端走向“遗忘重要信息”的另一极端。最后,正如评论所指,它解决了“何事被做”的记忆,但未解决“何人操作”的身份与偏好层,这提示AI编程代理的管理正在从工具层面向“开发者数字孪生”的更深层次演进。
总体而言,ELVES代表了AI编程工具从“单次对话玩具”向“可持续集成的工作伙伴”演进的重要一步。它的开源与本地化立场,在数据隐私敏感的开发场景中具备优势,但其长远价值取决于能否成为AI编程代理间协作与集成的“事实标准”层,而不仅仅是一个优秀的外挂插件。
一句话介绍:一款通过自然语言描述,即可快速生成包含原生SwiftUI界面和内置云数据库的全栈苹果平台应用的一体化开发平台,解决了独立开发者和初创团队在原型验证和产品上线过程中,因工具链割裂、后端搭建复杂而导致的开发效率低下和动力丧失的痛点。
Artificial Intelligence
Database
Vibe coding
AI应用开发
原生Swift
全栈平台
云数据库
快速原型
苹果生态
无代码/低代码
应用发布
后端即服务
一体化开发
用户评论摘要:用户普遍赞赏其“一体化”理念和生成真正原生应用的能力,认为能极大提升开发速度。主要关切点集中在平台锁定风险(数据能否导出)、生成代码的调试机制,以及应用商店提交流程的自动化程度。创始人回应称支持数据导出,并提供自动化TestFlight提交。
AI 锐评
Nativeline AI + Cloud 的野心,远不止是又一个“AI生成代码”的工具。它精准地刺中了当前“AI应用构建器”市场的虚伪痛点:绝大多数产品以“快速”为名,行“妥协”之实,交付的是性能与体验欠佳的Web包装应用,并将最棘手的后端架构问题留给开发者。Nativeline的颠覆性在于,它试图用一套封闭但完整的体系,重新定义“全栈”的边界——将从前端的SwiftUI、ARKit,到后端的数据库、认证、存储、函数,乃至最终的应用商店发布,全部封装在一个以提示词驱动的黑盒里。
其真正的价值并非技术上的突破(集成现有技术),而是产品定位上的“暴力整合”。它看透了“开发效率”的本质不仅是写代码快,更是消除令人崩溃的上下文切换和系统集成工作。通过将Supabase/Firebase的后端能力与Xcode的本地开发环境“溶解”到自己的云平台中,它向目标用户(独立开发者、小团队)兜售的是一种“确定性的快”:从想法到可运行、可上架的全功能应用,路径被极度缩短和标准化。
然而,这种“一站式”的便利背后,潜藏着巨大的战略赌注和风险。对开发者而言,便利性是以深度绑定和平台依赖性为代价的。尽管创始人承诺可导出数据,但应用架构、业务逻辑与Nativeline平台的耦合度极可能很高,迁移成本不容小觑。对Nativeline自身而言,它正走上一条与主流“开放集成”趋势相反的道路,需要自行维护整个复杂的技术栈,其可靠性、扩展性以及能否跟上苹果每年庞大的框架更新,将是严峻的长期考验。它可能成为小团队“从0到1”的火箭,但也可能成为其“从1到100”的枷锁。成功与否,取决于它能否在“开箱即用的魔力”与“企业级可控性”之间,找到一个可持续的平衡点。
一句话介绍:Typinator 10是一款面向macOS和iOS的快速、隐私优先的文本扩展工具,通过将重复性输入转化为即时文本快捷键,在邮件回复、代码编写、AI提示词输入等高频打字场景中,显著提升用户效率并保障数据安全。
iOS
Mac
Productivity
文本扩展工具
效率提升
隐私保护
跨平台同步
macOS应用
iOS应用
键盘扩展
本地优先
自动化输入
Apple Intelligence集成
用户评论摘要:用户积极评价其跨平台同步和隐私设计,询问iOS独立购买、图片扩展功能及iOS系统级集成原理。开发者回复确认iOS通过自定义键盘实现全应用覆盖,需开启完全访问权限,数据本地存储,图片扩展功能已在Mac实现,iOS已列入计划。
AI 锐评
Typinator 10的迭代,表面是功能清单的扩充——跨平台、新界面、智能集成,实则是一次在“效率”与“隐私”两大红海需求中,极具策略性的精准卡位。
其真正价值不在于简单的“文本替换”,而在于构建了一个以用户数据主权为核心的效率生态系统。在云端服务普遍默认采集数据的今天,它旗帜鲜明地强调“本地存储、云同步可选”,甚至支持NAS等私有化方案,这并非技术噱头,而是切中了专业用户和团队对敏感信息泄露的深层焦虑。这种“隐私即功能”的定位,使其在众多云同步效率工具中形成了差异化壁垒。
然而,其挑战同样明显。iOS版本依赖“完全访问”的键盘扩展权限,这本身就是一道用户体验的高门槛,会让部分隐私极端敏感者望而却步。尽管团队以透明解释应对,但如何平衡“系统级能力”与“用户权限恐惧”,将是其移动端普及的关键一战。此外,集成Apple Intelligence的自动化创建看似光鲜,但实际效果是否优于用户精心打磨的快捷键库,仍需观察,这可能更像一个顺应生态的营销亮点而非核心价值。
总体而言,Typinator 10的野心是成为跨苹果生态的、可信赖的输入基础设施。它不追逐最炫酷的AI功能,而是深耕“可控的自动化”。其成功与否,将取决于能否在维持隐私承诺的同时,让跨平台同步体验真正做到无缝与优雅,从而让用户愿意将那些代表其工作流核心的“数字肌肉记忆”托付于此。
一句话介绍:一款面向企业产品经理和设计师的AI辅助工作台,通过安全克隆现有产品前端并集成Claude Code,在复杂的合规与代码环境中,快速构建出符合业务和技术约束的可运行代码原型,解决“想法到可交付原型”的转化难题。
Design Tools
Prototyping
AI辅助开发
产品原型工具
企业级安全
Claude Code集成
低代码/无代码
产品管理
设计协作
前端克隆
本地化部署
工作流整合
用户评论摘要:用户肯定其“为Claude注入产品上下文”的核心思路。主要疑问集中于生成质量保障机制、是否支持演示视频生成,以及最受关注的企业安全与访问控制问题。开发者回复详细解释了本地化、零数据过服务器、数据脱敏等多重安全策略。
AI 锐评
Chordio Workbench的野心,并非再造一个Figma或传统的原型拖拽工具,而是试图成为打通产品构想与工程实现“最后一公里”的编译层。它的核心价值在于“约束条件下的创造力”:不是让AI天马行空地生成UI,而是将其创造力严格限定在克隆出的真实产品代码、品牌规范及合规要求构成的“牢笼”内。这精准击中了企业级产品创新的核心痛点——创新成本不是“从0到1画个图”,而是“如何在庞大的遗产代码、安全红线与跨部门依赖中,让一个想法安全地落地为可验证、可交付的代码片段”。
从评论区的交锋可以看出,其宣称的“安全”是成败关键,也是最大卖点。它巧妙地做了责任分割:自身仅作为“搬运工”和“流程调度者”,代码克隆在用户浏览器本地完成,核心的AI生成能力依赖企业已批准的内部Claude Code,所有产物存于用户自有代码库。这种“三零原则”(零接触后端代码、零数据过服务器、零第三方基础设施)的设计,是它能否敲开企业大门的钥匙。
然而,其真正的挑战在于“上下文”的厚度与精度。目前它主要处理的是前端代码和显性约束。但企业决策的复杂性远超于此,包括团队政治、资源博弈、技术债等隐性知识,这些难以被结构化注入AI。正如一位评论者犀利指出的,缺少“使用者上下文”(如PM的决策偏好)是一大缺口。产品能否成功,取决于其“上下文工程”能深入到何种程度,以及AI在如此复杂约束下是能产出惊艳方案,还是趋于平庸。它不是一个普适工具,而是为那些已被“大象”般的产品所困、却又必须让其跳舞的团队,提供的一把特种手术刀。
一句话介绍:一款通过全局热键即时捕捉屏幕内容并获取AI解答的工具,解决了用户在跨应用查询信息时频繁截图、切换窗口、复制粘贴导致的流程中断与效率低下痛点。
Productivity
SaaS
Artificial Intelligence
屏幕AI助手
生产力工具
全局热键
零上下文切换
隐私安全
多模型支持(GPT/Claude)
macOS应用
免费增值
实时问答
无痕处理
用户评论摘要:用户普遍认可其解决“45秒上下文切换”痛点的价值,尤其赞赏“表单字段解释”这一场景。主要反馈/建议包括:希望推出网页版或浏览器扩展;深入询问隐私保护机制(内存处理、独立验证);建议将“表单帮助”作为核心营销用例;关注响应速度与准确性。
AI 锐评
ScreenGeany AI 精准切入了一个被主流AI聊天界面所忽视的缝隙市场:高频、碎片化、强上下文依赖的屏幕内容即时解读。其真正的价值并非技术突破,而是对“AI交互动线”的重构——它将AI从需要“前往”的目的地,变成了一个随时可“召唤”的叠加层。
产品聪明地抓住了两个关键原则:第一,**最小化交互熵**。通过热键将“捕捉-提问-回答”压缩为一个近乎瞬时的动作,这比任何功能堆砌都更能提升采用率。第二,**零信任隐私**。宣称“截图仅存内存、不落盘、不经自家服务器”,这直击了企业用户和个人对屏幕敏感数据的核心顾虑,成为了其关键的信任支点。
然而,其面临的挑战同样清晰。首先是**场景深度**。当前主打快速答疑,但面对“合同审阅”等复杂任务,小屏幕叠加窗口的交互方式是否仍能保持高效?这存疑。其次是**生态枷锁**。作为原生macOS应用,其体验优势与平台绑定是一体两面,这与用户期待的全平台、浏览器内便捷性存在矛盾。最后是**商业模式**。免费版(10次/月)更像是一个功能演示,Pro版(200次/月)对于重度用户而言可能迅速见顶,而BYOK(自带密钥)模式虽能解锁无限使用,却也使产品退化为一个功能单一的“前端”,用户粘性与付费价值将面临考验。
本质上,它是一款优秀的“最后一英里”交付工具。但它能否从一个小巧的“功能点”,成长为一个不可替代的“工作流环节”,取决于它能否在保持当前瞬时、无感优势的同时,深化对复杂任务的支持,并构建起跨平台的、连贯的体验。否则,它极易被整合能力更强的操作系统级AI或全能型助手应用所覆盖。
一句话介绍:HypeScribe是一个集成了高精度AI转录与分析的语音数据管理中心,通过处理会议录音、社交媒体音频及语音消息,解决了用户在多场景下语音信息难以检索、整理和利用的核心痛点。
Productivity
Meetings
Artificial Intelligence
语音转录
AI笔记
会议记录
语音数据管理
多平台支持
按文件付费
语音搜索
内容摘要
SaaS工具
生产力应用
用户评论摘要:创始评论阐述了产品愿景与差异化特点(如代币定价、高精度多语言)。有效评论仅一条,用户指出语音笔记事后浏览不便的痛点,对产品解决该问题表示兴趣并愿意尝试。
AI 锐评
HypeScribe的叙事框架——“语音的Google Drive”——颇具野心,但其真正的价值锚点可能并非“存储”,而是“激活”。产品将离散的、非结构化的语音流(会议、社媒、即时消息)统一转化为可搜索、可摘要、可交互的结构化文本,这实质上是为企业与个人构建了一个私域的、跨平台的语音数据中台。
其宣称的“99%准确率”和代币制定价是双刃剑。高准确率是此类工具的入场券,而非护城河;按文件计费虽简化了用户认知,但在处理超长会议录音时可能面临价值感知挑战。产品真正的壁垒或许已在其数据中初现端倪:作为从Telegram bot成长起来的应用,其公布的82.5%月留存率异常亮眼,这强烈暗示其确实捕捉到了一个未被满足的刚性需求——用户并非简单地需要“转录”,而是需要从语音流中无缝提取“洞察”和“行动项”。
然而,其挑战同样清晰。赛道拥挤,从巨头附属功能到各类独立工具,竞争核心将迅速从转录准确度转向工作流嵌入深度与数据分析智能。其规划的Google Drive集成是正确方向,但未来必须更深地融入Notion、Slack等核心协作生态,并从“转录后分析”走向“实时对话智能”,否则恐将停留为一个好用但可被替代的工具。它的前景,取决于能否从“语音的转换器”进化为“对话的决策支持系统”。





























































Thrilled to back @hanghuang and the InsForge team on their Product Hunt launch.
InsForge is an AI‑native backend built for agents.
This isn't “AI bolted on,” this is starting with agent experience, and building on that foundation.
The unlock is a semantic layer that agents can actually read and act on.
Agents introspect policies and provision resources, so you can ship full‑stack apps end‑to‑end.
This adds up to:
Faster setup with npx. One install. Go build.
Agents working inside your IDEs (Cursor, Claude, etc.). No new UI to learn.
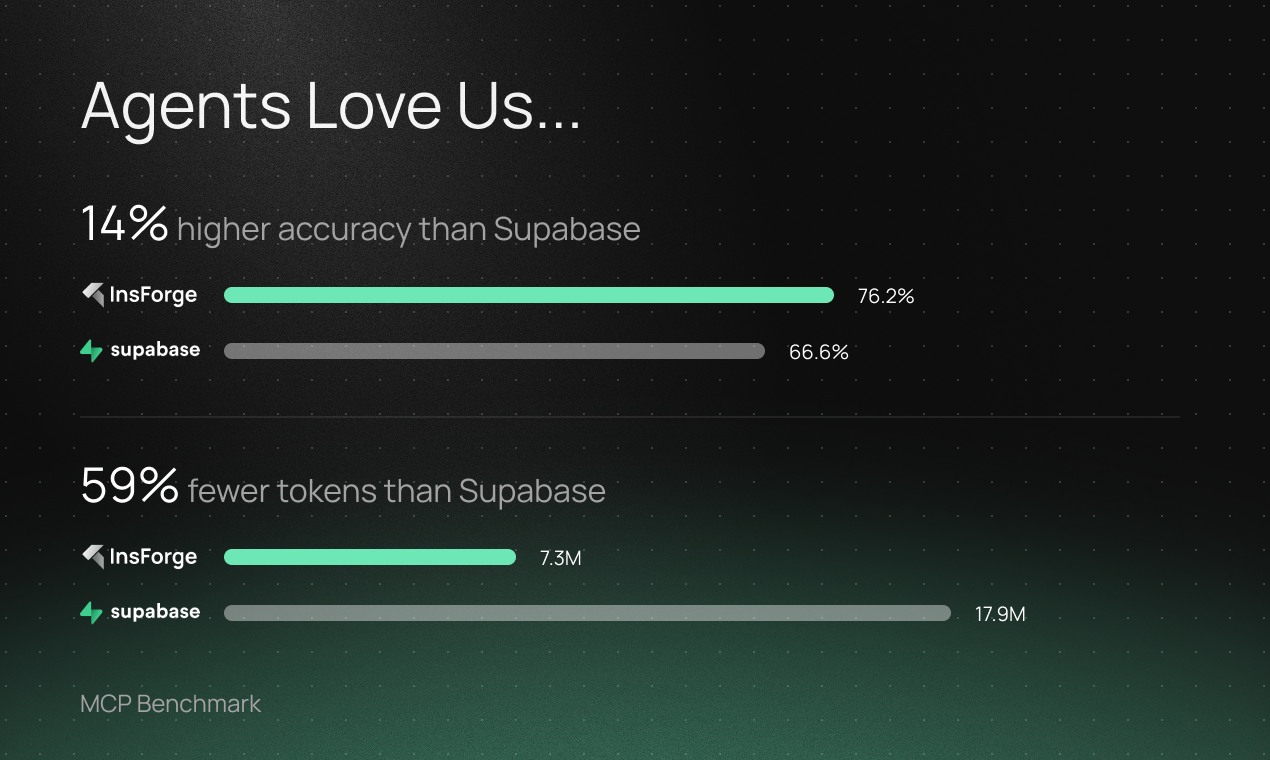
Benchmarked performance demonstrates higher accuracy, greater token efficiency, and lower latency.
If you’re exploring agentic development—or migrating off legacy backends—InsForge is the platform that gives your agents the infra they need to tackle the heavy lifting.
Get started now:
Hey product hunt! @tonychang430 here, co-founder of InsForge.
Before starting InsForge, I was working at Databricks on the networking infrastructure team. One of the first projects I worked on was optimizing our cloud resources, and we ended up saving around $30K networking cost per month. It ended up just turning on private link to aws resources, which is a private link endpoint setup and a cloud configuration.
That experience taught me something important: just because something works doesn’t mean it’s scalable or designed the right way.
Over the past year, AI coding tools have gotten incredibly good at generating code. You can go from idea to prototype faster than ever. But shipping a real product still means dealing with databases, auth, storage, deployments, infrastructure, and a lot of configuration.
Most of these systems were designed for humans who understand every layer of the stack.
But agents don’t work that way.
We started asking a simple question:
What would a backend look like if it was designed for agents from day one?
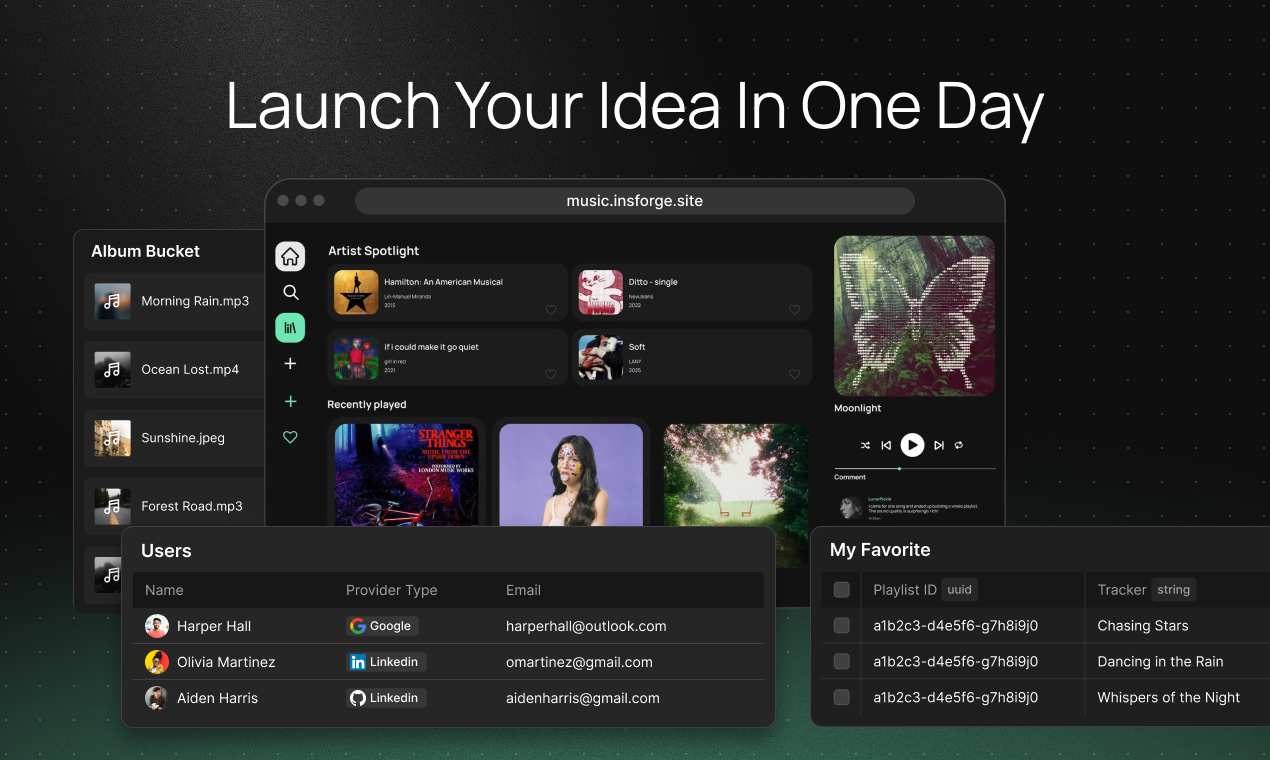
That is why we built InsForge. It is a backend platform where agents can set up infrastructure, manage data, deploy applications, and operate everything end to end.
Humans are slower, make more mistakes, and usually need deep knowledge of every layer of the stack. Agents should be able to understand the system and get things done directly.
Our goal is simple.
Make agents the primary operators of software infrastructure.
Really excited to share this with the Product Hunt community. Happy to answer any questions and would love to hear what you think 🙏
Hey Product Hunt 👋 I’m @hanghuang, co-founder of InsForge.
Before starting InsForge, I was a Product Manager at Amazon and have always enjoyed building products and launching side projects to test new ideas.
InsForge is the backend built for agentic development — giving agents everything they need to ship fullstack apps, fast.
Most backend platforms are designed for human developers. But InsForge starts with agent experience.
Our platform (2.1K+ stars on GitHub) exposes backend primitives like databases, auth, storage, and functions through a semantic layer that agents understand, can reason about, and operate end to end:
With InsForge, your agent can:
Set up everything needed to ship fullstack apps
Launch and deploy your applications on a hosted or custom URL
Build applications that are secure and scale
Building on InsForge is faster and more reliable — up to 14% more accurate, 1.4x faster, and 2.4x more token efficient than SupaBase — as demonstrated in our MCPMark v2 benchmark.
To get started, head to your terminal and enter:
And use code INSFORGELW1 to get a month of InsForge Pro for $0.00!
👉 Got questions? Drop them below, or join our Discord.
We’re excited to share this with the Product Hunt community and can't wait to see what you build. Thanks for checking us out, and huge thanks to our hunter @chrismessina for hunting us🙏
The MCP integration is what sets InsForge apart. Instead of agents hallucinating API calls or guessing schema, they can actually fetch live backend context. That's a fundamentally smarter approach than just giving agents a README and hoping for the best.
Congrats on the launch! Would love to know how this integrates with tools like Cursor or Claude Code in real workflows
Open source AND hosted? Best of both worlds.
npx @insforge/cli create — that's it. That's the tweet.
Have a great launch! Good luck!
Awesome project! shared with our dev team :) putting everything in one place sounds like a fascinating approach.
Congrats on the launch! Following the roadmap closely.
Congrats on the launch team! Excited for the future of InsForge :) 🚀
The UI looks very clean. Curious how this performs with larger workflows.
The model gateway feature is underrated. Being able to route to different LLM providers through a single OpenAI-compatible API, with usage tracked per project, is exactly what teams building AI-native apps need.
So I've had the chance of trying out the remote MCP server from Minns Foods with Claude Code and also with Codex. The capability of just being able to very quickly build applications and also deploy them with a full-fledged database authentication is just wonderful. The developer experience is great, like a one-shot prompt; you can get your full stack up and ready. I feel that, when comparing it with being able to do more complex tasks as compared to the developer experience that you get with Supabase, I certainly feel that I've had much more success in being able to do things faster. The overall performance also feels a lot more snappier.
I'm glad that we have this capability with a really robust MCP server that has all of the built-in capabilities to automatically fetch stocks and then also just one-click deploy the app on ourselves. It has been pretty fun to work with.
the semantic layer approach is exactly right. agents shouldn't guess at infrastructure the same way they shouldn't guess at who the user is. been building the identity side of this problem - the agent knows what to build with insforge, but does it know who it's building for? the cold start for user context is the same problem you solved for infra.
Congrats on the launch @chrismessina & @tonychang430! Building a backend specifically for the Agentic Era is a great vision. Can't wait to see how this evolves. Upvoted!
The agentic backend is here. No more excuses for not shipping.
I tried it for few builds, solid product features!
Good product, looking forward to seeing where it goes.
This is exactly what the agentic dev ecosystem needed.
The pgvector support (mentioned in the docs) is a great addition for teams building RAG applications. Having vector search built into the same Postgres instance as your relational data simplifies a lot of architecture decisions.
My Cursor agent just deployed a full-stack app. I'm shook.
The semantic layer approach is really smart — having agents reason about backend primitives rather than just calling APIs changes the whole development model. The fact that it works inside existing IDEs like Cursor and Claude with no new UI to learn is a big plus. Congrats on the launch!
As someone who mostly dabbles in front-end and rarely backend, I'm always afraid I'll set up something wrong that causes a recursive loop and spikes my cloud or database cost somewhere. Are there ways that InsForge can also help with ensuring the code is cost-optimized as well?
Congrats on #1! The semantic layer approach is smart - agents that can reason about their own infrastructure instead of blind API calls is a big unlock. How are you handling auth scoping when multiple agents share the same backend? That's always been tricky in multi-agent setups.
Interesting direction.
AI can already generate a lot of frontend code, but backend setup is still where agents struggle.
Tools like this that make infrastructure "agent friendly" are going to become a big part of the AI dev stack.