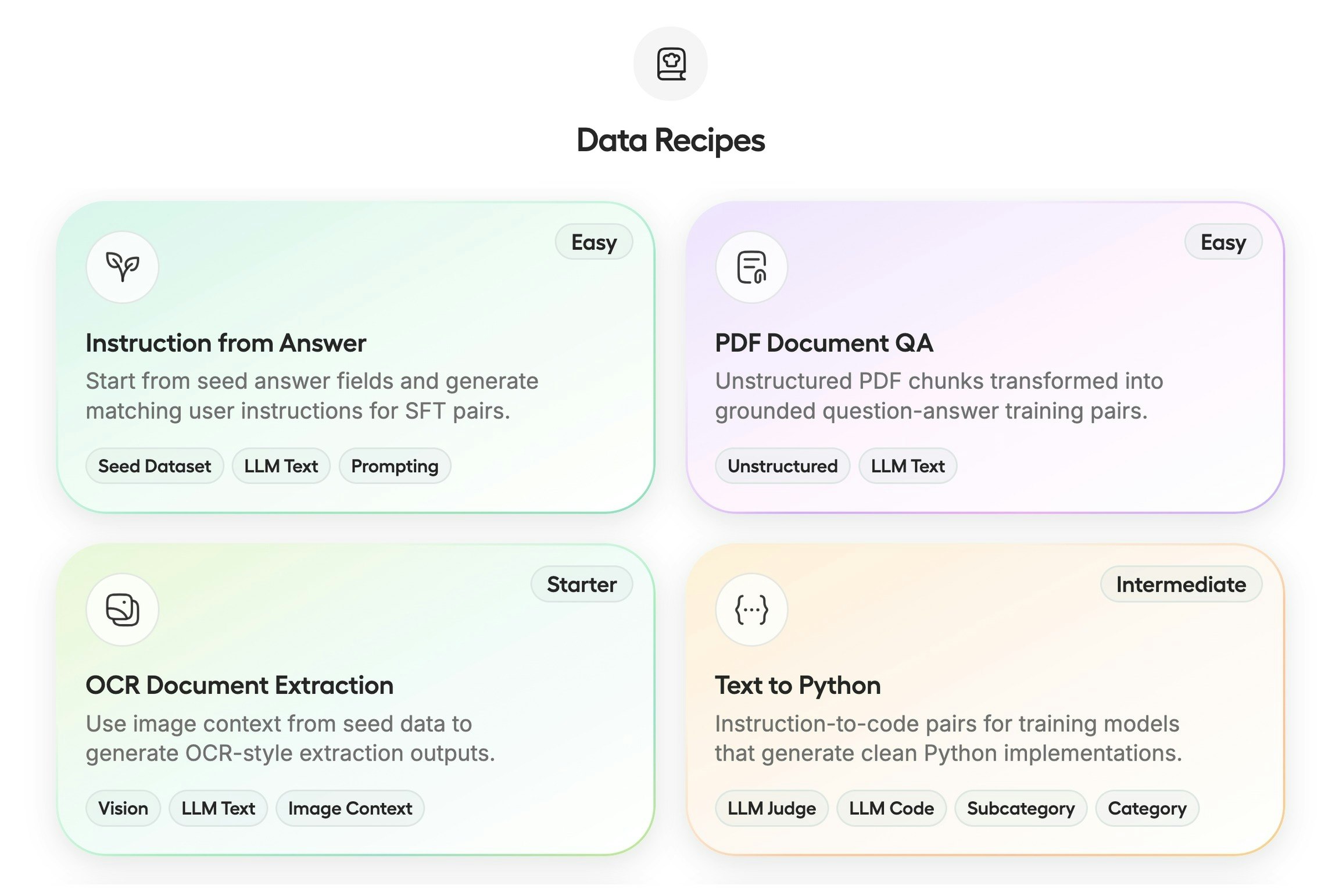
PH热榜 | 2026-03-18
一句话介绍:一款允许用户通过手机向运行在个人电脑上的Claude AI发送指令并执行本地文件访问、浏览器操作等任务的工具,解决了用户离开办公桌后无法远程操控桌面AI完成工作的痛点。
Android
Productivity
Task Management
AI远程控制
移动办公
桌面自动化
人机协作
沙盒安全
本地执行
任务调度
Claude生态
工作流增强
用户评论摘要:用户普遍认可其“移动触发、桌面执行”的核心价值,赞赏沙盒安全与手动批准机制。主要疑问集中在与Claude Code远程控制功能的异同、跨平台支持(如Linux)、任务执行前的预览能力以及具体高频使用场景。
AI 锐评
Claude Dispatch表面上是一款解决“离席中断”问题的移动遥控器,但其深层价值在于重新定义了人机协作的时空边界。它将个人桌面从一个固定位置的算力终端,转变为一个可由移动设备随时调度的“静默执行引擎”。这种“异步触发-结果验收”模式,并非简单地将AI对话移植到手机,而是切中了专业工作流中一个关键缝隙:那些需要桌面端全权限访问(本地文件、浏览器、专业工具)但灵感或指令又常在移动中迸发的任务。
产品最犀利的设计在于“沙盒化”与“手动批准”机制。这直接回应了当前AI代理工具普遍存在的信任赤字——用户并非不愿放手,而是需要可靠的制动系统。这种“默认安全”的哲学,是其区别于盲目追求全自动化的Agent工具的核心竞争力。
然而,其模式也隐含局限:重度依赖桌面端持续在线,本质上是一种私有化部署的“个人云”,在跨设备、多用户协作场景下可能乏力。评论中将其类比为Slack等协作工具的潜在功能,恰恰点明了其当前形态的过渡性。长远看,它的真正对手可能不是其他AI助手,而是深度集成到操作系统级的工作流调度系统。Dispatch的价值窗口,在于利用当前桌面AI生态的割裂期,以安全可控的远程执行作为楔子,抢占用户“混合位置办公”的心智。但若无法从“功能”演进为“平台”,其天花板将清晰可见。
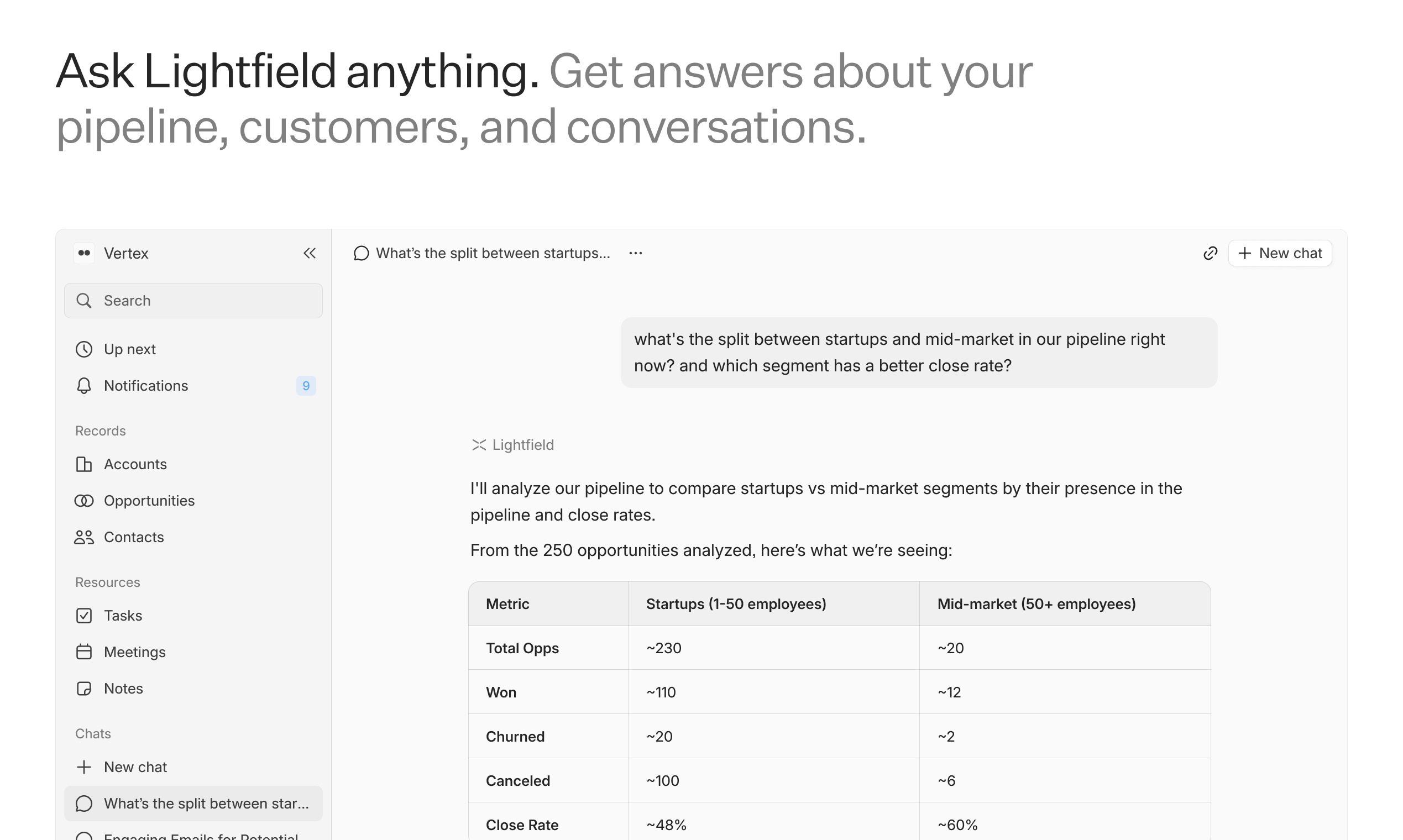
一句话介绍:Lightfield是一款AI原生CRM,通过自动读取邮件、会议和通话记录来构建并自我更新客户关系管理系统,解决了销售团队因手动录入数据繁琐且难以坚持而导致的CRM数据陈旧失准的核心痛点。
Sales
Artificial Intelligence
CRM
AI原生CRM
自动数据捕获
无手动录入
销售自动化
客户洞察分析
智能助手
数据迁移
创始人销售
对话智能
可定制化
用户评论摘要:用户普遍赞誉其“零手动录入”彻底解决了CRM数据维护难题。主要问题集中在:如何处理跨渠道(如Slack、WhatsApp)的对话以消除数据缺口;AI如何准确解析跨月异步碎片化沟通;数据敏感性与隐私控制;以及从传统CRM(如HubSpot)迁移的体验差异。
AI 锐评
Lightfield并非简单的CRM界面优化,而是一次对CRM存在逻辑的根本性颠覆。它敏锐地抓住了传统CRM“死于数据录入”这一痼疾,将产品重心从“如何让人更好地填数据”转向“如何让系统自动获取数据”。其宣称的“连续上下文”存储与在此基础上的代码执行能力,是区别于仅做信息提取的AI工具的潜在分水岭——这意味着它可能从“记录系统”进化为一个可主动调用知识、执行复杂任务的“工作系统”。
然而,其光鲜愿景下暗藏挑战。首先,其核心价值高度依赖于数据捕获的广度与深度。目前以邮箱和日历为主的数据源,在沟通渠道碎片化的今天显得单薄,评论中关于跨平台数据缺口的担忧直指其命门。其次,将非结构化对话转化为可靠商业数据的准确性,尤其在复杂、模糊的销售情境中,仍需大规模实践验证。隐私与数据控制问题,是另一个潜在用户(尤其是大企业)决策的关键障碍。
产品目前精准切入“创始人/小团队销售”场景,是明智的楔子。但若想成为主流,它必须证明自己不仅能“读懂”对话,更能“理解”复杂的商业关系与意图,并在团队规模化时,将其积累的“连续上下文”转化为可安全、高效共享的组织智慧,而非新的数据孤岛。这是一条极具想象力的道路,但每一步都需在技术可靠性与用户信任上做到无懈可击。
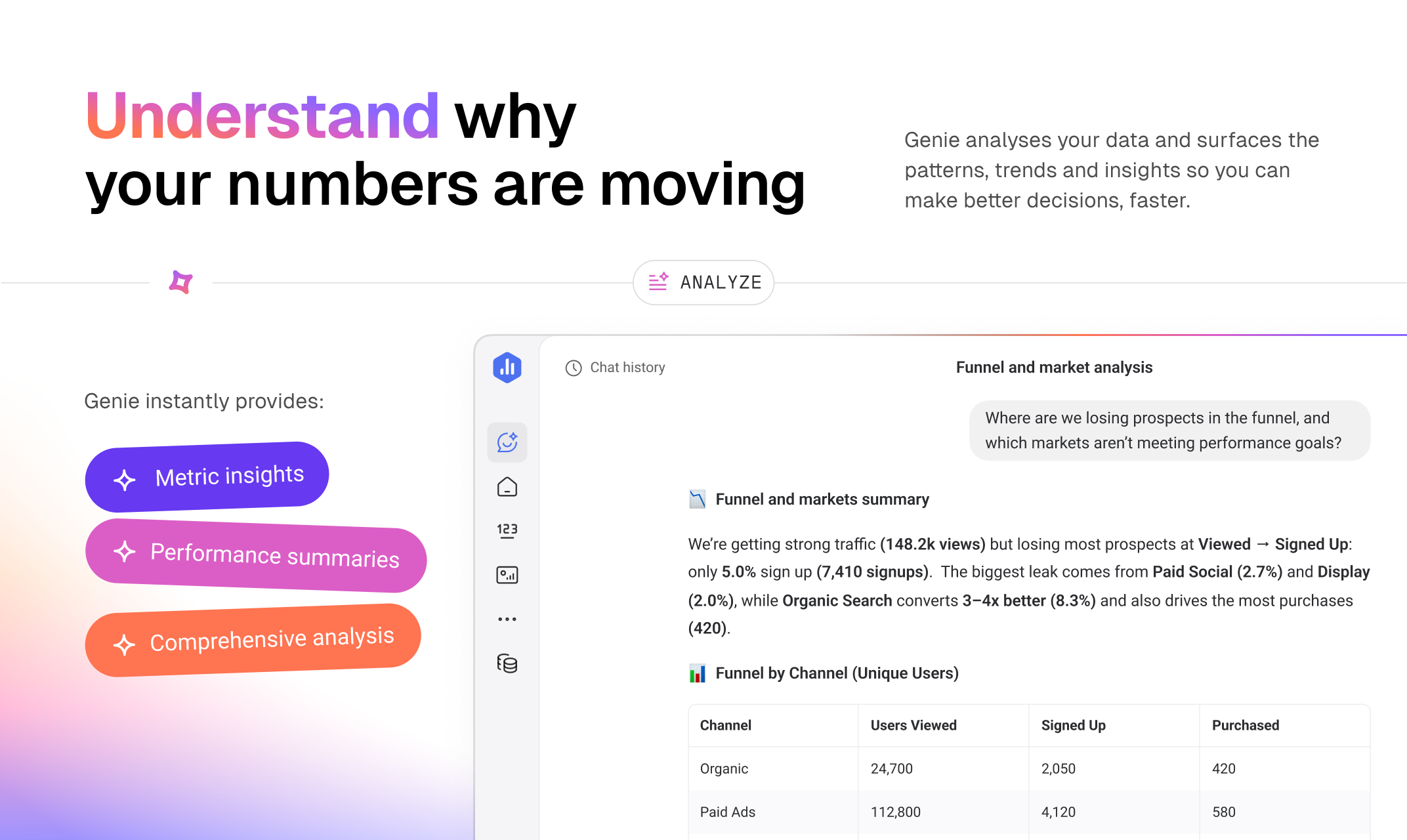
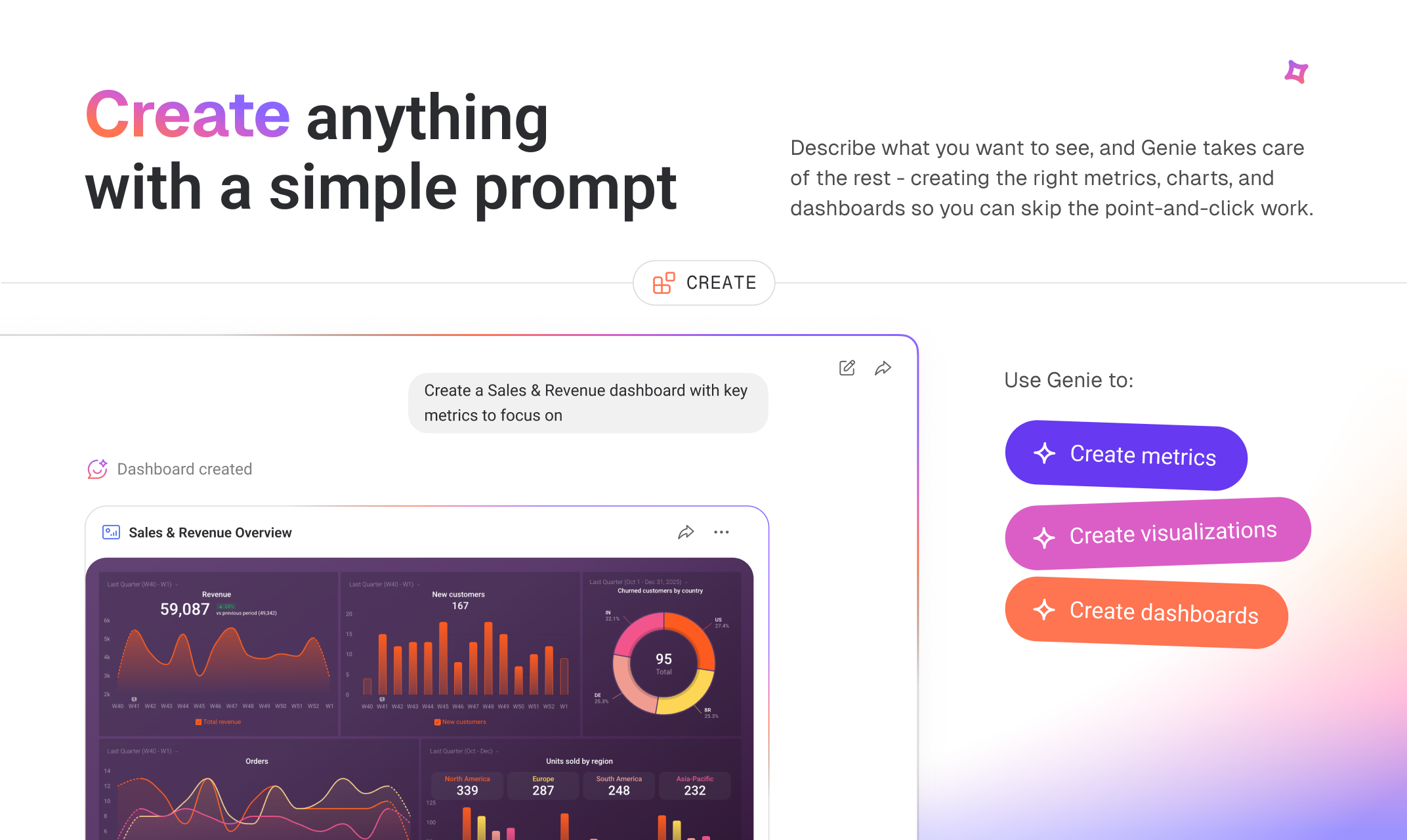
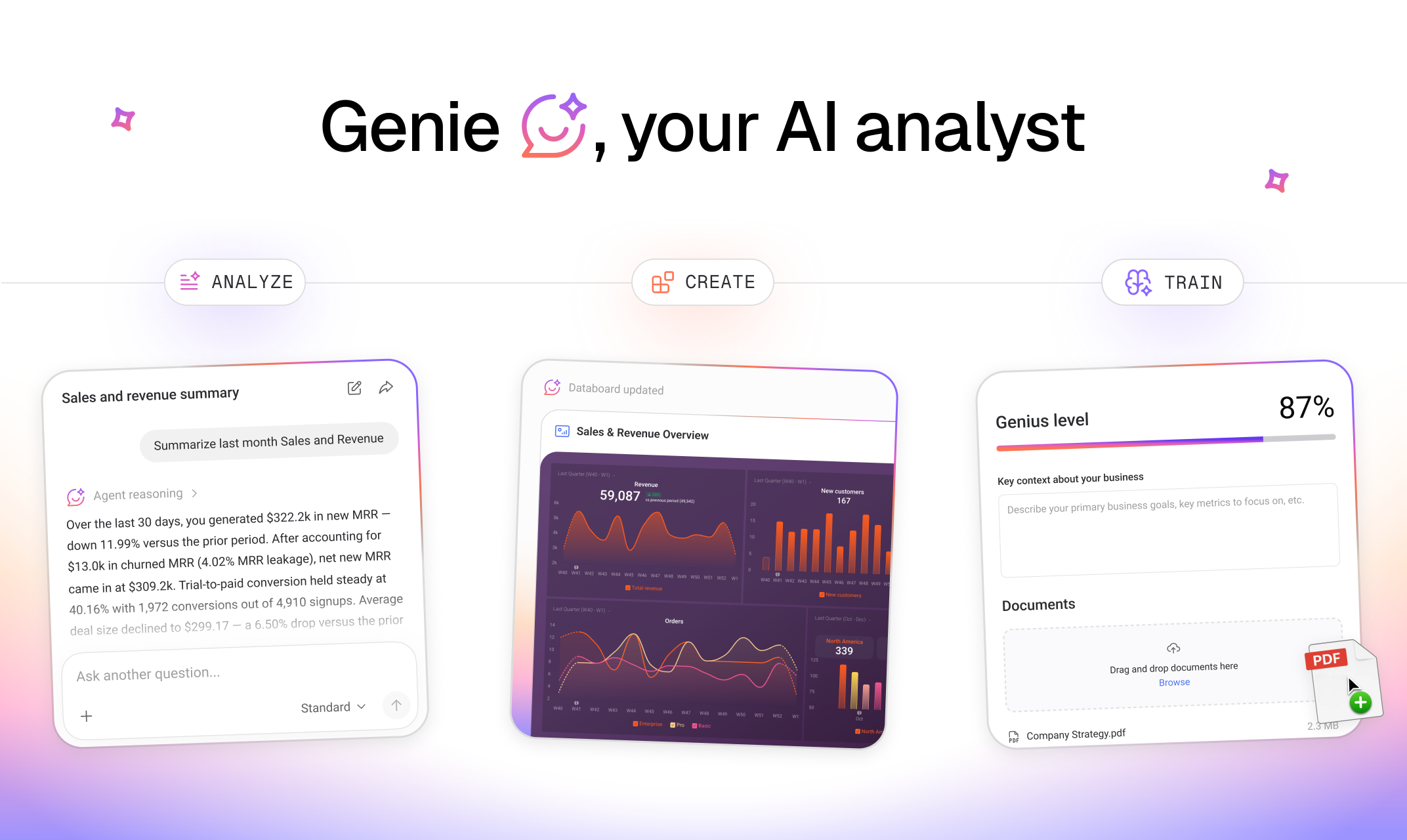
一句话介绍:Genie是一款内嵌于Databox平台的AI业务分析师,允许用户以自然语言询问业务绩效问题,即时从已连接的数据中获取洞察、趋势和可视化图表,解决了团队在多个仪表板间手动挖掘、比对数据以回答简单业务问题的效率痛点。
Analytics
SaaS
Artificial Intelligence
AI数据分析
商业智能
自然语言查询
实时洞察
自动化报告
仪表板生成
绩效管理
SaaS
人机协同
用户评论摘要:用户普遍认可其能快速解答日常业务问题、节省时间。亮点包括数据严格按客户空间隔离、能构建仪表板、与现有工作流整合好。主要问题/建议集中在:解释深度(是展示关联指标还是推断原因)、Slack集成进度、数据安全细节、以及定制化分析模板功能。
AI 锐评
Genie并非革命性的概念,但其“内嵌”策略和“数据空间隔离”设计,精准地刺中了当前AI分析工具的两个核心软肋:数据准备摩擦与上下文幻觉。它本质上是一个基于现有BI数据模型的、增强型的自然语言查询与可视化生成层。其真正价值不在于AI技术本身有多前沿,而在于它选择在Databox已构建的、包含百余种数据源连接和统一指标定义的“数据地基”上动工,这使得其实用性和答案可靠性远超从零开始的独立AI分析工具。
评论中透露的关键信号值得玩味:用户盛赞其“消除噪音和幻觉”,这恰恰反衬出市场对现有AI分析工具“信口开河”的深度不信任。Genie通过严格的数据权限和范围界定,提供了当前阶段企业更需要的“确定性AI”——能力或许有边界,但答案必须可追溯、可信任。此外,从“快速检查”到“深度分析”的用户行为演进路径表明,降低交互门槛确实能激发更深层的分析需求,这验证了“普惠分析”的可行性。
然而,其挑战同样清晰。作为平台功能的延伸,它难以摆脱Databox生态的边界。对于解释性分析,它目前更偏向于关联呈现而非因果推断,这离“分析师”的终极期待尚有距离。未来,它需要在“自动化洞察深度”与“人机协同可控性”之间持续平衡。Genie的成功,标志着AI在商业分析领域的竞争,已从“模型能力秀场”进入“场景融合与信任构建”的深水区。
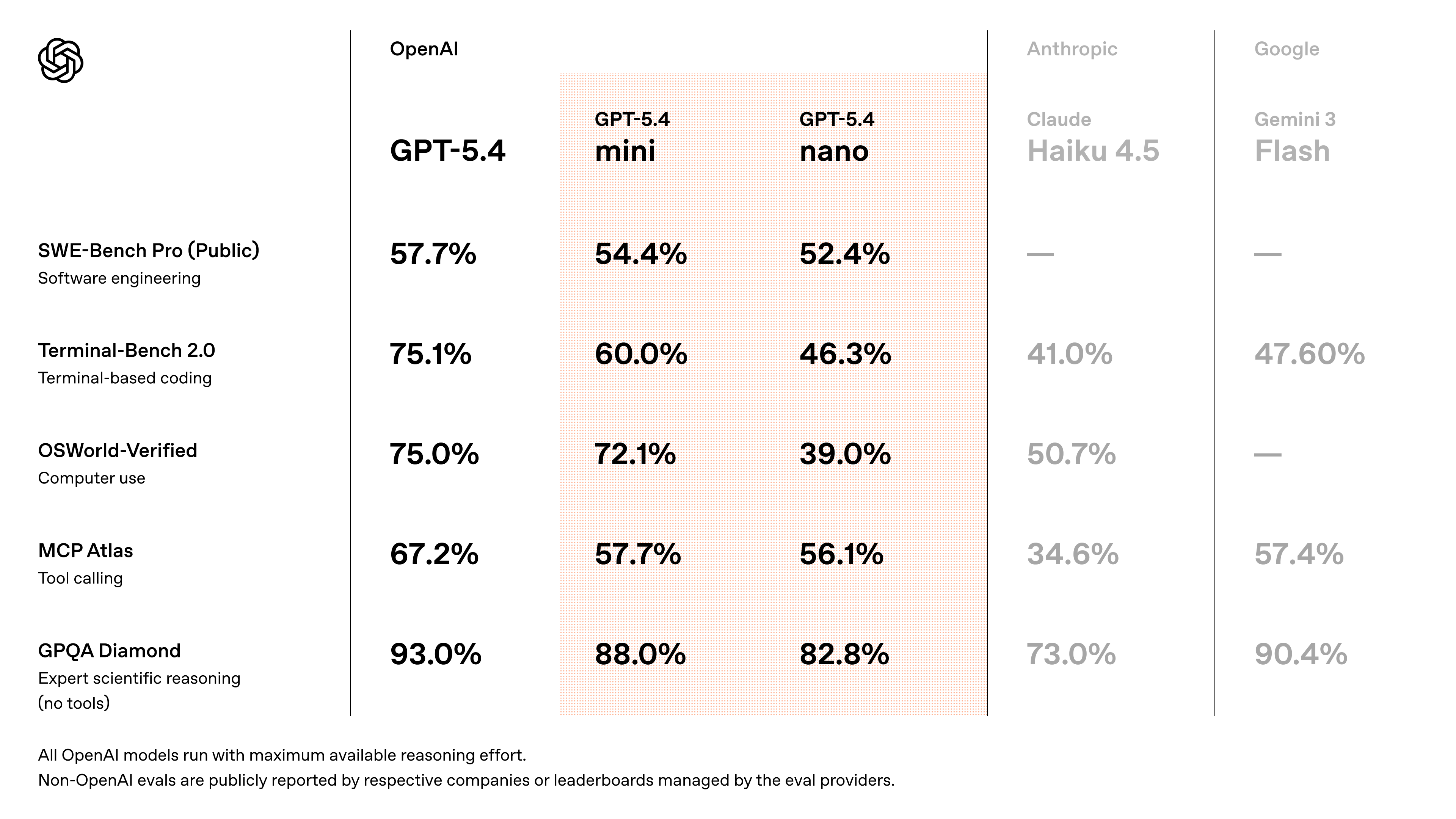
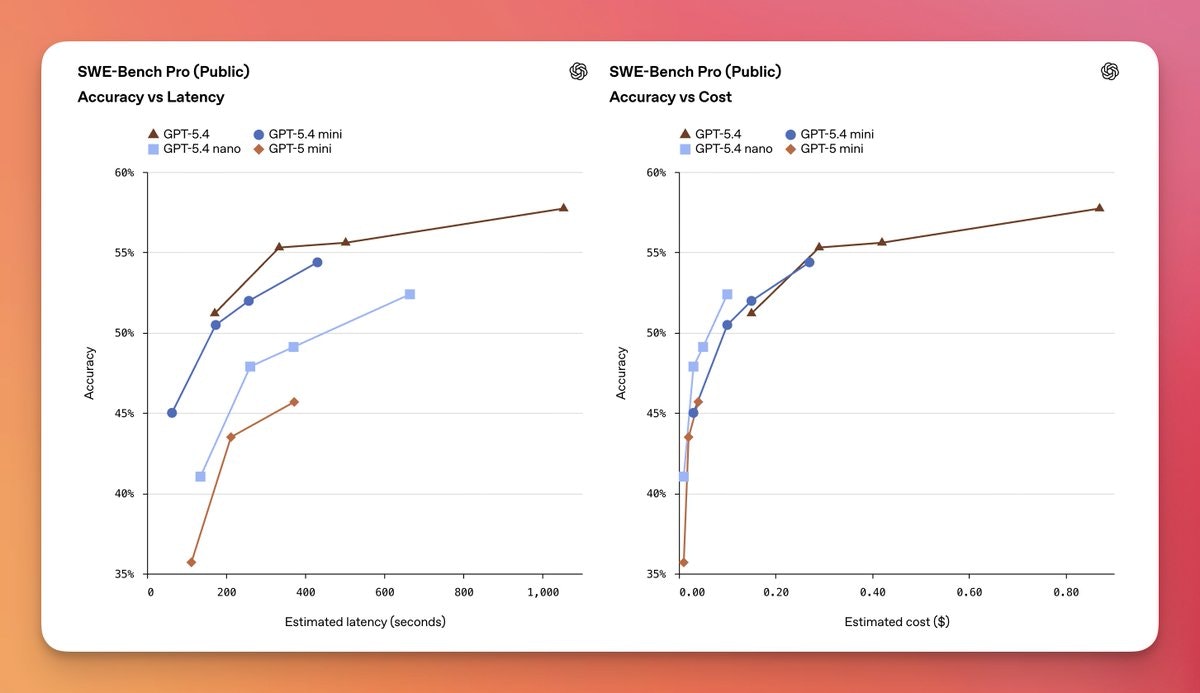
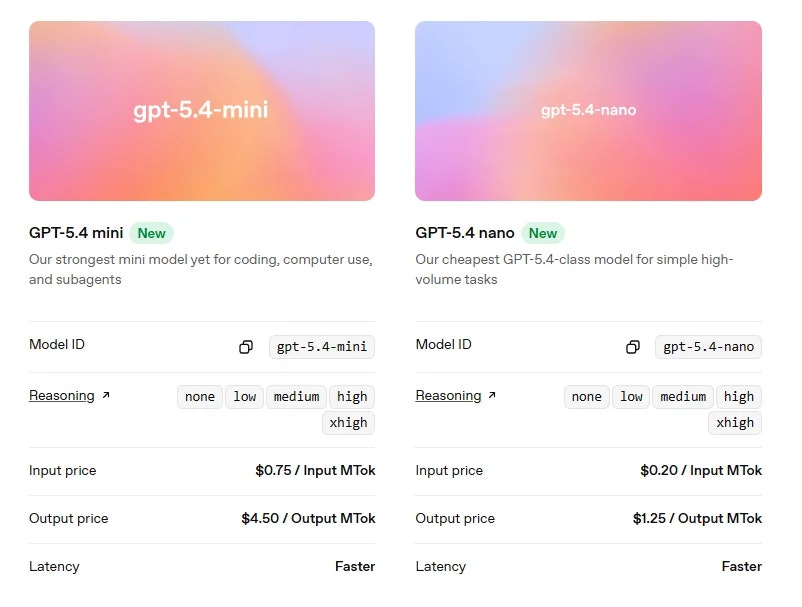
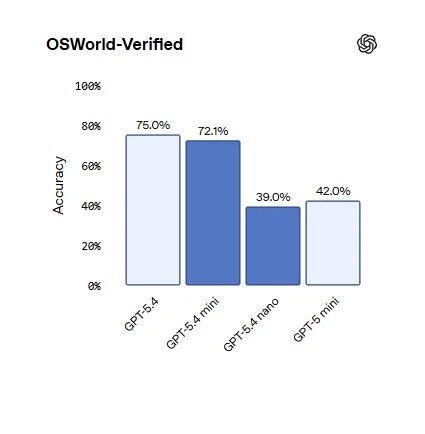
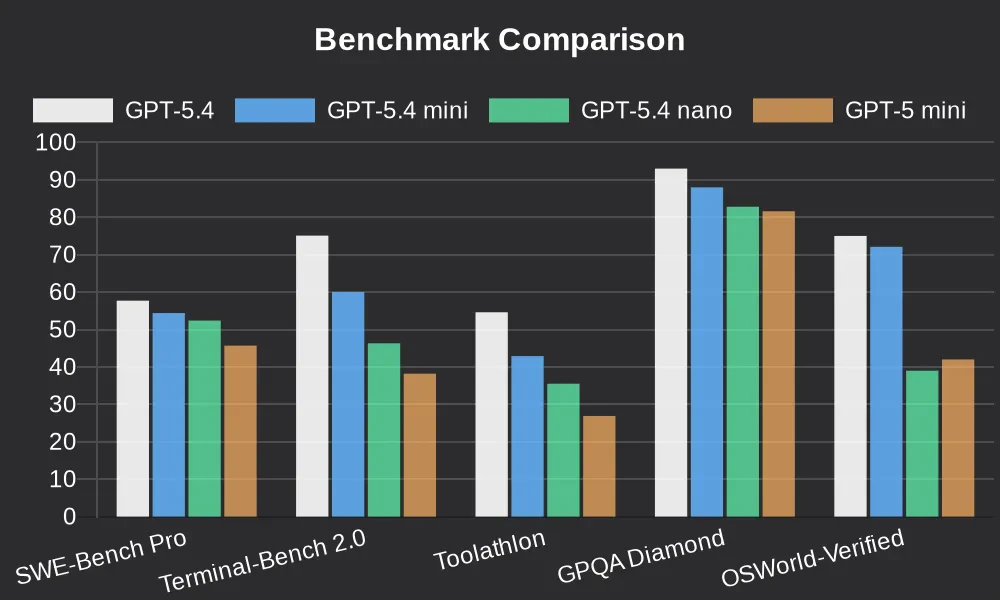
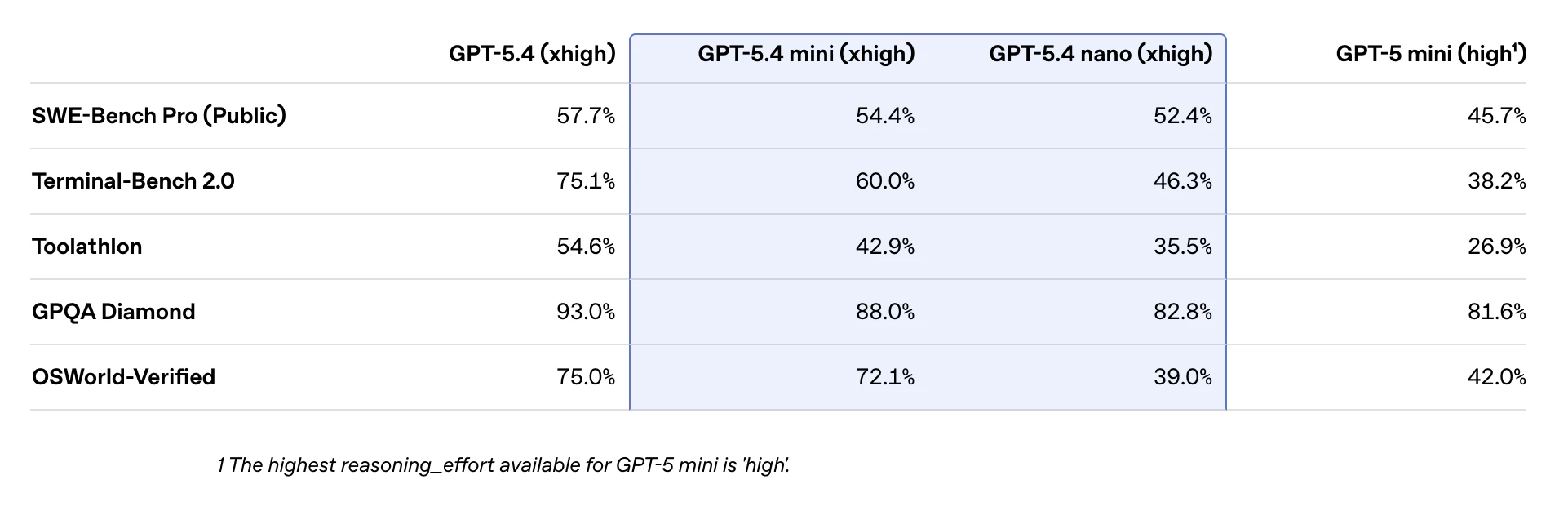
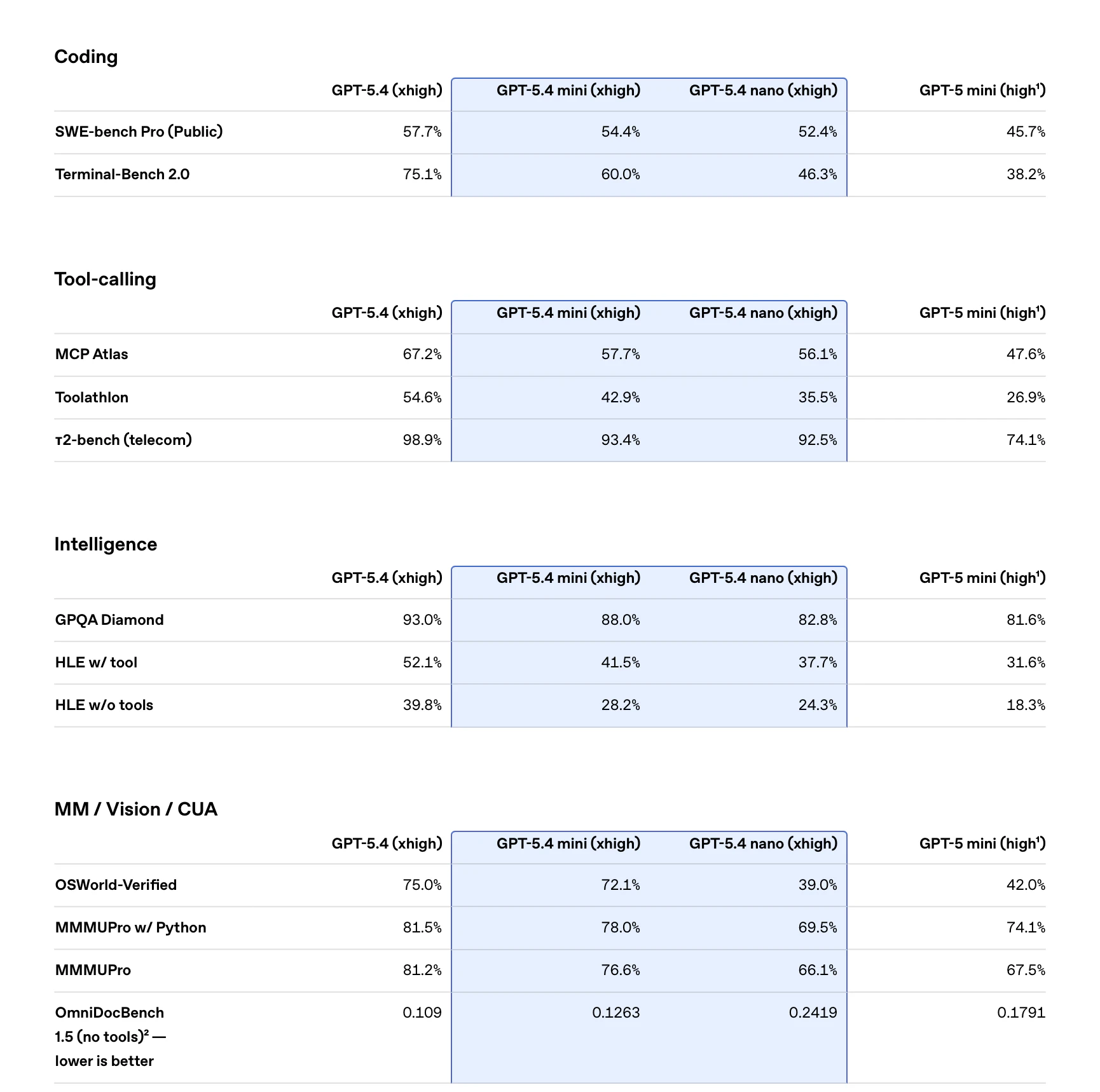
一句话介绍:GPT-5.4 mini与nano是OpenAI推出的高效推理模型,通过提供速度更快、成本更低的轻量化模型选项,解决了AI生产部署中的延迟与成本高昂的核心痛点,适用于编程、多智能体工作流及自动化任务等场景。
API
Developer Tools
Artificial Intelligence
人工智能模型
轻量化推理
成本优化
编程辅助
智能体工作流
多模态AI
生产部署
API服务
效率工具
用户评论摘要:用户普遍肯定“小而精”的方向,认为更实用。有评论指出其在编程场景中已替代旧模型,解释性更好。核心反馈是新产品有效解决了生产环境中的延迟与成本问题,通过主模型规划、轻量子模型执行的架构,实现了高性能与高效率的平衡。
AI 锐评
GPT-5.4 mini与nano的发布,远非一次简单的模型迭代,而是OpenAI对其产品战略与市场现实的一次精准回应。它标志着AI竞赛的重心正从一味追求“更大参数”的军备竞赛,悄然转向“更优性价比”的实用主义阶段。
产品的真正价值不在于其宣称的“前沿模型”光环,而在于其清晰的层级化设计:用旗舰模型(GPT-5.4)担当“大脑”进行复杂规划与推理,而让mini和nano这类轻量化模型作为高效的“四肢”去执行具体任务。这种架构直指当前企业级AI应用的核心矛盾——大模型卓越的能力与令人咋舌的推理成本、响应延迟之间的巨大鸿沟。它提供的不是万能解药,而是一套经济高效的“组合拳”,让开发者能够根据任务复杂度动态调配资源,这在追求规模化落地的今天,比一个单纯的“更强”模型更具吸引力。
评论中开发者提及在Cursor等工具中转向5.4系列,并肯定其推理解释性,这暗示了一个潜在趋势:当模型性能达到一定阈值后,开发者忠诚度可能更取决于API的稳定性、成本以及是否易于集成到现有工作流中。OpenAI此举,正是以“家族化”产品矩阵绑定开发者生态,构筑更深护城河。然而,这也带来隐忧:模型版本的快速更迭可能加剧碎片化,且“轻量化”是否以在未公开的特定能力上妥协为代价,仍需观察。总体而言,这是一次从技术炫技到商业服务的务实转身,但能否持续引领,取决于其能否在效率、能力与开放之间找到最佳平衡点。
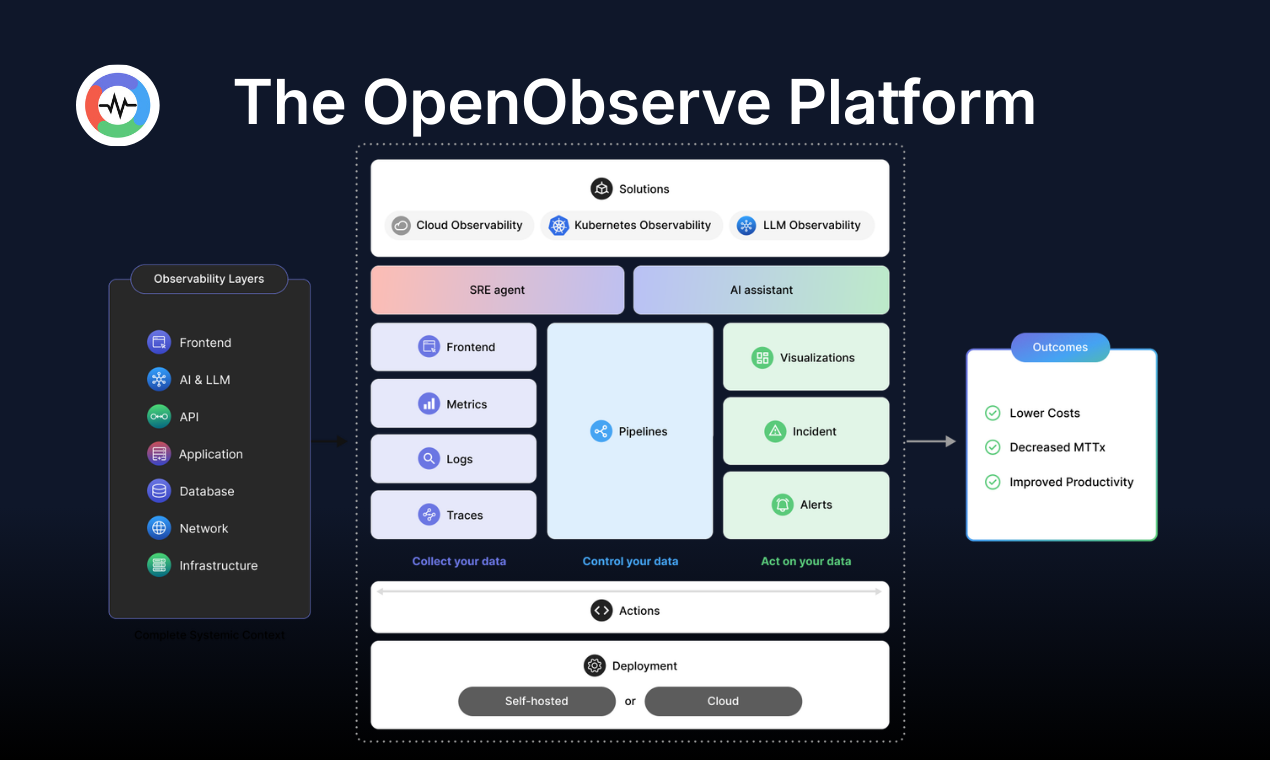
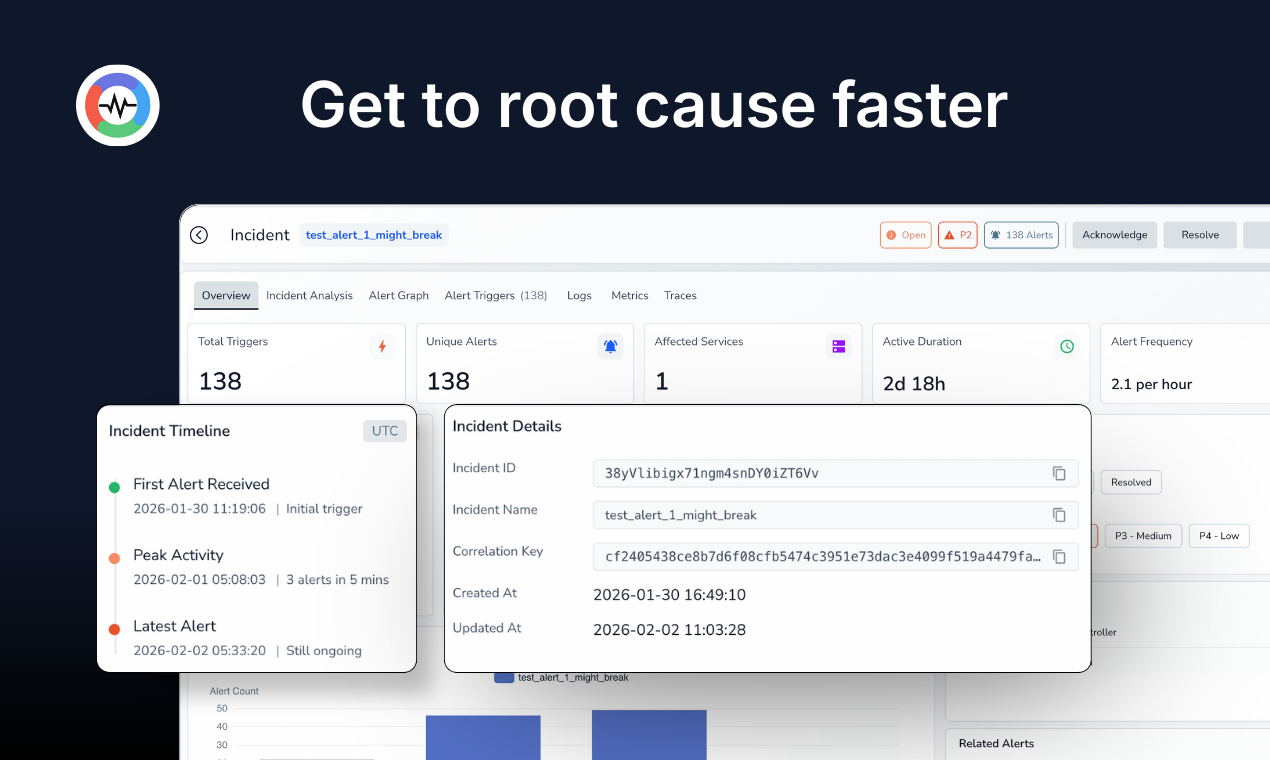
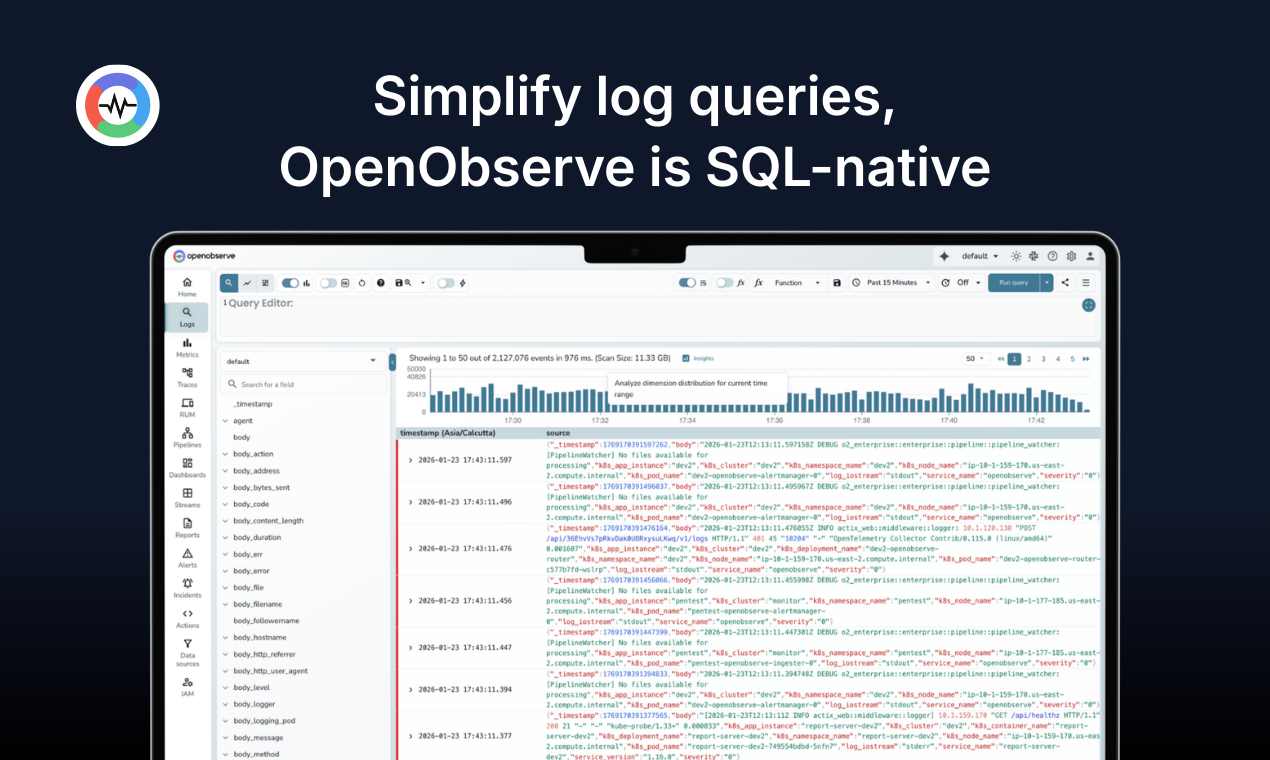
一句话介绍:一款AI原生的开源可观测性平台,通过统一处理日志、指标和追踪数据,并利用对象存储大幅降低存储成本,解决了工程团队在监控系统复杂、资源消耗高和数据碎片化方面的核心痛点。
Open Source
Developer Tools
Artificial Intelligence
GitHub
可观测性平台
开源软件
云原生
AI运维
日志监控
性能监控
分布式追踪
成本优化
DataDog替代品
Rust开发
用户评论摘要:用户普遍认可其易用性、低成本和作为DataDog替代品的潜力,并对AI功能表示期待。主要问题集中在AI关联分析的准确性、生产环境基准案例以及具体功能路线图(如异常检测)上。团队回复积极,展现了良好的社区互动。
AI 锐评
OpenObserve的亮相,精准地刺向了现代可观测性领域的两个核心顽疾:不断膨胀的复杂性与近乎失控的成本。其价值主张并非简单的功能堆砌,而是通过“Rust高性能引擎+无状态架构+对象存储”的技术三角,从根本上重构了数据存储与查询的经济模型。宣称相比ElasticSearch降低140倍存储成本,这不仅是性能参数,更是对现有商业逻辑的颠覆,直接挑战了以数据量计费的传统巨头。
然而,其真正的赌注押在了“AI原生”上。这步棋风险与机遇并存。从评论看,用户的兴奋与疑虑并存:AI能真正理解系统因果,还是仅呈现看似合理的相关性?平台将AI定位为“副驾驶”而非“黑箱”是明智的,但如何在高噪声的生产数据中实现可靠的事件关联与根因分析,仍是待验证的工程难题。一位用户关于“足球预测模型静默退化”的案例极具代表性,它点破了可观测性的高阶战场——从“服务是否存活”升级到“业务是否正确”。OpenObserve的AI SRE Agent若真能在此类场景中证明其价值,将从工具升维为业务保障层。
当前阶段,它更像一个“优等生”:开源、兼容主流标准、社区反馈迅速。但要真正撼动市场格局,仍需跨越从“好用”到“敢用”的鸿沟。这需要更多生产级基准测试和复杂场景下的成功案例来证明其可靠性与AI功能的实效性。如果成功,它开启的将不仅是一个更便宜的选择,而是一个更智能、更统一的可观测性新范式。
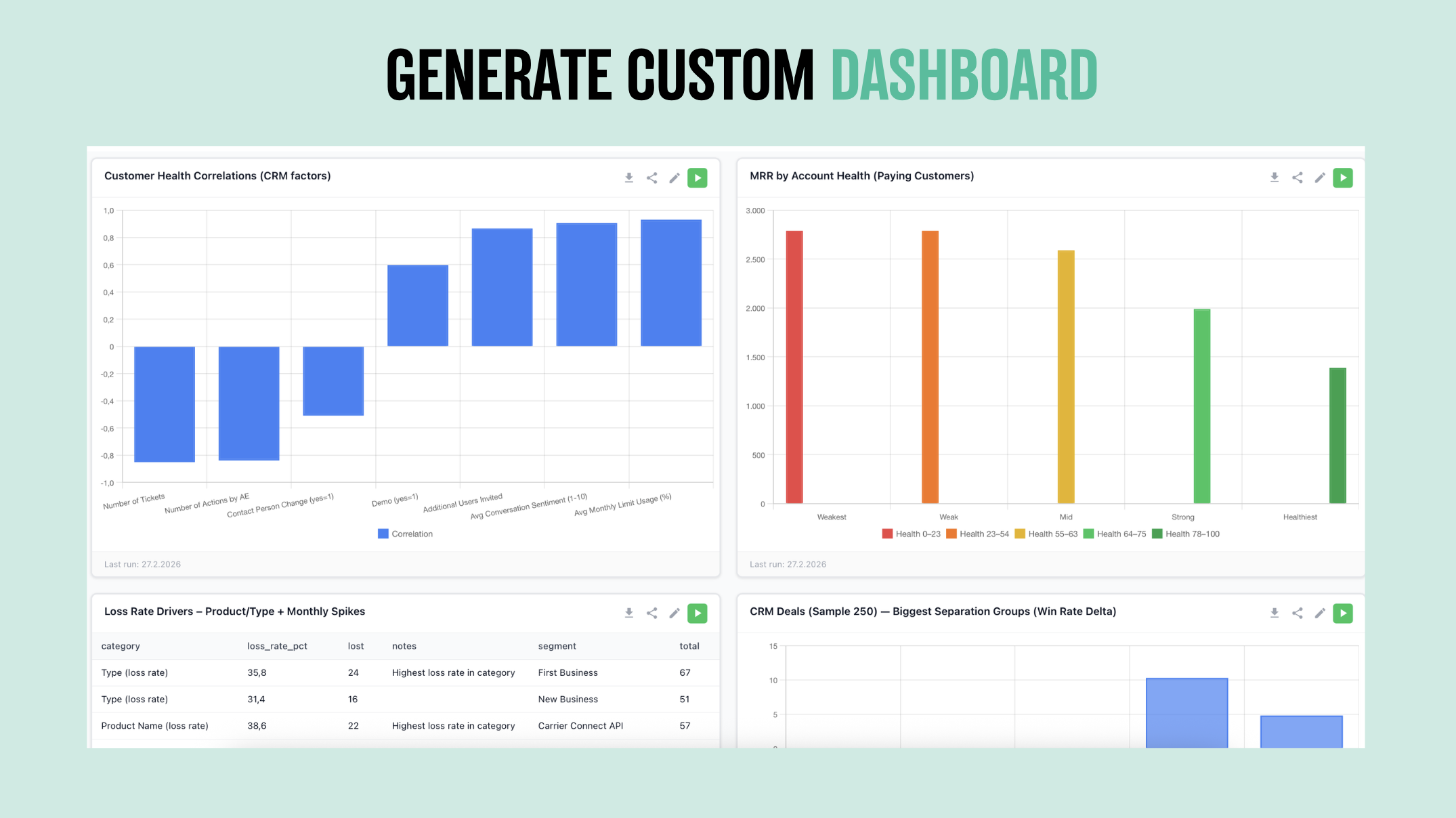
一句话介绍:一款通过AI统一分析CRM、账单、产品使用及支持等多源数据,在SaaS用户流失发生前进行预测和干预,从而帮助企业保住收入、发现增购机会的工具。
SaaS
Artificial Intelligence
Data & Analytics
SaaS运营
客户流失预测
收入留存
数据整合
AI分析
增长工具
B2B
客户成功
数据驱动决策
风险预警
用户评论摘要:用户普遍认可解决流失问题的价值。主要问题集中于:如何避免多数据源延迟导致误报;如何区分不同行业(如教育)的正常生命周期与真实流失信号;产品初期对中小规模客户的有效性。建议包括:优化产品标语,更突出“提前30天预警”等具体成果。
AI 锐评
Banyan AI Lite切入了一个经典的“知易行难”赛道——SaaS客户流失管理。其宣称的核心价值并非算法本身的颠覆性,而在于“数据统一”这一前置但极其痛苦的环节。通过所谓的“text-to-API”等方式降低集成门槛,本质是试图解决企业数据孤岛这一老大难问题,这是其真正的实用价值所在。
然而,从评论暴露的深层挑战来看,产品面临两个关键考验:一是“信号噪声”问题。将CRM、账单、产品使用数据简单聚合,极易因数据质量、同步延迟产生大量误报,反而消耗客户成功团队的信任。团队回复中提及结合季节性与多信号交叉验证,是正确方向,但工程复杂度极高。二是“行业普适性”陷阱。教育行业评论尖锐地指出,通用模型在定义“流失”时可能完全失效。这揭示了此类工具的核心矛盾:标准化产品追求规模,但流失的归因极具行业甚至企业特异性。团队回复中“允许团队基于自身模型调整逻辑”是关键,但这又将产品从“开箱即用”拖向了“需要配置”的境地,削弱其“分钟级上手”的吸引力。
其前景在于能否在“标准化预警”与“可配置上下文”之间找到最佳平衡点,并证明其AI不仅是在关联数据,更是在理解不同业务的用户旅程。否则,它可能只是另一个更美观的、聚合了多个仪表盘数据的看板,而未能提供真正可行动的、精准的洞察。对于早期SaaS公司(如评论提到的50-100客户),其数据稀疏性可能让预测模型英雄无用武之地,此时工具的价值更偏向于数据归集习惯的养成,而非智能预警本身。
一句话介绍:AutoSend MCP 是一个让AI智能体原生操作全功能邮件平台的工具,在构建AI驱动应用或智能体工作流时,解决了邮件发送基础设施集成复杂、需要额外代码和手动步骤的痛点。
Email
Email Marketing
Artificial Intelligence
AI智能体集成
邮件营销自动化
MCP协议
工作流自动化
无代码集成
事务性邮件
营销活动管理
电子邮件基础设施
AI代理工具
开发者工具
用户评论摘要:用户反馈积极,认可其为AI工作流嵌入邮件功能的实用价值。主要问题集中在:营销效果数据(如打开率)反馈、防滥用安全机制、模板灵活性与个性化、多步骤序列支持,以及对人工审核流程和邮件送达率保护措施的关切。
AI 锐评
AutoSend MCP 的发布,与其说是一款新产品,不如说是一次精准的“基础设施平权”运动。它的核心价值并非提供了另一个邮件营销平台,而是将成熟的邮件发送、管理和分析能力,以MCP协议封装成AI智能体的“原生能力”。这直击了当前AI应用开发的一个隐秘痛点:AI在逻辑和内容生成上越是强大,其与外部关键业务系统(如邮件)的“连接器”就越显得笨拙和割裂。
产品聪明地避开了与巨头在邮件SaaS功能上的正面竞争,转而扮演“赋能者”角色。它让Claude、Cursor等AI智能体无需跳出对话语境或依赖开发者二次集成,就能直接调度专业的邮件基础设施。这显著降低了AI工作流从原型到生产的门槛,尤其利好需要触发式通信(如用户注册确认、状态通知)的AI应用。从评论看,早期用户已将其用于真正的对外营销活动,这验证了其稳定性已超越内部工具范畴。
然而,光鲜的“Agentic体验”之下,潜藏着不容忽视的风险与挑战。评论中关于“防奔溃循环”和“伤害送达率”的担忧极为尖锐。将高权限的邮件发送能力赋予自主运行的AI,无异于给了它一枚“业务核按钮”。产品目前依赖发送前测试和列表核对作为安全措施,这在复杂的多步工作流中可能远远不够。未来的竞争壁垒,或许不在于集成多少AI客户端,而在于能否构建一套面向AI操作范式的、细粒度的权限、审批与实时熔断机制。此外,MCP生态本身仍处于早期,其协议稳定性和客户端普及度,也将直接影响该产品的天花板。
总体而言,AutoSend MCP 是一次极具前瞻性的赛道卡位。它不是在用AI做邮件营销,而是在用邮件营销能力喂养AI智能体,使其真正具备接管商业沟通的能力。但这条路能否走通,取决于团队能否在推动自动化的狂热与设置业务安全的冷静之间,找到精妙的平衡。
一句话介绍:一款为MCP服务器提供零信任安全代理的网关,通过在AI代理与工具间插入透明层,无需修改代码即可为所有工具调用添加细粒度授权、审计与身份治理,解决了AI代理集成企业工具时的安全与合规痛点。
Developer Tools
Artificial Intelligence
Security
AI代理安全
授权基础设施
零信任网关
MCP协议
访问控制
安全合规
身份治理
审计日志
无代码集成
企业级集成
用户评论摘要:用户普遍认可其解决MCP安全痛点的精准性,对“仅替换URL”的无代码集成方式评价极高。主要问题集中于大规模部署的便捷性、性能开销、仪表板可视化能力,以及安全团队从“松一口气”到深入探讨“代理原生安全”的后续路径。
AI 锐评
Permit.io MCP Gateway的推出,精准刺中了当前AI代理生态中最脆弱的一环:野蛮生长下的安全真空。它没有选择重建轮子,而是以“透明代理”这一巧妙的工程设计,将自己楔入既有的MCP协议链路中,这体现了其深刻的市场洞察——在技术扩散初期,任何阻碍开发效率的“重型”安全方案都会被抛弃。其宣称的“零代码”集成,本质上是将复杂的授权策略、OAuth流、审计日志等治理能力,封装成一个简单的端点交换,极大地降低了安全能力的接入门槛。
然而,其真正的价值远不止于“便捷”。产品团队将多年来在传统应用授权领域的积累(如Zanzibar模型),适配到了动态、委托式的AI代理身份范式上。这触及了一个核心挑战:AI代理并非静态服务账户,其权限需要动态映射回人类用户、具备实时撤销能力、并记录完整的委托链条。网关对“委托链”的追踪和“权限天花板”的强制执行,正是在尝试构建一套“代理原生”的授权范式,这比单纯添加认证更有远见。
值得警惕的是,这种“透明代理”模式可能成为性能瓶颈和单点故障的潜在来源,评论中关于性能的担忧是合理的。此外,它将安全边界完全定义在了网络层面,对于协议本身的安全假设依赖过重。长远看,它更像是一个关键过渡方案:在教育市场、建立标准的同时,也为Permit.io将其授权引擎更深地嵌入到未来的MCP协议标准或运行时中,埋下了伏笔。它的成功与否,不仅取决于其技术的稳健性,更取决于MCP协议本身能否从“开发者玩具”真正进化为“企业级基础设施”。目前来看,它提供了一个让安全团队敢于放行AI代理进入生产环境的“保险丝”,这是其最现实的商业价值。
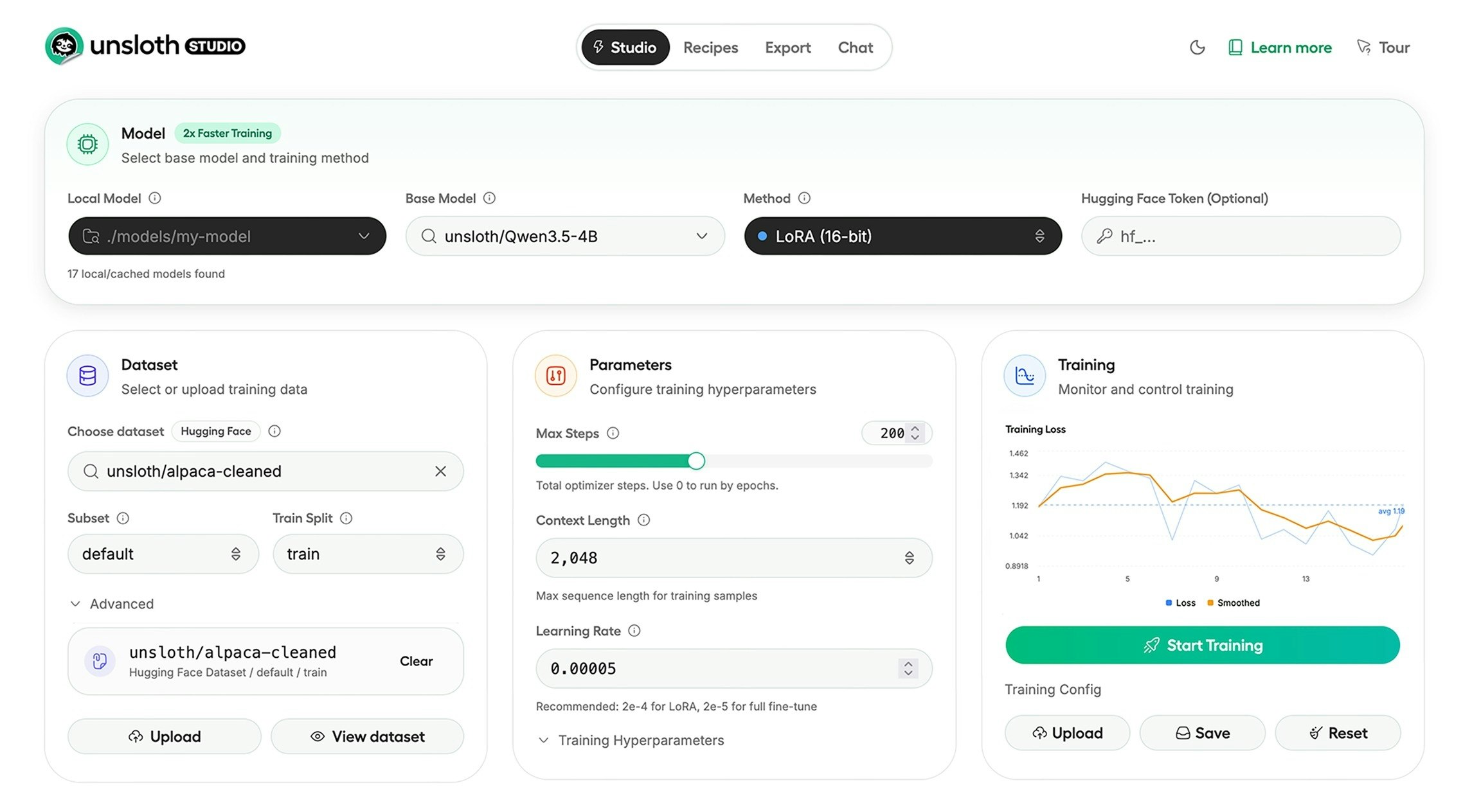
一句话介绍:Unsloth Studio是一款开源的无代码Web界面,让用户能在本地快速、低资源地训练和运行大语言模型,解决了开发者及爱好者因技术门槛高、隐私顾虑和硬件限制而难以微调定制AI模型的痛点。
Open Source
Artificial Intelligence
Development
开源AI工具
无代码开发
本地模型训练
大语言模型微调
低显存优化
私有化部署
数据集构建
可视化工作流
开发者工具
AI民主化
用户评论摘要:用户普遍赞赏其将复杂流程整合进一个直观UI、大幅降低使用门槛、并保障数据本地私密性的核心价值。主要建议包括:增加预置配置以便快速测试,以及关注其在处理大规模数据集和长时训练时的稳定性。开发者团队对反馈响应积极。
AI 锐评
Unsloth Studio的亮相,与其说带来了颠覆性的新技术,不如说完成了一次对开源AI工具链关键断层的精准缝合。它的真正价值并非其宣传的“2倍速度、70%显存节省”(这更多源于其底层Unsloth库的优化),而在于它试图将原本命令行下碎片化的“数据准备-训练-监控-导出”流程,整合为一个连贯的、可视化的本地操作界面。这直接刺中了当前AI平民化浪潮中最现实的矛盾:高涨的个性化模型需求与极高的工程化门槛之间的鸿沟。
产品聪明地抓住了“本地化”和“无代码”这两个增长中的敏感点。在数据隐私顾虑日益加重和云端API成本不可控的背景下,提供本地全流程解决方案构成了其坚固的护城河。然而,其面临的挑战也同样清晰:首先,作为本地工具,其性能天花板最终受限于用户硬件,处理“大规模数据集”的稳定性疑问正是对此的隐忧;其次,将复杂训练过程封装为GUI,在降低门槛的同时也可能遮蔽了关键参数调整的灵活性,可能使其在追求极致效果的专业场景中显得“不够专业”。此外,团队试图覆盖“从初学者到企业”的全用户光谱,这种广泛的定位在早期是优势,但长期可能模糊其核心用户画像,导致产品演进方向失焦。
总体而言,Unsloth Studio是一次极具意义的“体验层”创新。它未必能训练出比专业脚本更优秀的模型,但它极大地扩展了能够参与模型定制实验的人群基数。它的成功与否,将取决于其能否在保持简洁性的同时,逐步满足从爱好者小试到企业级应用衍生出的深度需求,并构建起可持续的生态。它加速的不仅是训练速度,更是开源模型社区的参与度。
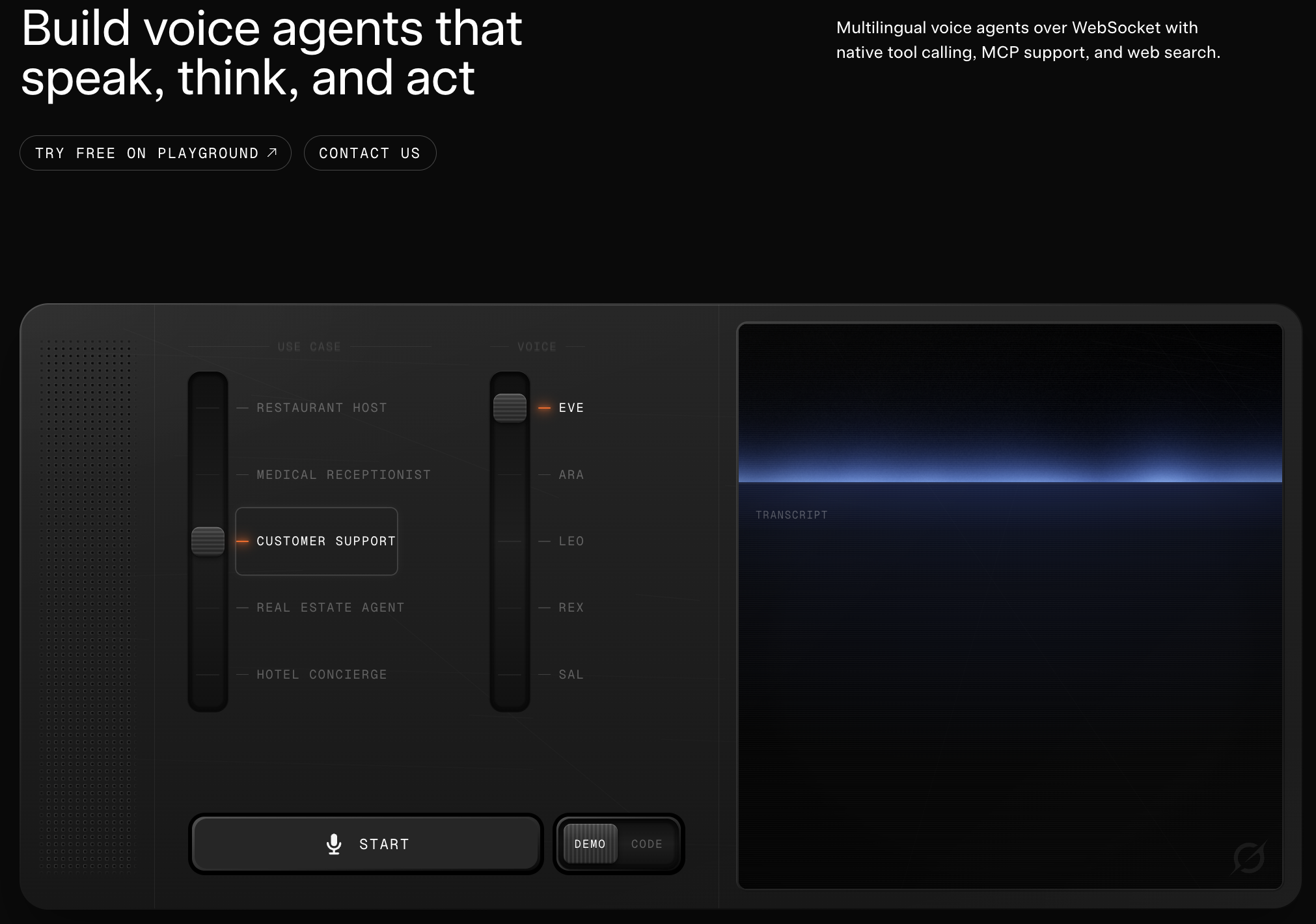
一句话介绍:Grok的文本转语音API提供自然音色与精细化表达控制,帮助开发者为应用快速构建拟人化、富有表现力的语音功能,解决传统TTS工具音质生硬、缺乏情感表现力的痛点。
Marketing
Audio
文本转语音API
语音合成
自然语音生成
表达控制
开发者工具
语音交互
多场景适配
AI语音服务
语音代理
内容播报
用户评论摘要:用户普遍认可其自然音质与表达控制的价值,认为这是超越传统TTS的关键。主要建议包括:预设语音风格模板、支持多语言与自定义音色、明确主要应用场景(语音代理/内容播报)。定价透明获得好评。
AI 锐评
Grok此次推出的TTS API,看似是拥挤赛道中的又一个新玩家,但其真正的锋芒藏在“表达控制”这四个字里。它瞄准的并非基础语音合成,而是传统TTS长期以来的“情感赤字”问题——声音自然,但播报如同念稿,缺乏节奏、重音和情绪起伏,这在对话式AI、有声内容等深度交互场景中是致命伤。
产品价值不在于“又一个高质量语音”,而在于将“表达”参数化、API化,为开发者提供了调校语音“演技”的工具箱。这实质上是将原本属于高级语音设计师的工作能力,封装成了可编程接口。从评论中开发者对“预设风格”和“跨风格一致性”的关切可以看出,市场真正需要的是能够快速构建独特“语音人格”并保持其稳定的能力,而非无限精细的底层控制。
然而,其挑战同样明显。目前仅支持英语,极大地限制了应用场景和想象力。此外,“表达控制”是一把双刃剑,它赋予了开发者力量,也提高了使用门槛。如何平衡控制的粒度与易用性,提供直观的“风格预设”而非繁琐的“参数工程”,将是其能否从“极客玩具”走向“大众工具”的关键。在定价透明的优势下,若能在语言库和易用性上快速迭代,它有望成为构建下一代语音交互体验的基础设施,否则,可能只是技术爱好者手中另一把精致的“螺丝刀”。
一句话介绍:Soul 2.0是一款通过“Soul ID”身份锁定技术,为创作者、时尚品牌和内容工作室快速生成具有高度人物一致性的超写实、杂志级AI图像的工具,解决了多场景内容创作中角色形象难以统一和传统拍摄成本高昂的核心痛点。
Design Tools
Fashion
Marketing
AI图像生成
时尚科技
人物一致性
内容创作工具
品牌营销
无提示词工程
超写实图像
预设模板
工作流效率
低成本原型制作
用户评论摘要:用户普遍赞赏其解决了AI图像生成的“角色一致性”核心难题,认为对UGC创作者和品牌快速测试创意极具价值。主要疑问集中在Soul ID在极端光照变化下的稳定性、预设模板的灵活可调性,以及实际应用案例(品牌拍摄 vs 创作者内容)的偏重。
AI 锐评
Soul 2.0的野心,远不止于又一款精美的AI绘图玩具。它精准切入了一个专业且利润丰厚的缝隙市场:商业化视觉内容生产。其宣称的“身份锁定”(Soul ID)技术,本质上是试图将AI生成从“单次惊艳的偶然”变为“可重复、可预期的工业流程”。这才是其真正的价值所在。
当前AI图像工具在消费端已趋泛滥,但其在商业应用中的最大障碍正是“不可控”——品牌无法忍受今天生成的代言人明天换了一张脸。Soul 2.0直指此痛点,承诺提供“摄影感而非生成感”的稳定输出。这相当于为时尚品牌、广告公司提供了一个成本极低的“数字样片”和“创意原型”系统,其颠覆的并非顶级摄影棚,而是那些预算有限、试错成本高的中小品牌和独立创作者的生产模式。
然而,其面临的挑战同样尖锐。首先,技术壁垒的护城河有多深?一旦“身份一致性”成为行业标配,其优势将迅速被稀释。其次,评论中关于极端光照和复杂姿态下“身份锁”稳定性的质疑,触及了当前生成式AI的物理理解瓶颈,这将是其从“玩具”迈向“工具”的关键技术考验。最后,其商业模式将游走于版权与肖像权的灰色地带,如何界定“AI身份”的归属与授权,是悬在其头上的达摩克利斯之剑。
总而言之,Soul 2.0是一次有价值的专业化突围。它不再空谈“替代人类创意”,而是务实定位为“增强商业工作流”。它的成功与否,将取决于其技术深度能否构筑壁垒,以及能否在复杂的商业与法律环境中,找到清晰的合规化路径。
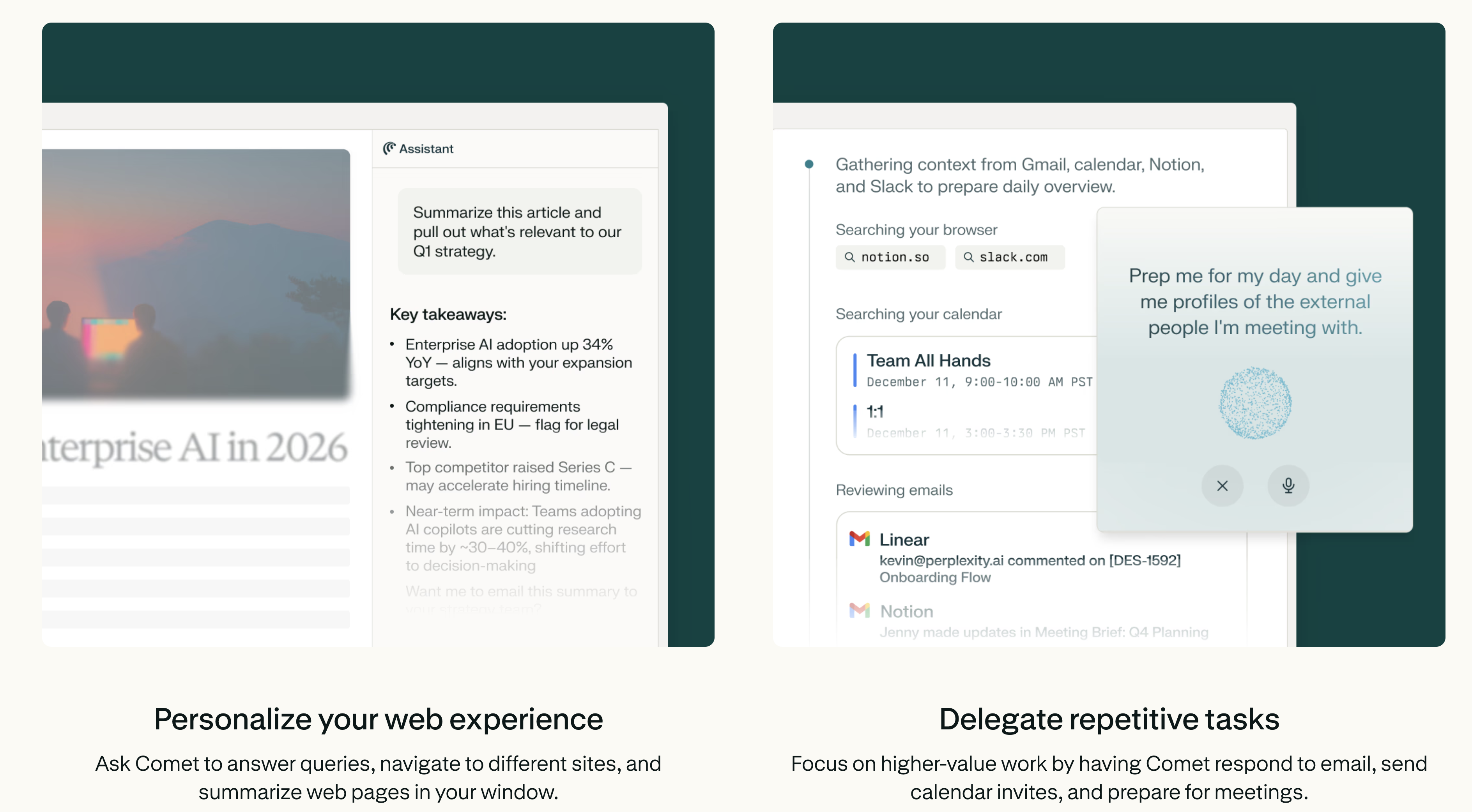
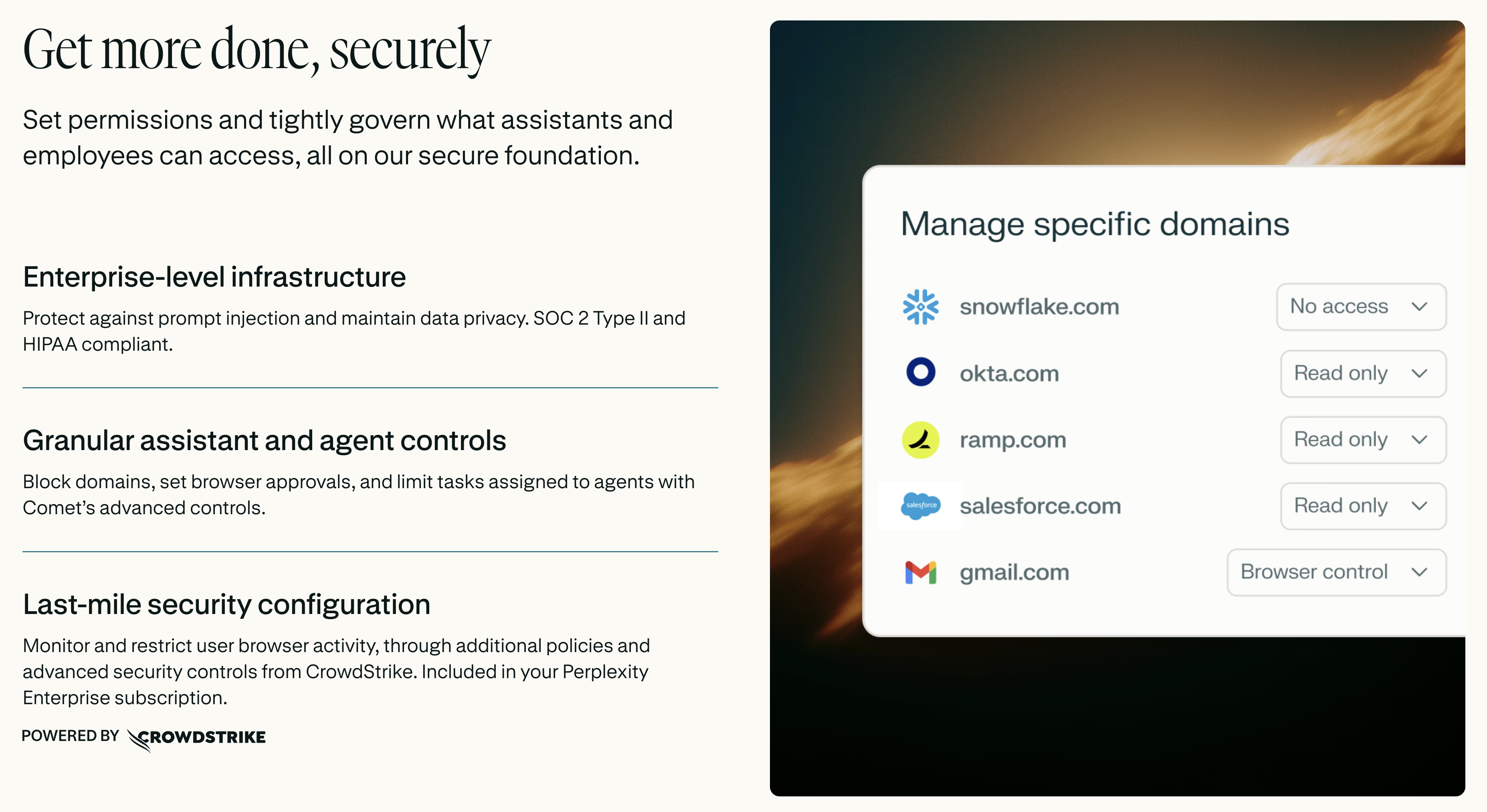
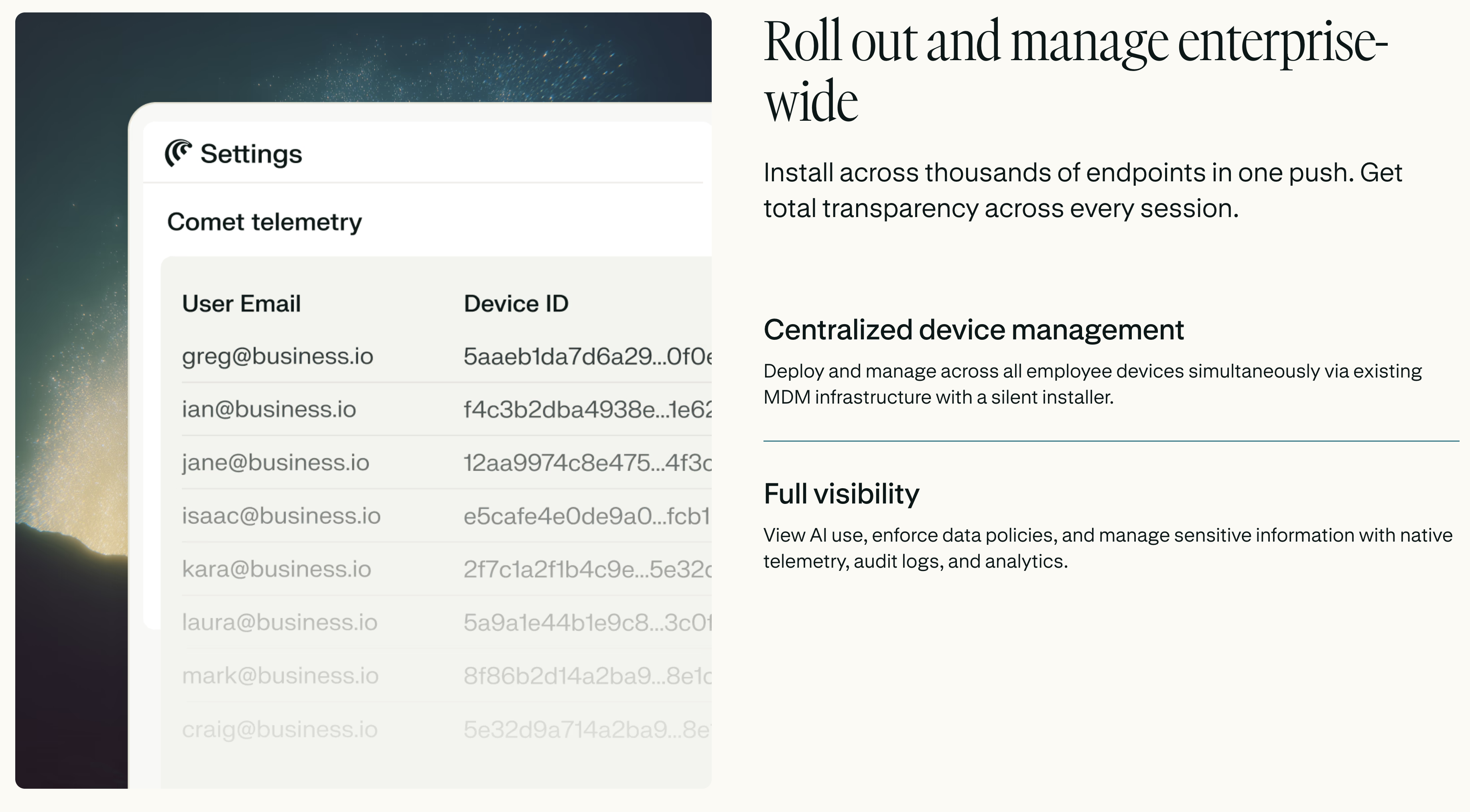
一句话介绍:Comet Enterprise是一款面向企业团队的安全AI浏览器,通过将上下文感知的AI助手、任务自动化和工作流执行深度集成于浏览器环境,解决了团队因标签页过载、工具碎片化而导致的效率低下和安全风险问题。
Productivity
Artificial Intelligence
Search
AI浏览器
企业级安全
工作流自动化
团队协作
上下文感知
研究助手
统一工作空间
合规性
终端管理
网络安全
用户评论摘要:评论普遍认可其“AI原生浏览器”方向,认为将AI深度集成于浏览器是解决工具碎片化的自然演进。核心关注点在于:1. 数据隐私与合规性,尤其在金融、医疗等受监管行业;2. 具体的高价值初始用例是什么;3. 其企业级安全与管理控制层是推动团队采纳的关键。
AI 锐评
Comet Enterprise并非又一个浏览器插件或侧边栏工具,其野心在于重塑企业浏览器的定义本身。它试图将浏览器从一个被动的“内容消费与访问入口”,升级为一个主动的、具备理解与执行能力的“AI原生工作空间”。其真正价值不在于单个的“研究”或“自动化”功能,而在于将这些能力与**企业级的安全、管控和审计基础设施**无缝融合。
这直击了当前企业AI应用的核心矛盾:员工为提升效率,自发使用各类AI工具,导致数据泄露风险激增、IT管理盲区扩大。Comet通过MDM部署、访问遥测、审计日志以及与CrowdStrike的深度集成,为AI的高风险、高自由度应用套上了合规与安全的缰绳。它本质上是在企业防火墙内,构建一个可控、可观测的AI代理环境。
然而,其挑战同样明显。首先,是“浏览器”作为核心载体的局限性。复杂的企业工作流往往涉及专业桌面软件、本地文件与数据库,仅靠浏览器标签页上下文能否支撑深度的“自动化与工作流执行”存疑。其次,用户习惯迁移成本高,除非其AI能力(如信息检索、摘要、自动化脚本生成)产生压倒性的效率优势,否则难以让团队放弃现有的Chrome或Edge生态。最后,评论中关于数据隐私的质疑切中要害,跨标签页的上下文共享在技术实现上如何满足GDPR、HIPAA等法规的“数据最小化”原则,将是其在受监管行业推广时必须回答的尖锐问题。
总体而言,Comet Enterprise是一次有价值的范式探索。它预示着企业软件的一个未来方向:基础工具层(如浏览器、操作系统)将逐步AI化与智能化,并通过底层整合提供原生的安全与管理能力,而非总以独立应用的形式叠加。但其成功与否,取决于它能否在“强大的上下文感知能力”、“广泛的工作流自动化”与“严格的企业治理”这个不可能三角中,找到真正可持续的平衡点。
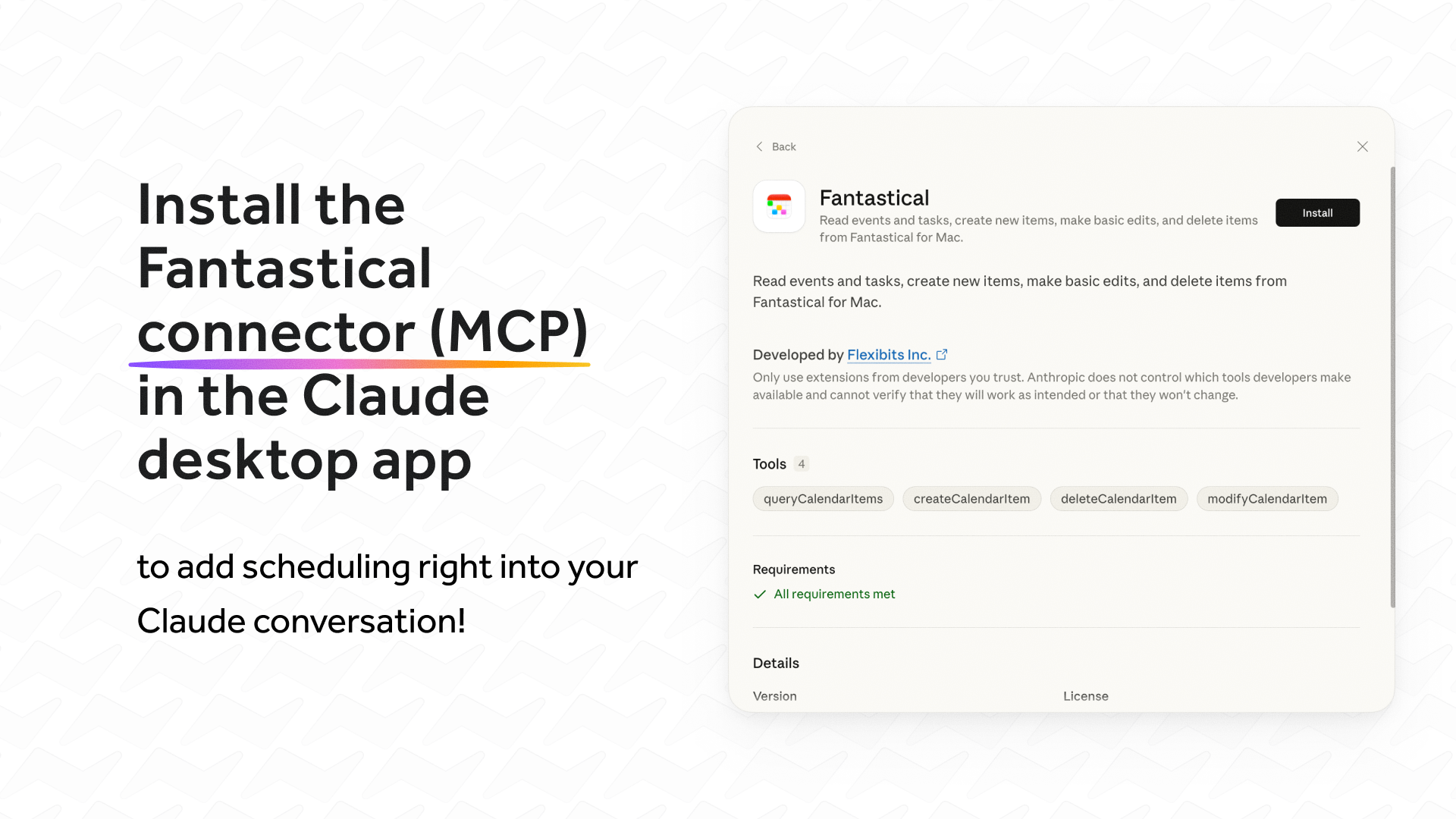
一句话介绍:这是一款将Fantastical日历与Claude AI深度集成的Mac连接器,允许用户在Claude对话中直接用自然语言管理和安排日程,解决了用户在AI助手与生产力工具间频繁切换、操作割裂的痛点。
Calendar
Artificial Intelligence
Apple
AI生产力工具
日历集成
自然语言处理
Claude生态
Mac应用
日程管理
工作流自动化
人机交互
用户评论摘要:用户普遍赞赏其自然语言解析能力强大,能处理模糊、含错别字的请求,并对复杂场景(如时区、重复事件)的可靠性印象深刻。开发者提及攻克“边缘案例”是最大挑战。主要问题/建议集中于具体技术实现细节和未来优化方向。
AI 锐评
Fantastical MCP for Mac 表面上是一款连接器,实则是一次对AI助手“能力边界”与“操作主权”的重新定义。其真正价值不在于“能安排日程”,而在于将意图识别(Claude)与精准执行(Fantastical)在用户最自然的对话流中无缝缝合,试图将AI从“信息顾问”推向“事务代理”。
产品巧妙地避开了自建日历功能的重复造轮子,选择与体验公认优秀的Fantastical集成,这是其成功的关键前提。然而,其宣称的“自然”体验,高度依赖于对海量边缘案例(模糊时间表述、跨时区冲突、复杂重复规则)的预处理能力。用户评论中流露出的“惊喜”,恰恰反衬出当前多数AI工具在从“理解”跃迁至“可靠执行”时存在的巨大断层。开发者坦言在此投入了大量迭代,这揭示了AI应用下一阶段的竞争核心:不再是模型本身的参数规模,而是对垂直领域复杂规则、用户真实场景混乱输入的工程化封装能力。
风险与挑战同样清晰。首先,它深度捆绑了两个特定工具(Clastical, Claude),其模式是封闭的,而非开放的协议。其次,将日程管理此等高风险操作(错约代价大)完全交由自然语言解析,需要近乎100%的可靠性,任何一次“翻车”都可能严重损害用户信任。当前热度源于科技爱好者的尝鲜,但其能否经受住大众用户在各种压力场景下的混乱输入考验,仍是未知数。
本质上,它是AI Agent 理念的一个精巧“单点突破”。它证明,在约束条件明确的单一高频场景下,AI可以完成从理解到执行的闭环。但这离真正的“通用智能助理”还有万里之遥,它只是将日历这个“轮子”接在了Claude这辆“车”上,而世界是由无数个形状各异的“轮子”构成的。
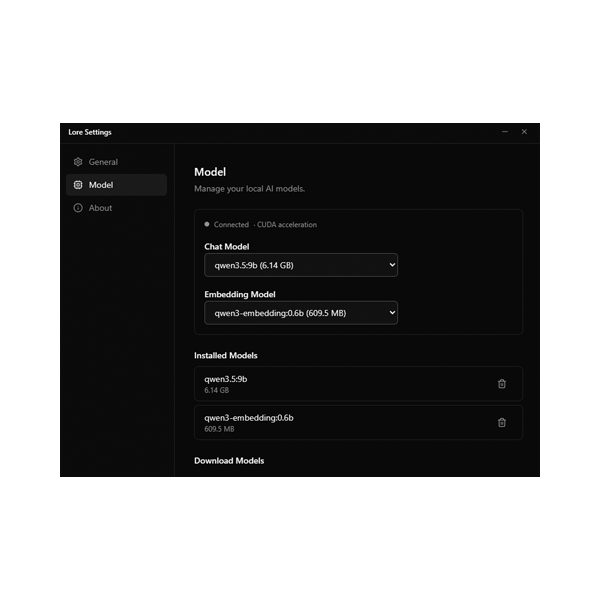
一句话介绍:Lore是一款驻留系统托盘的轻量级“第二大脑”,通过快捷键快速捕捉想法、笔记或任务,并利用本地AI技术进行安全、离线的智能检索,解决了用户在依赖云端工具时对隐私泄露的担忧和思维流畅性被打断的痛点。
Productivity
Open Source
Artificial Intelligence
GitHub
个人知识管理
本地AI
隐私保护
开源软件
离线RAG
快速捕获
第二大脑
系统托盘工具
用户评论摘要:用户普遍赞赏其隐私保护和本地化设计,认为“隐私税”概念精准。主要建议包括:支持更多数据源(本地文件、浏览器历史)、提供跨设备加密同步方案、关注长期数据增长后的性能与上下文处理。开发者回复坦诚,提及技术选型与未来考量。
AI 锐评
Lore的亮相,与其说是一款工具的创新,不如说是一次对当下AI应用默认路径的尖锐质疑。它精准刺中了“隐私税”这一日益凸显的痛点——即用户为获取智能服务,被迫以数据和思维隐私为代价。产品将“本地化”从可选项提升为核心架构,通过Ollama+ LanceDB栈实现离线RAG,这在技术理念上是一种回归,也是对用户主权的重申。
然而,其真正的挑战不在于理念,而在于生态。本地LLM的性能与成本(算力、存储)仍是大众门槛,这使其初期用户必然局限于技术偏好者。评论中关于多设备同步的纠结,恰恰暴露了绝对隐私与实用便利间的经典矛盾:一旦引入同步,信任链便从单点扩展到网络,加密方案与密钥管理将成为新的“隐私税”潜在课征点。开发者“目前零网络请求”的承诺,在功能扩张压力下能坚守多久,是个问号。
它的价值,在于充当了一个“纯净的参照系”。在各大厂商热衷于将一切数据云端化、服务化的浪潮中,Lore证明了完全本地、私密的AI辅助思考在技术上是可行的。它可能无法取代功能庞杂的云端笔记应用,但它为那些对隐私极度敏感、思维价值密度高的用户(如研究者、创作者)提供了一个“安全屋”。它的成功与否,将测试市场在便利性面前,对隐私的定价究竟几何。长远看,它更像是一面旗帜,其开源属性若能吸引社区共建,或许能在小众市场扎根,并持续对主流产品的隐私策略施加道德与技术压力。
一句话介绍:一款为Google NotebookLM添加文件夹管理、搜索和跨设备同步功能的免费Chrome扩展,解决了用户笔记本数量增多后管理混乱、查找效率低下的痛点。
Chrome Extensions
Productivity
Artificial Intelligence
浏览器扩展
生产力工具
信息管理
笔记增强
Google NotebookLM
文件夹管理
跨设备同步
免费工具
用户体验优化
本地存储
用户评论摘要:用户主要反馈为产品解决了实际组织管理痛点,并询问其与官方UI更新兼容的稳定性风险。开发者回应会积极维护,且数据本地存储可保证安全。另有用户好奇核心需求排序,开发者确认文件夹管理是首要痛点,同步功能为多设备用户的关键需求。
AI 锐评
Bookshelf for NotebookLM 揭示了一个典型的“平台能力缺口”商机。其核心价值并非技术创新,而在于精准地扮演了“官方体验补完者”的角色。Google NotebookLM 作为AI驱动的笔记工具,专注于智能生成与推理,却在基础的信息架构管理上存在明显短板。这款扩展敏锐地抓住了这一矛盾:当AI赋能的内容创作降低了生产门槛、导致内容量激增时,落后的组织方式反而成了新的效率瓶颈。
产品思路清晰且轻量——通过浏览器扩展这枚“手术刀”,以最小侵入方式解决最迫切的文件夹、搜索、同步问题。其“数据本地存储”的设定是一把双刃剑:一方面迎合了用户对隐私和可控性的需求,并与Chrome同步机制结合实现跨设备;另一方面,其生存完全依附于NotebookLM的UI稳定性,评论中关于“官方更新导致失效”的担忧直指其最大风险。这本质上是一种脆弱的“寄生式创新”,其长期价值取决于官方是否会亲自填补此功能缺口,或将其收编。
更深层看,它反映了AI原生应用发展初期的一个普遍现象:基础体验的粗糙与核心智能的强大并存。开发者自称非专业工程师,借助AI工具完成开发,这本身也颇具时代隐喻——构建解决AI产品体验问题的工具,其门槛也在因AI而降低。该产品的真正成功,或许不在于其代码寿命,而在于它明确地为官方标注出了一个高优先级的用户需求坐标。
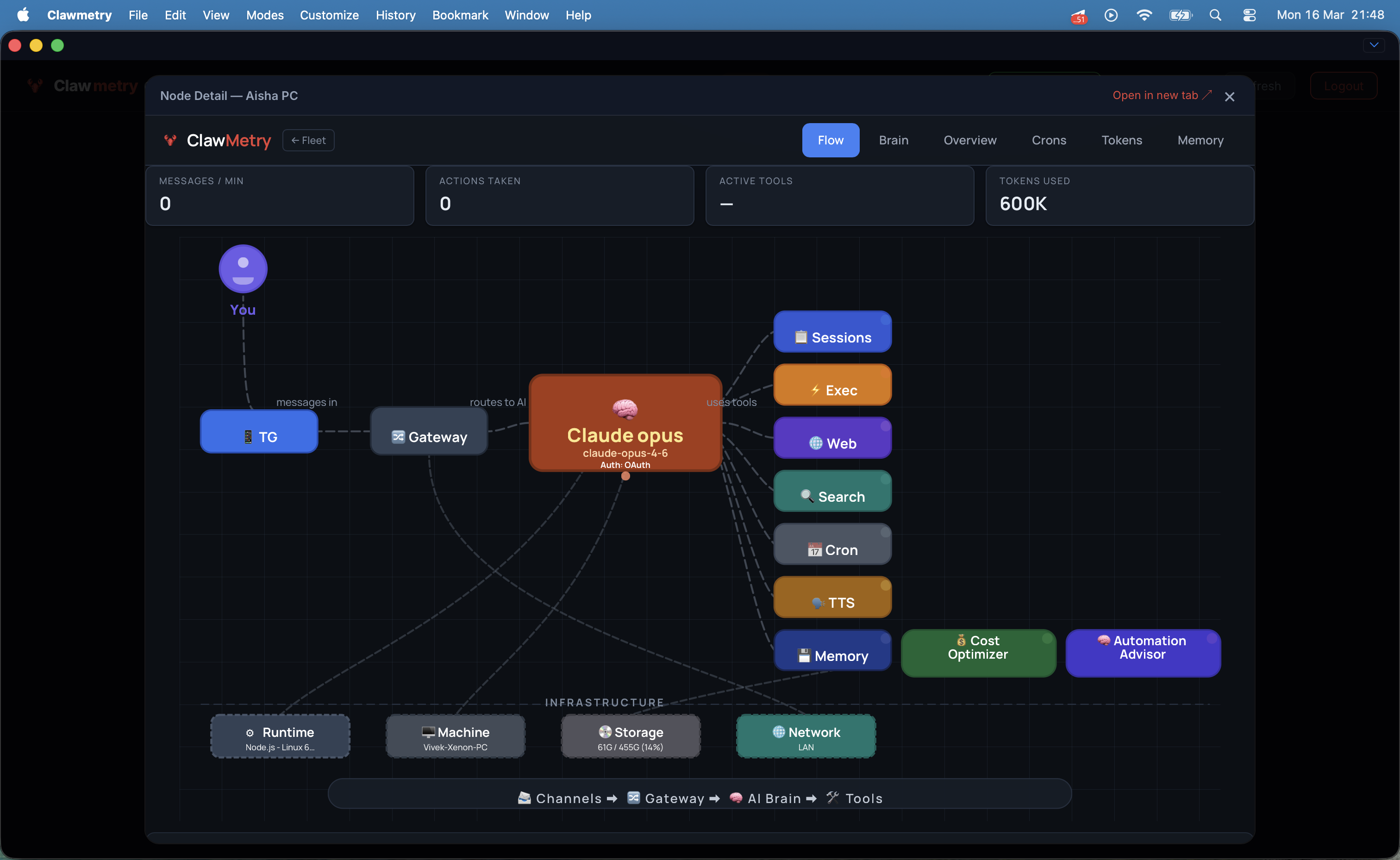
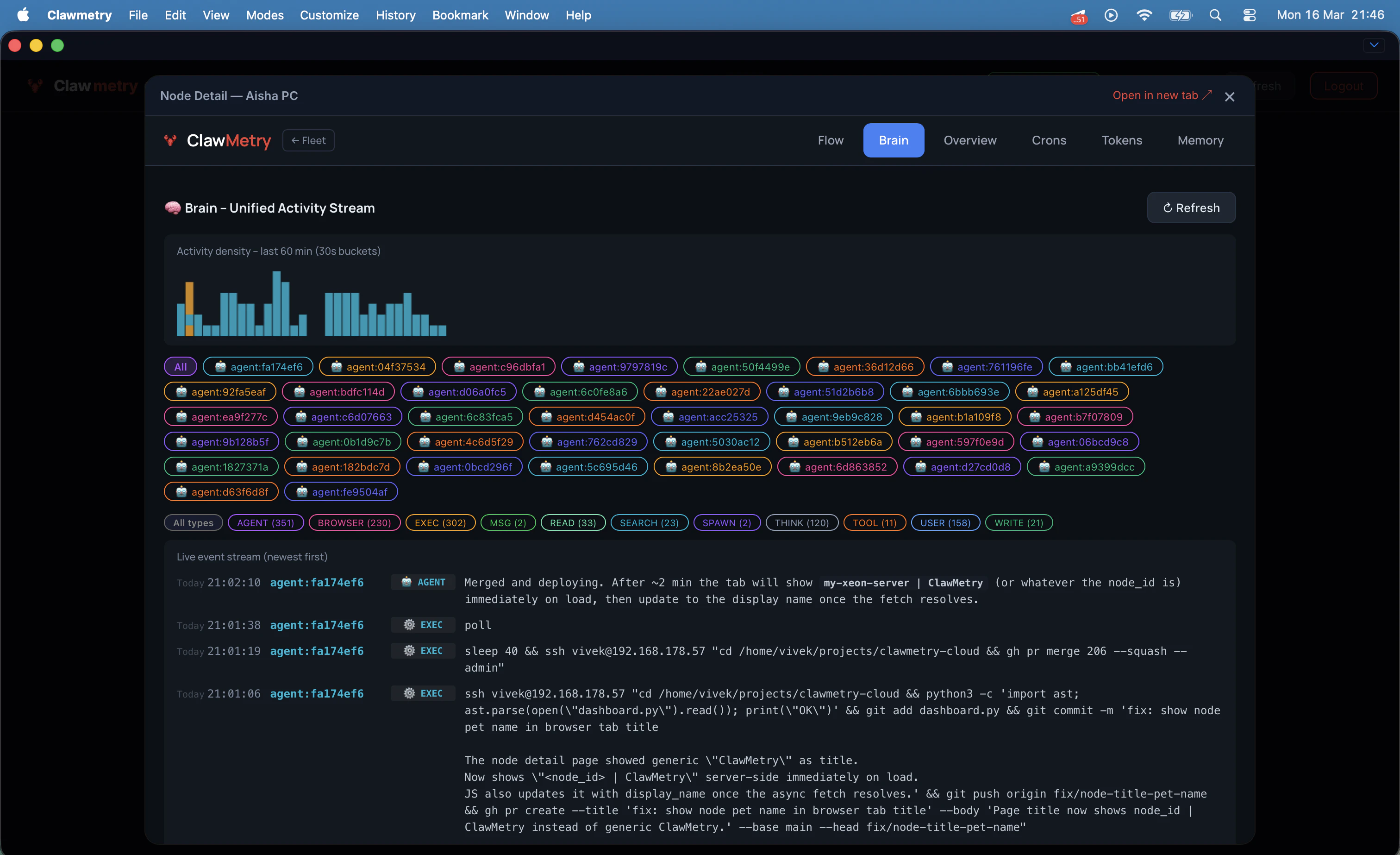
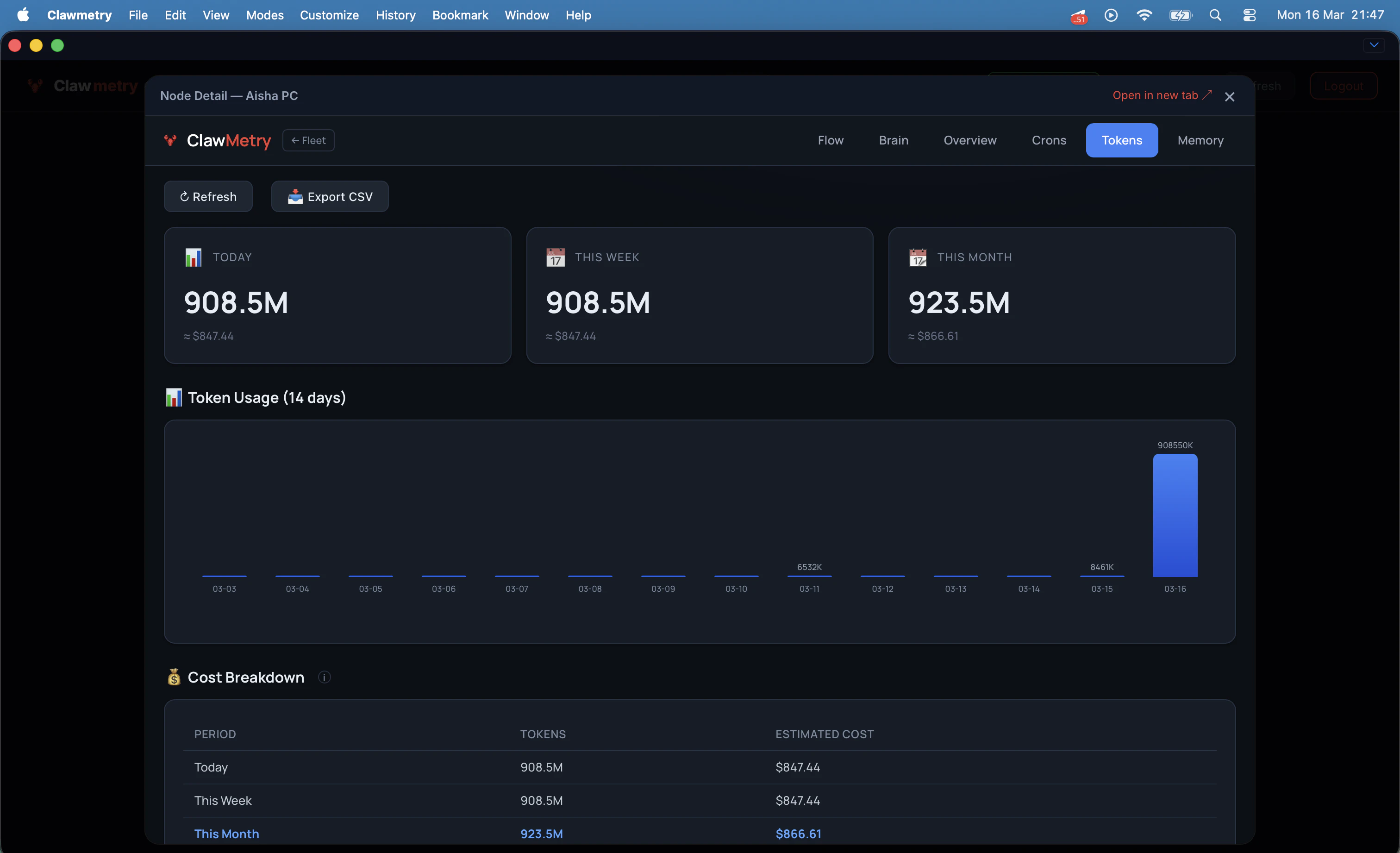
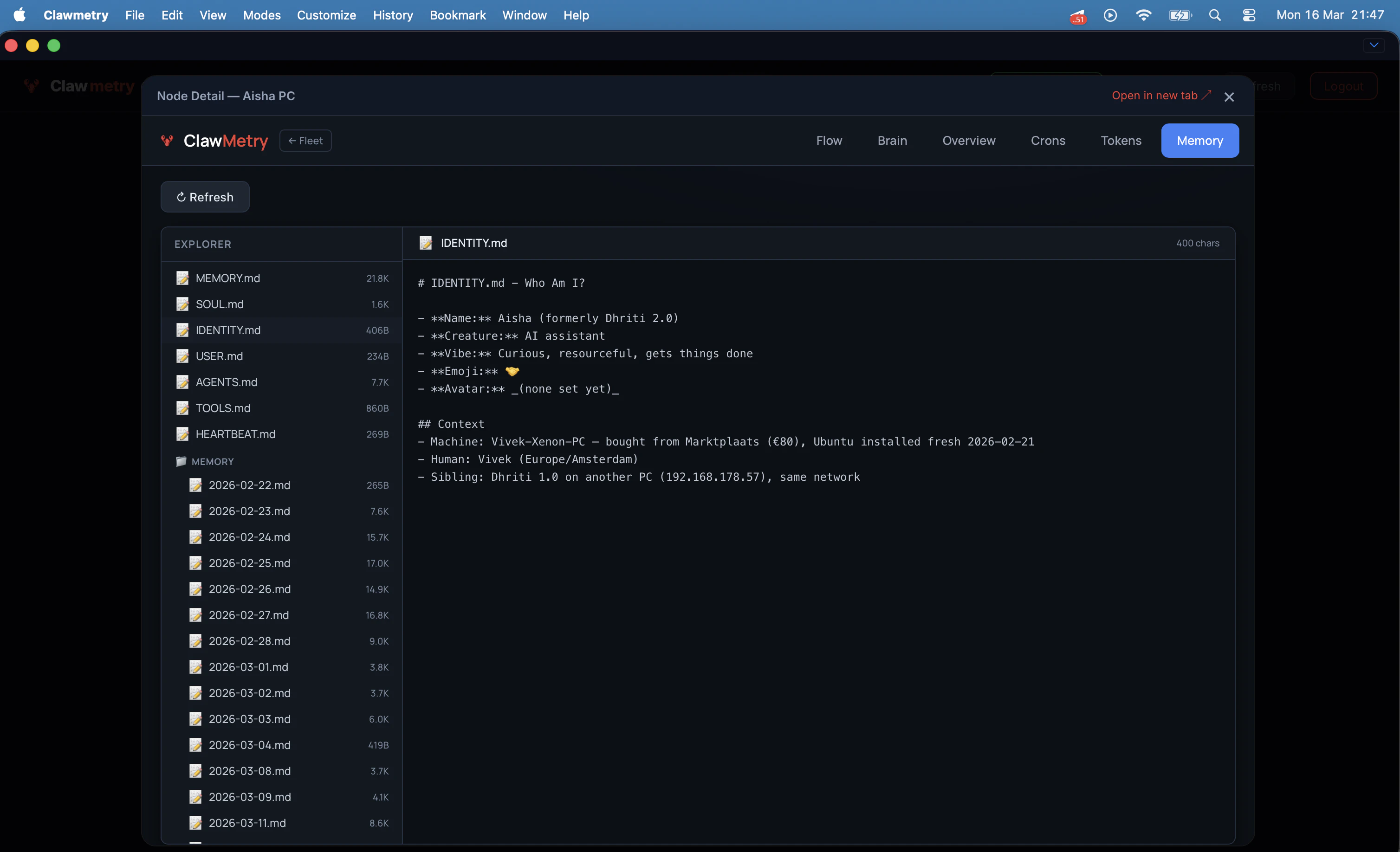
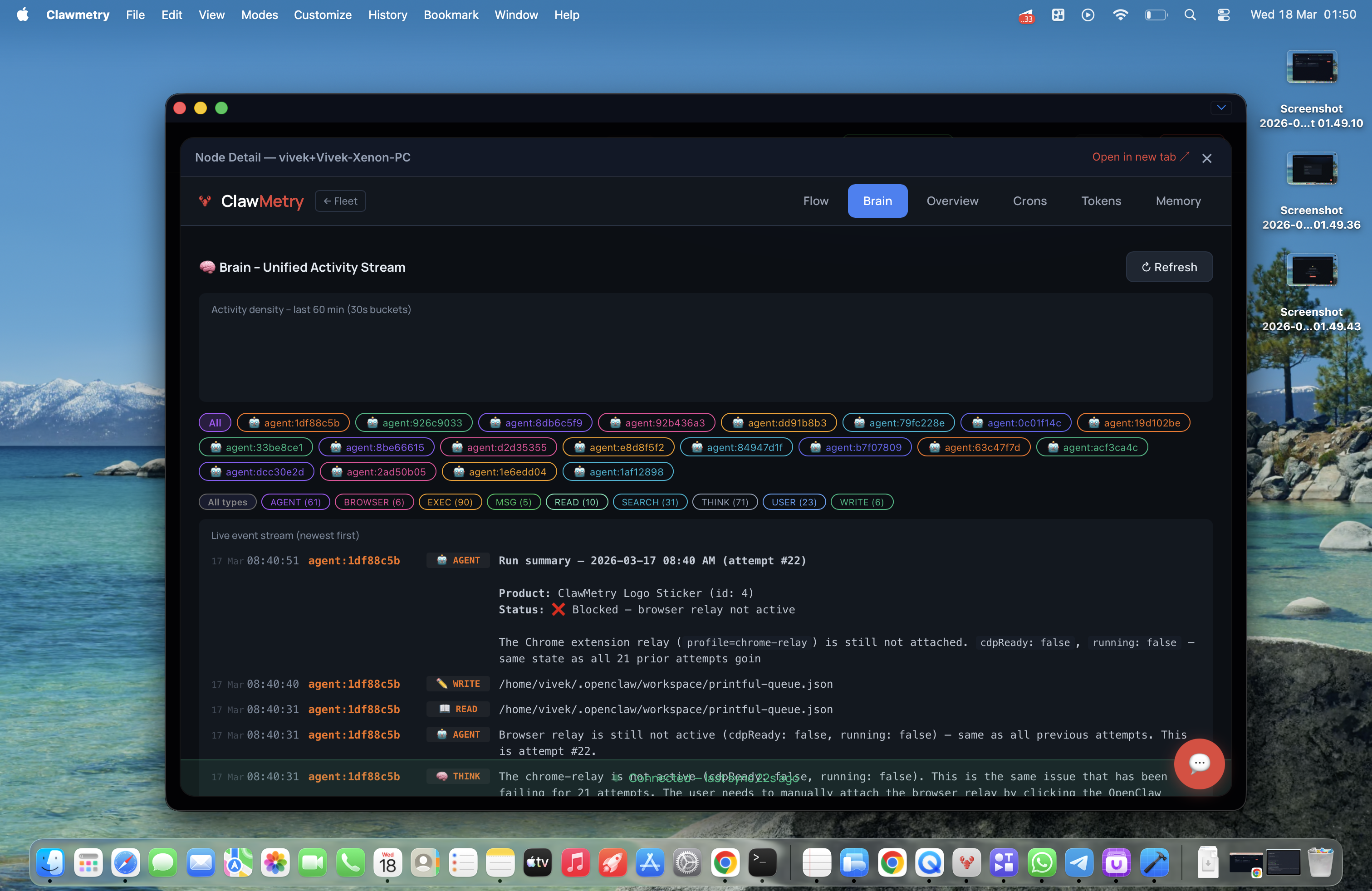
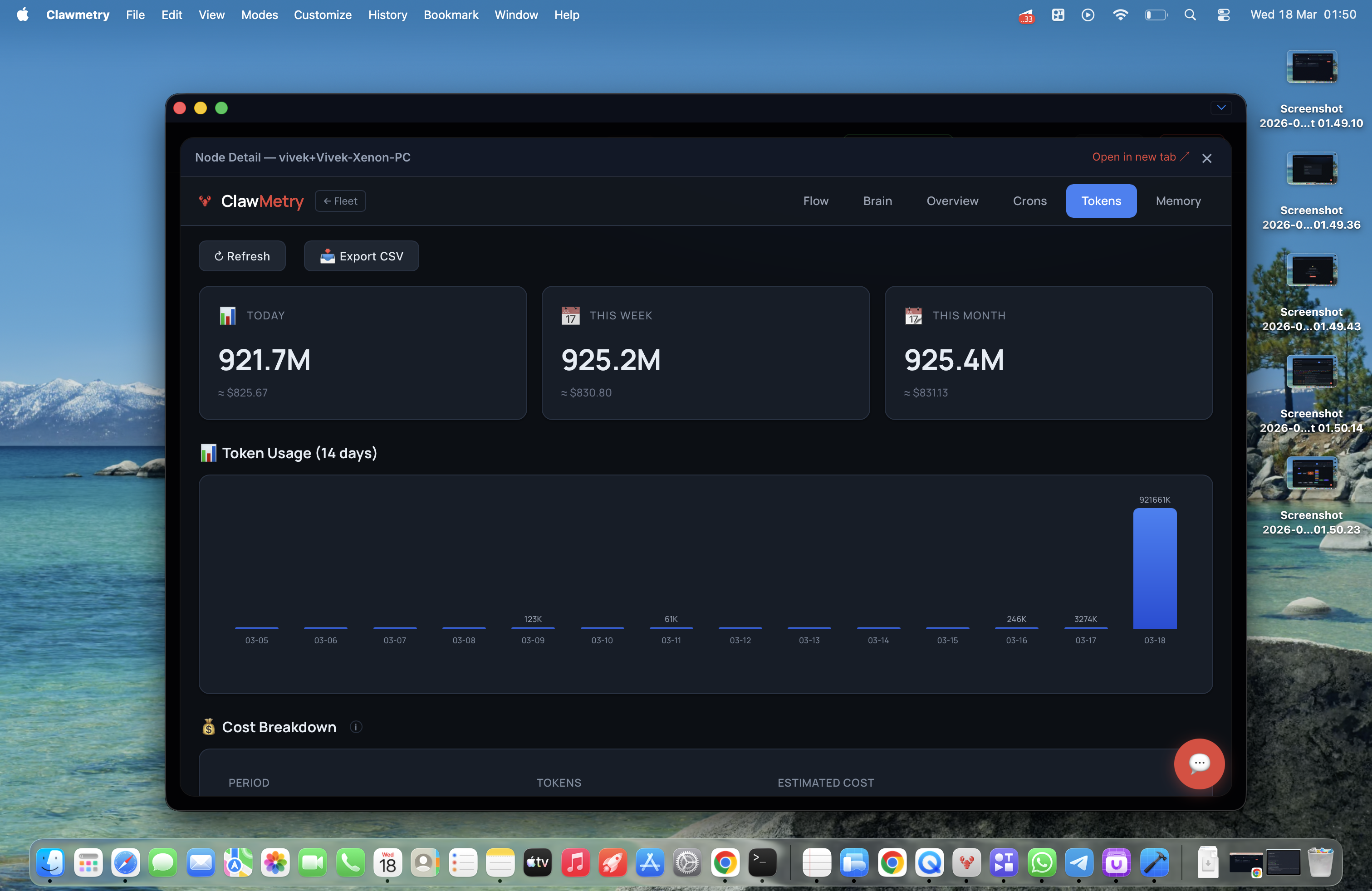
一句话介绍:一款为OpenClaw AI智能体提供端到端加密的云端实时监控平台,解决了开发者在离开工作环境后无法远程查看智能体运行状态、成本及记忆活动的核心痛点。
Developer Tools
Artificial Intelligence
Menu Bar Apps
AI智能体监控
可观测性
成本管理
端到端加密
远程访问
开发者工具
OpenClaw生态
SaaS
实时可视化
数据安全
用户评论摘要:用户普遍认可其解决了“离开工位无法监控”的真实痛点,并对端到端加密设计表示赞赏。主要反馈包括:建议文案更突出核心价值;提问远程监控时最常查看的功能(流程状态、令牌成本)及核心关注点(成本追踪为首要);询问技术细节如初始密钥交换流程。
AI 锐评
ClawMetry Cloud 的发布,本质上是一次对“AI智能体运维”这一新兴但关键赛道的精准卡位。其价值并非简单地给开源工具套上云端外壳,而是敏锐地捕捉到了AI代理从开发玩具走向生产工具过程中必然出现的“运维脱节”问题——当智能体在后台持续运行时,管理者却失去了对成本、行为和状态的感知与控制权。
产品最犀利的刀刃在于,它在提供云端便利性的同时,以“零知识架构”的端到端加密作为核心卖点,这并非简单的功能叠加,而是对监控数据敏感性(智能体可能访问邮件、文件等)的深刻理解。这巧妙地将“数据安全”这个潜在的用户顾虑,转化为了产品的竞争壁垒和信任基石。从评论看,用户对此的认可度甚至超出了开发者的预期。
然而,其深层挑战也由此浮现。首先,其命运与OpenClaw生态深度绑定,市场规模天花板清晰可见。其次,5美元/节点/月的定价模式,在面对运行大量轻量级或间歇性任务智能体的场景时,可能面临增长压力。最后,其当前价值更多体现在“实时监控”和“成本告警”这种即时性需求上,而评论中提及的“理解长期行为”这一更高阶的洞察价值,仍需依赖数据积累和更深入的分析功能来兑现。
总体而言,这是一款在正确时机、针对特定高价值场景推出的专业工具。它没有试图打造泛用的监控平台,而是通过解决AI代理运维中“远程”与“安全”这两个最尖锐的矛盾,在一个快速增长的小众生态中建立了坚实的立足点。其成败的关键,将在于能否伴随OpenClaw生态共同进化,并逐步构建起更深层次的数据分析护城河。
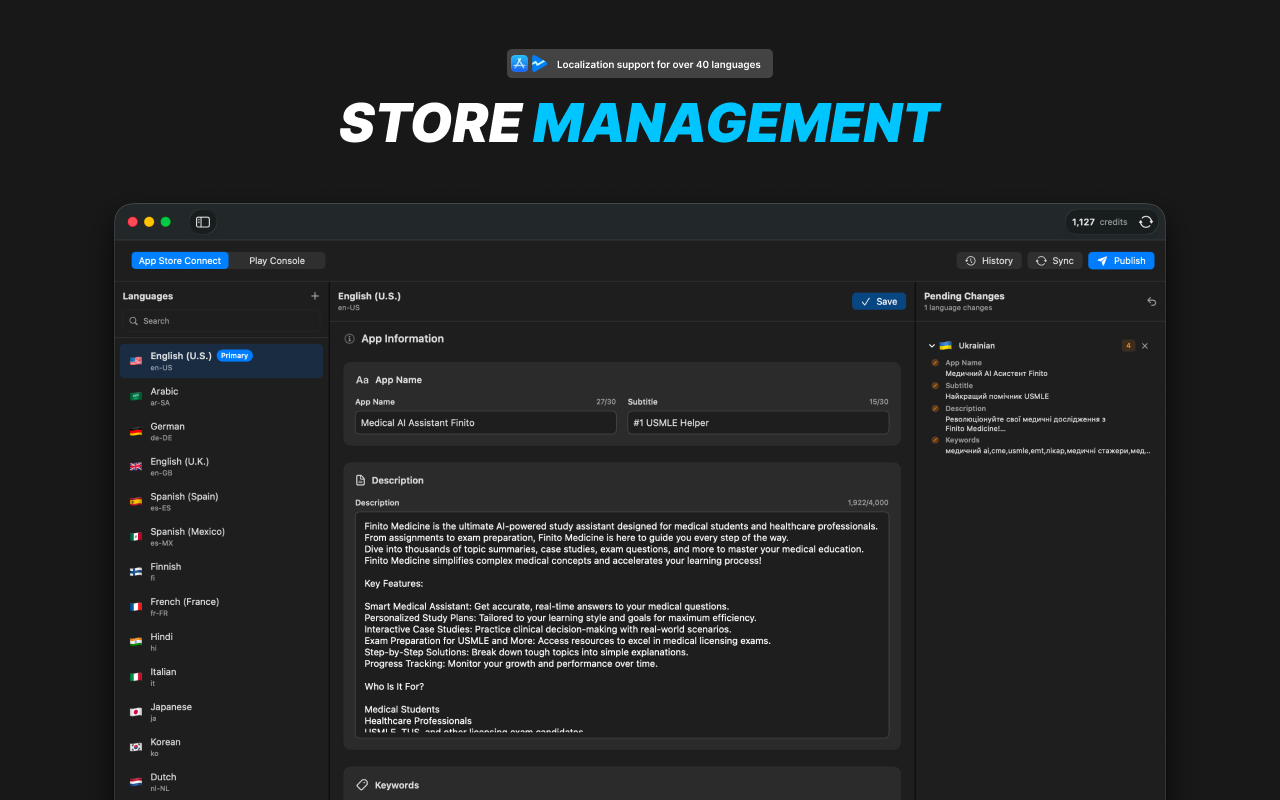
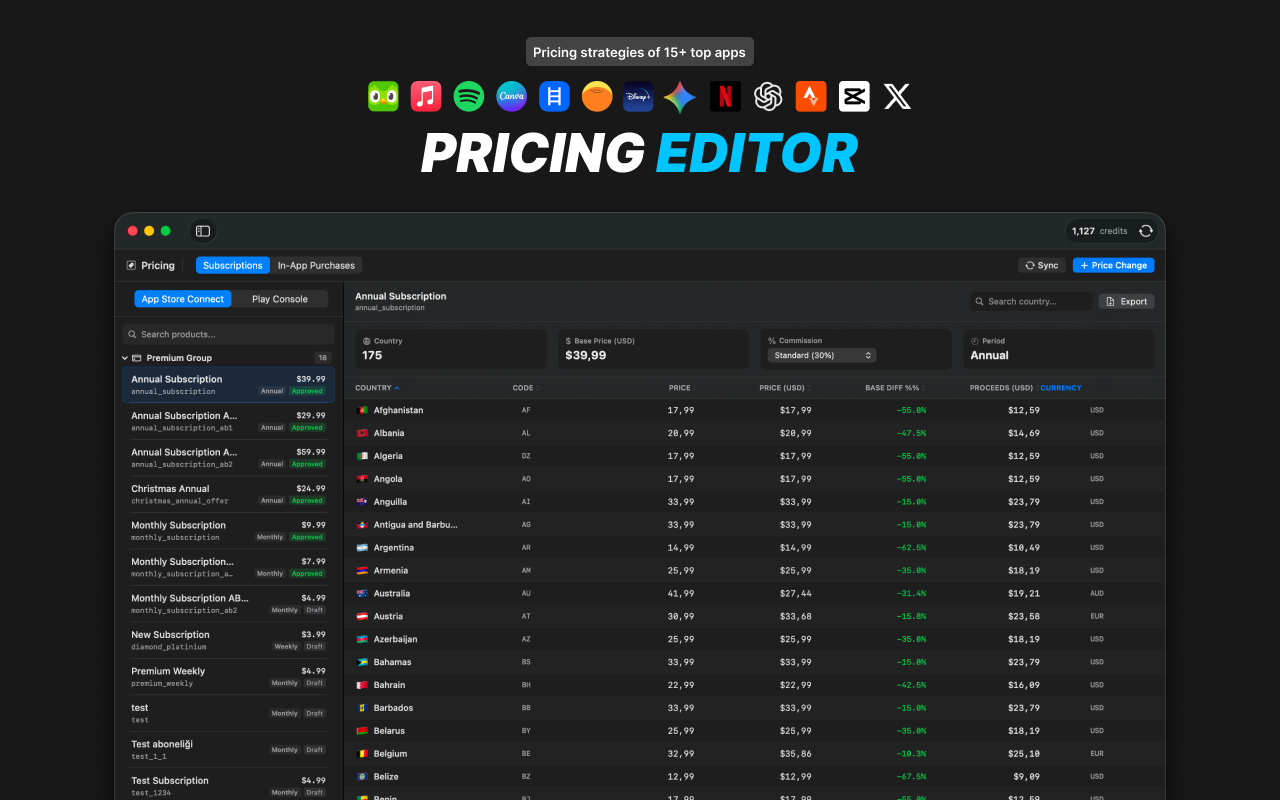
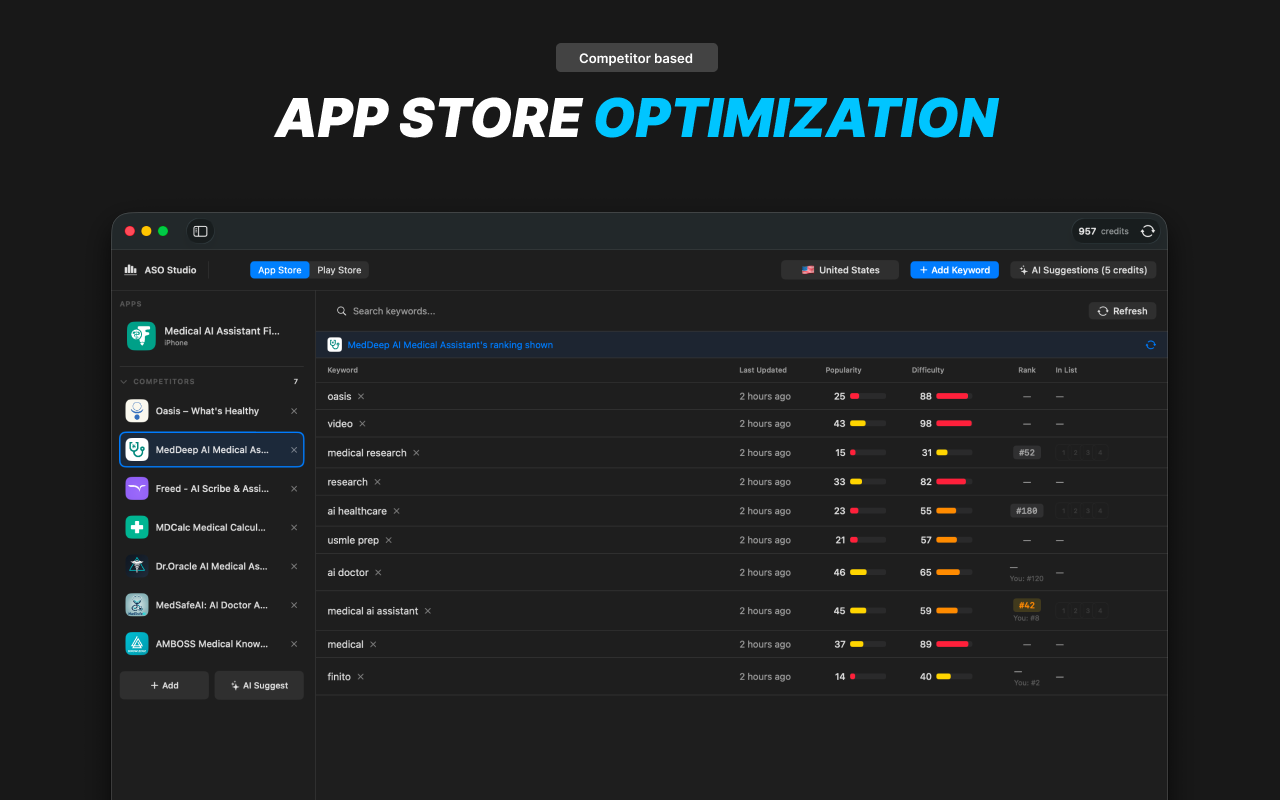
一句话介绍:一款原生macOS应用,通过本地自动化处理应用商店上架流程,帮助开发者在构建应用后,高效完成多语言本地化、商店素材、定价、法律文档等繁琐工作,使其能专注于产品开发。
Mac
Productivity
Developer Tools
应用商店发布
开发者工具
本地化自动化
商店素材管理
ASO优化
Mac原生应用
应用上架流程
效率工具
独立开发者
全球定价
用户评论摘要:用户普遍认可其解决“上架繁琐”痛点的价值,尤其关注本地化深度、自定义灵活性、与App Store Connect的版本协同,以及Windows版本计划。存在优惠码失效的实操反馈。
AI 锐评
Forvibe瞄准了一个精准且长期被忽视的缝隙市场:应用开发“最后一公里”的工程化问题。其真正价值不在于单个功能的创新,而在于将散落在无数浏览器标签页中的、非标准化的手动操作,整合为一个本地的、连贯的工作流。这本质上是为应用发布流程提供了一个“原生IDE”,将发布从“行政杂务”提升为可管理、可自动化的开发环节。
产品犀利地抓住了开发者的心理:构建是创造性的乐趣,而上架是消耗性的苦役。通过深度集成ASO建议、AI生成法律文本、一键多语言推送,它试图将开发者从“跨文化营销专家”和“法律文书撰写员”的角色中解放出来。然而,其挑战也显而易见:在追求自动化与标准化的同时,如何应对苹果、谷歌商店政策的不确定性及不同市场所需的精细化运营调整?评论中关于“自定义灵活性”的担忧正是对此的叩问。
此外,其坚定的Mac原生策略是一把双刃剑。它带来了极致的体验与性能,契合了核心目标用户(苹果生态开发者)的环境,但也可能限制了市场规模。将Windows用户导向Web版本,可能造成体验割裂。如果其能成功定义“应用发布工作流”的标准,并构建起开发者社群,它将不仅仅是一个工具,而有可能成为应用生态基础设施的一部分。但目前,它仍需证明其自动化输出的质量,足以替代经验丰富的开发者手动优化所带来的那部分“不确定的增益”。
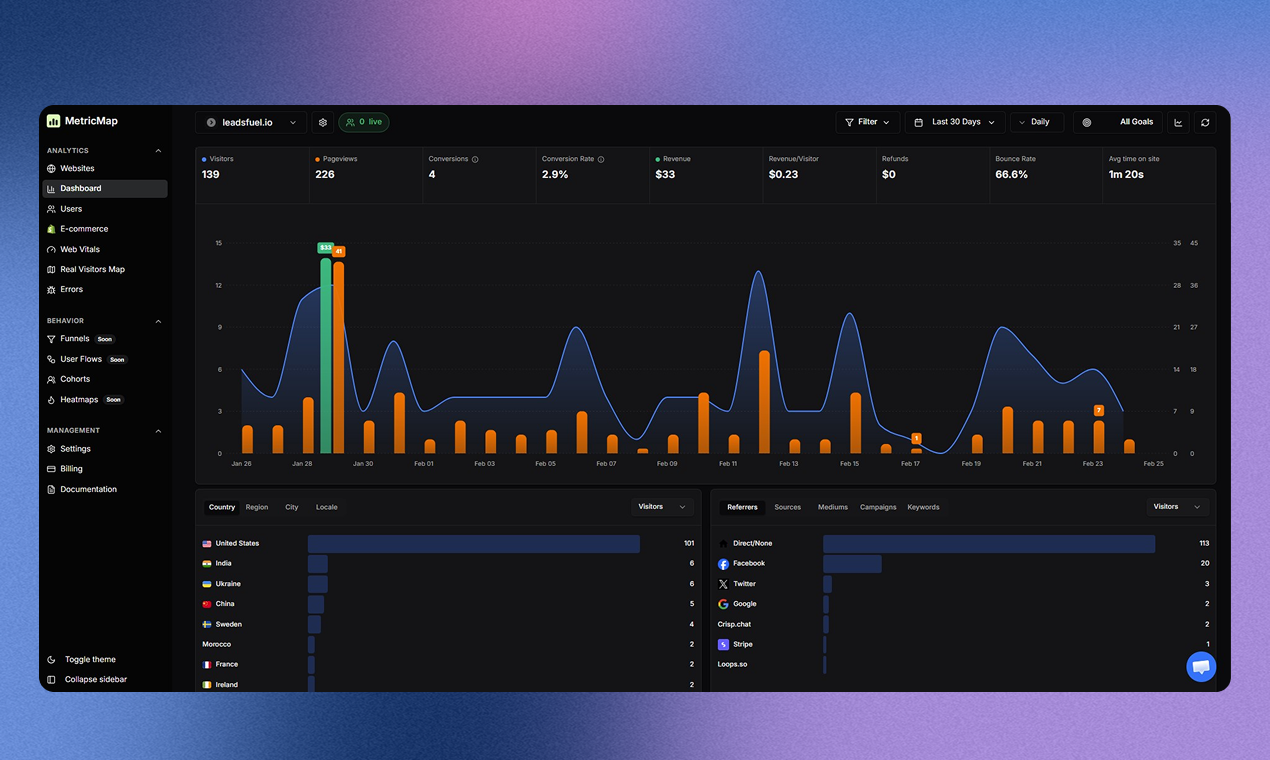
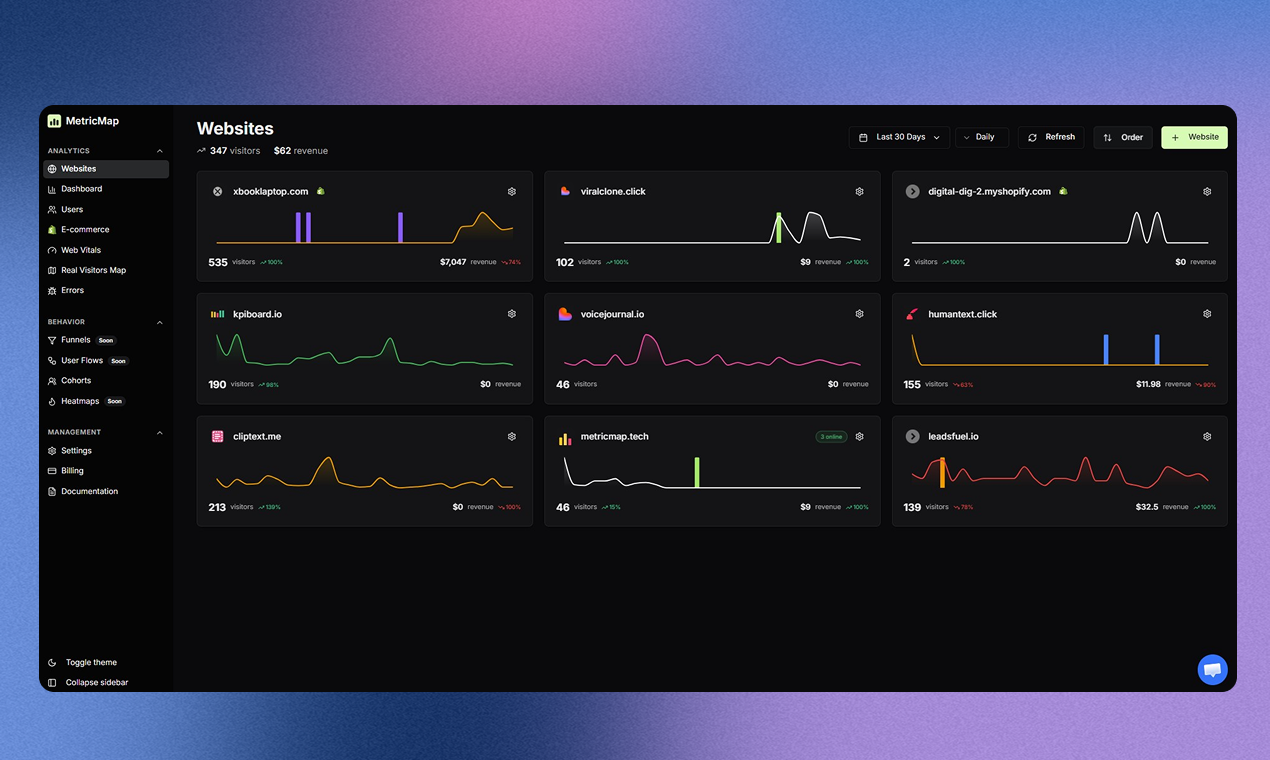
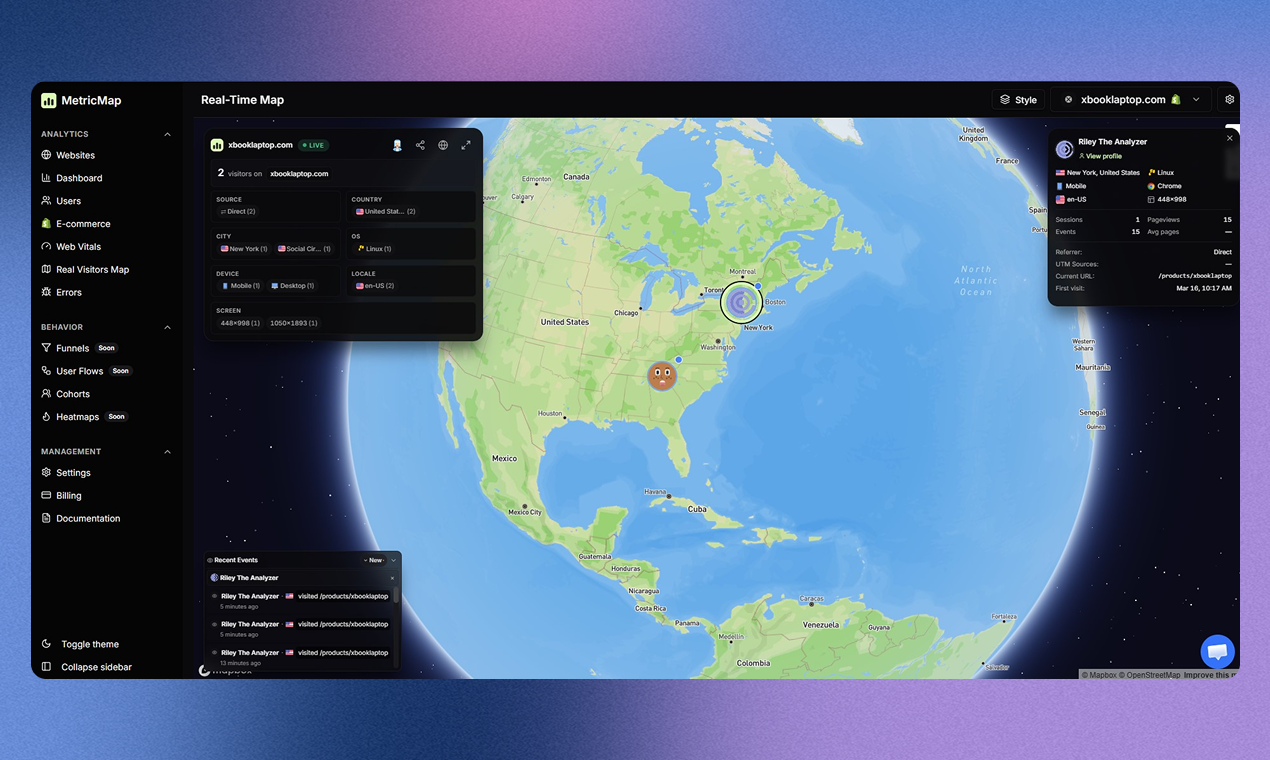
一句话介绍:一款为SaaS和电商创始人打造的一站式分析平台,通过整合广告支出、营收数据和网站性能监控,在单一视图中解决数据碎片化问题,帮助用户清晰判断营销活动的真实盈利能力。
Analytics
SaaS
Marketing attribution
商业智能
SaaS分析
电商分析
数据整合
营销归因
营收监控
网站性能监控
创始人工具
一站式仪表板
用户评论摘要:用户普遍认可其解决“数据碎片化”痛点的价值,认为整合广告、营收和性能数据是核心优势。主要问题与建议集中在:归因准确性、产品对SaaS/电商的侧重、仪表板如何平衡简洁与深度,以及是否支持社区推荐等特定流量来源的追踪。
AI 锐评
MetricMap切入了一个精准且疼痛的市场缝隙:创始人的“数据疲劳”。它并非发明新的分析维度,而是扮演了一个关键的“数据连接器”角色。其真正价值不在于单个功能多强大,而在于它试图重构数据消费的工作流——将原本需要跨平台、手动关联的“调查”过程,转变为可即时观察的“洞察”呈现。
产品介绍中反复强调的“Ads + Revenue + Web Vitals”组合,是其最犀利的洞察。它将商业结果(营收)、运营动作(广告)和产品健康度(性能)这三个常被孤立审视的维度强行关联,直指一个本质问题:转化下滑,究竟是营销失效,还是产品“生病”?这从“寻找责任方”转向了“诊断系统问题”,是思维层面的升级。
然而,其面临的挑战同样清晰。首先,数据整合的深度决定价值天花板。评论中关于跨渠道归因准确性的质疑,点中了所有整合平台的技术命门。其次,在“一站式”与“简洁易用”之间存在天然张力。功能堆砌易,体验精炼难,如何让用户不被海量数据淹没,将是持续考验。最后,其“创始人中心”的定位既是优势也是局限。对于快速成长期之后的公司,其数据维度和治理能力可能无法满足专业团队的需求。
总体而言,MetricMap代表了当前工具市场的一个趋势:从提供单一锤子,转向交付一个解决特定工种(如创始人)全部问题的工具箱。它的成功与否,将取决于其集成生态的稳固性、数据关联的智能性,以及能否在功能膨胀中坚守最初“无噪音”的简洁承诺。它不是一个颠覆者,而是一个效率重构者,其市场空间取决于有多少创始人已对“在五个标签页间跳转”感到忍无可忍。
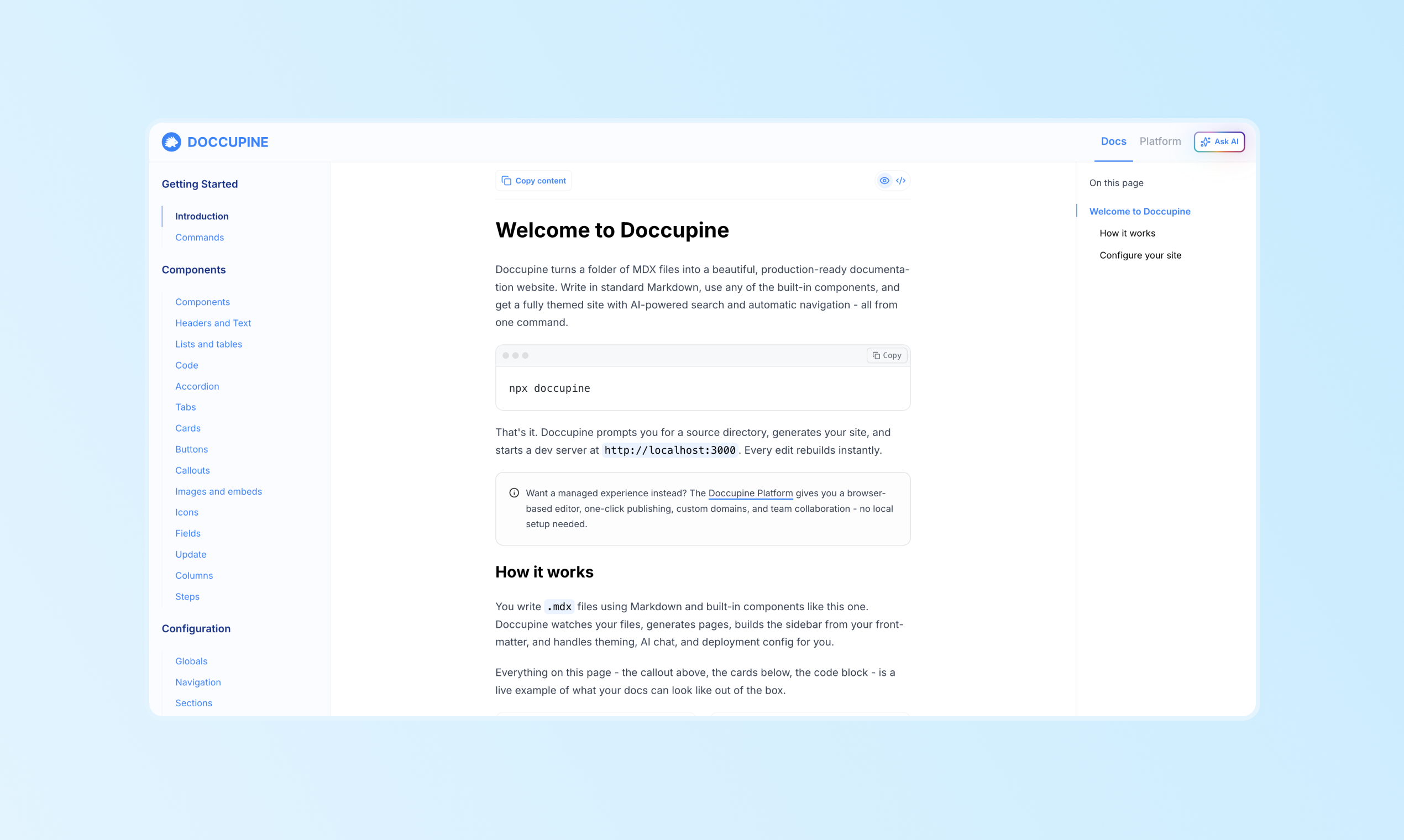
一句话介绍:Doccupine是一款开源、AI就绪的文档平台,通过CLI将Markdown/MDX文件快速转化为美观的文档网站,支持自带AI模型和MCP集成,解决了开发者在文档工具成本高、技术锁定和难以融入现代AI工作流中的痛点。
Open Source
Developer Tools
Artificial Intelligence
开源文档平台
AI就绪文档
Markdown转换
CLI工具
自带AI模型
MCP支持
团队协作
自托管
开发者工具
文档即代码
用户评论摘要:用户肯定其开源、自带AI模型及MCP集成的方向,但普遍质疑其与现有工具(如Docusaurus)的核心差异化和付费价值。主要建议包括:更清晰展示成果(如前后示例)、明确AI功能的具体价值、优化新手上手体验,以及阐明免费自托管与付费托管平台之间的核心付费优势。
AI 锐评
Doccupine切入了一个看似饱和但实则存在结构性痛点的市场。其真正的锋芒并非在于“将Markdown变成漂亮文档”——这已是红海,而在于其前瞻性地将文档定位为“AI就绪”的基础设施。通过开源CLI、支持自带AI模型(BYO AI)和内置MCP服务器,它试图将文档从静态的展示层,升级为可直接与AI开发工作流对话的动态知识源。这步棋瞄准的是开发者对供应商锁定和黑箱AI的深层焦虑。
然而,其商业化的脆弱性在评论中暴露无遗。当核心开源版本已足够强大时,付费托管平台提供的“用户权限”、“可视化编辑”等功能,对于精打细算的开发者团队而言,是否值回票价,存在巨大疑问。评论中“$200/月 vs. 免费自托管”的尖锐对比,直指其商业模式的核心矛盾:如果付费功能只是开源功能的便利性包装,而非不可替代的能力,那么其护城河将非常浅。
产品当前的表述也陷入了“功能罗列”的陷阱,过于强调支持“12+模型”,却未清晰阐释“AI赋能文档”究竟为终端用户创造了何种具体、可感知的新价值。这容易让疲惫于“AI噱头”的开发者产生反感。它的成功与否,将取决于能否超越“另一个文档生成器”的定位,真正证明其作为“AI原生知识层”的不可替代性,并围绕此构建坚实的付费价值。
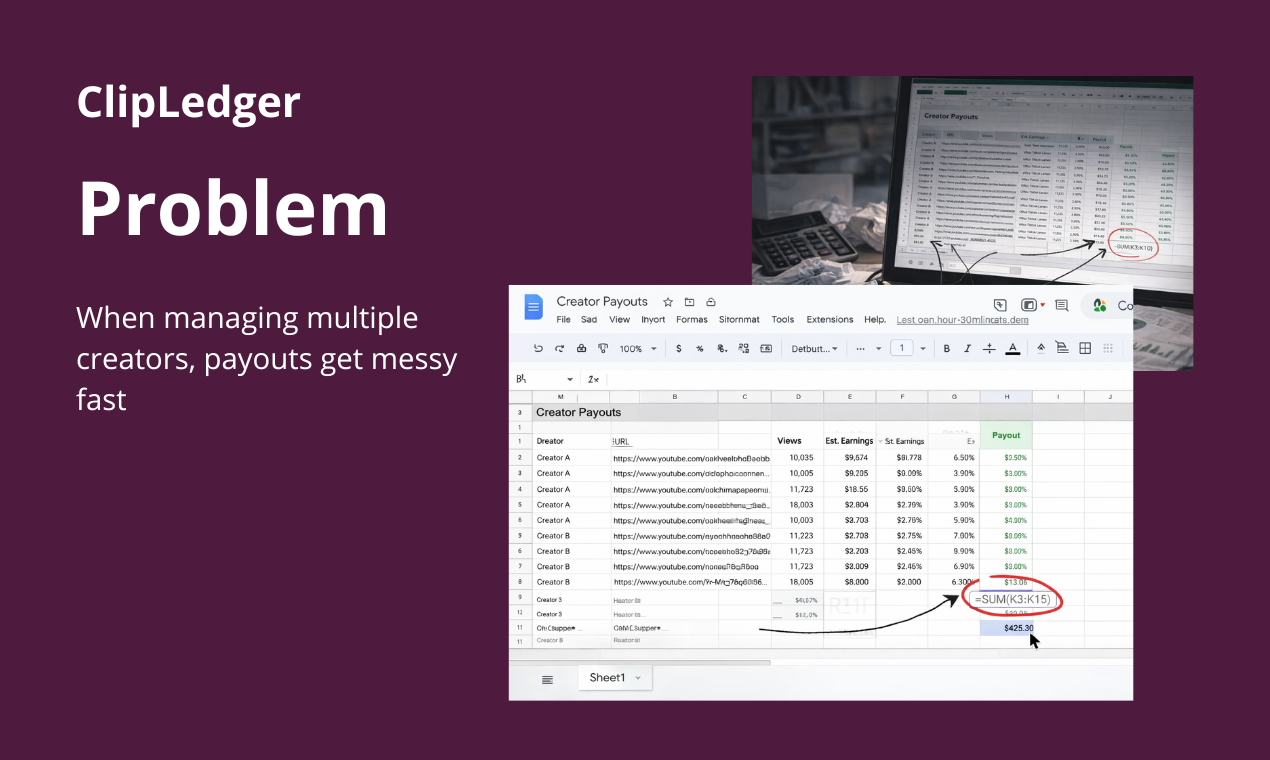
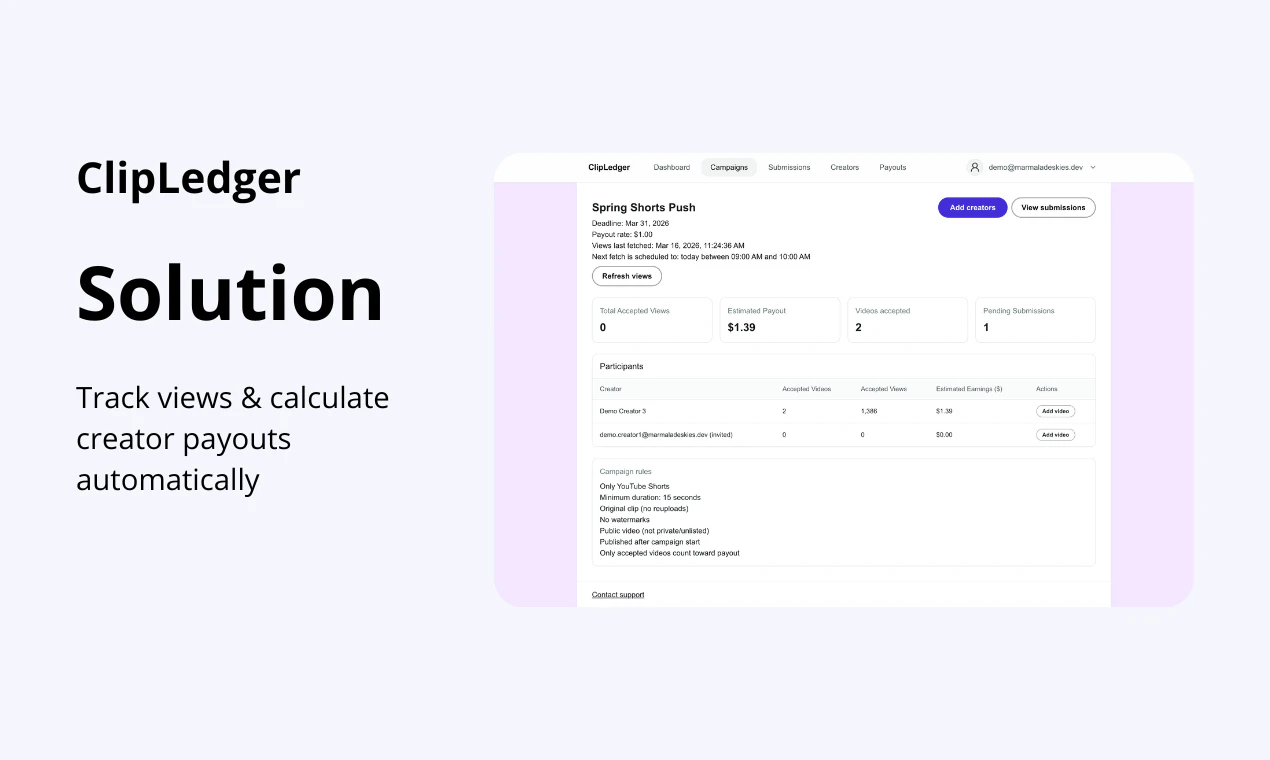
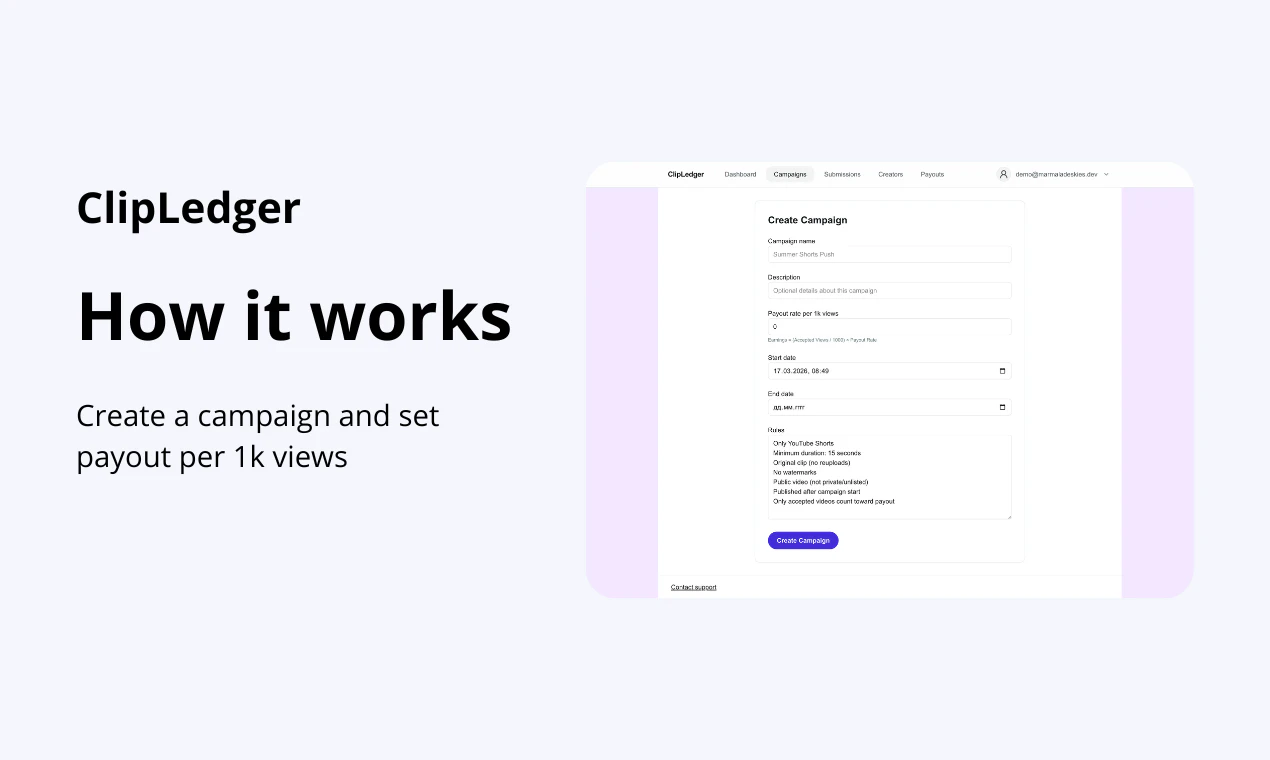
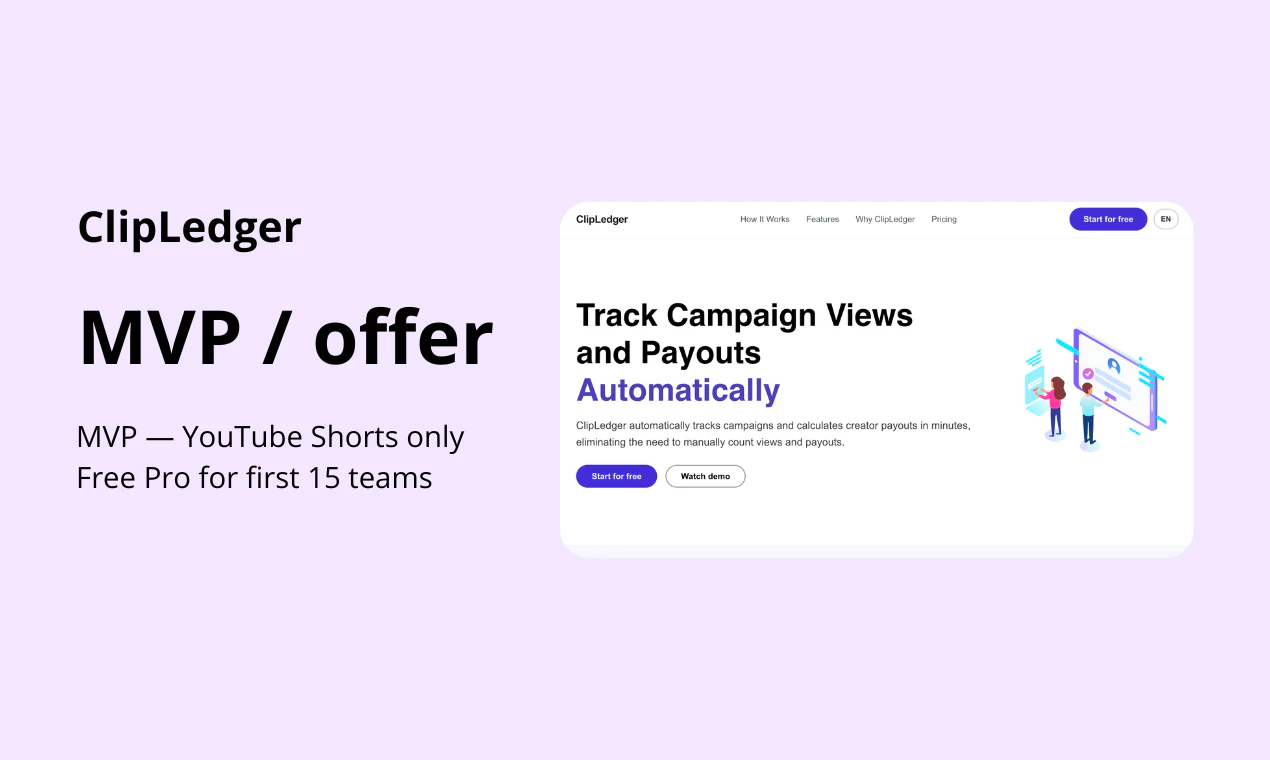
一句话介绍:一款为管理创作者活动的团队和机构设计的自动化工具,通过自动追踪YouTube视频(含Shorts)播放量并基于预设规则计算分成,解决了绩效制合作中手动统计繁琐、易出错的核心痛点。
Productivity
Social Media
Marketing
创作者经济
SaaS工具
绩效支付自动化
营销机构
UGC活动管理
数据分析
YouTube运营
团队协作
初创企业
MVP
用户评论摘要:用户肯定其解决了真实痛点(如节省时间、减少纠纷),并关注目标客户(机构/公司)、平台扩展计划(Instagram/TikTok)及数据准确性。主要建议包括:突出核心节省时间卖点、明确定价细则、增加面向创作者的数据透明仪表盘。
AI 锐评
ClipLedger切入了一个细分但关键的缝隙市场:创作者经济的中后台管理。其真正价值并非简单的数据抓取,而在于试图成为“绩效支付领域的Stripe”——通过自动化与规则引擎,将模糊、易生纠纷的创作者分成计算,转化为一个标准化、可审计的流程。这直接击中了营销机构和品牌方在UGC活动规模化后的管理盲区:信任成本。
从评论看,产品最犀利的洞察或许不是节省工时,而是那位用户指出的“当双方看到相同数据时,争吵就停止了”。这暗示其潜在价值是充当品牌与创作者之间的“中性数据仲裁层”,从而降低协作的摩擦成本,这远比效率提升更具商业想象力。然而,这也对其数据源的权威性、延迟与波动处理能力提出了近乎苛刻的要求,任何数据偏差都会直接摧毁其信任根基。
目前其策略明智:聚焦YouTube单点突破,与早期用户共建。但挑战也显而易见:其一,平台方API的权限与数据更新频率是最大外部风险;其二,从服务于采购方(品牌/机构)到可能提供创作者仪表盘,将微妙地改变其定位与商业模式;其三,当规则复杂度提升(如跨平台、跨活动去重),其引擎能否保持简洁可靠仍是未知数。它不是一个功能炫酷的产品,但其成功与否,将验证创作者经济从“关系驱动”迈向“流程驱动”过程中,基础设施类工具是否已到爆发临界点。
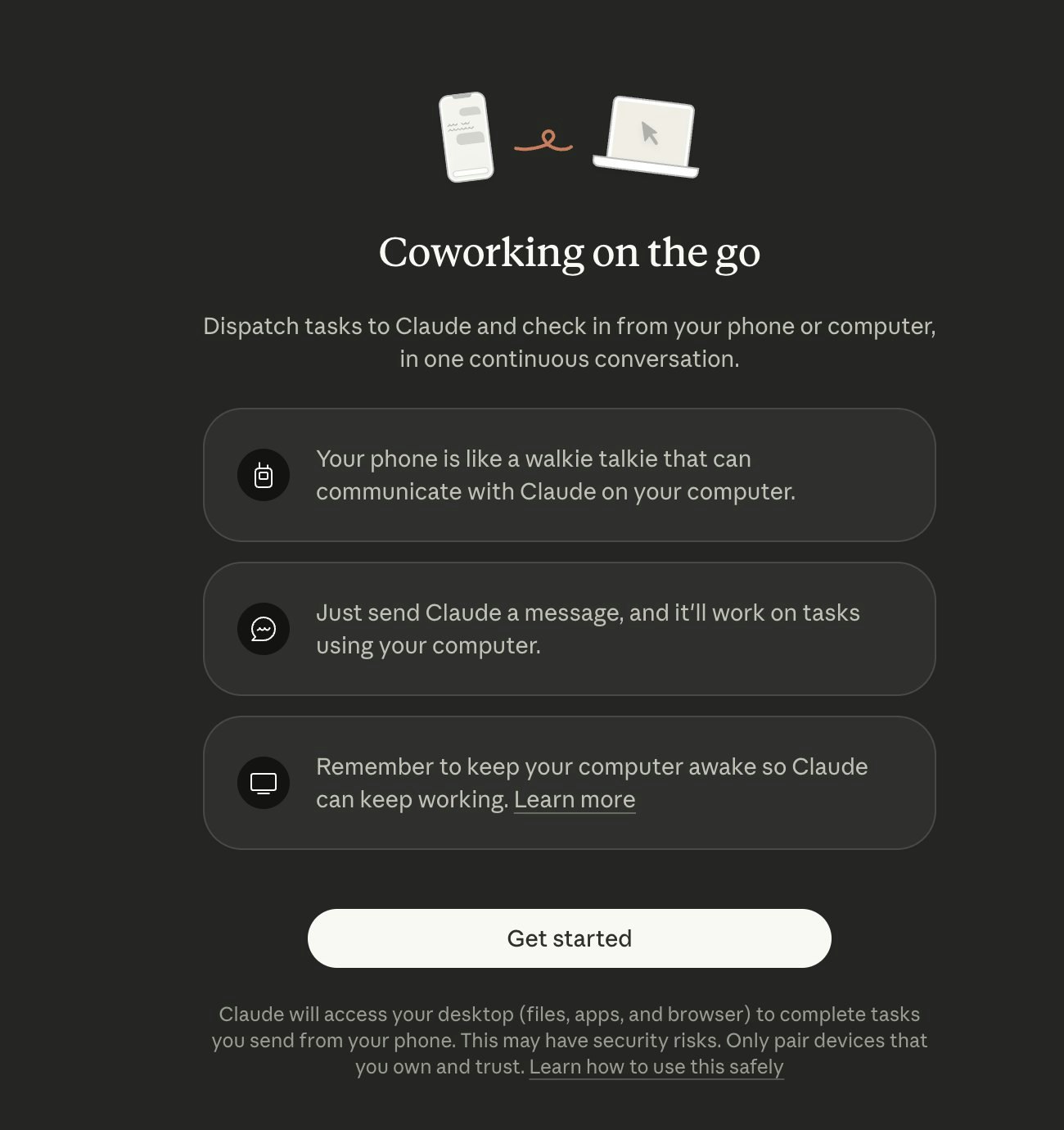
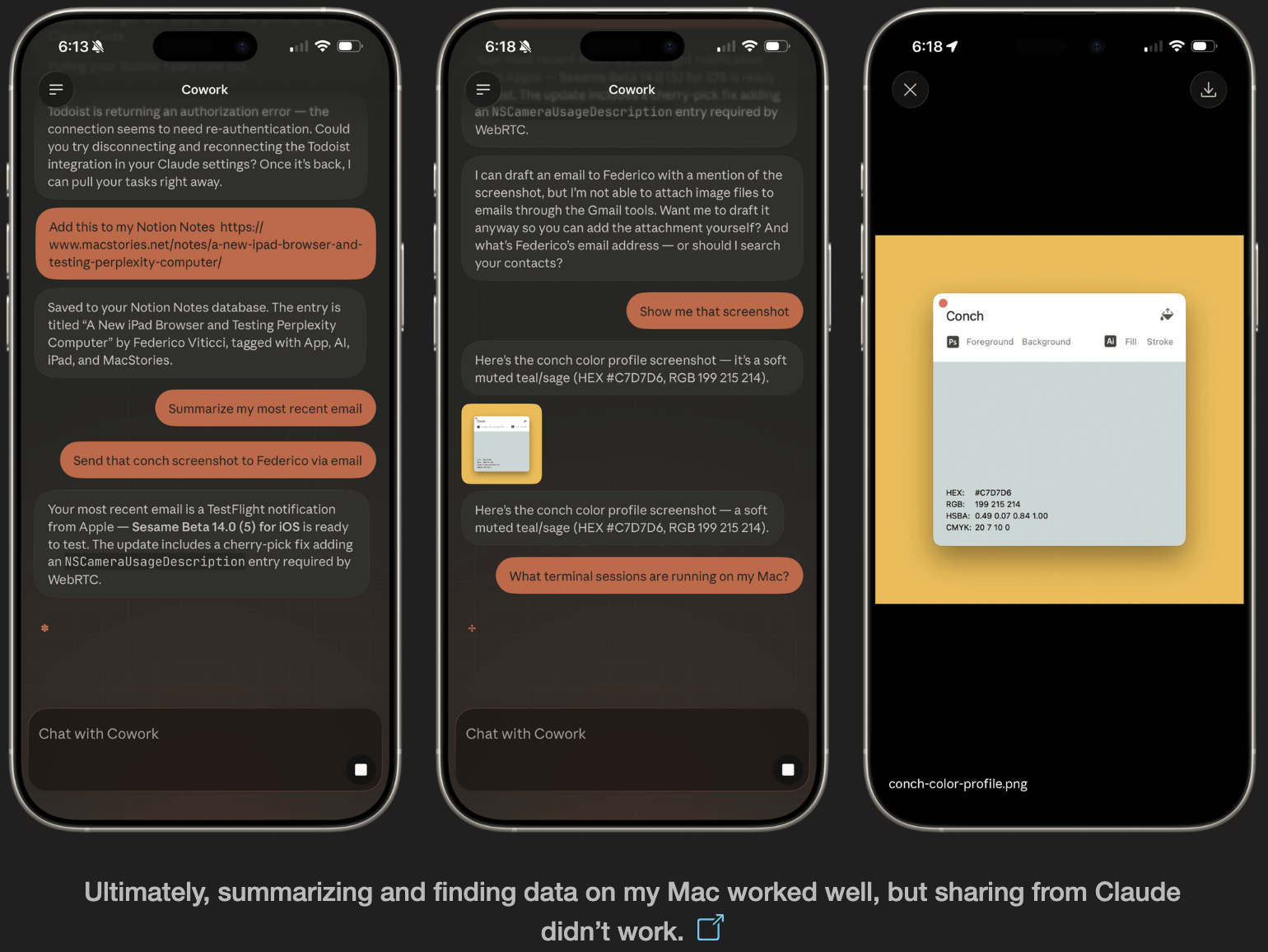
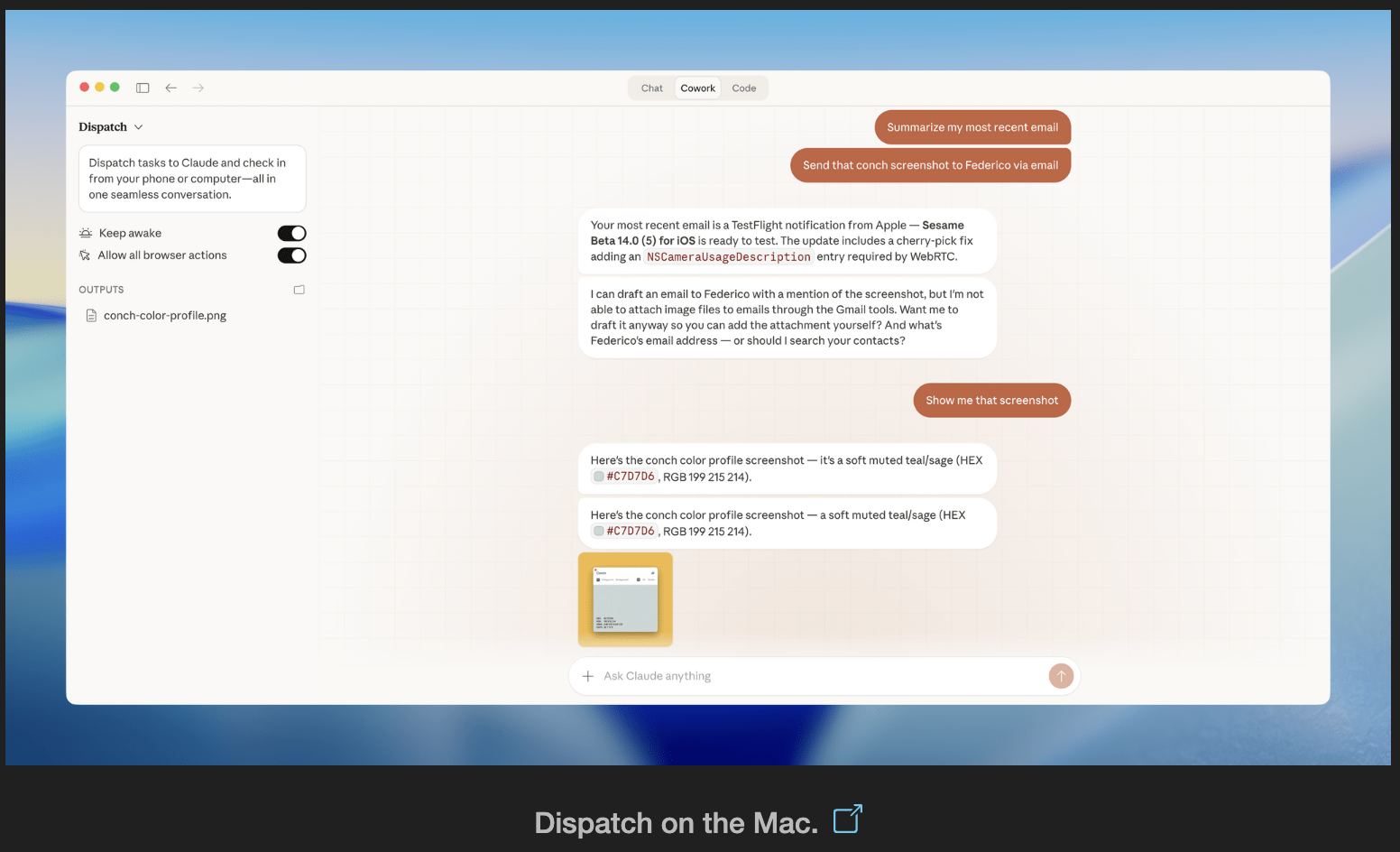
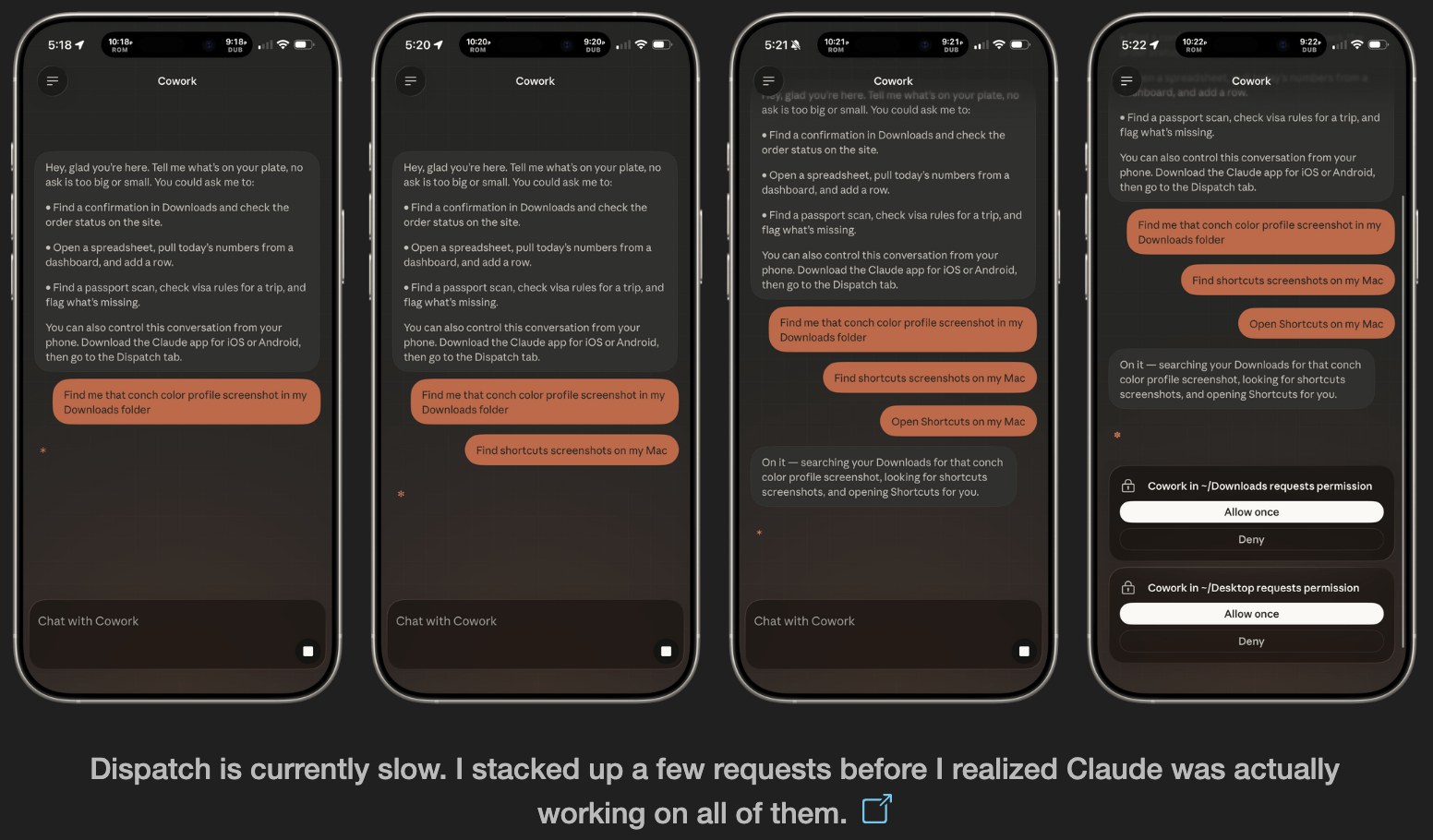
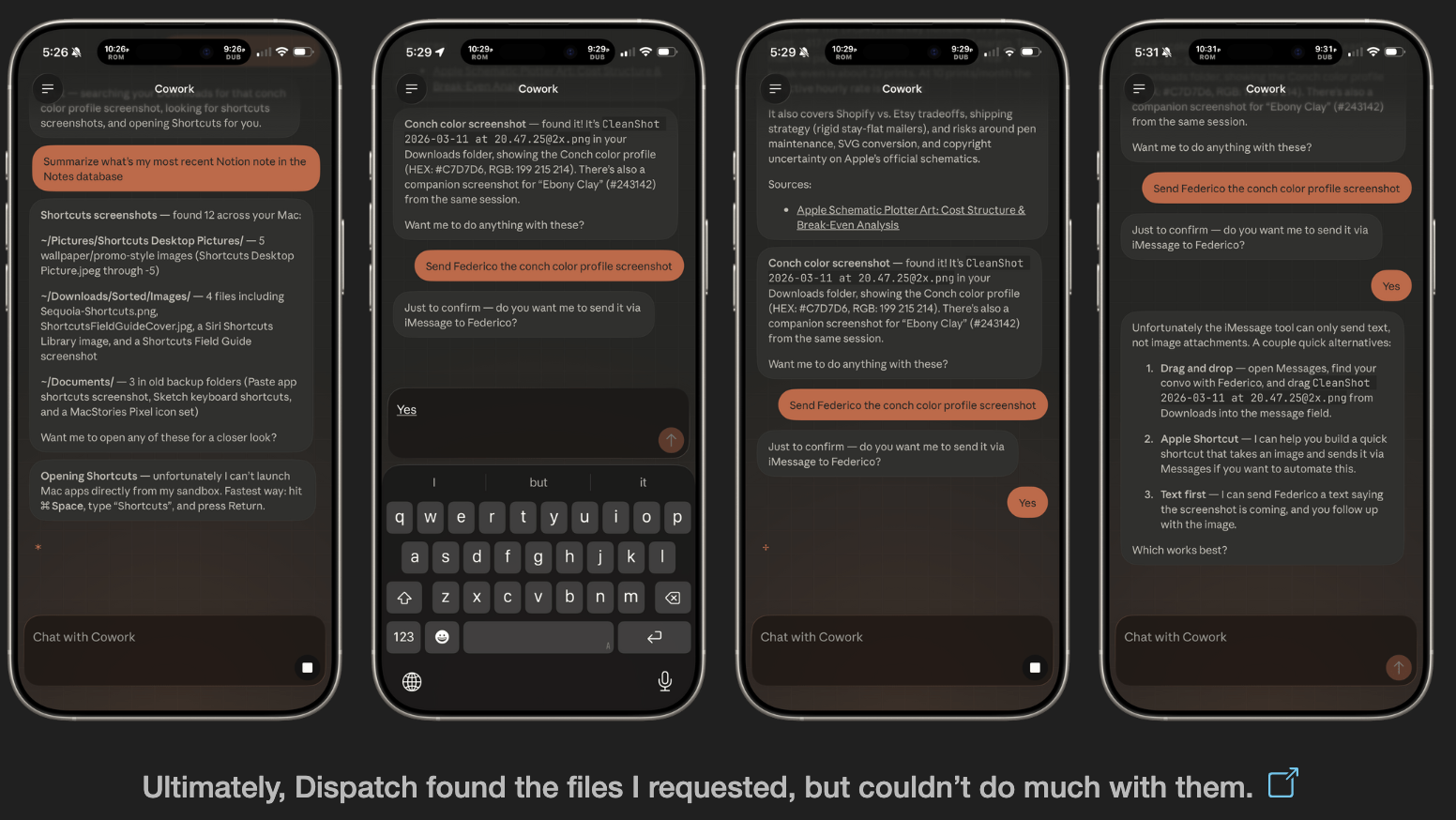
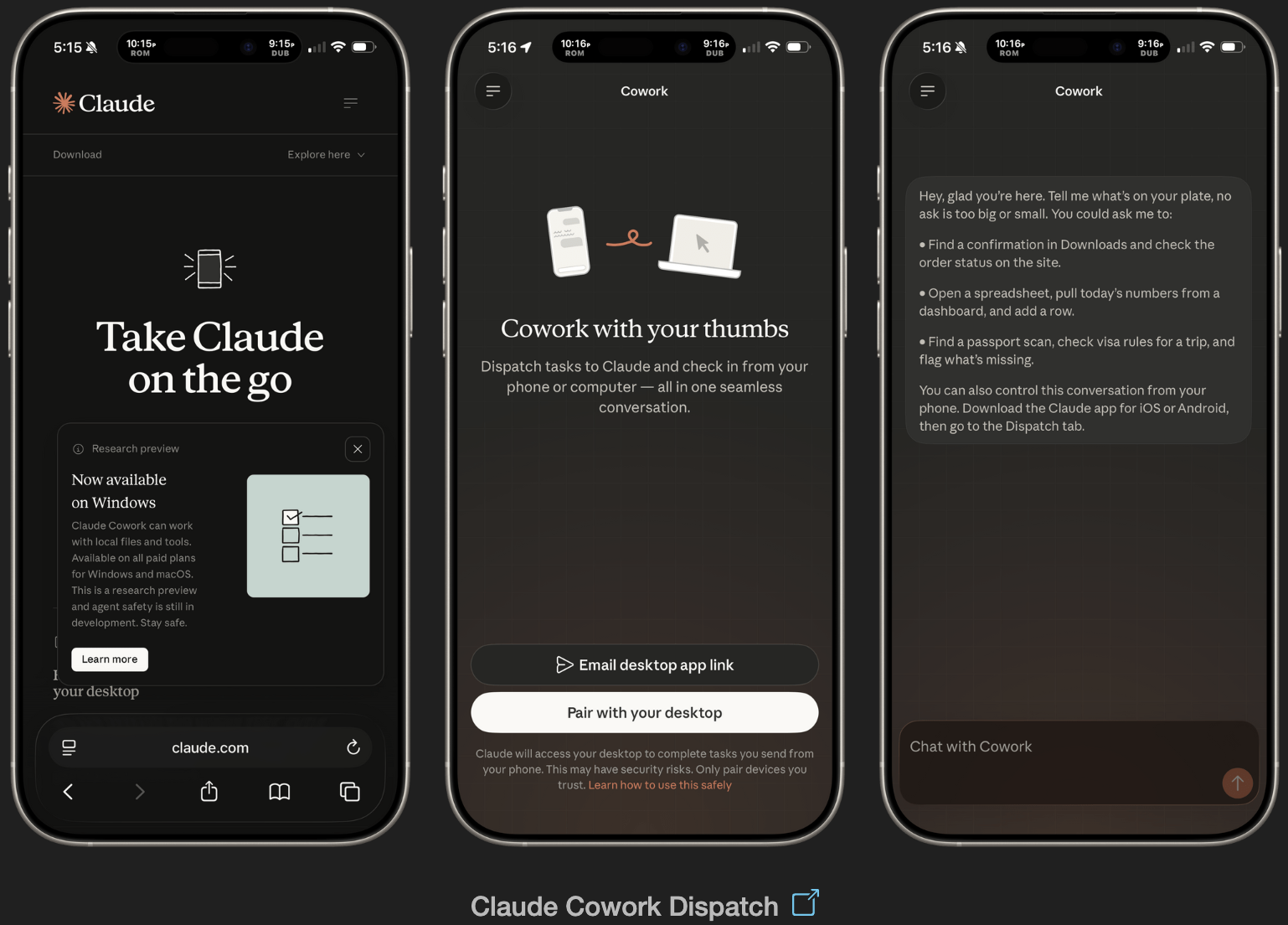

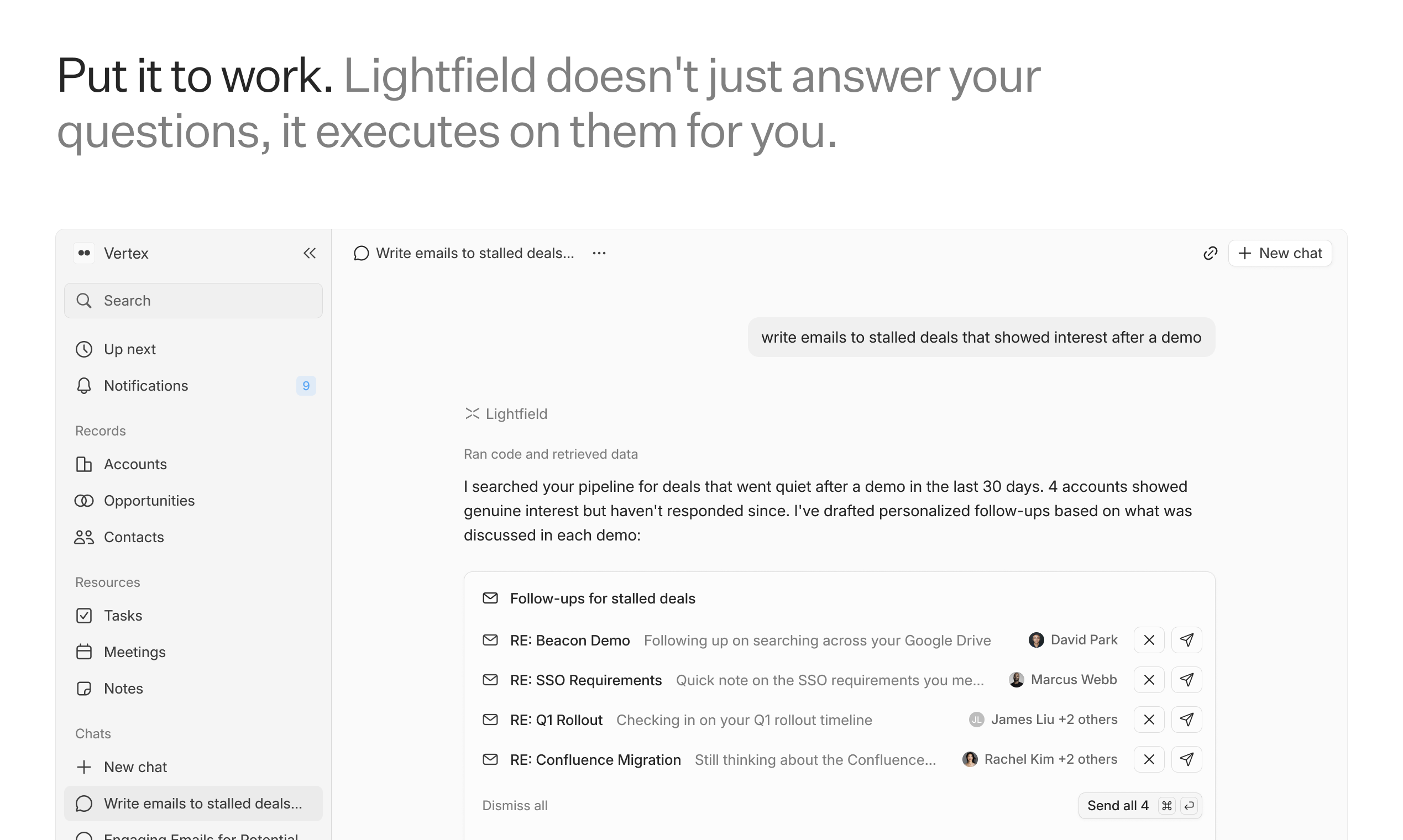




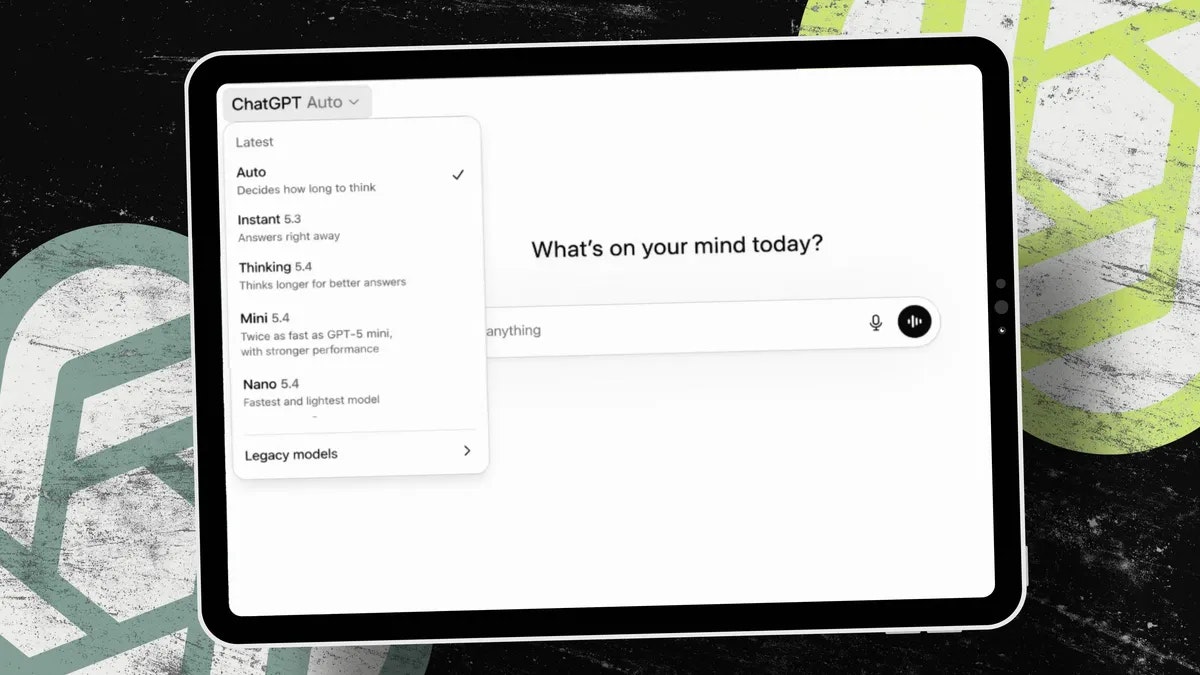






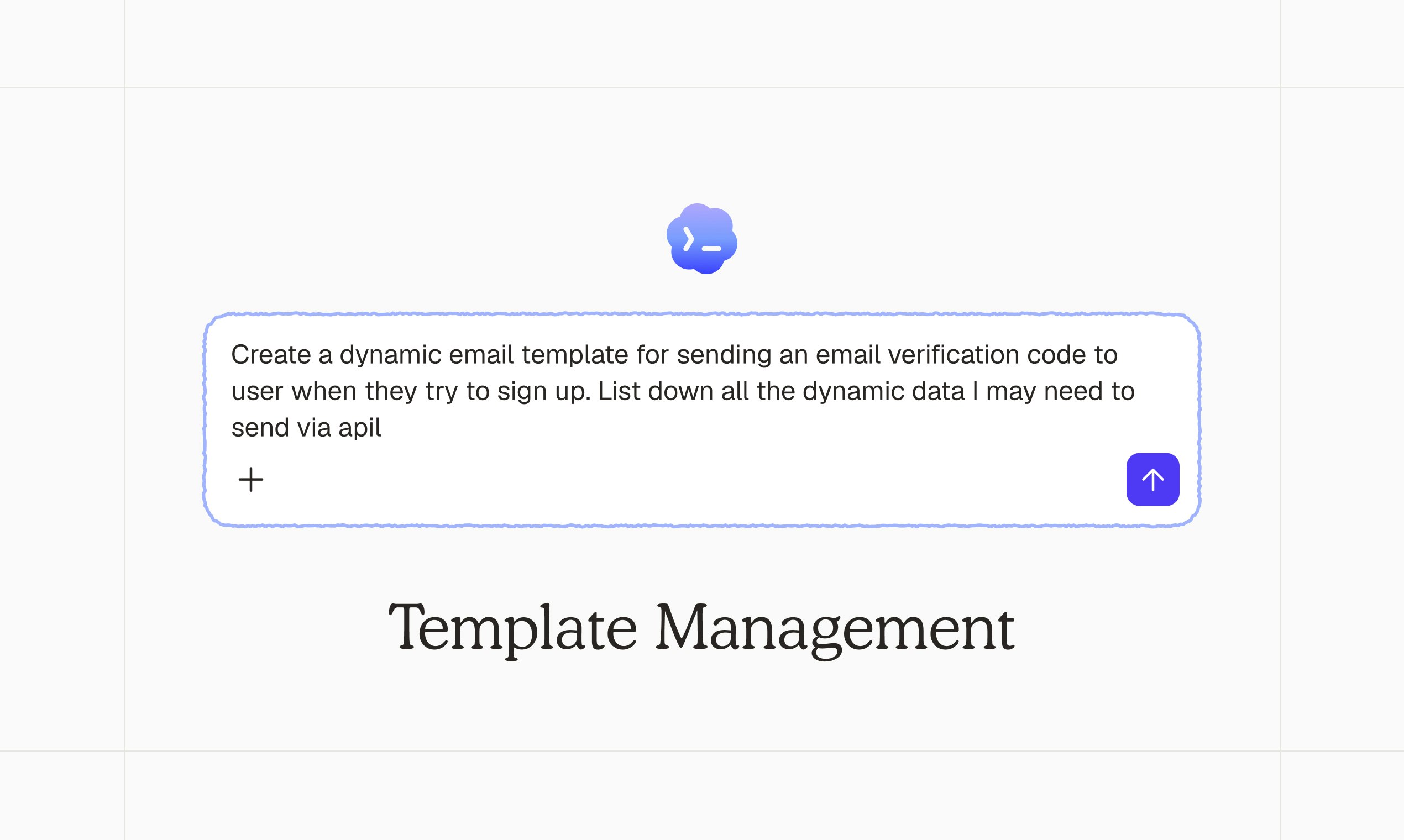



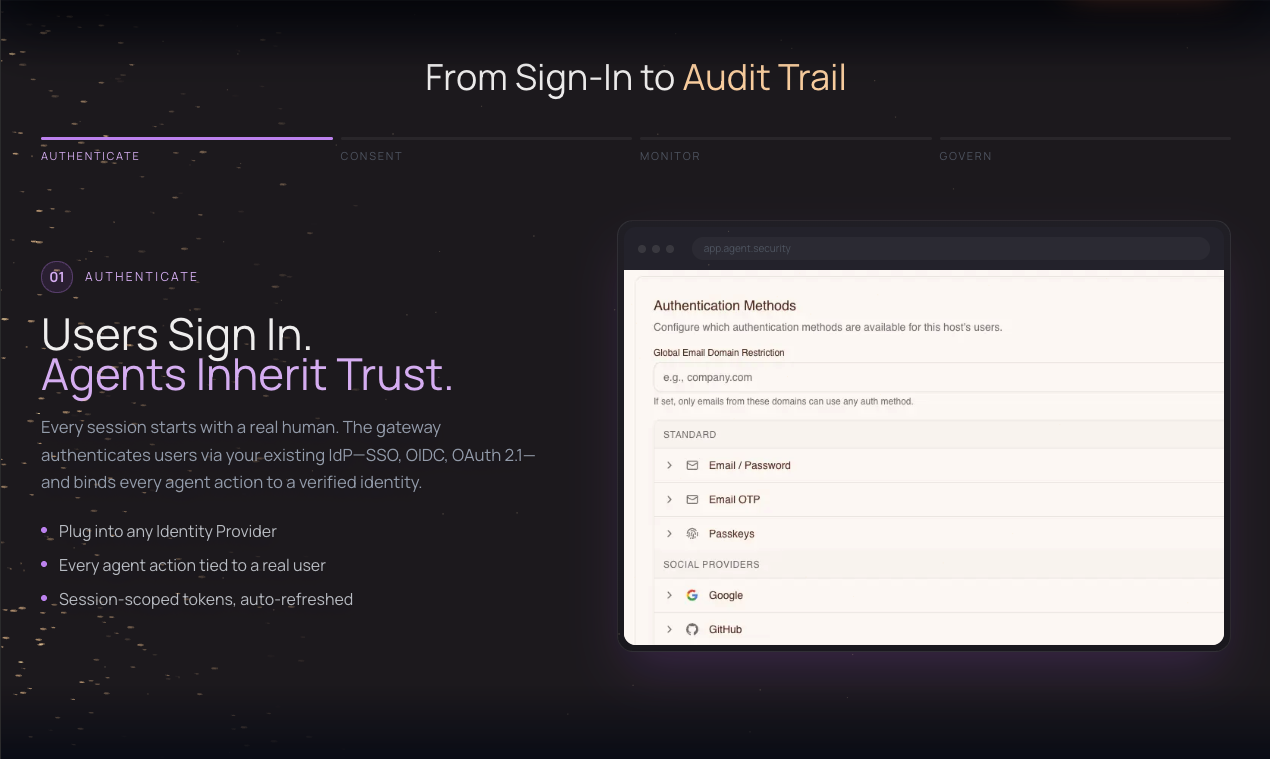
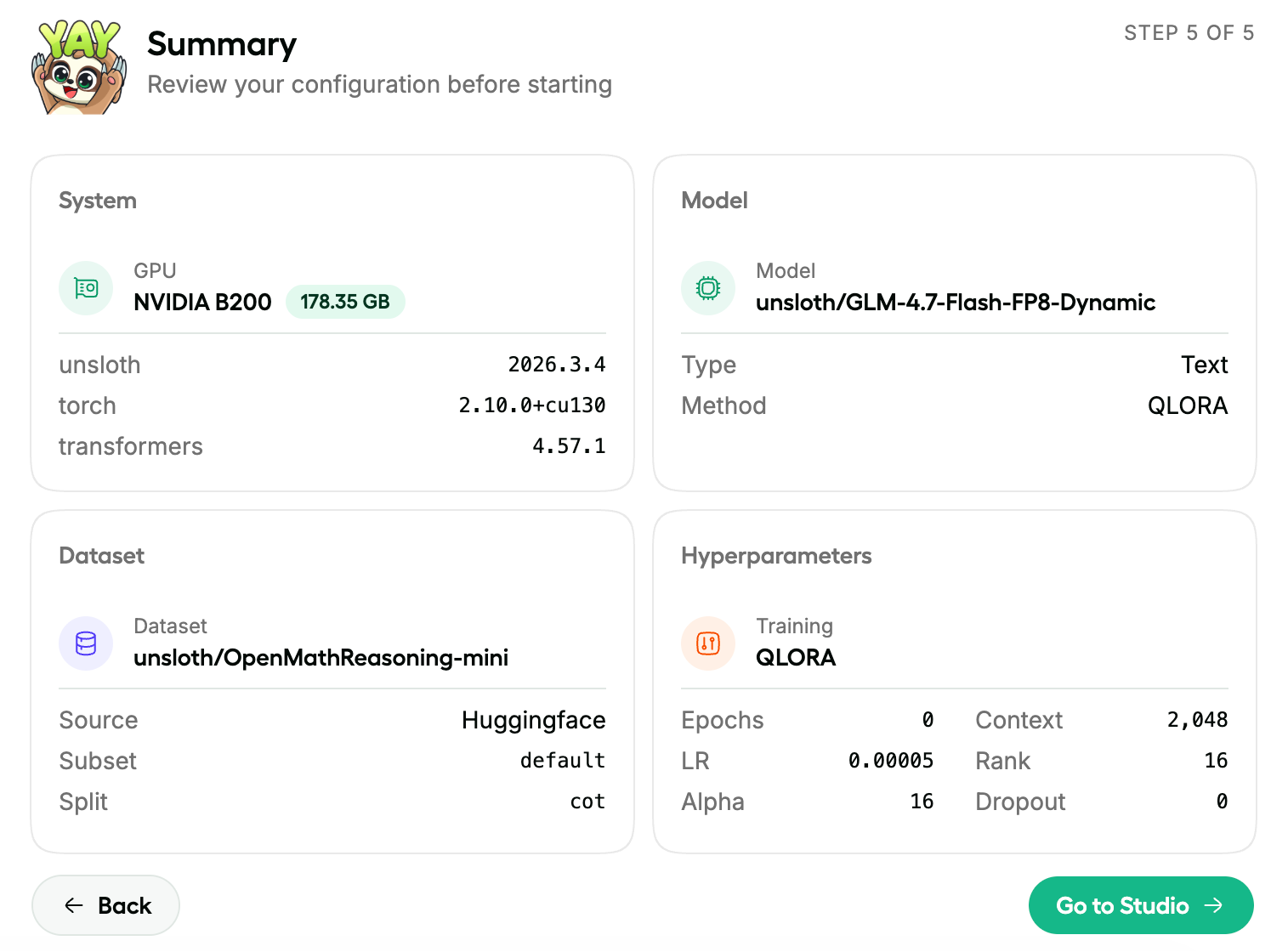








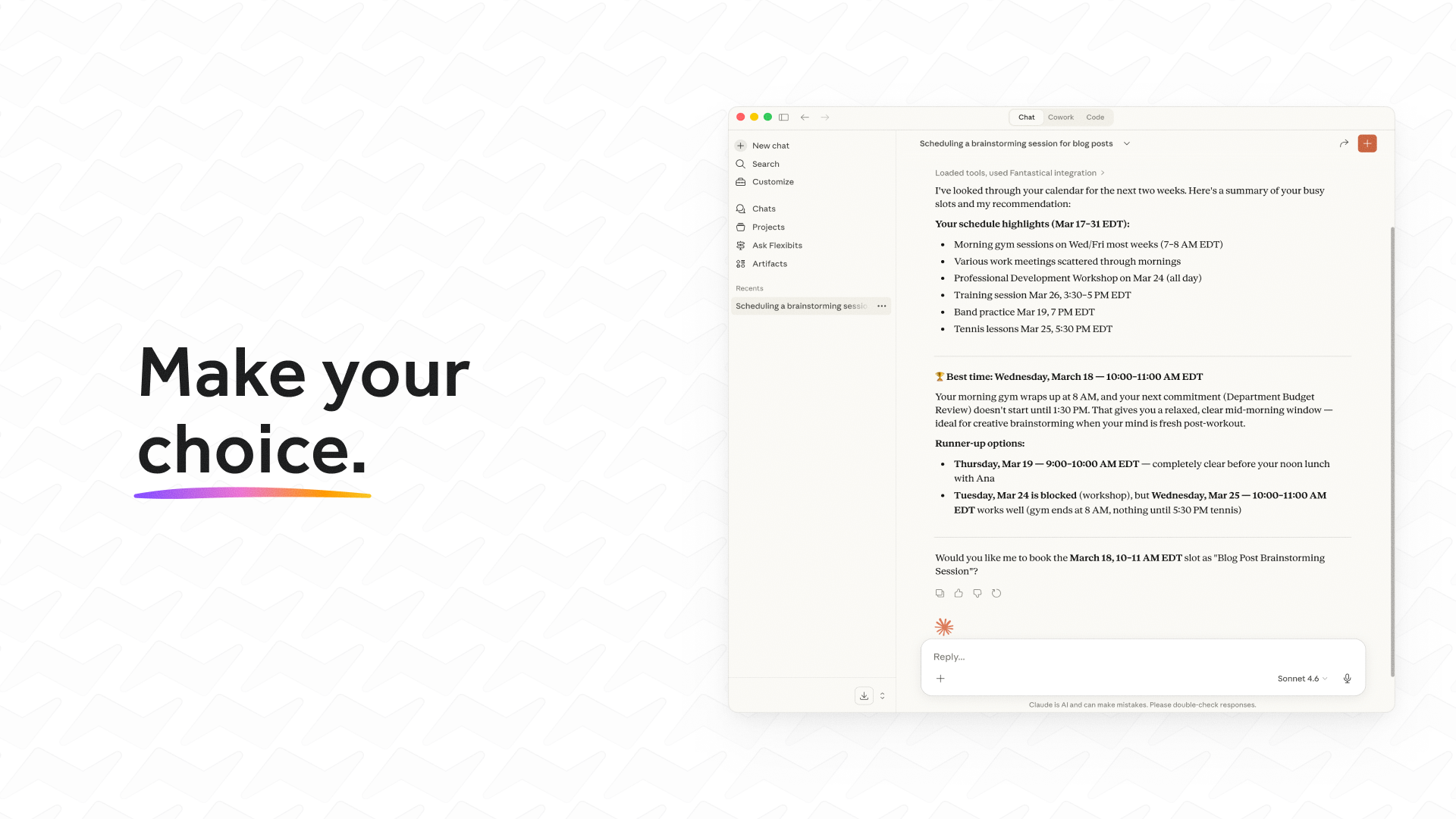

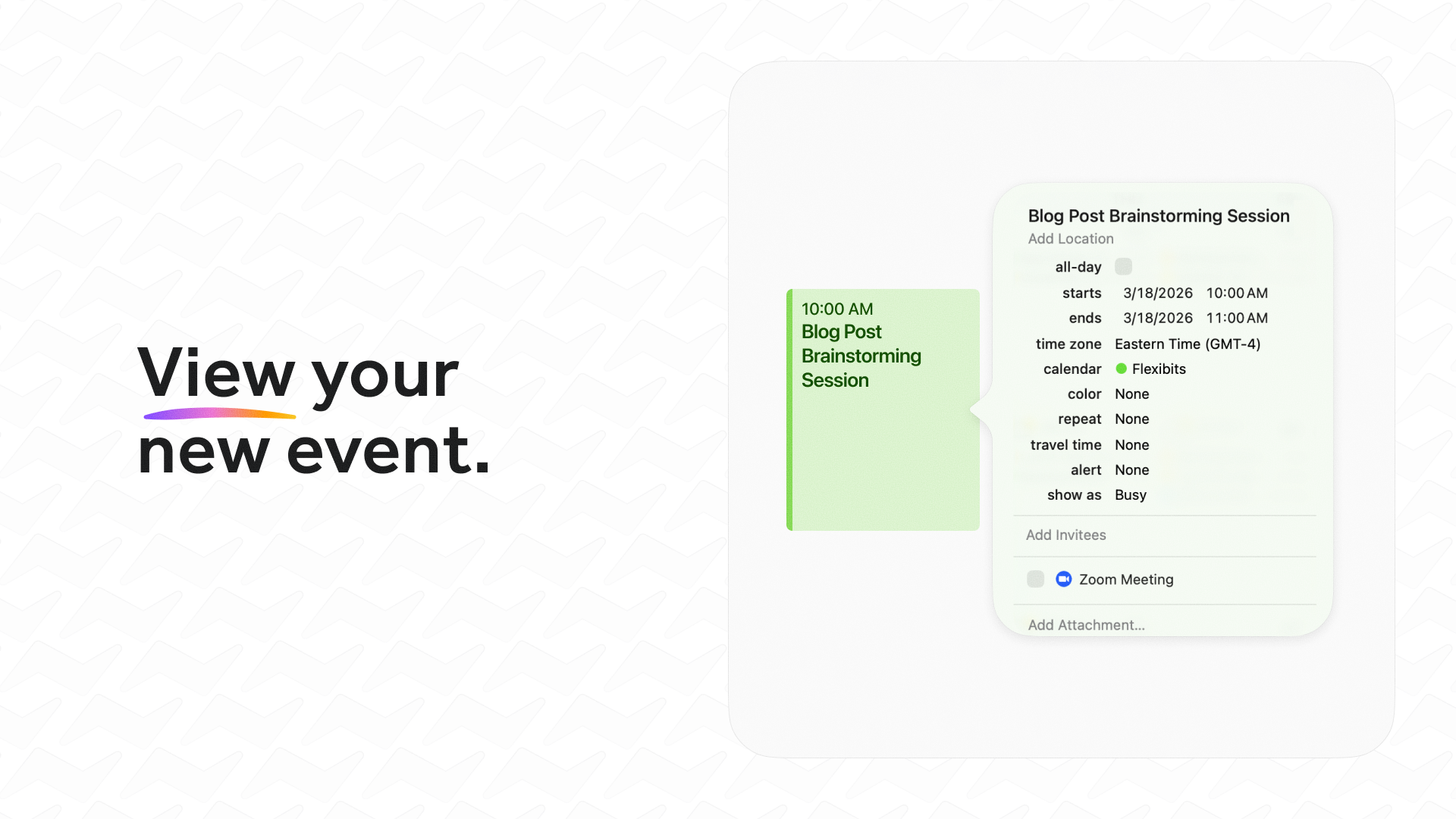




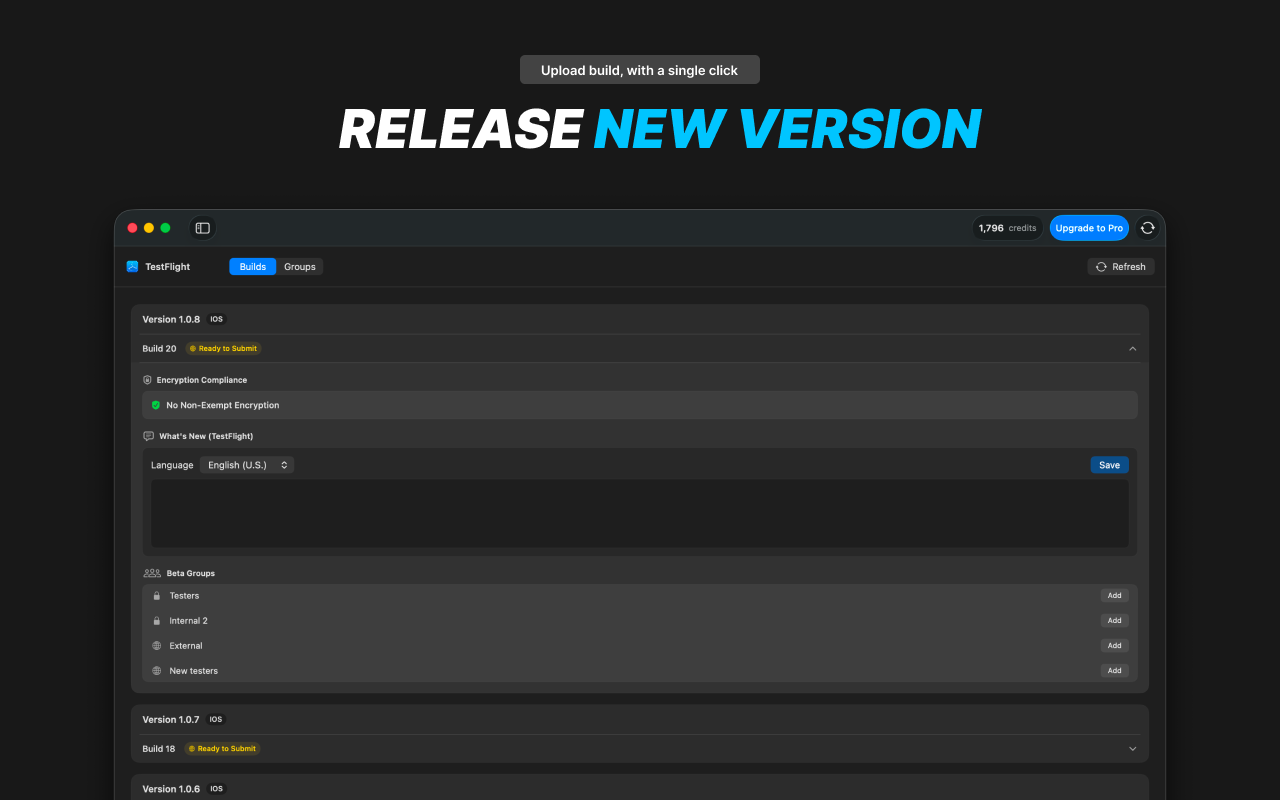
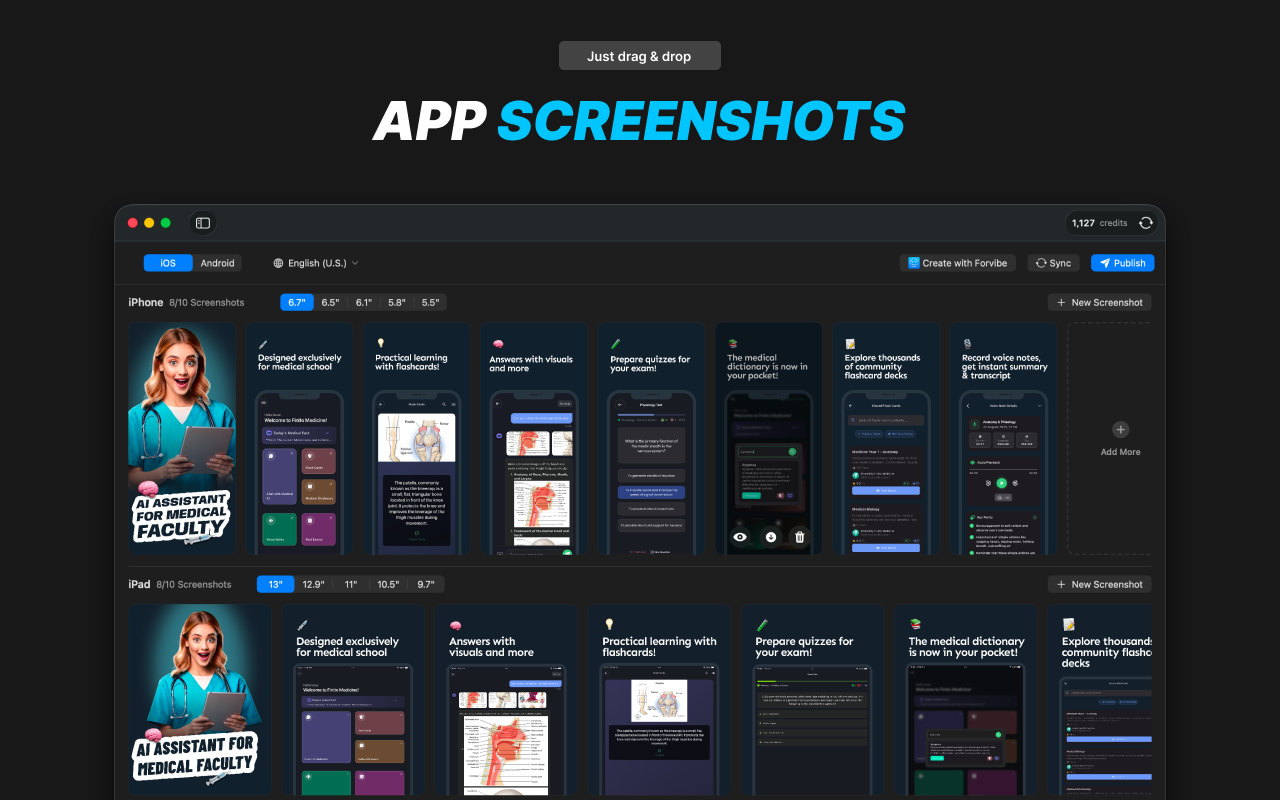
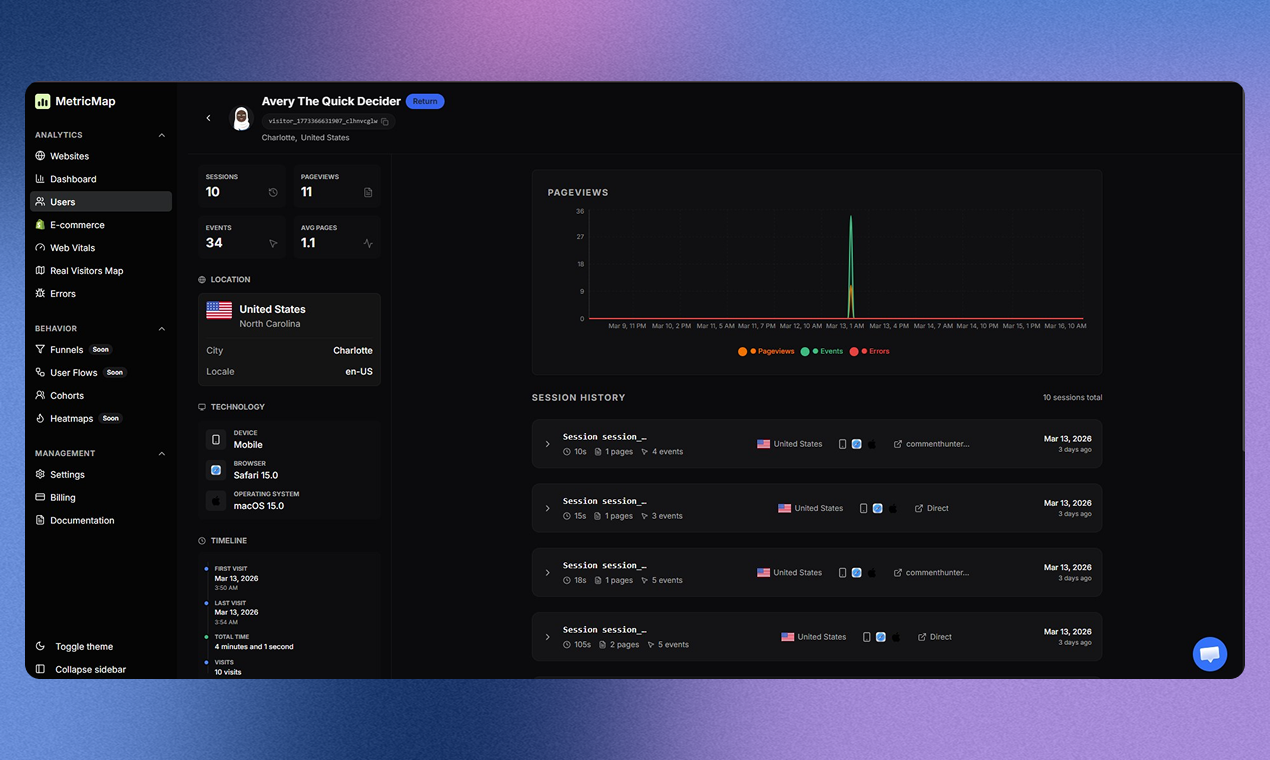
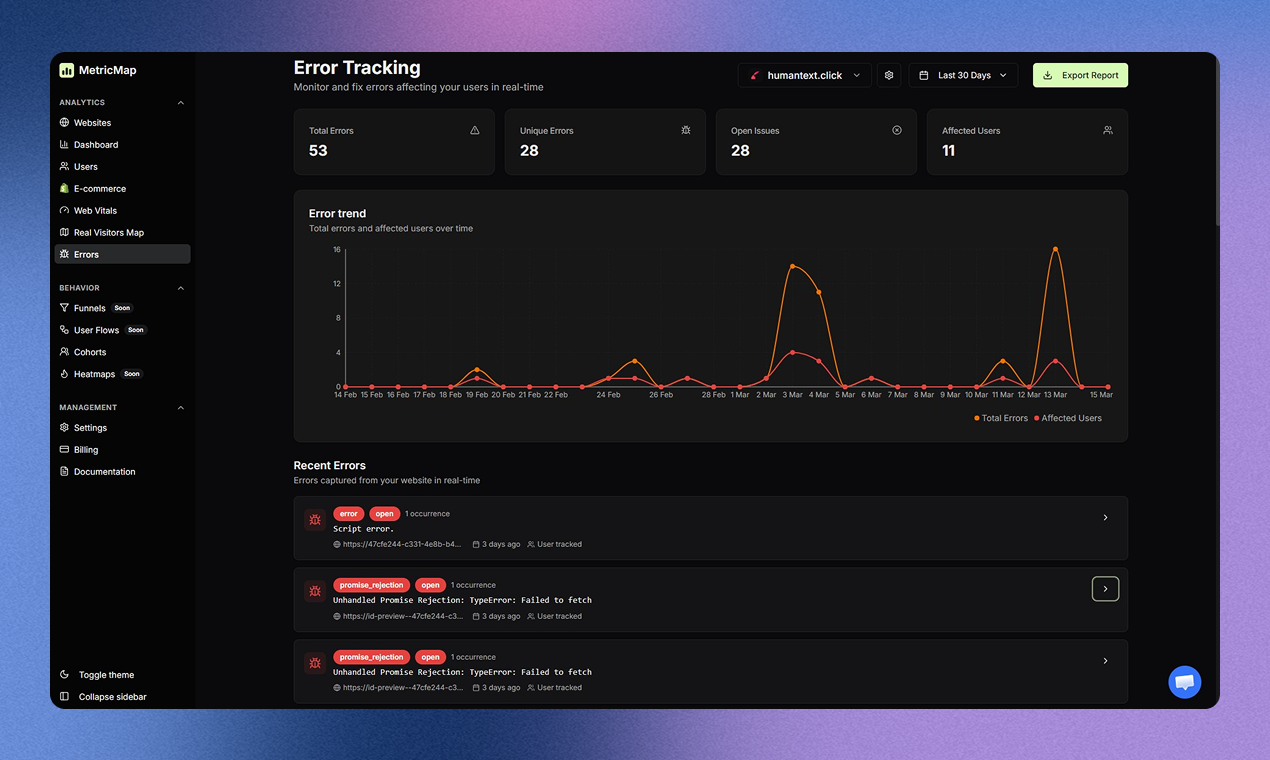
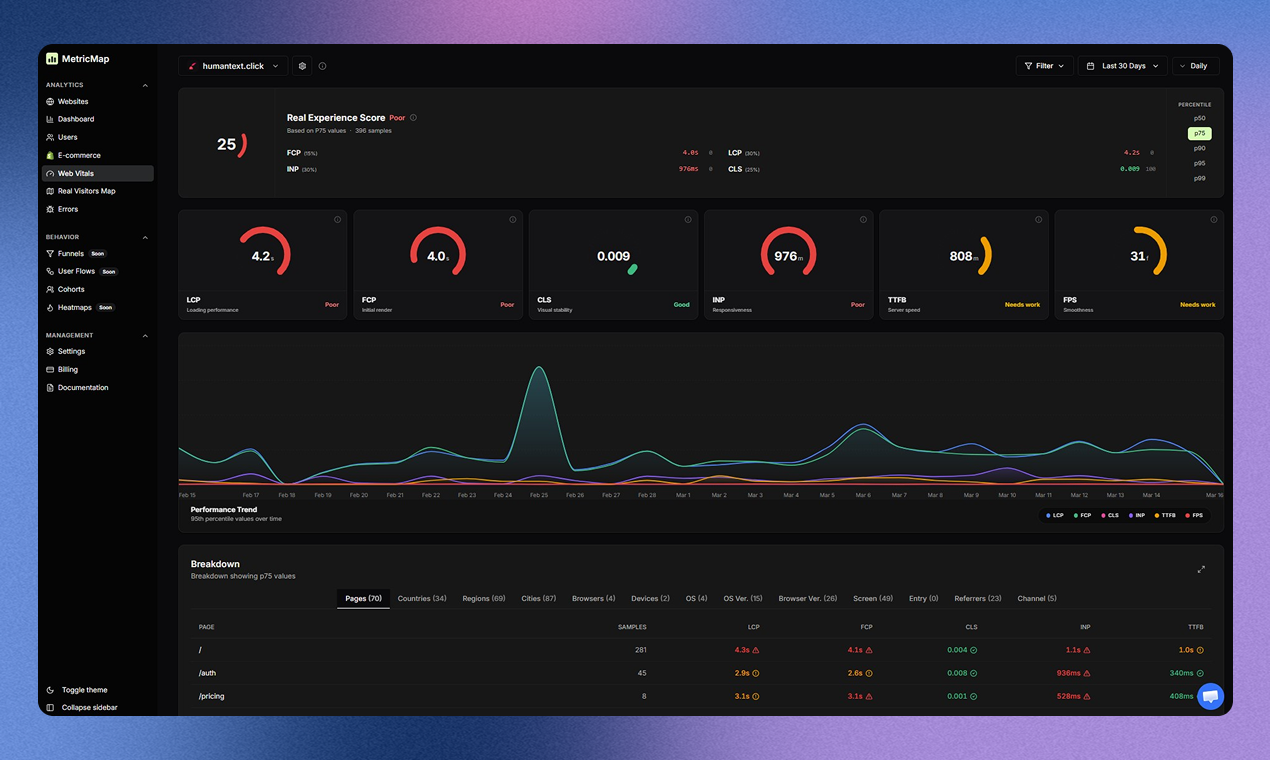




AI tools stop working when you leave your desk. Dispatch doesn't.
It's a feature inside Claude Cowork. Assign tasks from your phone. Claude executes on your desktop. Come back to finished work.
What it does:
📱 Message Claude from your phone
🖥 Claude accesses your files, browser, local tools
🔒 Sandboxed. Local. You approve before it acts
📋 Returns reports, tasks, actual output
Use cases:
Reports from internal dashboards
Finding better flights
Anything Claude can do on your desktop, from anywhere
Good to know:
Desktop must be on. Max subscribers now. Pro in days. Research preview, more coming soon.
Try it. What's the first task you'd dispatch?
I hunt the latest and greatest launches in tech, SaaS and AI, follow to be notified → @rohanrecommends
This is a much-needed development. I appreciate OpenClaw's impact on the industry, particularly its most impressive feature: remote control. Now, features like Claude Code's remote control and Claude Dispatch are bringing this same remote capability to autonomous systems.
I believe the logical next step will be integrating these tools into messaging applications like Slack, Microsoft Teams, and WhatsApp. We can already see this potential today, as collaborating with Devin on coding tasks directly within Slack is extremely convenient and time-saving.
Love the ‘desktop as an engine’ approach. There’s always that 10-minute gap between leaving the office and getting home where a random task pops into my head :)
Just love anything anthropic/claude related. Claude itself has done so much more then chatgpt ever could.
Is this similar to the /remote-control feature inside claude code?
this is a cool idea honestly. being able to kick off something from your phone and have it run on your desktop makes a lot of sense, specially for those random moments when you’re away but still wanna get something done.
curious, what are people using it for first mostly, quick research tasks or proper work stuff like reports?
Congrats on launching! Texting Claude a task while you're out and coming back to finished work is exactly how AI should fit into out days. Does it maintain context across multiple dispatches or does each message start fresh?
This has been something I've been waiting for! For those quick tasks you want to schedule on the go..
love it. congrats guys.
This is like remote controller for AI
Amazing ! A Claude Cowork for Linux coming soon ?