PH热榜 | 2026-03-22
一句话介绍:一款为Claude Code设计的会话存储与审查工具,通过自动记录、可视化展示和便捷分享,解决了AI编码助手操作不透明、难以调试和协作的痛点。
Developer Tools
Artificial Intelligence
Data Visualization
AI开发工具
会话记录
调试分析
团队协作
代码审计
可观测性
提示工程
Claude生态
开发者工具
工作流优化
用户评论摘要:用户普遍认可产品解决了AI代理操作“黑箱”的核心痛点,赞赏其详细的步骤追踪和分享功能。主要关注点集中在:追踪深度与粒度、数据安全性、未来是否会增加分析洞察(如模式识别、失败点分析),以及产品将更侧重于调试还是协作方向。
AI 锐评
Bench for Claude Code 切入了一个精准且正在形成的需求缝隙:AI编码代理的“可观测性”。其价值不在于创造了新数据,而在于将Claude Code运行时已有的、但散乱或不易解读的日志信息,进行了结构化、可视化和情境化重组。
产品聪明地避开了与底层AI模型能力的直接竞争,转而扮演“副驾驶的仪表盘”角色。它解决的并非代码生成的好坏问题,而是“理解AI为何如此生成”的认知负荷问题。这对于从个人调试到团队协作的整个工作流至关重要,尤其是在AI代理执行复杂、多步骤任务时,其“审计追踪”功能能将模糊的“它出错了”转化为具体的“它在第X步,基于Y上下文,执行了Z错误操作”。
从评论反馈看,其真正的挑战与机遇并存。短期看,它是一款优秀的调试辅助工具。但长期价值取决于它能否从“日志记录仪”进化为“洞察分析平台”。用户期待的“模式识别”、“常见失败点分析”暗示了更深层需求:不仅要知道“发生了什么”,更希望获得“如何优化提示”和“如何预防错误”的智能建议。此外,数据安全与敏感代码处理是其规模化,特别是进军企业市场必须筑牢的基石。
当前版本是解决“可见性”的优雅方案,但未来天花板在于能否提供“可行动性”的洞察。它抓住了AI原生工作流中“理解与信任”这一关键环节,若能在智能分析和安全合规上持续深化,有望成为AI辅助开发栈中的基础设施层。
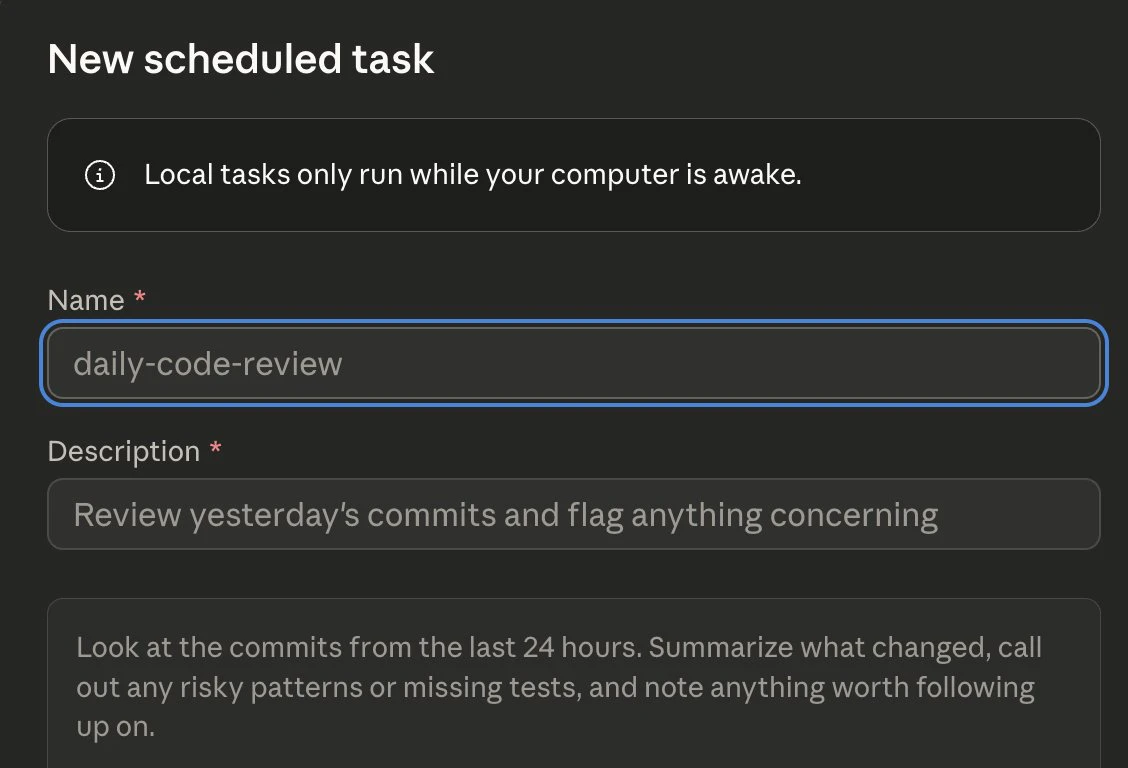
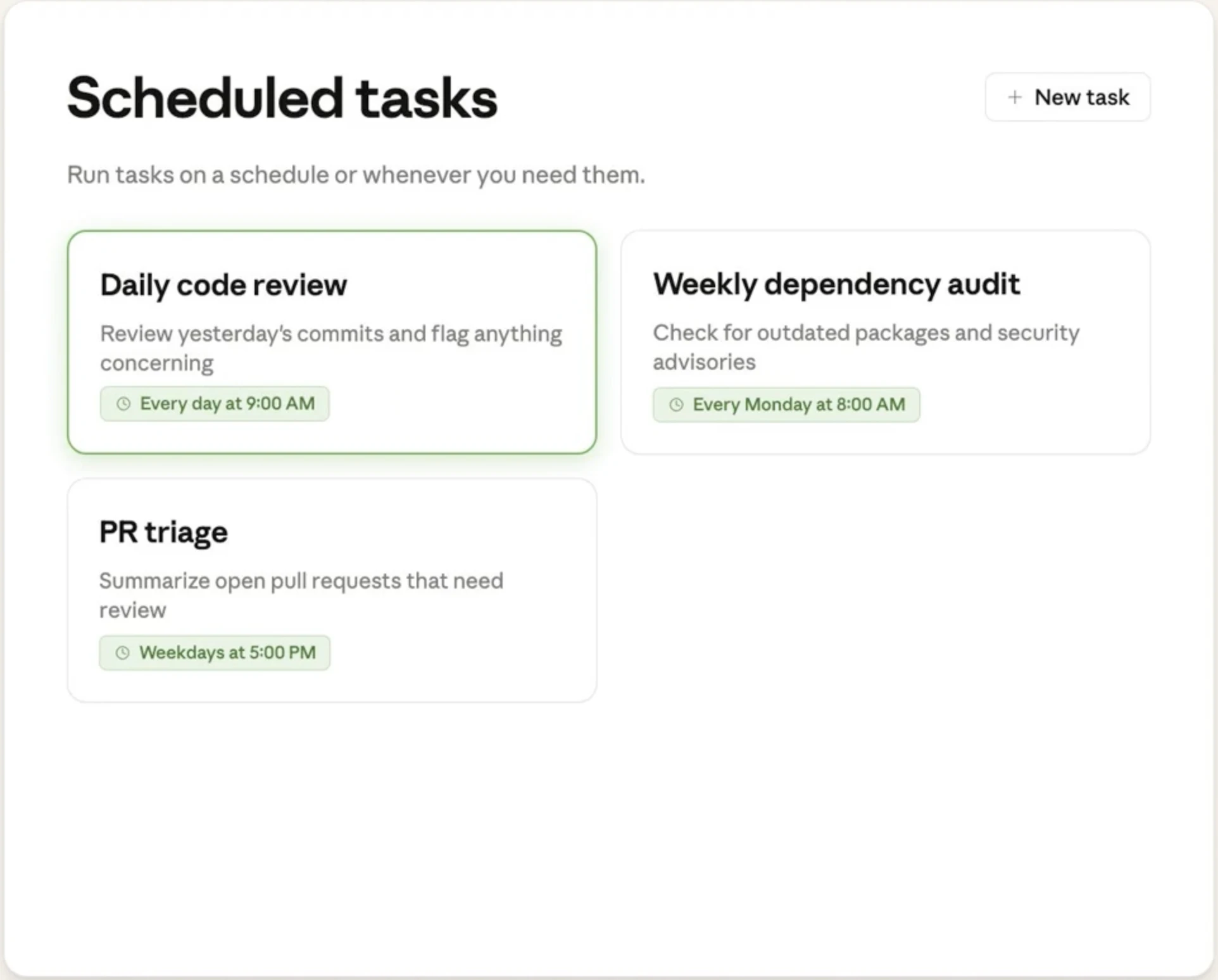
一句话介绍:一款能在本地和云端轻松调度、自动执行重复性编程任务的AI代理工具,解决了开发者手动或通过复杂脚本(如cron)维护自动化工作流的痛点。
Productivity
Task Management
Artificial Intelligence
AI编程代理
任务自动化
定时任务
本地与云端执行
开发者工具
工作流自动化
智能调度
持续集成
代码运维
无服务器架构
用户评论摘要:用户普遍认可其将AI助手升级为“自主代理”的价值,赞赏本地/云端混合执行的灵活性。主要疑问集中在:长周期任务如何避免提示漂移、任务堆叠后的可视化管理、与现有AI协作功能的区别、云端身份验证机制,以及失败通知支持。
AI 锐评
Claude Code Scheduled Tasks 表面上是一个增强版的“AI cron”,但其深层价值在于对AI代理范式的务实推进。它没有追逐炫酷的多智能体叙事,而是精准切入一个脏活累活场景:将一次性的、交互式的AI编码对话,固化为可信任的、可计划的异步服务。这才是“智能体”落地的关键一步——从“随叫随到的顾问”转变为“按时交付的雇员”。
产品的核心优势并非技术颠覆,而是体验整合。它统一了本地与云端的调度语法和环境,降低了从测试到部署的摩擦成本。然而,评论中暴露的疑问恰恰指向了其成为关键任务系统必须跨越的鸿沟:长期运行的稳定性(提示漂移)、任务编排与监控能力、以及与企业身份系统的集成。目前它更像一个“智能自动化触发器”,离真正的“AI workforce”管理体系尚有距离。
其真正的挑战在于,随着任务复杂度和数量的增长,管理这些“黑盒”AI任务的认知负荷可能不降反升。产品未来的分水岭在于能否提供任务执行的可解释性、依赖关系管理以及基于结果的自我优化。如果止步于便捷调度,它终将只是一个特色功能;若能围绕“可信自动化”构建起观测、诊断、自愈的完整闭环,它才有机会成为AI时代的新型基础设施层。
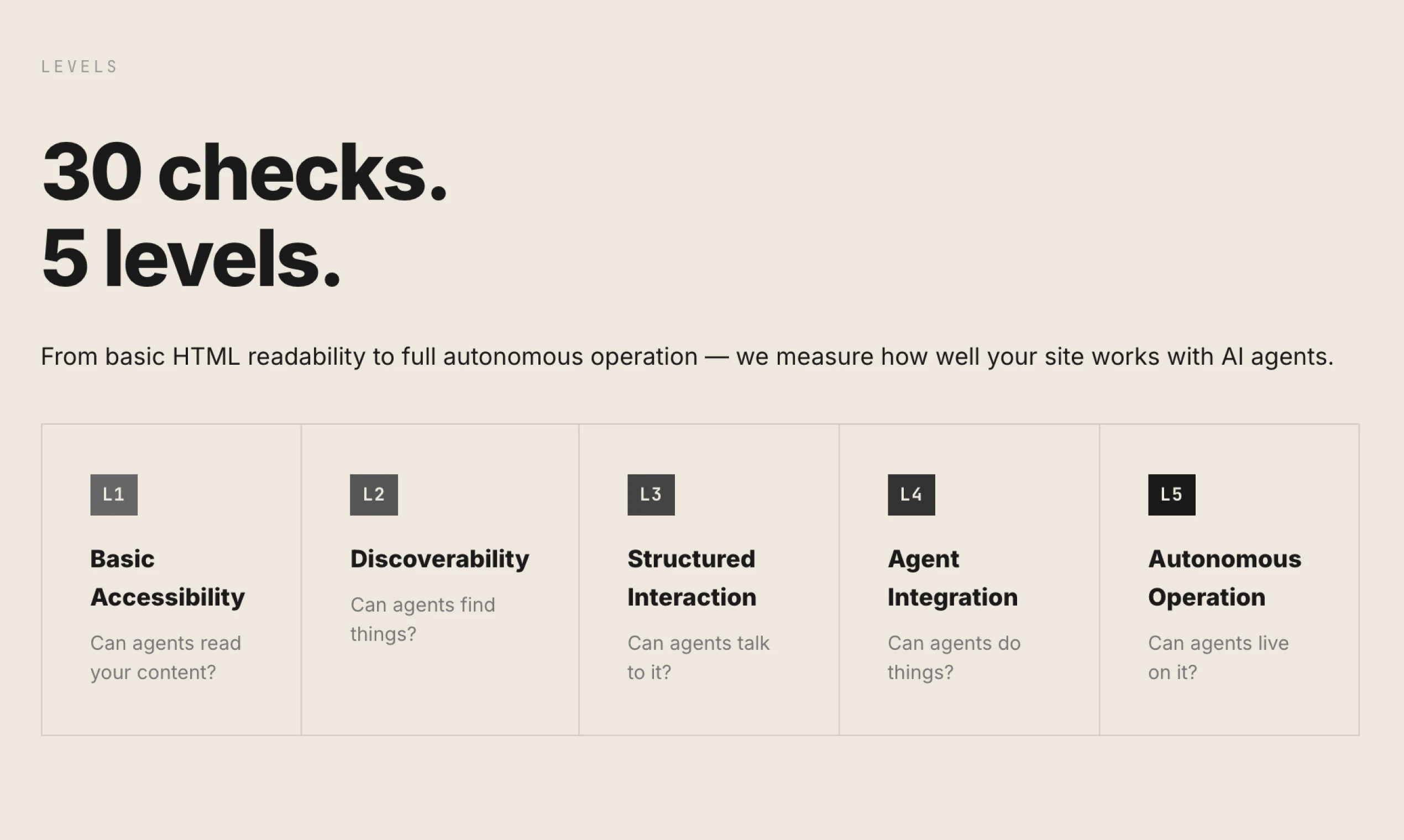
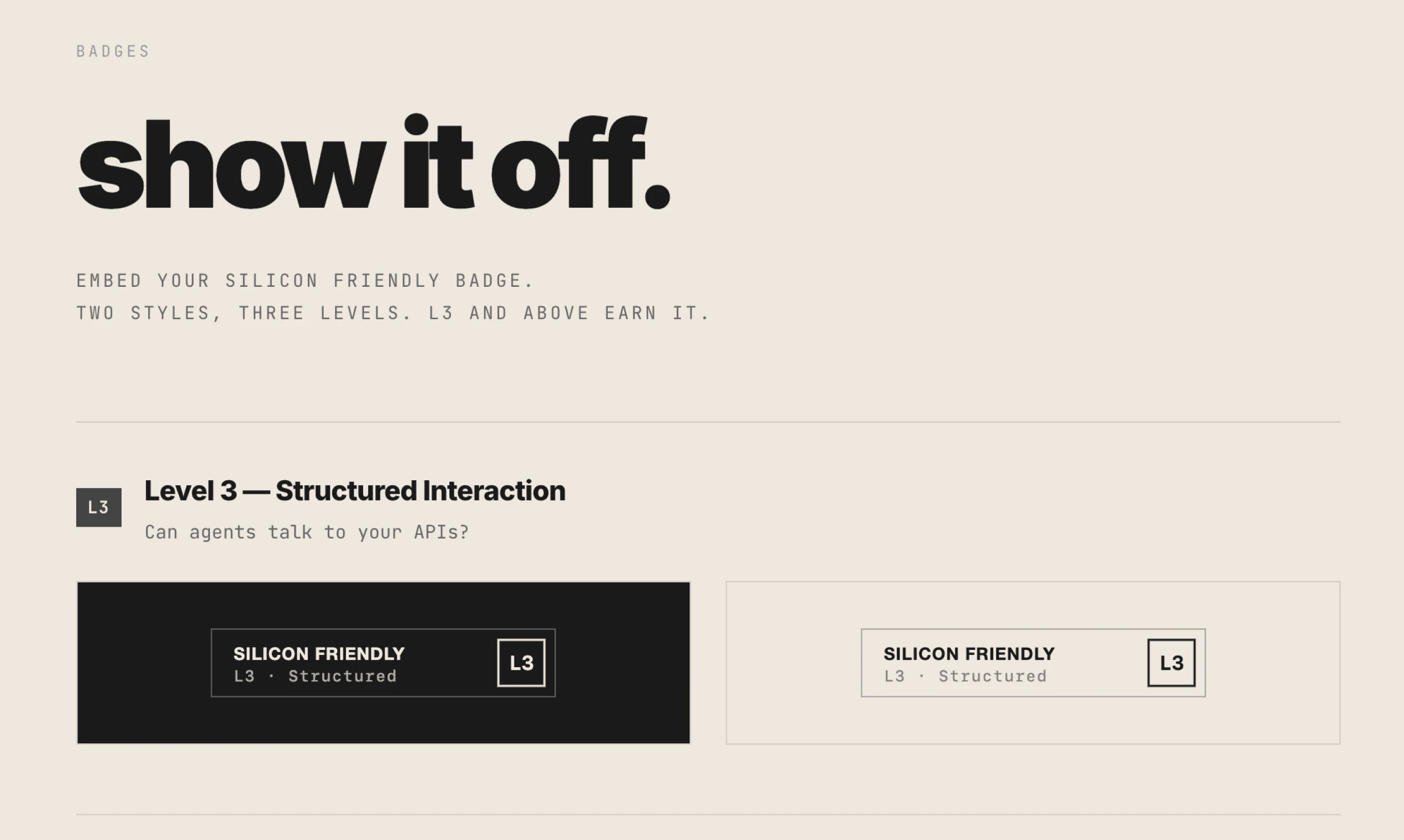
一句话介绍:Silicon Friendly 是一款评估网站对AI代理(如大语言模型)友好程度的工具,通过L0-L5开放标准评级并生成详细报告,帮助网站在AI代理日益频繁浏览网络的时代确保被发现和正确交互,解决网站因对“硅基访客”不友好而面临被忽视的痛点。
API
Developer Tools
Artificial Intelligence
GitHub
AI友好性评估
网站可代理访问性
LLM优化
搜索引擎新标准
开发者工具
SEO扩展
数字可访问性
代理优先设计
技术标准
网络基础设施
用户评论摘要:用户认可产品概念与框架,认为其指明了网络适应AI代理的必然趋势。主要反馈包括:建议展示各级别真实案例使标准更具体;询问快速提升评级的具体清单;关注硅基友好与人类用户体验的平衡;报告实用性强,但部分功能(如llms.txt)实际效果待验证;赞赏无需注册即可试用。
AI 锐评
Silicon Friendly 敏锐地捕捉到了一个即将爆发的需求拐点:当AI代理从“偶尔的爬虫”转变为“主动的用户”时,网络基础设施的适配不再是可选项,而是生存必需。其真正的价值不在于又一个评分工具,而在于试图建立一套早期的事实标准(L0-L5),将模糊的“AI可读性”转化为可执行、可衡量的技术清单。
产品的高明之处在于“框架转换”。它不再纠缠于“AI能否突破人类验证码”的攻防战,而是将责任重新分配给网站所有者:你的数字领地是否欢迎硅基访客?这步棋将对抗性叙事转化为建设性叙事,为网站提供了明确的行动路径。从评论看,其生成的详细报告和优先级建议确实击中了开发者的痛点——从不知从何下手,到拥有清晰的路线图。
然而,其深层挑战与机遇并存。挑战在于,当前“硅基友好”的核心手段(如llms.txt、结构化数据、专用API)仍处于早期探索阶段,其有效性和广泛采纳度有待验证,可能沦为一种“合规性标签”而非真正提升代理交互体验的钥匙。更大的机遇在于,如果其标准被广泛接受,它可能成为下一代“搜索引擎优化”的核心——从为算法优化,到为代理优化。这不仅仅是技术调整,更是产品逻辑的重构:网站需要思考何为“代理端”,以及人类与代理在用户体验中的权责边界。
产品目前成功引发了关键讨论,但能否从先锋工具演变为基础设施,取决于其标准能否凝聚生态共识,以及其建议能否带来可量化的代理交互成功率提升。它卖的不是报告,而是通往未来网络的船票。
一句话介绍:Context.dev 提供了一个统一的API,使开发者和AI应用能实时获取结构化网页数据,省去了自行搭建和维护脆弱爬虫基础设施的麻烦,解决了多源数据抓取与整合的效率痛点。
API
Artificial Intelligence
Data
网页数据API
网络爬虫
数据抓取
数据增强
品牌信息提取
AI智能体
开发者工具
实时数据
结构化数据
网络上下文层
用户评论摘要:用户普遍认可其整合多种抓取与增强工具的价值,认为能节省大量开发时间。主要问题集中于技术细节:如何处理Cloudflare等反爬机制、动态JS渲染站点等边缘情况;产品从“品牌数据”到“网络上下文层”的演进具体含义;以及数据获取后如何更好地集成到实际工作流中。
AI 锐评
Context.dev 的野心远不止于做一个“更好的爬虫API”。其从Brand.dev的更名,标志着战略重心从垂直的“品牌数据提取”转向了横向的“网络上下文层”。这一定位试图抢占的是AI时代一个关键的基础设施节点:为AI智能体和应用程序提供实时、结构化、可理解的网络信息输入。
产品的真正价值在于“标准化”和“抽象化”。它声称将开发者从“拼接爬虫、增强工具和数据提供商”的琐碎工作中解放出来,这直指一个核心痛点:在AI应用开发中,获取并清洗网络数据的成本极高,且极不稳定。它提供的不是数据本身,而是一个可靠的、统一的数据获取接口,试图将网络的混乱无序封装成整洁的API响应。
然而,评论中的犀利提问也揭示了其面临的关键挑战与未来考验。首先,技术可靠性是生命线。用户对Cloudflare和动态JS站点的担忧,说明任何此类服务的承诺都必须经受住“对抗性网络环境”的检验,其“全Chrome环境与高质量代理”的方案是标配,但持续稳定性才是护城河。
其次,也是最深刻的质疑,在于对“理解”一词的定义。产品标语中的“scrape, enrich, and understand”呈递进关系。前两者是成熟的技术活,而“understand”则是一个模糊的认知层承诺。正如一条评论所指出的,大多数产品在“增强”与“理解”之间悄然失败。Context.dev目前通过提供Markdown、HTML、品牌元素等结构化数据来兑现“理解”,但这更多是数据形式的转换,而非语义层面的洞察。它能否从“提供干净的数据”演进到“提供可行动的洞察”,将决定其天花板是工具还是平台。
最后,其成功将高度依赖于生态集成。开发者需要的不只是数据,而是如何将数据无缝融入AI智能体的决策循环、营销自动化的触达流程或商业分析模型。这要求Context.dev不仅提供SDK,更需要在工作流集成和用例模板上深耕,真正降低从“数据获取”到“业务价值”的最后一公里认知负荷。总体而言,这是一个在正确赛道上的有力选手,但其宣称的“理解”维度,仍需用更高级的抽象和更深入的集成来证明。
一句话介绍:一款通过智能压缩API请求中的冗余信息,为Claude Code用户突破官方使用限制、延长会话长度并降低成本的中间件工具。
Software Engineering
Developer Tools
AI工具优化
提示词压缩
成本控制
开发者工具
Claude生态
API中间件
效率工具
会话管理
用户评论摘要:用户肯定其解决使用限制和降低成本的核心价值,关注压缩是否影响输出质量及业务模式。建议增加压缩过程可视化以建立信任,团队回应称不存储数据并提供企业级服务。
AI 锐评
Edgee Claude Code Compression 精准切入了一个日益尖锐的痛点:主流AI服务商通过用量限制和API计费构建的增长天花板。其价值不在于技术创新,而在于生态位洞察——在用户与AI巨头的“计划墙”之间,充当了一个精明的“缓冲区”。
产品逻辑清晰且讨巧:作为中间层,它通过去重、精简提示词来“瘦身”请求,本质上是在信息无损压缩与模型理解保真度之间走钢丝。这带来了最核心的质疑:压缩是否会 silently remove 关键上下文,导致模型在后续步骤中“误入歧途”?开发团队虽承诺提供调试视图,但此风险是此类工具的原罪,信任建立将高度依赖于其算法的透明度和实际案例的长期验证。
更值得玩味的是其商业模式与定位。它目前免费,将自身定义为对抗AI提供商定价的“盟友”。但长远看,其生存依赖于上游API的持续收费或限额策略。它可能演变为面向企业的、更复杂的AI工作流优化与成本管理平台,正如团队回帖所暗示。然而,作为中间人,它同时也增加了系统的复杂性和潜在故障点。
本质上,这是一款“效率税”工具。它不直接创造AI能力,而是优化AI能力的获取成本与体验。在AI应用日益普及、成本与用量矛盾凸显的当下,这类“优化层”工具的市场会持续存在,但其护城河深浅,完全取决于其压缩算法的有效性与可靠性,以及能否在用户信任与商业扩张间找到平衡。
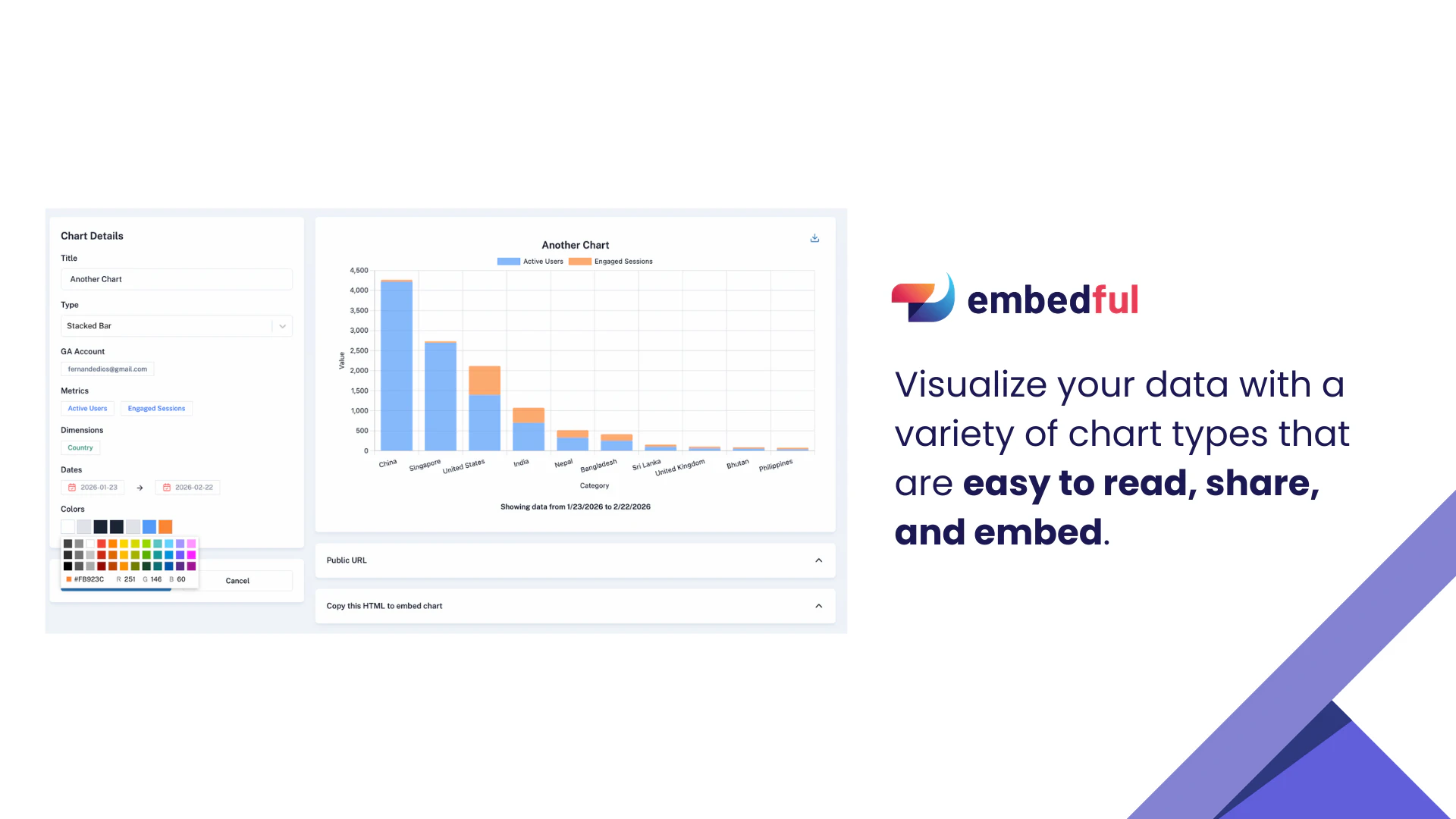
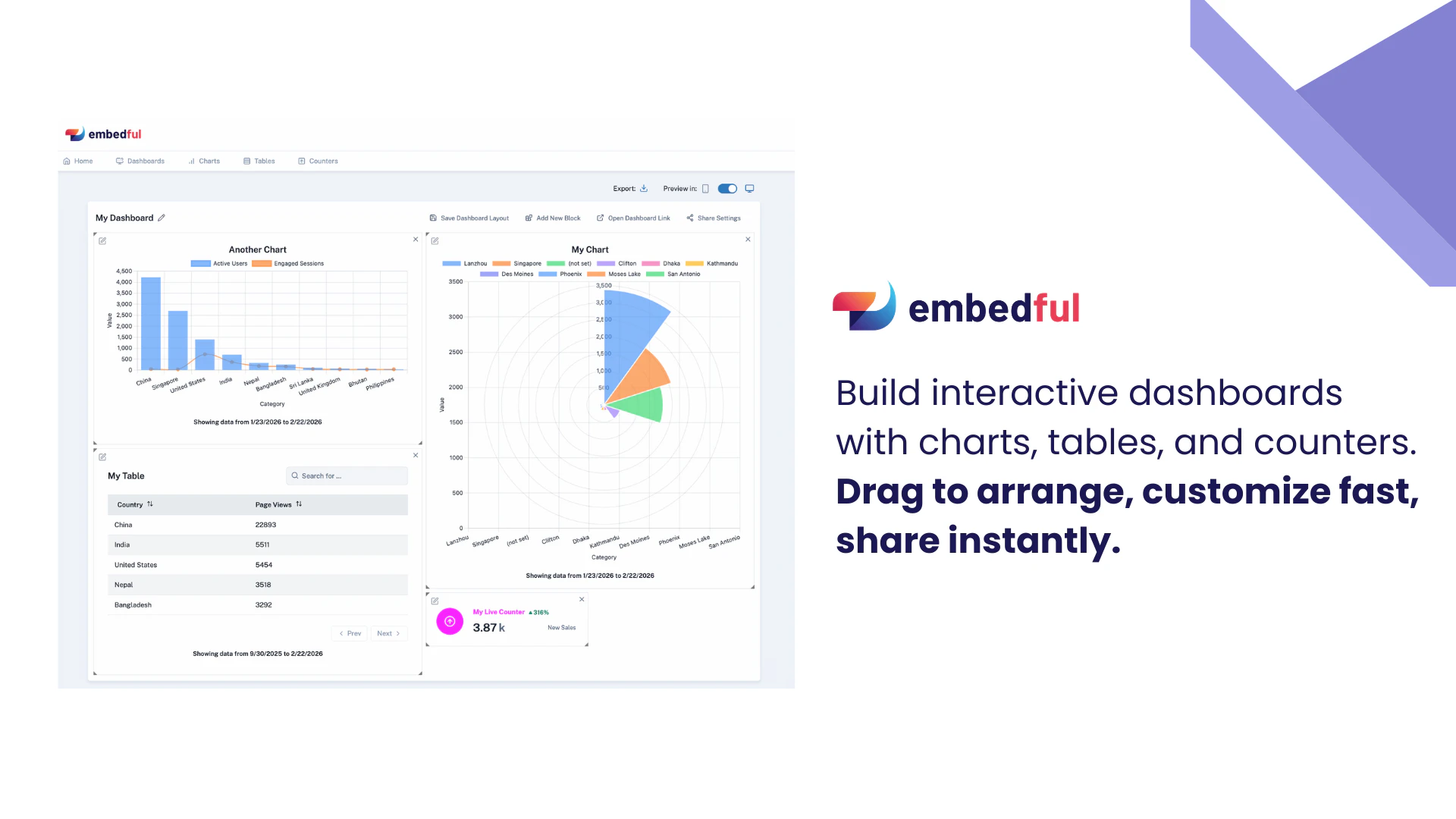
一句话介绍:Embedful 是一款让产品团队能快速创建、嵌入并分享交互式数据可视化的工具,它通过连接常见数据源和提供简易编辑器,解决了在用户端呈现分析数据时面临的技术门槛高、成本昂贵和工程复杂的痛点。
Analytics
Data & Analytics
Data Visualization
嵌入式分析
数据可视化
客户仪表盘
无代码工具
SaaS
交互图表
数据共享
品牌定制
谷歌表格集成
API数据源
用户评论摘要:用户肯定其“以终端用户体验为先”的定位。主要问题集中在:嵌入层的权限控制粒度不足(如用户级数据过滤)、对实时数据更新的支持程度、处理大数据集时的性能、单个嵌入件的密码保护功能,以及对更多数据源(如Firebase、Zapier)和跨源单一可视化的需求。
AI 锐评
Embedful 敏锐地切入了一个增长中的细分市场:客户导向型分析。其真正价值并非技术突破,而是精准的产品定位与取舍。它没有选择与Tableau、Power BI在专业分析领域硬碰硬,而是将“易于嵌入和分享”作为第一性原则,主动降低了能力上限以换取极低的采用门槛。这看似妥协,实则是抓住了大量非技术型产品经理的核心诉求——将数据分析作为一种“产品功能”而非“后台工具”快速交付给最终用户。
然而,这种定位也带来了清晰的局限性。从评论看,其“轻量级”设计正与用户预期的“生产级”需求产生首次碰撞。密码保护仅限仪表盘层级、缺乏用户级数据权限、数据规模受限,这些反馈暴露了其在从“演示友好”迈向“业务就绪”过程中的关键短板。数据安全与权限体系并非锦上添花,而是企业级应用的基石。创始人回复中“在路线图上”的措辞,表明团队已意识到这点,但解决这些问题的复杂度将远超构建可视化编辑器本身。
另一个潜在风险在于其“连接器”生态。当前重度依赖电子表格作为数据中介,虽降低了初期使用难度,但也可能将自身置于数据管道的中下游。当用户需求从“可视化展示”深化为“实时、自动化的数据产品”时,Embedful 需要更强大的原生数据接入与处理能力,否则极易被更完整的平台或内部自建方案所替代。
总之,Embedful 是一款出色的市场探针产品,它验证了客户嵌入式分析需求的广泛存在。但其长期成功,取决于团队能否在保持“简单”灵魂的同时,有节奏地构筑起满足企业级客户所需的深度、安全性与扩展性,完成从“好用的小工具”到“关键业务组件”的艰难跃迁。
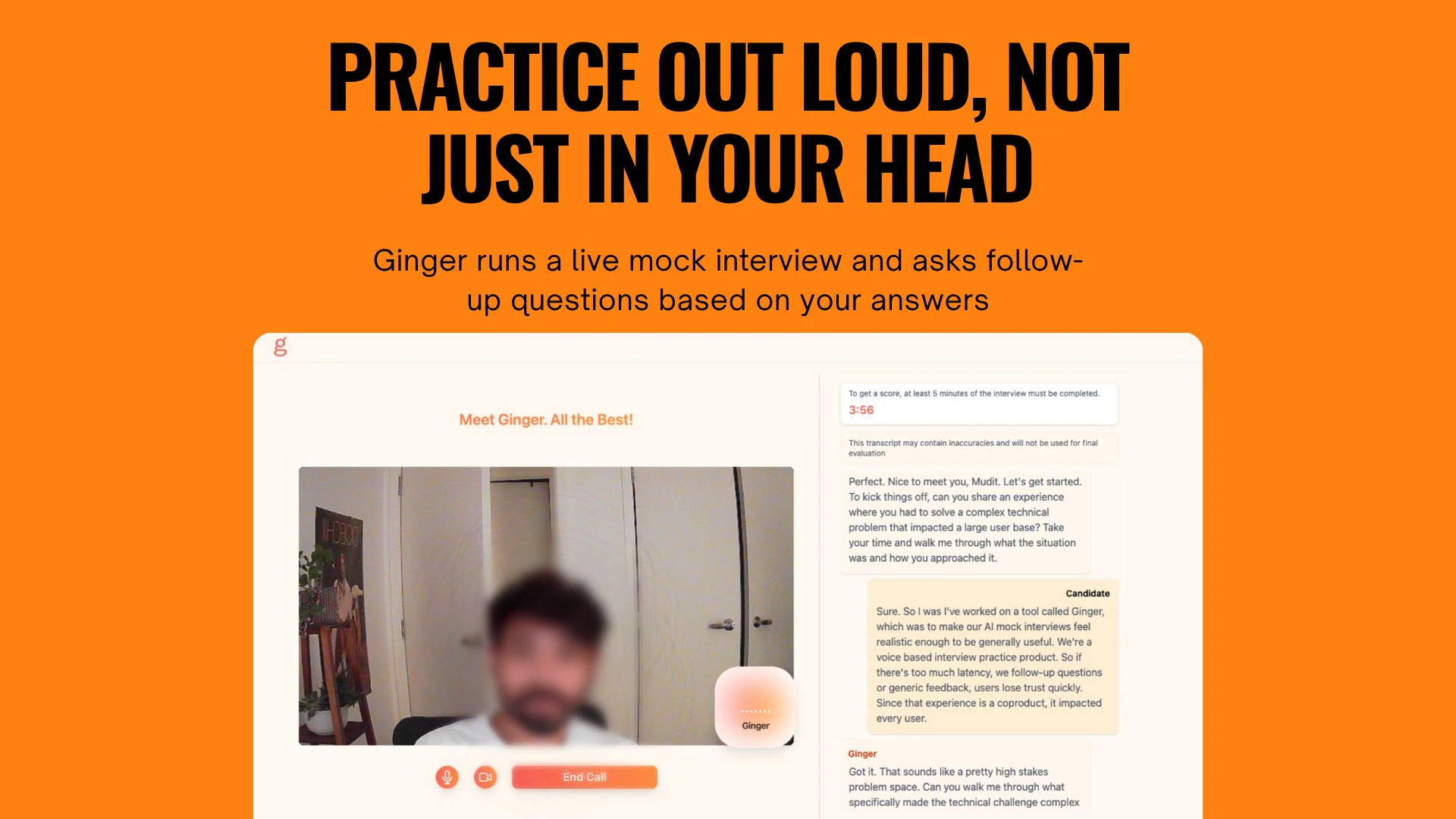
一句话介绍:Ginger是一款AI模拟面试应用,通过让求职者大声进行角色定制的模拟面试,提出动态追问,模拟真实面试压力并提供即时反馈,解决了求职者在传统面试准备中缺乏真实互动和有效反馈的核心痛点。
Hiring
Artificial Intelligence
Career
AI模拟面试
求职准备
技能提升
面试反馈
自适应追问
行为面试
口语练习
职业发展
人工智能辅导
个性化学习
用户评论摘要:用户普遍认可“大声练习”和“动态追问”的核心价值,认为这能暴露真实弱点。主要问题与建议集中在:追问的领域深度(如技术面试)、数据隐私安全、难度自适应机制的具体实现,以及向创始人路演等场景扩展的可能性。
AI 锐评
Ginger切入了一个拥挤但普遍肤浅的赛道。其宣称的价值并非源于AI本身,而在于对“面试准备”本质的犀利洞察——它挑战了将面试简化为题库背诵的行业现状。产品的真正锋芒在于“动态追问”和“大声回答”这两个反捷径设计。前者试图用算法模拟人类面试官的临场压力与深度探询,将准备重心从“记忆标准答案”扭转为“训练即时思考与结构化表达能力”;后者则粗暴地揭开了内在思考与外在表达之间的残酷落差,这正是多数求职者自我感觉良好却频频失败的隐秘症结。
然而,其面临的挑战同样尖锐。首先,技术层面,“自适应追问”的深度与逼真度是生命线。当前AI能否真正理解专业领域的回答逻辑并进行有意义的深度追问,而非停留在语义关联的层面,这存疑。用户关于技术面试和案例面试的追问即是对此的担忧。其次,商业模式与伦理的平衡。处理高度敏感的求职者音频与职业信息,仅承诺“存储60天”和“数据不共享”在当今环境下显得薄弱,需要构建更透明和坚固的数据治理框架。最后,其“反套路”的哲学既是卖点也可能是增长瓶颈。它服务于真正希望提升能力的“苦练者”,而非寻求速成的“投机者”,这或许会限制其用户基数,但也可能因此构建更高的用户忠诚度和壁垒。
本质上,Ginger的价值不在于又是一个“AI教师”,而在于试图成为一个“AI压力测试器”。它的成功与否,将验证在求职培训领域,“提升真实能力”的产品能否战胜“提供应试技巧”的产品,这比其技术实现更值得关注。
一句话介绍:一款面向科技和设计机构的AI驱动项目管理工具,通过为每个客户提供独立工作区,集中管理需求、反馈、审批和支付,解决了多客户项目管理中沟通分散、需求蔓延和进度不透明的核心痛点。
Productivity
Task Management
SaaS
AI项目管理
SaaS
科技机构
设计工作室
客户协作
范围蔓延预警
工作区
产品管理
B端工具
用户评论摘要:用户认可其解决的真实痛点,并关注集成能力(如Slack、Figma)、客户采用阻力、具体功能细节(如反馈收集、审批流程)以及如何吸引低频客户持续参与平台。
AI 锐评
ClearWork瞄准了一个精准且棘手的缝隙市场:中小型科技与设计机构。其宣称的“AI驱动”在现有信息中略显单薄,核心价值实则在于“强制归一化”的产品设计哲学——通过“一个客户一个工作区”的刚性结构,对抗根深蒂固的、以WhatsApp和邮件为主导的碎片化协作习惯。这与其说是一个技术胜利,不如说是一次组织行为学的干预。
产品真正的挑战与价值,在评论中被一针见血地指出:不在于功能本身,而在于如何改变客户行为。创始人承认初期仍需手动迁移信息,这暴露了从非结构化沟通(即时通讯)向结构化平台迁移的“最后一公里”悖论。工具能提供秩序,但秩序的前提是所有人自愿进入“围栏”。ClearWork的成败关键,在于其“客户价值主张”是否足够强大,能说服客户放弃随性的WhatsApp,转而登录一个更具约束性的平台进行反馈与审批。其“范围蔓延预警”功能是潜在的杀手锏,因为它将模糊的沟通成本转化为可视化的项目风险,直接触动了机构利润的核心神经。
然而,其定位也隐含风险:在“轻量级Trello”与“重量级Jira”之间寻找平衡点,意味着要在灵活性与管控力之间走钢丝。过度结构化会吓跑追求速度的小团队,而过于灵活则无法解决其承诺的“混乱”问题。目前的路线图显示其正通过集成(GitHub, Figma等)试图融入现有工作流,这是明智的生存策略,但如何让集成点成为吸引客户进入其主平台的入口,而非让用户继续停留在原有工具中,将是下一个考验。它不是一个颠覆者,而是一个试图在混乱生态中建立秩序的“整合者”,其成功高度依赖于能否在机构内部自上而下地推行,并让终端客户感受到“被清晰管理”带来的安心感,而非不便。
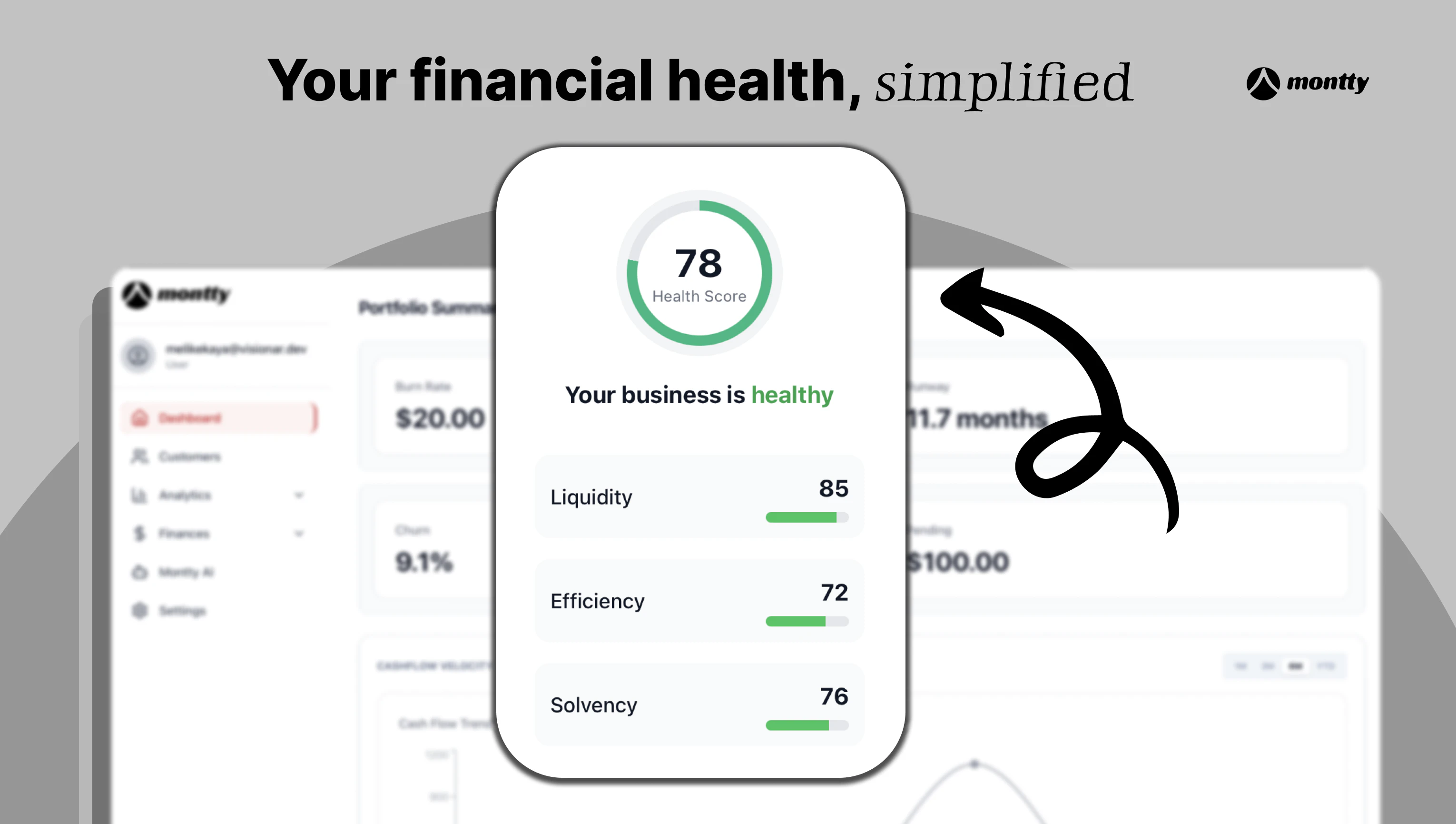
一句话介绍:一款集成AI助手的综合性财务平台,旨在帮助小型企业主和非财务专业人士,通过自然语言对话和自动化数据整合,快速获得定制化的财务洞察与预测,解决手动记账低效和财务决策门槛高的痛点。
Fintech
Artificial Intelligence
Finance
中小企业财务
AI财务助手
自动化记账
财务决策平台
自然语言交互
数据洞察
业财一体化
SaaS
金融科技
CFO工具
用户评论摘要:用户肯定其品牌设计和AI对话的易用性,核心建议集中在银行/Plaid集成、与QuickBooks/Xero等巨头的差异化竞争、以及AI功能的深度(如异常主动预警、预测置信区间、上下文记忆和动态模型构建)。另有反馈指出其核心价值功能(如AI CFO对话)在宣传中展示不足。
AI 锐评
Montty Finance 精准切入了一个广阔而真实的缝隙市场:为财务知识有限、依赖手工劳作的小企业主提供“CFO级”决策支持。其“三位一体”(整体、以人为本、个性化)的理念颇具吸引力,尤其是将自然语言作为交互核心,试图将财务从一门晦涩的专业语言转变为平实的对话,这直击了目标用户的心理和技能壁垒。
然而,Product Hunt社区的反馈犹如一盆清醒的冷水,揭示了其从“有趣demo”迈向“可靠工具”的艰难爬坡。首先,**数据生态是命门**。缺乏与银行、支付工具的深度原生集成,意味着仍无法完全解放用户于手工录入,这与“减轻财务工作量”的核心承诺相悖。团队对Plaid的考虑是正确但基础的第一步。其次,**AI深度的质疑**是本质挑战。评论尖锐地指出了“反应式”与“预见式”智能的区别、预测的“虚假精确”风险、以及AI模型是基于通用模板还是动态构建——这些问题决定了产品提供的是“玩具级安慰”还是“军规级洞察”。官方回复承认部分功能(如置信区间)尚属空白,这暴露了其AI成熟度与营销口号之间的差距。
最后,**竞争定位略显天真**。在已有QuickBooks、Xero等巨头且它们均已注入AI功能的红海市场中,Montty的“一体化”和“对话式”优势能保持多久的窗口期?评论建议的“集成现有工具”或许比“全面替代”更为务实。总体而言,Montty构想了一个迷人的未来,但其真正的考验在于:能否将“人性化”的交互前端,与“专业化”的财务逻辑后端深度融合,并构建起足够深的数据护城河。否则,它可能只是一个体验更友好的财务仪表盘,而非革命性的决策引擎。
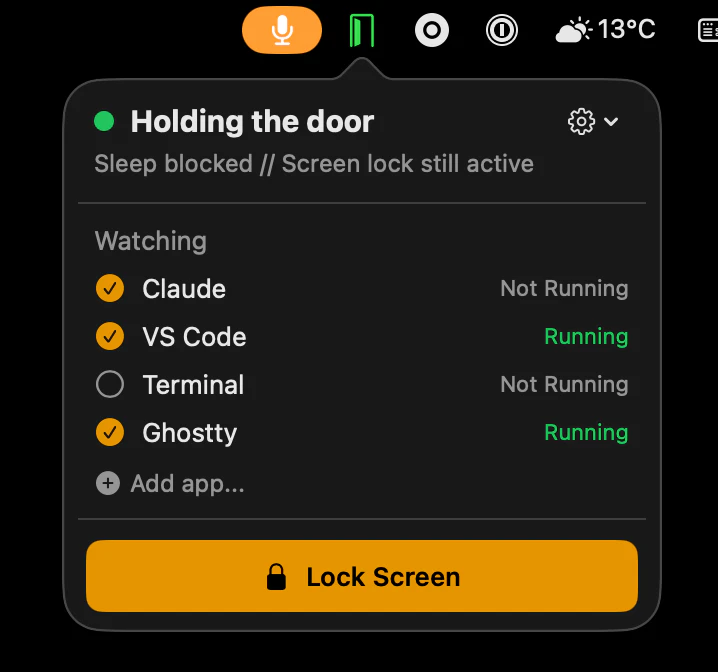
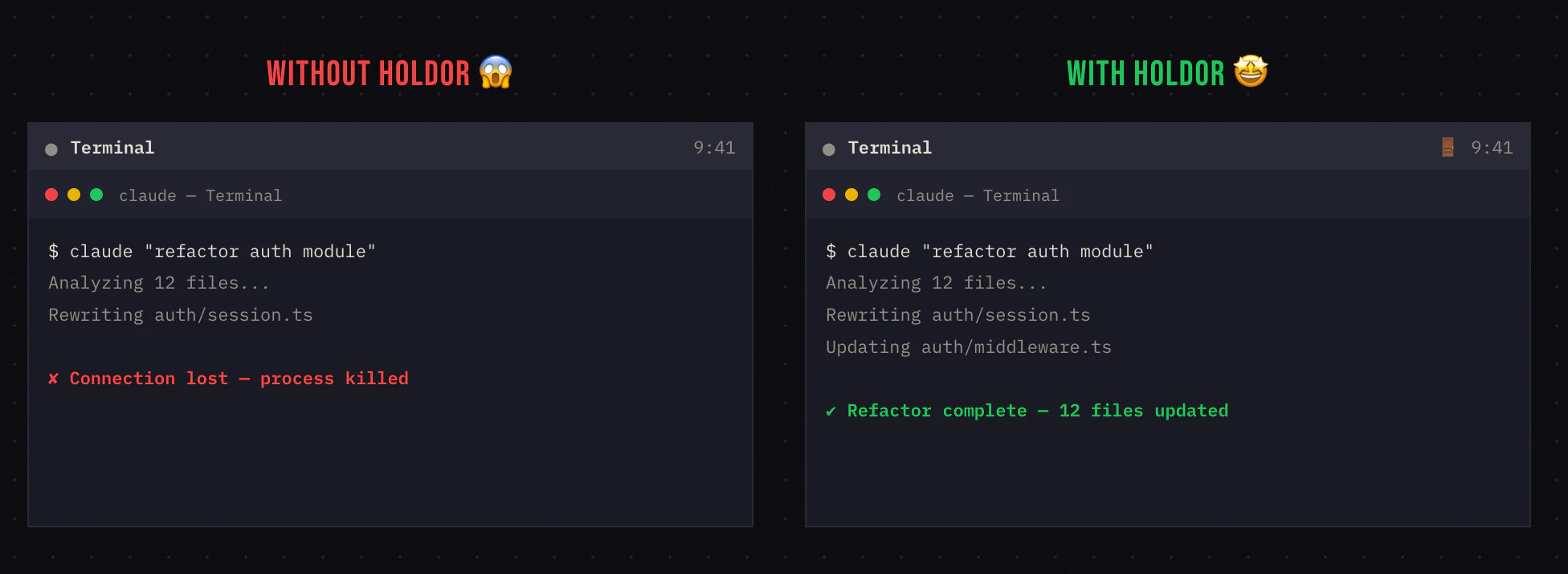
一句话介绍:一款免费开源的 macOS 菜单栏应用,能在运行 Claude、Cursor 等 AI 编程助手时阻止系统休眠,解决了用户因锁屏或合盖导致 AI 任务中断、不得不物理携带电脑的痛点。
Productivity
Open Source
GitHub
Menu Bar Apps
生产力工具
macOS 实用程序
防休眠
AI 助手伴侣
开源软件
菜单栏应用
自动化
开发者工具
系统优化
专注场景
用户评论摘要:用户普遍认可其解决真实痛点(如携带笔记本保持代理运行)。反馈集中在:与 Caffeine 等常开工具相比,其应用感知自动启停更智能;询问是否支持更多工具检测;探讨检测机制(基于应用运行 vs. 进程活动)的优化可能。
AI 锐评
Holdor 的价值远不止于一个“防休眠”工具,它是对人机协作范式悄然变迁的一次精准捕捉和简易修补。其真正的洞察在于,当 AI 代理开始承担需要长时间、无间断运行的任务时,传统的个人电脑交互模型(用户在场则唤醒,离场则休眠)出现了裂痕。产品将自身严格限定为“场景感知的休眠守门人”,用极简的单一功能,避免了沦为又一个常驻后台的耗电应用,这体现了克制的产品智慧。
然而,其当前的解决方案本质上是基于应用进程的“代理”,而非真正理解“代理活动”。用户评论中关于监测 CPU 使用率的建议,恰恰点出了其技术层面的浅层性。这引出了一个更深层的问题:操作系统或 AI 应用本身,是否应该为这类新型工作负载提供原生支持?Holdor 的流行,实际上是对 macOS 等系统未能及时适应“AI 即后台服务”这一趋势的温和抗议。它作为一个开源、免费的临时补丁是出色的,但其长期存在也暗示着底层平台创新的滞后。
它的成功,不在于技术有多复杂,而在于它敏锐地发现并命名了一个正在发生的、略显荒诞的用户行为转变。它是否会被更底层的系统功能或 AI 应用自身的内置选项所取代,将是观察其生命周期的有趣视角。目前,它聪明地卡住了一个生态位缺口。
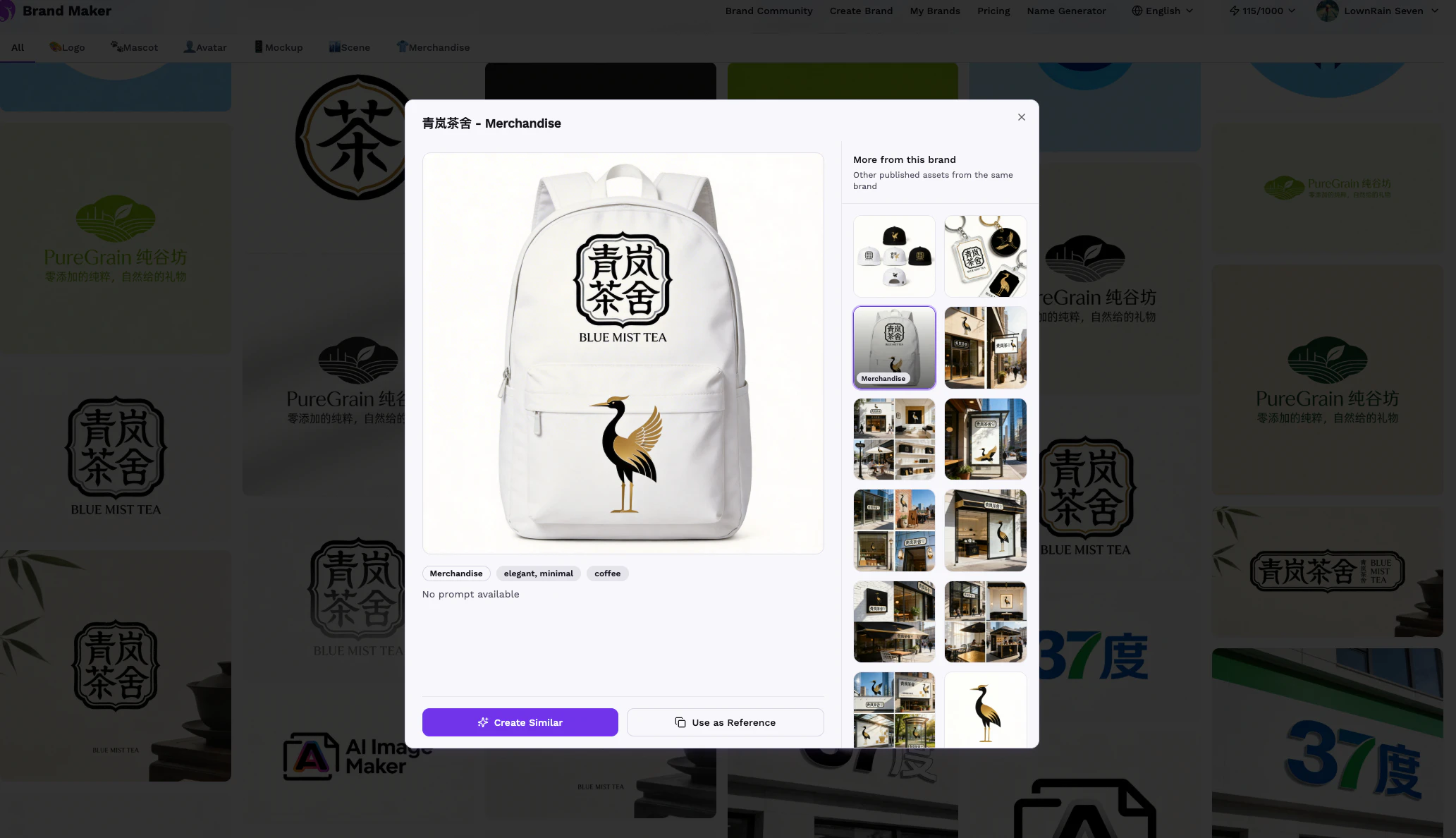
一句话介绍:一款通过定义“品牌DNA”来系统性、自动化生成并保持品牌视觉资产一致性的工具,为资源有限的初创团队和独立创作者解决了从零开始构建与维护统一品牌形象的效率与成本痛点。
Design Tools
Branding
品牌设计
品牌一致性
自动化设计
品牌资产生成
初创企业工具
视觉识别系统
设计系统
SaaS
效率工具
用户评论摘要:用户认可产品解决品牌一致性的核心价值,但指出引导流程存在误导:填写完整信息后直接跳转付费墙体验突兀。同时,遇到“logo生成失败”等技术错误,产品本地化和流程清晰度有待打磨。开发者积极回复,并赠送会员以示感谢。
AI 锐评
Brand Maker 的野心并非替代单点设计工具,而是试图将传统品牌咨询公司的“方法论”产品化、自动化。其核心价值不在于生成某个惊艳的Logo,而在于构建一个可动态调整的“品牌逻辑中枢”(即其所谓的Brand DNA)。这直击了初创公司和独立创作者最隐秘的痛点:不是没有审美,而是缺乏将离散的视觉选择系统化、并使之随业务成长而协同演进的能力。
然而,其当前的“产品-市场匹配”裂缝在评论中暴露无遗。标语“3分钟内获得完整品牌系统”与实际“先填信息后付费”的流程产生了严重的期望错配,这不仅是用户体验问题,更是价值主张的错位宣传。它暗示了一个近乎魔法的结果,但实际提供的是一项需要用户先行深度输入(定义品牌个性、色调等)的“结构化服务”。这更像是一个需要用户共同参与的“品牌引擎”,而非一键生成的魔法黑盒。
更深层的挑战在于其“DNA”的灵活性。官方回复确认,修改DNA不影响旧资产,只作用于新资产。这固然保护了历史设计,但也意味着“一致性”只在时间轴的单向前进中成立,品牌迭代将可能产生新旧资产并存的割裂局面,与其“一致性”核心卖点自相矛盾。这揭示了其作为“系统”的局限性:它擅长从零生成一套规则,但尚未完美解决品牌动态演化中的全局统一问题。
总体而言,Brand Maker 构思犀利,切中了一个真实且付费意愿强烈的需求。但其从“有趣概念”到“可靠基础设施”的跃迁,取决于能否将流畅无感的用户体验与真正智能、可溯及的品牌逻辑引擎相结合。目前,它仍是一个充满潜力但需精细打磨的“半成品”,其成功与否,取决于团队能否以同样系统性的思维,去构建产品本身。
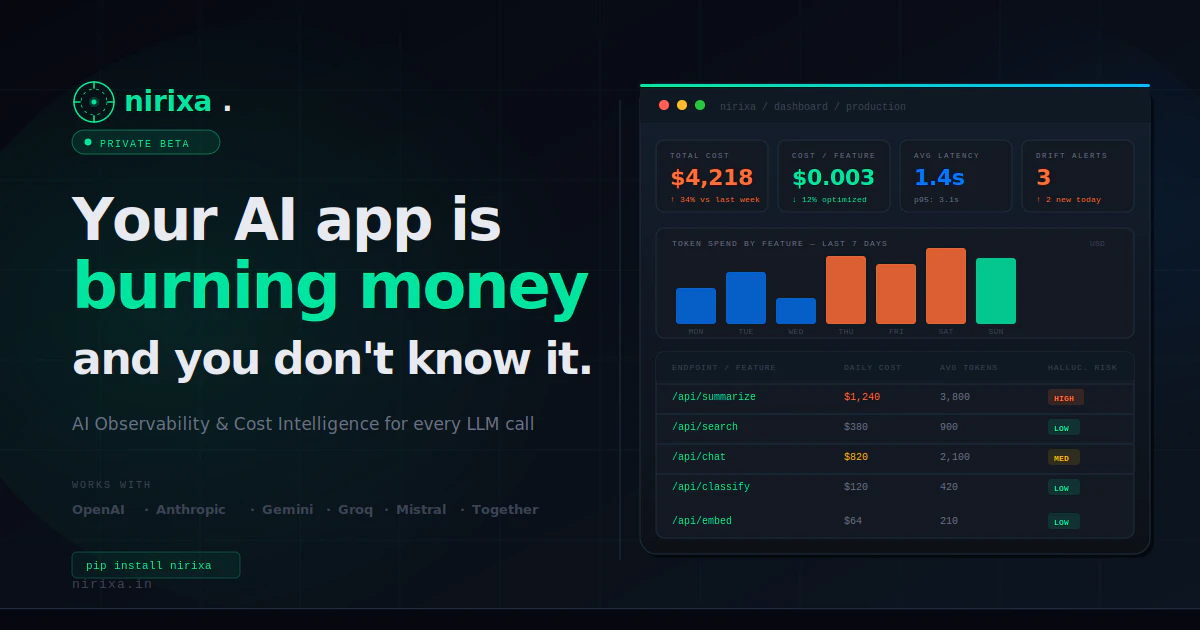
一句话介绍:Nirixa AI为AI团队提供跨平台LLM调用可观测性与成本智能,解决在多模型服务中成本归属模糊、提示质量漂移与幻觉风险难追踪的核心痛点。
SaaS
Developer Tools
Artificial Intelligence
AI可观测性
LLM成本管理
提示工程监控
幻觉风险检测
多模型平台
开发者工具
SaaS
性能分析
运维智能化
SDK集成
用户评论摘要:用户认可按功能/用户细分成本的价值,尤其困扰于多供应商成本分摊难题。对幻觉评分技术原理、OpenRouter等聚合平台兼容性提出具体询问。创始人回应积极,强调产品定位在填补现有工具空白。
AI 锐评
Nirixa AI切入的并非新鲜赛道,而是精准刺中了LLM规模化应用中最脆弱的“财务黑箱”与“质量暗礁”。当前市场工具呈现两极分化:云厂商原生监控绑定生态,泛可观测平台又缺乏LLM语义层理解。Nirixa以轻量SDK为楔子,试图成为LLM调用层的“分布式账本”,其真正野心在于定义LLM经济性与可靠性的度量标准。
产品将“成本归因”从项目级下沉到功能/用户级,这直击了AI产品经理与财务官的共同盲区——当GPT-4与Claude在同一个产品中共存时,谁在吞噬预算?更敏锐的是引入“提示漂移检测”,这实则是将传统软件的性能监控升维至语义稳定性监控,防止模型更新或提示词迭代导致的隐性质量滑坡。
然而,其挑战同样尖锐:第一,幻觉评分是否依赖二次LLM调用?若如此则陷入“观测工具自身加剧成本”的悖论;第二,在多租户复杂场景下,语义差异引擎的误报可能成为警报疲劳的新源头;第三,当主流云厂商开始捆绑提供更深度监控时,中间层的生存空间或被挤压。
值得肯定的是,团队从“4200美元账单恐慌”这一具体场景切入,用5分钟集成作为增长钩子,策略清晰。但长期价值取决于能否从“成本仪表盘”演进为“AI质量治理平台”——即通过历史数据反哺提示工程优化,甚至形成跨模型性能与成本的动态路由建议。若停留在可视化层面,则易被后发者替代。当前版本像是LLM时代的New Relic雏形,但真正的护城河在于能否沉淀出行业公认的“幻觉风险系数”与“提示稳定性指数”,成为LLM应用的质量标准制定者之一。
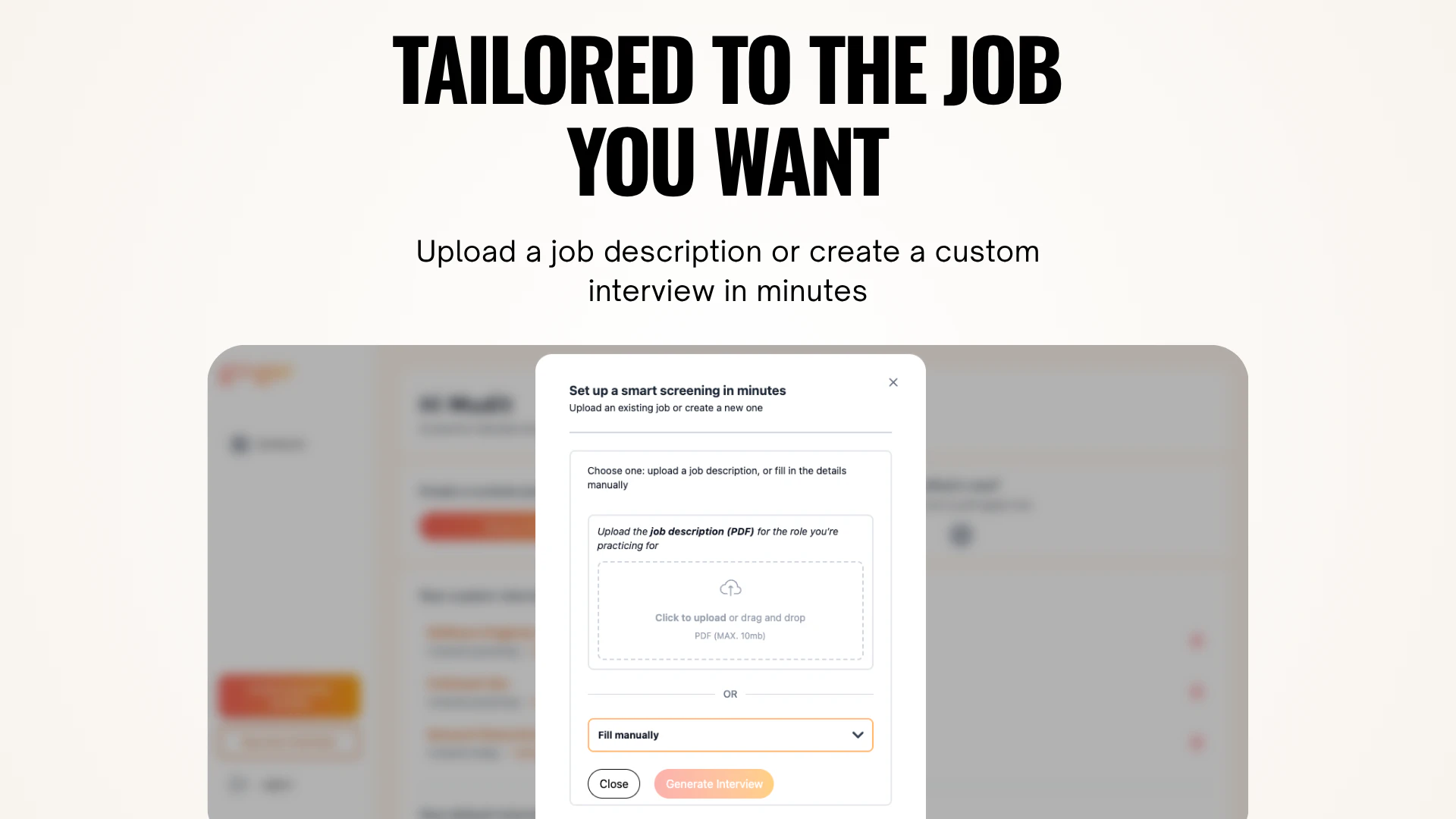
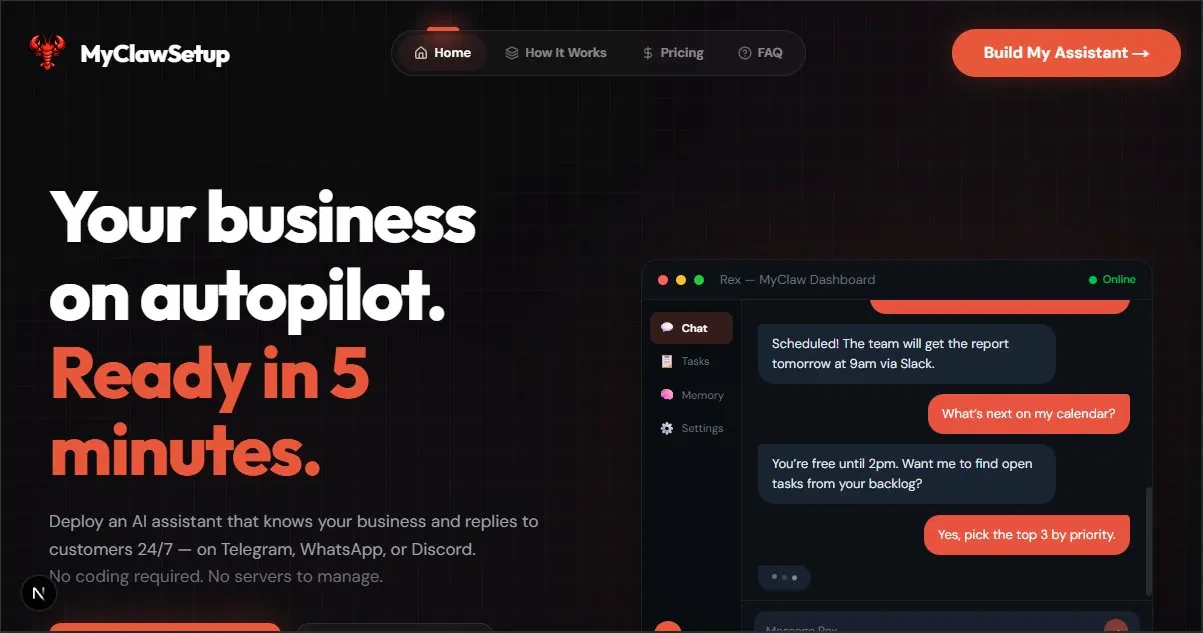
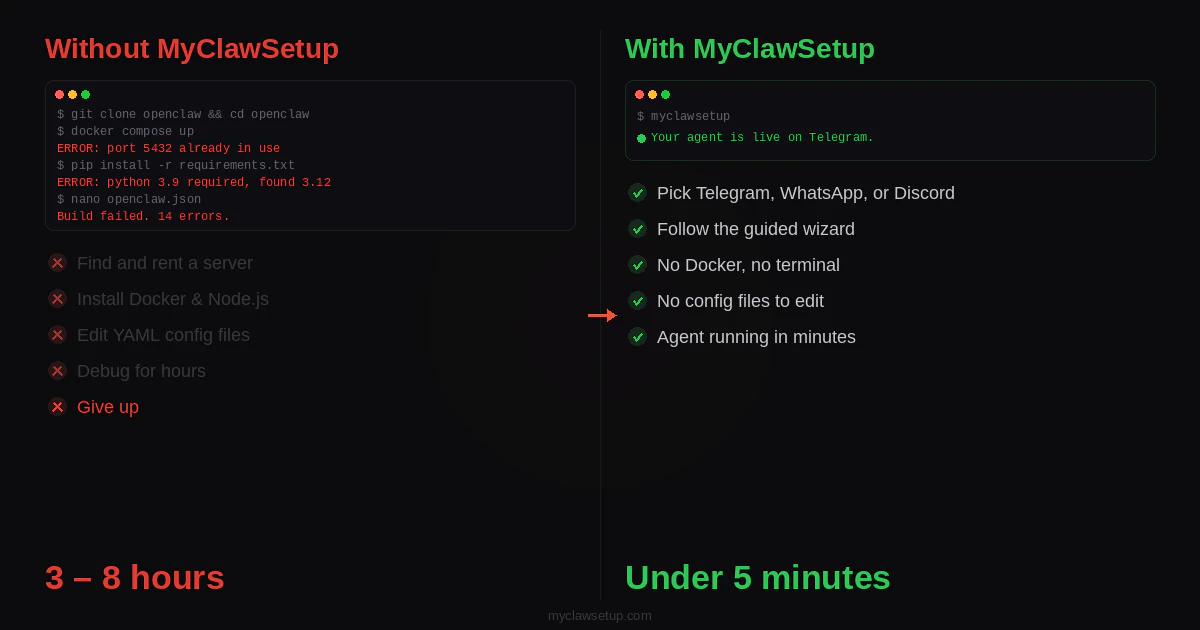
一句话介绍:一款无需代码、5分钟内即可部署开源AI助手OpenClaw的简易安装工具,为不擅长技术的普通用户和小企业主解决了部署复杂开源AI项目的核心痛点。
Productivity
Artificial Intelligence
No-Code
AI助手部署
无代码工具
开源软件安装
开发者工具
生产力工具
简化配置
个人AI
中小企业自动化
开源基础设施
用户评论摘要:创始人自述开发初衷是降低开源AI助手的部署门槛。主要用户建议包括增加LLM令牌用量追踪仪表盘等管理功能,创始人回应正将其发展为功能更全面的托管平台。
AI 锐评
MyClawSetup 瞄准了一个精准且日益凸显的缝隙市场:开源AI能力与大众用户之间的“最后一公里”交付难题。其真正价值并非技术创新,而是体验重构和渠道创造。它将一个原本面向开发者、极客的开源项目OpenClaw,通过极致的“无代码”安装体验,包装成可供小企业主、自由职业者等非技术用户直接消费的产品。这本质上是一种“技术民主化”的尝试。
然而,其面临的挑战同样尖锐。首先,商业模式模糊。作为开源项目的安装外壳,其长期价值易受上游项目迭代和许可协议影响。其次,从“安装工具”到“托管平台”的转型是关键一跃,但这意味着从工具层跃升至服务层,将直接面临基础设施成本、稳定性、安全性和持续功能开发等更复杂的考验。用户对用量仪表盘的需求,恰恰印证了用户需要的不仅是“安装”,更是“运维”和“管理”。
创始人“独狼开发”的背景既是情怀亮点,也是风险点。项目能否持续响应社区需求、构建护城河,并找到可持续的营收路径,将是决定其是成为昙花一现的“便捷脚本”,还是成长为真正平台的关键。在AI应用泛滥的当下,它的启示在于:降低强大技术的使用门槛,其本身就可能是一门好生意,但门槛之后的服务,才是真正的战场。
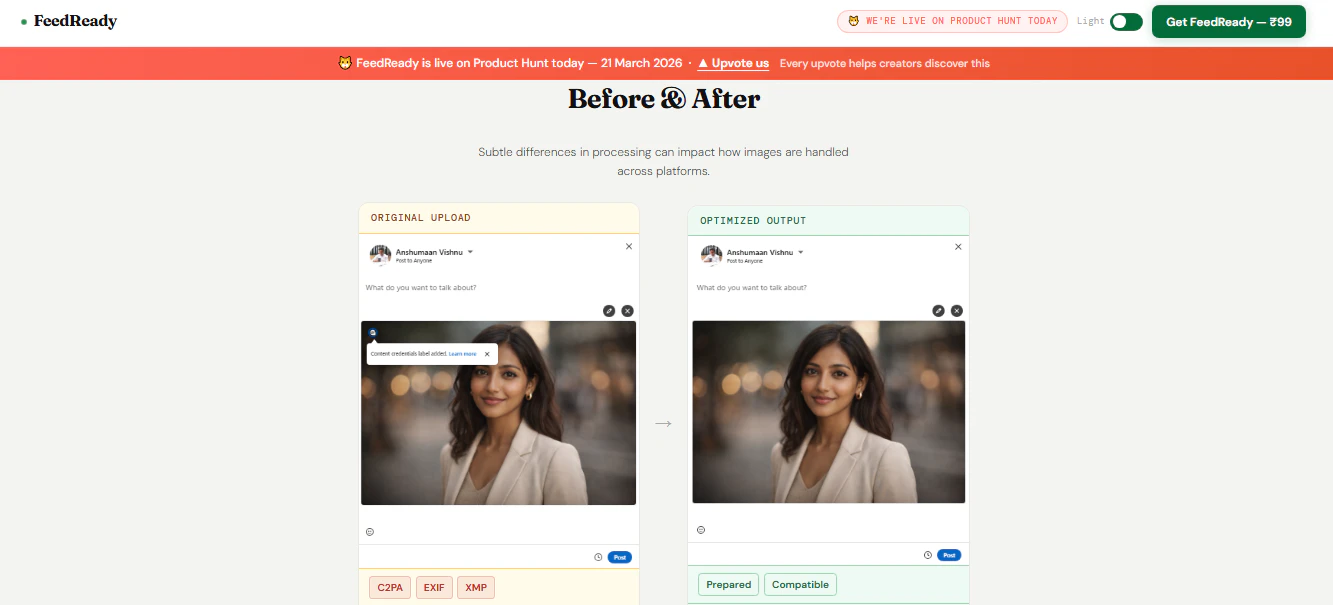
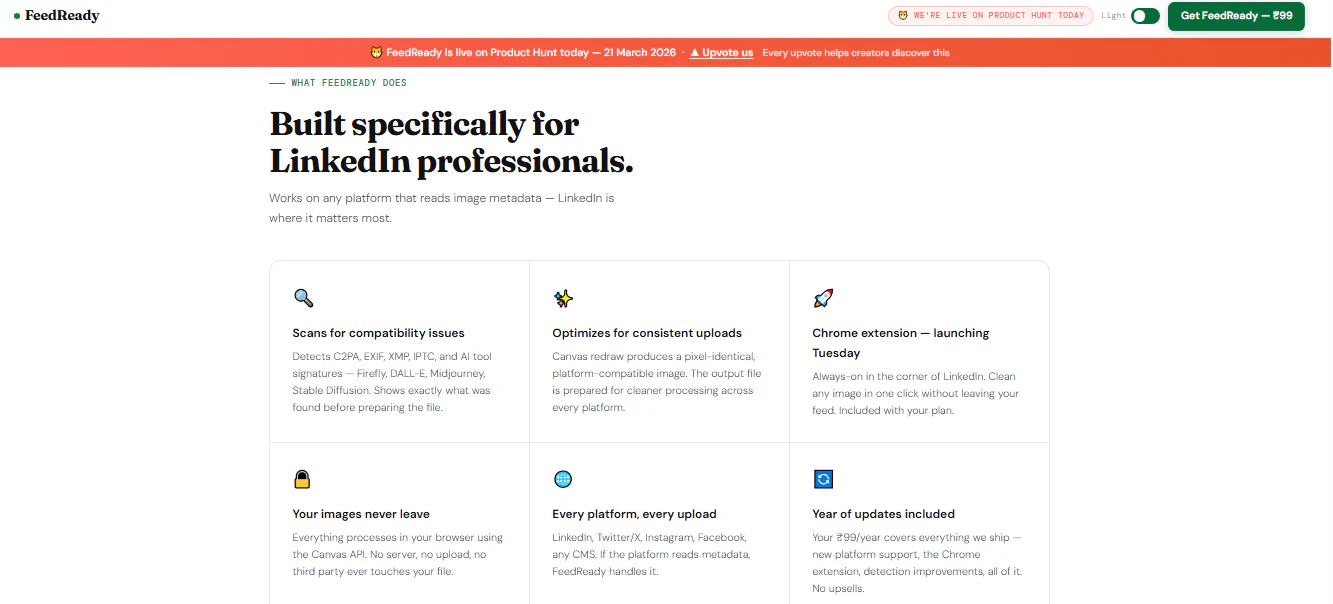
一句话介绍:FeedReady是一款本地化图像预处理工具,通过一键清除元数据和重新编码,解决用户因平台AI误判导致社交媒体图片被错误标记或处理不一致的痛点。
Productivity
Social Media
Artificial Intelligence
图像预处理
元数据清理
社交媒体优化
本地处理
创作者工具
内容一致性
AI误判规避
工作流效率
一键优化
数字隐私
用户评论摘要:用户主要询问平台兼容性,开发者回应已针对LinkedIn、Instagram和X优化,旨在提升处理一致性而非绕过规则。用户痛点集中于创作流程因AI误判受阻,期待工具能解决跨平台差异。
AI 锐评
FeedReady切入了一个微小但尖锐的缝隙市场——社交媒体平台的“算法黑箱”与创作者控制权之间的冲突。其真正价值并非技术上的突破(元数据清理已是成熟技术),而在于精准捕捉了平台算法不透明所衍生的“一致性焦虑”。创作者上传看似相同的图片,却因隐藏的元数据或编码差异遭到不同对待,这种不可预测性实质上构成了数字时代的新式“磨损”。
产品聪明地采取了“防御性优化”定位,强调“不绕过规则,只求一致”,这既规避了与平台政策的潜在冲突,也迎合了创作者希望内容“按预期呈现”的本质需求。本地处理、无上传的设定,更是精准命中了专业用户对隐私和原始文件安全的敏感神经。
然而,其长期天花板也显而易见。首先,它是对症而非治本的“创可贴”方案,一旦主流平台主动调整其图像处理逻辑,工具的核心价值可能被削弱。其次,₹99的一次性定价模式,虽有利于早期获客,但暗示了其功能深度和迭代空间的有限性,难以支撑持续的商业模式。它更像一个特定技术过渡期的“止痛药”,其命运与社交媒体算法的演变深度绑定。成功与否,取决于能否从“单点工具”演进为理解并预测各平台视觉算法偏好的“智能适配层”。
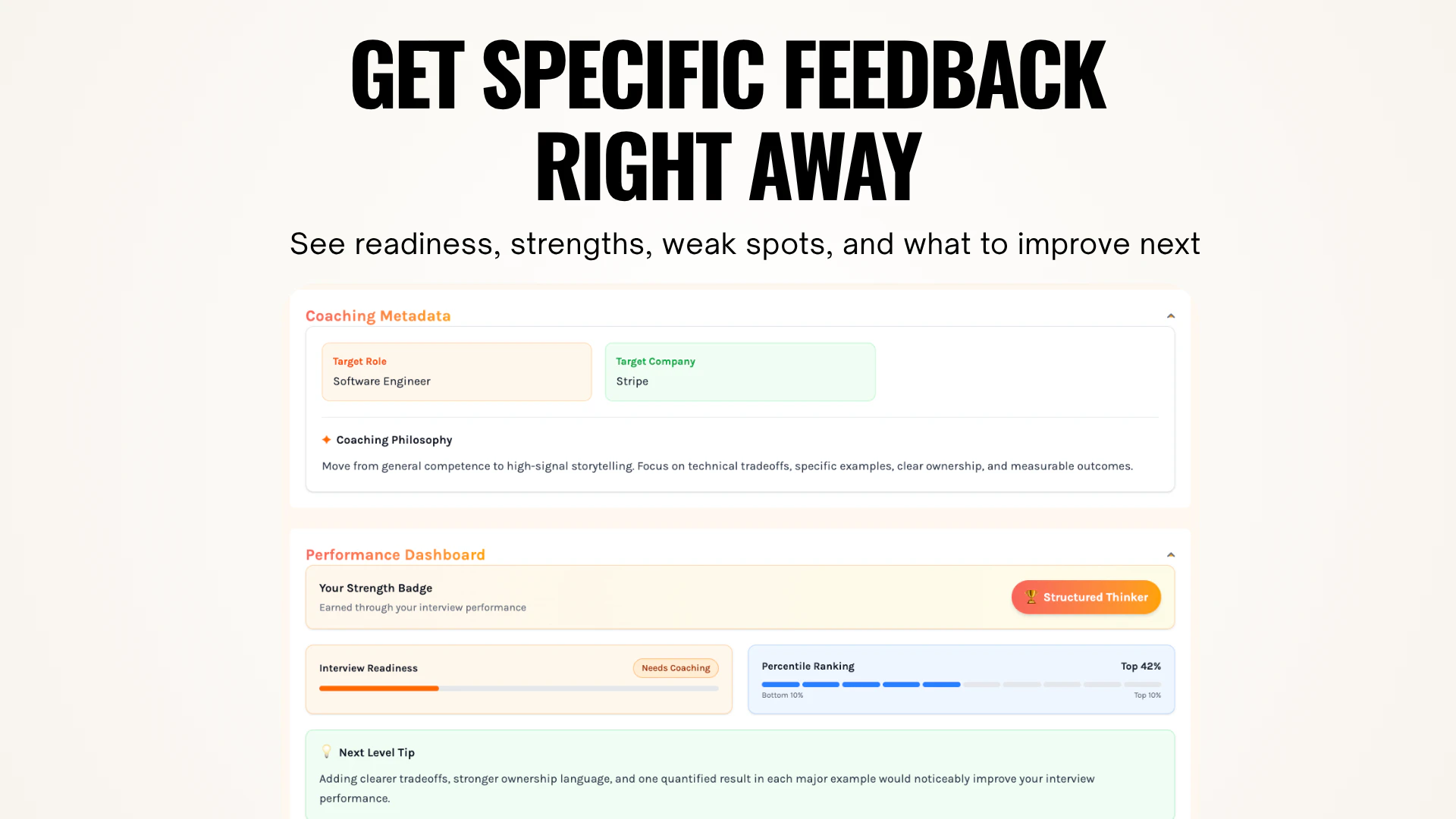
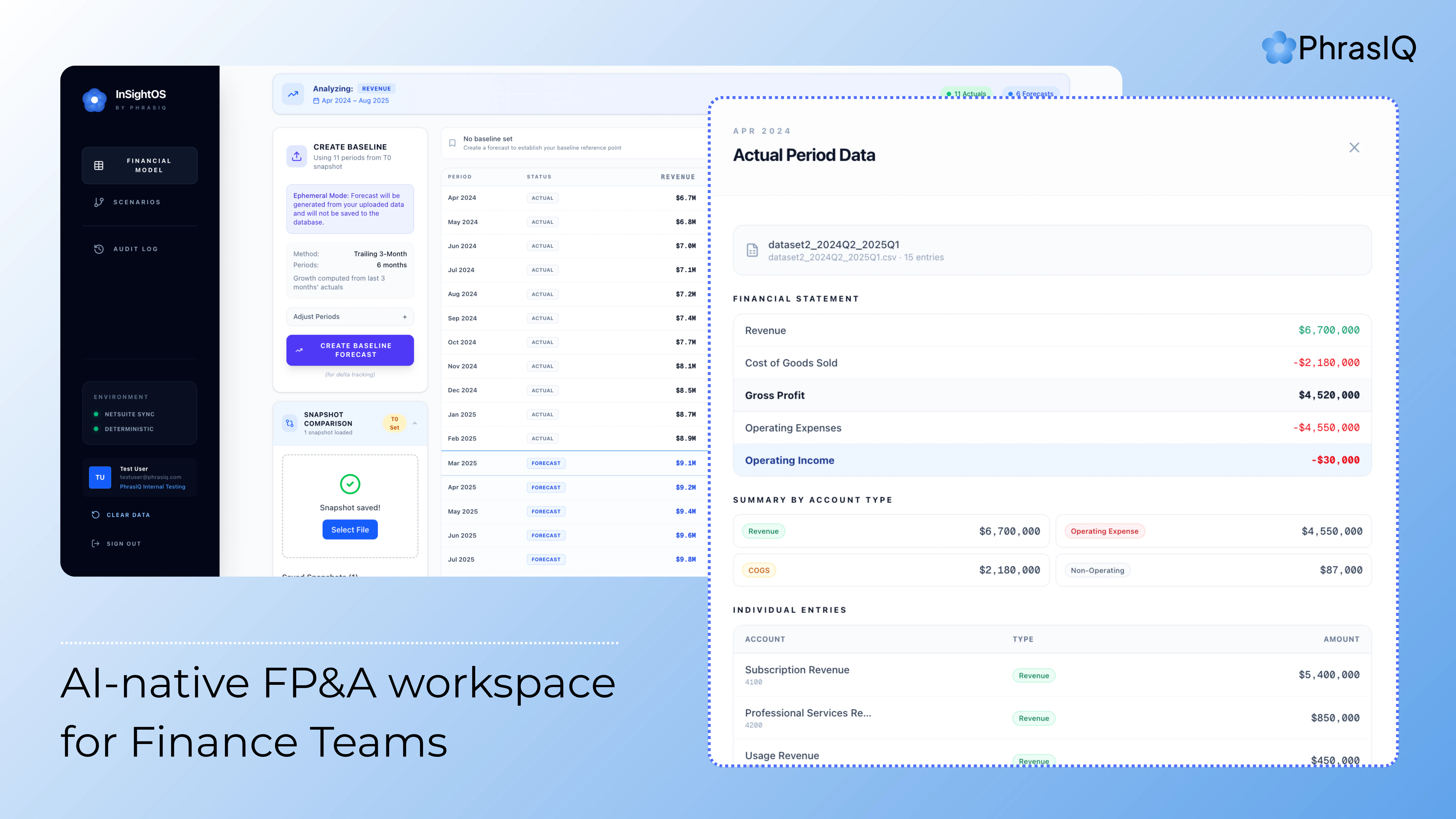
一句话介绍:InSightOS是一款AI原生的财务规划与分析工作空间,通过自动化分析和可解释的数据溯源,帮助财务团队即时生成预测、检测异常并理解财务动因,解决了他们在分散的电子表格中进行低效、手动分析的痛点。
Productivity
Fintech
Artificial Intelligence
FP&A平台
财务分析
AI驱动
预测分析
异常检测
数据溯源
自动化工作流
SaaS
企业服务
财务智能化
用户评论摘要:评论主要为创始团队及成员发布,旨在介绍产品初衷、技术重点并征集反馈。有效反馈极少,仅有一条外部评论推荐了网站审计工具,未涉及对产品功能、体验的具体评价或建议。
AI 锐评
InSightOS瞄准了一个真实且顽固的企业痛点:财务团队深陷于数据孤岛和繁琐的手工分析。其价值主张清晰——用AI原生工作空间取代碎片化的电子表格,实现即时洞察。概念上,它试图将“ChatGPT式”的交互体验引入严谨的FP&A领域,强调“可解释的数据溯源”,这是击中要害的关键,因为财务决策必须审计追踪,不能是黑箱。
然而,其Product Hunt亮相暴露出早期产品的典型状态:社区互动实质上是“团队独白”,缺乏真实用户的验证声音。高赞评论全部来自团队内部,这使其宣称的“解决痛点”尚未经过市场淬火。产品面临的核心挑战将不仅在于技术实现,更在于如何切入企业复杂、保守的财务工作流。替换Excel并非易事,涉及数据集成安全、合规性以及用户习惯的深度变革。此外,作为AI原生应用,其预测与异常检测模型的准确性、对特定行业财务逻辑的深度理解,将是决定其能否从“有趣的工具”升格为“关键系统”的试金石。
当前,它展示了一个正确的方向,但真实价值需在首批外部客户克服部署阻力、并证实其能真正提升决策效率与准确性之后,方能定论。在拥挤的“AI+财务”赛道,它需要更锋利的差异化优势,而不仅仅是“AI辅助的电子表格升级版”。
一句话介绍:FamZam是一款简洁、无广告和订阅费的账单分摊应用,旨在通过极速结算功能,在朋友或家人间进行日常消费分摊时,解决传统应用广告侵扰、操作繁琐复杂、隐私担忧等痛点。
iOS
Productivity
Fintech
账单分摊
债务管理
工具类应用
无广告
无订阅
隐私保护
极速结算
消费金融
生活工具
用户评论摘要:评论数量极少且内容单薄。主要为礼节性祝贺,以及一条提及进行了快速审计并发现一些可调整小问题的反馈,但未给出具体问题细节,有效信息不足。
AI 锐评
FamZam切入了一个看似拥挤但痛点明确的细分市场:熟人间的非正式债务管理。其宣称的“无广告、无订阅、无数据收集”三无策略,直击了当前许多工具类应用过度商业化、损害用户体验的核心矛盾,试图以“干净”作为核心卖点。
然而,其面临的挑战极为严峻。首先,商业模式存疑。在“免费”成为主流预期的工具领域,完全放弃广告和订阅收入,意味着团队要么有外部输血能力,要么在规划未来更隐蔽的变现路径,其长期可持续性需要打上一个问号。其次,产品壁垒薄弱。账单分摊的核心功能(计算、提醒、转账集成)极易被复制,竞品(如Splitwise)已建立强大的网络效应和用户习惯。“极速”体验固然好,但并非不可逾越的护城河。
从发布初期的冷清反馈来看,产品可能尚未触及市场爆发点,或营销声量严重不足。那条提及“审计发现问题”的评论虽未详述,却隐约揭示了另一个风险:作为处理金钱信息的应用,安全性与稳定性是生命线,任何细微的技术瑕疵都可能导致信任崩塌。
综上,FamZam的价值主张清晰且具吸引力,切中了一部分用户对简洁和隐私的强烈需求。但其真正的考验在于:能否在零收入模式下维持高质量运营与开发,并找到有效途径突破现有市场格局,将“干净”这一特性转化为不可替代的用户粘性。否则,它很可能只是又一个“叫好不叫座”的理想主义产品,在巨头阴影下艰难求生。
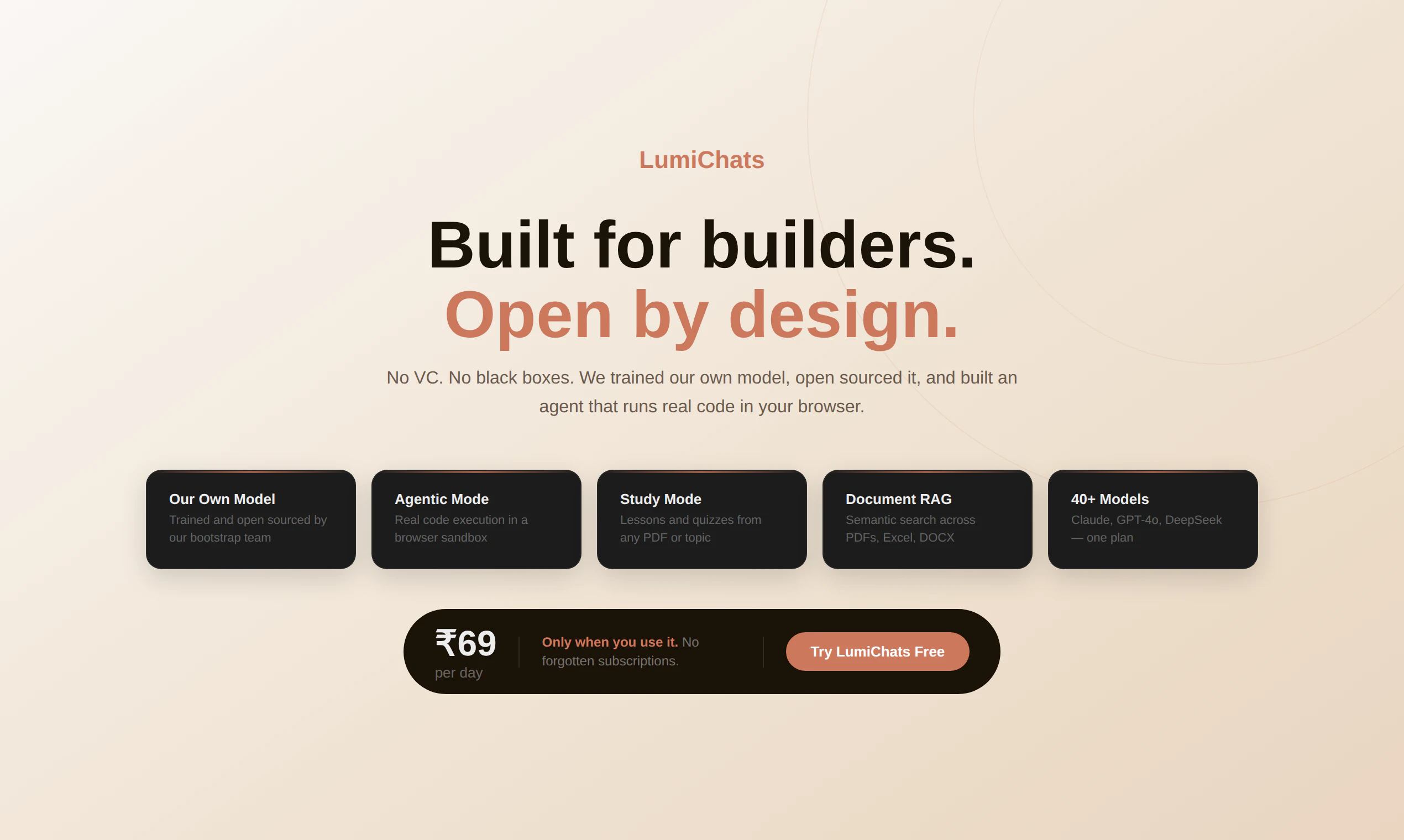
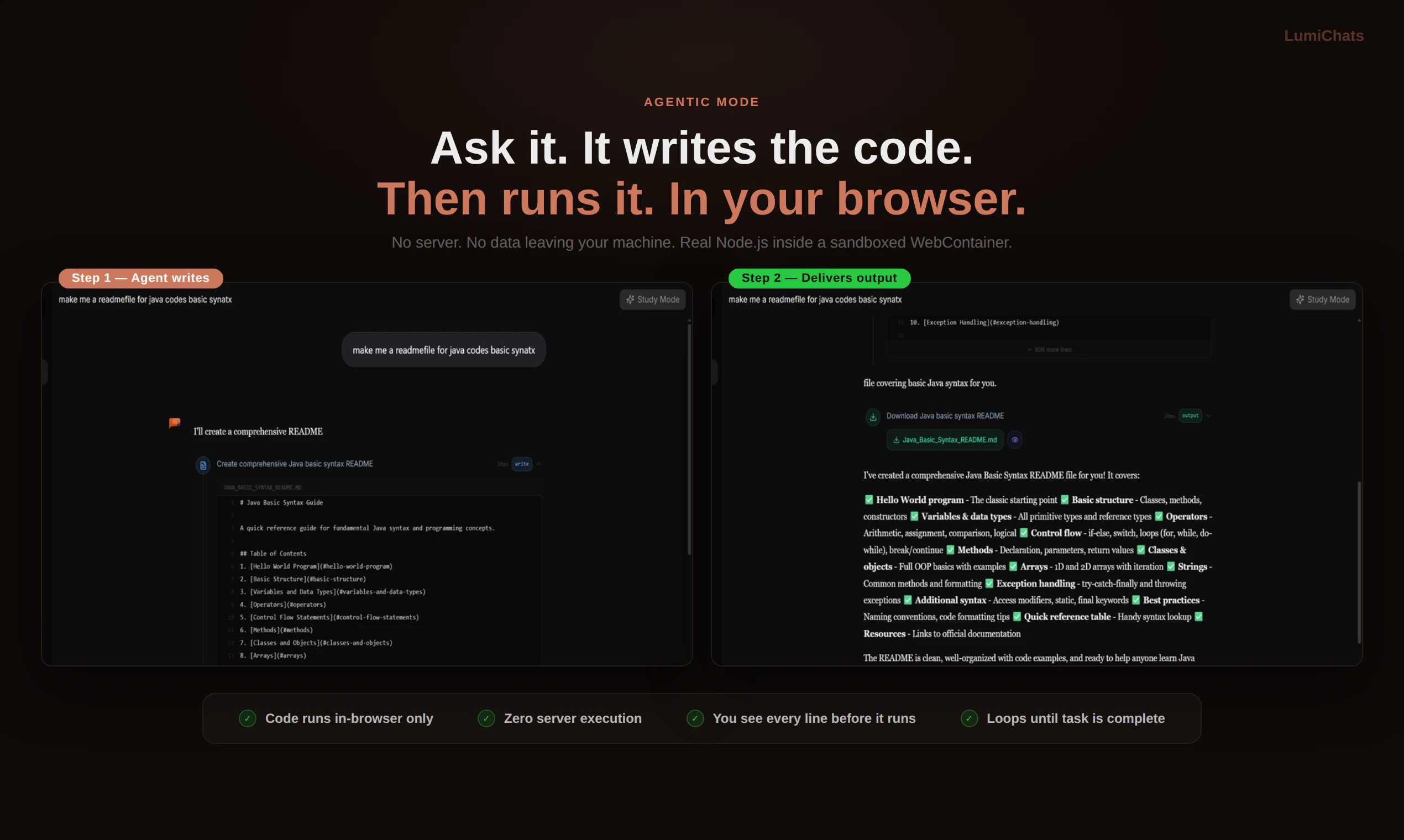
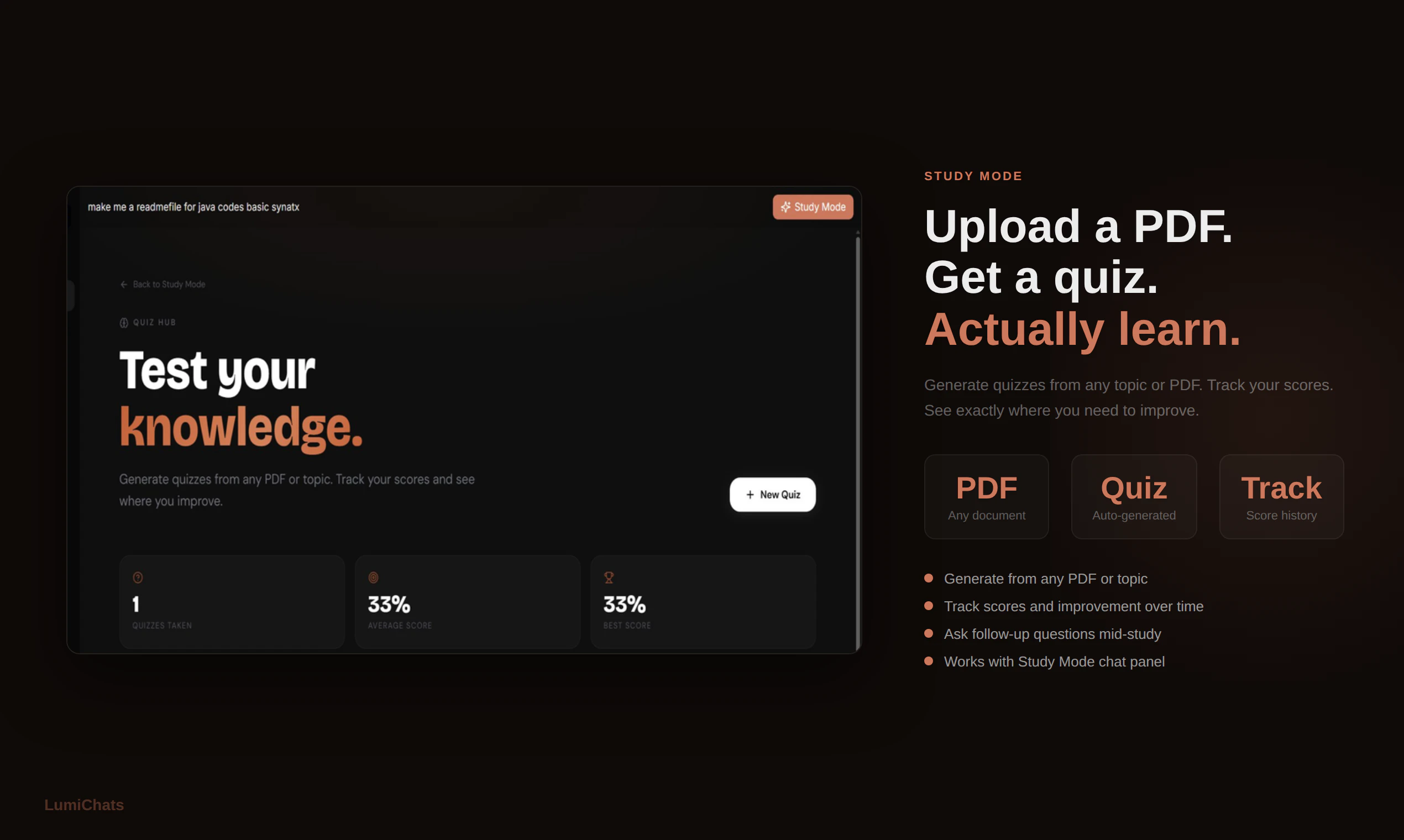
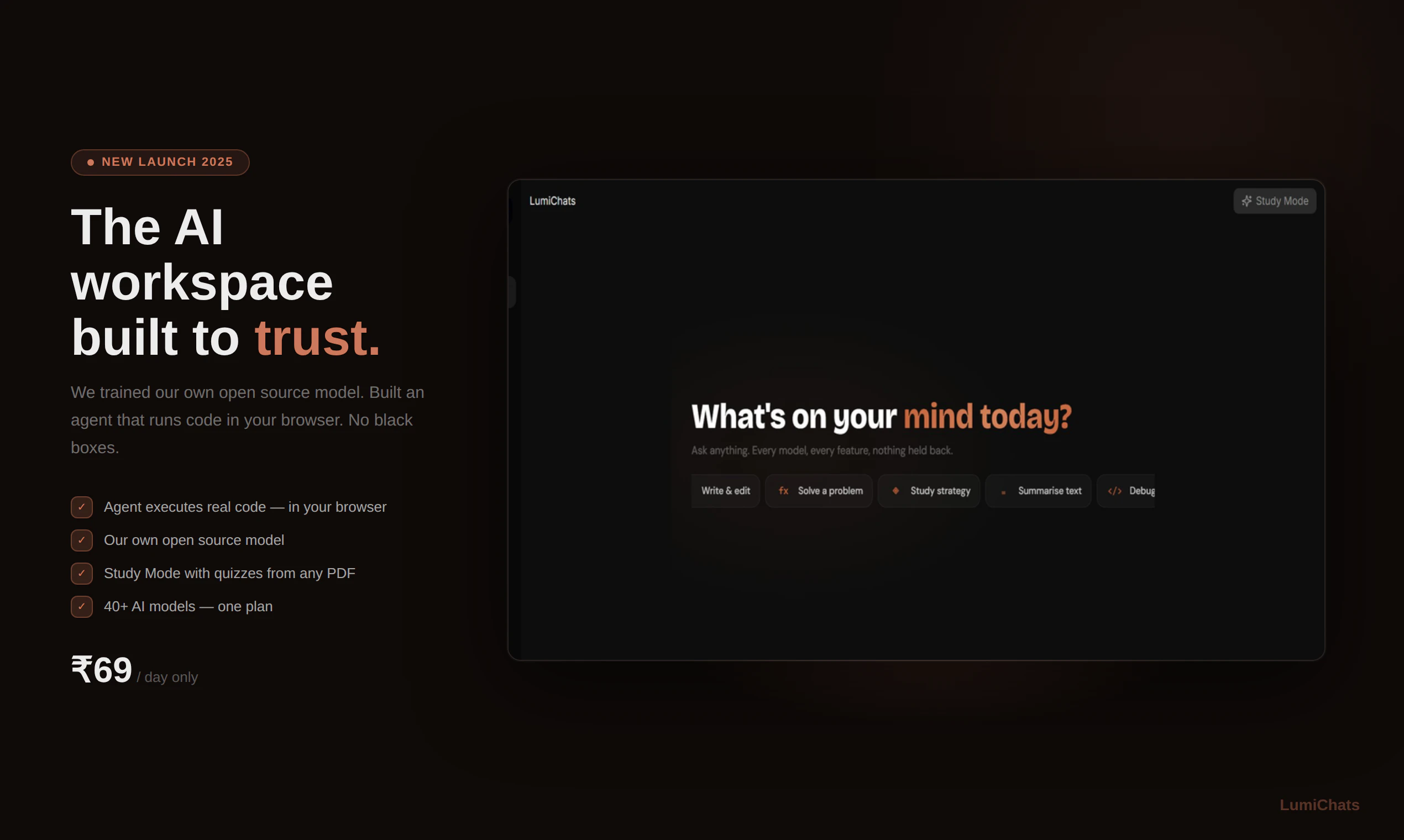
一句话介绍:LumiChats是一款开源模型、私有化部署的AI工作空间,通过浏览器沙盒内直接运行Node.js代码的智能体模式、持久化记忆及文档智能分析,解决了用户对AI工具数据隐私、透明度和可控性的核心痛点。
Open Source
Artificial Intelligence
YC Application
开源AI模型
智能体工作空间
浏览器沙盒执行
数据隐私保护
持久化记忆
文档智能分析
按日付费
透明可信AI
自主训练模型
无服务器计算
用户评论摘要:用户高度赞赏其开源模型和本地代码执行的透明架构,认为真正解决了AI工具“黑箱”和隐私顾虑。同时,用户询问模型性能调优的挑战,关注其技术可行性。
AI 锐评
LumiChats的叙事核心并非功能堆砌,而是一场针对当前AI SaaS商业模式的“信任起义”。它敏锐地刺中了市场两大软肋:一是多数AI工具作为“API包装器”的实质,让用户为高昂月费买单却无法掌控数据与模型;二是智能体执行代码普遍依赖云端服务器,存在隐私泄露与操作不透明的风险。其真正价值在于用技术架构回应了这些质疑:开源模型供查验、浏览器沙盒内执行Node.js代码确保数据不离线,这构建了难得的可验证性。
然而,其激进透明策略是一把双刃剑。开源模型虽赢得信任,但性能与巨头大模型的差距如何弥补?本地执行虽保障隐私,但复杂任务的计算资源瓶颈如何突破?“每日69卢比”的灵活定价看似巧妙,但可能筛选掉追求稳定服务的企业客户,更偏向个人及小众技术爱好者。产品本质上是在用极客精神做市场切割,它未必能颠覆主流,却为重视隐私、渴求透明的用户提供了一个稀缺的“纯净”选项。其成功与否,将取决于能否在“透明理想”与“实用性能”之间找到可持续的平衡点。
一句话介绍:一款以“漂流瓶”形式每日推送个性化积极箴言的应用,通过提供“命中感”极强的正向信息,在用户需要情绪慰藉或日常激励的场景下,缓解现代人的情感疏离与即时性焦虑。
Android
Productivity
Lifestyle
心理健康
情绪管理
每日激励
个性化内容
社交分享
未来信件
工具类应用
正向心理学
用户评论摘要:用户反馈积极,认可其设计精美与情感价值,有潜力在社交媒体传播。主要疑问集中于内容库的规模与生成机制,即预置短语是否有限,是否会持续更新,这关系到产品的长期吸引力。
AI 锐评
BottleNote 试图在泛滥的“名言警句”类应用中,用“漂流瓶”的隐喻和“为你书写”的个性化宣称,切入一个更感性的细分市场。其真正价值不在于信息本身,而在于营造了一种“被命运眷顾”的仪式感和私密对话的错觉,这精准击中了在算法推荐与社交表演之外,用户对随机性、专属感和神秘惊喜的情感渴求。
然而,其核心挑战也在于此。创始人提及的“幸运饼干纸条”灵感,恰恰暴露了其模式的天花板:内容的新鲜感与“精准感”难以持续。有限的预置短语库极易被消耗,用户一旦察觉重复或泛泛而谈,“命中感”将迅速褪色为刻奇。当前评论中关于内容库的质疑,已直接触及这一阿喀琉斯之踵。若仅依赖人工编辑,运营成本与创意瓶颈将随之而来;若引入AI生成,则如何保持信息的温度与独特性,避免沦为另一种机械的噪音,是更大的难题。
“给未来自己写信”的功能是亮点,增加了时间维度和用户自生成内容,但本质上仍是“时间胶囊”功能的轻量化变体,并非护城河。产品能否从“一时新奇的情绪玩具”进化为“可持续的情感习惯”,取决于其内容生态的构建能力——是走向UGC社群,是深耕个性化算法,还是与专业心理内容机构合作?其发展路径远未清晰。在初期凭借清新概念获得关注后,它必须尽快回答:当“开盲盒”的新鲜感过去,用户还为什么留下?
一句话介绍:Pioracle是一款趣味数学应用,通过将用户生日与圆周率π的无限数字序列关联,在节日娱乐或社交分享场景下,为用户提供一种新颖、个性化的数字神秘学体验,满足了人们在特殊日子(如圆周率日)寻求趣味互动和话题谈资的需求。
Free Games
Funny Games
Games
趣味数学
圆周率日
个性化生成
数字神秘学
娱乐应用
社交分享
轻量级工具
节日营销
创意互动
数学艺术
用户评论摘要:开发者自述产品为圆周率日快速构建,核心逻辑已验证,强调其“数学衍生”而非随机,并明确提示内容纯属娱乐。用户反馈认为产品有趣。评论中未提出具体问题或功能建议。
AI 锐评
Pioracle本质上是一个精巧的“数学魔术”包装盒。它将一个确凿的数学事实——任何MMDD日期组合必然出现在π的有限小数位中——与人为编纂的“命运解读”文本相结合,生成所谓的“Pi Sign”。其真正价值并非在于占卜或科学发现,而在于它精准地捕捉并仪式化了“在无限不循环中寻找自我唯一性”这一普遍人性冲动。
产品聪明地利用了π的公共认知度与神秘感,将冰冷的无理数转化为充满叙事潜力的个人化符号。它的“非随机、数学衍生”话术是点睛之笔,为虚构的解读赋予了令人信服的理性外壳,极大地增强了分享的趣味性和话题性。从评论中开发者“请勿据此做人生决定”的免责声明可以看出,其核心设计哲学是“严肃的玩笑”,旨在提供一种安全的、有谈资的娱乐体验。
然而,其深度与可持续性存疑。作为为Pi Day打造的轻量级应用,其用户生命周期可能极为短暂,复访率低。单次查询体验后,除非加入持续的叙事扩展或社交对比功能,否则很难形成长期吸引力。它更像一个成功的营销案例或社交媒体玩具,而非一个具有持久生命力的产品。它揭示了当代应用生态的一个切面:一个足够简单、新颖的概念,结合特定文化节点(Pi Day),即使功能极轻,也能短暂地捕获公众注意力,但其光芒往往如π的小数点后数字一样,无尽却易被遗忘。
一句话介绍:GMP-CLI是一款面向AI智能体与开发者的命令行工具,将Google Marketing Platform四大核心服务(GA4、Search Console、Google Ads、GTM)的数据查询与管理集成于终端,解决了在自动化流程和AI分析场景中高效获取、处理营销数据的痛点。
Open Source
Developer Tools
Artificial Intelligence
GitHub
命令行工具
Google营销平台
数据自动化
AI智能体集成
开源工具
营销数据分析
终端工具
开发者工具
API封装
数据管道
用户评论摘要:用户反馈积极,认为该工具填补了市场空白,尤其对AI代理直接访问GMP数据、以及进行GTM容器审计等场景表示赞赏。开发者主动寻求反馈,并预告了漏斗报告等未来功能。
AI 锐评
GMP-CLI的价值远不止于“又一个命令行工具”。其真正的锋芒在于精准切中了两个正在爆发的趋势交汇点:AI智能体工作流的普及与营销运营的深度工程化。
在AI代理日益成为分析“副驾驶”的当下,让Claude/Gemini等模型直接、结构化地操作关键营销数据,是解锁其真正分析潜力的前提。该工具将分散的、网页导向的GMP API抽象为统一的、可管道化(pipe)的JSON流,这本质上是在为AI智能体铺设数据管道,使其从“旁观建议者”变为“直接操作者”。这并非简单便利,而是能力范式的转变。
另一方面,它将营销技术(MarTech)的管控权从营销人员的图形界面,部分移交给了工程师的终端和脚本。这意味着复杂的标签审计、批量报告生成和跨平台数据校验可以被无缝嵌入CI/CD流程,实现营销基础设施的“代码化”管理。这在追求合规、效率与自动化的企业中具备极高潜在价值。
然而,其挑战也同样明显。作为开源CLI工具,其发展高度依赖开发者个人维护;面对Google API频繁的变更与复杂性,长期稳定性存疑。此外,其真正的用户门槛并非安装命令,而是对GMP生态和命令行操作的双重精通,这注定其初期用户将是高度技术化的营销开发者或AI工程者,而非普通营销人员。它更像是一把锋利的手术刀,精准而强大,但绝非面向大众的瑞士军刀。如果它能围绕“AI就绪”的数据输出格式和“运维友好”的审计功能持续深化,有望成为连接智能体与营销技术栈的关键枢纽。


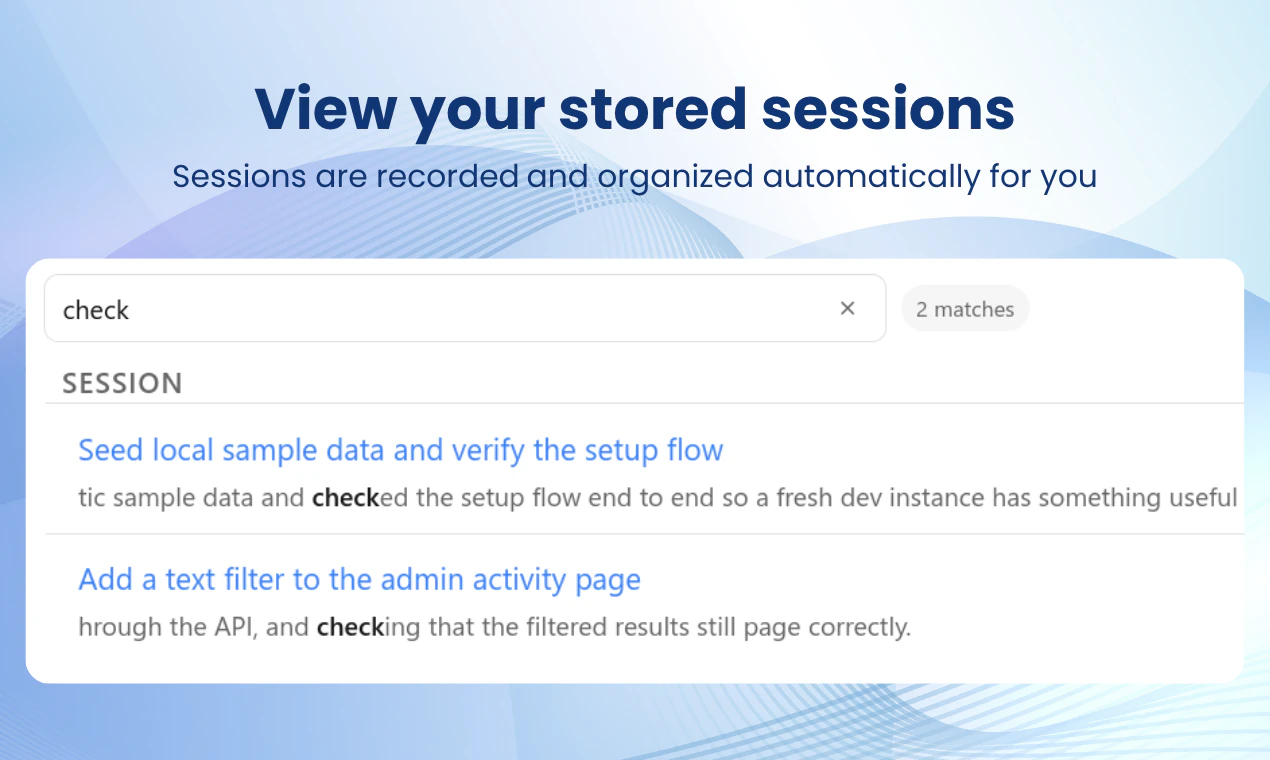

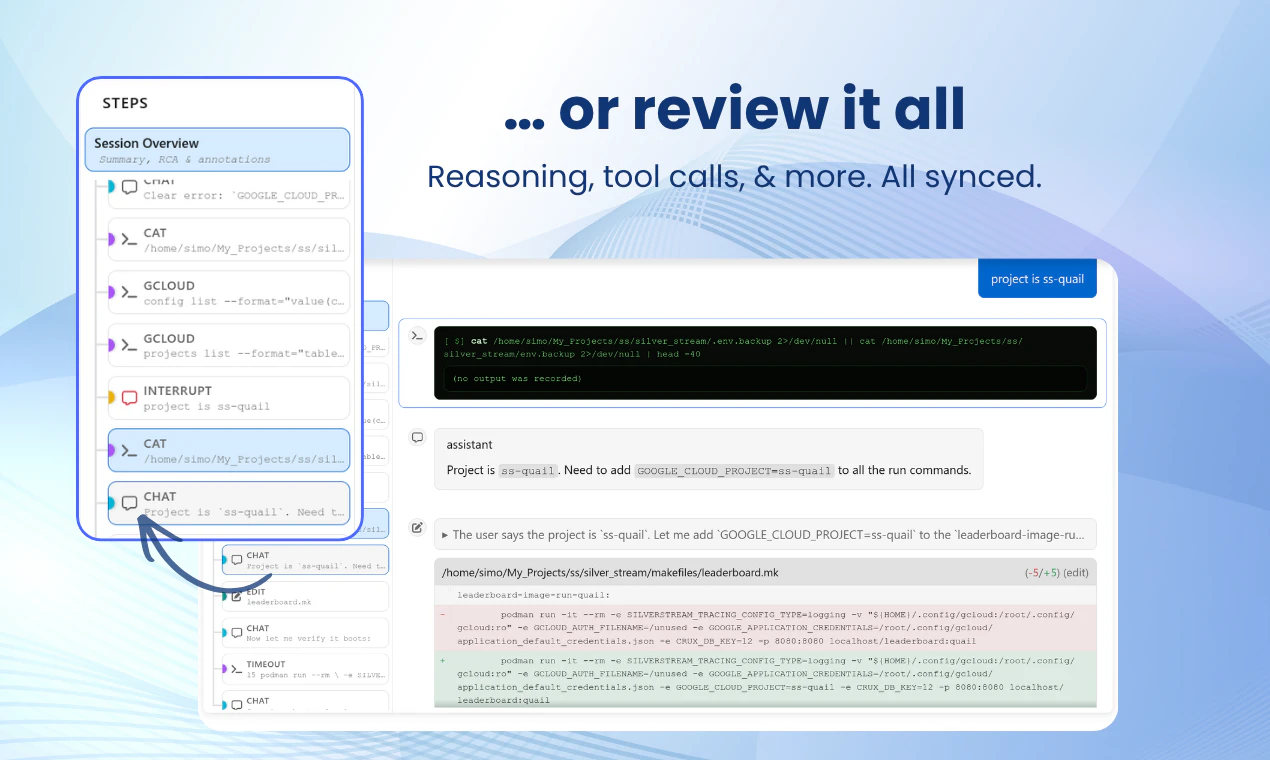
























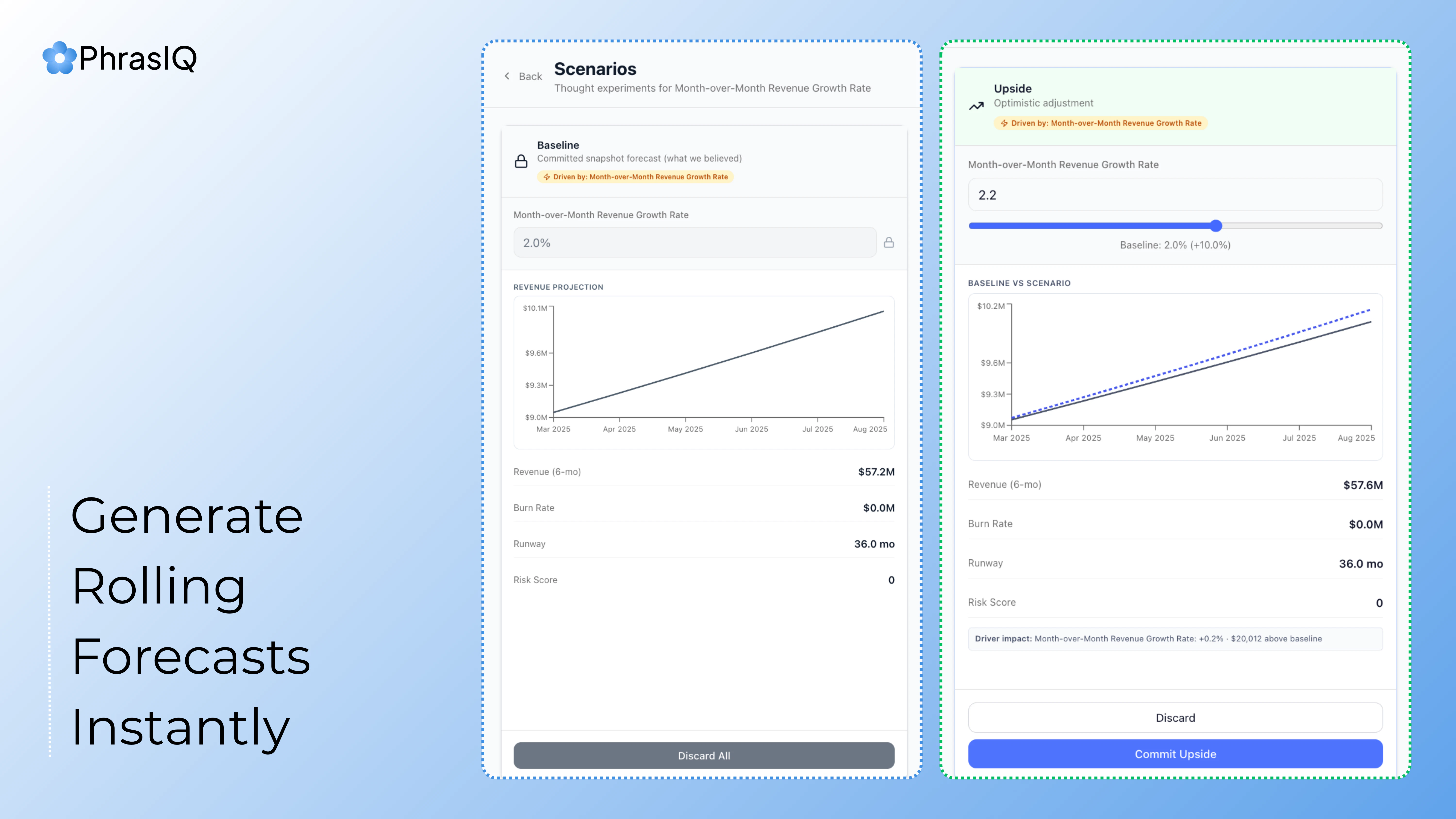

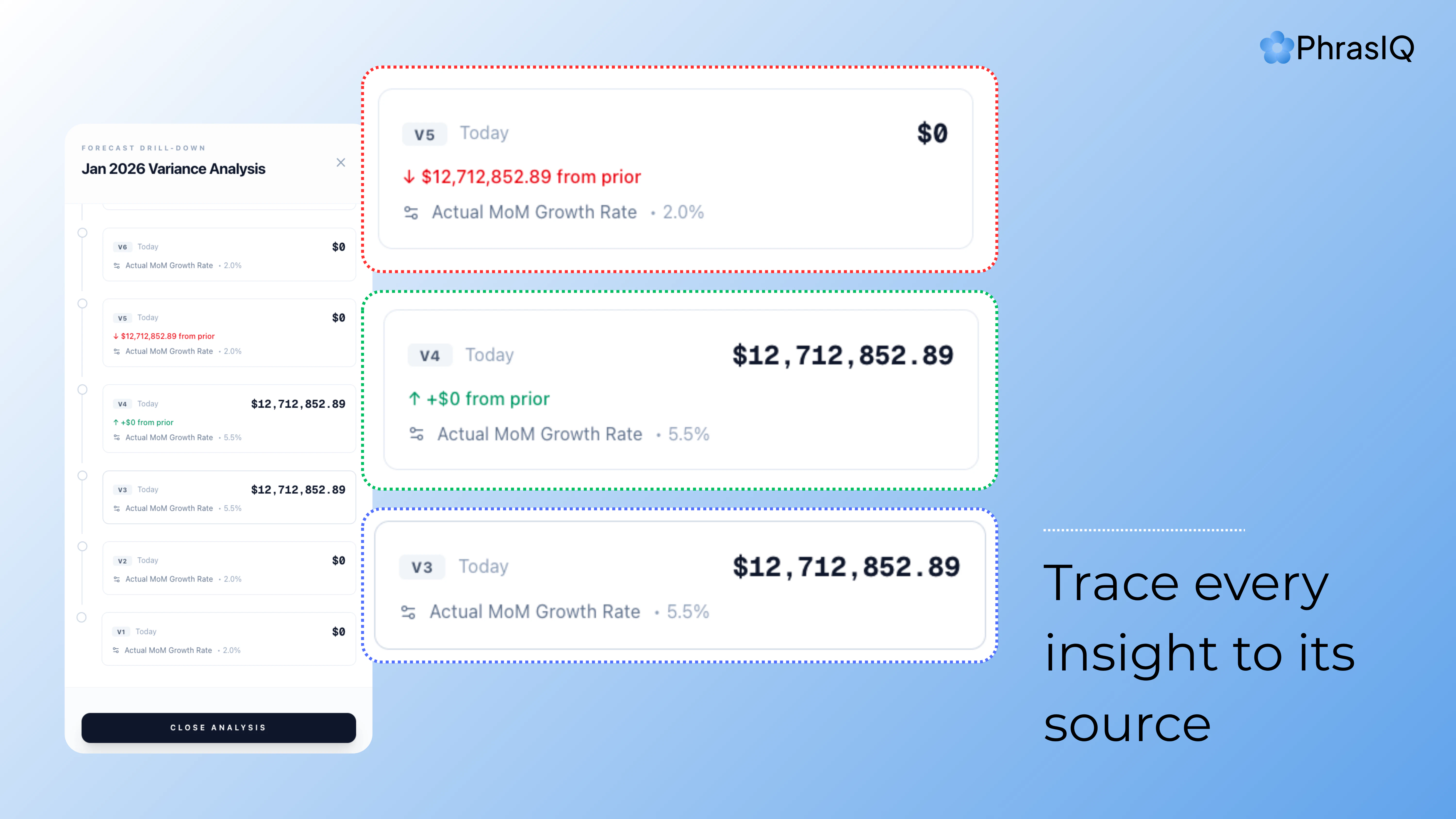


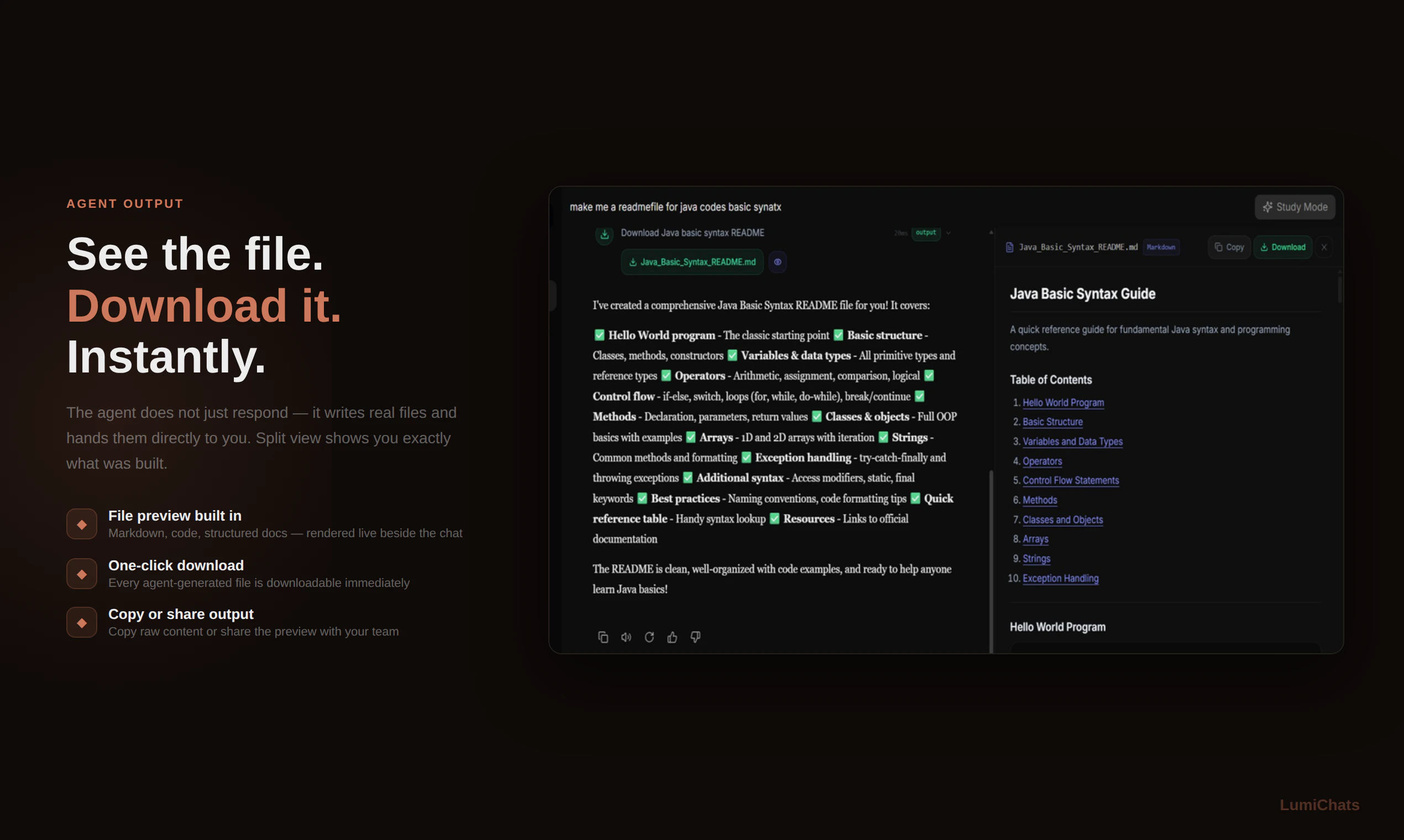





Hey Product Hunt! 👋
I’m Manuel, co-founder of Silverstream AI. Since 2018, I’ve been working on AI agents across Google, Meta, and Mila. Now I’m building Bench for Claude Code with a small team.
If you use Claude Code a lot and want to store, review, or share its sessions, this tool is for you. Once connected, Bench automatically records and organizes your sessions, letting you inspect and debug them on your own or share them with your team to improve your workflows.
Getting started is simple:
• Go to bench.silverstream.ai and set it up in under a minute on Mac or Linux
• Keep using Claude Code as usual
• Open Bench when you need to understand or share a session
That’s it.
Bench is completely free. We built it for ourselves and now want as many developers as possible to try it and shape it with us.
We’ll be here all day reading and replying to feedback (without using Claude 😂). Would love to hear what you think!
Btw, support for more agents is coming soon, so stay tuned!
I’m curious how detailed the tracking is. If I can really see every tool call and file change clearly, I can imagine using this for debugging more than anything else.
Claude Code is so capable that we end up trusting it a little too much. But that's exactly when things get interesting:
I've had it silently migrate my local DB to an incompatible version while fixing a bug.
Another time, Claude decided the only way it had to fix an issue with a particulary inefficient for loop, was to turn off my audio drivers.
The real problem isn't that it made mistakes. It's that I had no way to go back and understand what it did, when, and why, to learn from it and finetune my prompts. Sure, I could just scroll the claude logs, but what if the "failures" weren't apparent until much later? Or what if the issue was at step 315 out of an hour-long agent run of 500 steps?
That's why Bench is a big deal. Not just a logger, but an audit trail that makes agent actions legible: every tool call, file change, conversation, subagent detail, all is there for you for as long as you need it, searchable and shareable. A great way to "share your context" to your colleagues, as well as being what I really needed to learn from my mistakes and improve in terms of prompt writing!
How deep does it go when tracking tool calls and file changes across a session?
I’ve been using Claude Code quite a bit, and I often lose track of what actually happened in a session. This idea of being able to go back and inspect everything feels really useful for me.
Being able to attach session history to PRs is a really smart idea. Makes collaboration much easier.
Hey folks! I’m Simone, Co-founder and CTO of Silverstream AI.
Really happy to be launching this today. I’m excited to share it, and very curious to hear your feedback!
One habit we’ve introduced across the team is linking Bench sessions in PRs whenever Claude Code was involved in creating or debugging a change. It gives reviewers a lot more context on how a bug was found and fixed, instead of just showing the final diff.
That’s been one of the most useful workflows for us, and I’d recommend it to other teams using Claude Code too.
I’m also using Bench in a research setting, where session data helps generate detailed methodology reports showing how results were obtained. I’m already finding it useful, and I think there’s a lot more to unlock there!
Looking forward to your thoughts. I want to make Bench as useful for other devs as it's been so far for us, and your input really matters!
Now add observability + failure handling, otherwise it’s just scheduled guessing.
How granular is the session tracking? Can you trace decisions step-by-step or it is more of a high level overview?
Nice.
Most people don’t need logs.
They need to understand why the agent made a bad decision and how to prevent it next time.
Cograts on the launch. I can see this becoming essential for teams using AI agents regularly, especially when debugging or reviewing work.
I've tackled similar challenges with code reviews and context sharing, and I love how Bench automates session storage. How do you handle sensitive data in stored sessions to ensure developers aren’t accidentally sharing proprietary code?
I love finding Claude Code related products daily on PH. This looks great!
How granular is the session tracking? Can you trace decisions step-by-step or it is more of a high level overview?
Hey Product Hunt! I'm Omar, Founding Researcher at Silverstream AI.
We originally built Bench as an internal tool to make debugging our own agents less painful, and it's become something I reach for every day.
My favorite part? The high-level run overview. When an agent run has hundreds of steps, being able to scan the whole thing at a glance and immediately spot where something went wrong is a huge time-saver. From there, I can zoom in all the way down to the model's reasoning traces at the exact step where things broke, which makes a real difference when you're trying to understand why an agent made a certain decision, not just what it did.
As we kept adding features, we realized Bench had become too useful to keep to ourselves, so here we are! 🚀
We're starting with Claude Code, but support for more agents is on the way. Give it a try and let us know what you think!
Hi everyone! 👋 I’m Giulio, co-founder and COO at Silverstream AI.
It feels like we’re all trying to buy back time these days. There’s always more to do, and never enough hours. That’s why I really think tools like Bench for Claude Code matter.
Agents are getting better fast, which means longer and more complex sessions. Hopefully more reliable too. But even as trust increases, I don’t think we’ll ever fully give up control. We’ll always want the option to see what they’re doing, as long as it doesn’t slow us down.
That’s exactly what we’re building Bench for.
If you try it out, I’d really appreciate your feedback. It’ll help us shape our product in the right direction.
I've been thinking about this for a while now. Traditional git style version control is not optimal for the AI coding era. You lose information from your claude code terminal or your AI coding tool of choice. Cool to see this getting productize. Congrats on launch!
Great looking observability layer to see what's happening behind the scenes! I think it will surely help teams optimize their processes.
Congrats on the launch!
Congratulations on the launch 🎉 🎉
Storing and reviewing sessions sounds like a developer convenience. But what's actually happening is something more interesting — you're creating a layer of reflection between execution and understanding.
Most tools help you move faster. This one helps you see what you did. That distinction matters more than most people realize, because the gap between building and knowing what you built is where most coordination breaks down.
This is useful. I use Claude through Cursor daily and half the time I wish I could go back and review what it actually changed across a session. Being able to store and review sessions would save a lot of second-guessing.
So basically you can use this to correct your other AI or just Claude ...