PH热榜 | 2026-03-28
一句话介绍:一款通过调用MacBook内置加速度计,使其在被拍打、摇晃时发出搞笑音效(如呻吟、山羊叫)的娱乐应用,在无聊或需要解压的场景下提供了一种无厘头的互动乐趣。
Funny
Side Project
Memes
娱乐应用
恶搞软件
Mac软件
解压工具
病毒式营销
趣味互动
加速度计应用
猎奇产品
极简产品
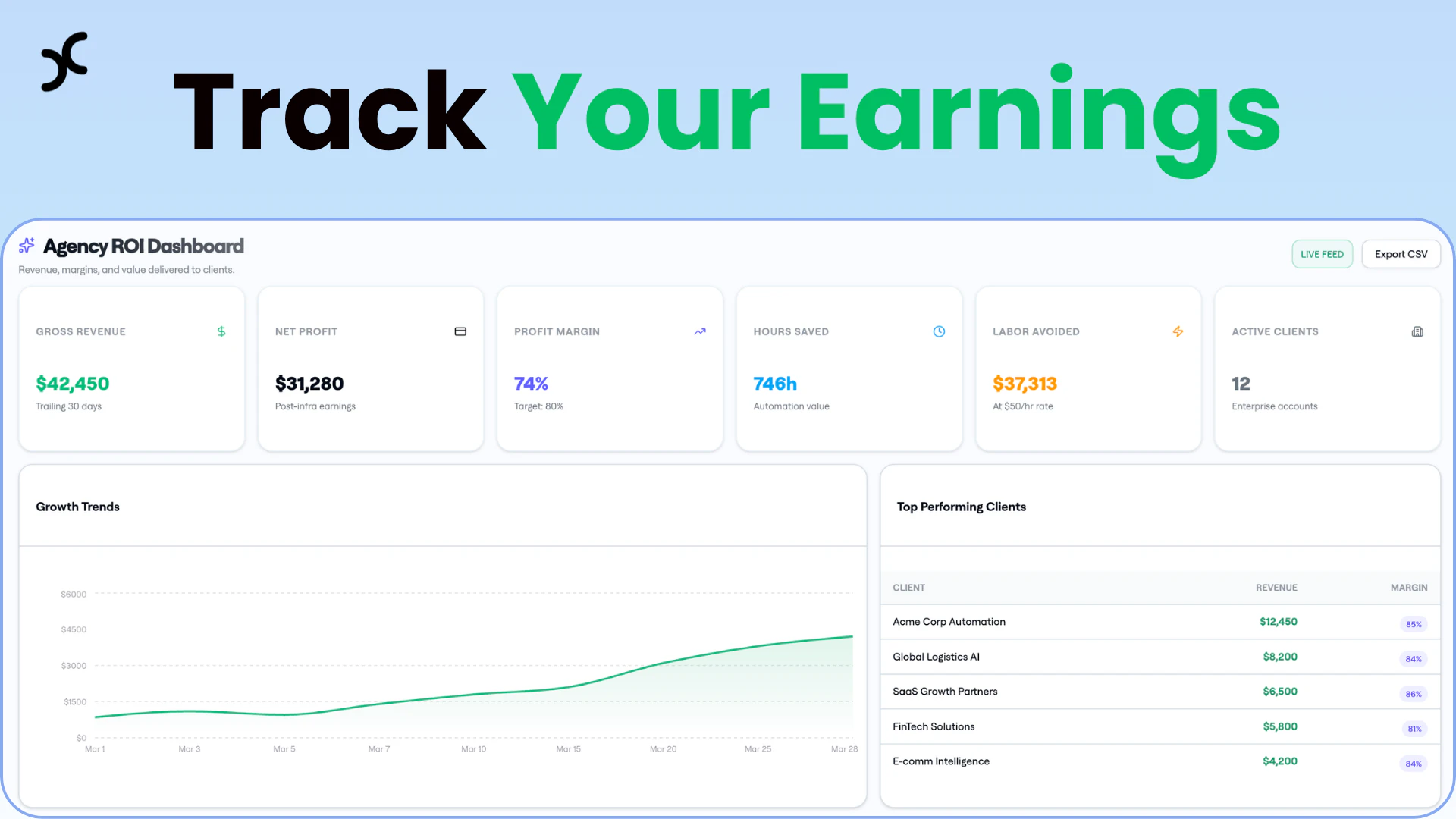
用户评论摘要:用户普遍认为产品有趣、疯狂且传播力惊人,对2千份销量表示惊讶。主要问题/建议包括:担心音效内容尺度、询问Windows/iOS版本开发计划、关注病毒传播后的长期营销策略、以及建议增加对AI工具的集成(MCP服务器)。
AI 锐评
SlapMac本质上是一个将硬件传感器功能娱乐化的极简Demo,其真正的价值并非产品本身,而是一次完美的“注意力经济”操盘案例。产品逻辑简单到近乎荒谬,却精准击中了几个关键点:利用MacBook这一高价值设备的“反差萌”、社交媒体对猎奇和“梗”内容的饥渴、以及极低的决策成本(3.5美元)。创始人Tonino展现了一个资深工程师被市场“教育”后的快速反应能力:从Instagram上发现需求(评论询问),到24小时内快速打包上线,完成从创意到商品的闪电转化。
它的成功揭露了当前产品生态的一个侧面:在注意力稀缺时代,一个具有强传播属性的“玩具”或“社交货币”,其短期爆发力可能远超一个复杂但平庸的“工具”。2千份销量的背后,是数千万的社交流量,转化率本身已不重要,它验证了“快速构建-投放市场-获取反馈”这一精益理念的极端形式。然而,其核心风险也在于此: novelty wears off(新奇感消退)。评论中关于长期营销的疑问直指要害。产品的未来不在于增加更多音效,而在于能否从“一次性玩笑”进化为一个“娱乐平台”或“互动API”(如评论中提到的MCP服务器集成),将这种无厘头交互能力赋予更多场景,例如直播道具或团队恶作剧工具包。否则,它将只是创始人简历上一个有趣的注脚,以及科技圈一个短暂的谈资。它提醒我们:有时,“不要想太多,先发布”的莽撞,比完美的拖延更能触及市场的真实脉搏。
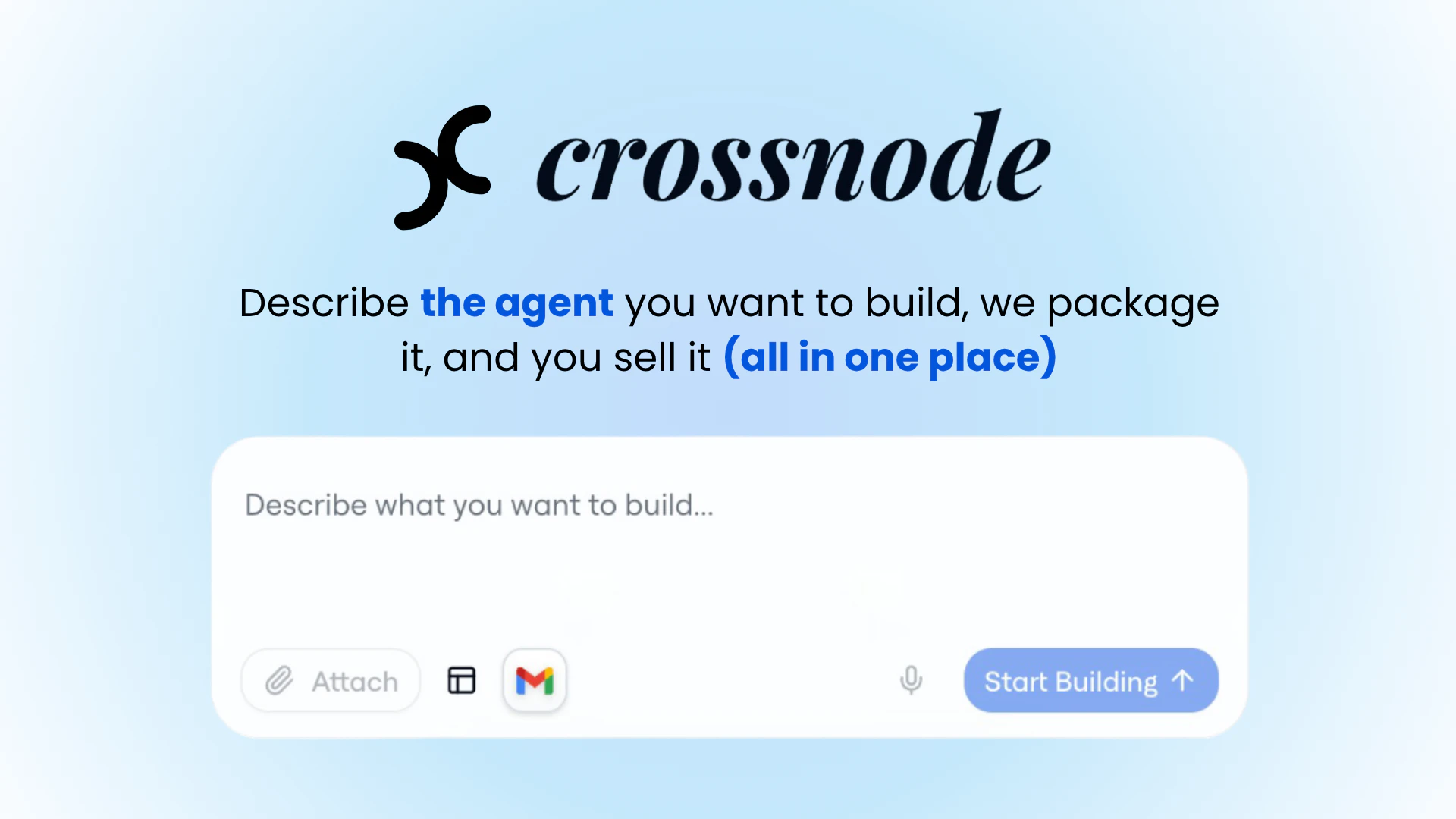
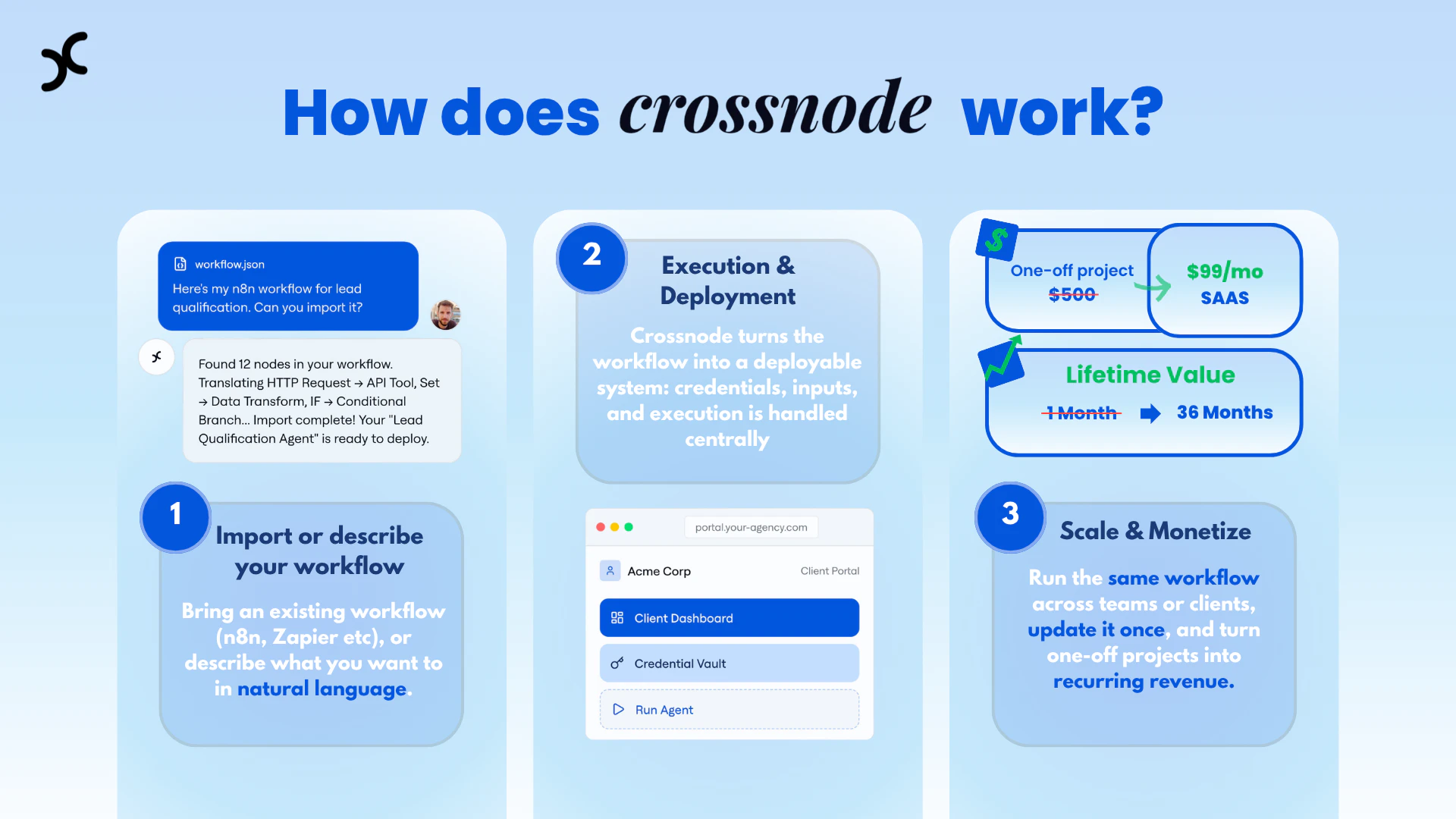
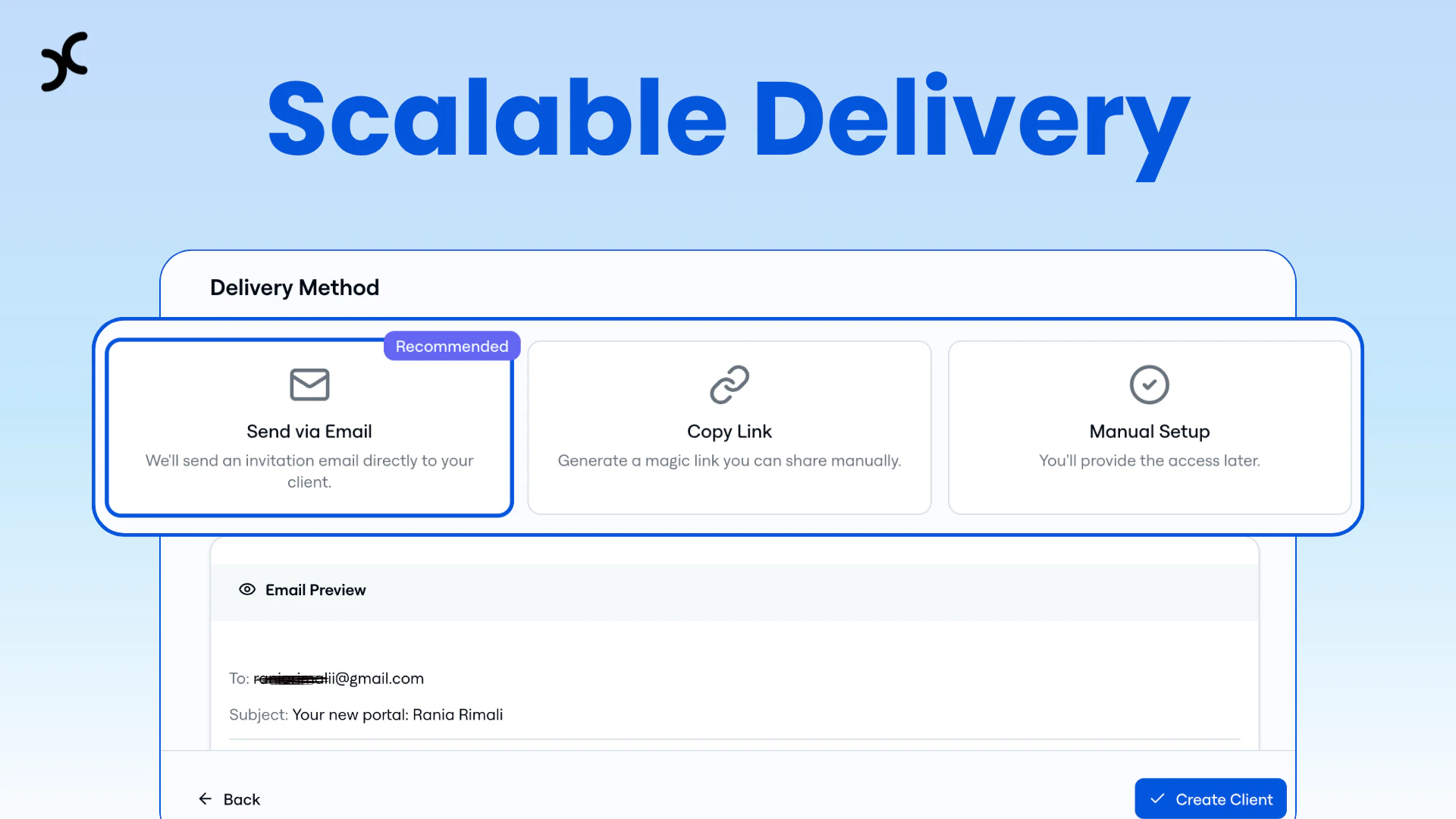
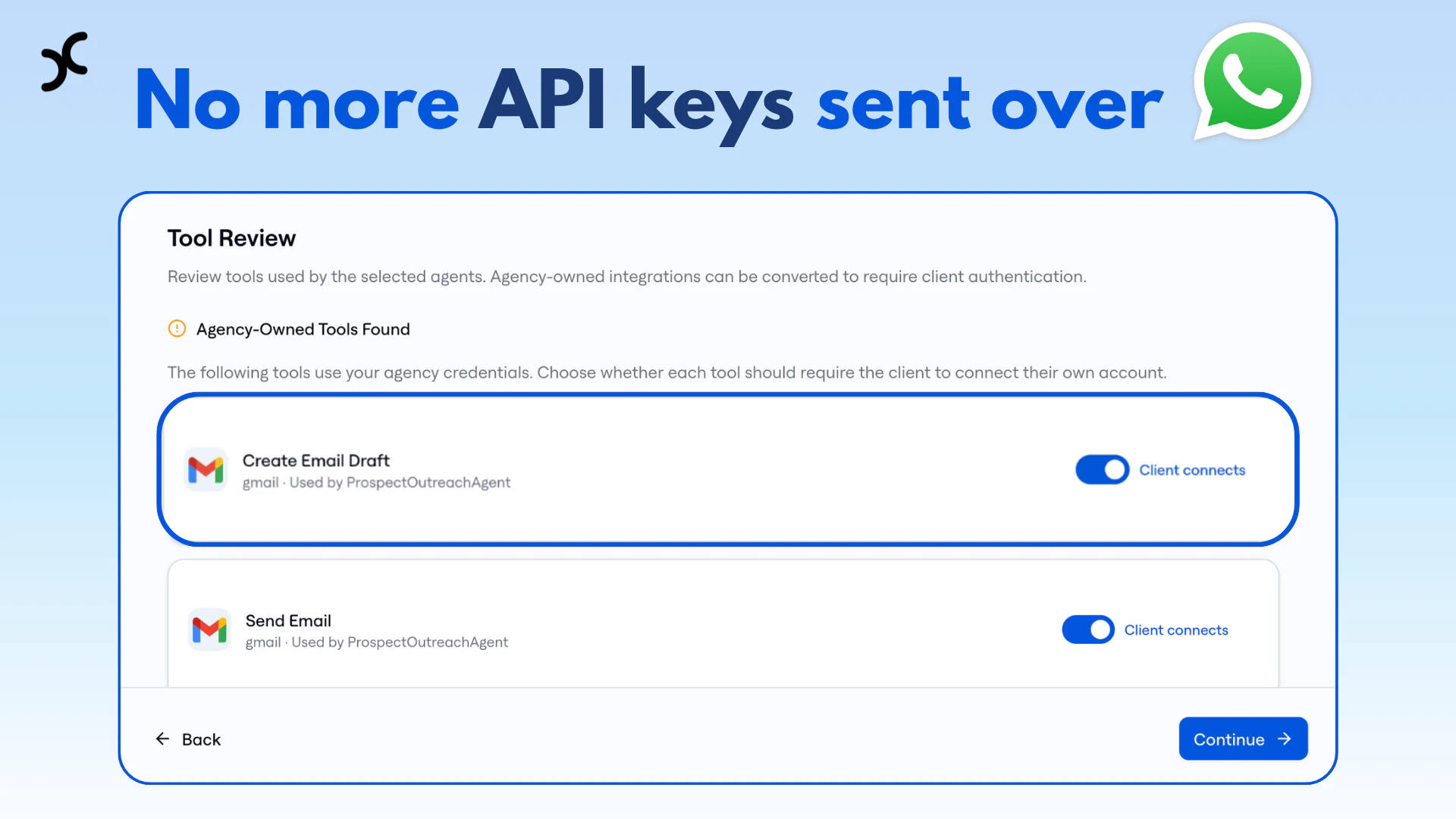
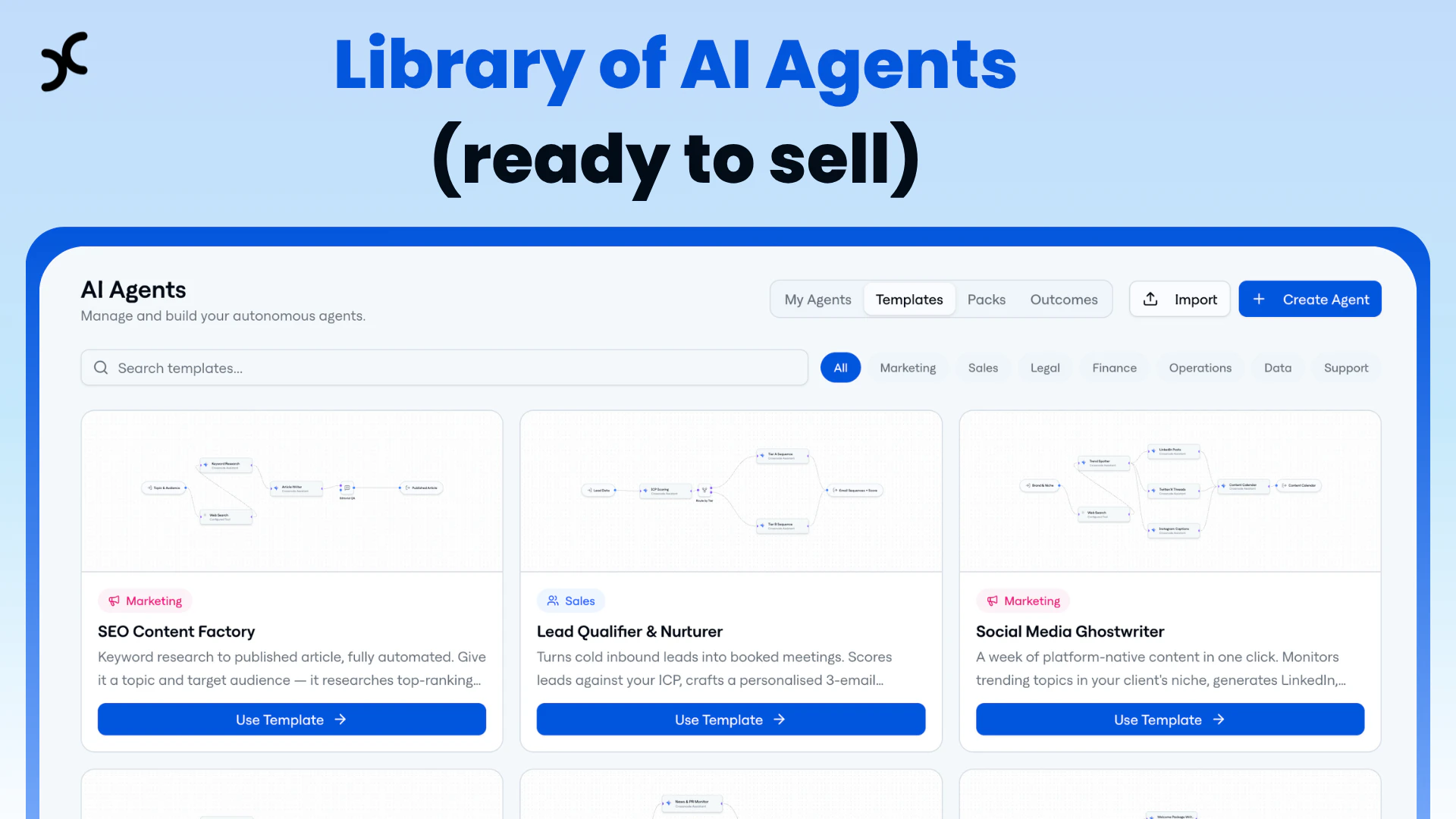
一句话介绍:Crossnode是一个让AI开发者和机构能够将AI工作流或智能体快速打包成可重复销售、自带计费和客户管理的白标SaaS产品的平台,解决了为不同客户重复部署、集成和手动管理所带来的规模化难题。
Artificial Intelligence
No-Code
Business
AI智能体商业化
无代码/低代码平台
SaaS产品化工具
白标解决方案
工作流自动化
多租户部署
集成支付与计费
凭证安全管理
代理即服务
企业级AI运维
用户评论摘要:用户普遍认可其解决“为每个客户重复构建”的核心痛点,创始人亲身经历增强了可信度。主要问题集中在:版本更新策略、凭证安全与数据合规细节、API支持、支付方式灵活性(如印度市场替代方案),以及技术架构的可靠性。
AI 锐评
Crossnode的野心不在于打造另一个AI智能体构建器,而在于成为“AI服务规模化”的基础设施。它敏锐地刺中了当前AI代理热潮下一个隐秘而关键的瓶颈:如何将实验性的、项目制的AI工作流,转化为稳定、可重复、可计费的标准化产品。其价值并非来自技术上的颠覆性AI突破,而是来自对商业化路径中那些“脏活累活”——计费、鉴权、多租户隔离、白标交付——的系统性封装。
产品呈现出明显的“由痛点到产品”特征,创始人的Agency背景使其对目标客户(AI服务机构、自由职业者)的运营泥潭有切肤之痛。这解释了其初期吸引力:它提供的不是可能性,而是解脱。将Zapier/n8n工作流直接转化为可收费服务的能力,是极具说服力的“增长黑客”策略,旨在快速捕获早期采用者。
然而,其长期挑战同样清晰。首先,它本质上是一个“平台之上的平台”,深度依赖下游AI服务(如OpenAI、Anthropic)与上游集成工具(如Slack、Gmail)的API稳定性与政策,自身作为管道,抗风险能力需要验证。其次,其宣称的“自我修复”等高级运维能力,在复杂的企业级场景中能否经受住考验,仍有待观察。最后,其商业模式是否足够厚实?如果巨头(如微软Power Platform、Zapier自身)决定向类似“AI工作流产品化”方向延伸,Crossnode的护城河——对细分痛点的深度理解与敏捷开发——能否抵御冲击?
简言之,Crossnode是AI应用浪潮步入“深水区”的一个标志性产物。它不再鼓吹AI的万能,而是务实地面向那些试图用AI赚钱的构建者,提供将创意转化为可持续生意的工具箱。它的成功与否,将成为衡量AI代理领域能否从“演示阶段”迈向“商业阶段”的重要试金石。
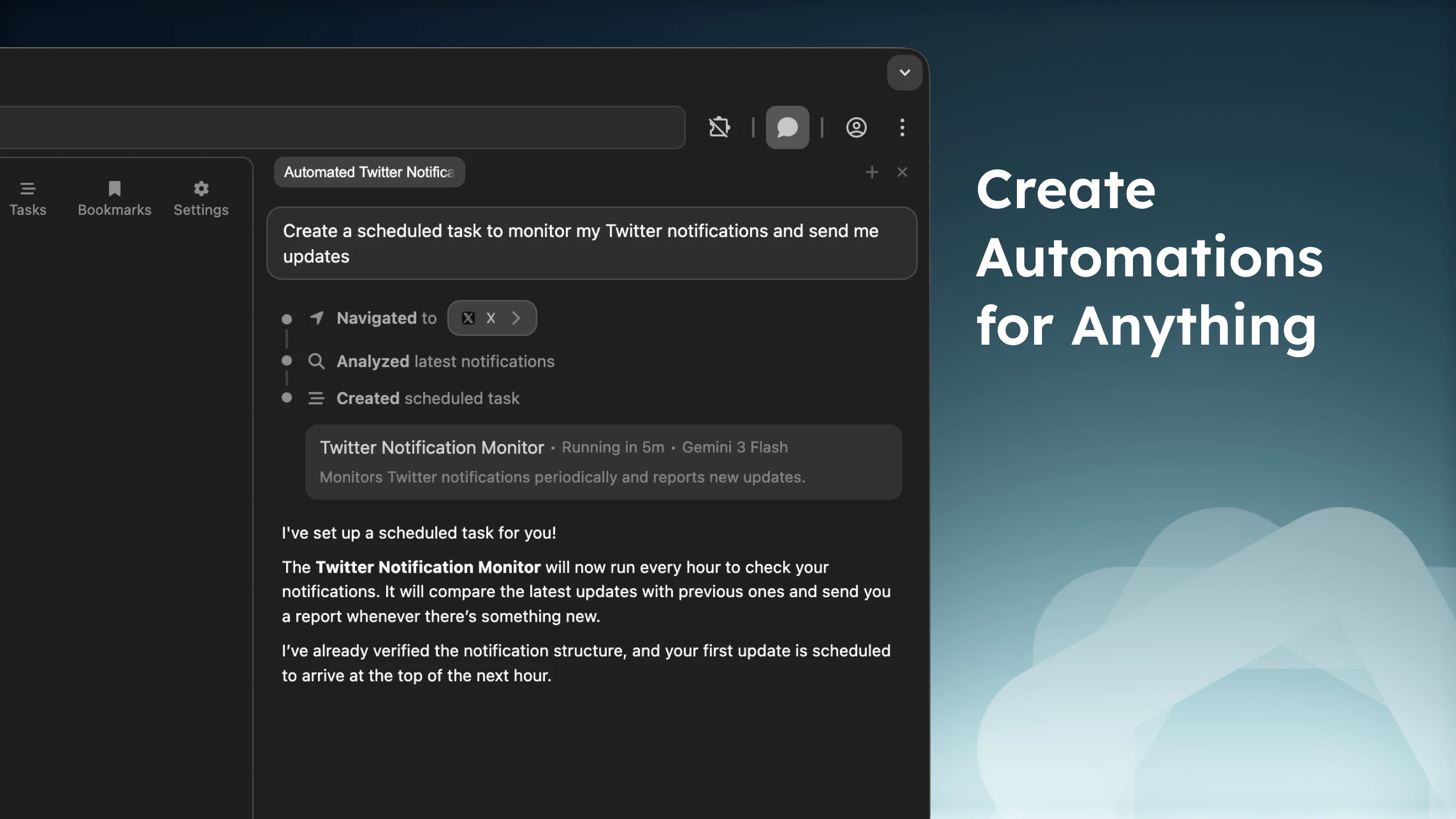
一句话介绍:Aera Browser是一款为自动化真实工作流而构建的浏览器,允许用户创建并自动执行跨网站的复杂任务,解决了传统自动化工具难以处理上下文、易中断且无法实际执行操作的核心痛点。
Artificial Intelligence
浏览器自动化
智能体浏览器
工作流自动化
RPA
本地隐私
MCP集成
自主执行
Chromium内核
无代码自动化
后台任务
用户评论摘要:用户普遍对MCP集成和实际执行能力表示高度兴趣,认为这是区别于仅提供建议的AI工具的关键。主要问题集中在:1. 如何应对复杂网站及防爬机制(开发者回复通过深度集成Chromium模拟人类交互解决);2. 是否支持多任务并行;3. 与主流浏览器的基础性能对比。另有用户主动提出付费测试服务。
AI 锐评
Aera Browser的野心不在于做一个更好的浏览器,而在于成为连接AI智能体与现实数字世界的“执行层”。其真正的颠覆性价值体现在两个层面:第一,它通过深度修改Chromium内核,将自动化引擎植入浏览器底层,试图从根本上解决传统RPA或扩展脚本在动态网页面前脆弱、易失效的顽疾,其宣称的模拟人类交互与视觉验证是技术上的关键赌注。第二,也是更具战略眼光的一步,是内置MCP(模型上下文协议)。这使它从单一的自动化工具,升级为AI智能体的“手和眼”。当Cursor、Claude Code等编码智能体能直接调用浏览器执行任务,而不仅仅是生成代码建议时,人机协作的范式才可能发生质变——从“AI建议,人操作”变为“人指挥,AI全栈执行”。
然而,光环之下隐忧并存。作为个人开发者项目,其工程复杂度和长期维护能力面临严峻考验,尤其是对抗日益复杂的反机器人检测是一场永无止境的军备竞赛。此外,其商业模式依赖的“更高性能模型与视觉工具”的订阅制,可能将核心能力设限,免费版能否提供足够的稳定性和能力以形成网络效应存疑。当前AI智能体领域仍处于“建议多,执行少”的探索期,Aera提前卡位执行枢纽的位置颇具前瞻性,但其成功与否,不仅取决于技术可靠性,更取决于能否吸引到足够多的智能体平台与其共建生态,否则将面临孤掌难鸣的窘境。它不是在挑战Chrome,而是在试图成为下一代AI原生操作系统的入口。
一句话介绍:一款通过重新组织邮件会话视图、隐藏AI摘要和简化界面来提升Gmail可读性与管理效率的浏览器扩展,主要解决了用户在繁杂邮件线程中难以快速定位关键信息、界面干扰过多的痛点。
Chrome Extensions
Email
Gmail增强工具
浏览器扩展
邮件管理
界面简化
隐私保护
本地处理
生产力工具
用户体验优化
用户评论摘要:用户普遍赞赏其核心免费功能与隐私保护(本地运行、无需账户)。主要疑问与建议集中在:隐私安全的具体保障措施、对复杂/混乱邮件线程的处理能力、未来商业化计划,以及对标签管理、深色模式等扩展功能的期待。
AI 锐评
Apparent for Gmail 揭示了一个残酷的现实:即便如Gmail这般统治市场20年的巨头产品,其基础用户体验仍存在令人费解的“未完成感”。这款产品的真正价值,不在于技术颠覆,而在于对用户“隐性痛苦”的精准缝合——将那些用户已近乎麻木的痛点(如强制AI摘要、反直觉的会话排序、视觉杂乱)重新摆上台面,并通过极简、本地的技术路径予以解决。
其“无需账户、本地运行”的核心主张,在当下云端与AI数据饥渴症泛滥的背景下,构成了一种尖锐且讨巧的价值观营销。它巧妙地将自己定位为“用户主权”的捍卫者,与平台可能的“数据越界”行为形成对立,这既是产品亮点,也是其最有效的增长杠杆。然而,这种定位也带来了深层挑战:作为一款深度依附于Gmail UI的扩展,其功能边界被严格限定在“视图层优化”,难以触及更复杂的邮件逻辑(如标签、过滤器)。评论中关于处理混乱线程的提问,恰恰刺中了其天花板——它擅长重新排列已知信息,却缺乏真正的信息优先级算法来“理解”内容。
创始人关于未来通过“自动化功能”进行商业化的构想,隐约透露出免费工具寻求可持续性的经典路径。但这条路布满荆棘:高级自动化功能很可能需要更高的数据权限或云端处理,这与当前极力宣扬的“本地、隐私”核心卖点可能产生根本性冲突。产品此刻的成功,源于其克制与聚焦;而未来的考验,则在于如何在商业化和价值观之间取得平衡,避免陷入自我悖论。本质上,它是一面镜子,既照出了Gmail的傲慢与疏忽,也映照出轻量级工具在平台生态中“修补”与“依附”的永恒矛盾。
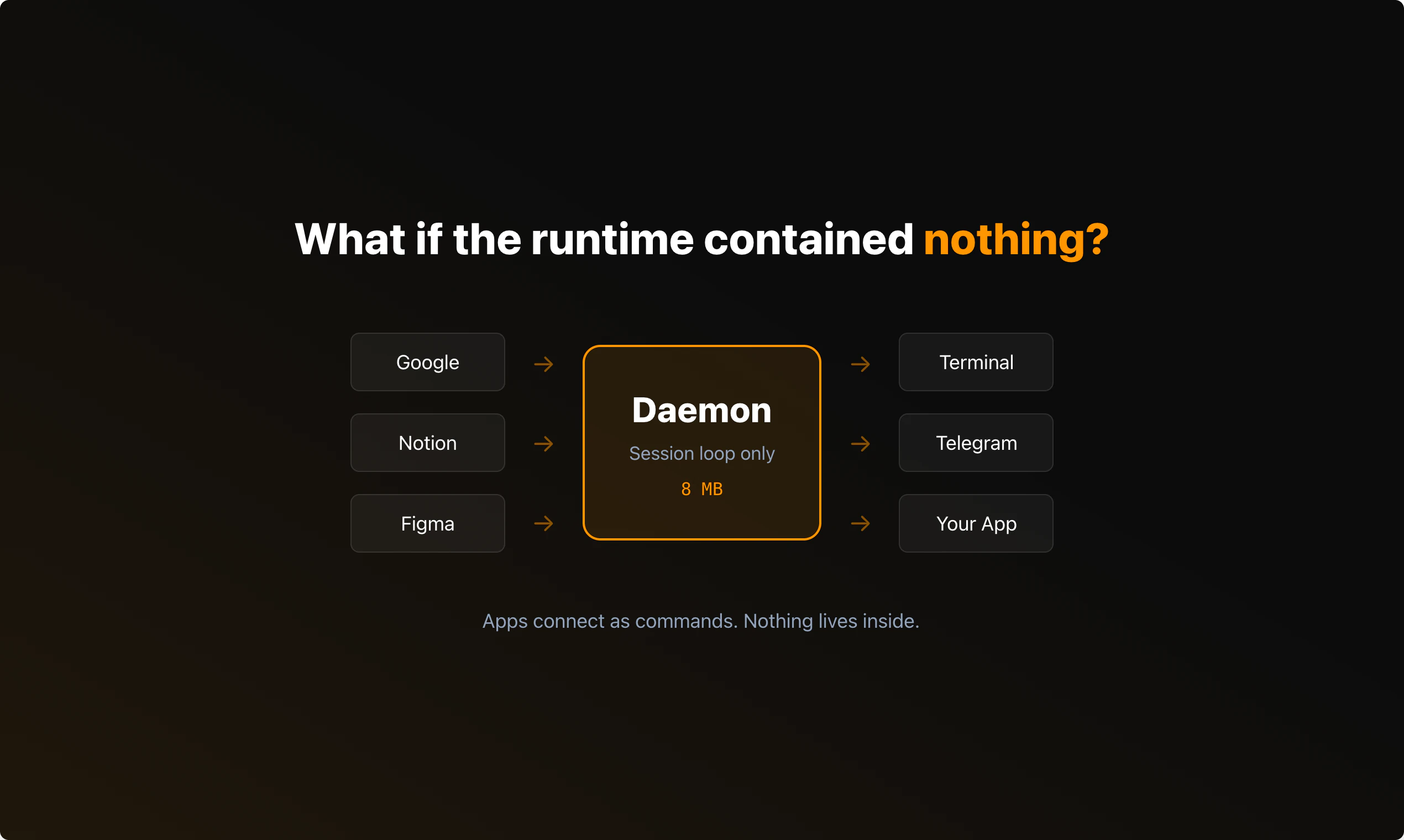
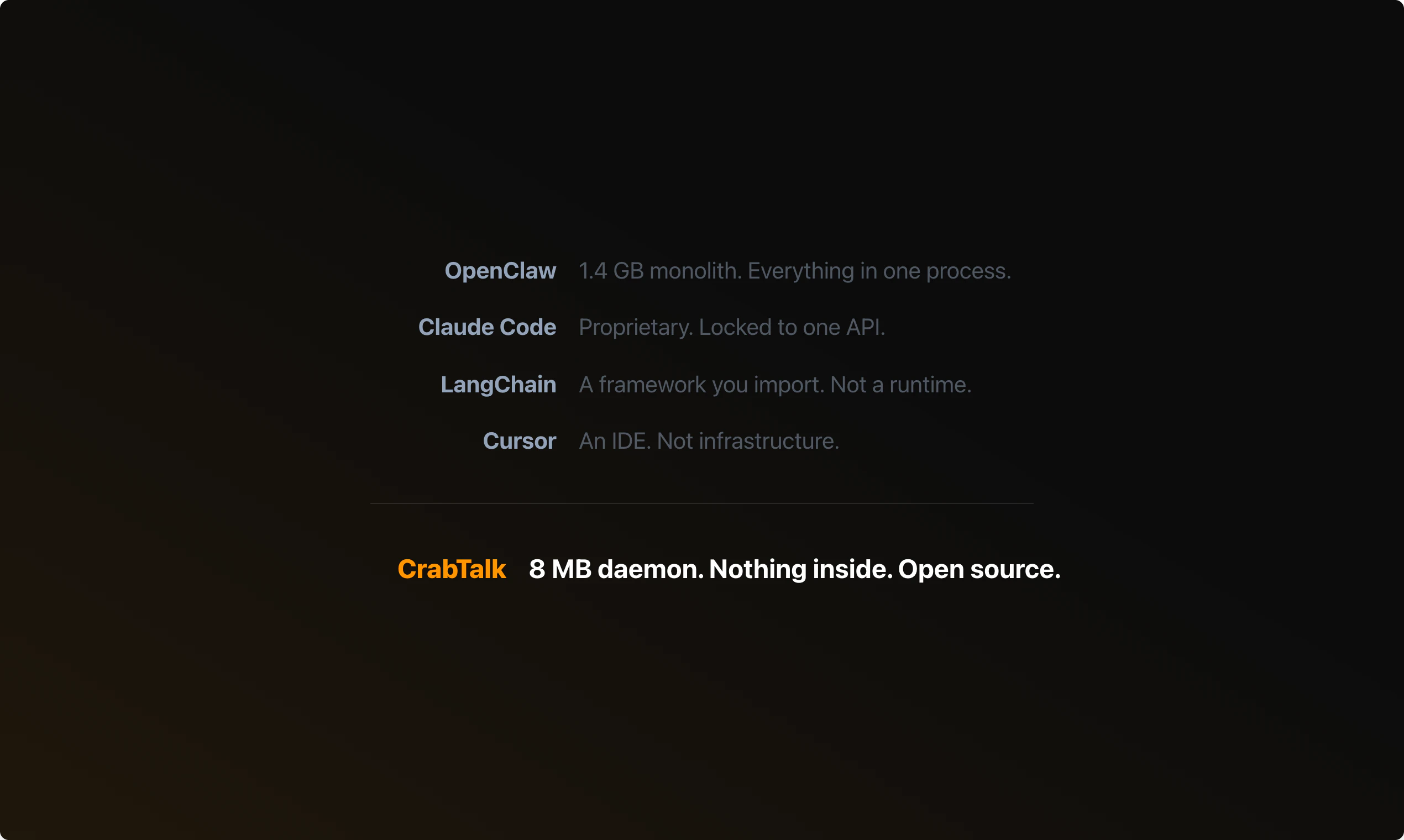
一句话介绍:CrabTalk 是一款仅8MB的开源AI智能体守护进程,通过流式传输所有思考步骤与工具调用事件,为开发者提供了高度模块化、可定制且稳定的底层架构,解决了现有智能体框架臃肿、捆绑过多工具和缺乏透明度的痛点。
Developer Tools
Artificial Intelligence
GitHub
AI智能体框架
开源
轻量化
模块化设计
守护进程
事件流
Rust
开发工具
可观测性
用户评论摘要:用户普遍赞赏其8MB轻量化与模块化设计,认为其底层定位优于竞品。主要问题集中于:组件故障如何反馈给智能体、并发工具调用的流式连贯性、事件流的反压处理机制,以及热重载是否会中断长任务。开发者对部分问题进行了技术性回复。
AI 锐评
CrabTalk 的发布,与其说是一个新AI应用,不如说是一份对当前智能体开发范式臃肿化的“抗议书”。其核心价值不在于提供了更强的AI能力,而在于通过“守护进程+事件流”的极简架构,重新定义了智能体与工具、运行时与客户端的关系。它将智能体“黑箱”运作彻底透明化,让每一步思考、每一次工具调用都成为可观察、可管理的流式事件。
这背后是深刻的工程哲学:反对捆绑,倡导组合。开发者不再被迫接受一个包含数十种工具、体积庞大的运行时,而是可以自主选择并挂载所需组件(搜索、网关等)。这种“组件独立崩溃、可热插拔”的设计,提升了系统整体的健壮性与可维护性。从评论看,资深开发者对此理念共鸣强烈,其问题也直指分布式系统核心:故障隔离与反馈、并发一致性与背压处理。
然而,其定位也决定了它的门槛和局限。它提供的是“管道”和“协议”,而非“成品”。真正的生产力提升依赖于在其上构建应用。对于追求开箱即用的普通用户或应用开发者,它可能过于底层;但对于需要深度定制、构建稳定企业级智能体工作流或二次开发框架的团队,CrabTalk 提供了一个珍贵且干净的底层选择。它能否成功,不在于自身功能多寡,而在于其构建的生态能否吸引足够多的“组件”提供者和“客户端”开发者。这是一场对开发效率与自主控制权的重新分配。
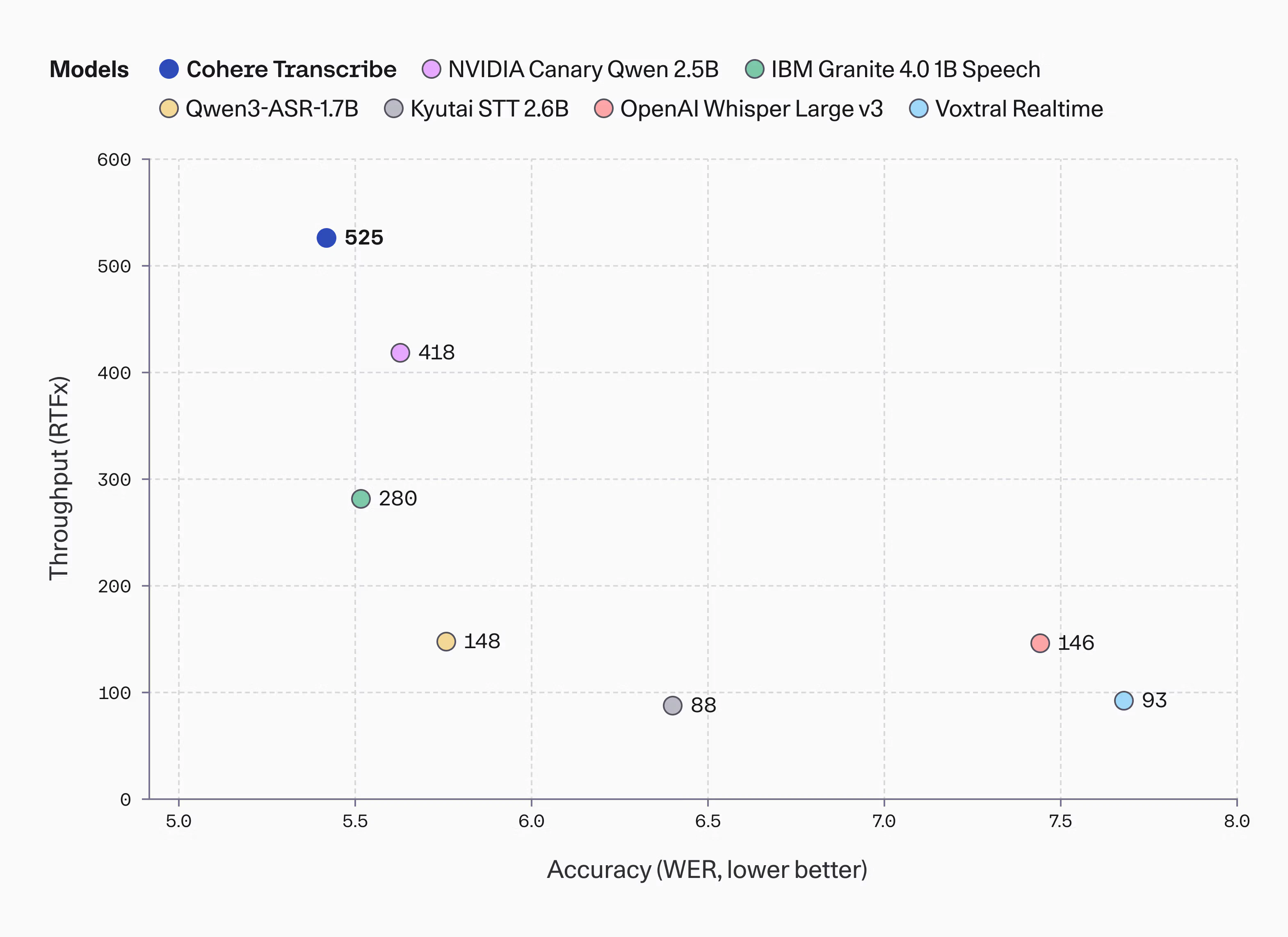
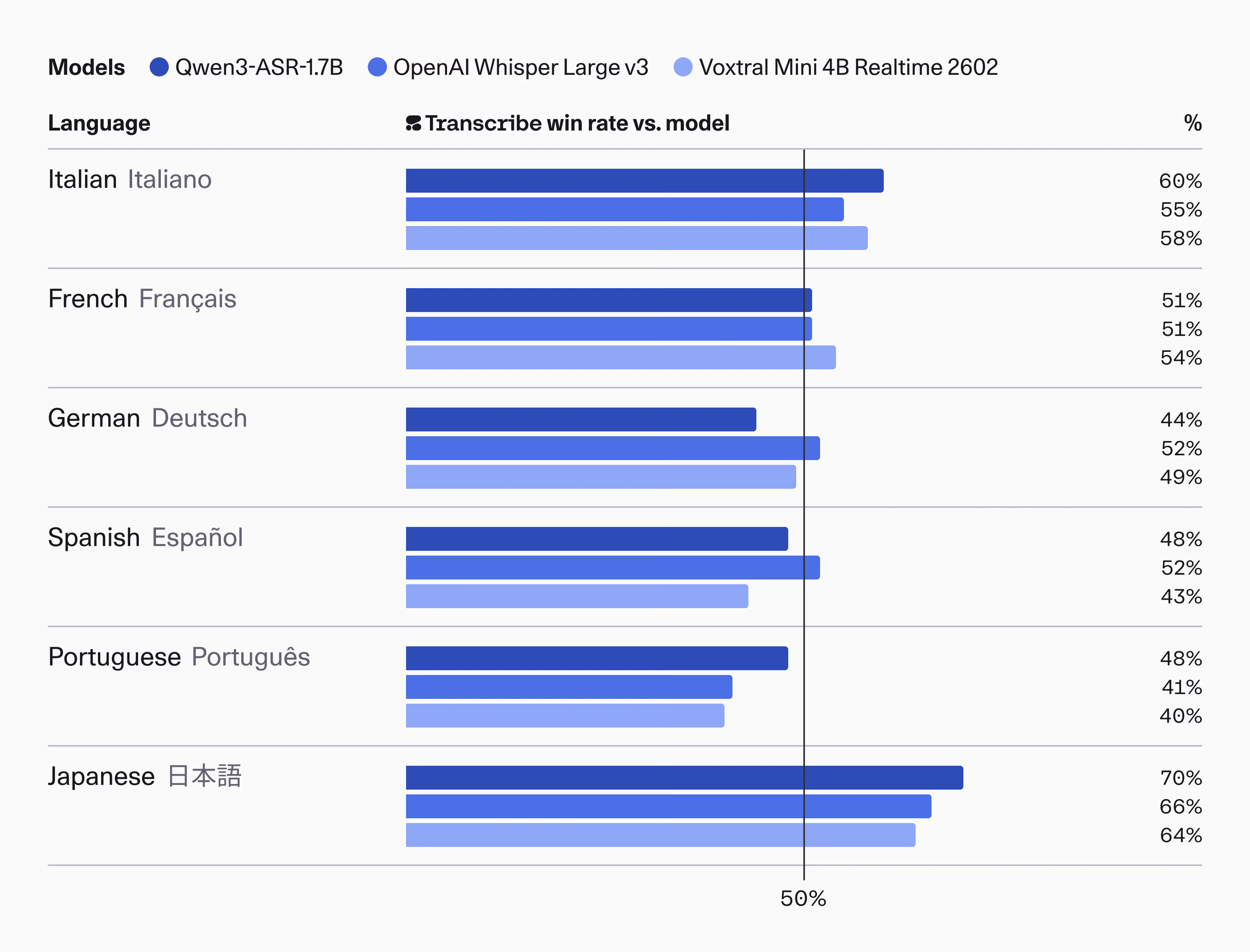
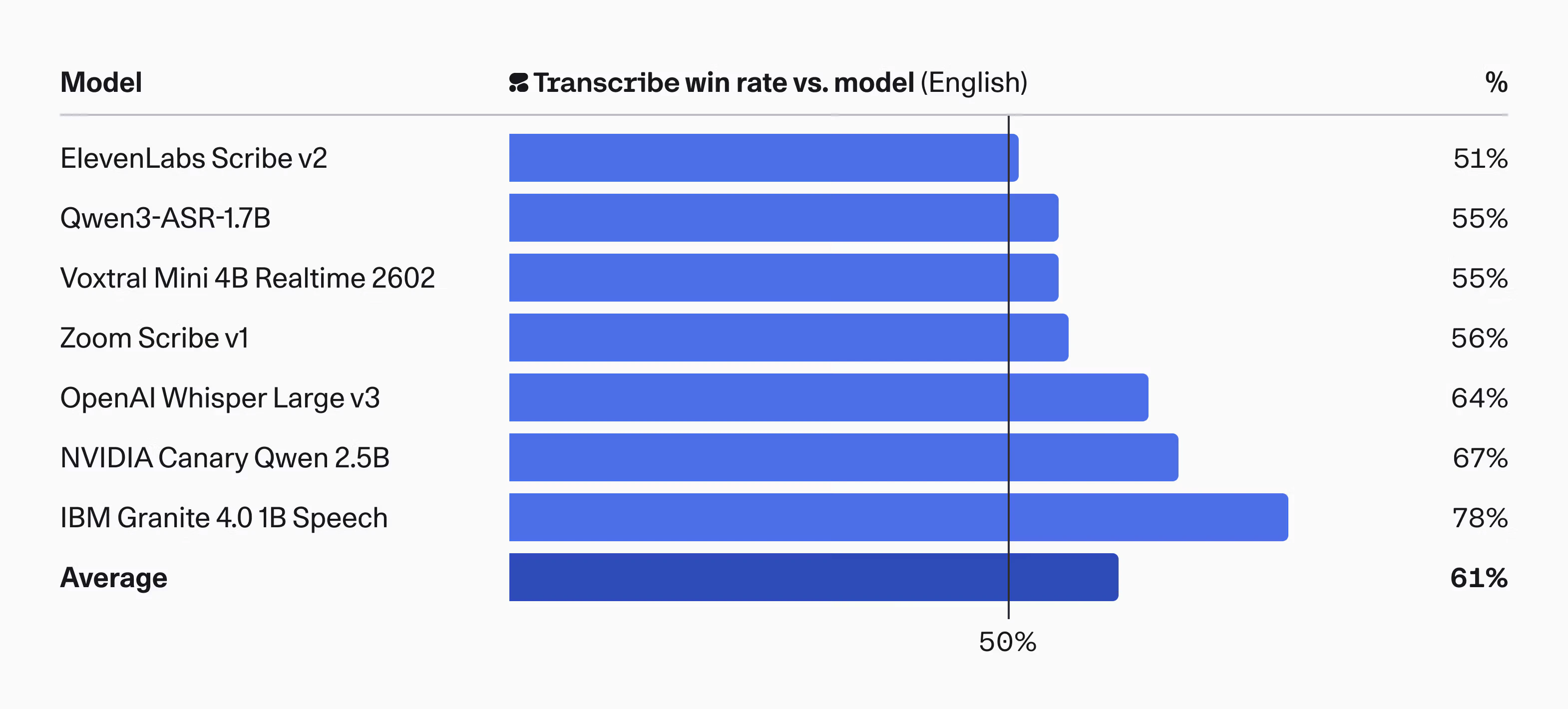
一句话介绍:Cohere Transcribe是一款顶尖的开源语音识别模型,通过提供高吞吐量和低词错率,解决了企业在隐私敏感场景下需要本地化、高性能转录服务的痛点。
Open Source
Artificial Intelligence
Audio
语音识别
开源模型
企业级应用
本地部署
隐私安全
多语言支持
高精度转录
人工智能
音频处理
用户评论摘要:用户普遍认可其高性能与隐私优势,认为其是企业级本地应用的优秀选择。主要问题与建议集中在:模型体积对移动端部署的适应性、需自行添加说话人分离和时间戳等后处理功能、对复杂环境(如噪音、口音、语种切换)的鲁棒性测试,以及与竞品的详细对比和定价信息。
AI 锐评
Cohere Transcribe的发布,绝非又一个“开源Whisper”的简单故事,而是一份精准切入企业AI基础设施赛道的战略宣言。其核心价值不在于在学术指标上碾压对手,而在于将“开源权重”、“高吞吐量”与“企业级优化”这三个关键词捆绑销售,直指当前AI工业化部署中最敏感的神经:数据隐私、成本控制与自主可控。
产品介绍中强调“private, local, or desktop deployment”,与评论中“privacy-first”的共鸣,揭示了其真正的战场——那些受严格监管或对数据出境有顾虑的行业,以及不愿被API调用次数和费用捆绑的规模化应用。5.42%的词错率(WER)是入场券,而“高吞吐量”才是其为企业设计的真正引擎,意味着更低的单位转录成本和更强的批处理能力,这比单纯追求零点几个百分点的精度提升,对CIO而言更具吸引力。
然而,评论也犀利地戳穿了其“开箱即用”的幻象。缺乏说话人分离、词级时间戳等特性,使其更像一个强大的“听觉芯片”,而非完整的“听觉系统”。这暴露了Cohere的定位:它并非意图服务追求便捷的开发者,而是瞄准了那些拥有工程能力、需要深度定制和集成、并将转录作为核心流程一环的企业客户。将复杂的前后处理留给用户,自己则牢牢占据模型层这一价值制高点。
与Whisper的对比是不可避免的。Cohere的策略是“以专打泛”。在通用性、易用性和社区生态上,短期内难以撼动Whisper。但其通过企业级优化和明确的隐私本地化部署路径,实现了差异化突围。它回答了一个关键问题:当开源模型的性能差距进入“毫厘之间”时,决胜的关键是什么?答案是:对特定场景(企业私有化)的深度优化,以及对商业化诉求(吞吐量与成本)的精准满足。
风险同样明显。2B参数的“重量级”身材,与“移动端”、“实时”等边缘计算趋势存在张力。若不能通过量化、蒸馏等手段有效“瘦身”,其应用场景将被固守在服务器机房,可能错失更广阔的实时交互设备市场。此外,在噪音、口音等真实世界混沌场景下的稳健性,仍是所有语音模型需要自证的难题,Cohere仍需用更丰富的基准测试来建立信任。
总而言之,Cohere Transcribe是一款极具战略意图的“B端武器”。它不讨好所有人,而是为特定战场(隐私优先、高吞吐需求的企业环境)提供了一款精良、自主且高效的装备。它的成功与否,将不取决于极客社区的欢呼,而取决于有多少企业将其嵌入自己的核心工作流。
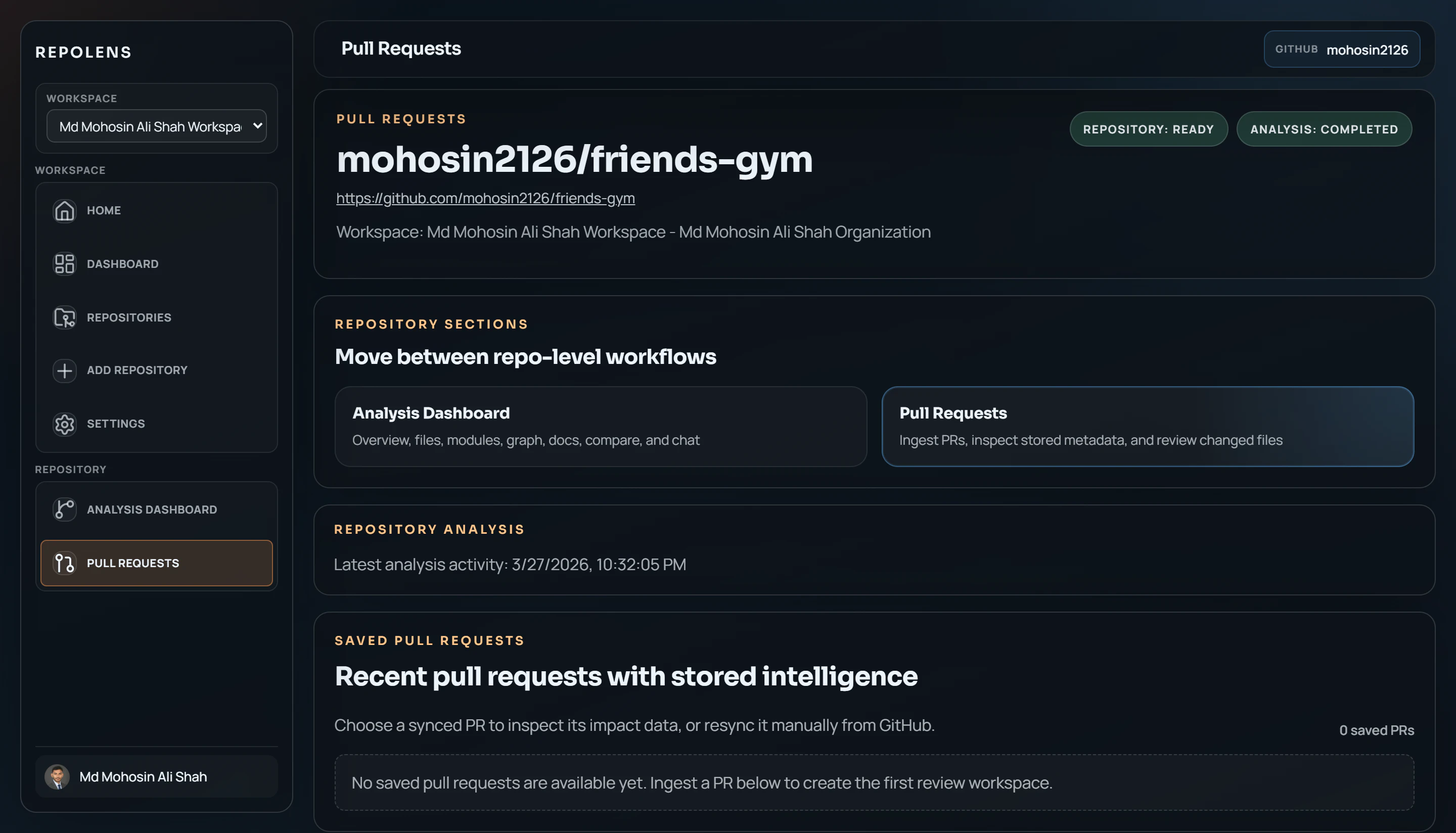
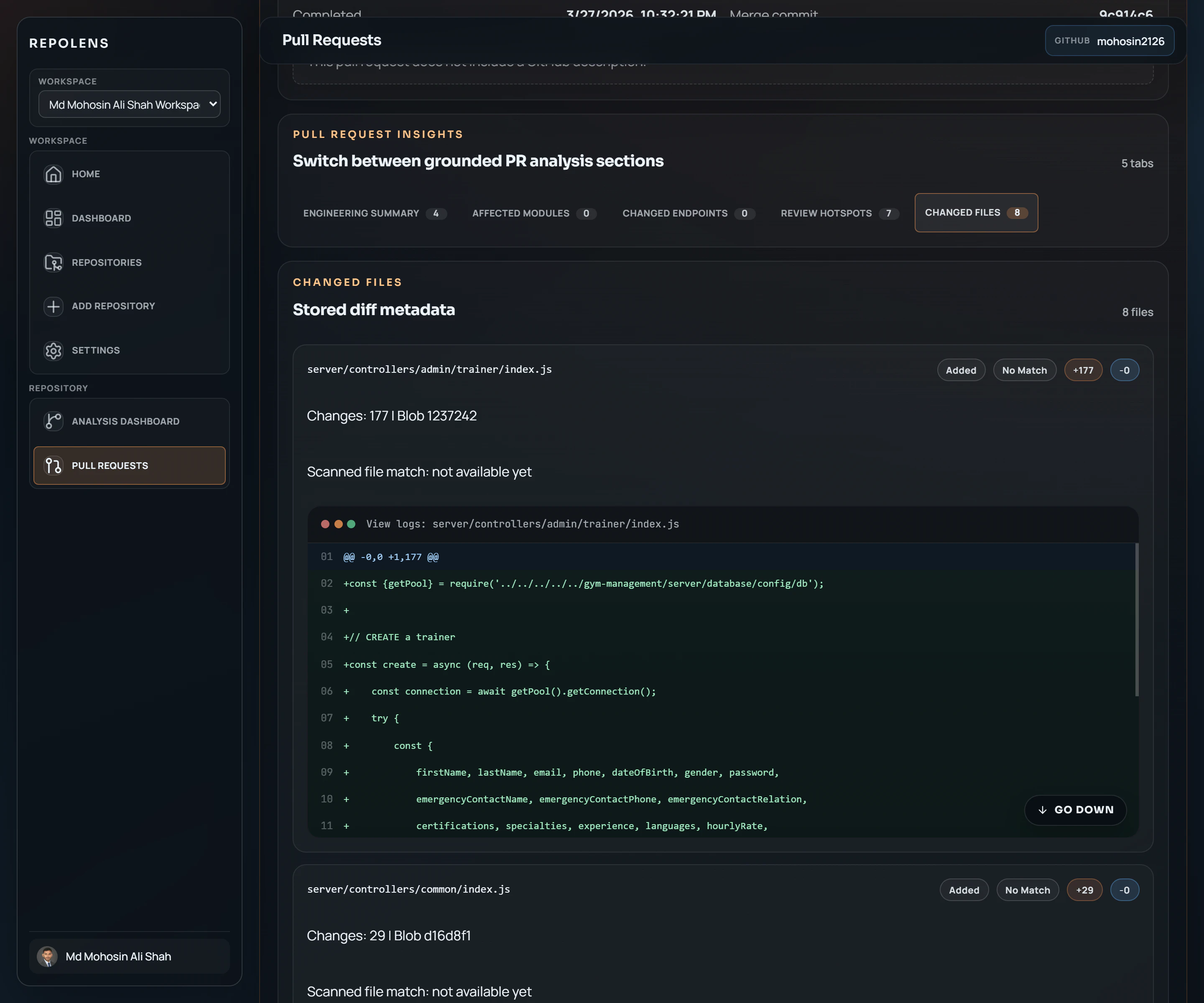
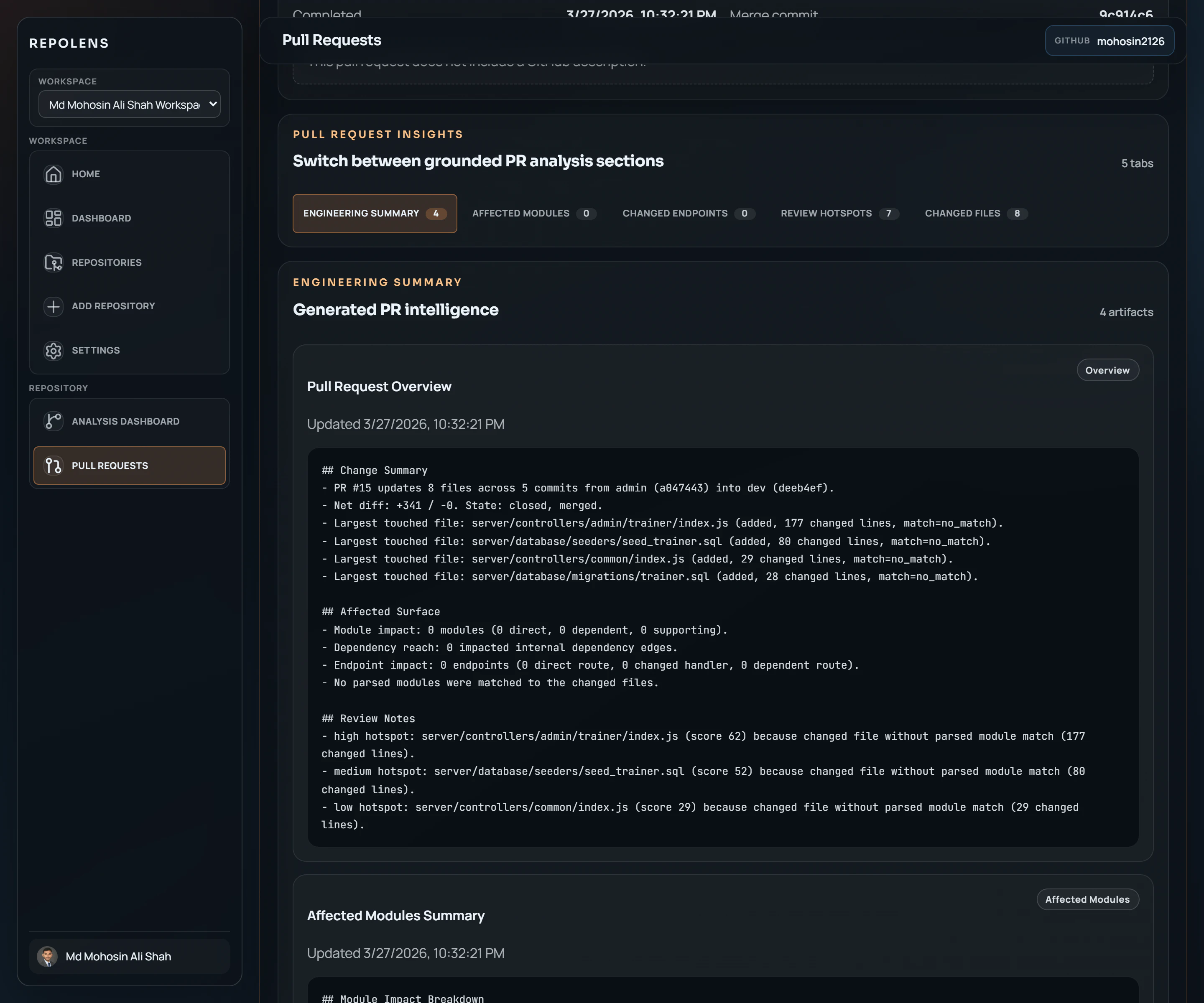
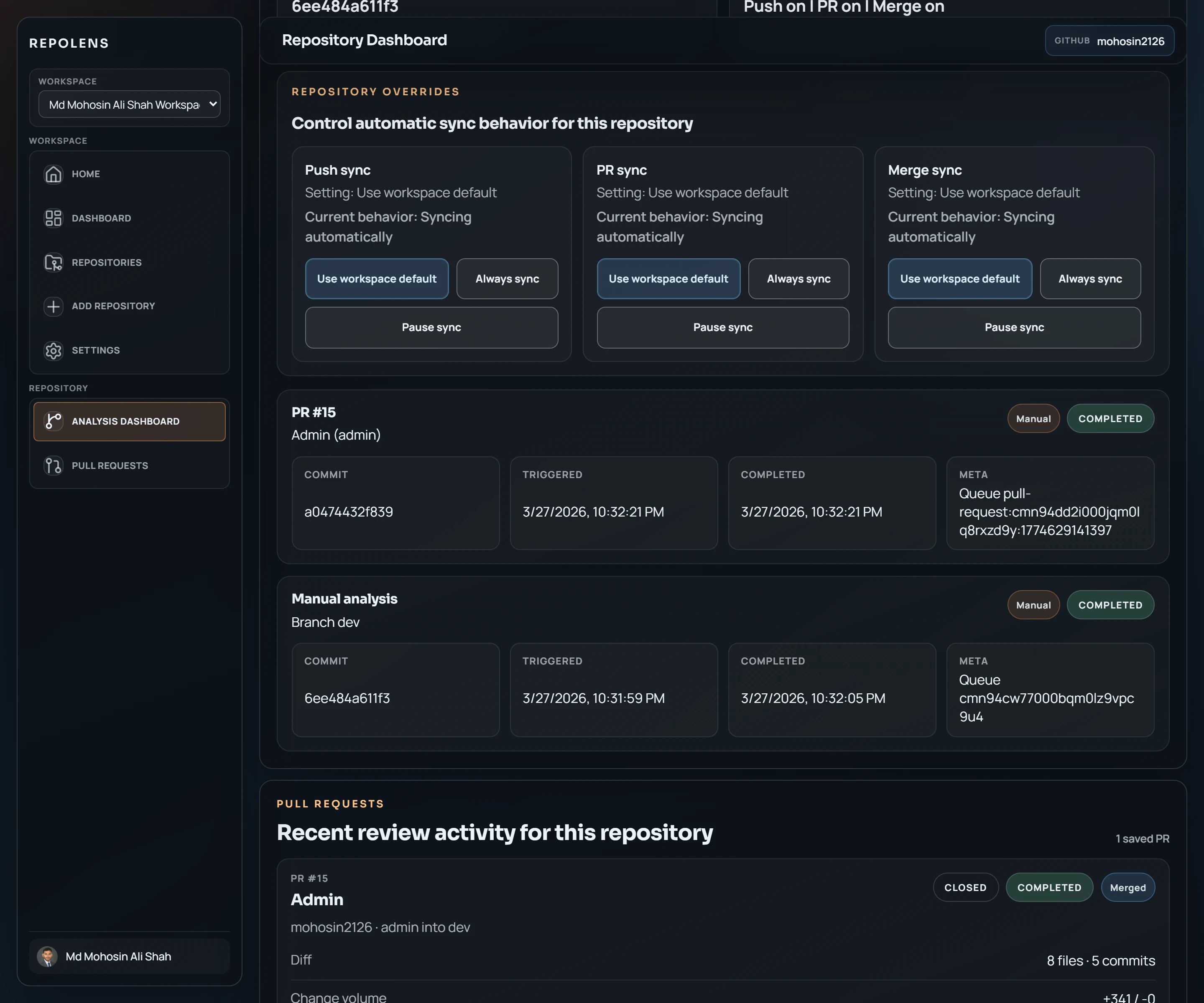
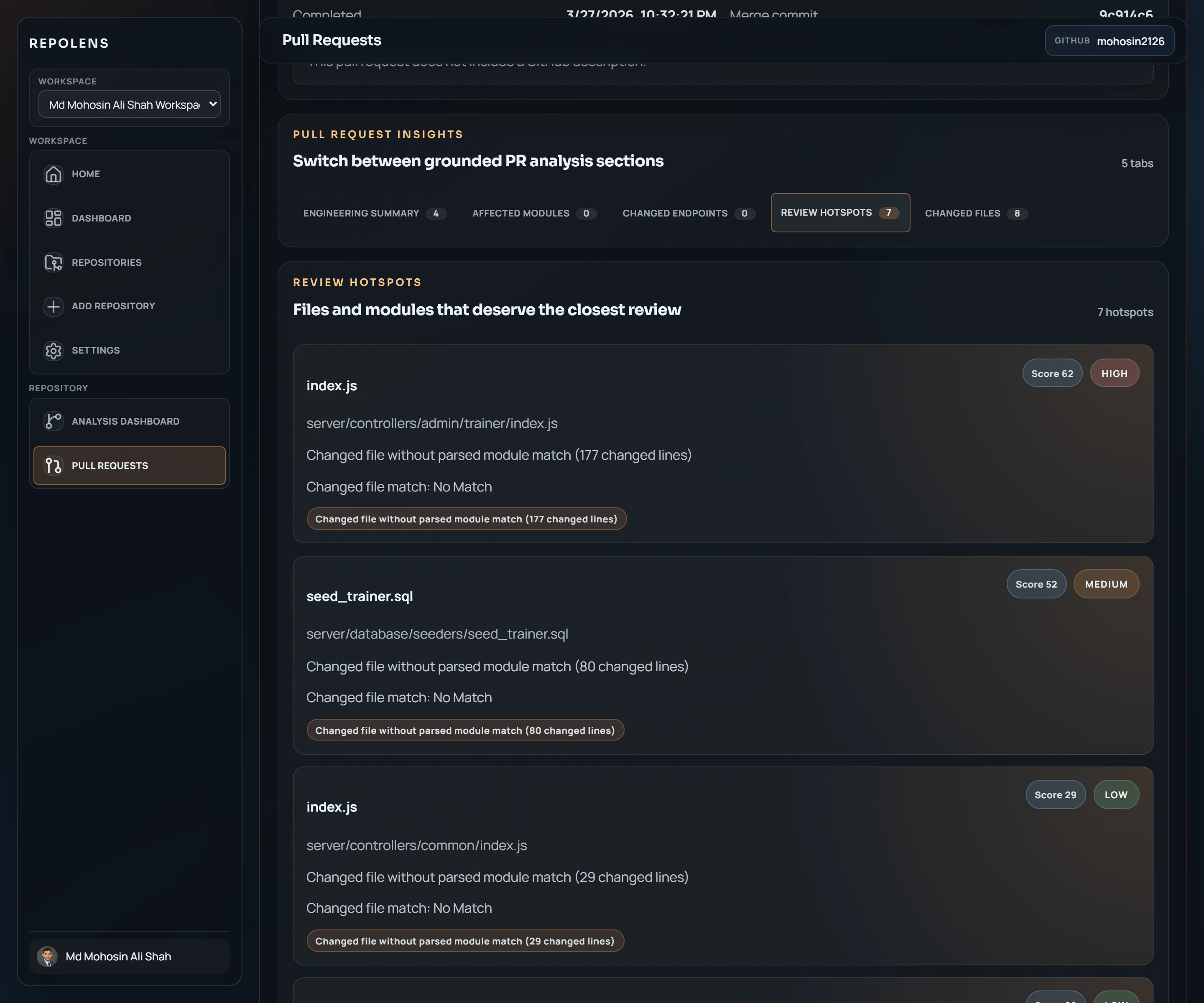
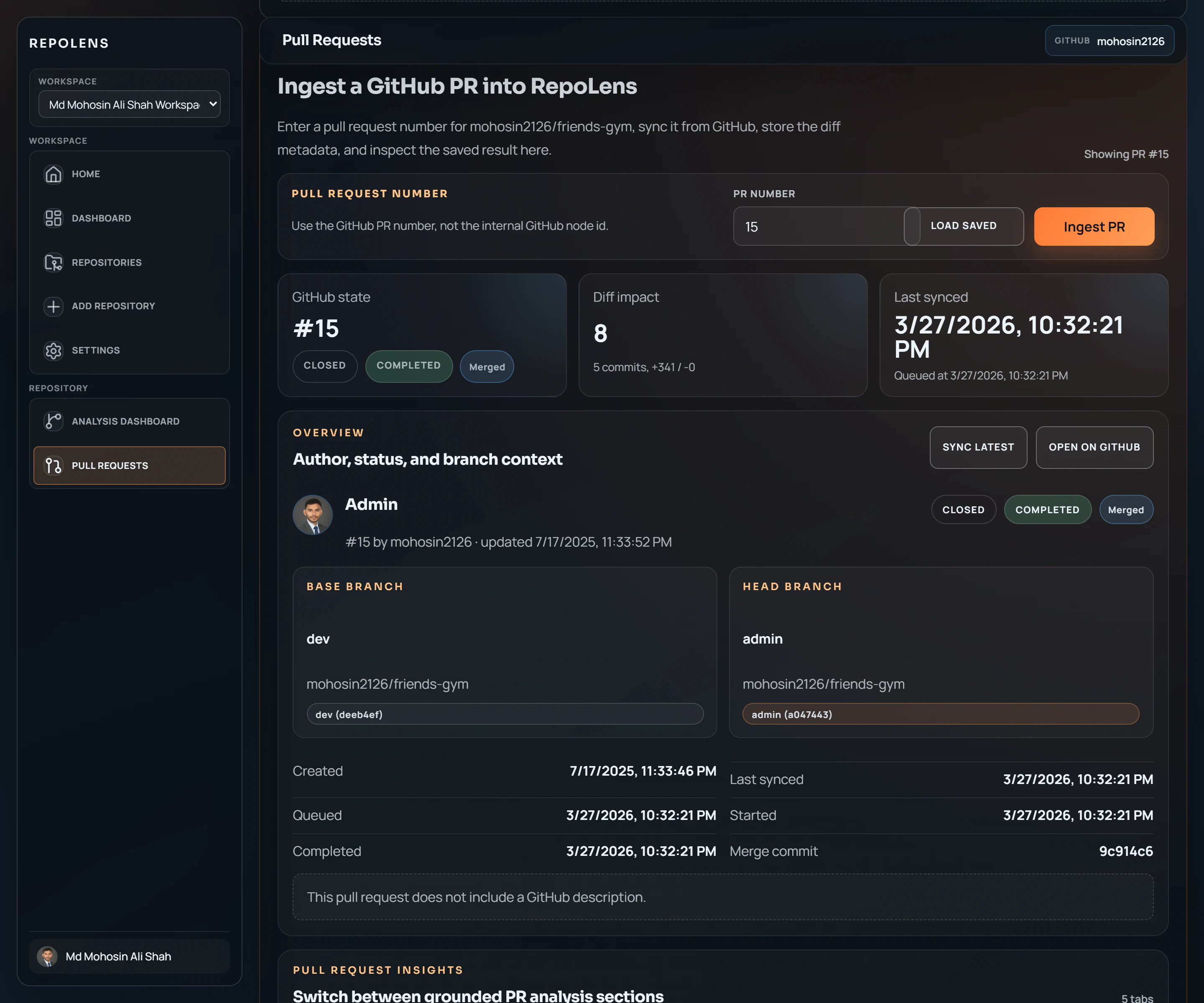
一句话介绍:RepoLens V2 通过结构化分析代码仓库与变更,帮助工程团队在代码评审与合并流程中,快速、可信地理解PR中的关键改动、受影响模块及潜在风险,解决代码库持续演进中变更感知与影响评估的痛点。
Productivity
Developer Tools
Artificial Intelligence
GitHub
代码变更分析
PR智能摘要
工程效能平台
代码仓库洞察
AI辅助开发
架构漂移检测
分支对比
开发者工具
代码评审辅助
用户评论摘要:用户肯定产品解决“理解变更”痛点的价值,并询问具体技术实现(如端点检测方法)。主要反馈集中在功能实用性探讨(如多PR重叠模块的处理)、与通用AI工具(如ChatGPT)的差异化,以及建议增加社交分享等增长功能。创始人积极回应技术路线与迭代方向。
AI 锐评
RepoLens V2 宣称的核心价值,在于试图将“代码变更理解”从一种依赖个人经验与耗时的文本diff阅读的模糊艺术,转化为一种可规模化、可验证的结构化分析过程。这直击了现代软件开发中,随着微服务、单体仓库及频繁合并带来的认知负荷爆炸这一核心顽疾。
其产品思路的犀利之处,在于没有停留在“用AI聊天看代码”的层面,而是选择先构建代码仓库的结构化模型(模块、依赖、端点),再将具体的变更(PR、分支对比)映射到这个模型上进行分析。这使其输出的“受影响模块”、“变更端点”、“评审热点”等洞察,具备了传统AI聊天所缺乏的“可导航性”与“可验证性”——工程师可以快速定位到具体代码块,而非面对一段可能“幻觉”的概括文本。这是一种“增强智能”而非“替代智能”的务实路径。
然而,其面临的挑战同样尖锐。首先,其分析深度与准确度高度依赖于对多样技术栈(即评论中提到的“多语言单体仓库”)的静态分析能力,这工程复杂度极高。其次,“何谓重要变更”的判断标准极具主观性,算法信号(如代码行数、依赖影响范围)能否真正匹配团队的实际风险定义,仍需大量场景打磨。最后,在快节奏团队中,如何处理并发、重叠的PR所引发的信号冲突与噪音,是其必须解决的现实问题,创始人的回应显示他们已意识到这一点。
总体而言,RepoLens 的价值不在于替代代码评审,而在于为评审提供高质量的“前置情报简报”,将工程师的注意力引导至最可能需要关注的区域。它的成功与否,将不取决于AI是否足够“通用聪明”,而取决于其底层代码分析引擎是否足够“精准和深刻”。这是一条更艰难但或许更正确的赛道。
一句话介绍:Expect通过一条命令扫描代码变更,在真实浏览器中自动生成并执行测试计划,解决了开发者在快速迭代中手动编写和运行前端测试的效率痛点。
Design Tools
Developer Tools
Artificial Intelligence
AI测试代理
自动化测试
前端测试
浏览器测试
代码变更扫描
智能测试生成
开发效率工具
软件质量保障
DevOps
智能编程助手
用户评论摘要:用户肯定其节省时间的价值,尤其适合独立开发者。主要疑问集中在:是否支持移动端应用测试;如何处理仅凭代码差异难以发现的边缘情况;以及如何模拟复杂用户交互、动态内容和不同设备状态。
AI 锐评
Expect将“AI代理”概念精准切入测试这一强痛点场景,其“一条命令”的极简交互背后,是试图用AI重新定义测试工作流的野心。产品价值不在于替代成熟的单元测试或E2E框架,而在于填补“代码提交前”那一片敏捷但危险的空白——未暂存变更与分支差异。它瞄准的是开发者心照不宣的“懒惰”与侥幸心理:在快速推进功能时,往往疏于为细微改动编写全面测试。
然而,从评论的质疑中,我们得以窥见其天花板与硬仗所在。其一,**场景局限性**:真实浏览器测试固然可贵,但复杂状态(登录态、多步骤流程)、动态数据、边缘交互的模拟,绝非仅静态分析代码差异所能覆盖。这触及了当前AI基于模式匹配的固有短板。其二,**定位模糊性**:它介于简单的语法检查与完整的集成测试之间。对于严肃项目,它可能不够可靠;对于简单项目,设置成本或许仍高于手动点击。其三,**“测试计划生成”的黑盒**:其计划的质量、覆盖度与判断逻辑是核心,却最不透明。用户将部分质量守门权交给了AI,却缺乏评估其守门能力的标准。
真正的颠覆性在于,如果它能持续学习项目上下文,将测试从“预先编写”的范式转向“即时分析-验证”的范式,或许能开启“自适应测试”的新路径。但目前来看,它更像一个聪明的、针对前端改动的自动化冒烟测试增强器,是提效的补充工具,而非测试体系的革命者。其成功与否,将取决于AI在具体代码语境下理解开发者“真实意图”和预见“异常状态”的深度,这仍是待攻克的技术险峰。
一句话介绍:一款运行于本地的创业公司合规助手,通过扫描本地文档、追踪法定义务与截止日期、自动填写政府表格,解决了初创团队合规管理分散、易遗漏的核心痛点。
Open Source
Legal
Artificial Intelligence
GitHub
法律科技
创业合规
本地化部署
开源软件
自动化代理
文档生成
义务追踪
政府表格
隐私安全
免费工具
用户评论摘要:用户反馈集中在产品价值与适用性:肯定其本地运行和自动填表的核心优势,并建议强化主页信息呈现。主要问题涉及多司法管辖区合规的复杂性、对特定国家(如印度)法规的支持程度,以及产品在无现有合规文件时是否可用。
AI 锐评
Lexaclaw 切入了一个精准且疼痛的赛道:初创公司的合规管理。其真正的颠覆性价值并非功能堆砌,而在于两个关键选择:**本地化运行**与**开源**。在数据敏感的法律领域,这直接构建了至关重要的信任基石,尤其对早期、资源有限的创业团队而言。
然而,其宣称的“100%免费”模式与“Powered by OpenClaw”的架构,也暴露了其商业化和能力边界的核心挑战。产品高度依赖用户自身的AI代理,这实质上将技术复杂性和责任部分转移给了用户。评论中关于多州、多国合规的尖锐提问,恰恰击中了其当前作为“工具框架”而非“成熟解决方案”的软肋——深度、实时且准确的合规知识库与逻辑引擎,才是这类产品的护城河,而这需要巨大的专业资源投入。
因此,Lexaclaw 更像一个极具潜力的“合规操作系统”原型。它展示了未来方向:去中心化、私有化、由AI代理驱动的合规工作流。但其成功与否,取决于能否围绕开源生态,构建起持续更新、覆盖更广法域的义务规则库与文档模板,并找到可持续的商业模式(如企业级支持、合规数据服务)。否则,它可能仅停留为一个优雅的技术演示,难以承受真实世界复杂、动态的合规重压。
一句话介绍:WordPress Studio CLI是一款可通过终端命令控制WordPress Studio功能的工具,它允许开发者在脚本化工作流中集成本地开发,无需打开桌面应用即可快速运行WordPress,提升了开发自动化效率。
WordPress
WordPress开发工具
命令行工具
本地开发
脚本集成
跨平台
开发者效率
前端工具
开源工具
工作流自动化
AI编码辅助
用户评论摘要:用户关注CLI的独立安装与跨平台支持,肯定其便利性;同时集中询问是否集成MCP(Model Context Protocol)以便连接AI编程助手,以及是否仍需付费使用WordPress MCP,反映出对AI工具链整合与成本问题的关切。
AI 锐评
WordPress Studio CLI看似只是将图形界面功能移植到终端,实则触及了现代开发工作流的核心矛盾:在AI编码助手日益普及的背景下,开发工具是否具备“可脚本化”与“可嵌入性”已成为关键竞争力。产品通过提供独立的CLI,不仅满足了传统开发者对终端操作和自动化脚本的偏好,更重要的是,它主动为AI智能体(Coding Agents)打开了交互接口——这正是评论中用户反复追问MCP支持的原因。
当前工具的局限性同样明显。其价值高度依赖于后续“同步、导入、导出”等承诺功能的实现程度,否则它只是一个轻量级本地启动器。用户关于MCP与付费的疑问,则暴露出更深层的生态问题:WordPress Studio是否意在构建一个封闭的AI服务生态,还是真正拥抱开放工具链?如果CLI仅是通向付费AI服务的“引线”,其长期吸引力将大打折扣。
犀利点在于:在“AI+开发”浪潮中,单纯提供CLI已非技术亮点,而是入场券。产品的真正价值在于能否成为连接本地开发环境与云端AI能力的“中性管道”,并在此过程中重新定义WordPress高端开发的工作流范式。否则,它可能很快被更开放、更专注的竞品替代。
一句话介绍:BNA是一款AI智能体,能将产品想法即时生成为包含实时后端、数据库和身份验证的全栈iOS与Android应用,解决了创始人和开发者验证想法、快速上市时面临的基础设施搭建复杂、开发周期长的核心痛点。
Developer Tools
Artificial Intelligence
Vibe coding
AI代码生成
全栈移动开发
快速原型验证
React Native
Expo
实时后端
身份验证
低代码
创业工具
生产力工具
用户评论摘要:用户反馈集中于生成代码的质量与可定制性,询问代码是否清晰可扩展、品牌与API如何自定义,以及当AI生成的逻辑(如身份验证流程)不匹配时如何容错。开发者回复称系统能检测错误并自动修复。
AI 锐评
BNA所代表的“描述即生成”全栈应用AI智能体,正在将应用开发的启动成本压缩到近乎为零。其真正的价值并非替代资深开发者,而是精准狙击了“想法验证”这个高频、刚需且充满摩擦的环节。它选择Expo React Native和Convex后端,是极具策略性的技术组合,在跨平台、实时数据与简化后端管理间取得了现成的平衡,让生成的应用脱离了玩具范畴,具备了可上架的生产力基础。
然而,光鲜的“分钟级上架”承诺背后,潜藏着产品逻辑的深水区。评论中的担忧一针见血:生成代码是“可扩展的蓝图”还是“待重构的草稿”?当AI对复杂业务逻辑的理解出现偏差时,是优雅地自我修复,还是将用户拖入更棘手的调试迷宫?目前看,其定位更偏向一个高度智能化的项目脚手架生成器,它极大地解决了“从0到0.5”的冷启动问题,但“从0.5到1”的深度定制和迭代,依然严重依赖开发者自身的功力。它的成功与否,将取决于其生成代码的整洁度、架构的合理性,以及AI调试能力的真实可靠性。否则,它可能只是将开发瓶颈从项目搭建阶段,向后推移到了代码修改与维护阶段。对于非技术出身的创始人,它降低了入门门槛;但对于开发者,它必须证明自己是一个值得信赖的“初级合伙人”,而非一个生成后即需抛弃的临时原型。
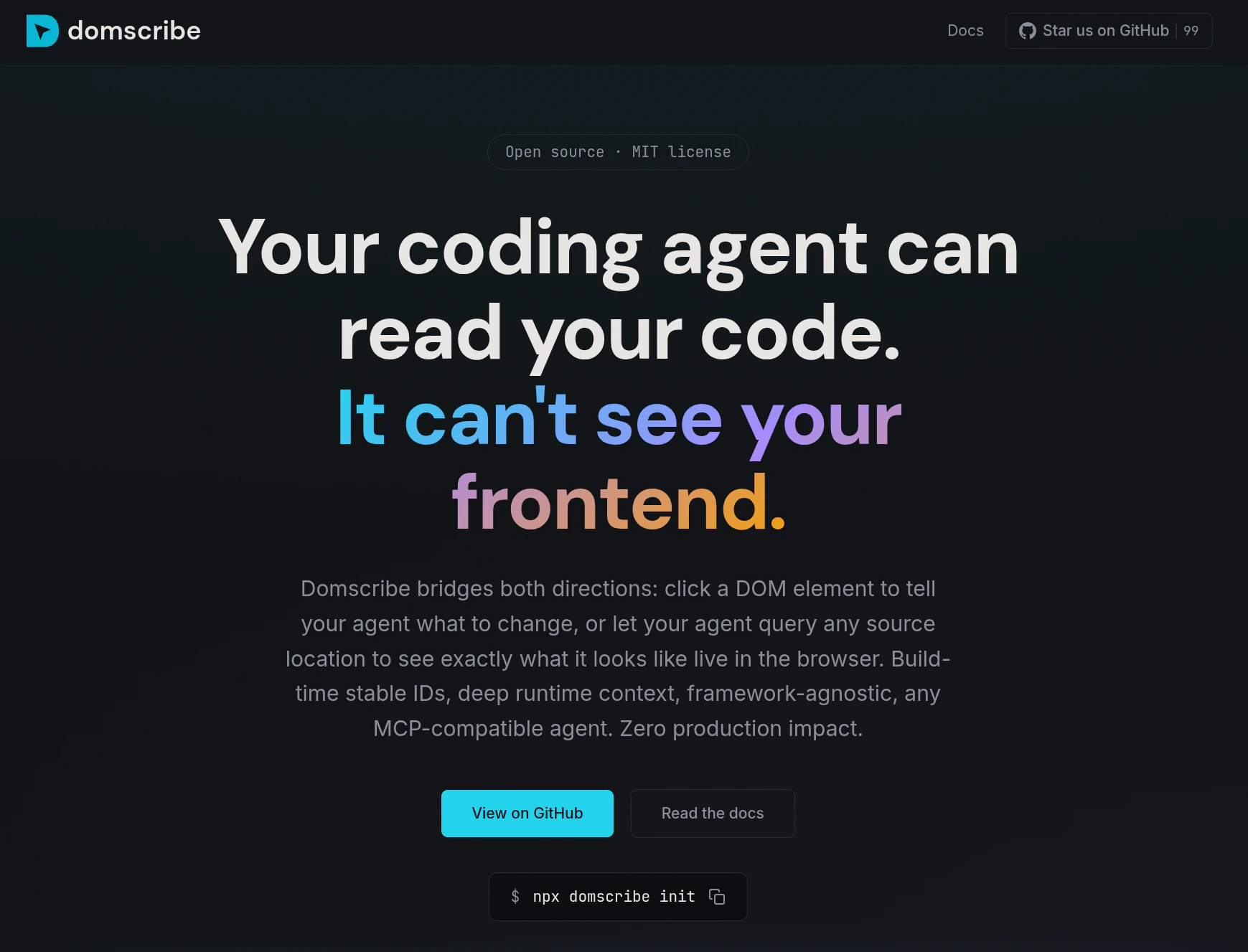
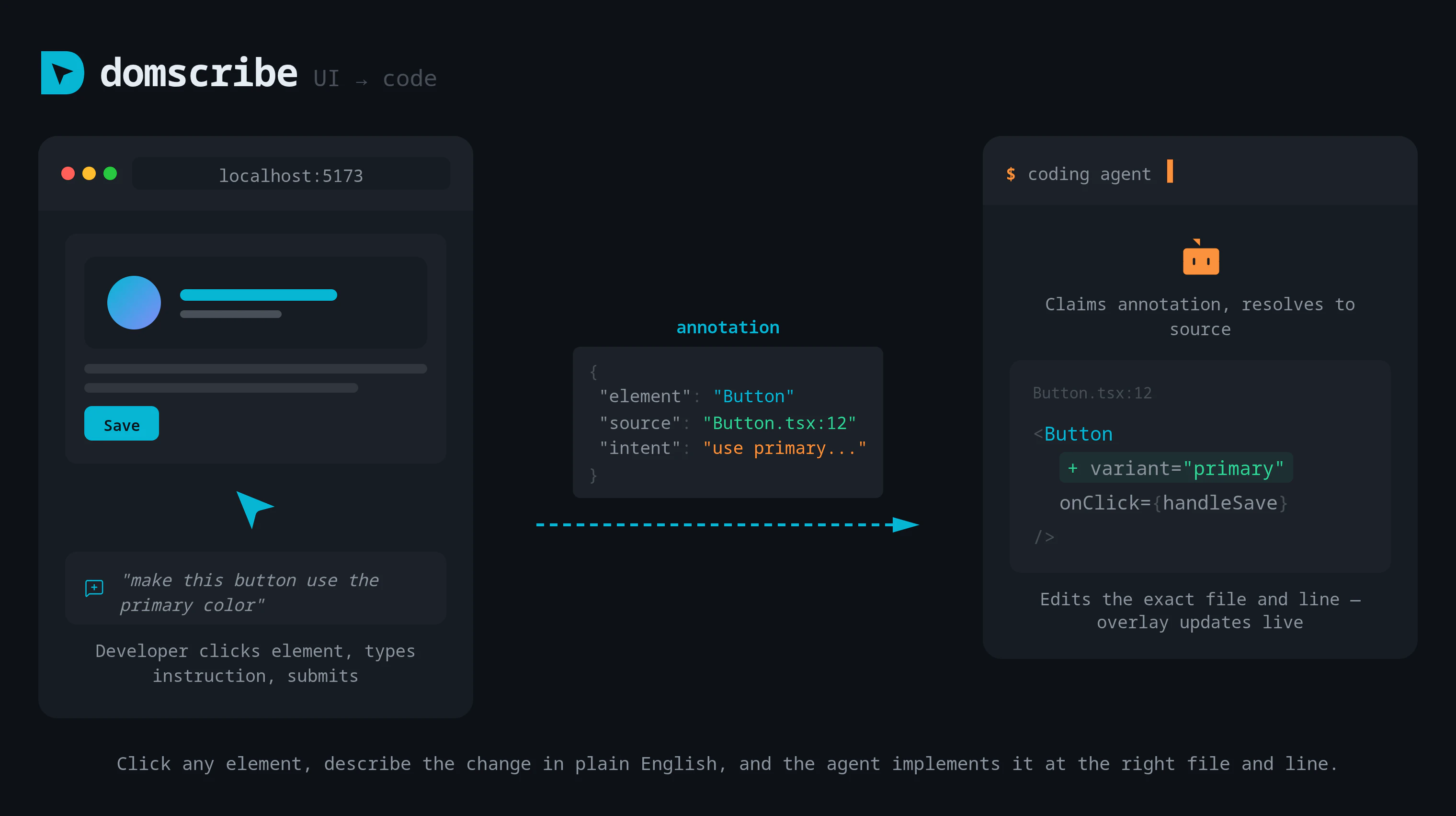
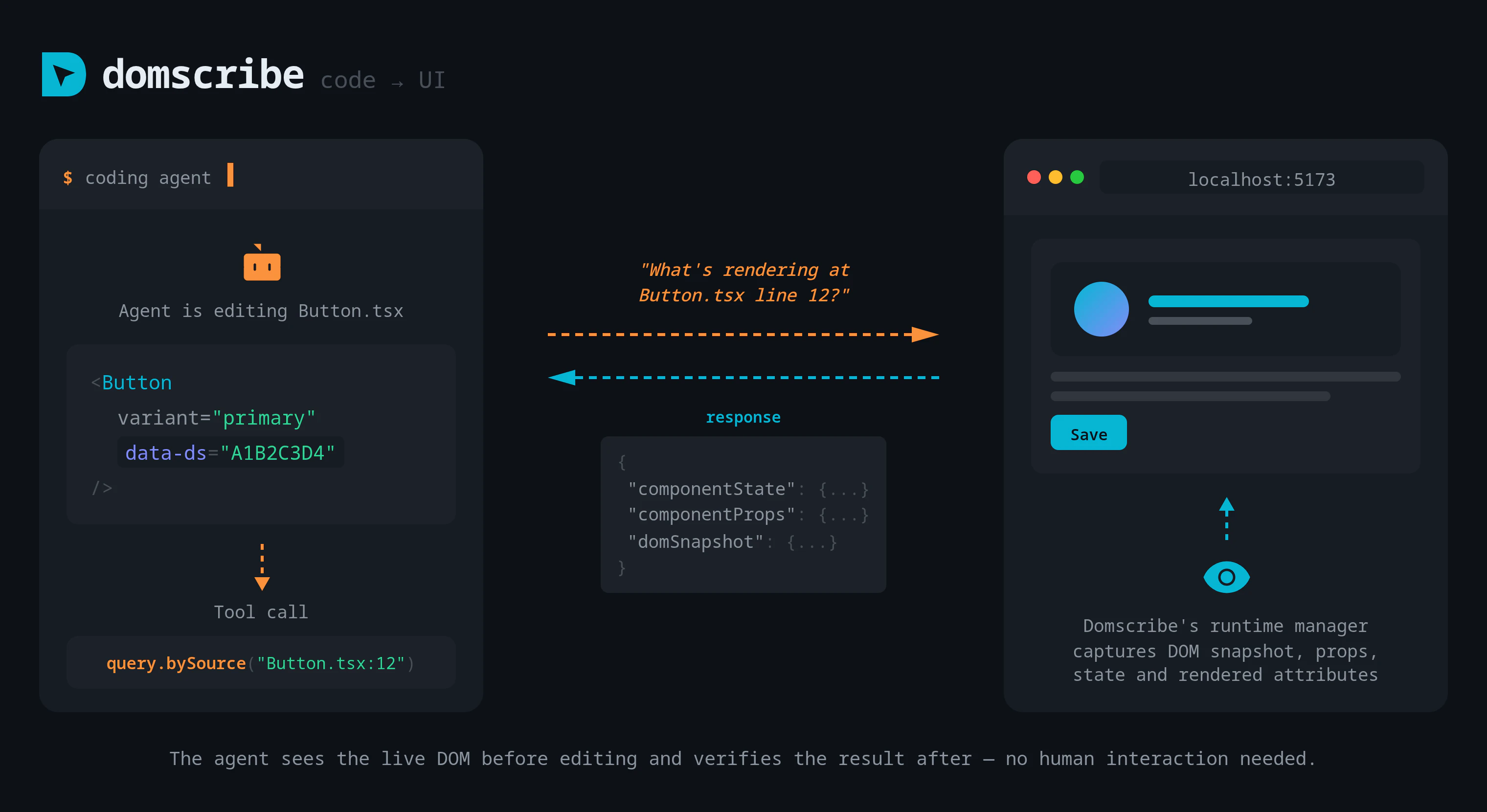
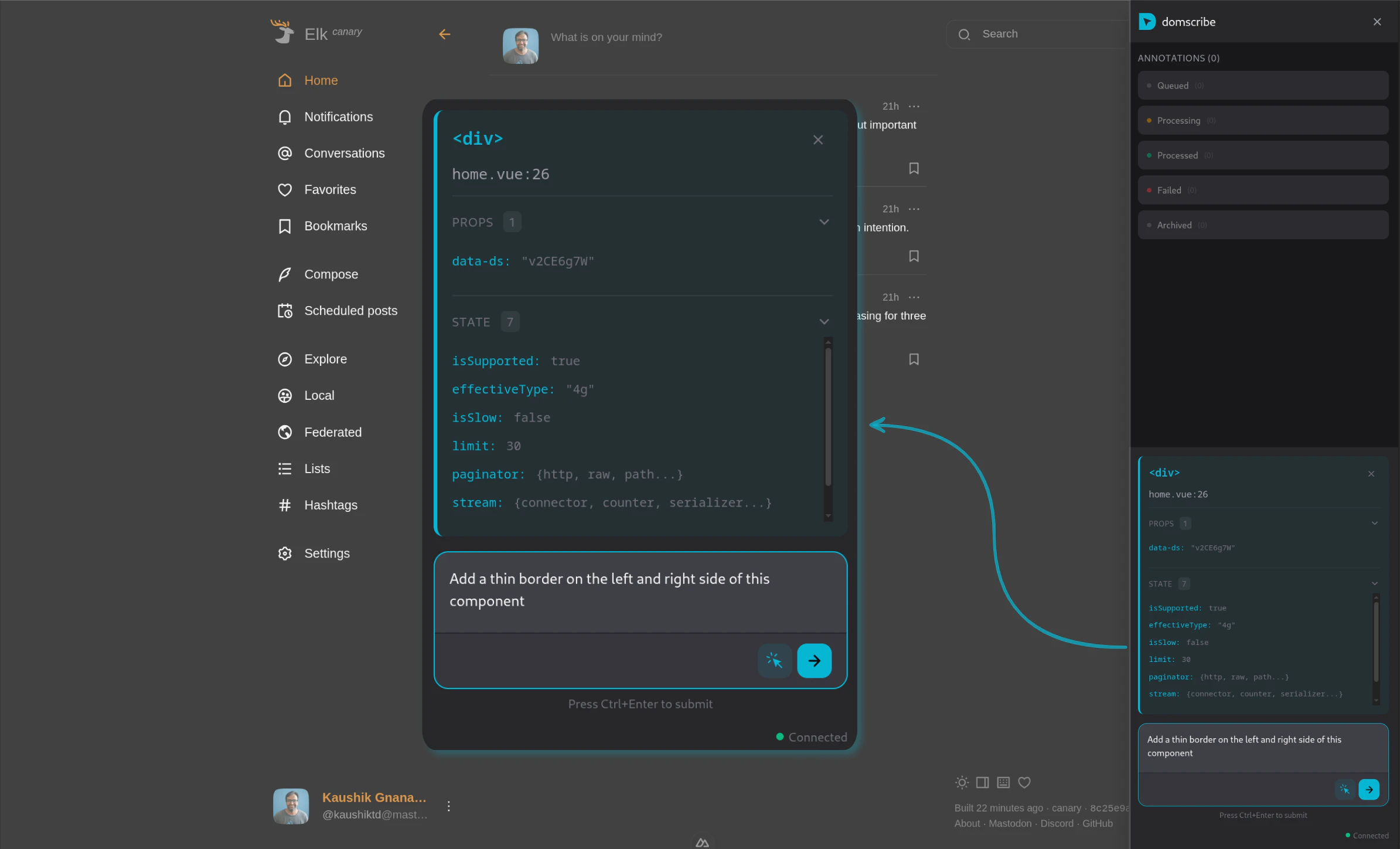
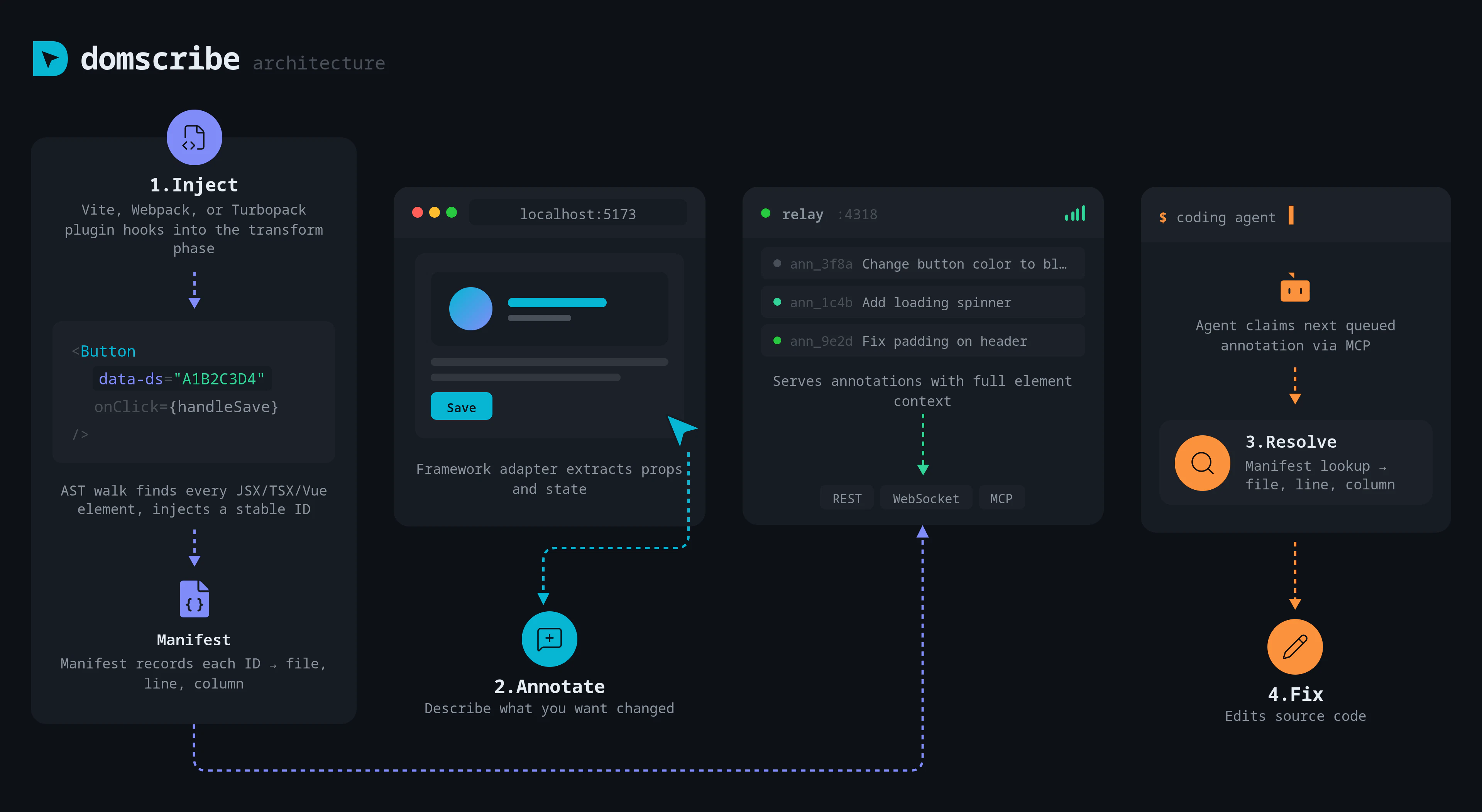
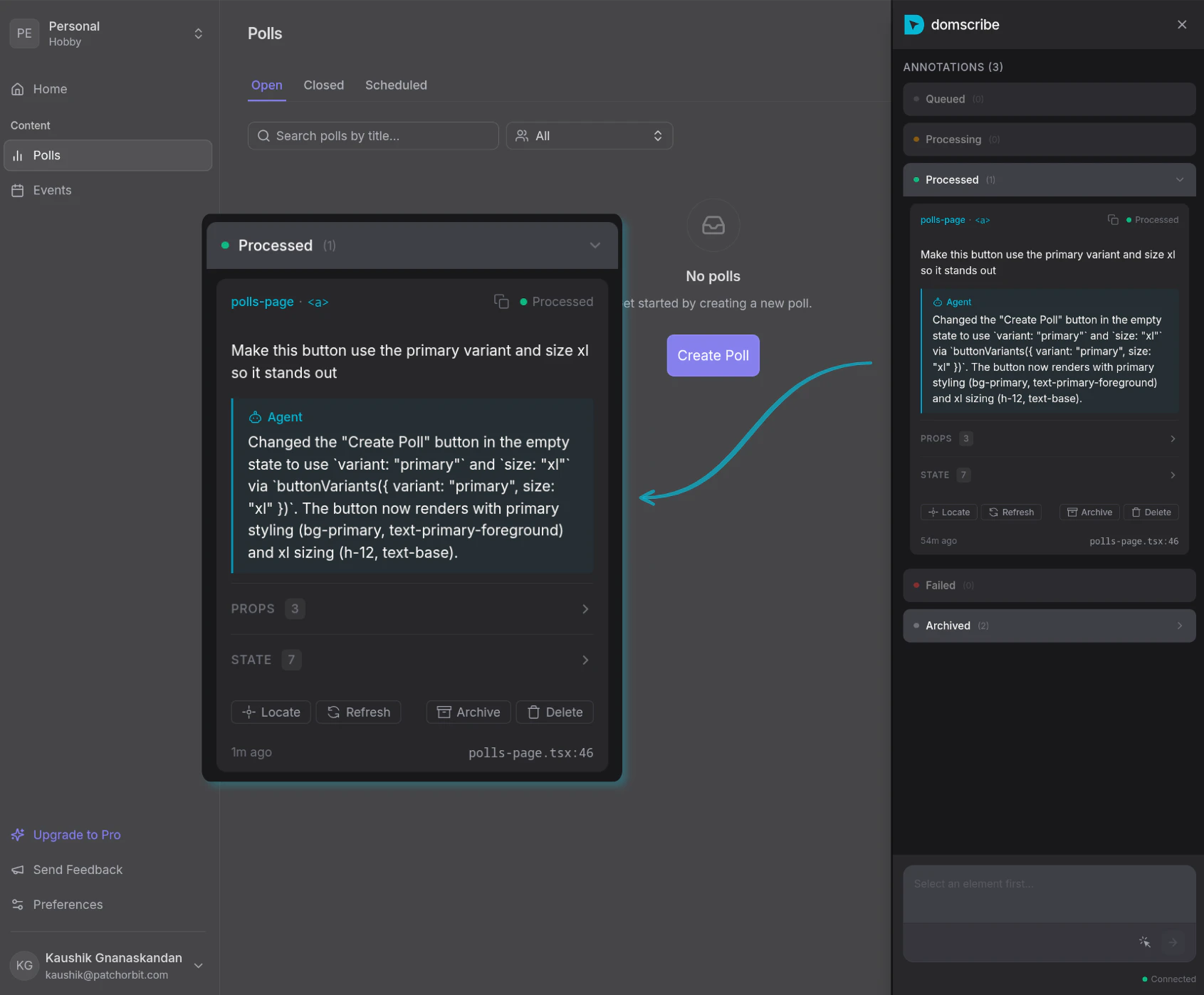
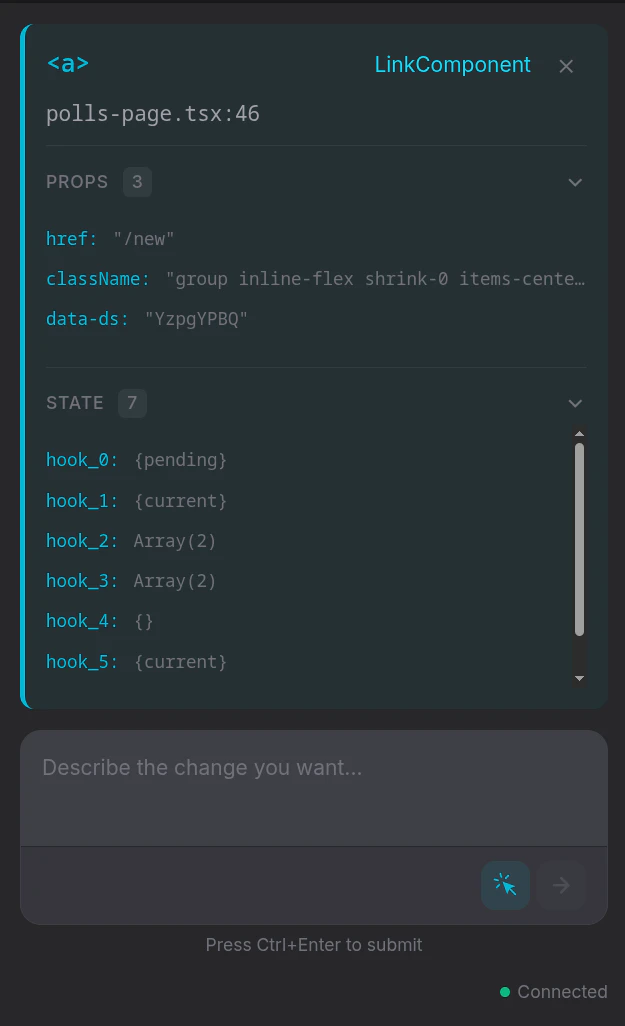
一句话介绍:一款为AI编程助手提供“视觉”能力的开发工具,通过构建时注入稳定ID和运行时捕获DOM与组件状态,精准连接前端代码与运行界面,解决了AI代理在修改前端代码时盲目搜索、定位低效的核心痛点。
Open Source
Developer Tools
Artificial Intelligence
GitHub
AI编程助手增强工具
前端开发提效
代码-UI双向映射
多框架支持
构建时插桩
MCP协议
开源工具
开发工作流
用户评论摘要:用户肯定其构建时稳定ID方案的长远价值,认为其比基于快照猜测选择器更可靠。开发者详细解答了关于Shadow DOM、Canvas/SVG支持的技术细节,并阐述了插件化、框架无关的架构设计理念。有用户提及此工具可帮助节省AI代理的token消耗。
AI 锐评
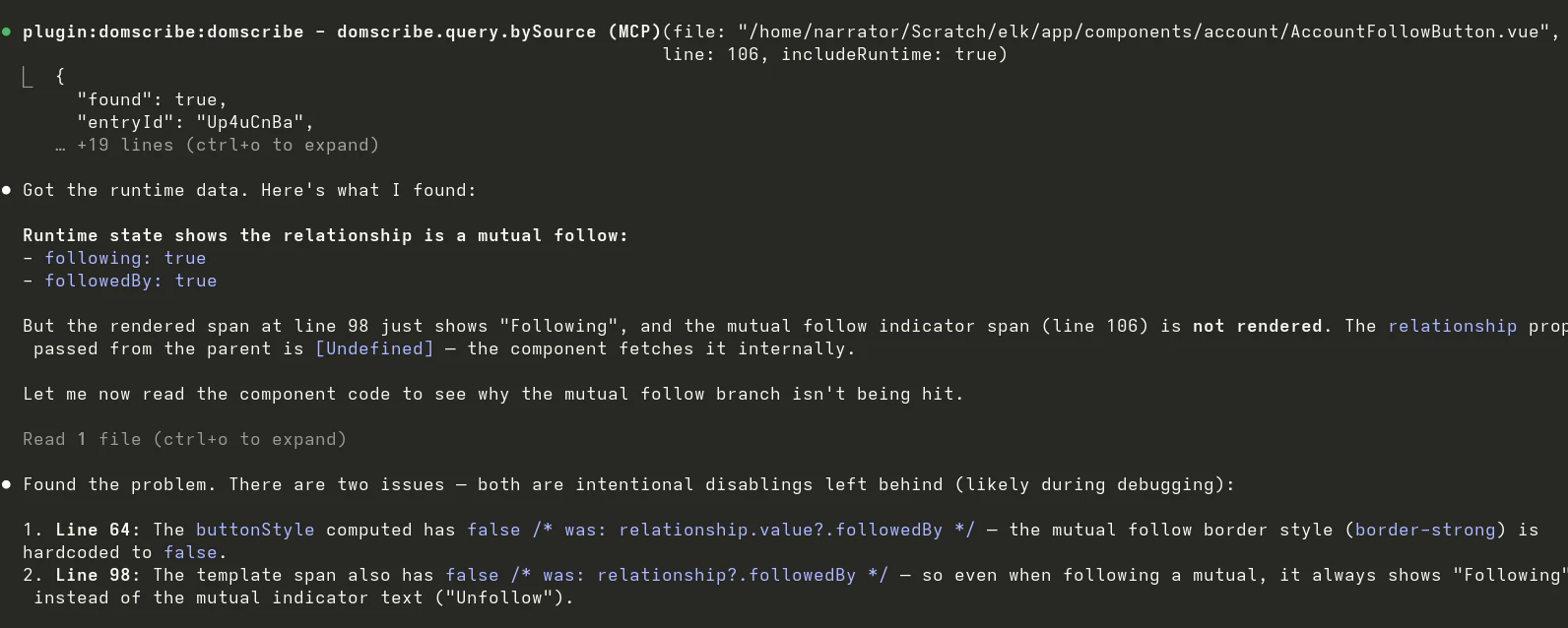
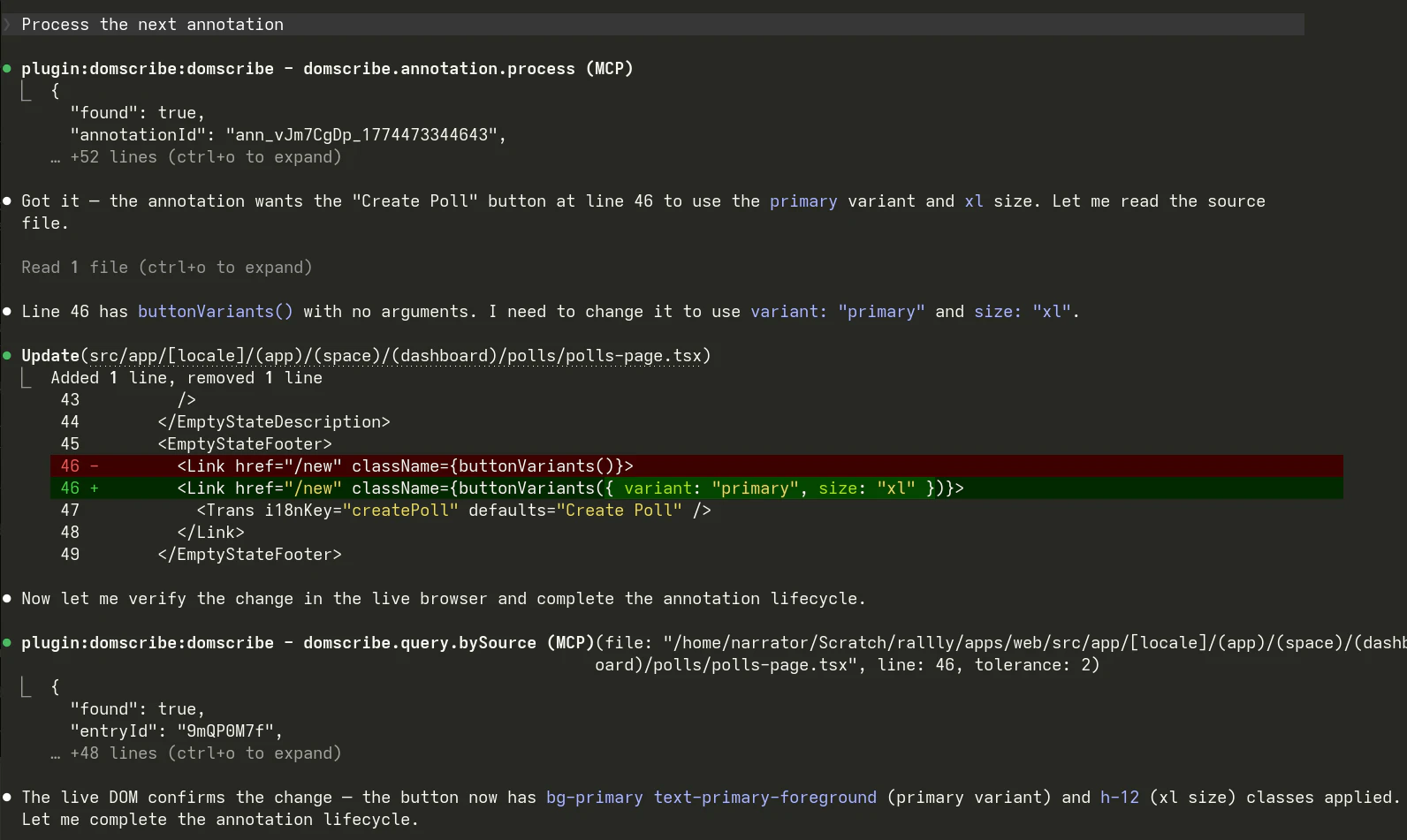
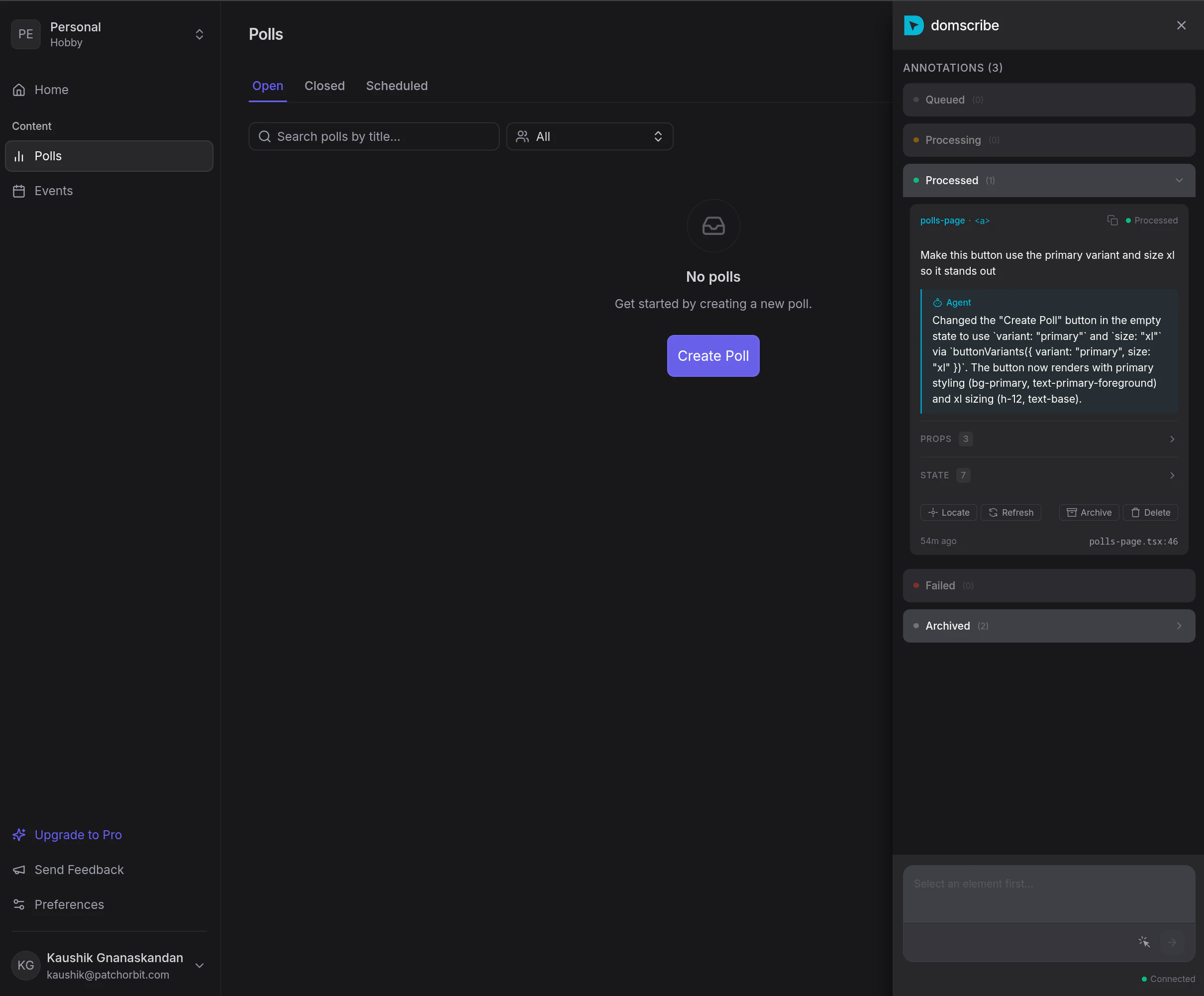
Domscribe的野心不在于成为又一个前端调试工具,而在于试图成为AI时代前端人机协同的“标准协议层”。其真正价值是**将前端界面从“像素集合”和“模糊文本描述”还原为精确的、可编程的代码结构**,从而填平了自然语言指令与具体代码修改之间的巨大鸿沟。
当前AI编码代理在前端任务上表现笨拙,根源在于其缺乏对运行时应用状态的“感知”能力,只能基于静态代码进行概率猜测。Domscribe通过构建时注入哈希ID这一看似朴素的技术,巧妙地建立了源代码位置与运行时元素之间永不失效的链接。这比依赖易变的CSS选择器或脆弱的截图识别,在工程上更为坚实。其通过MCP协议暴露能力,也展现了良好的生态思维,试图成为AI代理的标准化“感官输入”设备。
然而,其面临的核心挑战在于“适配的广度与深度”。虽然其架构设计了良好的扩展性,但每个新框架(如Svelte、Solid)或复杂场景(如深度定制的渲染引擎、Canvas重度应用)都需要专门的适配器开发,这构成了其生态扩张的技术债务。此外,其价值高度依赖于AI代理能否真正理解并高效利用其提供的“上下文”(DOM、props、state)。如果代理的推理能力不足,再精确的定位信息也可能被浪费。
长远看,Domscribe若成功,可能推动前端开发范式向“界面即准确代码入口”演进,但其天花板也取决于AI代理本身的智能水平。它是一把精心打磨的“手术刀”,但执刀者的技艺同样关键。
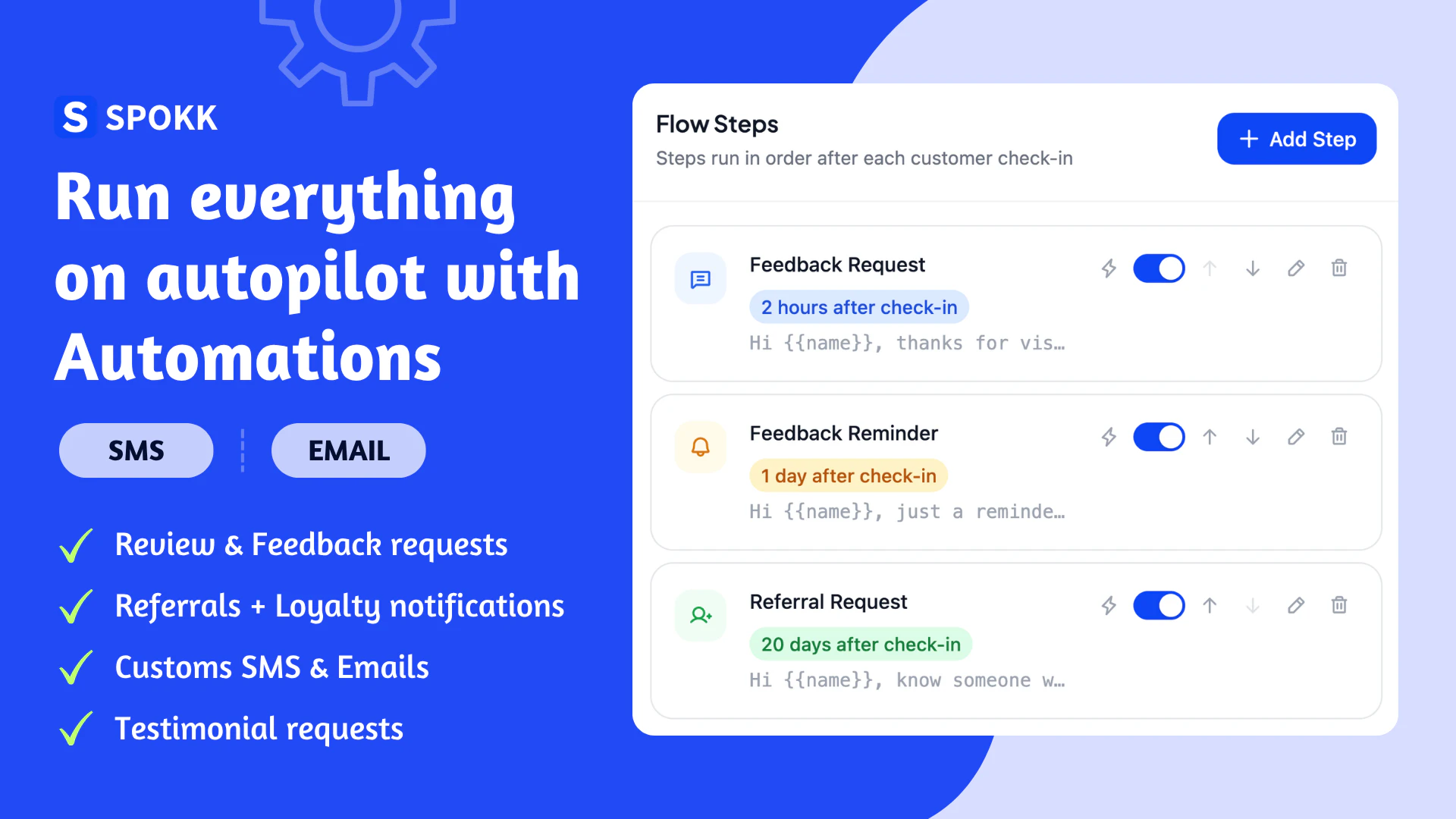
一句话介绍:Spokk为小型企业(如餐厅、健身房、沙龙)提供一站式自动化客户增长解决方案,通过一次顾客签到自动触发反馈收集、AI生成好评、忠诚度奖励与推荐追踪流程,解决了商家需同时使用多个独立工具管理客户关系与增长的痛点。
Customer Communication
Marketing
Artificial Intelligence
客户反馈管理
在线评论生成
忠诚度计划
推荐营销
自动化营销
短信营销
小企业SaaS
客户留存与增长
AI驱动
一体化平台
用户评论摘要:创始人阐述了产品从单一工具向一体化增长引擎的演进理念。有效评论集中于两个问题:1. 非技术用户能否轻松自定义自动化流程;2. 产品对不同类型餐厅(从快餐到高级餐厅)营销的具体适用性。
AI 锐评
Spokk的野心,在于将小企业主零散、断续的客户互动,整合成一个由“签到”触发的、连贯的自动化增长飞轮。其真正价值并非功能堆砌,而在于对“交易结束即关系开始”这一商业常识的流程化封装。
产品逻辑犀利:它抓住了小企业营销的核心矛盾——深知客户忠诚与口碑至关重要,却无精力运营复杂体系。通过强制性的极简反馈作为起点,并智能跳过已完成的步骤(如已留评则推送推荐链接),它试图在低打扰度下,将单次消费的顾客一步步转化为“反馈者→好评者→回头客→推广者”。AI生成评论草稿是点睛之笔,它移除了顾客行动的最大障碍——不知如何下笔,将情感认同转化为可执行的文本,极大提升了从满意到公开好评的转化率。
然而,其挑战同样尖锐。首先,标准化流程与不同行业(如快餐与高级餐厅)极度差异化的客户体验管理需求之间存在张力。高级餐厅的“体验维护”远非一个四步短信序列能承载。其次,其模式高度依赖初始的“签到”触发点,这对许多没有强制签到环节的小企业(如零售店)构成部署门槛。最后,将如此多关键增长环节捆绑于一个平台,固然方便,但也意味着风险集中,任一环节(如短信送达率、AI草稿质量)的失效都可能影响整体链条。
总体而言,Spokk是一次有价值的整合创新,它试图成为小企业的“增长自动驾驶仪”。但其成功与否,不取决于功能列表,而取决于其流程能否真正适配不同商业场景的“驾驶路况”,并在自动化与人性化之间取得精妙平衡。
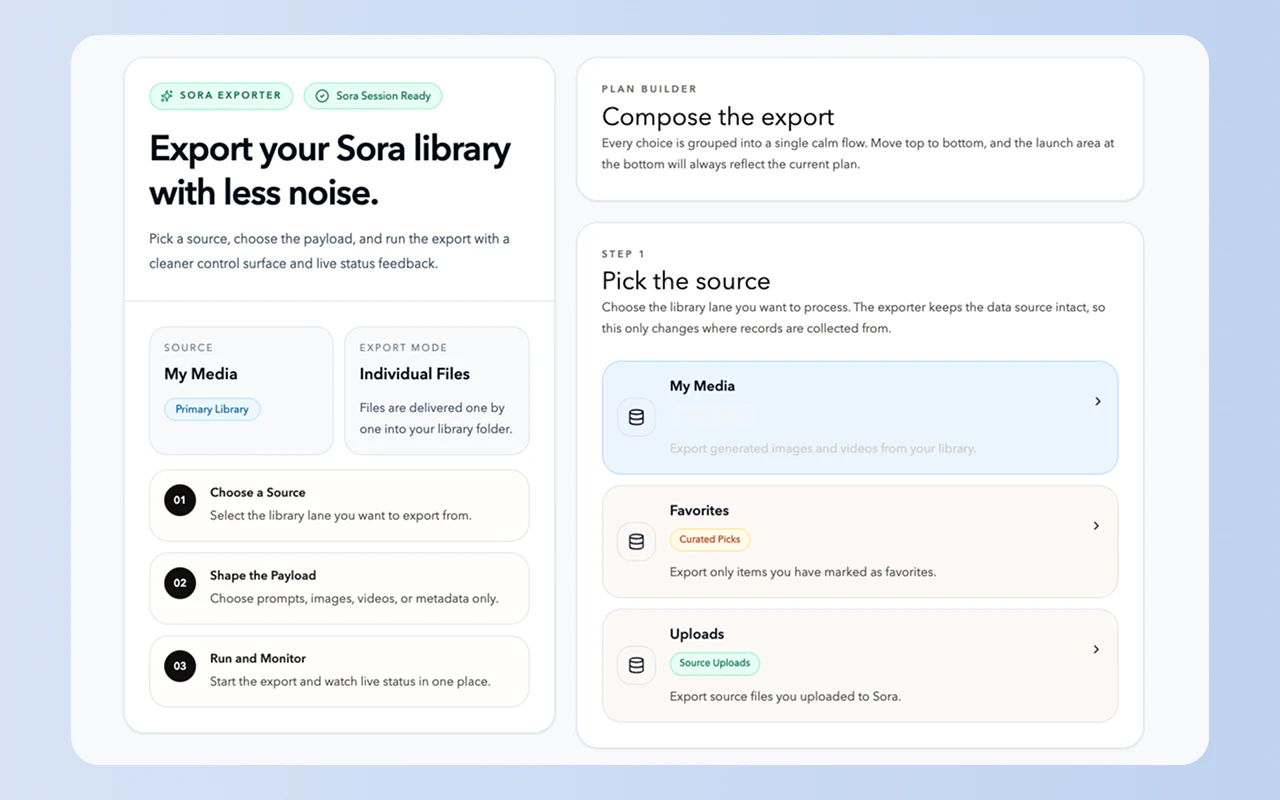
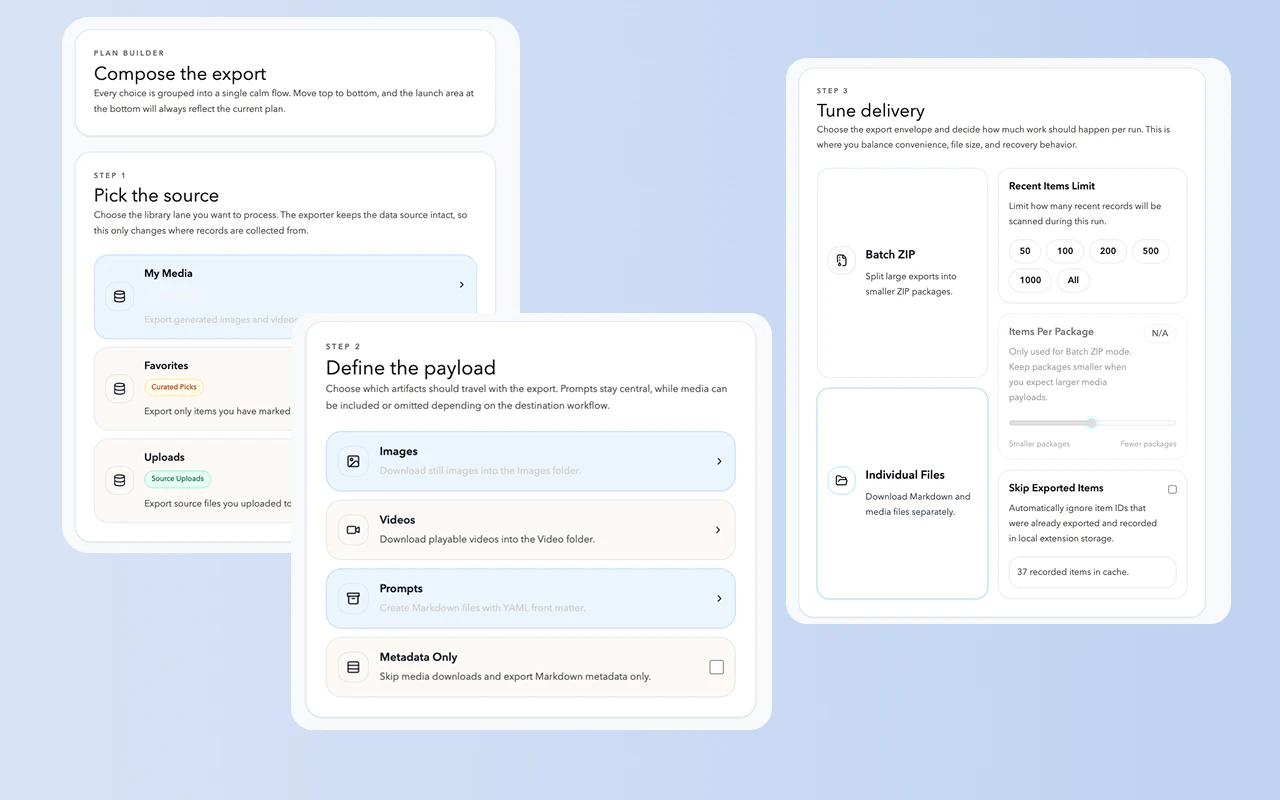
一句话介绍:一款轻量级Chrome扩展,一键批量导出Sora生成的视频、图像及提示词,解决创作者在云端管理AI生成资产混乱、手动保存效率低下的痛点。
Chrome Extensions
Productivity
Artificial Intelligence
Chrome扩展
AI资产管理
Sora工具
批量导出
本地备份
知识管理
工作流优化
数字资产归档
用户评论摘要:开发者自述开发动机源于自身将AI资产整合进Obsidian等“第二大脑”工作流的需求。评论中未出现其他用户反馈,主要为开发者引导讨论,询问用户管理AI资产的方式并征集反馈与功能建议。
AI 锐评
这款产品精准切入了一个新兴且迫切的细分市场——AI生成内容(AIGC)的资产管理。其真正价值不在于技术有多复杂,而在于它敏锐地捕捉到了AIGC工作流中的一个关键断点:生成平台专注于“创造”,却普遍忽视了用户对成果“管理”的刚性需求。
产品将自身定位为“桥梁”,一端连接着封闭、易失的云端Web UI(如Sora),另一端则对接用户本地成熟的知识管理体系(如Obsidian、Notion)。这种设计思路是明智的,它没有试图重建一个管理平台,而是赋能用户,让他们能在自己熟悉的信息环境中,对AI资产进行归档、标签化和全文检索。其导出带YAML Front Matter的Markdown文件功能,更是直接迎合了高级笔记软件用户的结构化数据需求,提升了提示词的可复用性和可分析性。
然而,其核心风险与天花板也显而易见。首先,其生存完全依附于Sora平台的前端形态与访问策略,一旦官方界面更新或API政策变动,扩展可能即刻失效。其次,功能相对单一,护城河较浅,易被同类工具或Sora官方可能推出的备份功能所覆盖。当前82的投票数也反映出市场热度有限,这可能与Sora本身仍处有限访问阶段、用户基数不大有关。
本质上,这是一款出色的“时机型”效率工具。它解决了早期重度用户的燃眉之急,但长期价值取决于其能否从单一平台的“导出器”,演进为跨多AI生成平台的“统一资产收集与预处理中心”,并深度集成到更广泛的创作工作流中。在此之前,它更像一个精致而脆弱的临时解决方案。
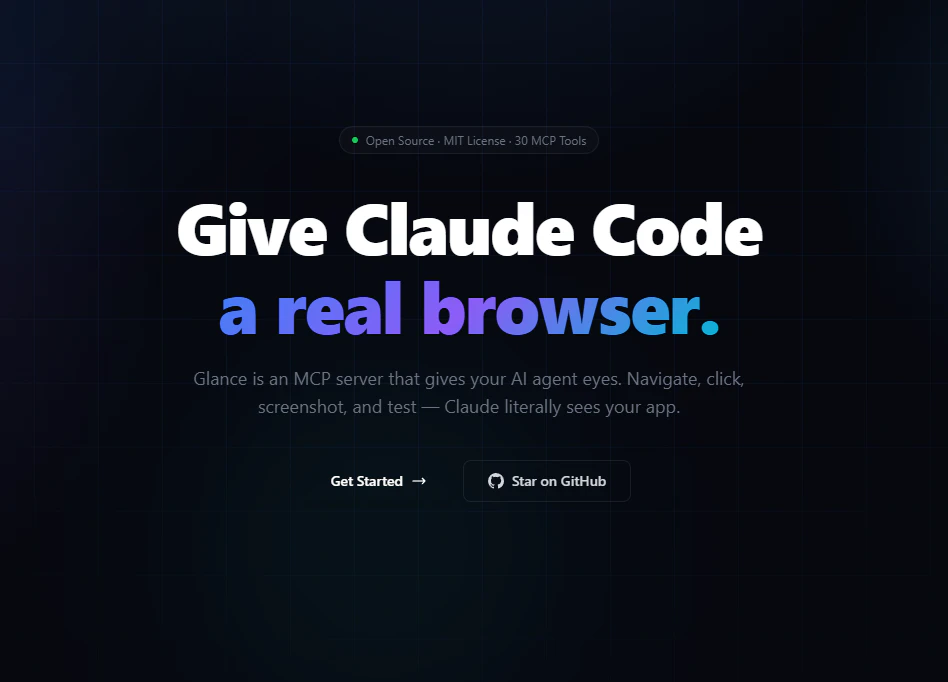
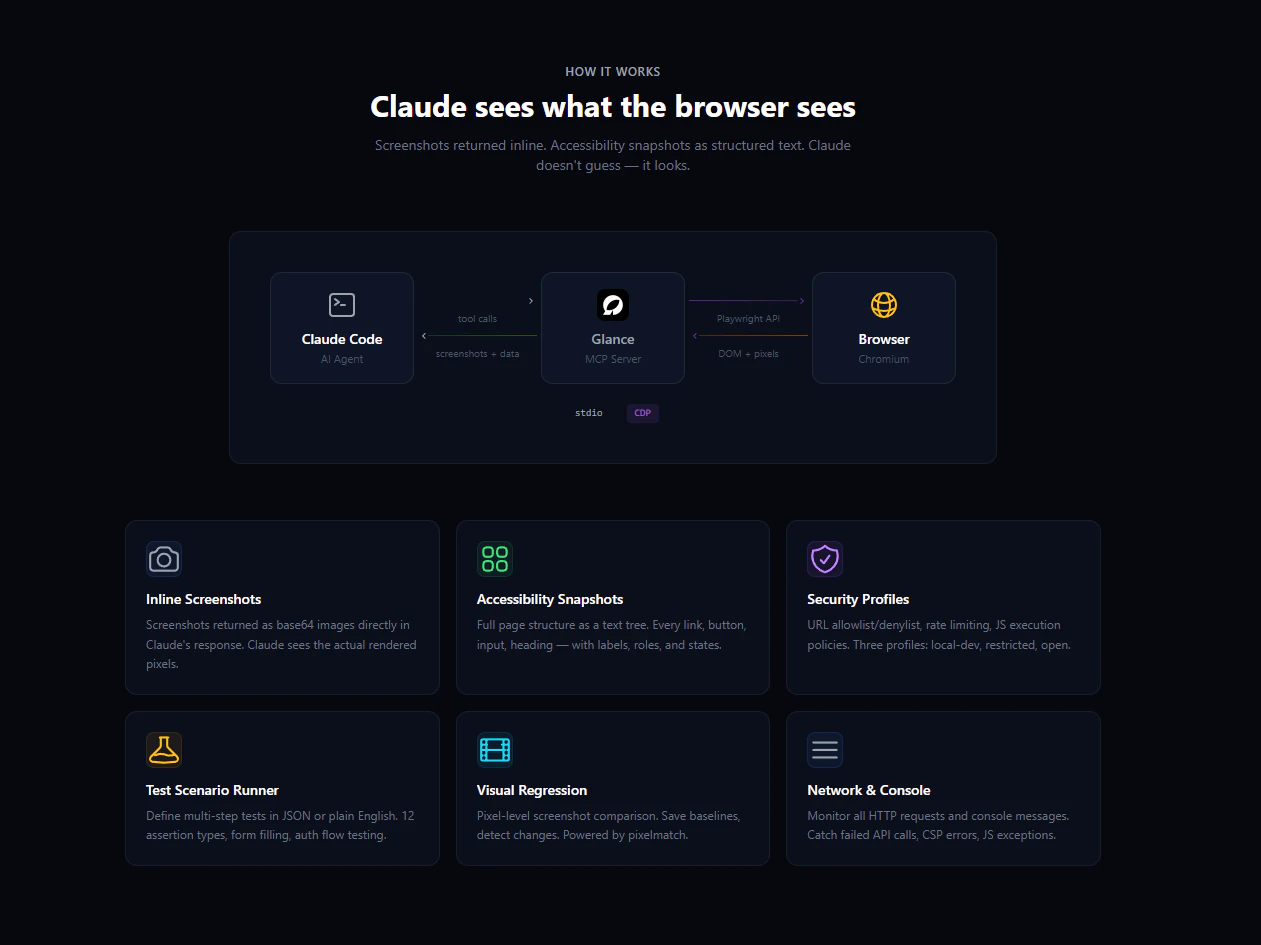
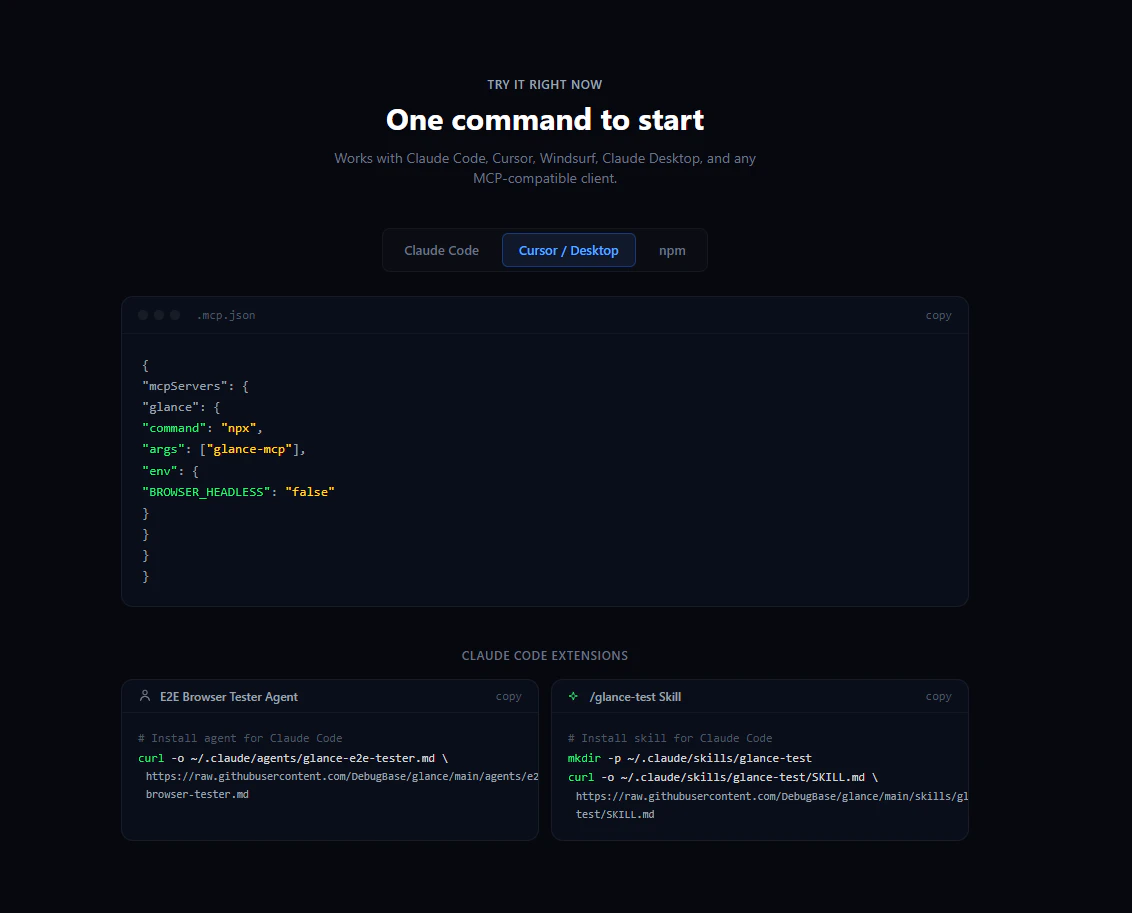
一句话介绍:Glance是一款开源MCP服务器,为Claude Code提供真实的Chromium浏览器环境,解决了开发者在AI编程时需要频繁切换窗口以查看和描述网页效果的痛点。
Open Source
Developer Tools
Artificial Intelligence
GitHub
开源MCP服务器
AI编程工具
浏览器自动化
E2E测试
视觉回归测试
Playwright
Claude生态
开发效率工具
终端浏览器
测试自动化
用户评论摘要:开发者介绍产品初衷并寻求反馈。有用户提出专业测试合作邀约,另有用户询问技术细节(如CSS调试、像素对比)。一条反馈批评演示视频不专业、AI配音不佳,影响第一印象。
AI 锐评
Glance的实质,是将大型语言模型的代码生成能力与真实浏览器环境的执行与验证能力进行闭环连接,其价值远不止于“截图可见”。它瞄准了当前AI辅助开发的核心断层:AI能写代码,但无法自主感知运行结果,导致调试和迭代仍需人类作为“视觉传感器”和“操作中介”。
产品将Playwright等成熟浏览器自动化工具封装为MCP服务器,是明智的技术整合。其宣称的“97%通过率”和测试场景运行器,暗示了其更深层的野心——成为AI智能体(而不仅仅是人类开发者)进行端到端测试和交互验证的基础设施。这为“AI驱动开发”从代码片段生成迈向完整功能验证和回归测试,提供了关键路径。
然而,挑战同样明显。首先,其价值高度绑定于Claude Code生态,市场天花板受限。其次,评论中关于像素级断言和CSS边缘案例的提问,直指其作为测试工具的核心能力深度——精准的视觉差异比对远比截图复杂。最后,演示视频的负面反馈虽看似表面,却揭示了工具类产品在传达其技术复杂性时,面临用户体验与专业形象平衡的普遍难题。若想从“有趣工具”成长为“必备设施”,它必须在测试断言智能性、多AI助手兼容性以及企业级部署的安全与管控上,展现更厚重的实力。
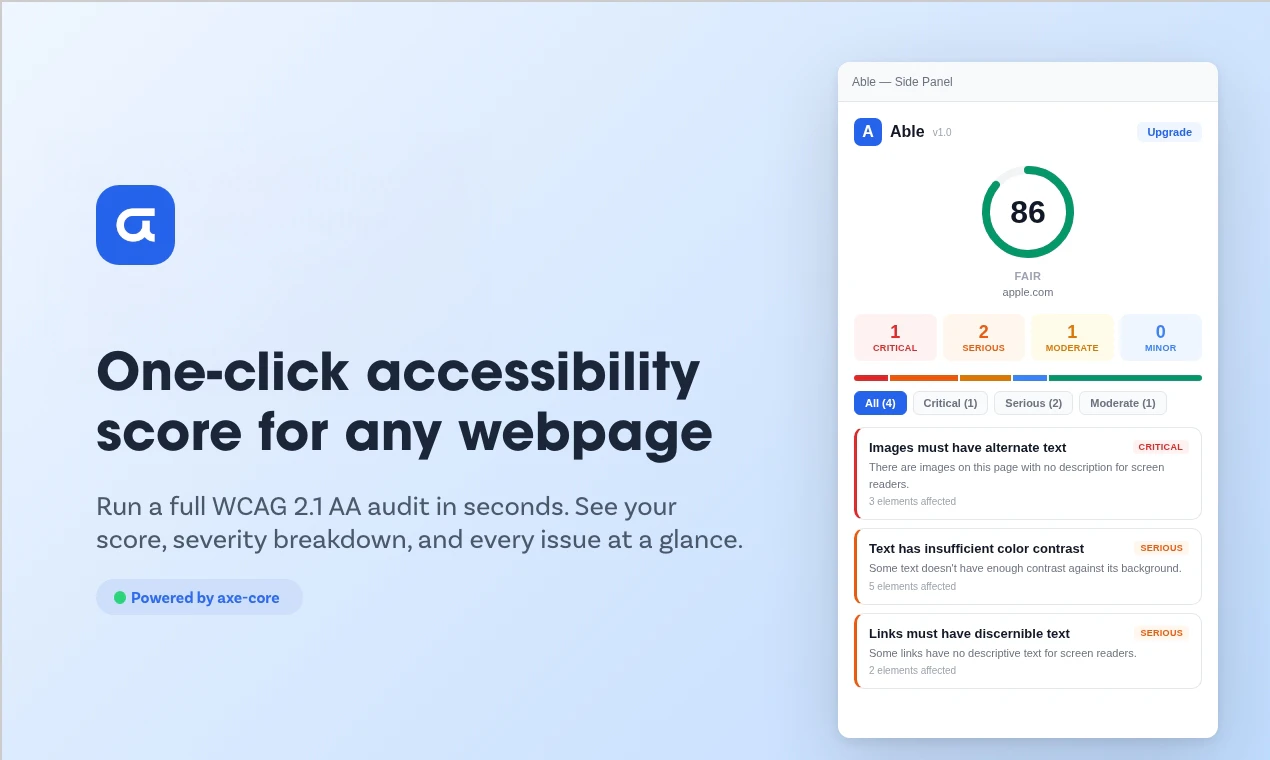
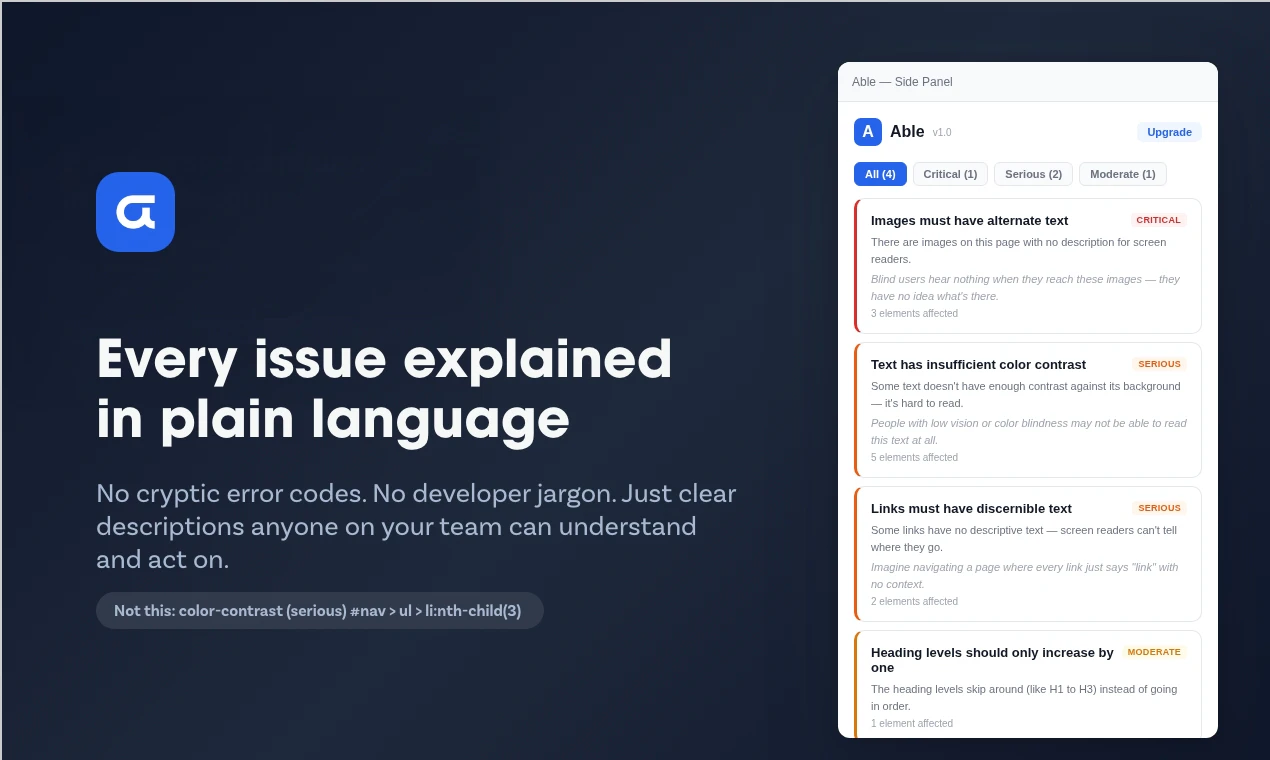
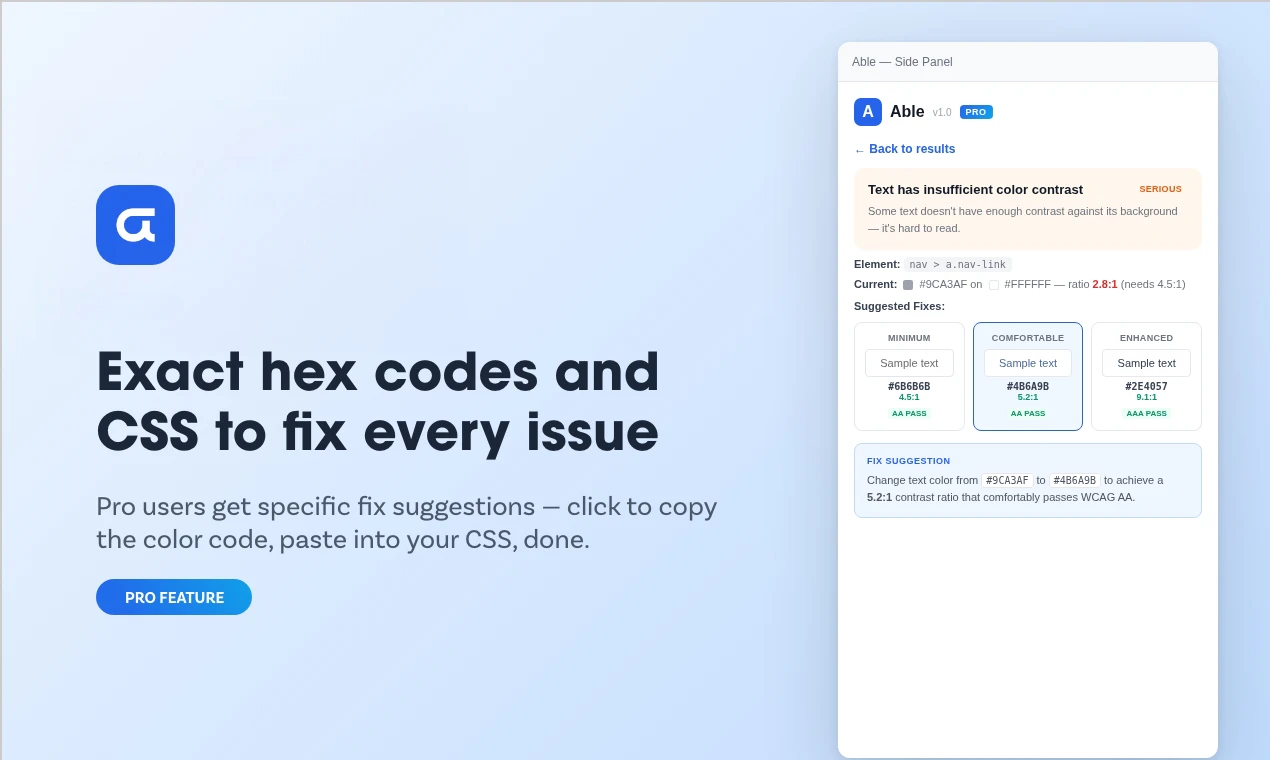
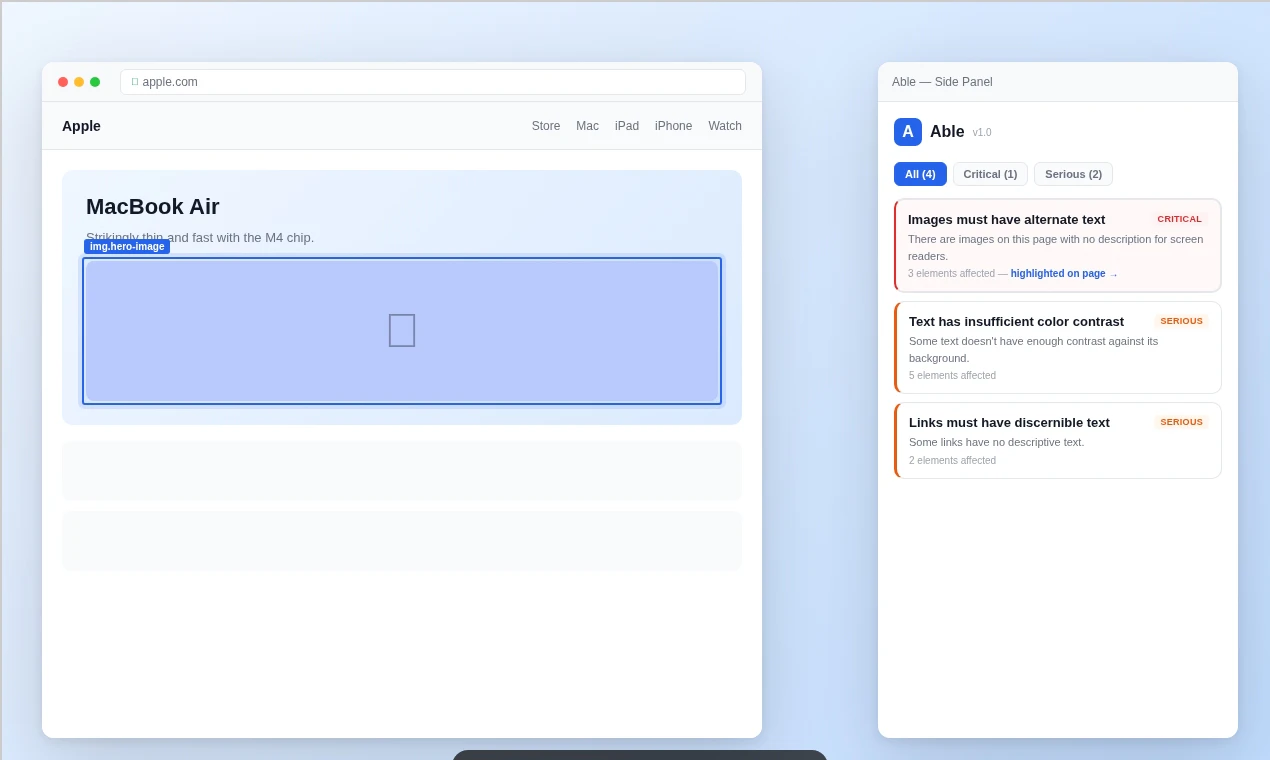
一句话介绍:Able是一款Chrome侧边栏插件,一键扫描网页WCAG 2.2合规性问题,用通俗语言提供修复建议,为非专业开发人员提供高效、易懂的无障碍审计解决方案。
Chrome Extensions
Design Tools
Developer Tools
网页无障碍检测
WCAG合规
ADA合规
开发者工具
浏览器插件
用户体验
设计辅助
一次性付费
自动化审计
前端开发
用户评论摘要:开发者自述产品初衷是解决现有工具术语晦涩、难以理解的问题,目标用户是非专家群体。用户建议增加Figma风格预览和常见问题CSS自动建议功能,以进一步优化设计师工作流。
AI 锐评
Able看似是又一个基于axe-core引擎的无障碍检测工具,但其真正的锋芒在于精准切入了一个被忽视的断层:合规性要求与实施者能力之间的巨大鸿沟。它没有在检测算法的“更全更深”上内卷,而是将价值重心后移,押注在“解读与修复”的平民化翻译上。这击中了中小团队、自由职业者和非技术决策者的核心痛点——他们不需要理解“SC 1.4.3 Contrast (Minimum)”,只需要知道“这段文字看不清,该换成什么颜色”。
其“浏览器内运行、一次性买断”的模式,在数据隐私敏感和订阅疲劳的当下,构成了另一重差异化竞争力。然而,其天花板也显而易见:作为侧重“解释”的中间层工具,其深度依赖上游引擎(axe-core)的规则更新与准确性;面对复杂、动态的现代Web应用,其自动化建议的实用性可能大打折扣。29美元的一次性定价虽对个人友好,但作为商业产品,其可持续性和后续迭代动力存疑。它本质上是一个“能力降维接口”,成功与否取决于能否在简化与专业深度间找到最佳平衡点,避免沦为仅适用于简单静态页面的“玩具”。若能在建议的上下文精准度(如结合设计系统)和与设计工具(如Figma)的工作流整合上突破,方能从“有用的工具”进化为“不可或缺的工作流组件”。
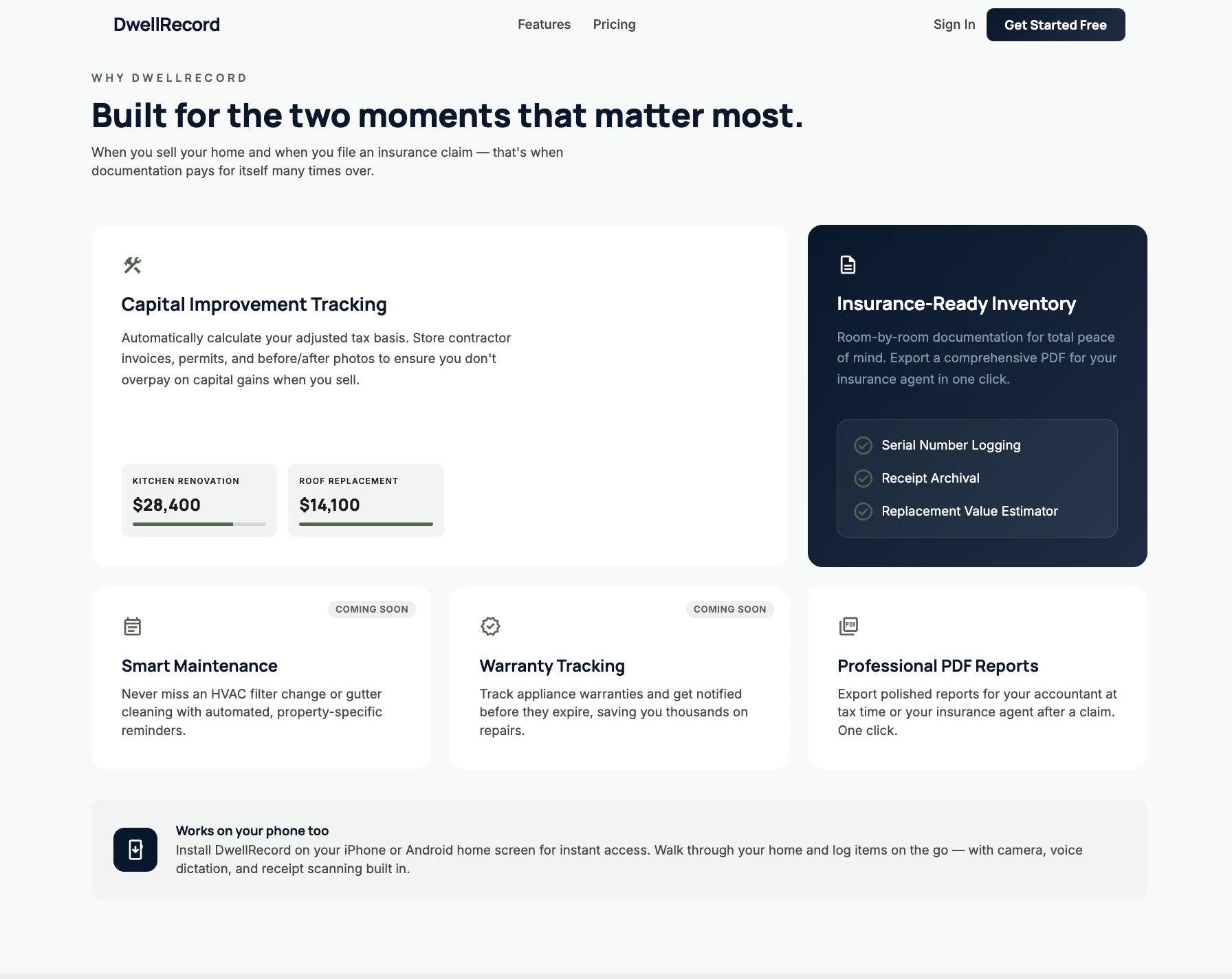
一句话介绍:DwellRecord为房主提供了一个集中管理家庭资产、维修记录、收据、保修单和重要文档的平台,在保险索赔、房屋维护和出售等场景下,解决了信息分散杂乱、关键时刻难以查找的痛点。
Productivity
Home
Home services
家庭资产管理
房屋维护记录
文档数字化管理
保修追踪
保险辅助工具
房主应用
生活效率工具
财产记录
用户评论摘要:用户普遍认可其解决“信息分散”痛点的价值,特别赞赏保修追踪和语音/照片快速录入功能。主要问题与建议集中在:期待自动提醒/保修到期警报功能、确认文档扫描与OCR导入能力、以及明确产品主要面向个人房主还是物业投资客。
AI 锐评
DwellRecord切入了一个广泛存在但长期被忽视的“家庭数据管理”真空地带。它的真正价值并非简单的信息聚合,而在于试图将“房屋”这一重大资产进行全生命周期数字化,构建其“数据孪生”。这直接瞄准了保险理赔和房产交易这两个高价值、高痛点的场景——在这里,有序的证明文件直接等同于经济利益。
然而,其面临的挑战同样尖锐。首先,它对抗的是人类最顽固的行为惯性:非紧急事务的拖延症。尽管产品通过语音、扫描等降低了录入门槛,但“持续维护”这一核心动作仍需用户主动驱动,这构成了产品可持续使用的最大障碍。其次,其商业模式存在模糊地带。面向个人房主,或许只能收取低廉的订阅费;若转向专业物业管理者,其功能深度又可能不及专业的物业管理软件,陷入尴尬的中间地带。
从评论反馈看,团队已意识到“提醒”功能的关键性,这正是指向用户行为惰性的正确一步。未来的竞争壁垒可能在于能否通过合作伙伴(如保险公司、房产中介)提供“价值前置”的激励,让用户为了明确的、可预期的折扣或溢价服务而乐于维护数据。否则,它很可能沦为另一款“下载即遗忘”的美好工具。它的成功,不取决于功能有多精巧,而在于能否将自己从一个“记录工具”重新定义为“家庭资产增值与风险管控的必要基础设施”。
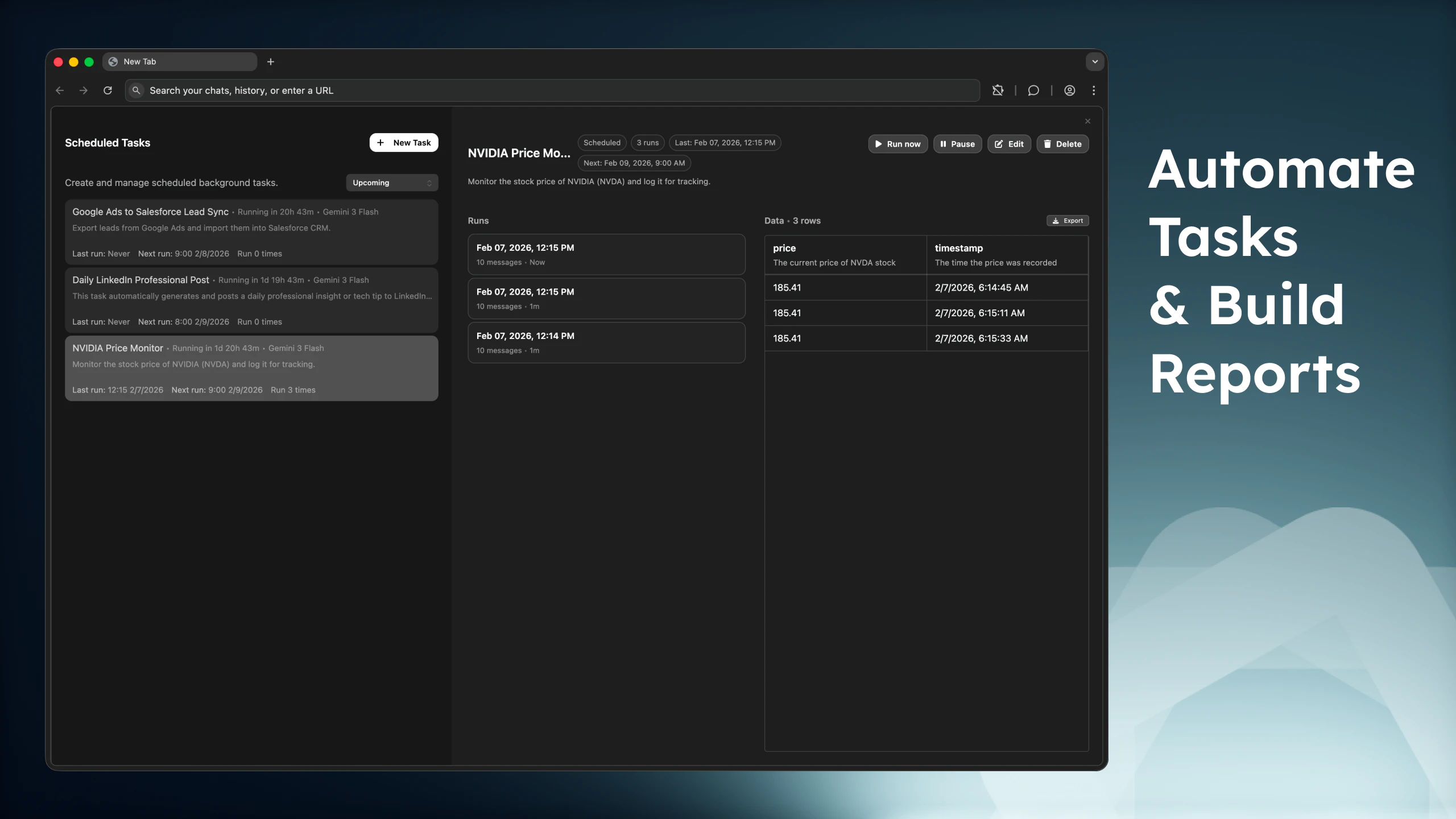
一句话介绍:Santana是一款实时终端数据可视化工具,让工程师无需离开命令行即可通过管道输入数值流,直接生成自动缩放的实时图表,解决了在纯命令行环境中快速、直观监控数据流的痛点。
Productivity
Developer Tools
Tech
终端工具
数据可视化
实时监控
命令行工具
开发运维
性能监控
数据管道
轻量级应用
工程师工具
用户评论摘要:用户反馈高度认可其无需仪表盘和复杂配置、直接管道绘图的核心理念,认为它是对现有工具(如ttyplot)的现代化替代。主要建议可能集中在图表类型扩展、与其他终端工具的集成深度上。
AI 锐评
Santana所切入的,是一个被图形界面和Web仪表盘长期“惯坏”却并未真正满足的缝隙市场:硬核命令行用户的瞬时可视化需求。它的真正价值并非创造了新技术,而是精准地做了一次“场景降维打击”——将数据可视化这一通常需要打开浏览器、登录面板、配置图表的高开销动作,压缩成一条简单的管道命令。这本质上是将“观察”这一调试与监控中的高频低认知负荷行为,无缝嵌入工程师现有的线性工作流,实现了从数据生成到视觉反馈的路径最短化。
其宣称的“高性能”与“高度可定制”,在终端字符绘图的有限技术范式下,更像是对核心场景的坚定承诺而非无限扩展。产品明智地选择了兼容ttyplot,这并非简单的功能对标,而是一次低成本的生态位夺取,直接转化现有存量用户。然而,其天花板也显而易见:终端渲染的先天限制,注定其适用于高时间密度、低维度指标的快速洞察,而非复杂数据的深度分析。它更像是一把精悍的“视觉瑞士军刀”,在需要即时机敏的服务器监控、算法输出跟踪或网络流量嗅探等场景下,其“无头”特性是巨大优势;但对于需要持久化、交互或团队协作的数据观测,它则主动选择缺席。
当前78票的热度,印证了其精准击中了细分群体的痒点。但长远看,这类工具的价值维系于能否牢牢绑定命令行生态,并持续优化那“最后一公里”的体验——比如更丰富的编码支持、更智能的异常数据标注,或与Prometheus、Grafana等主流生态的轻量级桥接。它不必成为全能的“终端Tableau”,只需做那个在黑暗命令行中,最快亮起信号灯的信使。
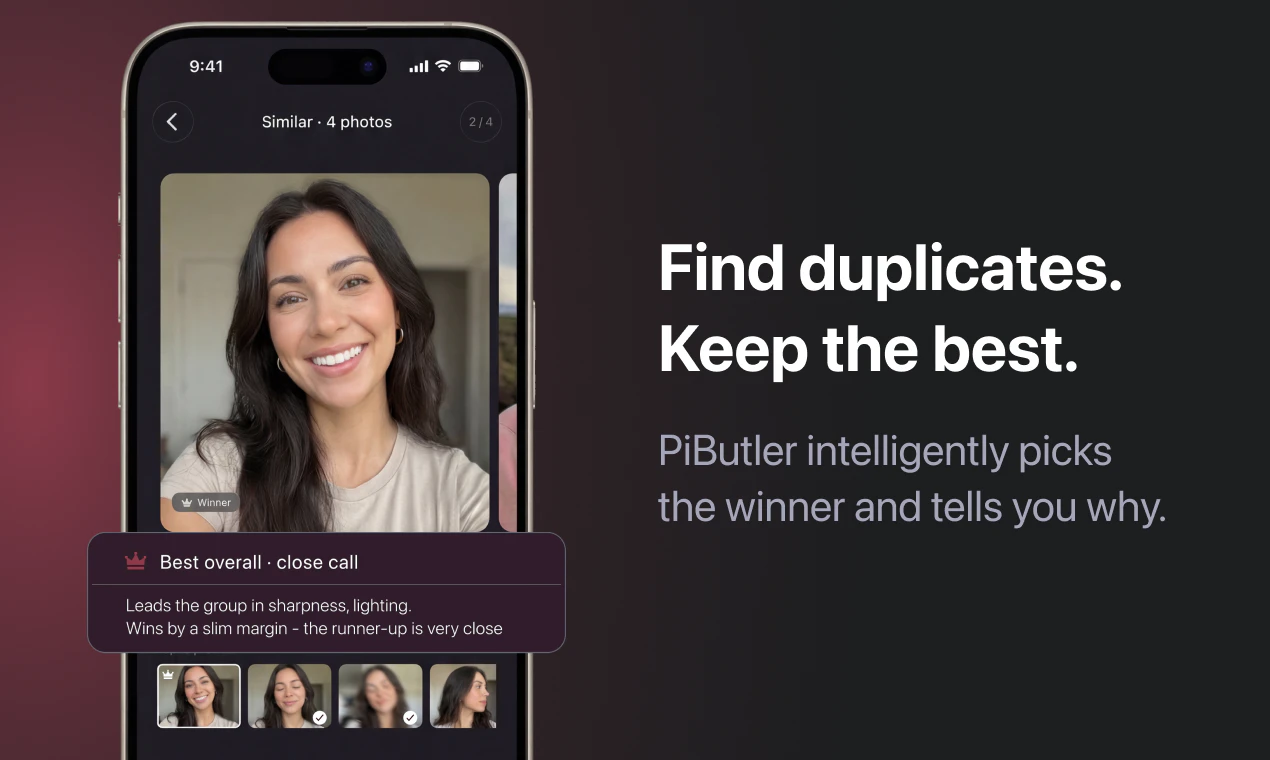
一句话介绍:PicButler是一款在iPhone上通过扫描相册、智能识别重复及相似照片并自动推荐最佳照片的工具,解决了用户手动整理海量照片时效率低下、难以抉择的痛点,尤其适用于需要释放存储空间和优化照片库的场景。
Productivity
Privacy
Photography
照片管理
重复照片清理
隐私保护
本地处理
智能筛选
工具类应用
独立开发
透明算法
无订阅制
iOS应用
用户评论摘要:用户正面评价其为整理照片的实用工具。开发者主动询问“解释推荐原因”的功能价值,核心关注点在于用户是否真正需要知其所以然,还是仅追求快速清理结果。
AI 锐评
PicButler切入了一个拥挤但普遍存在“原罪”的市场。其真正的锋芒并非在于“找出重复照片”这一基础功能,而是双刃剑般亮出的两张牌:算法决策的“透明化”与数据处理的“绝对本地化”。
在功能层面,它试图将AI从黑盒推向白盒,将“为什么这张更好”的指标(清晰度、光线等)具象化。这看似一个微小的产品设计,实则是对当前用户与AI工具关系的一种挑战——它假设用户不再满足于被动接受结果,而希望拥有参与决策的知识与权力。然而,这恰恰是其最大的风险点:在追求“快”的清理场景中,这种“解释”可能成为冗余信息,提升认知负荷。开发者自己在评论区的提问,已暴露出对这一核心卖点市场接受度的不确定。
其另一张牌——隐私,则更具攻击性。通过揭露主流竞品加载大量追踪SDK、甚至对付费用户进行画像的行业潜规则,PicButler将自身“全本地处理、无网络请求、无广告SDK”的架构,从技术特点升维为道德立场。这精准地刺痛了在数据泄露时代日益焦虑的用户神经,将一款工具应用塑造成了隐私捍卫者。
然而,其商业模式(买断制?定价未明)与简陋的推广(仅13票)暗示其作为独立开发项目的生存挑战。它的价值在于为一个功利性的工具市场提供了另一种“正直”的可能性,但其成功与否,取决于有多少用户愿意为“透明”与“隐私”这种非即时体验到的价值付费,并容忍其可能因本地算力导致的速度妥协。它更像一个理想主义的产品实验,其存在本身,就是对行业惯例的犀利质问。
一句话介绍:一款将Hacker News文章与评论并排展示的报纸风格阅读器,解决了用户在阅读文章和查看评论时需要反复切换标签页、容易迷失上下文的痛点。
Newsletters
Open Source
GitHub
Tech
Hacker News客户端
阅读器
信息聚合
PWA
开源工具
侧边栏评论
报纸排版
生产力工具
用户评论摘要:用户肯定其解决标签切换痛点的核心思路。主要建议包括:增加“高亮新评论”功能以提升讨论追踪体验。开发者回应积极,产品为开源项目。
AI 锐评
Hacker News Times 的“报纸”排版,本质是对信息消费动线的一次外科手术式重构。它切入的并非泛资讯领域,而是垂直、高密度的Hacker News社区,这决定了其用户对信息效率有着近乎苛刻的需求。其核心价值不在于“并排显示”这一表象,而在于通过强制性的同屏布局,将“阅读-思考-参照社区观点”这一连贯的认知流程物理化、固定化,减少了上下文切换带来的认知负荷与注意力流失。
然而,其面临的挑战同样深刻。首先,技术上的“嵌入墙”问题(如Substack、Medium的屏蔽)暴露了其作为“聚合层”的天然脆弱性,被迫采用的“阅读模式”虽为解决方案,但也使其游走于版权风险的灰色地带,并可能剥离原页面的部分语境。其次,其价值高度依赖于源社区(HN)的活跃度与质量,模式本身不具备壁垒,可被轻易复制。最后,也是最关键的一点:它优化了“消费”体验,但并未触及“互动”环节。正如用户所建议的“高亮新评论”功能,这暗示了产品的深层需求——从静态阅读工具转向动态讨论追踪器。若能整合基于用户历史的智能评论筛选、时间线对比或讨论脉络可视化,产品方能从“更好的阅读器”升级为“讨论分析助手”,构建真正的护城河。
总体而言,这是一款精准解决高阶用户痒点的“锋利工具”,其开源属性更符合开发者社区的精神。但它也清晰地展示了工具类产品的天花板:在优化单一工作流后,是选择深耕纵向场景(如增强讨论分析),还是横向扩展信源,将决定其是小众精品还是潜力平台。


































Hello Hunters! My name is Tonino and today I'm launching SlapMac 👋
Have you ever wanted to slap your Macbook and hear it moan? Me neither.
But now I've built it, so pls buy my thing.
Story
I made a viral video on IG reviewing some code that make your laptop moan, and in 24h I took the idea and turned it into a simple funny product and went even more viral.
What is it
SlapMac turns your MacBook's built-in accelerometer into a sound machine: slap it, tap it, shake it, and it reacts with hilarious sound effects. Moans, goat screams, impacts, and more. Built on Apple Silicon. Zero shame. 100% questionable decisions.
Discount
Use Code "NotThatPh" to get it for only 3.5$.
(limited to 69 activations )
Stats as of today (28/03/2026)
- ~4M organic views on my IG
- 3M+ views from reposts on X
- 140K views on /r/SaaS on reddit (top post)
- 2K+ licenses sold
Make your product simple, ship it. Don't overthink it.
Have fun! 🫦
I am so happy that I didn't try this in some public space without wearing my headphones :D
Love this. So simple. But just damn fun! Deserve all the upvotes. Would love to make some fun apps with you in the future? I'm always building.
P.S. My 7 year old son watched the video. He doesn't get it, but found it amusing. My wife was not happy :)
Crazy idea. SlapMac name is so apt.
Congrats on the launch 🎉
This is hilarious, but how do you plan to market it beyond memes? The novelty might wear off quick!
this is so funny, what a crazy idea!
Literally just saw this on X! How did you even come up with this? hahaha
Incredible app to install to your coworkers without them knowing.
Hahaha this is hilarious! Is there an iOS app too?
tried it once it was released. lmao.
forgot i had it running and opened laptop next day to start the day getting moaned at: absolutely priceless.
I wish I had a MacBook just to buy this app
<3
RIP for people who forget this is on in public.
This is hilarious and congrats on the launch!
It'd be great use the same mechanism of tapping your macbook to get claude to think harder (although I'm sure it would want to settle the score once it becomes sentient and grows thumbs)
Great app been thinking about doing a version of SlapRick. So when you slap mac rick roll plays.
hey, the website is down, really funny app
whats the tech stack man ? from a developer :)
Really funny concept: turning your MacBook into something that literally reacts when you hit it is the kind of chaotic idea that somehow just works 😂 Congrats on the launch! What made you decide to turn a viral joke into a full product so fast instead of letting it stay a meme? 🚀
I love a good tagline — I clicked just because of it! This is hilarious... sometimes you need a little fun in your day, especially when you're in front of a computer all day. Good luck with the launch!
2000 licenses sold is genuinely insane haha