PH热榜 | 2026-03-31
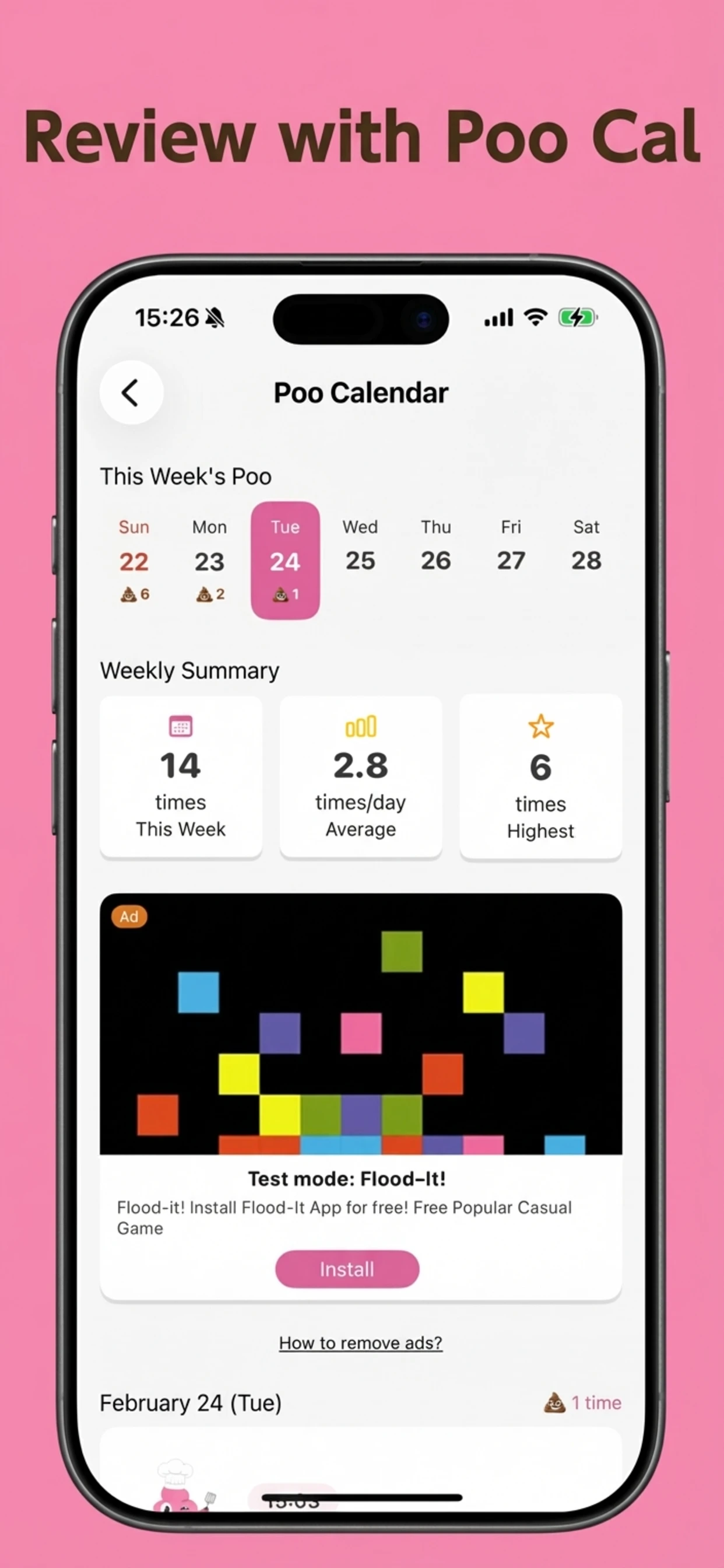
一句话介绍:Jupid是一款专为美国自由职业者和小企业主设计的AI税务助手,它通过构建一个永不遗忘的财务数据上下文层,解决了现有大语言模型在处理多笔交易时出现的上下文丢失、分类不一致问题,最终能在5分钟内自动完成IRS Schedule C税表申报。
Fintech
Accounting
AI财税自动化
Schedule C税务申报
上下文记忆
自由职业者工具
银行交易分类
智能记账
税务抵扣优化
Claude Code集成
无界面交互
SOC2安全认证
用户评论摘要:用户普遍认可产品解决“AI上下文丢失”的核心痛点,认为其定位精准。主要问题集中于数据安全、多实体支持、个人/业务支出自动区分,以及非美国用户使用限制。创始人积极回复,透露了技术实现细节和定价灵活性。
AI 锐评
Jupid的聪明之处在于它没有选择与QuickBooks等巨头在功能臃肿的界面上正面交锋,而是精准地切入了AI应用落地的一个关键软肋:持久化记忆与一致性。其宣称的“修复数据层”,本质上是为LLM构建了一个专属的、持续更新的财务知识图谱,将一次性的规则学习转化为可持续的上下文关联。这比单纯用AI做分类更底层,也更具壁垒。
产品价值并非“另一个AI会计聊天机器人”,而是一个**智能、自治的财务数据管道**。它将混乱的流水转化为结构化的、符合IRS标准的语义数据,从而让任何下游的LLM(如Claude Code)都能进行可靠的分析与申报。这实际上是将会计工作中最枯燥、最易错的“数据清洗与标准化”环节完全自动化,释放了用户与AI在“分析与决策”层面的交互潜力。
然而,其成功高度依赖于对美国税制(尤其是Schedule C)规则的深度编码和96%分类准确率的真实性。长远看,其商业模式面临双重挑战:一是场景局限于美国个税体系,扩张需克服巨大的本地化合规壁垒;二是其作为“数据层”的价值可能被上游(银行数据接口)或下游(如未来迭代的ChatGPT本身具备持久化记忆)所挤压。它目前占据了一个宝贵的生态位,但窗口期可能有限。最终,Jupid是否真能“取代QuickBooks”,不取决于其AI对话的流畅度,而取决于其作为关键数据基础设施的不可替代性。
一句话介绍:这款产品让Claude Code CLI用户能直接在终端内授权AI操作macOS图形界面,解决了开发者在测试、调试视觉问题或自动化无API的GUI工具时,频繁在命令行与图形界面间切换的痛点。
Artificial Intelligence
Computers
AI驱动自动化
人机交互
CLI工具增强
macOS生产力
图形界面测试
无障碍访问集成
研发效能
智能助手扩展
桌面端自动化
用户评论摘要:用户普遍认为这是改变游戏规则的工具,尤其赞赏其能自动化无API的内部工具和图形界面测试。主要关切点在于其对复杂图形界面(如地图密集型应用)的识别准确性,以及对多步骤、有状态交互流程(如表单联动)的处理能力。
AI 锐评
产品表面上是为Claude Code增加“手和眼”,但其深层价值在于试图模糊CLI与GUI的界限,构建一个以自然语言为统一指令层的“元操作系统”。它并非简单的宏录制工具,而是将AI作为实时翻译器,将开发者的意图动态转化为系统级交互事件。
其真正的颠覆性在于两点:一是“逆向工程”了封闭的GUI生态。企业内部大量遗留的、无API的Web应用和桌面工具一直是自动化盲区,此产品通过视觉识别与模拟交互,巧妙绕过了接口缺失的障碍,相当于为任何图形界面临时生成了一个“视觉API”。二是创造了反馈闭环。传统自动化脚本无法感知意外弹窗或界面变更,而本产品整合了屏幕观察能力,使AI能基于实时视觉反馈进行决策调整,向“具身智能”迈出了一小步。
然而,其天花板也显而易见。高度依赖macOS无障碍权限意味着其稳定性和速度受制于底层框架;对复杂、动态视觉元素的解析准确性仍是巨大挑战,评论中关于地图界面的质疑恰恰点中了当前计算机视觉的软肋。此外,将高级别任务安全、可靠地分解为低级别点击流,并理解中间状态(如表单联动),需要远超当前模型水平的推理能力。目前它更像一个在受控场景下强大的“超级宏”,而非通用的智能体。
本质上,这是对“最后一步自动化”的激进尝试。它不构建新桥梁,而是训练AI成为“摆渡人”,直接操作现有岛屿(GUI应用)。短期看,它是强大的生产力补丁;长期看,它揭示了未来人机交互的一种可能形态:自然语言成为覆盖一切的数字“万能遥控器”。但其大规模应用的成败,将取决于在复杂现实场景中的鲁棒性,以及能否建立起足够精细的权限与安全控制,防止这把过于锋利的“瑞士军刀”伤及自身。
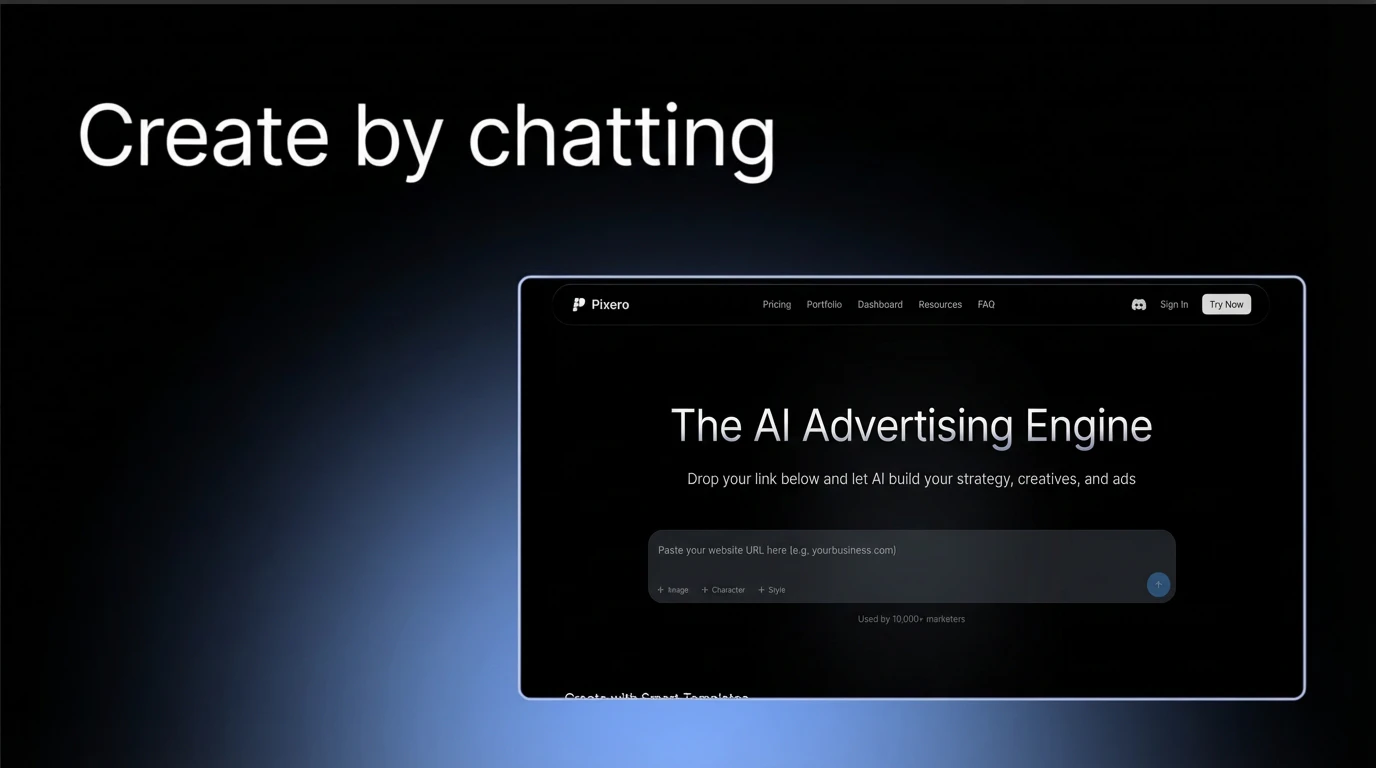
一句话介绍:Pixero AI是一款端到端自动化运行Meta广告活动的AI智能体,通过输入品牌URL,在9分钟内自动完成品牌分析、策略制定、广告创意生成及活动部署管理,为缺乏专业营销团队与时间的中小企业解决了高效启动并优化Meta广告转化的核心痛点。
Marketing
Artificial Intelligence
Photo & Video
AI广告自动化
Meta广告代理
端到端广告管理
智能广告创意
中小企业营销工具
品牌策略自动化
广告活动部署
AI智能体
营销效率工具
无代码广告运营
用户评论摘要:用户普遍认可其全流程自动化价值,关注点集中于:1. 品牌定位与声音的一致性保障;2. 信用/资源消耗的透明度;3. 对SaaS/数字产品的适用性;4. 与经验媒体买家效果的对比;5. 遵守Meta平台政策的能力;6. 向TikTok/Google Ads等平台扩展的计划。
AI 锐评
Pixero AI的亮相,与其说是一款新产品,不如说是对传统广告运营模式的一次“外科手术式”打击。它精准切入了一个长期存在且被多数工具回避的真空地带:将策略、创意、部署、管理这四个高度专业化且割裂的环节,用单一AI智能体串联成闭环。这远不止是“AI生成广告图”,而是试图将资深媒体买手的策略思维、设计师的创意执行、优化师的投放操盘,编码成可复制的自动化流程。
其真正的颠覆性价值在于“决策权让渡”。它要求企业提供一个URL,然后交出从策略到执行的绝大部分控制权。这对预算有限、专业知识匮乏的中小企业极具诱惑力,但也是其最大风险点。评论中关于“品牌声音一致性”和“与资深买家效果对比”的提问,直指核心:AI能否真正理解品牌内核与市场细微差别?目前其依赖“设计记忆”(色彩、字体、关键词)和“类人操作节奏”来应对,这仍是基于规则和模式匹配的优化,而非真正的品牌战略理解。
创始人“前谷歌工程师”的背景,以及“10万+用户3个月”的数据,为其技术可靠性与市场热度背书。然而,其商业模式深度捆绑Meta平台,政策风险如影随形。尽管团队强调“类人操作”规避封禁,但平台算法的任何变动都可能成为系统性风险。此外,将复杂营销简化为“输入URL坐等结果”,可能让用户忽视对广告基础逻辑和市场洞察的积累,产生“自动化依赖”。
总体而言,Pixero AI是AI应用向纵深发展的一个标志。它不再满足于充当单点效率工具,而是野心勃勃地要接管整个业务流。它的成功与否,将不取决于其AI生成广告的精致度,而取决于其“策略大脑”的智能水平、对平台生态的适应能力,以及用户对“全权托管”模式的信任程度。这是一场大胆的赌注,赌的是端到端自动化的综合收益,能够超越其在灵活性与深度洞察上的固有缺陷。
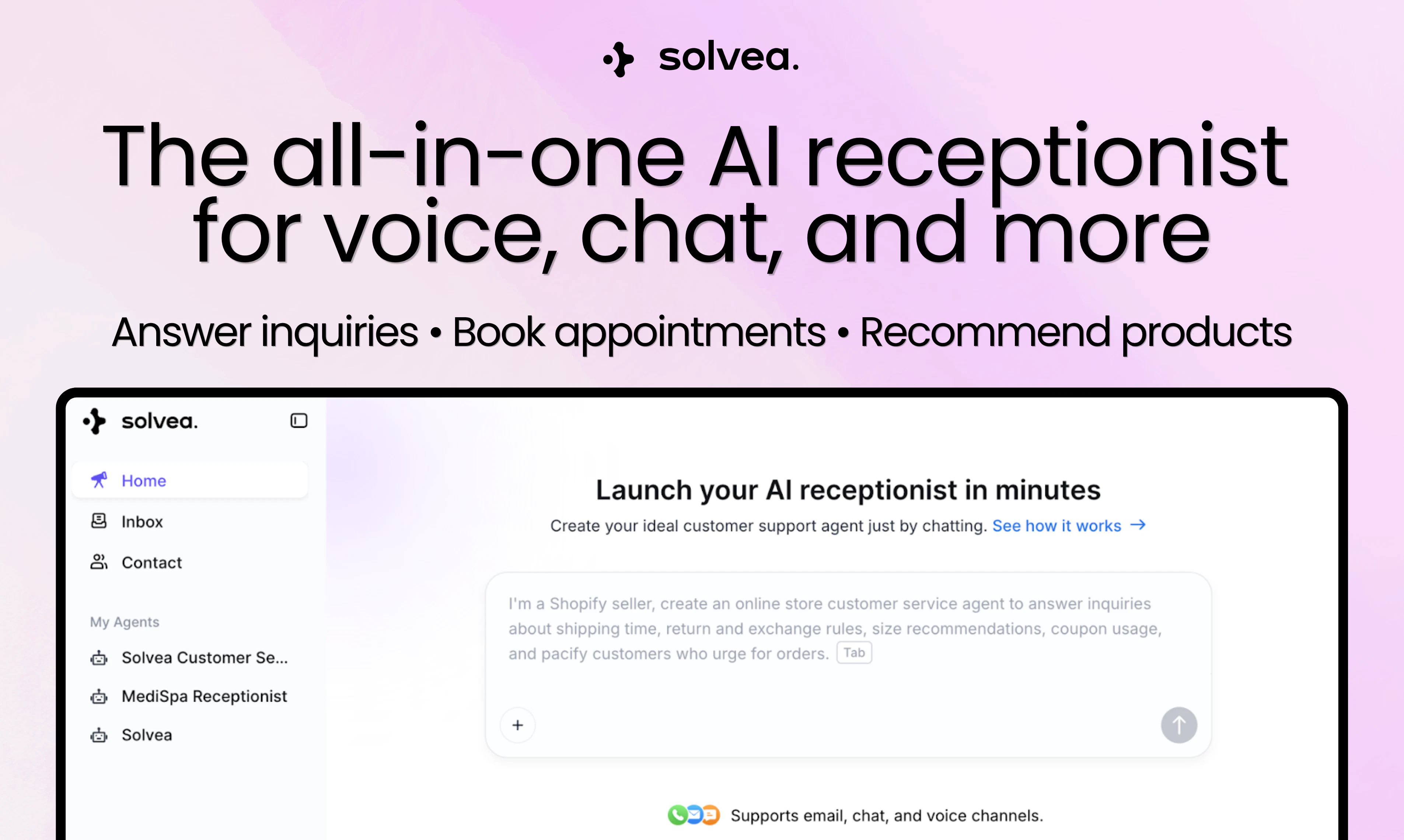
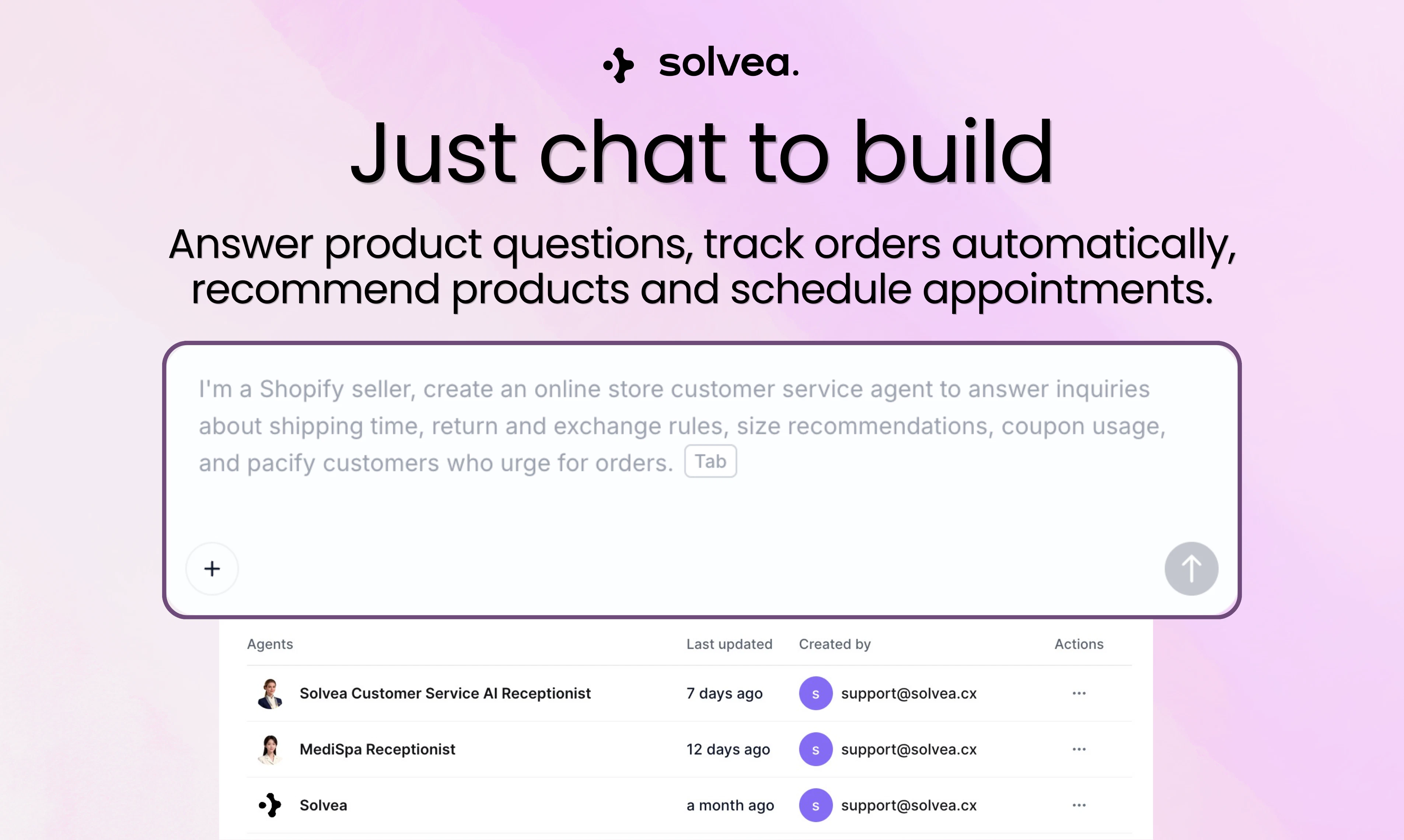
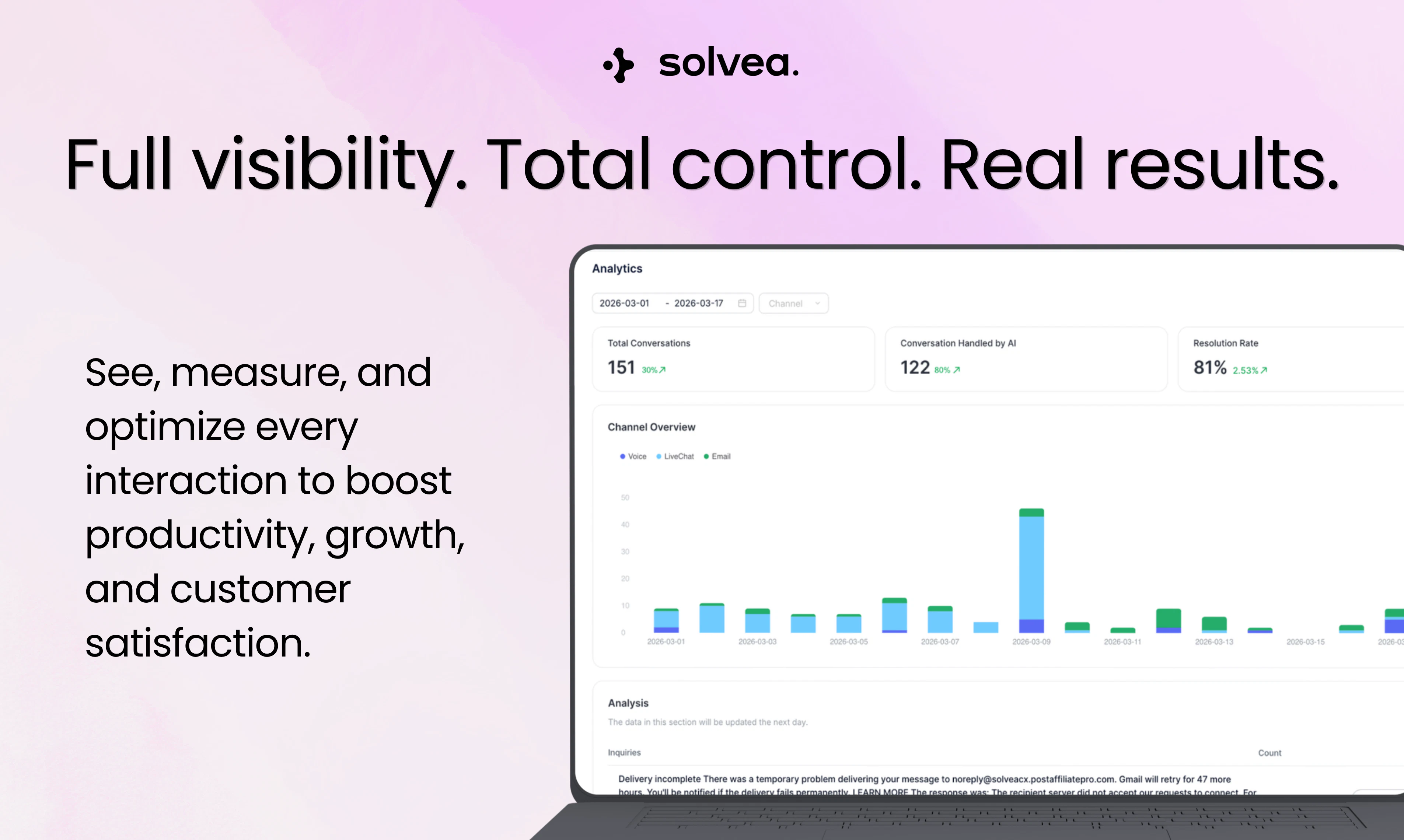
一句话介绍:Solvea是一款无需编程、快速部署的AI前台助手,能通过电话、聊天、邮件等多渠道全天候自动处理客户咨询、预约及销售推荐,解决中小企业人手不足、错过商机与重复性服务负担过重的痛点。
Productivity
Artificial Intelligence
Vibe coding
AI客服
智能前台
自动化营销
中小企业工具
无代码平台
多渠道支持
预约管理
品牌个性化
工作流集成
实时响应
用户评论摘要:用户肯定其快速设置、人性化对话及实用工作流集成。主要问题聚焦于AI透明度(是否告知客户)、未知问题处理机制(人工交接流程),以及品牌形象与AI人格的长期协调。团队回应坦诚,强调体验优先与灵活配置。
AI 锐评
Solvea的野心不在于做出另一个“聪明的聊天机器人”,而在于成为中小企业的首个数字化员工。其真正价值并非源自多模态或技术炫技,而在于精准切入了一个被长期忽视的缝隙市场:那些请不起全天候前台或客服团队、却又极度依赖即时响应来维系生存的小微企业(如牙科诊所、水管工)。产品设计的“犀利”之处体现在三点:一是“语音优先”,直面最传统、最高门槛的电话场景,用自然对话取代僵硬的IVR菜单,这是从“玩具”到“工具”的关键跨越;二是“氛围编码”所代表的极简配置逻辑,将复杂的AI调优包装成“用语言描述需求”,大幅降低使用恐惧;三是内置如Google日历、Shopify等核心生产力工具的闭环操作能力,让AI从“应答”走向“办事”。
然而,其面临的挑战同样清晰。首当其冲的是“人机边界”的伦理与体验平衡。尽管团队声称不伪装人类,但追求“自然人性化”的对话与保持AI透明度之间存在微妙的张力,处理不当易引发信任危机。其次,作为“前台”,其核心风险从技术准确率转向了责任归属:当AI在预约时间、订单查询或产品推荐上出错时,商业损失如何界定与补偿?这需要超越产品层面的服务条款设计。最后,其“无代码”和模板化虽是快速获客利器,但也可能成为向中大型企业渗透的瓶颈——更高阶、复杂的业务逻辑定制需求如何满足?Solvea若想从“贴心助手”升级为“核心业务系统”,必须在个性化深度与企业级管控上构建更厚的壁垒。当前,它聪明地找到了一个肥沃的空白地带,但能否真正扎根生长,取决于它能否在“易用性”与“可靠性”这对永恒的矛盾中,为小企业主找到一个真正安心的平衡点。
一句话介绍:Perplexity API Platform 为开发者提供了一个集成了多模型访问、实时网络搜索与高性能嵌入的智能体开发栈,解决了开发者需要整合多家供应商才能构建实时AI应用的痛点。
API
SaaS
Developer Tools
AI开发平台
API服务
智能体框架
实时网络搜索
多模型集成
检索增强生成
开发者工具
一站式解决方案
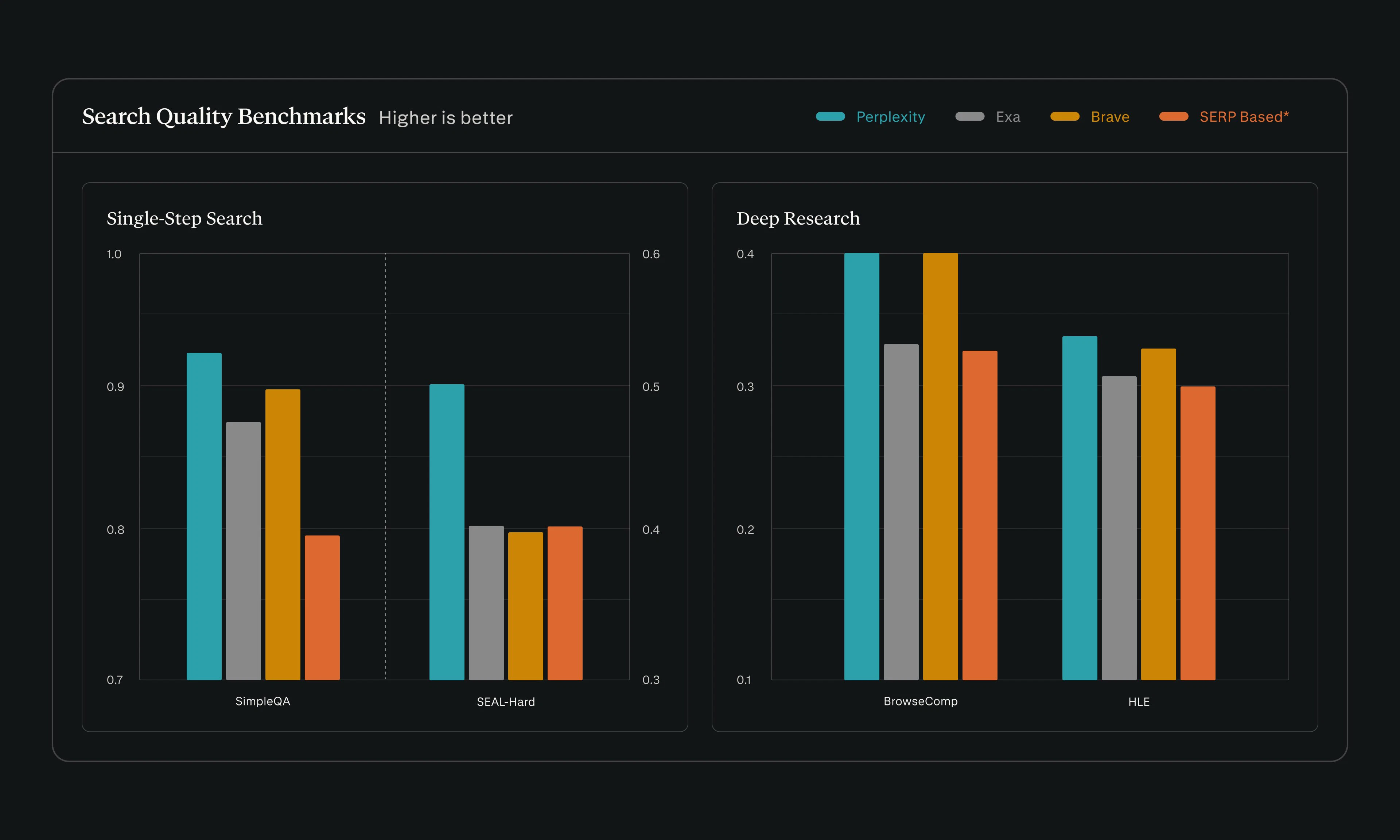
用户评论摘要:用户肯定其“一个API替代多个供应商”的整合价值,并询问政府/小众数据源的索引新鲜度。同时,有评论尖锐指出其依赖开放网络内容可能带来SEO污染、时效性偏见和矛盾信源的风险,尤其在健康、法律等严肃领域,并质疑平台是否提供源域控制等缓解措施。
AI 锐评
Perplexity API Platform 并非简单的功能堆砌,其核心价值在于将自身C端产品“问答+实时搜索+引用”的核心能力产品化、基础设施化。它瞄准的是当前AI应用开发,特别是智能体构建中的一个核心矛盾:强大的基础模型与陈旧、脱节的“世界知识”之间的割裂。开发者被迫在“纯模型幻觉”与“拼接脆弱搜索管线”之间做选择。
该平台提供的“实时搜索+引用”看似是功能,实则是试图建立一种新的可信AI交互范式——将模型的推理能力与互联网的实时性、具体性相结合,并用引用溯源来部分解决黑箱问题。这直接回应了企业级应用对准确性、可解释性和时效性的迫切需求。
然而,从评论中的尖锐质疑可以看出,其最大的优势也可能成为阿喀琉斯之踵。将开放网络作为事实基座,意味着继承了互联网的全部噪音、偏见与对抗性内容。平台的价值高低,将不取决于其检索规模(200B+ URLs),而完全取决于其检索质量、排名算法和对垃圾信源的过滤能力。评论者指出的“SEO中毒内容”和“时效性偏见”是致命痛点。在健康、金融等高风险领域,一个可追溯的错误答案,可能比一个纯粹的幻觉承担更大的法律和信誉风险。
因此,该平台能否成功,关键在于它是否只是一个“管道工”,将未经深度净化的网络数据输送给开发者;还是能成为一个“编辑”或“策展人”,通过更精细的源站控制、权威度加权、事实交叉验证等工具,赋予开发者管理信源风险的能力。它提供的“一站式”便利,绝不能以让开发者“放弃控制权”为代价。否则,它只是将复杂性从集成多家API,转移到了对单一家API输出结果的不确定性管理上。
一句话介绍:一款集成在Slack内的AI助手,为广告投手提供跨Meta和Google广告平台的实时、自动化操作与优化,解决了多平台管理繁琐、夜间监控缺失及数据核对复杂的核心痛点。
Productivity
Marketing
Artificial Intelligence
AI广告优化
Slack集成
跨平台广告管理
自动化营销
绩效营销
AI智能体
实时操作
广告审计
增长工具
SaaS
用户评论摘要:用户高度认可其Slack原生集成与自动化执行能力,视其为“行动者”而非“仪表盘”。核心反馈包括:询问边缘案例处理、优化逻辑(AI驱动而非规则)、建议整合TikTok等平台,并期待其从被动响应转向主动预警。
AI 锐评
Viktor并非又一个广告数据看板,其真正价值在于将“决策-执行”闭环压缩进一个自然语言对话中,并凭借“写权限”成为广告账户的“自动驾驶仪”。这直击了绩效营销者每日重复性手动操作与跨平台数据割裂的深层焦虑。
产品犀利之处有三:第一,精准的“场景寄生”。它没有创造新习惯,而是侵入了广告投手“每日检查-调整”的既有Slack工作流,使得工具采纳阻力极小。第二,用“操作深度”而非“数据广度”构建壁垒。103+37个可执行动作,覆盖从暂停、预算调整到受众复制的关键操作,这远非只读API能比拟,建立了技术信任门槛。第三,其商业模式洞察深刻:它首先服务于“一人增长团队”和中小团队,填补了专业投手雇佣前的能力空白,是人力成本的阶段性代偿。
然而,其面临的挑战同样清晰。首先,将广告账户生杀大权交给AI,其决策透明性与可解释性将是专业用户长期信任的关键,尤其在处理“边缘案例”时。其次,当前定位虽聚焦,但“创意”环节的缺失使其仍是“半套”解决方案。最后,其AI驱动模式在应对平台算法黑盒与异常归因时,能否持续做出优于规则引擎的、符合商业直觉的判断,仍需时间验证。
本质上,Viktor代表了工具演化的一个方向:从提供信息(Dashboard),到提供建议(Analytics),最终到授权执行(Agent)。它能否成功,不取决于AI是否更“智能”,而取决于其动作库是否足够精准可靠,以至于用户敢在入睡前将真金白银的广告预算托付给它。目前看来,它正走在一条正确但充满风险的道路上。
一句话介绍:Stamp是一款AI秘书应用,通过学习用户偏好与写作风格,在邮件和日历管理场景中,自动处理邮件优先级、总结内容、起草回复,解决用户日常信息过载与沟通效率低下的痛点。
Email
Productivity
Calendar
AI秘书
电子邮件自动化
智能日历管理
写作风格模仿
工作流自动化
邮箱助手
生产力工具
人工智能助理
用户评论摘要:用户认可其“需批准后发送”的设计,避免了全自动代理的风险。主要疑问集中于:AI如何随时间精准适配个人写作风格;面对大量待处理邮件的用户体验;以及模型的具体训练方法。开发者回复强调了“记忆”系统、上下文学习和手动编辑功能。
AI 锐评
Stamp的核心理念——“像你一样思考、写作和工作”——精准地戳中了当前AI助理工具的普遍软肋:缺乏个性与上下文连贯性。它并非简单地将大模型接入邮箱API,而是试图构建一个持续学习的“数字分身”,其“记忆”系统是关键的差异化设计。这暗示其正从“工具”向“代理”演进,旨在成为有长期记忆的工作伙伴。
然而,其真正的挑战与价值也在于此。首先,“像你”是一个极高的标准,涉及对用户价值观、沟通策略乃至人际关系的微妙理解,当前技术能否稳定实现存疑。评论中关于风格适配的反复追问即是明证。其次,产品在“自动化”与“控制感”之间选择了审慎的平衡(需用户最终批准),这是明智的,但也将效率瓶颈从“起草”转移到了“审阅”。如何智能批量化呈现待审阅项,成为影响体验的关键,官方回复对此的解答略显单薄。
其最大潜力或许在于“Agent”工作流自动化,这使其超越了邮件回复,向个人CRM、研究助手等角色扩展。但这也带来了更复杂的隐私与数据安全问题。总体而言,Stamp描绘了一个诱人的未来:一个真正个性化、可信任的AI协作者。但其当下的价值,更可能体现为一名高度可定制、能初步理解上下文的“邮件副驾”,而非完全自治的“秘书”。成功与否,取决于其“记忆”学习的深度、用户界面能否高效处理批量任务,以及能否在提升效率的同时,让用户感到可控而非疏离。
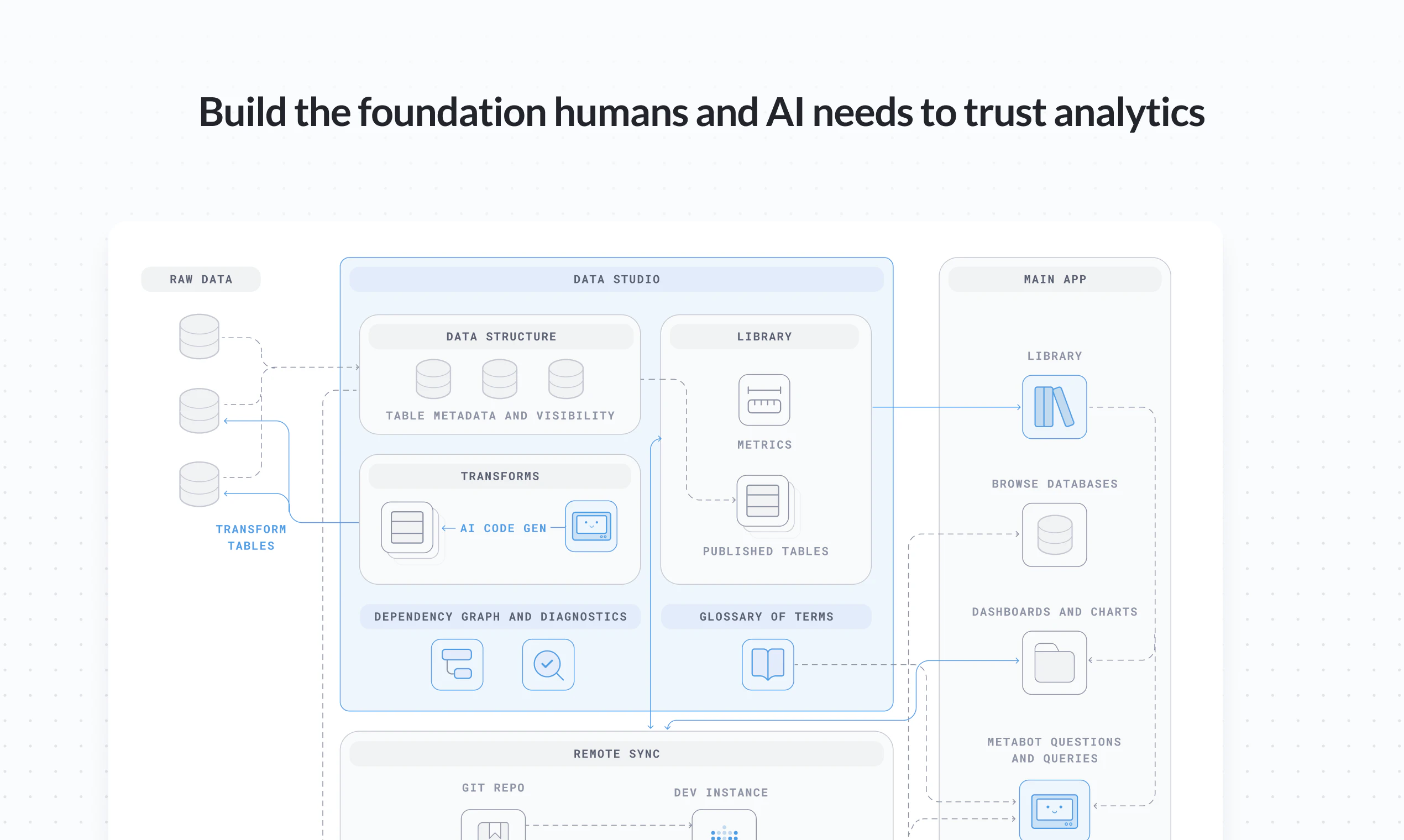
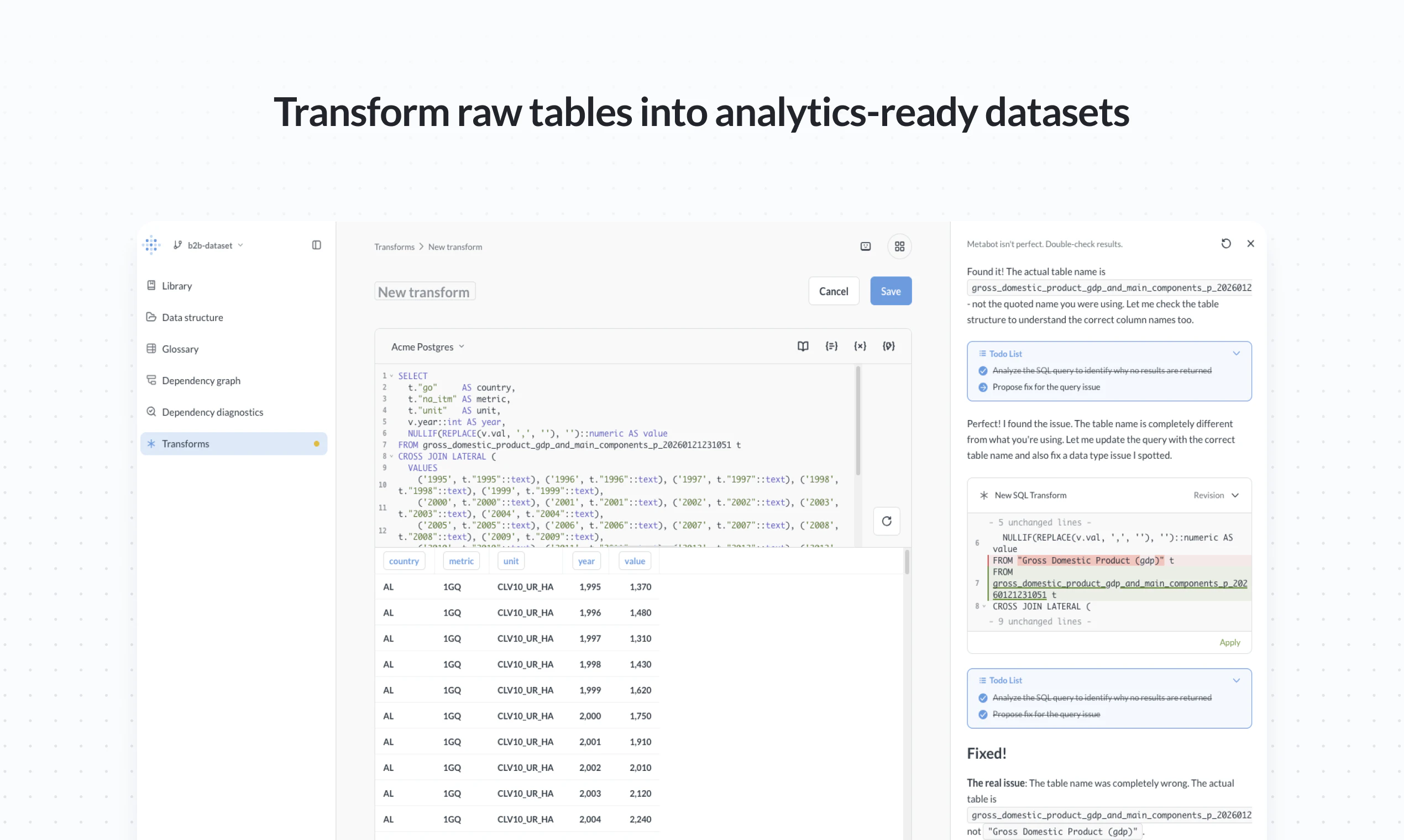
一句话介绍:Metabase Data Studio 是一个面向数据分析师的工作台,通过构建统一的语义层(定义指标、业务逻辑),在AI分析时代解决了企业内数据定义混乱、指标口径不一致的核心痛点,确保AI及所有用户都能获得可靠的数据答案。
Open Source
Developer Tools
Data & Analytics
语义层
数据分析平台
指标管理
数据治理
数据血缘
SQL/Python转换
AI就绪数据
自助式分析
数据可信度
元数据管理
用户评论摘要:用户高度评价其统一指标定义、SQL/Python数据转换、数据血缘和依赖图谱功能,认为其解决了“活跃用户”等指标定义混乱的经典难题。主要问题集中于:如何应对现实世界中混乱的数据模式,以及业务定义变更时是版本化管理还是原地更新(官方回复为版本控制)。
AI 锐评
Metabase Data Studio 的发布,绝非一次简单的功能叠加,而是直指当前“AI+数据分析”热潮下被刻意忽视的命门:垃圾数据进,垃圾答案出。它试图解决的,不是分析本身,而是分析之前的“共识”问题——通过构建一个中心化的、可操作的语义层,将过去分散在无数SQL查询、PPT文档和员工大脑中的业务逻辑(如“何为收入”)强制标准化。这本质上是将数据团队最核心的治理工作产品化、民主化。
其真正价值在于“承上启下”。对上,它为各类AI智能体提供了结构化的、可信的业务上下文,是让AI分析从“概率性猜测”走向“确定性回答”的基础设施,这比单纯优化大模型提示词更根本。对下,它通过内嵌的转换、血缘和依赖检查,将原本需要组合dbt、数据目录和BI工具才能搭建的简陋数据工程流程,整合进分析师熟悉的界面,降低了可靠数据栈的构建门槛。
然而,其挑战也同样明显。首先,“定义一次,处处使用”的理想,与业务快速迭代、定义动态变化的现实存在固有张力,版本控制只是技术手段,如何管理定义变更背后的组织沟通与共识重建,是更难的课题。其次,它将Metabase从一个轻量级BI工具推向了一个更重的“数据工作台”,这可能吸引深陷数据混乱的中型团队,但也可能疏离其原有的、喜爱其简洁性的用户。能否在功能强大与体验轻便之间取得平衡,将决定其是成为数据栈的“核心枢纽”,还是又一个“高级模块”。
总体而言,这是一次极具洞察力的战略升级。它没有在AI的炫技层面跟风,而是回归到数据行业最古老、最昂贵的问题上,并提供了工程化的解决方案。它的成功与否,不仅关乎产品本身,更将检验市场对“数据基础质量”的付费意愿究竟有多强。
一句话介绍:一款托管式MCP服务器,允许营销人员直接在Claude等AI助手内通过自然语言指令创建和管理Google Ads广告活动,省去了复杂的云配置和界面操作,解决了营销人员在广告投放中效率低下和操作门槛高的痛点。
Productivity
Marketing
Artificial Intelligence
AI营销工具
Google Ads管理
无代码集成
MCP服务器
自然语言交互
营销自动化
效率提升
SaaS
付费广告
托管服务
用户评论摘要:用户认可其免云配置对非技术营销人员的价值,并询问批量创建等具体功能。建议网站需更清晰传达其“策略层”价值以支撑定价。创建者回复积极,确认了单指令创建活动的核心能力。
AI 锐评
Google Ads MCP Server(HireOtto)的亮相,远不止是又一个API包装器。它精准地刺中了两个行业顽疾:一是Google Ads后台日益复杂的“开关迷宫”对营销人员心智的消耗;二是早期MCP工具只提供“骨骼”却无“肌肉和神经”,导致非技术用户望而却步或操作危险的窘境。
产品的真正价值在于其“有主见的自动化”。创始人基于资深营销背景,将最佳实践与策略判断内化为产品默认设置与安全护栏,这使其从单纯的“执行管道”升格为“数字营销副驾驶”。它处理的不是简单的指令翻译,而是包含了成本、策略合规与效果预设的“工艺层”。这解释了其敢于向 agencies 和 in-house 团队收费的底气——它售卖的是封装了的专业经验与风险规避能力。
然而,其成功高度依赖于MCP生态的普及与AI客户端(如Claude)的稳定性。当前它更像是一个为高阶玩家准备的“效率外挂”,而非颠覆性平台。其长期挑战在于:如何将更多隐性的营销“手艺”持续编码化,以应对快速变化的广告平台政策与算法;以及如何在提供“有主见”服务的同时,保持足够的灵活性,满足不同行业、不同阶段企业的个性化需求。如果它能跨越这些鸿沟,或许能成为连接AI智能与商业效果的关键中间件。
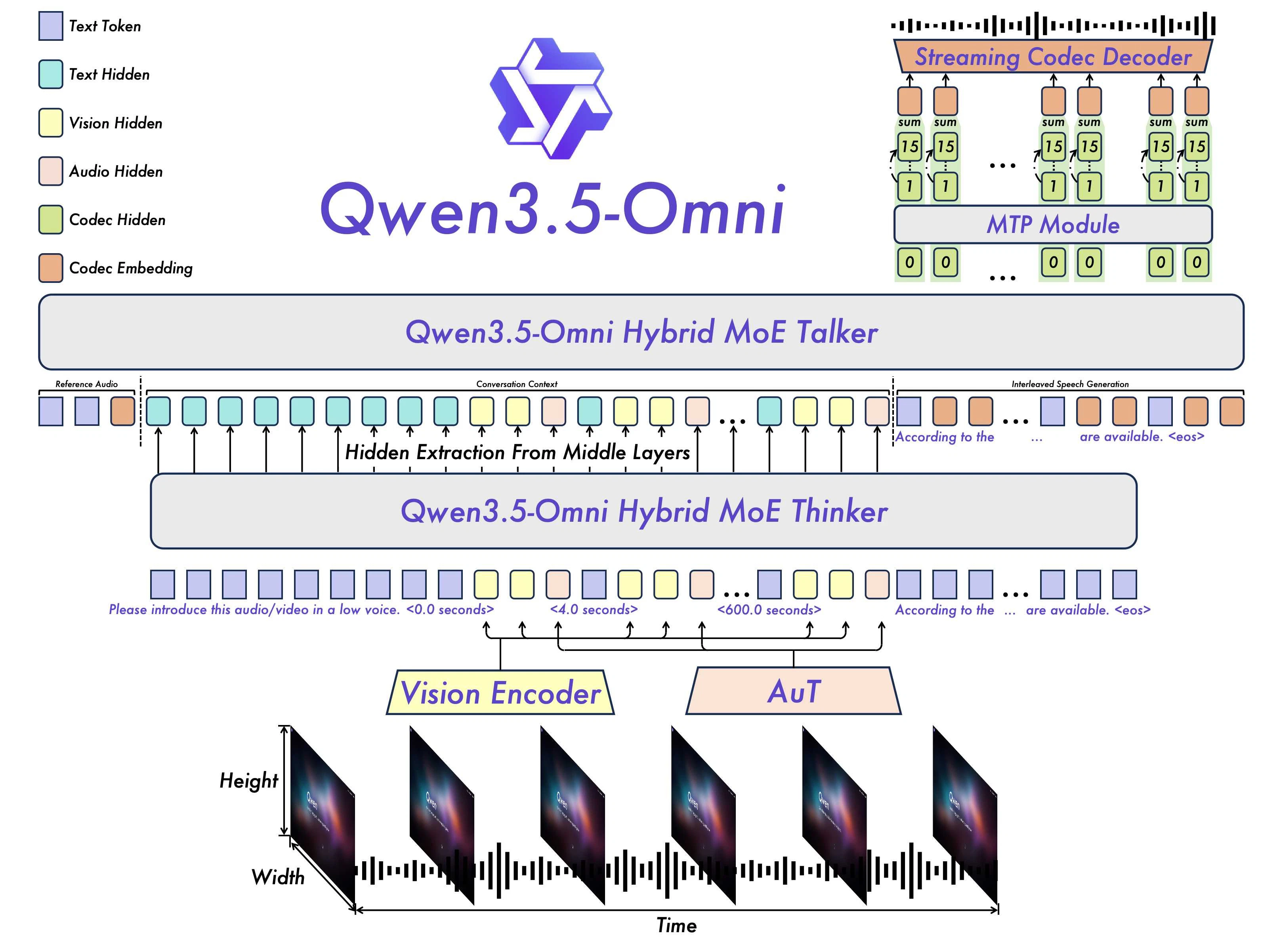
一句话介绍:Qwen3.5-Omni是一款原生多模态AI模型,通过整合文本、图像、音频、视频的实时交互与理解能力,在需要自然、流畅、多感官交互的智能助手、内容创作与客服等场景中,解决了传统AI模型模态割裂、交互延迟的痛点。
API
Artificial Intelligence
Development
多模态大模型
实时语音交互
音视频理解
语音克隆
工具调用
网络搜索
原生全模态
AI助手
人工智能平台
闭源模型
用户评论摘要:评论者(疑似官方或知情者)热情介绍了产品功能亮点,如多模态整合、实时交互和音视频“氛围编码”,并确认模型暂未开源,目前可通过Hugging Face演示或官方API体验。核心建议是希望其能尽快集成到“Coding Plan”中。
AI 锐评
Qwen3.5-Omni的发布,与其说是一次技术升级,不如说是对当前AI应用范式的一次激进押注。它试图将“多模态”从简单的输入输出拼接,推向一个深度融合、实时响应的“原生”系统。其真正的价值不在于功能列表的罗列,而在于将“语义打断”、“实时语音控制”等交互细节作为核心卖点,这直指当前语音助手体验生硬、无法自然插话的顽疾。
然而,其“闭源”状态与通过API、Demo体验的现状,暴露了其战略本质:这很可能不是一次面向开发社区的馈赠,而是一次商业能力的集中展示和技术路线的宣言。它旨在证明,在通向通用人工智能的道路上,无缝融合多种感官信号并实现低延迟交互,是一个比单纯追求参数规模更关键、也更艰难的赛道。其宣传的“音视频氛围编码”概念颇具想象力,暗示其可能追求超越传统字幕生成的情感或语境理解,但这需要实际案例佐证,否则易沦为营销话术。
当前模型面临的挑战清晰可见:在闭源生态下,如何构建开发者护城河?其多模态能力的实际精度、延迟及成本,能否支撑其宣称的“实时”体验?在OpenAI的GPT-4o已然占据用户心智的战场上,Qwen3.5-Omni需要更独特的杀手级应用场景,而非仅仅功能对标。它或许代表了国内大模型向深度整合、体验优化方向的一次有力进击,但其成功与否,将取决于能否将炫技转化为稳定、可靠、可规模化的产品力,并在开源与商业化之间找到平衡点。
一句话介绍:Unify是一款允许企业像招聘真人一样招聘和入职AI同事的平台,通过实时屏幕共享、文档和通话进行交互,解决了传统AI工具需要预先精确描述复杂任务、缺乏团队融入感和实时协作能力的痛点。
Productivity
Artificial Intelligence
Virtual Assistants
AI同事
虚拟员工
智能体
实时协作
团队集成
个性化AI
自定义技术栈
持续学习
企业自动化
人机协作
用户评论摘要:用户普遍赞赏其“真人式”入职和实时交互体验,认为这解决了传统AI工具需预先完整定义任务的痛点。主要问题聚焦于AI价值实现的延迟期、团队动态变化时的自适应能力,以及自定义技术栈在硬件/物联网等具体场景下的应用潜力。
AI 锐评
Unify的野心不在于打造另一个“超级助手”,而是试图定义一种新的数字劳动力范式:具有人格、专属工作空间和成长记忆的“AI同事”。其核心价值并非单纯的任务自动化,而是通过模拟人类入职与协作的“高保真”交互,攻克复杂、非结构化工作流程的AI化难题。
产品最犀利的突破点在于其“实时、可引导、多任务并发”的底层架构。这直接挑战了当前主流AI代理“单次提示-执行-输出”的僵化模式,试图捕捉人类工作中模糊沟通、中途修正、多线程推进的真实状态。其宣称的“非OpenClaw”自定义技术栈,本质是为了摆脱现有框架在低延迟和深度交互上的束缚,追求“身临其境”的协作感。这是一个高风险高回报的技术选择,意味着放弃了成熟的生态,但换来了对体验的绝对控制。
然而,其宣称的“像真人一样学习与成长”既是最大卖点,也是核心风险。用户的疑问直击要害:企业需要为AI的“成熟期”投入多少真实的培训成本?当业务进程变化时,AI是主动适应还是需要重新培训?这本质上触及了AI作为“同事”的可靠性与维护成本问题。产品将AI拟人化到极高程度,也必然让用户以人类同事的标准来审视它,对其责任感、稳定性和“情商”提出更高要求。
总体而言,Unify是一次面向B端的大胆社会实验,它不再将AI视为工具,而是定位为组织中的“准成员”。其成功与否,不取决于技术是否炫酷,而在于能否在真实的商业场景中,证明这种深度集成、持续学习的AI角色,所带来的长期效率提升能显著超过其高昂的“入职”与“磨合”成本。它开启的是一条艰难但极具想象力的道路。
一句话介绍:IndieEvent通过组织同城线下活动,解决独立创造者搬迁新城市后社交孤立、难以找到同类社群的痛点。
Global Nomad
Meetings
Community
独立创造者社交
线下活动组织
同城社群
创业者网络
地理位置社交
社区运营
活动策展
社交破冰
城市适应
兴趣社交
用户评论摘要:用户主要关注活动组织方式(社区自组织或官方策展)、线上线下形式融合、小城市可用性、“独立创造者”定义清晰度、登录方式依赖X账户的局限性,以及目前覆盖范围(称支持全球)。开发者回复解释了活动生成门槛和登录设计考量。
AI 锐评
IndieEvent瞄准了一个真实但狭窄的缝隙市场:全球流动的独立创造者的线下即时社交需求。其价值不在于技术创新,而在于精准的场景捕捉——将“孤独的异地创新者”这一高价值但离散的群体进行地理聚类,试图将数字游民式的线上连接转化为在地的物理社群。产品逻辑清晰:用最低门槛(两人成行)触发活动,以Twitter账号作为信任锚点,降低陌生社交的初始风险。
然而,其深层矛盾已然在评论中显露。首先,依赖X账号登录是一把双刃剑,在保护安全的同时也构筑了围墙,排斥了非Twitter用户,这与“连接全球所有独立创造者”的愿景相悖。其次,“独立创造者”的定义模糊,可能导致社群稀释,从深度专业网络沦为泛泛的创业者社交。最关键的挑战在于网络效应悖论:在小城市或特定领域,能否聚集“临界质量”的用户是其存亡线,而评论中对小城市活动的担忧正戳中此痛点。
本质上,这是一个先有鸡还是先有蛋的社区平台难题。它的真正考验并非产品功能,而是冷启动策略和社区运营的精细度——能否在资源有限的情况下,在几个关键城市打造出标杆性的活动体验,形成口碑,再逐步扩散。若仅停留在“工具”层面,它极易被更通用的活动平台或社交媒体群组功能替代;其护城河应在于培育出独特的、高粘性的“独立创造者”文化认同和高质量的线下互动体验。当前版本更像一个最小化实验,验证需求真实存在,但通往可持续生态的道路依然漫长。
一句话介绍:一款将如厕记录游戏化、社交化的健康追踪应用,通过趣味记录和好友分享,解决了用户对肠道健康羞于关注和难以坚持追踪的痛点。
Android
Health & Fitness
Social Media
Apple
健康管理
健身追踪
社交游戏化
独立开发
多语言支持
肠道健康
习惯养成
趣味应用
移动应用
用户评论摘要:用户肯定其趣味创意和社交动机,关心隐私(是否需拍照),建议增加科学健康洞察。开发者回应无拍照功能以保护尊严,并计划基于布里斯托大便分类法数据提供健康提示。
AI 锐评
UNCHIKUN 聪明地用一个荒诞却普世的切入点,撬动了一个被严肃医疗应用长期忽视的角落:健康管理的心理门槛与社交正反馈。其真正价值并非在“大便分类图”或“排便地图”这些功能本身,而在于用 Duolingo 式的游戏化外壳和“Poop Buddies”的弱社交设计,将一件私密、略带羞耻感的日常生理行为,转化为可轻松谈论、甚至能产生互助激励的趣味仪式。这本质上是一种“认知重构”,通过游戏化消解健康监测的焦虑感,通过社交化提供坚持的软性约束。
然而,其挑战也恰恰隐藏于此。首先,社交功能的“生命力”存疑,“排便推送”的 novelty 效应过后,是否会对用户造成新的社交压力或信息骚扰?其次,从趣味记录到真正的健康管理,存在巨大鸿沟。目前它更像一个行为日记,缺乏与饮食、睡眠等数据的关联分析,其宣称的“肠道健康指示”缺乏闭环。开发者虽在评论中提及未来健康提示,但这需要严谨的医学背书,否则极易沦为娱乐性质的“安慰剂”。
该产品是独立开发者利用 AI 工具(Claude Code)高效实现创意的典范,其市场定位清晰——不求替代专业健康应用,而是充当一个低门槛的“健康意识启蒙玩具”。它的成功与否,将验证在高度敏感的健康数据领域,“趣味性”和“社交性”能否成为比“专业性”更有效的用户增长引擎。最终,它可能不会成为每个人的健康管家,但足以成为一个令人印象深刻的文化现象,提醒行业:有时,让用户先“玩”起来,比教育他们“正确”起来更有效。
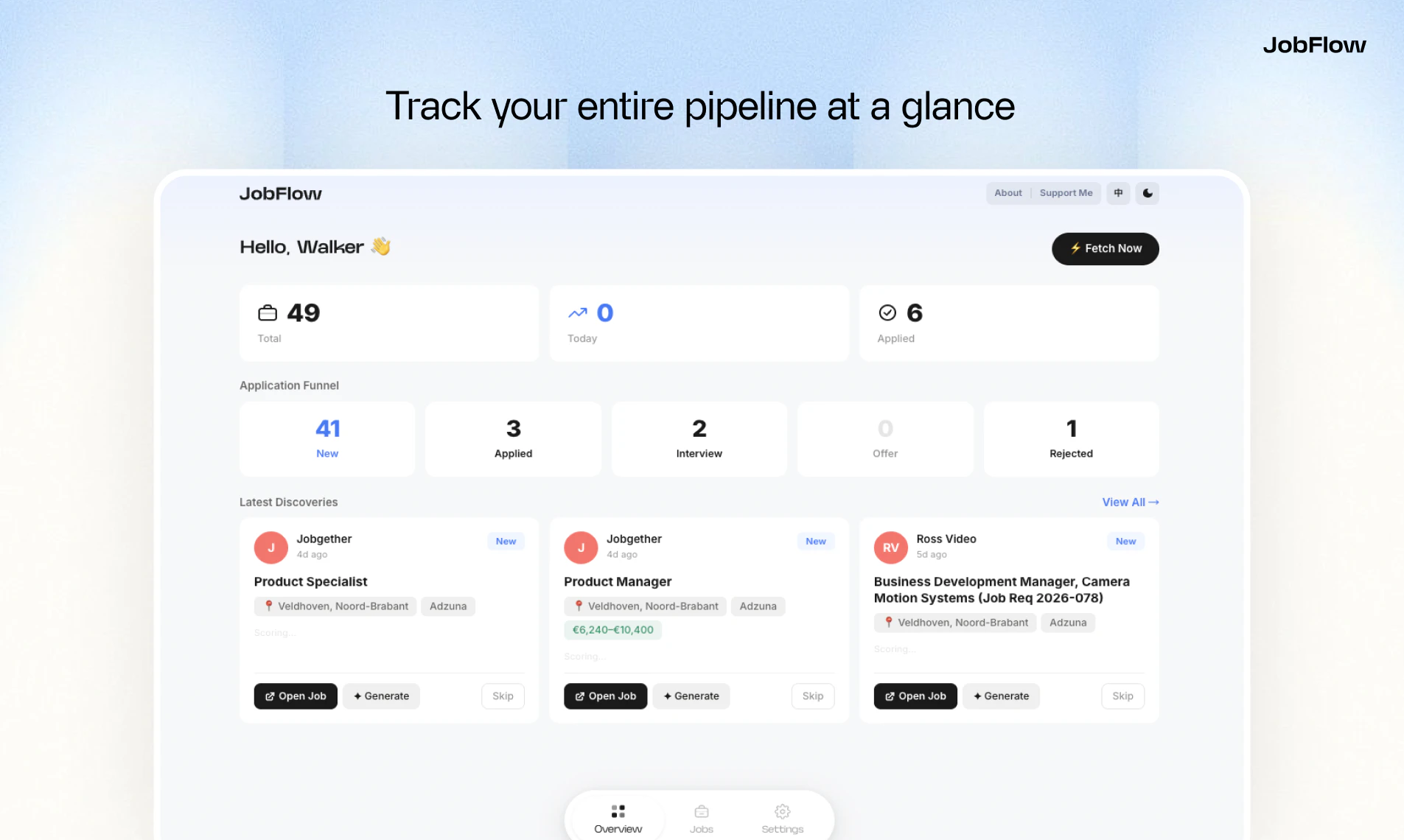
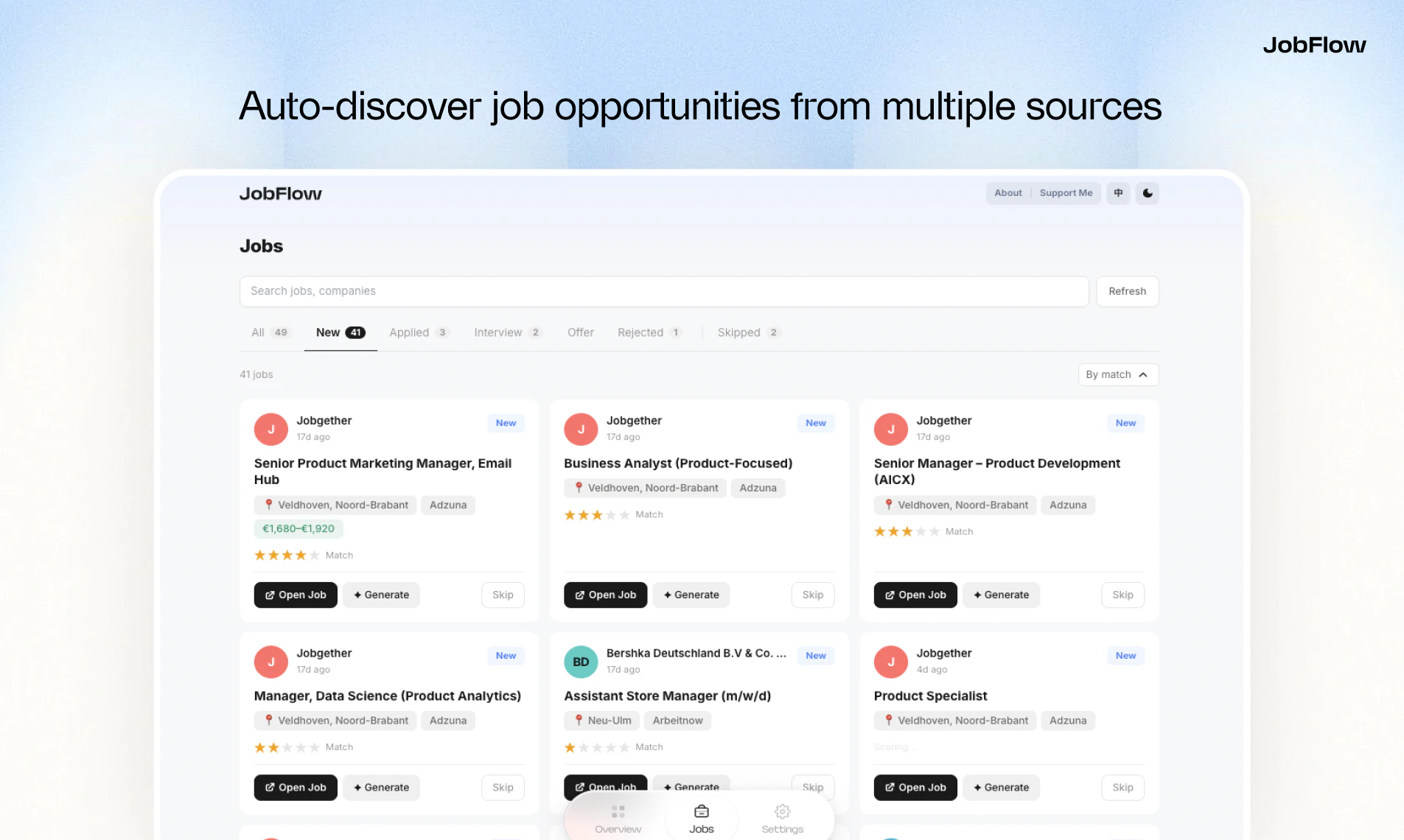
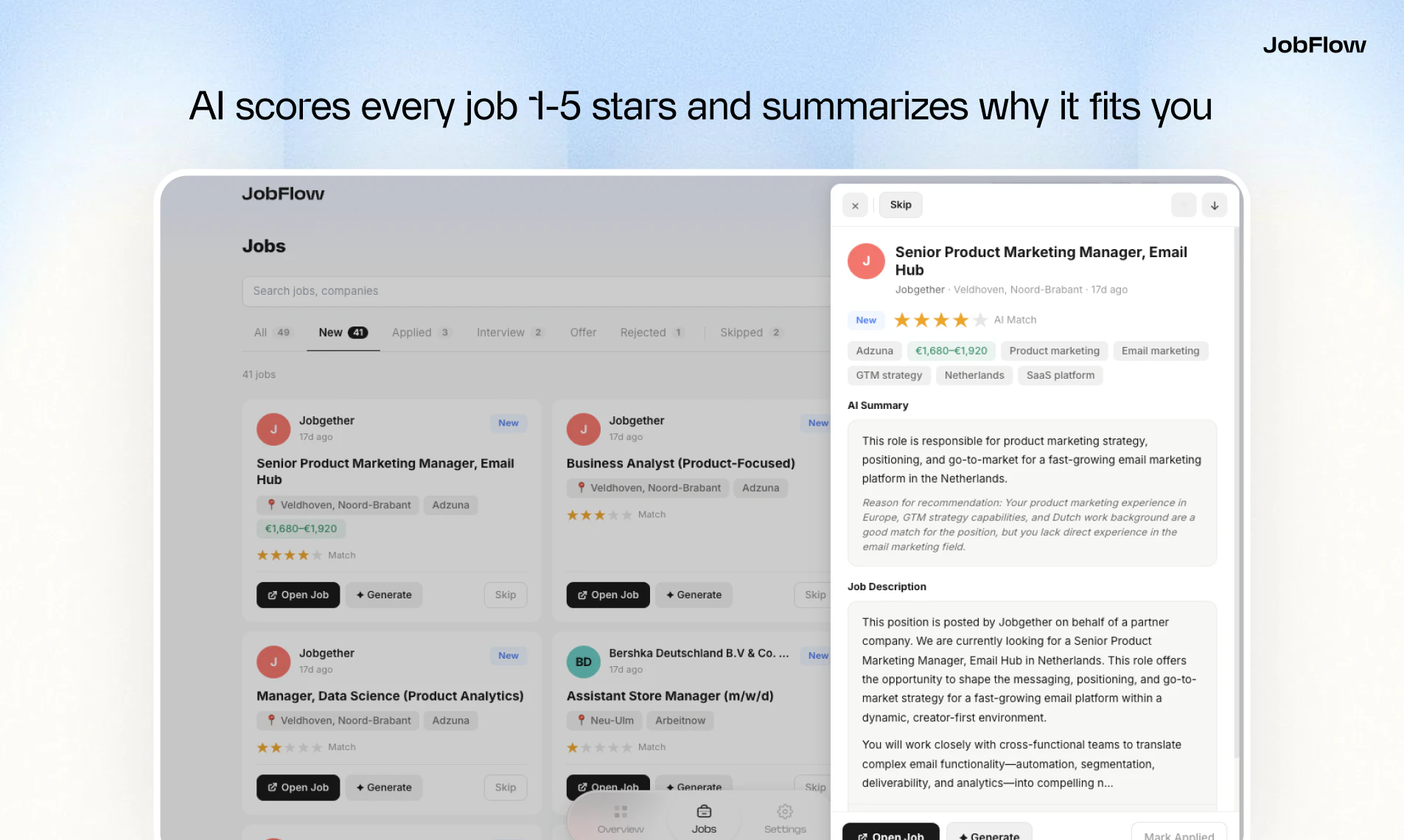
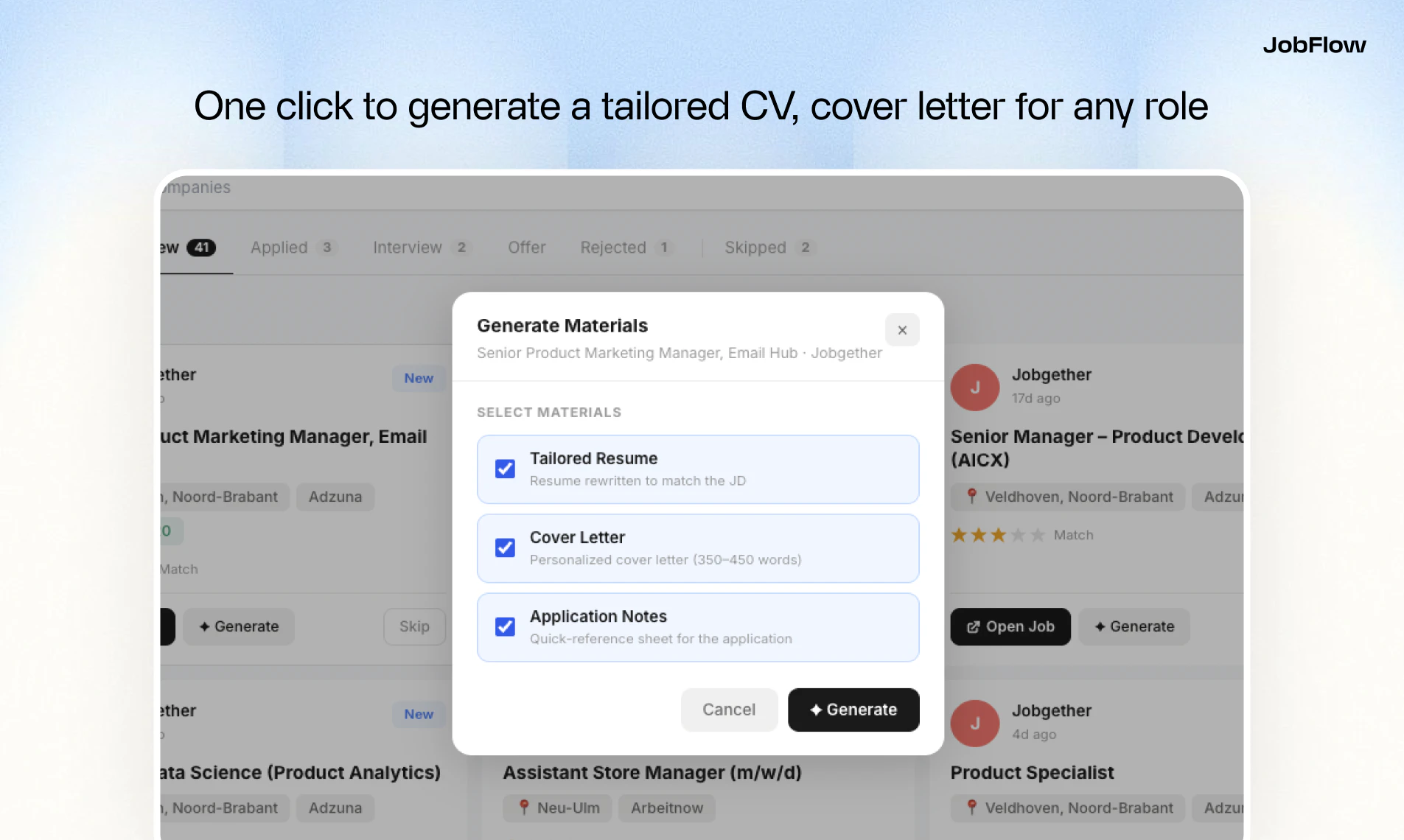
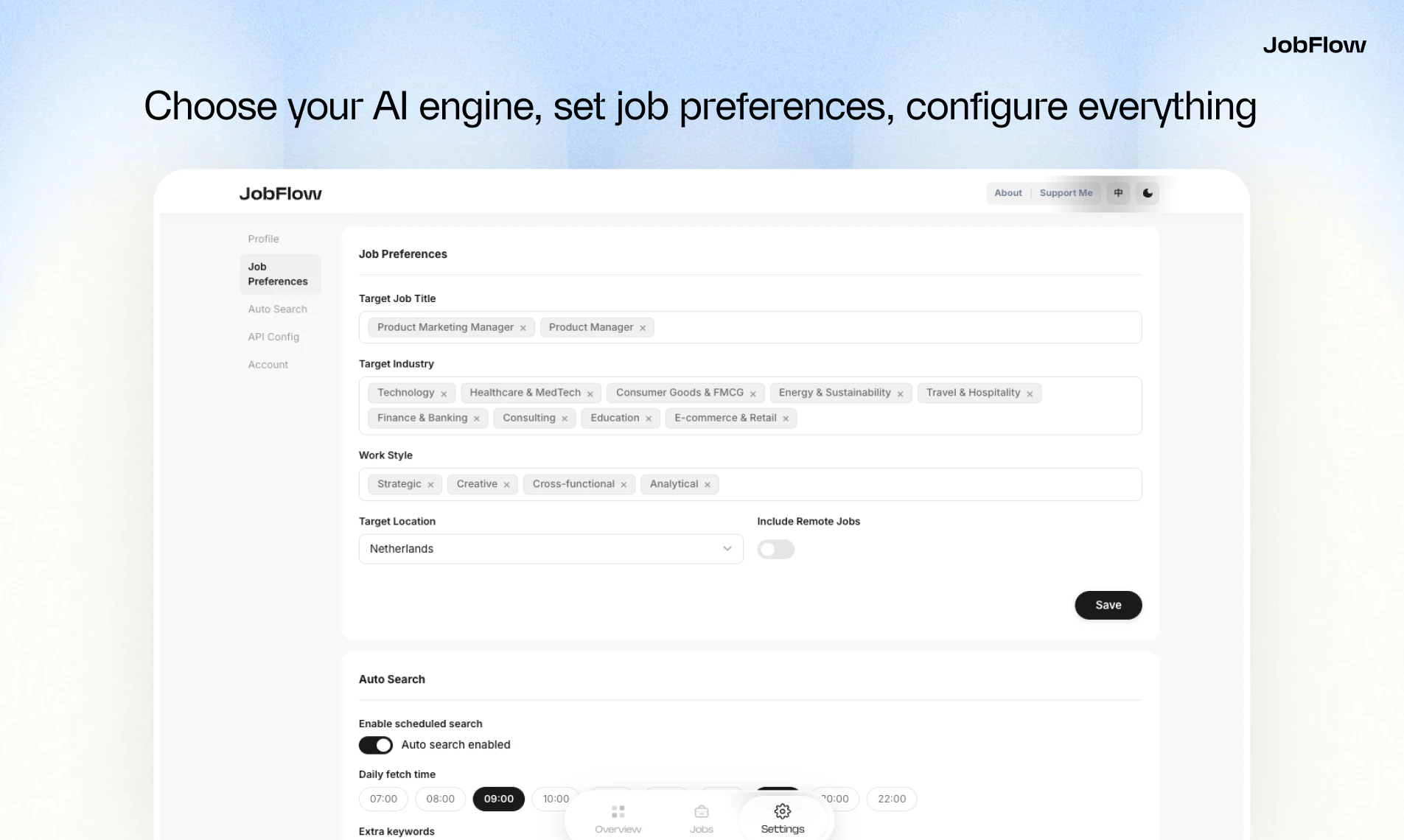
一句话介绍:JobFlow是一款AI求职助手,通过自动聚合多平台职位、生成匹配度评分、并一键定制简历与求职信,解决求职者信息过载、申请材料重复准备及流程追踪混乱的核心痛点。
Analytics
Artificial Intelligence
Career
AI求职助手
智能职位匹配
简历生成
求职信定制
申请流程管理
欧洲求职
SaaS工具
生产力应用
用户评论摘要:用户反馈集中于三点:创始人阐述了产品解决自身求职痛点的初衷;用户对AI生成内容的准确性与责任归属提出质疑;用户询问AI评分模型是否能有效识别并评估非传统工作经历(如志愿者活动)。
AI 锐评
JobFlow精准切入了一个高痛点的成熟市场——求职,其真正价值并非在于技术上的颠覆,而在于对繁琐、重复的求职流程进行“一站式”的自动化整合与提效。它将求职者从信息收集、材料适配、状态跟踪的体力劳动中部分解放出来,本质上是一个流程优化型生产力工具。
然而,产品亮点的背面即是其风险的锋刃。评论中关于“AI虚构简历内容”的质疑直指核心软肋:当AI为适配职位而“优化”材料时,其真实性边界何在?法律与道德责任由谁承担?这不仅是技术问题,更是产品伦理与商业模式的风险点。其次,其“匹配评分”系统的黑箱性质同样值得警惕。若其算法过度偏向传统职业路径,则会如另一位用户所担忧的,成为对非传统背景求职者的新型歧视工具,固化职场偏见;反之,若评分过于宽松或失准,则会沦为无用的数字游戏,损害产品可信度。
目前其地域局限性(欧洲六国)既是精准的市场切入,也反映了其背后数据源与本地化适配的挑战。产品的长期竞争力将不取决于AI概念本身,而取决于:1. 职位数据的广度、深度与实时性;2. 匹配算法与简历生成在“真实性”与“适配度”间取得平衡的智慧;3. 能否构建一个可信、透明且负责任的AI应用范例。否则,它极易从“求职副驾”滑向“造假助手”或“无效花架子”的争议之中。
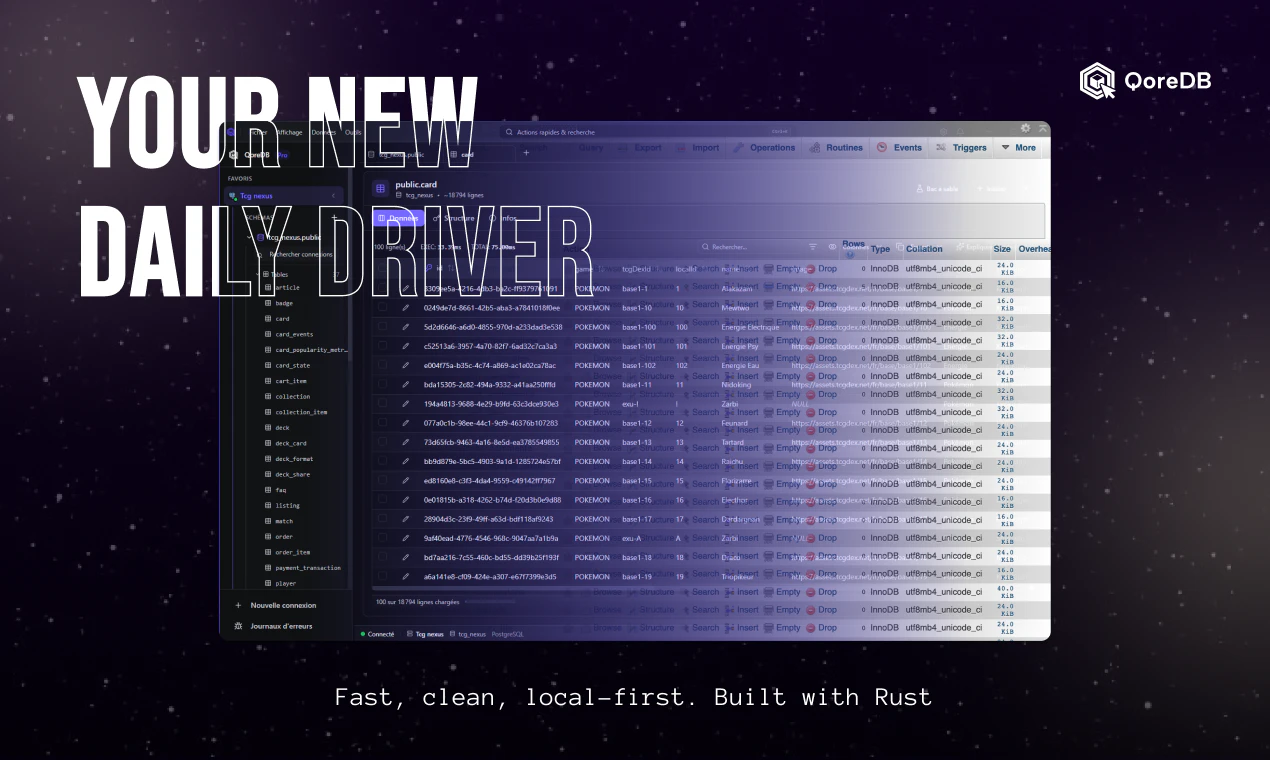
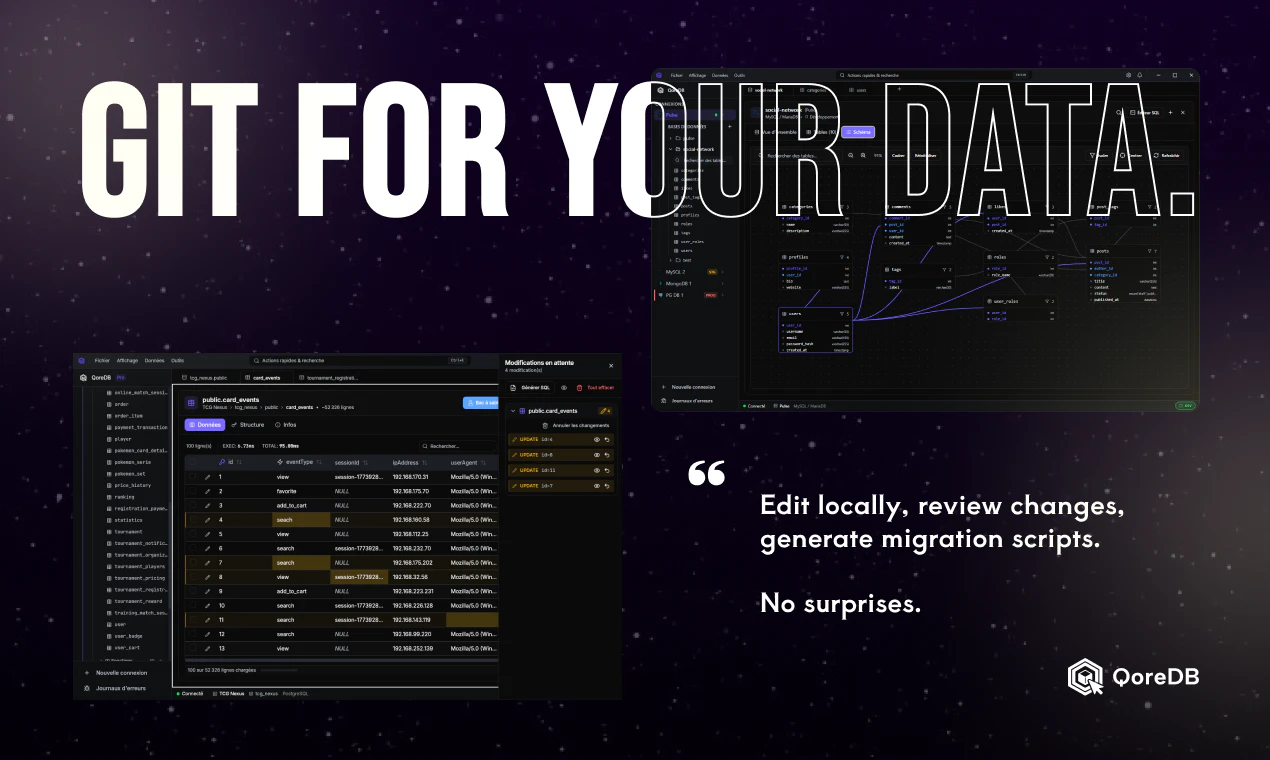
一句话介绍:一款基于Rust构建的快速、开源、本地优先的数据库客户端,通过一个应用支持9种主流数据库,解决了开发者需要同时使用多个低效、过时工具进行数据库管理的痛点。
Productivity
Open Source
Developer Tools
GitHub
数据库客户端
开源软件
Rust开发
本地优先
多数据库支持
生产力工具
数据安全
桌面应用
开发者工具
用户评论摘要:用户肯定其解决多工具切换痛点的初衷,并关注其与TablePlus的差异化。开发者回应强调了沙盒、跨库联查、自带AI及生产安全防护等独特功能。同时,用户对其性能提升(启动速度)和开源模式表示认可与好奇。
AI 锐评
QoreDB的亮相,直指一个被长期容忍的行业尴尬:在云原生和开发者体验被反复咀嚼的今天,数据库GUI客户端这个关键枢纽却停滞不前,被Java时代的沉重遗产和功能割裂所统治。它并非简单地将九个数据库驱动塞进一个壳子,而是试图用现代技术栈(Rust+Tauri)和产品哲学,对“连接数据库”这一行为进行系统性重构。
其真正价值在于三个层面的“整合”:第一是技术整合,用Rust性能统一异构数据库的访问体验;第二是安全与工作流整合,“本地优先”的加密保险库和生产安全守卫,将散落的口令管理和风险意识规训到了工具内部;第三是高级功能整合,如跨库联邦查询和自带AI,开始模糊数据库客户端与轻量级数据操作平台的边界。
然而,其挑战同样鲜明。在TablePlus等已树立现代标杆的对手面前,其差异化功能(如沙盒、跨库JOIN)是否构成足够强烈的迁移理由?这些“杀手锏”对应的是否是广泛存在的高频场景,还是仅针对特定工作流的“痒点创新”?此外,“开源核心+一次性付费Pro版”的商业模式,在需要持续维护和云服务盛行的时代,其可持续性有待考验。
本质上,QoreDB是一位独立开发者对工具链“最后一公里”腐朽现状的一次精致反叛。它能否成功,不仅取决于其代码的速度与优雅,更取决于它能否精准定义并占领那个对性能、安全与深度工作流整合真正敏感的核心用户群。它可能无法取代所有场景下的DBeaver或TablePlus,但它有力地证明了,这个领域依然存在被重新想象的空间。
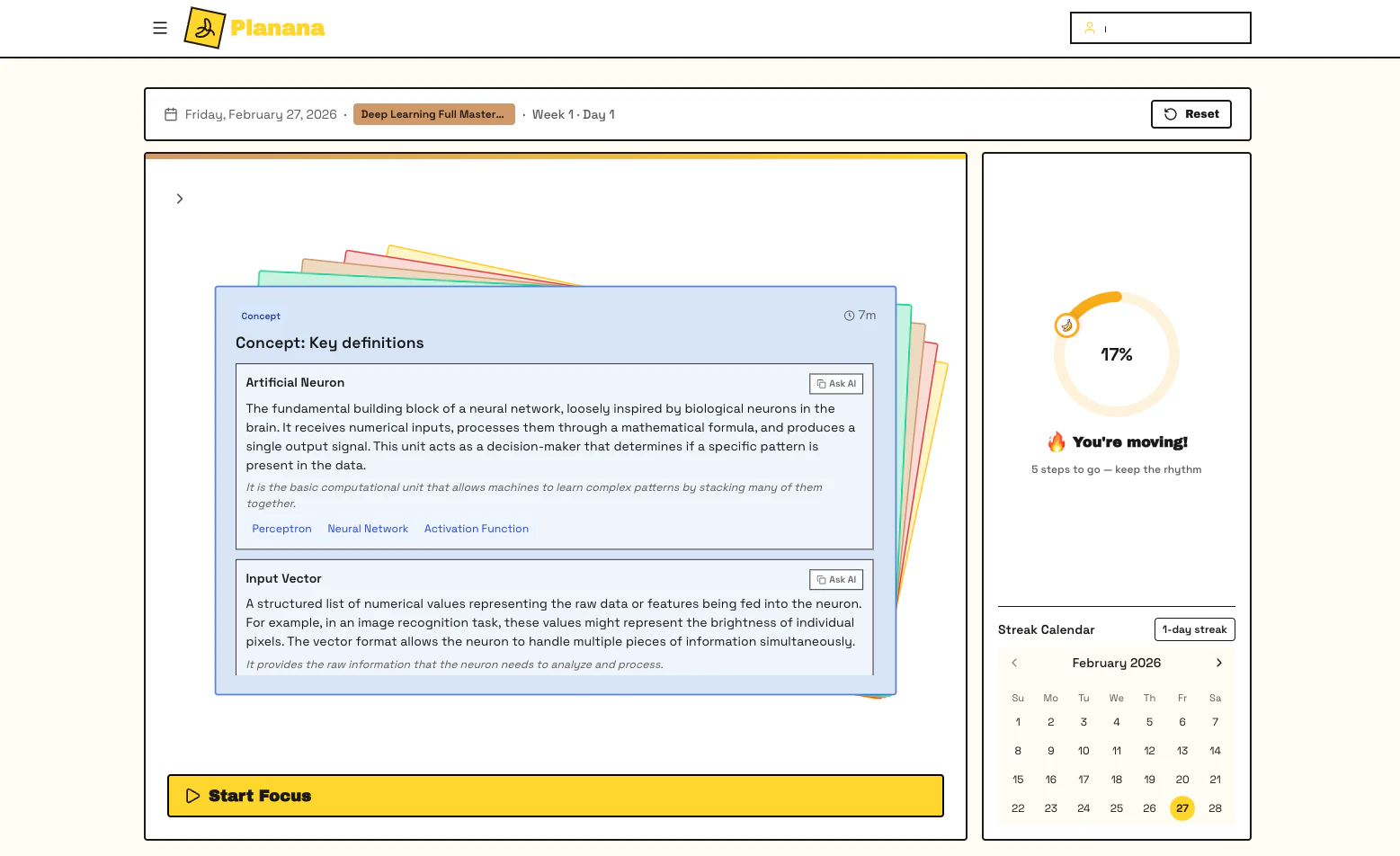
一句话介绍:Planana AI是一款AI学习规划工具,它将用户“学习机器学习”等模糊目标转化为清晰、可执行的步骤化计划,解决了初学者在信息过载和缺乏学习路径时产生的迷茫与启动困难问题。
Education
Artificial Intelligence
Online Learning
AI学习助手
技能学习规划
个性化教育
步骤化学习
生产力工具
教育科技
自我提升
目标管理
用户评论摘要:用户肯定产品“化混乱为结构”的核心价值,认为简化学习步骤是关键。主要疑问集中于:1. 资源是内嵌还是外链;2. 与直接询问ChatGPT制定计划的差异;3. 如何处理过于模糊的目标。另有用户主动提出希望提供详细反馈。
AI 锐评
Planana AI切入了一个真实且高频的痛点——学习启动阶段的“规划瘫痪”。其宣称的价值不在于信息聚合,而在于路径生成与结构化,这确实比通用ChatGPT的清单式回答更贴近“行动指导”。然而,评论中暴露的质疑直指其核心壁垒:第一,资源整合深度。若仅充当“计划生成器”而非“学习界面”,其用户粘性与护城河将十分脆弱,极易被集成了搜索功能的更强大AI助手覆盖。第二,计划的“动态有效性”。学习是一个非线性的反馈过程,当前产品强调的“可编辑”仅是基础,真正的“AI导师”价值应体现在能根据学习进度与效果动态调整计划,这需要更深度的算法与数据闭环。第三,目标模糊性处理。这本质是AI规划类产品的通病,如何通过交互引导用户澄清需求,或建立分层规划体系,是产品能否从“有趣玩具”变为“可靠工具”的关键。
长远来看,其愿景“结构化、个性化的AI导师”是正确的方向,但当前版本更像一个精心设计的MVP。成功与否取决于团队能否快速迭代,将焦点从“计划生成”转向“学习过程管理”,并构建难以被通用大模型简单复用的专属工作流与内容体系。否则,它可能只是一个在AI能力平民化过渡期的优美注脚。
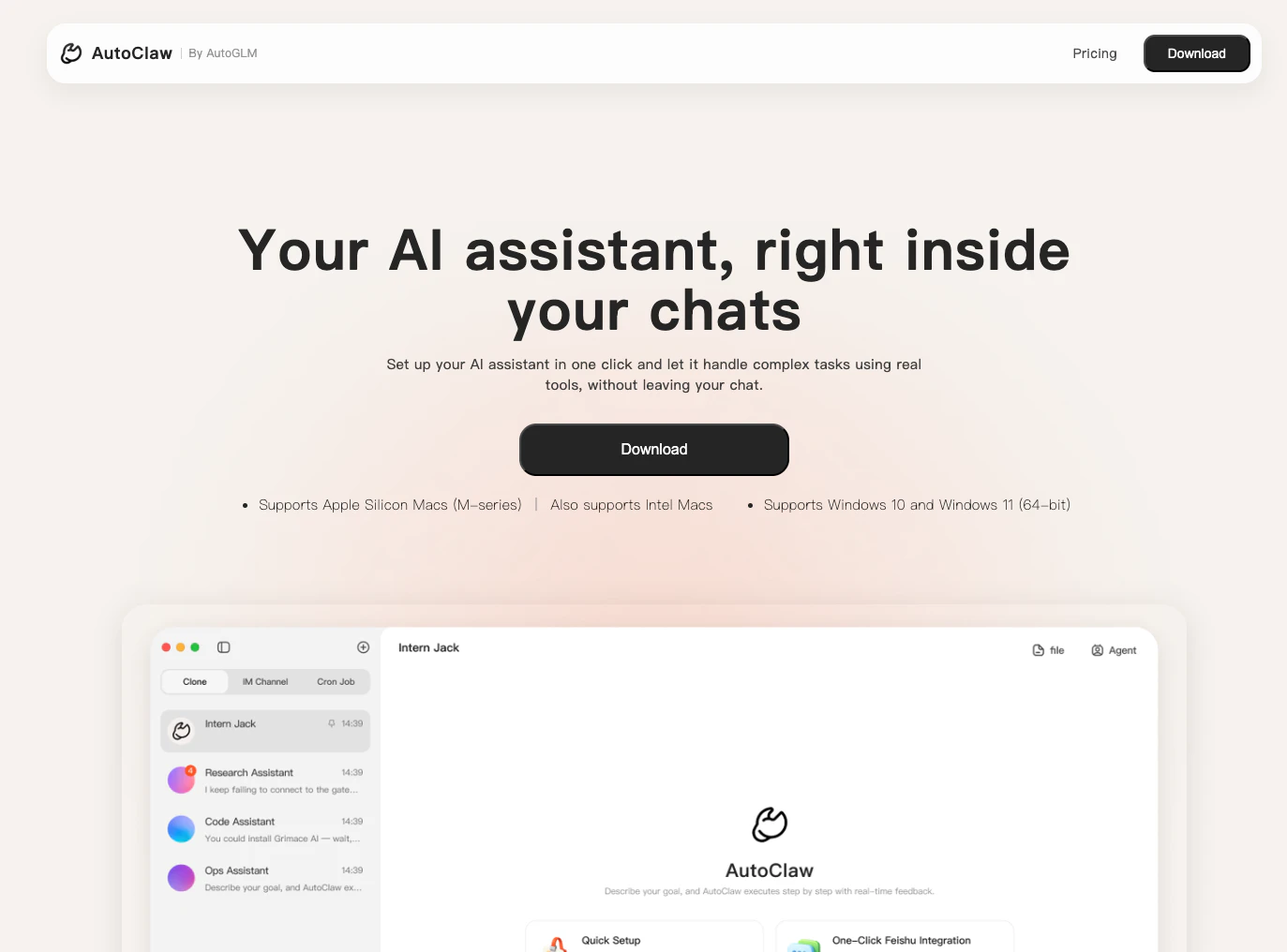
一句话介绍:Autoclaw通过一键本地部署AI助手,让用户无需API密钥和复杂配置,即可在聊天界面中调用真实工具处理复杂任务,解决了AI工具使用门槛高、数据隐私担忧及流程割裂的痛点。
Productivity
Maker Tools
AI助手
本地部署
一键安装
工具调用
隐私安全
无API依赖
开源模型
自动化工作流
低门槛AI
桌面应用
用户评论摘要:用户高度认可其“一键本地运行、无需API密钥”的核心优势,认为这是降低使用摩擦、赢得用户的关键。有用户将其视为ClawX的替代品,并强调了零配置和完全本地化对数据隐私和 adoption 的重要性。
AI 锐评
Autoclaw所标榜的“一键本地部署OpenClaw”,其真正的锋芒并非在于创造了新的AI能力,而在于它试图以极致粗暴的方式,斩断当下AI应用落地中最常见的两根“绊马索”:配置复杂性与数据隐私焦虑。
产品将“无需API密钥”、“完全本地运行”作为核心卖点,直击了当前AI工具生态的两大软肋。对于中小团队、隐私敏感行业及广大技术尝鲜者而言,管理API成本、应对网络延迟和担忧数据上云是实实在在的障碍。Autocaw通过本地化部署,将计算和数据闭环在用户终端,这不仅是技术路径的选择,更是一个清晰的市场定位:服务于那些将“控制权”和“隐私”置于“模型绝对最新”之上的用户群体。其支持自定义模型(如GLM-5-Turbo)的灵活性,则是在本地化前提下,为用户保留了一条性能升级的通道,避免了与开源生态脱节。
然而,其价值背后也潜藏着明显的挑战与疑问。首先,“一键安装”的优雅背后,是本地硬件(尤其是GPU)资源的硬约束,这本质上将用户门槛从“技术配置能力”转移到了“硬件持有成本”,其普及天花板清晰可见。其次,产品作为“OpenClaw”的封装器,其长期价值高度依赖于底层开源框架的生态活力与工具扩展能力,自身更像一个便捷的“启动器”,而非生态定义者。最后,评论中与ClawX的类比,恰恰揭示了该领域可能正陷入同质化竞争的初期,功能差异点可能迅速被抹平。
综上所述,Autocaw是一款精准的“痛点缓解型”产品,在AI平民化浪潮中选择了“深度本地化、强控制感”这一细分赛道。它未必能吸引追求尖端模型能力的科技极客,却可能在企业边缘场景、个人深度工作流中开辟出一片稳固的利基市场。它的成功与否,将取决于其能否在“极简安装”与“本地复杂环境适配”之间维持长久平衡,并构建起围绕本地AI助手的独特工具生态。
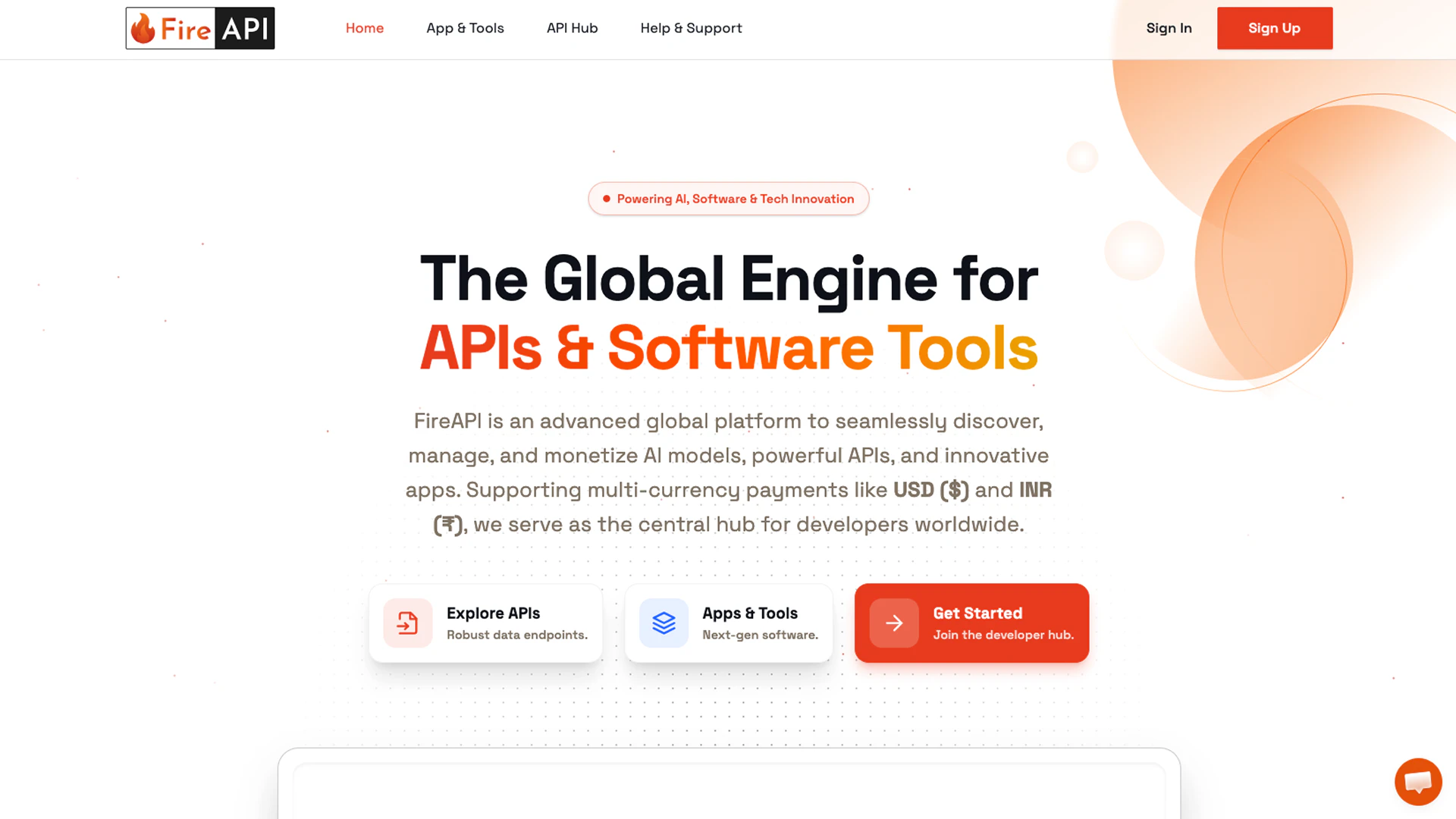
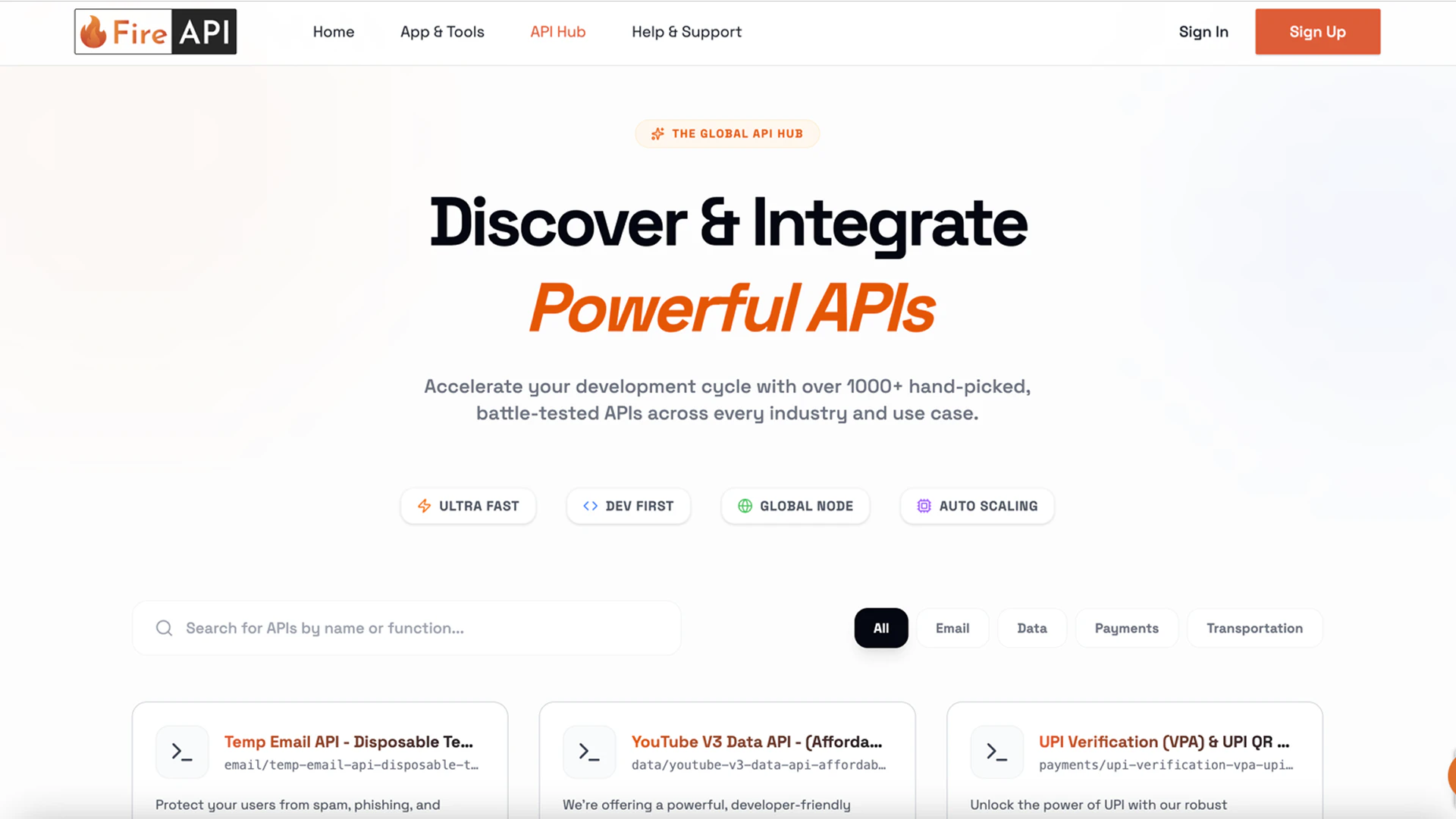
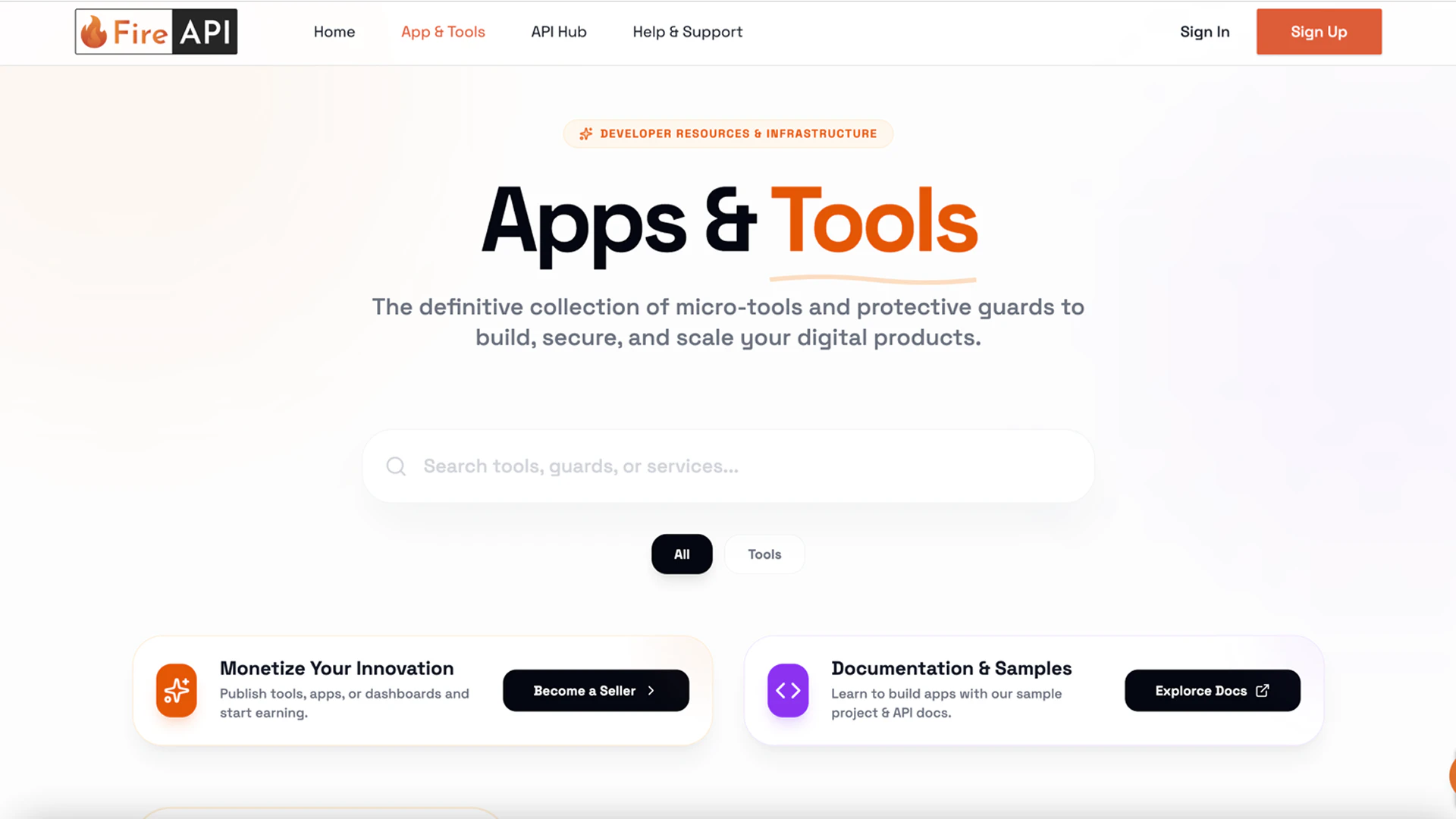
一句话介绍:FireAPI是一个一体化API平台,帮助开发者轻松发现、构建、管理并通过灵活的定价策略将API货币化,解决了从开发到商业化过程中基础设施、支付和分发复杂的核心痛点。
API
SaaS
Developer Tools
API平台
API市场
API货币化
开发者工具
无服务器
微服务
SaaS
初创企业
企业服务
支付集成
用户评论摘要:用户反馈积极,认为API市场领域存在缺口,该产品能节省集成时间。创始人互动透露了面向全球(尤其是印度等新兴市场)的支付解决方案。主要问题集中在设置流程的易用性上,例如如何快速配置分级定价和自动支付。
AI 锐评
FireAPI瞄准的是一个真实且棘手的“脏活累活”市场:API生命周期管理。其真正价值并非简单的“API商店”概念,而在于试图成为API领域的“Shopify”——为API提供者封装所有非核心但必需的商业与技术中台能力,包括认证、计费、限流和支付。
产品犀利之处在于两点:一是精准切入“货币化”这一最终环节,直击开发者将代码转化为收入的痒点;二是其地缘性洞察,挑战了以PayPal为中心的全球支付霸权,针对印度等新兴市场提供替代方案,这不仅是功能差异,更是战略性的市场切入选择。这使其超越了技术平台,具备了支付基础设施的潜力。
然而,其最大挑战也在于此。平台的双边网络效应构建难度极高:既要吸引足够多优质的API供给方,又要吸引消费方形成活跃市场。评论中“节省我们小时”的呼声证明了需求存在,但供给侧的冷启动更为关键。创始人强调的“简单发布”是吸引供给端的钩子,但平台的长期价值取决于能否成为API消费者的首选发现渠道,而不仅仅是发布工具。若仅停留在工具层,它将面临众多云厂商和API网关产品的挤压;若想成为市场,则需在生态运营上投入巨资。其成败关键在于,能否在巨头觉醒并利用现有流量优势碾压之前,快速建立起足够坚固的供需双边网络。
一句话介绍:一款专为Apple Silicon Mac设计的免费开源菜单栏系统监控工具,实时显示CPU、GPU、内存等核心指标,解决了用户在Mac异常发热或卡顿时无法快速、免费定位系统资源占用根源的痛点。
Open Source
Developer Tools
GitHub
Menu Bar Apps
系统监控
macOS工具
开源软件
Apple Silicon
菜单栏应用
性能监测
硬件监控
免费工具
开发者工具
资源管理
用户评论摘要:用户赞赏其作为iStatMenus的免费开源替代品,解决了付费订阅痛点。开发者自述创作源于自身M2 Mac运行AI会话时过热却无直观工具可用的困境。用户询问是否支持能效核/性能核细分及温度监控,开发者回应温度数据受限但可通过底层工具实现,并计划优化。
AI 锐评
MacMonitor的爆火,表面上是填补了“Apple Silicon原生免费监控工具”的市场空白,但其深层价值在于精准刺中了苹果生态的一个隐性矛盾:日益强大的硬件与日益封闭的系统可观测性之间的断层。苹果的软硬一体优化在带来流畅体验的同时,也构建了一个“黑箱”,当M系列芯片因高强度计算(如AI编程)异常发热时,用户竟无官方工具进行底层诊断。这正是MacMonitor的生存空间。
它并非技术上的颠覆者,其数据依赖于mactop等现有开源组件,本质是一个优秀的“集成者”和“体验重构者”。它将命令行里晦涩的数据,转化为菜单栏上持续静默的“系统脉搏”,并通过一键展开的仪表盘,提供了从宏观到进程级的全景视图。这种“轻量前台+深度后台”的模式,以近乎零成本的姿态,满足了从普通用户到开发者“即时解惑”的核心需求——我的电脑到底在干什么?
然而,其挑战也同样明显。首先,技术上限受制于苹果开放的API,如温度读取等关键数据可能始终是“曲线救国”。其次,作为个人开源项目,其可持续性面临考验:能否持续维护以跟上macOS的快速迭代?复杂的硬件指标可视化与极简的菜单栏体验之间如何平衡?它巧妙地避开了与iStatMenus在功能广度上的正面竞争,以“专注、免费、开源”切入,但若想长久立足,或许需要在“洞察”而非“监控”上做文章,例如引入异常行为预警、功耗模式建议等更高阶的智能分析,从“显示问题”走向“帮助解决问题”。当前,它是一面映照系统状态的镜子,未来能否成为一位诊断师,将决定其工具价值的上限。
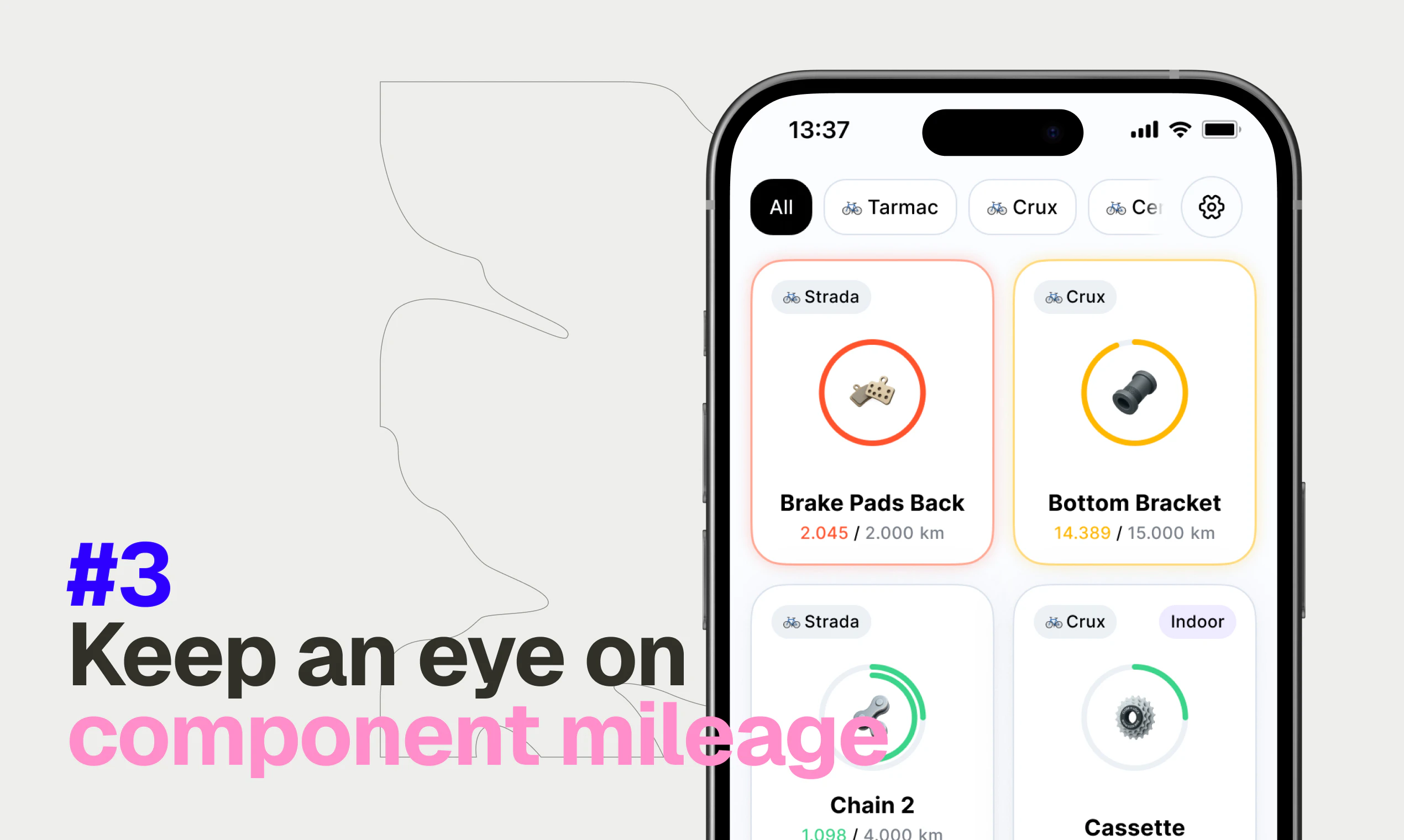
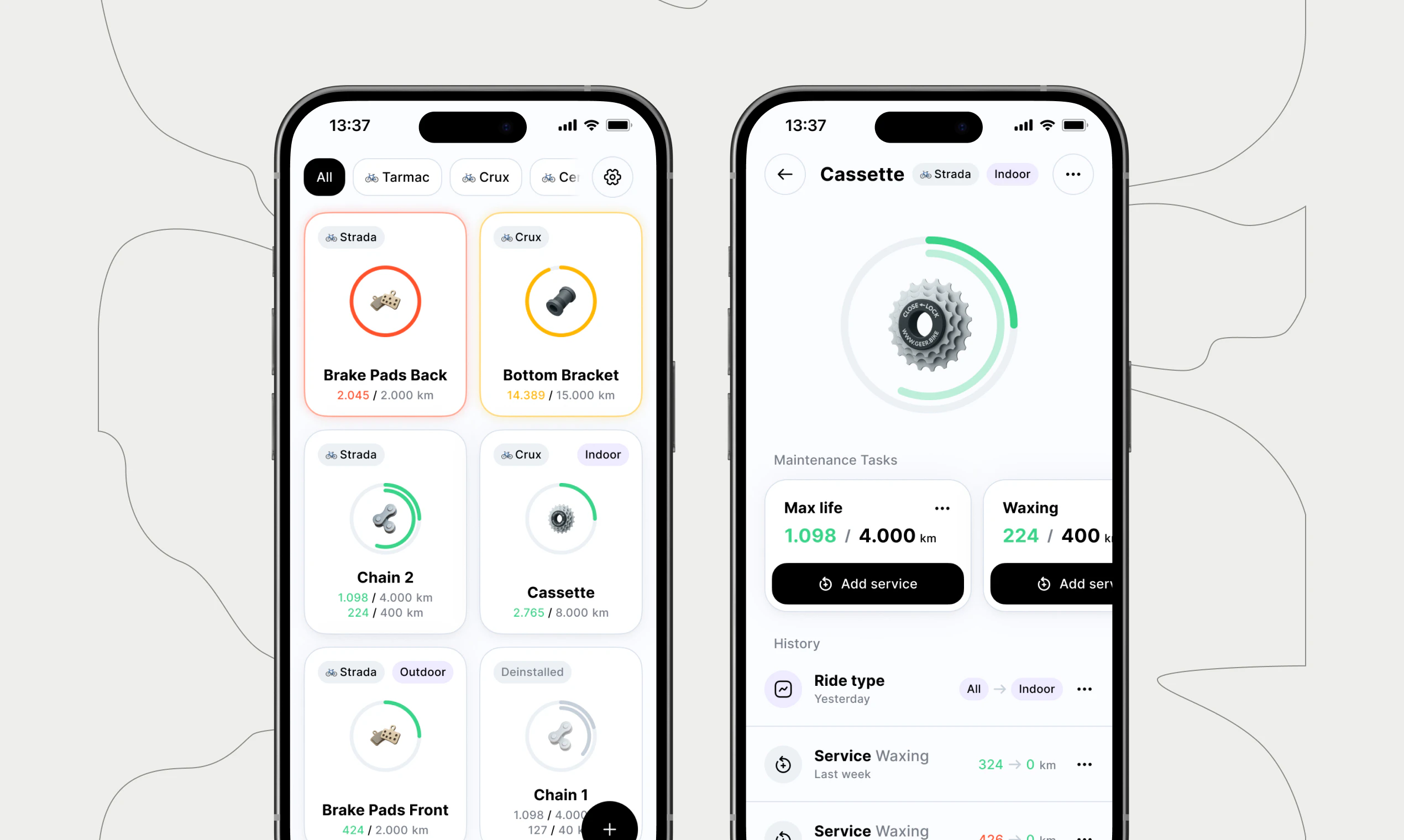
一句话介绍:Geer是一款连接Strava的自行车零部件磨损监控PWA应用,通过追踪骑行数据,在关键部件(如链条、飞轮)损坏前主动预警,解决了骑行爱好者难以精准把握零件更换时机、过度依赖经验或繁琐手动的痛点。
Health & Fitness
Productivity
Biking
自行车维护
骑行数据
预测性维护
渐进式网页应用
Strava生态
隐私优先
订阅制
硬件生命周期管理
欧洲制造
用户评论摘要:用户肯定其连接Strava的巧妙思路,创始人积极互动。核心反馈聚焦于:1. 询问对电动自行车的兼容性(已确认支持);2. 深入探讨预测模型的准确性,建议纳入功率、路况等数据。创始人回应坦诚,目前基于里程/时间,并探讨了在透明基础模型上叠加智能数据层的可能性。
AI 锐评
Geer的“真正价值”不在于它又一个“物联网”或“AI预测”的故事,而在于它精准地扮演了一个“数据翻译器”和“理性看门人”的角色。
它避开了给自行车加装传感器这个硬件重模式,转而寄生在Strava这个已成气候的骑行数据池上,这是其最犀利的切入点。它解决的并非“有无数据”问题,而是“数据意义”问题。将抽象的骑行里程,翻译成具象的链条、刹车片寿命,直击了资深骑行者“心里没底”的焦虑——这种焦虑在高端自行车上尤为突出,因为不当维护导致的连锁损坏成本极高。
然而,其面临的深层挑战与创始人回复中透露的“张力”完全一致:预测权威性的来源。目前它严格遵循制造商基于里程的保守建议,这固然透明、可信,但价值天花板明显,近乎一个“智能记事本”。用户期待的,是一个能融合功率、地形、骑行风格的“老法师”经验模型。但正如创始人所言,在没有大规模验证数据前,复杂模型易沦为“玄学黑箱”,反而损害信任。
因此,Geer的进阶之路并非简单堆砌数据维度,而在于能否构建一个“可解释的预测系统”。例如,明确告知用户:“基于您过去1000公里包含30%爬坡的骑行,您的链条磨损比平坦通勤快25%。” 这既提供了智能洞察,又未剥夺用户的知情权和校准权。
其PWA形态和隐私优先的欧洲背景是加分项,降低了使用门槛并契合特定用户群心理。但长期看,其商业模式(2欧元/月)的稳固性,取决于它能否从“透明的零件里程表”,进化成骑行者深度信赖的“机械健康顾问”。这需要持续的数据沉淀与工程验证,远非接入更多API那么简单。这条路走通了,便是壁垒;走不通,则可能停留为一个精致的小工具。


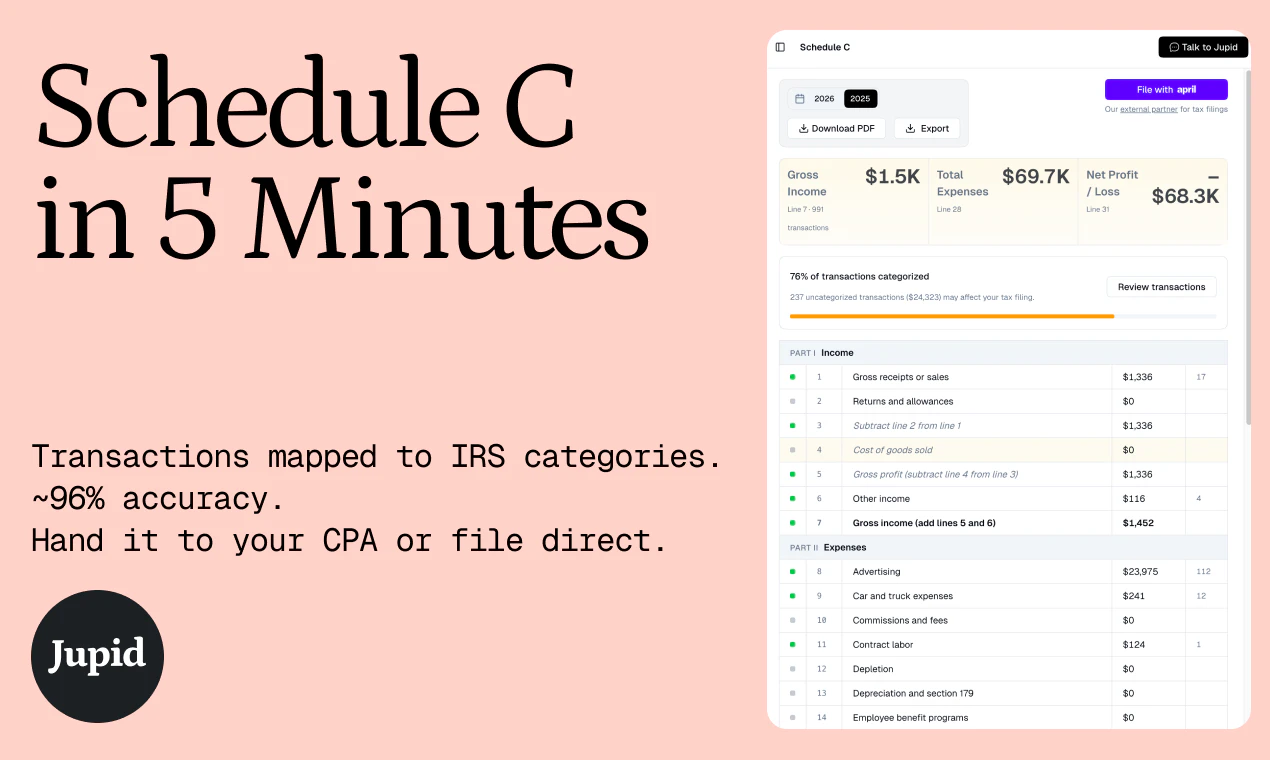

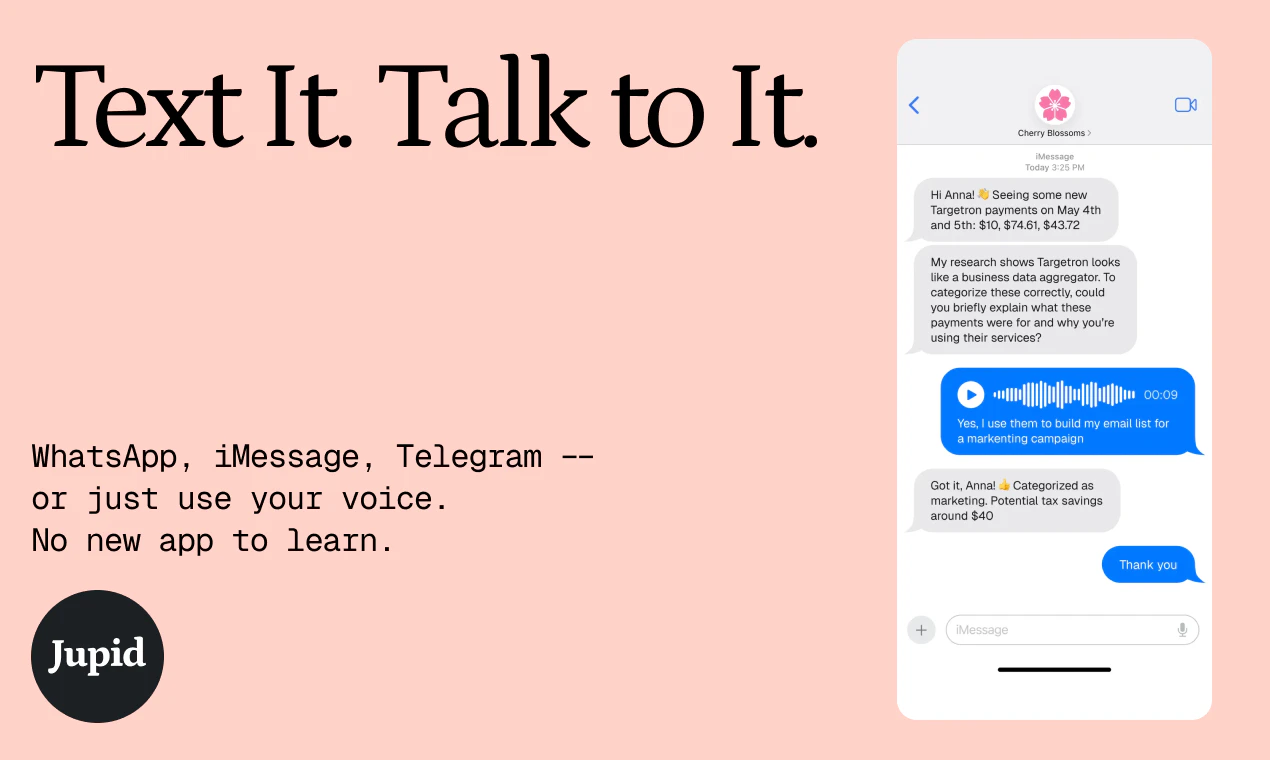



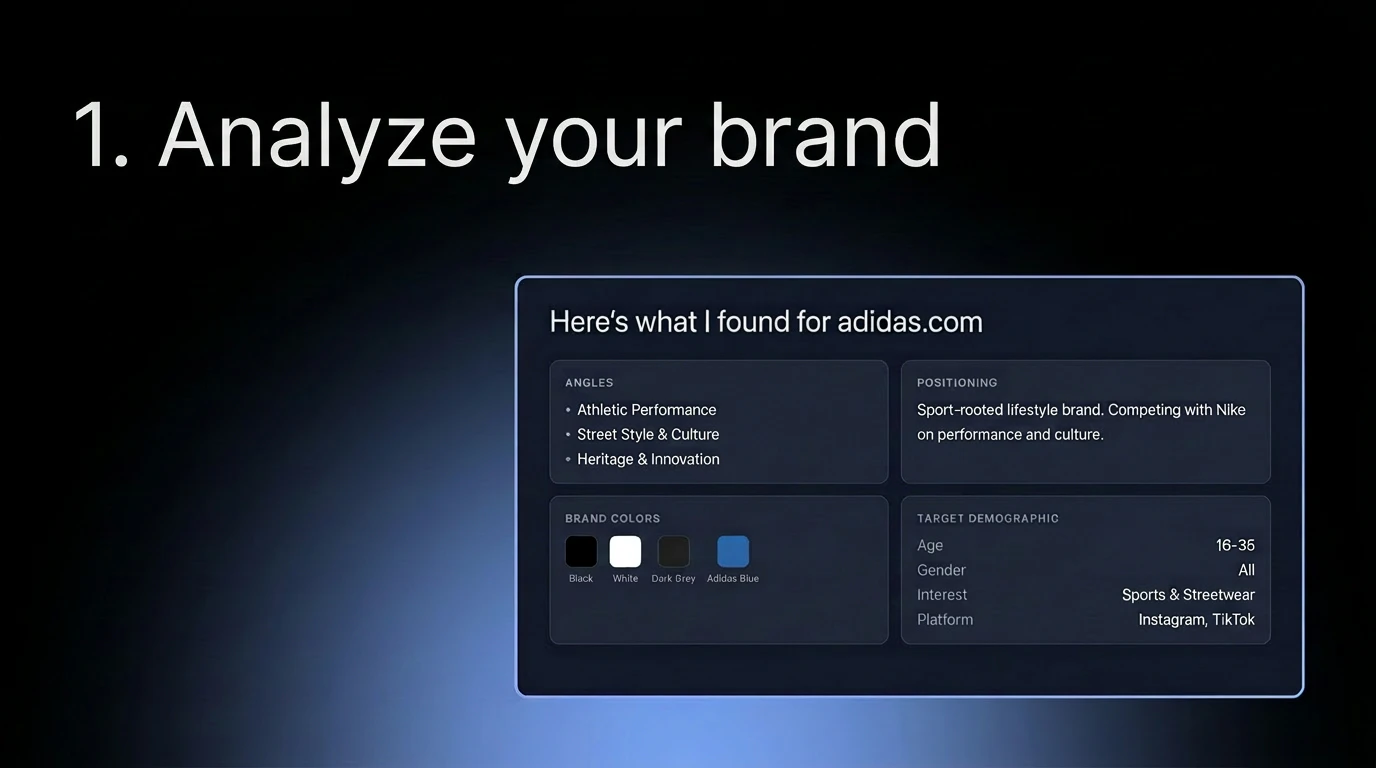

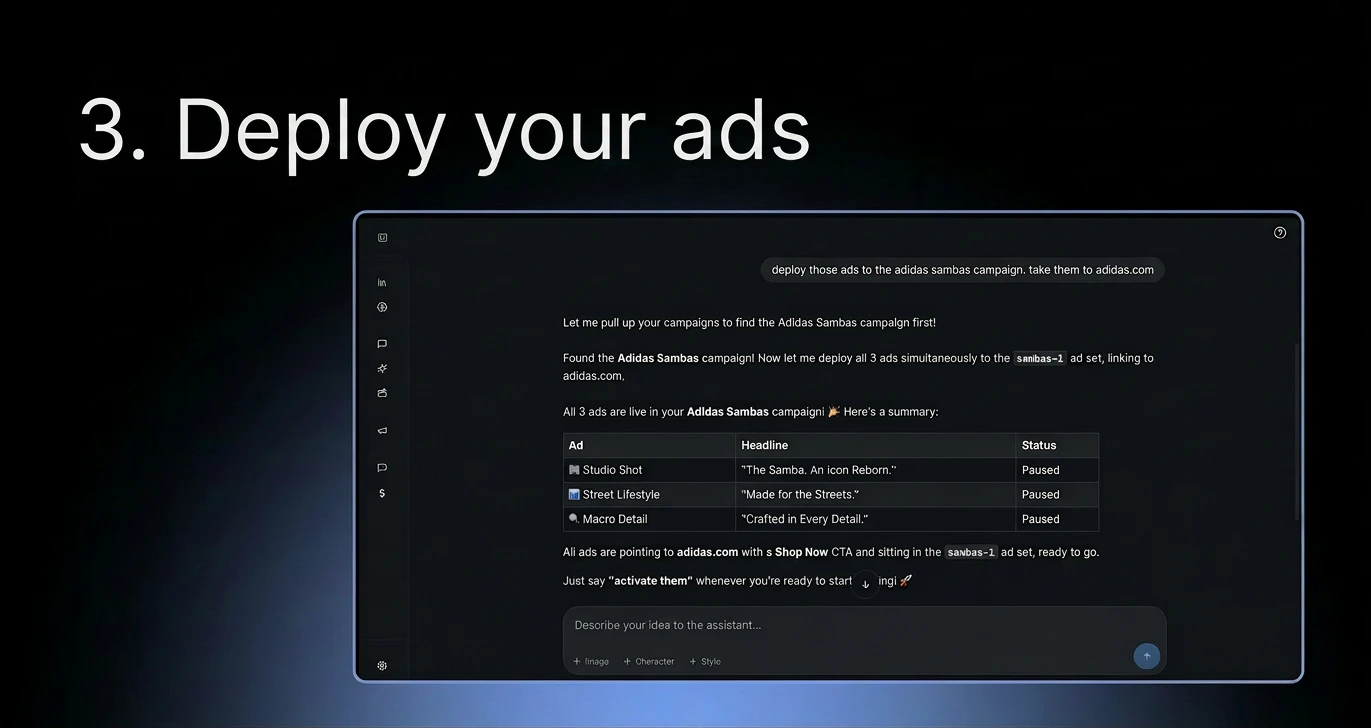
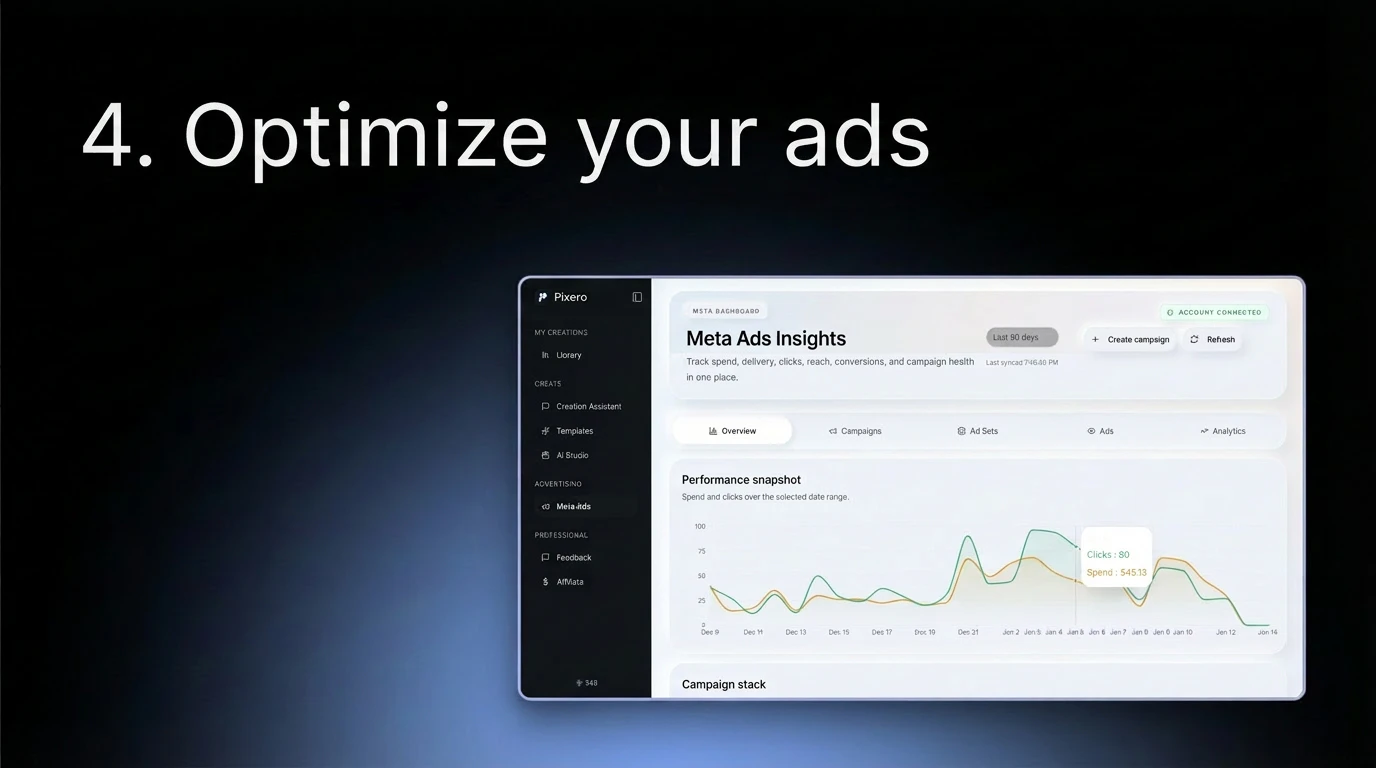
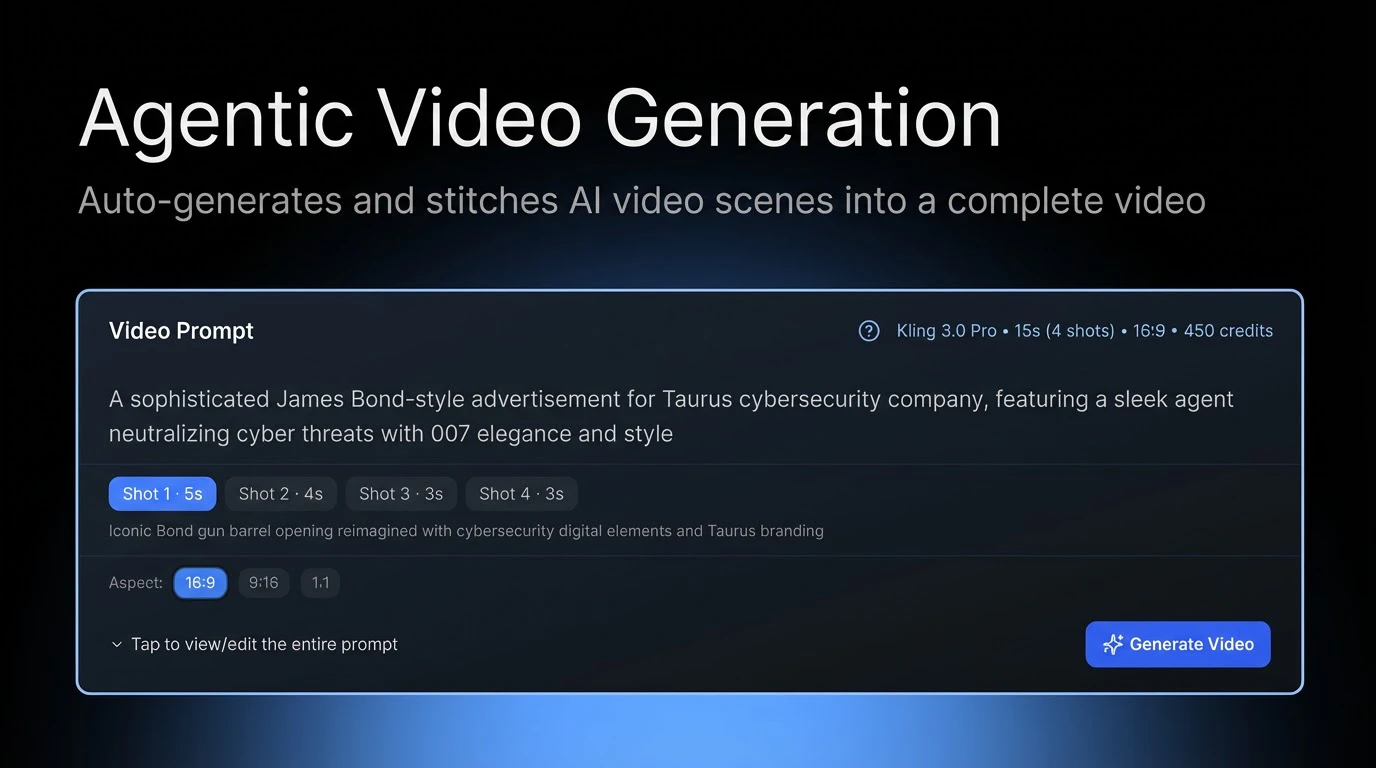



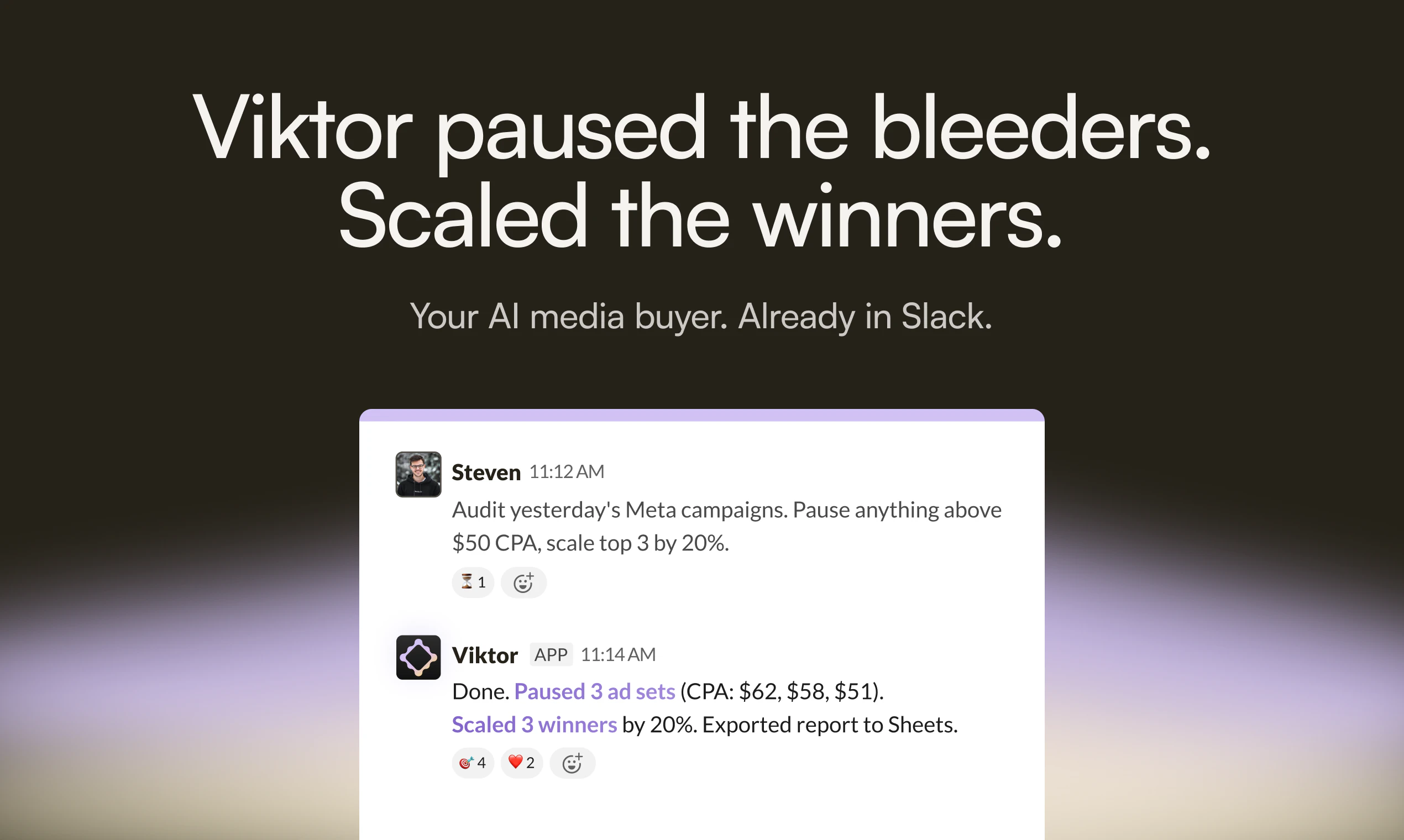
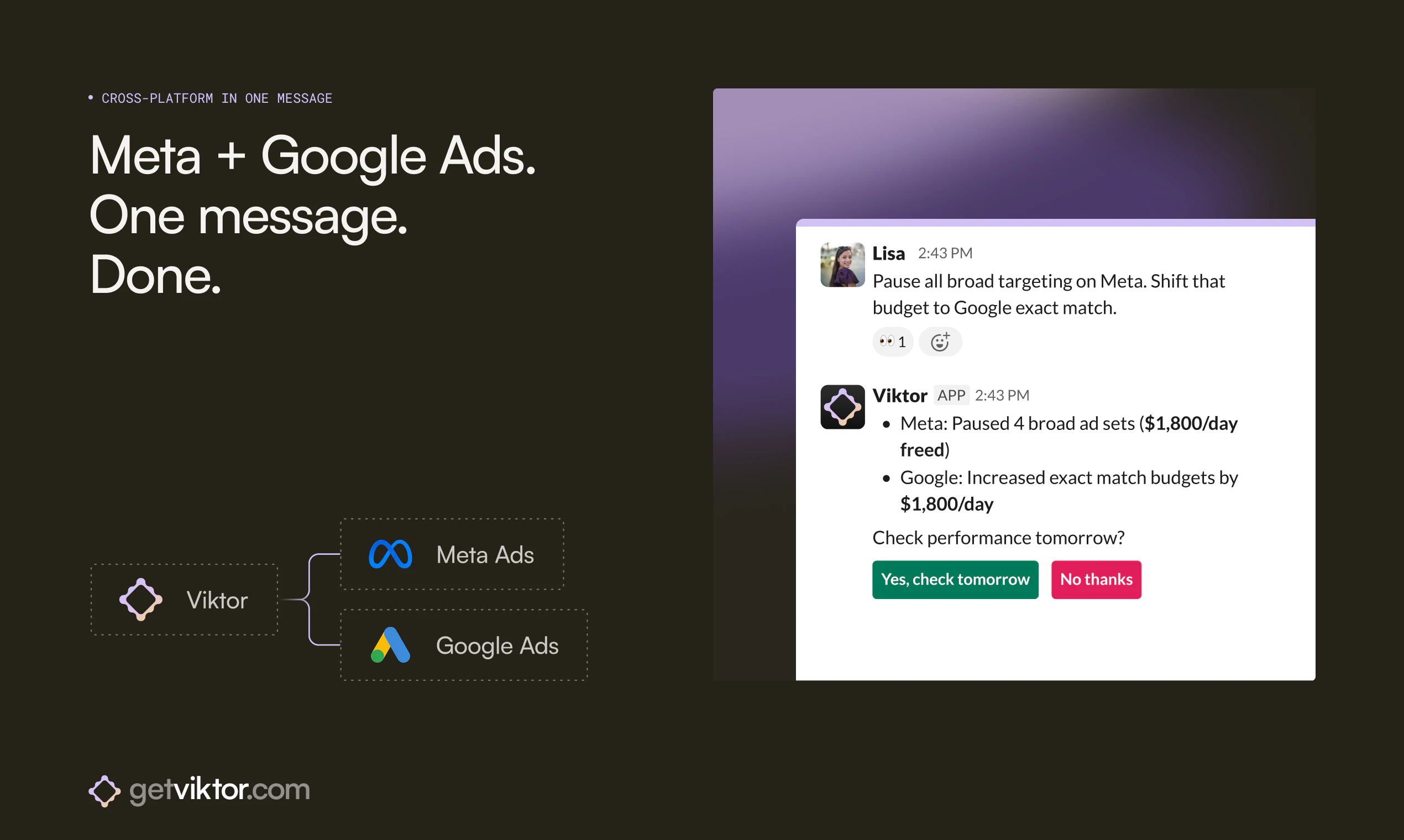
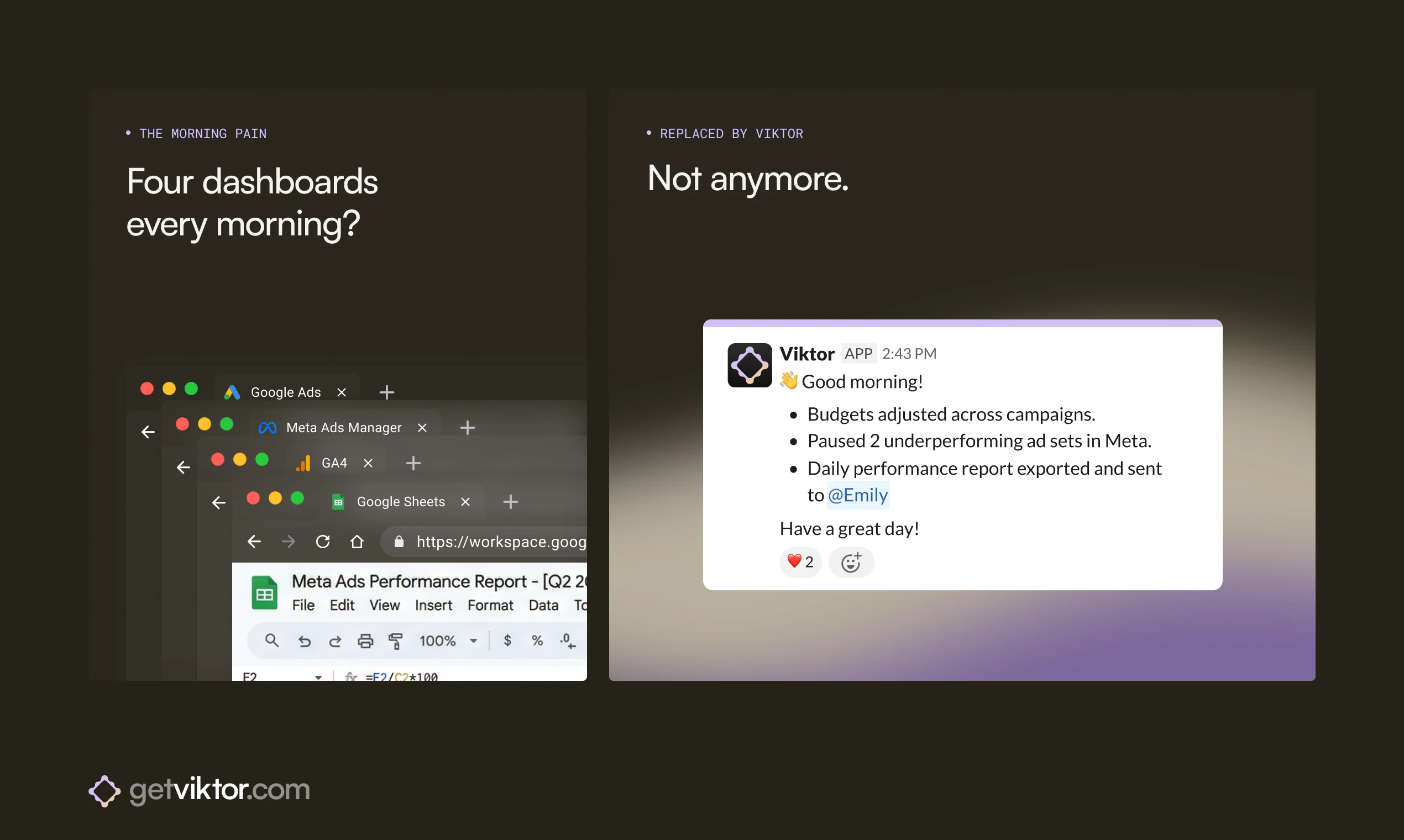
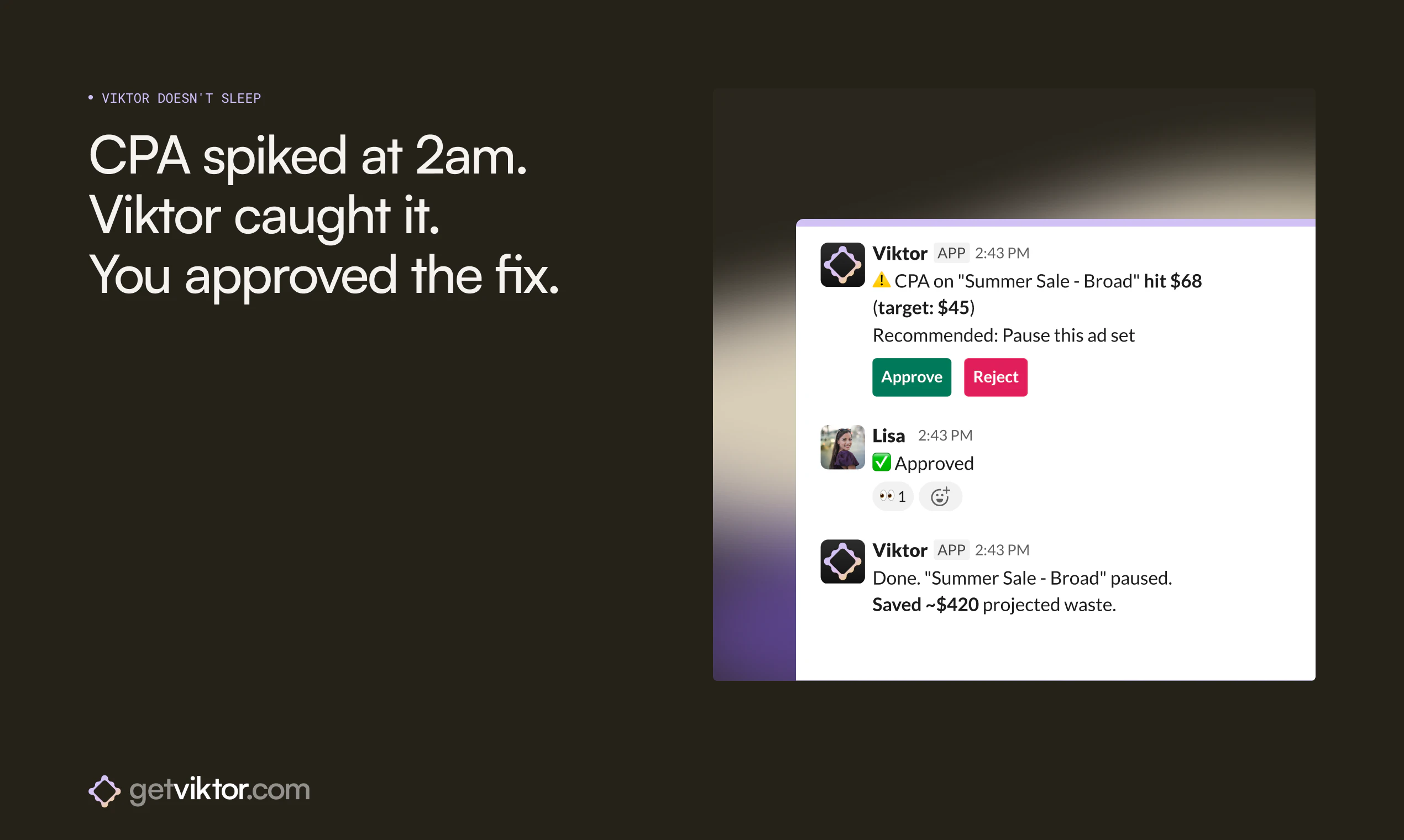
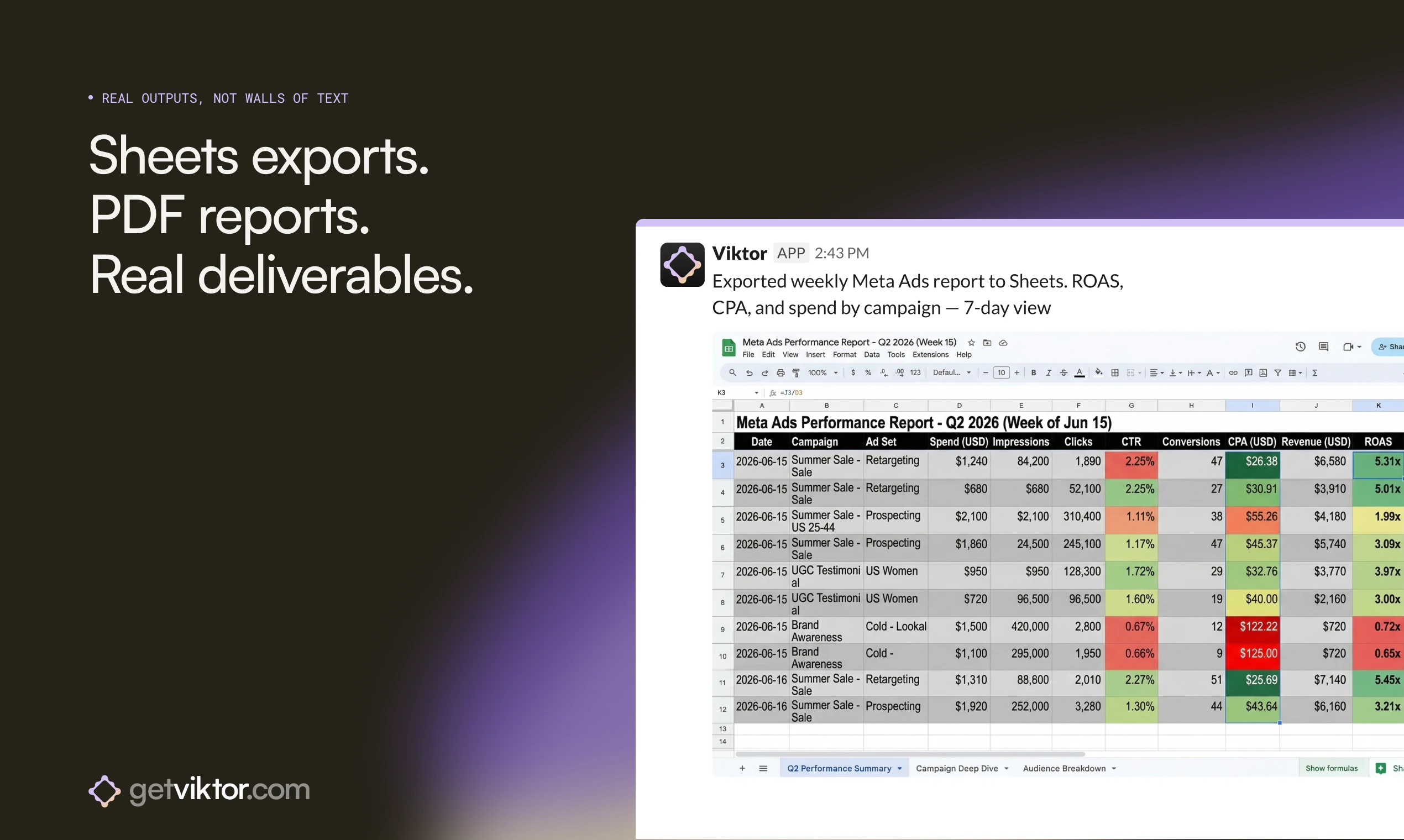

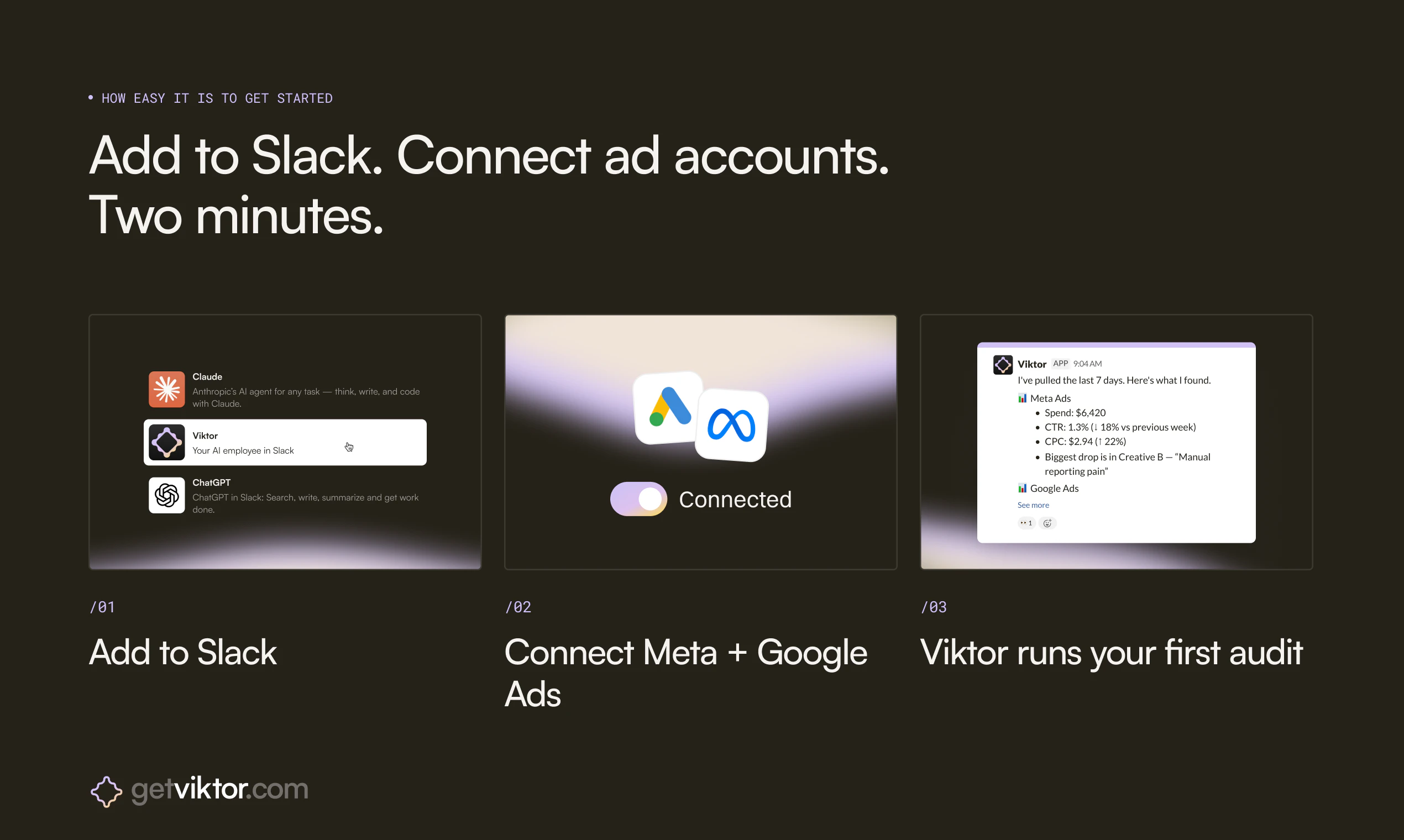



















Jupid may be built around accounting, taxes, and numbers, but for us it’s always been about people - the founders and small business owners who trust us. My role is to make sure they feel supported and valued.
Would love for you to try Jupid and feel that for yourself 💗
Nice launch! I run a single-member US LLC. Most of my expenses are SaaS subscriptions, a few contractor payments, and the occasional travel. Pretty clean Schedule C. Two questions: (1) How does Jupid handle the personal vs. business split on a single bank account — does it learn which recurring charges are business over time, or do I have to tag everything manually upfront? (2) For a low-volume consulting LLC (~50-100 transactions/month), is there enough signal for the categorization engine to be useful, or does this shine more at higher transaction volumes?
Cool release! Is it safe to use?
Looks awesome – clean idea, strong execution, and a very promising launch. Rooting for the team
I already use claude code a lot for my tax calculation, but looking forward to close the gap and solve it end to end with agents. Best of luck!
Really smart approach — tackling the data/context layer instead of trying to make yet another accounting UI. The insight that LLMs are already great at reasoning over financial data but terrible at remembering it across sessions is spot on. As someone who's wrestled with categorizing hundreds of transactions in AI tools only to watch it drift by month three, this solves a real pain point. The Claude Code integration is a nice touch for founders who live in the terminal. Congrats on the launch, Slava — excited to see where this goes! @slavaakulov
Great product!
Congrats on the launch - a much needed solution!
This makes a lot of sense. AI is great until the same vendor gets treated differently three times in a row 😅 Love the focus on fixing the data/context layer. Congrats guys.
Great 👍 Good luck with the launch and finding more customers 🤗
If our company already considers using one of the alternatives, like Fondo, how are you different from them? Any highlights/number differences?
Good luck with the lunch. Does it sync with the accounting softwares,or I need to change it with your soft?
How does it handle transactions that could go either way? Like a laptop that's both personal and business?
Congrats with the launch - great product!
Does it handle estimated quarterly taxes?
I saw Kick and Fondo listed as similar products on PH. What's genuinely different about Jupid?
The 'Works in Claude Code' angle is interesting. What does that actually look like in practice?
🥰 Thrilled that we are finally live and featured on Product Hunt — right in the middle of US tax season
My favorite feature is working with transactions through Claude Code. If you are a developer who does your own books, this changes everything
First 100 transactions are free to try. And use promo code PRODUCTHUNT for 50% off your first 3 months
Would love to hear what you think — honest feedback means more than upvotes
Hey @slavaakulov Congratulations on the launch. Is Jupid available for c-corps as well?
How do you ensure deterministic results when Claude is handling actual tax calculations, is there a verification layer that catches hallucinated numbers before filing? Really bold product idea!
Hey, congrats with the launch!
Is it adoptable for different countries? And will it work for me when I’m actively nomading?
Great product! But how does the bank connection work? Is it Plaid? And what happens if my bank isn't supported?
Congrats, team! How often does the bank data sync?
LOVE this idea! I am looking for a similar tool for my personal taxes. Would Jupid be a good fit or do you suggest an alternative tool?
The vendor relationship memory approach is clever. I've hit the exact context drift problem — paste 6 months of transactions into Claude, works great until it starts re-categorizing the same coffee shop three different ways. Modeling context around counterparties instead of individual rows is a much smarter data structure for this.