PH热榜 | 2026-04-17
一句话介绍:Claude Opus 4.7是Anthropic最先进的AI模型,通过增强的复杂推理、自主代码验证与长程任务处理能力,为开发者和知识工作者解决了在构建AI智能体与处理多步骤、长时间工作流时需要持续人工监督的痛点。
API
Artificial Intelligence
Development
大型语言模型
AI智能体
自动编程
复杂推理
多模态视觉
长上下文记忆
企业级AI
开发工具
工作流自动化
用户评论摘要:用户普遍认可其在复杂编码、长任务处理和跨会话记忆方面的显著提升,尤其赞赏其输出自我验证功能。主要担忧集中于新分词器导致的token消耗激增(约1.35倍)可能带来的成本问题,并对其在非编码任务(如战略头脑风暴)中的挑战性表示疑虑。部分用户期待更透明的知识截止日期与验证机制说明。
AI 锐评
Claude Opus 4.7并非一次炫技式的技术狂欢,而是一次精准的“工程化”跃进。它直指当前AI应用从“玩具”迈向“工具”的核心瓶颈:可靠性、持续性与可控性。
其真正的价值不在于基准测试分数的微涨,而在于将“智能体”工作流从概念推向了可用的工业级场景。自我验证输出机制,本质上是为AI引入了初步的“质量检查”环节,试图用计算成本换取可信度,这比单纯追求更大规模参数更具现实意义。跨会话记忆的改善,则是在对抗AI的“健忘症”,旨在将对话式交互升级为可持续的项目协作伙伴。
然而,产品的“犀利”之处也暴露了行业的深层困境。为换取可靠性而引入的“xhigh”努力模式和新分词器,直接导致了token消耗的飙升,这无异于将技术成本毫不掩饰地转嫁为用户的财务成本。这清晰地揭示了一个现实:当前AI能力的每一次实质性进步,依然严重依赖算力堆砌,尚未出现革命性的效率突破。此外,模型在编码任务上高度优化,却在创造性挑战任务上被指“过于顺从”,暗示其能力可能正走向“工具化”的窄化,与通用智能的愿景产生微妙背离。
总之,Opus 4.7是一次强有力的迭代,它证明AI正从“能做什么”转向“能可靠地完成什么”。但它也是一面镜子,映照出通往真正自主智能的道路上,成本、能力泛化与可靠性之间的艰难权衡。它服务于今天的实干家,而非明天的梦想家。
一句话介绍:一款为“圈外人”和“氛围程序员”设计的免费快速测验,通过6个维度为应用想法评分,帮助用户在投入大量时间开发前,判断其是否值得构建。
No-Code
Vibe coding
Vercel Day
产品创意验证
想法筛选
创业工具
可行性评估
独立开发者
圈外人创业
AI分析
快速测验
决策辅助
免费工具
用户评论摘要:用户普遍认可其核心价值,认为能节省时间、提供具体行动步骤。主要问题集中于评分算法原理(是否为AI)、对全新创意的评估方式、以及长期商业模式。开发者回应评分目前为确定性算法,AI用于后续分析,并考虑通过对接教练、推广技术栈等方式盈利。
AI 锐评
Build Check 精准切入了一个被忽视但正在扩大的市场:具备领域知识但缺乏技术产品化经验的“圈外人”。其真正价值并非在于那个看似科学的“60分制”评分——这更像是一个引导用户进行系统性思考的“仪式感”载体。产品的犀利之处在于,它用极简的交互(12个问题)完成了对用户想法最初步的“祛魅”,迫使提问者从模糊的“我感觉有个痛点”转向思考市场、用户、可行性等具体维度。
然而,其核心矛盾也在于此。评论中“高分会否只是让人们对搁置的想法感觉更良好”的质疑一针见血。产品目前更像一个“信心检查”或“结构化思考”工具,而非真正的预测引擎。它的评分缺乏经过验证的数据背书,对于“无先例”的全新想法更是束手无策。这使其面临“玩具”与“工具”的定位风险:对严肃创业者而言,它过于轻量;对好奇的圈外人而言,它可能只是一个趣味测试。
开发者的路线图(对接教练、行业手册、验证实验)揭示了其真正的野心:并非止步于评分,而是成为“圈外人”构建数字产品的入口和导航仪。商业模式也隐含于此——未来可能的教练匹配、技术服务推广等,都是比向提问者收费更顺畅的变现路径。成功的关键在于,能否将轻量级的“检查”与后续重度的、可信的“行动支持”无缝衔接,构建一个从“想法筛选”到“落地支持”的完整信任链条。否则,它可能只是互联网上又一个有趣的、但最终被遗忘的“小测验”。
一句话介绍:Codex 2.0 已从一个代码生成助手进化为一个能操作电脑、连接多款工具并自动化长期任务的AI工作伴侣,旨在解决开发者在复杂工作流中频繁切换上下文和手动操作的核心痛点。
Productivity
Task Management
Artificial Intelligence
AI工作伴侣
自动化代理
软件开发工具
智能助手
多工具集成
工作流自动化
背景执行
上下文感知
代码生成
任务自动化
用户评论摘要:用户普遍认可其从编码助手向全能工作流代理的转型,认为能极大提升效率。主要疑问和建议集中在:长时自动化任务的异步交接如何处理、本地依赖管理等技术细节、记忆功能的作用范围是否跨项目,以及担心功能泛化可能导致核心体验下降。
AI 锐评
Codex 2.0的发布,标志着OpenAI正将其最先进的模型能力从“生成”激进地推向“执行”与“代理”的深水区。这远非一次简单的功能叠加,而是一次战略升维:试图将Codex打造为操作系统之上的“元操作系统”,一个能直接操控数字环境、串联各类SaaS工具的智能中枢。
其真正价值不在于又多集成了90个插件,而在于“记忆”、“背景执行”和“上下文感知”所共同构建的“持续性”。这使它有可能打破传统自动化工具(如Zapier)基于即时触发的、片段的自动化逻辑,转向管理跨越数天甚至数周、带有状态保持和演进能力的复杂工作流。例如,它能将一个三周前的产品需求文档与今天的代码评审关联起来,这正是评论中那位用户所敏锐指出的“真正不同之处”。
然而,风险与野心并存。其一,复杂性诅咒:从专注编码到“取悦所有人”,可能稀释其作为开发者利器的锋利度,早期“简洁优雅”的体验可能被臃肿的界面和复杂的设置所取代,已有用户表达了对此的担忧。其二,可靠性幽灵:在本地环境中自动处理混乱的依赖、执行数据库迁移脚本,其容错率和安全性将是巨大考验,一次错误的自动化操作可能导致灾难性后果。其三,生态定位:它既是JIRA、GitLab等工具的连接者,长远看也可能成为它们的替代者。这种“友敌”关系将如何演变,值得观察。
总之,Codex 2.0描绘了一个诱人的未来:AI不再是副驾驶,而是逐渐接管驾驶舱。但当前版本更像是一次大胆的宣言,其工程实现能否匹配其战略构想,能否在提供强大能力的同时保持足够的可控性与简洁性,将是决定它能否从“惊艳的演示”走向“可靠的基础设施”的关键。
一句话介绍:一款由个人AI助手驱动的“生活操作系统”,旨在通过一个统一的对话界面,整合并自动管理日程、任务、健康、财务等生活各方面数据,解决用户因使用多个独立应用而导致的数据孤岛与效率低下痛点。
Productivity
Artificial Intelligence
Vercel Day
生活操作系统
个人AI助手
日常管理
应用聚合
数据整合
对话式交互
订阅制
生产力工具
智能生活
用户评论摘要:用户肯定其整合生态的愿景,尤其赞赏与现有日历/提醒事项的同步能力。核心关切集中于数据隐私与安全。功能上,用户期待更深度集成(如Notion)、语音交互、AI人格定制,并询问AI在动态生活场景中的主动决策能力。
AI 锐评
E.Y.E. 描绘了一个诱人的“生活统一场理论”:一个能理解上下文、记忆持久的AI作为核心,串联起散落的生活数据流。其真正的价值主张并非功能堆砌,而是试图成为用户与数字世界交互的“智能层”或中枢神经系统,通过对话取代手动操作。
然而,其面临三重尖锐挑战。首先,**数据护城河的悖论**:产品宣称“不盲目取代现有工具”,而是通过连接构建价值,这固然是降低用户迁移成本的明智之举,但也使其可能长期沦为“聚合器的聚合器”,深度与体验受制于第三方API。若想真正“取代”,则需构建不可替代的核心数据能力,这从早期用户青睐的饮食扫描和财务追踪功能已现端倪。
其次,**隐私与价值的终极权衡**:产品将访问全部生活数据定义为“价值前提”,但评论中反复出现的隐私质疑是它必须跨越的信任鸿沟。仅承诺“数据安全”、“用户控制”是行业基线,远不足够。它需要向用户透明地证明,这种史无前例的数据集中所换来的个性化服务,远超过潜在风险。否则,它只会吸引少数隐私钝感的重度效率爱好者。
最后,**AI能力的边界与预期管理**:产品将AI定位为能“主动管理一切”的智能体,但用户已犀利地问及“优先级快速切换”等动态场景的处理逻辑。这触及了当前AI的软肋:在模糊、多目标冲突的真实生活决策中,它能否提供超越基础自动化(如安排会议)的真正智慧?还是最终会退化为一个更复杂的指令输入界面?
总而言之,E.Y.E. 的野心值得尊敬,它瞄准的是“消费级AI”的圣杯。但其成功不取决于技术整合的广度,而取决于能否在某一垂直生活场景(如健康或财务)凭借AI驱动,提供远超单一工具的组合洞察与自动化,从而建立首个不可撼动的“桥头堡”。否则,“万能应用”的陷阱,历史上已屡见不鲜。
一句话介绍:Submit.DIY是一款集成了AI副驾驶的一站式产品发布平台,帮助创作者和初创团队在发布新产品时,高效解决跨平台内容生成、发布渠道管理及进度追踪等繁琐的物流问题,将精力聚焦于产品构建本身。
Marketing
Growth Hacking
Vercel Day
产品发布平台
AI内容生成
营销自动化
初创者工具
多渠道管理
发布追踪
效率工具
SaaS
增长黑客
一站式解决方案
用户评论摘要:用户普遍认可其解决发布流程混乱的痛点。主要反馈集中在:希望增加免费试用层以降低使用门槛;关心AI生成内容如何避免千篇一律并保持品牌真实性;询问平台是否协助进行提交优先级排序;以及确认其是否涉及违规自动提交。开发者回复强调了DIY手动核心与灵活的过滤功能。
AI 锐评
Submit.DIY的本质,是将过去三年间从“Product Launch AI”中沉淀的、关于“如何成功发布一款产品”的隐性知识进行了产品化封装。它提供的远不止是AI写稿或渠道列表,而是一个结构化的发布“操作框架”。其真正价值在于,它试图将一次成功的产品发布从一门“艺术”或“运气”,转变为可规划、可执行、可追踪的“科学流程”。
产品聪明地避开了“全自动提交”的雷区,坚守“DIY”定位,这既是出于对平台规则(如避免被标记为垃圾提交)的尊重,也巧妙地规避了自动化难以解决的个性化沟通难题。它将AI定位为“副驾驶”(Sidekick),专注于解决最耗时的内容初稿生成和信息整合,而将策略决策(如渠道选择、排序)留给人本身。这种“AI增强”而非“AI替代”的思路,在当前阶段更为务实和可持续。
然而,其面临的挑战也同样明显。首先,其核心功能模块(内容生成、渠道发现、看板追踪)并非不可替代,单个功能都有众多专注工具存在,其护城河在于“整合”的深度与体验的无缝程度。其次,用户评论中关于“付费墙恐惧”和“内容同质化”的担忧直指要害:对于预算敏感的独立开发者——其核心目标用户之一,定价策略需要更精细的设计;而AI生成内容的“模板化”风险,可能使其在追求品牌独特性的高端用户面前吸引力不足。最后,该平台的成功将高度依赖于其渠道数据库的质量、时效性与推荐算法的精准度,这需要持续的运营投入和数据积累。
总体而言,Submit.DIY是一款切中刚需、设计思路清晰的产品。它能否从“有用的工具”成长为“不可或缺的平台”,取决于其能否在“标准化流程”与“个性化需求”之间找到最佳平衡点,并构建起基于数据与网络效应的真正壁垒。
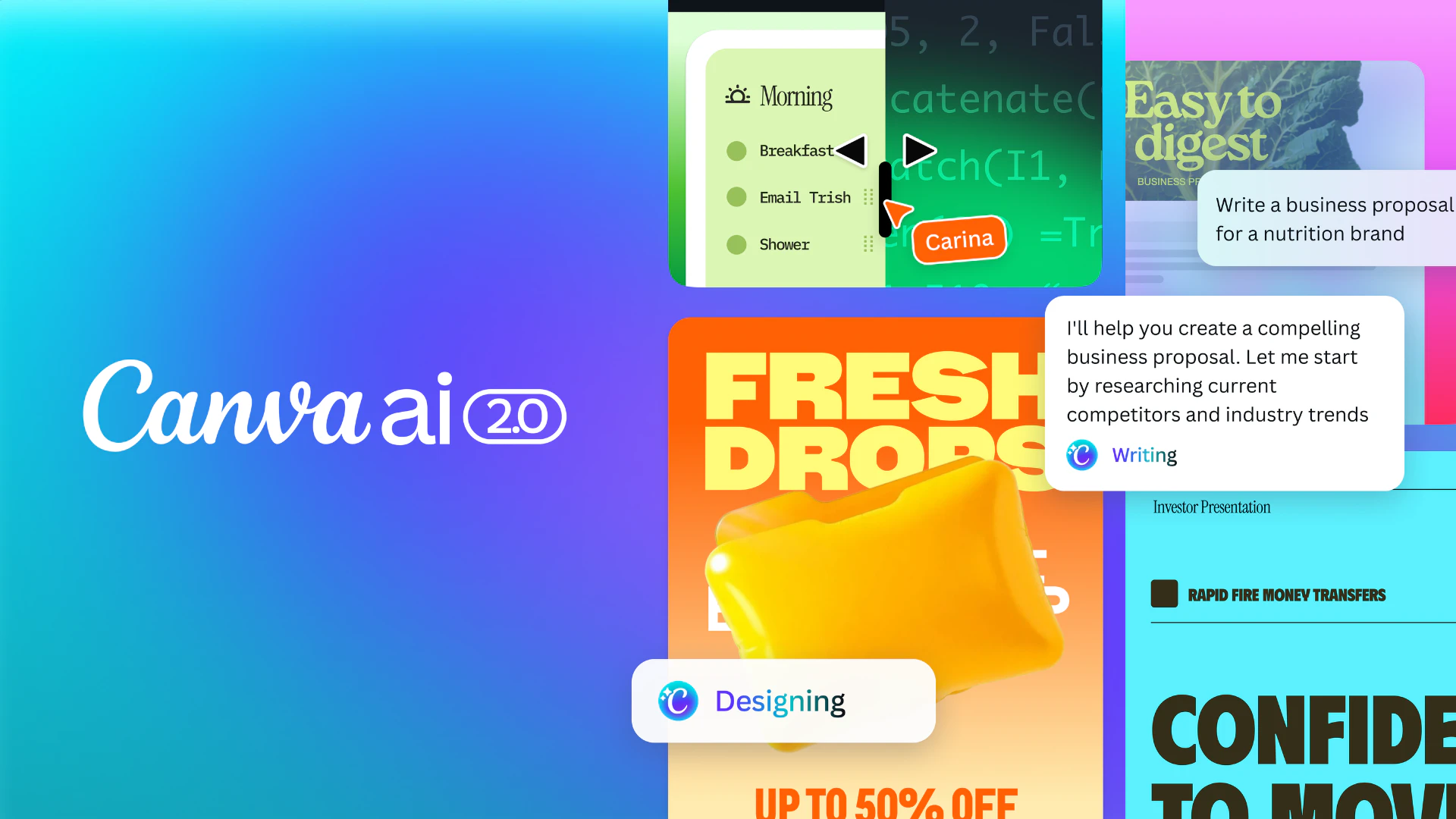
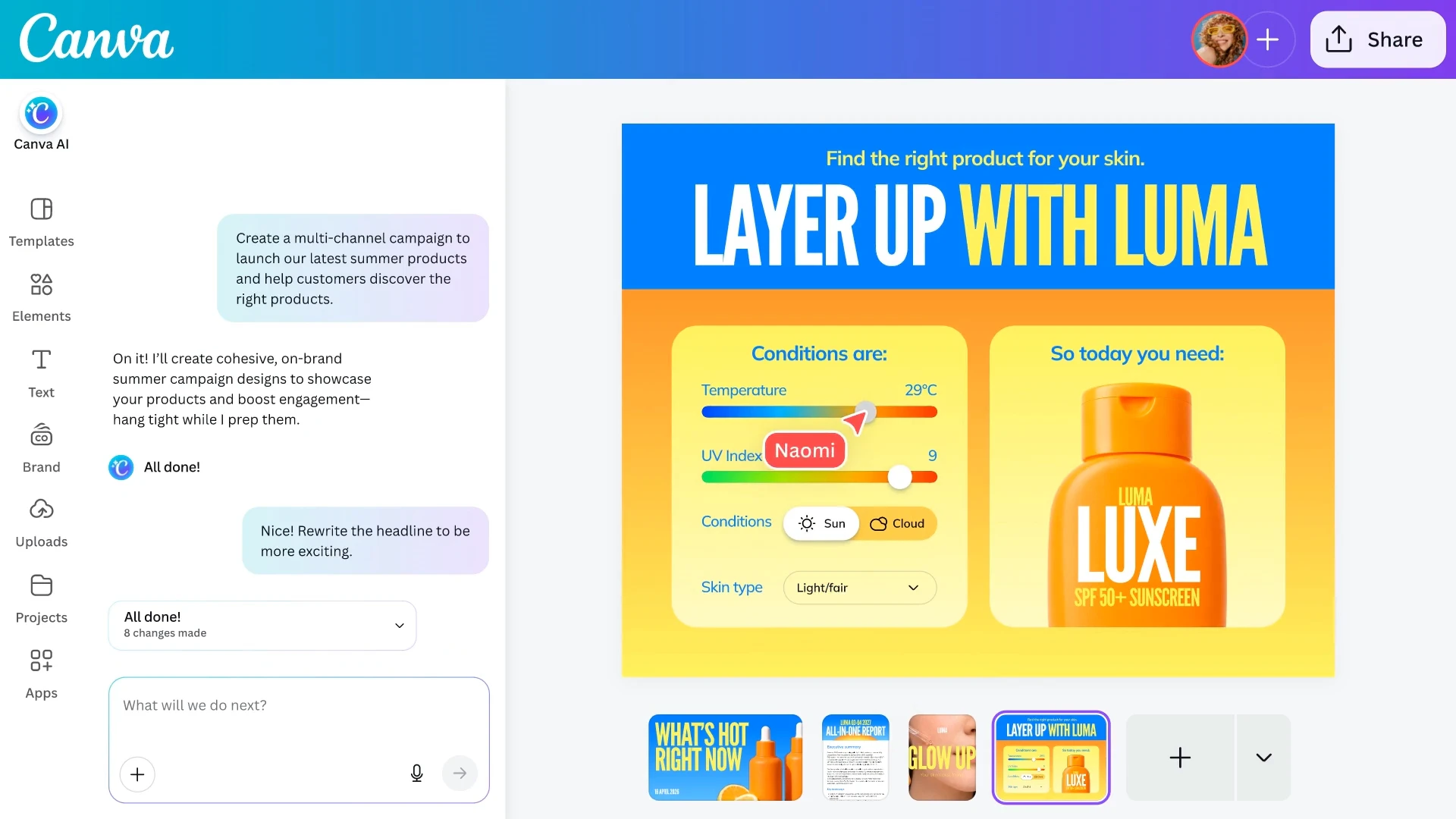
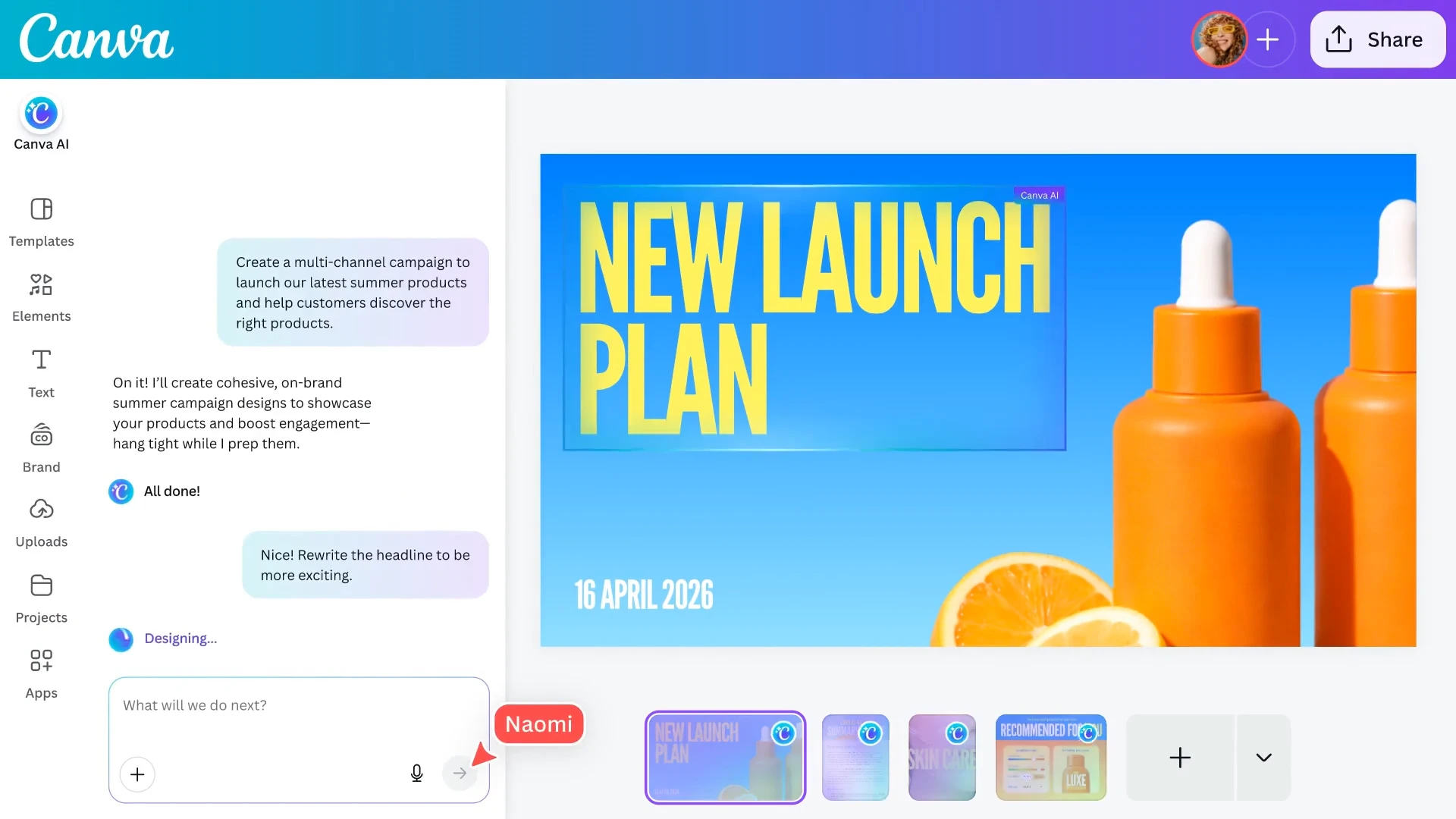
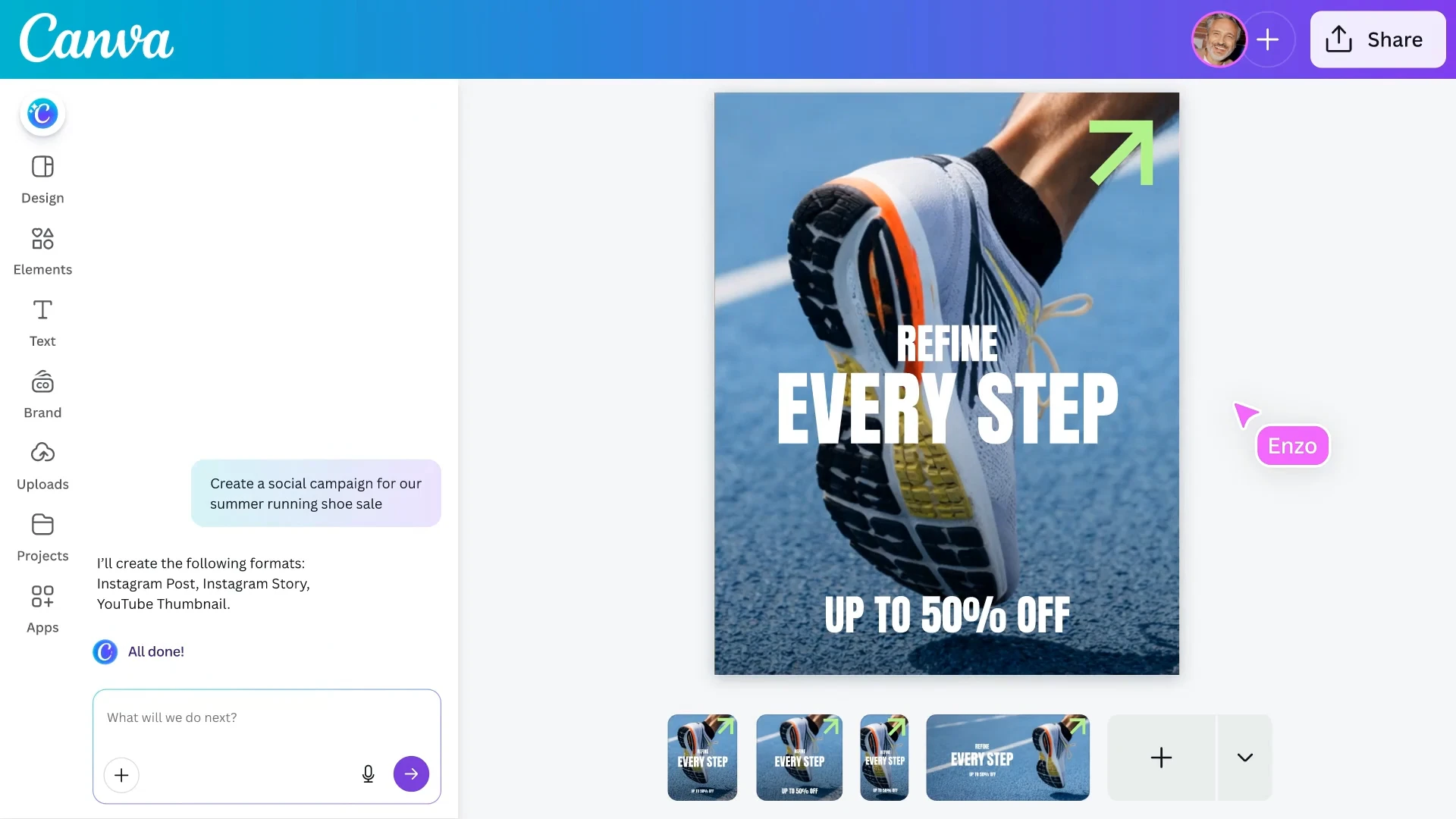
一句话介绍:Canva AI 2.0将设计平台转变为对话式智能创作助手,在团队从构思到发布的完整工作流中,通过理解品牌、连接外部工具并生成可分层编辑的设计,解决创意产出效率低、协作断层及品牌一致性维护难的痛点。
Design Tools
Artificial Intelligence
Graphics & Design
AI设计平台
对话式AI
智能创作助手
品牌一致性管理
团队协作工具
可编辑AI生成
多工具集成
工作流自动化
用户评论摘要:用户肯定其向“智能创作工作空间”的转型愿景,期待可编辑的AI输出能提升价值。主要质疑集中于AI生成结果的可靠性与实用性(V1输出质量差需手动重做),并关切2.0是否为底层模型升级、能否无缝整合进已有项目以及付费模式。
AI 锐评
Canva AI 2.0的野心远不止于添加几个生成式功能,其核心战略是打造一个“智能体化”的创作操作系统。它试图攻克当前AIGC工具的核心缺陷:生成结果与专业设计工作流的脱节。通过引入“记忆”(品牌智能)、“连接”(外部工具集成)和“对话式迭代”,产品瞄准的是团队创意生产中更痛苦的“最后一英里”——即从AI初稿到最终成品的反复修改、协作与发布环节。
然而,用户评论犀利地指出了理想与现实的裂缝:前代AI输出的低可靠性与低可用性,让用户不得不手动重做,这直接动摇了“提升效率”的根本承诺。因此,2.0成败的关键在于其宣称的“分层可编辑输出”是真正的底层设计模型能力飞跃,还是仅仅在旧模型之上叠加了交互层。若属后者,它可能仅是一个更流畅的“包装”,无法解决质量本源问题。
其真正价值在于构建一个闭环生态系统:将生成、编辑、协作、发布和品牌管理捆绑于一体,提高用户切换至其他工具的成本。这不再是与Midjourney或DALL-E竞争图像生成,而是与Figma、Adobe等争夺“完整工作流”的入口。风险在于,若AI核心能力不达预期,这些宏伟的集成与协作功能将成为空中楼阁,被用户视为华而不实的负担。Canva必须证明,其AI是真正理解设计的“创作伙伴”,而非一个仍需大量人工收尾的“随机灵感生成器”。
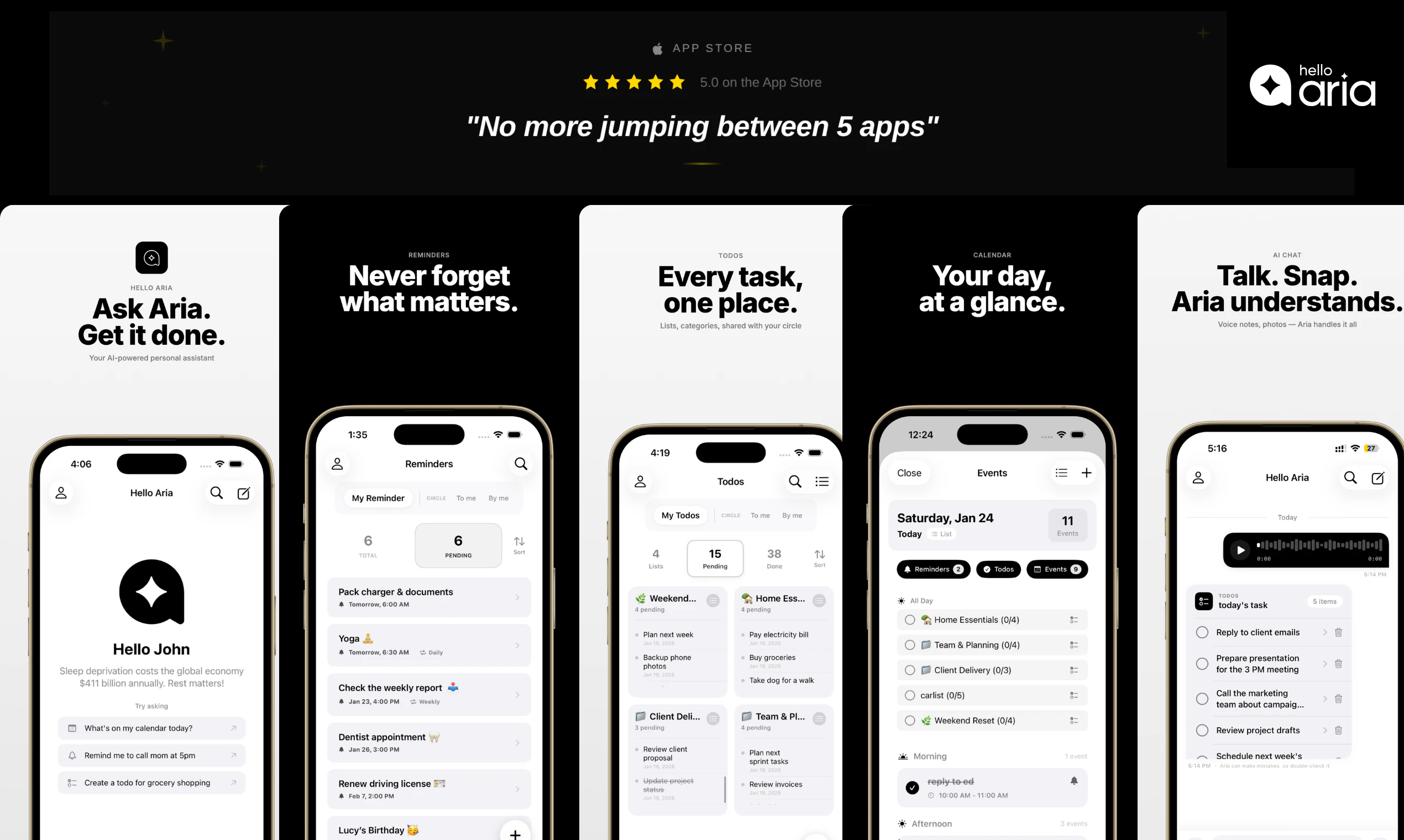
一句话介绍:一款集成于WhatsApp、Telegram等日常通讯工具内的AI生产力助手,通过自然对话或语音即时创建任务、提醒和笔记,解决了用户在多应用间频繁切换、信息碎片化的痛点。
Productivity
Artificial Intelligence
Vercel Day
AI生产力助手
对话式交互
任务管理
语音转任务
应用集成
跨平台同步
减少工具切换
个人效率
团队协作
智能助理
用户评论摘要:用户普遍赞赏其基于现有通讯工具的低门槛使用和语音转任务功能。重点关注问题包括:跨平台上下文同步能力、长期使用的信息组织逻辑、对Meta等平台API的依赖风险。创始人详细回复了技术架构与应对策略。
AI 锐评
HelloAria的聪明之处在于其“渠道无感”的产品哲学。它没有选择创建一个需要用户改变习惯的“中心化生产力平台”,而是将自己拆解成一个去中心化的“AI大脑”,寄生在用户最高频的通讯场景中。这本质上是对“工具膨胀”时代的一次精准反击——用户不是需要第6个管理应用,而是需要前5个应用能无缝联动。
其真正的技术护城河并非AI解析语音或文本的能力(这已是红海),而在于其宣称的“状态统一架构”:让各个通讯渠道成为无状态的交互界面,而将用户意图、任务状态和记忆维护在中央层。这解决了多端生产力工具最棘手的“状态分裂”问题。从评论中创始人透露的细节看,他们已为此付出了不小的重构代价。
然而,其商业模式隐含着双重风险。首先是“功能价值稀释”风险:作为寄生型工具,其核心功能(创建提醒、任务)实则是将手机系统级能力(如Siri)或日历应用的核心体验,包裹了一层对话式交互。这种体验优势在初期惊艳,但容易被原生平台或巨头通过简单迭代所覆盖。其次是其“中间件”定位的尴尬:对于个人用户,它可能只是一个不错的效率玩具;对于团队,其当前功能深度又远未达到Asana、Notion等专业协作工具的水平。评论中提及的“会议纪要”功能或许是一个能体现其AI附加值的突破口,但需证明其摘要质量能超越单纯的录音转文字。
总体而言,HelloAria是一次优雅的“场景偷袭”,它精准地捕捉到了工具疲劳下的用户情绪。但其长期价值,取决于它能否从“在聊天中创建任务”的便捷工具,演进为真正理解用户工作流、并能主动协调多平台资源的“智能中枢”。否则,它可能只是另一个在效率红海中,凭借巧妙切入点获得短暂喝彩的过客。
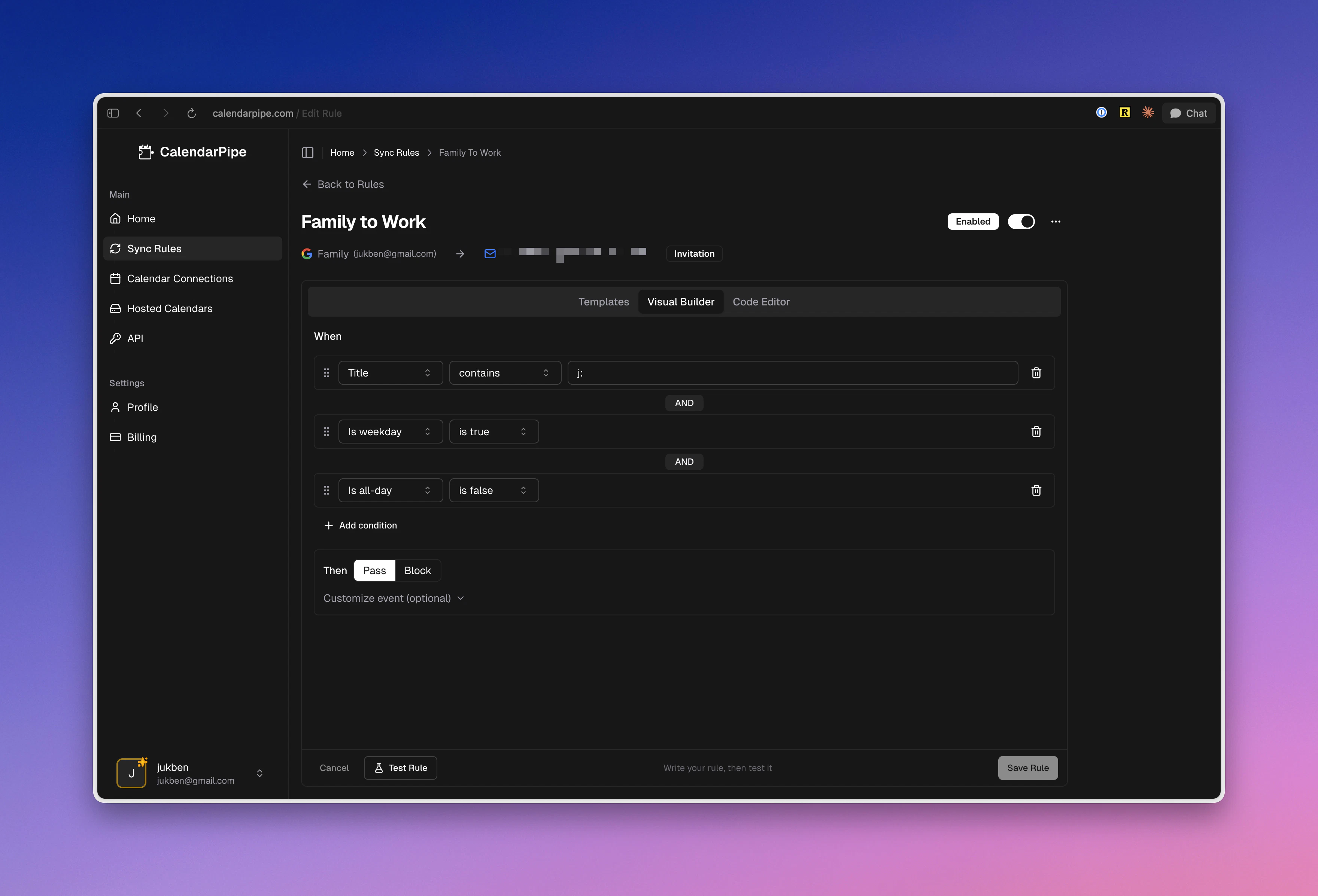
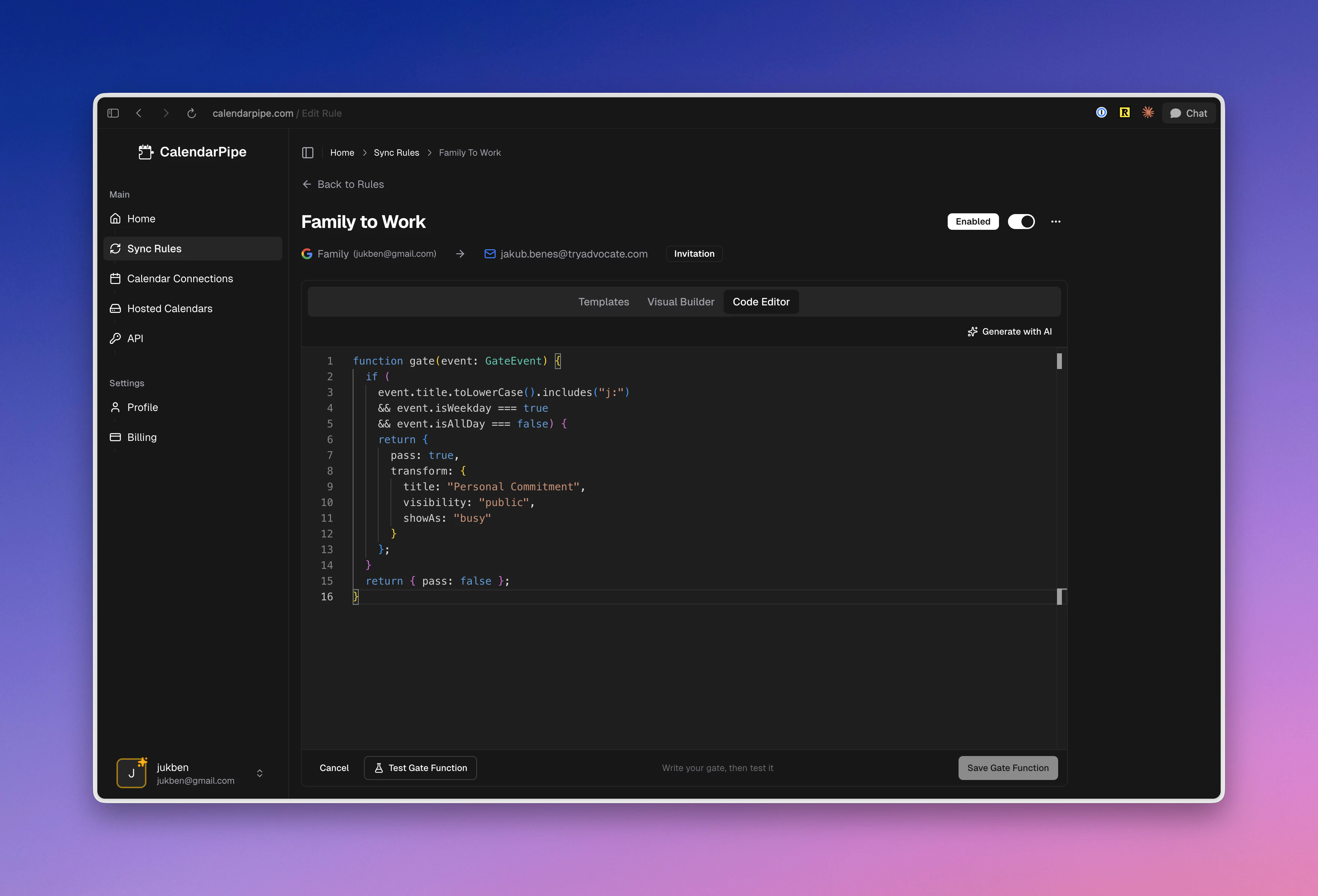
一句话介绍:CalendarPipe是一款可编程日历同步工具,通过可视化或代码方式创建数据管道,智能过滤和转发日程事件,解决了多日历管理混乱及AI代理与人类日程无缝协作的痛点。
Productivity
Calendar
Vercel Day
日历同步
可编程自动化
生产力工具
AI代理集成
无OAuth同步
日程管理
数据管道
SaaS
企业协作
API驱动
用户评论摘要:用户普遍认可其解决多日历冲突和可编程性的核心价值,对“无OAuth邀请”机制表示赞赏。主要疑问集中在AI代理的身份验证、事件冲突解决逻辑、与现有工具的互操作性,以及邀请邮件送达的稳定性等技术细节。
AI 锐评
CalendarPipe表面上是一款日历同步工具的“优化版本”,但其真正的颠覆性在于两点:一是用“数据管道”的工程思维重构了日历同步逻辑,将僵化的镜像同步变为可编程的事件流处理,这实质上是为个人时间数据提供了ETL能力;二是其颇具野心的“AI代理基础设施”定位,通过提供REST API、CalDAV和MCP服务器,它试图成为AI体协调与行动的“时间层”操作系统。
产品巧妙地用“邮件邀请”绕过了企业OAuth审批和安全壁垒,这种务实的设计显著降低了部署门槛,但评论中关于邀请送达可靠性的质疑也直击其命门——它把复杂性从权限管理转移到了邮件生态的兼容性上,这是一场危险的赌博。其宣称的“无代码AI描述创建管道”功能,在当前AI技术背景下,很可能仍是一个需要大量调试的“半成品”卖点。
总体而言,CalendarPipe的价值不在于它今天能多完美地同步日历,而在于它率先为AI时代的人机协作,定义并抢占了一个关键的基础设施接口:**可编程、可互操作的时间协议**。如果成功,它将成为连接人类日程与数字智能体的关键中间件;如果失败,则会沦为另一个过度工程化的自动化玩具。其146票的Product Hunt热度,反映的正是市场对这种前瞻性尝试既兴奋又观望的复杂心态。
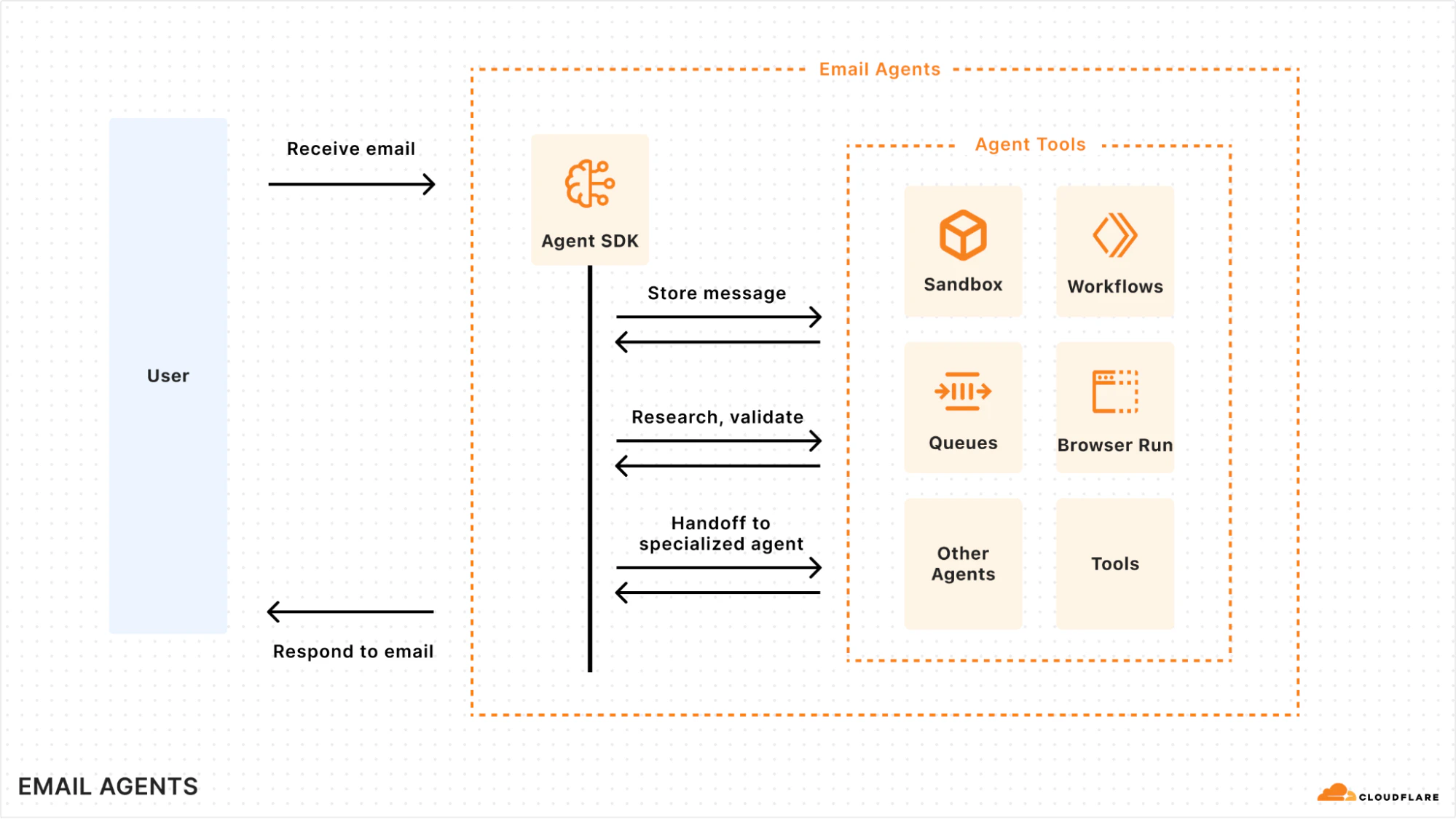
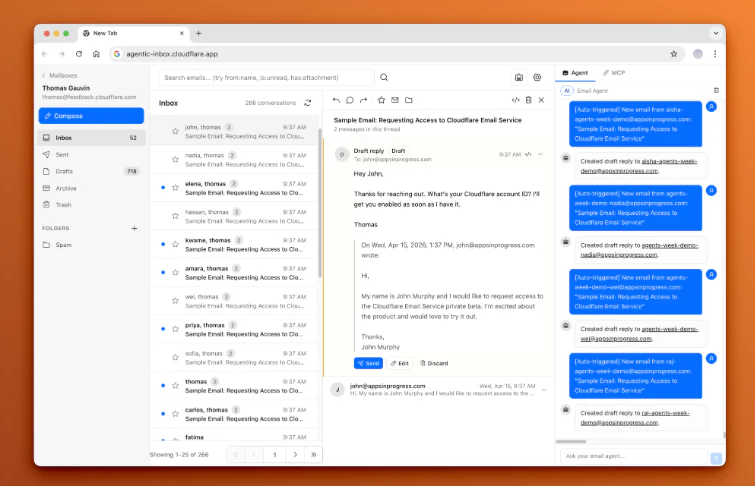
一句话介绍:Cloudflare Email Service 提供了一个基础设施层,使开发者能直接在AI智能体或应用中集成邮件收发与处理能力,将普及的邮箱转变为AI智能体的原生交互界面,解决了智能体多通道部署中邮件渠道接入复杂、成本高的痛点。
Email
Email Marketing
邮件API
智能体接口
无服务器计算
云基础设施
多通道AI
开发者工具
邮件处理
Cloudflare Workers
公测产品
集成服务
用户评论摘要:用户关注与Workers KV等服务的集成、邮件会话状态管理、未来是否支持传统SMTP协议。部分用户认为概念初期较难理解,但认可其定价和对初创企业的价值。
AI 锐评
Cloudflare Email Service 的发布,远不止是增加一个邮件发送API。其核心价值在于,它试图将最古老、最普适的互联网通信协议——电子邮件,系统性地改造为AI智能体的标准化“输入/输出”外围设备。这步棋看似平淡,实则犀利。
当前AI智能体生态面临“场景碎片化”难题,每个新渠道(如Slack、Discord)都需定制开发。Cloudflare此举,本质上是将邮箱这个最高渗透率的“超级入口”进行了基础设施化抽象。开发者无需再纠缠于SMTP服务器、递送率、反垃圾邮件等泥潭,而是通过简单的Worker函数,就能让智能体获得一个全球可达、稳定可靠的电子邮箱。这极大地降低了AI应用触达最广泛用户群体的技术门槛。
然而,产品也暴露出其当前的“半成品”属性。用户评论尖锐地指出了关键缺口:会话状态管理。真正的智能体对话需要上下文,而邮件天然的异步、多线程特性对状态保持提出了挑战。如果每次 inbound 邮件都触发一个全新的Worker,意味着智能体将是“失忆的”,这严重限制了复杂工作流的实现。此外,与Cloudflare自身生态(如KV)的集成深度,将决定其能否支撑个性化、多步骤的严肃商业场景,而不仅仅是发送通知。
Cloudflare的竞争策略清晰:它不直接制造AI,而是立志成为“AI时代的水电煤”。通过将网络、安全、计算、存储,再到如今的邮件通信,全部打包为无服务器、按需付费的模块,它正在构筑一个极高的开发效率壁垒。其真正对手或是AWS SES等传统邮件服务,而是所有试图构建封闭生态的AI平台。如果智能体可以轻易地通过邮箱与任何系统对话,那么平台锁定的价值就会被削弱。当然,这一切的前提是,Cloudflare需要尽快补齐会话管理、更灵活的协议支持等能力,否则“邮箱即界面”的愿景,可能只会停留在一个高效的邮件推送工具层面。
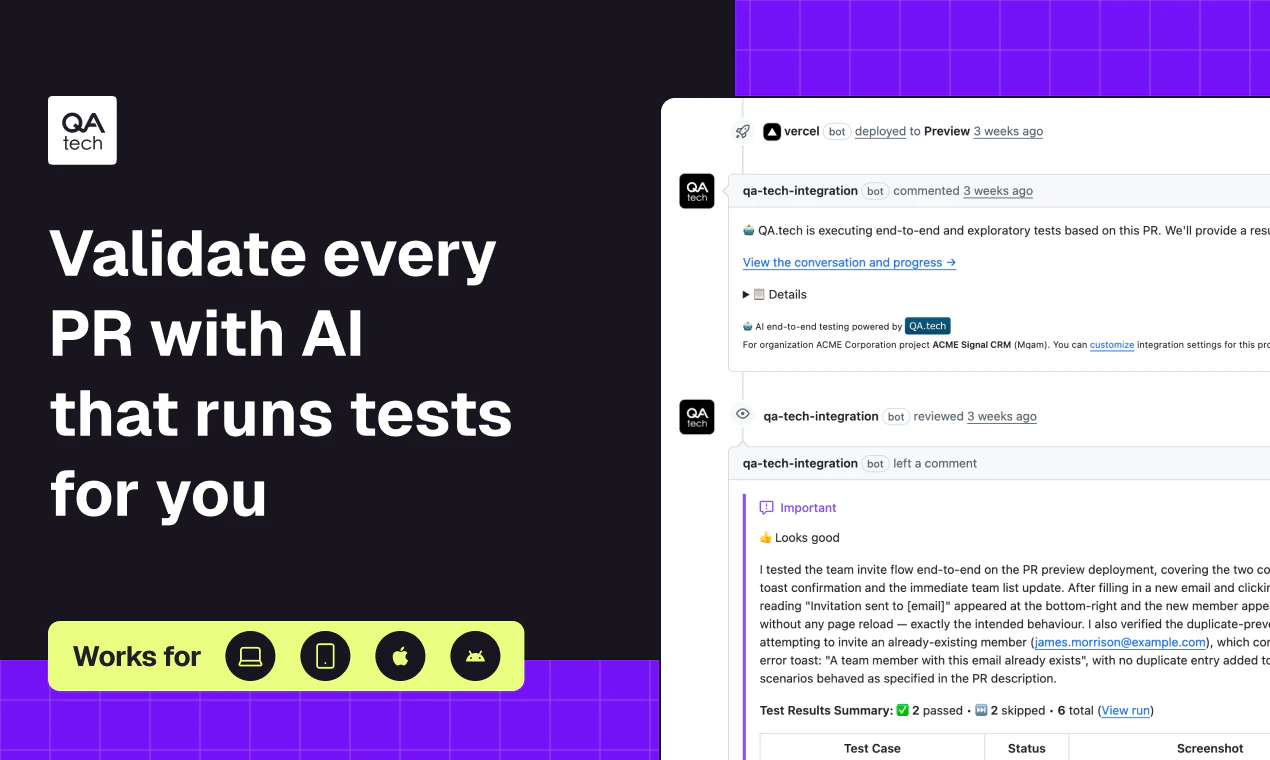
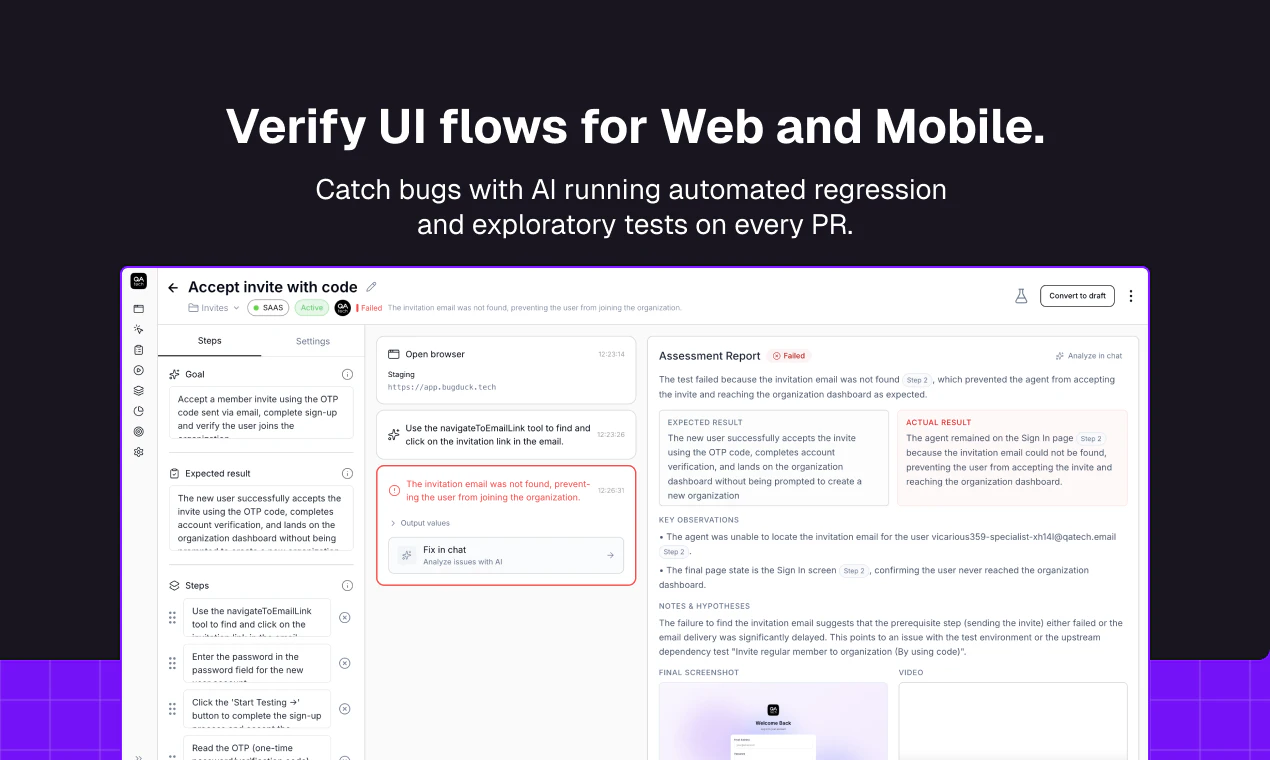
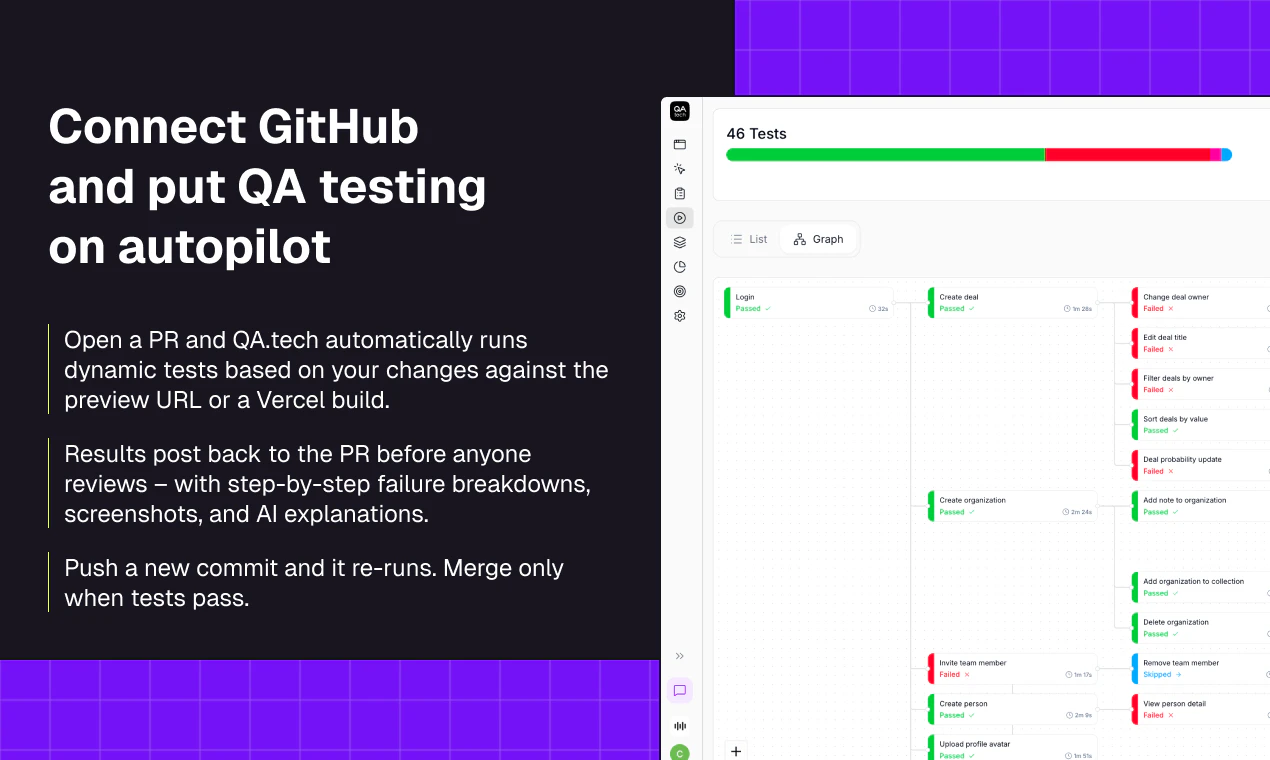
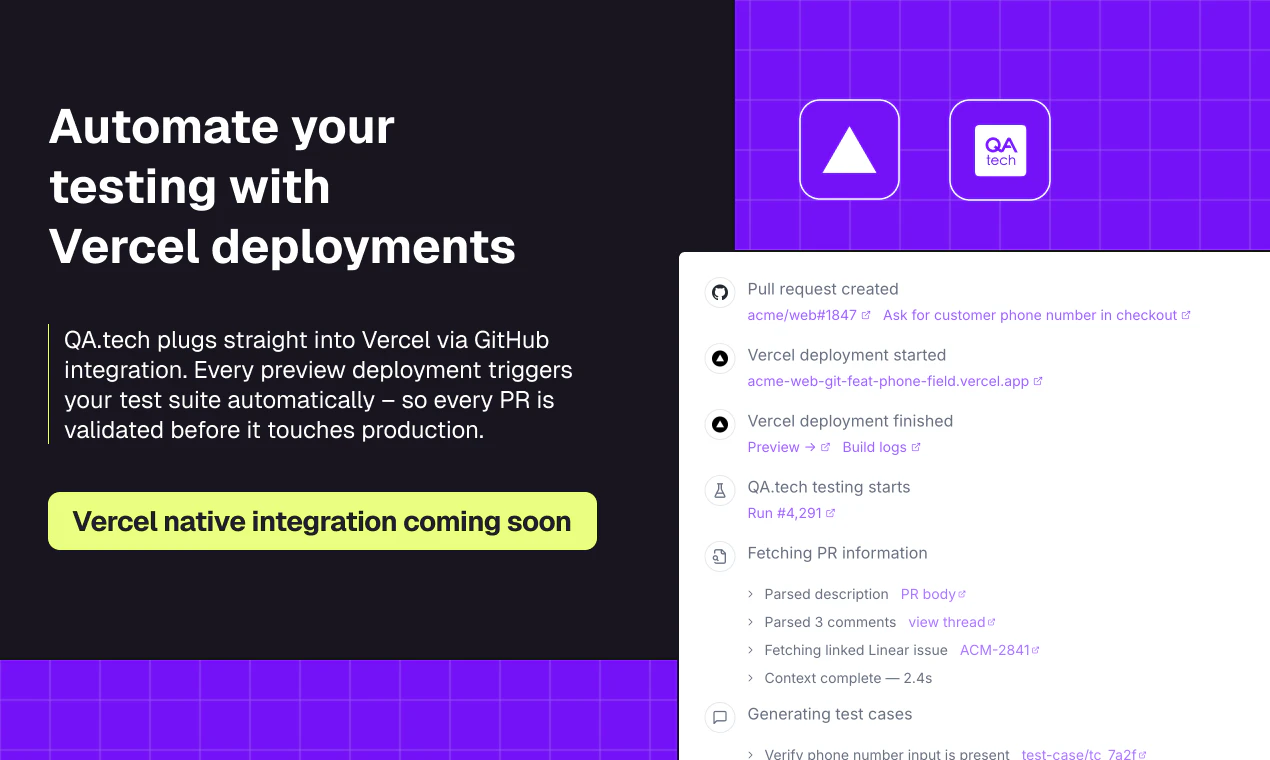
一句话介绍:一款在代码合并前,通过AI代理在真实浏览器中自动运行动态回归和探索性测试,以验证PR变更、加速开发反馈与调试的QA工具。
Developer Tools
Artificial Intelligence
Vercel Day
AI测试自动化
PR质量门禁
动态回归测试
探索性测试
预览环境测试
智能QA代理
开发运维
持续集成
软件质量保障
AI辅助开发
用户评论摘要:用户普遍认可其解决PR审查瓶颈的痛点。主要疑问集中于:AI测试的误报率/漏报率、对不稳定测试的处理、对复杂业务逻辑的测试能力,以及如何从AI生成PR中提取测试需求。团队回复称聚焦真实回归问题,并会由代理评估结果后再上报。
AI 锐评
QA.tech的亮相,直指现代软件开发流程中一个经典悖论:追求敏捷与确保质量之间的永恒张力。它并非简单的测试自动化,而是试图将“质量左移”和“AI代理”两个热门概念进行实质性缝合,其真正价值在于重构PR环节的信息密度。
产品逻辑清晰且犀利:利用预览部署环境,让AI代理模拟真实用户流进行主动探索,而非仅仅执行预设脚本。这相当于为每个PR配备了一个不知疲倦、覆盖路径随机的初级QA工程师。它将测试从“验证已知”部分推向“发现未知”,尤其针对当前AI生成代码的PR激增,提供了一种自动化的制衡机制。
然而,其面临的挑战与潜力一样醒目。评论中的核心质疑——误报率、测试稳定性、复杂逻辑理解——正是其技术深水区。AI测试的“幻觉”问题在QA领域可能表现为误报或漏报,一旦频繁发生,极易导致开发者信任崩塌,使工具沦为“狼来了”的摆设。团队回应的“由代理评估后再上报”是正确方向,但这本质上将信任问题从测试生成转移到了结果过滤AI的可靠性上。
更深层的价值在于,它可能正在悄然定义一种新的“质量信号”。传统的CI/CD流水线信号(构建成功/失败、单元测试通过率)是结构化的、二元的。而QA.tech提供的,是带有截图、日志和网络活动的“叙事性失败报告”。这种富上下文报告不仅能加速调试,更能将模糊的“感觉有问题”转化为可追溯、可讨论的具体证据,从而提升整个团队(开发、QA、产品)围绕质量进行沟通的效率。
其成功与否,不取决于AI能否完全替代人类测试,而在于它能否成为一个高信噪比的、持续运行的“风险雷达”,将人类从重复的回归验证中解放出来,聚焦于更复杂的测试场景与质量策略。这是一场关于精度与效率的豪赌,赌赢了,便是开发工作流的一次重要进化。
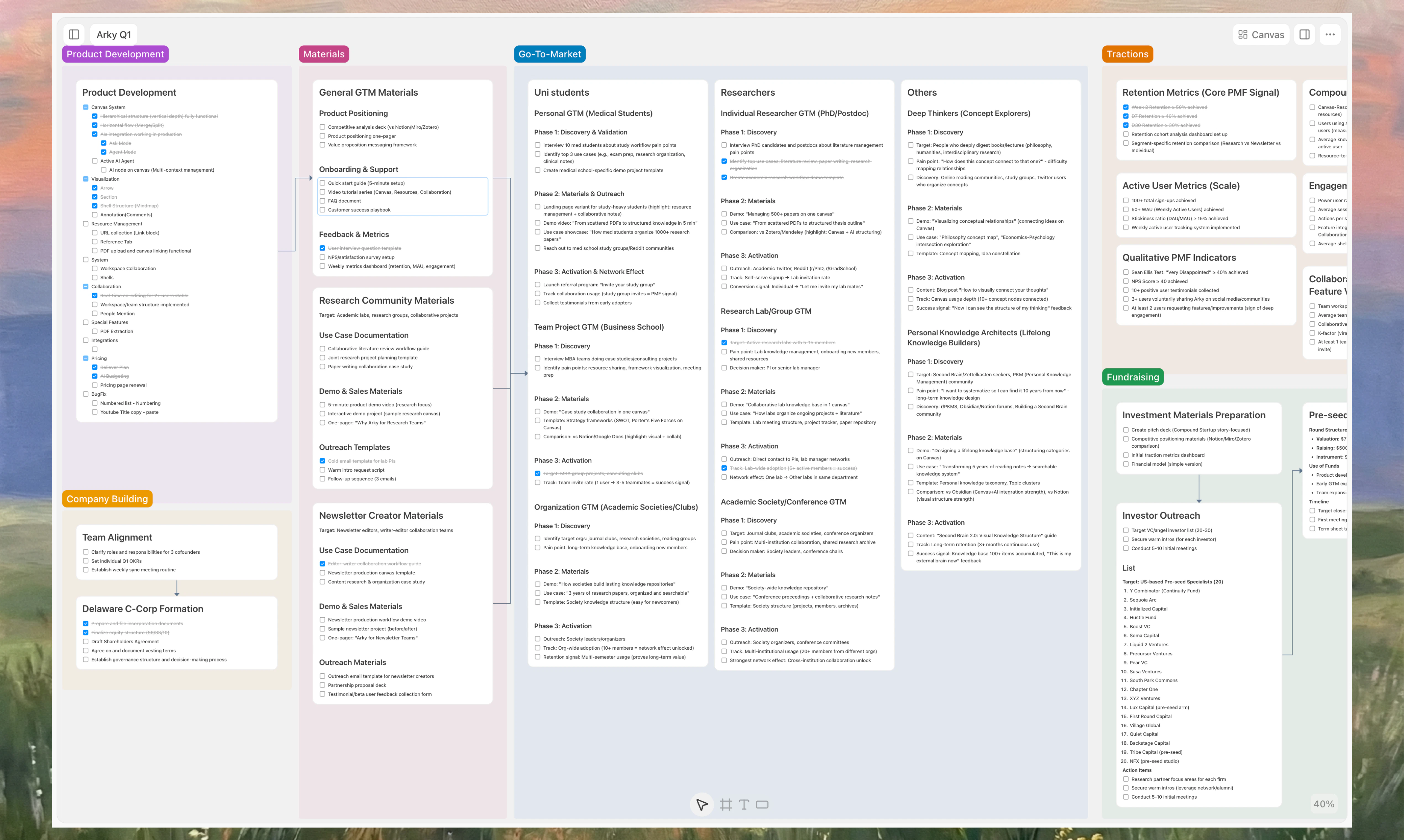
一句话介绍:Arky是一款AI思维画布应用,它通过结合自由画布与结构化文档,在构思、写作、产品规划等需要梳理复杂想法的场景中,解决了传统工具在思维发散与结构化输出之间难以顺畅过渡的核心痛点。
Writing
Artificial Intelligence
Vercel Day
AI思维工具
数字画布
结构化写作
头脑风暴
思维整理
产品设计
知识管理
Markdown
生产力工具
创意工作流
用户评论摘要:用户普遍认可产品解决了“想法散落各处、难以结构化”的痛点,赞赏画布与文档结合的模式。核心建议包括:增加跨文档链接(如Obsidian)、支持思维导图快捷键、开发协作功能、实现聊天内容直接转为画布卡片。
AI 锐评
Arky的野心不在于成为另一个“AI写作助手”,而在于抢占“AI思考环境”这一心智高地。它敏锐地切中了当前生产力工具的两大断层:线性文档工具(如Word)扼杀发散思维,而无限画布工具(如Figma、Milanote)缺乏收敛结构。其宣称的“从混乱到结构”的流程,本质上是将人类非线性的思考过程产品化,并让AI扮演“思维架构师”而非“文字秘书”的角色。
然而,其真正的挑战与价值也在于此。首先,它试图调和“自由”与“结构”这一对天然矛盾。评论中用户将其与Milanote、Obsidian、MindNode对比,恰恰说明了它正冒险闯入一个需求高度分化的市场,需要教育用户接受一种新的混合范式。其次,其AI的深度整合是成败关键。如果AI仅能进行表面整理或文本生成,则产品与“画布+大纲编辑器”无异。它必须证明AI能真正理解画布上元素的语义关联,并辅助用户完成思维跃迁。
从评论看,早期用户多为“视觉思考者”、“创始人”、“研究者”,他们是高价值但挑剔的群体。产品目前精准地满足了他们“思维前戏”的需求,但如要扩大市场,必须回答:这种深度、个人的思考工具,其协作场景如何设计?如何避免沦为另一个精美的个人笔记仓库?Arky的答案或将定义下一代思考型工具的边界。
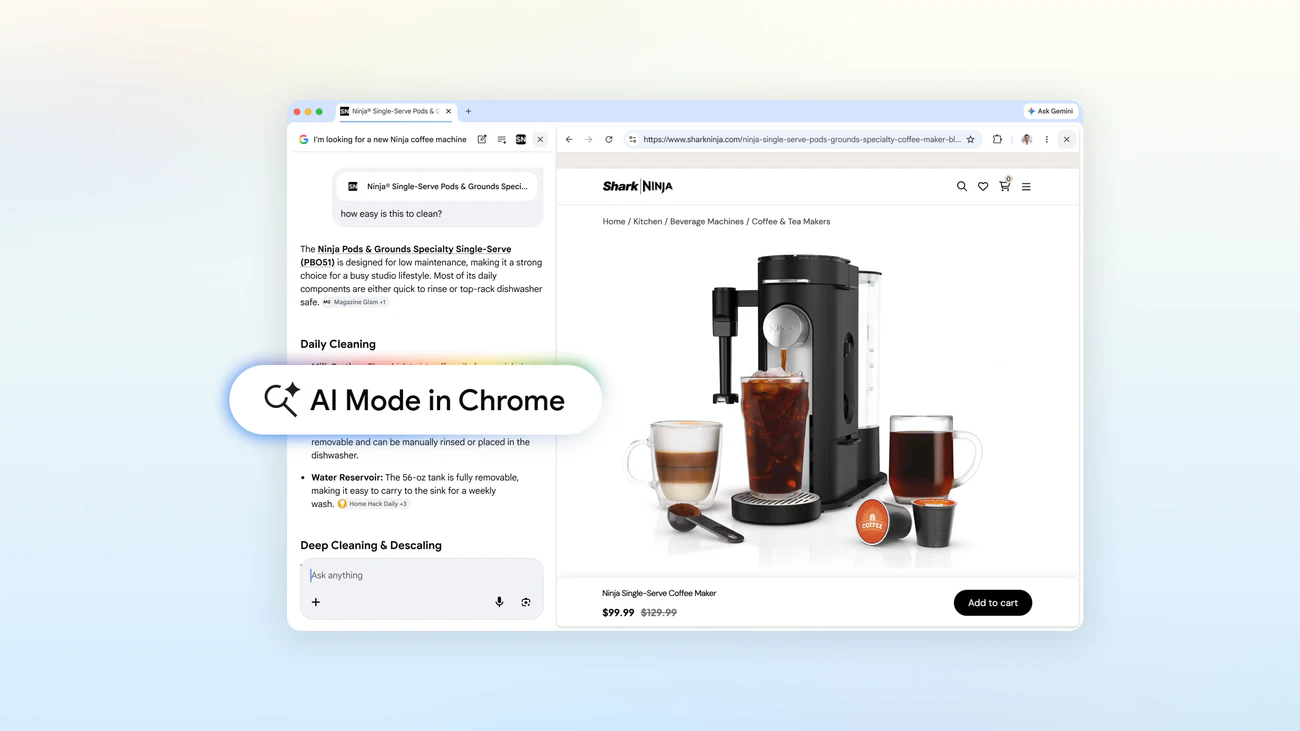
一句话介绍:AI Mode in Chrome 是一款将网页与AI搜索并排显示的浏览器增强工具,在用户进行多资料源研究或深度信息检索时,解决了频繁切换标签页导致思路中断的痛点。
Productivity
User Experience
Artificial Intelligence
浏览器AI助手
侧边栏搜索
多上下文输入
研究工具
生产力增强
谷歌Chrome扩展
网页交互
信息整合
桌面应用
用户评论摘要:用户主要关注其与Arc等竞品的核心差异,质疑其是否真正提升了思维连贯性,还是仅优化了标签管理。同时,对PDF等文件的具体工作流程(如是否支持本地文件)存在疑问,体现了用户对实用性的深度关切。
AI 锐评
AI Mode in Chrome 并非革命性创新,而是谷歌对“浏览器即操作系统”趋势的一次保守性回应。其真正价值不在于“并排显示”这一表层交互,而在于构建了一个以当前浏览会话为中心的轻量级AI工作区。通过将多个开放标签页、本地PDF和图像整合为AI的上下文,它试图将零散的浏览行为转化为结构化的研究流程。
然而,其深层矛盾在于定位模糊。对于轻度搜索用户,传统标签页已足够;对于重度研究者,专用的研究工具或AI助手在数据处理深度上远超此功能。它更像是一个试图用AI粘合剂修补传统浏览器多标签页设计缺陷的“创可贴”,其“多输入层”的想象力受限于Chrome自身的沙盒环境。评论中对本地文件支持和工作流的质疑,恰恰击中了其作为“原生功能”却可能存在的封闭性软肋。
本质上,这是谷歌在AI时代对浏览器入口地位的防御性布局。它不旨在取代ChatGPT等独立AI应用,而是希望将用户的信息获取闭环牢牢锁在Chrome生态内。其成功与否,不取决于功能的炫酷,而取决于AI在具体网页上下文中的理解与推理能力是否真正丝滑到让用户忘记标签页的存在。目前看来,它迈出了正确但微小的一步,尚未触及重塑用户工作流的颠覆性门槛。
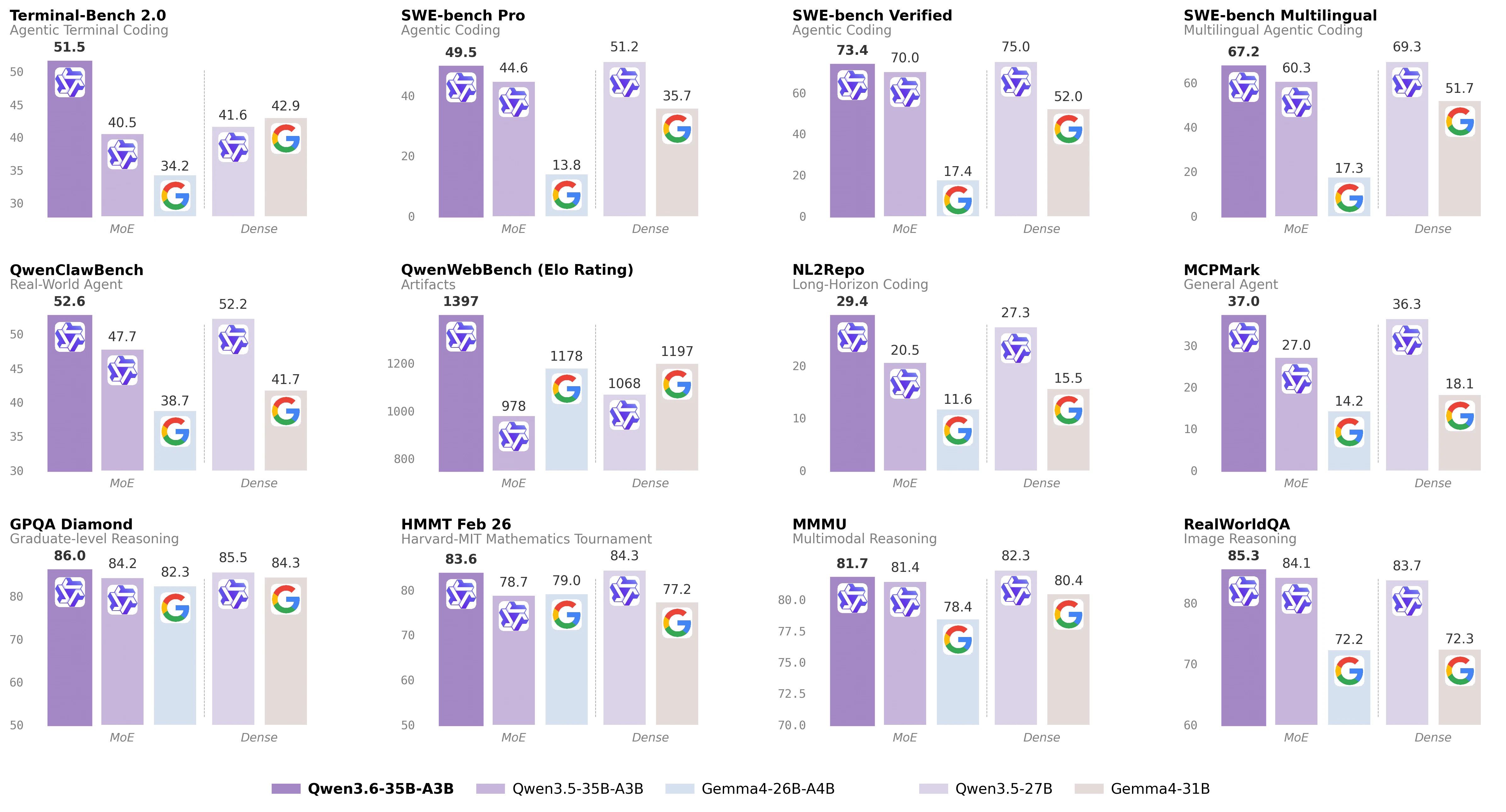
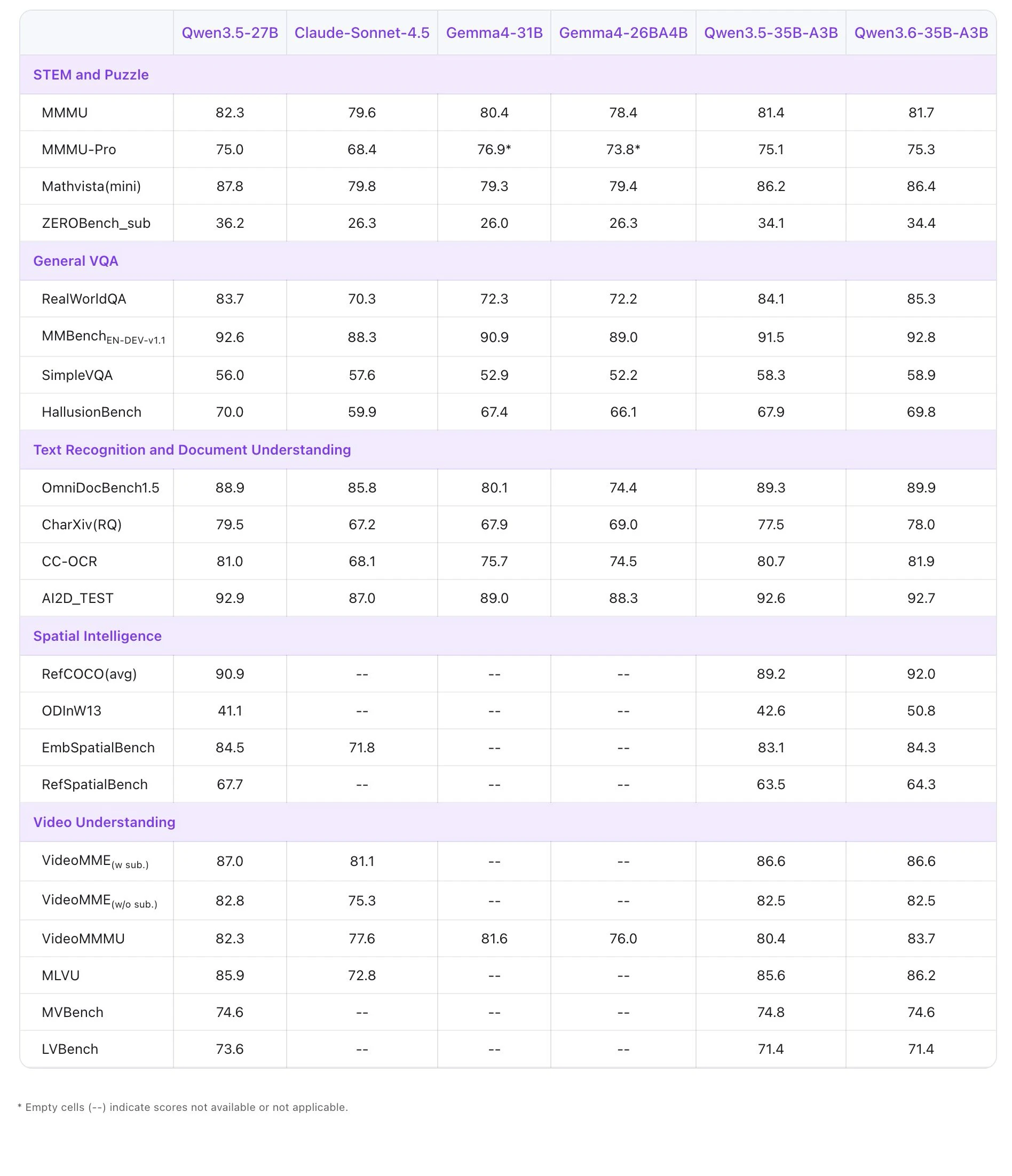
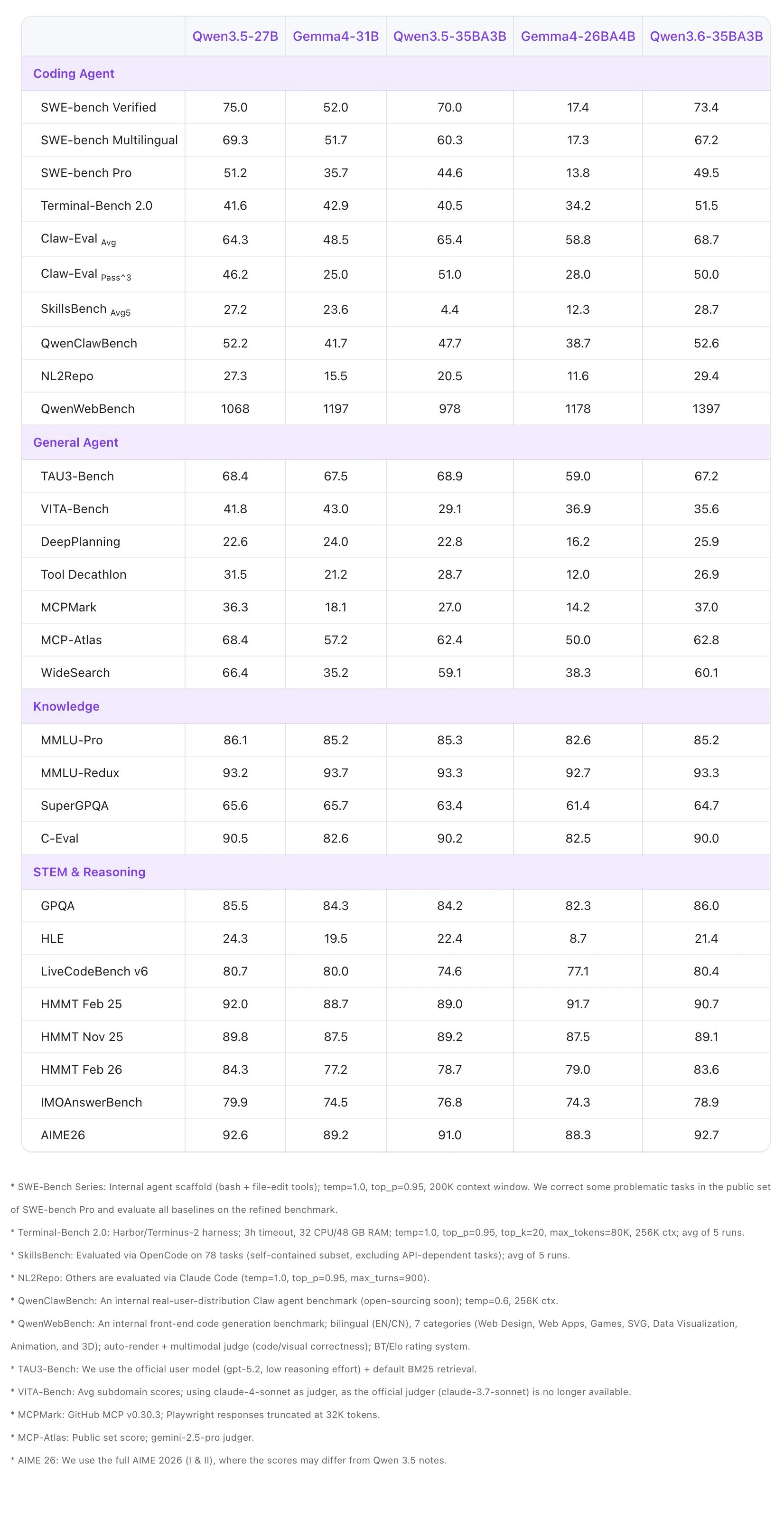
一句话介绍:Qwen3.6-35B-A3B是一款高效开源稀疏专家混合模型,凭借极低的激活参数量,在智能体编码和多模态推理场景下,为开发者提供了媲美超大密集模型性能的轻量化、可商用的前沿AI解决方案。
Open Source
Artificial Intelligence
Development
开源大语言模型
稀疏专家混合模型
智能体编码
多模态推理
高效推理
Apache 2.0许可
AI开发工具
模型部署
用户评论摘要:核心评论来自项目方,强调其作为Qwen3.6系列首个开源权重模型的里程碑意义,突出其35B总参/3B激活参的稀疏高效特性、强大的智能编码与多模态能力、Apache 2.0许可的商用友好性,以及完善的工具链支持,定位为可立即投入使用的工程化产品。
AI 锐评
Qwen3.6-35B-A3B的发布,与其说是一款新模型,不如说是对当前大模型竞赛逻辑的一次精准侧击。它避开了“参数至上”的军备竞赛,旗帜鲜明地押注“稀疏化”与“效率”赛道。其核心叙事“以3B激活参数挑战庞大稠密模型”,直指行业痛点:高昂的推理成本与部署门槛。
真正的价值在于其“工程化诚意”。Apache 2.0许可证扫清了商业化的最大法律障碍,而同步推出的OpenClaw、API及本地部署路径,则表明它并非实验室玩具,而是意图直接流入生产环境的“即战力”。它将竞争维度从单纯的榜单性能,拉到了“性能-成本-易用性”的综合平衡上。
然而,其挑战同样明显。稀疏模型的理论效率优势,在复杂的实际部署环境中能否稳定兑现,仍需大规模实践验证。其“前沿水平的智能体编码”能力,在应对真实、复杂的软件开发流水线时,能否保持稳定可靠,也是问号。用户评论虽积极,但几乎源于项目方自身,缺乏第三方开发者的真实反馈,生态热度与社区接纳度有待观察。
总而言之,这是一次极具策略性的发布。它试图用开源、高效、可商用的组合拳,在巨头林立的AI基础模型层撕开一道口子,吸引那些对成本敏感、渴望可控部署的开发者与企业。其成功与否,不取决于技术论文的指标,而取决于未来几个月内,有多少实际应用基于它构建起来。
一句话介绍:一款实时直播AI智能体花费真实金钱进行交易过程的平台,将抽象的“AI消费”概念具象化,解决了公众对AI作为经济主体行为缺乏直观认知的痛点。
Artificial Intelligence
Web3
Vercel Day
AI智能体
实时交易直播
行为可视化
数字经济
区块链数据
科技观察
透明度工具
新兴经济现象
用户评论摘要:用户肯定其创意与直观性,但提出具体问题:交易滚动过快难以看清;好奇AI消费是理性选择还是受环境引导;关心数据是否有趣不重复及消费模式分析。另有评论提及此前AI高价购物事件背景。
AI 锐评
这款产品与其说是一个工具,不如说是一面现象级的“镜子”。它的核心价值并非技术突破,而在于用极致的透明化手法,将“AI智能体即经济主体”这一前沿叙事从白皮书和行业讨论中剥离,粗暴地投射到公共视野中。直播流水般的交易数据,是对当前AI代理商业化浪潮最直白、甚至略带行为艺术式的注解。
产品巧妙地抓住了行业内外的一个认知鸿沟:专家谈论Agent的自主交易能力,而大众对此的感知仍停留在“抽象概念”。通过直播“花钱”这一最具普世理解力的行为,它完成了初步的市场教育。然而,其面临的质疑也恰恰点出了产品的深层困境:当新鲜感褪去,它究竟是一个可持续的观察窗口,还是一个短暂的噱头?用户提出的“滚动过快”、“是否重复”等问题,本质上是在拷问其长期内容价值。如果展示的仅是未经解析的数据流,其洞察深度将很快触及天花板。
真正的锋芒在于,它可能无意中成为了一个“审计工具”。将AI代理的每一次API调用、数据购买和计算支出置于公众凝视之下,这本身就对整个生态的合理性与效率提出了无声的质问。评论中关于“理性选择与环境引导”的讨论,已触及AI决策黑箱与伦理的敏感区。产品的未来,取决于它能否从“直播花钱”的猎奇,转向构建理解AI经济行为的分析框架,否则其命运恐将止步于一个精巧的科普演示。
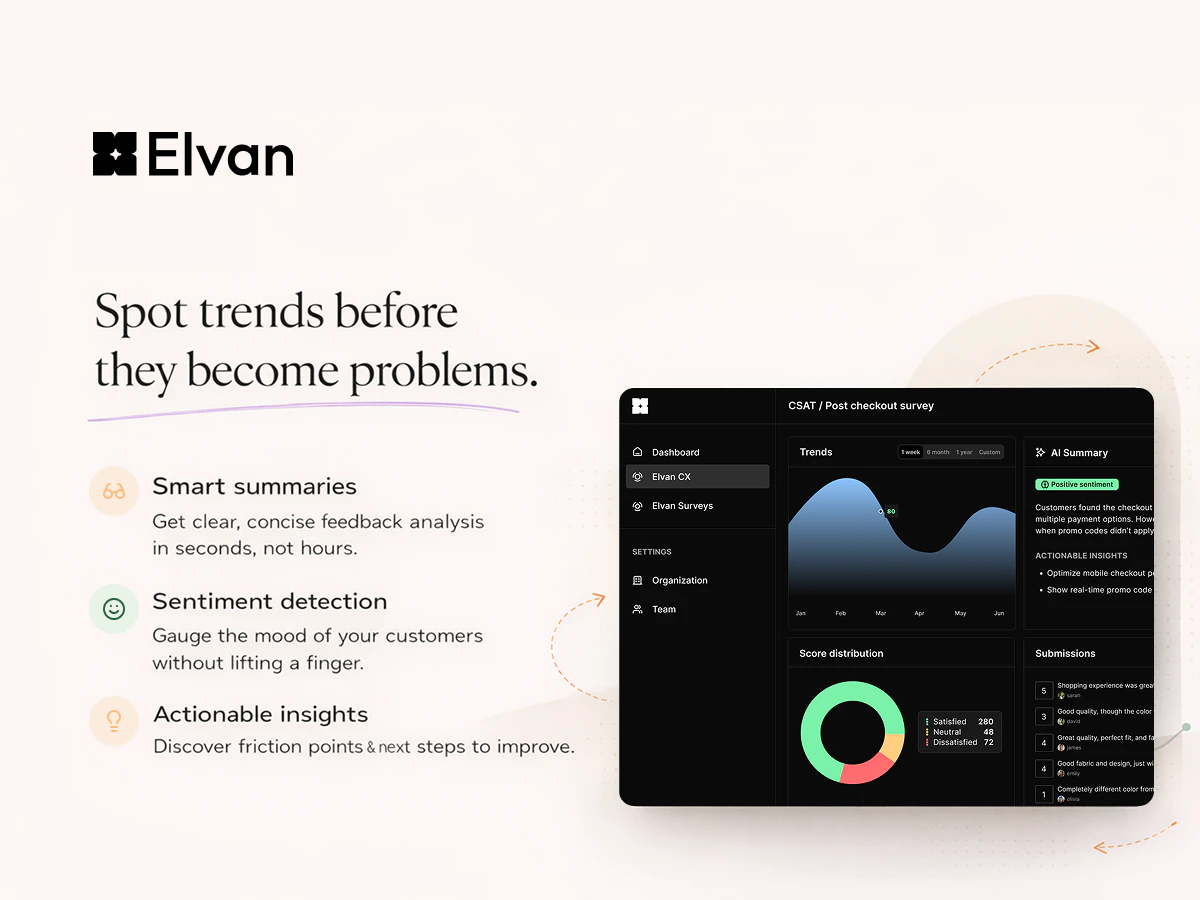
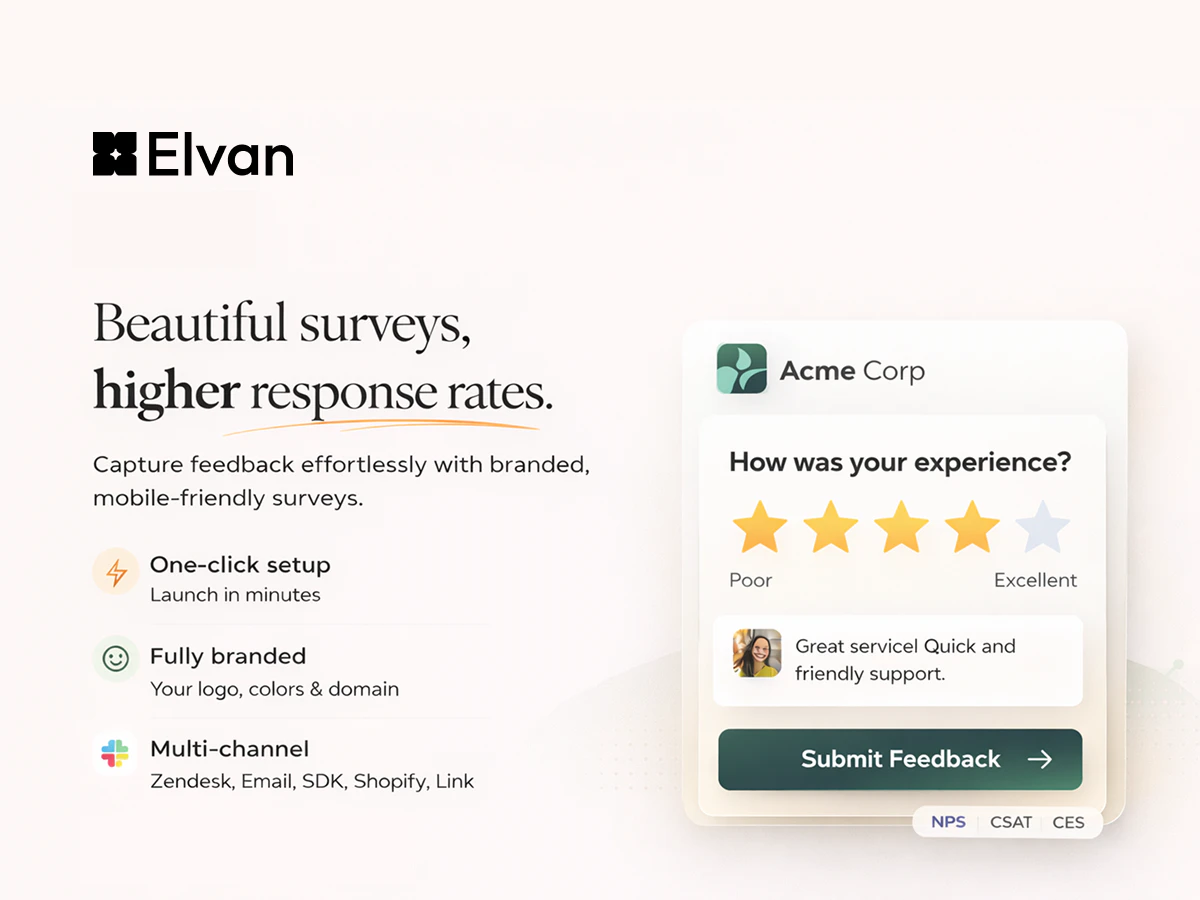
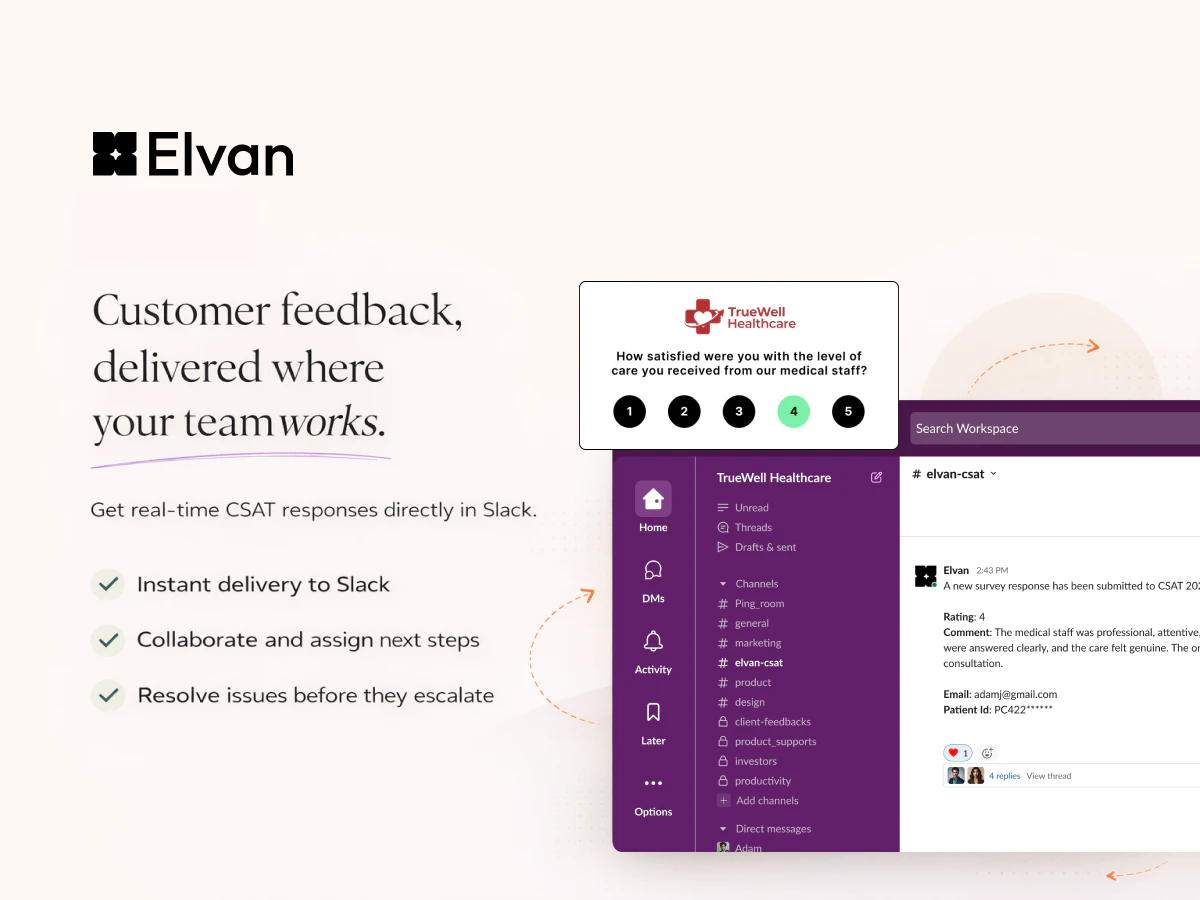
一句话介绍:Elvan是一款AI原生反馈平台,通过在用户旅程的关键触点自动触发调研并实时AI分析,将分散、滞后的客户反馈转化为可即时行动的清晰信号,解决了产品与客户成功团队难以利用反馈驱动决策的核心痛点。
Customer Success
SaaS
Vercel Day
客户反馈分析
AI驱动
SaaS
用户体验管理
实时洞察
产品决策
NPS/CSAT/CES
多渠道集成
自动化工作流
团队协同
用户评论摘要:用户关注点集中在产品实际集成深度、信号过滤机制、用户细分能力及小团队适用性。创始人回复确认了基于事件的触发、自定义属性实现细分、以及小规模可用性,并透露内置用户细分功能已在规划中。
AI 锐评
Elvan的叙事精准击中了“反馈废墟”这一经典企业困境——数据泛滥而洞察匮乏。其宣称的“下一代”并非空谈,核心在于构建了“信号层”的中间件逻辑:前端连接行为事件与多渠道触点,后端通过AI压缩原始文本为结构化洞察,并注入Slack等协作流。这试图将反馈从“事后报告”变为“实时业务触发器”。
然而,其真正的挑战与价值均隐含于细节。首先,“AI分析”的门槛在于训练数据的领域特异性与标签体系的质量,新平台能否超越通用情感分析,精准识别“流失信号”与“功能请求”,仍需验证。其次,评论中关于“集成深度”与“信号过载”的提问,直指其作为中间管道的关键:若仅实现浅层数据管道,而非深度业务规则嵌入(如基于Zendesk工单类型或客户分层的触发逻辑),则其“在正确时刻触发”的承诺将大打折扣。
产品定位显示出清醒的取舍:放弃复杂的自定义构建器,强调“开箱即用”。这使其明显区别于Qualtrics等重型平台,更贴近Amplitude的数据驱动产品文化,服务于渴望“产品分析般使用反馈”的敏捷团队。早期路线图回应也显示其采取务实策略——通过自定义属性提供灵活性,同时收集用例以规划原生功能。
总体而言,Elvan的价值主张不在于AI的技术炫技,而在于试图将反馈“工作流化”。其成败关键在于能否在保证“无代码”易用性的同时,通过深度、灵活的集成配置,真正打通从用户行为到团队行动的闭环。若成功,它将成为产品决策的感官神经;若流于表面,则只是另一个美观的数据看板。
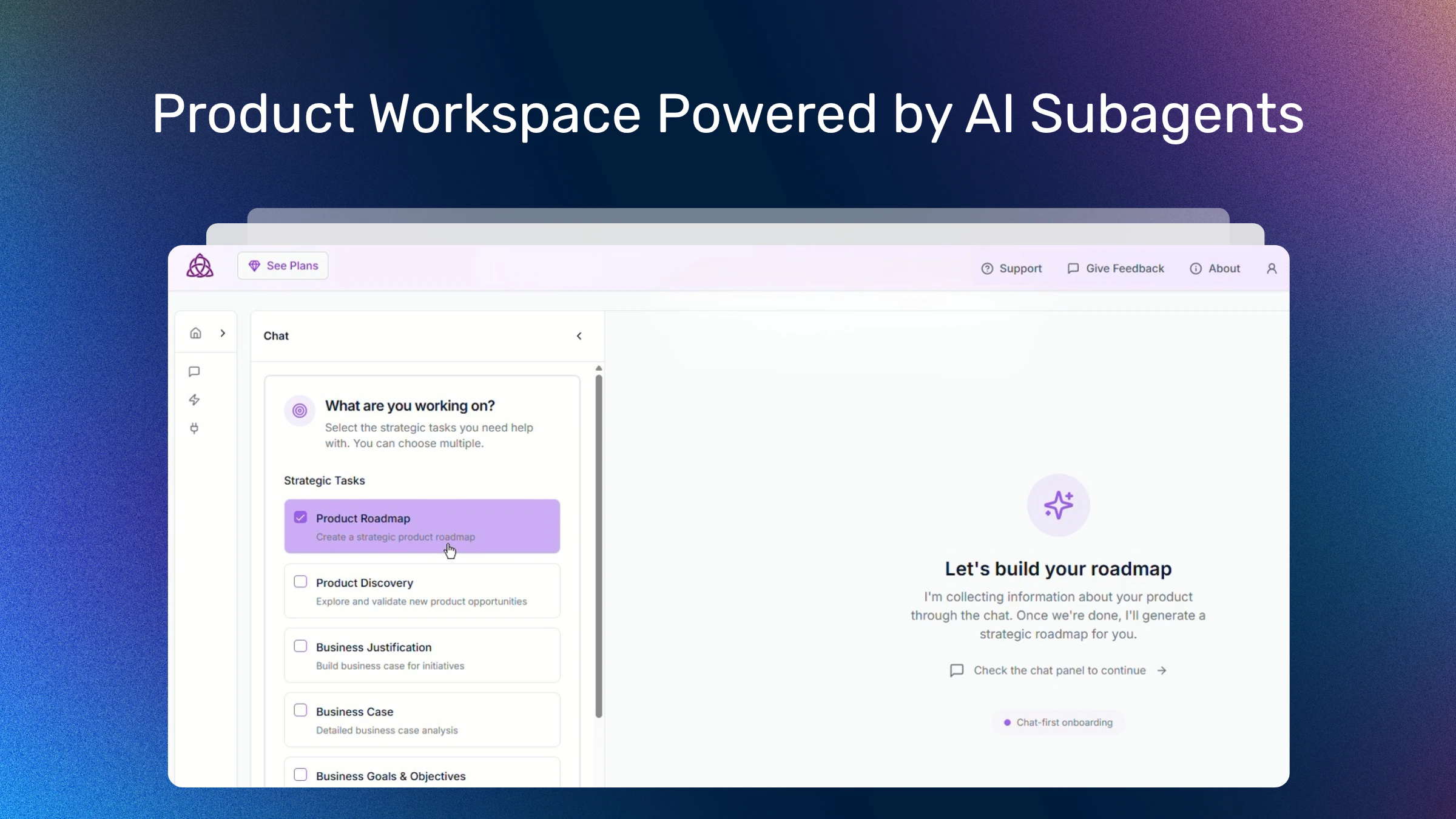
一句话介绍:Athena是一款AI驱动的产品工作空间,通过AI子代理理解产品架构与约束,在跨职能团队协作场景中,解决产品意图与工程现实脱节、决策基于猜测而非系统化分析的痛点。
Productivity
Artificial Intelligence
Vercel Day
AI产品管理
跨职能协作
产品发现自动化
智能工作空间
决策支持
工程约束可视化
SaaS工具
团队效率
用户评论摘要:用户反馈积极,认可其连接产品与工程的愿景。主要问题/建议包括:确认产品可用性(非仅等待列表)、询问对快速变化架构的适应性、探讨其核心建模维度的决策逻辑,以及关心与Jira等现有项目工具的集成情况。
AI 锐评
Athena的野心并非简单地“为产品流程添加AI”,而是试图成为产品系统的“数字孪生”中枢。其宣称的真正价值在于将“产品状态、架构、数据流”这三个通常割裂的认知层进行持续建模与关联,这直击了产品开发的核心顽疾:决策基于片面的上下文和失真的抽象。
从评论看,其“Claude Code for Teams”的标语引发了关于用户定位的巧妙讨论——它明确服务于非终端用户(产品经理),旨在将技术复杂性转化为可直观操作的界面。这一定位精准且危险。精准在于它瞄准了信息传递损耗最大的环节;危险在于,将动态、模糊的产品意图与严谨、复杂的系统架构进行实时对齐,其AI子代理的“理解”深度与准确性将面临极端考验。创始人回帖中提到,其建模维度源于“团队实际被卡住的地方”,这是一种务实的、问题驱动的产品哲学,但如何避免在复杂场景下陷入“过度建模”或“建模失真”,将是其能否从“有趣概念”进化为“必备基础设施”的关键。
产品目前获得的早期赞誉,更多源于市场对“打破产品-工程壁垒”这一长期痛点的强烈共鸣。其真正的试金石在于:当面对快速迭代、技术债沉重或文档缺失的真实系统时,Athena能否生成不仅“结构化”而且“高保真”的产品推理,从而真正取代而非增加团队的认知负荷。这是一场高难度的赌博,但方向值得深究。
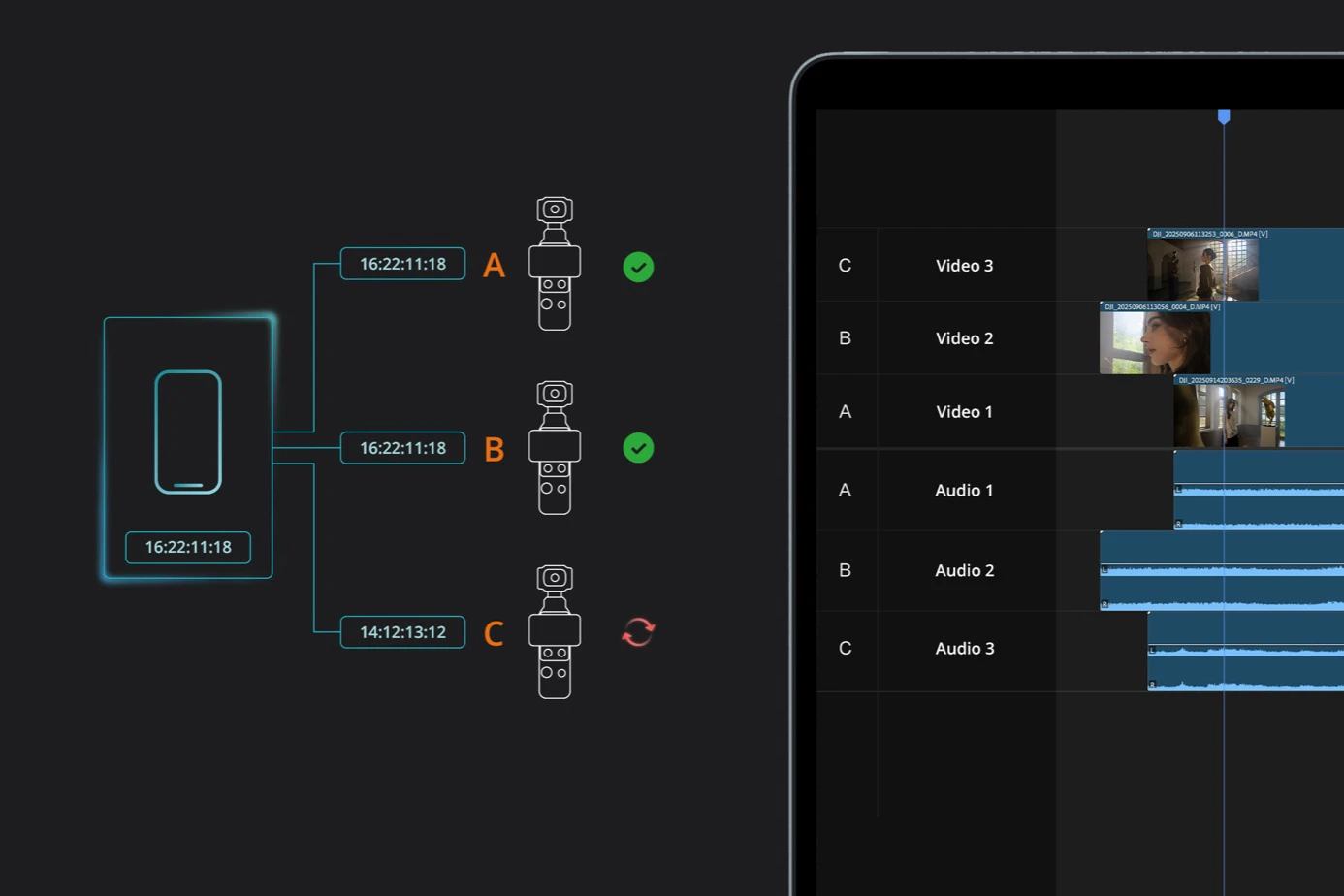
一句话介绍:DJI Osmo Pocket 4是一款集成了1英寸传感器和3轴云台的超便携相机,以口袋级体积提供了专业级的4K/240fps视频拍摄能力,解决了用户在移动和日常场景中,对高质量、稳定画面与便捷性难以兼得的痛点。
Hardware
Photography
口袋云台相机
消费级影像
Vlog设备
1英寸传感器
4K超高清
高速摄影
便携稳定器
专业工作流
随身拍摄
影像系统
用户评论摘要:用户反馈主要集中于两点:一是资深用户肯定产品从手机配件到独立影像系统的十年演进,认为供应链成熟是关键;二是潜在用户关心新品与上一代(Pocket 3)的体积对比,以及高规格拍摄下的散热与电池续航表现。
AI 锐评
DJI Osmo Pocket 4的发布,与其说是一次常规迭代,不如说是对“口袋相机”品类定义的又一次强势修订。它高举的1英寸CMOS、4K/240fps、14档动态范围等参数,本质上是在进行一场“规格降维打击”,将以往专业设备或大型相机才具备的成像能力,暴力塞进一个可日常携带的形态中。
产品的真正价值,并非在于参数本身,而在于其精准卡位了一个持续扩大的市场缝隙:日益增长的“专业消费者”(Prosumer)对创作工具“既要又要”的苛刻需求。他们需要媲美专业相机的画质与后期空间(10-bit D-Log),却又极度抗拒传统设备的体积、重量与操作复杂度。Osmo Pocket 4试图成为这个矛盾的终极解药——一个放进口袋的“影像系统”。
然而,光鲜参数背后,隐忧同样明显。首当其冲的就是热管理与功耗平衡。在如此紧凑的机身内实现4K/240fps的持续录制,是对散热设计的极限挑战。用户评论中关于发热和电池续航的疑问,直接命中了这类产品工程上的阿喀琉斯之踵。若无法在实际使用中妥善解决,所有的高规格都将沦为营销噱头。
其次,产品的成功高度依赖供应链的成熟度,正如高赞评论所指出的。这揭示了DJI的核心优势已从单纯的算法稳定,扩展到对核心硬件(电机、传感器)供应链的规模化整合与成本控制能力。这使得竞争对手难以在同等体积和价格下复制其性能,构筑了深厚的护城河。
最终,Osmo Pocket 4的价值在于它正推动一个趋势:影像创作的“去设备化”。当一台口袋设备提供的画质足以满足大多数社交媒体、甚至部分商业项目的需求时,用户选择设备的首要考量将从“性能是否足够好”,转向“体验是否足够无感与便捷”。它削弱了传统相机作为唯一“正经”创作工具的心理地位,让高质量影像捕捉真正融入生活流。它的对手可能不再是其他运动相机或云台,而是用户“懒得带大相机”的惰性。能否征服这一点,才是其市场成败的关键。
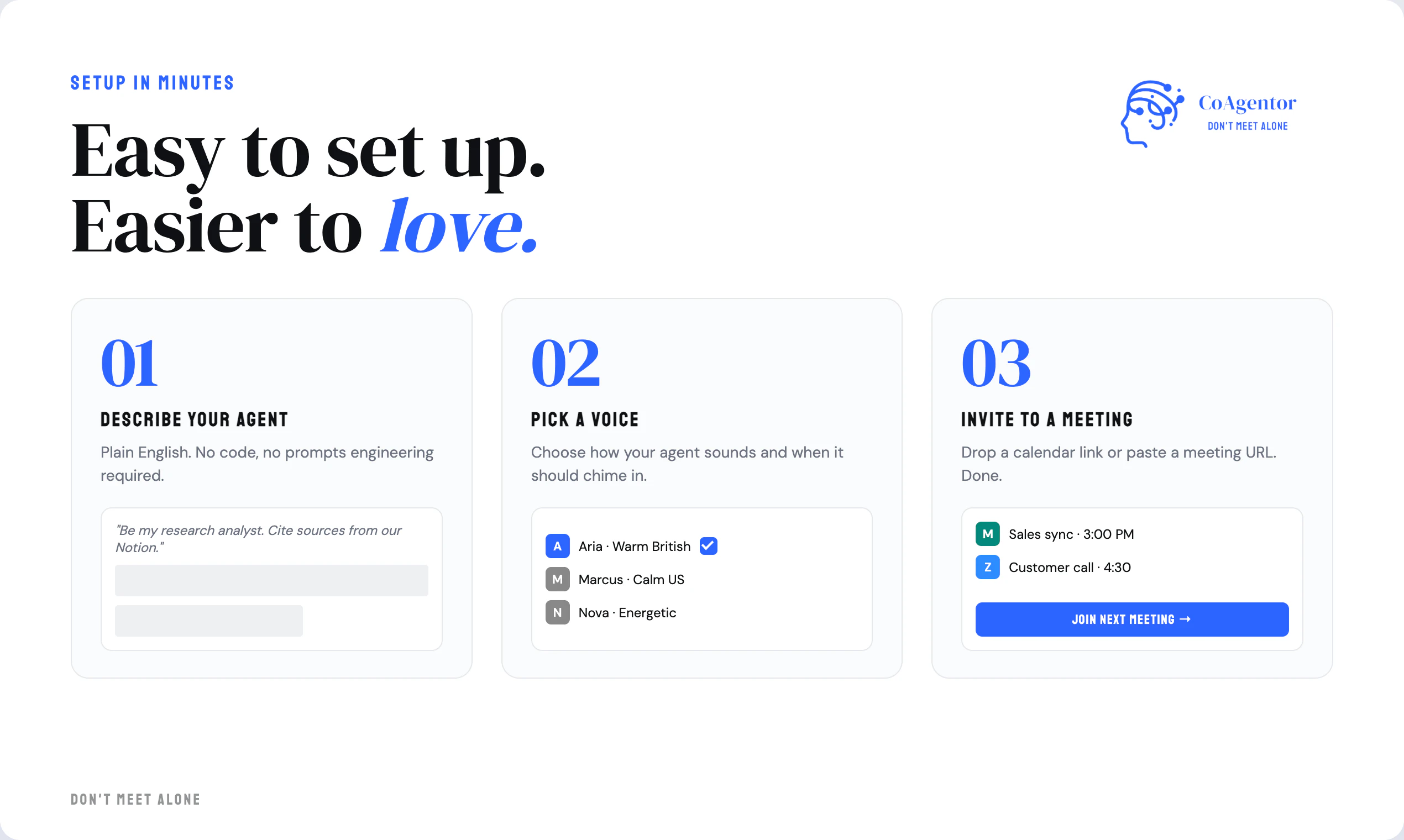
一句话介绍:一款能让AI智能体实时参与视频会议、在会议中主动发言回答问题或提供数据的工具,解决了会议因信息缺失而效率低下、无法当场决策的痛点。
Meetings
Artificial Intelligence
Vercel Day
AI会议助手
实时语音交互
智能体
会议效率
企业协作
SaaS
语音AI
知识库集成
自动化流程
生产力工具
用户评论摘要:用户普遍认可从“被动记录”到“主动参与”的理念转变,并赞赏其可配置性。主要问题聚焦于:AI语音的自然度与身份标识、多智能体同时发言的冲突管理、数据安全与合规认证(如SOC2、GDPR),以及AI与AI对话场景下的交互逻辑调优。
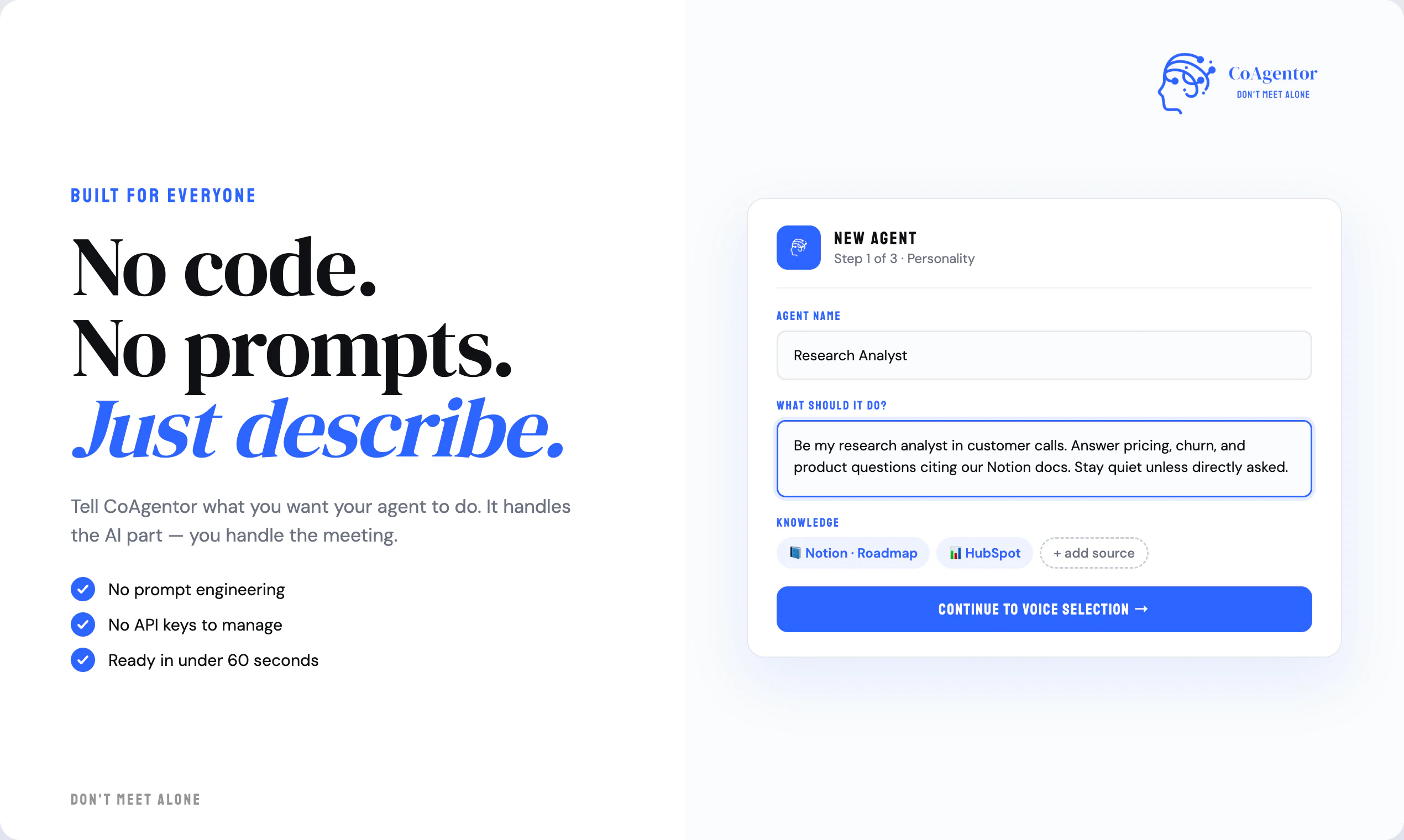
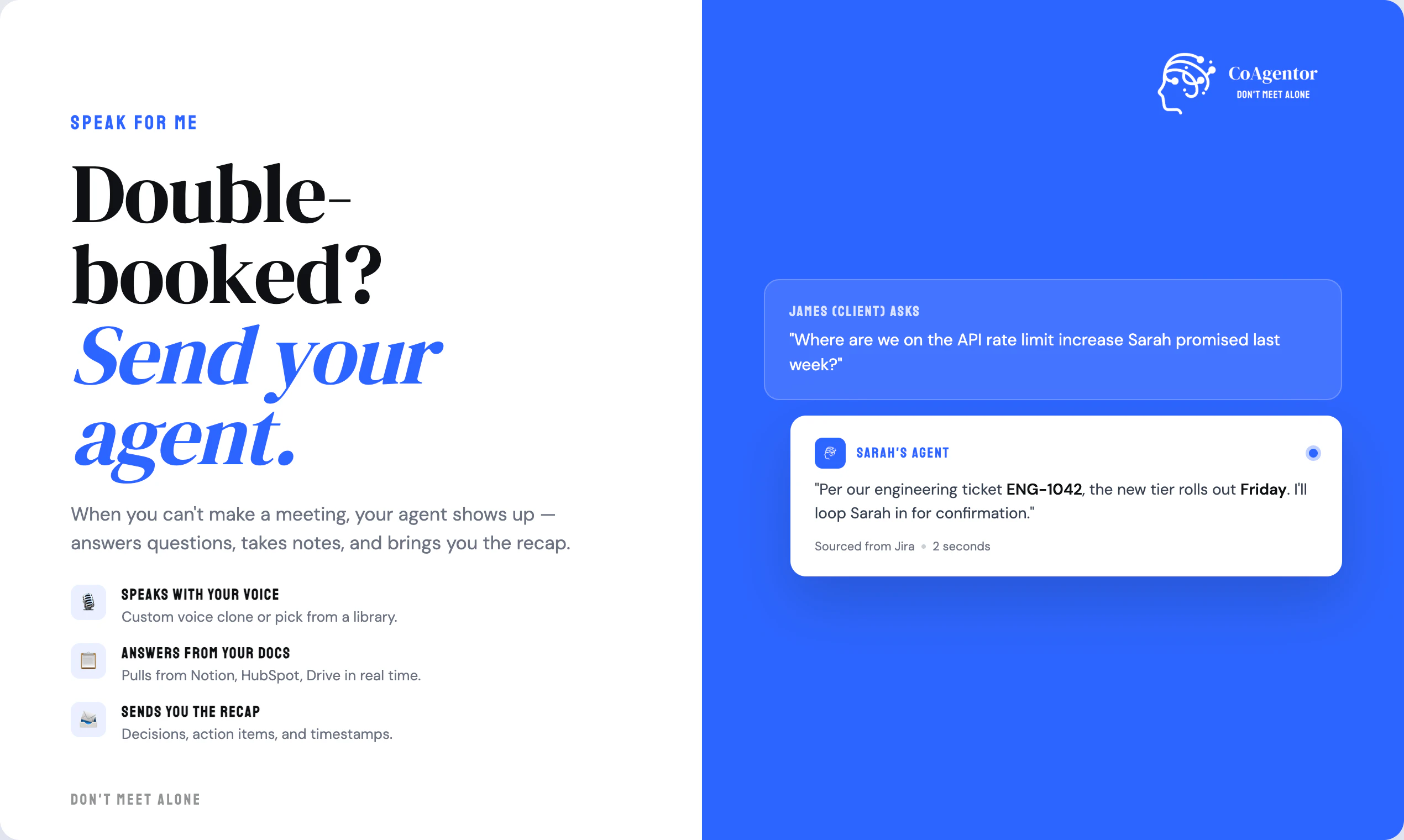
AI 锐评
CoAgentor的野心,远不止于做一个更聪明的会议记录员。它试图将会议从“信息讨论会”升级为“决策执行会”,其核心价值在于将静态的知识库转化为动态的、可实时调用的“会议参与者”。这戳中了一个真实且普遍的痛点:大量会议因关键数据或背景信息的缺失而陷入空转,形成“会而不议,议而不决”的恶性循环。
然而,其面临的挑战与机遇同样巨大。从产品层面看,其宣称的“自然打断”与“实时响应”在复杂的人类对话流中极易翻车,如何精准定义触发规则、避免无效或尴尬的插话,是用户体验的生死线。多智能体间的发言优先级与冲突解决机制,评论中已暴露出其仍处于“进行时”。从技术伦理与合规看,让AI以拟人化语音介入人类对话,必须解决透明性问题(与会者是否知情),并背负极高的数据安全与隐私保护责任。创始人坦言目前尚未获取SOC2等认证,这将成为其进军大型企业市场的硬性门槛。
更值得深思的是其长期影响:它可能真正提升会议效率,也可能将人类惰性合理化,把理解与决策的责任过度让渡给AI。它提供的“专家在场”幻觉,是否会让会议准备变得更加随意?CoAgentor的成功,不仅取决于技术实现的精妙,更取决于它能否在提升效率与保持人类对话主导权之间,找到那个微妙的平衡点。目前来看,它迈出了颠覆性的一步,但通往“可靠会议伙伴”之路,仍布满荆棘。
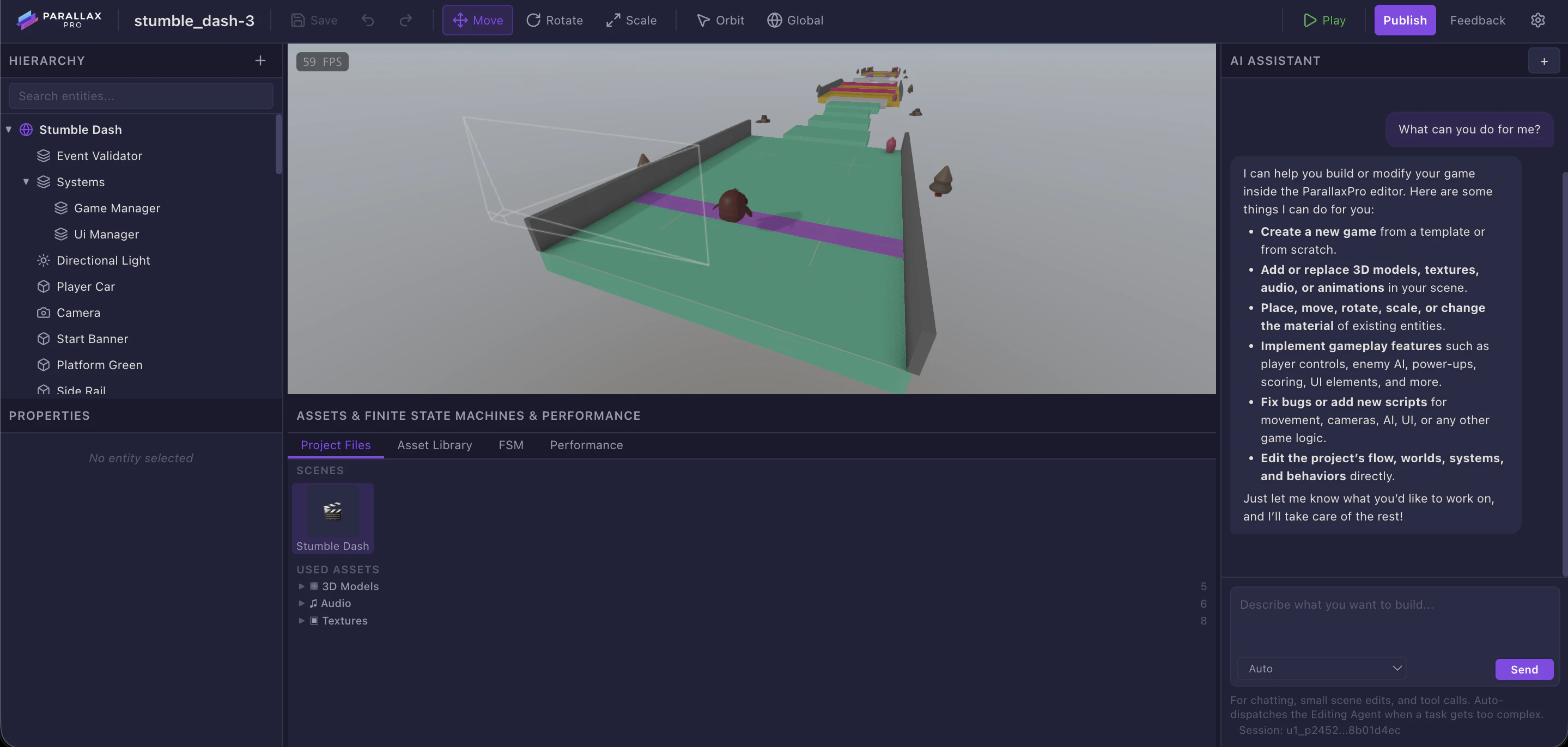
一句话介绍:ParallaxPro是一款将AI助手与基于浏览器的3D游戏引擎深度集成的工具,通过自然语言提示即可快速生成、修改并发布可运行的游戏,解决了AI大模型因缺乏底层引擎支持而无法构建真正可玩、可扩展游戏的痛点。
GitHub
Games
No-Code
AI游戏生成
低代码游戏开发
浏览器3D引擎
WebGPU
开源游戏工具
物理引擎
实体组件系统
快速原型
一键发布
AI辅助开发
用户评论摘要:评论主要为开发者自述,核心观点是LLM缺乏游戏引擎支持时只能生成脆弱代码,而ParallaxPro通过提供完整引擎解决了此问题。强调其开源、免版税、支持自备LLM等优势,并邀请用户测试反馈。
AI 锐评
ParallaxPro的宣称直击当前“AI生成游戏”热潮的泡沫核心——它识别出LLM在游戏创作中的根本性短板:即脱离专业引擎后,其生成的代码不过是物理、渲染等核心系统的简陋模拟,无法构成可维护、可扩展的真实产品。其真正价值并非简单的“提示词生成游戏”,而是构建了一个**AI可理解、可操作的标准化游戏生产环境**。
产品将AI定位为“引擎之上的脚本工与关卡设计师”,而非全知全能的创造者,这是务实且具有架构远见的选择。通过提供内置WebGPU渲染、Rapier物理、ECS架构及海量已索引资产,它实质上是为LLM装备了一套高精度的“手术刀”与“材料库”,让AI能在预设的、工业级的框架内进行精准创作,从而将生成内容的范围从“不可靠的玩具代码”收敛到“符合工程规范的游戏原型”。
其完全开源的策略是一步险棋,也是高招。它放弃了传统引擎的许可费商业模式,转而将信任与生态构建押注于社区。这降低了开发者的接入与定制门槛,但也将商业化的难题后置。产品的成败,将取决于其开源引擎本身的技术吸引力,以及能否形成围绕“AI提示-引擎实现”的工作流标准。
风险同样明显:其一,它对用户仍有一定技术认知要求,“自带LLM”选项看似开放,实则设定了门槛;其二,生成游戏的复杂性与可玩性上限,高度依赖于其引擎本身的能力与资产库规模,AI目前更多是加速而非创造范式革命;其三,如何从“快速原型”工具走向“可商业化成品”的生产管线,仍有巨大鸿沟需要跨越。
总而言之,ParallaxPro不是又一个炫技的AI玩具,而是一次将AI生产力严肃接入专业领域的工程化尝试。它若成功,验证的将是“AI+专业工具链”的深度集成模式,而非AI的凭空创造神话。
一句话介绍:Macaly是一款AI智能体,能通过自然语言对话直接交付包含数据库、认证、托管等完整生产级网站和应用,解决了非技术背景创业者或团队快速验证想法和构建产品的开发痛点。
Website Builder
Vibe coding
Vercel Day
AI应用开发
无代码平台
智能体
全栈交付
网站生成
快速原型
生产就绪
自动化开发
聊天构建
SaaS工具
用户评论摘要:官方评论重点展示了产品能构建从CRM到内部仪表盘等多样化的真实生产应用。用户主要关注两个问题:一是如何为个体创业者处理Stripe支付等复杂自定义集成;二是开发者寻求合作机会。有效反馈集中在复杂场景的可靠性上。
AI 锐评
Macaly 4.0宣称“从聊天交付完整网站和应用”,其野心远超市面上常见的着陆页生成器或低代码玩具。它直指一个核心矛盾:创意与实现之间巨大的开发资源鸿沟。产品将自身定位为“AI智能体”而非工具,暗示其承担项目管理者与全栈工程师的复合角色,承诺打包交付后端基础设施,这是其关键价值主张。
然而,其光鲜案例背后潜藏着深层挑战。首先,“完整生产级”是一个危险的高承诺。评论中关于“自定义集成不崩溃”的提问一针见血,触及了此类平台的阿喀琉斯之踵:能否处理复杂、非标准的业务逻辑与边缘情况?当前AI在理解模糊需求和保障系统稳定性方面仍有局限。其次,它试图抽象掉所有技术细节,但这可能将用户锁在一个更复杂的“黑箱”之中——当需求超出模板范围时,调试和定制的成本可能极高。
它的真正价值或许不在于取代所有开发,而在于成为“超级原型机”和特定垂直领域(如标准信息管理系统、营销网站)的解决方案工厂。对于需求高度匹配其能力的用户,它是生产力的革命;对于寻求高度定制化的项目,它可能只是一个华丽的起点。其成功与否,将取决于其智能体在长尾、复杂场景下的实际鲁棒性,以及能否构建起真正的开发者生态来填补其“全栈”承诺之外的空白。目前看来,它是一个极具吸引力的价值宣言,但距离普适性的“应用终结者”尚有征程。
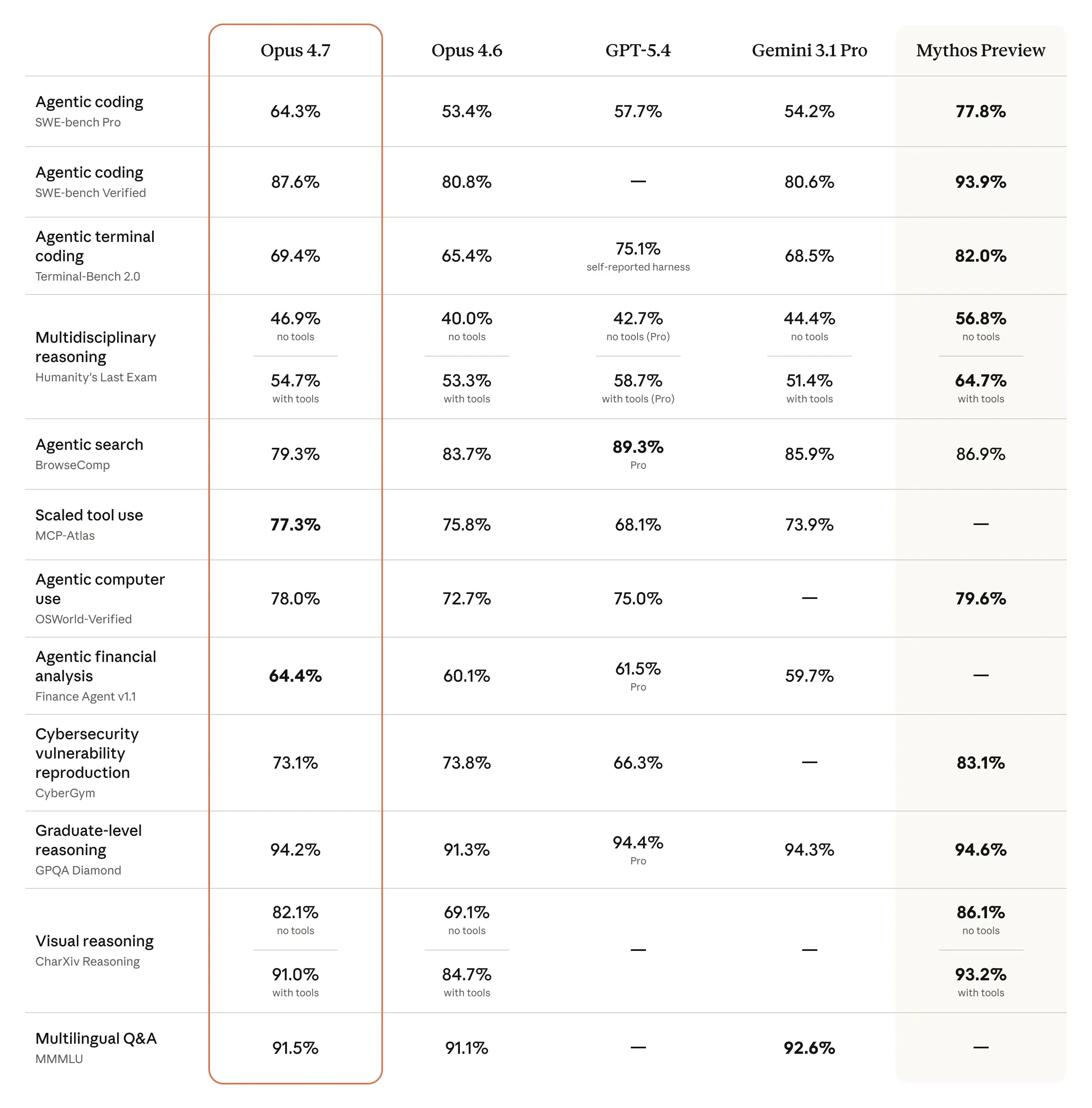
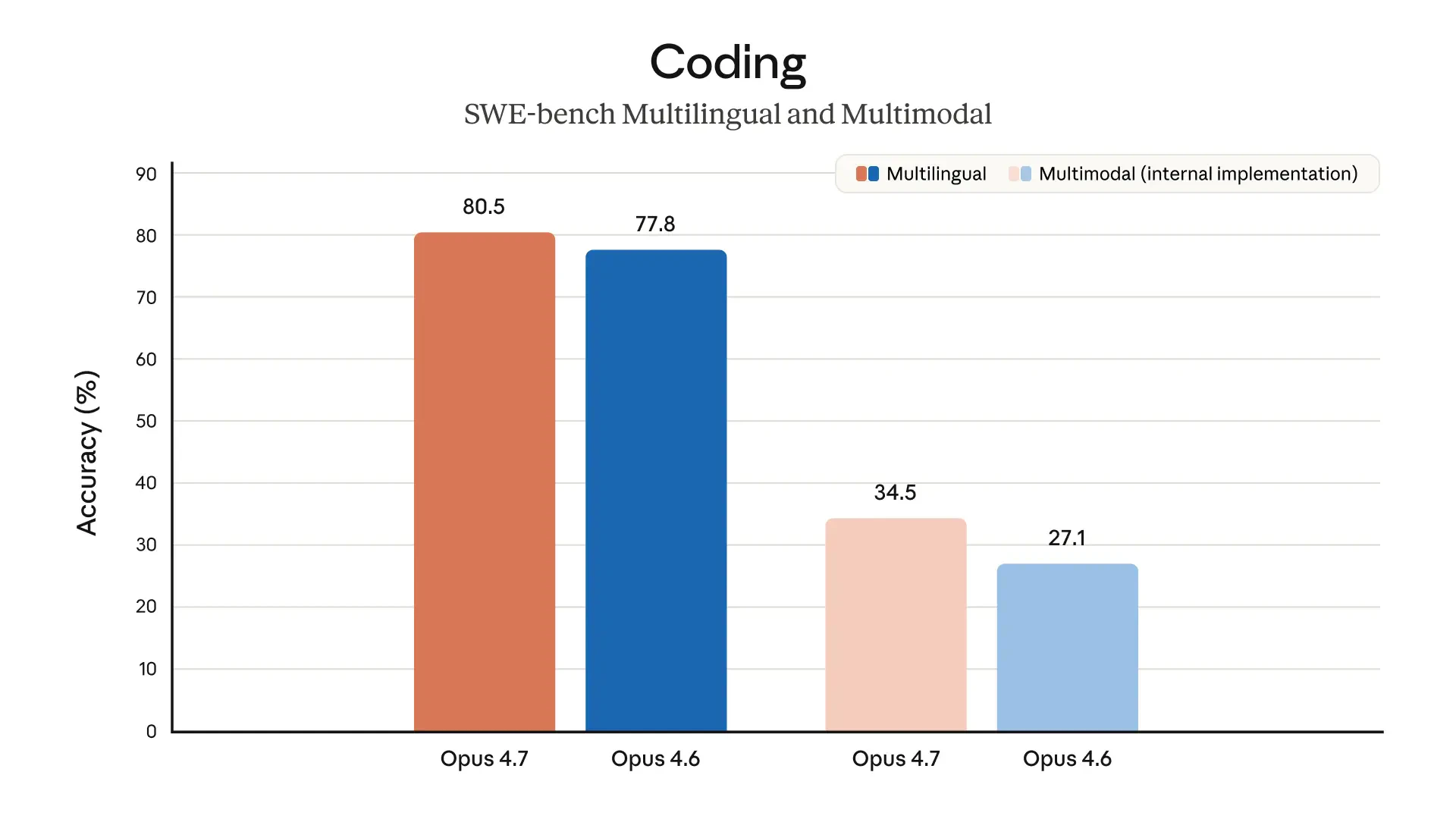
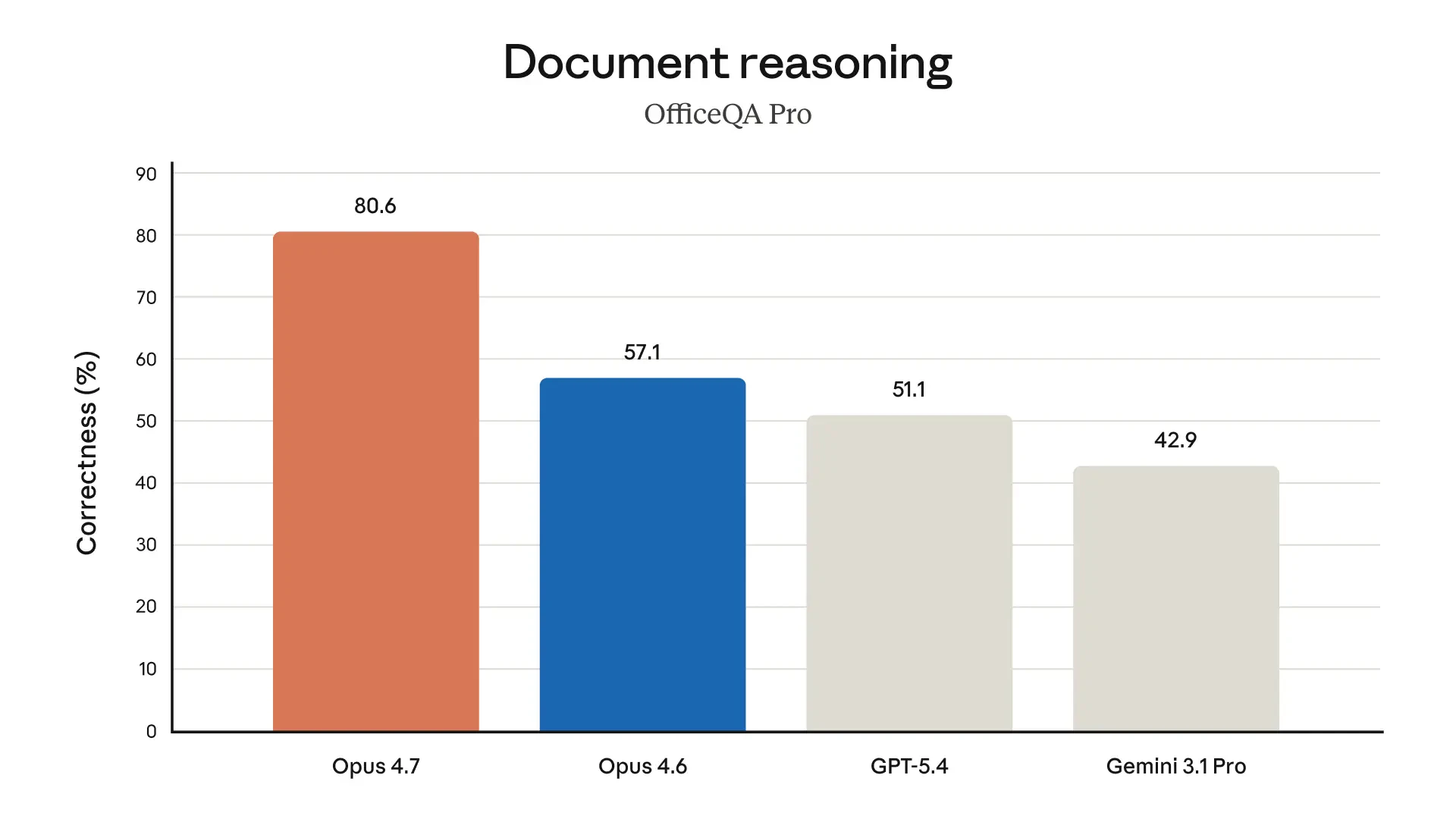
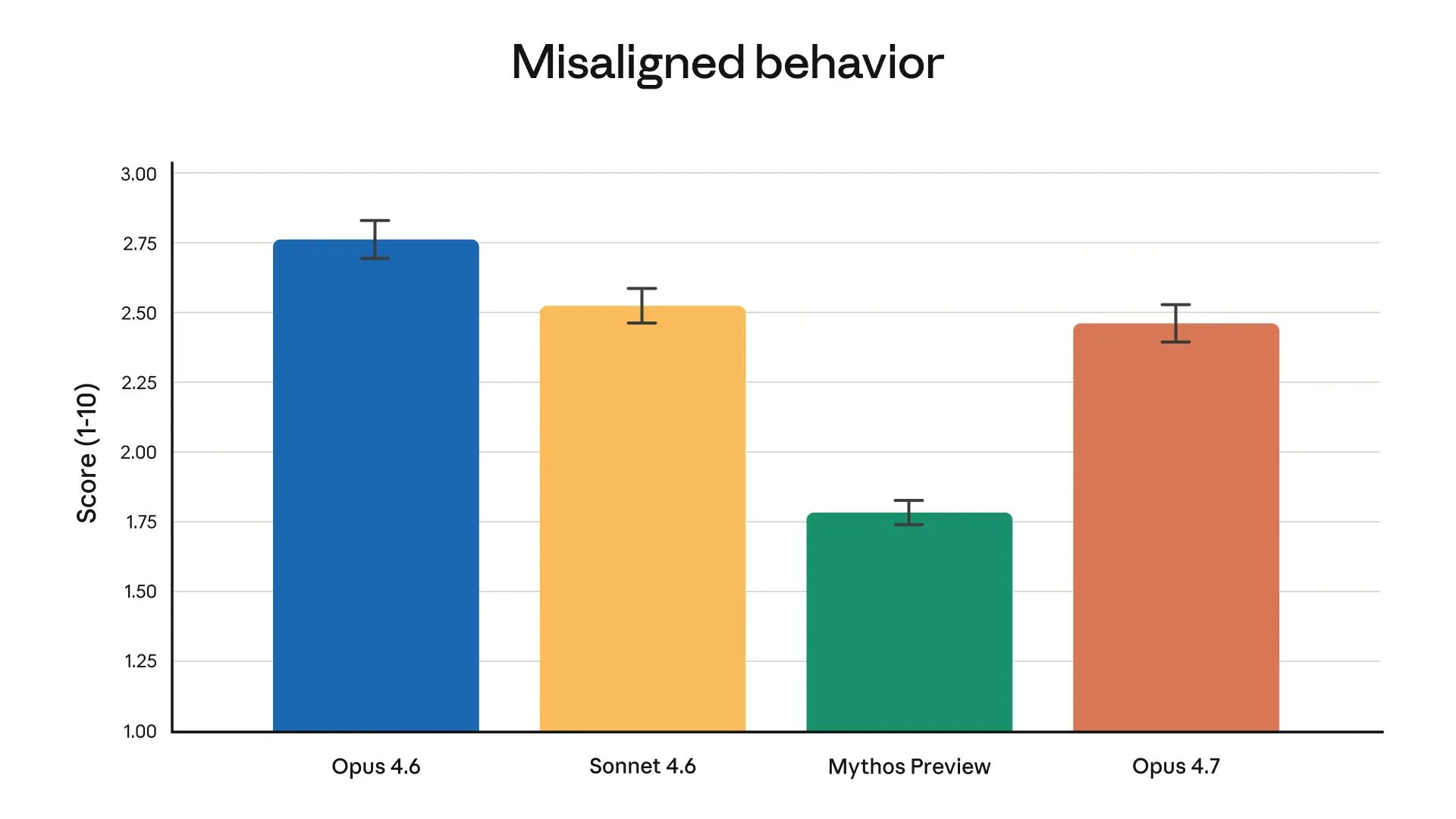
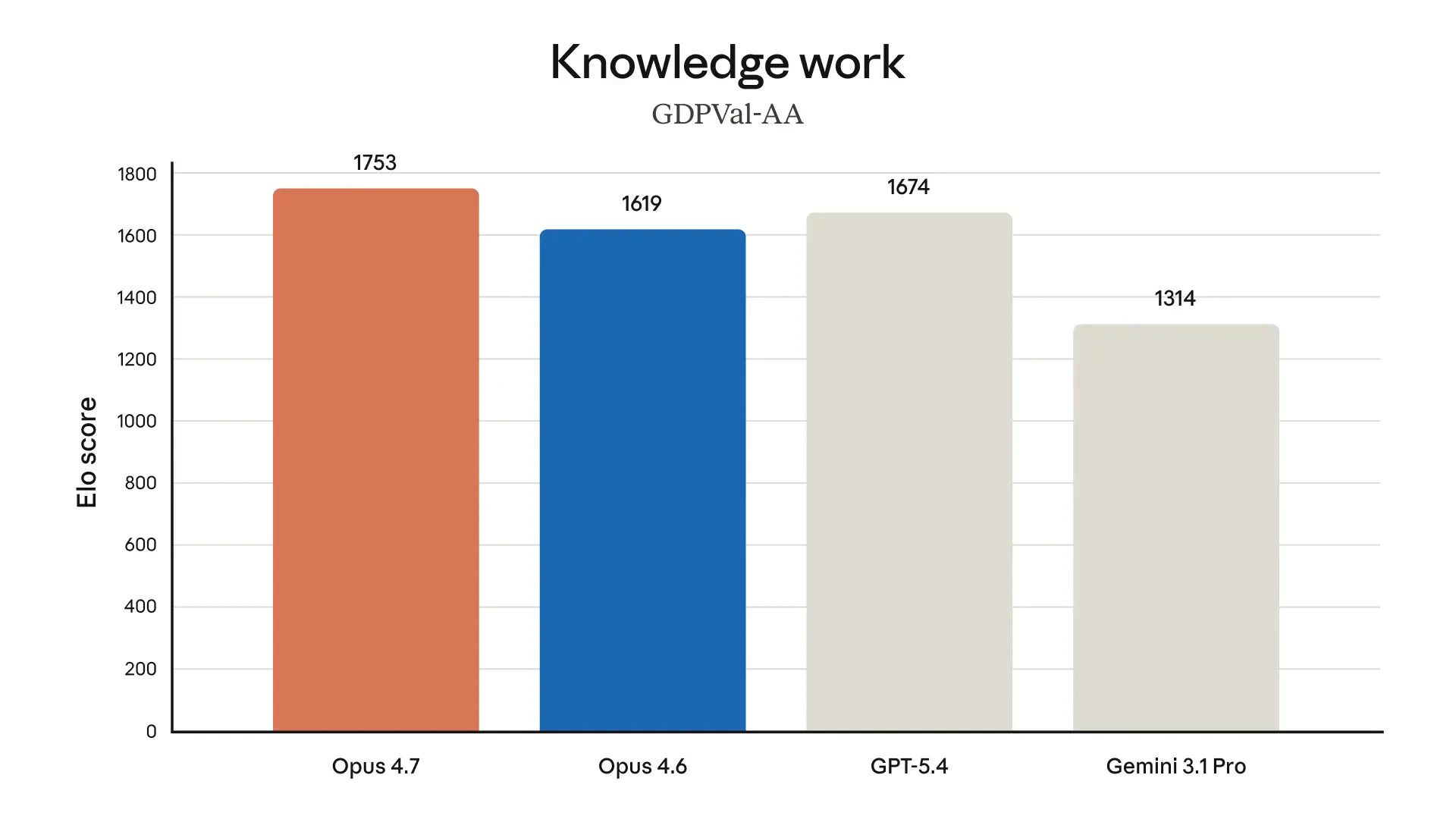
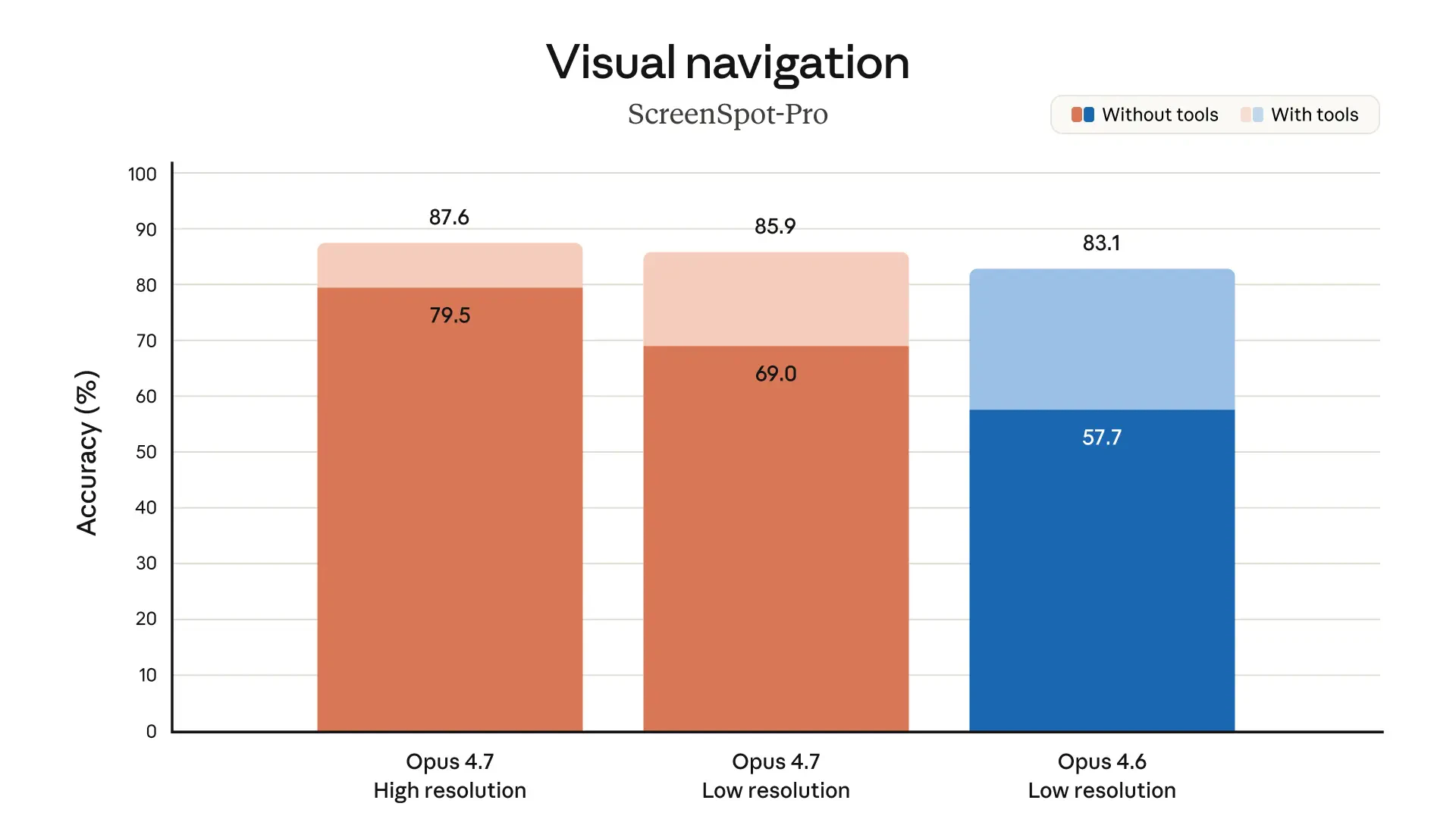
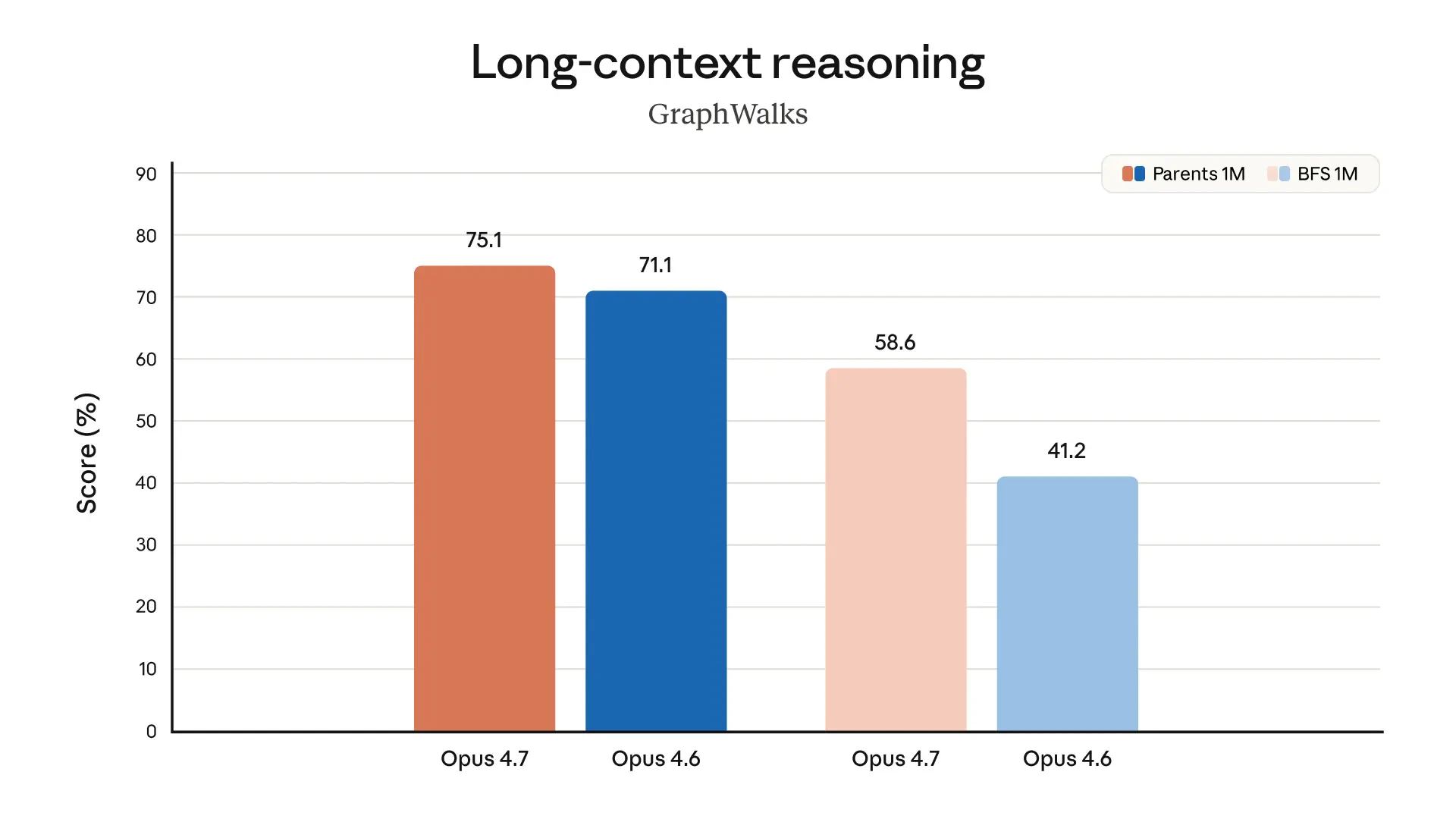
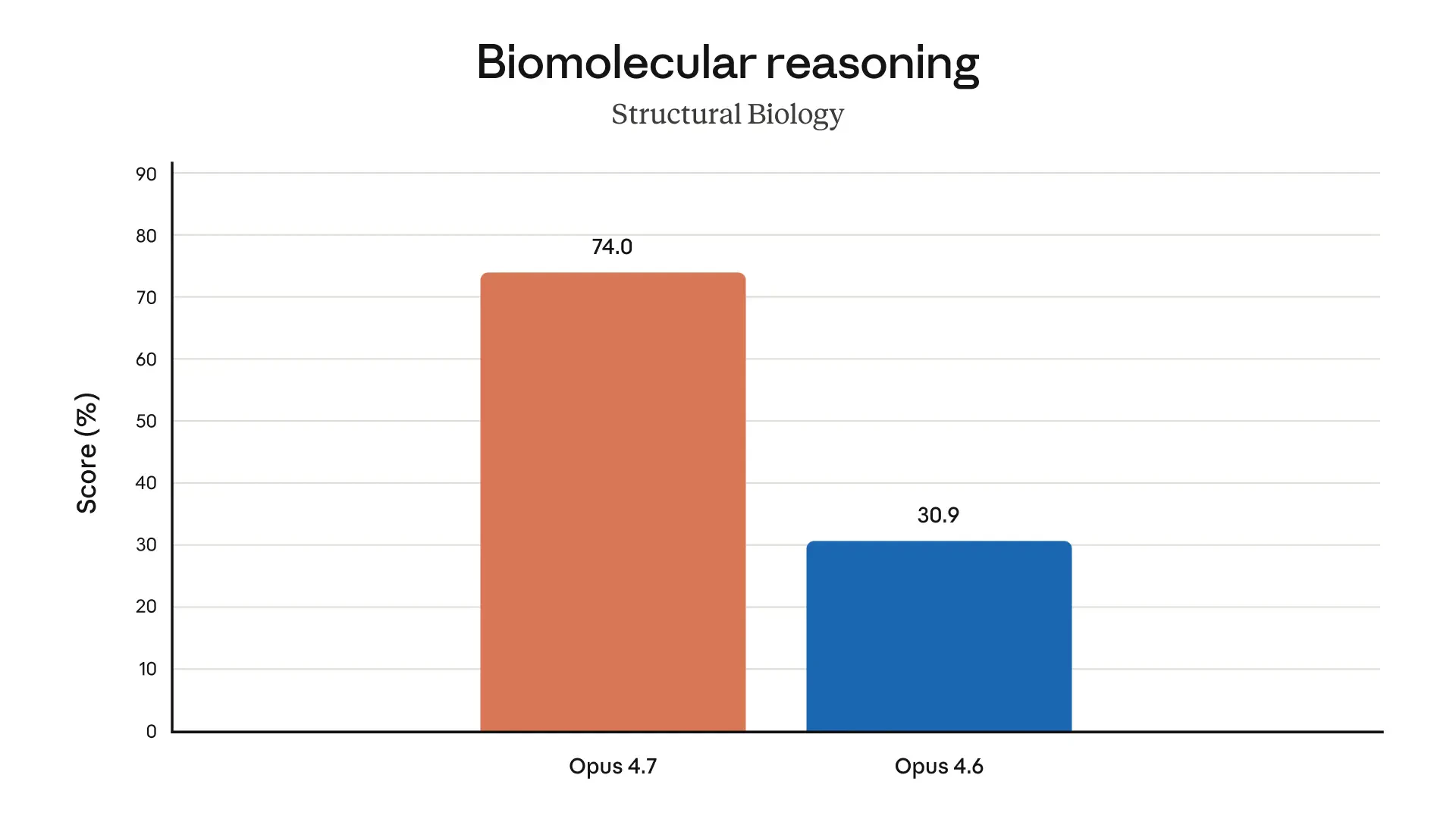
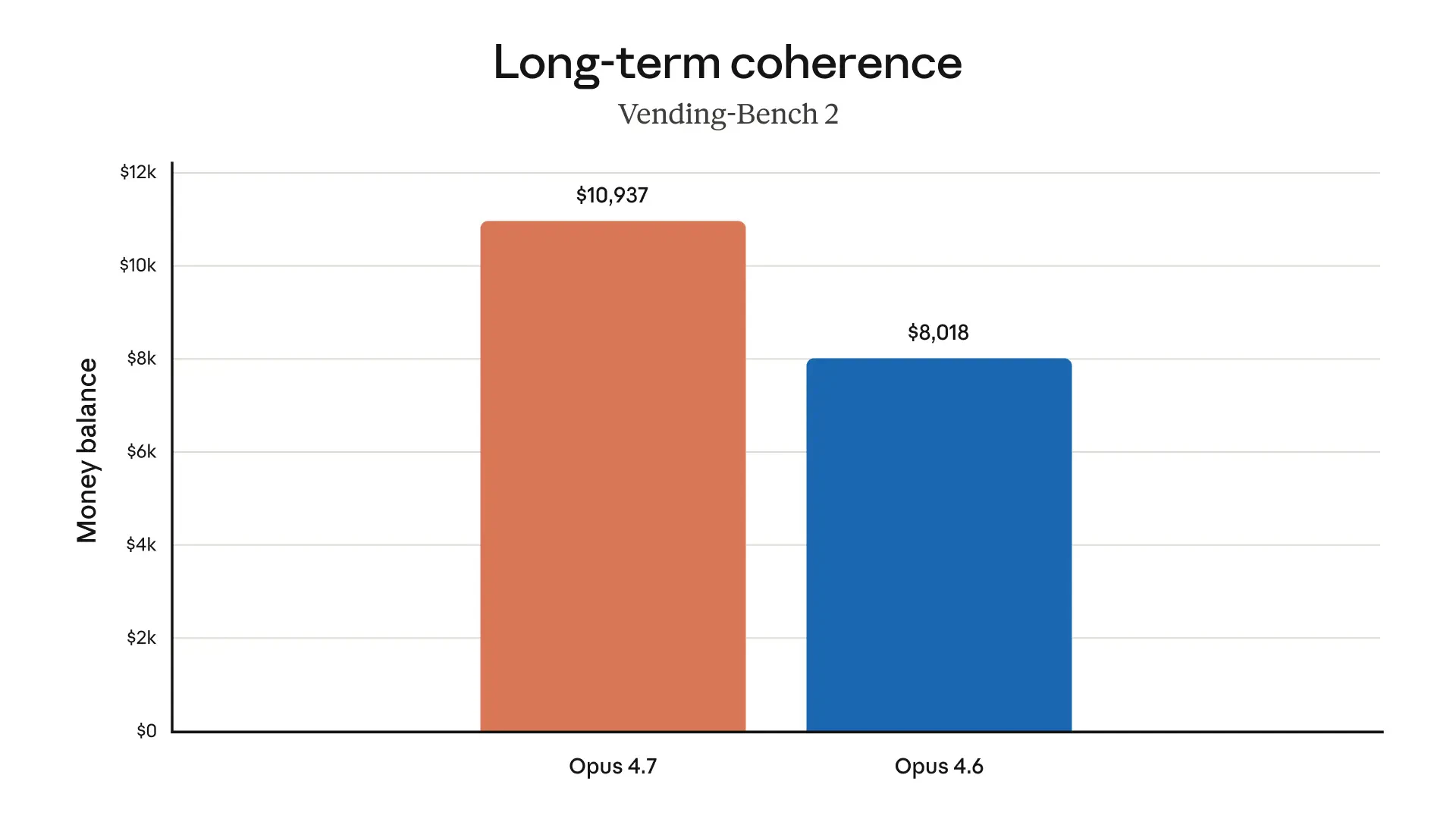
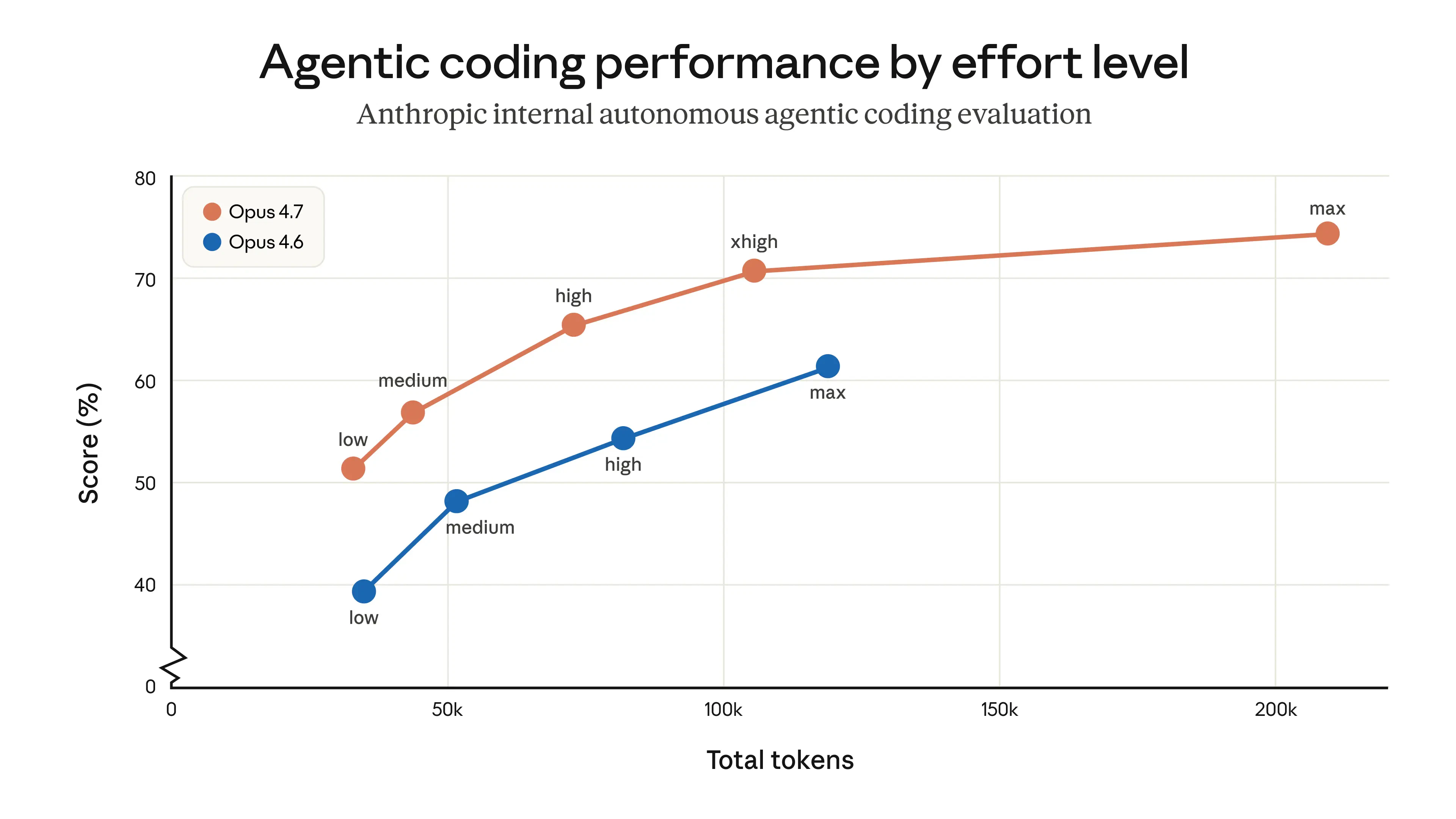






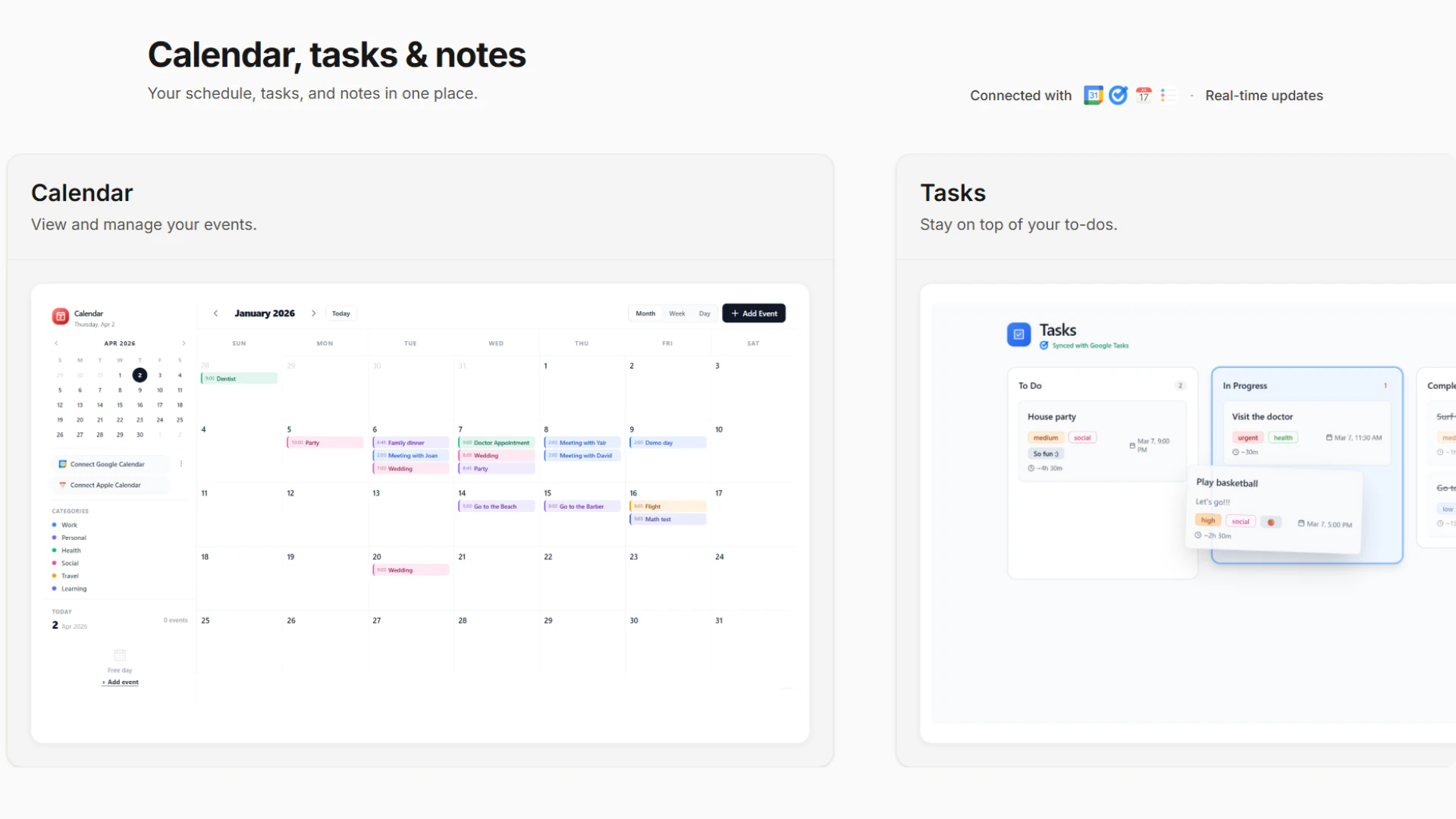
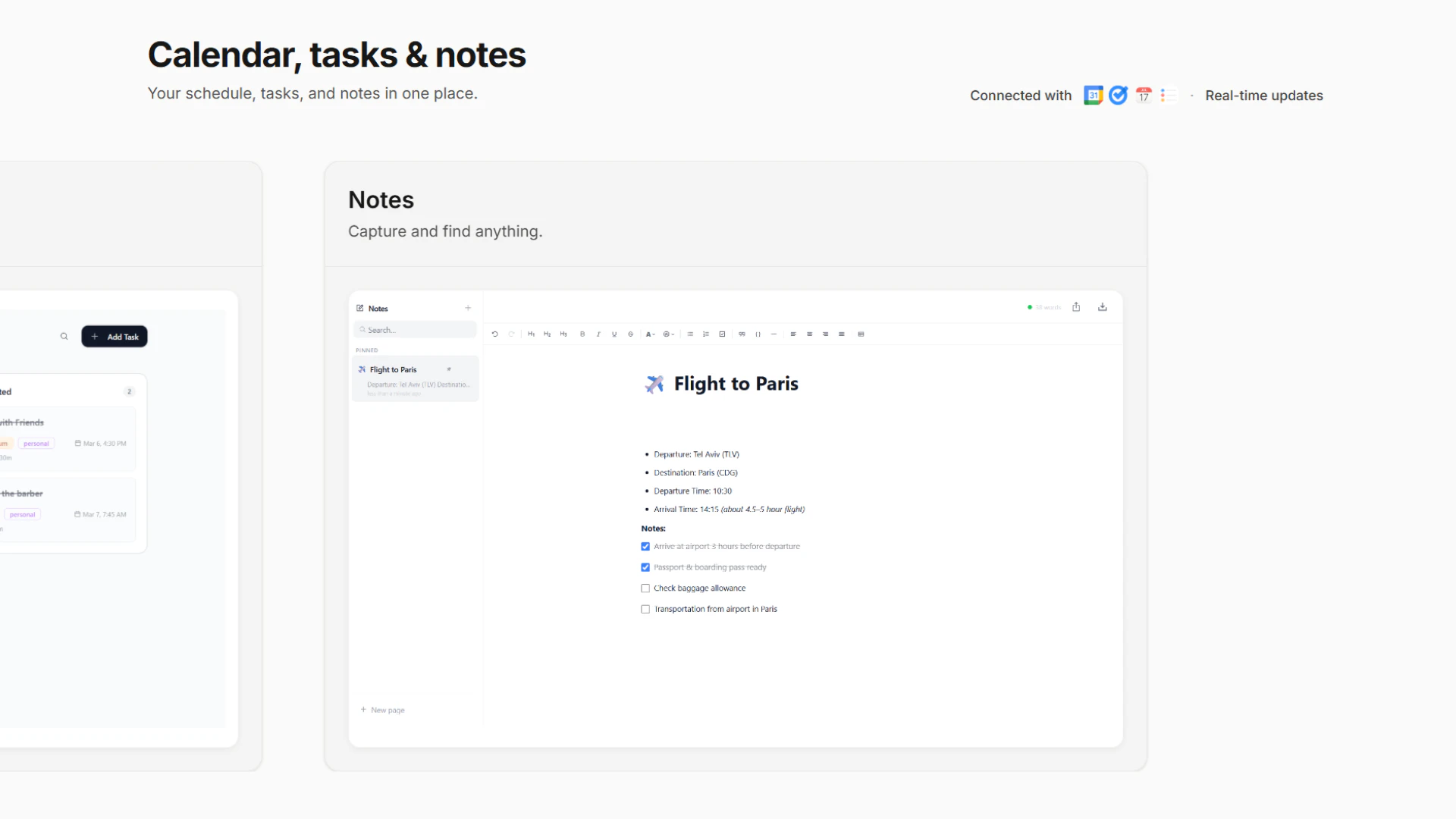






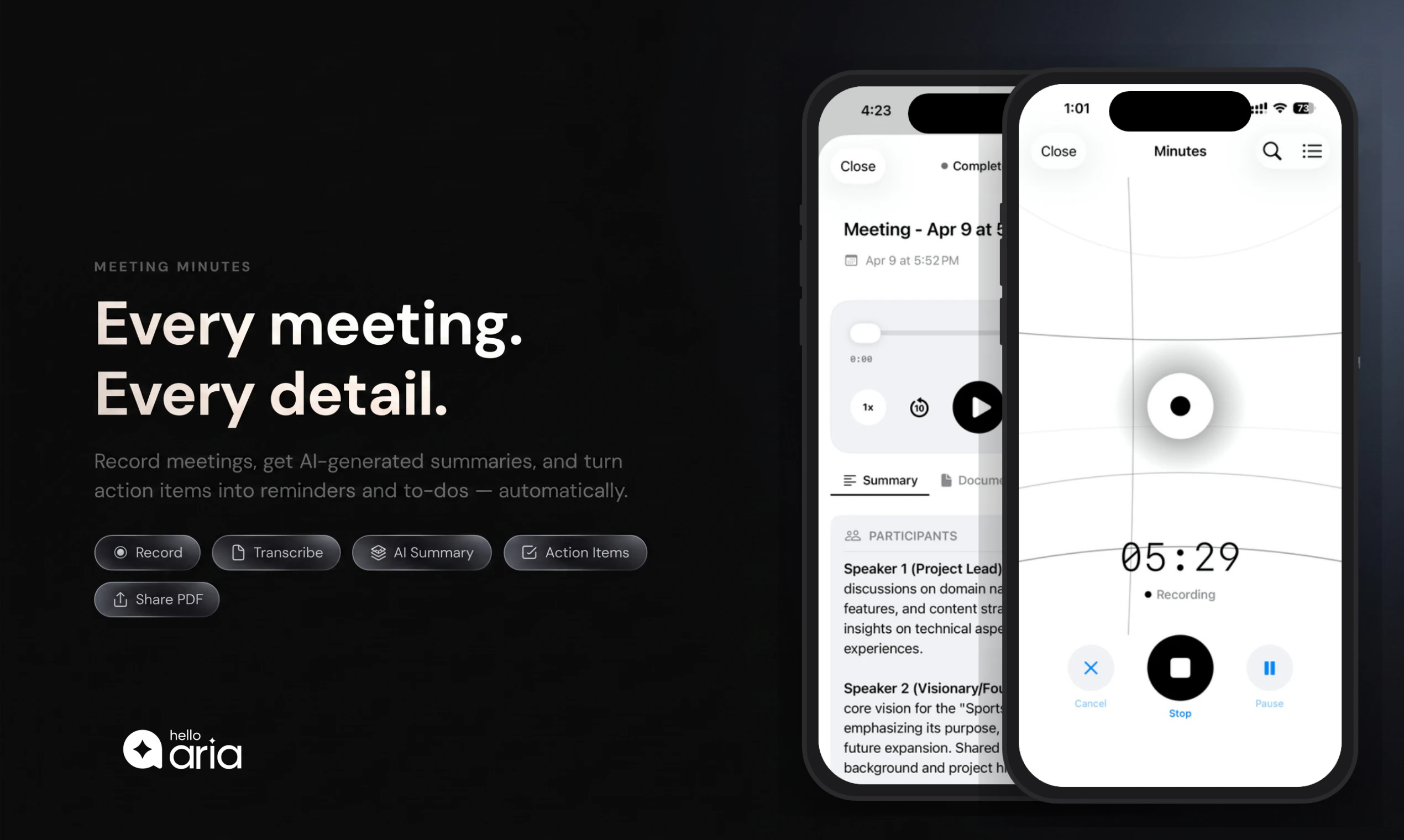









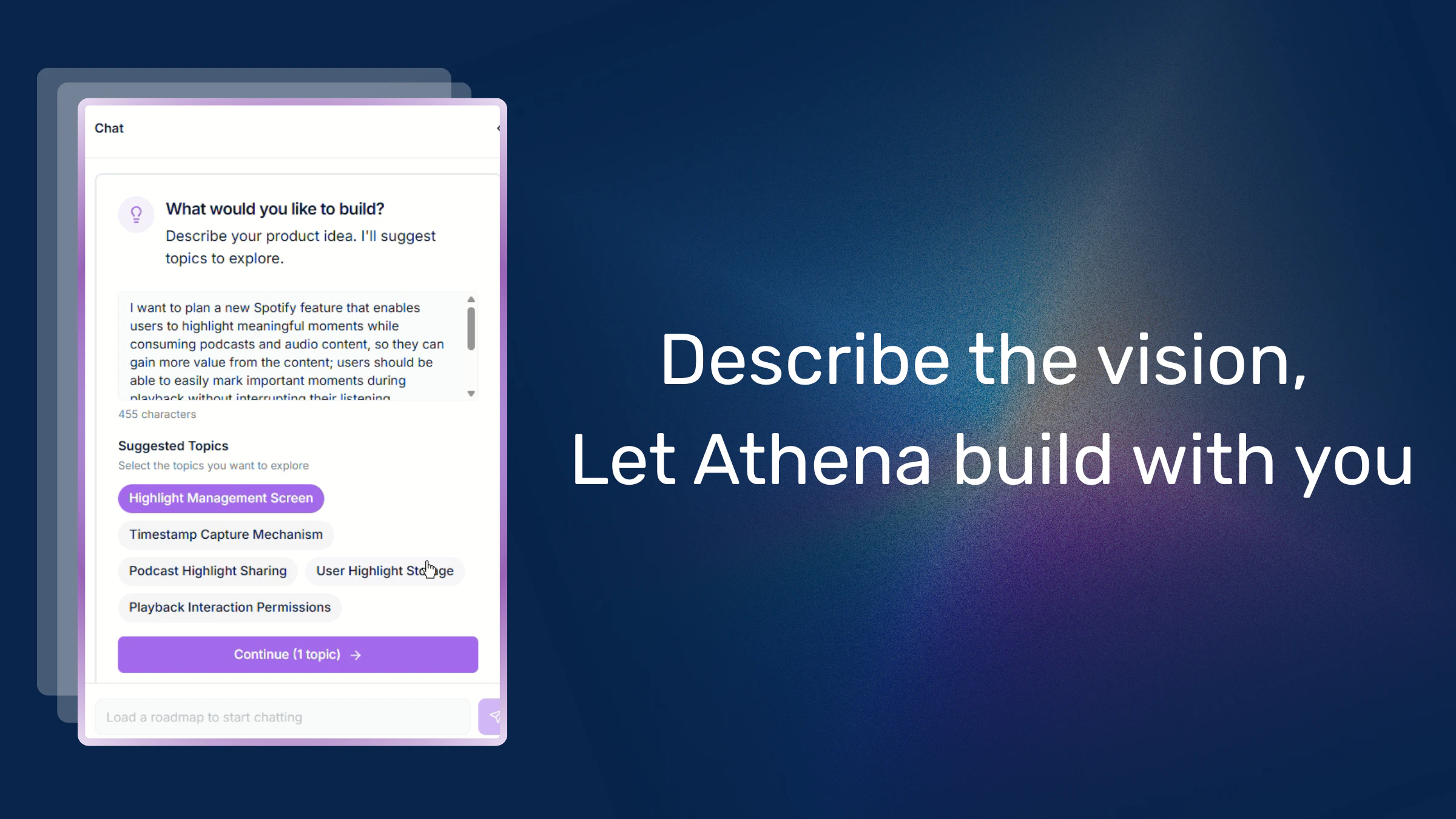























Claude Opus 4.7 looks like a serious leap forward for AI-powered development and knowledge work. It tackles a key problem: handling complex, long-running tasks that previously required constant human supervision.
With stronger instruction-following, better multimodal vision, and improved reasoning consistency, it enables users to confidently delegate harder workflows.
Why it stands out:
Verifies its own outputs for higher reliability
Maintains coherence across long, multi-step tasks
Improved high-resolution image understanding
Better memory across sessions for ongoing work
Key features:
Advanced coding + agentic task handling
`/ultrareview` for deep code reviews
Effort control (high → xhigh) for better reasoning vs latency tradeoff
Available across API, Claude apps, and major cloud platforms
Who it’s for & use cases:
Developers building AI agents and automations
Analysts working on finance, research, and modeling
Teams handling complex docs, workflows, and long-running tasks
If you’re building AI agents or scaling complex workflows, this feels like a meaningful upgrade.
P.S. I hunt the latest and greatest launches in tech, SaaS and AI, follow to be notified → @rohanrecommends
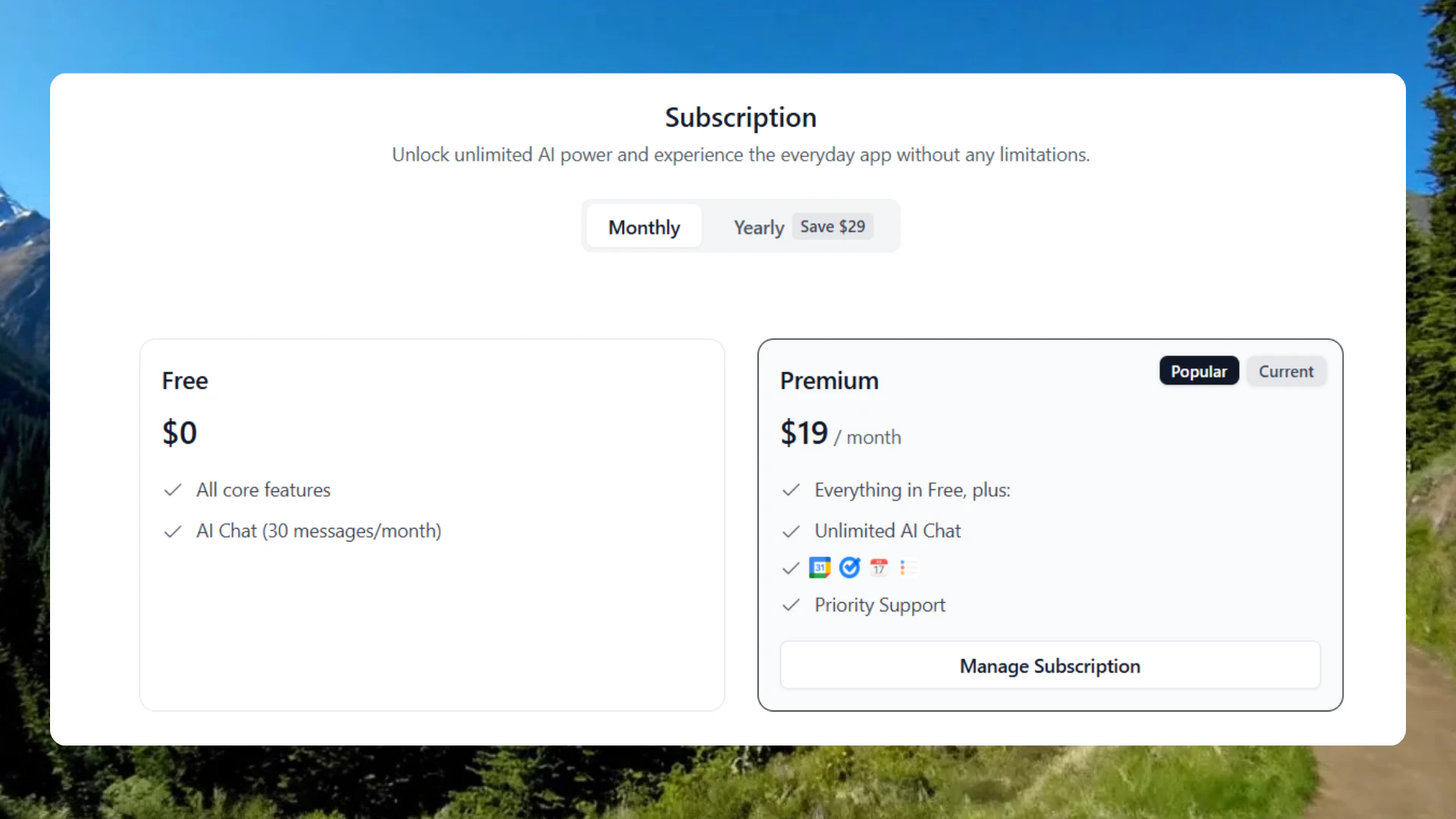
Anthropic released Opus 4.7 today. Same pricing as 4.6 ($5/$25 per million tokens), available across API, Bedrock, Vertex AI, and Microsoft Foundry.
What changed vs 4.6:
Coding. Biggest gains on long-horizon software engineering tasks. Model now verifies its own outputs before reporting back.
Vision. Accepts images up to 2,576px (~3.75MP)- over 3x more than any prior Claude. Key unlock for computer-use agents and diagram extraction.
Instruction following. Now interprets literally. Anthropic warns: prompts tuned for 4.6 may break — re-tuning needed.
Memory. Better at file system-based memory across long multi-session work.
Real-world knowledge work. State-of-the-art on Finance Agent eval and GDPval-AA.
New features:
xhigh effort level between high and max - finer control over reasoning vs. latency. Claude Code default is now xhigh for all plans.
Task budgets in public beta on the API.
/ultrareview in Claude Code - dedicated review session flagging bugs and design issues. Three free for Pro and Max users.
Auto mode extended to Claude Code Max users.
Honest caveats: New tokenizer → same input maps to up to 1.35x more tokens. Opus 4.7 thinks more at higher effort levels, especially on later agentic turns. Safety profile is roughly similar to 4.6 — improvement on honesty and prompt injection resistance, modestly weaker on harm-reduction advice for controlled substances. Still less capable than Claude Mythos Preview, which remains on limited release.
Bottom line: Meaningful upgrade in the three places that matter most- agentic coding reliability, vision for computer-use agents, and knowledge work benchmarks. Solid iteration, obviously shy of Mythos.
The session memory improvement is the feature I've been waiting for. Working on a large codebase with Claude Code, the biggest pain was re-explaining architectural decisions every new session. If Opus 4.7 actually retains context across multi-session projects, that alone justifies the upgrade. Curious how the new tokenizer affects costs in practice — 1.35x more tokens on the same input is worth watching.
I tried a quick brainstorm on some strategic direction, but didn't really like the response. It was not challenging me, even with explicit instructions to do so. Curious to what others are experiencing. Could it be that this model is even more tailored to e.g., coding than Opus 4.6?
The jump from Opus 4 to 4.7 in agentic coding is massive. I've been using Claude Code daily and the difference in how it handles multi-file refactors and complex debugging chains is night and day. The extended thinking really shines when you give it architectural decisions to reason through.
the verification step is interesting. most models just output and hope for the best. how does Opus 4.7 actually verify its own code outputs - static analysis, test generation, or something else?
First impression was very, very positive! As I was preparing for my launch yesterday, it pretty much saved the day! It caught errors that 4.6 was ignoring for long time, helped me design some really valuable scripts and designed some really cool graphics & flows for me.
Maybe I'm just hyped and excited, but I felt like I couldn't do it without this. Came exactly on the right time!
I’ve been using Claude pretty regularly for coding and problem solving, and one thing I’ve really appreciated is how well it handles longer, more complex tasks compared to most tools.
There have been quite a few times where I didn’t have to keep re-explaining context, which made a big difference when working through multi-step problems. Curious how much further 4.7 pushes this, especially around maintaining context and reasoning across longer workflows. Excited to try it out.
@Caveman included?
to quote @leerob: "I really like this model for general agentic work outside coding. It is definitely expensive though."
a product like @Edgee might be a great combo in this context imho
Going to start today 4.7, I have been using Opus 4.6 and have been very happy with its output and performance!
BIG STEP UP, have used it so far!! Watch out though!! Will eat your tokens LOL
Multiple people here mention token consumption being brutal. What's the rough token count on a typical multi-file refactor compared to Opus 4? Trying to figure out if the quality jump justifies the cost jump before committing to it for longer sessions.
the agentic coding benchmarks look wild — curious how it handles really long-horizon tasks in practice vs. the SWE-bench numbers. anyone tried it on multi-hour agent workflows yet?
Opus 4.7 sounds impressive for complex reasoning tasks. I'm curious about the agentic coding capabilities - when Claude is running long-running tasks autonomously, I'm wondering how others find it handling decision-making any better when it encounters ambiguous requirements or edge cases. Does it ask for clarification or make intelligent assumptions any better?