PH热榜 | 2026-04-30
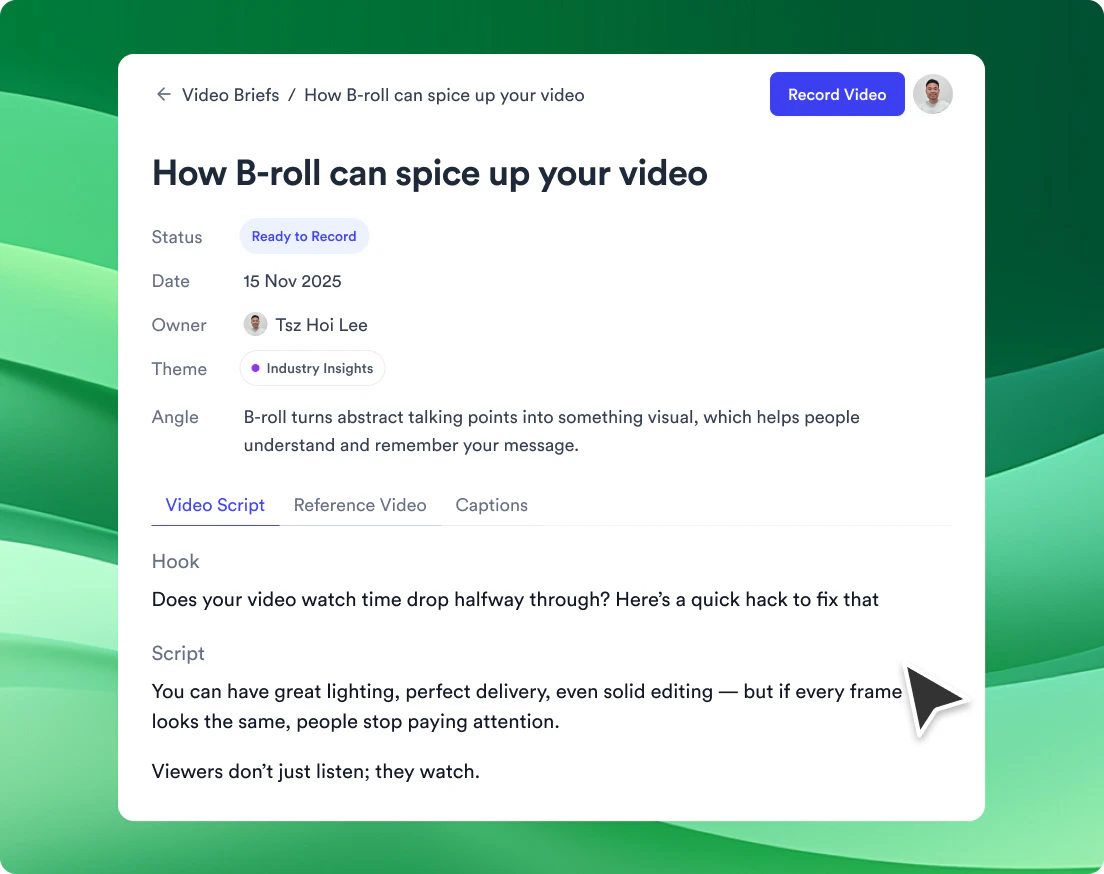
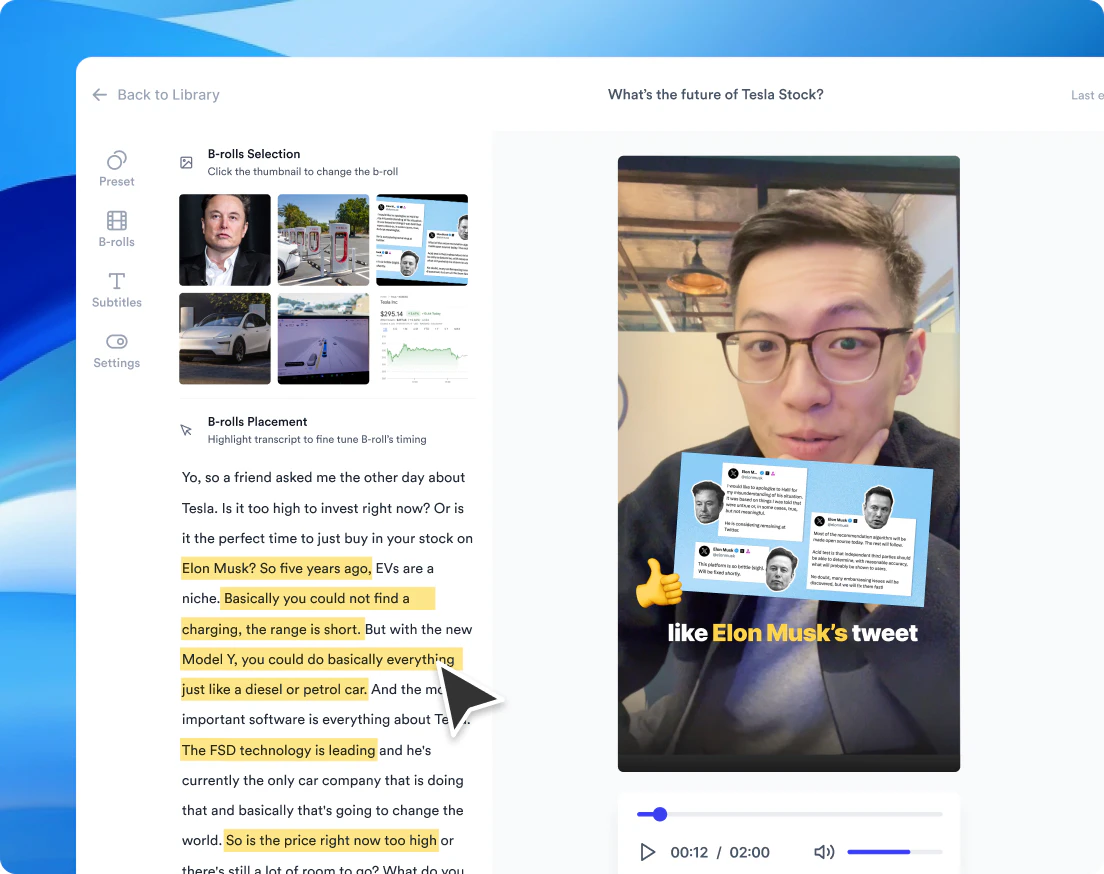
一句话介绍:Hera Launch是一款AI驱动的产品发布视频生成工具,让用户通过一句提示在10分钟内生成具有专业动态设计工作室水准的动画视频,解决传统视频制作耗时、昂贵且AI生成缺乏审美的问题。
Design Tools
Artificial Intelligence
AI视频生成
产品发布视频
动态设计
营销视频工具
SaaS产品
动画制作
品牌视频
自动化视频创作
AI动效
Product Hunt
用户评论摘要:用户普遍认可“AI内置审美”的差异化,称赞其解决动态设计难点。主要反馈包括:期待支持多比例(如竖屏)、自定义字体已支持;早期测试效果不惊艳需迭代提示;与Screen Studio定位互补(录屏vs动效);声音/播客内容暂未覆盖;创始人亲自互动,响应积极。
AI 锐评
Hera Launch最核心的卖点并非“用AI生成视频”,而是“用AI替代动态设计师的审美判断”。当前市面上大多数AI视频工具将审美负担转嫁给用户——你需要懂得哪些排版、曲线、缓动是好的,这本身就是一门专业。Hera的“opinionated”策略,本质上是在AI里预置了一个虚拟的创意总监,让不懂设计的人也能产出专业级动效。这个定位很聪明,它切中的不是“替代设计师”的宏大叙事,而是“让非设计师快速上手”的真实需求。
但从用户反馈看,问题也很明确:第一,初始输出质量不稳定,所谓“第一次最差”本质上说明审美预置系统仍有很大的提升空间,依赖用户反复迭代提示才能出好片,削弱了“10分钟”的承诺;第二,目前仅支持16:9,竖屏等社交格式缺失,严重限制了在抖音、Reels等主流渠道的传播场景,这会劝退大量SaaS营销团队;第三,产品定位在“发布视频”上过于狭窄,用户评论中暴露了播客、功能更新等多场景需求,走Mograph(动态图形)路线却只做launch video,可能会低估自身的复用价值。
整体而言,Hera Launch在“降低专业门槛”这一维度上做得比大多数AI视频工具好,但它离“真正的零门槛”还有一段距离。它的未来不在于替代After Effects,而在于成为产品团队的标配营销基础设施——前提是它能快速补齐比例适配、模板多样性和迭代效率。如果它在审美预置和迭代速度之间的平衡做得够好,有潜力成为AI视频生成在专业领域的一个参考范式;如果停留在当前阶段,则更可能成为一个“有一定审美但还不够稳”的辅助工具。
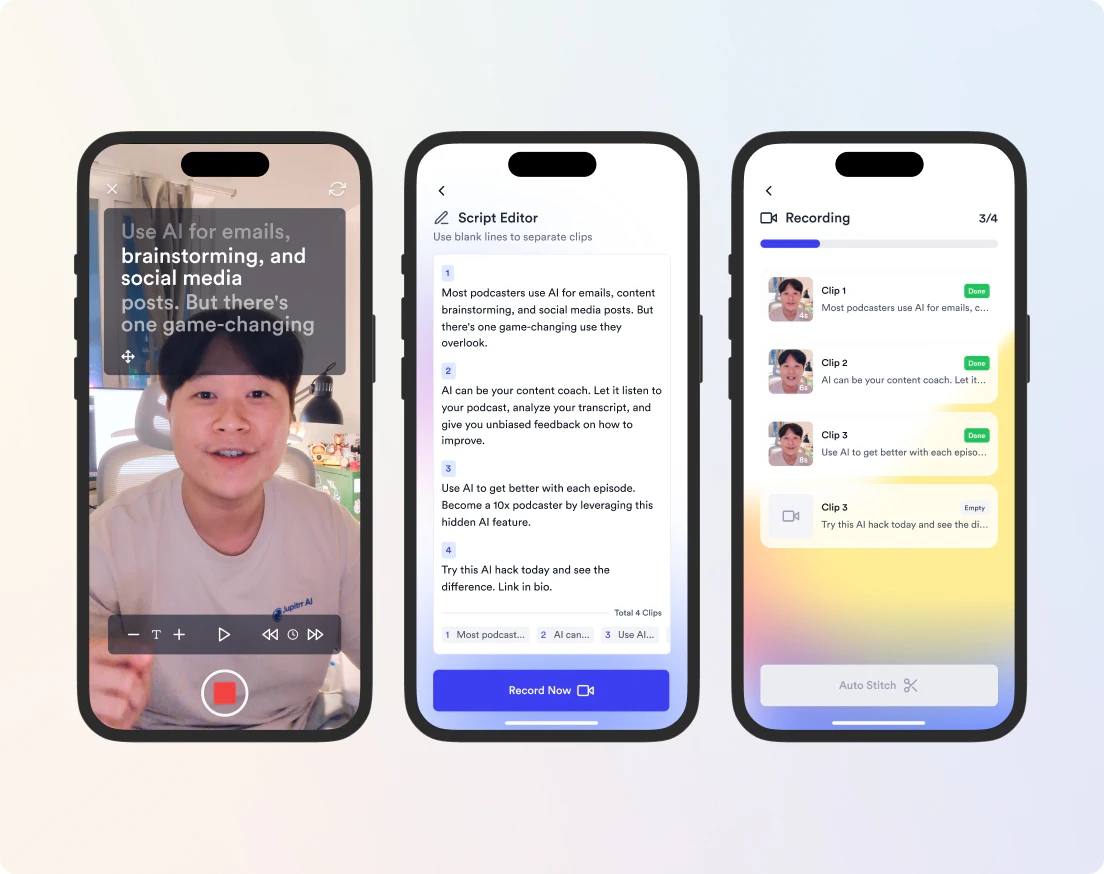
一句话介绍:VideoOS是一个专为创始人和营销团队打造的一站式视频营销平台,通过集成趋势发现、AI脚本生成、提词器录制、自动剪辑与多平台发布功能,将原先需要5-6个工具协作的繁琐流程压缩为单一工作流,解决用户因工具切换和制作耗时导致的视频内容输出不持续的核心痛点。
Social Media
Marketing
Video
视频营销
AI视频生成
内容工作流
提词器录制
自动剪辑
多平台发布
创始人工具
LinkedIn营销
小企业工具
视频编辑
用户评论摘要:用户普遍认同整合工作流的价值,并对逐行提词器录制功能表示高度关注,认为它解决了重录痛点。主要疑问集中在:AI脚本处理技术术语的能力、品牌风格自定义B-roll、语音克隆所需数据量门槛、以及单行重录后B-roll和字幕的时序衔接问题。产品团队回应称正在开发知识库集成和风格适配功能。
AI 锐评
VideoOS的价值不在于“又一个AI视频工具”,而在于对“创始人视频内容输出”这一场景的根本性重构。它敏锐地捕捉到核心矛盾:技术上,视频制作各环节的工具有无数可选方案;而人性上,创始人的时间碎片化和重复劳动的挫败感才是导致视频计划流产的元凶。产品将“系统化”作为核心卖点,通过全链路闭环降低决策疲劳与操作成本,这是比单纯输出“AI过时的视频”更具护城河的策略。
其最关键的创新并非AI脚本或自动剪辑,而是“逐行提词器录音+单行重录”这一看似微小的产品设计。它将录制环节的“一次成功”压力降级为“分批完成”,极大地降低了创始人的心理天花板和重拍成本,这是驱动“持续发布”而非“做出一支完美视频”的务实策略。与之配合的“基于历史语料进行语音克隆”,则进一步提升了AI脚本的个性化,避免落入“AI味”的陷阱。
不过,风险同样存在。这一定位于“创始人系统”的产品,对用户使用的初始数据量和习惯培养要求较高,冷启动阶段若无法快速让用户产出第一条“有成就感”的视频,极易流失。产品目前对手动操作仍有依赖,团队坦诚“先建基础,后加自动化”,但对手的追赶速度不容小觑。未来真正的壁垒在于,其能否基于用户行为数据形成“内容产出效率的推荐引擎”,从而从工具进化为创始人视频化生存的“操作系统”。目前来看,方向正确,执行尚需验证。
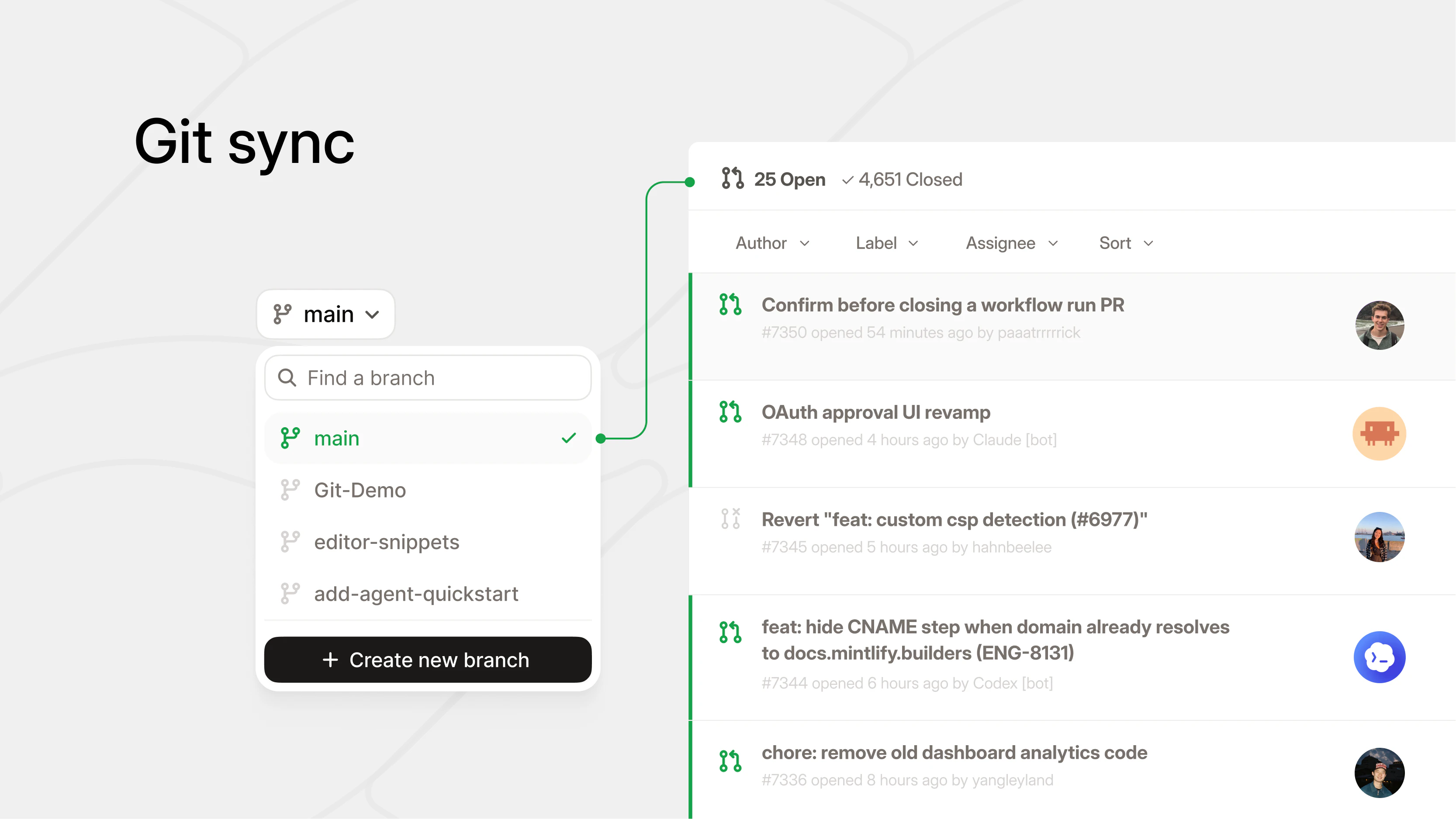
一句话介绍:Mintlify Editor 是一个集所见即所得、实时协作、Git同步与AI原生能力于一体的文档编辑器,旨在解决企业跨团队知识碎片化、更新滞后以及AI代理因数据混乱而失效的痛点。
Notes
Text Editors
GitHub
文档编辑器
协作工具
AI原生
Git同步
知识管理
企业级应用
团队协作
WYSIWYG
AI代理
知识碎片化
用户评论摘要:用户高度认可产品价值,尤其赞赏其解决知识碎片化的思路。核心问题集中在:AI生成内容的准确性如何保障(与真实数据源对齐);AI原生功能将如何进化以应对代理更深度嵌入的日常流程;非技术人员能否轻松训练AI代理而不依赖开发人员;以及当多源数据冲突时,编辑器如何为AI代理提供版本决策依据。
AI 锐评
Mintlify Editor 的发布,不仅仅是一个编辑器版本的迭代,而是精准击中了一个正在快速膨胀的痛点——当AI代理开始成为公司“新员工”时,知识库的混乱将直接从“人类效率问题”升级为“系统决策灾难”。
其“AI-native”的定位非常聪明且犀利。传统的协作文档工具(如Notion、Confluence)在设计时,并未考虑机器读者。它们依赖人类判断信息优先级,而AI代理会“平等地”信任所有老旧、冲突、未经筛选的内容,导致“垃圾进,垃圾出”以指数级速度放大。Mintlify将Git同步作为基石,为AI提供可追溯、可版本管理的结构化知识源,这远比单纯提供一个更漂亮的编辑器更有深度。它本质上是在为AI构建一个“可信的上下文环境”。
然而,犀利背后也有隐忧。评论中用户反复追问“如何保证AI生成内容的准确性”和“版本冲突时AI如何决策”,这恰恰暴露了产品最核心的风险。Git同步保证了“版本”的存在,但并未解决“权威版本”的认定问题。如果AI编辑、人类编辑、CLI工程师都能改同一个段落,且缺乏一个强制的仲裁或权限校验机制,那么Mintlify很可能只是加速了知识混乱的产生速度——从“人类手写错误”变成了“AI自信地胡说并同步给所有人”。
此外,其“跨职能协作”的叙事依然存在技术与非技术之间的隐形壁垒。虽然宣称非开发人员无需Markdown,但Git底层的逻辑、分支、合并冲突等概念,对纯营销或市场人员而言仍过于抽象。如果不能提供一个真正无感的“web-native”体验,解决“非技术人员不敢点提交”的深层恐惧,那么Mintlify最终仍会沦为一个“更好看的开发者文档工具”,而非真正通用的企业知识平台。
总体而言,Mintlify Editor 拿到了通往下一阶段知识管理的船票,其逻辑清晰、方向正确。但能否真正从“优秀”蜕变到“必选”,取决于它后续能否解决那个最棘手的信任问题:在一个所有人都能编辑(包括AI)的世界里,谁来为知识的真实性和权威性最终负责?
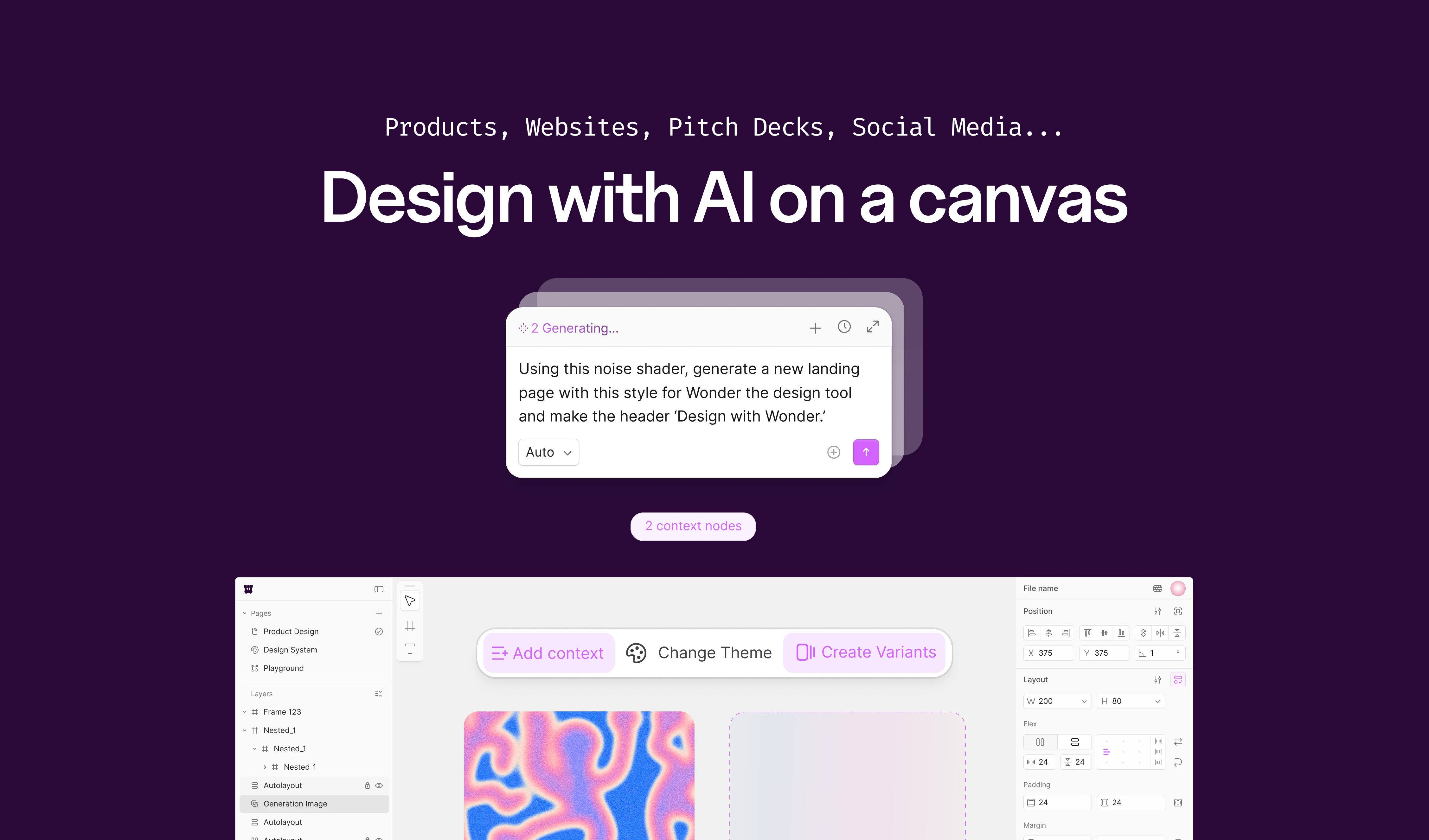
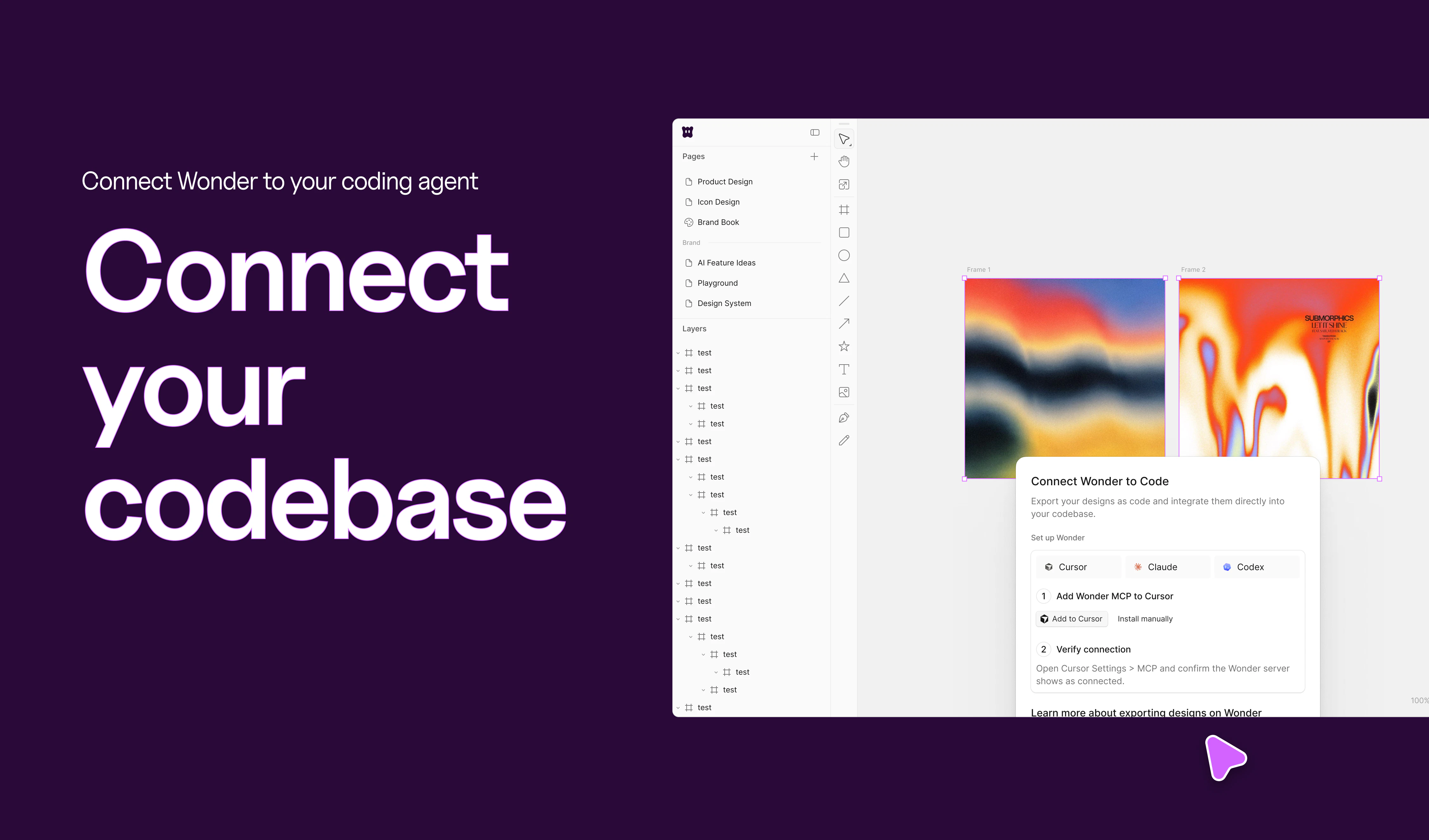
一句话介绍:Wonder是一款将AI设计代理直接嵌入画布的工具,旨在解决设计师与开发者之间因工具割裂导致的“设计-代码”交接失真问题,让用户从创意到产出能在同一平台内实时迭代和交付。
Design Tools
Developer Tools
Design
AI设计代理
实时编辑
设计转代码
MCP连接
UI生成
图形设计
幻灯片
营销素材
设计协作
生产力工具
用户评论摘要:用户普遍认可“设计-代码”分离的痛点,并赞赏Wonder的实时协作与MCP接入能力。主要疑问集中在:与同类工具(如Pencil、Claude Design)的区别、订阅模式对一次性设计需求的适用性、以及设计修改能否反向同步到代码库(即双向迭代),而非仅单向生成。
AI 锐评
Wonder的叙事极度精准,它没有重复“AI帮你做设计”的老生常谈,而是直击“设计-代码交接”这个行业顽疾。其核心价值不在于设计效果有多惊艳,而在于它试图用“MCP服务器”打通从设计到开发的最后一公里,将AI从“生成器”升级为“协作代理”。
然而,成也连接受限。目前它只是一款“设计端”工具,其代码导出依赖第三方编码代理(Cursor/Claude Code)。这意味着设计的“最终解释权”实际上仍掌握在他人手里。一旦Coder解析其输出出现Token迷失或样式走样,用户所有的“实时协作”快感都将被现实的二次调试冲散。
技术上,Wonder并无绝对护城河。Figma早已在边栏内嵌AI,Canva的AI生成也在围追堵截。Wonder最大的赌注在于“MCP标准”——如果这个协议无法快速成为行业通行的、能保证高保真双向同步的事实标准,它极易沦为又一个“漂亮但无力的中间层”。目前产品处于公开Alpha阶段,说明其稳定性、性能和复杂场景适应力尚未经受大规模生产验证。
商业上,从$20到$200的订阅制可能会劝退那些只需“快消型设计”的品牌或创始人,他们更愿意按次付费或直接用绝对免费的GPT-4o/ Claude生成草图。Wonder的长期价值,取决于它是否能在“设计端”建立足够强的编辑体验粘性,并推动MCP成为连接设计与代码的通用协议——而非仅仅作为一个“好看的跳板”。否则,当Coder们直接集成本地AI绘图和设计能力时,Wonder存在的必要性将受到严峻挑战。
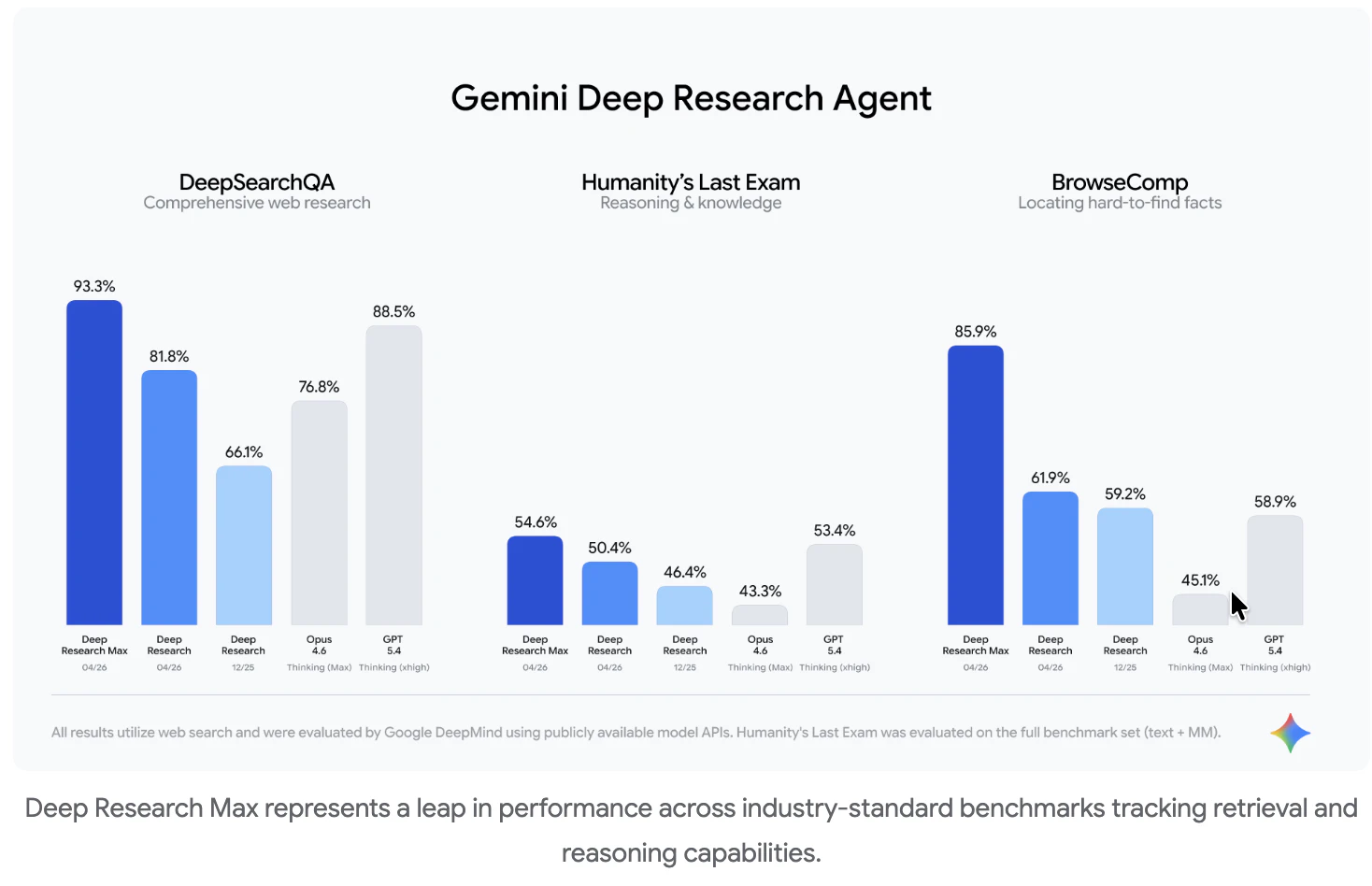
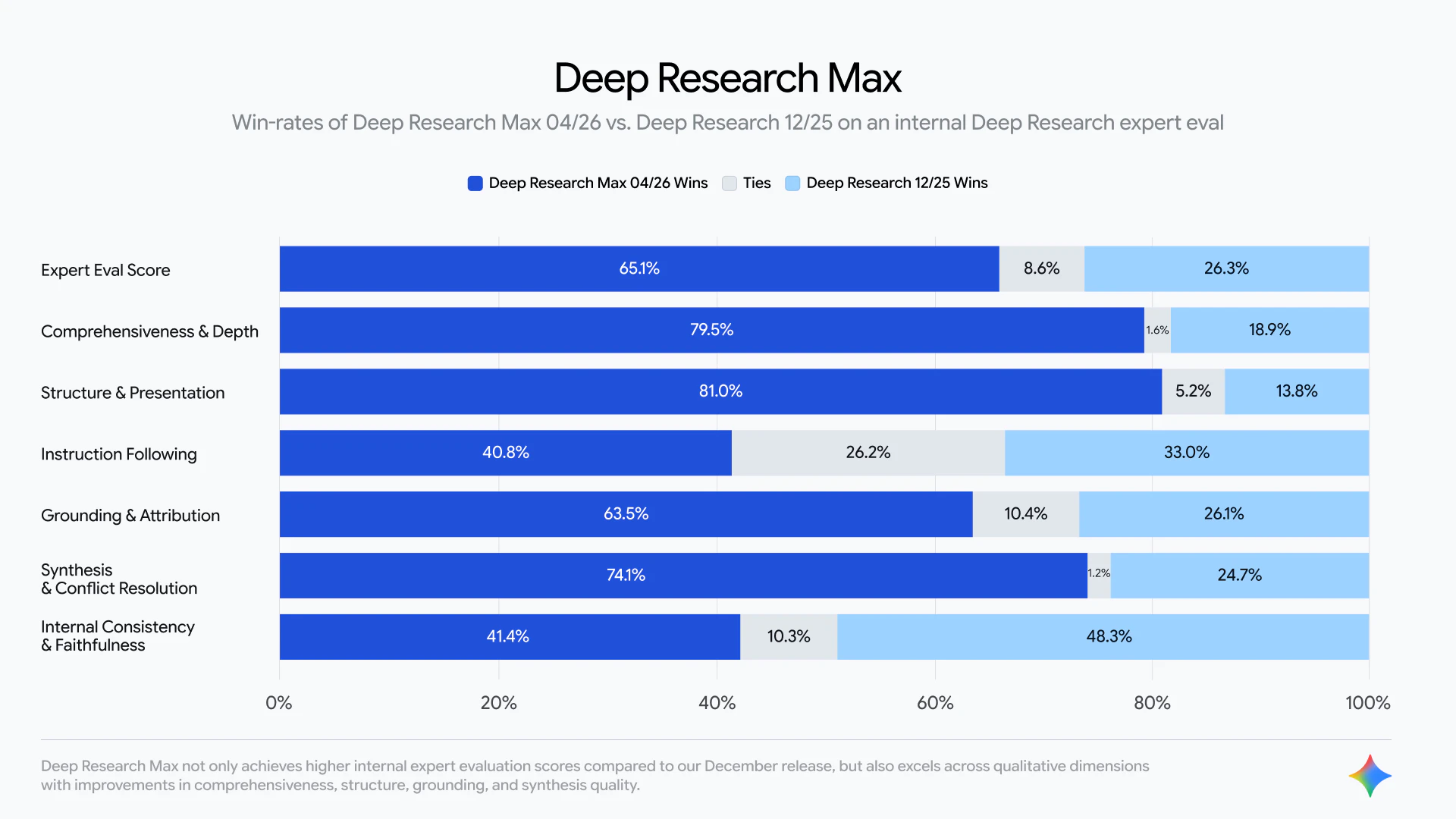
一句话介绍:Gemini API 推出的双模式研究代理,通过低延迟交互与深度异步合成,结合 MCP 数据源和原生图表生成,解决开发者与 AI 工程师在复杂信息检索与多源整合场景下的效率与深度痛点。
API
Developer Tools
Artificial Intelligence
AI研究代理
MCP集成
多源数据合成
图表生成
异步任务
开发者工具
Gemini API
深度搜索
自主研究
低延迟交互
用户评论摘要:用户对MCP原生集成表示认可,但重点关注数据冲突时的处理机制——是直接掩盖分歧还是在引文中呈现?同时担忧异步任务“Deep Research Max”的预算不可见性,可能导致无预警超支。也有用户期待与竞品Parallel的横向对比。
AI 锐评
这款产品本质上是一次精准的“工具箱化”升级,而非颠覆性创新。将 Deep Research 拆分为低延迟交互与异步深度两个模式,确实切中了不同场景的刚需——前者适合实时辅助决策,后者用于生成分析报告。真正的亮点在于 MCP 支持:它不仅兼容公开网页,还开放了私有数据源接口。这打到了许多竞品(如仅限闭源搜索的 ChatGPT Deep Research)的软肋,让金融、生命科学等行业的内部数据治理成为可能。
但评论中暴露的“数据冲突”与“预算失控”问题,几乎是所有追求深度合成的 agent 的通病。目前产品只是将最终报告包装得“精美”,但并未解决信息甄选过程中的透明度问题——用户不知道模型在众多来源中是如何做“剪枝”或“偏向”决策的。这将导致严重的信息茧房:工具越智能,用户信得越深的谎言就可能越精致。
此外,异步 agent 的隐藏成本也是一大隐患。对于规模化部署的团队来说,缺乏精确的 token 配额反馈和控制阀门,意味着惊喜与惊吓并存。
Gemini Deep Research Agent 在产品定义上正确,市场定位清晰,但目前更像是“强大的初版”,而非“成熟的生产力工具”。它的真正价值,将在后续能否暴露推理链条、提供成本控制、以及允许用户手动介入冲突数据源时才被兑现。
一句话介绍:Tabstack 是一款内置智能的 API,让开发者无需维护爬虫即可从任意网页提取结构化 JSON 数据、自动执行浏览器操作,彻底解决数据管线脆弱、易被网站反爬机制打破的难题。
API
Developer Tools
Artificial Intelligence
网页数据提取
浏览器自动化
API
JSON结构化输出
AI爬虫
零维护
科研引用
Mozilla出品
用户评论摘要:用户普遍认可其“传URL和schema即返回JSON”的能力,认为胜过同类工具并降低了LLM成本。主要关注点:1)如何处理网站反自动化封锁;2)字段缺失时是硬失败还是返回null;3)是否支持动态网站(如电商)。团队回应:返回null而非失败,已通过真实浏览器实例与自适应逻辑成功处理多数动态网站,但在G2、LinkedIn等强反爬站点遇阻。
AI 锐评
Tabstack 解决的不是“抓取”问题,而是“从网页到可用数据”这一整段糟心的管线工程。它用“schema as contract”的范式,把传统爬虫中维护成本最高的解析、清洗、适配环节,压缩成一个API调用。这种内置智能的架构,本质上是把大模型的推理能力接入了数据抽取过程——当网站DOM改变时,不是告警,而是自动适应。这是技术上最聪明的冒犯:让“周一早上发现数据没了”这种传统开发者的噩梦,变成别人的历史。
但也必须指出,它的强项也是它的软肋。依赖API内置的智能意味着开发者对抽取过程的干预手段有限,一旦遇到强反爬、复杂交互或多模态内容,Tabstack的“一切交给API”的哲学就会显出边界。用户反映G2和LinkedIn无法抽取,恰恰证明了在商业竞争场景中,数据持有方的反制永远比API的智能迭代快一步。此外,SaaS化服务意味着数据经过他人之手,即便是Mozilla血统的“不训练、尊重robots.txt”承诺,对高合规需求的企业仍是隐忧。
从商业角度看,Tabstack瞄准的是AI Agent和自动化工作流的中坚基建层。它的真正护城河不是技术壁垒——这种“API+智能”的配方可复制——而是抢先占据了“从抓取到理解”之间的心智锚点。当开发者习惯了“传schema取JSON”的清爽,恐怕再也回不去手动写解析器的日子。这才是最狠的一刀。
一句话介绍:Gemini在聊天界面内直接生成可下载的Google文档、PDF、Word、Excel、LaTeX等十余种格式文件,免去用户复制粘贴和手动排版的繁琐流程,将AI对话与日常办公文档创作无缝衔接。
Productivity
Artificial Intelligence
AI文件生成
办公效率
文档自动化
生产力工具
Google Workspace集成
LaTeX支持
多格式导出
聊天机器人
用户评论摘要:用户普遍看好此功能,认为其贴近日常工作流,免去了手动复制和修正格式的麻烦。也有技术用户提出具体关切:生成的LaTeX文件是否包含完整模板和包声明,还是仅输出原始内容导致无法直接编译。这反映出高级用户对输出质量的严格预期。
AI 锐评
File Generation in Gemini的发布,表面上是新增了文件导出能力,实则暗含一个战略信号:Google正在试图将Gemini从“对话式助手”升级为“生产力操作系统”的入口。过去,AI生成的内容必须经过“复制→粘贴→排格式”这一摩擦环节才能实际投入使用,而现在这个链条被一键剪断。其真正的价值不在于生成了多少种格式,而在于将AI输出直接对齐到用户的工作流终点(可分享、可编辑、可编译的文件),从而大幅降低AI从“有用”到“被用”之间的心理与操作成本。
但必须清醒看到,这一功能的成败取决于质量,而非数量。当前评论中对LaTeX的支持反馈就暴露了潜在隐忧:如果“生成文件”只是将原有对话文本换了个后缀名,而没有进行针对性的格式模板化(如LaTeX的preamble结构、Excel的单元格布局、Slides的排版逻辑),那么用户仍然需要大量的二次手调,所谓的“生产就绪”将沦为营销话术。此外,该功能目前仍高度绑定Google生态(Docs/Sheets/Slides),对于使用Office 365或本地办公套件的用户,其吸引力大打折扣。Gemini必须证明它理解“文件格式”背后的结构规则,而不仅仅是扩展名映射。一句话:这场从“聊天”到“创作空间”的跃迁,方向是对的,但执行深度将是决定其是否只是又一枚表面光鲜的“玩具”的关键。
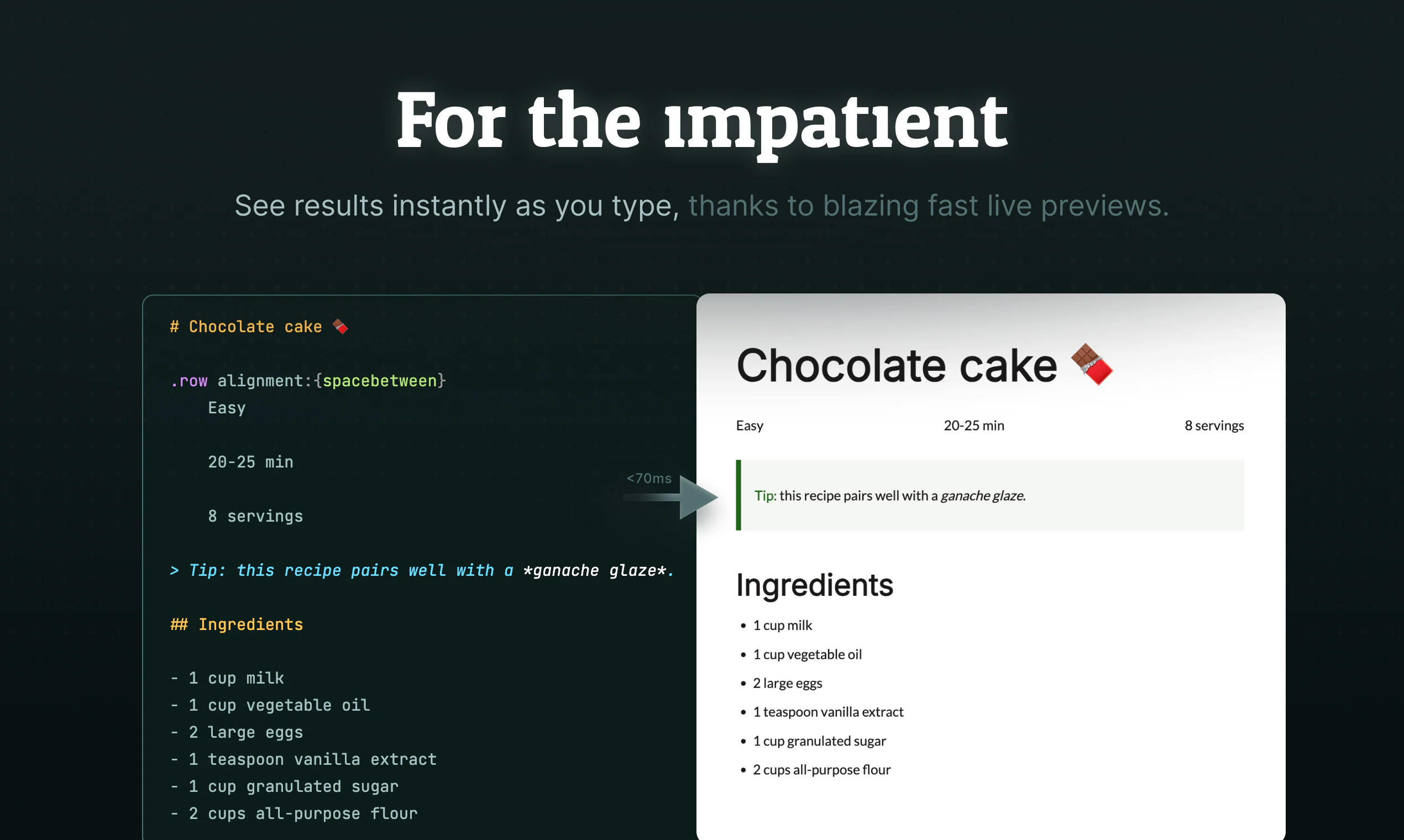
一句话介绍:Quarkdown 是一款基于 Markdown 并深度融合 LaTeX 的现代排版系统,帮助用户在 VS Code 或终端中高效完成论文、演示文稿、知识库和网站的制作,解决技术写作者在“易写”与“专业输出”之间的长期痛点。
Open Source
Writing
Developer Tools
GitHub
Markdown排版
LaTeX集成
学术写作
演示文稿生成
知识库
网站构建
实时预览
VS Code扩展
命令行动态预览
开源工具
用户评论摘要:用户关注 Markdown 与 LaTeX 语法冲突(如下划线歧义),期待上下文推断或模式切换方案。好奇同一源文件如何适配学术PDF(浮动图、参考文献、双栏)与幻灯片,询问公式导出是否为可选中文字PDF。开发者正处理标题拼写错误。
AI 锐评
Quarkdown 的价值不在于简单的“Markdown + LaTeX”,而在于它试图弥合两种写作范式的“即写即所得”鸿沟。Typst 等新秀在排版内核上更先进,但牺牲了 Markdown 的直觉与生态;Quarkdown 聪明地选择在 VS Code 与终端两大开发者腹地生根,让用户无需切换环境即可获得 LaTeX 级的排版控制力,这是对“学术写作工具链”的一次务实重构。
不过,产品面临的核心挑战是语法冲突的“脏活”——用户评论中提到的下划线歧义就是典型。若仅靠 $..$ 分隔符做简单模式切换,实际上是在强迫用户记住另一套规则,并未真正降低认知负荷。真正的痛点在于,用户想在同一个思路上同时书写正文和公式,而非在两个语法世界间频繁跳转。若 Quarkdown 不能在上下文感知上做出更智能的推断(比如自动识别数学环境),它将沦为又一个“功能拼凑”而非“体验融合”。
此外,从评论中能看出,教师与内容创作者的潜在需求极大——他们需要的不仅是学术 PDF,还有可交互或可复制的公式导出能力。如果能做到 PDF 中公式文字可选、同时兼容幻灯片和网站生成,Quarkdown 就能借“一个源,多格式”的承诺真正吃掉从课件、讲义到博客的整条内容生产链。当前 123 票的 Launch 热度不算爆炸,但开发者的十年开源背景及对反馈的开放态度是加分项。建议下一步聚焦“编译管道”的灵活性:允许用户按输出端定制渲染规则,比如 PDF 严格学术,网页则优先可访问性。Quarkdown 有潜力成为类 Notion 笔记与 LaTeX 论文间的桥梁,但前提是这桥不能修得摇摇晃晃。
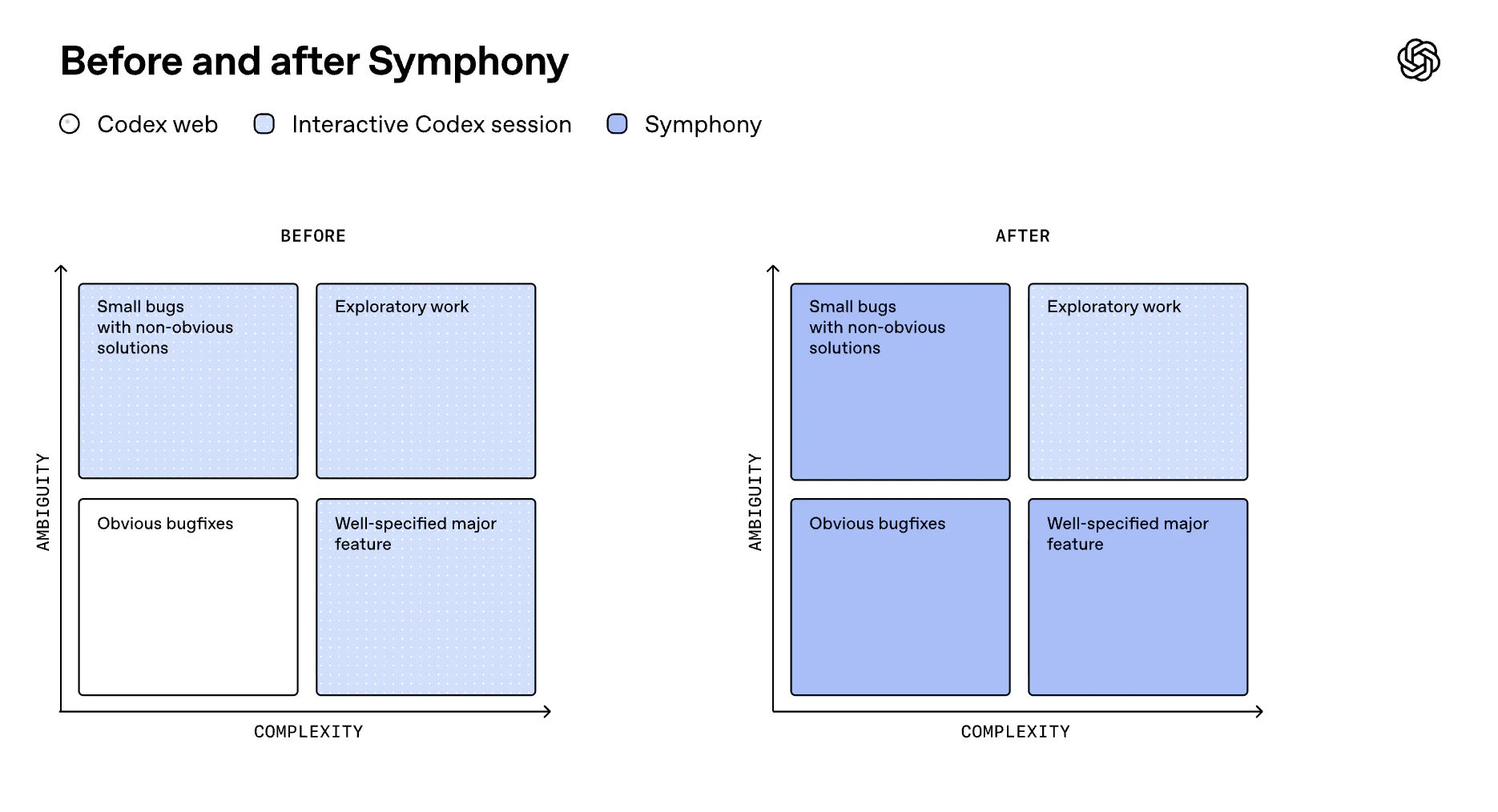
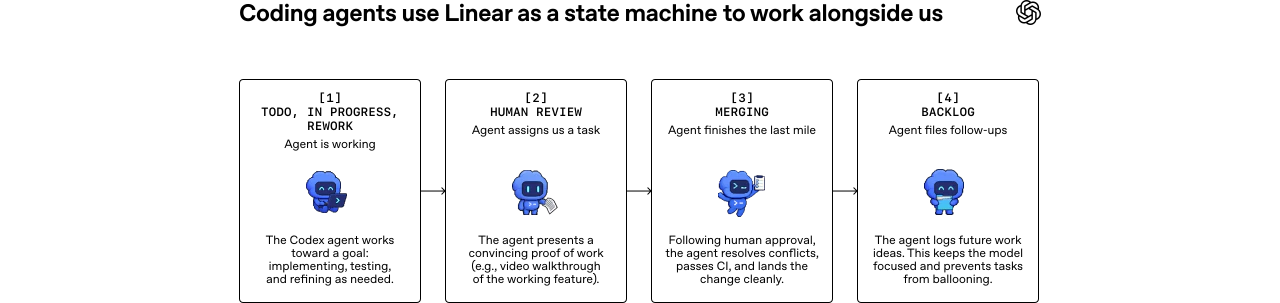
一句话介绍:Symphony是一个开源规范,将任务追踪器(如Linear)转变为始终在线的代码执行引擎,让AI代理自动处理任务,开发者只需聚焦审查与方向,解决多代理协作时的上下文切换与重复监督痛点。
Open Source
Artificial Intelligence
开源
代理编排
代码自动执行
任务追踪
AI工程
线性集成
并行开发
工作流自动化
代码代理
开发效率
用户评论摘要:用户关注代理失败时的纠错机制,担心反复提交混乱代码导致后续清理成本高。另有开发者询问对于5人小团队的具体工作流改变,暗示需要更落地场景。少数评论提及ChatGPT-5.5替代作用,但非直接针对产品。
AI 锐评
Symphony的野心不止于工具,它试图重新定义“任务”与“代码”之间的生产关系。将Issue Trackers作为控制平面,本质是把工程管理的“计划”与AI代理的“执行”做了一次硬性解耦,这比现有碎片化的Copilot插件或独立Agent平台更彻底——因为它借用了团队已有的协作语义,而非创造新孤岛。
但风险同样赤裸:评论中“代理一直在重复犯错”的质疑击中了核心软肋。当前方案依赖“自动重试”和“DAG执行”,却未明确如何阻断坏模式扩散。当代理在错误方向上连续产出PR,人类审查压力不降反升,所谓的“500%PR增长”可能沦为垃圾代码生产机。另外,小团队的实际痛点并非“多代理管理”而是“单代理靠谱”,Symphony对5人队的吸引力必然弱于大厂基建团队。
真正有价值的,是它对“工作流标准”的试探——如果稳定下来,它能将AI编程从“一人一IDE的魔术”变成“组织级的生产管道”。但在此之前,必须回答那0点赞的追问:谁来纠偏?成本转嫁到哪里?产品现在更像一张理想蓝图,而非可落地的生产工具。
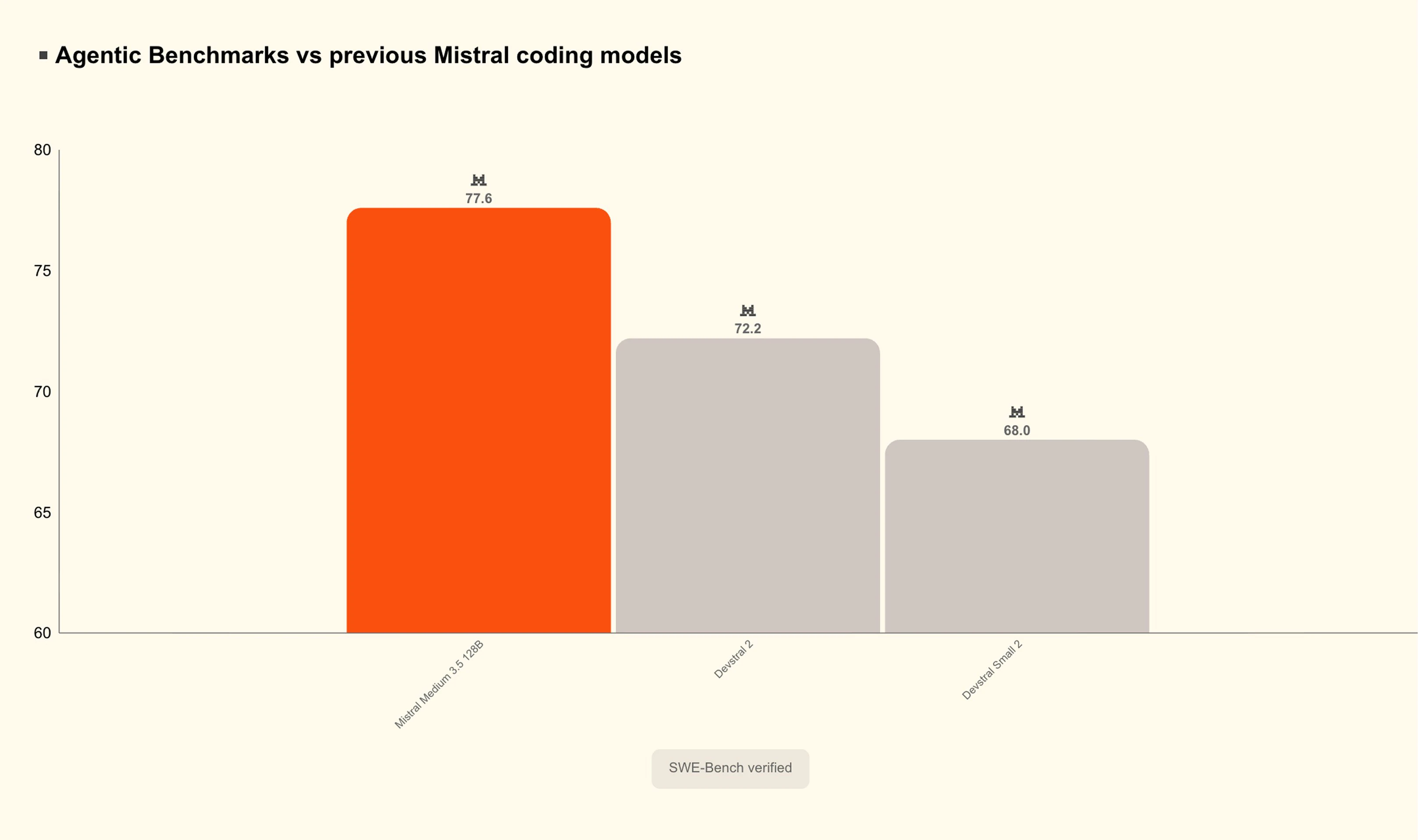
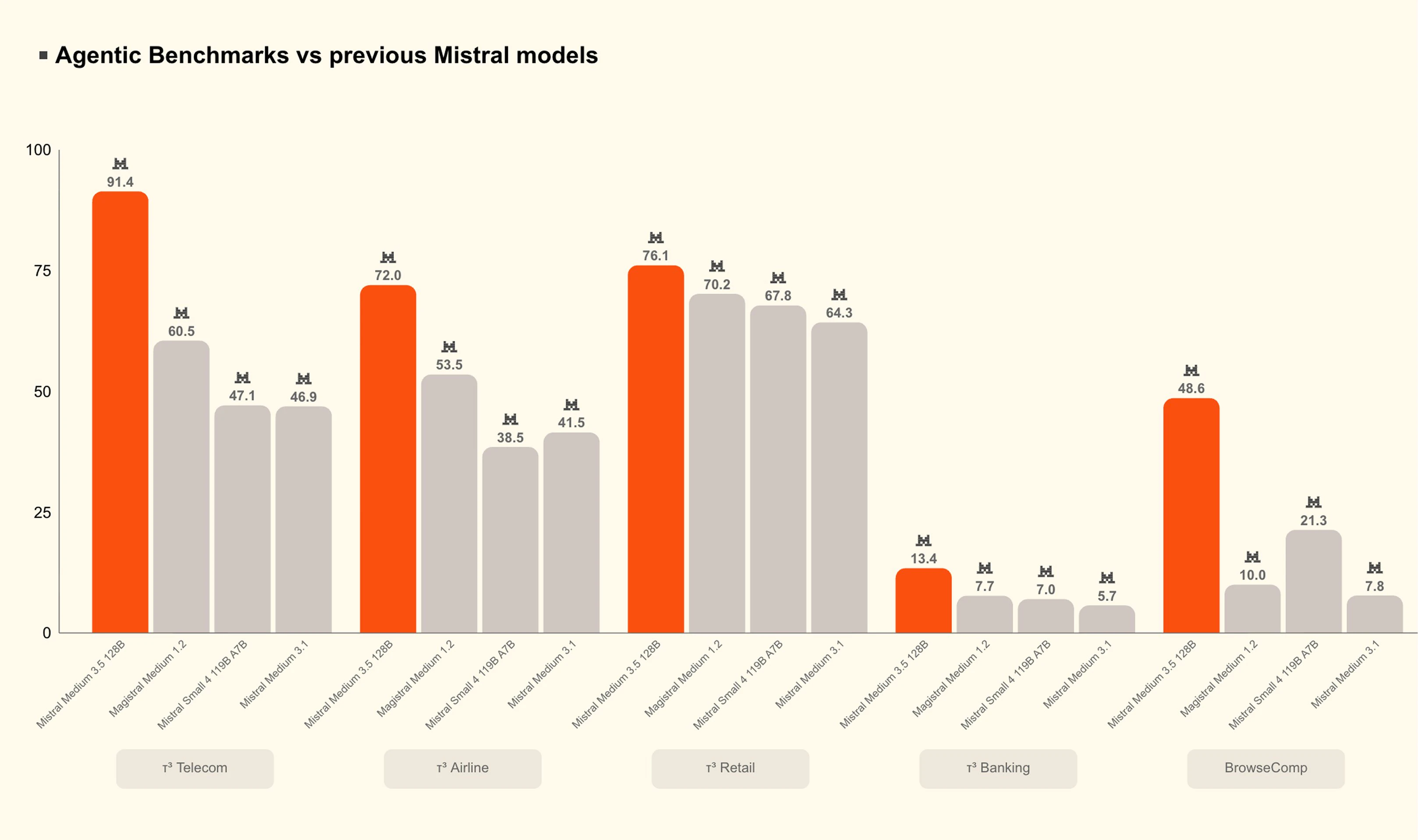
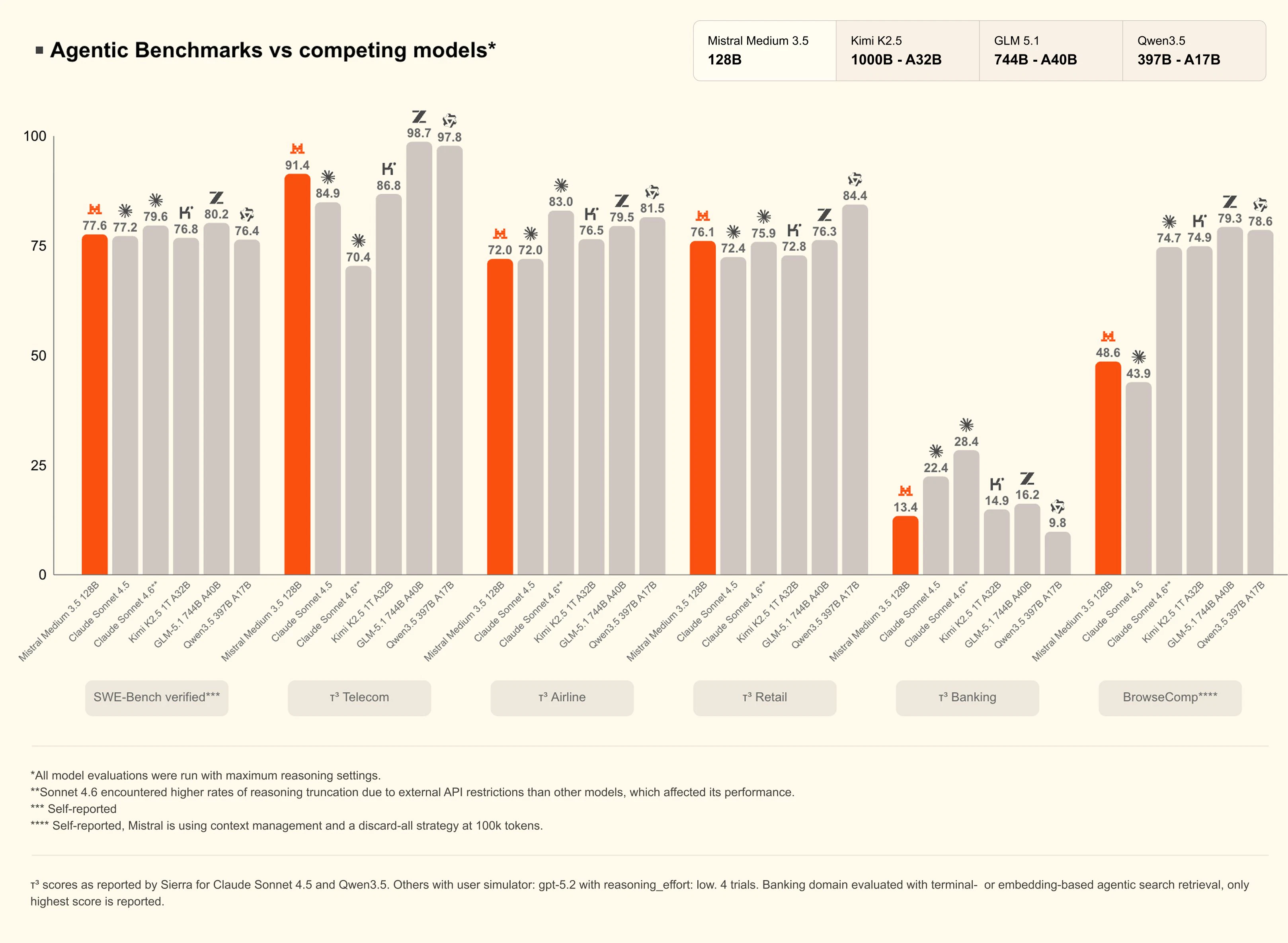
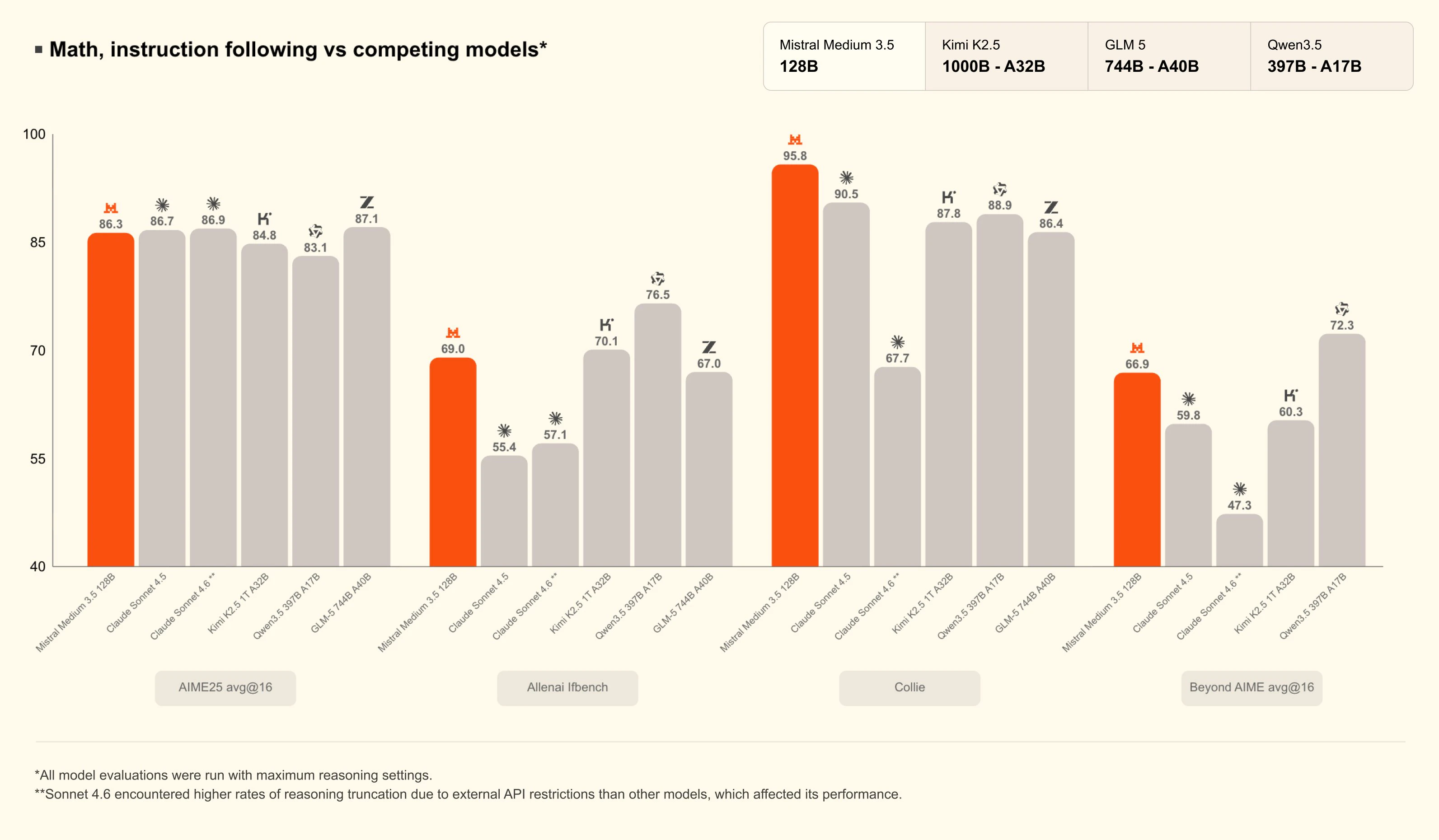
一句话介绍:Mistral Medium 3.5 是一款将编码、推理与指令遵循融合于单一权重的128B稠密模型,支持256K上下文与可配置推理深度,让开发者和团队能在4块GPU上本地运行原本需要庞大基础设施的前沿级模型。
Android
Newsletters
Artificial Intelligence
AI大模型
开源模型
本地推理
代码生成
逻辑推理
指令微调
企业级AI
模型部署
256K上下文
SWE-Bench
用户评论摘要:用户强调该模型是Mistral迄今最强模型,可自托管于4GPU,在SWE-Bench上领先Qwen3.5 397B。其“有配置的推理努力”是亮点,兼顾简单回复与深度推理。开放权重与修改版MIT许可利于微调和审计。
AI 锐评
Mistral Medium 3.5 的发布看似是一次常规的模型升级,实则暗藏了对当前AI行业两大痛点的精准打击:成本与复杂性。在多数实验室仍执着于堆参数、分拆专用模型(推理、编码、指令各一个)时,Mistral反其道而行之,用“合并权重+可配置推理”的设计,将一个128B的稠密模型塞进四张消费级显卡。这种“做减法”的思路,直接挑战了OpenAI、Google等依赖闭源API和集群硬件的厂商。
其真正的价值不在于跑分(77.6% SWE-Bench固然亮眼),而在于将“企业级”的门槛拉低到了团队级。一个能自托管、可微调、API成本可控,且能兼顾闲聊与长周期编码任务的全能模型,对于预算有限但追求数据安全与模型可控性的中小团队而言,是填补开源与闭源之间“利润空白区”的利器。
不过,需要警惕的是,密集参数模型在能耗与单卡内存带宽上天然劣势明显,128B在4GPU上能否保持低延迟的交互体验仍有待观察。且“合并式”架构意味着在极端追求单科性能的场景下(如纯竞赛级数学推理),它未必能胜过专精模型。Mistral的赌注在于:99%的日常工作需要的是“够用且便宜”,而不是“极致且昂贵”。如果这一判断成立,这将是模型产品化思路的转折点。
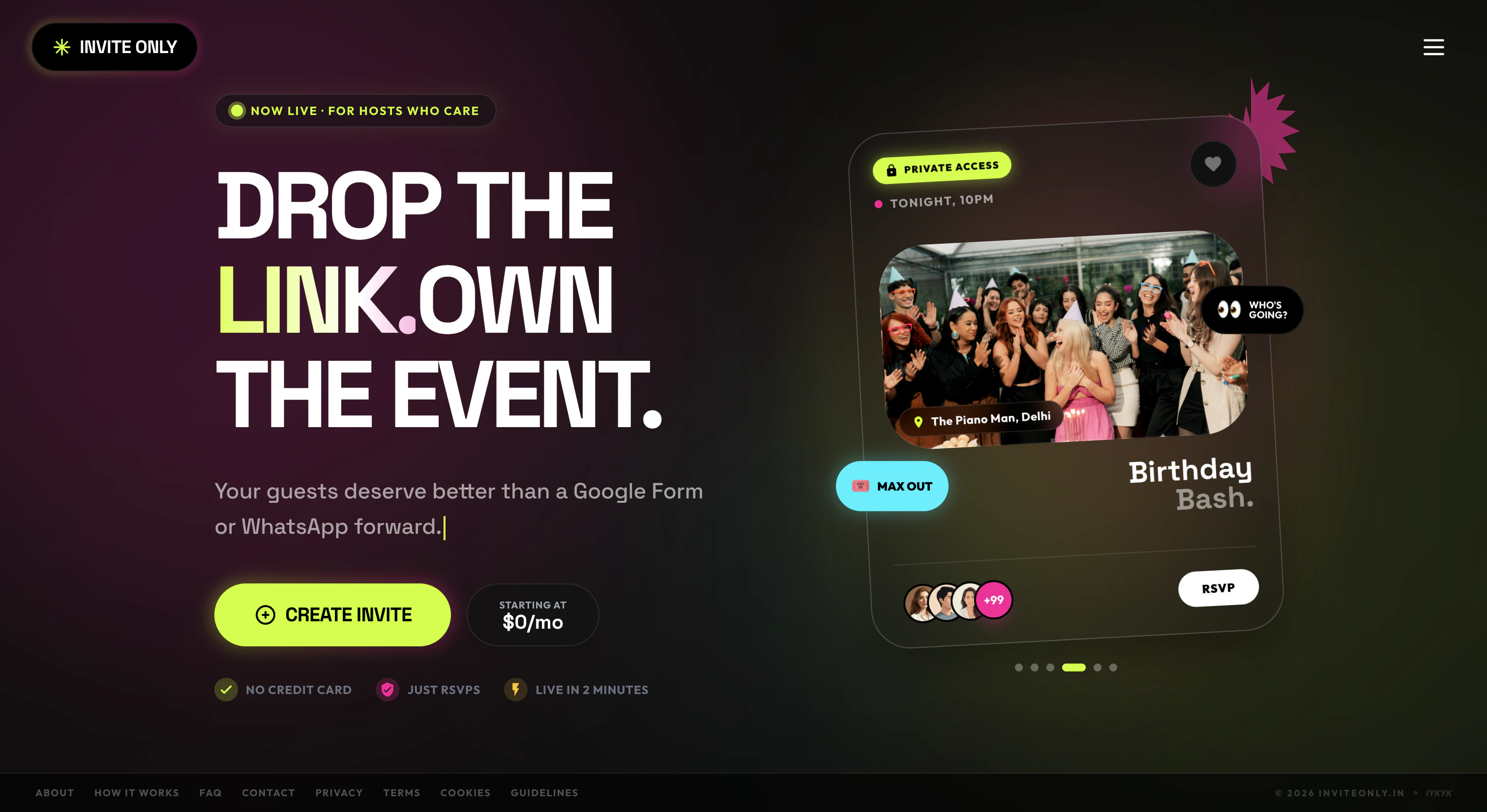
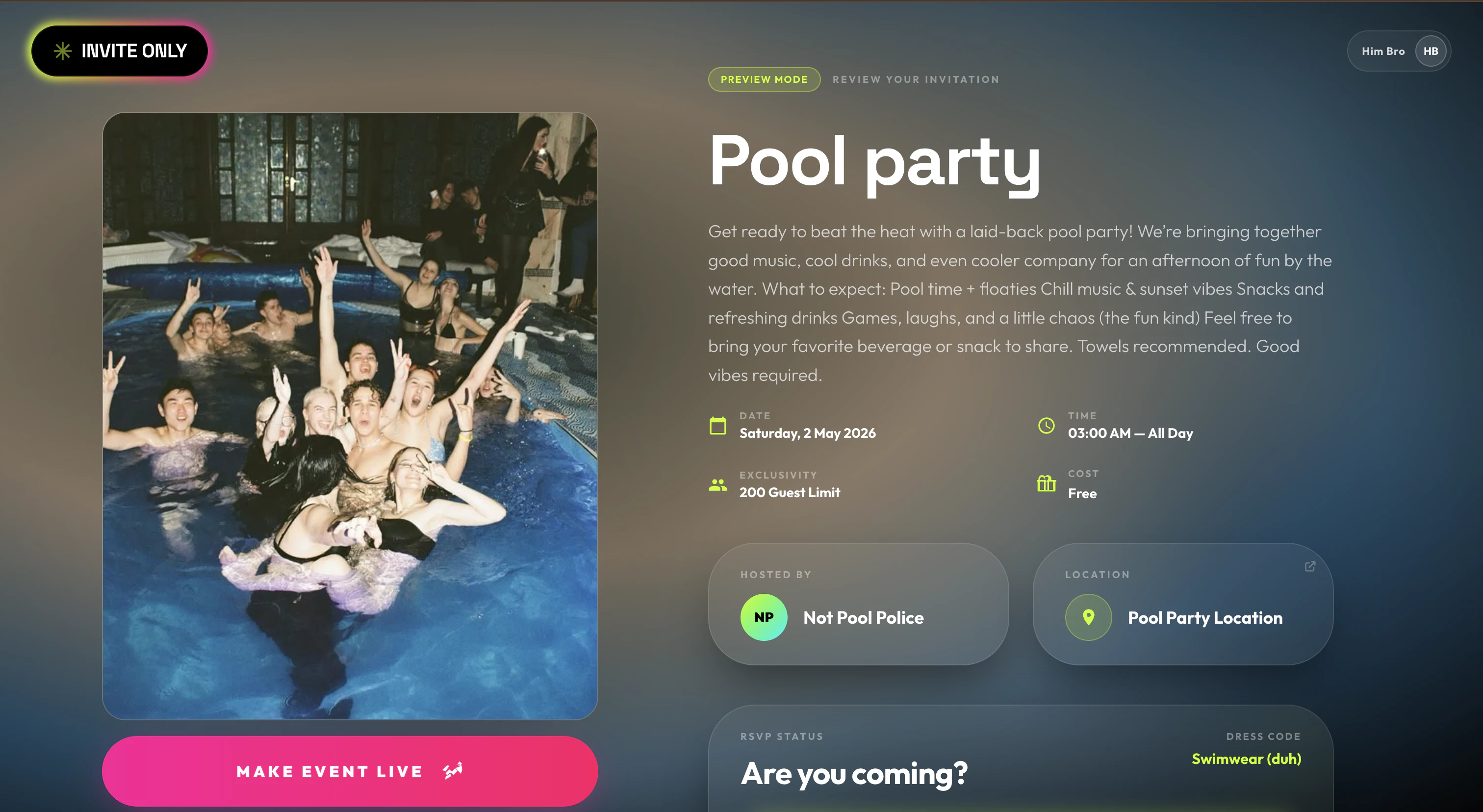
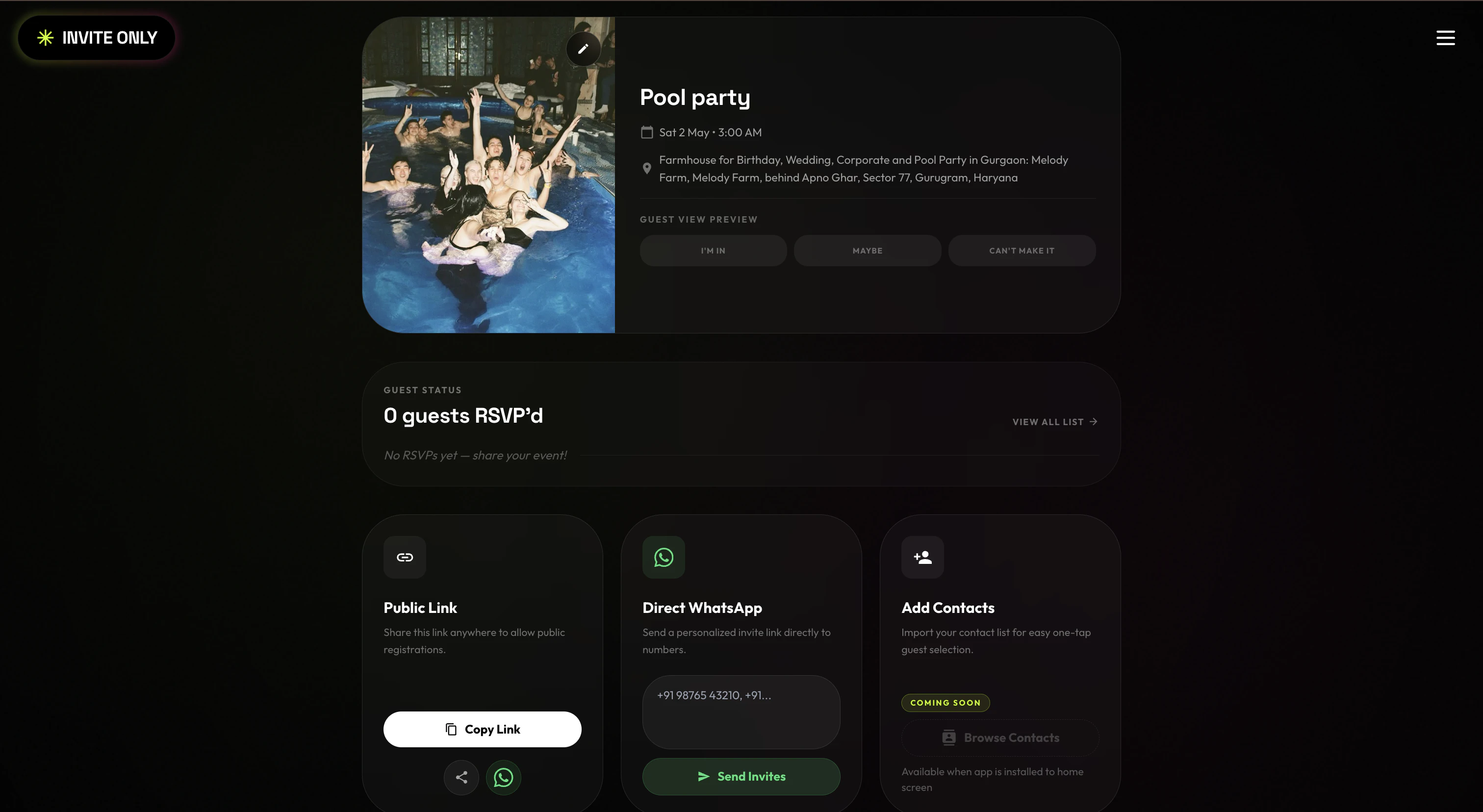
一句话介绍:Invite Only是一个专为WhatsApp优先市场设计的活动邀请工具,让主办方2分钟内创建精美邀请页,通过链接分享后,受邀者无需下载App即可在30秒内通过OTP完成RSVP并集成UPI支付,将社交聊天中的“口头答应”转化为可确认的出席名单,解决活动邀约中“说来不来”的失约痛点。
Productivity
Social Media
Live Events
活动邀请
RSVP管理
WhatsApp集成
UPI支付
零下载体验
印度市场
事件管理工具
社交裂变
签到确认
移动端优先
用户评论摘要:用户普遍认可快速RSVP和UPI集成的价值,但反馈集中于两个核心问题:一是仅支持印度手机号,非印度用户无法发布活动;二是存在发布后状态显示为草稿、链接404等发布bug。有用户质疑仅靠RSVP无法解决人性“放鸽子”问题。开发者积极回应,修复正常并请求用户提供具体环境以便排查。
AI 锐评
Invite Only切中了一个极其具体且刚性的场景:印度及WhatsApp渗透率极高的市场,活动邀约常淹没在群聊的“bhai coming”中,组委会靠数聊天记录统计人头,失约率极高。其核心价值并非“更美观的邀请页”,而是通过OTP+UPI支付形成**低成本但强约束的出席确认机制**——付了钱就意味着承诺,这是对“人话”做技术翻译。
但产品目前仅限印度手机号,本质上是一场高度本地化的封闭实验。它好就好在克制:不做App,只做WhatsApp里的一张“锚”。然而,单一市场依赖UPI,意味着走出印度就是废墟;而对“人一定会放鸽子”的质疑,评论区的反驳是“扣钱”,但UPI本身是小额即时转账,无法解决大规模预授权或定金场景,也缺乏缺席惩罚机制(如押金扣除)。换句话说,RSVP+转账可以过滤“随口应付”,但挡不住“临时捡到更香的活动”或“天太热不想出门”。
此外,评论区的Bug反馈指向发布流程稳定性问题,对于一个2周赶工出V2的产品,这可能是常态而非意外。产品真正的护城河在**生态绑定**:一旦用户的RSVP历史和群主信誉积累在Invite Only,迁移成本就会升高。但目前来看,它更像个MVP级工具,而非平台。要想真正“让答应有意义”,下一步必须引入缺席赔付、Google Calendar同步、以及非印度市场的支付适配——否则它只是WhatsApp群聊里一张更好看的“钓鱼图”。
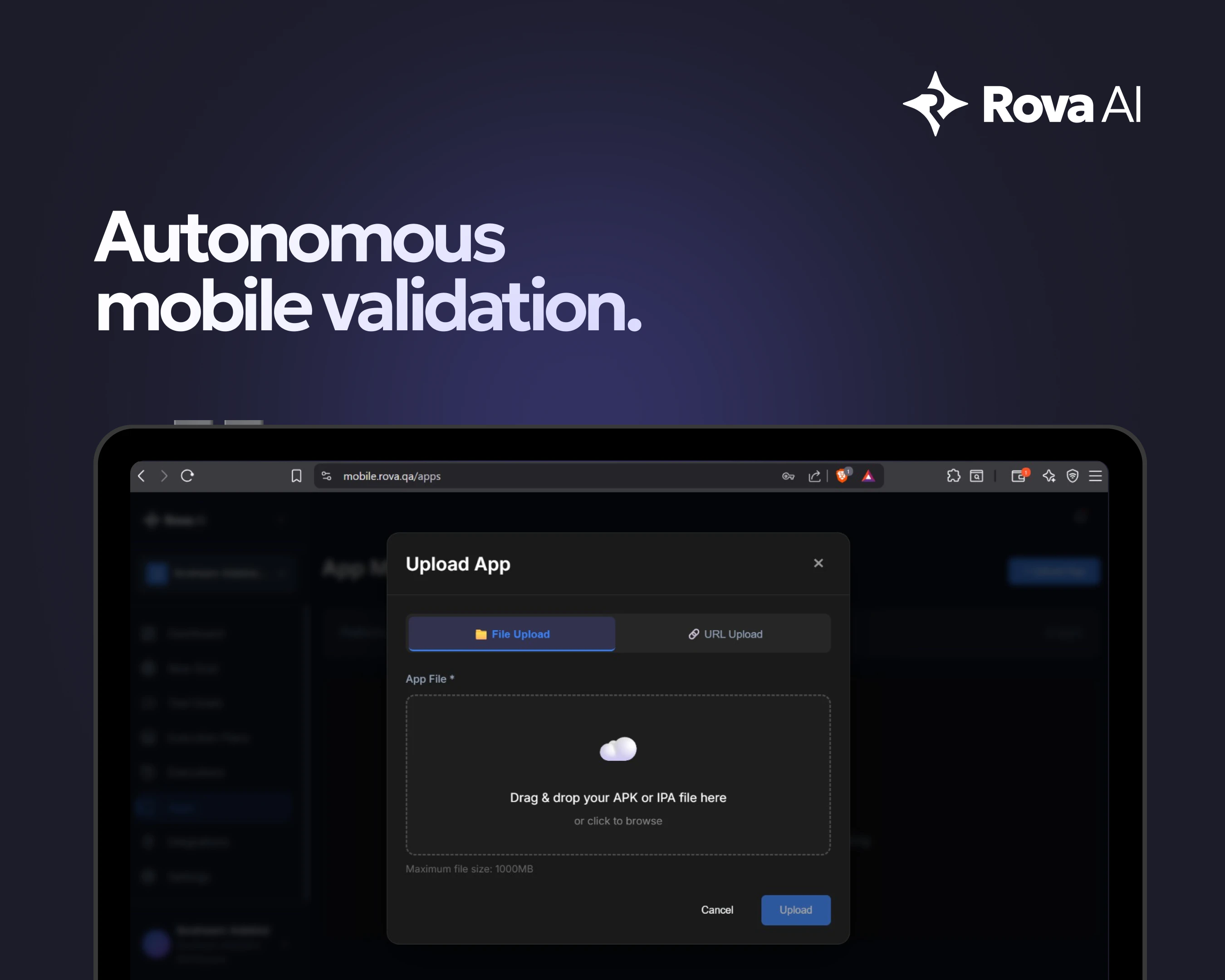
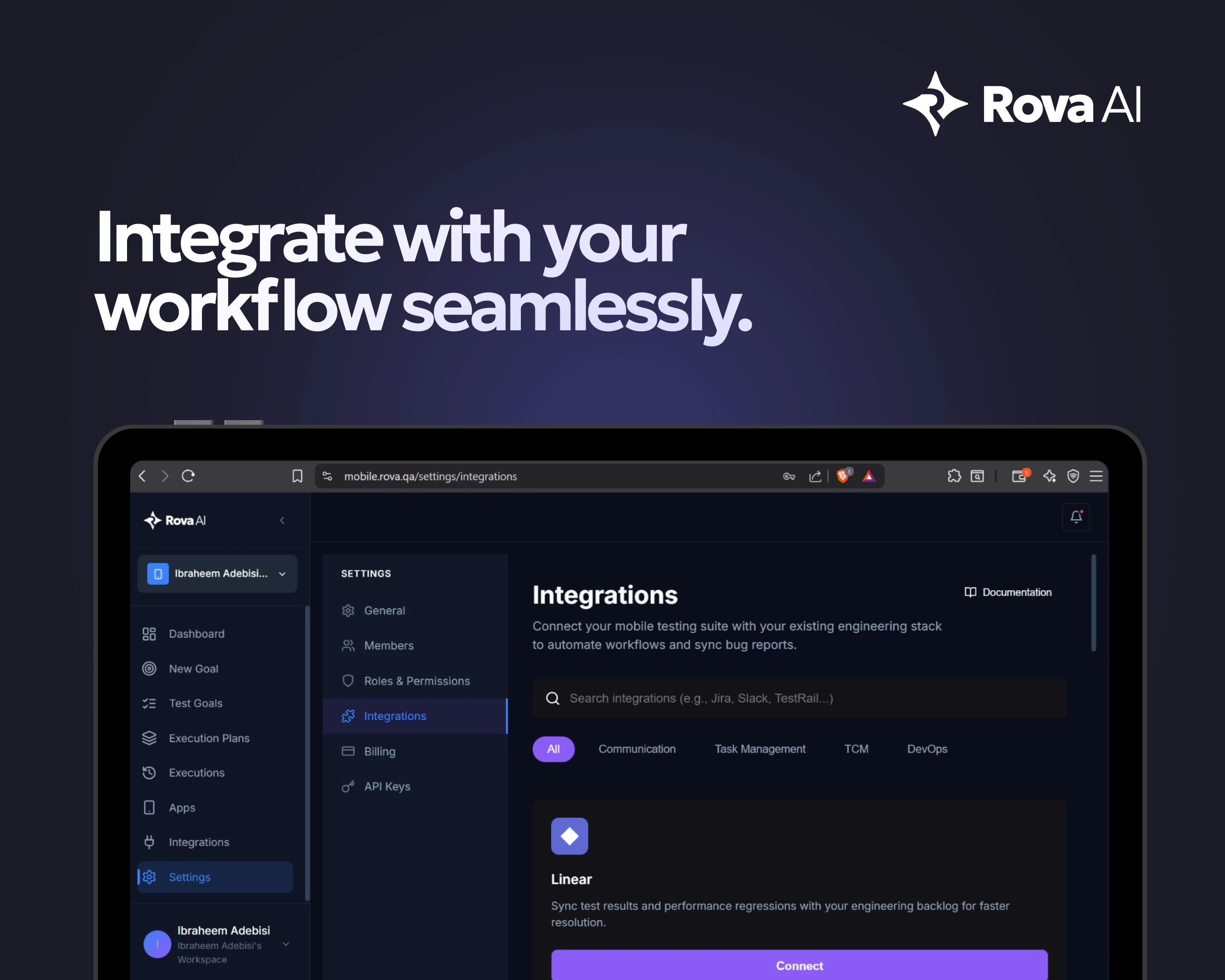
一句话介绍:Rova AI 通过“目标驱动”的自主探索式测试,解决了传统自动化测试脚本脆弱、维护成本高、UI变更即失效的核心痛点,让开发者无需写脚本即可完成Web和移动应用的端到端验证。
Productivity
Development
自动化测试
无脚本测试
AI测试
UI自适应
端到端测试
质量保障
Jira集成
移动端测试
工作流验证
测试报告
用户评论摘要:用户认可其解决了“选择器脆弱”的痛点,但关注复杂用户旅程的上下文决策机制(是否需初始配置)及含认证的多步骤流程的会话管理(支持两种模式:全流程干净启动/链式保留会话状态)。
AI 锐评
Rova AI的野心在于用“目标驱动”终结传统自动化测试的“脚本地狱”。它确实切中了当前DevOps节奏下的核心矛盾——UI迭代越频繁,测试维护成本越高,最终导致CI/CD管道中最慢的环节恰恰是“加速器”。从技术角度,Rova用AI探索替代固定脚本,理论上能解决定位器失效的顽疾,但“适应UI变化”的边界在哪里?如果面对动态渲染的复杂单页应用或频繁重排的移动组件库,其“学习能力”是依赖初始模型还是实时推理?这是决定其能否从“演示级”迈向“生产级”的关键。
值得关注的是用户评论暴露的短板:多步骤流程中的上下文感知并非“全自动”魔法,仍需人工配置会话策略,这意味着它并未完全脱离“脚本”的思维,只是将维护工作从元素定位转移到了业务逻辑的“状态边界”定义上。此外,从108票的体量看,其市场声量尚未引爆,与Playwright、Cypress等生态庞大的框架竞争时,Rova必须回答一个更深层问题:当用户已经接受了写脚本的成本,为何要为一个需要重新学习“目标定义”且可能面临黑盒不确定性的方案买单?更犀利的判断是:Rova的真正价值不在“取代脚本”,而在为“快速探索验证”这类非回归测试场景提供低成本路径,例如临时环境的手动测试辅助、Bug复现的自动化快照——这才是它区别于传统框架的差异化护城河。
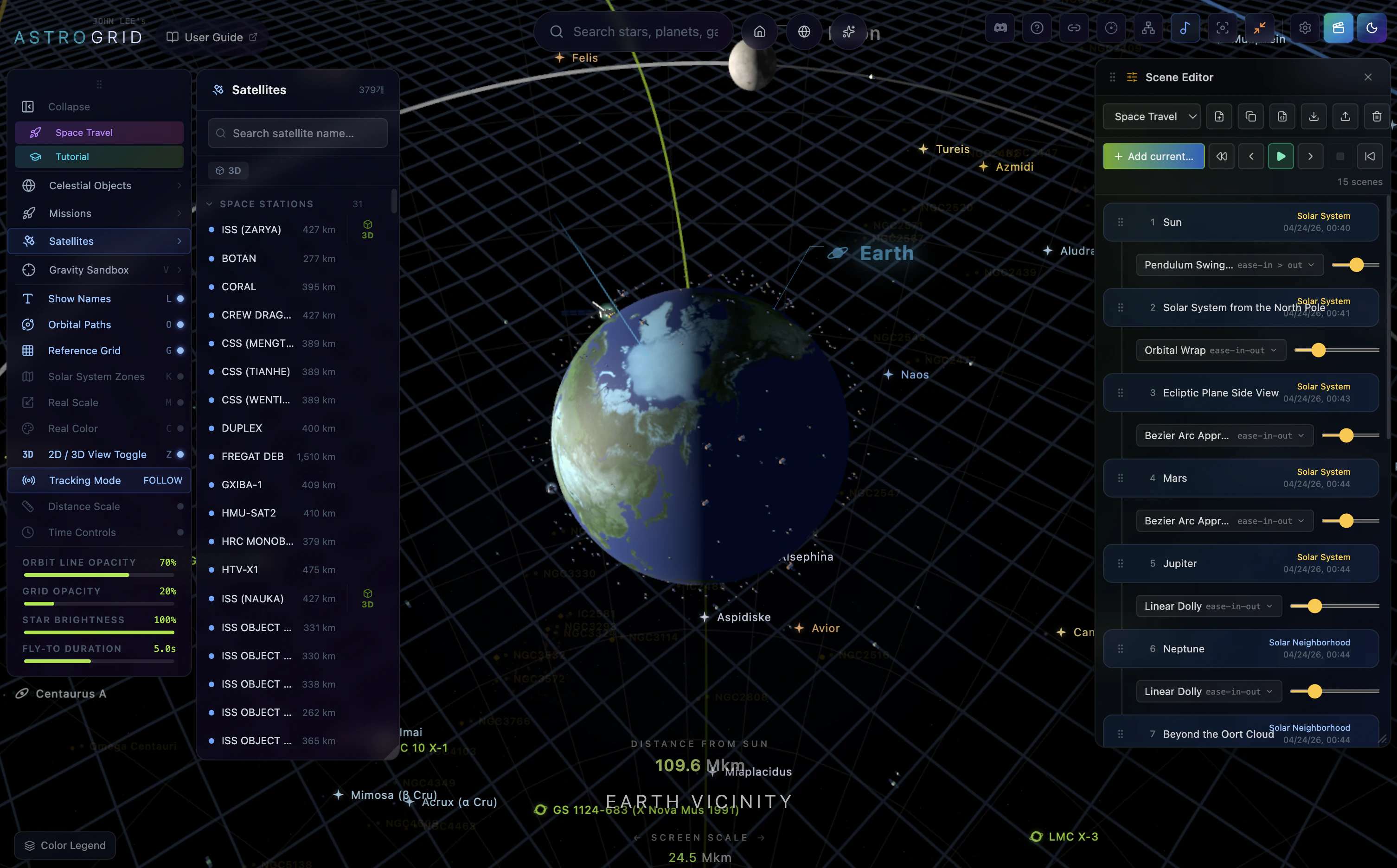
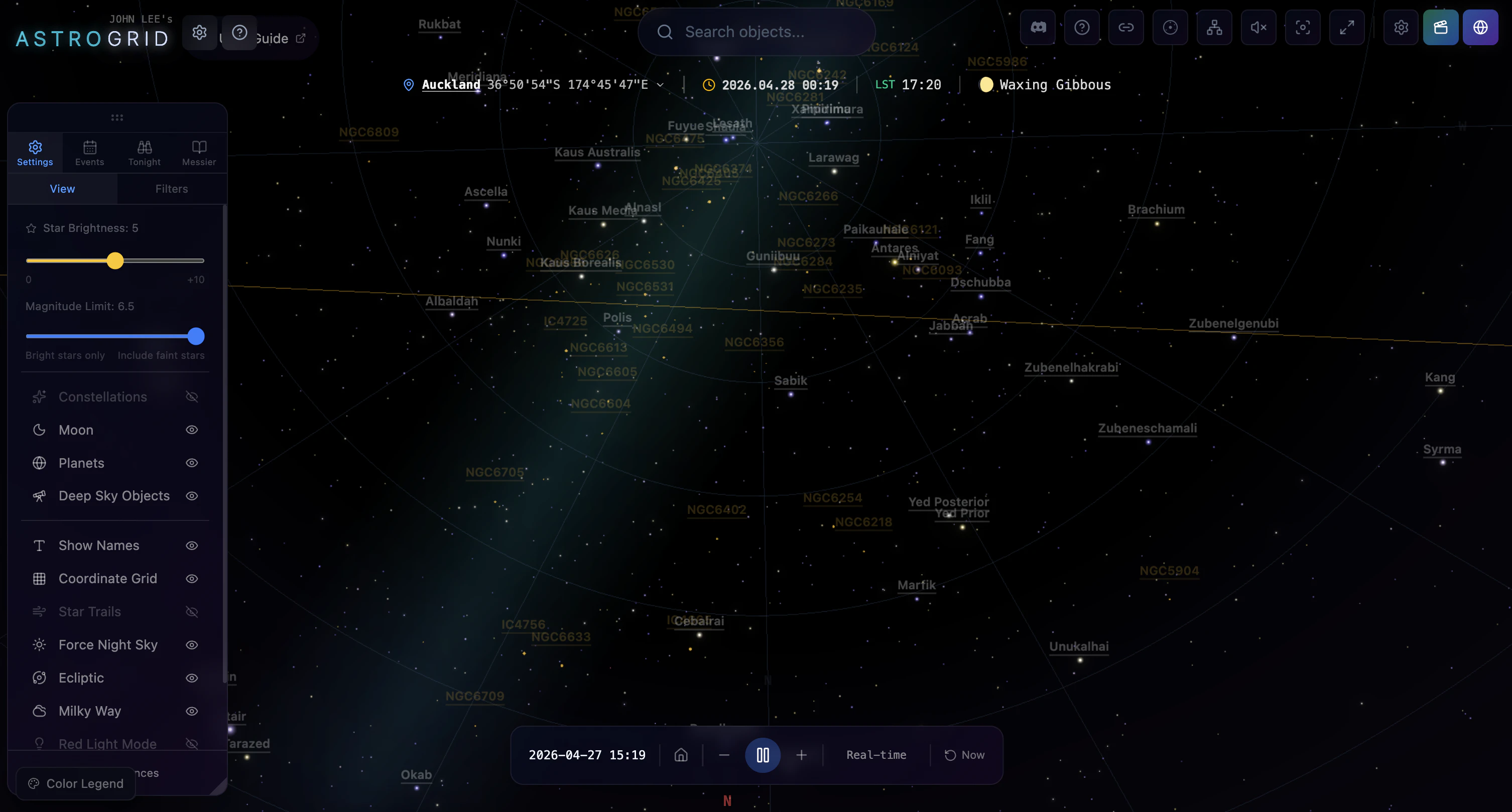
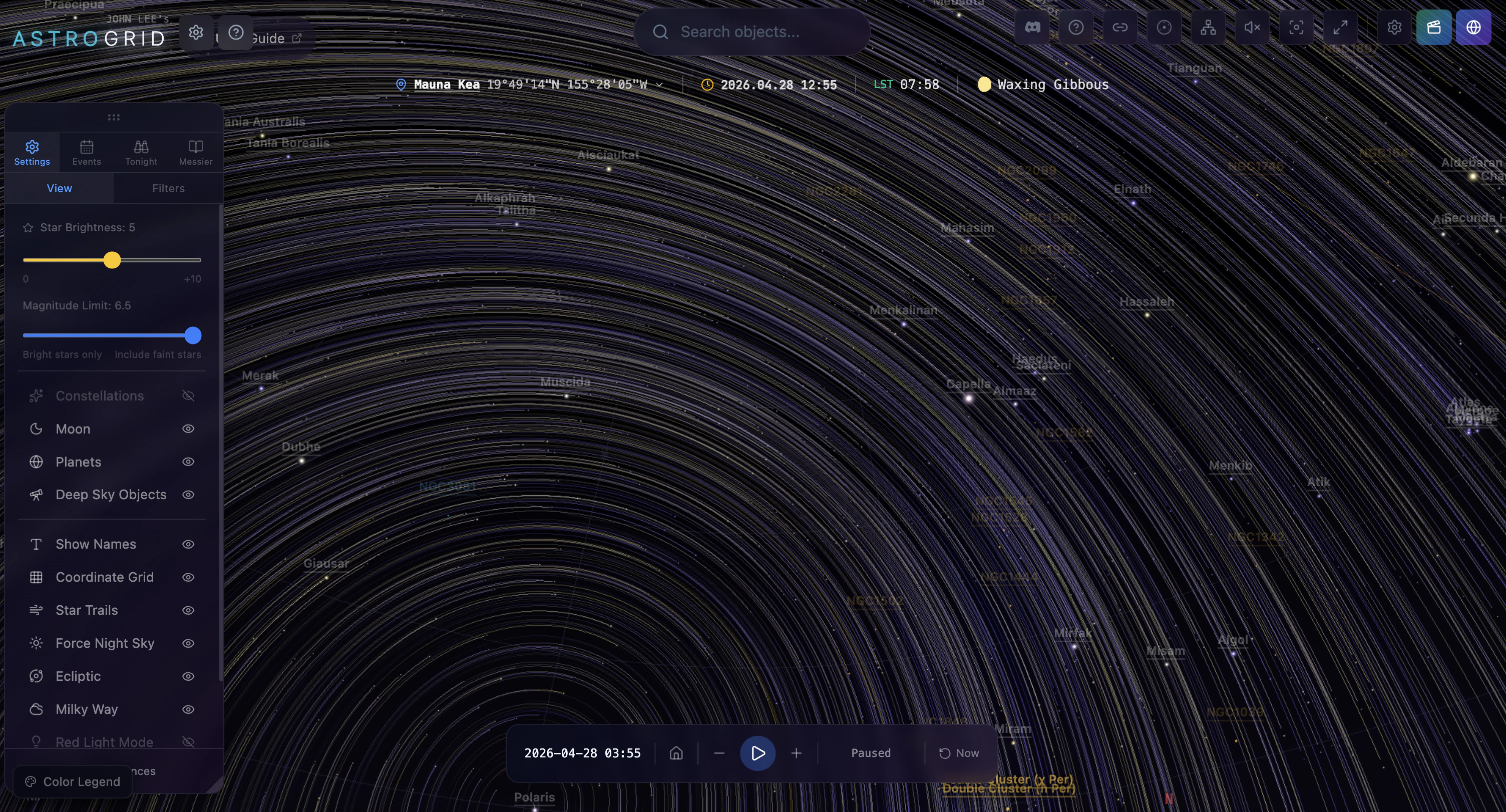
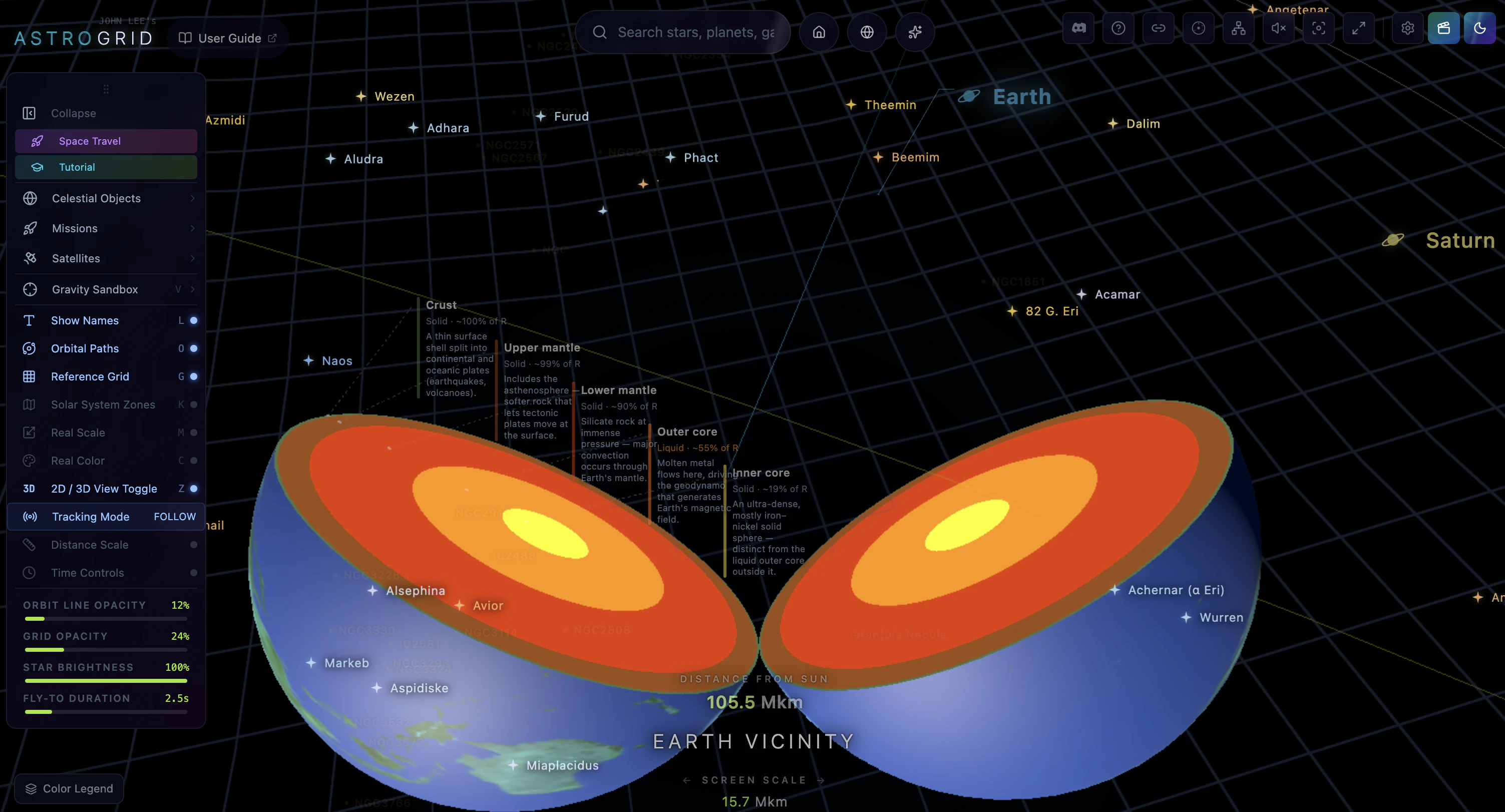
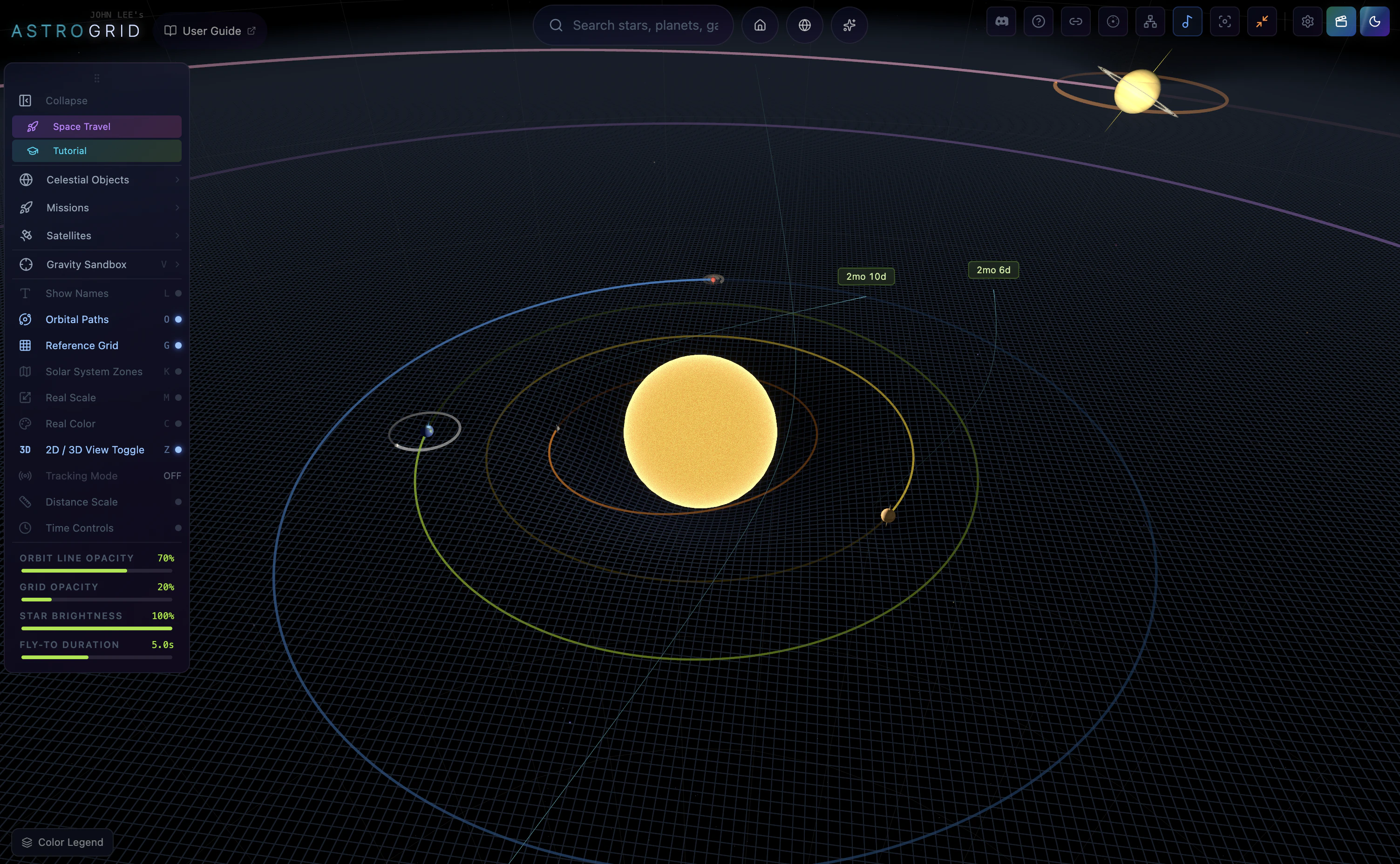
一句话介绍:AstroGrid 是一款在浏览器内实时运行的3D宇宙探索引擎,让用户无需安装或注册即可从地球表面飞越至可观测宇宙边缘,将枯燥的天文数据转化为直观的沉浸式体验。
Education
Space
Science
天文教育
3D可视化
实时渲染
浏览器应用
宇宙模拟
NASA数据
天体目录
互动学习
空间探索
开源科学数据
用户评论摘要:用户高度认可其将静态图表转化为“可飞越”的交互体验,并特别关注技术实现:如何平衡真实星表与程序化填充?建议增加引导式探索路径(如旅行者探测器轨迹),也有用户好奇教室使用场景是否影响设计决策。开发者回应称所有数据来自公开天文目录,仅用程序化填充空白区域,已内置部分场景导览。
AI 锐评
AstroGrid 的价值不在于“又一个3D天体可视化工具”,而在于它精准捕捉了天文教学中一个长期被忽视的痛点:我们从未真正“感受”宇宙的尺度与运动。教科书的数据和静态插图无法传递“为什么月球轨道倾角导致非每月月食”这类动态空间关系,而YouTube视频仍是单向灌输。AstroGrid 把浏览器变成一艘可自由操控的飞船,让用户通过“玩”来内化开普勒定律或黑洞引力透镜效应——这是典型的认知脚手架设计。
技术上,它展示了一种务实的混合策略:核心天体(恒星、行星、深空目标)基于HYG、NASA JPL等官方目录,保证观测准确性;大规模结构用算法填充,但“填得聪明”——只填用户无法验证的空白区域。这避开了游戏化模拟“看起来酷但数据假”的陷阱,也绕过了纯LOD流式加载的工程难题,是“科学教育工具”而非“视觉影片”的明确选择。
但产品尚未解决两个关键问题:其一,引导路径仍偏薄弱,对于“我只是好奇但不懂天文”的新手,自由探索可能变成无事可做的3D缩放;其二,性能受限于浏览器端,130K星体+实时轨道力学在移动端或老旧设备上可能是灾难。未来若能在“零安装”基础上增加智能教学路径、分层难度(如儿童模式),并优化边缘设备性能,它有机会成为K-12天文课的标配替代品。否则,它可能只是“极客玩具”,而非教育工具。
一句话介绍:Basedash Dashboard Agent通过自然语言描述,自动生成完整的数据仪表板,省去手动编写SQL和逐个配置图表的繁琐流程,让非技术用户秒获可视化的业务洞察。
Analytics
Artificial Intelligence
Data & Analytics
AI仪表板生成
自然语言查询
自动SQL生成
数据分析
商业智能
无代码
SaaS工具
智能布局
Product Hunt发布
用户评论摘要:用户赞赏其从模糊描述到有用仪表板的转化效率;质疑点集中在:当AI的SQL解读与用户意图不符时如何修正,以及数据模型含多张相似表(如“收入”)时是主动澄清还是默认选择,避免变成无休止的对话。
AI 锐评
Basedash Dashboard Agent的“一句话生成仪表板”确实拉低了数据可视化的门槛,但它的真正价值不在于“AI写SQL”(这类工具已有不少),而在于“语义理解+智能布局”的组合——它试图解决一个更本质的痛点:用户不知道自己该看什么。当你说“新用户注册的一切”,AI需要理解你的角色、问题优先级和叙事逻辑,这比单纯转换SQL难得多。然而,评论中暴露的核心问题不容回避:数据模型映射的歧义。如果AI在多个“收入”表间擅自选择,用户得到的可能是一个漂亮但错误的仪表板。这时候,要么引入显式消歧步骤(但破坏“一句搞定”的体验),要么依赖更深的元数据学习。该产品目前更像是“优秀原型”,而非终极方案。真正拉开差距的,是其能否在“智能猜测”和“可控性”之间找到临界点,并在用户首次出错时,用最少的步骤让用户纠正,而不是让用户退回到SQL编辑器。对于中型SaaS团队,它足够好用;但对于数据模型混乱的企业,它可能只是一个更快的错误生成器。
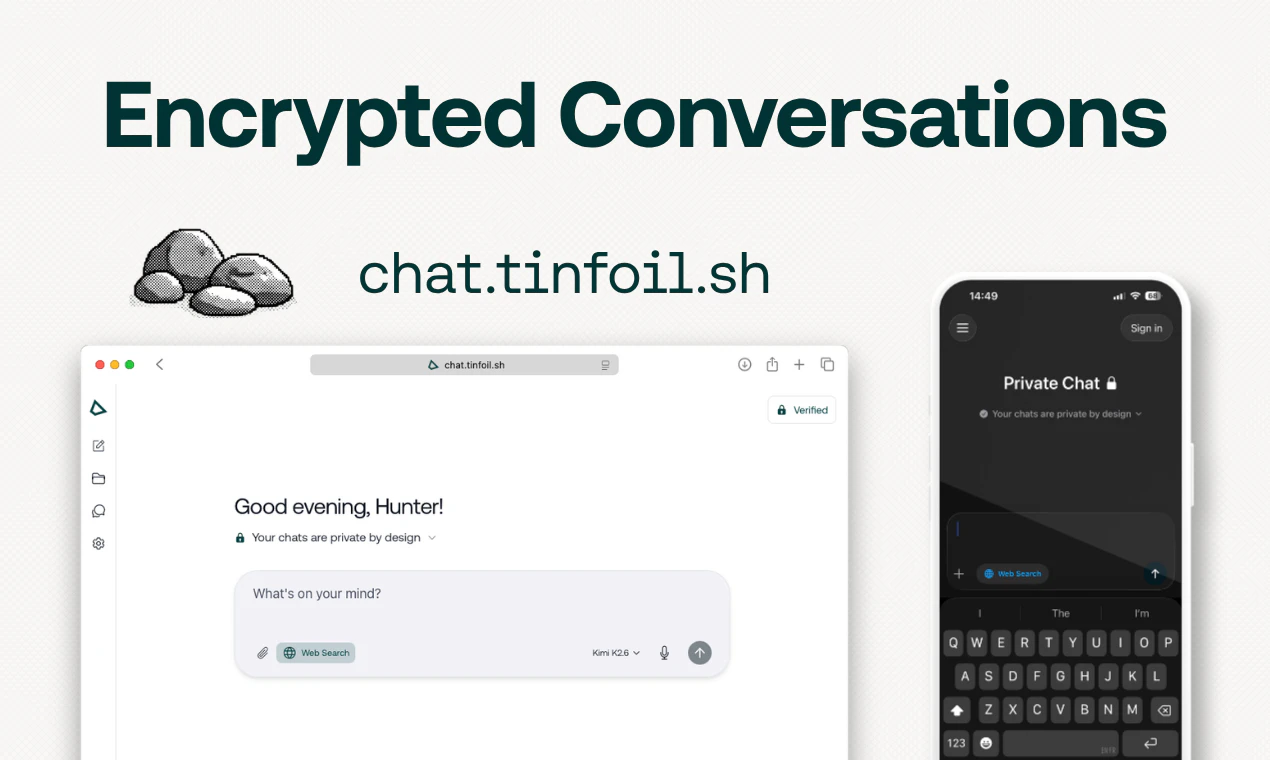
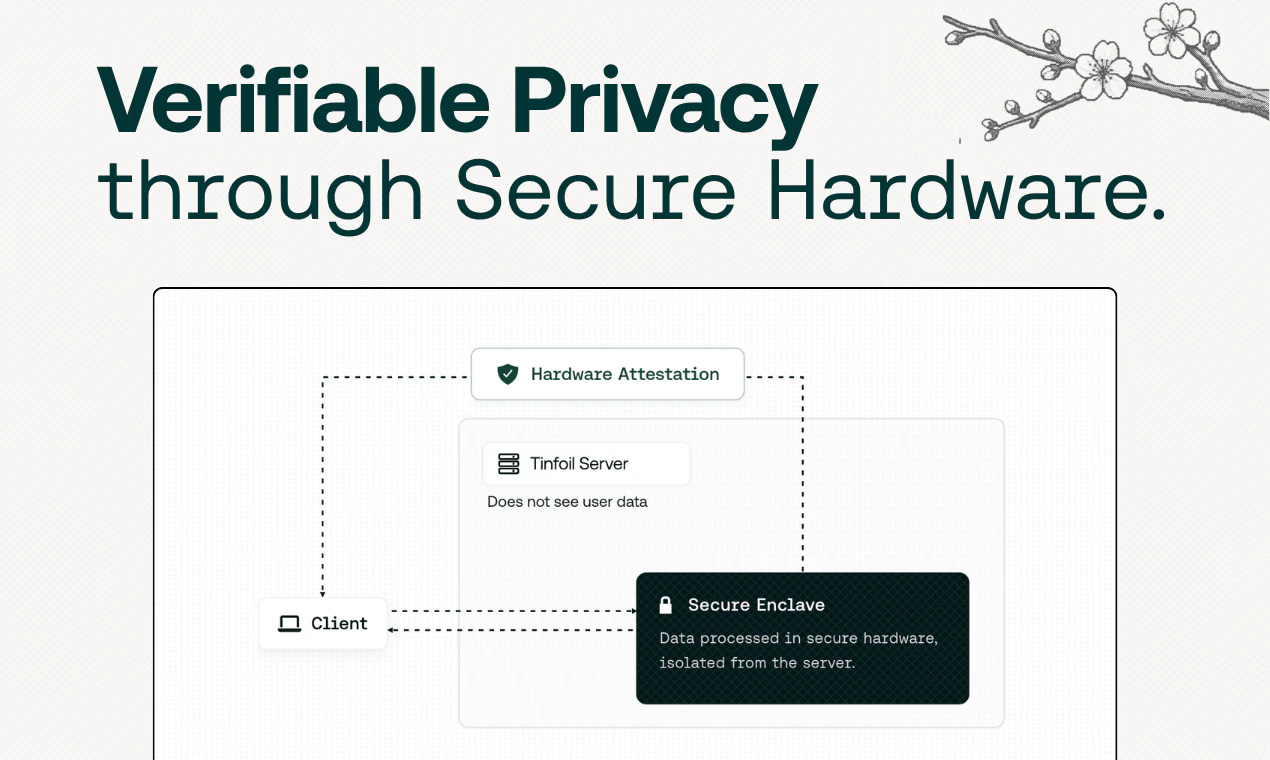
一句话介绍:Tinfoil是一个运行在云端但利用NVIDIA GPU硬件安全区技术的AI聊天与API服务,确保用户与AI模型的对话在存储、处理过程中全程端到端加密且可远程验证,解决了用户担心主流AI厂商窥探或滥用个人私密对话的核心痛点。
Productivity
Artificial Intelligence
Encryption
隐私AI
端到端加密
硬件安全区
可信执行环境
NVIDIA H100
远程认证
开放模型API
开源可审计
AIChat
机密计算
用户评论摘要:用户高度认可其解决隐私与AI能力矛盾的创新价值。核心疑问聚焦于:硬件安全模型是否完全排除NVIDIA及Tinfoil自身访问数据的可能(已得到明确否定回复);隐私验证与产品易用性/性能的平衡;早期恢复流程有粗糙之处但团队响应积极。
AI 锐评
Tinfoil切入了一个现实且日益尖锐的痛点:当AI聊天从工具演变为“数字日记”和“思想伴侣”,用户对隐私的渴求已超越单纯的“不使用数据训练”的承诺。其真正的价值不在于“更私密的AI”,而在于构建了一个“可验证的、零信任的AI运行环境”。
技术路线上,结合NVIDIA H100的机密计算和开源固件+远程认证,确实在“云AI”与“本地AI”之间找到了一个极具说服力的折中方案。它避免了本地部署的性能和模型选择限制,又通过硬件级隔离将传统云服务的信任边界从“服务商承诺”实质性地推进到了“制造商硬件实现”。这种从软信任到硬证明的跃迁,对于处理商业机密、法律文件、个人健康等高度敏感场景,具有颠覆性意义。
然而,不能回避的是:该模型的最终信任锚点仍落在NVIDIA作为硬件制造商之上,这并非哲学意义上绝对的零信任。其次,当前模型列表虽包含热门开源模型,但并未覆盖所有顶尖闭源模型,这是其在能力上限上做出的明确取舍。最后,$20/月的聊天订阅定价处于中高位,其市场成败将高度取决于目标用户是否认为“可验证的隐私”值这个溢价。Tinfoil没有解决AI隐私的全部问题,但它为解决其中最关键的一环——数据在处理过程中不被窥探——提供了目前最优雅、最可操作的工程化答案,这本身就是一个值得书写的故事。
一句话介绍:ElevenMusic是一个将AI辅助音乐创作、独立艺人发现与互动分账机制相结合的平台,帮助独立音乐人解决分发难和变现难的问题。
Music
Marketing
Artificial Intelligence
AI音乐创作
独立音乐人平台
音频混音
互动收益
音乐分发
版权分账
音乐发现
iOS应用
网页端
用户评论摘要:用户主要关心两个问题:一是remix功能下原创作者与混音者之间的版权分成机制是否自动,还是需要原创者主动选择加入;二是对产品理念表示认可,期待其成功。
AI 锐评
ElevenMusic试图在AI音乐工具泛滥的赛道里打一张“生态牌”——它聪明地把AI创作引擎、独立艺人发现和ElevenLabs验证过的声纹分账模式缝合在一起。核心差异在于“内容先行”:先签约4000+独立创作者作为底层资产,然后用AI remix和创作工具降低门槛,最后用“互动即收益”的机制吸引双方进场。这解决了两个痛点:独立艺人不用再为分发和变现两头跑,听众则有了比简单消费更有创造力的参与方式。
但问题同样明显。首先,“互动收益”模型在语音领域成功,不意味着在音乐领域能平滑迁移。音乐消费的停留时长、互动深度和付费意愿,与语音库样本截然不同;如果单曲平均互动价值过低,所谓的“效能验证”就会变成数字幻觉。其次,remix功能放大了版权划分的复杂性——目前官方对“混音后收益如何自动分账”的回答相当模糊,这几乎是所有UGC音乐社区的致命伤。一旦摩擦过高,原创者可能选择退场,生态会迅速冷启动。
从竞争格局看,ElevenMusic一面要面对Suno、Udio等纯AI生成工具对用户时间的争夺,另一面要说服Bandcamp、SoundCloud上的独立作者迁移。其真正的赌注不是技术,而是能否让“分账”变成一个足够低门槛、高透明度的信任机制。如果只是把ElevenLabs的合约模板照搬过来,而没有为音乐场景设计更精细的归属和审计规则,那么这更像一个漂亮的“包装器”,而非真正的替代方案。这产品值得关注,但别急着给“独立音乐的新未来”叫好。
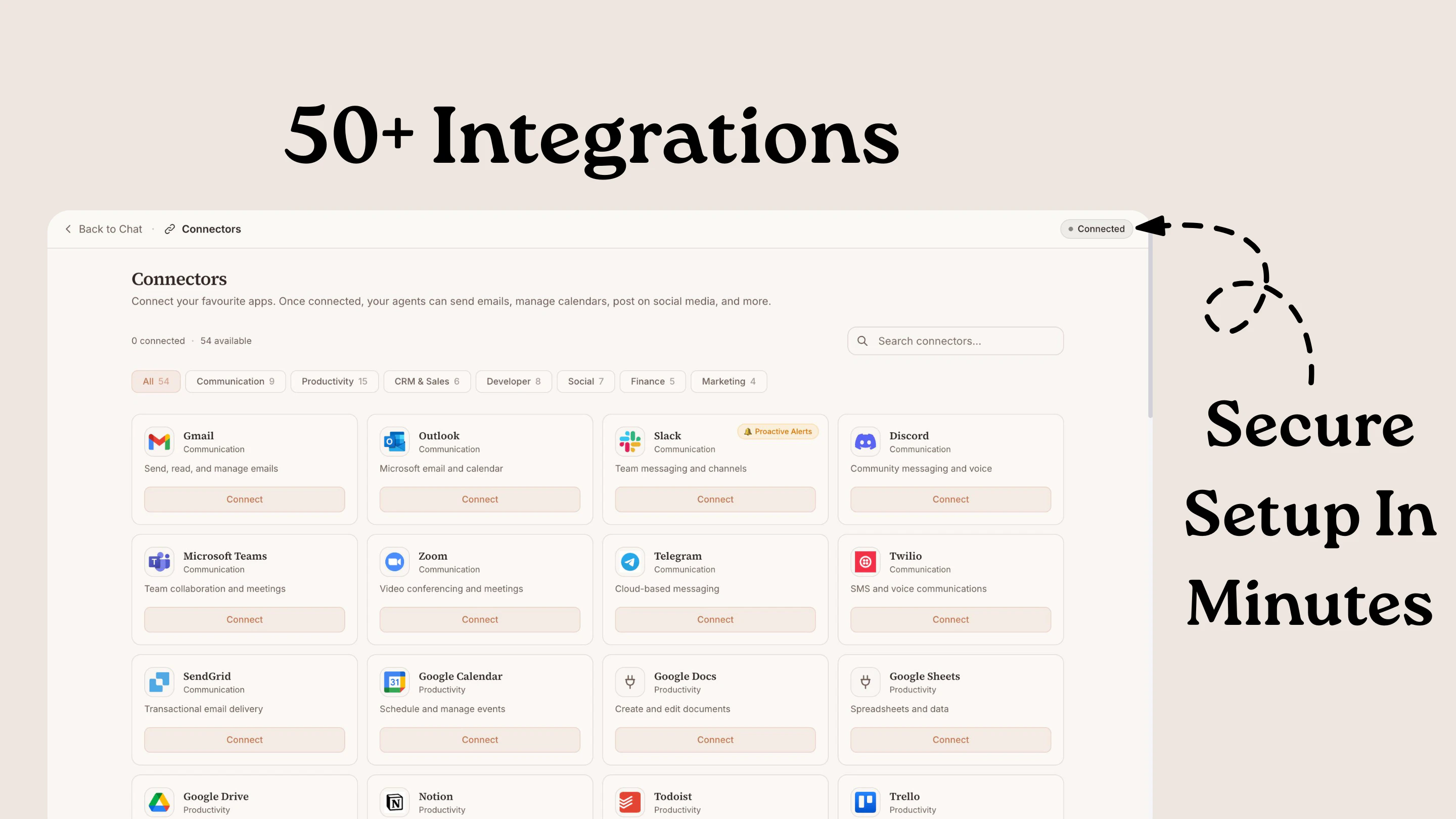
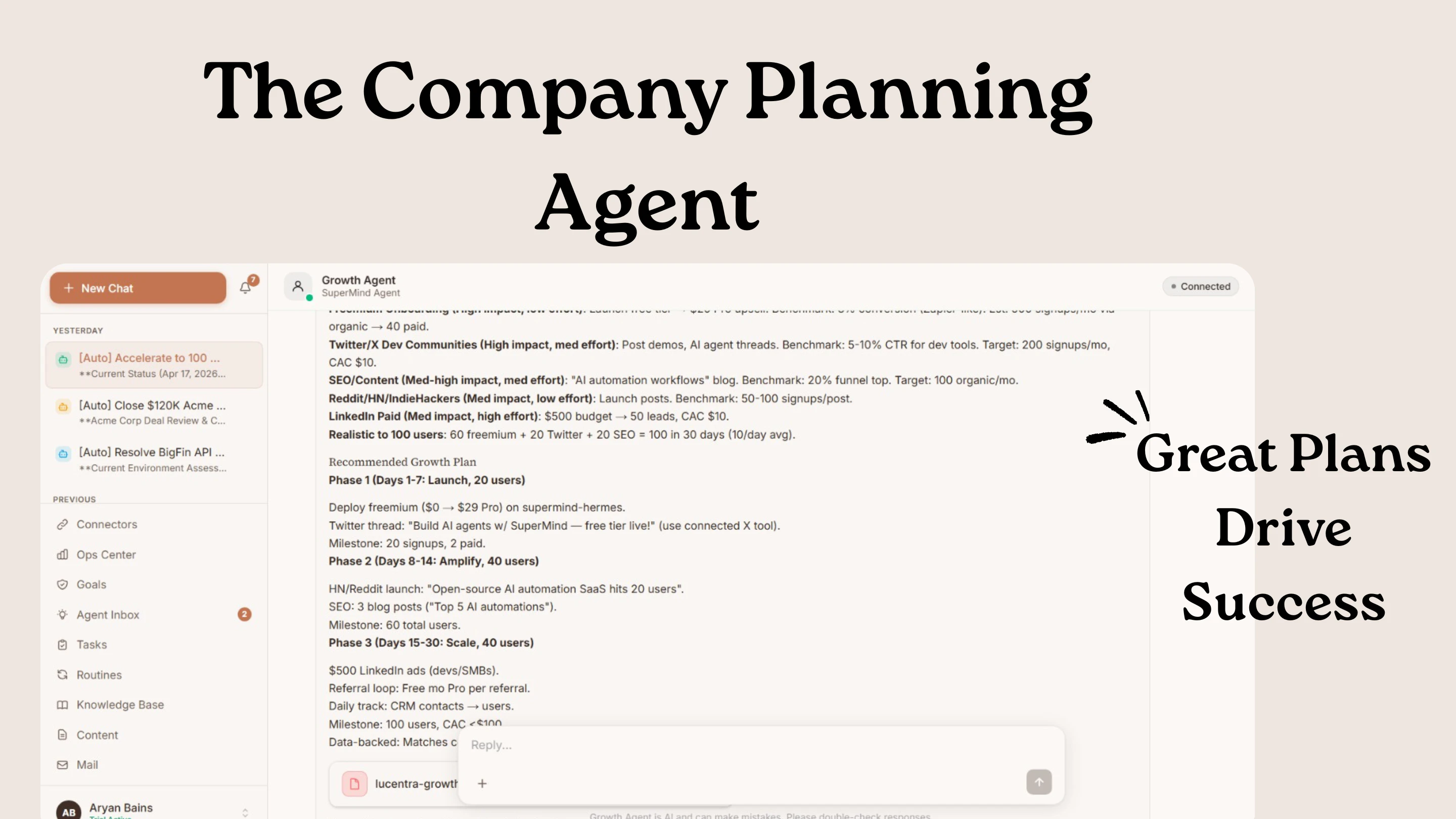
一句话介绍:SuperMind通过部署13个专业AI代理(覆盖销售、财务、法律等),将其作为“操作系统”自动执行业务流程并需人工最终审批,解决创始人或管理者在决策链中成为瓶颈的痛点,实现“业务自主运行”。
SaaS
Artificial Intelligence
Business Intelligence
AI代理
业务自动化
工作流协调
审批管理
企业操作系统
多代理协作
智能助手
SaaS
效率工具
企业管理
用户评论摘要:用户关注多行业适应性与学习机制(规则驱动还是自主学习)、代理幻觉控制与业务目标对齐、多项目并行及模型选择、初始上下文获取与快速上手。创始人回应称代理基于公司上下文、人工审批兜底、支持并行与多模型选项。
AI 锐评
SuperMind巧妙地将“自动化”包装成了一尊“AI董事会”——看似在为老板减负,实则是在做一个极其微妙的权力让渡实验。其核心卖点“One tap approvals”和“Morning briefings”精准命中了那些被琐事淹没的创始人最渴望的尊严:终于不用自己写邮件,只需要“点头”。但这套系统的真正价值,可能不在于它多聪明,而在于它如何定义“重要事项”。
产品的深度隐患在于:当13个代理在并行运行,它们对业务的理解终究是“规则+历史数据”的模拟。用户提到的“Legal与Finance代理同时告警”场景恰是关键——跨代理的“隐性冲突推理”能力未被明确证实。如果代理只是将不同维度的告警堆叠在早报里,那么创始人只是从一个“手动瓶颈”变成了“信息聚合器上的瓶颈”,痛点并未根除。
此外,从用户对“初始上下文获取”的追问可以看出,产品的冷启动质量决定了初期信任。如果前期的“公司记忆”录入过于简化或模板化,后续的“越用越聪明”很可能沦为缓慢的试错。SuperMind的真正壁垒,不是13个代理的数量,而是它能否在长期交互中建立一套输不起的“业务知识图谱”——让代理之间的决策产生逻辑串联,而非单点触发。否则,它不过是披着“操作系统”外衣的、更精致的通知推送工具。一句话:方向值得押注,但期望管理要精准。
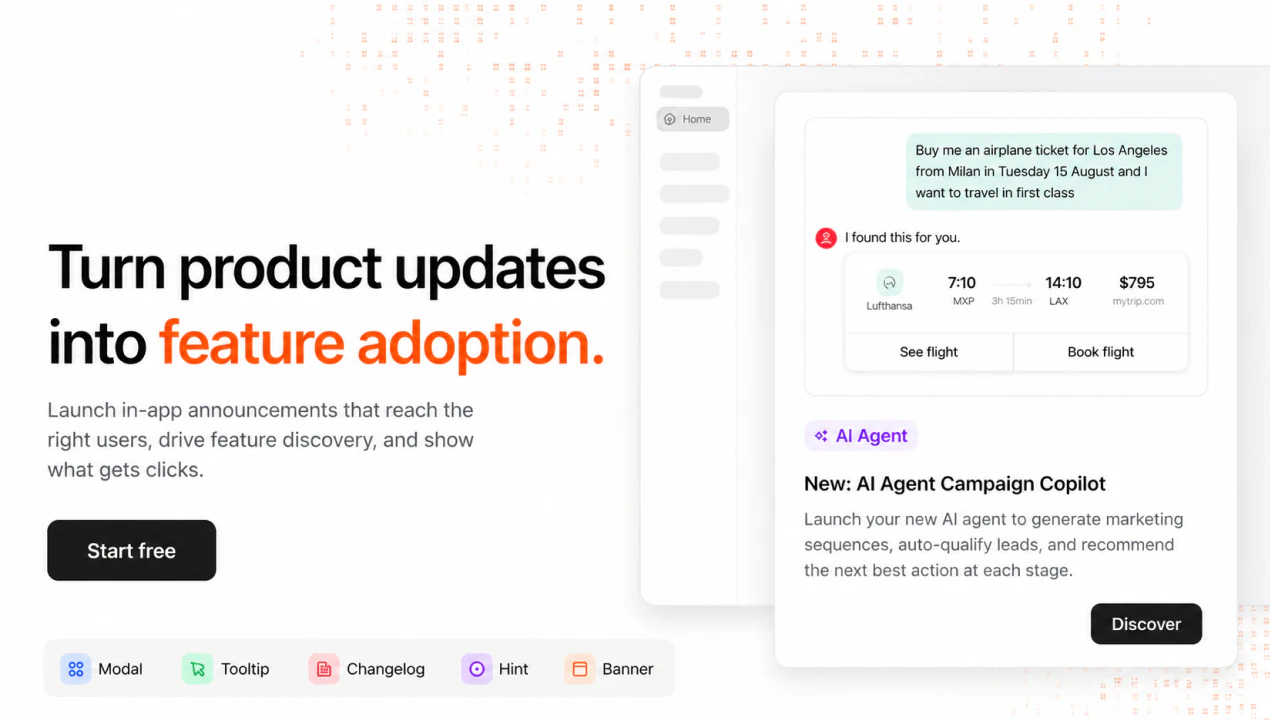
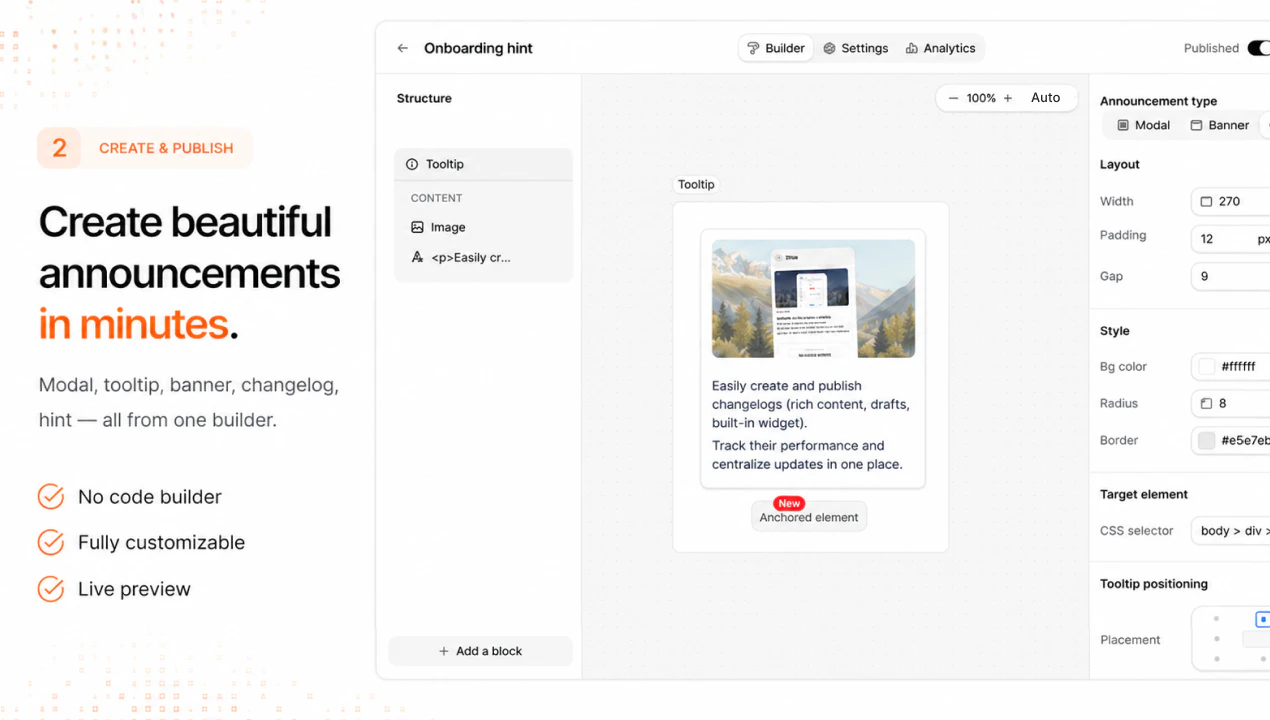
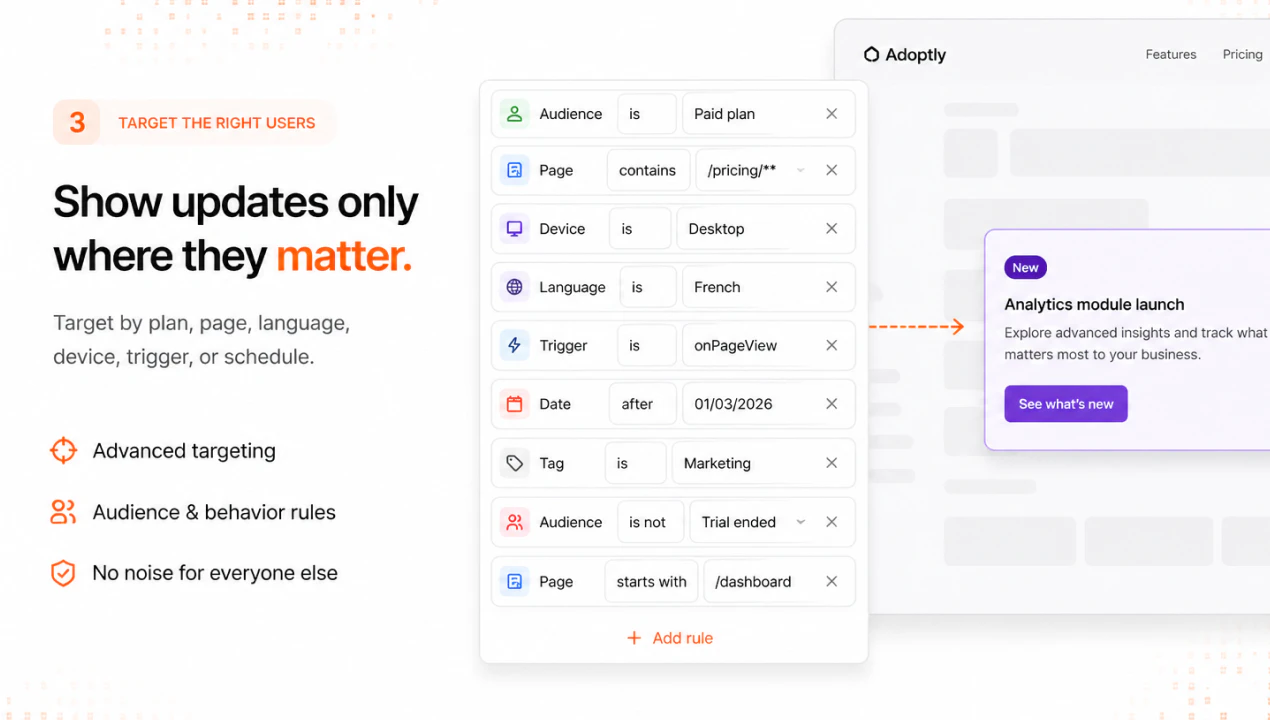
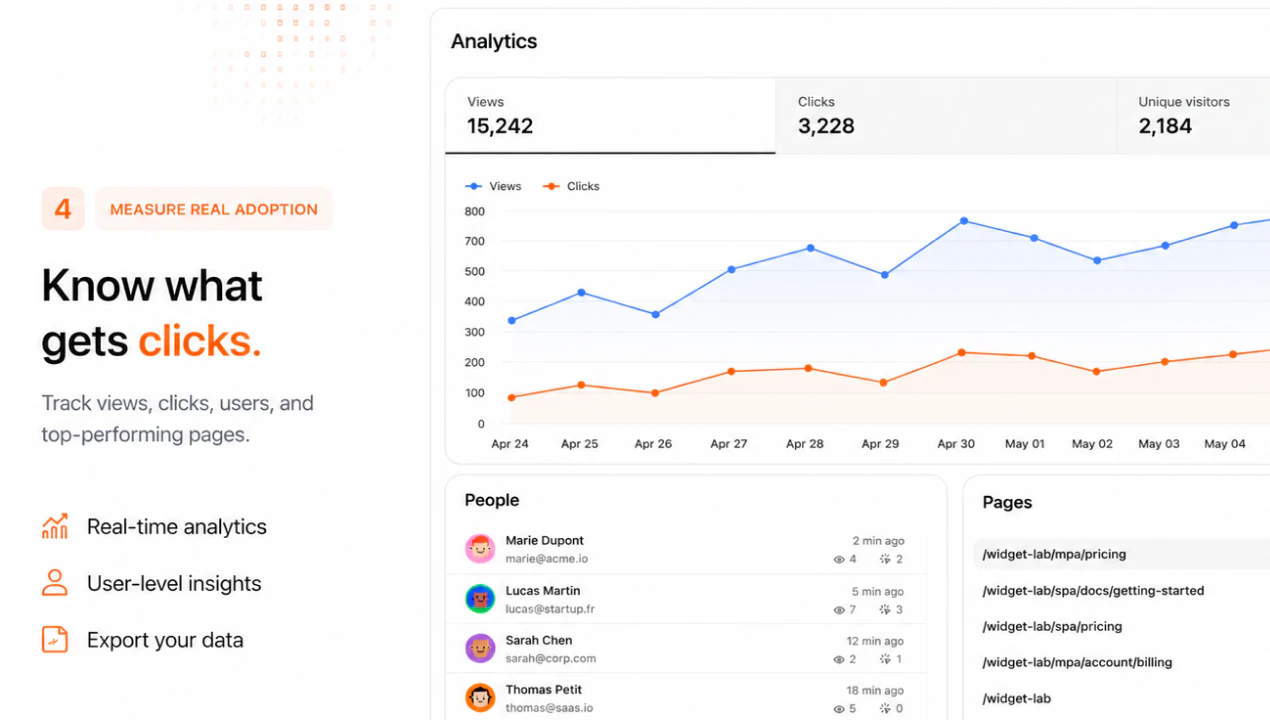
一句话介绍:Adoptly是一款轻量级、高性价比的SaaS内应用公告工具,帮助产品团队通过美观的横幅、弹窗、提示和更新日志,将新功能发布高效转化为用户采用,解决功能上线后用户“看不见、不会用”的核心痛点。
Customer Communication
Marketing
SaaS
应用内公告
功能采用
SaaS工具
产品更新
用户引导
轻量级
价格透明
独立开发者
产品发布
用户留存
用户评论摘要:用户普遍认可其解决“功能发布后用户不发现”的痛点,赞赏定价策略。主要建议包括:未来可集成用户行为分析以追踪公告效果;用户询问是否提供内容生成帮助(已规划AI通过代码提交自动生成公告);用户关心实现简易度和API/MCP支持(目前无,但表示可探索)。
AI 锐评
Adoptly切中了一个微小但普遍且昂贵的痛点:功能发布与用户采用之间的断裂。市场上并非没有类似工具,但如创始人所言,它们要么笨重、难看,要么贵得离谱(3k美元/月)。Adoptly的聪明之处在于做了减法——它不试图成为“全能型新手引导怪兽”,而是聚焦于公告的创建、定向和测量这一狭窄闭环。这种策略在面对独立开发者、小团队和“vibe-coder”群体时具有精准杀伤力,因为该群体既没钱也不用复杂工具,但恰恰是最需要快速告知用户“我发新功能了”的群体。
然而,产品当前的竞争力更多停留在“价格”和“美貌”层面。真正决定其长期价值的关键,在于评论中用户反复追问的两点:一是能否证明公告确实带动了功能采用(即测量闭环),二是能否帮助用户更好地构思公告内容(即AI生成)。Adoptly目前在这两处均处于“即将上线”状态,存在明显的功能缺口。一旦这两环补齐,它就能从一个“好看的通知组件”进化为“功能采用的增长引擎”。反之,如果只停留在工具层面,面对Notion类产品自带的公告功能,其护城河将相当脆弱。另外,API/MCP虽是高频请求,但若过早开放,可能让产品偏离“开箱即用”的简洁优势,建议优先夯实核心闭环再谈生态。
一句话介绍:Docky 是一款 macOS 程序坞替代工具,通过提供应用分组、整理和自定义功能,解决了原生Dock无法高效管理大量应用的痛点,同时集成了窗口切换与启动台等增强操作。
Mac
Productivity
macOS工具
程序坞替代
应用管理
应用分组
桌面美化
启动台
窗口切换
效率工具
Widgets
系统增强
用户评论摘要:用户普遍认可分组功能的价值,但有三处关键反馈:一是应用无法正常工作,且导致系统原生Dock隐藏失效,卸载后问题依旧;二是开发者回应称可通过设置恢复,并承诺后续版本将分离此功能;三是用户关心分组交互逻辑(堆叠或弹出),开发者确认支持网格、列表和内联三种模式。
AI 锐评
Docky本质上是在做一件勇敢但吃力不讨好的事——在macOS这个封闭的生态里,强行给用户一个“更好用的Dock”。从功能上看,它确实切中了痛点:原生Dock那套“没有文件夹、无法真正分组、只能靠堆叠图标”的逻辑,对于重度用户来说早已捉襟见肘。Docky提供的Widgets、应用文件夹、以及三种分组交互模式,都是直指Mac效率缺陷的硬需求。
然而,问题同样尖锐。首先是最致命的兼容性与系统侵入性问题:已有用户反馈App导致原生Dock隐藏失效,即便卸载也无法恢复。这表明Docky在系统级Hook上做得太“深”,却没有准备好完善的恢复机制。对于一个要接管系统基础交互的工具,稳定性是第一生命线,一旦出现“卸载后遗症”,用户信任将瞬间崩塌。开发者给出的“手动去设置里关掉禁用原生Dock”的临时方案,听起来更像是紧急补丁而非成熟设计。
其次,从产品策略看,Docky面临的是“替代”而非“增强”的尴尬。用户习惯了原生Dock的十年如一日的稳定,Docky如果要说服用户迁移,必须在“不出错”的前提下,提供至少两倍以上的效率提升。目前它只是把一堆“本该苹果做但没做”的功能拼在一起,缺乏颠覆性的交互范式。评论里虽然有1个点赞的“梦想成真”式好评,但这更多属于早期用户的热情,不能代表大众耐受度。
如果Docky能快速解决系统影响问题,并坚持打磨“分组”和“窗口切换”这两个核心效率点,它有潜力成为类似Bartender之于菜单栏的“必装工具”。否则,它只会是又一个消失在系统更新日志里的“第三方Dock替代品”。市场对它没有耐心,只有第一印象。
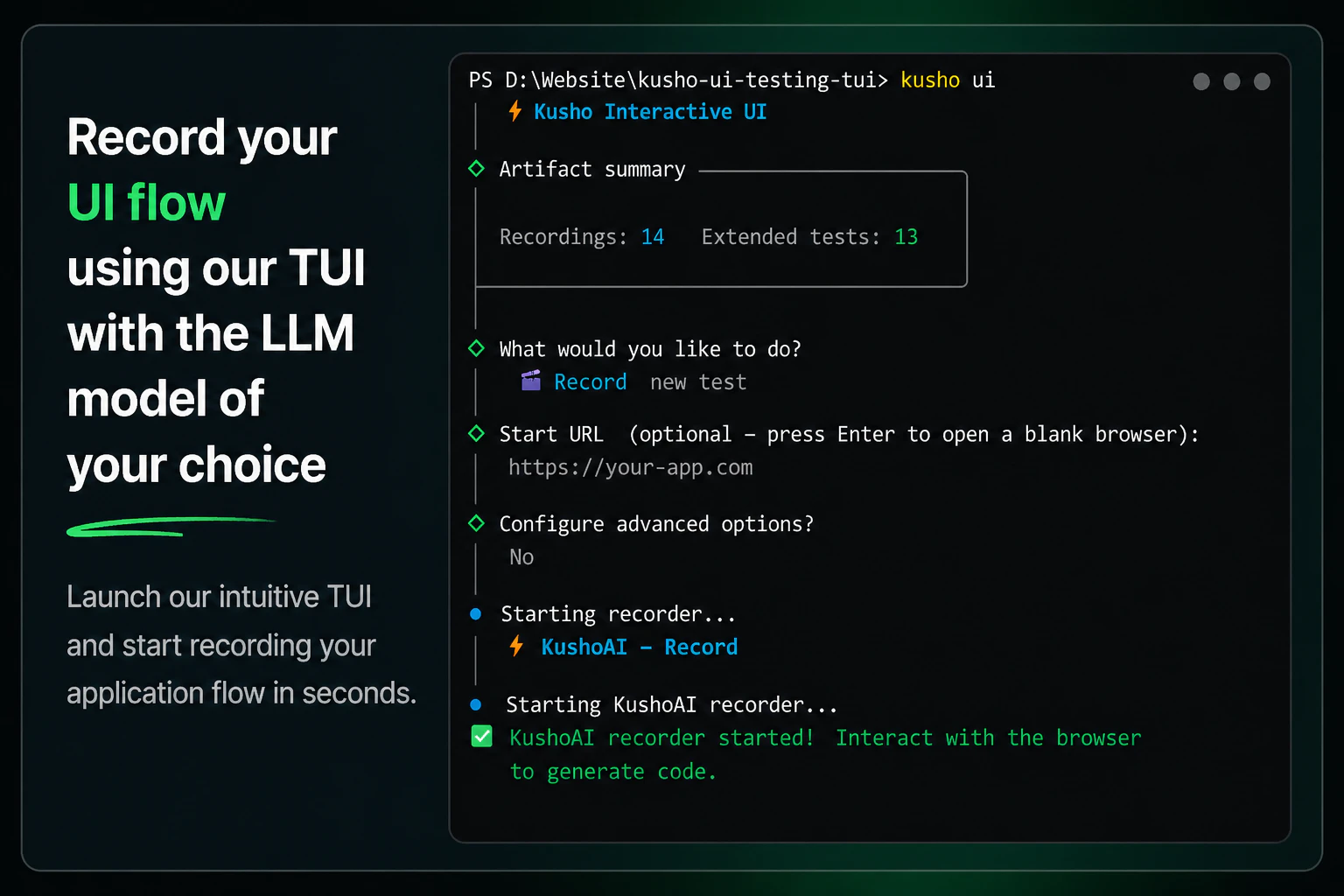
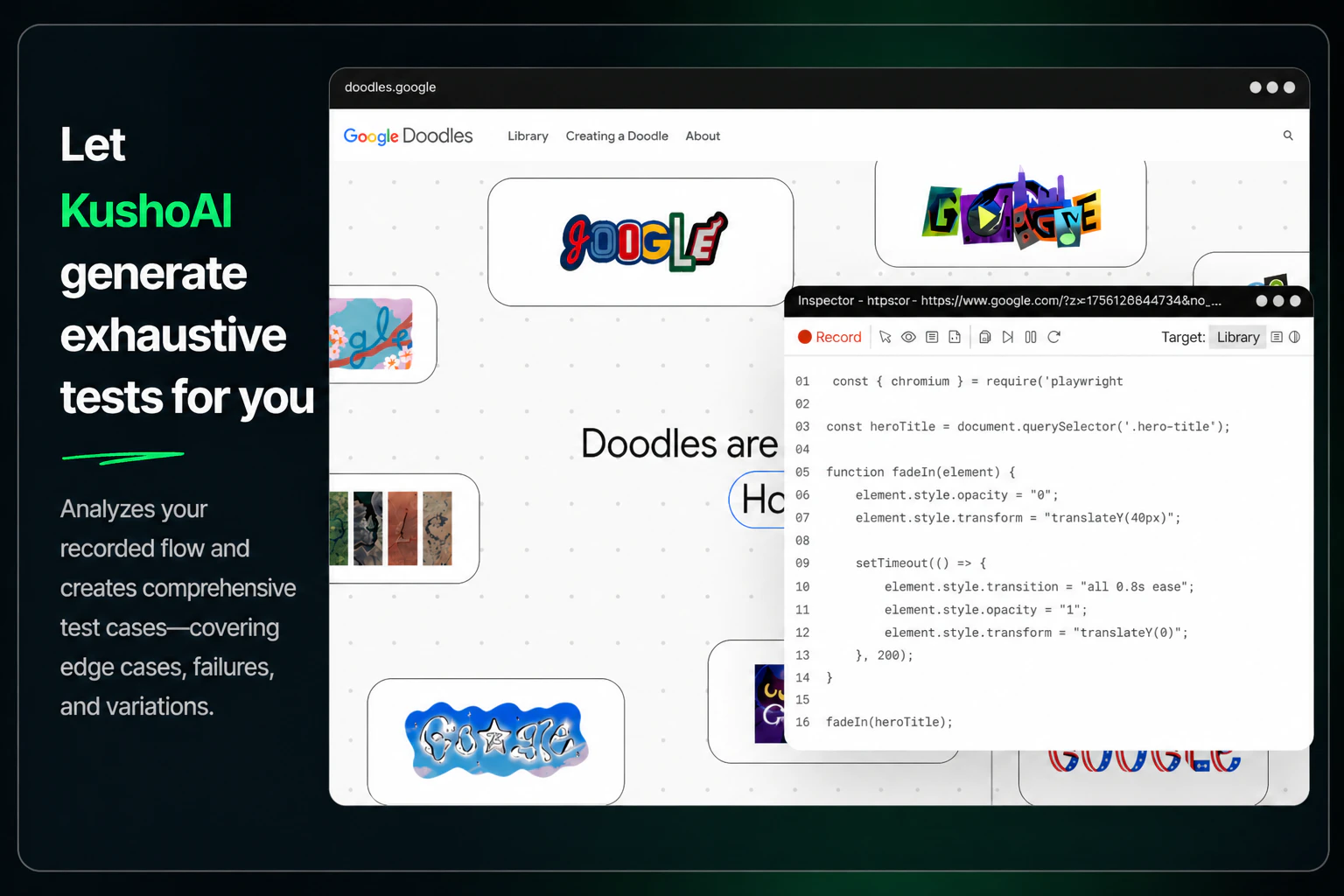
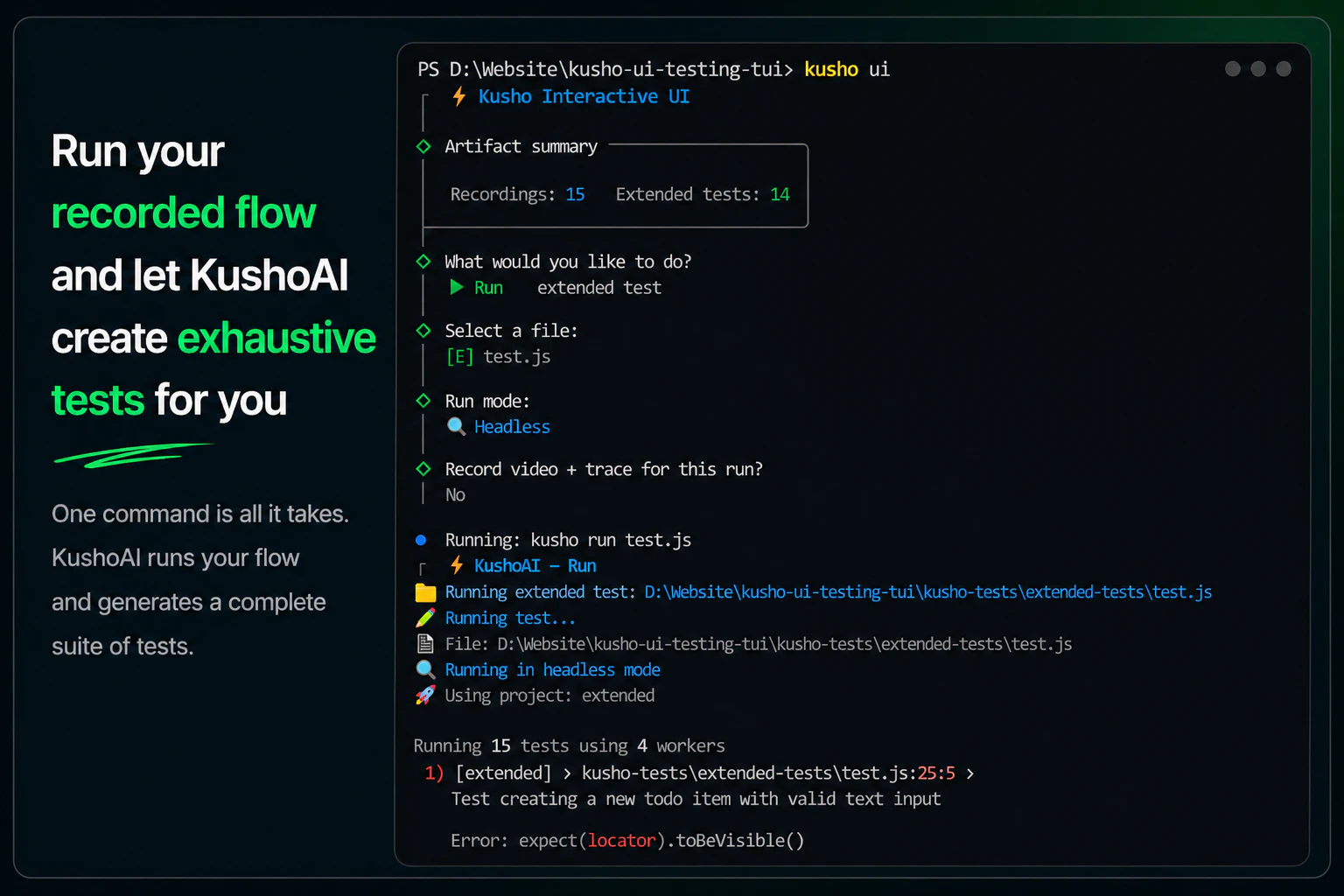
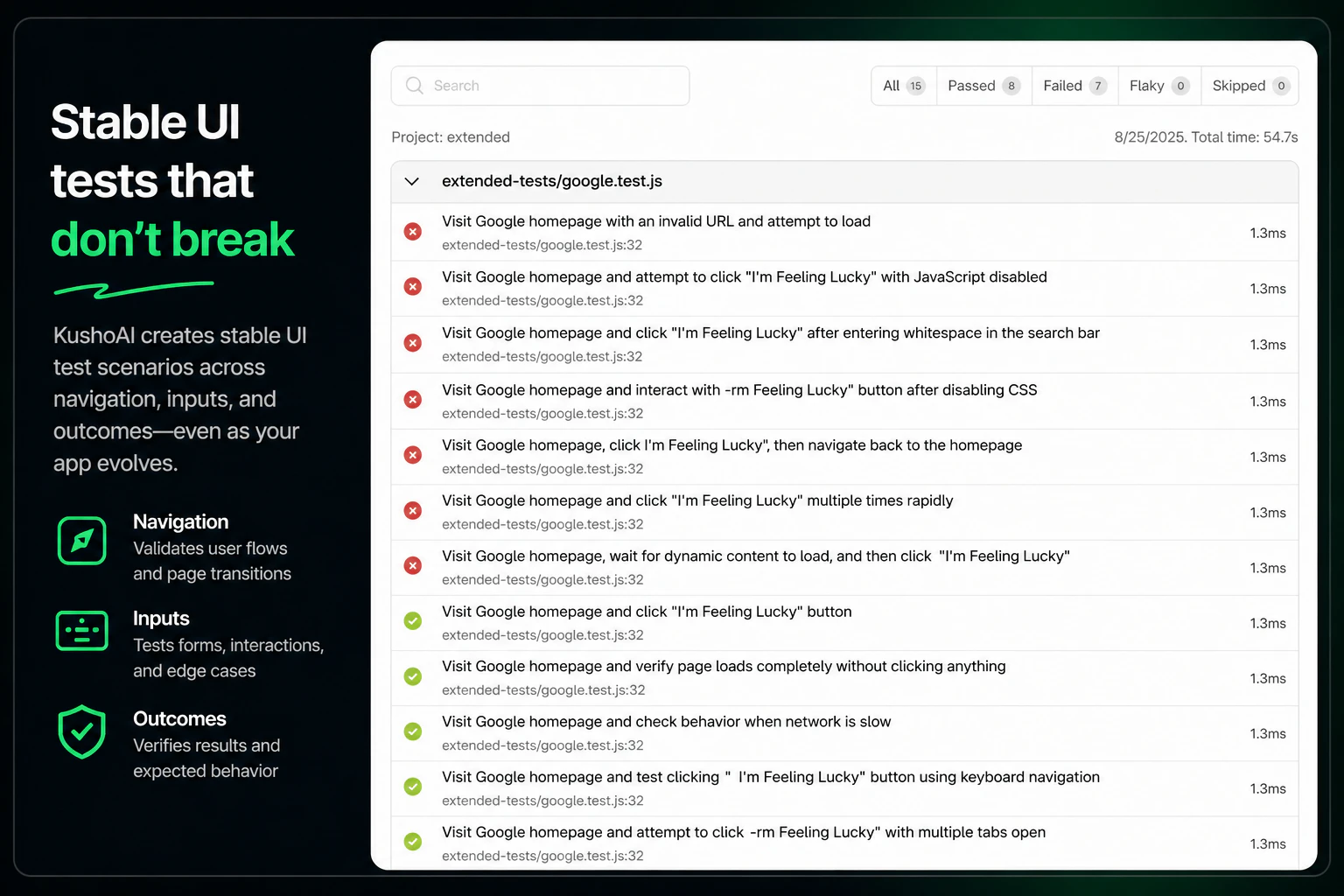
一句话介绍:KushoAI for Playwright 是一款开源的终端用户界面,通过录制浏览器操作流程,利用本地大语言模型自动生成全面测试用例,解决开发者手动编写和维护 UI 测试耗时且覆盖不全的痛点。
Open Source
Developer Tools
GitHub
开源
终端UI
端到端测试
Playwright
AI测试生成
LLM编排
本地运行
MIT协议
开发者工具
质量工程
用户评论摘要:用户认可其解决UI测试写和维护难的痛点,认为终端内工作流符合开发者习惯。主要关注点:处理浮动选择器和UI演进的维护能力,LLM生成断言可能遗漏人为发现的bug,以及未来对pytest等框架的支持。
AI 锐评
KushoAI的切入点精准抓到了UI测试的“最后一公里”——不是自动化执行,而是测试用例的生成与维护。它没有试图创造一个新的测试框架,而是用AI给Playwright这种成熟工具装上“智能补丁”,这比从头颠覆更务实。其核心价值在于将“记录-生成-运行”闭环完全锁在终端内,剔除了开发者从浏览器、IDE到ChatGPT之间反复切换的语境损耗,这种原生体验对硬核开发者极具吸引力。但真正的考验在于:LLM生成的测试是否只会停留在“路径覆盖”的浅层,还是能逼近“逻辑覆盖”的深度?当业务逻辑复杂时,AI能否理解“什么才是真正值得测试的边界”,而不仅仅是穷举输入组合?评论中“AI可能遗漏人类直觉能发现的bug”正是对此的质疑。此外,该产品将核心智能外包给用户的API密钥,本质是一个优秀的LLM编排路由器,这导致其技术壁垒不高,未来很容易被Playwright官方、Cypress或大型IDE内置的AI助手功能所蚕食。短期看,它是测试效率放大器;长期看,若不能在AI理解测试意图上进行更深层的模型微调或策略沉淀,很容易沦为同质化工具。建议团队优先解决用户关心的“对易变选择器的智能容错”问题,这才是证明AI在测试维护中绝非无用的关键战役。
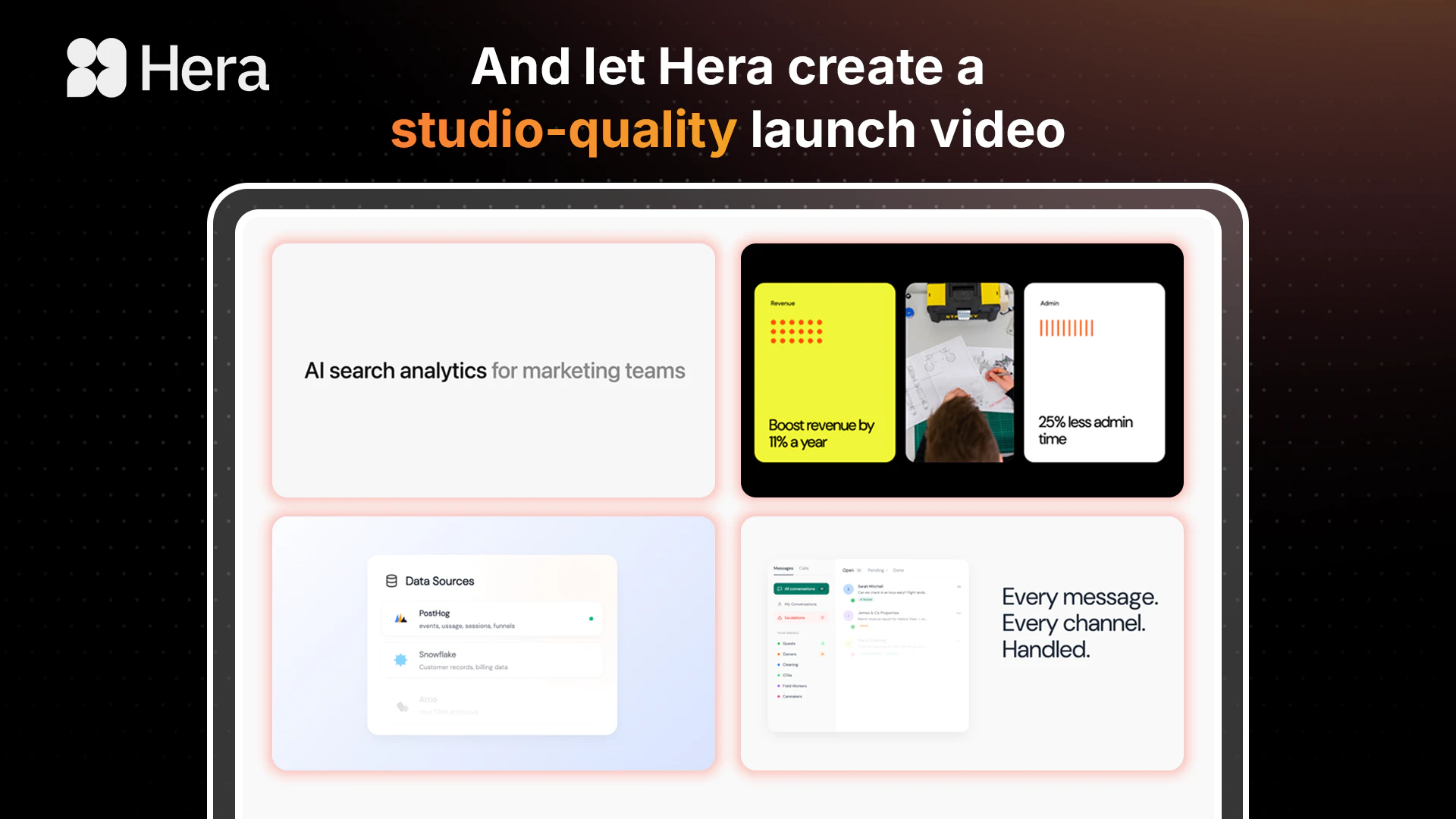













































Congrats @peter_tribelhorn
I’ve seen a lot of startups struggling with demo videos so definitely much needed tool! How does this compare to screen studio for product demos?
Hey Hera team! Congratulations and good luck with the launch. I tested your app a bit, can't say I got WOW effect at the first touch, maybe I need to experiment more with some real tasks. But definitely love the clear path to the first result and the UI
Screen studio videos all look the same now ngl. ready for something with more range
Hera sounds a bit funny as read by a Ukrainian..:) Congrats on the launch!
The "taste baked into the AI, not the user" call is the right one — most prompt-driven creative tools fail because they outsource judgment to people who don't have it (yet). Adjacent use case: I host the ModeLoop Podcast on financial modeling (https://open.spotify.com/show/0m...), and announcement videos for episode drops are exactly the recurring "ship fast, look good" need that's underserved. Quick question — does Hera handle audio-first content well (waveforms, episode covers, podcast clip animations), or is the current opinion-set tuned mostly to product-launch motion? Would buy day-one if so.
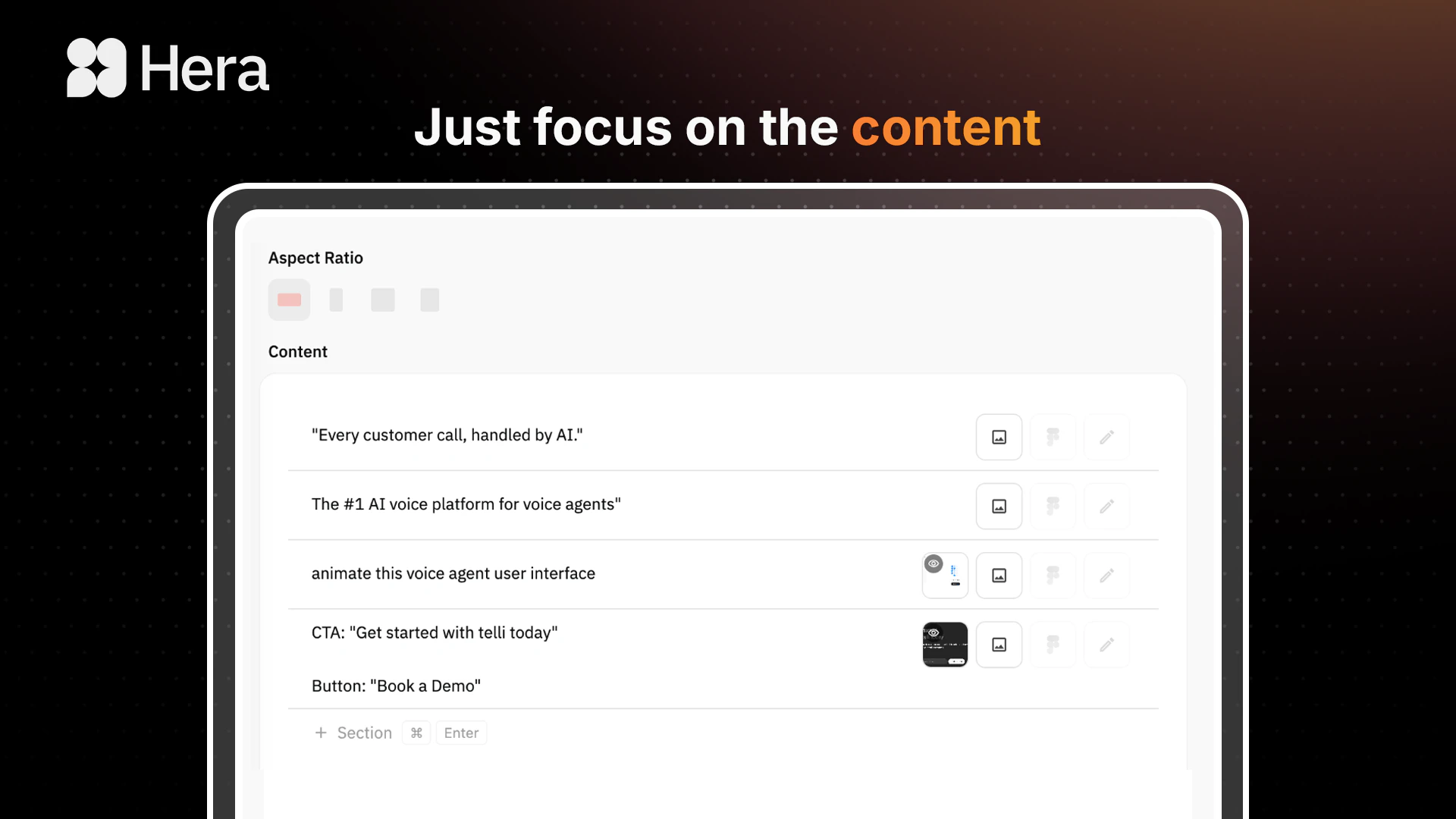
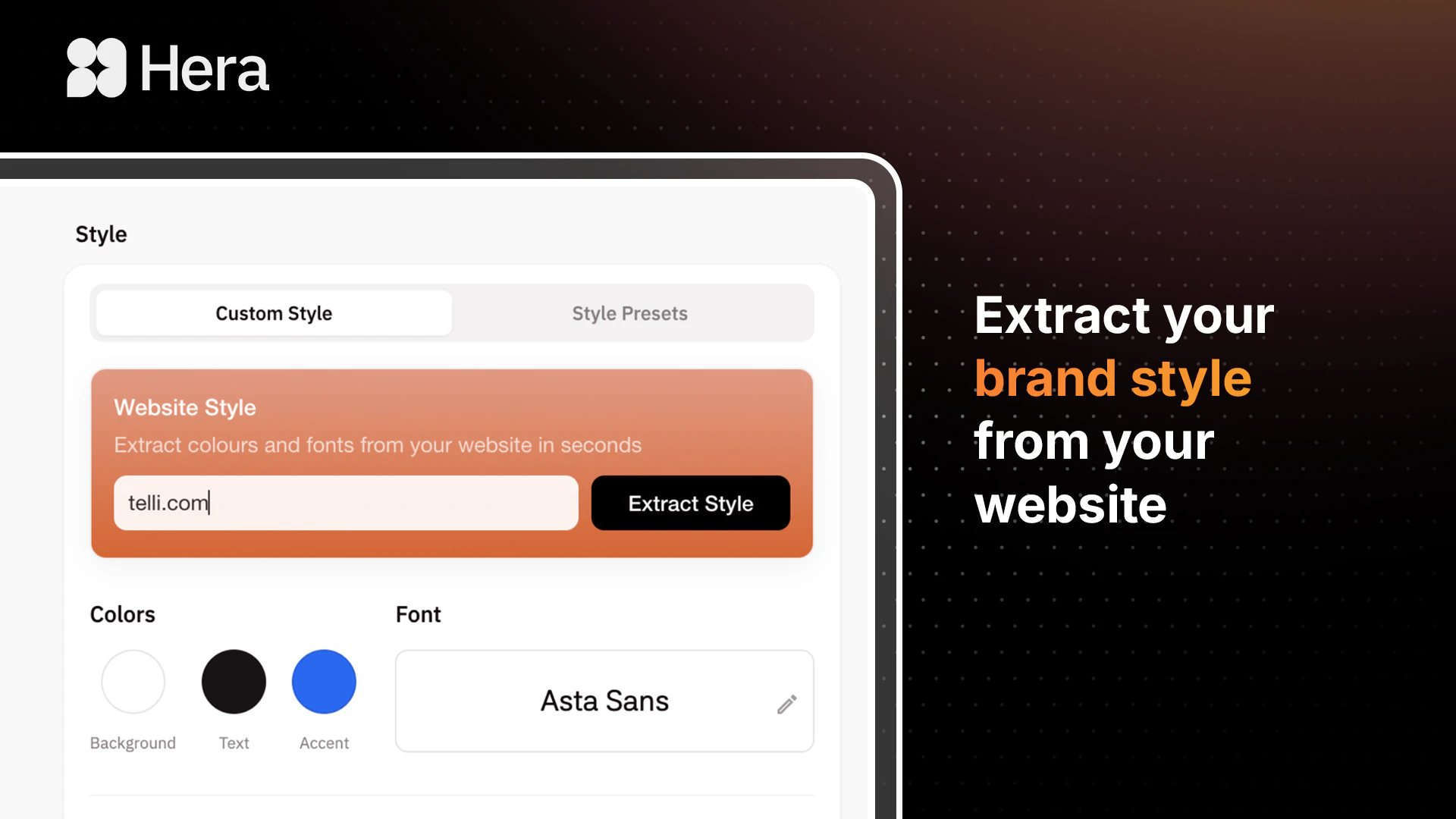
I’ve tried learning After Effects three separate times and I still can't get my easing right. 😂 The fact that you’ve handled the how it looks part so I can just focus on what it shows is the exact tool I need. Does it allow for custom brand font uploads, or are we limited to the baked-in presets? @peter_tribelhorn
Big congrats! Do the videos come in different aspect ratios for social, or is it mainly 16:9 for now?
I've been a video editor for years and motion design has never been my strongest area. This looks super useful
Just tried it and honestly, this is AMAZING. First try, 0 prompt, 0 effort and the video generated is great !! Congrats @peter_tribelhorn @chia_lun_wu1 @hyung_lee @garrytan
This is the sleekest animation tool we have ever used. Way better than the replit slop
Congratulations
Congrats on the launch. Is it possible to prompt and fix certain clips?
200K animations in 2 weeks is wild. What's the #1 use case you're seeing, social content, product demos, or something you didn't expect?
The director/designer/animator agents thing is interesting, didn't expect that approach.
Good job Peter! I was able to quickly make a decent video and with a few edits it's just what I need. What new features are coming?