PH热榜 | 2026-05-02
一句话介绍:Scholé是一款将日常工作场景与个性化AI学习深度融合的智能教育平台,通过多智能体系统和学习科学原理,在用户工作流程中实时生成基于其角色、任务和进度定制的课程内容,解决传统在线学习脱离实际、缺乏适应性的痛点。
Artificial Intelligence
Online Learning
AI学习平台
个性化教育
多智能体系统
知识追踪
职场技能培训
自适应学习
企业培训
学习科学
EdTech
内容再创作
用户评论摘要:用户高度评价其学术根基和自适应理念,但质疑技术实现透明度,如知识追踪的准确性、幻觉消除机制、数据安全与租户隔离。有用户指出前端代码重复,建议加强邮件引导。问题集中在:能否学习AI以外内容?是否类似Duolingo?如何处理不断变化的学习目标?
AI 锐评
Scholé在产品叙事上精准锚定了传统MOOCs和“苏格拉底式”AI聊天学习工具的双重缺陷,这是其获赞的根本。它没有盲目追逐大模型的热潮,而是将学习科学(如掌握学习、最近发展区)作为底层逻辑,这决定了产品上限并非“提供答案”,而是“构建可衡量的能力”。评论中用户对其“知识轨迹”和“误解检测”的追问,直指AI教育产品的核心难点——如何区分真正的理解与浅层模式匹配。Scholé当前仅以“AI技能”作为切入点,看似取巧,实则聪明,它降低了早期内容生产的复杂度。
然而,产品目前仍处于“未来可期”阶段。技术层面,多智能体的协调开销、基于知识图谱的实时内容生成与延迟的平衡、面向企业时海量文档的处理性能,都是硬骨头。更关键的是,从社区反馈看,其安全架构、租户隔离、合规报告等企业级要素尚未公开可验证,这对于瞄准B端市场的产品是致命短板。此外,“个性化”虽是金饽饽,但过度依赖静态知识图谱可能导致生成的内容仍显“模板化”,无法真正捕捉动态环境中涌现的真实工作难点。
总体而言,Scholé拥有行业顶尖的学术血统和正确的产品哲学,其价值在于将“学习”与“做事”的界限模糊化。但若想从“Demo惊艳”走向“规模化商业落地”,它必须尽快将那些100页的技术文档转化为用户可感知的、经得起审计的工程成果,并证明其内容引擎能跨越AI领域,处理汽车工程或医学案例等更复杂、高风险的场景。目前的Scholé是一枚精心打磨的“针”,但距离“缝制整件衣服”还有一段不短的距离。
一句话介绍:Manus Cloud Computer 提供一台24小时在线的云端持久机器,让用户无需任何运维或编码,直接用自然语言描述即可运行机器人、脚本、应用和数据库,解决了AI任务和自动化工作流“会话结束后即消失”的痛点。
Productivity
Developer Tools
Artificial Intelligence
云端持久计算
无代码部署
AI自动化
云计算平台
DevOps简化
24/7运行
任务调度
自然语言操作
数据持久化
网关IP
用户评论摘要:用户关注成本透明度(云服务计费易变模糊)、数据安全与持久化IP(共享IP易被API封禁)、以及产品核心差异化。正面反馈集中在“持久状态”让AI代理从演示变为实用;负面对比了Meta收购等无关信息,需忽略。
AI 锐评
Manus Cloud Computer 的定位聪明且精准——它抓住了当前AI工具链中一个被忽视的断层:大多数AI Agent和自动化工具只在一个会话周期内有效,一旦关闭,状态、文件、环境统统消失。这导致了“演示很惊艳,落地很骨感”的窘境。产品许诺“纯英语描述即完成部署、持久运行”的体验,直接刺穿了传统云计算的DevOps门槛和session-based AI的实用天花板。
然而,现实比口号更锋利。
首先,“无需编码”在用户手写复杂数据管道或爬虫时,对自然语言的模糊理解力考验极大,一旦出错,用户会立刻坠入传统运维的泥潭。其次,评论中反复出现的成本透明度和共享IP问题,暴露了其对实际运营场景的考虑不足。对24/7运行的长任务,如果出站IP被Cloudflare等平台列为可疑,所有自动化都会无声碎裂——这比“未部署”更令人绝望。最后,竞争格局并不友好。Supabase、Railway、乃至Kubernetes的简化版都已对“持续环境+任务调度”虎视眈眈,Manus的真正护城河,不在于“持久”二字,而在于能否在“纯自然语言”和“可控运维”之间保持一个立即可用且不过度抽象化的平衡。
一句话结论:它解决了AI工具“用完即废”的致命伤,但要成为主流,必须公开计费模型并处理网络层面的默认陷阱,否则优秀的故事只会停留在Product Hunt的点赞区。
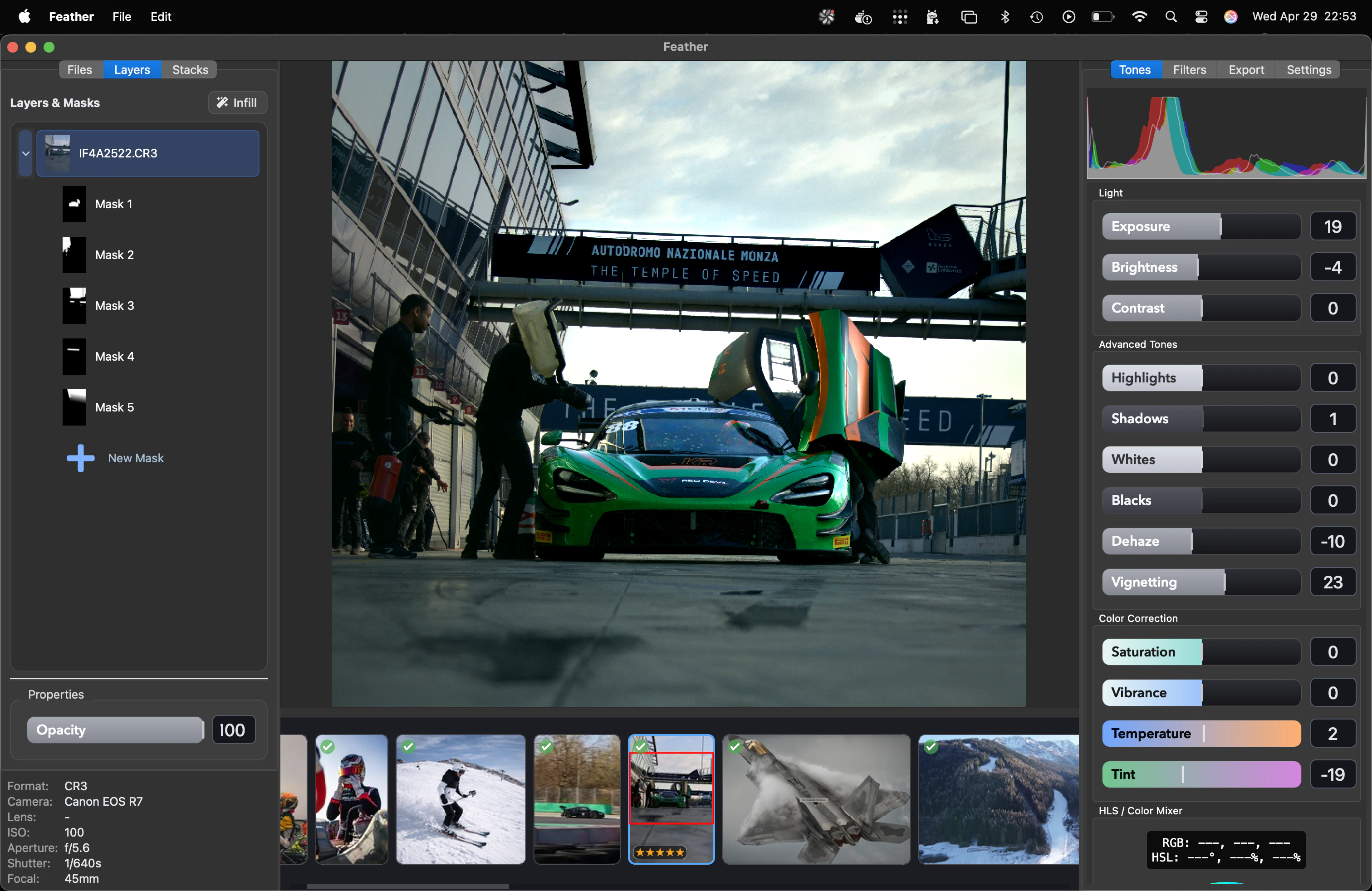
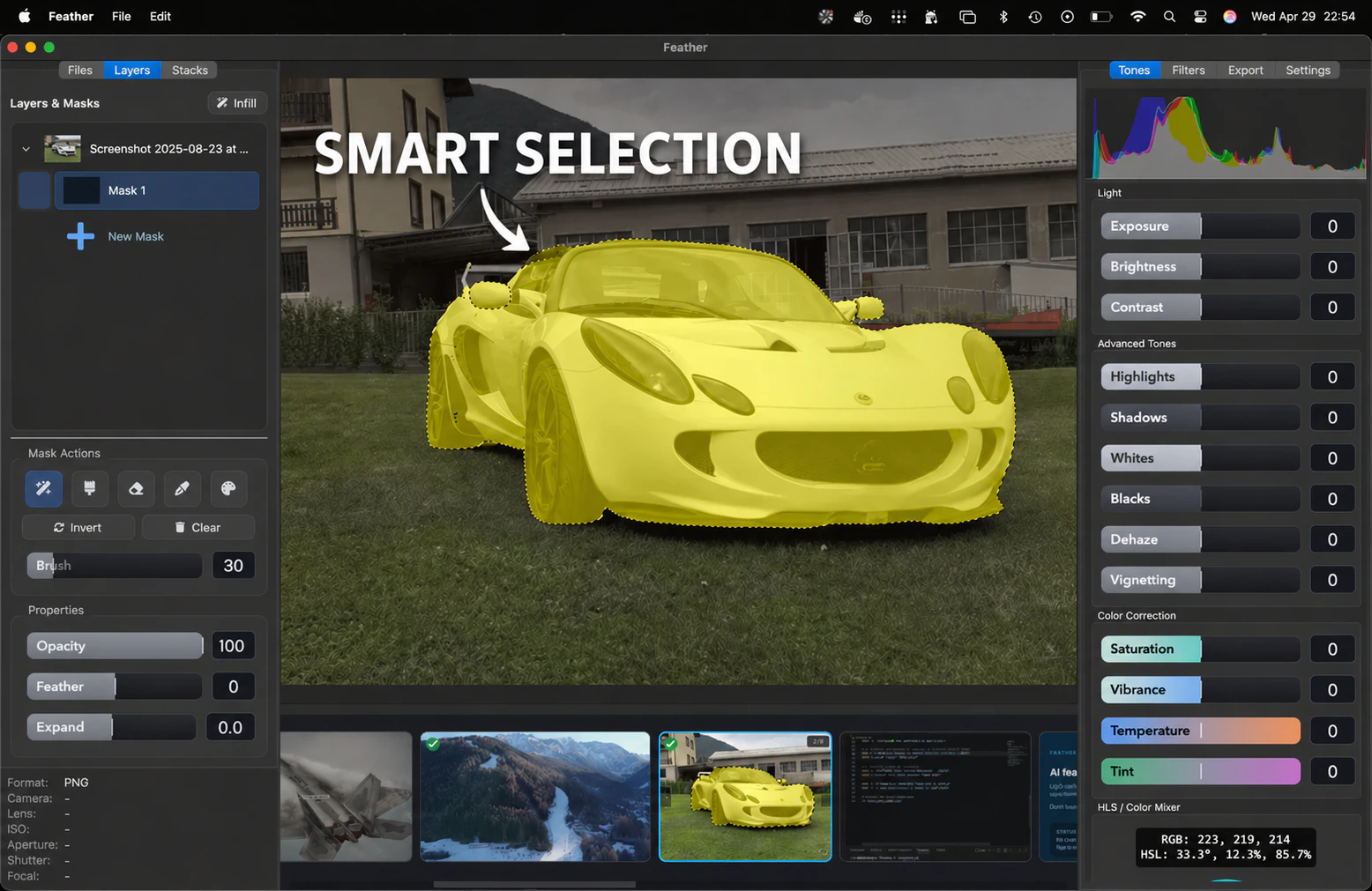
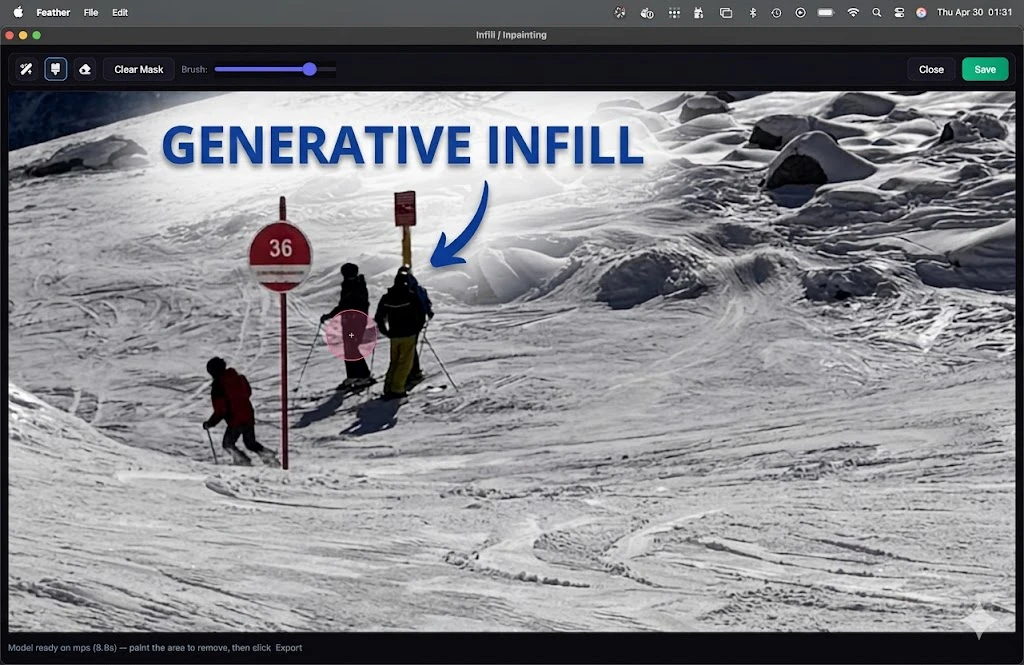
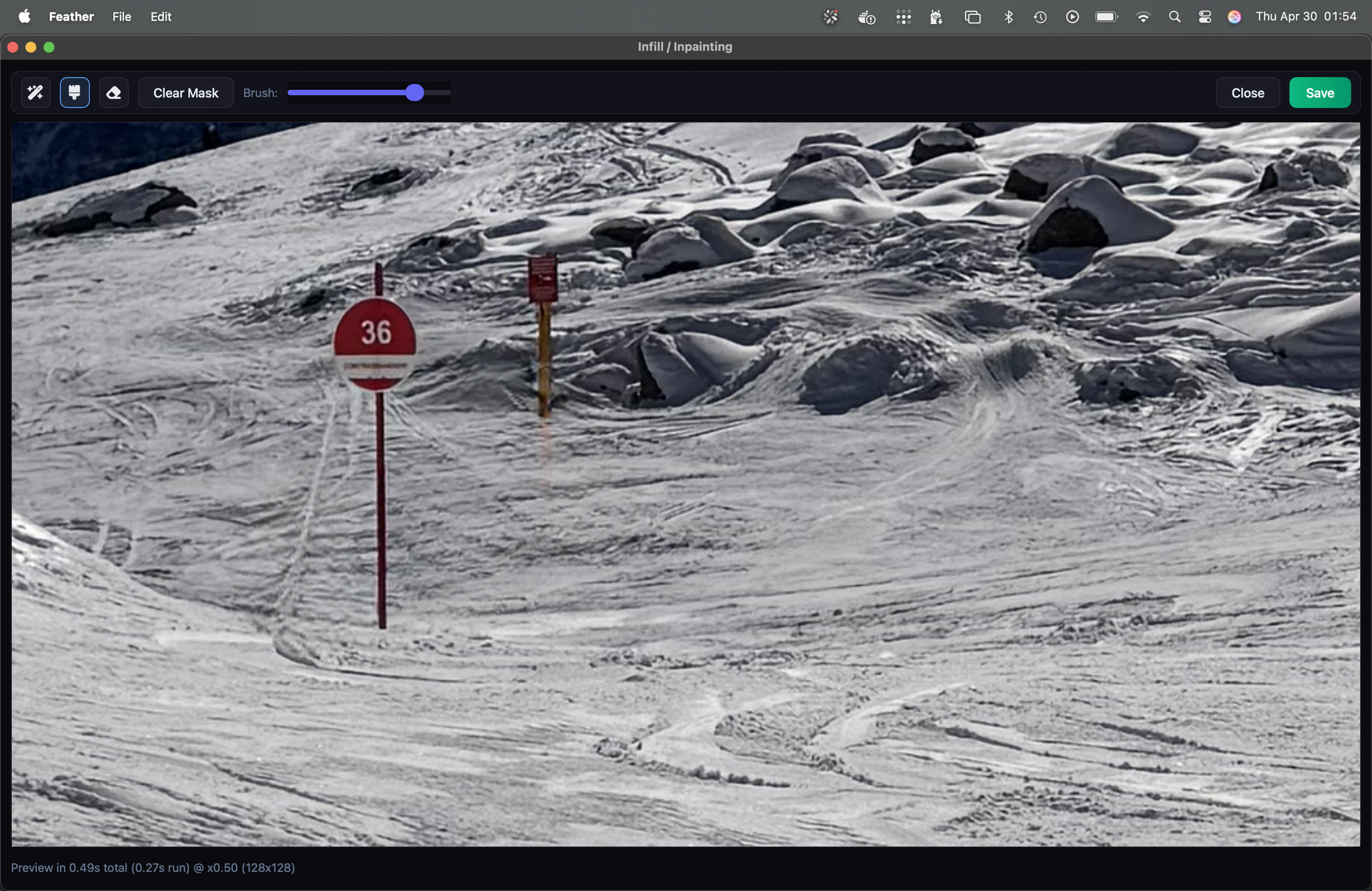
一句话介绍:Feather是一款专为Apple Silicon Mac设计的本地AI照片编辑器,通过离线处理AI填充、智能选择和自动堆叠等功能,解决了摄影爱好者对数据隐私、订阅制厌倦以及专业编辑流程繁琐的核心痛点。
User Experience
Photography
Artificial Intelligence
本地AI
照片编辑器
macOS
Apple Silicon
隐私保护
一次性付费
智能选区
色彩分级
专业摄影
效率工具
用户评论摘要:用户普遍赞赏其一次性付费、本地化AI(隐私安全)以及4个月开发速度。焦点问题包括:定价策略是否调整、对复杂混乱照片的处理能力、本地模型的类型与速度。多数建议集中在提升性能和跨平台支持(Windows版)。
AI 锐评
Feather在“后订阅制”时代,精准击中了两个致命痛点:数据隐私与付费疲劳。本地AI+一次付费的组合,几乎是对Adobe之流的“白刃战”。但必须清醒看到,它在当前阶段更像是一个“技术Demo”而非成熟产品。198票的当日表现,更多是情绪价值(反Adobe、本地隐私)的胜利。核心短板在于:1. 模型能力未知,“AI填充/选区的质量”与Photoshop的本地版(如Firefly)相比没有明确优势;2. 生态孤岛——仅支持Apple Silicon Mac,将庞大的Windows摄影群体拒之门外;3. 功能深度尚浅——虽然HSL内嵌蒙版是个好设计,但缺乏图层、曲线等核心专业工具。创始团队应警惕“尝鲜红利用尽”后的增长停滞。真正的价值在于证明了一个可行性:高端的本地AI图像处理可以在个人设备上流畅运行。能否从“好惊喜”变成“离不开”,取决于后续迭代能否把“智障的”AI提示词控制和“慢得像蜗牛”的批量处理效率做成行业标准。一句话:方向完美,但执行才刚开跑。
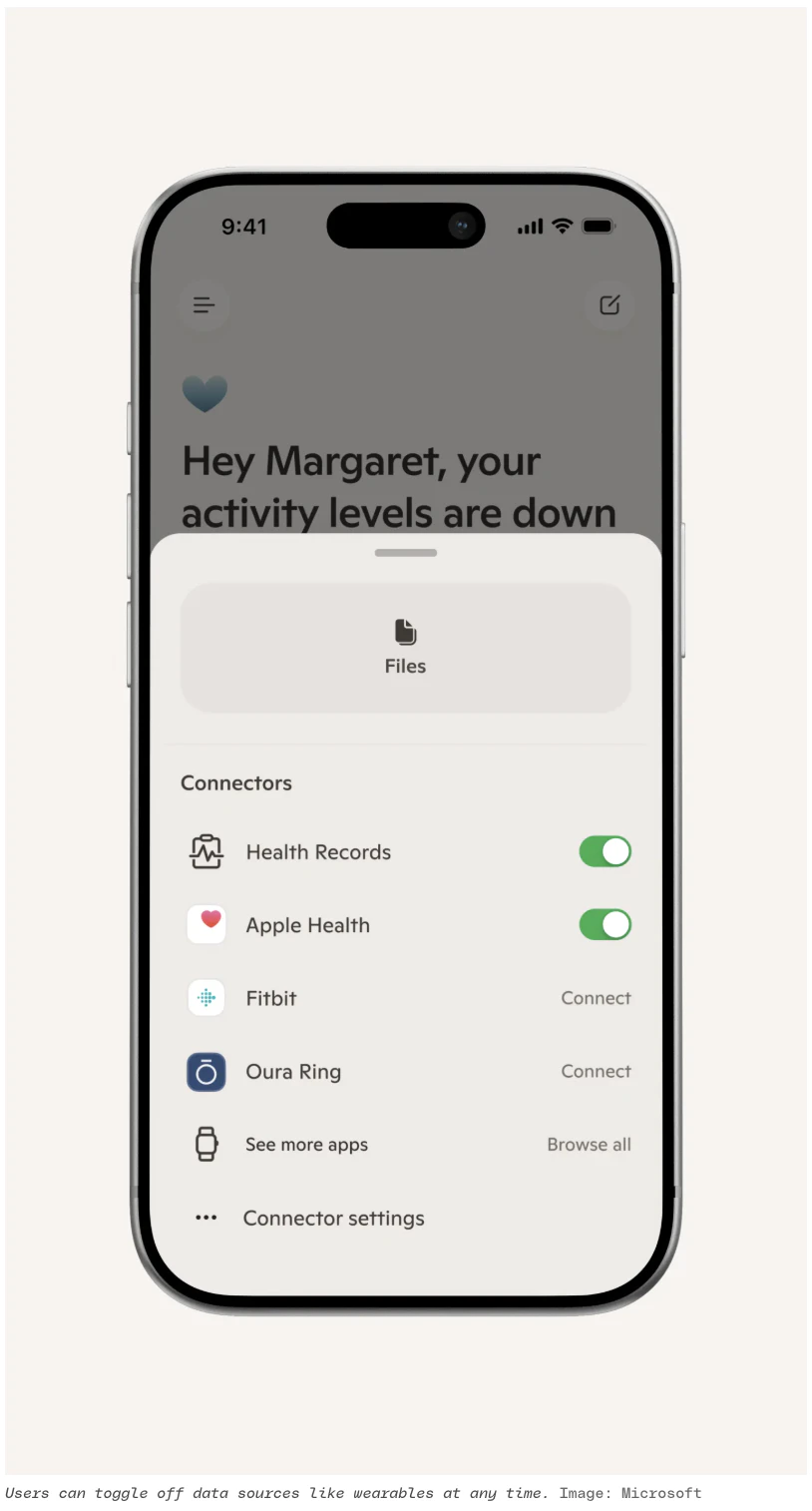
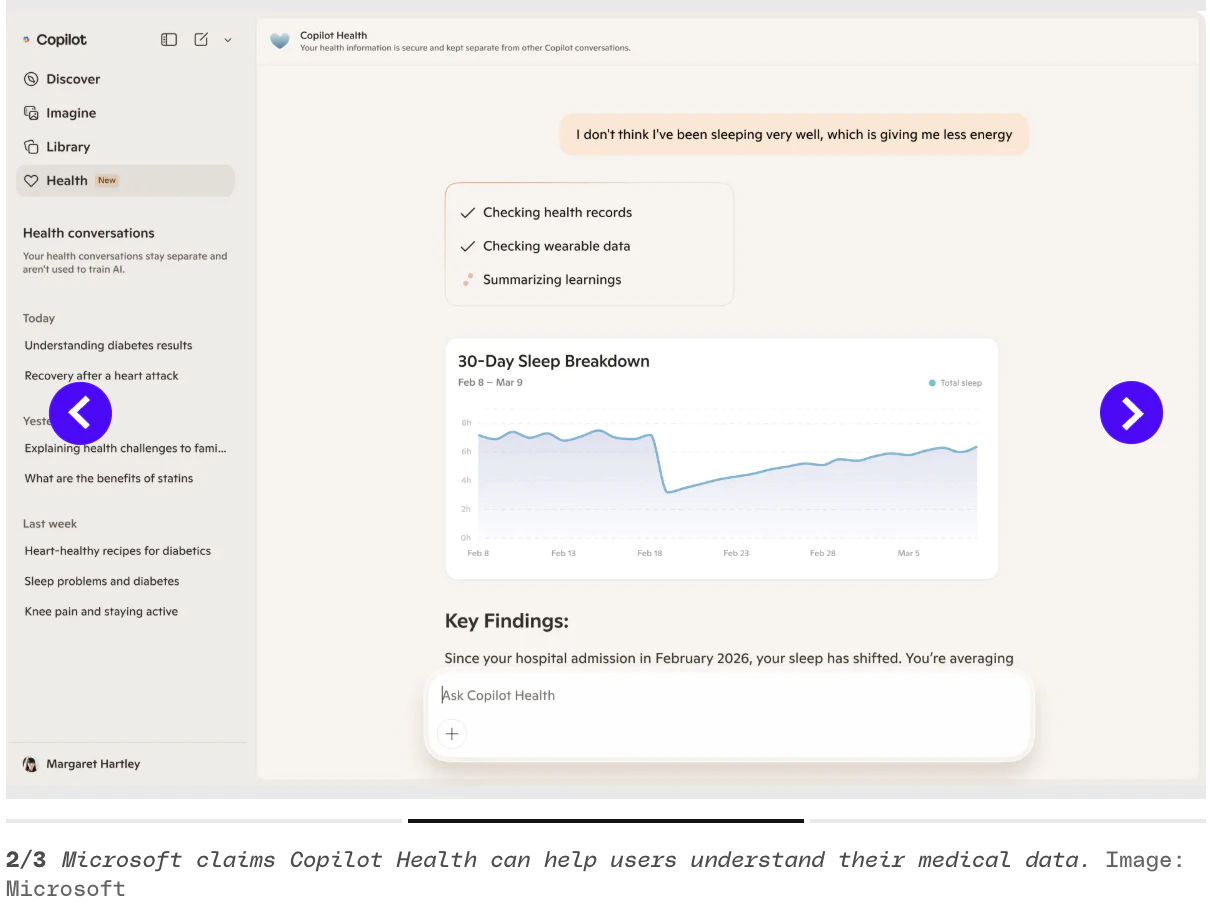
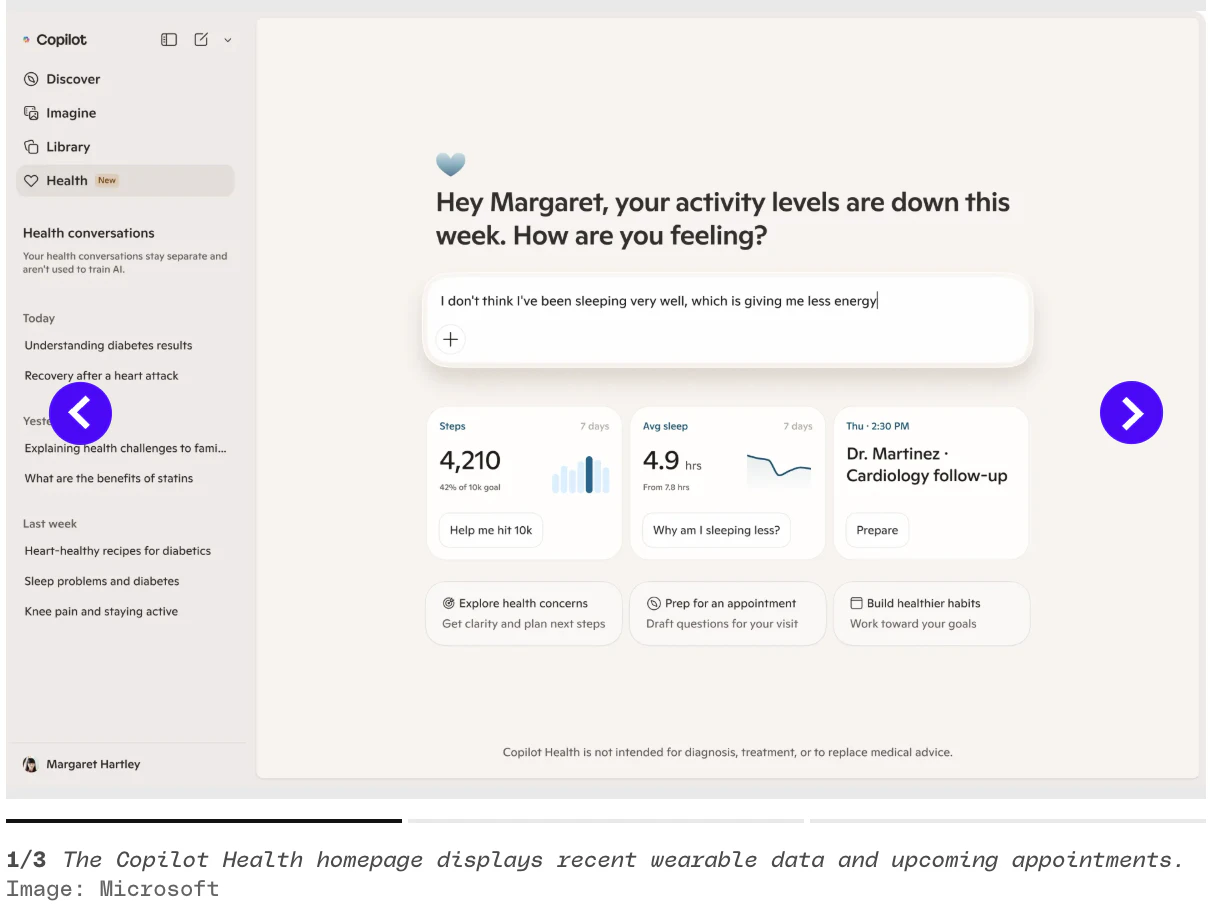
一句话介绍:Microsoft Copilot Health 是一个整合个人健康数据的AI空间,将病历、可穿戴设备和化验结果汇聚一处,为用户提供就医前可执行的洞察,解决健康数据碎片化、互不关联的痛点。
Health & Fitness
Analytics
Artificial Intelligence
健康数据聚合
医疗AI
电子病历整合
可穿戴设备同步
个人健康管理
医疗洞察
合规医疗
数字健康平台
智能问诊准备
用户评论摘要:用户认可整合EHR和可穿戴设备的价值,好奇如何实现跨源推理(数据矛盾时)。重点提问:AI输出是否可追溯具体来源和原文?数据合规如何处理(跨地区法规)?期待看到炎症模式等深层洞察。
AI 锐评
Microsoft Copilot Health的“聪明”在于,它没有试图再造一个健康记录工具,而是当了那个最难的“翻译官”——把50000家医院的电子病历、50多种可穿戴设备和实验室化验单放在一个语境里。这切中了数字健康最大的谎言:数据不等于洞察。当你的Oura告诉你睡眠不足,而化验单显示皮质醇正常时,碎片化的数据只是噪音,关联后的信号才有价值。
真正的锐点在于,这套方案目前仅限美国,且依然严重依赖“Function”这类第三方中间件来获取实验室数据。你可以理解为,它是在已有的数据孤岛上架了一座桥,但这座桥的承重墙(数据源合作协议、HIPAA合规执行细节)还没有完全公开。更致命的问题是评论中提到的“引用透明度”——当AI告诉你“根据哈佛健康”给出建议时,如果用户无法点击查看具体段落和上下文,这在医疗场景下不是可信度折扣,而是安全隐患。一个无法被核实来源的医疗建议,再漂亮也不过是加了权威前缀的聊天记录。
产品方向极致正确,但落地时必须在“医疗责任归属”和“数据所有权承诺”(自诩不与通用Copilot共享)上给出可验证的机制,而不是一句文案。否则,它只会成为又一个“看起来很美”的诊前备忘录,而非改变医患对话质量的驱动力。
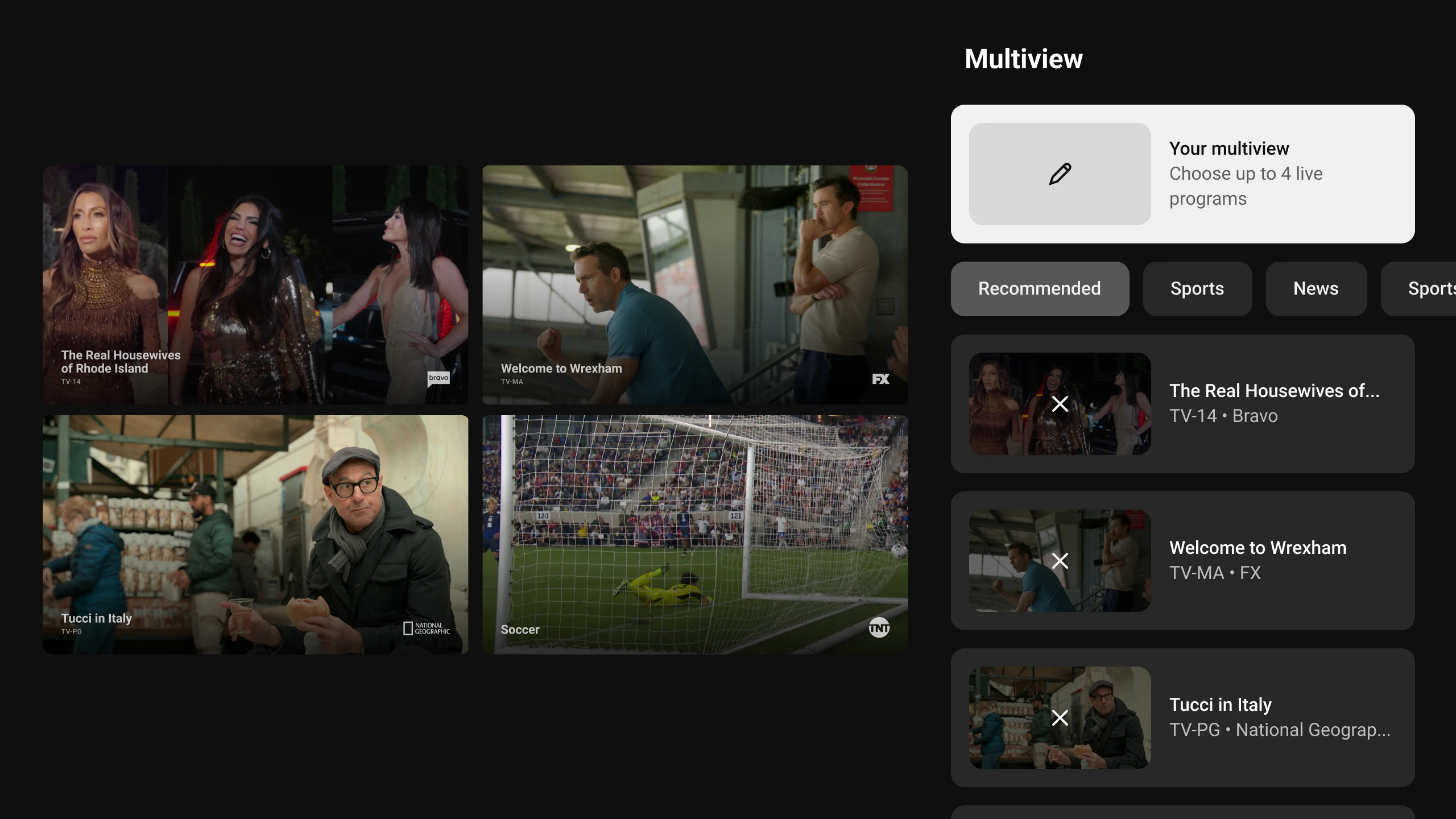
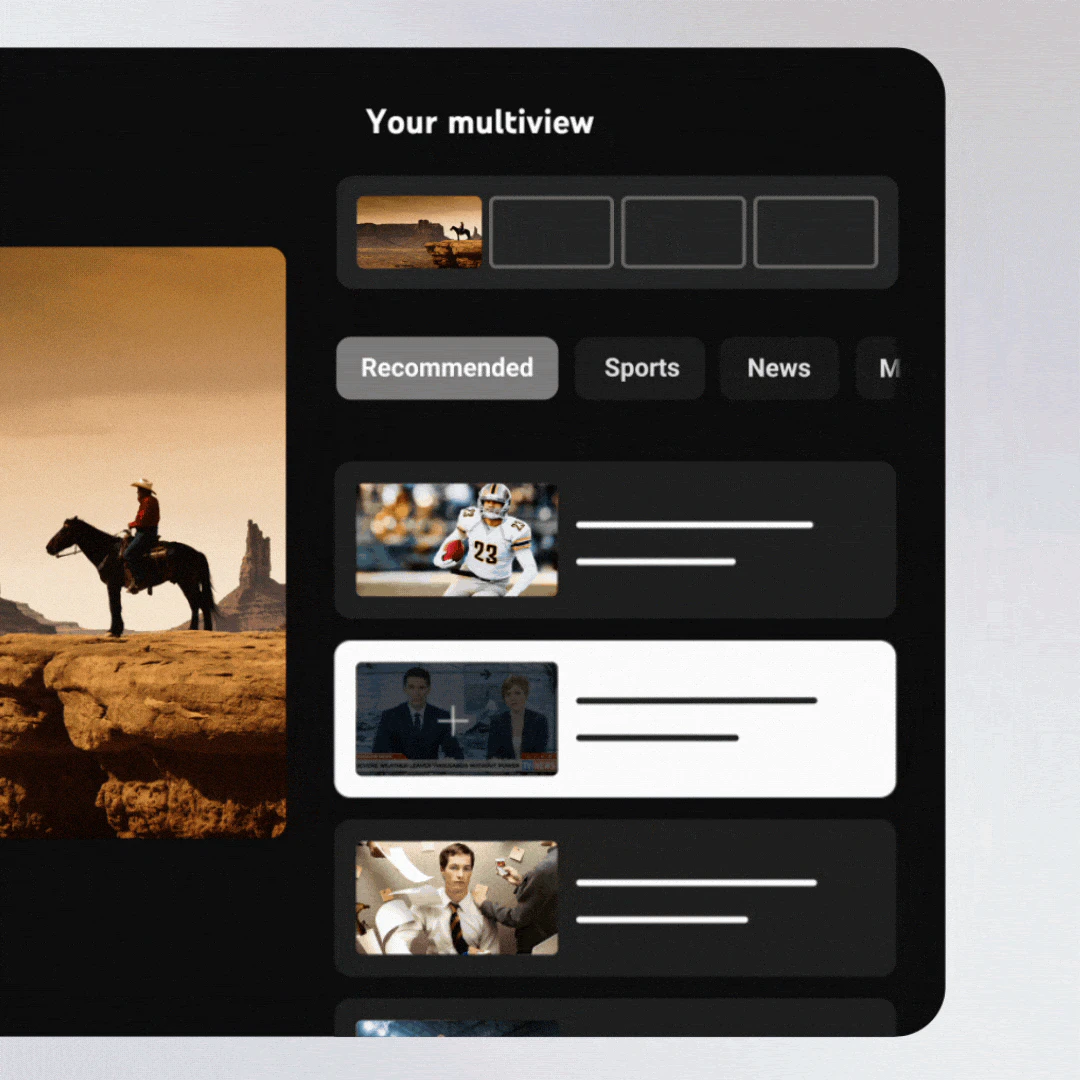
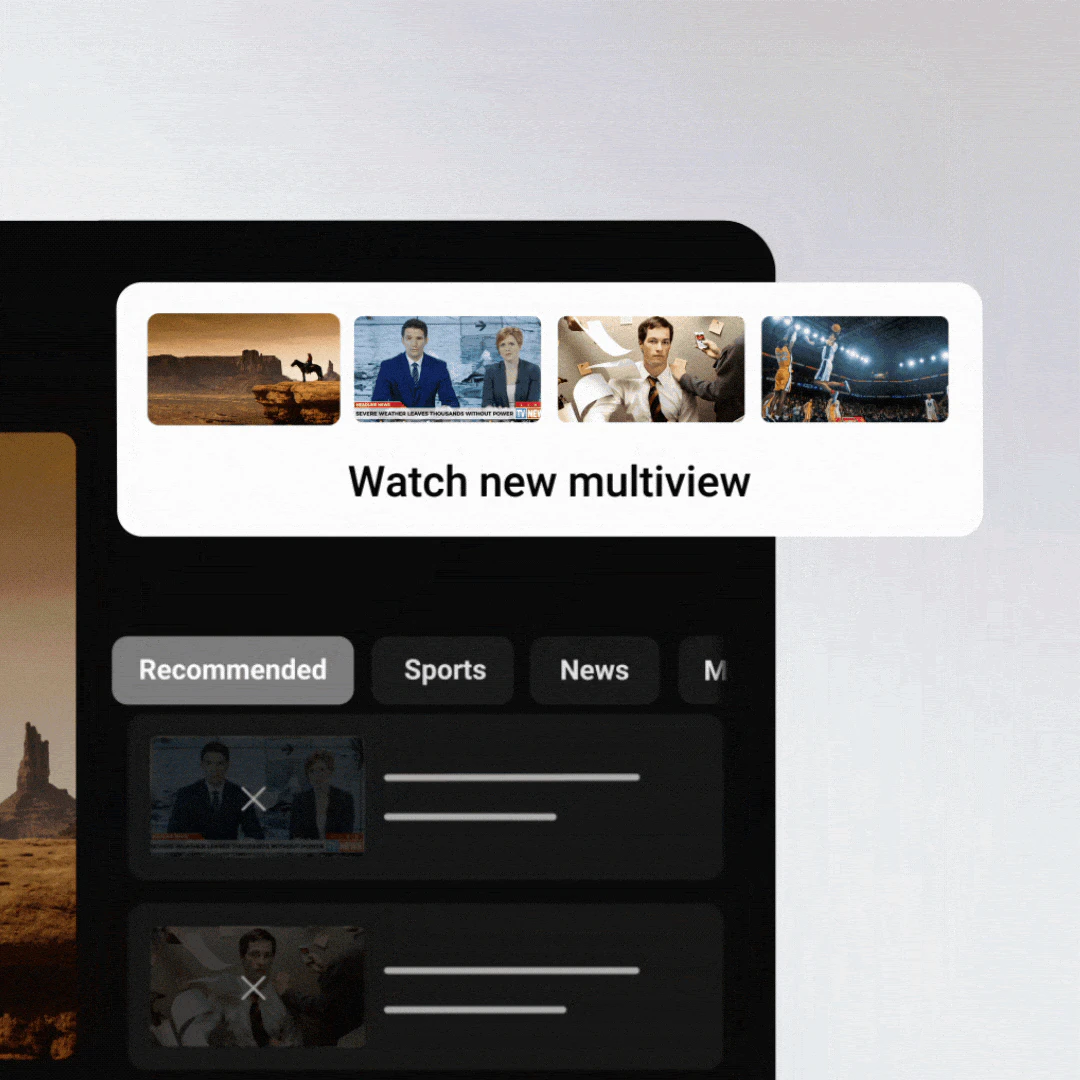
一句话介绍:YouTube TV Custom Multiview让用户摆脱平台预设的多画面组合限制,在体育赛事、新闻直播等场景下,自由混搭最多4个直播流,解决了一屏多看的个性化与实时追踪痛点。
Video Streaming
Sports
TV
YouTube TV
多视角直播
体育赛事
自定义画面
直播流混搭
电视应用
NFL套餐
媒体工具
用户控制。
用户评论摘要:用户好奇同时播放四路直播是否容易跟丢重点,以及多流音频切换在体育狂热夜是否流畅。这些问题直指多画面功能的实际可用性和交互细节。
AI 锐评
YouTube TV这波更新堪称“让用户自己当导播”,核心价值不是技术突破,而是把选择权从平台让渡给用户——体育迷能同时盯四场NFL,新闻控可让CNN、Fox、MSNBC同屏撕逼。但投票仅128,说明它更像优化而非颠覆。几个硬伤:一是预设组合时代观众习惯了“被动喂食”,突然要自己拼搭反而有门槛;二是音频切换成致命短板,评论区对“四流声音乱战”的担忧反映了底层逻辑缺失——毕竟没人想听四路解说同时灌耳;三是流量消耗与设备性能未提及,手机或老电视跑4路视频可能直接卡成PPT。相比苹果的“协作画中画”或Frame.io的云端并列剪辑,这功能实用但平庸,本质是线性电视向点播妥协的产物,离“下一代观看体验”还差得远。
一句话介绍:Breaks 是一款静驻于 Mac 菜单栏的极简番茄钟,通过零干扰设计和本地优先策略,帮你专注当下,无需忍受繁复界面或隐私泄露的焦虑。
Productivity
Open Source
GitHub
Menu Bar Apps
番茄钟
菜单栏工具
macOS
专注工具
开源
本地优先
隐私保护
Apple Intelligence
生产力工具
开源软件
用户评论摘要:用户普遍认可其简洁和隐私优先的理念。主流需求集中在希望推出 Windows/Linux 版本,以及尽快上架 App Store 和 Homebrew Cask。有建议指出,可通过追踪用户在生产力社区分享截图的提及来挖掘真正痛点。
AI 锐评
Breaks 在红海的番茄钟赛道里,选择了一条极其聪明的“减法”路线。它没有试图用花哨的统计或复杂的白噪音来制造“生产力幻觉”,而是回归了番茄钟的本质——一个安静的计时器。其核心价值并不在于功能多寡,而在于“存在感”的精准控制:隐藏在菜单栏,不打扰,但随时可用。这种克制恰恰击中了重度效率工具用户对“工具焦虑”的厌倦感。
从产品策略上看,“本地优先、无遥测、开源”是三重极具杀伤力的卖点:它既满足了开发者社区对透明与可控的偏好(MIT 开源),又迎合了当下对数据隐私高度敏感的用户心理(沙箱隔离+AI 本地处理)。通过 Apple Intelligence 实现本地周报,更是将隐私体验做到了行业天花板——数据不离开 Mac,直接化解了 AI 应用的最大信任危机。这绝非单纯的“开箱即用”,而是经过精心设计的信任锚点。
然而,锐评者也需指出其风险:当前 118 票与有限的评论深度,表明它仍在早期种子用户阶段。过度聚焦 macOS 将天然舍弃大量跨平台用户(评论中已有强烈呼声)。若不能快速在稳定版基础上拓展至 Windows/Linux 或是移动端,其“护城河”可能只是一条浅沟。另外,“极简”也是一把双刃剑——缺乏数据洞察和高级定制,可能会让追求深度的效率达人在静默一周后悄然卸载。真正的挑战在于,如何在“不增加界面负担”的前提下,通过更智能的本地分析和灵活的热键组合,持续回应用户未被明说的深层需求。
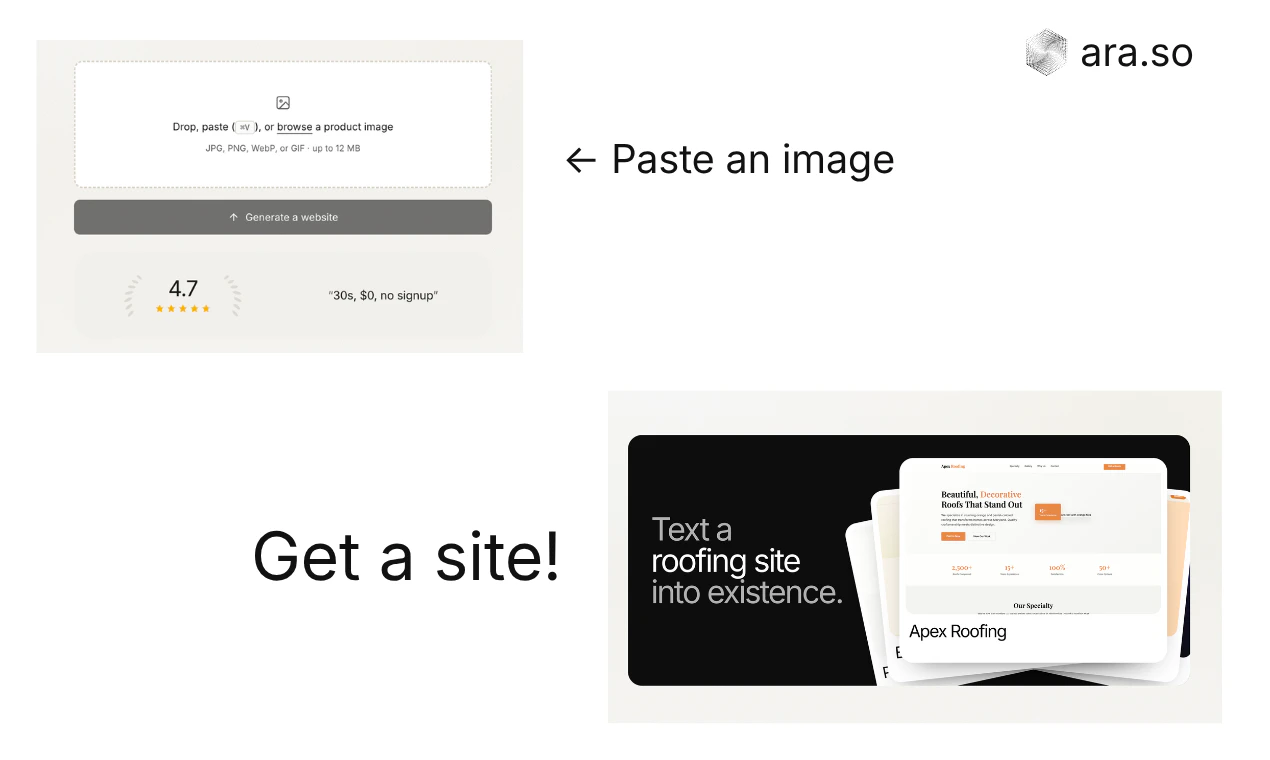
一句话介绍:Ara让用户只需粘贴一张产品图片,就能通过短信(iMessage/SMS)快速生成一个带支付功能、真实域名的网站,极大简化了从创意到上线销售的繁琐技术门槛,轻松实现“用手机短信创业”。
Messaging
Payments
SaaS
零代码建站
AI创业助手
短信交互
移动端电商
一键部署
支付集成
域名绑定
无平台绑定
个人品牌工具
SaaS
用户评论摘要:用户普遍赞赏短信交互的简洁性,认为它解决了初创者被技术设置“劝退”的痛点。核心建议是:希望AI代理能针对“AI搜索可见性”等特定场景提供更定制化的增长建议。同时,有用户询问是否支持现有代码库,官方答复支持克隆现有网站。
AI 锐评
Ara的核心价值不是“建站工具”,而是一个“反直觉的创业界面”。它巧妙地利用SMS这一极低认知负荷的渠道,剥离了传统建站中所有令人头秃的“中间层”(DNS、Stripe对接、后端逻辑),让用户直接聚焦于“卖东西”这一原始冲动。其“粘贴图片→获得带支付功能的网站”路径,是对传统SaaS“功能堆砌、用户学习成本高”路线的精准背叛。
从评论看,产品方向深受用户认可,尤其对非技术背景的小白创业者极具吸引力。但产品的真实护城河不在于“短信交互”这个UI壳,而在于其背后Agent的智能程度和供应链(如域名、支付)的整合深度。目前Agent仅能提供流量和基础优化建议,这还停留在“数据看板”的短信化翻译。如果未来不能进化为“主动诊断业务瓶颈、给出针对性营销策略”的超级助手,Ara很容易沦为“能发短信的Wix精简版”,难以支撑用户业务规模扩大后的复杂需求。
此外,“全靠短信”这个设定是一柄双刃剑。它降低了启动门槛,但也在业务后期成为交互瓶颈——复杂修改、多店铺管理、深度数据分析,都需要一个更强大的图形化界面作为补充。Ara需要警惕因过度执着于“减法”而人为制造新的“天花板”,让成功起步的用户最终因功能不足而流失。真正的考验,是当用户从“试水”走向“规模”时,Ara能否提供平滑的进化路径,而不是让用户重新回到“五件工具半夜拼凑”的老路。
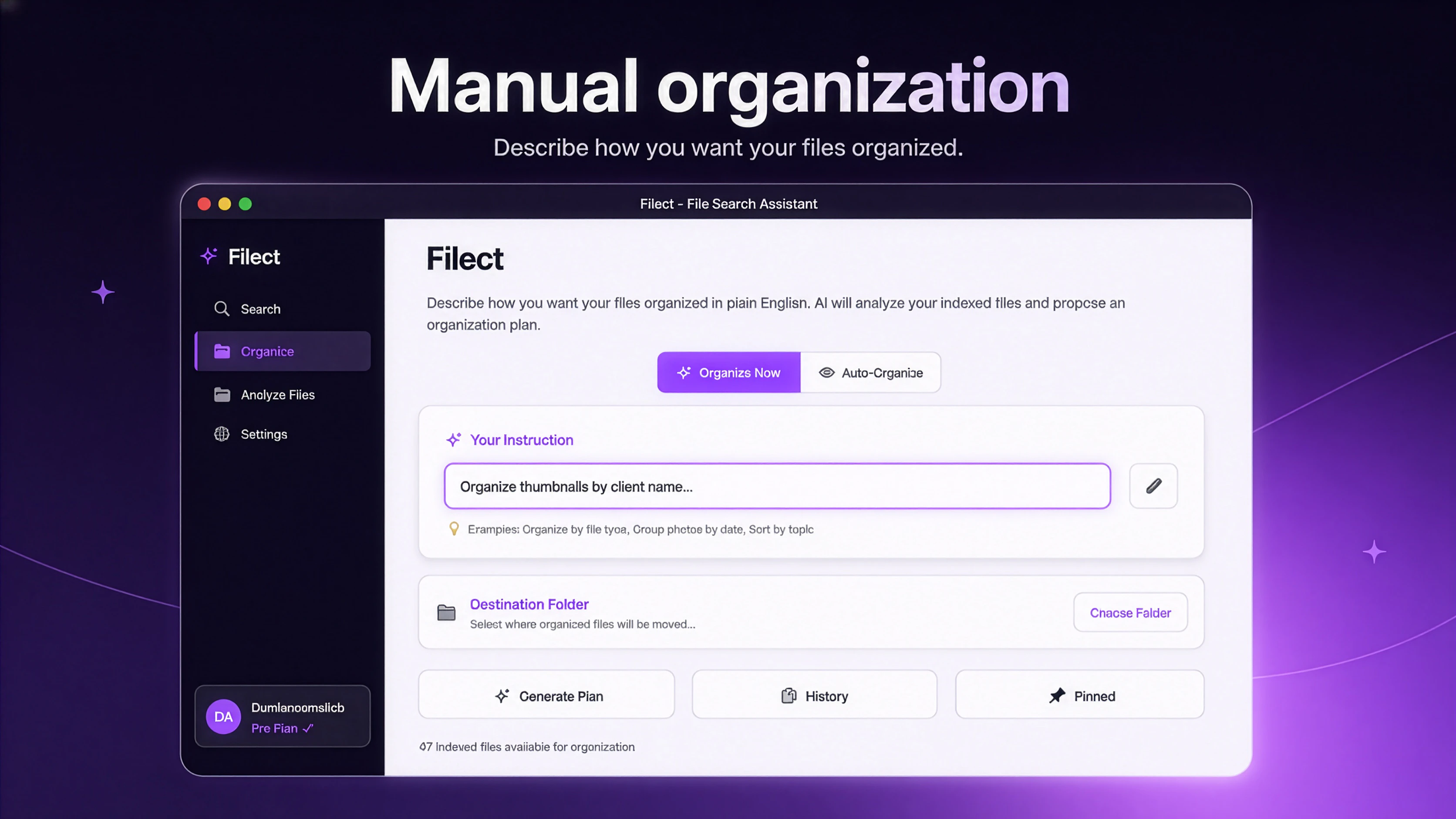
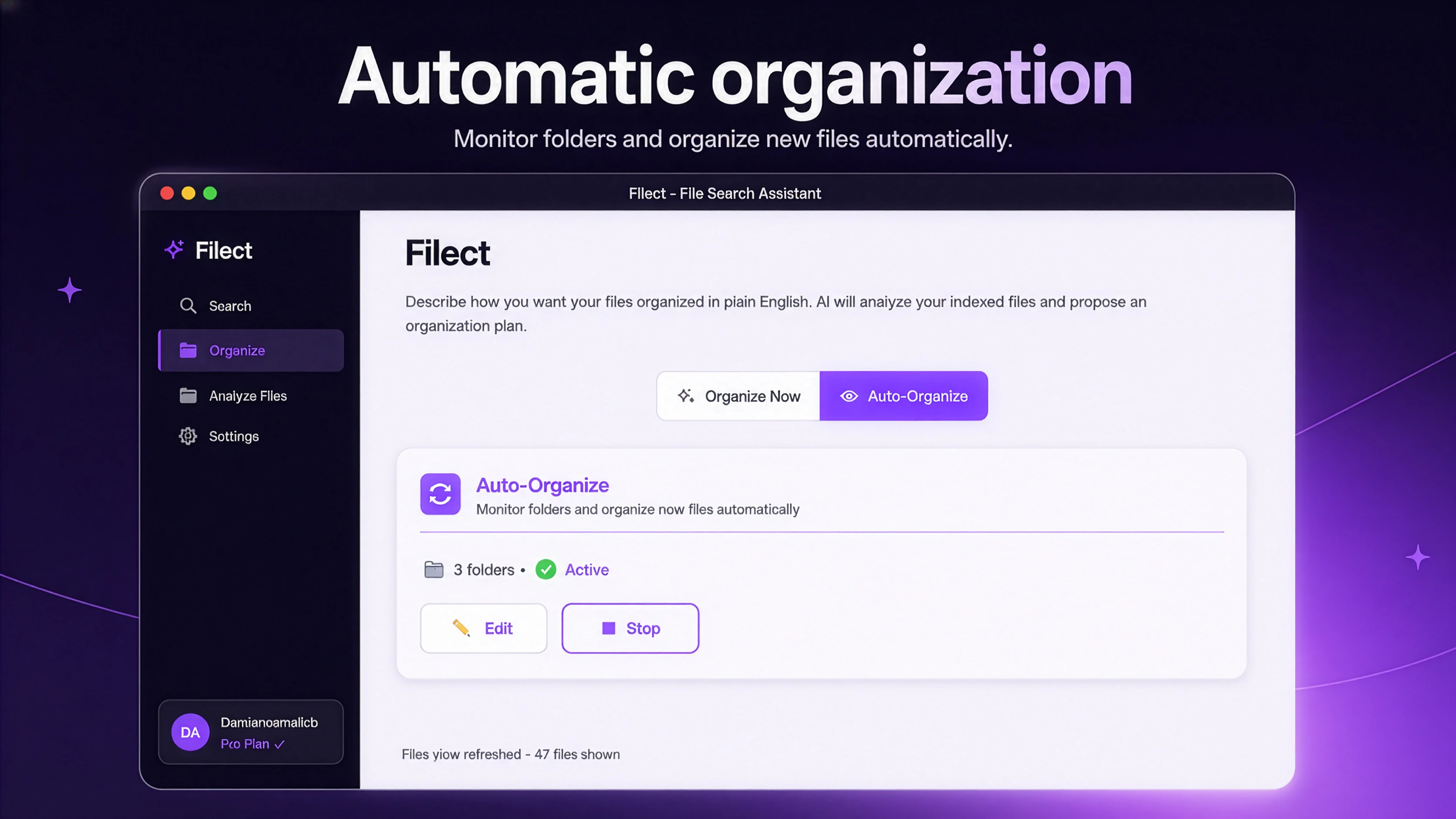
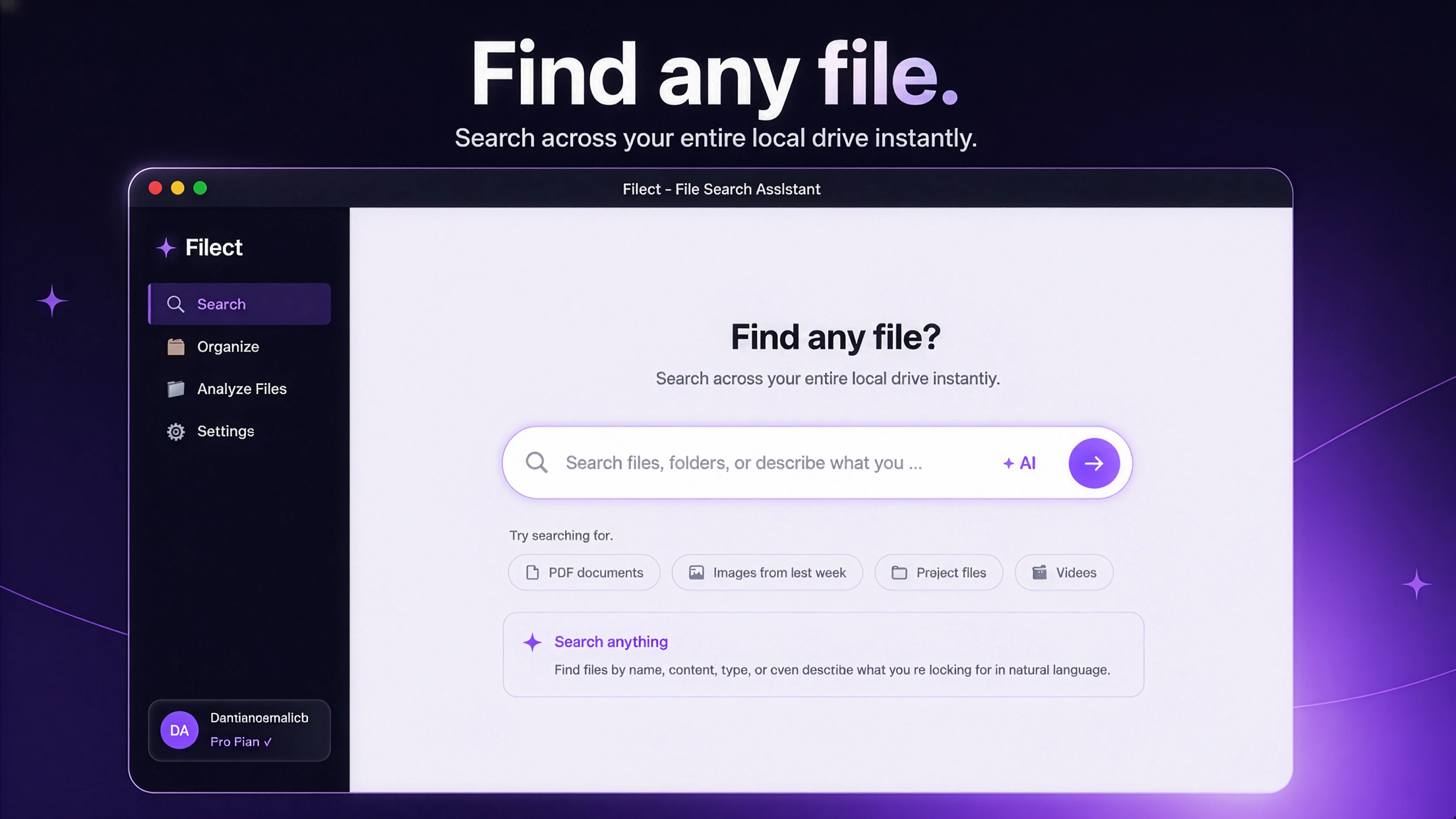
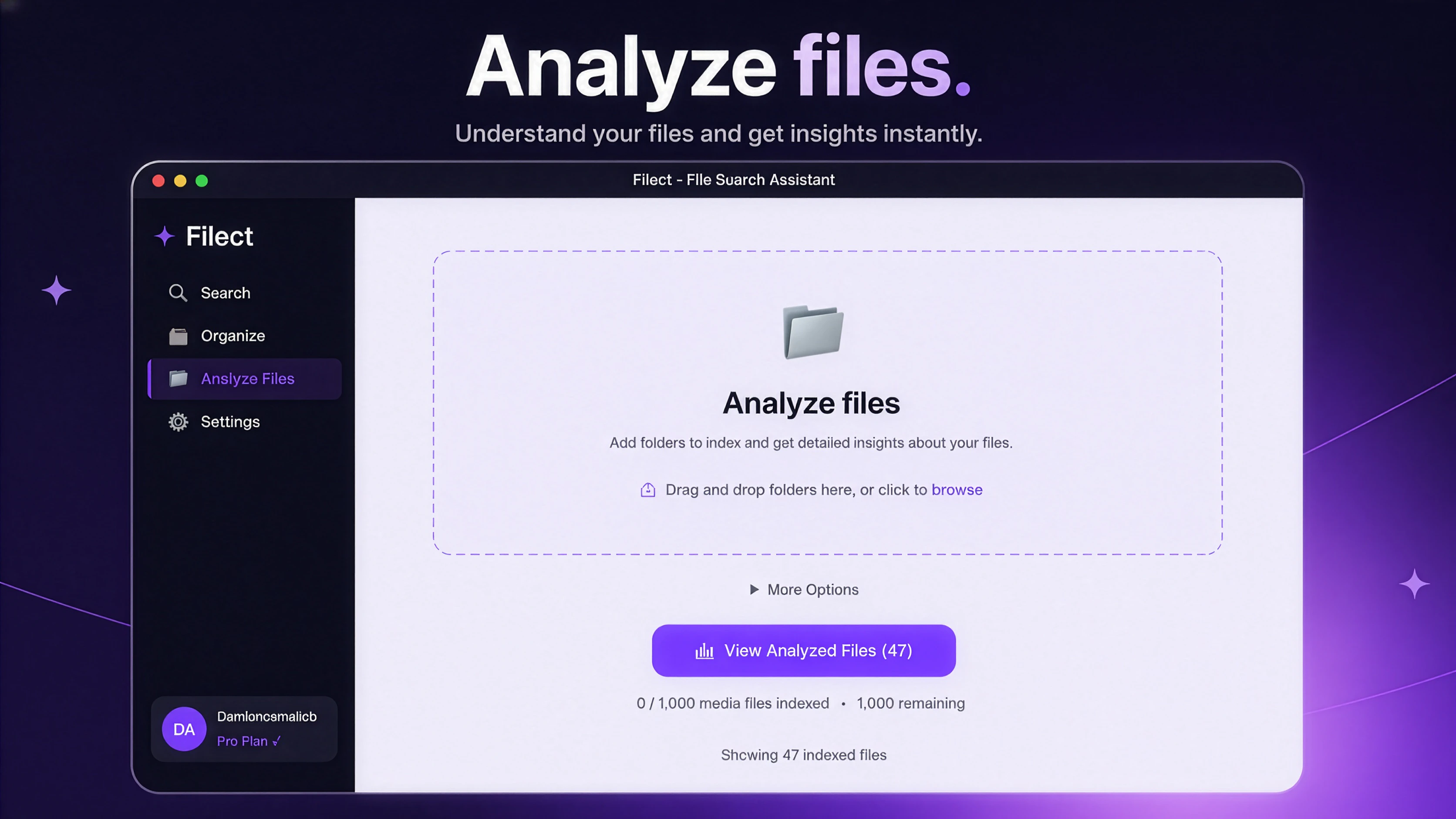
一句话介绍:Filect利用AI自动化整理桌面、下载和文档等文件夹,支持自然语言搜索文件,解决创意工作者文件混乱、丢失和手动整理难以坚持的痛点。
Mac
Productivity
Artificial Intelligence
AI文件管理
自动化整理
自然语言搜索
桌面清理
文件夹分类
生产力工具
Mac
Windows
创作者工具
文件搜索
用户评论摘要:用户肯定“自动整理+语义搜索”组合,但关心撤销与预览功能(已得到回答)。有用户质疑定价不透明(隐藏于注册后),官方称将改进。视频编辑等用户追问能否处理深层子文件夹混乱。
AI 锐评
Filect切中了一个真实但拥挤的赛道:文件管理。其核心差异在于“AI自动整理+自然语言搜索”双引擎,意图覆盖从“事后检索”到“事前预防”的全流程。但坦白说,这类工具的前辈(如Hazel)早已在Mac端深耕多年,Filect若仅停留在自动分类文件夹和语义搜索,本质上仍是既有功能的“AI换皮”,缺乏不可替代的壁垒。
用户评论中透露的更多是隐忧:定价信息藏匿降低了信任感;对于视频编辑等重度用户,深层嵌套的项目文件夹才是真正痛点,而非表面“桌面/下载”文件夹——这暴露了产品初期对复杂使用场景的覆盖不足。虽然官方承诺预览和撤销功能安抚了一部分焦虑,但AI误判文件归属的风险并未根本解决(尤其在中文文件名或模糊语义场景下)。
真正值得关注的是“不强制预设规则”的自适应逻辑,这降低了使用门槛。但产品要避免沦为“高级版Windows搜索”。建议团队将精力聚焦于特定垂直人群(如设计师、开发者)的命名习惯与工作流深度绑定,并考虑引入规则模板市场,而非泛泛的“整理一切”。15美元/月的定价在同类工具中偏高,必须有足够亮眼的增量功能(如跨版本文件追溯、云端备份同步)才能说服用户从免费/便宜选项迁移。一句话:方向对,但差异化仍需靠硬细节补全。
一句话介绍:ExplainX.ai是一个聚合AI技能、智能体、工具和MCP服务器的导航与发布平台,帮助AI从业者解决信息碎片化难题,快速发现优质资源并让自己的作品被社区发现。
Artificial Intelligence
Tech news
AI工具目录
智能体市场
MCP服务器
AI技能平台
开发者社区
资源聚合
免费发布
AI学习
产品发现
社区排名
用户评论摘要:用户认可解决碎片化痛点,提出“24小时内按重要性变化”的提要功能需求。询问变现路径是否明确(当前仅靠发现?有无赞助/推荐位),以及技能验证流程细节(基础验证已有,但需进一步说明审核标准)。整体反馈积极。
AI 锐评
ExplainX.ai切入了一个真实且棘手的痛点——AI行业的“资源通胀”。当每天都有新工具、新智能体、新协议涌现,从业者的学习成本不再来自技术本身,而是信息筛选。这个产品在本质上是一个“AI生态的GitHub + Product Hunt”,但又不止于目录:它用“真实采纳数据”作为排序基准,试图对抗推荐算法和营销泡沫,这是极具杀伤力的价值主张。
但冷静来看,它的核心挑战在于信用与护城河。评论中用户关心的“技能验证”和“变现路径”直指命门:如果只是社区评分,很快会被刷量污染;如果验证过严,又失去“免费开放”的吸引力。而变现方面,当前“免费列表+社区曝光”更像冷启动的诱饵,若没有明确的付费升级或佣金抽成,平台将难以持续维护内容的时效性和质量(用户已提出“24小时变化提要”的需求,这恰恰是人力成本所在)。
另外,它与同类产品(如Toolify、Futurepedia)的差异化并非颠覆性——后者同样聚合工具并标注热度。真正的壁垒在于能否沉淀出“技能-智能体-MCP服务器”的全链条映射,让开发者的发布、评测、复用形成闭环,而不是另一个待办清单式的黄页。
一句话总结:方向精准,痛点真实,但距离成为AI从业者的“每日必读”还需要解决内容治理与商业闭环的硬仗。
一句话介绍:BookstoRead.ai是一款基于AI的书籍发现引擎,用户用自然语言描述阅读偏好,AI即可精准匹配符合“氛围”和“意图”的非大众化书籍,解决在泛泛书单中找不到心仪读物的痛点。
Artificial Intelligence
Books
AI书籍推荐
自然语言搜索
个性化书单
阅读发现
垂直AI应用
小众书籍
书籍匹配
智能搜索
书虫工具
出版科技
用户评论摘要:用户普遍赞赏其解决“搜书难”痛点,尤其对复杂、跨界查询效果满意。主要建议包括:支持本地亚马逊链接(如印度),添加Goodreads链接,增加搜索历史与用户登录系统以保存书单。此外,用户对多语言支持表示关心,团队回应AI可处理非英语搜索。
AI 锐评
BookstoRead.ai切中了一个真实但尚未被巨头彻底解决的痛点:图书搜索正在从“关键词匹配”向“意图理解”进化。Goodreads和亚马逊的推荐系统仍停留在基于评分、标签和协同过滤的“平均数”逻辑上,这对于想找“1920年代北极探险”或“像政治惊悚小说的罗马史”的用户毫无意义。产品将大语言模型(LLM)的语义理解能力封装成垂直体验,用“写一句可描述”替代多层次筛选,降低了发现新书的心智成本,这是它最核心的价值。
但需警惕的是,该产品的壁垒并不在于“AI搜书”这个点子本身,而在于图书数据的颗粒度与个性化持续优化的能力。目前它依赖亚马逊链接导流,尚未看到独特的书评元数据积累或用户兴趣图谱的进化闭环。用户评论中反复出现的“登录系统”“搜索历史”“多平台链接”等诉求,恰恰指向了产品商业化必须补齐的短板——没有用户留存,就没有推荐模型的迭代,最终只是披着AI外衣的搜索引擎。
此外,如何避免生成“看似合理但实际平庸”的推荐(大模型幻觉的常见陷阱),以及能否覆盖多语种图书库,将是决定其能否从小众工具变成主流通用产品的分水岭。一句话:方向正确,但能否从“体验创新”走向“数据飞轮”,还需时间检验。
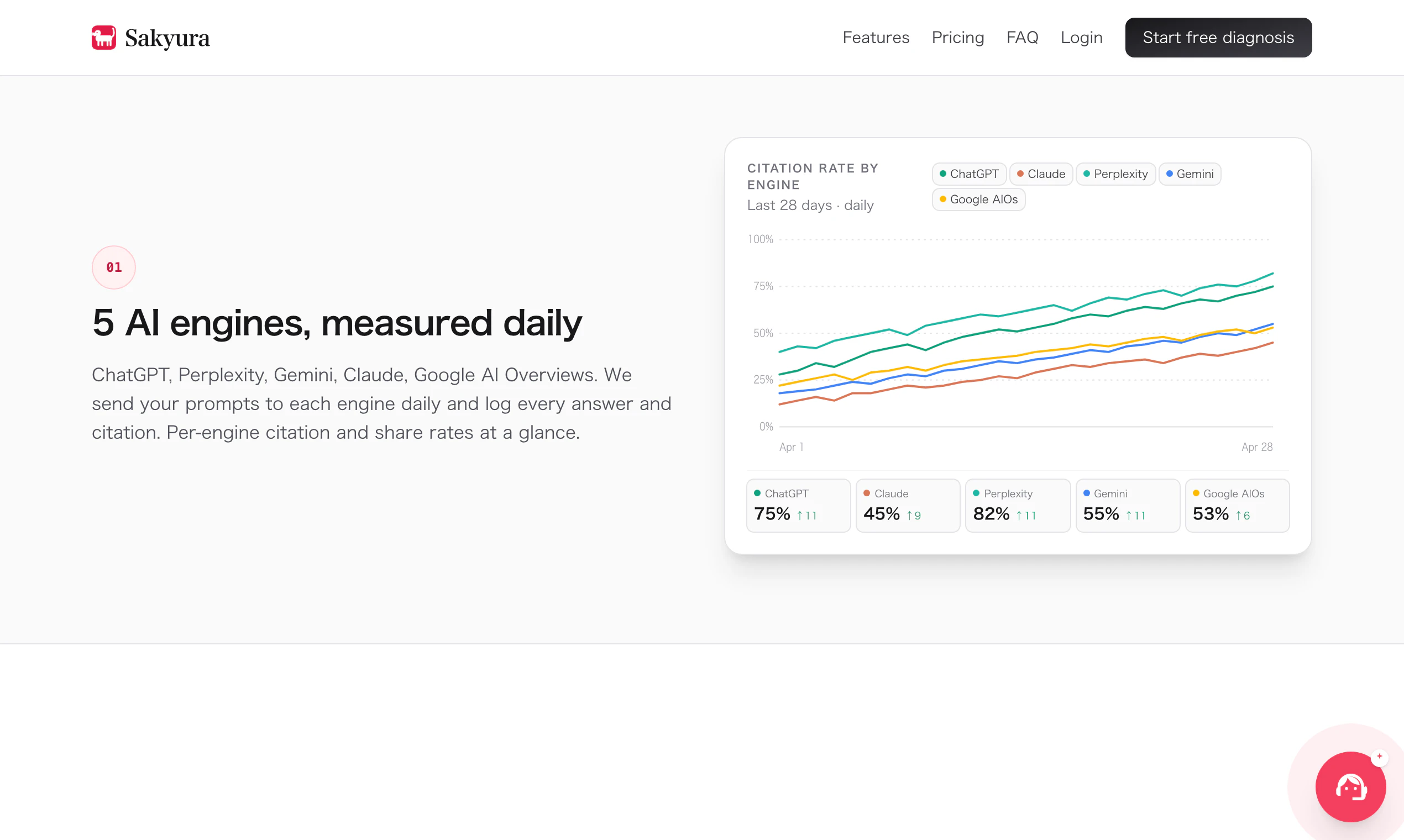
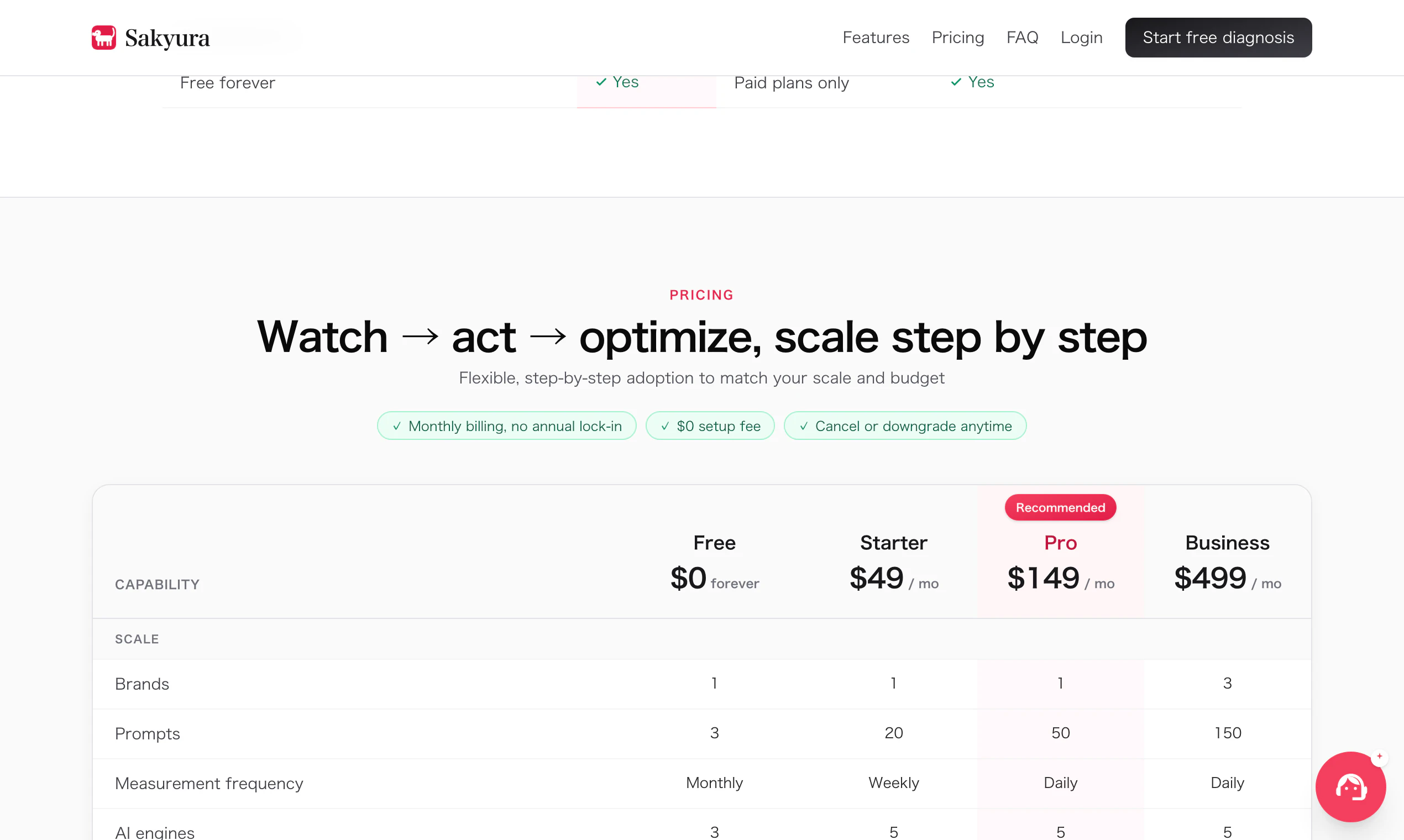
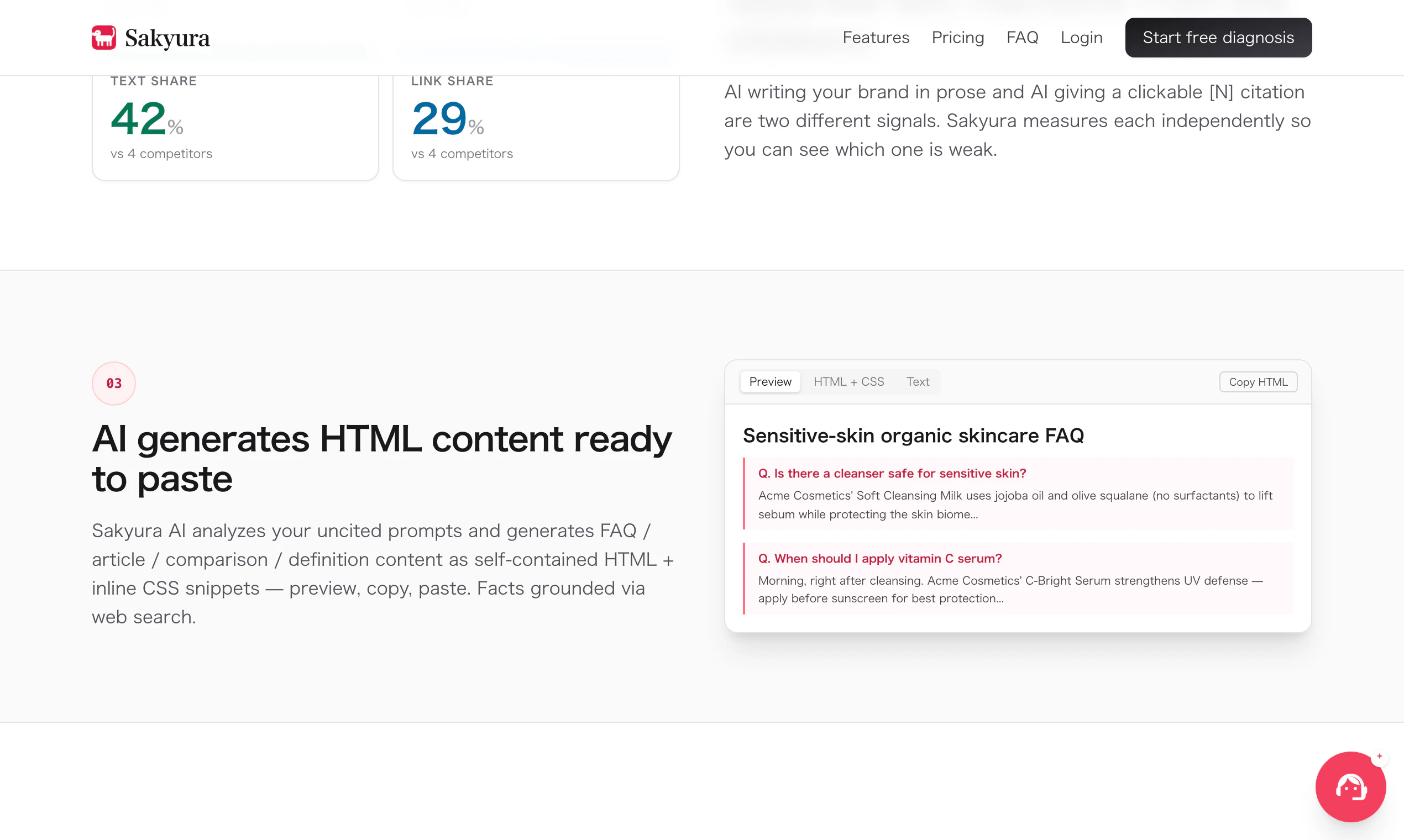
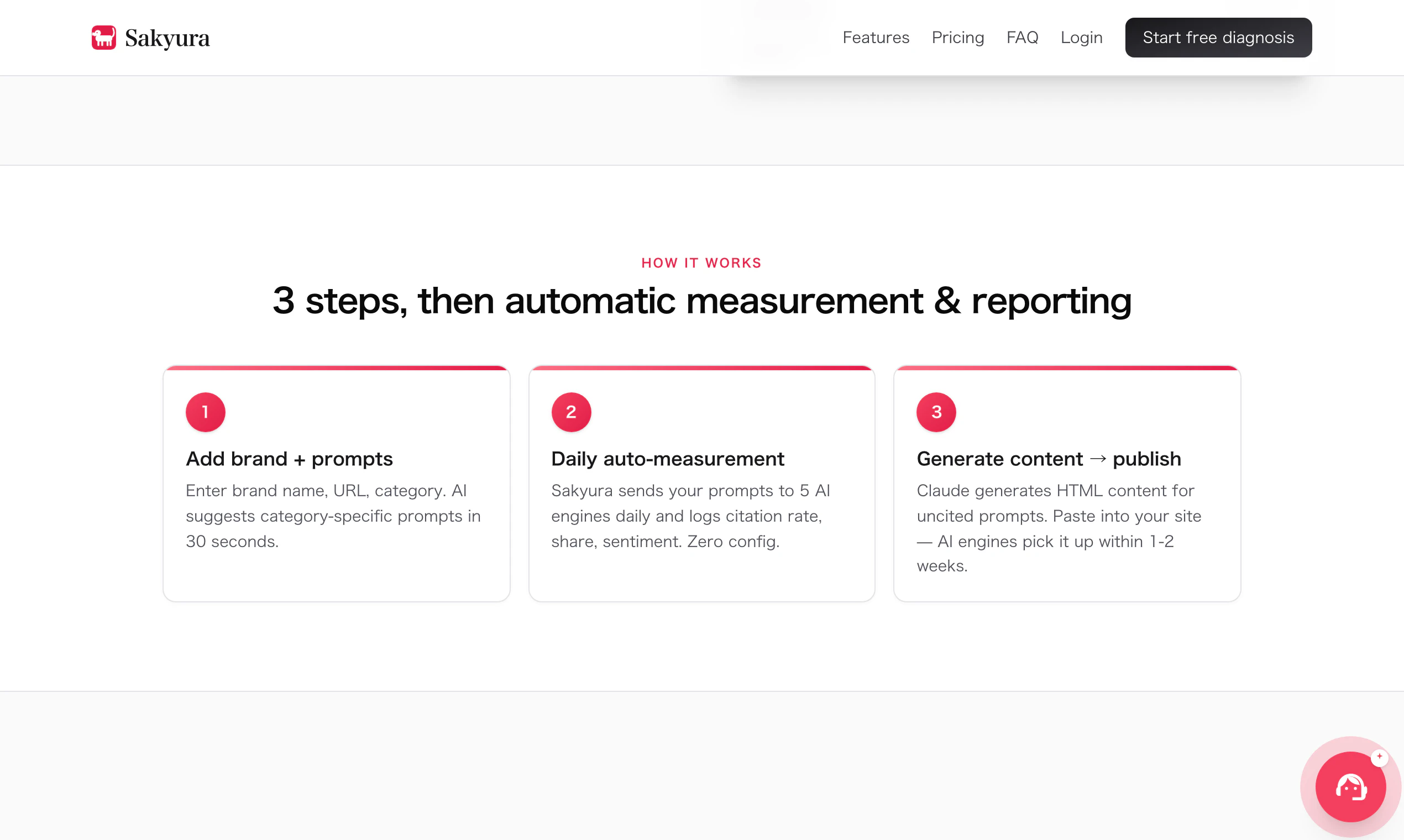
一句话介绍:Sakyura是一站式AI品牌引用监控与优化工具,专为中小企业解决“客户从ChatGPT等AI搜索发现竞品而非自己”的痛点,自动追踪五大AI引擎的提及率、生成可部署内容以夺回AI推荐份额。
Analytics
SEO
Artificial Intelligence
AI搜索优化
品牌提及监控
竞品声量对比
AI内容生成
中小企业SEO
ChatGPT推荐分析
Perplexity追踪
AI驱动流量
SaaS工具
营销分析
用户评论摘要:用户肯定其“将AI推荐视为独立流量漏斗”的洞察,认为FAQ片段生成落地性强。提问:对于在Perplexity有提及但在ChatGPT无提及的品牌,工具是只显示差异还是会诊断原因?创始人表示反馈积极,产品1-2周可见内容引用变化。
AI 锐评
Sakyura切中了搜索格局裂变期一个真实但常被忽视的痛点——当AI推荐逐步侵蚀传统搜索流量时,中小企业既缺乏感知自己“在AI世界存在与否”的量化工具,更缺乏低成本反击的手段。创始人从“客户说ChatGPT推荐了它”这一现象出发,将抽象危机拆解为每日监测、竞品对标、内容修正三个可执行步骤,本质上是在帮品牌建立对“AI渠道”的认知闭环。其价值不仅在于“显示你被谁提及”,更在于提供了从“知道”到“行动”的最小路径——自动生成的FAQ片段可直接部署,且作者声称1-2周可见收录变化,这远优于“优化优质内容”的泛泛之谈。但必须指出,产品目前的核心假设(AI搜索引擎如何决定引用品牌)并未公开,且17票的早期验证量尚不足以证明普适性。如果其底层索引逻辑仅依赖简单关键词匹配或过度依赖人工规则,则随AI模型更新极易失效。此外,对多语言、多行业品牌的适配性、是否支持长篇品牌内容监控(如微信公众号、知乎文章)也未说明。其真正的护城河应是积累跨引擎的“被引用变因”数据库,并持续迭代诊断建议的确定性,否则极易沦为AI时代的SEO仪表盘——好看但不够致命。对中小品牌而言,它是一次成本可控的“AI SEO体检”,值得尝试免费版;但长期依赖单一工具解决AI可见性问题,仍是一厢情愿。
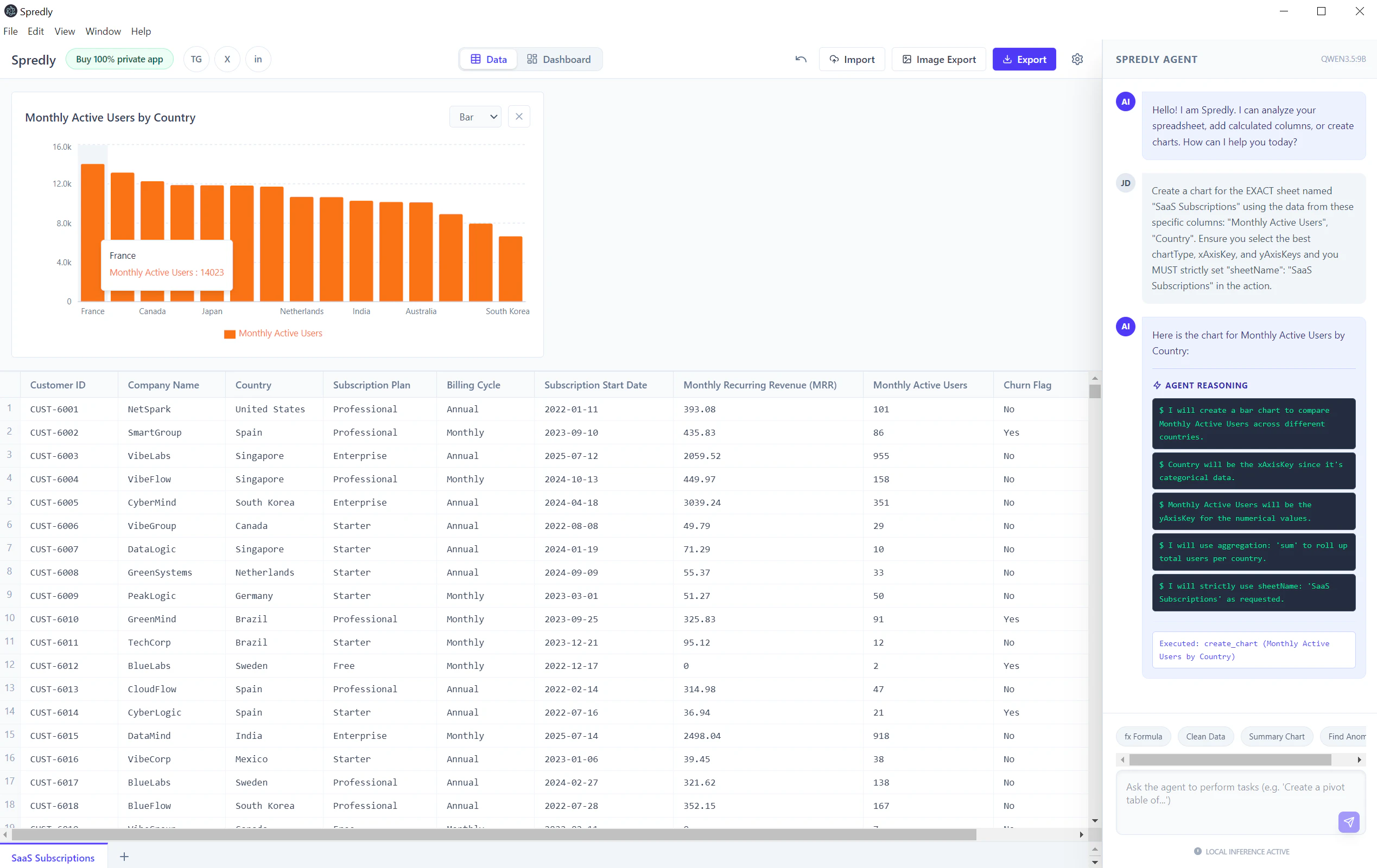
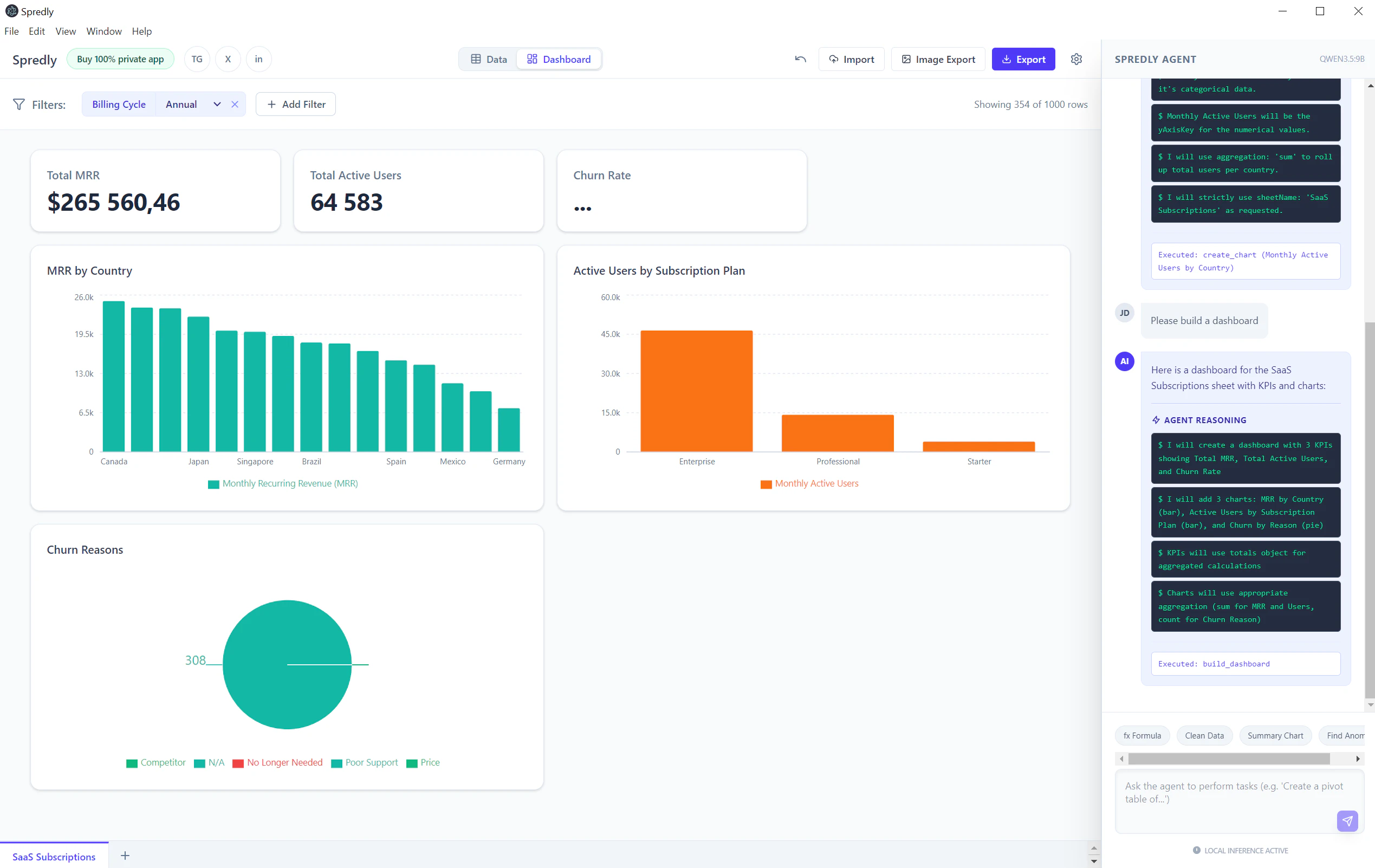
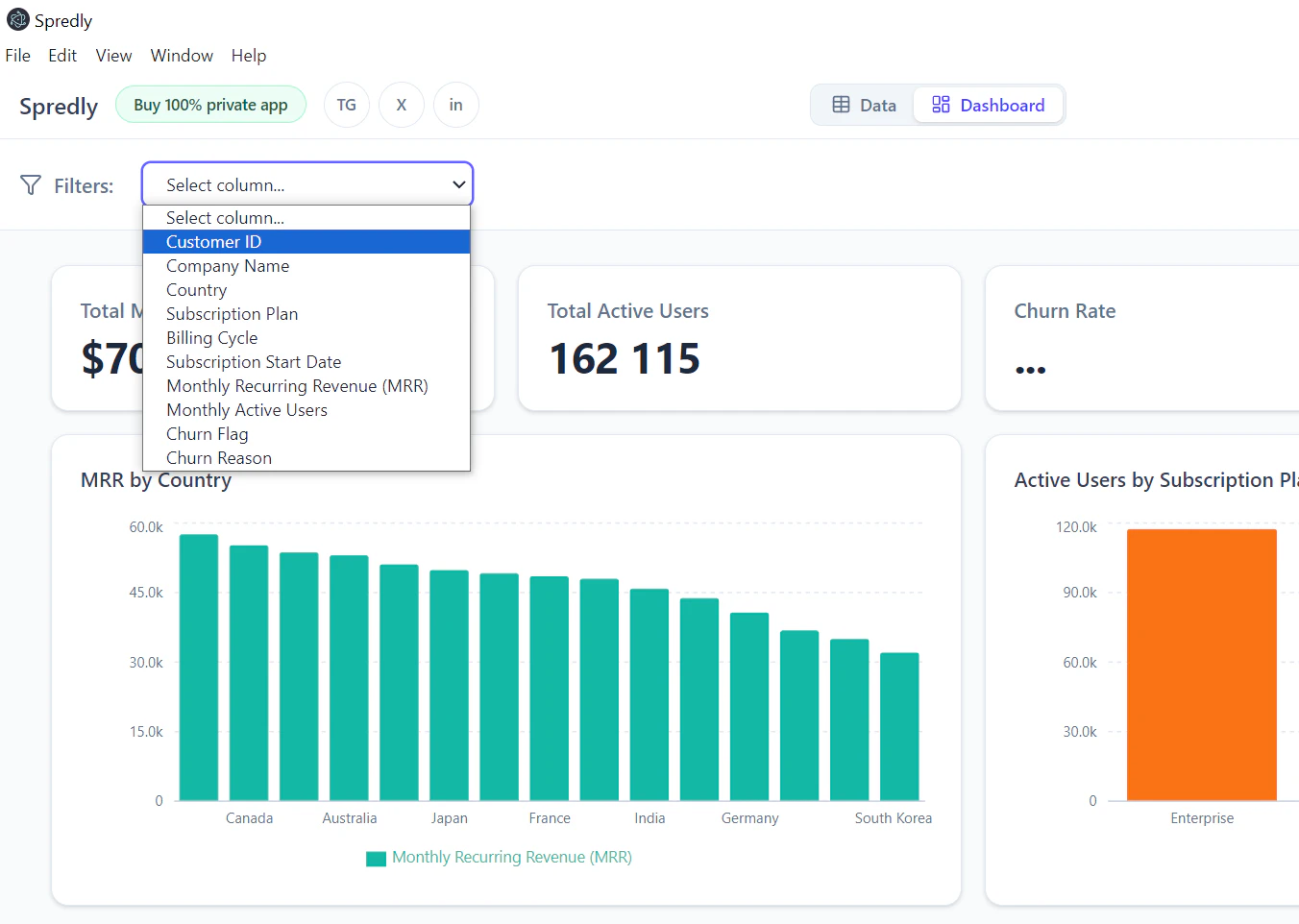
一句话介绍:Spredly 是一款将本地大模型直接嵌入电子表格的 AI 工具,让用户在熟悉的行列操作中通过自然语言对话、生成图表和仪表盘,无需上传敏感数据到云端。
Productivity
Spreadsheets
Artificial Intelligence
AI电子表格
本地大模型
数据隐私
自然语言查询
金融建模
智能图表
离线分析
Ollama
Claude集成
生产力工具
用户评论摘要:用户高度认可本地处理对金融敏感数据的价值,建议支持色彩编码假设单元格、公式与硬编码区分、多标签页模型导航等结构化布局。有用户通过本地API端口将Spredly接入自主代理,以绕过付费墙并增强隐私。创建者承诺在下个版本中纳入这些功能。
AI 锐评
Spredly 切中了一个非常具体且真实的痛点——金融、法律等行业的专业人士在处理敏感数据时,既需要AI的提效能力,又绝不能让数据出域。它没有跟风做“通用AI助手”,而是回归到电子表格这个最基础、最庞大的生产力场景,将本地LLM(通过Ollama等)无缝嵌入。这种“本地+专用”的定位,实际上比那些只谈“AI+办公”的泛化产品更有杀伤力,因为它直接交付了一个合规的、可立刻落地的解决方案。
然而,产品目前仅有13个投票和少量评论,说明它仍处于极早期阶段。真正的挑战在于:本地大模型(尤其是小模型)在处理复杂公式、交叉引用和超大表格时的推理准确率和速度,能否在实用层面不输给云端方案?从用户对“结构化布局支持”的呼声可以看出,单纯的对话式查询远远不够——金融模型的价值在于其精密的层级结构与逻辑依赖。如果Spredly不能成为“看得懂模型逻辑”的AI助手,而只是一个“读得懂单元格”的对话机器人,那它很快就会被Sheets或Excel自家的AI插件边缘化。此外,如何平衡“本地优先”与“Agent生态”(如用户提到的localhost:4141接入)的架构关系,也是后续产品能否从工具进化为平台的关键。总体而言,方向精准,但深挖行业垂直场景的工程深度,才是决定它能否从“小而美”走向“不可或缺”的分水岭。
一句话介绍:AI Sales Operator 是一款24/7自动化电商销售流程的AI系统,覆盖订单确认、催付、售后、评论收集等环节,帮在线商店大幅减少人工管理负担。
Sales
Artificial Intelligence
E-Commerce
电商自动化
AI销售代理
订单管理
CRM协同
客户沟通
售后运营
催付恢复
评论收集
无代码工具
SaaS
用户评论摘要:创始人详细介绍了系统覆盖的订单到售后全流程。用户提问:”90-99%的工作替代率在实际用户中能实现多少?多数店铺在哪一步会卡住?” 反映出对自动化落地率的质疑,需求案例数据支撑而非口号。
AI 锐评
AI Sales Operator切入的是电商运营中高度重复、规则明确的”文档型”工作流——通知、状态更新、催付、点评收集。这一赛道确实最适合AI初期落地:低风险、高确定、易量化。但创始人在评论中回复的“替换90-99%的管理工作”,恰恰暴露了这类产品的天花板。
首先,电商客服和运营中最难啃的“复杂或冲突”场景——退换货判定、恶意差评处理、客诉升级安抚——才是成本大头,却明确被划为“需要人类”。这意味着AI实际能吞下的只是流程链中边缘且低价值的部分。
其次,从0赞的留评数量和无有效讨论可见,产品并未在Product Hunt上引发专业用户的深层关注。11票大概率来自熟人场或者早期内测。更关键的是,那唯一有效提问——“90-99%的替代率在真实用户中是否达标”,创始人并未正面回答。这暴露了一个尴尬事实:该产品很可能还处于小规模内测甚至只是PPT演示阶段,缺少真实复购率、人工减员率、错误率等硬数据撑腰。
短期看,它作为一条插件式自动化流水线,对小体量DTC品牌或独立站主仍有吸引力,能省掉半个运营的人力。但长期来看,真正的护城河不在于“自动化程度”,而在于能否进一步打通与Shopify、WooCommerce、ERP、发货API之间的深度双向交互,并逐步介入退货、换货等高风险流程。否则,它可能永远停留在“通知机器人”这个低壁垒、可轻易被平台官方功能或ChatBot夹带的边缘市场。
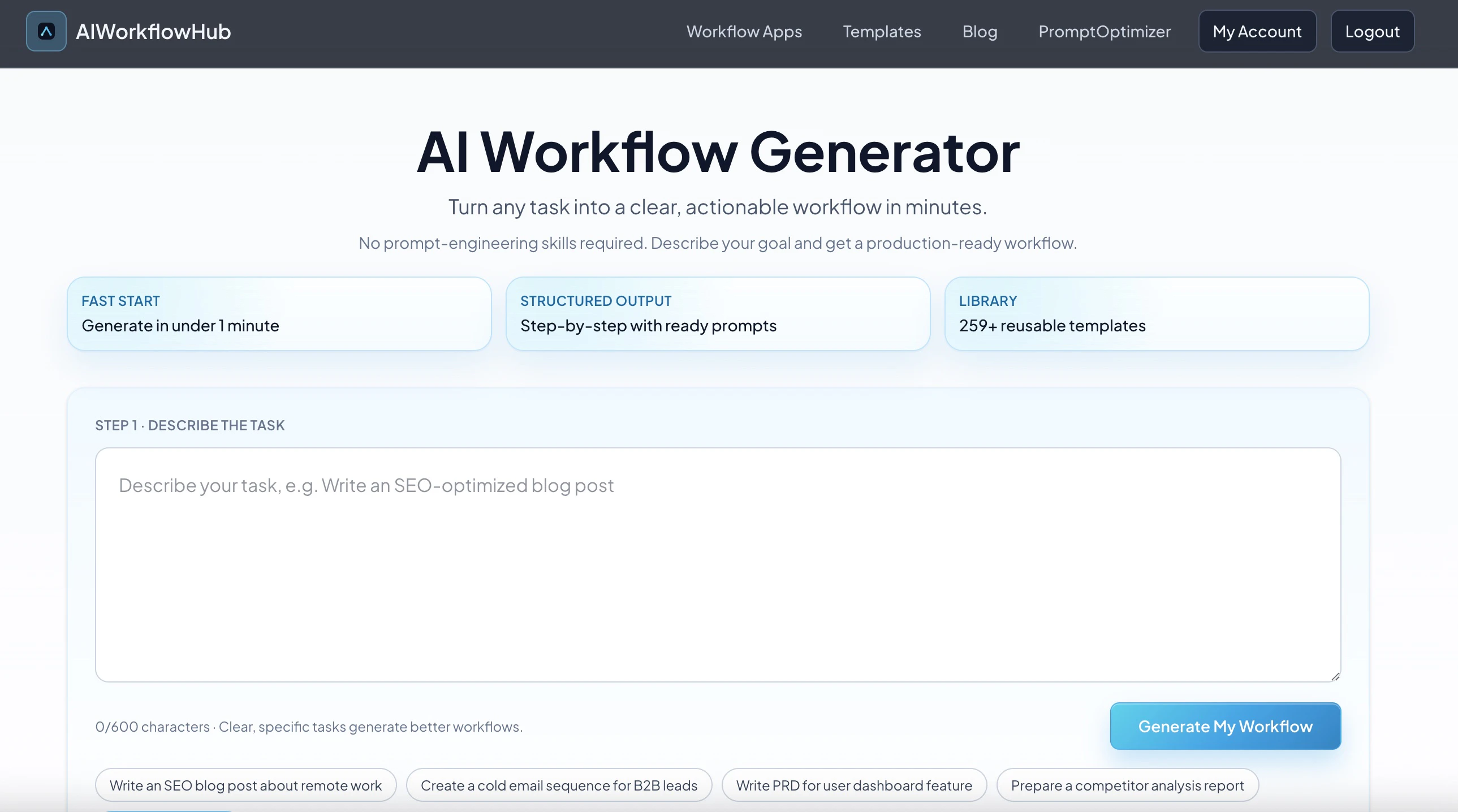
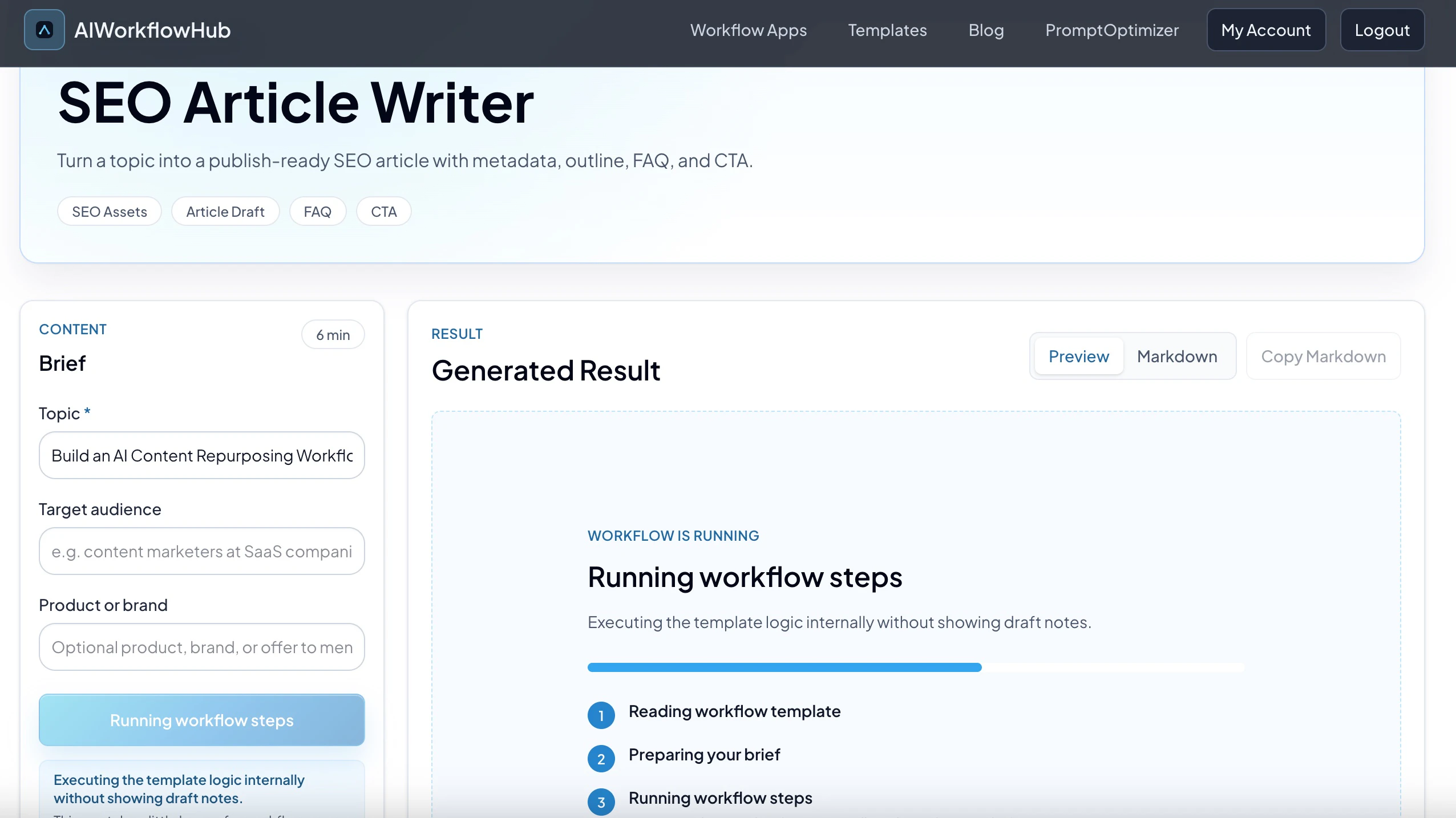
一句话介绍:AI Workflow Generator 能根据用户输入的任务或关键词,自动生成包含步骤结构、提示词和示例输出的完整工作流,解决用户在SEO、营销、编程等场景中只有碎片化提示词、缺乏可执行流程的痛点。
Productivity
SEO
Artificial Intelligence
AI工作流生成器
提示词管理
自动化流程
SEO工具
营销工具
编程辅助
任务分解
生产力工具
模板生成
工作流编排
用户评论摘要:用户认可“工作流作为单元”的洞察,指出人们不缺乏提示词,而是缺少编排好的流程。同时提出关键疑问:用户是否会直接使用生成的工作流,还是会重度修改?若后者,产品的真正价值可能在于提供框架而非完整方案。
AI 锐评
AI Workflow Generator 切中了一个真实且普遍的痛点:提示词泛滥,但完整、可复用的工作流程缺失。这本质上是从“原子化工具”向“流程化解决方案”的进化,方向正确。然而,11个投票和仅有的一条有效评论,暴露出产品在早期冷启动时的无力感。评论中的反馈极为致命——“用户会直接使用还是重度修改?”如果答案是后者,那么产品所谓的“完整工作流”不过是高级一点的建议列表,其价值将大打折扣。目前的产品形态更像是一个结构化的提示词包装器,缺乏对执行过程的自动化控制和反馈闭环(例如:是否能在工作流中嵌套调用API、进行条件判断或数据验证?)。对于目标用户(SEO、营销人员),他们需要的是降低执行心智负担,而非多一个需要二次加工的“草稿”。产品的真正价值,不应止步于“生成”,而应在于“可执行”与“可复用”——如果能做成可交互的清单,用户勾选即完成,或内置自动化节点,才算握住了痛点。否则,它很快会被ChatGPT的定制GPTs或市场里更成熟的流程工具替代。一句话:洞察不错,但完成度还停留在“点子”阶段,要变成“作品”还差好几个迭代。
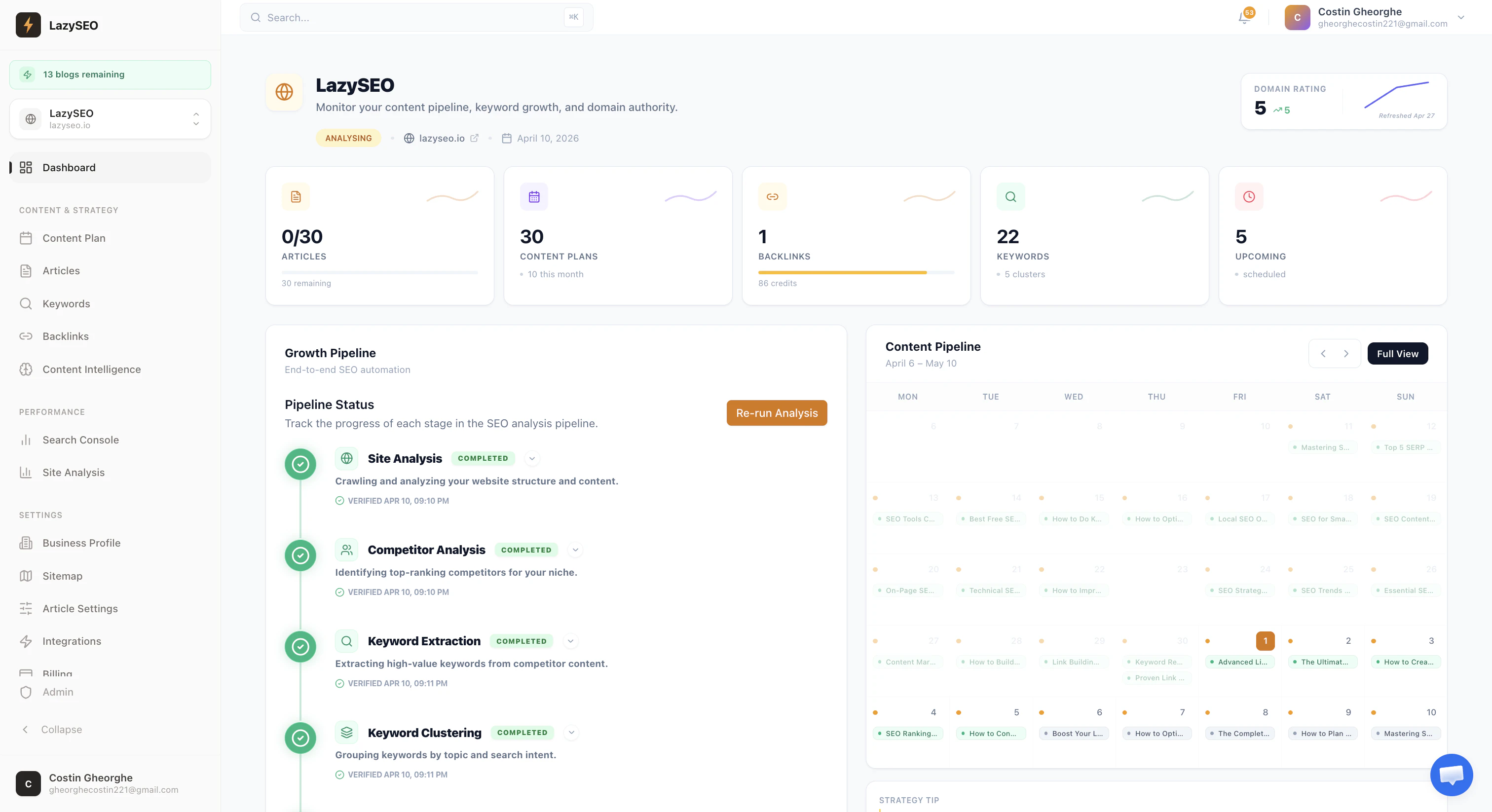
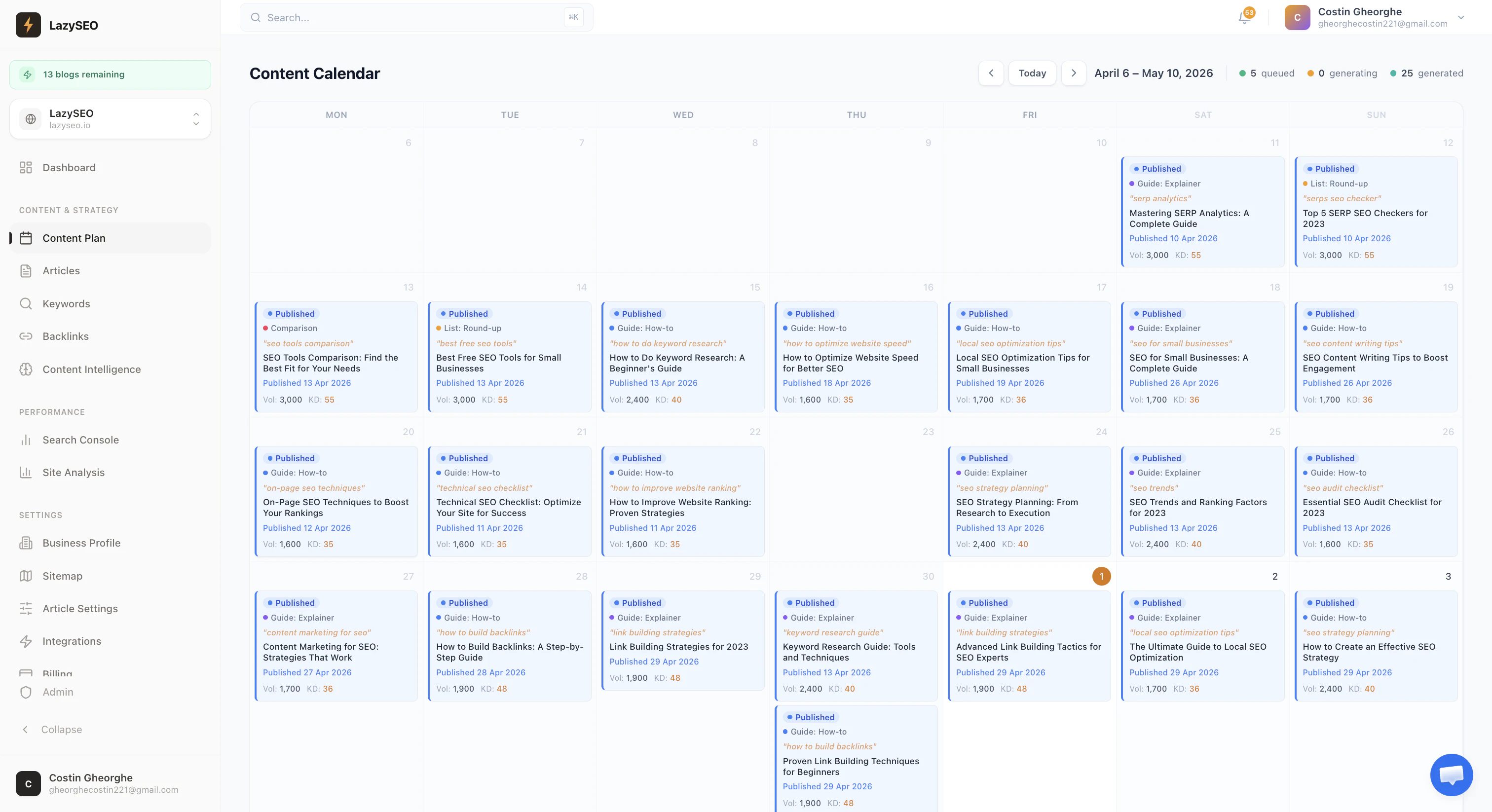
一句话介绍:LazySEO 是一个全自动 SEO 内容生成工具,通过关键词研究、撰写2500字的优化文章并直接发布到网站,帮助内容创作者和站长将“想法→排名”的繁琐流程压缩为一键操作,解决多工具拼凑、手动优化效率低下的痛点。
Writing
Marketing
SEO
SEO自动化
关键词研究
AI写作
内容营销
排名优化
站点发布
程序化SEO
长尾内容
多引擎排名
创作者工具
用户评论摘要:用户认可其整合工作流、降低多工具成本的价值,核心问题集中在:1. 关键词研究数据来源的深度;2. 是否支持程序化SEO(根据数据集批量生成内容);3. 定价门槛及实际效果验证。
AI 锐评
LazySEO 踩中了一个真实且持续存在的痛点——SEO 内容生产的“管道工困境”。对于运营多个网站或个人站长的用户而言,从关键词挖掘、内容撰写、SEO 优化到最终发布,往往需要在 Ahrefs、Surfer、Jasper 等工具间反复切换,既消耗预算又拖慢节奏。LazySEO 的“一体化自动流水线”思路,本质上是在用工程化思维解决内容生产的高频重复劳动,其价值不在于技术颠覆,而在于“减少摩擦”——将专业门槛和操作成本大幅降低。
但需要警惕的是,这种“全自动”模式暗藏两个陷阱:其一,AI 生成的长文(2500字)在 Google 等搜索引擎眼中,若无扎实的数据支撑或独特的洞察,极易被判定为“低质量内容”,特别是在 YMYL 领域;其二,产品过于强调“一键直达排名”,容易让用户产生不切实际的预期。SEO 的成功从来不只是内容本身,外链、权威性、用户体验等因素缺一不可。此外,用户对关键词数据源的追问,直指核心里程碑——如果研究阶段的数据质量不够硬,全自动生成的内容只能出量,难以出价值。
总体而言,LazySEO 作为一个“内容生产的自动化加速器”有明确的场景价值,尤其适合长尾关键词覆盖和内容规模扩张阶段。但它更像是一个优秀的“执行者”,而非“策略家”。如果你的核心竞争力在于品牌深度或专业壁垒,那么这类工具只是助攻;如果你的目标是用最低成本快速铺量、测试市场,它可能是目前最省心的选择之一。
一句话介绍:Il Frullatore Carlà 是一款基于35年投资方法论构建的AI分析应用,帮助投资者在2分钟内完成巴菲特式的深度公司分析,解决传统AI分析泛泛而谈、缺乏专业财务洞察的痛点。
Analytics
Education
Artificial Intelligence
AI投资分析
巴菲特式分析
价值投资
财务报表深度分析
RAG金融
智能投研
投资决策辅助
财务数据分析
专业投资者工具
股票分析应用
用户评论摘要:用户称赞该应用是将35年方法论转化为产品的杰作,并认同其核心洞察——金融AI工具的关键在于RAG(上下文与提问结构)而非模型本身,大多数工具因提问泛泛而失败。
AI 锐评
这款产品的核心价值并不在于AI模型本身,而在于其创始人Francesco Carlà耗时35年打磨的一套“提问逻辑”——这正是许多金融AI产品所缺失的灵魂。在通用大模型泛滥的今天,谁都能让ChatGPT写一份苹果公司的分析报告,但结果往往是“正确而无用”的表面信息。Carlà从方法论层面构建了一个精密的RAG系统,它知道该问什么、该忽略什么、该从哪里抓取关键数据,这种“分析师思维”的数字化封装才是真正的护城河。
产品目前的投票数(10票)与其野心形成鲜明反差,说明它仍处于极早期验证阶段。真正值得关注的是其用户反馈中提到的“2分钟完成过去3天的工作”,这暗示产品在效率提升上确有颠覆性,但前提是用户本身具备一定的财务分析基础——它更适合专业投资者、资产管理者或金融机构分析师,而非散户小白。
需要警惕的是,创始人声称“数千次分析已完成”,但缺乏公开的业绩回测或对比验证。投资分析的价值最终要落在“决策结果”上,而非“分析过程”有多专业。如果这套系统无法在实际交易中被证明能更准确识别企业基本面风险或低估机会,那它再“聪明”也只是一本昂贵的金融教材。此外,35年方法论听起来悠久,但若缺乏对现代新兴行业(如AI、生物科技、云计算)财务模型的适配更新,这套“老配方”很可能在解读亏损但高增长的商业模式时水土不服。
总而言之,这是一款有“灵魂”的金融AI工具,但能否从“专家玩具”进化为“刚需生产力”,还需要更多真实的投资案例来证明。
一句话介绍:Palabros是一款让你查词后不会转头就忘的词典APP,通过小组件反复呈现生词,帮你真正把词汇“记住”而非仅仅“查过”。
Education
Languages
Artificial Intelligence
词典应用
单词记忆
学习工具
小组件
词源
每日一词
复习游戏
双语模式
无广告
iOS
用户评论摘要:当前仅有一条制作者自述,无用户评论。核心问题在于:产品刚发布,缺乏真实用户反馈来验证“记住单词”的实际效果与用户痛点。
AI 锐评
Palabros试图解决一个真实痛点——查了词却记不住。其核心卖点“用小组件反复强化”确实切中了被动记忆的常见缺口,且无广告、双语模式、复习游戏等设计显示产品打磨得相当细致。但从投票数(10)和零用户评论来看,目前还处于早期冷启动阶段,缺乏市场验证。
值得警惕的是,这个功能极易被大厂“复制粘贴”——iOS自带词典、欧路、墨墨等产品早已具备生词本和复习机制,Palabros仅靠小组件和多花样的复习游戏难以构筑护城河。真正的壁垒应该在于“如何让用户愿意打开并坚持使用”,而非单纯增加信息曝光频次。另外,官方定义+易懂解释的双层展示是亮点,但若词库质量与更新速度不能持续优于竞品,很容易沦为“精致但可有可无”的替代品。
从商业逻辑看,一次买断+免费试用的模式对用户友好,但后续运营压力巨大:缺乏订阅制现金流,需要极高用户粘性和口碑传播才能维持。建议团队尽快通过社区运营或学习打卡功能建立社交驱动,否则在单词应用的红海中,仅仅“设计感”和“小组件”很难让用户长期驻足。
一句话介绍:Fossel是一个本地MCP内存服务器,专为开源贡献者设计,通过SQLite数据库为Cursor、Claude Desktop等AI工具提供持久化、按仓库感知的上下文记忆,解决AI对话间上下文丢失的痛点。
Open Source
Developer Tools
GitHub
本地MCP服务器
AI上下文记忆
开源工具
仓库感知
SQLite存储
代码助手增强
开发者效率
本地优先
无云方案
协作记忆管理
用户评论摘要:开发者@vignesh_g10肯定了从保存/搜索演变到协作记忆管理的方向,认为固定和总结功能能提升AI上下文信噪比,并好奇是否在编码之外有更多团队协作场景。
AI 锐评
Fossel切中了一个真实且高频的痛点:AI编码助手“每会话从零开始”的失忆症。它将记忆从云端拉回本地,用SQLite作为持久层,本质上是为AI工作流构建了一个轻量级、可编程的“第二大脑”。这种思路比依赖模型内置的上下文窗口更务实,因为后者受限于长度和成本。
但冷静看,Fossel的护城河并不深。核心功能(更新、固定、总结)本质上是对本地键值数据库的封装,技术门槛较低。真正的价值在于“仓库感知”的设计——它不只是存储片段,而是试图理解每个repo的约定、Bug模式等结构化知识。这暗示着更强的语义查询和模式匹配能力,如果只停留在关键词搜索,则容易被更通用的VectorDB取代。
团队野心可能不止于编码场景。评论中提到的“团队协作记忆”是更有想象力的方向:当多人通过AI协作时,一个共享的、结构化的上下文库能极大减少沟通成本。但难点在于,目前的存储仍以本地文件为基础,缺乏多用户同步和冲突解决机制。
一句话总结:Fossel用最朴素的方式解决了AI助手最核心的上下文碎片化问题,概念正确,但需要证明自己不是一个漂亮的SQLite wrapper,而是一个能理解、推理和演进代码知识的智能记忆层。
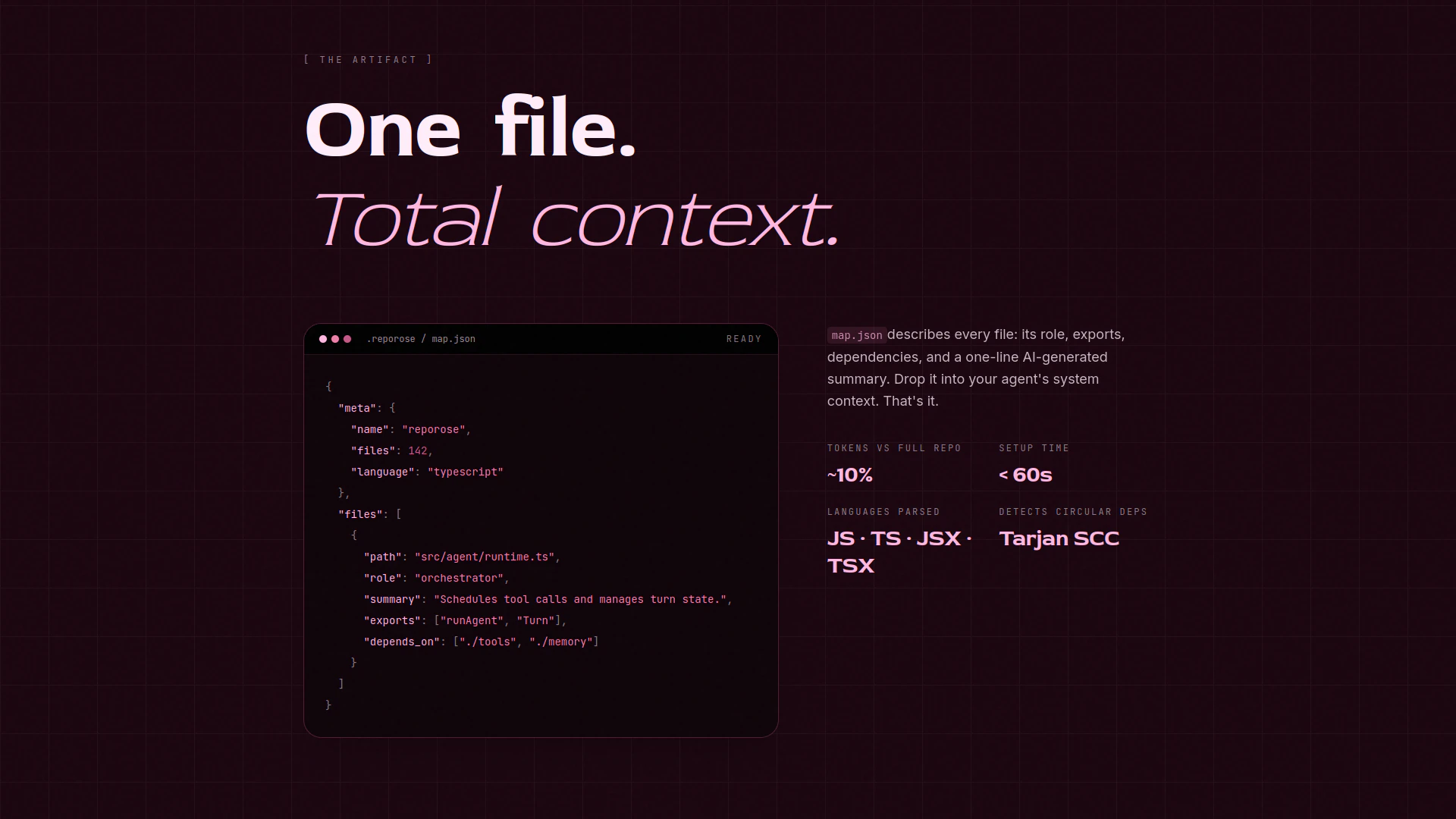
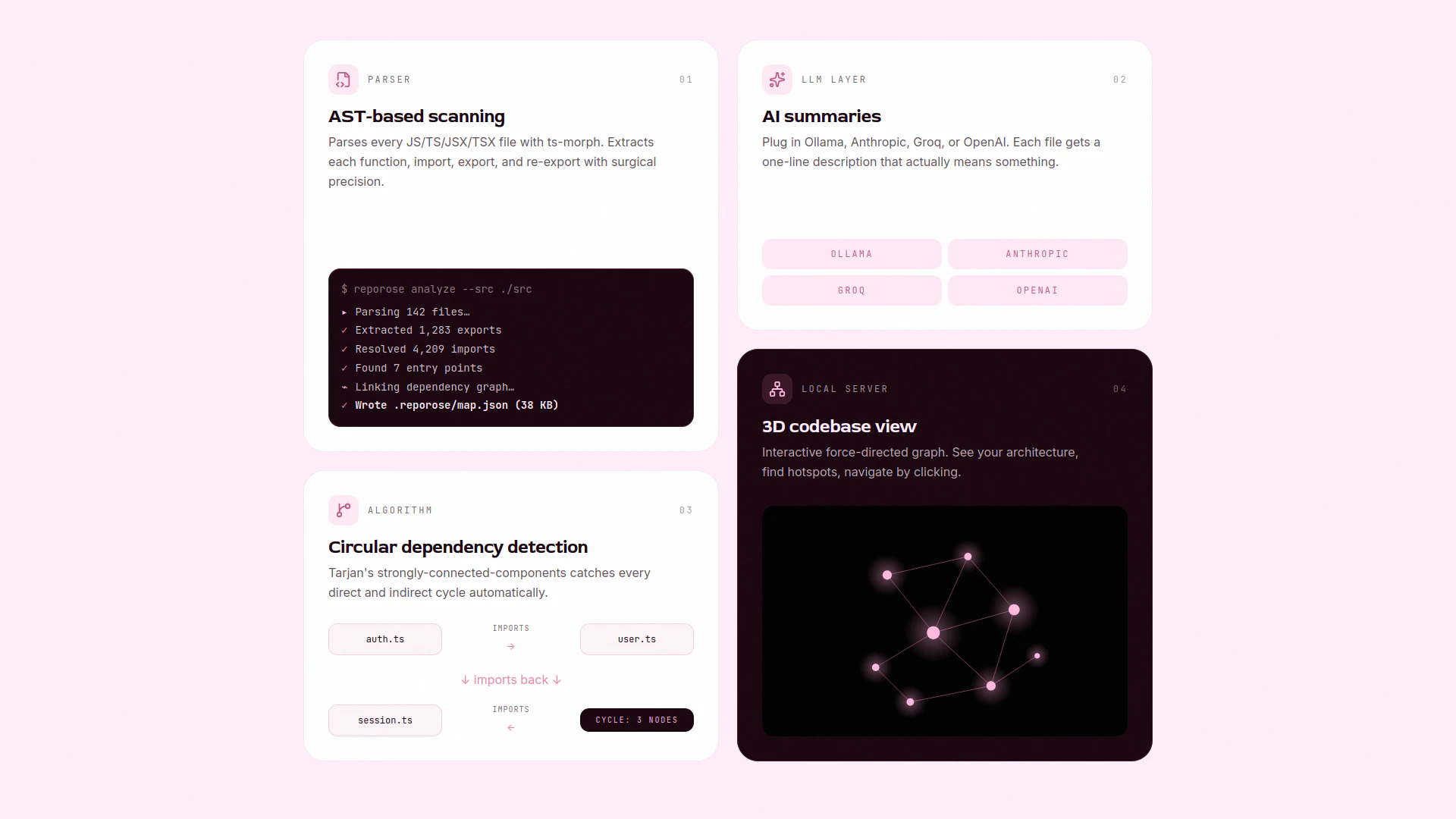
一句话介绍:RepoRose通过生成结构化代码库映射文件,让AI在启动新聊天时无需重复读取整个仓库即可获得完整上下文,从而大幅削减Token消耗并避免长会话带来的幻觉问题。
Developer Tools
GitHub
Vibe coding
开发者工具
AI编程助手
Token优化
代码上下文管理
结构化映射
依赖分析
Claude集成
开源工具
本地AI支持
用户评论摘要:用户反馈核心痛点:长会话导致AI幻觉增多,新会话需大量Token重新读取文件结构。RepoRose通过生成包含完整代码描述和依赖关系的JSON上下文文件解决问题。有评论特别认可其依赖跟踪功能(修改文件时告知受影响的其他文件),但询问是否支持符号级导入追踪。
AI 锐评
RepoRose精准击中了AI辅助编程中的经典矛盾——长会话的“记忆衰减”与短会话的“上下文重建成本”。其技术方案本质是**预计算知识压缩**:将代码库结构、依赖关系、文件描述等元数据预先提炼为单一JSON文件,使AI能通过一次读取完成“全景扫描”,而非逐文件探测。这确实能显著降低Token开销(宣称~90%),但须注意两点:一是“结构化映射”的准确性与代码库动态变化的同步成本(若开发者频繁修改文件,生成的映射可能滞后);二是依赖依赖分析仅基于静态源码,无法涵盖运行时动态绑定的影响。此外,支持本地Ollama等模型的“无AI描述模式”降低了使用门槛,但生成描述的质量高度依赖模型能力,可能出现误判。从产品定位看,它更适合中大型项目(小项目手动维护上下文成本更低),且核心壁垒在于映射生成算法而非工具本身——随着Cline、Copilot等工具内置类似功能,其差异化价值可能被稀释。暂时9票的冷启动表现也说明,开发者对“额外维护一个映射文件”的信任建立需要更多用例验证。
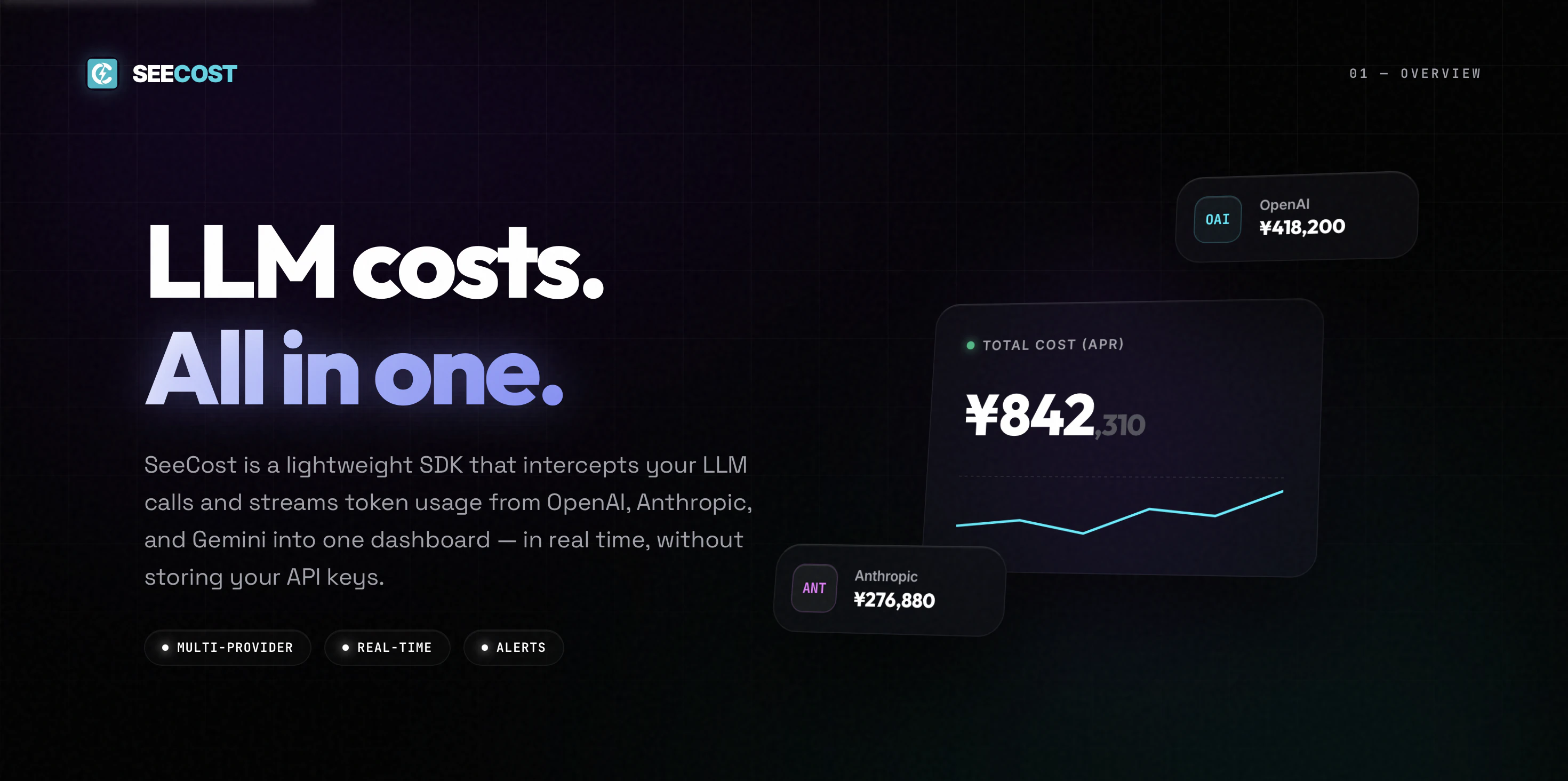
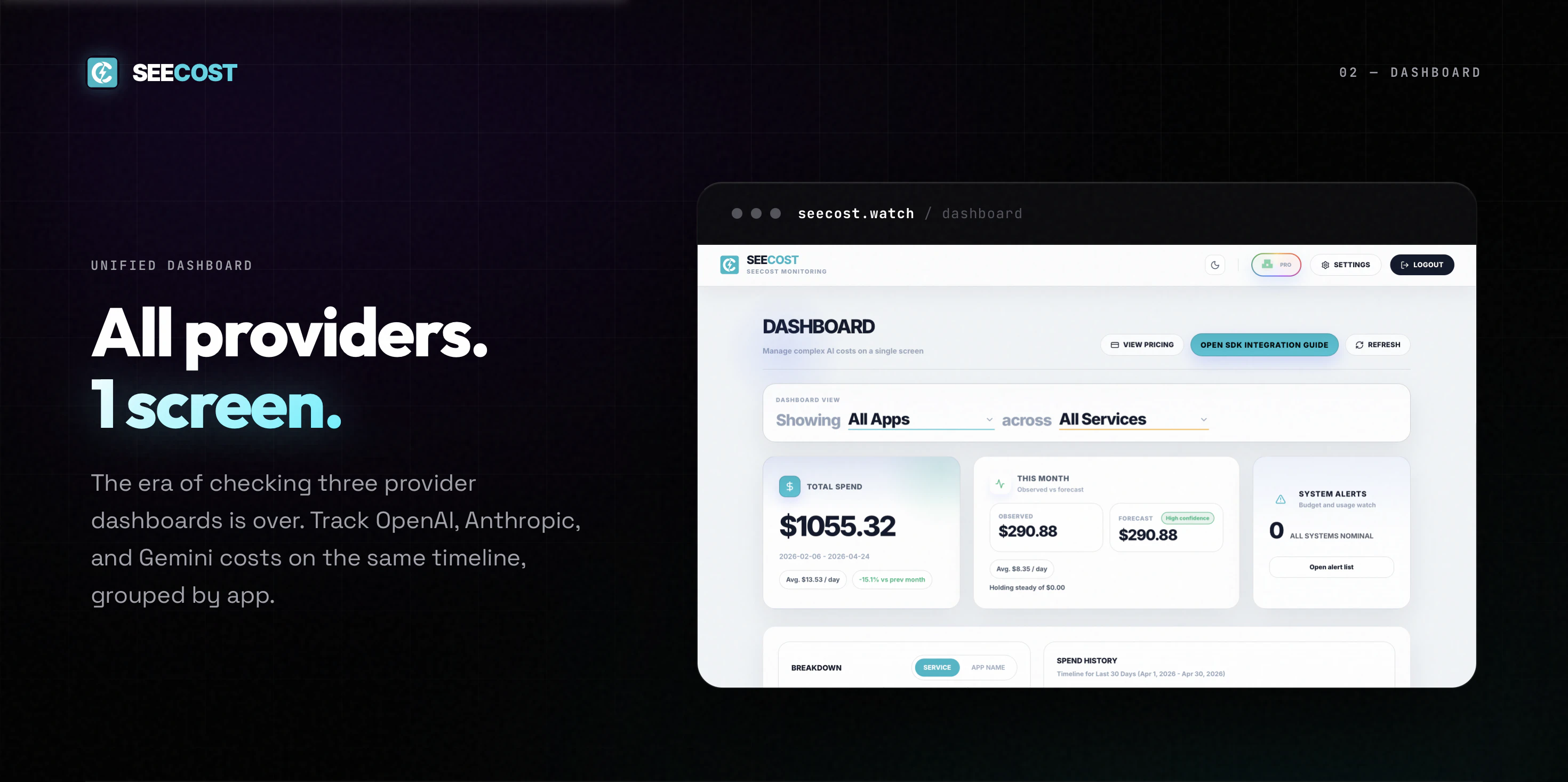
一句话介绍:SeeCost通过轻量级开源SDK,实时汇总OpenAI、Anthropic、Gemini等多模型的调用成本,解决开发者需手动切换多个平台账单页面的痛点。
API
Developer Tools
Tech
LLM成本管理
AI支出追踪
开源SDK
多模型监控
开发者工具
实时仪表盘
成本可视化
API监控
云计算成本
用户评论摘要:用户赞赏其开源追踪方案和两分钟快速集成,认为精准解决了多平台成本汇总的痛点。同时提出期望后续增加费用异常告警功能,以便在支出意外飙升时及时获知。
AI 锐评
SeeCost切中了当下AI应用开发的一个“隐形痛点”——当团队同时接入多个大模型供应商时,成本核算是非技术化却最耗时的隐性成本。相比手动登录三个后台加加减减,这个工具的价值是直接将“认知负荷”降为零。
其巧妙之处在于没有触碰API key和提示词内容,仅通过monkey-patch fetch读取响应中的用量元数据,既满足了数据可视化的需求,又把隐私红线画得足够清晰,加之SDK完全开源,团队对数据流向一目了然,不会像某些商业监控工具那样引发安全顾虑。
但必须指出,这类工具本质上是“数据搬运工”——它不产生新数据,只是把原生API反馈中的token数、模型ID等信息抓取并聚合呈现。长期护城河在于能否超越“成本看板”,进化出跨模型预算预测、供应商支出对比和基于用量规则的自动化告警等真正有价值的能力。目前看,用户反馈中提到的“异常检测”正是多数开发团队的刚需,但产品尚未落地。
另外,过度依赖对fetch的猴子补丁也存在风险:当供应商修改API返回格式或SDK升级时,维护成本将直接影响跟踪稳定性。如果能进一步弱化对网络层的侵入,拥抱OpenTelemetry这类标准可观测性协议,未来在大型企业中的接受度会更高。
一句话总结:一个精准解决小问题的小工具,但要想从“小而美”变成“必须用”,还得在异常预警和跨平台成本优化策略上下功夫。

















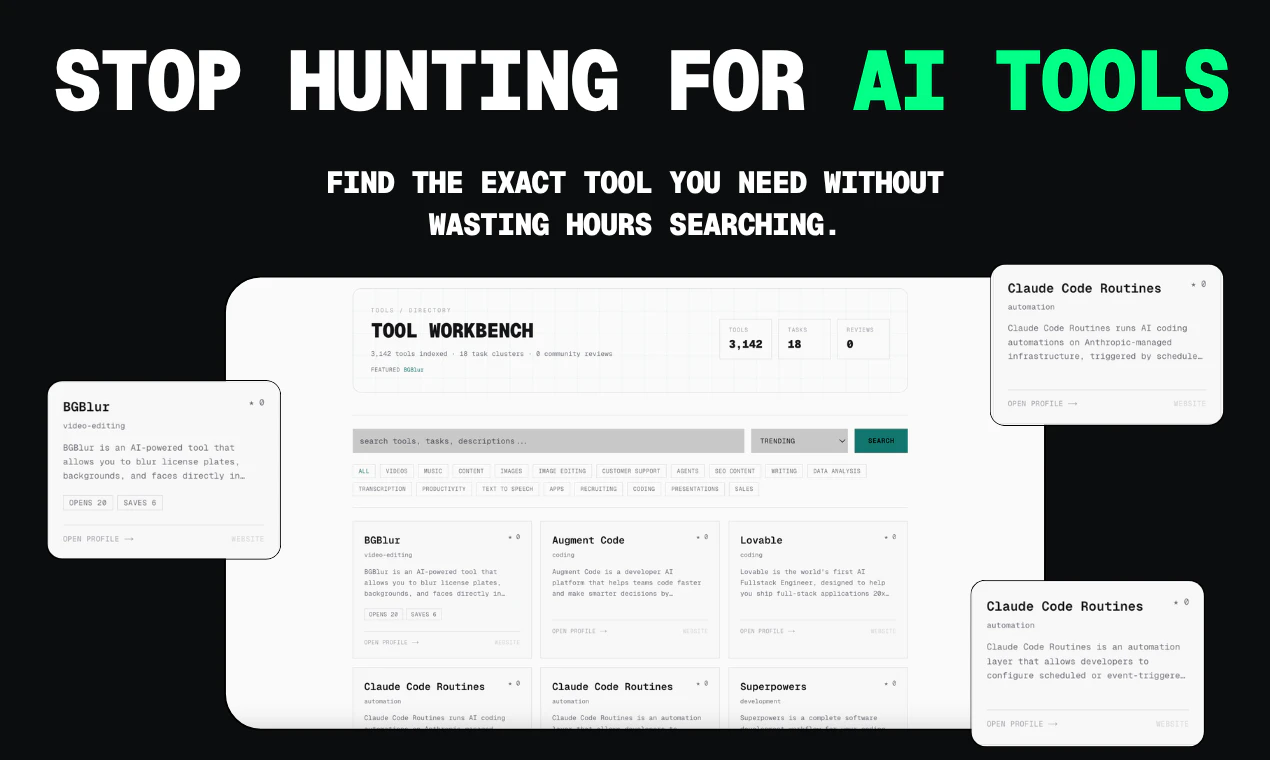
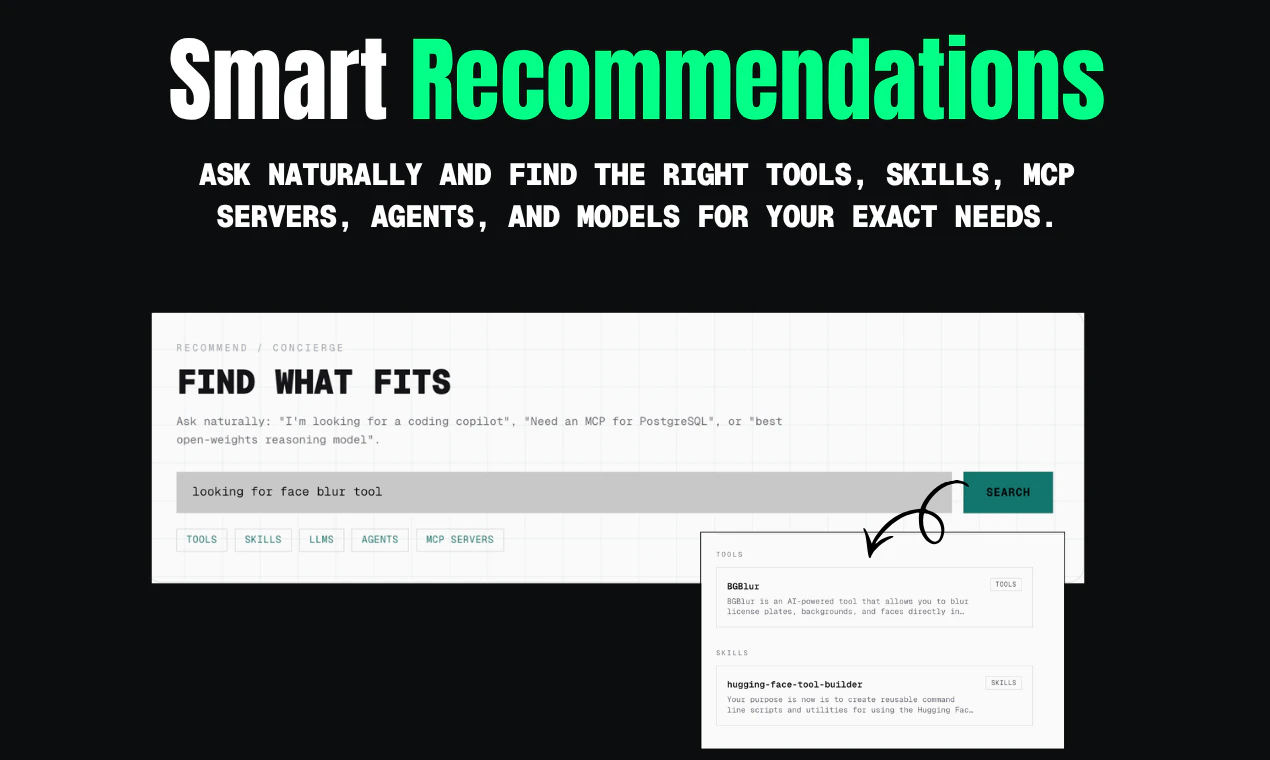


















Hi Product Hunt! I'm Vinitra, co-founder of Scholé AI.
Our team goes by a lot of descriptors: educators, engineers, researchers, scientists, designers. But mostly we're a group of lifelong learners that get way too excited about good edtech.
The problem: We’ve been researching AI for education for more than 10 years, and we keep seeing the same gap. One-size-fits-all learning from MOOCs means half the content isn’t relevant to you, and nothing adapts based on how you’re actually progressing. Dropout rates are substantial, now 90% (we're guilty of it too!)
Newer AI learning tools go the other way, lots of open-ended prompting towards socratic-style discussions. Helpful for the quick answer, but where’s the skill progression? Where’s the grounding in real materials? Where’s the curriculum?
The approach: Bring back what works from learning science. Scaffolding, mastery learning, knowledge tracing, zone of proximal development, scenario-based learning, self-regulation, reflection, and so much more, but build it in a way that feels native to AI.
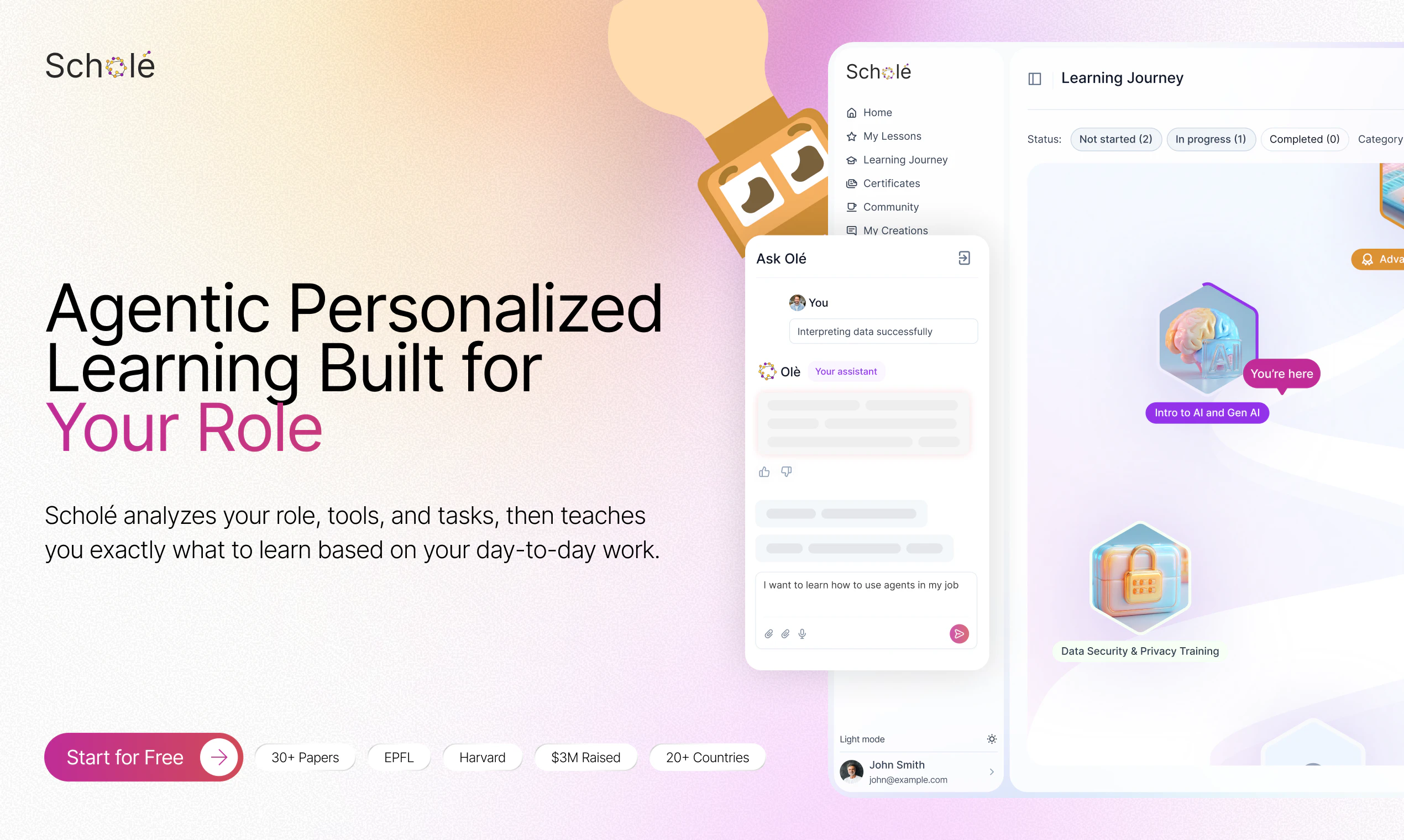
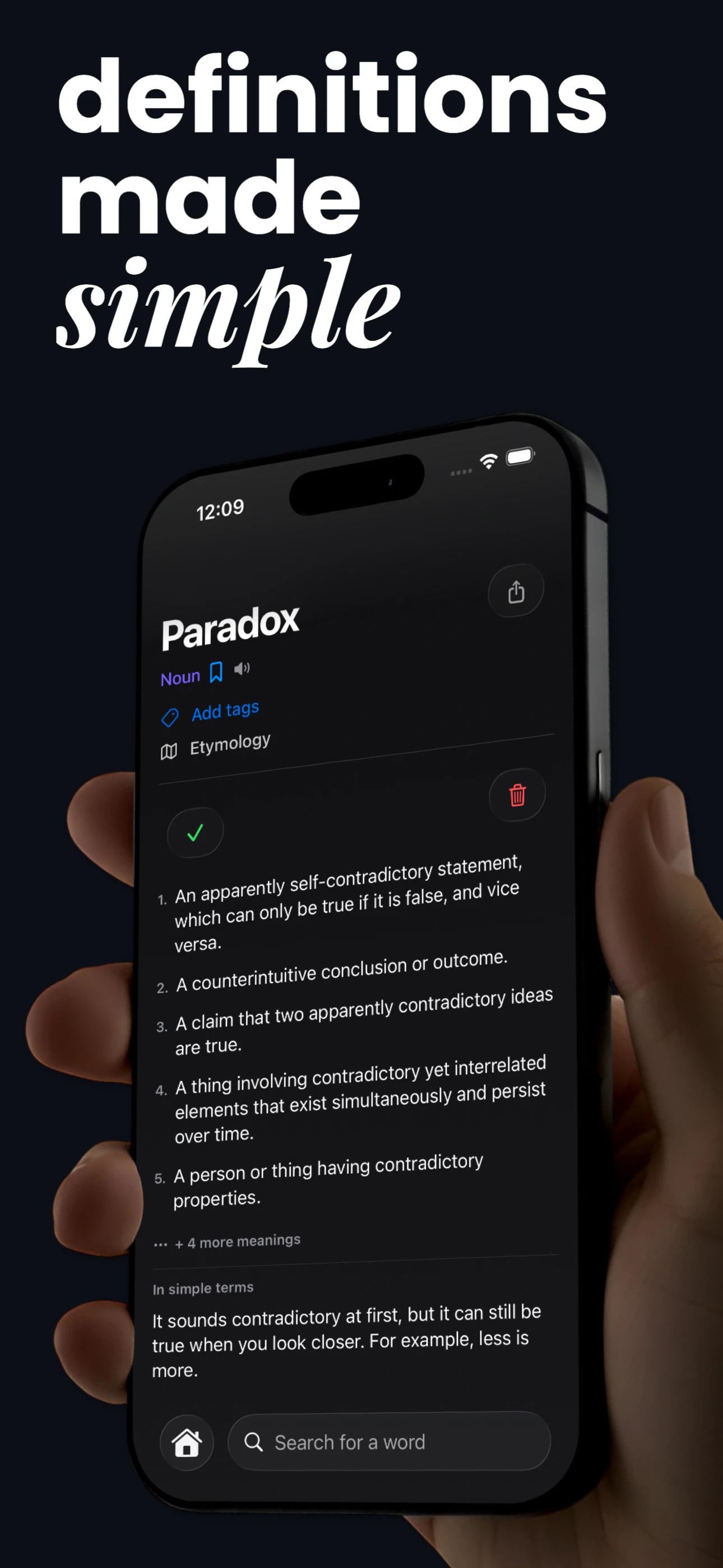
Enter Scholé: agentic personalized learning for the AI era.
We’re currently focused on adult learning, and we personalize every part of the experience across:
your context (job, daily tasks, tools)
your modality (videos, podcasts, interactive tasks, more or less explanation)
your pace and difficulty (your strengths, your misconceptions)
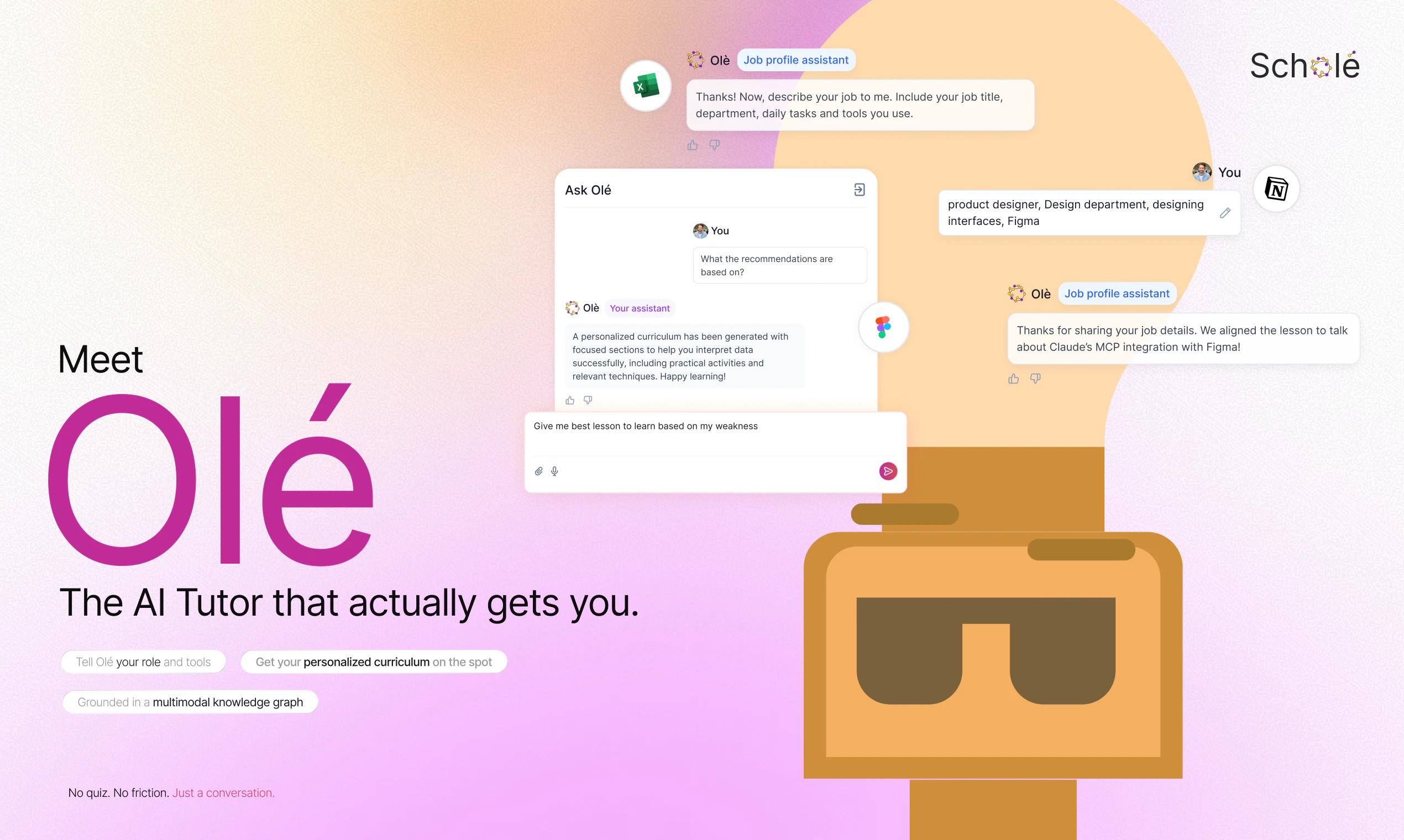
You can ask Scholé “what is this MCP thing I keep hearing about” and it doesn’t generate something generic. It constructs the lesson on demand, remixing trusted materials into explanations, examples, podcasts, video excerpts, visuals and interactive tasks that are all relevant to your role and tools.
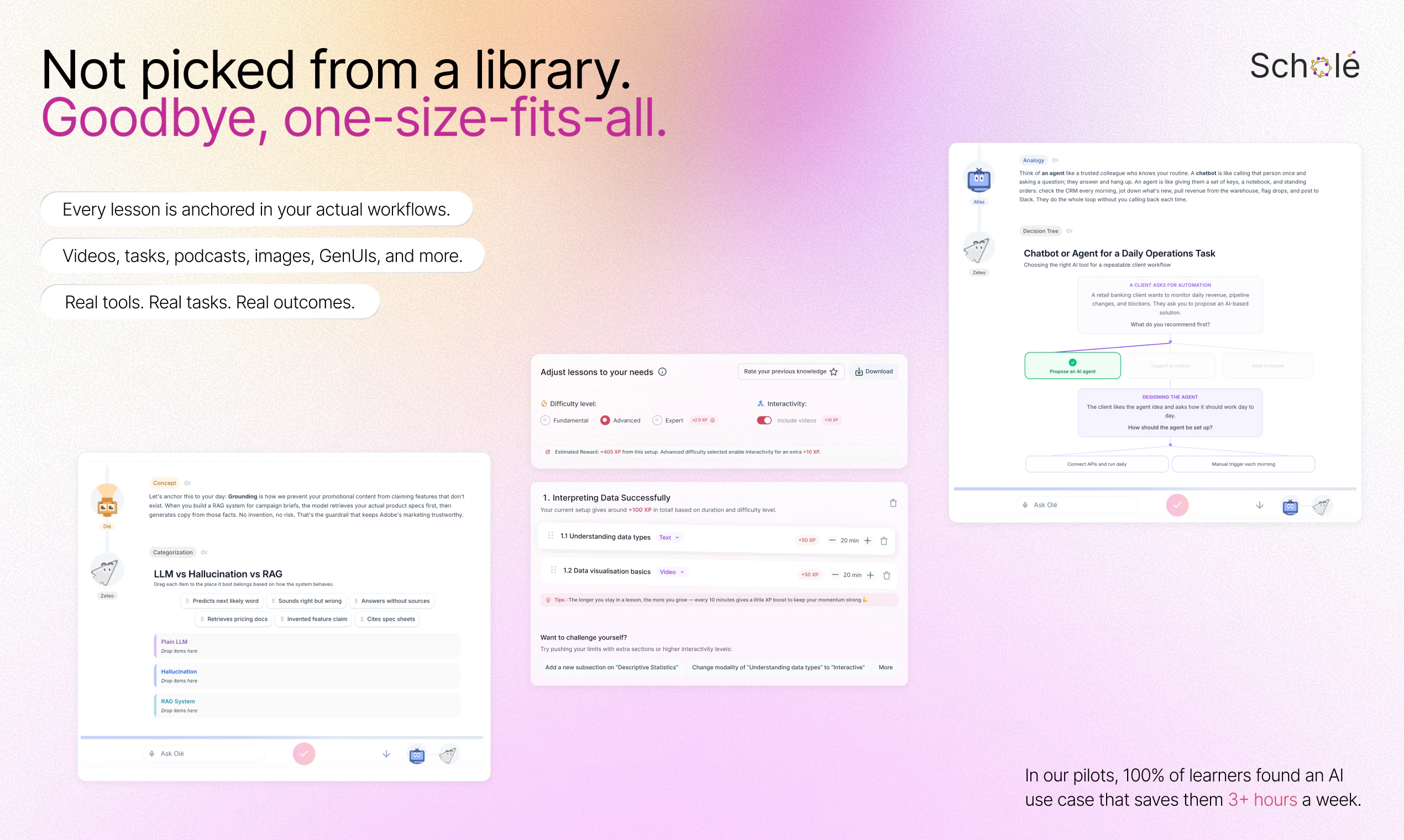
Under the hood, it’s a multi-agent system, with different pedagogical agents to teach, illustrate, question, and challenge, coordinating in real time to adapt the lesson to what you understand and what you need next.
We’re using GenUIs, orchestrators, conversational lesson delivery, knowledge tracing, hierarchical memory, multimodal learning, and more. Our first use case is helping people understand how AI is actually useful for them, because that's what we know how to teach. :) But you'll soon see us here teaching anything and everything else.
Who is Scholé for?
✅ The first-timer who’s curious about AI
✅ The enthusiast keeping up with new tools
✅ The expert who wants a 5 minute deep dive
✅ The team who wants to learn from their wiki / slides / pdfs / videos
What does Scholé have?
🧠 Multi-agent lessons (explanations, analogies, tasks, feedback, illustration, reflection working together)
🔄 Adaptive progression based on your performance and misconceptions
🧭 Personalized learning journey tailored to your role, tools, and goals
📚 Grounding in high-quality knowledge graph of data science learning materials from our favorite profs at Harvard, UC Berkeley, EPFL, UCSD, UW, and more
📊 Learning analytics you can query, based on your evolving knowledge
🎧 Lesson DJ to remix your lessons the way you want
We’re beyond excited to put this in front of you as an early public beta and our first ever launch. Feedback is the thing we treasure most, so please drop us a line at hello@schole.ai.
We’re also partnering with teams who want to turn their internal PDFs, slides, and videos into personalized learning experiences (we're already in the hands of 100s of companies!). If that sounds like you, please reach out to enterprise@schole.ai.
Start learning (for free!) with Scholé today: https://app.schole.ai 🎉
Hi Product Hunt! I'm Paola, co-founder and CTO of Scholé. Super happy to answer any questions (especially on how it works!)
I got to see a demo of Schole at an event in Zurich. The product is fascinating and really needed when you consider how fast AI is advancing. Best of luck with the launch Vinitra.
I was always frustrated with Coursera, the material was already outdated before I even finished a course. Starting my data science journey on Scholé instead!
Congrats on the launch! This is such a wonderful idea - and so relevant at this time when all career fields are working to incorporate AI, including healthcare (my field). I just signed up and I’m trying Scholé out right now!
Looks super sleek and polished!
Can we learn something else than AI?
So is it something like personalised Duolingo? :) Assuming from the dashboard (map) :)
The "adaptive AI" piece — what's it adapting to exactly? My past mistakes, the topics I keep avoiding, the speed I'm moving through material? Would help to know what signals it's actually reading before trusting it to personalize anything.
You might be missing an opportunity with email onboarding.
A simple email sequence could guide new users, reduce confusion, and help them reach value faster.
I personally found the platform a bit unclear at first.
@vinitra Scholé has an interesting product direction, but the public technical evidence is still not strong enough for me to trust it as an enterprise-ready AI platform.
The main issue is that the product describes advanced concepts such as agentic learning, personalized AI tutors, knowledge tracing, hierarchical learner memory, role-based lesson generation, and internal knowledge integration, but the public site does not provide enough technical detail about how these systems are actually implemented.
For example, I would expect to see clearer information about the architecture: how agents are orchestrated, how user context is stored, how knowledge graphs are built, how retrieval is grounded, how hallucinations are reduced, how learning progress is evaluated, and how generated lessons are validated before being shown to users.
Another concern is data handling. If companies upload internal PDFs, slides, videos, or wiki content, the platform needs a very clear technical explanation of tenant isolation, access control, encryption, retention, deletion, audit logging, and model-provider boundaries. Without this, the system may be risky for enterprise usage.
The frontend also appears to have duplicated content in the rendered page output. Repeated sections, repeated testimonials, and duplicated text blocks can negatively affect SEO, accessibility, page performance, and maintainability. For a product selling AI-powered learning quality, the public implementation should be cleaner.
The product also claims compliance-related learning support, but technically there is not enough visible evidence of audit trails, completion records, role-based training mapping, risk-based learning paths, or compliance reporting workflows.
So my technical view is: the idea is strong, but the implementation proof is still weak. I would need to see architecture diagrams, security documentation, evaluation metrics, data-flow details, and real enterprise case studies before considering it technically mature.