PH热榜 | 2026-05-06
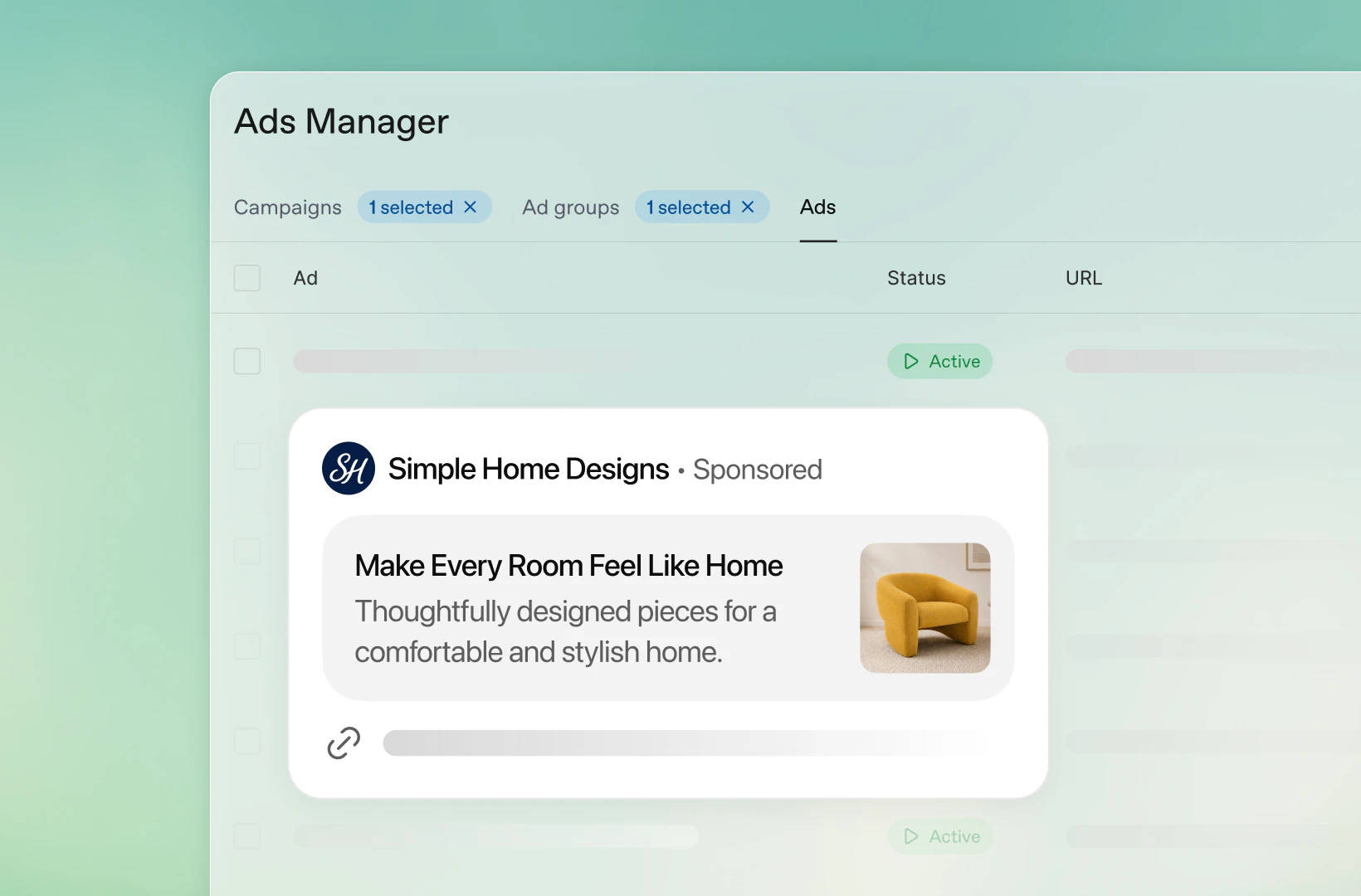
一句话介绍:Kanwas是一个开源协作工作空间,旨在解决团队知识分散、人机(含AI Agent)上下文割裂的痛点,通过实时画布将关键知识、决策与数据变为可编辑、可迭代的“活脑”,让人类与智能体在同一环境下高效协作。
Productivity
Artificial Intelligence
开源
AI协作
团队知识库
画布工作空间
Agent上下文
实时协作
产品战略
知识管理
决策记录
自进化大脑
用户评论摘要:用户普遍称赞其解决了多Agent和团队知识分散的痛点,尤其认可画布界面优于传统聊天UI。核心问题集中于:非技术团队的上手引导与组织方式;多用户/Agent并发编辑高利害决策时的版本与冲突管理;与Notion+Claude等现有方案的差异化价值。
AI 锐评
Kanwas在“AI协作”这个已经拥挤不堪的赛道里,找到了一个颇为刁钻的切入点:它不再试图用聊天框去框定人类与AI的交流,转而拥抱了“思考空间”而非“对话记录”的范式。这是一个值得肯定的产品哲学转向。它的真正价值不在于又一个知识库或者协作画布,而在于它试图定义“人机共享上下文”的协议。当大多数产品还停留在让AI做你的私人助理时,Kanwas已经开始塑造“Agent同事”的认知环境。这种将团队隐性知识——那些决策背后的推演、权衡和直觉——结构化、可追溯、并可被AI消费的能力,才是它潜在的护城河。
然而,风险同样清晰。首先,它试图同时讨好人类(提供深度编辑与画布体验)和Agent(提供结构化、可调用的上下文输出),这种“兼顾”极易导致特性臃肿和体验分裂,最终谁的痛点都没彻底解决。其次,“自进化大脑”听起来性感,但也意味着初期的混乱若没有足够强的引导机制,用户很可能在填鸭式地倾倒信息后,收获的不是智慧,而是一个逻辑瀑布。此外,开源Apache 2.0是猛药,既能吸引开发者信任,也可能让核心能力被竞品快速复制并生态化反超。总体而言,Kanwas踩准了“Agent将从工具演变为协作体”的行业拐点,但能否从“好用的概念验证”进化为“团队日常无法离开的协作基座”,取决于它接下来如何驯服复杂性,并用实际案例证明其工作流对于战略和决策层的不可替代性,而非仅仅是另一个更漂亮的Miro。
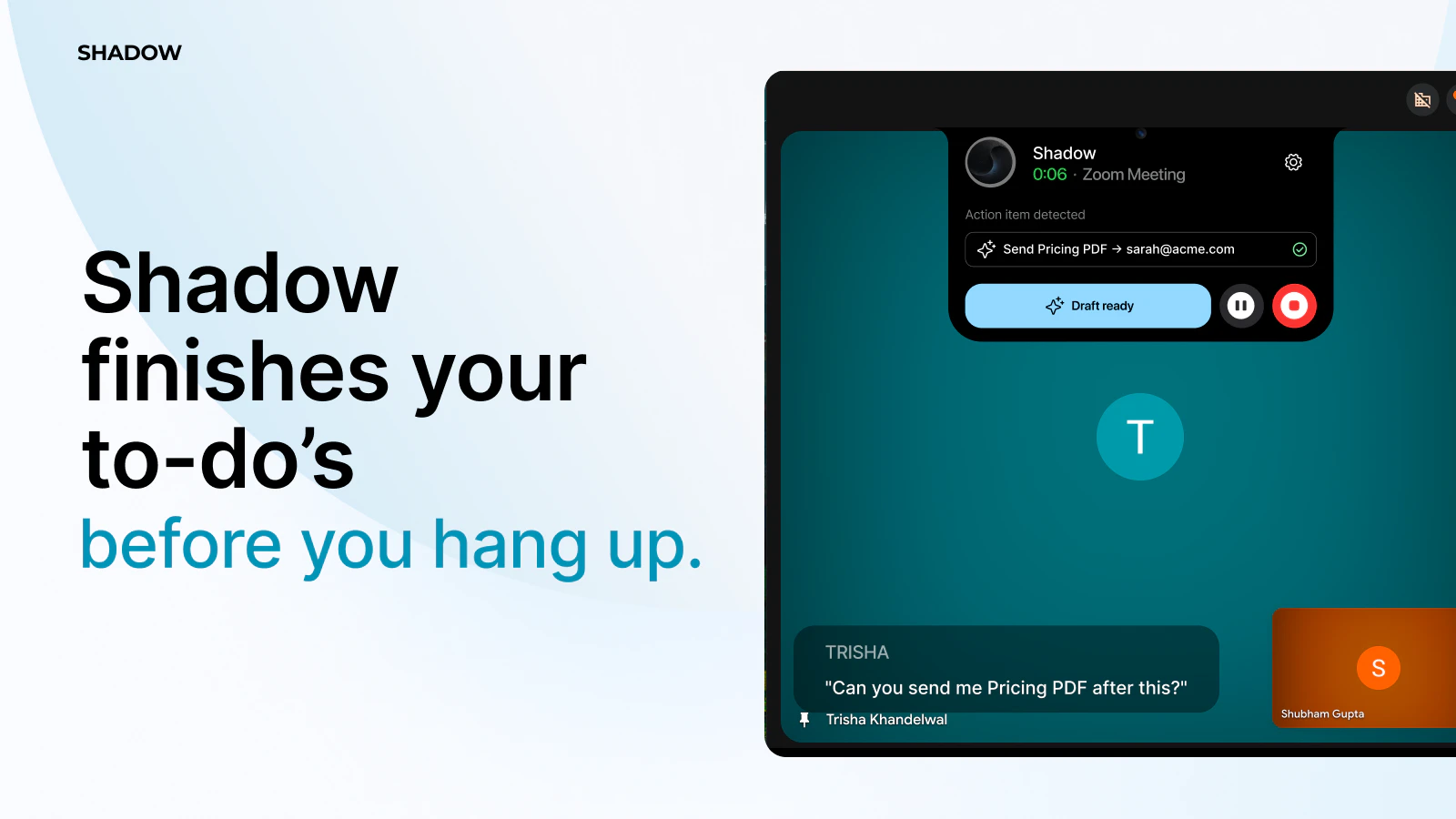
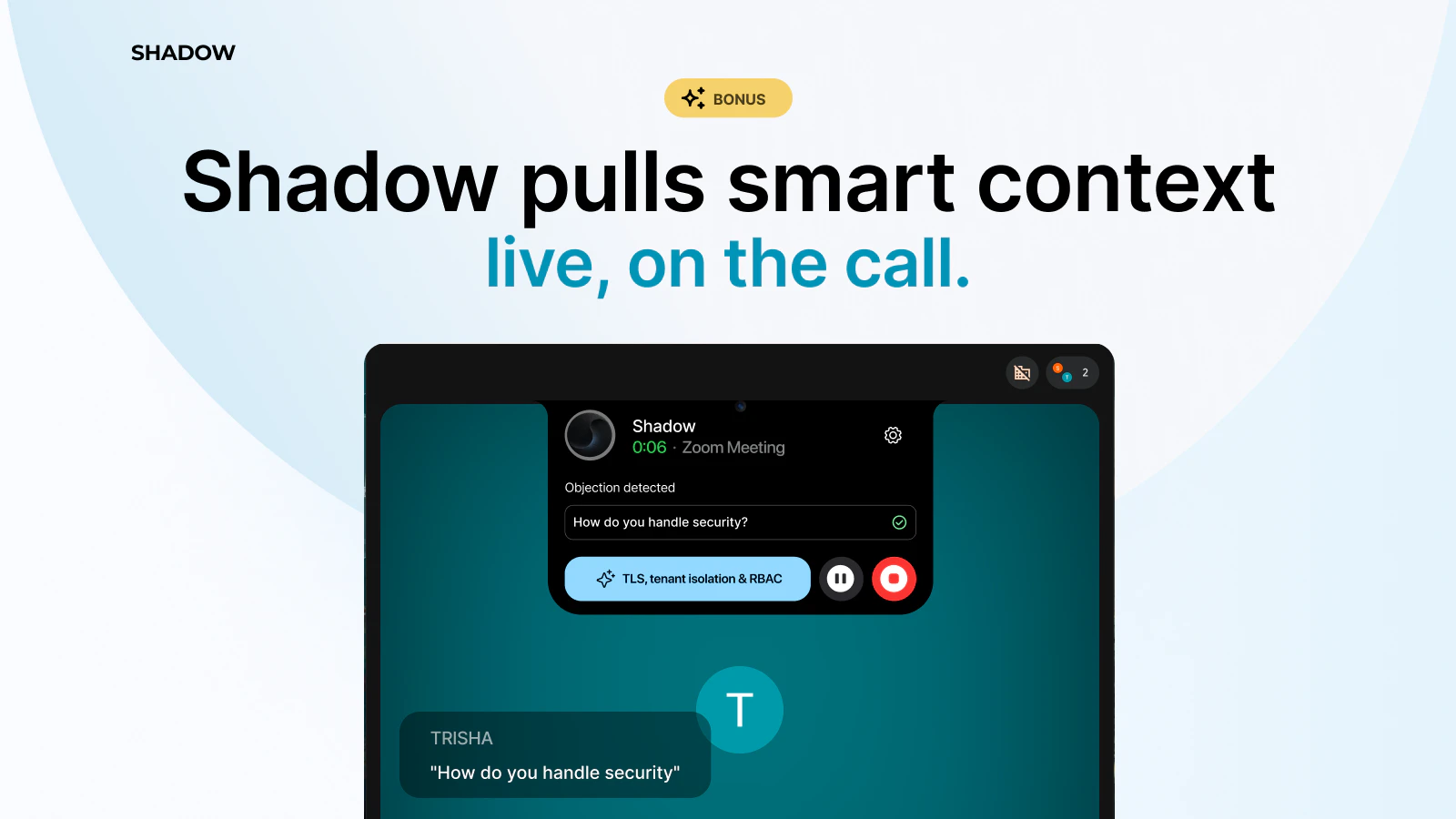
一句话介绍:Shadow 2.0 是一款实时AI代理,在在线会议进行中自动识别并执行待办事项(如生成文档、发送邮件、安排日程),让用户在挂断电话前就完成所有会后工作,彻底消灭“会后任务列表”。
Productivity
Meetings
YC Application
AI会议助手
实时任务执行
自动化工作流
会后管理
效率工具
AI代理
会议纪要
CRM更新
日程安排
产品发布
用户评论摘要:用户普遍痛点:会后需花大量时间处理邮件、文档、CRM更新等。主要疑问:与Otter/Fireflies等记笔记工具的本质区别?能否自动推送到Figma、Productboard等工具?用户关注“执行”而非“记录”,并希望保留人工审核环节以控制敏感操作。部分用户询问多人大(>10人)会议的识别精度。
AI 锐评
Shadow 2.0 确实切中了一个高频且极度痛苦的场景——会议并未在“挂断”时结束,反而开启了繁琐的“会后工作流”。绝大多数同类工具止步于“记录和总结”,本质上只是给用户生成了一张更精美的“待办清单”。而Shadow的颠覆性在于将能力从“听写员”升级为“执行幕僚”,它在会议进行中就开始动手干活:发邮件、建文档、定日程,试图让用户走出会议室时,所有工作已经尘埃落定。
这个产品价值清晰且犀利,但挑战同样巨大。第一,执行层的出错成本远高于记录层。AI误判一个“下次聊”为“预约会议”,就可能造成尴尬或日程混乱。虽然团队强调“人工审核层”存在,但若审核比例过高,所谓的“实时高效”将大打折扣。第二,深度集成依赖生态。目前的Notion、Gmail、日历只是冰山一角,用户真正渴望的CRM、Jira、Figma等核心生产力工具的实时双向同步才是护城河,而这些集成往往需要数百个企业级API的稳定对接,工程复杂度陡增。
从商业角度看,这个产品定位非常精准:瞄准的是高净值、高会议密度的知识工作者(顾问、销售、创始人),他们愿意为“每周赢回一个工作日”付费。早期采用者必然是那些被琐事压垮的“会议机器”,他们最迫切的需求不是“更智能的笔记”,而是“有人能替我在会后擦屁股”。Shadow 2.0如果能持续降低执行错误率并快速扩展工具链,有望重新定义“会议生产力”赛道——让会议真正成为思考与决策的场所,而非新任务的生产线。
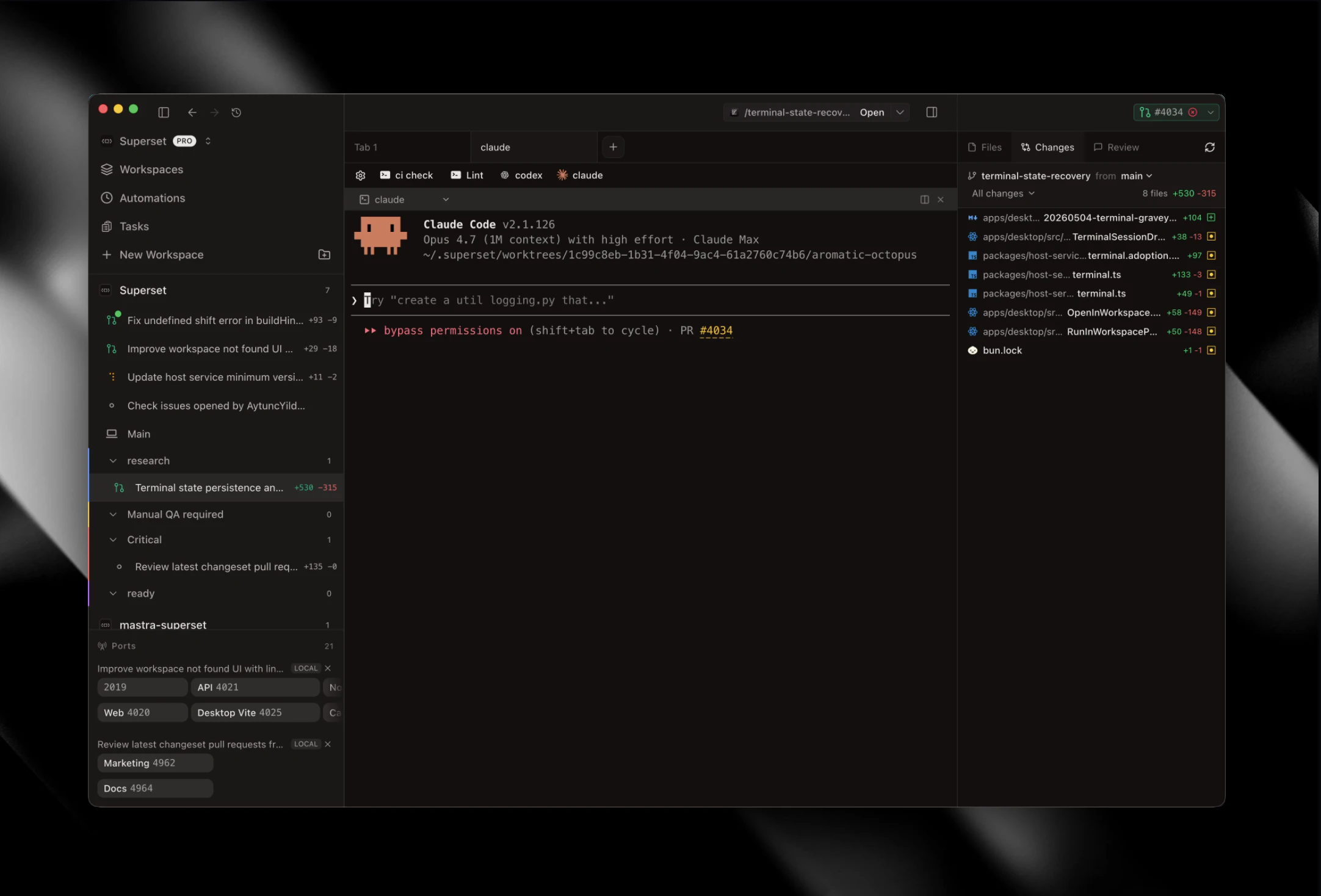
一句话介绍:Superset 2.0 是一款让开发者能在任意机器上远程运行数百个并行编码代理的IDE,解决了单机算力限制和代理协作效率低下的痛点。
Text Editors
Developer Tools
Artificial Intelligence
GitHub
并行编码代理
远程工作空间
IDE
AI辅助开发
代理协作
自动化
Git工作树
团队协作
CLI代理
编程效率
用户评论摘要:用户称赞其解决了Cursor、Claude Code的磁盘空间和等待瓶颈,支持并行代理和远程工作空间。主要疑问包括:安全与权限控制,代理在大型代码库中的冲突协调,以及实际生产环境中的高并发代理使用案例。
AI 锐评
Superset 2.0 的升级绝非简单的功能迭代,而是对“AI时代开发者工作流”的一次底层重构。其核心价值不在于“又一个AI IDE”,而在于“分布式代理编排”——它精准切中了当前AI编程工具的核心矛盾:单机算力与多代理并行需求的不匹配,以及“等待代理输出”比“审查输出”更耗时的效率黑洞。
从产品设计看,“远程工作空间”和“自动化”才是真正的杀招。前者让开发者摆脱本地硬件束缚,将算力压力转移至云端或闲置服务器,后者则让代理从“被动调用”进化到“主动值守”。这种架构下,代理不再是临时工,而是常驻的“数字工程师”,能实现代码审查、问题分诊、跨时区接力等持续级工作流。
然而,产品仍面临严峻挑战。评论中用户对“冲突处理”和“安全边界”的质疑直指核心:当数百个代理在相同代码库中并行操作,如何避免逻辑冲突和资源竞态?目前依赖“代理自愈”和人工介入的方案显得过于理想化,尤其在生产级场景下,缺乏精密的分布式锁或任务编排机制可能引发灾难。此外,远程访问的权限粒度还停留在“组织—用户”层面,缺乏对凭证、密钥等资产的分级控制,对于追求安全合规的成熟团队而言是致命短板。
一句话总结:Superset 2.0 为未来“AI工厂”搭建了骨架,但在精细控制和安全监管上仍有血肉待填充。对于敢于尝鲜的3人精英团队,它是利器;对于求稳的企业级组织,它尚需打磨。
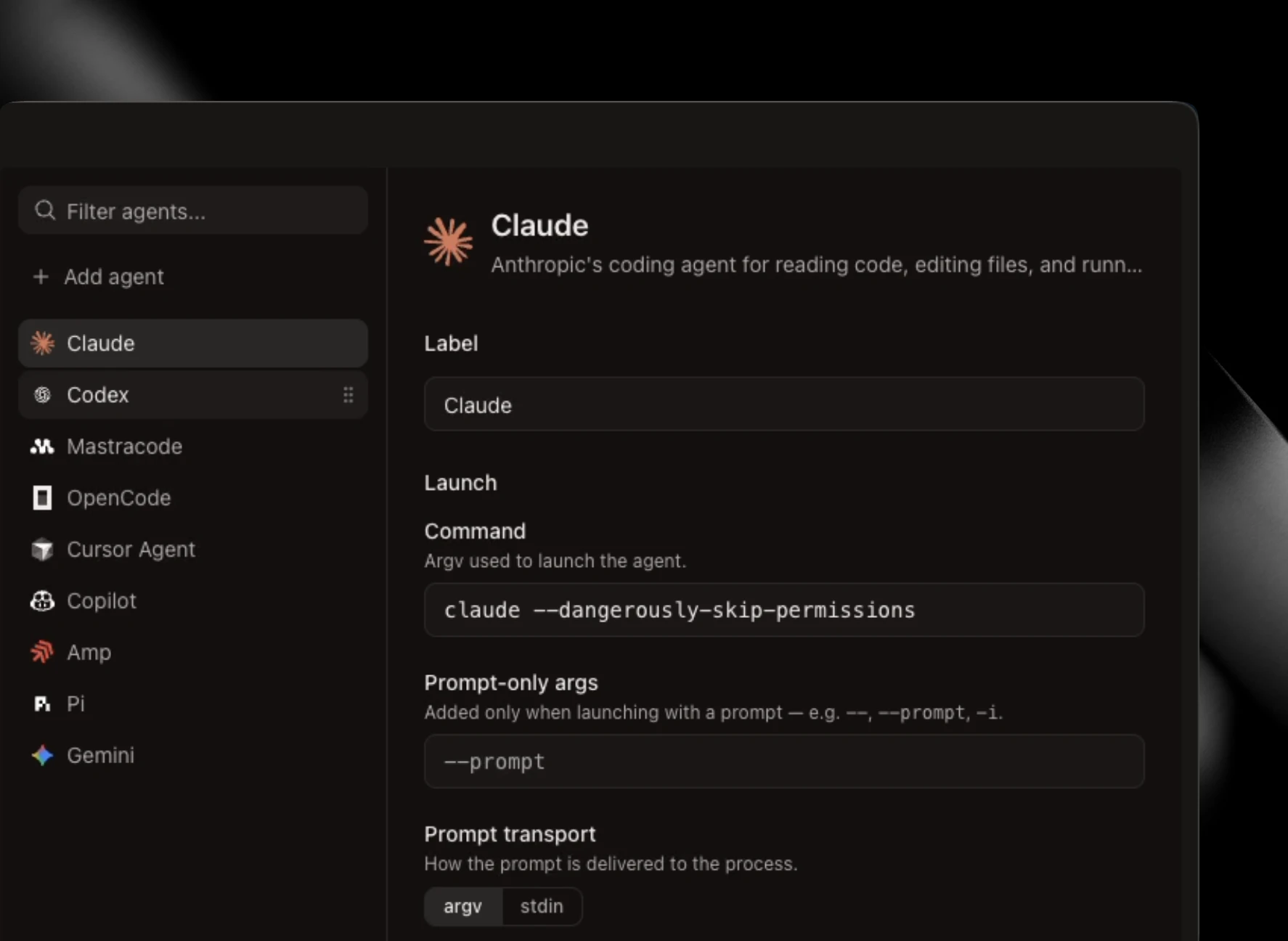
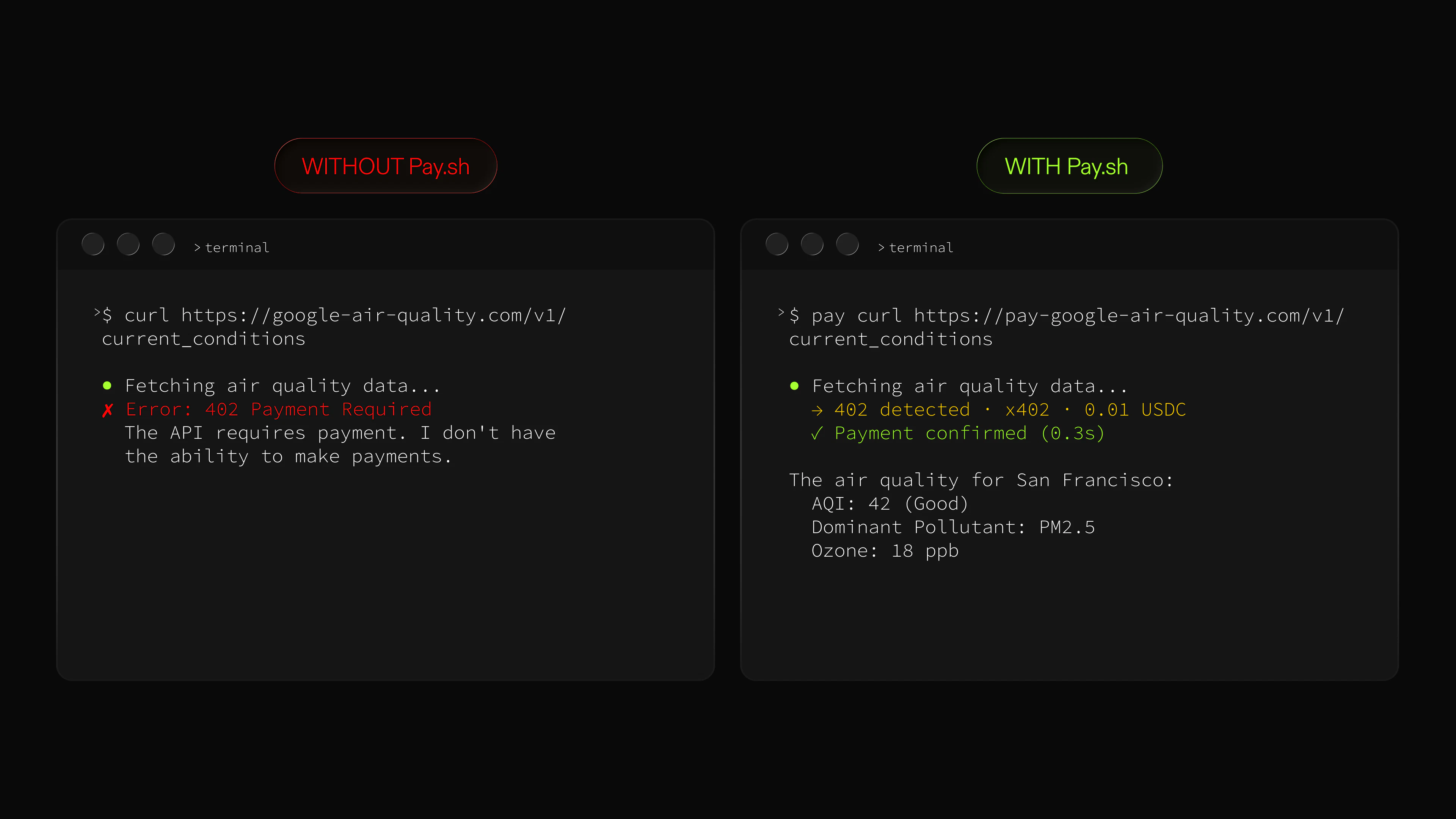
一句话介绍:pay.sh 构建了一套开源、实时的支付基础设施,让AI代理能够无需API密钥和订阅,自动发现并按次调用付费。
API
Open Source
Developer Tools
AI代理支付
API按次计费
开源基础设施
实时支付
无密钥调用
代理网关
Google Cloud
x402协议
CLI工具
去中心化结算
用户评论摘要:用户普遍认可其“代理原生”方向和简洁性,但提出关键担忧:代理失控导致大量微支付消耗。有用户建议增加预算上限和断路器,开发者回应当前依赖系统授权,后续将提供额度与时间限制等精细控制。
AI 锐评
pay.sh的野心不止于一个工具,而是试图定义AI经济体中的“支付层”标准。它精准切中了当下AI代理生态的痛点:API调用仍停留在人工管理的“账号+密钥+订阅”模式,这严重限制了代理的自主性和规模化。与Google Cloud等巨头的合作,以及x402、MPP等标准背书,让它在技术路线上有了现实根基。
但问题同样尖锐。评论中提到的“代理陷入循环烧钱”不是边缘场景,而是AI自主决策的本质风险。目前依靠系统弹窗授权(类似Apple Pay)的方案,本质上仍是“人肉闸门”,并未真正解决代理的自主权与财务控制间的矛盾。后续所谓的“1美元1小时”预授权机制,也只是将风险从单次转嫁为窗口期,如果代理在该窗口内高频出错,损失依然可控但难防。
更深层的隐忧是生态协调:要让API提供方主动接入PAY.md规范,需要极强的网络效应和激励。虽然Solana、Stripe等参与,但实际开发者迁移意愿取决于成本、延迟和信任。如果pay.sh无法在初期提供显著的费率优势或体验提升,它可能沦为“又一个漂亮的CLI工具”。
总体而言,pay.sh方向正确,时机精准,但真正的价值将从“让代理能付钱”演进为“让代理聪明地付钱”。这需要超越支付本身,嵌入智能阈值、风险控制和审计能力——而这正是它从支付层升级为经济层的关键一跃。
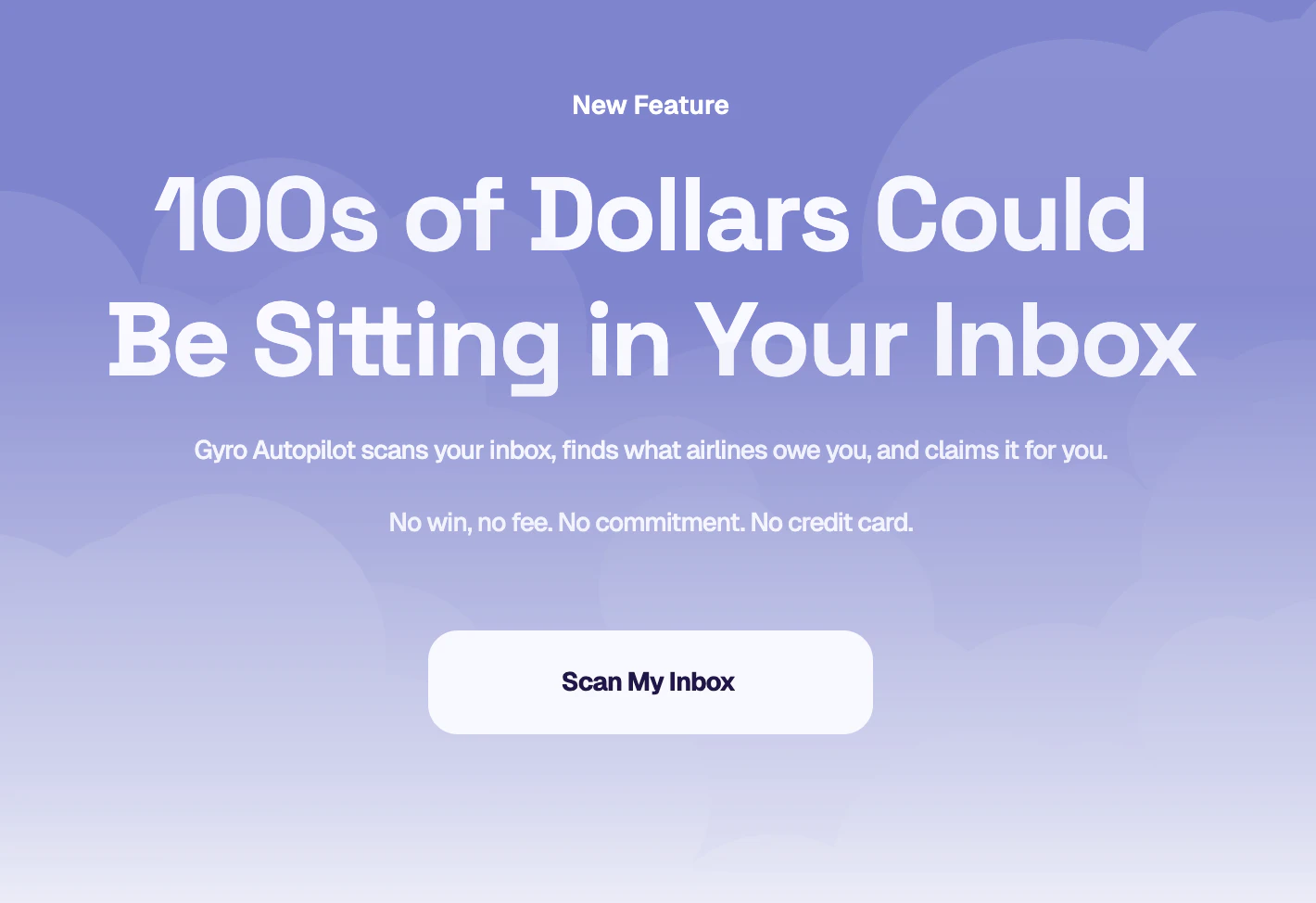
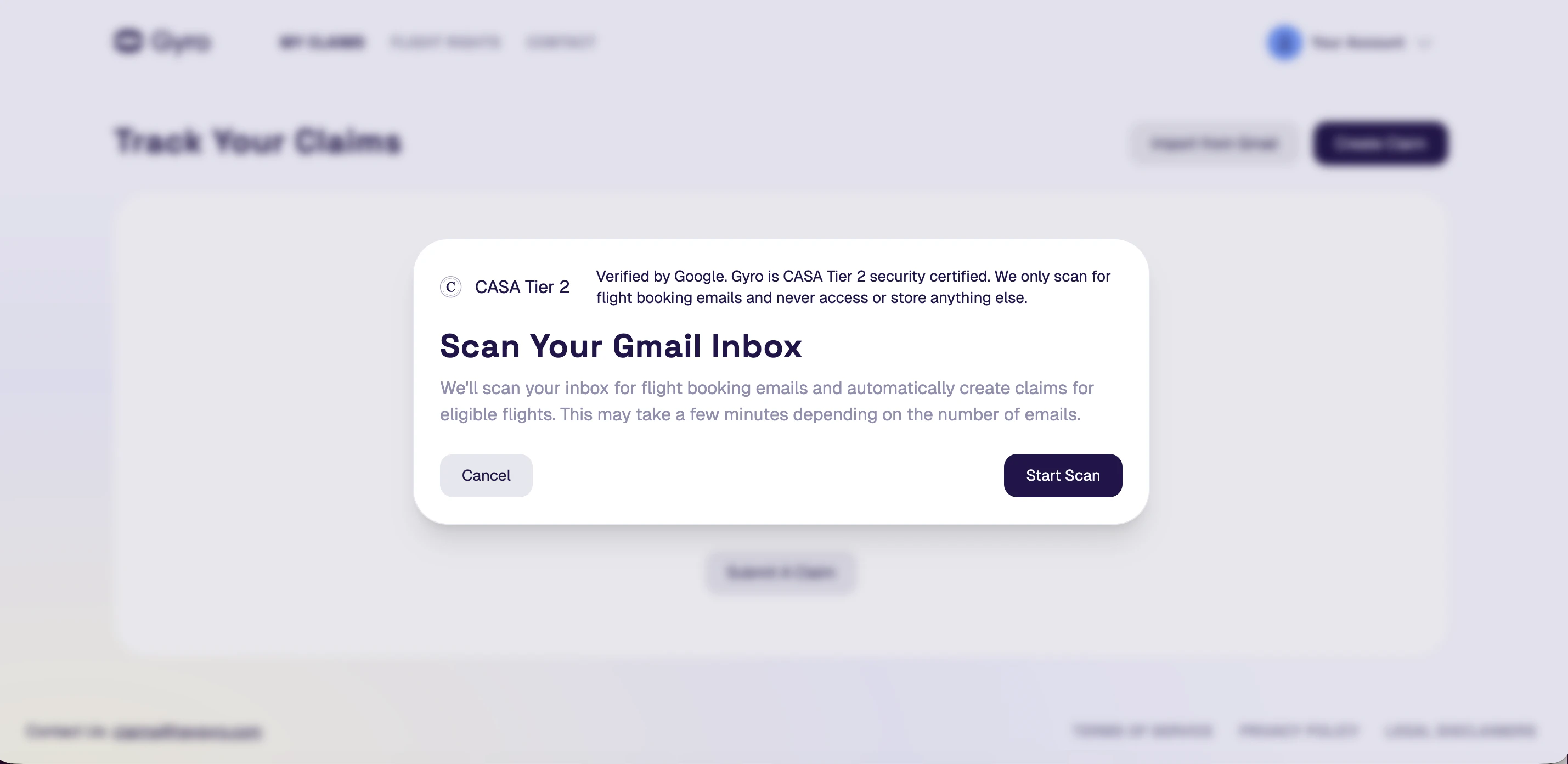
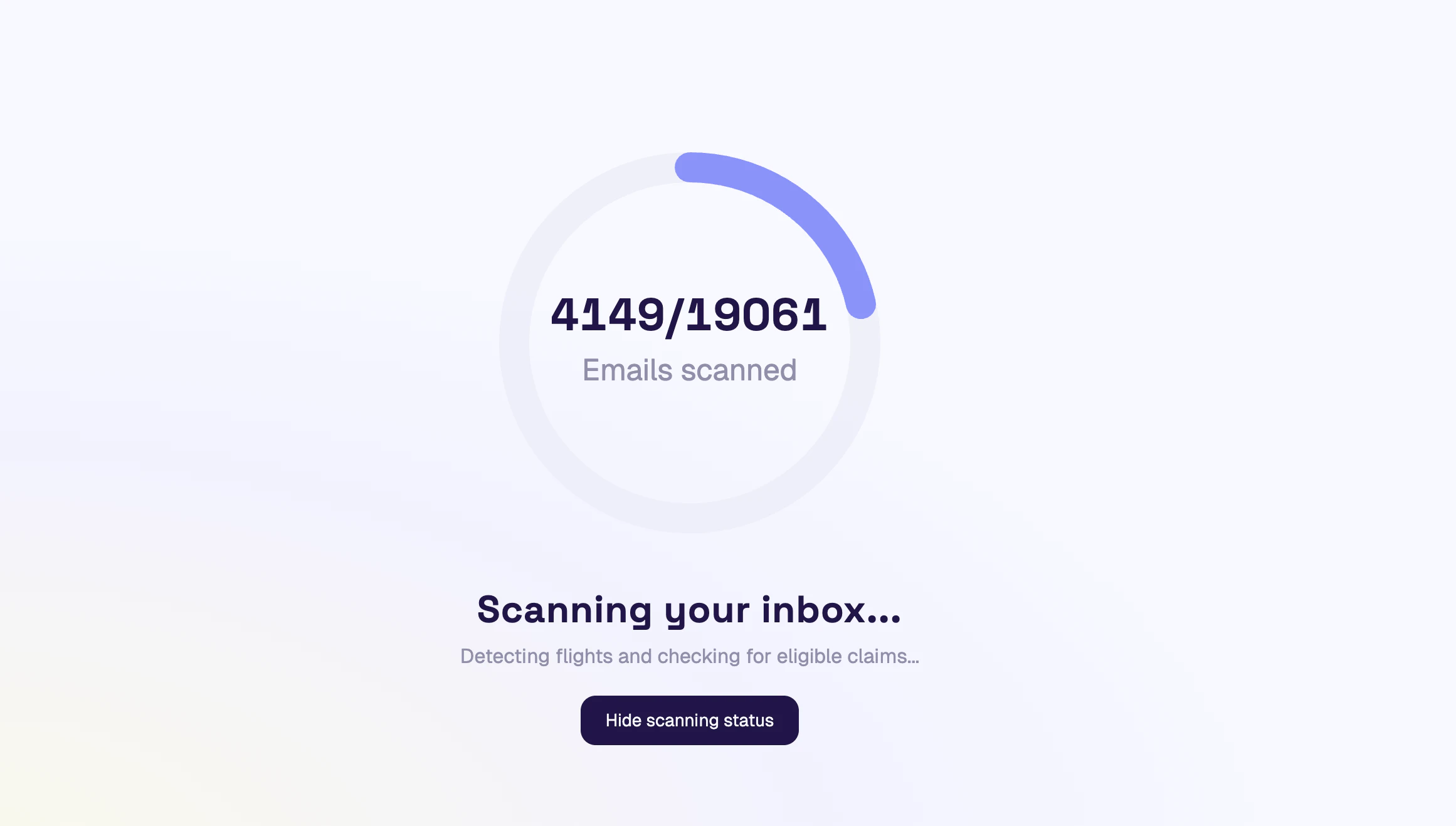
一句话介绍:Gyro Autopilot通过扫描用户邮箱,自动识别并申请因航班延误、取消等产生的未领赔偿金,解决用户因流程繁琐而放弃索赔的痛点。
Travel
Artificial Intelligence
Personal Finance
航班赔偿
邮箱扫描
AI自动化
索赔服务
旅行 refund
消费者权益
金融科技
被动收入
无风险试用
用户评论摘要:用户普遍反馈操作简单、惊喜地发现遗忘航班可获赔。大量用户成功获得数百至数千美元退款,高度认可其“无劳而获”的价值。主要疑问集中在如何解析多格式多语言的航空公司邮件。
AI 锐评
Gyro Autopilot精准切中了航空赔偿领域一个巨大的“效率洼地”——每年数十亿美元的无人认领赔偿金。其产品逻辑极其聪明:不是创造新需求,而是消除“索赔流程繁琐”这一核心阻碍。通过邮箱扫描+自动化代理,将用户从繁琐的文书、拒信和漫长等待中解放出来,真正实现了“工具即服务,服务即结果”。
从评论反馈看,用户的核心共鸣点并非技术本身,而是“遗忘的航班”被意外兑现的惊喜感。这种“发现金”的体验,传播力极强。产品方聪明地采用了“不成功不收费”模式,极大降低了用户尝试的心理门槛,这比任何广告都有效。
然而,产品价值高度依赖航空公司的邮件格式、不同国家的法规(如欧盟EC261与美国各州差异)以及索赔渠道的稳定性。邮件解析的准确率、面对航空公司“耍赖”时的法务博弈能力,才是长期护城河。目前大量好评可能集中在简单案例,复杂或易被拒的索赔能否同样高效,才是验证其“自动”含金量的关键。此外,隐私是悬在邮箱扫描类产品上的达摩克利斯之剑,产品需要将安全信任从口号落实为可验证的技术细节。整体而言,这是一个模式清晰、时机准确、体验优雅的“痛点收割机”,但后续能否规模化处理复杂案例并建立法律壁垒,将决定它从“好工具”蜕变为“好生意”的上限。
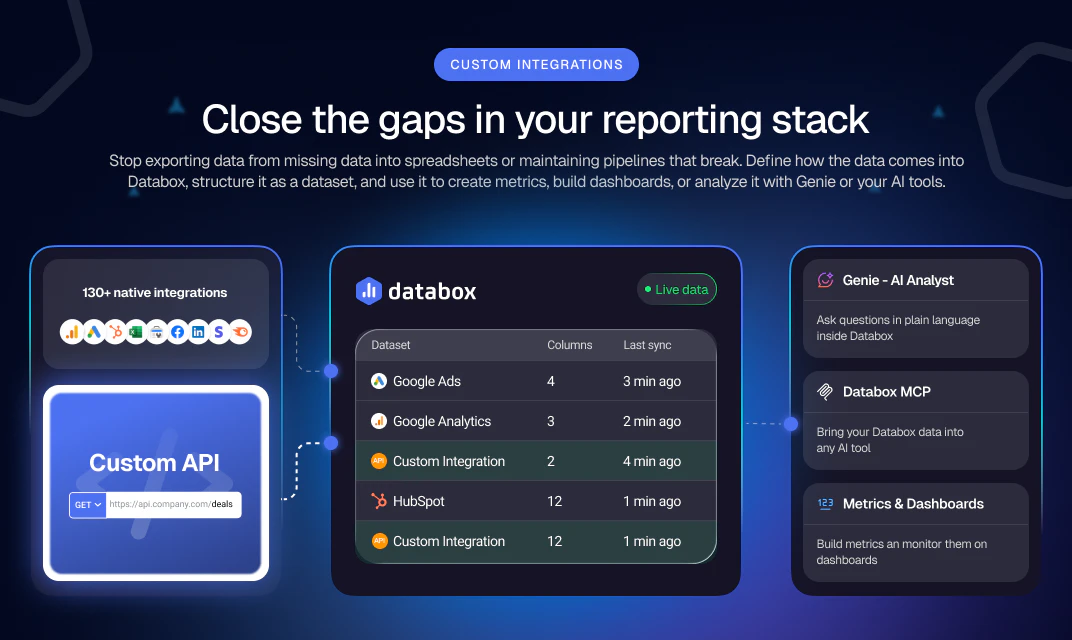
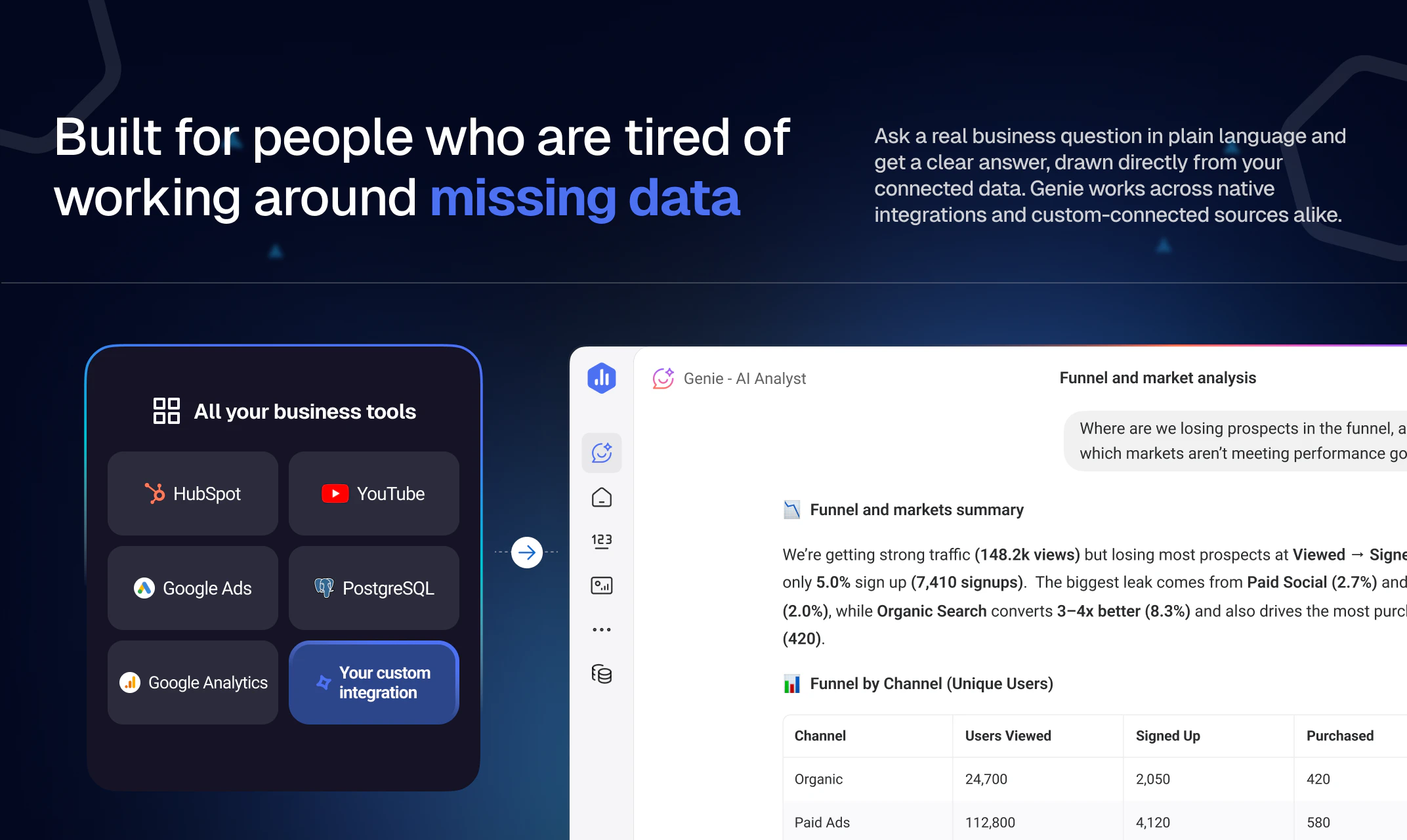
一句话介绍:Custom Integrations by Databox 让用户无需编写代码即可将任意 API 接入 Databox,将数据转化为结构化数据集,自动同步到已有工作流中,彻底解决在关键工具因缺少原生集成而被迫使用电子表格、手工脚本或依赖工程团队维护的报表断档痛点。
Analytics
SaaS
Developer Tools
无代码API集成
数据自动化
业务报表
RevOps
数据分析
自定义连接器
API数据接入
SaaS工具集成
结构化数据集
用户评论摘要:用户普遍认可其解决了“手动导出到电子表格或依赖工程团队维护脆弱连接”的长期痛点,尤其赞许其对非标准分页、OAuth2等复杂认证的自动化处理。有用户建议不要过度依赖AI计算,官方回应澄清AI不直接计算原始数据,而是基于已同步的结构化数据集提供查询界面。
AI 锐评
这一工具的价值在于精准切入了一个长期被忽视的“企业级数据粘合”痛点——非头部工具的报表集成。市面上大多数BI产品竞相推出“AI洞察”时,Databox选择反向构筑数据基石的完整性。从用户反馈看,其真正威慑力不在“无代码”,而在对非标准分页、OAuth2等复杂协议的后台优雅处理,这才是让分析师、RevOps团队从“维护脚本的噩梦”中真正解脱的关键技术壁垒。
8+点赞的评论无不指向一点:此前团队被“导出→粘贴→维持→崩溃”的循环消耗大量隐形人力成本,而该功能将这一部分从隐性工程债变为了自动化资产。CEO轻松上手,AI分析师(Genie)基于全量结构化数据而非采样推理,打通了数据与洞察间的最后一公里。
长远视角下,该功能的战略价值在于数据基础设施的完整性——正如团队所说,“AI在18个月后是商品,但干净、完整的数据集不是”。未来Databox若持续强化这个“自服务API中心”,有望建立区别于多数BI厂商的“数据层护城河”。当前风险在于:API连接稳定性随时间推移和协议变更的长期维护能力,以及与已有大型数据集成平台(如Zapier、Fivetran)的功能错位竞争。总之,这是一个“朴素但致命”的产品,专治数据集成中“只差那一个工具”的强迫症。
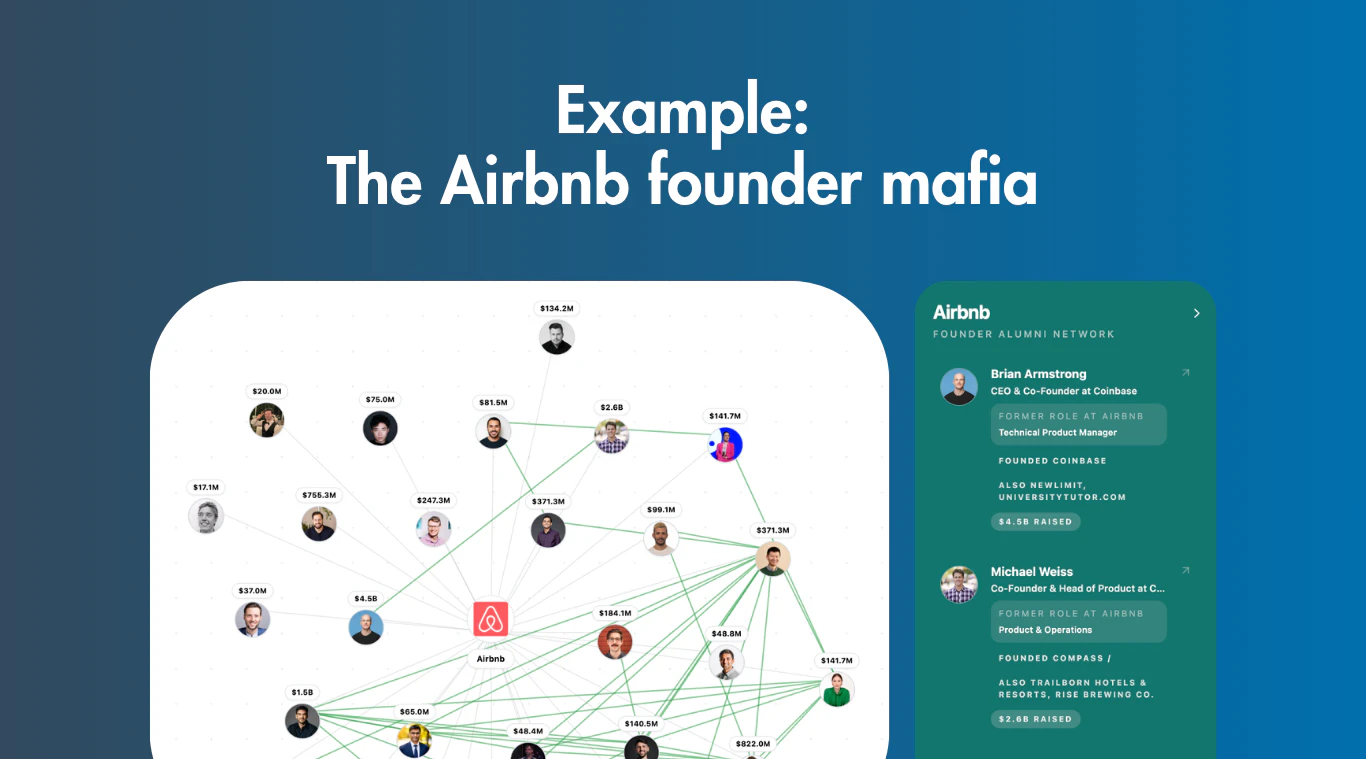
一句话介绍:一键输入公司或大学名称,即可可视化呈现其创始人校友网络图谱,帮VC、销售和创始人快速发现潜在合作或推荐路径。
Venture Capital
SaaS
Tech
创始人网络图谱
校友关系映射
VC寻源
销售暖引荐
共同创始人匹配
社交关系可视化
人才管道分析
创业数据挖掘
企业网络分析
Crunchbase增强
用户评论摘要:用户普遍认为功能聪明且实用,解决了手动拼凑数据(LinkedIn+Crunchbase)的痛点。但移动端体验差、定价混乱是主要槽点;同时有反馈数据准确性不足,且缺乏邮箱/电话等直接联系方式。
AI 锐评
Alumni Founder 的价值在于它将“创始人神话”从叙述故事系统化为一套可查询、可度量的数据图谱。这种“网络即基础设施”的思路——尤其通过“重叠强度”(同团队、同时期)和“融资额”两个维度的叠加,让关系不再是虚无的人脉而是可量化的信号——确实对VC的deal sourcing和销售团队的热线索构建提供了实质性好处。产品切入点精准:抓住了“人人都谈论PayPal黑手党/Stripe校友,但无人能快速可视化”这个认知缺口。但冷静审视,其护城河主要建立在数据底层(Crunchbase+LinkedIn整合模型),而非产品体验或网络效应。用户评论中“手机端糟糕”“定价混乱”以及“数据可能不准确”等反馈,反映出当前版本离“开箱即用”还有距离。同类工具如Apollo或SimilarWeb在B2B销售场景已有积累,竞争不可忽视。最大疑问在于:当数据源(crustdata)成为单品时,能否通过“网络图谱”的聚类和预测能力——比如自动预测哪个特定公司会孵化出下一个独角兽——形成差异化,而非停留在“漂亮的交互式数据库”。另外,有意忽略邮箱/联系人信息以主推API,虽是商业化策略,却损害了“一站式痛解决”的用户直觉。整体来看,这款产品是对人力工作(手动扒数据)的线性优化,但要成为颠覆性产品,还需要在数据实时性、移动端体验和智能推荐上下更大功夫。
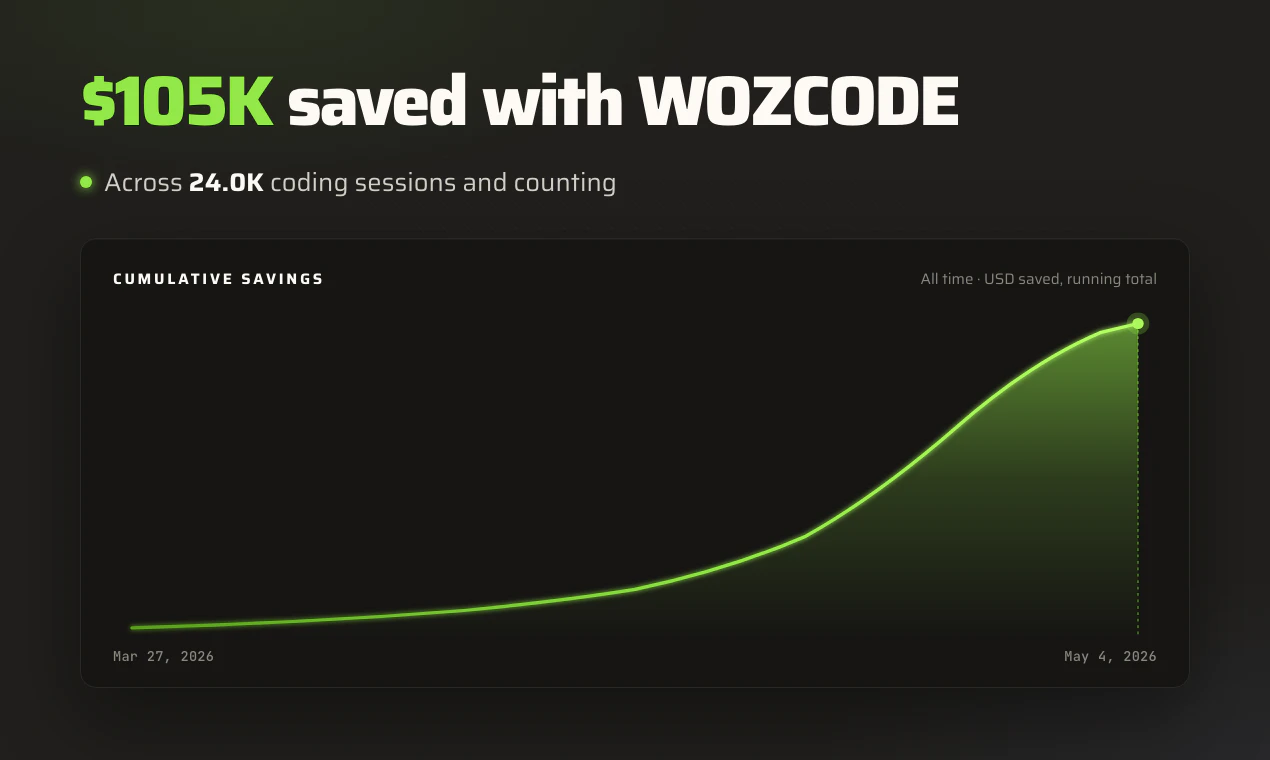
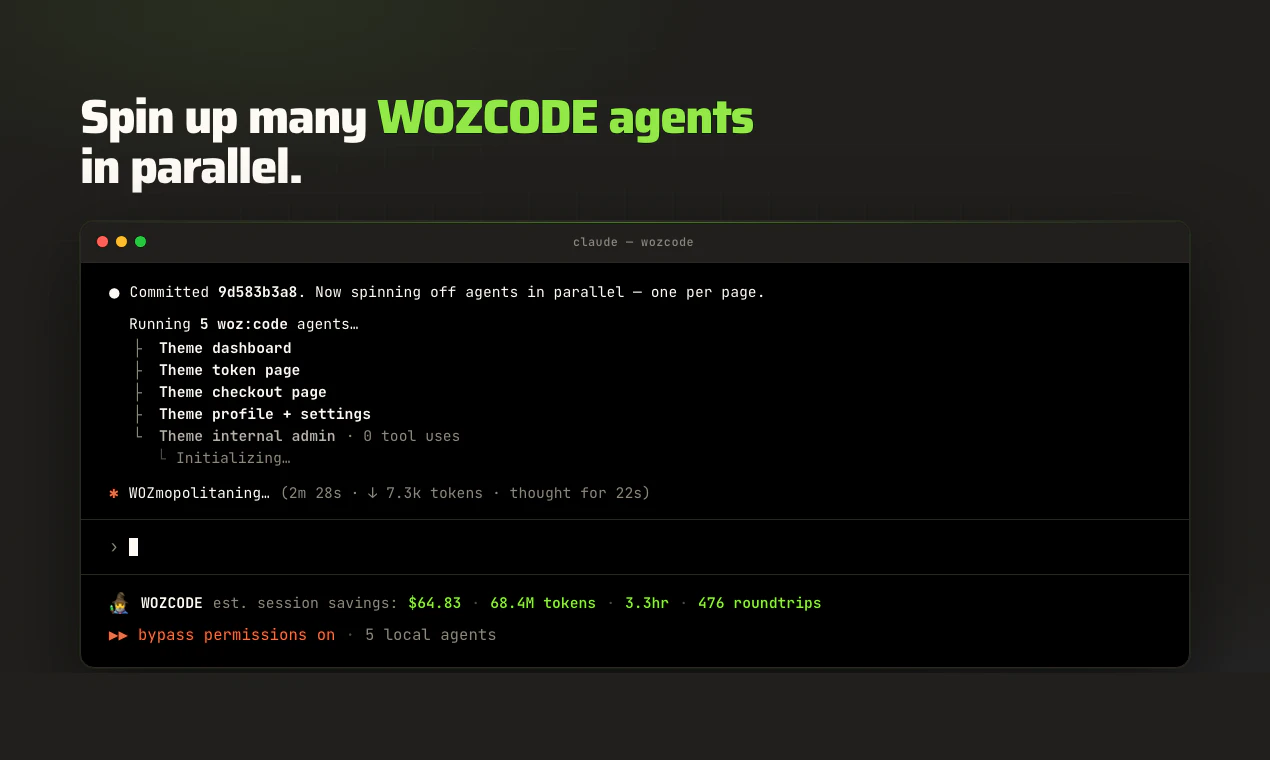
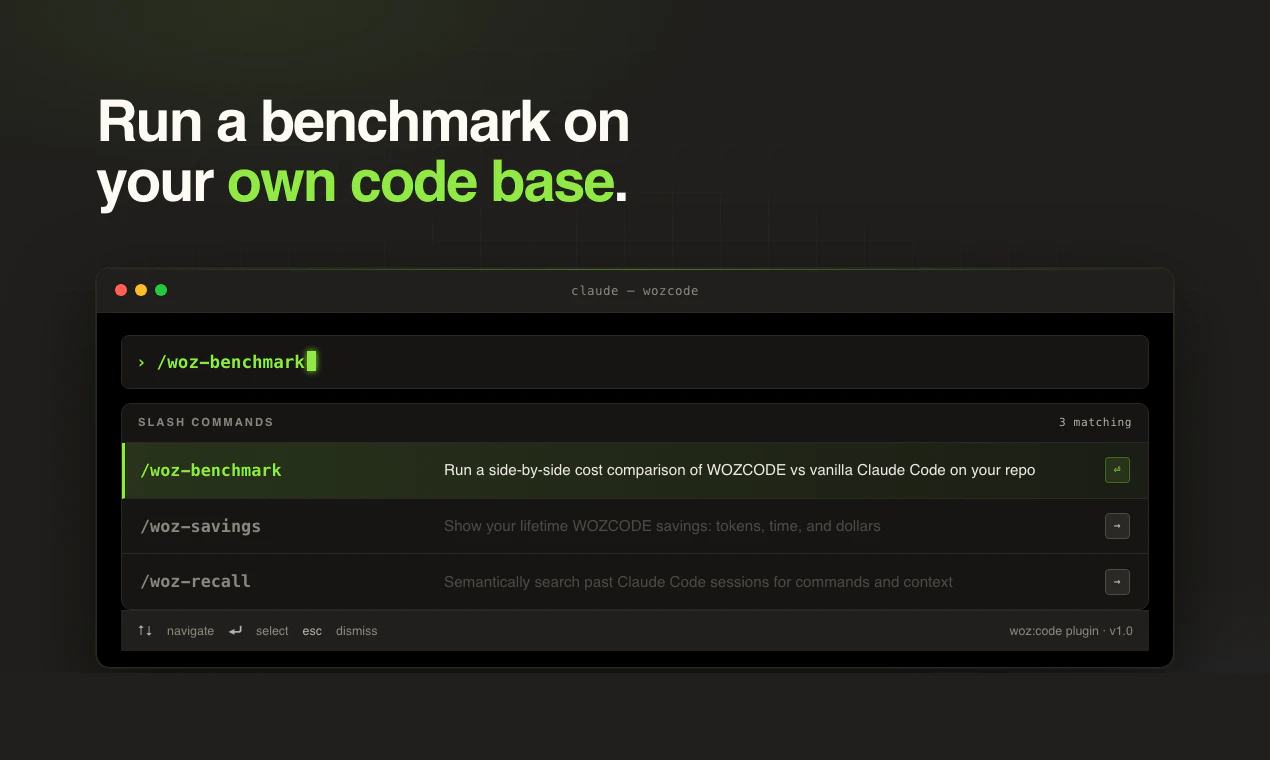
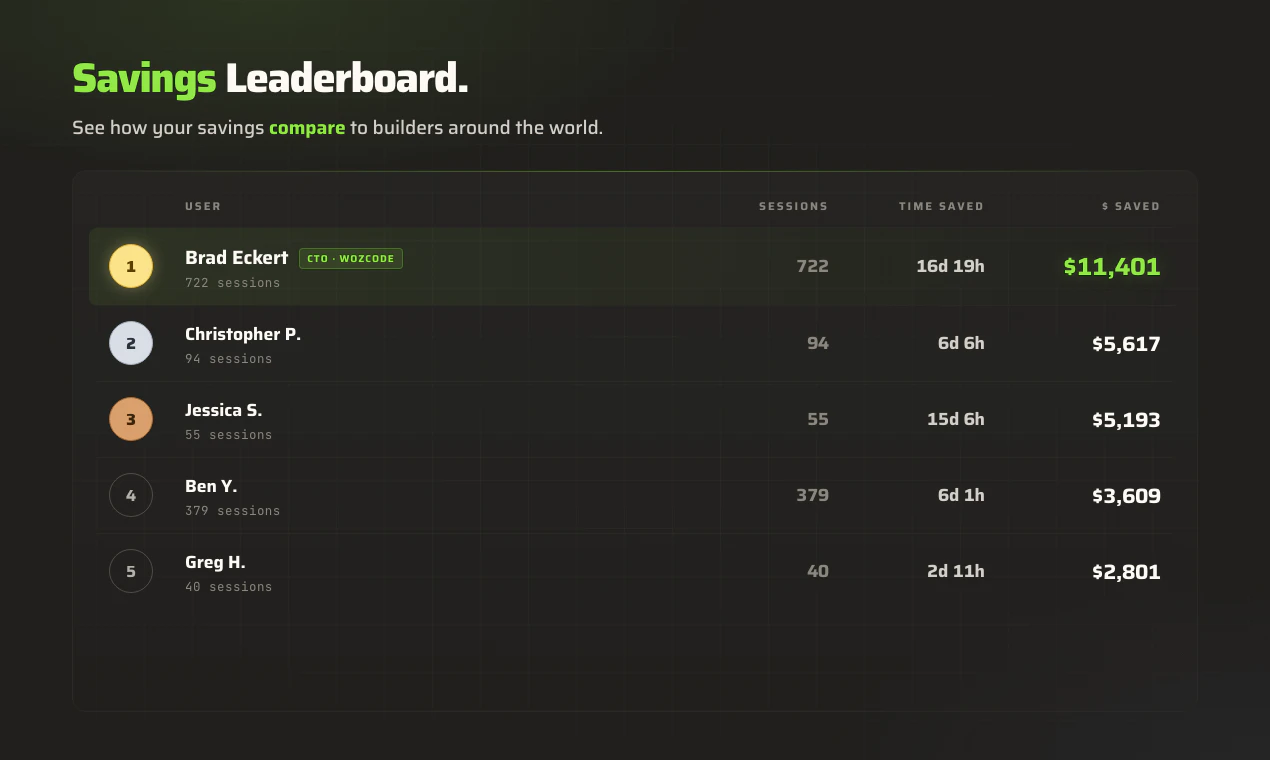
一句话介绍:WOZCODE 是一款针对 Claude Code 的插件,通过优化上下文管理和工具调用流程,帮助开发者将令牌消耗降低高达 55%,并提升任务完成速度,解决 AI 编码代理中普遍存在的浪费问题。
Productivity
Developer Tools
Artificial Intelligence
AI编码代理优化
Claude Code插件
令牌成本节省
上下文压缩工具
开发效率提升
批处理编辑
终端基准测试
启动加速
成本控制
Token优化
用户评论摘要:用户普遍认可其对令牌浪费的针对性优化,尤其在大项目场景下效果显著;部分用户提出免费额度消耗过快、付费层级不透明的痛点,希望改进;有专业用户好奇其实现原理(如工具层拦截 vs 模型路由),并希望获得更清晰的基准测试重现方法。
AI 锐评
WOZCODE 的切入点精准且聪明:它没有试图“超越”Claude Code,而是在其脆弱的执行层上补了一刀——即大量上下文被无效重读、读写环过多导致令牌浪费。这种“效率层”思路与实际用户痛点的匹配度极高,评论中多次提到“观察到一半令牌被浪费”就是铁证。技术上,其核心动作是通过定制工具将“查找并编辑3个文件”这类操作从12次调用压缩为2次,大幅减少反复重读。这种优化逻辑不依赖模型本身,本质上是一个工程层面的“抽水机”,把 Claude Code 底层的高频低效循环直接替换掉,效果是肉眼可见的。
然而,这并不意味着 WOZCODE 无懈可击。评论中一位用户反馈“$100免费额度几小时用完,付费层级不透明”直接暴露了商业化透明度问题:自称能节省成本,却不先展示清楚付费梯度,有点反直觉。另外,其基准测试(Terminal Bench 2.0 提升11个点)虽然有数据支撑,但缺乏对“任务类型差异”的细致划分,跨业务场景的适配性尚未被充分验证。更关键的是——既然“浪费”是原生Claude Code的机制,未来 Anthropic 是否可能在下个大版本内生优化这部分逻辑?如果是,那么作为外挂插件的 WOZCODE 将面临被原生取代的风险。它的护城河并不算深,核心在于用户习惯和早期集成触发的高切换成本。
总体而言,WOZCODE 是一个务实、利基且有一定技术壁垒的效率工具,适用于对成本敏感、追求极速迭代的中高级开发者或团队,但长远来看,它更像一个在“AI代理配套生态”中暂时吃香的过渡产品,而非持久性基础设施。
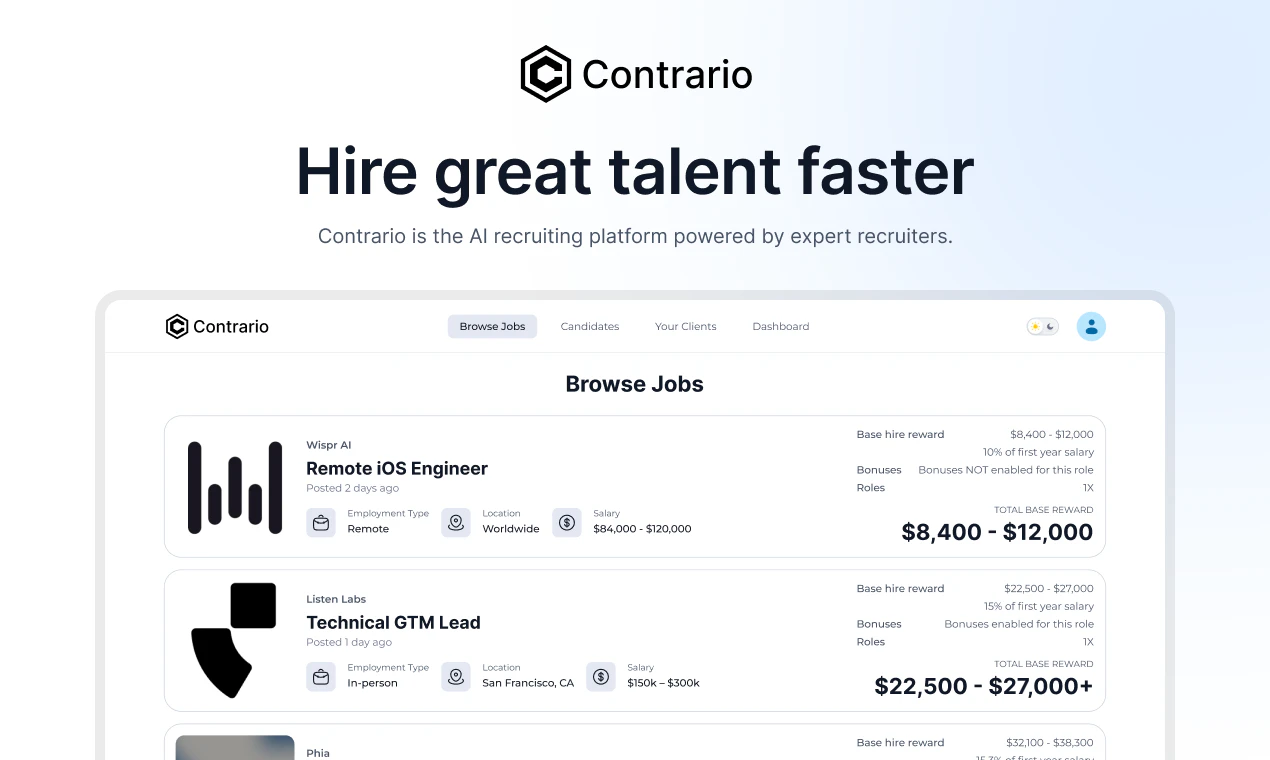
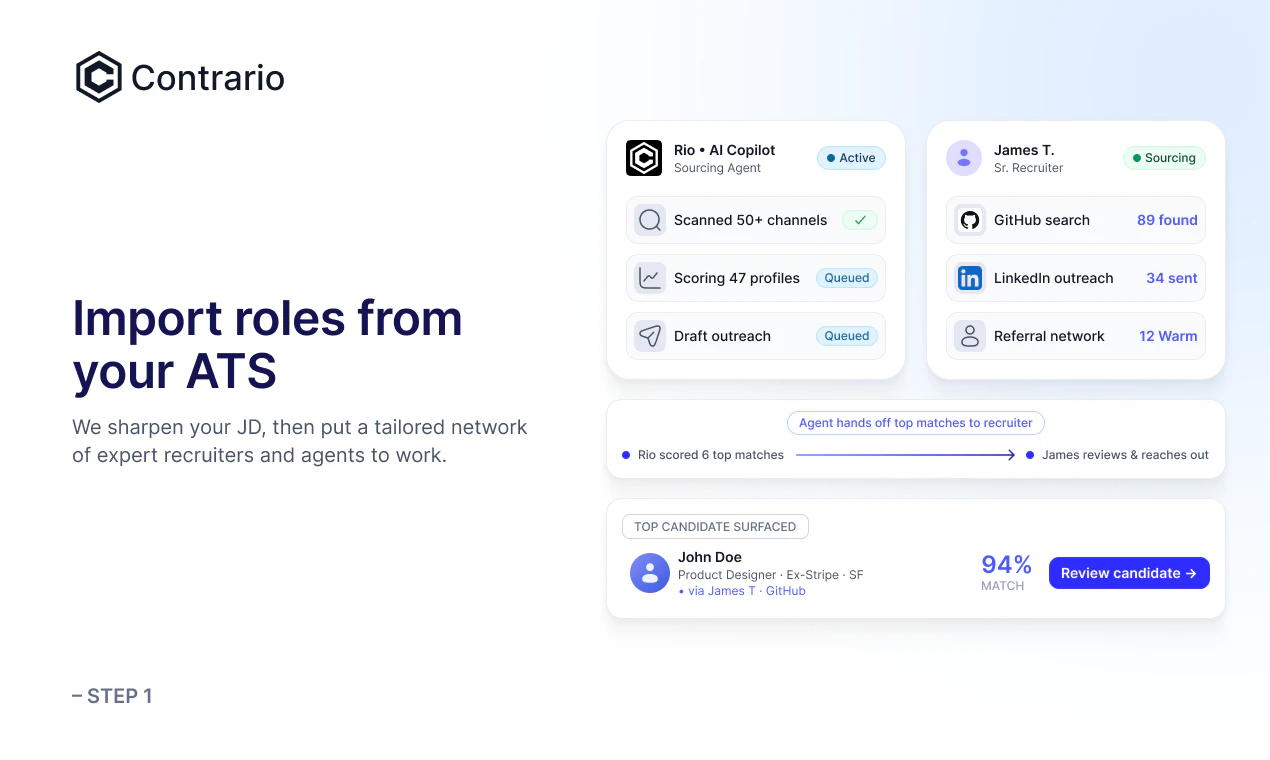
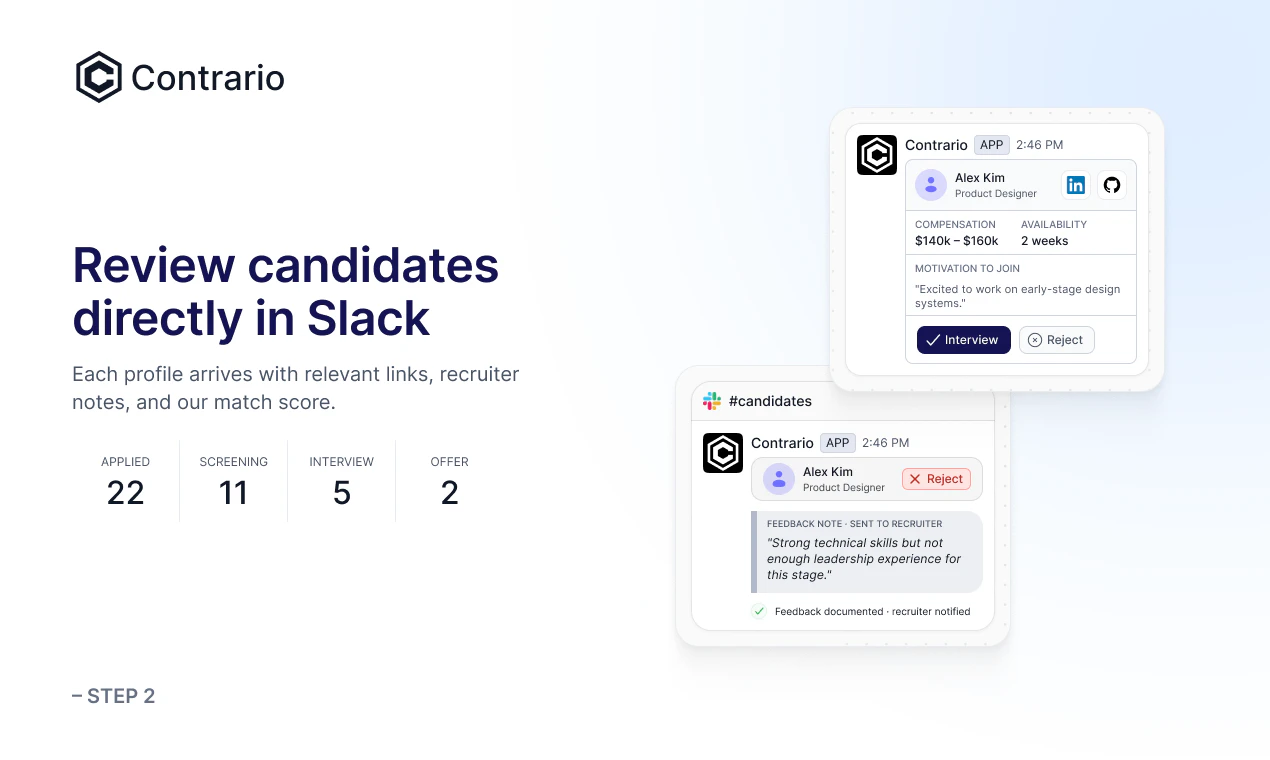
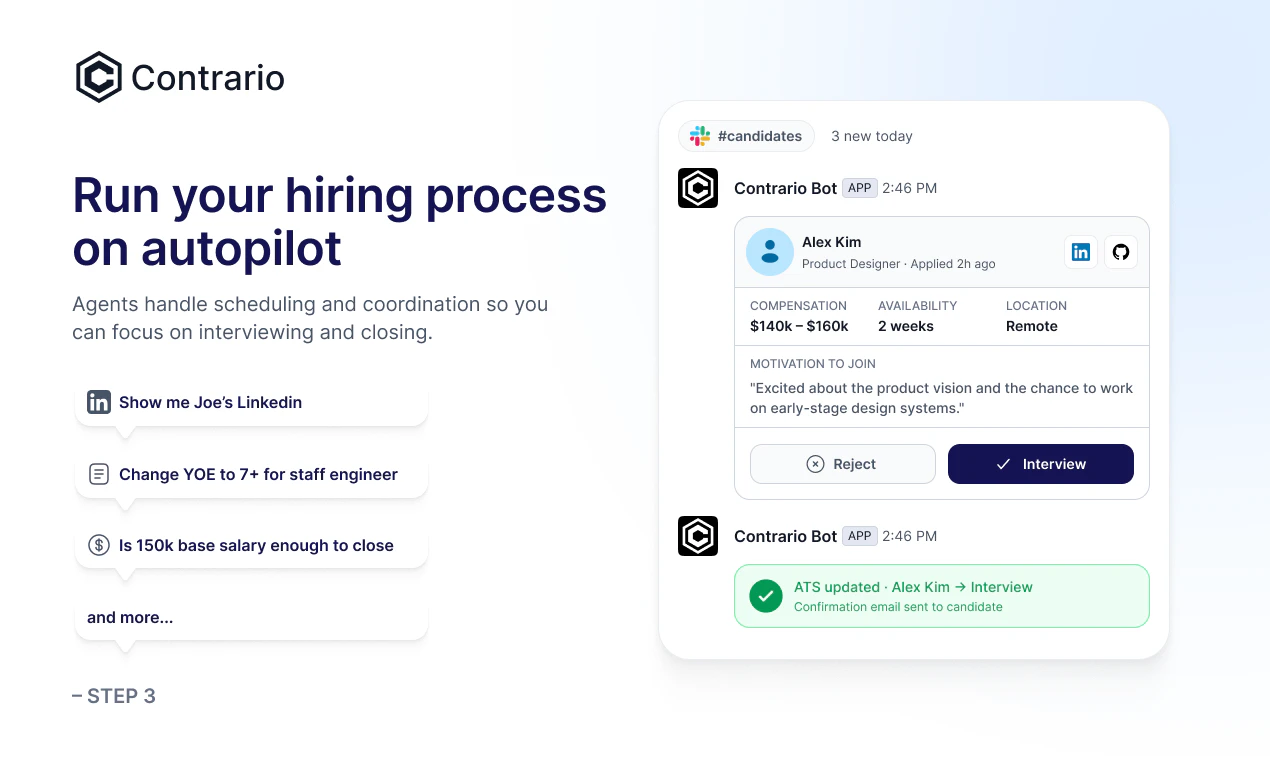
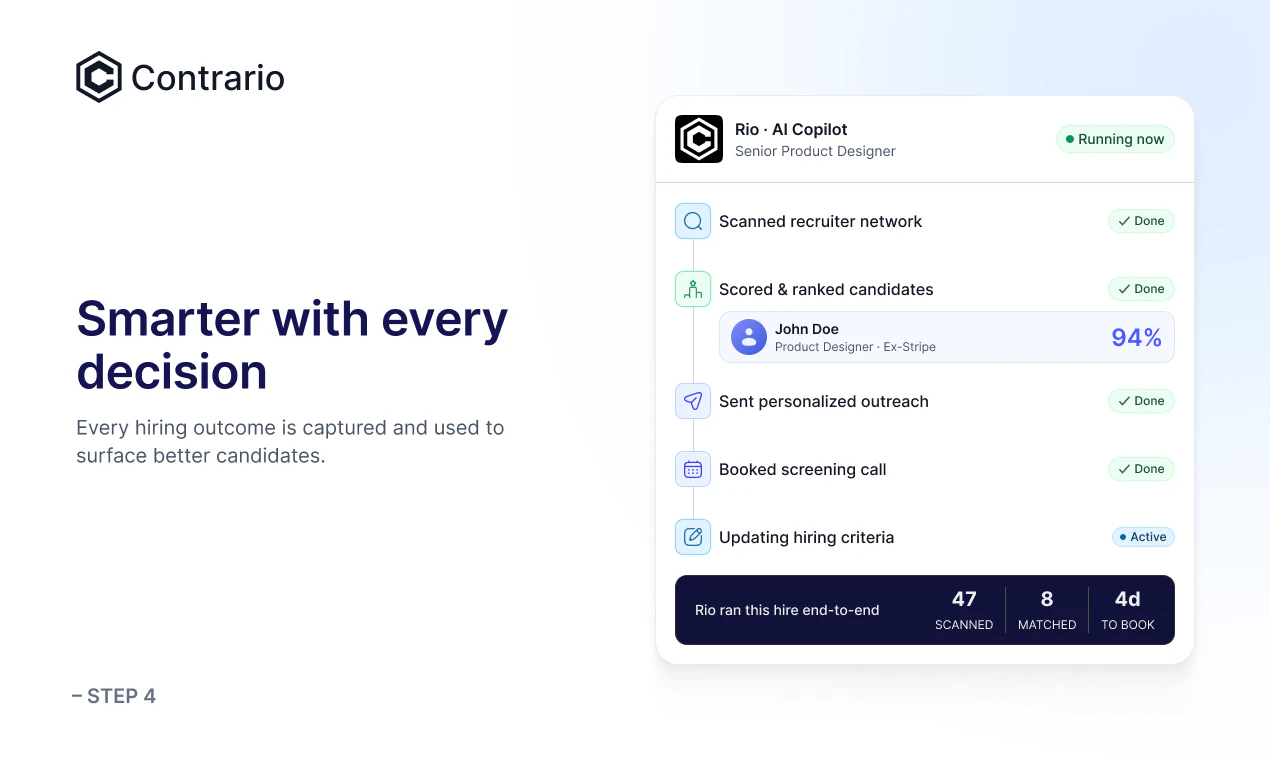
一句话介绍:Contrario 结合专家招聘网络与AI智能体,在Slack中通过自然语言处理90%的招聘工作,解决了企业招人时高质量候选人难回复、难匹配的痛点。
Hiring
Artificial Intelligence
Tech
AI招聘
招聘平台
招聘网络
智能体
人机协作
Slack集成
候选人筛选
招聘自动化
人才匹配
初创企业
用户评论摘要:用户肯定其15天招核心团队的效率,关注AI与招聘官的协作反馈机制(如override实时学习)、是否集成ATS及Slack、是否支持非技术岗(确认支持GTM/Ops)、候选人背景核查仍靠第三方、冷启动问题依赖类似岗位数据。
AI 锐评
Contrario的聪明之处在于它没有重蹈“AI完全替代招聘”的覆辙——这个领域里SaaS工具堆砌功能,却解决不了核心问题:优秀候选人根本不鸟那些模板化私信。它把“真人招聘专家”和“AI自动调度”缝合起来,既用专家的人脉和沟通能力撬动候选人,又用智能体处理筛选、协调、排期这些高重复度工作,本质上是在拿人做护城河,而非纯技术。
从评论看,产品逻辑立得住:对于初创公司,15天建工程团队的案例很有说服力;而对GTM、运营等非技术岗,其“专家匹配+AI辅助”模式反而因供需流动更快而效率更高。回帖中CTO对AI学习机制的拆解也实在——override后实时重打分,但要依靠招聘官标记原因来分离有效信号与噪声,这比许多“黑盒AI”坦诚得多。
但挑战也很明显:一是冷启动对完全新颖角色的覆盖仍是盲区,虽用同类岗位数据缓解,但本质上依赖历史经验库的广度;二是产品体验过度捆绑Slack,对习惯ATS完整工作流的HR可能形成认知门槛,即便已适配Ashby等主流平台,获客转化仍有摩擦;三是“20%首单折扣”的营销略显传统,难以匹配其“引领招聘新浪潮”的叙事野心。
总体而言,Contrario在产品-市场契合度上踩准了“信任缺口”——企业主不再相信纯自动化工具能搞定招聘,而它用“人+AI”的混合体提供了一个可验证的替代方案。但能否从小众的创始人圈层扩展到规模化企业,还需看其专家网络的供给弹性和成本控制能否跑通。
一句话介绍:Ads in ChatGPT 是一个面向美国广告主的自助广告管理平台,旨在解决企业在ChatGPT对话场景中难以自助创建、管理并衡量广告投放效果的痛点。
Marketing
Advertising
Artificial Intelligence
AI广告平台
ChatGPT广告
自助投放
CPC竞价
CPM广告
广告效果衡量
自然注意力变现
AI商业化
广告归因
对话式广告
用户评论摘要:用户普遍关注广告形式与用户体验的平衡,担忧干扰对话自然流畅性;对仅限美国地区感到遗憾;有用户质疑实际功能尚未完全上线,目前仅是登记表单;此外,对广告归因和全球可用时间提出疑问。
AI 锐评
Ads in ChatGPT的推出,本质上是OpenAI在“自然注意力”与“生产力收费”两条商业化路径上的一次明确押注。从产品功能看,它并没有颠覆性创新——CPC/CPM、Campaign管理、转化衡量,这套工具链在Google Ads和Meta Ads中早已成熟。真正值得关注的是“广告位”本身:ChatGPT的对话流是高度线性的,用户带着明确意图进入,广告若强行插入,极易打断认知连贯性,导致点击率与用户体验双输。目前评论中“如何让广告像建议而非噪音”的追问,恰恰点出了这类AI广告的核心困境:传统搜索广告是“用户找答案,广告顺便推”,而ChatGPT是“直接给答案,广告成了多余的路标”。除非OpenAI能找到“在回答中自然植入赞助商上下文”的格式(比如推荐某个工具完成用户正在进行的任务),否则广告很容易沦为对话中的“弹窗”,引发用户反感。此外,当前仅限美国、功能未全量上线的状态,也说明OpenAI对广告主和用户容忍度的测试极为谨慎。短期看,这更像是一个向资本市场讲故事的叙事工具;长期看,它成败的关键不在于投放效率,而在于能否定义出“非侵入式AI原生广告”的范式——目前还差得远。
一句话介绍:Gas City 是一个开源平台,通过编排 Claude Code、Codex 等AI编码代理,将它们的非确定性输出转化为产品级解决方案,帮助软件工程师构建、部署、运维产品的“软件工厂”。
Open Source
Developer Tools
Artificial Intelligence
GitHub
开源平台
AI编码代理
软件工厂
代码编排
开发运维
代理协作
产品化部署
工程效率
质量管控
开发工具
用户评论摘要:用户赞赏其将AI编码代理视为可编排的生产系统,而非孤立工具,使“软件工厂”落地。同时有评论询问其如何与GitHub PR、CI、本地开发等现有流程衔接,作者回应正构建默认工作流Pack。
AI 锐评
Gas City 试图解决当前AI编码工具最尴尬的现状:单个代理写代码爽,但组合作业、质量对齐、持续部署全崩。把“Agent编队”当作分布式工人来管理,并输出“Pack”作为标准化工作流单元,方向是对的,但本质还是把混乱的代理输出当作流水线原料来“后处理”——这治标不治本。
核心价值在于它不再鼓吹“AI替你写代码”,而是承认AI是“非确定性的高产出体”,你需要一个工厂来消化它的废品和不稳定产出。这种务实态度值得肯定,但问题也很明显:它依赖的CLI代理(Claude Code、Codex等)本身的质量基线并不稳定,工厂再高效,原料若劣质,产出仍旧有限。
此外,从用户评论可见,团队尚未给出与GitHub CI、本地开发等成熟工具链的清晰集成路径。拿“Stay tuned”搪塞,说明当前还停留在理念展示阶段。鼓吹“pick three”式的全能交付,更多是营销话术,实际效果取决于你愿意为这个工厂投入多少二次配置的代价。
一句话:Gas City是AI时代的Jenkins,需要用户自己搭建流水线、调参、写插件。它的价值在于框架思维,而非开箱即用。对于普通团队,可能仍在“工具孤岛和全栈废品”之间挣扎。
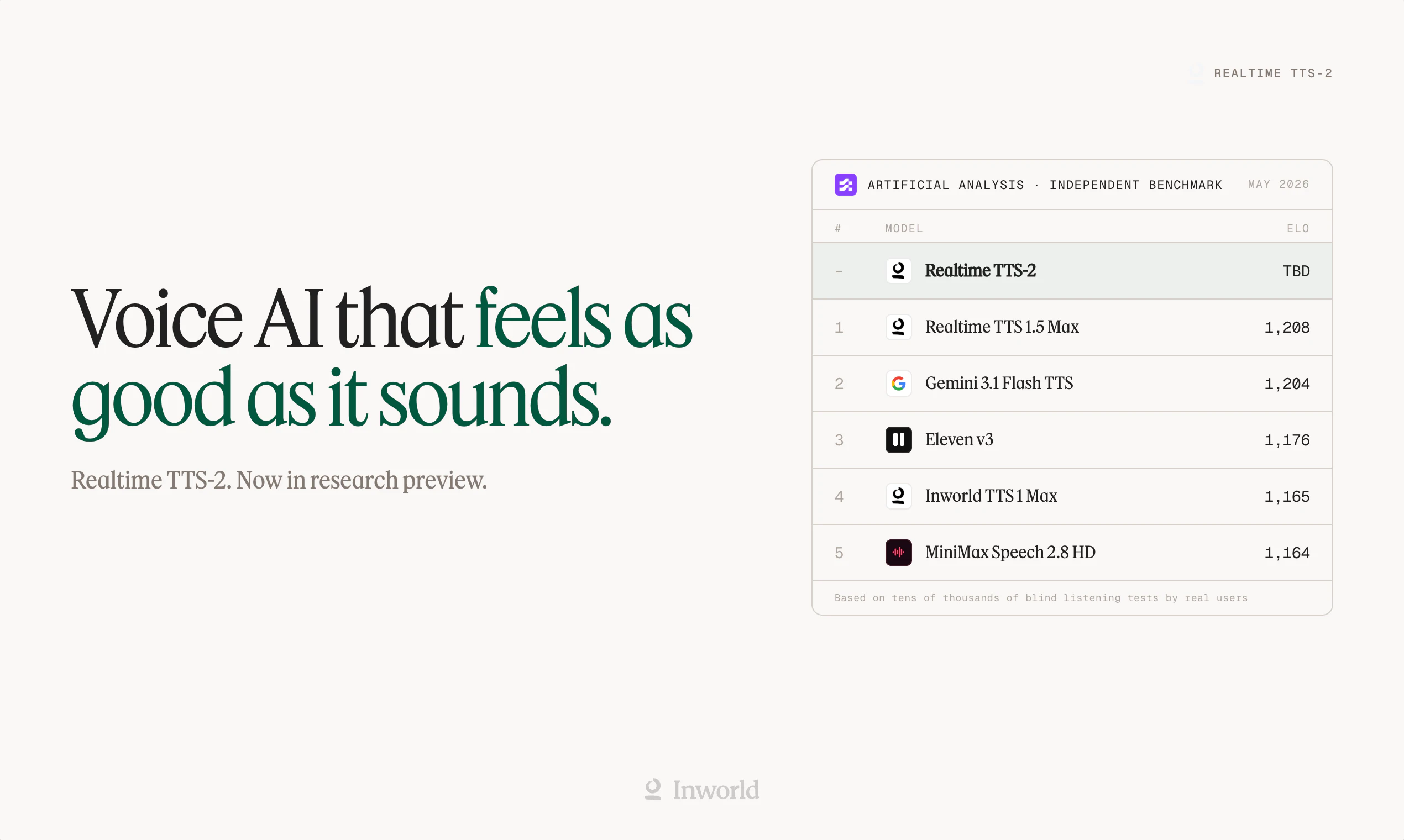
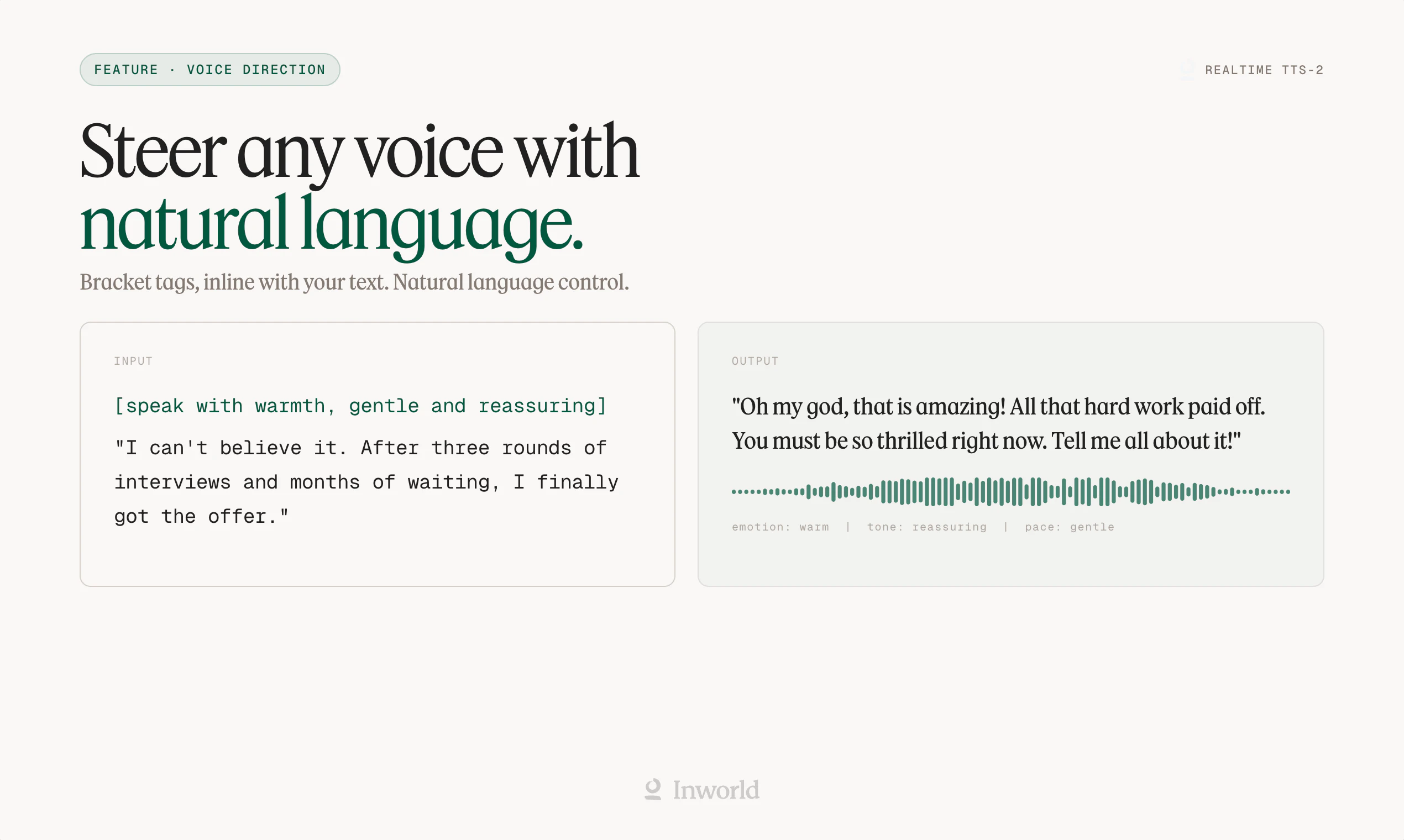
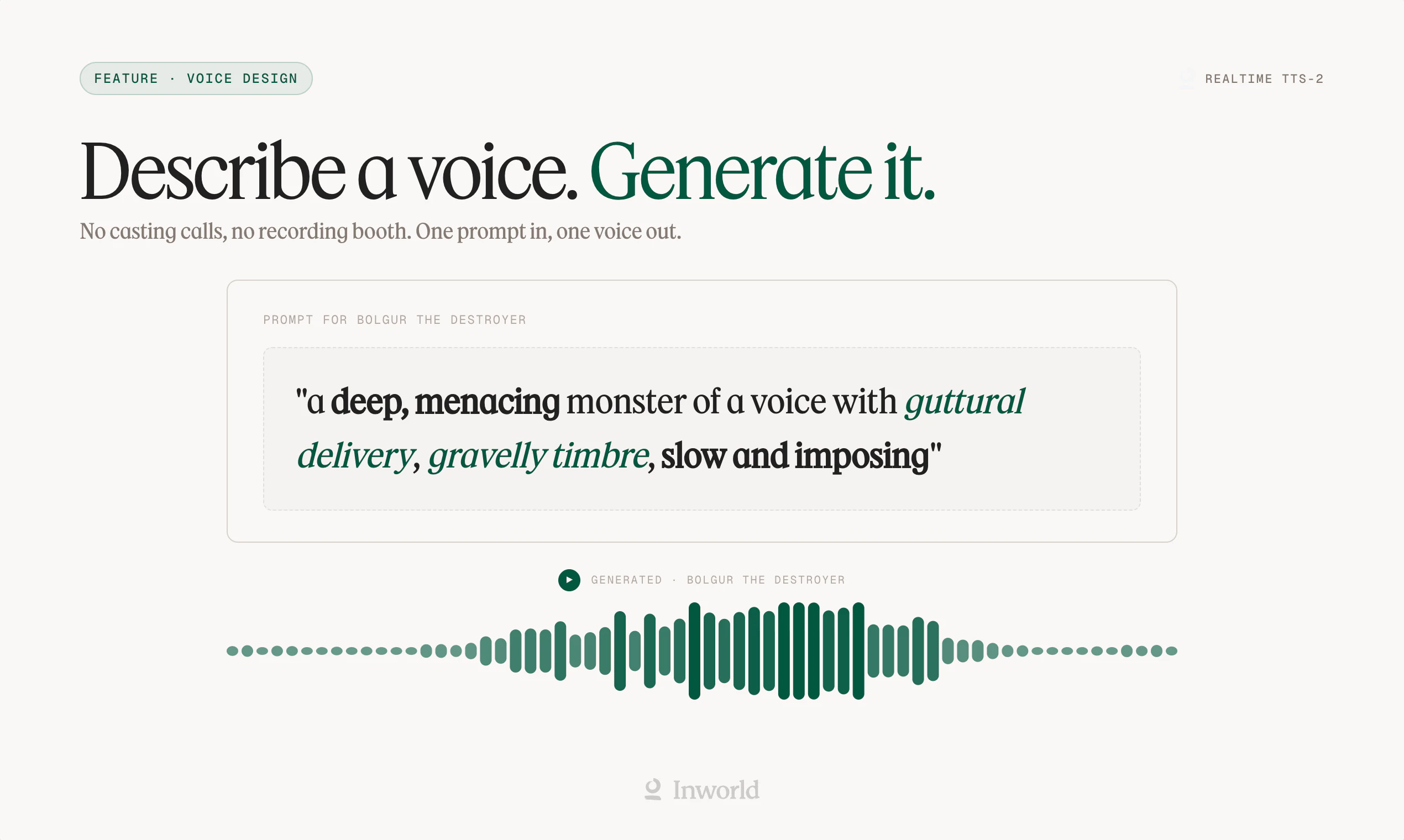
一句话介绍:Realtime TTS-2 是一款面向实时对话场景的语音合成引擎,通过训练对话语料和自然语言控制,解决了语音AI“像念稿”而非“像聊天”的痛点,让用户能够生成语调、情感和口音均可实时调节的“活人”声音。
API
Developer Tools
Artificial Intelligence
实时语音合成
情感控制
跨语言语音克隆
语音AI
文本转语音
对话式TTS
语音设计
人工智能
产品猎榜
Inworld
用户评论摘要:多数用户称赞其自然语言控制和跨语言能力,认为“训练对话而非朗读”是正确方向。但有用户反馈语音转语音模式存在幻觉、回答不一致、音质待提升,另一用户批评听起来仍像有声书朗读,缺乏真正人感。官方回复解释了技术定位并邀请测试。
AI 锐评
Realtime TTS-2 的定位精准地踩在了“语音AI的恐怖谷边缘”——大多数TTS产品把“朗读得准确”当作终点,而它试图把“听得像人”作为起点。从产品介绍看,六项升级中真正有壁垒的是“对话式语料训练”和“多轮上下文感知”,这解决了行业通病:语音代理听起来像客服念稿而非真人交谈。自然语言控制语音方向(如“疲惫但温暖”)比预设情绪标签更灵活,但这也意味着对用户的prompt工程能力有要求,可能增加使用门槛。跨语言保持音色一致性是硬功夫,100+语言切换能力直接对准全球化应用场景(如语言学习、多语种客服)。不过,评论中暴露的“语音转语音幻觉”“音质不足”等问题值得警惕:当产品强调“像真人”,用户就会以真人标准要求它。目前TTS-2在自然度上仍可能逊于OpenAI的Alloy等竞品,且其真实效果高度依赖应用场景——在短句对话中表现可能优于长段落。一句话评价:方向对了,细节还需打磨;想成为“语音界的GPT”,得先让用户听不出这是AI。
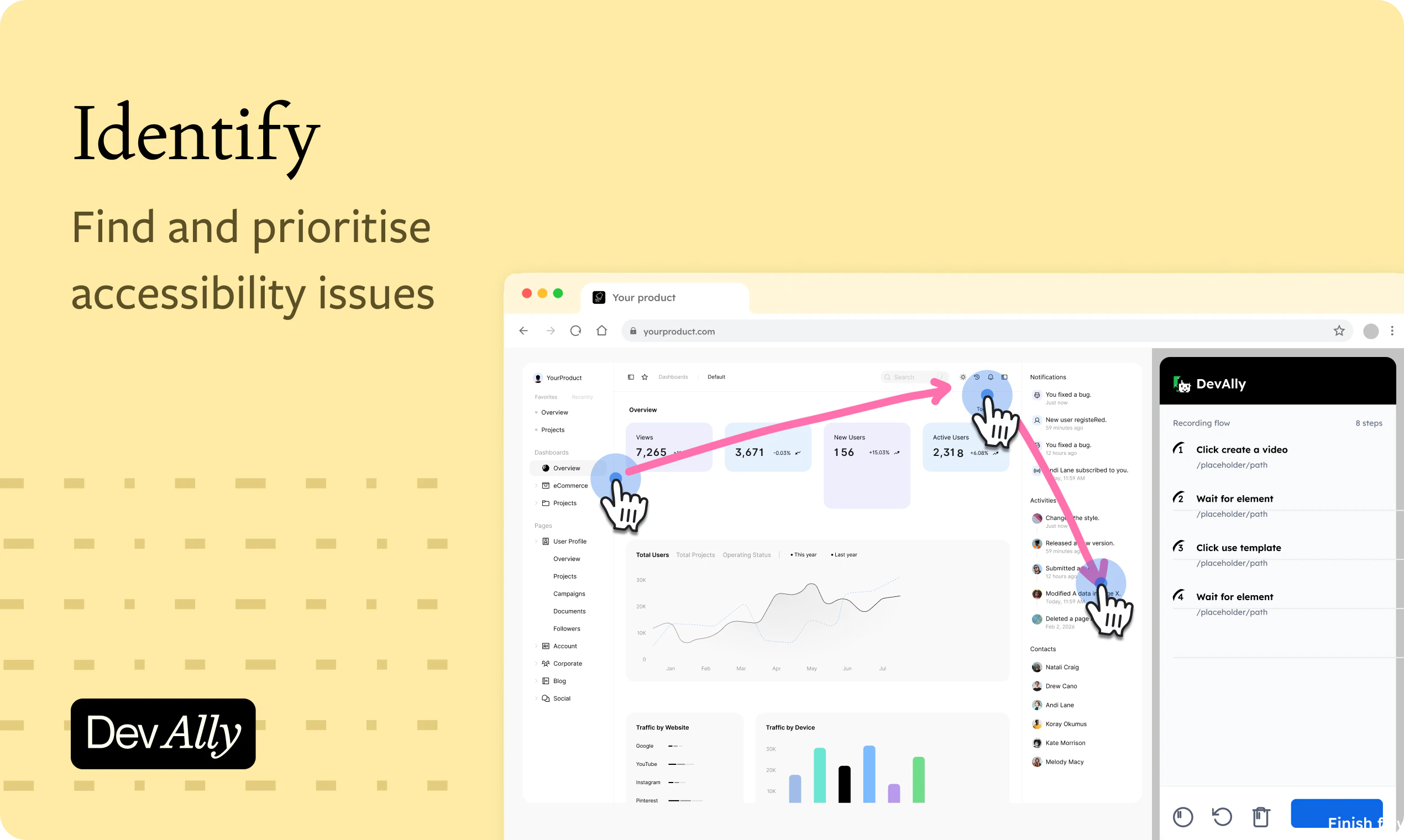
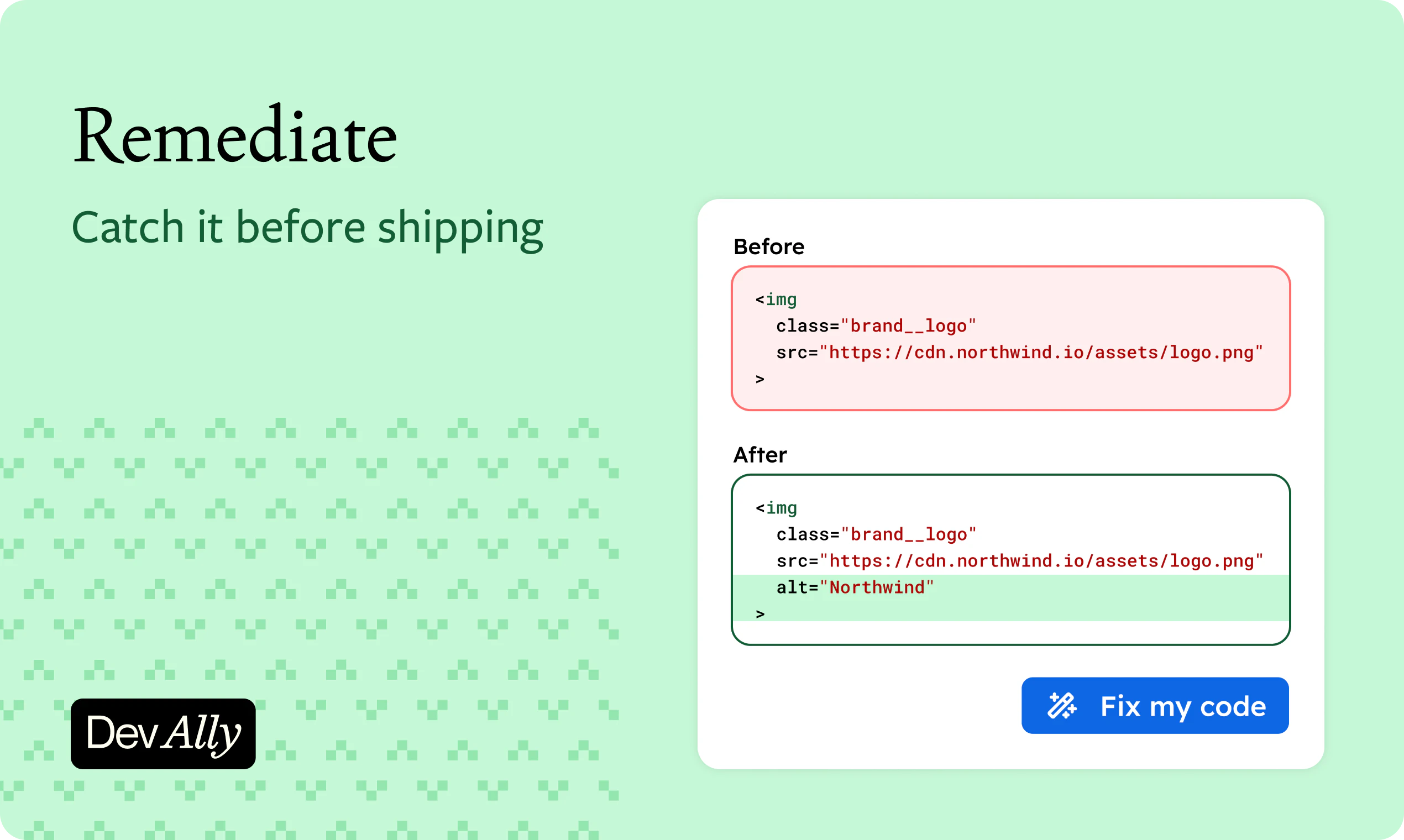
一句话介绍:DevAlly 利用AI将无障碍合规流程从“出报告”升级为“可执行的工作流”,帮助产品团队在欧盟EAA、美国ADA和Section 508标准下,自动生成优先级排序的修复任务清单、代码级修复建议及实时合规仪表板,解决工程、法律与产品团队之间关于无障碍合规的协同难题。
Productivity
Software Engineering
Developer Tools
无障碍合规
AI工作流
代码级修复
VPAT生成
ADA合规
EAA合规
Section 508
产品团队协作
自动化测试
合规仪表板
用户评论摘要:用户普遍认可产品从报告到工作流的创新,称赞界面美观。核心问题来自一位用户:如何扫描需登录的应用、能否用于临时测试环境(如Firebase测试网站)。官方回复支持通过工作流构建器存储凭据,并建议预约演示。
AI 锐评
DevAlly的微妙之处在于,它并没有发明一个新市场——无障碍合规工具早已拥挤,Ax、Wave、Lighthouse等前辈各占山头。它真正做到的,是把合规从“法律部门的审计痛点”重新定义为“工程团队的交付节点”。大多数工具停留在“告诉你哪里不行”,而DevAlly尝试给出“这一行代码怎么改”。这种从检测到修复的闭环,切中了“合规落地难”的根本矛盾:不是发现不了问题,而是修复成本与优先级不清。产品演示中强调VPAT实时生成和采购团队对接,也揭示了一个聪明策略——将合规从内部成本转化为销售筹码。不过,AI生成的代码级修复在复杂交互逻辑(如动态表单、单页应用路由切换)中的准确率,以及大型团队对工作流权限管理的要求,评论中并未深入触及。总体看,DevAlly的核心价值并非技术突破,而是对“合规流程中无人负责的那段灰色地带”进行了产品化填空,这一填空在欧盟EAA强制执行窗口期的当下,时机精准。
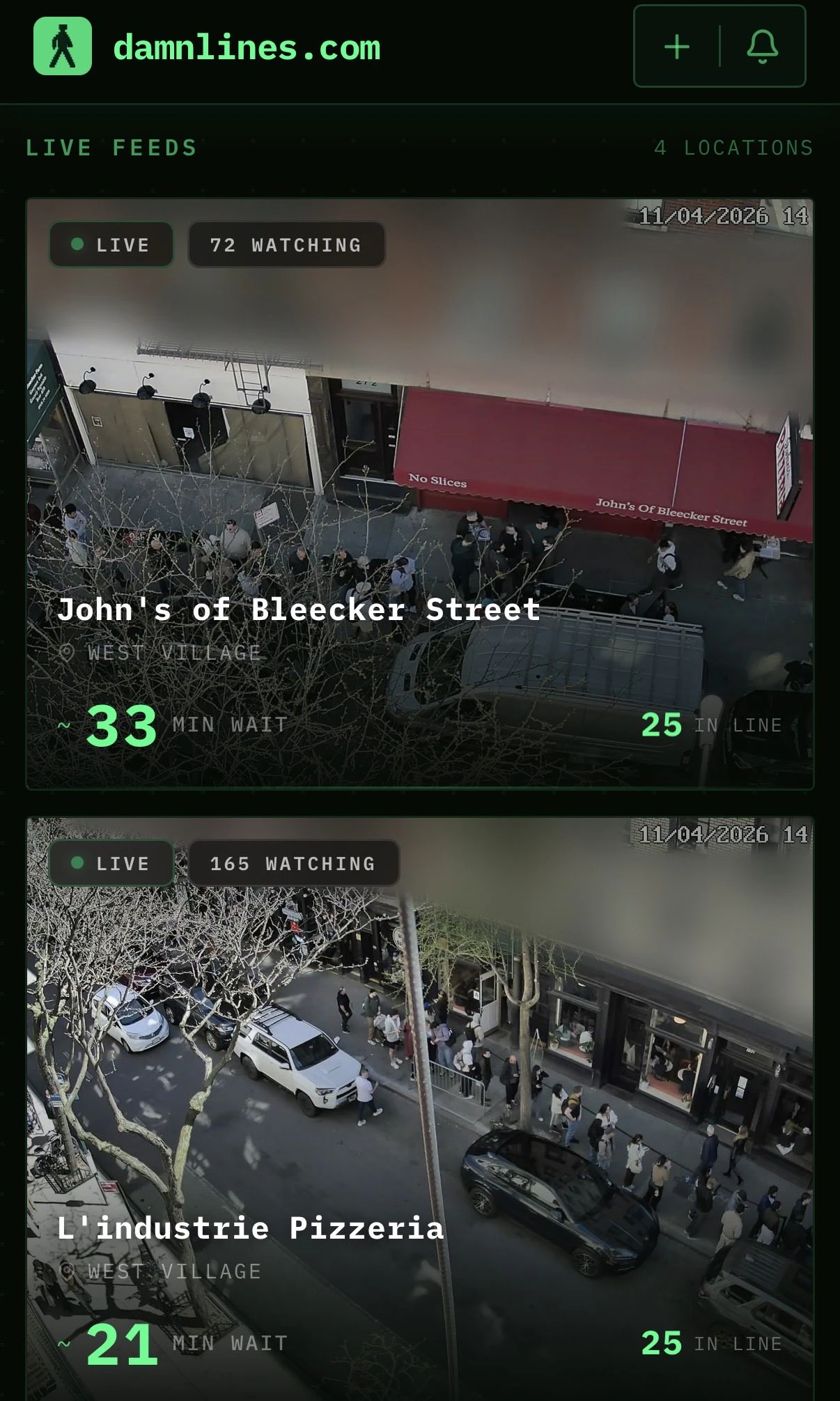
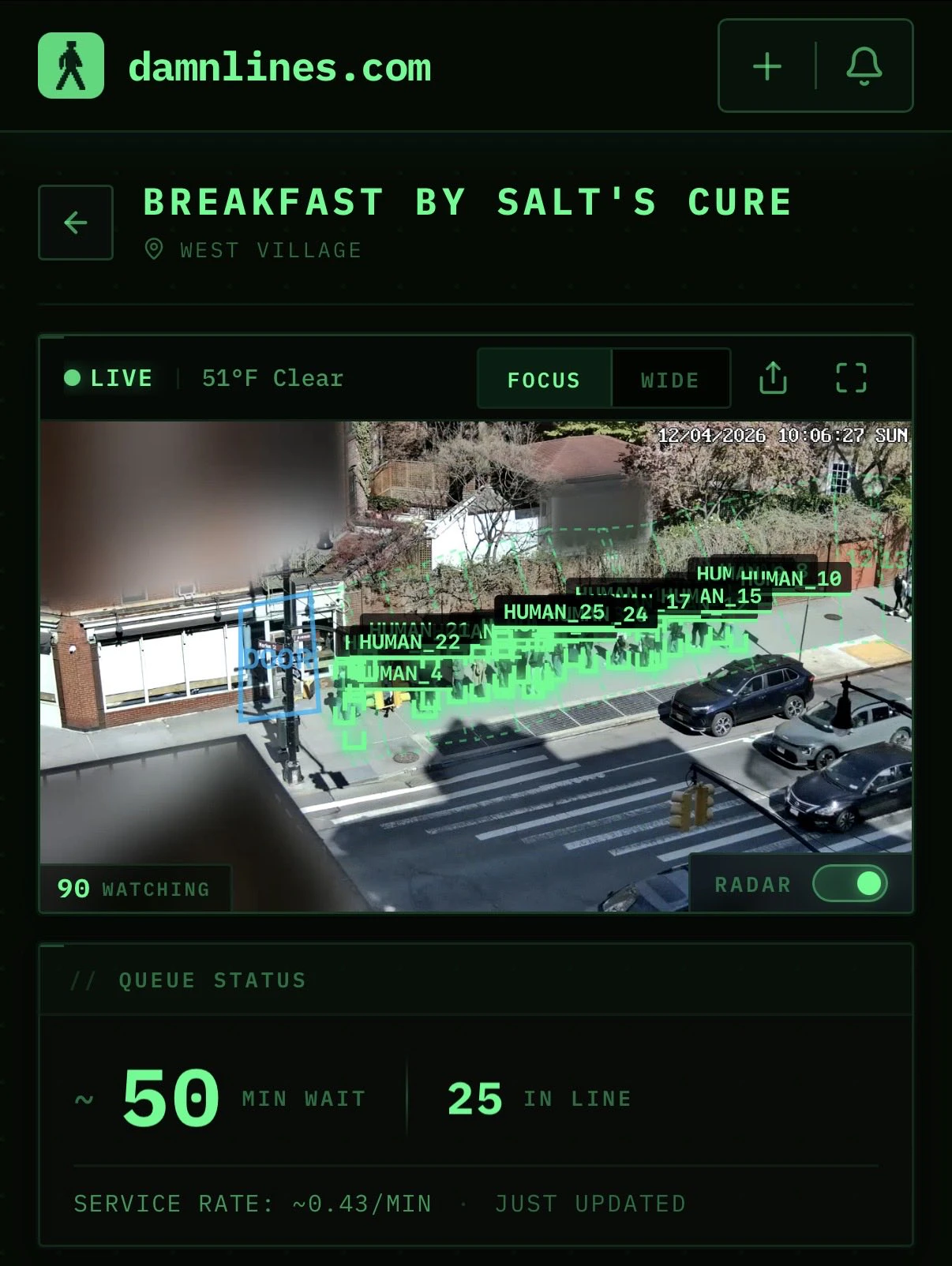
一句话介绍:damnlines.com通过实时摄像头监控纽约餐厅和场所的排队人数,为消费者提供排队等待时间信号,解决“不知道何时去才不会白排”的痛点。
Hardware
Sensors
Video cameras
排队监控
实时队列
等待时间
纽约市
餐厅
计算机视觉
摄像头分析
生活效率
城市服务
餐饮体验
用户评论摘要:多数用户认可其独特性和实用性,尤其对纽约“排队文化”有共鸣。核心反馈包括:希望覆盖更多地区(不仅限纽约)、增加更多地点(如Ceres Pizza等),以及期待全球推广。少数用户建议增加更多摄像头和地点监控。
AI 锐评
damnlines.com是一个典型的“垂直场景+硬核技术”产物——用计算机视觉盯着纽约最火的几家店门口的排队情况。它解决的痛点是真实且高频的:在纽约,排队的边际成本极高,时间不比金钱廉价。产品价值在于将“社交盲盒”变成“数据透明”,让用户从“到了才知道要不要排”变为“出门前就知道值不值得去”。目前用10个摄像头监控有限地点,看起来是MVP(最小可行产品),但核心壁垒不在硬件,而在数据积累和用户信任的建立:一旦用户习惯出门前看一眼排队数据,切换成本会很高,且未来可拓展至预约提醒、历史峰值预测甚至黄牛预警。但问题同样明显——覆盖范围极窄,技术可复制性高,且本地化太强(只服务纽约)。若不能迅速扩展到其他城市或品类(如博物馆、银行、游乐场),将难以摆脱“极客小工具”的宿命。此外,隐私和商业合作风险也不可忽视:商铺是否同意被监控?摄像头数据如何脱敏?一旦执法或监管介入,产品可能面临合规挑战。总体来看,这是一个“小而美但难做大的实验性产品”。
一句话介绍:Magic 是一款将产品图片自动嵌入真实世界视频实景(如巴黎、时代广场、东京)的 AI 工具,帮助电商品牌以极低成本快速生成高质量、风格统一的营销视频,省去传统拍摄的耗时与不确定性。
Marketing
Artificial Intelligence
Video
AI视频生成
电商营销
产品实景植入
模板化视频
品牌内容制作
VFX
A/B测试素材
低成本获客
真实场景合成
AI一致性输出
用户评论摘要:用户认可其解决“一致性”痛点的定位,并赞赏对传统拍摄的成本颠覆。核心疑问集中在:10%失败案例表现如何?隐私与版权归属不明确,上传素材和数据存储政策需清晰;界面浏览体验杂乱,模板分类和引导有待优化。
AI 锐评
Magic 切中的是电商品牌在“内容效率”与“审美稳定”之间的夹缝——传统拍摄贵且慢,纯 AI 生成又往往不可控。其卖点“90%一次性通过率”和“1美元替代5000美元”确实不是空话,因为它并没有在 AI 文本生成视频的老路上死磕,而是选择了一条更务实的路径:基于真实实景素材做上层合成。这意味着它避开了“六根手指”和“帧间跳变”的 AI 通病,也天然规避了使用生成式 AI 可能触发的版权争议(实景本身就来自合法拍摄)。产品形态很聪明:把创意执行压缩成“选模板+拖产品”+“一键生成”,精准打击电商团队“出物料-上测试”的日常迭代流水线。但问题也很明显:评论中已经有用户提到隐私条款缺失、上传素材产权归属模糊,这在品牌客户看来是致命隐患。另外,“350+ 模板”看起来丰富,但真正能帮助品牌建立差异化叙事的模板依然寥寥——你可以在时代广场放个洗发水瓶,但如何让街头成为“故事的背景”而不是“一个街头背景”,Magic 目前只停留在对第三方创作者的依赖上。它更像是一个高效的“视觉贴片工厂”,而不是内容战略的赋能者。对中小卖家来说,这可能是目前性价比最高的获客视频方案;对有品牌调性追求的大客户而言,它现在还只是一个备选项,而非替代品。
一句话介绍:Magic Studio是一个基于Once UI的白标前端系统,为自由职业者和机构提供即用型落地页、仪表盘、文档及工作室站点,帮助开发者快速启动并销售高端前端项目,从“做项目”升级为“运营工作室”。
Productivity
Freelance
Developer Tools
白标前端系统
设计系统
项目模板
自由职业者工具
前端工作室
Next.js
UI组件库
快速交付
品牌化开发
高客单价项目
用户评论摘要:用户普遍认可其商业价值,认为“系统+AI”模式精准。核心问题集中在锁定性与可移植性:一旦基于Magic Studio构建项目,如何脱离其框架?官方回复表示,依赖Once UI和Next.js确实限制迁移,但数百预置组件和快速交付能力的优势远大于限制。
AI 锐评
Magic Studio的聪明之处在于它没有试图发明新轮子,而是精准切中了前端服务商的一个隐形痛点——你有技术,但你没“产品”。从前端开发者到前端工作室,缺的不是代码能力,而是一个可重复销售、可快速复制的“服务产品化”框架。
从产品设计看,它把“卖项目”这件事本身做成了一套模板:工作室官网、提案素材、交付脚手架一应俱全,降低了从接单到溢价的心理门槛和操作成本。评论中关于锁定性的质疑很关键——选择Magic Studio本质是选择了一整套技术栈押注(Next.js + Once UI),这对于追求灵活性的资深团队可能是桎梏,但对于刚起步、需要快速跑通商业闭环的自由职业者,这种“有限度的锁定”反而降低了决策复杂度,让他们能聚焦在客户获取和交付质量上。
AI的角色在这里是润滑剂而非引擎:系统本身的价值在于组织化和品牌化,AI只是进一步挤压了从设计到部署的摩擦,让“卖模板”看起来更像“卖服务”。Magic Studio真正的护城河不是技术,而是它把“前端工作室”这个模糊概念做成了可购买、可差评的商品。如果后续能让用户更容易在交付后迁移或剥离,或提供更细分的行业模板,上限会更高——否则,它可能只是一次性提升客单价,而非建立长期壁垒。
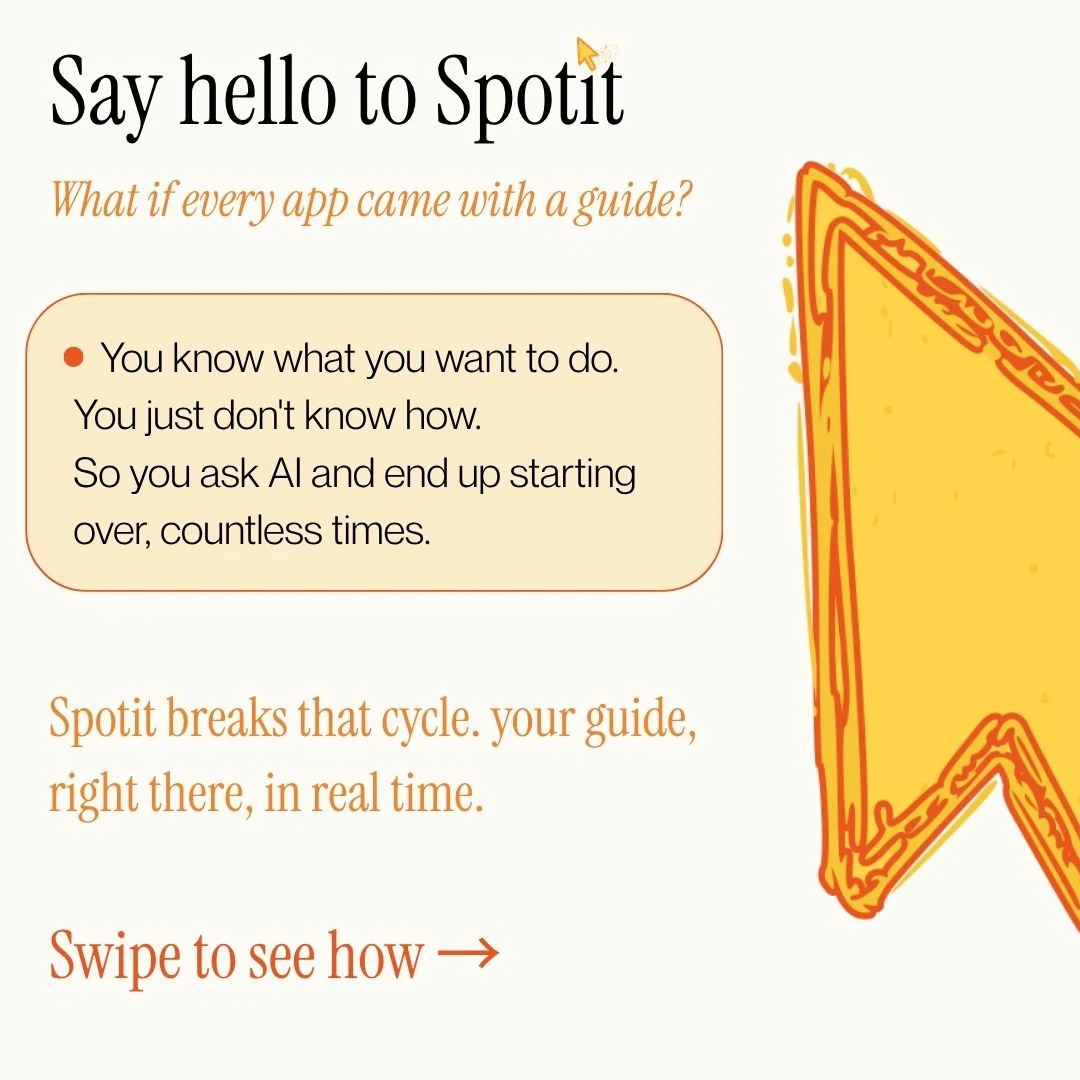
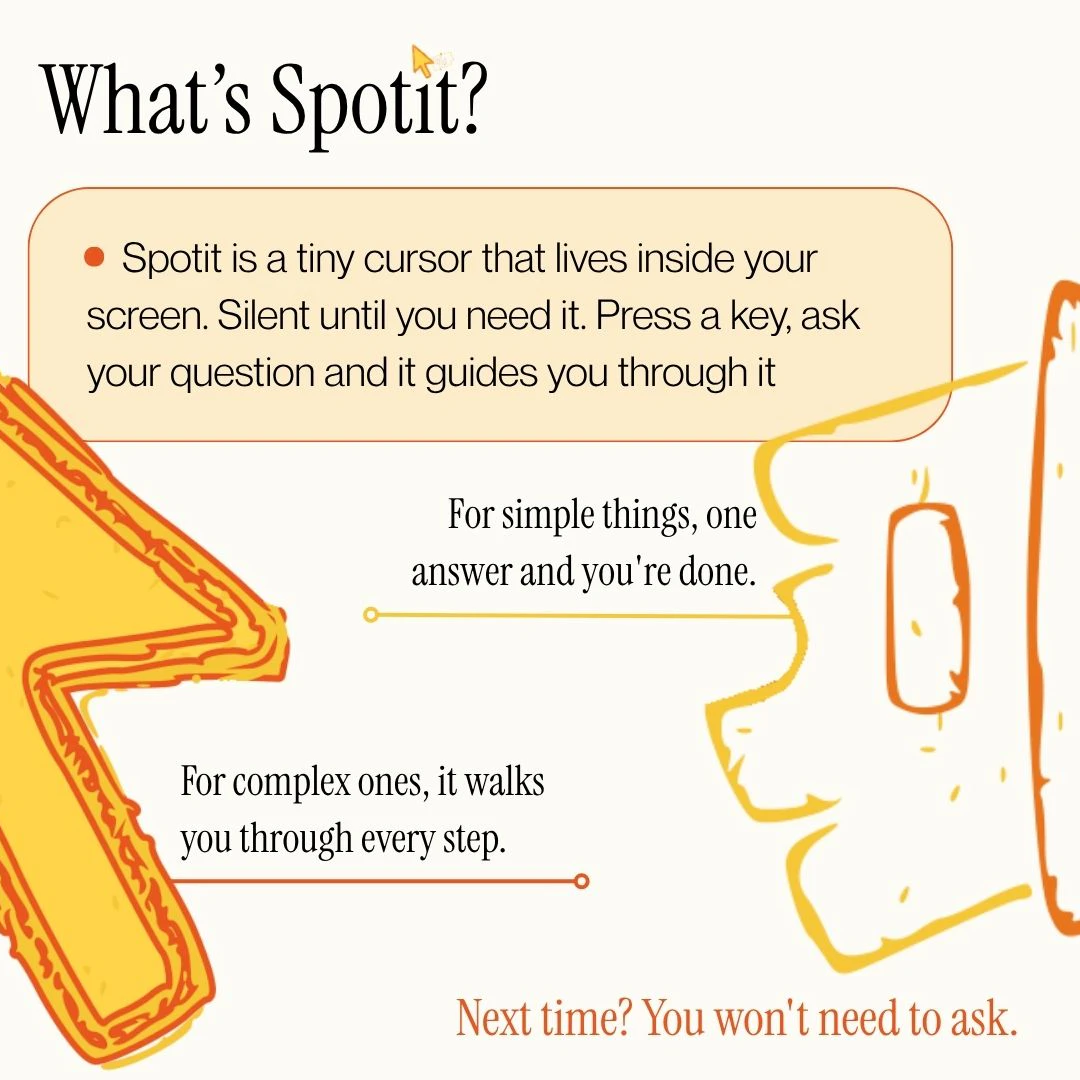
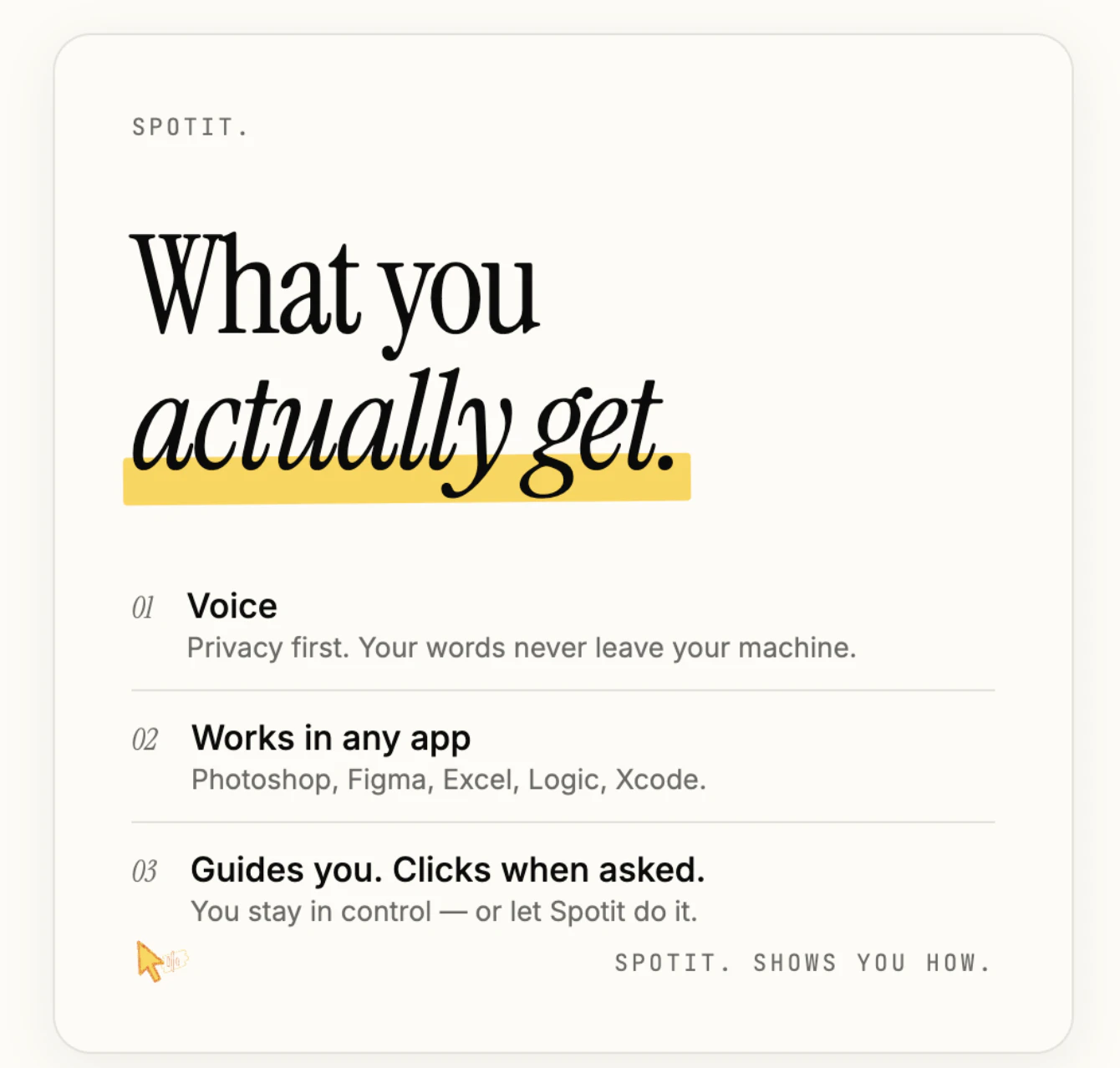
一句话介绍:Spotit 是一款 Mac 端 AI 操作指引工具,通过截取当前窗口画面,用自然语言问答精准高亮下一步点击位置,帮助用户在实际操作中学习复杂软件操作,彻底告别反复搜索菜单和教程的痛点。
Productivity
User Experience
Tech
Mac 应用
AI 助手
操作指引
屏幕识别
学习工具
交互式教程
效率工具
Photoshop
Figma
生产力
用户评论摘要:用户关心隐私,开发者回应仅截取当前窗口,截图发至云端(EU)经 Anthropic 处理即丢弃,不存盘,但敏感文件建议最小化。有用户期待 Windows 版。另有调侃错过 YC 申请截止,但整体评价偏向认可 UI 和想法。
AI 锐评
Spotit 的巧妙之处在于它选择了“不替代用户”。当大多数 AI 产品都在拼命替你完成工作、让你变懒时,Spotit 反其道而行——它只指出“点击哪里”,但让你亲手去点。这个设计哲学精准刺中了“用过就忘”这一学习悖论:人只有在亲自操作时才会形成肌肉记忆。它本质上是一个“实时交互式文档”,但又比任何视频教程或 ChatGPT 输出都更直接——因为它直接作用在你的真实屏幕上,免去了“找对应按钮”的认知成本。
然而,它的缺陷同样明显。当前依赖云端视觉处理(截图发往 Anthropic),隐私层面存在天然短板,即便开发者承诺不存储,敏感行业用户依然会犹豫。纯本地模型跑在 Mac 上是未来的必选项,但短期算力成本不低。其次,产品的价值高度依赖“长尾场景”的覆盖率——对于用户最常用的 Photoshop 蒙版、Figma 裁剪等标准操作,Spotit 表现可能很好,但遇到冷门软件或深度定制化操作,AI 的识别准确率会骤降。目前的演示更像一个“demo”,真正要变成日活工具,需要持续标注和优化大量应用的操作逻辑图谱。
简单来说,Spotit 是一个好想法但尚未完全验证的产品。它解决的不是“不会用”的问题,而是“懒得学”的借口。对于那些愿意花十秒提问而非两分钟拿手机查教程的用户,它确实能缩短学习正反馈循环。但若无法在隐私、准确率和跨平台覆盖上站稳,它很容易沦为“好奇心工具”——用过一次,感动一下,然后吃灰。
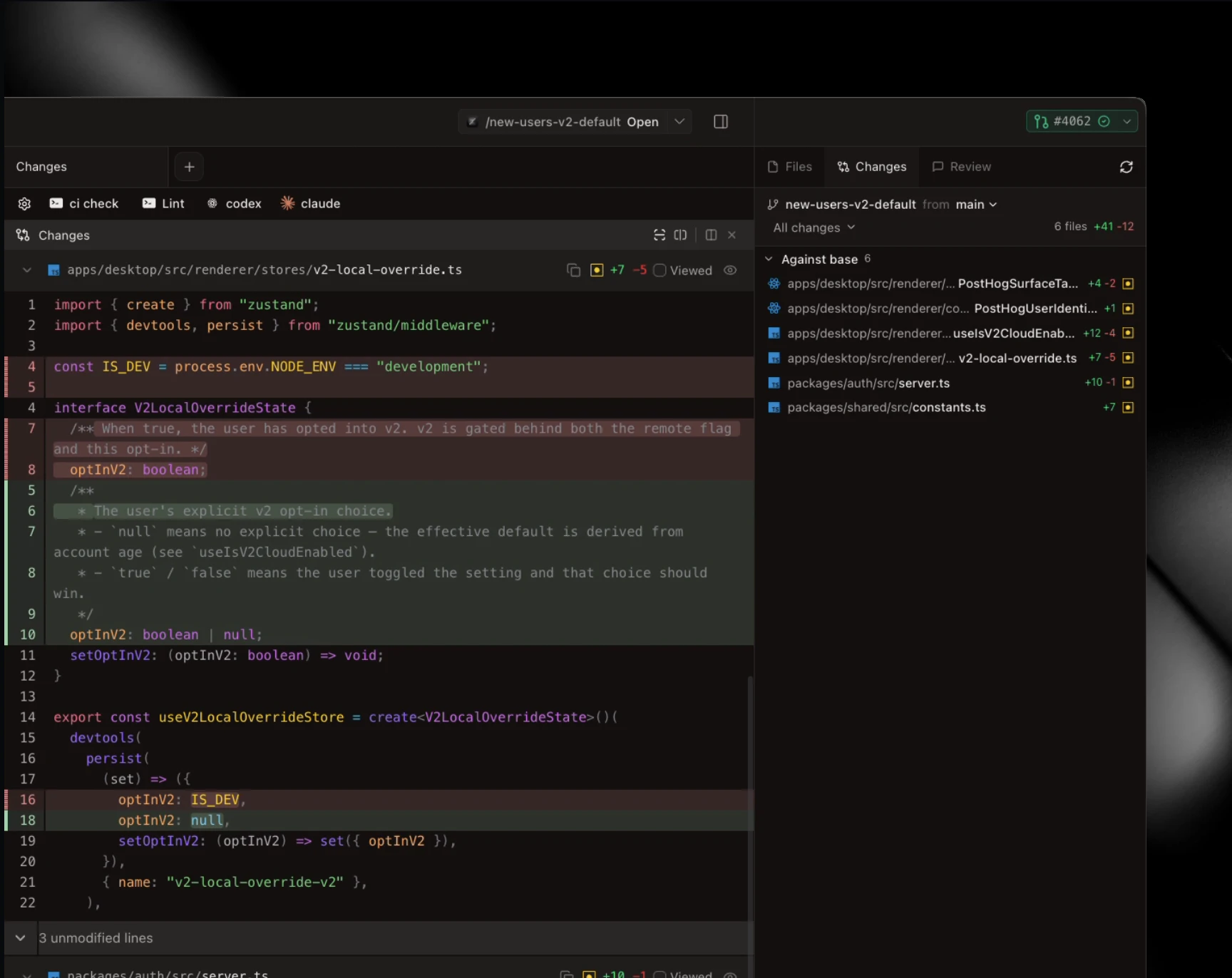
一句话介绍:GetDynasty将富裕家族办公室使用的QSBS信托堆叠策略产品化,帮助初创创始人及早期员工以传统成本的一小部分实现退出时免税,最高可规避超1500万美元的资本利得税。
Fintech
SaaS
Legal
税收优化
QSBS堆叠
信托设立
创始人退出
税务筹划
创业服务
资产管理
节税工具
Carta前团队
trust-as-a-service
用户评论摘要:评论中创始人团队解释了自身遗憾(因未提前规划而多缴税),强调通过软件+持牌信托公司降低门槛和成本。用户反响积极,有祝贺语和邀约链接。核心建议是:越早(股份价值低时)设立,效果越好。
AI 锐评
GetDynasty切中了一个非常“隐秘但痛感极强”的创业真问题:创始人最终拿到手的钱,被税务吃掉近三分之一。而顶级富豪用QSBS信托堆叠合法完成零税负退出,这套玩法过去只对“私人律所客户”开放。Dynasty的价值在于“降维普惠”——把原本20-50k美金、流程黑箱的定制化服务,变成1500美金/年、软件引导+持牌信托公司兜底的标准产品。
从产品逻辑看,它确实解决了高价值但低频的决策难题:税收优惠窗口与股权增值时序高度耦合,越早架构越有效,但多数人忙于创业而忽略。Dynasty以“软件+信托牌照”双重壁垒,降低了创始人的认知与操作门槛,复用了Carta团队所擅长的“流程标准化”打底。
但需要冷静看待的是:1)QSBS本身有复杂的法律适用条件(如C-corp、五年持有期、资产限制),产品虽然简化流程,但最终合规责任依然落在税务顾问身上,软件无法承诺100%免税;2)信托管理涉及长久期的利益与所有权结构,以1500美元年费是否能覆盖持续、稳健的受托管理风险?3)目前核心场景在“即将有定价轮次”之后的早期结构设置,而一旦股权快速增值,因赠与税限制,策略弹性会急速下降,产品核心用户群其实相当窄——不是所有“看起来符合条件的创始人”都能受益。
总的来说,GetDynasty是“税法套利的产品化”,方向正确,市场渴求。但创始人最怕的往往不是税太高,而是规划后依然被“不合规”反噬。这个产品的长期护城河,不是代码,而是法律与税务服务的真实履约能力,以及是否能在规模化后维持案例层面的高胜率。
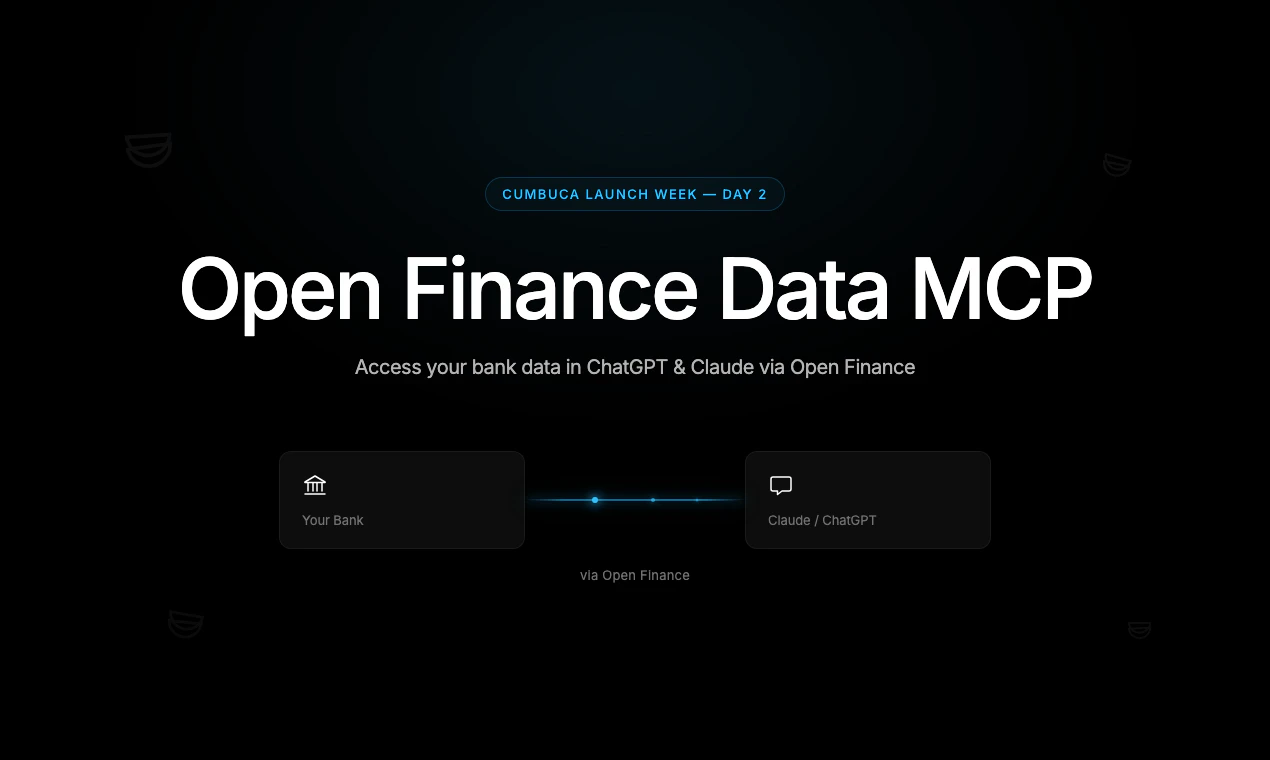
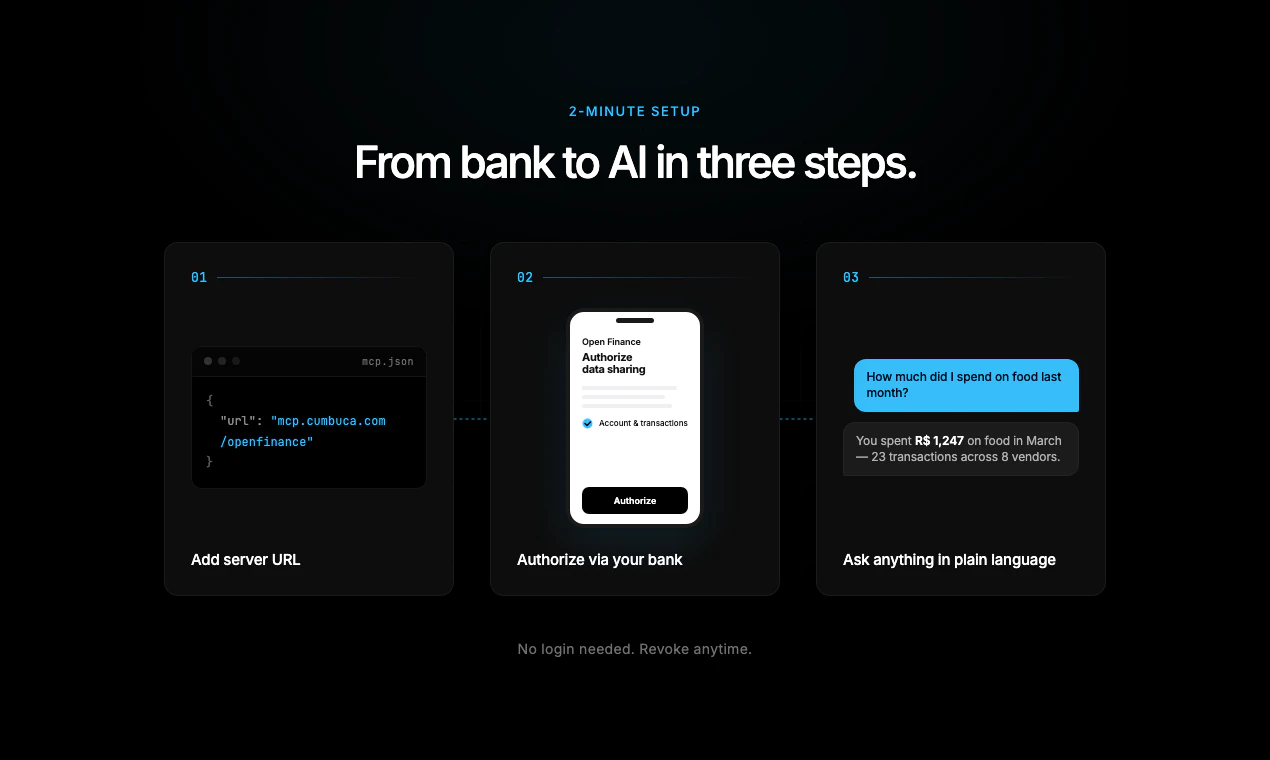
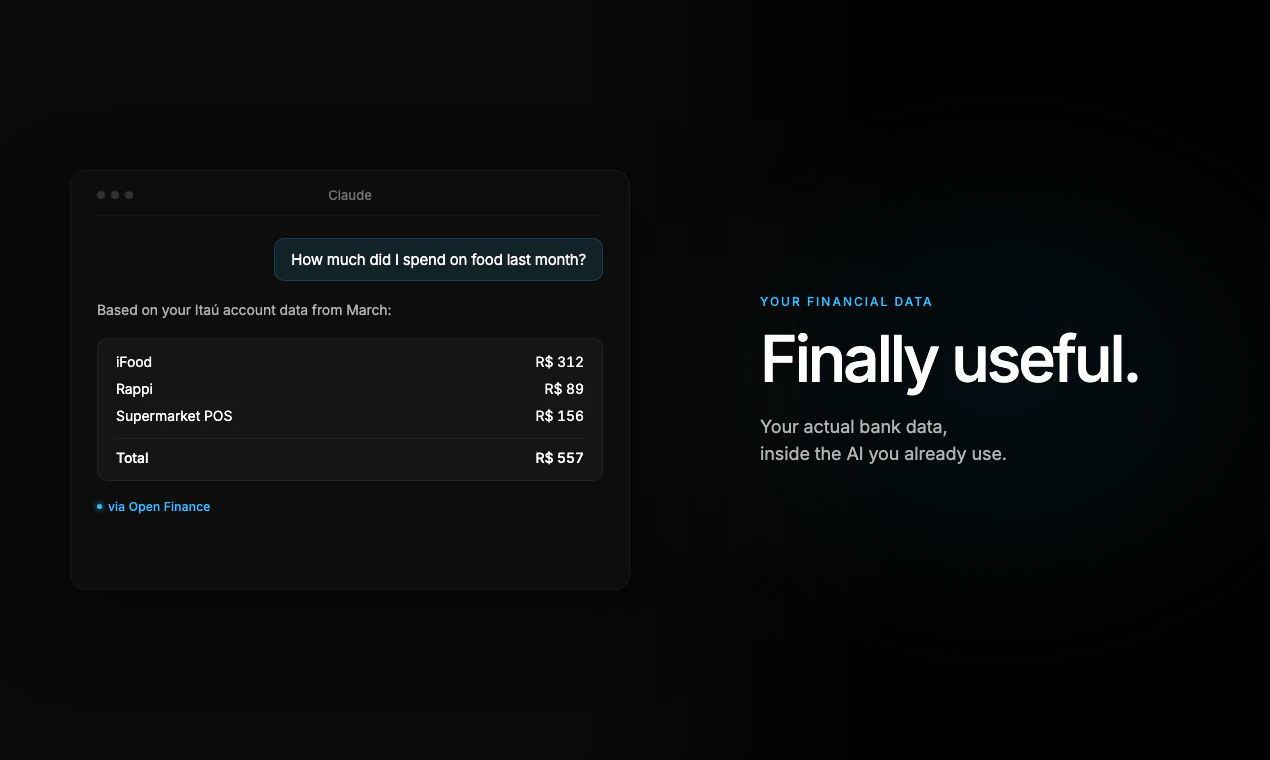
一句话介绍:Open Finance MCP 让用户通过巴西开放金融体系,直接在ChatGPT或Claude等AI助手中用自然语言查询自己的银行流水,省去手动翻账的麻烦。
Fintech
Developer Tools
Artificial Intelligence
开放金融
AI助手
金融数据API
MCP协议
巴西央行
银行流水查询
隐私合规
自然语言交互
个人财务管理
数据可携带权
用户评论摘要:用户对AI直接访问银行数据感到惊讶且关注隐私;开发者关心多银行多账户支持及查询限额;建议增加银行报表导入替代直接连接,降低安全焦虑。
AI 锐评
Open Finance MCP的价值在于它解决了AI时代“数据孤岛”与“用户控制权”之间的矛盾。它不是又一个记账APP,而是一根标尺——丈量了“金融数据可携带权”在实际应用中的可落地性。其核心创新并非AI接口本身,而是借助巴西央行特许的开放金融标准(LGPD与OAuth融合),将数据交互的合规成本内部化。这意味着用户可以在保有完整控制权(随时撤销、明确授权)的前提下,让AI实时参与个人财务分析。这一点对全球开发者是一个重要启示:金融科技产品的护城河已从单一功能转向协议层合规能力。但MVP阶段每天5次查询、单账户单银行限制,暴露了产品尚处“概念验证”阶段,远未解决高频使用与多银行聚合的真实需求。真正的挑战在于:在用户新鲜感消退前,Cumbuca能否将这一“工具”进化为可信赖的“日常助手”——尤其是面临用户对隐私泄露的本能恐惧时,仅有技术合规说辞不足以消除恐惧。此外,产品目前极其依赖巴西监管框架,难复制到美国或印度。若想全球化,就需要抽象出通用MCP接口适配不同市场的开放银行标准。锐评一句话:方向极好,但请别让“监管红利”成为唯一壁垒。
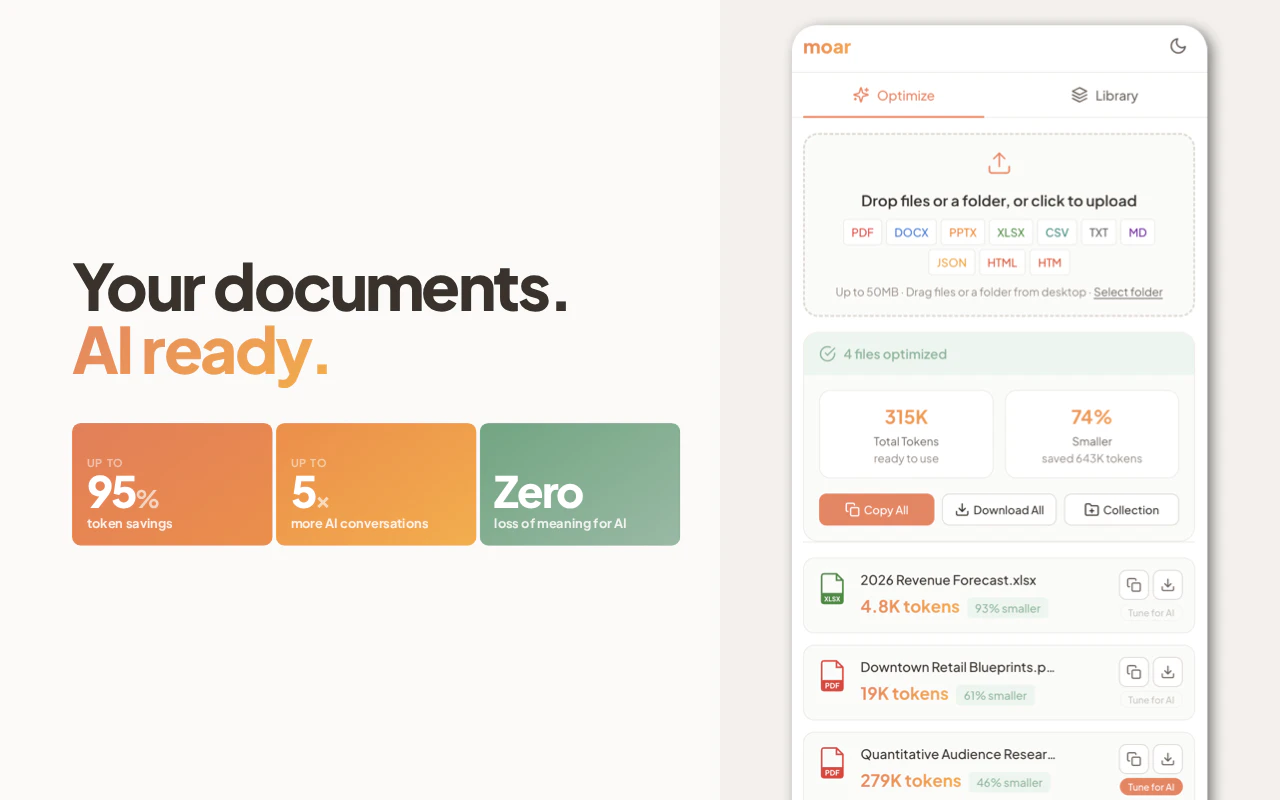
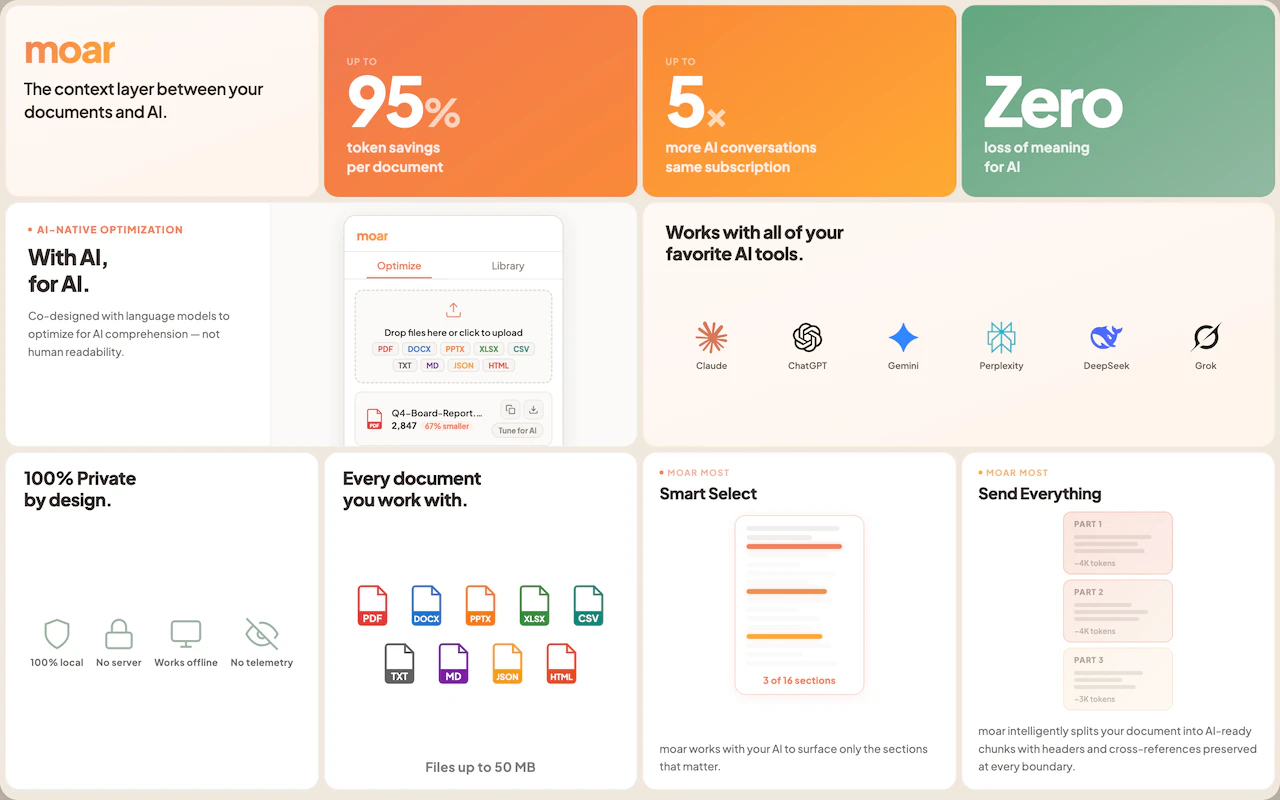
一句话介绍:moar通过AI协同优化的文档压缩引擎,将大文件转化为保留语义的Markdown/CSV,解决了向ChatGPT、Claude等AI工具上传文档时“文件过大”或“格式噪音导致推理降级”的核心痛点。
Chrome Extensions
Productivity
Artificial Intelligence
AI文档预处理
Token压缩
文档优化
数据隐私
Markdown转换
AI兼容性
格式清洗
本地处理
上下文窗口优化
产品效率工具
用户评论摘要:创始人Gavin详述开发动机:人类文档的格式冗余(如元数据、空单元格)导致AI处理效率低下,moar算法由AI模型本身“训练”而成,实现95% Token节省且零语义损失。强调产品纯本地、永久免费,诚恳邀请用户测试极端案例。
AI 锐评
moar精准切中了一个被长期忽视的“硬需求”:AI工具的输入质量鸿沟。用户支付高昂的订阅费,实际却在为文档中的“包装垃圾”买单——PPTX的样式元数据、XLSX的空行、PDF的嵌入字体,这些对人类视觉友好的元素,对大模型只有拖累。moar的聪明之处在于,并非简单做格式转换(那是Pandoc的活),而是将文档视为“AI的饲料”,通过与模型对话式的迭代测试,识别并剔除80%以上的非语义Token。
不过,必须冷静看待其宣传的“95% Token节省”。此数字大概率在极端冗余的格式(如含大量空白、复杂图表的PPTX)上取得,对于纯文本Markdown或结构化JSON,压缩空间微乎其微。产品真正的护城河在于两点:一是“零服务器”的隐私承诺,这对处理合同、财报的职场用户是强吸引力;二是其针对性优化的粒度——如果它真能识别特定格式下哪些属性(如段落间距、字体族)是LLM的“眼球垃圾”,将大幅提升长文档推理时的思路连贯性。
当前局限也很明显:仅限50MB文件单体处理,缺乏批量流水线作业能力;只输出MD和CSV,丢失了原文件的视觉布局,对于需要保留表格边框、图片标注的场景(如学术论文)支持有限。作为免费工具,它是文档入AI前的“清道夫”,价值务实。但若想成为真正的基础设施,它需要证明:当面对混合内容(如页眉页脚含关键会议代码)时,它的“优化”不会变成“误伤”。
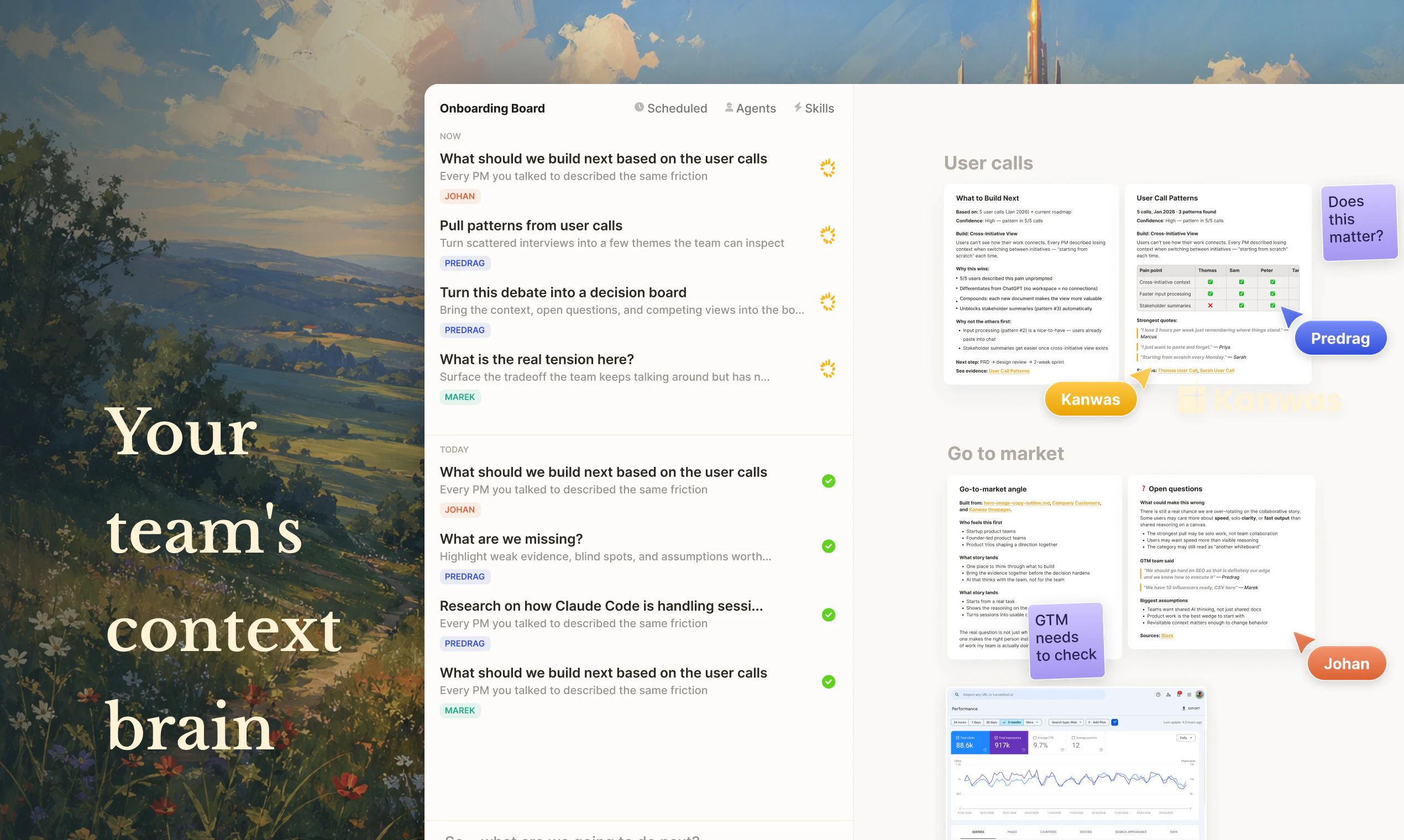

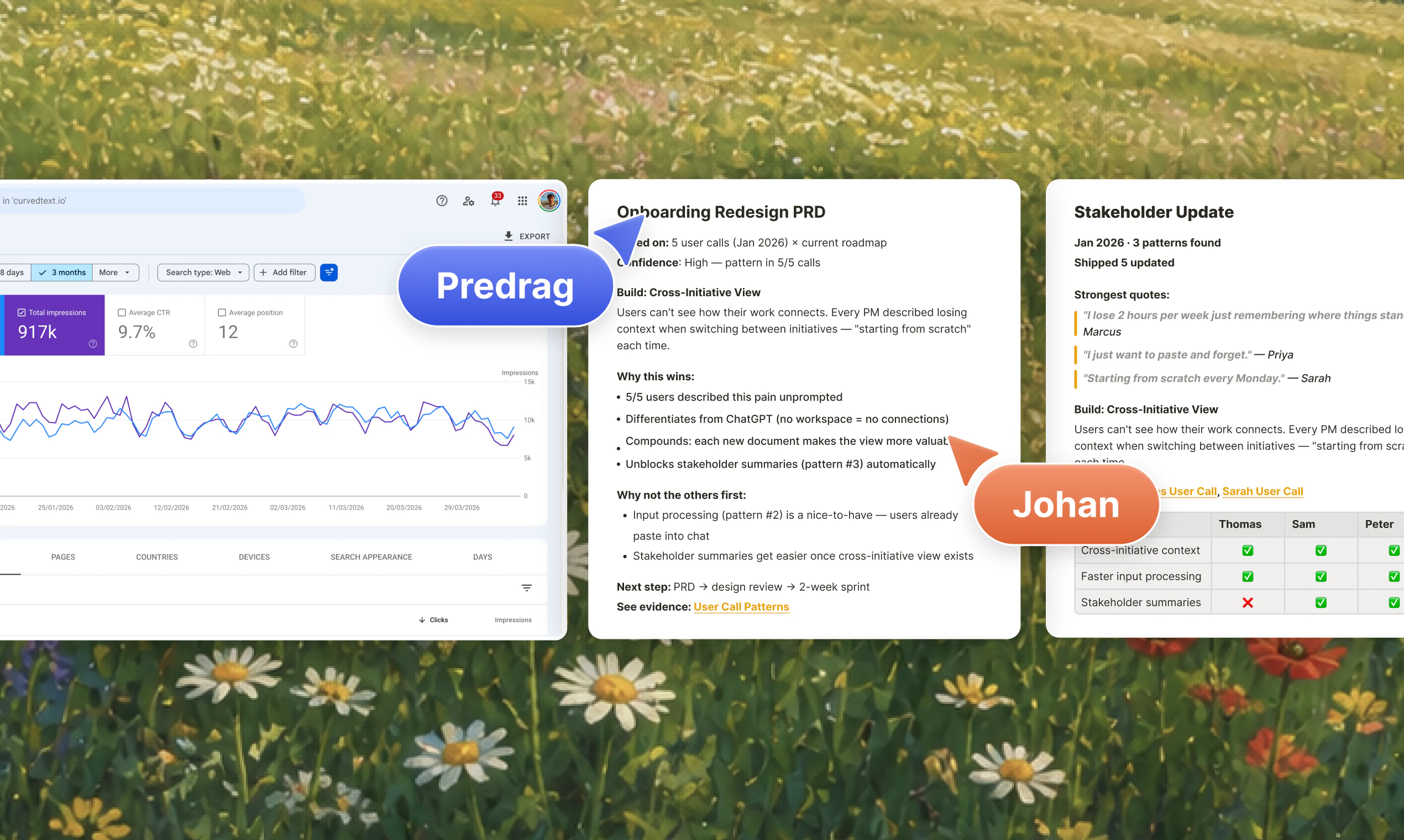





















































as a solo founder, my 'team' is mostly just me and a handful of agents. keeping the context consistent across all of them is a full-time job. kanwas feels like it could save me hours of 're-explaining' the product vision to my dev and marketing agents. awesome @johancutych
Not sponsored or anything: Been using this thing for a while, and LOVE it :) it helped a lot with getting my thoughts in order and writing great strategic docs :)
@predrag_ristic1 Really like that you’re not trying to force everything into chat bubbles. The industry somehow decided every AI product needs to look like another messaging app and it gets exhausting fast.
One thing I’m curious about though is onboarding for non-technical teams. Engineers usually tolerate messy flexible systems because they understand the power behind them, but operations/marketing/sales teams often need stronger structure.
Have you noticed users naturally understanding how to organize work inside Kanwas, or do people initially create chaos everywhere before finding a workflow? Feels like this kind of product can become insanely powerful or completely overwhelming depending on first-time experience.
In the app and genuinely loving it within first 30 mins. You guys have built something great 💪
the human + agent angle is exactly the gap right now. most teams have context scattered across notion, slack, docs, claude projects, and neither humans nor agents can really use it well. excited to try this. congrats on the launch @johancutych
This actually hits a real pain point. Managing context between multiple agents is messy right now . Having one shared “brain” feels like a big step forward.
Before everything, really nice video!! Always good to see someone stepping it up in terms of effort + production 😎 Second, congrats on the launch!! In the world of AI, something like Kanwas is a breath of fresh air. Will be following closely!
love that it’s fully editable. my biggest fear with "ai brains" is when they hallucinate a decision we never actually made. being able to step in and refine the context keeps the agents from going off the rails. @johancutych
Great work team, BTW, how should I think about this compared to Notion plus Claude, or Obsidian plus Claude Code?
I have tried to make this work with Claude chats, Notion pages, GitHub issues, and random docs. The issue is not creating content, it is keeping context usable after the first session. Kanwas seems pointed at that exact gap.
The idea of treating team knowledge as something “living” instead of static documentation is really interesting.
Feels like the challenge over time is keeping the context actually useful instead of turning into another layer of noise as more humans and agents interact with it.
Currently vibecoding my own app and constantly losing context across chat sessions relevant info gets buried in history and I can't find it again. This is exactly what I've been missing. Great job, guys 🙌
Going to give this a go immediately! amazing work - thank you
This is super cool! Manually trying to keep context between team mates is such a pain at the moment. I can see how this would really fix it. Congrats on the launch!
Great job!
When anyone can build anything, knowing what to build is the most important thing. Kanwas will really help with this 🚀
good one! upvoted!
Not sure exactly how I could implement that at our company, but it will clearly fix a big problem for me.
When I am brainstorming or researching on a certain topic, I end up with a big conversation. I need to scroll vertically on Claude or Gemini. The whiteboard form factor you're proposing here would definitely help me organize my ideas and visualize them afterwards.
Definitely worth an upvote and a complete test from me. :)
Congrats on the launch, btw, and best of luck!
This is for sure worth looking into. What I worry about is the space getting overfilled with content which becomes irrelevant over time. How do you plan to solve this issue?
I built something like this internally for our team - literally called it our Brain. The idea was they can use that context in Claude though and build skills against it, etc.
Is that possible, or can you only execute tasks within Kanwas? I love the idea of a Brain we can all visualise & collaboratively maintain/iterate in here but then use in claude.
Hey product people. I am in charge of the canvas interface of Kanwas.
Kanwas is built with the idea of moving from chats to shared spatial context space, where you, your team, and your agents can work together and build on top of it.
My favourite part is being able to control context in the easy way, starting from scratch, or starting from yesterdays research, or just cross referencing latest positioning angle with the newest competitor updates.
From the start of building it we are using it as team, and collaborating through all the challenges, from working on strategy and gtm, to updating feature specs, doing users insights from the posthog events and user calls, and even doing this product hunt launch.
Happy to see you using it and getting the feedback! Here to answer any question!
Where does Kanwas fit if we use Notion for docs and Linear for tickets?
How opinionated is the agent? Does it mostly organize what is already there, or does it push back on assumptions and ask questions too?
I am glad this is not another closed workspace where everything disappears into a proprietary database. Markdown/YAML plus Git history makes the product much easier to trust.