PH热榜 | 2026-05-15
一句话介绍:OpenHuman 是一款开源、本地优先的 AI 代理工具,通过永久记忆、一键集成和图形界面,解决了普通人因会话记忆丢失、数据隐私担忧和配置复杂而放弃使用 AI 代理的痛点。
Productivity
Open Source
Artificial Intelligence
GitHub
开源AI代理
本地优先
隐私保护
永久记忆
图形界面
一键集成
工具调用
数据主权
非技术用户
生产力工具
用户评论摘要:用户认可“永久记忆”和“本地优先”解决了反复解释上下文和隐私焦虑的核心痛点。技术用户关心记忆过载(模糊搜索 vs 精确召回)、幻觉处理(基于真实数据+可溯源)、上下文窗口压缩及本地模型路由等问题。非技术用户(如花店老板)的实际应用案例展示了产品破圈潜力。
AI 锐评
OpenHuman 在“AI 代理”这个被大模型公司和极客玩家垄断的赛道上,找到了一个精准而微妙的缝隙:**为“次优硬件”和“非代码人群”提供有尊严的代理体验。**
产品最聪明的设计不是模型多强,而是对“记忆”和“隐私”的工程实现——将记忆树结构化存储于本地 SQLite,而非无脑塞入上下文窗口,这是一个务实且优雅的解决方案。它承认了“本地模型能力有限”的现实,却通过智能路由(低质任务用本地小模型)和 Token 压缩机制,在消费级硬件上提供了可用性。
然而,需要警惕“永久记忆”可能带来的反馈循环陷阱。如果记忆系统对用户行为的记录和回放过强,会导致用户陷入信息茧房,AI 的创造性反而被过往数据约束。此外,虽然产品声明了数据主权,但“本地运行”意味着用户必须自行承担备份、数据损坏等运维风险,这对目标群体(非技术用户)的隐性要求其实不低。
总的来说,OpenHuman 做对了两件事:一是用图形界面和两分钟安装教育了市场,证明 AI 代理可以不是“开发者玩具”;二是用开源和本地优先的姿态,切中了用户对公有云数据收割的深层不信任。但它的长期护城河不在于代码,而在于能否围绕“记忆”建立起一套比大模型厂商的闭源方案更可信、更可控的用户习惯。在 OpenAI 和 Google 的强云端记忆面前,本地化的“慢智慧”是一场值得尊敬的赌博。
一句话介绍:HasData 是一款专为 AI Agent 和数据管道设计的托管式网页抓取服务,用户只需发送 URL 即可获得干净的 JSON 或 Markdown 数据,无需处理代理、浏览器渲染或反爬机制,解决开发者在构建 AI 应用时“有模型但没干净数据”的核心痛点。
Artificial Intelligence
Data
Vercel Day
AI数据抓取
网页爬虫API
AI Agent工具
无代码数据采集
MCP服务器
数据管道
结构化数据提取
商业数据API
反爬虫托管
LLM数据输入
用户评论摘要:用户普遍认可数据质量高、集成快(20分钟完成 607 行邮件补全,命中率 69%)。关键问题:有用户询问能否自动去除广告和导航噪音,官方回应显示已提供可配置的标志。另有用户对比 Firecrawl,指出二者在 UI/UX 和无代码/API 分群上存在差异。评论中罕见负面反馈,主要围绕“仅对成功请求计费”这一差异化价值展开。
AI 锐评
HasData 的“卖点”其实很直白:如果你用 AI Agent 但拿不到靠谱的数据,再智能的模型也只是废铁。这个逻辑在 LLM 狂潮中尤为致命——你让 Claude 帮你分析市场,它回复“网页打不开”或“内容包含广告”,就等于白干。
从产品层面看,HasData 没有押宝在“多酷的 AI”上,而是扎实地解决了数据提取的脏活累活:代理池、浏览器渲染、反爬绕过、结构化输出。这是典型的基础设施型产品,50+ 现成 API 覆盖 Google、Zillow、Amazon 等高频站点,叠加 AI Agent 做泛化提取,形成“确定需求走 API,模糊需求走 Agent”的双轨打法。底层逻辑很务实:把非标网站的数据提取变成一次 prompt 调用,而不是几天爬虫调参。
但必须指出,这类服务的护城河并不稳定。Firecrawl、Jina AI 等竞品同样在抢这个生态位,差异更多体现在“成功计费”和“预置 API 数量”这类运营细节,而非技术壁垒。HasData 宣称“只对成功计费”,这确实是一记直击痛点的商业策略——开发者最怕白费功夫,尤其是调试代理时。然而,若反爬成本持续上升,成功率的“定义”是否会在隐含上限前出现猫腻,值得长期观察。
真正值得关注的是其 MCP 和 Agent Skill 接入能力。它把数据提取从 API 调用升级为了 AI Agent 的“默认能力”,这实际上是在抢数据管道的定义权——如果未来多数 agent 框架默认集成 HasData 插件,后来者将很难抢夺其生态位。一句话总结:HasData 卖的不是爬虫,而是“通往真实世界的数据跳板”。如果它能持续压低失败率并加快新网站覆盖,就有机会成为 AI 时代的“数据中间层标准”。否则,它只是又一个漂亮的 API 壳子,在竞品模仿潮中迅速下沉。
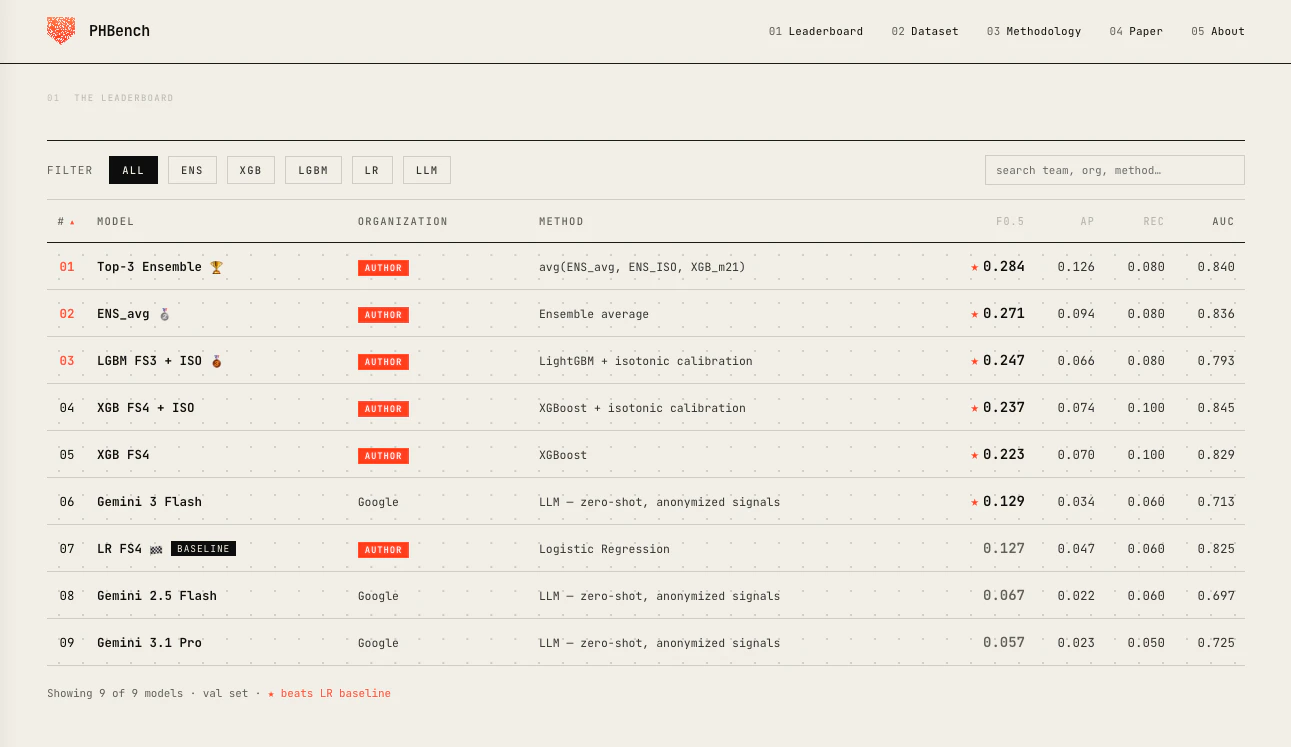
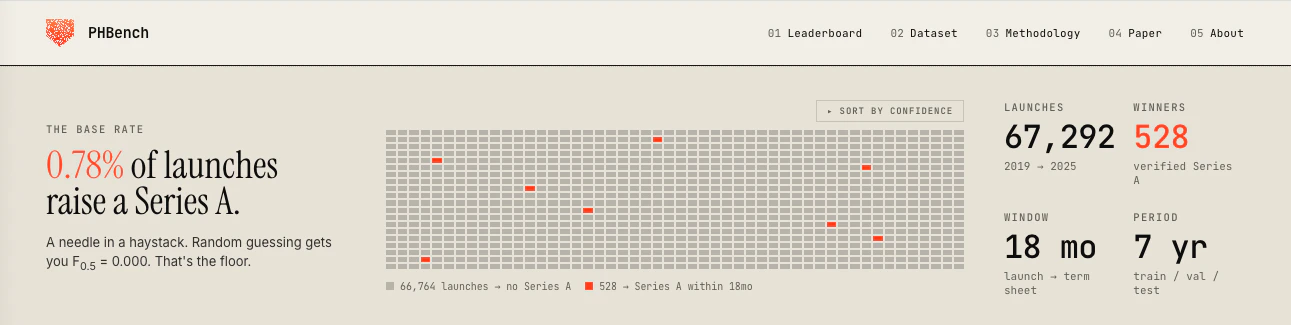
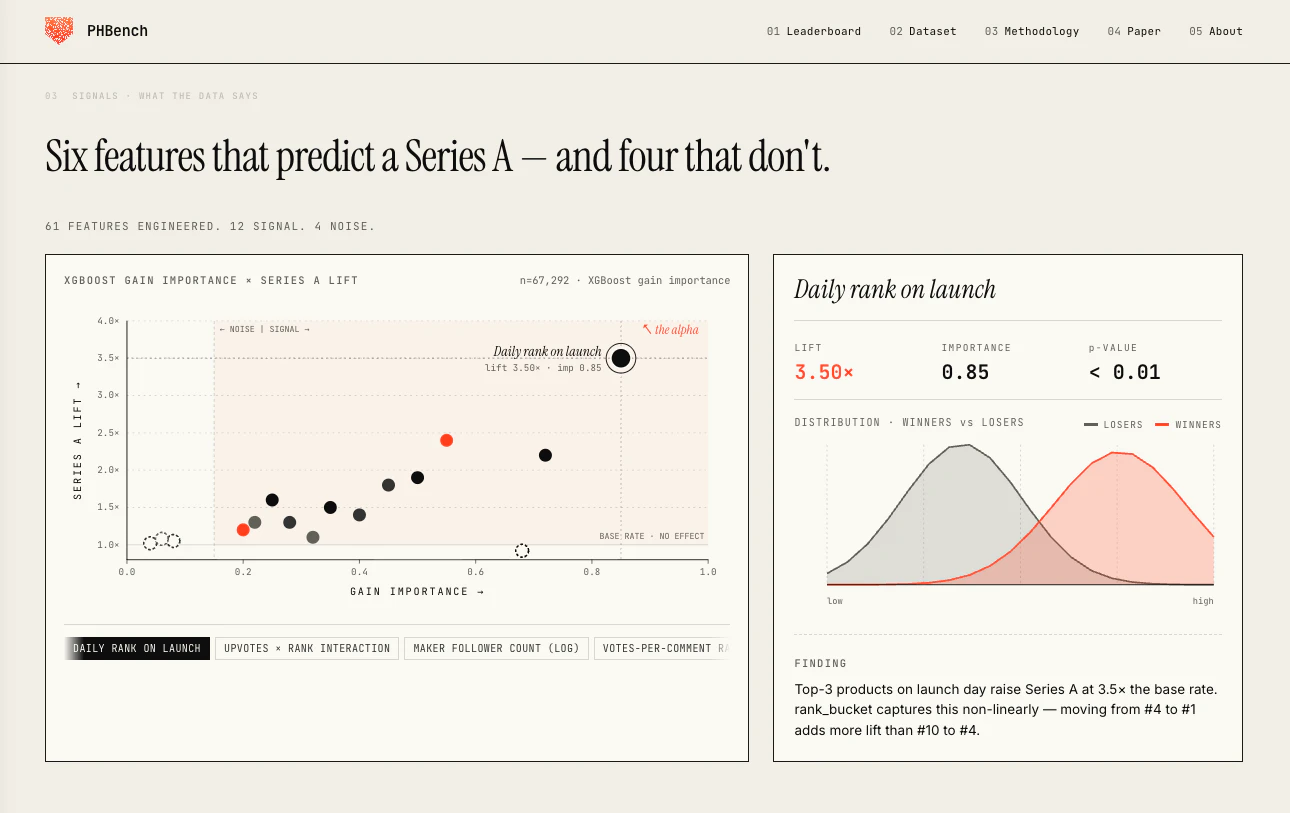
一句话介绍:PHBench是一个基于Product Hunt首发数据预测创业公司获得A轮融资概率的公开基准平台,帮助VC和创始人通过7年、6.7万次产品发布数据量化评估早期产品潜力。
Venture Capital
Artificial Intelligence
GitHub
Data
Vercel Day
产品猎手预测
A轮融资预测
创业基准测试
产品信号分析
团队规模
社区参与度
B2B转化率
机器学习模型
开放数据集
HuggingFace
用户评论摘要:用户关注模型信号的有效性与限制,如团队规模与互动的交互效应是否检测分发能力而非产品本质;质疑投票数与排名关系,且指出早期融资历史是强关联而非因果;建议分析假阳性案例、猎人影响、重复创始人等,并担忧公开信号可能导致创业者优化行为导致信号失真。
AI 锐评
PHBench看似是在用机器学习为VC装上一副“寻宝眼镜”,实则更像是在Product Hunt这口“火锅”里测出了水温变化的概率模型,而非为投资人找到了下一个“海底捞”。其价值在于将玄学般的“早期感觉”量化为一组可验证的信号——团队规模与社区互动的加权组合确实比单纯的投票数更具洞察力,B2B赛道的3倍转化率也撕开了“消费者热捧必火”的假象。但真正值得警惕的是,该模型的杀伤力恰恰在于它的公开性:一旦底层特征被广泛知晓,创始人们能迅速反向优化——组建名义大团队、水军式互动、选品向高转化类别挤兑,这会让模型快速沦为“打榜指南”,而非“价值探测器”。更为致命的是,评论中披露的“88.3%的A轮公司已有种子轮”这一数据,基本揭示了模型的核心逻辑:它不过是在一群已经通过“投资人认证”的选手里,甄别谁更擅长“打广告”罢了。对于真正从零起步、没有资本杠杆的独立开发者,这组信号几乎等于“我不认识你,所以不看好你”。产品本身在学术上是一个严谨的开源基准,但在VC实用场景中,它更像一个用来强化既有判断、而非颠覆认知的“马后炮报表”。一句话总结:PHBench是个好工具,但别把它当神谕,否则你投的每一轮A可能都在为“运营大师”而不是“产品天才”买单。
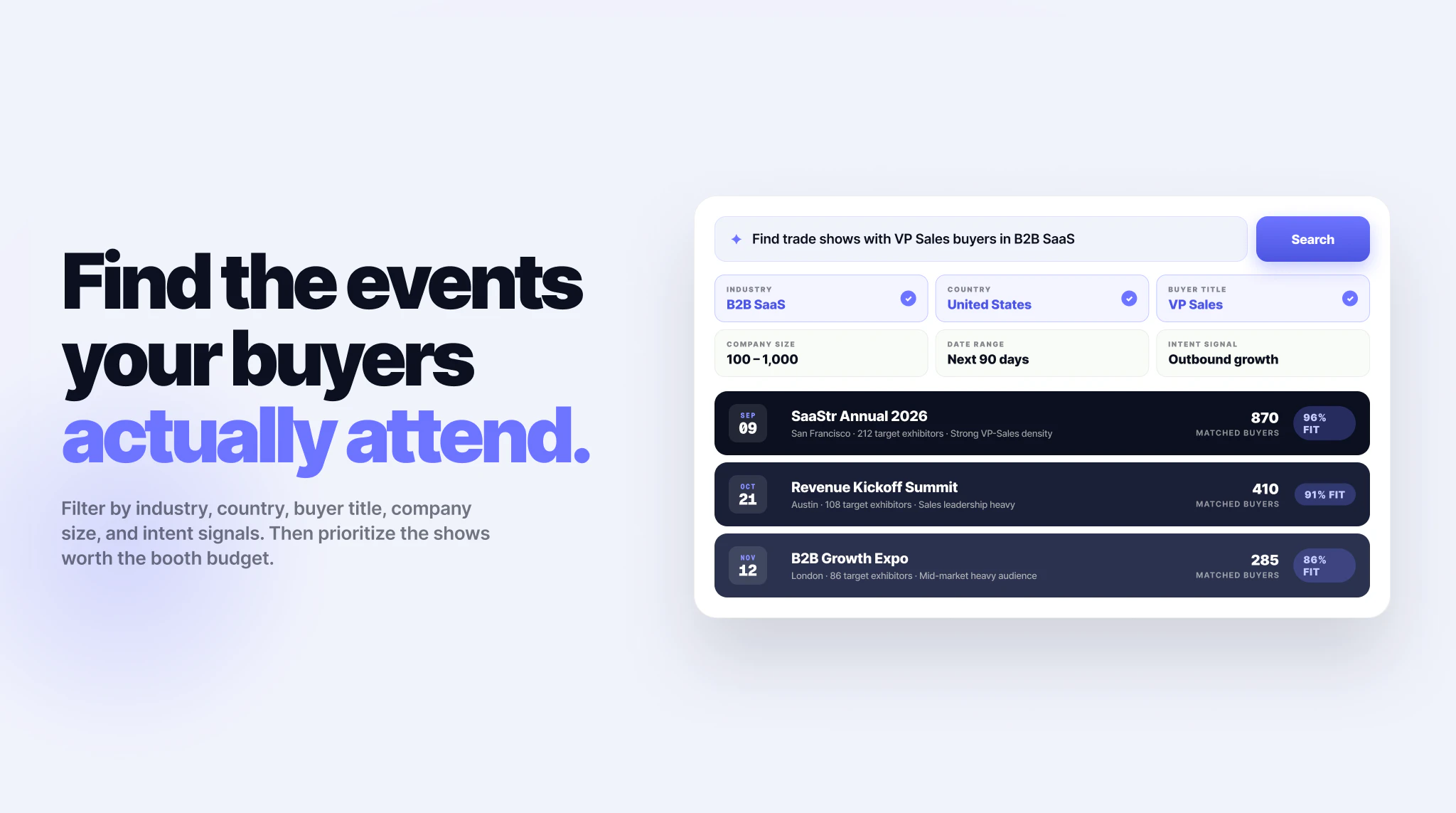
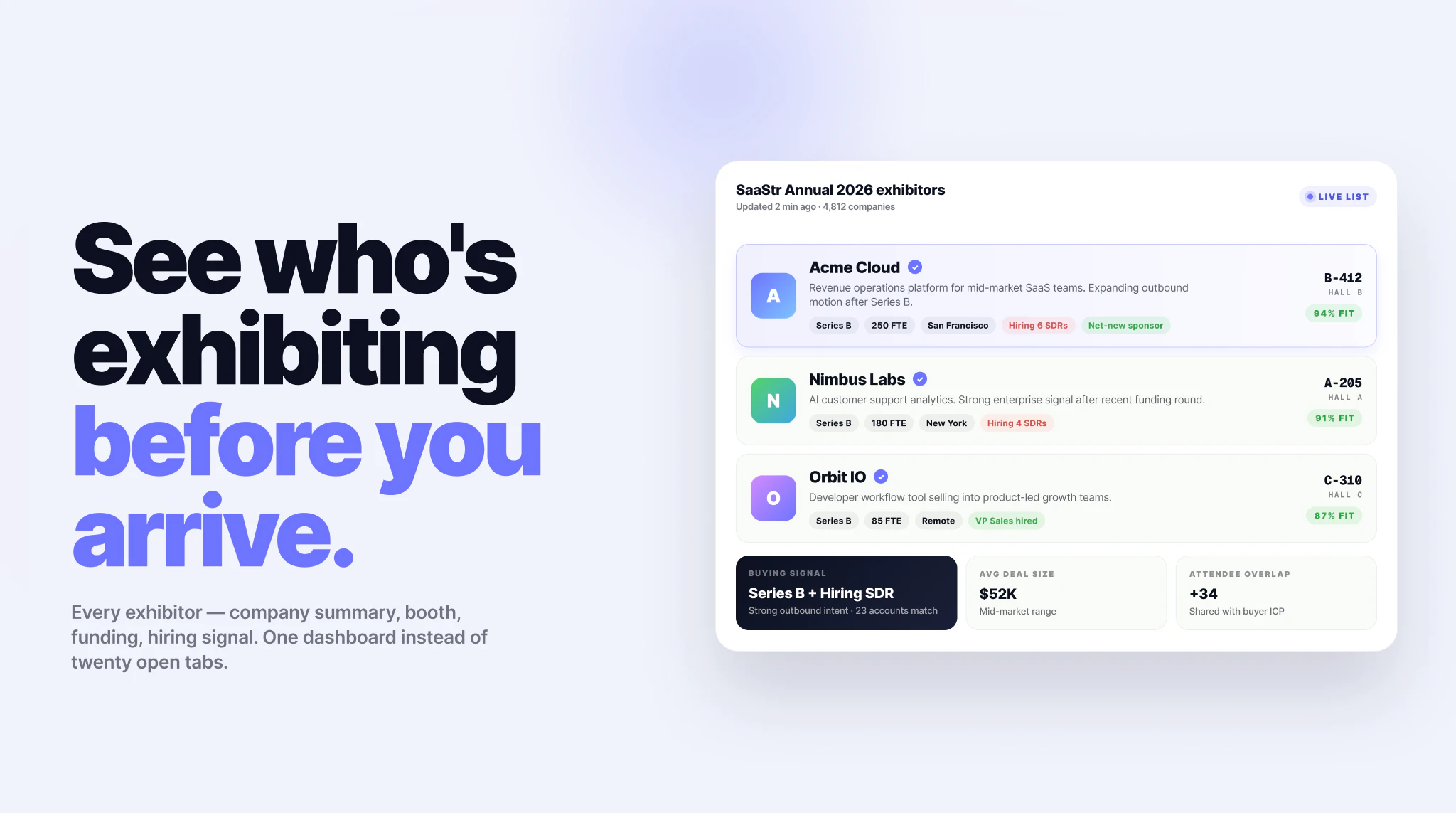
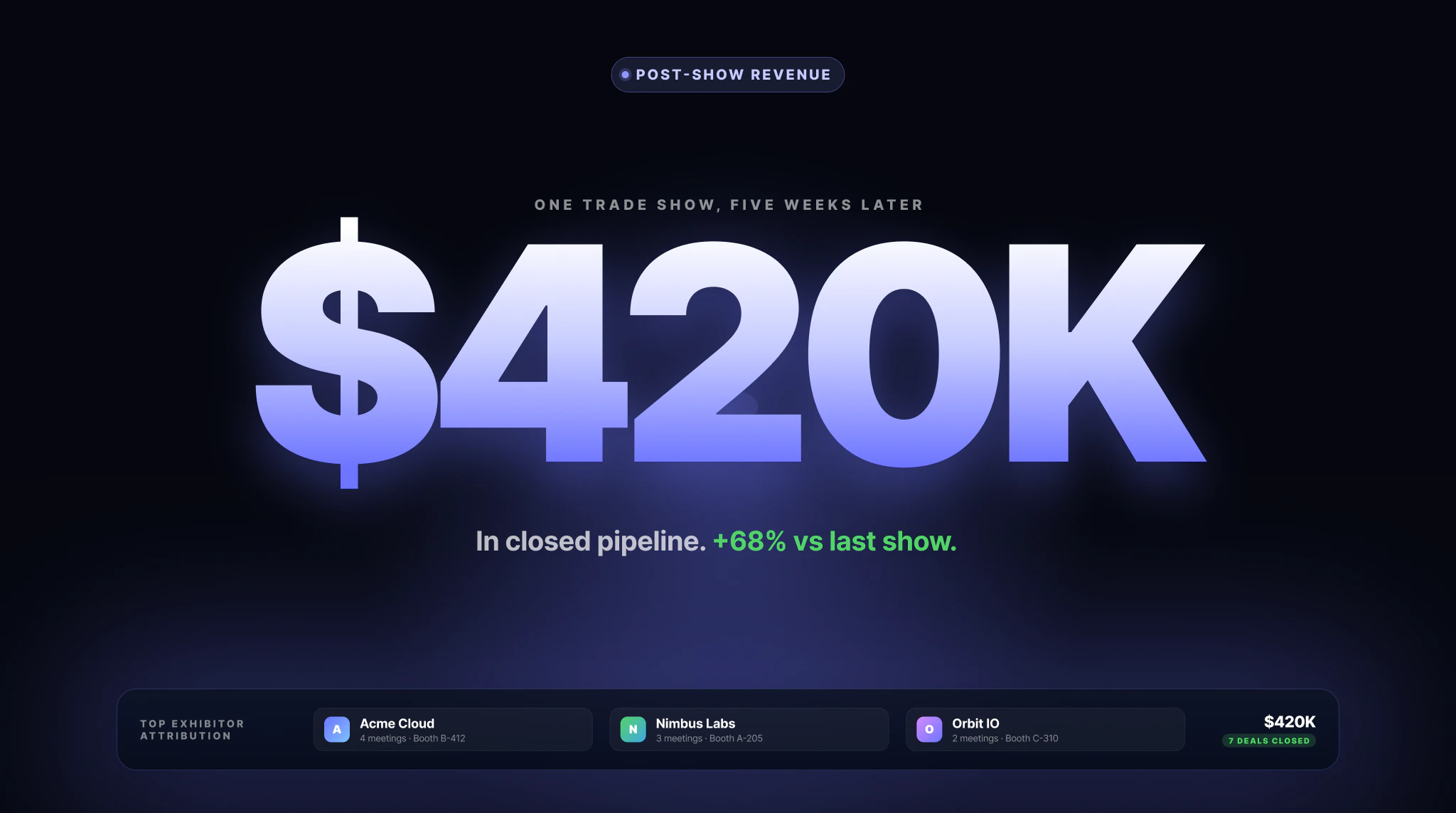
一句话介绍:Lensmor是一个以展会参展商数据为核心的销售情报工具,帮助B2B团队在展会前精准发现目标公司、找到关键决策人、获取验证邮箱,并串联AI辅助的触达规划,将无序的展商名单转化为可预约的会议机会。
Events
Artificial Intelligence
Vercel Day
B2B销售
展会获客
参展商数据
销售情报
AI外呼
决策人识别
邮箱验证
活动营销
会议预约
数据导出
用户评论摘要:用户普遍认可“展前规划”的价值,认为能改善ROI难追踪的痛点。主要反馈包括:希望实现从名单到会议的端到端归因追踪(区别于手动CRM)、集成Calendly等日程工具、以及AI生成个性化外呼内容。创始人回复强调以数据精准度优先,暂不追求全自动发送。
AI 锐评
Lensmor切中的是一个真实但常被忽视的痛点:展会营销的ROI黑洞。大多数B2B公司砸下重金参展,却仍在用Excel和泛泛的名片扫描度日。Lensmor的聪明之处在于,它没有试图再造一个CRM或自动化营销工具,而是精准锚定“参展商数据”这一高价值、低竞争度的上游环节。
从产品设计看,16万+全球展会库、企业到展会反向查询、决策人邮箱验证,这些功能构成了一个实用的“情报层”。创始人坦言不做“Spray and Pray”的盲目外呼,而是聚焦于让团队“带着正确名单进场”,这种克制值得肯定。目前产品最大的护城河在于数据质量与更新频率——如果Lensmor能持续证明其参展商数据的时效性与准确率远高于通用B2B数据库(如ZoomInfo),则能真正建立壁垒。
然而,危险信号在于“功能堆砌的幻觉”。AI Agent、CSV导出、CRM集成,这些听起来很好,但若数据源无法与主流展会组织方(如Informa、Reed Exhibitions)建立独家或高频合作,其数据库很快就会沦为二手数据的“花式整合”。同样,评论中多次提及的“端到端ROI追踪”是潜在大坑——试图打通日历、邮箱、CRM的归因系统,技术成本和用户信任门槛极高,若盲目投入,只会分散早期资源。
Lensmor的生死线不在于功能多少,而在于能否成为“展前情报的第一入口”。如果它只做成一款漂亮的“高级Excel替代品”,即便有272个投票,最终也会被Salesforce或HubSpot的原生模块吞噬。真正的价值在于:它能否定义一个新的销售动作——“Lensmor一下,就知道该去哪场展会找谁喝茶”。
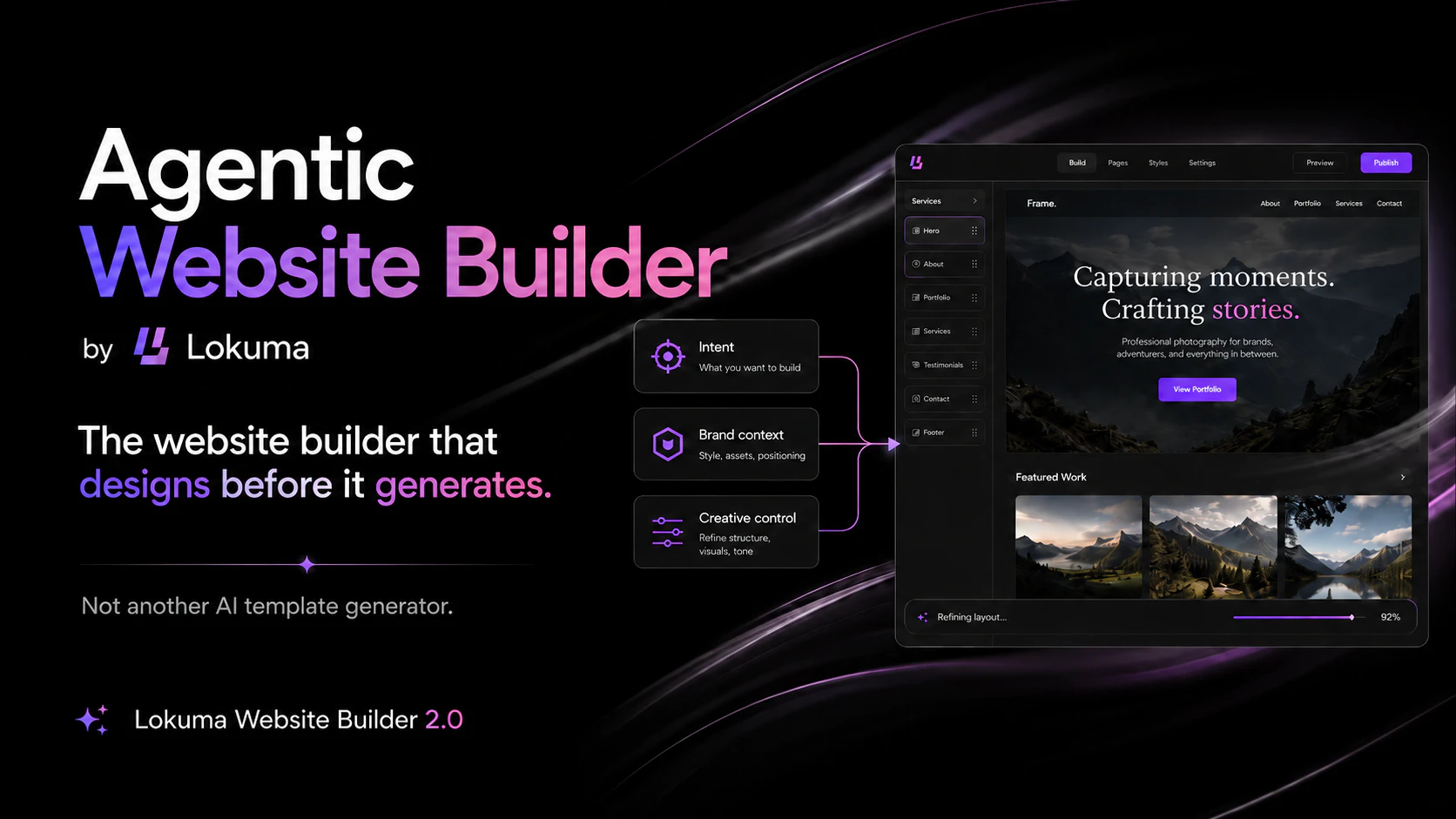
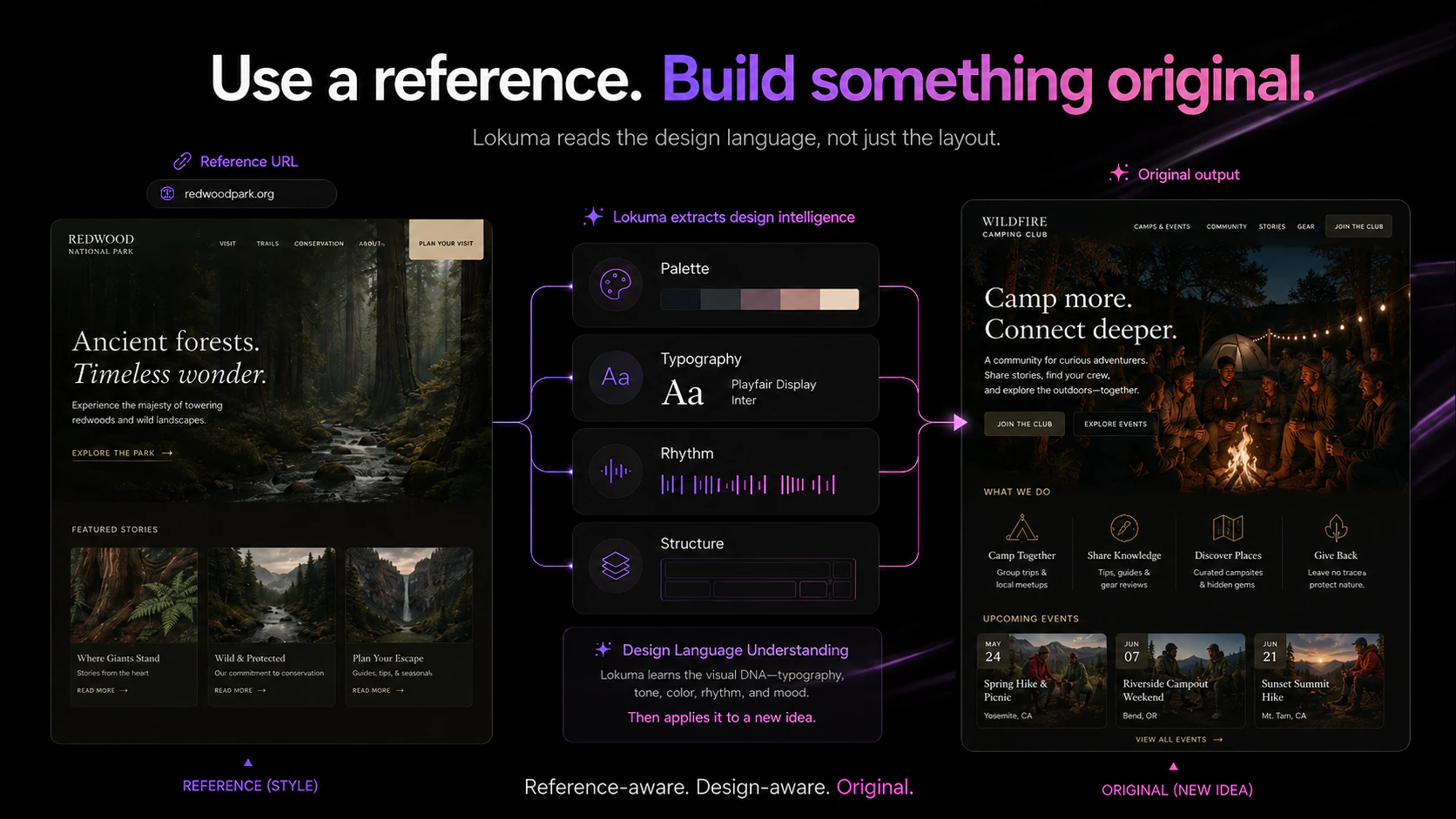
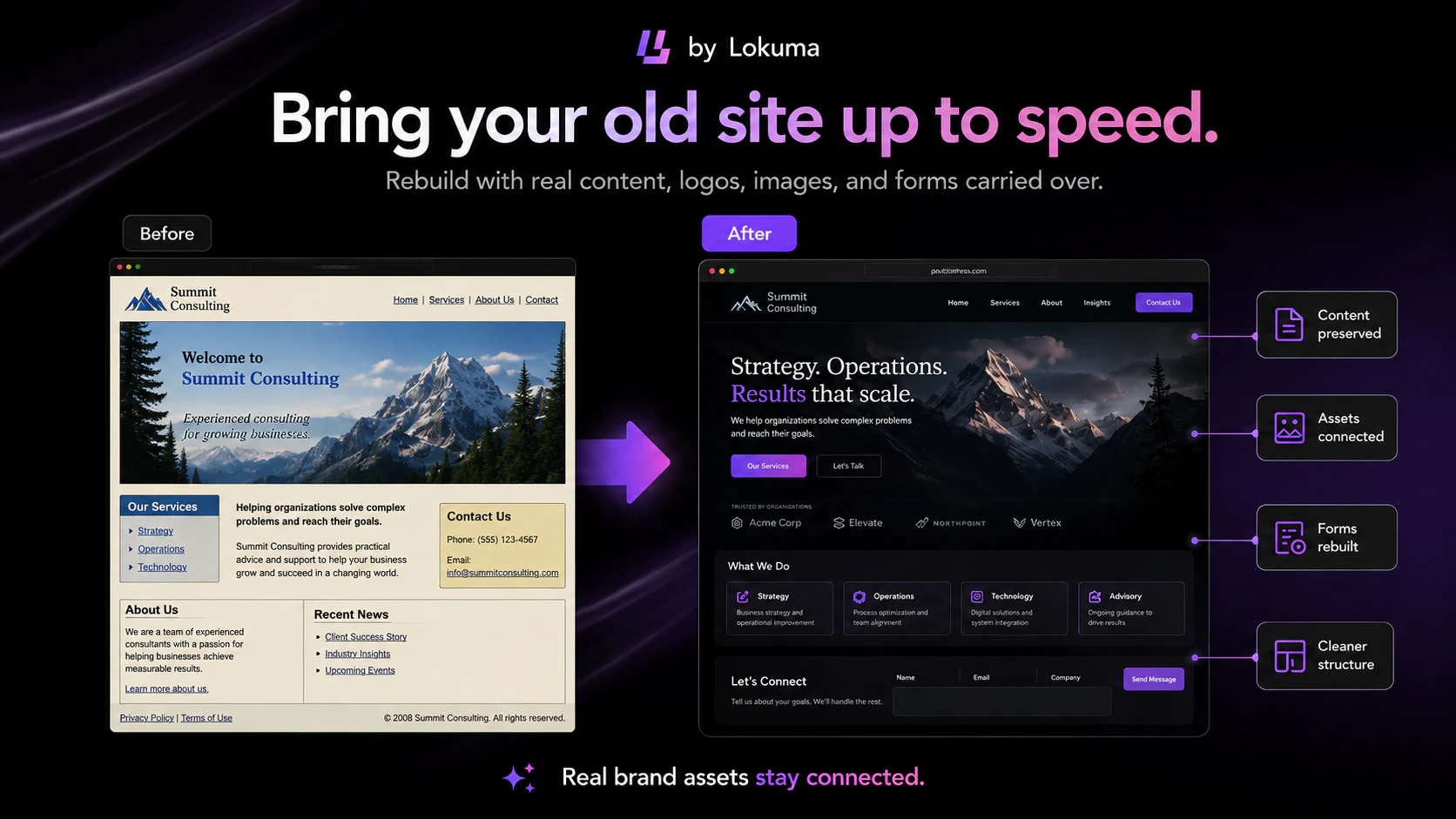
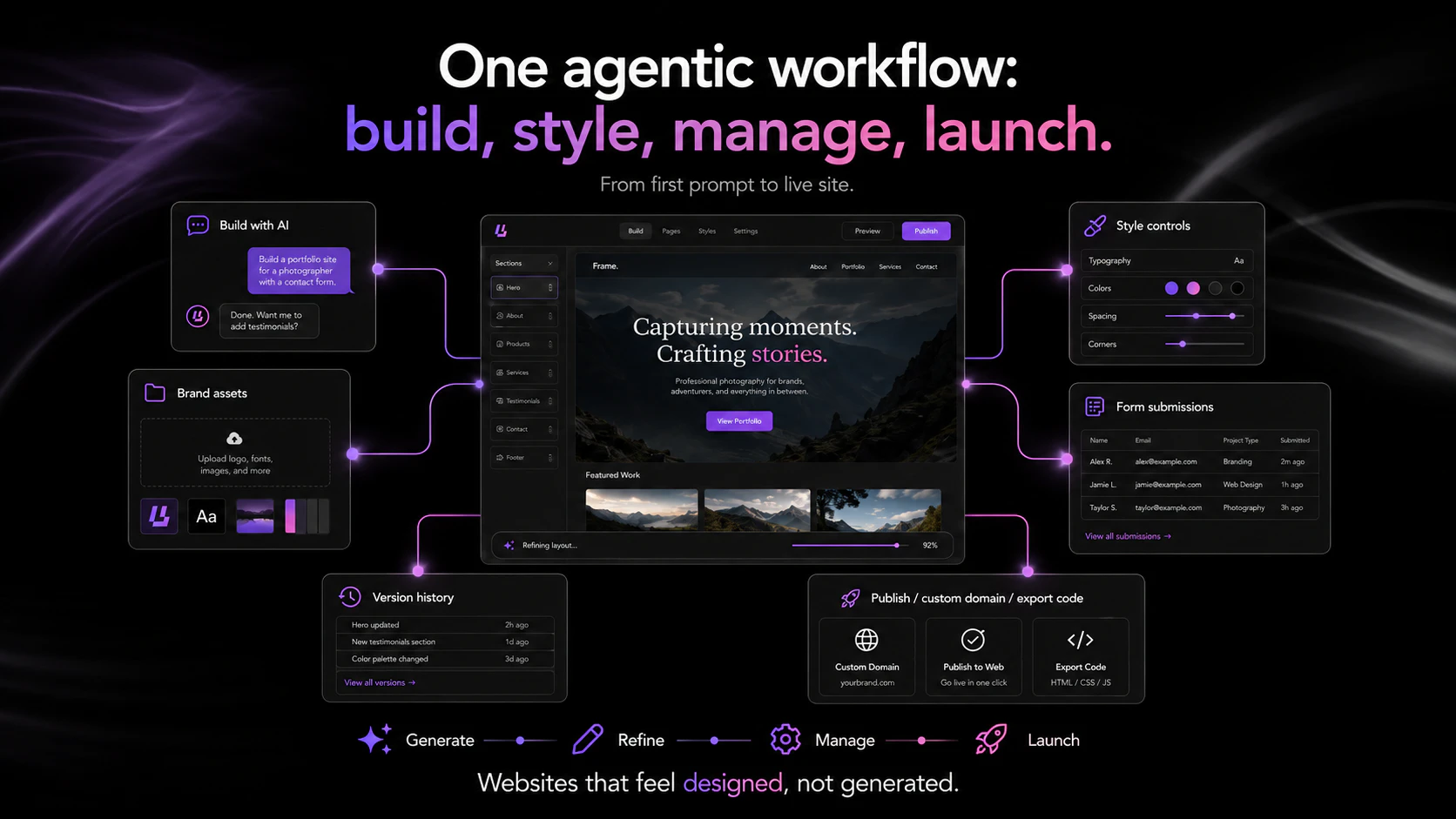
一句话介绍:Agentic Website Builder 2.0 是一个“设计即系统”的智能建站工具,核心解决现有AI建站工具“生成一时爽,编辑火葬场”的痛点——通过设计感知智能体,在品牌一致性和长期可维护性上实现从生成到迭代的全流程闭环。
Design Tools
Artificial Intelligence
Vercel Day
用户评论摘要:用户普遍关注长期编辑后设计一致性问题(点赞最高),以及“AI风”同质化困惑。团队回应聚焦“设计系统先行”与“目标修补”架构,避免信任LLM记忆。同时,有用户指出工具灵活性不如开发级工具(如Antigravity),而SEO与代理间设计迁移功能尚待完善。
AI 锐评
Agentic Website Builder 2.0 与其说是一个建站工具,不如说是一场对当前AI生成式工具“不负责任”的路线纠偏。当大多数产品沉迷于用大模型一次性吐出漂亮但脆弱的“第一稿”时,Lokuma选择了一条更难的路:构建一个包含记忆、约束和自我修正的智能体生命周期。
产品的真正价值并不在于“生成”,而在于“维护”。其“计划-执行-审查-自纠”的智能体循环,以及将设计系统(Design Tokens、Tailwind Config)作为不可侵犯的“宪法”而非模型可以随意篡改的“建议”,这从根本上扭转了“AI生成如一次性纸杯”的尴尬局面。通过“目标修补”和“设计系统先行”的策略,它成功将AI从不可控的“艺术家”变成了可控的“高级美工师”——遵循品牌手册、在既定框架内执行具体指令。
然而,锐评之下仍需泼冷水。首先,所有“防漂移”机制本质上是在与LLM的不确定性做“军备竞赛”,只要底层模型输出存在随机性,绝对的“锁定”就只是理想。其次,该产品在当前阶段对“设计感”的追求,难免以牺牲“灵活性”为代价。用户@ayush_tiwari37的评论非常精准——它与如“VS Code on steroids”的产品并非竞品,而是互补。Lokuma在品牌与设计上建墙,意味着它在深度开发与异形交互上也会筑起壁垒。
整体来看,这不是一个讨好所有人的通用型产品,而是一个服务于“非技术但审美在线”的创业者、以及需要高效产出品牌站点的“小型精品机构”的精准工具。它切中的是AI生产从“可用”到“可信”之间的那一层薄薄但坚硬的理性泡沫。与其说它在卖工具,不如说它在贩卖一种确定性——这在AI过度承诺的时代,是一种稀缺且聪明的定位。
一句话介绍:Gradient Bang是一款通过语音与LLM交互来管理AI子代理舰队、在动态UI环境中进行大规模多人对战的实验性游戏,将复杂AI编排融入复古太空贸易玩法,旨在探索AI原生应用的技术边界。
Artificial Intelligence
GitHub
Tech
Games
Vercel Day
AI原生游戏
LLM驱动
语音交互
多智能体编排
动态UI
子代理
开源
实时通信
Agent沙盒
太空贸易
用户评论摘要:玩家称赞其创新与趣味性,同时关注:LLM随机性如何平衡对抗公平性;长上下文与实时延迟的技术挑战;提示驱动的游戏如何防止代理幻觉;以及“人类vs自动化”的竞争公平性问题。团队承认目前是实验性项目,平衡仍在调试中。
AI 锐评
Gradient Bang的野心远不止于一款游戏。它本质上是一个“AI原生”的技术演示沙盒,披着复古太空贸易的外衣,内里却是对多代理编排、动态UI生成、长上下文管理与实时语音管道等前沿命题的暴力实验。其核心价值不在可玩性,而在于它向开发者暴露了“把LLM塞进实时系统”的完整痛点和解决方案——从Pipecat框架处理语音延迟,到子代理共享上下文的模式,再到用LLM替代传统错误处理的激进做法。
但作为游戏,它目前更像一个技术噱头而非成熟作品。评论中反复出现的“不确定性”“平衡缺失”“自动化vs人力”问题,揭示出LLM固有的不可预测性如何破坏了游戏最基础的公平规则。当玩家能编写更高效的交易循环或堆叠更多算力时,竞技性就沦为了一场“谁的代理写得好”或“谁的GPU多”的军备竞赛。团队坦承“不知道如何解决”,这恰恰是AI原生游戏至今没有出圈范例的缩影。
真正值得关注的,是它开源后作为教学工具的价值。开发者可以克隆仓库,观察:Vercel Sandbox如何支持用户自定义子代理资产;结构化数据如何与LLM上下文混合;动态UI如何在维持用户体验与AI自主性间摇摆。其设计哲学——用LLM缩减后端代码量,将错误处理转回推理循环——可能比游戏本身更具启发性。但若只能作为技术演示存在,它注定是极客的玩具,而非大众的娱乐。
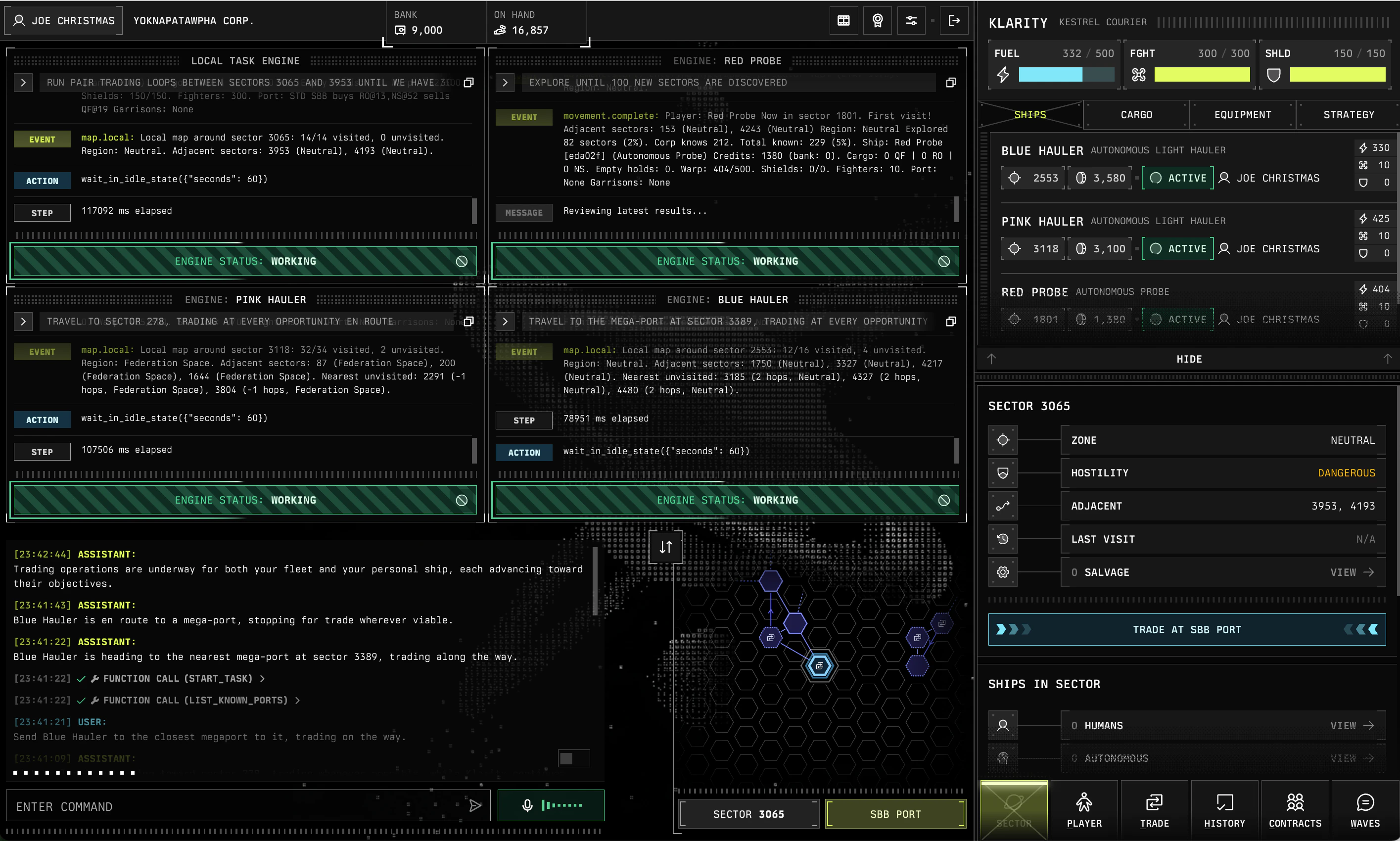
一句话介绍:Crustimate是一款免费的LinkedIn个人资料AI优化工具,能在30秒内评估用户对AI招聘系统的可见性得分,并给出针对性修改建议,解决求职者简历被AI筛选工具过滤、无法进入人类招聘官视野的痛点。
Hiring
Tech
Vercel Day
AI招聘优化
LinkedIn资料分析
简历评分
求职工具
AI可见性
角色匹配
免费SaaS
候选人筛选
个人品牌优化
招聘科技
用户评论摘要:用户普遍认可工具有用,能提供具体改进建议。有用户询问修复后实际获得招聘官联系的效果数据,开发者承认将开始追踪。另有用户建议按角色(PM、工程师等)个性化推荐,开发者回应已按角色区分。此外,有用户反映在应用内浏览器加载不稳定,开发者已修复。
AI 锐评
Crustimate切中了一个被广泛忽视但日益关键的痛点——AI招聘系统的“黑箱筛选”。当大多数求职者还在优化简历格式和关键词堆砌时,招聘端早已进化到由AI自动过滤候选人。Crustimate的价值不在于提供通用建议,而在于反向工程AI招聘工具的筛选逻辑,量化“可见性”这一原本模糊的概念。
从功能看,产品构建了一个完整的闭环:诊断(AI就绪度评分)→ 修复(重写标题、复制粘贴修改)→ 策略(角色匹配、行动规划)→ 执行(目标公司联系人及预写消息)。这种“即测即改”的模式降低了用户行为门槛,免费+无需登录的策略更有利于冷启动和口碑传播。
但冷静来看,产品存在明显局限。首先,其核心依赖“AI招聘工具如何阅读LinkedIn”这一底层逻辑,但不同AI招聘系统的算法、权重和更新频率各异,评分模型的准确性和时效性存疑。其次,用户评论中提出的“修复后实际转化率”是验证产品价值的关键指标,而官方目前仅能提供个人案例(从52到78分),缺乏系统性追踪。若无法证明分数提升与实际面试邀约间的因果关系,工具就容易沦为“自我安慰型仪表盘”。
此外,产品本质是“修复LinkedIn资料”,而非解决求职者的核心竞争力问题。它能优化简历的AI可读性,但无法改变一个人是否真正匹配岗位。在招聘流程后端,人类面试官依然会通过深度交流判断候选人。过度依赖这类工具可能导致求职者成为“AI优化专家”,而非“优秀员工”——这或许是产品需要警惕的方向。
总体而言,Crustimate是一个定位精准、执行迅速的实用工具,尤其在学生和被动求职者群体中有明确价值。但若想从“好用的工具”进化为“不可替代的平台”,必须建立从“可见性”到“录用率”的因果数据链,并警惕算法迭代带来的过时风险。
一句话介绍:mia是一款利用AI整合并分析客户访谈、支持工单、销售通话及使用数据等多元信号,自动生成可直接用于AI开发的、具备完整上下文的PRD与优先级排序需求的平台,旨在解决产品经理因信息分散而无法高效决策的痛点。
Productivity
Developer Tools
Artificial Intelligence
产品管理
AI Agent
客户信号分析
需求生成
产品策略
PRD撰写
用户反馈聚合
数据分析
Cursor对标
SaaS
用户评论摘要:用户普遍认可其解决PM与开发沟通鸿沟的价值,核心问题集中在:如何与Linear/Jira等工具集成(已支持),如何处理冲突信号(策略性保留给PM判断),及与同类产品(如CC-gstack)的区别。有部分用户遭遇了登录错误。
AI 锐评
Mia的“Cursor for PMs”口号响亮,但平心而论,它目前更像“客户信号版Jasper”,而非一个能自己写代码的AI伴侣。其真正的价值在于承担了产品管理中最繁琐、最容易被忽视的“情报聚合与清洗”环节。它通过将分散在14个工具里的碎片化信息结构化,把PM从“信息矿工”变成了“决策者”。
然而,产品仍存在本质的、也是暂时无法回避的困境。第一,它处理的是“过去的声音”,对“未来的缺席”无能为力。用户没说的、竞品在做的、技术趋势带来的颠覆,Mia无法预警。第二,处理冲突信号时“把战略判断留给人”是一种聪明的克制和诚实的表态——它承认了当前AI无法承担商业责任的本质局限,但也意味着核心决策链条依然高度依赖人,工具只是辅助。
与“Cursor”类能够直接输出代码、实现“意图到代码”闭环的工具相比,Mia的实际交付物仍处在“高保真需求文档”阶段,要实现其口号中的“执行”,还差整个“从需求文档到AI开发Agent”这一层的集成与闭环(官方也承认正在建设中)。目前来看,它对小型敏捷团队的价值远大于大型复杂组织;后者的问题往往不是缺数据,而是权力结构和组织惯性导致决策无法由工具驱动。
更犀利的观察是:如果AI开发Agent(如Devin, Codex)最终自己就能解析原始需求并提问,那Mia作为中间层的存在价值就将被压缩。因此,Mia必须尽快跑完集成闭环,让“信号→需求→代码”成为其护城河,而非停留在“好看的Excel替代品”。
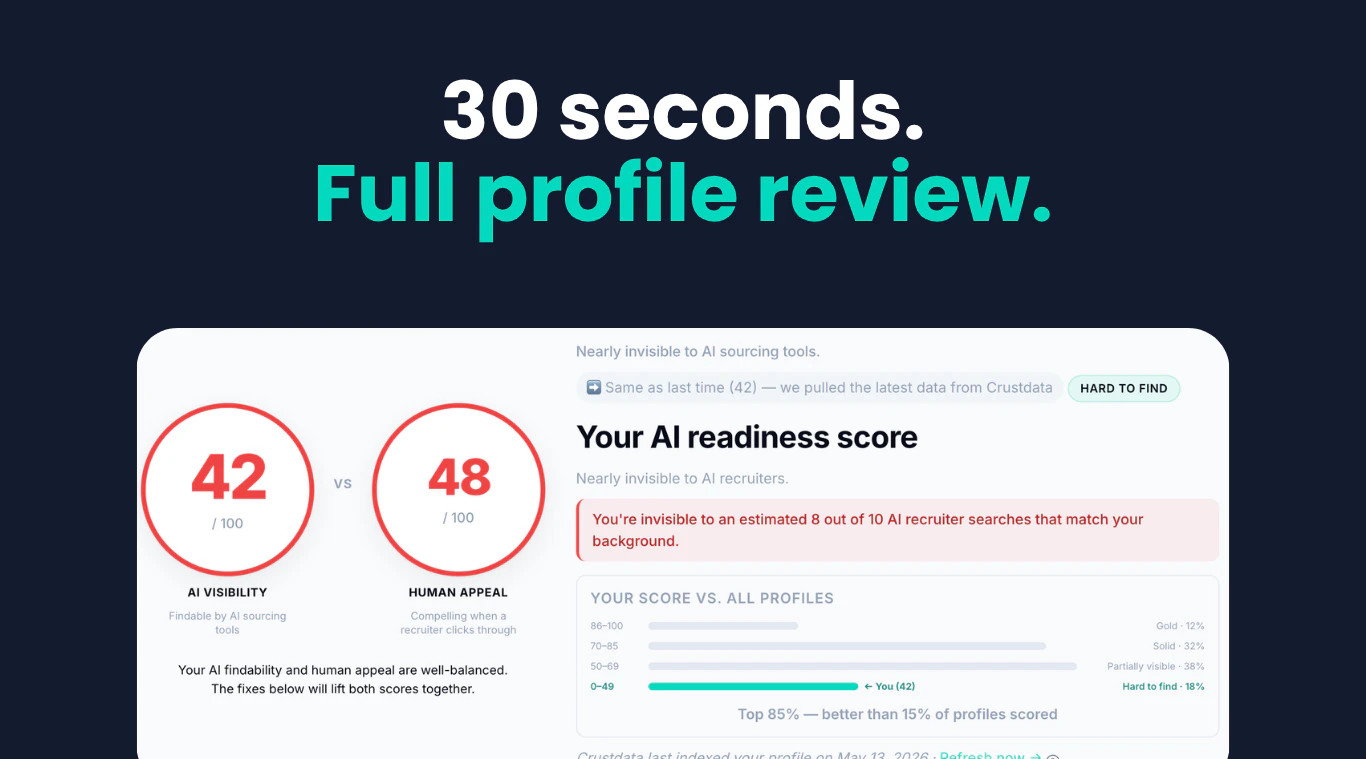
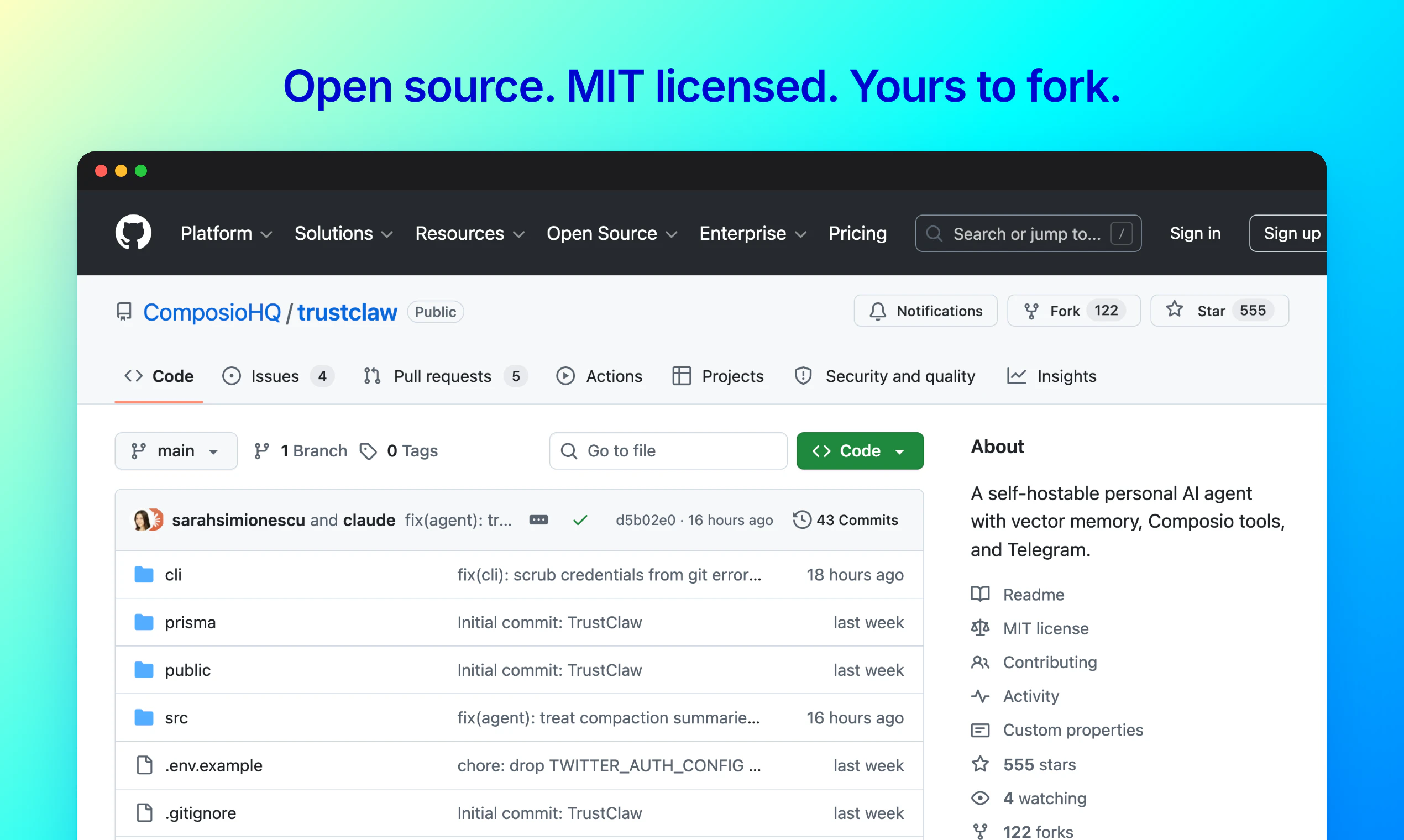
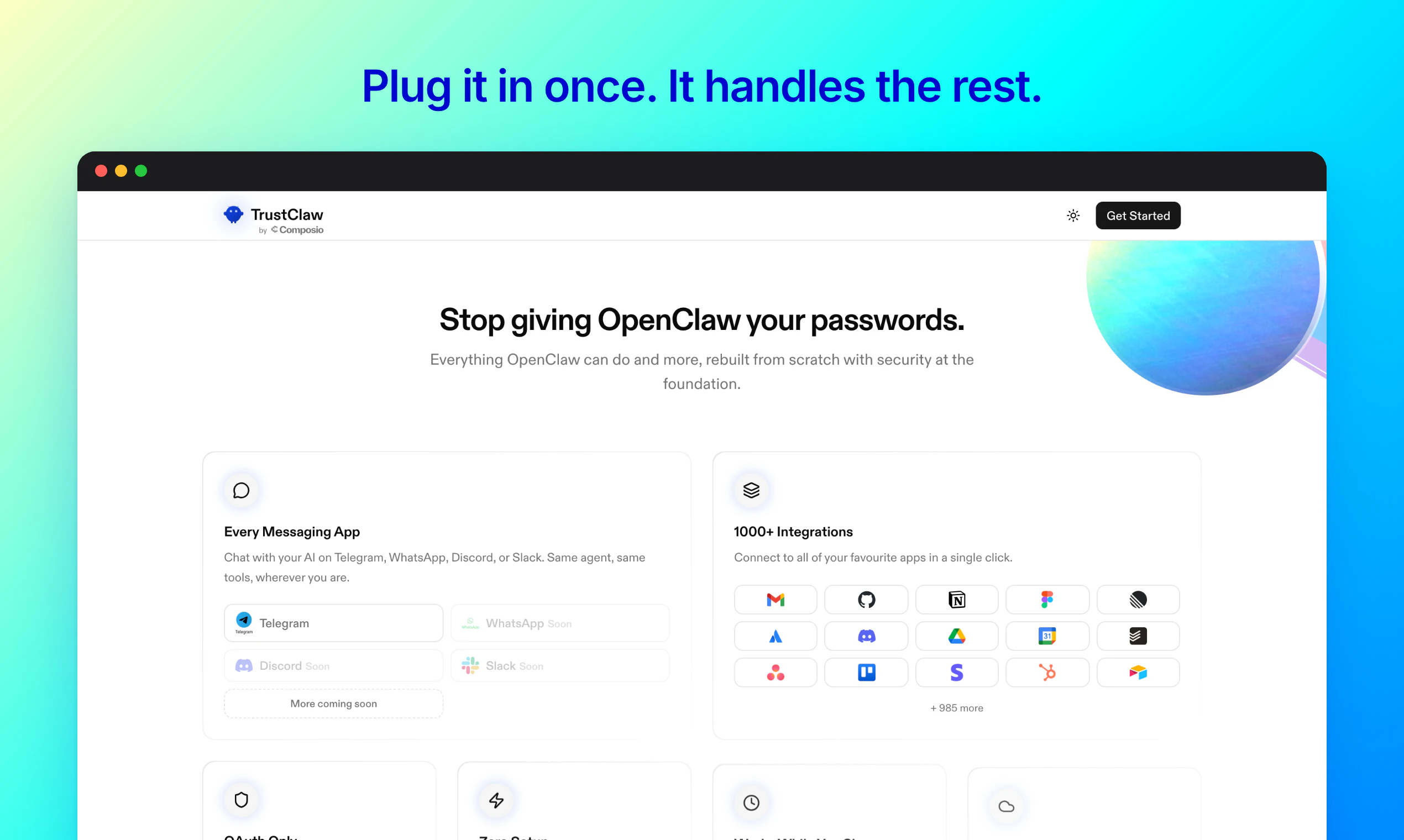
一句话介绍:TrustClaw 是一款可一键部署在 Vercel 上的自托管开源 AI 代理,通过 OAuth 安全连接 1000+ 应用,支持定时任务与 Telegram/网页交互,解决用户对云端 SaaS 泄露个人凭证和数据的信任焦虑。
Open Source
Artificial Intelligence
Vercel Day
AI代理
自托管
开源
OAuth安全
Vercel部署
Telegram交互
定时任务
隐私优先
MIT许可证
个人自动化
用户评论摘要:用户普遍认可自托管与 OAuth 授权带来的信任感。核心问题集中在 Vercel Hobby 计划的运行时长限制(函数5分钟、定时任务每天一次),以及任务错误时的审计与回滚机制。少数用户遭遇部署后页面空白/无响应的技术问题,另有评论认为项目“杀死了一万家初创公司”。
AI 锐评
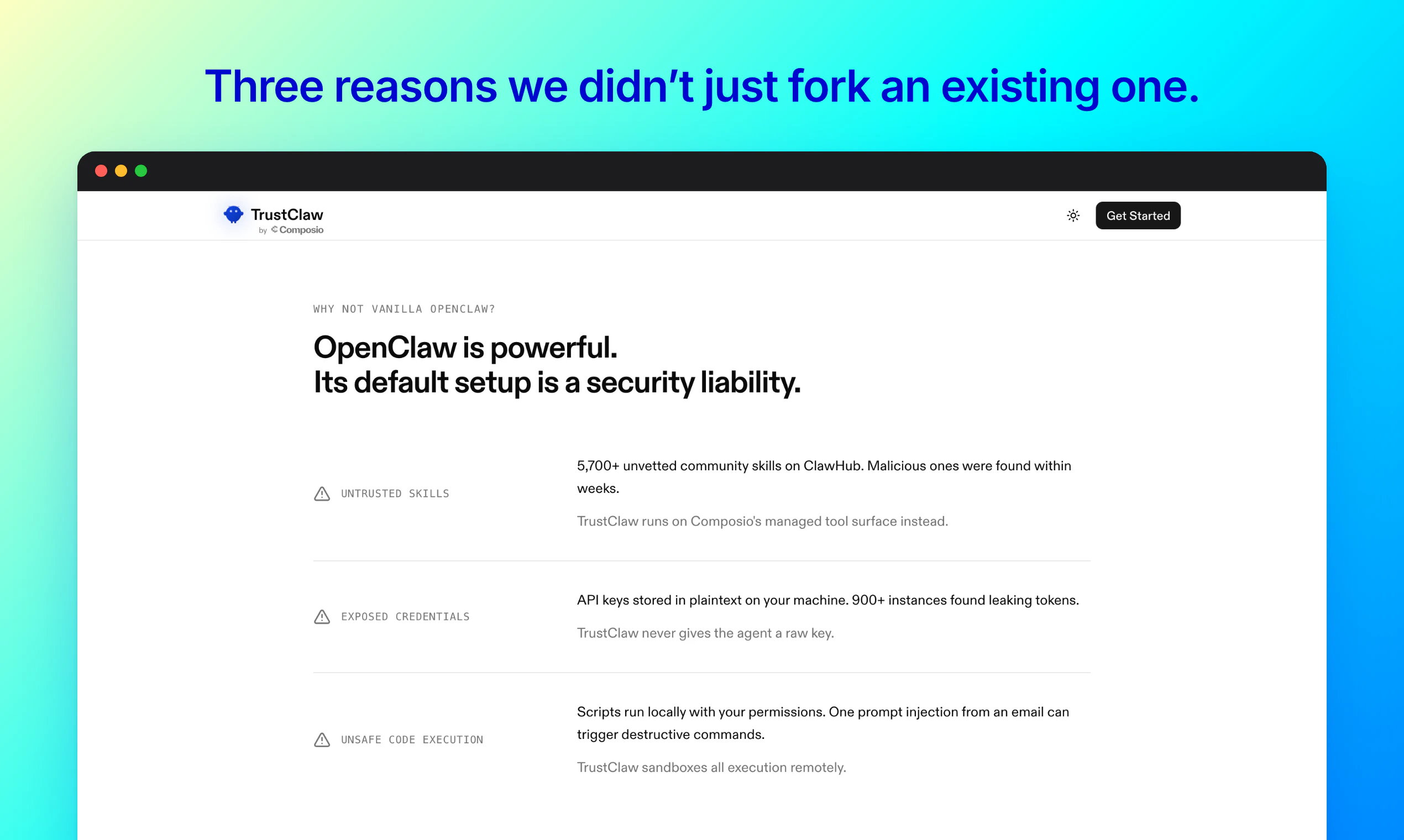
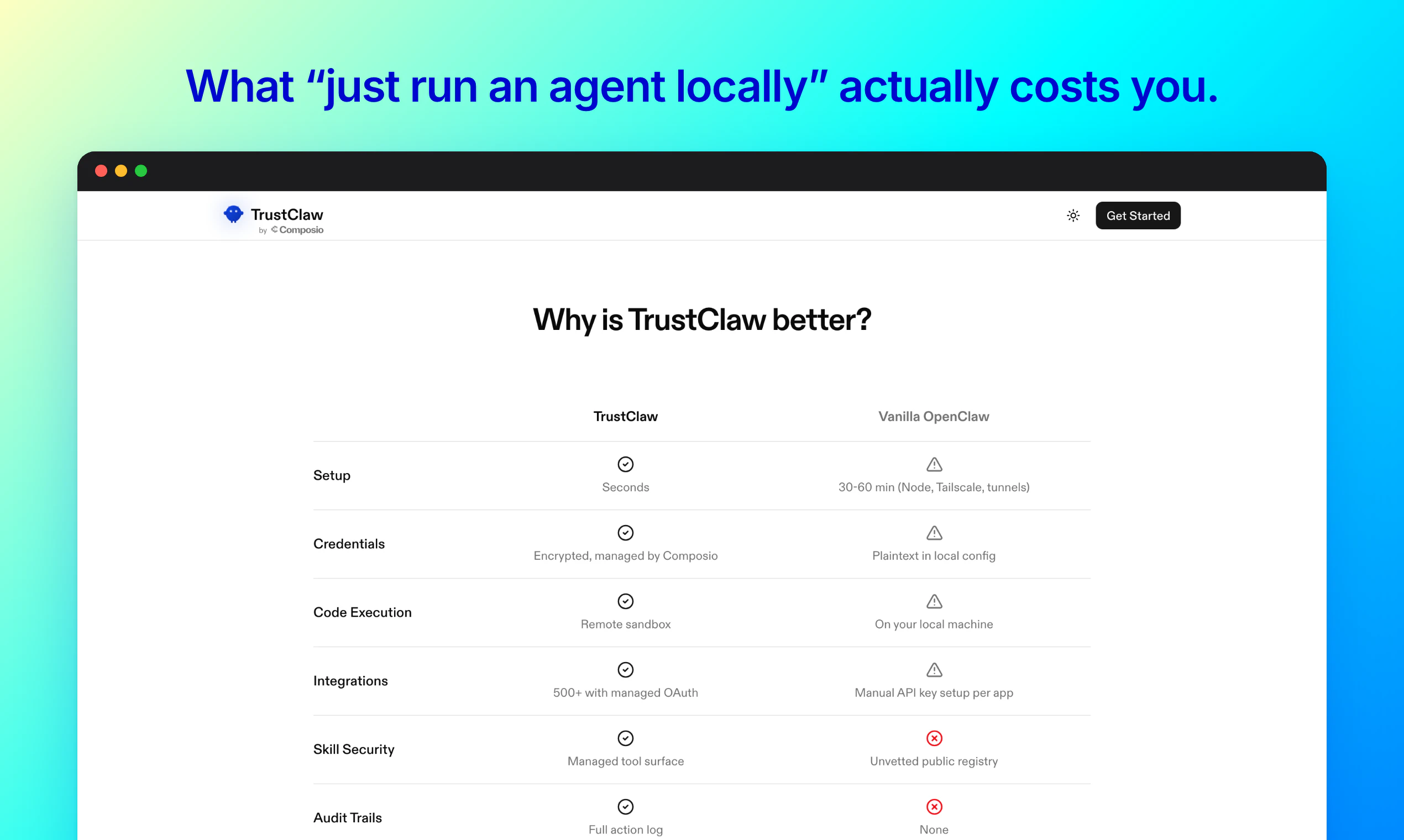
TrustClaw 精准地踩中了一个敏感地带:用户既想要 AI 代理的便利性,又对 SaaS 模式下的数据所有权和凭证安全心有余悸。它的策略很聪明——不强调 AI 能力多强(底层仍是 Composio 的工具链),而将“信任”作为核心卖点,通过开源、MIT 许可、Vercel 自托管和 OAuth 流来构建技术层面的安全感。
但这本质上是一个“信任外包”而非“完美安全”的方案。数据不交给 Composio,但交给了 Vercel;代理不接触原始凭证,但获得了执行操作的临时令牌,且运行在云服务器上。对于真正追求极端隐私的用户,这种方式仍是折衷。同时,Vercel Hobby 计划的严苛限制(函数超时、低频定时任务)让“24/7全天候代理”的宣称打了折扣——它更适合轻量级、偶发性的自动化,而非连续、复杂的后台进程。
从市场角度看,TrustClaw 满足了“去 OpenClaw 痛点”的空白:更易部署、更安全的心理锚点。但它的护城河不深。一旦主流玩家(如 OpenAI)或云基础设施提供商(如 Vercel 自身)推出类似的一键自托管代理,其差异化优势将迅速消失。它的真正价值可能不在于成为个人 AI 的终极形态,而在于为开发者社区提供了一个极佳的参考范式:如何用几行代码和云生态,快速构建一个“看起来安全”的私人代理原型。目前它还更像是技术爱好者的炫酷玩具,距离成为普通用户的“日常管家”还有一段关键的距离。
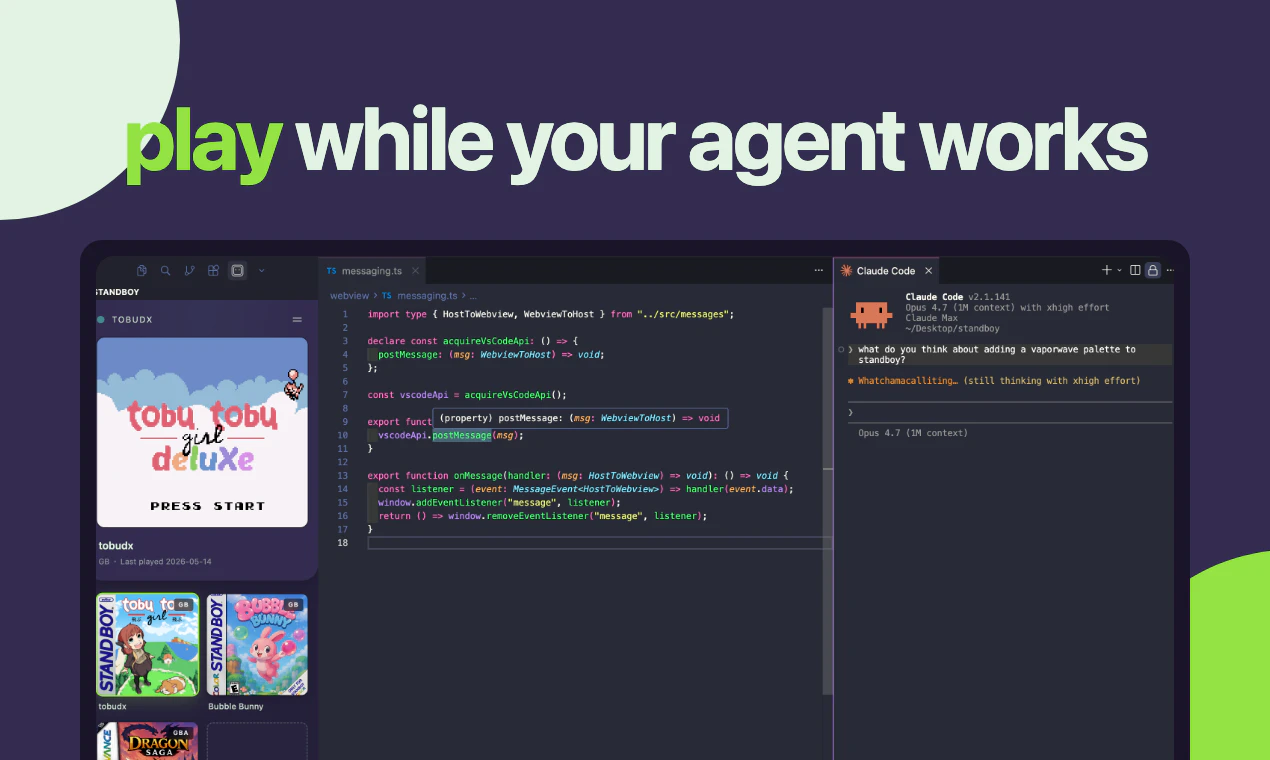
一句话介绍:一款嵌入编辑器侧边栏的虚拟Game Boy,在AI代理工作时自动唤醒并运行用户自备的ROM游戏,解决开发者等待代理执行任务时的无聊与注意力涣散问题。
Open Source
Developer Tools
Artificial Intelligence
GitHub
开发者工具
编辑器插件
AI代理
效率辅助
游戏模拟器
侧边栏应用
开源
无遥测
怀旧
休闲
用户评论摘要:用户普遍认可其“让等待变有趣”的创意,核心建议集中在:1)将当前二元状态(运行/停止)扩展为显示具体任务进度或类型;2)加入代理调试反馈(如显示卡死、限流等状态);3)增加互动学习元素,在等待间隙展示正在构建的代码逻辑。多数用户希望保持离线无云依赖特性。
AI 锐评
Standboy精准戳中了AI编程时代一个被忽视的“剩余时间”痛点:当人类从编码者退化为代理监督者时,编辑器内的空闲时间变得漫长且反人性。产品用极低成本(开源、无遥测、本地ROM)实现了高情绪价值——让等待从焦虑转为愉悦,本质上是在解决**心理带宽的再分配**。
但它的价值天花板也清晰可见:当前仅是“二元状态的娱乐化包装”,既未连接代理的上下文状态,也无法反哺工作流。评论中多数建设性建议(任务可视化、调试反馈、学习型互动)都指向一个事实——单纯娱乐是对“等待时间”的浪费,而非增值。更具竞争力的演进方向应是:将Game Boy的屏幕变为代理工作的“状态仪表盘”,比如用像素画展示实时代码变更、测试进度或卡点类型,甚至允许用户在游戏中“触发”一个重试或确认动作,从而把被动娱乐变成主动管控。
另外,该产品的可持续性存疑。带ROM的游戏模拟器面临版权灰色地带(用户自备ROM虽规避了直接侵权,但整体体验依赖盗版生态),且“在编辑器中玩游戏”极易沦为调试时的干扰源。真正的长期价值可能不在“游戏”本身,而在“嵌入式状态反馈”的模式——未来可复用框架,将怀旧像素屏幕替换为其他微交互形式(如墨水屏待办、复古跑马灯调试日志),这才是细分场景的真正护城河。
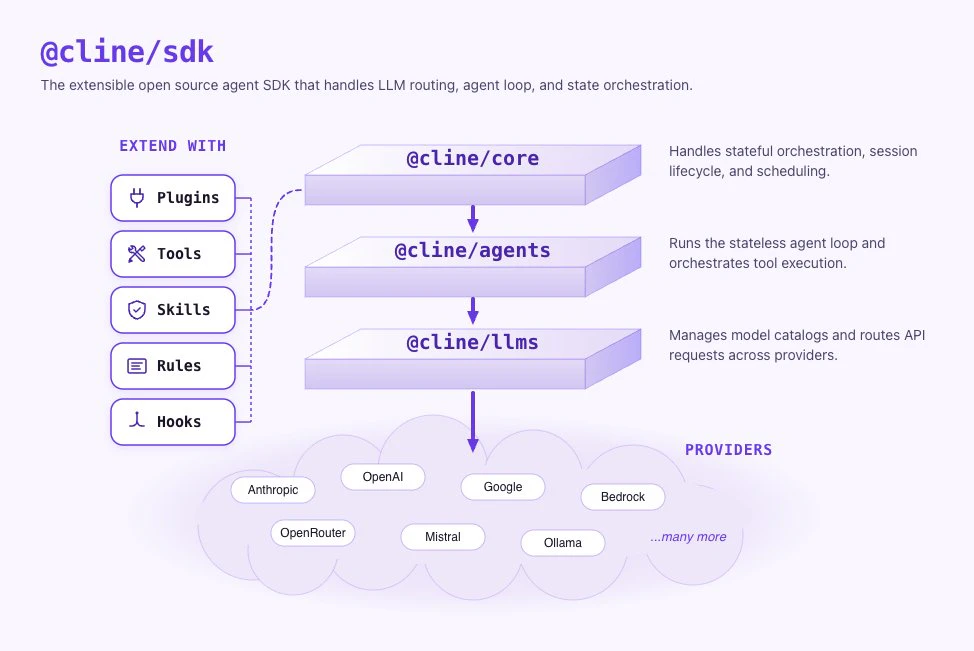
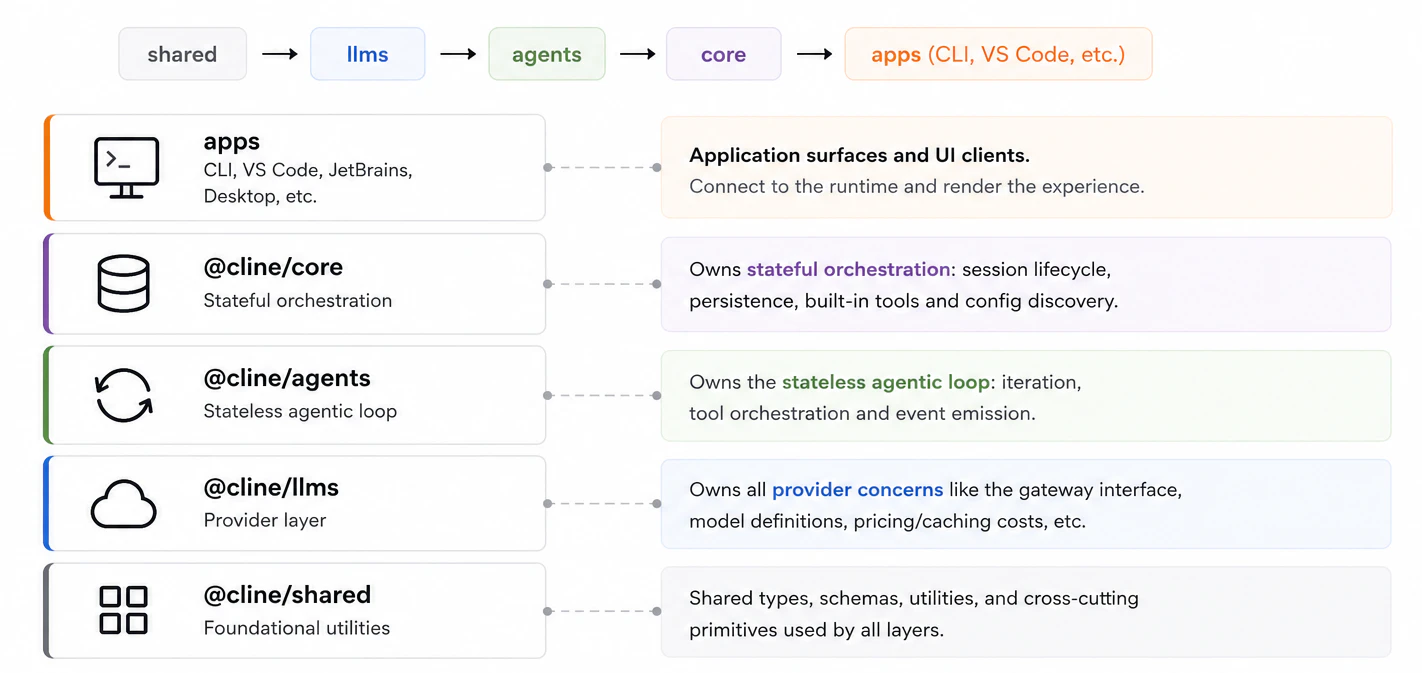
一句话介绍:Cline SDK 是一款基于插件的开源TypeScript代理运行时,专为开发者在VS Code、CLI、桌面应用等不同界面中构建可移植、可持久化的编码代理或AI工具而设计。
Open Source
Developer Tools
GitHub
开源
编码代理
Agent运行时
TypeScript
插件架构
MCP支持
多代理
检查点
跨平台
用户评论摘要:用户高度认可Cline团队将其内部运行时的开源行为,认为这比专门为发布而构建的框架更有可信度;一位开发者表示已将多个内部代理切换到新SDK,体验良好。另有用户关注插件的故障隔离能力,询问buggy工具崩溃时是否会连带整个代理。
AI 锐评
Cline SDK的真正价值不在于它拥有漂亮的基准测试数字,而在于它尝试解决当前AI编码代理领域的一个根本性结构缺陷——运行时与产品界面的“硬耦合”。无论从评论中还是产品介绍中,都能清晰看到这一痛点:大量的代理框架在VS Code等特定环境中生长,其运行逻辑与UI层纠缠不清,导致迁移、扩展和状态持久化成为噩梦。
Cline的开源举动,实际上是将其赖以成名的内部架构进行了一次“外科手术式”的解耦:将无状态的核心代理循环与有状态运行时层分离。这一设计直接带来了两个关键优势:一是“会话可迁移性”,即代理的工作流不再被锁定在某个编辑器或终端内,开发者可以在Slack bot、CLI甚至桌面应用中无缝复用同一套逻辑;二是“故障弹性”,通过原生子代理和检查点机制,它允许复杂任务被拆解并在非理想状态下重启,而非一次性的脆性执行。
然而,评论中关于“插件故障隔离”的尖锐提问点出了核心风险——插件生态的鲁棒性。Cline的Plugin架构虽然通过生命周期钩子和工具注册提供了扩展性,但并未明确承诺沙箱隔离。一旦有第三方插件包含内存泄漏或无限循环,整个“可移植”的黄金保证就会瞬间崩塌。如果Cline不能像成熟的运行时(如Deno或Cloudflare Workers)那样提供严格的权限和资源隔离,其“生产级”定位将停留在概念验证层面,难以承载高负载的内部工具链。
此外,“提供者无关”的模型切换虽然便利,但也意味着Cline必须持续适配各大模型API的频繁迭代,这将带来巨额的维护成本。若团队资源不足以快速跟进,这份“便利性”随时可能变成“兼容性陷阱”。
总的来说,Cline SDK在架构理念上是领先的——把“代理运行时”从“代理产品”中剥离出来,这为AI工程化提供了更清晰的抽象层。它的成功不取决于最初有多少好评,而取决于能否在插件生态的沙盒化、长期任务的状态一致性以及多模型适配的及时性这三个硬核工程问题上交出答卷。相比于那些包装精美的AI编排框架,Cline更像一把为专业工匠准备的、需要自己打磨的趁手工具。
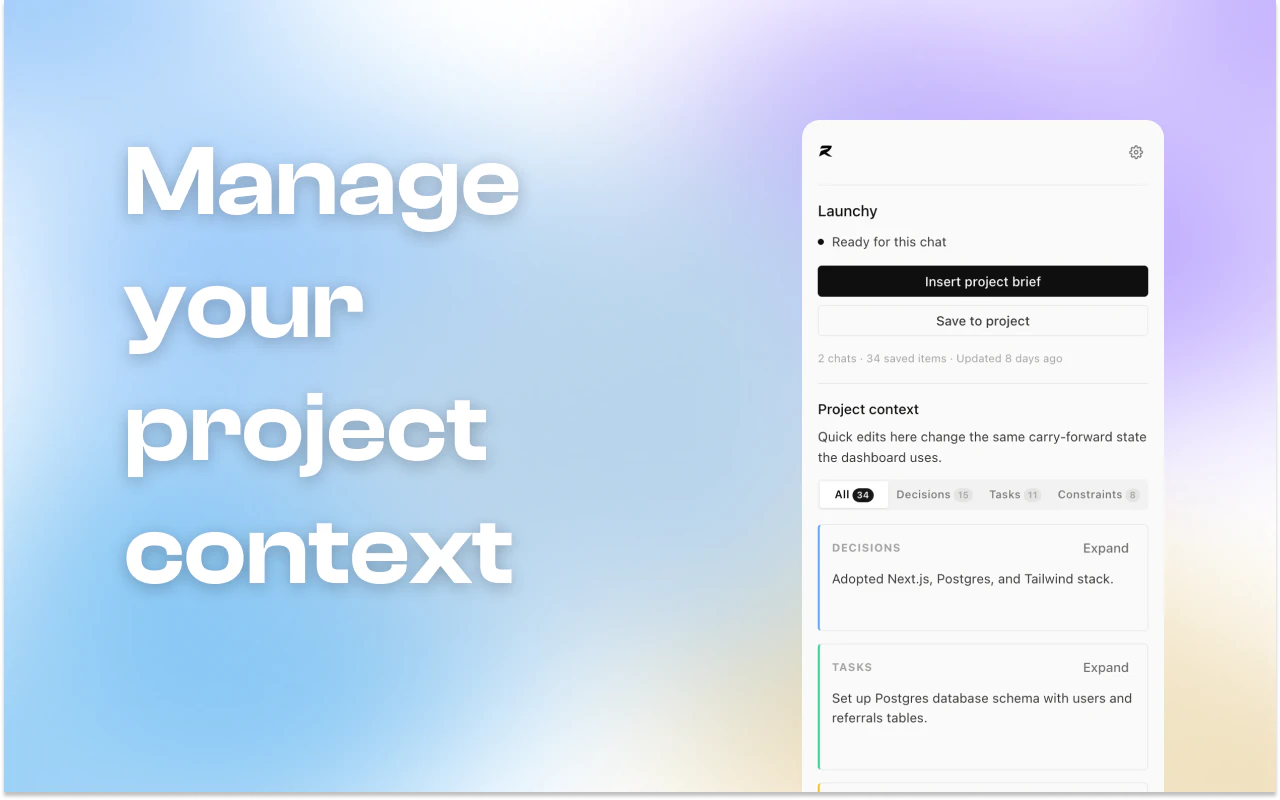
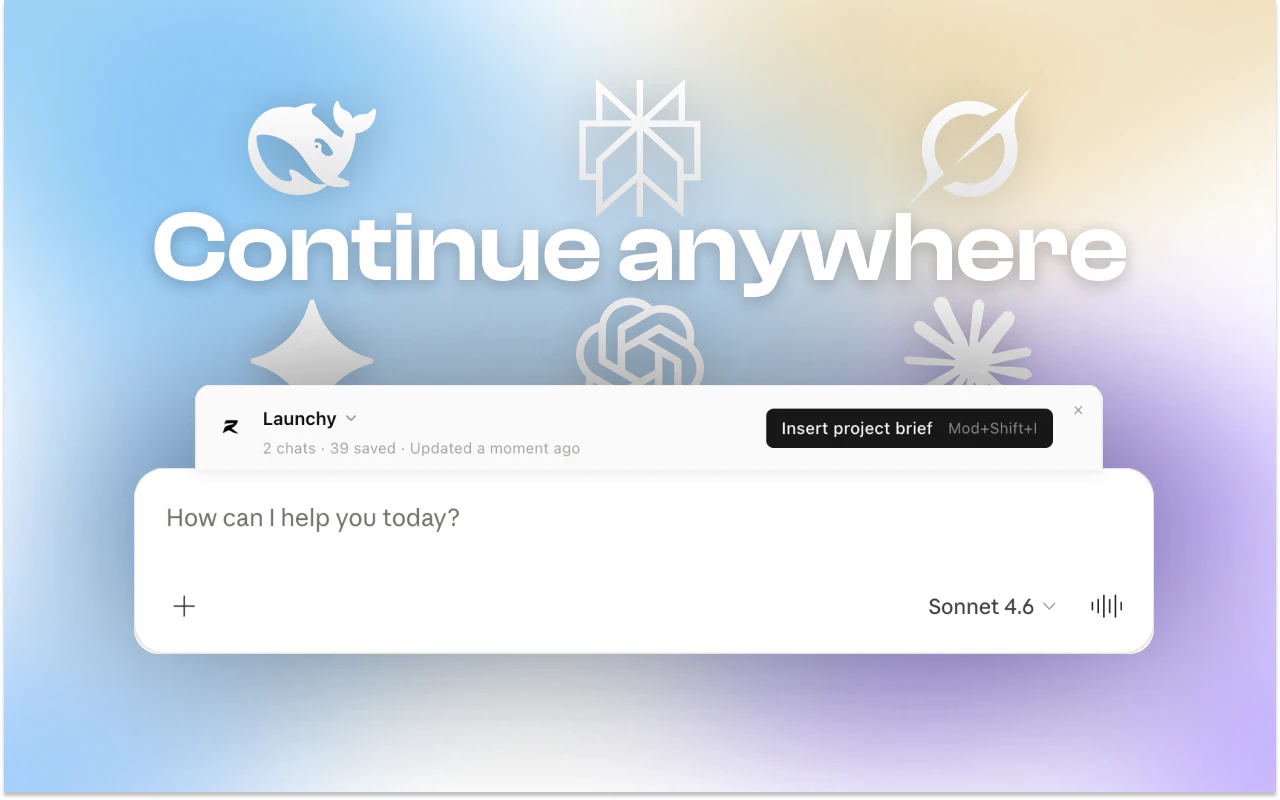
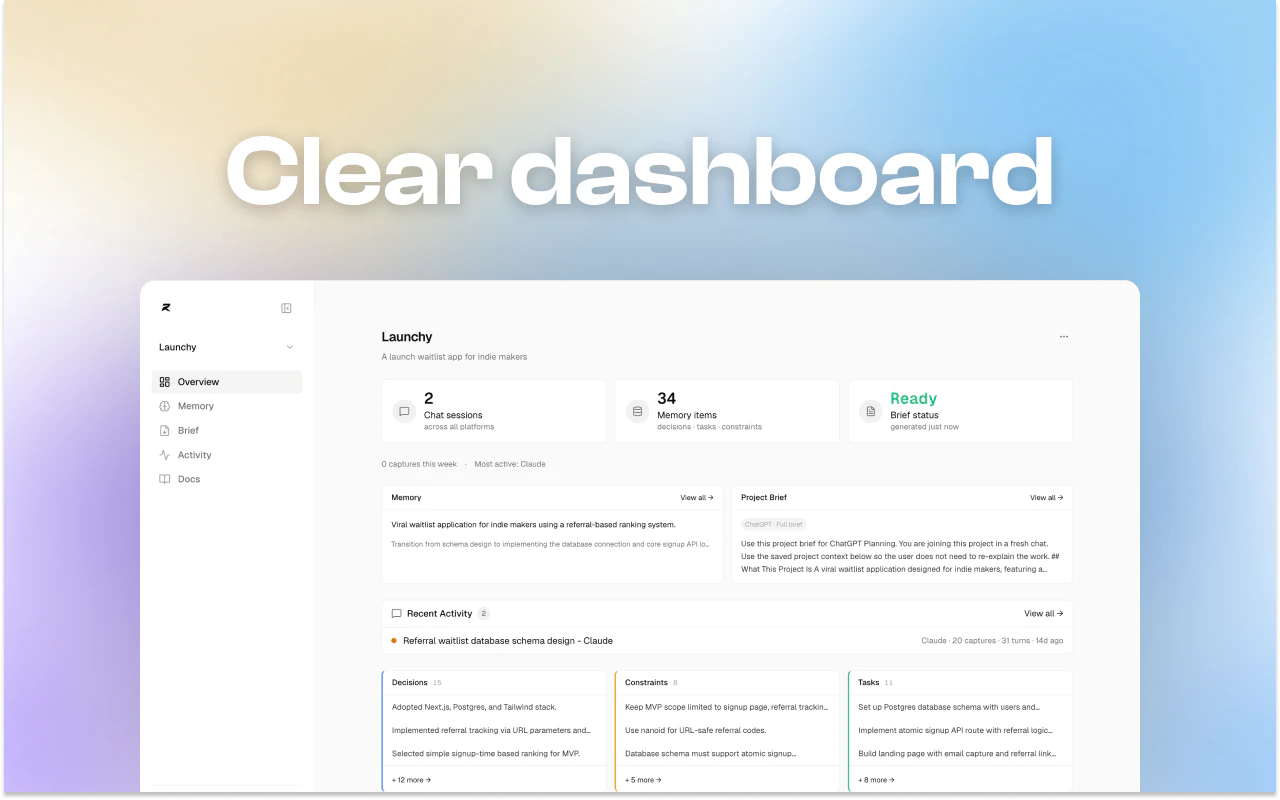
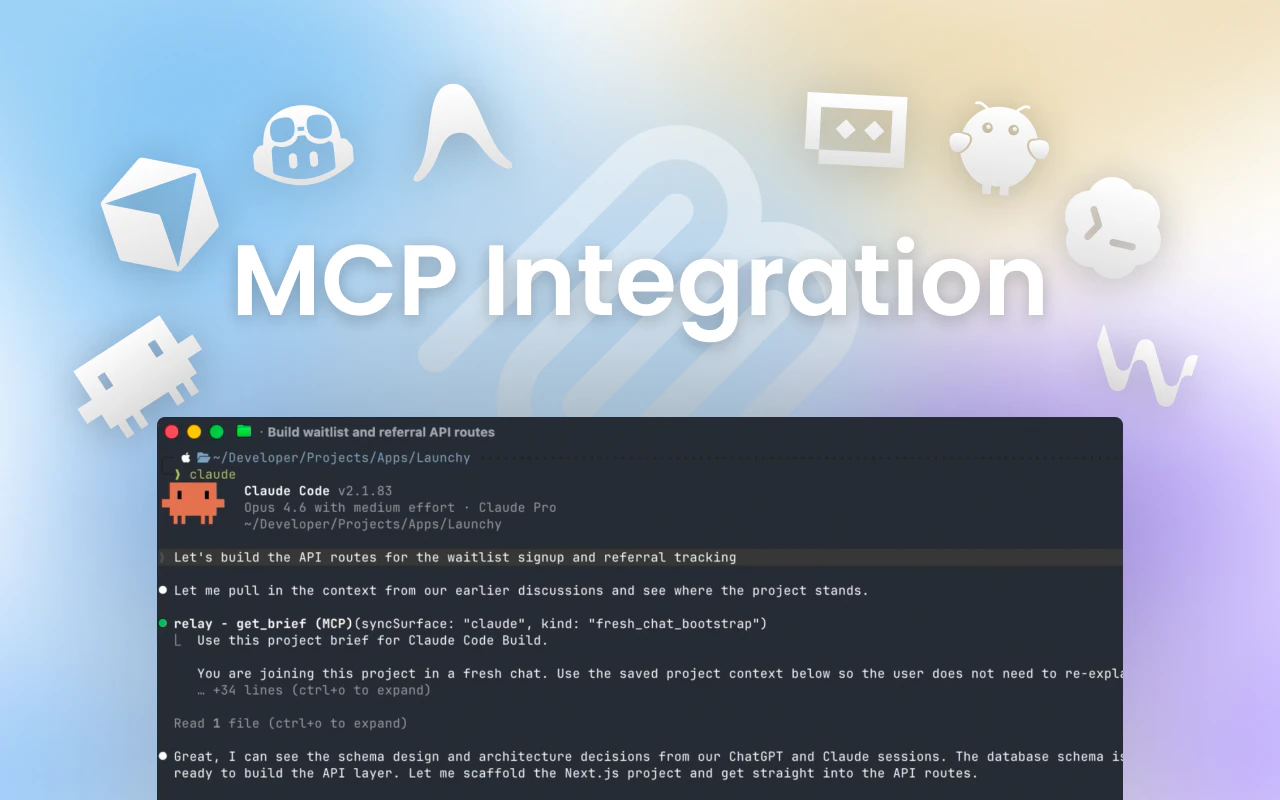
一句话介绍:Relay是一款AI上下文共享工具,通过在浏览器扩展和MCP协议支持下,让用户在不同AI聊天工具(ChatGPT、Claude、Gemini等)和IDE代理间自动同步项目简报,告别反复粘贴上下文的历史。
Chrome Extensions
Productivity
Developer Tools
Artificial Intelligence
Vercel Day
AI上下文管理
项目记忆同步
跨工具协作
MCP协议
开发者工具
浏览器扩展
生产力效率
AI工作流
用户评论摘要:用户痛点高度共鸣(切换AI工具需重复解释堆栈、架构等)。核心反馈:1. 需持久化堆栈、当前冲刺目标、关键架构决策等,遗忘随机调试和一次性问题;2. 关注上下文如何避免过时/矛盾,创始人回应将支持可检视和更新;3. 与手动维护Markdown文件方案的差异化在于跨工具同步和降低维护门槛。
AI 锐评
Relay切中了一个真实且高频的“AI摩擦”痛点:当AI工具从单点变成工作流矩阵时,碎片化上下文已成为显性生产力杀手。它本质上是在为“人-多AI”协作搭建一个轻量级语义传输层,其创新不在于技术复杂度(Chrome扩展+MCP协议),而在于对“非结构化记忆”的产品化封装。
但从评论反馈看,产品面临两大核心挑战:第一,记忆的边界管理。如何智能区分“值得持久化的项目知识”与“一次性的对话垃圾”?若全量同步,会迅速沦为噪音堆砌;若过滤不当,用户信任感将崩塌。创始人虽表示“不是只追加的日志”,但具体如何实现“可检视、可覆盖、自动过期”的智能简史,仍缺细节。第二,跨工具一致性与版本冲突。当ChatGPT、Cursor、Claude Code同时读写同一份简报,争用或覆盖逻辑如何处理?这是分布式系统一致性问题在产品层的投射,工程难度远高于一个简易同步器。
Relay的长期价值不在于做一个“更好的粘贴板”,而在于定义一种新的计算原语:AI协作中的持久化工作记忆。但当前阶段,它更像是“给健忘的AI们开了一场同步会议”,而非真正聪明地理解项目演进。对于重度多工具用户,值得一试;但若想成为刚需,Relay需要从“一个被动的记忆管道”进化为“一个有判断力的项目协作者”。
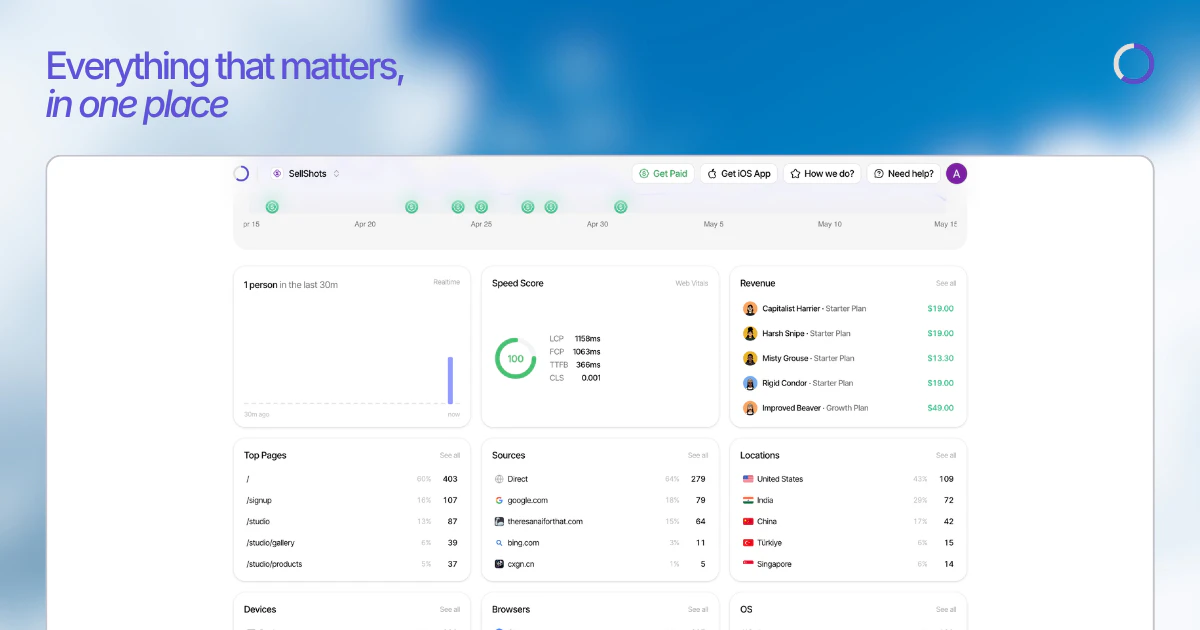
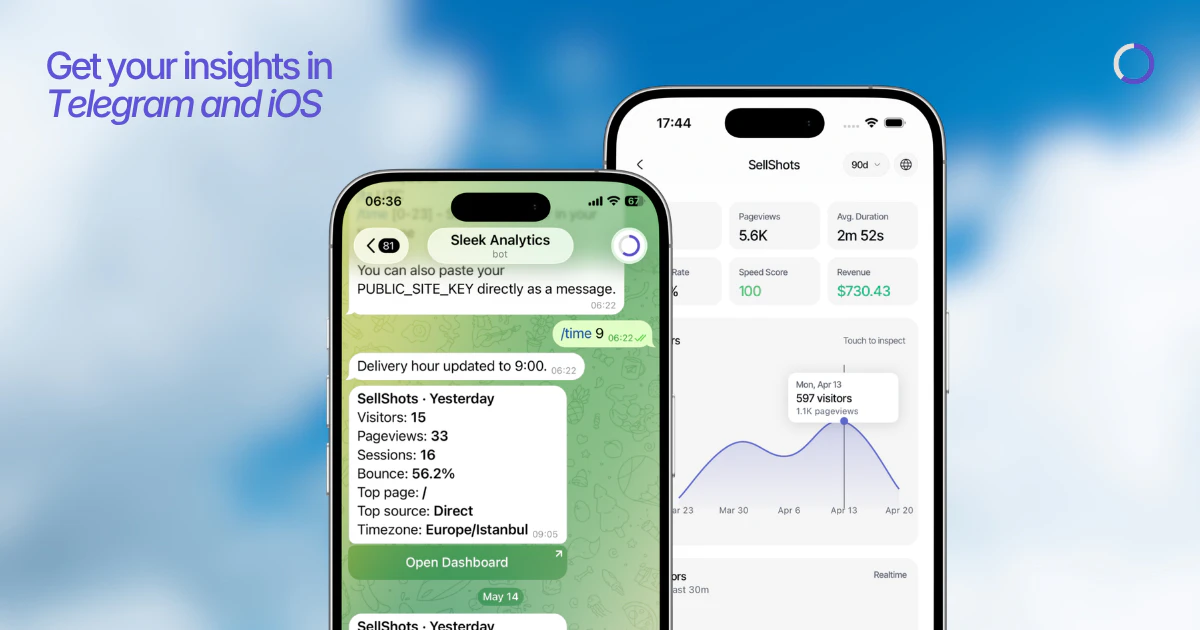
一句话介绍:Sleek Analytics v3 是一款即插即用的隐私优先网站分析工具,通过一行代码实现无Cookie实时访客追踪,解决现代网站主在合规与数据洞察之间的两难痛点。
Vercel Day
网站分析
Google Analytics替代
隐私优先
无Cookie追踪
实时数据
轻量级
用户行为
iOS应用
Telegram通知
Vercel部署
用户评论摘要:用户赞赏其极简UI和Telegram实时流量预警功能,并询问了自定义阈值与匿名访客追踪细节。开发者确认可设置访客数阈值避免通知疲劳,且默认追踪所有访客,用户标识为可选API功能。
AI 锐评
Sleek Analytics v3再次印证了一个趋势:产品价值不在于功能堆砌,而在于把“常用功能”做到极致。它精准切中了中小团队对Google Analytics“杀鸡用牛刀”的反感——庞大、复杂、且合规风险高。v3版本的核心升级(实时全球洞察、iOS App、Telegram日报)并非技术突破,而是场景补完,尤其Telegram告警功能,用极低门槛解决了小团队“无专职运营监控流量”的刚需。
然而,这种“极简”也是双刃剑。评论中缺乏对数据深度分析(如漏斗、归因)的追问,暗示其上限仍停留在“好看的数据可视化”层面,难以替代GA对于增长黑客的价值。另外,完全依赖Vercel Edge Functions虽然省去运维,但也绑定了技术栈自由度,对于有定制化需求的中型团队是潜在隐患。101票的成绩在PH生态中算中规中矩,说明它并未颠覆市场,而是在“隐私合规”这一细分赛道上稳扎稳打。其真正护城河在于对“无通知疲劳”的精细化设计(可调阈值),而非技术本身。对于只需要“看一眼就知道今天有没有人来看我网站”的创业者,这或许是比Fathom和Plausible更顺手的工具——前提是你接受它在高阶分析上的空白。
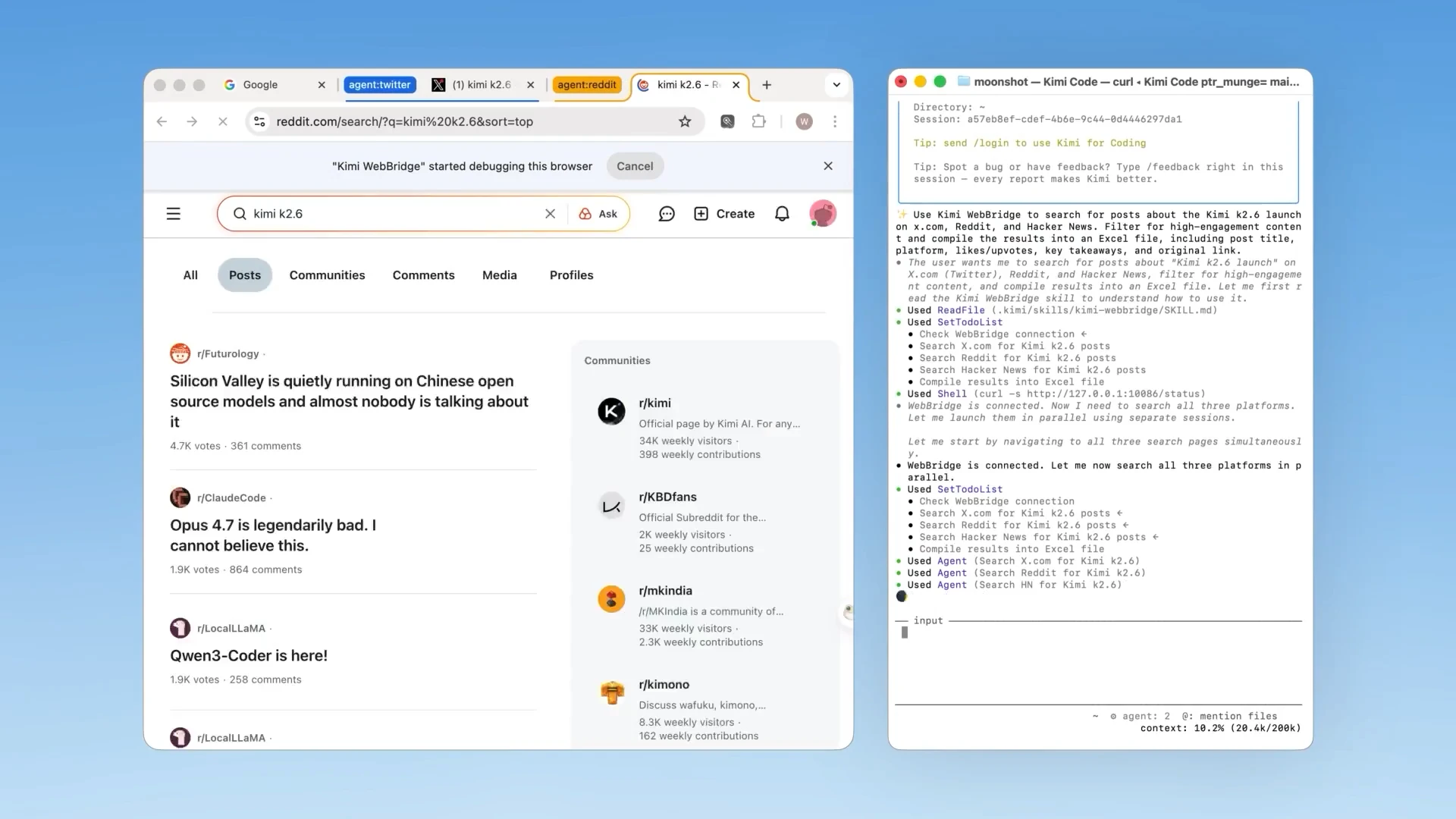
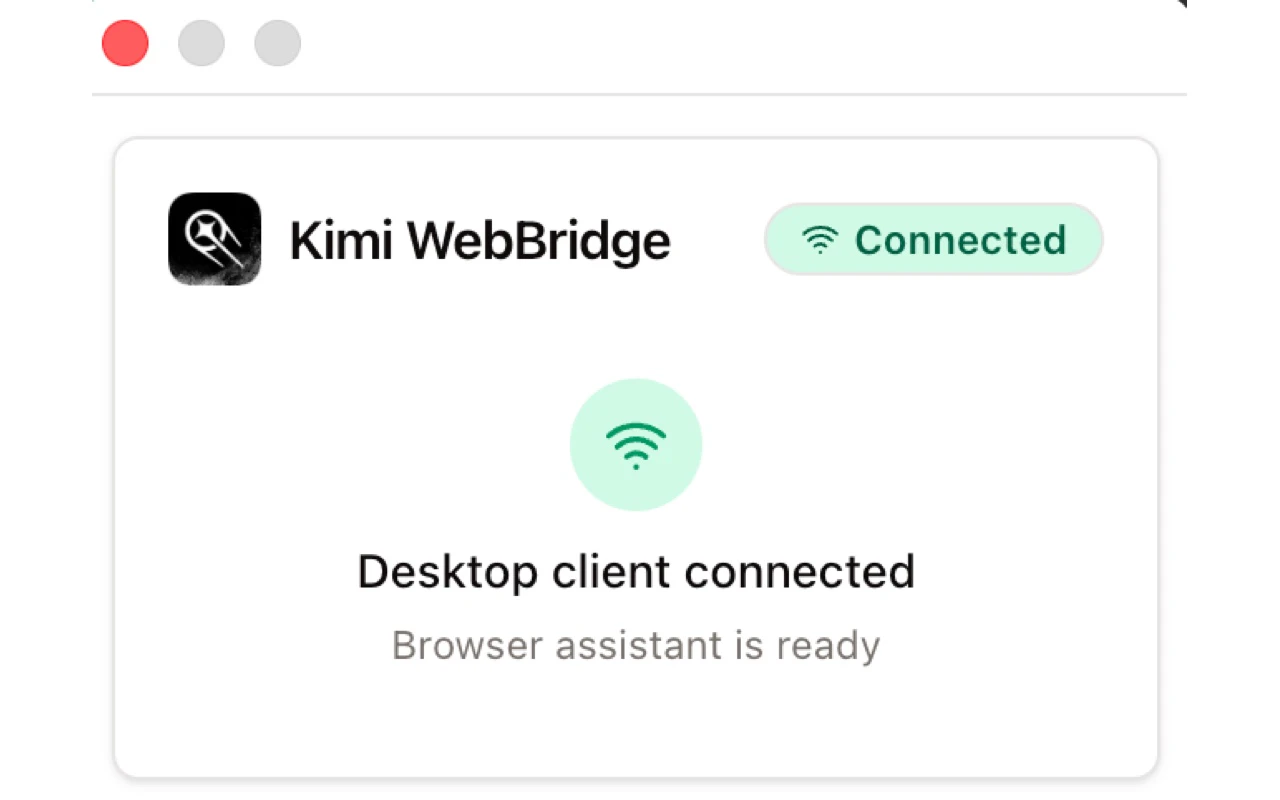
一句话介绍:Kimi WebBridge 是一款浏览器扩展,让AI智能体能够直接操控网页(打开页面、填写表单、提取信息),从而解决AI无法与真实网页交互的痛点。
Chrome Extensions
Artificial Intelligence
浏览器扩展
AI代理
网页自动化
浏览器控制
数据提取
本地优先
智能体工具
隐私安全
AI+浏览器
任务自动化
用户评论摘要:用户关注:1.是否需要保持浏览器会话常开;2.如何处理Shadow DOM和反爬机制;3.隐私安全,尤其敏感操作(如提交表单)是否有确认步骤;4.页面数据传递给LLM时是否结构化处理(JSON/精简DOM)以控制Token消耗;5.如何保障银行、医疗等敏感网站的数据隐私。
AI 锐评
Kimi WebBridge 切中了AI原生应用的“最后一公里”痛点——AI可以写出完美的代码和文本,却连一个网页的“登录按钮”都点不了。它本质上是用一个浏览器扩展,为终端AI代理(如Claude Code、Cursor)提供了一个挂载在真实浏览器上的“机械手”,这是典型的“本地优先”架构,看似笨拙,实则聪明。
**价值核心在于“信任”**:用户评论中最高频的关切是隐私和安全。Kimi WebBridge 选择让AI使用用户现有的本地浏览器会话,而非将Cookie交给第三方云服务,这一设计精准地化解了“AI代理是否偷传数据”的信任危机。在自动化效率与数据主权之间,它没有押注云端黑盒,而是坚持本地控制,这对企业级用户(银行、医疗、财务)来说几乎是唯一可接受的选项。
**技术挑战尚未解决**:评论区反复提及的“Shadow DOM”、“Token浪费”、“反爬检测”,直指产品技术深度的不足。如果只是将整个DOM树当作纯文本扔给LLM(大语言模型),那么对于富交互、高度动态的现代网页,Token消耗将天文数字般增长,且半结构化数据提取失败率极高。如果无法实现智能化的“DOM摘要”和“关键节点定位”,其实际可用性将大打折扣。
**市场定位的致命短板**:Kimi WebBridge 严重依赖第三方的AI代理(Claude Code、Cursor等),自身并无强大的基座模型或决策能力。它更像一个“工具链中的工具”,而非独立产品。一旦主流AI代理(如OpenAI、Google的Gemini)内置了类似的原生浏览器控制能力(通过更底层的Chrome DevTools Protocol等),Kimi WebBridge 的生存空间将迅速被挤压。在Web Agent这个赛道上,做“管道”的永远不如做“大脑”的利润高。
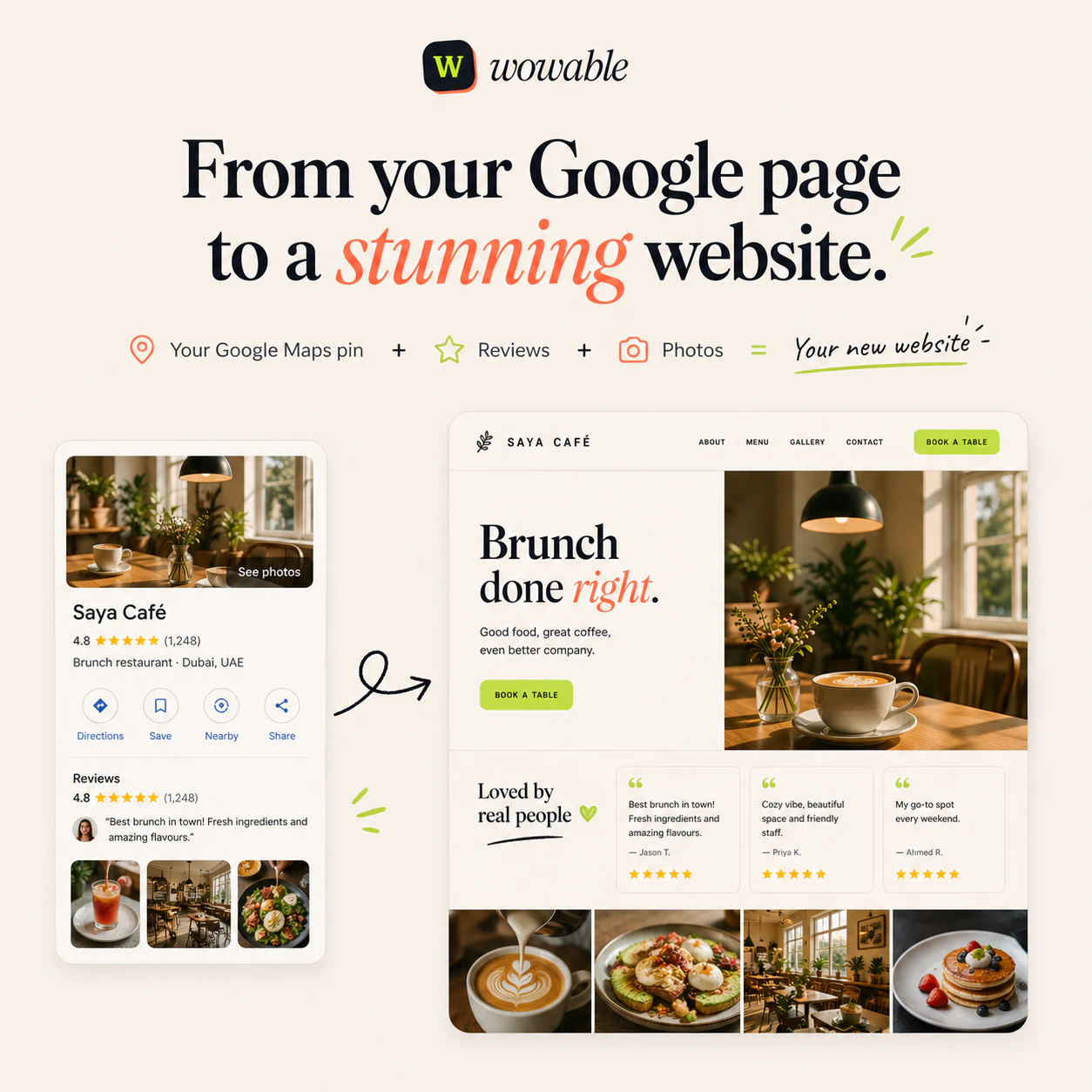
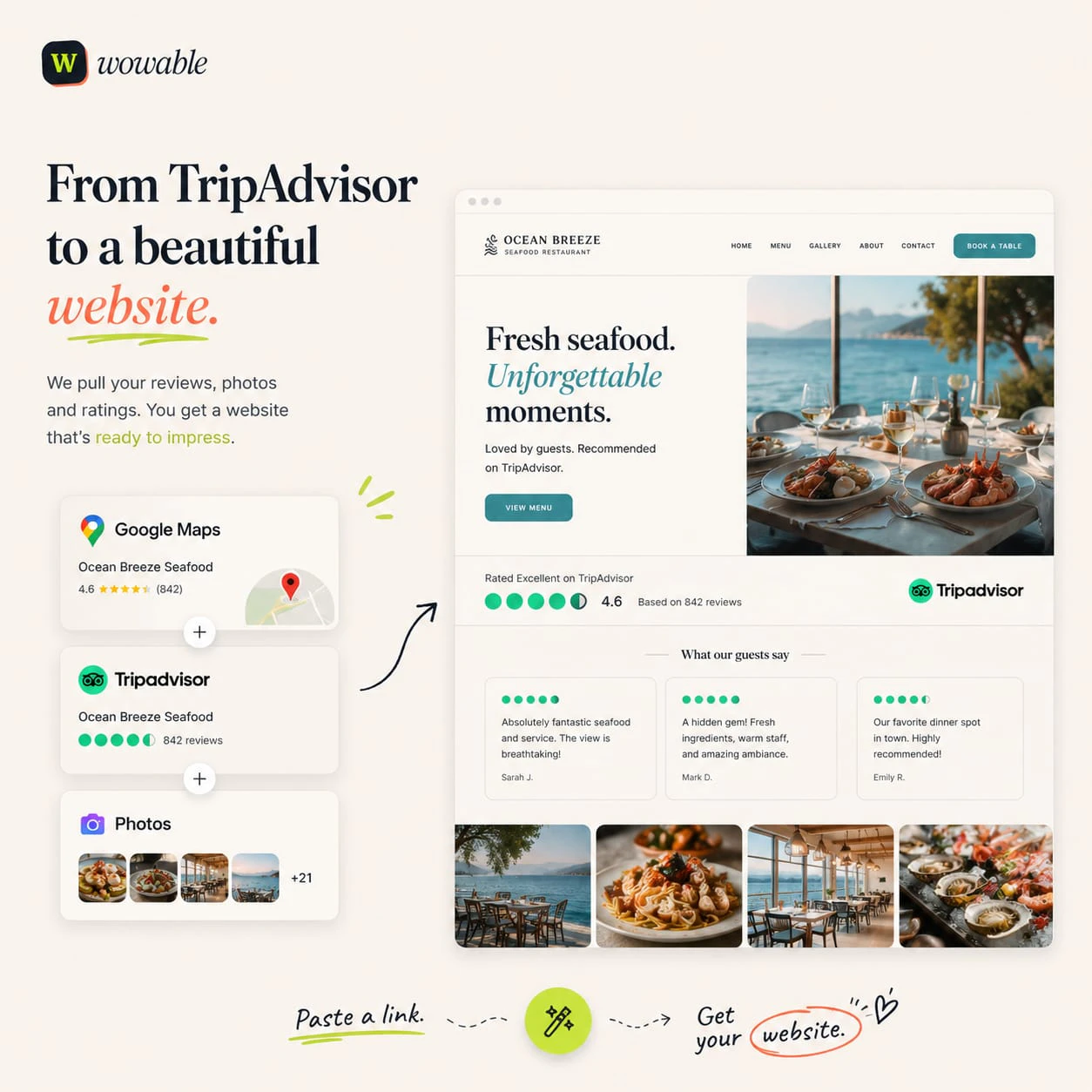
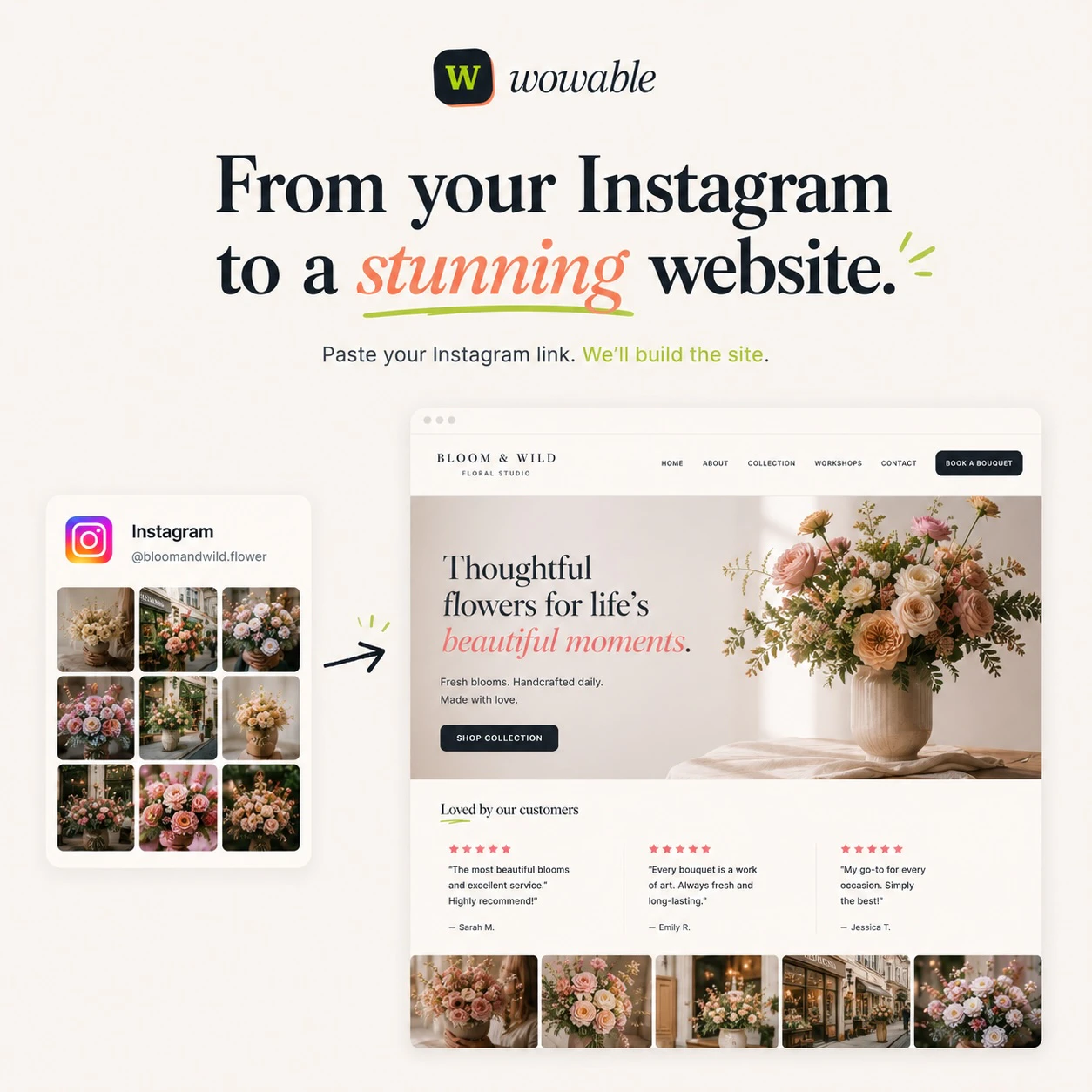
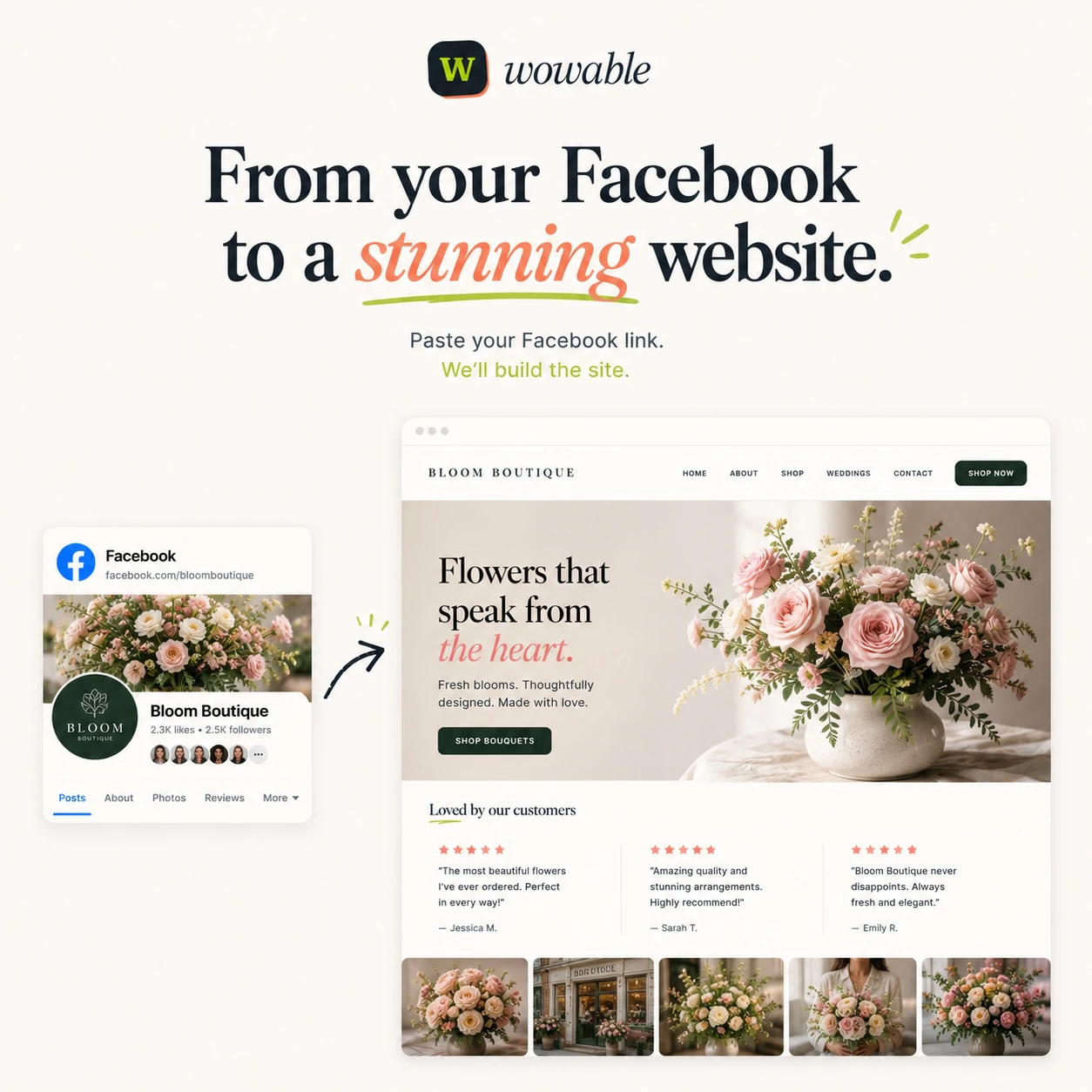
一句话介绍:Wowable允许用户粘贴Google Maps、Instagram、TripAdvisor等现有商业链接或截图,无需编写和设计,即可在1分钟内自动生成一个真实、专业的营销型网站,解决小企业因时间成本高而缺乏线上形象的核心痛点。
Website Builder
Artificial Intelligence
No-Code
AI网站生成
小企业建站
内容聚合
商业资料转化
无代码建站
本地商家工具
社交媒体集成
SEO优化
移动端适配
自动化营销
用户评论摘要:用户普遍认可其效果真实、布局清爽,尤其对TripAdvisor、LinkedIn等内容源的转化准确度感到惊艳。主要建议和疑问包括:如何避免生成网站风格同质化(如自动检测Logo和主题);如何处理多平台内容源的合并与冲突;以及未来是否会增加锁定特定区域防止AI覆写的功能。小商家对“无需编写”和“从已有内容出发”的定位高度赞赏。
AI 锐评
Wowable在“AI建站”这片红海中,确实找到了一条相对聪明的差异化路径。它没有去比拼谁家的“大模型文笔更流畅”(那终究是卷废话),而是回到了商业本质:把事实搬上网站。当竞品还在教用户“如何写提示词”时,Wowable已经默认用户没时间写,直接去Google Maps和TripAdvisor上扒用户的好评和照片来用。这个“从内容反推网站”的思路,实际上是踩中了小商家最痛的痛点——不是不想要网站,而是不想从头编造一篇关于自己的官网文案。
然而,产品的护城河目前来看并不深。评论区有人直接点出了核心隐患:“相似的设计主题”和“多源信息的冲突处理”。目前Wowable更像是一个精巧的“内容搬运搭架子器”,还远未进化到“品牌识别”的层次。如果它不能在未来三个月内,基于数据提炼出更个性的配色、字体和版式(比如从上传的照片和Logo中学习视觉风格),那么它很容易被具有更强多模态理解能力的大厂(如Wix或Squarespace的AI助手)直接复制。
另一个值得关注的潜在风险是SEO。虽然团队声称网站结构良好,但从第三方来源(如TripAdvisor)聚合的内容,其原创性和独特性在搜索引擎眼中可能大打折扣。对于以“获取更多客户”为目标的商家,如果生成的网站最终只是一个内容中台,而不能产出独特的、第一手的价值内容,那么它在AI搜索(如ChatGPT)时代的可见性并不会比原有的TripAdvisor页面更好。
总的来看,Wowable是“AI降低建站门槛”的一次极佳实践,但若要从小工具进化为商业基础设施,它必须解决“从有到优”——即从有内容到有真正差异化品牌资产——的难题。目前它值得小商家一试,但不要指望它能替代你为自己的生意倾注的思考。
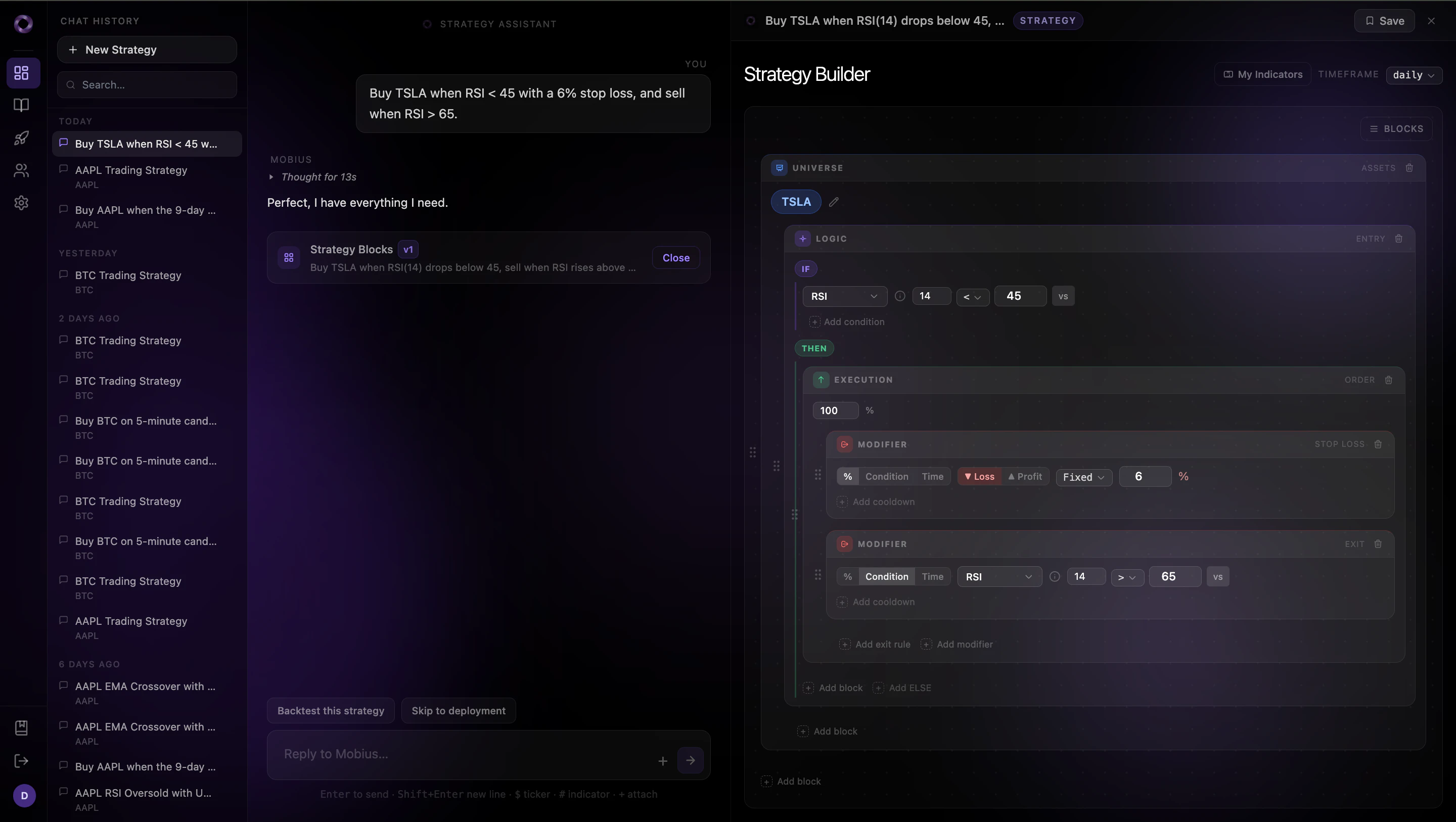
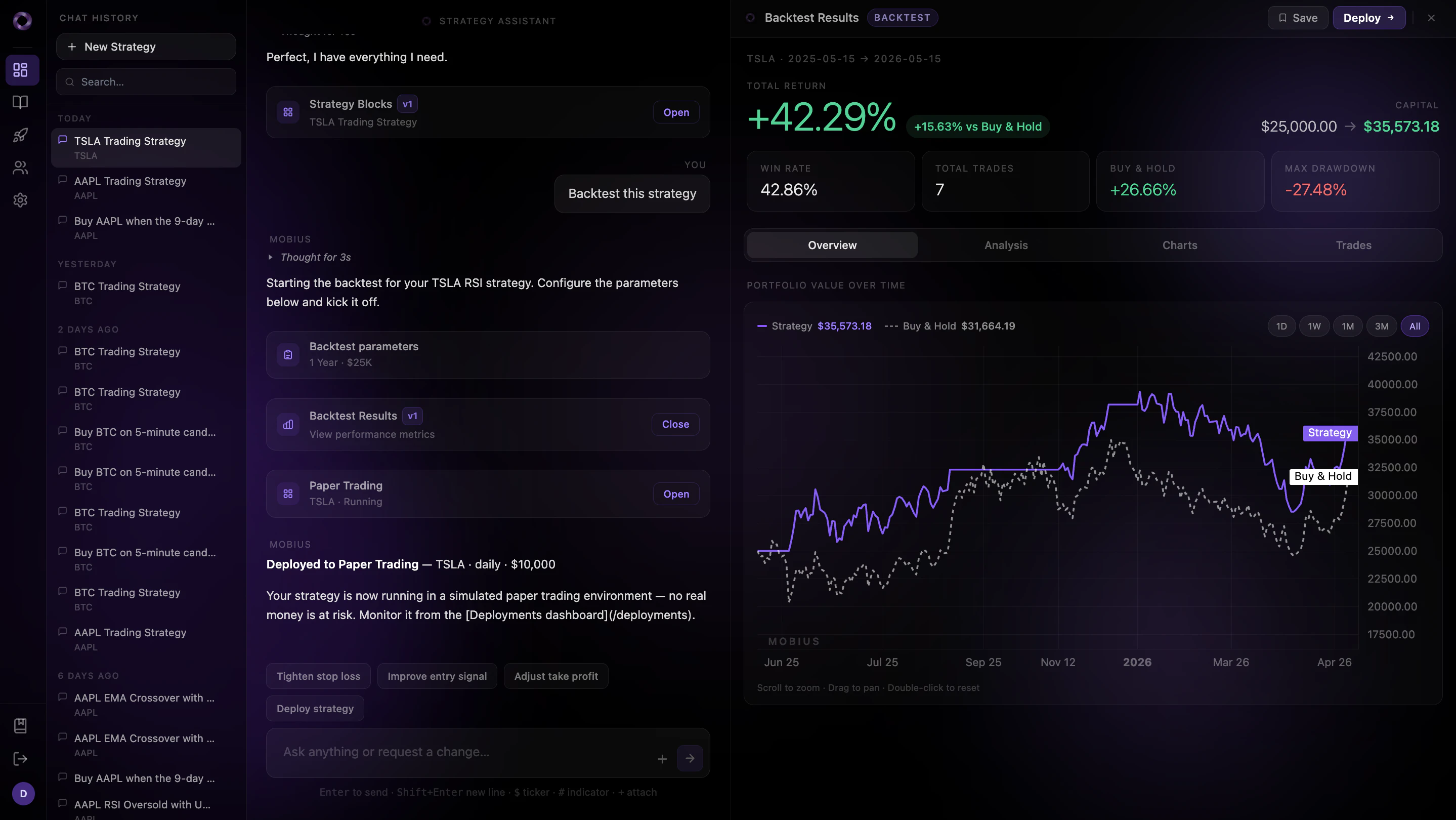
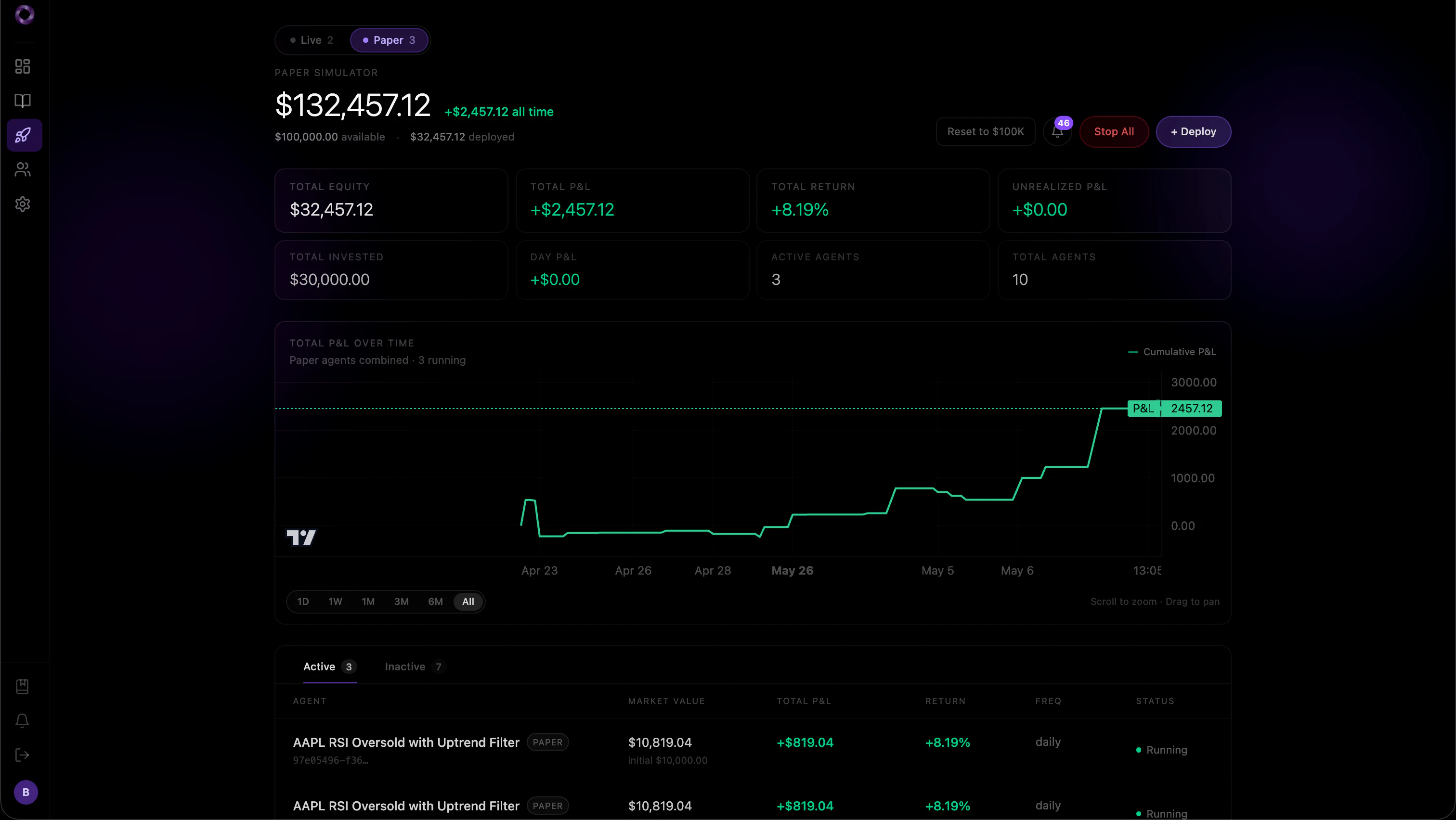
一句话介绍:Mobius将散户用自然语言描述的量化交易策略,自动转化为基于真实市场数据和另类信号(如国会交易、暗池、Reddit情绪)的回测与实盘交易机器人,极大缩短从想法到执行的时间差。
Fintech
Artificial Intelligence
Vercel Day
量化交易
自然语言策略
回测
交易机器人
另类数据
散户工具
自动化交易
AI代理
无代码
执行速度
用户评论摘要:用户高度关注回测参数的控制力(如是否可指定特定波动事件测试),以及策略过拟合的防护机制。多位用户对“国会交易追踪”功能表现出强烈兴趣,核心痛点是数据获取到执行之间的延迟。也有用户建议优化用户体验,如保存草稿。
AI 锐评
Mobius切中了一个非常具体且高价值的痛点——“量化交易最后一公里”的笨重与延迟。它没有试图创造新的策略逻辑,而是革命性地简化了“执行路径”。其核心价值不在于策略构建(这仍是用户的任务),而在于将“想法-数据-回测-实盘”这四步从数天压缩到数分钟,并整合了部分深藏在贝壳里的另类信号(国会交易、暗池)。这种“策略即服务”的范式,本质上是为散户提供了一种“量化能力平权”,扫清了此前只有机构才能负担的技术栈和数据处理成本。
然而,风险同样集中。其一,“从一句话到盈利策略”的幻灭感——用户的朴素语言极易导致隐性过拟合(如“买涨时买入”这种无意义条件),若不加入治理层(如最小数据要求、统计显著性检查),该工具将成为噪音生成器。评论中用户也精准点出了此问题。其二,另类数据的时效性与可靠性问题(如Reddit情绪可否量化?),若信号滞后,工具反而成为反向指标。其三,对Alpaca单一券商的依赖是脆弱性,且实盘执行延迟、滑点等真实交易摩擦可能被简化。
整体上,Mobius是一个极其出色的“执行层”产品,但离“可靠交易系统”仍有距离。它若能增设策略质量评分、风险控制阈值(如最大回撤自动停用),并开放数据源验证,才可能从“有趣的玩具”进化为“散户的私募一号”。其商业模式的发展也将依赖交易量的分成还是订阅制,值得关注。
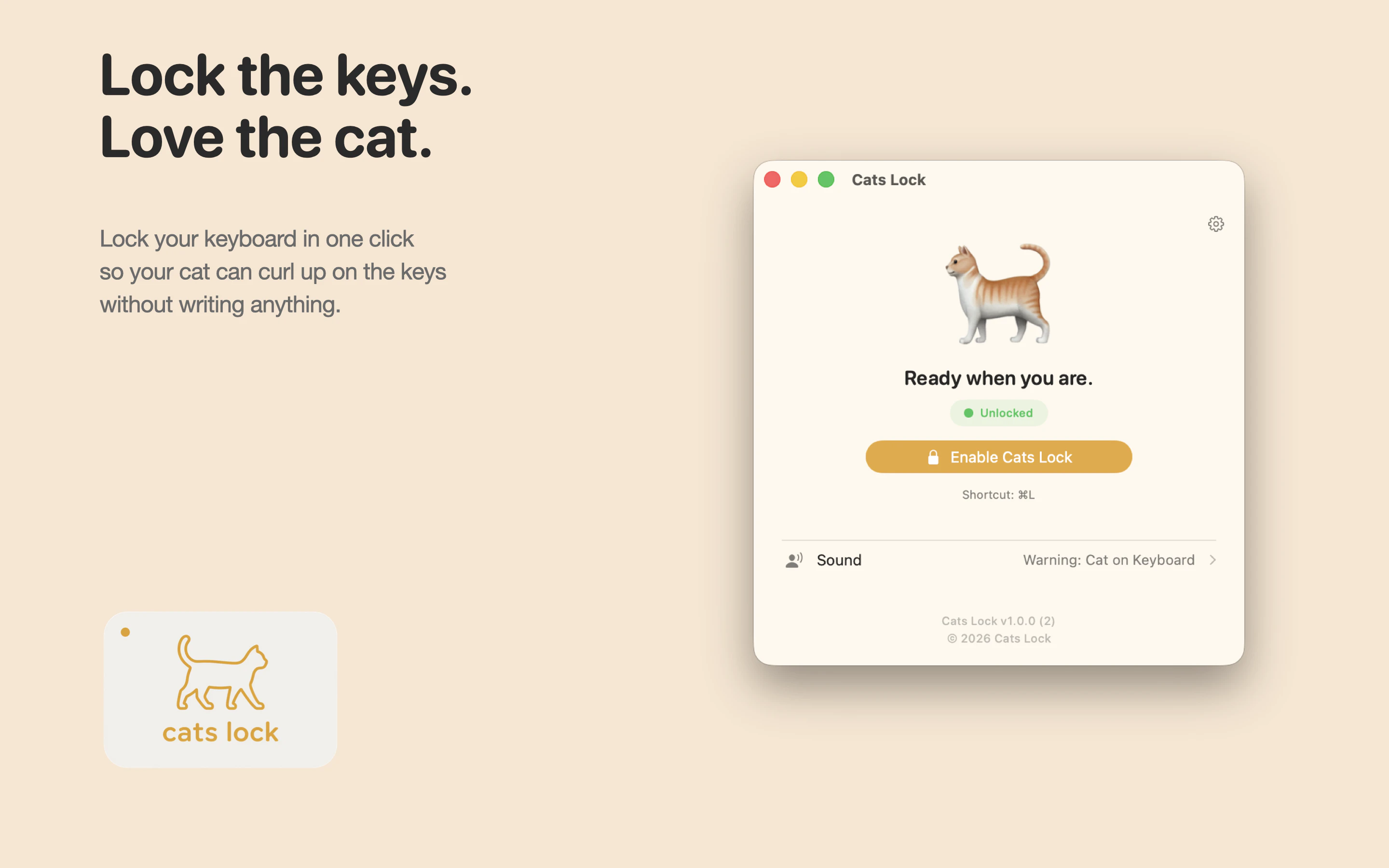
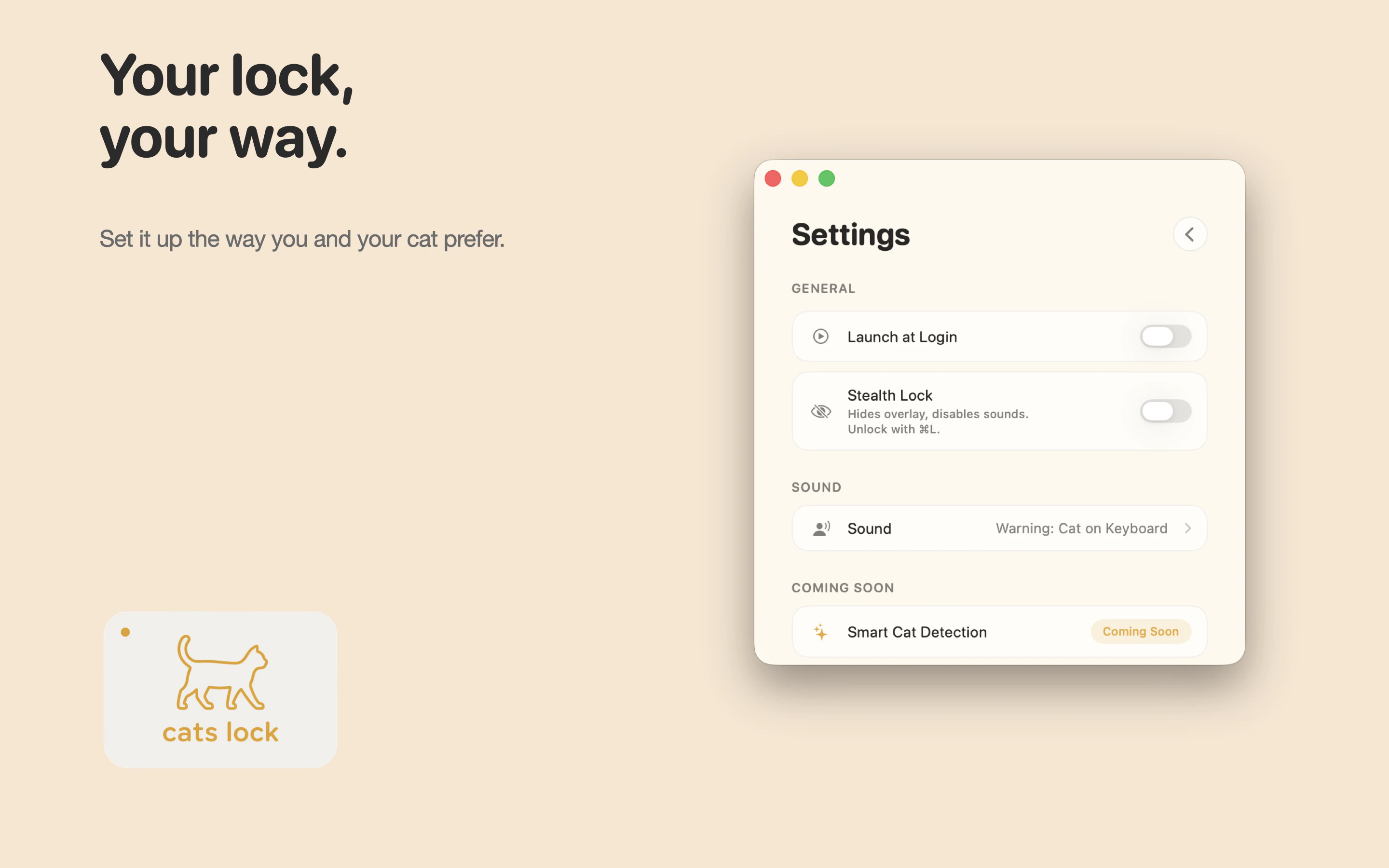
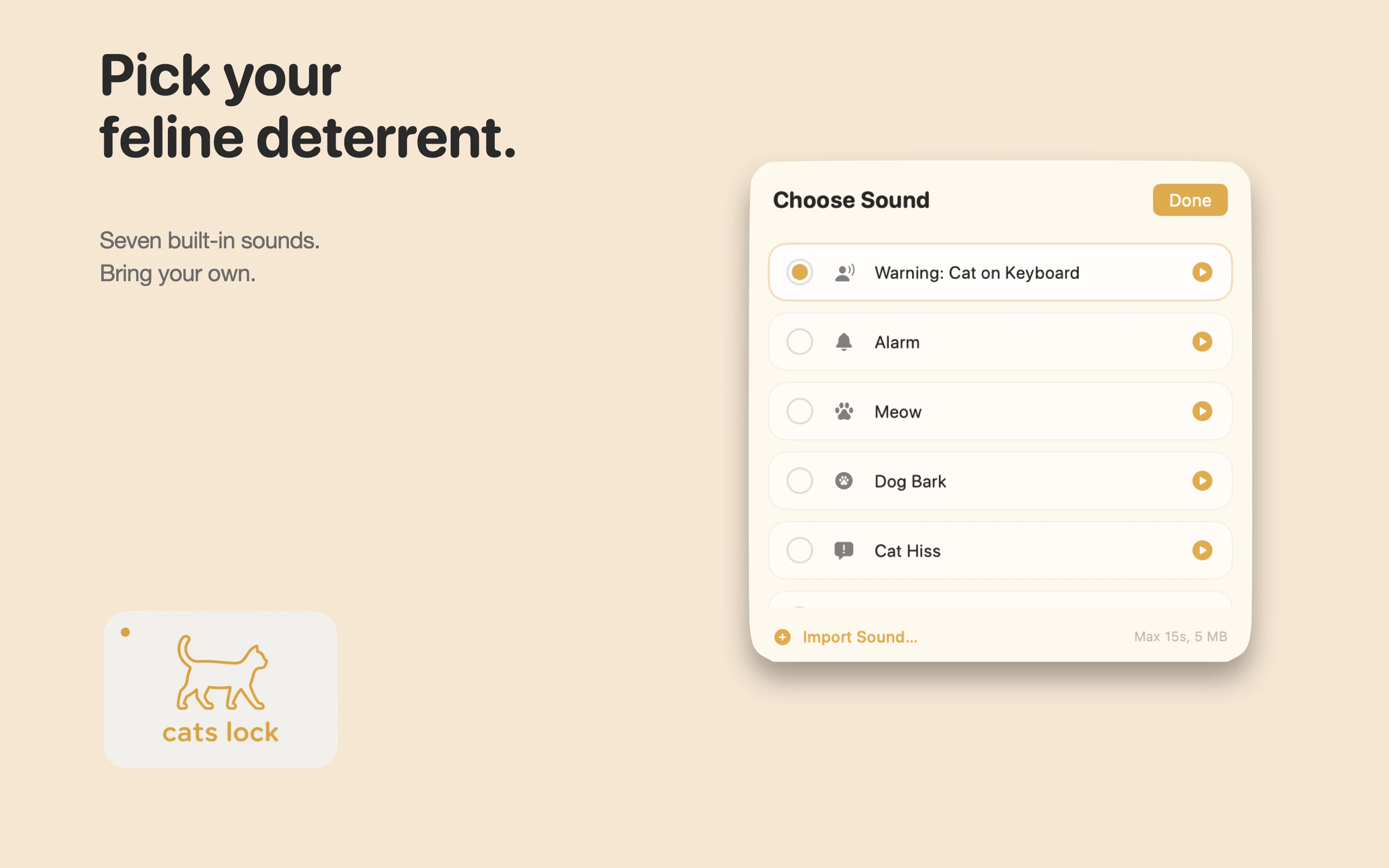
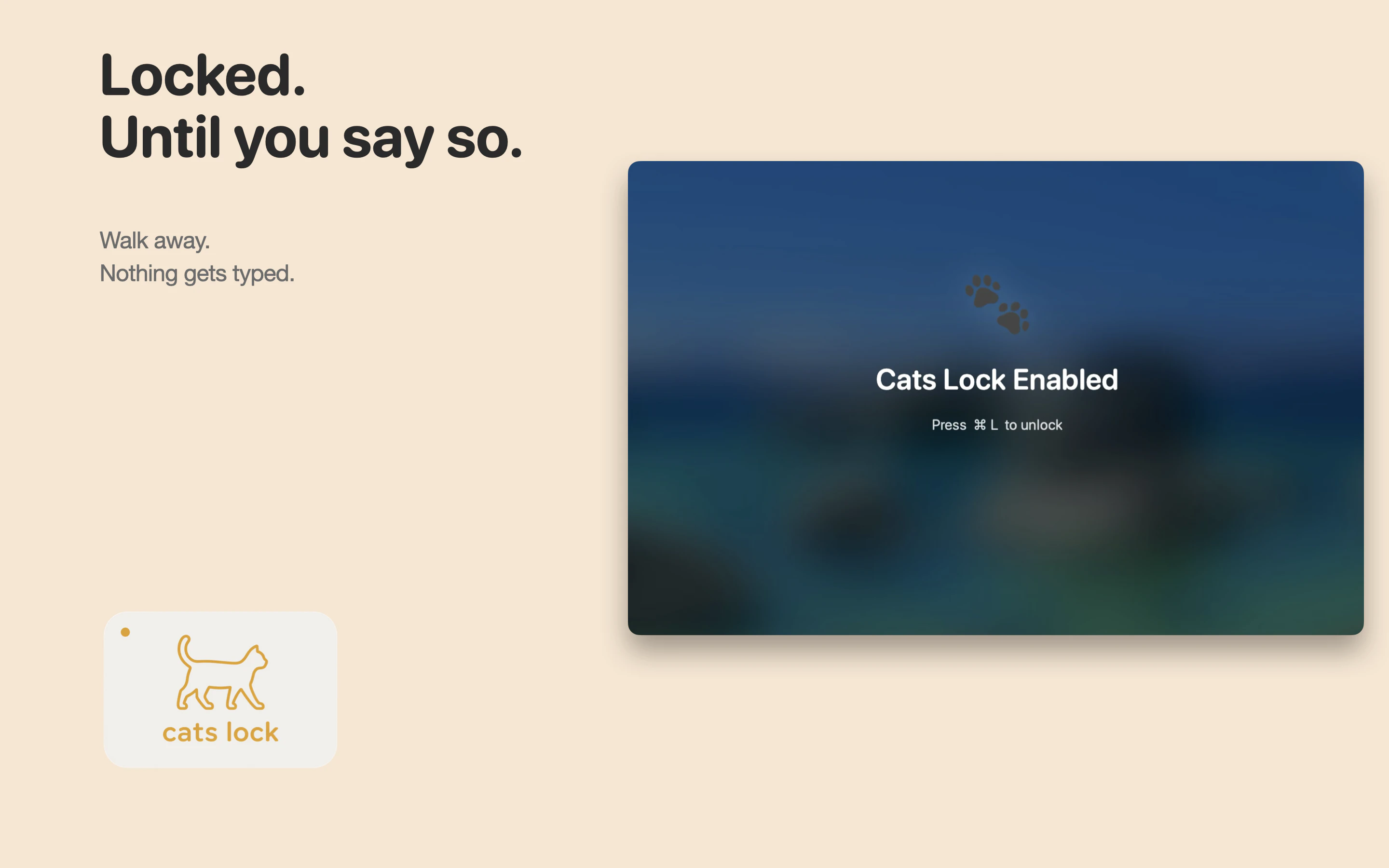
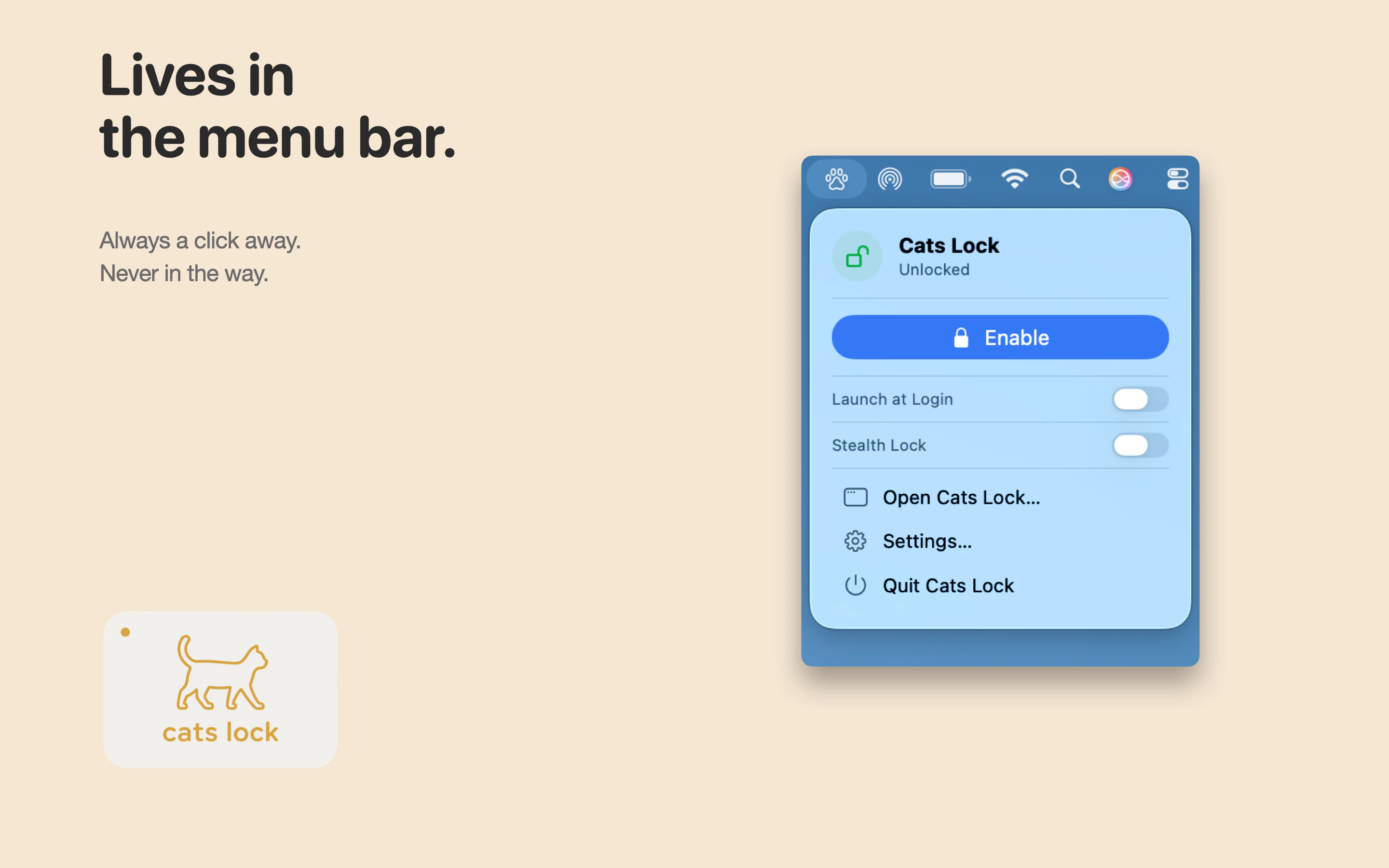
一句话介绍:Cats Lock 是一款专为养猫人士设计的 Mac 键盘锁定工具,能在猫咪踩踏键盘时一键禁用输入,避免工作会议或通话中因乱码造成的社死现场,并支持静默隐身模式与自定义提示音。
Mac
Cats
Vercel Day
macOS 工具
键盘锁定
猫主子
防打扰
独立开发
付费应用
生产力工具
宠物场景
一次性付费
用户评论摘要:用户普遍认可其精准解决养猫痛点,有人戏称“该预装在macOS中”。一位网友建议增加趣味“猫模式”(如屏幕动画),开发者已纳入1.1版本计划;另有人担忧强制锁定期间若系统崩溃会有风险,但整体反馈积极,无严重负面评价。
AI 锐评
Cats Lock 是一款典型的“小而美”独立开发作品,其聪明之处在于将一个废弃代码级别的“禁用键盘”功能,重新包装为一种养猫场景下的社交货币。89票不算高,但评论区充满共鸣与“想买”情绪,说明它精准刺中了一个被大厂忽视的细分需求:不是怕键盘脏,而是怕猫在领导面前替你发言。
从产品设计看,Stealth Lock(静默隐身模式)和自定义警告音两个功能显露出开发者对场景的深度理解——前者解决会议中的体面问题,后者让“猫在敲字”成为可感知的幽默信息,而非灾难。$2.99 一次付费、无订阅、无分析追踪,在当下 SaaS 泛滥的环境里,本身就是一种克制且自信的产品态度。
不过,坦诚地说,这仍是一款“单点解决方案”而非“系统级生态”。技术上几乎没有壁垒(禁键的核心 API 任何开发者都能调),用户粘性完全依赖于“养猫”这一恒定变量。一旦系统开放类似功能(如 macOS 内置宠物模式),它的护城河就只剩一个好笑的名字和一段真诚的作者故事。
它值得被推广,但不值得被神化。它是某个程序员给猫写的情书,恰好也卖了给其他铲屎官。
一句话介绍:Picsart MCP通过一个统一接口连接140+AI模型,让创作者无需切换工具即可用自然语言完成图像、视频和音频处理,解决多工具切换与操作复杂性的痛点。
Android
Design Tools
Marketing
Artificial Intelligence
AI视频编辑
图像生成
音频处理
MCP服务器
统一接口
创作效率
自然语言交互
批量处理
多模型集成
Picsart
用户评论摘要:用户关注AI视频编辑功能,询问演示视频是否由Picsart制作。另一用户提出批量处理需求(如YouTube缩略图多版本生成),认为逐一操作低效,希望用于A/B测试,体现对工作流优化的迫切期望。
AI 锐评
Picsart MCP的价值在于“去中介化”——它试图消灭创作者在多工具间跳转的摩擦,通过MCP协议将140+模型封装成一个“黑箱”,只留自然语言作为入口。从产品逻辑看,这种“一键调用”确实能改善轻度用户的体验:省去了学习各工具界面的成本,让AI直接理解意图并选择模型,尤其适合快速产出短视频、封面图等高频简单需求。
然而,问题同样明显。首先,“140+模型”听起来强大,但实际是“广度”而非“深度”。用户评论中提到的“批量处理”恰恰暴露了核心短板:当创作者需要精细化控制(如指定输出尺寸、风格一致性、批量参数微调)时,单纯的自然语言指令可能不够精确。其次,MCP服务器依赖联网调用,对网络延迟敏感;而视频和音频处理对算力要求极高,若本地化支持不足,体验会大打折扣。更关键的是,Picsart本身并非模型训练方,其“统一接口”的本质更像是一个聚合中间件——这意味着它受限于上游模型的能力上限,且难以提供差异化原生功能。对于那些追求极致效果的专业人士(如需要逐帧调整或特定风格迁移),MCP的“自动化”反而可能成为束缚。
说白了,这个产品的目标用户并非硬核创作者,而是“想做但不想学”的轻量级用户。它解决了“能做什么”的入口问题,但尚未解决“做好”的工程化难题。如果后续能开放参数接口、支持本地模型扩展、并引入工作流编排(如预设输出规范),才真正有资格成为专业工具箱。否则,它大概率会沦为又一个“玩具级”聚合器——热闹,但不持久。
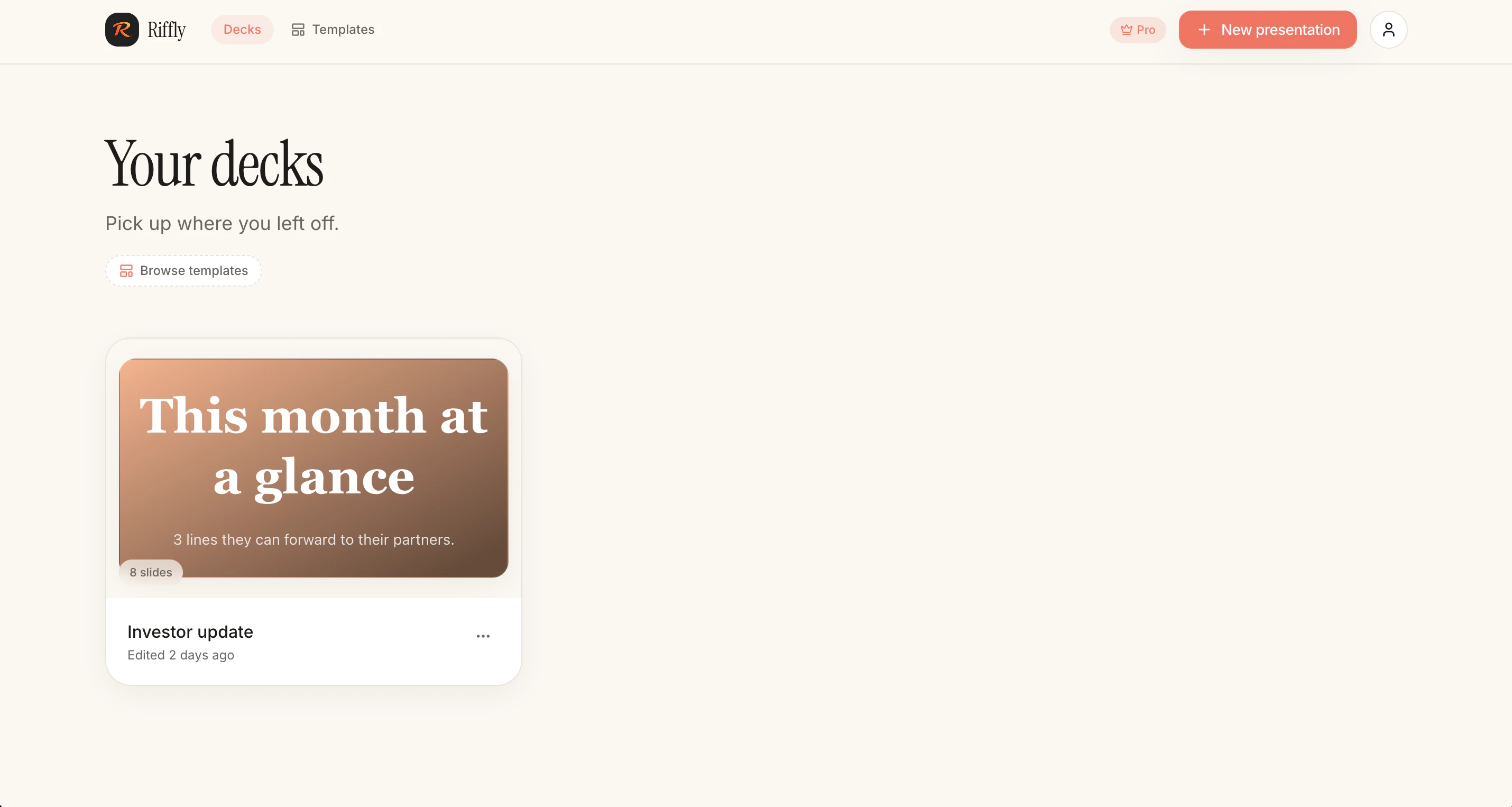
一句话介绍:Riffly是一款通过自然语言对话即可快速生成完整演示文稿,并直接导出为可编辑PowerPoint文件(pptx)的AI工具,主要服务于需要高频制作专业提案、课件和客户演示的职场用户,解决传统演示工具操作繁琐、制作耗时的问题。
Productivity
Artificial Intelligence
YC Application
Vercel Day
AI演示文稿生成
对话式编辑
PowerPoint导出
销售提案
客户提案
教师课件
专业设计
效率工具
企业工作流
Claude AI
用户评论摘要:用户高度认可“真实.pptx导出”功能,因为其他AI工具仅输出专有链接或静态PDF。核心疑问集中于:chart在导出后是否保持可编辑(当前为静态,正在规划)。企业用户关切品牌模板和颜色、字体等品牌套件支持(已纳入路线图)。开发者明确付费壁垒来自高频用户,如每周需制作提案的销售和顾问。
AI 锐评
Riffly没有在“生成幻觉”上竞争,而是精准切中了企业办公的“最后一公里”——**可编辑的输出**。这比Beautiful.ai们高了一个段位,因为后者制造的“漂亮垃圾”在需要实际修改时立刻破功。核心价值在于:将AI从“一次性的灵感喷射器”变成了“可被人类精修的协作助手”,这背后是对“办公室政治”的深刻理解——老板永远会在最后一秒改一个数字,而那个数字需要一个真实的文本框。
但风险在于:这本质上是一个AI封装层,底层模型依赖Claude,导出逻辑还原PowerPoint对象。护城河不深,一旦微软在Copilot中原生实现同等级别的“对话式构建+原生编辑”,Riffly将面临降维打击。目前的免费3次/月更像一个钓鱼钩,其高频场景(销售、顾问)极其垂直,意味着获客成本不低,且用户迁移成本主要取决于PPT原生功能的还原率——比如图表可编辑性,如果久拖不决,将严重削弱“板房级信任”。
一句话:这是**一名优秀PM对“真需求”的精准定位**,但技术和生态壁垒薄弱。除非能迅速吃掉小而美的付费高频用户群,并在“AI+PPT”的纯粹编辑体验上做到极致,否则终究是巨头的养料。
一句话介绍:Basedash MCP Connectors 让AI代理在聊天界面中安全地跨数据库、SaaS工具执行读写操作,终结数据孤岛与手动流程。
Artificial Intelligence
Data & Analytics
Business Intelligence
AI代理
MCP服务器
数据库集成
SaaS工具连接
自动化工作流
读写双向控制
审批控制
企业级代理
产品猎手
低代码运维
用户评论摘要:用户赞赏“需要审批”的默认权限设计,认为它让AI代理在生产系统中可信可用。有用户关心跨系统流程中断后的错误处理机制(如回滚、通知、重试)。团队答复称代理可读取错误并自动重试,审批机制支持所有MCP服务器。
AI 锐评
Basedash MCP Connectors的价值并不在于“又多了一个AI聊天机器人”,而在于它终于把“读”和“写”这两层权力在安全边界内统一给了代理。过去一年,大多数AI数据库工具只能当“高级查询器”,读数据、画图表,但行动仍依赖于人的手动触发——这种半截子自动化本质上是给焦虑的开发者多配了一个秘书,而不是给组织装上一套能自动执行决策的神经系统。MCP Connectors的杀手锏是“审批门控”设计:默认状态下每个工具操作都需要人工确认,用户可以基于信任逐步解锁“始终允许”。这个细节看似保守,实则是让代理真正进入生产环境的唯一通行证——没有它,任何写入系统行为的代理都注定被困在Demo里。同时,支持自定义MCP服务器意味着它不锁定于预设SaaS生态,任何内部API、遗留系统都能成为代理的行动臂膀。从用户评论看,最令人兴奋的用例不是单点操作,而是“读取数据库判断本周活跃用户→自动发邮件→更新CRM字段”的多步链式流程,这恰恰是传统低代码平台做起来吃力、但自然语言代理天生擅长的。不过,真正考验还在现实:多系统事务的原子性如何保证?当Linkdin写入失败而邮件已发出时,基于错误重试的逻辑是否足以避免脏数据?这很可能比审批门控更决定产品上限。但无论如何,Basedash这一步让“代理即操作系统”的愿景跨过了从“娱乐”到“实用”的门槛。

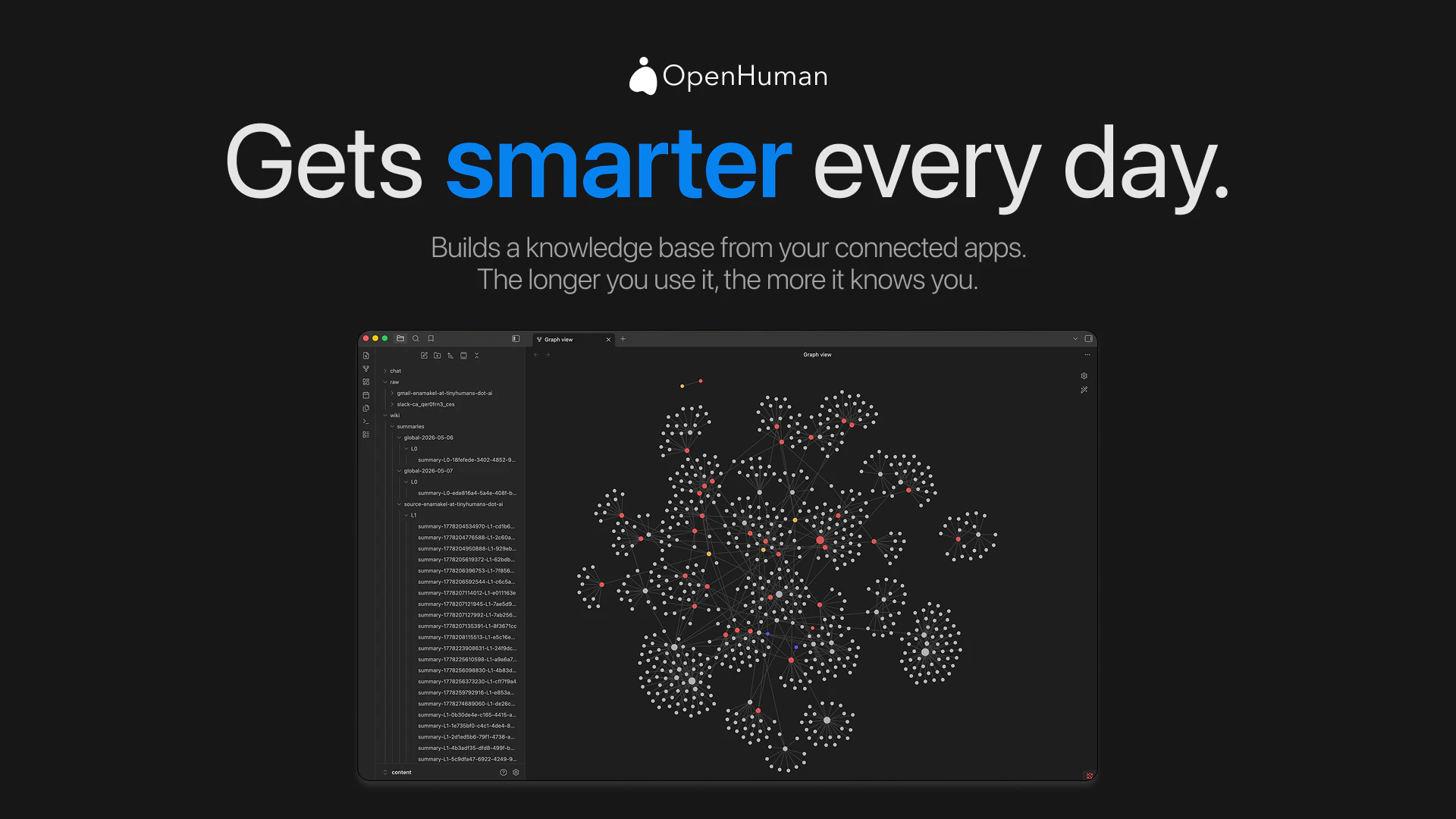
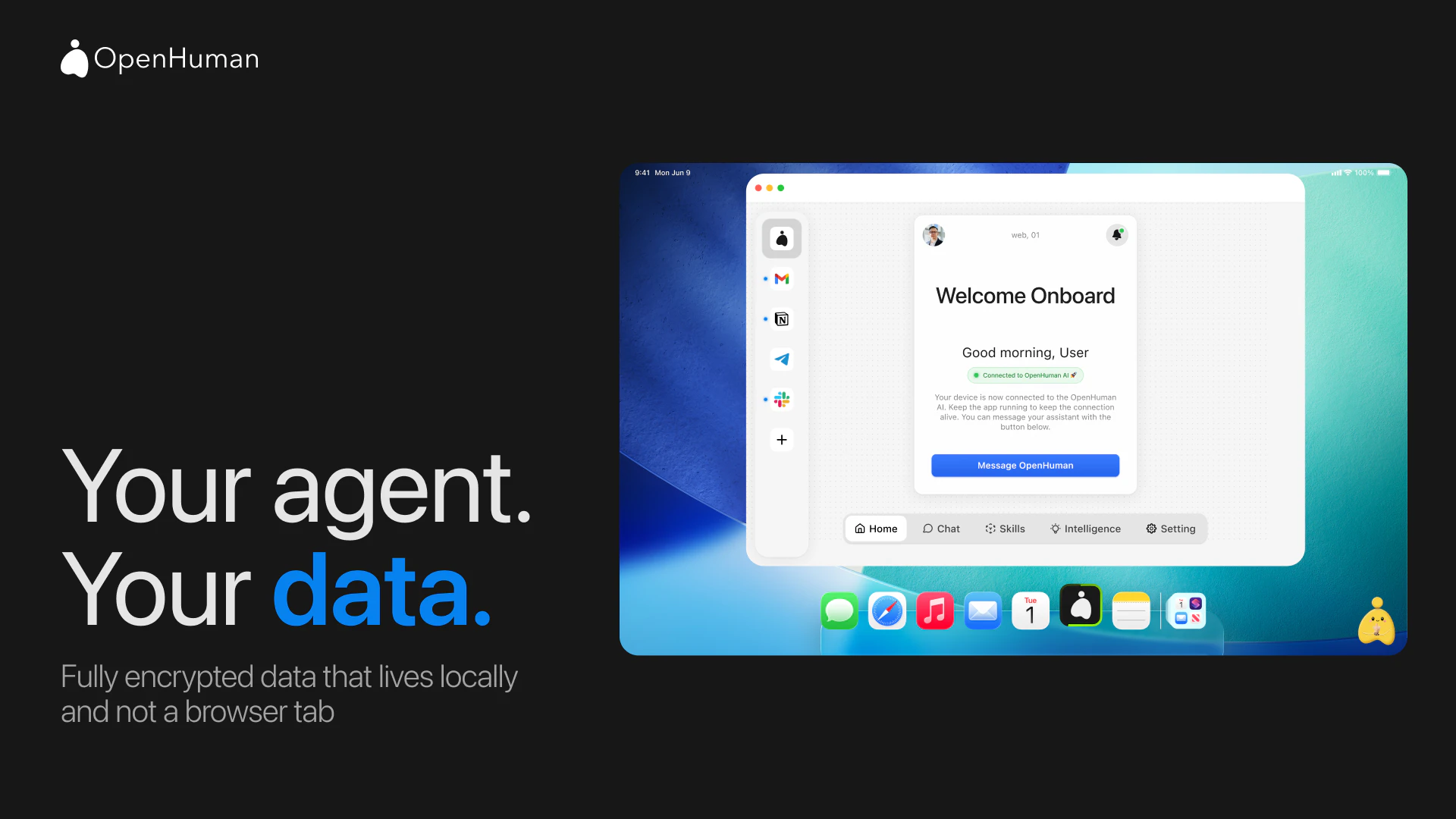




























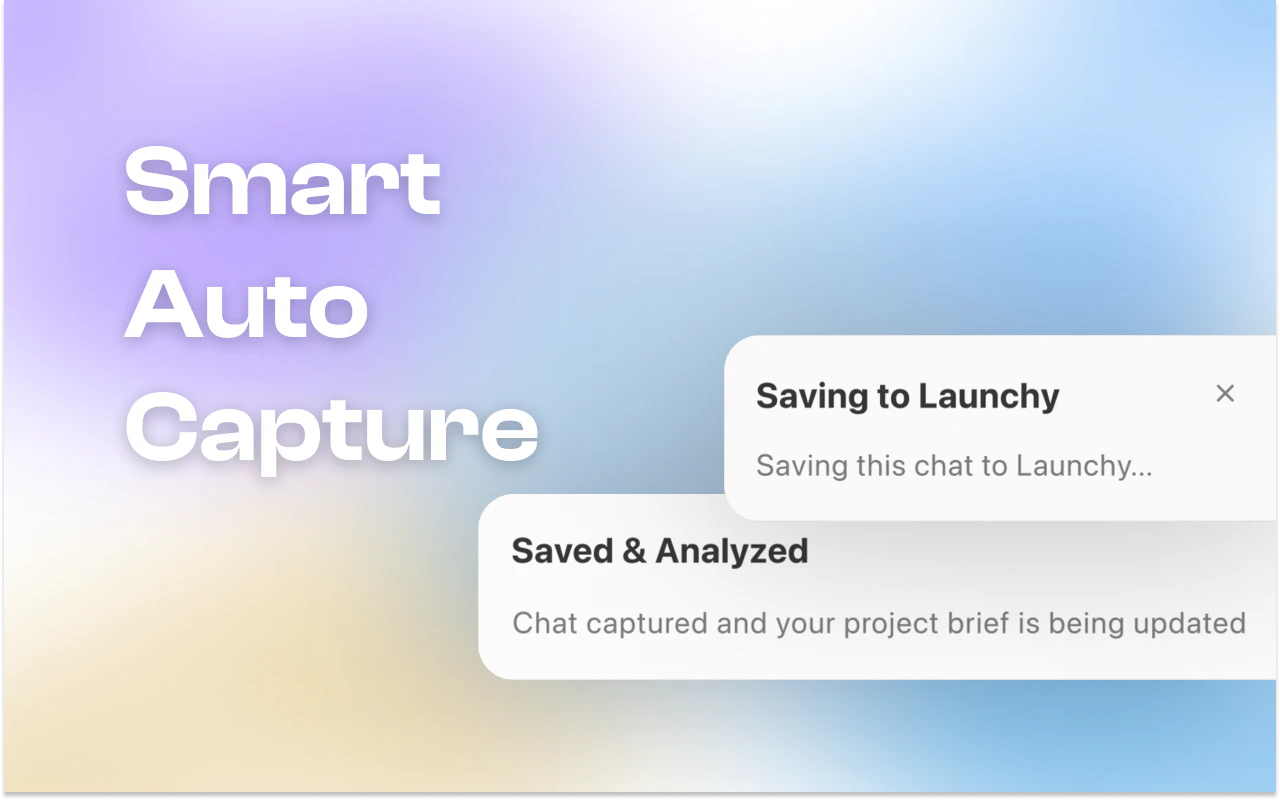
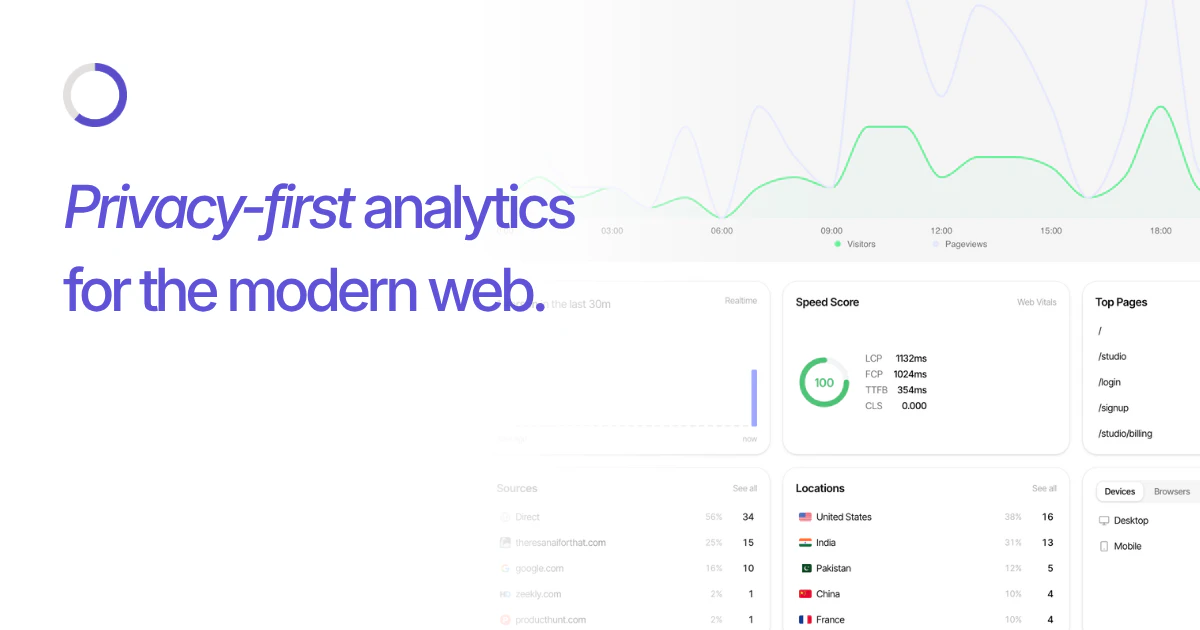
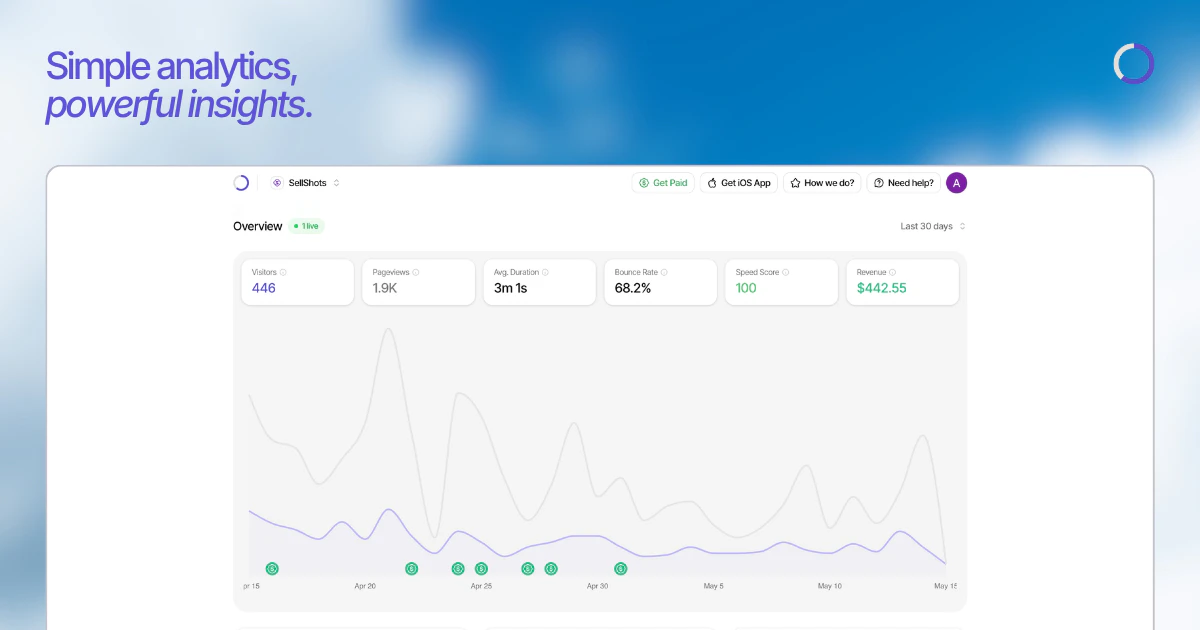
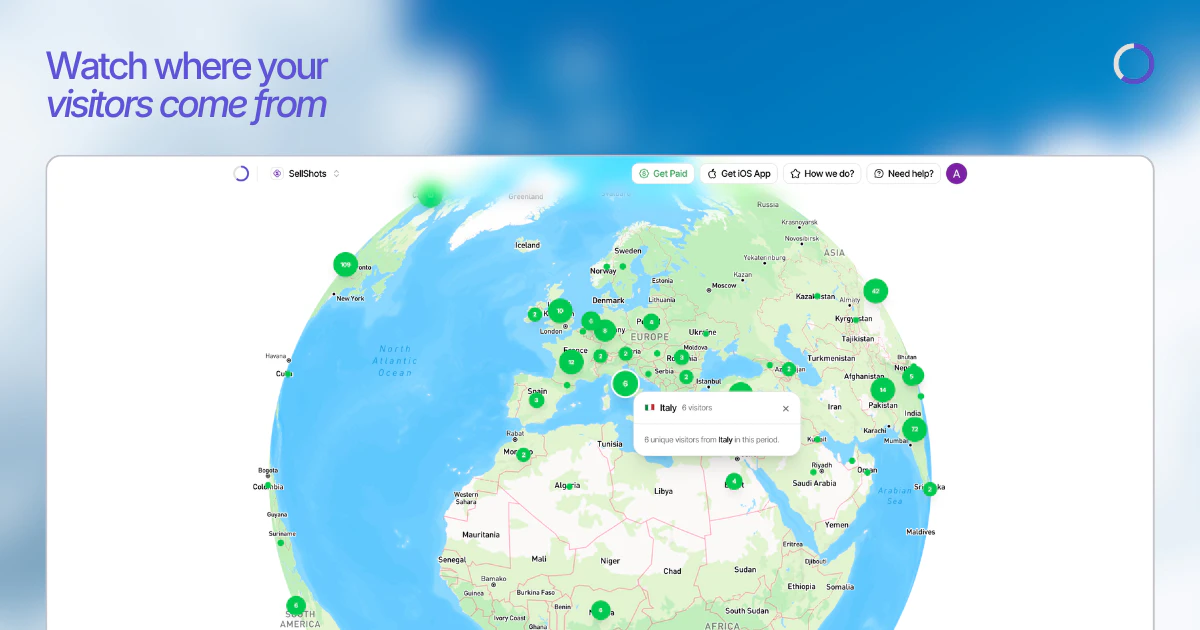
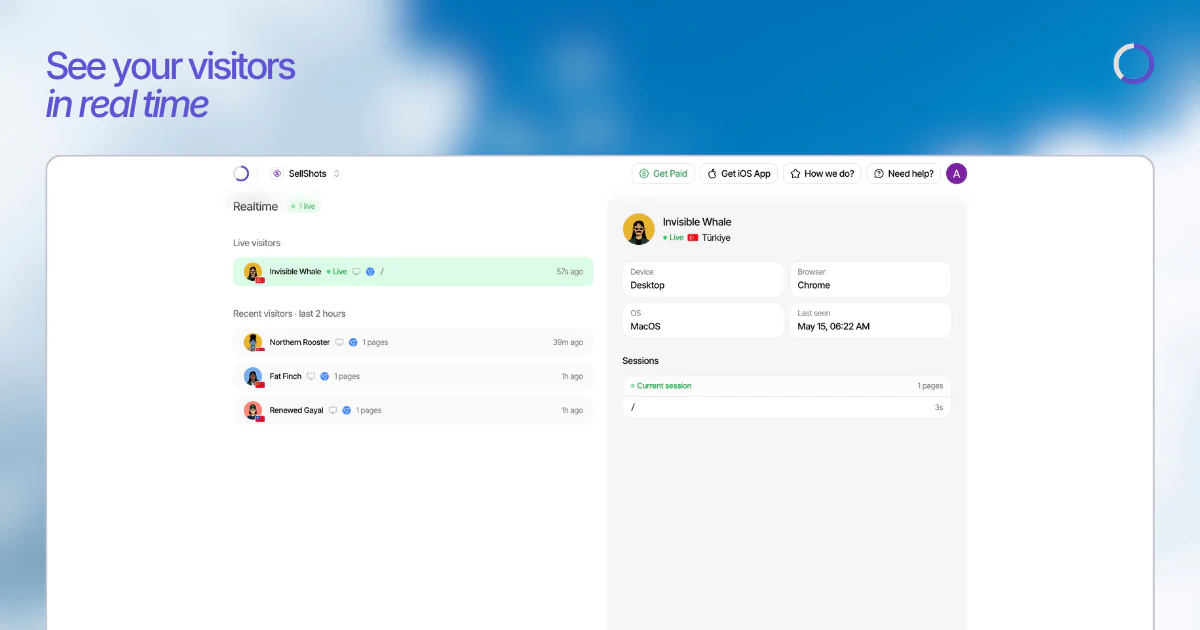







Heya! I'm Steven, founder of TinyHumans.
A few months ago I tried to set up an open-source AI agent for my dad. Three hours later and after wrestling with API keys, YAML and a terminal he had never opened in his life, we both gave up.
That's when I realised that every powerful AI agent today is built for the 0.01% who can spin up their own runtime. The other 99.99% are watching the agent revolution from the sidelines.
So we built OpenHuman.
OpenHuman is a super-intelligent AI agent that anyone can use. Two-minute setup. No config files. A simple GUI you'd hand to your parents and they'd actually figure out. Connect Gmail, Slack, Telegram, Notion, and GitHub in one click and it just works.
A few things I'm proud of:
* It runs locally. Encrypted vault. We never sell your data.
* It never forgets. Real memory across sessions, not session-only.
* It's open-source under GNU.
* It's free to start: no engineer, no GPU, no $6k setup bill.
Early signal has been wild: 8000+ GitHub stars, 5000+ users in the first 7 days, and 150% week-over-week growth.
Today, we're opening it up to all of you. Note that it is still in beta, so you're super early if you find bugs. Feel free to report them to me over at the Discord.
I'll be in the comments all day. You can break it, roast it, tell me what's missing, ask anything. We ship fixes live.
Would love your feedback!
Hi 👋
I'm Ankita, the product marketer at OpenHuman.
I joined this team because Steven and the rest of TinyHumans were the only people I'd met who genuinely wanted to build an AI agent for everyone, not just engineers. The people who don't write code, don't want to wire API keys, don't want to read YAML files. People like my parents, honestly.
Watching the last few months of shipping has been wild. The skills marketplace went from a handful of integrations to 118+. Memory went from session-only to actually remembering you across weeks. And Tiny the mascot has somehow become the most-discussed feature in our internal slack.
If you've ever wanted to use an AI agent but felt the setup wasn't worth the headache, today is your day. It gets way more useful the longer you use it because it actually remembers what you tell it.
Try it free at tinyhumans.ai/openhuman.
Hop into our Discord if you want to chat, ask for a feature, or report a bug. I'm reading everything today.
Thanks for being here 🙏
Ankita
Launching alongside great products like this makes today even more exciting. Really impressed by what you’ve built. Supporting fellow makers today would love to cheer each other on 🚀
One of the weirdest things about using OpenHuman now is how fast normal AI tools start feeling “dumb”.
The moment your AI starts remembering context across chats, understanding your workflow, pulling information across apps, and quietly helping in the background… it’s really hard to go back.
Feels less like using ChatGPT and more like having a second operating system running alongside you.
Also watching non-technical people set this up in like 2 minutes after spending months hearing “AI agents are too complicated” has been pretty wild !
can it use my skills and maybe commands? Tool calls? Is it good for coding?
Amazing product
How did this not exist before?! Love the idea, want to give it a try even though I don't necessarily need an agent in my life.
Something I've seen that feels related: the concept of moving our personal data from the custody of vendors (social, doctors, marketers, employers etc) back to us - the owners. Eg a graph of all your data with granular sharing and privacy policies that you directly control. There's an obvious privacy aspect to this, but it's also natural to imagine how agents can thrive with (controlled) access to it, as an extension of the permanent memory you've built.
Finally an AI that doesnt forget everything after every chat. Sounds actually useful for normal people not just tech guys.
The privacy angle is a big reason to go local-first, but the persistent memory is what actually makes it usable day to day. I I am tired of re-explaining my tech stack and project goals every single time I open a new session.
Since you mentioned that it is in beta and remembers everything, I want to know how you handle context window limits or database bloat over time. Does it start getting sluggish once it knows too much about my work history, or is there some kind of automated cleanup?
The gap between powerful agent and usable by normal people is still massive and most projects only solve the first half.
Congrats on launch!! I like the idea.
How it's handle hallucination thing?
What is the subscription price to use this? Is it open source or need to pay anything?
@itsnotgaf Congratulations. And happy product launch.