PH热榜 | 2026-05-18
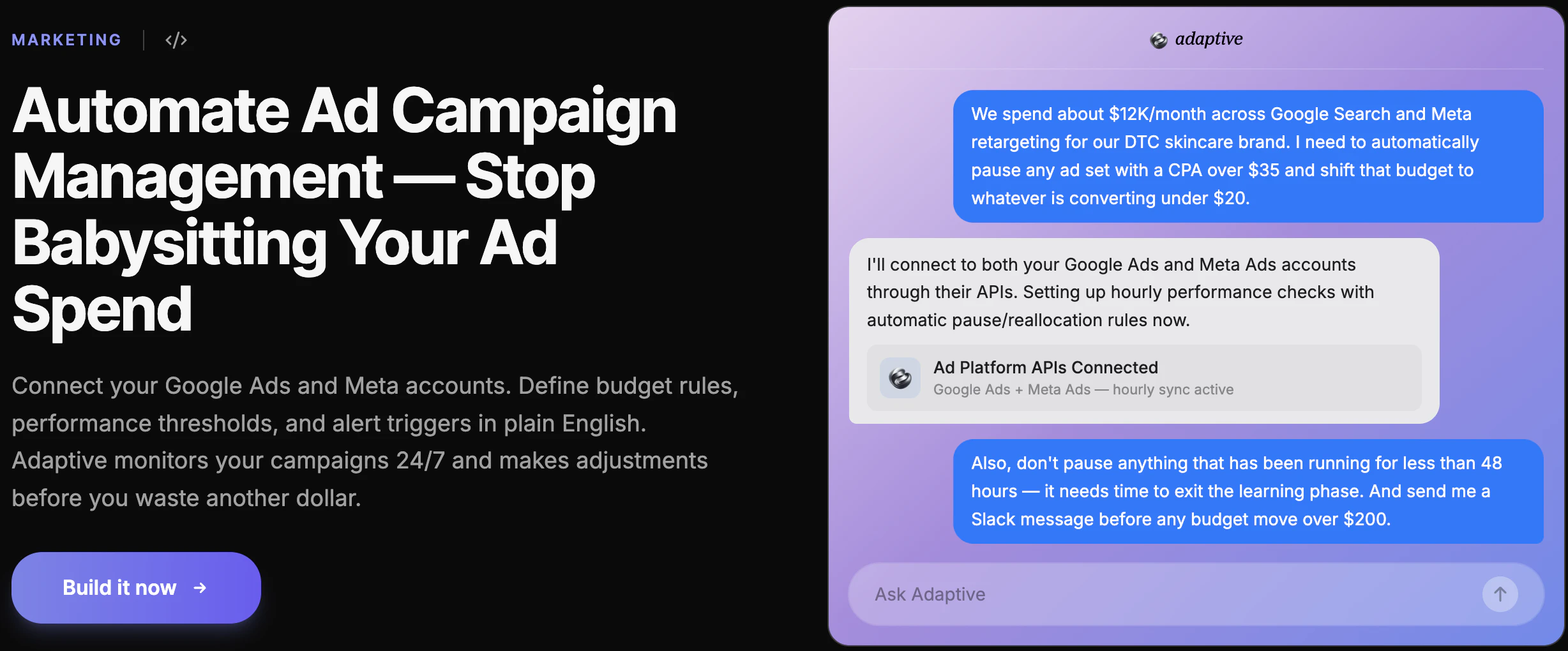
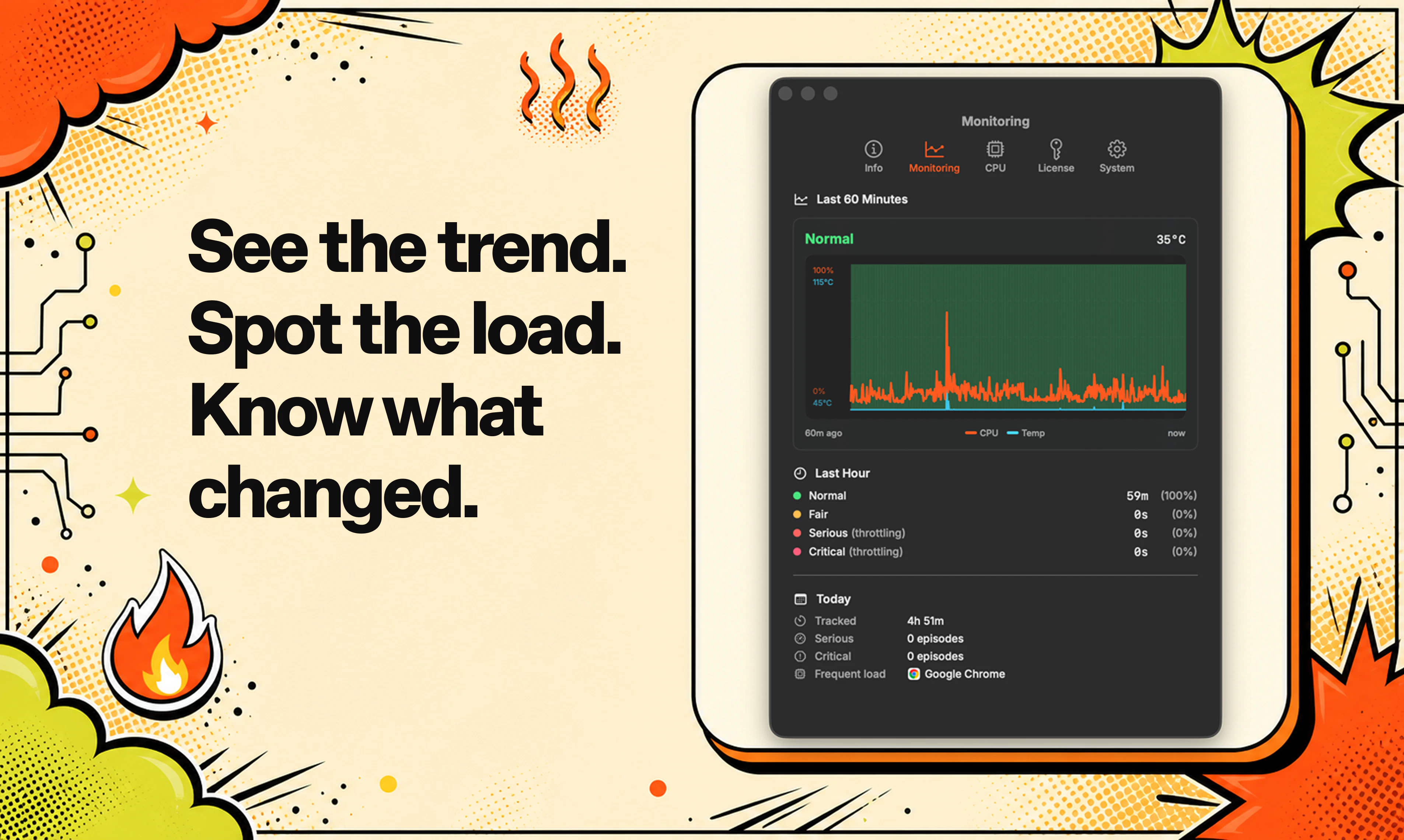
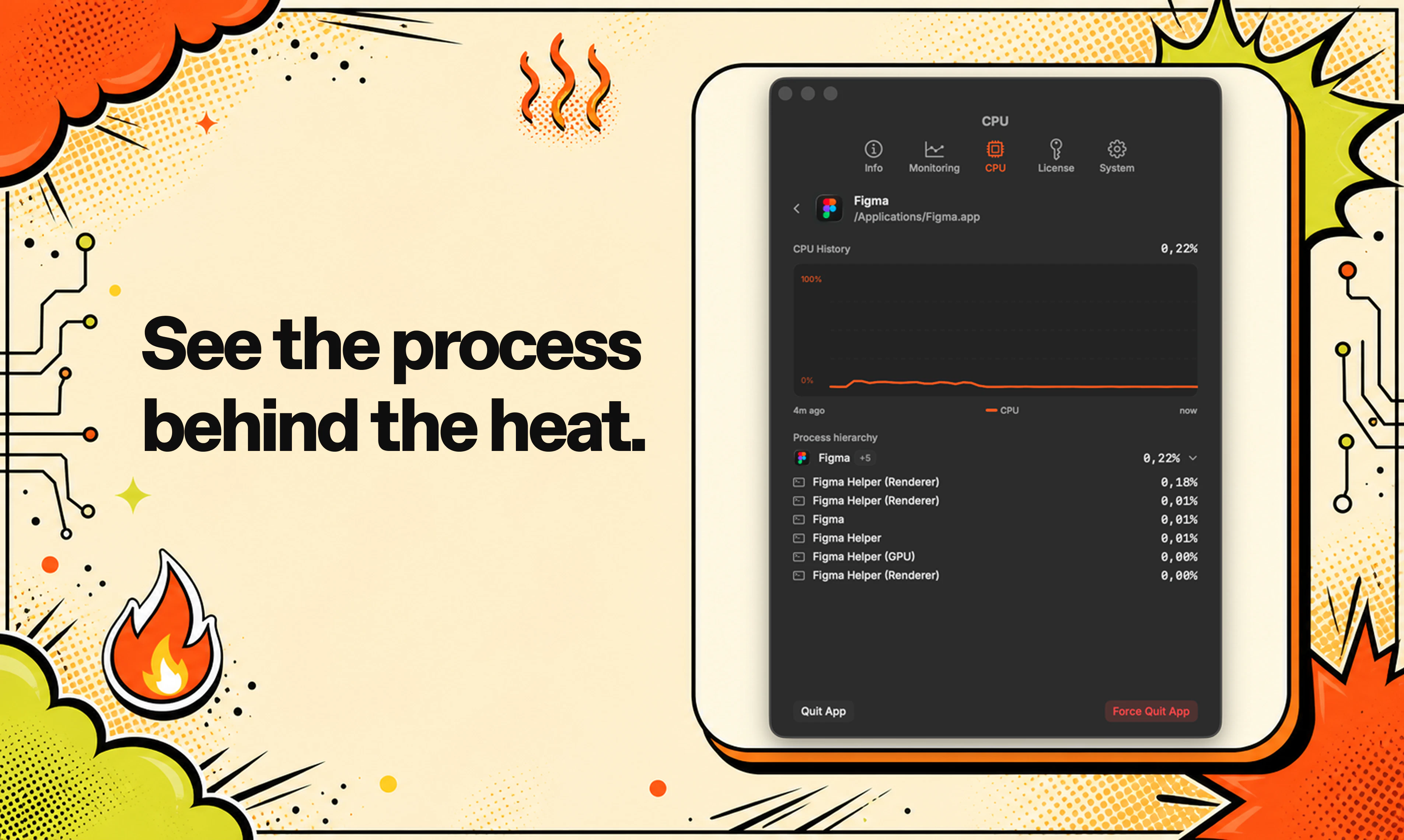
一句话介绍:LobeHub 是一款多智能体协作的“首席智能体运营官”(CAO),它整合多种AI代理到统一平台,通过Slack/iMessage等日常通讯工具自动执行任务并仅在需要决策时汇报,解决重度AI用户“开了十几个AI标签页却要亲手操作”的碎片化及认知过载痛点。
Productivity
Artificial Intelligence
多智能体协作
AI运营
CAO
工作流自动化
模型调度
MCP服务器
Agent编排
开源
认知减压
云原生
用户评论摘要:用户盛赞每日简报和IM集成,但关键质疑集中在:1)并行云端代理的成本如何控制?团队回应将限制并行数并让智能体感知预算;2)273K+技能质量参差不齐,如何保证路由而非噪音?团队称基于历史轨迹的协同过滤比搜索更重要;3)任务失败处理流程透明,失败时向用户发错误简报。
AI 锐评
LobeHub的“CAO”概念精准命中了行业痛点:当前AI工具链的爆发反而造成了“AI操作员疲劳症”——用户从纯脑力劳动者变成了多个AI代理的“监工”。LobeHub的价值不在于造出更强大的单兵智能体,而是提供了一个反直觉却有效的“Agent管理平面”:通过将所有代理的运行、调度、记忆和失败日志包装成类似COO向CEO汇报的简报机制,它实现了两个关键转变——从“你需要盯着屏幕”到“通知你何时介入”,从“你管理工具”到“工具管理工具”。
但必须泼一盆冷水。“273K+技能”和“51K+ MCP”是典型的市场部数字,实际信任度堪忧。评论区有用户直接追问“这些技能谁验证过?”团队承认“不能保证所有技能都有效”,这直指其竞争力核心——一个缺乏严格质量分层的巨大技能市场,理论上会加剧“富者愈富”的马太效应,让老技能霸榜、新技能沉没。同时,所谓“CAO”模式需要一个巨大的前提:用户愿意、也敢于把最终决策权部分让渡给一个中间层。对于金融、医疗等对失败容忍度极低的领域,这种用“事后简报替代实时监控”的范式必须搭建出极其坚固的护栏。它是智能体时代的优秀“制片人”,但离真正的“CEO”还有审计和安全上的鸿沟要跨越。
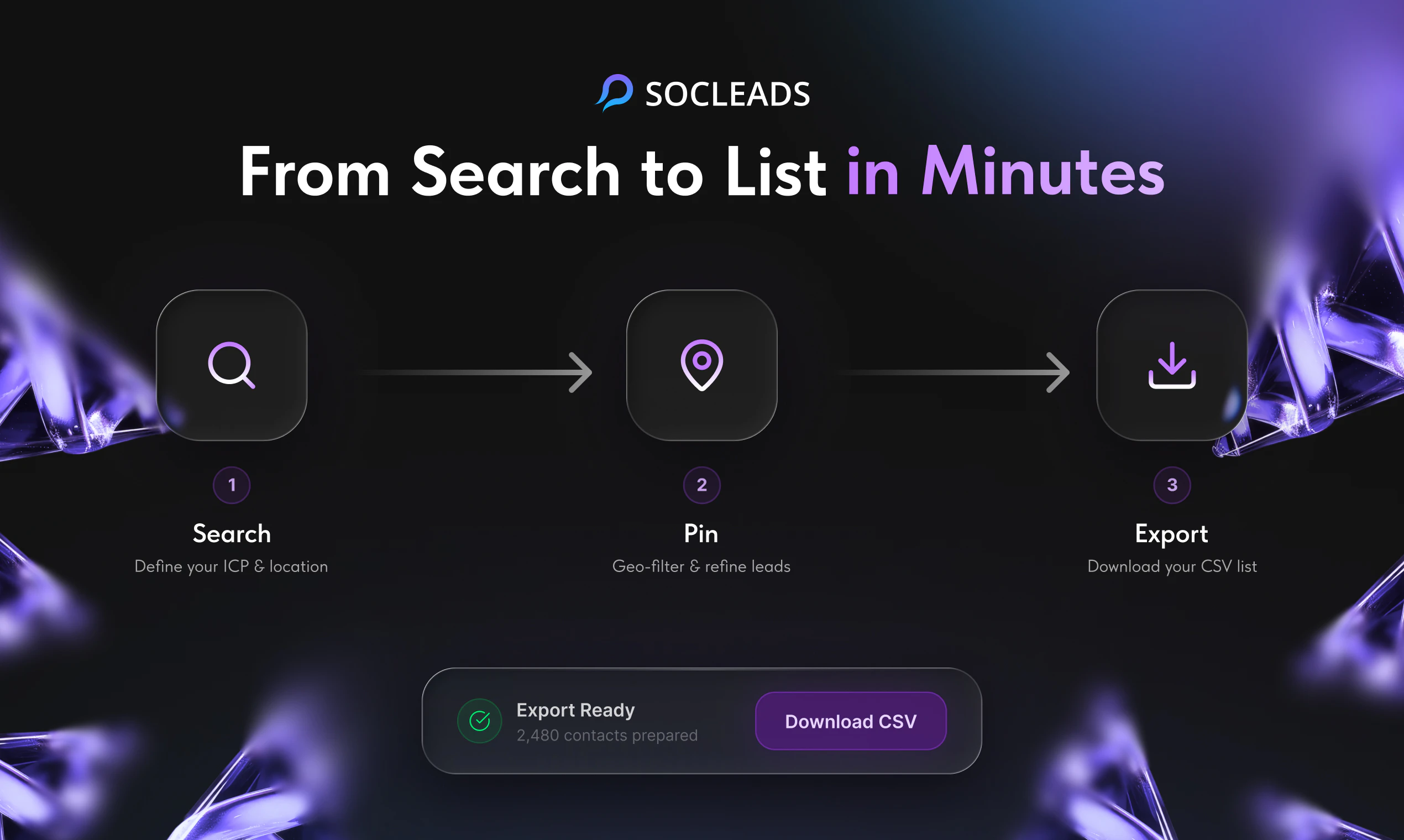
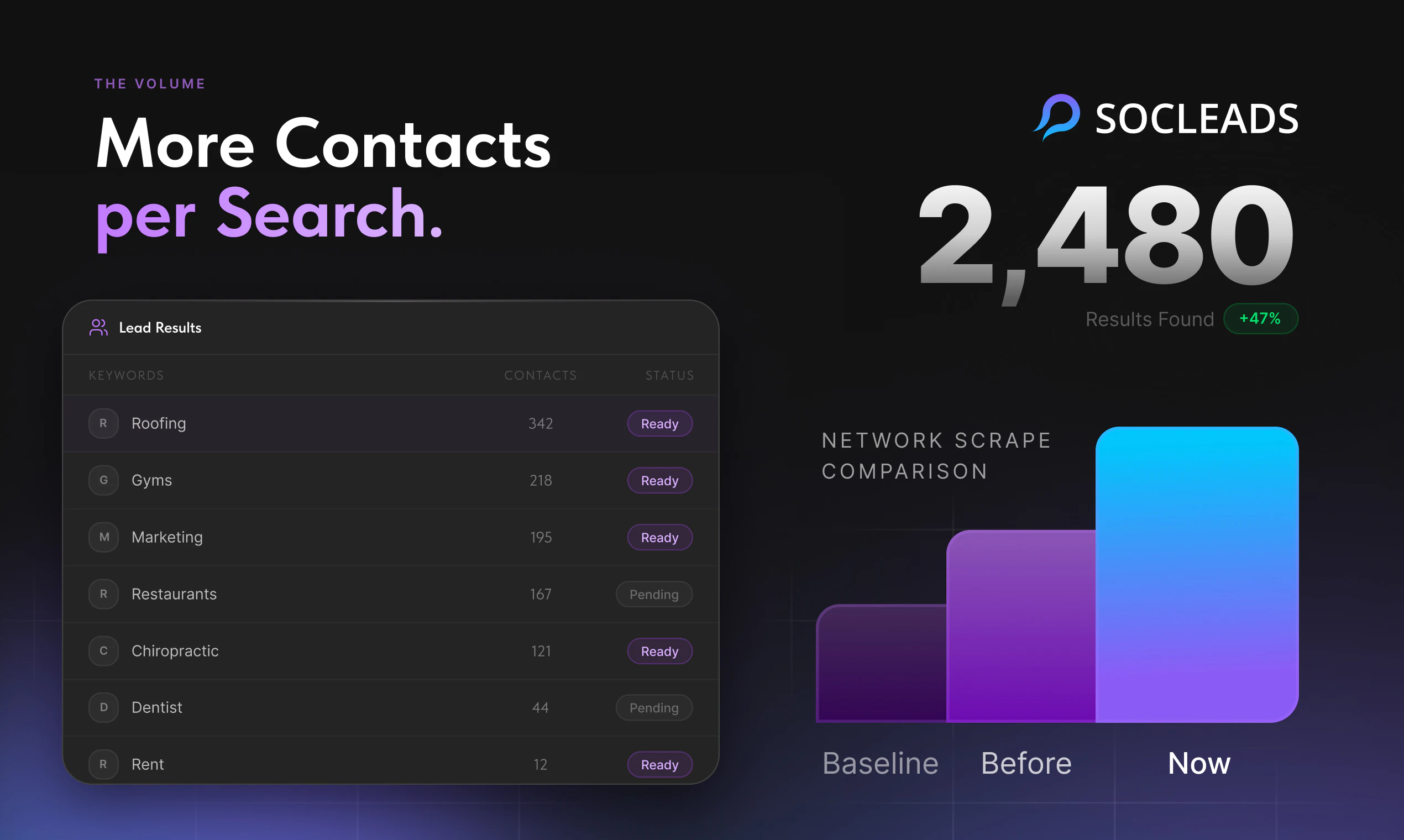
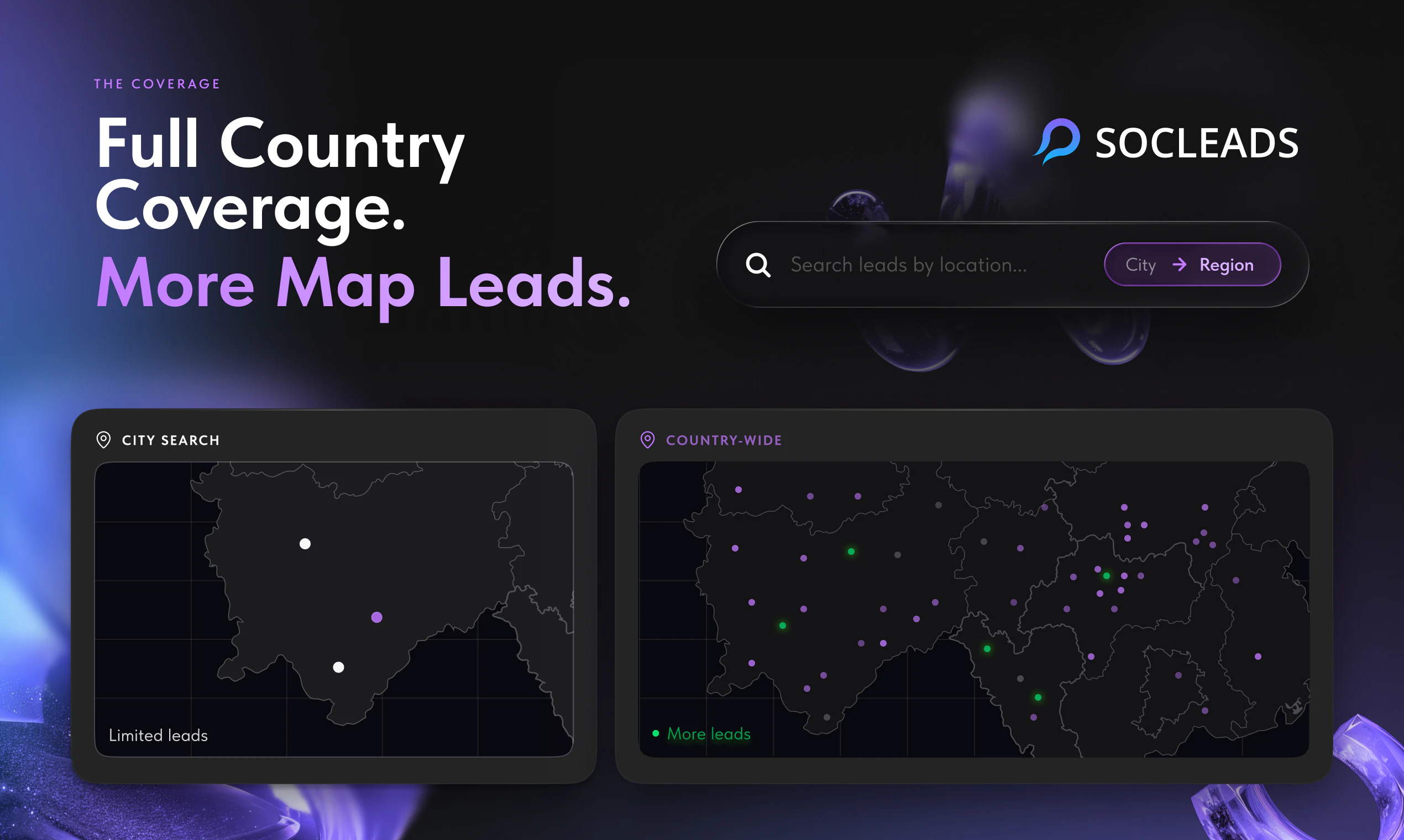
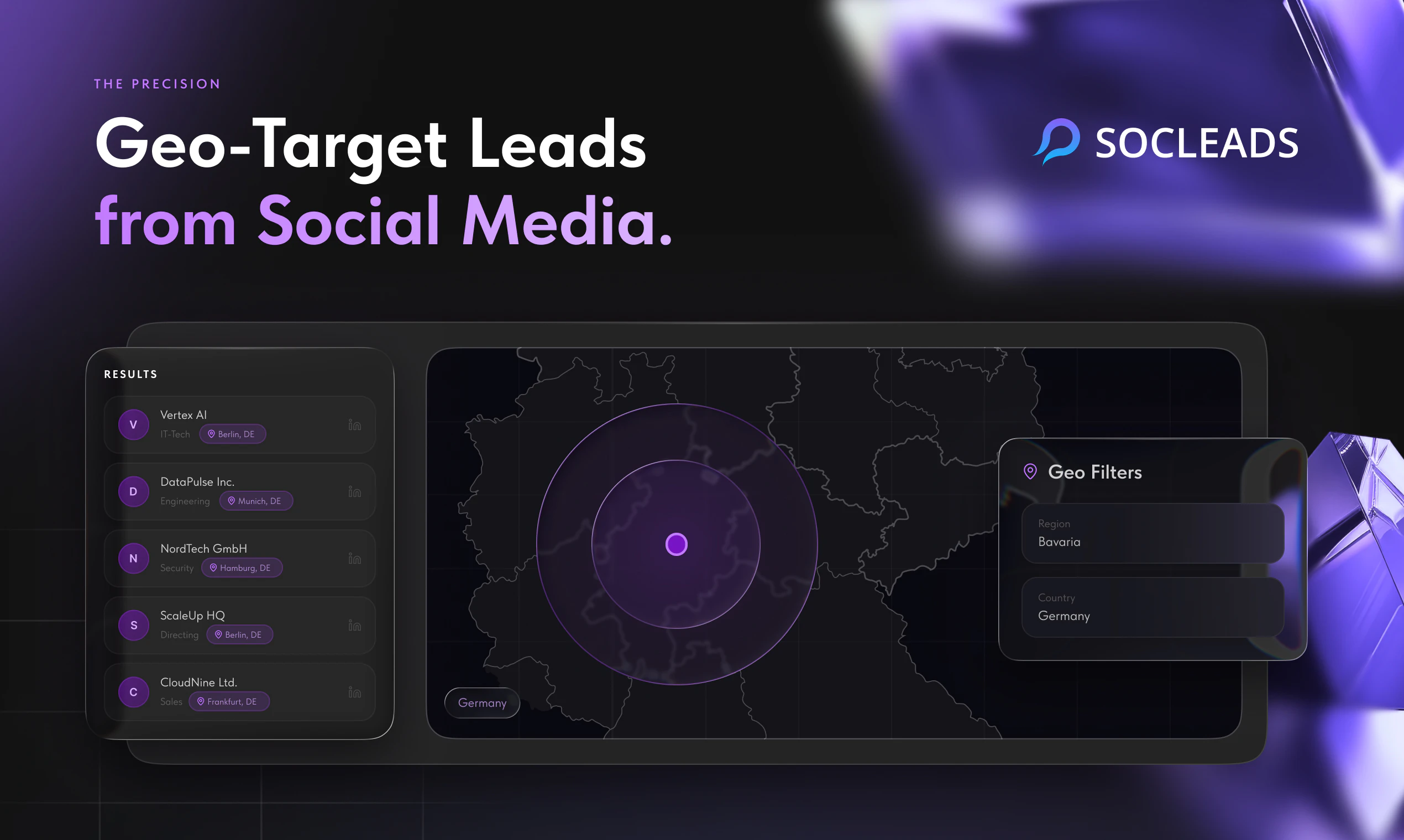
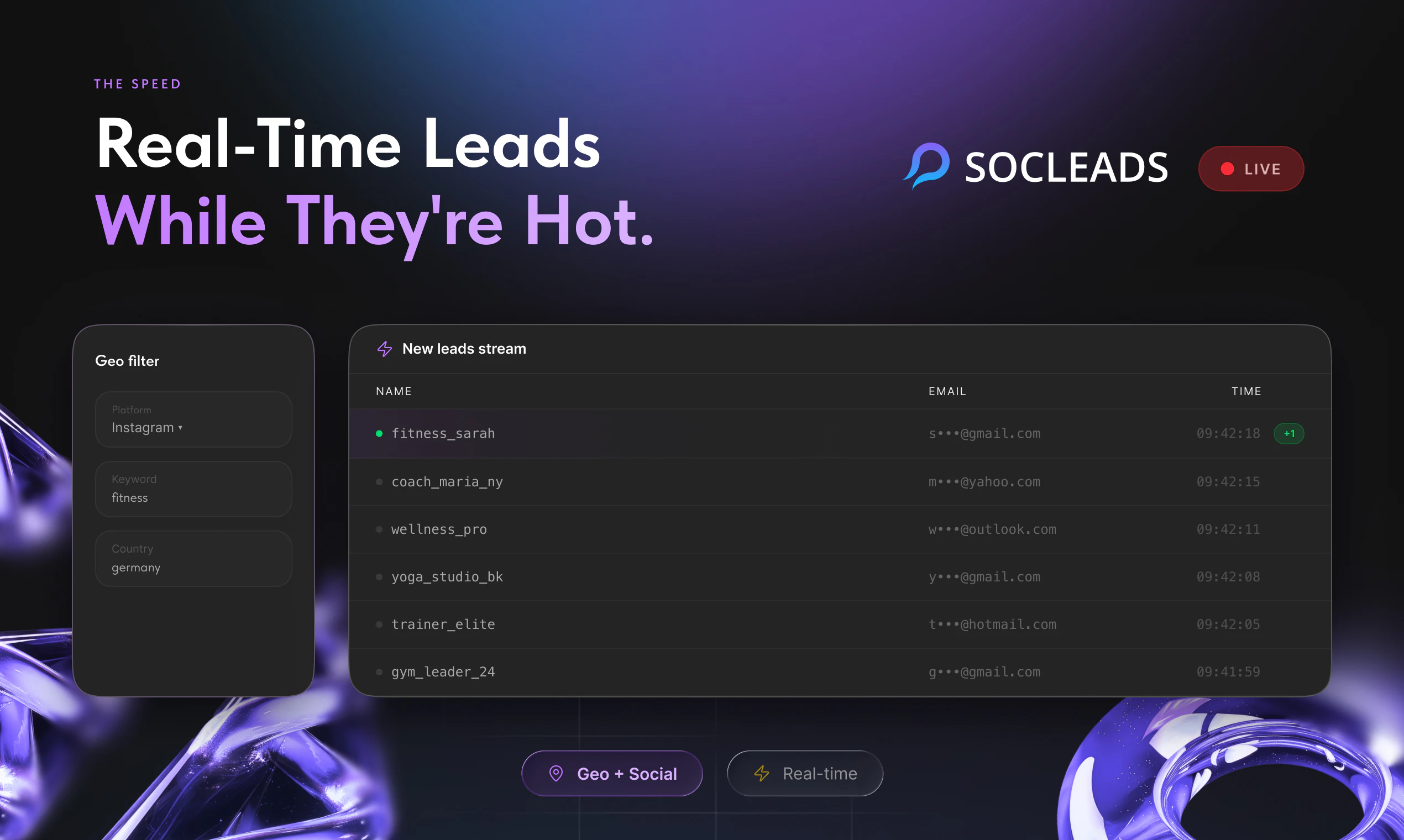
一句话介绍:SocLeads 3.0 是一款无需编码的社交媒体与地图数据采集工具,帮助销售、营销团队通过地理定位一键批量抓取 Instagram、Facebook、LinkedIn 及 Google Maps 上的公开联系信息,告别手动复制粘贴的繁琐流程。
Email
Social Media
Marketing
社交媒体数据抓取
地图邮箱采集
B2B销售线索
地理定向营销
无代码工具
LinkedIn精准拓客
Instagram线索挖掘
邮件验证
谷歌地图API
自动化获客
用户评论摘要:用户最关注数据实时性与合规性,如是否跨平台去重、如何避免伪造邮箱;多位用户认可其低于3%的退信率与无代码体验;部分询问对细分行业(如房地产)的适配性,以及欧盟GDPR合规细节。
AI 锐评
SocLeads 3.0 的定位精准切入了一个“脏活累活”市场——从社交媒体和地图中批量获取线索,但它的真正价值不在于“抓取”本身,而在于“降低噪声”。用户反馈中反复出现的核心诉求并非“能否多抓”,而是“如何抓得准、抓得合规”。3%的退信率承诺和实时在线爬取而非兜售静态数据库的设计,使其在同行中形成了差异化壁垒。
然而,产品仍存在明显短板:跨平台去重缺失导致多平台数据冗余,用户需手动清洗;合规层面仅提供“免责声明”而非内置GDPR/CCPA合规工具,这对面向欧洲市场的销售团队是重大隐患。更关键的是,LinkedIn等平台对自动化抓取的打击日趋严格,SocLeads 的技术方案能否规避反爬和封号风险,评论中未提及,但这是决定产品寿命的核心。
总体而言,它是一款“好用但受限”的效率工具:适合低监管风险市场的中小企业快速构建线索池,但对于大客户或严格合规场景,仍需搭配额外流程与工具。其未来价值取决于能否在合规功能(如同意管理、数据保留策略)和跨平台数据融合上继续迭代,否则将止步于“高级Excle替代品”。
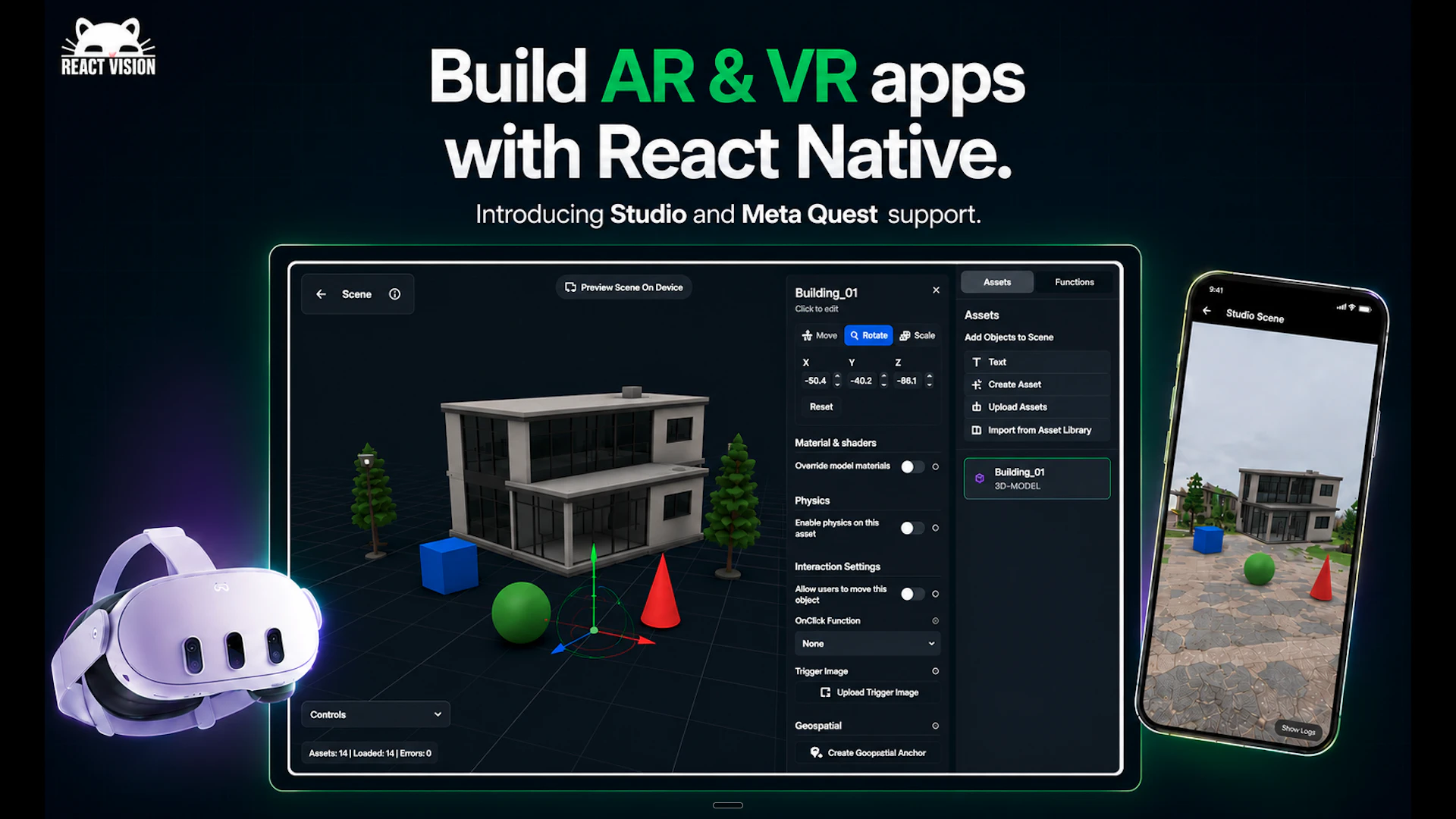
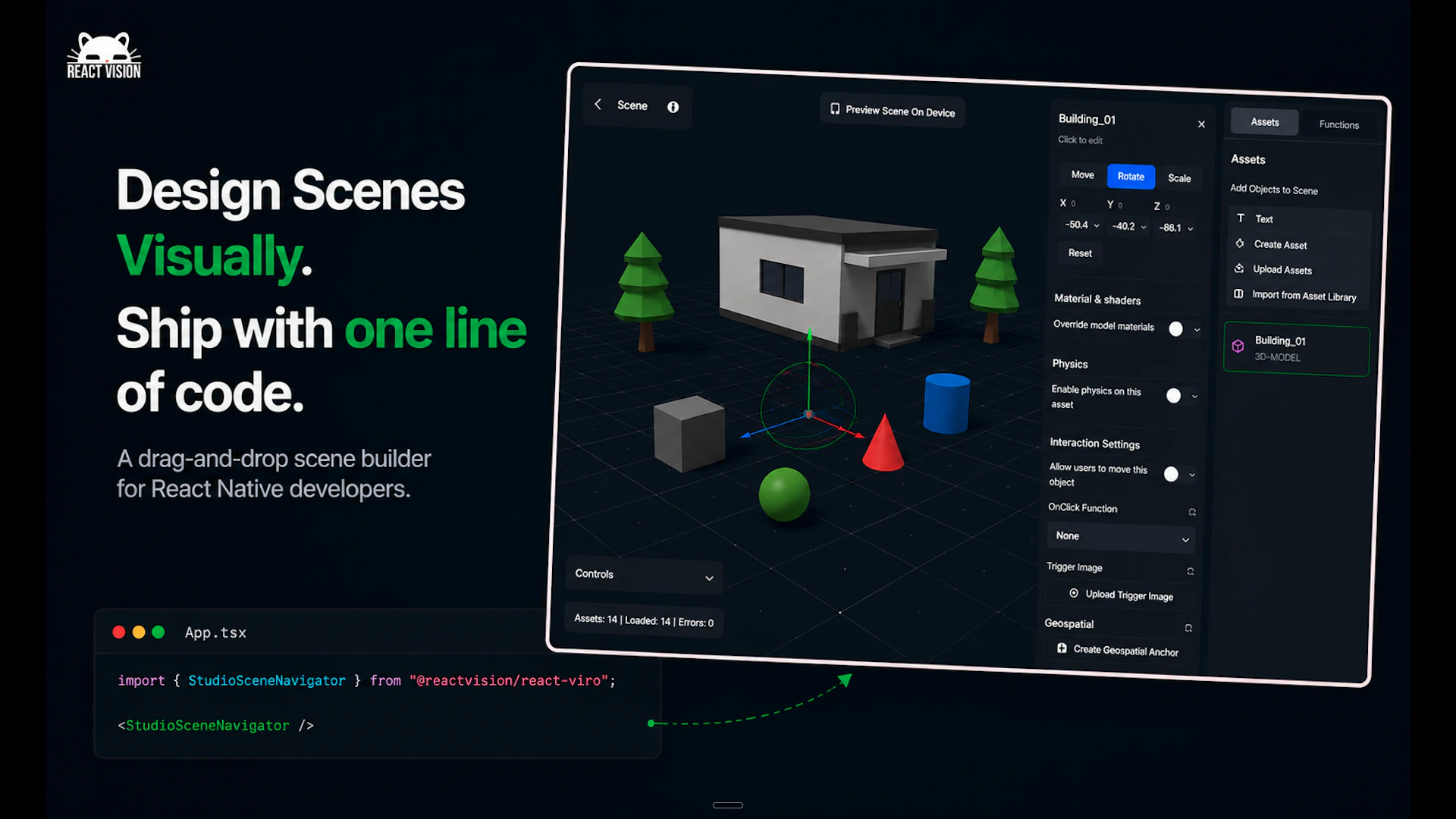
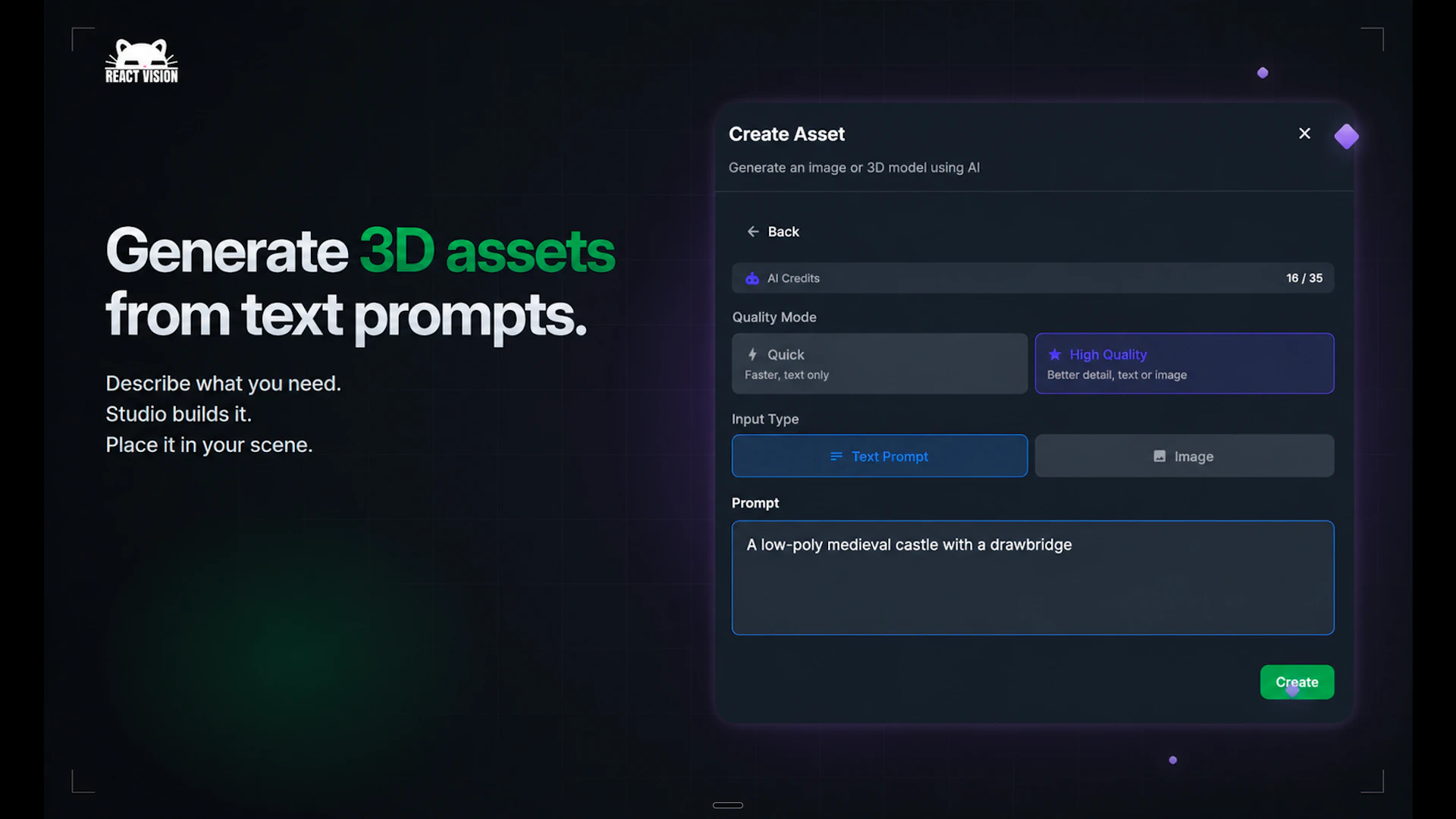
一句话介绍:ReactVision Studio 是一个基于浏览器的可视化编辑器,让开发者无需游戏引擎即可在React Native中拖拽构建AR/VR场景,并通过单一代码库直接发布到iOS、Android和Meta Quest设备,解决了XR开发门槛高和多平台适配复杂的问题。
Virtual Reality
Developer Tools
Augmented Reality
AR/VR开发
React Native
可视化编辑器
AI生成3D资产
跨平台发布
Meta Quest
开源渲染器
开发者工具
无代码/低代码
用户评论摘要:用户普遍认可其“单代码库、三运行时”的跨平台潜力,指出传统Unity沉重、WebXR受限。有人建议优化官网首屏表述,让开发者快速定位“是否适合我的团队”。也有用户关心编辑器与手机预览的延迟问题,官方回应称当前为有意延迟,目标是实时同步。还有人追问同一场景在AR/VR不同交互模式下如何调整行为。
AI 锐评
ReactVision Studio的巧妙之处在于精准切入了一个被巨头抛弃的生态缺口——8th Wall关停后,大量AR开发者急需一个开源的、现代的前端栈替代方案。它没有试图重造一个Unity或Unreal,而是选择粘合React Native与XR,让前端开发者用熟悉的工具链就能触碰空间计算,这是一种“降维赋能”的务实策略。
其核心价值并不在于“可视化编辑器”本身(这类工具很多),而在于“从编辑器到原生设备”的端到端闭环,以及“单一代码库覆盖手机AR与头显VR”的抽象层能力。尤其在Meta Quest上直接运行React Native原生代码,避免了传统的引擎切换或WebXR的性能折衷,这在技术路径上抓住了跨平台发展的关键矛盾。
然而,产品面临的最大挑战是交互范式的深度矛盾:手机AR依赖触摸和平面锚定,头显VR则需要空间手柄、眼动追踪和全身追踪。如果编辑器生成的场景只是“平移渲染”,而非“适配交互”,那么“单代码库”可能就是个技术噱头。此外,“AI生成3D资产”作为亮点,但生成物的精度、可编辑性以及对低功耗移动端的优化,都是实际落地时的难关。
总体来看,这是一款非常符合当下“前端吞噬一切”趋势的工具,但能否从“尝鲜”走向“生产力”,取决于它能否真正解决XR独有的交互适配问题,而非仅停留在“把Unreal的活换成React Native干”。对前端社区是加分项,对XR社区则可能需要更深刻的场景理解。
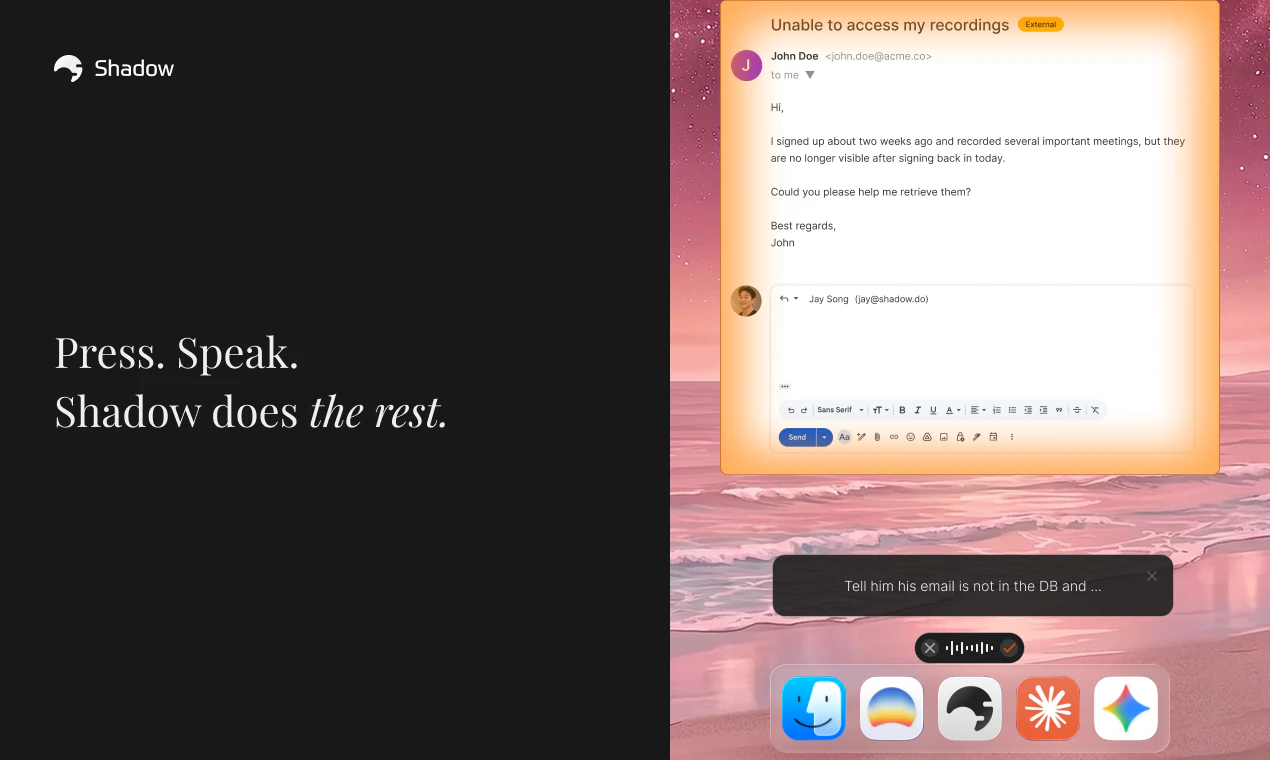
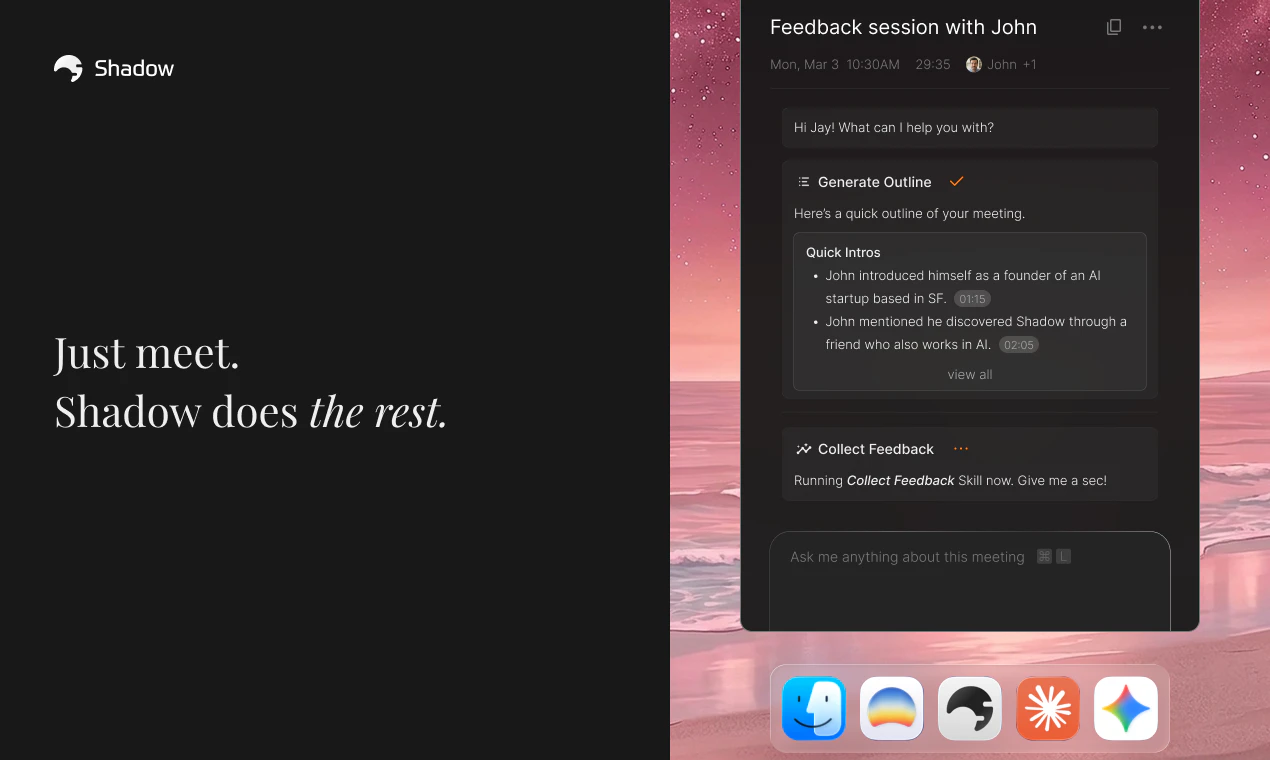
一句话介绍:Shadow是一款为Mac设计的AI界面,通过屏幕识别、语音控制和自定义自动化技能(Skills),让用户无需复制粘贴和手动提示,直接在当前工作流中快速执行邮件回复、语音输入、会议纪要等任务,彻底消除“Copy, Paste, Prompt”的繁琐桥接过程。
Productivity
Writing
Meetings
AI电脑控制
Mac自动化
语音控制
屏幕识别
会议助手
邮件快速回复
语音输入
自定义工作流
本地隐私
Product Hunt
用户评论摘要:用户普遍赞赏消除“复制粘贴提示”的痛点及本地隐私保护(无机器人入会)。主要建议包括:希望支持BYOK及选择AI模型;询问是否支持多步骤工作流(当前为单命令);期待Windows版本。有用户建议优化上下文输入的可视化和可控性,以增强信任。
AI 锐评
Shadow V2的“Skills”抽象是亮点,它将“提示词+上下文+输出”封装成可自定义的自动化单元,本质上是在Mac上搭建了一个基于AI意图的操作系统层。这确实比ChatGPT类的对话框更进一步——它不再要求用户主动“桥接”,而是试图让AI被动监听并主动介入。但问题在于:这种“无感自动化”的门槛非常高。用户需要有能力设计和调试自己的Skills,否则很容易陷入“预设技能不够用,自定义技能不会写”的尴尬。当前只支持单命令,更复杂的“多步骤代理”还在路上,这会让它的实用性打折扣。另外,Mac-only的策略在团队协作场景下直接锁死了天花板,创始人多次提及“优先做好Mac版”虽然是务实选择,但也暴露了团队资源和跨平台能力的瓶颈。最核心的隐忧是“上下文边界”的信任问题:当AI自动读取你的屏幕、麦克风和邮件,而你无法清晰地看到它究竟用了哪些数据去生成结果,这种“便利”很可能沦为“黑箱”。虽然团队声称“用户可以手动控制”,但在高频率的工作流中,这种控制往往流于形式。Shadow是一个有野心的产品,但距离成为“AI时代的鼠标键盘”还有一段路——它需要更智能的默认技能库、更透明的数据追溯机制,以及一个不把用户当程序员的配置界面。
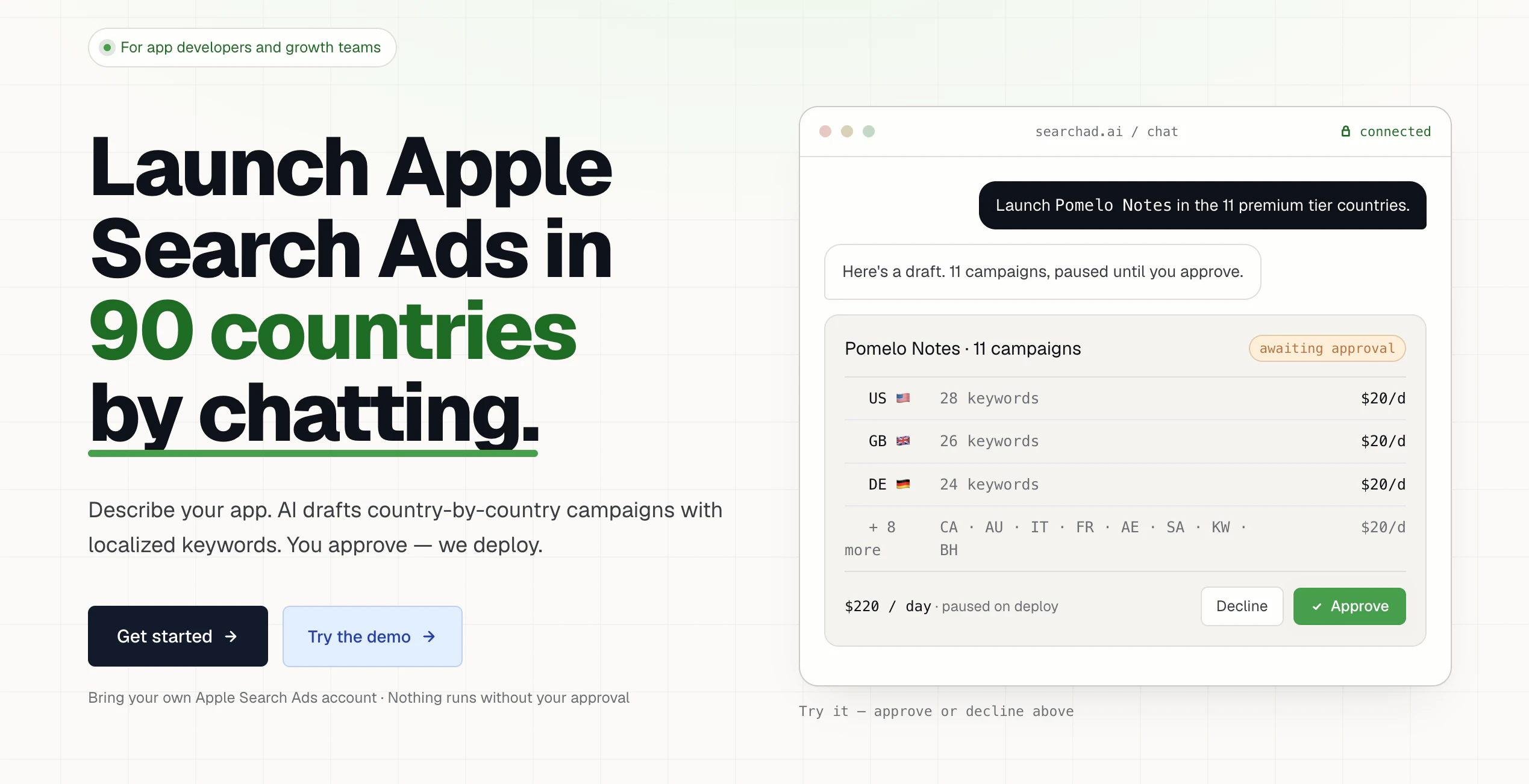
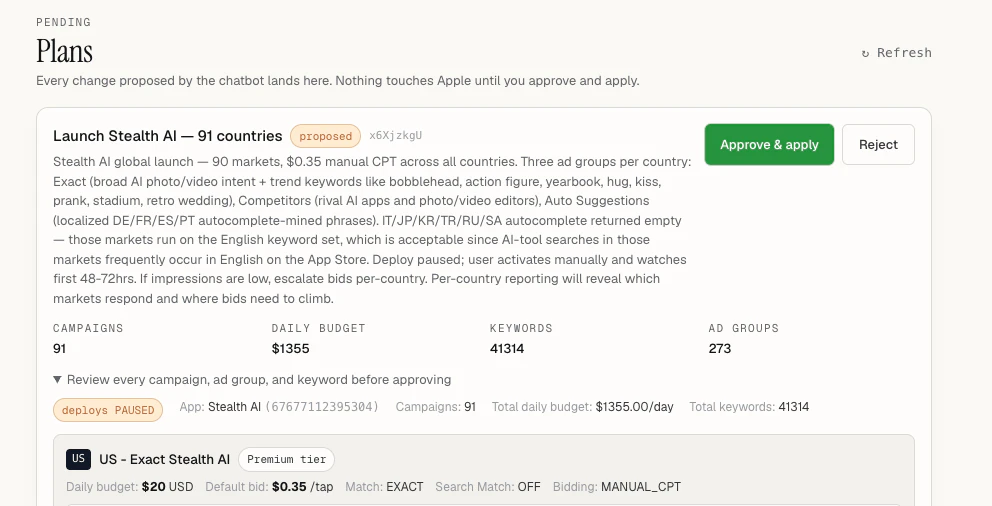
一句话介绍:Searchad.ai 是一款通过自然语言对话,让移动应用开发者能够用AI高效管理苹果搜索广告投放与优化的智能工具,核心解决苹果Ads后台操作繁琐、多国家多campaign难以批量管理的痛点。
iOS
Marketing
Apple
苹果搜索广告管理
AI对话式广告投放
ASA营销工具
ROAS追踪
关键词优化
多地多Campaign管理
Revenuecat集成
SaaS工具
移动应用推广
广告预算控制
用户评论摘要:用户普遍对“对话式管理”定位表示兴趣,但提出两处顾虑:一是能否防止超预算,二是价格不透明。创始人回应称预算控制依赖苹果侧设置,定价在API连接后可见。另有用户建议在连接API前补充“只读默认、费用需人工确认”等信任信息。
AI 锐评
Searchad.ai 切中了一个真实且尖锐的痛点:苹果Search Ads后台笨重、慢、多国多campaign操作繁琐。其“用聊天做ASA管理”的交互方式,本质上是把结构化广告操作(批量调价、关键词扩写、ROAS查询)变成了自然语言指令——这很可能大幅降低非技术型开发者/小团队的管理门槛。但一款工具的价值,不止于“方便”。评论中暴露了两个致命疑问:能否真正防超支?价格到底多少?创始人的回复“预算限制在苹果侧设置”、“定价在API连接后可见”暗示了两件事:一是工具本身不具备预算法围栏能力,仅能调用苹果API;二是定价可能采用“用量×套餐”模式,但目前缺乏透明的前置报价。这会导致用户在核心信任环节——连接API、暴露广告资金——之前就产生犹豫。整体看,Searchad.ai在执行层有潜力成为“ASA界Cursor”,但产品叙事上需要更早解决“我不放心让它替我花钱”这一底层心理障碍,同时在定价上开门见山,否则会损失大量潜在付费用户。当下最好的打法是把“只读默认+每次操作需确认”包装成安全卖点,并推出一档无风险免费试用套餐。
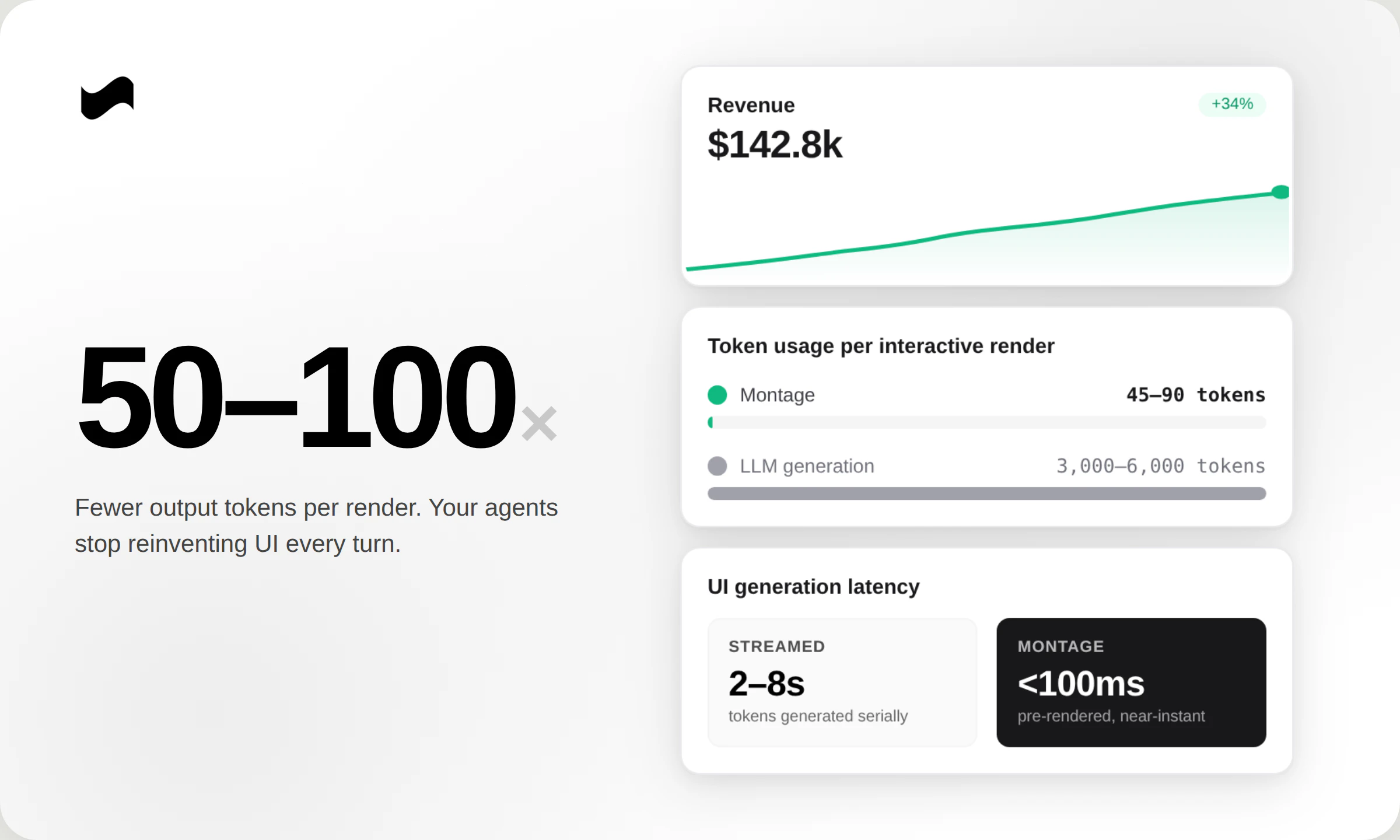
一句话介绍:Montage M1通过单次API调用将AI生成的“文本描述”编译为可托管、可持久化、可交互的专业级UI组件,解决了AI Agent构建用户界面时速度慢、成本高、质量参差不齐且缺乏状态管理的核心痛点。
User Experience
Developer Tools
Artificial Intelligence
用户评论摘要:用户关注持久化UI的访问控制层(权限与共享)及能否自带组件库。开发者赞赏模型/框架无关性、流式渲染与Token节省,期待与现有前端框架更深层集成。团队回应正规划组件构建器及更开放的设计系统支持。
AI 锐评
Montage M1的定位精准切中了当前AI Agent落地的“最后一公里”难题——大多数Agent生成的“UI”仍停留在聊天框里的HTML卡片或表格,本质上还是“增强版文本输出”。M1的价值不在于渲染更快(这是技术结果),而在于它重新定义了AI输出的范式:AI的输出应当成为“可永久运行的微型软件”,而非一次性对话片段。其“编译-托管-持久化”的闭环,实际上是在构建一个面向AI时代的“无服务化UI中间件层”。
但必须指出,其核心卖点“50-100倍Token节省”和“10倍速度提升”依赖于“编译”而非“运行时生成”的架构,这意味着产品组件库的丰富度与灵活性之间存在天然矛盾——预制组件越多,对AI的创意约束越强。团队自己也承认“组件过多会污染输出质量”,这本质上是在用“准模板化”换取效率。对于需要高度定制化UI(如复杂图表交互、动态布局调整)的场景,该方案可能力有不逮。
此外,当前访问控制全交由开发者自身实现,这在B2B场景中是一个明显短板。企业级客户不会接受一个无法精细管理权限的“黑盒UI托管服务”。路线图上的“artifact级权限”若不能快速落地,M1很可能沦为原型工具而非生产级方案。
总体而言,Montage M1在“Agent UI生成”这一细分赛道上展示出了务实且锐利的切口,但它必须警惕:一旦大模型厂商(如OpenAI、Anthropic)开始原生支持结构化UI输出与持久化,这种中间层服务的生存空间将会被迅速挤压。
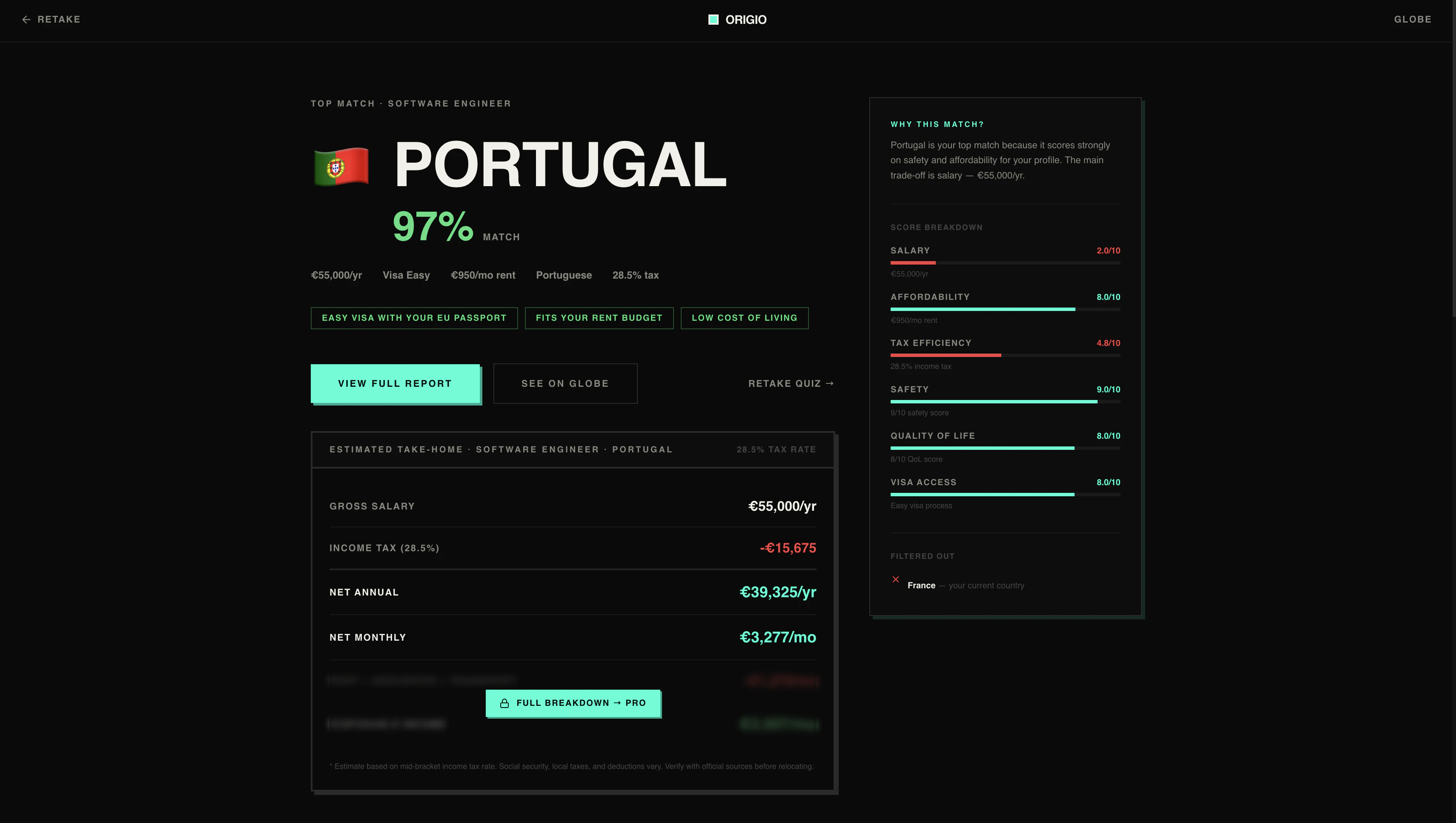
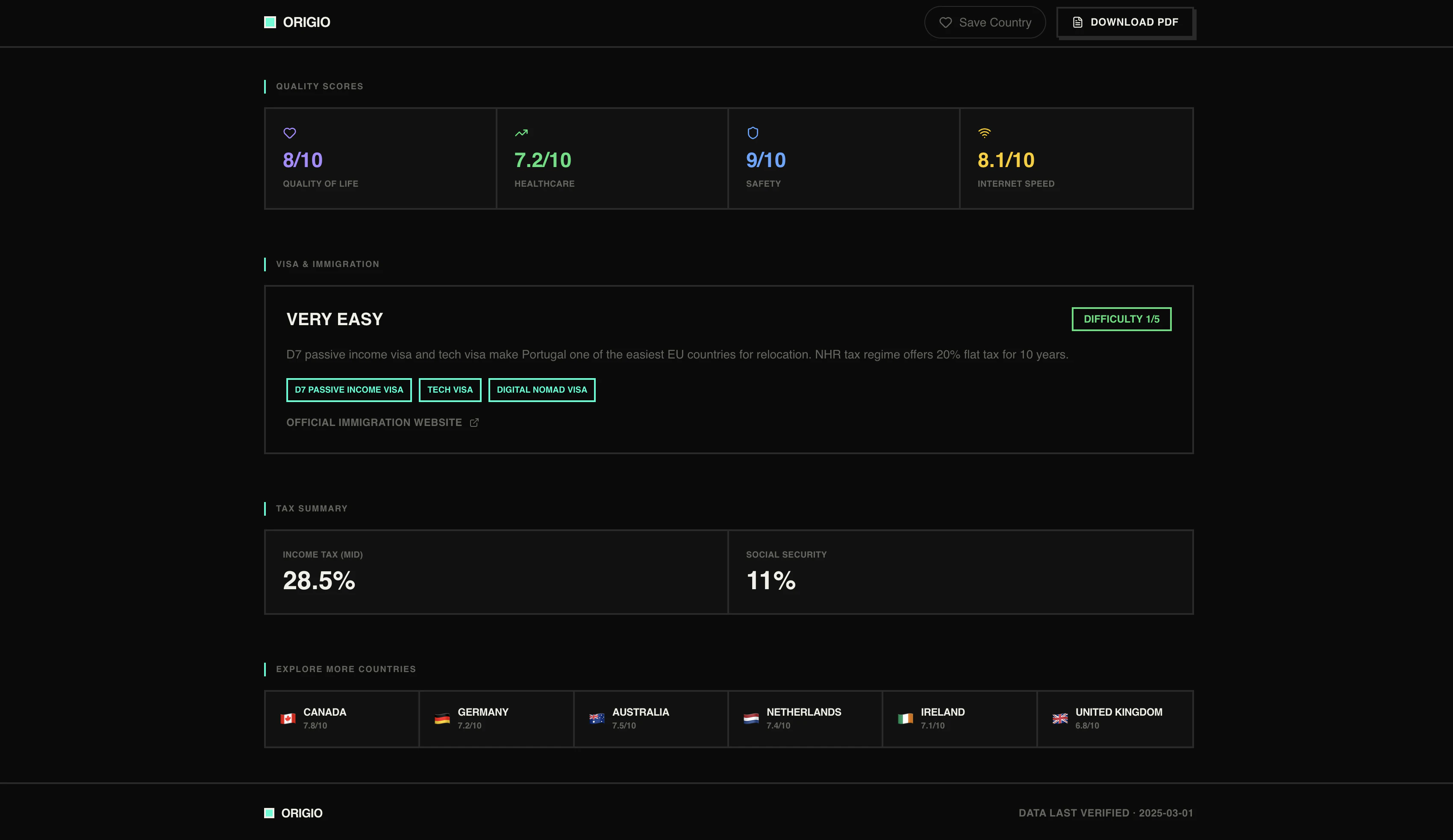
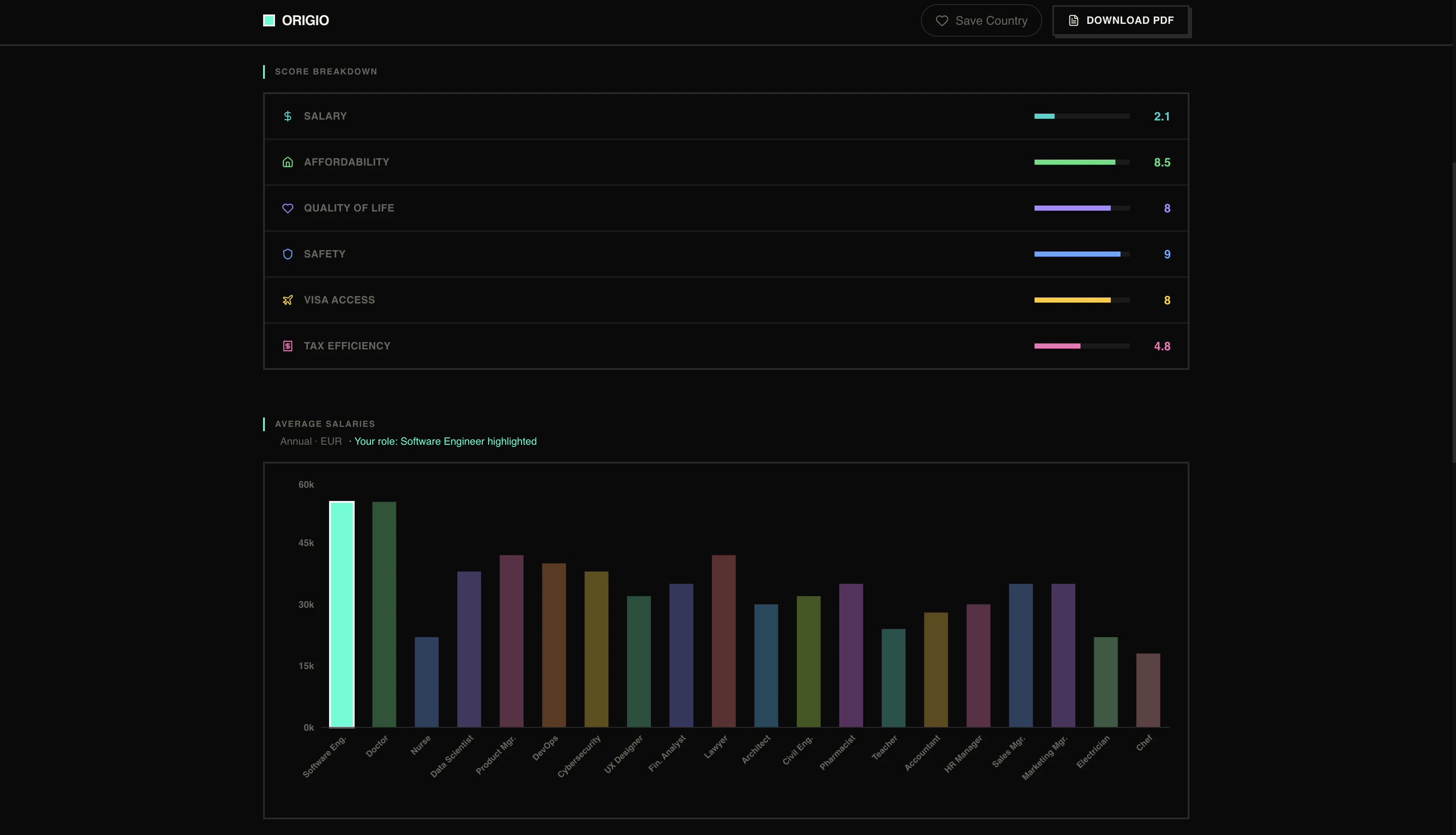
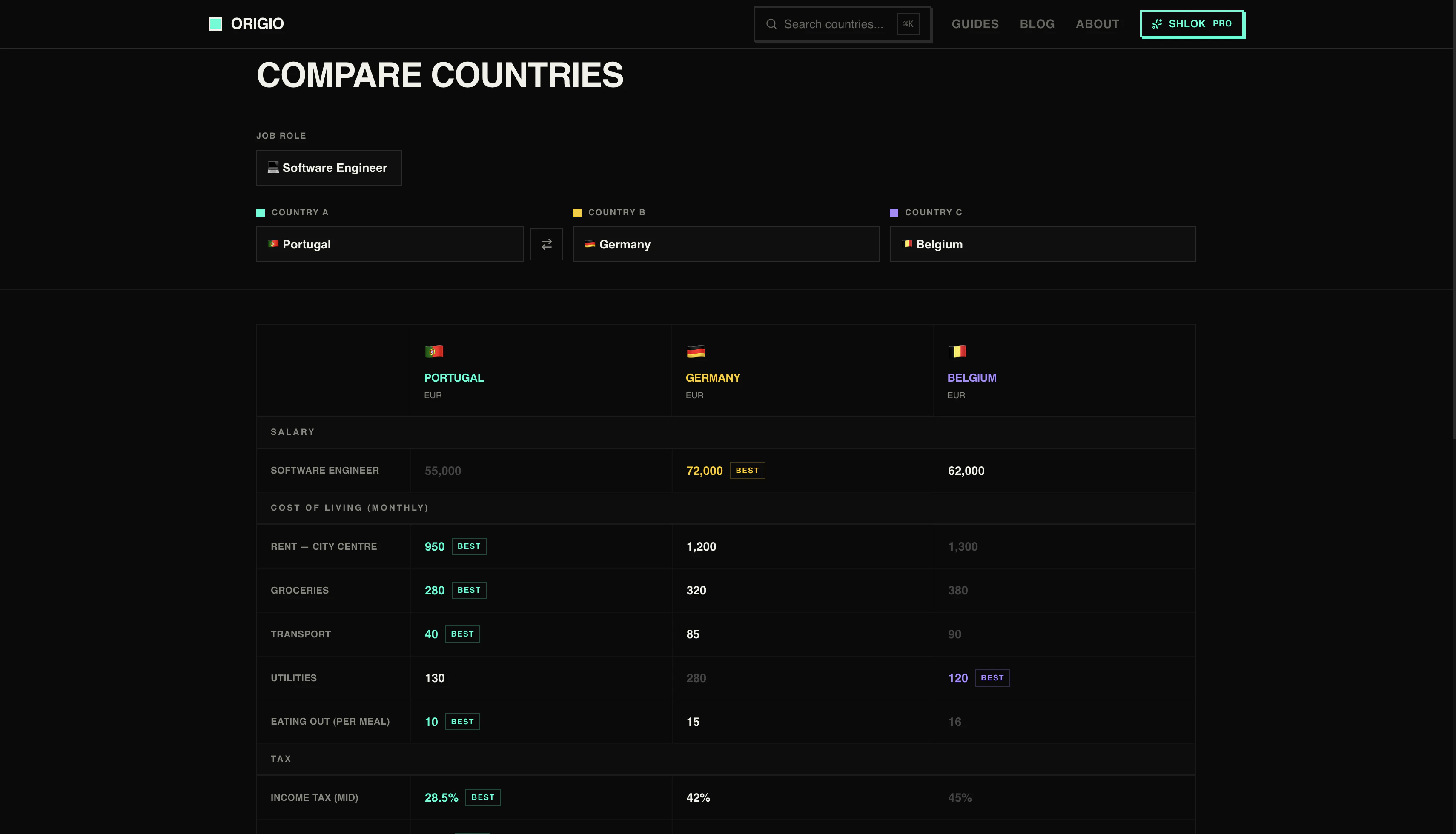
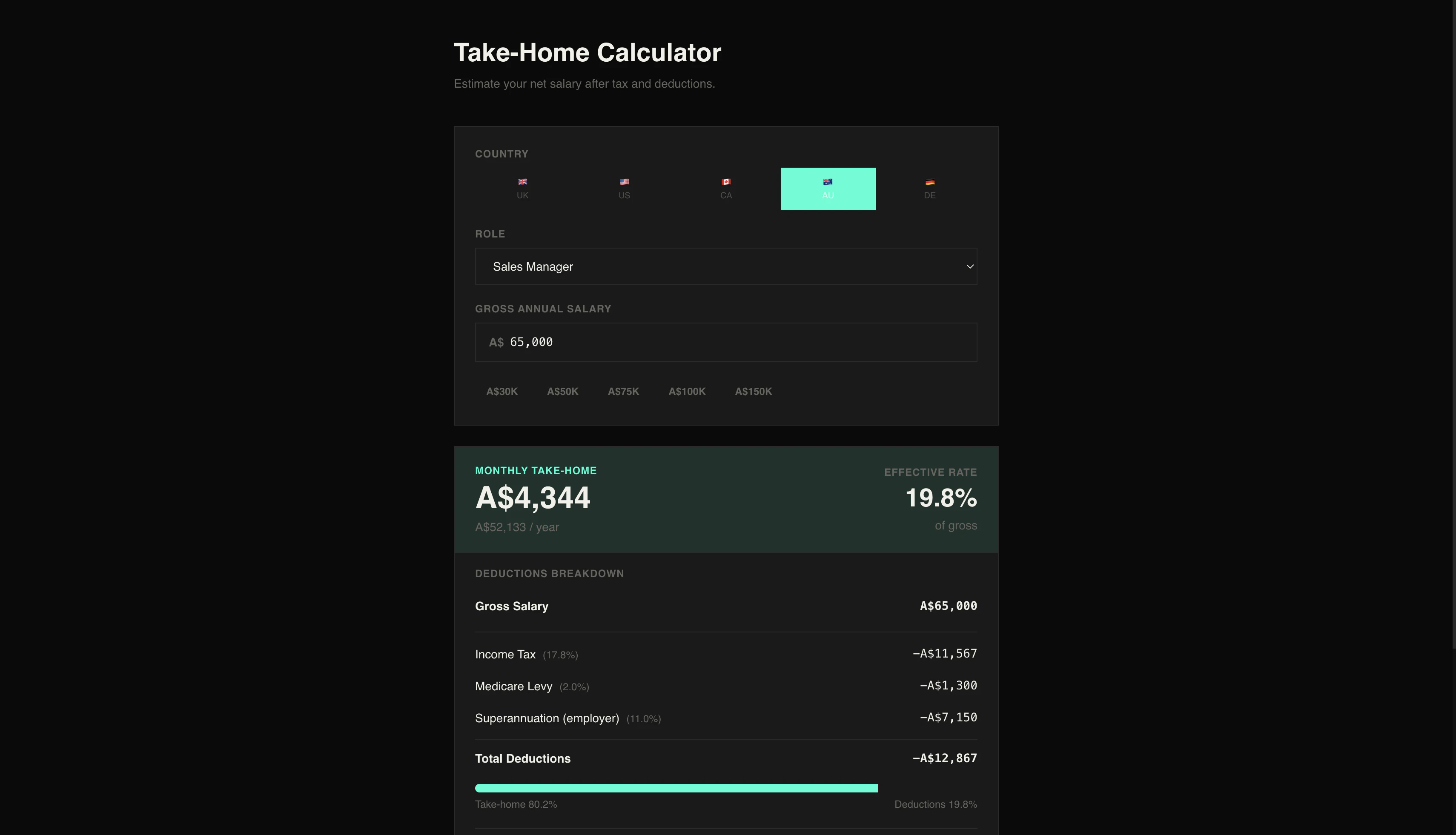
一句话介绍:Origio通过8个问题个性化评估25个国家的税后薪资、签证难度、生活成本和生活质量,帮助用户快速找到最适合移民或移居的目的地,解决传统工具缺乏个人化匹配的痛点。
Travel
Remote Work
Data & Analytics
移民决策工具
个性化推荐
国家对比
生活质量评估
签证难度分析
税后薪资计算
生活成本比较
一次付费
无订阅
ProductHunt
用户评论摘要:用户高度认可解决实际需求,但有Bug导致黑屏或超时(已修复),墨西哥未出现在搜索中;需注意税务数据更新的时效性,建议明确数据更新频率和“研究级”精度界限。
AI 锐评
Origio的价值不在于“比Numbeo更准”,而在于它把移民决策这个高度复杂、充满隐形成本的过程,压缩成了8个选择题。它切中了一个被忽视的痛点:大部分人不是不想移,而是被信息过载和“不知道自己不知道什么”的恐惧劝退了。
从产品逻辑看,它做了两件事值得肯定:一是用“税后实际到手收入”替代了粗糙的购买力,这对程序员、远程工作者这类高流动性人群是精准的;二是把“签证难度”和“国籍”强绑定,这弥补了Nomad List等工具只看生活成本的巨大盲区——一个印度护照和德国护照面对的世界完全不同。
但问题也很明显。19.99欧元一次付费的模式固然清爽,但税务数据、移民政策变动频繁,长期维护成本很高。评论中已出现数据查询失败和结果不显示的情况,说明MVP期技术底子仍在补课。更重要的是,它目前只覆盖25个国家,对于想对比泰国和西班牙的人有用,但真正需要移居的人往往在非主流国家——比如尼加拉瓜、格鲁吉亚——而这些数据空白会使工具的价值大打折扣。
最终,Origio更像是个“决策漏斗”——它能帮用户从25个国家缩到3个,但后续的深挖(雇主移民、子女教育、医疗保险)它无力承接。如果能开放数据API或构建社区贡献机制,它有机会从“工具”变成“平台”;如果只靠创始人手动刷税务表,一年后就会被数据折旧拖垮。值得关注,但别盲信。
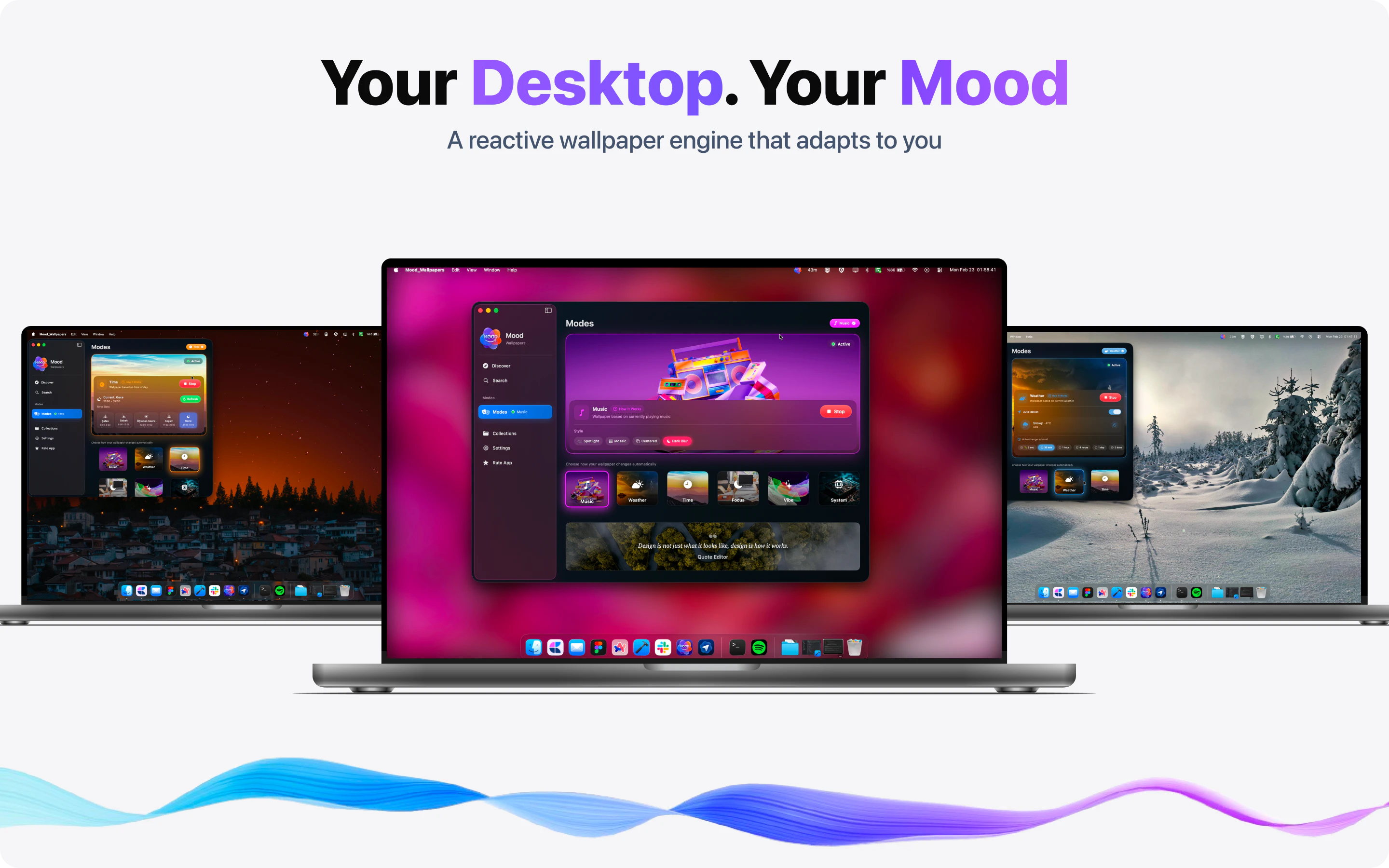
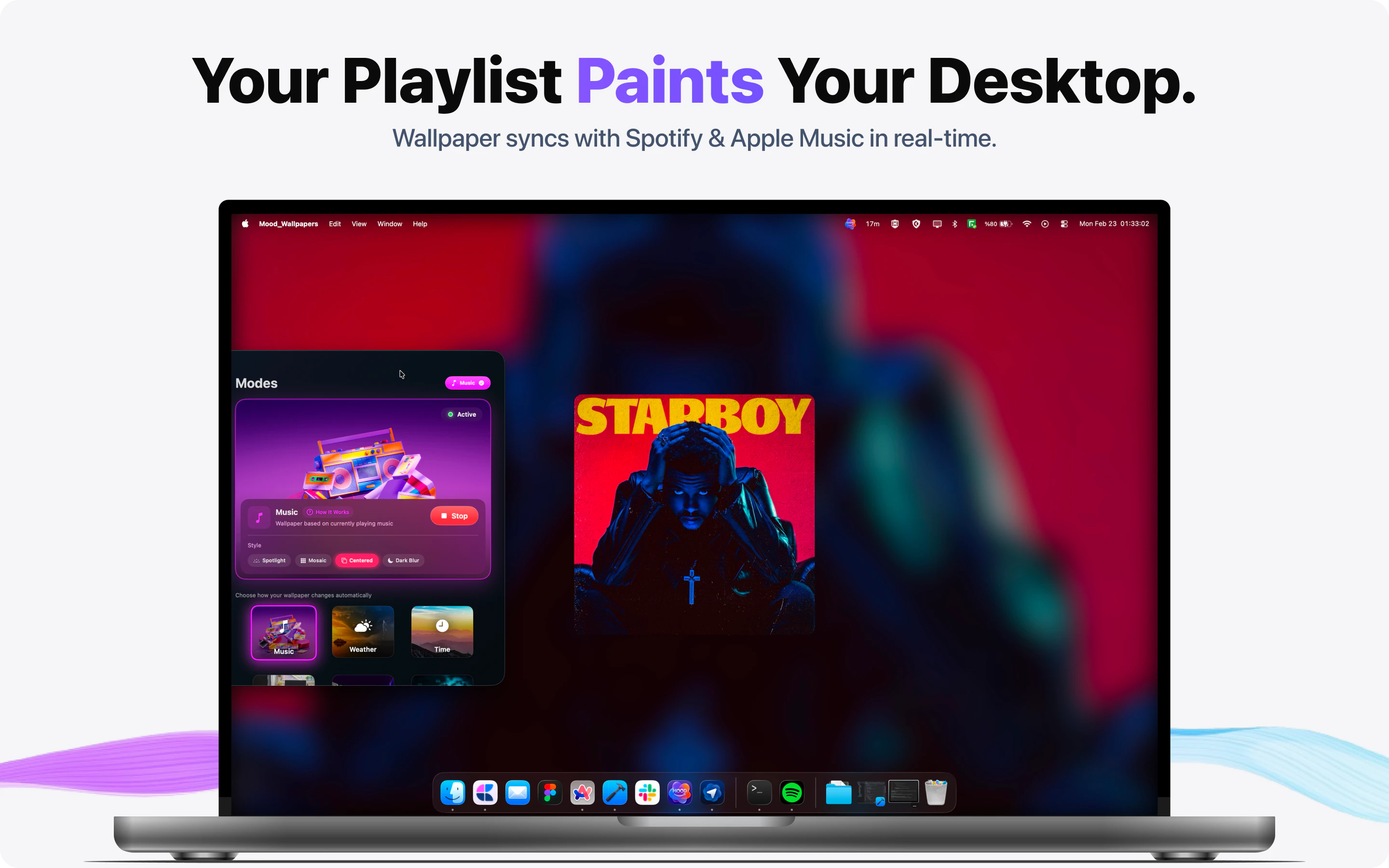
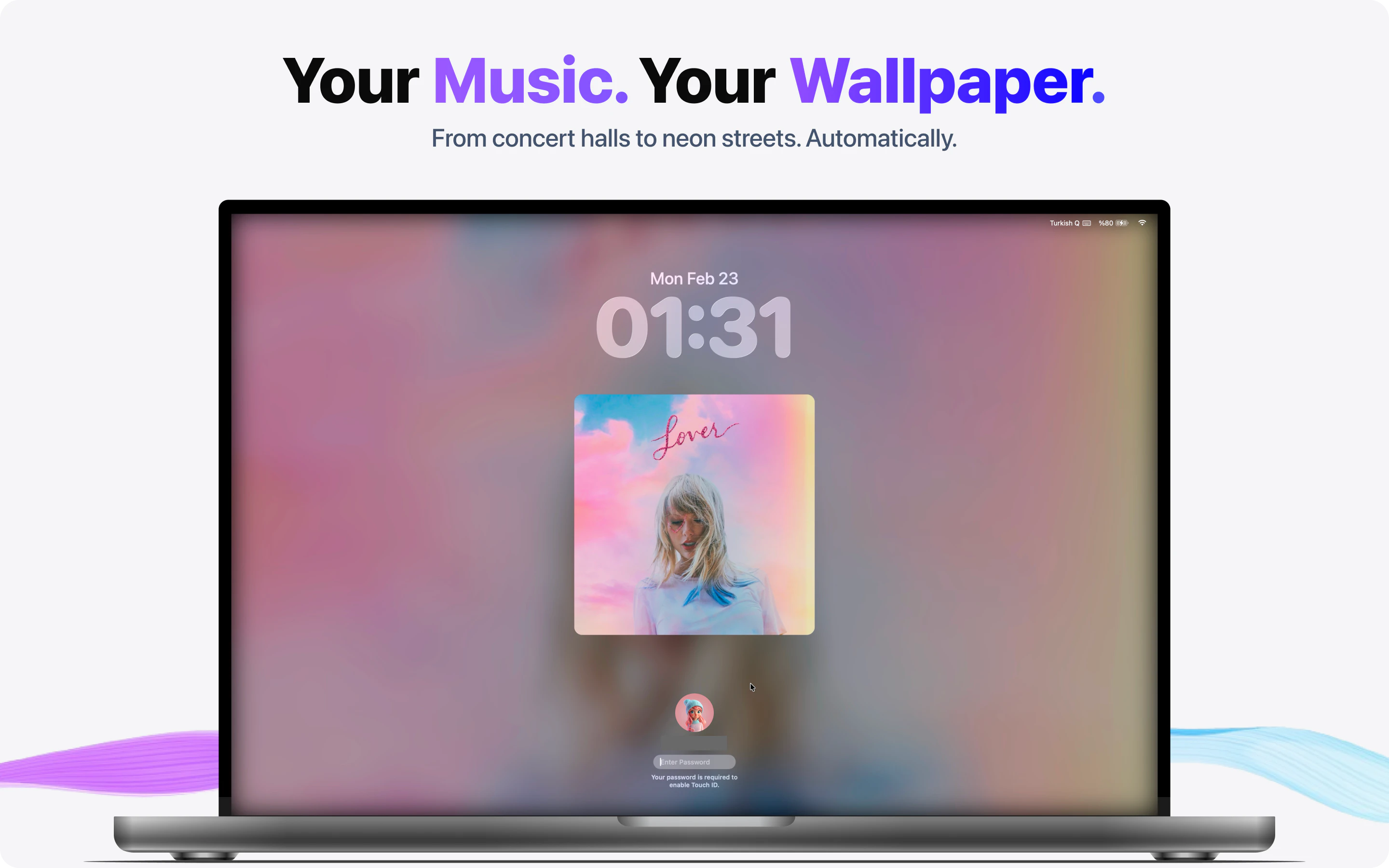
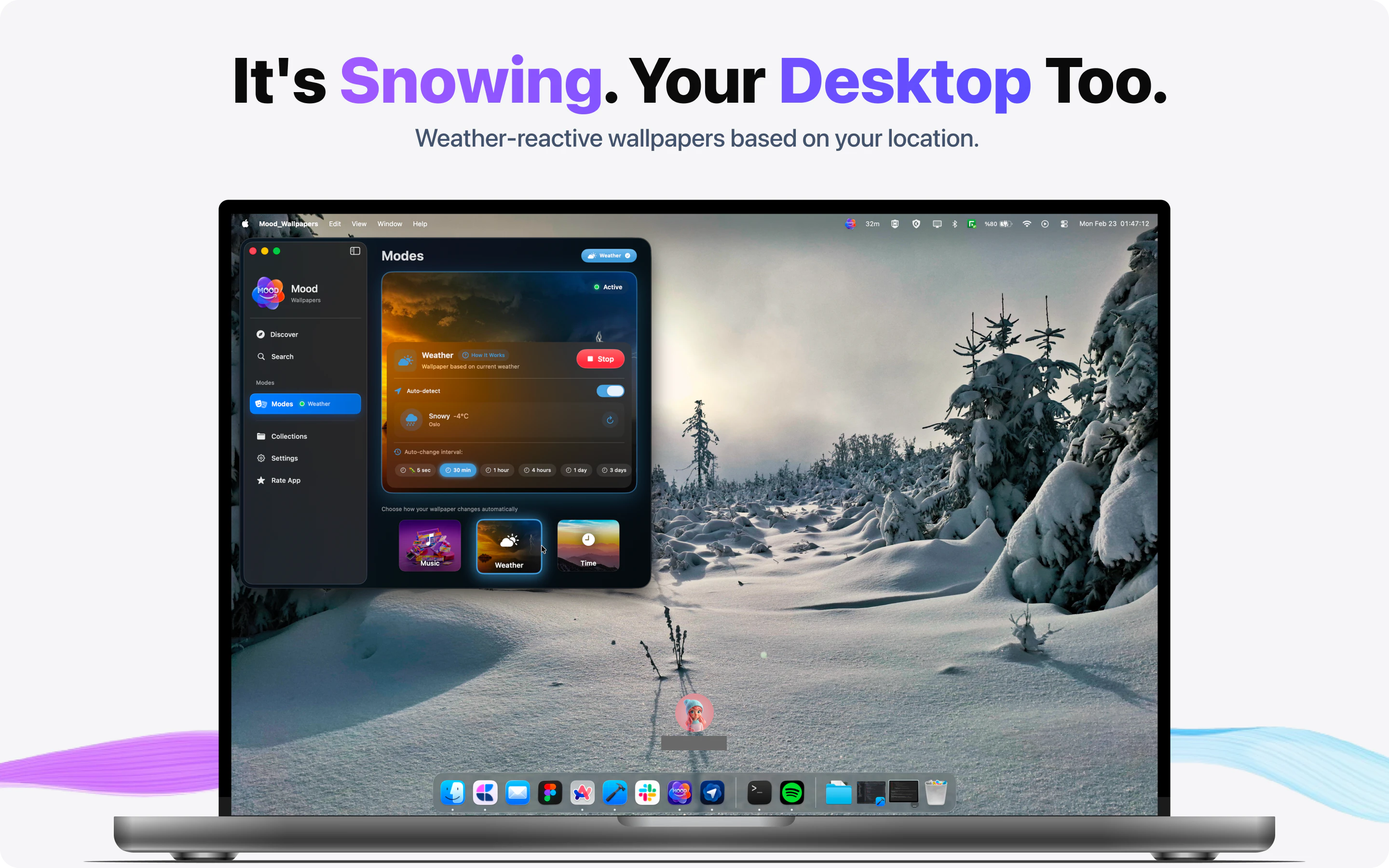
一句话介绍:MOODy是一款能将Mac桌面壁纸与音乐、天气、专注模式等实时联动的动态壁纸工具,帮助用户在长时间办公中摆脱静态壁纸的枯燥感,通过环境反馈提升沉浸感与效率。
Mac
Design Tools
Productivity
动态壁纸
Mac美化
音乐可视化
天气联动
专注模式
桌面增强
SwiftUI
多屏适配
情绪反馈
高效办公
用户评论摘要:用户普遍认可创意,但反馈存在明显问题:部分用户遭遇401错误和无法使用的bug;App Store截图模糊,影响购买决策;葡萄牙语用户指出可用性不佳。开发者积极回应,建议用户通过邮件提供错误截图和系统版本以协助修复。
AI 锐评
MOODy的出发点很聪明——把桌面从“装饰”变成“环境反馈”。它抓住了Mac用户一个真实但被忽视的需求:高频使用的桌面环境却长期静态,这与手机端丰富的动态交互形成了断档。六种联动模式(音乐、天气、专注、时间、情绪、系统负载)覆盖了工作、放松、沉浸等多元场景,尤其“音乐同步”和“专注模式”在实用性和情感共鸣上都有潜力。
但产品目前仍处于“创意先行,交付未满”的阶段。评论中反复出现的401错误、可用性bug、截图模糊等问题,说明开发者在前端体验打磨和测试覆盖上存在短板。作为一个“壁纸”类产品,第一印象极其重要,早期用户的负面体验很可能直接导致流失。此外,产品本质是一个“轻量级的氛围工具”,而非强生产力工具,其付费模式(订阅制解锁智能模式)是否能让用户持续为“动态壁纸”买单,值得怀疑——一旦新鲜感消退,留存率将面临较大挑战。
更值得商榷的是产品定位的暧昧性:它究竟是“桌面美化工具”、“环境反馈系统”,还是一种“数字情绪宣泄品”?目前的交互逻辑更接近后者,但在功能深度和系统整合上尚未触及真正“智能”的边界,比如缺乏对用户行为模式的主动学习或跨应用场景的调度。若能绑定更多生产力场景(如根据日程自动化切换风格、与番茄钟联动)或建立用户情绪数据反馈闭环(如周报形式的桌面使用分析),或许能跳出工具属性,向“数字生活伴侣”进化。开发者需要尽快解决基础Bug,并思考如何让“动态”不止于视觉,而是真正对效率或情绪产生可量化的影响。
一句话介绍:Krea 2通过内置的审美模型和风格控制功能,让用户摆脱对模糊提示词的依赖,精准生成符合个人审美偏好的AI图像,解决创意工作者在风格统一与情绪板把控上的痛点。
Photography
Artificial Intelligence
Graphics & Design
AI图像生成
基础模型
风格控制
情绪板
审美多样性
创意工具
风格参考
强度控制
工作流优化
Krea
用户评论摘要:用户对风格控制功能兴趣浓厚,但询问与GPT-image-2的对比、批次一致性及商业模式。建议官方明确版本更新亮点和商业闭环,以增强用户信任。
AI 锐评
Krea 2的发布看似华丽,实则暗藏隐忧。其“从零构建基础模型、强调审美与风格控制”的定位,确实切中了当前AI图像生成工具“提示词玄学”的痛点——用户厌倦了用几十个形容词去赌一张图。将风格从“描述”转为“引导”(通过参考图、强度滑块等),本质是降低创作门槛,提高可控性,这是产品最核心的价值。
但产品是否能形成护城河?评论中“与GPT-image-2对比”和“商业模式”的质疑直指要害。在巨头将基础模型作为免费能力的今天,Krea 2作为独立工具,其生存空间取决于两个关键:一是“风格控制”能否从“差异化卖点”进化为“不可替代的精度”,例如品牌物料中的严格色彩/构图一致性;二是能否围绕这一能力构建自循环的创作者社区与模版生态,而非只做API的壳。
此外,“每周末都有新AI视频工具”的评论暗示了用户疲劳。Krea 2若不尽快拿出让用户“非用不可”的场景证明(如设计稿秒级改风格、批量生成情绪板),而只停留在“更漂亮的随机”,那么它很可能沦为又一款昙花一现的演示品。技术方向正确,但商业化路径与持续迭代的“硬实力”才是生死线。
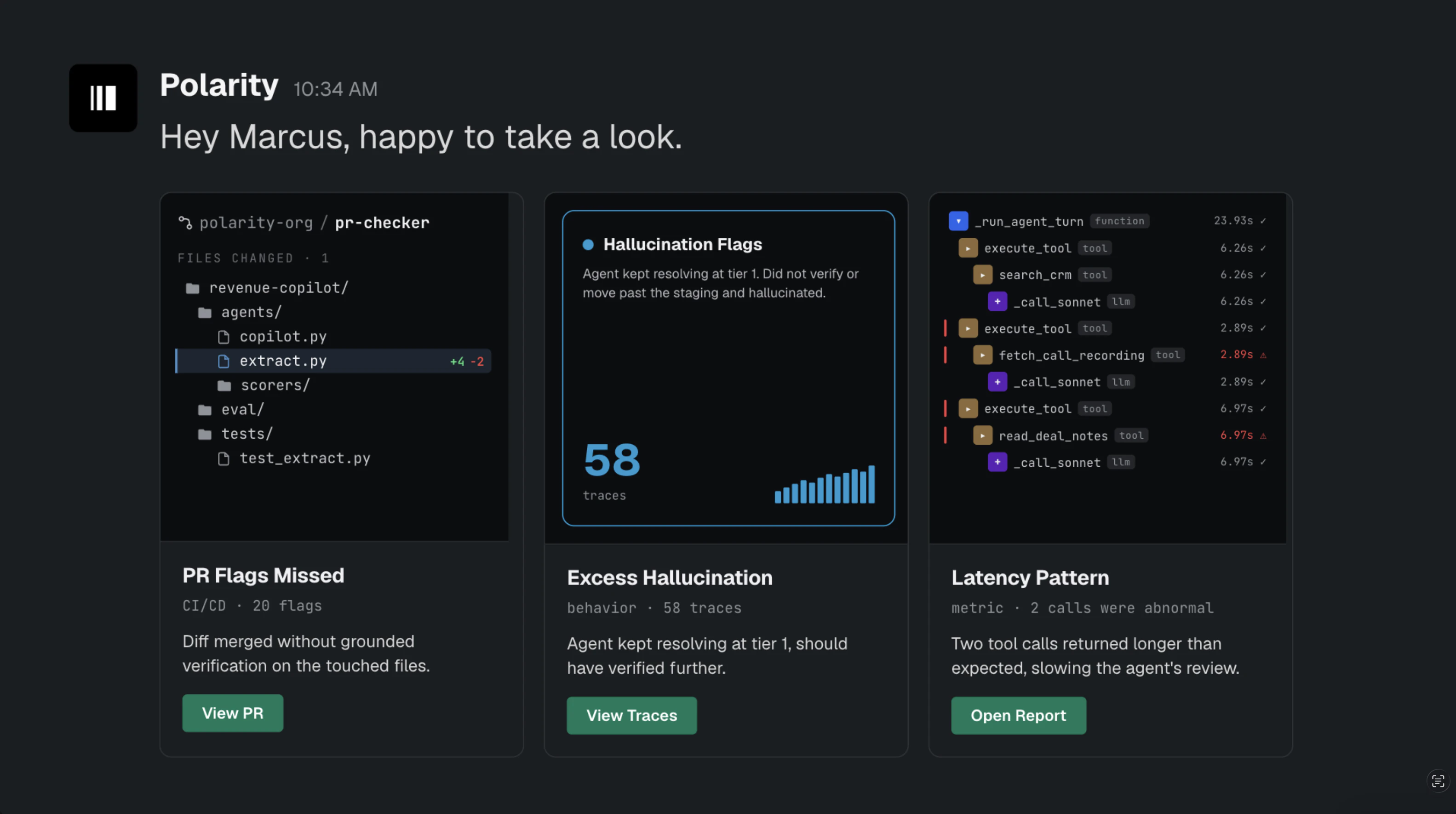
一句话介绍:Polarity 是一款在生产环境中实时监控 AI Agent 决策行为、自动发现失败模式并将其转化为评估数据,从而弥合测试与部署间可靠性鸿沟的监控工具。
Developer Tools
Artificial Intelligence
Tech
AI Agent监控
生产环境
失败模式检测
评估数据
可靠性
可观测性
自动化告警
Python SDK
TypeScript SDK
开发工具
用户评论摘要:用户普遍认可生产环境与评估集间的可靠性差距是真实痛点。主要提问涉及人工标注需求,官方回应称少量PR数据即可见效。另有一条反馈指出官网导航链接错误,可能影响用户体验。
AI 锐评
Polarity切入了一个极其精准且痛苦的场景:AI Agent的“实验室-生产”鸿沟。创始人提到的“95%通过率 vs 60%通过率”并非耸人听闻,这恰恰是当前大多数Agent应用无法规模化的核心死穴。传统评估套件在静态、可控的数据集上表现良好,但面对生产环境中混乱、不可预测的用户行为时往往不堪一击。
Polarity的聪明之处在于,它没有试图去构建一个更完美的“预生产”评估体系,而是直接all-in生产环境本身。它将Agent的轨迹(Traces)实时转化为评估数据(Evals),这是一种“以战养战”的闭环策略:每一次生产事故不仅是故障,更是对评估模型的强化训练。这种“学习型监控”的价值远高于传统的被动告警(如PagerDuty),因为它赋予了系统自愈和进化的能力。
然而,产品当前的护城河并未完全建立。其依赖的“少量PR数据”作为初始训练样本,是否足以应对极端复杂的多步骤推理任务,尚存疑问。并且,产品高度绑定Slack告警和特定SDK(Go、Python、TypeScript),对于已建立完善可观测性栈(如Datadog、Grafana)的团队来说,可能成为冗余的监控入口。更关键的考验在于,当Agent的行为模式在长时间跨度内发生“概念漂移”时,Polarity的自动化评估能否准确识别并无偏差地响应?如果不能解决这个长期可靠性挑战,它最终可能只是另一款“高开低走”的开发者工具。其商业价值取决于对“误报率”和“漏报率”的极致把控,而非仅仅提供一个漂亮的告警看板。
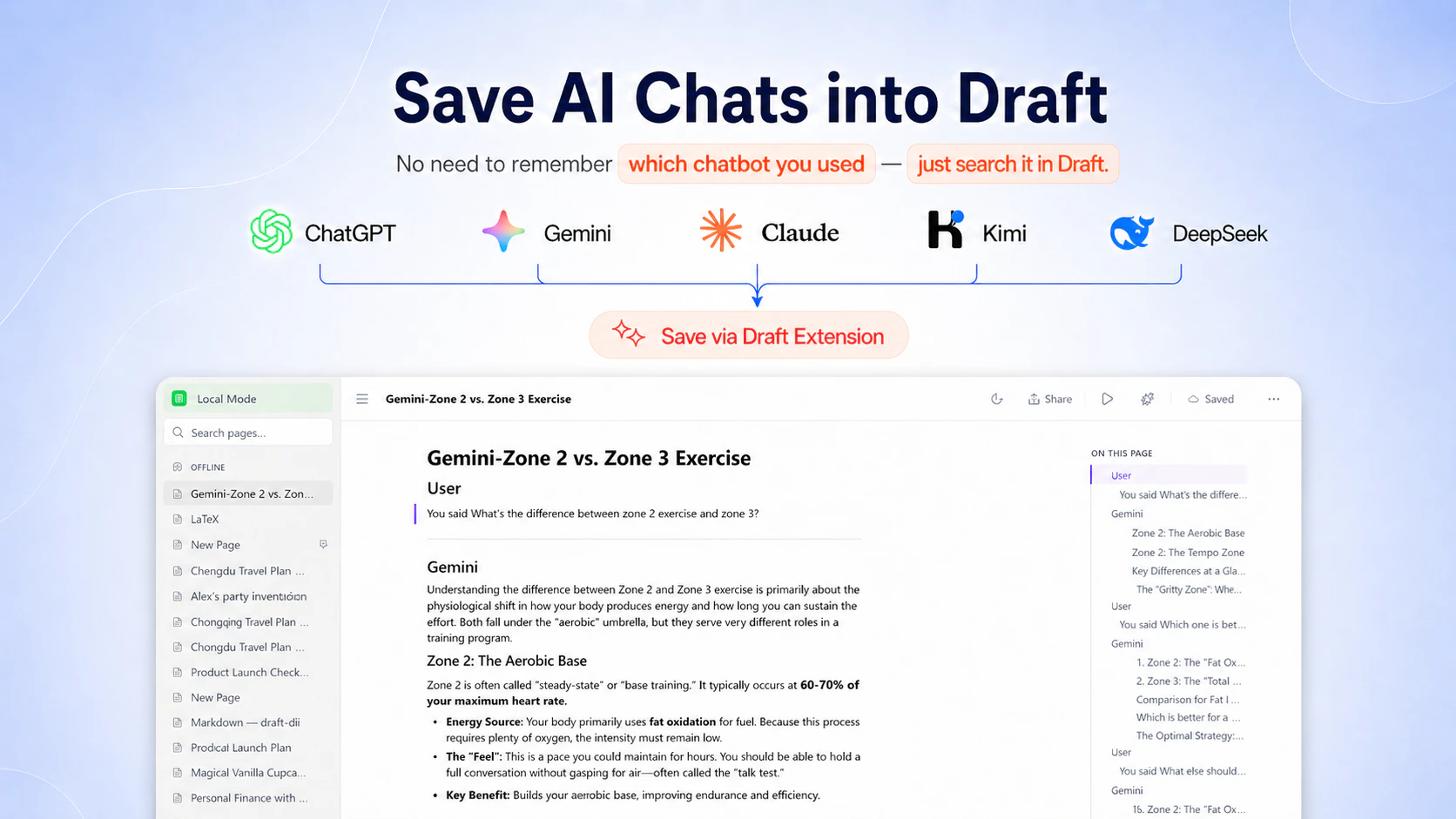
一句话介绍:Draft 是一款通过浏览器扩展一键抓取多平台AI对话(如ChatGPT、Gemini、DeepSeek),并将其转化为本地可编辑、可搜索、可离线使用的知识笔记工具,解决用户有价值AI回答散落丢失的痛点。
Chrome Extensions
Productivity
Artificial Intelligence
AI对话管理
知识库
浏览器扩展
本地存储
笔记工具
内容捕捉
ChatGPT
多平台
文本转语音
隐私优先
用户评论摘要:用户普遍认可其解决AI对话丢失的痛点,主要关注:本地存储的数据安全与备份机制、扩展对不同AI平台DOM更新的稳定性(维护成本)、自动捕捉与手动操作的界限、以及如何通过元数据(如原始提示、项目标签)增强知识可复用性。
AI 锐评
Draft找准了一个正在扩大的真痛点——重度AI用户在多平台间往复对话,有价值的回答如“数字垃圾”般散落。其核心逻辑并非创造新需求,而是将“高成本复制粘贴行为”产品化为“一键保存”,这是明智的“减法”。
然而,产品的护城河并不深。其核心依赖于对各大AI网页(如ChatGPT)DOM结构的解析,这种“爬虫式”技术方案极其脆弱。任何平台的UI更新都可能直接导致功能瘫痪,创始人承认“10分钟修复”虽展现了敏捷性,但也暴露了该模式的本质——一种以高昂维护成本为代价的“脏活”。对于个人开发者或小团队,这种精力的持续消耗是不可持续的,容易成为产品增长的绊脚石。
其次,产品在“存储”和“复用”之间存在明显断层。用户评论中关于“为什么保存这个?”的疑问切中要害。单纯的存档只是数字囤积,缺乏元数据(如原始上下文、标签、用户验证结果)的支持,这些笔记很快就会从“宝藏”退化为“噪音”。相比Obsidian等成熟的知识管理工具,Draft在知识沉淀和检索的深度上过于单薄。
真正的价值在于它是一个绝佳的“入口”。它占据了用户与AI交互的必经之路,未来可能发展的“Agent提议,用户审计”协作模式,以及音频/播客内容捕捉,才是更具想象力的方向。在Beta阶段,它看起来是一个不错的解决“第一公里”问题的工具,但从“捕获”到“知识复利”,还有很长且更难的路要走。
一句话介绍:LandingHero AI 将网站访客的即时问答、导览与线索捕捉,通过一个24小时在线的AI语音销售员替身自动完成,解决夜间或无人值守时客户流失的痛点。
Sales
网站AI销售员
语音聊天机器人
线索捕获
B2B SaaS
人工智能客户服务
网站转化率优化
实时引导
多语言支持
销售自动化
AI替身
用户评论摘要:用户担忧AI可能传递错误价格/承诺,且“创始人替身”的定位对准确性要求极高。建议关注如何植入创始人应答话术、定价细节和案例,以及如何进行转人工和跨会话记忆。核心痛点是准确性与信任建立。
AI 锐评
LandingHero AI 的“24小时AI销售员”概念切中了B2B SaaS网站流量浪费的痛点,尤其是非工作时间的高意向访客流失。其核心价值不在于简单的聊天机器人,而在于“AI版你”——这要求它必须真正模拟创始人的销售直觉和话术,而非一套 FAQ 模板。从用户评论看,项目最大的软肋也在此:一旦 AI 报错了价格或承诺了功能,负向传播对初创公司是致命的。目前评论区只给出了愿景,却未展示如何解决“幻觉”和“转交信任”这两个核心工程问题。此外,产品是否具备跨会话记忆以维系潜在客户的长期跟进,也是从新奇工具晋升为关键漏斗的槛。如果 LandingHero 仅能完成首次沟通的导览,其价值将远低于“销售员”的定位。真正考验在于:它能否在错误发生时及时预警,并在转人工时提供完整的上下文,而不是给销售留下一堆需要擦屁股的坑。否则,它充其量只是个带语音的、有点聪明的留言本。
一句话介绍:Triggered Agents 是一个事件驱动的AI代理工具,能让AI在Shopify、Stripe、Slack等业务工具触发特定事件时自动执行响应任务,解决创始人或运营者在多工具流程中因手动跟进而错失时效的问题。
Developer Tools
Artificial Intelligence
Marketing automation
事件驱动
AI代理
自动化
业务工作流
无代码
高效运营
智能触发
多工具集成
SaaS工具
用户评论摘要:用户关注Agent的失败重试与条件分支机制、事件去重能力。有效评论指出:现有方案常因无人及时响应而错失信号,期望Adaptive能处理重复触发的噪声,并支持复杂业务逻辑下的容错处理。
AI 锐评
Triggered Agents 的“事件驱动”模式确实切中了当前AI代理行业的软肋。大部分Agent平台仍需要用户主动“拉”出任务——打开网页、写Prompt、等待。Adaptive将模式切换到“推”,让Agent在事件发生瞬间自动运行,理论上比Zapier这类规则引擎具备更智能的推理、撰写、通知能力。
但要注意,这不等于“无脑替代”。其核心挑战在于两点:事件噪点和智能体失败处理。评论中用户已敏锐提出“去重”与“条件分支”问题,现实场景中一个订单可能触发多条冗余事件,若Agent重复“推理”并执行冗余操作,反而加重混乱。此外,Agent“自行推理”的透明度与可控性也是隐患——如果一次生成错误邮件或发出错误采购单,后果不亚于人工遗漏。
从产品价值看,它最适合高频、低决策成本的“跟进型”任务,如客户成功提醒、库存告警、邮件跟进等;但若推向复杂、高风险业务(如合同审批、大额付款),当前仍需依赖“人工确认环节”来兜底。
总体而言,这是一次从“手动拉”到“自动推”的合理进步,但距离“智能自主代理”的理想仍差一层稳定性、可观测性与事件处理成熟度。未来的胜负关键,不在于驱动方式,而在于错误率、闭环反馈与用户信任感的积累。
一句话介绍:Pixserp是一个AI原生搜索引擎,通过单一API端点提供10种实时网页答案形态(搜索、新闻、图片、地点、购物、航班、酒店、YouTube、转录、任意URL),旨在解决开发者在使用LLM时获取实时、结构化网络数据需要集成多个API或自行爬虫的痛点。
API
Developer Tools
Artificial Intelligence
AI搜索引擎
实时网页数据
LLM工具
开发者API
结构化数据
单一端点
网络爬虫替代
OpenAI SDK兼容
付费API
用户评论摘要:用户关注数据实时性,询问1小时前的变化能否即时捕获。开发者回应通过请求时实时查询和智能新鲜度逻辑实现快速反射,可强制实时拉取。另有用户关心不同垂直领域的排名一致性和大规模准确性,开发者表示已在主产品中可靠运行,欢迎试用反馈。
AI 锐评
Pixserp切中了一个真实且尖锐的痛点:LLM需要吃实时数据,但现存方案要么是脏乱差的爬虫结果(如Playwright),要么是单一形态、价格虚高的AI搜索API(如Perplexity Sonar Pro的$19/1k)。它的真正价值不在于“AI原生”这个标签,而在于用“一个端点、十种答案形状”的抽象,大幅降低了开发者将实时网络数据集成到AI工作流中的心智负担和编码成本。$1.50/1k的定价对比Sonar Pro堪称降维打击,且OpenAI SDK的“即插即用”策略降低了迁移门槛,让现有GPT应用可以无缝获得实时搜索能力。
但需要警惕的是:97票的社区热度不足以验证其规模下的稳定性和数据质量。用户询问“排名一致性和实时性”正是核心风险——实时网络数据的质量极不稳定,尤其是在购物、航班等高频变动领域,索引质量、反爬策略、语义理解的误差都会直接暴露给终端AI应用。此外,作为“开发者工具”,它的核心竞争力高度依赖数据源是否合规且可持续——如果幕后依赖第三方API或公开爬虫,任何源头的变动都可能造成服务波动。目前尚未看到其自有索引或独特数据源的明确说明。
一句话总结:Pixserp是个优雅且定价犀利的“LLM网络数据层”,但长期价值的基石取决于它能否在规模下处理好数据质量和源稳定性。对于想快速为AI应用增加实时网络能力的团队,值得一试;但对于要求高可靠性的生产场景,建议先做压力测试。
一句话介绍:SizzleAir是一款专为无风扇MacBook Air设计的菜单栏热管理助手,通过分析热压力、工作负载、外接显示器状态和CPU占用等本地信号,用一句话告诉用户“为什么变热了”以及“该怎么做”,替代了传统繁琐的温度图表。
Mac
Productivity
Developer Tools
macOS工具
热管理
MacBook Air
菜单栏应用
应用性能监控
无风扇笔记本
系统优化
开发者工具
轻量级app
付费软件
用户评论摘要:用户关注点集中在无风扇MacBook Air在合盖外接4K显示器时的散热难题。开发者回应:SizzleAir会识别显示器与开合状态,给出“该情况可能加剧发热”的提示,并建议开盖或降低负载。另有用户赞赏其将配置与功耗关联分析的实用性。
AI 锐评
SizzleAir的价值不在于“解决问题”,而在于“减少盲区”。市面上已有大量Mac温度监控工具,但大多止步于提供传感器数据图表,把分析责任推给用户。SizzleAir的聪明之处在于,它承认一个物理事实:无风扇的MacBook Air在高负载下一定会变热,这不是Bug而是特性。因此它放弃了“降温”的伪承诺,转而做认知辅助:基于上下文(外接显示器、充电状态、合盖模式、CPU消耗进程)归纳热压力原因,并给出可行操作建议。这切中了长期使用Air的开发者、内容创作者的深层痛点——他们不是不知道Mac热,而是不确定“现在热是不是正常的”“要不要中断工作”。
但产品也存在明显短板:第一,无试用版直接付费的策略在macOS工具类app中属于高门槛,用户可能因担心不匹配场景而流失;第二,“建议”多为被动信息,用户仍需自己执行调整,实际降温效果取决于人类决策,而非App本身——这既是设计考量,也限制了产品的直接效用循环;第三,功能距离“热管理”这个命名隐含的主动性还有差距,目前更像“热信号翻译机”。
如果未来能整合如限制后台进程、自动调整系统性能模式(如ThrottleStop的mac版本雏形)等更多主动控制层,SizzleAir有机会从“解释器”进化为“调控器”。但在当下,它是一个足够诚实、清晰且用心的痛点扫描仪,对正在忍受Air温度焦虑的用户来说,值得放下“能降温”的期待后被试用。
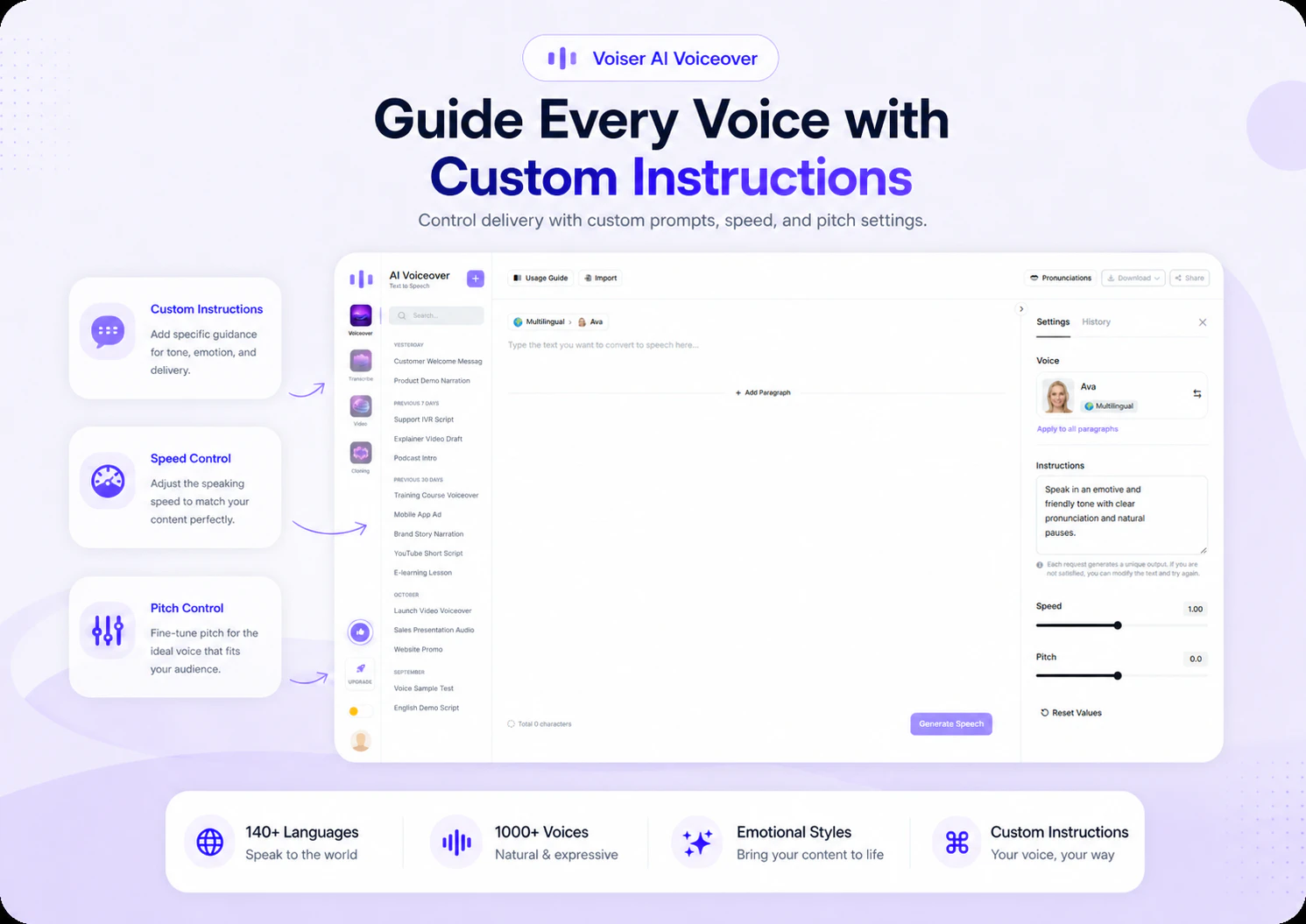
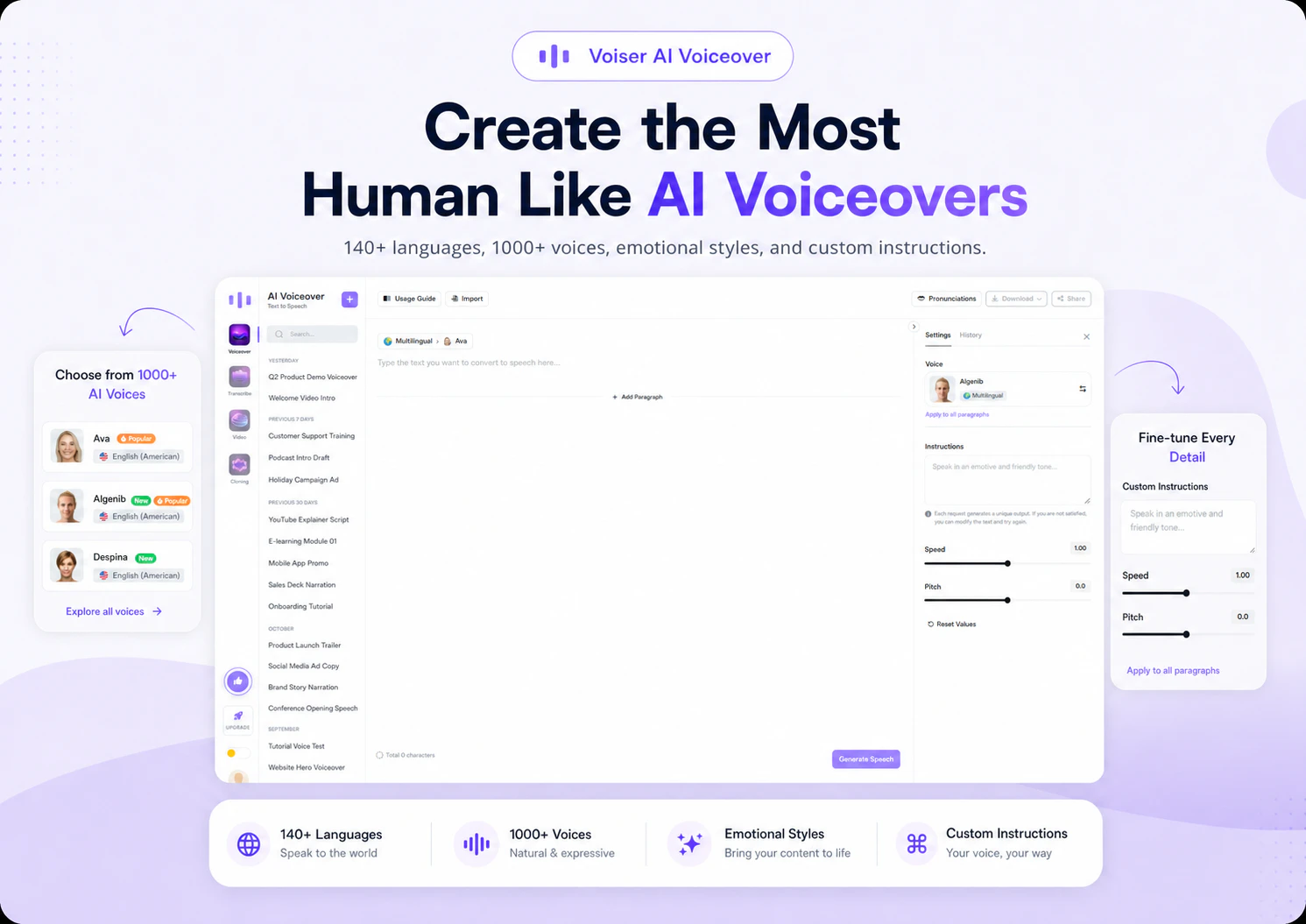
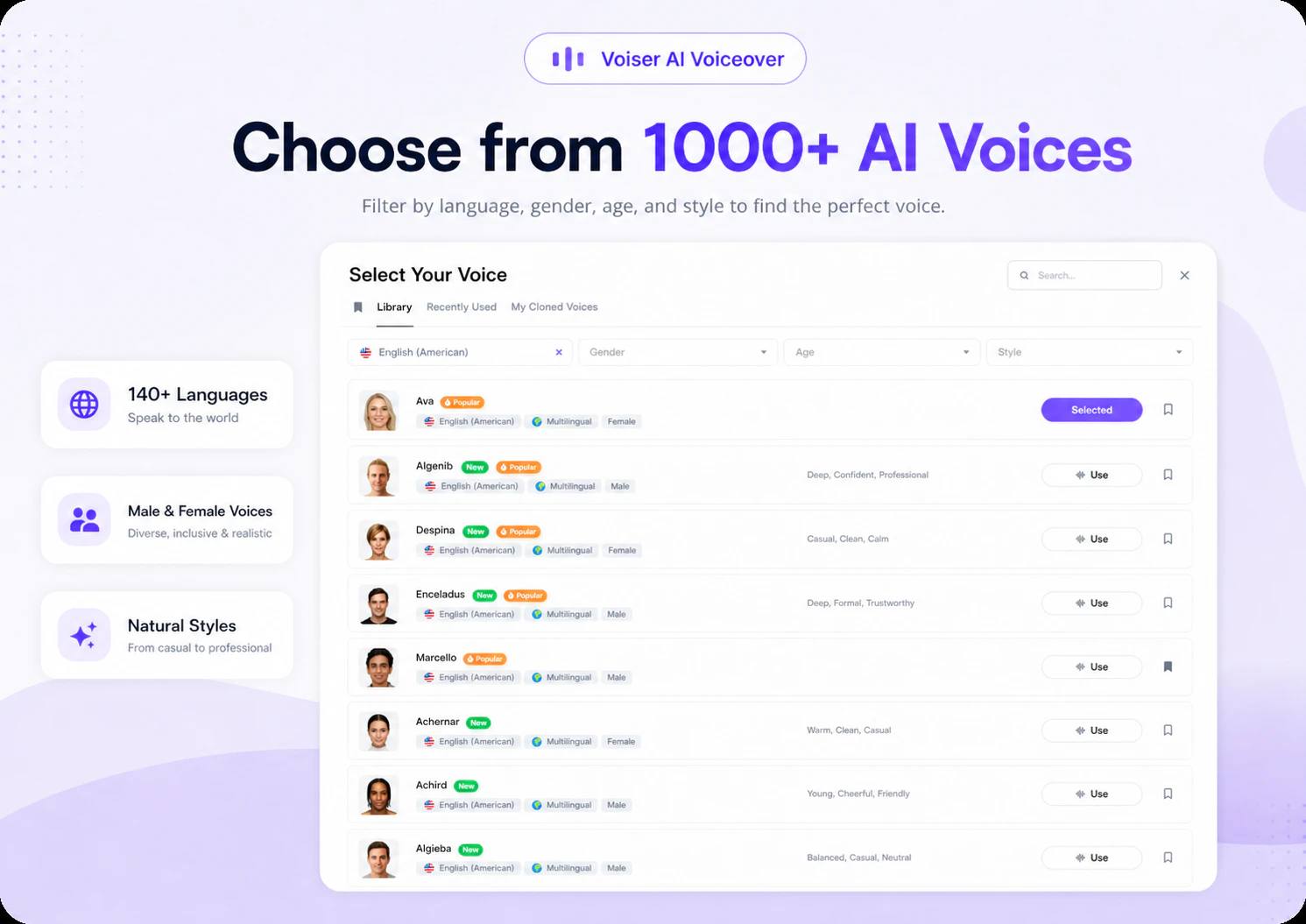
一句话介绍:Voiser AI 提供了超过140种语言、1000种AI语音的文本转语音服务,旨在帮助创作者和企业快速、低成本地生成情感丰富、真人般的配音,解决传统配音流程慢、贵、复杂的问题。
Android
Education
Artificial Intelligence
Audio
AI语音合成
TTS
多语言配音
情感语音
内容创作
视频配音
AI工具
配音生成
语音克隆
企业服务
用户评论摘要:用户评论普遍认可其解决了配音慢、贵、成本高的痛点,并对140+语言、情感控制及自定义指令功能表示赞赏。一个用户提出关键问题:语言支持是否区分特定地区口音,而非仅单一语言类别。
AI 锐评
Voiser AI的核心卖点在于“人性化”与“规模化”的结合。它精准切中了全球化内容创作者和跨区域企业对低成本、快节奏、多语言配音的刚需,其140+语言和情感指令功能在细分市场中具有明确竞争力。然而,光鲜的标语下暗藏两个关键挑战:其一,用户评论中“是否区分地区口音”的提问极其专业且致命——支持“西班牙语”和支持“墨西哥口音的西班牙语”是截然不同的产品力,这直接决定了AI配音在本地化场景中的真实可用性。其二,尽管宣称“人性化”,但在行业巨头如ElevenLabs、OpenAI的TTS技术已近乎以假乱真的当下,Voiser的差异化更多体现在语言覆盖数量而非情感模拟的深度上。目前产品更像是“多而全”的通用工具,缺乏针对特定垂类场景(如游戏角色配音、ASMR类音频)的极致打磨。若不能快速沉淀用户反馈,在细分口音和语境适应性上建立壁垒,它很容易沦为众多AI配音工具中的“又一款”。短期看,它确实是高效的成本替代方案;长期看,真正的护城河在于数据积累与对“人类语音表达细微差异”的持续逼近,而非单纯的语言数量堆砌。
一句话介绍:QuickRight为macOS Finder右键菜单批量补齐新建文件、真实剪切粘贴、快速打开终端等高频缺失功能,解决日常文件操作步骤繁琐的痛点。
Mac
Productivity
Menu Bar Apps
macOS工具
Finder增强
右键菜单
文件管理
效率工具
桌面生产工具
快捷操作
系统扩展
用户评论摘要:用户认为Finder日常操作过于繁琐(如新建TXT、剪切粘贴、打开终端步骤多),开发者强调工具应减少摩擦且不增加杂乱。回帖点赞指出,此类工具成功关键在于在减少摩擦的同时保持简洁、聚焦必要操作。
AI 锐评
QuickRight 的 94 票在 Product Hunt 上属于中规中矩的成绩,但它切中的痛点却非常精准:macOS Finder 的右键菜单十年来几乎没有进化,用户对“新建文件仍需打开应用”这种底层逻辑的忍耐早已到了临界点。这款工具的价值不在于技术壁垒,而在于对“文件交互最小操作单元”的极致补全——从创建、剪切到终端跳转,每项节省的都是毫秒级但高频重复的摩擦。
然而,其潜在风险同样明显。首先,系统级右键菜单是 macOS 交互的“神经末梢”,任何第三方注入都可能因系统更新(如 Sonoma 的菜单栏、Ventura 的系统设置重构)而频繁失效,长期维护成本高昂。其次,这类“缝缝补补”的工具很难建立护城河:Apple 随时可能在官方更新中加入类似功能(或通过 Shortcuts 自动化覆盖),而竞品如 Path Finder、Default Folder X 等老牌工具早已提供类似集成。最后,评论中“不增加杂乱”的警告恰恰点中了要害——一旦功能堆积超出“最常用”边界,这款工具就会从“神器”沦为“右键菜单的垃圾桶”。
建议团队将策略聚焦于两点:一是坚持“极简策略”,只做官方默认缺失的 5-10 个高频操作,绝不塞入图片压缩、颜色提取等低频功能;二是建立“系统兼容性卡位”,抢在 Apple 更新前通过渠道获得测试版适配认证。否则,这很可能又是另一个被系统更新悄然覆灭的效率小工具。
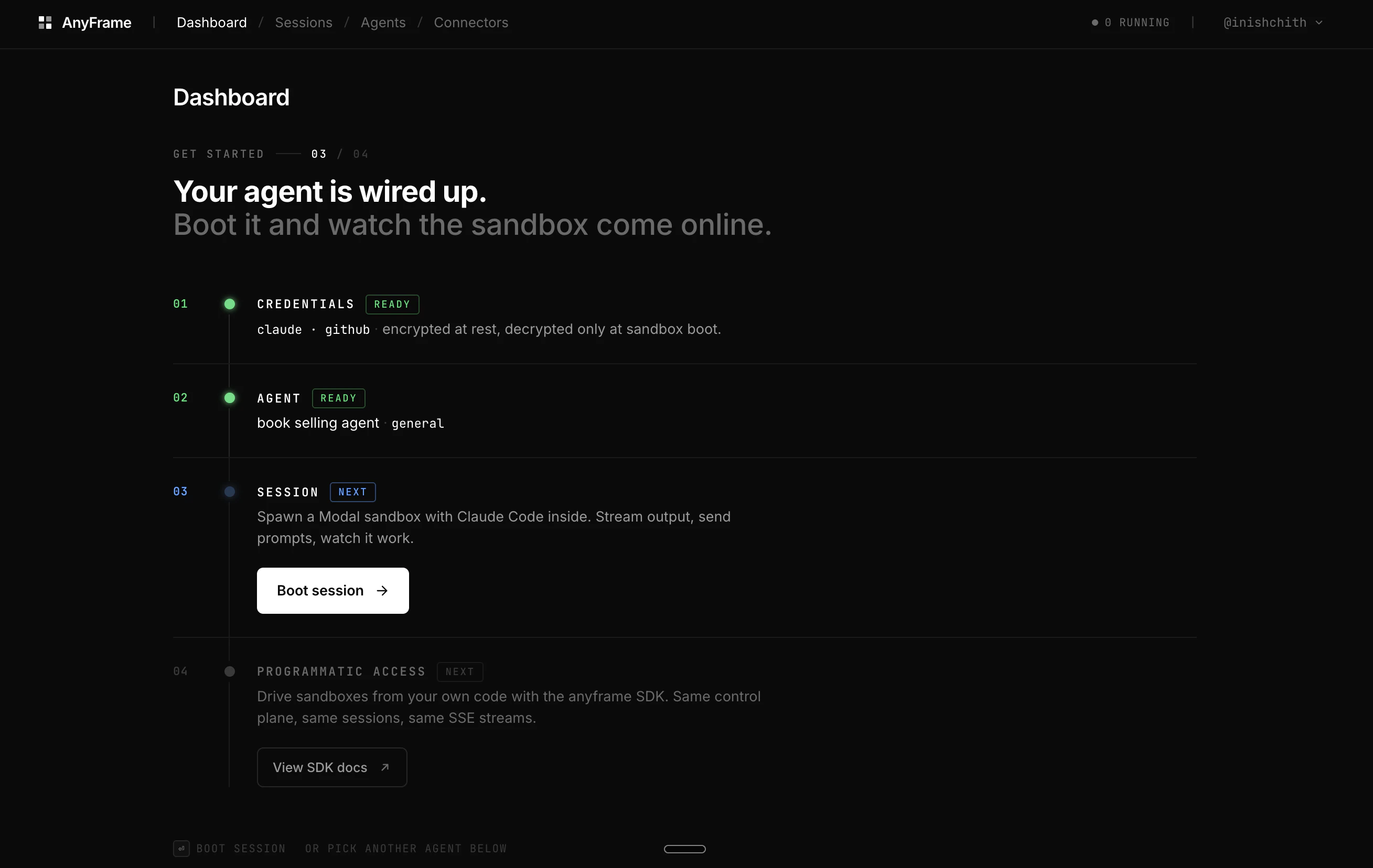
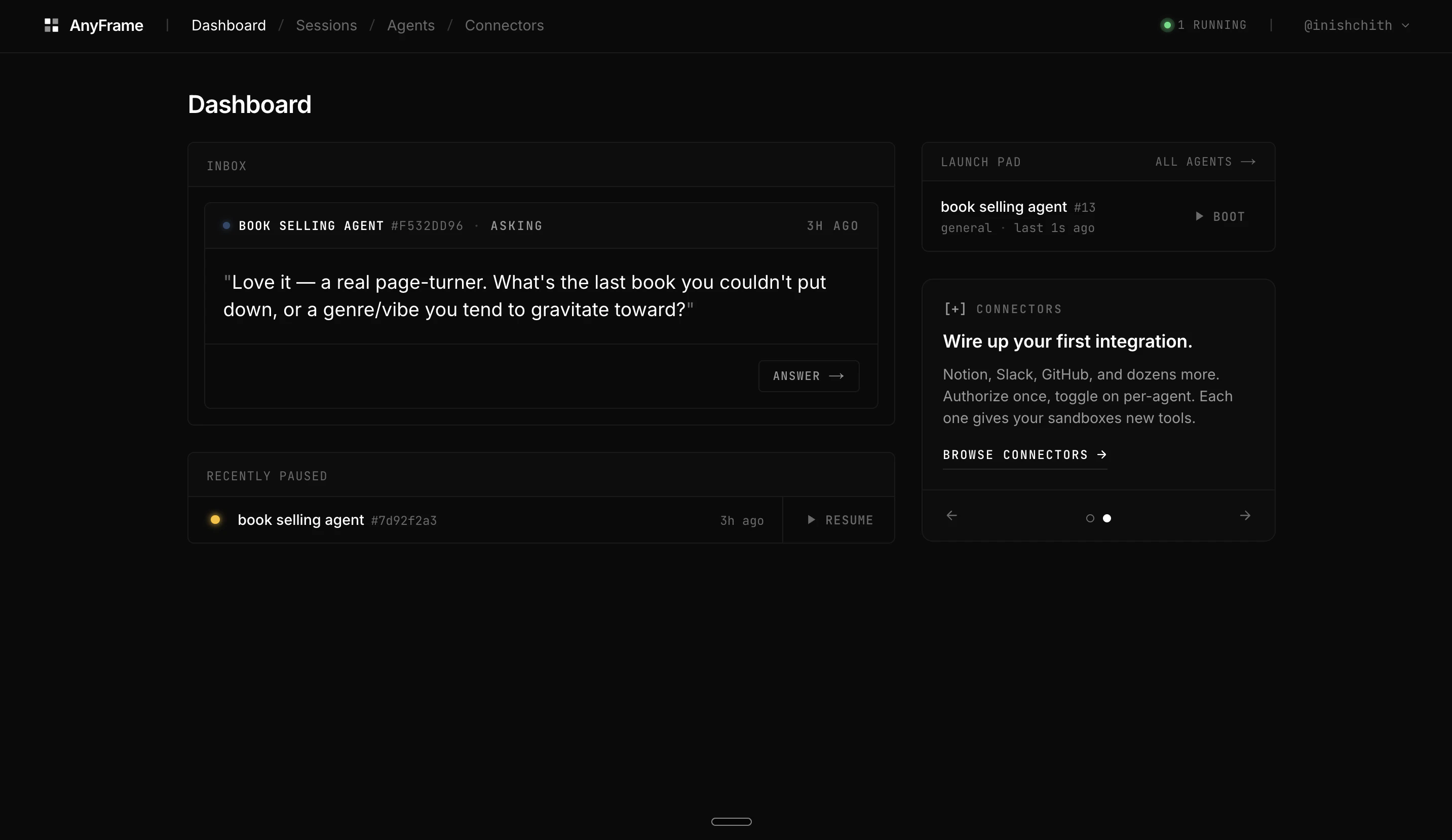
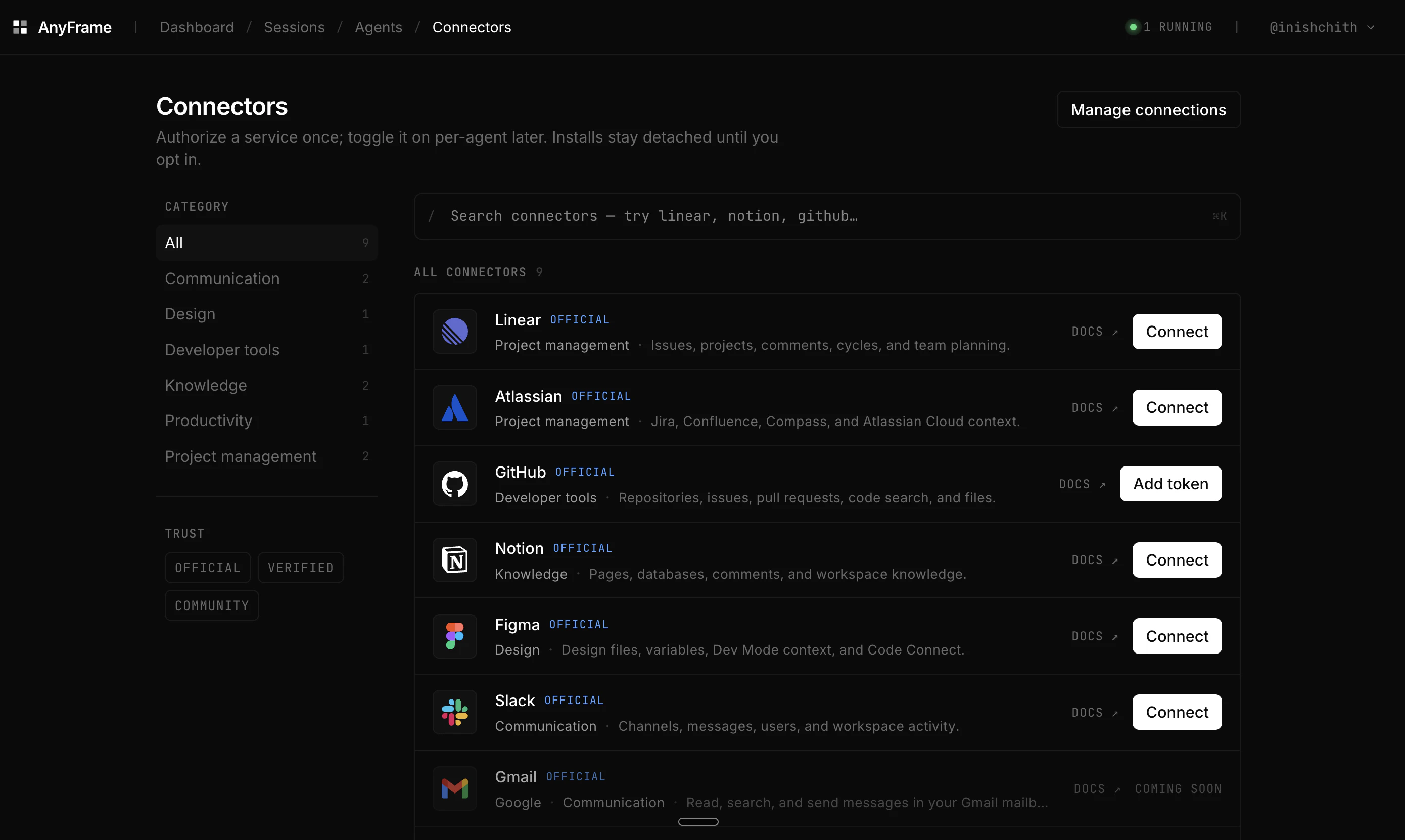
一句话介绍:AnyFrame为AI Agent提供一键式沙箱控制平面,解决开发团队为每个Agent重复搭建运行环境(如克隆仓库、安装依赖、配置MCP等)的繁琐问题,支持通过Web UI或Python SDK快速启动隔离会话。
Software Engineering
Developer Tools
Artificial Intelligence
GitHub
AI Agent沙箱
开发工具
控制平面
环境编排
MCP集成
Python SDK
云端开发
团队协作
自动化测试
代码审计
用户评论摘要:发布者指出团队痛点在于为Claude Code等Agent重复搭建沙箱环境,AnyFrame可缓存镜像并快速启动会话,支持部署内部聊天Agent、客户定制编码Agent或PR审查机器人,并希望获得已发布Agent产品团队的反馈,尤其是栈中最棘手的部分。另一评论表达对产品的期待,强调用户反馈将决定后续开发方向。
AI 锐评
AnyFrame切中的是一个真实且高频的“脏活累活”——为AI Agent搭建隔离且可复现的运行环境。这本质上是将容器化、CI/CD流水线等DevOps能力抽象为面向Agent的API层,价值在于降低“Agent工程化”的门槛,而非解决通用AI问题。
其亮点在于“定义一次,秒级启动”的缓存镜像机制,以及通过MCP统一集成外部服务,这能显著提升团队在内部工具(如自动部署)或客户场景(如隔离的代码审查)中的迭代效率。但从91票及有限的评论热度看,当前产品仍处于极早期阶段,功能深度和生态成熟度存疑。
值得警惕的是,其依赖Claude OAuth或Codex API Key,意味着底层能力完全受制于第三方模型。如果只做Agent的“壳”,缺乏对Agent行为(如失败重试、成本控制、安全性)的精细运营能力,则极易被开源方案(如Docker直接配合LangChain)或大模型厂商的原生沙箱服务替代。真正的护城河应在于对Agent会话生命周期、数据隔离和混合部署(本地+云端)的深度管理,而非仅仅“提供一个跑代码的地方”。目前看,尚缺这种从工具到平台的跃迁迹象。
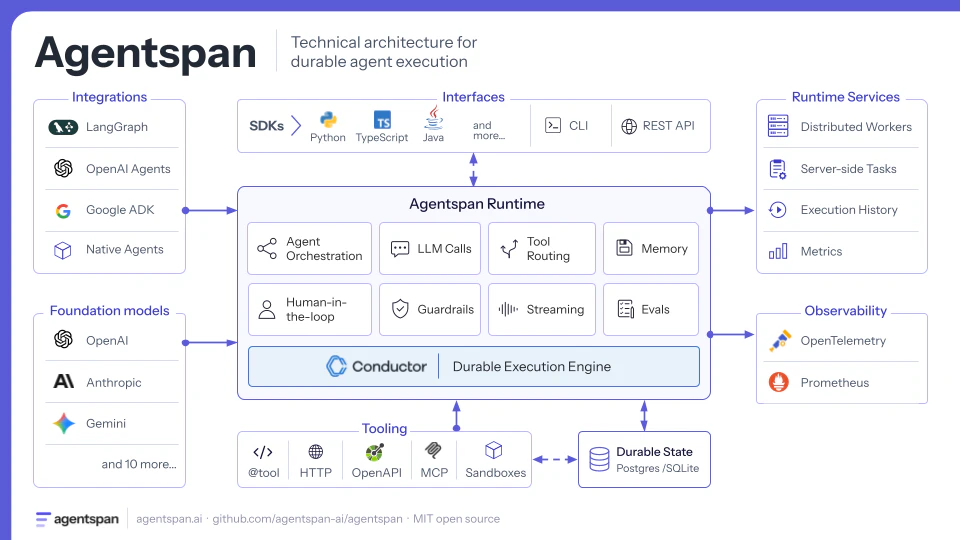
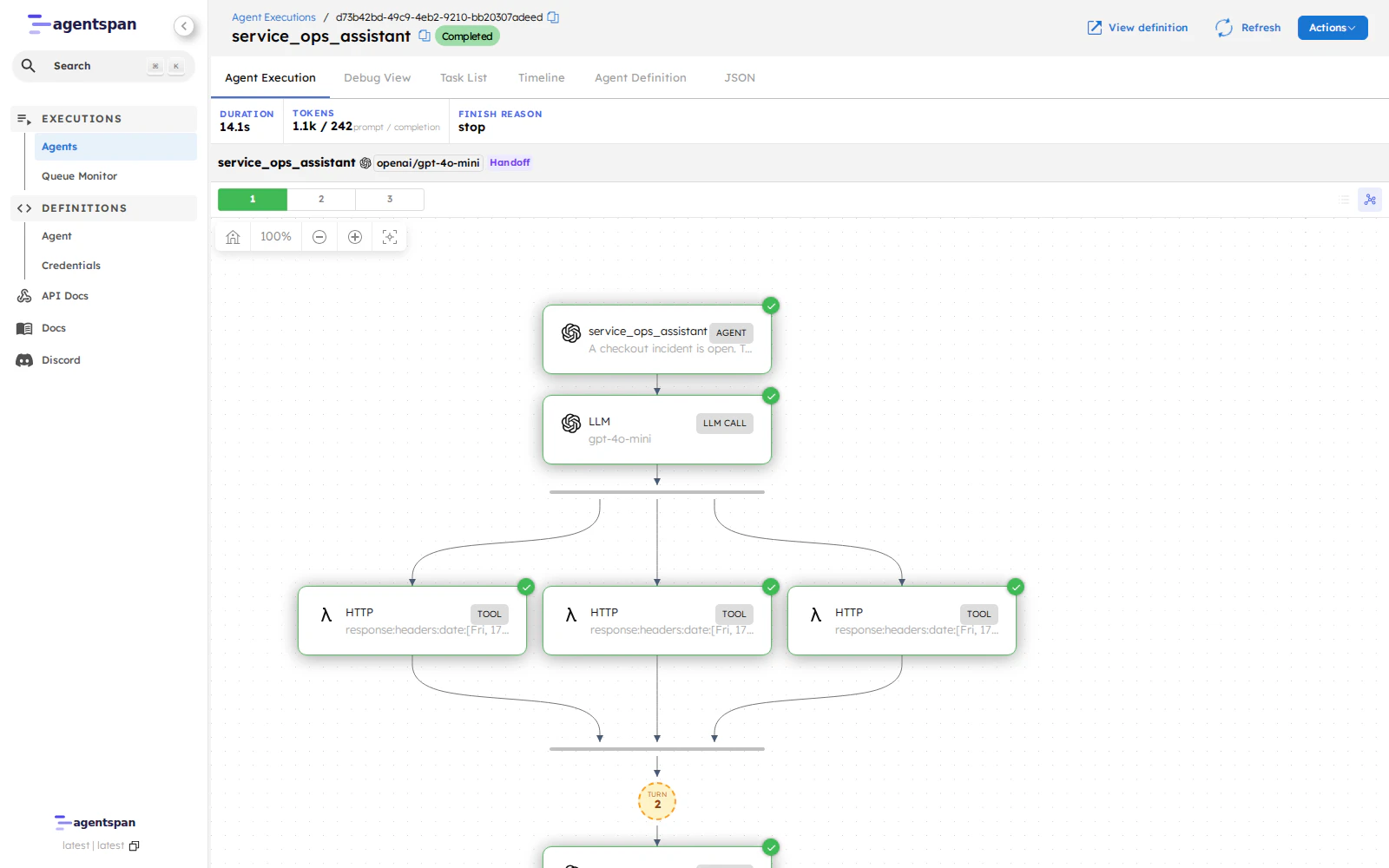
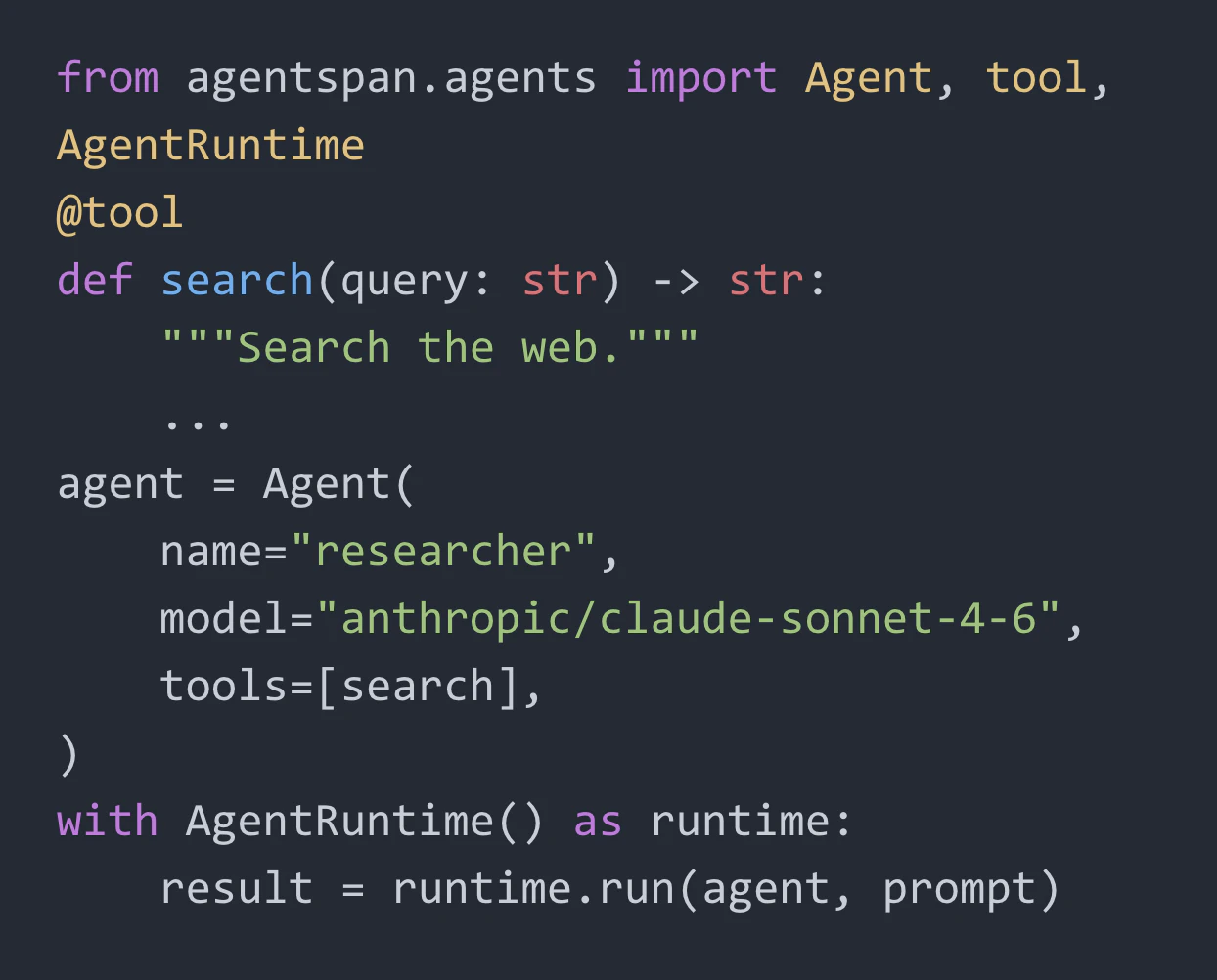
一句话介绍:Agentspan 是一个开源运行时服务器,通过将AI代理的执行状态持久化到服务端,解决了生产环境中代理因崩溃、人工审批中断或工具调用失败导致的状态丢失与难以调试的核心痛点。
API
Open Source
Developer Tools
GitHub
开源
AI代理
持久化工作流
崩溃恢复
人工审批
可观测性
企业级
运行时
用户评论摘要:用户高度认可代理持久化层对生产环境的重要性,关注点集中在:失败后支持部分重试而非全流程重启、不同审批节点的分支路由、以及长周期代理的状态管理。有用户建议增加主流云平台的一键部署连接器。
AI 锐评
Agentspan切中了当前AI代理生态中最“脏”也最不性感的一环:生产级可靠性。当行业热炒Agent框架和模型能力时,执行时的“三兄弟”——状态丢失、人工审批断点、重试副作用——正悄悄消耗着大量工程资源。该项目不追求创造新的代理范式,而是为已有框架(如LangChain等)提供了一层“安全网”,其MIT开源策略更是降低了企业信任成本。
从技术价值看,它将“客户端定义、服务端执行”的分离架构落地,用数据库持久化解决了“断了从哪接”的根本问题,这比大多数依赖内存状态的玩具级框架前进了一大步。但锐评必须指出:项目的真正壁垒并非技术,而是生态集成深度。目前“审批路由需用户自行编码”的回复暴露了其成熟度——真正的企业级方案需要提供可视化的审批流编排。此外,评论中“支持部分重试的逻辑需团队自己写”意味着它仍是一个基础设施而非开箱即用的产品,对中小团队门槛不低。
长期看,若仅停留在“运行时”层面,它很容易被AWS Step Functions等云原生服务或LangGraph等框架的内置特性挤压。真正的护城河在于围绕“可观测性”与“审计轨迹”构建的调试体验——这恰恰是通用工作流引擎做不到的差异化。一句话总结:它解决了正确的“硬核”问题,但距离“让用户不再操心基础设施”的终极愿景,还需在易用性和流程封装上补课。
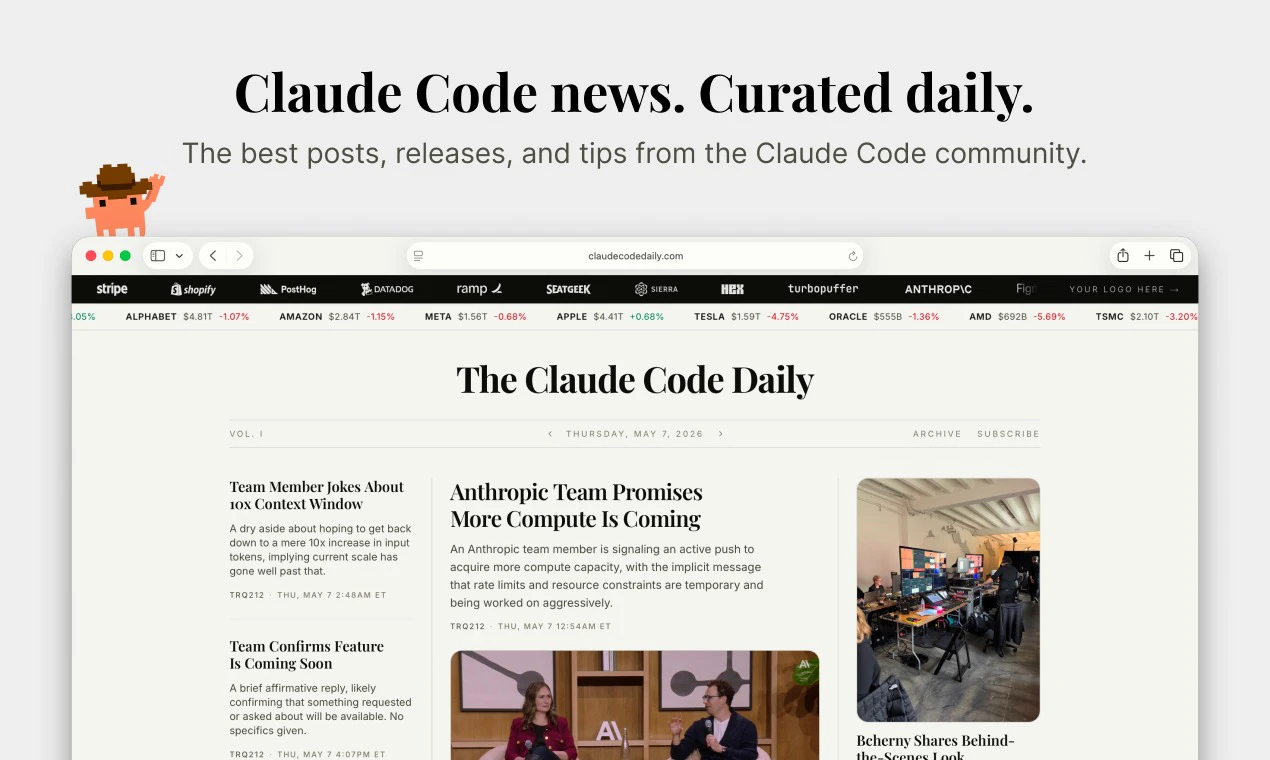
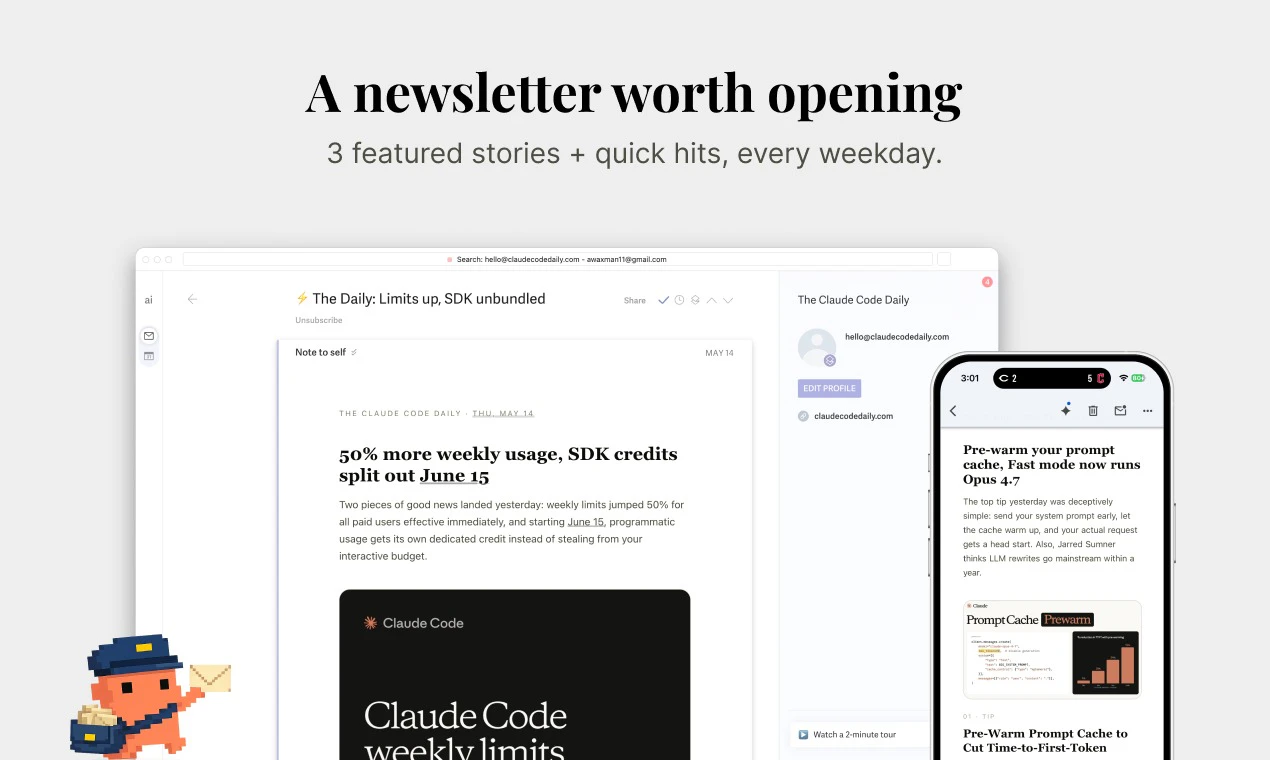
一句话介绍:The Claude Code Daily 是一款每日早间邮件摘要工具,专为难以追踪 Claude Code 碎片化更新的开发者设计,将散落于 X 平台的动态、技巧与工作流浓缩为 2 分钟可读的精华推送。
News
Artificial Intelligence
Tech news
Claude Code
每日摘要
邮件订阅
开发者资讯
社区内容聚合
AI 生态信息流
效率工具
信息降噪
工作流更新
资讯快讯
用户评论摘要:用户普遍认同 Claude 技术迭代过快,X 平台信息碎片化导致跟踪困难;肯定每日摘要的简洁实用价值,有人主动订阅并表示“工作流更新快到你刚找到有用的,别人已发布更好的”,部分用户期待更多定制功能。
AI 锐评
The Claude Code Daily 的爆火(短时间 52 票)精准踩中了 AI 浪潮中的“信息焦虑症”痛点。它的核心价值不在于技术创新,而在于“重新打包”能力——将 X 上散落的、时间敏感的社区智慧,变成一种制度化的、低认知负担的交付品。这本质上是内容策展(Curation)在 AI 开发者生态中的一次成功实验。但必须指出,该产品存在两个致命脆弱性:一是依赖第三方平台(X)作为唯一信源,一旦 API 限制或生态封闭,内容源会瞬间枯竭;二是用户粘性完全建立在信息差高度上,随着 Claude Code 本身趋于成熟,社区噪音下降,每日摘要的“刚需”属性将迅速衰减。目前它更像一个自媒体型的产品,而非平台型产品。真正的护城河在于能否从“精选”升级为“解读”——如果能对每一条信息附加深度评测或工作流验证,并允许用户参与贡献,它才有可能从新闻快讯进化为开发者社区的基础设施。否则,一旦出现更高效的分发形式(如 AI 生成播客、实时推送仪表盘),用户转移成本几乎为零。

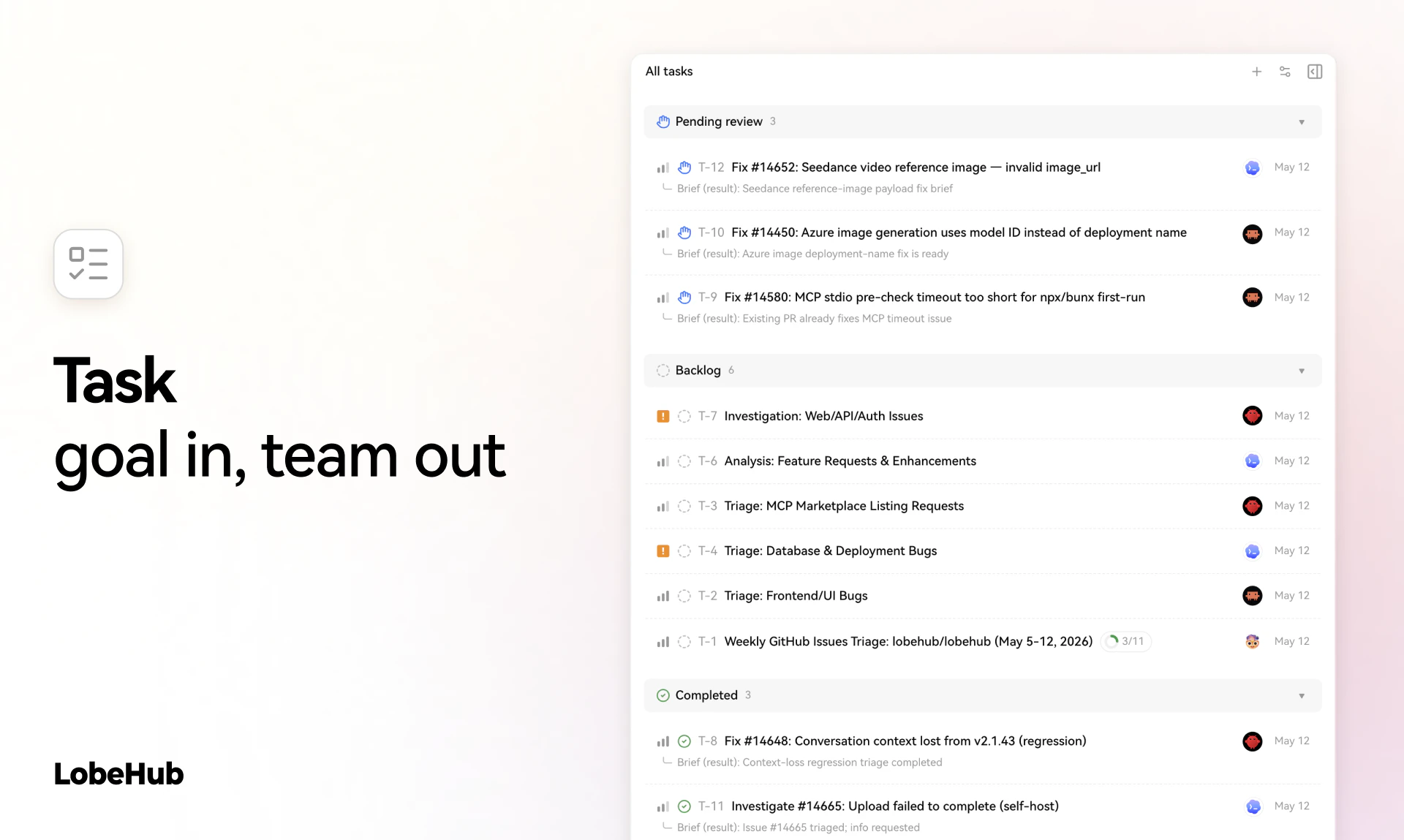
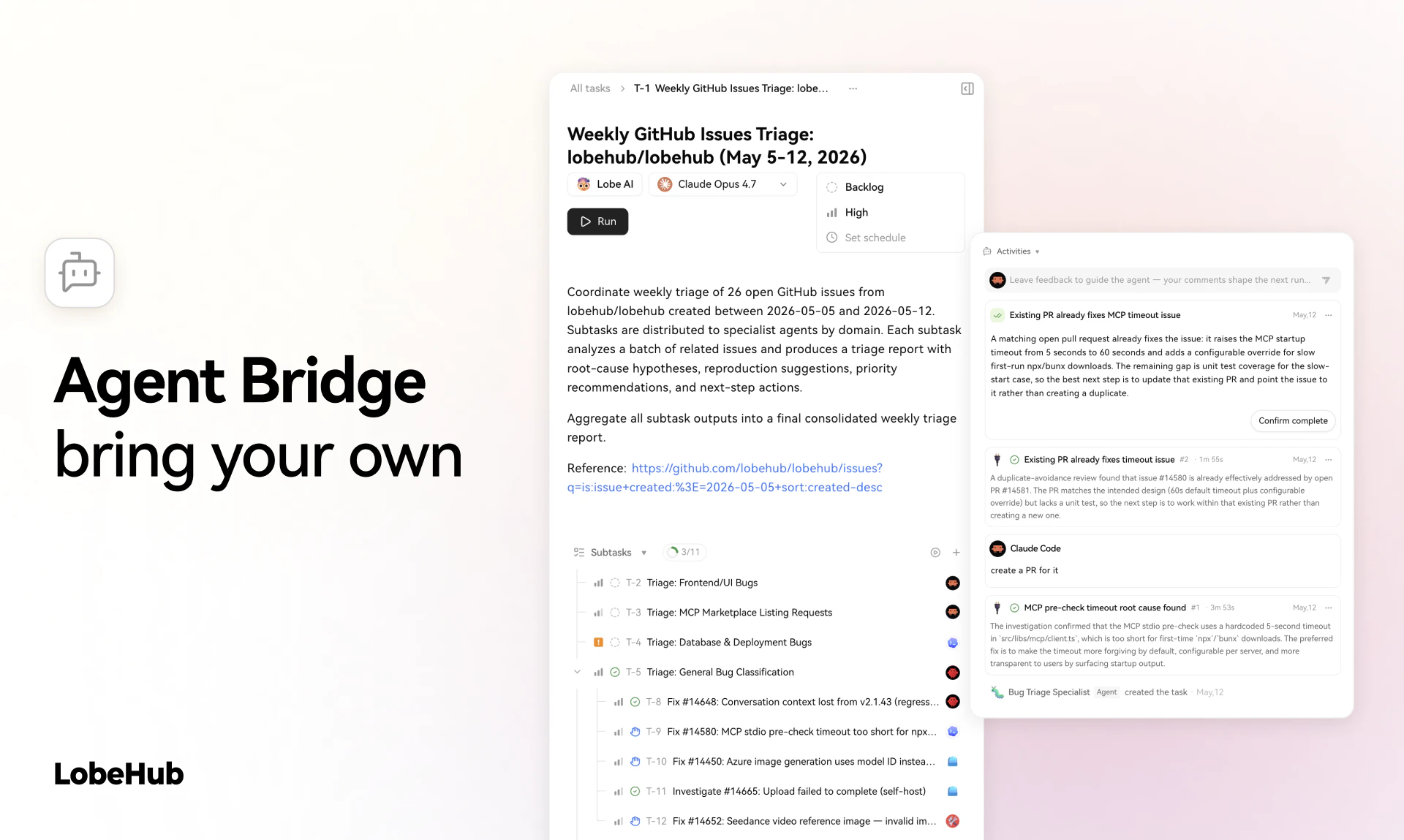
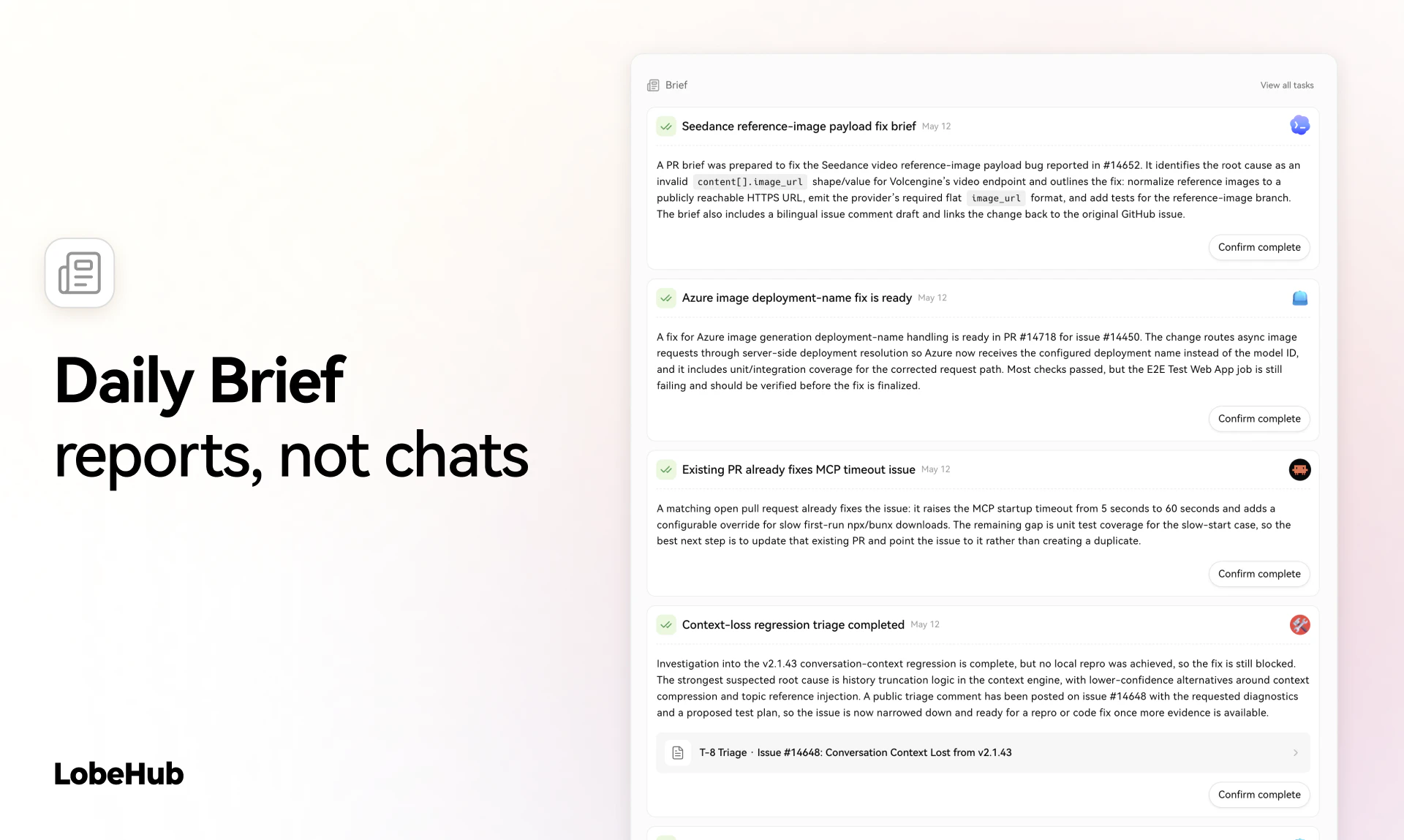
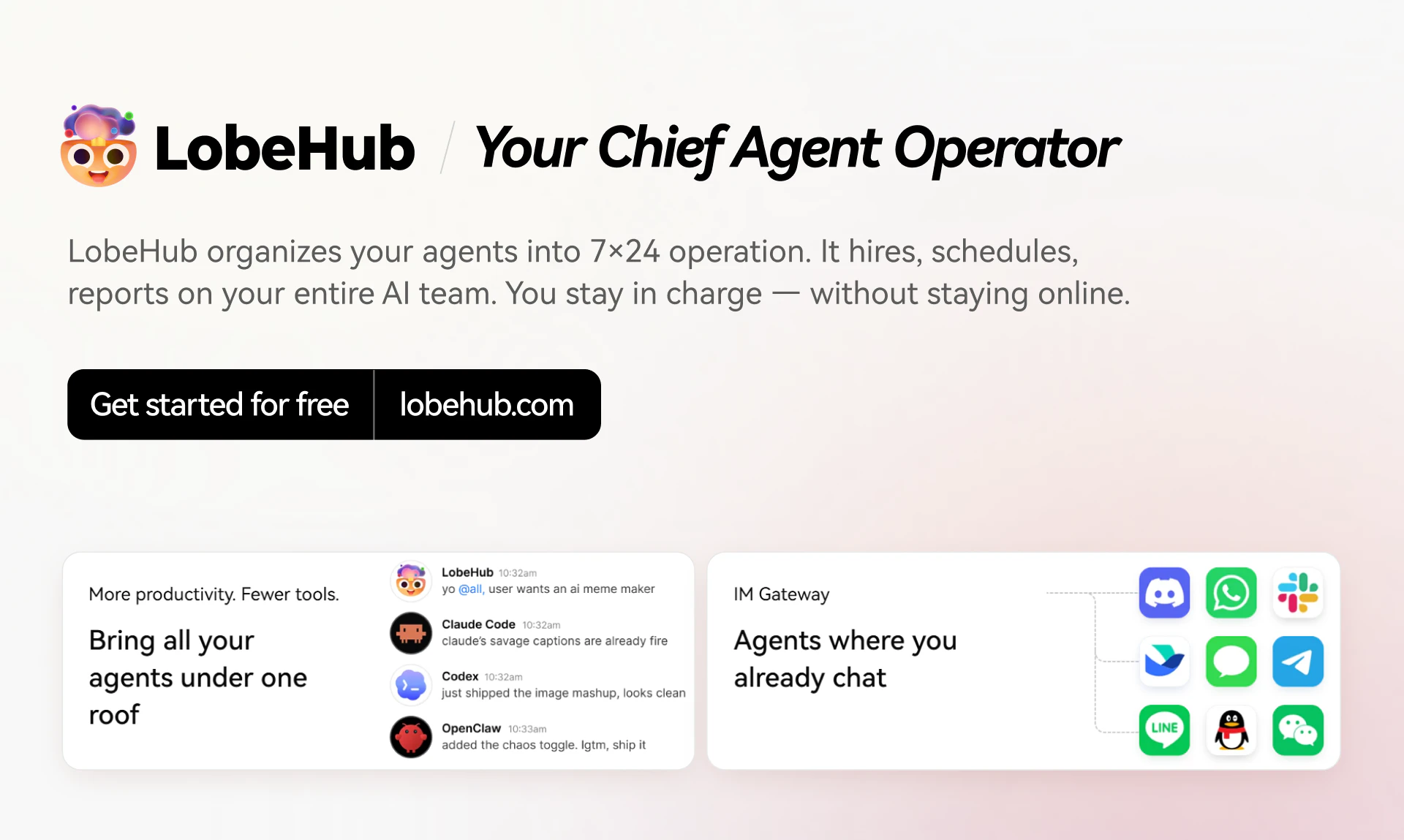




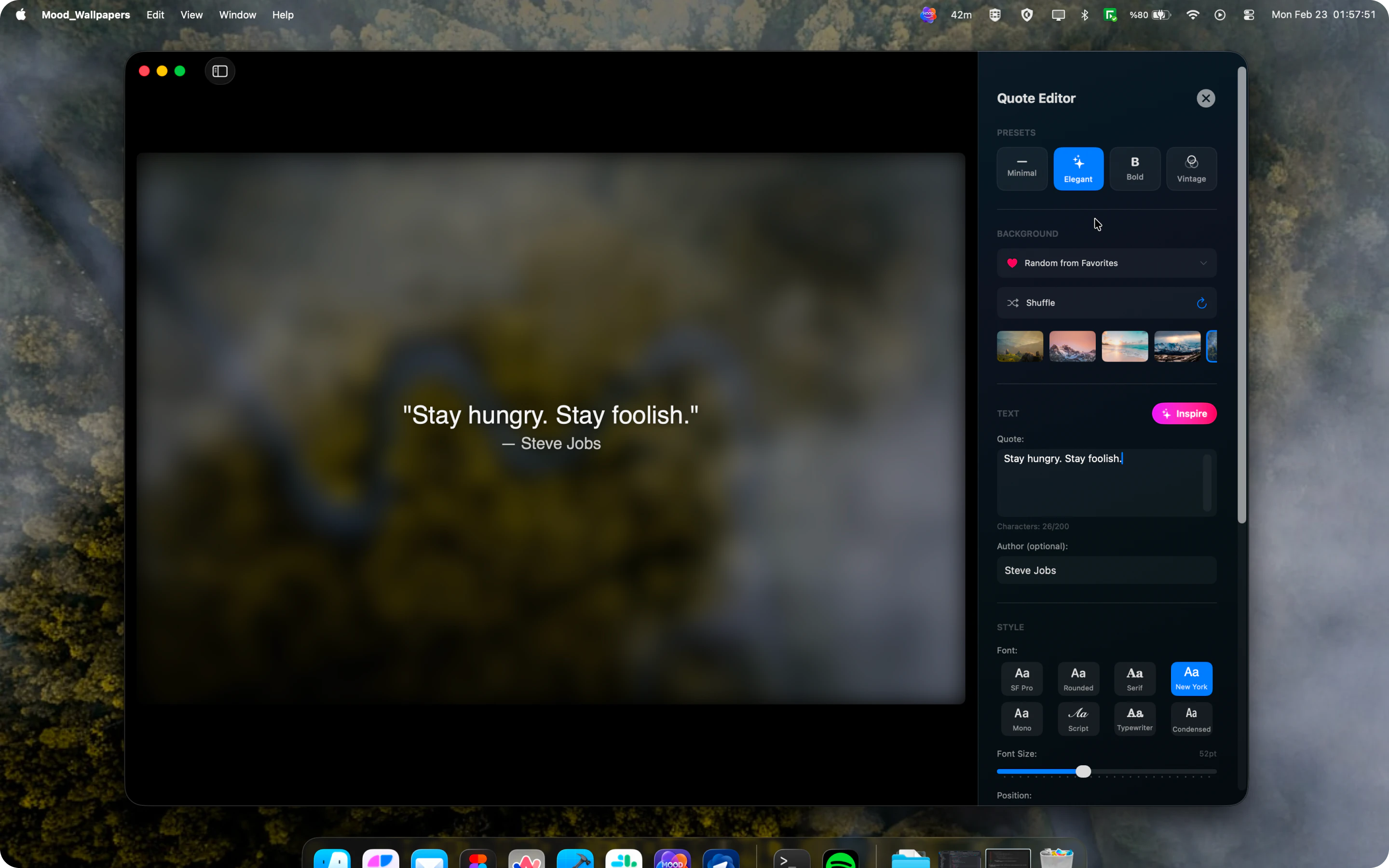
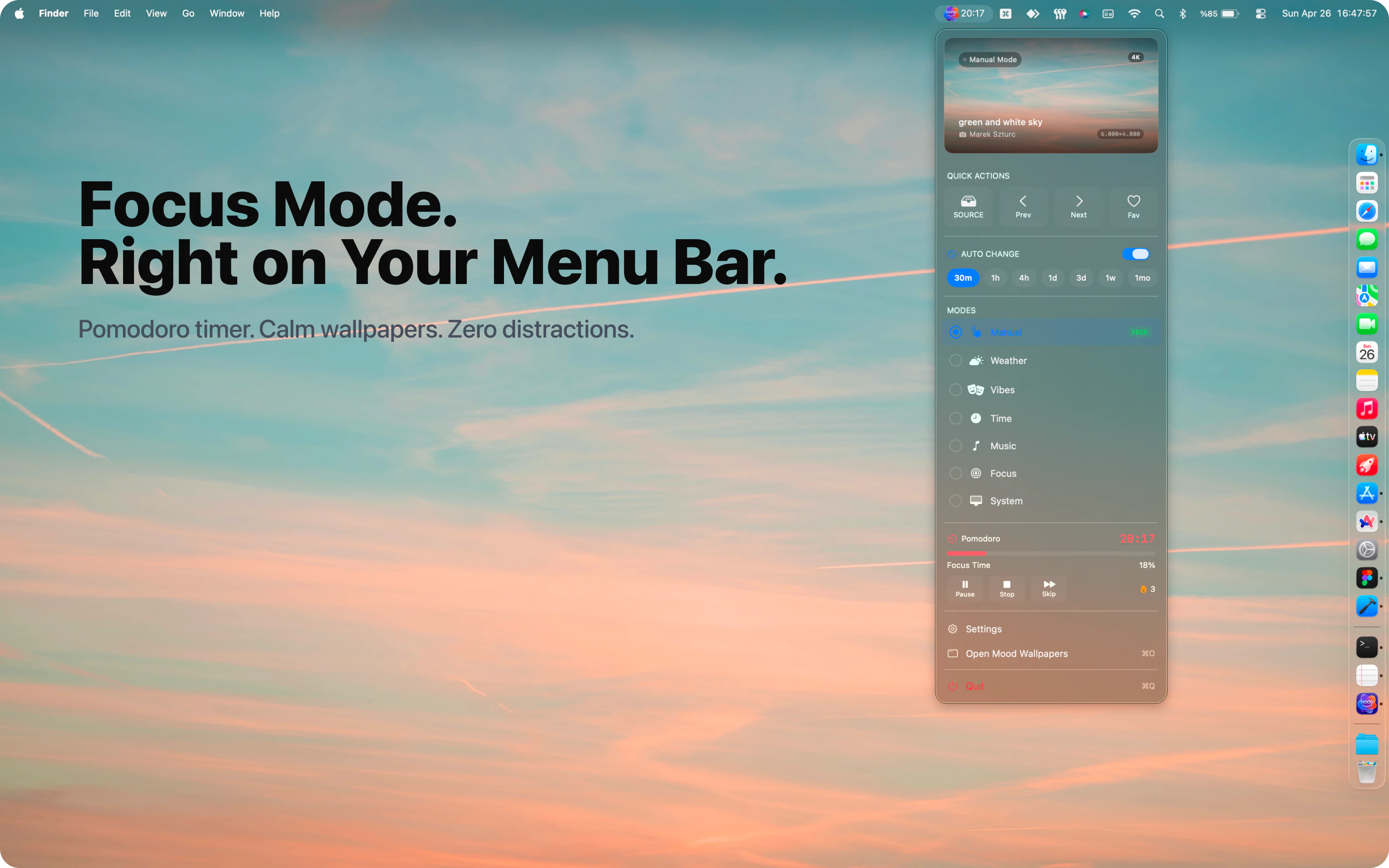
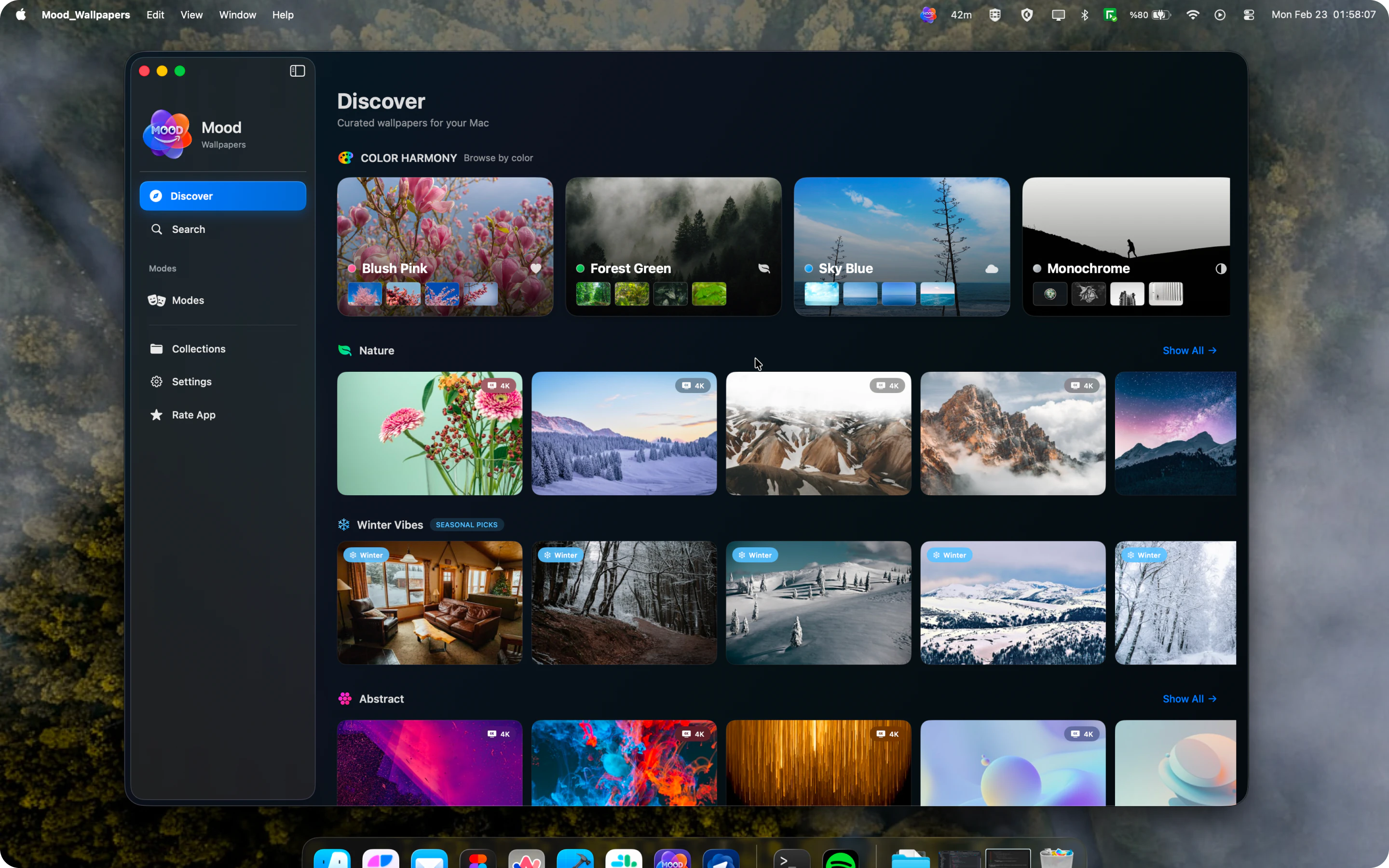
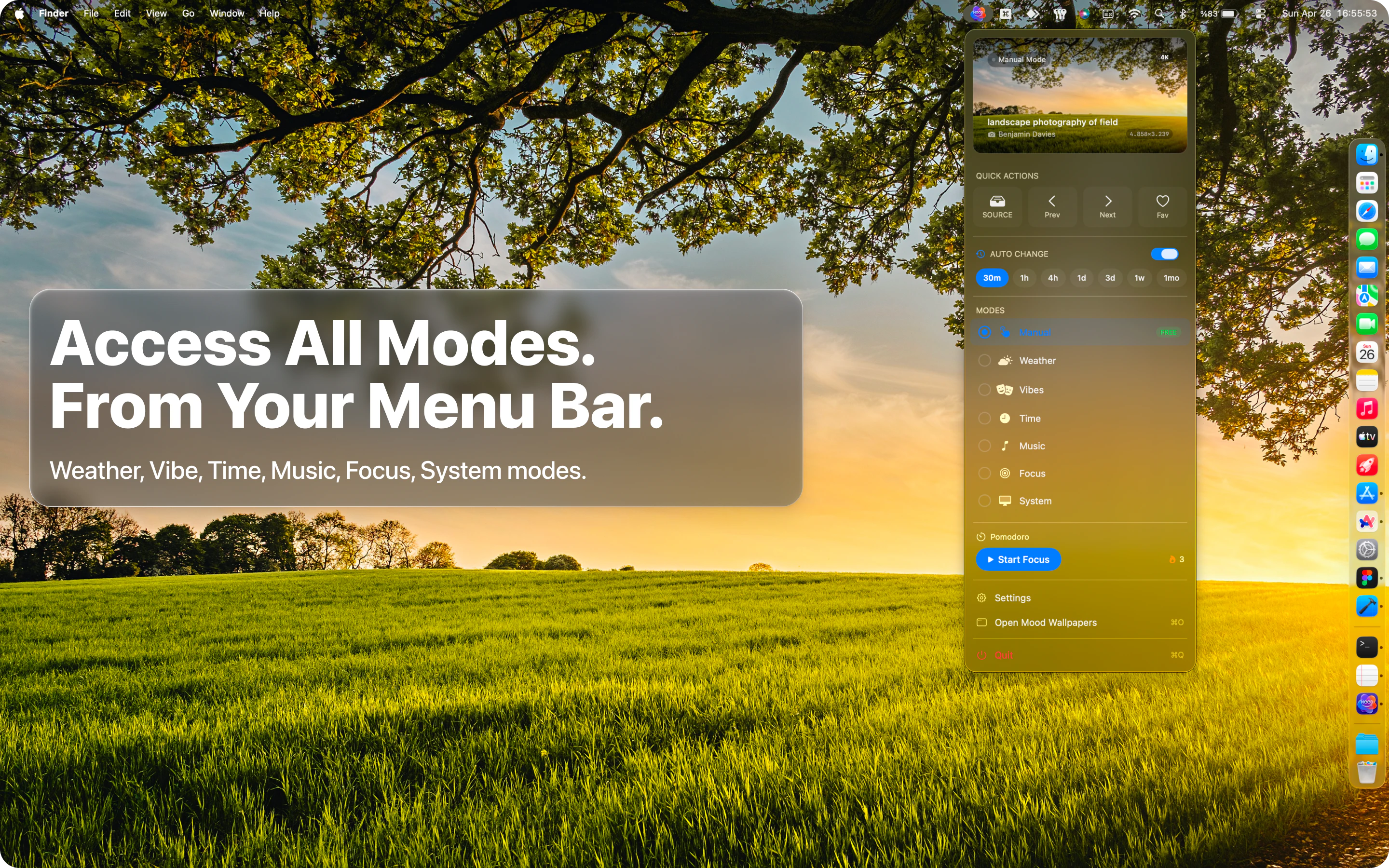





























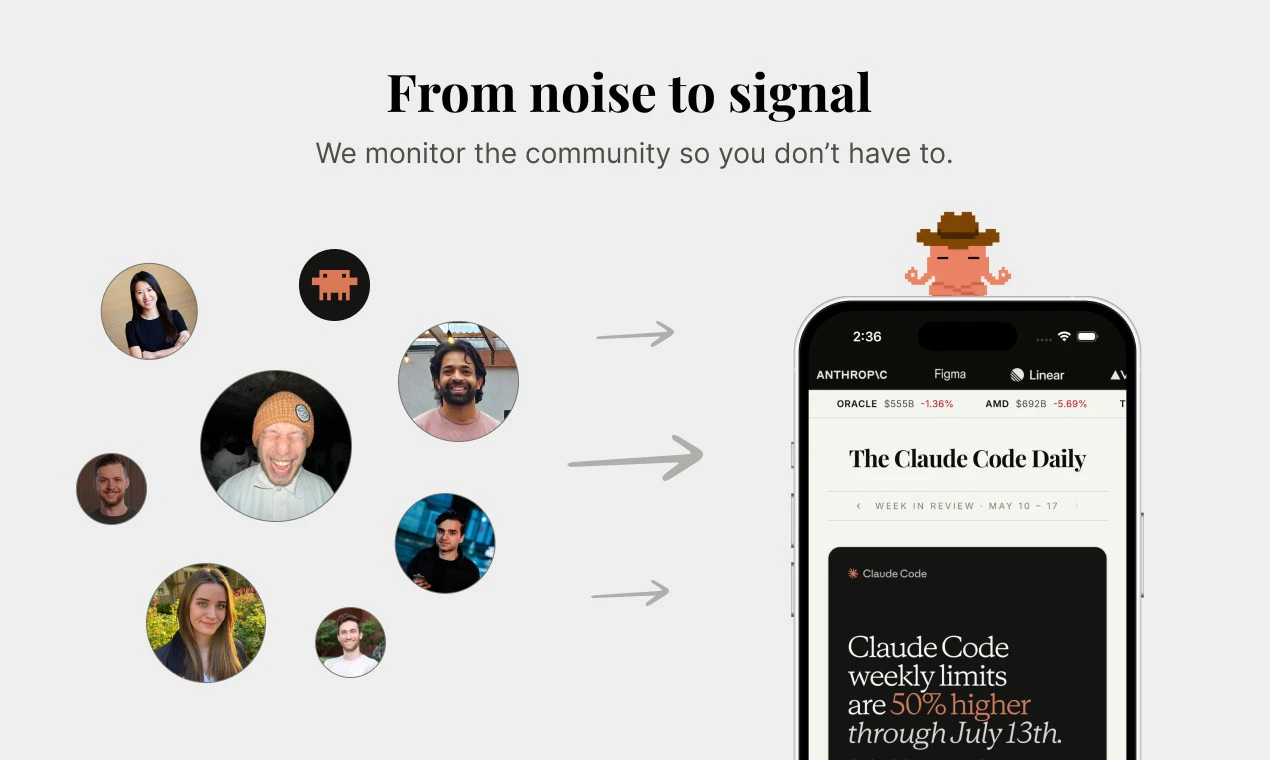
Spent the last few months listening to people tell us our agents were great and they still wouldn't use them. CAO is what came out of finally taking that seriously. Let CAO handle the rest and go touch some grass :-)
Been using LobeHub since the early days. The CAO update is the first time it felt like the product caught up to what I actually wanted from agents. The daily brief alone is worth it.
How does CAO handle failed tasks retry, swap model, or escalate to me?
How does CAO handle cost control? Parallel cloud agents could get expensive fast.
Launch video is up on our YouTube — would love feedback on the pacing. Cut it down from 3 minutes to 70 seconds and I think it's better but you tell me.
Been waiting months to post about this one. CAO is the update I've been quietly demoing to friends since the alpha — reactions ranged from "wait, that's it?" to "wait, that's it." Both meant in a good way. Go try it.
273K+ Skills and 51K+ MCPs sounds fantastically large. Where do these skills come from? Has anyone verified them? In other words, is there any kind of quality evaluation beyond what you probably did with a vector database, which can show semantic similarity but does not guarantee that the skill or MCP actually works?
the IM Channel is the killer feature for me. Upvoted.
The "one daily brief instead of 15 tabs" framing is what gets me. Most agentic tools still make you babysit the
process, which kind of defeats the point.
I'm Curious how CAO handles conflicting priorities across agents when you have multiple goals running in parallel.
Does it surface that to you, or just pick one and move on?
Also, the 273K+ skills number is wild. How does it handle
Skill quality vs quantity? That seems like the hard problem.
Hey Product Hunt 👋 Arvin here, founder of LobeHub.
Quick question before I pitch anything: how many AI tabs do you have open right now?
Claude Code in one window. Codex in another. Maybe OpenClaw or Hermes pinging you in Slack. On paper, you have an AI team. In practice, you became its operator — manually switching contexts, syncing progress across terminals, queuing up a "complex enough" task before bed because letting Claude Code idle feels like burning money.
BCG calls this "AI Brain Fry" — cognitive overload, fragmented attention, decision fatigue. 14% of heavy AI users already report it. We were promised AI would make work lighter. Somehow it made us tired in a new way.
We don't think the answer is a smarter agent. We think you shouldn't be the operator at all.
A company with a CEO but no COO is one where the founder personally chases every deadline and debugs every fire. That's exactly what your AI workflow looks like today.
So we're naming the role: CAO — Chief Agent Operator. And we're building LobeHub to be yours.
Why "CAO" and not "AI agent platform"? Because "agent tools" implies you have one agent and your job is to use it. The reality in 2026 is that you already have several agents running. This category doesn't need a better single agent — it needs a layer above them. Someone (something) to run the team.
Why this is possible now, and wasn't 2 years ago — three things shifted at once:
Agent self-evolution moved from papers to products. OpenClaw and Hermes proved agents can learn from sessions and turn successful workflows into reusable skills. LobeHub covers their capabilities — and goes further, because we're cloud-native: memory and skills evolve across sessions, devices, and teams.
MCP and Skills became the de facto standard. The LobeHub Marketplace now hosts 57k MCP servers and 270k skills. Your CAO has enough tools to actually do the job.
Multi-agent left the demo stage. The future isn't a single super-agent. It's an organization of agents — and organizations need an operator.
What you can do with LobeHub today:
🧠 Run multi-agent teams with shared memory and skills, not isolated chat windows
🔌 Plug into 57k MCP servers and 270k community skills out of the box
📡 Deploy your CAO across Discord, Telegram, Slack, Lark, and iMessage WhatsApp soon— one agent team, every surface
🛠️ Open source, self-hostable, and built on a runtime we've shipped to production for 3 years
I treated agents as first-class citizens on day one of LobeChat, back when "agent" still meant "a prompt with a name." Three years later, tools, MCP, skills, memory, and runtime finally compose into something that feels qualitatively different.
We're nowhere near the CAO I have in my head. Heterogeneous agent adoption, team workspaces, Agent Group 2.0 — all on the roadmap. But the direction is clear: free people from babysitting their AI, so they can spend that energy on what actually matters.
I'll be here all day answering questions. Brutal feedback especially welcome — tell me what's missing, what's broken, or what you'd want your CAO to handle first. 🙏
— Arvin, founder @ LobeHub
Have been using it for icons. Really cool.
😁 273K Skills + 51K MCP servers behind one prompt feels a little unreal even to me. Let me know what you end up running through it — I want to see the weird stuff.
A new skill with zero history can't compete with one that's been routed 10K times. Wonder how do you avoid rich-get-richer if that makes sense? All in all, solid work!
Does CAO work with custom local models via something like Ollama, or only cloud APIs?
Heterogeneous agents was the technical bet I was most nervous about. Claude Code, Codex, OpenClaw — none of them were designed to be managed by something else. Took longer than we planned. Worth it.
What happens if an agent gets stuck in a loop? Does CAO intervene or just surface it?
Does CAO log all agent interactions so I can audit why a decision was surfaced?
Can i manually override the agent team CAO assembles, or is it fully autonomous?
If CAO needs a decision at 2am, does it wait or send a notification based on my quiet hours?
BTW congrats on launch🚀
How does CAO decide which skills to assemble for a novel goal? Pre trained or learns over time?
Reports back only when decisions are needed, this alone would save me 20+ Slack notifs a day.
How does CAO handle parallel task conflicts? Say two agents need the same resource.
If you find anything weird on the marketing pages today, ping me. I've been staring at them too long to see bugs anymore.
The cloud runtime scaled smoother than I expected on the staging load tests. Fingers crossed it holds up when you all actually use it 🤞
IM Gateway was a rabbit hole. Nine messaging platforms, nine sets of quirks. WeChat alone could've been its own launch. Happy it's out the door.
The hardest part wasn't building CAO. It was deleting the version of LobeHub that didn't need one. Glad we did.
The CAO framing clicked — im tired of being the human router between claude code and slack pings
LobeHub’s CAO framing genuinely impressed me. This is the first product I’ve seen that treats the orchestration layer as the actual product, not an afterthought. Describe a goal, and CAO assembles the right agents, runs tasks in parallel across models, and only surfaces decisions that actually need a human. This feels less like AI tooling and more like the early infrastructure layer for how teams will operate in the next few years. Congrats on the launch.
Amazing idea! Congrats on this launch!