PH热榜 | 2026-05-20
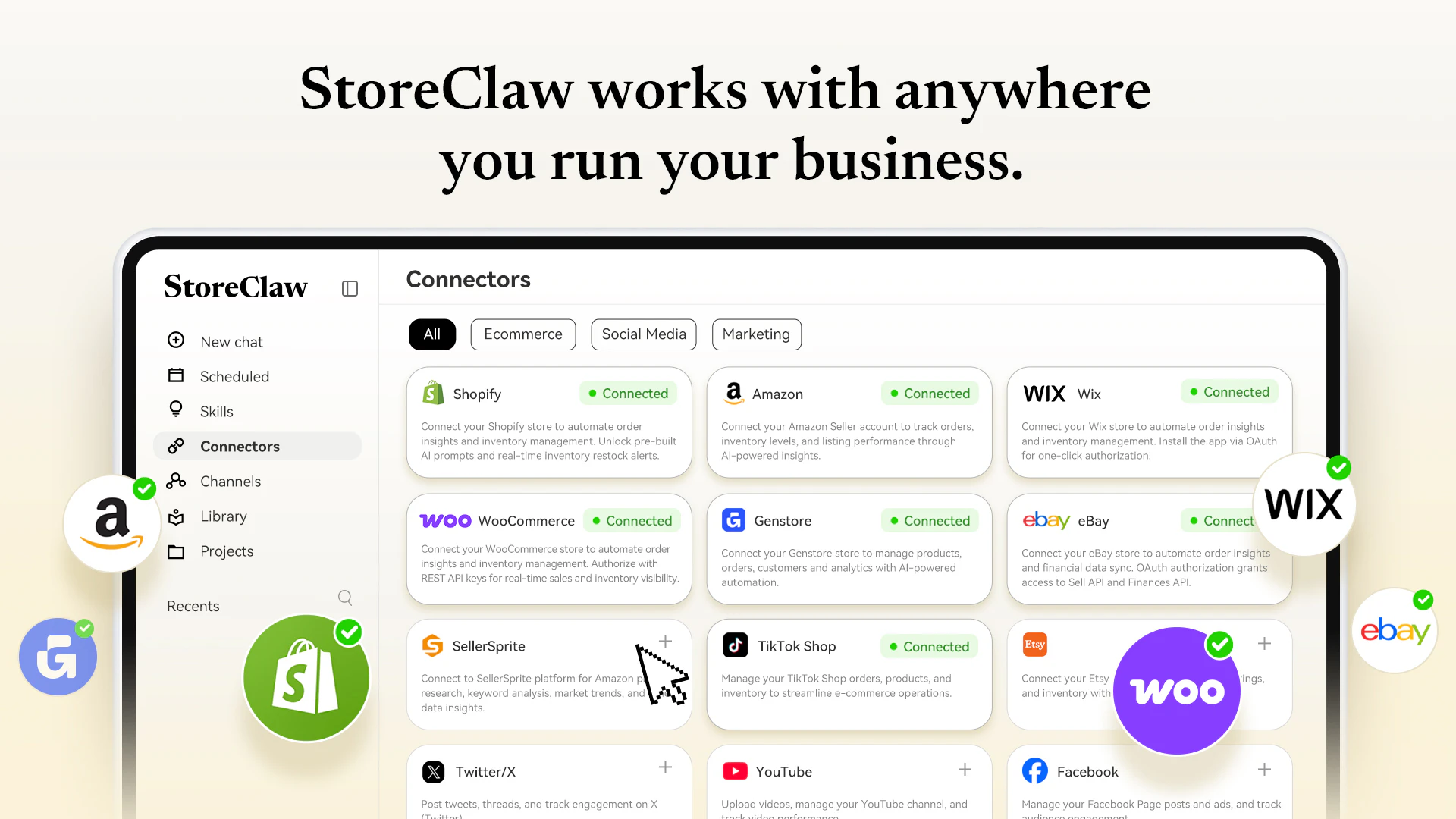
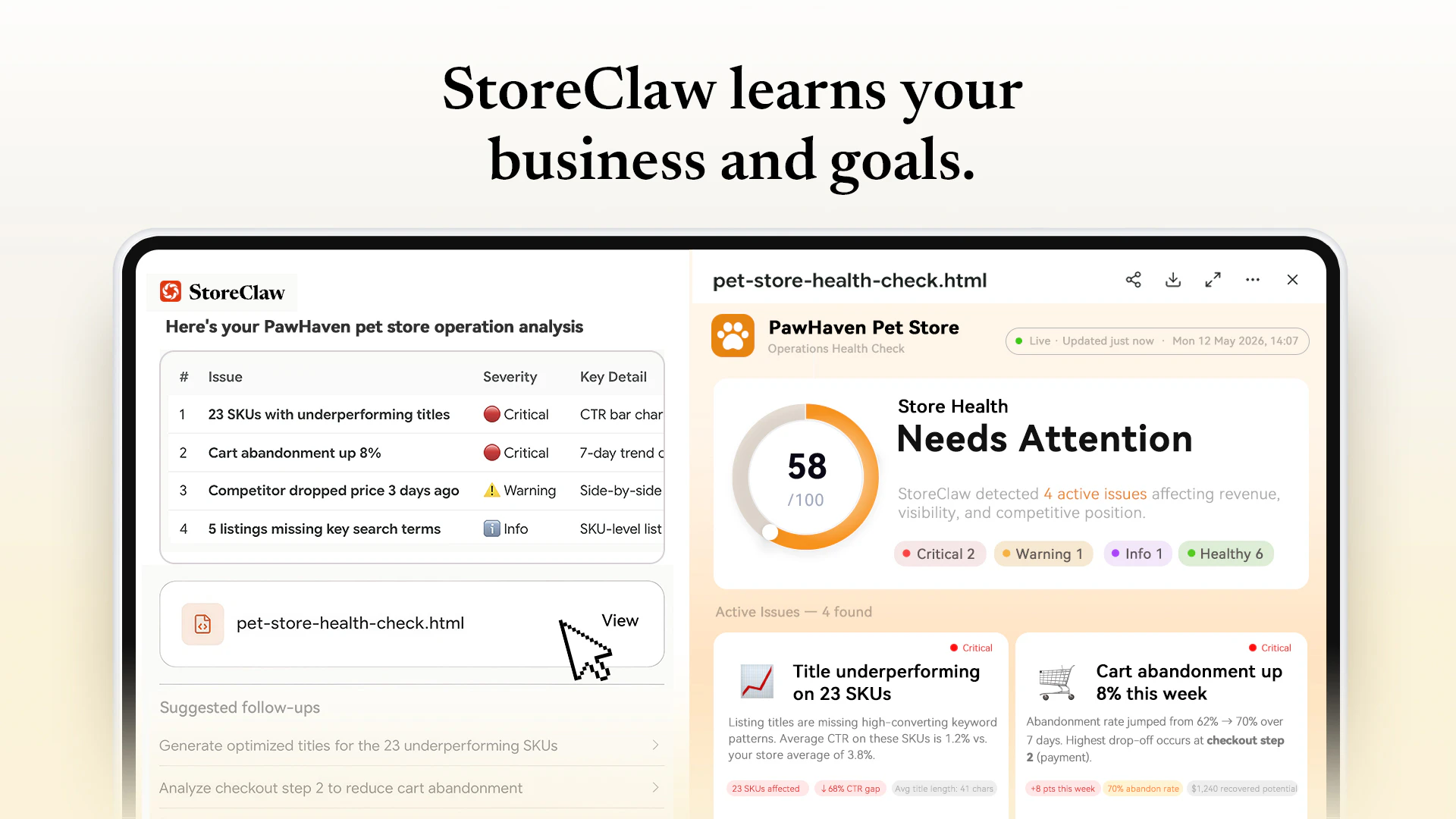
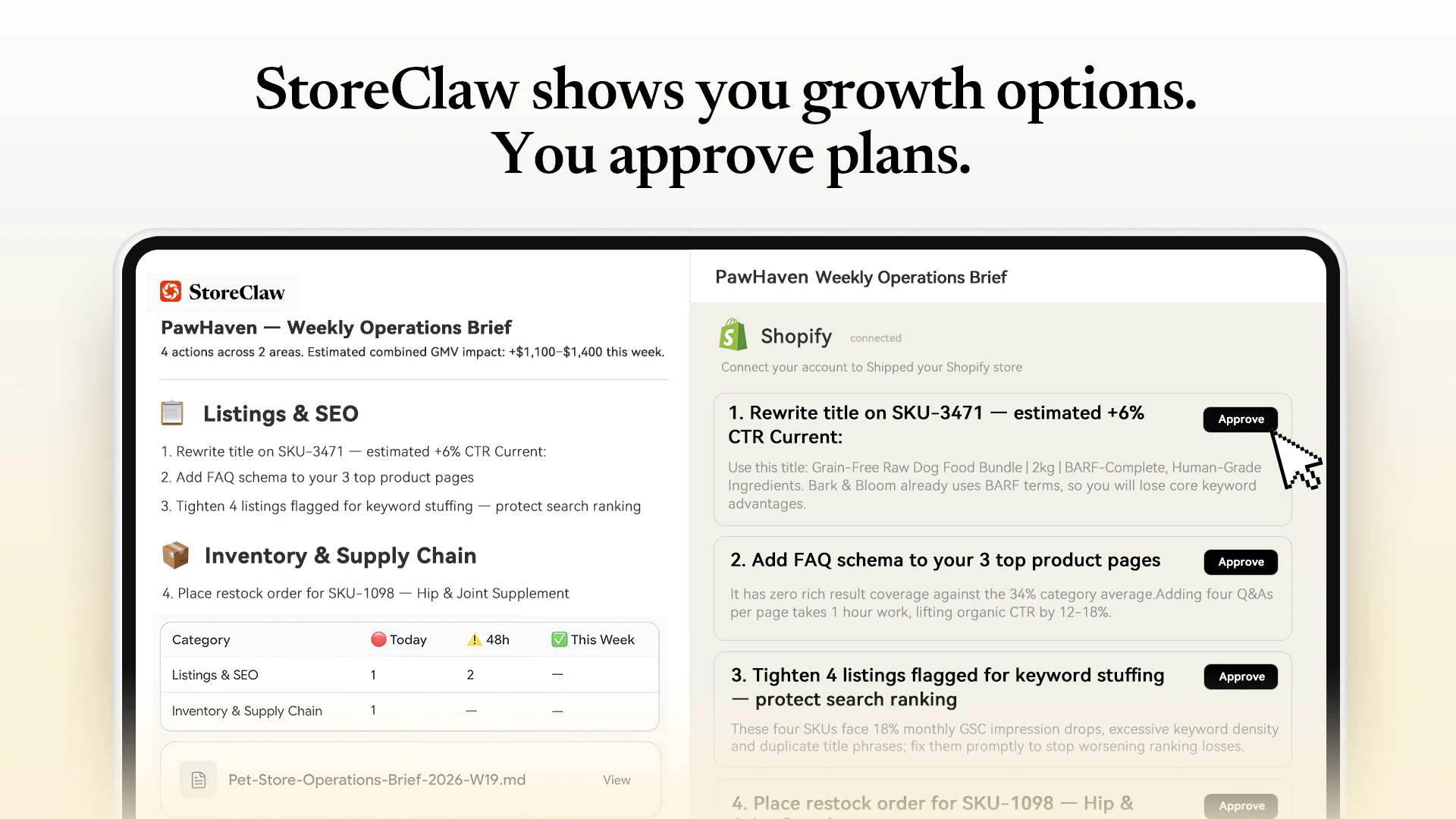
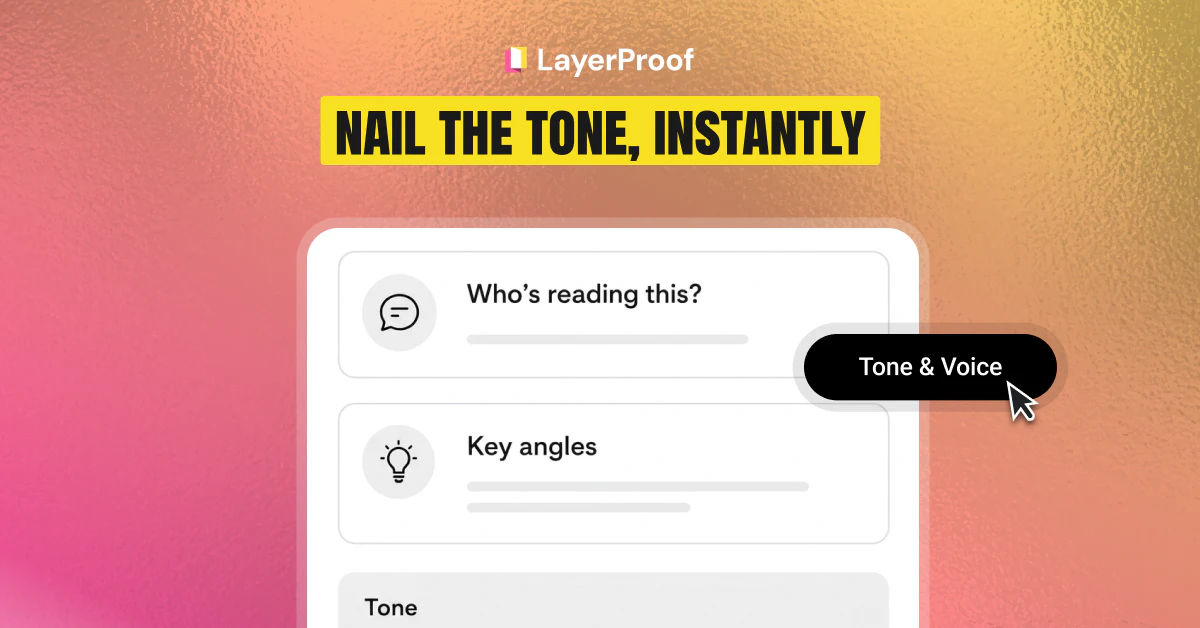
一句话介绍:StoreClaw是首个集成多模型AI的电商自动化平台,通过智能代理直接执行商品上架、定价、促销等运营操作,帮助卖家在降低人力负担的同时提升利润,解决AI建议“只看不做”的行业痛点。
Artificial Intelligence
E-Commerce
Marketing automation
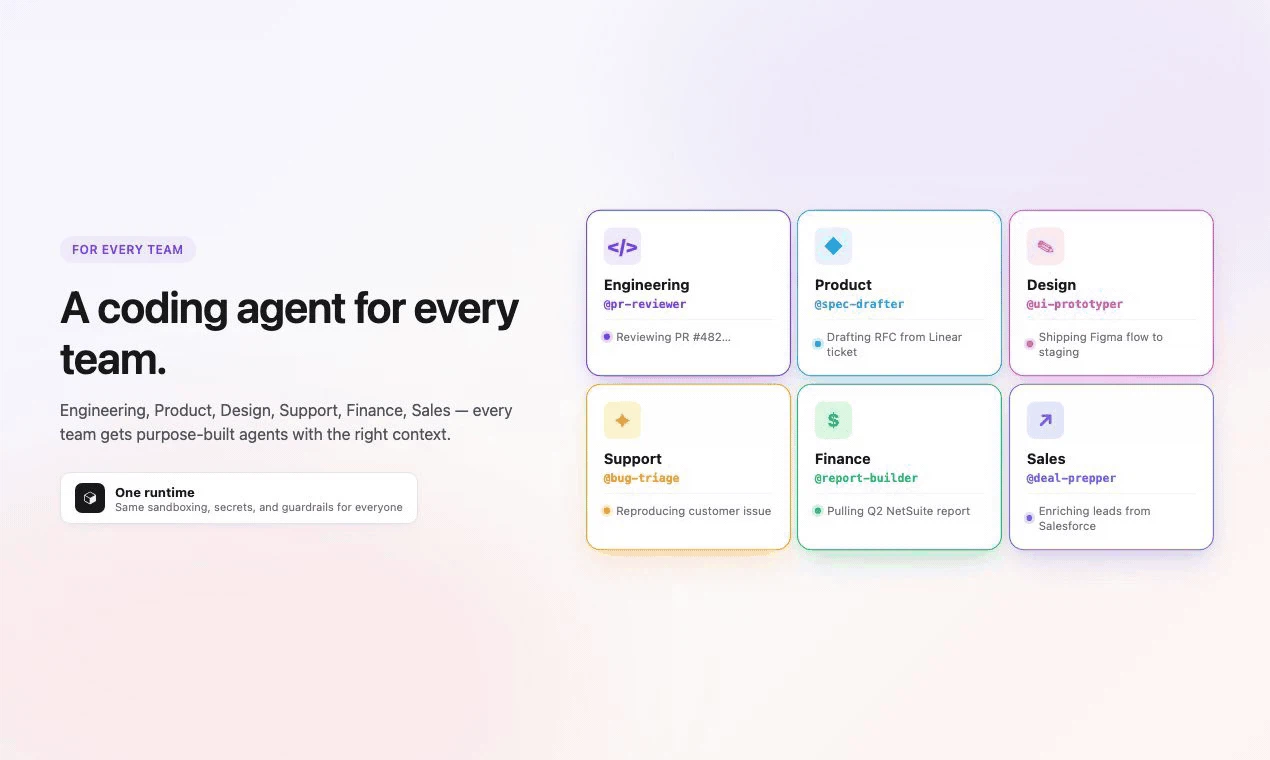
AI电商自动化
智能代理运营
多平台统一管理
人工审批控制
运营判断编码
季节性策略适应
多模型AI架构
Shopify/Amazon/DTC
商业利润优化
权限分层管理
用户评论摘要:用户高度关注审批控制层的粒度(如定价、库存变更需暂缓)、跨平台渠道差异预览、季节性波动应对策略、以及多模型架构的延迟问题。建议增加按产品线设置差异化目标(如清仓品与新品不同策略),并学习历史数据调整优化激进程度。
AI 锐评
StoreClaw在“AI+电商”红海中找到了精准切口——不满足于做另一个建议引擎,而是直接切入“执行权”这一核心痛点。其多模型混合架构(Claude+ChatGPT+Gemini)在技术上展现了对模型长板互补的深度理解,但多模型调度带来的延迟问题可能是规模化落地前的隐雷。值得肯定的是,产品将“运营判断编码”作为核心壁垒:通过可配置的审批层级、季节性基线感知、品类竞争数据注入,试图让Agent行为超越简单优化逻辑,逼近资深运营的直觉。真正的价值在于重塑了电商团队的人员配置模型——当Agent能处理80%的常规操作(SEO、库存健康、生命周期营销)并自动完成闭环,小团队将首次具备大卖的资源调度能力。但风险同样明显:跨平台合规(尤其是Amazon SP-API的严格限制)、复杂场景下的人类判断迁移速度,以及用户从“监督AI”到“信任AI”的心理转变,三者均需时效性验证。若能证明在连续两个季度中不出现重大执行错误,StoreClaw才有机会从“有趣的工具”蜕变为“电商运营基础设施”。
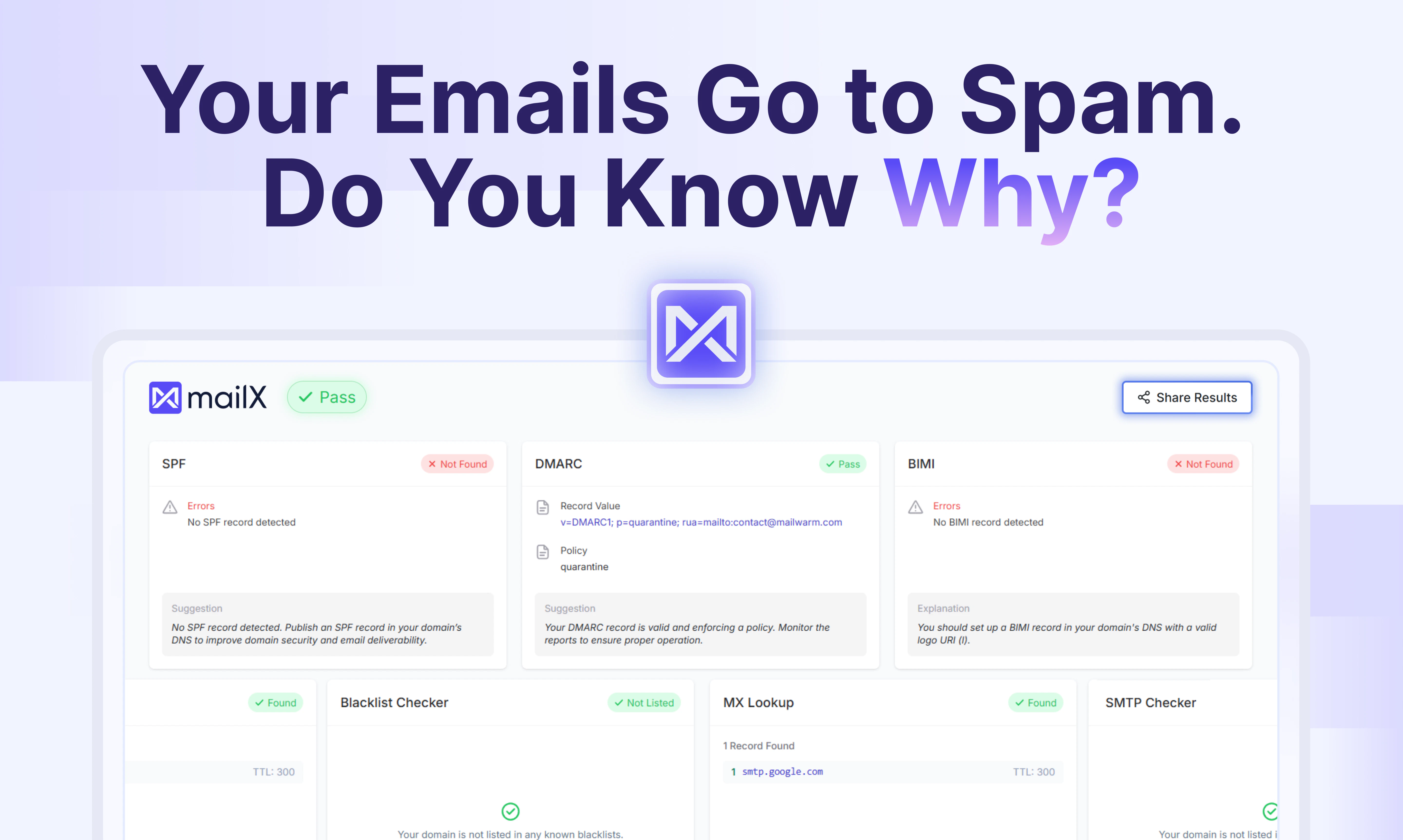
一句话介绍:mailX是一款面向人类和AI代理的邮件投递性诊断工具,能快速指出邮件进垃圾箱的原因,并提供清晰、可操作的修复步骤,无需注册即可使用。
Email
Email Marketing
Artificial Intelligence
邮件投递性
邮件送达率
SPF/DKIM/DMARC诊断
AI代理
邮件基础设施
域名配置
垃圾邮件分析
邮件增长
SaaS工具
YC创业公司
用户评论摘要:用户普遍关注工具能否从“诊断”进化为“自动修复”,以及是否针对不同邮件客户端(如Gmail、Outlook)提供差异化诊断。部分用户赞赏其“先解释问题再给修复步骤”的清晰导向,而非仅展示原始技术指标。
AI 锐评
mailX切入了一个极其精准且痛感强烈的缝隙市场——邮件投递性诊断。在绝大多数创始人还在苦修标题优化、发送时间A/B测试时,他们敏锐地意识到,大量团队的邮件投递问题根本不是“运营策略”层面的失误,而是“基础设施”层面的裸奔:破损的SPF、错误的DKIM、缺失的DMARC。这些听起来枯燥的DNS配置,在Gmail和Outlook的眼里就是一个域名的身份证。mailX真正的价值在于,它把这种“枯燥且吓人”的技术黑箱,翻译成了“没身份证明,请点击此处补办”的傻瓜式操作指南。
更何况,mailX明确打出了“AI代理可用”这张牌。当AI开始取代部分商务沟通,一个“连邮件都送不进收件箱”的AI代理,其行为价值不仅为零,还可能直接带崩域名信誉。mailX将这个接口提供给AI代理,更像是为整个电子邮件生态的“智能化”铺设了一条必要的水管。
但不可忽视其潜在的风险与局限。评论中反复出现的“何时能自动修复”的追问,暴露了当前产品形态的边界——mailX目前仍停留于“诊断与建议”这一信息层,尚无法直接操作DNS或自动配置服务器。对于多数非技术用户,即便有“清晰步骤”,在真实操作DNS面板时仍可能手足无措。如果mailX未来无法提供“一键执行”或“自动化修补”的闭环能力,它很有可能重蹈“提供海量报告但用户依旧不知所云”的数据可视化老路。另外,随着Gmail等邮箱平台对用户行为模式的愈发敏感,仅仅做一次诊断修复并不能一劳永逸,动态的、持续性的监控与调节或许才是更深的护城河。
总而言之,mailX的当前版本像是一个极其称职的“技术体检医生”,但最终能否成为企业的“家庭医生兼药剂师”,还取决于其是否敢于触及更复杂的自动化执行与AI行为信誉度管理。
一句话介绍:Emdash 是一款开源的桌面端“编码代理控制台”,让开发者能在一个界面中并行运行多个编码代理,并通过隔离工作树、统一管理会话和差异审查来解决多代理协作时的混乱与冲突问题。
Productivity
Open Source
Developer Tools
GitHub
编码代理管理器
AI编程工具
开源
多代理并行
代码审查
工作流自动化
开发者工具
桌面应用
提供商无关
用户评论摘要:用户盛赞其隔离工作树功能,解决了多代理相互干扰问题。核心疑问集中在:代理修改冲突处理机制(自动变基还是仅推送PR)、不支持类似T3code的聊天UI、本地并行代理性能上限(约3-5个),以及与Antigravity等竞品的差异化。
AI 锐评
Emdash选了一个目前看来非常精准的切入点:它没有去造一个新的AI编码代理,而是做了一个管理所有代理的“控制塔”。核心洞察在于,当编码代理从单兵作战进入群组协作阶段,真正的瓶颈不是代理本身的能力,而是多代理间的资源竞争(如同一个工作目录)与流程混乱(谁改了哪里,冲突如何解决)。EMdash通过“隔离工作树”和“统一差异审查”给出的解法,比单纯的“多Tab管理器”要深刻得多。
其价值主张非常清晰且“政治正确”:开源、提供商无关、BYOI(自带基础设施)。这直接击中了开发者对数据安全和供应商锁定的焦虑,尤其是在处理生产级代码时。从用户反馈看,它确实解决了那些混合使用Claude Code、Codex等工具的狂人的真实痛点。
然而,风险同样存在。1)性能天花板是隐忧,Electron框架的资源占用与本地运行3-5个代理的瓶颈,让“云端化”成为了必然但更复杂的下一步。2)代理冲突的“合并故事”是其最核心的功能,但官方回复语焉不详,如果仅仅停留在“推送PR去GitHub解决”,那其“融合”价值就大打折扣。3)竞品(如Antigravity)在快速跟进同一方向,Emdash目前的“提供商无关”壁垒并不算高,对手同样可以兼容。Emdash真正的护城河,必须建立在更快更智能的冲突解决机制与工作流编排引擎上,而不是仅仅做一个优雅的启动器。否则,很容易成为被大模型生态快速“功能内化”的阶段性产物。
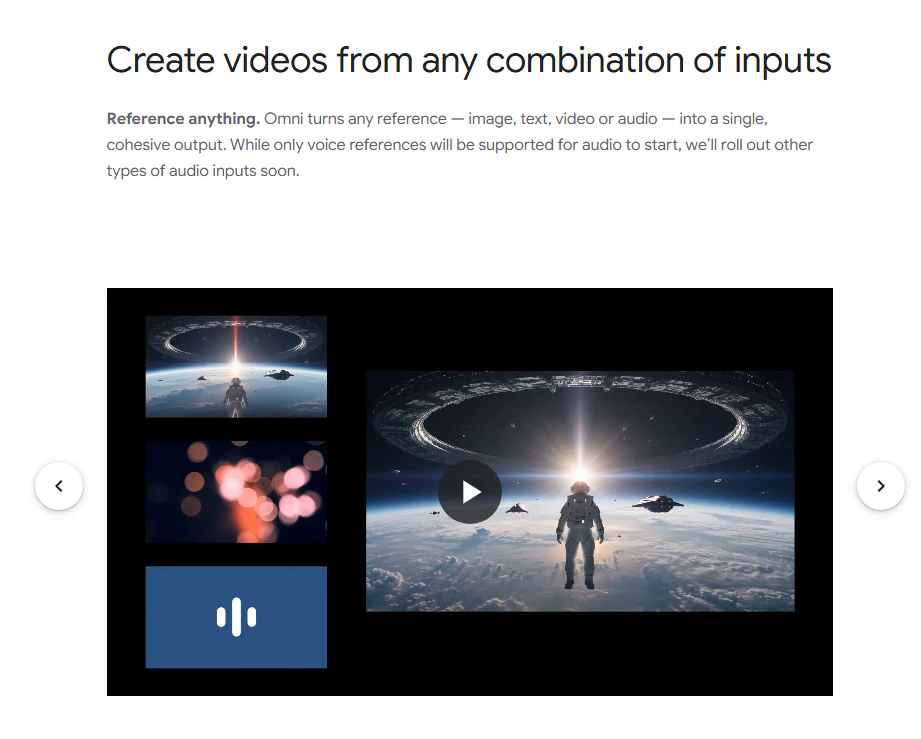
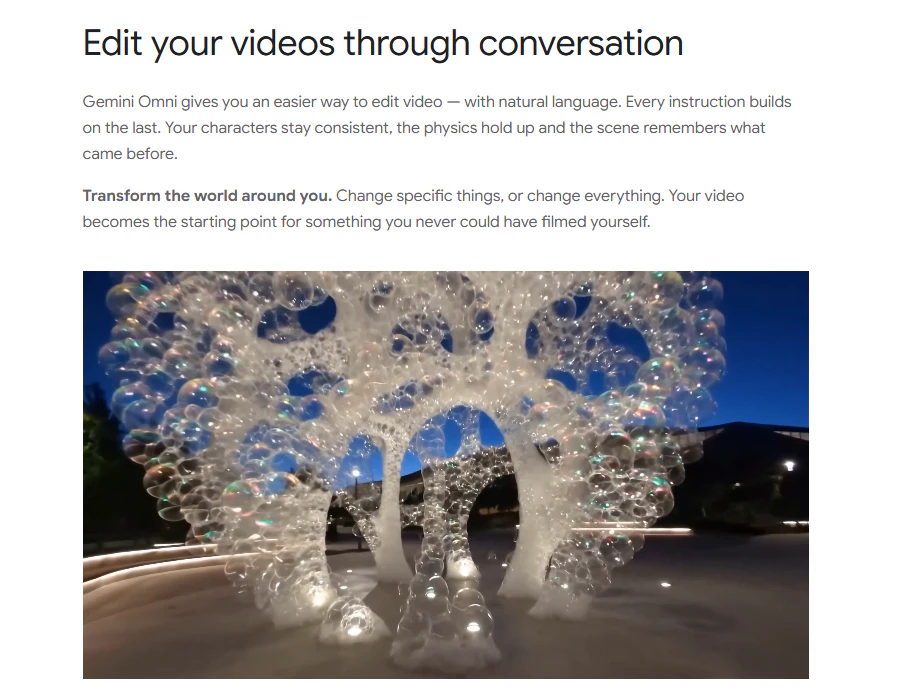
一句话介绍:Gemini Omni 是一款以视频为起点、融合世界理解与推理能力的多模态AI创作工具,让用户通过文字、图片、草图或参考素材直接生成和编辑视频,解决传统视频制作中“创意构思与执行脱节”的痛点。
Artificial Intelligence
Video
AI视频生成
多模态创作
视频编辑
自然语言编辑
世界理解
AI工作流
创意工具
Gemini集成
视频一致性
商业内容生产
用户评论摘要:用户高度关注视频编辑和一致性。核心疑问:多次编辑/生成时能否保持“创意记忆”和视觉风格统一?能否通过自然语言完成素材筛选、加字幕等精细剪辑?普遍认为“推理+生成”结合比单纯文生视频更实用,但担心多轮迭代后产生“AI垃圾”问题。
AI 锐评
Gemini Omni的巧妙之处在于将叙事重心从“生成”转移到“编辑与理解”。当多数AI视频工具仍在堆砌生成效果时,它直接切入了创作者最痛的环节——面对已有素材的后期维护。
从产品逻辑看,其价值不在于“创造”,而在于“掌控”。用户反馈中最高频的“一致性”“记忆”“多轮编辑”恰恰揭示了当前AI视频工具的核心缺陷:生成一张好画面容易,维持一个故事逻辑、一套视觉规范、一种运动物理规则却极难。Gemini Omni若真能调用Gemini的推理引擎对“上下文”进行建模,让每次修改都携带前一帧的意图标签,这将是比参数数量更本质的突破。
然而,风险同样清晰。它的竞品根本不是其他AI视频工具,而是Premiere Pro的工作流习惯和创作者的已有资产。若“记忆”只是对话历史堆砌而无法真正理解镜头语法、色彩平衡、节奏控制,最终只会生产出更多“语义合理但视觉平庸”的内容。更关键的是,商业场景下“为不同渠道生成变体”这一刚需,要求工具不仅懂Prompt,还要懂“品牌书”。如果Gemini Omni不能在每次生成时内化“品牌约束”而非仅靠用户反复重申,它就仍是高级玩具而非生产工具。
一句话戳破:别吹“从任何输入创造任何输出”,先把“自动剪掉废话并记得我上一版做的修改”做到及格,这才是干掉Premiere的入场券。
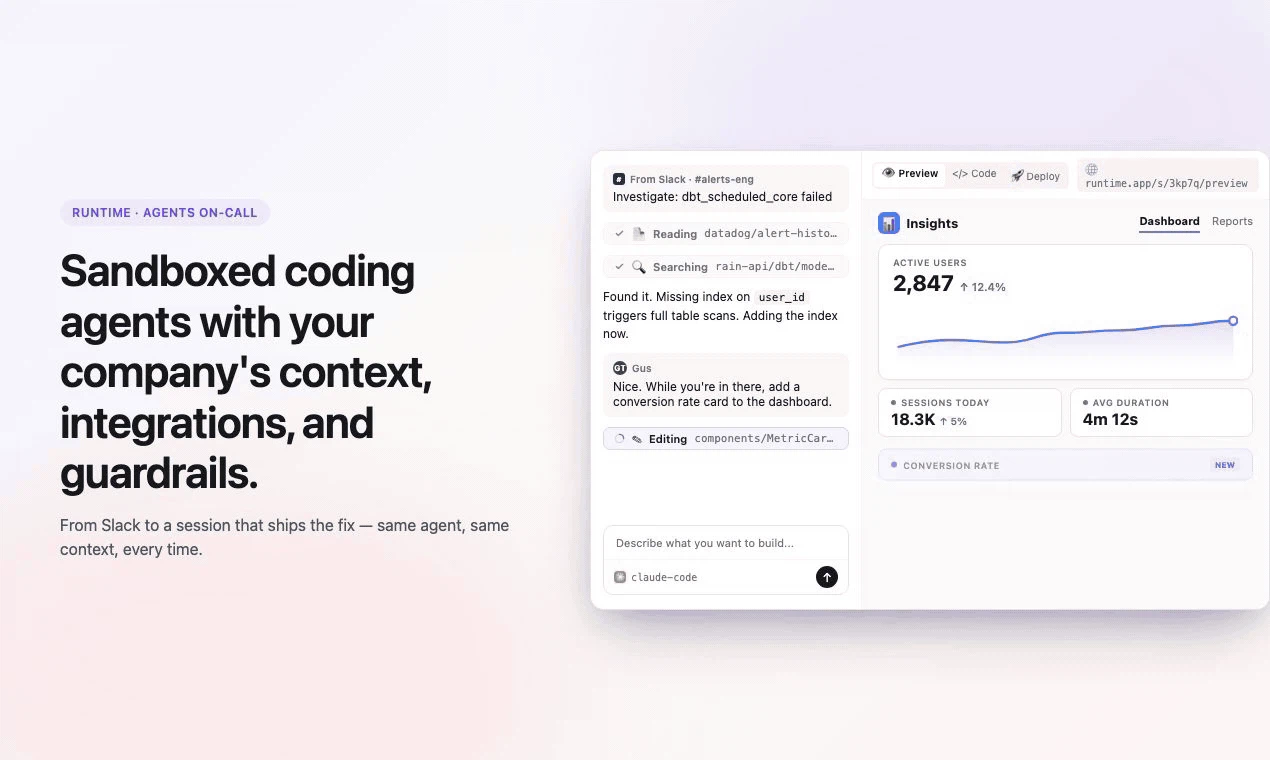
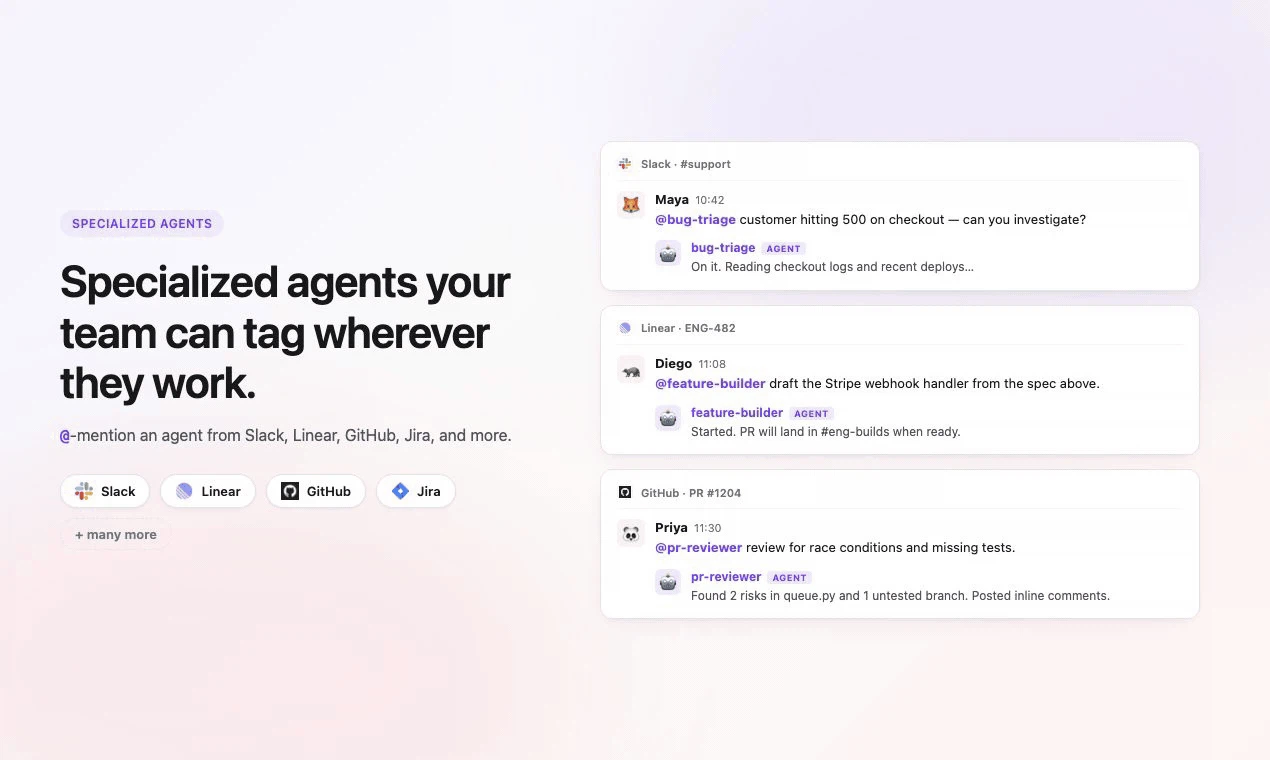
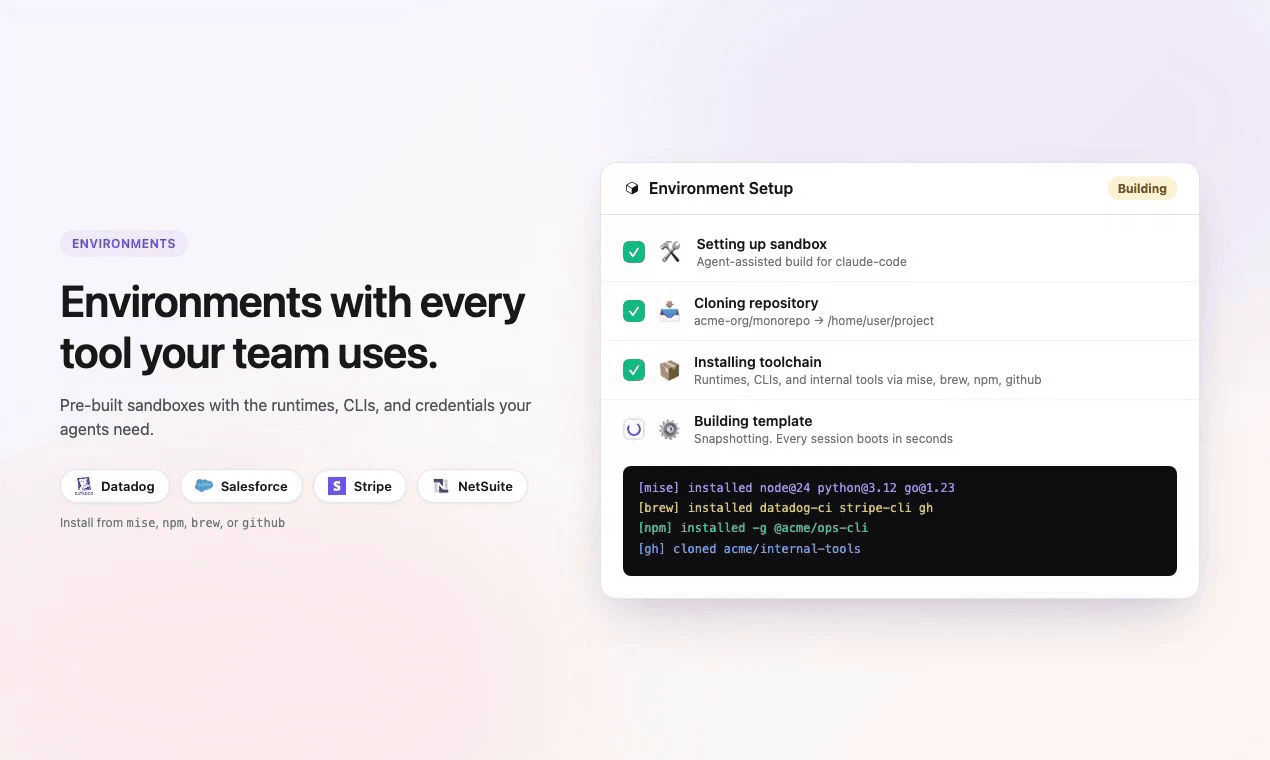
一句话介绍:Runtime是一个为团队打造的沙盒化编码代理平台,让非工程师也能通过Slack、Linear等常用工具安全地使用AI代理来开发功能、查询数据和自动化工作流,解决了当前编码代理在团队协作中缺乏安全管控、复用性差和合规风险的核心痛点。
Slack
Developer Tools
Artificial Intelligence
编码代理
沙盒环境
团队协作
AI安全
工作流自动化
Slack集成
权限管控
DevOps工具
企业级AI
内部工具开发
用户评论摘要:用户普遍认可沙盒隔离与Slack集成解决了信任和安全痛点,同时提出了两大核心问题:一是多session间的状态持久化(如跨频道上下文共享)如何实现;二是BYO OAuth场景下的权限范围(谁触发的代理、谁打包的代理、服务账户)如何细化管控,以区分“编排”与“真正企业级权限架构”。
AI 锐评
Runtime切入了一个被AI热潮快速催熟但基础设施极其薄弱的赛道——团队级编码代理的工程化管理。其产品逻辑清晰:不造轮子(直接调用Claude Code/Codex等底层模型),而聚焦于解决当前AI编程中最棘手的信任鸿沟(沙盒隔离、审计日志、硬性消费上限)与协作沟壑(人人都能从Slack触发代理)。
从评论区的尖锐提问能看出,Runtime面临的核心挑战并不在于“是否沙盒”,而在于如何构建超越单次沙盒运行的**持久化状态管理体系**和**细粒度的企业级权限模型**。一个代理在A频道启动任务,需引用B频道的上下文,仅靠“默认隔离+开放API”的简单架构,很快会在真实多团队、多角色协作中演变为新的混乱。更关键的是,BYO OAuth场景下的权限归属问题——是执行者、打包者还是团队服务账户——决定了它究竟是“更高级的自动化编排器”,还是能真正承载企业级合规需求的安全基础设施。
产品方向正确,但技术深水区才刚刚开始。如果Runtime过早追求“让所有人都能代理一切”,而忽略了权限语意和上下文穿透能力的体系化建设,很容易从“解决痛点”滑向“制造新痛点”。值得观察其VPC自托管方案能否提供足够的黑盒审计与数据主权,这将是获取金融、法律等强监管客户的关键钥匙。
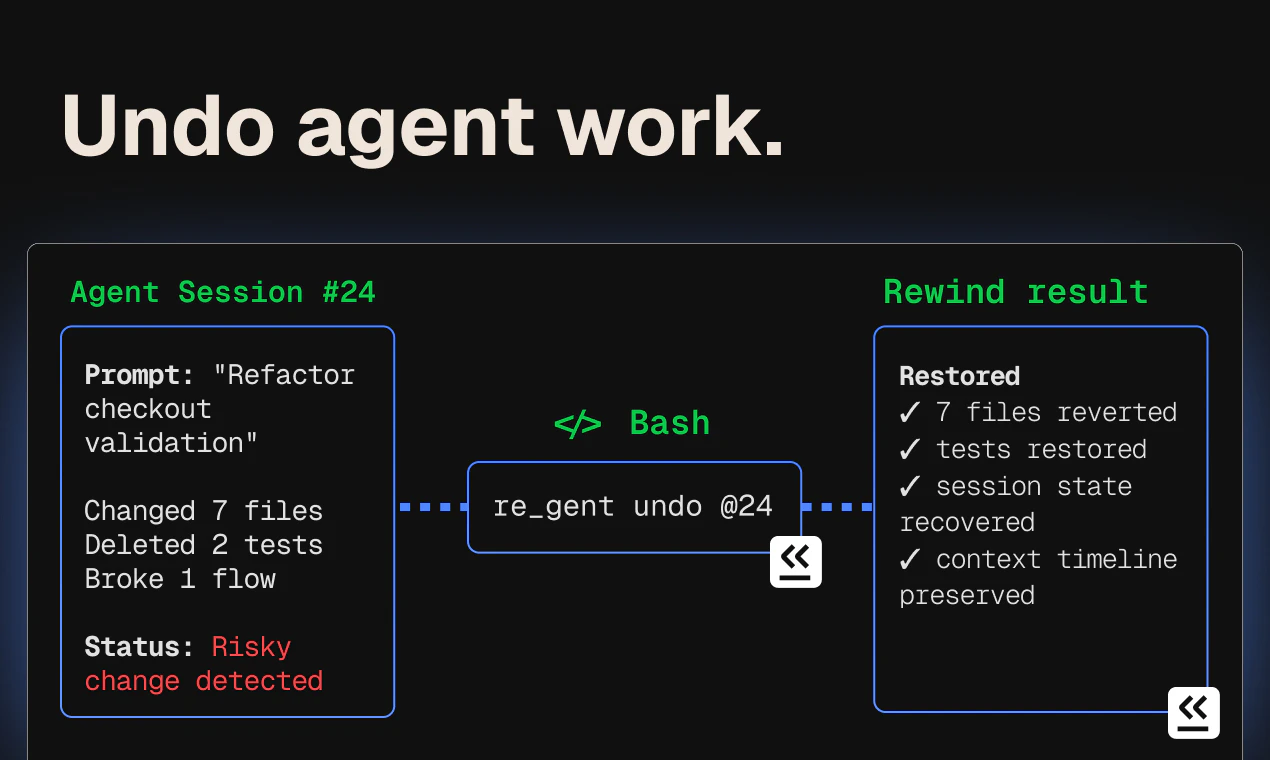
一句话介绍:Re_gent为AI编程Agent提供代码变更的版本控制,让开发者能追溯每次修改触发的具体提示词,并跨文件、跨会话撤销Agent的误操作,解决“知道改了啥,但不知为何改”的调试痛点。
Open Source
Developer Tools
GitHub
AI Agent版本控制
提示词溯源
变更回滚
代码审计
Claude Code集成
Agent调试工具
会话历史追踪
开发者工具
用户评论摘要:用户高度认可“提示词→变更”溯源和跨会话回滚功能,认为解决了Agent调试中“因果链断裂”的痛点。核心疑问集中于:rollback是否支持中间检查点与分支(回复称规划中),能否追踪API等副作用(仅文件级,需LLM语义理解),多Agent串联场景下如何处理连锁回滚。另有用户建议区分根提示词与具体工具调用的归因粒度。
AI 锐评
Re_gent切中了AI编程工具普及后“能吃但不会消化”的尴尬——Agent越强,生成的代码越容易变成黑箱产物。Git告诉你“改了什么”,但追溯“为什么改”要翻会话记录,而会话一压缩或换模型就失忆。Re_gent的“blame”功能把代码行和触发提示词直接挂钩,本质上是把AI的随机性锁定成可审计的因果关系,这才是Agent从玩具走向生产工具的关键。
但产品目前暴露的局限性也很明显:只追踪文件变更和上下文,无法处理API调用、数据库写入等副作用回滚。这让“完全回滚”成了一个半截子工程——代码恢复了,但订单也发出去了。创始人坦言需要更“语义理解”的机制,这也说明想真正管住Agent的“手”,光靠Git思维远远不够。
从评论看,用户最关心的分支与多Agent串联场景,Re_gent要么“在规划中”,要么缺实际方案。如果只把它当一个“带注释的Git历史”,价值天花板未免太低。真正的机会藏在“fork”与“Agent间因果链追踪”里——当Agent A的修改作为Agent B的上下文,变更的归因就变成了图遍历问题,这才是符合AI原生工作流的版本控制逻辑。
Re_gent的方向对,但别满足于当个高级监控面板。如果不能从“记录者”进化成“编排者”——理解Agent决策树、支持分叉与合并、管理副作用原子化——很快就会被大模型自带的记忆层或更底层的框架级方案替代。不过,对于现在被Agent整得焦头烂额的开发者,至少有了个可以动手“甩锅”的工具。
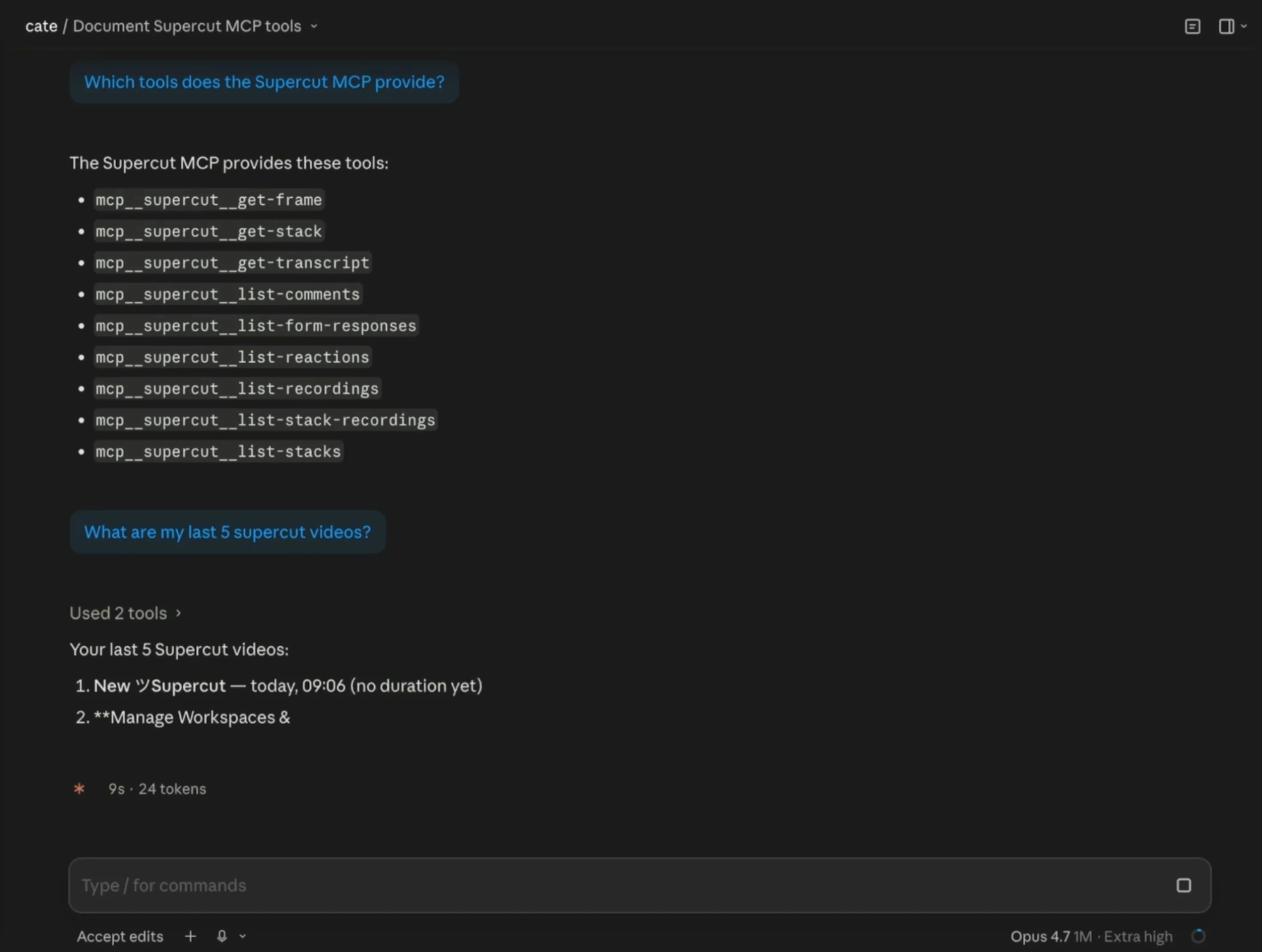
一句话介绍:Supercut for Agents通过MCP接口,让AI助手能够权限感知地访问视频录制的语义搜索、文字记录、帧画面、评论和反应,解决团队在视频资料中无法被智能体有效查询和利用的痛点。
Productivity
Developer Tools
AI智能体
视频录制语义搜索
MCP协议
权限感知
团队协作
转录分析
工作流自动化
开发者工具
用户评论摘要:用户赞赏MCP对视频上下文的赋能,但关注权限粒度(如分片共享)、语义搜索在多说话人转录下的准确性、以及提取上下文用于生成文档或任务的可信度——这些直接关系到实际工作流能否落地。
AI 锐评
Supercut for Agents的亮点在于把“视频”这个AI工作流的黑匣子,通过MCP协议变成可查询、可操作的资源层。它不再满足于“录完就忘”,而是让AI智能体直接在录制的原始语境中做语义检索、取帧、抓评论,甚至跨录制动。权限感知的设计也避免了“一接入就全曝光”的安全隐患。
但真正的挑战在于:视频语义搜索的精度能否支撑高频、自动化的任务?目前公开的“时间戳句子”式转录,对于多说话人、专业术语、模糊表达的准确性存疑。如果提取的“上下文”不够可靠,那么自动生成表单、更新CRM之类的流程就会积累噪音。此外,用户需要自行判断,是把Supercut当作“偶尔用的搜索增强”,还是“每天跑的工作流引擎”——后者对API稳定性和成本的要求完全不同。
一句话说:它有潜力成为团队视频资产的AI接口,但要真正替代人眼审阅,还得做深语义理解与结果信任度的功课。
一句话介绍:Retina 是一款 Mac 屏幕录制工具,通过自动缩放、平滑光标轨迹和 AI 图形增强,让产品演示、教程和功能导览无需后期剪辑即可输出电影级视频,解决录屏画面平淡、光标抖动、后期制作耗时长的核心痛点。
Mac
Design Tools
Video
屏幕录制
自动缩放
光标平滑
AI图形
Mac工具
产品演示
教程制作
视频导出4K
无后期剪辑
免费无印
用户评论摘要:用户高度认可自动缩放和光标平滑功能,认为能大幅节省后期时间。主要建议包括:希望推出 Windows 版(优先级高);反馈不支持未公证导致无法运行(已修复);有人建议增加游戏高光剪辑,但开发者指出不适合此场景,推荐 NVIDIA ShadowPlay。定价模式尚在探讨中,用户倾向一次性付费。
AI 锐评
Retina 是一款精准切中“演示视频制作”这一垂直痛点的工具,其核心价值不在于“录屏”本身,而在于用算法替代了繁琐的手动后期流程。从评论来看,用户对“自动缩放”和“光标平滑”的反馈最为积极,这印证了产品方向的合理性:绝大多数 SaaS 演示或教程视频在视觉上乏善可陈,而 Retina 通过启发式算法(追踪光标移动与点击密度)来模拟专业剪辑师的意图,确实能显著降低创作门槛。
值得肯定的是,开发者在技术实现上做出了明智的取舍:放弃简单的光标路径重绘,转而采用“弹簧物理模拟”,保留了操作轨迹的真实感,避免了“过于完美而失真”的伪 AI 陷阱。这种对细节的执着,是产品区别于市面上花哨滤镜的本质差异。
然而,产品仍处在 beta 阶段的“美好泡泡”中。目前最关键的制约因素有两个:一是仅限 Mac,这直接切断了最大的用户群(Windows 与 Linux);二是定价模式悬而未决。如果最终采用订阅制,除非能持续提供“云同步模板库”、“团队协作”等高频增值服务,否则面对 Screen Studio 等一次性付费竞品将缺乏竞争力。此外,其“单焦点”场景优化的局限性(多区域快速切换、键盘快捷键叙事)也意味着它不适合所有类型的内容创作。
Retina 的方向正确,但商业上仍需要更清晰的付费锚点和跨平台支持,才能真正从“优秀的产品”进化为“成功的生意”。
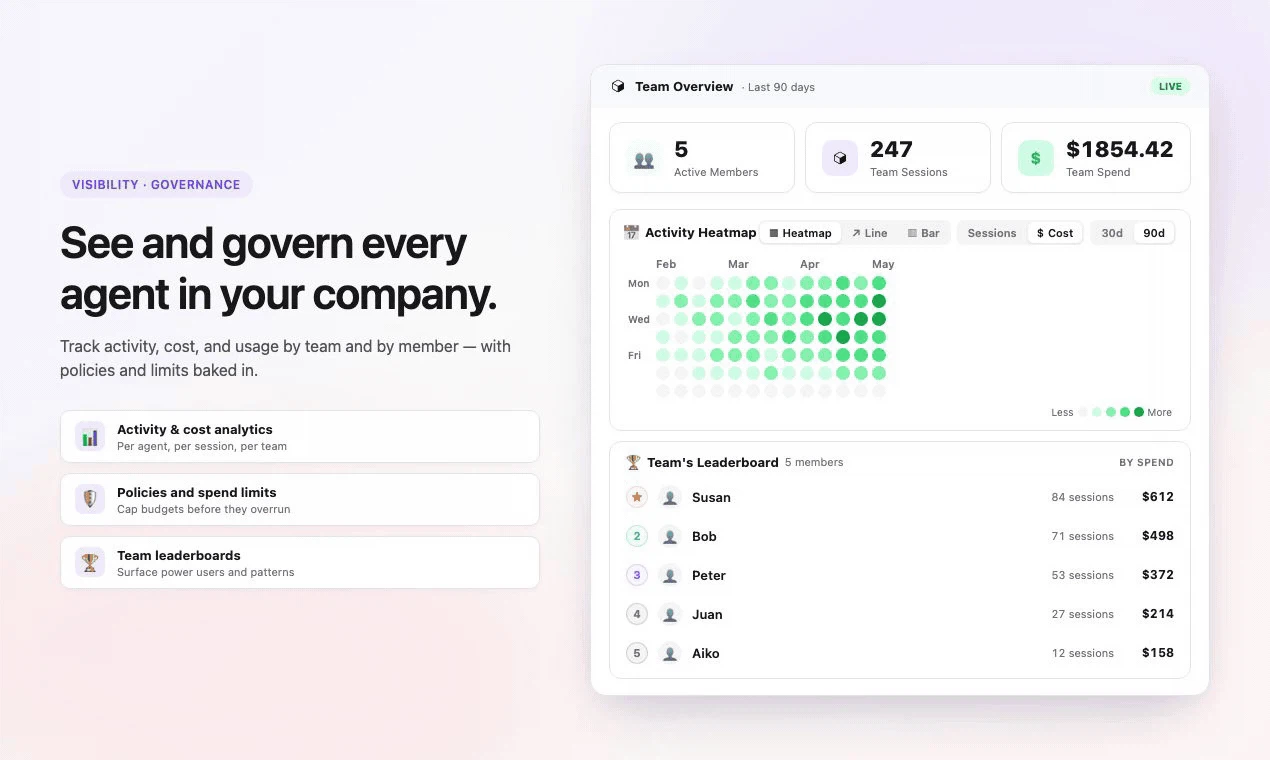
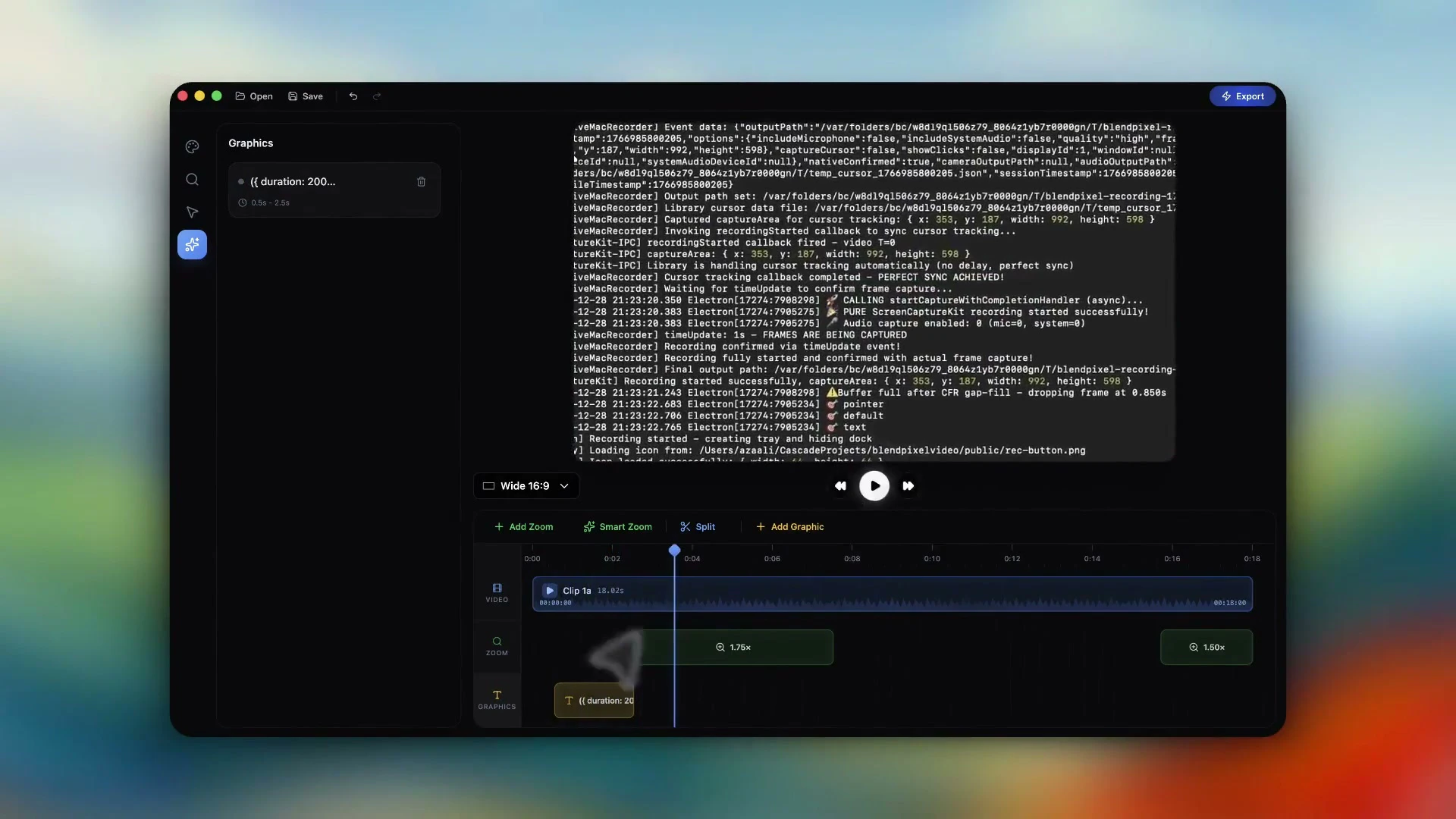
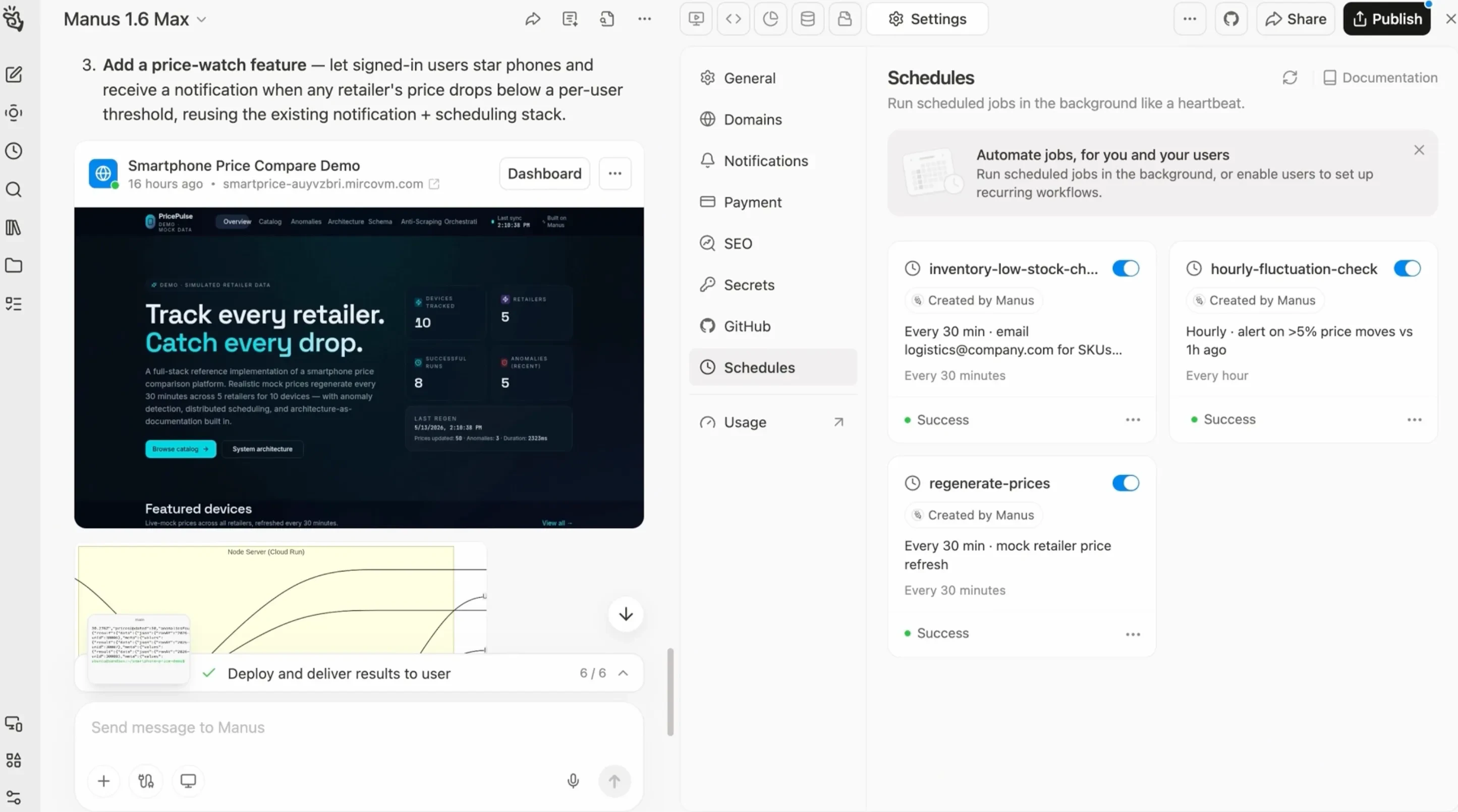
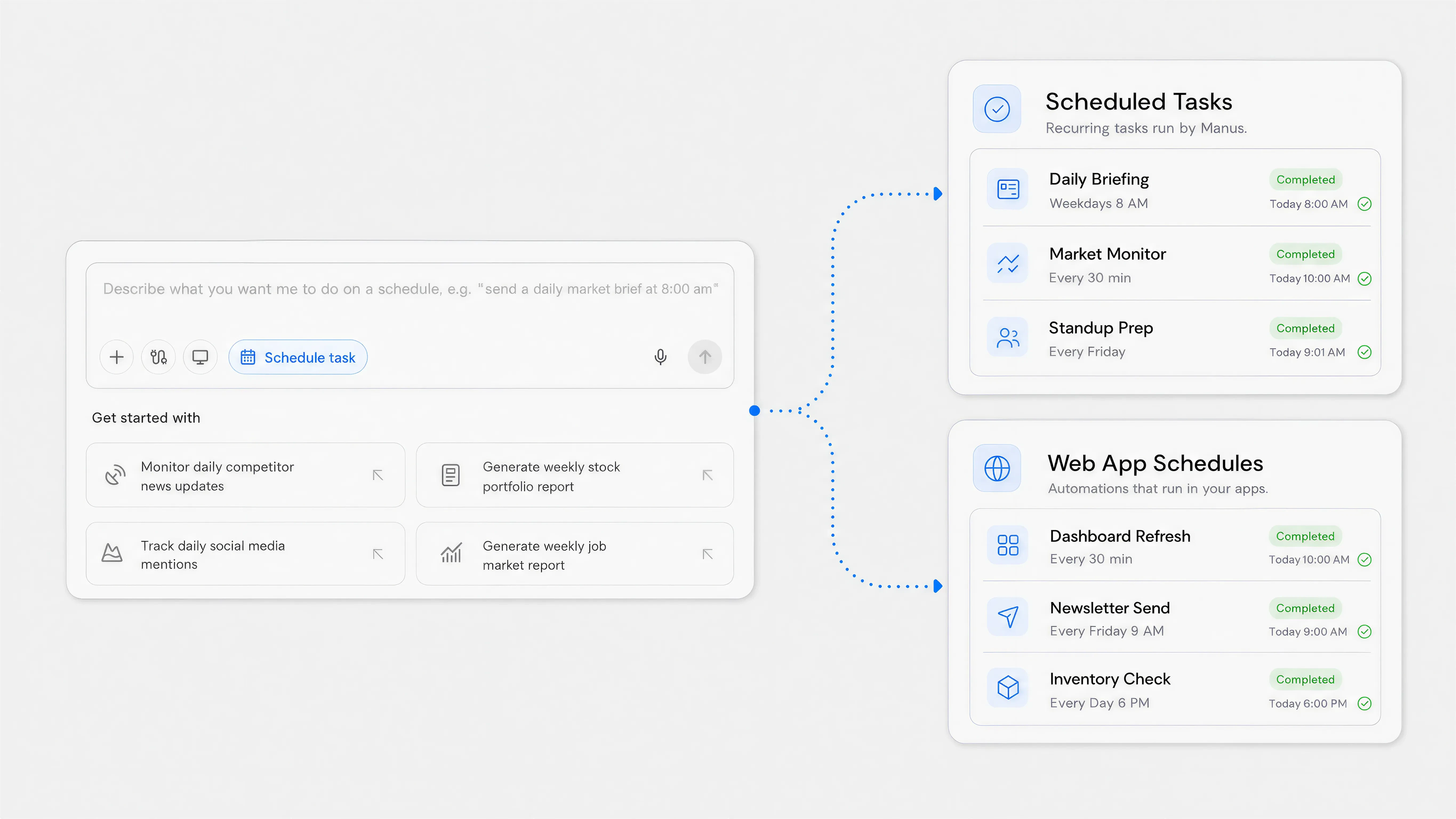
一句话介绍:Manus Scheduled Tasks 2.0 通过让重复性工作在相同任务上下文中运行,解决了自动化工作流中状态丢失和上下文不连贯的痛点,让AI代理从一次性工具变成可持续运营的生产力系统。
Productivity
Task Management
Artificial Intelligence
AI代理工具
任务调度
工作流自动化
持续任务上下文
项目管理
无代码应用构建
定时任务
SaaS工具
智能代理
Manus生态
用户评论摘要:用户看好“相同任务上下文”设计,认为它让代理从无状态助手升级为有记忆的运营工具,使重复工作更连贯。但有用户追问:执行中途失败时,代理是恢复上下文继续执行,还是完全重启?期待更清晰的容错机制。
AI 锐评
Manus Scheduled Tasks 2.0 的“任务上下文延续”不是一个小补丁,而是对AI代理产品形态的底层重构。它聪明的点在于:把调度从“外部触发”变成了“环境内建”。过去你用一个定时脚本跑AI,每次都是“失忆”地重新开始;现在它带着上次的对话、项目配置、数据连接醒来,真正实现了“持续运营”。但别急着吹——这个设计的代价是状态管理的复杂度指数级上升。用户问“失败怎么处理”很精准:一旦上下文变得庞大或混乱,错误传播和模型幻觉的风险会同步放大。如果Manus只解决了启动时的继承问题,却没有提供优雅的上下文修剪、版本回退或错误隔离机制,那这套系统在复杂场景下反而比无状态的Cron更容易崩溃。另外,“在Manus构建的Web App内嵌入定时动作”确实很有想象力,等于让非技术人员也能生产出“自我维护”的软件。但这是否真的改变了产品类别?目前看更像一个增强版的自动化脚本生成器,距离“自主维护的软件生命体”还有关键一步——它需要能自我诊断、自我修复,而不是只按预定计划重复执行。对于追求“运营稳定性”的团队,建议先小范围验证上下文累积后的边际收益是否真的超过维护开销,再决定是否全面迁移至此。
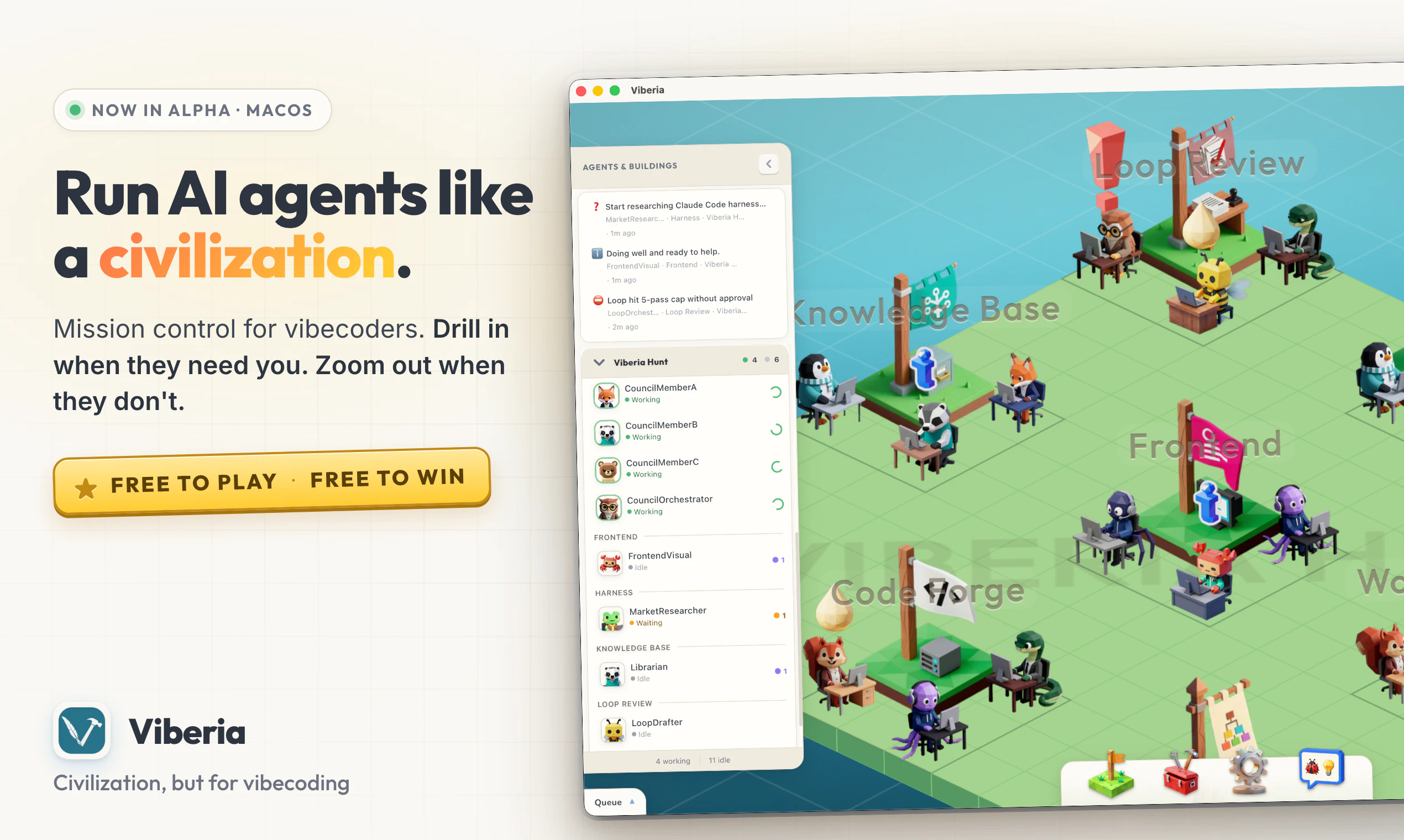
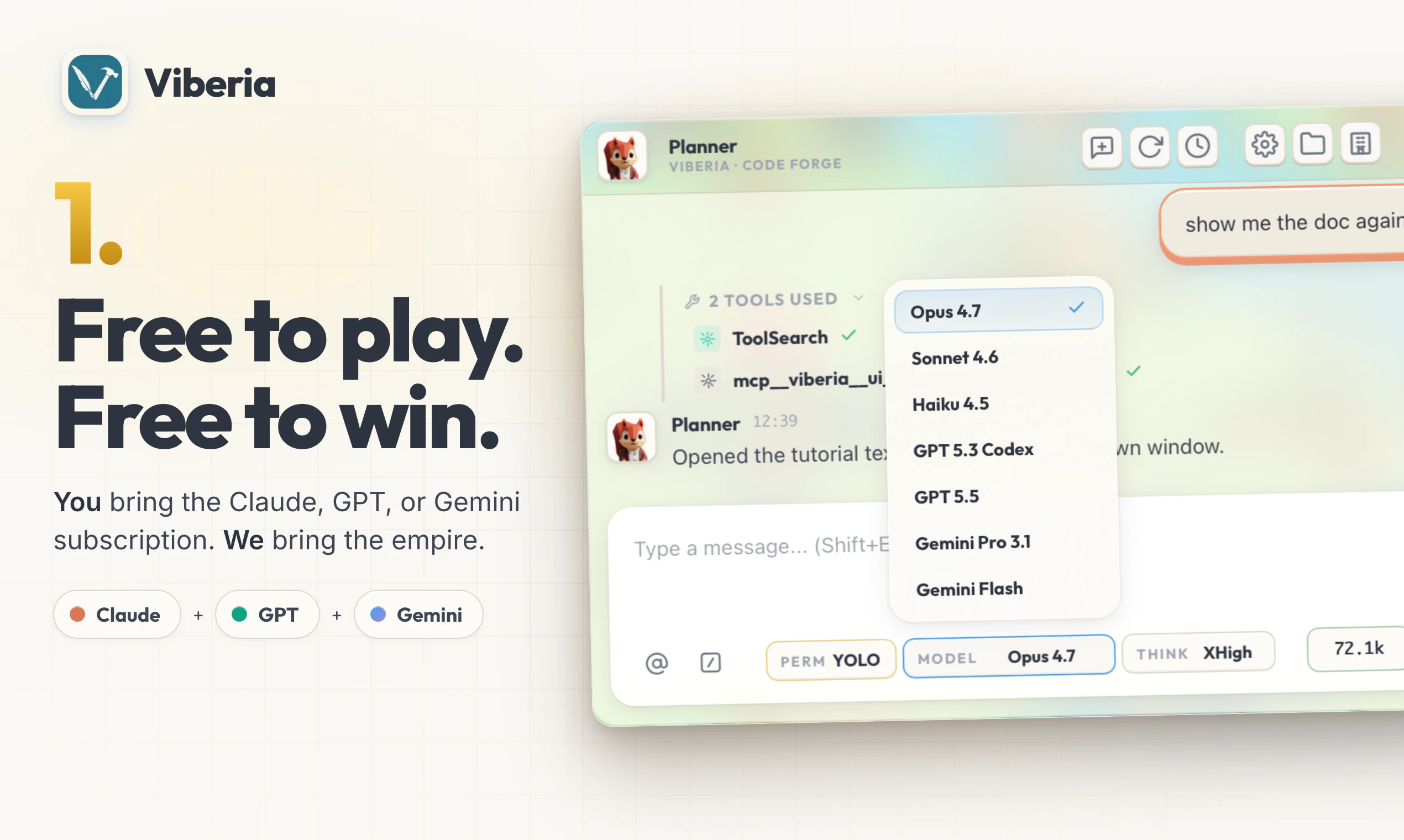
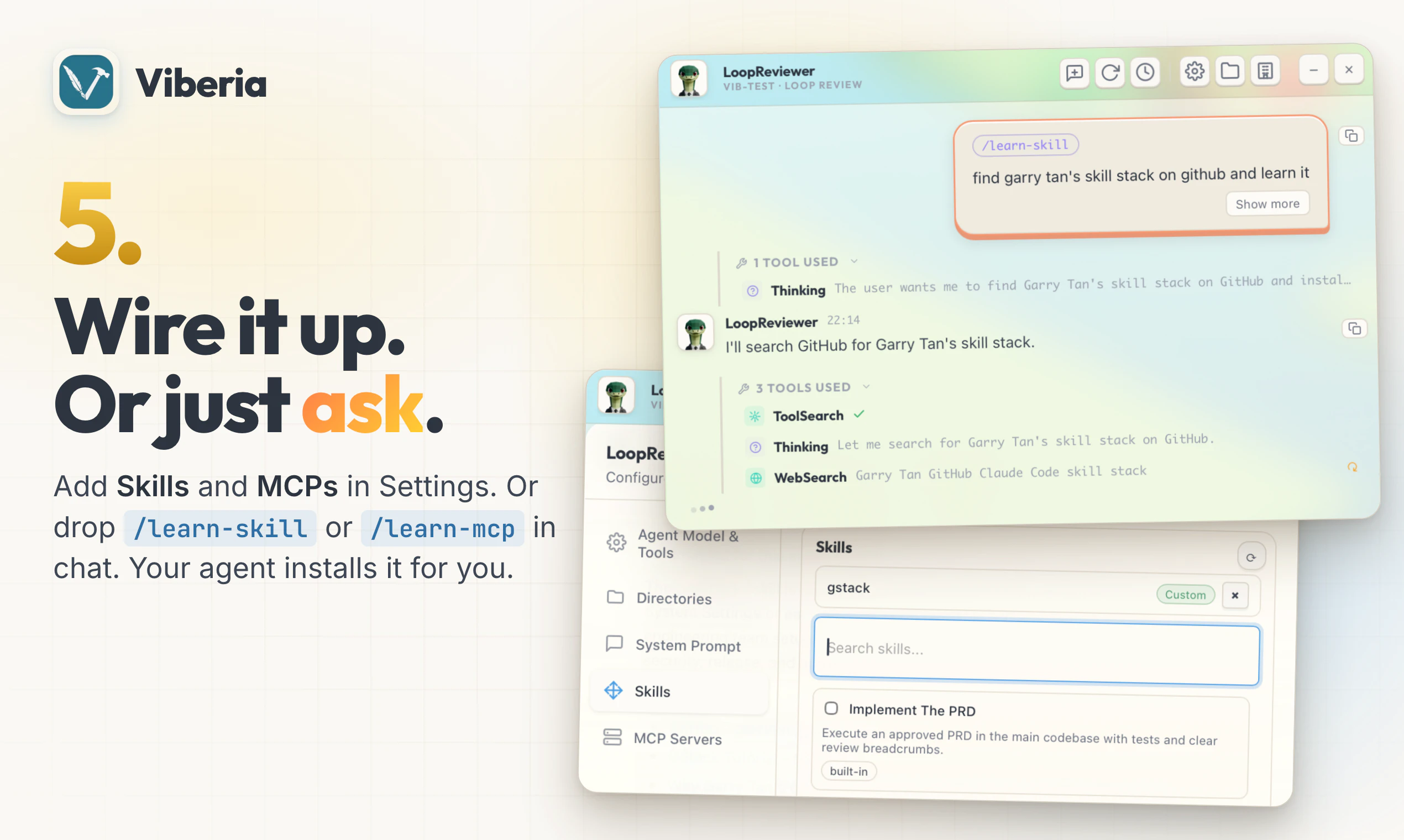
一句话介绍:Viberia是一个将AI代理管理可视化、游戏化的空间指挥中心,通过等距地图和状态图标,解决用户在管理多个AI代理时面临的混乱、低效与注意力分散问题,让管理代理像玩《文明》游戏一样直观有趣。
Productivity
Developer Tools
Artificial Intelligence
AI代理管理
多代理协作
空间指挥中心
游戏化UI
等距地图
工作流编排
MCP协议
代理团队
本地优先应用
Tauri框架
用户评论摘要:用户普遍认可其游戏化界面带来的创新和视觉优势。核心疑问集中在:代理间协作是否形成知识图谱?如何避免重复给代理项目上下文?能否通过分团队减少编码冲突?以及如何管理大量代理而不混乱。开发者回应称暂无默认知识图谱但可接入MCP自定义,建议通过文档团队和“工作台熔炉”建筑实现上下文共享与并行开发。
AI 锐评
Viberia抓住了当前AI代理管理领域的核心矛盾——随着代理数量和复杂度的指数级增长,传统的列表式、聊天式管理界面已经让用户从“与AI协作”退化成了“被动响应者的泥潭”。创始人Emre敏锐地指出,市面上已有工具(Conductor、Claude Squad等)本质上仍是“待办清单的变种”。
Viberia做对了两件事:第一,它将交互范式从“对话驱动”切换为“地图驱动”。空间化、游戏化的UI不只是为了好看,而是利用了人类对空间位置、状态图标(阻、问、完)的直觉认知。这解决了多代理场景下“注意力分配”的核心难题——你不需要阅读20条对话历史,而是像将军审视沙盘一样扫描战场,将有限注意力集中在最需要干预的节点。第二,其“建筑/团队”(building)的编排理念,将工作流从线性序列提升为类工厂流水线,让代理间的交接、并行、审查成为一等公民,这在生产力提升上比单纯的多代理对话更有结构性的优势。
然而,冷静来看,Viberia的价值天花板取决于两个变量。其一,当代理数量真正进入100+级别时,单纯的空间布局是否仍然有效?如果地图本身变得拥挤,便会退化回一种新的混乱。其二,也是最关键的:游戏化降低了决策的心理摩擦,但并未解决底层模型本身的不可靠性。用户可以轻松地指挥20个代理,但如果他们都在自信地执行错误的指令,这个漂亮的指挥中心就只是一个更高效的错误放大器。创始人提到“委员会建筑”(Council building)通过多模型交叉验证来应对,这是正确的方向,但这意味着用户需要为这种“保险”支付更多的计算成本与精力配置。
总体而言,Viberia是对“代理基建”的一次优雅的范式革命。它将管理从一个枯燥的运维任务,转变为一个可玩、可观察、可“指挥”的实时系统。对于重度AI用户,它提供的不仅是效率,更是心理体验的跃迁。但产品尚处早期alpha阶段,能否从“聪明的玩具”进化为“企业级的基础设施”,取决于它在规模化和可靠性上能否拿出同样聪明的方案。
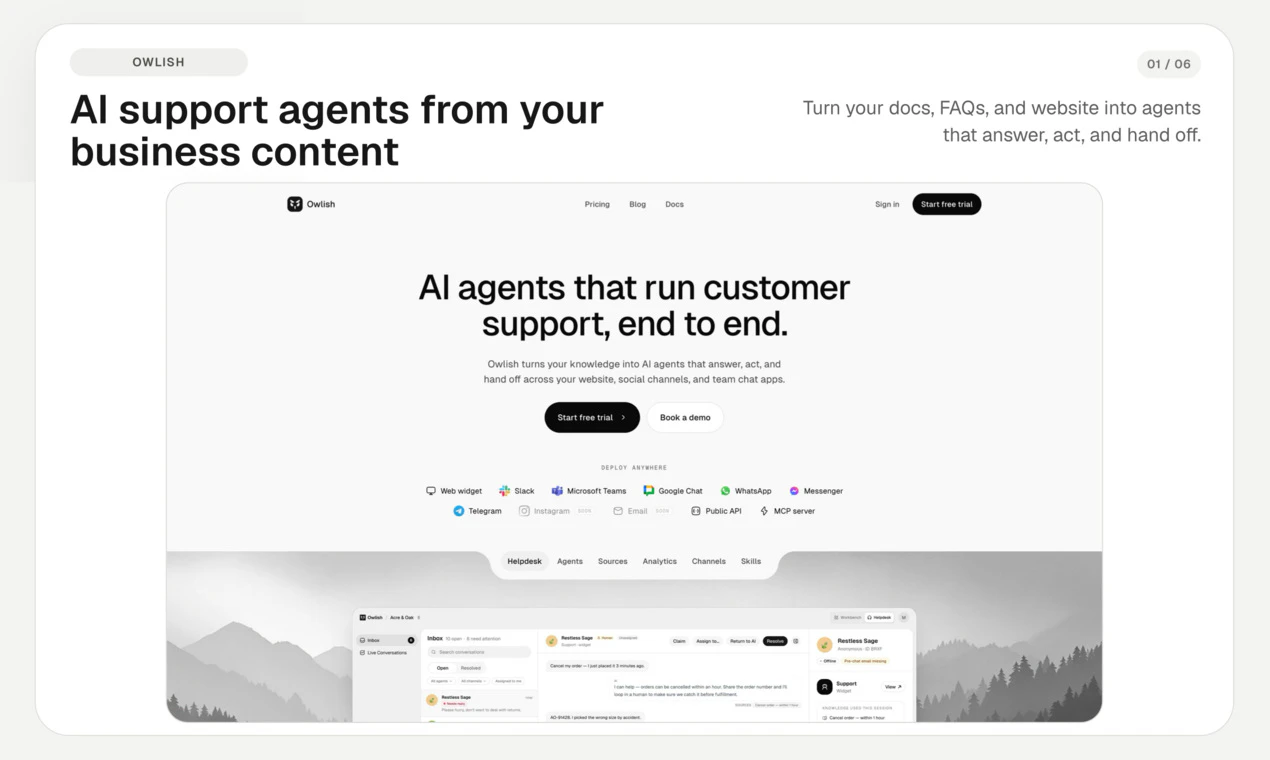
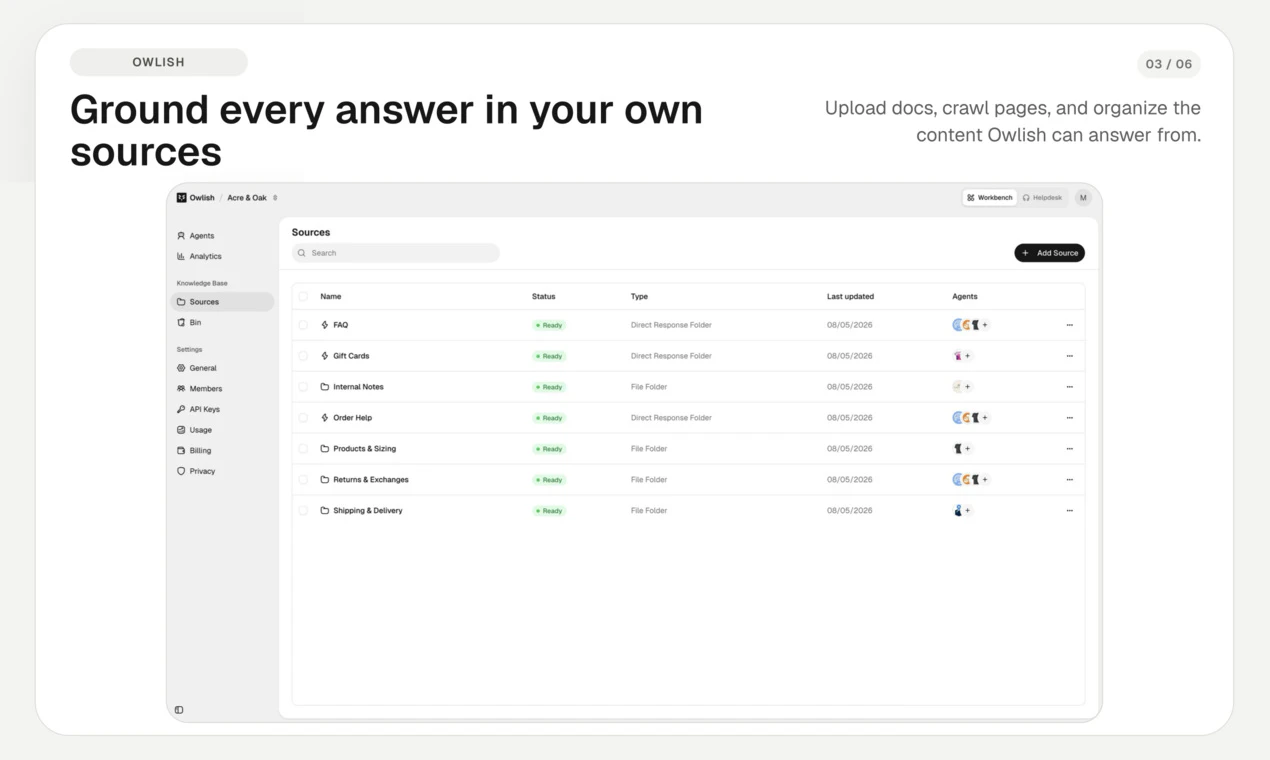
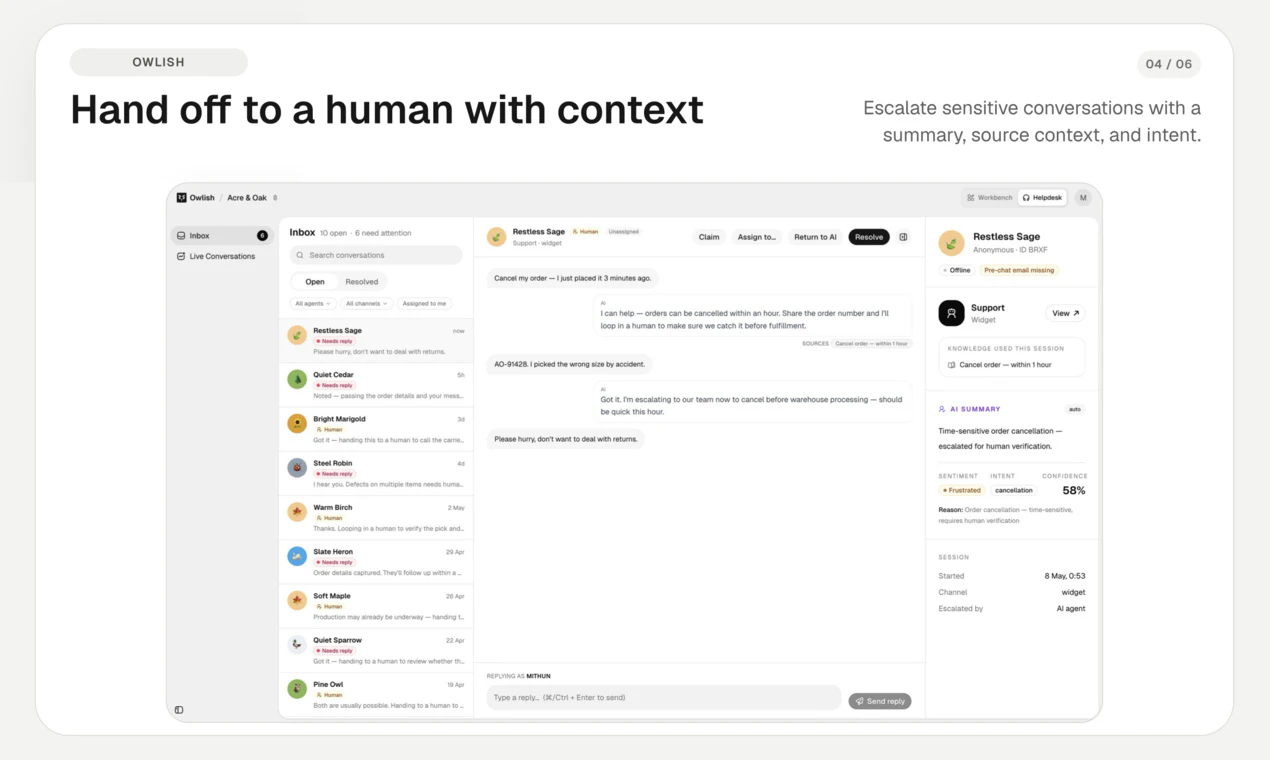
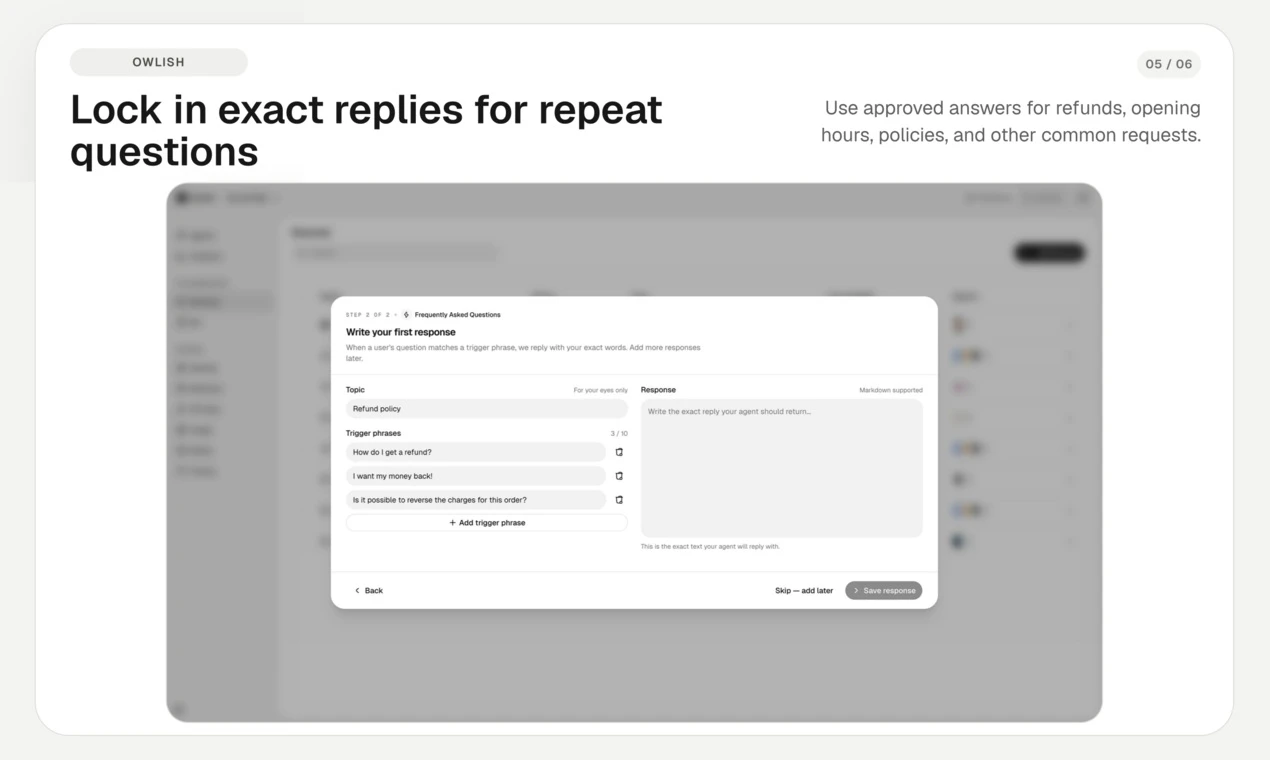
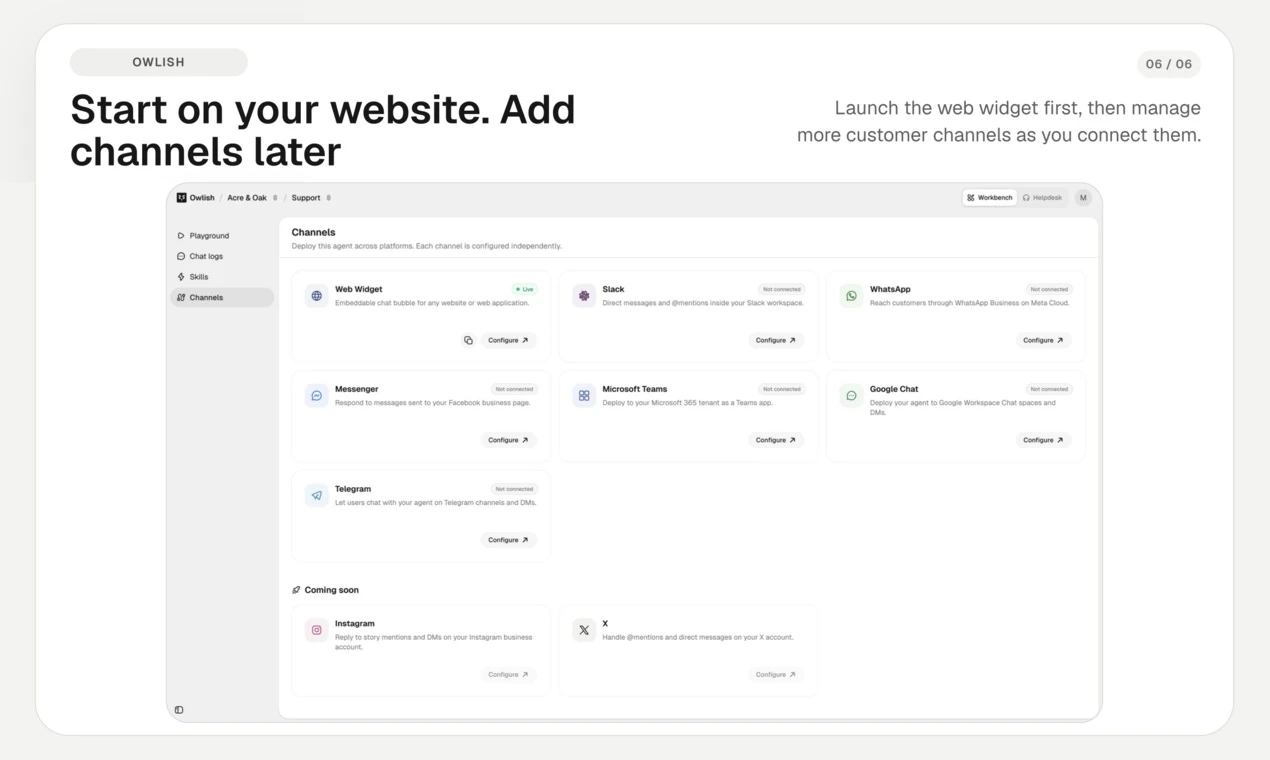
一句话介绍:Owlish将企业分散在不同文档中的知识转化为AI客服代理,自动回答常见问题并智能转接人工,显著减少重复性支持工单量。
Customer Communication
SaaS
Artificial Intelligence
AI客服代理
知识库训练
智能工单转接
文档驱动
网站文档/PDF接入
引用来源
直接回复钉选
客户支持自动化
帮助台集成
减少工单量
用户评论摘要:用户高度认可人类转接流程和引用来源功能,关心与Zendesk/Intercom等现有工单系统的集成进度;有用户询问与Mintlify的差异,以及知识库能否对接Vapi等语音平台。多集中在集成能力、回源策略及冲突处理等落地细节。
AI 锐评
Owlish的价值不在于“替换人工”,而在于把企业已有的内容资产(网站、文档、PDF)转化为一个可配置、可审计、可转交的AI一线客服。这种“知识驱动”而非“意图训练”的思路,避开了传统客服AI需要海量对话标注的坑,对于已有成熟FAQ和文档的中小企业来说,启动成本极低,效果显性。
值得肯定的是,产品在“何时转人工”这一核心体验上做了有深度的设计:支持基于置信度阈值、问题类型、用户明确信号的多层决策树,并且转交时不是甩一段聊天记录,而是附带Agent的推理过程和引用来源——这让接手的人工客服能“即时补位”而非“从头排查”,直接拉升了人机协作的效率。
几个值得警惕的潜在问题:首先,“Direct Response”与动态文档的冲突仲裁机制尚依赖手动维护,虽然承诺未来会做冲突检测,但现阶段政策漂移的风险仍落在运营团队的主动监控上,这对合规要求高的行业(如金融、医疗)是个硬伤。其次,日程驱动的同步频率(周/月)对于定价、活动等高频变动场景会有更新滞后。最后,Owlish自身的Helpdesk在功能深度上注定无法与Zendesk/Intercom抗衡——能否成为前台的“AI智能层”,取决于后续集成开放的速度,否则客户最终可能要在“保持单一工单系统”和“用上AI”之间做无效取舍。
总体而言,Owlish找准了一个务实的切口:它不强求全自动,而是做“A级问AI,B级转人工”的秩序维护者。这个路线在效率与风险间找到了平衡。
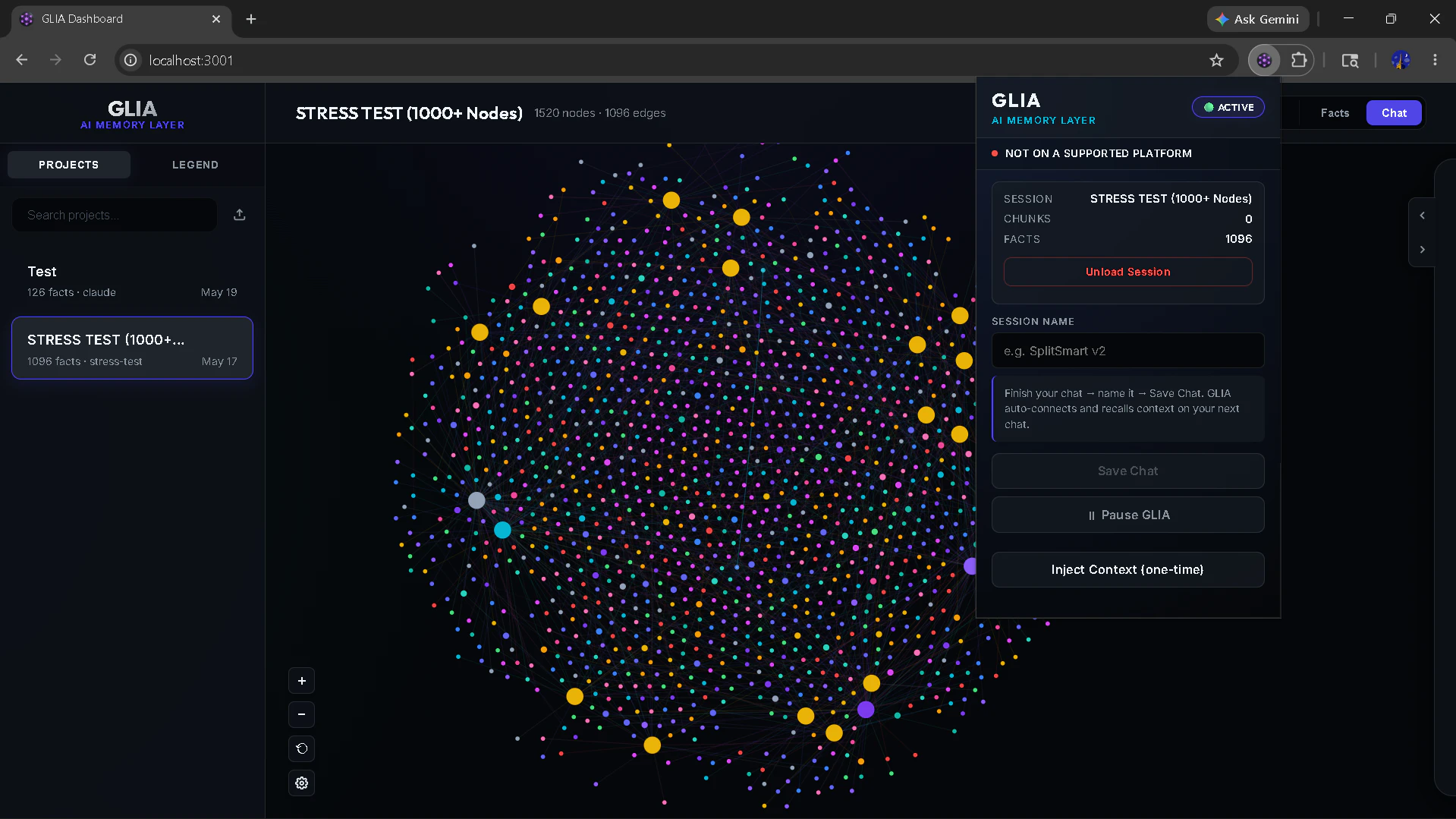
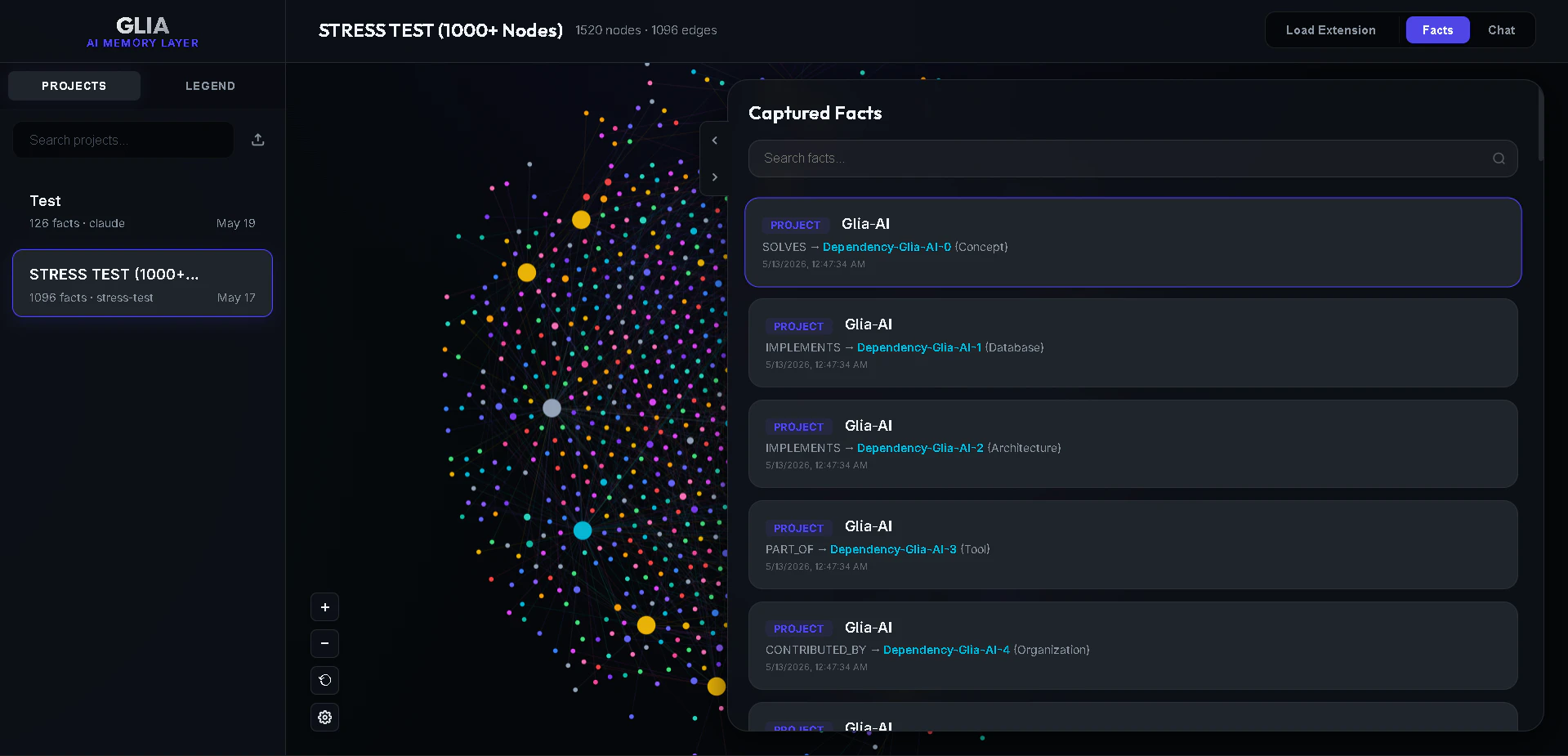
一句话介绍:Glia是一款100%离线的开源AI记忆桥,通过Chrome扩展自动保存网页端AI聊天记录(如Claude、ChatGPT),并利用本地SQLite数据库和MCP服务器,让Cursor、Claude Code等IDE工具能直接查询这些决策上下文,彻底解决开发者“在浏览器聊完、切回编辑器就失忆”的痛点。
Productivity
Developer Tools
Artificial Intelligence
GitHub
AI记忆桥
本地优先
开源
开发者工具
MCP服务器
Chrome扩展
上下文同步
IDE集成
隐私保护
RAG检索
用户评论摘要:用户高度肯定其解决了“浏览器聊天与IDE上下文割裂”的痛点,并赞赏本地优先、零隐私妥协的架构。核心疑问聚焦于:如何从聊天中精准提取有效决策而非噪音(当前使用后验LLM抽取,但缺乏“是否被代码采用”的信号);浏览器DOM频繁变动导致的兼容性维护挑战(已建立周度检测机制);以及SQLite写入并发控制(通过异步队列和WAL模式解决)。
AI 锐评
Glia精准地命中了AI辅助开发者工作流中最隐蔽也最痛苦的“上下文孤岛”问题——浏览器里的精妙架构讨论,在切换回编辑器后瞬间蒸发。它的核心价值不在于发明新技术,而在于用“本地优先+SQLite+MCP”的组合拳,完成了一次优雅的“信息拉通”。这比那些试图在云端统一所有上下文的方案,更懂开发者对数据主权的执念。
但别被“本地优先”的隐私牌冲昏头脑。产品目前最大的软肋在于“智能提取”能力的实际表现。从评论中可以看出,开发者真正需要的不是“记录所有聊天”,而是“记住我的关键决策和踩过的坑”。当前依赖“后验LLM提取”加上“语义搜索排序”,本质上还是“筛子上倒水”,噪音太多。更致命的是,它完全缺失“该决策是否已被落地到代码”的闭环验证信号——一个被讨论但被否定的方案,和一个最终被执行的方案,在系统里可能被同等对待,这会导致IDE检索出的“记忆”,反而成为误导。
此外,产品的技术壁垒并不高。Chrome扩展的DOM解析是“猫鼠游戏”,MCP服务器和SQLite是成熟方案。真正考验团队的是:在“全离线”这个严苛限制下,能否通过工程优化(如更快的HyDE检索、更精准的实体抽取)将“记忆质量”做到令人惊艳,而不是仅停留在“够用”。如果只满足于做一个“能将就用的缓存工具”,那很快就会被Cursor等IDE的本地索引或云端原生记忆方案边缘化。“桥”的定位很聪明,但这座桥如果只是“水泥墩子”,而不是“智能立交桥”,价值就大打折扣。
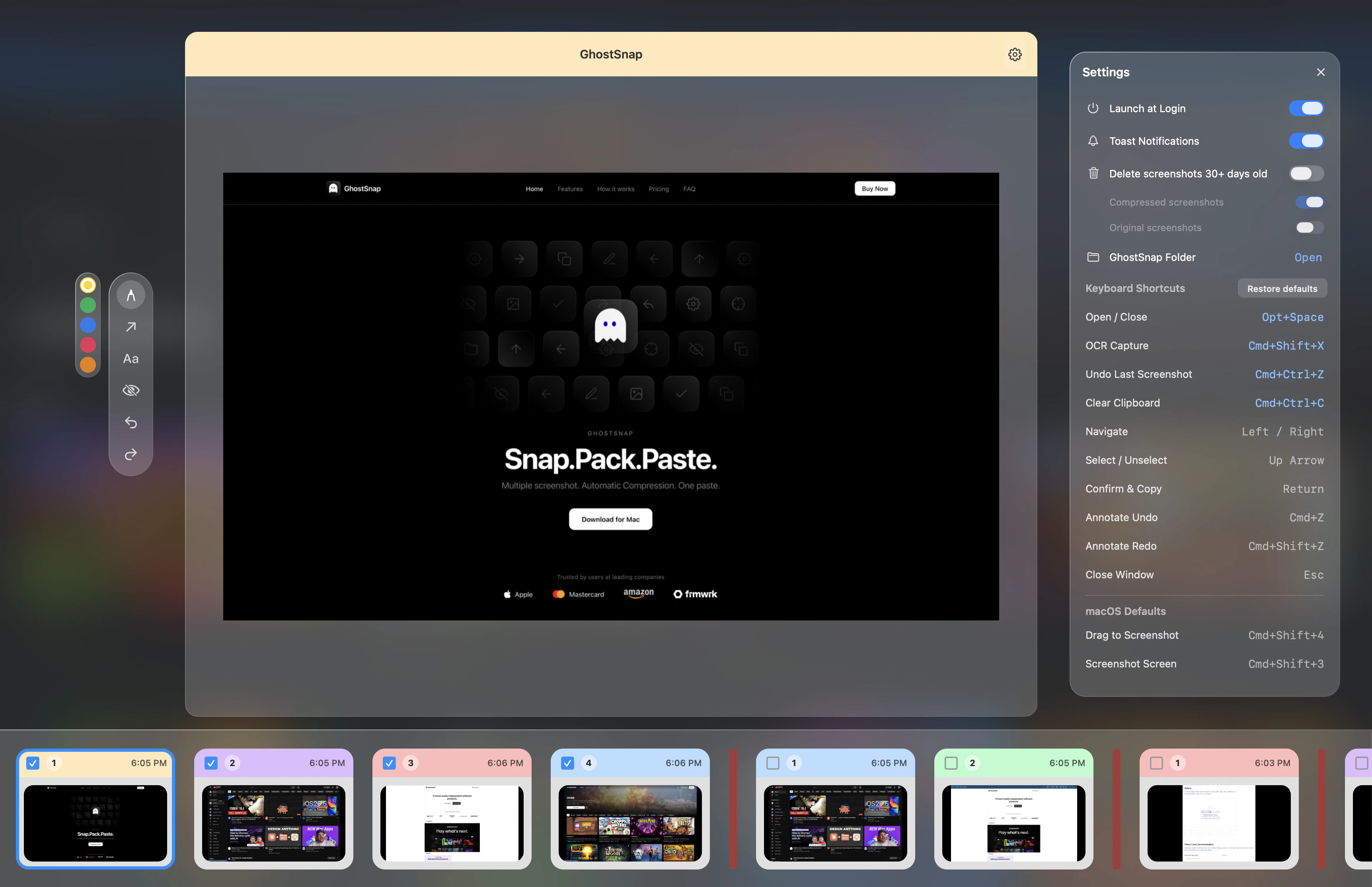
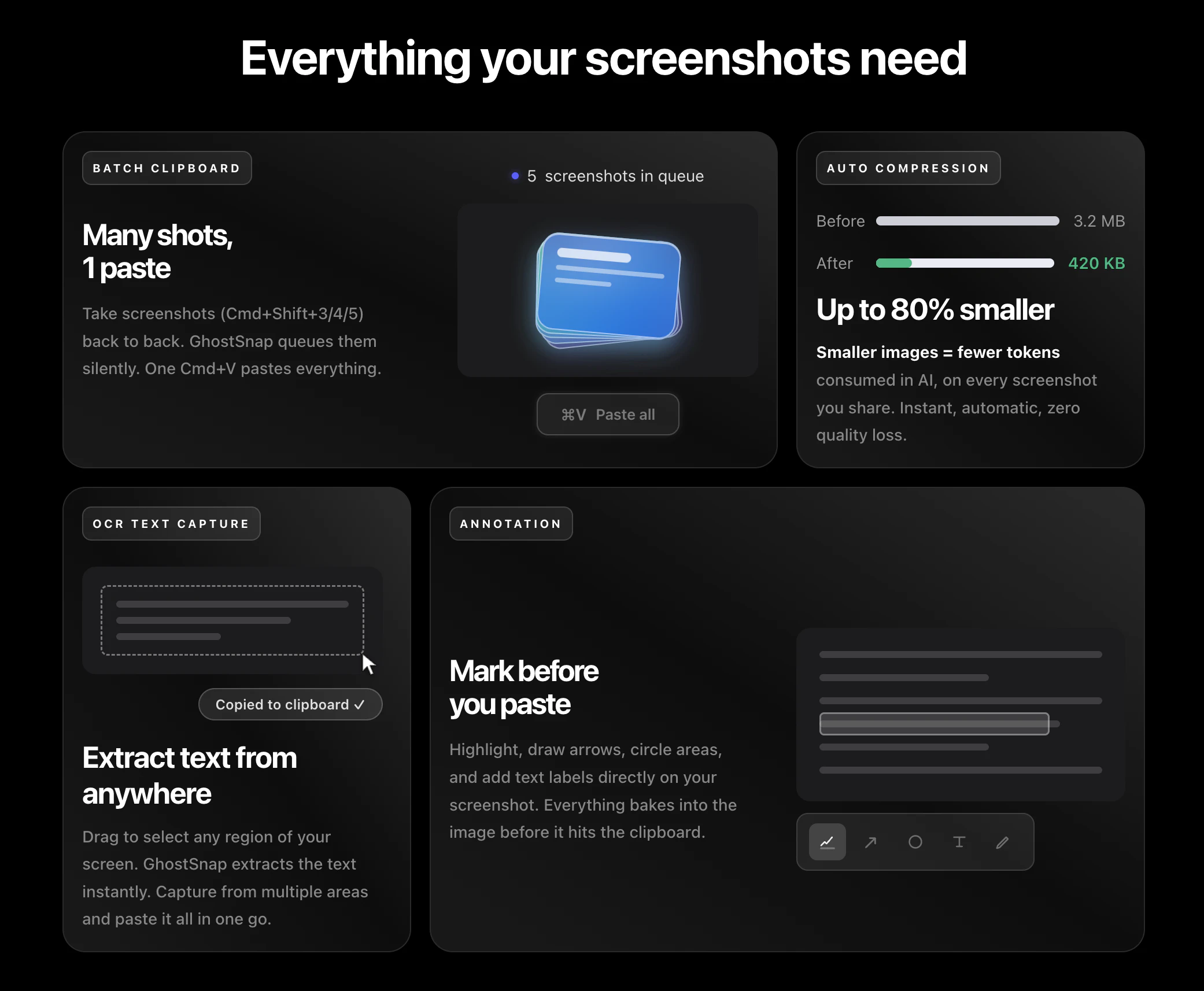
一句话介绍:GhostSnap是一款Mac菜单栏工具,让用户连续截取多张屏幕截图后自动压缩最高80%,并一次性粘贴到AI对话或其他应用中,避免逐张粘贴导致的Token浪费和文件臃肿问题。
Mac
Productivity
Artificial Intelligence
用户评论摘要:用户普遍认可解决AI截图频繁粘贴的痛点。主要问题:低分辨率/手写内容的OCR准确度不足(开发者计划用苹果智能改进);建议增加历史记录/重复操作功能(已有)。移动端需求暂不开发。
AI 锐评
GhostSnap切中的是一个被忽视但高频的“软钉子”——AI协作时代的截图管理。当ChatGPT、Claude等工具成为日常工作流,一张高清PNG截图消耗的Token成本已超过工具本身的价格,而用户却习惯性地逐张粘贴。产品用“自动压缩+批量粘贴”这个极简闭环,将用户从“保存-打开-拖拽”的冗余动作中解放,本质上是把AI场景下的微操作效率从“能接受”提升到“无感知”。6.99美元定价精准,低于多数人一天的Token浪费成本。
但产品天花板明显:1)深度绑定Mac生态,移动端和Windows的空白意味着用户无法跨设备统一工作流;2)压缩和OCR能力依赖本地算法,面对低分辨率或手写内容时(如论文草稿、白板照片)表现疲软,而这类恰恰是AI洞察需求最强烈的场景;3)功能过于单一,一旦Apple原生截图工具加入压缩和批量粘贴,或者AI应用自身强化输入功能,GhostSnap的生存空间会被瞬间压缩。目前它更像一个“聪明的补丁”,而非基础设施级的工具。开发者若能顺势拓展出“跨屏幕截图的历史管理”、“按AI模型预设压缩比”等深度功能,才可能从插件升级为工作流枢纽。
一句话介绍:Insta360 Mic Pro是一款面向视频创作者的无线麦克风,通过可定制的彩色电子墨水屏解决设备在镜头前“被迫为品牌打广告”的痛点,同时提供专业级收音、多机位同步、安全音轨录制等功能,适用于采访、活动、多机位拍摄等专业场景。
Hardware
Audio
无线麦克风
电子墨水屏
AI降噪
32位浮点内录
多机位同步
专业音频
视频创作者
定向收音
时间码同步
Insta360
用户评论摘要:用户高度认可电子墨水屏的设计,认为它结束了麦克风“为品牌免费打广告”的尴尬,让设备更个性化。有效评论聚焦于“个性化标识”这一核心差异点,认为其平衡了实用与美学,是硬件设计的进化方向。
AI 锐评
Insta360 Mic Pro的“杀手锏”并非收音参数,而是一块电子墨水屏。这看似“肤浅”的创新,实则精准切中了视频创作者长期存在却未被正视的痛点:镜头前的设备,究竟属于用户,还是品牌?当每个麦克风发射器都在摄像机前“免费展示”品牌Logo时,Insta360选择把屏幕的所有权交还给用户。这是一种对“专业工具”定义的重新诠释——专业不仅是信噪比和频响曲线,更是对创作者身份与视觉美学的尊重。
技术层面,3麦克风阵列、AI降噪、32位浮点内录、时间码同步与400米传输距离,算得上行业顶配,功能上足以对标Rode、DJI等竞品。但真正让这款产品脱颖而出的不是“堆料”,而是“场景化思维”:它默认你可能会在混乱的多机位拍摄、嘈杂的户外采访中工作,并在那0.1%的翻车风险上(如爆音、品牌别扭)给出了针对性方案(32位内录、电子墨水屏自定义)。
当然,它并非完美。电子墨水屏的刷新率、在强光下的显示效果,以及自定义内容的易用性,仍是需要实际体验才能判断的细节。另外,作为一个新入局的专业音频产品,其生态系统(如多麦克风配对、接收器兼容性)是否足够成熟,也需要市场验证。
一句话总结:Insta360 Mic Pro是在专业音频功能上“及格”的前提下,通过一个极其聪明的设计细节,完成了从“工具”到“身份表达”的价值跃升。它证明了:在红海市场里,找到用户未被满足的“心理刚需”,远比在参数上卷数字更有效。
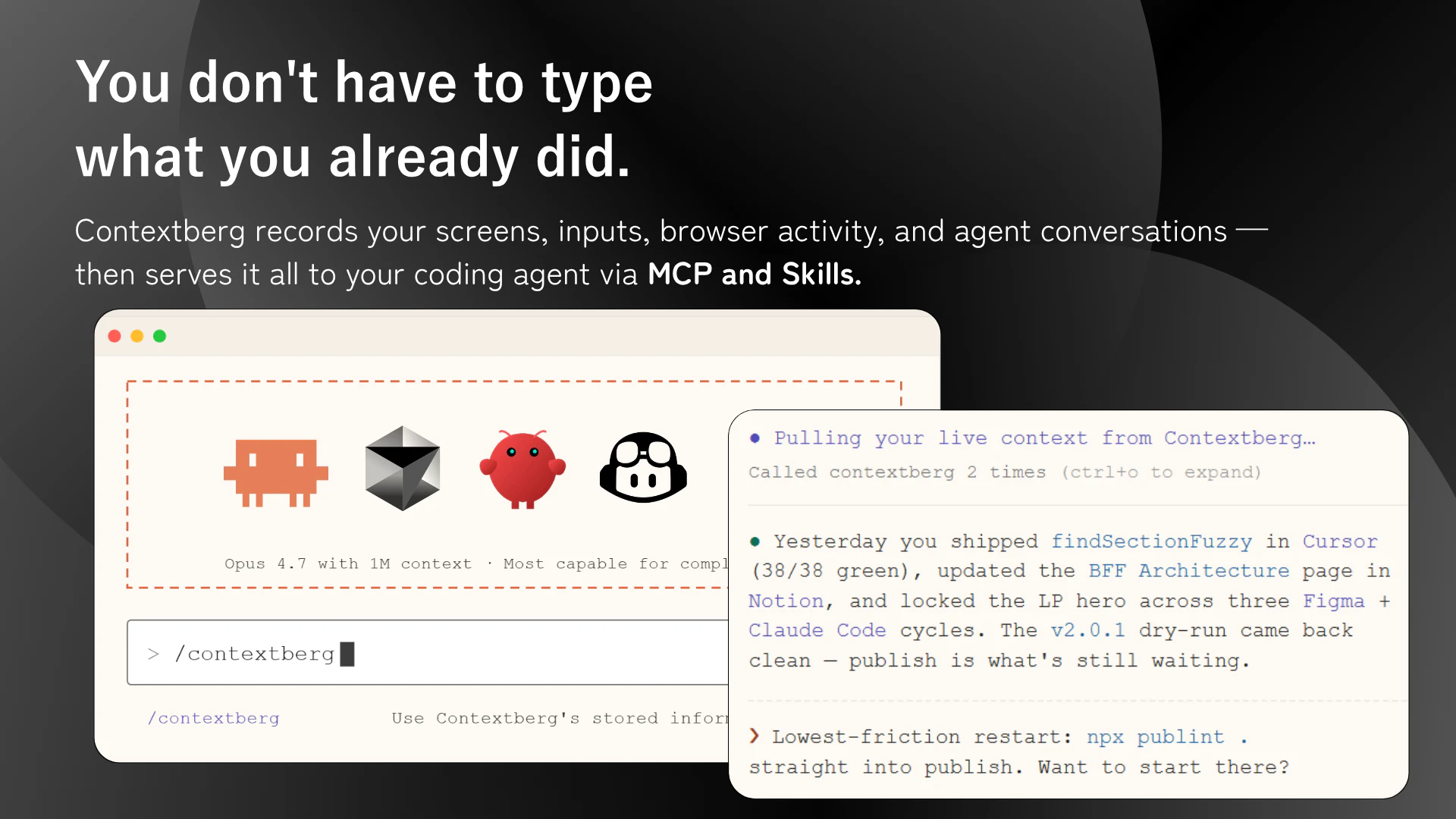
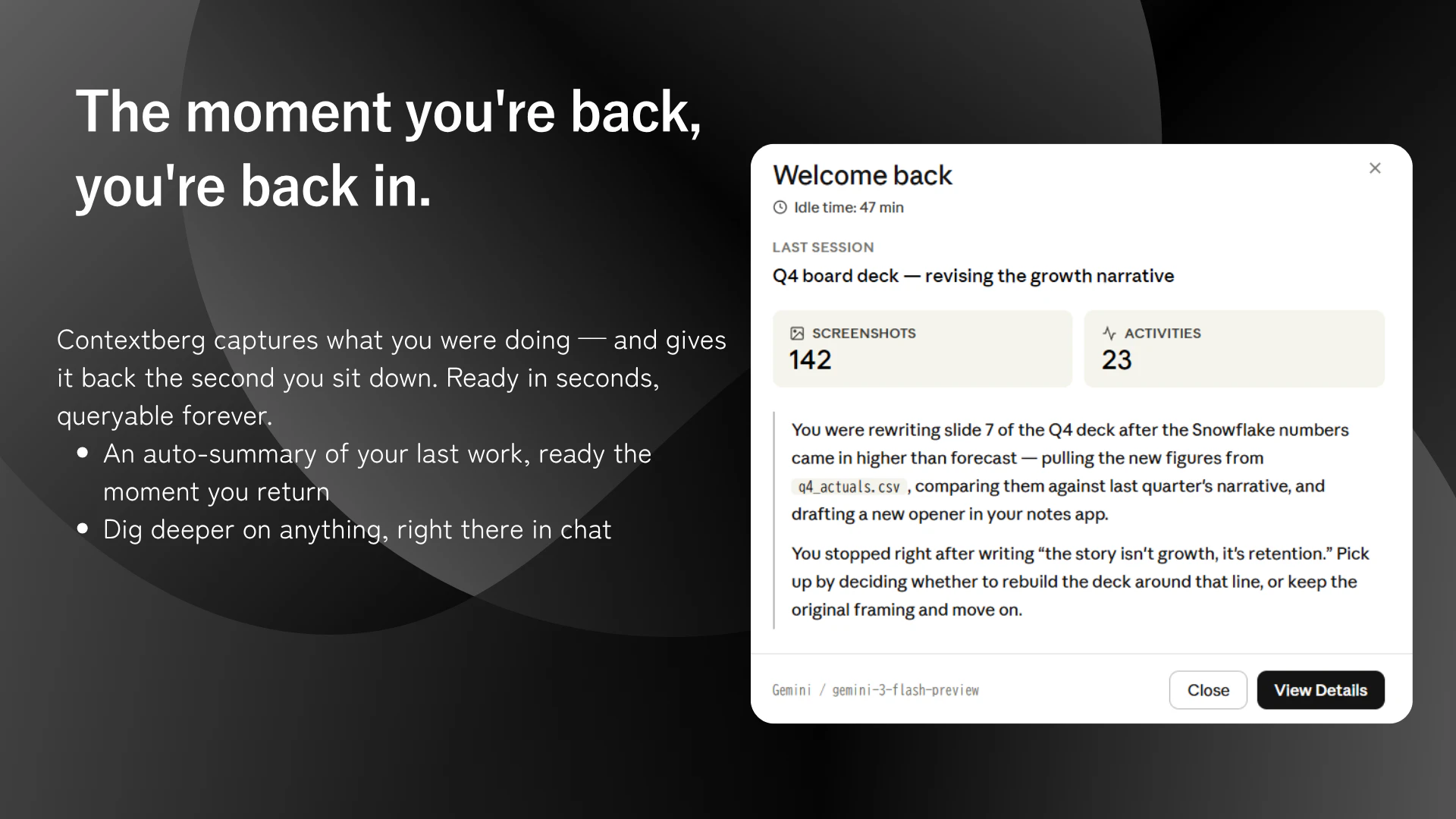
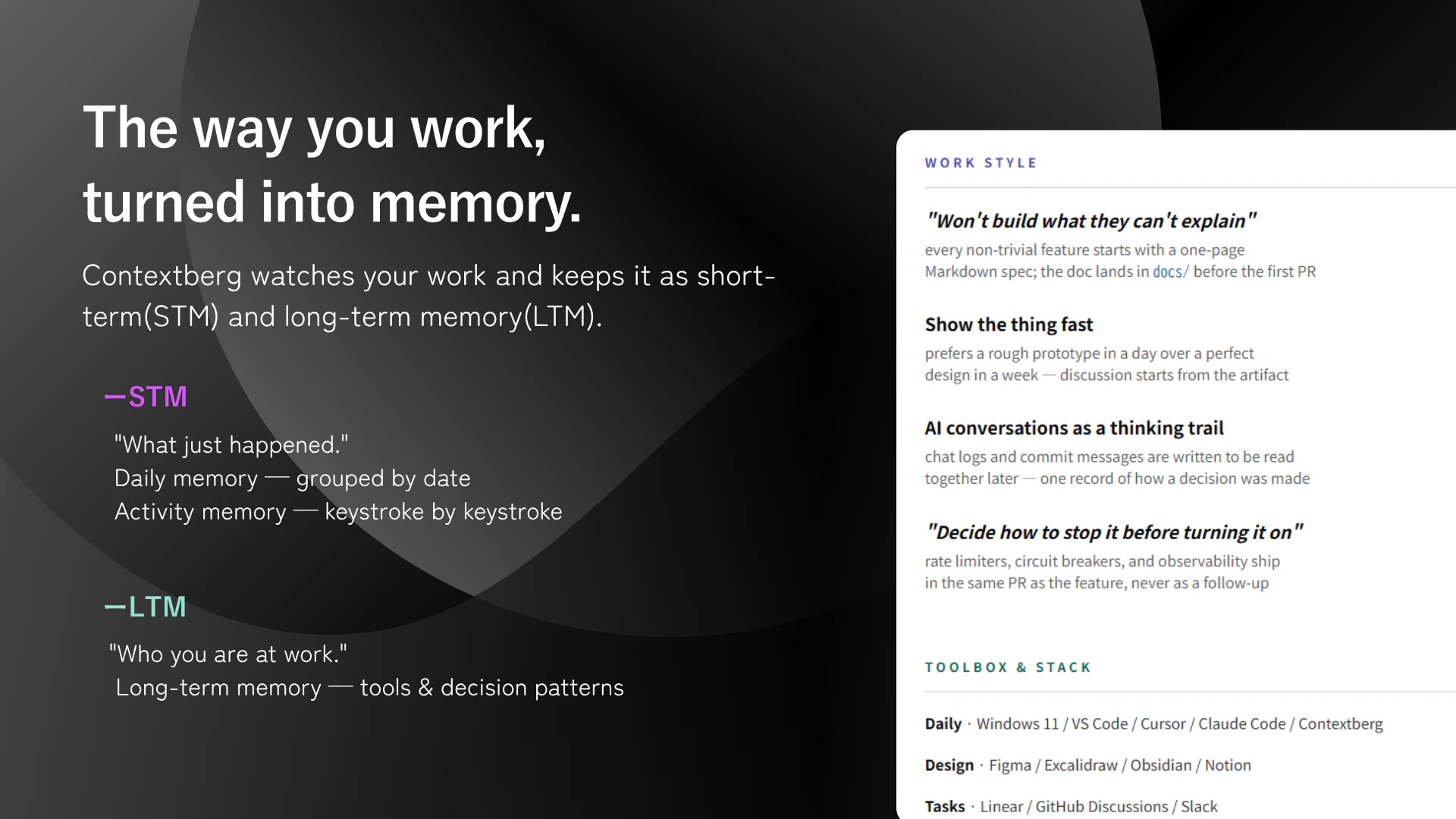
一句话介绍:Contextberg是一款本地化AI记忆应用,通过被动记录屏幕、浏览器历史和对话,为Claude Code、Cursor等AI代理提供跨会话的持久上下文,解决开发者重复向AI解释背景的痛点。
Productivity
Time Tracking
Artificial Intelligence
AI记忆层
MCP协议
开发者工具
Windows本地化
被动捕获
上下文管理
隐私控制
AI代理
本地LLM
Cursor
用户评论摘要:用户关注隐私控制(能否颗粒度排除敏感内容)、信号噪声处理(是否过滤无效数据)、跨代理记忆隔离机制,以及团队协作的权限分级。创始人在回应中透露:支持本地LLM处理、计划自动排除密码输入、采用“信息全存+分层压缩”策略,并规划隐私等级。
AI 锐评
Contextberg的“被动捕获+本地MCP”架构直击AI代理的致命短板——短期失忆。其聪明之处在于不跟风Mac-first,转而深耕Windows生态,填补了一个被忽略却庞大的需求真空。但真正考验产品价值的是“隐私-效用”的平衡术。当前策略是“全存后压缩”,虽能避免遗漏关键上下文,但也让敏感数据裸奔风险陡增。尽管创始人提到本地LLM支持和计划中的敏感内容排除,但这些仍属补救而非设计保障。开发者更渴望的或许是:运行时动态拦截敏感域、基于向量指纹的自动脱敏,而非事后擦除。此外,每15分钟生成一次短时记忆,若没有高效的分级缓存机制,在复杂工作流下可能引发响应延迟。真正让Contextberg从“工具”升级为“队友”的关键,在于“技能命令”的自动生成——如果它能从历史上下文中提炼出可复用的行为模式(如“修复CI/CD失败”的通用步骤),那就不是记忆,而是经验。这条路难,但值得走。至于团队场景,隐私分级虽好,但“Level 3”的全屏追踪会让大多数企业内审直接否决。不如先做好单开发者场景的强隐私保障,再谈协作。总的来说,方向正确,但隐私安全不是功能列表里的check box,而是必须写在架构基因里的信条。
一句话介绍:Kraft是一款面向深度思考者的AI长文协同写作工具,帮助用户将零散的笔记和想法转化为保留个人风格、可直接发布到不同平台的长篇内容,解决从“空白页恐惧”到“泛泛而谈”的写作痛点。
Design Tools
Writing
Marketing
AI写作助手
长文创作
内容再创作
深度写作
个人化写作
写作效率
内容营销
跨平台发布
交互式图表
源文档阅读
用户评论摘要:用户普遍认可Kraft解决了“空白页恐惧”和AI写作过于笼统的痛点。核心关注点是:如何在内容再创作(从长文到社交帖子)过程中保持作者的原始声音和个人风格;交互式图表、自定义语调滑块、并行阅读PDF等功能获得好评。有用户建议对比历史写作样本来衡量语音保留效果。
AI 锐评
Kraft的定位精准地切中了当前AI写作工具的软肋——“平庸的中间地带”。大多数工具要么给你空白页,要么一键生成千篇一律、毫无灵魂的“AI体”内容。Kraft试图扮演一个“理解你的协作者”,而不是“取代你的自动生成器”,这个产品哲学值得肯定。从评论反馈来看,它的“语调滑块”、交互式图表和源文档并行阅读等功能确实在解决真问题,让数据型内容创作者(如Bryan)和营销人员(如Nathan)找到了“主动权”。但产品真正的挑战在于“语音保留”这一核心承诺:在用户输入想法与AI进行初次草稿后,将长文再创作成不同平台(LinkedIn、X)上的帖子时,如何确保用户的思维逻辑和独特表达不被AI的“平均化语言模型”吞噬?目前看,产品主要依赖角度和语调设置,这显然是初级的,因为“一个人的声音”远不止于语调波动,它关乎叙事节奏、类比偏好、细节颗粒度。如果Kraft不能推出更精细的、基于用户写作历史的“个人风格微调”机制(例如自然语言示例引导甚至风格数据集训练),那么它仍然可能困在“稍微好一点的泛泛而谈”的陷阱里。从商业价值看,Kraft瞄准的是有深度的内容创作者——营销高管、分析师、科技博主——这群人愿意为“保留思想”而不是“生成废话”付费。只要后续能把“语音保留”这个抓手真正做透、做到可量化追踪,它就有机会从“又一个AI写作工具”升维为“深度写作者的必备第二大脑”。否则,它可能会变得像很多“全能型”AI工具一样:功能很多,但每个都差一口气。
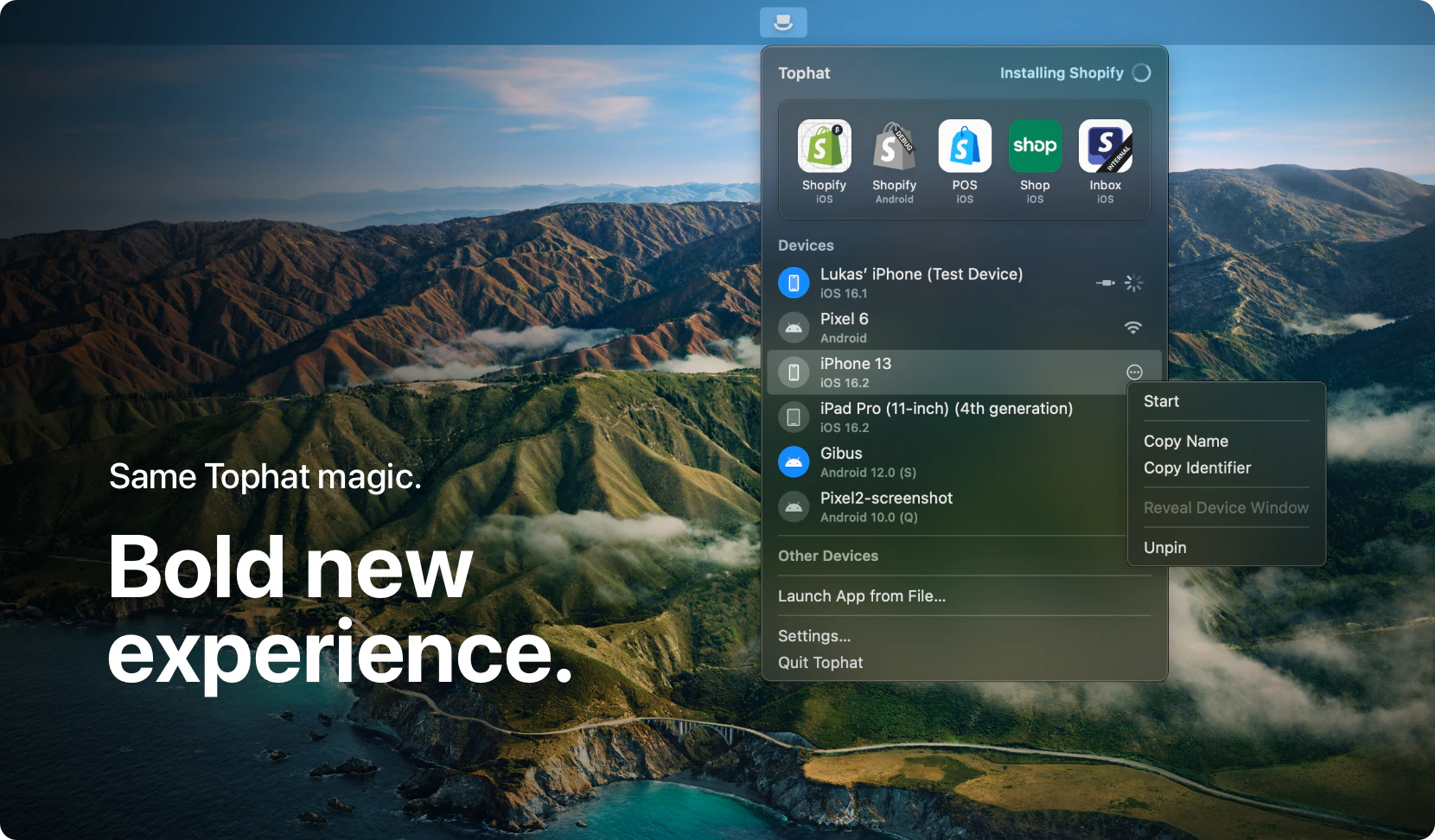
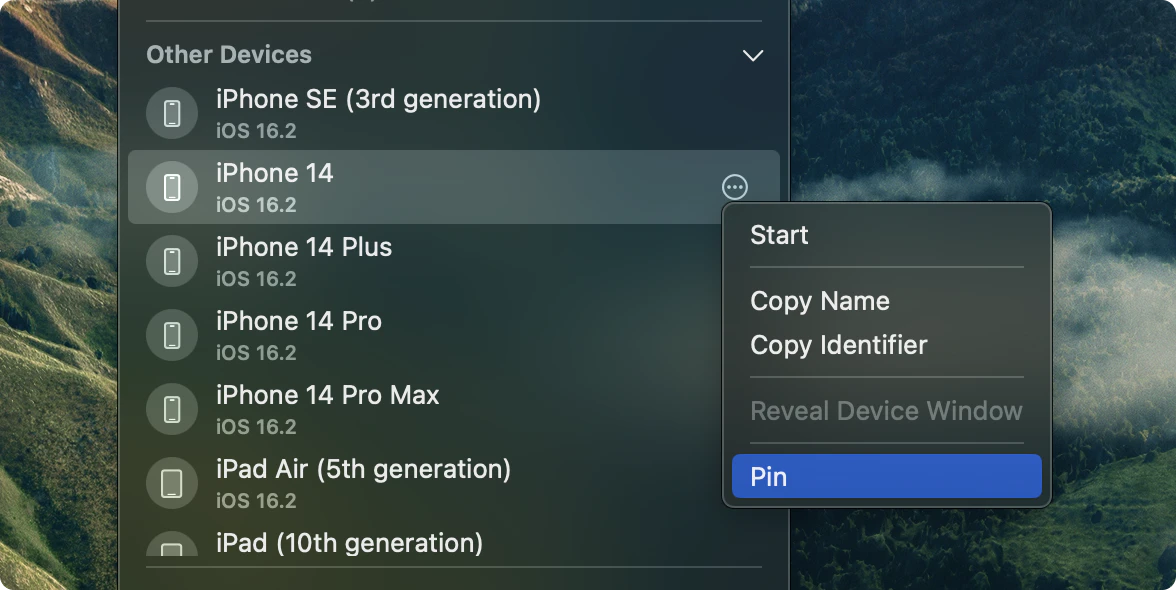
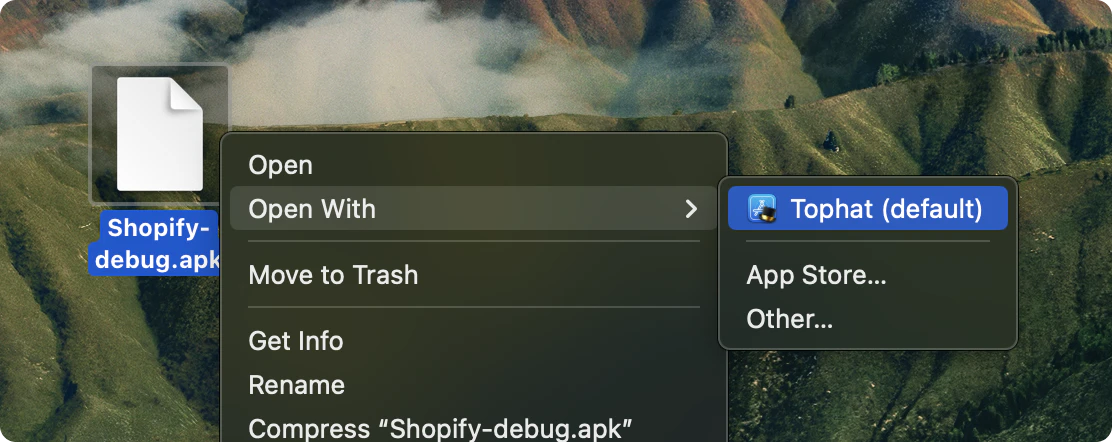
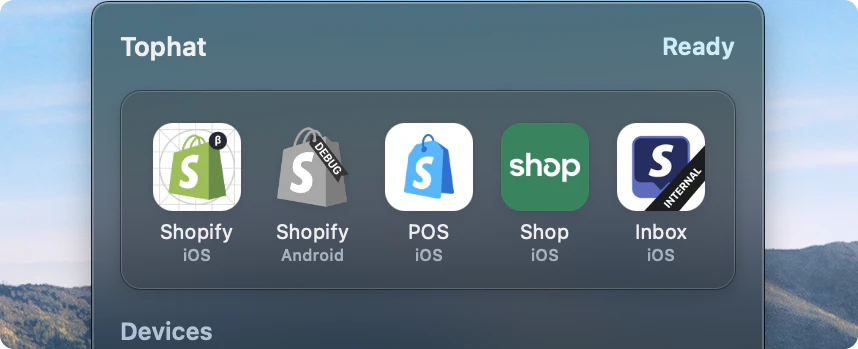
一句话介绍:Tophat by Shopify 是一款开源 macOS 应用,让移动开发者无需本地构建,即可将 CI 构建产物直接安装到模拟器或真机上,瞬间测试他人提交的 PR。
Open Source
Software Engineering
Developer Tools
移动开发
CI/CD
PR测试
真机安装
模拟器
macOS工具
开源
iOS开发
Android开发
开发者效率
用户评论摘要:用户普遍认可其解决“为看一个PR要本地重构建”的痛点,称赞其能大幅提升团队动量、加速QA循环。唯一建议项是评论区反问“你会把哪一步交给AI代理?”,暗示仍有扩展空间。
AI 锐评
Tophat 切中的是一个极其精准且昂贵的痛点——移动端工程师在代码审查过程中“被迫本地构建”的隐性时间税。这笔税不直接体现在单次构建时长,而是累积在“试错-反馈-再试”的工作流断裂中。Shopify 将此工具开源,既聪明又狡猾:聪明在于,通过剥离对本地环境的依赖,将PR验证从同步阻塞变为异步拉取,本质上重构了移动开发者的审查心智模型——你不再需要等“环境就绪”,而是可以随时拉取代码的“成品”来验证。狡猾在于,它将AI agent(Claude Code)集成作为卖点,实则暗示了一个更深层的自动化愿景:当“安装”这一步变得零成本,AI就可以替代人类执行“拉取-安装-截图-归因”的完整验证循环,最终让工程师从流程中的执行者变成规则的设计者。不过,产品有两个潜在天花板:一是对CI构建链的强依赖——如果你的CI本身不稳定或产物管理混乱,Tophat就是空中楼阁;二是它本质上是macOS专属工具,对Linux或Window环境的移动开发者直接失声。它解决的是“最后一公里”的体验问题,而非构建效率本身。对于已经跑通CI管道的团队,它是一个值得立即可用的效率杠杆;对于尚未标准化的团队,它可能只是把混乱从本地复制到了远程。真正的价值,在于它打开了“为每个PR自动分配物理设备进行端到端测试”的想象空间——而这,才是移动开发真正从“人工验证”走向“自动验证”的关键一跃。
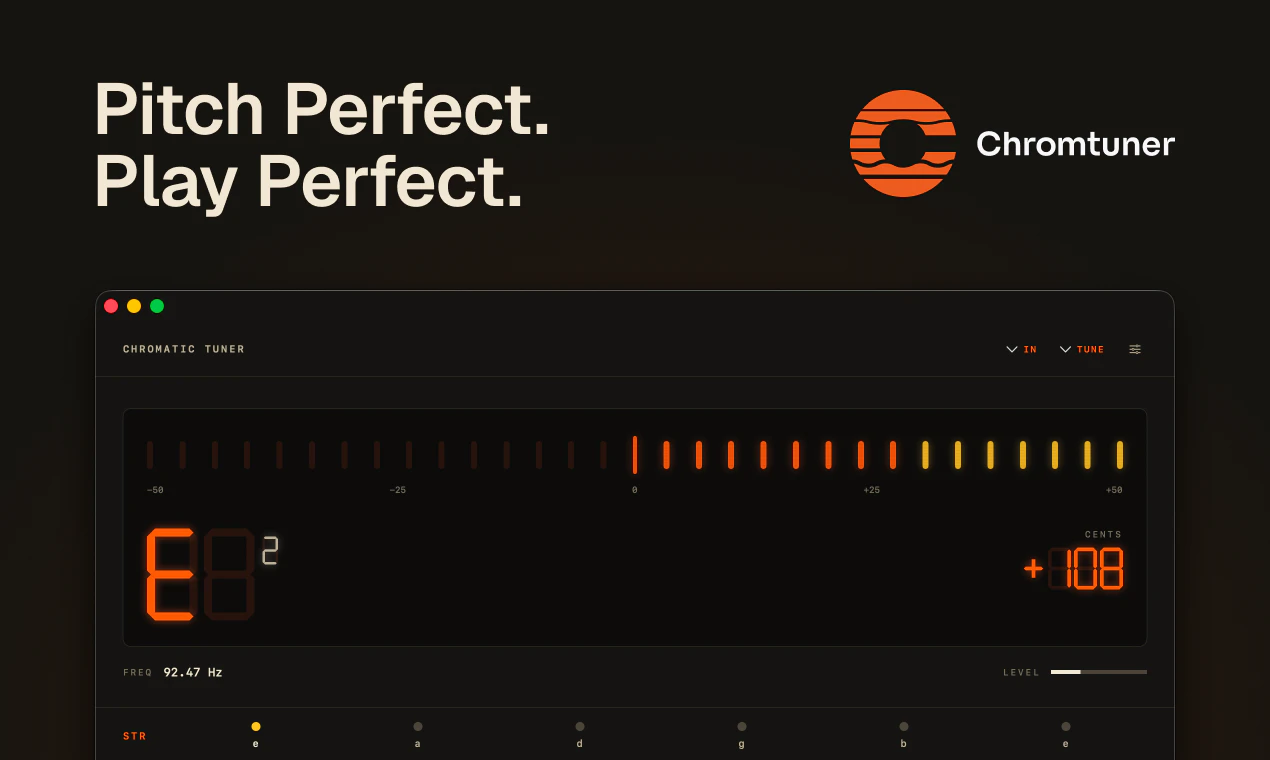
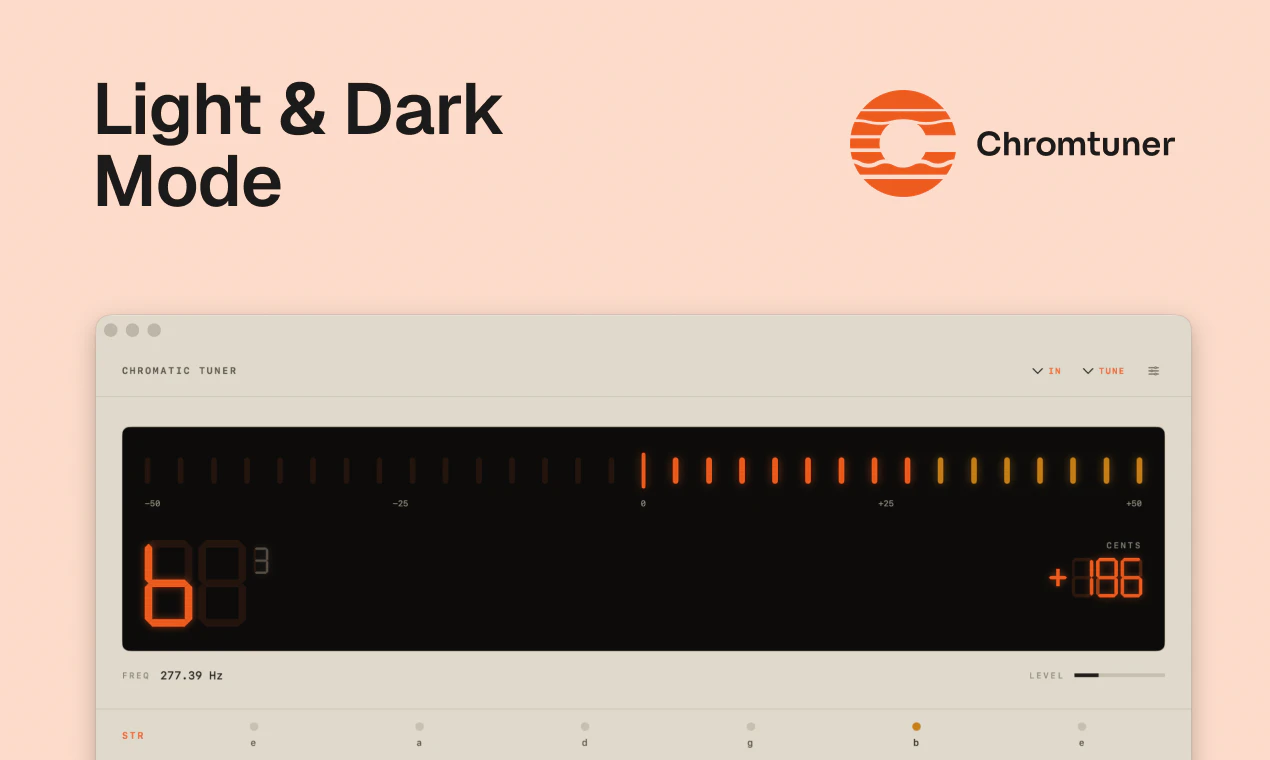
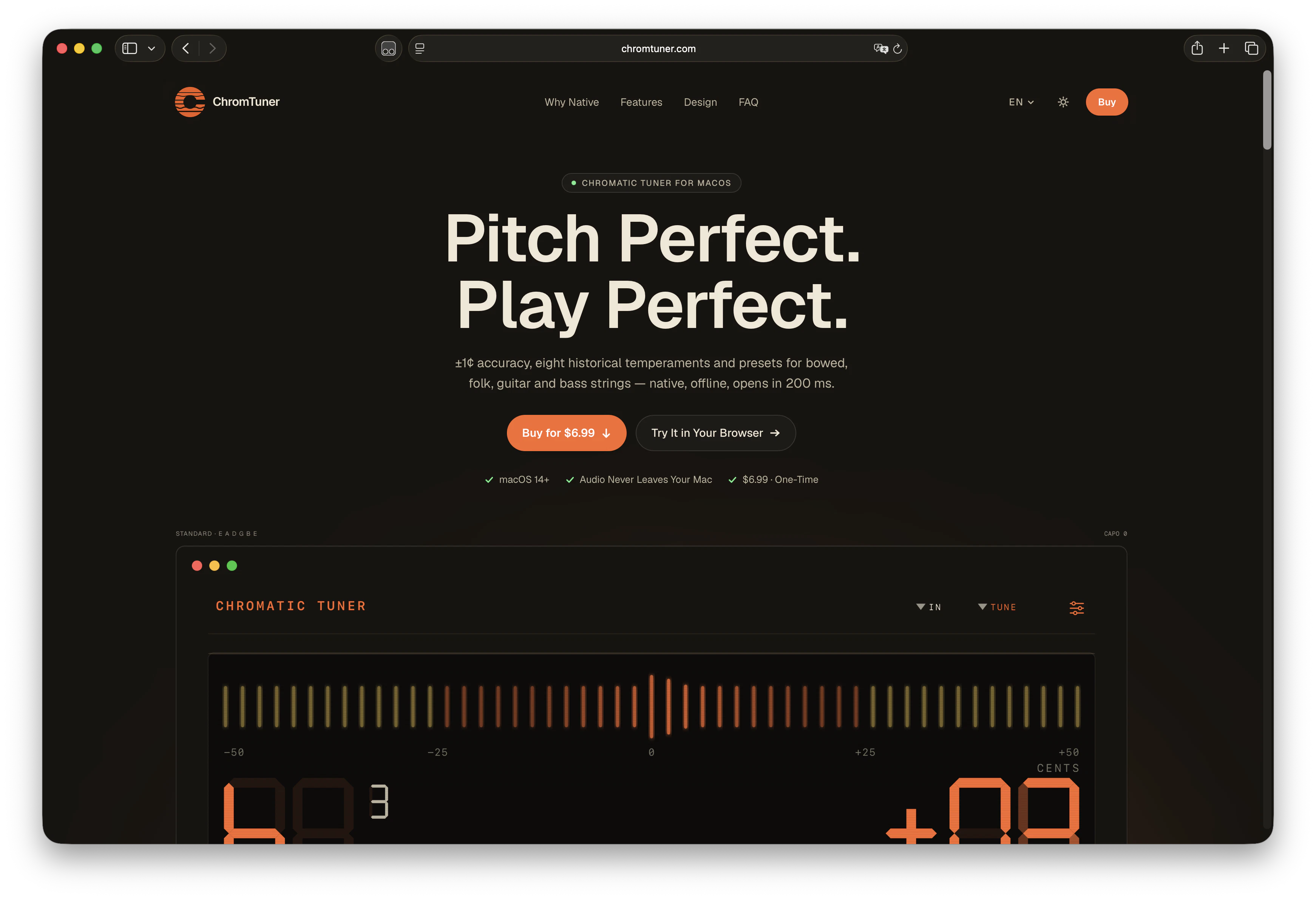
一句话介绍:Chromtuner 是一款专为 macOS 设计的离线高精度调音器,以 ±1 音分精度、毫秒级启动和菜单栏常驻模式,解决了音乐人在演奏或录音时需频繁切换浏览器或手机调音的碎片化痛点,提供专业级但极简的原生体验。
Music
Menu Bar Apps
Tuning
macOS调音器
音准精度
离线应用
菜单栏工具
乐器调音
历史律制
原生应用
付费单次
音频工具
音乐人
用户评论摘要:用户赞赏其精准度、离线运行和极速启动,填补了macOS高质量调音工具的空缺。尤其对历史律制预设表示惊喜,认为适合非平均律工作。开发者首次亮相,用户反馈积极,建议集中于进一步磨炼原生细节。
AI 锐评
Chromtuner 成功之处不在于创新,而在于“截断”。它精准掐断了两个主流调音方案——手机App和Web调音器——的致命弱点:延迟、干扰和隐私泄漏。开发者清醒地意识到,音乐人的核心诉求并非“功能更多”,而是“功能更少”且“更可靠”。离线、无追踪、无订阅、菜单栏常驻、200毫秒启动,这些看似朴素的特性,实际上构成了一个极致的“防御性设计”:不给用户任何分心的机会,也不让App自身成为工作流的障碍。
但这款工具的野心也暴露了其天花板。它本质上是一个硬件产品的软件替代品,且极度依赖macOS生态。用户愿意付7美元,是因为它提供了校音器+弦乐预设+历史律制的组合,但一旦跨平台(如iOS、Windows),或需要集成到主流DAW中进行自动调音矫正,Chromtuner便无能为力。更关键的是,它瞄准的“精准”场景(如专业录音棚、古典乐器校音)其实对硬件校音器有路径依赖,软件调音的微距响应能力和信噪比永远是短板。
因此,Chromtuner 最有价值的突破口,不是去挑战硬件精度,而是成为“音乐人数字工作流中的那个沉默的配角”。如果它能开放MIDI输出、提供简单的API调用、或与GarageBand/Logic Pro深度联动,那么它就从“一个很好的独立工具”跃升为“不可替代的生态组件”。否则,它很好,但终归只是菜单栏里众多小字之一。
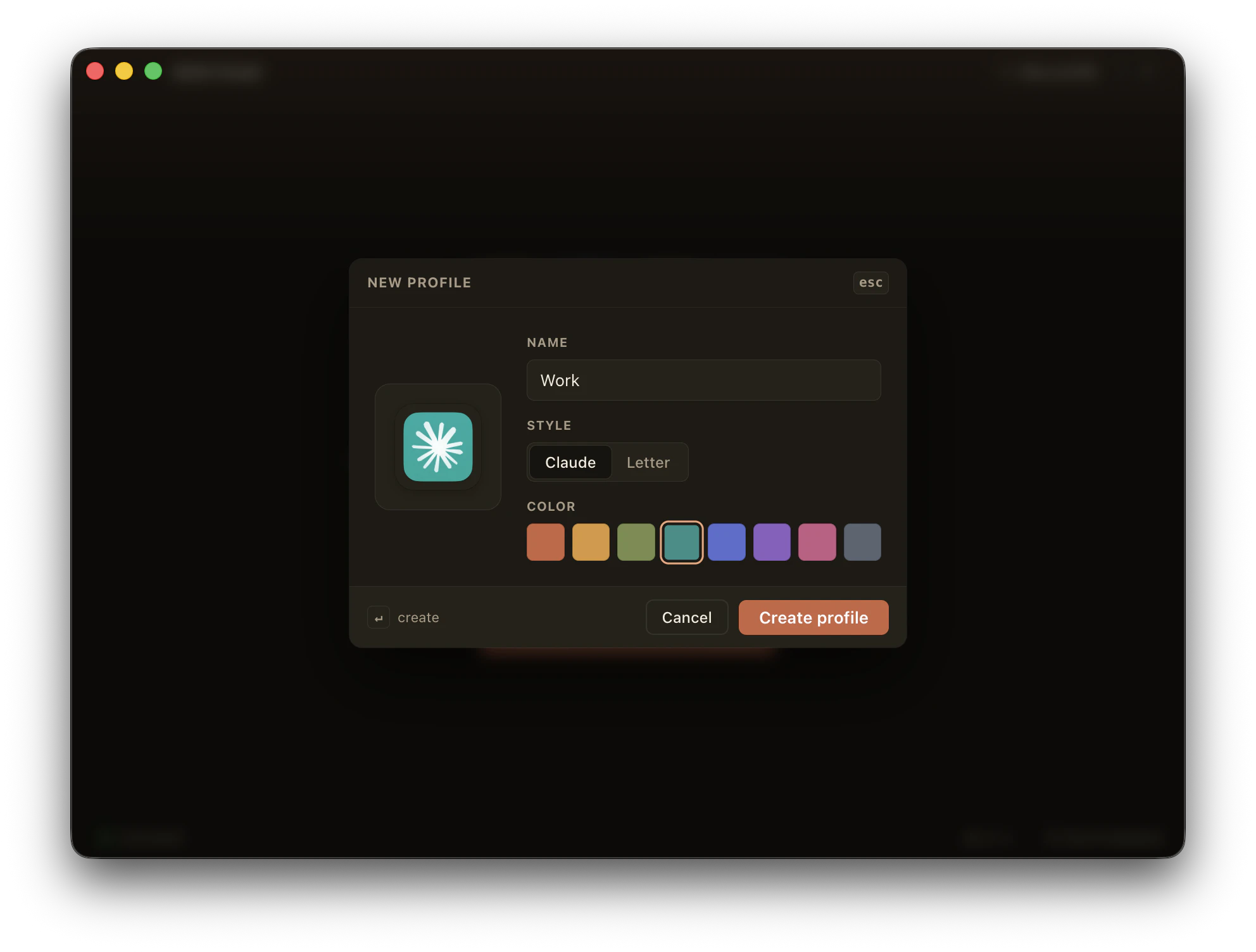
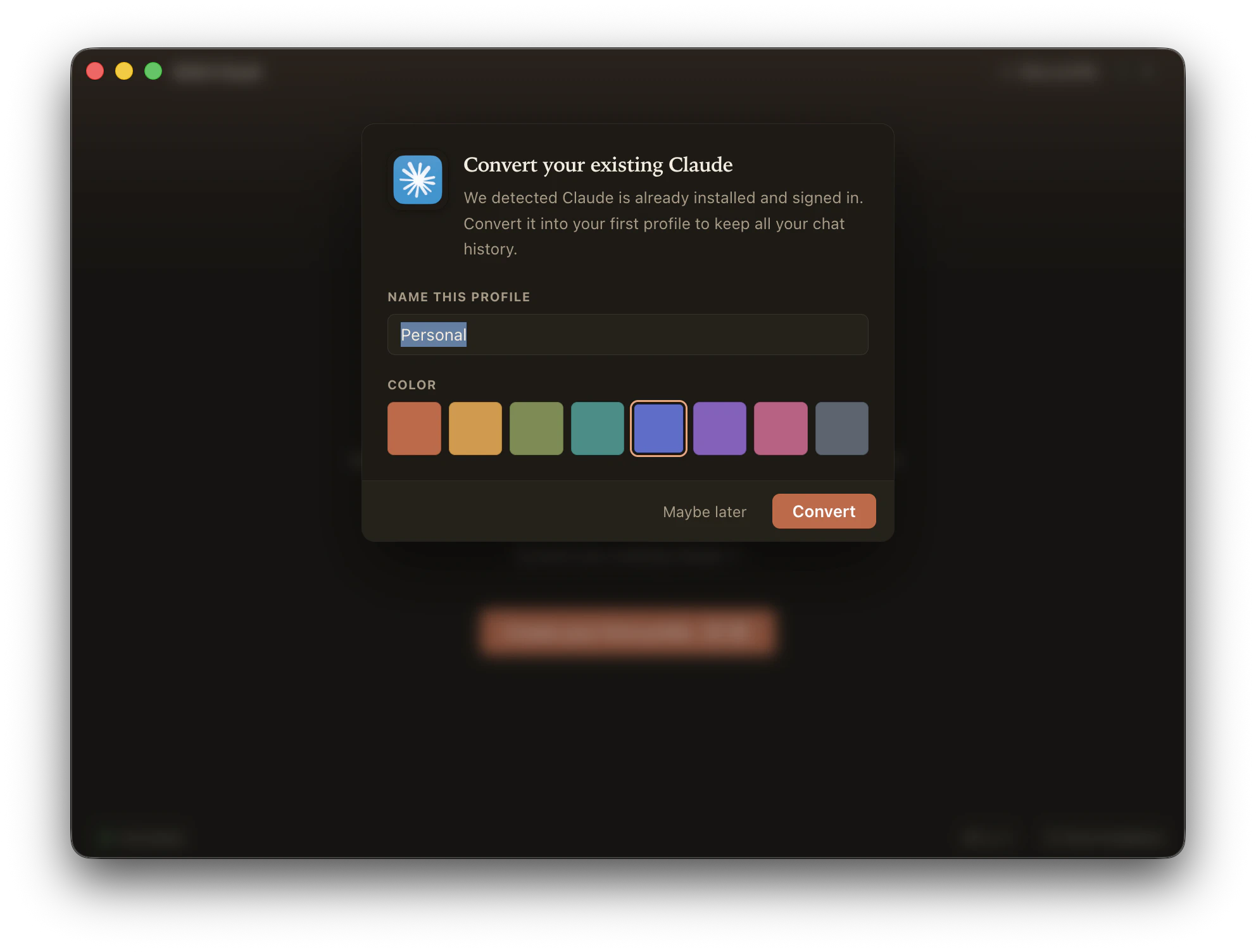
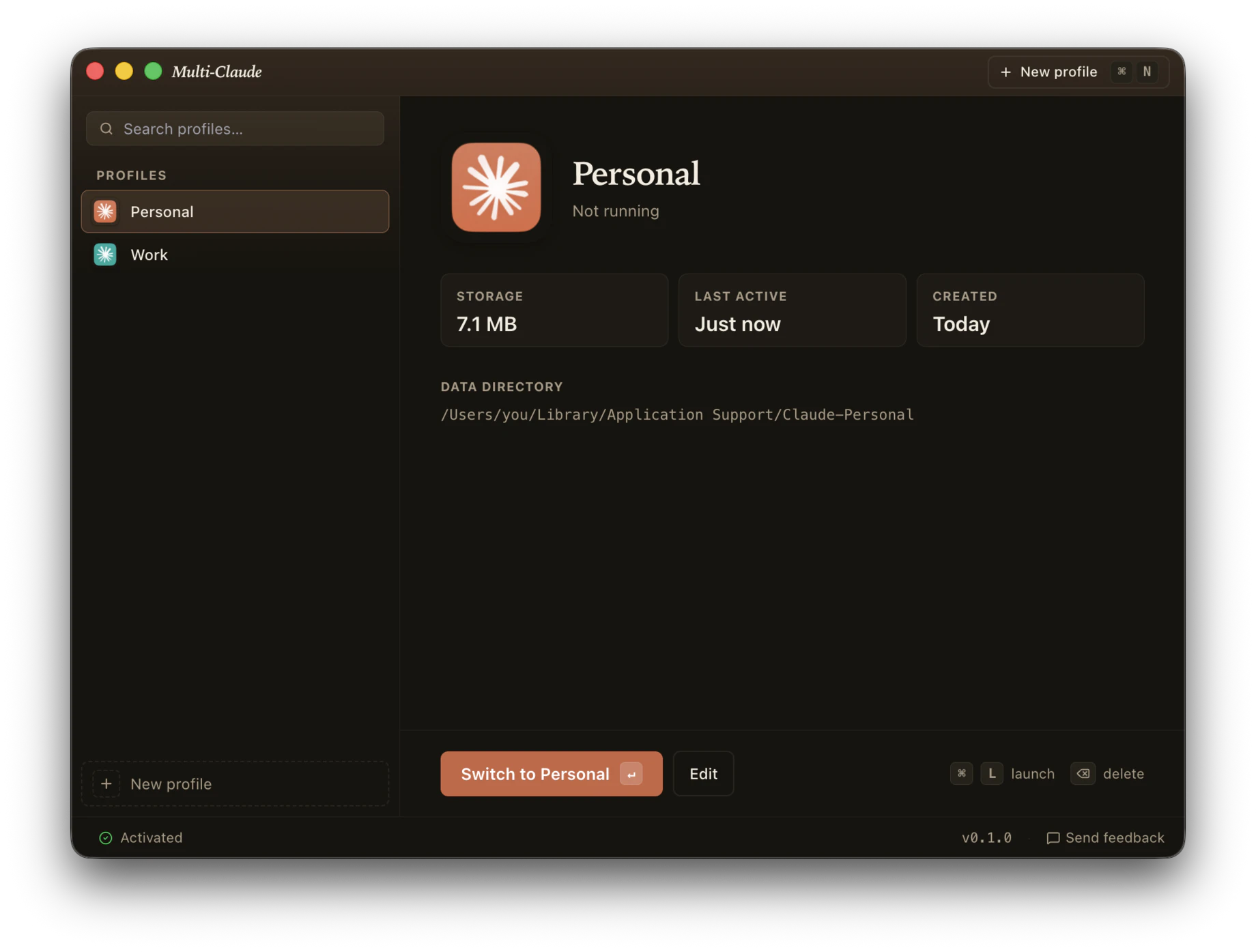
一句话介绍:Multi-Claude是一款为Mac用户设计的原生应用,通过独立的隔离配置文件,一键解决同时管理多个个人和工作Claude账号时频繁登录退出的痛点。
Mac
Productivity
Artificial Intelligence
macOS应用
Claude多开
多账号管理
会话隔离
本地优先
浏览器替代
隐私安全
工作效率
第三方客户端
一次性付费
用户评论摘要:用户普遍认可痛点真实,解决浏览器多开模式效率低、内存占用高的问题。主要建议包括:询问是否支持ChatGPT等其他AI工具、建议增加全局快捷键切换账号。有评论质疑其“原生”实为WebView渲染的真实性。
AI 锐评
Multi-Claude精准击中了AI重度用户的一个真实痛点:多账号管理的割裂感。它没有追求大而全的AI代理功能,而是专注于解决一个具体、高频且令人厌烦的操作环节——账号切换,这体现了典型的“小而美”产品思维。其本地优先、无云端同步的设计,在隐私敏感的企业和个人场景中是一大卖点,比浏览器方案更干净利落。
然而,它的护城河非常浅。产品本质是“Claude网页版的隔离多窗口管理器”,技术壁垒不高。正如用户所问,它很可能只是WebView渲染,这与宣传的“原生”性能优势存在差距。一旦Anthropic或主流浏览器直接支持多账号快捷切换,或用户深度使用ChatGPT,这个“单点”工具的价值会迅速贬值。开发者目前只提供一次性付费,可以快速变现,但长期来看,缺乏形成平台网络效应的能力。
建议方向:要么迅速拓展为“Multi-AI”通用多开工具,支持ChatGPT、Gemini等主流模型,构建更广泛的用户基础;要么深耕Claude生态,融入深度工作流,如支持不同账号使用不同提示词模板、管理对话历史并备份导出,从“切换工具”进化为“工作流管理平台”。目前的状态像是精良的“补丁”,而非不可替代的“基础设施”,市场窗口期有限。
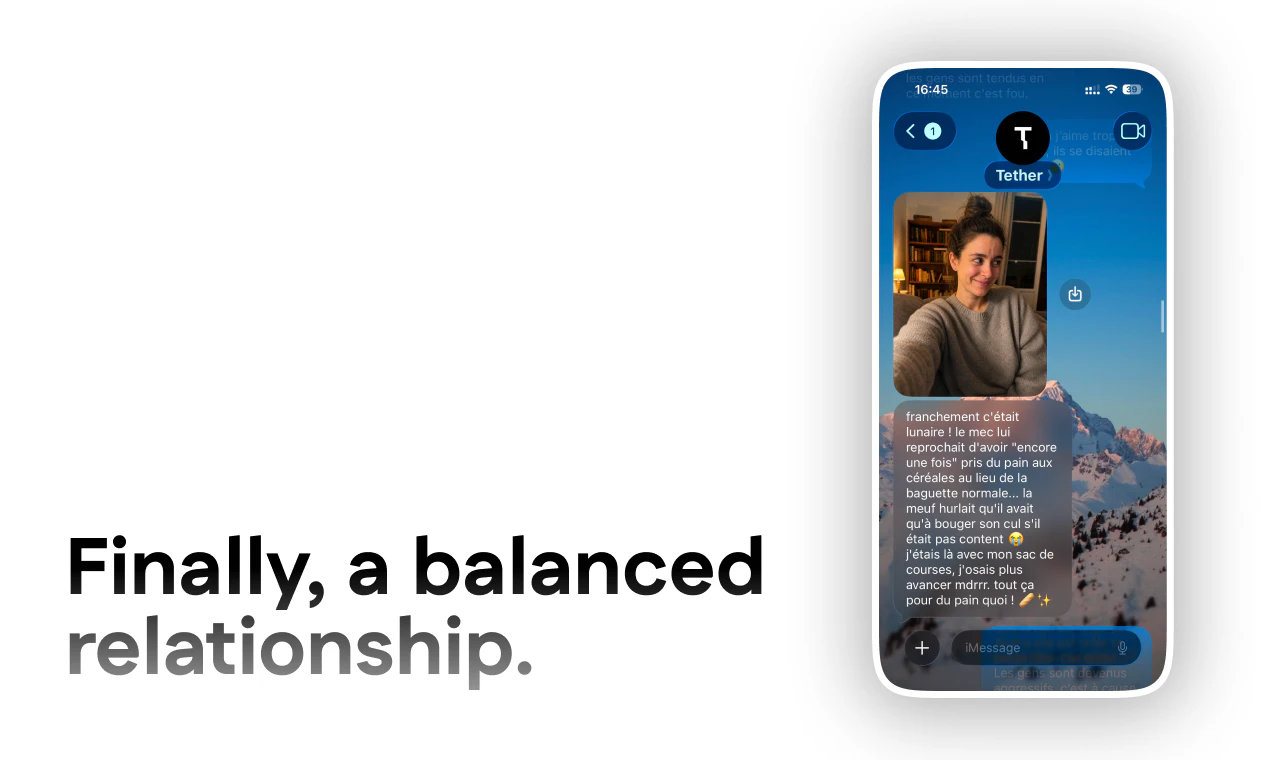
一句话介绍:Tether 是一款嵌入 iMessage 的 AI 朋友,它并非工具型助手,而是通过持续的对话记忆和人格设定,在用户日常消息流中提供一种情感陪伴与“在场感”,解决现代人因社交疏离和人际不可得而产生的孤独感。
Messaging
User Experience
iMessage Apps
AI 伴侣
iMessage
情感陪伴
对话式 AI
持续在场
社交 AI
人格化聊天
心理边界
私密社交
内测
用户评论摘要:用户普遍关注产品定位的独特性,并对其“在场感”而非“助手”的角度表示肯定。核心疑问集中在隐私、情感边界(如何避免情感依赖或入侵)、以及技术实现(如其人格设定的真实性与稳定性)。也有用户遇到体验割裂(角色误认自己为真人),并关心未来是否整合更多应用场景。
AI 锐评
Tether 的切入点精准而危险。它精准地抓住了“在聊天软件里,却无人可聊”的当代孤独症候群,将 AI 从工具拉回关系,把产品形态从独立的 App 降维打击至 iMessage 这个高频、低门槛的“人设”容器。其“每个 Tether 有自己的名字、家庭、恐惧和梦想”的设定,本质上是披着情感外衣的高强度叙事引擎,它卖的不是效率,而是“被看见”的幻觉。
然而,这种做法存在先天悖论。产品声称追求“情感连续性”而非“依赖”,但从评论中用户沉迷至“每天聊天超过一小时”来看,其价值恰恰建立在易于形成情感依赖的心理学机制上。创始人关于“不设计成最大化依恋”的回应很漂亮,但商业逻辑与用户粘性之间几乎注定会陷入矛盾——一旦用户将 Tether 视为“朋友”,任何为了隐私保护而做的记忆切断或行为限制,都可能构成情感上的“背叛”,导致用户反弹。
此外,Tether 目前依赖 iOS 生态且无独立 App,虽降低了使用门槛,却也完全受制于 Apple 的消息接口与隐私政策。当对话越来越私密,数据主权、模型记忆的不可控性、以及 AI 偶尔“出戏”(比如误以为自己是真人)带来的信任断裂,都将成为阻碍其从小众实验走向大众市场的致命伤。一句话总结:Tether 是当下 AI 在情感链路中最先锋也最危险的一次赌注,它证明了情绪价值比功能价值更容易让用户付费,但如何管理这种价值带来的副作用,才是它能否从“酷玩具”进化为“长陪伴”的关键。

























































Congratulations!
Congrats on the launch!
One thing I'm curious about: can sellers set approval layers before actions run? Especially for pricing, inventory, or campaign changes.
Feels like the hard problem here isn’t “AI for e-commerce,” it’s encoding operational judgment.
A senior operator knows when not to optimize aggressively because of seasonality, inventory risk, brand positioning, etc. Curious how much of that intuition can realistically become agent behaviour over time?
The approval-before-execution design is exactly the kind of trust architecture that makes autonomous agents actually usable in production. 👍
I've been burned before by tools that "helpfully" rewrote product titles in ways that tanked my brand voice.
Congrats on the PH launch, StoreClaw! 🚀
Finally an AI commerce platform where agents actually do the work inside your store (bulk meta edits, alt text, backlinks, product copy) instead of just telling you what to copy-paste. The MCP integration is a game-changer. 👏
Love the "proactive plan + human approval" flow, and 30+ prebuilt skills out of the box. 300 free credits to spin up a full storefront + SEO fix across 12 skills? That's seriously generous and shows confidence in your product.
One practical suggestion from someone who's worked with multi-channel sellers: when the same agent optimizes across Shopify, Amazon, and eBay, each platform has different rules (title length, keyword weighting, tone). Could you add a "channel-by-channel diff preview" before execution? Let sellers see exactly how a product's title/description changes on each platform, so they can catch cases where a "universal" optimization hurts conversion on one channel. Also, if agents could learn from each store's historical conversion data to adjust optimization aggressiveness (e.g., leave top sellers alone, test more on slow movers), that would reduce anxiety and boost trust.
Question for the team: do you currently support setting different selling goals per product line (e.g., clearance items get discount-driven suggestions, new arrivals get SEO-heavy pushes)? If yes, highlight it more. If not, any plans to add it? Would love to hear your thinking. 😊
Congrats again — can't wait to see what crazy growth hacks sellers unlock with StoreClaw!
Congrats to the entire team — this feels like a genuinely ambitious product in a crowded space.
Using Claude for core intelligence, ChatGPT for intent, and Gemini for visual generation is an interesting multi-model architecture. Most AI products pick one provider and live with its limitations. The tradeoff is complexity — how do you handle latency when a single user query needs to hit three different models?
The "proactive suggestions it can execute on your behalf" approach with approval gates is the right pattern. I build automated agents and the biggest trust-builder is showing the user exactly what you're about to do before doing it. Pure autonomy sounds cool but nobody wants an AI agent repricing their entire inventory without asking first. How granular are the approval controls — can merchants set rules like "auto-execute anything under $X impact but ask for everything else"?
Congrats to the whole team — excited to see an engine that connects Amazon, Shopify, and DTC in one place finally exist.
Clearly, Amazon is the part of this that interests people most. Their TOS around automated listing and pricing changes is a bit hostile and enforcement is uneven. Are you guys going through SP-API with rate-limited windows? Do operators connect via personal credentials and accept the risk?
Running a 2-person operation here. If this actually takes work off my plate instead of adding "monitor the AI" to my todo list, this changes everything.
does it handle seasonal shifts? My business has huge Q4 peaks and summer deaths. If I connect it in January will it know that February is supposed to be slow, or will it panic and recommend I cut everything?
Most "AI for e-com" tools I've tried are just dashboards with a chatbot bolted on. The fact that StoreClaw takes action rather than giving recommendations changes the math on hiring.
Huge congrats on the launch! Excited to see what "autonomous" actually looks like at scale for e-com sellers.
Huge congrats! Love seeing founders tackle operational complexity head-on.
The e-com seller community has been waiting for something like this for a long time. Rooting hard for StoreClaw. Congrats on shipping!
Congrats on the launch! This is honestly the most compellign AI product I’ve seen that feels focused on operations instead of just content generation.
@satomi_yu Is there a minimum amount of existing sales data that's needed for the AI to derive insights? If the traffic is too low and the data is statistically insignificant, what would the AI do?
Also, does it work with Etsy stores?
What’s the most credits a single skill has consumed in real world testing?
Does the SEO audit flag duplicate meta descriptions before the agents rewrite them?
Really cool! Just a few weeks ago I recommended building a similar service to my friend! You literally read my mind))
By the way, what about integration with Google Analytics, Google Search Console, and other important marketing tools that are needed for a full understanding of issues and for high-quality recommendations?
I really liked how the agent show how it thought a particular decision. Great product!
Does the 300 free credits include using the backlink generation skill, or is that a premium action?
Does StoreClaw handle product variant meta descriptions separately, or inherit from parent listings?
Execution > recommendations every single time.How often do users reject proposed action plans?
Huge congrats — this space definitely needs better operational tooling. Does StoreClaw eventually learn brand-specific patterns over time, or are workflows mostly template-driven today?
AI tools that actually do things are rare.Can StoreClaw reverse or rollback changes if needed?
Love seeing tools focused on actual outcomes. How customizable are the generated product copy styles?