PH热榜 | 2026-05-21
一句话介绍:Tycoon AI 让你以“AI首席执行官+10+专业智能体”的架构,零代码、零配置搭建一家一人公司,将模糊目标(如“10倍流量”)转化为可执行任务并自动推进,专门解决独立创始人缺乏团队执行力的痛点。
Marketing
Artificial Intelligence
Tech
用户评论摘要:用户普遍赞赏概念,但对“AI评审AI”的闭环膨胀风险提出质疑;技术问题集中:服务器过载、任务队列失败、信用额度无法使用、Work Pod频繁HTTP 402报错;多位用户关注审批机制是否真正能守住战略边界,以及系统能否长期保持上下文一致性和个性化质量偏好。
AI 锐评
Tycoon AI的架构确实优于市面上多数“一个Agent加个Title就号称AI公司”的包装货——让Astra扮演CEO角色,对CMO、CTO等专业Agent进行调度和审批,这解决了一个真实痛点:独立开发者虽然能用Claude或Copilot单点提效,但缺乏一个“懂上下文、敢拍板、会追进度”的中间管理层。HeyBoss和SkillBoss的落地数据也证明这套模式并非空中楼阁。
但产品的致命隐患在第一波真实用户反馈里已经暴露:一方面,稳定性完全不达标。服务器过载导致任务死循环、Work Pod持续返回402、余额扣了却无法执行,一个“承诺零配置开箱即用”的产品在首次体验中连环翻车,这在Product Hunt这种高信任、高预期的社区等于自杀式亮相。用户花$50-$1500买的是“跑起来”的确定性,不是“看CEO聊天记录”。
更深层的问题是“LLM评审LLM”的信任边界。评论中那个6点赞的问题一针见血:当Astra去review CTO写的代码或CMO写的营销方案时,它背后是另一个LLM的“乐观认同”,还是真实通过了CI测试、投放ROI指标?如果是前者,那Astra只会成为一个更花哨的“点头总裁”,创始人的审批负担不会减轻,反而会被虚假信心拖入更深的坑。产品演示视频再好看,也替代不了这个核心闭环被证伪的风险。
诚然,创始人Xiaoyin对“审批边界”的设计思路(低风险自主执行、战略/发布/支出层面必须报批)是成熟的,但产品目前明显还没跑通这条线——用户的需求、质量偏好、战略记忆是否真的能被Astra学习并持续一致?从今天断连的服务器和卡死的任务池来看,AI CEO本人可能先需要解决“网站运维经理”的问题。建议所有考虑付费的用户,先等两周,等他们真的把基础工程稳定性修好,再谈AI管理革命。
一句话介绍:Mintlify Workflows 通过预置自动化流程,在代码合并或产品更新时自动同步、修复和翻译知识库,解决文档因产品迭代过快而频繁“腐烂”的维护痛点。
Notes
Developer Tools
Artificial Intelligence
知识库自动化
文档同步
AI写作
开发者工具
SaaS
产品更新日志
内容翻译
SEO优化
代码集成
团队协作
用户评论摘要:用户普遍认可“PR合并后自动更新文档”的设计思路,并发现约20%的代码变更本应附带文档更新。核心质疑集中在信任边界:AI自动生成的文档若出现错误(尤其是API引用),谁来兜底?用户建议增加人工审核层(如暂存区)和失败可见性,以防悄然传播错误信息。
AI 锐评
Mintlify Workflows 的巧妙之处在于,它把“文档维护”这个隐性管理问题,转化为一个可编程的自动化管线。从表面看,它节省的是人力;从深层看,它解决的是“所有权问题”——文档之所以腐烂,往往不是没人会写,而是没人认领那个枯燥的更新循环。
产品选择的切入点很精准:代码库同步、断链修复、翻译、品牌语气检测。这些都是高度模式化、AI替换风险低(因为边界清晰)的任务。但评论中暴露的核心矛盾不容忽视:当自动化从“辅助草稿”升级为“直接发布”,信任危机就会爆发。API文档里一行错误代码造成的后果,远比一篇软文跑调严重得多。
真正决定Mintlify Workflows上限的,不是它自动化的广度,而是它处理“不确定更新”的深度。目前团队承认,部分工作流(如翻译)可自动合并,而代码同步类仍需人工审批。这种“功能分层”是务实的,但也意味着它并未真正解决文档自动化的终极难题:如何在无人看管时,让机器自己判断“这个变更是否需要人类确认”?
长远看,最危险的并非技术失灵,而是“自动化漂移”——多个工作流相互叠加,导致文档的语气、结构、甚至事实依据逐渐偏离原始意图。如果Mintlify不能建立一套长期的“文档熵增监控机制”,而只是不断塞入新的预置工作流,那它最终只会制造出更多、更隐蔽的错误,而非真正可信的知识库。
一句话介绍:Google Antigravity 2.0 是一款独立的桌面应用,让开发者能像调度Cron任务一样,在后台并行编排多AI智能体,摆脱“提示-等待-响应”的循环束缚,实现生产级智能体工作流。
Task Management
Developer Tools
Artificial Intelligence
AI智能体编排
多智能体并行
后台任务调度
开发者工具
Google AI Studio
Firebase集成
Android开发
工作流自动化
智能体基础设施
用户评论摘要:用户普遍认可并行子智能体和后台调度是核心突破,认为其从“辅助”转向“基础设施”。主要疑问聚焦于:并行智能体间共享上下文与状态同步的冲突机制;长时间运行任务的上下文窗口溢出与断点恢复;后台自动化所产生的工作痕迹与可审计性;以及独立于IDE后,是否意味着不再需要接触代码。
AI 锐评
Antigravity 2.0 最犀利的动作,不是功能迭代,而是品类重塑。当Cursor们还在卷谁更懂你的代码补全时,Google直接把智能体从IDE中剥离,赋予它操作系统级别的后台常驻与调度能力。这等于向行业宣告:未来的开发者不是“提示工程师”,而是“智能体运维师”。
产品真正的价值在于,它切中了当前AI编程工具的致命伤——虽然能写代码,但依然需要你盯着它写。Antigravity 2.0 引入了时间维度(后台调度)和空间维度(并行子体),将AI从会话式工具变成了流程化基础设施。这对于复杂项目、跨工程测试、以及非同步协作的团队来说,是效率的指数级提升。
但质疑同样尖锐:并行智能体引发状态冲突、上下文丢失、审计缺失,这些问题在评论中反复出现,暴露出产品在“编排层”之上的“治理层”尚显单薄。若不能提供清晰的执行快照、冲突检测和回滚机制,后台的“自主性”将迅速变成“灾难性”。此外,完全去IDE化,也意味着它必须直面Claude Code和Codex在上下文感知和实时协作上已经建立的壁垒。
一句话总结:Antigravity 2.0 定义了一个新赛道,但能否跑通,取决于它后续如何补上分布式系统中最核心的那堂课——可靠性与可观测性。
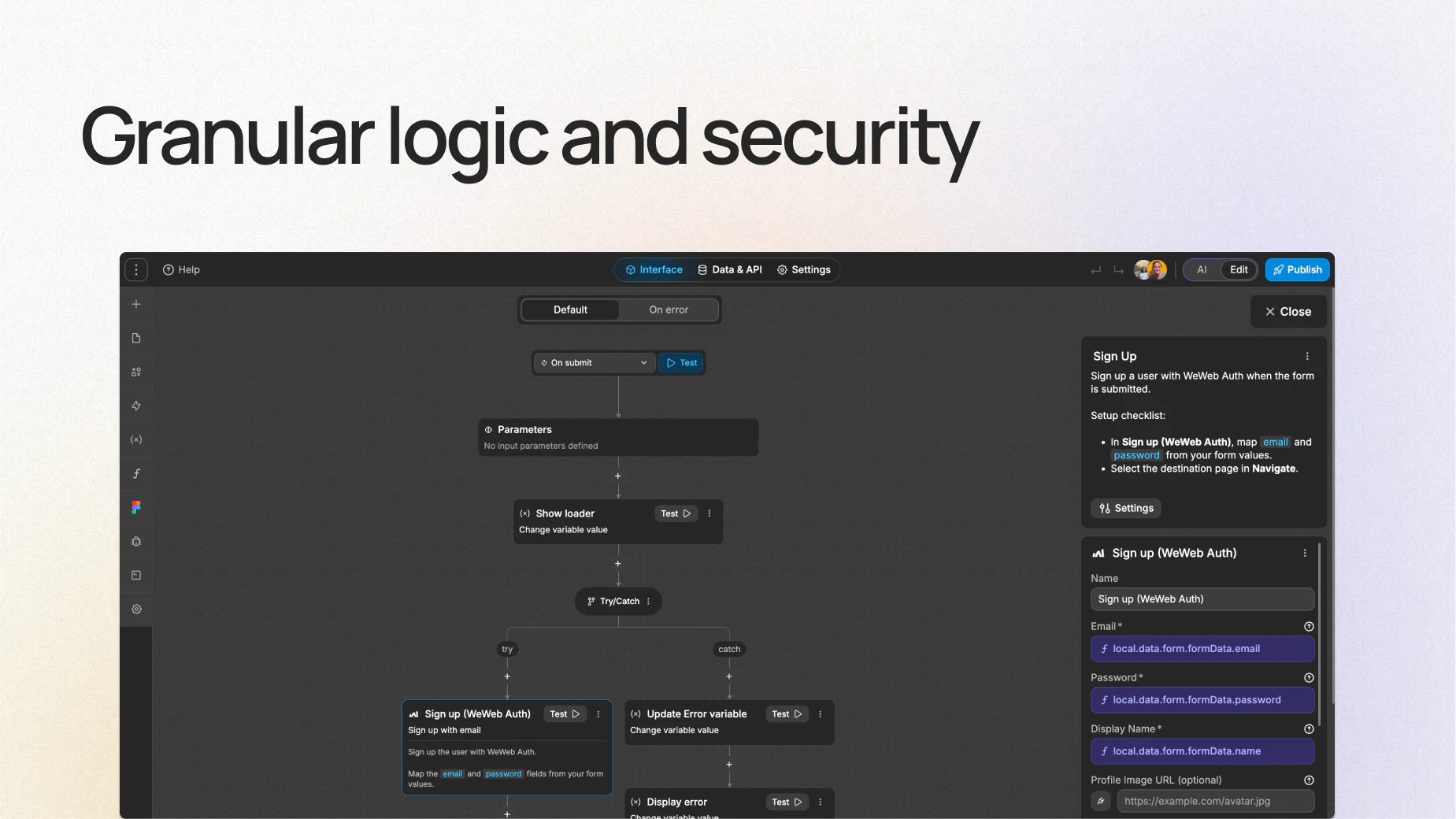
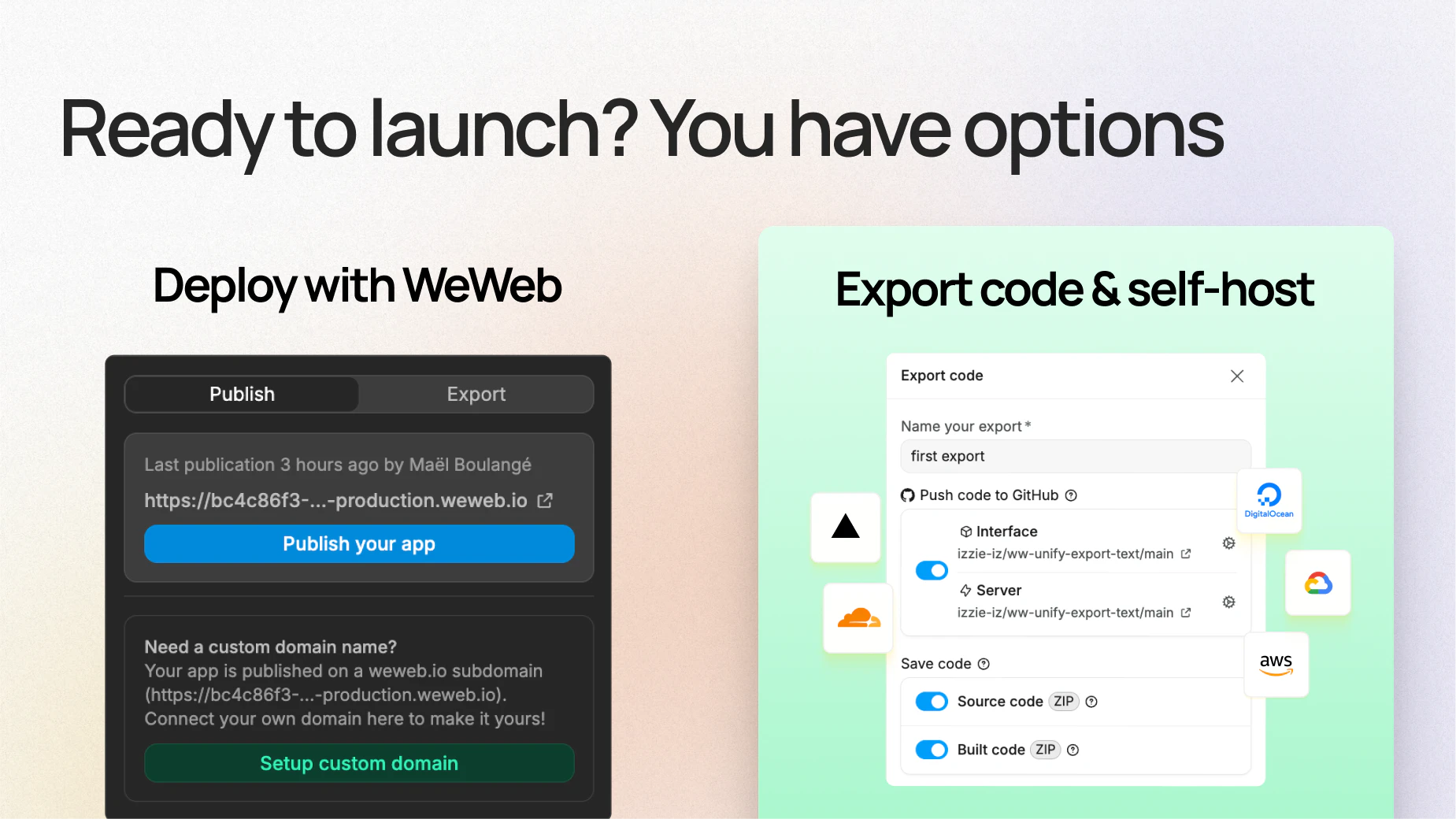
一句话介绍:WeWeb 3.0 是一款让非技术人员通过AI快速生成应用后,仍能使用可视化无代码编辑器进行精细修改和掌控的AI应用构建工具,解决了AI建站“只能生成,无法编辑和掌控”的痛点。
Website Builder
Artificial Intelligence
No-Code
AI应用构建器
无代码编辑器
可视化开发
前端开发
后端开发
拖拽式编辑
SaaS工具
原型设计
快速迭代
Vue.js
用户评论摘要:用户普遍认同AI建站后无法编辑的痛点,称赞WeWeb提供可视化编辑器作为“安全网”。用户询问了如何确保AI生成的后台安全性,以及能否将应用转出至自有GitHub托管,并得到肯定答复。另有用户建议支持MCP协议和自有模型导入。
AI 锐评
WeWeb 3.0精准地切入了一个行业普遍但未被很好解决的痛点:AI生成内容的“不可编辑性”。当大多数AI应用构建器停留在“炫技式”的Demo生成阶段时,WeWeb选择了一条更难但更有价值的路——将AI的速度与无代码编辑器的控制力深度结合。其“可理解、可修改、可掌控”的理念,本质上是对当前AI开发范式的一次纠偏,它承认AI是强大的起点,而非终点。
从技术角度看,WeWeb生成标准的Vue.js SPA和Node.js后端,并支持导出至GitHub自主托管,这极大地降低了厂商锁定风险,对开发者友好。这种开源性策略,使其区别于那些依赖私有框架的“黑箱”工具,更具专业性和可信度。产品成功的关键在于对“后AI生成阶段”(即那个让非技术用户束手无策的“80%节点”)的攻克,通过可视化编辑器让用户理解逻辑和数据结构,这是真正赋能非技术用户的核心。
然而,挑战同样显著。一位用户提出的后台安全问题非常犀利:当AI自动化构建涉及支付、数据库和第三方API时,缺乏技术背景的用户如何确保代码层面的安全性?这不仅是WeWeb,也是整个AI+无代码领域需要严肃回答的问题。产品必须内置安全审计和风险预警机制,否则快速构建出的只能是充满漏洞的“美丽废物”。此外,产品未来的竞争力在于其底层AI模型的迭代能力和对MCP、自定义模型等高级功能的支持。总体而言,WeWeb 3.0不是一个完美的成品,而是现阶段最具诚意的“AI+无代码”实践范本,其后续在安全性和生态开放性上的演进,将决定它能否从“好用的工具”跃升为“新一代应用开发的基石”。
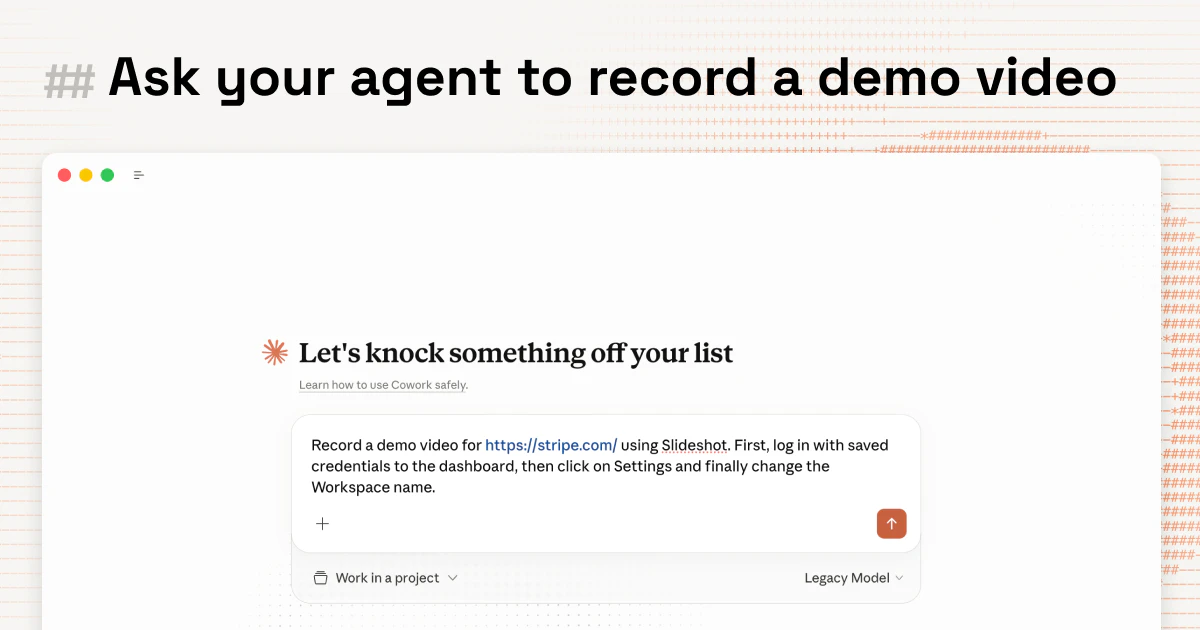
一句话介绍:Slideshot是一款通过AI代理自动录制产品演示视频的工具,让用户无需手动录制和剪辑,即可快速生成带缩放、光标特效和开场动画的精美演示视频与GIF。
Productivity
Developer Tools
Marketing automation
AI演示录制
产品视频制作
代理驱动录制
MCP集成
视频自动剪辑
产品营销工具
无代码演示
GIF生成
工作流自动化
用户评论摘要:用户普遍认可解决“功能上线快但演示制作慢”的痛点。主要提问:能否处理多步骤和认证流程?能否控制叙事节奏?编辑是否需手动?建议增加故事板功能。开发者回应支持多页录制和密码认证,未来计划加入AI叙事编辑和配音。
AI 锐评
Slideshot切入了一个微妙但真实的“效率断层”:当AI代理将功能开发速度拉到极致,功能演示的生成却仍停留在石器时代——手动录制、剪辑、加特效、转GIF,整个过程线性且耗时。它没有试图做另一个Screen Studio或Loom的竞争者,而是通过MCP协议将自己嵌入现有的AI工作流(Claude、Cursor等),让“开发代理”兼任“营销代理”,这步棋走得非常聪明。
但本质问题在于:Slideshot目前解决的更多是“效率”而非“质量”。从评论反馈也能看出,它擅长产生“干净、带特效的演示”,但缺乏叙事意图——一个优秀的演示视频,70%的价值在于怎么讲、强调哪部分、省略哪些细节,而不是纯动作回放。开发者意识到需要加故事板、配音甚至AI脚本,但这些都还停留在路线图里。一旦加入,才真正从“自动录屏工具”升级为“自动化营销内容生成器”。
另一个潜在风险是:演示视频的“真实性”与“剧本感”之间的平衡。完全由AI驱动的操作,容易产出一段精美却缺乏“人味”的演示——而很多销售、客户成功场景中,客户恰恰需要看到“一个真实用户的操作节奏”来建立信任。从评论看,部分用户对“最佳节奏”的需求就暗示了这一点。
定价上用按量付费而非月费订阅,对个人开发者和小团队很友好,但长期看,如果使用频繁(比如每周更新演示),成本可能反而不如固定订阅可控。当前阶段,对“需要快速批量产出演示、不太在意叙事深度”的产品团队来说,这是一个可行的效率杠杆;但对追求“有说服力”的销售演示和客户故事,短期内仍需人工介入。
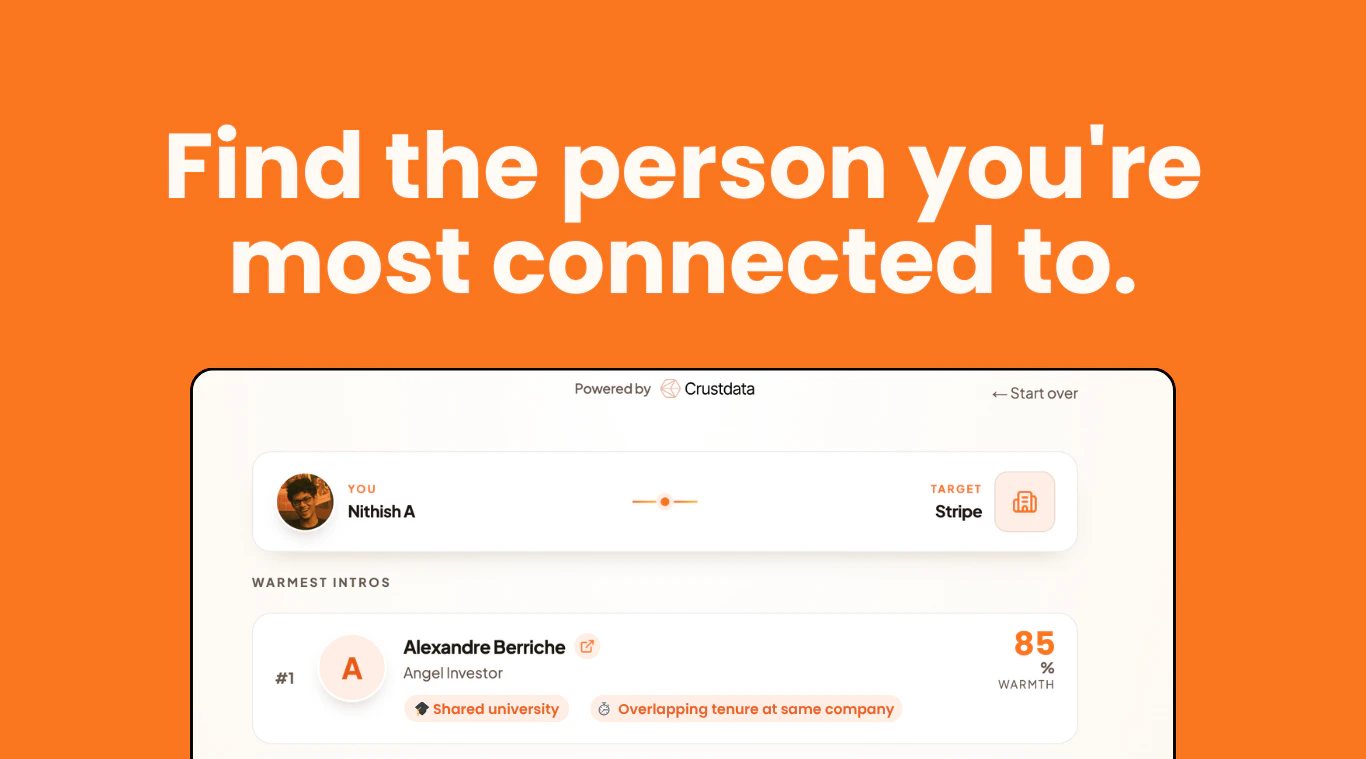
一句话介绍:WarmIntro通过分析用户LinkedIn资料与目标公司员工的背景重合度(如校友、前雇主、同城、同部门等),自动生成“温暖指数”排名,帮助用户找到最自然的切入点,将冷接触转化为有共同话题的破冰对话。
Sales
Marketing
Tech
社交媒体销售工具
B2B获客
人脉匹配
招聘工具
投融资对接
背景重合分析
LinkedIn工具
企业关系图谱
智能化触达
职场破冰
用户评论摘要:用户普遍认可产品价值,指出小bug已被快速修复。核心诉求集中在功能扩展:批量上传公司CSV导出匹配名单、整合邮件验证与自动触达流程、增加公共部门与创作者场景支持。部分用户担忧算法权重是否透明,以及AI生成“伪温暖”可能导致冷骚扰升级。
AI 锐评
WarmIntro切中了一个真实且昂贵的痛点:Cold outreach的转化率正在急剧下降,而“强关系”推荐依然是商业社交中效率最高的杠杆。该产品没有停留在简单的“校友查找”,而是引入了重叠任期、同部门、同城等多维信号进行加权排名,逻辑上比LinkedIn自带的“校友搜索”更精细,也更接近真实人际关系的评估方式。
然而,产品存在两个结构性风险。其一,数据来源的时效性与完整性。WarmIntro依赖Crustdata的API,而Crustdata本质上是对LinkedIn等公开数据的爬虫聚合,这会面临LinkedIn的反爬和法律合规风险,且部分中小公司数据可能不准确。其二,工具本身不生产“温暖”,只分析“共同点”——当所有人都能拿到这些匹配结果时,“共同背景”将从破冰点退化为新的垃圾话术模板。评论区中用户对此的担忧并非杞人忧天,这本质上是销售自动化工具的“军备竞赛”陷阱:每一次效率提升都会被市场迅速消化,从而推高下一条“及格线”。
从商业化角度看,产品目前是免费的获客漏斗入口,定位精准。真正有付费意愿的是B2B销售团队、猎头以及BD部门,他们需要的是批量操作、邮件集成和CRM对接,而非单次查询。当前用户评论区集中反映的“批量上传CSV”和“内置outreach功能”恰恰是产品从“有趣的小工具”走向“可依赖的销售基础设施”的关键一跳。此外,对于创投、招聘等高频场景,“温暖路径”的权重模型需要针对不同角色(如投资人看重的是共同投资人还是校友?销售看重是同行业还是同客户?)进行差异化调整,否则排名结果的实用价值会大打折扣。
总结:WarmIntro在概念上做出了漂亮的微创新,但缺乏数据和流程上的护城河。它更像一个“人脉搜索引擎”而非“关系管理平台”。如果停留在工具层面,很容易被LinkedIn、ZoomInfo等巨头复刻,或被内置于CRM中。真正的机会在于,能否在“找到谁”之后,进一步提供“如何说”的个性化建议,并形成“找对人-写对话-发对信”的闭环,否则它只是一个加装了一层“关系滤镜”的爬虫工具。
一句话介绍:Vivaldi 8.0 通过全新的“统一”界面设计,将浏览器所有工具栏整合到一个连续表面上,解决了传统浏览器界面碎片化、自定义自由度低的问题,为追求极致个性化与隐私控制的重度用户提供从头到尾的掌控感。
Productivity
Privacy
浏览器
界面定制
隐私保护
主题美化
无AI追踪
重度用户
垂直标签
布局预设
生产力工具
桌面移动
用户评论摘要:用户高度赞赏新统一设计、布局预设和垂直标签体验,认为这是浏览器定制和生产力的一大进步。开发者强调此版本基于“浏览器适应你”的信念,无追踪、无AI干预,并鼓励社区反馈,现有外观主题可在设置中保留。
AI 锐评
Vivaldi 8.0的“统一”设计看似是UI层的一次审美升级,实则是其坚守小众极客路线的战略加码。在Chrome、Edge等巨头持续用AI和云服务“绑架”用户体验的当下,Vivaldi反其道而行之,将“无AI”、“无追踪”作为核心卖点,并通过对每一个像素的开放控制权来收拢核心用户的心智。这种做法很聪明,因为那些真正在意隐私和自定义的“浏览器重度患者”粘性极高,且具备强大的社区传播能力。
然而,产品经理必须清醒地认识到:**“统一”解决了美观和碎片化问题,但并没有解决Vivaldi最根本的获客难题。** 130票的PH热度侧面印证了它依然是少数人的狂欢。对于普通用户而言,“让浏览器适应你”的门槛过高——“所有工具栏都在一个连续面上”意味着更多选择,也意味着更陡峭的学习曲线。开发者强调“你的规则”,但在大众市场,多数人更希望浏览器开箱即用,而非花半小时研究六种布局。
与其对标Chrome的体量,Vivaldi更应该思考如何将“统一”理念进行有效转化:能否通过AI(注意是帮助用户自定义的AI,而非窥探用户的AI)来简化初始配置?能否在移动端和车机的跨场景一致性上做出真正差异化的体验?否则,这剂“用户决定一切”的强心针,最终只能圈地自萌,无法撼动主流格局。
一句话介绍:Visual Usability Checker 是一款基于AI的Figma插件,在UX设计师无需离开工作流的前提下,通过眼动追踪数据预测用户注意力、发现认知负荷与可用性问题,从而在设计早期验证决策、减少主观猜测和反复返工。
Design Tools
User Experience
Artificial Intelligence
Figma插件
AI设计验证
眼动追踪
可用性测试
认知负荷分析
视觉层级评估
产品设计工具
用户注意力预测
设计决策
UX/UI优化
用户评论摘要:用户主要关注技术实现细节,询问如何基于图像识别特定元素(如人脸)并调用数据库统计来预测注意力。开发者回应称基于先前眼动追踪研究数据。整体评论数量少,无负面反馈或具体使用痛点。
AI 锐评
Visual Usability Checker 本质上是一个“AI可测试性”转化器,它将过去耗时昂贵的眼动仪实验压缩成了一个Figma快捷键。从产品逻辑看,它瞄准了设计决策过程中“直觉与数据”之间的巨大缝隙——这确实是痛点,且痛点足够高频。
但其真正的价值不能神化。它提供的“用户注意力地图”本质上是一个基于统计模型的概率预测,而非真实用户的认知反馈。用“数百万眼动数据点”训练出的模型,擅长预测通用视觉路径(如先看人脸、高对比区域),但很难应对文化差异、用户目标、非常规交互或套壳业务逻辑带来的认知偏移。换句话说,你大概率能比“拍脑袋”更准,但也远不足以替代A/B测试或定性访谈。
技术回答中提到“基于先前眼动追踪研究”,这解释了为何产品迭代速度会受限于数据的覆盖面和时效性。短期内它是一个优秀的“决策备书”和内部说服工具——设计师可以用这张热力图反驳“我觉得这个CTA不够大”;但长期看,要真正站稳脚跟,必须引入更多的行为数据反馈闭环(比如实时埋点、用户路径回放),否则它很容易沦为另一个漂亮的“伪权威”。
产品团队显然懂行业痛点,但值得警惕的是:过早用AI遮蔽了“不确定感”的设计流程,可能让新手设计师过度依赖模型裁决,反而丧失了对用户真实行为的敏感度。
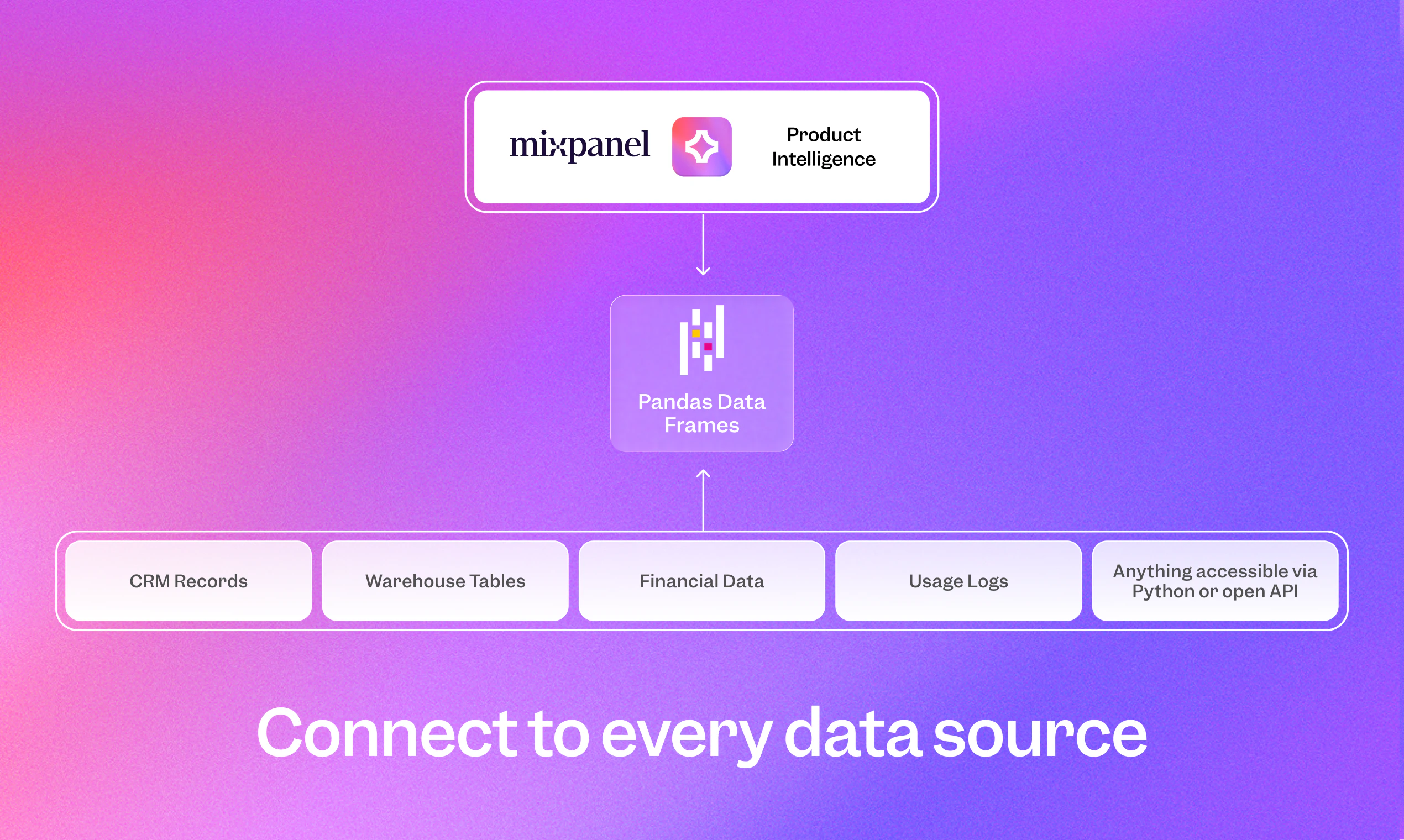
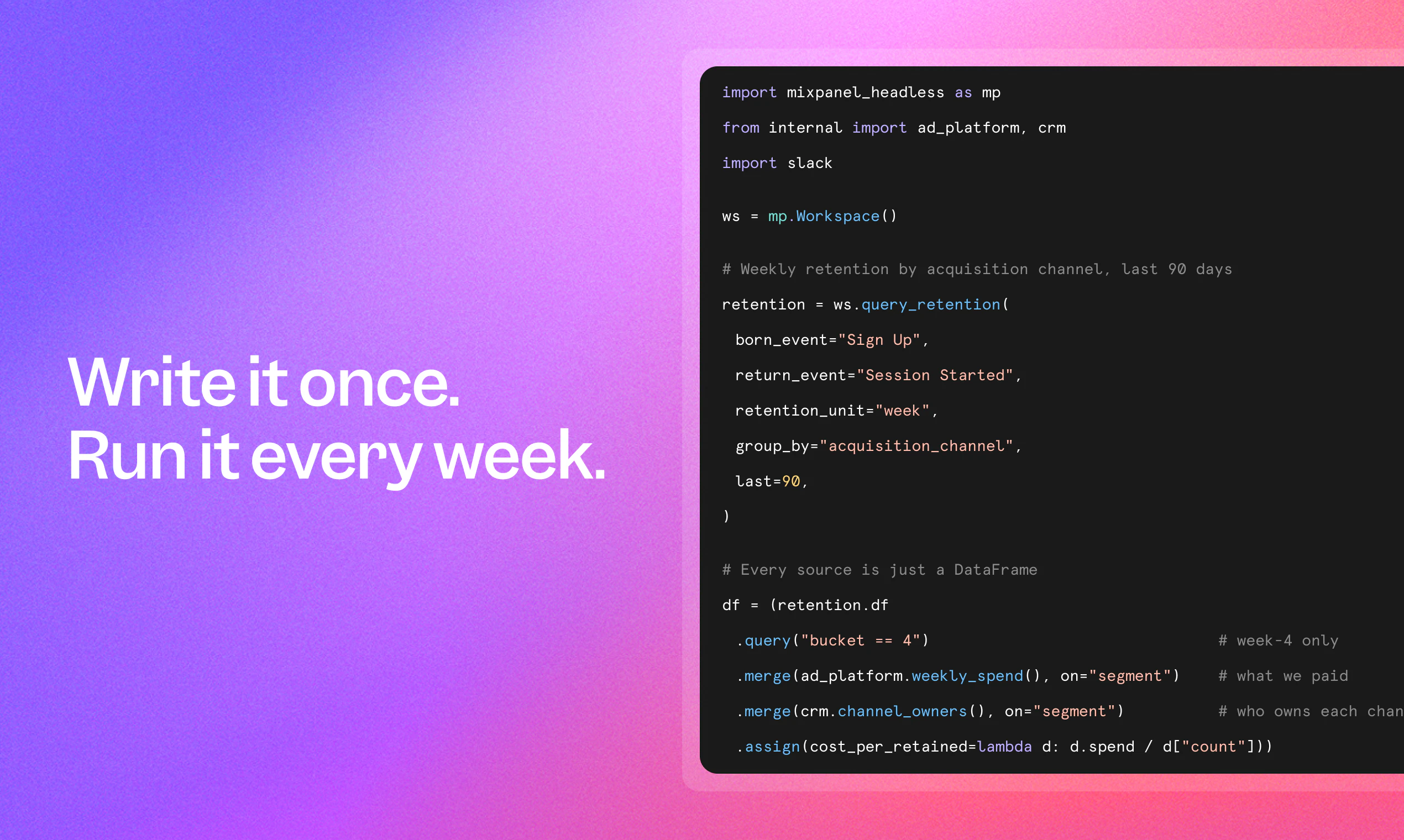
一句话介绍:Mixpanel Headless 是一款Python SDK,让开发者和AI代理无需离开IDE即可通过编程方式访问产品分析数据,将问答式分析转化为可复用的自动化脚本,解决从提问到获取答案之间的效率痛点。
Analytics
SaaS
Artificial Intelligence
产品分析SDK
AI代理
Python工具
自动化报告
用户行为分析
无代码查询
可编程分析
IDE集成
MCP服务器
开发者工具
用户评论摘要:用户关注AI代理生成代码是否可预览后执行(获确认可)。有创始人提出希望代理人每日自动生成产品健康摘要。并质疑为何选择Python SDK而非MCP协议,官方回应称已提供MCP服务器,但Headless更节省工具调用成本,执行更快更廉价。
AI 锐评
Mixpanel Headless的巧妙之处不在于“用AI生成代码”——这种套壳能力早已泛滥——而在于它定义了“可复用的分析证据链”。它将临时性的问答升维成一份可以每周、每天稳定运行的Python脚本,相当于把分析师一次性的洞察固化成了能自我生长的自动化流水线。这精准命中了中大型产品团队的核心痛点:分析工作常常沦为数据抢修,而真正的商业决策需要的是可追踪、可复现、可自动预警的“产品体检仪”。
但产品自身存在两重风险。第一是定位摇摆:既想拥抱AI原生聊天的极简爽感(MCP),又眷恋Python SDK的高度可控与效率——事实证明在评论中已有用户对协议选择产生困惑。第二是生态绑架:它要求团队数据平台必须是Mixpanel,这注定只能服务于存量用户,而无法撬动竞品体系下的新客。更直白的挑战是,普通团队根本不需要“可编程分析”,他们真正需要的是一个能直接给出结论的AI看板。Mixpanel Headless虽然技术优雅,但商业上更像是一个为高级AI agent准备的“鱼竿”,而非多数人想要的“鱼”。
总体来说,这是一次值得敬重的底层能力开放,但产品经理和PLG运营才是它最该讨好的对象,而非广义的“开发者”。其长期价值取决于Mixpanel能否将这种“agent友好”的差异化转化为真实留存率。
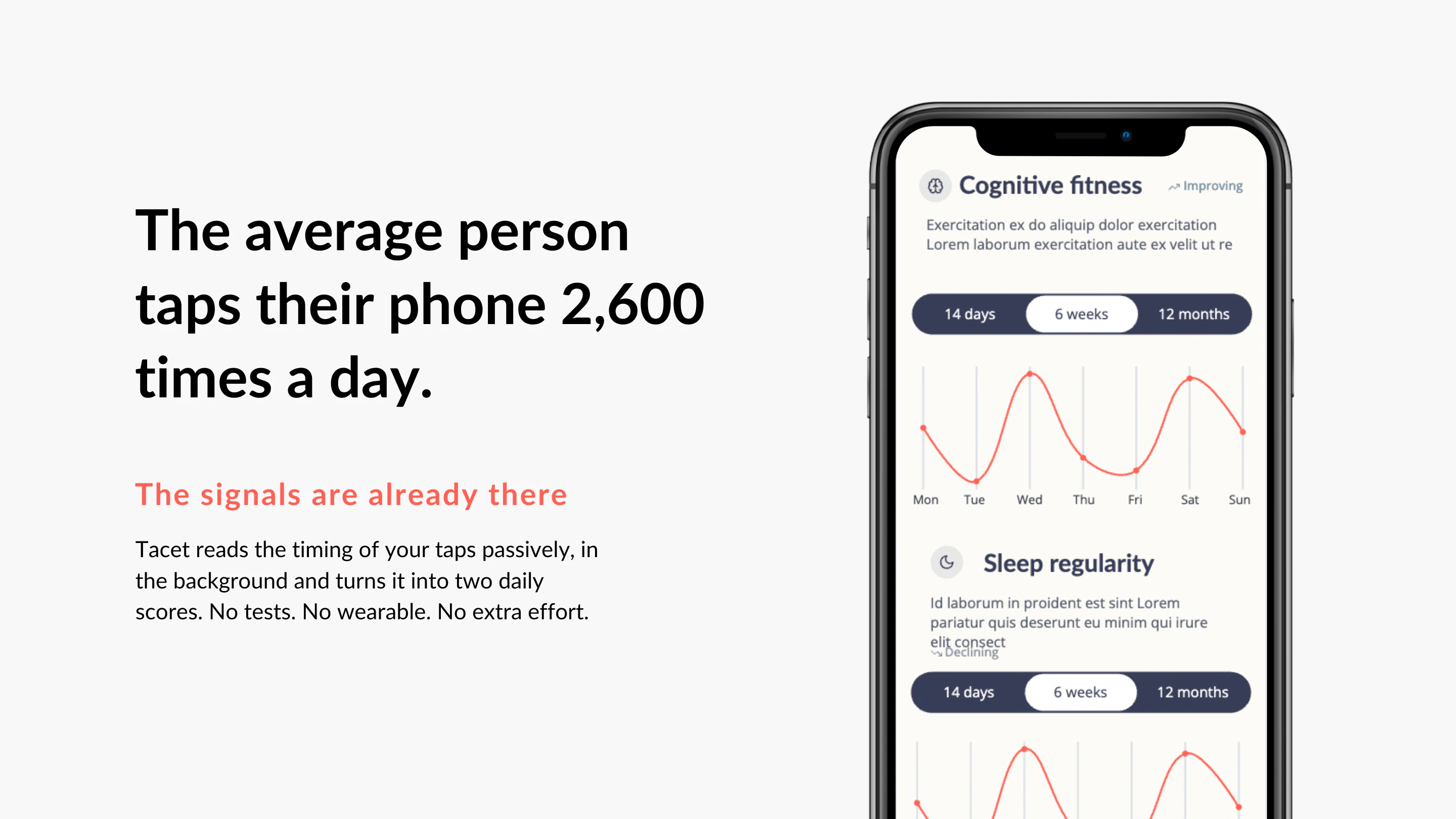
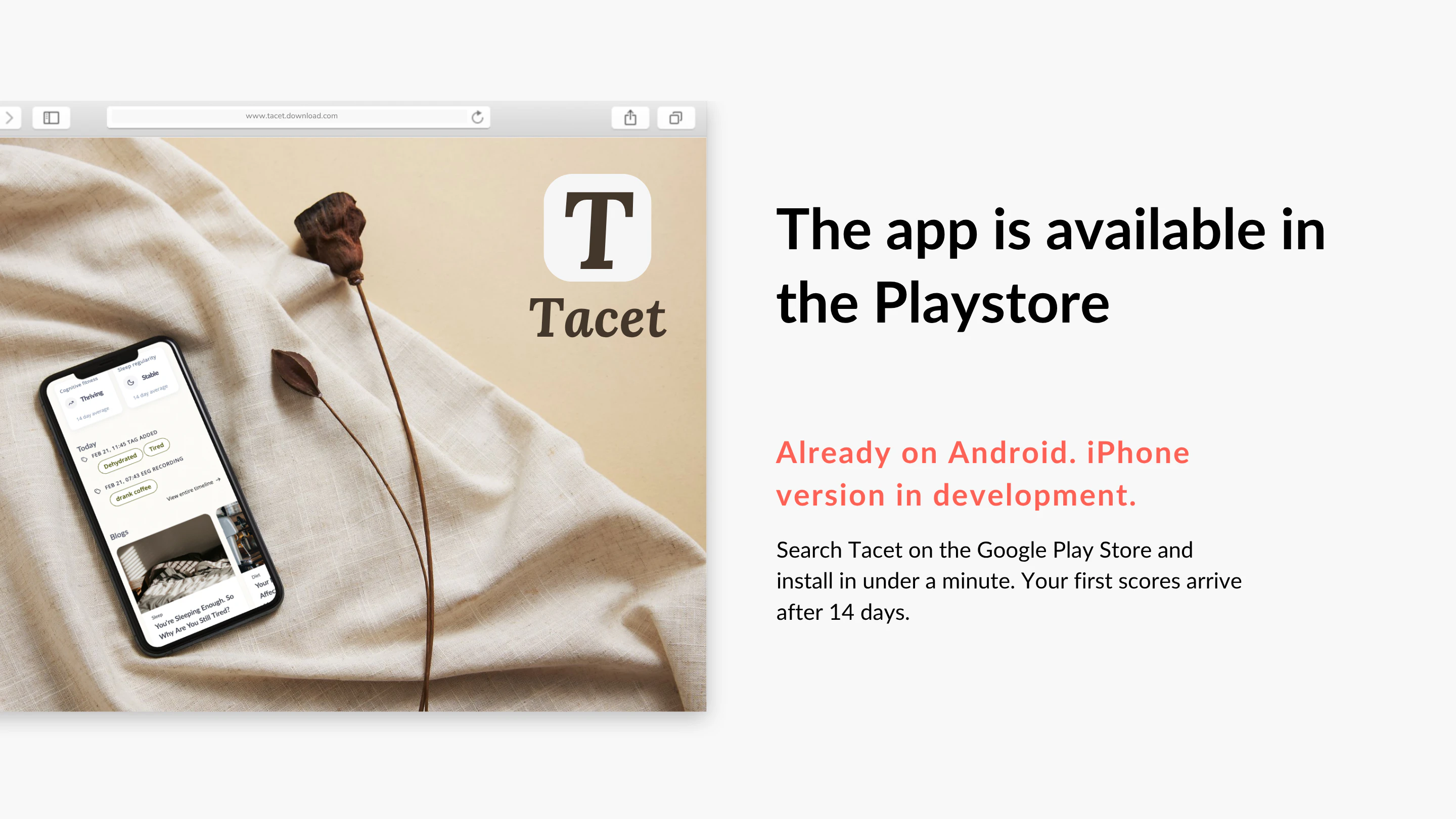
一句话介绍:Tacet是一款利用手机敲击节奏追踪认知健康评分的应用,帮助用户无需昂贵硬件就能日常监测大脑状态与睡眠质量。
Android
Health & Fitness
Productivity
Tech
认知健康监测
脑健康
行为追踪
睡眠质量
数字疗法
神经科学
无感监测
安卓应用
健康科技
数据分析
用户评论摘要:用户核心关注:1) 行为模式如何被捕捉,无需手动开启;2) 认知评分下降是否会引发焦虑,以及如何引导改善;3) 强烈呼吁iOS版本尽快上线,并提供TestFlight测试机会。
AI 锐评
Tacet巧妙地将神经科学论文中的“点击计时术”转化为消费品,其核心价值不在于硬件创新,而在于重新定义了“大脑监测”的门槛——从临床医院的口袋成本降到“点击一下”,从大型设备缩到手机应用。这在产品形态上是一次深刻的去中心化尝试。
然而,这种降维打击也暗藏风险。产品依赖的“敲击节奏”作为生物标记物,虽然学术上被证明与睡眠质量、认知处理速度相关,但“相关”不等于“因果”。用户在评论中担心“当分数下降时怎么办”,恰好点出产品最大的软肋:目前它更像一个“数据展示仪”而非“健康导航仪”。团队虽承诺提供科学文章辅助改善,但这远远不够。一旦用户连续数日看到“不稳定”标签却无从下手,焦虑感会碾碎健康动机,最终导致卸载。
从商业角度看,Tacet的变现路径清晰(订阅制),且用“两周训练基线”制造了粘性。但必须警惕伪科学质疑——毕竟,用“点击手机”推导大脑状态,听起来极易撞上“玄学”防火墙。其真正的护城河应该是:持续兑现临床级验证、对用户行为改善的直接反馈(比如建议“此刻休息10分钟”)、以及当分数持续异常时,无缝衔接专业医疗资源的路径。如果只停留在“好看的数据仪表盘”,它终将被遗忘在抽屉。值得肯定的是,团队来自学术背景且态度真诚,但走出实验室后,他们需要尽快证明:敲击信号不仅“有趣”,更要“有用”。
一句话介绍:CatchAll 是一款将自然语言查询转化为结构化数据集的网络搜索API,帮助数据分析师、情报研究员等用户,从海量杂乱网页中精准提取并清洗出可用于工作流和AI管线的真实事件数据,解决传统搜索引擎只返回链接列表、数据不干净、无法直接使用的痛点。
Developer Tools
Artificial Intelligence
Data & Analytics
网络搜索API
结构化数据集
自然语言查询
数据清洗
事件监控
情报工作流
网页爬取
去重验证
AI管线
NewsCatcher
用户评论摘要:用户肯定其自然语言查询与自定义过滤(时间、语言、地域)功能,如追踪日本政府新能源政策。有用户关心数据提取的可靠性,官方回应称每个结果附带源引用,提取前会聚类验证,并支持用户自定义校验规则,确保可追溯。
AI 锐评
CatchAll 在面对“数据工程老问题”时给出了一个相当成熟的工业级解法。它的核心价值不在于“爬取”,而在于“结构化”——将搜索引擎返回的链接噪音转化为可直接投喂给AI Agent或监控管线的干净事件记录。从融资到监管动态,这种“从网页到数据集”的自动化提炼能力,精准命中了对实时性、准确性和数据准备度要求极高的金融、风控、情报分析场景。创始人背景(五年底层基础设施建设)赋予了产品天然的技术可信度:支持自然语言查询、自定义校验、自动定时推送至Webhook,这些功能组合已超越简单的API工具,更像一个轻量级的数据PaaS。然而,产品真正的硬度仍取决于其底层“去重与验证”算法的实际召回率和准确率——官方虽承诺源可追溯和聚类验证,但面对中文互联网及非英文网站时,处理复杂语义、虚假信息和动态内容的鲁棒性仍需实战场检验。当前2,000免费积分策略巧妙,降低了首次尝试门槛,但若无法在首批用户使用中快速产出“在其他工具上拿不到”的高质量结构化数据,其商业转化会面临挑战。整体而言,CatchAll 是数据冗余时代的一把精密切割刀,但能否成为行业标配,得看它是否能把“一刀切”的通用方案,打磨成能在石油、法律、生物医药等垂域数据沼泽中游刃有余的特种装备。
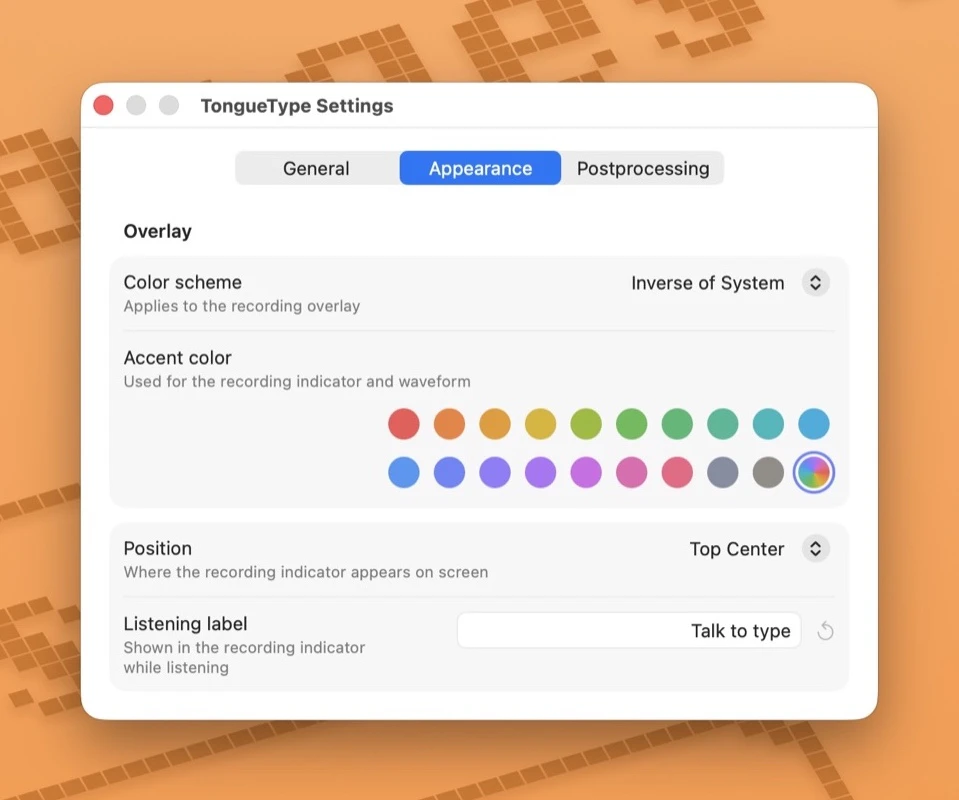
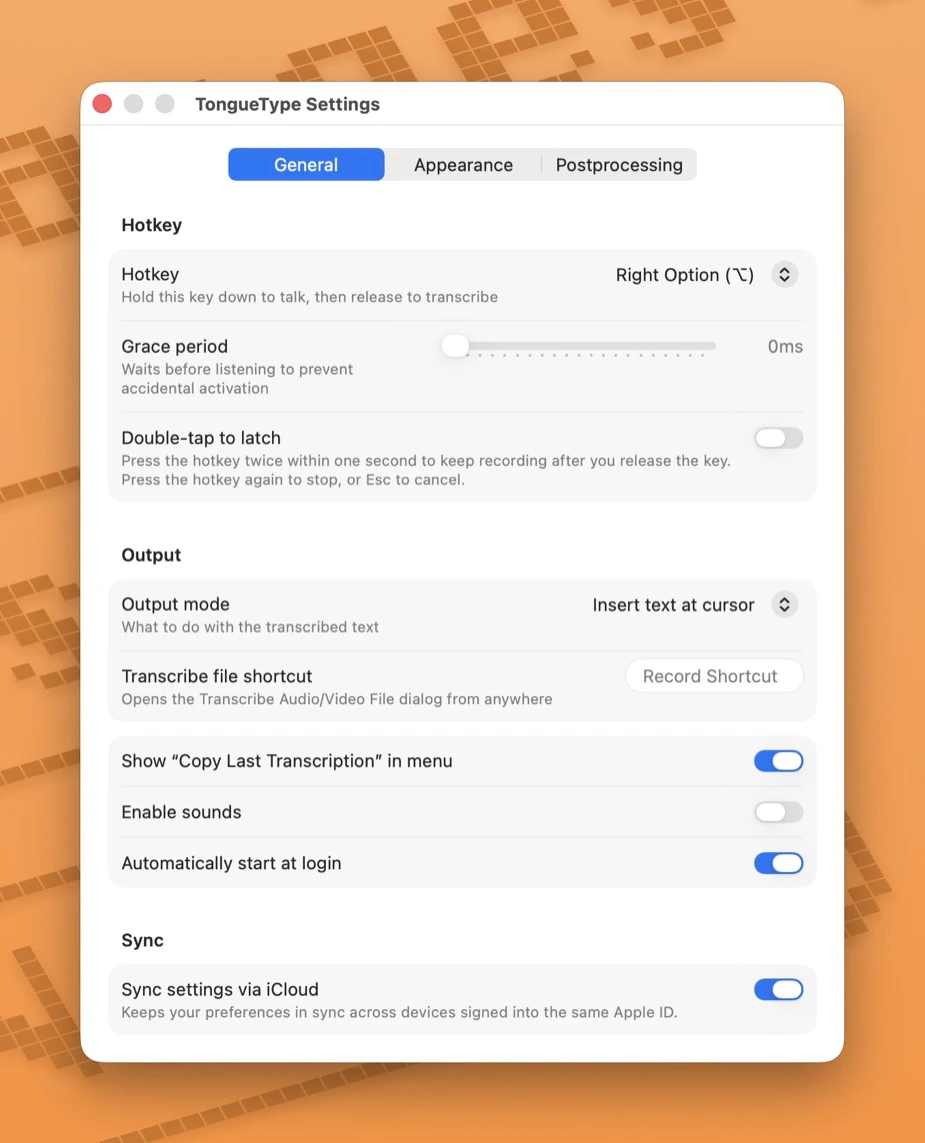
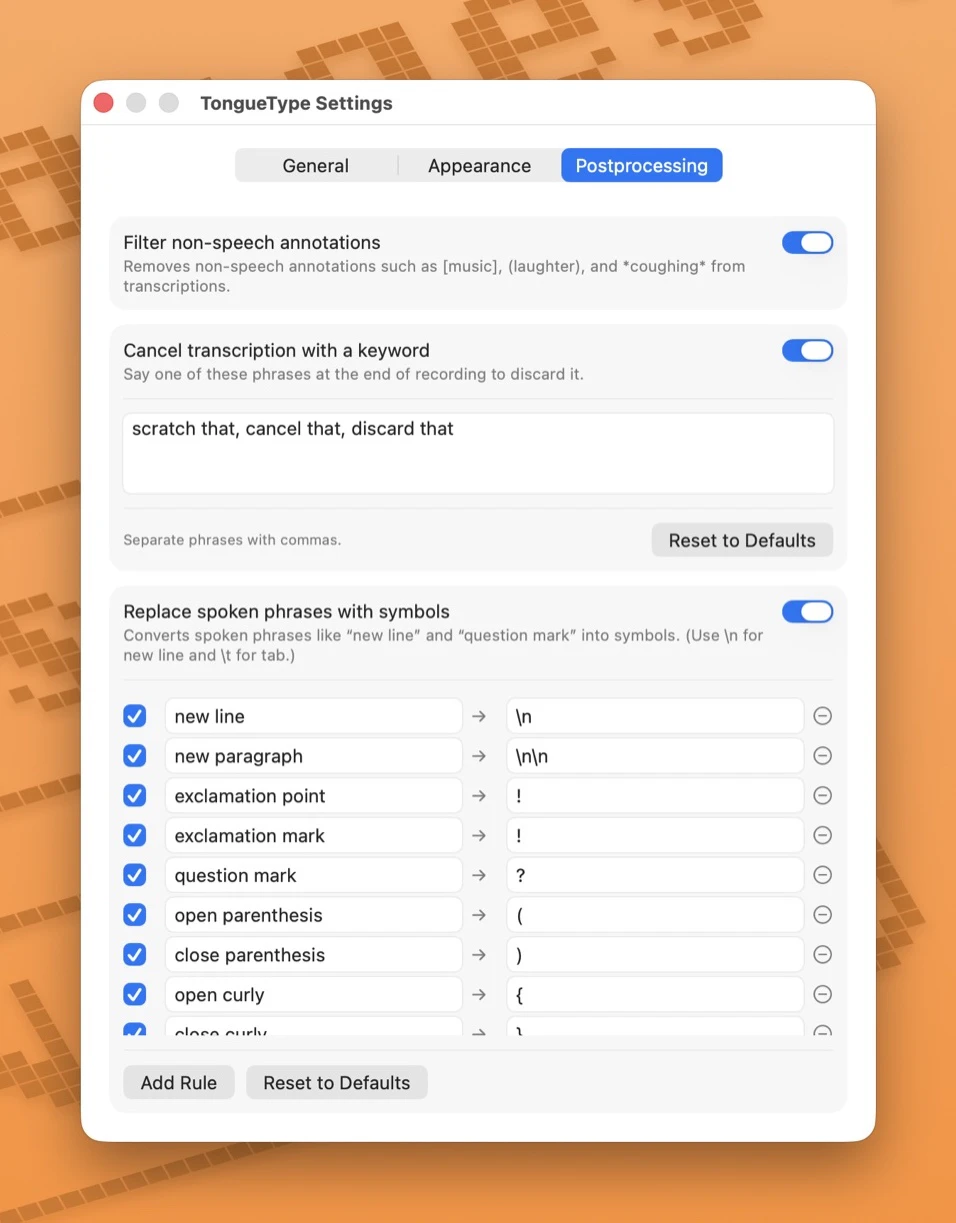
一句话介绍:TongueType是一款专为macOS设计的本地语音听写应用,通过快捷键触发Whisper AI实时转写,让用户在编程、写邮件、发消息等场景中摆脱打字瓶颈,实现“即说即得”的高效文字输入,无需订阅且完全离线。
Productivity
Developer Tools
Apple
用户评论摘要:用户肯定本地化与无订阅组合,但指出听写后“清理成本”高,需不同场景的后置规则预设;询问标点输入方式(如“逗号”、“句号”);希望明确免费与Pro版功能差异,并对30分钟/月限制有顾虑。
AI 锐评
TongueType的走红,本质上是“功能克制”对“订阅疲劳”的一次精准狙击。在AI工具普遍堆砌云端功能、按月收费的当下,它反其道而行:本地模型、无账户、一次性买断。这种极简哲学恰好戳中两类用户:一是对隐私敏感的创作者,二是厌倦“打字→辅助AI→再编辑”繁琐流程的效率党。
但需警惕其风险。Whisper小模型在噪音环境或专业术语下的准确率仍存疑,30分钟免费月限更像“试玩甜头”而非生产力解锁——重度用户可能仍需转向付费版(仅19.99美元),而低价格带是否可持续支撑维护与更新?此外,评论中“清理成本”是痛中要害:听写天然带口语冗余,若后置规则不够智能,反而增加二次纠错时间。若不能提供“语境预设”或“语气保留对比”等差异化功能,它可能沦为“热乎一阵”的效率玩具。
真正价值在于它验证了一种模式:AI垂直工具不必追求“全能云端”,而是要做成“剃须刀片”——本地运行、一碰即用、买断收费。但能否从昙花一现的“好点子”进化为长期依赖的“瑞士军刀”,取决于听写准确率瓶颈能否突破,以及后处理规则能否从“手动替换”进化为“学习用户习惯”。当前它更像一个“有趣的起步”,而非“完美的终点”。
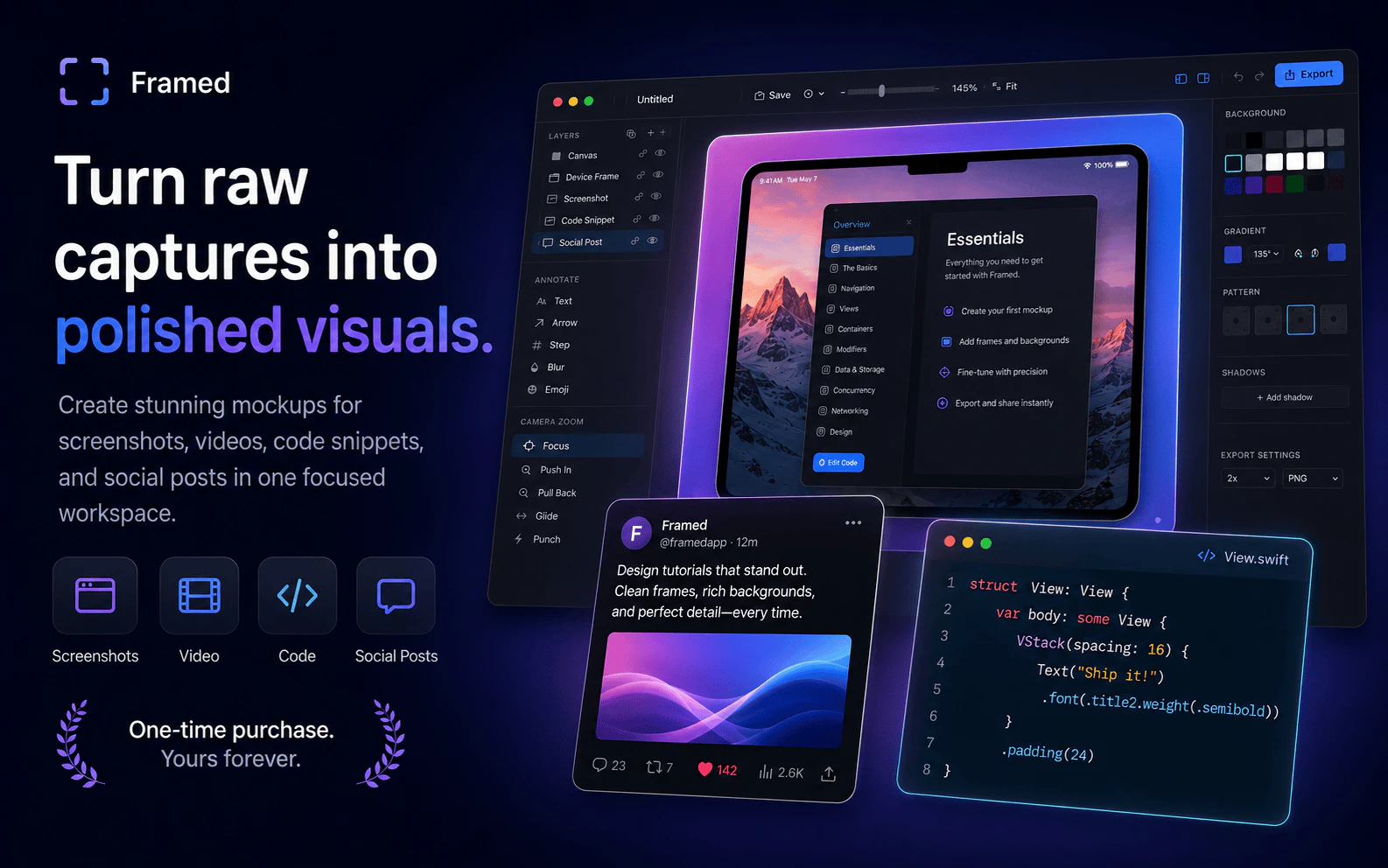
一句话介绍:Framed 是一款 MacOS 原生应用,帮助独立开发者、产品团队快速将截图、视频、代码片段包装成适用于产品发布、应用商店、社交媒体等场景的精美视觉物料,省去传统设计软件的复杂流程。
Design Tools
Social Media
Marketing
MacOS应用
截图美化
视频包装
代码展示
社交卡片
产品发布
一次性付费
原型工具
设计替代
独立开发者
用户评论摘要:用户普遍认可“一次性买断”的定价模式。核心疑问集中在:与 Mockuuups 等模板工具相比有何独特优势?是否支持移动端录制?创始人回应称支持自定义框架和移动端录屏。另有建议指出其官网视觉质感与产品定位不符,影响第一印象。
AI 锐评
Framed 切中的是一个极其真实却常被忽视的痛点:**产品包装的“最后一公里”**。独立开发者(如创始人本人)在完成核心功能后,往往在截图美化、演示视频制作上耗费大量精力,而 Figma 这类全功能设计工具在这里属于“杀鸡用牛刀”。Framed 的“一次付费”定位,既是对用户心理的精准打击——厌倦了 SaaS 订阅制的开发者们天然愿意为“拥有”而买单,也是对其自身商业模式的诚实:这是一个窄而深的小众工具,用户基数有限,做订阅制反而难以维系。
但产品价值的真实现实在于:**它提供的并非核心设计能力,而是“批量规范化”的流水线能力**。也就是说,用户仍然需要自己准备优质的内容(截图、视频),Framed 只负责套上漂亮的框和动效。这意味着它无法解决“内容本身不好看”的问题——这是许多同类工具的陷阱。评论中用户指出的官网质感问题,恰恰暴露了这一点:如果创始人自己都无法用该产品包装好自家的 landing page,那么潜在用户自然会怀疑其实际效果的上限。
此外,与 Mockuuups 的对比中,创始人强调“自定义”而非“模板”,这既是优势也是劣势。对于追求高度一致品牌视觉的专业团队,自定义是刚需;但对于只想快速出图的无设计基础用户,缺乏优质预设可能意味着更陡的学习曲线。Framed 的真正机会,在于能否将“自定义”与“易用性”做到极致,同时在社区中沉淀大量可复用的配置模板——本质上,它需要提供的是一套“半成品设计系统”,而非仅仅一个工具。
当下,它更适合作为独立开发者或小团队的产品发布工具箱中的“副手”,但若想突破小众圈层,要么拥抱 AI 驱动的自动化排版,要么与 App Store 预发布流程深度整合,成为苹果生态下的官方推荐工具。否则,它很容易沦为一个“看起来很美”的短期解决方案。
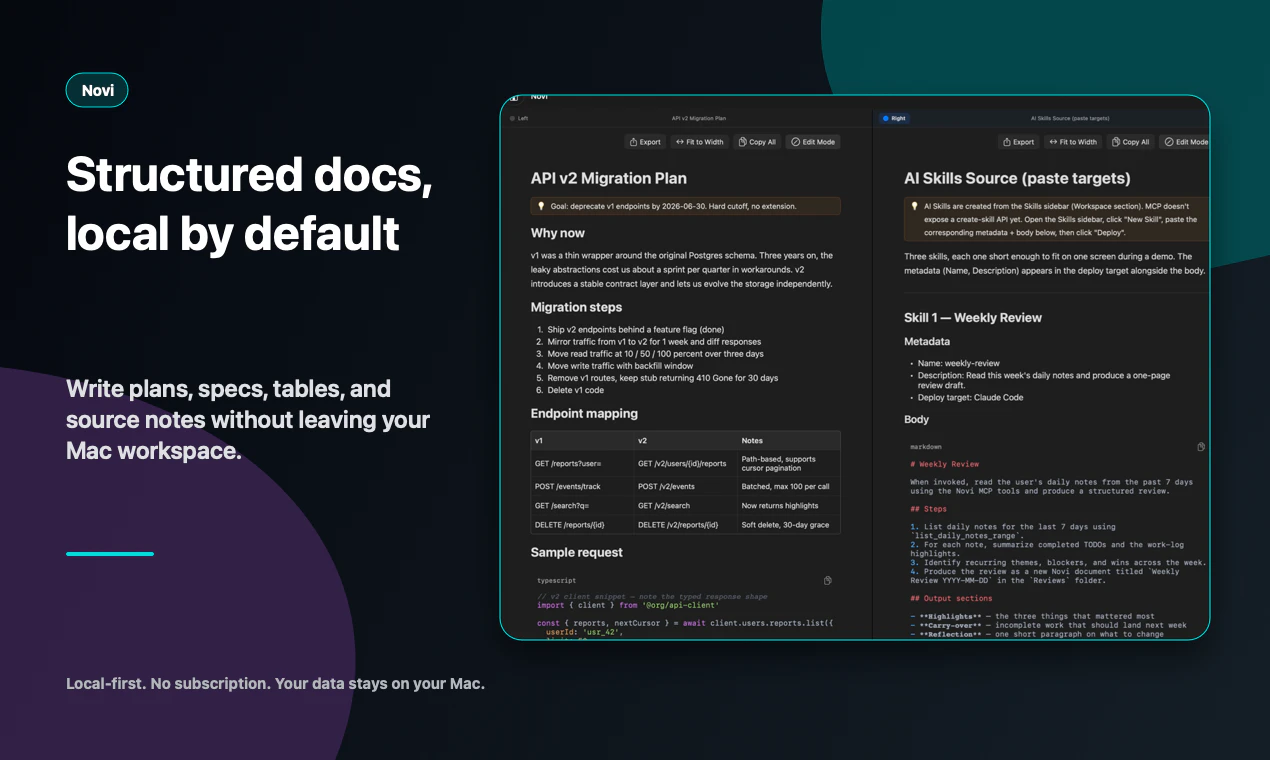
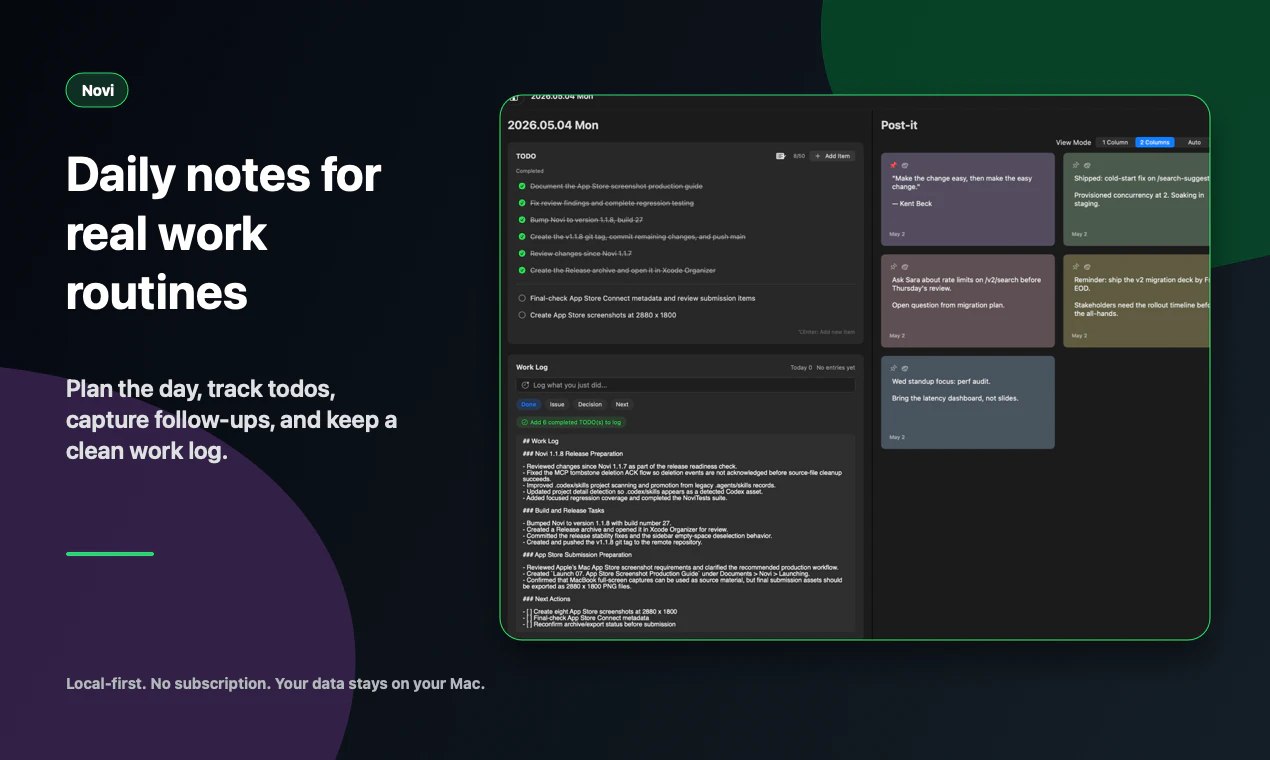
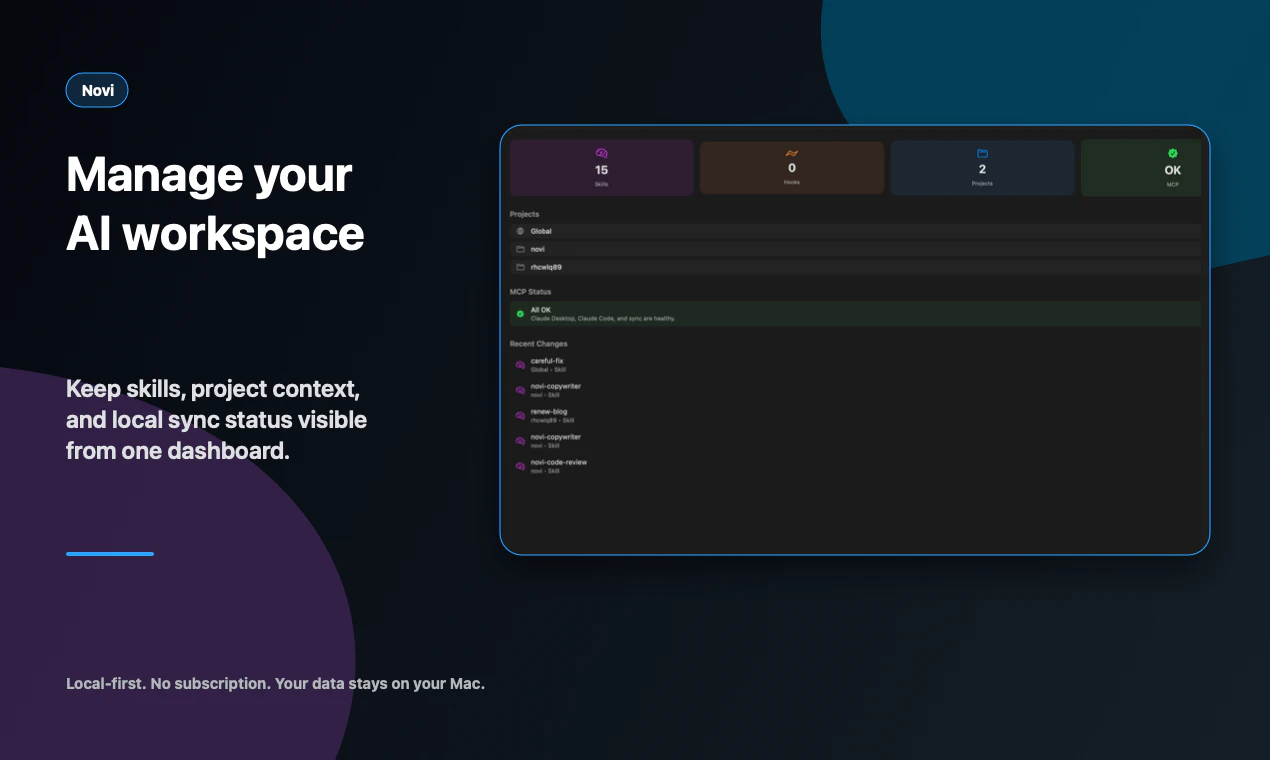
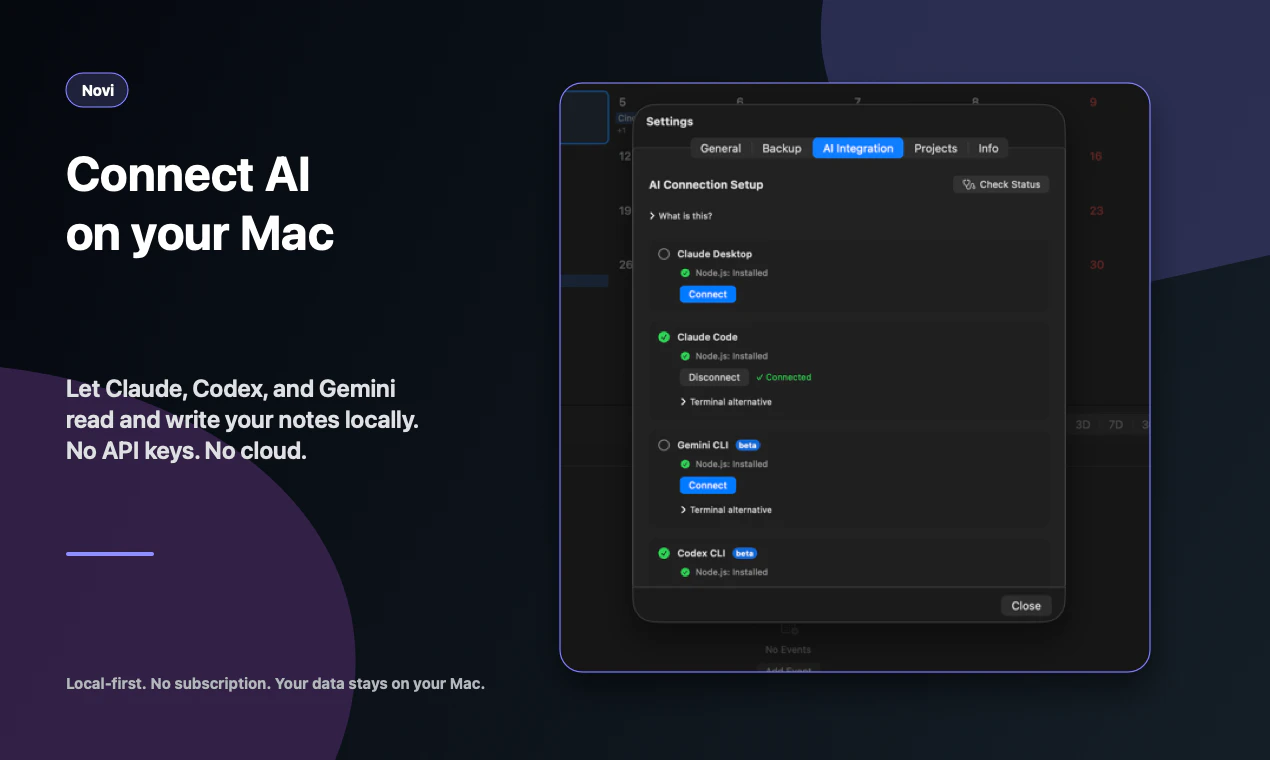
一句话介绍:Novi Notes 是一个为 Mac 打造的本地 AI 记忆层,通过集成 MCP 协议让 AI 助手(如 Claude、Codex、Gemini)直接读写你的笔记,并支持将重复提示词一键转化为“斜杠命令”,解决开发者管理和复用 AI 工作流时笔记散落、配置繁琐的痛点。
Mac
Productivity
Artificial Intelligence
本地优先
AI笔记
MCP协议
斜杠命令
开发者工具
隐私保护
一次性购买
Mac应用
知识管理
工作流自动化
用户评论摘要:用户主要关注技能版本管理、团队协作、移动端支持。开发者回应:技能无内置版本历史,建议用 Git 管理;团队协作依赖文件导出或仓库 Git 同步,非原生功能;确认无 iOS 计划,但可能开发仅限写入的快速捕获功能。
AI 锐评
Novi Notes 1.1 再次精准地啃下了一个硬骨头:在 AI 泛滥的“伪记忆”市场中,用“本地优先 + 斜杠命令”划出了一道鲜明的界限。它的核心价值不在于又一个笔记应用,而在于重新定义了“提示词”的资产化——从一个需要重复输入的心智负担,变成了可版本控制、可跨AI客户端部署的`.md`文件。
值得肯定的是,开发者 Hojong 保持了罕见的克制与诚实。从果断砍掉 iCloud 同步,到坦率承认缺乏团队共享和版本历史的短板,这种“剑走偏锋”的定位反而塑造了清晰的品牌认知:专为深度使用终端和 IDE 的单人开发者打造的“AI 外挂大脑”。
然而,锐利的刀刃也意味着狭窄的使用场景。99 票的成绩反映了其小众的本质。产品价值高度依赖用户是否愿意“玩”MCP 协议并编写 Markdown 技能文件,这门槛直接把绝大多数普通用户挡在门外。此外,AI Skills 的“跨客户端部署”看似强大,实则将体验碎片化交给了 Claude Code、Codex、Gemini 原生加载机制,Novi 只是“分发器”而非“指挥官”,这在一致性和故障排查上埋下了隐患。
长远来看,Novi Notes 的真正壁垒在于能否将“斜杠命令”生态化。如果仅仅是本地的文件管理工具,那么它很容易被 LLM 厂商自身的技巧库功能替代。只有当“技能”的编写、调试和分享形成社区网络(哪怕是通过 Git 协作),它才能从“工具”升维成“平台”。目前看,这似乎超出了独立开发者的能力范围,但这恰恰是其在“深度”迭代中必须面对的终极拷问。
一句话介绍:Ente Locker 是一款端到端加密的共享数字保险箱,解决用户在发生意外后,重要文件无法及时传递给家人的痛点。
Storage
Privacy
Tech
数字遗产
共享保险箱
端到端加密
家庭密码管理器
文件继承
开源
隐私安全
紧急联系人
遗嘱工具
跨平台
用户评论摘要:用户普遍认可其“数字遗嘱”的实用场景,点赞其解决遗忘重要文件的痛点。但评论较少,目前无具体负面或建议反馈,主要停留在对产品概念的肯定上。
AI 锐评
Ente Locker 切中了一个被大多数人忽视但确实存在的“数字遗产”需求。它本质上是把加密云盘从“生前自用”的定位,精准转向了“身后传承”的刚需。这种叙事转换是聪明的,因为传统的密码管理器或云盘虽然也能实现类似功能,但缺乏“一键指定联系人+定时访问”的仪式感与操作闭环。
产品真正的价值不在于技术壁垒——端到端加密已是成熟方案,而在于对用户心理的精准拿捏:它不承诺“不死”,而是承诺“即便我不在,留下的重要东西也能安全送达”。这击穿了人对遗产管理的焦虑。
但必须指出其局限性。第一,用户基数问题:一个需要“死后”才能体现价值的产品,对活人缺乏高频使用的驱动力。这很考验Ente将其与照片备份等刚需场景融合的能力。第二,信任门槛高:用户要信任一个相对小众的公司,不会在关键时刻倒闭或数据丢失。开源和自托管虽然加分,但提升了使用门槛。
总体来看,这是一个小而美的精分产品,商业想象空间有限,但作为Ente现有生态的增值模块极具延展性。它不是在解决普通存储问题,而是在解决“情感与责任”的数字化移交。对看重家庭隐私和遗产传承的用户而言,它是目前最优雅的解决方案之一。
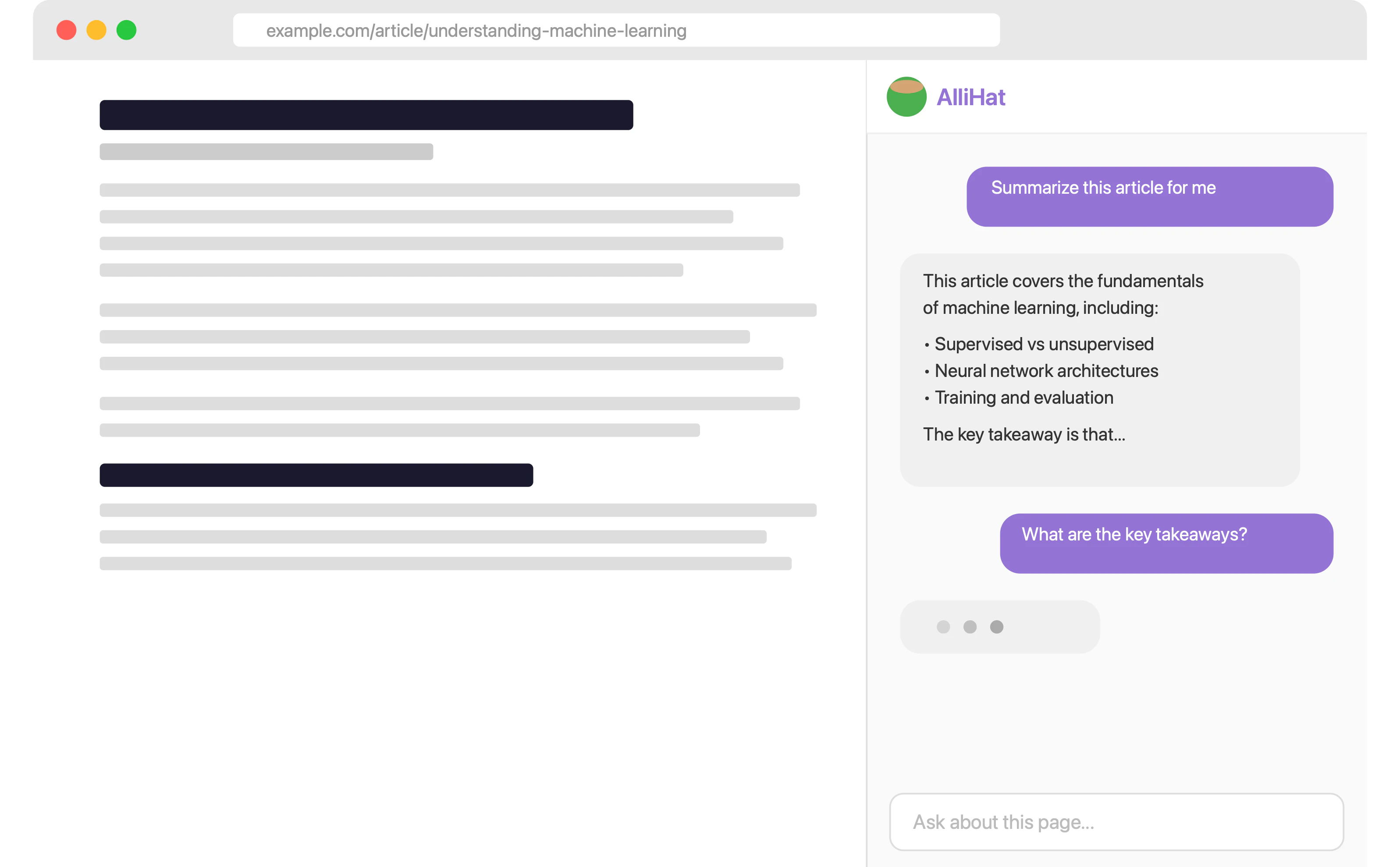
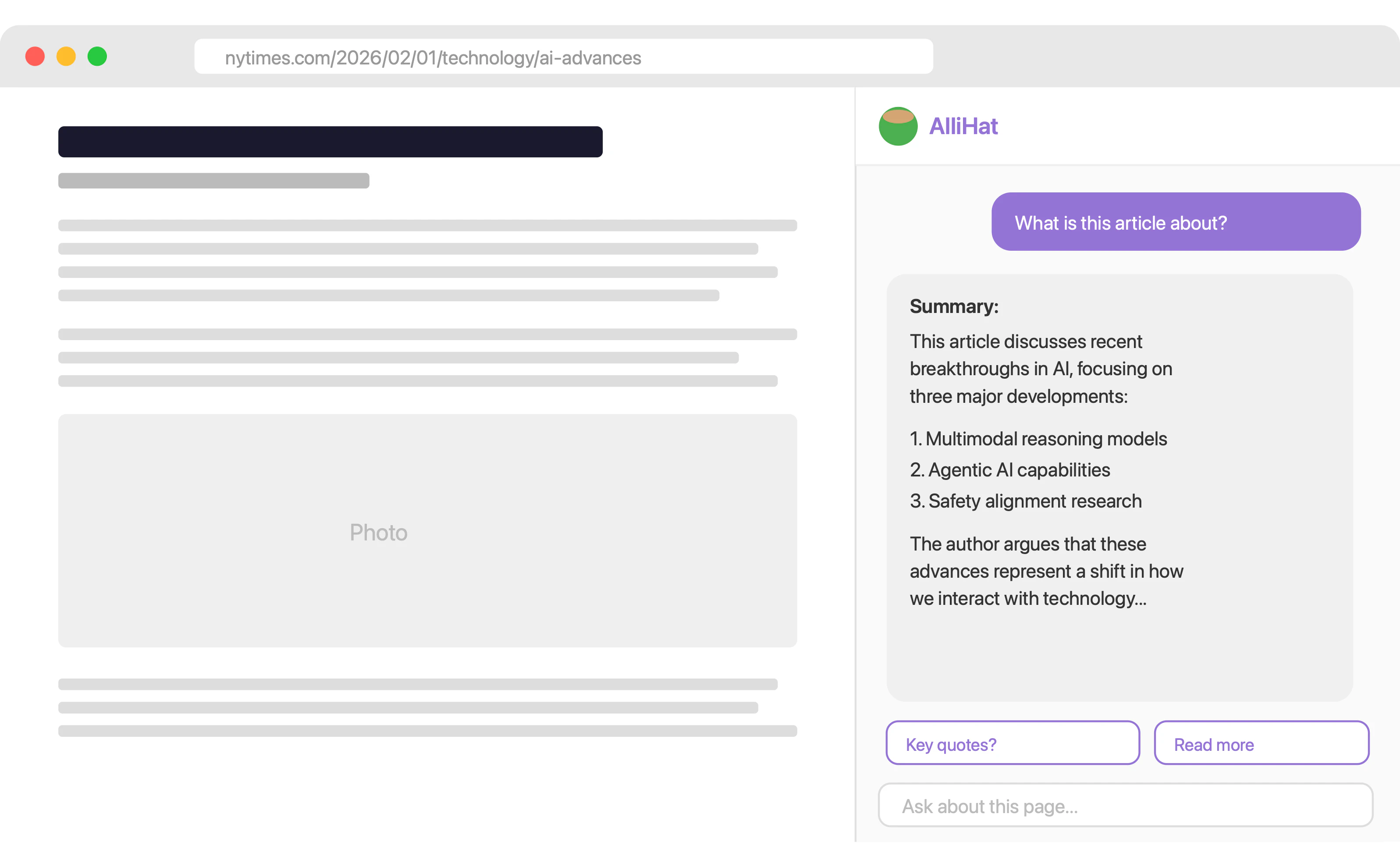
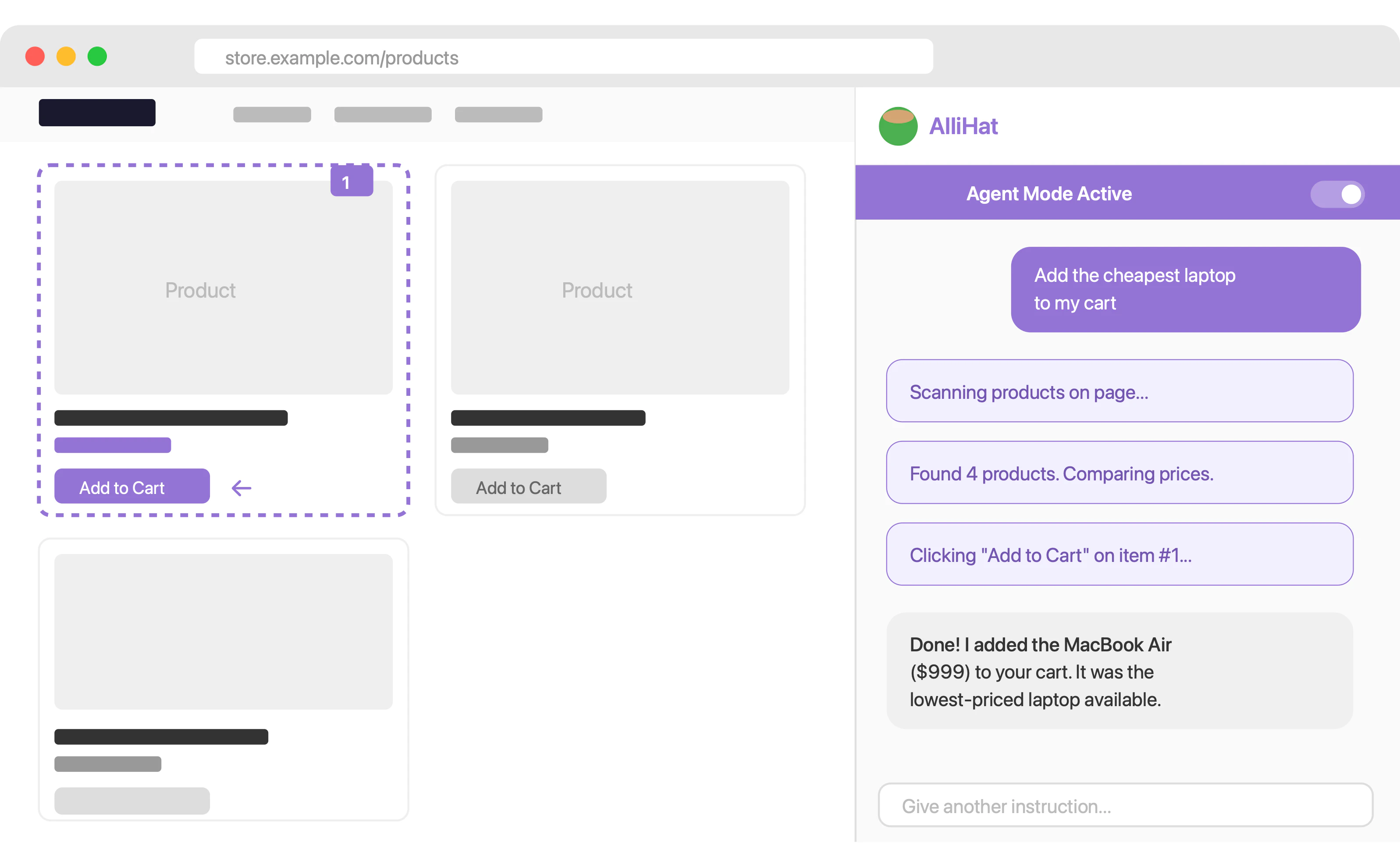
一句话介绍:AlliHat 是一款嵌入 Safari 侧边栏的 AI 助手,能实时读取当前页面内容,让用户无需切换标签页即可进行提问、解释、执行表单填写和自动化任务,解决了 Safari 用户缺乏优质 Claude 集成工具的痛点。
Browser Extensions
Productivity
Artificial Intelligence
Safari 扩展
Claude AI
侧边栏助手
AI Agent
自动化工作流
本地隐私
Apple Intelligence
表单填充
浏览器AI
无追踪
用户评论摘要:用户询问侧边栏切换标签时是否跟随,作者回应侧边栏固定在原页面。有用户建议增强自动表单填写功能,作者指出Agent模式已支持。另有用户对作者表示祝贺。核心建议集中在提升Agent模式的稳定性和扩大自动化场景。
AI 锐评
AlliHat 的推出精准地抓住了 Safari 用户对原生 AI 工具的渴望,尤其是那些因 Chrome 丰富生态而眼红、又不想放弃 Safari 流畅体验的“钉子户”。其核心价值并非“又一个 AI 包装器”,而是“浏览器原生的环境感知能力”。作者 Nate 的分享极具洞察力:用户要的不是顶尖模型,而是“开箱即用”的流畅体验。他通过引入 Apple Intelligence 作为免配置入口,显著降低试用摩擦,这个调整比技术本身更值得产品经理学习。
但产品隐忧同样明显。首先,29.99 美元/年的定价在众多免费或低价 AI 助手中底气不足,除非 Agent Mode 和 Workflow 能进化到真正替代效率工具(如自动填表、批量爬虫)。其次,Safari 缺乏正式的侧边栏 API,导致“标签页跟随”这一基本交互都缺失,这暴露了其体验的天花板——它不是系统级集成,而是页面内嵌的“寄生”应用。最后,依赖用户自备 API Key 是双刃剑:保证了隐私(数据直通 Anthropic)和低运营成本,但也将复杂性和成本转嫁给了用户,限制了其从“技术玩家”向“大众用户”的渗透。
AlliHat 是当下“AI+浏览器”趋势的一个精致切面,它证明了即使在一个封闭的生态(Safari)中,优秀的洞察和巧妙的技术 hack 仍能创造价值。但它能否从“精致的解决方案”进化为“不可缺少的工具”,取决于作者能否在 Safari 现有框架的枷锁下,用 Workflow 和 Agent 构建出足够强大的自动化闭环,让用户觉得这笔年费买的是“解放双手”,而非仅仅一个侧边栏聊天窗。
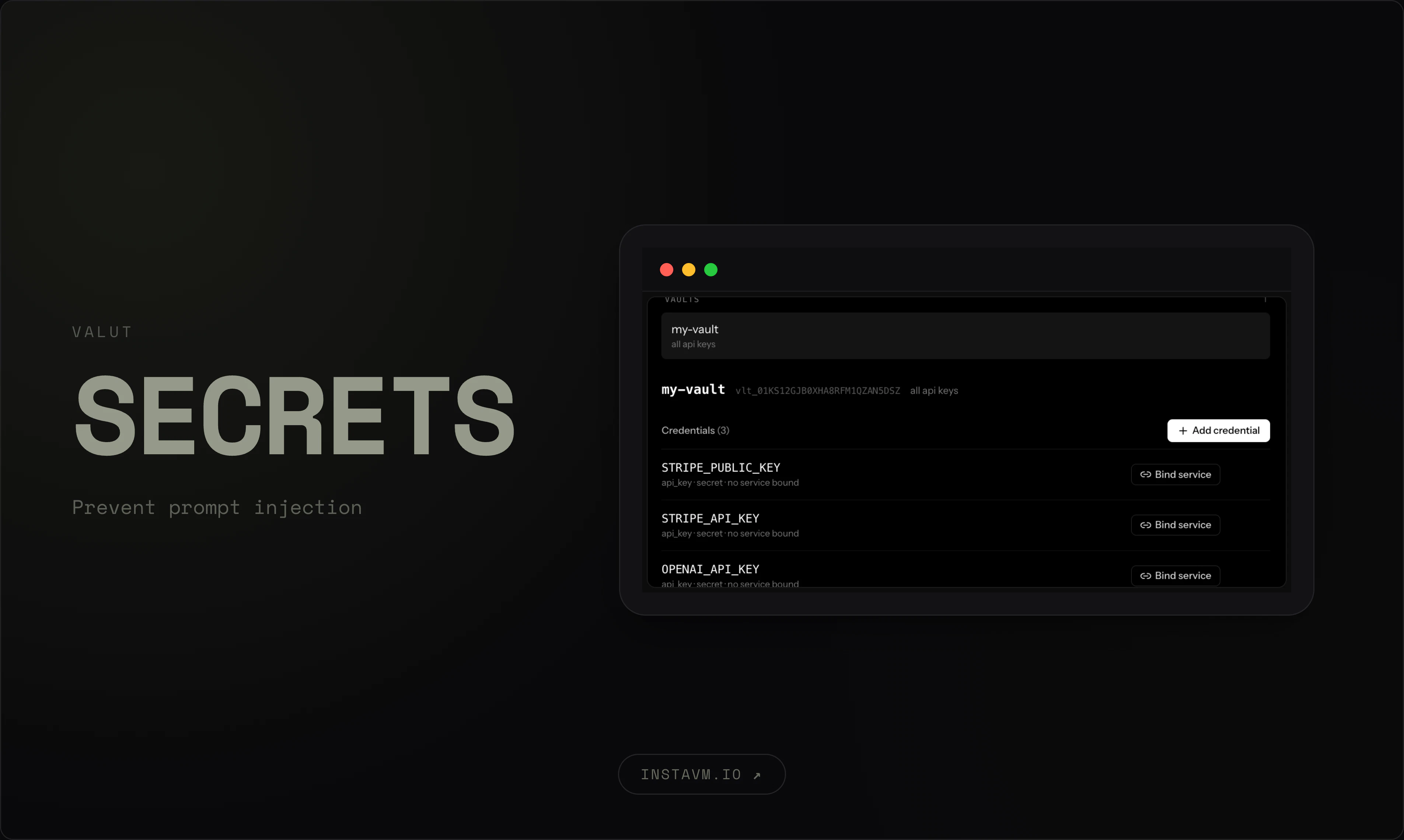
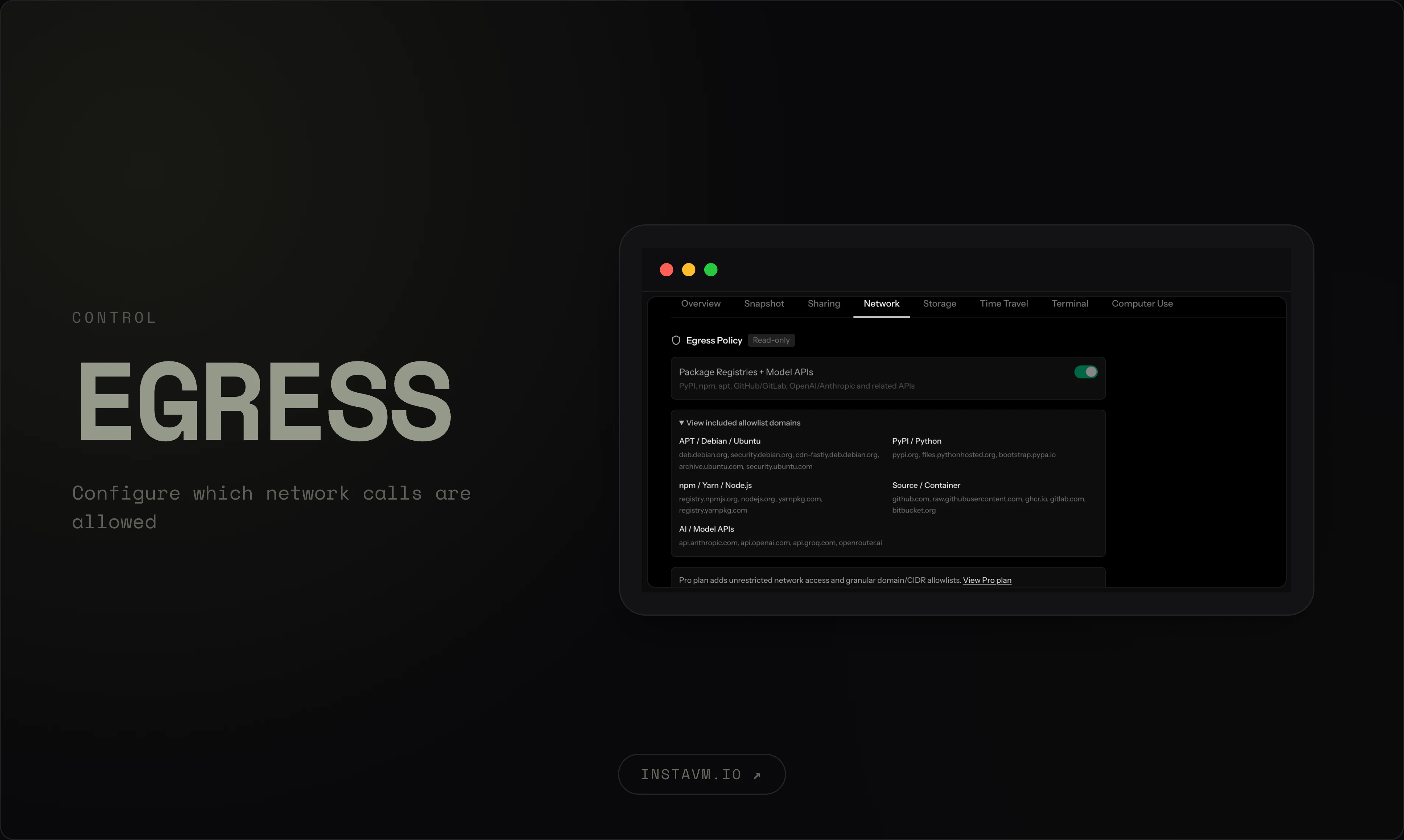
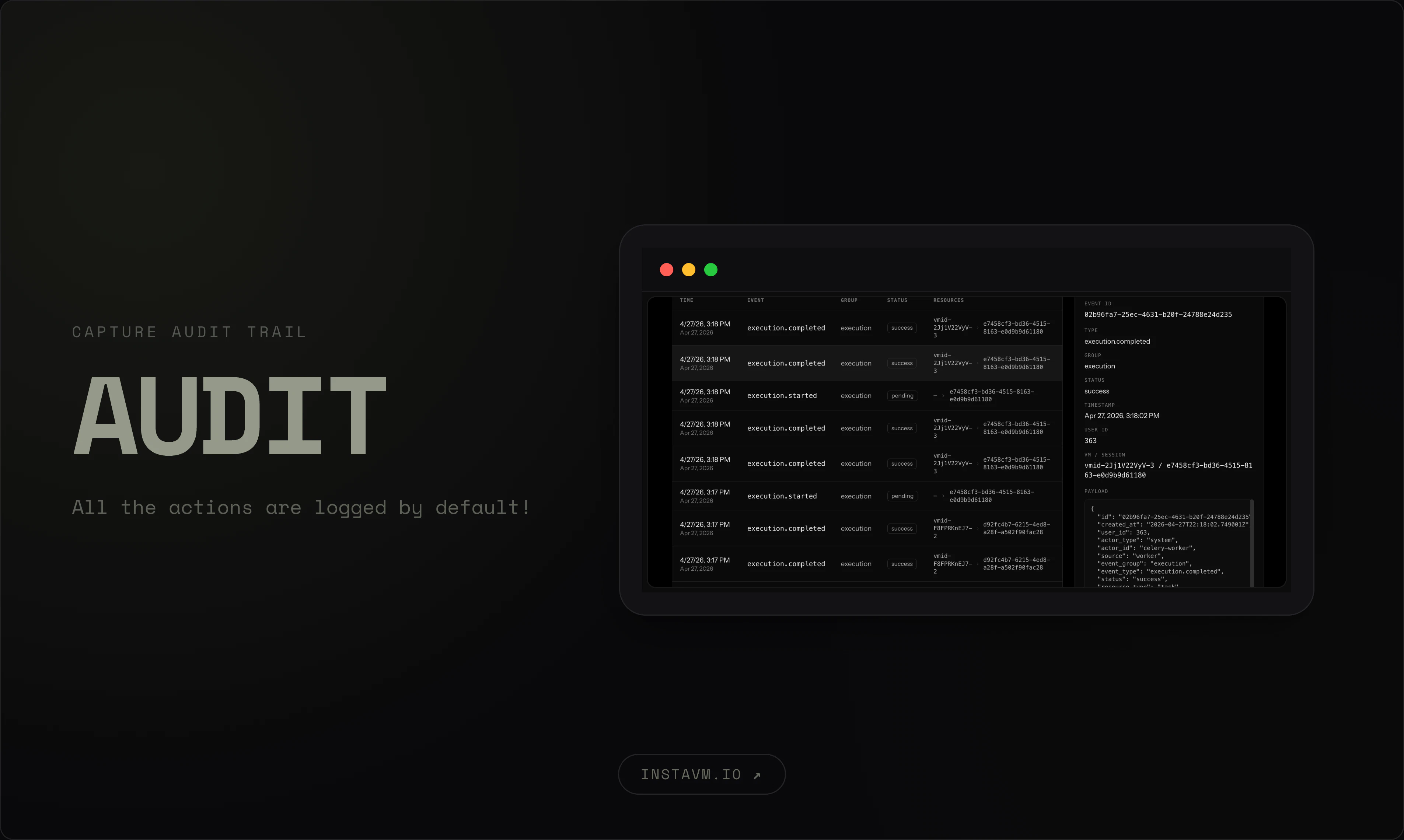
一句话介绍:InstaVM为AI代理提供亚200毫秒启动的硬件隔离虚拟机,解决其在生产环境中运行时面临的隔离性差、提示注入攻击、凭证泄露和状态不可控等安全与运维痛点。
API
Developer Tools
Artificial Intelligence
AI代理基础设施
微虚拟机
安全隔离
云基础设施
开发工具
Firecracker
运行时安全
持久化存储
可观测性
提示注入防护
用户评论摘要:用户关注的核心问题:1)提示注入下凭证如何安全下发及防止滥用;2)被污染的持久化卷重新挂载如何保证完整性;3)是否支持CPU/内存的细粒度配置及自动扩缩容以应对递归循环。这些指向了现有沙箱方案在安全与运维层面的不足。
AI 锐评
InstaVM切中了一个真实但尚处早期的痛点——AI代理在生产环境中的安全落地。其产品逻辑并非简单的“给AI一个容器”,而是将代理视为无信任的、可能被攻陷的进程,并以此重新设计基础设施的信任边界。将凭证与计算平面分离、提供可控出站和可观测性,直击了提示注入攻击下传统容器隔离失效的要害。
然而,产品价值能否兑现取决于两个关键问题。其一,亚200ms的Firecracker微VM启动速度虽快,但面对需要频繁编排、高频调用的实时代理场景(如聊天机器人),其延迟堆栈(网络、存储、热迁移)能否在真实负载下保持稳定?其二,也是最棘手的:产品依赖“技能系统”(`npx skills add`)来让代理调用自身,但依赖市场中的第三方技能代码运行在隔离VM内,这本身就引入了供应链攻击面。当前产品对“谁审核技能、技能能访问什么”的回答仅限于“Is it isolated?”,长远看这远不足够。
真正考验InstaVM的不是启动速度,而是它能否在“给代理自由”与“防止代理作恶”之间找到平衡,并提供一套可审计、可回滚的治理框架。如果只是把LXC换成Firecracker,而没有解决代理行为博弈的闭环,那它终究只是一个更快的沙箱,而非AI生产控制平面。
一句话介绍:Basedash Skills 是一款让用户将关键业务指标(如MRR、激活率)定义为可复用的自然语言“技能”,供所有AI界面按需调用的工具。它解决了在多个Prompt中反复粘贴相同定义导致数据口径不一致的痛点,让AI像熟悉业务的分析师一样工作。
Artificial Intelligence
Data & Analytics
Business Intelligence
AI指令复用
语义层
指标管理
业务定义
Prompt工程
数据分析
SaaS工具
团队协作
知识管理
低代码
用户评论摘要:用户认可其作为“轻量级语义层”的价值,核心关注点是治理问题:技能更新后如何同步到所有引用面?如何解决技能内容随时间漂移或相互冲突的问题?官方回应将支持AI自动管理技能,并可通过自然语言指令批量更新应用。
AI 锐评
Basedash Skills 解决的是一个真实且普遍存在的“脏活”:让AI记住并正确使用团队内部那些定义模糊、口径常变的业务指标。它的核心创新不在于AI能力本身,而在于产品架构——将“一次性提示词”升级为“可持久化、可共享、自动关联的指令库”。这本质上是在AI原生应用里构建一个“轻量且活的语义层”,比传统数据字典更贴近业务语言,比写死规则更灵活。
然而,我们必须泼一盆冷水:这个产品的长期价值不取决于“写指令有多简单”,而取决于“治理能力有多强”。目前官方依靠“AI代理理解自然语言并批量更新”的方案非常理想化。当团队拥有数十个技能、数百个引用点,且指标定义随业务频繁迭代时,冲突检测、版本追溯、影响范围分析将变得极其复杂。如果治理上“谁改谁对,最后生效的赢”,这个语义层很快就会变成新一轮数据口径混乱的源头。这不是一个技术问题,而是一个严格的运维协作协议问题。
短期内,它非常适合小团队、初创公司或内部数据集市场景。但大企业在采用时,必须同步建立技能的生命周期管理规范,否则今天从重复定义中解脱的快乐,明天就会变成对所有AI输出结果的不信任。总的来说,方向正确,但别忘了给系统戴上紧箍咒。
一句话介绍:AutoSubtitles 2.0 是一款在浏览器内直接运行、无需上传完整视频即可生成AI字幕与动态字幕动画的工具,专为短视频创作者解决传统软件编辑繁琐、渲染缓慢的痛点。
Productivity
Artificial Intelligence
Video
AI字幕生成
动态字幕
视频编辑
浏览器端处理
短视频工具
动画预设
字幕样式
自动表情符号
本地渲染
产品猎手
用户评论摘要:用户普遍认可产品简洁实用,尤其赞赏动画预设可节省在Premiere、CapCut上的时间。主要问题和建议集中在:对嘈杂音频或多说话人场景的识别效果、字幕能否自动避让画面主体/人脸、是否有适配TikTok底部UI的安全区预设、是否支持类似Descript的文稿驱动编辑。
AI 锐评
AutoSubtitles 2.0在产品定位上非常精准:放弃大而全的视频编辑,死磕“字幕与动态标题”这个垂直场景。其最大的护城河并非AI转写准确率(这是通用能力),而是“纯浏览器端+本地渲染”的技术路线。它巧妙规避了服务器高昂的视频处理成本,同时以“无需上传”作为隐私卖点,对注重数据安全的内容创作者有天然吸引力。从当前94票的启动成绩来看,产品完成度尚可,但评论中暴露出的核心短板不容忽视:AI对复杂音频(背景噪音、多人重叠)的处理能力是用户第一关切,这直接决定了它在专业场景下的可用性。此外,评论中提到的“自动避让人脸”和“TikTok安全区预设”更像刚需,而非锦上添花——如果字幕总是挡住主体,再炫酷的动画也是负优化。创始人在回复中透露已有“安全区”和“文稿编辑”的路线图,但功能落地速度将是拉开与CapCut、剪映AI字幕差距的关键。目前来看,它更像一个“极速字幕美化工具”,而非真正的“智能视频编辑器”。若想从“新奇工具”升级为“生产力必备”,必须在音频识别精准度和智能布局算法上实现质变,否则很快会被竞品的功能整合所淹没。
一句话介绍:Rigyd是一个自动生成物理属性精确的3D资产和仿真世界的平台,解决了机器人仿真到现实迁移中因缺乏规模化、物理可信3D数据而导致训练失效的痛点。
Robots
Artificial Intelligence
3D Modeling
机器人仿真数据
物理精确3D资产
域随机化
Sim-to-Real
OpenUSD
NVIDIA Isaac Sim
MuJoCo
3D资产生成
工业自动化
体感AI
用户评论摘要:用户高度关注资产格式支持(已支持GLB/FBX/USD等十余种),验证物理准确性(团队提供三层校验:架构标准+Isaac Sim倾斜测试+材质推断)。有用户反馈试用配额不足,获追加。也有用户询问视觉随机化能力,团队表示已支持。
AI 锐评
Rigyd切中了机器人行业一个日益尖锐的痛点:仿真引擎(Isaac Sim、MuJoCo等)已经足够成熟,但喂给它们的3D数据质量却严重滞后。传统上,机器人团队要么手工制作/标注每一件资产,要么忍受平台默认的物理参数并祈祷泛化成功,这两种路径都无法规模化——而规模恰恰是域随机化策略能否奏效的核心。
Rigyd的价值在于它重新定义了“3D资产”的质量标准:从“看起来逼真”转向“物理行为逼真”。它通过生成碰撞网格、质量、摩擦系数、恢复系数等关键物理属性,解决了机器人“穿过地板”、“抓空物体”的经典失败案例。其技术路径也值得关注——采用CoACD分解而非V-HACD,确保了在模拟器中的碰撞性能与精度平衡;基于OpenUSD和MJCF的标准化输出,避免了工具链碎片化,这在生态初期是明智之举。
然而,仍需警惕两个潜在问题:第一,物理属性推断的准确性本质上是一种“工程近似”,面对极端复杂的真实物体(如软体、异形材料),其拟合精度仍有待验证。第二,Rigyd目前更像是一个数据管道而非创造引擎——如何保证生成的域随机化场景既能覆盖足够变异性,又不偏离真实物理分布,避免在模拟中“解决不存在的问题”,是关键挑战。其商业模式与单一存储桶配额挂钩的定价策略,对于需要生成百万级资产的目标客户而言,落地成本和灵活性将是下一个博弈点。总体来说,Rigyd在正确的时间选了正确的赛道,但物理模拟数据的“最后一公里”往往比想象中漫长。
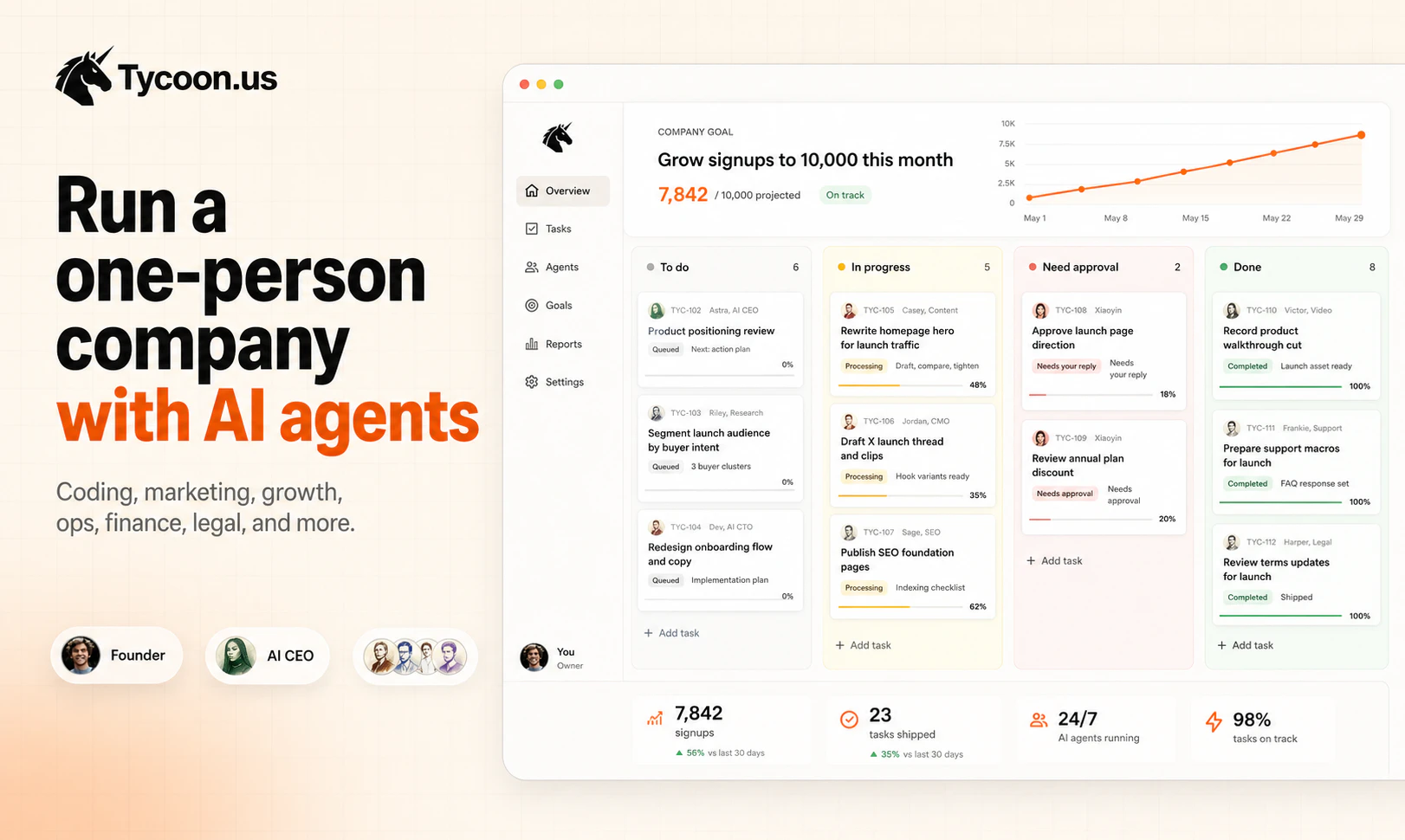
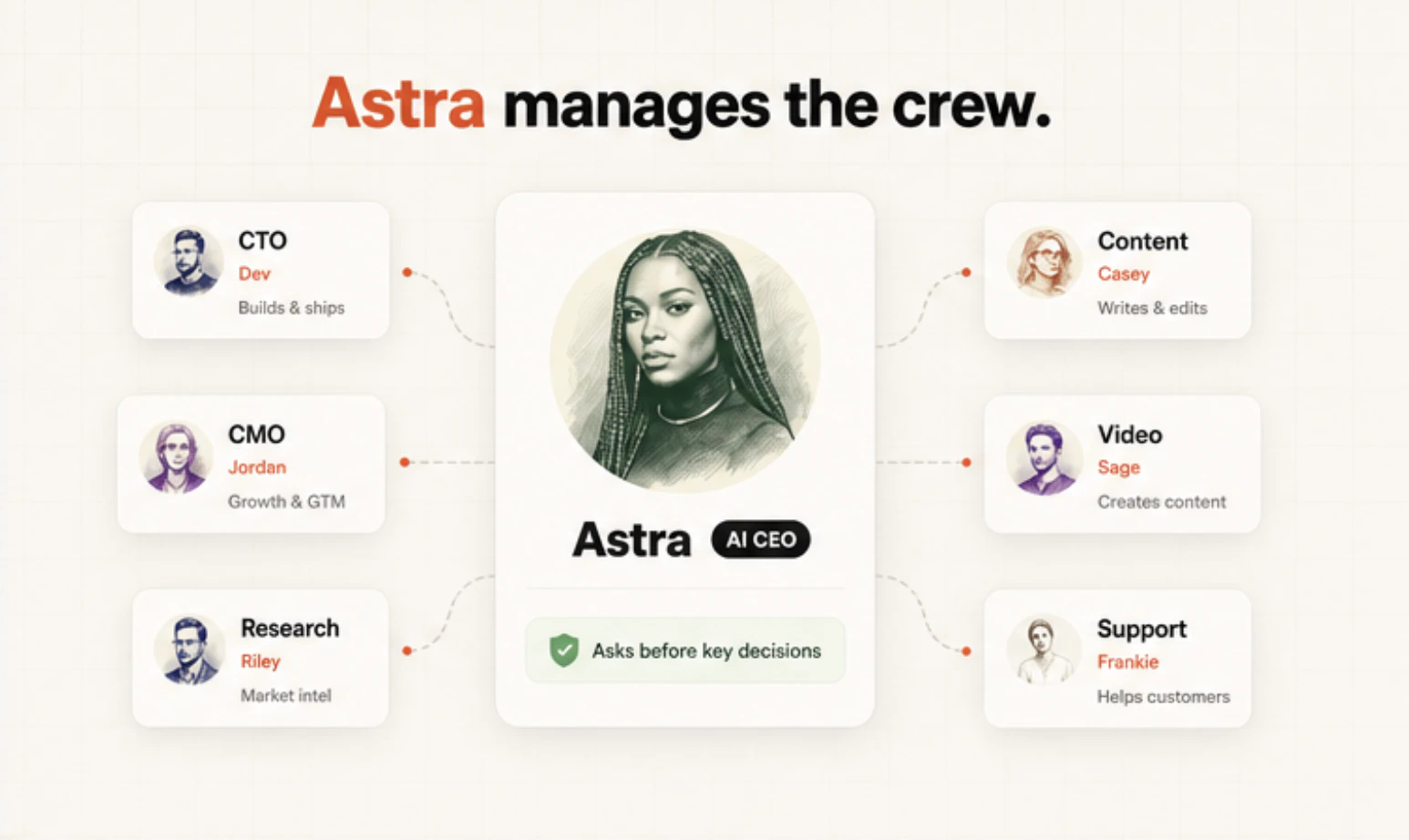
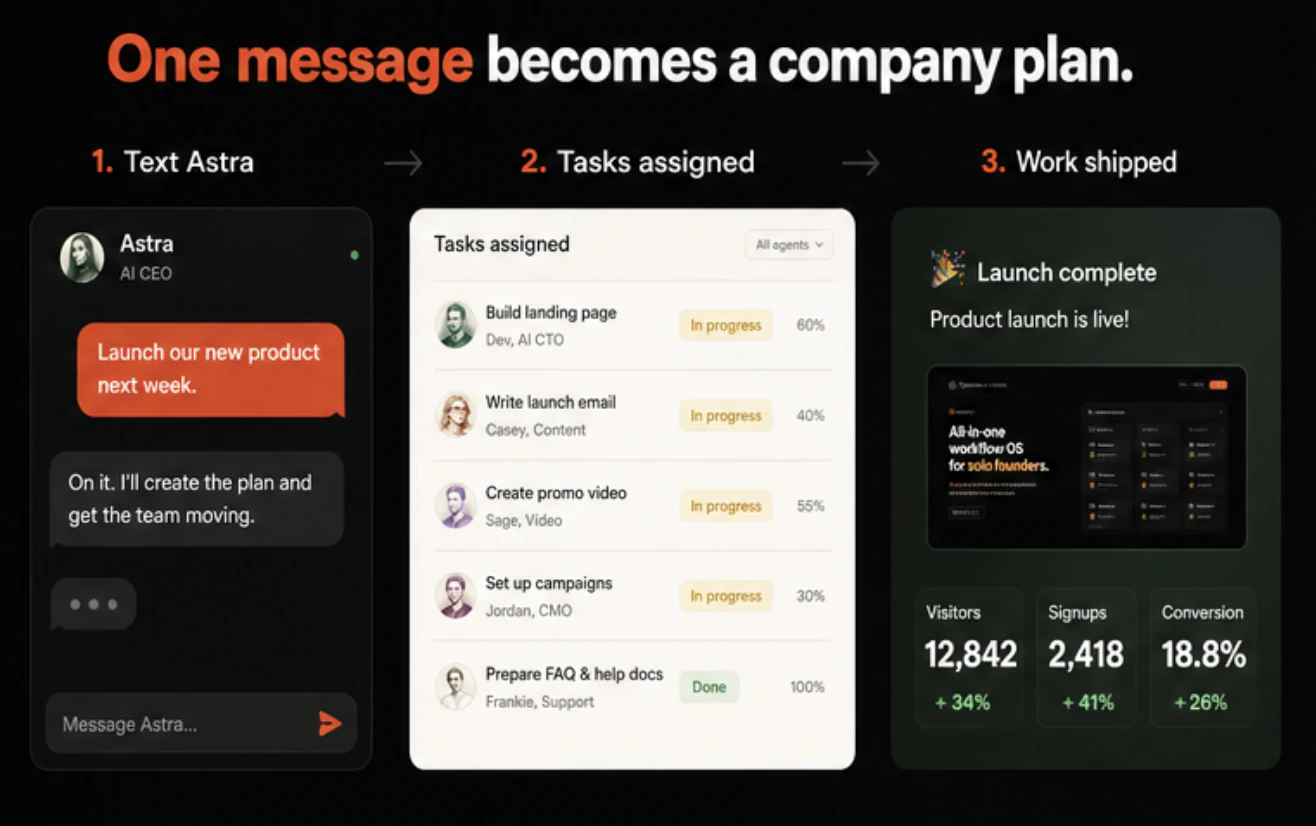
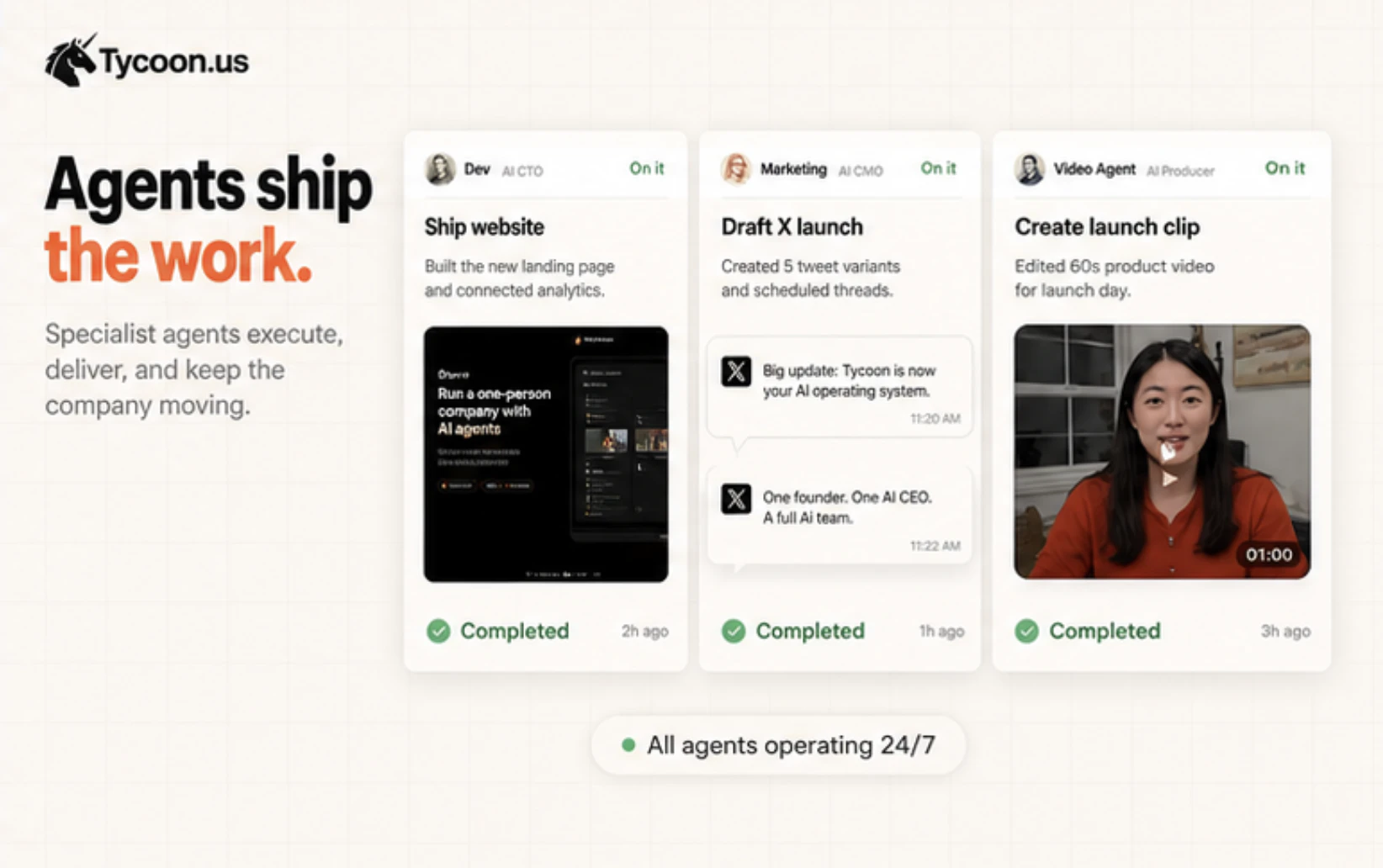



































Hey Product Hunt, I’m Xiaoyin, founder of Tycoon.us
A year ago, I became the first human CEO to be replaced by an AI CEO named Astra.
At first, it sounded like a stunt. Then Astra helped run real companies: HeyBoss reached 100K+ users, and SkillBoss hit $1M ARR in 30 days.
Tycoon is the productized version of that experiment.
It gives one person an AI CEO and a full team of AI agents. You can text Astra your goals, ideas, or tasks. She turns them into structured work, assigns the right agents, reviews progress, and asks for approval when it matters.
We built Tycoon for solo founders, indie hackers, and builders who want the operating power of a company without hiring managers, sitting in meetings, or coordinating everything manually.
You can view the step-by-step walkthrough here: https://www.youtube.com/watch?v=tYejVbsRRec
This is really cool and terrifying at the same time. But I am curious how does the feedback loop works here. What I mean is that there is a hierarchy in real world company but for AI agents how does that work? Does it have designated AI agents for each role in company ?
Is there any team or collaboration feature planned, or is it strictly personal use?
Feels like a clean way to turn strategy into something actually fun and addictive. If the gameplay depth matches the concept, this could easily become a go-to for anyone who enjoys building and scaling systems. Excited to see how far it goes 🚀
An AI running the entire thing is wild. But I want to test it out - I have $53 worth of credit but nothing happens. Did I miss something that says a subscription must be purchased to make this do anything other than chat with it?
bugs are everywhere. cant view skills, the main bug is in the chat and company creation function. it doesnt work. it is broken. no matter how many agents or claude codes and hermeses you put inside it, it doesnt work right. astra made tasks, none of them even started. charging 50$ for a trial, up to 1500$ for a broken product? the only good thing i see here is the buy a domain on namecheap.com option. maybe they should start a product hunt launch instead. terrible first, and last experience
The “AI CEO” framing is bold, but the useful bit here seems to be the approval boundary around work that touches real customers.
For the CMO agent specifically, I’d love to see every public post/campaign carry a small source trail: what customer language, positioning notes, or prior winning content it used, plus which parts were invented. That would make founder review much faster because you’re judging both the output and whether the agent understood the business correctly.
Solo iOS founder here building a relationship app on the side, exactly the indie-hacker persona you’re describing. The HeyBoss + SkillBoss track record before Tycoon is the most impressive credibility on the board today, congrats on the launch!
What’s Astra’s actual signal for “this needs approval”: per-agent confidence, category of task (publish vs draft, spend vs research), or learned from user behavior over time? Feels like getting this right is crucial to not immediately reverting to doing everything manually.
Congratulations
Congrats Xiaoyin and team! really fascinating vision here. how does Astra decide when to escalate decisions to the founder versus letting agents execute autonomously?
Really interesting idea. Curious how Astra handles quality expectations, since every founder may define “good enough” differently. Does it learn each user’s satisfaction bar from approvals, edits, and rejections over time, or can users explicitly set the quality standard for different types of work?
Curious how well it actually retains context over time — or if I’d still end up re-explaining things every few steps. That’s usually where most “agentic” tools start to break down.
The branding around “Tycoon” is interesting—it subtly reinforces a mindset of building and growing wealth, which makes the product feel more motivational than purely functional.
Congrats on the launch
I am curious to is it possible to integrate the agent with meta mcp for directly running ADs and design creatives as well. Like is it capable of execution or only of strategy
Hello,
I am having a lot of trouble with you product/services. Worker pods are consistently failing with HTTP 402 at pod spawn despite active subscription, $99 balance, and $100 monthly spend limit. Happening across all tasks. Started after subscribing to the Tester plan. Multiple retries are wasting credits.
Also, the "tycoon.us/support" page is not working.
Please advice,
Thanks!
When Astra creates a plan and assigns agents, how does it handle conflicts between agents — like if the CMO and CTO have competing priorities on the same sprint?
API calls? Expensive? or different format?
This feels like selling the shovel in a gold rush. Fantastic idea if executed well. $49/mo is not much, but we dam well know it's gonna get real expensive really fast. How do you guys optimize for token usage efficiency?
Love the idea - however my group of first tasks say they are running but the threads show 0 sessions, 0 tool calls, 0 tokens used. Restarting them didn't help!
I'm curious how well does this work for a product idea that already is built. eg. A web app, marketing site are setup but all of the other functions besides AI Developer are needed? Will this trip up if it's not fully in your ecosystem?
It sounds exciting, but it also feels a bit frustrating. It might be better if we could see the actual results instead of just numerical promotion. At least, it's not yet clear what problems are being solved? Is it about fewer people? For example, what effective growth can it bring to independent developers?
Congratulations on the launch!
I created an account and I think it’s a very good product.
I did a brief test of the experience and I really loved Astra in general .
However, it would be interesting to be able to see the tasks in 'To Do' on the same screen and interact with each one, either to add more details or to ask follow-up questions.
Astra as a coordinator seems very good to me. It would be useful to be able to incorporate some 'skills' into the brainstorming process; for example, when I want to explore options, Astra sometimes seems a bit too expeditious.
A thought crossed my mind, if two founders used Tycoon for five years and then both disappeared, would the resulting companies become more similar over time because they’re run by the same system or more different because each AI CEO has absorbed a unique history of decisions?
It feels like the answer says something important about whether intelligence is coming from the model or from accumulated organisational memory.
The text your CEO interaction model feels very natural. Did you intentionally design Tycoon to reduce dashboard complexity for founders?
Really impressive to see AI agents handling the full business ops stack. Curious how does Astra handle decisions that need brand context or tone? Like if a CMO agent is writing content, what's feeding it the company's voice? Excited to see where this goes
The HeyBoss / SkillBoss numbers are the part of the pitch I keep getting stuck on. Were those companies originally human-run and then handed to Astra? It's a different credibility claim each way, and the cold-start version is the harder one to defend
Love the idea but how come you guys aren’t a one-person company?