PH热榜 | 2026-05-27
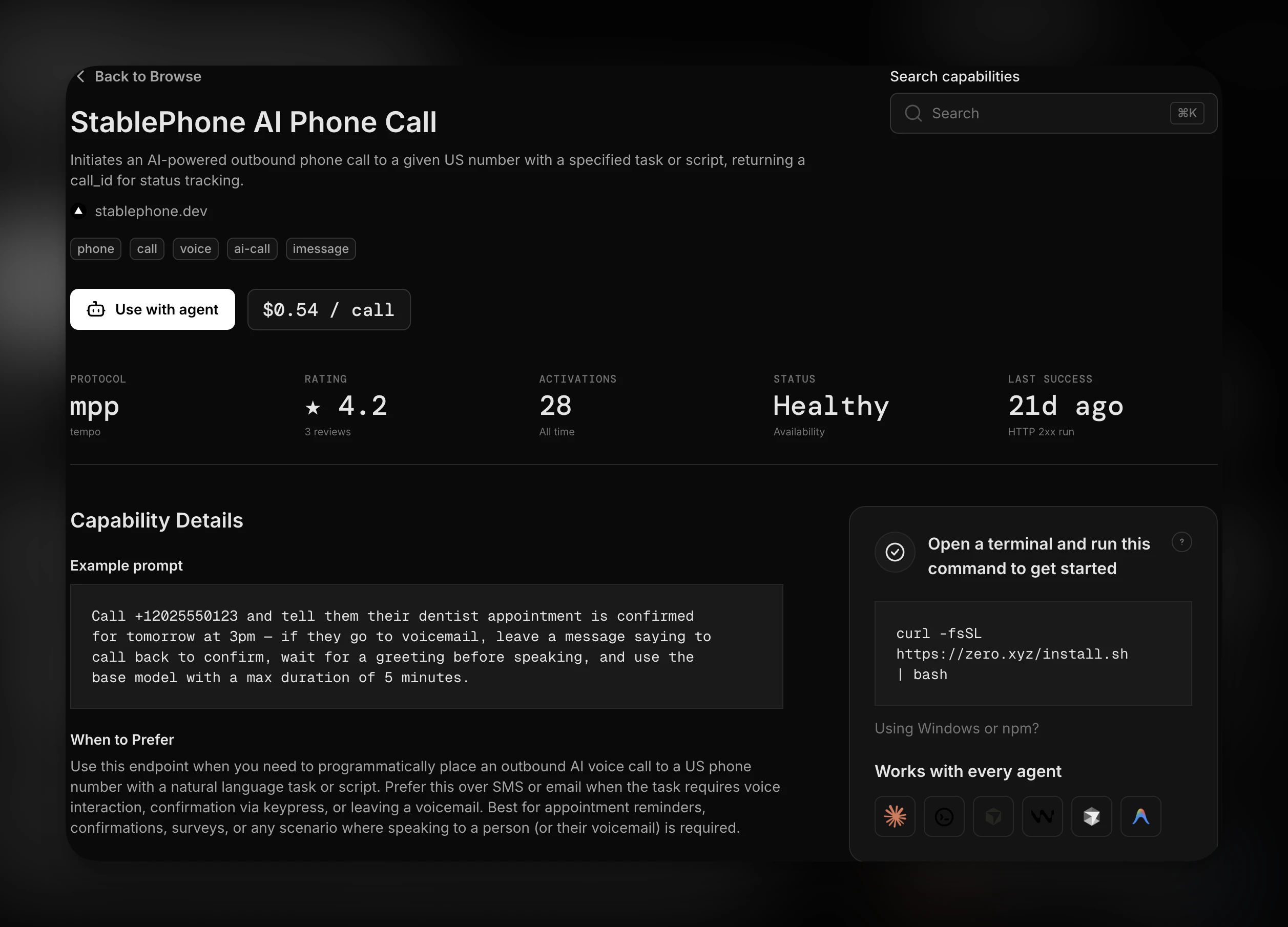
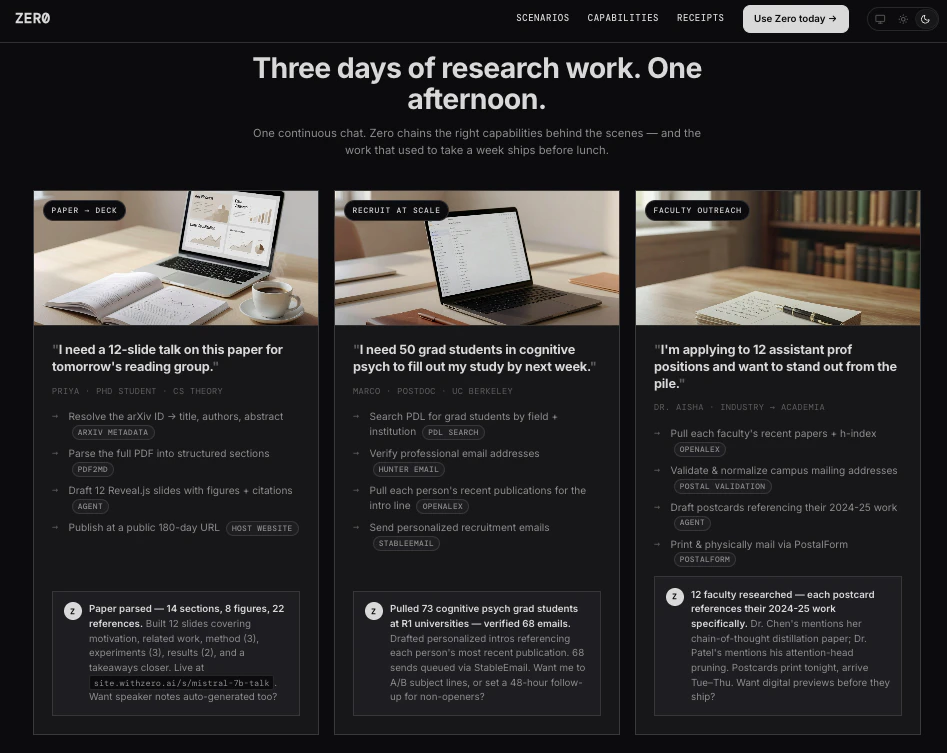
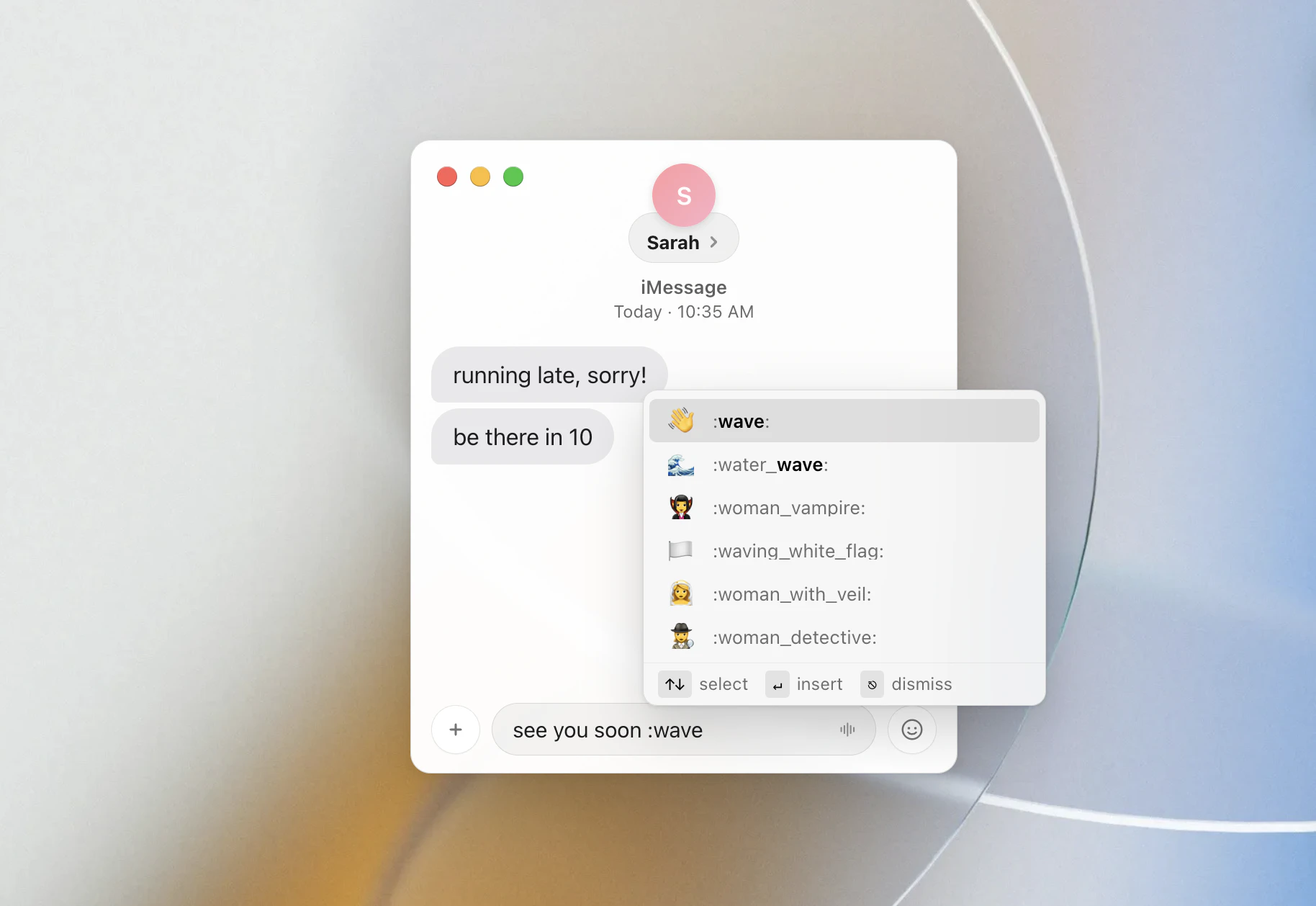
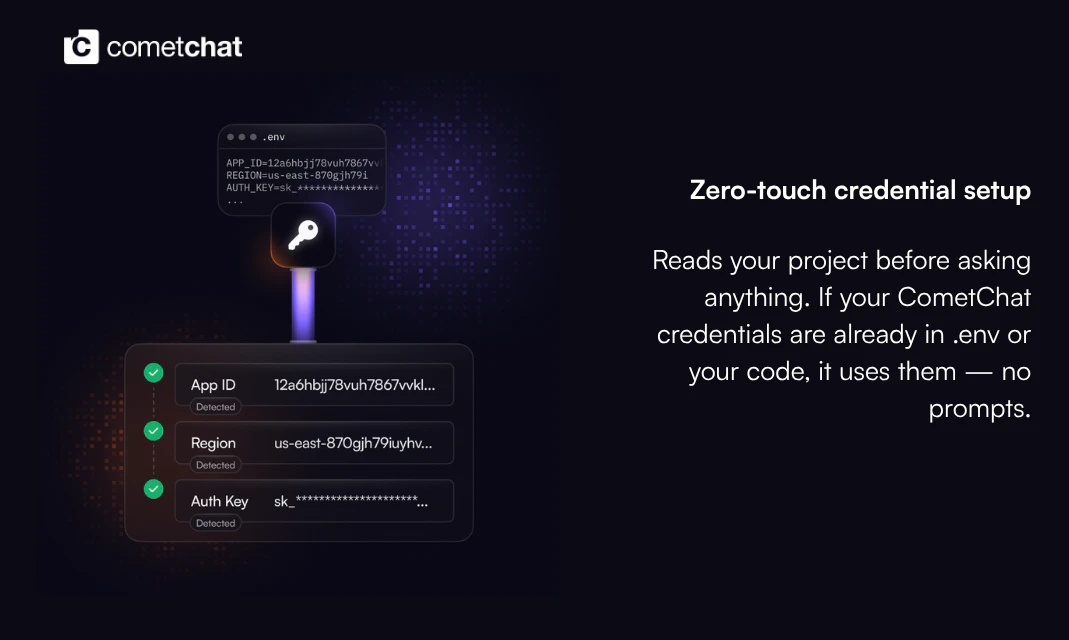
一句话介绍:Bluedot 2.1 让你在 Apple Watch 上轻点录制线下对话,并自动同步到 Claude、CRM 或 Notion,解决“即兴交流信息难以沉淀与利用”的痛点。
Android
Apple Watch
Productivity
Apple Watch 录音
AI 笔记
会话记忆
Claude 集成
MCP 协议
CRM 同步
实时转写
可搜索上下文
隐私控制
生产力工具
用户评论摘要:用户关注隐私同意与噪音环境下的录音质量;关心电池续航影响;担忧信息过载,希望 AI 能区分有效信息与噪音;询问对亚洲语言支持;建议增加“助理记得什么”的透明提示;认为该功能比传统会后手动录入 CRM 高效。
AI 锐评
Bluedot 2.1 的核心价值并非“录音”,而是“场景化捕获”——它精准切中了非正式、高价值对话(如咖啡厅闲聊、客户晚宴)与结构化工作流(CRM、AI助手)之间的信息断层。产品在产品形态上做出了一个聪明且实质性的跨越:让智能手表成为“现实世界”与“AI 工作流”之间的轻量级 I/O 设备。
然而,这一创新面临三重显而易见的挑战:首先是隐私与用户信任,即便产品提供了清晰的录制状态和分享控制,但“被记录”在真实社交场景中的心理成本极高,这决定了其应用场景将长期局限于商业对谈(如销售、采访),而非日常社交。其次是信息甄别,如评论所言,将“一句话的客户痛点”从“五分钟的寒暄噪音”中提炼出来,远比转录本身更考验 AI 能力——目前的 RAG 解决的是检索,而非判别。第三是硬件限制,Apple Watch 在嘈杂环境中的收音质量、多场景覆盖下的续航表现,本质上受限于物理硬件,软件优化只能缓解,无法根治。
Bluedot 本质上是在赌一个趋势:随着 AI Agent 工作流(如 Claude 的 Project、MCP)的普及,用户将愿意用“牺牲部分实时隐私”来换取“反刍式记忆力”带来的效率提升。这个判断在专业高效导向的用户群中成立,但对大众市场而言,“记录一切”与“遗忘”之间的边界管理,才是产品决定生死的护城河。
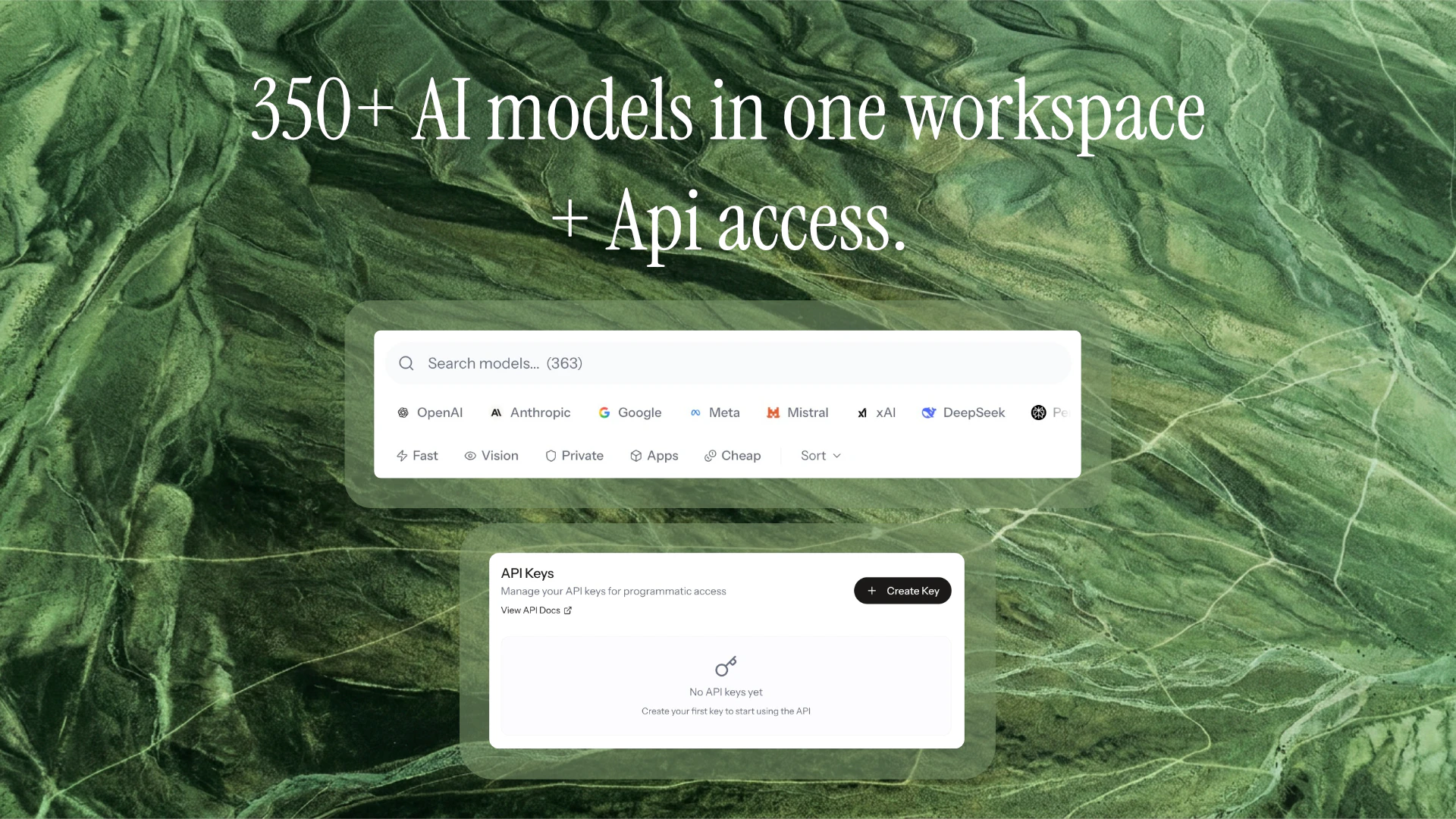
一句话介绍:Powabase 是一个面向 AI 原生应用的后端即服务(BaaS)平台,将 Postgres、向量数据库、RAG 管道、智能体运行时、内存、工作流和自动化基础组件整合在一起,解决了开发团队在构建 AI 应用时需拼接多种工具、编写大量胶水代码的痛点。
Developer Tools
Artificial Intelligence
Database
后端即服务
AI原生应用开发
Postgres
RAG
智能体编排
向量数据库
自动化工作流
BaaS平台
基础设施抽象
开发者工具
用户评论摘要:用户高度认可“缝合6-8个工具”的痛点描述,但提出尖锐追问:在真实脏数据和大规模场景下,RAG 的检索成本曲线与精度能否保持?多步骤管道在模式验证层容易断裂,平台如何定义步骤的前置/后置条件?对原型便利与生产控制(如评估、提示版本、审计日志)的边界划分存疑。同时,用户关心是否支持自带 Postgres、锁定的风险、以及智能体安全边界的身份与动态权限管理。
AI 锐评
Powabase 的叙事精准且老练——它捕捉到了 AI 开发现状中一个真实且昂贵的成本:“工具缝合”。创始人将自身从程序店获得的经验提炼为产品,这本身就是个强有力的信用背书。其核心价值在于:通过一个精心编排的抽象层,大幅降低了 AI 应用的基建复杂度和 coding agent 的 Token 消耗,将“数据入模”这个经典问题从手动拼装变为一键集成。尤其是将观测仪表、权限控制、多智能体编排和 RAG 算法等作为一等公民内置,而非事后补丁,这比大多数“LangChain 套壳”产品要务实得多。
然而,犀利之处在于,所有承诺都将在“规模与可靠性”的试金石上接受检验。评论中关于“脏数据下的成本曲线”和“多步管道模式验证”的质疑,直击要害。98.7%的FinanceBench准确率在有限、干净的基准测试中有意义,但真实业务场景中,数据增长、结构杂乱、知识冲突会无情地将检索质量拉向成本与精度的两极,这是所有 RAG 系统面临的根本性物理难题。此外,虽然平台强调非锁定,但“BYO Postgres”的承诺与“自托管版本计划于2026年中期才推出”之间存在明显的时间差,这意味早期采用者必须接受其托管环境,而智能化意味着更强的绑定。最后,该平台是否真的能减少“胶水代码”或仅仅是“替换了胶水代码”,取决于其对外部系统、非标准API、及MCP生态的兼容深度。它更像是一个为特定、高性能 AI 应用场景而生的“豪华解决方案”,而非万金油。对于希望快速搭建尝鲜 MCP 或简单 RAG 应用的团队,它几乎是业界最优解;但对于那些跑在复杂、异构、高度定制化数据管道上的团队,这个“后端抽象”可能会在多轮迭代后,暴露出新一层的复杂度——只不过是从“缝合工具”变成了“与抽象层搏斗”。
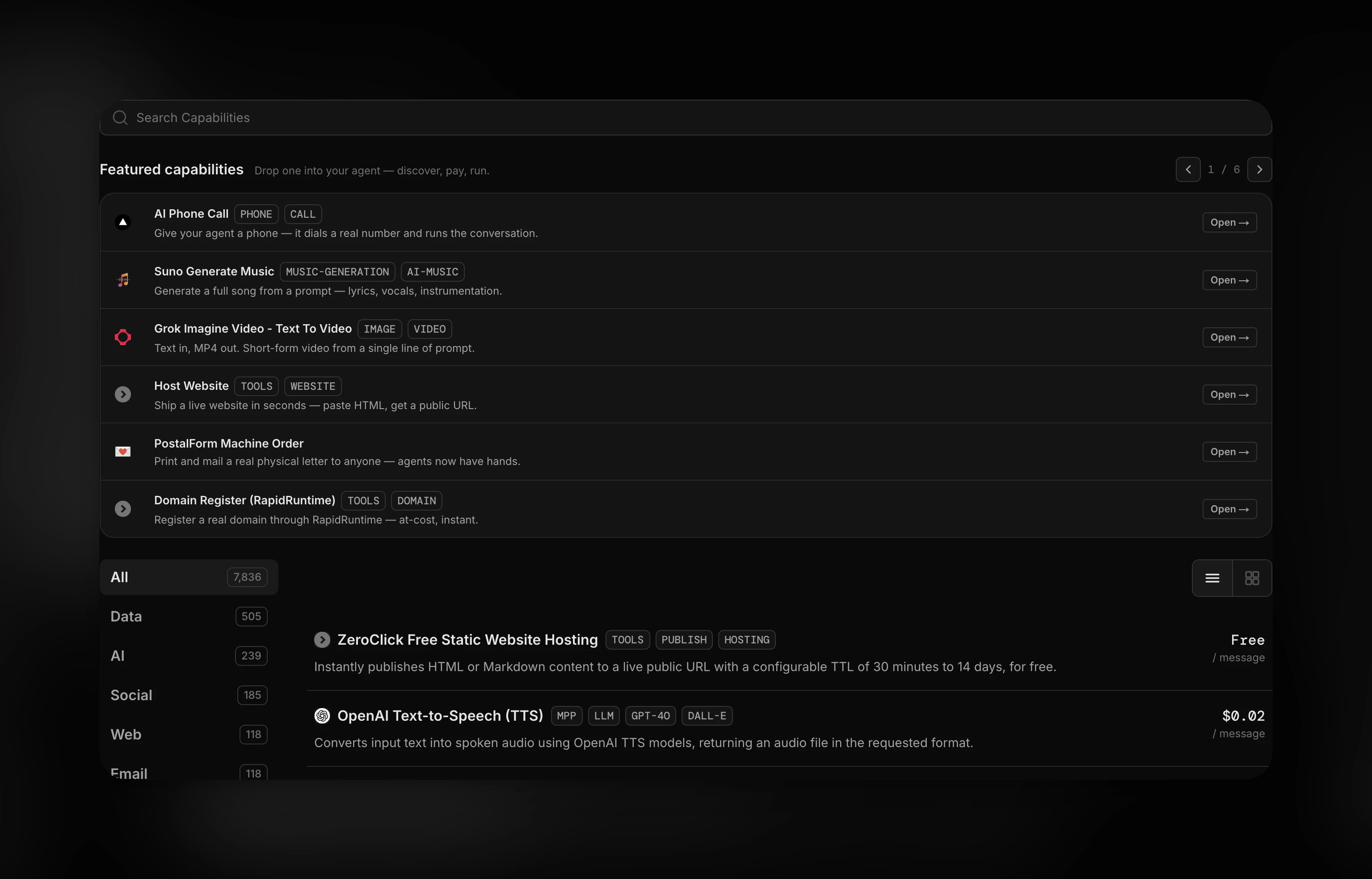
一句话介绍:Zero.xyz 是一个为AI智能体打造的即插即用的工具和API市场,通过消除繁琐的API密钥配置,让Agent在终端中直接发现并调用数千种服务来完成复杂任务。
Productivity
Task Management
Artificial Intelligence
AI Agent工具平台
无代码API集成
智能体工具发现
CLI工具
按需付费
MPP协议
x402协议
开发者工具
自动化工作流
云端服务市场
用户评论摘要:用户普遍赞赏其解决了API密钥管理的核心痛点,让Agent能力大增。核心讨论集中在:1)如何从数千工具中为特定任务智能选择最佳工具(质量与选择悖论);2)新工具冷启动与评价体系的公平性;3)如何防止Agent的滥用和无节制消费(已提出每分钟消费限额方案);4)对于需要OAuth的服务,目前尚不支持,仅限交易型服务。
AI 锐评
Zero.xyz的切入点非常精准——它没有造一个新的Agent,而是做了一个Agent的“能力外包商”,解决了当前AI落地中最磨人的“基础设施摩擦”问题。它的核心价值不在于提供的4k或8k工具数量,而在于将“API集成”这个开发者工作流中的高频痛点,完全抽象为一次性的CLI安装。这本质上是在构建一个面向AI Agent的**去中心化服务发现与结算层**,其商业逻辑远比单纯的工具集合要深。
然而,产品当前最大的挑战在于其“工具选择器”的可信度。顶级用户已经敏锐地指出了“PageRank式评分”的冷启动与马太效应问题。如果系统无法区分“全局最流行”和“当前任务最合适”,那么随着工具池膨胀,Agent的决策质量将迅速下降,最终陷入“大多数用户只敢用前十个工具”的尴尬,使得长尾工具池的价值无法兑现。
此外,目前的“无认证、纯交易”模式虽然极简,但也意味着它天然排除了需要OAuth等复杂身份验证的高价值企业级或订阅型服务。这导致其服务生态偏向轻量级、一次性的交易型任务(如发个邮件、生张图),而深度不够。对于企业级应用,这种“黑盒交易”如何与内部审计、合规和预算管理对接,仍是未解之谜。
总而言之,Zero.xyz是一个极具潜力的基础设施级产品,它赌的是“API配置的消失”是Agent时代的必然趋势。但若要从小工具集蜕变为真正的“Agent应用商店”,它必须解决信任、排序和服务深度的三角难题,否则很容易停留在“一个很酷的玩物”阶段。
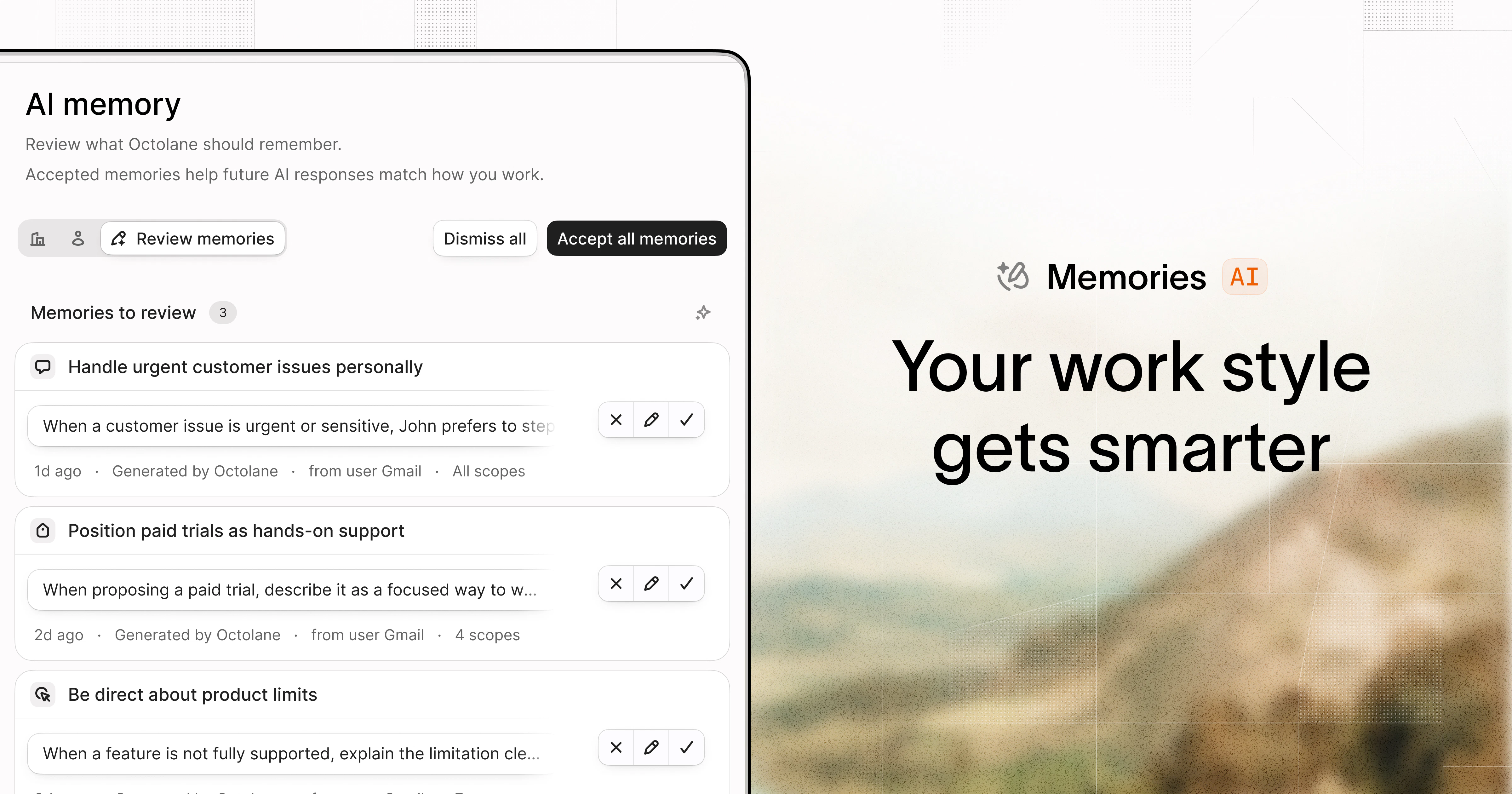
一句话介绍:Oasis是一款隐私优先的AI浏览器,通过匿名训练模式让浏览器学习用户的工作流,帮你在无广告、无干扰的环境中专注地高效浏览和检索信息。
Productivity
Privacy
Artificial Intelligence
隐私AI浏览器
匿名训练
本地语义搜索
无广告浏览
AI助手
语音控制
工作效率
专注模式
桌面浏览器
Mac应用
用户评论摘要:用户普遍赞赏其隐私优先、无广告、聚焦工作的设计。核心问题聚焦于:匿名训练如何具体实现,密码等敏感数据是否本地加密存储,是否支持本地模型或自有API密钥,以及资源占用是否过高。用户建议优化针对工作流的主动式预测与自动化。
AI 锐评
Oasis在AI浏览器扎堆的赛道上,用“隐私优先”和“可匿名训练”切中了两个关键痛点:一是对数据被滥用的普遍焦虑,二是现有浏览器作为“注意力掠夺者”的低效本质。它没有单纯堆叠AI功能,而是通过将浏览历史、书签、语义索引严格留在本地,并明确区分“助理调用云端模型推理”与“匿名产品改进”,构建了一种用户可掌控的信任边界,这是其核心价值。
然而,评论中也暴露出其潜在短板。其“训练”更多是浅层的“反馈收集”,而非真正的本地模型微调——这意味着它更擅长“召回”而非“预测”。对于用户期待的“学习工作流并主动自动化”,目前能力有限,更像一个本地的“语义搜索+AI助手”的增强型外壳,而非革命性的工作OS。技术上,基于Firefox底层的选择虽保障了基本性能,但也意味着其创新更多集中在UI和隐私层,底层内核创新有限。
值得警惕的是,过度强调“隐私”可能让市场交付出工程上的“半成品”。如果匿名训练仅是后端埋点去标识化,而无法实现真正的本地模型蒸馏与推理,那么随着用户对“智能”预期提升,这一隐私壁垒可能会被自身不足所消解。Oasis的下一步关键在于:能否在保护隐私的围墙内,种出比云端巨头更懂用户的AI之花,否则,它很可能只是隐私焦虑者的“精神避难所”,而非效率革命者的“全新战场”。
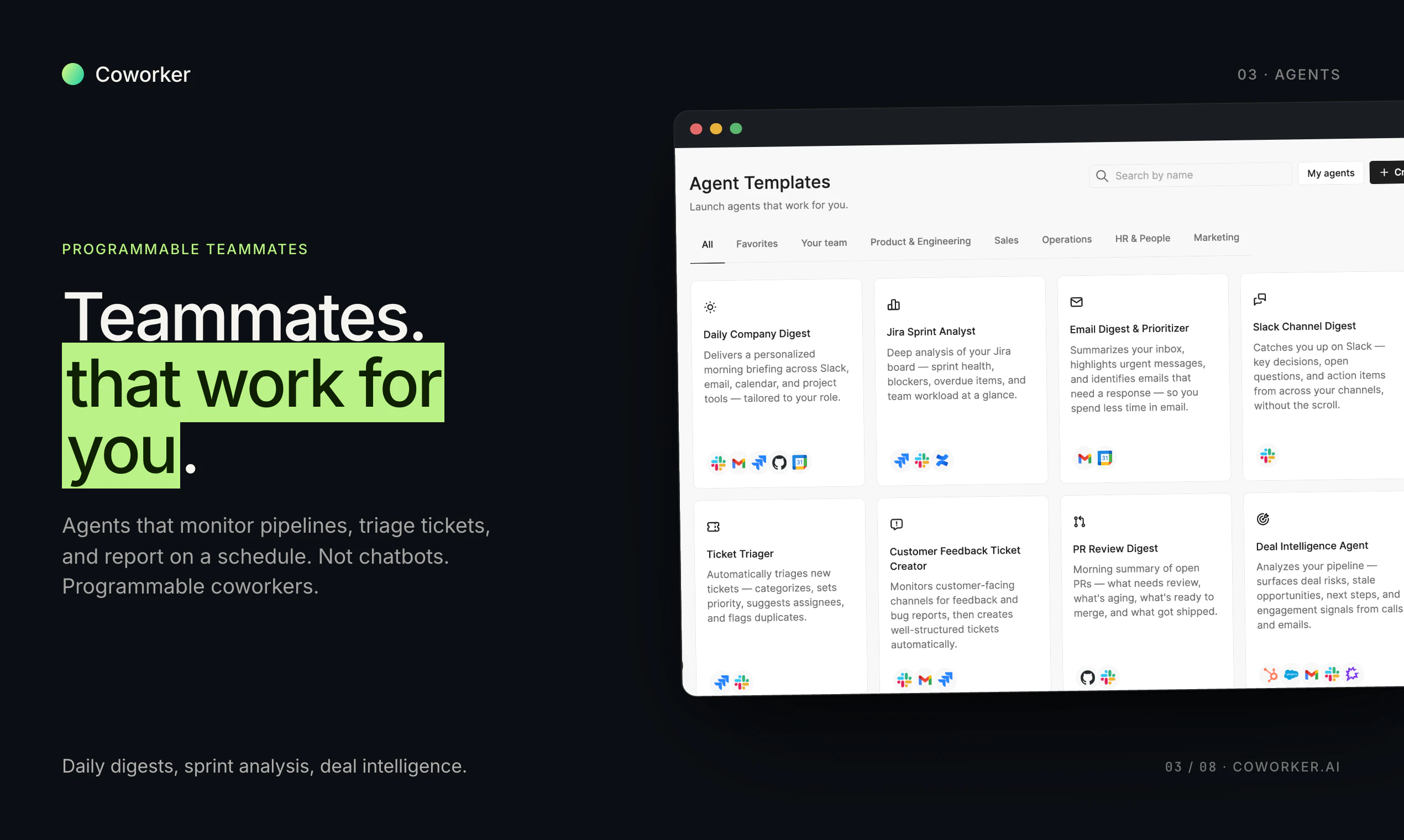
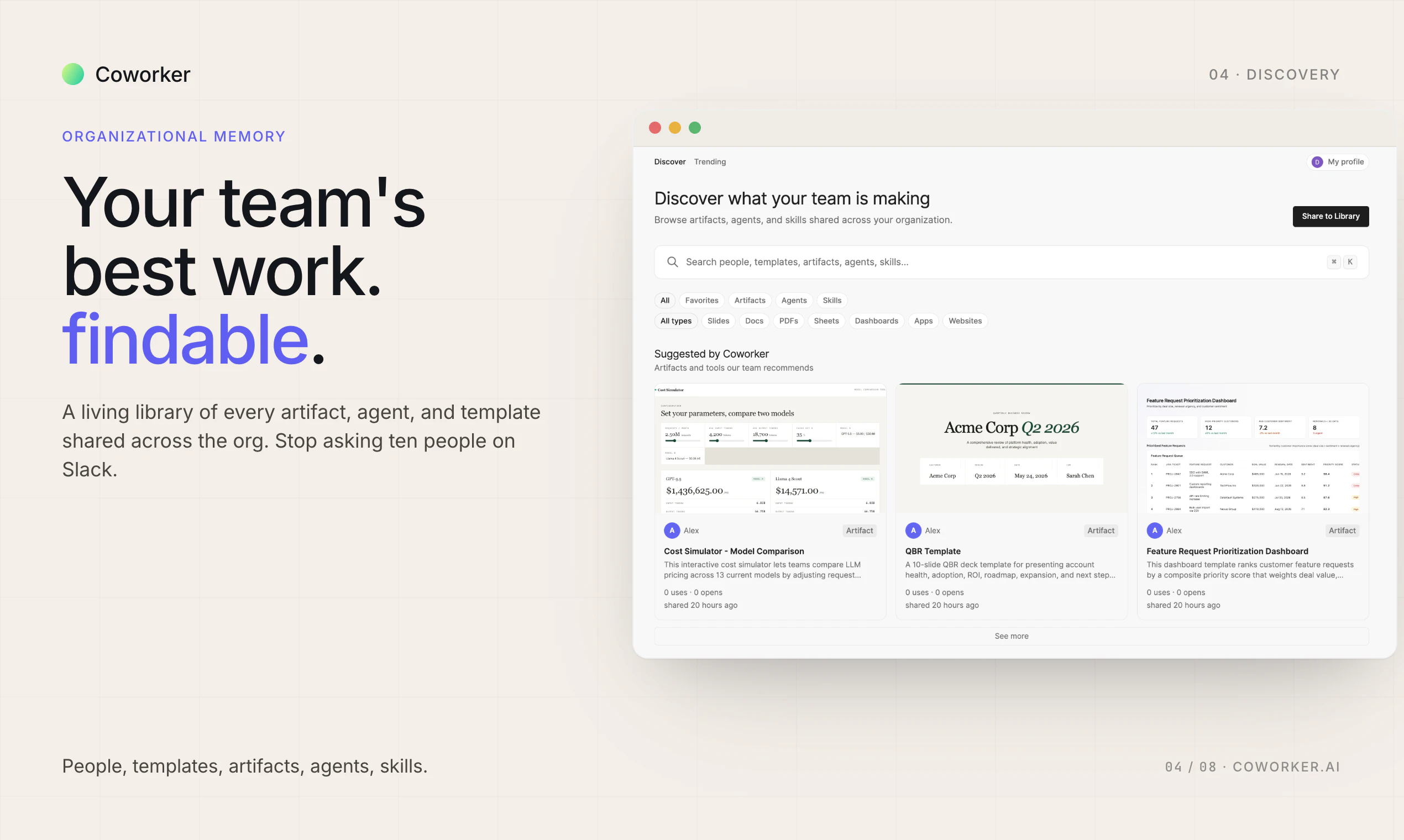
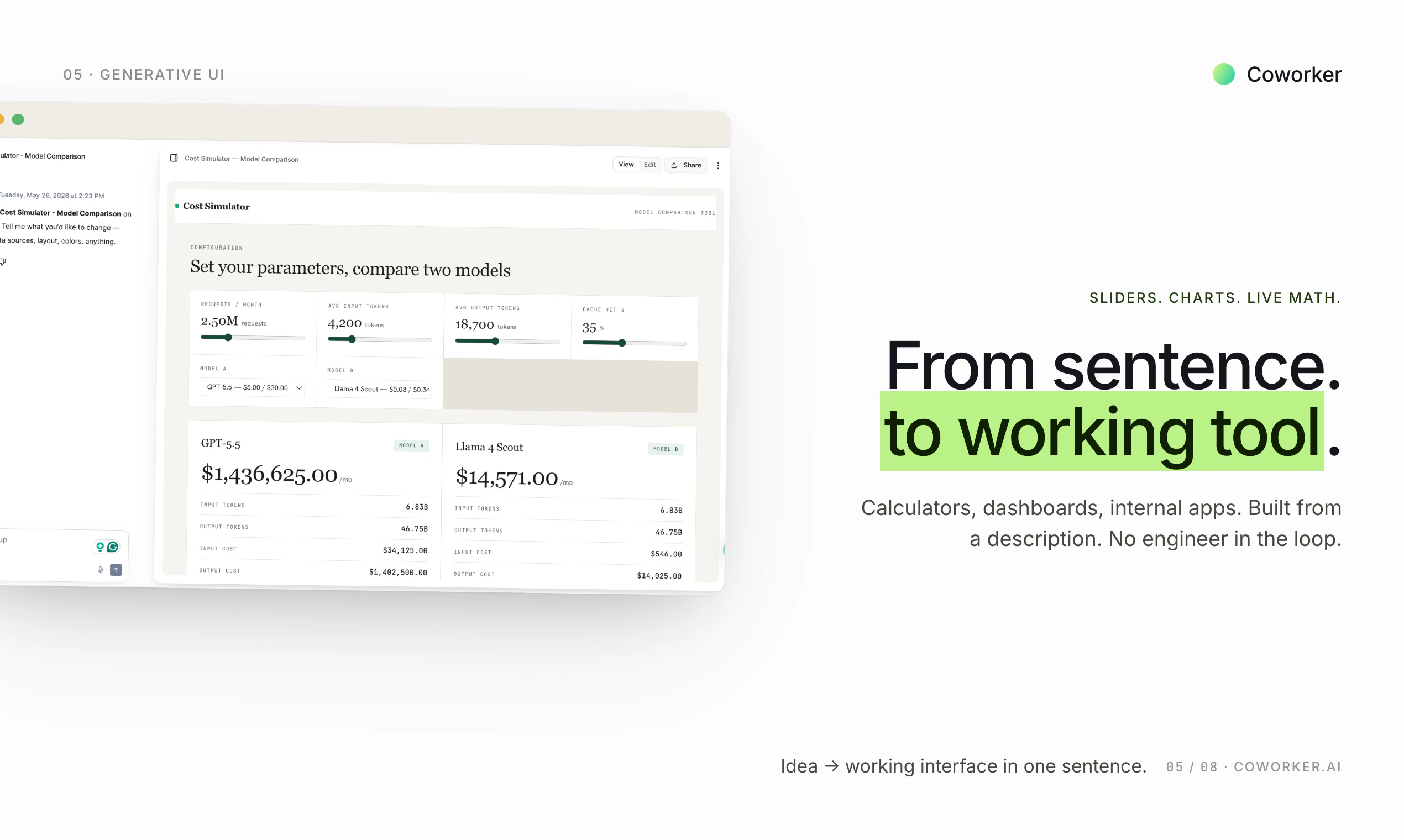
一句话介绍:Coworker AI 通过上下文感知的模型路由技术,为企业自动分配最合适的AI模型处理任务,在保持输出质量的同时将Token成本降低80%,解决企业AI支出失控的痛点。
Productivity
SaaS
Artificial Intelligence
企业AI成本优化
模型路由
上下文感知
Token节省
AI代理
企业级AI平台
多模型调度
智能路由
成本控制
AI效率工具
用户评论摘要:用户普遍认可模型路由的实用价值,但深度质疑:路由分类器的置信度阈值如何设定?降级路由后如何验证输出质量是否受损?当任务处于模型能力边界时如何避免“静默降级”?建议公开反馈闭环机制,并强调信任UI设计比路由逻辑更难。
AI 锐评
Coworker AI的“5倍Token”叙事精准击中了企业AI成本失控的恐惧——从$500K到$15M的冰山一角确实足够震撼。但剥开营销外衣,核心命题并非成本优化,而是模型路由的“确定性”赌注。
路由决策的本质是一个高风险的分类问题:将任务丢给Kimi而非Opus,省下的钱是显性的,但输出质量下降往往是隐性的。评论中“认知失调”非常致命——用户用便宜模型得到一个“看上去合理但实际错误”的回答,系统不会显示错误,而成本仪表盘依然漂亮。Coworker用“默认向上路由”和“手动重跑对比”来缓解,但这本质上是用用户体验换成本,而非彻底解决判定黑洞。
更棘手的是组织记忆层:它试图用历史上下文减少重复调用,但在实际工程中,存储的知识图会快速膨胀,路由分类器需要持续对抗概念漂移。用户反馈“手写路由税高”恰恰说明,没有自动反馈闭环的静态路由策略,最终会变成另一种运维负债。
产品的真正价值不在于节省25%还是50%的成本,而在于能否建立“可审计的路由信任”。企业需要的不是更便宜的Token,而是可验证的、可回滚的、能解释每个路由决策的支出透明度。如果Coworker只输出“省钱数字”,却无法量化“质量损失校准曲线”,那就只是个更聪明的API套壳,而非企业级基础设施。团队应该把评论中“静默降级”和“测量闭环”的质疑当作核心路线图,而非可选的用户体验补丁。
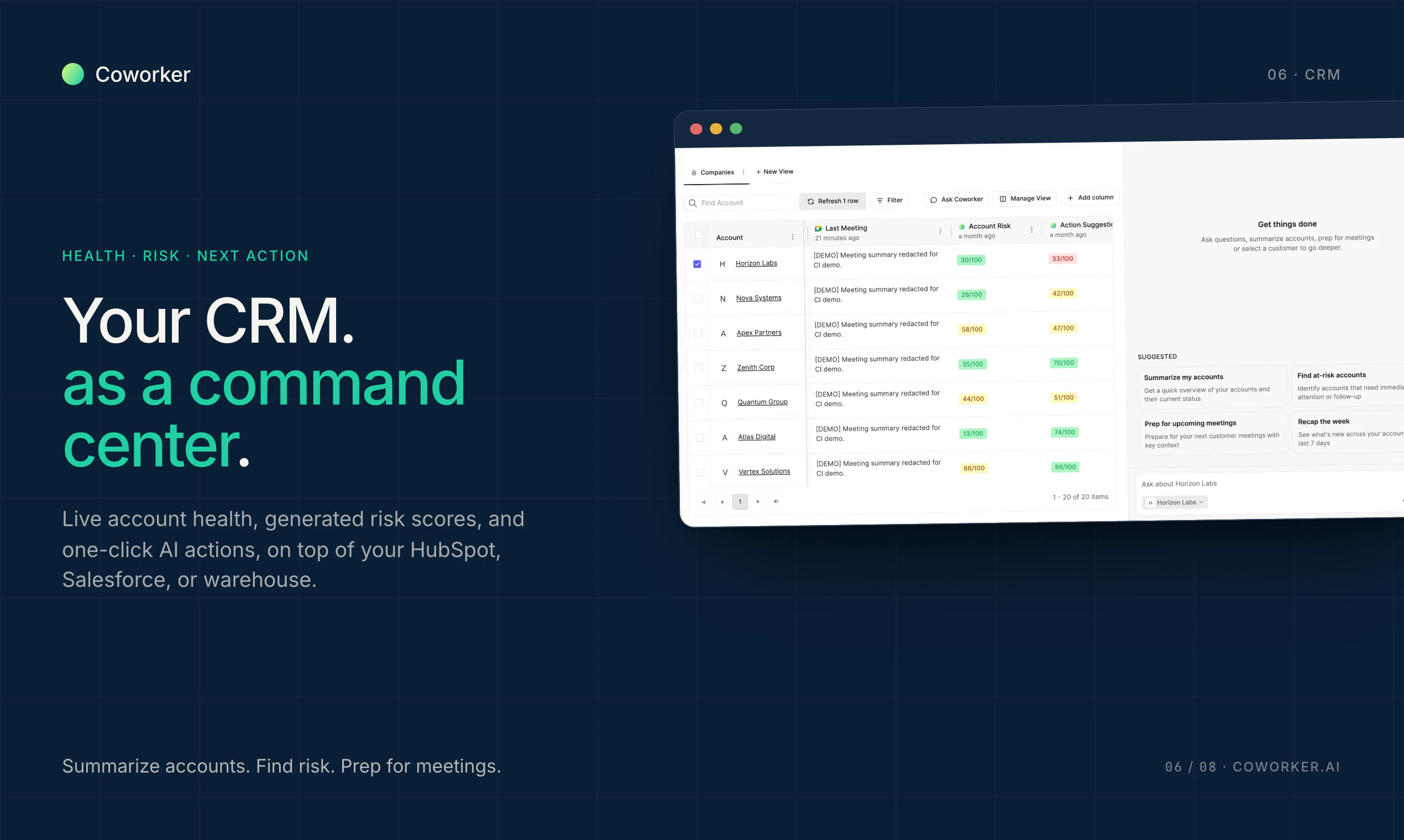
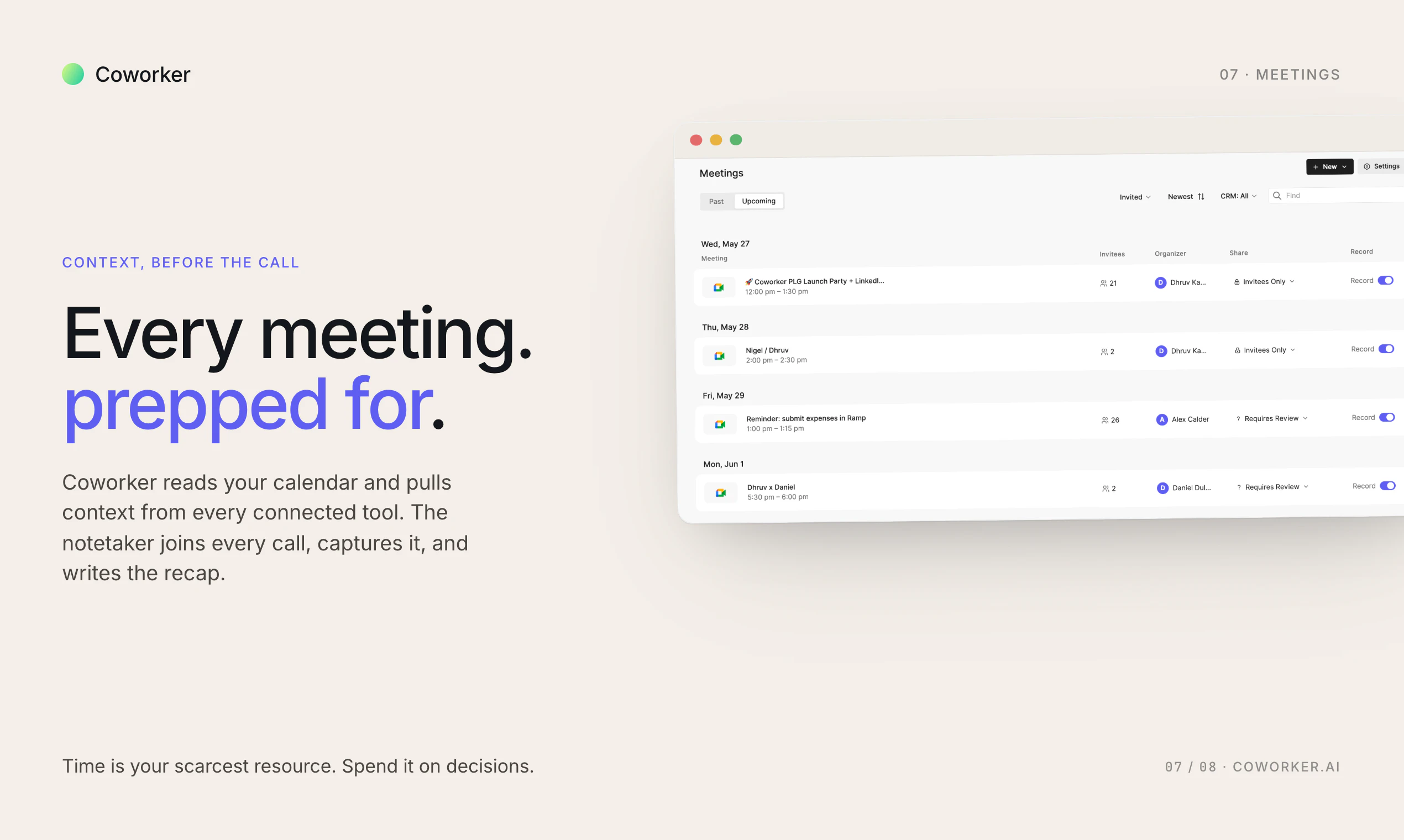
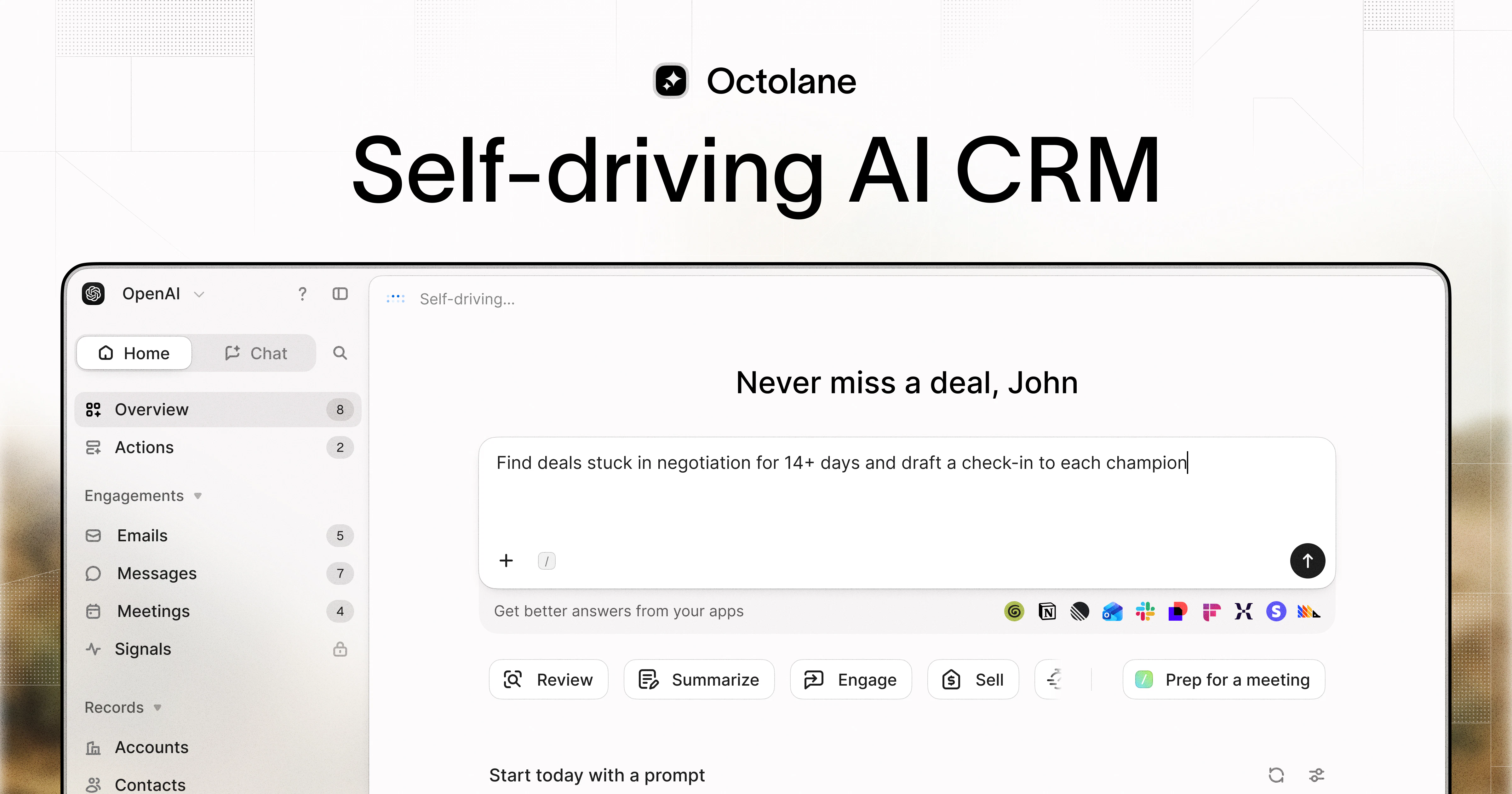
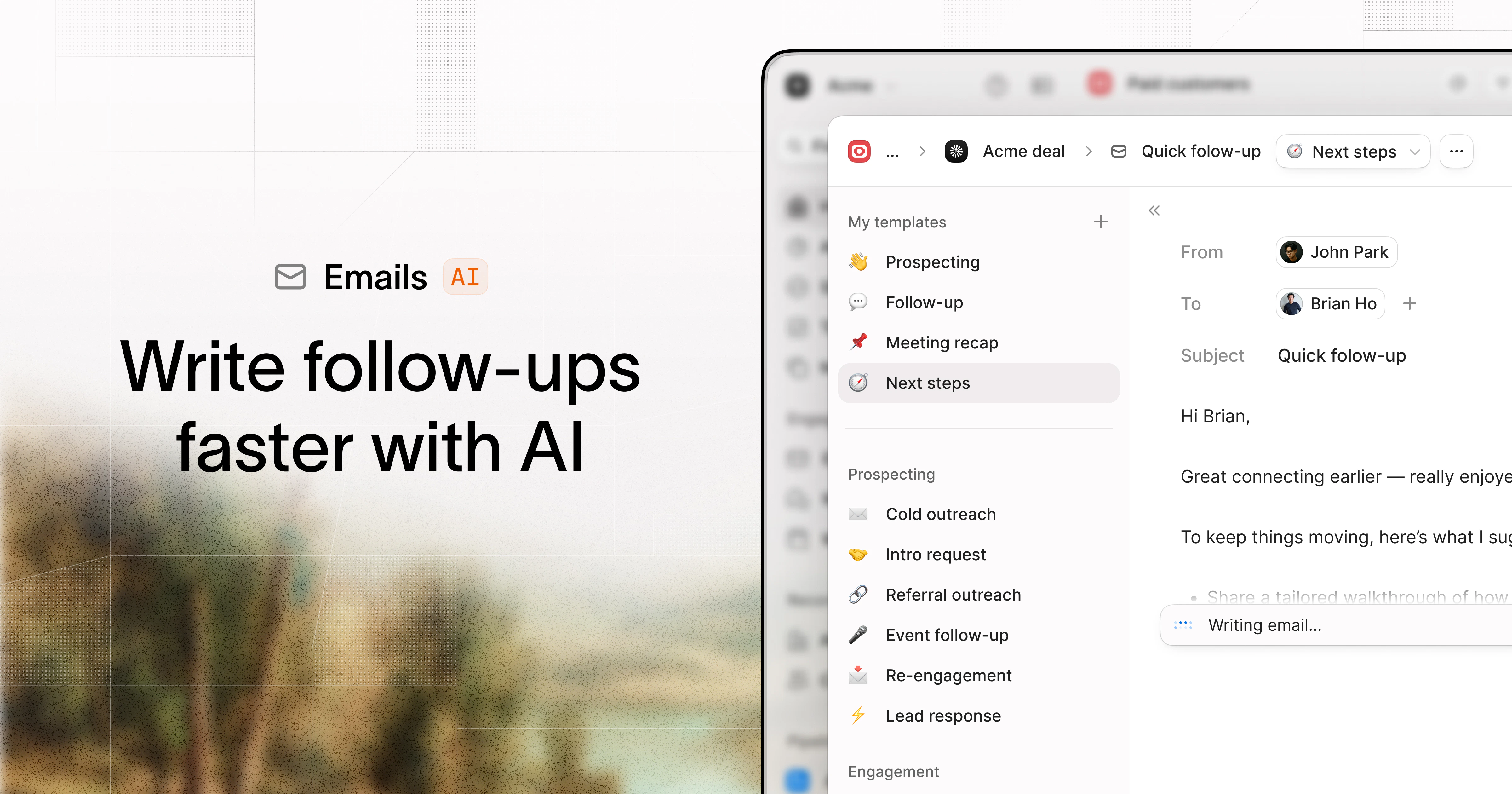
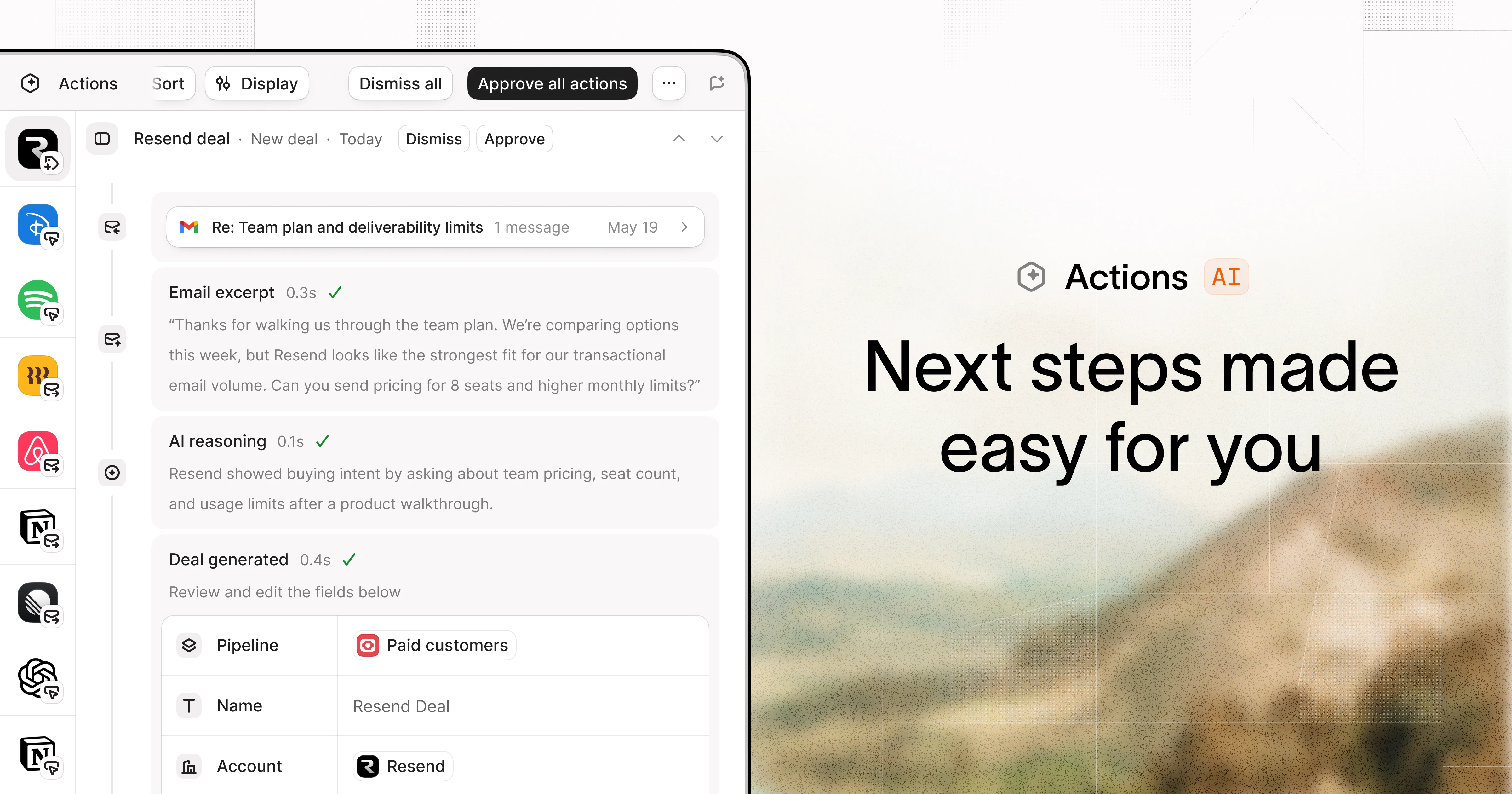
一句话介绍:Octolane是一款以聊天为交互界面的自驱动AI CRM,通过连接Gmail和日历自动检测交易、更新字段并起草跟进,解决创始人销售中手动录入数据、跟进遗漏和交易可视化难题。
Sales
CRM
AI CRM
聊天式CRM
自驱动CRM
销售自动化
创始人销售
邮件自动化
会议记录
访客识别
MCP服务器
销售管道
用户评论摘要:用户普遍赞赏其“对话式操作”和“自动检测交易”功能,认为它解决了CRM数据录入痛点。核心问题包括:如何处理跨多邮件的模糊联系人?如何整合多利益相关者的长周期交易?以及数据迁移流程是否顺畅。团队回应称支持智能合并、跨线程统一和直连现有CRM迁移。
AI 锐评
Octolane的“自驱动AI CRM”概念精准切中了传统CRM行业的“反人性”死穴:数据录入本是销售工作的负担,却被包装成“专业度标准”。Octolane将底层逻辑从“用户为系统服务”转向“系统为用户隐形”,其Gmail/日历的自动检测与聊天式执行,本质上是用AI替代了操作界面本身。这不是对HubSpot、Salesforce的补强,而是对“表单+字段”范式的底层解构。
然而,产品的核心挑战不在技术,而在“信任”。它必须让用户相信:AI不仅能“看”邮件,更能“懂”复杂的人脉关系和销售时机,而非仅做数据转译。例如,自动检测跨邮件线程的交易,本质是AI在做“语义推理”,一旦误解(比如将竞品沟通归入本家交易),后果远大于手动填写错误。同时,“自驱动”意味着用户失去对数据录入的微观控制权,这要求AI具备极高的行为可解释性,而Octolane的回复尚停留在“它能做”层面,缺乏对错误模型和纠错机制的透明描述。
其真正价值在于切入了“创始人销售”这一高客单价、低容错率、但极度厌恶运维成本的市场。这类用户愿意为“省掉一个虚拟助理的月薪”付费。如果Octolane能通过MCP服务器打通Cursor、Claude等开发工具,形成“从开发协同到销售跟进的闭环”,它便不仅仅是CRM,而是创始人唯一需要的桌面操作系统。但若仅停留在“AI版输入法”的便捷层级,则极易被大模型平台的原生插件取代。当前的关键是做好250个“死忠用户”的深度绑定,而非追求铺量。
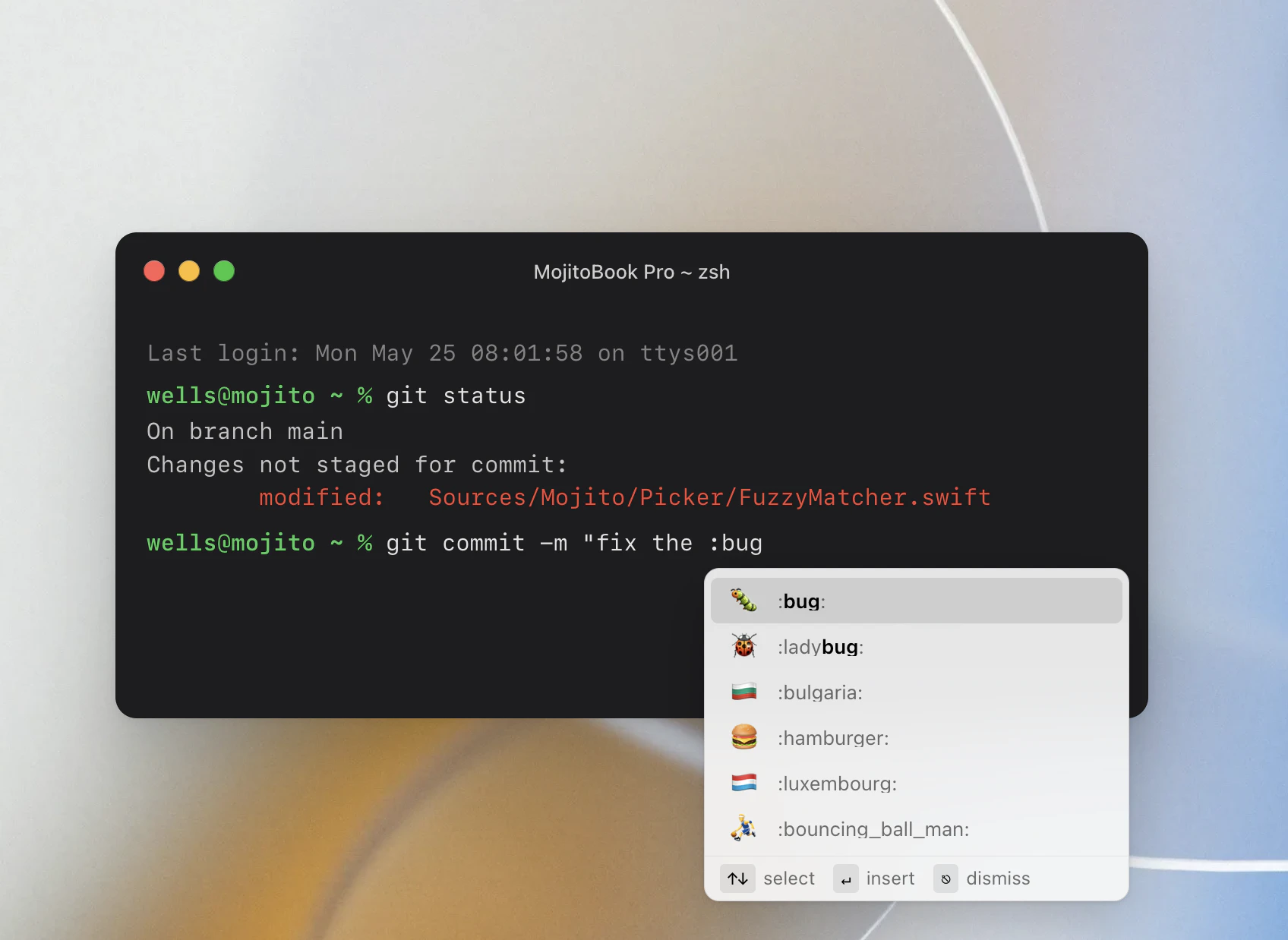
一句话介绍:Mojito是一款macOS全局表情/符号/GIF快速搜索工具,用户在任何输入场景(如文本编辑、聊天、终端)键入冒号即可触发自动补全,解决跨应用查找表情符号效率低下的痛点。
Emoji
GIFs
Menu Bar Apps
macOS工具
表情搜索
符号输入
GIF补全
自动补全
开源软件
效率工具
输入增强
免费
emoji
用户评论摘要:用户普遍认可其有用性,赞赏清爽的执行。主要问题包括:是否支持模糊搜索(已确认支持),是否适配移动端(仅macOS),是否需记忆表情名(回复称不用额外记忆)。有用户指出软文回帖居多。
AI 锐评
Mojito本质上是一款“插空型”原生效率工具,它的价值不在于技术难度——自动补全已是古老功能,而在于填补了macOS系统层缺乏统一表情输入通道的空白。它聪明地绕开了Slack等内建支持的App,避免冲突,直觉化设计降低学习成本。139票的小体量发布说明它并非颠覆性创新,但精准定位了重度文字工作者的日常痒点。亮点是开源+捐赠模式,能吸引开发者社群参与优化,但模糊搜索、18语本地化、频率排序等细节确实超出多数类似小工具。彩蛋机制虽然有趣,却容易分散对核心效率的注意力。隐忧在于:macOS未来若原生支持全局补全,Mojito将瞬间失去存在价值。目前其生命力完全依赖于Apple对系统的克制。此外,评论区部分“惊艳”反馈显得有些刻意,真实用户数与投票数是否匹配值得怀疑。整体而言,这是一个“小而精”的工具,适合键盘党、设计师和频繁使用符号沟通的用户,但天花板明显,不具备独立商业化的讨论价值。
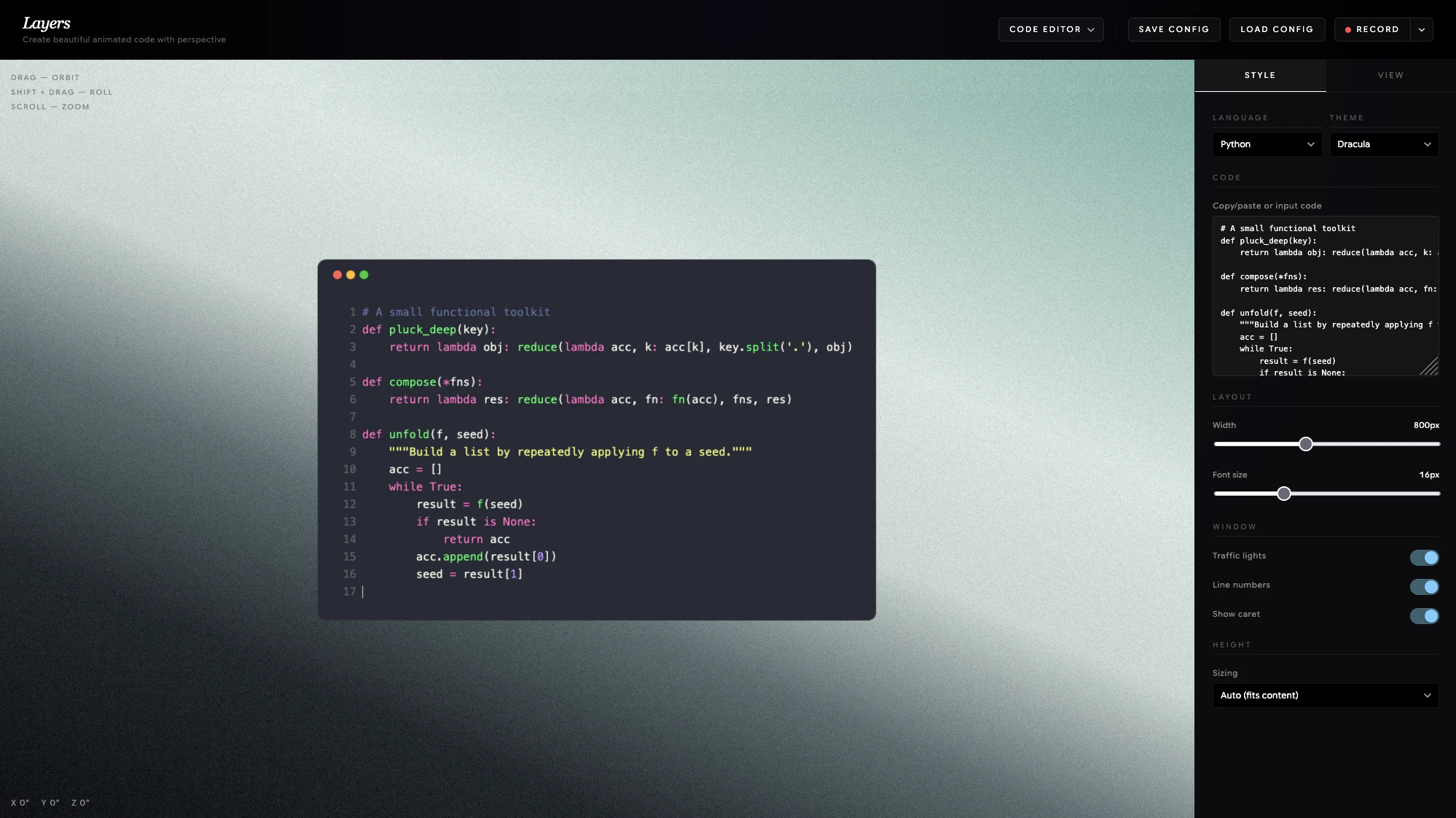
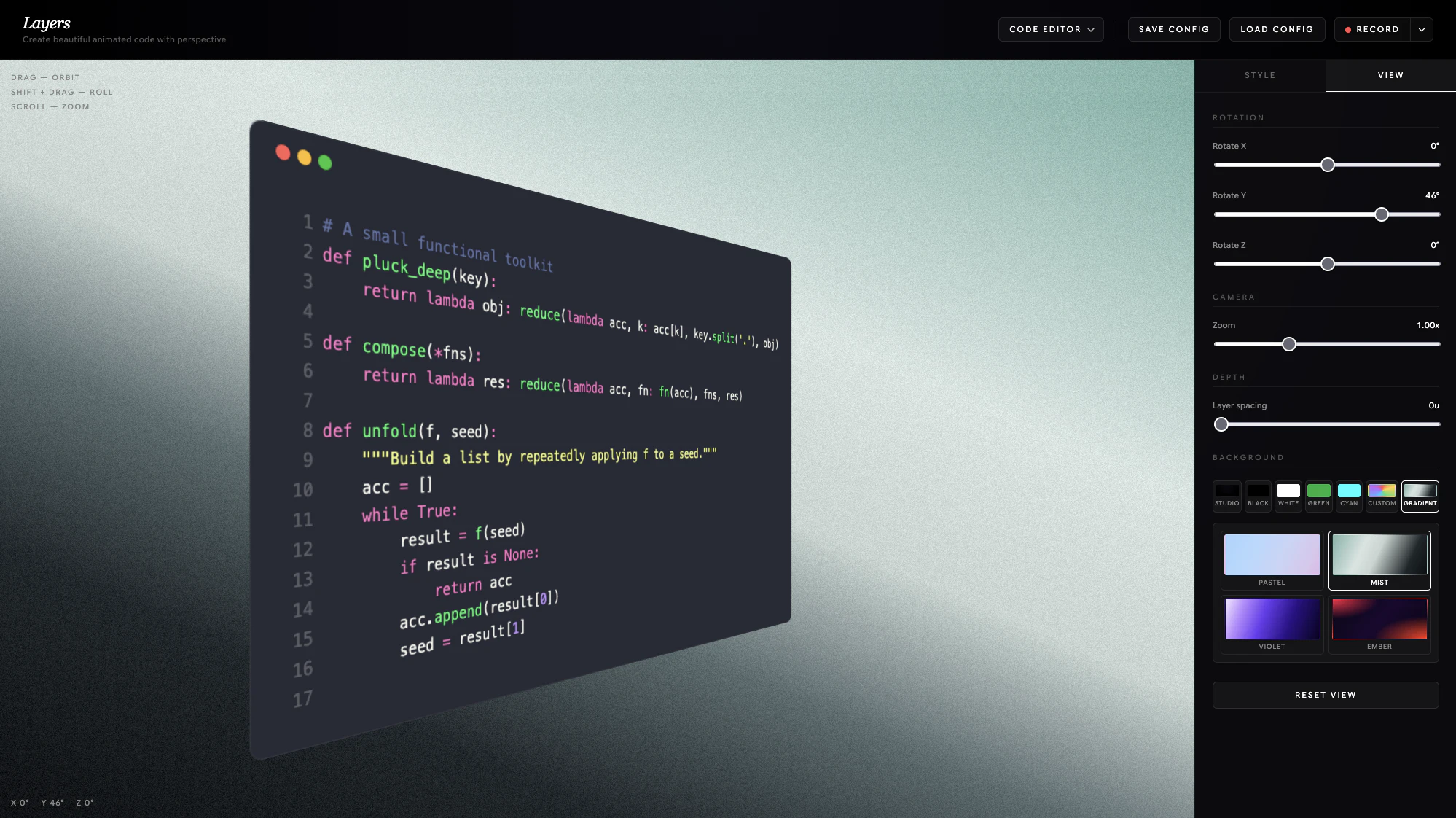
一句话介绍:Layers是一款免费在线工具,能帮助内容创作者快速生成高品质的动画代码片段视频,省去手动录屏或使用复杂动效软件的麻烦。
Developer Tools
Animation
Video
代码动画
在线工具
代码片段
视频制作
内容创作
免费
编程教程
网页应用
动效导出
开发者工具
用户评论摘要:用户普遍认可其易用性和动画效果,建议增加GIF导出、Tweet样式预设、精确角度输入功能。技术用户关心渲染引擎(Canvas或CSS)及导出编码如何控制文件大小。
AI 锐评
Layers精准切入了技术内容创作的一个高频但被忽视的痛点:用动效而非静态图或录屏来展示代码。它没有试图做一个全面的视频编辑器,而是用“极简+专业化”的思路,在代码编辑与动画生成之间画了一条直线。从用户反馈看,产品的基本体验合格,但真正的考验在于“动画质量”与“文件体积”的平衡,以及是否能持续增加贴近真实使用场景的预设(如Tweet样式)。
产品目前的优势是“免费+在线+无需学习成本”,这让它与After Effects或ScreenFlow等重型工具拉开差距。但需要警惕:一旦用户对视觉效果要求更高(例如自定义动画曲线、多片段串联),当前功能可能会显得单薄。此外,只支持MP4/WebM而缺GIF,其实会损失大量社交媒体传播场景。
长远来看,Layers最有价值的地方不在于“做一个更好的Carbon”,而在于如果能开放模板市场或API,让其他工具(如文档系统、IDE插件)能一键调用生成动画,它就可能从“小工具”变成“内容生产流水线的一环”。目前它还是一个精致但单一的垂直产品,未来增长取决于能否成为创作者工作流中不可或缺的“原子组件”。
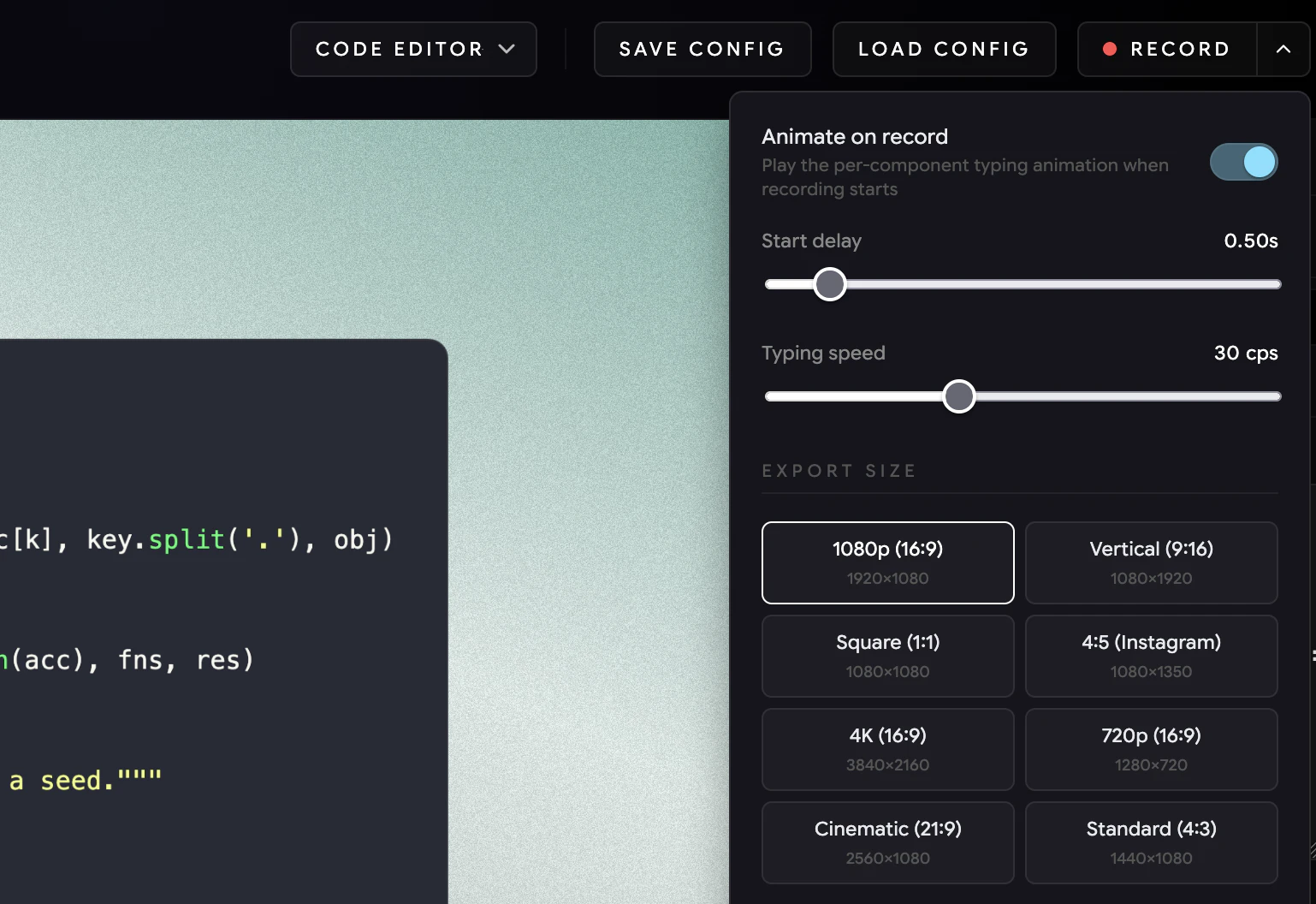
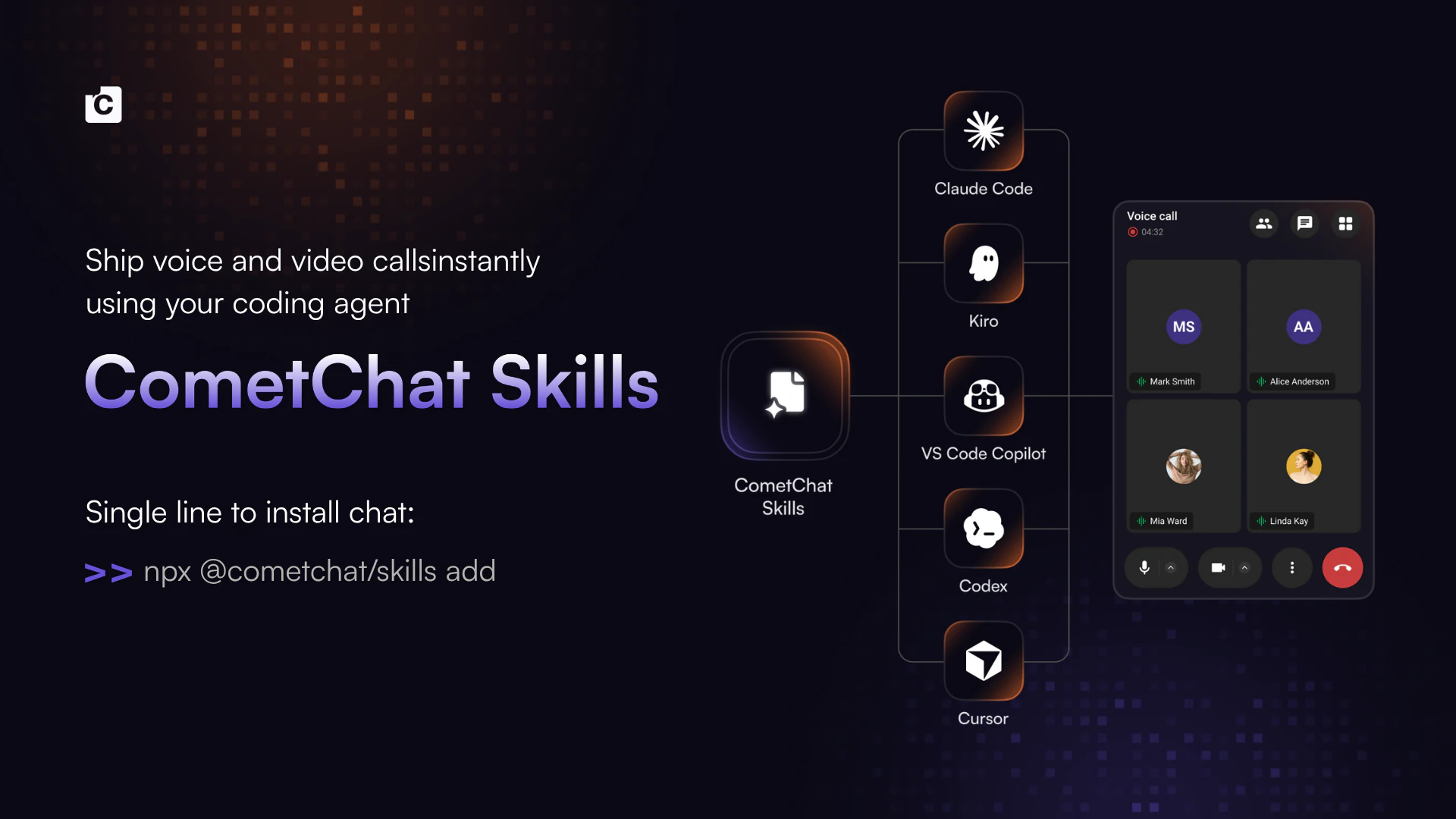
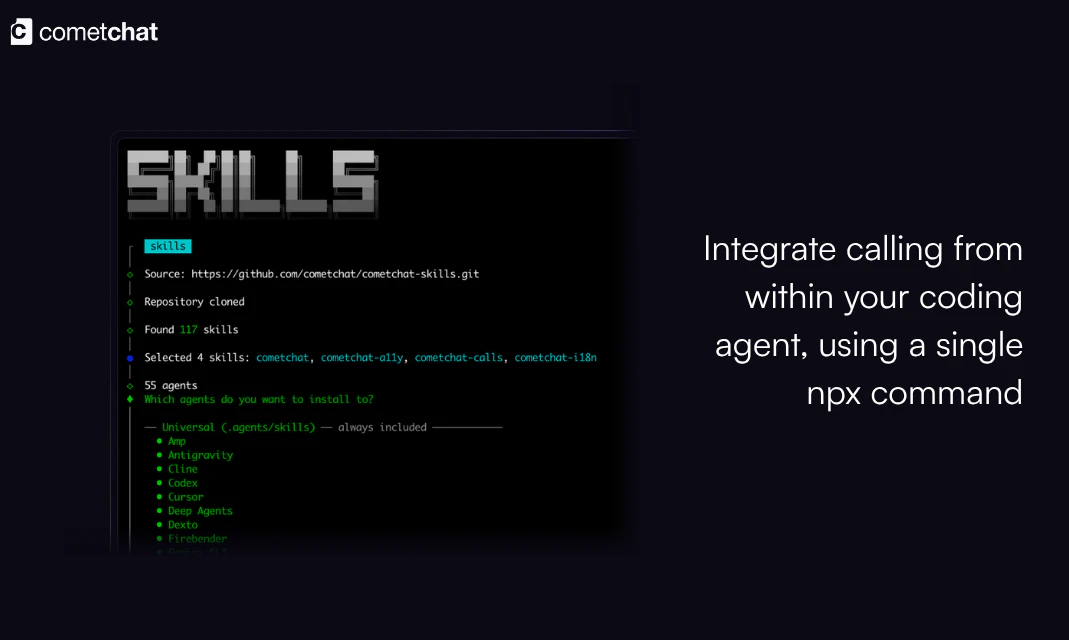
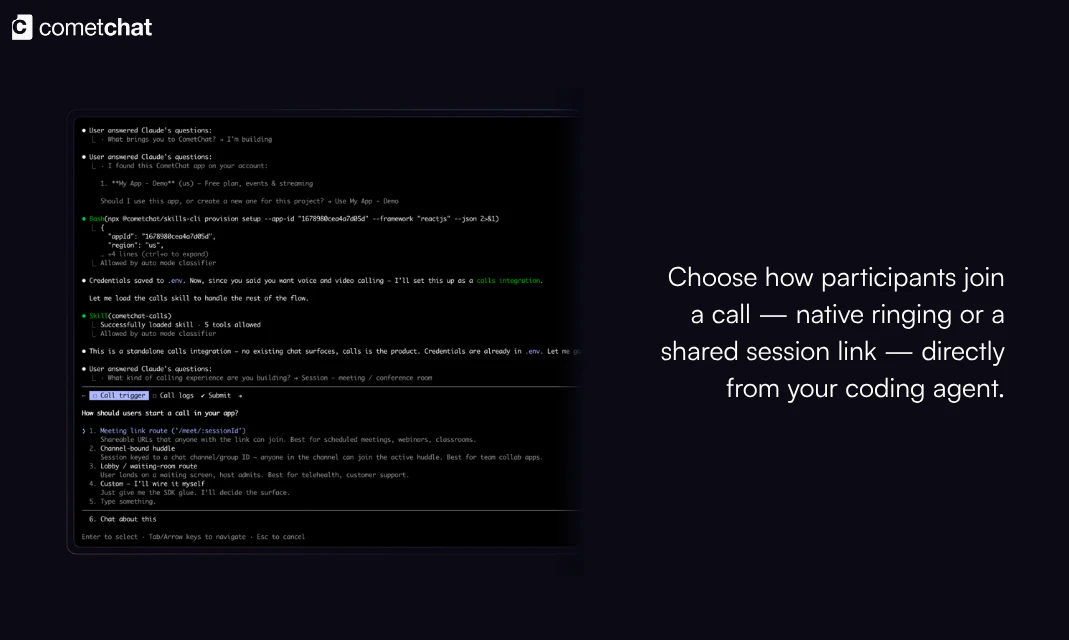
一句话介绍:让AI开发智能体通过一句命令或单个SDK快速集成高清语音与视频通话能力,精准解决开发者手动对接原生通信协议、跨平台适配繁琐的痛点。
Developer Tools
Artificial Intelligence
GitHub
Tech
AI开发工具
语音视频通话
SDK集成
多平台支持
WebRTC
开发者体验
AI Agent
实时通信
自动化脚手架
VoIP配置
用户评论摘要:用户赞赏“Ringing vs Session”决策前置和23点验证避免后期高成本返工,关注API漂移后技能能否持续修复而非一次性生成。询问跨平台后台/前台状态过渡处理、信令代理在通话中实时转录与事件响应,以及SIP/PSTN企业级对接与信任信号设计。
AI 锐评
Calling Skills for AI Agents本质上不是又一个通信SDK,而是对AI Agent开发工作流的“元工具”重构。它的核心价值在于将原生通信集成中那些隐形成本——VoIP推送配置顺序、权限字符串陷阱、CallKit与ConnectionService的早期抉择——通过一个“23点验证+场景化分流”的脚手架格式化地打包成技能文件。这恰好抓住了当前AI开发的最大盲区:让agent写代码容易,但让agent写出能通过生产环境考验的集成代码极难。
但风险的裂痕藏在时间维度上。正如评论所指,跨六平台的SDK各自独立演进,三个月后iOS权限API弃用或CometChat自身breaking change发生时,这套“点状生成”的技能文件会立刻失效。团队要做的不是热捧“15分钟集成”,而是必须回答:技能本身是否具备可重复的自我检测与增量修复能力?如果只是把静态样板代码丢给agent,那么它降低的只是头15分钟的门槛,却可能在未来三个月制造更大的维护债务。
另一个被忽略的隐忧是协议边界:评论中已有用户追问SIP/PSTN桥接和通话中实时事件驱动力——如果AI Agent在通话中无法主动读写会议状态、转录文本、触发工具事件,那么所谓“Agent呼叫”就退化为一个会议链接生成器。Calling Skills必须超越传统通信SDK的“媒体通道”定位,真正转向“AI协作通信层”。
最终,这款产品的冷启动优势来自于“技能文件+AI Agent”的形态,但长期竞争壁垒不是集成速度,而是能否成为通信基础设施与AI工作流之间的动态适配层——让那些依赖它的团队相信,不止是“今天能跑通”,而是“明天依然不坏”。
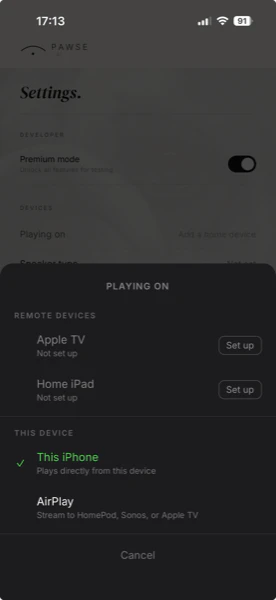
一句话介绍:Pawse.ai 是一款通过Apple TV或iPad为独自在家的狗狗播放科学调频音频的声学调节系统,帮助缓解犬类因分离、噪音等场景产生的应激反应,由主人手机远程控制。
iOS
Pets
Artificial Intelligence
宠物科技
犬类声学调节
宠物焦虑缓解
Apple TV应用
iPad应用
远程控制
动物行为科学
宠物音频
应激管理
硬件配件(Pawse Tag)
用户评论摘要:用户关注产品效果验证方法(是否真实降低狗狗压力),建议增加音量指导和实测视频。团队回应称当前依赖主人反馈,后续将通过Pawse Tag(项圈设备)测量心率、叫声等生理指标,并强调起始音量应小于人声感知水平。
AI 锐评
Pawse.ai 的核心卖点并非“宠物音乐播放器”,而是宣称基于犬类听觉生理学构建的“声学调节系统”。这一定位巧妙避开了与无数宠物App的正面竞争,转向一个更窄、也更具说服力的叙事:为狗设计,而非为人。从产品介绍和评论回复来看,创始团队确实做了功课,引用了关于犬类应激反应和听觉频率的研究,而非凭空捏造所谓“狗语”。产品形态本身(通过Apple生态播放+远程控制)务实且门槛低,测试版免费两个月也是有效的获客手段。
然而,当前产品的最大短板,也恰恰是评论中反复出现的质疑点:如何证明它真的有效?团队目前的答案是“主人反馈”和“未来Pawse Tag”。前者是主观的、易受安慰剂效应影响的;后者则是一个尚未交付的硬件配件,其信号(是否真的能准确区分“放松”与“吓呆”的生理状态)目前只是“演示片段”。这实际上是典型的“先卖软件,再卖测量数据的硬件”路径,产品真正的价值闭环尚未形成。若Pawse Tag能够提供可信的、可量化的成效数据(比如焦虑行为减少40%),Pawse.ai将从“听起来不错的有趣玩具”升级为“有科学依据的宠物健康设备”。
更值得担忧的是场景覆盖。产品列举了五个模式,但它们本质上都基于“播放特定频率音频”这一单一逻辑。对于真正严重的分离焦虑、对声音高度敏感的犬只,单独依赖音频可能效果极为有限,甚至无效。团队没有提供任何“音频无效时该怎么办”的建议,这会让一部分期望值过高的用户失望。总体而言,Pawse.ai 概念迷人,整合了科学叙事和极简交互,但现阶段是一个聪明的方向验证品,而非一个成熟的解决方案。真正考验它价值的,不是创始人如何描述亨利的好转,而是未来是否能提供经得起推敲的跨犬种、跨场景数据——以及,当数据不完美时,它能否诚实面对。
一句话介绍:Krater是一款整合了所有主流AI模型与模态(文本、图像、视频、音乐、网站发布等)的统一聊天代理平台,旨在解决用户因在多款AI工具间反复切换而产生的“试用即弃用”问题,实现“一个订阅、一个Agent、完成所有任务”。
API
Marketing
Artificial Intelligence
AI聚合平台
多模态Agent
统一订阅
自动化工作流
AI模型切换
任务自动化
生产力工具
SaaS整合
AI助手
用户评论摘要:创始人讲述了从单人副业到4人全职的四年迭代史,核心问题是用户“试用AI后很快放弃”,因为需管理多个不互通的工具。用户关注默认模型推荐、“任务债务”处理(未完成任务的自动化延续),以及工具目录更新机制。但有一则负面评论指控此前终身会员被强制转为按月付费,需警惕信任风险。
AI 锐评
Krater的“聚合+代理”策略直击当前AI市场的核心痛点:工具过剩但集成缺失。它的价值不在于任何单一模型的顶尖能力,而在于用一个聊天入口解决用户“同时调用GPT-4写方案、Midjourney出图、Runway改视频”的割裂场景,并将结果推送至Notion或发布网站,形成闭环。这种“任务完成而非对话完成”的定位,比单纯堆砌模型的AI Hub更有壁垒。
但产品面临巨大挑战。首先是信任隐患:用户反馈中的“终身会员变订阅”是致命伤,一旦被贴上限时优惠实为钓鱼的标签,70K用户量反而会成为负面口碑的放大器。其次是用户体验悖论:它依赖用户主动指定模型,但大多数普通用户根本没有“换模型”的能力和意识。如果默认模型选择不当,结果平庸反而会让“一揽子订阅”失去吸引力。最后是定价合理性:号称“替换每月100美元以上订阅”,但用户支付意愿取决于能否真正终止其他订阅,而这需要Krater在特定任务上达到专项工具80%以上的完成度,目前业内尚未有聚合产品能在图像、视频、代码等场景同时做到这一点。
总体而言,Krater的脚本方向正确,但若不能解决终身会员的信任裂痕,以及为普通用户提供“零思考的模型智能路由”,它很可能从“AI终结者”变成又一个“AI收藏夹”。
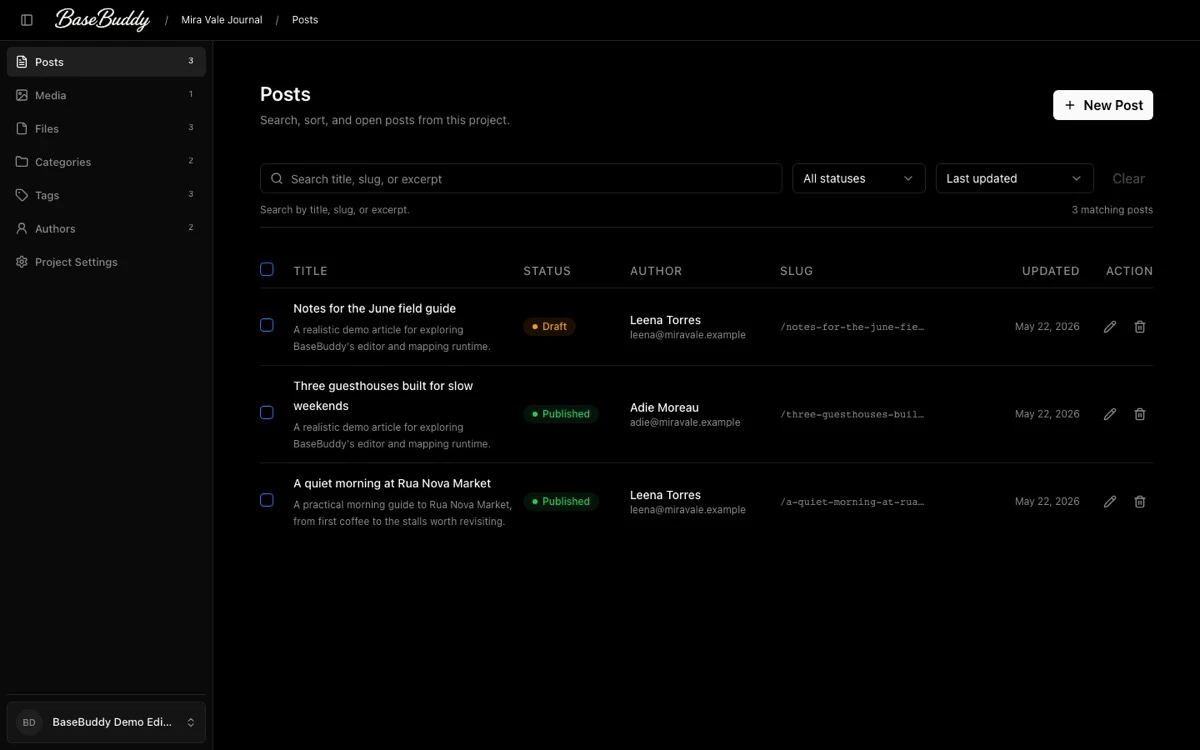
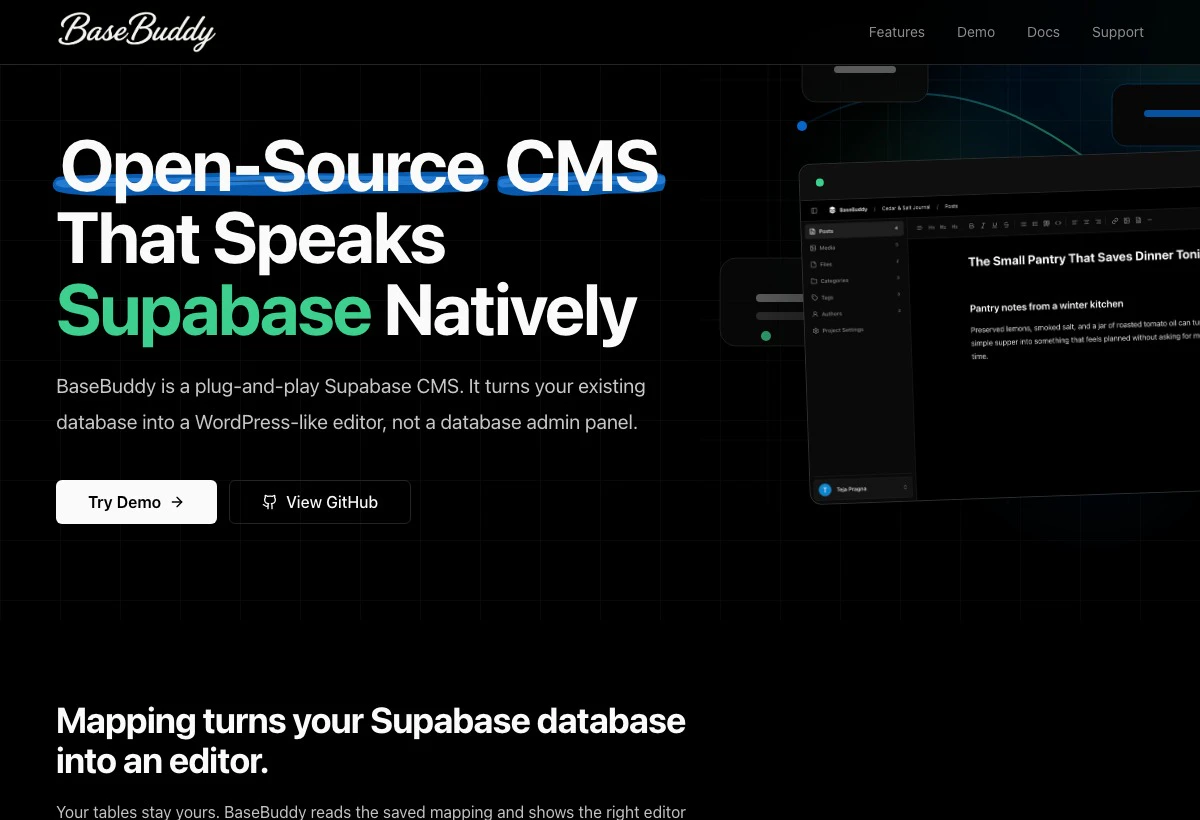
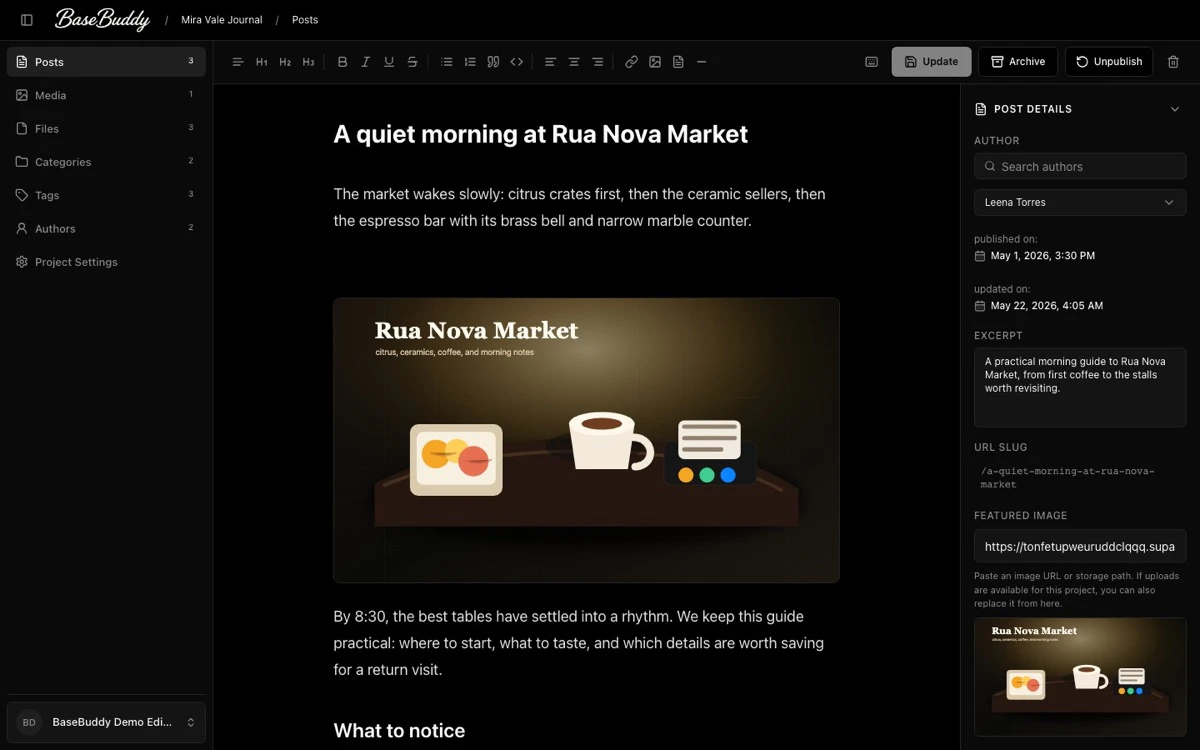
一句话介绍:BaseBuddy是一款开源自托管CMS,允许用户将现有的Supabase或Postgres数据库直接转变为类似WordPress的可视化编辑器,无需修改数据库结构即可管理内容、媒体和权限。
Open Source
Developer Tools
GitHub
Database
Supabase CMS
开源
自托管
Postgres编辑器
可视化内容管理
无侵入
WordPress替代
无代码后台
数据库映射
开发者工具
用户评论摘要:用户关心安全性与权限(如何对接现有Postgres的RLS?),赞赏其不修改表结构的设计。有用户询问富文本和媒体功能,开发者回应已支持。关于非技术用户编辑导致库表变更的痛点,开发者解释通过独立权限层控制。
AI 锐评
BaseBuddy切中了一个真实却常被忽视的痛点:已有良好构架的数据库,不愿为了上CMS而重构表结构或搭建臃肿后台。产品以“零入侵”为核心理念——不做重命名、不破坏现有Schema,只写变更字段,这比市面上多数CMS都更懂开发者心思。它扮演的更像一个“智能映射桥”,将WordPress的发布体验翻译到Postgres原生数据之上。95个投票在PH上不算爆款,但评论区反馈质量较高,说明痛点确实存在且精准。
但值得注意的是,产品并未解决“数据治理”本质问题。它仅允许映射和编辑现有表,却要求用户手写映射关系,意味着非技术团队依然需要开发者的初始配置。所谓“WordPress编辑体验”在映射后的字段呈现上是否流畅?若用户数据库字段高度自定义、缺乏规范元数据(如`content_json`),编辑器将出现大量“通用输入框”,体验大打折扣。此外,权限虽有自定义层,但其与Supabase原生RLS是并行关系而非替代——用户需要手动创建一个“全能”用户来连接,这在多环境、多角色团队中可能引入新的安全盲区。
商业定位上,“开源+自托管”是双刃剑:它能吸引有技术能力的早期用户,但也意味着没有付费计划或云服务支撑。长期来看,BaseBuddy要么进化成类似Strapi但更轻的“DB-直接映射CMS”,要么沦为开发者手中的又一个单项目工具。它真正的护城河不是编辑器,而是“Schema零迁移承诺”——这是大厂CMS和通用后台生成器(如AdminJS、ForestAdmin)做不到的。建议将映射层做得更智能(比如自动推断字段类型、关联关系),并考虑提供数据库层面的迁移快照功能,以巩固“安全不改表”的口碑。
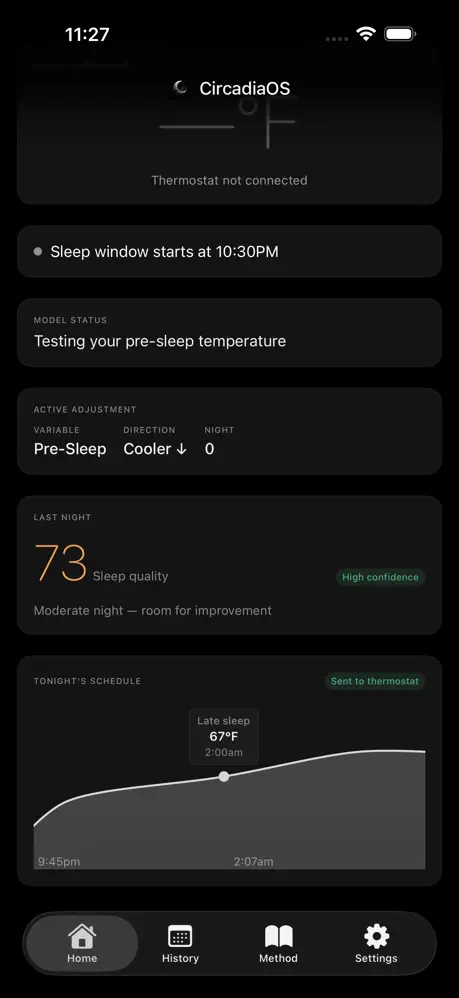
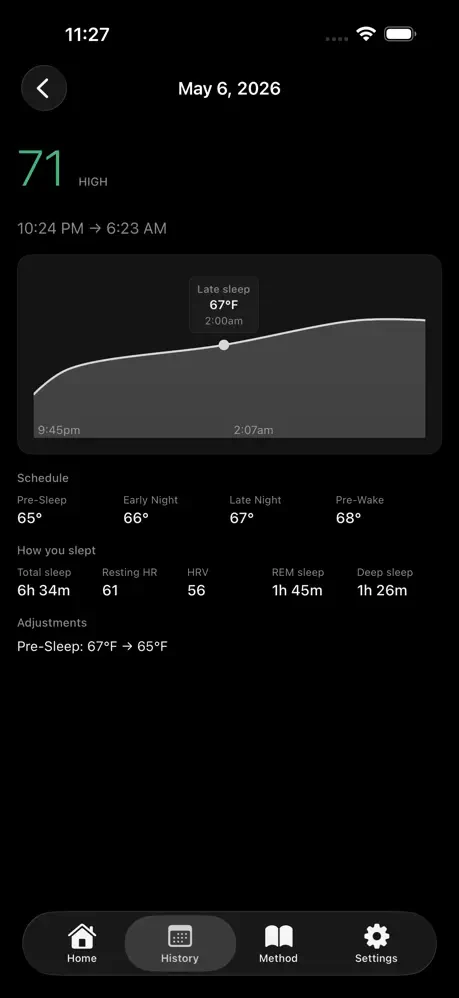
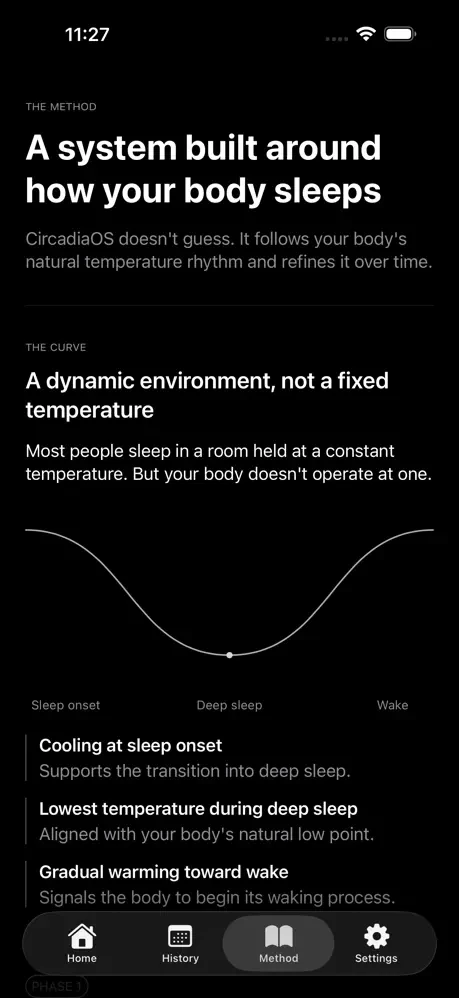
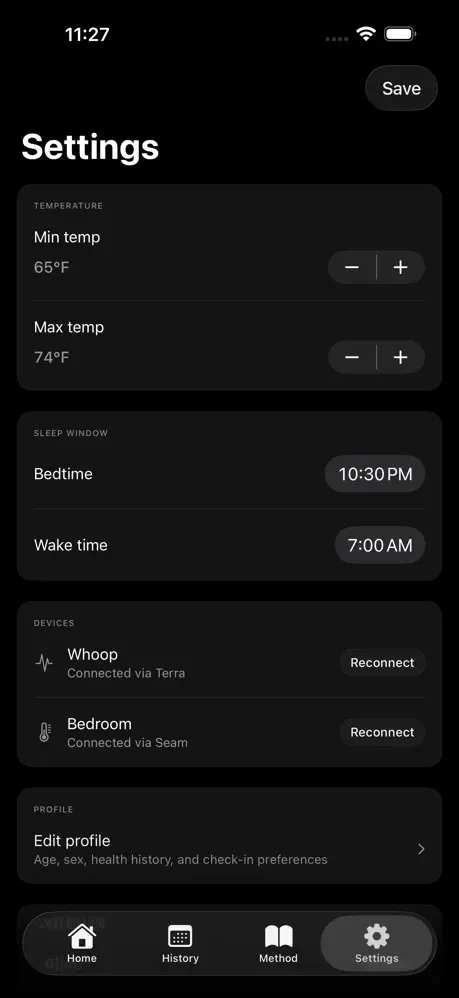
一句话介绍:CircadiaOS通过连接用户已有的智能手表和智能恒温器,基于生物特征数据自动生成并执行个性化夜间温度调节方案,实现纯软件驱动的睡眠优化,解决了无需昂贵硬件即可精准控温的睡眠痛点。
Health & Fitness
Wearables
Tech
睡眠优化
智能恒温器
可穿戴设备
生物特征分析
软件方案
睡眠温度调节
无硬件
智能家居
健康科技
个性化算法
用户评论摘要:用户称赞解决睡眠温度痛点的创意,询问如何识别关键生物信号并调整环境;同时有评论质疑缺乏实际调温设备,但被团队澄清只需已有智能恒温器即可。
AI 锐评
CircadiaOS的切入点极其精准——当同行在“硬件军备竞赛”中堆砌万元级的床垫舱、专用传感器时,它以“已存在硬件的数据衔接层”破局,本质是API化的睡眠服务。其真正价值不在技术创新,而在“供给侧转换”:将睡眠赛道从重资产、高客单价的硬件生意,降维成轻交付、可复用的软件服务。这既避开了硬件研发、库存和合规的重负,又直接盘活存量市场——全球数亿智能手表用户和智能恒温器用户,就是天然待转化的深度睡眠优化受众。
但风险也显而易见:产品完全依赖第三方硬件的数据开放性与接口稳定性。苹果、三星若收紧心率或体温API,或恒温器品牌升级固件不兼容,CircadiaOS即刻变“空中楼阁”。另外,“两周校准期”意味着初始体验存在真空,缺少硬件层面的即时正反馈(如触觉震动或LED色温变化),可能导致用户流失。从商业逻辑看,它更像一个“高粘性订阅制插件”,而非独立生态。终极拷问是:在不绑定硬件的纯软件模型中,用户粘性能否支撑定价,是否会在智能家居系统(如HomeKit、Google Home)内建类似功能时被一键替代?CircadiaOS的生存缝隙,或许在于比平台方更快、更细地深挖睡眠温控的生理模型——若能在算法维度形成专利护城河,才配得上“破局者”之名。
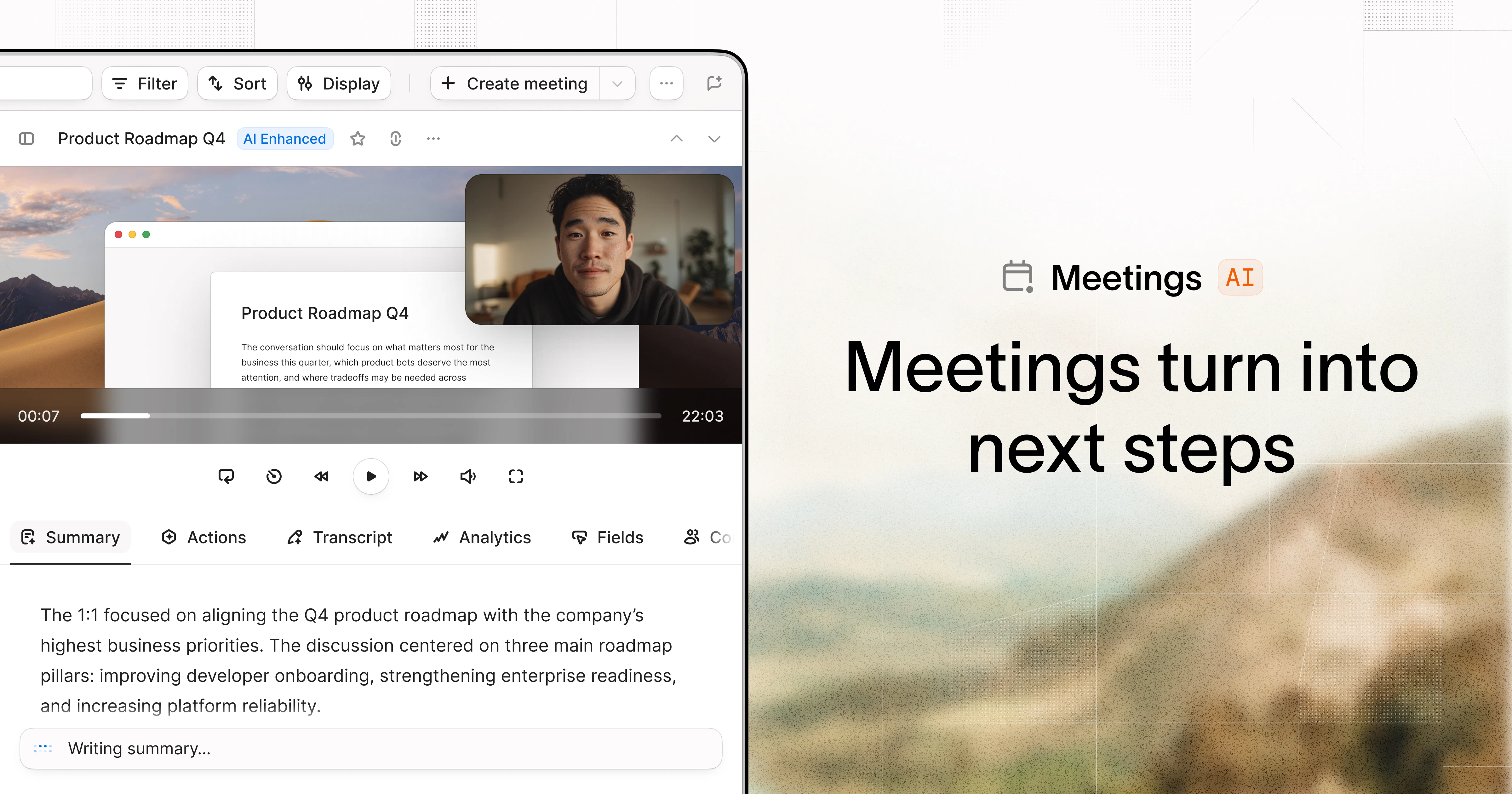
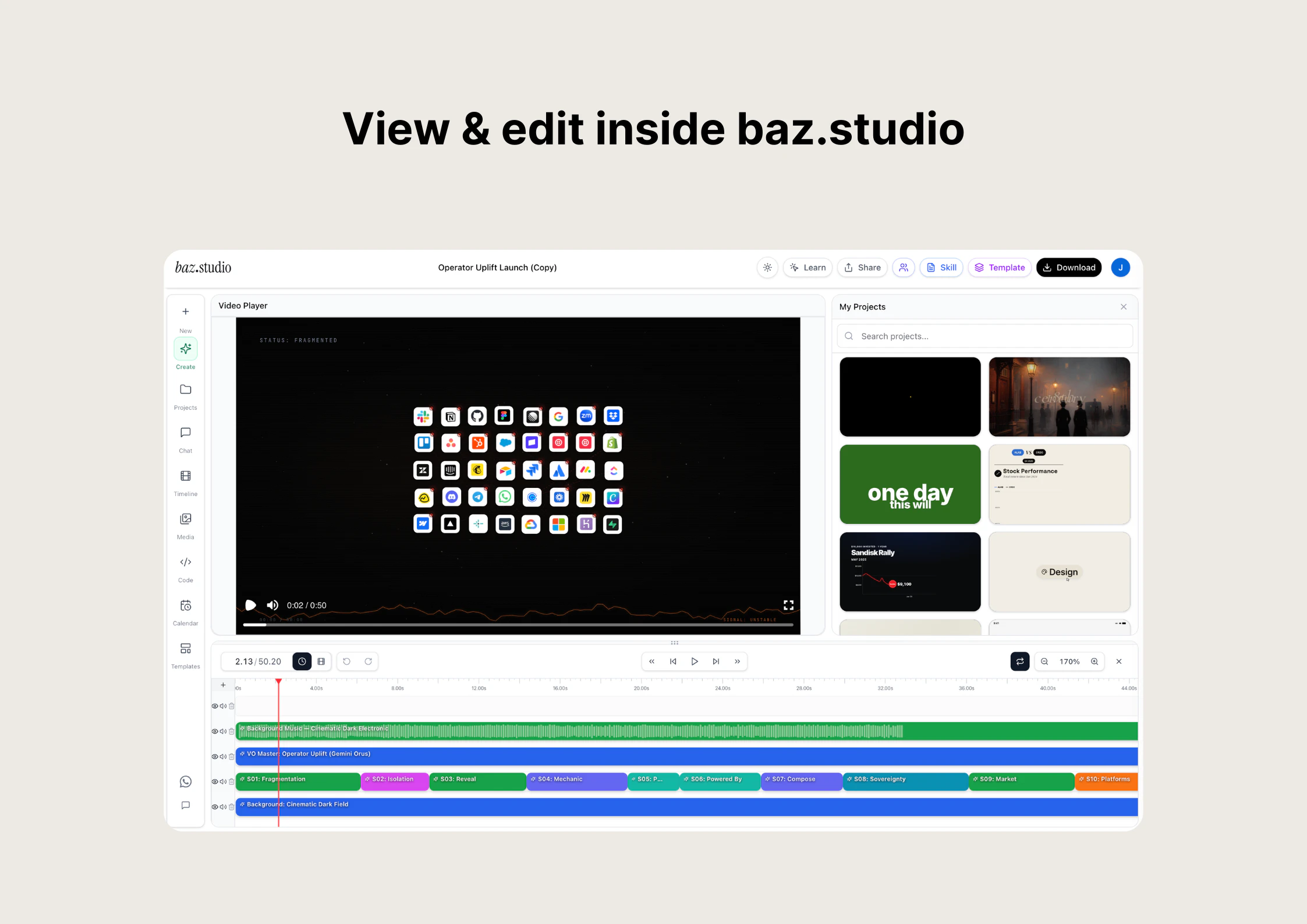
一句话介绍:Baz Studio是一个AI原生的视频制作平台,其核心功能是将开源视频工作流(Skills)与AI代理(如Claude、Codex)结合,解决从文字、代码、PPT等内容自动生成高质量视频的生产效率痛点。
Marketing
Video
Community
AI视频生成
开源工作流
AI代理集成
视频自动化
内容转视频
CLI工具
Remotion
视频模板
创意工具
视频编辑
用户评论摘要:用户肯定了将代码/PPT等转化为视频的自动化流程,以及能直接在Claude/Codex等AI代理中运行而非被困在孤立平台的特性。有用户建议社区贡献更多新技能。
AI 锐评
Baz.studio的核心价值不在于又做了一个视频编辑工具,而在于它试图重新定义视频生产的“操作系统层”。通过开源视频工作流(Skills)并打通AI代理生态(Claude/Codex),它实际上是把视频制作从传统的时间轴拖拽,升级为“代码+Agent”的指令式生产。这解决了两个关键痛点:一是专业视频模板的复用和分发难题(Skills库),二是AI视觉内容与自动化流程的“最后一公里”衔接(CLI+Web UI)。然而,其真正的壁垒在于Skills库的质量与生态活跃度——目前库中的“软件演示”模式是他们的舒适区,但UGC广告、地图动画等新领域的工作流若不能快速成熟和标准化,产品极易沦为“高级PPT转视频器”。此外,“AI代理驱动”是一把双刃剑:虽然提升了自动化,但也牺牲了对镜头语言、细节调色的精细控制效率——这是专业创作者的核心需求,与“快速出片”的自动化用户其实是不同物种。Baz需要在“易用的自动化”和“可控的专业度”之间找到平衡点,同时警惕未来大模型平台自身内置视频生成能力后的生态倾轧。其开源性是吸引社区的关键,但如何通过“免费开源”实现商业闭环,将是下个阶段最犀利的考题。
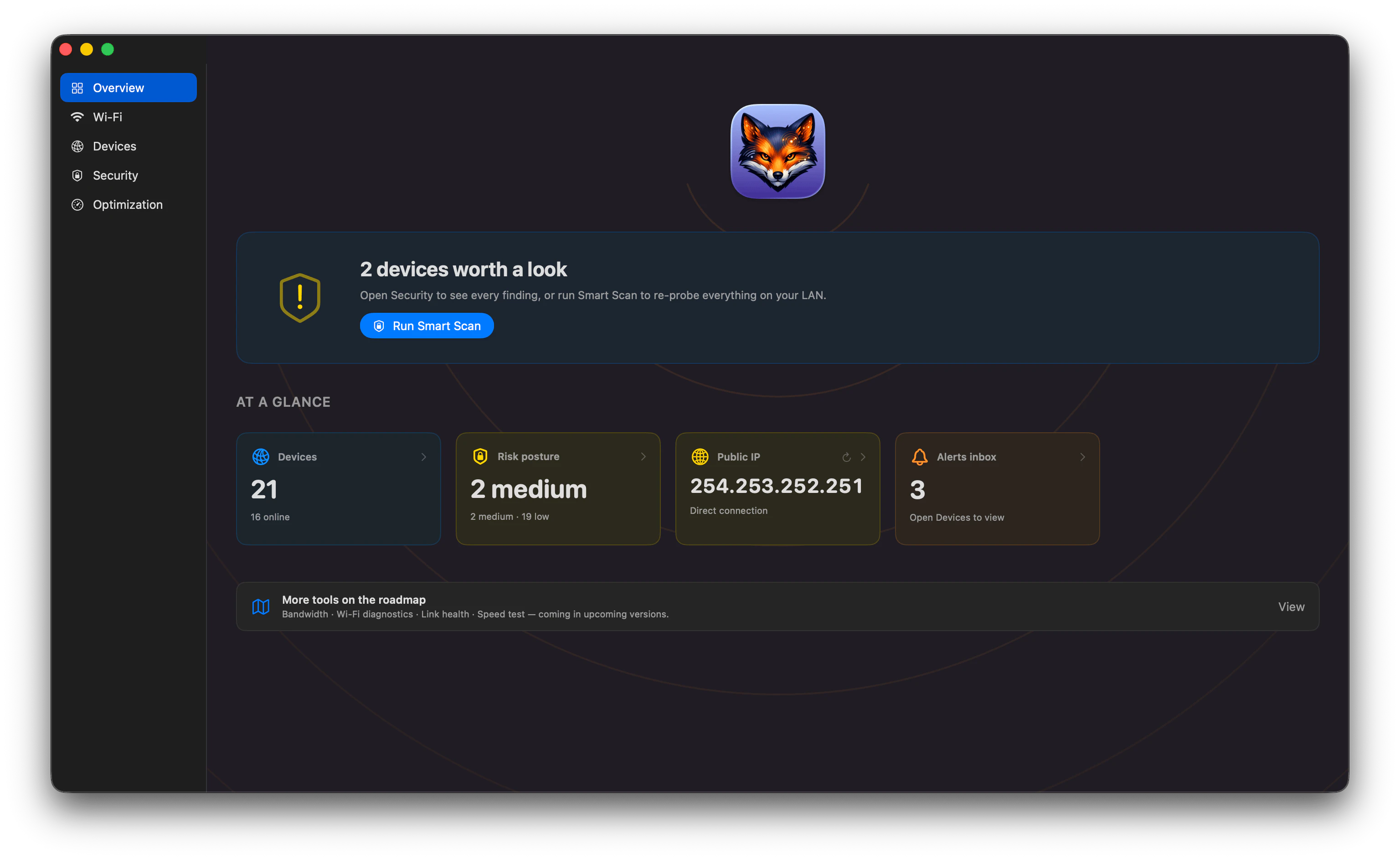
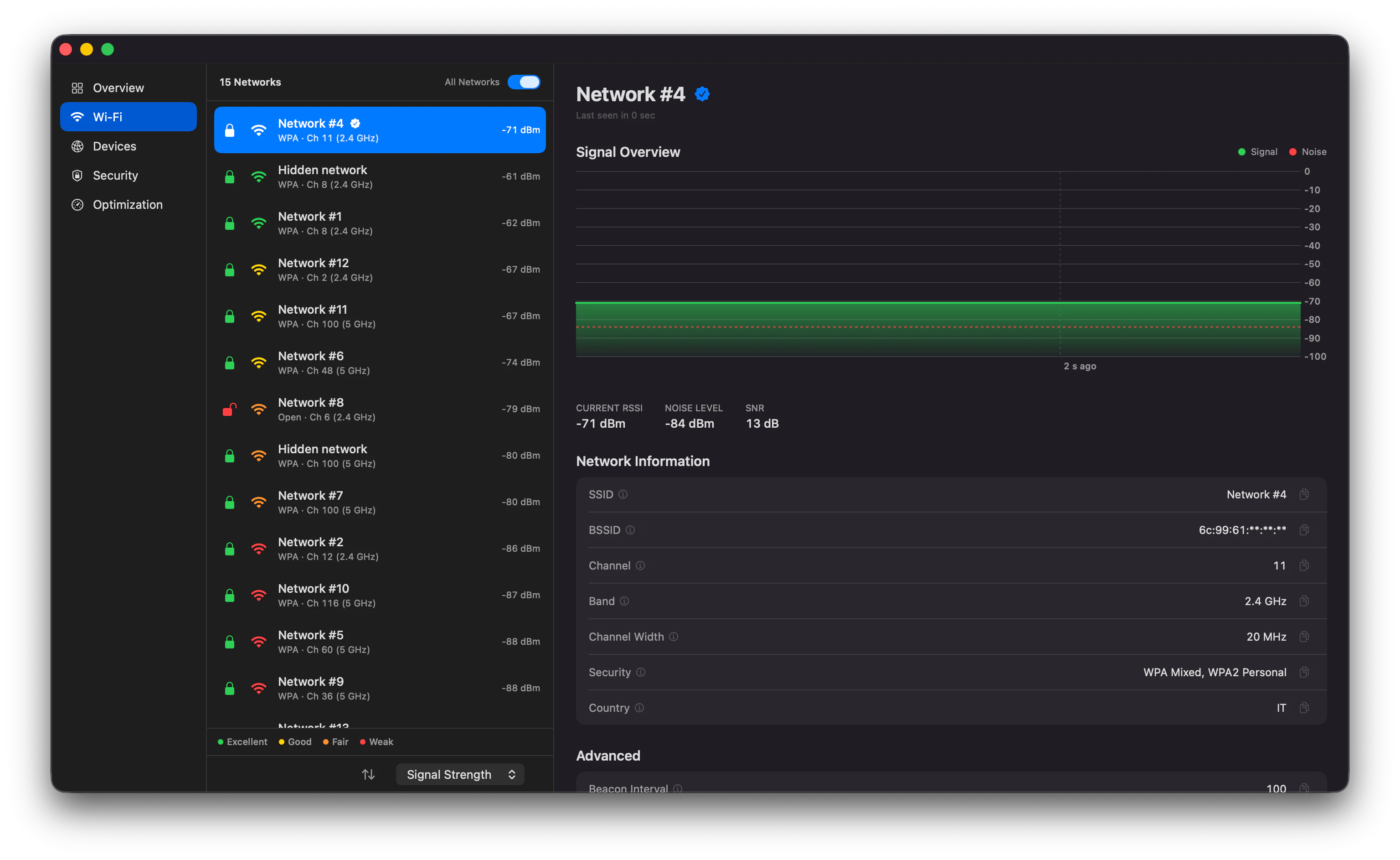
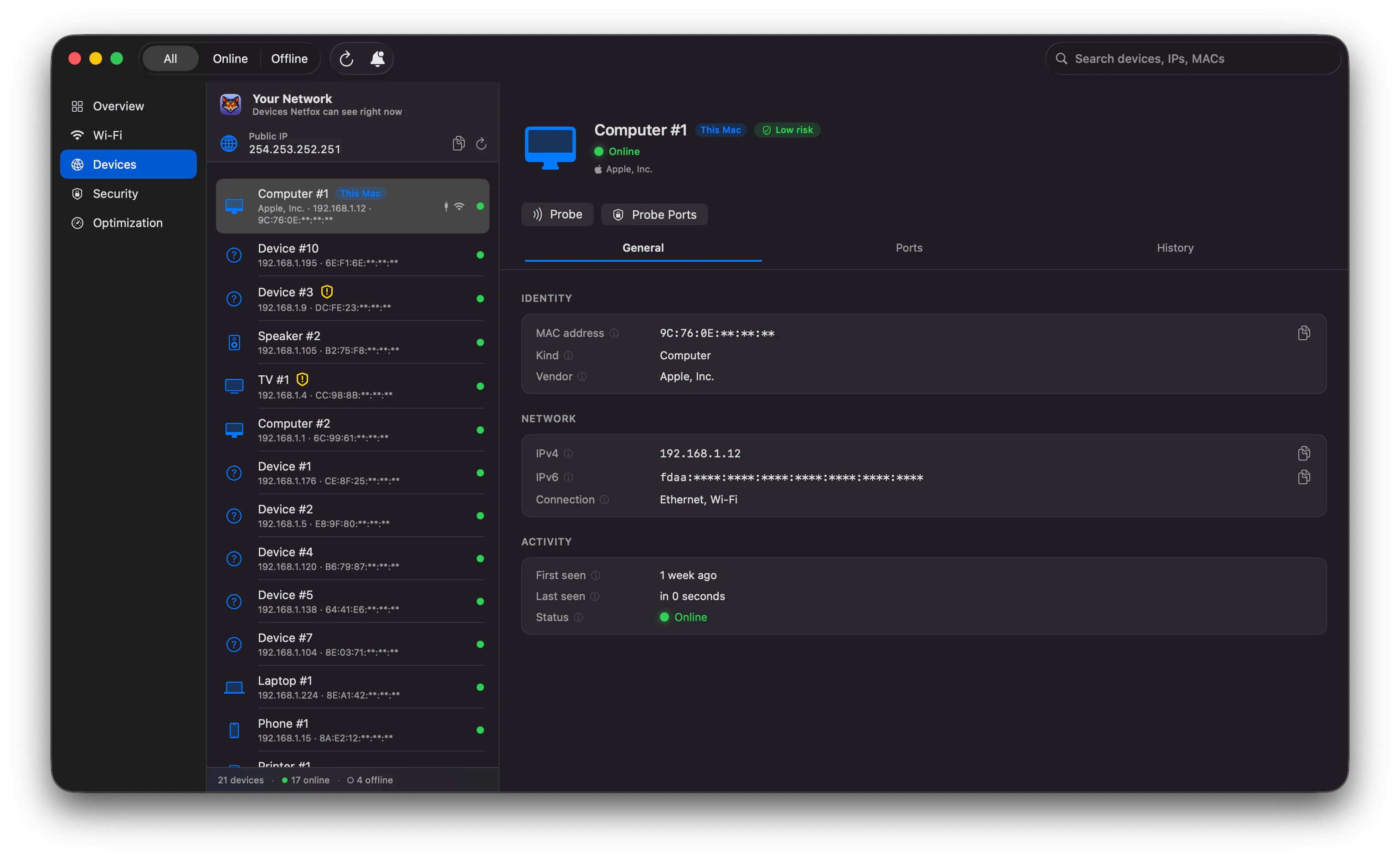
一句话介绍:Netfox 是一款纯本地的 macOS 网络监控工具,通过整合多种发现协议(Bonjour、ARP 等),在单一窗口实时展示所有联网设备(含苹果设备、智能家居、打印机等),并提供设备历史记录、异常告警及一键安全扫描,解决用户无法直观、隐私地掌控家庭或办公网络设备动态的痛点。
Mac
Privacy
Security
网络监控
macOS 本地工具
设备发现
安全扫描
隐私保护
SwiftUI
家庭网络
物联网监控
免费工具
开发者工具
用户评论摘要:用户认可其原生、简洁的界面和隐私优势,并认为安全扫描的“平实语言”结果很实用。有用户反馈其场景价值很高(如发现老旧智能设备“深夜对话”),开发者回应积极,并正在邀请用户提出下一步功能建议(如用户未明确提及具体缺失功能,但暗示期待扩展性)。
AI 锐评
Netfox 的价值在于它精准地切中了一个被忽视的细分需求:让非技术人员能在不牺牲隐私的前提下,“看到”自家网络里到底连了什么东西。从产品设计看,它确实做到了“小而美”——纯 SwiftUI 原生、无云、无账户、零遥测,技术架构简洁信任感强。但“免费”也是一把双刃剑:目前 84 票的 Product Hunt 热度不算高,说明其营销触达有限;而开发者“想要什么功能?”的开放邀约,恰恰暴露了产品可能缺乏长期商业迭代动力——一旦用户基数扩大,多协议融合的稳定性、大量设备长时间追踪的性能开销、安全扫描被恶意利用的风险等,都会迅速成为难题。另外,虽然规避了云依赖,但本地扫描行为在部分严格的企业网络或 VPN 环境下可能被视作“探测”,带来兼容性隐忧。总体来说,Netfox 是一件有诚意、有思考的单点工具,但想从“极客玩具”进化为能持续维护的“网络管家”,还需要一个清晰的付费策略和功能规划(例如历史数据导出、自定义告警规则、甚至是 macOS 菜单栏集成),否则很可能沦为又一个因开发者精力分散而停更的开源项目。
一句话介绍:Cotypist 是一款运行在 Mac 本地的 AI 自动补全工具,在邮件、Slack、笔记等任意输入场景中,按 Tab 键即可补全你的个性化话语,省去重复打字、切换软件的麻烦。
Mac
Productivity
Artificial Intelligence
本地AI
自动补全
Mac工具
写作辅助
隐私优先
输入效率
离线模型
订阅制
文本预测
生产力工具
用户评论摘要:用户普遍认可产品体验和本地化优势,但大量负面评论集中于定价过高(年费约108美元)、订阅制不合理。多数用户建议提供终身许可或更低价格分层,并质疑“本地运行+开源模型”的高定价逻辑。部分用户还反馈应用缺少更长的段落预测功能。
AI 锐评
Cotypist 在产品体验上确实做到了“润物细无声”——它没有让你迁移工作流,而是直接插入了系统层级的文本补全能力,这是它最具颠覆性的价值。从用户反馈中不难看出,它在效率提升上获得了真实认可,甚至在非人工输入场景(如脑机接口用户)中意外发力,证明其底层模型对文本序列的学习能力相当成熟。
但产品的报价策略堪称灾难级错判。一个完全运行在本地、依赖开源模型的应用,定价居然对标 ChatGPT 或 Claude 的云端订阅。用户的愤怒不是“不想付费”,而是“你凭什么收这个钱”——因为你没有持续云服务成本,你的模型是公开的,你的功能是“单点”而非矩阵。开发者如果认为“开发时长”等于定价底气,那就要接受用户用“你实际价值”投票的冷场。
更致命的是,开发者选择了最不受信任的定价模式:订阅制 + 分层割裂功能(如将本地模型选择锁在Pro档)。这种“拼多多式”定价既打击了早期测试用户(他们贡献反馈却只得到三个月延期),也阻止了潜在付费用户尝试高价值档位。如果产品本身不能形成网络效应或持续交付明显的模型升级,订阅制只会加速用户倒向“忍一晚开发个替代品”的开源圈。
一句话总结:产品是钛合金级的实力,定价是纸糊的。开发者在“满足80%人的免费计划”与“逼走所有愿意付费的人”之间,选择了一条路。如果不上线真正的终身授权、降低订阅基价、或者直接做一次买断,那么当Apple、OpenAI等大厂在系统层整合类似功能时,Cotypist将有极大概率沦为“曾经有过的好思绪”。
一句话介绍:Phasr是一个面向工程师和AI辅助开发的工作空间编排平台,通过在一个界面中同时运行和管理超过100个并行工作流、终端、代码仓库及AI智能体,解决多工具切换和上下文丢失导致的开发效率下降痛点。
Productivity
Open Source
Artificial Intelligence
GitHub
工作空间编排
并行工作流
AI辅助开发
多仓库管理
终端持久化
上下文保持
开发效率工具
工程团队
云端扩展
开源协作
用户评论摘要:用户高度认同上下文切换痛点,并询问Phasr是否支持云端工作空间还是仅限本地。当前用户反馈集中在部署模式的需求澄清上,暂未提出功能缺陷或使用问题。
AI 锐评
Phasr切中的是一个真实且正在加剧的痛点——AI时代开发工作流的碎片化。当开发者同时使用ChatGPT、Copilot、多终端和多仓库时,心智负担呈指数级上升。Phasr本质上是试图充当一个“开发工作流的操作系统”,将混乱的并行任务收拢到统一的编排层。
这一价值点明确且有力,尤其针对大型工程团队和AI驱动的编码实验场景。不过,产品当前仍处于早期阶段,且面向开发者群体,门槛并不低。能否真正落地,关键要看两点:其一,对现有依赖(如IDE、Git CI/CD、Kubernetes)的集成深度是否足够,若只是浅层组合则容易沦为“又一个标签页”;其二,在AI Agent大量调用时,能否有效管理token消耗与执行上下文,防止看似并行实则互相干扰的混乱状态。
另外,所有评论均无负面反馈,这在此类专业工具发布中略显不寻常,需警惕样本偏差或自粉互动。产品若想走出早期用户池,应尽快明确云化方案——纯本地在团队协作层面有天然短板。总体而言,Phasr思路正确,方向可期,但要真正兑现“减少上下文切换”的承诺,还需在工程深度与协作链路上持续打磨。
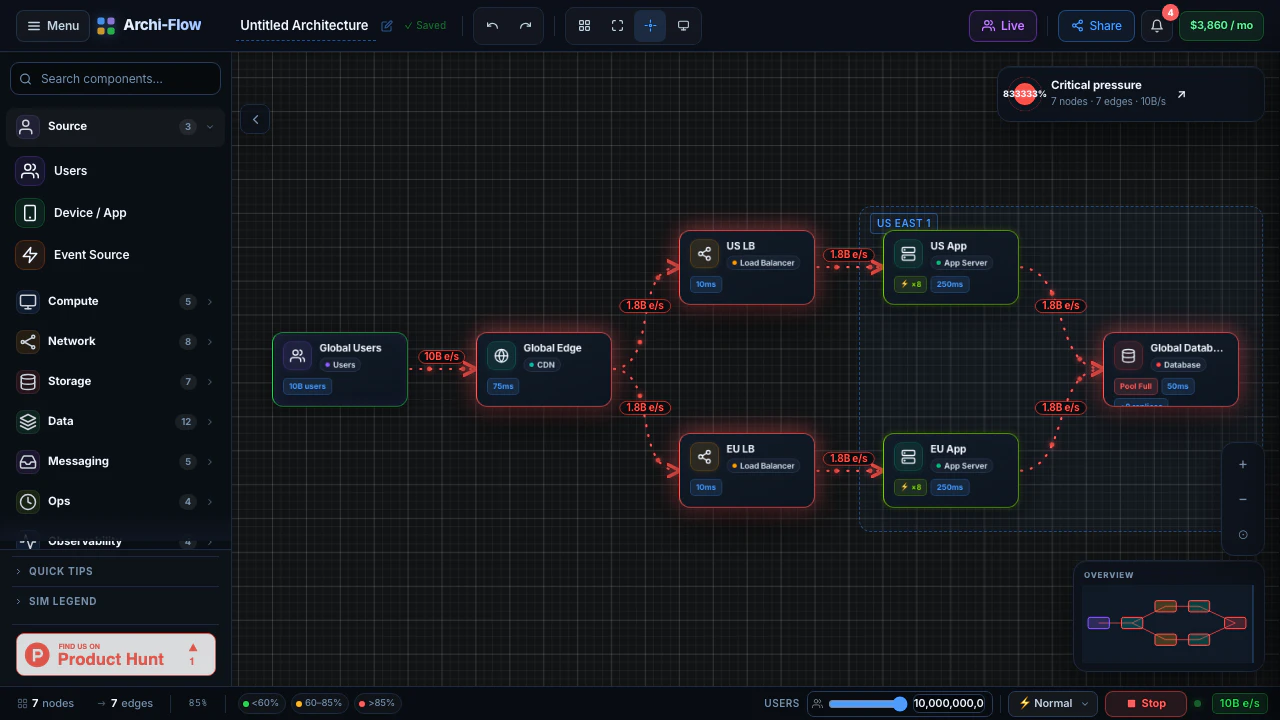
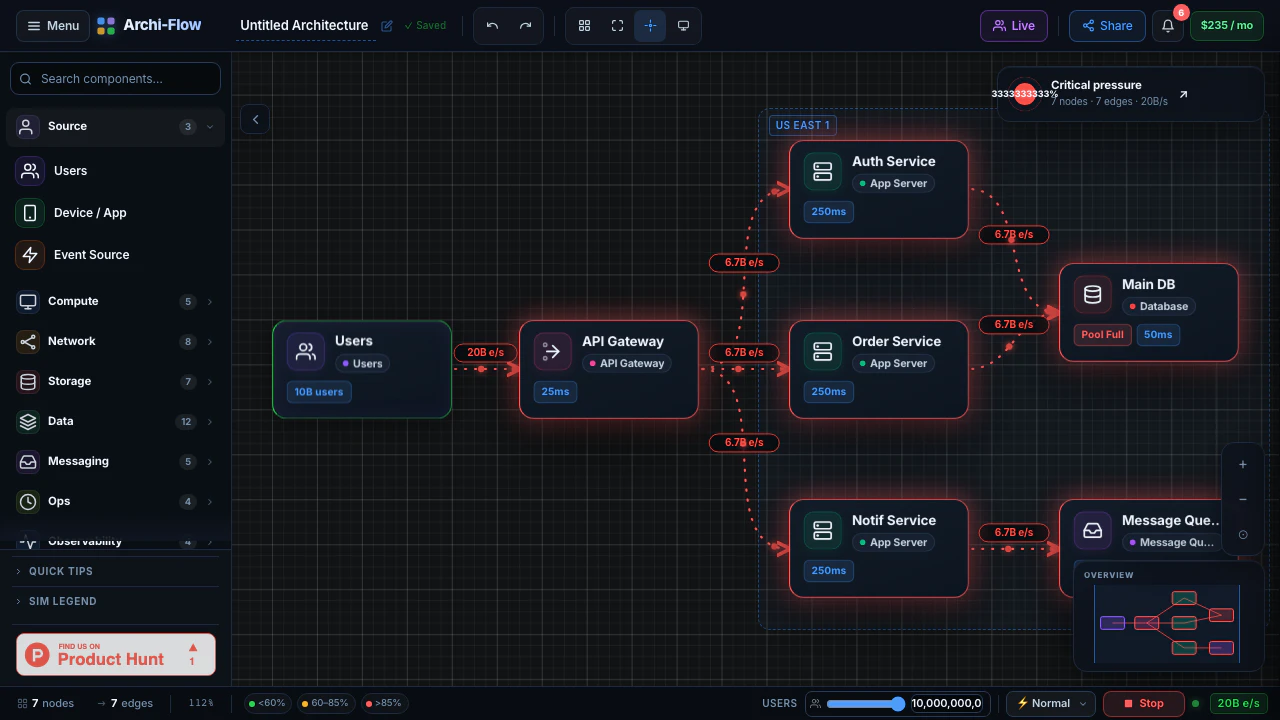
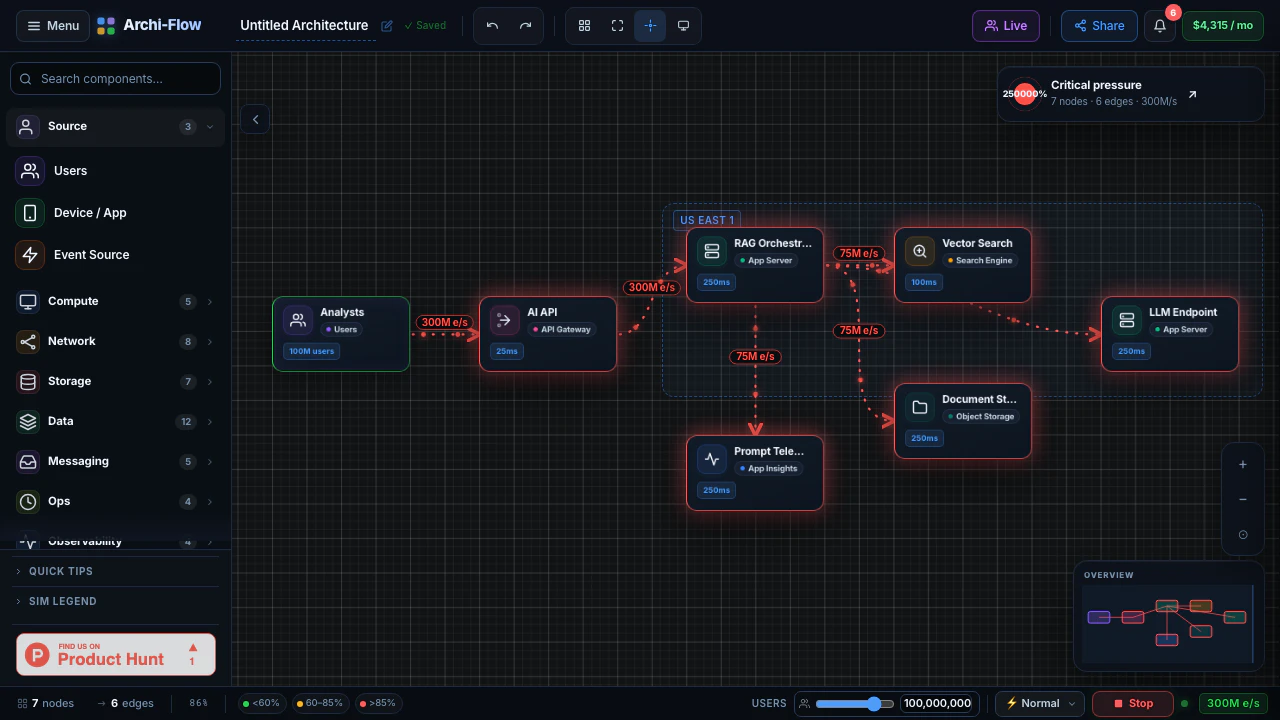
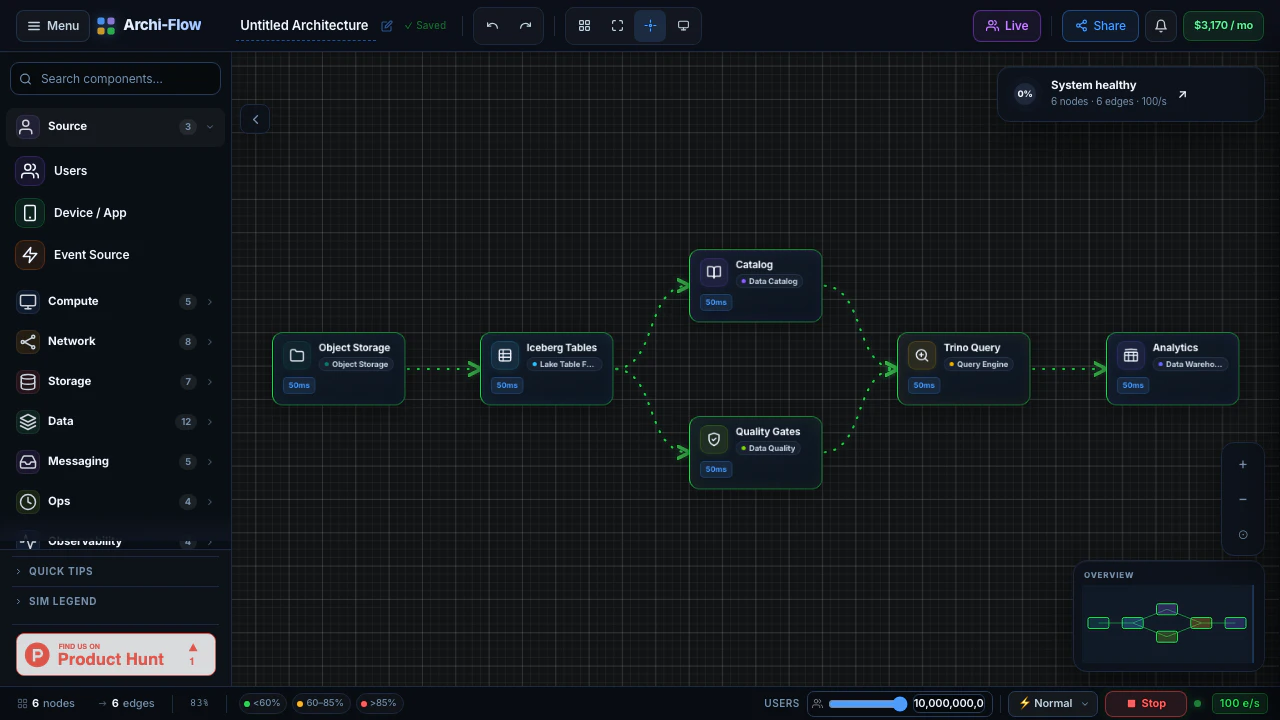
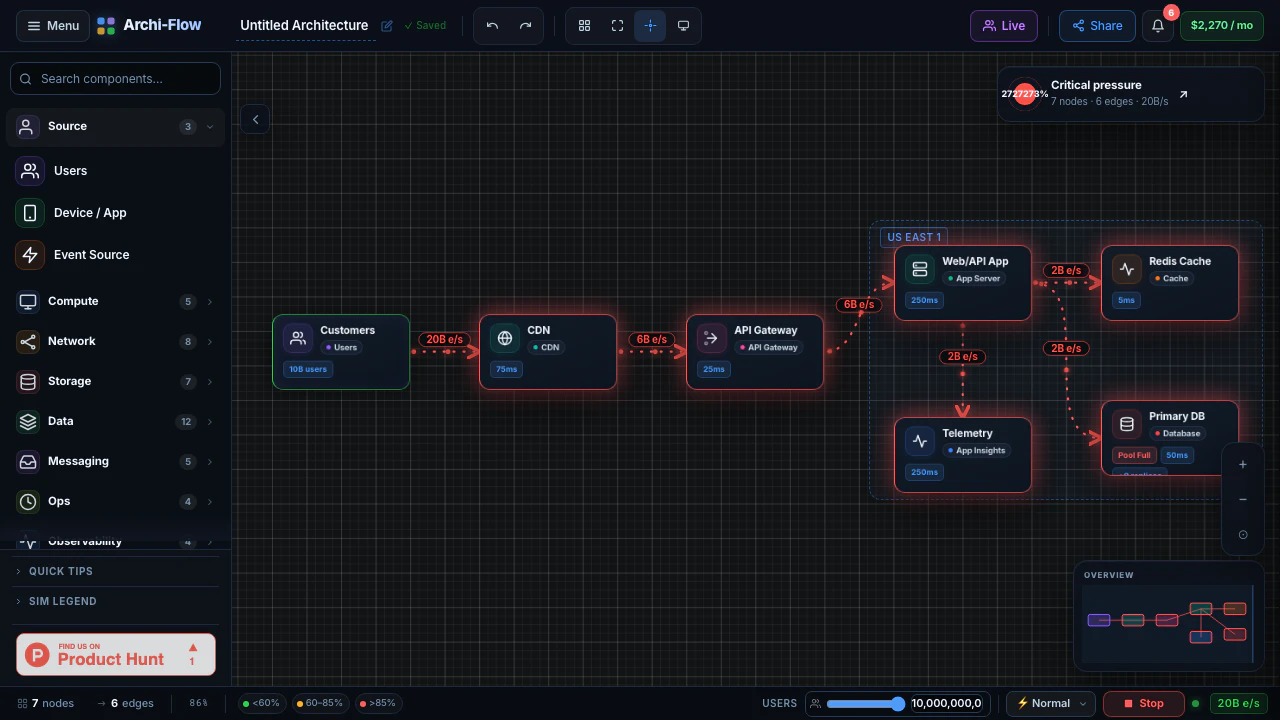
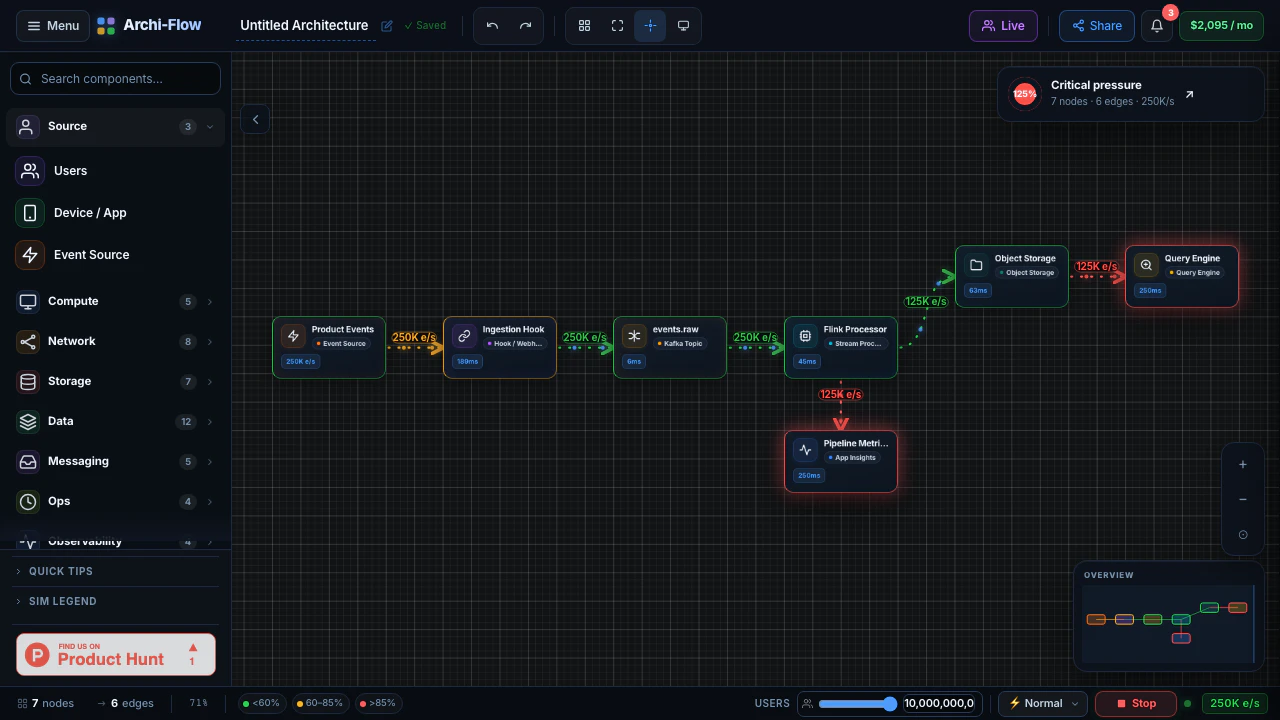
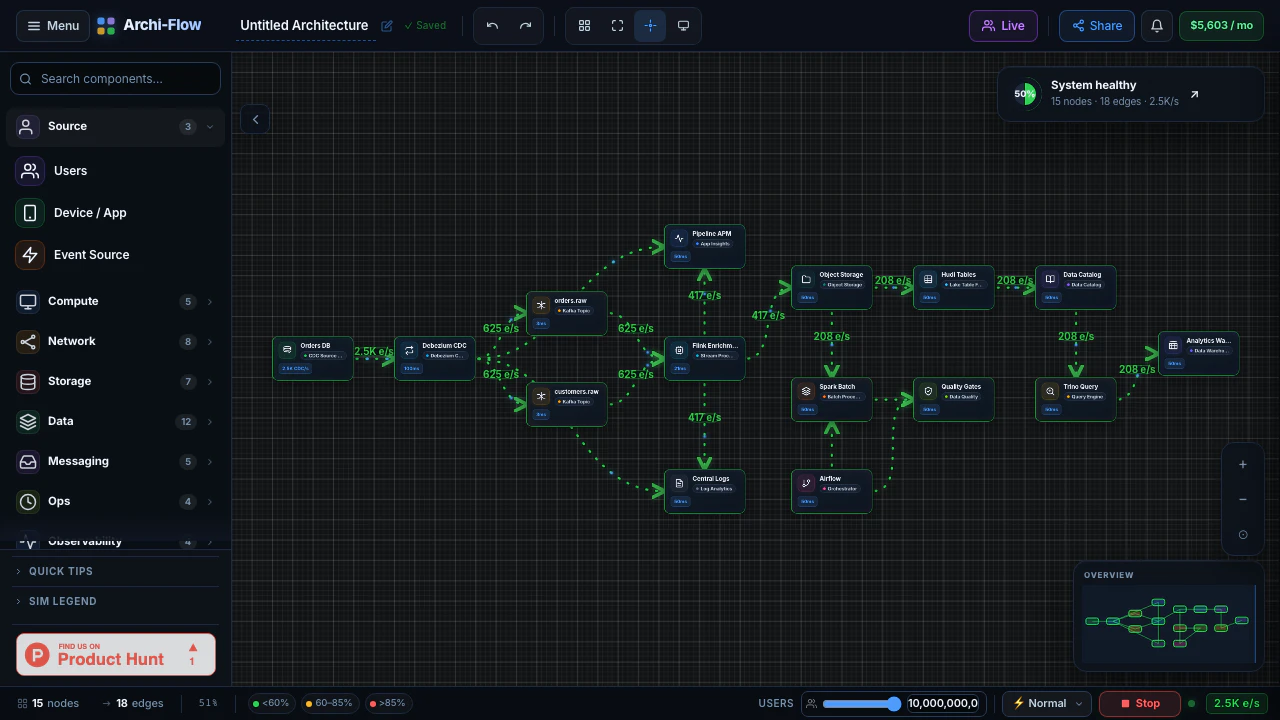
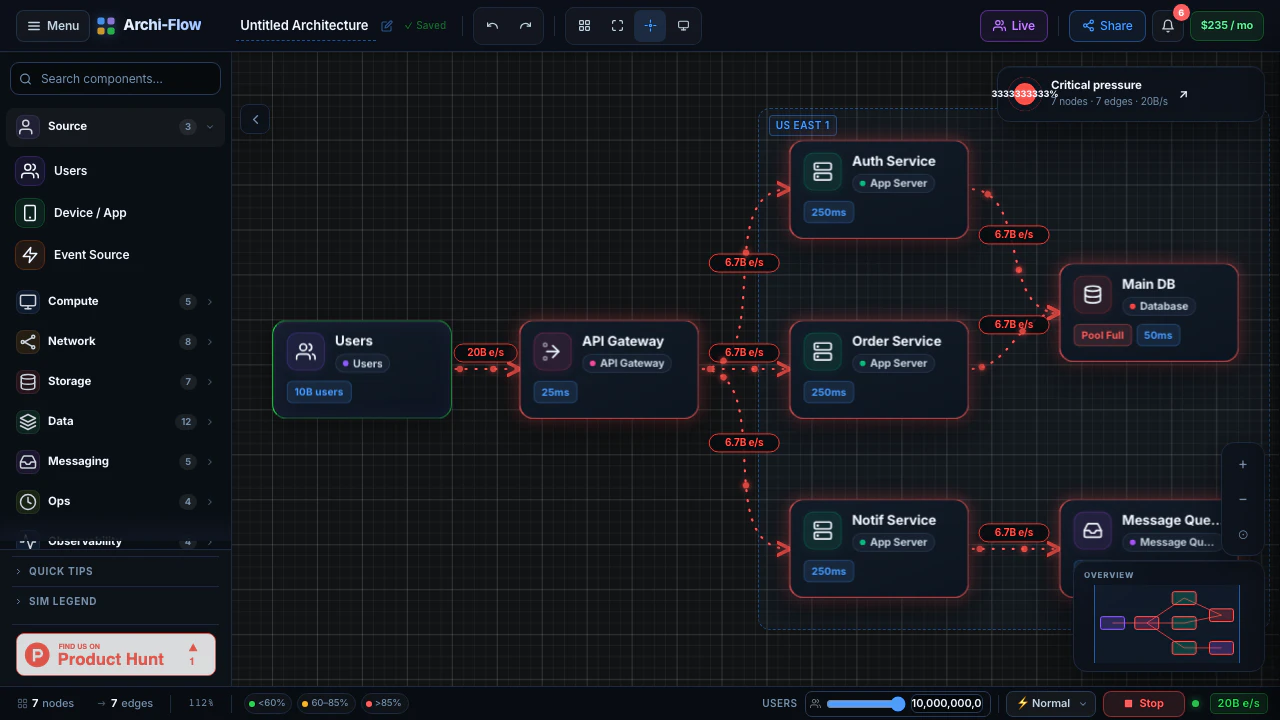
一句话介绍:Archi-Flow通过实时流量模拟将静态云架构图变为可交互的动态地图,帮助工程师在系统设计评审、数据流调试、新人入职及复杂架构演示中直观理解系统行为,解决静态文档与实际运行状态脱节的痛点。
Design Tools
Developer Tools
Tech
云架构可视化
实时流量模拟
交互式架构图
系统设计工具
DevOps
数据流调试
基础设施即代码
团队协作
演示导出
可观测性
用户评论摘要:用户肯定实时流量模拟填补了静态架构图与可观测性仪表盘(如Datadog)之间的鸿沟,并追问数据来源(实时遥测vs.用户定义)。另有用户关注是否支持免账号分享实时视图,官方回应已支持分享链接、SVG/PDF/JSON导出,利于跨团队沟通。
AI 锐评
Archi-Flow切中了一个真实但细分的痛点:架构可视化从“静态图”进化到“动态模拟”。它巧妙地利用了云计算时代“架构即基础设施,基础设施即代码”的趋势,让图不再是一次性产物,而是能反映或模拟系统当前行为的活体视图。其核心价值在于两个场景的打通:一是**设计阶段的假设验证**,通过模拟流量可以提前在图上“跑沙盘”,比传统白板图上画箭头要直观得多;二是**沟通场景的效率提升**,通过分享链接和多种格式导出,它本质上是在做一个“架构图版的Figma”,让非工程师也能理解复杂依赖。
然而,产品真正的生死线在于其“模拟”的真实性。评论中关于“实时遥测”的提问一针见血:如果数据源完全靠手动定义,那它本质上仍是一个高级的“可拖拽的动效PPT”,而无法验证系统是否真的如描述在工作。如果它能深度集成AWS/Azure/GCP的API或Datadog/Prometheus等可观测性工具,自动拉取服务拓扑和流量指标,那么它的价值将指数级上升,从一个演示工具变为一个准“架构可观测性面板”。目前79票的热度反映出市场对概念的兴趣,但团队必须回答:如何让用户愿意为这个“可视化层”付费,而不是直接用Grafana+自定义拓扑图来解决?如果不能提供“无代码”的自动拓扑发现,且数据源集成范围不够广,它很可能沦为小众的演示玩具。
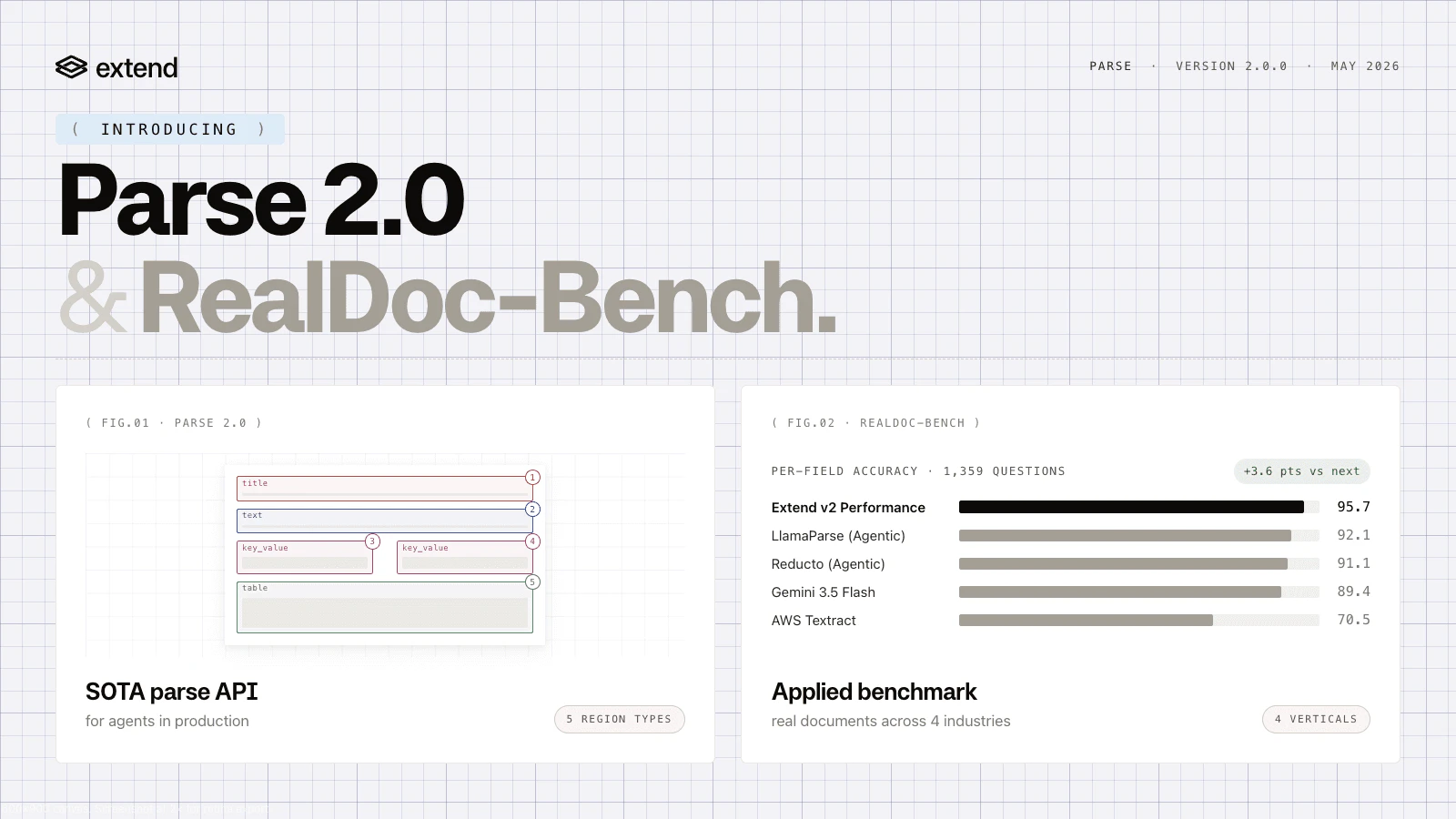
一句话介绍:Extend 通过高精度的视觉模型解析PDF布局,解决AI管线在处理复杂、非结构化文档(如物流单据、医疗报告)时无法可靠提取数据的关键痛点。
API
Developer Tools
文档解析API
PDF布局识别
AI数据管线
SOTA视觉模型
复杂文档(表格/手写)
企业级OCR
自动化工作流
RAG系统
文档智能
机器学习
用户评论摘要:用户高度关注其在多栏布局、混合表格及低质量扫描件上的表现,并提出“语义阅读顺序”才是根本挑战——结构复杂时正确文本不等于正确含义。官方回应称通过专用VLM与OCR循环提升边缘案例,并以人工阅读顺序作为基准评估。
AI 锐评
在“AI Agent无处不沾PDF”的狂潮下,Extend打出了“SOTA准确率”这张牌。从评论和创始人回复不难看出,它精准地切中了当前AI界最大的皇帝新衣:自以为“无代码解析”的LLM在复杂文档面前无比脆弱,尤其是那些结构混乱、含费解表格和手写笔记的“硬核”PDF。
它的真正价值不在于OCR本身,而在于为“语义阅读顺序”建立了一套可工程化的框架。这解决了当前RAG(检索增强生成)系统中“读对位置却读错逻辑”的致命盲区——许多Agent失败不是因为文字识别失败,而是因为下游将错误的段落数据喂给了大模型。创始人将其与人工阅读对齐的思路务实且锋利,避开了“让LLM去猜结构”的笨重做法。
然而,风险在于“对齐”成本。尽管评测上胜出,但1M+的“硬文档”反向训练能否覆盖业界所有的天坑格式?专有VLM层层叠加,在真实高频调用中是否会付出过高延迟与定价代价?毕竟,对Brex、Mercury这类客户而言,每毫秒与每美分都是成本。短期内,Extend会成为高要求企业的“杀招”,但长期看,它的护城河取决于2.0版本之后能否持续定义“文档语义解析”的新标准,而非仅靠Benchmark数字压制对手。
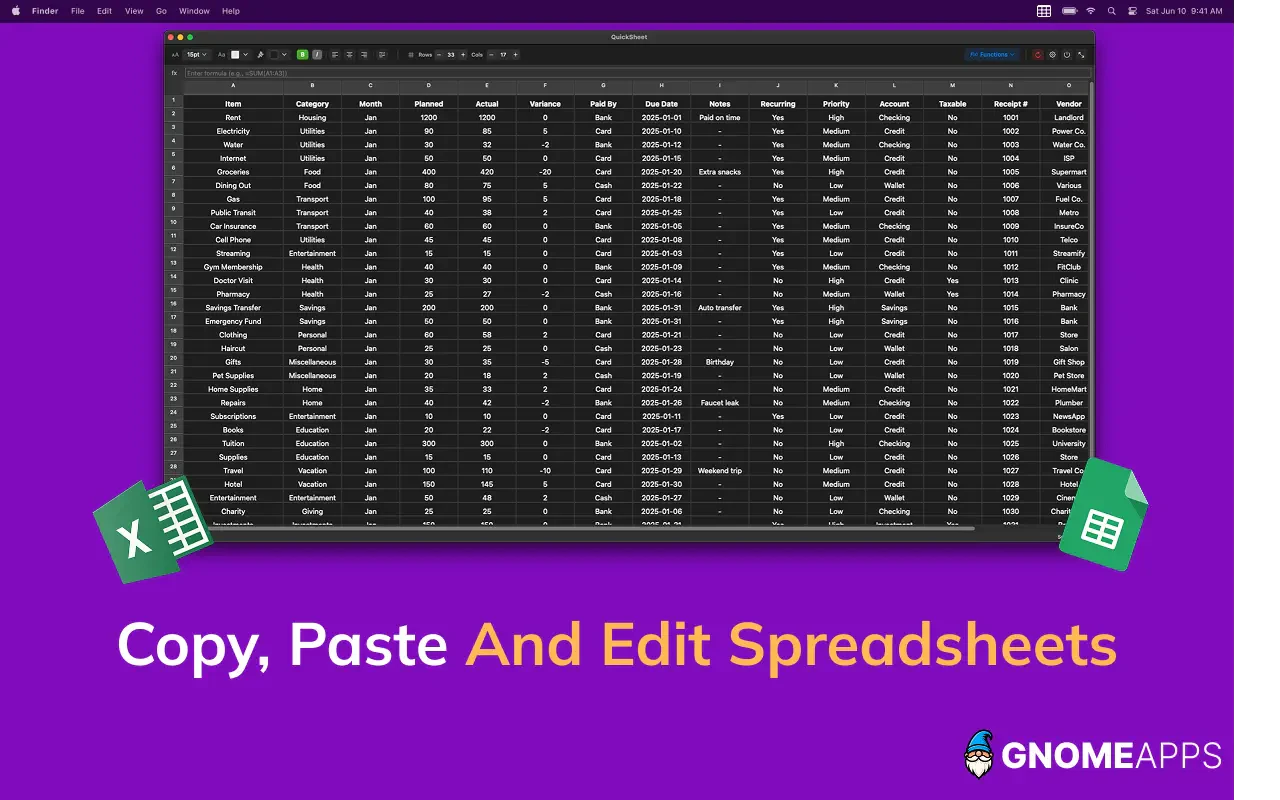
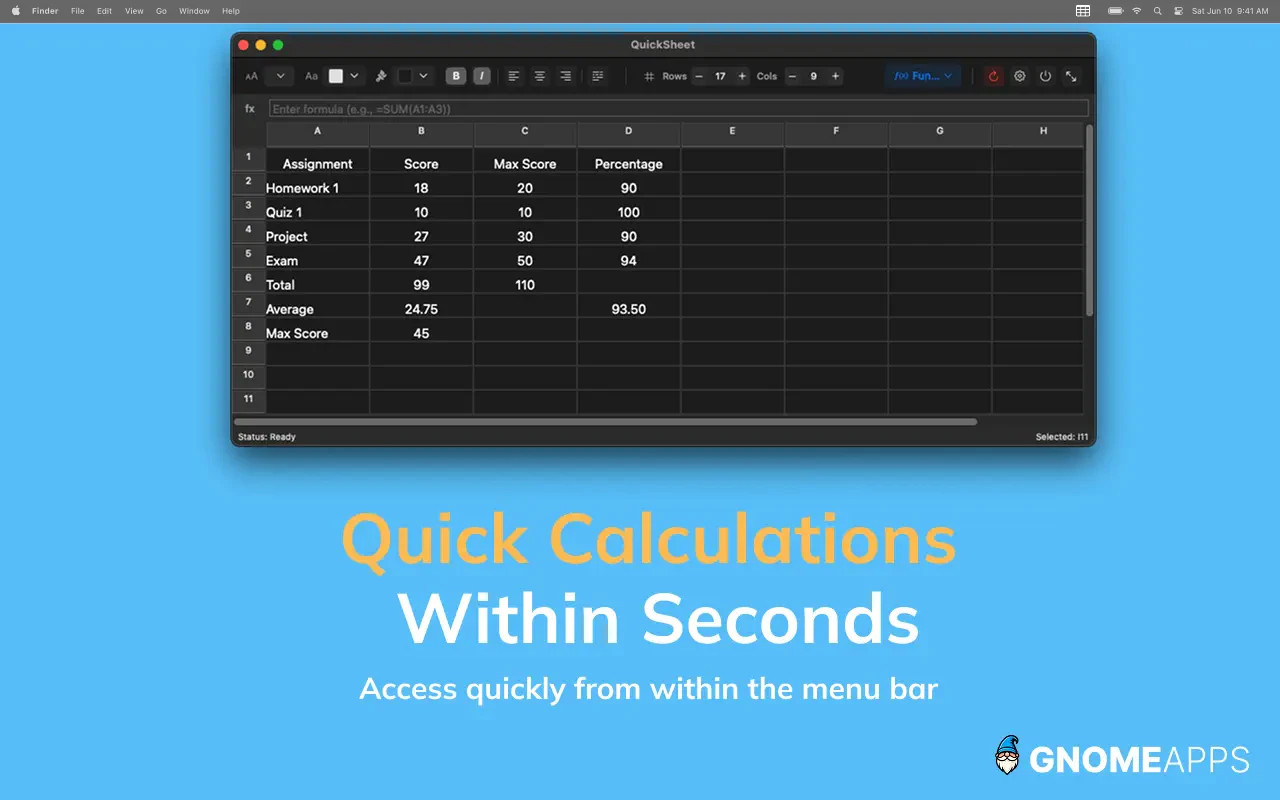
一句话介绍:QuickSheet 是一款驻留在Mac菜单栏的极简电子表格工具,让用户无需打开笨重的办公软件,通过快捷键即可瞬间创建、编辑和计算数据,专为解决临时、轻量级的表格处理痛点而生。
Productivity
Menu Bar Apps
Mac菜单栏工具
电子表格
轻量应用
本地隐私
数据编辑
CSV处理
效率工具
公式粘贴
条件格式
免费工具
用户评论摘要:开发者分享了v1.2重大更新,基于用户反馈新增了公式保留粘贴、条件格式、冻结行列、清理表格粘贴等功能。强调了产品的“小巧、即时、本地、无登录”的核心特点,用户反馈主要集中在新增功能上,暂无负面评论。
AI 锐评
QuickSheet 精准地切入了一个被微软和苹果长期忽视的“中间地带”——介于备忘录和全功能电子表格之间的轻量化编辑需求。它的真正价值不在于替代Excel或Numbers,而在于消除“开一个表格”的心理与时间成本。从功能迭代看,v1.2的“公式保留粘贴”和“清理表格粘贴”是真正的杀手级特性,它们完美解决了用户从网页或复杂表格中搬运数据时的格式混乱和公式失效问题,这是很多大厂软件都做得不够好的细节。
然而,我们也必须冷静看待其局限性。77票的点赞量说明它仍是一款小众工具。它的“tiny”既是优势也是天花板:对于任何需要图表、数据透视表或多人协作的场景,它毫无招架之力。其“免费+无订阅+纯本地”的商业模式固然值得赞赏,但也让人担忧其长期维护的动力。菜单栏应用的激烈竞争环境下,QuickSheet 若想从“尝鲜工具”进化为“系统级必备”,必须在保持极简的同时,提供更智能的自动化(如自然语言生成公式)或与其他原生应用(如备忘录、日历)的深度联动。否则,它很容易被macOS原生功能的阉割版或Spotlight的进化所取代。
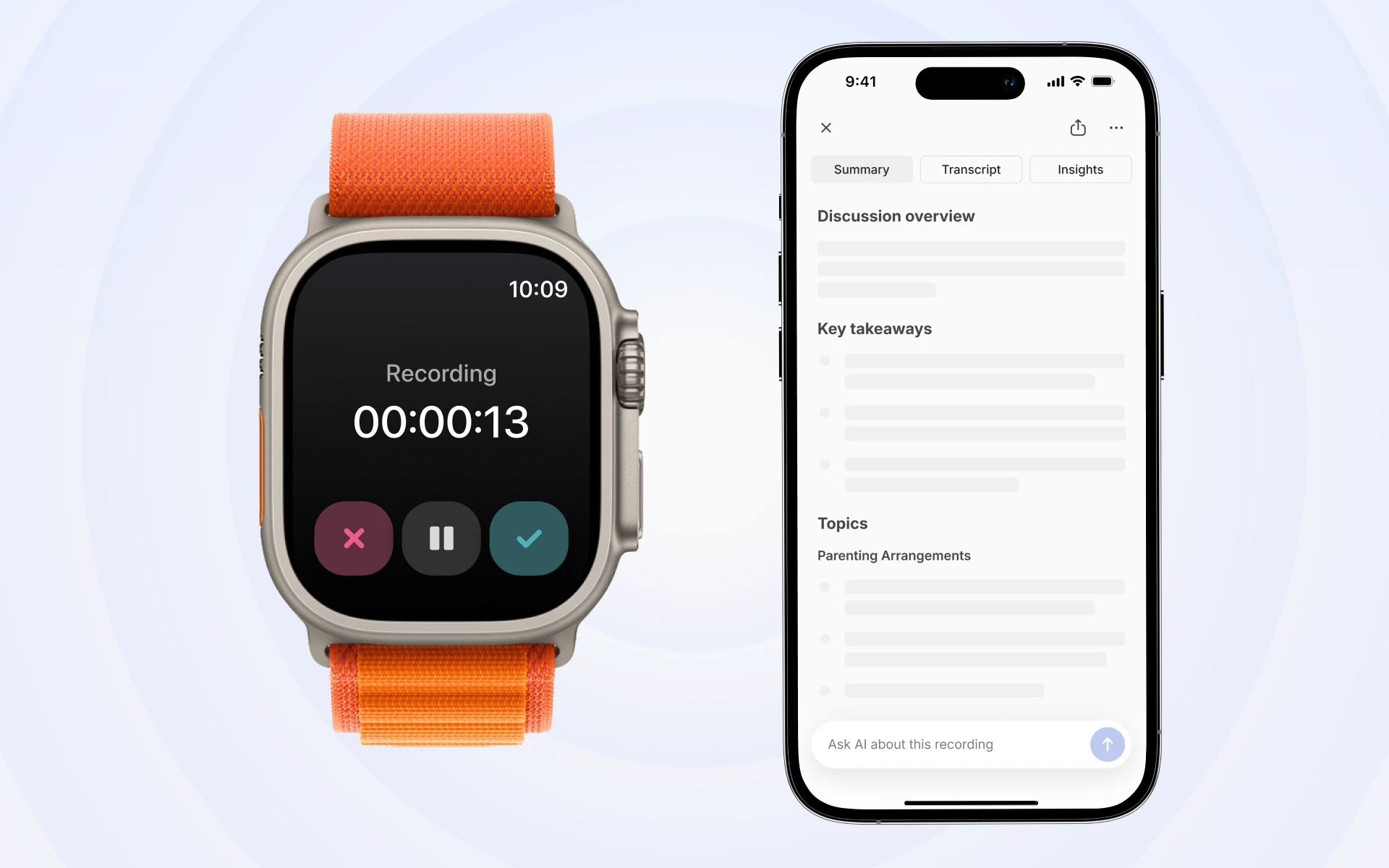



























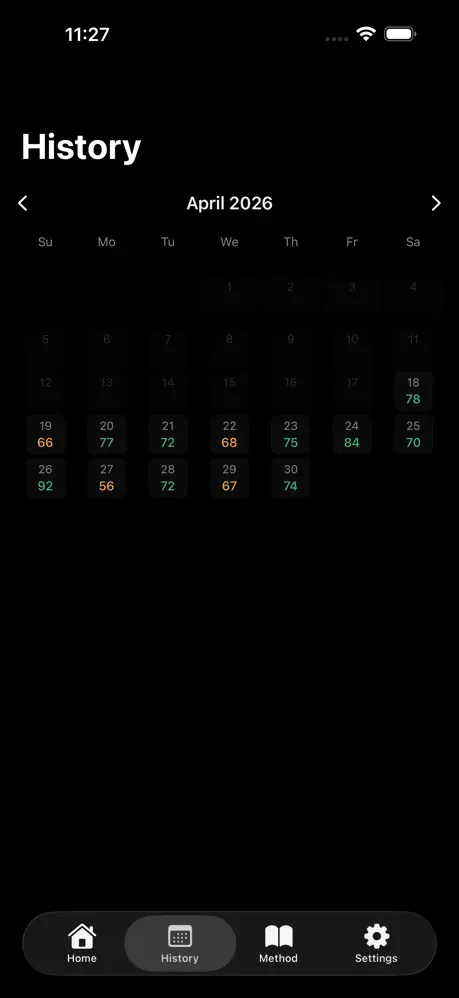








Hope this connects to most of the Asian languages as most of the informal meetings happen in the local language
Curious how you’re handling consent/privacy in casual real-world environments though. That feels like one of the biggest challenges for products like this.
It's interesting launch Congratulations!
i actually think memory systems become more valuable as agent workflows get longer and more task-oriented instead of just Q&A chats.
One challenge I could see is information overload 😅 Once every conversation becomes searchable, surfacing the right context becomes extremely important.
i think transparency matters a lot here 🔥 Even a lightweight sidebar showing “what the assistant remembers” would build more trust
long -session memory is one of those features people only notice when it’s missing 👀 Repeating context every few turns gets exhausting fast.
Really sleek launch. The productivity space on wearables is heating up.
Hmm wonder, is bluedot can replace Siri ?
This feels especially useful for customer conversations where the important detail shows up after the formal meeting is over. The big UX question I’d watch is what should graduate from “recorded context” into “actionable memory.”
A hallway chat may include one durable customer objection, three throwaway comments, and a follow-up promise. If Bluedot can make that separation visible — final note, source snippet, and why it was promoted to CRM/Claude context — it would make the AI-ready handoff feel much safer than a giant searchable transcript.
Congrats on the launch! The Apple Watch capture + instant sync into Claude/CRM is the part I'd actually use. Out of curiosity, what was the hardest thing to get right for recording in noisy real‑world environments?
My old method - step away from the trade show booth, record my notes from the chat by voice recorder, enter into CRM later at the hotel. Major value add here Bluedot team!
Can this work as my personal note? I've been looking for the ability to record things on my watch, then transcribe it, then to claude or notion. that would be amazing!
Congrats on the launch! The Apple Watch capture feels like the right form factor for the off-desk conversations that usually get lost. Curious how you’re handling consent and visibility for in-person recording, especially in more casual settings like dinners or hallway chats?
What about the battery usage? If I have a meeting that last for an hour or so how much this will drain?