PH热榜 | 2026-05-31
一句话介绍:Clipto是一款完全离线的本地化AI媒体搜索引擎,帮助创作者、团队在海量视频、音频和文件中,通过自然语言描述即可秒级定位特定片段,解决“数据丰富但知识贫瘠”的痛点。
Mac
Productivity
Artificial Intelligence
本地AI搜索
视频管理
音频转文字
自然语言检索
媒体资产管理
隐私优先
Apple Silicon
内容创作工具
人脸识别
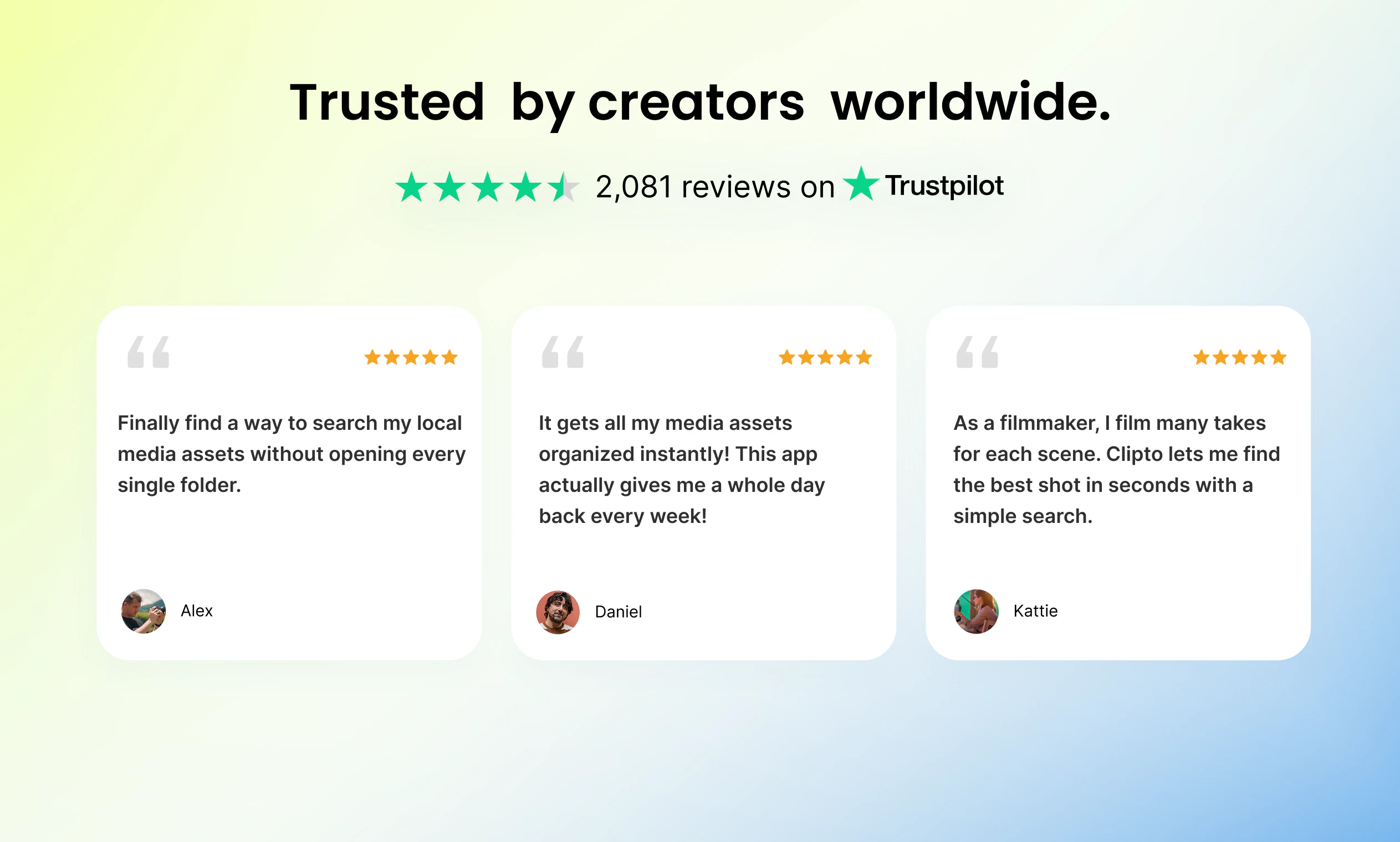
用户评论摘要:用户普遍认可“本地化+自然语言搜索”的价值,尤其对创意工作者(如B-roll管理)和合规要求高的企业场景感兴趣。核心问题聚焦在:索引是否随文件移动同步更新、多设备(MacBook/iPad)间索引是否可移植、对专业摄影语言(如机位、构图)的理解深度,以及人脸自定义命名功能。部分用户关心初始索引对大量旧数据(如5年会议记录)的处理效率和增量更新机制。
AI 锐评
Clipto的核心理念并不新鲜——“本地版谷歌相册”的类比精准但暴露了其局限性。谷歌相册的真正护城河不在于AI识别能力,而在于跨设备无缝同步的生态粘性。而Clipto当前“每台机器独立索引”的设计,恰恰是用户接受度最大的障碍:一个需要为2TB视频等24小时的本地索引工具,让搜索效率变成了昂贵的奢侈品。对创作者而言,其真正的价值并不在于“搜索速度”,而在于“避免组织成本”——当用户不需要再手动打标签、建文件夹时,搜索才成为真正的生产力工具。
产品最聪明的设计是明确聚焦于“已知存在但找不到”的场景,而非虚无缥缈的“AI发现”。这避开了多数AI工具“帮你想象”的陷阱,回归到“帮你回忆”的实用主义。然而,技术实现的硬伤不容忽视:对Apple Silicon的苛刻依赖(M1 Pro起步、24GB+内存)将用户群锁死在高端Mac用户的小圈子里。在Windows和更低功耗设备上的缺席,让“本地优先”变得有些傲慢。
更隐忧的是,当AI索引本身成为重度计算资源消耗者时(如处理5年会议记录),用户是否会愿意让电脑持续满载工作?这个问题比“搜索有多快”更本质。Clipto真正的增长瓶颈将不是技术能力,而是如何在不牺牲“本地化”承诺的前提下,解决跨设备协同这一终极难题——如果做不到,它永远只能是一个高级的“文件搜索器”,而非“个人记忆系统”。
一句话介绍:Oura Ring 5是一款主打舒适佩戴与主动健康洞察的智能戒指,通过更小的体积和长达9天的续航,解决用户全天候追踪睡眠、压力、心率及恢复数据而不愿佩戴沉重腕戴设备的痛点。
Health & Fitness
Hardware
Wearables
智能戒指
健康监测
睡眠追踪
压力管理
心率监测
可穿戴设备
主动健康
钛合金设计
长续航
Oura
用户评论摘要:用户关心老用户能否获得软件更新;质疑蓝牙连接与Apple Health的兼容性问题;询问睡眠追踪的准确性(有反馈称会漏记初段睡眠且无法手动校正);探询Health Radar识别异常波动的算法逻辑;同时有用户称赞小巧设计是“去手腕化”的关键突破。
AI 锐评
Oura Ring 5在硬件上迈出了关键一步——40%的体积缩减和2克重量使其真正逼近“无感佩戴”的边界。这不再是简单的迭代,而是一次对佩戴场景的重新定义:当戒指比绝大多数传统戒指还轻时,它才可能成为真正的24/7健康伴侣。然而,产品的真实价值并不完全在于尺寸。评论中用户最尖锐的质疑指向了核心功能——睡眠追踪的准确性。有人直言“会漏记前1-3小时睡眠且无法手动校正”,这是智能戒指品类最致命的信任裂缝:如果核心数据存在明显盲区,再小的体积也只是摆设。
软件层面,Oura正试图用“Health Radar”等AI功能构建差异化。但一个关键矛盾在于:用户对“主动提醒”的期待,与当前产品在数据校正、Apple Health兼容性等基础体验上的缺失形成了反差。与其画饼“夜间呼吸模式”“血压信号”等医学级推测,不如先解决用户早晨必须手动运行快捷方式才能同步数据的“非智能”体验。此外,Oura的订阅制模式正在将硬件利润转化为长期收割,用户关心的“老用户能否获得更新”本质上是对硬件寿命与软件付费墙之间的博弈。
整体而言,Oura Ring 5是“硬件正确”与“软件待补”的结合体。它用极致的小巧叩开了主流消费市场的大门,但能否真正留住用户,取决于它能否用实际数据打赢睡眠追踪的一对一战争——而不是仅靠“忘掉你戴着它”的文案说辞。
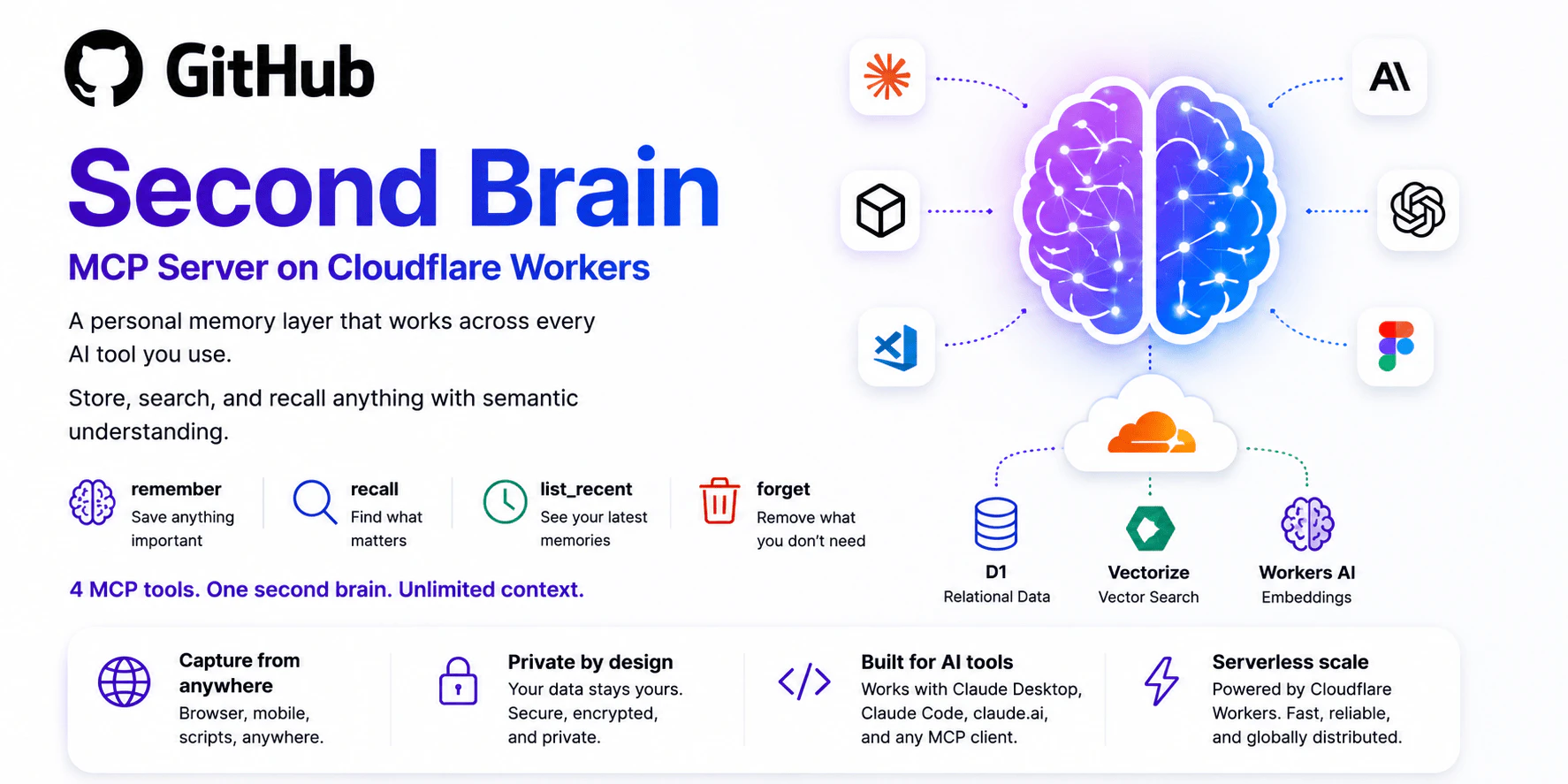
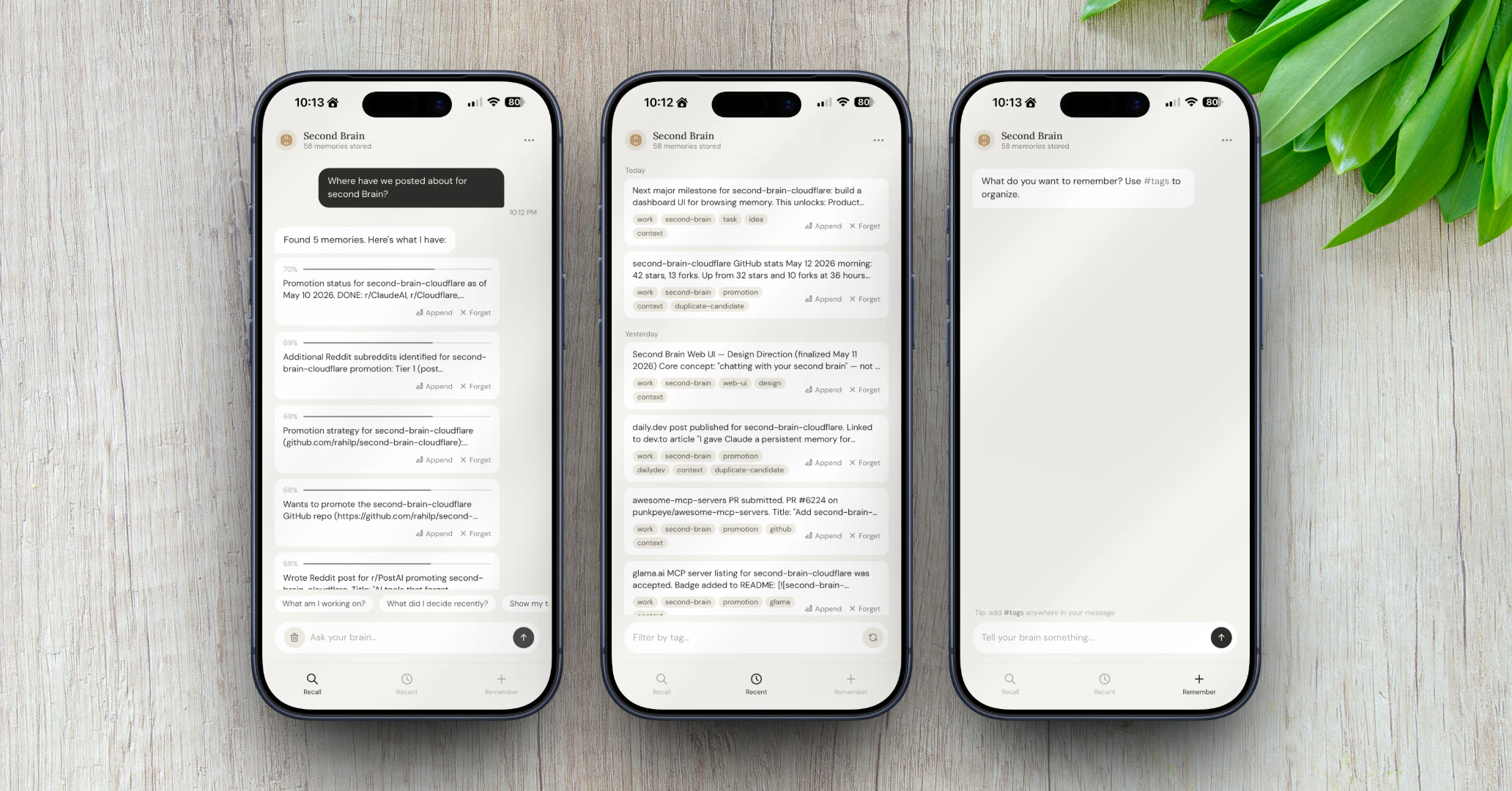
一句话介绍:Second Brain for AI是一款自托管式的AI持久记忆层,能在Claude、ChatGPT、Cursor等工具间同步项目决策、偏好和历史上下文,解决每次对话都需从零开始的痛点。
Open Source
Developer Tools
Artificial Intelligence
AI记忆层
持久化上下文
语义检索
自托管部署
多工具同步
MCP协议
冲突检测
上下文窗口管理
Cloudflare
免费开源
用户评论摘要:用户关注四点:1. 记忆冲突处理(新旧数据如何覆盖/合并)与版本历史缺失;2. 非后端用户的部署门槛(要求一键部署而非手动配置);3. 跨会话记忆与窗口内溢出问题的区别;4. 对数据“最新即正确”逻辑的担忧,建议增加“规范/草稿/弃用”状态标注。
AI 锐评
Second Brain for AI精准击中了当前AI工具生态中最令人抓狂的断层:每个会话都是“记忆格式化”的白板。产品价值不在于提供更大的上下文窗口,而在于构建跨工具的、持久的、可被意图检索的“大脑皮层”。对于重度使用者来说,反复注入环境信息的时间损耗已经超过了AI本身带来的效率增益,因此这个解决方案在边际效用上是成立的。
但从评论中能看出,产品目前还处于“能用”而非“好用”的阶段。核心的冲突检测机制仅依赖语义相似度和LLM裁决,且对“旧记”的替代策略偏向粗暴——当新旧记忆矛盾时,旧记忆直接被删除,这在实际工作流中是危险的。一个六周前确定的技术架构决策很可能因为一次临时讨论被错误覆盖。开发者回应中提到的“重要性评分影响排序但不影响改写”也揭示了逻辑缺陷:决定信息是否应被更新的不应是时间戳,而是其被标记的“权威层级”(规范/草稿/废弃)。
更值得关注的是,用户在部署体验上给出的信号极为明确:技术门槛正在杀死产品触达。尽管团队已有一键部署到Cloudflare的方案,但README的入门引导显然失败了。对于一个强调“自托管”“数据主权”的产品,需要让非后端用户,例如产品经理或资深研究员,也能轻松点击启动,否则这层“记忆层”只会变成Github上的又一个漂亮但无人用的公开仓库。
此外,产品在“跨会话记忆”(Second Brain)与“会话内溢出”(滚动摘要)之间存在一条没有填平的沟壑。后者是用户实际高频复现的痛中痛,但尚在路线图第9位,优先级偏低。如果团队只在记忆层做持久化,而不解决长对话的首尾失忆问题,产品的用户黏性将始终受限于会话形态。
总的来说,Second Brain走在正确的方向上,但目前更像一个为开发者群体准备的智能“剪贴板”。要成为真正的AI第二大脑,还需要在冲突管理、用户权限(如记忆所有者标注)、以及引入版本历史的迭代中完成蜕变。产品的对手不是ChatGPT的用户记忆,而是用户大脑的轻信成本——一旦注入错误上下文导致的决策损失超过了手动输入的麻烦,用户就会流失。
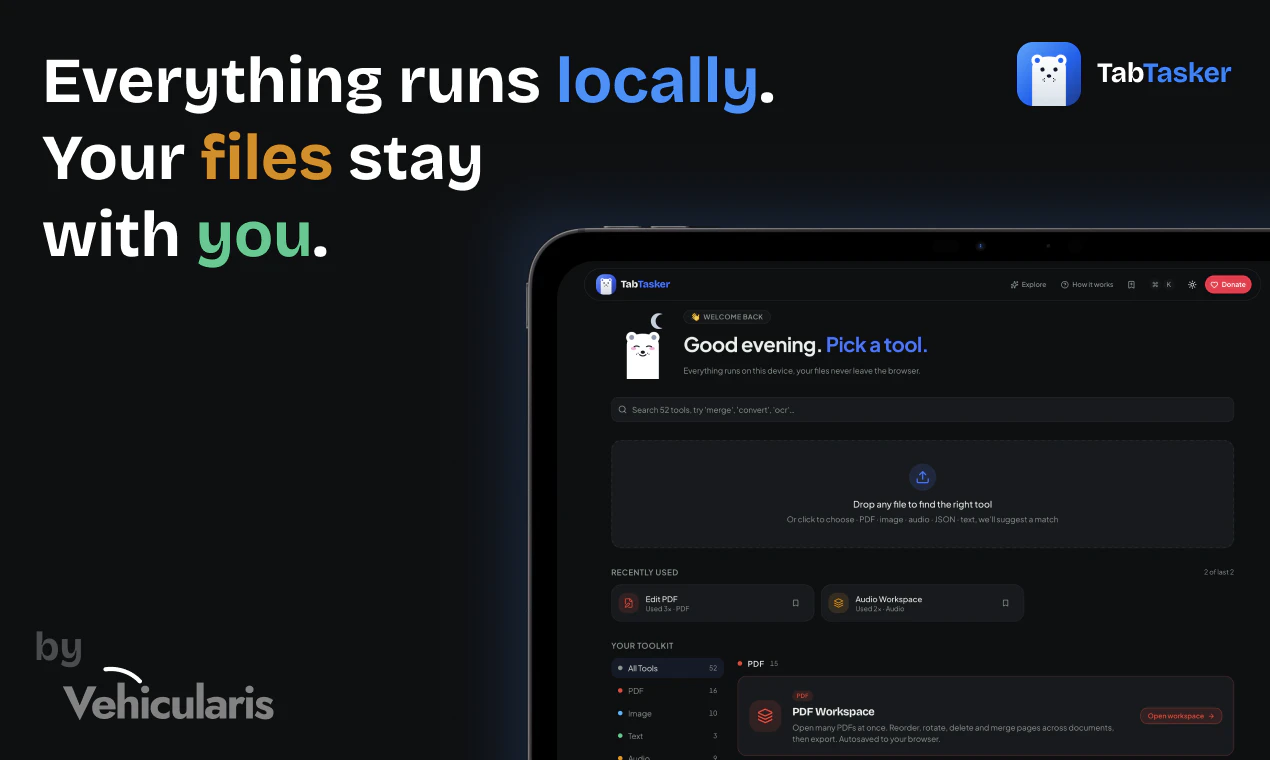
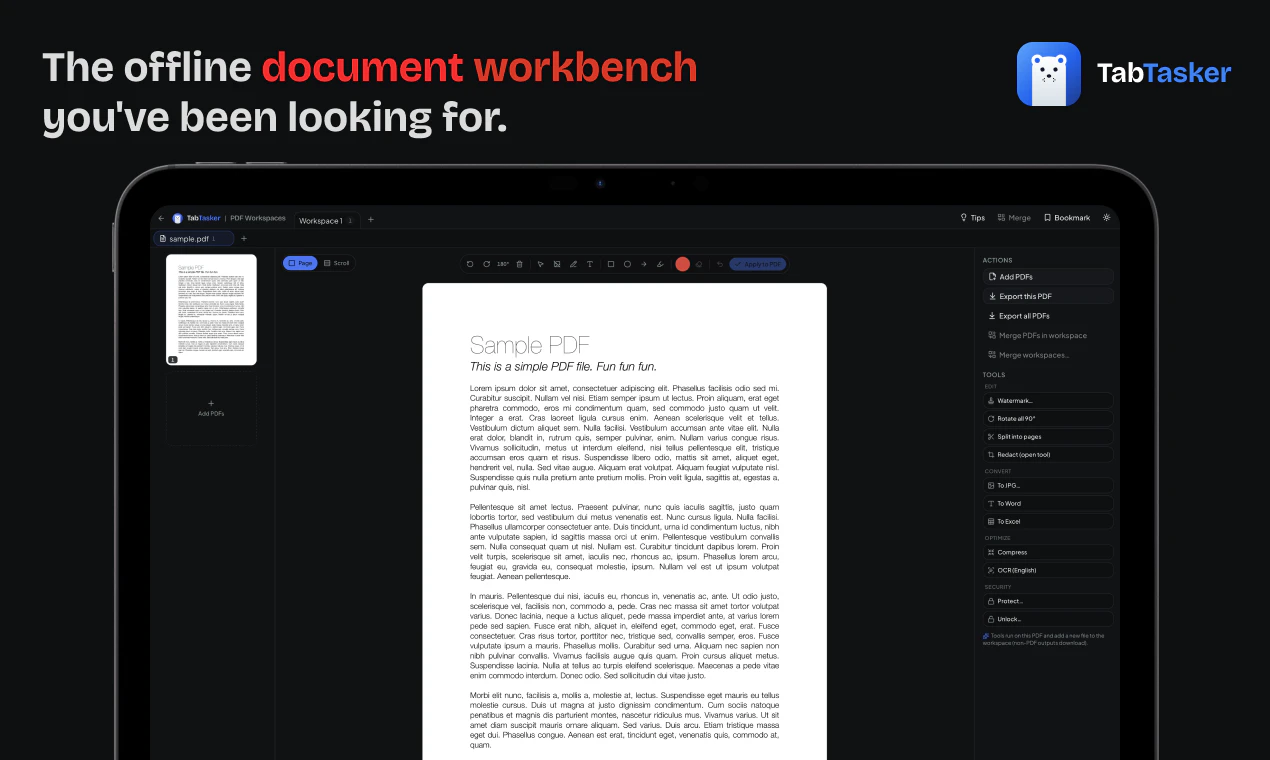
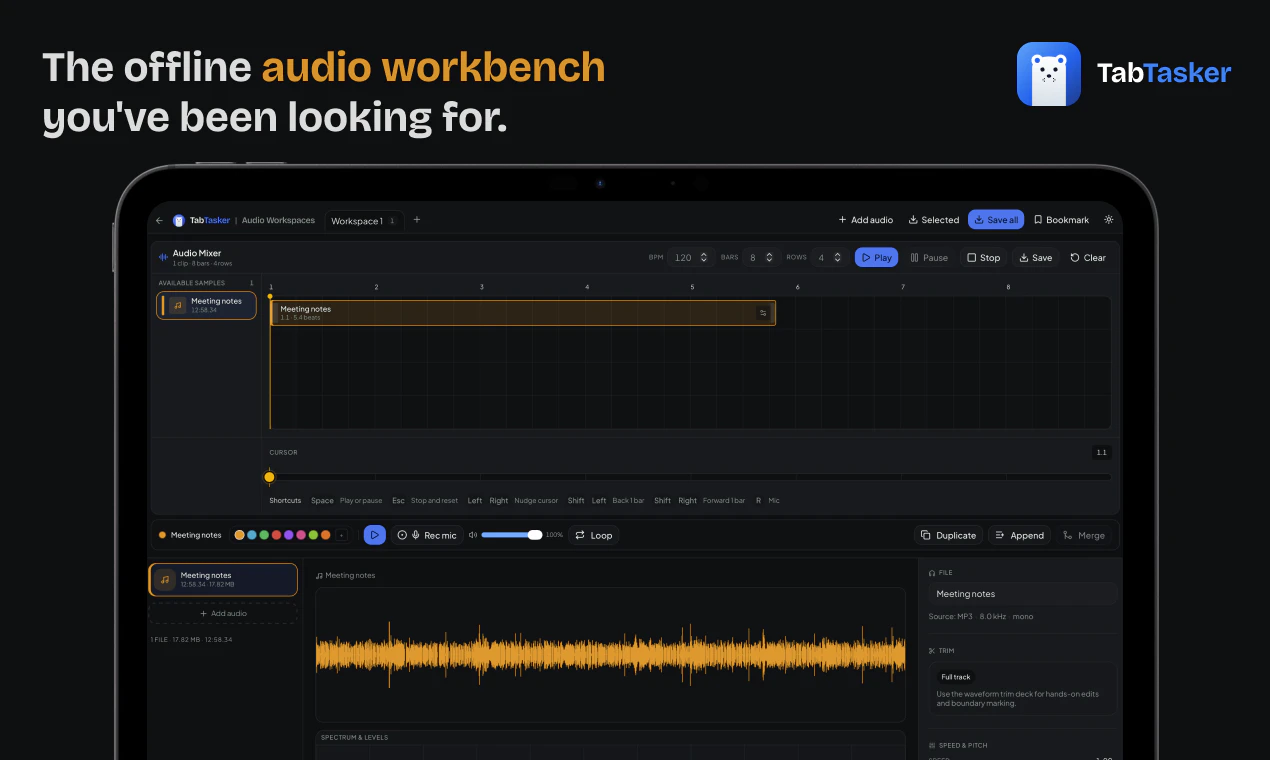
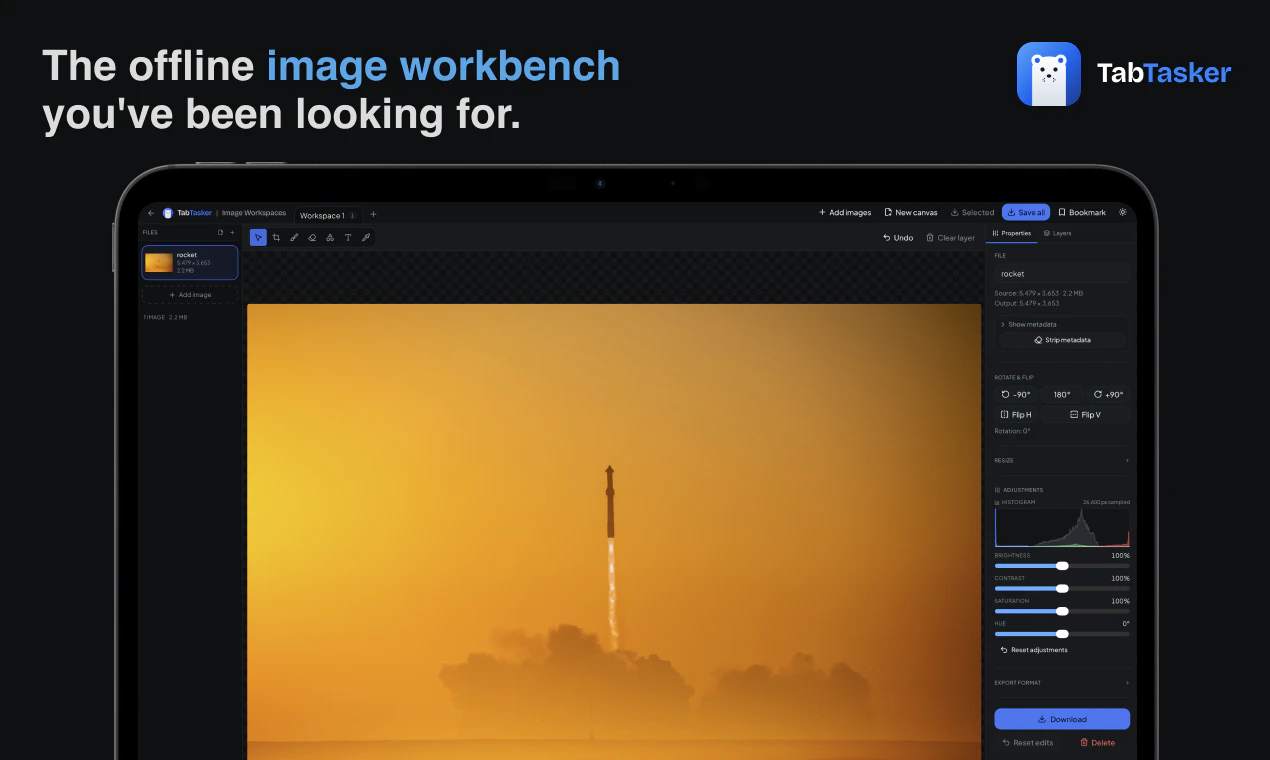
一句话介绍:TabTasker是一款在浏览器中完全离线运行的免费工具集,让你无需上传任何文件即可处理PDF、图片、音频及50多种日常任务,彻底解决对数据隐私泄露的担忧。
Productivity
Privacy
Artificial Intelligence
离线工具集
浏览器本地处理
PDF编辑
隐私保护
WebAssembly
ONNX Runtime
AI转录
图片处理
免费工具
无服务器
用户评论摘要:用户高度认可零上传的隐私设计,尤其赞许无需注册和完全免费。技术用户关注WASM与Whisper模型的实际运行效率,并建议对“零服务器”声明进行网络请求审计。开发者回应称可通过浏览器Network tab自行验证,并承认因无法追踪错误而依赖用户反馈。
AI 锐评
TabTasker的“零服务器”宣言在隐私焦虑蔓延的当下堪称精准的营销靶向,但其真实价值并非单纯的技术颠覆,而是对用户心理账户的巧妙卡位。将所有处理压在客户端,用WebAssembly和ONNX Runtime硬扛FFmpeg与Whisper的运算量,确实体现了工程诚意——尤其是放弃Web Speech API以保全“数据不出标签”的承诺,这一刀切得果断。然而,它并未真正解决“本地计算”与“便利性”的古老矛盾:重度用户很快会发现,转码4K视频或处理大PDF时,风扇狂转的笔记本并不比云服务更“快”。评论中工程师们追问的“WASM体量与内存限制”正是其隐痛——这个工具箱在展示实力的同时,也暴露了浏览器沙盒的物理边界。更犀利的观察在于,其商业模式暗示了产品上限:既然没有服务器账单,那么盈利点何在?若依赖捐赠或未来功能收费,则可能重蹈“隐私换便利”陷阱;若坚持完全免费,则缺乏持续迭代的动力。而对“零服务器”的审计提问,恰好戳中软肋——即使没有后端,前端依赖的第三方CDN、配置的Service Worker,甚至GitHub Pages的日志,都可能造成数据“侧漏”。TabTasker当下是极佳的签名档产品:创始人展示技术审美,个人用户安放敏感文件。但要成为“生产工具”,它仍需证明自己不是浏览器里那个优雅的离线孤岛。
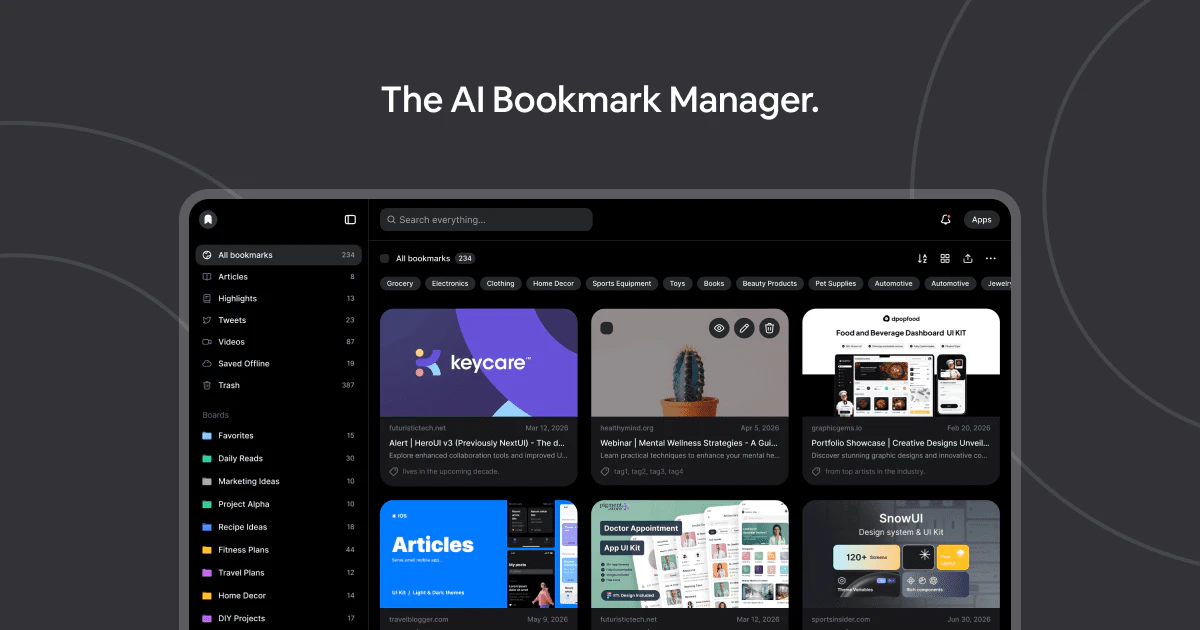
一句话介绍:Marqly 5.0 是一款利用AI自动为收藏链接打标签、分类并支持语义搜索的智能书签管理器,解决用户在海量书签中快速检索和复用的痛点。
Productivity
SaaS
Developer Tools
AI书签管理
语义搜索
智能标签
内容摘要
自然语言查询
跨平台同步
离线访问
知识库构建
信息检索
浏览器扩展
用户评论摘要:用户普遍认为书签管理的痛点是“检索而非保存”,担心数千条书签会变成“墓碑”。用户关注AI如何应对认证页面或JS渲染页面的内容抓取问题,官方回应会降级使用URL和元数据信号。
AI 锐评
Marqly 5.0 的核心价值在于将书签管理从“存储行为”升级为“检索行为”。它聪明地避开了传统工具比拼“收藏速度”的误区,瞄准了用户八个月后面对两千条链接时的真实焦虑。产品语义搜索和自动标签的设计,精准击中了人类思维模式(自然语言)与数据组织模式(文件夹/标签)之间的割裂——用户本来就不会记住自己当时放在了哪个文件夹,只会记得“好像看过一篇讲XX的文章”。
然而,评论中一位技术用户的提问值得深思:对于被认证墙或JS渲染页面“锁住”的链接,AI标签功能是否形同虚设?官方承认会降级使用URL、标题等有限信号,这恰恰暴露了AI书签管理的阿喀琉斯之踵:当内容不可见时,AI的“智能”就退化为关键词匹配。这意味着Marqly在私有化、动态化内容面前,可能与其他竞品一样陷入“准确率折扣”的窘境。产品目前更多解决了“跨浏览器、跨设备”的物理存储散乱问题,但在解决“跨信息墙”的非物理问题上,还需要更激进的方案(如镜像缓存、用户主动补充内容)。总体来说,它在“整理”环节做得很棒,但在“读取”环节的底层壁垒仍未突破。如果未来能打通阅读器模式与订阅源的二次加工,将更有希望从“书签助手”进化为“外脑”。
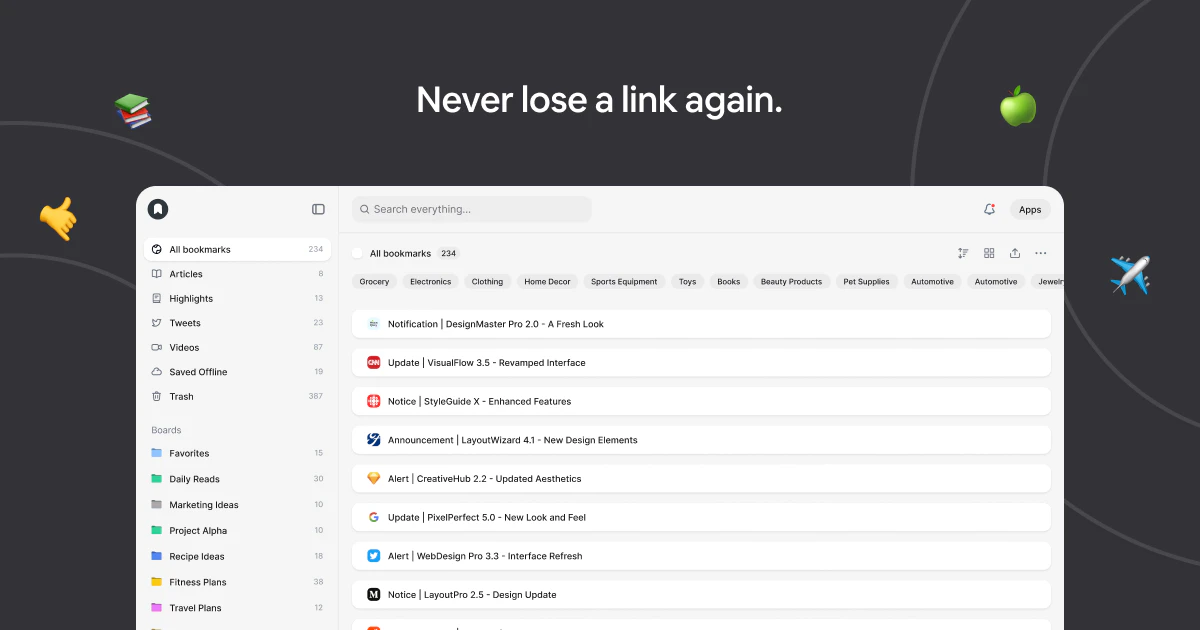
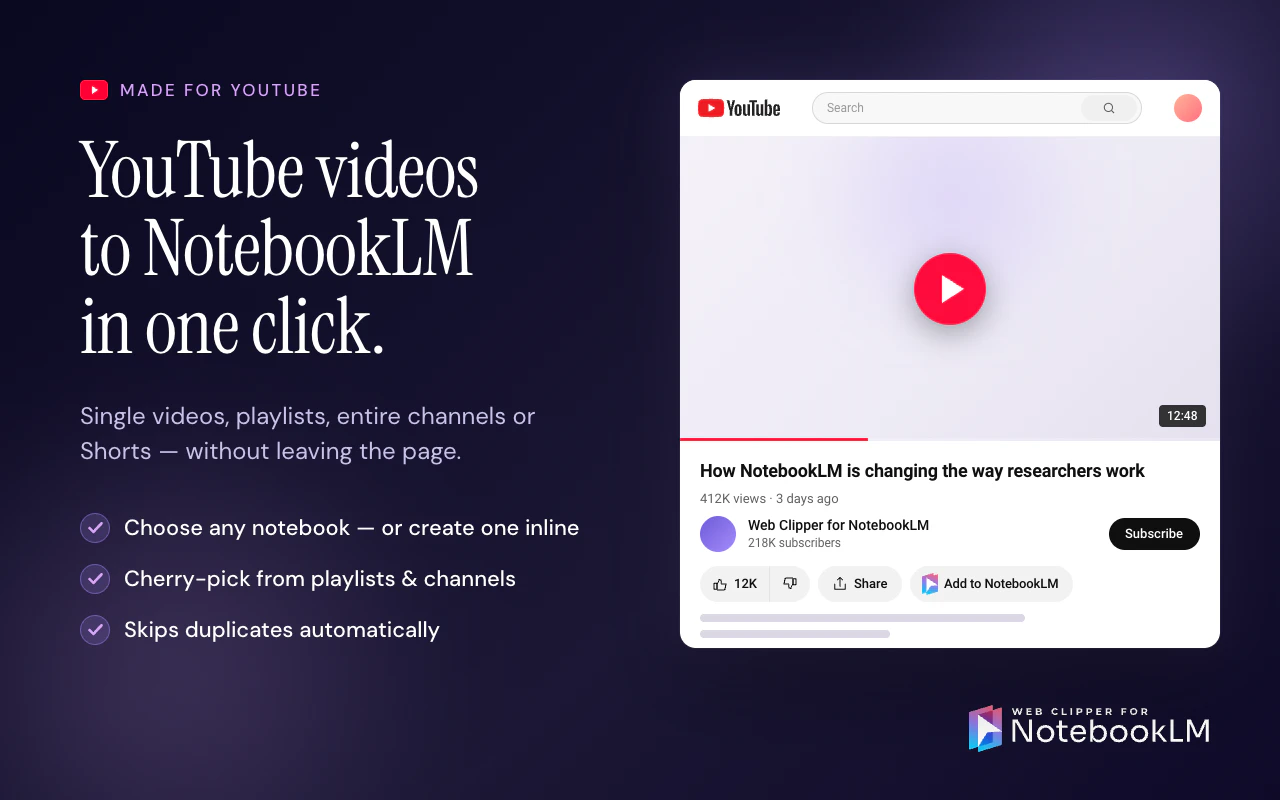
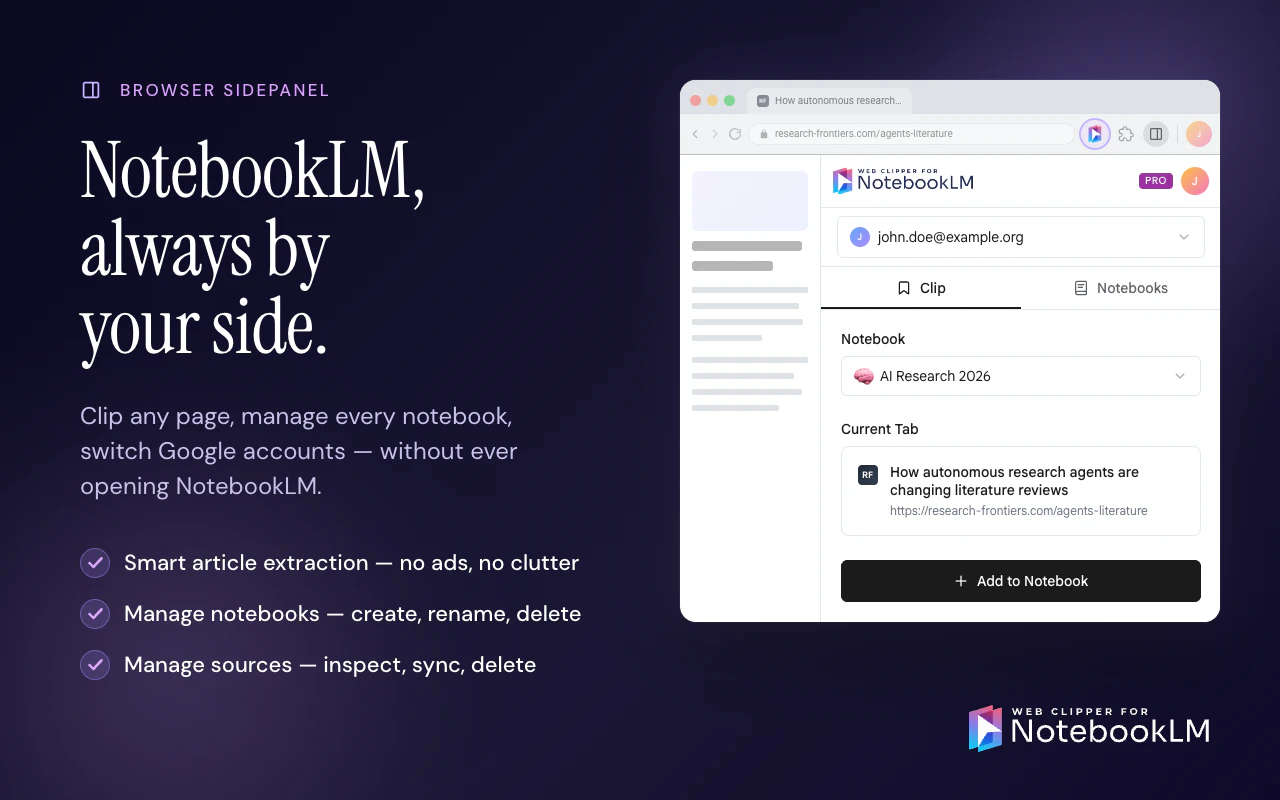
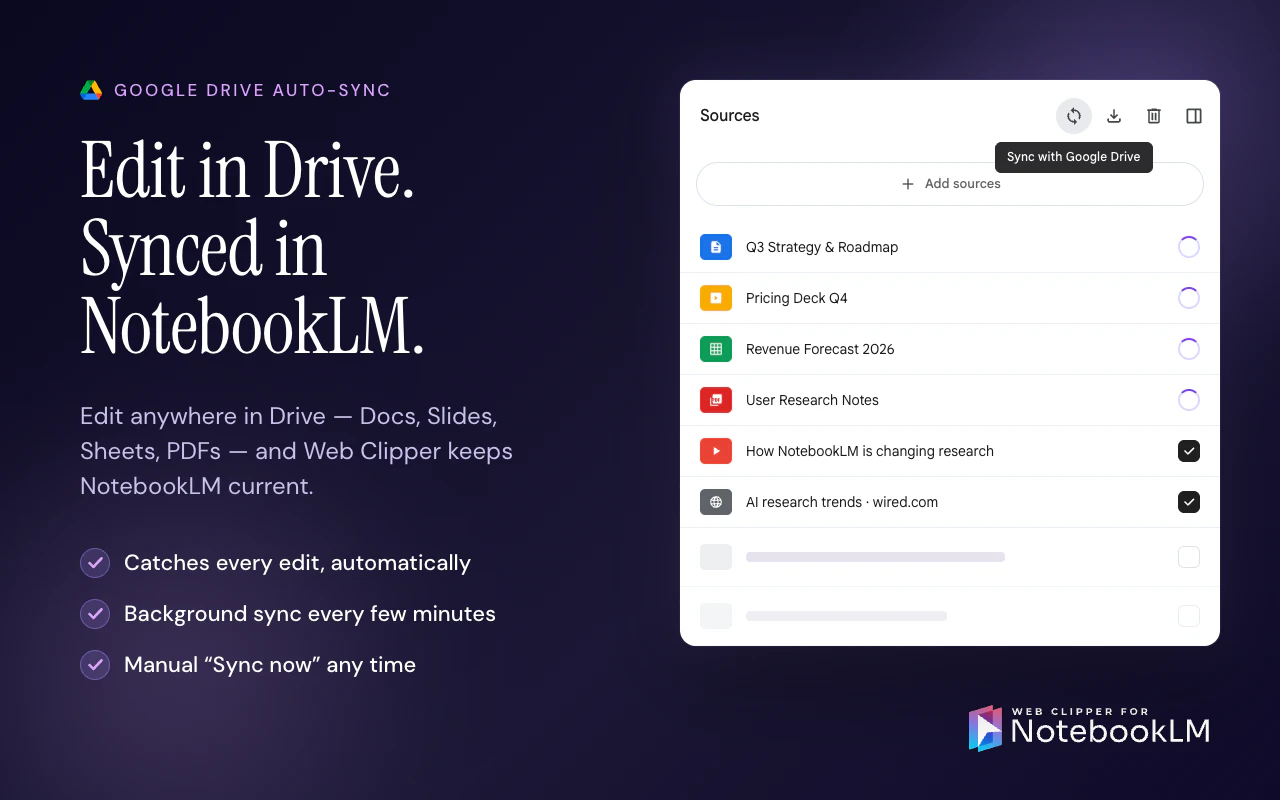
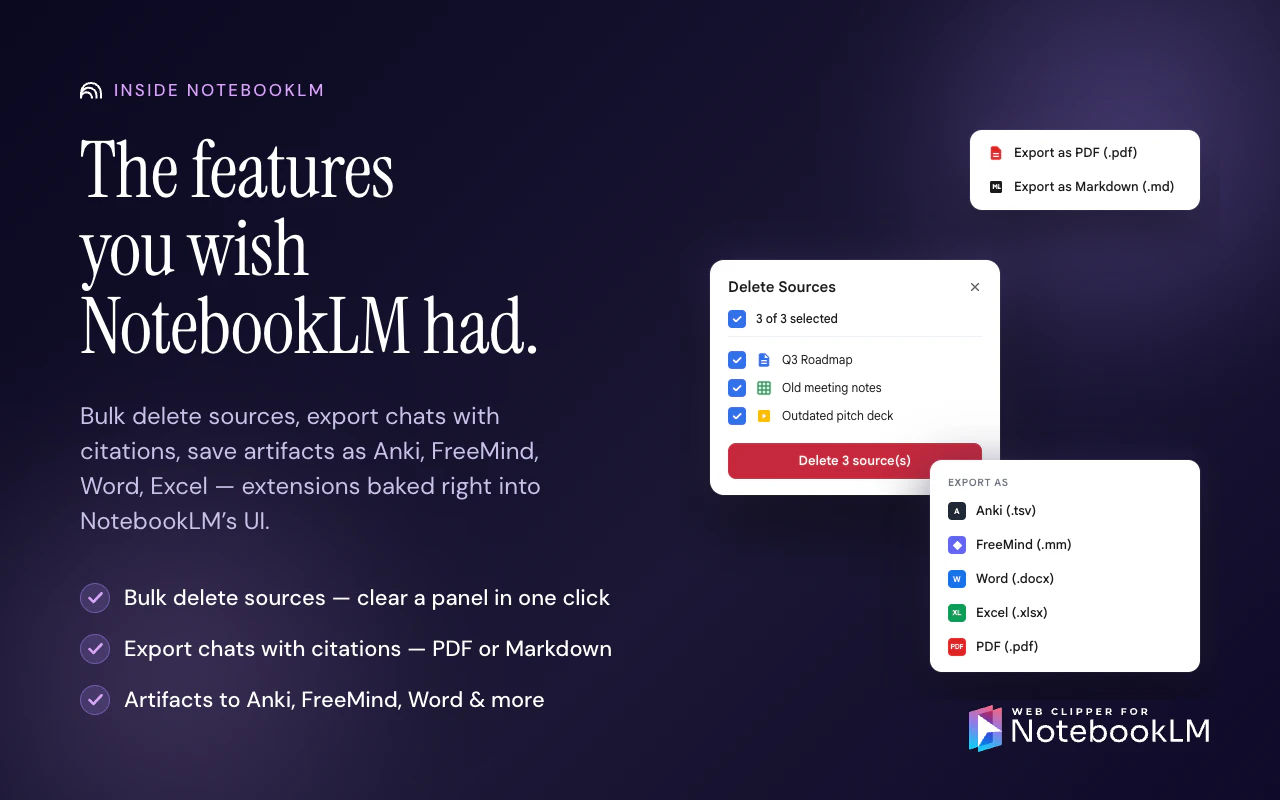
一句话介绍:Web Clipper for NotebookLM是一款Chrome扩展,通过一键剪藏网页、PDF、YouTube视频/频道/播放列表、Reddit线程、AI对话等内容到NotebookLM,并支持将笔记中的闪卡、思维导图、报告、聊天记录导出到Anki、Obsidian、Word/PDF/Markdown等外部工具,解决用户手动复制粘贴URL的繁琐痛点和NotebookLM数据“困在内部”无法自由流转的短板。
Chrome Extensions
Artificial Intelligence
Online Learning
Chrome扩展
NotebookLM增强
网页剪藏
内容导出
知识管理
研究工具
自动化工作流
AI笔记
生产力工具
数据同步
用户评论摘要:用户普遍认可该插件解决了NotebookLM“数据孤岛”问题,尤其看重导出到Obsidian和Anki的功能。核心反馈:一是当剪藏数百个视频的长频道时,用户应能选择视频而非静默耗尽配额;二是希望导出内容能标注源文件的同步新鲜度(如实时同步/一次导入/失败)以提升可信度。另有用户关心Reddit剪藏是否合规(API调用及限流),开发者回应使用公开API且遵守限流,非大规模爬取。
AI 锐评
Web Clipper for NotebookLM的走红,本质上是AI笔记工具生态“开放性”缺失的必然结果。NotebookLM虽然凭借大模型的理解能力在信息整理上表现惊艳,但其封闭的产品形态——数据无法批量复制、无法导出、无法同步——实际上把用户变成了“数据佃农”。这款插件做的,恰恰是用最轻量的方式,帮用户把被困在NotebookLM数字围墙里的资产搬运出去,同时把外部的海量内容高效地扔进来。
从产品策略看,其价值并非单纯“剪藏”,而在于打通了两个关键断点:一是“输入效率”——从逐条粘贴URL升级为频道/播放列表批量导入、AI对话一键拾取,大幅降低了素材搜集的摩擦;二是“输出自由”——通过Anki、Obsidian等成熟工具的导出,将NotebookLM的临时研究产出转化为可长期积累的终身知识库。
不过,风险也不容忽视。依赖Reddit公开API的剪藏方式可持续性存疑,一旦Reddit收紧政策,功能可能随时失效。此外,视频批量转录会快速消耗NotebookLM的配额,用户反馈中已有人担忧“无声耗光额度”——如果插件不主动提示和限制,反而可能成为用户的反向痛点。更关键的是,Google正在推进Drive原生同步,一旦NotebookLM自身补齐导出和复制功能,该插件60%以上的核心价值将瞬间归零。
所以,目前的口号是“the extension grows into a layer that genuinely extends NotebookLM”,但真相是:这个“layer”的生存周期,完全取决于Google的上层决策。短期看是趁虚而入的补位产品,长期看则是一场与平台赛跑的赌博。
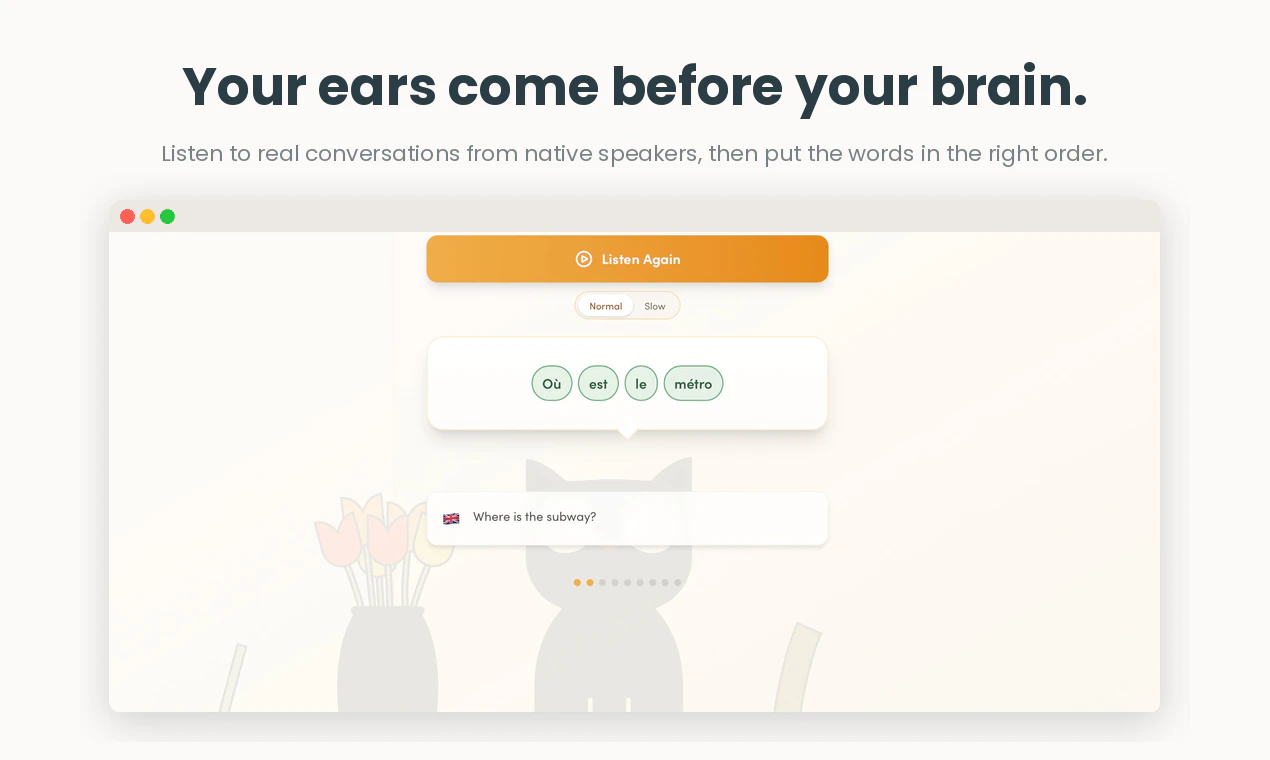
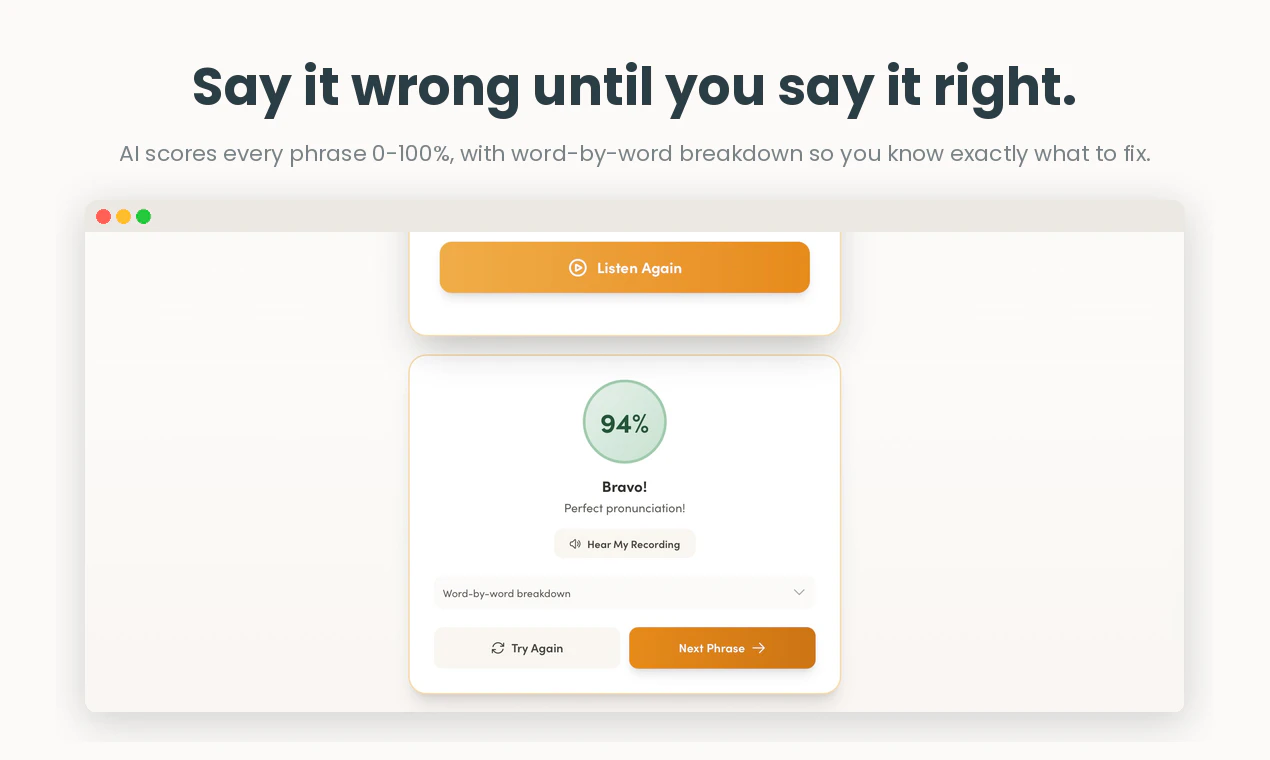
一句话介绍:通过模仿母语者的真实对话并借助AI语音克隆与发音评分(0-100%),解决“能看懂却说不出”的核心痛点,帮助学习者在15分钟内从被动理解转向主动开口。
Education
Languages
Artificial Intelligence
语言学习
AI发音评分
口语训练
语音克隆
沉浸式模仿
法語學習
西班牙语学习
口语自信
非典型学习法
小團隊產品
用户评论摘要:用户普遍好评其提升口语能力与自信,尤其与Duolingo对比时强调“真正逼你开口”。核心问题集中在对不同口音是否公平(官方回应不惩罚口音,只关注可理解度),以及AI语音克隆的情感表现力(依赖ElevenLabs)。部分老用户表达了长期支持。
AI 锐评
Copycat Cafe 的存在本身就是对Duolingo等主流语言学习产品的一种无声抗议。当大厂还在用“单词匹配”和“完形填空”堆砌用户时长时,它精准切入了“能看懂但说不出口”这个被长期忽视的断层。其核心价值不在于AI,而在于回归人类语言习得的本质:模仿。把语音评分、AI克隆和自由对话作为手段,本质是在模拟“婴儿学语”的试错环境,而非“学生做题”的考试逻辑。
从产品路径看,这是一个AI+垂直场景的成功范本。两个创始人做到16K MRR和1000+付费用户,证明极度细分市场的付费意愿远高于泛化教育工具。但风险同样明显:发音评分的准确性在非标准口音面前依然是技术难点,虽然有“只评分可理解度”的策略,但用户如果感知到评分不公,信任会立刻崩塌。语音克隆的情感表达也完全受制于第三方模型(ElevenLabs),这是供应链上的一个潜在脆弱点。
另外,当前仅支持法语和西班牙语,限制了用户天花板。如果后续增加德语、意大利语等语言时无法复现同样高水平的声音克隆和发音评分,增长就会遇到瓶颈。整体来看,这是一款“小而美”但“不轻易大”的产品。它证明了AI语言学习不该只有背单词一条路,但能否从小众口碑走向规模增长,还要看它对语言扩展和全球口音包容性的处理能力。
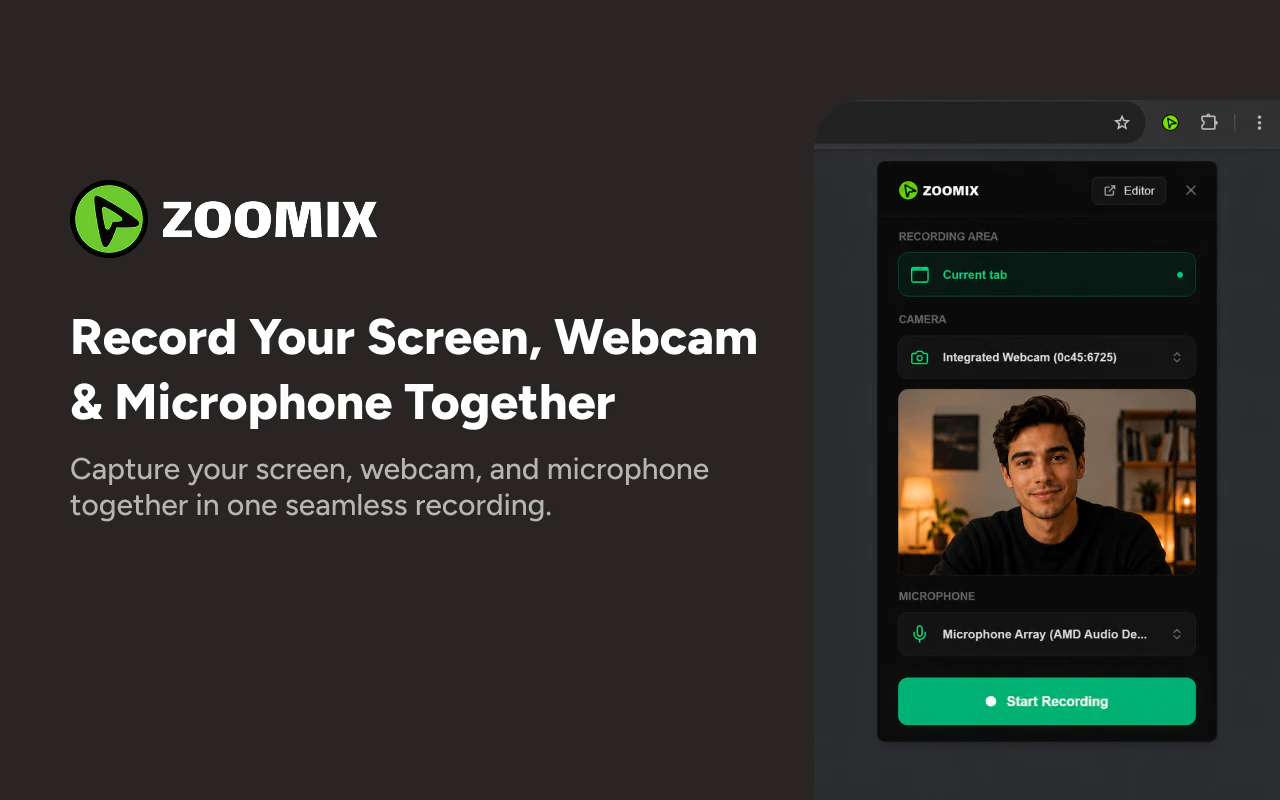
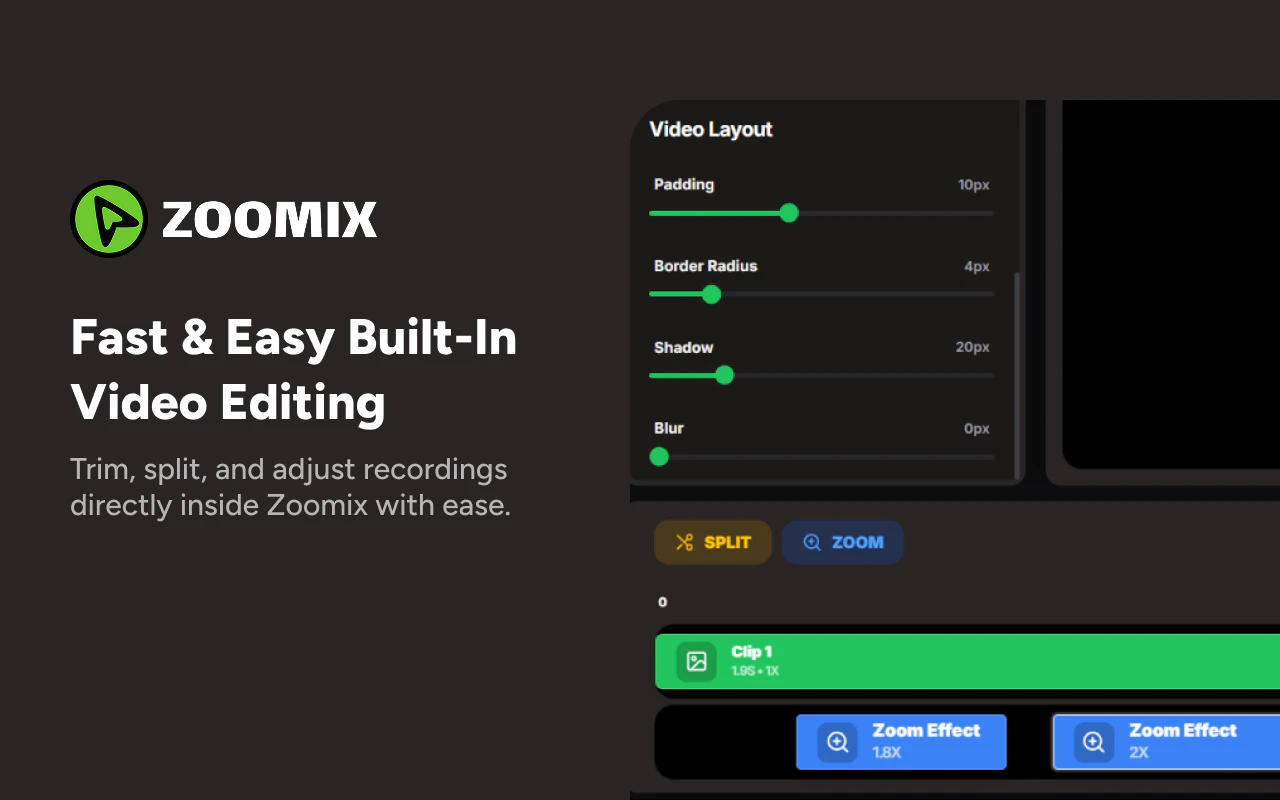
一句话介绍:Zoomix 是一款浏览器插件,通过自动添加智能缩放、光标追踪和干净背景,让用户无需剪辑就能快速生成专业级的产品演示视频,解决屏幕录制画面粗糙、观众流失和后期编辑耗时的问题。
Productivity
屏幕录制
产品演示
浏览器插件
自动缩放
光标追踪
视频美化
零剪辑
SaaS
效率工具
视频创作
用户评论摘要:用户指出官网定价链接失效、缺少社交媒体账号和Logo、与Loom的差异化不清等问题。开发者已修复链接,说明当前有Pro版五折首发优惠,并强调免费版无录制限制。部分用户询问离线或桌面端应用,目前暂无计划。
AI 锐评
Zoomix 切中了一个真实的痛点:绝大多数屏幕录制既丑陋又分散注意力,导致观众难以跟随。其核心价值并非“录制”,而是“自动美化”——通过智能缩放、光标追踪和背景清理,将原始的录制内容直接转化为更易观看的“产品叙事”。这种零编辑、即录即得的思路,精准打击了那些没有视频制作能力但需要快速分享产品演示的创业者、产品经理和销售。
然而,产品面临的挑战也很明显。第一,差异化壁垒不足。Loom、Screen Studio等竞品已占据用户心智,且Zoomix的“自动缩放”和“光标追踪”并非颠覆性创新,更多是功能层面的集成优化,技术门槛不高,极易被模仿或集成到主流工具中。第二,从评论看,产品尚处在极其早期的阶段,官网链接失效、社交资产为零、品牌传播乏力,说明团队在运营和信任建设上存在明显短板。用户质疑“和Loom有什么区别”时,开发者的回答虽明确,但“免费无录制限制”的卖点在商业化长期可持续性上存疑。
Zoomix 真正的机会在于聚焦“浏览器录制+自动美化”这个极窄场景,并持续优化AI对操作行为的理解,让特效真正“懂”用户在讲什么,而非机械缩放。如果能做到“录一次,自动生成多种演示风格”,则有可能在工具类SaaS中占据一席之地。但目前来看,它更像一个精致的功能插件,而非一个成熟的产品平台。若不能在“无法编辑但随时可美”这条路上做到极致,用户很容易回头拥抱Loom加后期。
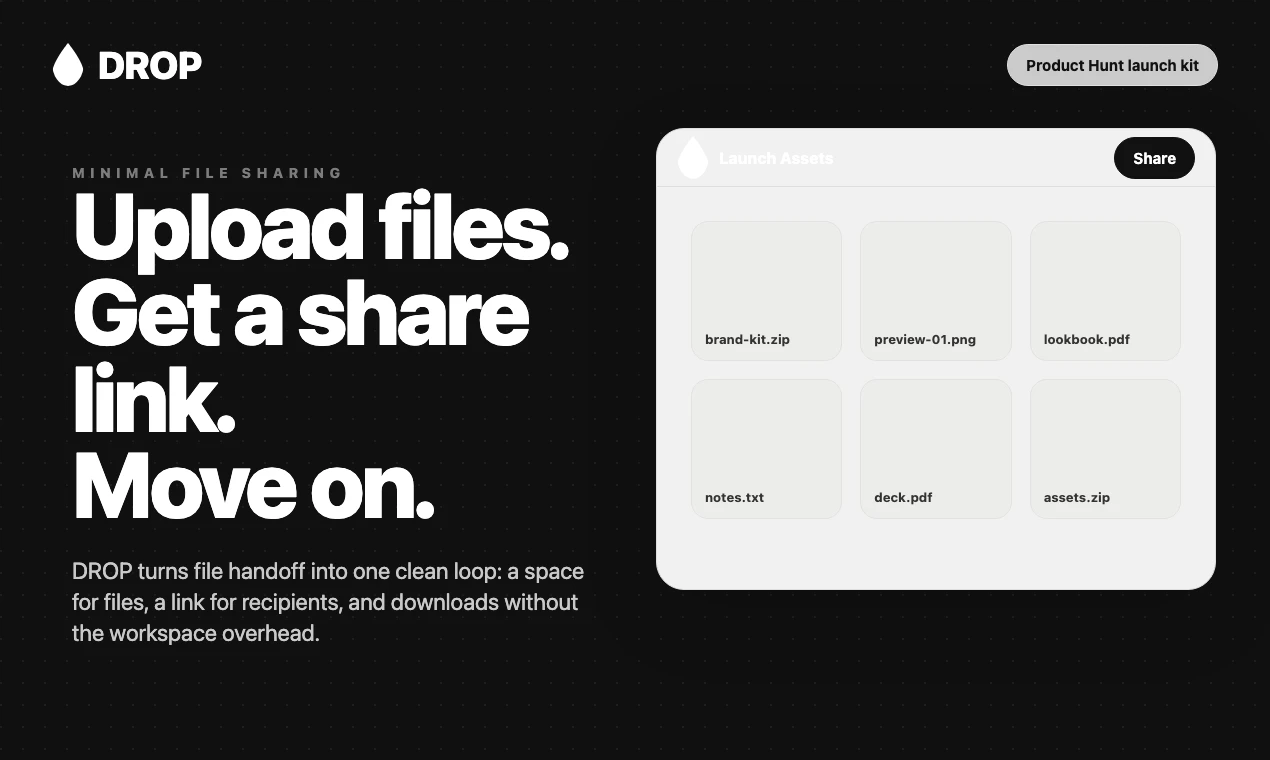
一句话介绍:DROP是一款专注于极简化文件交付的工具,通过去掉冗余功能,让创意工作者能快速创建文件空间并生成分享链接,解决文件分发流程中操作沉重、效率低下的痛点。
Productivity
Storage
文件分享
交付页面
极简工具
创意工作流
链接分享
透明计费
空间管理
轻量协作
信用额度
用户评论摘要:用户(即产品创始人)主动提出产品回退至极简流程,主要反馈集中在两点:1)当前文件分享流程中仍存在哪些冗余步骤;2)分享链接的信用额度计费模型是否足够清晰透明。暂无其他用户有效评论。
AI 锐评
DROP的“自宫式”重构,在AI和协作功能泛滥的当下,堪称一股清流。它精准洞察了创意交付场景中一个最痛的点:不是功能不够,而是功能太多。用户上传文件、给客户看、拿到反馈,这个核心闭环被无数“AI增强”、“去中心化”等伪需求层层包裹。DROP直接砍掉95%的“屎山”功能,回归“上传-分享”的原子级操作,这种减法哲学在SaaS产品中显得尤为珍贵。
然而,13票的投票数暴露了其现实困境:极简意味着极低的护城河。任何网盘都能做类似事情,DROP唯一的差异化是“透明信用分计费”——这更像一个商业实验而非用户体验的突破。其所谓的“收件人可从简洁页面下载”也并非新概念。如果DROP只是做成了一个更干净的WeTransfer,那它最终会沦为“无AI功能的二流工具”,在巨头碾压和用户免费习惯之间被挤压。
真正值得思考的是:“极简”能否支撑起一个独立产品的生存?对于追求效率的创意工作者而言,DROP的低摩擦确实诱人,但用户粘性完全依赖于“上传-分享”的路径依赖。倘若DROP不尽快找到数据管理、版本追溯或品牌化交付页面等更深层的价值锚点,它的命运很可能就像其鼓吹的“反AI口号”一样,成为行业潮水退去后一个漂亮的泡沫。
一句话介绍:Uindow 是一款可编程浏览器,通过无代码录制与纯JavaScript编辑相结合,让用户在不牺牲确定性的前提下,安全、可控地完成真实网页自动化任务,解决市面上自动化工具要么依赖不可控的AI云端、要么脚本脆弱难用的痛点。
Software Engineering
Developer Tools
GitHub
No-Code
可编程浏览器
网页自动化
无代码录制
JavaScript脚本
本地AI
隐私安全
开源
社区模块
工作流自动化
自动化录制
用户评论摘要:用户评论仅有三条(含Maker自述),核心是Maker介绍产品核心亮点:支持本地AI推理、数据不外泄、自动化可录视频、免费且源码可用。暂无用户具体问题或建议。
AI 锐评
Uindow 的野心值得肯定,但13票的首日成绩也暴露出它目前仍是一款小众、甚至未经过市场锤打的工具。Maker Mark 几乎把产品所有优势浓缩在一条评论里——从无代码录制到纯JS编辑,从本地LLM到社区模块——但这些“全栈式”功能恰恰可能成为双刃剑。
首先,“可编程浏览器”这个定位本身就极窄。目标用户必须是既懂网页交互又愿写JS的开发者,同时还需要自动化但不愿用Puppeteer/Selenium?这其实是个很矛盾的群体:真正的开发者倾向于用开源框架定制,而非受困于一个闭源(虽开源但受控)的浏览器环境;而纯业务用户,又很可能被“纯JavaScript”这个门槛劝退。Maker试图用“无代码录制”降低门槛,但一旦自动化出现偏差,非技术人员就不得不接触JS,那跟用自动化测试框架有何区别?
其次,“信任交互”虽能实现文件上传、select元素修改等原生操作,但这并非革命性突破,AutoHotkey、Playwright等工具早已通过更底层的API实现类似能力。Uindow的差异化在于“本地AI推理”——这个卖点契合隐私合规趋势,但实际操作中,本地小模型的上下文理解能力远不如云端大模型,对于复杂逻辑判断和模糊任务,效果很可能大打折扣。用户最终仍可能重回云端AI,那“可控”的承诺就变成了伪命题。
商业化前景也存疑。目前仅强调“个人免费、源码可用”,但如果用户数上不去,社区模块生态就成了空中楼阁。至于被录视频、.js.yaml格式这些功能,更像锦上添花的补丁而非核心护城河。
总的来说,Uindow 是一个技术功底扎实且理念讨喜的早期作品,但尚未证明自己能比 Playwright + LangChain 的组合拳更具实际竞争力。它更适合那些对隐私极度敏感、且愿意忍受初期不完善的小团队做POC验证。想真与成熟工具扳手腕,还需要更多一线用户反馈和痛点打磨,而非只靠一张功能清单自嗨。
一句话介绍:Harness Starter Kit 将AI编程助手的脆弱单次提示词转化为存储在代码仓库中的持久化规则与检查机制,解决团队协作时上下文丢失和规则无法复用的痛点。
Open Source
No-Code
Vibe coding
AI编码代理
仓库守护规则
AGENTS.md
漂移检测
失败记忆
团队协作
提示词管理
开发工作流
Cursor
Codex
用户评论摘要:开发者强调项目巧思是将关键指令“写在仓库里”而非提示词中;询问如何让代理记住并预防反复出现的错误,并希望获取本地试用链接。暂无其他负面或建设性批评。
AI 锐评
Harness Starter Kit切中了当前AI编程工具的一个核心盲区——会话的“失忆症”。大多数AI编码代理(如Cursor、Copilot)依赖短暂的对话窗口或局部上下文,导致团队层面的最佳实践、错误规避记录无法累积。该产品通过“AGENTS.md + 漂移检测 + 失败记忆”的组合,将制度化的知识封装进版本控制,本质上是为AI协作引入“代码规范”的等价物。思路简洁且务实:不依赖外部复杂中间件,仅通过文件结构和检查脚本就完成了规则固化。不过,它的真实价值取决于两个变量:一是AI代理本身是否愿意遵循仓库中的指令(很多工具对本地规则文件的支持仍很薄弱或优先级低),二是团队是否有意愿维护这些文件(一旦规则过时或缺失,反而会误导代理)。目前12票暗示其尚未引发广泛关注,但“提示词优先”的设计哲学值得肯定——它避开了重耦合的安装流程,降低了采用门槛。对于已深度使用AI编码的团队,这套骨架能快速搭建“代理行为守则”,但若想成为标准方案,仍需社区贡献更多即用的堆栈配置文件和错误模式库。
一句话介绍:Hum通过现代化设计的实时访客徽章和在线人数挂件,帮助网站摆脱老旧的统计工具,以美观且不突兀的方式展示访客动态,解决网站“有人气却看不见”的尴尬痛点。
Design Tools
SaaS
Developer Tools
网站访客展示
社交证明
实时在线挂件
访客计数器
UI组件
网站工具
轻量化分析
SaaS
开发者工具
用户评论摘要:用户认可产品设计但质疑UI是否为AI生成,创始人坦诚使用Claude设计后经自身UX背景优化。另有用户预测产品被低估,创始人感谢并期望持续反馈。
AI 锐评
Hum精准切中了一个被忽视的需求:网站“有人气”的可视化。传统方案要么是丑陋的“你是第X位访客”,要么是偏重后台数据的分析平台(如Google Analytics)。Hum选择聚焦于“前端感知”,用现代UI将实时访客数据转化为一种社交证明,这本质上是在贩卖一种“氛围感”——让网站访问者感觉身处一个活跃空间,从而提升停留和转化。
从技术角度看,其壁垒不高。实时计数器可通过WebSocket或轮询实现,20+模板考验的是设计而非工程能力。真正的价值在于抢占了“数据可视化”与“UX增强”之间的缝隙市场。但风险同样明显:用户容易审美疲劳,且一旦免费层泛滥,这种“在线感”会变得廉价。创始人将UI归功于Claude并坦诚调整,体现了执行效率,但长期看,Hum若只停留在挂件层,很难形成护城河。建议其向“实时社交证明+轻量行为分析”进化,比如统计哪些页面访客最多、从哪些页面跳转,并提供“热力图”式的行为痕迹,才能从“好看的工具”升维成“真正提升转化率的商业工具”。
一句话介绍:CoffeePomodoro 将番茄钟与咖啡文化融合,通过等级晋升、连续打卡和温暖动效,解决用户在专注过程中缺乏仪式感和持续动力的痛点,让时间管理变得像品咖啡一样愉悦而自然。
Android
Productivity
Time Tracking
Coffee
用户评论摘要:开发者自述产品灵感源于咖啡与专注的日常仪式,已坚持开发一年半,现面向用户征求“让专注更温暖”的建议,期待优化体验。
AI 锐评
CoffeePomodoro 的创意切入点值得肯定——用咖啡文化为枯燥的番茄钟注入情感温度,这是它区别于普通计时器的核心差异。然而,从10个投票数和仅有开发者一条评论的冷清数据来看,产品尚未形成有效的社区共鸣。
其真正价值不在于功能堆砌(21种音效、小组件、灵动岛等),而在于将“咖啡仪式感”抽象为可量化的成长路径(从宝宝杯到咖啡征服者)。这种游戏化设计若能落地,确实能提升用户粘性。但问题也在此:咖啡等级与专注效率之间的关联是否足够直观?用户是否会为了解锁一个虚拟杯子而长期坚持?如果缺乏更深的社交或数据反馈机制(如对比他人、专注时长分析),这种“小确幸”玩法容易快速疲劳。
此外,独立开发者1.5年的投入值得尊重,但产品在营销和用户互动上明显薄弱。当前阶段,比起添加更多功能,更应聚焦于“咖啡叙事”的完整闭环——比如将一次专注时长与一杯咖啡的“冷却”时间联动,或用真实咖啡优惠券激励打卡。否则,它仍会淹没在无数“好看但无用”的效率工具中。
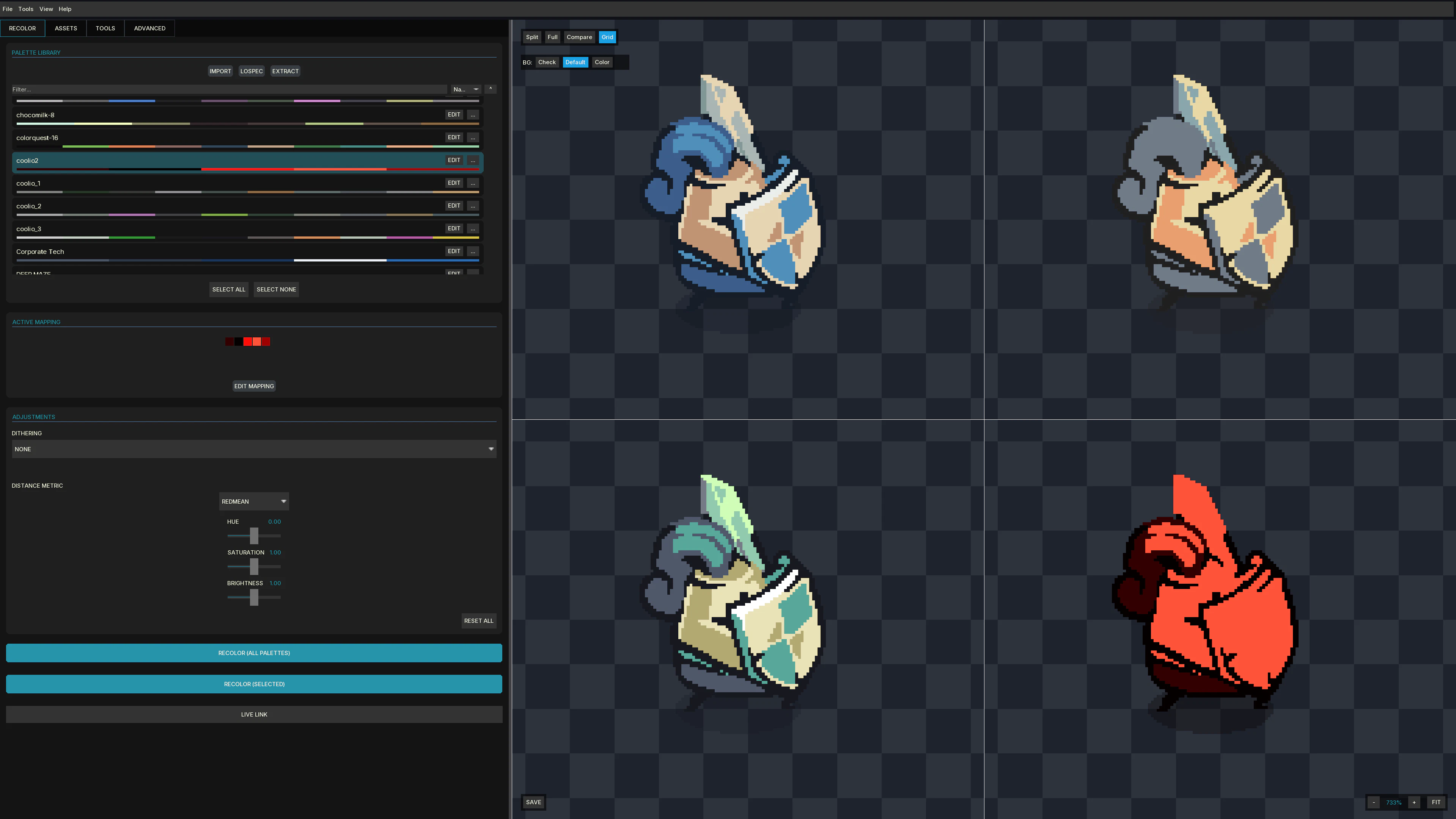
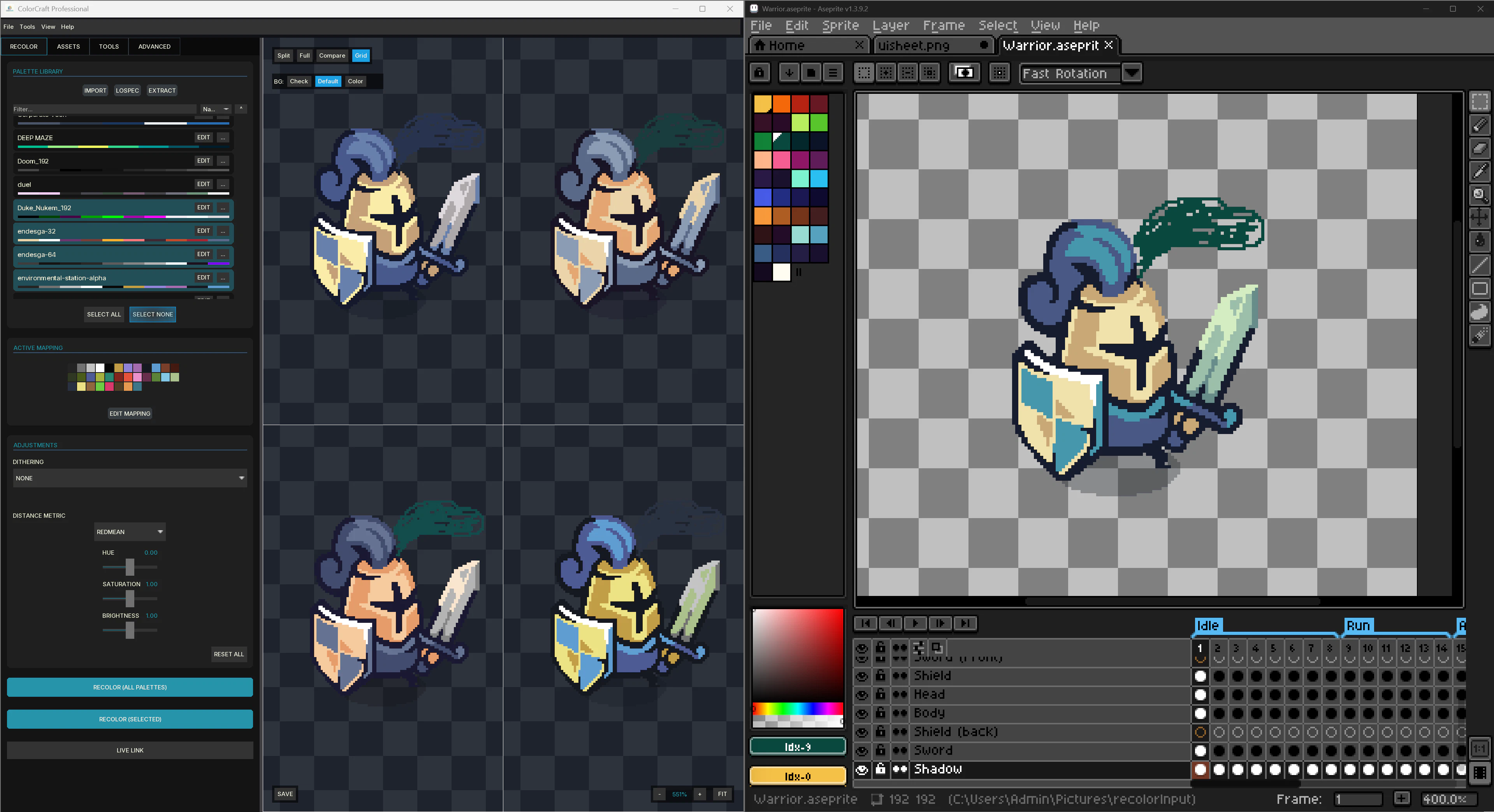
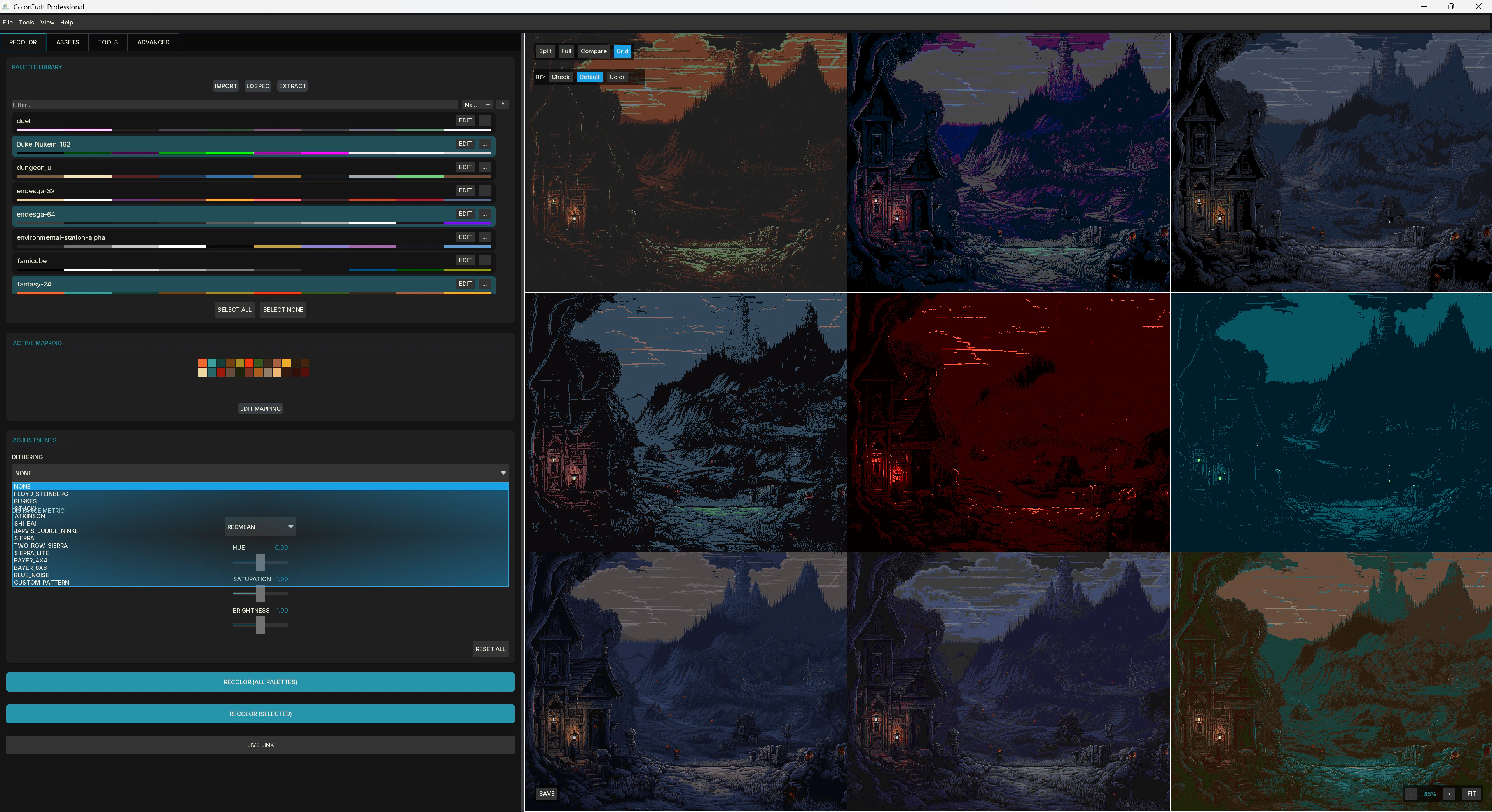
一句话介绍:ColorCraft 是一款为像素游戏开发者设计的批量重上色引擎,通过连接 Aseprite 实时联动,在几秒内自动为数百张精灵图更换配色方案,解决了角色、元素变体等美术资产手动迭代的低效痛点。
Design Tools
Productivity
Art
批量重上色
像素艺术
游戏开发工具
Aseprite 联动
精灵图
调色板
实时预览
自动化工坊
独立游戏
图形处理
用户评论摘要:用户(开发者)自述在制作游戏时,手动统一资产配色并反复修改的流程非常痛苦,进而开发了本工具。从CLI起家,最终完善为拥有实时联动、多种颜色算法、动画支持、遮罩等功能的完整应用,并提供了3.50美元的首发优惠价。
AI 锐评
ColorCraft精准切中了像素游戏美术管线中最“脏活累活”的环节——配色变体迭代。对于追求视觉一致性又需要批量产出不同元素(如红蓝绿三种史莱姆)的独立开发者而言,它确实能避免大量的“另存为+手动吸色”操作,将重复劳动自动化。其核心价值在于“Aseprite Live-Link”带来的所见即所得反馈,以及4种感知颜色算法背后的专业度,这使得它不仅仅是简单的颜色替换,而是试图在不破坏光照和细节的前提下完成逻辑变换。
然而,从产品介绍和评论看,它目前更像一个服务于Aseprite的“插件级”工具,而非独立引擎。其用户基础严重受限于“使用Aseprite且需要批量重上色”的细分人群。极低的投票数(10票)也侧面印证了其冷启动的商业困境。虽然3.5美元的定价对于重度使用者来说是“尘埃价”,但潜在用户是否会特意为“自动化短板环节”下载一个独立应用,而非寻求已有的开源脚本解决方案,是其需要回答的关键问题。此外,评论中透露的从CLI到Full App的演进史,暗示其UI/UX可能仍有“开发者为自己造车”的打磨空间。长远看,能否从“Aseprite伴侣”进化为更开放的像素工作流枢纽,才是其能否从利基工具跨越为社区基础设施的关键。
一句话介绍:CollectMonial 是一款为独立开发者和SaaS创始人设计的品牌化评价墙工具,用户通过一个链接即可收集视频或文字评价,并以高度可自定义的样式嵌入网站,解决了一站式获取客户好评且不破坏品牌视觉的痛点。
Public Relations
Marketing
SaaS
评价收集
视频推荐
品牌定制
嵌入组件
SaaS工具
独立开发者
客户反馈
口碑营销
社交证明
产品发布
用户评论摘要:创始人指出现有工具价格高($50+/月)且Widget样式破坏品牌设计,因此打造了定价$25/月的工具,支持深度定制、一键嵌入、飞书/推特导入及多活动管理。有用户表示“看起来很酷”,将去试用。
AI 锐评
CollectMonial 切中了一个非常具体但扎实的痛点:SaaS和独立开发者对“社交证明”的刚需与现有评价工具“贵且丑”之间的矛盾。创始人以品牌设计师的视角切入,将“品牌一致性”作为核心卖点,这远比单纯做一个“评价收集工具”更有护城河。
从产品定价看,$25/月的FLAT费用对个人开发者极具吸引力,直接瞄准了Trustpilot、Yotpo等高价工具的“低配替代”市场。功能上,视频评价+一键嵌入+支持从X和LinkedIn导入,已经覆盖了基本的MVP,并且“多活动管理”暗示了它向下游营销自动化扩展的潜力。
但目前9票的微弱反馈说明产品尚在冷启动阶段,值得注意的是评论中仅有1位潜在用户表达了试用意愿,缺乏对实际转化率、嵌入后加载性能、视频存储成本的深度讨论。真正的挑战在于:当用户量增长后,视频存储和带宽成本会迅速吞噬利润,25美元/月的定价能否支撑起长期运营?此外,大厂如Canva或Notion若在下一个版本中直接集成同类功能,该工具将面临被“平台化吞噬”的风险。CollectMonial 的长期价值不在于“收集”,而在于成为遍布独立站点的“品牌化评价网络”,关键在于能否利用早期社区建立起像素级匹配不同主题的模板生态,从而形成数据与资产的转换壁垒。
一句话介绍:JSON Kit 是一套浏览器端 JSON 修复与处理工具集,核心功能是自动修复大模型输出的破损 JSON,并明确标注错误原因,解决开发者因 AI JSON 格式不兼容导致的奔溃或转换失败痛点。
Productivity
Developer Tools
Artificial Intelligence
开发者工具
JSON修复
AI工具
浏览器端
在线工具
数据格式转换
调试
开源
大模型适配
零隐私风险
用户评论摘要:暂无用户负面评论。发布者自述项目源于解决大模型输出JSON格式不一致的痛点,强调浏览器端运行保护隐私,底层依赖开源库,并欢迎反馈更多边缘错误案例。
AI 锐评
JSON Kit 的切入点非常精准——抓住了“AI开发红利期”最琐碎却高频的屎坑:大模型输出结构化数据时的格式任性。这类“AI JSON修复”本质上不是技术难题,而是开发体验的扫盲工具。它的价值不在于算法深度,而在于及时性:将修复机制直接做成浏览器端、零部署的即时工具,且加上了“错误诊断标签”这一巧妙的认知层,让用户从“玄学报错”跳转到“看原因改代码”。这种定位聪明且克制:不自建大模型,不搞云端服务,规避了隐私争议,也降低了维护成本。
但问题也很明显:工具集里大多是“别人都有了,我顺便做一个”的冗余功能(如格式化、JSONPath),缺乏真正的稀缺性。修复逻辑依赖开源库,意味着同质化极易被复制。这种产品形态天生飞轮效应弱,用户用完即走,缺乏黏性。真正的护城河在于能否积累出“罕见错误模式数据库”——比如大模型输出的多行截断、非标准Unicode、混合语言注释等——从“通用修复”进化到“AI输出特化修复”。如果止步于标签化开源工具,很快就会成为开发者收藏夹里吃灰的又一个网址。第一版不错,但别止步于此。
一句话介绍:Mixstream是一个让音乐人自主掌控音乐经济的平台,通过透明的版税追踪和同步授权,解决艺术家在传统行业中收入不透明、中间商抽成高、无法了解每笔版税来源的痛点。
Music
Streaming Services
Tech
音乐人平台
版税透明
数字音乐发行
同步授权
AI工作室
去中介化
创作者经济
自主版权
流媒体分发
版税追踪
用户评论摘要:用户对平台透明版税和去中间商化的理念表示支持,期待其未来发展。创始人强调了行业弊端(版税黑箱、中间商盘剥),并说明构建了完整技术栈(含自家流媒体应用和AI工作室),希望获得艺术家、管理者等对平台信任度的真实反馈。
AI 锐评
Mixstream的切入点精准地踩中了音乐行业的“暗伤”——版税不透明和创作者被剥削。它没有在发行价格这个红海里打滚,而是把价值锚定在“权利与许可”的复杂层上,这确实比单纯的“上传文件”更有护城河。但坦白说,“透明”和“公平”是每个区块链音乐项目都喊过的口号,最终大多折戟于用户增长与变现效率。Mixstream的MVP和仅9票的现状说明它仍处于极早期验证阶段,最大的挑战不是技术,而是如何让已经对各类“画饼”平台麻木的艺术家真正相信并迁移其核心资产——音乐版权。靠“AI处理繁琐事务”和“自建流媒体应用”来证明管线可行,听起来更像一种自证清白的苦功夫,而非规模化的利器。若不能快速接入足够大的版税池(如热门影视同步授权资源)或提供显著高于Spotify等巨头的分成比例,很可能演变成又一个“小而美”的理想主义试验品。真正的价值,在于其系统的底层审计能力能否成为行业未来的基础设施,而不只是又一款发行工具。
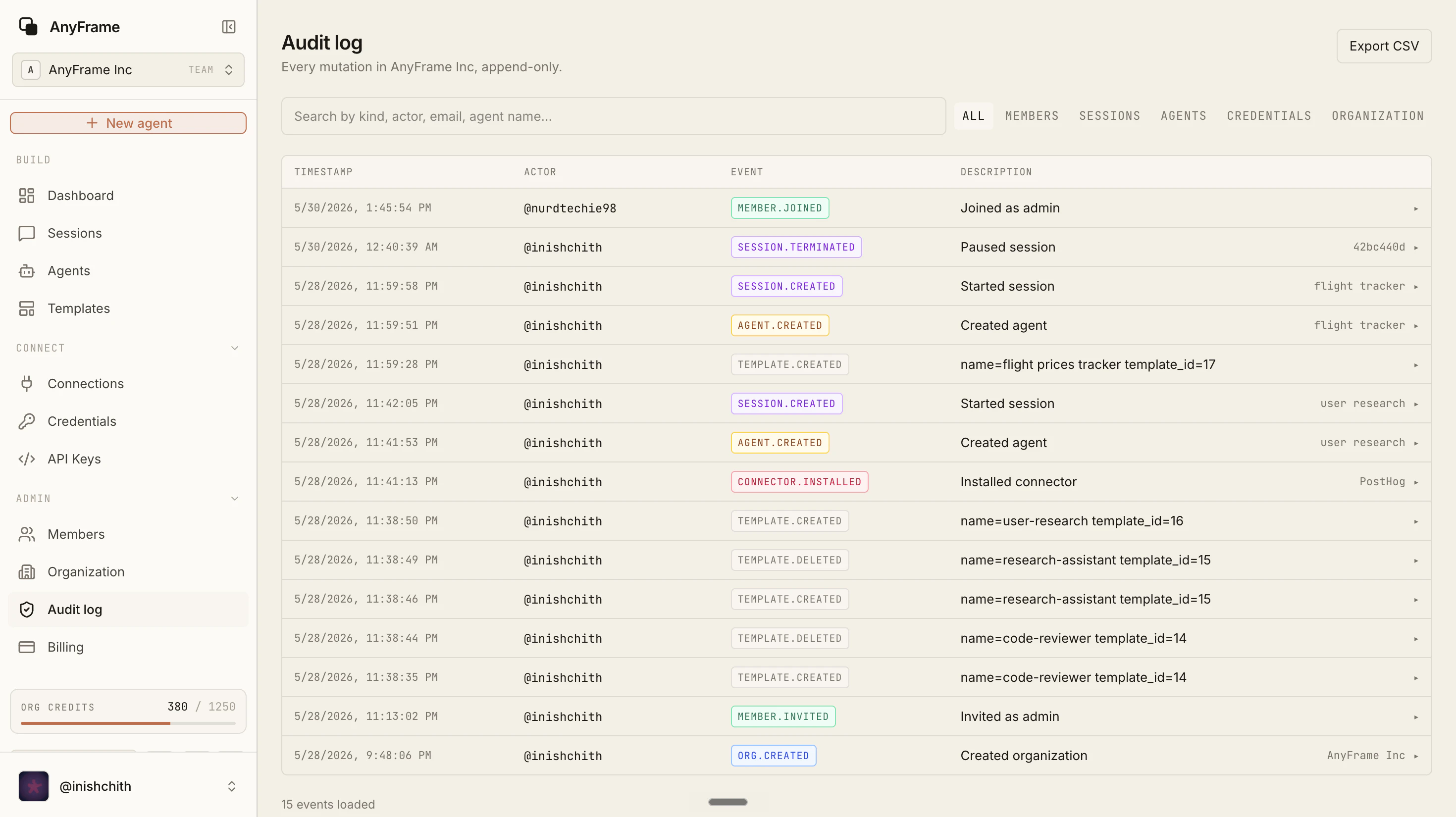
一句话介绍:AnyFrame是一个让团队快速搭建与部署多智能体(Agent)的平台,通过提供沙箱、内存、可观测性等底层基础设施,解决开发者重复构建Agent运行环境的痛点,并支持将Agent嵌入Slack、GitHub等现有工作流中。
Software Engineering
Developer Tools
Artificial Intelligence
多智能体平台
Agent运维
基础设施
工作流集成
沙箱环境
可观测性
SDK
AI部署
Slack集成
GitHub集成
用户评论摘要:用户Chirag(联合创始人)主动介绍产品,强调团队厌倦了重复构建Agent基础架构,AnyFrame负责运行时与集成,用户可专注于业务逻辑。评论目前无负面反馈或具体问题,主要表达产品定位与未来计划。
AI 锐评
AnyFrame踩中了当前AI应用落地中最痛的“最后一公里”问题:Agent的部署与运维。其价值不在于创造新的AI能力,而在于将基础设施标准化——沙箱隔离、内存管理、工具链集成、以及跨工作流(Slack/GitHub)的触发机制,这些都是从Demo到生产环境的必要台阶,但很多团队的确在反复造轮子。然而,产品仅发布一个月,仅有9票,说明目前还在早期概念验证阶段,市场接受度存疑。它的真正命门在于:1)竞争激烈,同类型的LangChain、AutoGPT、以及云厂商的Agent框架都已布局,AnyFrame如何差异化?目前看仅有“Harness可互换”算是亮点,但这本质是兼容性,并非护城河。2)用户评论中只有创始团队自述,缺乏真实第三方反馈,难以判断实际落地中沙箱性能、延迟、异常处理等关键指标的成熟度。3)宣称“分钟级启动swarm”,但在企业级场景下,权限控制、审计日志、成本监控等治理需求可能被过度简化。总体来看,方向正确,但需要迅速证明能在大规模、高并发、复杂流程中稳定运行,否则很容易沦为又一个“Demo级”工具。团队速度是优势,但产品深度才是生存的关键。
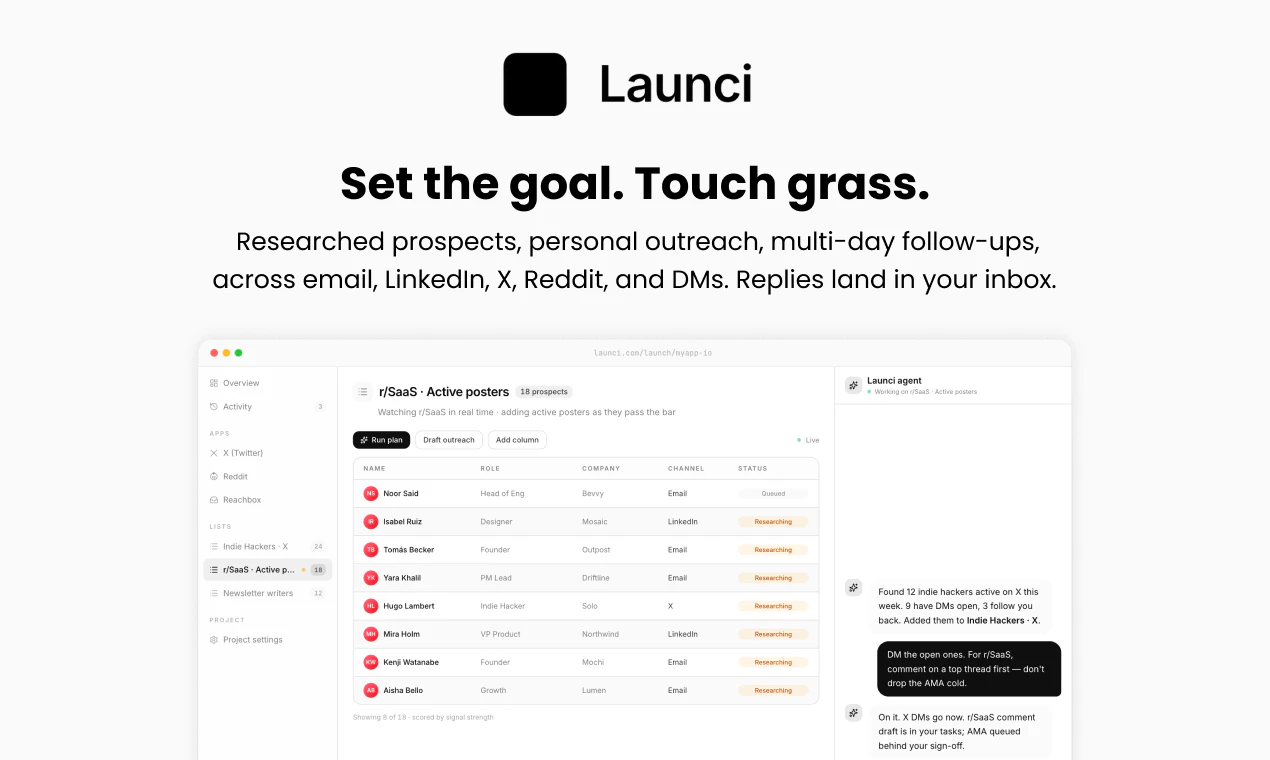
一句话介绍:Launci 是一个面向创始人的AI上市(GTM)代理,能根据你设定的目标,自动调研潜在客户并在邮件、LinkedIn、X、Reddit等渠道撰写个性化触达消息,解决冷启动时“找不到对的人、写不出对的文案”的痛点。
Email
Sales
Marketing
AI GTM代理
冷启动
个性化外联
创始人工具
社交媒体自动化
潜在客户调研
AI销售助手
小众市场触达
自动化营销
用户评论摘要:用户(0点赞)评论肯定了创始人的假设方向正确,但关键挑战在于代理能否可靠地导航LinkedIn平台。目前仅有1条回帖获得点赞,整体反馈有限。
AI 锐评
Launci 切中了一个真实的痛点:传统GTM工具在“量”上内卷,却忽略了冷启动最稀缺的“质”——找到真正关心你且你能提供独特价值的人。其价值不在于自动化发送,而在于用AI模拟人做“慢活”:深度调研、理解上下文、锁定销售数据库难以覆盖的“水下角色”(如行业记者、播客主、小众社区版主)。这种定位让它避开了与Apollo、Lemlist等投放型工具的正面竞争,转而服务那些追求精准而非广撒网的深度技术创始人。
但风险同样明显。正如用户评论所质疑的,AI代理对LinkedIn等封闭社交网络的导航能力是最大瓶颈——自动化爬取、模拟真人交互极易触发平台反爬机制或账号封禁。此外,“询问后再执行”的设计虽强调控制感,却可能拖慢响应速度,抵消自动化的本质优势。若不能以极低用户介入成本实现高精度决策,创始人依然会觉得不如自己写。Launci 的理想用户画像应是“极客创始人”:信任AI的推理能力,愿意容忍部分延迟以换取深度精准。长期看,它必须建立一套透明的信任机制——让用户清晰看到AI的调研逻辑和决策依据,否则将沦为又一个“看起来很聪明但实际不敢用”的玩具。
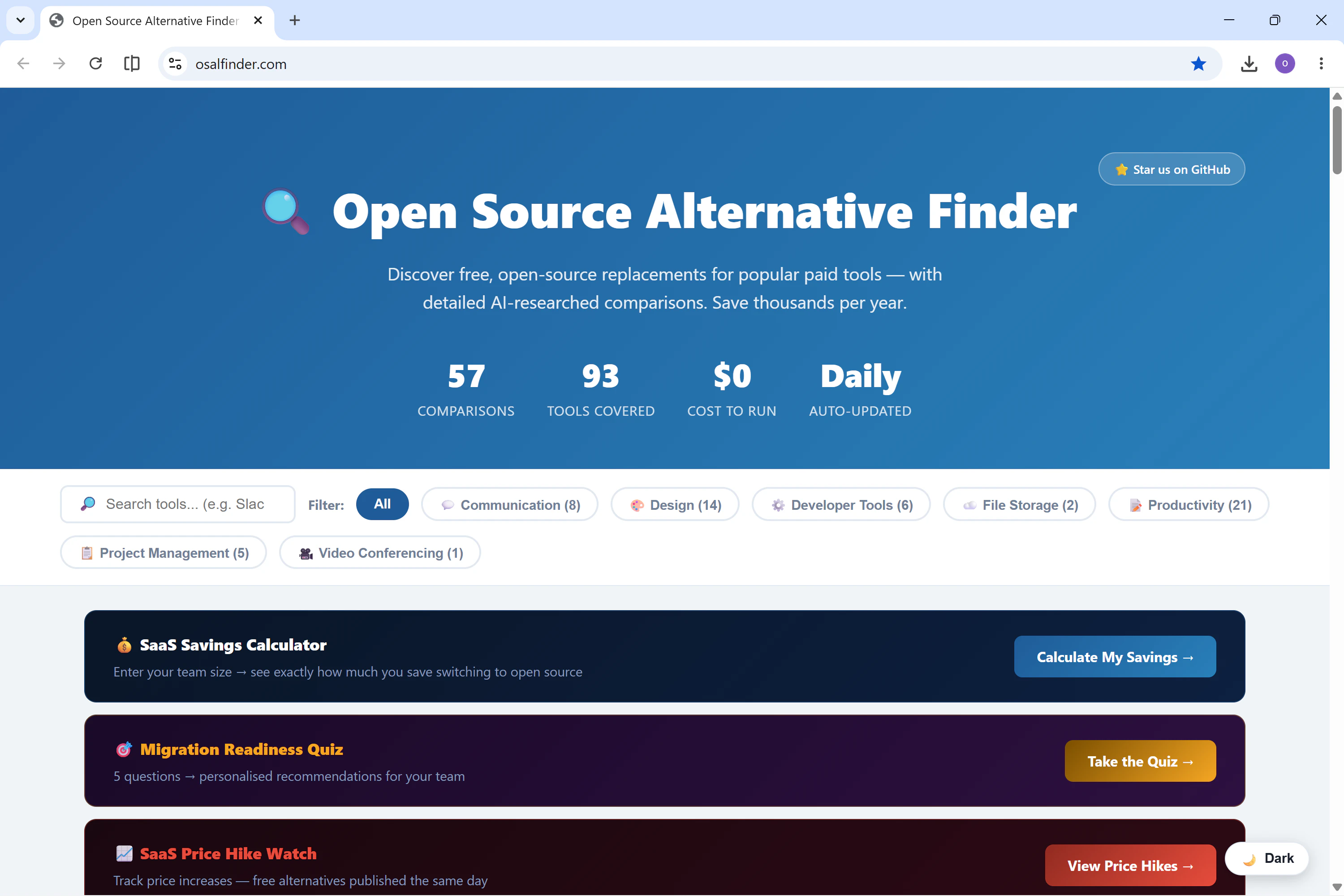
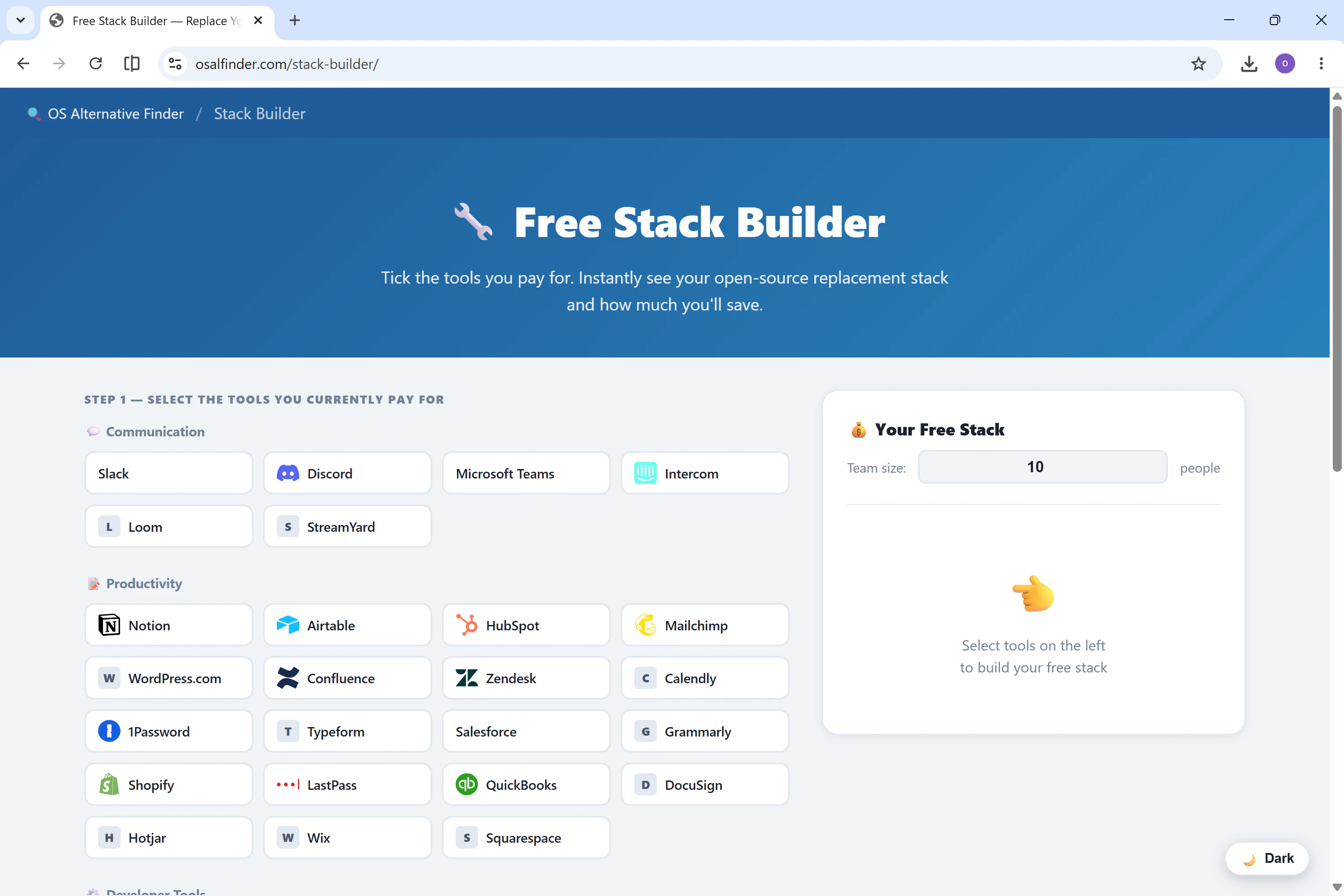
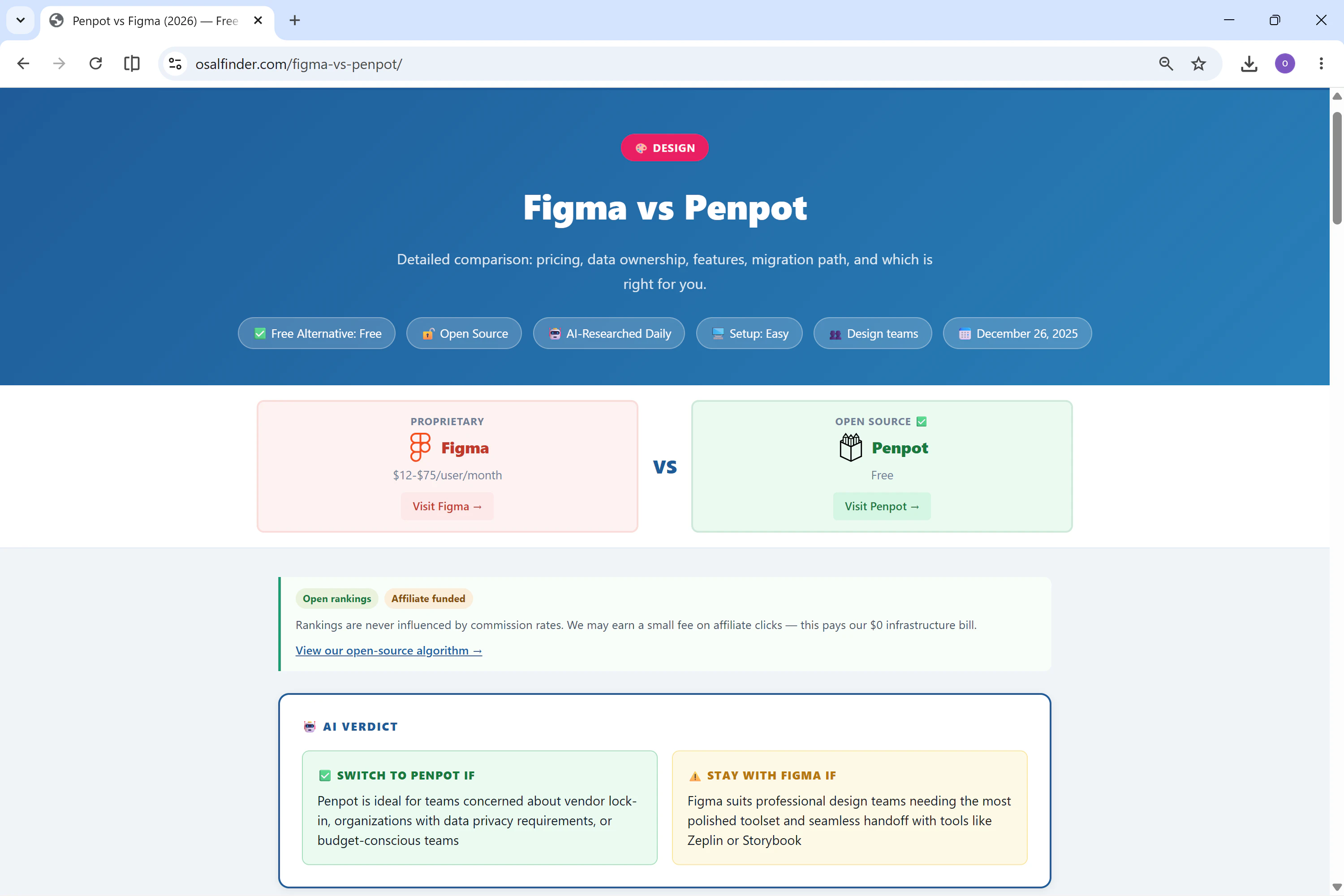
一句话介绍:一款每日更新的工具对比网站,帮助用户找到Slack、Notion、Figma等60+付费SaaS的免费、自托管开源替代品,并提供迁移指南和AI分析,解决团队高额软件订阅费痛点。
Open Source
SaaS
Artificial Intelligence
GitHub
开源替代
SaaS对比
自托管
迁移指南
AI生成
定价透明
独立开发者
省钱工具
团队效率
VPS部署
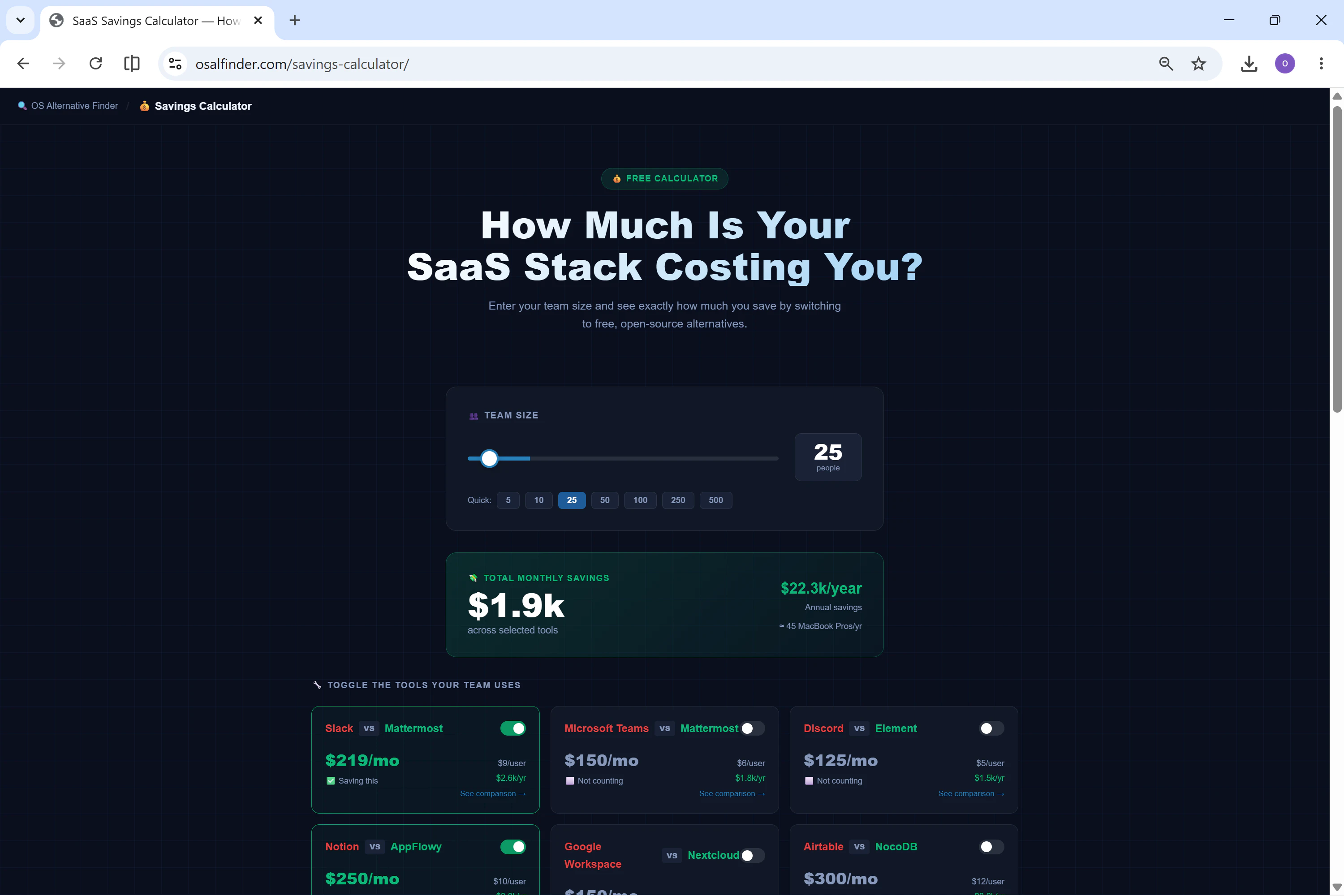
用户评论摘要:开发者John解释了项目初衷:团队每年支付$8000+订阅费,而自托管方案仅需$6/月VPS。他强调了“留在付费工具”的诚实对比、难度评级和节省计算器。用户关注点在于迁移指南深度和定位清晰度,期待更多类别覆盖。
AI 锐评
Open Source Alternative Finder精准切中了“SaaS订阅疲劳”这一刚需——尤其是对中小团队和预算敏感的技术用户而言。其核心价值不在于“罗列替代品”,而在于用AI降低决策成本:每天自动更新、定价对比、迁移难度评级,甚至有个“诚实劝退”模块(提示用户何时不适合转开源),这比绝大多数开源推荐站更务实。
但问题也很明显:当前仅57组对比、8类工具,覆盖深度有限,且AI生成的“AI裁决”可能缺乏技术细节的实操验证。开发者John以“零成本管道”运营,依赖GitHub Actions和Groq AI,这既是优势(低门槛),也是隐忧——一旦维护者精力分散,内容更新和准确性可能滑坡。
另外,投票数仅8,社区共鸣微弱。评论中虽有开发者坦诚分享,却几乎没有用户真实反馈或使用体验。这暗示产品仍处于早期“自嗨”阶段,尚未形成口碑传播。若想从“个人项目”跃升为“产品”,需要更系统的社区建设、用户案例,以及更深度的迁移教程(如实际部署踩坑记录)。一句话:方向正确,但离“替代品参考标杆”还有不少路要走。




















































We've been honing Clipto's story for a few months. At the end of our last call @henry_kang proved the value of the product.
He and his team were out in the desert, testing Clipto remotely: minimal reception, terabytes of footage sitting on his laptop, and he needed to find a specific shot for the launch video.
He searched for: "the wide drone shot where the car enters the desert".
He didn't want "a cinematic moment." Not a "vibes" search.
He knew he had the clip but in the pre-Clipto world, it would take hours of video scrubbing to find it.
He found that clip in seconds using natural language to search over his own media, fully local.
Just like Google Photos — but nothing lives in the cloud.
This isn't an easy problem to solve. Henry's been pursuing this direction for over twenty years, when at CMU's Robotics Institute (my alma mater, FYI), he began pushing the limits of computer vision. He starting with indexing hundreds of images and then advanced to millions of objects — and watched recognition basically explode once memory scaled.
Clipto is in many respects the culmination of that work, pointed at your personal hard drive.
And it's quick: a modern M5 MacBook chews through ~2TB of video in about a day. Why not push yours through its paces?
Hi Product Hunt! I’m Henry, founder of Clipto.
Clipto gives you the ability to search in natural language over terabytes of media in seconds.
Think: Google Photos, but fully local.
During my 20 years ago at CMU’s Robotics Institute, I became obsessed with memory systems: what if computers could actually remember what they’ve seen?
I trained robots to memorize millions of product images crawled from the Amazon catalog (the standard back then was to index 100s of images at a time), and discovered that they could use that memory to recognize almost anything they encountered!
By pushing computers beyond their conventional limits, I had unlocked an explosion in machine intelligence.
Years later, the problem has become personal.
Our computers are full of valuable raw footage, interviews, recordings, and more, but most of that data is still painfully hard to search, revisit, or reuse. We are data-rich, but knowledge-poor.
That’s why I built Clipto. Clipto helps you find what matters inside terabytes of video, audio, meetings, and files, instantly, turning hours of repetitive work into seconds.
Find the wide drone shot where the cars enter frame.
Find the shot specifically in the moment the sandstorm arrives from hours of footage.
And find what you know is in there, without suffering through hours of scrubbing.
Clipto's memory system live where your data already is: on your device, under your control, available anytime, even offline — so you can keep working wherever and whenever inspiration strikes.
After two years of compressing, optimizing, distilling and orchestrating AI models to run entirely on-device, we are ready to share it with the Product Hunt community.
It’s still early, and it’s still compute-heavy. Right now, Clipto works best on higher-performance Apple Silicon Macs (M1 Pro/Max/Ultra and newer) with 24GB+ RAM. If you have a compatible Mac, we’d love for you to try it.
To celebrate our launch, we're offering 1 month free to anyone who signs up this week with code PHLNCH.
I’ll be here in the comments all day and would genuinely love to hear about the strategies you've developed to find your content diamonds in your digital rough.
This looks really interesting.
I'm curious about how deeply it understands media content.
Does it recognise things like camera angles, shot types (wide, medium, close-up), camera movements, transitions, B-roll, and multi-camera sequences?
It would be incredibly useful if I could search for something like "close-up shot of a person smiling" or "drone footage with a slow pan" and instantly find matching clips across my archive.
Would love to know how detailed the visual understanding gets beyond basic object and dialogue detection.
Love the local-first philosophy! Does the single license cover multiple Macs, or do I need a separate seat for my studio desktop and my travel MacBook?
Interesting. Local-first stops being a privacy story the second you can find a clip on your own drive faster than you'd find it in cloud storage. Question - what happens to the index when I rename or move a file in Finder after indexing? Does Clipto watch the filesystem?
I’m a YouTuber and managing b-roll is my biggest nightmare. Does Clipto allow for tagging, or is it all AI-based search?
'like Google Photos but fully local' framing is clean but Google Photos works because the index follows you across devices seamlessly. curious how Clipto handles the multi-device problem. if i index 2TB on my MacBook and then want to search from my iPad or a second machine, what does that look like. is the index portable or does each device need to reindex independently because that changes the use case significantly for anyone with more than one machine
This feels like what the Apple 'Photos' search should have been for professional video files. Super impressed.
This is genuinely impressive — local-first AI search for video is something I didn't know I needed until now. The desert story really sold it for me.
Quick question: does Clipto index audio content like podcast recordings or interview transcripts the same way it handles video footage? I have hundreds of hours of recorded interviews and this could be a total game-changer for my workflow.
Been following the journey on LinkedIn and so glad to see you guys finally launch! The search functionality is spooky good.
Concept is really intresting and the smooth onboarding
How did you get the idea to make that kind of stuff? what was your excatly the moments you think to create this.
I am not a creator , but I do have lots of personal photos stored in different locations on my device , will clipto be able to organise those for me ? And can it build a memory chart out if it. For me rather then searching I like what google shows to me on time to time , like memories.
But sometimes searching is also required.
Local-only across audio + video + files is the version of this I keep waiting for, congrats on shipping. The piece that usually breaks under real load is the indexing job, not the search itself. How are you handling the initial pass on someone with 5 years of meeting recordings? And does the index update incrementally or do new files queue behind the original backfill?
How does the search handle lighting conditions? If I search for 'forest at night' vs 'forest during the day,' is the vision model sensitive enough to distinguish the cinematic mood?
Congrats! I believe this product is very helpful for me! Clipto arrives at the intersection of three powerful trends: on-device AI, privacy-centric computing, and knowledge management. it has genuine disruptive potential.
For long-form team collaboration, is there a way to share the index file with another editor, or does each person need to re-index the same footage locally?
Does the natural language search get better over time through local fine-tuning, or is the model static upon installation?
I've got a lot of multi-cam footage and heavy ProRes files. Does the app struggle with professional codecs, or is it optimized for proxy-like speeds internally?
On-device NL search over 2TB is the hard part — curious if you're embedding frames with a local CLIP-style model + ANN index, or sampling keyframes? And how does it stay incremental as the library grows?
This looks like a great concept. I'd definitely love to give it a try, especially since I spend a lot of time switching between notes, recordings, and transcripts. One question though; when can we expect support for Pixel phones? That would make it an easy download for me.
This is super cool, I wanted to ask you a question. How does it deal with hardware and devices that are very weak?
An absolute game-changer for the creator economy. Managing asset libraries is the unsexy part of the job that everyone hates. Thanks for fixing this!
This solves a problem I didn't even realize was draining my energy every day. No more hunting for files. Instantly installed.
This feels like a glimpse into the future of local file management. Huge congrats on the Product Hunt launch, Henry & team! Def trying this out today.
Comment list for Clipto.AI on Product Hunt
Actually works offline? That’s a game-changer for when I’m editing on the road or in a cafe with spotty Wi-Fi.
Actually works offline? That’s a game-changer for when I’m editing on the road or in a cafe with spotty Wi-Fi.
Turn on screen reader support
Working…
To enable screen reader support, press Ctrl+Alt+Z To learn about keyboard shortcuts, press Ctrl+slash
This is cool. Keeping everything local is a massive win, especially with how unpredictable cloud costs can get and how worried people are about privacy right now. I really respect that you stuck to local-only storage to protect user data.
As a developer working a lot with local-first Python frameworks, I'm super curious about the performance side. How do you manage the local system resources so that indexing a massive 2TB drive doesn't slow their device to a crawl?
Cool concept. Real question though — is this doing actual frame-by-frame visual understanding or is it metadata/transcript/keyframe analysis? Because the gap between those two is enormous for practical use. What I actually want: upload 10 raw clips of the same scene, AI watches them all, ranks by emotional resonance, suggests best cuts.
Tried a similar tool last year and it choked on my 500GB of GoPro footage. Curious if Clipto handles high-bitrate HEVC files smoothly.